
language:
- en
task_categories:
- image-to-3d
tags:
- 3d-object-detection
- monocular
- open-set
3D-MOOD Dataset
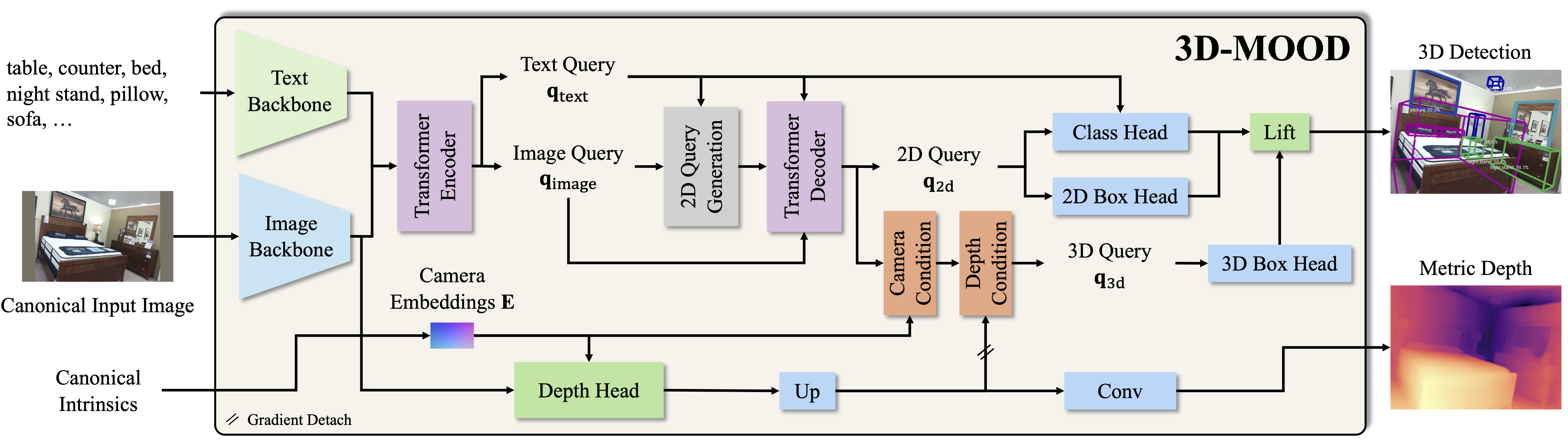
This dataset is for 3D-MOOD: Lifting 2D to 3D for Monocular Open-Set Object Detection. It contains selected images and annotations from Argoverse 2 and ScanNetV2, and also the depth ground truth (GT) for Omni3D data. We provide the HDF5 data and annotation in JSON format.
- Paper: 3D-MOOD: Lifting 2D to 3D for Monocular Open-Set Object Detection
- Project Page: https://royyang0714.github.io/3D-MOOD
- Code: https://github.com/cvg/3D-MOOD
Introduction
Monocular 3D object detection is valuable for various applications such as robotics and AR/VR. This dataset is associated with 3D-MOOD, the first end-to-end 3D Monocular Open-set Object Detector, which addresses monocular 3D object detection in an open-set setting. The approach involves lifting open-set 2D detection into 3D space, enabling end-to-end joint training for both 2D and 3D tasks to yield better overall performance.
Data Preparation
The HDF5 files and annotations for ScanNet v2, Argoverse 2, and the depth GT for Omni3D datasets are provided. For training and testing with Omni3D, please refer to the DATA guide in the GitHub repository to set up the Omni3D data.
The final data folder structure should be like:
REPO_ROOT
├── data
│ ├── omni3d
│ │ └── annotations
├── KITTI_object
├── KITTI_object_depth
├── nuscenes
├── nuscenes_depth
├── objectron
├── objectron_depth
├── SUNRGBD
├── ARKitScenes
├── ARKitScenes_depth
├── hypersim
├── hypersim_depth
├── argoverse2
│ ├── annotations
│ └── val.hdf5
└── scannet
├── annotations
└── val.hdf5
By default, in our provided config, we use HDF5 as the data backend. You can convert each folder using the script to generate them, or you can just change the data_backend in the configs to FileBackend.
Sample Usage
We provide the demo.py to test whether the installation is complete.
First, install the necessary packages (for full installation instructions, refer to the GitHub repository):
conda create -n opendet3d python=3.11 -y
conda activate opendet3d
# Install Vis4D
# It should also install the PyTorch with CUDA support. But please check.
pip install vis4d==1.0.0
# Install CUDA ops
pip install git+https://github.com/SysCV/vis4d_cuda_ops.git --no-build-isolation --no-cache-dir
# Install 3D-MOOD
pip install -v -e .
Then, run the demo script:
python scripts/demo.py
It will save the prediction as follows to assets/demo/output.png.
You can also try the live demo on Hugging Face Spaces!
Citation
If you find our work useful in your research please consider citing our publications:
@article{yang20253d,
title={3D-MOOD: Lifting 2D to 3D for Monocular Open-Set Object Detection},
author={Yang, Yung-Hsu and Piccinelli, Luigi and Segu, Mattia and Li, Siyuan and Huang, Rui and Fu, Yuqian and Pollefeys, Marc and Blum, Hermann and Bauer, Zuria},
journal={arXiv preprint arXiv:2507.23567},
year={2025}
}