
RAGulator-deberta-v3-large
This is the out-of-context detection model from our work:
RAGulator: Lightweight Out-of-Context Detectors for Grounded Text Generation
This repository contains model files for the deberta-v3-large variant of RAGulator. Code can be found here.
Key Points
- RAGulator predicts whether a sentence is out-of-context (OOC) from retrieved text documents in a RAG setting.
- We preprocess a combination of summarisation and semantic textual similarity datasets (STS) to construct training data using minimal resources.
- We demonstrate 2 types of trained models: tree-based meta-models trained on features engineered on preprocessed text, and BERT-based classifiers fine-tuned directly on original text.
- We find that fine-tuned DeBERTa is not only the best-performing model under this pipeline, but it is also fast and does not require additional text preprocessing or feature engineering.
Model Details
Dataset
Training data for RAGulator is adapted from a combination of summarisation and STS datasets to simulate RAG:
The datasets were transformed before concatenation into the final dataset. Each row of the final dataset consists [sentence, context, OOC label].
- For summarisation datasets, transformation was done by randomly pairing summary abstracts with unrelated articles to create OOC pairs, then sentencizing the abstracts to create one example for each abstract sentence.
- For STS datasets, transformation was done by inserting random sentences from the datasets to one of the sentences in the pair to simulate a long "context". The original labels were mapped to our OOC definition. If the original pair was indicated as dissimilar, we consider the pair as OOC.
To enable training of BERT-based classifiers, each training example was split into sub-sequences of maximum 512 tokens. The OOC label for each sub-sequence was derived through a generative labelling process with Llama-3.1-70b-Instruct.
Model Training
RAGulator is fine-tuned from microsoft/deberta-v3-large (He et al., 2023).
Model Performance
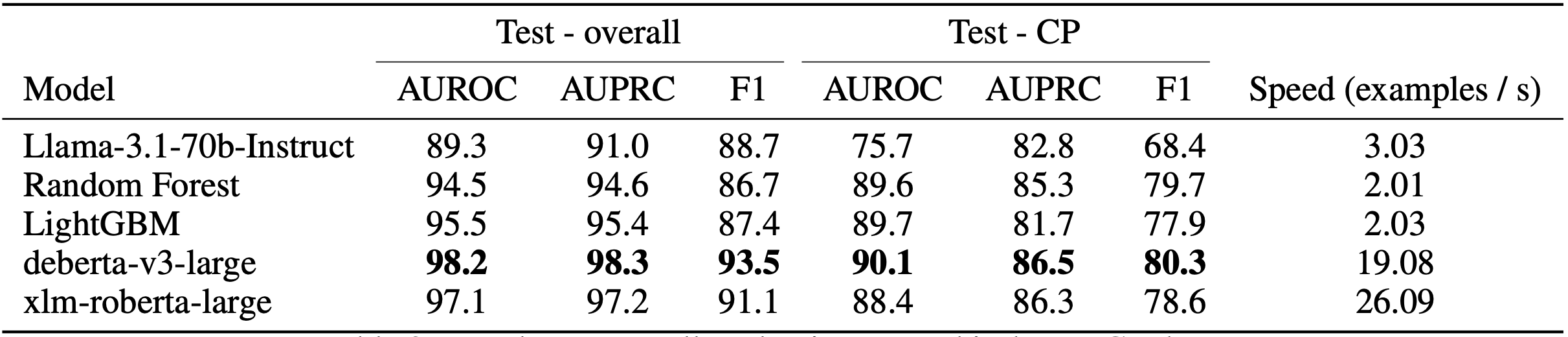
We compare our models to LLM-as-a-judge (Llama-3.1-70b-Instruct) as a baseline. We evaluate on both a held-out data split of our simulated RAG dataset, as well as an out-of-distribution collection of private enterprise data, which consists of RAG responses from a real use case.
The deberta-v3-large variant is our best-performing model, showing a 19% increase in AUROC and a 17% increase in F1 score despite being significantly smaller than Llama-3.1.
Basic Usage
import torch
from transformers import DebertaV2Tokenizer, DebertaV2ForSequenceClassification
model_path = "./ragulator-deberta-v3-large" # assuming model folder located here
tokenizer = DebertaV2Tokenizer.from_pretrained(model_path)
model = DebertaV2ForSequenceClassification.from_pretrained(
model_path,
num_labels=2
)
model.eval()
# input
sentences = ["This is the first sentence", "This is the second sentence"]
contexts = ["This is the first context", "This is the second context"]
inputs = tokenizer(
sentences,
contexts,
add_special_tokens=True,
return_token_type_ids=True,
return_attention_mask=True,
padding='max_length',
max_length=512,
truncation='longest_first',
return_tensors='pt'
)
# forward pass
with torch.no_grad():
outputs = self.model(**inputs)
# OOC score
fn = torch.nn.Softmax(dim=-1)
ooc_scores = fn(outputs.logits).cpu().numpy()[:,1]
Usage - batch and long-context inference
We provide a simple wrapper to demonstrate batch inference and accommodation for long-context examples. First, install the package:
pip install "ragulator @ git+https://github.com/ipoeyke/RAGulator.git@main"
from ragulator import RAGulator
model = RAGulator(
model_name='deberta-v3-large', # only value supported for now
batch_size=32,
device='cpu'
)
# input
sentences = ["This is the first sentence", "This is the second sentence"]
contexts = ["This is the first context", "This is the second context"]
# batch inference
model.infer_batch(
sentences,
contexts,
return_probas=True # True for OOC probabilities, False for binary labels
)
Citation
@misc{poey2024ragulatorlightweightoutofcontextdetectors,
title={RAGulator: Lightweight Out-of-Context Detectors for Grounded Text Generation},
author={Ian Poey and Jiajun Liu and Qishuai Zhong and Adrien Chenailler},
year={2024},
eprint={2411.03920},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2411.03920},
}
- Downloads last month
- 10