
Product2Query
Collection
Models for generating realistic user queries from E-commerce product text.
•
5 items
•
Updated
🤖 ✨ 🔍 Generate precise, realistic user-focused search queries from product text 🛒 🚀 📊
| Model | ROUGE-1 | ROUGE-2 | ROUGE-L | ROUGE-Lsum |
|---|---|---|---|---|
| T5-GenQ-T-v1 | 75.2151 | 54.8735 | 74.5142 | 74.5262 |
| T5-GenQ-TD-v1 | 78.2570 | 58.9586 | 77.5308 | 77.5466 |
| T5-GenQ-TDE-v1 | 76.9075 | 57.0980 | 76.1464 | 76.1502 |
| T5-GenQ-TDC-v1 (best) | 80.0754 | 61.5974 | 79.3557 | 79.3427 |
This model is designed to improve e-commerce search functionality by generating user-friendly search queries based on product descriptions. It is particularly suited for applications where product descriptions are the primary input, and the goal is to create concise, descriptive queries that align with user search intent.
| Model | ROUGE-1 | ROUGE-2 | ROUGE-L | ROUGE-Lsum |
|---|---|---|---|---|
| T5-GenQ-TD-v1 | 76.15 | 56.23 | 75.49 | 75.49 |
| query-gen-msmarco-t5-base-v1 | 34.92 | 15.28 | 34.17 | 34.17 |
Note: This evaluation is done after training, based on the test split of the smartcat/Amazon-2023-GenQ dataset.
| Input Text | Target Query | Before Fine-tuning | After Fine-tuning |
|---|---|---|---|
| Dr. Scholl's Women's Trance Slip Resistant Clog Our trance work shoe combines exceptional style and performance. An oil and slip-resistant outsole combined with a molded EVA construction will add layers of safety and comfort. |
Dr. Scholl's Women's Trance Clog | dr scholl trance shoes | Dr. Scholl's Trance Clog |
| Girls Birthday Tutu Skirts Dress with Mermaid Birthday Girl Tshirt, Headband, Satin Sash Girls Mermaid Dress Set with Tshirt, Dress, Headband and sash. |
girls mermaid dress set | what to wear for a mermaid birthday | Girls Mermaid Birthday Dress Set |
| Saucony Women's Omni 15 Running Shoe If we could design shoelaces for pronators, we’d do that too. The omni 15 delivers everything a moderate to severe pronator could need, including enhanced cushioning, exceptional support, flexibility and a smooth, fluid ride. |
Saucony Omni 15 Women's Running Shoe | what shoes are good for pronators | Saucony Omni 15 Running Shoe |
Use the code below to get started with the model.
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
model = AutoModelForSeq2SeqLM.from_pretrained("smartcat/T5-GenQ-TD-v1")
tokenizer = AutoTokenizer.from_pretrained("smartcat/T5-GenQ-TD-v1")
description = "Silver-colored cuff with embossed braid pattern. Made of brass, flexible to fit wrist."
inputs = tokenizer(description, return_tensors="pt", padding=True, truncation=True)
generated_ids = model.generate(inputs["input_ids"], max_length=30, num_beams=4, early_stopping=True)
generated_text = tokenizer.decode(generated_ids[0], skip_special_tokens=True)
The model was trained on the smartcat/Amazon-2023-GenQ dataset, which consists of user-like queries generated from product descriptions. The dataset was created using Claude Haiku 3, incorporating key product attributes such as the title, description, and images to ensure relevant and realistic queries. For more information, read the Dataset Card. 😊
A6000 GPU:
ROUGE, or Recall-Oriented Understudy for Gisting Evaluation, is a set of metrics used for evaluating automatic summarization and machine translation in NLP. The metrics compare an automatically produced summary or translation against a reference or a set of references (human-produced) summary or translation. ROUGE metrics range between 0 and 1, with higher scores indicating higher similarity between the automatically produced summary and the reference.
In our evaluation, ROUGE scores are scaled to resemble percentages for better interpretability. The metric used in the training was ROUGE-L.
| Epoch | Step | Loss | Grad Norm | Learning Rate | Eval Loss | ROUGE-1 | ROUGE-2 | ROUGE-L | ROUGE-Lsum |
|---|---|---|---|---|---|---|---|---|---|
| 1.0 | 4285 | 0.2515 | 1.890405 | 0.000049 | 0.165247 | 76.4578 | 56.4813 | 75.7754 | 75.7835 |
| 2.0 | 8570 | 0.1744 | 1.433518 | 0.000042 | 0.157739 | 77.2138 | 57.4609 | 76.5478 | 76.5589 |
| 3.0 | 12855 | 0.1595 | 1.340541 | 0.000035 | 0.154977 | 77.5761 | 57.9620 | 76.8824 | 76.8854 |
| 4.0 | 17140 | 0.1488 | 1.370982 | 0.000028 | 0.153134 | 77.9366 | 58.5720 | 77.2561 | 77.2692 |
| 5.0 | 21425 | 0.1407 | 1.549360 | 0.000021 | 0.153177 | 78.1102 | 58.7207 | 77.4106 | 77.4241 |
| 6.0 | 25710 | 0.1344 | 1.258538 | 0.000014 | 0.152852 | 78.1691 | 58.8640 | 77.4554 | 77.4651 |
| 7.0 | 29995 | 0.1299 | 1.200458 | 0.000007 | 0.153884 | 78.2001 | 58.8603 | 77.4833 | 77.4984 |
| 8.0 | 34280 | 0.1267 | 1.079393 | 0.000000 | 0.154507 | 78.2570 | 58.9586 | 77.5308 | 77.5466 |
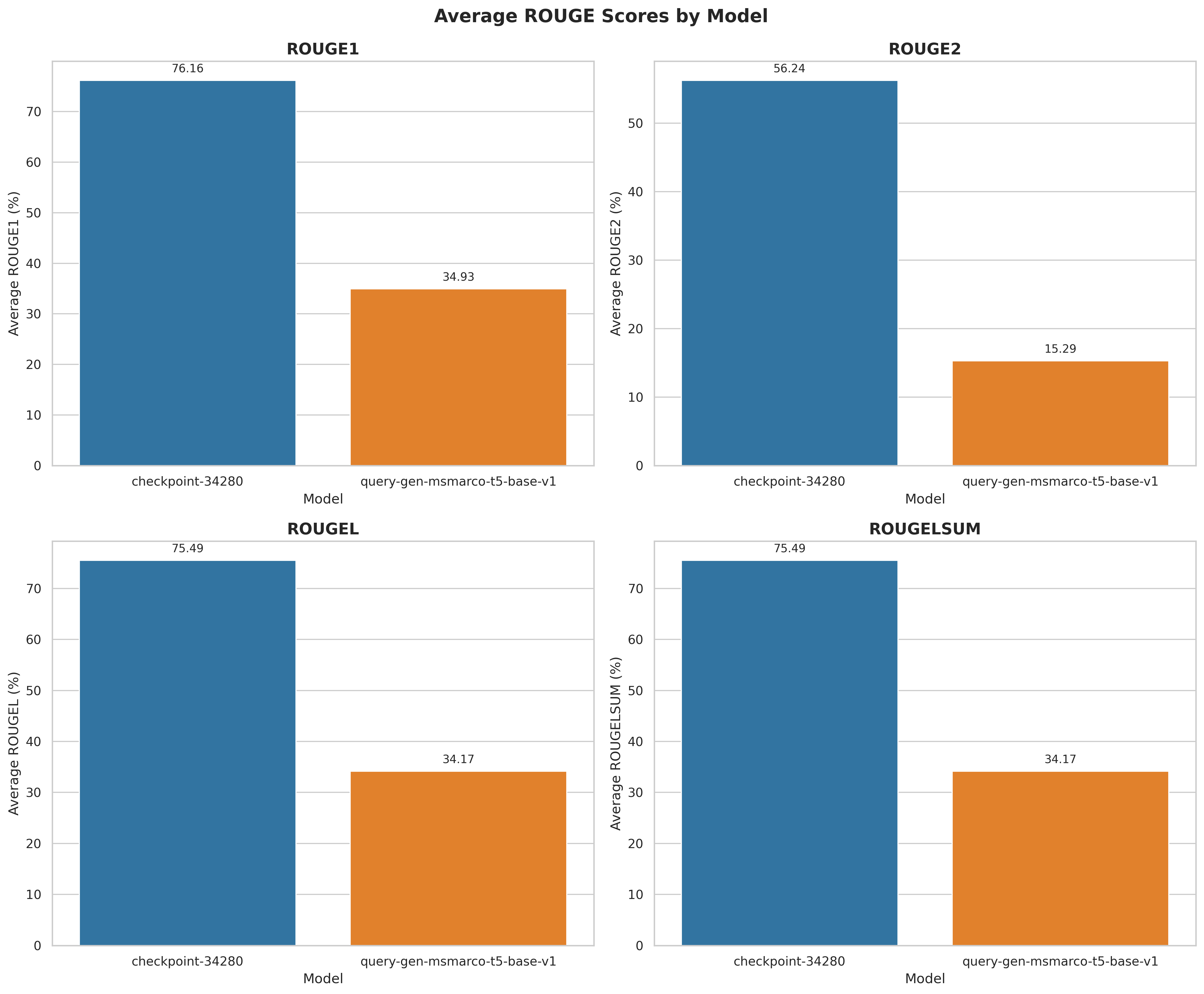 |
The difference is most notable in ROUGE-2, where These results suggest |
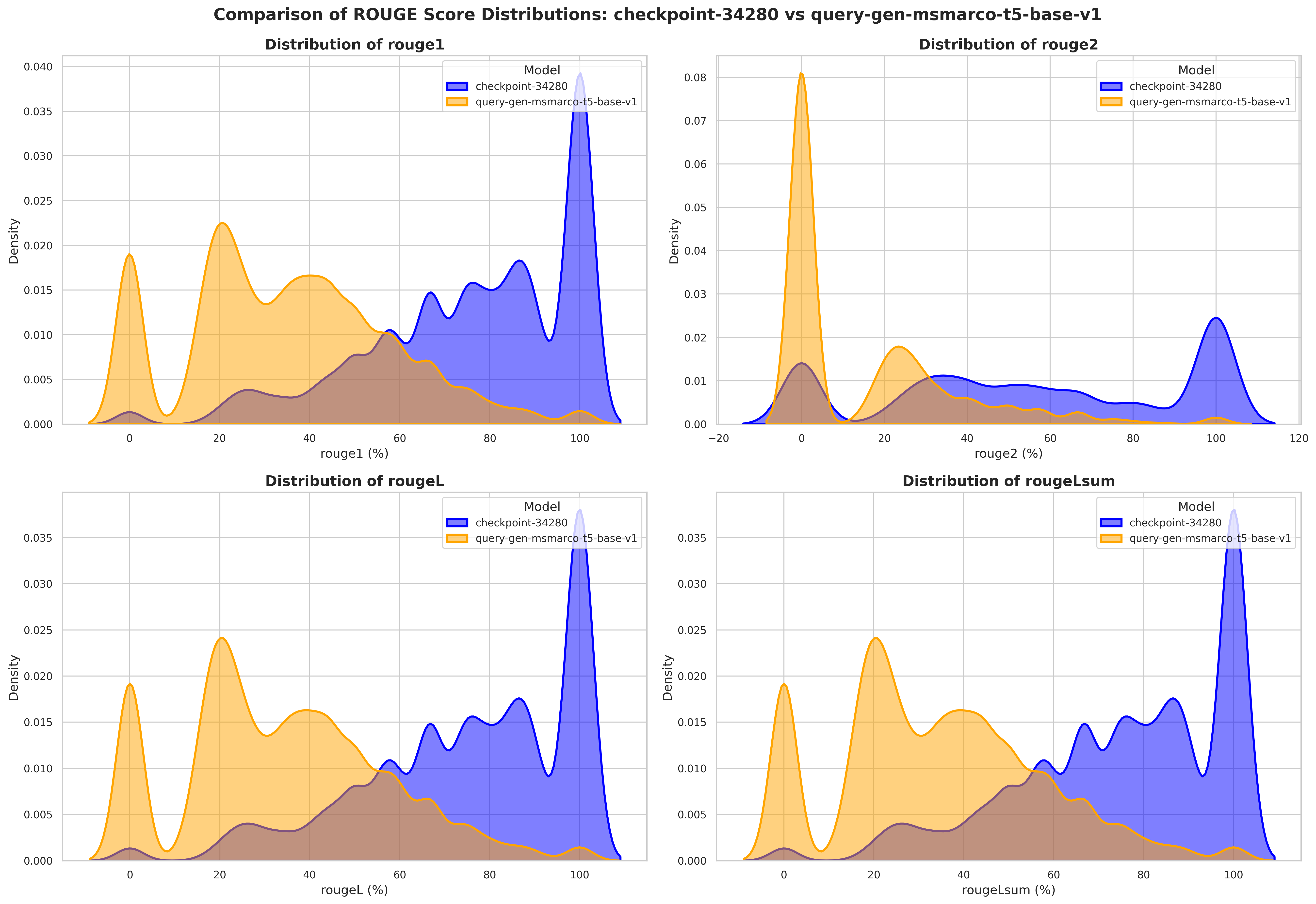 |
ROUGE-2 has a high density at 0% for the baseline model, implying many instances with no bigram overlap. |
 |
These histograms confirm that |
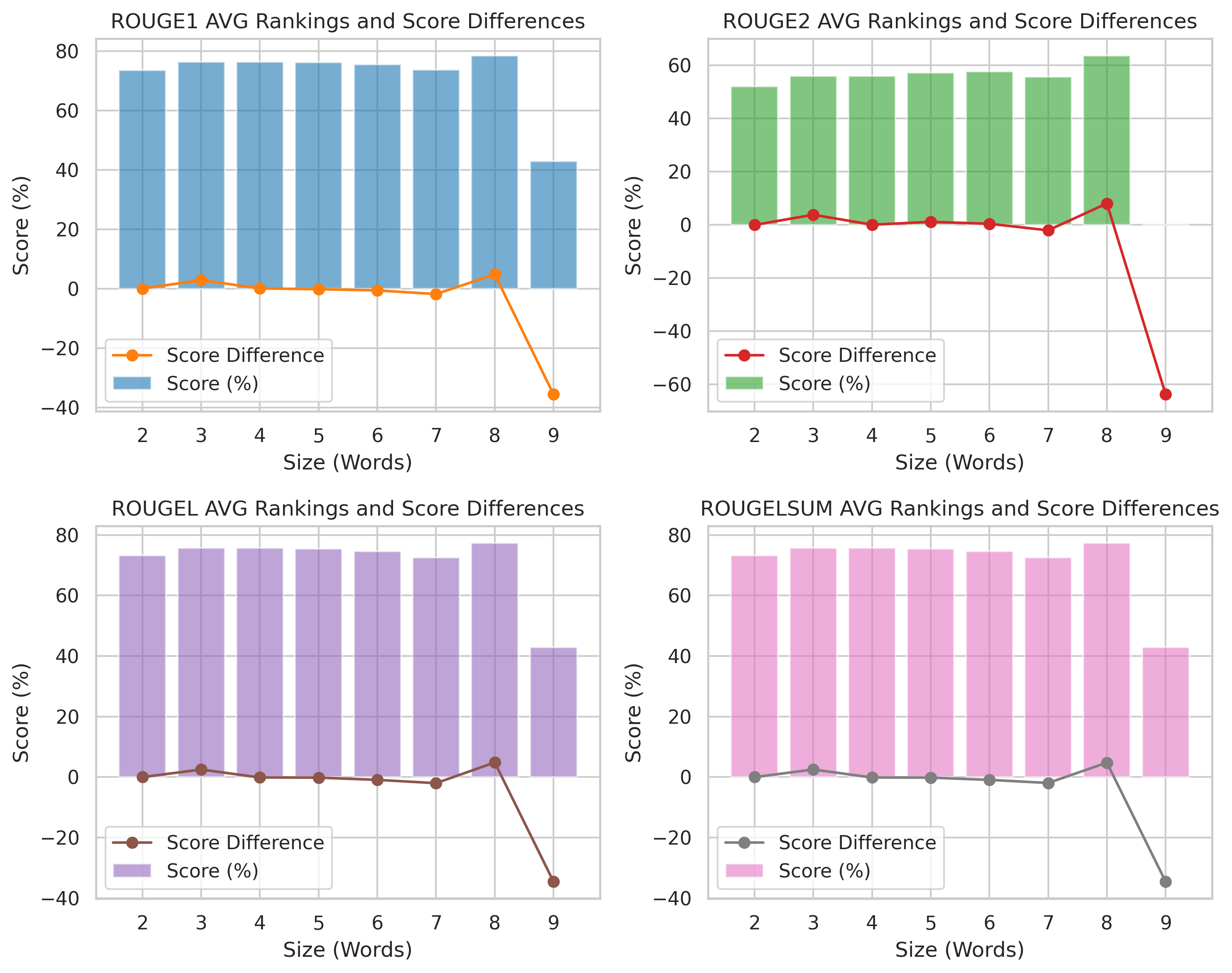 |
This visualization compares average ROUGE scores and score differences across different word sizes.
Consistent ROUGE Scores (Sizes 2-8): ROUGE-1, ROUGE-2, ROUGE-L, and ROUGE-LSUM scores remain high and stable across most word sizes. Sharp Drop at Size 9: A significant decrease in scores occurs for size 9 words, with negative score differences, suggesting longer phrases are less aligned with reference texts. Score Differences Stay Near Zero (Sizes 2-8): Models perform similarly for shorter text spans but diverge at larger word sizes. |
 |
This histogram visualizes the distribution of cosine similarity scores, which measure the semantic similarity between paired texts (generated query and target query).
A strong peak near 1.0 indicates that most pairs are highly semantically similar. Low similarity scores (0.0–0.4) are rare, suggesting the dataset consists mostly of highly related text pairs. |
 |
This scatter plot matrix shows the relationship between semantic similarity (cosine similarity) and ROUGE scores:
Higher similarity → Higher ROUGE scores, indicating a positive correlation. ROUGE-1 & ROUGE-L show the strongest alignment, while ROUGE-2 has greater variance. Some low-similarity outliers still achieve moderate ROUGE scores, suggesting surface-level overlap without deep semantic alignment. This analysis helps understand how semantic similarity aligns with n-gram overlap metrics for evaluating text models. |
For questions, please open an issue on the GitHub Repository
Base model
BeIR/query-gen-msmarco-t5-base-v1