

pipeline_tag: audio-text-to-text
library_name: transformers
license: mit
PyTorch Implementation of Audio Flamingo 2
Sreyan Ghosh, Zhifeng Kong, Sonal Kumar, S Sakshi, Jaehyeon Kim, Wei Ping, Rafael Valle, Dinesh Manocha, Bryan Catanzaro
[paper] [Demo website] [GitHub]
This repo contains the PyTorch implementation of Audio Flamingo 2: An Audio-Language Model with Long-Audio Understanding and Expert Reasoning Abilities. Audio Flamingo 2 achieves state-of-the-art performance across over 20 benchmarks, using only a 3B parameter small language model. It is improved from our previous Audio Flamingo.
We introduce two datasets, AudioSkills for expert audio reasoning, and LongAudio for long audio understanding, to advance the field of audio understanding.
Audio Flamingo 2 has advanced audio understanding and reasoning capabilities. Especially, Audio Flamingo 2 has expert audio reasoning abilities, and can understand long audio up to 5 minutes.
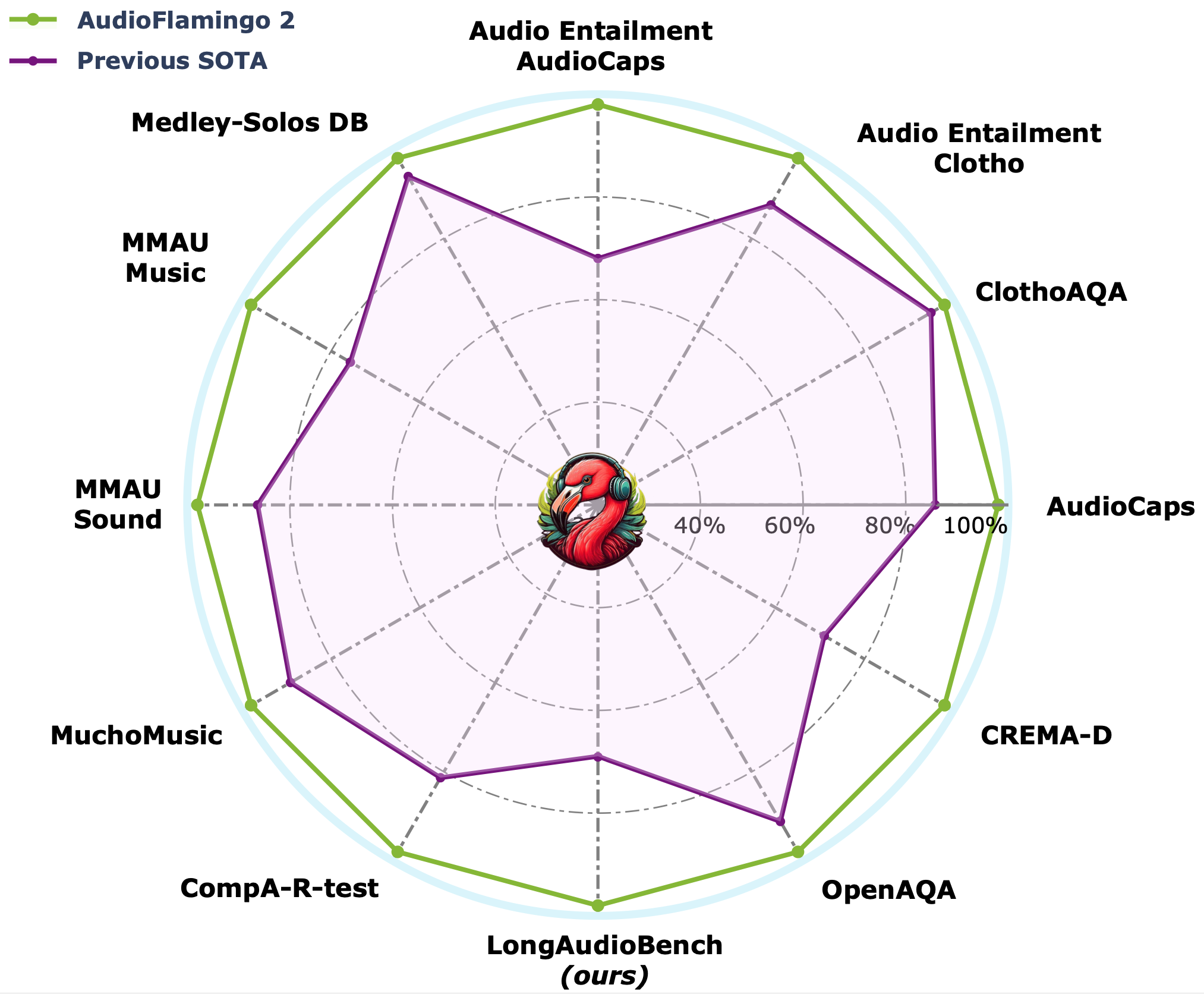
Audio Flamingo 2 outperforms larger and proprietary LALMs across 20+ benchmarks, despite being smaller (3B) and trained exclusively on public datasets.
Main Results
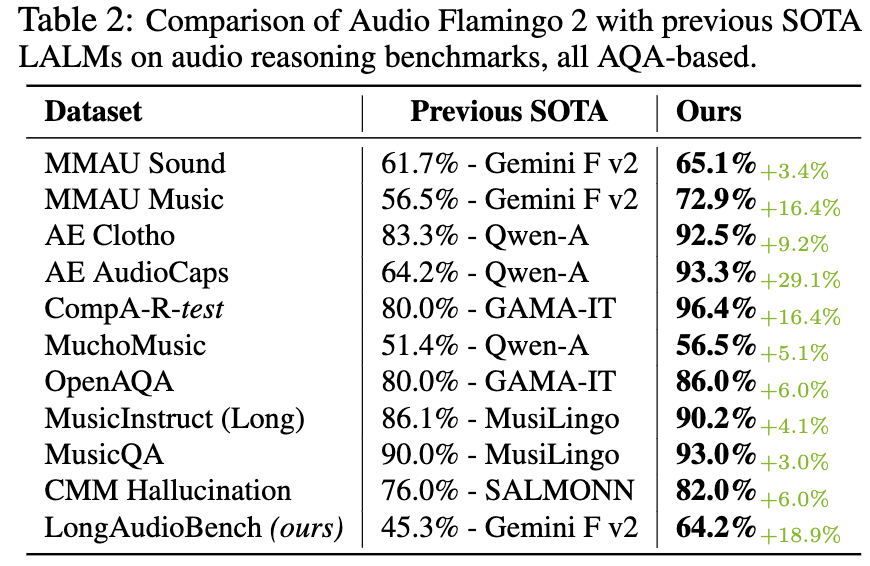
Audio Flamingo 2 outperforms prior SOTA models including GAMA, Audio Flamingo, Qwen-Audio, Qwen2-Audio, LTU, LTU-AS, SALMONN, AudioGPT, Gemini Flash v2, Gemini Pro v1.5, and GPT-4o-audio on a number of understanding and reasoning benchmarks.
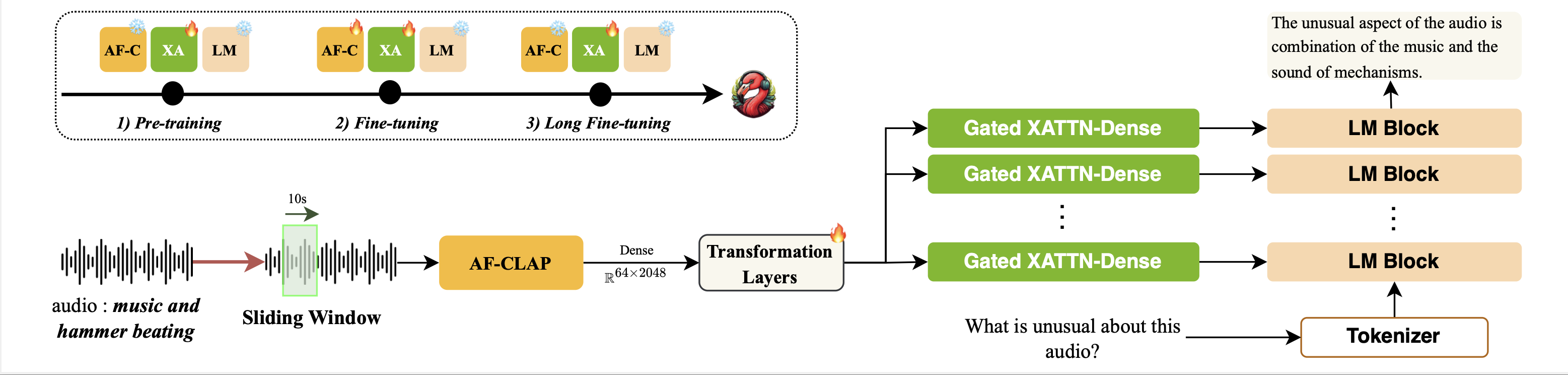
Audio Flamingo 2 Architecture
Audio Flamingo 2 uses a cross-attention architecture similar to Audio Flamingo and Flamingo. Audio Flamingo 2 can take up to 5 minutes of audio inputs.
License
The code in this repo is under MIT license. The checkpoints are for non-commercial use only (see NVIDIA OneWay Noncommercial License). They are also subject to the Qwen Research license, the Terms of Use of the data generated by OpenAI, and the original licenses accompanying each training dataset.
- Notice: Audio Flamingo 2 is built with Qwen-2.5. Qwen is licensed under the Qwen RESEARCH LICENSE AGREEMENT, Copyright (c) Alibaba Cloud. All Rights Reserved.
Citation
- Audio Flamingo
@inproceedings{kong2024audio,
title={Audio Flamingo: A Novel Audio Language Model with Few-Shot Learning and Dialogue Abilities},
author={Kong, Zhifeng and Goel, Arushi and Badlani, Rohan and Ping, Wei and Valle, Rafael and Catanzaro, Bryan},
booktitle={International Conference on Machine Learning},
pages={25125--25148},
year={2024},
organization={PMLR}
}
- Audio Flamingo 2
@article{ghosh2025audio,
title={Audio Flamingo 2: An Audio-Language Model with Long-Audio Understanding and Expert Reasoning Abilities},
author={Ghosh, Sreyan and Kong, Zhifeng and Kumar, Sonal and Sakshi, S and Kim, Jaehyeon and Ping, Wei and Valle, Rafael and Manocha, Dinesh and Catanzaro, Bryan},
journal={arXiv preprint arXiv:2503.03983},
year={2025}
}