

library_name: transformers
tags:
- e-commerce
- query-generation
license: mit
datasets:
- smartcat/Amazon-2023-GenQ
language:
- en
metrics:
- rouge
base_model:
- BeIR/query-gen-msmarco-t5-base-v1
pipeline_tag: text2text-generation
Model Card for T5-GenQ-TDE-v1
🤖 ✨ 🔍 Generate precise, realistic user-focused search queries from product text 🛒 🚀 📊
Model Description
- Model Name: Fine-Tuned Query-Generation Model
- Model type: Text-to-Text Transformer
- Finetuned from model: BeIR/query-gen-msmarco-t5-base-v1
- Dataset: smartcat/Amazon-2023-GenQ
- Primary Use Case: Generating accurate and relevant search queries from item descriptions
- Repository: smartcat-labs/product2query
Model variations
| Model | ROUGE-1 | ROUGE-2 | ROUGE-L | ROUGE-Lsum |
|---|---|---|---|---|
| T5-GenQ-T-v1 | 75.2151 | 54.8735 | 74.5142 | 74.5262 |
| T5-GenQ-TD-v1 | 78.2570 | 58.9586 | 77.5308 | 77.5466 |
| T5-GenQ-TDE-v1 | 76.9075 | 57.0980 | 76.1464 | 76.1502 |
| T5-GenQ-TDC-v1 (best) | 80.0754 | 61.5974 | 79.3557 | 79.3427 |
Uses
This model is designed to improve e-commerce search functionality by generating user-friendly search queries based on product descriptions. It is particularly suited for applications where product descriptions are the primary input, and the goal is to create concise, descriptive queries that align with user search intent.
Examples of Use:
Comparison of ROUGE scores:
| Model | ROUGE-1 | ROUGE-2 | ROUGE-L | ROUGE-Lsum |
|---|---|---|---|---|
| T5-GenQ-TDE-v1 | 74.71 | 54.31 | 74.06 | 74.06 |
| query-gen-msmarco-t5-base-v1 | 37.63 | 17.40 | 36.69 | 36.69 |
Note: This evaluation is done after training, based on the test split of the smartcat/Amazon-2023-GenQ.
Examples
Expand to see the table with examples
| Input Text | Target Query | Before Fine-tuning | After Fine-tuning |
|---|---|---|---|
| KIDSCOOL SPACE Baby Denim Overall,Hooded Little Kid Jean Jumper | KIDSCOOL SPACE Baby Denim Overall | what is kidscool space denim | baby denim overalls |
| NCAA Mens Long Sleeve Shirt Arm Team
Show your Mountaineers pride with this West Virginia long sleeve shirt. Its soft cotton material and unique graphics make this a great addition to any West Virginia apparel collection. Features: -100% cotton -Ribbed and double stitched collar and sleeves -Officially licensed West Virginia University long sleeve shirt |
West Virginia long sleeve shirt | wvu long sleeve shirt | West Virginia long sleeve shirt |
| The Body Shop Mattifying Lotion (Vegan), Tea Tree, 1.69 Fl Oz
Product Description Made with community trade tea tree oil, The Body Shop's Tea Tree Mattifying Lotion provides lightweight hydration, helps tackles excess oil and visibly reduces the appearance of blemishes, revealing a clearer looking, mattifed finish. 100 percent vegan, suitable for blemish prone skin. From the Manufacturer Made with Community Trade tea tree oil, The Body Shop's Tea Tree Mattifying Lotion provides lightweight hydration, helps tackles excess oil and visibly reduces the appearance of blemishes, revealing a clearer-looking, mattifed finish. 100% vegan, suitable for blemish-prone skin. Paraben-free. Gluten-free. 100% Vegan. |
Tea Tree Mattifying Lotion | what is body shop tea tree lotion | vegan matte lotion |
How to Get Started with the Model
Use the code below to get started with the model.
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
model = AutoModelForSeq2SeqLM.from_pretrained("smartcat/T5-GenQ-TDE-v1")
tokenizer = AutoTokenizer.from_pretrained("smartcat/T5-GenQ-TDE-v1")
description = "Silver-colored cuff with embossed braid pattern. Made of brass, flexible to fit wrist."
inputs = tokenizer(description, return_tensors="pt", padding=True, truncation=True)
generated_ids = model.generate(inputs["input_ids"], max_length=30, num_beams=4, early_stopping=True)
generated_text = tokenizer.decode(generated_ids[0], skip_special_tokens=True)
Training Details
Training Data
The model was trained on the smartcat/Amazon-2023-GenQ dataset, which consists of user-like queries generated from product descriptions. The dataset was created using Claude Haiku 3, incorporating key product attributes such as the title, description, and images to ensure relevant and realistic queries. For more information, read the Dataset Card. 😊
Preprocessing
- Trained on titles + descriptions of the products and a duplicate set of products with titles only
- Tokenized using T5’s default tokenizer with truncation to handle long text.
Training Hyperparameters
- max_input_length: 512
- max_target_length: 30
- batch_size: 48
- num_train_epochs: 8
- evaluation_strategy: epoch
- save_strategy: epoch
- learning_rate: 5.6e-05
- weight_decay: 0.01
- predict_with_generate: true
- load_best_model_at_end: true
- metric_for_best_model: eval_rougeL
- greater_is_better: true
- logging_strategy: epoch
Train time: 25.62 hrs
Hardware
A6000 GPU:
- Memory Size: 48 GB
- Memory Type: GDDR6
- CUDA: 8.6
Metrics
Metrics
ROUGE, or Recall-Oriented Understudy for Gisting Evaluation, is a set of metrics used for evaluating automatic summarization and machine translation in NLP. The metrics compare an automatically produced summary or translation against a reference or a set of references (human-produced) summary or translation. ROUGE metrics range between 0 and 1, with higher scores indicating higher similarity between the automatically produced summary and the reference.
In our evaluation, ROUGE scores are scaled to resemble percentages for better interpretability. The metric used in the training was ROUGE-L.
| Epoch | Step | Loss | Grad Norm | Learning Rate | Eval Loss | ROUGE-1 | ROUGE-2 | ROUGE-L | ROUGE-Lsum |
|---|---|---|---|---|---|---|---|---|---|
| 1.0 | 8569 | 0.7955 | 2.9784 | 4.9e-05 | 0.6501 | 75.3001 | 55.0195 | 74.6632 | 74.6678 |
| 2.0 | 17138 | 0.6595 | 3.2943 | 4.2e-05 | 0.6293 | 76.2210 | 56.2050 | 75.5728 | 75.5670 |
| 3.0 | 25707 | 0.5982 | 4.0392 | 3.5e-05 | 0.6207 | 76.5493 | 56.7006 | 75.8775 | 75.8796 |
| 4.0 | 34276 | 0.5552 | 2.8237 | 2.8e-05 | 0.6267 | 76.5433 | 56.7025 | 75.8319 | 75.8343 |
| 5.0 | 42845 | 0.5225 | 2.7701 | 2.1e-05 | 0.6303 | 76.7192 | 56.9090 | 75.9884 | 75.9972 |
| 6.0 | 51414 | 0.4974 | 3.1344 | 1.4e-05 | 0.6316 | 76.8851 | 57.1349 | 76.1420 | 76.1484 |
| 7.0 | 59983 | 0.4798 | 3.5027 | 7e-06 | 0.6355 | 76.8884 | 57.1055 | 76.1433 | 76.1501 |
| 8.0 | 68552 | 0.4674 | 4.5172 | 0.0 | 0.6408 | 76.9075 | 57.0980 | 76.1464 | 76.1502 |
Model Analysis
Average scores by model
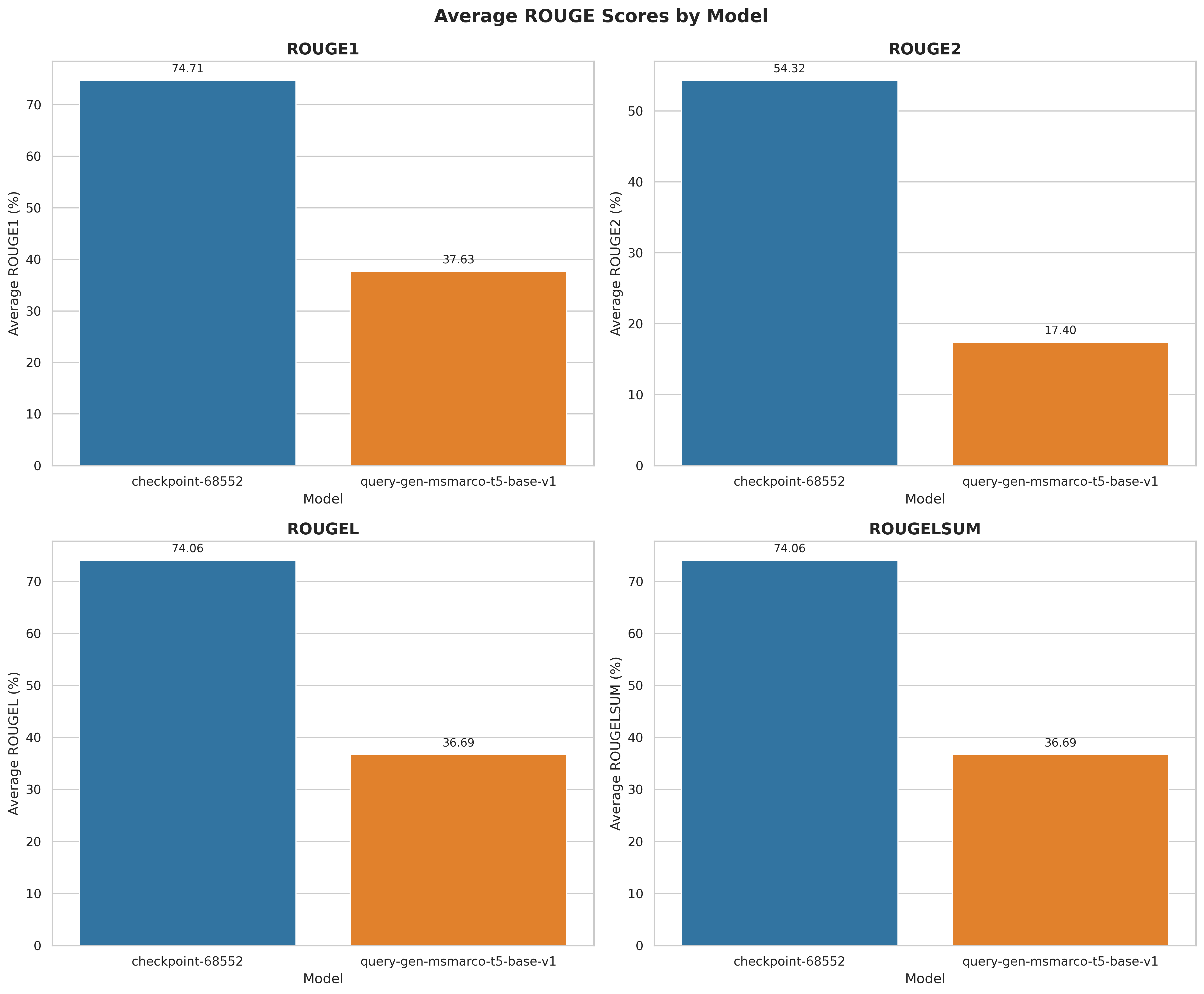 |
The most significant difference is in ROUGE-2, where |
Density comparison
 |
ROUGE-2 has a high density at 0% for the baseline model, meaning many outputs lack bigram overlap. |
Histogram comparison
 |
These histograms confirm |
Scores by generated query length
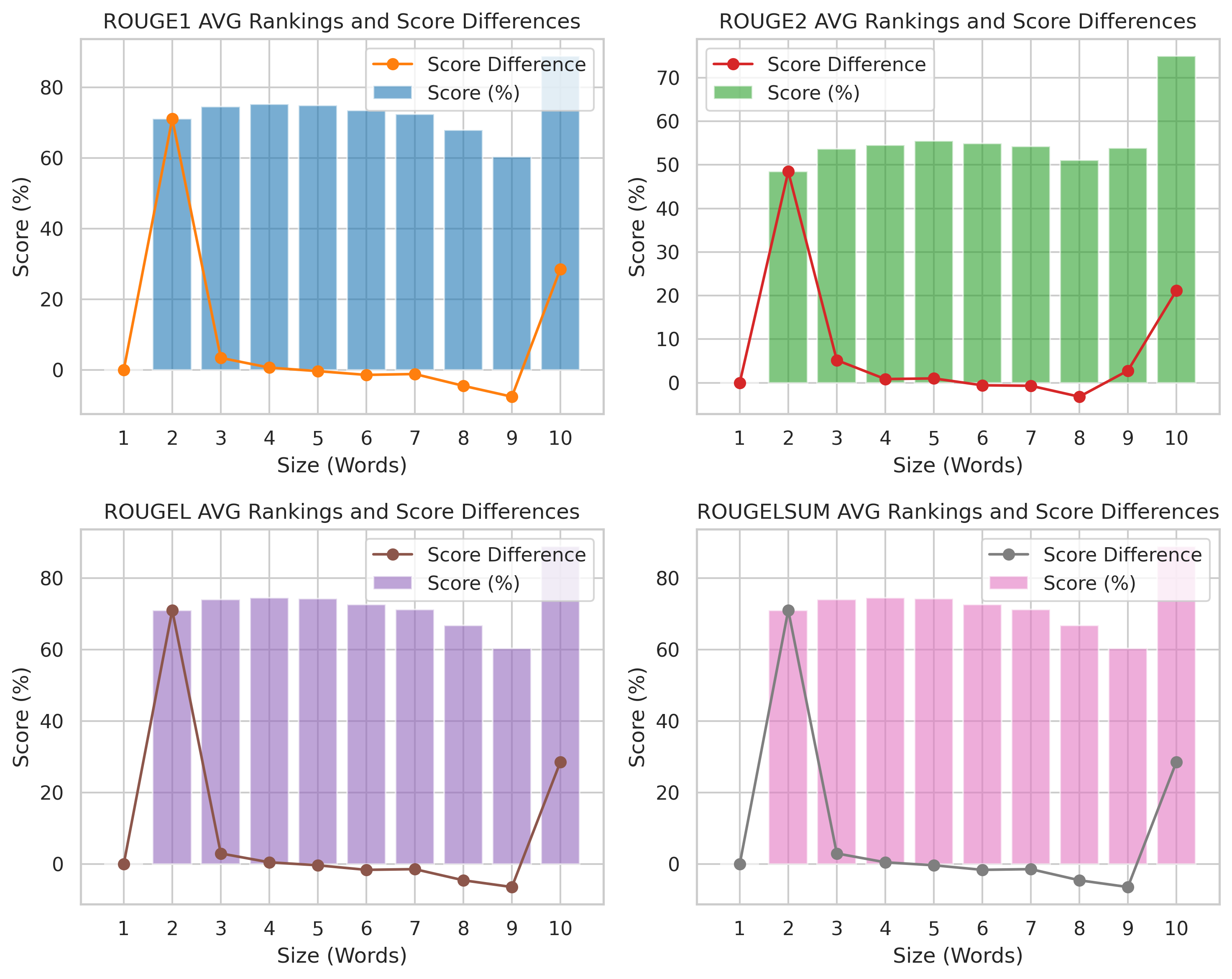 |
Stable ROUGE scores (Sizes 3-9): All metrics remain consistently high.
Score spike at 2 words: Indicates better alignment for short phrases, followed by stability. Score differences remain near zero for most sizes, meaning consistent model performance across phrase lengths. |
Semantic similarity distribution
 |
This histogram visualizes the distribution of cosine similarity scores, which measure the semantic similarity between paired texts (generated query and target query).
A strong peak near 1.0 suggests most pairs are highly semantically similar. Low similarity scores (0.0–0.4) are rare, meaning the dataset contains mostly closely related text pairs. |
Semantic similarity score against ROUGE scores
 |
Higher similarity → Higher ROUGE scores, indicating strong correlation.
ROUGE-1 & ROUGE-L show the strongest alignment, while ROUGE-2 has more variation. Some low-similarity outliers still achieve moderate ROUGE scores, suggesting surface-level overlap without deep semantic alignment. |
More Information
- Please visit the GitHub Repository
Authors
- Mentor: Milutin Studen
- Engineers: Petar Surla, Andjela Radojevic
Model Card Contact
For questions, please open an issue on the GitHub Repository