
thom continuing
#53
by
thomwolf
HF Staff
- opened
- assets/images/torch-compile-triton-kernel.png +3 -0
- assets/images/torch-compile-triton.png +3 -0
- dist/assets/images/torch-compile-triton-kernel.png +3 -0
- dist/assets/images/torch-compile-triton.png +3 -0
- dist/index.html +72 -14
- dist/style.css +12 -0
- src/index.html +72 -14
- src/style.css +12 -0
assets/images/torch-compile-triton-kernel.png
ADDED

|
Git LFS Details
|
assets/images/torch-compile-triton.png
ADDED
|
Git LFS Details
|
dist/assets/images/torch-compile-triton-kernel.png
ADDED
|
Git LFS Details
|
dist/assets/images/torch-compile-triton.png
ADDED

|
Git LFS Details
|
dist/index.html
CHANGED
|
@@ -1901,11 +1901,62 @@
|
|
| 1901 |
|
| 1902 |
<p>To run the kernel, you will also need a specific code part, called <strong>host code</strong>, which is executed on the <strong>CPU/host</strong> and will take care of preparing data allocations and loading data and code.</p>
|
| 1903 |
|
| 1904 |
-
<
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1905 |
<p>Figure 5: Host code for a CUDA kernel for adding two vectors from https://blog.codingconfessions.com/p/gpu-computing</p>
|
| 1906 |
<p><img alt="image.png" src="/assets/images/placeholder.png" /></p>
|
| 1907 |
-
|
| 1908 |
-
|
| 1909 |
<p>Kernels are generally scheduled as follow:</p>
|
| 1910 |
|
| 1911 |
<ul>
|
|
@@ -1941,8 +1992,9 @@
|
|
| 1941 |
|
| 1942 |
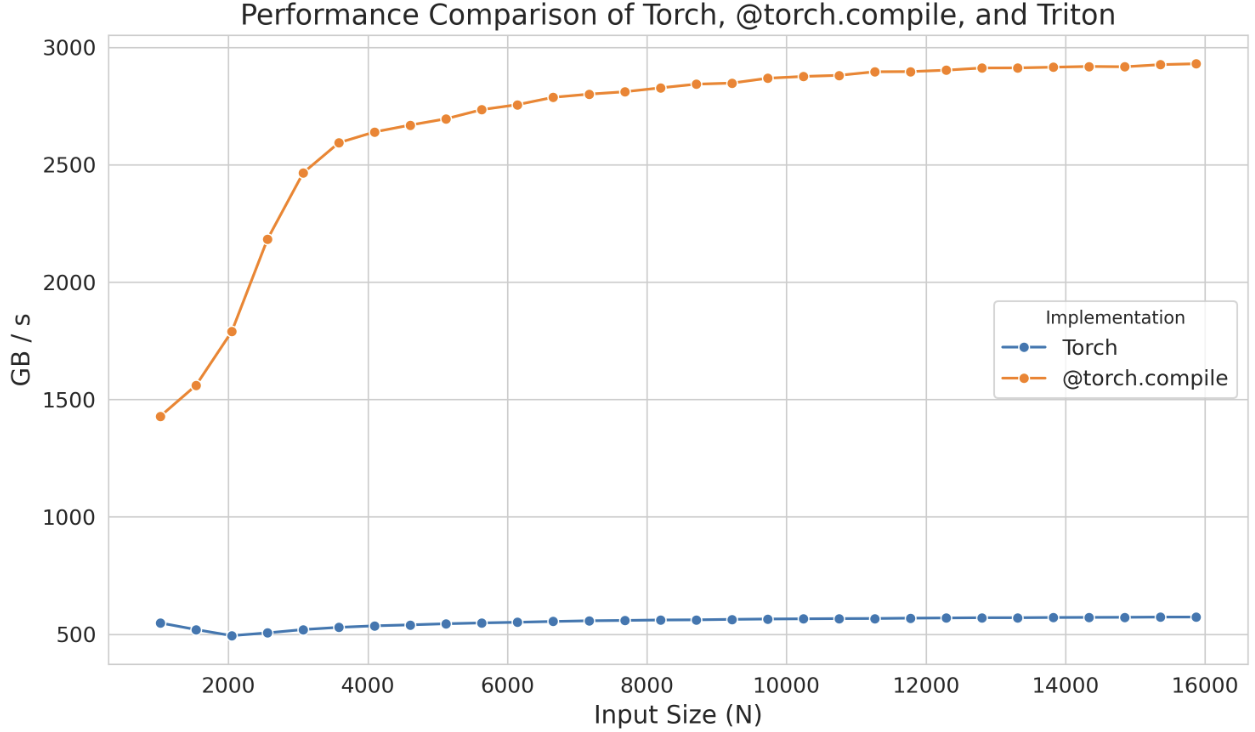
<p>The distinction between the compiled and non-compiled versions is striking, especially given that we only added a single decorator. This remarkable difference is illustrated in the graph below (N is the number of columns):</p>
|
| 1943 |
|
| 1944 |
-
<p><img alt="image.png" src="/assets/images/
|
| 1945 |
|
|
|
|
| 1946 |
|
| 1947 |
<p>However, if this performance increase is insufficient, you can consider implementing Triton kernels. As a starting point, you can take a look at the triton kernel generated by @torch.compile . To do so, you simply need to set the environment variable <code>TORCH_LOGS</code> to <code>"output_code"</code>:</p>
|
| 1948 |
|
|
@@ -1970,7 +2022,7 @@
|
|
| 1970 |
tl.store(out_ptr0 + (x0), tmp6, xmask)
|
| 1971 |
</d-code>
|
| 1972 |
|
| 1973 |
-
<p>To enhance readability, we can modify the variable names, add comments, and make slight adjustments, as demonstrated below:</p>
|
| 1974 |
|
| 1975 |
<d-code block language="python">
|
| 1976 |
@triton.jit
|
|
@@ -2001,23 +2053,25 @@
|
|
| 2001 |
|
| 2002 |
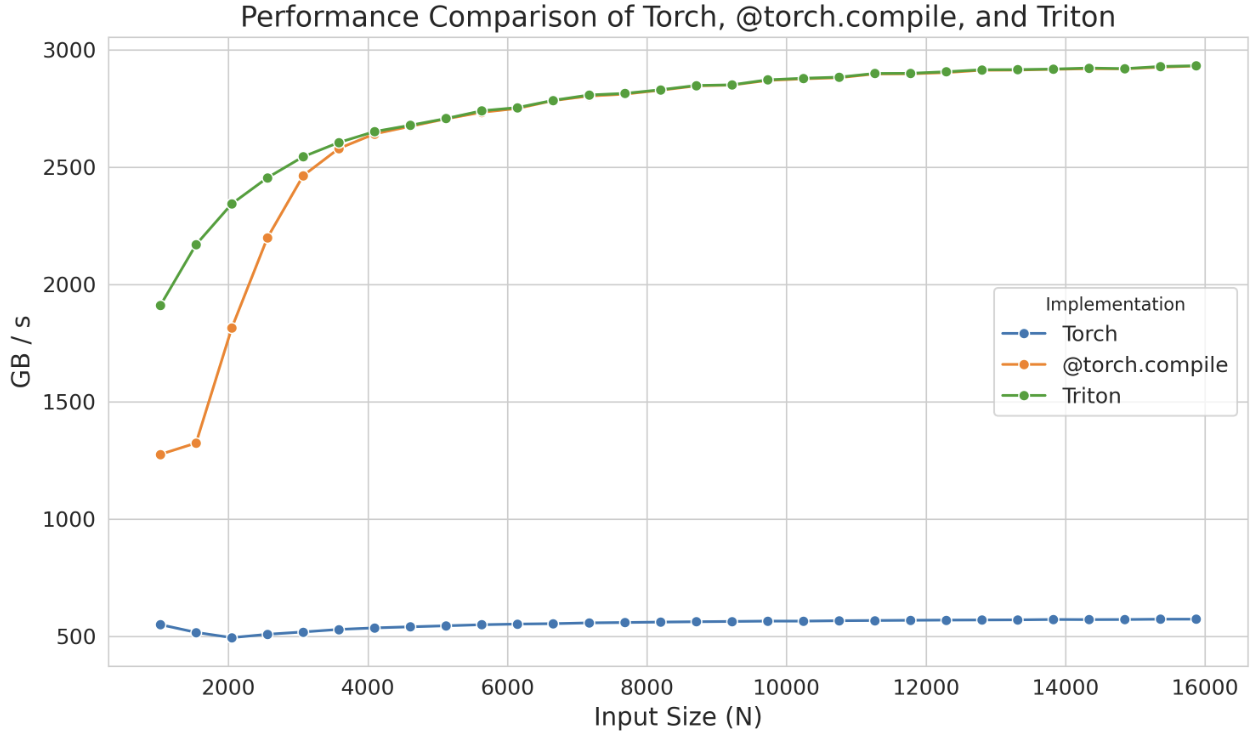
<p>When we benchmark the generated kernel using <code>triton.testing.Benchmark</code> we have the following performance:</p>
|
| 2003 |
|
| 2004 |
-
<p><img alt="image.png" src="/assets/images/
|
| 2005 |
|
| 2006 |
-
<p>This standalone kernel demonstrates superior performance with smaller sizes compared to <code>@torch.compile</code> but this is likely
|
| 2007 |
|
| 2008 |
-
<p>
|
| 2009 |
|
| 2010 |
-
<p>
|
|
|
|
|
|
|
| 2011 |
|
| 2012 |
-
<
|
| 2013 |
<li>Pytorch: easy but slow</li>
|
| 2014 |
<li>torch.compile: easy, fast, but not flexible</li>
|
| 2015 |
<li>triton: harder, faster, and more flexible</li>
|
| 2016 |
<li>CUDA: hardest, fastest, and flexiblest (if you get it right)</li>
|
| 2017 |
|
| 2018 |
-
</
|
| 2019 |
|
| 2020 |
-
<p>Let’s talk about one of the most frequent technique we can use: optimizing memory access. The global memory in GPUs (the largest memory in our above graph) has a long latency and low bandwidth in comparison to the cache which often creates a major bottleneck for most applications. Efficiently accessing data from global memory can improve a lot the performance.</p>
|
| 2021 |
|
| 2022 |
<h4>Memory Coalescing</h4>
|
| 2023 |
|
|
@@ -2048,8 +2102,12 @@
|
|
| 2048 |
|
| 2049 |
<p>However, when profiling this kernel with a tool like <code>ncu</code>, we can see issues, including low memory throughput and uncoalesced memory accesses.</p>
|
| 2050 |
|
| 2051 |
-
<
|
| 2052 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 2053 |
|
| 2054 |
|
| 2055 |
<p>The reason for this is that in this kernel, two threads in the same block with Thread IDs <code>(0, 0)</code> and <code>(1, 0)</code> (which will end up in the same warp) will both load from the same column of matrix <code>B</code> but different rows of matrix <code>A</code>. Since matrix elements are stored in row-major order (meaning each row's elements are in consecutive memory addresses, as shown in the figure below), in the first iteration with <code>i = 0</code>, thread <code>(0, 0)</code> will load <d-math>A_{0,0}</d-math>, and thread <code>(1, 0)</code> will load <d-math>A_{1,0}</d-math>. These elements are not stored close to each other in memory, and this misalignment repeats across all iterations along the shared dimension, preventing memory accesses from being coalesced.</p>
|
|
|
|
| 1901 |
|
| 1902 |
<p>To run the kernel, you will also need a specific code part, called <strong>host code</strong>, which is executed on the <strong>CPU/host</strong> and will take care of preparing data allocations and loading data and code.</p>
|
| 1903 |
|
| 1904 |
+
<div class="l-body" style="display: grid; grid-template-columns: 1fr 1fr; align-items: center;">
|
| 1905 |
+
<div>
|
| 1906 |
+
<d-code block language="python">
|
| 1907 |
+
// Host code
|
| 1908 |
+
void vecAdd(float* h_A, float *h_B, float *h_c, int n) {
|
| 1909 |
+
// Allocate vectors in device memory
|
| 1910 |
+
int size = n * sizeof(float);
|
| 1911 |
+
float *d_A, *d_B, *d_C;
|
| 1912 |
+
cudaMalloc(&d_A, size);
|
| 1913 |
+
cudaMalloc(&d_B, size);
|
| 1914 |
+
cudaMalloc(&d_C, size);
|
| 1915 |
+
|
| 1916 |
+
// Copy vectors from host memory to device memory
|
| 1917 |
+
cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);
|
| 1918 |
+
cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);
|
| 1919 |
+
|
| 1920 |
+
// Invoke kernel
|
| 1921 |
+
int threadsPerBlock = 256;
|
| 1922 |
+
int blocksPerGrid =
|
| 1923 |
+
(N + threadsPerBlock - 1) / threadsPerBlock;
|
| 1924 |
+
VecAdd<<<blocksPerGrid, threadsPerBlock>>>(d_A, d_B, d_C, N);
|
| 1925 |
+
|
| 1926 |
+
// Copy result from device memory to host memory
|
| 1927 |
+
// h_C contains the result in host memory
|
| 1928 |
+
cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);
|
| 1929 |
+
|
| 1930 |
+
// Free device memory
|
| 1931 |
+
cudaFree(d_A);
|
| 1932 |
+
cudaFree(d_B);
|
| 1933 |
+
cudaFree(d_C);
|
| 1934 |
+
}</d-code>
|
| 1935 |
+
<div class="figure-legend">
|
| 1936 |
+
<p>Host code for a CUDA kernel for adding two vectors. Adapted from https://docs.nvidia.com/cuda/cuda-c-programming-guide/ and https://blog.codingconfessions.com/p/gpu-computing</p>
|
| 1937 |
+
</div>
|
| 1938 |
+
</div>
|
| 1939 |
+
<div>
|
| 1940 |
+
<d-code block language="python">
|
| 1941 |
+
// Device code
|
| 1942 |
+
__global__ void VecAdd(float* A, float* B, float* C, int N)
|
| 1943 |
+
{
|
| 1944 |
+
int i = blockDim.x * blockIdx.x + threadIdx.x;
|
| 1945 |
+
if (i < N)
|
| 1946 |
+
C[i] = A[i] + B[i];
|
| 1947 |
+
}
|
| 1948 |
+
</d-code>
|
| 1949 |
+
<div class="figure-legend">
|
| 1950 |
+
<p>Device code containing the definition of the vector addition kernel adapted from https://docs.nvidia.com/cuda/cuda-c-programming-guide/ and https://blog.codingconfessions.com/p/gpu-computing</p>
|
| 1951 |
+
|
| 1952 |
+
</div>
|
| 1953 |
+
</div>
|
| 1954 |
+
</div>
|
| 1955 |
+
|
| 1956 |
+
<!-- <p><img alt="image.png" src="/assets/images/placeholder.png" /></p>
|
| 1957 |
<p>Figure 5: Host code for a CUDA kernel for adding two vectors from https://blog.codingconfessions.com/p/gpu-computing</p>
|
| 1958 |
<p><img alt="image.png" src="/assets/images/placeholder.png" /></p>
|
| 1959 |
+
-->
|
|
|
|
| 1960 |
<p>Kernels are generally scheduled as follow:</p>
|
| 1961 |
|
| 1962 |
<ul>
|
|
|
|
| 1992 |
|
| 1993 |
<p>The distinction between the compiled and non-compiled versions is striking, especially given that we only added a single decorator. This remarkable difference is illustrated in the graph below (N is the number of columns):</p>
|
| 1994 |
|
| 1995 |
+
<p><img alt="image.png" src="/assets/images/torch-compile-triton.png" /></p>
|
| 1996 |
|
| 1997 |
+
<!-- <p><img alt="image.png" src="/assets/images/dp_scaling.svg"/></p> -->
|
| 1998 |
|
| 1999 |
<p>However, if this performance increase is insufficient, you can consider implementing Triton kernels. As a starting point, you can take a look at the triton kernel generated by @torch.compile . To do so, you simply need to set the environment variable <code>TORCH_LOGS</code> to <code>"output_code"</code>:</p>
|
| 2000 |
|
|
|
|
| 2022 |
tl.store(out_ptr0 + (x0), tmp6, xmask)
|
| 2023 |
</d-code>
|
| 2024 |
|
| 2025 |
+
<p>To enhance readability, we can modify the variable names, add comments, and make slight adjustments (or ask an LLM to do it for us), as demonstrated below:</p>
|
| 2026 |
|
| 2027 |
<d-code block language="python">
|
| 2028 |
@triton.jit
|
|
|
|
| 2053 |
|
| 2054 |
<p>When we benchmark the generated kernel using <code>triton.testing.Benchmark</code> we have the following performance:</p>
|
| 2055 |
|
| 2056 |
+
<p><img alt="image.png" src="/assets/images/torch-compile-triton-kernel.png" /></p>
|
| 2057 |
|
| 2058 |
+
<p>This standalone kernel even demonstrates superior performance with smaller sizes compared to <code>@torch.compile</code> but this is likely just an artifact of the compilation time of <code>torch.compile</code>. In any case, instead of starting from scratch, remember that you can start from such generated kernels and focus your attention to optimizing its performance, saving you a lot of time in the process. </p>
|
| 2059 |
|
| 2060 |
+
<p>Even in Triton, sometimes, we cannot fully achieve the peak performance of the device due to the language limitations to handle low level details like shared memory and scheduling within streaming multiprocessors (SMs). Triton capabilities are restricted to blocks and scheduling of blocks across SMs. To gain an even deeper control, you will need to implement kernels directly in CUDA, where you will have access to all the underlying low-level details.</p>
|
| 2061 |
|
| 2062 |
+
<p>Moving down to CUDA, various techniques can be employed to improve the efficiency of kernels. We will just cover a few here: optimizing memory access patterns to reduce latency, using shared memory to store frequently accessed data, and managing thread workloads to minimize idle times.</p>
|
| 2063 |
+
|
| 2064 |
+
<p> Before we dive deeper in CUDA examples, let's summarize the tools we've seen that let us write kernel code to execute instructions on the GPU:</p>
|
| 2065 |
|
| 2066 |
+
<ol>
|
| 2067 |
<li>Pytorch: easy but slow</li>
|
| 2068 |
<li>torch.compile: easy, fast, but not flexible</li>
|
| 2069 |
<li>triton: harder, faster, and more flexible</li>
|
| 2070 |
<li>CUDA: hardest, fastest, and flexiblest (if you get it right)</li>
|
| 2071 |
|
| 2072 |
+
</ol>
|
| 2073 |
|
| 2074 |
+
<p>Let’s talk about one of the most frequent technique we can use in CUDA: optimizing memory access. The global memory in GPUs (the largest memory in our above graph) has a long latency and low bandwidth in comparison to the cache which often creates a major bottleneck for most applications. Efficiently accessing data from global memory can improve a lot the performance.</p>
|
| 2075 |
|
| 2076 |
<h4>Memory Coalescing</h4>
|
| 2077 |
|
|
|
|
| 2102 |
|
| 2103 |
<p>However, when profiling this kernel with a tool like <code>ncu</code>, we can see issues, including low memory throughput and uncoalesced memory accesses.</p>
|
| 2104 |
|
| 2105 |
+
<div class="large-image-background">
|
| 2106 |
+
<img width="1200px" alt="image.png" src="/assets/images/memorycoalescing2.png" />
|
| 2107 |
+
</div>
|
| 2108 |
+
<div class="large-image-background">
|
| 2109 |
+
<img width="1200px" alt="image.png" src="/assets/images/memorycoalescing3.png" />
|
| 2110 |
+
</div>
|
| 2111 |
|
| 2112 |
|
| 2113 |
<p>The reason for this is that in this kernel, two threads in the same block with Thread IDs <code>(0, 0)</code> and <code>(1, 0)</code> (which will end up in the same warp) will both load from the same column of matrix <code>B</code> but different rows of matrix <code>A</code>. Since matrix elements are stored in row-major order (meaning each row's elements are in consecutive memory addresses, as shown in the figure below), in the first iteration with <code>i = 0</code>, thread <code>(0, 0)</code> will load <d-math>A_{0,0}</d-math>, and thread <code>(1, 0)</code> will load <d-math>A_{1,0}</d-math>. These elements are not stored close to each other in memory, and this misalignment repeats across all iterations along the shared dimension, preventing memory accesses from being coalesced.</p>
|
dist/style.css
CHANGED
|
@@ -424,3 +424,15 @@ d-article {
|
|
| 424 |
d-code {
|
| 425 |
font-size: 12px;
|
| 426 |
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 424 |
d-code {
|
| 425 |
font-size: 12px;
|
| 426 |
}
|
| 427 |
+
|
| 428 |
+
.large-image-background {
|
| 429 |
+
width: 100vw;
|
| 430 |
+
padding-top: 10px;
|
| 431 |
+
padding-bottom: 10px;
|
| 432 |
+
margin-left: calc(-50vw + 50%);
|
| 433 |
+
margin-right: calc(-50vw + 50%);
|
| 434 |
+
background: white;
|
| 435 |
+
height: fit-content; /* This will make it match the image height */
|
| 436 |
+
display: flex;
|
| 437 |
+
justify-content: center; /* This will center your image */
|
| 438 |
+
}
|
src/index.html
CHANGED
|
@@ -1901,11 +1901,62 @@
|
|
| 1901 |
|
| 1902 |
<p>To run the kernel, you will also need a specific code part, called <strong>host code</strong>, which is executed on the <strong>CPU/host</strong> and will take care of preparing data allocations and loading data and code.</p>
|
| 1903 |
|
| 1904 |
-
<
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1905 |
<p>Figure 5: Host code for a CUDA kernel for adding two vectors from https://blog.codingconfessions.com/p/gpu-computing</p>
|
| 1906 |
<p><img alt="image.png" src="/assets/images/placeholder.png" /></p>
|
| 1907 |
-
|
| 1908 |
-
|
| 1909 |
<p>Kernels are generally scheduled as follow:</p>
|
| 1910 |
|
| 1911 |
<ul>
|
|
@@ -1941,8 +1992,9 @@
|
|
| 1941 |
|
| 1942 |
<p>The distinction between the compiled and non-compiled versions is striking, especially given that we only added a single decorator. This remarkable difference is illustrated in the graph below (N is the number of columns):</p>
|
| 1943 |
|
| 1944 |
-
<p><img alt="image.png" src="/assets/images/
|
| 1945 |
|
|
|
|
| 1946 |
|
| 1947 |
<p>However, if this performance increase is insufficient, you can consider implementing Triton kernels. As a starting point, you can take a look at the triton kernel generated by @torch.compile . To do so, you simply need to set the environment variable <code>TORCH_LOGS</code> to <code>"output_code"</code>:</p>
|
| 1948 |
|
|
@@ -1970,7 +2022,7 @@
|
|
| 1970 |
tl.store(out_ptr0 + (x0), tmp6, xmask)
|
| 1971 |
</d-code>
|
| 1972 |
|
| 1973 |
-
<p>To enhance readability, we can modify the variable names, add comments, and make slight adjustments, as demonstrated below:</p>
|
| 1974 |
|
| 1975 |
<d-code block language="python">
|
| 1976 |
@triton.jit
|
|
@@ -2001,23 +2053,25 @@
|
|
| 2001 |
|
| 2002 |
<p>When we benchmark the generated kernel using <code>triton.testing.Benchmark</code> we have the following performance:</p>
|
| 2003 |
|
| 2004 |
-
<p><img alt="image.png" src="/assets/images/
|
| 2005 |
|
| 2006 |
-
<p>This standalone kernel demonstrates superior performance with smaller sizes compared to <code>@torch.compile</code> but this is likely
|
| 2007 |
|
| 2008 |
-
<p>
|
| 2009 |
|
| 2010 |
-
<p>
|
|
|
|
|
|
|
| 2011 |
|
| 2012 |
-
<
|
| 2013 |
<li>Pytorch: easy but slow</li>
|
| 2014 |
<li>torch.compile: easy, fast, but not flexible</li>
|
| 2015 |
<li>triton: harder, faster, and more flexible</li>
|
| 2016 |
<li>CUDA: hardest, fastest, and flexiblest (if you get it right)</li>
|
| 2017 |
|
| 2018 |
-
</
|
| 2019 |
|
| 2020 |
-
<p>Let’s talk about one of the most frequent technique we can use: optimizing memory access. The global memory in GPUs (the largest memory in our above graph) has a long latency and low bandwidth in comparison to the cache which often creates a major bottleneck for most applications. Efficiently accessing data from global memory can improve a lot the performance.</p>
|
| 2021 |
|
| 2022 |
<h4>Memory Coalescing</h4>
|
| 2023 |
|
|
@@ -2048,8 +2102,12 @@
|
|
| 2048 |
|
| 2049 |
<p>However, when profiling this kernel with a tool like <code>ncu</code>, we can see issues, including low memory throughput and uncoalesced memory accesses.</p>
|
| 2050 |
|
| 2051 |
-
<
|
| 2052 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 2053 |
|
| 2054 |
|
| 2055 |
<p>The reason for this is that in this kernel, two threads in the same block with Thread IDs <code>(0, 0)</code> and <code>(1, 0)</code> (which will end up in the same warp) will both load from the same column of matrix <code>B</code> but different rows of matrix <code>A</code>. Since matrix elements are stored in row-major order (meaning each row's elements are in consecutive memory addresses, as shown in the figure below), in the first iteration with <code>i = 0</code>, thread <code>(0, 0)</code> will load <d-math>A_{0,0}</d-math>, and thread <code>(1, 0)</code> will load <d-math>A_{1,0}</d-math>. These elements are not stored close to each other in memory, and this misalignment repeats across all iterations along the shared dimension, preventing memory accesses from being coalesced.</p>
|
|
|
|
| 1901 |
|
| 1902 |
<p>To run the kernel, you will also need a specific code part, called <strong>host code</strong>, which is executed on the <strong>CPU/host</strong> and will take care of preparing data allocations and loading data and code.</p>
|
| 1903 |
|
| 1904 |
+
<div class="l-body" style="display: grid; grid-template-columns: 1fr 1fr; align-items: center;">
|
| 1905 |
+
<div>
|
| 1906 |
+
<d-code block language="python">
|
| 1907 |
+
// Host code
|
| 1908 |
+
void vecAdd(float* h_A, float *h_B, float *h_c, int n) {
|
| 1909 |
+
// Allocate vectors in device memory
|
| 1910 |
+
int size = n * sizeof(float);
|
| 1911 |
+
float *d_A, *d_B, *d_C;
|
| 1912 |
+
cudaMalloc(&d_A, size);
|
| 1913 |
+
cudaMalloc(&d_B, size);
|
| 1914 |
+
cudaMalloc(&d_C, size);
|
| 1915 |
+
|
| 1916 |
+
// Copy vectors from host memory to device memory
|
| 1917 |
+
cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);
|
| 1918 |
+
cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);
|
| 1919 |
+
|
| 1920 |
+
// Invoke kernel
|
| 1921 |
+
int threadsPerBlock = 256;
|
| 1922 |
+
int blocksPerGrid =
|
| 1923 |
+
(N + threadsPerBlock - 1) / threadsPerBlock;
|
| 1924 |
+
VecAdd<<<blocksPerGrid, threadsPerBlock>>>(d_A, d_B, d_C, N);
|
| 1925 |
+
|
| 1926 |
+
// Copy result from device memory to host memory
|
| 1927 |
+
// h_C contains the result in host memory
|
| 1928 |
+
cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);
|
| 1929 |
+
|
| 1930 |
+
// Free device memory
|
| 1931 |
+
cudaFree(d_A);
|
| 1932 |
+
cudaFree(d_B);
|
| 1933 |
+
cudaFree(d_C);
|
| 1934 |
+
}</d-code>
|
| 1935 |
+
<div class="figure-legend">
|
| 1936 |
+
<p>Host code for a CUDA kernel for adding two vectors. Adapted from https://docs.nvidia.com/cuda/cuda-c-programming-guide/ and https://blog.codingconfessions.com/p/gpu-computing</p>
|
| 1937 |
+
</div>
|
| 1938 |
+
</div>
|
| 1939 |
+
<div>
|
| 1940 |
+
<d-code block language="python">
|
| 1941 |
+
// Device code
|
| 1942 |
+
__global__ void VecAdd(float* A, float* B, float* C, int N)
|
| 1943 |
+
{
|
| 1944 |
+
int i = blockDim.x * blockIdx.x + threadIdx.x;
|
| 1945 |
+
if (i < N)
|
| 1946 |
+
C[i] = A[i] + B[i];
|
| 1947 |
+
}
|
| 1948 |
+
</d-code>
|
| 1949 |
+
<div class="figure-legend">
|
| 1950 |
+
<p>Device code containing the definition of the vector addition kernel adapted from https://docs.nvidia.com/cuda/cuda-c-programming-guide/ and https://blog.codingconfessions.com/p/gpu-computing</p>
|
| 1951 |
+
|
| 1952 |
+
</div>
|
| 1953 |
+
</div>
|
| 1954 |
+
</div>
|
| 1955 |
+
|
| 1956 |
+
<!-- <p><img alt="image.png" src="/assets/images/placeholder.png" /></p>
|
| 1957 |
<p>Figure 5: Host code for a CUDA kernel for adding two vectors from https://blog.codingconfessions.com/p/gpu-computing</p>
|
| 1958 |
<p><img alt="image.png" src="/assets/images/placeholder.png" /></p>
|
| 1959 |
+
-->
|
|
|
|
| 1960 |
<p>Kernels are generally scheduled as follow:</p>
|
| 1961 |
|
| 1962 |
<ul>
|
|
|
|
| 1992 |
|
| 1993 |
<p>The distinction between the compiled and non-compiled versions is striking, especially given that we only added a single decorator. This remarkable difference is illustrated in the graph below (N is the number of columns):</p>
|
| 1994 |
|
| 1995 |
+
<p><img alt="image.png" src="/assets/images/torch-compile-triton.png" /></p>
|
| 1996 |
|
| 1997 |
+
<!-- <p><img alt="image.png" src="/assets/images/dp_scaling.svg"/></p> -->
|
| 1998 |
|
| 1999 |
<p>However, if this performance increase is insufficient, you can consider implementing Triton kernels. As a starting point, you can take a look at the triton kernel generated by @torch.compile . To do so, you simply need to set the environment variable <code>TORCH_LOGS</code> to <code>"output_code"</code>:</p>
|
| 2000 |
|
|
|
|
| 2022 |
tl.store(out_ptr0 + (x0), tmp6, xmask)
|
| 2023 |
</d-code>
|
| 2024 |
|
| 2025 |
+
<p>To enhance readability, we can modify the variable names, add comments, and make slight adjustments (or ask an LLM to do it for us), as demonstrated below:</p>
|
| 2026 |
|
| 2027 |
<d-code block language="python">
|
| 2028 |
@triton.jit
|
|
|
|
| 2053 |
|
| 2054 |
<p>When we benchmark the generated kernel using <code>triton.testing.Benchmark</code> we have the following performance:</p>
|
| 2055 |
|
| 2056 |
+
<p><img alt="image.png" src="/assets/images/torch-compile-triton-kernel.png" /></p>
|
| 2057 |
|
| 2058 |
+
<p>This standalone kernel even demonstrates superior performance with smaller sizes compared to <code>@torch.compile</code> but this is likely just an artifact of the compilation time of <code>torch.compile</code>. In any case, instead of starting from scratch, remember that you can start from such generated kernels and focus your attention to optimizing its performance, saving you a lot of time in the process. </p>
|
| 2059 |
|
| 2060 |
+
<p>Even in Triton, sometimes, we cannot fully achieve the peak performance of the device due to the language limitations to handle low level details like shared memory and scheduling within streaming multiprocessors (SMs). Triton capabilities are restricted to blocks and scheduling of blocks across SMs. To gain an even deeper control, you will need to implement kernels directly in CUDA, where you will have access to all the underlying low-level details.</p>
|
| 2061 |
|
| 2062 |
+
<p>Moving down to CUDA, various techniques can be employed to improve the efficiency of kernels. We will just cover a few here: optimizing memory access patterns to reduce latency, using shared memory to store frequently accessed data, and managing thread workloads to minimize idle times.</p>
|
| 2063 |
+
|
| 2064 |
+
<p> Before we dive deeper in CUDA examples, let's summarize the tools we've seen that let us write kernel code to execute instructions on the GPU:</p>
|
| 2065 |
|
| 2066 |
+
<ol>
|
| 2067 |
<li>Pytorch: easy but slow</li>
|
| 2068 |
<li>torch.compile: easy, fast, but not flexible</li>
|
| 2069 |
<li>triton: harder, faster, and more flexible</li>
|
| 2070 |
<li>CUDA: hardest, fastest, and flexiblest (if you get it right)</li>
|
| 2071 |
|
| 2072 |
+
</ol>
|
| 2073 |
|
| 2074 |
+
<p>Let’s talk about one of the most frequent technique we can use in CUDA: optimizing memory access. The global memory in GPUs (the largest memory in our above graph) has a long latency and low bandwidth in comparison to the cache which often creates a major bottleneck for most applications. Efficiently accessing data from global memory can improve a lot the performance.</p>
|
| 2075 |
|
| 2076 |
<h4>Memory Coalescing</h4>
|
| 2077 |
|
|
|
|
| 2102 |
|
| 2103 |
<p>However, when profiling this kernel with a tool like <code>ncu</code>, we can see issues, including low memory throughput and uncoalesced memory accesses.</p>
|
| 2104 |
|
| 2105 |
+
<div class="large-image-background">
|
| 2106 |
+
<img width="1200px" alt="image.png" src="/assets/images/memorycoalescing2.png" />
|
| 2107 |
+
</div>
|
| 2108 |
+
<div class="large-image-background">
|
| 2109 |
+
<img width="1200px" alt="image.png" src="/assets/images/memorycoalescing3.png" />
|
| 2110 |
+
</div>
|
| 2111 |
|
| 2112 |
|
| 2113 |
<p>The reason for this is that in this kernel, two threads in the same block with Thread IDs <code>(0, 0)</code> and <code>(1, 0)</code> (which will end up in the same warp) will both load from the same column of matrix <code>B</code> but different rows of matrix <code>A</code>. Since matrix elements are stored in row-major order (meaning each row's elements are in consecutive memory addresses, as shown in the figure below), in the first iteration with <code>i = 0</code>, thread <code>(0, 0)</code> will load <d-math>A_{0,0}</d-math>, and thread <code>(1, 0)</code> will load <d-math>A_{1,0}</d-math>. These elements are not stored close to each other in memory, and this misalignment repeats across all iterations along the shared dimension, preventing memory accesses from being coalesced.</p>
|
src/style.css
CHANGED
|
@@ -424,3 +424,15 @@ d-article {
|
|
| 424 |
d-code {
|
| 425 |
font-size: 12px;
|
| 426 |
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 424 |
d-code {
|
| 425 |
font-size: 12px;
|
| 426 |
}
|
| 427 |
+
|
| 428 |
+
.large-image-background {
|
| 429 |
+
width: 100vw;
|
| 430 |
+
padding-top: 10px;
|
| 431 |
+
padding-bottom: 10px;
|
| 432 |
+
margin-left: calc(-50vw + 50%);
|
| 433 |
+
margin-right: calc(-50vw + 50%);
|
| 434 |
+
background: white;
|
| 435 |
+
height: fit-content; /* This will make it match the image height */
|
| 436 |
+
display: flex;
|
| 437 |
+
justify-content: center; /* This will center your image */
|
| 438 |
+
}
|