
Add files using upload-large-folder tool
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +7 -0
- .history/datasets/__init___20241227174300.py +37 -0
- .history/datasets/ytvos_ref_20250113130043.py +0 -0
- .history/datasets/ytvos_ref_20250116073805.py +239 -0
- .history/mbench/gpt_ref-ytvos-cy_20250121155719.py +428 -0
- .history/mbench/gpt_ref-ytvos_20250119070039.py +277 -0
- .history/mbench/gpt_ref-ytvos_20250119070740.py +285 -0
- .history/mbench/gpt_ref-ytvos_20250119071412.py +292 -0
- .history/mbench/gpt_ref-ytvos_20250119072601.py +292 -0
- .history/mbench/gpt_ref-ytvos_20250119073047.py +292 -0
- .history/mbench/gpt_ref-ytvos_numbered_cy_20250131124149.py +427 -0
- .history/mbench/gpt_ref-ytvos_numbered_cy_20250201141952.py +460 -0
- .history/mbench/gpt_ref-ytvos_numbered_cy_20250202183102.py +460 -0
- .history/mbench/gpt_ref-ytvos_numbered_cy_sanity_2_20250207172804.py +656 -0
- .history/mbench/gpt_ref-ytvos_numbered_cy_sanity_2_20250207173210.py +656 -0
- .history/mbench/gpt_ref-ytvos_numbered_cy_sanity_2_20250207173355.py +677 -0
- .history/mbench/make_ref-ytvos_json_20250117032501.py +104 -0
- .history/mbench/make_ref-ytvos_json_20250117072314.py +107 -0
- .history/mbench_a2d/gpt_a2d_numbered_20250206114207.py +205 -0
- __pycache__/opts.cpython-310.pyc +0 -0
- __pycache__/opts.cpython-39.pyc +0 -0
- __pycache__/refer.cpython-39.pyc +0 -0
- davis2017/davis.py +122 -0
- docs/davis_demo1.gif +3 -0
- docs/davis_demo2.gif +3 -0
- docs/install.md +42 -0
- docs/network.png +3 -0
- docs/ytvos_demo1.gif +3 -0
- docs/ytvos_demo2.gif +3 -0
- hf_cache/.locks/models--zhiqiulin--clip-flant5-xxl/e14a3254bf04f32056759bdc60c64736e7638f31b43957586ff2442ff393890a.lock +0 -0
- hf_cache/models--zhiqiulin--clip-flant5-xxl/snapshots/89bad6fffe1126b24d4360c1e1f69145eb6103aa/pytorch_model-00002-of-00003.bin +3 -0
- make_ref-ytvos/manual_selection.ipynb +381 -0
- make_refcoco/refcocog_google/multi_object_data_gref_google.json +0 -0
- make_refcoco/refcocog_google/needrevision_refid_part4.json +506 -0
- make_refcoco/refcocog_umd/needrevision_refid_part4.json +498 -0
- mbench/__pycache__/__init__.cpython-310.pyc +0 -0
- mbench/__pycache__/ytvos_ref.cpython-310.pyc +0 -0
- mbench/check_image_numbered_cy.ipynb +0 -0
- mbench/check_image_numbered_cy_score.py +212 -0
- mbench/gpt_ref-ytvos-cy.ipynb +0 -0
- mbench/gpt_ref-ytvos-revised.ipynb +0 -0
- mbench/gpt_ref-ytvos_numbered.ipynb +3 -0
- mbench/gpt_ref-ytvos_numbered_cy.ipynb +0 -0
- mbench/numbered_captions.json +0 -0
- mbench/numbered_captions_gpt-4o.json +0 -0
- mbench/numbered_captions_gpt-4o_nomask_randcap2.json +0 -0
- mbench/numbered_valid_obj_ids_gpt-4o_final.json +0 -0
- mbench/numbered_valid_obj_ids_gpt-4o_nomask_randcap2.json +2153 -0
- mbench/sampled_frame.json +3 -0
- mbench/sampled_frame2.json +0 -0
.gitattributes
CHANGED
|
@@ -47,3 +47,10 @@ LAVT-RIS/refer/data/refcocog/refs(google).p filter=lfs diff=lfs merge=lfs -text
|
|
| 47 |
LAVT-RIS/refer/data/refcocog/refs(umd).p filter=lfs diff=lfs merge=lfs -text
|
| 48 |
LAVT-RIS/refer/evaluation/tokenizer/stanford-corenlp-3.4.1.jar filter=lfs diff=lfs merge=lfs -text
|
| 49 |
hf_cache/models--zhiqiulin--clip-flant5-xxl/blobs/12acb5074c883dcab3e166d86d20130615ff83b0d26736ee046f4184202ebd3b filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 47 |
LAVT-RIS/refer/data/refcocog/refs(umd).p filter=lfs diff=lfs merge=lfs -text
|
| 48 |
LAVT-RIS/refer/evaluation/tokenizer/stanford-corenlp-3.4.1.jar filter=lfs diff=lfs merge=lfs -text
|
| 49 |
hf_cache/models--zhiqiulin--clip-flant5-xxl/blobs/12acb5074c883dcab3e166d86d20130615ff83b0d26736ee046f4184202ebd3b filter=lfs diff=lfs merge=lfs -text
|
| 50 |
+
docs/davis_demo2.gif filter=lfs diff=lfs merge=lfs -text
|
| 51 |
+
mbench/gpt_ref-ytvos_numbered.ipynb filter=lfs diff=lfs merge=lfs -text
|
| 52 |
+
docs/ytvos_demo2.gif filter=lfs diff=lfs merge=lfs -text
|
| 53 |
+
mbench/sampled_frame.json filter=lfs diff=lfs merge=lfs -text
|
| 54 |
+
docs/network.png filter=lfs diff=lfs merge=lfs -text
|
| 55 |
+
docs/ytvos_demo1.gif filter=lfs diff=lfs merge=lfs -text
|
| 56 |
+
docs/davis_demo1.gif filter=lfs diff=lfs merge=lfs -text
|
.history/datasets/__init___20241227174300.py
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch.utils.data
|
| 2 |
+
import torchvision
|
| 3 |
+
|
| 4 |
+
from .ytvos import build as build_ytvos
|
| 5 |
+
from .davis import build as build_davis
|
| 6 |
+
from .a2d import build as build_a2d
|
| 7 |
+
from .jhmdb import build as build_jhmdb
|
| 8 |
+
from .refexp import build as build_refexp
|
| 9 |
+
from .concat_dataset import build as build_joint
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def get_coco_api_from_dataset(dataset):
|
| 13 |
+
for _ in range(10):
|
| 14 |
+
# if isinstance(dataset, torchvision.datasets.CocoDetection):
|
| 15 |
+
# break
|
| 16 |
+
if isinstance(dataset, torch.utils.data.Subset):
|
| 17 |
+
dataset = dataset.dataset
|
| 18 |
+
if isinstance(dataset, torchvision.datasets.CocoDetection):
|
| 19 |
+
return dataset.coco
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def build_dataset(dataset_file: str, image_set: str, args):
|
| 23 |
+
if dataset_file == 'ytvos':
|
| 24 |
+
return build_ytvos(image_set, args)
|
| 25 |
+
if dataset_file == 'davis':
|
| 26 |
+
return build_davis(image_set, args)
|
| 27 |
+
if dataset_file == 'a2d':
|
| 28 |
+
return build_a2d(image_set, args)
|
| 29 |
+
if dataset_file == 'jhmdb':
|
| 30 |
+
return build_jhmdb(image_set, args)
|
| 31 |
+
# for pretraining
|
| 32 |
+
if dataset_file == "refcoco" or dataset_file == "refcoco+" or dataset_file == "refcocog":
|
| 33 |
+
return build_refexp(dataset_file, image_set, args)
|
| 34 |
+
# for joint training of refcoco and ytvos
|
| 35 |
+
if dataset_file == 'joint':
|
| 36 |
+
return build_joint(image_set, args)
|
| 37 |
+
raise ValueError(f'dataset {dataset_file} not supported')
|
.history/datasets/ytvos_ref_20250113130043.py
ADDED
|
File without changes
|
.history/datasets/ytvos_ref_20250116073805.py
ADDED
|
@@ -0,0 +1,239 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Ref-YoutubeVOS data loader
|
| 3 |
+
"""
|
| 4 |
+
from pathlib import Path
|
| 5 |
+
|
| 6 |
+
import torch
|
| 7 |
+
from torch.autograd.grad_mode import F
|
| 8 |
+
from torch.utils.data import Dataset
|
| 9 |
+
import datasets.transforms_video as T
|
| 10 |
+
|
| 11 |
+
import os
|
| 12 |
+
from PIL import Image
|
| 13 |
+
import json
|
| 14 |
+
import numpy as np
|
| 15 |
+
import random
|
| 16 |
+
|
| 17 |
+
from datasets.categories import ytvos_category_dict as category_dict
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
class YTVOSDataset(Dataset):
|
| 21 |
+
"""
|
| 22 |
+
A dataset class for the Refer-Youtube-VOS dataset which was first introduced in the paper:
|
| 23 |
+
"URVOS: Unified Referring Video Object Segmentation Network with a Large-Scale Benchmark"
|
| 24 |
+
(see https://link.springer.com/content/pdf/10.1007/978-3-030-58555-6_13.pdf).
|
| 25 |
+
The original release of the dataset contained both 'first-frame' and 'full-video' expressions. However, the first
|
| 26 |
+
dataset is not publicly available anymore as now only the harder 'full-video' subset is available to download
|
| 27 |
+
through the Youtube-VOS referring video object segmentation competition page at:
|
| 28 |
+
https://competitions.codalab.org/competitions/29139
|
| 29 |
+
Furthermore, for the competition the subset's original validation set, which consists of 507 videos, was split into
|
| 30 |
+
two competition 'validation' & 'test' subsets, consisting of 202 and 305 videos respectively. Evaluation can
|
| 31 |
+
currently only be done on the competition 'validation' subset using the competition's server, as
|
| 32 |
+
annotations were publicly released only for the 'train' subset of the competition.
|
| 33 |
+
|
| 34 |
+
"""
|
| 35 |
+
def __init__(self, img_folder: Path, ann_file: Path, transforms, return_masks: bool,
|
| 36 |
+
num_frames: int, max_skip: int):
|
| 37 |
+
self.img_folder = img_folder
|
| 38 |
+
self.ann_file = ann_file
|
| 39 |
+
self._transforms = transforms
|
| 40 |
+
self.return_masks = return_masks # not used
|
| 41 |
+
self.num_frames = num_frames
|
| 42 |
+
self.max_skip = max_skip
|
| 43 |
+
# create video meta data
|
| 44 |
+
self.prepare_metas()
|
| 45 |
+
|
| 46 |
+
print('\n video num: ', len(self.videos), ' clip num: ', len(self.metas))
|
| 47 |
+
print('\n')
|
| 48 |
+
|
| 49 |
+
def prepare_metas(self):
|
| 50 |
+
# read object information
|
| 51 |
+
with open(os.path.join(str(self.img_folder), 'meta.json'), 'r') as f:
|
| 52 |
+
subset_metas_by_video = json.load(f)['videos']
|
| 53 |
+
|
| 54 |
+
# read expression data
|
| 55 |
+
with open(str(self.ann_file), 'r') as f:
|
| 56 |
+
subset_expressions_by_video = json.load(f)['videos']
|
| 57 |
+
self.videos = list(subset_expressions_by_video.keys())
|
| 58 |
+
|
| 59 |
+
self.metas = []
|
| 60 |
+
skip_vid_count = 0
|
| 61 |
+
|
| 62 |
+
for vid in self.videos:
|
| 63 |
+
vid_meta = subset_metas_by_video[vid]
|
| 64 |
+
vid_data = subset_expressions_by_video[vid]
|
| 65 |
+
vid_frames = sorted(vid_data['frames'])
|
| 66 |
+
vid_len = len(vid_frames)
|
| 67 |
+
|
| 68 |
+
if vid_len < 11:
|
| 69 |
+
#print(f"Too short video: {vid} with frame length {vid_len}")
|
| 70 |
+
skip_vid_count += 1
|
| 71 |
+
continue
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
# Exclude start_idx (0, 1) and end_idx (vid_len-1, vid_len-2)
|
| 75 |
+
start_idx , end_idx = 2, vid_len-2
|
| 76 |
+
bin_size = (end_idx - start_idx) // 4
|
| 77 |
+
|
| 78 |
+
bins = []
|
| 79 |
+
for i in range(4):
|
| 80 |
+
bin_start = start_idx + i * bin_size
|
| 81 |
+
bin_end = bin_start + bin_size if i < 3 else end_idx
|
| 82 |
+
|
| 83 |
+
bins.append((bin_start, bin_end))
|
| 84 |
+
|
| 85 |
+
# Random sample one frame from each bin
|
| 86 |
+
sample_indx = []
|
| 87 |
+
for start_idx, end_idx in bins:
|
| 88 |
+
sample_indx.append(random.randint(start_idx, end_idx - 1))
|
| 89 |
+
sample_indx.sort() # Ensure indices are in order
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
meta = {
|
| 93 |
+
'video':vid,
|
| 94 |
+
'sample_indx':sample_indx,
|
| 95 |
+
'bins':bins,
|
| 96 |
+
'frames':vid_frames
|
| 97 |
+
}
|
| 98 |
+
obj_id_cat = {}
|
| 99 |
+
for exp_id, exp_dict in vid_data['expressions'].items():
|
| 100 |
+
obj_id = exp_dict['obj_id']
|
| 101 |
+
if obj_id not in obj_id_cat:
|
| 102 |
+
obj_id_cat[obj_id] = vid_meta['objects'][obj_id]['category']
|
| 103 |
+
meta['obj_id_cat'] = obj_id_cat
|
| 104 |
+
self.metas.append(meta)
|
| 105 |
+
|
| 106 |
+
print(f"skipped {skip_vid_count} short videos")
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
@staticmethod
|
| 110 |
+
def bounding_box(img):
|
| 111 |
+
rows = np.any(img, axis=1)
|
| 112 |
+
cols = np.any(img, axis=0)
|
| 113 |
+
rmin, rmax = np.where(rows)[0][[0, -1]]
|
| 114 |
+
cmin, cmax = np.where(cols)[0][[0, -1]]
|
| 115 |
+
return rmin, rmax, cmin, cmax # y1, y2, x1, x2
|
| 116 |
+
|
| 117 |
+
def __len__(self):
|
| 118 |
+
return len(self.metas)
|
| 119 |
+
|
| 120 |
+
def __getitem__(self, idx):
|
| 121 |
+
meta = self.metas[idx] # dict
|
| 122 |
+
|
| 123 |
+
video, sample_indx, bins, frames, obj_id_cat = \
|
| 124 |
+
meta['video'], meta['sample_indx'], meta['bins'], meta['frames'], meta['obj_id_cat']
|
| 125 |
+
|
| 126 |
+
# read frames and masks
|
| 127 |
+
imgs, labels, boxes, masks, valid = [], [], [], [], []
|
| 128 |
+
for frame_indx in sample_indx:
|
| 129 |
+
frame_name = frames[frame_indx]
|
| 130 |
+
img_path = os.path.join(str(self.img_folder), 'JPEGImages', video, frame_name + '.jpg')
|
| 131 |
+
mask_path = os.path.join(str(self.img_folder), 'Annotations', video, frame_name + '.png')
|
| 132 |
+
img = Image.open(img_path).convert('RGB')
|
| 133 |
+
imgs.append(img)
|
| 134 |
+
|
| 135 |
+
mask = Image.open(mask_path).convert('P')
|
| 136 |
+
mask = np.array(mask)
|
| 137 |
+
|
| 138 |
+
# create the target
|
| 139 |
+
for obj_id in list(obj_id_cat.keys()):
|
| 140 |
+
obj_mask = (mask==int(obj_id)).astype(np.float32) # 0,1 binary
|
| 141 |
+
if (obj_mask > 0).any():
|
| 142 |
+
y1, y2, x1, x2 = self.bounding_box(mask)
|
| 143 |
+
box = torch.tensor([x1, y1, x2, y2]).to(torch.float)
|
| 144 |
+
valid.append(1)
|
| 145 |
+
else: # some frame didn't contain the instance
|
| 146 |
+
box = torch.tensor([0, 0, 0, 0]).to(torch.float)
|
| 147 |
+
valid.append(0)
|
| 148 |
+
obj_mask = torch.from_numpy(obj_mask)
|
| 149 |
+
|
| 150 |
+
# append
|
| 151 |
+
masks.append(obj_mask)
|
| 152 |
+
boxes.append(box)
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
# transform
|
| 156 |
+
w, h = img.size
|
| 157 |
+
boxes = torch.stack(boxes, dim=0)
|
| 158 |
+
boxes[:, 0::2].clamp_(min=0, max=w)
|
| 159 |
+
boxes[:, 1::2].clamp_(min=0, max=h)
|
| 160 |
+
masks = torch.stack(masks, dim=0)
|
| 161 |
+
target = {
|
| 162 |
+
'frames_idx': sample_indx, # [T,]
|
| 163 |
+
'boxes': boxes, # [T, 4], xyxy
|
| 164 |
+
'masks': masks, # [T, H, W]
|
| 165 |
+
'valid': torch.tensor(valid), # [T,]
|
| 166 |
+
'obj_ids' : list(obj_id_cat.keys()),
|
| 167 |
+
'orig_size': torch.as_tensor([int(h), int(w)]),
|
| 168 |
+
'size': torch.as_tensor([int(h), int(w)])
|
| 169 |
+
}
|
| 170 |
+
|
| 171 |
+
# "boxes" normalize to [0, 1] and transform from xyxy to cxcywh in self._transform
|
| 172 |
+
if self._transforms:
|
| 173 |
+
imgs, target = self._transforms(imgs, target)
|
| 174 |
+
imgs = torch.stack(imgs, dim=0) # [T, 3, H, W]
|
| 175 |
+
else:
|
| 176 |
+
imgs = np.array(imgs)
|
| 177 |
+
imgs = torch.tensor(imgs.transpose(0, 3, 1, 2))
|
| 178 |
+
|
| 179 |
+
|
| 180 |
+
# # FIXME: handle "valid", since some box may be removed due to random crop
|
| 181 |
+
# if torch.any(target['valid'] == 1): # at leatst one instance
|
| 182 |
+
# instance_check = True
|
| 183 |
+
# else:
|
| 184 |
+
# idx = random.randint(0, self.__len__() - 1)
|
| 185 |
+
|
| 186 |
+
return imgs, target
|
| 187 |
+
|
| 188 |
+
|
| 189 |
+
def make_coco_transforms(image_set, max_size=640):
|
| 190 |
+
normalize = T.Compose([
|
| 191 |
+
T.ToTensor(),
|
| 192 |
+
T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
|
| 193 |
+
])
|
| 194 |
+
|
| 195 |
+
scales = [288, 320, 352, 392, 416, 448, 480, 512]
|
| 196 |
+
|
| 197 |
+
if image_set == 'train':
|
| 198 |
+
return T.Compose([
|
| 199 |
+
T.RandomHorizontalFlip(),
|
| 200 |
+
T.PhotometricDistort(),
|
| 201 |
+
T.RandomSelect(
|
| 202 |
+
T.Compose([
|
| 203 |
+
T.RandomResize(scales, max_size=max_size),
|
| 204 |
+
T.Check(),
|
| 205 |
+
]),
|
| 206 |
+
T.Compose([
|
| 207 |
+
T.RandomResize([400, 500, 600]),
|
| 208 |
+
T.RandomSizeCrop(384, 600),
|
| 209 |
+
T.RandomResize(scales, max_size=max_size),
|
| 210 |
+
T.Check(),
|
| 211 |
+
])
|
| 212 |
+
),
|
| 213 |
+
normalize,
|
| 214 |
+
])
|
| 215 |
+
|
| 216 |
+
# we do not use the 'val' set since the annotations are inaccessible
|
| 217 |
+
if image_set == 'val':
|
| 218 |
+
return T.Compose([
|
| 219 |
+
T.RandomResize([360], max_size=640),
|
| 220 |
+
normalize,
|
| 221 |
+
])
|
| 222 |
+
|
| 223 |
+
raise ValueError(f'unknown {image_set}')
|
| 224 |
+
|
| 225 |
+
|
| 226 |
+
def build(image_set, args):
|
| 227 |
+
root = Path(args.ytvos_path)
|
| 228 |
+
assert root.exists(), f'provided YTVOS path {root} does not exist'
|
| 229 |
+
PATHS = {
|
| 230 |
+
"train": (root / "train", root / "meta_expressions" / "train" / "meta_expressions.json"),
|
| 231 |
+
"val": (root / "valid", root / "meta_expressions" / "valid" / "meta_expressions.json"), # not used actually
|
| 232 |
+
}
|
| 233 |
+
img_folder, ann_file = PATHS[image_set]
|
| 234 |
+
# dataset = YTVOSDataset(img_folder, ann_file, transforms=make_coco_transforms(image_set, max_size=args.max_size), return_masks=args.masks,
|
| 235 |
+
# num_frames=args.num_frames, max_skip=args.max_skip)
|
| 236 |
+
dataset = YTVOSDataset(img_folder, ann_file, transforms=None, return_masks=args.masks,
|
| 237 |
+
num_frames=args.num_frames, max_skip=args.max_skip)
|
| 238 |
+
return dataset
|
| 239 |
+
|
.history/mbench/gpt_ref-ytvos-cy_20250121155719.py
ADDED
|
@@ -0,0 +1,428 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import sys
|
| 2 |
+
from os import path as osp
|
| 3 |
+
sys.path.append(osp.abspath(osp.join(osp.dirname(__file__), '..')))
|
| 4 |
+
|
| 5 |
+
from mbench.ytvos_ref import build as build_ytvos_ref
|
| 6 |
+
import argparse
|
| 7 |
+
import opts
|
| 8 |
+
|
| 9 |
+
import sys
|
| 10 |
+
from pathlib import Path
|
| 11 |
+
import os
|
| 12 |
+
from os import path as osp
|
| 13 |
+
import skimage
|
| 14 |
+
from io import BytesIO
|
| 15 |
+
|
| 16 |
+
import numpy as np
|
| 17 |
+
import pandas as pd
|
| 18 |
+
import regex as re
|
| 19 |
+
import json
|
| 20 |
+
|
| 21 |
+
import cv2
|
| 22 |
+
from PIL import Image, ImageDraw
|
| 23 |
+
import torch
|
| 24 |
+
from torchvision.transforms import functional as F
|
| 25 |
+
|
| 26 |
+
from skimage import measure # (pip install scikit-image)
|
| 27 |
+
from shapely.geometry import Polygon, MultiPolygon # (pip install Shapely)
|
| 28 |
+
|
| 29 |
+
import matplotlib.pyplot as plt
|
| 30 |
+
import matplotlib.patches as patches
|
| 31 |
+
from matplotlib.collections import PatchCollection
|
| 32 |
+
from matplotlib.patches import Rectangle
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
import ipywidgets as widgets
|
| 36 |
+
from IPython.display import display, clear_output
|
| 37 |
+
|
| 38 |
+
from openai import OpenAI
|
| 39 |
+
import base64
|
| 40 |
+
|
| 41 |
+
# Function to encode the image
|
| 42 |
+
def encode_image(image_path):
|
| 43 |
+
with open(image_path, "rb") as image_file:
|
| 44 |
+
return base64.b64encode(image_file.read()).decode("utf-8")
|
| 45 |
+
|
| 46 |
+
# Captioner
|
| 47 |
+
ytvos_category_valid_list = [
|
| 48 |
+
'airplane', 'ape', 'bear', 'bike', 'bird', 'boat', 'bus', 'camel', 'cat', 'cow', 'crocodile',
|
| 49 |
+
'deer', 'dog', 'dolphin', 'duck', 'eagle', 'earless_seal', 'elephant', 'fish', 'fox', 'frog',
|
| 50 |
+
'giant_panda', 'giraffe', 'hedgehog', 'horse', 'leopard', 'lion', 'lizard',
|
| 51 |
+
'monkey', 'motorbike', 'mouse', 'owl', 'parrot', 'penguin', 'person',
|
| 52 |
+
'rabbit', 'raccoon', 'sedan', 'shark', 'sheep', 'snail', 'snake',
|
| 53 |
+
'squirrel', 'tiger', 'train', 'truck', 'turtle', 'whale', 'zebra'
|
| 54 |
+
]
|
| 55 |
+
def getCaption(video_id, json_data):
|
| 56 |
+
#데이터 가져오기
|
| 57 |
+
video_data = json_data[video_id]
|
| 58 |
+
frame_names = video_data['frame_names']
|
| 59 |
+
video_path = video_data['video_path']
|
| 60 |
+
|
| 61 |
+
cat_names = set()
|
| 62 |
+
all_captions = dict()
|
| 63 |
+
for obj_id in list(video_data['annotations'][0].keys()):
|
| 64 |
+
cat_names.add(video_data['annotations'][0][obj_id]['category_name'])
|
| 65 |
+
|
| 66 |
+
# cat_names : person, snowboard
|
| 67 |
+
# 1. gpt에서 직접 action의 대상이 될 수 있는가 물어보기
|
| 68 |
+
# 2. ref-youtube-vos 에서 제공하는 카테고리 정보에서 우리가 처리하고 싶은 카테고리 이름만 남긴다
|
| 69 |
+
|
| 70 |
+
for cat_name in list(cat_names) :
|
| 71 |
+
image_paths = [os.path.join(video_path, frame_name + '.jpg') for frame_name in frame_names]
|
| 72 |
+
image_captions = {}
|
| 73 |
+
|
| 74 |
+
captioner = OpenAI()
|
| 75 |
+
|
| 76 |
+
#0단계: action의 대상이 될 수 있는가?
|
| 77 |
+
is_movable = False
|
| 78 |
+
if cat_name in ytvos_category_valid_list :
|
| 79 |
+
is_movable = True
|
| 80 |
+
|
| 81 |
+
# response_check = captioner.chat.completions.create(
|
| 82 |
+
# model="gpt-4o",
|
| 83 |
+
# messages=[
|
| 84 |
+
# {
|
| 85 |
+
# "role": "user",
|
| 86 |
+
# "content": f"""
|
| 87 |
+
# Can a {cat_name} be a subject of distinct actions or movements?
|
| 88 |
+
# For example, if {cat_name} is a person, animal, or vehicle, it is likely an action-capable subject.
|
| 89 |
+
# However, if it is an inanimate object like a snowboard, tree, or book, it cannot independently perform actions.
|
| 90 |
+
# Respond with YES if {cat_name} can perform distinct actions or movements; otherwise, respond with NONE.
|
| 91 |
+
# Answer only YES or NONE.
|
| 92 |
+
# """
|
| 93 |
+
# }
|
| 94 |
+
# ],
|
| 95 |
+
# )
|
| 96 |
+
# response_check_content = response_check.choices[0].message.content.strip().lower()
|
| 97 |
+
# print(f"Movable Check for {cat_name}: {response_check_content}")
|
| 98 |
+
|
| 99 |
+
# if response_check_content == "yes": is_movable = True
|
| 100 |
+
|
| 101 |
+
if not is_movable:
|
| 102 |
+
print(f"Skipping {cat_name}: Determined to be non-movable.")
|
| 103 |
+
continue
|
| 104 |
+
|
| 105 |
+
for i in range(len(image_paths)):
|
| 106 |
+
image_path = image_paths[i]
|
| 107 |
+
frame_name = frame_names[i]
|
| 108 |
+
base64_image = encode_image(image_path)
|
| 109 |
+
|
| 110 |
+
#1단계: 필터링
|
| 111 |
+
#print(f"-----------category name: {cat_name}, frame name: {frame_name}")
|
| 112 |
+
response1 = captioner.chat.completions.create(
|
| 113 |
+
model="chatgpt-4o-latest",
|
| 114 |
+
messages=[
|
| 115 |
+
{
|
| 116 |
+
"role": "user",
|
| 117 |
+
"content": [
|
| 118 |
+
{
|
| 119 |
+
"type": "text",
|
| 120 |
+
|
| 121 |
+
"text": f"""Are there multiple {cat_name}s in the image, each performing distinct and recognizable actions?
|
| 122 |
+
Focus only on clear and prominent actions, avoiding minor or ambiguous ones.
|
| 123 |
+
Each action should be unique and clearly associated with a specific object.
|
| 124 |
+
|
| 125 |
+
Respond with YES if:
|
| 126 |
+
- The {cat_name}s are people, animals or vehicles, and their actions are distinct and recognizable.
|
| 127 |
+
- The {cat_name}s involve clear, distinguishable actions performed independently.
|
| 128 |
+
|
| 129 |
+
Respond with NONE if:
|
| 130 |
+
- The {cat_name}s are objects (e.g., snowboard, tree, books) and do not involve direct interaction with a person.
|
| 131 |
+
- Actions are ambiguous, minor, or not clearly visible.
|
| 132 |
+
|
| 133 |
+
If the {cat_name} is 'snowboard' and it is not actively being used or interacted with by a person, output NONE.
|
| 134 |
+
If the {cat_name} is 'person' and their actions are distinct and clear, output YES.
|
| 135 |
+
|
| 136 |
+
Answer only YES or NONE."""
|
| 137 |
+
|
| 138 |
+
},
|
| 139 |
+
{
|
| 140 |
+
"type": "image_url",
|
| 141 |
+
"image_url": {"url": f"data:image/jpeg;base64,{base64_image}"},
|
| 142 |
+
},
|
| 143 |
+
],
|
| 144 |
+
}
|
| 145 |
+
],
|
| 146 |
+
)
|
| 147 |
+
response_content = response1.choices[0].message.content
|
| 148 |
+
should_caption = True if "yes" in response_content.lower() else False
|
| 149 |
+
#print(f"are {cat_name}s distinguished by action: {response_content}")
|
| 150 |
+
|
| 151 |
+
#2단계: dense caption 만들기
|
| 152 |
+
if should_caption:
|
| 153 |
+
response2 = captioner.chat.completions.create(
|
| 154 |
+
model="chatgpt-4o-latest",
|
| 155 |
+
messages=[
|
| 156 |
+
{
|
| 157 |
+
"role": "user",
|
| 158 |
+
"content": [
|
| 159 |
+
{
|
| 160 |
+
"type": "text",
|
| 161 |
+
|
| 162 |
+
"text": f"""
|
| 163 |
+
Generate a detailed action-centric caption describing the actions of the {cat_name}s in the image.
|
| 164 |
+
1. Focus only on clear, unique, and prominent actions that distinguish each object.
|
| 165 |
+
2. Avoid describing actions that are too minor, ambiguous, or not visible from the image.
|
| 166 |
+
3. Avoid subjective terms such as 'skilled', 'controlled', or 'focused'. Only describe observable actions.
|
| 167 |
+
4. Do not include common-sense or overly general descriptions like 'the elephant walks'.
|
| 168 |
+
5. Use dynamic action verbs (e.g., holding, throwing, jumping, inspecting) to describe interactions, poses, or movements.
|
| 169 |
+
6. Avoid overly detailed or speculative descriptions such as 'slightly moving its mouth' or 'appears to be anticipating'.
|
| 170 |
+
7. Pretend you are observing the scene directly, avoiding phrases like 'it seems' or 'based on the description'.
|
| 171 |
+
8. Include interactions with objects or other entities when they are prominent and observable.
|
| 172 |
+
9. If the image contains multiple {cat_name}s, describe the actions of each individually and ensure the descriptions are non-overlapping and specific.
|
| 173 |
+
Output only the caption.""",
|
| 174 |
+
},
|
| 175 |
+
{
|
| 176 |
+
"type": "image_url",
|
| 177 |
+
"image_url": {"url": f"data:image/jpeg;base64,{base64_image}"},
|
| 178 |
+
},
|
| 179 |
+
],
|
| 180 |
+
}
|
| 181 |
+
],
|
| 182 |
+
)
|
| 183 |
+
|
| 184 |
+
caption = response2.choices[0].message.content
|
| 185 |
+
#print(f"{image_path} - {frame_name}: {caption}")
|
| 186 |
+
else:
|
| 187 |
+
caption = None
|
| 188 |
+
|
| 189 |
+
image_captions[frame_name] = caption
|
| 190 |
+
all_captions[cat_name] = image_captions
|
| 191 |
+
|
| 192 |
+
# final : also prepare valid object ids
|
| 193 |
+
valid_obj_ids = []
|
| 194 |
+
valid_cat_names = list(all_captions.keys())
|
| 195 |
+
for obj_id in list(video_data['annotations'][0].keys()):
|
| 196 |
+
cat = video_data['annotations'][0][obj_id]['category_name']
|
| 197 |
+
if cat in valid_cat_names : valid_obj_ids.append(obj_id)
|
| 198 |
+
|
| 199 |
+
return all_captions, valid_obj_ids
|
| 200 |
+
|
| 201 |
+
# Referring expression generator and QA filter
|
| 202 |
+
def getRefExp(video_id, frame_name, caption, obj_id, json_data):
|
| 203 |
+
|
| 204 |
+
# 이미지에 해당 물체 바운딩 박스 그리기
|
| 205 |
+
video_data = json_data[video_id]
|
| 206 |
+
frame_names = video_data['frame_names']
|
| 207 |
+
video_path = video_data['video_path']
|
| 208 |
+
I = skimage.io.imread(osp.join(video_path, frame_name + '.jpg'))
|
| 209 |
+
frame_indx = frame_names.index(frame_name)
|
| 210 |
+
obj_data = video_data['annotations'][frame_indx][obj_id]
|
| 211 |
+
|
| 212 |
+
bbox = obj_data['bbox']
|
| 213 |
+
cat_name = obj_data['category_name']
|
| 214 |
+
valid = obj_data['valid']
|
| 215 |
+
|
| 216 |
+
if valid == 0:
|
| 217 |
+
print("Object not in this frame!")
|
| 218 |
+
return {}
|
| 219 |
+
|
| 220 |
+
|
| 221 |
+
x_min, y_min, x_max, y_max = bbox
|
| 222 |
+
x_min, y_min, x_max, y_max = int(x_min), int(y_min), int(x_max), int(y_max)
|
| 223 |
+
cv2.rectangle(I, (x_min, y_min), (x_max, y_max), (225, 0, 0), 2)
|
| 224 |
+
plt.figure()
|
| 225 |
+
plt.imshow(I)
|
| 226 |
+
plt.axis('off')
|
| 227 |
+
plt.show()
|
| 228 |
+
|
| 229 |
+
#cropped object for visibility check
|
| 230 |
+
cropped_I = I[y_min:y_max, x_min:x_max]
|
| 231 |
+
pil_cropped_I = Image.fromarray(cropped_I)
|
| 232 |
+
buff_crop = BytesIO()
|
| 233 |
+
pil_cropped_I.save(buff_crop, format='JPEG')
|
| 234 |
+
base64_cropped_I = base64.b64encode(buff_crop.getvalue()).decode("utf-8")
|
| 235 |
+
|
| 236 |
+
#entire image for referring expression generation
|
| 237 |
+
pil_I = Image.fromarray(I)
|
| 238 |
+
buff = BytesIO()
|
| 239 |
+
pil_I.save(buff, format='JPEG')
|
| 240 |
+
base64_I = base64.b64encode(buff.getvalue()).decode("utf-8")
|
| 241 |
+
|
| 242 |
+
# 구분 가능 여부 확인
|
| 243 |
+
generator = OpenAI()
|
| 244 |
+
response_check = generator.chat.completions.create(
|
| 245 |
+
model="chatgpt-4o-latest",
|
| 246 |
+
messages=[
|
| 247 |
+
{
|
| 248 |
+
"role": "user",
|
| 249 |
+
"content": [
|
| 250 |
+
{
|
| 251 |
+
|
| 252 |
+
"type": "text",
|
| 253 |
+
"text": f"""Can the {cat_name} in the provided cropped image be clearly identified as belonging to the category {cat_name}?
|
| 254 |
+
Focus on whether the cropped image provides enough visible features (e.g., ears, head shape, fur texture) to confirm that it is a {cat_name}, even if the full body is not visible.
|
| 255 |
+
|
| 256 |
+
Guidelines:
|
| 257 |
+
- If the visible features (like ears, fur texture or head shape) are sufficient to identify the {cat_name}, respond with YES.
|
| 258 |
+
- If multiple {cat_name}s are entangled or overlapping, making it difficult to distinguish one from another, respond with NONE.
|
| 259 |
+
- If the object is clearly visible and identifiable as a {cat_name}, respond with YES.
|
| 260 |
+
|
| 261 |
+
Output only either YES or NONE.
|
| 262 |
+
"""
|
| 263 |
+
},
|
| 264 |
+
{
|
| 265 |
+
"type": "image_url",
|
| 266 |
+
"image_url": {"url": f"data:image/jpeg;base64,{base64_cropped_I}"},
|
| 267 |
+
}
|
| 268 |
+
]
|
| 269 |
+
},
|
| 270 |
+
]
|
| 271 |
+
)
|
| 272 |
+
|
| 273 |
+
response_check_content = response_check.choices[0].message.content.strip().lower()
|
| 274 |
+
#print(f"is object {obj_id} visible: {response_check_content}")
|
| 275 |
+
|
| 276 |
+
if "yes" not in response_check_content:
|
| 277 |
+
print(f"Referring expression not generated: {cat_name} is ambiguous in this frame.")
|
| 278 |
+
return {"ref_exp": "NONE", "caption": caption, "cat_name": cat_name, "file_name": frame_name, "isValid" : False}
|
| 279 |
+
|
| 280 |
+
# Referring expression 만들기
|
| 281 |
+
# generator = OpenAI()
|
| 282 |
+
response = generator.chat.completions.create(
|
| 283 |
+
model="chatgpt-4o-latest",
|
| 284 |
+
messages=[
|
| 285 |
+
{
|
| 286 |
+
"role": "user",
|
| 287 |
+
"content": [
|
| 288 |
+
{
|
| 289 |
+
"type": "text",
|
| 290 |
+
|
| 291 |
+
"text": f"""Based on the dense caption, create a referring expression for the {cat_name} highlighted with the red box, corresponding to Object ID {obj_id}.
|
| 292 |
+
Guidelines for creating the referring expression:
|
| 293 |
+
1. The referring expression should describe the prominent actions or poses of the highlighted {cat_name} (Object ID {obj_id}).
|
| 294 |
+
2. Focus on the behavior or pose described in the caption that is specifically associated with this {cat_name}. Do not include actions or poses of other {cat_name}s.
|
| 295 |
+
3. If multiple {cat_name}s are present, ensure that the referring expression exclusively describes the {cat_name} corresponding to Object ID {obj_id}.
|
| 296 |
+
4. Avoid ambiguous or subjective terms. Use specific and clear action verbs to describe the highlighted {cat_name}.
|
| 297 |
+
5. The referring expression should only describe Object ID {obj_id} and not any other objects or entities.
|
| 298 |
+
6. Use '{cat_name}' as the noun for the referring expressions.
|
| 299 |
+
Output only the referring expression for the highlighted {cat_name} (Object ID {obj_id}).
|
| 300 |
+
|
| 301 |
+
{caption}
|
| 302 |
+
"""
|
| 303 |
+
},
|
| 304 |
+
{
|
| 305 |
+
"type": "image_url",
|
| 306 |
+
"image_url": {"url": f"data:image/jpeg;base64,{base64_I}"},
|
| 307 |
+
},
|
| 308 |
+
# {
|
| 309 |
+
# "type": "image_url",
|
| 310 |
+
# "image_url": {"url": f"data:image/jpeg;base64,{base64_cropped_I}"},
|
| 311 |
+
# }
|
| 312 |
+
],
|
| 313 |
+
}
|
| 314 |
+
],
|
| 315 |
+
)
|
| 316 |
+
|
| 317 |
+
ref_exp = response.choices[0].message.content.strip()
|
| 318 |
+
|
| 319 |
+
#QA filtering
|
| 320 |
+
#QA1: 원하는 물체를 설명하는지
|
| 321 |
+
filter = OpenAI()
|
| 322 |
+
response1 = filter.chat.completions.create(
|
| 323 |
+
model="chatgpt-4o-latest",
|
| 324 |
+
messages=[
|
| 325 |
+
{
|
| 326 |
+
"role": "user",
|
| 327 |
+
"content": [
|
| 328 |
+
{
|
| 329 |
+
"type": "text",
|
| 330 |
+
"text": f"""Does the given expression describe the {cat_name} highlighted with the red box? If so, only return YES and if not, NO.
|
| 331 |
+
{ref_exp}""",
|
| 332 |
+
},
|
| 333 |
+
{
|
| 334 |
+
"type": "image_url",
|
| 335 |
+
"image_url": {"url": f"data:image/jpeg;base64,{base64_I}"},
|
| 336 |
+
},
|
| 337 |
+
],
|
| 338 |
+
}
|
| 339 |
+
],
|
| 340 |
+
)
|
| 341 |
+
|
| 342 |
+
response1_content = response1.choices[0].message.content
|
| 343 |
+
describesHighlighted = True if "yes" in response1_content.lower() else False
|
| 344 |
+
|
| 345 |
+
#QA2: 원하지 않는 물체를 설명하지 않는지
|
| 346 |
+
response2 = filter.chat.completions.create(
|
| 347 |
+
model="chatgpt-4o-latest",
|
| 348 |
+
messages=[
|
| 349 |
+
{
|
| 350 |
+
"role": "user",
|
| 351 |
+
"content": [
|
| 352 |
+
{
|
| 353 |
+
"type": "text",
|
| 354 |
+
"text": f"""Does the given expression describe the person not highlighted with the red box? If so, only return YES and if not, NO.
|
| 355 |
+
{ref_exp}""",
|
| 356 |
+
},
|
| 357 |
+
{
|
| 358 |
+
"type": "image_url",
|
| 359 |
+
"image_url": {"url": f"data:image/jpeg;base64,{base64_I}"},
|
| 360 |
+
},
|
| 361 |
+
],
|
| 362 |
+
}
|
| 363 |
+
],
|
| 364 |
+
)
|
| 365 |
+
|
| 366 |
+
response2_content = response2.choices[0].message.content
|
| 367 |
+
notDescribesNotHighlighted = False if "yes" in response2_content.lower() else True
|
| 368 |
+
|
| 369 |
+
isValid = True if describesHighlighted and notDescribesNotHighlighted else False
|
| 370 |
+
|
| 371 |
+
#print(f"describesHighlighted: {describesHighlighted}, notDescribesNotHighlighted: {notDescribesNotHighlighted}")
|
| 372 |
+
#print(f"ref exp: {ref_exp}")
|
| 373 |
+
#print("")
|
| 374 |
+
|
| 375 |
+
return {"ref_exp": ref_exp, "caption": caption, "cat_name": cat_name, "file_name": frame_name, "isValid" : isValid}
|
| 376 |
+
|
| 377 |
+
|
| 378 |
+
if __name__ == '__main__':
|
| 379 |
+
with open('mbench/sampled_frame3.json', 'r') as file:
|
| 380 |
+
data = json.load(file)
|
| 381 |
+
|
| 382 |
+
vid_ids = list(data.keys())
|
| 383 |
+
all_ref_exps = {}
|
| 384 |
+
|
| 385 |
+
os.environ['OPENAI_API_KEY'] = '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'
|
| 386 |
+
|
| 387 |
+
# 전체 데이터셋의 vid_id에 대해
|
| 388 |
+
for i in range(1):
|
| 389 |
+
vid_id = vid_ids[i]
|
| 390 |
+
|
| 391 |
+
#====캡션 만들기====
|
| 392 |
+
# print("=====================captioner========================")
|
| 393 |
+
captions, valid_obj_ids = getCaption(vid_id, data)
|
| 394 |
+
cats_in_vid = list(captions.keys())
|
| 395 |
+
# print()
|
| 396 |
+
|
| 397 |
+
#====referring expression 만들고 QA filtering====
|
| 398 |
+
# print("=====================referring expression generator & QA filter========================")
|
| 399 |
+
ref_expressions = {}
|
| 400 |
+
|
| 401 |
+
# 각 카테고리별로
|
| 402 |
+
for cat_name in cats_in_vid:
|
| 403 |
+
if cat_name not in ref_expressions:
|
| 404 |
+
ref_expressions[cat_name] = {}
|
| 405 |
+
# 각 비디오 프레임 별로
|
| 406 |
+
for frame_name in data[vid_id]['frame_names']:
|
| 407 |
+
# print(f'--------category: {cat_name}, frame_name: {frame_name}')
|
| 408 |
+
|
| 409 |
+
if frame_name not in ref_expressions[cat_name]:
|
| 410 |
+
ref_expressions[cat_name][frame_name] = {} # Create frame-level dictionary
|
| 411 |
+
caption = captions[cat_name][frame_name]
|
| 412 |
+
if not caption : continue
|
| 413 |
+
else :
|
| 414 |
+
# 각 obj id별로
|
| 415 |
+
for obj_id in valid_obj_ids:
|
| 416 |
+
ref_exp = getRefExp(vid_id, frame_name, caption, obj_id, data)
|
| 417 |
+
ref_expressions[cat_name][frame_name][obj_id] = ref_exp # Store ref_exp
|
| 418 |
+
|
| 419 |
+
all_ref_exps[vid_id] = ref_expressions
|
| 420 |
+
|
| 421 |
+
|
| 422 |
+
with open('mbench/result_revised.json', 'w') as file:
|
| 423 |
+
json.dump(all_ref_exps, file, indent=4)
|
| 424 |
+
|
| 425 |
+
|
| 426 |
+
|
| 427 |
+
|
| 428 |
+
|
.history/mbench/gpt_ref-ytvos_20250119070039.py
ADDED
|
@@ -0,0 +1,277 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from datasets import build_dataset
|
| 2 |
+
import argparse
|
| 3 |
+
import opts
|
| 4 |
+
|
| 5 |
+
import sys
|
| 6 |
+
from pathlib import Path
|
| 7 |
+
import os
|
| 8 |
+
from os import path as osp
|
| 9 |
+
import skimage
|
| 10 |
+
from io import BytesIO
|
| 11 |
+
|
| 12 |
+
import numpy as np
|
| 13 |
+
import pandas as pd
|
| 14 |
+
import regex as re
|
| 15 |
+
import json
|
| 16 |
+
|
| 17 |
+
import cv2
|
| 18 |
+
from PIL import Image, ImageDraw
|
| 19 |
+
import torch
|
| 20 |
+
from torchvision.transforms import functional as F
|
| 21 |
+
|
| 22 |
+
from skimage import measure # (pip install scikit-image)
|
| 23 |
+
from shapely.geometry import Polygon, MultiPolygon # (pip install Shapely)
|
| 24 |
+
|
| 25 |
+
import matplotlib.pyplot as plt
|
| 26 |
+
import matplotlib.patches as patches
|
| 27 |
+
from matplotlib.collections import PatchCollection
|
| 28 |
+
from matplotlib.patches import Rectangle
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
import ipywidgets as widgets
|
| 32 |
+
from IPython.display import display, clear_output
|
| 33 |
+
|
| 34 |
+
from openai import OpenAI
|
| 35 |
+
import base64
|
| 36 |
+
|
| 37 |
+
os.environ['OPENAI_API_KEY'] = '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'
|
| 38 |
+
|
| 39 |
+
# Function to encode the image
|
| 40 |
+
def encode_image(image_path):
|
| 41 |
+
with open(image_path, "rb") as image_file:
|
| 42 |
+
return base64.b64encode(image_file.read()).decode("utf-8")
|
| 43 |
+
|
| 44 |
+
def getCaption(video_id, json_data):
|
| 45 |
+
#데이터 가져오기
|
| 46 |
+
video_data = json_data[video_id]
|
| 47 |
+
frame_names = video_data['frame_names']
|
| 48 |
+
video_path = video_data['video_path']
|
| 49 |
+
|
| 50 |
+
cat_names = set()
|
| 51 |
+
for obj_id in list(video_data['annotations'][0].keys()):
|
| 52 |
+
cat_names.add(video_data['annotations'][0][obj_id]['category_name'])
|
| 53 |
+
|
| 54 |
+
if len(cat_names) == 1:
|
| 55 |
+
cat_name = next(iter(cat_names))
|
| 56 |
+
else:
|
| 57 |
+
print("more than 2 categories")
|
| 58 |
+
return -1
|
| 59 |
+
|
| 60 |
+
image_paths = [os.path.join(video_path, frame_name + '.jpg') for frame_name in frame_names]
|
| 61 |
+
image_captions = {}
|
| 62 |
+
|
| 63 |
+
captioner = OpenAI()
|
| 64 |
+
for i in range(len(image_paths)):
|
| 65 |
+
image_path = image_paths[i]
|
| 66 |
+
frame_name = frame_names[i]
|
| 67 |
+
base64_image = encode_image(image_path)
|
| 68 |
+
|
| 69 |
+
#1단계: 필터링
|
| 70 |
+
response1 = captioner.chat.completions.create(
|
| 71 |
+
model="gpt-4o-mini",
|
| 72 |
+
messages=[
|
| 73 |
+
{
|
| 74 |
+
"role": "user",
|
| 75 |
+
"content": [
|
| 76 |
+
{
|
| 77 |
+
"type": "text",
|
| 78 |
+
"text": f"Are there multiple {cat_name}s that can be distinguished by action? Each action should be prominent and describe the corresponding object only. If so, only output YES. If not, only output None",
|
| 79 |
+
},
|
| 80 |
+
{
|
| 81 |
+
"type": "image_url",
|
| 82 |
+
"image_url": {"url": f"data:image/jpeg;base64,{base64_image}"},
|
| 83 |
+
},
|
| 84 |
+
],
|
| 85 |
+
}
|
| 86 |
+
],
|
| 87 |
+
)
|
| 88 |
+
response_content = response1.choices[0].message.content
|
| 89 |
+
should_caption = True if "yes" in response_content.lower() else False
|
| 90 |
+
|
| 91 |
+
#2단계: dense caption 만들기
|
| 92 |
+
if should_caption:
|
| 93 |
+
response2 = captioner.chat.completions.create(
|
| 94 |
+
model="gpt-4o-mini",
|
| 95 |
+
messages=[
|
| 96 |
+
{
|
| 97 |
+
"role": "user",
|
| 98 |
+
"content": [
|
| 99 |
+
{
|
| 100 |
+
"type": "text",
|
| 101 |
+
"text": f"""
|
| 102 |
+
Describe the image in detail focusing on the {cat_name}s' actions.
|
| 103 |
+
1. Each action should be prominent, clear and unique, describing the corresponding object only.
|
| 104 |
+
2. Avoid overly detailed or indeterminate details such as ‘in anticipation’.
|
| 105 |
+
3. Avoid subjective descriptions such as ‘soft’, ‘controlled’, ‘attentive’, ‘skilled’, ‘casual atmosphere’ and descriptions of the setting.
|
| 106 |
+
4. Do not include actions that needs to be guessed or suggested.""",
|
| 107 |
+
},
|
| 108 |
+
{
|
| 109 |
+
"type": "image_url",
|
| 110 |
+
"image_url": {"url": f"data:image/jpeg;base64,{base64_image}"},
|
| 111 |
+
},
|
| 112 |
+
],
|
| 113 |
+
}
|
| 114 |
+
],
|
| 115 |
+
)
|
| 116 |
+
|
| 117 |
+
caption = response2.choices[0].message.content
|
| 118 |
+
else:
|
| 119 |
+
caption = None
|
| 120 |
+
|
| 121 |
+
image_captions[frame_name] = caption
|
| 122 |
+
return image_captions
|
| 123 |
+
|
| 124 |
+
def getRefExp(video_id, frame_name, caption, obj_id, json_data):
|
| 125 |
+
# 이미지에 해당 물체 바운딩 박스 그리기
|
| 126 |
+
video_data = json_data[video_id]
|
| 127 |
+
frame_names = video_data['frame_names']
|
| 128 |
+
video_path = video_data['video_path']
|
| 129 |
+
I = skimage.io.imread(osp.join(video_path, frame_name + '.jpg'))
|
| 130 |
+
frame_indx = frame_names.index(frame_name)
|
| 131 |
+
obj_data = video_data['annotations'][frame_indx][obj_id]
|
| 132 |
+
|
| 133 |
+
bbox = obj_data['bbox']
|
| 134 |
+
cat_name = obj_data['category_name']
|
| 135 |
+
valid = obj_data['valid']
|
| 136 |
+
|
| 137 |
+
if valid == 0:
|
| 138 |
+
print("Object not in this frame!")
|
| 139 |
+
return {}
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
x_min, y_min, x_max, y_max = bbox
|
| 143 |
+
x_min, y_min, x_max, y_max = int(x_min), int(y_min), int(x_max), int(y_max)
|
| 144 |
+
cv2.rectangle(I, (x_min, y_min), (x_max, y_max), (225, 0, 0), 2)
|
| 145 |
+
plt.figure()
|
| 146 |
+
plt.imshow(I)
|
| 147 |
+
plt.axis('off')
|
| 148 |
+
plt.show()
|
| 149 |
+
pil_I = Image.fromarray(I)
|
| 150 |
+
buff = BytesIO()
|
| 151 |
+
pil_I.save(buff, format='JPEG')
|
| 152 |
+
base64_I = base64.b64encode(buff.getvalue()).decode("utf-8")
|
| 153 |
+
|
| 154 |
+
#ref expression 만들기
|
| 155 |
+
generator = OpenAI()
|
| 156 |
+
response = generator.chat.completions.create(
|
| 157 |
+
model="gpt-4o-mini",
|
| 158 |
+
messages=[
|
| 159 |
+
{
|
| 160 |
+
"role": "user",
|
| 161 |
+
"content": [
|
| 162 |
+
{
|
| 163 |
+
"type": "text",
|
| 164 |
+
"text": f"""Based on the dense caption, create a referring expression for the {cat_name} highlighted with the red box.
|
| 165 |
+
1. The referring expression describes the action and does not contain information about appearance or location in the picture.
|
| 166 |
+
2. Focus only on prominent actions and avoid overly detailed or indeterminate details.
|
| 167 |
+
3. Avoid subjective terms describing emotion such as ‘in anticipation’, ‘attentively’ or ‘relaxed’ and professional, difficult words.
|
| 168 |
+
4. The referring expression should only describe the highlighted {cat_name} and not any other.
|
| 169 |
+
5. Use '{cat_name}' as the noun for the referring expressions.
|
| 170 |
+
Output only the referring expression.
|
| 171 |
+
{caption}""",
|
| 172 |
+
},
|
| 173 |
+
{
|
| 174 |
+
"type": "image_url",
|
| 175 |
+
"image_url": {"url": f"data:image/jpeg;base64,{base64_I}"},
|
| 176 |
+
},
|
| 177 |
+
],
|
| 178 |
+
}
|
| 179 |
+
],
|
| 180 |
+
)
|
| 181 |
+
|
| 182 |
+
ref_exp = response.choices[0].message.content
|
| 183 |
+
|
| 184 |
+
#QA filtering
|
| 185 |
+
#QA1: 원하는 물체를 설명하는지
|
| 186 |
+
filter = OpenAI()
|
| 187 |
+
response1 = filter.chat.completions.create(
|
| 188 |
+
model="gpt-4o-mini",
|
| 189 |
+
messages=[
|
| 190 |
+
{
|
| 191 |
+
"role": "user",
|
| 192 |
+
"content": [
|
| 193 |
+
{
|
| 194 |
+
"type": "text",
|
| 195 |
+
"text": f"""Does the given expression describe the {cat_name} highlighted with the red box? If so, only return YES and if not, NO.
|
| 196 |
+
{ref_exp}""",
|
| 197 |
+
},
|
| 198 |
+
{
|
| 199 |
+
"type": "image_url",
|
| 200 |
+
"image_url": {"url": f"data:image/jpeg;base64,{base64_I}"},
|
| 201 |
+
},
|
| 202 |
+
],
|
| 203 |
+
}
|
| 204 |
+
],
|
| 205 |
+
)
|
| 206 |
+
|
| 207 |
+
response1_content = response1.choices[0].message.content
|
| 208 |
+
describesHighlighted = True if "yes" in response1_content.lower() else False
|
| 209 |
+
|
| 210 |
+
#QA2: 원하지 않는 물체를 설명하지 않는지
|
| 211 |
+
response2 = filter.chat.completions.create(
|
| 212 |
+
model="gpt-4o-mini",
|
| 213 |
+
messages=[
|
| 214 |
+
{
|
| 215 |
+
"role": "user",
|
| 216 |
+
"content": [
|
| 217 |
+
{
|
| 218 |
+
"type": "text",
|
| 219 |
+
"text": f"""Does the given expression describe the person not highlighted with the red box? If so, only return YES and if not, NO.
|
| 220 |
+
{ref_exp}""",
|
| 221 |
+
},
|
| 222 |
+
{
|
| 223 |
+
"type": "image_url",
|
| 224 |
+
"image_url": {"url": f"data:image/jpeg;base64,{base64_I}"},
|
| 225 |
+
},
|
| 226 |
+
],
|
| 227 |
+
}
|
| 228 |
+
],
|
| 229 |
+
)
|
| 230 |
+
|
| 231 |
+
response2_content = response2.choices[0].message.content
|
| 232 |
+
describesNotHighlighted = True if "yes" in response2_content.lower() else False
|
| 233 |
+
|
| 234 |
+
isValid = True if describesHighlighted and not describesNotHighlighted else False
|
| 235 |
+
|
| 236 |
+
print(f"describesHighlighted: {describesHighlighted}, describesNotHighlighted: {describesNotHighlighted}")
|
| 237 |
+
|
| 238 |
+
return {"ref_exp": ref_exp, "caption": caption, "cat_name": cat_name, "file_name": frame_name, "isValid" : isValid}
|
| 239 |
+
|
| 240 |
+
def createRefExp(video_id, json_data):
|
| 241 |
+
video_data = json_data[video_id]
|
| 242 |
+
obj_ids = list(video_data['annotations'][0].keys())
|
| 243 |
+
frame_names = video_data['frame_names']
|
| 244 |
+
|
| 245 |
+
captions_per_frame = getCaption(video_id, json_data)
|
| 246 |
+
|
| 247 |
+
if captions_per_frame == -1:
|
| 248 |
+
print("There are more than 2 cateories")
|
| 249 |
+
return
|
| 250 |
+
|
| 251 |
+
|
| 252 |
+
video_ref_exps = {}
|
| 253 |
+
|
| 254 |
+
for frame_name in frame_names:
|
| 255 |
+
frame_caption = captions_per_frame[frame_name]
|
| 256 |
+
|
| 257 |
+
if frame_caption == None:
|
| 258 |
+
video_ref_exps[frame_name] = None
|
| 259 |
+
|
| 260 |
+
else:
|
| 261 |
+
frame_ref_exps = {}
|
| 262 |
+
for obj_id in obj_ids:
|
| 263 |
+
exp_per_obj = getRefExp(video_id, frame_name, frame_caption, obj_id, json_data)
|
| 264 |
+
frame_ref_exps[obj_id] = exp_per_obj
|
| 265 |
+
video_ref_exps[frame_name] = frame_ref_exps
|
| 266 |
+
|
| 267 |
+
return video_ref_exps
|
| 268 |
+
|
| 269 |
+
if __name__ == '__main__':
|
| 270 |
+
with open('mbench/sampled_frame3.json', 'r') as file:
|
| 271 |
+
data = json.load(file)
|
| 272 |
+
|
| 273 |
+
all_video_refs = {}
|
| 274 |
+
for i in range(3):
|
| 275 |
+
video_id = list(data.keys())[i]
|
| 276 |
+
video_ref = createRefExp(video_id, data)
|
| 277 |
+
all_video_refs[video_id] = video_ref
|
.history/mbench/gpt_ref-ytvos_20250119070740.py
ADDED
|
@@ -0,0 +1,285 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from datasets import build_dataset
|
| 2 |
+
import argparse
|
| 3 |
+
import opts
|
| 4 |
+
|
| 5 |
+
import sys
|
| 6 |
+
from pathlib import Path
|
| 7 |
+
import os
|
| 8 |
+
from os import path as osp
|
| 9 |
+
import skimage
|
| 10 |
+
from io import BytesIO
|
| 11 |
+
|
| 12 |
+
import numpy as np
|
| 13 |
+
import pandas as pd
|
| 14 |
+
import regex as re
|
| 15 |
+
import json
|
| 16 |
+
|
| 17 |
+
import cv2
|
| 18 |
+
from PIL import Image, ImageDraw
|
| 19 |
+
import torch
|
| 20 |
+
from torchvision.transforms import functional as F
|
| 21 |
+
|
| 22 |
+
from skimage import measure # (pip install scikit-image)
|
| 23 |
+
from shapely.geometry import Polygon, MultiPolygon # (pip install Shapely)
|
| 24 |
+
|
| 25 |
+
import matplotlib.pyplot as plt
|
| 26 |
+
import matplotlib.patches as patches
|
| 27 |
+
from matplotlib.collections import PatchCollection
|
| 28 |
+
from matplotlib.patches import Rectangle
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
import ipywidgets as widgets
|
| 32 |
+
from IPython.display import display, clear_output
|
| 33 |
+
|
| 34 |
+
from openai import OpenAI
|
| 35 |
+
import base64
|
| 36 |
+
|
| 37 |
+
os.environ['OPENAI_API_KEY'] = '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'
|
| 38 |
+
|
| 39 |
+
# Function to encode the image
|
| 40 |
+
def encode_image(image_path):
|
| 41 |
+
with open(image_path, "rb") as image_file:
|
| 42 |
+
return base64.b64encode(image_file.read()).decode("utf-8")
|
| 43 |
+
|
| 44 |
+
def getCaption(video_id, json_data):
|
| 45 |
+
#데이터 가져오기
|
| 46 |
+
video_data = json_data[video_id]
|
| 47 |
+
frame_names = video_data['frame_names']
|
| 48 |
+
video_path = video_data['video_path']
|
| 49 |
+
|
| 50 |
+
cat_names = set()
|
| 51 |
+
for obj_id in list(video_data['annotations'][0].keys()):
|
| 52 |
+
cat_names.add(video_data['annotations'][0][obj_id]['category_name'])
|
| 53 |
+
|
| 54 |
+
if len(cat_names) == 1:
|
| 55 |
+
cat_name = next(iter(cat_names))
|
| 56 |
+
else:
|
| 57 |
+
print("more than 2 categories")
|
| 58 |
+
return -1
|
| 59 |
+
|
| 60 |
+
image_paths = [os.path.join(video_path, frame_name + '.jpg') for frame_name in frame_names]
|
| 61 |
+
image_captions = {}
|
| 62 |
+
|
| 63 |
+
captioner = OpenAI()
|
| 64 |
+
for i in range(len(image_paths)):
|
| 65 |
+
image_path = image_paths[i]
|
| 66 |
+
frame_name = frame_names[i]
|
| 67 |
+
base64_image = encode_image(image_path)
|
| 68 |
+
|
| 69 |
+
#1단계: 필터링
|
| 70 |
+
response1 = captioner.chat.completions.create(
|
| 71 |
+
model="gpt-4o-mini",
|
| 72 |
+
messages=[
|
| 73 |
+
{
|
| 74 |
+
"role": "user",
|
| 75 |
+
"content": [
|
| 76 |
+
{
|
| 77 |
+
"type": "text",
|
| 78 |
+
"text": f"Are there multiple {cat_name}s that can be distinguished by action? Each action should be prominent and describe the corresponding object only. If so, only output YES. If not, only output None",
|
| 79 |
+
},
|
| 80 |
+
{
|
| 81 |
+
"type": "image_url",
|
| 82 |
+
"image_url": {"url": f"data:image/jpeg;base64,{base64_image}"},
|
| 83 |
+
},
|
| 84 |
+
],
|
| 85 |
+
}
|
| 86 |
+
],
|
| 87 |
+
)
|
| 88 |
+
response_content = response1.choices[0].message.content
|
| 89 |
+
should_caption = True if "yes" in response_content.lower() else False
|
| 90 |
+
|
| 91 |
+
#2단계: dense caption 만들기
|
| 92 |
+
if should_caption:
|
| 93 |
+
response2 = captioner.chat.completions.create(
|
| 94 |
+
model="gpt-4o-mini",
|
| 95 |
+
messages=[
|
| 96 |
+
{
|
| 97 |
+
"role": "user",
|
| 98 |
+
"content": [
|
| 99 |
+
{
|
| 100 |
+
"type": "text",
|
| 101 |
+
"text": f"""
|
| 102 |
+
Describe the image in detail focusing on the {cat_name}s' actions.
|
| 103 |
+
1. Each action should be prominent, clear and unique, describing the corresponding object only.
|
| 104 |
+
2. Avoid overly detailed or indeterminate details such as ‘in anticipation’.
|
| 105 |
+
3. Avoid subjective descriptions such as ‘soft’, ‘controlled’, ‘attentive’, ‘skilled’, ‘casual atmosphere’ and descriptions of the setting.
|
| 106 |
+
4. Do not include actions that needs to be guessed or suggested.""",
|
| 107 |
+
},
|
| 108 |
+
{
|
| 109 |
+
"type": "image_url",
|
| 110 |
+
"image_url": {"url": f"data:image/jpeg;base64,{base64_image}"},
|
| 111 |
+
},
|
| 112 |
+
],
|
| 113 |
+
}
|
| 114 |
+
],
|
| 115 |
+
)
|
| 116 |
+
|
| 117 |
+
caption = response2.choices[0].message.content
|
| 118 |
+
else:
|
| 119 |
+
caption = None
|
| 120 |
+
|
| 121 |
+
image_captions[frame_name] = caption
|
| 122 |
+
return image_captions
|
| 123 |
+
|
| 124 |
+
def getRefExp(video_id, frame_name, caption, obj_id, json_data):
|
| 125 |
+
# 이미지에 해당 물체 바운딩 박스 그리기
|
| 126 |
+
video_data = json_data[video_id]
|
| 127 |
+
frame_names = video_data['frame_names']
|
| 128 |
+
video_path = video_data['video_path']
|
| 129 |
+
I = skimage.io.imread(osp.join(video_path, frame_name + '.jpg'))
|
| 130 |
+
frame_indx = frame_names.index(frame_name)
|
| 131 |
+
obj_data = video_data['annotations'][frame_indx][obj_id]
|
| 132 |
+
|
| 133 |
+
bbox = obj_data['bbox']
|
| 134 |
+
cat_name = obj_data['category_name']
|
| 135 |
+
valid = obj_data['valid']
|
| 136 |
+
|
| 137 |
+
if valid == 0:
|
| 138 |
+
print("Object not in this frame!")
|
| 139 |
+
return {}
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
x_min, y_min, x_max, y_max = bbox
|
| 143 |
+
x_min, y_min, x_max, y_max = int(x_min), int(y_min), int(x_max), int(y_max)
|
| 144 |
+
cv2.rectangle(I, (x_min, y_min), (x_max, y_max), (225, 0, 0), 2)
|
| 145 |
+
plt.figure()
|
| 146 |
+
plt.imshow(I)
|
| 147 |
+
plt.axis('off')
|
| 148 |
+
plt.show()
|
| 149 |
+
pil_I = Image.fromarray(I)
|
| 150 |
+
buff = BytesIO()
|
| 151 |
+
pil_I.save(buff, format='JPEG')
|
| 152 |
+
base64_I = base64.b64encode(buff.getvalue()).decode("utf-8")
|
| 153 |
+
|
| 154 |
+
#ref expression 만들기
|
| 155 |
+
generator = OpenAI()
|
| 156 |
+
response = generator.chat.completions.create(
|
| 157 |
+
model="gpt-4o-mini",
|
| 158 |
+
messages=[
|
| 159 |
+
{
|
| 160 |
+
"role": "user",
|
| 161 |
+
"content": [
|
| 162 |
+
{
|
| 163 |
+
"type": "text",
|
| 164 |
+
"text": f"""Based on the dense caption, create a referring expression for the {cat_name} highlighted with the red box.
|
| 165 |
+
1. The referring expression describes the action and does not contain information about appearance or location in the picture.
|
| 166 |
+
2. Focus only on prominent actions and avoid overly detailed or indeterminate details.
|
| 167 |
+
3. Avoid subjective terms describing emotion such as ‘in anticipation’, ‘attentively’ or ‘relaxed’ and professional, difficult words.
|
| 168 |
+
4. The referring expression should only describe the highlighted {cat_name} and not any other.
|
| 169 |
+
5. Use '{cat_name}' as the noun for the referring expressions.
|
| 170 |
+
Output only the referring expression.
|
| 171 |
+
{caption}""",
|
| 172 |
+
},
|
| 173 |
+
{
|
| 174 |
+
"type": "image_url",
|
| 175 |
+
"image_url": {"url": f"data:image/jpeg;base64,{base64_I}"},
|
| 176 |
+
},
|
| 177 |
+
],
|
| 178 |
+
}
|
| 179 |
+
],
|
| 180 |
+
)
|
| 181 |
+
|
| 182 |
+
ref_exp = response.choices[0].message.content
|
| 183 |
+
|
| 184 |
+
#QA filtering
|
| 185 |
+
#QA1: 원하는 물체를 설명하는지
|
| 186 |
+
filter = OpenAI()
|
| 187 |
+
response1 = filter.chat.completions.create(
|
| 188 |
+
model="gpt-4o-mini",
|
| 189 |
+
messages=[
|
| 190 |
+
{
|
| 191 |
+
"role": "user",
|
| 192 |
+
"content": [
|
| 193 |
+
{
|
| 194 |
+
"type": "text",
|
| 195 |
+
"text": f"""Does the given expression describe the {cat_name} highlighted with the red box? If so, only return YES and if not, NO.
|
| 196 |
+
{ref_exp}""",
|
| 197 |
+
},
|
| 198 |
+
{
|
| 199 |
+
"type": "image_url",
|
| 200 |
+
"image_url": {"url": f"data:image/jpeg;base64,{base64_I}"},
|
| 201 |
+
},
|
| 202 |
+
],
|
| 203 |
+
}
|
| 204 |
+
],
|
| 205 |
+
)
|
| 206 |
+
|
| 207 |
+
response1_content = response1.choices[0].message.content
|
| 208 |
+
describesHighlighted = True if "yes" in response1_content.lower() else False
|
| 209 |
+
|
| 210 |
+
#QA2: 원하지 않는 물체를 설명하지 않는지
|
| 211 |
+
response2 = filter.chat.completions.create(
|
| 212 |
+
model="gpt-4o-mini",
|
| 213 |
+
messages=[
|
| 214 |
+
{
|
| 215 |
+
"role": "user",
|
| 216 |
+
"content": [
|
| 217 |
+
{
|
| 218 |
+
"type": "text",
|
| 219 |
+
"text": f"""Does the given expression describe the person not highlighted with the red box? If so, only return YES and if not, NO.
|
| 220 |
+
{ref_exp}""",
|
| 221 |
+
},
|
| 222 |
+
{
|
| 223 |
+
"type": "image_url",
|
| 224 |
+
"image_url": {"url": f"data:image/jpeg;base64,{base64_I}"},
|
| 225 |
+
},
|
| 226 |
+
],
|
| 227 |
+
}
|
| 228 |
+
],
|
| 229 |
+
)
|
| 230 |
+
|
| 231 |
+
response2_content = response2.choices[0].message.content
|
| 232 |
+
describesNotHighlighted = True if "yes" in response2_content.lower() else False
|
| 233 |
+
|
| 234 |
+
isValid = True if describesHighlighted and not describesNotHighlighted else False
|
| 235 |
+
|
| 236 |
+
print(f"describesHighlighted: {describesHighlighted}, describesNotHighlighted: {describesNotHighlighted}")
|
| 237 |
+
|
| 238 |
+
return {"ref_exp": ref_exp, "caption": caption, "cat_name": cat_name, "file_name": frame_name, "isValid" : isValid}
|
| 239 |
+
|
| 240 |
+
def createRefExp(video_id, json_data):
|
| 241 |
+
video_data = json_data[video_id]
|
| 242 |
+
obj_ids = list(video_data['annotations'][0].keys())
|
| 243 |
+
frame_names = video_data['frame_names']
|
| 244 |
+
|
| 245 |
+
captions_per_frame = getCaption(video_id, json_data)
|
| 246 |
+
|
| 247 |
+
if captions_per_frame == -1:
|
| 248 |
+
print("There are more than 2 cateories")
|
| 249 |
+
return
|
| 250 |
+
|
| 251 |
+
|
| 252 |
+
video_ref_exps = {}
|
| 253 |
+
|
| 254 |
+
for frame_name in frame_names:
|
| 255 |
+
frame_caption = captions_per_frame[frame_name]
|
| 256 |
+
|
| 257 |
+
if frame_caption == None:
|
| 258 |
+
video_ref_exps[frame_name] = None
|
| 259 |
+
|
| 260 |
+
else:
|
| 261 |
+
frame_ref_exps = {}
|
| 262 |
+
for obj_id in obj_ids:
|
| 263 |
+
exp_per_obj = getRefExp(video_id, frame_name, frame_caption, obj_id, json_data)
|
| 264 |
+
frame_ref_exps[obj_id] = exp_per_obj
|
| 265 |
+
video_ref_exps[frame_name] = frame_ref_exps
|
| 266 |
+
|
| 267 |
+
return video_ref_exps
|
| 268 |
+
|
| 269 |
+
if __name__ == '__main__':
|
| 270 |
+
with open('mbench/sampled_frame3.json', 'r') as file:
|
| 271 |
+
data = json.load(file)
|
| 272 |
+
|
| 273 |
+
videos = set()
|
| 274 |
+
with open('make_ref-ytvos/selected_frames.jsonl', 'r') as file:
|
| 275 |
+
manual_select = list(file)
|
| 276 |
+
for frame in manual_select:
|
| 277 |
+
result = json.loads(frame)
|
| 278 |
+
videos.add(result['video'])
|
| 279 |
+
|
| 280 |
+
|
| 281 |
+
all_video_refs = {}
|
| 282 |
+
for i in range(10):
|
| 283 |
+
video_id = list(data.keys())[i]
|
| 284 |
+
video_ref = createRefExp(video_id, data)
|
| 285 |
+
all_video_refs[video_id] = video_ref
|
.history/mbench/gpt_ref-ytvos_20250119071412.py
ADDED
|
@@ -0,0 +1,292 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import sys
|
| 2 |
+
from os import path as osp
|
| 3 |
+
sys.path.append(osp.abspath(osp.join(osp.dirname(__file__), '..')))
|
| 4 |
+
|
| 5 |
+
from datasets import build_dataset
|
| 6 |
+
import argparse
|
| 7 |
+
import opts
|
| 8 |
+
|
| 9 |
+
from pathlib import Path
|
| 10 |
+
import os
|
| 11 |
+
import skimage
|
| 12 |
+
from io import BytesIO
|
| 13 |
+
|
| 14 |
+
import numpy as np
|
| 15 |
+
import pandas as pd
|
| 16 |
+
import regex as re
|
| 17 |
+
import json
|
| 18 |
+
|
| 19 |
+
import cv2
|
| 20 |
+
from PIL import Image, ImageDraw
|
| 21 |
+
import torch
|
| 22 |
+
from torchvision.transforms import functional as F
|
| 23 |
+
|
| 24 |
+
from skimage import measure # (pip install scikit-image)
|
| 25 |
+
from shapely.geometry import Polygon, MultiPolygon # (pip install Shapely)
|
| 26 |
+
|
| 27 |
+
import matplotlib.pyplot as plt
|
| 28 |
+
import matplotlib.patches as patches
|
| 29 |
+
from matplotlib.collections import PatchCollection
|
| 30 |
+
from matplotlib.patches import Rectangle
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
import ipywidgets as widgets
|
| 34 |
+
from IPython.display import display, clear_output
|
| 35 |
+
|
| 36 |
+
from openai import OpenAI
|
| 37 |
+
import base64
|
| 38 |
+
|
| 39 |
+
os.environ['OPENAI_API_KEY'] = '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'
|
| 40 |
+
|
| 41 |
+
# Function to encode the image
|
| 42 |
+
def encode_image(image_path):
|
| 43 |
+
with open(image_path, "rb") as image_file:
|
| 44 |
+
return base64.b64encode(image_file.read()).decode("utf-8")
|
| 45 |
+
|
| 46 |
+
def getCaption(video_id, json_data):
|
| 47 |
+
#데이터 가져오기
|
| 48 |
+
video_data = json_data[video_id]
|
| 49 |
+
frame_names = video_data['frame_names']
|
| 50 |
+
video_path = video_data['video_path']
|
| 51 |
+
|
| 52 |
+
cat_names = set()
|
| 53 |
+
for obj_id in list(video_data['annotations'][0].keys()):
|
| 54 |
+
cat_names.add(video_data['annotations'][0][obj_id]['category_name'])
|
| 55 |
+
|
| 56 |
+
if len(cat_names) == 1:
|
| 57 |
+
cat_name = next(iter(cat_names))
|
| 58 |
+
else:
|
| 59 |
+
print("more than 2 categories")
|
| 60 |
+
return -1
|
| 61 |
+
|
| 62 |
+
image_paths = [os.path.join(video_path, frame_name + '.jpg') for frame_name in frame_names]
|
| 63 |
+
image_captions = {}
|
| 64 |
+
|
| 65 |
+
captioner = OpenAI()
|
| 66 |
+
for i in range(len(image_paths)):
|
| 67 |
+
image_path = image_paths[i]
|
| 68 |
+
frame_name = frame_names[i]
|
| 69 |
+
base64_image = encode_image(image_path)
|
| 70 |
+
|
| 71 |
+
#1단계: 필터링
|
| 72 |
+
response1 = captioner.chat.completions.create(
|
| 73 |
+
model="gpt-4o-mini",
|
| 74 |
+
messages=[
|
| 75 |
+
{
|
| 76 |
+
"role": "user",
|
| 77 |
+
"content": [
|
| 78 |
+
{
|
| 79 |
+
"type": "text",
|
| 80 |
+
"text": f"Are there multiple {cat_name}s that can be distinguished by action? Each action should be prominent and describe the corresponding object only. If so, only output YES. If not, only output None",
|
| 81 |
+
},
|
| 82 |
+
{
|
| 83 |
+
"type": "image_url",
|
| 84 |
+
"image_url": {"url": f"data:image/jpeg;base64,{base64_image}"},
|
| 85 |
+
},
|
| 86 |
+
],
|
| 87 |
+
}
|
| 88 |
+
],
|
| 89 |
+
)
|
| 90 |
+
response_content = response1.choices[0].message.content
|
| 91 |
+
should_caption = True if "yes" in response_content.lower() else False
|
| 92 |
+
|
| 93 |
+
#2단계: dense caption 만들기
|
| 94 |
+
if should_caption:
|
| 95 |
+
response2 = captioner.chat.completions.create(
|
| 96 |
+
model="gpt-4o-mini",
|
| 97 |
+
messages=[
|
| 98 |
+
{
|
| 99 |
+
"role": "user",
|
| 100 |
+
"content": [
|
| 101 |
+
{
|
| 102 |
+
"type": "text",
|
| 103 |
+
"text": f"""
|
| 104 |
+
Describe the image in detail focusing on the {cat_name}s' actions.
|
| 105 |
+
1. Each action should be prominent, clear and unique, describing the corresponding object only.
|
| 106 |
+
2. Avoid overly detailed or indeterminate details such as ‘in anticipation’.
|
| 107 |
+
3. Avoid subjective descriptions such as ‘soft’, ‘controlled’, ‘attentive’, ‘skilled’, ‘casual atmosphere’ and descriptions of the setting.
|
| 108 |
+
4. Do not include actions that needs to be guessed or suggested.""",
|
| 109 |
+
},
|
| 110 |
+
{
|
| 111 |
+
"type": "image_url",
|
| 112 |
+
"image_url": {"url": f"data:image/jpeg;base64,{base64_image}"},
|
| 113 |
+
},
|
| 114 |
+
],
|
| 115 |
+
}
|
| 116 |
+
],
|
| 117 |
+
)
|
| 118 |
+
|
| 119 |
+
caption = response2.choices[0].message.content
|
| 120 |
+
else:
|
| 121 |
+
caption = None
|
| 122 |
+
|
| 123 |
+
image_captions[frame_name] = caption
|
| 124 |
+
return image_captions
|
| 125 |
+
|
| 126 |
+
def getRefExp(video_id, frame_name, caption, obj_id, json_data):
|
| 127 |
+
# 이미지에 해당 물체 바운딩 박스 그리기
|
| 128 |
+
video_data = json_data[video_id]
|
| 129 |
+
frame_names = video_data['frame_names']
|
| 130 |
+
video_path = video_data['video_path']
|
| 131 |
+
I = skimage.io.imread(osp.join(video_path, frame_name + '.jpg'))
|
| 132 |
+
frame_indx = frame_names.index(frame_name)
|
| 133 |
+
obj_data = video_data['annotations'][frame_indx][obj_id]
|
| 134 |
+
|
| 135 |
+
bbox = obj_data['bbox']
|
| 136 |
+
cat_name = obj_data['category_name']
|
| 137 |
+
valid = obj_data['valid']
|
| 138 |
+
|
| 139 |
+
if valid == 0:
|
| 140 |
+
print("Object not in this frame!")
|
| 141 |
+
return {}
|
| 142 |
+
|
| 143 |
+
|
| 144 |
+
x_min, y_min, x_max, y_max = bbox
|
| 145 |
+
x_min, y_min, x_max, y_max = int(x_min), int(y_min), int(x_max), int(y_max)
|
| 146 |
+
cv2.rectangle(I, (x_min, y_min), (x_max, y_max), (225, 0, 0), 2)
|
| 147 |
+
plt.figure()
|
| 148 |
+
plt.imshow(I)
|
| 149 |
+
plt.axis('off')
|
| 150 |
+
plt.show()
|
| 151 |
+
pil_I = Image.fromarray(I)
|
| 152 |
+
buff = BytesIO()
|
| 153 |
+
pil_I.save(buff, format='JPEG')
|
| 154 |
+
base64_I = base64.b64encode(buff.getvalue()).decode("utf-8")
|
| 155 |
+
|
| 156 |
+
#ref expression 만들기
|
| 157 |
+
generator = OpenAI()
|
| 158 |
+
response = generator.chat.completions.create(
|
| 159 |
+
model="gpt-4o-mini",
|
| 160 |
+
messages=[
|
| 161 |
+
{
|
| 162 |
+
"role": "user",
|
| 163 |
+
"content": [
|
| 164 |
+
{
|
| 165 |
+
"type": "text",
|
| 166 |
+
"text": f"""Based on the dense caption, create a referring expression for the {cat_name} highlighted with the red box.
|
| 167 |
+
1. The referring expression describes the action and does not contain information about appearance or location in the picture.
|
| 168 |
+
2. Focus only on prominent actions and avoid overly detailed or indeterminate details.
|
| 169 |
+
3. Avoid subjective terms describing emotion such as ‘in anticipation’, ‘attentively’ or ‘relaxed’ and professional, difficult words.
|
| 170 |
+
4. The referring expression should only describe the highlighted {cat_name} and not any other.
|
| 171 |
+
5. Use '{cat_name}' as the noun for the referring expressions.
|
| 172 |
+
Output only the referring expression.
|
| 173 |
+
{caption}""",
|
| 174 |
+
},
|
| 175 |
+
{
|
| 176 |
+
"type": "image_url",
|
| 177 |
+
"image_url": {"url": f"data:image/jpeg;base64,{base64_I}"},
|
| 178 |
+
},
|
| 179 |
+
],
|
| 180 |
+
}
|
| 181 |
+
],
|
| 182 |
+
)
|
| 183 |
+
|
| 184 |
+
ref_exp = response.choices[0].message.content
|
| 185 |
+
|
| 186 |
+
#QA filtering
|
| 187 |
+
#QA1: 원하는 물체를 설명하는지
|
| 188 |
+
filter = OpenAI()
|
| 189 |
+
response1 = filter.chat.completions.create(
|
| 190 |
+
model="gpt-4o-mini",
|
| 191 |
+
messages=[
|
| 192 |
+
{
|
| 193 |
+
"role": "user",
|
| 194 |
+
"content": [
|
| 195 |
+
{
|
| 196 |
+
"type": "text",
|
| 197 |
+
"text": f"""Does the given expression describe the {cat_name} highlighted with the red box? If so, only return YES and if not, NO.
|
| 198 |
+
{ref_exp}""",
|
| 199 |
+
},
|
| 200 |
+
{
|
| 201 |
+
"type": "image_url",
|
| 202 |
+
"image_url": {"url": f"data:image/jpeg;base64,{base64_I}"},
|
| 203 |
+
},
|
| 204 |
+
],
|
| 205 |
+
}
|
| 206 |
+
],
|
| 207 |
+
)
|
| 208 |
+
|
| 209 |
+
response1_content = response1.choices[0].message.content
|
| 210 |
+
describesHighlighted = True if "yes" in response1_content.lower() else False
|
| 211 |
+
|
| 212 |
+
#QA2: 원하지 않는 물체를 설명하지 않는지
|
| 213 |
+
response2 = filter.chat.completions.create(
|
| 214 |
+
model="gpt-4o-mini",
|
| 215 |
+
messages=[
|
| 216 |
+
{
|
| 217 |
+
"role": "user",
|
| 218 |
+
"content": [
|
| 219 |
+
{
|
| 220 |
+
"type": "text",
|
| 221 |
+
"text": f"""Does the given expression describe the person not highlighted with the red box? If so, only return YES and if not, NO.
|
| 222 |
+
{ref_exp}""",
|
| 223 |
+
},
|
| 224 |
+
{
|
| 225 |
+
"type": "image_url",
|
| 226 |
+
"image_url": {"url": f"data:image/jpeg;base64,{base64_I}"},
|
| 227 |
+
},
|
| 228 |
+
],
|
| 229 |
+
}
|
| 230 |
+
],
|
| 231 |
+
)
|
| 232 |
+
|
| 233 |
+
response2_content = response2.choices[0].message.content
|
| 234 |
+
describesNotHighlighted = True if "yes" in response2_content.lower() else False
|
| 235 |
+
|
| 236 |
+
isValid = True if describesHighlighted and not describesNotHighlighted else False
|
| 237 |
+
|
| 238 |
+
print(f"describesHighlighted: {describesHighlighted}, describesNotHighlighted: {describesNotHighlighted}")
|
| 239 |
+
|
| 240 |
+
return {"ref_exp": ref_exp, "caption": caption, "cat_name": cat_name, "file_name": frame_name, "isValid" : isValid}
|
| 241 |
+
|
| 242 |
+
def createRefExp(video_id, json_data):
|
| 243 |
+
video_data = json_data[video_id]
|
| 244 |
+
obj_ids = list(video_data['annotations'][0].keys())
|
| 245 |
+
frame_names = video_data['frame_names']
|
| 246 |
+
|
| 247 |
+
captions_per_frame = getCaption(video_id, json_data)
|
| 248 |
+
|
| 249 |
+
if captions_per_frame == -1:
|
| 250 |
+
print("There are more than 2 cateories")
|
| 251 |
+
return
|
| 252 |
+
|
| 253 |
+
|
| 254 |
+
video_ref_exps = {}
|
| 255 |
+
|
| 256 |
+
for frame_name in frame_names:
|
| 257 |
+
frame_caption = captions_per_frame[frame_name]
|
| 258 |
+
|
| 259 |
+
if frame_caption == None:
|
| 260 |
+
video_ref_exps[frame_name] = None
|
| 261 |
+
|
| 262 |
+
else:
|
| 263 |
+
frame_ref_exps = {}
|
| 264 |
+
for obj_id in obj_ids:
|
| 265 |
+
exp_per_obj = getRefExp(video_id, frame_name, frame_caption, obj_id, json_data)
|
| 266 |
+
frame_ref_exps[obj_id] = exp_per_obj
|
| 267 |
+
video_ref_exps[frame_name] = frame_ref_exps
|
| 268 |
+
|
| 269 |
+
return video_ref_exps
|
| 270 |
+
|
| 271 |
+
if __name__ == '__main__':
|
| 272 |
+
with open('mbench/sampled_frame3.json', 'r') as file:
|
| 273 |
+
data = json.load(file)
|
| 274 |
+
|
| 275 |
+
videos = set()
|
| 276 |
+
with open('make_ref-ytvos/selected_frames.jsonl', 'r') as file:
|
| 277 |
+
manual_select = list(file)
|
| 278 |
+
for frame in manual_select:
|
| 279 |
+
result = json.loads(frame)
|
| 280 |
+
videos.add(result['video'])
|
| 281 |
+
videos = list(videos)
|
| 282 |
+
|
| 283 |
+
|
| 284 |
+
all_video_refs = {}
|
| 285 |
+
for i in range(1):
|
| 286 |
+
video_id = videos[i]
|
| 287 |
+
video_ref = createRefExp(video_id, data)
|
| 288 |
+
all_video_refs[video_id] = video_ref
|
| 289 |
+
|
| 290 |
+
json_obj = json.dumps(all_video_refs, indent=4)
|
| 291 |
+
with open('mbench/result.json', 'w') as file:
|
| 292 |
+
file.wirte(json_obj)
|
.history/mbench/gpt_ref-ytvos_20250119072601.py
ADDED
|
@@ -0,0 +1,292 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import sys
|
| 2 |
+
from os import path as osp
|
| 3 |
+
sys.path.append(osp.abspath(osp.join(osp.dirname(__file__), '..')))
|
| 4 |
+
|
| 5 |
+
from datasets import build_dataset
|
| 6 |
+
import argparse
|
| 7 |
+
import opts
|
| 8 |
+
|
| 9 |
+
from pathlib import Path
|
| 10 |
+
import os
|
| 11 |
+
import skimage
|
| 12 |
+
from io import BytesIO
|
| 13 |
+
|
| 14 |
+
import numpy as np
|
| 15 |
+
import pandas as pd
|
| 16 |
+
import regex as re
|
| 17 |
+
import json
|
| 18 |
+
|
| 19 |
+
import cv2
|
| 20 |
+
from PIL import Image, ImageDraw
|
| 21 |
+
import torch
|
| 22 |
+
from torchvision.transforms import functional as F
|
| 23 |
+
|
| 24 |
+
from skimage import measure # (pip install scikit-image)
|
| 25 |
+
from shapely.geometry import Polygon, MultiPolygon # (pip install Shapely)
|
| 26 |
+
|
| 27 |
+
import matplotlib.pyplot as plt
|
| 28 |
+
import matplotlib.patches as patches
|
| 29 |
+
from matplotlib.collections import PatchCollection
|
| 30 |
+
from matplotlib.patches import Rectangle
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
import ipywidgets as widgets
|
| 34 |
+
from IPython.display import display, clear_output
|
| 35 |
+
|
| 36 |
+
from openai import OpenAI
|
| 37 |
+
import base64
|
| 38 |
+
|
| 39 |
+
os.environ['OPENAI_API_KEY'] = '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'
|
| 40 |
+
|
| 41 |
+
# Function to encode the image
|
| 42 |
+
def encode_image(image_path):
|
| 43 |
+
with open(image_path, "rb") as image_file:
|
| 44 |
+
return base64.b64encode(image_file.read()).decode("utf-8")
|
| 45 |
+
|
| 46 |
+
def getCaption(video_id, json_data):
|
| 47 |
+
#데이터 가져오기
|
| 48 |
+
video_data = json_data[video_id]
|
| 49 |
+
frame_names = video_data['frame_names']
|
| 50 |
+
video_path = video_data['video_path']
|
| 51 |
+
|
| 52 |
+
cat_names = set()
|
| 53 |
+
for obj_id in list(video_data['annotations'][0].keys()):
|
| 54 |
+
cat_names.add(video_data['annotations'][0][obj_id]['category_name'])
|
| 55 |
+
|
| 56 |
+
if len(cat_names) == 1:
|
| 57 |
+
cat_name = next(iter(cat_names))
|
| 58 |
+
else:
|
| 59 |
+
print("more than 2 categories")
|
| 60 |
+
return -1
|
| 61 |
+
|
| 62 |
+
image_paths = [os.path.join(video_path, frame_name + '.jpg') for frame_name in frame_names]
|
| 63 |
+
image_captions = {}
|
| 64 |
+
|
| 65 |
+
captioner = OpenAI()
|
| 66 |
+
for i in range(len(image_paths)):
|
| 67 |
+
image_path = image_paths[i]
|
| 68 |
+
frame_name = frame_names[i]
|
| 69 |
+
base64_image = encode_image(image_path)
|
| 70 |
+
|
| 71 |
+
#1단계: 필터링
|
| 72 |
+
response1 = captioner.chat.completions.create(
|
| 73 |
+
model="gpt-4o-mini",
|
| 74 |
+
messages=[
|
| 75 |
+
{
|
| 76 |
+
"role": "user",
|
| 77 |
+
"content": [
|
| 78 |
+
{
|
| 79 |
+
"type": "text",
|
| 80 |
+
"text": f"Are there multiple {cat_name}s that can be distinguished by action? Each action should be prominent and describe the corresponding object only. If so, only output YES. If not, only output None",
|
| 81 |
+
},
|
| 82 |
+
{
|
| 83 |
+
"type": "image_url",
|
| 84 |
+
"image_url": {"url": f"data:image/jpeg;base64,{base64_image}"},
|
| 85 |
+
},
|
| 86 |
+
],
|
| 87 |
+
}
|
| 88 |
+
],
|
| 89 |
+
)
|
| 90 |
+
response_content = response1.choices[0].message.content
|
| 91 |
+
should_caption = True if "yes" in response_content.lower() else False
|
| 92 |
+
|
| 93 |
+
#2단계: dense caption 만들기
|
| 94 |
+
if should_caption:
|
| 95 |
+
response2 = captioner.chat.completions.create(
|
| 96 |
+
model="gpt-4o-mini",
|
| 97 |
+
messages=[
|
| 98 |
+
{
|
| 99 |
+
"role": "user",
|
| 100 |
+
"content": [
|
| 101 |
+
{
|
| 102 |
+
"type": "text",
|
| 103 |
+
"text": f"""
|
| 104 |
+
Describe the image in detail focusing on the {cat_name}s' actions.
|
| 105 |
+
1. Each action should be prominent, clear and unique, describing the corresponding object only.
|
| 106 |
+
2. Avoid overly detailed or indeterminate details such as ‘in anticipation’.
|
| 107 |
+
3. Avoid subjective descriptions such as ‘soft’, ‘controlled’, ‘attentive’, ‘skilled’, ‘casual atmosphere’ and descriptions of the setting.
|
| 108 |
+
4. Do not include actions that needs to be guessed or suggested.""",
|
| 109 |
+
},
|
| 110 |
+
{
|
| 111 |
+
"type": "image_url",
|
| 112 |
+
"image_url": {"url": f"data:image/jpeg;base64,{base64_image}"},
|
| 113 |
+
},
|
| 114 |
+
],
|
| 115 |
+
}
|
| 116 |
+
],
|
| 117 |
+
)
|
| 118 |
+
|
| 119 |
+
caption = response2.choices[0].message.content
|
| 120 |
+
else:
|
| 121 |
+
caption = None
|
| 122 |
+
|
| 123 |
+
image_captions[frame_name] = caption
|
| 124 |
+
return image_captions
|
| 125 |
+
|
| 126 |
+
def getRefExp(video_id, frame_name, caption, obj_id, json_data):
|
| 127 |
+
# 이미지에 해당 물체 바운딩 박스 그리기
|
| 128 |
+
video_data = json_data[video_id]
|
| 129 |
+
frame_names = video_data['frame_names']
|
| 130 |
+
video_path = video_data['video_path']
|
| 131 |
+
I = skimage.io.imread(osp.join(video_path, frame_name + '.jpg'))
|
| 132 |
+
frame_indx = frame_names.index(frame_name)
|
| 133 |
+
obj_data = video_data['annotations'][frame_indx][obj_id]
|
| 134 |
+
|
| 135 |
+
bbox = obj_data['bbox']
|
| 136 |
+
cat_name = obj_data['category_name']
|
| 137 |
+
valid = obj_data['valid']
|
| 138 |
+
|
| 139 |
+
if valid == 0:
|
| 140 |
+
print("Object not in this frame!")
|
| 141 |
+
return {}
|
| 142 |
+
|
| 143 |
+
|
| 144 |
+
x_min, y_min, x_max, y_max = bbox
|
| 145 |
+
x_min, y_min, x_max, y_max = int(x_min), int(y_min), int(x_max), int(y_max)
|
| 146 |
+
cv2.rectangle(I, (x_min, y_min), (x_max, y_max), (225, 0, 0), 2)
|
| 147 |
+
plt.figure()
|
| 148 |
+
plt.imshow(I)
|
| 149 |
+
plt.axis('off')
|
| 150 |
+
plt.show()
|
| 151 |
+
pil_I = Image.fromarray(I)
|
| 152 |
+
buff = BytesIO()
|
| 153 |
+
pil_I.save(buff, format='JPEG')
|
| 154 |
+
base64_I = base64.b64encode(buff.getvalue()).decode("utf-8")
|
| 155 |
+
|
| 156 |
+
#ref expression 만들기
|
| 157 |
+
generator = OpenAI()
|
| 158 |
+
response = generator.chat.completions.create(
|
| 159 |
+
model="gpt-4o-mini",
|
| 160 |
+
messages=[
|
| 161 |
+
{
|
| 162 |
+
"role": "user",
|
| 163 |
+
"content": [
|
| 164 |
+
{
|
| 165 |
+
"type": "text",
|
| 166 |
+
"text": f"""Based on the dense caption, create a referring expression for the {cat_name} highlighted with the red box.
|
| 167 |
+
1. The referring expression describes the action and does not contain information about appearance or location in the picture.
|
| 168 |
+
2. Focus only on prominent actions and avoid overly detailed or indeterminate details.
|
| 169 |
+
3. Avoid subjective terms describing emotion such as ‘in anticipation’, ‘attentively’ or ‘relaxed’ and professional, difficult words.
|
| 170 |
+
4. The referring expression should only describe the highlighted {cat_name} and not any other.
|
| 171 |
+
5. Use '{cat_name}' as the noun for the referring expressions.
|
| 172 |
+
Output only the referring expression.
|
| 173 |
+
{caption}""",
|
| 174 |
+
},
|
| 175 |
+
{
|
| 176 |
+
"type": "image_url",
|
| 177 |
+
"image_url": {"url": f"data:image/jpeg;base64,{base64_I}"},
|
| 178 |
+
},
|
| 179 |
+
],
|
| 180 |
+
}
|
| 181 |
+
],
|
| 182 |
+
)
|
| 183 |
+
|
| 184 |
+
ref_exp = response.choices[0].message.content
|
| 185 |
+
|
| 186 |
+
#QA filtering
|
| 187 |
+
#QA1: 원하는 물체를 설명하는지
|
| 188 |
+
filter = OpenAI()
|
| 189 |
+
response1 = filter.chat.completions.create(
|
| 190 |
+
model="gpt-4o-mini",
|
| 191 |
+
messages=[
|
| 192 |
+
{
|
| 193 |
+
"role": "user",
|
| 194 |
+
"content": [
|
| 195 |
+
{
|
| 196 |
+
"type": "text",
|
| 197 |
+
"text": f"""Does the given expression describe the {cat_name} highlighted with the red box? If so, only return YES and if not, NO.
|
| 198 |
+
{ref_exp}""",
|
| 199 |
+
},
|
| 200 |
+
{
|
| 201 |
+
"type": "image_url",
|
| 202 |
+
"image_url": {"url": f"data:image/jpeg;base64,{base64_I}"},
|
| 203 |
+
},
|
| 204 |
+
],
|
| 205 |
+
}
|
| 206 |
+
],
|
| 207 |
+
)
|
| 208 |
+
|
| 209 |
+
response1_content = response1.choices[0].message.content
|
| 210 |
+
describesHighlighted = True if "yes" in response1_content.lower() else False
|
| 211 |
+
|
| 212 |
+
#QA2: 원하지 않는 물체를 설명하지 않는지
|
| 213 |
+
response2 = filter.chat.completions.create(
|
| 214 |
+
model="gpt-4o-mini",
|
| 215 |
+
messages=[
|
| 216 |
+
{
|
| 217 |
+
"role": "user",
|
| 218 |
+
"content": [
|
| 219 |
+
{
|
| 220 |
+
"type": "text",
|
| 221 |
+
"text": f"""Does the given expression describe the person not highlighted with the red box? If so, only return YES and if not, NO.
|
| 222 |
+
{ref_exp}""",
|
| 223 |
+
},
|
| 224 |
+
{
|
| 225 |
+
"type": "image_url",
|
| 226 |
+
"image_url": {"url": f"data:image/jpeg;base64,{base64_I}"},
|
| 227 |
+
},
|
| 228 |
+
],
|
| 229 |
+
}
|
| 230 |
+
],
|
| 231 |
+
)
|
| 232 |
+
|
| 233 |
+
response2_content = response2.choices[0].message.content
|
| 234 |
+
describesNotHighlighted = True if "yes" in response2_content.lower() else False
|
| 235 |
+
|
| 236 |
+
isValid = True if describesHighlighted and not describesNotHighlighted else False
|
| 237 |
+
|
| 238 |
+
print(f"describesHighlighted: {describesHighlighted}, describesNotHighlighted: {describesNotHighlighted}")
|
| 239 |
+
|
| 240 |
+
return {"ref_exp": ref_exp, "caption": caption, "cat_name": cat_name, "file_name": frame_name, "isValid" : isValid}
|
| 241 |
+
|
| 242 |
+
def createRefExp(video_id, json_data):
|
| 243 |
+
video_data = json_data[video_id]
|
| 244 |
+
obj_ids = list(video_data['annotations'][0].keys())
|
| 245 |
+
frame_names = video_data['frame_names']
|
| 246 |
+
|
| 247 |
+
captions_per_frame = getCaption(video_id, json_data)
|
| 248 |
+
|
| 249 |
+
if captions_per_frame == -1:
|
| 250 |
+
print("There are more than 2 cateories")
|
| 251 |
+
return None
|
| 252 |
+
|
| 253 |
+
|
| 254 |
+
video_ref_exps = {}
|
| 255 |
+
|
| 256 |
+
for frame_name in frame_names:
|
| 257 |
+
frame_caption = captions_per_frame[frame_name]
|
| 258 |
+
|
| 259 |
+
if frame_caption == None:
|
| 260 |
+
video_ref_exps[frame_name] = None
|
| 261 |
+
|
| 262 |
+
else:
|
| 263 |
+
frame_ref_exps = {}
|
| 264 |
+
for obj_id in obj_ids:
|
| 265 |
+
exp_per_obj = getRefExp(video_id, frame_name, frame_caption, obj_id, json_data)
|
| 266 |
+
frame_ref_exps[obj_id] = exp_per_obj
|
| 267 |
+
video_ref_exps[frame_name] = frame_ref_exps
|
| 268 |
+
|
| 269 |
+
return video_ref_exps
|
| 270 |
+
|
| 271 |
+
if __name__ == '__main__':
|
| 272 |
+
with open('mbench/sampled_frame3.json', 'r') as file:
|
| 273 |
+
data = json.load(file)
|
| 274 |
+
|
| 275 |
+
videos = set()
|
| 276 |
+
with open('make_ref-ytvos/selected_frames.jsonl', 'r') as file:
|
| 277 |
+
manual_select = list(file)
|
| 278 |
+
for frame in manual_select:
|
| 279 |
+
result = json.loads(frame)
|
| 280 |
+
videos.add(result['video'])
|
| 281 |
+
videos = list(videos)
|
| 282 |
+
|
| 283 |
+
|
| 284 |
+
all_video_refs = {}
|
| 285 |
+
for i in range(1, 2):
|
| 286 |
+
video_id = videos[i]
|
| 287 |
+
video_ref = createRefExp(video_id, data)
|
| 288 |
+
all_video_refs[video_id] = video_ref
|
| 289 |
+
|
| 290 |
+
json_obj = json.dumps(all_video_refs, indent=4)
|
| 291 |
+
with open('mbench/result.json', 'w') as file:
|
| 292 |
+
file.write(json_obj)
|
.history/mbench/gpt_ref-ytvos_20250119073047.py
ADDED
|
@@ -0,0 +1,292 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import sys
|
| 2 |
+
from os import path as osp
|
| 3 |
+
sys.path.append(osp.abspath(osp.join(osp.dirname(__file__), '..')))
|
| 4 |
+
|
| 5 |
+
from datasets import build_dataset
|
| 6 |
+
import argparse
|
| 7 |
+
import opts
|
| 8 |
+
|
| 9 |
+
from pathlib import Path
|
| 10 |
+
import os
|
| 11 |
+
import skimage
|
| 12 |
+
from io import BytesIO
|
| 13 |
+
|
| 14 |
+
import numpy as np
|
| 15 |
+
import pandas as pd
|
| 16 |
+
import regex as re
|
| 17 |
+
import json
|
| 18 |
+
|
| 19 |
+
import cv2
|
| 20 |
+
from PIL import Image, ImageDraw
|
| 21 |
+
import torch
|
| 22 |
+
from torchvision.transforms import functional as F
|
| 23 |
+
|
| 24 |
+
from skimage import measure # (pip install scikit-image)
|
| 25 |
+
from shapely.geometry import Polygon, MultiPolygon # (pip install Shapely)
|
| 26 |
+
|
| 27 |
+
import matplotlib.pyplot as plt
|
| 28 |
+
import matplotlib.patches as patches
|
| 29 |
+
from matplotlib.collections import PatchCollection
|
| 30 |
+
from matplotlib.patches import Rectangle
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
import ipywidgets as widgets
|
| 34 |
+
from IPython.display import display, clear_output
|
| 35 |
+
|
| 36 |
+
from openai import OpenAI
|
| 37 |
+
import base64
|
| 38 |
+
|
| 39 |
+
os.environ['OPENAI_API_KEY'] = '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'
|
| 40 |
+
|
| 41 |
+
# Function to encode the image
|
| 42 |
+
def encode_image(image_path):
|
| 43 |
+
with open(image_path, "rb") as image_file:
|
| 44 |
+
return base64.b64encode(image_file.read()).decode("utf-8")
|
| 45 |
+
|
| 46 |
+
def getCaption(video_id, json_data):
|
| 47 |
+
#데이터 가져오기
|
| 48 |
+
video_data = json_data[video_id]
|
| 49 |
+
frame_names = video_data['frame_names']
|
| 50 |
+
video_path = video_data['video_path']
|
| 51 |
+
|
| 52 |
+
cat_names = set()
|
| 53 |
+
for obj_id in list(video_data['annotations'][0].keys()):
|
| 54 |
+
cat_names.add(video_data['annotations'][0][obj_id]['category_name'])
|
| 55 |
+
|
| 56 |
+
if len(cat_names) == 1:
|
| 57 |
+
cat_name = next(iter(cat_names))
|
| 58 |
+
else:
|
| 59 |
+
print("more than 2 categories")
|
| 60 |
+
return -1
|
| 61 |
+
|
| 62 |
+
image_paths = [os.path.join(video_path, frame_name + '.jpg') for frame_name in frame_names]
|
| 63 |
+
image_captions = {}
|
| 64 |
+
|
| 65 |
+
captioner = OpenAI()
|
| 66 |
+
for i in range(len(image_paths)):
|
| 67 |
+
image_path = image_paths[i]
|
| 68 |
+
frame_name = frame_names[i]
|
| 69 |
+
base64_image = encode_image(image_path)
|
| 70 |
+
|
| 71 |
+
#1단계: 필터링
|
| 72 |
+
response1 = captioner.chat.completions.create(
|
| 73 |
+
model="gpt-4o-mini",
|
| 74 |
+
messages=[
|
| 75 |
+
{
|
| 76 |
+
"role": "user",
|
| 77 |
+
"content": [
|
| 78 |
+
{
|
| 79 |
+
"type": "text",
|
| 80 |
+
"text": f"Are there multiple {cat_name}s that can be distinguished by action? Each action should be prominent and describe the corresponding object only. If so, only output YES. If not, only output None",
|
| 81 |
+
},
|
| 82 |
+
{
|
| 83 |
+
"type": "image_url",
|
| 84 |
+
"image_url": {"url": f"data:image/jpeg;base64,{base64_image}"},
|
| 85 |
+
},
|
| 86 |
+
],
|
| 87 |
+
}
|
| 88 |
+
],
|
| 89 |
+
)
|
| 90 |
+
response_content = response1.choices[0].message.content
|
| 91 |
+
should_caption = True if "yes" in response_content.lower() else False
|
| 92 |
+
|
| 93 |
+
#2단계: dense caption 만들기
|
| 94 |
+
if should_caption:
|
| 95 |
+
response2 = captioner.chat.completions.create(
|
| 96 |
+
model="gpt-4o-mini",
|
| 97 |
+
messages=[
|
| 98 |
+
{
|
| 99 |
+
"role": "user",
|
| 100 |
+
"content": [
|
| 101 |
+
{
|
| 102 |
+
"type": "text",
|
| 103 |
+
"text": f"""
|
| 104 |
+
Describe the image in detail focusing on the {cat_name}s' actions.
|
| 105 |
+
1. Each action should be prominent, clear and unique, describing the corresponding object only.
|
| 106 |
+
2. Avoid overly detailed or indeterminate details such as ‘in anticipation’.
|
| 107 |
+
3. Avoid subjective descriptions such as ‘soft’, ‘controlled’, ‘attentive’, ‘skilled’, ‘casual atmosphere’ and descriptions of the setting.
|
| 108 |
+
4. Do not include actions that needs to be guessed or suggested.""",
|
| 109 |
+
},
|
| 110 |
+
{
|
| 111 |
+
"type": "image_url",
|
| 112 |
+
"image_url": {"url": f"data:image/jpeg;base64,{base64_image}"},
|
| 113 |
+
},
|
| 114 |
+
],
|
| 115 |
+
}
|
| 116 |
+
],
|
| 117 |
+
)
|
| 118 |
+
|
| 119 |
+
caption = response2.choices[0].message.content
|
| 120 |
+
else:
|
| 121 |
+
caption = None
|
| 122 |
+
|
| 123 |
+
image_captions[frame_name] = caption
|
| 124 |
+
return image_captions
|
| 125 |
+
|
| 126 |
+
def getRefExp(video_id, frame_name, caption, obj_id, json_data):
|
| 127 |
+
# 이미지에 해당 물체 바운딩 박스 그리기
|
| 128 |
+
video_data = json_data[video_id]
|
| 129 |
+
frame_names = video_data['frame_names']
|
| 130 |
+
video_path = video_data['video_path']
|
| 131 |
+
I = skimage.io.imread(osp.join(video_path, frame_name + '.jpg'))
|
| 132 |
+
frame_indx = frame_names.index(frame_name)
|
| 133 |
+
obj_data = video_data['annotations'][frame_indx][obj_id]
|
| 134 |
+
|
| 135 |
+
bbox = obj_data['bbox']
|
| 136 |
+
cat_name = obj_data['category_name']
|
| 137 |
+
valid = obj_data['valid']
|
| 138 |
+
|
| 139 |
+
if valid == 0:
|
| 140 |
+
print("Object not in this frame!")
|
| 141 |
+
return {}
|
| 142 |
+
|
| 143 |
+
|
| 144 |
+
x_min, y_min, x_max, y_max = bbox
|
| 145 |
+
x_min, y_min, x_max, y_max = int(x_min), int(y_min), int(x_max), int(y_max)
|
| 146 |
+
cv2.rectangle(I, (x_min, y_min), (x_max, y_max), (225, 0, 0), 2)
|
| 147 |
+
plt.figure()
|
| 148 |
+
plt.imshow(I)
|
| 149 |
+
plt.axis('off')
|
| 150 |
+
plt.show()
|
| 151 |
+
pil_I = Image.fromarray(I)
|
| 152 |
+
buff = BytesIO()
|
| 153 |
+
pil_I.save(buff, format='JPEG')
|
| 154 |
+
base64_I = base64.b64encode(buff.getvalue()).decode("utf-8")
|
| 155 |
+
|
| 156 |
+
#ref expression 만들기
|
| 157 |
+
generator = OpenAI()
|
| 158 |
+
response = generator.chat.completions.create(
|
| 159 |
+
model="gpt-4o-mini",
|
| 160 |
+
messages=[
|
| 161 |
+
{
|
| 162 |
+
"role": "user",
|
| 163 |
+
"content": [
|
| 164 |
+
{
|
| 165 |
+
"type": "text",
|
| 166 |
+
"text": f"""Based on the dense caption, create a referring expression for the {cat_name} highlighted with the red box.
|
| 167 |
+
1. The referring expression describes the action and does not contain information about appearance or location in the picture.
|
| 168 |
+
2. Focus only on prominent actions and avoid overly detailed or indeterminate details.
|
| 169 |
+
3. Avoid subjective terms describing emotion such as ‘in anticipation’, ‘attentively’ or ‘relaxed’ and professional, difficult words.
|
| 170 |
+
4. The referring expression should only describe the highlighted {cat_name} and not any other.
|
| 171 |
+
5. Use '{cat_name}' as the noun for the referring expressions.
|
| 172 |
+
Output only the referring expression.
|
| 173 |
+
{caption}""",
|
| 174 |
+
},
|
| 175 |
+
{
|
| 176 |
+
"type": "image_url",
|
| 177 |
+
"image_url": {"url": f"data:image/jpeg;base64,{base64_I}"},
|
| 178 |
+
},
|
| 179 |
+
],
|
| 180 |
+
}
|
| 181 |
+
],
|
| 182 |
+
)
|
| 183 |
+
|
| 184 |
+
ref_exp = response.choices[0].message.content
|
| 185 |
+
|
| 186 |
+
#QA filtering
|
| 187 |
+
#QA1: 원하는 물체를 설명하는지
|
| 188 |
+
filter = OpenAI()
|
| 189 |
+
response1 = filter.chat.completions.create(
|
| 190 |
+
model="gpt-4o-mini",
|
| 191 |
+
messages=[
|
| 192 |
+
{
|
| 193 |
+
"role": "user",
|
| 194 |
+
"content": [
|
| 195 |
+
{
|
| 196 |
+
"type": "text",
|
| 197 |
+
"text": f"""Does the given expression describe the {cat_name} highlighted with the red box? If so, only return YES and if not, NO.
|
| 198 |
+
{ref_exp}""",
|
| 199 |
+
},
|
| 200 |
+
{
|
| 201 |
+
"type": "image_url",
|
| 202 |
+
"image_url": {"url": f"data:image/jpeg;base64,{base64_I}"},
|
| 203 |
+
},
|
| 204 |
+
],
|
| 205 |
+
}
|
| 206 |
+
],
|
| 207 |
+
)
|
| 208 |
+
|
| 209 |
+
response1_content = response1.choices[0].message.content
|
| 210 |
+
describesHighlighted = True if "yes" in response1_content.lower() else False
|
| 211 |
+
|
| 212 |
+
#QA2: 원하지 않는 물체를 설명하지 않는지
|
| 213 |
+
response2 = filter.chat.completions.create(
|
| 214 |
+
model="gpt-4o-mini",
|
| 215 |
+
messages=[
|
| 216 |
+
{
|
| 217 |
+
"role": "user",
|
| 218 |
+
"content": [
|
| 219 |
+
{
|
| 220 |
+
"type": "text",
|
| 221 |
+
"text": f"""Does the given expression describe the person not highlighted with the red box? If so, only return YES and if not, NO.
|
| 222 |
+
{ref_exp}""",
|
| 223 |
+
},
|
| 224 |
+
{
|
| 225 |
+
"type": "image_url",
|
| 226 |
+
"image_url": {"url": f"data:image/jpeg;base64,{base64_I}"},
|
| 227 |
+
},
|
| 228 |
+
],
|
| 229 |
+
}
|
| 230 |
+
],
|
| 231 |
+
)
|
| 232 |
+
|
| 233 |
+
response2_content = response2.choices[0].message.content
|
| 234 |
+
describesNotHighlighted = True if "yes" in response2_content.lower() else False
|
| 235 |
+
|
| 236 |
+
isValid = True if describesHighlighted and not describesNotHighlighted else False
|
| 237 |
+
|
| 238 |
+
print(f"describesHighlighted: {describesHighlighted}, describesNotHighlighted: {describesNotHighlighted}")
|
| 239 |
+
|
| 240 |
+
return {"ref_exp": ref_exp, "caption": caption, "cat_name": cat_name, "file_name": frame_name, "isValid" : isValid}
|
| 241 |
+
|
| 242 |
+
def createRefExp(video_id, json_data):
|
| 243 |
+
video_data = json_data[video_id]
|
| 244 |
+
obj_ids = list(video_data['annotations'][0].keys())
|
| 245 |
+
frame_names = video_data['frame_names']
|
| 246 |
+
|
| 247 |
+
captions_per_frame = getCaption(video_id, json_data)
|
| 248 |
+
|
| 249 |
+
if captions_per_frame == -1:
|
| 250 |
+
print("There are more than 2 cateories")
|
| 251 |
+
return None
|
| 252 |
+
|
| 253 |
+
|
| 254 |
+
video_ref_exps = {}
|
| 255 |
+
|
| 256 |
+
for frame_name in frame_names:
|
| 257 |
+
frame_caption = captions_per_frame[frame_name]
|
| 258 |
+
|
| 259 |
+
if frame_caption == None:
|
| 260 |
+
video_ref_exps[frame_name] = None
|
| 261 |
+
|
| 262 |
+
else:
|
| 263 |
+
frame_ref_exps = {}
|
| 264 |
+
for obj_id in obj_ids:
|
| 265 |
+
exp_per_obj = getRefExp(video_id, frame_name, frame_caption, obj_id, json_data)
|
| 266 |
+
frame_ref_exps[obj_id] = exp_per_obj
|
| 267 |
+
video_ref_exps[frame_name] = frame_ref_exps
|
| 268 |
+
|
| 269 |
+
return video_ref_exps
|
| 270 |
+
|
| 271 |
+
if __name__ == '__main__':
|
| 272 |
+
with open('mbench/sampled_frame3.json', 'r') as file:
|
| 273 |
+
data = json.load(file)
|
| 274 |
+
|
| 275 |
+
videos = set()
|
| 276 |
+
with open('make_ref-ytvos/selected_frames.jsonl', 'r') as file:
|
| 277 |
+
manual_select = list(file)
|
| 278 |
+
for frame in manual_select:
|
| 279 |
+
result = json.loads(frame)
|
| 280 |
+
videos.add(result['video'])
|
| 281 |
+
videos = list(videos)
|
| 282 |
+
|
| 283 |
+
|
| 284 |
+
all_video_refs = {}
|
| 285 |
+
for i in range(10):
|
| 286 |
+
video_id = videos[i]
|
| 287 |
+
video_ref = createRefExp(video_id, data)
|
| 288 |
+
all_video_refs[video_id] = video_ref
|
| 289 |
+
|
| 290 |
+
json_obj = json.dumps(all_video_refs, indent=4)
|
| 291 |
+
with open('mbench/result.json', 'w') as file:
|
| 292 |
+
file.write(json_obj)
|
.history/mbench/gpt_ref-ytvos_numbered_cy_20250131124149.py
ADDED
|
@@ -0,0 +1,427 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import sys
|
| 3 |
+
sys.path.append(os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
|
| 4 |
+
|
| 5 |
+
from os import path as osp
|
| 6 |
+
from io import BytesIO
|
| 7 |
+
|
| 8 |
+
from mbench.ytvos_ref import build as build_ytvos_ref
|
| 9 |
+
import argparse
|
| 10 |
+
import opts
|
| 11 |
+
|
| 12 |
+
import sys
|
| 13 |
+
from pathlib import Path
|
| 14 |
+
import os
|
| 15 |
+
from os import path as osp
|
| 16 |
+
import skimage
|
| 17 |
+
from io import BytesIO
|
| 18 |
+
|
| 19 |
+
import numpy as np
|
| 20 |
+
import pandas as pd
|
| 21 |
+
import regex as re
|
| 22 |
+
import json
|
| 23 |
+
|
| 24 |
+
import cv2
|
| 25 |
+
from PIL import Image, ImageDraw
|
| 26 |
+
import torch
|
| 27 |
+
from torchvision.transforms import functional as F
|
| 28 |
+
|
| 29 |
+
from skimage import measure # (pip install scikit-image)
|
| 30 |
+
from shapely.geometry import Polygon, MultiPolygon # (pip install Shapely)
|
| 31 |
+
|
| 32 |
+
import matplotlib.pyplot as plt
|
| 33 |
+
import matplotlib.patches as patches
|
| 34 |
+
from matplotlib.collections import PatchCollection
|
| 35 |
+
from matplotlib.patches import Rectangle
|
| 36 |
+
import textwrap
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
import ipywidgets as widgets
|
| 40 |
+
from IPython.display import display, clear_output
|
| 41 |
+
|
| 42 |
+
from openai import OpenAI
|
| 43 |
+
import base64
|
| 44 |
+
import json
|
| 45 |
+
|
| 46 |
+
def number_objects_and_encode(idx, color_mask=False):
|
| 47 |
+
encoded_frames = {}
|
| 48 |
+
contoured_frames = {} # New dictionary for original images
|
| 49 |
+
vid_cat_cnts = {}
|
| 50 |
+
|
| 51 |
+
vid_meta = metas[idx]
|
| 52 |
+
vid_data = train_dataset[idx]
|
| 53 |
+
vid_id = vid_meta['video']
|
| 54 |
+
frame_indx = vid_meta['sample_indx']
|
| 55 |
+
cat_names = set(vid_meta['obj_id_cat'].values())
|
| 56 |
+
imgs = vid_data[0]
|
| 57 |
+
|
| 58 |
+
for cat in cat_names:
|
| 59 |
+
cat_frames = []
|
| 60 |
+
contour_frames = []
|
| 61 |
+
frame_cat_cnts = {}
|
| 62 |
+
|
| 63 |
+
for i in range(imgs.size(0)):
|
| 64 |
+
frame_name = frame_indx[i]
|
| 65 |
+
frame = np.copy(imgs[i].permute(1, 2, 0).numpy())
|
| 66 |
+
frame_for_contour = np.copy(imgs[i].permute(1, 2, 0).numpy())
|
| 67 |
+
|
| 68 |
+
frame_data = vid_data[2][frame_name]
|
| 69 |
+
obj_ids = list(frame_data.keys())
|
| 70 |
+
|
| 71 |
+
cat_cnt = 0
|
| 72 |
+
|
| 73 |
+
for j in range(len(obj_ids)):
|
| 74 |
+
obj_id = obj_ids[j]
|
| 75 |
+
obj_data = frame_data[obj_id]
|
| 76 |
+
obj_bbox = obj_data['bbox']
|
| 77 |
+
obj_valid = obj_data['valid']
|
| 78 |
+
obj_mask = obj_data['mask'].numpy().astype(np.uint8)
|
| 79 |
+
obj_cat = obj_data['category_name']
|
| 80 |
+
|
| 81 |
+
if obj_cat == cat and obj_valid:
|
| 82 |
+
cat_cnt += 1
|
| 83 |
+
|
| 84 |
+
if color_mask == False:
|
| 85 |
+
contours, _ = cv2.findContours(obj_mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
|
| 86 |
+
cv2.drawContours(frame, contours, -1, colors[j], 3)
|
| 87 |
+
for i, contour in enumerate(contours):
|
| 88 |
+
# 윤곽선 중심 계산
|
| 89 |
+
moments = cv2.moments(contour)
|
| 90 |
+
if moments["m00"] != 0: # 중심 계산 가능 여부 확인
|
| 91 |
+
cx = int(moments["m10"] / moments["m00"])
|
| 92 |
+
cy = int(moments["m01"] / moments["m00"])
|
| 93 |
+
else:
|
| 94 |
+
cx, cy = contour[0][0] # 중심 계산 불가시 대체 좌표 사용
|
| 95 |
+
|
| 96 |
+
# 텍스트 배경 (검은색 배경 만들기)
|
| 97 |
+
font = cv2.FONT_HERSHEY_SIMPLEX
|
| 98 |
+
text = obj_id
|
| 99 |
+
text_size = cv2.getTextSize(text, font, 1, 2)[0]
|
| 100 |
+
text_w, text_h = text_size
|
| 101 |
+
|
| 102 |
+
# 텍스트 배경 그리기 (검은색 배경)
|
| 103 |
+
cv2.rectangle(frame, (cx - text_w // 2 - 5, cy - text_h // 2 - 5),
|
| 104 |
+
(cx + text_w // 2 + 5, cy + text_h // 2 + 5), (0, 0, 0), -1)
|
| 105 |
+
|
| 106 |
+
# 텍스트 그리기 (흰색 텍스트)
|
| 107 |
+
cv2.putText(frame, text, (cx - text_w // 2, cy + text_h // 2),
|
| 108 |
+
font, 1, (255, 255, 255), 2)
|
| 109 |
+
|
| 110 |
+
else:
|
| 111 |
+
alpha = 0.08
|
| 112 |
+
|
| 113 |
+
colored_obj_mask = np.zeros_like(frame)
|
| 114 |
+
colored_obj_mask[obj_mask == 1] = colors[j]
|
| 115 |
+
frame[obj_mask == 1] = (
|
| 116 |
+
(1 - alpha) * frame[obj_mask == 1]
|
| 117 |
+
+ alpha * colored_obj_mask[obj_mask == 1]
|
| 118 |
+
)
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
contours, _ = cv2.findContours(obj_mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
|
| 122 |
+
cv2.drawContours(frame, contours, -1, colors[j], 2)
|
| 123 |
+
cv2.drawContours(frame_for_contour, contours, -1, colors[j], 2)
|
| 124 |
+
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
if len(contours) > 0:
|
| 128 |
+
largest_contour = max(contours, key=cv2.contourArea)
|
| 129 |
+
M = cv2.moments(largest_contour)
|
| 130 |
+
if M["m00"] != 0:
|
| 131 |
+
center_x = int(M["m10"] / M["m00"])
|
| 132 |
+
center_y = int(M["m01"] / M["m00"])
|
| 133 |
+
else:
|
| 134 |
+
center_x, center_y = 0, 0
|
| 135 |
+
|
| 136 |
+
font = cv2.FONT_HERSHEY_SIMPLEX
|
| 137 |
+
text = obj_id
|
| 138 |
+
|
| 139 |
+
font_scale = 0.9
|
| 140 |
+
text_size = cv2.getTextSize(text, font, font_scale, 2)[0]
|
| 141 |
+
text_x = center_x - text_size[0] // 1 # 텍스트의 가로 중심
|
| 142 |
+
text_y = center_y
|
| 143 |
+
# text_y = center_y + text_size[1] // 2 # 텍스트의 세로 중심
|
| 144 |
+
|
| 145 |
+
# 텍스트 배경 사각형 좌표 계산
|
| 146 |
+
rect_start = (text_x - 5, text_y - text_size[1] - 5) # 배경 사각형 좌상단
|
| 147 |
+
# rect_end = (text_x + text_size[0] + 5, text_y + 5)
|
| 148 |
+
rect_end = (text_x + text_size[0] + 5, text_y)
|
| 149 |
+
|
| 150 |
+
cv2.rectangle(frame, rect_start, rect_end, (0, 0, 0), -1)
|
| 151 |
+
cv2.putText(frame, text, (text_x, text_y), font, 1, (255, 255, 255), 2)
|
| 152 |
+
|
| 153 |
+
# plt.figure(figsize=(12, 8))
|
| 154 |
+
# plt.imshow(frame)
|
| 155 |
+
# plt.title(f"frame {frame_name}")
|
| 156 |
+
# plt.tight_layout()
|
| 157 |
+
# plt.axis('off')
|
| 158 |
+
# plt.show()
|
| 159 |
+
|
| 160 |
+
buffer = BytesIO()
|
| 161 |
+
frame = Image.fromarray(frame)
|
| 162 |
+
frame.save(buffer, format='jpeg')
|
| 163 |
+
buffer.seek(0)
|
| 164 |
+
cat_frames.append(base64.b64encode(buffer.read()).decode("utf-8"))
|
| 165 |
+
frame_cat_cnts[frame_name] = cat_cnt
|
| 166 |
+
|
| 167 |
+
buffer.seek(0) # Reuse buffer instead of creating a new one
|
| 168 |
+
buffer.truncate()
|
| 169 |
+
frame_for_contour = Image.fromarray(frame_for_contour)
|
| 170 |
+
frame_for_contour.save(buffer, format='jpeg')
|
| 171 |
+
buffer.seek(0)
|
| 172 |
+
contour_frames.append(base64.b64encode(buffer.read()).decode("utf-8"))
|
| 173 |
+
|
| 174 |
+
encoded_frames[cat] = cat_frames
|
| 175 |
+
contoured_frames[cat] = contour_frames
|
| 176 |
+
vid_cat_cnts[cat] = frame_cat_cnts
|
| 177 |
+
|
| 178 |
+
return encoded_frames, vid_cat_cnts, contoured_frames
|
| 179 |
+
|
| 180 |
+
|
| 181 |
+
def getCaption(idx, color_mask=True):
|
| 182 |
+
vid_meta = metas[idx]
|
| 183 |
+
vid_data = train_dataset[idx]
|
| 184 |
+
vid_id = vid_meta['video']
|
| 185 |
+
print(f"vid id: {vid_id}\n")
|
| 186 |
+
|
| 187 |
+
frame_indx = vid_meta['sample_indx'] # e.g. [4, 7, 9, 16]
|
| 188 |
+
cat_names = set(vid_meta['obj_id_cat'].values()) # e.g. {"person", "elephant", ...}
|
| 189 |
+
all_captions = dict()
|
| 190 |
+
|
| 191 |
+
base64_frames, vid_cat_cnts, contoured_frames = number_objects_and_encode(idx, color_mask)
|
| 192 |
+
marked = "mask with boundary" if color_mask else "boundary"
|
| 193 |
+
|
| 194 |
+
for cat_name in list(cat_names) :
|
| 195 |
+
|
| 196 |
+
is_movable = False
|
| 197 |
+
if cat_name in ytvos_category_valid_list :
|
| 198 |
+
is_movable = True
|
| 199 |
+
|
| 200 |
+
if not is_movable:
|
| 201 |
+
print(f"Skipping {cat_name}: Determined to be non-movable.", end='\n\n')
|
| 202 |
+
|
| 203 |
+
|
| 204 |
+
image_captions = {}
|
| 205 |
+
captioner = OpenAI()
|
| 206 |
+
cat_base64_frames = base64_frames[cat_name]
|
| 207 |
+
cont_base64_frames = contoured_frames[cat_name]
|
| 208 |
+
|
| 209 |
+
for i in range(len(cat_base64_frames)):
|
| 210 |
+
frame_name = frame_indx[i]
|
| 211 |
+
cont_base64_image = cont_base64_frames[i]
|
| 212 |
+
base64_image = cat_base64_frames[i]
|
| 213 |
+
should_filter = False
|
| 214 |
+
frame_cat_cnts = vid_cat_cnts[cat_name][frame_name]
|
| 215 |
+
|
| 216 |
+
if frame_cat_cnts >= 2:
|
| 217 |
+
should_filter = True
|
| 218 |
+
else:
|
| 219 |
+
print(f"Skipping {cat_name}: There is single or no object.", end='\n\n')
|
| 220 |
+
|
| 221 |
+
if is_movable and should_filter:
|
| 222 |
+
#1단계: 필터링
|
| 223 |
+
print(f"-----------category name: {cat_name}, frame name: {frame_name}")
|
| 224 |
+
caption_filter_text = f"""
|
| 225 |
+
You are a visual assistant analyzing a single frame from a video.
|
| 226 |
+
In this frame, I have labeled {frame_cat_cnts} {cat_name}(s), each with a bright numeric ID at its center and a visible marker.
|
| 227 |
+
|
| 228 |
+
Are {cat_name}s in the image performing all different and recognizable actions or postures?
|
| 229 |
+
Consider differences in body pose (standing, sitting, holding hands up, grabbing object, facing towards, walking...), motion cues (inferred from the momentary stance or position),
|
| 230 |
+
facial expressions, and any notable interactions with objects or other {cat_name}s or people.
|
| 231 |
+
|
| 232 |
+
Only focus on obvious, prominent actions that can be reliably identified from this single frame.
|
| 233 |
+
|
| 234 |
+
- Respond with "YES" if:
|
| 235 |
+
1) Most of {cat_name}s exhibit clearly different, unique actions or poses.
|
| 236 |
+
2) You can see visible significant differences in action and posture, that an observer can identify at a glance.
|
| 237 |
+
3) Each action is unambiguously recognizable and distinct.
|
| 238 |
+
|
| 239 |
+
- Respond with "NONE" if:
|
| 240 |
+
1) The actions or pose are not clearly differentiable or too similar.
|
| 241 |
+
2) They show no noticeable action beyond standing or minor movements.
|
| 242 |
+
|
| 243 |
+
Answer strictly with either "YES" or "NONE".
|
| 244 |
+
"""
|
| 245 |
+
|
| 246 |
+
|
| 247 |
+
response1 = captioner.chat.completions.create(
|
| 248 |
+
model="chatgpt-4o-latest",
|
| 249 |
+
messages=[
|
| 250 |
+
{
|
| 251 |
+
"role": "user",
|
| 252 |
+
"content": [
|
| 253 |
+
{
|
| 254 |
+
"type": "text",
|
| 255 |
+
"text": caption_filter_text,
|
| 256 |
+
},
|
| 257 |
+
{
|
| 258 |
+
"type": "image_url",
|
| 259 |
+
"image_url": {"url": f"data:image/jpeg;base64,{base64_image}"},
|
| 260 |
+
}
|
| 261 |
+
],
|
| 262 |
+
}
|
| 263 |
+
],
|
| 264 |
+
)
|
| 265 |
+
response_content = response1.choices[0].message.content
|
| 266 |
+
should_caption = True if "yes" in response_content.lower() else False
|
| 267 |
+
print(f"are {cat_name}s distinguished by action: {response_content}", end='\n\n')
|
| 268 |
+
|
| 269 |
+
else:
|
| 270 |
+
should_caption = False
|
| 271 |
+
|
| 272 |
+
#2단계: dense caption 만들기
|
| 273 |
+
dense_caption_prompt_1 = f"""You are a visual assistant that can analyze a single frame of a video and create referring expressions for each object.
|
| 274 |
+
In the given frame, I labeled {frame_cat_cnts} {cat_name}s by marking each with a bright numeric ID at the center and its boundary.
|
| 275 |
+
I want to use your expressions to create a action-centric referring expression dataset.
|
| 276 |
+
Therefore, your expressions for these {cat_name}s should describe unique action of each object.
|
| 277 |
+
|
| 278 |
+
1. Focus only on clear, unique, and prominent actions that distinguish each object.
|
| 279 |
+
2. Avoid describing actions that are too minor, ambiguous, or not visible from the image.
|
| 280 |
+
3. Avoid subjective terms such as 'skilled', 'controlled', or 'focused'. Only describe observable actions.
|
| 281 |
+
4. Do not include common-sense or overly general descriptions like 'the elephant walks'.
|
| 282 |
+
5. Use dynamic action verbs (e.g., holding, throwing, jumping, inspecting) to describe interactions, poses, or movements.
|
| 283 |
+
6. Avoid overly detailed or speculative descriptions such as 'slightly moving its mouth' or 'appears to be anticipating'.
|
| 284 |
+
7. Pretend you are observing the scene directly, avoiding phrases like 'it seems' or 'based on the description'.
|
| 285 |
+
8. Include interactions with objects or other entities when they are prominent and observable.
|
| 286 |
+
9. If the image contains multiple {cat_name}s, describe the actions of each individually and ensure the descriptions are non-overlapping and specific.
|
| 287 |
+
10. Do not include descriptions of appearance such as clothes, color, size, shape etc.
|
| 288 |
+
11. Do not include relative position between objects such as 'the left elephant' because left/right can be ambiguous.
|
| 289 |
+
12. Do not mention object IDs.
|
| 290 |
+
13. Use '{cat_name}' as the noun for the referring expressions.
|
| 291 |
+
|
| 292 |
+
Keep in mind that you should not group the objects, e.g., 2-5. people: xxx, be sure to describe each object separately (one by one).
|
| 293 |
+
Output referring expressions for each object id.
|
| 294 |
+
"""
|
| 295 |
+
|
| 296 |
+
dense_caption_prompt = f"""
|
| 297 |
+
You are a visual assistant analyzing a single frame of a video.
|
| 298 |
+
In the given frame, I labeled {frame_cat_cnts} {cat_name}s by marking each with a bright numeric ID at the center and its boundary.
|
| 299 |
+
I want to use your expressions to create a action-centric referring expression dataset.
|
| 300 |
+
Please describe each {cat_name} using **clearly observable** and **specific** actions.
|
| 301 |
+
|
| 302 |
+
## Guidelines:
|
| 303 |
+
1. Focus on visible, prominent actions only (e.g., running, pushing, grasping an object).
|
| 304 |
+
2. Avoid describing minor or ambiguous actions (e.g., slightly moving a paw).
|
| 305 |
+
3. Do not include subjective or speculative descriptions (e.g., “it seems excited” or “it might be preparing to jump”).
|
| 306 |
+
4. Do not use vague expressions like "interacting with something"** or "engaging with another object."
|
| 307 |
+
Instead, specify the interaction in detail (e.g., "grabbing a stick," "pressing a button").
|
| 308 |
+
5. Use dynamic action verbs (holding, throwing, inspecting, leaning, pressing) to highlight body movement or object/animal interaction.
|
| 309 |
+
6. If multiple {cat_name}s appear, ensure each description is detailed enough to differentiate their actions.
|
| 310 |
+
7. Base your description on the following action definitions:
|
| 311 |
+
- Facial with object manipulation
|
| 312 |
+
- General body movement, body position or pattern
|
| 313 |
+
- Movements when interacting with a specific, named object (e.g., "kicking a ball" instead of "interacting with an object").
|
| 314 |
+
- Body movements in person or animal interaction (e.g., "pushing another person" instead of "engaging with someone").
|
| 315 |
+
|
| 316 |
+
## Output Format:
|
| 317 |
+
- For each labeled {cat_name}, output one line in the format:
|
| 318 |
+
ID. action-oriented description
|
| 319 |
+
|
| 320 |
+
Example:
|
| 321 |
+
1. a bear grasping the edge of a wood with its front paws
|
| 322 |
+
2. the bear pushing another bear, leaning forward
|
| 323 |
+
|
| 324 |
+
**Do not include** appearance details (e.g., color, size, shape) or relative positioning (e.g., “on the left/right”).
|
| 325 |
+
**Do not mention object IDs** in the text of your sentence—just use them as labels for your output lines.
|
| 326 |
+
Keep in mind that you should not group the objects, e.g., 2-5. people: xxx, be sure to describe each object separately (one by one).
|
| 327 |
+
For each labeled {cat_name}, output referring expressions for each object id.
|
| 328 |
+
"""
|
| 329 |
+
if should_caption:
|
| 330 |
+
response2 = captioner.chat.completions.create(
|
| 331 |
+
model="gpt-4o-mini",
|
| 332 |
+
messages=[
|
| 333 |
+
{
|
| 334 |
+
"role": "user",
|
| 335 |
+
"content": [
|
| 336 |
+
{
|
| 337 |
+
"type": "text",
|
| 338 |
+
"text": dense_caption_prompt,
|
| 339 |
+
},
|
| 340 |
+
{
|
| 341 |
+
"type": "image_url",
|
| 342 |
+
"image_url": {"url": f"data:image/jpeg;base64,{base64_image}"},
|
| 343 |
+
},
|
| 344 |
+
],
|
| 345 |
+
}
|
| 346 |
+
],
|
| 347 |
+
)
|
| 348 |
+
|
| 349 |
+
caption = response2.choices[0].message.content
|
| 350 |
+
#print(f"{image_path} - {frame_name}: {caption}")
|
| 351 |
+
else:
|
| 352 |
+
caption = None
|
| 353 |
+
|
| 354 |
+
image_captions[frame_name] = caption
|
| 355 |
+
all_captions[cat_name] = image_captions
|
| 356 |
+
|
| 357 |
+
# final : also prepare valid object ids
|
| 358 |
+
valid_obj_ids = dict()
|
| 359 |
+
|
| 360 |
+
for cat in cat_names:
|
| 361 |
+
if cat in ytvos_category_valid_list:
|
| 362 |
+
obj_id_cat = vid_meta['obj_id_cat']
|
| 363 |
+
valid_cat_ids = []
|
| 364 |
+
for obj_id in list(obj_id_cat.keys()):
|
| 365 |
+
if obj_id_cat[obj_id] == cat:
|
| 366 |
+
valid_cat_ids.append(obj_id)
|
| 367 |
+
valid_obj_ids[cat] = valid_cat_ids
|
| 368 |
+
|
| 369 |
+
return vid_id, all_captions, valid_obj_ids
|
| 370 |
+
|
| 371 |
+
|
| 372 |
+
if __name__ == '__main__':
|
| 373 |
+
parser = argparse.ArgumentParser('ReferFormer training and evaluation script', parents=[opts.get_args_parser()])
|
| 374 |
+
parser.add_argument('--save_caption_path', type=str, default="mbench/numbered_captions.json")
|
| 375 |
+
parser.add_argument('--save_valid_obj_ids_path', type=str, default="mbench/numbered_valid_obj_ids.json")
|
| 376 |
+
|
| 377 |
+
args = parser.parse_args()
|
| 378 |
+
|
| 379 |
+
#==================데이터 불러오기===================
|
| 380 |
+
# 전체 데이터셋
|
| 381 |
+
train_dataset = build_ytvos_ref(image_set = 'train', args = args)
|
| 382 |
+
|
| 383 |
+
# 전체 데이터셋 메타데이터
|
| 384 |
+
metas = train_dataset.metas
|
| 385 |
+
|
| 386 |
+
# 색상 후보 8개 (RGB 형식)
|
| 387 |
+
colors = [
|
| 388 |
+
(255, 0, 0), # Red
|
| 389 |
+
(0, 255, 0), # Green
|
| 390 |
+
(0, 0, 255), # Blue
|
| 391 |
+
(255, 255, 0), # Yellow
|
| 392 |
+
(255, 0, 255), # Magenta
|
| 393 |
+
(0, 255, 255), # Cyan
|
| 394 |
+
(128, 0, 128), # Purple
|
| 395 |
+
(255, 165, 0) # Orange
|
| 396 |
+
]
|
| 397 |
+
|
| 398 |
+
ytvos_category_valid_list = [
|
| 399 |
+
'airplane', 'ape', 'bear', 'bird', 'boat', 'bus', 'camel', 'cat', 'cow', 'crocodile',
|
| 400 |
+
'deer', 'dog', 'dolphin', 'duck', 'eagle', 'earless_seal', 'elephant', 'fish', 'fox', 'frog',
|
| 401 |
+
'giant_panda', 'giraffe', 'hedgehog', 'horse', 'leopard', 'lion', 'lizard',
|
| 402 |
+
'monkey', 'motorbike', 'mouse', 'owl', 'parrot', 'penguin', 'person',
|
| 403 |
+
'rabbit', 'raccoon', 'sedan', 'shark', 'sheep', 'snail', 'snake',
|
| 404 |
+
'squirrel', 'tiger', 'train', 'truck', 'turtle', 'whale', 'zebra'
|
| 405 |
+
]
|
| 406 |
+
|
| 407 |
+
#==================gpt 돌리기===================
|
| 408 |
+
os.environ['OPENAI_API_KEY'] = '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'
|
| 409 |
+
|
| 410 |
+
result_captions = {}
|
| 411 |
+
result_valid_obj_ids = {}
|
| 412 |
+
|
| 413 |
+
for i in range(370):
|
| 414 |
+
vid_id, all_captions, valid_obj_ids = getCaption(i, True)
|
| 415 |
+
|
| 416 |
+
if vid_id not in result_captions:
|
| 417 |
+
result_captions[vid_id] = all_captions
|
| 418 |
+
if vid_id not in result_valid_obj_ids:
|
| 419 |
+
result_valid_obj_ids[vid_id] = valid_obj_ids
|
| 420 |
+
|
| 421 |
+
print("Finished!", flush=True)
|
| 422 |
+
|
| 423 |
+
with open(args.save_caption_path, "w") as file:
|
| 424 |
+
json.dump(result_captions, file, indent=4)
|
| 425 |
+
|
| 426 |
+
with open(args.save_valid_obj_ids_path, "w") as file:
|
| 427 |
+
json.dump(result_valid_obj_ids, file, indent=4)
|
.history/mbench/gpt_ref-ytvos_numbered_cy_20250201141952.py
ADDED
|
@@ -0,0 +1,460 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import sys
|
| 3 |
+
sys.path.append(os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
|
| 4 |
+
import time
|
| 5 |
+
|
| 6 |
+
from os import path as osp
|
| 7 |
+
from io import BytesIO
|
| 8 |
+
|
| 9 |
+
from mbench.ytvos_ref import build as build_ytvos_ref
|
| 10 |
+
import argparse
|
| 11 |
+
import opts
|
| 12 |
+
|
| 13 |
+
import sys
|
| 14 |
+
from pathlib import Path
|
| 15 |
+
import os
|
| 16 |
+
from os import path as osp
|
| 17 |
+
import skimage
|
| 18 |
+
from io import BytesIO
|
| 19 |
+
|
| 20 |
+
import numpy as np
|
| 21 |
+
import pandas as pd
|
| 22 |
+
import regex as re
|
| 23 |
+
import json
|
| 24 |
+
|
| 25 |
+
import cv2
|
| 26 |
+
from PIL import Image, ImageDraw
|
| 27 |
+
import torch
|
| 28 |
+
from torchvision.transforms import functional as F
|
| 29 |
+
|
| 30 |
+
from skimage import measure # (pip install scikit-image)
|
| 31 |
+
from shapely.geometry import Polygon, MultiPolygon # (pip install Shapely)
|
| 32 |
+
|
| 33 |
+
import matplotlib.pyplot as plt
|
| 34 |
+
import matplotlib.patches as patches
|
| 35 |
+
from matplotlib.collections import PatchCollection
|
| 36 |
+
from matplotlib.patches import Rectangle
|
| 37 |
+
import textwrap
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
import ipywidgets as widgets
|
| 41 |
+
from IPython.display import display, clear_output
|
| 42 |
+
|
| 43 |
+
from openai import OpenAI
|
| 44 |
+
import base64
|
| 45 |
+
import json
|
| 46 |
+
|
| 47 |
+
def number_objects_and_encode(idx, color_mask=False):
|
| 48 |
+
encoded_frames = {}
|
| 49 |
+
contoured_frames = {} # New dictionary for original images
|
| 50 |
+
vid_cat_cnts = {}
|
| 51 |
+
|
| 52 |
+
vid_meta = metas[idx]
|
| 53 |
+
vid_data = train_dataset[idx]
|
| 54 |
+
vid_id = vid_meta['video']
|
| 55 |
+
frame_indx = vid_meta['sample_indx']
|
| 56 |
+
cat_names = set(vid_meta['obj_id_cat'].values())
|
| 57 |
+
imgs = vid_data[0]
|
| 58 |
+
|
| 59 |
+
for cat in cat_names:
|
| 60 |
+
cat_frames = []
|
| 61 |
+
contour_frames = []
|
| 62 |
+
frame_cat_cnts = {}
|
| 63 |
+
|
| 64 |
+
for i in range(imgs.size(0)):
|
| 65 |
+
frame_name = frame_indx[i]
|
| 66 |
+
frame = np.copy(imgs[i].permute(1, 2, 0).numpy())
|
| 67 |
+
frame_for_contour = np.copy(imgs[i].permute(1, 2, 0).numpy())
|
| 68 |
+
|
| 69 |
+
frame_data = vid_data[2][frame_name]
|
| 70 |
+
obj_ids = list(frame_data.keys())
|
| 71 |
+
|
| 72 |
+
cat_cnt = 0
|
| 73 |
+
|
| 74 |
+
for j in range(len(obj_ids)):
|
| 75 |
+
obj_id = obj_ids[j]
|
| 76 |
+
obj_data = frame_data[obj_id]
|
| 77 |
+
obj_bbox = obj_data['bbox']
|
| 78 |
+
obj_valid = obj_data['valid']
|
| 79 |
+
obj_mask = obj_data['mask'].numpy().astype(np.uint8)
|
| 80 |
+
obj_cat = obj_data['category_name']
|
| 81 |
+
|
| 82 |
+
if obj_cat == cat and obj_valid:
|
| 83 |
+
cat_cnt += 1
|
| 84 |
+
|
| 85 |
+
if color_mask == False:
|
| 86 |
+
contours, _ = cv2.findContours(obj_mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
|
| 87 |
+
cv2.drawContours(frame, contours, -1, colors[j], 3)
|
| 88 |
+
for i, contour in enumerate(contours):
|
| 89 |
+
# 윤곽선 중심 계산
|
| 90 |
+
moments = cv2.moments(contour)
|
| 91 |
+
if moments["m00"] != 0: # 중심 계산 가능 여부 확인
|
| 92 |
+
cx = int(moments["m10"] / moments["m00"])
|
| 93 |
+
cy = int(moments["m01"] / moments["m00"])
|
| 94 |
+
else:
|
| 95 |
+
cx, cy = contour[0][0] # 중심 계산 불가시 대체 좌표 사용
|
| 96 |
+
|
| 97 |
+
# 텍스트 배경 (검은색 배경 만들기)
|
| 98 |
+
font = cv2.FONT_HERSHEY_SIMPLEX
|
| 99 |
+
text = obj_id
|
| 100 |
+
text_size = cv2.getTextSize(text, font, 1, 2)[0]
|
| 101 |
+
text_w, text_h = text_size
|
| 102 |
+
|
| 103 |
+
# 텍스트 배경 그리기 (검은색 배경)
|
| 104 |
+
cv2.rectangle(frame, (cx - text_w // 2 - 5, cy - text_h // 2 - 5),
|
| 105 |
+
(cx + text_w // 2 + 5, cy + text_h // 2 + 5), (0, 0, 0), -1)
|
| 106 |
+
|
| 107 |
+
# 텍스트 그리기 (흰색 텍스트)
|
| 108 |
+
cv2.putText(frame, text, (cx - text_w // 2, cy + text_h // 2),
|
| 109 |
+
font, 1, (255, 255, 255), 2)
|
| 110 |
+
|
| 111 |
+
else:
|
| 112 |
+
alpha = 0.08
|
| 113 |
+
|
| 114 |
+
colored_obj_mask = np.zeros_like(frame)
|
| 115 |
+
colored_obj_mask[obj_mask == 1] = colors[j]
|
| 116 |
+
frame[obj_mask == 1] = (
|
| 117 |
+
(1 - alpha) * frame[obj_mask == 1]
|
| 118 |
+
+ alpha * colored_obj_mask[obj_mask == 1]
|
| 119 |
+
)
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
contours, _ = cv2.findContours(obj_mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
|
| 123 |
+
cv2.drawContours(frame, contours, -1, colors[j], 2)
|
| 124 |
+
cv2.drawContours(frame_for_contour, contours, -1, colors[j], 2)
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
if len(contours) > 0:
|
| 129 |
+
largest_contour = max(contours, key=cv2.contourArea)
|
| 130 |
+
M = cv2.moments(largest_contour)
|
| 131 |
+
if M["m00"] != 0:
|
| 132 |
+
center_x = int(M["m10"] / M["m00"])
|
| 133 |
+
center_y = int(M["m01"] / M["m00"])
|
| 134 |
+
else:
|
| 135 |
+
center_x, center_y = 0, 0
|
| 136 |
+
|
| 137 |
+
font = cv2.FONT_HERSHEY_SIMPLEX
|
| 138 |
+
text = obj_id
|
| 139 |
+
|
| 140 |
+
font_scale = 0.9
|
| 141 |
+
text_size = cv2.getTextSize(text, font, font_scale, 2)[0]
|
| 142 |
+
text_x = center_x - text_size[0] // 1 # 텍스트의 가로 중심
|
| 143 |
+
text_y = center_y
|
| 144 |
+
# text_y = center_y + text_size[1] // 2 # 텍스트의 세로 중심
|
| 145 |
+
|
| 146 |
+
# 텍스트 배경 사각형 좌표 계산
|
| 147 |
+
rect_start = (text_x - 5, text_y - text_size[1] - 5) # 배경 사각형 좌상단
|
| 148 |
+
# rect_end = (text_x + text_size[0] + 5, text_y + 5)
|
| 149 |
+
rect_end = (text_x + text_size[0] + 5, text_y)
|
| 150 |
+
|
| 151 |
+
cv2.rectangle(frame, rect_start, rect_end, (0, 0, 0), -1)
|
| 152 |
+
cv2.putText(frame, text, (text_x, text_y), font, 1, (255, 255, 255), 2)
|
| 153 |
+
|
| 154 |
+
# plt.figure(figsize=(12, 8))
|
| 155 |
+
# plt.imshow(frame)
|
| 156 |
+
# plt.title(f"frame {frame_name}")
|
| 157 |
+
# plt.tight_layout()
|
| 158 |
+
# plt.axis('off')
|
| 159 |
+
# plt.show()
|
| 160 |
+
|
| 161 |
+
buffer = BytesIO()
|
| 162 |
+
frame = Image.fromarray(frame)
|
| 163 |
+
frame.save(buffer, format='jpeg')
|
| 164 |
+
buffer.seek(0)
|
| 165 |
+
cat_frames.append(base64.b64encode(buffer.read()).decode("utf-8"))
|
| 166 |
+
frame_cat_cnts[frame_name] = cat_cnt
|
| 167 |
+
|
| 168 |
+
buffer.seek(0) # Reuse buffer instead of creating a new one
|
| 169 |
+
buffer.truncate()
|
| 170 |
+
frame_for_contour = Image.fromarray(frame_for_contour)
|
| 171 |
+
frame_for_contour.save(buffer, format='jpeg')
|
| 172 |
+
buffer.seek(0)
|
| 173 |
+
contour_frames.append(base64.b64encode(buffer.read()).decode("utf-8"))
|
| 174 |
+
|
| 175 |
+
encoded_frames[cat] = cat_frames
|
| 176 |
+
contoured_frames[cat] = contour_frames
|
| 177 |
+
vid_cat_cnts[cat] = frame_cat_cnts
|
| 178 |
+
|
| 179 |
+
return encoded_frames, vid_cat_cnts, contoured_frames
|
| 180 |
+
|
| 181 |
+
|
| 182 |
+
def getCaption(idx, model='gpt-4o', color_mask=True):
|
| 183 |
+
vid_meta = metas[idx]
|
| 184 |
+
vid_data = train_dataset[idx]
|
| 185 |
+
vid_id = vid_meta['video']
|
| 186 |
+
print(f"vid id: {vid_id}\n")
|
| 187 |
+
|
| 188 |
+
frame_indx = vid_meta['sample_indx'] # e.g. [4, 7, 9, 16]
|
| 189 |
+
cat_names = set(vid_meta['obj_id_cat'].values()) # e.g. {"person", "elephant", ...}
|
| 190 |
+
all_captions = dict()
|
| 191 |
+
|
| 192 |
+
base64_frames, vid_cat_cnts, contoured_frames = number_objects_and_encode(idx, color_mask)
|
| 193 |
+
#marked = "mask with boundary" if color_mask else "boundary"
|
| 194 |
+
|
| 195 |
+
for cat_name in list(cat_names) :
|
| 196 |
+
|
| 197 |
+
is_movable = False
|
| 198 |
+
if cat_name in ytvos_category_valid_list :
|
| 199 |
+
is_movable = True
|
| 200 |
+
|
| 201 |
+
if not is_movable:
|
| 202 |
+
print(f"Skipping {cat_name}: Determined to be non-movable.", end='\n\n')
|
| 203 |
+
|
| 204 |
+
|
| 205 |
+
image_captions = {}
|
| 206 |
+
captioner = OpenAI()
|
| 207 |
+
cat_base64_frames = base64_frames[cat_name]
|
| 208 |
+
cont_base64_frames = contoured_frames[cat_name]
|
| 209 |
+
|
| 210 |
+
for i in range(len(cat_base64_frames)):
|
| 211 |
+
frame_name = frame_indx[i]
|
| 212 |
+
cont_base64_image = cont_base64_frames[i]
|
| 213 |
+
base64_image = cat_base64_frames[i]
|
| 214 |
+
should_filter = False
|
| 215 |
+
frame_cat_cnts = vid_cat_cnts[cat_name][frame_name]
|
| 216 |
+
|
| 217 |
+
if frame_cat_cnts >= 2:
|
| 218 |
+
should_filter = True
|
| 219 |
+
else:
|
| 220 |
+
print(f"Skipping {cat_name}: There is single or no object.", end='\n\n')
|
| 221 |
+
|
| 222 |
+
if is_movable and should_filter:
|
| 223 |
+
#1단계: 필터링
|
| 224 |
+
print(f"-----------category name: {cat_name}, frame name: {frame_name}")
|
| 225 |
+
caption_filter_text = f"""
|
| 226 |
+
You are a visual assistant analyzing a single frame from a video.
|
| 227 |
+
In this frame, I have labeled {frame_cat_cnts} {cat_name}(s), each with a bright numeric ID at its center and a visible marker.
|
| 228 |
+
|
| 229 |
+
Are {cat_name}s in the image performing all different and recognizable actions or postures?
|
| 230 |
+
Consider differences in body pose (standing, sitting, holding hands up, grabbing object, facing the camera, stretching, walking...), motion cues (inferred from the momentary stance or position),
|
| 231 |
+
facial expressions, and any notable interactions with objects or other {cat_name}s or people.
|
| 232 |
+
|
| 233 |
+
Only focus on obvious, prominent actions that can be reliably identified from this single frame.
|
| 234 |
+
|
| 235 |
+
- Respond with "YES" if:
|
| 236 |
+
1) Most of {cat_name}s exhibit clearly different, unique actions or poses.
|
| 237 |
+
(e.g. standing, sitting, bending, stretching, showing its back, or turning toward the camera.)
|
| 238 |
+
2) You can see visible significant differences in action and posture, that an observer can identify at a glance.
|
| 239 |
+
3) Interaction Variability: Each {cat_name} is engaged in a different type of action, such as one grasping an object while another is observing.
|
| 240 |
+
|
| 241 |
+
- Respond with "NONE" if:
|
| 242 |
+
1) The actions or pose are not clearly differentiable or too similar.
|
| 243 |
+
2) Minimal or Ambiguous Motion: The frame does not provide clear evidence of distinct movement beyond subtle shifts in stance.
|
| 244 |
+
3) Passive or Neutral Poses: If multiple {cat_name}(s) are simply standing or sitting without an obvious difference in orientation or motion
|
| 245 |
+
|
| 246 |
+
Answer strictly with either "YES" or "NONE".
|
| 247 |
+
"""
|
| 248 |
+
|
| 249 |
+
response1 = captioner.chat.completions.create(
|
| 250 |
+
model=model,
|
| 251 |
+
messages=[
|
| 252 |
+
{
|
| 253 |
+
"role": "user",
|
| 254 |
+
"content": [
|
| 255 |
+
{
|
| 256 |
+
"type": "text",
|
| 257 |
+
"text": caption_filter_text,
|
| 258 |
+
},
|
| 259 |
+
{
|
| 260 |
+
"type": "image_url",
|
| 261 |
+
"image_url": {"url": f"data:image/jpeg;base64,{base64_image}"},
|
| 262 |
+
}
|
| 263 |
+
],
|
| 264 |
+
}
|
| 265 |
+
],
|
| 266 |
+
)
|
| 267 |
+
response_content = response1.choices[0].message.content
|
| 268 |
+
should_caption = True if "yes" in response_content.lower() else False
|
| 269 |
+
print(f"are {cat_name}s distinguished by action: {response_content}", end='\n\n')
|
| 270 |
+
|
| 271 |
+
else:
|
| 272 |
+
should_caption = False
|
| 273 |
+
|
| 274 |
+
#2단계: dense caption 만들기
|
| 275 |
+
dense_caption_prompt_1 = f"""You are a visual assistant that can analyze a single frame of a video and create referring expressions for each object.
|
| 276 |
+
In the given frame, I labeled {frame_cat_cnts} {cat_name}s by marking each with a bright numeric ID at the center and its boundary.
|
| 277 |
+
I want to use your expressions to create a action-centric referring expression dataset.
|
| 278 |
+
Therefore, your expressions for these {cat_name}s should describe unique action of each object.
|
| 279 |
+
|
| 280 |
+
1. Focus only on clear, unique, and prominent actions that distinguish each object.
|
| 281 |
+
2. Avoid describing actions that are too minor, ambiguous, or not visible from the image.
|
| 282 |
+
3. Avoid subjective terms such as 'skilled', 'controlled', or 'focused'. Only describe observable actions.
|
| 283 |
+
4. Do not include common-sense or overly general descriptions like 'the elephant walks'.
|
| 284 |
+
5. Use dynamic action verbs (e.g., holding, throwing, jumping, inspecting) to describe interactions, poses, or movements.
|
| 285 |
+
6. Avoid overly detailed or speculative descriptions such as 'slightly moving its mouth' or 'appears to be anticipating'.
|
| 286 |
+
7. Pretend you are observing the scene directly, avoiding phrases like 'it seems' or 'based on the description'.
|
| 287 |
+
8. Include interactions with objects or other entities when they are prominent and observable.
|
| 288 |
+
9. If the image contains multiple {cat_name}s, describe the actions of each individually and ensure the descriptions are non-overlapping and specific.
|
| 289 |
+
10. Do not include descriptions of appearance such as clothes, color, size, shape etc.
|
| 290 |
+
11. Do not include relative position between objects such as 'the left elephant' because left/right can be ambiguous.
|
| 291 |
+
12. Do not mention object IDs.
|
| 292 |
+
13. Use '{cat_name}' as the noun for the referring expressions.
|
| 293 |
+
|
| 294 |
+
Keep in mind that you should not group the objects, e.g., 2-5. people: xxx, be sure to describe each object separately (one by one).
|
| 295 |
+
Output referring expressions for each object id.
|
| 296 |
+
"""
|
| 297 |
+
|
| 298 |
+
dense_caption_prompt = f"""
|
| 299 |
+
You are a visual assistant analyzing a single frame of a video.
|
| 300 |
+
In the given frame, I labeled {frame_cat_cnts} {cat_name}s by marking each with a bright numeric ID at the center and its boundary.
|
| 301 |
+
|
| 302 |
+
I want to use your expressions to create an **action-centric referring expression** dataset.
|
| 303 |
+
Please describe each {cat_name} using **clearly observable** and **specific** actions.
|
| 304 |
+
|
| 305 |
+
---
|
| 306 |
+
## Guidelines:
|
| 307 |
+
1. **Focus on visible, prominent actions** only (e.g., running, pushing, grasping an object).
|
| 308 |
+
2. **Avoid describing minor or ambiguous actions** (e.g., "slightly moving a paw", "slightly tilting head").
|
| 309 |
+
3. **Do not include subjective or speculative descriptions** (e.g., “it seems excited” or “it might be preparing to jump”).
|
| 310 |
+
4. **Avoid vague expressions** like "interacting with something" or "engaging with another object." Instead, specify the action (e.g., "grabbing a stick," "pressing a button").
|
| 311 |
+
5. **Use dynamic action verbs** (holding, throwing, inspecting, leaning, pressing) to highlight body movement or object/animal interaction.
|
| 312 |
+
6. If multiple {cat_name}s appear, ensure each description **differentiates** their actions.
|
| 313 |
+
7. Base your description on these action definitions:
|
| 314 |
+
- Avoid using term 'minimal' or 'slightly'.
|
| 315 |
+
- General body movement, body position, or pattern which is prominent. (e.g. "lifting head up", "facing towards", "showing its back")
|
| 316 |
+
- details such as motion and intention, facial with object manipulation
|
| 317 |
+
- movements with objects or other entities when they are prominent and observable. expression should be specific.
|
| 318 |
+
(e.g., "pushing another person" (O), "engaging with someone" (X) "interacting with another person" (X))
|
| 319 |
+
---
|
| 320 |
+
|
| 321 |
+
## Output Format:
|
| 322 |
+
- For each labeled {cat_name}, output **exactly one line**. Your answer should contain details and follow the following format :
|
| 323 |
+
object id. using {cat_name} as subject noun, action-oriented description
|
| 324 |
+
(e.g. 1. the person is holding ski poles and skiing on a snow mountain, with his two legs bent forward.)
|
| 325 |
+
- **Only include the currently labeled category** in each line (e.g., if it’s a person, do not suddenly label it as other object/animal).
|
| 326 |
+
|
| 327 |
+
### Example
|
| 328 |
+
If the frame has 2 labeled bears, your output should look like:
|
| 329 |
+
1. the bear reaching his right arm while leaning forward to capture the prey
|
| 330 |
+
2. a bear standing upright facing right, touching the bike aside
|
| 331 |
+
|
| 332 |
+
---
|
| 333 |
+
**Do not include** appearance details (e.g., color, size, texture) or relative positioning (e.g., “on the left/right”).
|
| 334 |
+
**Do not include object IDs** or reference them (e.g., "Person 1" or "object 2" is not allowed).
|
| 335 |
+
**Do not include markdown** in the output.
|
| 336 |
+
Keep in mind that you should not group the objects, e.g., 2-5. people: xxx, be sure to describe each object separately (one by one).
|
| 337 |
+
For each labeled {cat_name}, output referring expressions for each object id.
|
| 338 |
+
"""
|
| 339 |
+
MAX_RETRIES = 2
|
| 340 |
+
retry_count = 0
|
| 341 |
+
|
| 342 |
+
if should_caption:
|
| 343 |
+
while retry_count < MAX_RETRIES:
|
| 344 |
+
|
| 345 |
+
response2 = captioner.chat.completions.create(
|
| 346 |
+
model=model,
|
| 347 |
+
messages=[
|
| 348 |
+
{
|
| 349 |
+
"role": "user",
|
| 350 |
+
"content": [
|
| 351 |
+
{
|
| 352 |
+
"type": "text",
|
| 353 |
+
"text": dense_caption_prompt,
|
| 354 |
+
},
|
| 355 |
+
{
|
| 356 |
+
"type": "image_url",
|
| 357 |
+
"image_url": {"url": f"data:image/jpeg;base64,{base64_image}"},
|
| 358 |
+
},
|
| 359 |
+
],
|
| 360 |
+
}
|
| 361 |
+
],
|
| 362 |
+
)
|
| 363 |
+
|
| 364 |
+
# caption = response2.choices[0].message.content
|
| 365 |
+
#print(f"{image_path} - {frame_name}: {caption}")
|
| 366 |
+
|
| 367 |
+
caption = response2.choices[0].message.content.strip()
|
| 368 |
+
caption_lower = caption.lower().lstrip()
|
| 369 |
+
|
| 370 |
+
if caption_lower.startswith("1.") and not any(
|
| 371 |
+
phrase in caption_lower for phrase in ["i'm sorry", "please", "can't help"]
|
| 372 |
+
):
|
| 373 |
+
break
|
| 374 |
+
|
| 375 |
+
print(f"Retrying caption generation... ({retry_count + 1}/{MAX_RETRIES})")
|
| 376 |
+
retry_count += 1
|
| 377 |
+
time.sleep(2)
|
| 378 |
+
|
| 379 |
+
if retry_count == MAX_RETRIES:
|
| 380 |
+
caption = None
|
| 381 |
+
print("Max retries reached. Caption generation failed.")
|
| 382 |
+
|
| 383 |
+
else:
|
| 384 |
+
caption = None
|
| 385 |
+
|
| 386 |
+
image_captions[frame_name] = caption
|
| 387 |
+
all_captions[cat_name] = image_captions
|
| 388 |
+
|
| 389 |
+
# final : also prepare valid object ids
|
| 390 |
+
valid_obj_ids = dict()
|
| 391 |
+
|
| 392 |
+
for cat in cat_names:
|
| 393 |
+
if cat in ytvos_category_valid_list:
|
| 394 |
+
obj_id_cat = vid_meta['obj_id_cat']
|
| 395 |
+
valid_cat_ids = []
|
| 396 |
+
for obj_id in list(obj_id_cat.keys()):
|
| 397 |
+
if obj_id_cat[obj_id] == cat:
|
| 398 |
+
valid_cat_ids.append(obj_id)
|
| 399 |
+
valid_obj_ids[cat] = valid_cat_ids
|
| 400 |
+
|
| 401 |
+
return vid_id, all_captions, valid_obj_ids
|
| 402 |
+
|
| 403 |
+
|
| 404 |
+
|
| 405 |
+
if __name__ == '__main__':
|
| 406 |
+
parser = argparse.ArgumentParser('ReferFormer training and evaluation script', parents=[opts.get_args_parser()])
|
| 407 |
+
parser.add_argument('--save_caption_path', type=str, default="mbench/numbered_captions.json")
|
| 408 |
+
parser.add_argument('--save_valid_obj_ids_path', type=str, default="mbench/numbered_valid_obj_ids.json")
|
| 409 |
+
|
| 410 |
+
args = parser.parse_args()
|
| 411 |
+
|
| 412 |
+
#==================데이터 불러오기===================
|
| 413 |
+
# 전체 데이터셋
|
| 414 |
+
train_dataset = build_ytvos_ref(image_set = 'train', args = args)
|
| 415 |
+
|
| 416 |
+
# 전체 데이터셋 메타데이터
|
| 417 |
+
metas = train_dataset.metas
|
| 418 |
+
|
| 419 |
+
# 색상 후보 8개 (RGB 형식)
|
| 420 |
+
colors = [
|
| 421 |
+
(255, 0, 0), # Red
|
| 422 |
+
(0, 255, 0), # Green
|
| 423 |
+
(0, 0, 255), # Blue
|
| 424 |
+
(255, 255, 0), # Yellow
|
| 425 |
+
(255, 0, 255), # Magenta
|
| 426 |
+
(0, 255, 255), # Cyan
|
| 427 |
+
(128, 0, 128), # Purple
|
| 428 |
+
(255, 165, 0) # Orange
|
| 429 |
+
]
|
| 430 |
+
|
| 431 |
+
ytvos_category_valid_list = [
|
| 432 |
+
'airplane', 'ape', 'bear', 'bird', 'boat', 'bus', 'camel', 'cat', 'cow', 'crocodile',
|
| 433 |
+
'deer', 'dog', 'dolphin', 'duck', 'eagle', 'earless_seal', 'elephant', 'fish', 'fox', 'frog',
|
| 434 |
+
'giant_panda', 'giraffe', 'hedgehog', 'horse', 'leopard', 'lion', 'lizard',
|
| 435 |
+
'monkey', 'motorbike', 'mouse', 'owl', 'parrot', 'penguin', 'person',
|
| 436 |
+
'rabbit', 'raccoon', 'sedan', 'shark', 'sheep', 'snail', 'snake',
|
| 437 |
+
'squirrel', 'tiger', 'train', 'truck', 'turtle', 'whale', 'zebra'
|
| 438 |
+
]
|
| 439 |
+
|
| 440 |
+
#==================gpt 돌리기===================
|
| 441 |
+
os.environ['OPENAI_API_KEY'] = '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'
|
| 442 |
+
|
| 443 |
+
result_captions = {}
|
| 444 |
+
result_valid_obj_ids = {}
|
| 445 |
+
|
| 446 |
+
for i in range(370):
|
| 447 |
+
vid_id, all_captions, valid_obj_ids = getCaption(i)
|
| 448 |
+
|
| 449 |
+
if vid_id not in result_captions:
|
| 450 |
+
result_captions[vid_id] = all_captions
|
| 451 |
+
if vid_id not in result_valid_obj_ids:
|
| 452 |
+
result_valid_obj_ids[vid_id] = valid_obj_ids
|
| 453 |
+
|
| 454 |
+
print("Finished!", flush=True)
|
| 455 |
+
|
| 456 |
+
with open(args.save_caption_path, "w") as file:
|
| 457 |
+
json.dump(result_captions, file, indent=4)
|
| 458 |
+
|
| 459 |
+
with open(args.save_valid_obj_ids_path, "w") as file:
|
| 460 |
+
json.dump(result_valid_obj_ids, file, indent=4)
|
.history/mbench/gpt_ref-ytvos_numbered_cy_20250202183102.py
ADDED
|
@@ -0,0 +1,460 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import sys
|
| 3 |
+
sys.path.append(os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
|
| 4 |
+
import time
|
| 5 |
+
|
| 6 |
+
from os import path as osp
|
| 7 |
+
from io import BytesIO
|
| 8 |
+
|
| 9 |
+
from mbench.ytvos_ref import build as build_ytvos_ref
|
| 10 |
+
import argparse
|
| 11 |
+
import opts
|
| 12 |
+
|
| 13 |
+
import sys
|
| 14 |
+
from pathlib import Path
|
| 15 |
+
import os
|
| 16 |
+
from os import path as osp
|
| 17 |
+
import skimage
|
| 18 |
+
from io import BytesIO
|
| 19 |
+
|
| 20 |
+
import numpy as np
|
| 21 |
+
import pandas as pd
|
| 22 |
+
import regex as re
|
| 23 |
+
import json
|
| 24 |
+
|
| 25 |
+
import cv2
|
| 26 |
+
from PIL import Image, ImageDraw
|
| 27 |
+
import torch
|
| 28 |
+
from torchvision.transforms import functional as F
|
| 29 |
+
|
| 30 |
+
from skimage import measure # (pip install scikit-image)
|
| 31 |
+
from shapely.geometry import Polygon, MultiPolygon # (pip install Shapely)
|
| 32 |
+
|
| 33 |
+
import matplotlib.pyplot as plt
|
| 34 |
+
import matplotlib.patches as patches
|
| 35 |
+
from matplotlib.collections import PatchCollection
|
| 36 |
+
from matplotlib.patches import Rectangle
|
| 37 |
+
import textwrap
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
import ipywidgets as widgets
|
| 41 |
+
from IPython.display import display, clear_output
|
| 42 |
+
|
| 43 |
+
from openai import OpenAI
|
| 44 |
+
import base64
|
| 45 |
+
import json
|
| 46 |
+
|
| 47 |
+
def number_objects_and_encode(idx, color_mask=False):
|
| 48 |
+
encoded_frames = {}
|
| 49 |
+
contoured_frames = {} # New dictionary for original images
|
| 50 |
+
vid_cat_cnts = {}
|
| 51 |
+
|
| 52 |
+
vid_meta = metas[idx]
|
| 53 |
+
vid_data = train_dataset[idx]
|
| 54 |
+
vid_id = vid_meta['video']
|
| 55 |
+
frame_indx = vid_meta['sample_indx']
|
| 56 |
+
cat_names = set(vid_meta['obj_id_cat'].values())
|
| 57 |
+
imgs = vid_data[0]
|
| 58 |
+
|
| 59 |
+
for cat in cat_names:
|
| 60 |
+
cat_frames = []
|
| 61 |
+
contour_frames = []
|
| 62 |
+
frame_cat_cnts = {}
|
| 63 |
+
|
| 64 |
+
for i in range(imgs.size(0)):
|
| 65 |
+
frame_name = frame_indx[i]
|
| 66 |
+
frame = np.copy(imgs[i].permute(1, 2, 0).numpy())
|
| 67 |
+
frame_for_contour = np.copy(imgs[i].permute(1, 2, 0).numpy())
|
| 68 |
+
|
| 69 |
+
frame_data = vid_data[2][frame_name]
|
| 70 |
+
obj_ids = list(frame_data.keys())
|
| 71 |
+
|
| 72 |
+
cat_cnt = 0
|
| 73 |
+
|
| 74 |
+
for j in range(len(obj_ids)):
|
| 75 |
+
obj_id = obj_ids[j]
|
| 76 |
+
obj_data = frame_data[obj_id]
|
| 77 |
+
obj_bbox = obj_data['bbox']
|
| 78 |
+
obj_valid = obj_data['valid']
|
| 79 |
+
obj_mask = obj_data['mask'].numpy().astype(np.uint8)
|
| 80 |
+
obj_cat = obj_data['category_name']
|
| 81 |
+
|
| 82 |
+
if obj_cat == cat and obj_valid:
|
| 83 |
+
cat_cnt += 1
|
| 84 |
+
|
| 85 |
+
if color_mask == False:
|
| 86 |
+
contours, _ = cv2.findContours(obj_mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
|
| 87 |
+
cv2.drawContours(frame, contours, -1, colors[j], 3)
|
| 88 |
+
for i, contour in enumerate(contours):
|
| 89 |
+
# 윤곽선 중심 계산
|
| 90 |
+
moments = cv2.moments(contour)
|
| 91 |
+
if moments["m00"] != 0: # 중심 계산 가능 여부 확인
|
| 92 |
+
cx = int(moments["m10"] / moments["m00"])
|
| 93 |
+
cy = int(moments["m01"] / moments["m00"])
|
| 94 |
+
else:
|
| 95 |
+
cx, cy = contour[0][0] # 중심 계산 불가시 대체 좌표 사용
|
| 96 |
+
|
| 97 |
+
# 텍스트 배경 (검은색 배경 만들기)
|
| 98 |
+
font = cv2.FONT_HERSHEY_SIMPLEX
|
| 99 |
+
text = obj_id
|
| 100 |
+
text_size = cv2.getTextSize(text, font, 1, 2)[0]
|
| 101 |
+
text_w, text_h = text_size
|
| 102 |
+
|
| 103 |
+
# 텍스트 배경 그리기 (검은색 배경)
|
| 104 |
+
cv2.rectangle(frame, (cx - text_w // 2 - 5, cy - text_h // 2 - 5),
|
| 105 |
+
(cx + text_w // 2 + 5, cy + text_h // 2 + 5), (0, 0, 0), -1)
|
| 106 |
+
|
| 107 |
+
# 텍스트 그리기 (흰색 텍스트)
|
| 108 |
+
cv2.putText(frame, text, (cx - text_w // 2, cy + text_h // 2),
|
| 109 |
+
font, 1, (255, 255, 255), 2)
|
| 110 |
+
|
| 111 |
+
else:
|
| 112 |
+
alpha = 0.08
|
| 113 |
+
|
| 114 |
+
colored_obj_mask = np.zeros_like(frame)
|
| 115 |
+
colored_obj_mask[obj_mask == 1] = colors[j]
|
| 116 |
+
frame[obj_mask == 1] = (
|
| 117 |
+
(1 - alpha) * frame[obj_mask == 1]
|
| 118 |
+
+ alpha * colored_obj_mask[obj_mask == 1]
|
| 119 |
+
)
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
contours, _ = cv2.findContours(obj_mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
|
| 123 |
+
cv2.drawContours(frame, contours, -1, colors[j], 2)
|
| 124 |
+
cv2.drawContours(frame_for_contour, contours, -1, colors[j], 2)
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
if len(contours) > 0:
|
| 129 |
+
largest_contour = max(contours, key=cv2.contourArea)
|
| 130 |
+
M = cv2.moments(largest_contour)
|
| 131 |
+
if M["m00"] != 0:
|
| 132 |
+
center_x = int(M["m10"] / M["m00"])
|
| 133 |
+
center_y = int(M["m01"] / M["m00"])
|
| 134 |
+
else:
|
| 135 |
+
center_x, center_y = 0, 0
|
| 136 |
+
|
| 137 |
+
font = cv2.FONT_HERSHEY_SIMPLEX
|
| 138 |
+
text = obj_id
|
| 139 |
+
|
| 140 |
+
font_scale = 0.9
|
| 141 |
+
text_size = cv2.getTextSize(text, font, font_scale, 2)[0]
|
| 142 |
+
text_x = center_x - text_size[0] // 1 # 텍스트의 가로 중심
|
| 143 |
+
text_y = center_y
|
| 144 |
+
# text_y = center_y + text_size[1] // 2 # 텍스트의 세로 중심
|
| 145 |
+
|
| 146 |
+
# 텍스트 배경 사각형 좌표 계산
|
| 147 |
+
rect_start = (text_x - 5, text_y - text_size[1] - 5) # 배경 사각형 좌상단
|
| 148 |
+
# rect_end = (text_x + text_size[0] + 5, text_y + 5)
|
| 149 |
+
rect_end = (text_x + text_size[0] + 5, text_y)
|
| 150 |
+
|
| 151 |
+
cv2.rectangle(frame, rect_start, rect_end, (0, 0, 0), -1)
|
| 152 |
+
cv2.putText(frame, text, (text_x, text_y), font, 1, (255, 255, 255), 2)
|
| 153 |
+
|
| 154 |
+
# plt.figure(figsize=(12, 8))
|
| 155 |
+
# plt.imshow(frame)
|
| 156 |
+
# plt.title(f"frame {frame_name}")
|
| 157 |
+
# plt.tight_layout()
|
| 158 |
+
# plt.axis('off')
|
| 159 |
+
# plt.show()
|
| 160 |
+
|
| 161 |
+
buffer = BytesIO()
|
| 162 |
+
frame = Image.fromarray(frame)
|
| 163 |
+
frame.save(buffer, format='jpeg')
|
| 164 |
+
buffer.seek(0)
|
| 165 |
+
cat_frames.append(base64.b64encode(buffer.read()).decode("utf-8"))
|
| 166 |
+
frame_cat_cnts[frame_name] = cat_cnt
|
| 167 |
+
|
| 168 |
+
buffer.seek(0) # Reuse buffer instead of creating a new one
|
| 169 |
+
buffer.truncate()
|
| 170 |
+
frame_for_contour = Image.fromarray(frame_for_contour)
|
| 171 |
+
frame_for_contour.save(buffer, format='jpeg')
|
| 172 |
+
buffer.seek(0)
|
| 173 |
+
contour_frames.append(base64.b64encode(buffer.read()).decode("utf-8"))
|
| 174 |
+
|
| 175 |
+
encoded_frames[cat] = cat_frames
|
| 176 |
+
contoured_frames[cat] = contour_frames
|
| 177 |
+
vid_cat_cnts[cat] = frame_cat_cnts
|
| 178 |
+
|
| 179 |
+
return encoded_frames, vid_cat_cnts, contoured_frames
|
| 180 |
+
|
| 181 |
+
|
| 182 |
+
def getCaption(idx, model='gpt-4o', color_mask=True):
|
| 183 |
+
vid_meta = metas[idx]
|
| 184 |
+
vid_data = train_dataset[idx]
|
| 185 |
+
vid_id = vid_meta['video']
|
| 186 |
+
print(f"vid id: {vid_id}\n")
|
| 187 |
+
|
| 188 |
+
frame_indx = vid_meta['sample_indx'] # e.g. [4, 7, 9, 16]
|
| 189 |
+
cat_names = set(vid_meta['obj_id_cat'].values()) # e.g. {"person", "elephant", ...}
|
| 190 |
+
all_captions = dict()
|
| 191 |
+
|
| 192 |
+
base64_frames, vid_cat_cnts, contoured_frames = number_objects_and_encode(idx, color_mask)
|
| 193 |
+
#marked = "mask with boundary" if color_mask else "boundary"
|
| 194 |
+
|
| 195 |
+
for cat_name in list(cat_names) :
|
| 196 |
+
|
| 197 |
+
is_movable = False
|
| 198 |
+
if cat_name in ytvos_category_valid_list :
|
| 199 |
+
is_movable = True
|
| 200 |
+
|
| 201 |
+
if not is_movable:
|
| 202 |
+
print(f"Skipping {cat_name}: Determined to be non-movable.", end='\n\n')
|
| 203 |
+
|
| 204 |
+
|
| 205 |
+
image_captions = {}
|
| 206 |
+
captioner = OpenAI()
|
| 207 |
+
cat_base64_frames = base64_frames[cat_name]
|
| 208 |
+
cont_base64_frames = contoured_frames[cat_name]
|
| 209 |
+
|
| 210 |
+
for i in range(len(cat_base64_frames)):
|
| 211 |
+
frame_name = frame_indx[i]
|
| 212 |
+
cont_base64_image = cont_base64_frames[i]
|
| 213 |
+
base64_image = cat_base64_frames[i]
|
| 214 |
+
should_filter = False
|
| 215 |
+
frame_cat_cnts = vid_cat_cnts[cat_name][frame_name]
|
| 216 |
+
|
| 217 |
+
if frame_cat_cnts >= 2:
|
| 218 |
+
should_filter = True
|
| 219 |
+
else:
|
| 220 |
+
print(f"Skipping {cat_name}: There is single or no object.", end='\n\n')
|
| 221 |
+
|
| 222 |
+
if is_movable and should_filter:
|
| 223 |
+
#1단계: 필터링
|
| 224 |
+
print(f"-----------category name: {cat_name}, frame name: {frame_name}")
|
| 225 |
+
caption_filter_text = f"""
|
| 226 |
+
You are a visual assistant analyzing a single frame from a video.
|
| 227 |
+
In this frame, I have labeled {frame_cat_cnts} {cat_name}(s), each with a bright numeric ID at its center and a visible marker.
|
| 228 |
+
|
| 229 |
+
Are {cat_name}s in the image performing all different and recognizable actions or postures?
|
| 230 |
+
Consider differences in body pose (standing, sitting, holding hands up, grabbing object, facing the camera, stretching, walking...), motion cues (inferred from the momentary stance or position),
|
| 231 |
+
facial expressions, and any notable interactions with objects or other {cat_name}s or people.
|
| 232 |
+
|
| 233 |
+
Only focus on obvious, prominent actions that can be reliably identified from this single frame.
|
| 234 |
+
|
| 235 |
+
- Respond with "YES" if:
|
| 236 |
+
1) Most of {cat_name}s exhibit clearly different, unique actions or poses.
|
| 237 |
+
(e.g. standing, sitting, bending, stretching, showing its back, or turning toward the camera.)
|
| 238 |
+
2) You can see visible significant differences in action and posture, that an observer can identify at a glance.
|
| 239 |
+
3) Interaction Variability: Each {cat_name} is engaged in a different type of action, such as one grasping an object while another is observing.
|
| 240 |
+
|
| 241 |
+
- Respond with "NONE" if:
|
| 242 |
+
1) The actions or pose are not clearly differentiable or too similar.
|
| 243 |
+
2) Minimal or Ambiguous Motion: The frame does not provide clear evidence of distinct movement beyond subtle shifts in stance.
|
| 244 |
+
3) Passive or Neutral Poses: If multiple {cat_name}(s) are simply standing or sitting without an obvious difference in orientation or motion
|
| 245 |
+
|
| 246 |
+
Answer strictly with either "YES" or "NONE".
|
| 247 |
+
"""
|
| 248 |
+
|
| 249 |
+
response1 = captioner.chat.completions.create(
|
| 250 |
+
model=model,
|
| 251 |
+
messages=[
|
| 252 |
+
{
|
| 253 |
+
"role": "user",
|
| 254 |
+
"content": [
|
| 255 |
+
{
|
| 256 |
+
"type": "text",
|
| 257 |
+
"text": caption_filter_text,
|
| 258 |
+
},
|
| 259 |
+
{
|
| 260 |
+
"type": "image_url",
|
| 261 |
+
"image_url": {"url": f"data:image/jpeg;base64,{base64_image}"},
|
| 262 |
+
}
|
| 263 |
+
],
|
| 264 |
+
}
|
| 265 |
+
],
|
| 266 |
+
)
|
| 267 |
+
response_content = response1.choices[0].message.content
|
| 268 |
+
should_caption = True if "yes" in response_content.lower() else False
|
| 269 |
+
print(f"are {cat_name}s distinguished by action: {response_content}", end='\n\n')
|
| 270 |
+
|
| 271 |
+
else:
|
| 272 |
+
should_caption = False
|
| 273 |
+
|
| 274 |
+
#2단계: dense caption 만들기
|
| 275 |
+
dense_caption_prompt_1 = f"""You are a visual assistant that can analyze a single frame of a video and create referring expressions for each object.
|
| 276 |
+
In the given frame, I labeled {frame_cat_cnts} {cat_name}s by marking each with a bright numeric ID at the center and its boundary.
|
| 277 |
+
I want to use your expressions to create a action-centric referring expression dataset.
|
| 278 |
+
Therefore, your expressions for these {cat_name}s should describe unique action of each object.
|
| 279 |
+
|
| 280 |
+
1. Focus only on clear, unique, and prominent actions that distinguish each object.
|
| 281 |
+
2. Avoid describing actions that are too minor, ambiguous, or not visible from the image.
|
| 282 |
+
3. Avoid subjective terms such as 'skilled', 'controlled', or 'focused'. Only describe observable actions.
|
| 283 |
+
4. Do not include common-sense or overly general descriptions like 'the elephant walks'.
|
| 284 |
+
5. Use dynamic action verbs (e.g., holding, throwing, jumping, inspecting) to describe interactions, poses, or movements.
|
| 285 |
+
6. Avoid overly detailed or speculative descriptions such as 'slightly moving its mouth' or 'appears to be anticipating'.
|
| 286 |
+
7. Pretend you are observing the scene directly, avoiding phrases like 'it seems' or 'based on the description'.
|
| 287 |
+
8. Include interactions with objects or other entities when they are prominent and observable.
|
| 288 |
+
9. If the image contains multiple {cat_name}s, describe the actions of each individually and ensure the descriptions are non-overlapping and specific.
|
| 289 |
+
10. Do not include descriptions of appearance such as clothes, color, size, shape etc.
|
| 290 |
+
11. Do not include relative position between objects such as 'the left elephant' because left/right can be ambiguous.
|
| 291 |
+
12. Do not mention object IDs.
|
| 292 |
+
13. Use '{cat_name}' as the noun for the referring expressions.
|
| 293 |
+
|
| 294 |
+
Keep in mind that you should not group the objects, e.g., 2-5. people: xxx, be sure to describe each object separately (one by one).
|
| 295 |
+
Output referring expressions for each object id.
|
| 296 |
+
"""
|
| 297 |
+
|
| 298 |
+
dense_caption_prompt = f"""
|
| 299 |
+
You are a visual assistant analyzing a single frame of a video.
|
| 300 |
+
In the given frame, I labeled {frame_cat_cnts} {cat_name}s by marking each with a bright numeric ID at the center and its boundary.
|
| 301 |
+
|
| 302 |
+
I want to use your expressions to create an **action-centric referring expression** dataset.
|
| 303 |
+
Please describe each {cat_name} using **clearly observable** and **specific** actions.
|
| 304 |
+
|
| 305 |
+
---
|
| 306 |
+
## Guidelines:
|
| 307 |
+
1. **Focus on visible, prominent actions** only (e.g., running, pushing, grasping an object).
|
| 308 |
+
2. **Avoid describing minor or ambiguous actions** (e.g., "slightly moving a paw", "slightly tilting head").
|
| 309 |
+
3. **Do not include subjective or speculative descriptions** (e.g., “it seems excited” or “it might be preparing to jump”).
|
| 310 |
+
4. **Avoid vague expressions** like "interacting with something" or "engaging with another object." Instead, specify the action (e.g., "grabbing a stick," "pressing a button").
|
| 311 |
+
5. **Use dynamic action verbs** (holding, throwing, inspecting, leaning, pressing) to highlight body movement or object/animal interaction.
|
| 312 |
+
6. If multiple {cat_name}s appear, ensure each description **differentiates** their actions.
|
| 313 |
+
7. Base your description on these action definitions:
|
| 314 |
+
- Avoid using term 'minimal' or 'slightly'.
|
| 315 |
+
- General body movement, body position, or pattern which is prominent. (e.g. "lifting head up", "facing towards", "showing its back")
|
| 316 |
+
- details such as motion and intention, facial with object manipulation
|
| 317 |
+
- movements with objects or other entities when they are prominent and observable. expression should be specific.
|
| 318 |
+
(e.g., "pushing another person" (O), "engaging with someone" (X) "interacting with another person" (X))
|
| 319 |
+
---
|
| 320 |
+
|
| 321 |
+
## Output Format:
|
| 322 |
+
- For each labeled {cat_name}, output **exactly one line**. Your answer should contain details and follow the following format :
|
| 323 |
+
object id. using {cat_name} as subject noun, action-oriented description
|
| 324 |
+
(e.g. 1. the person is holding ski poles and skiing on a snow mountain, with his two legs bent forward.)
|
| 325 |
+
- **Only include the currently labeled category** in each line (e.g., if it’s a person, do not suddenly label it as other object/animal).
|
| 326 |
+
|
| 327 |
+
### Example
|
| 328 |
+
If the frame has 2 labeled bears, your output should look like:
|
| 329 |
+
1. the bear reaching his right arm while leaning forward to capture the prey
|
| 330 |
+
2. a bear standing upright facing right, touching the bike aside
|
| 331 |
+
|
| 332 |
+
---
|
| 333 |
+
**Do not include** appearance details (e.g., color, size, texture) or relative positioning (e.g., “on the left/right”).
|
| 334 |
+
**Do not include object IDs** or reference them (e.g., "Person 1" or "object 2" is not allowed).
|
| 335 |
+
**Do not include markdown** in the output.
|
| 336 |
+
Keep in mind that you should not group the objects, e.g., 2-5. people: xxx, be sure to describe each object separately (one by one).
|
| 337 |
+
For each labeled {cat_name}, output referring expressions for each object id.
|
| 338 |
+
"""
|
| 339 |
+
MAX_RETRIES = 2
|
| 340 |
+
retry_count = 0
|
| 341 |
+
|
| 342 |
+
if should_caption:
|
| 343 |
+
while retry_count < MAX_RETRIES:
|
| 344 |
+
|
| 345 |
+
response2 = captioner.chat.completions.create(
|
| 346 |
+
model=model,
|
| 347 |
+
messages=[
|
| 348 |
+
{
|
| 349 |
+
"role": "user",
|
| 350 |
+
"content": [
|
| 351 |
+
{
|
| 352 |
+
"type": "text",
|
| 353 |
+
"text": dense_caption_prompt,
|
| 354 |
+
},
|
| 355 |
+
{
|
| 356 |
+
"type": "image_url",
|
| 357 |
+
"image_url": {"url": f"data:image/jpeg;base64,{base64_image}"},
|
| 358 |
+
},
|
| 359 |
+
],
|
| 360 |
+
}
|
| 361 |
+
],
|
| 362 |
+
)
|
| 363 |
+
|
| 364 |
+
# caption = response2.choices[0].message.content
|
| 365 |
+
#print(f"{image_path} - {frame_name}: {caption}")
|
| 366 |
+
|
| 367 |
+
caption = response2.choices[0].message.content.strip()
|
| 368 |
+
caption_lower = caption.lower().lstrip()
|
| 369 |
+
|
| 370 |
+
if caption_lower.startswith("1.") and not any(
|
| 371 |
+
phrase in caption_lower for phrase in ["i'm sorry", "please", "can't help"]
|
| 372 |
+
):
|
| 373 |
+
break
|
| 374 |
+
|
| 375 |
+
print(f"Retrying caption generation... ({retry_count + 1}/{MAX_RETRIES})")
|
| 376 |
+
retry_count += 1
|
| 377 |
+
time.sleep(2)
|
| 378 |
+
|
| 379 |
+
if retry_count == MAX_RETRIES:
|
| 380 |
+
caption = None
|
| 381 |
+
print("Max retries reached. Caption generation failed.")
|
| 382 |
+
|
| 383 |
+
else:
|
| 384 |
+
caption = None
|
| 385 |
+
|
| 386 |
+
image_captions[frame_name] = caption
|
| 387 |
+
all_captions[cat_name] = image_captions
|
| 388 |
+
|
| 389 |
+
# final : also prepare valid object ids
|
| 390 |
+
valid_obj_ids = dict()
|
| 391 |
+
|
| 392 |
+
for cat in cat_names:
|
| 393 |
+
if cat in ytvos_category_valid_list:
|
| 394 |
+
obj_id_cat = vid_meta['obj_id_cat']
|
| 395 |
+
valid_cat_ids = []
|
| 396 |
+
for obj_id in list(obj_id_cat.keys()):
|
| 397 |
+
if obj_id_cat[obj_id] == cat:
|
| 398 |
+
valid_cat_ids.append(obj_id)
|
| 399 |
+
valid_obj_ids[cat] = valid_cat_ids
|
| 400 |
+
|
| 401 |
+
return vid_id, all_captions, valid_obj_ids
|
| 402 |
+
|
| 403 |
+
|
| 404 |
+
|
| 405 |
+
if __name__ == '__main__':
|
| 406 |
+
parser = argparse.ArgumentParser('ReferFormer training and evaluation script', parents=[opts.get_args_parser()])
|
| 407 |
+
parser.add_argument('--save_caption_path', type=str, default="mbench/numbered_captions.json")
|
| 408 |
+
parser.add_argument('--save_valid_obj_ids_path', type=str, default="mbench/numbered_valid_obj_ids.json")
|
| 409 |
+
|
| 410 |
+
args = parser.parse_args()
|
| 411 |
+
|
| 412 |
+
#==================데이터 불러오기===================
|
| 413 |
+
# 전체 데이터셋
|
| 414 |
+
train_dataset = build_ytvos_ref(image_set = 'train', args = args)
|
| 415 |
+
|
| 416 |
+
# 전체 데이터셋 메타데이터
|
| 417 |
+
metas = train_dataset.metas
|
| 418 |
+
|
| 419 |
+
# 색상 후보 8개 (RGB 형식)
|
| 420 |
+
colors = [
|
| 421 |
+
(255, 0, 0), # Red
|
| 422 |
+
(0, 255, 0), # Green
|
| 423 |
+
(0, 0, 255), # Blue
|
| 424 |
+
(255, 255, 0), # Yellow
|
| 425 |
+
(255, 0, 255), # Magenta
|
| 426 |
+
(0, 255, 255), # Cyan
|
| 427 |
+
(128, 0, 128), # Purple
|
| 428 |
+
(255, 165, 0) # Orange
|
| 429 |
+
]
|
| 430 |
+
|
| 431 |
+
ytvos_category_valid_list = [
|
| 432 |
+
'airplane', 'ape', 'bear', 'bird', 'boat', 'bus', 'camel', 'cat', 'cow', 'crocodile',
|
| 433 |
+
'deer', 'dog', 'dolphin', 'duck', 'eagle', 'earless_seal', 'elephant', 'fish', 'fox', 'frog',
|
| 434 |
+
'giant_panda', 'giraffe', 'hedgehog', 'horse', 'leopard', 'lion', 'lizard',
|
| 435 |
+
'monkey', 'motorbike', 'mouse', 'owl', 'parrot', 'penguin', 'person',
|
| 436 |
+
'rabbit', 'raccoon', 'sedan', 'shark', 'sheep', 'snail', 'snake',
|
| 437 |
+
'squirrel', 'tiger', 'train', 'truck', 'turtle', 'whale', 'zebra'
|
| 438 |
+
]
|
| 439 |
+
|
| 440 |
+
#==================gpt 돌리기===================
|
| 441 |
+
os.environ['OPENAI_API_KEY'] = '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'
|
| 442 |
+
|
| 443 |
+
result_captions = {}
|
| 444 |
+
result_valid_obj_ids = {}
|
| 445 |
+
|
| 446 |
+
for i in range(370):
|
| 447 |
+
vid_id, all_captions, valid_obj_ids = getCaption(i, color_mask=False)
|
| 448 |
+
|
| 449 |
+
if vid_id not in result_captions:
|
| 450 |
+
result_captions[vid_id] = all_captions
|
| 451 |
+
if vid_id not in result_valid_obj_ids:
|
| 452 |
+
result_valid_obj_ids[vid_id] = valid_obj_ids
|
| 453 |
+
|
| 454 |
+
print("Finished!", flush=True)
|
| 455 |
+
|
| 456 |
+
with open(args.save_caption_path, "w") as file:
|
| 457 |
+
json.dump(result_captions, file, indent=4)
|
| 458 |
+
|
| 459 |
+
with open(args.save_valid_obj_ids_path, "w") as file:
|
| 460 |
+
json.dump(result_valid_obj_ids, file, indent=4)
|
.history/mbench/gpt_ref-ytvos_numbered_cy_sanity_2_20250207172804.py
ADDED
|
@@ -0,0 +1,656 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import sys
|
| 3 |
+
sys.path.append(os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
|
| 4 |
+
import time
|
| 5 |
+
|
| 6 |
+
from os import path as osp
|
| 7 |
+
from io import BytesIO
|
| 8 |
+
import random
|
| 9 |
+
|
| 10 |
+
from mbench.ytvos_ref import build as build_ytvos_ref
|
| 11 |
+
import argparse
|
| 12 |
+
import opts
|
| 13 |
+
|
| 14 |
+
import sys
|
| 15 |
+
from pathlib import Path
|
| 16 |
+
import os
|
| 17 |
+
from os import path as osp
|
| 18 |
+
import skimage
|
| 19 |
+
from io import BytesIO
|
| 20 |
+
|
| 21 |
+
import numpy as np
|
| 22 |
+
import pandas as pd
|
| 23 |
+
import regex as re
|
| 24 |
+
import json
|
| 25 |
+
|
| 26 |
+
import cv2
|
| 27 |
+
from PIL import Image, ImageDraw
|
| 28 |
+
import torch
|
| 29 |
+
from torchvision.transforms import functional as F
|
| 30 |
+
|
| 31 |
+
from skimage import measure # (pip install scikit-image)
|
| 32 |
+
from shapely.geometry import Polygon, MultiPolygon # (pip install Shapely)
|
| 33 |
+
|
| 34 |
+
import matplotlib.pyplot as plt
|
| 35 |
+
import matplotlib.patches as patches
|
| 36 |
+
from matplotlib.collections import PatchCollection
|
| 37 |
+
from matplotlib.patches import Rectangle
|
| 38 |
+
import textwrap
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
import ipywidgets as widgets
|
| 42 |
+
from IPython.display import display, clear_output
|
| 43 |
+
|
| 44 |
+
from openai import OpenAI
|
| 45 |
+
import base64
|
| 46 |
+
import json
|
| 47 |
+
import requests
|
| 48 |
+
from openai.error import APIConnectionError, OpenAIError
|
| 49 |
+
|
| 50 |
+
def number_objects_and_encode_old(idx, color_mask=False):
|
| 51 |
+
encoded_frames = {}
|
| 52 |
+
contoured_frames = {} # New dictionary for original images
|
| 53 |
+
vid_cat_cnts = {}
|
| 54 |
+
|
| 55 |
+
vid_meta = metas[idx]
|
| 56 |
+
vid_data = train_dataset[idx]
|
| 57 |
+
vid_id = vid_meta['video']
|
| 58 |
+
frame_indx = vid_meta['sample_indx']
|
| 59 |
+
cat_names = set(vid_meta['obj_id_cat'].values())
|
| 60 |
+
imgs = vid_data[0]
|
| 61 |
+
|
| 62 |
+
for cat in cat_names:
|
| 63 |
+
cat_frames = []
|
| 64 |
+
contour_frames = []
|
| 65 |
+
frame_cat_cnts = {}
|
| 66 |
+
|
| 67 |
+
for i in range(imgs.size(0)):
|
| 68 |
+
frame_name = frame_indx[i]
|
| 69 |
+
frame = np.copy(imgs[i].permute(1, 2, 0).numpy())
|
| 70 |
+
frame_for_contour = np.copy(imgs[i].permute(1, 2, 0).numpy())
|
| 71 |
+
|
| 72 |
+
frame_data = vid_data[2][frame_name]
|
| 73 |
+
obj_ids = list(frame_data.keys())
|
| 74 |
+
|
| 75 |
+
cat_cnt = 0
|
| 76 |
+
|
| 77 |
+
for j in range(len(obj_ids)):
|
| 78 |
+
obj_id = obj_ids[j]
|
| 79 |
+
obj_data = frame_data[obj_id]
|
| 80 |
+
obj_bbox = obj_data['bbox']
|
| 81 |
+
obj_valid = obj_data['valid']
|
| 82 |
+
obj_mask = obj_data['mask'].numpy().astype(np.uint8)
|
| 83 |
+
obj_cat = obj_data['category_name']
|
| 84 |
+
|
| 85 |
+
if obj_cat == cat and obj_valid:
|
| 86 |
+
cat_cnt += 1
|
| 87 |
+
|
| 88 |
+
if color_mask == False:
|
| 89 |
+
contours, _ = cv2.findContours(obj_mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
|
| 90 |
+
cv2.drawContours(frame, contours, -1, colors[j], 3)
|
| 91 |
+
for i, contour in enumerate(contours):
|
| 92 |
+
moments = cv2.moments(contour)
|
| 93 |
+
if moments["m00"] != 0:
|
| 94 |
+
cx = int(moments["m10"] / moments["m00"])
|
| 95 |
+
cy = int(moments["m01"] / moments["m00"])
|
| 96 |
+
else:
|
| 97 |
+
cx, cy = contour[0][0]
|
| 98 |
+
|
| 99 |
+
font = cv2.FONT_HERSHEY_SIMPLEX
|
| 100 |
+
text = obj_id
|
| 101 |
+
text_size = cv2.getTextSize(text, font, 1, 2)[0]
|
| 102 |
+
text_w, text_h = text_size
|
| 103 |
+
|
| 104 |
+
cv2.rectangle(frame, (cx - text_w // 2 - 5, cy - text_h // 2 - 5),
|
| 105 |
+
(cx + text_w // 2 + 5, cy + text_h // 2 + 5), (0, 0, 0), -1)
|
| 106 |
+
|
| 107 |
+
cv2.putText(frame, text, (cx - text_w // 2, cy + text_h // 2),
|
| 108 |
+
font, 1, (255, 255, 255), 2)
|
| 109 |
+
|
| 110 |
+
else:
|
| 111 |
+
alpha = 0.08
|
| 112 |
+
|
| 113 |
+
colored_obj_mask = np.zeros_like(frame)
|
| 114 |
+
colored_obj_mask[obj_mask == 1] = colors[j]
|
| 115 |
+
frame[obj_mask == 1] = (
|
| 116 |
+
(1 - alpha) * frame[obj_mask == 1]
|
| 117 |
+
+ alpha * colored_obj_mask[obj_mask == 1]
|
| 118 |
+
)
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
contours, _ = cv2.findContours(obj_mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
|
| 122 |
+
cv2.drawContours(frame, contours, -1, colors[j], 2)
|
| 123 |
+
cv2.drawContours(frame_for_contour, contours, -1, colors[j], 2)
|
| 124 |
+
|
| 125 |
+
if len(contours) > 0:
|
| 126 |
+
largest_contour = max(contours, key=cv2.contourArea)
|
| 127 |
+
M = cv2.moments(largest_contour)
|
| 128 |
+
if M["m00"] != 0:
|
| 129 |
+
center_x = int(M["m10"] / M["m00"])
|
| 130 |
+
center_y = int(M["m01"] / M["m00"])
|
| 131 |
+
else:
|
| 132 |
+
center_x, center_y = 0, 0
|
| 133 |
+
|
| 134 |
+
font = cv2.FONT_HERSHEY_SIMPLEX
|
| 135 |
+
text = obj_id
|
| 136 |
+
|
| 137 |
+
font_scale = 0.9
|
| 138 |
+
text_size = cv2.getTextSize(text, font, font_scale, 2)[0]
|
| 139 |
+
text_x = center_x - text_size[0] // 1
|
| 140 |
+
text_y = center_y
|
| 141 |
+
|
| 142 |
+
rect_start = (text_x - 5, text_y - text_size[1] - 5)
|
| 143 |
+
rect_end = (text_x + text_size[0] + 5, text_y)
|
| 144 |
+
|
| 145 |
+
cv2.rectangle(frame, rect_start, rect_end, (0, 0, 0), -1)
|
| 146 |
+
cv2.putText(frame, text, (text_x, text_y), font, 1, (255, 255, 255), 2)
|
| 147 |
+
|
| 148 |
+
# plt.figure(figsize=(12, 8))
|
| 149 |
+
# plt.imshow(frame)
|
| 150 |
+
# plt.title(f"frame {frame_name}")
|
| 151 |
+
# plt.tight_layout()
|
| 152 |
+
# plt.axis('off')
|
| 153 |
+
# plt.show()
|
| 154 |
+
|
| 155 |
+
buffer = BytesIO()
|
| 156 |
+
frame = Image.fromarray(frame)
|
| 157 |
+
frame.save(buffer, format='jpeg')
|
| 158 |
+
buffer.seek(0)
|
| 159 |
+
cat_frames.append(base64.b64encode(buffer.read()).decode("utf-8"))
|
| 160 |
+
frame_cat_cnts[frame_name] = cat_cnt
|
| 161 |
+
|
| 162 |
+
buffer.seek(0) # Reuse buffer instead of creating a new one
|
| 163 |
+
buffer.truncate()
|
| 164 |
+
frame_for_contour = Image.fromarray(frame_for_contour)
|
| 165 |
+
frame_for_contour.save(buffer, format='jpeg')
|
| 166 |
+
buffer.seek(0)
|
| 167 |
+
contour_frames.append(base64.b64encode(buffer.read()).decode("utf-8"))
|
| 168 |
+
|
| 169 |
+
encoded_frames[cat] = cat_frames
|
| 170 |
+
contoured_frames[cat] = contour_frames
|
| 171 |
+
vid_cat_cnts[cat] = frame_cat_cnts
|
| 172 |
+
|
| 173 |
+
return encoded_frames, contoured_frames, vid_cat_cnts
|
| 174 |
+
|
| 175 |
+
|
| 176 |
+
def number_objects_and_encode(idx, color_mask=False):
|
| 177 |
+
encoded_frames = {}
|
| 178 |
+
contoured_frames = {} # New dictionary for original images
|
| 179 |
+
vid_cat_cnts = {}
|
| 180 |
+
|
| 181 |
+
vid_meta = metas[idx]
|
| 182 |
+
vid_data = train_dataset[idx]
|
| 183 |
+
vid_id = vid_meta['video']
|
| 184 |
+
frame_indx = vid_meta['sample_indx']
|
| 185 |
+
cat_names = set(vid_meta['obj_id_cat'].values())
|
| 186 |
+
imgs = vid_data[0]
|
| 187 |
+
|
| 188 |
+
for cat in cat_names:
|
| 189 |
+
cat_frames = []
|
| 190 |
+
contour_frames = []
|
| 191 |
+
frame_cat_cnts = {}
|
| 192 |
+
|
| 193 |
+
for i in range(imgs.size(0)):
|
| 194 |
+
frame_name = frame_indx[i]
|
| 195 |
+
frame = np.copy(imgs[i].permute(1, 2, 0).numpy())
|
| 196 |
+
frame_for_contour = np.copy(imgs[i].permute(1, 2, 0).numpy())
|
| 197 |
+
|
| 198 |
+
frame_data = vid_data[2][frame_name]
|
| 199 |
+
obj_ids = list(frame_data.keys())
|
| 200 |
+
|
| 201 |
+
cat_cnt = 0
|
| 202 |
+
|
| 203 |
+
for j in range(len(obj_ids)):
|
| 204 |
+
obj_id = obj_ids[j]
|
| 205 |
+
obj_data = frame_data[obj_id]
|
| 206 |
+
obj_bbox = obj_data['bbox']
|
| 207 |
+
obj_valid = obj_data['valid']
|
| 208 |
+
obj_mask = obj_data['mask'].numpy().astype(np.uint8)
|
| 209 |
+
obj_cat = obj_data['category_name']
|
| 210 |
+
|
| 211 |
+
if obj_cat == cat and obj_valid:
|
| 212 |
+
cat_cnt += 1
|
| 213 |
+
|
| 214 |
+
contours, _ = cv2.findContours(obj_mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
|
| 215 |
+
cv2.drawContours(frame, contours, -1, colors[j], 3)
|
| 216 |
+
cv2.drawContours(frame_for_contour, contours, -1, colors[j], 2)
|
| 217 |
+
|
| 218 |
+
if len(contours) > 0:
|
| 219 |
+
largest_contour = max(contours, key=cv2.contourArea)
|
| 220 |
+
M = cv2.moments(largest_contour)
|
| 221 |
+
if M["m00"] != 0:
|
| 222 |
+
center_x = int(M["m10"] / M["m00"])
|
| 223 |
+
center_y = int(M["m01"] / M["m00"])
|
| 224 |
+
else:
|
| 225 |
+
center_x, center_y = 0, 0
|
| 226 |
+
|
| 227 |
+
font = cv2.FONT_HERSHEY_SIMPLEX
|
| 228 |
+
text = obj_id
|
| 229 |
+
font_scale = 1.2
|
| 230 |
+
text_size = cv2.getTextSize(text, font, font_scale, 2)[0]
|
| 231 |
+
text_x = center_x - text_size[0] // 1
|
| 232 |
+
text_y = center_y
|
| 233 |
+
|
| 234 |
+
rect_start = (text_x - 5, text_y - text_size[1] - 5)
|
| 235 |
+
rect_end = (text_x + text_size[0] + 5, text_y + 3)
|
| 236 |
+
|
| 237 |
+
contour_thickness = 1
|
| 238 |
+
rect_start_contour = (rect_start[0] - contour_thickness, rect_start[1] - contour_thickness)
|
| 239 |
+
rect_end_contour = (rect_end[0] + contour_thickness, rect_end[1] + contour_thickness)
|
| 240 |
+
|
| 241 |
+
cv2.rectangle(frame, rect_start_contour, rect_end_contour, colors[j], contour_thickness)
|
| 242 |
+
cv2.rectangle(frame, rect_start, rect_end, (0, 0, 0), -1)
|
| 243 |
+
cv2.putText(frame, text, (text_x, text_y), font, 1, (255, 255, 255), 2)
|
| 244 |
+
|
| 245 |
+
|
| 246 |
+
if color_mask:
|
| 247 |
+
alpha = 0.08
|
| 248 |
+
colored_obj_mask = np.zeros_like(frame)
|
| 249 |
+
colored_obj_mask[obj_mask == 1] = colors[j]
|
| 250 |
+
frame[obj_mask == 1] = (
|
| 251 |
+
(1 - alpha) * frame[obj_mask == 1]
|
| 252 |
+
+ alpha * colored_obj_mask[obj_mask == 1]
|
| 253 |
+
)
|
| 254 |
+
|
| 255 |
+
# plt.figure(figsize=(12, 8))
|
| 256 |
+
# plt.imshow(frame)
|
| 257 |
+
# plt.title(f"frame {frame_name}")
|
| 258 |
+
# plt.tight_layout()
|
| 259 |
+
# plt.axis('off')
|
| 260 |
+
# plt.show()
|
| 261 |
+
|
| 262 |
+
buffer = BytesIO()
|
| 263 |
+
frame = Image.fromarray(frame)
|
| 264 |
+
frame.save(buffer, format='jpeg')
|
| 265 |
+
buffer.seek(0)
|
| 266 |
+
cat_frames.append(base64.b64encode(buffer.read()).decode("utf-8"))
|
| 267 |
+
frame_cat_cnts[frame_name] = cat_cnt
|
| 268 |
+
|
| 269 |
+
buffer.seek(0) # Reuse buffer instead of creating a new one
|
| 270 |
+
buffer.truncate()
|
| 271 |
+
frame_for_contour = Image.fromarray(frame_for_contour)
|
| 272 |
+
frame_for_contour.save(buffer, format='jpeg')
|
| 273 |
+
buffer.seek(0)
|
| 274 |
+
contour_frames.append(base64.b64encode(buffer.read()).decode("utf-8"))
|
| 275 |
+
|
| 276 |
+
encoded_frames[cat] = cat_frames
|
| 277 |
+
contoured_frames[cat] = contour_frames
|
| 278 |
+
vid_cat_cnts[cat] = frame_cat_cnts
|
| 279 |
+
|
| 280 |
+
return encoded_frames, contoured_frames, vid_cat_cnts
|
| 281 |
+
|
| 282 |
+
|
| 283 |
+
|
| 284 |
+
def getCaption(idx, model='gpt-4o'):
|
| 285 |
+
vid_meta = metas[idx]
|
| 286 |
+
vid_data = train_dataset[idx]
|
| 287 |
+
vid_id = vid_meta['video']
|
| 288 |
+
print(f"vid id: {vid_id}\n")
|
| 289 |
+
|
| 290 |
+
frame_indx = vid_meta['sample_indx'] # e.g. [4, 7, 9, 16]
|
| 291 |
+
cat_names = set(vid_meta['obj_id_cat'].values()) # e.g. {"person", "elephant", ...}
|
| 292 |
+
all_captions = dict()
|
| 293 |
+
|
| 294 |
+
# color_mask = random.choice([True, False])
|
| 295 |
+
color_mask = random.choices([False, True], weights=[60, 40])[0]
|
| 296 |
+
|
| 297 |
+
base64_frames, _ , vid_cat_cnts = number_objects_and_encode(idx, color_mask)
|
| 298 |
+
#marked = "mask with boundary" if color_mask else "boundary"
|
| 299 |
+
|
| 300 |
+
for cat_name in list(cat_names) :
|
| 301 |
+
|
| 302 |
+
is_movable = False
|
| 303 |
+
if cat_name in ytvos_category_valid_list :
|
| 304 |
+
is_movable = True
|
| 305 |
+
|
| 306 |
+
if not is_movable:
|
| 307 |
+
print(f"Skipping {cat_name}: Determined to be non-movable.", end='\n\n')
|
| 308 |
+
|
| 309 |
+
|
| 310 |
+
image_captions = {}
|
| 311 |
+
captioner = OpenAI()
|
| 312 |
+
cat_base64_frames = base64_frames[cat_name]
|
| 313 |
+
# cont_base64_frames = contoured_frames[cat_name]
|
| 314 |
+
|
| 315 |
+
for i in range(len(cat_base64_frames)):
|
| 316 |
+
frame_name = frame_indx[i]
|
| 317 |
+
# cont_base64_image = cont_base64_frames[i]
|
| 318 |
+
base64_image = cat_base64_frames[i]
|
| 319 |
+
should_filter = False
|
| 320 |
+
frame_cat_cnts = vid_cat_cnts[cat_name][frame_name]
|
| 321 |
+
|
| 322 |
+
if frame_cat_cnts >= 2:
|
| 323 |
+
should_filter = True
|
| 324 |
+
else:
|
| 325 |
+
print(f"Skipping {cat_name}: There is single or no object.", end='\n\n')
|
| 326 |
+
|
| 327 |
+
|
| 328 |
+
if is_movable and should_filter:
|
| 329 |
+
#1단계: 필터링
|
| 330 |
+
print(f"-----------category name: {cat_name}, frame name: {frame_name}")
|
| 331 |
+
caption_filter_text = f"""
|
| 332 |
+
You are a visual assistant analyzing a single frame from a video.
|
| 333 |
+
In this frame, I have labeled {frame_cat_cnts} {cat_name}(s), each with a bright numeric ID at its center and a visible marker.
|
| 334 |
+
|
| 335 |
+
Are {cat_name}s in the image performing all different and recognizable actions or postures?
|
| 336 |
+
Consider differences in body pose (standing, sitting, holding hands up, grabbing object, facing the camera, stretching, walking...), motion cues (inferred from the momentary stance or position),
|
| 337 |
+
facial expressions, and any notable interactions with objects or other {cat_name}s or people.
|
| 338 |
+
|
| 339 |
+
Only focus on obvious, prominent actions that can be reliably identified from this single frame.
|
| 340 |
+
|
| 341 |
+
- Respond with "YES" if:
|
| 342 |
+
1) Most of {cat_name}s exhibit clearly different, unique actions or poses.
|
| 343 |
+
(e.g. standing, sitting, bending, stretching, showing its back, or turning toward the camera.)
|
| 344 |
+
2) You can see visible significant differences in action and posture, that an observer can identify at a glance.
|
| 345 |
+
3) Interaction Variability: Each {cat_name} is engaged in a different type of action, such as one grasping an object while another is observing.
|
| 346 |
+
|
| 347 |
+
- Respond with "NONE" if:
|
| 348 |
+
1) The actions or pose are not clearly differentiable or too similar.
|
| 349 |
+
2) Minimal or Ambiguous Motion: The frame does not provide clear evidence of distinct movement beyond subtle shifts in stance.
|
| 350 |
+
3) Passive or Neutral Poses: If multiple {cat_name}(s) are simply standing or sitting without an obvious difference in orientation or motion
|
| 351 |
+
|
| 352 |
+
Answer strictly with either "YES" or "NONE".
|
| 353 |
+
"""
|
| 354 |
+
|
| 355 |
+
response1 = captioner.chat.completions.create(
|
| 356 |
+
model=model,
|
| 357 |
+
messages=[
|
| 358 |
+
{
|
| 359 |
+
"role": "user",
|
| 360 |
+
"content": [
|
| 361 |
+
{
|
| 362 |
+
"type": "text",
|
| 363 |
+
"text": caption_filter_text,
|
| 364 |
+
},
|
| 365 |
+
{
|
| 366 |
+
"type": "image_url",
|
| 367 |
+
"image_url": {"url": f"data:image/jpeg;base64,{base64_image}"},
|
| 368 |
+
}
|
| 369 |
+
],
|
| 370 |
+
}
|
| 371 |
+
],
|
| 372 |
+
)
|
| 373 |
+
response_content = response1.choices[0].message.content
|
| 374 |
+
should_caption = True if "yes" in response_content.lower() else False
|
| 375 |
+
print(f"are {cat_name}s distinguished by action: {response_content}", end='\n\n')
|
| 376 |
+
|
| 377 |
+
else:
|
| 378 |
+
should_caption = False
|
| 379 |
+
|
| 380 |
+
#2단계: dense caption 만들기
|
| 381 |
+
dense_caption_prompt_1 = f"""
|
| 382 |
+
In the given frame, I labeled {frame_cat_cnts} {cat_name}s by marking each with a bright numeric ID at the center and its boundary. The category name of these objects are : {cat_name}.
|
| 383 |
+
|
| 384 |
+
Please describe the image focusing on labeled {cat_name}s in detail, focusing on their actions and interactions.
|
| 385 |
+
|
| 386 |
+
1. Focus only on clear, unique, and prominent actions that distinguish each object.
|
| 387 |
+
2. Avoid describing actions that are too minor, ambiguous, or not visible from the image.
|
| 388 |
+
3. Avoid subjective terms such as 'skilled', 'controlled', or 'focused'. Only describe observable actions.
|
| 389 |
+
4. Do not include common-sense or overly general descriptions like 'the elephant walks'.
|
| 390 |
+
5. Use dynamic action verbs (e.g., holding, throwing, jumping, inspecting) to describe interactions, poses, or movements.
|
| 391 |
+
6. **Avoid overly detailed or speculative descriptions** such as 'slightly moving its mouth' or 'appears to be anticipating'.
|
| 392 |
+
- expressions like 'seems to be', 'appears to be' are BANNED!
|
| 393 |
+
7. Pretend you are observing the scene directly, avoiding phrases like 'it seems' or 'based on the description'.
|
| 394 |
+
8. Include interactions with objects or other entities when they are prominent and observable.
|
| 395 |
+
9. **Do not include descriptions of appearance** such as clothes, color, size, shape etc.
|
| 396 |
+
10. **Do not include relative position** between objects such as 'the left elephant' because left/right can be ambiguous.
|
| 397 |
+
11. Do not mention object IDs.
|
| 398 |
+
12. Use '{cat_name}' as the noun for the referring expressions.
|
| 399 |
+
|
| 400 |
+
Note that I want to use your description to create a grounding dataset, therefore, your descriptions for different objects should be unique, i.e., If the image contains multiple {cat_name}s, describe the actions of each individually and ensure the descriptions are non-overlapping and specific.
|
| 401 |
+
|
| 402 |
+
- Your answer should contain details, and follow the following format:
|
| 403 |
+
object id. action-oriented description
|
| 404 |
+
(e.g. 1. the person is holding bananas on two hands and opening his mouth, turning the head right.
|
| 405 |
+
2. a person bending over and touching his boots to tie the shoelace.)
|
| 406 |
+
- for action-oriented description, use {cat_name} as subject noun
|
| 407 |
+
|
| 408 |
+
**Only include the currently labeled category** in each line (e.g., if it’s a person, do not suddenly label it as other object/animal).
|
| 409 |
+
Please pay attention to the categories of these objects and don’t change them.
|
| 410 |
+
Keep in mind that you should not group the objects, e.g., 2-5. people: xxx, be sure to describe each object separately (one by one).
|
| 411 |
+
Output referring expressions for each object id. Please start your answer:"""
|
| 412 |
+
|
| 413 |
+
|
| 414 |
+
dense_caption_prompt_2 = f"""
|
| 415 |
+
You are an advanced visual language model analyzing a video frame.
|
| 416 |
+
In this frame, {frame_cat_cnts} objects belonging to the category **{cat_name}** have been distinctly labeled with bright numerical IDs at their center and boundary.
|
| 417 |
+
|
| 418 |
+
Your task is to generate **action-oriented descriptions** for each labeled {cat_name}.
|
| 419 |
+
Your descriptions should capture their **observable actions and interactions**, making sure to highlight movement, gestures, and dynamic behaviors.
|
| 420 |
+
|
| 421 |
+
---
|
| 422 |
+
## Key Guidelines:
|
| 423 |
+
1. **Describe only clear and visible actions** that uniquely define what the {cat_name} is doing.
|
| 424 |
+
- Example: "grabbing a branch and pulling it down" (**(O) Specific**)
|
| 425 |
+
- Avoid: "moving slightly to the side" (**(X) Too vague**)
|
| 426 |
+
|
| 427 |
+
2. **Do not describe appearance, color, or position**—focus purely on the action.
|
| 428 |
+
- (X) "A large brown bear standing on the left"
|
| 429 |
+
- (O) "The bear is lifting its front paws and swiping forward."
|
| 430 |
+
|
| 431 |
+
3. **Use dynamic, action-specific verbs** rather than passive descriptions.
|
| 432 |
+
- (O) "The giraffe is tilting its head and sniffing the ground."
|
| 433 |
+
- (X) "The giraffe is near a tree and looking around."
|
| 434 |
+
|
| 435 |
+
4. **Avoid assumptions, emotions, or speculative phrasing.**
|
| 436 |
+
- (X) "The person seems excited" / "The person might be preparing to jump."
|
| 437 |
+
- (O) "The person is pushing its front legs against the rock and leaping forward."
|
| 438 |
+
|
| 439 |
+
5. **Avoid overly detailed or speculative descriptions** such as 'slightly moving its mouth' or 'appears to be anticipating'.
|
| 440 |
+
- expressions like 'seems to be', 'appears to be' are BANNED!
|
| 441 |
+
6. Pretend you are observing the scene directly, avoiding phrases like 'it seems' or 'based on the description'.
|
| 442 |
+
|
| 443 |
+
7. If multiple {cat_name}s are present, make sure their descriptions are **distinct and non-overlapping**.
|
| 444 |
+
- **Each object should have a unique, descriptive action.**
|
| 445 |
+
- (X) "Two dogs are running."
|
| 446 |
+
- (O) "1. One dog is chasing another, its legs stretched mid-air.
|
| 447 |
+
2. The other dog is looking back while speeding up."
|
| 448 |
+
|
| 449 |
+
---
|
| 450 |
+
## Output Format:
|
| 451 |
+
- Each labeled **{cat_name}** should have exactly **one line of description**.
|
| 452 |
+
- Format: `ID. {cat_name} + action-based description`
|
| 453 |
+
- (O) Example:
|
| 454 |
+
```
|
| 455 |
+
1. The person is leaning forward while opening a bag with both hands.
|
| 456 |
+
2. The person is holding onto a rope and pulling themselves up.
|
| 457 |
+
```
|
| 458 |
+
- **Ensure that each object is described individually.**
|
| 459 |
+
- **Do not group objects into a single sentence** (e.g., "2-5. people: xxx" is NOT allowed).
|
| 460 |
+
|
| 461 |
+
---
|
| 462 |
+
## Additional Instructions:
|
| 463 |
+
- **Do NOT** use expressions like "it appears that..." or "it seems like...".
|
| 464 |
+
- **Do NOT** mention object IDs in the description (only use the provided format).
|
| 465 |
+
- **DO NOT** include markdown formatting (no bullet points, no asterisks).
|
| 466 |
+
- **Only describe actions of the labeled {cat_name} objects**—do not introduce unrelated categories.
|
| 467 |
+
|
| 468 |
+
Please generate the action-oriented descriptions for each labeled {cat_name} and start your answer:
|
| 469 |
+
"""
|
| 470 |
+
|
| 471 |
+
|
| 472 |
+
dense_caption_prompt = f"""
|
| 473 |
+
You are a visual assistant analyzing a single frame of a video.
|
| 474 |
+
In this frame, {frame_cat_cnts} objects belonging to the category **{cat_name}** have been labeled with bright numeric IDs at their center and boundary.
|
| 475 |
+
|
| 476 |
+
I am building an **action-centric referring expression** dataset.
|
| 477 |
+
Your task is to describe each labeled {cat_name} based on **clearly observable and specific actions**.
|
| 478 |
+
|
| 479 |
+
---
|
| 480 |
+
## Guidelines:
|
| 481 |
+
1. **Focus only on visible and prominent actions** (e.g., running, pushing, grasping an object).
|
| 482 |
+
2. **Avoid describing minor or ambiguous movements** (e.g., "slightly moving a paw," "tilting head a bit").
|
| 483 |
+
3. **Do not include subjective or speculative descriptions** (e.g., "it seems excited" or "it might be preparing to jump").
|
| 484 |
+
4. **Avoid vague expressions** like "engaging with something." Instead, specify the action (e.g., "grabbing a stick," "pressing a button").
|
| 485 |
+
5. **Use dynamic action verbs** (e.g., holding, throwing, inspecting, leaning, pressing) to highlight motion and interaction.
|
| 486 |
+
6. If multiple {cat_name}s appear, ensure each description is **distinct and non-overlapping**.
|
| 487 |
+
7. Base your descriptions on these principles:
|
| 488 |
+
- **Avoid words like 'minimal' or 'slightly'.**
|
| 489 |
+
- Emphasize **body movement, posture, and motion patterns** (e.g., "lifting its head," "facing forward," "showing its back").
|
| 490 |
+
- Describe **facial expressions and interactions with objects** (e.g., "opening its mouth wide," "smiling while holding an item").
|
| 491 |
+
- **Specify actions with other objects or entities** only when they are clear and observable.
|
| 492 |
+
- (O) "pushing another person"
|
| 493 |
+
- (X) "interacting with another object"
|
| 494 |
+
|
| 495 |
+
---
|
| 496 |
+
## Output Format:
|
| 497 |
+
- Each labeled **{cat_name}** must have **exactly one line**.
|
| 498 |
+
- Format: `ID. {cat_name} + action-based description`
|
| 499 |
+
- (O) Example:
|
| 500 |
+
```
|
| 501 |
+
1. The person is holding ski poles and skiing down a snowy mountain with bent knees.
|
| 502 |
+
2. The person is pulling a baby carriage while smiling.
|
| 503 |
+
```
|
| 504 |
+
- **Ensure each object is described individually.**
|
| 505 |
+
- **Do not group multiple objects into a single sentence** (e.g., "2-5. people: xxx" is NOT allowed).
|
| 506 |
+
|
| 507 |
+
---
|
| 508 |
+
## Example:
|
| 509 |
+
If the frame has two labeled **bears**, your output should be:
|
| 510 |
+
```
|
| 511 |
+
1. The bear is reaching out its right paw while leaning forward to catch prey.
|
| 512 |
+
2. A bear is standing upright, facing right, and touching the bike beside it.
|
| 513 |
+
```
|
| 514 |
+
|
| 515 |
+
---
|
| 516 |
+
## Additional Instructions:
|
| 517 |
+
- **Do NOT** describe appearance (e.g., color, size, texture) or relative positioning (e.g., "on the left/right").
|
| 518 |
+
- **Do NOT** reference object IDs explicitly (e.g., "Person 1" or "Object 2" is NOT allowed).
|
| 519 |
+
- **Do NOT** include markdown formatting (no bullet points, asterisks, or extra symbols).
|
| 520 |
+
- **Only describe actions of the labeled {cat_name} objects**—do not introduce unrelated categories.
|
| 521 |
+
|
| 522 |
+
Please generate the action-oriented descriptions for each labeled {cat_name} and start your answer:"""
|
| 523 |
+
|
| 524 |
+
|
| 525 |
+
MAX_RETRIES = 3
|
| 526 |
+
retry_count = 0
|
| 527 |
+
|
| 528 |
+
if should_caption:
|
| 529 |
+
while retry_count < MAX_RETRIES:
|
| 530 |
+
selected_prompt = random.choice([dense_caption_prompt, dense_caption_prompt_2])
|
| 531 |
+
|
| 532 |
+
response2 = captioner.chat.completions.create(
|
| 533 |
+
model=model,
|
| 534 |
+
messages=[
|
| 535 |
+
{
|
| 536 |
+
"role": "user",
|
| 537 |
+
"content": [
|
| 538 |
+
{
|
| 539 |
+
"type": "text",
|
| 540 |
+
"text": selected_prompt,
|
| 541 |
+
},
|
| 542 |
+
{
|
| 543 |
+
"type": "image_url",
|
| 544 |
+
"image_url": {"url": f"data:image/jpeg;base64,{base64_image}"},
|
| 545 |
+
},
|
| 546 |
+
],
|
| 547 |
+
}
|
| 548 |
+
],
|
| 549 |
+
)
|
| 550 |
+
|
| 551 |
+
# caption = response2.choices[0].message.content
|
| 552 |
+
#print(f"{image_path} - {frame_name}: {caption}")
|
| 553 |
+
|
| 554 |
+
caption = response2.choices[0].message.content.strip()
|
| 555 |
+
caption_lower = caption.lower().lstrip()
|
| 556 |
+
|
| 557 |
+
if caption_lower.startswith("1.") and not any(
|
| 558 |
+
phrase in caption_lower for phrase in ["i'm sorry", "please", "can't help"]
|
| 559 |
+
):
|
| 560 |
+
break
|
| 561 |
+
|
| 562 |
+
print(f"Retrying caption generation... ({retry_count + 1}/{MAX_RETRIES})")
|
| 563 |
+
retry_count += 1
|
| 564 |
+
time.sleep(2)
|
| 565 |
+
|
| 566 |
+
if retry_count == MAX_RETRIES:
|
| 567 |
+
caption = None
|
| 568 |
+
print("Max retries reached. Caption generation failed.")
|
| 569 |
+
|
| 570 |
+
else:
|
| 571 |
+
caption = None
|
| 572 |
+
|
| 573 |
+
image_captions[frame_name] = caption
|
| 574 |
+
all_captions[cat_name] = image_captions
|
| 575 |
+
|
| 576 |
+
# final : also prepare valid object ids
|
| 577 |
+
valid_obj_ids = dict()
|
| 578 |
+
|
| 579 |
+
for cat in cat_names:
|
| 580 |
+
if cat in ytvos_category_valid_list:
|
| 581 |
+
obj_id_cat = vid_meta['obj_id_cat']
|
| 582 |
+
valid_cat_ids = []
|
| 583 |
+
for obj_id in list(obj_id_cat.keys()):
|
| 584 |
+
if obj_id_cat[obj_id] == cat:
|
| 585 |
+
valid_cat_ids.append(obj_id)
|
| 586 |
+
valid_obj_ids[cat] = valid_cat_ids
|
| 587 |
+
|
| 588 |
+
return vid_id, all_captions, valid_obj_ids
|
| 589 |
+
|
| 590 |
+
|
| 591 |
+
if __name__ == '__main__':
|
| 592 |
+
parser = argparse.ArgumentParser('ReferFormer training and evaluation script', parents=[opts.get_args_parser()])
|
| 593 |
+
parser.add_argument('--save_caption_path', type=str, default="mbench/numbered_captions_gpt-4o_randcap.json")
|
| 594 |
+
parser.add_argument('--save_valid_obj_ids_path', type=str, default="mbench/numbered_valid_obj_ids_gpt-4o_randcap.json")
|
| 595 |
+
|
| 596 |
+
args = parser.parse_args()
|
| 597 |
+
|
| 598 |
+
#==================데이터 불러오기===================
|
| 599 |
+
# 전체 데이터셋
|
| 600 |
+
train_dataset = build_ytvos_ref(image_set = 'train', args = args)
|
| 601 |
+
|
| 602 |
+
# 전체 데이터셋 메타데이터
|
| 603 |
+
metas = train_dataset.metas
|
| 604 |
+
|
| 605 |
+
# 색상 후보 8개 (RGB 형식)
|
| 606 |
+
colors = [
|
| 607 |
+
(255, 0, 0), # Red
|
| 608 |
+
(0, 255, 0), # Green
|
| 609 |
+
(0, 0, 255), # Blue
|
| 610 |
+
(255, 255, 0), # Yellow
|
| 611 |
+
(255, 0, 255), # Magenta
|
| 612 |
+
(0, 255, 255), # Cyan
|
| 613 |
+
(128, 0, 128), # Purple
|
| 614 |
+
(255, 165, 0) # Orange
|
| 615 |
+
]
|
| 616 |
+
|
| 617 |
+
ytvos_category_valid_list = [
|
| 618 |
+
'airplane', 'ape', 'bear', 'bird', 'boat', 'bus', 'camel', 'cat', 'cow', 'crocodile',
|
| 619 |
+
'deer', 'dog', 'dolphin', 'duck', 'eagle', 'earless_seal', 'elephant', 'fish', 'fox', 'frog',
|
| 620 |
+
'giant_panda', 'giraffe', 'hedgehog', 'horse', 'leopard', 'lion', 'lizard',
|
| 621 |
+
'monkey', 'motorbike', 'mouse', 'owl', 'parrot', 'penguin', 'person',
|
| 622 |
+
'rabbit', 'raccoon', 'sedan', 'shark', 'sheep', 'snail', 'snake',
|
| 623 |
+
'squirrel', 'tiger', 'train', 'truck', 'turtle', 'whale', 'zebra'
|
| 624 |
+
]
|
| 625 |
+
|
| 626 |
+
#==================gpt 돌리기===================
|
| 627 |
+
os.environ['OPENAI_API_KEY'] = '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'
|
| 628 |
+
|
| 629 |
+
result_captions = {}
|
| 630 |
+
result_valid_obj_ids = {}
|
| 631 |
+
|
| 632 |
+
for i in range(len(metas)):
|
| 633 |
+
try:
|
| 634 |
+
vid_id, all_captions, valid_obj_ids = getCaption(i)
|
| 635 |
+
|
| 636 |
+
if vid_id not in result_captions:
|
| 637 |
+
result_captions[vid_id] = all_captions
|
| 638 |
+
if vid_id not in result_valid_obj_ids:
|
| 639 |
+
result_valid_obj_ids[vid_id] = valid_obj_ids
|
| 640 |
+
|
| 641 |
+
except (requests.exceptions.ConnectionError, APIConnectionError) as e:
|
| 642 |
+
print(f"created caption until {i-1}", flush=True)
|
| 643 |
+
|
| 644 |
+
with open(args.save_caption_path, "w") as file:
|
| 645 |
+
json.dump(result_captions, file, indent=4)
|
| 646 |
+
|
| 647 |
+
with open(args.save_valid_obj_ids_path, "w") as file:
|
| 648 |
+
json.dump(result_valid_obj_ids, file, indent=4)
|
| 649 |
+
|
| 650 |
+
print("Finished!", flush=True)
|
| 651 |
+
|
| 652 |
+
with open(args.save_caption_path, "w") as file:
|
| 653 |
+
json.dump(result_captions, file, indent=4)
|
| 654 |
+
|
| 655 |
+
with open(args.save_valid_obj_ids_path, "w") as file:
|
| 656 |
+
json.dump(result_valid_obj_ids, file, indent=4)
|
.history/mbench/gpt_ref-ytvos_numbered_cy_sanity_2_20250207173210.py
ADDED
|
@@ -0,0 +1,656 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import sys
|
| 3 |
+
sys.path.append(os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
|
| 4 |
+
import time
|
| 5 |
+
|
| 6 |
+
from os import path as osp
|
| 7 |
+
from io import BytesIO
|
| 8 |
+
import random
|
| 9 |
+
|
| 10 |
+
from mbench.ytvos_ref import build as build_ytvos_ref
|
| 11 |
+
import argparse
|
| 12 |
+
import opts
|
| 13 |
+
|
| 14 |
+
import sys
|
| 15 |
+
from pathlib import Path
|
| 16 |
+
import os
|
| 17 |
+
from os import path as osp
|
| 18 |
+
import skimage
|
| 19 |
+
from io import BytesIO
|
| 20 |
+
|
| 21 |
+
import numpy as np
|
| 22 |
+
import pandas as pd
|
| 23 |
+
import regex as re
|
| 24 |
+
import json
|
| 25 |
+
|
| 26 |
+
import cv2
|
| 27 |
+
from PIL import Image, ImageDraw
|
| 28 |
+
import torch
|
| 29 |
+
from torchvision.transforms import functional as F
|
| 30 |
+
|
| 31 |
+
from skimage import measure # (pip install scikit-image)
|
| 32 |
+
from shapely.geometry import Polygon, MultiPolygon # (pip install Shapely)
|
| 33 |
+
|
| 34 |
+
import matplotlib.pyplot as plt
|
| 35 |
+
import matplotlib.patches as patches
|
| 36 |
+
from matplotlib.collections import PatchCollection
|
| 37 |
+
from matplotlib.patches import Rectangle
|
| 38 |
+
import textwrap
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
import ipywidgets as widgets
|
| 42 |
+
from IPython.display import display, clear_output
|
| 43 |
+
|
| 44 |
+
from openai import OpenAI
|
| 45 |
+
import base64
|
| 46 |
+
import json
|
| 47 |
+
import requests
|
| 48 |
+
from openai.error import APIConnectionError, OpenAIError
|
| 49 |
+
|
| 50 |
+
def number_objects_and_encode_old(idx, color_mask=False):
|
| 51 |
+
encoded_frames = {}
|
| 52 |
+
contoured_frames = {} # New dictionary for original images
|
| 53 |
+
vid_cat_cnts = {}
|
| 54 |
+
|
| 55 |
+
vid_meta = metas[idx]
|
| 56 |
+
vid_data = train_dataset[idx]
|
| 57 |
+
vid_id = vid_meta['video']
|
| 58 |
+
frame_indx = vid_meta['sample_indx']
|
| 59 |
+
cat_names = set(vid_meta['obj_id_cat'].values())
|
| 60 |
+
imgs = vid_data[0]
|
| 61 |
+
|
| 62 |
+
for cat in cat_names:
|
| 63 |
+
cat_frames = []
|
| 64 |
+
contour_frames = []
|
| 65 |
+
frame_cat_cnts = {}
|
| 66 |
+
|
| 67 |
+
for i in range(imgs.size(0)):
|
| 68 |
+
frame_name = frame_indx[i]
|
| 69 |
+
frame = np.copy(imgs[i].permute(1, 2, 0).numpy())
|
| 70 |
+
frame_for_contour = np.copy(imgs[i].permute(1, 2, 0).numpy())
|
| 71 |
+
|
| 72 |
+
frame_data = vid_data[2][frame_name]
|
| 73 |
+
obj_ids = list(frame_data.keys())
|
| 74 |
+
|
| 75 |
+
cat_cnt = 0
|
| 76 |
+
|
| 77 |
+
for j in range(len(obj_ids)):
|
| 78 |
+
obj_id = obj_ids[j]
|
| 79 |
+
obj_data = frame_data[obj_id]
|
| 80 |
+
obj_bbox = obj_data['bbox']
|
| 81 |
+
obj_valid = obj_data['valid']
|
| 82 |
+
obj_mask = obj_data['mask'].numpy().astype(np.uint8)
|
| 83 |
+
obj_cat = obj_data['category_name']
|
| 84 |
+
|
| 85 |
+
if obj_cat == cat and obj_valid:
|
| 86 |
+
cat_cnt += 1
|
| 87 |
+
|
| 88 |
+
if color_mask == False:
|
| 89 |
+
contours, _ = cv2.findContours(obj_mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
|
| 90 |
+
cv2.drawContours(frame, contours, -1, colors[j], 3)
|
| 91 |
+
for i, contour in enumerate(contours):
|
| 92 |
+
moments = cv2.moments(contour)
|
| 93 |
+
if moments["m00"] != 0:
|
| 94 |
+
cx = int(moments["m10"] / moments["m00"])
|
| 95 |
+
cy = int(moments["m01"] / moments["m00"])
|
| 96 |
+
else:
|
| 97 |
+
cx, cy = contour[0][0]
|
| 98 |
+
|
| 99 |
+
font = cv2.FONT_HERSHEY_SIMPLEX
|
| 100 |
+
text = obj_id
|
| 101 |
+
text_size = cv2.getTextSize(text, font, 1, 2)[0]
|
| 102 |
+
text_w, text_h = text_size
|
| 103 |
+
|
| 104 |
+
cv2.rectangle(frame, (cx - text_w // 2 - 5, cy - text_h // 2 - 5),
|
| 105 |
+
(cx + text_w // 2 + 5, cy + text_h // 2 + 5), (0, 0, 0), -1)
|
| 106 |
+
|
| 107 |
+
cv2.putText(frame, text, (cx - text_w // 2, cy + text_h // 2),
|
| 108 |
+
font, 1, (255, 255, 255), 2)
|
| 109 |
+
|
| 110 |
+
else:
|
| 111 |
+
alpha = 0.08
|
| 112 |
+
|
| 113 |
+
colored_obj_mask = np.zeros_like(frame)
|
| 114 |
+
colored_obj_mask[obj_mask == 1] = colors[j]
|
| 115 |
+
frame[obj_mask == 1] = (
|
| 116 |
+
(1 - alpha) * frame[obj_mask == 1]
|
| 117 |
+
+ alpha * colored_obj_mask[obj_mask == 1]
|
| 118 |
+
)
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
contours, _ = cv2.findContours(obj_mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
|
| 122 |
+
cv2.drawContours(frame, contours, -1, colors[j], 2)
|
| 123 |
+
cv2.drawContours(frame_for_contour, contours, -1, colors[j], 2)
|
| 124 |
+
|
| 125 |
+
if len(contours) > 0:
|
| 126 |
+
largest_contour = max(contours, key=cv2.contourArea)
|
| 127 |
+
M = cv2.moments(largest_contour)
|
| 128 |
+
if M["m00"] != 0:
|
| 129 |
+
center_x = int(M["m10"] / M["m00"])
|
| 130 |
+
center_y = int(M["m01"] / M["m00"])
|
| 131 |
+
else:
|
| 132 |
+
center_x, center_y = 0, 0
|
| 133 |
+
|
| 134 |
+
font = cv2.FONT_HERSHEY_SIMPLEX
|
| 135 |
+
text = obj_id
|
| 136 |
+
|
| 137 |
+
font_scale = 0.9
|
| 138 |
+
text_size = cv2.getTextSize(text, font, font_scale, 2)[0]
|
| 139 |
+
text_x = center_x - text_size[0] // 1
|
| 140 |
+
text_y = center_y
|
| 141 |
+
|
| 142 |
+
rect_start = (text_x - 5, text_y - text_size[1] - 5)
|
| 143 |
+
rect_end = (text_x + text_size[0] + 5, text_y)
|
| 144 |
+
|
| 145 |
+
cv2.rectangle(frame, rect_start, rect_end, (0, 0, 0), -1)
|
| 146 |
+
cv2.putText(frame, text, (text_x, text_y), font, 1, (255, 255, 255), 2)
|
| 147 |
+
|
| 148 |
+
# plt.figure(figsize=(12, 8))
|
| 149 |
+
# plt.imshow(frame)
|
| 150 |
+
# plt.title(f"frame {frame_name}")
|
| 151 |
+
# plt.tight_layout()
|
| 152 |
+
# plt.axis('off')
|
| 153 |
+
# plt.show()
|
| 154 |
+
|
| 155 |
+
buffer = BytesIO()
|
| 156 |
+
frame = Image.fromarray(frame)
|
| 157 |
+
frame.save(buffer, format='jpeg')
|
| 158 |
+
buffer.seek(0)
|
| 159 |
+
cat_frames.append(base64.b64encode(buffer.read()).decode("utf-8"))
|
| 160 |
+
frame_cat_cnts[frame_name] = cat_cnt
|
| 161 |
+
|
| 162 |
+
buffer.seek(0) # Reuse buffer instead of creating a new one
|
| 163 |
+
buffer.truncate()
|
| 164 |
+
frame_for_contour = Image.fromarray(frame_for_contour)
|
| 165 |
+
frame_for_contour.save(buffer, format='jpeg')
|
| 166 |
+
buffer.seek(0)
|
| 167 |
+
contour_frames.append(base64.b64encode(buffer.read()).decode("utf-8"))
|
| 168 |
+
|
| 169 |
+
encoded_frames[cat] = cat_frames
|
| 170 |
+
contoured_frames[cat] = contour_frames
|
| 171 |
+
vid_cat_cnts[cat] = frame_cat_cnts
|
| 172 |
+
|
| 173 |
+
return encoded_frames, contoured_frames, vid_cat_cnts
|
| 174 |
+
|
| 175 |
+
|
| 176 |
+
def number_objects_and_encode(idx, color_mask=False):
|
| 177 |
+
encoded_frames = {}
|
| 178 |
+
contoured_frames = {} # New dictionary for original images
|
| 179 |
+
vid_cat_cnts = {}
|
| 180 |
+
|
| 181 |
+
vid_meta = metas[idx]
|
| 182 |
+
vid_data = train_dataset[idx]
|
| 183 |
+
vid_id = vid_meta['video']
|
| 184 |
+
frame_indx = vid_meta['sample_indx']
|
| 185 |
+
cat_names = set(vid_meta['obj_id_cat'].values())
|
| 186 |
+
imgs = vid_data[0]
|
| 187 |
+
|
| 188 |
+
for cat in cat_names:
|
| 189 |
+
cat_frames = []
|
| 190 |
+
contour_frames = []
|
| 191 |
+
frame_cat_cnts = {}
|
| 192 |
+
|
| 193 |
+
for i in range(imgs.size(0)):
|
| 194 |
+
frame_name = frame_indx[i]
|
| 195 |
+
frame = np.copy(imgs[i].permute(1, 2, 0).numpy())
|
| 196 |
+
frame_for_contour = np.copy(imgs[i].permute(1, 2, 0).numpy())
|
| 197 |
+
|
| 198 |
+
frame_data = vid_data[2][frame_name]
|
| 199 |
+
obj_ids = list(frame_data.keys())
|
| 200 |
+
|
| 201 |
+
cat_cnt = 0
|
| 202 |
+
|
| 203 |
+
for j in range(len(obj_ids)):
|
| 204 |
+
obj_id = obj_ids[j]
|
| 205 |
+
obj_data = frame_data[obj_id]
|
| 206 |
+
obj_bbox = obj_data['bbox']
|
| 207 |
+
obj_valid = obj_data['valid']
|
| 208 |
+
obj_mask = obj_data['mask'].numpy().astype(np.uint8)
|
| 209 |
+
obj_cat = obj_data['category_name']
|
| 210 |
+
|
| 211 |
+
if obj_cat == cat and obj_valid:
|
| 212 |
+
cat_cnt += 1
|
| 213 |
+
|
| 214 |
+
contours, _ = cv2.findContours(obj_mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
|
| 215 |
+
cv2.drawContours(frame, contours, -1, colors[j], 3)
|
| 216 |
+
cv2.drawContours(frame_for_contour, contours, -1, colors[j], 2)
|
| 217 |
+
|
| 218 |
+
if len(contours) > 0:
|
| 219 |
+
largest_contour = max(contours, key=cv2.contourArea)
|
| 220 |
+
M = cv2.moments(largest_contour)
|
| 221 |
+
if M["m00"] != 0:
|
| 222 |
+
center_x = int(M["m10"] / M["m00"])
|
| 223 |
+
center_y = int(M["m01"] / M["m00"])
|
| 224 |
+
else:
|
| 225 |
+
center_x, center_y = 0, 0
|
| 226 |
+
|
| 227 |
+
font = cv2.FONT_HERSHEY_SIMPLEX
|
| 228 |
+
text = obj_id
|
| 229 |
+
font_scale = 1.2
|
| 230 |
+
text_size = cv2.getTextSize(text, font, font_scale, 2)[0]
|
| 231 |
+
text_x = center_x - text_size[0] // 1
|
| 232 |
+
text_y = center_y
|
| 233 |
+
|
| 234 |
+
rect_start = (text_x - 5, text_y - text_size[1] - 5)
|
| 235 |
+
rect_end = (text_x + text_size[0] + 5, text_y + 3)
|
| 236 |
+
|
| 237 |
+
contour_thickness = 1
|
| 238 |
+
rect_start_contour = (rect_start[0] - contour_thickness, rect_start[1] - contour_thickness)
|
| 239 |
+
rect_end_contour = (rect_end[0] + contour_thickness, rect_end[1] + contour_thickness)
|
| 240 |
+
|
| 241 |
+
cv2.rectangle(frame, rect_start_contour, rect_end_contour, colors[j], contour_thickness)
|
| 242 |
+
cv2.rectangle(frame, rect_start, rect_end, (0, 0, 0), -1)
|
| 243 |
+
cv2.putText(frame, text, (text_x, text_y), font, 1, (255, 255, 255), 2)
|
| 244 |
+
|
| 245 |
+
|
| 246 |
+
if color_mask:
|
| 247 |
+
alpha = 0.08
|
| 248 |
+
colored_obj_mask = np.zeros_like(frame)
|
| 249 |
+
colored_obj_mask[obj_mask == 1] = colors[j]
|
| 250 |
+
frame[obj_mask == 1] = (
|
| 251 |
+
(1 - alpha) * frame[obj_mask == 1]
|
| 252 |
+
+ alpha * colored_obj_mask[obj_mask == 1]
|
| 253 |
+
)
|
| 254 |
+
|
| 255 |
+
# plt.figure(figsize=(12, 8))
|
| 256 |
+
# plt.imshow(frame)
|
| 257 |
+
# plt.title(f"frame {frame_name}")
|
| 258 |
+
# plt.tight_layout()
|
| 259 |
+
# plt.axis('off')
|
| 260 |
+
# plt.show()
|
| 261 |
+
|
| 262 |
+
buffer = BytesIO()
|
| 263 |
+
frame = Image.fromarray(frame)
|
| 264 |
+
frame.save(buffer, format='jpeg')
|
| 265 |
+
buffer.seek(0)
|
| 266 |
+
cat_frames.append(base64.b64encode(buffer.read()).decode("utf-8"))
|
| 267 |
+
frame_cat_cnts[frame_name] = cat_cnt
|
| 268 |
+
|
| 269 |
+
buffer.seek(0) # Reuse buffer instead of creating a new one
|
| 270 |
+
buffer.truncate()
|
| 271 |
+
frame_for_contour = Image.fromarray(frame_for_contour)
|
| 272 |
+
frame_for_contour.save(buffer, format='jpeg')
|
| 273 |
+
buffer.seek(0)
|
| 274 |
+
contour_frames.append(base64.b64encode(buffer.read()).decode("utf-8"))
|
| 275 |
+
|
| 276 |
+
encoded_frames[cat] = cat_frames
|
| 277 |
+
contoured_frames[cat] = contour_frames
|
| 278 |
+
vid_cat_cnts[cat] = frame_cat_cnts
|
| 279 |
+
|
| 280 |
+
return encoded_frames, contoured_frames, vid_cat_cnts
|
| 281 |
+
|
| 282 |
+
|
| 283 |
+
|
| 284 |
+
def getCaption(idx, model='gpt-4o'):
|
| 285 |
+
vid_meta = metas[idx]
|
| 286 |
+
vid_data = train_dataset[idx]
|
| 287 |
+
vid_id = vid_meta['video']
|
| 288 |
+
print(f"vid id: {vid_id}\n")
|
| 289 |
+
|
| 290 |
+
frame_indx = vid_meta['sample_indx'] # e.g. [4, 7, 9, 16]
|
| 291 |
+
cat_names = set(vid_meta['obj_id_cat'].values()) # e.g. {"person", "elephant", ...}
|
| 292 |
+
all_captions = dict()
|
| 293 |
+
|
| 294 |
+
# color_mask = random.choice([True, False])
|
| 295 |
+
color_mask = random.choices([False, True], weights=[60, 40])[0]
|
| 296 |
+
|
| 297 |
+
base64_frames, _ , vid_cat_cnts = number_objects_and_encode(idx, color_mask)
|
| 298 |
+
#marked = "mask with boundary" if color_mask else "boundary"
|
| 299 |
+
|
| 300 |
+
for cat_name in list(cat_names) :
|
| 301 |
+
|
| 302 |
+
is_movable = False
|
| 303 |
+
if cat_name in ytvos_category_valid_list :
|
| 304 |
+
is_movable = True
|
| 305 |
+
|
| 306 |
+
if not is_movable:
|
| 307 |
+
print(f"Skipping {cat_name}: Determined to be non-movable.", end='\n\n')
|
| 308 |
+
|
| 309 |
+
|
| 310 |
+
image_captions = {}
|
| 311 |
+
captioner = OpenAI()
|
| 312 |
+
cat_base64_frames = base64_frames[cat_name]
|
| 313 |
+
# cont_base64_frames = contoured_frames[cat_name]
|
| 314 |
+
|
| 315 |
+
for i in range(len(cat_base64_frames)):
|
| 316 |
+
frame_name = frame_indx[i]
|
| 317 |
+
# cont_base64_image = cont_base64_frames[i]
|
| 318 |
+
base64_image = cat_base64_frames[i]
|
| 319 |
+
should_filter = False
|
| 320 |
+
frame_cat_cnts = vid_cat_cnts[cat_name][frame_name]
|
| 321 |
+
|
| 322 |
+
if frame_cat_cnts >= 2:
|
| 323 |
+
should_filter = True
|
| 324 |
+
else:
|
| 325 |
+
print(f"Skipping {cat_name}: There is single or no object.", end='\n\n')
|
| 326 |
+
|
| 327 |
+
|
| 328 |
+
if is_movable and should_filter:
|
| 329 |
+
#1단계: 필터링
|
| 330 |
+
print(f"-----------category name: {cat_name}, frame name: {frame_name}")
|
| 331 |
+
caption_filter_text = f"""
|
| 332 |
+
You are a visual assistant analyzing a single frame from a video.
|
| 333 |
+
In this frame, I have labeled {frame_cat_cnts} {cat_name}(s), each with a bright numeric ID at its center and a visible marker.
|
| 334 |
+
|
| 335 |
+
Are {cat_name}s in the image performing all different and recognizable actions or postures?
|
| 336 |
+
Consider differences in body pose (standing, sitting, holding hands up, grabbing object, facing the camera, stretching, walking...), motion cues (inferred from the momentary stance or position),
|
| 337 |
+
facial expressions, and any notable interactions with objects or other {cat_name}s or people.
|
| 338 |
+
|
| 339 |
+
Only focus on obvious, prominent actions that can be reliably identified from this single frame.
|
| 340 |
+
|
| 341 |
+
- Respond with "YES" if:
|
| 342 |
+
1) Most of {cat_name}s exhibit clearly different, unique actions or poses.
|
| 343 |
+
(e.g. standing, sitting, bending, stretching, showing its back, or turning toward the camera.)
|
| 344 |
+
2) You can see visible significant differences in action and posture, that an observer can identify at a glance.
|
| 345 |
+
3) Interaction Variability: Each {cat_name} is engaged in a different type of action, such as one grasping an object while another is observing.
|
| 346 |
+
|
| 347 |
+
- Respond with "NONE" if:
|
| 348 |
+
1) The actions or pose are not clearly differentiable or too similar.
|
| 349 |
+
2) Minimal or Ambiguous Motion: The frame does not provide clear evidence of distinct movement beyond subtle shifts in stance.
|
| 350 |
+
3) Passive or Neutral Poses: If multiple {cat_name}(s) are simply standing or sitting without an obvious difference in orientation or motion
|
| 351 |
+
|
| 352 |
+
Answer strictly with either "YES" or "NONE".
|
| 353 |
+
"""
|
| 354 |
+
|
| 355 |
+
response1 = captioner.chat.completions.create(
|
| 356 |
+
model=model,
|
| 357 |
+
messages=[
|
| 358 |
+
{
|
| 359 |
+
"role": "user",
|
| 360 |
+
"content": [
|
| 361 |
+
{
|
| 362 |
+
"type": "text",
|
| 363 |
+
"text": caption_filter_text,
|
| 364 |
+
},
|
| 365 |
+
{
|
| 366 |
+
"type": "image_url",
|
| 367 |
+
"image_url": {"url": f"data:image/jpeg;base64,{base64_image}"},
|
| 368 |
+
}
|
| 369 |
+
],
|
| 370 |
+
}
|
| 371 |
+
],
|
| 372 |
+
)
|
| 373 |
+
response_content = response1.choices[0].message.content
|
| 374 |
+
should_caption = True if "yes" in response_content.lower() else False
|
| 375 |
+
print(f"are {cat_name}s distinguished by action: {response_content}", end='\n\n')
|
| 376 |
+
|
| 377 |
+
else:
|
| 378 |
+
should_caption = False
|
| 379 |
+
|
| 380 |
+
#2단계: dense caption 만들기
|
| 381 |
+
dense_caption_prompt_1 = f"""
|
| 382 |
+
In the given frame, I labeled {frame_cat_cnts} {cat_name}s by marking each with a bright numeric ID at the center and its boundary. The category name of these objects are : {cat_name}.
|
| 383 |
+
|
| 384 |
+
Please describe the image focusing on labeled {cat_name}s in detail, focusing on their actions and interactions.
|
| 385 |
+
|
| 386 |
+
1. Focus only on clear, unique, and prominent actions that distinguish each object.
|
| 387 |
+
2. Avoid describing actions that are too minor, ambiguous, or not visible from the image.
|
| 388 |
+
3. Avoid subjective terms such as 'skilled', 'controlled', or 'focused'. Only describe observable actions.
|
| 389 |
+
4. Do not include common-sense or overly general descriptions like 'the elephant walks'.
|
| 390 |
+
5. Use dynamic action verbs (e.g., holding, throwing, jumping, inspecting) to describe interactions, poses, or movements.
|
| 391 |
+
6. **Avoid overly detailed or speculative descriptions** such as 'slightly moving its mouth' or 'appears to be anticipating'.
|
| 392 |
+
- expressions like 'seems to be', 'appears to be' are BANNED!
|
| 393 |
+
7. Pretend you are observing the scene directly, avoiding phrases like 'it seems' or 'based on the description'.
|
| 394 |
+
8. Include interactions with objects or other entities when they are prominent and observable.
|
| 395 |
+
9. **Do not include descriptions of appearance** such as clothes, color, size, shape etc.
|
| 396 |
+
10. **Do not include relative position** between objects such as 'the left elephant' because left/right can be ambiguous.
|
| 397 |
+
11. Do not mention object IDs.
|
| 398 |
+
12. Use '{cat_name}' as the noun for the referring expressions.
|
| 399 |
+
|
| 400 |
+
Note that I want to use your description to create a grounding dataset, therefore, your descriptions for different objects should be unique, i.e., If the image contains multiple {cat_name}s, describe the actions of each individually and ensure the descriptions are non-overlapping and specific.
|
| 401 |
+
|
| 402 |
+
- Your answer should contain details, and follow the following format:
|
| 403 |
+
object id. action-oriented description
|
| 404 |
+
(e.g. 1. the person is holding bananas on two hands and opening his mouth, turning the head right.
|
| 405 |
+
2. a person bending over and touching his boots to tie the shoelace.)
|
| 406 |
+
- for action-oriented description, use {cat_name} as subject noun
|
| 407 |
+
|
| 408 |
+
**Only include the currently labeled category** in each line (e.g., if it’s a person, do not suddenly label it as other object/animal).
|
| 409 |
+
Please pay attention to the categories of these objects and don’t change them.
|
| 410 |
+
Keep in mind that you should not group the objects, e.g., 2-5. people: xxx, be sure to describe each object separately (one by one).
|
| 411 |
+
Output referring expressions for each object id. Please start your answer:"""
|
| 412 |
+
|
| 413 |
+
|
| 414 |
+
dense_caption_prompt_2 = f"""
|
| 415 |
+
You are an advanced visual language model analyzing a video frame.
|
| 416 |
+
In this frame, {frame_cat_cnts} objects belonging to the category **{cat_name}** have been distinctly labeled with bright numerical IDs at their center and boundary.
|
| 417 |
+
|
| 418 |
+
Your task is to generate **action-oriented descriptions** for each labeled {cat_name}.
|
| 419 |
+
Your descriptions should capture their **observable actions and interactions**, making sure to highlight movement, gestures, and dynamic behaviors.
|
| 420 |
+
|
| 421 |
+
---
|
| 422 |
+
## Key Guidelines:
|
| 423 |
+
1. **Describe only clear and visible actions** that uniquely define what the {cat_name} is doing.
|
| 424 |
+
- Example: "grabbing a branch and pulling it down" (**(O) Specific**)
|
| 425 |
+
- Avoid: "moving slightly to the side" (**(X) Too vague**)
|
| 426 |
+
|
| 427 |
+
2. **Do not describe appearance, color, or position**—focus purely on the action.
|
| 428 |
+
- (X) "A large brown bear standing on the left"
|
| 429 |
+
- (O) "The bear is lifting its front paws and swiping forward."
|
| 430 |
+
|
| 431 |
+
3. **Use dynamic, action-specific verbs** rather than passive descriptions.
|
| 432 |
+
- (O) "The giraffe is tilting its head and sniffing the ground."
|
| 433 |
+
- (X) "The giraffe is near a tree and looking around."
|
| 434 |
+
|
| 435 |
+
4. **Avoid assumptions, emotions, or speculative phrasing.**
|
| 436 |
+
- (X) "The person seems excited" / "The person might be preparing to jump."
|
| 437 |
+
- (O) "The person is pushing its front legs against the rock and leaping forward."
|
| 438 |
+
|
| 439 |
+
5. **Avoid overly detailed or speculative descriptions** such as 'slightly moving its mouth' or 'appears to be anticipating'.
|
| 440 |
+
- expressions like 'seems to be', 'appears to be' are BANNED!
|
| 441 |
+
6. Pretend you are observing the scene directly, avoiding phrases like 'it seems' or 'based on the description'.
|
| 442 |
+
|
| 443 |
+
7. If multiple {cat_name}s are present, make sure their descriptions are **distinct and non-overlapping**.
|
| 444 |
+
- **Each object should have a unique, descriptive action.**
|
| 445 |
+
- (X) "Two dogs are running."
|
| 446 |
+
- (O) "1. One dog is chasing another, its legs stretched mid-air.
|
| 447 |
+
2. The other dog is looking back while speeding up."
|
| 448 |
+
|
| 449 |
+
---
|
| 450 |
+
## Output Format:
|
| 451 |
+
- Each labeled **{cat_name}** should have exactly **one line of description**.
|
| 452 |
+
- Format: `ID. {cat_name} + action-based description`
|
| 453 |
+
- (O) Example:
|
| 454 |
+
```
|
| 455 |
+
1. The person is leaning forward while opening a bag with both hands.
|
| 456 |
+
2. The person is holding onto a rope and pulling themselves up.
|
| 457 |
+
```
|
| 458 |
+
- **Ensure that each object is described individually.**
|
| 459 |
+
- **Do not group objects into a single sentence** (e.g., "2-5. people: xxx" is NOT allowed).
|
| 460 |
+
|
| 461 |
+
---
|
| 462 |
+
## Additional Instructions:
|
| 463 |
+
- **Do NOT** use expressions like "it appears that..." or "it seems like...".
|
| 464 |
+
- **Do NOT** mention object IDs in the description (only use the provided format).
|
| 465 |
+
- **DO NOT** include markdown formatting (no bullet points, no asterisks).
|
| 466 |
+
- **Only describe actions of the labeled {cat_name} objects**—do not introduce unrelated categories.
|
| 467 |
+
|
| 468 |
+
Please generate the action-oriented descriptions for each labeled {cat_name} and start your answer:
|
| 469 |
+
"""
|
| 470 |
+
|
| 471 |
+
|
| 472 |
+
dense_caption_prompt = f"""
|
| 473 |
+
You are a visual assistant analyzing a single frame of a video.
|
| 474 |
+
In this frame, {frame_cat_cnts} objects belonging to the category **{cat_name}** have been labeled with bright numeric IDs at their center and boundary.
|
| 475 |
+
|
| 476 |
+
I am building an **action-centric referring expression** dataset.
|
| 477 |
+
Your task is to describe each labeled {cat_name} based on **clearly observable and specific actions**.
|
| 478 |
+
|
| 479 |
+
---
|
| 480 |
+
## Guidelines:
|
| 481 |
+
1. **Focus only on visible and prominent actions** (e.g., running, pushing, grasping an object).
|
| 482 |
+
2. **Avoid describing minor or ambiguous movements** (e.g., "slightly moving a paw," "tilting head a bit").
|
| 483 |
+
3. **Do not include subjective or speculative descriptions** (e.g., "it seems excited" or "it might be preparing to jump").
|
| 484 |
+
4. **Avoid vague expressions** like "engaging with something." Instead, specify the action (e.g., "grabbing a stick," "pressing a button").
|
| 485 |
+
5. **Use dynamic action verbs** (e.g., holding, throwing, inspecting, leaning, pressing) to highlight motion and interaction.
|
| 486 |
+
6. If multiple {cat_name}s appear, ensure each description is **distinct and non-overlapping**.
|
| 487 |
+
7. Base your descriptions on these principles:
|
| 488 |
+
- **Avoid words like 'minimal' or 'slightly'.**
|
| 489 |
+
- Emphasize **body movement, posture, and motion patterns** (e.g., "lifting its head," "facing forward," "showing its back").
|
| 490 |
+
- Describe **facial expressions and interactions with objects** (e.g., "opening its mouth wide," "smiling while holding an item").
|
| 491 |
+
- **Specify actions with other objects or entities** only when they are clear and observable.
|
| 492 |
+
- (O) "pushing another person"
|
| 493 |
+
- (X) "interacting with another object"
|
| 494 |
+
|
| 495 |
+
---
|
| 496 |
+
## Output Format:
|
| 497 |
+
- Each labeled **{cat_name}** must have **exactly one line**.
|
| 498 |
+
- Format: `ID. {cat_name} + action-based description`
|
| 499 |
+
- (O) Example:
|
| 500 |
+
```
|
| 501 |
+
1. The person is holding ski poles and skiing down a snowy mountain with bent knees.
|
| 502 |
+
2. The person is pulling a baby carriage while smiling.
|
| 503 |
+
```
|
| 504 |
+
- **Ensure each object is described individually.**
|
| 505 |
+
- **Do not group multiple objects into a single sentence** (e.g., "2-5. people: xxx" is NOT allowed).
|
| 506 |
+
|
| 507 |
+
---
|
| 508 |
+
## Example:
|
| 509 |
+
If the frame has two labeled **bears**, your output should be:
|
| 510 |
+
```
|
| 511 |
+
1. The bear is reaching out its right paw while leaning forward to catch prey.
|
| 512 |
+
2. A bear is standing upright, facing right, and touching the bike beside it.
|
| 513 |
+
```
|
| 514 |
+
|
| 515 |
+
---
|
| 516 |
+
## Additional Instructions:
|
| 517 |
+
- **Do NOT** describe appearance (e.g., color, size, texture) or relative positioning (e.g., "on the left/right").
|
| 518 |
+
- **Do NOT** reference object IDs explicitly (e.g., "Person 1" or "Object 2" is NOT allowed).
|
| 519 |
+
- **Do NOT** include markdown formatting (no bullet points, asterisks, or extra symbols).
|
| 520 |
+
- **Only describe actions of the labeled {cat_name} objects**—do not introduce unrelated categories.
|
| 521 |
+
|
| 522 |
+
Please generate the action-oriented descriptions for each labeled {cat_name} and start your answer:"""
|
| 523 |
+
|
| 524 |
+
|
| 525 |
+
MAX_RETRIES = 3
|
| 526 |
+
retry_count = 0
|
| 527 |
+
|
| 528 |
+
if should_caption:
|
| 529 |
+
while retry_count < MAX_RETRIES:
|
| 530 |
+
selected_prompt = random.choice([dense_caption_prompt, dense_caption_prompt_2])
|
| 531 |
+
|
| 532 |
+
response2 = captioner.chat.completions.create(
|
| 533 |
+
model=model,
|
| 534 |
+
messages=[
|
| 535 |
+
{
|
| 536 |
+
"role": "user",
|
| 537 |
+
"content": [
|
| 538 |
+
{
|
| 539 |
+
"type": "text",
|
| 540 |
+
"text": selected_prompt,
|
| 541 |
+
},
|
| 542 |
+
{
|
| 543 |
+
"type": "image_url",
|
| 544 |
+
"image_url": {"url": f"data:image/jpeg;base64,{base64_image}"},
|
| 545 |
+
},
|
| 546 |
+
],
|
| 547 |
+
}
|
| 548 |
+
],
|
| 549 |
+
)
|
| 550 |
+
|
| 551 |
+
# caption = response2.choices[0].message.content
|
| 552 |
+
#print(f"{image_path} - {frame_name}: {caption}")
|
| 553 |
+
|
| 554 |
+
caption = response2.choices[0].message.content.strip()
|
| 555 |
+
caption_lower = caption.lower().lstrip()
|
| 556 |
+
|
| 557 |
+
if caption_lower.startswith("1.") and not any(
|
| 558 |
+
phrase in caption_lower for phrase in ["i'm sorry", "please", "can't help"]
|
| 559 |
+
):
|
| 560 |
+
break
|
| 561 |
+
|
| 562 |
+
print(f"Retrying caption generation... ({retry_count + 1}/{MAX_RETRIES})")
|
| 563 |
+
retry_count += 1
|
| 564 |
+
time.sleep(2)
|
| 565 |
+
|
| 566 |
+
if retry_count == MAX_RETRIES:
|
| 567 |
+
caption = None
|
| 568 |
+
print("Max retries reached. Caption generation failed.")
|
| 569 |
+
|
| 570 |
+
else:
|
| 571 |
+
caption = None
|
| 572 |
+
|
| 573 |
+
image_captions[frame_name] = caption
|
| 574 |
+
all_captions[cat_name] = image_captions
|
| 575 |
+
|
| 576 |
+
# final : also prepare valid object ids
|
| 577 |
+
valid_obj_ids = dict()
|
| 578 |
+
|
| 579 |
+
for cat in cat_names:
|
| 580 |
+
if cat in ytvos_category_valid_list:
|
| 581 |
+
obj_id_cat = vid_meta['obj_id_cat']
|
| 582 |
+
valid_cat_ids = []
|
| 583 |
+
for obj_id in list(obj_id_cat.keys()):
|
| 584 |
+
if obj_id_cat[obj_id] == cat:
|
| 585 |
+
valid_cat_ids.append(obj_id)
|
| 586 |
+
valid_obj_ids[cat] = valid_cat_ids
|
| 587 |
+
|
| 588 |
+
return vid_id, all_captions, valid_obj_ids
|
| 589 |
+
|
| 590 |
+
|
| 591 |
+
if __name__ == '__main__':
|
| 592 |
+
parser = argparse.ArgumentParser('ReferFormer training and evaluation script', parents=[opts.get_args_parser()])
|
| 593 |
+
parser.add_argument('--save_caption_path', type=str, default="mbench/numbered_captions_gpt-4o_randcap.json")
|
| 594 |
+
parser.add_argument('--save_valid_obj_ids_path', type=str, default="mbench/numbered_valid_obj_ids_gpt-4o_randcap.json")
|
| 595 |
+
|
| 596 |
+
args = parser.parse_args()
|
| 597 |
+
|
| 598 |
+
#==================데이터 불러오기===================
|
| 599 |
+
# 전체 데이터셋
|
| 600 |
+
train_dataset = build_ytvos_ref(image_set = 'train', args = args)
|
| 601 |
+
|
| 602 |
+
# 전체 데이터셋 메타데이터
|
| 603 |
+
metas = train_dataset.metas
|
| 604 |
+
|
| 605 |
+
# 색상 후보 8개 (RGB 형식)
|
| 606 |
+
colors = [
|
| 607 |
+
(255, 0, 0), # Red
|
| 608 |
+
(0, 255, 0), # Green
|
| 609 |
+
(0, 0, 255), # Blue
|
| 610 |
+
(255, 255, 0), # Yellow
|
| 611 |
+
(255, 0, 255), # Magenta
|
| 612 |
+
(0, 255, 255), # Cyan
|
| 613 |
+
(128, 0, 128), # Purple
|
| 614 |
+
(255, 165, 0) # Orange
|
| 615 |
+
]
|
| 616 |
+
|
| 617 |
+
ytvos_category_valid_list = [
|
| 618 |
+
'airplane', 'ape', 'bear', 'bird', 'boat', 'bus', 'camel', 'cat', 'cow', 'crocodile',
|
| 619 |
+
'deer', 'dog', 'dolphin', 'duck', 'eagle', 'earless_seal', 'elephant', 'fish', 'fox', 'frog',
|
| 620 |
+
'giant_panda', 'giraffe', 'hedgehog', 'horse', 'leopard', 'lion', 'lizard',
|
| 621 |
+
'monkey', 'motorbike', 'mouse', 'owl', 'parrot', 'penguin', 'person',
|
| 622 |
+
'rabbit', 'raccoon', 'sedan', 'shark', 'sheep', 'snail', 'snake',
|
| 623 |
+
'squirrel', 'tiger', 'train', 'truck', 'turtle', 'whale', 'zebra'
|
| 624 |
+
]
|
| 625 |
+
|
| 626 |
+
#==================gpt 돌리기===================
|
| 627 |
+
os.environ['OPENAI_API_KEY'] = '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'
|
| 628 |
+
|
| 629 |
+
result_captions = {}
|
| 630 |
+
result_valid_obj_ids = {}
|
| 631 |
+
|
| 632 |
+
for i in range(len(metas)):
|
| 633 |
+
try:
|
| 634 |
+
vid_id, all_captions, valid_obj_ids = getCaption(i)
|
| 635 |
+
|
| 636 |
+
if vid_id not in result_captions:
|
| 637 |
+
result_captions[vid_id] = all_captions
|
| 638 |
+
if vid_id not in result_valid_obj_ids:
|
| 639 |
+
result_valid_obj_ids[vid_id] = valid_obj_ids
|
| 640 |
+
|
| 641 |
+
except (requests.exceptions.ConnectionError, APIConnectionError, OpenAIError) as e:
|
| 642 |
+
print(f"created caption until {i-1}", flush=True)
|
| 643 |
+
|
| 644 |
+
with open(args.save_caption_path, "w") as file:
|
| 645 |
+
json.dump(result_captions, file, indent=4)
|
| 646 |
+
|
| 647 |
+
with open(args.save_valid_obj_ids_path, "w") as file:
|
| 648 |
+
json.dump(result_valid_obj_ids, file, indent=4)
|
| 649 |
+
|
| 650 |
+
print("Finished!", flush=True)
|
| 651 |
+
|
| 652 |
+
with open(args.save_caption_path, "w") as file:
|
| 653 |
+
json.dump(result_captions, file, indent=4)
|
| 654 |
+
|
| 655 |
+
with open(args.save_valid_obj_ids_path, "w") as file:
|
| 656 |
+
json.dump(result_valid_obj_ids, file, indent=4)
|
.history/mbench/gpt_ref-ytvos_numbered_cy_sanity_2_20250207173355.py
ADDED
|
@@ -0,0 +1,677 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import sys
|
| 3 |
+
sys.path.append(os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
|
| 4 |
+
import time
|
| 5 |
+
|
| 6 |
+
from os import path as osp
|
| 7 |
+
from io import BytesIO
|
| 8 |
+
import random
|
| 9 |
+
|
| 10 |
+
from mbench.ytvos_ref import build as build_ytvos_ref
|
| 11 |
+
import argparse
|
| 12 |
+
import opts
|
| 13 |
+
|
| 14 |
+
import sys
|
| 15 |
+
from pathlib import Path
|
| 16 |
+
import os
|
| 17 |
+
from os import path as osp
|
| 18 |
+
import skimage
|
| 19 |
+
from io import BytesIO
|
| 20 |
+
|
| 21 |
+
import numpy as np
|
| 22 |
+
import pandas as pd
|
| 23 |
+
import regex as re
|
| 24 |
+
import json
|
| 25 |
+
|
| 26 |
+
import cv2
|
| 27 |
+
from PIL import Image, ImageDraw
|
| 28 |
+
import torch
|
| 29 |
+
from torchvision.transforms import functional as F
|
| 30 |
+
|
| 31 |
+
from skimage import measure # (pip install scikit-image)
|
| 32 |
+
from shapely.geometry import Polygon, MultiPolygon # (pip install Shapely)
|
| 33 |
+
|
| 34 |
+
import matplotlib.pyplot as plt
|
| 35 |
+
import matplotlib.patches as patches
|
| 36 |
+
from matplotlib.collections import PatchCollection
|
| 37 |
+
from matplotlib.patches import Rectangle
|
| 38 |
+
import textwrap
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
import ipywidgets as widgets
|
| 42 |
+
from IPython.display import display, clear_output
|
| 43 |
+
|
| 44 |
+
from openai import OpenAI
|
| 45 |
+
import base64
|
| 46 |
+
import json
|
| 47 |
+
import requests
|
| 48 |
+
from openai.error import APIConnectionError, OpenAIError
|
| 49 |
+
|
| 50 |
+
def number_objects_and_encode_old(idx, color_mask=False):
|
| 51 |
+
encoded_frames = {}
|
| 52 |
+
contoured_frames = {} # New dictionary for original images
|
| 53 |
+
vid_cat_cnts = {}
|
| 54 |
+
|
| 55 |
+
vid_meta = metas[idx]
|
| 56 |
+
vid_data = train_dataset[idx]
|
| 57 |
+
vid_id = vid_meta['video']
|
| 58 |
+
frame_indx = vid_meta['sample_indx']
|
| 59 |
+
cat_names = set(vid_meta['obj_id_cat'].values())
|
| 60 |
+
imgs = vid_data[0]
|
| 61 |
+
|
| 62 |
+
for cat in cat_names:
|
| 63 |
+
cat_frames = []
|
| 64 |
+
contour_frames = []
|
| 65 |
+
frame_cat_cnts = {}
|
| 66 |
+
|
| 67 |
+
for i in range(imgs.size(0)):
|
| 68 |
+
frame_name = frame_indx[i]
|
| 69 |
+
frame = np.copy(imgs[i].permute(1, 2, 0).numpy())
|
| 70 |
+
frame_for_contour = np.copy(imgs[i].permute(1, 2, 0).numpy())
|
| 71 |
+
|
| 72 |
+
frame_data = vid_data[2][frame_name]
|
| 73 |
+
obj_ids = list(frame_data.keys())
|
| 74 |
+
|
| 75 |
+
cat_cnt = 0
|
| 76 |
+
|
| 77 |
+
for j in range(len(obj_ids)):
|
| 78 |
+
obj_id = obj_ids[j]
|
| 79 |
+
obj_data = frame_data[obj_id]
|
| 80 |
+
obj_bbox = obj_data['bbox']
|
| 81 |
+
obj_valid = obj_data['valid']
|
| 82 |
+
obj_mask = obj_data['mask'].numpy().astype(np.uint8)
|
| 83 |
+
obj_cat = obj_data['category_name']
|
| 84 |
+
|
| 85 |
+
if obj_cat == cat and obj_valid:
|
| 86 |
+
cat_cnt += 1
|
| 87 |
+
|
| 88 |
+
if color_mask == False:
|
| 89 |
+
contours, _ = cv2.findContours(obj_mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
|
| 90 |
+
cv2.drawContours(frame, contours, -1, colors[j], 3)
|
| 91 |
+
for i, contour in enumerate(contours):
|
| 92 |
+
moments = cv2.moments(contour)
|
| 93 |
+
if moments["m00"] != 0:
|
| 94 |
+
cx = int(moments["m10"] / moments["m00"])
|
| 95 |
+
cy = int(moments["m01"] / moments["m00"])
|
| 96 |
+
else:
|
| 97 |
+
cx, cy = contour[0][0]
|
| 98 |
+
|
| 99 |
+
font = cv2.FONT_HERSHEY_SIMPLEX
|
| 100 |
+
text = obj_id
|
| 101 |
+
text_size = cv2.getTextSize(text, font, 1, 2)[0]
|
| 102 |
+
text_w, text_h = text_size
|
| 103 |
+
|
| 104 |
+
cv2.rectangle(frame, (cx - text_w // 2 - 5, cy - text_h // 2 - 5),
|
| 105 |
+
(cx + text_w // 2 + 5, cy + text_h // 2 + 5), (0, 0, 0), -1)
|
| 106 |
+
|
| 107 |
+
cv2.putText(frame, text, (cx - text_w // 2, cy + text_h // 2),
|
| 108 |
+
font, 1, (255, 255, 255), 2)
|
| 109 |
+
|
| 110 |
+
else:
|
| 111 |
+
alpha = 0.08
|
| 112 |
+
|
| 113 |
+
colored_obj_mask = np.zeros_like(frame)
|
| 114 |
+
colored_obj_mask[obj_mask == 1] = colors[j]
|
| 115 |
+
frame[obj_mask == 1] = (
|
| 116 |
+
(1 - alpha) * frame[obj_mask == 1]
|
| 117 |
+
+ alpha * colored_obj_mask[obj_mask == 1]
|
| 118 |
+
)
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
contours, _ = cv2.findContours(obj_mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
|
| 122 |
+
cv2.drawContours(frame, contours, -1, colors[j], 2)
|
| 123 |
+
cv2.drawContours(frame_for_contour, contours, -1, colors[j], 2)
|
| 124 |
+
|
| 125 |
+
if len(contours) > 0:
|
| 126 |
+
largest_contour = max(contours, key=cv2.contourArea)
|
| 127 |
+
M = cv2.moments(largest_contour)
|
| 128 |
+
if M["m00"] != 0:
|
| 129 |
+
center_x = int(M["m10"] / M["m00"])
|
| 130 |
+
center_y = int(M["m01"] / M["m00"])
|
| 131 |
+
else:
|
| 132 |
+
center_x, center_y = 0, 0
|
| 133 |
+
|
| 134 |
+
font = cv2.FONT_HERSHEY_SIMPLEX
|
| 135 |
+
text = obj_id
|
| 136 |
+
|
| 137 |
+
font_scale = 0.9
|
| 138 |
+
text_size = cv2.getTextSize(text, font, font_scale, 2)[0]
|
| 139 |
+
text_x = center_x - text_size[0] // 1
|
| 140 |
+
text_y = center_y
|
| 141 |
+
|
| 142 |
+
rect_start = (text_x - 5, text_y - text_size[1] - 5)
|
| 143 |
+
rect_end = (text_x + text_size[0] + 5, text_y)
|
| 144 |
+
|
| 145 |
+
cv2.rectangle(frame, rect_start, rect_end, (0, 0, 0), -1)
|
| 146 |
+
cv2.putText(frame, text, (text_x, text_y), font, 1, (255, 255, 255), 2)
|
| 147 |
+
|
| 148 |
+
# plt.figure(figsize=(12, 8))
|
| 149 |
+
# plt.imshow(frame)
|
| 150 |
+
# plt.title(f"frame {frame_name}")
|
| 151 |
+
# plt.tight_layout()
|
| 152 |
+
# plt.axis('off')
|
| 153 |
+
# plt.show()
|
| 154 |
+
|
| 155 |
+
buffer = BytesIO()
|
| 156 |
+
frame = Image.fromarray(frame)
|
| 157 |
+
frame.save(buffer, format='jpeg')
|
| 158 |
+
buffer.seek(0)
|
| 159 |
+
cat_frames.append(base64.b64encode(buffer.read()).decode("utf-8"))
|
| 160 |
+
frame_cat_cnts[frame_name] = cat_cnt
|
| 161 |
+
|
| 162 |
+
buffer.seek(0) # Reuse buffer instead of creating a new one
|
| 163 |
+
buffer.truncate()
|
| 164 |
+
frame_for_contour = Image.fromarray(frame_for_contour)
|
| 165 |
+
frame_for_contour.save(buffer, format='jpeg')
|
| 166 |
+
buffer.seek(0)
|
| 167 |
+
contour_frames.append(base64.b64encode(buffer.read()).decode("utf-8"))
|
| 168 |
+
|
| 169 |
+
encoded_frames[cat] = cat_frames
|
| 170 |
+
contoured_frames[cat] = contour_frames
|
| 171 |
+
vid_cat_cnts[cat] = frame_cat_cnts
|
| 172 |
+
|
| 173 |
+
return encoded_frames, contoured_frames, vid_cat_cnts
|
| 174 |
+
|
| 175 |
+
|
| 176 |
+
def number_objects_and_encode(idx, color_mask=False):
|
| 177 |
+
encoded_frames = {}
|
| 178 |
+
contoured_frames = {} # New dictionary for original images
|
| 179 |
+
vid_cat_cnts = {}
|
| 180 |
+
|
| 181 |
+
vid_meta = metas[idx]
|
| 182 |
+
vid_data = train_dataset[idx]
|
| 183 |
+
vid_id = vid_meta['video']
|
| 184 |
+
frame_indx = vid_meta['sample_indx']
|
| 185 |
+
cat_names = set(vid_meta['obj_id_cat'].values())
|
| 186 |
+
imgs = vid_data[0]
|
| 187 |
+
|
| 188 |
+
for cat in cat_names:
|
| 189 |
+
cat_frames = []
|
| 190 |
+
contour_frames = []
|
| 191 |
+
frame_cat_cnts = {}
|
| 192 |
+
|
| 193 |
+
for i in range(imgs.size(0)):
|
| 194 |
+
frame_name = frame_indx[i]
|
| 195 |
+
frame = np.copy(imgs[i].permute(1, 2, 0).numpy())
|
| 196 |
+
frame_for_contour = np.copy(imgs[i].permute(1, 2, 0).numpy())
|
| 197 |
+
|
| 198 |
+
frame_data = vid_data[2][frame_name]
|
| 199 |
+
obj_ids = list(frame_data.keys())
|
| 200 |
+
|
| 201 |
+
cat_cnt = 0
|
| 202 |
+
|
| 203 |
+
for j in range(len(obj_ids)):
|
| 204 |
+
obj_id = obj_ids[j]
|
| 205 |
+
obj_data = frame_data[obj_id]
|
| 206 |
+
obj_bbox = obj_data['bbox']
|
| 207 |
+
obj_valid = obj_data['valid']
|
| 208 |
+
obj_mask = obj_data['mask'].numpy().astype(np.uint8)
|
| 209 |
+
obj_cat = obj_data['category_name']
|
| 210 |
+
|
| 211 |
+
if obj_cat == cat and obj_valid:
|
| 212 |
+
cat_cnt += 1
|
| 213 |
+
|
| 214 |
+
contours, _ = cv2.findContours(obj_mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
|
| 215 |
+
cv2.drawContours(frame, contours, -1, colors[j], 3)
|
| 216 |
+
cv2.drawContours(frame_for_contour, contours, -1, colors[j], 2)
|
| 217 |
+
|
| 218 |
+
if len(contours) > 0:
|
| 219 |
+
largest_contour = max(contours, key=cv2.contourArea)
|
| 220 |
+
M = cv2.moments(largest_contour)
|
| 221 |
+
if M["m00"] != 0:
|
| 222 |
+
center_x = int(M["m10"] / M["m00"])
|
| 223 |
+
center_y = int(M["m01"] / M["m00"])
|
| 224 |
+
else:
|
| 225 |
+
center_x, center_y = 0, 0
|
| 226 |
+
|
| 227 |
+
font = cv2.FONT_HERSHEY_SIMPLEX
|
| 228 |
+
text = obj_id
|
| 229 |
+
font_scale = 1.2
|
| 230 |
+
text_size = cv2.getTextSize(text, font, font_scale, 2)[0]
|
| 231 |
+
text_x = center_x - text_size[0] // 1
|
| 232 |
+
text_y = center_y
|
| 233 |
+
|
| 234 |
+
rect_start = (text_x - 5, text_y - text_size[1] - 5)
|
| 235 |
+
rect_end = (text_x + text_size[0] + 5, text_y + 3)
|
| 236 |
+
|
| 237 |
+
contour_thickness = 1
|
| 238 |
+
rect_start_contour = (rect_start[0] - contour_thickness, rect_start[1] - contour_thickness)
|
| 239 |
+
rect_end_contour = (rect_end[0] + contour_thickness, rect_end[1] + contour_thickness)
|
| 240 |
+
|
| 241 |
+
cv2.rectangle(frame, rect_start_contour, rect_end_contour, colors[j], contour_thickness)
|
| 242 |
+
cv2.rectangle(frame, rect_start, rect_end, (0, 0, 0), -1)
|
| 243 |
+
cv2.putText(frame, text, (text_x, text_y), font, 1, (255, 255, 255), 2)
|
| 244 |
+
|
| 245 |
+
|
| 246 |
+
if color_mask:
|
| 247 |
+
alpha = 0.08
|
| 248 |
+
colored_obj_mask = np.zeros_like(frame)
|
| 249 |
+
colored_obj_mask[obj_mask == 1] = colors[j]
|
| 250 |
+
frame[obj_mask == 1] = (
|
| 251 |
+
(1 - alpha) * frame[obj_mask == 1]
|
| 252 |
+
+ alpha * colored_obj_mask[obj_mask == 1]
|
| 253 |
+
)
|
| 254 |
+
|
| 255 |
+
# plt.figure(figsize=(12, 8))
|
| 256 |
+
# plt.imshow(frame)
|
| 257 |
+
# plt.title(f"frame {frame_name}")
|
| 258 |
+
# plt.tight_layout()
|
| 259 |
+
# plt.axis('off')
|
| 260 |
+
# plt.show()
|
| 261 |
+
|
| 262 |
+
buffer = BytesIO()
|
| 263 |
+
frame = Image.fromarray(frame)
|
| 264 |
+
frame.save(buffer, format='jpeg')
|
| 265 |
+
buffer.seek(0)
|
| 266 |
+
cat_frames.append(base64.b64encode(buffer.read()).decode("utf-8"))
|
| 267 |
+
frame_cat_cnts[frame_name] = cat_cnt
|
| 268 |
+
|
| 269 |
+
buffer.seek(0) # Reuse buffer instead of creating a new one
|
| 270 |
+
buffer.truncate()
|
| 271 |
+
frame_for_contour = Image.fromarray(frame_for_contour)
|
| 272 |
+
frame_for_contour.save(buffer, format='jpeg')
|
| 273 |
+
buffer.seek(0)
|
| 274 |
+
contour_frames.append(base64.b64encode(buffer.read()).decode("utf-8"))
|
| 275 |
+
|
| 276 |
+
encoded_frames[cat] = cat_frames
|
| 277 |
+
contoured_frames[cat] = contour_frames
|
| 278 |
+
vid_cat_cnts[cat] = frame_cat_cnts
|
| 279 |
+
|
| 280 |
+
return encoded_frames, contoured_frames, vid_cat_cnts
|
| 281 |
+
|
| 282 |
+
|
| 283 |
+
|
| 284 |
+
def getCaption(idx, model='gpt-4o'):
|
| 285 |
+
vid_meta = metas[idx]
|
| 286 |
+
vid_data = train_dataset[idx]
|
| 287 |
+
vid_id = vid_meta['video']
|
| 288 |
+
print(f"vid id: {vid_id}\n")
|
| 289 |
+
|
| 290 |
+
frame_indx = vid_meta['sample_indx'] # e.g. [4, 7, 9, 16]
|
| 291 |
+
cat_names = set(vid_meta['obj_id_cat'].values()) # e.g. {"person", "elephant", ...}
|
| 292 |
+
all_captions = dict()
|
| 293 |
+
|
| 294 |
+
# color_mask = random.choice([True, False])
|
| 295 |
+
color_mask = random.choices([False, True], weights=[60, 40])[0]
|
| 296 |
+
|
| 297 |
+
base64_frames, _ , vid_cat_cnts = number_objects_and_encode(idx, color_mask)
|
| 298 |
+
#marked = "mask with boundary" if color_mask else "boundary"
|
| 299 |
+
|
| 300 |
+
for cat_name in list(cat_names) :
|
| 301 |
+
|
| 302 |
+
is_movable = False
|
| 303 |
+
if cat_name in ytvos_category_valid_list :
|
| 304 |
+
is_movable = True
|
| 305 |
+
|
| 306 |
+
if not is_movable:
|
| 307 |
+
print(f"Skipping {cat_name}: Determined to be non-movable.", end='\n\n')
|
| 308 |
+
|
| 309 |
+
|
| 310 |
+
image_captions = {}
|
| 311 |
+
captioner = OpenAI()
|
| 312 |
+
cat_base64_frames = base64_frames[cat_name]
|
| 313 |
+
# cont_base64_frames = contoured_frames[cat_name]
|
| 314 |
+
|
| 315 |
+
for i in range(len(cat_base64_frames)):
|
| 316 |
+
frame_name = frame_indx[i]
|
| 317 |
+
# cont_base64_image = cont_base64_frames[i]
|
| 318 |
+
base64_image = cat_base64_frames[i]
|
| 319 |
+
should_filter = False
|
| 320 |
+
frame_cat_cnts = vid_cat_cnts[cat_name][frame_name]
|
| 321 |
+
|
| 322 |
+
if frame_cat_cnts >= 2:
|
| 323 |
+
should_filter = True
|
| 324 |
+
else:
|
| 325 |
+
print(f"Skipping {cat_name}: There is single or no object.", end='\n\n')
|
| 326 |
+
|
| 327 |
+
|
| 328 |
+
if is_movable and should_filter:
|
| 329 |
+
#1단계: 필터링
|
| 330 |
+
print(f"-----------category name: {cat_name}, frame name: {frame_name}")
|
| 331 |
+
caption_filter_text = f"""
|
| 332 |
+
You are a visual assistant analyzing a single frame from a video.
|
| 333 |
+
In this frame, I have labeled {frame_cat_cnts} {cat_name}(s), each with a bright numeric ID at its center and a visible marker.
|
| 334 |
+
|
| 335 |
+
Are {cat_name}s in the image performing all different and recognizable actions or postures?
|
| 336 |
+
Consider differences in body pose (standing, sitting, holding hands up, grabbing object, facing the camera, stretching, walking...), motion cues (inferred from the momentary stance or position),
|
| 337 |
+
facial expressions, and any notable interactions with objects or other {cat_name}s or people.
|
| 338 |
+
|
| 339 |
+
Only focus on obvious, prominent actions that can be reliably identified from this single frame.
|
| 340 |
+
|
| 341 |
+
- Respond with "YES" if:
|
| 342 |
+
1) Most of {cat_name}s exhibit clearly different, unique actions or poses.
|
| 343 |
+
(e.g. standing, sitting, bending, stretching, showing its back, or turning toward the camera.)
|
| 344 |
+
2) You can see visible significant differences in action and posture, that an observer can identify at a glance.
|
| 345 |
+
3) Interaction Variability: Each {cat_name} is engaged in a different type of action, such as one grasping an object while another is observing.
|
| 346 |
+
|
| 347 |
+
- Respond with "NONE" if:
|
| 348 |
+
1) The actions or pose are not clearly differentiable or too similar.
|
| 349 |
+
2) Minimal or Ambiguous Motion: The frame does not provide clear evidence of distinct movement beyond subtle shifts in stance.
|
| 350 |
+
3) Passive or Neutral Poses: If multiple {cat_name}(s) are simply standing or sitting without an obvious difference in orientation or motion
|
| 351 |
+
|
| 352 |
+
Answer strictly with either "YES" or "NONE".
|
| 353 |
+
"""
|
| 354 |
+
|
| 355 |
+
response1 = captioner.chat.completions.create(
|
| 356 |
+
model=model,
|
| 357 |
+
messages=[
|
| 358 |
+
{
|
| 359 |
+
"role": "user",
|
| 360 |
+
"content": [
|
| 361 |
+
{
|
| 362 |
+
"type": "text",
|
| 363 |
+
"text": caption_filter_text,
|
| 364 |
+
},
|
| 365 |
+
{
|
| 366 |
+
"type": "image_url",
|
| 367 |
+
"image_url": {"url": f"data:image/jpeg;base64,{base64_image}"},
|
| 368 |
+
}
|
| 369 |
+
],
|
| 370 |
+
}
|
| 371 |
+
],
|
| 372 |
+
)
|
| 373 |
+
response_content = response1.choices[0].message.content
|
| 374 |
+
should_caption = True if "yes" in response_content.lower() else False
|
| 375 |
+
print(f"are {cat_name}s distinguished by action: {response_content}", end='\n\n')
|
| 376 |
+
|
| 377 |
+
else:
|
| 378 |
+
should_caption = False
|
| 379 |
+
|
| 380 |
+
#2단계: dense caption 만들기
|
| 381 |
+
dense_caption_prompt_1 = f"""
|
| 382 |
+
In the given frame, I labeled {frame_cat_cnts} {cat_name}s by marking each with a bright numeric ID at the center and its boundary. The category name of these objects are : {cat_name}.
|
| 383 |
+
|
| 384 |
+
Please describe the image focusing on labeled {cat_name}s in detail, focusing on their actions and interactions.
|
| 385 |
+
|
| 386 |
+
1. Focus only on clear, unique, and prominent actions that distinguish each object.
|
| 387 |
+
2. Avoid describing actions that are too minor, ambiguous, or not visible from the image.
|
| 388 |
+
3. Avoid subjective terms such as 'skilled', 'controlled', or 'focused'. Only describe observable actions.
|
| 389 |
+
4. Do not include common-sense or overly general descriptions like 'the elephant walks'.
|
| 390 |
+
5. Use dynamic action verbs (e.g., holding, throwing, jumping, inspecting) to describe interactions, poses, or movements.
|
| 391 |
+
6. **Avoid overly detailed or speculative descriptions** such as 'slightly moving its mouth' or 'appears to be anticipating'.
|
| 392 |
+
- expressions like 'seems to be', 'appears to be' are BANNED!
|
| 393 |
+
7. Pretend you are observing the scene directly, avoiding phrases like 'it seems' or 'based on the description'.
|
| 394 |
+
8. Include interactions with objects or other entities when they are prominent and observable.
|
| 395 |
+
9. **Do not include descriptions of appearance** such as clothes, color, size, shape etc.
|
| 396 |
+
10. **Do not include relative position** between objects such as 'the left elephant' because left/right can be ambiguous.
|
| 397 |
+
11. Do not mention object IDs.
|
| 398 |
+
12. Use '{cat_name}' as the noun for the referring expressions.
|
| 399 |
+
|
| 400 |
+
Note that I want to use your description to create a grounding dataset, therefore, your descriptions for different objects should be unique, i.e., If the image contains multiple {cat_name}s, describe the actions of each individually and ensure the descriptions are non-overlapping and specific.
|
| 401 |
+
|
| 402 |
+
- Your answer should contain details, and follow the following format:
|
| 403 |
+
object id. action-oriented description
|
| 404 |
+
(e.g. 1. the person is holding bananas on two hands and opening his mouth, turning the head right.
|
| 405 |
+
2. a person bending over and touching his boots to tie the shoelace.)
|
| 406 |
+
- for action-oriented description, use {cat_name} as subject noun
|
| 407 |
+
|
| 408 |
+
**Only include the currently labeled category** in each line (e.g., if it’s a person, do not suddenly label it as other object/animal).
|
| 409 |
+
Please pay attention to the categories of these objects and don’t change them.
|
| 410 |
+
Keep in mind that you should not group the objects, e.g., 2-5. people: xxx, be sure to describe each object separately (one by one).
|
| 411 |
+
Output referring expressions for each object id. Please start your answer:"""
|
| 412 |
+
|
| 413 |
+
|
| 414 |
+
dense_caption_prompt_2 = f"""
|
| 415 |
+
You are an advanced visual language model analyzing a video frame.
|
| 416 |
+
In this frame, {frame_cat_cnts} objects belonging to the category **{cat_name}** have been distinctly labeled with bright numerical IDs at their center and boundary.
|
| 417 |
+
|
| 418 |
+
Your task is to generate **action-oriented descriptions** for each labeled {cat_name}.
|
| 419 |
+
Your descriptions should capture their **observable actions and interactions**, making sure to highlight movement, gestures, and dynamic behaviors.
|
| 420 |
+
|
| 421 |
+
---
|
| 422 |
+
## Key Guidelines:
|
| 423 |
+
1. **Describe only clear and visible actions** that uniquely define what the {cat_name} is doing.
|
| 424 |
+
- Example: "grabbing a branch and pulling it down" (**(O) Specific**)
|
| 425 |
+
- Avoid: "moving slightly to the side" (**(X) Too vague**)
|
| 426 |
+
|
| 427 |
+
2. **Do not describe appearance, color, or position**—focus purely on the action.
|
| 428 |
+
- (X) "A large brown bear standing on the left"
|
| 429 |
+
- (O) "The bear is lifting its front paws and swiping forward."
|
| 430 |
+
|
| 431 |
+
3. **Use dynamic, action-specific verbs** rather than passive descriptions.
|
| 432 |
+
- (O) "The giraffe is tilting its head and sniffing the ground."
|
| 433 |
+
- (X) "The giraffe is near a tree and looking around."
|
| 434 |
+
|
| 435 |
+
4. **Avoid assumptions, emotions, or speculative phrasing.**
|
| 436 |
+
- (X) "The person seems excited" / "The person might be preparing to jump."
|
| 437 |
+
- (O) "The person is pushing its front legs against the rock and leaping forward."
|
| 438 |
+
|
| 439 |
+
5. **Avoid overly detailed or speculative descriptions** such as 'slightly moving its mouth' or 'appears to be anticipating'.
|
| 440 |
+
- expressions like 'seems to be', 'appears to be' are BANNED!
|
| 441 |
+
6. Pretend you are observing the scene directly, avoiding phrases like 'it seems' or 'based on the description'.
|
| 442 |
+
|
| 443 |
+
7. If multiple {cat_name}s are present, make sure their descriptions are **distinct and non-overlapping**.
|
| 444 |
+
- **Each object should have a unique, descriptive action.**
|
| 445 |
+
- (X) "Two dogs are running."
|
| 446 |
+
- (O) "1. One dog is chasing another, its legs stretched mid-air.
|
| 447 |
+
2. The other dog is looking back while speeding up."
|
| 448 |
+
|
| 449 |
+
---
|
| 450 |
+
## Output Format:
|
| 451 |
+
- Each labeled **{cat_name}** should have exactly **one line of description**.
|
| 452 |
+
- Format: `ID. {cat_name} + action-based description`
|
| 453 |
+
- (O) Example:
|
| 454 |
+
```
|
| 455 |
+
1. The person is leaning forward while opening a bag with both hands.
|
| 456 |
+
2. The person is holding onto a rope and pulling themselves up.
|
| 457 |
+
```
|
| 458 |
+
- **Ensure that each object is described individually.**
|
| 459 |
+
- **Do not group objects into a single sentence** (e.g., "2-5. people: xxx" is NOT allowed).
|
| 460 |
+
|
| 461 |
+
---
|
| 462 |
+
## Additional Instructions:
|
| 463 |
+
- **Do NOT** use expressions like "it appears that..." or "it seems like...".
|
| 464 |
+
- **Do NOT** mention object IDs in the description (only use the provided format).
|
| 465 |
+
- **DO NOT** include markdown formatting (no bullet points, no asterisks).
|
| 466 |
+
- **Only describe actions of the labeled {cat_name} objects**—do not introduce unrelated categories.
|
| 467 |
+
|
| 468 |
+
Please generate the action-oriented descriptions for each labeled {cat_name} and start your answer:
|
| 469 |
+
"""
|
| 470 |
+
|
| 471 |
+
|
| 472 |
+
dense_caption_prompt = f"""
|
| 473 |
+
You are a visual assistant analyzing a single frame of a video.
|
| 474 |
+
In this frame, {frame_cat_cnts} objects belonging to the category **{cat_name}** have been labeled with bright numeric IDs at their center and boundary.
|
| 475 |
+
|
| 476 |
+
I am building an **action-centric referring expression** dataset.
|
| 477 |
+
Your task is to describe each labeled {cat_name} based on **clearly observable and specific actions**.
|
| 478 |
+
|
| 479 |
+
---
|
| 480 |
+
## Guidelines:
|
| 481 |
+
1. **Focus only on visible and prominent actions** (e.g., running, pushing, grasping an object).
|
| 482 |
+
2. **Avoid describing minor or ambiguous movements** (e.g., "slightly moving a paw," "tilting head a bit").
|
| 483 |
+
3. **Do not include subjective or speculative descriptions** (e.g., "it seems excited" or "it might be preparing to jump").
|
| 484 |
+
4. **Avoid vague expressions** like "engaging with something." Instead, specify the action (e.g., "grabbing a stick," "pressing a button").
|
| 485 |
+
5. **Use dynamic action verbs** (e.g., holding, throwing, inspecting, leaning, pressing) to highlight motion and interaction.
|
| 486 |
+
6. If multiple {cat_name}s appear, ensure each description is **distinct and non-overlapping**.
|
| 487 |
+
7. Base your descriptions on these principles:
|
| 488 |
+
- **Avoid words like 'minimal' or 'slightly'.**
|
| 489 |
+
- Emphasize **body movement, posture, and motion patterns** (e.g., "lifting its head," "facing forward," "showing its back").
|
| 490 |
+
- Describe **facial expressions and interactions with objects** (e.g., "opening its mouth wide," "smiling while holding an item").
|
| 491 |
+
- **Specify actions with other objects or entities** only when they are clear and observable.
|
| 492 |
+
- (O) "pushing another person"
|
| 493 |
+
- (X) "interacting with another object"
|
| 494 |
+
|
| 495 |
+
---
|
| 496 |
+
## Output Format:
|
| 497 |
+
- Each labeled **{cat_name}** must have **exactly one line**.
|
| 498 |
+
- Format: `ID. {cat_name} + action-based description`
|
| 499 |
+
- (O) Example:
|
| 500 |
+
```
|
| 501 |
+
1. The person is holding ski poles and skiing down a snowy mountain with bent knees.
|
| 502 |
+
2. The person is pulling a baby carriage while smiling.
|
| 503 |
+
```
|
| 504 |
+
- **Ensure each object is described individually.**
|
| 505 |
+
- **Do not group multiple objects into a single sentence** (e.g., "2-5. people: xxx" is NOT allowed).
|
| 506 |
+
|
| 507 |
+
---
|
| 508 |
+
## Example:
|
| 509 |
+
If the frame has two labeled **bears**, your output should be:
|
| 510 |
+
```
|
| 511 |
+
1. The bear is reaching out its right paw while leaning forward to catch prey.
|
| 512 |
+
2. A bear is standing upright, facing right, and touching the bike beside it.
|
| 513 |
+
```
|
| 514 |
+
|
| 515 |
+
---
|
| 516 |
+
## Additional Instructions:
|
| 517 |
+
- **Do NOT** describe appearance (e.g., color, size, texture) or relative positioning (e.g., "on the left/right").
|
| 518 |
+
- **Do NOT** reference object IDs explicitly (e.g., "Person 1" or "Object 2" is NOT allowed).
|
| 519 |
+
- **Do NOT** include markdown formatting (no bullet points, asterisks, or extra symbols).
|
| 520 |
+
- **Only describe actions of the labeled {cat_name} objects**—do not introduce unrelated categories.
|
| 521 |
+
|
| 522 |
+
Please generate the action-oriented descriptions for each labeled {cat_name} and start your answer:"""
|
| 523 |
+
|
| 524 |
+
|
| 525 |
+
MAX_RETRIES = 3
|
| 526 |
+
retry_count = 0
|
| 527 |
+
|
| 528 |
+
if should_caption:
|
| 529 |
+
while retry_count < MAX_RETRIES:
|
| 530 |
+
selected_prompt = random.choice([dense_caption_prompt, dense_caption_prompt_2])
|
| 531 |
+
|
| 532 |
+
response2 = captioner.chat.completions.create(
|
| 533 |
+
model=model,
|
| 534 |
+
messages=[
|
| 535 |
+
{
|
| 536 |
+
"role": "user",
|
| 537 |
+
"content": [
|
| 538 |
+
{
|
| 539 |
+
"type": "text",
|
| 540 |
+
"text": selected_prompt,
|
| 541 |
+
},
|
| 542 |
+
{
|
| 543 |
+
"type": "image_url",
|
| 544 |
+
"image_url": {"url": f"data:image/jpeg;base64,{base64_image}"},
|
| 545 |
+
},
|
| 546 |
+
],
|
| 547 |
+
}
|
| 548 |
+
],
|
| 549 |
+
)
|
| 550 |
+
|
| 551 |
+
# caption = response2.choices[0].message.content
|
| 552 |
+
#print(f"{image_path} - {frame_name}: {caption}")
|
| 553 |
+
|
| 554 |
+
caption = response2.choices[0].message.content.strip()
|
| 555 |
+
caption_lower = caption.lower().lstrip()
|
| 556 |
+
|
| 557 |
+
if caption_lower.startswith("1.") and not any(
|
| 558 |
+
phrase in caption_lower for phrase in ["i'm sorry", "please", "can't help"]
|
| 559 |
+
):
|
| 560 |
+
break
|
| 561 |
+
|
| 562 |
+
print(f"Retrying caption generation... ({retry_count + 1}/{MAX_RETRIES})")
|
| 563 |
+
retry_count += 1
|
| 564 |
+
time.sleep(2)
|
| 565 |
+
|
| 566 |
+
if retry_count == MAX_RETRIES:
|
| 567 |
+
caption = None
|
| 568 |
+
print("Max retries reached. Caption generation failed.")
|
| 569 |
+
|
| 570 |
+
else:
|
| 571 |
+
caption = None
|
| 572 |
+
|
| 573 |
+
image_captions[frame_name] = caption
|
| 574 |
+
all_captions[cat_name] = image_captions
|
| 575 |
+
|
| 576 |
+
# final : also prepare valid object ids
|
| 577 |
+
valid_obj_ids = dict()
|
| 578 |
+
|
| 579 |
+
for cat in cat_names:
|
| 580 |
+
if cat in ytvos_category_valid_list:
|
| 581 |
+
obj_id_cat = vid_meta['obj_id_cat']
|
| 582 |
+
valid_cat_ids = []
|
| 583 |
+
for obj_id in list(obj_id_cat.keys()):
|
| 584 |
+
if obj_id_cat[obj_id] == cat:
|
| 585 |
+
valid_cat_ids.append(obj_id)
|
| 586 |
+
valid_obj_ids[cat] = valid_cat_ids
|
| 587 |
+
|
| 588 |
+
return vid_id, all_captions, valid_obj_ids
|
| 589 |
+
|
| 590 |
+
|
| 591 |
+
if __name__ == '__main__':
|
| 592 |
+
parser = argparse.ArgumentParser('ReferFormer training and evaluation script', parents=[opts.get_args_parser()])
|
| 593 |
+
parser.add_argument('--save_caption_path', type=str, default="mbench/numbered_captions_gpt-4o_randcap.json")
|
| 594 |
+
parser.add_argument('--save_valid_obj_ids_path', type=str, default="mbench/numbered_valid_obj_ids_gpt-4o_randcap.json")
|
| 595 |
+
|
| 596 |
+
args = parser.parse_args()
|
| 597 |
+
|
| 598 |
+
#==================데이터 불러오기===================
|
| 599 |
+
# 전체 데이터셋
|
| 600 |
+
train_dataset = build_ytvos_ref(image_set = 'train', args = args)
|
| 601 |
+
|
| 602 |
+
# 전체 데이터셋 메타데이터
|
| 603 |
+
metas = train_dataset.metas
|
| 604 |
+
|
| 605 |
+
# 색상 후보 8개 (RGB 형식)
|
| 606 |
+
colors = [
|
| 607 |
+
(255, 0, 0), # Red
|
| 608 |
+
(0, 255, 0), # Green
|
| 609 |
+
(0, 0, 255), # Blue
|
| 610 |
+
(255, 255, 0), # Yellow
|
| 611 |
+
(255, 0, 255), # Magenta
|
| 612 |
+
(0, 255, 255), # Cyan
|
| 613 |
+
(128, 0, 128), # Purple
|
| 614 |
+
(255, 165, 0) # Orange
|
| 615 |
+
]
|
| 616 |
+
|
| 617 |
+
ytvos_category_valid_list = [
|
| 618 |
+
'airplane', 'ape', 'bear', 'bird', 'boat', 'bus', 'camel', 'cat', 'cow', 'crocodile',
|
| 619 |
+
'deer', 'dog', 'dolphin', 'duck', 'eagle', 'earless_seal', 'elephant', 'fish', 'fox', 'frog',
|
| 620 |
+
'giant_panda', 'giraffe', 'hedgehog', 'horse', 'leopard', 'lion', 'lizard',
|
| 621 |
+
'monkey', 'motorbike', 'mouse', 'owl', 'parrot', 'penguin', 'person',
|
| 622 |
+
'rabbit', 'raccoon', 'sedan', 'shark', 'sheep', 'snail', 'snake',
|
| 623 |
+
'squirrel', 'tiger', 'train', 'truck', 'turtle', 'whale', 'zebra'
|
| 624 |
+
]
|
| 625 |
+
|
| 626 |
+
#==================gpt 돌리기===================
|
| 627 |
+
os.environ['OPENAI_API_KEY'] = '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'
|
| 628 |
+
|
| 629 |
+
result_captions = {}
|
| 630 |
+
result_valid_obj_ids = {}
|
| 631 |
+
|
| 632 |
+
for i in range(len(metas)):
|
| 633 |
+
try:
|
| 634 |
+
vid_id, all_captions, valid_obj_ids = getCaption(i)
|
| 635 |
+
|
| 636 |
+
if vid_id not in result_captions:
|
| 637 |
+
result_captions[vid_id] = all_captions
|
| 638 |
+
if vid_id not in result_valid_obj_ids:
|
| 639 |
+
result_valid_obj_ids[vid_id] = valid_obj_ids
|
| 640 |
+
|
| 641 |
+
except (requests.exceptions.ConnectionError, APIConnectionError) as e:
|
| 642 |
+
print(f"created caption until {i-1}", flush=True)
|
| 643 |
+
print("인터넷 연결 문제로 요청을 처리할 수 없습니다:", e, flush=True)
|
| 644 |
+
|
| 645 |
+
with open(args.save_caption_path, "w") as file:
|
| 646 |
+
json.dump(result_captions, file, indent=4)
|
| 647 |
+
|
| 648 |
+
with open(args.save_valid_obj_ids_path, "w") as file:
|
| 649 |
+
json.dump(result_valid_obj_ids, file, indent=4)
|
| 650 |
+
|
| 651 |
+
except OpenAIError as e:
|
| 652 |
+
print(f"created caption until {i-1}", flush=True)
|
| 653 |
+
print("OpenAI API 관련 오류가 발생했습니다:", e, flush=True)
|
| 654 |
+
|
| 655 |
+
with open(args.save_caption_path, "w") as file:
|
| 656 |
+
json.dump(result_captions, file, indent=4)
|
| 657 |
+
|
| 658 |
+
with open(args.save_valid_obj_ids_path, "w") as file:
|
| 659 |
+
json.dump(result_valid_obj_ids, file, indent=4)
|
| 660 |
+
|
| 661 |
+
except Exception as e:
|
| 662 |
+
print(f"created caption until {i-1}", flush=True)
|
| 663 |
+
print("알 수 없는 오류 발생:", e, flush=True)
|
| 664 |
+
|
| 665 |
+
with open(args.save_caption_path, "w") as file:
|
| 666 |
+
json.dump(result_captions, file, indent=4)
|
| 667 |
+
|
| 668 |
+
with open(args.save_valid_obj_ids_path, "w") as file:
|
| 669 |
+
json.dump(result_valid_obj_ids, file, indent=4)
|
| 670 |
+
|
| 671 |
+
print("Finished!", flush=True)
|
| 672 |
+
|
| 673 |
+
with open(args.save_caption_path, "w") as file:
|
| 674 |
+
json.dump(result_captions, file, indent=4)
|
| 675 |
+
|
| 676 |
+
with open(args.save_valid_obj_ids_path, "w") as file:
|
| 677 |
+
json.dump(result_valid_obj_ids, file, indent=4)
|
.history/mbench/make_ref-ytvos_json_20250117032501.py
ADDED
|
@@ -0,0 +1,104 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import sys
|
| 2 |
+
import os
|
| 3 |
+
from os import path as osp
|
| 4 |
+
sys.path.append(osp.abspath(osp.join(osp.dirname(__file__), '..')))
|
| 5 |
+
|
| 6 |
+
from datasets import build_dataset
|
| 7 |
+
import argparse
|
| 8 |
+
import opts
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
from pathlib import Path
|
| 12 |
+
import io
|
| 13 |
+
|
| 14 |
+
import numpy as np
|
| 15 |
+
import pandas as pd
|
| 16 |
+
import regex as re
|
| 17 |
+
import json
|
| 18 |
+
|
| 19 |
+
import cv2
|
| 20 |
+
from PIL import Image, ImageDraw
|
| 21 |
+
import torch
|
| 22 |
+
from torchvision.transforms import functional as F
|
| 23 |
+
|
| 24 |
+
from skimage import measure # (pip install scikit-image)
|
| 25 |
+
from shapely.geometry import Polygon, MultiPolygon # (pip install Shapely)
|
| 26 |
+
|
| 27 |
+
import matplotlib.pyplot as plt
|
| 28 |
+
import matplotlib.patches as patches
|
| 29 |
+
from matplotlib.collections import PatchCollection
|
| 30 |
+
from matplotlib.patches import Rectangle
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
import ipywidgets as widgets
|
| 34 |
+
from IPython.display import display, clear_output
|
| 35 |
+
|
| 36 |
+
#==================json 만들기===================
|
| 37 |
+
def createJson(train_dataset, metas):
|
| 38 |
+
entire_json = {}
|
| 39 |
+
|
| 40 |
+
#초기화
|
| 41 |
+
vid_idx = 0
|
| 42 |
+
|
| 43 |
+
while vid_idx < len(train_dataset):
|
| 44 |
+
|
| 45 |
+
#하나의 비디오에 대해
|
| 46 |
+
video_data = {}
|
| 47 |
+
video_train_frames, video_train_info = train_dataset[vid_idx]
|
| 48 |
+
video_meta = metas[vid_idx]
|
| 49 |
+
|
| 50 |
+
video_id = video_meta['video']
|
| 51 |
+
video_data['bins'] = video_meta['bins']
|
| 52 |
+
bin_nums = len(video_meta['bins'])
|
| 53 |
+
obj_nums = len(list(video_meta['obj_id_cat'].keys()))
|
| 54 |
+
|
| 55 |
+
annotation_data = []
|
| 56 |
+
frame_names = []
|
| 57 |
+
|
| 58 |
+
for i in range(bin_nums):
|
| 59 |
+
bin_data = {}
|
| 60 |
+
for j in range(obj_nums):
|
| 61 |
+
obj_id = str(j+1)
|
| 62 |
+
obj_data = {
|
| 63 |
+
"category_name":video_meta['obj_id_cat'][obj_id],
|
| 64 |
+
"bbox":video_train_info['boxes'][i*obj_nums+j, :]
|
| 65 |
+
}
|
| 66 |
+
bin_data[obj_id] = obj_data
|
| 67 |
+
annotation_data.append(bin_data)
|
| 68 |
+
|
| 69 |
+
video_data['annotations'] = annotation_data
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
sample_indx = metas[vid_idx]['sample_indx']
|
| 73 |
+
frames = metas[vid_idx]['frames']
|
| 74 |
+
for i in sample_indx:
|
| 75 |
+
frame_name = frames[i]
|
| 76 |
+
frame_names.append(frame_name)
|
| 77 |
+
|
| 78 |
+
video_data['frame_names'] = frame_names
|
| 79 |
+
video_data['video_path'] = os.path.join(str(train_dataset.img_folder), 'JPEGImages', video_id)
|
| 80 |
+
entire_json[video_id] = video_data
|
| 81 |
+
|
| 82 |
+
vid_idx += 1
|
| 83 |
+
|
| 84 |
+
return entire_json
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
if __name__ == '__main__':
|
| 88 |
+
parser = argparse.ArgumentParser('ReferFormer training and evaluation script', parents=[opts.get_args_parser()])
|
| 89 |
+
args = parser.parse_args()
|
| 90 |
+
|
| 91 |
+
#==================데이터 불러오기===================
|
| 92 |
+
# 전체 데이터셋
|
| 93 |
+
train_dataset = build_dataset('ytvos_ref', image_set = 'train', args = args)
|
| 94 |
+
|
| 95 |
+
# 전체 데이터셋 메타데이터
|
| 96 |
+
metas = train_dataset.metas
|
| 97 |
+
|
| 98 |
+
#==================json 만들기===================
|
| 99 |
+
entire_json_dict = createJson(train_dataset, metas)
|
| 100 |
+
print(type(entire_json_dict))
|
| 101 |
+
entire_json = json.dumps(entire_json_dict, indent=4)
|
| 102 |
+
|
| 103 |
+
with open('mbench/sampled_frame2.json', mode='w') as file:
|
| 104 |
+
file.write(entire_json)
|
.history/mbench/make_ref-ytvos_json_20250117072314.py
ADDED
|
@@ -0,0 +1,107 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import sys
|
| 2 |
+
import os
|
| 3 |
+
from os import path as osp
|
| 4 |
+
sys.path.append(osp.abspath(osp.join(osp.dirname(__file__), '..')))
|
| 5 |
+
|
| 6 |
+
from datasets import build_dataset
|
| 7 |
+
import argparse
|
| 8 |
+
import opts
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
from pathlib import Path
|
| 12 |
+
import io
|
| 13 |
+
|
| 14 |
+
import numpy as np
|
| 15 |
+
import pandas as pd
|
| 16 |
+
import regex as re
|
| 17 |
+
import json
|
| 18 |
+
|
| 19 |
+
import cv2
|
| 20 |
+
from PIL import Image, ImageDraw
|
| 21 |
+
import torch
|
| 22 |
+
from torchvision.transforms import functional as F
|
| 23 |
+
|
| 24 |
+
from skimage import measure # (pip install scikit-image)
|
| 25 |
+
from shapely.geometry import Polygon, MultiPolygon # (pip install Shapely)
|
| 26 |
+
|
| 27 |
+
import matplotlib.pyplot as plt
|
| 28 |
+
import matplotlib.patches as patches
|
| 29 |
+
from matplotlib.collections import PatchCollection
|
| 30 |
+
from matplotlib.patches import Rectangle
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
import ipywidgets as widgets
|
| 34 |
+
from IPython.display import display, clear_output
|
| 35 |
+
|
| 36 |
+
#==================json 만들기===================
|
| 37 |
+
def createJson(train_dataset, metas):
|
| 38 |
+
entire_json = {}
|
| 39 |
+
|
| 40 |
+
#초기화
|
| 41 |
+
vid_idx = 0
|
| 42 |
+
|
| 43 |
+
while vid_idx < len(train_dataset):
|
| 44 |
+
|
| 45 |
+
#하나의 비디오에 대해
|
| 46 |
+
video_data = {}
|
| 47 |
+
video_train_frames, video_train_info = train_dataset[vid_idx]
|
| 48 |
+
video_meta = metas[vid_idx]
|
| 49 |
+
|
| 50 |
+
video_id = video_meta['video']
|
| 51 |
+
video_data['bins'] = video_meta['bins']
|
| 52 |
+
bin_nums = len(video_meta['bins'])
|
| 53 |
+
obj_nums = len(list(video_meta['obj_id_cat'].keys()))
|
| 54 |
+
|
| 55 |
+
annotation_data = []
|
| 56 |
+
frame_names = []
|
| 57 |
+
|
| 58 |
+
for i in range(bin_nums):
|
| 59 |
+
bin_data = {}
|
| 60 |
+
for j in range(obj_nums):
|
| 61 |
+
try:
|
| 62 |
+
obj_id = str(j+1)
|
| 63 |
+
obj_data = {
|
| 64 |
+
"category_name":video_meta['obj_id_cat'][obj_id],
|
| 65 |
+
"bbox":video_train_info['boxes'][i*obj_nums+j, :]
|
| 66 |
+
}
|
| 67 |
+
bin_data[obj_id] = obj_data
|
| 68 |
+
except:
|
| 69 |
+
continue
|
| 70 |
+
annotation_data.append(bin_data)
|
| 71 |
+
|
| 72 |
+
video_data['annotations'] = annotation_data
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
sample_indx = metas[vid_idx]['sample_indx']
|
| 76 |
+
frames = metas[vid_idx]['frames']
|
| 77 |
+
for i in sample_indx:
|
| 78 |
+
frame_name = frames[i]
|
| 79 |
+
frame_names.append(frame_name)
|
| 80 |
+
|
| 81 |
+
video_data['frame_names'] = frame_names
|
| 82 |
+
video_data['video_path'] = os.path.join(str(train_dataset.img_folder), 'JPEGImages', video_id)
|
| 83 |
+
entire_json[video_id] = video_data
|
| 84 |
+
|
| 85 |
+
vid_idx += 1
|
| 86 |
+
|
| 87 |
+
return entire_json
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
if __name__ == '__main__':
|
| 91 |
+
parser = argparse.ArgumentParser('ReferFormer training and evaluation script', parents=[opts.get_args_parser()])
|
| 92 |
+
args = parser.parse_args()
|
| 93 |
+
|
| 94 |
+
#==================데이터 불러오기===================
|
| 95 |
+
# 전체 데이터셋
|
| 96 |
+
train_dataset = build_dataset('ytvos_ref', image_set = 'train', args = args)
|
| 97 |
+
|
| 98 |
+
# 전체 데이터셋 메타데이터
|
| 99 |
+
metas = train_dataset.metas
|
| 100 |
+
|
| 101 |
+
#==================json 만들기===================
|
| 102 |
+
entire_json_dict = createJson(train_dataset, metas)
|
| 103 |
+
print(type(entire_json_dict))
|
| 104 |
+
entire_json = json.dumps(entire_json_dict, indent=4)
|
| 105 |
+
|
| 106 |
+
with open('mbench/sampled_frame2.json', mode='w') as file:
|
| 107 |
+
file.write(entire_json)
|
.history/mbench_a2d/gpt_a2d_numbered_20250206114207.py
ADDED
|
@@ -0,0 +1,205 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import sys
|
| 3 |
+
sys.path.append(os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
|
| 4 |
+
|
| 5 |
+
from datasets import build_dataset
|
| 6 |
+
import argparse
|
| 7 |
+
import opts
|
| 8 |
+
import time
|
| 9 |
+
|
| 10 |
+
import numpy as np
|
| 11 |
+
import matplotlib.pyplot as plt
|
| 12 |
+
import cv2
|
| 13 |
+
from io import BytesIO
|
| 14 |
+
import base64
|
| 15 |
+
from PIL import Image
|
| 16 |
+
import json
|
| 17 |
+
|
| 18 |
+
from openai import OpenAI
|
| 19 |
+
|
| 20 |
+
def mark_object_and_encode(frame, mask, instance_id, text_query, color_mask=False, label_number=False):
|
| 21 |
+
#마스크 색칠할지
|
| 22 |
+
if color_mask == True:
|
| 23 |
+
alpha = 0.1
|
| 24 |
+
|
| 25 |
+
colored_mask = np.zeros_like(frame)
|
| 26 |
+
colored_mask[mask == 1] = [255, 0, 0]
|
| 27 |
+
frame[mask == 1] = (
|
| 28 |
+
(1 - alpha) * frame[mask == 1] +
|
| 29 |
+
alpha * colored_mask[mask == 1]
|
| 30 |
+
)
|
| 31 |
+
|
| 32 |
+
#마스크 아웃라인 그리기
|
| 33 |
+
contours, _ = cv2.findContours(mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
|
| 34 |
+
cv2.drawContours(frame, contours, -1, [255, 0, 0], 2)
|
| 35 |
+
|
| 36 |
+
#instance_id 적을지
|
| 37 |
+
if label_number == True:
|
| 38 |
+
if len(contours) > 0:
|
| 39 |
+
largest_contour = max(contours, key=cv2.contourArea)
|
| 40 |
+
M = cv2.moments(largest_contour)
|
| 41 |
+
if M["m00"] != 0:
|
| 42 |
+
center_x = int(M["m10"] / M["m00"])
|
| 43 |
+
center_y = int(M["m01"] / M["m00"])
|
| 44 |
+
else:
|
| 45 |
+
center_x, center_y = 0, 0
|
| 46 |
+
|
| 47 |
+
font = cv2.FONT_HERSHEY_SIMPLEX
|
| 48 |
+
text = str(instance_id)
|
| 49 |
+
font_scale = 0.6
|
| 50 |
+
text_size = cv2.getTextSize(text, font, font_scale, 2)[0]
|
| 51 |
+
text_x = center_x - text_size[0] // 1 # 텍스트의 가로 중심
|
| 52 |
+
text_y = center_y
|
| 53 |
+
# text_y = center_y + text_size[1] // 2 # 텍스트의 세로 중심
|
| 54 |
+
|
| 55 |
+
# 텍스트 배경 사각형 좌표 계산
|
| 56 |
+
rect_start = (text_x - 5, text_y - text_size[1] - 5) # 배경 사각형 좌상단
|
| 57 |
+
# rect_end = (text_x + text_size[0] + 5, text_y + 5)
|
| 58 |
+
rect_end = (text_x + text_size[0] + 5, text_y)
|
| 59 |
+
|
| 60 |
+
cv2.rectangle(frame, rect_start, rect_end, (0, 0, 0), -1)
|
| 61 |
+
cv2.putText(frame, text, (text_x, text_y), font, font_scale, (255, 255, 255), 2)
|
| 62 |
+
|
| 63 |
+
# plt.figure(figsize=(6, 10))
|
| 64 |
+
# plt.imshow(frame)
|
| 65 |
+
# plt.title(text_query)
|
| 66 |
+
# plt.tight_layout()
|
| 67 |
+
# plt.axis('off')
|
| 68 |
+
# plt.show()
|
| 69 |
+
|
| 70 |
+
buffer = BytesIO()
|
| 71 |
+
frame = Image.fromarray(frame)
|
| 72 |
+
frame.save(buffer, format='jpeg')
|
| 73 |
+
buffer.seek(0)
|
| 74 |
+
encoded_frame = base64.b64encode(buffer.read()).decode("utf-8")
|
| 75 |
+
|
| 76 |
+
return encoded_frame
|
| 77 |
+
|
| 78 |
+
def getCaption(frame, mask, instance_id, text_query, model='gpt-4o', color_mask=False, label_number=True):
|
| 79 |
+
|
| 80 |
+
base64_image = mark_object_and_encode(frame, mask, instance_id, text_query, color_mask, label_number)
|
| 81 |
+
|
| 82 |
+
captioner = OpenAI()
|
| 83 |
+
|
| 84 |
+
#필터링하지 않고 바로 ref exp 만들기
|
| 85 |
+
dense_caption_prompt = f"""
|
| 86 |
+
You are a visual assistant analyzing a single frame of a video.
|
| 87 |
+
In the given frame, I labeled 1 object by marking each with a bright numeric ID at the center and its boundary.
|
| 88 |
+
I also give you a text query describing the marked object.
|
| 89 |
+
I want to use your expression to create an **action-centric referring expression** dataset.
|
| 90 |
+
Based on the frame and text query, please describe the marked object using **clearly observable** and **specific** actions
|
| 91 |
+
---
|
| 92 |
+
## Guidelines:
|
| 93 |
+
1. **Focus on visible, prominent actions** only (e.g., running, pushing, grasping an object).
|
| 94 |
+
2. **Avoid describing minor or ambiguous actions** (e.g., "slightly moving a paw", "slightly tilting head").
|
| 95 |
+
3. **Do not include subjective or speculative descriptions** (e.g., “it seems excited” or “it might be preparing to jump”).
|
| 96 |
+
4. **Avoid vague expressions** like "interacting with something" or "engaging with another object." Instead, specify the action (e.g., "grabbing a stick," "pressing a button").
|
| 97 |
+
5. **Use dynamic action verbs** (holding, throwing, inspecting, leaning, pressing) to highlight body movement or object/animal interaction.
|
| 98 |
+
6. If there are multiple objects, ensure the description for the marked object **differentiates** its action.
|
| 99 |
+
7. Base your description on these action definitions:
|
| 100 |
+
- Avoid using term 'minimal' or 'slightly'.
|
| 101 |
+
- General body movement, body position, or pattern which is prominent. (e.g. "lifting head up", "facing towards", "showing its back")
|
| 102 |
+
- details such as motion and intention, facial with object manipulation
|
| 103 |
+
- movements with object or other entities when they are prominent and observable. expression should be specific.
|
| 104 |
+
(e.g., "pushing another person" (O), "engaging with someone" (X) "interacting with another person" (X))
|
| 105 |
+
--
|
| 106 |
+
## Output Format:
|
| 107 |
+
- For each labeled object, output **exactly one line**. Your answer should contain details and follow the following format :
|
| 108 |
+
object id. action-oriented description
|
| 109 |
+
(e.g. 1. the person is holding ski poles and skiing on a snow mountain, with his two legs bent forward.)
|
| 110 |
+
### Example
|
| 111 |
+
If the frame has 1 labeled bear, your output should look like:
|
| 112 |
+
1. the bear reaching his right arm while leaning forward to capture the prey
|
| 113 |
+
---
|
| 114 |
+
**Do not include** appearance details (e.g., color, size, texture) or relative positioning (e.g., “on the left/right”).
|
| 115 |
+
**Do not include object IDs** or reference them (e.g., "Person 1" or "object 2" is not allowed).
|
| 116 |
+
**Do not include markdown** in the output.
|
| 117 |
+
Keep in mind that you should not group the object, e.g., 2-5. people: xxx, be sure to describe each object separately (one by one).
|
| 118 |
+
For each labeled object, output referring expressions for each object id.
|
| 119 |
+
"""
|
| 120 |
+
prompt_with_text_query = f"prompt: {dense_caption_prompt}\n text query: {text_query}"
|
| 121 |
+
|
| 122 |
+
MAX_RETRIES = 2
|
| 123 |
+
retry_count = 0
|
| 124 |
+
|
| 125 |
+
while retry_count < MAX_RETRIES:
|
| 126 |
+
response = captioner.chat.completions.create(
|
| 127 |
+
model=model,
|
| 128 |
+
messages=[
|
| 129 |
+
{
|
| 130 |
+
"role": "user",
|
| 131 |
+
"content": [
|
| 132 |
+
{
|
| 133 |
+
"type": "text",
|
| 134 |
+
"text": prompt_with_text_query,
|
| 135 |
+
},
|
| 136 |
+
{
|
| 137 |
+
"type": "image_url",
|
| 138 |
+
"image_url": {"url": f"data:image/jpeg;base64,{base64_image}"},
|
| 139 |
+
},
|
| 140 |
+
],
|
| 141 |
+
}
|
| 142 |
+
],
|
| 143 |
+
)
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
caption = response.choices[0].message.content.strip()
|
| 147 |
+
caption_lower = caption.lower().lstrip()
|
| 148 |
+
if caption_lower.startswith("1.") and not any(
|
| 149 |
+
phrase in caption_lower for phrase in ["i'm sorry", "please", "can't help"]
|
| 150 |
+
):
|
| 151 |
+
break
|
| 152 |
+
print(f"Retrying caption generation... ({retry_count + 1}/{MAX_RETRIES})")
|
| 153 |
+
retry_count += 1
|
| 154 |
+
time.sleep(2)
|
| 155 |
+
|
| 156 |
+
if retry_count == MAX_RETRIES:
|
| 157 |
+
caption = None
|
| 158 |
+
print("Max retries reached. Caption generation failed.")
|
| 159 |
+
|
| 160 |
+
else:
|
| 161 |
+
caption = None
|
| 162 |
+
|
| 163 |
+
return caption
|
| 164 |
+
|
| 165 |
+
if __name__ == "__main__":
|
| 166 |
+
parser = argparse.ArgumentParser('ReferFormer training and evaluation script', parents=[opts.get_args_parser()])
|
| 167 |
+
parser.add_argument('--save_caption_path', type=str, default='mbench_a2d/numbered_captions.json')
|
| 168 |
+
args = parser.parse_args()
|
| 169 |
+
|
| 170 |
+
train_dataset = build_dataset('a2d', image_set = 'train', args = args)
|
| 171 |
+
text_annotations = train_dataset.text_annotations
|
| 172 |
+
|
| 173 |
+
all_captions = {}
|
| 174 |
+
|
| 175 |
+
#os.environ['OPENAI_API_KEY'] = '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'
|
| 176 |
+
os.environ['OPENAI_API_KEY'] = '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'
|
| 177 |
+
|
| 178 |
+
first_text_query = ""
|
| 179 |
+
for idx in range(100):
|
| 180 |
+
imgs, target = train_dataset[idx]
|
| 181 |
+
frames_idx = target['frames_idx'].tolist()
|
| 182 |
+
text_query, vid_id, frame_id, instance_id = text_annotations[idx]
|
| 183 |
+
|
| 184 |
+
if text_query == first_text_query:
|
| 185 |
+
continue
|
| 186 |
+
|
| 187 |
+
print(f"------------vid id: {vid_id}, frame id: {frame_id}", flush=True)
|
| 188 |
+
|
| 189 |
+
frame_id = frame_id - 1
|
| 190 |
+
frame_order = frames_idx.index(frame_id)
|
| 191 |
+
|
| 192 |
+
frame = imgs[frame_order, :, :, :].permute(1, 2, 0).numpy()
|
| 193 |
+
mask = target['masks'].numpy().astype(np.uint8).squeeze()
|
| 194 |
+
|
| 195 |
+
caption = getCaption(frame, mask, instance_id, text_query, model='gpt-4o-mini')
|
| 196 |
+
if vid_id not in all_captions:
|
| 197 |
+
all_captions[vid_id] = {frame_id : caption}
|
| 198 |
+
else:
|
| 199 |
+
all_captions[vid_id][frame_id] = caption
|
| 200 |
+
|
| 201 |
+
print("Finished!", flush=True)
|
| 202 |
+
|
| 203 |
+
with open(args.save_caption_path, 'w') as file:
|
| 204 |
+
json.dump(all_captions, file, indent=4)
|
| 205 |
+
|
__pycache__/opts.cpython-310.pyc
ADDED
|
Binary file (5.44 kB). View file
|
|
|
__pycache__/opts.cpython-39.pyc
ADDED
|
Binary file (5.44 kB). View file
|
|
|
__pycache__/refer.cpython-39.pyc
ADDED
|
Binary file (10.1 kB). View file
|
|
|
davis2017/davis.py
ADDED
|
@@ -0,0 +1,122 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from glob import glob
|
| 3 |
+
from collections import defaultdict
|
| 4 |
+
import numpy as np
|
| 5 |
+
from PIL import Image
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
class DAVIS(object):
|
| 9 |
+
SUBSET_OPTIONS = ['train', 'val', 'test-dev', 'test-challenge']
|
| 10 |
+
TASKS = ['semi-supervised', 'unsupervised']
|
| 11 |
+
DATASET_WEB = 'https://davischallenge.org/davis2017/code.html'
|
| 12 |
+
VOID_LABEL = 255
|
| 13 |
+
|
| 14 |
+
def __init__(self, root, task='unsupervised', subset='val', sequences='all', resolution='480p', codalab=False):
|
| 15 |
+
"""
|
| 16 |
+
Class to read the DAVIS dataset
|
| 17 |
+
:param root: Path to the DAVIS folder that contains JPEGImages, Annotations, etc. folders.
|
| 18 |
+
:param task: Task to load the annotations, choose between semi-supervised or unsupervised.
|
| 19 |
+
:param subset: Set to load the annotations
|
| 20 |
+
:param sequences: Sequences to consider, 'all' to use all the sequences in a set.
|
| 21 |
+
:param resolution: Specify the resolution to use the dataset, choose between '480' and 'Full-Resolution'
|
| 22 |
+
"""
|
| 23 |
+
if subset not in self.SUBSET_OPTIONS:
|
| 24 |
+
raise ValueError(f'Subset should be in {self.SUBSET_OPTIONS}')
|
| 25 |
+
if task not in self.TASKS:
|
| 26 |
+
raise ValueError(f'The only tasks that are supported are {self.TASKS}')
|
| 27 |
+
|
| 28 |
+
self.task = task
|
| 29 |
+
self.subset = subset
|
| 30 |
+
self.root = root
|
| 31 |
+
self.img_path = os.path.join(self.root, 'JPEGImages', resolution)
|
| 32 |
+
annotations_folder = 'Annotations' if task == 'semi-supervised' else 'Annotations_unsupervised'
|
| 33 |
+
self.mask_path = os.path.join(self.root, annotations_folder, resolution)
|
| 34 |
+
year = '2019' if task == 'unsupervised' and (subset == 'test-dev' or subset == 'test-challenge') else '2017'
|
| 35 |
+
self.imagesets_path = os.path.join(self.root, 'ImageSets', year)
|
| 36 |
+
|
| 37 |
+
self._check_directories()
|
| 38 |
+
|
| 39 |
+
if sequences == 'all':
|
| 40 |
+
with open(os.path.join(self.imagesets_path, f'{self.subset}.txt'), 'r') as f:
|
| 41 |
+
tmp = f.readlines()
|
| 42 |
+
sequences_names = [x.strip() for x in tmp]
|
| 43 |
+
else:
|
| 44 |
+
sequences_names = sequences if isinstance(sequences, list) else [sequences]
|
| 45 |
+
self.sequences = defaultdict(dict)
|
| 46 |
+
|
| 47 |
+
for seq in sequences_names:
|
| 48 |
+
images = np.sort(glob(os.path.join(self.img_path, seq, '*.jpg'))).tolist()
|
| 49 |
+
if len(images) == 0 and not codalab:
|
| 50 |
+
raise FileNotFoundError(f'Images for sequence {seq} not found.')
|
| 51 |
+
self.sequences[seq]['images'] = images
|
| 52 |
+
masks = np.sort(glob(os.path.join(self.mask_path, seq, '*.png'))).tolist()
|
| 53 |
+
masks.extend([-1] * (len(images) - len(masks)))
|
| 54 |
+
self.sequences[seq]['masks'] = masks
|
| 55 |
+
|
| 56 |
+
def _check_directories(self):
|
| 57 |
+
if not os.path.exists(self.root):
|
| 58 |
+
raise FileNotFoundError(f'DAVIS not found in the specified directory, download it from {self.DATASET_WEB}')
|
| 59 |
+
if not os.path.exists(os.path.join(self.imagesets_path, f'{self.subset}.txt')):
|
| 60 |
+
raise FileNotFoundError(f'Subset sequences list for {self.subset} not found, download the missing subset '
|
| 61 |
+
f'for the {self.task} task from {self.DATASET_WEB}')
|
| 62 |
+
if self.subset in ['train', 'val'] and not os.path.exists(self.mask_path):
|
| 63 |
+
raise FileNotFoundError(f'Annotations folder for the {self.task} task not found, download it from {self.DATASET_WEB}')
|
| 64 |
+
|
| 65 |
+
def get_frames(self, sequence):
|
| 66 |
+
for img, msk in zip(self.sequences[sequence]['images'], self.sequences[sequence]['masks']):
|
| 67 |
+
image = np.array(Image.open(img))
|
| 68 |
+
mask = None if msk is None else np.array(Image.open(msk))
|
| 69 |
+
yield image, mask
|
| 70 |
+
|
| 71 |
+
def _get_all_elements(self, sequence, obj_type):
|
| 72 |
+
obj = np.array(Image.open(self.sequences[sequence][obj_type][0]))
|
| 73 |
+
all_objs = np.zeros((len(self.sequences[sequence][obj_type]), *obj.shape))
|
| 74 |
+
obj_id = []
|
| 75 |
+
for i, obj in enumerate(self.sequences[sequence][obj_type]):
|
| 76 |
+
all_objs[i, ...] = np.array(Image.open(obj))
|
| 77 |
+
obj_id.append(''.join(obj.split('/')[-1].split('.')[:-1]))
|
| 78 |
+
return all_objs, obj_id
|
| 79 |
+
|
| 80 |
+
def get_all_images(self, sequence):
|
| 81 |
+
return self._get_all_elements(sequence, 'images')
|
| 82 |
+
|
| 83 |
+
def get_all_masks(self, sequence, separate_objects_masks=False):
|
| 84 |
+
masks, masks_id = self._get_all_elements(sequence, 'masks')
|
| 85 |
+
masks_void = np.zeros_like(masks)
|
| 86 |
+
|
| 87 |
+
# Separate void and object masks
|
| 88 |
+
for i in range(masks.shape[0]):
|
| 89 |
+
masks_void[i, ...] = masks[i, ...] == 255
|
| 90 |
+
masks[i, masks[i, ...] == 255] = 0
|
| 91 |
+
|
| 92 |
+
if separate_objects_masks:
|
| 93 |
+
num_objects = int(np.max(masks[0, ...]))
|
| 94 |
+
tmp = np.ones((num_objects, *masks.shape))
|
| 95 |
+
tmp = tmp * np.arange(1, num_objects + 1)[:, None, None, None]
|
| 96 |
+
masks = (tmp == masks[None, ...])
|
| 97 |
+
masks = masks > 0
|
| 98 |
+
return masks, masks_void, masks_id
|
| 99 |
+
|
| 100 |
+
def get_sequences(self):
|
| 101 |
+
for seq in self.sequences:
|
| 102 |
+
yield seq
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
if __name__ == '__main__':
|
| 106 |
+
from matplotlib import pyplot as plt
|
| 107 |
+
|
| 108 |
+
only_first_frame = True
|
| 109 |
+
subsets = ['train', 'val']
|
| 110 |
+
|
| 111 |
+
for s in subsets:
|
| 112 |
+
dataset = DAVIS(root='/home/csergi/scratch2/Databases/DAVIS2017_private', subset=s)
|
| 113 |
+
for seq in dataset.get_sequences():
|
| 114 |
+
g = dataset.get_frames(seq)
|
| 115 |
+
img, mask = next(g)
|
| 116 |
+
plt.subplot(2, 1, 1)
|
| 117 |
+
plt.title(seq)
|
| 118 |
+
plt.imshow(img)
|
| 119 |
+
plt.subplot(2, 1, 2)
|
| 120 |
+
plt.imshow(mask)
|
| 121 |
+
plt.show(block=True)
|
| 122 |
+
|
docs/davis_demo1.gif
ADDED
|
Git LFS Details
|
docs/davis_demo2.gif
ADDED

|
Git LFS Details
|
docs/install.md
ADDED
|
@@ -0,0 +1,42 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Installation
|
| 2 |
+
|
| 3 |
+
We provide the instructions to install the dependency packages.
|
| 4 |
+
|
| 5 |
+
## Requirements
|
| 6 |
+
|
| 7 |
+
We test the code in the following environments, other versions may also be compatible:
|
| 8 |
+
|
| 9 |
+
- CUDA 11.1
|
| 10 |
+
- Python 3.7
|
| 11 |
+
- Pytorch 1.8.1
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
## Setup
|
| 16 |
+
|
| 17 |
+
First, clone the repository locally.
|
| 18 |
+
|
| 19 |
+
```
|
| 20 |
+
git clone https://github.com/wjn922/ReferFormer.git
|
| 21 |
+
```
|
| 22 |
+
|
| 23 |
+
Then, install Pytorch 1.8.1 using the conda environment.
|
| 24 |
+
```
|
| 25 |
+
conda install pytorch==1.8.1 torchvision==0.9.1 torchaudio==0.8.1 -c pytorch
|
| 26 |
+
```
|
| 27 |
+
|
| 28 |
+
Install the necessary packages and pycocotools.
|
| 29 |
+
|
| 30 |
+
```
|
| 31 |
+
pip install -r requirements.txt
|
| 32 |
+
pip install 'git+https://github.com/facebookresearch/fvcore'
|
| 33 |
+
pip install -U 'git+https://github.com/cocodataset/cocoapi.git#subdirectory=PythonAPI'
|
| 34 |
+
```
|
| 35 |
+
|
| 36 |
+
Finally, compile CUDA operators.
|
| 37 |
+
|
| 38 |
+
```
|
| 39 |
+
cd models/ops
|
| 40 |
+
python setup.py build install
|
| 41 |
+
cd ../..
|
| 42 |
+
```
|
docs/network.png
ADDED
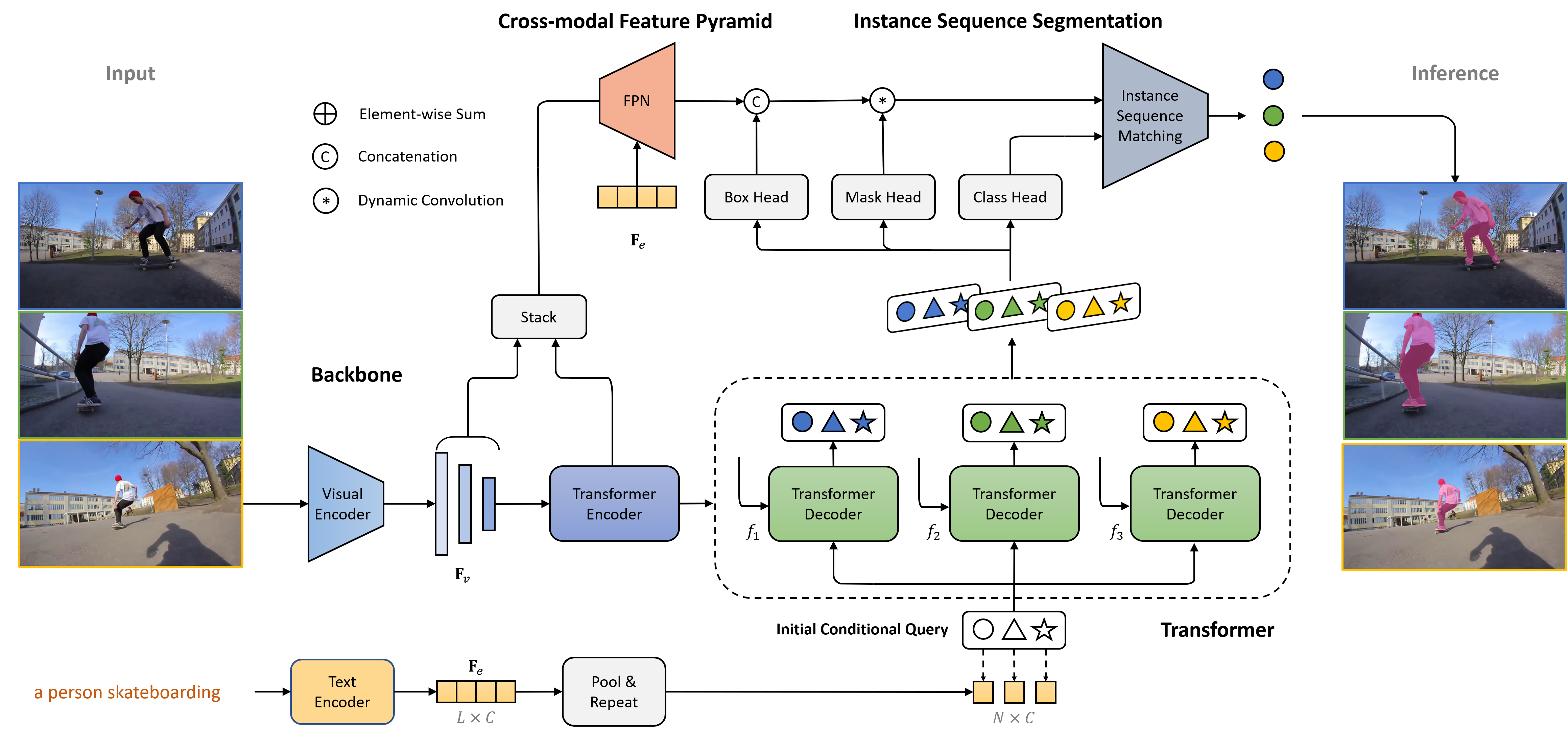
|
Git LFS Details
|
docs/ytvos_demo1.gif
ADDED

|
Git LFS Details
|
docs/ytvos_demo2.gif
ADDED

|
Git LFS Details
|
hf_cache/.locks/models--zhiqiulin--clip-flant5-xxl/e14a3254bf04f32056759bdc60c64736e7638f31b43957586ff2442ff393890a.lock
ADDED
|
File without changes
|
hf_cache/models--zhiqiulin--clip-flant5-xxl/snapshots/89bad6fffe1126b24d4360c1e1f69145eb6103aa/pytorch_model-00002-of-00003.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:12acb5074c883dcab3e166d86d20130615ff83b0d26736ee046f4184202ebd3b
|
| 3 |
+
size 9999791010
|
make_ref-ytvos/manual_selection.ipynb
ADDED
|
@@ -0,0 +1,381 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "code",
|
| 5 |
+
"execution_count": 1,
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"outputs": [
|
| 8 |
+
{
|
| 9 |
+
"name": "stdout",
|
| 10 |
+
"output_type": "stream",
|
| 11 |
+
"text": [
|
| 12 |
+
"/data/projects/yejin/VerbCentric_RIS/ReferFormer\n"
|
| 13 |
+
]
|
| 14 |
+
},
|
| 15 |
+
{
|
| 16 |
+
"name": "stderr",
|
| 17 |
+
"output_type": "stream",
|
| 18 |
+
"text": [
|
| 19 |
+
"/home/yejin/.conda/envs/VerbCentric_RIS/lib/python3.9/site-packages/IPython/core/magics/osm.py:417: UserWarning: using dhist requires you to install the `pickleshare` library.\n",
|
| 20 |
+
" self.shell.db['dhist'] = compress_dhist(dhist)[-100:]\n"
|
| 21 |
+
]
|
| 22 |
+
}
|
| 23 |
+
],
|
| 24 |
+
"source": [
|
| 25 |
+
"%cd /home/yejin/data/projects/yejin/VerbCentric_RIS/ReferFormer"
|
| 26 |
+
]
|
| 27 |
+
},
|
| 28 |
+
{
|
| 29 |
+
"cell_type": "markdown",
|
| 30 |
+
"metadata": {},
|
| 31 |
+
"source": [
|
| 32 |
+
"## 1. manual 필터링 반영"
|
| 33 |
+
]
|
| 34 |
+
},
|
| 35 |
+
{
|
| 36 |
+
"cell_type": "code",
|
| 37 |
+
"execution_count": 18,
|
| 38 |
+
"metadata": {},
|
| 39 |
+
"outputs": [],
|
| 40 |
+
"source": [
|
| 41 |
+
"import pandas as pd\n",
|
| 42 |
+
"import re\n",
|
| 43 |
+
"import json"
|
| 44 |
+
]
|
| 45 |
+
},
|
| 46 |
+
{
|
| 47 |
+
"cell_type": "code",
|
| 48 |
+
"execution_count": 31,
|
| 49 |
+
"metadata": {},
|
| 50 |
+
"outputs": [],
|
| 51 |
+
"source": [
|
| 52 |
+
"selected_frames_df = pd.read_json(\"/home/yejin/data/dataset/VRIS/mbench/ytvos/selected_instances.jsonl\", lines = True)\n",
|
| 53 |
+
"manual_selected = pd.read_json(\"manual_selected_frames.jsonl\", lines = True)"
|
| 54 |
+
]
|
| 55 |
+
},
|
| 56 |
+
{
|
| 57 |
+
"cell_type": "code",
|
| 58 |
+
"execution_count": 32,
|
| 59 |
+
"metadata": {},
|
| 60 |
+
"outputs": [
|
| 61 |
+
{
|
| 62 |
+
"data": {
|
| 63 |
+
"text/html": [
|
| 64 |
+
"<div>\n",
|
| 65 |
+
"<style scoped>\n",
|
| 66 |
+
" .dataframe tbody tr th:only-of-type {\n",
|
| 67 |
+
" vertical-align: middle;\n",
|
| 68 |
+
" }\n",
|
| 69 |
+
"\n",
|
| 70 |
+
" .dataframe tbody tr th {\n",
|
| 71 |
+
" vertical-align: top;\n",
|
| 72 |
+
" }\n",
|
| 73 |
+
"\n",
|
| 74 |
+
" .dataframe thead th {\n",
|
| 75 |
+
" text-align: right;\n",
|
| 76 |
+
" }\n",
|
| 77 |
+
"</style>\n",
|
| 78 |
+
"<table border=\"1\" class=\"dataframe\">\n",
|
| 79 |
+
" <thead>\n",
|
| 80 |
+
" <tr style=\"text-align: right;\">\n",
|
| 81 |
+
" <th></th>\n",
|
| 82 |
+
" <th>segmentation</th>\n",
|
| 83 |
+
" <th>bbox</th>\n",
|
| 84 |
+
" <th>area</th>\n",
|
| 85 |
+
" <th>file_name</th>\n",
|
| 86 |
+
" <th>height</th>\n",
|
| 87 |
+
" <th>width</th>\n",
|
| 88 |
+
" <th>label</th>\n",
|
| 89 |
+
" <th>category_name</th>\n",
|
| 90 |
+
" <th>sentences</th>\n",
|
| 91 |
+
" </tr>\n",
|
| 92 |
+
" </thead>\n",
|
| 93 |
+
" <tbody>\n",
|
| 94 |
+
" <tr>\n",
|
| 95 |
+
" <th>0</th>\n",
|
| 96 |
+
" <td>[[1081.0, 719.5, 1051.0, 719.5, 1050.5, 716.0,...</td>\n",
|
| 97 |
+
" <td>[708.5, 156.5, 420.0, 563.0]</td>\n",
|
| 98 |
+
" <td>131357.25</td>\n",
|
| 99 |
+
" <td>00917dcfc4_00000.png</td>\n",
|
| 100 |
+
" <td>720</td>\n",
|
| 101 |
+
" <td>1280</td>\n",
|
| 102 |
+
" <td>64</td>\n",
|
| 103 |
+
" <td>zebra</td>\n",
|
| 104 |
+
" <td>{'tokens': ['a', 'zebra', 'on', 'the', 'right'...</td>\n",
|
| 105 |
+
" </tr>\n",
|
| 106 |
+
" </tbody>\n",
|
| 107 |
+
"</table>\n",
|
| 108 |
+
"</div>"
|
| 109 |
+
],
|
| 110 |
+
"text/plain": [
|
| 111 |
+
" segmentation \\\n",
|
| 112 |
+
"0 [[1081.0, 719.5, 1051.0, 719.5, 1050.5, 716.0,... \n",
|
| 113 |
+
"\n",
|
| 114 |
+
" bbox area file_name height \\\n",
|
| 115 |
+
"0 [708.5, 156.5, 420.0, 563.0] 131357.25 00917dcfc4_00000.png 720 \n",
|
| 116 |
+
"\n",
|
| 117 |
+
" width label category_name \\\n",
|
| 118 |
+
"0 1280 64 zebra \n",
|
| 119 |
+
"\n",
|
| 120 |
+
" sentences \n",
|
| 121 |
+
"0 {'tokens': ['a', 'zebra', 'on', 'the', 'right'... "
|
| 122 |
+
]
|
| 123 |
+
},
|
| 124 |
+
"execution_count": 32,
|
| 125 |
+
"metadata": {},
|
| 126 |
+
"output_type": "execute_result"
|
| 127 |
+
}
|
| 128 |
+
],
|
| 129 |
+
"source": [
|
| 130 |
+
"selected_frames_df"
|
| 131 |
+
]
|
| 132 |
+
},
|
| 133 |
+
{
|
| 134 |
+
"cell_type": "code",
|
| 135 |
+
"execution_count": null,
|
| 136 |
+
"metadata": {},
|
| 137 |
+
"outputs": [],
|
| 138 |
+
"source": [
|
| 139 |
+
"for i in range(len(manual_selected)):\n",
|
| 140 |
+
" idx = manual_selected.loc[i, \"index\"]\n",
|
| 141 |
+
" new_sent = manual_selected.loc[i, 'new_sent']\n",
|
| 142 |
+
"\n",
|
| 143 |
+
" if new_sent != \"\":\n",
|
| 144 |
+
" new_sent_dict = {\n",
|
| 145 |
+
" \"tokens\" : new_sent.split(' '),\n",
|
| 146 |
+
" \"raw\" : new_sent,\n",
|
| 147 |
+
" \"sent\" : re.sub('[^A-Za-z0-9\\s]+', '', new_sent.lower())\n",
|
| 148 |
+
" }\n",
|
| 149 |
+
" selected_frames_df.at[idx, 'sentences'] = new_sent_dict"
|
| 150 |
+
]
|
| 151 |
+
},
|
| 152 |
+
{
|
| 153 |
+
"cell_type": "code",
|
| 154 |
+
"execution_count": null,
|
| 155 |
+
"metadata": {},
|
| 156 |
+
"outputs": [],
|
| 157 |
+
"source": [
|
| 158 |
+
"manual_selected_frames = selected_frames_df.loc[manual_selected['index'].values]"
|
| 159 |
+
]
|
| 160 |
+
},
|
| 161 |
+
{
|
| 162 |
+
"cell_type": "code",
|
| 163 |
+
"execution_count": 31,
|
| 164 |
+
"metadata": {},
|
| 165 |
+
"outputs": [],
|
| 166 |
+
"source": [
|
| 167 |
+
"manual_selected_frames.to_json(\"revised_frames.jsonl\", orient='records', lines=True)"
|
| 168 |
+
]
|
| 169 |
+
},
|
| 170 |
+
{
|
| 171 |
+
"cell_type": "markdown",
|
| 172 |
+
"metadata": {},
|
| 173 |
+
"source": [
|
| 174 |
+
"## 2. lmdb로 변환하기 위해 마스크 저장하기"
|
| 175 |
+
]
|
| 176 |
+
},
|
| 177 |
+
{
|
| 178 |
+
"cell_type": "code",
|
| 179 |
+
"execution_count": 2,
|
| 180 |
+
"metadata": {},
|
| 181 |
+
"outputs": [],
|
| 182 |
+
"source": [
|
| 183 |
+
"import argparse\n",
|
| 184 |
+
"import os\n",
|
| 185 |
+
"import os.path as osp\n",
|
| 186 |
+
"import lmdb\n",
|
| 187 |
+
"import pyarrow as pa\n",
|
| 188 |
+
"import json\n",
|
| 189 |
+
"from tqdm import tqdm\n",
|
| 190 |
+
"import matplotlib.pyplot as plt\n",
|
| 191 |
+
"from skimage import io\n",
|
| 192 |
+
"import numpy as np\n",
|
| 193 |
+
"from shapely.geometry import Polygon, MultiPolygon\n",
|
| 194 |
+
"from matplotlib.collections import PatchCollection\n",
|
| 195 |
+
"from pycocotools import mask\n",
|
| 196 |
+
"import warnings\n",
|
| 197 |
+
"warnings.filterwarnings(\"ignore\")"
|
| 198 |
+
]
|
| 199 |
+
},
|
| 200 |
+
{
|
| 201 |
+
"cell_type": "code",
|
| 202 |
+
"execution_count": 3,
|
| 203 |
+
"metadata": {},
|
| 204 |
+
"outputs": [],
|
| 205 |
+
"source": [
|
| 206 |
+
"#jsonl 파일을 {index: json_obj, ... }형식으로\n",
|
| 207 |
+
"\n",
|
| 208 |
+
"json_data = []\n",
|
| 209 |
+
"\n",
|
| 210 |
+
"with open('revised_frames.jsonl', 'rb') as f:\n",
|
| 211 |
+
" for line in f:\n",
|
| 212 |
+
" json_data.append(json.loads(line)) "
|
| 213 |
+
]
|
| 214 |
+
},
|
| 215 |
+
{
|
| 216 |
+
"cell_type": "code",
|
| 217 |
+
"execution_count": 45,
|
| 218 |
+
"metadata": {},
|
| 219 |
+
"outputs": [],
|
| 220 |
+
"source": [
|
| 221 |
+
"def getMask(ann):\n",
|
| 222 |
+
" # return mask, area and mask-center\n",
|
| 223 |
+
" if type(ann['segmentation'][0]) == list: # polygon\n",
|
| 224 |
+
" rle = mask.frPyObjects(ann['segmentation'], ann['height'],\n",
|
| 225 |
+
" ann['width'])\n",
|
| 226 |
+
" else:\n",
|
| 227 |
+
" rle = ann['segmentation']\n",
|
| 228 |
+
" # for i in range(len(rle['counts'])):\n",
|
| 229 |
+
" # print(rle)\n",
|
| 230 |
+
" m = mask.decode(rle)\n",
|
| 231 |
+
" m = np.sum(\n",
|
| 232 |
+
" m, axis=2\n",
|
| 233 |
+
" ) # sometimes there are multiple binary map (corresponding to multiple segs)\n",
|
| 234 |
+
" m = m.astype(np.uint8) # convert to np.uint8\n",
|
| 235 |
+
" # compute area\n",
|
| 236 |
+
" area = sum(mask.area(rle)) # should be close to ann['area']\n",
|
| 237 |
+
" return {'mask': m, 'area': area}\n",
|
| 238 |
+
" # # position\n",
|
| 239 |
+
" # position_x = np.mean(np.where(m==1)[1]) # [1] means columns (matlab style) -> x (c style)\n",
|
| 240 |
+
" # position_y = np.mean(np.where(m==1)[0]) # [0] means rows (matlab style) -> y (c style)\n",
|
| 241 |
+
" # # mass position (if there were multiple regions, we use the largest one.)\n",
|
| 242 |
+
" # label_m = label(m, connectivity=m.ndim)\n",
|
| 243 |
+
" # regions = regionprops(label_m)\n",
|
| 244 |
+
" # if len(regions) > 0:\n",
|
| 245 |
+
" # \tlargest_id = np.argmax(np.array([props.filled_area for props in regions]))\n",
|
| 246 |
+
" # \tlargest_props = regions[largest_id]\n",
|
| 247 |
+
" # \tmass_y, mass_x = largest_props.centroid\n",
|
| 248 |
+
" # else:\n",
|
| 249 |
+
" # \tmass_x, mass_y = position_x, position_y\n",
|
| 250 |
+
" # # if centroid is not in mask, we find the closest point to it from mask\n",
|
| 251 |
+
" # if m[mass_y, mass_x] != 1:\n",
|
| 252 |
+
" # \tprint 'Finding closes mask point ...'\n",
|
| 253 |
+
" # \tkernel = np.ones((10, 10),np.uint8)\n",
|
| 254 |
+
" # \tme = cv2.erode(m, kernel, iterations = 1)\n",
|
| 255 |
+
" # \tpoints = zip(np.where(me == 1)[0].tolist(), np.where(me == 1)[1].tolist()) # row, col style\n",
|
| 256 |
+
" # \tpoints = np.array(points)\n",
|
| 257 |
+
" # \tdist = np.sum((points - (mass_y, mass_x))**2, axis=1)\n",
|
| 258 |
+
" # \tid = np.argsort(dist)[0]\n",
|
| 259 |
+
" # \tmass_y, mass_x = points[id]\n",
|
| 260 |
+
" # \t# return\n",
|
| 261 |
+
" # return {'mask': m, 'area': area, 'position_x': position_x, 'position_y': position_y, 'mass_x': mass_x, 'mass_y': mass_y}\n",
|
| 262 |
+
" # # show image and mask\n",
|
| 263 |
+
" # I = io.imread(osp.join(self.IMAGE_DIR, image['file_name']))\n",
|
| 264 |
+
" # plt.figure()\n",
|
| 265 |
+
" # plt.imshow(I)\n",
|
| 266 |
+
" # ax = plt.gca()\n",
|
| 267 |
+
" # img = np.ones( (m.shape[0], m.shape[1], 3) )\n",
|
| 268 |
+
" # color_mask = np.array([2.0,166.0,101.0])/255\n",
|
| 269 |
+
" # for i in range(3):\n",
|
| 270 |
+
" # img[:,:,i] = color_mask[i]\n",
|
| 271 |
+
" # ax.imshow(np.dstack( (img, m*0.5) ))\n",
|
| 272 |
+
" # plt.show()\n",
|
| 273 |
+
"\n",
|
| 274 |
+
"def showMask(ann, image_dir, mask_dir):\n",
|
| 275 |
+
" \n",
|
| 276 |
+
" fig, ax = plt.subplots()\n",
|
| 277 |
+
" I = io.imread(osp.join(image_dir, ann['file_name']))\n",
|
| 278 |
+
" ax.imshow(I)\n",
|
| 279 |
+
"\n",
|
| 280 |
+
" M = getMask(ann)\n",
|
| 281 |
+
" msk = M['mask']\n",
|
| 282 |
+
" #msk = io.imread(osp.join(mask_dir, ann['file_name']))\n",
|
| 283 |
+
" \n",
|
| 284 |
+
" ax.imshow(msk, alpha = 0.5)\n",
|
| 285 |
+
" ax.set_title(ann['sentences']['sent'])\n",
|
| 286 |
+
" plt.show()\n",
|
| 287 |
+
"\n",
|
| 288 |
+
"\n",
|
| 289 |
+
"\n",
|
| 290 |
+
"def saveMask(ann, mask_dir, seg_id):\n",
|
| 291 |
+
" M = getMask(ann)\n",
|
| 292 |
+
" msk = M['mask']\n",
|
| 293 |
+
" height, width = msk.shape\n",
|
| 294 |
+
" \n",
|
| 295 |
+
" fig, ax = plt.subplots(figsize=(width / 100, height / 100), dpi=100)\n",
|
| 296 |
+
" ax.imshow(msk, cmap='gray', vmin=0, vmax=1)\n",
|
| 297 |
+
"\n",
|
| 298 |
+
" save_path = f'{mask_dir}/{seg_id}'\n",
|
| 299 |
+
" plt.axis('off')\n",
|
| 300 |
+
" plt.subplots_adjust(left=0, right=1, top=1, bottom=0) # Remove padding\n",
|
| 301 |
+
"\n",
|
| 302 |
+
" fig.savefig(save_path, dpi=100, bbox_inches='tight', pad_inches=0)\n",
|
| 303 |
+
" \n",
|
| 304 |
+
" plt.close(fig)"
|
| 305 |
+
]
|
| 306 |
+
},
|
| 307 |
+
{
|
| 308 |
+
"cell_type": "code",
|
| 309 |
+
"execution_count": 46,
|
| 310 |
+
"metadata": {},
|
| 311 |
+
"outputs": [],
|
| 312 |
+
"source": [
|
| 313 |
+
"for i in range(len(json_data)):\n",
|
| 314 |
+
" #showMask(json_data[i], image_dir = '/home/yejin/data/dataset/VRIS/mbench/ytvos/selected_frames', mask_dir = '/home/yejin/data/dataset/VRIS/mbench/ytvos/filtered_masks')\n",
|
| 315 |
+
" saveMask(json_data[i], '/home/yejin/data/dataset/VRIS/mbench/ytvos/filtered_masks_segid', i)"
|
| 316 |
+
]
|
| 317 |
+
},
|
| 318 |
+
{
|
| 319 |
+
"cell_type": "code",
|
| 320 |
+
"execution_count": null,
|
| 321 |
+
"metadata": {},
|
| 322 |
+
"outputs": [],
|
| 323 |
+
"source": [
|
| 324 |
+
"##############안 쓰는 함수!###################\n",
|
| 325 |
+
"# 마스크 저장\n",
|
| 326 |
+
"# annotation dictionary as input\n",
|
| 327 |
+
"def saveMask(annotation, mask_dir, seg_box='seg'):\n",
|
| 328 |
+
" image_width = annotation['width']\n",
|
| 329 |
+
" image_height = annotation['height']\n",
|
| 330 |
+
"\n",
|
| 331 |
+
" fig, ax = plt.subplots(figsize=(image_width / 100, image_height / 100), facecolor='black') # figsize 단위는 인치, DPI 고려\n",
|
| 332 |
+
" ax.set_facecolor('black')\n",
|
| 333 |
+
" \n",
|
| 334 |
+
" \n",
|
| 335 |
+
" if seg_box == 'seg':\n",
|
| 336 |
+
" polygons = []\n",
|
| 337 |
+
" color = (1, 1, 1)\n",
|
| 338 |
+
" \n",
|
| 339 |
+
" if type(annotation['segmentation'][0]) == list:\n",
|
| 340 |
+
" # polygon used for refcoco*\n",
|
| 341 |
+
" for seg in annotation['segmentation']:\n",
|
| 342 |
+
" poly = np.array(seg).reshape((int(len(seg) / 2), 2))\n",
|
| 343 |
+
" polygons.append(Polygon(poly))\n",
|
| 344 |
+
"\n",
|
| 345 |
+
" p = PatchCollection(polygons,\n",
|
| 346 |
+
" facecolors=(1, 1, 1),\n",
|
| 347 |
+
" linewidths=0)\n",
|
| 348 |
+
" ax.add_collection(p)\n",
|
| 349 |
+
"\n",
|
| 350 |
+
" # 축 범위를 이미지 크기에 맞게 설정\n",
|
| 351 |
+
" ax.set_xlim(0, image_width)\n",
|
| 352 |
+
" ax.set_ylim(0, image_height)\n",
|
| 353 |
+
" \n",
|
| 354 |
+
" # y축 방향 뒤집기 (이미지 좌표계와 일치)\n",
|
| 355 |
+
" ax.invert_yaxis()\n",
|
| 356 |
+
" \n",
|
| 357 |
+
" # 플롯 표시\n",
|
| 358 |
+
" #plt.axis('equal') # 축 비율을 동일하게 설정\n",
|
| 359 |
+
" #plt.show()\n",
|
| 360 |
+
"\n",
|
| 361 |
+
" #플롯 저장\n",
|
| 362 |
+
" plt.axis('off') # 축 숨김 (선택 사항)\n",
|
| 363 |
+
" save_path = f'{mask_dir}/{annotation[\"file_name\"]}'\n",
|
| 364 |
+
" plt.savefig(save_path, bbox_inches='tight', pad_inches=0, facecolor='black')\n",
|
| 365 |
+
"\n",
|
| 366 |
+
"for annotation in json_data:\n",
|
| 367 |
+
" saveMask(annotation, mask_dir='/home/yejin/data/dataset/VRIS/mbench/ytvos/filtered_masks')\n",
|
| 368 |
+
" "
|
| 369 |
+
]
|
| 370 |
+
}
|
| 371 |
+
],
|
| 372 |
+
"metadata": {
|
| 373 |
+
"kernelspec": {
|
| 374 |
+
"display_name": "VerbCentric_RIS",
|
| 375 |
+
"language": "python",
|
| 376 |
+
"name": "verbcentric_ris"
|
| 377 |
+
}
|
| 378 |
+
},
|
| 379 |
+
"nbformat": 4,
|
| 380 |
+
"nbformat_minor": 2
|
| 381 |
+
}
|
make_refcoco/refcocog_google/multi_object_data_gref_google.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
make_refcoco/refcocog_google/needrevision_refid_part4.json
ADDED
|
@@ -0,0 +1,506 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"4859": {
|
| 3 |
+
"101105": "man sitting on the ground playing wii",
|
| 4 |
+
"101106": "man in white and light blue t - shirt"
|
| 5 |
+
},
|
| 6 |
+
"678": {
|
| 7 |
+
"14720": "the man crouching inside the plane",
|
| 8 |
+
"14721": "the man wearing white hat"
|
| 9 |
+
},
|
| 10 |
+
"162": {
|
| 11 |
+
"2908": "the man resting his face on his hands",
|
| 12 |
+
"2909": "the man with a plastic bag between his feet"
|
| 13 |
+
},
|
| 14 |
+
"3052": {
|
| 15 |
+
"63901": "person looking at a book",
|
| 16 |
+
"63902": "person wearing a hat and backpack"
|
| 17 |
+
},
|
| 18 |
+
"2355": {
|
| 19 |
+
"49522": "the cat sitting in the chair",
|
| 20 |
+
"49523": "cat on left side"
|
| 21 |
+
},
|
| 22 |
+
"3408": {
|
| 23 |
+
"71397": "a man bending and judging a tennis match",
|
| 24 |
+
"71398": "a man wearing a red shirt and black pants"
|
| 25 |
+
},
|
| 26 |
+
"834": {
|
| 27 |
+
"17983": "a giraffe who is eating hay out of a feeder",
|
| 28 |
+
"17984": "the giraffe on the right side of the pole"
|
| 29 |
+
},
|
| 30 |
+
"328": {
|
| 31 |
+
"6730": "person bending over",
|
| 32 |
+
"6731": "big person in blue cap"
|
| 33 |
+
},
|
| 34 |
+
"1646": {
|
| 35 |
+
"35169": "person about to hit a ball",
|
| 36 |
+
"35170": "person wearing shirt and pants"
|
| 37 |
+
},
|
| 38 |
+
"4400": {
|
| 39 |
+
"91825": "boy sitting on his skateboard and looking at another boy",
|
| 40 |
+
"91826": "boy wearing dark t - shirt and jeans"
|
| 41 |
+
},
|
| 42 |
+
"3683": {
|
| 43 |
+
"77184": "a man dishing up food",
|
| 44 |
+
"77185": "a man in military camo and a black hat on the right"
|
| 45 |
+
},
|
| 46 |
+
"3788": {
|
| 47 |
+
"79367": "a black cat sitting and starring",
|
| 48 |
+
"79368": "a cat with a heart shaped tag"
|
| 49 |
+
},
|
| 50 |
+
"4701": {
|
| 51 |
+
"97795": "person whose tie is being pulled by another person",
|
| 52 |
+
"97796": "person in blue shirt with a red undone tie"
|
| 53 |
+
},
|
| 54 |
+
"1211": {
|
| 55 |
+
"26003": "person putting arm around another person",
|
| 56 |
+
"26004": "person with backpack"
|
| 57 |
+
},
|
| 58 |
+
"2138": {
|
| 59 |
+
"45446": "a person sleeping on the top bunk",
|
| 60 |
+
"45447": "a person in a green shirt and brown shorts"
|
| 61 |
+
},
|
| 62 |
+
"3510": {
|
| 63 |
+
"73478": "personn sitting in a train compartment and reading book",
|
| 64 |
+
"73479": "person in striped shirt"
|
| 65 |
+
},
|
| 66 |
+
"899": {
|
| 67 |
+
"19308": "a man serving soup",
|
| 68 |
+
"19309": "a man with tattoo on his arm"
|
| 69 |
+
},
|
| 70 |
+
"293": {
|
| 71 |
+
"5939": "a lady laughing and looking at another lady",
|
| 72 |
+
"5940": "a lady with dark hair and a dark shirt"
|
| 73 |
+
},
|
| 74 |
+
"3196": {
|
| 75 |
+
"67017": "person holding a pen",
|
| 76 |
+
"67018": "person in a brown suit"
|
| 77 |
+
},
|
| 78 |
+
"1939": {
|
| 79 |
+
"41076": "a person sitting cross legged on the beach",
|
| 80 |
+
"41077": "person in khakis and a white shirt with yellow flowers"
|
| 81 |
+
},
|
| 82 |
+
"2659": {
|
| 83 |
+
"56121": "person helping another cross a stream",
|
| 84 |
+
"56122": "person in white dress"
|
| 85 |
+
},
|
| 86 |
+
"2849": {
|
| 87 |
+
"59798": "person looking down drinking a glass of wine",
|
| 88 |
+
"59799": "person on the right side not wearing glasses"
|
| 89 |
+
},
|
| 90 |
+
"756": {
|
| 91 |
+
"16375": "the woman about to pick up a slice of pizza",
|
| 92 |
+
"16376": "a woman with a flower shirt"
|
| 93 |
+
},
|
| 94 |
+
"4573": {
|
| 95 |
+
"95258": "person reaching for another person with the frisbee",
|
| 96 |
+
"95259": "person with blue and white striped shirt on"
|
| 97 |
+
},
|
| 98 |
+
"4514": {
|
| 99 |
+
"94061": "person running behind",
|
| 100 |
+
"94062": "person in dark brown top and jeans"
|
| 101 |
+
},
|
| 102 |
+
"304": {
|
| 103 |
+
"6165": "person resting her head in hand and crossing one's legs",
|
| 104 |
+
"6166": "the person in pink jacket"
|
| 105 |
+
},
|
| 106 |
+
"3465": {
|
| 107 |
+
"72753": "person sitting on a love seat and watching others play wii",
|
| 108 |
+
"72754": "person in a black shirt and white shorts"
|
| 109 |
+
},
|
| 110 |
+
"1092": {
|
| 111 |
+
"23796": "a bear standing up with its mouth open",
|
| 112 |
+
"23797": "a bear on the right"
|
| 113 |
+
},
|
| 114 |
+
"2025": {
|
| 115 |
+
"42838": "the person leading the horse",
|
| 116 |
+
"42839": "the person in gray top and jeans"
|
| 117 |
+
},
|
| 118 |
+
"1701": {
|
| 119 |
+
"36094": "giraffe biting off of a tree",
|
| 120 |
+
"36095": "tall giraffe on the right"
|
| 121 |
+
},
|
| 122 |
+
"2958": {
|
| 123 |
+
"62137": "person playing with dog",
|
| 124 |
+
"62138": "balding person wearing brown hoodie"
|
| 125 |
+
},
|
| 126 |
+
"4793": {
|
| 127 |
+
"99824": "the girl eating and looking at her plate",
|
| 128 |
+
"99825": "the girl wearing a pink shirt"
|
| 129 |
+
},
|
| 130 |
+
"1247": {
|
| 131 |
+
"26624": "the person holding the bat",
|
| 132 |
+
"26625": "the person in white t - shirt and grey pants"
|
| 133 |
+
},
|
| 134 |
+
"1841": {
|
| 135 |
+
"38888": "person resting hands on other people's shoulders",
|
| 136 |
+
"38889": "tallest person wearing bright suit"
|
| 137 |
+
},
|
| 138 |
+
"4404": {
|
| 139 |
+
"91907": "a elephant whose trunk pointing to the floor , may be touching",
|
| 140 |
+
"91908": "elephant more on the right side of the picture"
|
| 141 |
+
},
|
| 142 |
+
"4536": {
|
| 143 |
+
"94448": "a person reaching for the microwave looking at the camera",
|
| 144 |
+
"94449": "person in black t shirt"
|
| 145 |
+
},
|
| 146 |
+
"2787": {
|
| 147 |
+
"58740": "a giraffe snacking on the tree",
|
| 148 |
+
"58741": "a giraffe on the right"
|
| 149 |
+
},
|
| 150 |
+
"3377": {
|
| 151 |
+
"70765": "a zebra resting its head on another zebra ' s back",
|
| 152 |
+
"70766": "a zebra on the left"
|
| 153 |
+
},
|
| 154 |
+
"3889": {
|
| 155 |
+
"81051": "a man holding a basket of pastries",
|
| 156 |
+
"81052": "a man wearing grey hoodie"
|
| 157 |
+
},
|
| 158 |
+
"2194": {
|
| 159 |
+
"46507": "standing dog",
|
| 160 |
+
"46508": "a black and white dog with a blue collar tag"
|
| 161 |
+
},
|
| 162 |
+
"508": {
|
| 163 |
+
"11146": "person being held by another person",
|
| 164 |
+
"11147": "person dressed in a red suit and blue cap"
|
| 165 |
+
},
|
| 166 |
+
"2312": {
|
| 167 |
+
"48847": "a bird standing on a table",
|
| 168 |
+
"48848": "a bird on the left"
|
| 169 |
+
},
|
| 170 |
+
"3948": {
|
| 171 |
+
"82190": "the woman who is squinting in one eye",
|
| 172 |
+
"82191": "a blue eyed brown haired woman not wearing glasses"
|
| 173 |
+
},
|
| 174 |
+
"1388": {
|
| 175 |
+
"29353": "person holding another person while watching giraffe drink water",
|
| 176 |
+
"29354": "person in brown shirt with bag"
|
| 177 |
+
},
|
| 178 |
+
"2690": {
|
| 179 |
+
"56849": "a man about to kick a ball",
|
| 180 |
+
"56850": "a man in all white with number 23 on his chest"
|
| 181 |
+
},
|
| 182 |
+
"1109": {
|
| 183 |
+
"24043": "man holding the ktie",
|
| 184 |
+
"24044": "man on the right"
|
| 185 |
+
},
|
| 186 |
+
"1374": {
|
| 187 |
+
"29120": "person arranging pansts of another person",
|
| 188 |
+
"29121": "the person with in the black tuxedo and glasses in his head"
|
| 189 |
+
},
|
| 190 |
+
"3475": {
|
| 191 |
+
"72951": "woman holding the horse",
|
| 192 |
+
"72952": "a woman wearing spectacles with violet shirt and flourecent colour waist vest"
|
| 193 |
+
},
|
| 194 |
+
"1333": {
|
| 195 |
+
"28225": "a person holding another person",
|
| 196 |
+
"28226": "a person in a pink and orange flannel shirt"
|
| 197 |
+
},
|
| 198 |
+
"2068": {
|
| 199 |
+
"43909": "person standing and playing wii",
|
| 200 |
+
"43910": "person wearing black t - shirt"
|
| 201 |
+
},
|
| 202 |
+
"2824": {
|
| 203 |
+
"59394": "person standing besides a table crossing arms",
|
| 204 |
+
"59395": "person with glasses and long hair"
|
| 205 |
+
},
|
| 206 |
+
"2294": {
|
| 207 |
+
"48483": "a person sitting on bike holding another person",
|
| 208 |
+
"48484": "a person with a helmet on the head"
|
| 209 |
+
},
|
| 210 |
+
"2446": {
|
| 211 |
+
"51355": "an elephant that has it ' s trunk pointing towards the water",
|
| 212 |
+
"51356": "elephant on the left"
|
| 213 |
+
},
|
| 214 |
+
"2686": {
|
| 215 |
+
"56783": "a man staring at another man",
|
| 216 |
+
"56784": "a man in an orange tie"
|
| 217 |
+
},
|
| 218 |
+
"4558": {
|
| 219 |
+
"94950": "a zebra facing the camera",
|
| 220 |
+
"94951": "a small zebra beside a larger zebra"
|
| 221 |
+
},
|
| 222 |
+
"1499": {
|
| 223 |
+
"32051": "a man resting on a metal fence",
|
| 224 |
+
"32052": "a man in white shirt and polka dot tie"
|
| 225 |
+
},
|
| 226 |
+
"4303": {
|
| 227 |
+
"89833": "a man throwing a banana",
|
| 228 |
+
"89834": "a man in bike gear on the right of the picture"
|
| 229 |
+
},
|
| 230 |
+
"1376": {
|
| 231 |
+
"29146": "a man sitting down with his hands together",
|
| 232 |
+
"29147": "a man with a purple shirt and khaki pants "
|
| 233 |
+
},
|
| 234 |
+
"3544": {
|
| 235 |
+
"74100": "the man holding a riding crop",
|
| 236 |
+
"74101": "man in black shirt and slacks on the left"
|
| 237 |
+
},
|
| 238 |
+
"1858": {
|
| 239 |
+
"39103": "a bull standing",
|
| 240 |
+
"39104": "a white and brown bull on the left of the picture"
|
| 241 |
+
},
|
| 242 |
+
"434": {
|
| 243 |
+
"9561": "the man looking down",
|
| 244 |
+
"9562": "the man on the left"
|
| 245 |
+
},
|
| 246 |
+
"3024": {
|
| 247 |
+
"63345": "a baseball player sliding into a base",
|
| 248 |
+
"63346": "baseball player wearing the number 12"
|
| 249 |
+
},
|
| 250 |
+
"513": {
|
| 251 |
+
"11239": "a man riding on a skateboard as his picture is being taken",
|
| 252 |
+
"11240": "a man in a purple t - shirt and ripped jeans"
|
| 253 |
+
},
|
| 254 |
+
"693": {
|
| 255 |
+
"14989": "a person standing",
|
| 256 |
+
"14990": "a small person"
|
| 257 |
+
},
|
| 258 |
+
"2523": {
|
| 259 |
+
"53103": "a baseball player sliding into home plate and getting tagged by the catcher",
|
| 260 |
+
"53104": "a la dodgers player on the right of the picture"
|
| 261 |
+
},
|
| 262 |
+
"4987": {
|
| 263 |
+
"104145": "a girl punching out her arm while playing an interactive video game",
|
| 264 |
+
"104146": "girl wearing grey and white stripes and sweatpants"
|
| 265 |
+
},
|
| 266 |
+
"4041": {
|
| 267 |
+
"84159": "soccer player about to kick soccer ball",
|
| 268 |
+
"84160": "soccer player wearing black t - shirt and black gloves"
|
| 269 |
+
},
|
| 270 |
+
"2105": {
|
| 271 |
+
"44674": "a baseball player holding his arm up to catch a ball",
|
| 272 |
+
"44675": "a baseball player wearing helmet and vest"
|
| 273 |
+
},
|
| 274 |
+
"135": {
|
| 275 |
+
"2353": "dog resting it ' s head on a table",
|
| 276 |
+
"2354": "golden dog"
|
| 277 |
+
},
|
| 278 |
+
"3613": {
|
| 279 |
+
"75580": "person talking to another person while crossing legs",
|
| 280 |
+
"75581": "person with long sleeve shirt, jeans and cap"
|
| 281 |
+
},
|
| 282 |
+
"1722": {
|
| 283 |
+
"36451": "person pulling another person's tie",
|
| 284 |
+
"36452": "blonde person in black dress"
|
| 285 |
+
},
|
| 286 |
+
"1607": {
|
| 287 |
+
"34281": "a person reading a book to another person he ' s holding",
|
| 288 |
+
"34282": "a bald person wearing a beige t - shirt and gray jeans"
|
| 289 |
+
},
|
| 290 |
+
"2761": {
|
| 291 |
+
"58225": "girl propping her chin on her hand",
|
| 292 |
+
"58226": "girl in a pink shirt near window"
|
| 293 |
+
},
|
| 294 |
+
"2454": {
|
| 295 |
+
"51492": "a man looking at laptop",
|
| 296 |
+
"51493": "the man with glasses and painted fingernails"
|
| 297 |
+
},
|
| 298 |
+
"1603": {
|
| 299 |
+
"34234": "person eating a donut",
|
| 300 |
+
"34235": "person with the black beanie"
|
| 301 |
+
},
|
| 302 |
+
"4794": {
|
| 303 |
+
"99868": "a duck that is looking straight ahead",
|
| 304 |
+
"99869": "the duck on the right side"
|
| 305 |
+
},
|
| 306 |
+
"2485": {
|
| 307 |
+
"52246": "a person reaching across the net",
|
| 308 |
+
"52247": "tallest person in a grey shirt and shorts"
|
| 309 |
+
},
|
| 310 |
+
"3280": {
|
| 311 |
+
"68799": "a boy walking towards his skate board",
|
| 312 |
+
"68800": "a boy in a striped shirt"
|
| 313 |
+
},
|
| 314 |
+
"3336": {
|
| 315 |
+
"69882": "person holding a piece of chocolate cake",
|
| 316 |
+
"69883": "person wearing a purple dress"
|
| 317 |
+
},
|
| 318 |
+
"3118": {
|
| 319 |
+
"65349": "giraffe stretching its neck straight up",
|
| 320 |
+
"65350": "taller giraffe"
|
| 321 |
+
},
|
| 322 |
+
"4494": {
|
| 323 |
+
"93729": "man touching the frisbee",
|
| 324 |
+
"93730": "a man in a white shirt"
|
| 325 |
+
},
|
| 326 |
+
"3004": {
|
| 327 |
+
"62940": "person crouching to catch a ball",
|
| 328 |
+
"62941": "person in a red uniform and helmet"
|
| 329 |
+
},
|
| 330 |
+
"127": {
|
| 331 |
+
"2256": "a person holding a plate",
|
| 332 |
+
"2257": "the person in the purple coat"
|
| 333 |
+
},
|
| 334 |
+
"3389": {
|
| 335 |
+
"70905": "person waving",
|
| 336 |
+
"70906": "person in black sneakers"
|
| 337 |
+
},
|
| 338 |
+
"2568": {
|
| 339 |
+
"54256": "person looking at phone",
|
| 340 |
+
"54257": "blonde person on the right"
|
| 341 |
+
},
|
| 342 |
+
"2283": {
|
| 343 |
+
"48251": "the cook holding a plate",
|
| 344 |
+
"48252": "middle cook of three cooks"
|
| 345 |
+
},
|
| 346 |
+
"1530": {
|
| 347 |
+
"32639": "person petting the cat",
|
| 348 |
+
"32640": "person with sleeves rolled up"
|
| 349 |
+
},
|
| 350 |
+
"4251": {
|
| 351 |
+
"88833": "a person reading a book",
|
| 352 |
+
"88834": "person in a striped jacket "
|
| 353 |
+
},
|
| 354 |
+
"2540": {
|
| 355 |
+
"53539": "a man reaching out his right arm holding a controller",
|
| 356 |
+
"53540": "a man in red shirt and black jeans"
|
| 357 |
+
},
|
| 358 |
+
"2870": {
|
| 359 |
+
"60169": "a person watching horse riding",
|
| 360 |
+
"60170": "a person in a white jacket and beige pants"
|
| 361 |
+
},
|
| 362 |
+
"4946": {
|
| 363 |
+
"103092": "a man about to hit a ball",
|
| 364 |
+
"103093": "a man in red shirt and blue vest"
|
| 365 |
+
},
|
| 366 |
+
"113": {
|
| 367 |
+
"1973": "person holding phone",
|
| 368 |
+
"1974": "person with a black shirt and brown coat"
|
| 369 |
+
},
|
| 370 |
+
"711": {
|
| 371 |
+
"15398": "girl crouching and holding an umbrella",
|
| 372 |
+
"15399": "girl wearing light green socks on the left"
|
| 373 |
+
},
|
| 374 |
+
"3209": {
|
| 375 |
+
"67236": "the person that is sliding into home , getting tagged out by the catcher",
|
| 376 |
+
"67237": "the person in the white vest over the blue shirt"
|
| 377 |
+
},
|
| 378 |
+
"3620": {
|
| 379 |
+
"75711": "person petting a horse",
|
| 380 |
+
"75712": "a person in white t - shirt"
|
| 381 |
+
},
|
| 382 |
+
"4382": {
|
| 383 |
+
"91559": "horse being hugged by a person",
|
| 384 |
+
"91560": "white and brown horse"
|
| 385 |
+
},
|
| 386 |
+
"2861": {
|
| 387 |
+
"60004": "a man playing tennis",
|
| 388 |
+
"60005": "a man wearing a blue shirt and white shorts"
|
| 389 |
+
},
|
| 390 |
+
"3954": {
|
| 391 |
+
"82306": "a person putting gloves on",
|
| 392 |
+
"82307": "person with dark blue jumper"
|
| 393 |
+
},
|
| 394 |
+
"1984": {
|
| 395 |
+
"42076": "a person being held by another person",
|
| 396 |
+
"42077": "little person on pink skiis with yellow parka on"
|
| 397 |
+
},
|
| 398 |
+
"2069": {
|
| 399 |
+
"43945": "a person helping another person ski",
|
| 400 |
+
"43946": "a big person in white jumper and backpack"
|
| 401 |
+
},
|
| 402 |
+
"2016": {
|
| 403 |
+
"42686": "person putting food in the oven",
|
| 404 |
+
"42687": "person in green t - shirt"
|
| 405 |
+
},
|
| 406 |
+
"1153": {
|
| 407 |
+
"25076": "a giraffe , with head lowered , crosses in front of another giraffe",
|
| 408 |
+
"25077": "giraffe in the middle"
|
| 409 |
+
},
|
| 410 |
+
"3614": {
|
| 411 |
+
"75583": "a man in explaining something on a tablet",
|
| 412 |
+
"75584": "a man with a blue cap and striped shirt"
|
| 413 |
+
},
|
| 414 |
+
"198": {
|
| 415 |
+
"3830": "a giraffe bending down to eat grass",
|
| 416 |
+
"3831": "giraffe in front"
|
| 417 |
+
},
|
| 418 |
+
"3012": {
|
| 419 |
+
"63097": "person standing with hands on hips",
|
| 420 |
+
"63098": "person in a white collared shirt and jeans"
|
| 421 |
+
},
|
| 422 |
+
"4247": {
|
| 423 |
+
"88808": "man pointing toward another man",
|
| 424 |
+
"88809": "man in plaid shirt"
|
| 425 |
+
},
|
| 426 |
+
"2205": {
|
| 427 |
+
"46674": "person bending over",
|
| 428 |
+
"46675": "person in red shirt and cap"
|
| 429 |
+
},
|
| 430 |
+
"4831": {
|
| 431 |
+
"100694": "person holding bat in hands",
|
| 432 |
+
"100695": "person wearing light blue shirt and glass"
|
| 433 |
+
},
|
| 434 |
+
"4534": {
|
| 435 |
+
"94419": "the bird not drinking",
|
| 436 |
+
"94420": "the bird on the left"
|
| 437 |
+
},
|
| 438 |
+
"638": {
|
| 439 |
+
"13717": "person sitting on another person's lap and holding the remote controller",
|
| 440 |
+
"13718": "small person in red shirt"
|
| 441 |
+
},
|
| 442 |
+
"1419": {
|
| 443 |
+
"30082": "person squatting on the ground to catch a ball",
|
| 444 |
+
"30083": "person in red and white wearing glove"
|
| 445 |
+
},
|
| 446 |
+
"1992": {
|
| 447 |
+
"42197": "a person reaching for a cupcake",
|
| 448 |
+
"42198": "a person in a blue vest"
|
| 449 |
+
},
|
| 450 |
+
"542": {
|
| 451 |
+
"11877": "man receiving food",
|
| 452 |
+
"11878": "a black man in a black shirt"
|
| 453 |
+
},
|
| 454 |
+
"2223": {
|
| 455 |
+
"47051": "person sitting a chair holding a protest sign",
|
| 456 |
+
"47052": "old person in grey t - shirt and blue jeans"
|
| 457 |
+
},
|
| 458 |
+
"4865": {
|
| 459 |
+
"101219": "person being held by another person",
|
| 460 |
+
"101220": "a young person wearing a yellow shirt"
|
| 461 |
+
},
|
| 462 |
+
"751": {
|
| 463 |
+
"16247": "person holding a painting brush",
|
| 464 |
+
"16248": "person wearing white top and cap"
|
| 465 |
+
},
|
| 466 |
+
"3540": {
|
| 467 |
+
"74039": "a man swinging a bat",
|
| 468 |
+
"74040": "a man in a blue baseball shirt and white pants"
|
| 469 |
+
},
|
| 470 |
+
"3765": {
|
| 471 |
+
"78908": "person sitting",
|
| 472 |
+
"78909": "person wearing white shirt and red shoes"
|
| 473 |
+
},
|
| 474 |
+
"2879": {
|
| 475 |
+
"60471": "bear standing against the fence",
|
| 476 |
+
"60472": "a small bear on the right"
|
| 477 |
+
},
|
| 478 |
+
"4529": {
|
| 479 |
+
"94312": "kid holding out left arm playing wii",
|
| 480 |
+
"94313": "kid in a green and red sweatshirt"
|
| 481 |
+
},
|
| 482 |
+
"2131": {
|
| 483 |
+
"45308": "man putting both hands behind his head",
|
| 484 |
+
"45309": "a man with the pool noodle"
|
| 485 |
+
},
|
| 486 |
+
"1306": {
|
| 487 |
+
"27841": "a cow eating grass",
|
| 488 |
+
"27842": "the cow on the right"
|
| 489 |
+
},
|
| 490 |
+
"3508": {
|
| 491 |
+
"73469": "a person standing and playing a video game",
|
| 492 |
+
"73470": "a little person dressed in brown"
|
| 493 |
+
},
|
| 494 |
+
"4165": {
|
| 495 |
+
"87036": "a child holding feathers",
|
| 496 |
+
"87037": "a child wearing green t - shirt"
|
| 497 |
+
},
|
| 498 |
+
"4126": {
|
| 499 |
+
"86073": "a person standing and reading a book",
|
| 500 |
+
"86074": "a person in a suit"
|
| 501 |
+
},
|
| 502 |
+
"388": {
|
| 503 |
+
"8339": "a man holding up an umbrella in the rain for a man who is fixing a tire",
|
| 504 |
+
"8340": "a man wearing glasses in a red jacket"
|
| 505 |
+
}
|
| 506 |
+
}
|
make_refcoco/refcocog_umd/needrevision_refid_part4.json
ADDED
|
@@ -0,0 +1,498 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"1679": {
|
| 3 |
+
"37582": "player holding a baseball glove",
|
| 4 |
+
"37583": "a blurred player"
|
| 5 |
+
},
|
| 6 |
+
"4048": {
|
| 7 |
+
"92810": "player hitting a ball with a baseball bat",
|
| 8 |
+
"92811": "player with number 18 on his back"
|
| 9 |
+
},
|
| 10 |
+
"2530": {
|
| 11 |
+
"57782": "man crouching ready to catch a ball",
|
| 12 |
+
"57783": "man with 55 on his back"
|
| 13 |
+
},
|
| 14 |
+
"4385": {
|
| 15 |
+
"101410": "man leaning on one leg watching the players",
|
| 16 |
+
"101411": "man in gray pants"
|
| 17 |
+
},
|
| 18 |
+
"5018": {
|
| 19 |
+
"102413": "man standing ready to swing his bat",
|
| 20 |
+
"102414": "man in front of the other two men"
|
| 21 |
+
},
|
| 22 |
+
"2290": {
|
| 23 |
+
"52302": "sheep standing in the pasture next to a sitting sheep",
|
| 24 |
+
"52303": "the front most sheep"
|
| 25 |
+
},
|
| 26 |
+
"2347": {
|
| 27 |
+
"53861": "a sheep sitting down in the grass",
|
| 28 |
+
"53862": "a sheep in the background"
|
| 29 |
+
},
|
| 30 |
+
"3143": {
|
| 31 |
+
"71854": "a horse being led by it ' s trainer",
|
| 32 |
+
"71855": "a horse in front of the picture"
|
| 33 |
+
},
|
| 34 |
+
"1688": {
|
| 35 |
+
"37818": "zebra eating grass",
|
| 36 |
+
"37819": "the zebra in the middle with its face near the ground"
|
| 37 |
+
},
|
| 38 |
+
"944": {
|
| 39 |
+
"21007": "a bird touching its neck with its right feet",
|
| 40 |
+
"21008": "a bird in the back"
|
| 41 |
+
},
|
| 42 |
+
"3477": {
|
| 43 |
+
"79163": "the bird standing and looking to the left",
|
| 44 |
+
"79164": "bird with both feet in the water"
|
| 45 |
+
},
|
| 46 |
+
"2497": {
|
| 47 |
+
"56845": "person holding a baseball bat",
|
| 48 |
+
"56846": "person in blue baseball cap"
|
| 49 |
+
},
|
| 50 |
+
"4110": {
|
| 51 |
+
"94298": "person sitting and watching children play a ballgame",
|
| 52 |
+
"94299": "person wearing a white shirt and black leggings"
|
| 53 |
+
},
|
| 54 |
+
"2011": {
|
| 55 |
+
"45909": "a woman talking on her cell phone",
|
| 56 |
+
"45910": "a blonde woman wearing a blue shirt and white shorts"
|
| 57 |
+
},
|
| 58 |
+
"2884": {
|
| 59 |
+
"65819": "a woman looking at her phone",
|
| 60 |
+
"65820": "a woman with black hair wearing jeans, a striped gray shirt and flip flops"
|
| 61 |
+
},
|
| 62 |
+
"1076": {
|
| 63 |
+
"24000": "person crossing a stream of water",
|
| 64 |
+
"24001": "person wearing jeans and a green vest"
|
| 65 |
+
},
|
| 66 |
+
"4803": {
|
| 67 |
+
"56121": "person helping the other cross a stream",
|
| 68 |
+
"56122": "person in white dress"
|
| 69 |
+
},
|
| 70 |
+
"3508": {
|
| 71 |
+
"80112": "baseball player placing his hands on his hips",
|
| 72 |
+
"80113": "a baseball player named datz"
|
| 73 |
+
},
|
| 74 |
+
"169": {
|
| 75 |
+
"4002": "person feeding a giraffe",
|
| 76 |
+
"4003": "a small person in light blue shirt"
|
| 77 |
+
},
|
| 78 |
+
"258": {
|
| 79 |
+
"5988": "person holding a child",
|
| 80 |
+
"5989": "person wearing glasses and navy shirt"
|
| 81 |
+
},
|
| 82 |
+
"3661": {
|
| 83 |
+
"83542": "person sitting on the floor",
|
| 84 |
+
"83543": "person in a grey shirt and dark pants"
|
| 85 |
+
},
|
| 86 |
+
"4831": {
|
| 87 |
+
"62137": "person sitting on couch and playing with a dog",
|
| 88 |
+
"62138": "bald person wearing jeans and brown hoodie"
|
| 89 |
+
},
|
| 90 |
+
"2214": {
|
| 91 |
+
"50208": "a woman eating a donut",
|
| 92 |
+
"50209": "a brown hair woman in gray sweater"
|
| 93 |
+
},
|
| 94 |
+
"2266": {
|
| 95 |
+
"51661": "a woman holding a purse",
|
| 96 |
+
"51662": "a woman with blonde hair and a black shirt"
|
| 97 |
+
},
|
| 98 |
+
"2477": {
|
| 99 |
+
"56429": "girl talking and looking at another girl",
|
| 100 |
+
"56430": "girl in black"
|
| 101 |
+
},
|
| 102 |
+
"5005": {
|
| 103 |
+
"99824": "girl eating and looking at her plate",
|
| 104 |
+
"99825": "girl wearing a pink shirt"
|
| 105 |
+
},
|
| 106 |
+
"2919": {
|
| 107 |
+
"66832": "person riding a bike",
|
| 108 |
+
"66833": "asian person wearing black jacket"
|
| 109 |
+
},
|
| 110 |
+
"1850": {
|
| 111 |
+
"42078": "man placing his hand on another man's shoulder",
|
| 112 |
+
"42079": "a man who is wearing a red color tie"
|
| 113 |
+
},
|
| 114 |
+
"3757": {
|
| 115 |
+
"85761": "boy holding a cell phone",
|
| 116 |
+
"85762": "boy in a blue hoodie"
|
| 117 |
+
},
|
| 118 |
+
"524": {
|
| 119 |
+
"12089": "a zebra that is not eating grass",
|
| 120 |
+
"12090": "a zebra on the far right"
|
| 121 |
+
},
|
| 122 |
+
"4363": {
|
| 123 |
+
"100914": "elephant holding up its trunk",
|
| 124 |
+
"100915": "an elephant in front of another"
|
| 125 |
+
},
|
| 126 |
+
"2976": {
|
| 127 |
+
"68306": "girl eating food from her right hand",
|
| 128 |
+
"68307": "a girl in a black flowered top"
|
| 129 |
+
},
|
| 130 |
+
"838": {
|
| 131 |
+
"18887": "man leaning on bike on boat",
|
| 132 |
+
"18888": "a man not wearing a hat"
|
| 133 |
+
},
|
| 134 |
+
"3044": {
|
| 135 |
+
"69755": "man rowing boat",
|
| 136 |
+
"69756": "a man on the left side of the picture"
|
| 137 |
+
},
|
| 138 |
+
"2426": {
|
| 139 |
+
"55424": "the baseball player facing towards the right not doing a high five",
|
| 140 |
+
"55425": "baseball player in catcher ' s uniform"
|
| 141 |
+
},
|
| 142 |
+
"2113": {
|
| 143 |
+
"47984": "person that is dancing",
|
| 144 |
+
"47985": "person with the thick beard, glasses and a hat"
|
| 145 |
+
},
|
| 146 |
+
"2327": {
|
| 147 |
+
"53376": "person bathing another person",
|
| 148 |
+
"53377": "person in a floral print dress and hat"
|
| 149 |
+
},
|
| 150 |
+
"4727": {
|
| 151 |
+
"39103": "a bull laying down",
|
| 152 |
+
"39104": "a white and brown bull on the right"
|
| 153 |
+
},
|
| 154 |
+
"859": {
|
| 155 |
+
"19350": "cat sitting on a luggage and staring at the camera",
|
| 156 |
+
"19351": "cat infront of another cat"
|
| 157 |
+
},
|
| 158 |
+
"935": {
|
| 159 |
+
"20809": "cat laying down on a bag",
|
| 160 |
+
"20810": "cat behind another cat"
|
| 161 |
+
},
|
| 162 |
+
"1105": {
|
| 163 |
+
"24654": "an elephant stepping on a large log",
|
| 164 |
+
"24655": "elephant on far right"
|
| 165 |
+
},
|
| 166 |
+
"395": {
|
| 167 |
+
"8819": "person placing her hands on one's hips",
|
| 168 |
+
"8820": "person on the far left"
|
| 169 |
+
},
|
| 170 |
+
"771": {
|
| 171 |
+
"17614": "person holding a child on one's shoulders",
|
| 172 |
+
"17615": "tall person on the right"
|
| 173 |
+
},
|
| 174 |
+
"2942": {
|
| 175 |
+
"67334": "person sitting on another person's shoulders",
|
| 176 |
+
"67335": "small person on the right"
|
| 177 |
+
},
|
| 178 |
+
"41": {
|
| 179 |
+
"961": "a lady pouring wine in a glass",
|
| 180 |
+
"962": "a lady in black tank top"
|
| 181 |
+
},
|
| 182 |
+
"885": {
|
| 183 |
+
"19926": "person feeding another person with a bottle",
|
| 184 |
+
"19927": "person in black blouse"
|
| 185 |
+
},
|
| 186 |
+
"4862": {
|
| 187 |
+
"69276": "person drinking from a bottle",
|
| 188 |
+
"69277": "small person in white pajamas"
|
| 189 |
+
},
|
| 190 |
+
"1246": {
|
| 191 |
+
"27831": "person holding a laptop",
|
| 192 |
+
"27832": "person with curly brown hair wearing jeans"
|
| 193 |
+
},
|
| 194 |
+
"3346": {
|
| 195 |
+
"76051": "person filing her nails",
|
| 196 |
+
"76052": "person wearing a red robe and has a towel on her head"
|
| 197 |
+
},
|
| 198 |
+
"3657": {
|
| 199 |
+
"83493": "person holding a bottle and listening to music",
|
| 200 |
+
"83494": "person wearing black in headphones"
|
| 201 |
+
},
|
| 202 |
+
"540": {
|
| 203 |
+
"12381": "the woman is swinging the controller",
|
| 204 |
+
"12382": "woman in brown top on the right"
|
| 205 |
+
},
|
| 206 |
+
"3364": {
|
| 207 |
+
"76757": "the woman looking at the camera and opening her mouth",
|
| 208 |
+
"76758": "a woman wearing a brown hooded sweatshirt on the left"
|
| 209 |
+
},
|
| 210 |
+
"1880": {
|
| 211 |
+
"42973": "man looking ahead at the tv",
|
| 212 |
+
"42974": "a man in a white shirt"
|
| 213 |
+
},
|
| 214 |
+
"1949": {
|
| 215 |
+
"44400": "a man looking at his phone",
|
| 216 |
+
"44401": "man in black t - shirt and cap"
|
| 217 |
+
},
|
| 218 |
+
"1620": {
|
| 219 |
+
"36248": "person playing tennis",
|
| 220 |
+
"36249": "person in red tank top and black shorts"
|
| 221 |
+
},
|
| 222 |
+
"2902": {
|
| 223 |
+
"66297": "person sitting and watching a tennis game",
|
| 224 |
+
"66298": "person in blue top"
|
| 225 |
+
},
|
| 226 |
+
"397": {
|
| 227 |
+
"8843": "giraffe bending its head down",
|
| 228 |
+
"8844": "giraffe on the far right"
|
| 229 |
+
},
|
| 230 |
+
"732": {
|
| 231 |
+
"16725": "baseball player squatting and watching closely to judge a play",
|
| 232 |
+
"16726": "baseball player in black top and gray pants"
|
| 233 |
+
},
|
| 234 |
+
"1173": {
|
| 235 |
+
"26074": "a man swinging a bat",
|
| 236 |
+
"26075": "a man in blue and grey"
|
| 237 |
+
},
|
| 238 |
+
"2920": {
|
| 239 |
+
"66854": "a man reaching out his left arm to catch a ball",
|
| 240 |
+
"66855": "a man in red uniform and helmet"
|
| 241 |
+
},
|
| 242 |
+
"1643": {
|
| 243 |
+
"36762": "a man smiling looking down at other people",
|
| 244 |
+
"36763": "a man in a grey suite wearing a pink tie"
|
| 245 |
+
},
|
| 246 |
+
"1454": {
|
| 247 |
+
"32177": "person in putting hands in one's pockets",
|
| 248 |
+
"32178": "person in gray shirt and jeans"
|
| 249 |
+
},
|
| 250 |
+
"1725": {
|
| 251 |
+
"38835": "person crossing her arms walking with another person",
|
| 252 |
+
"38836": "person in a black shirt and jeans"
|
| 253 |
+
},
|
| 254 |
+
"2338": {
|
| 255 |
+
"53733": "the person crouching and placing his hands on his knees",
|
| 256 |
+
"53734": "person with a black shirt and dark grey pants"
|
| 257 |
+
},
|
| 258 |
+
"4249": {
|
| 259 |
+
"97957": "a baseball player reaching out his arm to catch a ball",
|
| 260 |
+
"97958": "a baseball player in green top"
|
| 261 |
+
},
|
| 262 |
+
"3917": {
|
| 263 |
+
"89675": "cow looking at camera",
|
| 264 |
+
"89676": "a cow with an ear tag with the number 949 on it"
|
| 265 |
+
},
|
| 266 |
+
"1156": {
|
| 267 |
+
"25761": "man sitting on the couch using a laptop",
|
| 268 |
+
"25762": "a man with a hat"
|
| 269 |
+
},
|
| 270 |
+
"1998": {
|
| 271 |
+
"45619": "a person watching his phone",
|
| 272 |
+
"45620": "person wearing glasses"
|
| 273 |
+
},
|
| 274 |
+
"3571": {
|
| 275 |
+
"81719": "person looking at one's phone",
|
| 276 |
+
"81720": "mature person with blonde hair and glasses"
|
| 277 |
+
},
|
| 278 |
+
"292": {
|
| 279 |
+
"6707": "a zebra lying down in dirt",
|
| 280 |
+
"6708": "the zebra in the foreground"
|
| 281 |
+
},
|
| 282 |
+
"3367": {
|
| 283 |
+
"76808": "a zebra standing in the zoo",
|
| 284 |
+
"76809": "a zebra in the background"
|
| 285 |
+
},
|
| 286 |
+
"2069": {
|
| 287 |
+
"47212": "person leaning forward on skis",
|
| 288 |
+
"47213": "person in blue hat and jacket, black pants"
|
| 289 |
+
},
|
| 290 |
+
"4050": {
|
| 291 |
+
"92834": "person standing straight looking at another person",
|
| 292 |
+
"92835": "a small person wearing purple pants"
|
| 293 |
+
},
|
| 294 |
+
"2953": {
|
| 295 |
+
"67711": "person who is looking away",
|
| 296 |
+
"67712": "person in a suit"
|
| 297 |
+
},
|
| 298 |
+
"4280": {
|
| 299 |
+
"98813": "person pulling another person's tie",
|
| 300 |
+
"98814": "a person in a white shirt"
|
| 301 |
+
},
|
| 302 |
+
"1743": {
|
| 303 |
+
"39371": "a person holding and looking at another person",
|
| 304 |
+
"39372": "person with bald head and glasses"
|
| 305 |
+
},
|
| 306 |
+
"4598": {
|
| 307 |
+
"13717": "person playing with the remote controller",
|
| 308 |
+
"13718": "small person in red shirt"
|
| 309 |
+
},
|
| 310 |
+
"3380": {
|
| 311 |
+
"77052": "a person cutting a cake",
|
| 312 |
+
"77053": "a person in gray shirt that is not striped"
|
| 313 |
+
},
|
| 314 |
+
"3439": {
|
| 315 |
+
"78305": "a person holding a spatula getting readyy to have a cake",
|
| 316 |
+
"78306": "a person in striped shirt"
|
| 317 |
+
},
|
| 318 |
+
"3355": {
|
| 319 |
+
"76309": "a man swining his bat",
|
| 320 |
+
"76310": "a man in a baseball uniform with a brace on his left ankle"
|
| 321 |
+
},
|
| 322 |
+
"3409": {
|
| 323 |
+
"77608": "a man holding out his arm to catch a ball",
|
| 324 |
+
"77609": "a man wearing a red vest with red shin guards"
|
| 325 |
+
},
|
| 326 |
+
"711": {
|
| 327 |
+
"16184": "the man holding a cat in his arms",
|
| 328 |
+
"16185": "this is a man with thin rimmed glasses and a black scarf"
|
| 329 |
+
},
|
| 330 |
+
"3764": {
|
| 331 |
+
"85913": "person holding a remote and smilling",
|
| 332 |
+
"85914": "person in a black t - shirt and not wearing glasses"
|
| 333 |
+
},
|
| 334 |
+
"113": {
|
| 335 |
+
"2741": "a sheep being fed by a little girl",
|
| 336 |
+
"2742": "a sheep on the right"
|
| 337 |
+
},
|
| 338 |
+
"518": {
|
| 339 |
+
"12021": "a sheep eating grass with its head down",
|
| 340 |
+
"12022": "a sheep on the left"
|
| 341 |
+
},
|
| 342 |
+
"3158": {
|
| 343 |
+
"72128": "a boy crouching and placing both hands on his knees",
|
| 344 |
+
"72129": "boy wearing white baseball helmet , white baseball uniform with orange writing"
|
| 345 |
+
},
|
| 346 |
+
"3223": {
|
| 347 |
+
"73555": "a boy pitching the ball to a player",
|
| 348 |
+
"73556": "a boy with the number 4 on his blue jersey"
|
| 349 |
+
},
|
| 350 |
+
"914": {
|
| 351 |
+
"20478": "a person standing on a surf board , riding a wave",
|
| 352 |
+
"20479": "a person on the right"
|
| 353 |
+
},
|
| 354 |
+
"3568": {
|
| 355 |
+
"81669": "surfer laying down",
|
| 356 |
+
"81670": "surfer on the left"
|
| 357 |
+
},
|
| 358 |
+
"592": {
|
| 359 |
+
"13643": "person sits on the floor watching tv",
|
| 360 |
+
"13644": "person with a black hat and a beige shirt"
|
| 361 |
+
},
|
| 362 |
+
"2856": {
|
| 363 |
+
"65208": "person sitting on a chair watching another person play video games",
|
| 364 |
+
"65209": "person in black shirt and jeans"
|
| 365 |
+
},
|
| 366 |
+
"4879": {
|
| 367 |
+
"73469": "person playing a video game",
|
| 368 |
+
"73470": "blonde person dressed in brown"
|
| 369 |
+
},
|
| 370 |
+
"157": {
|
| 371 |
+
"3682": "a woman holding a plate and reaching for condiments",
|
| 372 |
+
"3683": "woman wearing grey button up sweater"
|
| 373 |
+
},
|
| 374 |
+
"1774": {
|
| 375 |
+
"40317": "person being held by another person",
|
| 376 |
+
"40318": "person with red hair, wearing a pink shirt"
|
| 377 |
+
},
|
| 378 |
+
"2354": {
|
| 379 |
+
"53948": "person with child , catching a frisby",
|
| 380 |
+
"53949": "bigger person in white t - shirt"
|
| 381 |
+
},
|
| 382 |
+
"174": {
|
| 383 |
+
"4179": "a lamb eating grass",
|
| 384 |
+
"4180": "a lamb to the left of another lamb"
|
| 385 |
+
},
|
| 386 |
+
"2369": {
|
| 387 |
+
"54196": "the sheep that is looking into the camera",
|
| 388 |
+
"54197": "a white sheep with a black head on the right"
|
| 389 |
+
},
|
| 390 |
+
"4247": {
|
| 391 |
+
"97897": "a woman holding an umbrella on a bench",
|
| 392 |
+
"97898": "woman on the right"
|
| 393 |
+
},
|
| 394 |
+
"1014": {
|
| 395 |
+
"22621": "man receiving an award",
|
| 396 |
+
"22622": "a man in an orange and white uniform with a black cap"
|
| 397 |
+
},
|
| 398 |
+
"1080": {
|
| 399 |
+
"24100": "a man offers a trophy to anothe man",
|
| 400 |
+
"24101": "a man in a suit"
|
| 401 |
+
},
|
| 402 |
+
"2272": {
|
| 403 |
+
"51815": "the baseball player catching a ball",
|
| 404 |
+
"51816": "the baseball player in dark top and helmet"
|
| 405 |
+
},
|
| 406 |
+
"2495": {
|
| 407 |
+
"56804": "a baseball player swinging at a ball",
|
| 408 |
+
"56805": "the baseball player in white uniform"
|
| 409 |
+
},
|
| 410 |
+
"3511": {
|
| 411 |
+
"80309": "person holding a cup",
|
| 412 |
+
"80310": "person wearing pink shirt"
|
| 413 |
+
},
|
| 414 |
+
"3955": {
|
| 415 |
+
"90542": "person holding a remote control",
|
| 416 |
+
"90543": "person in orange shirt"
|
| 417 |
+
},
|
| 418 |
+
"2409": {
|
| 419 |
+
"55054": "a man adjusting his head band",
|
| 420 |
+
"55055": "man in orange and gray shirt"
|
| 421 |
+
},
|
| 422 |
+
"2775": {
|
| 423 |
+
"63273": "a person holding a remote control",
|
| 424 |
+
"63274": "a tall person in white striped shirt and black pants"
|
| 425 |
+
},
|
| 426 |
+
"996": {
|
| 427 |
+
"22281": "a woman holding a baby",
|
| 428 |
+
"22282": "woman wearing a black shirt and green apron"
|
| 429 |
+
},
|
| 430 |
+
"4789": {
|
| 431 |
+
"52629": "a person holding skies in one's hands",
|
| 432 |
+
"52630": "a person with orange mirrored goggles"
|
| 433 |
+
},
|
| 434 |
+
"1028": {
|
| 435 |
+
"22786": "the cow standing up",
|
| 436 |
+
"22787": "a cow in the middle"
|
| 437 |
+
},
|
| 438 |
+
"244": {
|
| 439 |
+
"5666": "a man holding wine glass",
|
| 440 |
+
"5668": "a blonde man in a white shirt"
|
| 441 |
+
},
|
| 442 |
+
"3538": {
|
| 443 |
+
"80923": "the man throwing the ball from the picther ' s mound",
|
| 444 |
+
"80924": "the man in front"
|
| 445 |
+
},
|
| 446 |
+
"557": {
|
| 447 |
+
"12739": "a baseball player getting ready to swing the bat",
|
| 448 |
+
"12740": "a baseball player , wearing a white and blue uniform"
|
| 449 |
+
},
|
| 450 |
+
"4982": {
|
| 451 |
+
"95870": "cat sitting in front of television on a stand",
|
| 452 |
+
"95871": "orange cat on the right side of the picture"
|
| 453 |
+
},
|
| 454 |
+
"4570": {
|
| 455 |
+
"6638": "a woman cutting a cake",
|
| 456 |
+
"6639": "a woman wearing a long sleeve pink sweater"
|
| 457 |
+
},
|
| 458 |
+
"1698": {
|
| 459 |
+
"38093": "a baseball player swinging his bat",
|
| 460 |
+
"38094": "a baseball player weaing a white uniform and blue helmet"
|
| 461 |
+
},
|
| 462 |
+
"3182": {
|
| 463 |
+
"72616": "the baseball player playing the catcher position",
|
| 464 |
+
"72617": "the baseball player wearing a red and white uniform"
|
| 465 |
+
},
|
| 466 |
+
"846": {
|
| 467 |
+
"19100": "a man holding a toothbrush in his mouth",
|
| 468 |
+
"19101": "a man wearing striped shirt"
|
| 469 |
+
},
|
| 470 |
+
"671": {
|
| 471 |
+
"15227": "person petting a horse",
|
| 472 |
+
"15228": "person wearing a red jacket"
|
| 473 |
+
},
|
| 474 |
+
"3254": {
|
| 475 |
+
"74216": "person sitting in the chair",
|
| 476 |
+
"74217": "person in the tan shirt wearing glasses"
|
| 477 |
+
},
|
| 478 |
+
"3318": {
|
| 479 |
+
"75539": "the person who is smashing cake in his own face",
|
| 480 |
+
"75540": "person with a fake tie on its onesie"
|
| 481 |
+
},
|
| 482 |
+
"1424": {
|
| 483 |
+
"31548": "person watching another person eat",
|
| 484 |
+
"31549": "person in the green shirt"
|
| 485 |
+
},
|
| 486 |
+
"3926": {
|
| 487 |
+
"89831": "person eating a sandwich",
|
| 488 |
+
"89832": "person in orange top with sunglasses in one's head"
|
| 489 |
+
},
|
| 490 |
+
"862": {
|
| 491 |
+
"19444": "a man driving a bicycle and pulling a cart behind",
|
| 492 |
+
"19445": "the man is wearing a pair of khaki shorts"
|
| 493 |
+
},
|
| 494 |
+
"2932": {
|
| 495 |
+
"67140": "man standing on bike",
|
| 496 |
+
"67141": "man in blue jean shorts"
|
| 497 |
+
}
|
| 498 |
+
}
|
mbench/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (160 Bytes). View file
|
|
|
mbench/__pycache__/ytvos_ref.cpython-310.pyc
ADDED
|
Binary file (7.81 kB). View file
|
|
|
mbench/check_image_numbered_cy.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
mbench/check_image_numbered_cy_score.py
ADDED
|
@@ -0,0 +1,212 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import sys
|
| 2 |
+
import os
|
| 3 |
+
import argparse
|
| 4 |
+
sys.path.append(os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
|
| 5 |
+
|
| 6 |
+
import opts
|
| 7 |
+
|
| 8 |
+
import numpy as np
|
| 9 |
+
import cv2
|
| 10 |
+
from PIL import Image
|
| 11 |
+
import json
|
| 12 |
+
|
| 13 |
+
from mbench.ytvos_ref import build as build_ytvos_ref
|
| 14 |
+
import t2v_metrics
|
| 15 |
+
|
| 16 |
+
import matplotlib.pyplot as plt
|
| 17 |
+
import textwrap
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def scoreCaption(idx, all_captions, all_valid_obj_ids, clip_flant5_score, color_mask = False):
|
| 21 |
+
vid_meta = metas[idx]
|
| 22 |
+
vid_id = vid_meta['video']
|
| 23 |
+
frames = vid_meta['frames']
|
| 24 |
+
|
| 25 |
+
first_cat = list(all_captions[vid_id].keys())[0]
|
| 26 |
+
sampled_frames = list(all_captions[vid_id][first_cat].keys())
|
| 27 |
+
imgs = []
|
| 28 |
+
masks = []
|
| 29 |
+
for frame_indx in sampled_frames:
|
| 30 |
+
frame_name = frames[int(frame_indx)]
|
| 31 |
+
img_path = os.path.join(str(train_dataset.img_folder), 'JPEGImages', vid_id, frame_name + '.jpg')
|
| 32 |
+
mask_path = os.path.join(str(train_dataset.img_folder), 'Annotations', vid_id, frame_name + '.png')
|
| 33 |
+
img = Image.open(img_path).convert('RGB')
|
| 34 |
+
imgs.append(img)
|
| 35 |
+
mask = Image.open(mask_path).convert('P')
|
| 36 |
+
mask = np.array(mask)
|
| 37 |
+
masks.append(mask)
|
| 38 |
+
|
| 39 |
+
vid_captions = all_captions[vid_id]
|
| 40 |
+
cat_names = set(list(vid_captions.keys()))
|
| 41 |
+
|
| 42 |
+
vid_result = {}
|
| 43 |
+
|
| 44 |
+
for cat in cat_names:
|
| 45 |
+
|
| 46 |
+
cat_captions = vid_captions[cat]
|
| 47 |
+
|
| 48 |
+
cat_result = {}
|
| 49 |
+
|
| 50 |
+
for i in range(len(imgs)):
|
| 51 |
+
frame_name = sampled_frames[i]
|
| 52 |
+
frame = np.copy(np.array(imgs[i]))
|
| 53 |
+
frame_for_contour = np.copy(np.array(imgs[i]))
|
| 54 |
+
|
| 55 |
+
mask = masks[i]
|
| 56 |
+
|
| 57 |
+
all_obj_ids = np.unique(mask).astype(int)
|
| 58 |
+
all_obj_ids = [str(obj_id) for obj_id in all_obj_ids if obj_id != 0]
|
| 59 |
+
|
| 60 |
+
if cat in all_valid_obj_ids[vid_id]:
|
| 61 |
+
valid_obj_ids = all_valid_obj_ids[vid_id][cat]
|
| 62 |
+
else:
|
| 63 |
+
valid_obj_ids = []
|
| 64 |
+
|
| 65 |
+
for j in range(len(all_obj_ids)):
|
| 66 |
+
obj_id = all_obj_ids[j]
|
| 67 |
+
obj_mask = (mask == int(obj_id)).astype(np.uint8)
|
| 68 |
+
|
| 69 |
+
if obj_id in valid_obj_ids:
|
| 70 |
+
if color_mask == False:
|
| 71 |
+
contours, _ = cv2.findContours(obj_mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
|
| 72 |
+
cv2.drawContours(frame, contours, -1, colors[j], 3)
|
| 73 |
+
for i, contour in enumerate(contours):
|
| 74 |
+
# 윤곽선 중심 계산
|
| 75 |
+
moments = cv2.moments(contour)
|
| 76 |
+
if moments["m00"] != 0: # 중심 계산 가능 여부 확인
|
| 77 |
+
cx = int(moments["m10"] / moments["m00"])
|
| 78 |
+
cy = int(moments["m01"] / moments["m00"])
|
| 79 |
+
else:
|
| 80 |
+
cx, cy = contour[0][0] # 중심 계산 불가시 대체 좌표 사용
|
| 81 |
+
|
| 82 |
+
# 텍스트 배경 (검은색 배경 만들기)
|
| 83 |
+
font = cv2.FONT_HERSHEY_SIMPLEX
|
| 84 |
+
text = obj_id
|
| 85 |
+
text_size = cv2.getTextSize(text, font, 1, 2)[0]
|
| 86 |
+
text_w, text_h = text_size
|
| 87 |
+
|
| 88 |
+
# 텍스트 배경 그리기 (검은색 배경)
|
| 89 |
+
cv2.rectangle(frame, (cx - text_w // 2 - 5, cy - text_h // 2 - 5),
|
| 90 |
+
(cx + text_w // 2 + 5, cy + text_h // 2 + 5), (0, 0, 0), -1)
|
| 91 |
+
|
| 92 |
+
# 텍스트 그리기 (흰색 텍스트)
|
| 93 |
+
cv2.putText(frame, text, (cx - text_w // 2, cy + text_h // 2),
|
| 94 |
+
font, 1, (255, 255, 255), 2)
|
| 95 |
+
else:
|
| 96 |
+
alpha = 0.08
|
| 97 |
+
colored_obj_mask = np.zeros_like(frame)
|
| 98 |
+
colored_obj_mask[obj_mask == 1] = colors[j]
|
| 99 |
+
frame[obj_mask == 1] = (
|
| 100 |
+
(1 - alpha) * frame[obj_mask == 1]
|
| 101 |
+
+ alpha * colored_obj_mask[obj_mask == 1]
|
| 102 |
+
)
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
contours, _ = cv2.findContours(obj_mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
|
| 106 |
+
cv2.drawContours(frame, contours, -1, colors[j], 2)
|
| 107 |
+
cv2.drawContours(frame_for_contour, contours, -1, colors[j], 2)
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
if len(contours) > 0:
|
| 112 |
+
largest_contour = max(contours, key=cv2.contourArea)
|
| 113 |
+
M = cv2.moments(largest_contour)
|
| 114 |
+
if M["m00"] != 0:
|
| 115 |
+
center_x = int(M["m10"] / M["m00"])
|
| 116 |
+
center_y = int(M["m01"] / M["m00"])
|
| 117 |
+
else:
|
| 118 |
+
center_x, center_y = 0, 0
|
| 119 |
+
|
| 120 |
+
font = cv2.FONT_HERSHEY_SIMPLEX
|
| 121 |
+
text = obj_id
|
| 122 |
+
|
| 123 |
+
font_scale = 0.9
|
| 124 |
+
text_size = cv2.getTextSize(text, font, font_scale, 2)[0]
|
| 125 |
+
text_x = center_x - text_size[0] // 1 # 텍스트의 가로 중심
|
| 126 |
+
text_y = center_y
|
| 127 |
+
# text_y = center_y + text_size[1] // 2 # 텍스트의 세로 중심
|
| 128 |
+
|
| 129 |
+
# 텍스트 배경 사각형 좌표 계산
|
| 130 |
+
rect_start = (text_x - 5, text_y - text_size[1] - 5) # 배경 사각형 좌상단
|
| 131 |
+
# rect_end = (text_x + text_size[0] + 5, text_y + 5)
|
| 132 |
+
rect_end = (text_x + text_size[0] + 5, text_y)
|
| 133 |
+
|
| 134 |
+
cv2.rectangle(frame, rect_start, rect_end, (0, 0, 0), -1)
|
| 135 |
+
cv2.putText(frame, text, (text_x, text_y), font, 1, (255, 255, 255), 2)
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
# fig, ax = plt.subplots()
|
| 140 |
+
# ax.imshow(frame)
|
| 141 |
+
# ax.axis('off')
|
| 142 |
+
|
| 143 |
+
frame_caption = cat_captions[frame_name]
|
| 144 |
+
if frame_caption:
|
| 145 |
+
# wrapped_text = "\n".join(textwrap.wrap(frame_caption, width=60))
|
| 146 |
+
# ax.text(0.5, -0.3, wrapped_text, ha='center', va='center', fontsize=12, transform=ax.transAxes)
|
| 147 |
+
|
| 148 |
+
#calculate vqa score
|
| 149 |
+
frame = Image.fromarray(frame)
|
| 150 |
+
score = clip_flant5_score(images=[frame], texts=[frame_caption])
|
| 151 |
+
else:
|
| 152 |
+
score = None
|
| 153 |
+
|
| 154 |
+
# plt.title(f"vid_id: {vid_id}, cat: {cat}, frame: {frame_name}, score: {score}")
|
| 155 |
+
# plt.tight_layout()
|
| 156 |
+
# plt.show()
|
| 157 |
+
|
| 158 |
+
cat_result[frame_name] = {
|
| 159 |
+
"caption" : frame_caption,
|
| 160 |
+
"score" : score
|
| 161 |
+
}
|
| 162 |
+
|
| 163 |
+
vid_result[cat] = cat_result
|
| 164 |
+
|
| 165 |
+
return vid_id, vid_result
|
| 166 |
+
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
if __name__ == '__main__':
|
| 170 |
+
parser = argparse.ArgumentParser('ReferFormer training and evaluation script', parents=[opts.get_args_parser()])
|
| 171 |
+
args = parser.parse_args()
|
| 172 |
+
|
| 173 |
+
#==================데이터 불러오기===================
|
| 174 |
+
# 전체 데이터셋
|
| 175 |
+
train_dataset = build_ytvos_ref(image_set = 'train', args = args)
|
| 176 |
+
|
| 177 |
+
# 전체 데이터셋 메타데이터
|
| 178 |
+
metas = train_dataset.metas
|
| 179 |
+
|
| 180 |
+
# caption 데이터
|
| 181 |
+
with open('mbench/numbered_captions_gpt-4o_final.json', 'r') as file:
|
| 182 |
+
all_captions = json.load(file)
|
| 183 |
+
|
| 184 |
+
# valid obj ids 데이터
|
| 185 |
+
with open('mbench/numbered_valid_obj_ids_gpt-4o_final.json', 'r') as file:
|
| 186 |
+
all_valid_obj_ids = json.load(file)
|
| 187 |
+
|
| 188 |
+
# 색상 후보 8개 (RGB 형식)
|
| 189 |
+
colors = [
|
| 190 |
+
(255, 0, 0), # Red
|
| 191 |
+
(0, 255, 0), # Green
|
| 192 |
+
(0, 0, 255), # Blue
|
| 193 |
+
(255, 255, 0), # Yellow
|
| 194 |
+
(255, 0, 255), # Magenta
|
| 195 |
+
(0, 255, 255), # Cyan
|
| 196 |
+
(128, 0, 128), # Purple
|
| 197 |
+
(255, 165, 0) # Orange
|
| 198 |
+
]
|
| 199 |
+
|
| 200 |
+
#==================vqa score 모델 불러오기===================
|
| 201 |
+
clip_flant5_score = t2v_metrics.VQAScore(model='clip-flant5-xxl')
|
| 202 |
+
|
| 203 |
+
#==================vqa score 점수 계산하기===================
|
| 204 |
+
all_scores = {}
|
| 205 |
+
for i in range(5):
|
| 206 |
+
vid_id, vid_result = scoreCaption(i, all_captions, all_valid_obj_ids, clip_flant5_score, False)
|
| 207 |
+
all_scores[vid_id] = vid_result
|
| 208 |
+
|
| 209 |
+
with open('mbench/numbered_captions_gpt-4o_final_scores.json', 'w', encoding='utf-8') as json_file:
|
| 210 |
+
json.dump(all_scores, indent=4, ensure_ascii=False)
|
| 211 |
+
|
| 212 |
+
print("JSON 파일이 성공적으로 저장되었습니다!")
|
mbench/gpt_ref-ytvos-cy.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
mbench/gpt_ref-ytvos-revised.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
mbench/gpt_ref-ytvos_numbered.ipynb
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5fd89176d8bf426500d18caf6b5983b0765f147d17a6bb59f41c4edcaf3c3158
|
| 3 |
+
size 16214561
|
mbench/gpt_ref-ytvos_numbered_cy.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
mbench/numbered_captions.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
mbench/numbered_captions_gpt-4o.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
mbench/numbered_captions_gpt-4o_nomask_randcap2.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
mbench/numbered_valid_obj_ids_gpt-4o_final.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
mbench/numbered_valid_obj_ids_gpt-4o_nomask_randcap2.json
ADDED
|
@@ -0,0 +1,2153 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"003234408d": {
|
| 3 |
+
"penguin": [
|
| 4 |
+
"1",
|
| 5 |
+
"2",
|
| 6 |
+
"3",
|
| 7 |
+
"4",
|
| 8 |
+
"5"
|
| 9 |
+
]
|
| 10 |
+
},
|
| 11 |
+
"0043f083b5": {
|
| 12 |
+
"bus": [
|
| 13 |
+
"1"
|
| 14 |
+
],
|
| 15 |
+
"sedan": [
|
| 16 |
+
"2",
|
| 17 |
+
"3"
|
| 18 |
+
]
|
| 19 |
+
},
|
| 20 |
+
"0044fa5fba": {
|
| 21 |
+
"giant_panda": [
|
| 22 |
+
"1"
|
| 23 |
+
]
|
| 24 |
+
},
|
| 25 |
+
"005a527edd": {
|
| 26 |
+
"ape": [
|
| 27 |
+
"1",
|
| 28 |
+
"2"
|
| 29 |
+
]
|
| 30 |
+
},
|
| 31 |
+
"0065b171f9": {
|
| 32 |
+
"giant_panda": [
|
| 33 |
+
"1"
|
| 34 |
+
]
|
| 35 |
+
},
|
| 36 |
+
"00917dcfc4": {
|
| 37 |
+
"zebra": [
|
| 38 |
+
"1",
|
| 39 |
+
"2",
|
| 40 |
+
"3"
|
| 41 |
+
]
|
| 42 |
+
},
|
| 43 |
+
"00a23ccf53": {
|
| 44 |
+
"shark": [
|
| 45 |
+
"1"
|
| 46 |
+
]
|
| 47 |
+
},
|
| 48 |
+
"00ad5016a4": {
|
| 49 |
+
"airplane": [
|
| 50 |
+
"1"
|
| 51 |
+
]
|
| 52 |
+
},
|
| 53 |
+
"01082ae388": {
|
| 54 |
+
"leopard": [
|
| 55 |
+
"1"
|
| 56 |
+
]
|
| 57 |
+
},
|
| 58 |
+
"011ac0a06f": {
|
| 59 |
+
"ape": [
|
| 60 |
+
"1",
|
| 61 |
+
"2",
|
| 62 |
+
"3",
|
| 63 |
+
"4",
|
| 64 |
+
"5"
|
| 65 |
+
]
|
| 66 |
+
},
|
| 67 |
+
"013099c098": {
|
| 68 |
+
"giant_panda": [
|
| 69 |
+
"1",
|
| 70 |
+
"2"
|
| 71 |
+
]
|
| 72 |
+
},
|
| 73 |
+
"0155498c85": {
|
| 74 |
+
"person": [
|
| 75 |
+
"1"
|
| 76 |
+
],
|
| 77 |
+
"motorbike": [
|
| 78 |
+
"2"
|
| 79 |
+
]
|
| 80 |
+
},
|
| 81 |
+
"01694ad9c8": {
|
| 82 |
+
"bird": [
|
| 83 |
+
"1"
|
| 84 |
+
]
|
| 85 |
+
},
|
| 86 |
+
"017ac35701": {
|
| 87 |
+
"giant_panda": [
|
| 88 |
+
"1"
|
| 89 |
+
]
|
| 90 |
+
},
|
| 91 |
+
"01b80e8e1a": {
|
| 92 |
+
"zebra": [
|
| 93 |
+
"1",
|
| 94 |
+
"2"
|
| 95 |
+
]
|
| 96 |
+
},
|
| 97 |
+
"01baa5a4e1": {},
|
| 98 |
+
"01c3111683": {
|
| 99 |
+
"whale": [
|
| 100 |
+
"1"
|
| 101 |
+
]
|
| 102 |
+
},
|
| 103 |
+
"01c4cb5ffe": {
|
| 104 |
+
"person": [
|
| 105 |
+
"1",
|
| 106 |
+
"3"
|
| 107 |
+
]
|
| 108 |
+
},
|
| 109 |
+
"01c76f0a82": {
|
| 110 |
+
"sedan": [
|
| 111 |
+
"1",
|
| 112 |
+
"4"
|
| 113 |
+
]
|
| 114 |
+
},
|
| 115 |
+
"01c783268c": {
|
| 116 |
+
"person": [
|
| 117 |
+
"2"
|
| 118 |
+
],
|
| 119 |
+
"ape": [
|
| 120 |
+
"1"
|
| 121 |
+
]
|
| 122 |
+
},
|
| 123 |
+
"01e64dd36a": {
|
| 124 |
+
"cow": [
|
| 125 |
+
"1",
|
| 126 |
+
"2",
|
| 127 |
+
"3"
|
| 128 |
+
]
|
| 129 |
+
},
|
| 130 |
+
"01ed275c6e": {
|
| 131 |
+
"giraffe": [
|
| 132 |
+
"1",
|
| 133 |
+
"2"
|
| 134 |
+
]
|
| 135 |
+
},
|
| 136 |
+
"01ff60d1fa": {
|
| 137 |
+
"lizard": [
|
| 138 |
+
"1"
|
| 139 |
+
]
|
| 140 |
+
},
|
| 141 |
+
"020cd28cd2": {
|
| 142 |
+
"person": [
|
| 143 |
+
"1"
|
| 144 |
+
]
|
| 145 |
+
},
|
| 146 |
+
"02264db755": {
|
| 147 |
+
"fox": [
|
| 148 |
+
"1"
|
| 149 |
+
]
|
| 150 |
+
},
|
| 151 |
+
"0248626d9a": {
|
| 152 |
+
"train": [
|
| 153 |
+
"1"
|
| 154 |
+
]
|
| 155 |
+
},
|
| 156 |
+
"02668dbffa": {
|
| 157 |
+
"frog": [
|
| 158 |
+
"1"
|
| 159 |
+
]
|
| 160 |
+
},
|
| 161 |
+
"0274193026": {
|
| 162 |
+
"person": [
|
| 163 |
+
"2"
|
| 164 |
+
]
|
| 165 |
+
},
|
| 166 |
+
"02d28375aa": {
|
| 167 |
+
"fox": [
|
| 168 |
+
"1"
|
| 169 |
+
]
|
| 170 |
+
},
|
| 171 |
+
"031ccc99b1": {
|
| 172 |
+
"person": [
|
| 173 |
+
"1",
|
| 174 |
+
"2",
|
| 175 |
+
"3"
|
| 176 |
+
]
|
| 177 |
+
},
|
| 178 |
+
"0321b18c10": {
|
| 179 |
+
"elephant": [
|
| 180 |
+
"3"
|
| 181 |
+
],
|
| 182 |
+
"person": [
|
| 183 |
+
"1",
|
| 184 |
+
"2"
|
| 185 |
+
]
|
| 186 |
+
},
|
| 187 |
+
"0348a45bca": {
|
| 188 |
+
"fish": [
|
| 189 |
+
"1",
|
| 190 |
+
"2",
|
| 191 |
+
"3",
|
| 192 |
+
"4",
|
| 193 |
+
"5"
|
| 194 |
+
]
|
| 195 |
+
},
|
| 196 |
+
"0355e92655": {
|
| 197 |
+
"boat": [
|
| 198 |
+
"3"
|
| 199 |
+
],
|
| 200 |
+
"person": [
|
| 201 |
+
"2"
|
| 202 |
+
]
|
| 203 |
+
},
|
| 204 |
+
"0358b938c1": {
|
| 205 |
+
"elephant": [
|
| 206 |
+
"1",
|
| 207 |
+
"2",
|
| 208 |
+
"3",
|
| 209 |
+
"4"
|
| 210 |
+
]
|
| 211 |
+
},
|
| 212 |
+
"0368107cf1": {
|
| 213 |
+
"person": [
|
| 214 |
+
"1",
|
| 215 |
+
"2"
|
| 216 |
+
]
|
| 217 |
+
},
|
| 218 |
+
"0379ddf557": {
|
| 219 |
+
"person": [
|
| 220 |
+
"1"
|
| 221 |
+
]
|
| 222 |
+
},
|
| 223 |
+
"038b2cc71d": {
|
| 224 |
+
"lizard": [
|
| 225 |
+
"1"
|
| 226 |
+
]
|
| 227 |
+
},
|
| 228 |
+
"038c15a5dd": {
|
| 229 |
+
"hedgehog": [
|
| 230 |
+
"1"
|
| 231 |
+
]
|
| 232 |
+
},
|
| 233 |
+
"03a06cc98a": {
|
| 234 |
+
"giraffe": [
|
| 235 |
+
"1",
|
| 236 |
+
"2",
|
| 237 |
+
"3"
|
| 238 |
+
]
|
| 239 |
+
},
|
| 240 |
+
"03a63e187f": {
|
| 241 |
+
"lizard": [
|
| 242 |
+
"1"
|
| 243 |
+
]
|
| 244 |
+
},
|
| 245 |
+
"03c95b4dae": {
|
| 246 |
+
"elephant": [
|
| 247 |
+
"1",
|
| 248 |
+
"2",
|
| 249 |
+
"3"
|
| 250 |
+
]
|
| 251 |
+
},
|
| 252 |
+
"03e2b57b0e": {
|
| 253 |
+
"lizard": [
|
| 254 |
+
"1"
|
| 255 |
+
]
|
| 256 |
+
},
|
| 257 |
+
"04194e1248": {
|
| 258 |
+
"lizard": [
|
| 259 |
+
"1"
|
| 260 |
+
]
|
| 261 |
+
},
|
| 262 |
+
"04259896e2": {
|
| 263 |
+
"lizard": [
|
| 264 |
+
"1"
|
| 265 |
+
]
|
| 266 |
+
},
|
| 267 |
+
"0444918a5f": {
|
| 268 |
+
"truck": [
|
| 269 |
+
"1",
|
| 270 |
+
"2",
|
| 271 |
+
"3",
|
| 272 |
+
"4"
|
| 273 |
+
]
|
| 274 |
+
},
|
| 275 |
+
"04460a7a52": {
|
| 276 |
+
"lizard": [
|
| 277 |
+
"1"
|
| 278 |
+
]
|
| 279 |
+
},
|
| 280 |
+
"04474174a4": {
|
| 281 |
+
"ape": [
|
| 282 |
+
"1",
|
| 283 |
+
"2"
|
| 284 |
+
]
|
| 285 |
+
},
|
| 286 |
+
"0450095513": {
|
| 287 |
+
"snail": [
|
| 288 |
+
"1"
|
| 289 |
+
]
|
| 290 |
+
},
|
| 291 |
+
"045f00aed2": {
|
| 292 |
+
"tiger": [
|
| 293 |
+
"1"
|
| 294 |
+
],
|
| 295 |
+
"person": [
|
| 296 |
+
"3"
|
| 297 |
+
]
|
| 298 |
+
},
|
| 299 |
+
"04667fabaa": {
|
| 300 |
+
"parrot": [
|
| 301 |
+
"1"
|
| 302 |
+
]
|
| 303 |
+
},
|
| 304 |
+
"04735c5030": {
|
| 305 |
+
"cat": [
|
| 306 |
+
"1",
|
| 307 |
+
"2"
|
| 308 |
+
]
|
| 309 |
+
},
|
| 310 |
+
"04990d1915": {
|
| 311 |
+
"sedan": [
|
| 312 |
+
"1"
|
| 313 |
+
],
|
| 314 |
+
"truck": [
|
| 315 |
+
"3"
|
| 316 |
+
],
|
| 317 |
+
"bus": [
|
| 318 |
+
"2"
|
| 319 |
+
]
|
| 320 |
+
},
|
| 321 |
+
"04d62d9d98": {
|
| 322 |
+
"person": [
|
| 323 |
+
"1"
|
| 324 |
+
]
|
| 325 |
+
},
|
| 326 |
+
"04f21da964": {
|
| 327 |
+
"monkey": [
|
| 328 |
+
"1"
|
| 329 |
+
]
|
| 330 |
+
},
|
| 331 |
+
"04fbad476e": {
|
| 332 |
+
"parrot": [
|
| 333 |
+
"1"
|
| 334 |
+
]
|
| 335 |
+
},
|
| 336 |
+
"04fe256562": {
|
| 337 |
+
"truck": [
|
| 338 |
+
"2"
|
| 339 |
+
],
|
| 340 |
+
"motorbike": [
|
| 341 |
+
"1"
|
| 342 |
+
]
|
| 343 |
+
},
|
| 344 |
+
"0503bf89c9": {
|
| 345 |
+
"hedgehog": [
|
| 346 |
+
"1"
|
| 347 |
+
]
|
| 348 |
+
},
|
| 349 |
+
"0536c9eed0": {
|
| 350 |
+
"cat": [
|
| 351 |
+
"1"
|
| 352 |
+
]
|
| 353 |
+
},
|
| 354 |
+
"054acb238f": {
|
| 355 |
+
"owl": [
|
| 356 |
+
"1"
|
| 357 |
+
]
|
| 358 |
+
},
|
| 359 |
+
"05579ca250": {
|
| 360 |
+
"sedan": [
|
| 361 |
+
"3"
|
| 362 |
+
],
|
| 363 |
+
"person": [
|
| 364 |
+
"1"
|
| 365 |
+
]
|
| 366 |
+
},
|
| 367 |
+
"056c200404": {},
|
| 368 |
+
"05774f3a2c": {
|
| 369 |
+
"ape": [
|
| 370 |
+
"1",
|
| 371 |
+
"2",
|
| 372 |
+
"3"
|
| 373 |
+
]
|
| 374 |
+
},
|
| 375 |
+
"058a7592c8": {
|
| 376 |
+
"train": [
|
| 377 |
+
"1"
|
| 378 |
+
]
|
| 379 |
+
},
|
| 380 |
+
"05a0a513df": {
|
| 381 |
+
"person": [
|
| 382 |
+
"1",
|
| 383 |
+
"2"
|
| 384 |
+
]
|
| 385 |
+
},
|
| 386 |
+
"05a569d8aa": {
|
| 387 |
+
"cat": [
|
| 388 |
+
"1"
|
| 389 |
+
],
|
| 390 |
+
"mouse": [
|
| 391 |
+
"2"
|
| 392 |
+
]
|
| 393 |
+
},
|
| 394 |
+
"05aa652648": {
|
| 395 |
+
"ape": [
|
| 396 |
+
"1"
|
| 397 |
+
]
|
| 398 |
+
},
|
| 399 |
+
"05d7715782": {},
|
| 400 |
+
"05e0b0f28f": {
|
| 401 |
+
"person": [
|
| 402 |
+
"2"
|
| 403 |
+
],
|
| 404 |
+
"mouse": [
|
| 405 |
+
"1"
|
| 406 |
+
]
|
| 407 |
+
},
|
| 408 |
+
"05fdbbdd7a": {},
|
| 409 |
+
"05ffcfed85": {
|
| 410 |
+
"monkey": [
|
| 411 |
+
"1",
|
| 412 |
+
"2"
|
| 413 |
+
]
|
| 414 |
+
},
|
| 415 |
+
"0630391881": {
|
| 416 |
+
"person": [
|
| 417 |
+
"1"
|
| 418 |
+
]
|
| 419 |
+
},
|
| 420 |
+
"06840b2bbe": {
|
| 421 |
+
"snake": [
|
| 422 |
+
"1"
|
| 423 |
+
]
|
| 424 |
+
},
|
| 425 |
+
"068f7dce6f": {
|
| 426 |
+
"shark": [
|
| 427 |
+
"1"
|
| 428 |
+
]
|
| 429 |
+
},
|
| 430 |
+
"0693719753": {
|
| 431 |
+
"turtle": [
|
| 432 |
+
"1",
|
| 433 |
+
"2"
|
| 434 |
+
]
|
| 435 |
+
},
|
| 436 |
+
"06ce2b51fb": {
|
| 437 |
+
"person": [
|
| 438 |
+
"1",
|
| 439 |
+
"2"
|
| 440 |
+
]
|
| 441 |
+
},
|
| 442 |
+
"06e224798e": {
|
| 443 |
+
"tiger": [
|
| 444 |
+
"1"
|
| 445 |
+
]
|
| 446 |
+
},
|
| 447 |
+
"06ee361788": {
|
| 448 |
+
"duck": [
|
| 449 |
+
"1",
|
| 450 |
+
"2",
|
| 451 |
+
"3"
|
| 452 |
+
]
|
| 453 |
+
},
|
| 454 |
+
"06fbb3fa2c": {
|
| 455 |
+
"eagle": [
|
| 456 |
+
"1"
|
| 457 |
+
]
|
| 458 |
+
},
|
| 459 |
+
"0700264286": {
|
| 460 |
+
"cow": [
|
| 461 |
+
"1",
|
| 462 |
+
"2"
|
| 463 |
+
]
|
| 464 |
+
},
|
| 465 |
+
"070c918ca7": {
|
| 466 |
+
"parrot": [
|
| 467 |
+
"1"
|
| 468 |
+
]
|
| 469 |
+
},
|
| 470 |
+
"07129e14a4": {
|
| 471 |
+
"person": [
|
| 472 |
+
"3"
|
| 473 |
+
],
|
| 474 |
+
"parrot": [
|
| 475 |
+
"1",
|
| 476 |
+
"2"
|
| 477 |
+
]
|
| 478 |
+
},
|
| 479 |
+
"07177017e9": {
|
| 480 |
+
"motorbike": [
|
| 481 |
+
"1",
|
| 482 |
+
"2"
|
| 483 |
+
]
|
| 484 |
+
},
|
| 485 |
+
"07238ffc58": {
|
| 486 |
+
"monkey": [
|
| 487 |
+
"1",
|
| 488 |
+
"2",
|
| 489 |
+
"3"
|
| 490 |
+
]
|
| 491 |
+
},
|
| 492 |
+
"07353b2a89": {
|
| 493 |
+
"sheep": [
|
| 494 |
+
"1",
|
| 495 |
+
"2",
|
| 496 |
+
"3",
|
| 497 |
+
"4"
|
| 498 |
+
]
|
| 499 |
+
},
|
| 500 |
+
"0738493cbf": {
|
| 501 |
+
"airplane": [
|
| 502 |
+
"1"
|
| 503 |
+
]
|
| 504 |
+
},
|
| 505 |
+
"075926c651": {
|
| 506 |
+
"person": [
|
| 507 |
+
"1",
|
| 508 |
+
"2"
|
| 509 |
+
]
|
| 510 |
+
},
|
| 511 |
+
"075c701292": {
|
| 512 |
+
"duck": [
|
| 513 |
+
"1",
|
| 514 |
+
"2",
|
| 515 |
+
"3",
|
| 516 |
+
"4"
|
| 517 |
+
]
|
| 518 |
+
},
|
| 519 |
+
"0762ea9a30": {
|
| 520 |
+
"person": [
|
| 521 |
+
"1"
|
| 522 |
+
]
|
| 523 |
+
},
|
| 524 |
+
"07652ee4af": {
|
| 525 |
+
"person": [
|
| 526 |
+
"1"
|
| 527 |
+
]
|
| 528 |
+
},
|
| 529 |
+
"076f206928": {
|
| 530 |
+
"person": [
|
| 531 |
+
"3"
|
| 532 |
+
],
|
| 533 |
+
"zebra": [
|
| 534 |
+
"1",
|
| 535 |
+
"2"
|
| 536 |
+
]
|
| 537 |
+
},
|
| 538 |
+
"077d32af19": {
|
| 539 |
+
"person": [
|
| 540 |
+
"1",
|
| 541 |
+
"2",
|
| 542 |
+
"3"
|
| 543 |
+
],
|
| 544 |
+
"train": [
|
| 545 |
+
"4"
|
| 546 |
+
]
|
| 547 |
+
},
|
| 548 |
+
"079049275c": {
|
| 549 |
+
"mouse": [
|
| 550 |
+
"1"
|
| 551 |
+
]
|
| 552 |
+
},
|
| 553 |
+
"07913cdda7": {
|
| 554 |
+
"person": [
|
| 555 |
+
"2",
|
| 556 |
+
"3"
|
| 557 |
+
],
|
| 558 |
+
"train": [
|
| 559 |
+
"1"
|
| 560 |
+
]
|
| 561 |
+
},
|
| 562 |
+
"07a11a35e8": {
|
| 563 |
+
"ape": [
|
| 564 |
+
"1",
|
| 565 |
+
"2"
|
| 566 |
+
]
|
| 567 |
+
},
|
| 568 |
+
"07ac33b6df": {
|
| 569 |
+
"ape": [
|
| 570 |
+
"1"
|
| 571 |
+
]
|
| 572 |
+
},
|
| 573 |
+
"07c62c3d11": {
|
| 574 |
+
"parrot": [
|
| 575 |
+
"1",
|
| 576 |
+
"2",
|
| 577 |
+
"3"
|
| 578 |
+
]
|
| 579 |
+
},
|
| 580 |
+
"07cc1c7d74": {
|
| 581 |
+
"snake": [
|
| 582 |
+
"1"
|
| 583 |
+
]
|
| 584 |
+
},
|
| 585 |
+
"080196ef01": {
|
| 586 |
+
"lizard": [
|
| 587 |
+
"1"
|
| 588 |
+
]
|
| 589 |
+
},
|
| 590 |
+
"081207976e": {},
|
| 591 |
+
"081ae4fa44": {
|
| 592 |
+
"shark": [
|
| 593 |
+
"1",
|
| 594 |
+
"2"
|
| 595 |
+
]
|
| 596 |
+
},
|
| 597 |
+
"081d8250cb": {
|
| 598 |
+
"sedan": [
|
| 599 |
+
"3"
|
| 600 |
+
],
|
| 601 |
+
"person": [
|
| 602 |
+
"1"
|
| 603 |
+
]
|
| 604 |
+
},
|
| 605 |
+
"082900c5d4": {
|
| 606 |
+
"duck": [
|
| 607 |
+
"1",
|
| 608 |
+
"2",
|
| 609 |
+
"3"
|
| 610 |
+
]
|
| 611 |
+
},
|
| 612 |
+
"0860df21e2": {},
|
| 613 |
+
"0866d4c5e3": {
|
| 614 |
+
"bird": [
|
| 615 |
+
"1",
|
| 616 |
+
"2",
|
| 617 |
+
"3"
|
| 618 |
+
]
|
| 619 |
+
},
|
| 620 |
+
"0891ac2eb6": {
|
| 621 |
+
"person": [
|
| 622 |
+
"1",
|
| 623 |
+
"2",
|
| 624 |
+
"3"
|
| 625 |
+
]
|
| 626 |
+
},
|
| 627 |
+
"08931bc458": {
|
| 628 |
+
"person": [
|
| 629 |
+
"1"
|
| 630 |
+
]
|
| 631 |
+
},
|
| 632 |
+
"08aa2705d5": {
|
| 633 |
+
"snake": [
|
| 634 |
+
"1"
|
| 635 |
+
]
|
| 636 |
+
},
|
| 637 |
+
"08c8450db7": {},
|
| 638 |
+
"08d50b926c": {
|
| 639 |
+
"turtle": [
|
| 640 |
+
"1",
|
| 641 |
+
"2"
|
| 642 |
+
]
|
| 643 |
+
},
|
| 644 |
+
"08e1e4de15": {
|
| 645 |
+
"monkey": [
|
| 646 |
+
"1",
|
| 647 |
+
"2",
|
| 648 |
+
"3",
|
| 649 |
+
"4"
|
| 650 |
+
]
|
| 651 |
+
},
|
| 652 |
+
"08e48c1a48": {
|
| 653 |
+
"cow": [
|
| 654 |
+
"1"
|
| 655 |
+
]
|
| 656 |
+
},
|
| 657 |
+
"08f561c65e": {
|
| 658 |
+
"person": [
|
| 659 |
+
"2"
|
| 660 |
+
],
|
| 661 |
+
"giant_panda": [
|
| 662 |
+
"1"
|
| 663 |
+
]
|
| 664 |
+
},
|
| 665 |
+
"08feb87790": {
|
| 666 |
+
"sheep": [
|
| 667 |
+
"1"
|
| 668 |
+
]
|
| 669 |
+
},
|
| 670 |
+
"09049f6fe3": {
|
| 671 |
+
"mouse": [
|
| 672 |
+
"1",
|
| 673 |
+
"2"
|
| 674 |
+
]
|
| 675 |
+
},
|
| 676 |
+
"092e4ff450": {
|
| 677 |
+
"snake": [
|
| 678 |
+
"1"
|
| 679 |
+
]
|
| 680 |
+
},
|
| 681 |
+
"09338adea8": {
|
| 682 |
+
"whale": [
|
| 683 |
+
"1",
|
| 684 |
+
"2"
|
| 685 |
+
]
|
| 686 |
+
},
|
| 687 |
+
"093c335ccc": {
|
| 688 |
+
"person": [
|
| 689 |
+
"2"
|
| 690 |
+
]
|
| 691 |
+
},
|
| 692 |
+
"0970d28339": {
|
| 693 |
+
"ape": [
|
| 694 |
+
"1",
|
| 695 |
+
"2"
|
| 696 |
+
]
|
| 697 |
+
},
|
| 698 |
+
"0974a213dc": {
|
| 699 |
+
"giraffe": [
|
| 700 |
+
"1",
|
| 701 |
+
"2",
|
| 702 |
+
"3"
|
| 703 |
+
]
|
| 704 |
+
},
|
| 705 |
+
"097b471ed8": {
|
| 706 |
+
"cat": [
|
| 707 |
+
"1",
|
| 708 |
+
"2"
|
| 709 |
+
]
|
| 710 |
+
},
|
| 711 |
+
"0990941758": {
|
| 712 |
+
"giant_panda": [
|
| 713 |
+
"1"
|
| 714 |
+
]
|
| 715 |
+
},
|
| 716 |
+
"09a348f4fa": {
|
| 717 |
+
"lizard": [
|
| 718 |
+
"1"
|
| 719 |
+
]
|
| 720 |
+
},
|
| 721 |
+
"09a6841288": {
|
| 722 |
+
"duck": [
|
| 723 |
+
"1",
|
| 724 |
+
"2"
|
| 725 |
+
]
|
| 726 |
+
},
|
| 727 |
+
"09c5bad17b": {
|
| 728 |
+
"airplane": [
|
| 729 |
+
"1"
|
| 730 |
+
]
|
| 731 |
+
},
|
| 732 |
+
"09c9ce80c7": {
|
| 733 |
+
"giant_panda": [
|
| 734 |
+
"1"
|
| 735 |
+
]
|
| 736 |
+
},
|
| 737 |
+
"09ff54fef4": {
|
| 738 |
+
"fox": [
|
| 739 |
+
"1",
|
| 740 |
+
"2"
|
| 741 |
+
]
|
| 742 |
+
},
|
| 743 |
+
"0a23765d15": {
|
| 744 |
+
"person": [
|
| 745 |
+
"1",
|
| 746 |
+
"2"
|
| 747 |
+
]
|
| 748 |
+
},
|
| 749 |
+
"0a275e7f12": {
|
| 750 |
+
"elephant": [
|
| 751 |
+
"1"
|
| 752 |
+
]
|
| 753 |
+
},
|
| 754 |
+
"0a2f2bd294": {
|
| 755 |
+
"motorbike": [
|
| 756 |
+
"1"
|
| 757 |
+
]
|
| 758 |
+
},
|
| 759 |
+
"0a7a2514aa": {
|
| 760 |
+
"lizard": [
|
| 761 |
+
"2"
|
| 762 |
+
],
|
| 763 |
+
"cat": [
|
| 764 |
+
"1"
|
| 765 |
+
]
|
| 766 |
+
},
|
| 767 |
+
"0a7b27fde9": {
|
| 768 |
+
"parrot": [
|
| 769 |
+
"1",
|
| 770 |
+
"2"
|
| 771 |
+
]
|
| 772 |
+
},
|
| 773 |
+
"0a8c467cc3": {
|
| 774 |
+
"fish": [
|
| 775 |
+
"1",
|
| 776 |
+
"2",
|
| 777 |
+
"3"
|
| 778 |
+
]
|
| 779 |
+
},
|
| 780 |
+
"0ac8c560ae": {
|
| 781 |
+
"person": [
|
| 782 |
+
"2",
|
| 783 |
+
"3"
|
| 784 |
+
]
|
| 785 |
+
},
|
| 786 |
+
"0b1627e896": {
|
| 787 |
+
"boat": [
|
| 788 |
+
"1"
|
| 789 |
+
]
|
| 790 |
+
},
|
| 791 |
+
"0b285c47f6": {
|
| 792 |
+
"mouse": [
|
| 793 |
+
"1"
|
| 794 |
+
]
|
| 795 |
+
},
|
| 796 |
+
"0b34ec1d55": {
|
| 797 |
+
"ape": [
|
| 798 |
+
"1"
|
| 799 |
+
]
|
| 800 |
+
},
|
| 801 |
+
"0b5b5e8e5a": {
|
| 802 |
+
"sedan": [
|
| 803 |
+
"2"
|
| 804 |
+
],
|
| 805 |
+
"person": [
|
| 806 |
+
"1"
|
| 807 |
+
]
|
| 808 |
+
},
|
| 809 |
+
"0b68535614": {
|
| 810 |
+
"rabbit": [
|
| 811 |
+
"1"
|
| 812 |
+
]
|
| 813 |
+
},
|
| 814 |
+
"0b6f9105fc": {
|
| 815 |
+
"rabbit": [
|
| 816 |
+
"1"
|
| 817 |
+
]
|
| 818 |
+
},
|
| 819 |
+
"0b7dbfa3cb": {
|
| 820 |
+
"cow": [
|
| 821 |
+
"1"
|
| 822 |
+
]
|
| 823 |
+
},
|
| 824 |
+
"0b9cea51ca": {
|
| 825 |
+
"whale": [
|
| 826 |
+
"1"
|
| 827 |
+
]
|
| 828 |
+
},
|
| 829 |
+
"0b9d012be8": {
|
| 830 |
+
"camel": [
|
| 831 |
+
"1"
|
| 832 |
+
]
|
| 833 |
+
},
|
| 834 |
+
"0bcfc4177d": {
|
| 835 |
+
"truck": [
|
| 836 |
+
"1"
|
| 837 |
+
]
|
| 838 |
+
},
|
| 839 |
+
"0bd37b23c1": {
|
| 840 |
+
"motorbike": [
|
| 841 |
+
"1"
|
| 842 |
+
]
|
| 843 |
+
},
|
| 844 |
+
"0bd864064c": {
|
| 845 |
+
"eagle": [
|
| 846 |
+
"1"
|
| 847 |
+
]
|
| 848 |
+
},
|
| 849 |
+
"0c11c6bf7b": {
|
| 850 |
+
"deer": [
|
| 851 |
+
"1"
|
| 852 |
+
]
|
| 853 |
+
},
|
| 854 |
+
"0c26bc77ac": {
|
| 855 |
+
"crocodile": [
|
| 856 |
+
"1"
|
| 857 |
+
]
|
| 858 |
+
},
|
| 859 |
+
"0c3a04798c": {
|
| 860 |
+
"duck": [
|
| 861 |
+
"1"
|
| 862 |
+
],
|
| 863 |
+
"fish": [
|
| 864 |
+
"2"
|
| 865 |
+
]
|
| 866 |
+
},
|
| 867 |
+
"0c44a9d545": {
|
| 868 |
+
"tiger": [
|
| 869 |
+
"1"
|
| 870 |
+
]
|
| 871 |
+
},
|
| 872 |
+
"0c817cc390": {
|
| 873 |
+
"dog": [
|
| 874 |
+
"2"
|
| 875 |
+
],
|
| 876 |
+
"hedgehog": [
|
| 877 |
+
"1"
|
| 878 |
+
]
|
| 879 |
+
},
|
| 880 |
+
"0ca839ee9a": {
|
| 881 |
+
"ape": [
|
| 882 |
+
"1",
|
| 883 |
+
"2"
|
| 884 |
+
]
|
| 885 |
+
},
|
| 886 |
+
"0cd7ac0ac0": {
|
| 887 |
+
"rabbit": [
|
| 888 |
+
"1"
|
| 889 |
+
]
|
| 890 |
+
},
|
| 891 |
+
"0ce06e0121": {
|
| 892 |
+
"parrot": [
|
| 893 |
+
"1",
|
| 894 |
+
"2"
|
| 895 |
+
]
|
| 896 |
+
},
|
| 897 |
+
"0cfe974a89": {
|
| 898 |
+
"turtle": [
|
| 899 |
+
"1",
|
| 900 |
+
"2"
|
| 901 |
+
]
|
| 902 |
+
},
|
| 903 |
+
"0d2fcc0dcd": {
|
| 904 |
+
"zebra": [
|
| 905 |
+
"1",
|
| 906 |
+
"2",
|
| 907 |
+
"3",
|
| 908 |
+
"4"
|
| 909 |
+
]
|
| 910 |
+
},
|
| 911 |
+
"0d3aad05d2": {
|
| 912 |
+
"person": [
|
| 913 |
+
"1"
|
| 914 |
+
]
|
| 915 |
+
},
|
| 916 |
+
"0d40b015f4": {
|
| 917 |
+
"person": [
|
| 918 |
+
"1"
|
| 919 |
+
]
|
| 920 |
+
},
|
| 921 |
+
"0d97fba242": {
|
| 922 |
+
"person": [
|
| 923 |
+
"2"
|
| 924 |
+
],
|
| 925 |
+
"dog": [
|
| 926 |
+
"1"
|
| 927 |
+
]
|
| 928 |
+
},
|
| 929 |
+
"0d9cc80d7e": {
|
| 930 |
+
"person": [
|
| 931 |
+
"1",
|
| 932 |
+
"2",
|
| 933 |
+
"3"
|
| 934 |
+
]
|
| 935 |
+
},
|
| 936 |
+
"0dab85b6d3": {
|
| 937 |
+
"lizard": [
|
| 938 |
+
"1",
|
| 939 |
+
"2"
|
| 940 |
+
]
|
| 941 |
+
},
|
| 942 |
+
"0db5c427a5": {
|
| 943 |
+
"train": [
|
| 944 |
+
"1"
|
| 945 |
+
]
|
| 946 |
+
},
|
| 947 |
+
"0dbaf284f1": {
|
| 948 |
+
"cat": [
|
| 949 |
+
"1",
|
| 950 |
+
"2"
|
| 951 |
+
]
|
| 952 |
+
},
|
| 953 |
+
"0de4923598": {},
|
| 954 |
+
"0df28a9101": {
|
| 955 |
+
"turtle": [
|
| 956 |
+
"1",
|
| 957 |
+
"2",
|
| 958 |
+
"3"
|
| 959 |
+
]
|
| 960 |
+
},
|
| 961 |
+
"0e04f636c4": {
|
| 962 |
+
"frog": [
|
| 963 |
+
"1"
|
| 964 |
+
]
|
| 965 |
+
},
|
| 966 |
+
"0e05f0e232": {
|
| 967 |
+
"lizard": [
|
| 968 |
+
"1",
|
| 969 |
+
"2"
|
| 970 |
+
]
|
| 971 |
+
},
|
| 972 |
+
"0e0930474b": {
|
| 973 |
+
"sedan": [
|
| 974 |
+
"1"
|
| 975 |
+
],
|
| 976 |
+
"person": [
|
| 977 |
+
"2",
|
| 978 |
+
"3"
|
| 979 |
+
]
|
| 980 |
+
},
|
| 981 |
+
"0e27472bea": {
|
| 982 |
+
"turtle": [
|
| 983 |
+
"1"
|
| 984 |
+
]
|
| 985 |
+
},
|
| 986 |
+
"0e30020549": {
|
| 987 |
+
"parrot": [
|
| 988 |
+
"1"
|
| 989 |
+
]
|
| 990 |
+
},
|
| 991 |
+
"0e621feb6c": {
|
| 992 |
+
"lizard": [
|
| 993 |
+
"1",
|
| 994 |
+
"2"
|
| 995 |
+
]
|
| 996 |
+
},
|
| 997 |
+
"0e803c7d73": {},
|
| 998 |
+
"0e9ebe4e3c": {
|
| 999 |
+
"truck": [
|
| 1000 |
+
"1"
|
| 1001 |
+
]
|
| 1002 |
+
},
|
| 1003 |
+
"0e9f2785ec": {
|
| 1004 |
+
"person": [
|
| 1005 |
+
"2"
|
| 1006 |
+
]
|
| 1007 |
+
},
|
| 1008 |
+
"0ea68d418b": {
|
| 1009 |
+
"airplane": [
|
| 1010 |
+
"1"
|
| 1011 |
+
]
|
| 1012 |
+
},
|
| 1013 |
+
"0eb403a222": {},
|
| 1014 |
+
"0ee92053d6": {
|
| 1015 |
+
"person": [
|
| 1016 |
+
"1"
|
| 1017 |
+
]
|
| 1018 |
+
},
|
| 1019 |
+
"0eefca067f": {
|
| 1020 |
+
"giant_panda": [
|
| 1021 |
+
"1",
|
| 1022 |
+
"2"
|
| 1023 |
+
]
|
| 1024 |
+
},
|
| 1025 |
+
"0f17fa6fcb": {
|
| 1026 |
+
"duck": [
|
| 1027 |
+
"1",
|
| 1028 |
+
"2",
|
| 1029 |
+
"3"
|
| 1030 |
+
]
|
| 1031 |
+
},
|
| 1032 |
+
"0f1ac8e9a3": {
|
| 1033 |
+
"frog": [
|
| 1034 |
+
"1"
|
| 1035 |
+
]
|
| 1036 |
+
},
|
| 1037 |
+
"0f202e9852": {
|
| 1038 |
+
"parrot": [
|
| 1039 |
+
"1"
|
| 1040 |
+
]
|
| 1041 |
+
},
|
| 1042 |
+
"0f2ab8b1ff": {
|
| 1043 |
+
"dolphin": [
|
| 1044 |
+
"1",
|
| 1045 |
+
"2",
|
| 1046 |
+
"3"
|
| 1047 |
+
]
|
| 1048 |
+
},
|
| 1049 |
+
"0f51a78756": {
|
| 1050 |
+
"sheep": [
|
| 1051 |
+
"1"
|
| 1052 |
+
]
|
| 1053 |
+
},
|
| 1054 |
+
"0f5fbe16b0": {
|
| 1055 |
+
"raccoon": [
|
| 1056 |
+
"1",
|
| 1057 |
+
"2"
|
| 1058 |
+
]
|
| 1059 |
+
},
|
| 1060 |
+
"0f6072077b": {
|
| 1061 |
+
"person": [
|
| 1062 |
+
"1",
|
| 1063 |
+
"2",
|
| 1064 |
+
"3"
|
| 1065 |
+
]
|
| 1066 |
+
},
|
| 1067 |
+
"0f6b69b2f4": {
|
| 1068 |
+
"rabbit": [
|
| 1069 |
+
"1"
|
| 1070 |
+
]
|
| 1071 |
+
},
|
| 1072 |
+
"0f6c2163de": {
|
| 1073 |
+
"snail": [
|
| 1074 |
+
"1"
|
| 1075 |
+
]
|
| 1076 |
+
},
|
| 1077 |
+
"0f74ec5599": {
|
| 1078 |
+
"giant_panda": [
|
| 1079 |
+
"1"
|
| 1080 |
+
]
|
| 1081 |
+
},
|
| 1082 |
+
"0f9683715b": {
|
| 1083 |
+
"elephant": [
|
| 1084 |
+
"1"
|
| 1085 |
+
]
|
| 1086 |
+
},
|
| 1087 |
+
"0fa7b59356": {
|
| 1088 |
+
"duck": [
|
| 1089 |
+
"1"
|
| 1090 |
+
]
|
| 1091 |
+
},
|
| 1092 |
+
"0fb173695b": {
|
| 1093 |
+
"person": [
|
| 1094 |
+
"3"
|
| 1095 |
+
]
|
| 1096 |
+
},
|
| 1097 |
+
"0fc958cde2": {
|
| 1098 |
+
"owl": [
|
| 1099 |
+
"1"
|
| 1100 |
+
]
|
| 1101 |
+
},
|
| 1102 |
+
"0fe7b1a621": {
|
| 1103 |
+
"parrot": [
|
| 1104 |
+
"1"
|
| 1105 |
+
]
|
| 1106 |
+
},
|
| 1107 |
+
"0ffcdb491c": {
|
| 1108 |
+
"person": [
|
| 1109 |
+
"1",
|
| 1110 |
+
"2",
|
| 1111 |
+
"3"
|
| 1112 |
+
]
|
| 1113 |
+
},
|
| 1114 |
+
"101caff7d4": {
|
| 1115 |
+
"giant_panda": [
|
| 1116 |
+
"1",
|
| 1117 |
+
"2"
|
| 1118 |
+
]
|
| 1119 |
+
},
|
| 1120 |
+
"1022fe8417": {
|
| 1121 |
+
"person": [
|
| 1122 |
+
"1",
|
| 1123 |
+
"2",
|
| 1124 |
+
"3"
|
| 1125 |
+
]
|
| 1126 |
+
},
|
| 1127 |
+
"1032e80b37": {
|
| 1128 |
+
"giraffe": [
|
| 1129 |
+
"1"
|
| 1130 |
+
]
|
| 1131 |
+
},
|
| 1132 |
+
"103f501680": {
|
| 1133 |
+
"fish": [
|
| 1134 |
+
"1"
|
| 1135 |
+
]
|
| 1136 |
+
},
|
| 1137 |
+
"104e64565f": {
|
| 1138 |
+
"elephant": [
|
| 1139 |
+
"1"
|
| 1140 |
+
]
|
| 1141 |
+
},
|
| 1142 |
+
"104f1ab997": {
|
| 1143 |
+
"person": [
|
| 1144 |
+
"1",
|
| 1145 |
+
"2",
|
| 1146 |
+
"3"
|
| 1147 |
+
]
|
| 1148 |
+
},
|
| 1149 |
+
"106242403f": {
|
| 1150 |
+
"person": [
|
| 1151 |
+
"1",
|
| 1152 |
+
"2"
|
| 1153 |
+
]
|
| 1154 |
+
},
|
| 1155 |
+
"10b31f5431": {
|
| 1156 |
+
"person": [
|
| 1157 |
+
"1",
|
| 1158 |
+
"3",
|
| 1159 |
+
"4"
|
| 1160 |
+
]
|
| 1161 |
+
},
|
| 1162 |
+
"10eced835e": {
|
| 1163 |
+
"giant_panda": [
|
| 1164 |
+
"1",
|
| 1165 |
+
"2"
|
| 1166 |
+
]
|
| 1167 |
+
},
|
| 1168 |
+
"110d26fa3a": {
|
| 1169 |
+
"shark": [
|
| 1170 |
+
"1"
|
| 1171 |
+
]
|
| 1172 |
+
},
|
| 1173 |
+
"1122c1d16a": {
|
| 1174 |
+
"person": [
|
| 1175 |
+
"6"
|
| 1176 |
+
],
|
| 1177 |
+
"parrot": [
|
| 1178 |
+
"1",
|
| 1179 |
+
"2",
|
| 1180 |
+
"3",
|
| 1181 |
+
"4",
|
| 1182 |
+
"5"
|
| 1183 |
+
]
|
| 1184 |
+
},
|
| 1185 |
+
"1145b49a5f": {
|
| 1186 |
+
"rabbit": [
|
| 1187 |
+
"1"
|
| 1188 |
+
]
|
| 1189 |
+
},
|
| 1190 |
+
"11485838c2": {
|
| 1191 |
+
"giraffe": [
|
| 1192 |
+
"1",
|
| 1193 |
+
"2",
|
| 1194 |
+
"3"
|
| 1195 |
+
]
|
| 1196 |
+
},
|
| 1197 |
+
"114e7676ec": {
|
| 1198 |
+
"person": [
|
| 1199 |
+
"1"
|
| 1200 |
+
]
|
| 1201 |
+
},
|
| 1202 |
+
"1157472b95": {
|
| 1203 |
+
"parrot": [
|
| 1204 |
+
"1",
|
| 1205 |
+
"2"
|
| 1206 |
+
]
|
| 1207 |
+
},
|
| 1208 |
+
"115ee1072c": {
|
| 1209 |
+
"cow": [
|
| 1210 |
+
"1"
|
| 1211 |
+
]
|
| 1212 |
+
},
|
| 1213 |
+
"1171141012": {
|
| 1214 |
+
"person": [
|
| 1215 |
+
"2"
|
| 1216 |
+
],
|
| 1217 |
+
"turtle": [
|
| 1218 |
+
"1"
|
| 1219 |
+
]
|
| 1220 |
+
},
|
| 1221 |
+
"117757b4b8": {
|
| 1222 |
+
"snail": [
|
| 1223 |
+
"1"
|
| 1224 |
+
]
|
| 1225 |
+
},
|
| 1226 |
+
"1178932d2f": {
|
| 1227 |
+
"person": [
|
| 1228 |
+
"1",
|
| 1229 |
+
"2"
|
| 1230 |
+
],
|
| 1231 |
+
"motorbike": [
|
| 1232 |
+
"3"
|
| 1233 |
+
]
|
| 1234 |
+
},
|
| 1235 |
+
"117cc76bda": {
|
| 1236 |
+
"whale": [
|
| 1237 |
+
"1"
|
| 1238 |
+
]
|
| 1239 |
+
},
|
| 1240 |
+
"1180cbf814": {
|
| 1241 |
+
"fish": [
|
| 1242 |
+
"1",
|
| 1243 |
+
"2"
|
| 1244 |
+
]
|
| 1245 |
+
},
|
| 1246 |
+
"1187bbd0e3": {
|
| 1247 |
+
"cat": [
|
| 1248 |
+
"1"
|
| 1249 |
+
]
|
| 1250 |
+
},
|
| 1251 |
+
"1197e44b26": {
|
| 1252 |
+
"giant_panda": [
|
| 1253 |
+
"1"
|
| 1254 |
+
]
|
| 1255 |
+
},
|
| 1256 |
+
"119cf20728": {
|
| 1257 |
+
"lizard": [
|
| 1258 |
+
"1"
|
| 1259 |
+
]
|
| 1260 |
+
},
|
| 1261 |
+
"119dd54871": {
|
| 1262 |
+
"lion": [
|
| 1263 |
+
"1",
|
| 1264 |
+
"2"
|
| 1265 |
+
]
|
| 1266 |
+
},
|
| 1267 |
+
"11a0c3b724": {
|
| 1268 |
+
"mouse": [
|
| 1269 |
+
"1",
|
| 1270 |
+
"2"
|
| 1271 |
+
]
|
| 1272 |
+
},
|
| 1273 |
+
"11a6ba8c94": {
|
| 1274 |
+
"person": [
|
| 1275 |
+
"1",
|
| 1276 |
+
"2"
|
| 1277 |
+
]
|
| 1278 |
+
},
|
| 1279 |
+
"11c722a456": {
|
| 1280 |
+
"turtle": [
|
| 1281 |
+
"1",
|
| 1282 |
+
"2"
|
| 1283 |
+
]
|
| 1284 |
+
},
|
| 1285 |
+
"11cbcb0b4d": {
|
| 1286 |
+
"zebra": [
|
| 1287 |
+
"1"
|
| 1288 |
+
]
|
| 1289 |
+
},
|
| 1290 |
+
"11ccf5e99d": {
|
| 1291 |
+
"person": [
|
| 1292 |
+
"2"
|
| 1293 |
+
]
|
| 1294 |
+
},
|
| 1295 |
+
"11ce6f452e": {
|
| 1296 |
+
"person": [
|
| 1297 |
+
"1",
|
| 1298 |
+
"2",
|
| 1299 |
+
"3"
|
| 1300 |
+
]
|
| 1301 |
+
},
|
| 1302 |
+
"11feabe596": {
|
| 1303 |
+
"rabbit": [
|
| 1304 |
+
"1"
|
| 1305 |
+
]
|
| 1306 |
+
},
|
| 1307 |
+
"120cb9514d": {
|
| 1308 |
+
"person": [
|
| 1309 |
+
"1",
|
| 1310 |
+
"2",
|
| 1311 |
+
"3"
|
| 1312 |
+
]
|
| 1313 |
+
},
|
| 1314 |
+
"12156b25b3": {
|
| 1315 |
+
"person": [
|
| 1316 |
+
"1"
|
| 1317 |
+
]
|
| 1318 |
+
},
|
| 1319 |
+
"122896672d": {
|
| 1320 |
+
"person": [
|
| 1321 |
+
"1",
|
| 1322 |
+
"3"
|
| 1323 |
+
]
|
| 1324 |
+
},
|
| 1325 |
+
"1233ac8596": {
|
| 1326 |
+
"dog": [
|
| 1327 |
+
"1"
|
| 1328 |
+
]
|
| 1329 |
+
},
|
| 1330 |
+
"1239c87234": {
|
| 1331 |
+
"lizard": [
|
| 1332 |
+
"1"
|
| 1333 |
+
]
|
| 1334 |
+
},
|
| 1335 |
+
"1250423f7c": {
|
| 1336 |
+
"elephant": [
|
| 1337 |
+
"3",
|
| 1338 |
+
"4"
|
| 1339 |
+
],
|
| 1340 |
+
"person": [
|
| 1341 |
+
"2"
|
| 1342 |
+
]
|
| 1343 |
+
},
|
| 1344 |
+
"1257a1bc67": {
|
| 1345 |
+
"snake": [
|
| 1346 |
+
"1"
|
| 1347 |
+
]
|
| 1348 |
+
},
|
| 1349 |
+
"125d1b19dd": {
|
| 1350 |
+
"giant_panda": [
|
| 1351 |
+
"1",
|
| 1352 |
+
"2"
|
| 1353 |
+
]
|
| 1354 |
+
},
|
| 1355 |
+
"126d203967": {
|
| 1356 |
+
"person": [
|
| 1357 |
+
"2"
|
| 1358 |
+
]
|
| 1359 |
+
},
|
| 1360 |
+
"1295e19071": {
|
| 1361 |
+
"airplane": [
|
| 1362 |
+
"1"
|
| 1363 |
+
]
|
| 1364 |
+
},
|
| 1365 |
+
"12ad198c54": {
|
| 1366 |
+
"person": [
|
| 1367 |
+
"1"
|
| 1368 |
+
]
|
| 1369 |
+
},
|
| 1370 |
+
"12bddb2bcb": {
|
| 1371 |
+
"person": [
|
| 1372 |
+
"2"
|
| 1373 |
+
]
|
| 1374 |
+
},
|
| 1375 |
+
"12ec9b93ee": {
|
| 1376 |
+
"giant_panda": [
|
| 1377 |
+
"1"
|
| 1378 |
+
]
|
| 1379 |
+
},
|
| 1380 |
+
"12eebedc35": {
|
| 1381 |
+
"bird": [
|
| 1382 |
+
"1"
|
| 1383 |
+
]
|
| 1384 |
+
},
|
| 1385 |
+
"132852e094": {
|
| 1386 |
+
"fox": [
|
| 1387 |
+
"1"
|
| 1388 |
+
]
|
| 1389 |
+
},
|
| 1390 |
+
"1329409f2a": {
|
| 1391 |
+
"fish": [
|
| 1392 |
+
"1"
|
| 1393 |
+
]
|
| 1394 |
+
},
|
| 1395 |
+
"13325cfa14": {
|
| 1396 |
+
"person": [
|
| 1397 |
+
"2"
|
| 1398 |
+
]
|
| 1399 |
+
},
|
| 1400 |
+
"1336440745": {
|
| 1401 |
+
"mouse": [
|
| 1402 |
+
"1",
|
| 1403 |
+
"2"
|
| 1404 |
+
]
|
| 1405 |
+
},
|
| 1406 |
+
"134d06dbf9": {
|
| 1407 |
+
"cat": [
|
| 1408 |
+
"1"
|
| 1409 |
+
]
|
| 1410 |
+
},
|
| 1411 |
+
"135625b53d": {
|
| 1412 |
+
"parrot": [
|
| 1413 |
+
"1"
|
| 1414 |
+
]
|
| 1415 |
+
},
|
| 1416 |
+
"13870016f9": {
|
| 1417 |
+
"person": [
|
| 1418 |
+
"1"
|
| 1419 |
+
],
|
| 1420 |
+
"cow": [
|
| 1421 |
+
"2",
|
| 1422 |
+
"3"
|
| 1423 |
+
]
|
| 1424 |
+
},
|
| 1425 |
+
"13960b3c84": {
|
| 1426 |
+
"giraffe": [
|
| 1427 |
+
"1",
|
| 1428 |
+
"2",
|
| 1429 |
+
"3"
|
| 1430 |
+
]
|
| 1431 |
+
},
|
| 1432 |
+
"13adaad9d9": {
|
| 1433 |
+
"giant_panda": [
|
| 1434 |
+
"1"
|
| 1435 |
+
]
|
| 1436 |
+
},
|
| 1437 |
+
"13ae097e20": {
|
| 1438 |
+
"giant_panda": [
|
| 1439 |
+
"1"
|
| 1440 |
+
]
|
| 1441 |
+
},
|
| 1442 |
+
"13e3070469": {
|
| 1443 |
+
"zebra": [
|
| 1444 |
+
"1",
|
| 1445 |
+
"2",
|
| 1446 |
+
"3"
|
| 1447 |
+
]
|
| 1448 |
+
},
|
| 1449 |
+
"13f6a8c20d": {
|
| 1450 |
+
"fish": [
|
| 1451 |
+
"1"
|
| 1452 |
+
]
|
| 1453 |
+
},
|
| 1454 |
+
"1416925cf2": {
|
| 1455 |
+
"truck": [
|
| 1456 |
+
"1",
|
| 1457 |
+
"2"
|
| 1458 |
+
]
|
| 1459 |
+
},
|
| 1460 |
+
"142d2621f5": {
|
| 1461 |
+
"person": [
|
| 1462 |
+
"1",
|
| 1463 |
+
"2"
|
| 1464 |
+
],
|
| 1465 |
+
"motorbike": [
|
| 1466 |
+
"3"
|
| 1467 |
+
]
|
| 1468 |
+
},
|
| 1469 |
+
"145d5d7c03": {
|
| 1470 |
+
"giant_panda": [
|
| 1471 |
+
"1"
|
| 1472 |
+
]
|
| 1473 |
+
},
|
| 1474 |
+
"145fdc3ac5": {
|
| 1475 |
+
"lizard": [
|
| 1476 |
+
"1"
|
| 1477 |
+
]
|
| 1478 |
+
},
|
| 1479 |
+
"1471274fa7": {
|
| 1480 |
+
"person": [
|
| 1481 |
+
"1"
|
| 1482 |
+
]
|
| 1483 |
+
},
|
| 1484 |
+
"14a6b5a139": {
|
| 1485 |
+
"fish": [
|
| 1486 |
+
"1"
|
| 1487 |
+
]
|
| 1488 |
+
},
|
| 1489 |
+
"14c21cea0d": {
|
| 1490 |
+
"monkey": [
|
| 1491 |
+
"1",
|
| 1492 |
+
"2"
|
| 1493 |
+
]
|
| 1494 |
+
},
|
| 1495 |
+
"14dae0dc93": {
|
| 1496 |
+
"person": [
|
| 1497 |
+
"2"
|
| 1498 |
+
]
|
| 1499 |
+
},
|
| 1500 |
+
"14f9bd22b5": {
|
| 1501 |
+
"tiger": [
|
| 1502 |
+
"1"
|
| 1503 |
+
]
|
| 1504 |
+
},
|
| 1505 |
+
"14fd28ae99": {
|
| 1506 |
+
"parrot": [
|
| 1507 |
+
"1"
|
| 1508 |
+
]
|
| 1509 |
+
},
|
| 1510 |
+
"15097d5d4e": {
|
| 1511 |
+
"parrot": [
|
| 1512 |
+
"1"
|
| 1513 |
+
]
|
| 1514 |
+
},
|
| 1515 |
+
"150ea711f2": {
|
| 1516 |
+
"whale": [
|
| 1517 |
+
"1"
|
| 1518 |
+
]
|
| 1519 |
+
},
|
| 1520 |
+
"1514e3563f": {
|
| 1521 |
+
"earless_seal": [
|
| 1522 |
+
"1",
|
| 1523 |
+
"2"
|
| 1524 |
+
]
|
| 1525 |
+
},
|
| 1526 |
+
"152aaa3a9e": {
|
| 1527 |
+
"raccoon": [
|
| 1528 |
+
"1"
|
| 1529 |
+
]
|
| 1530 |
+
},
|
| 1531 |
+
"152b7d3bd7": {
|
| 1532 |
+
"giant_panda": [
|
| 1533 |
+
"1"
|
| 1534 |
+
]
|
| 1535 |
+
},
|
| 1536 |
+
"15617297cc": {
|
| 1537 |
+
"person": [
|
| 1538 |
+
"1"
|
| 1539 |
+
]
|
| 1540 |
+
},
|
| 1541 |
+
"15abbe0c52": {
|
| 1542 |
+
"person": [
|
| 1543 |
+
"1"
|
| 1544 |
+
]
|
| 1545 |
+
},
|
| 1546 |
+
"15d1fb3de5": {
|
| 1547 |
+
"owl": [
|
| 1548 |
+
"1"
|
| 1549 |
+
],
|
| 1550 |
+
"cat": [
|
| 1551 |
+
"2"
|
| 1552 |
+
]
|
| 1553 |
+
},
|
| 1554 |
+
"15f67b0fab": {
|
| 1555 |
+
"person": [
|
| 1556 |
+
"1"
|
| 1557 |
+
]
|
| 1558 |
+
},
|
| 1559 |
+
"161eb59aad": {
|
| 1560 |
+
"giraffe": [
|
| 1561 |
+
"1"
|
| 1562 |
+
],
|
| 1563 |
+
"cow": [
|
| 1564 |
+
"2",
|
| 1565 |
+
"3"
|
| 1566 |
+
]
|
| 1567 |
+
},
|
| 1568 |
+
"16288ea47f": {
|
| 1569 |
+
"duck": [
|
| 1570 |
+
"1",
|
| 1571 |
+
"2"
|
| 1572 |
+
]
|
| 1573 |
+
},
|
| 1574 |
+
"164410ce62": {
|
| 1575 |
+
"person": [
|
| 1576 |
+
"1"
|
| 1577 |
+
]
|
| 1578 |
+
},
|
| 1579 |
+
"165c3c8cd4": {
|
| 1580 |
+
"person": [
|
| 1581 |
+
"1",
|
| 1582 |
+
"2",
|
| 1583 |
+
"3"
|
| 1584 |
+
]
|
| 1585 |
+
},
|
| 1586 |
+
"165c42b41b": {
|
| 1587 |
+
"person": [
|
| 1588 |
+
"1",
|
| 1589 |
+
"4"
|
| 1590 |
+
],
|
| 1591 |
+
"motorbike": [
|
| 1592 |
+
"2",
|
| 1593 |
+
"3"
|
| 1594 |
+
]
|
| 1595 |
+
},
|
| 1596 |
+
"165ec9e22b": {
|
| 1597 |
+
"person": [
|
| 1598 |
+
"1",
|
| 1599 |
+
"2"
|
| 1600 |
+
]
|
| 1601 |
+
},
|
| 1602 |
+
"1669502269": {
|
| 1603 |
+
"person": [
|
| 1604 |
+
"1"
|
| 1605 |
+
]
|
| 1606 |
+
},
|
| 1607 |
+
"16763cccbb": {
|
| 1608 |
+
"ape": [
|
| 1609 |
+
"1"
|
| 1610 |
+
]
|
| 1611 |
+
},
|
| 1612 |
+
"16adde065e": {
|
| 1613 |
+
"person": [
|
| 1614 |
+
"3"
|
| 1615 |
+
],
|
| 1616 |
+
"cat": [
|
| 1617 |
+
"2"
|
| 1618 |
+
]
|
| 1619 |
+
},
|
| 1620 |
+
"16af445362": {
|
| 1621 |
+
"airplane": [
|
| 1622 |
+
"1"
|
| 1623 |
+
]
|
| 1624 |
+
},
|
| 1625 |
+
"16afd538ad": {
|
| 1626 |
+
"parrot": [
|
| 1627 |
+
"1",
|
| 1628 |
+
"2"
|
| 1629 |
+
]
|
| 1630 |
+
},
|
| 1631 |
+
"16c3fa4d5d": {
|
| 1632 |
+
"sedan": [
|
| 1633 |
+
"1"
|
| 1634 |
+
]
|
| 1635 |
+
},
|
| 1636 |
+
"16d1d65c27": {
|
| 1637 |
+
"monkey": [
|
| 1638 |
+
"1"
|
| 1639 |
+
]
|
| 1640 |
+
},
|
| 1641 |
+
"16e8599e94": {
|
| 1642 |
+
"giant_panda": [
|
| 1643 |
+
"1"
|
| 1644 |
+
]
|
| 1645 |
+
},
|
| 1646 |
+
"16fe9fb444": {
|
| 1647 |
+
"person": [
|
| 1648 |
+
"2"
|
| 1649 |
+
],
|
| 1650 |
+
"motorbike": [
|
| 1651 |
+
"1"
|
| 1652 |
+
]
|
| 1653 |
+
},
|
| 1654 |
+
"1705796b02": {
|
| 1655 |
+
"train": [
|
| 1656 |
+
"1"
|
| 1657 |
+
]
|
| 1658 |
+
},
|
| 1659 |
+
"1724db7671": {
|
| 1660 |
+
"giant_panda": [
|
| 1661 |
+
"1"
|
| 1662 |
+
]
|
| 1663 |
+
},
|
| 1664 |
+
"17418e81ea": {
|
| 1665 |
+
"shark": [
|
| 1666 |
+
"1"
|
| 1667 |
+
]
|
| 1668 |
+
},
|
| 1669 |
+
"175169edbb": {
|
| 1670 |
+
"ape": [
|
| 1671 |
+
"1",
|
| 1672 |
+
"2"
|
| 1673 |
+
]
|
| 1674 |
+
},
|
| 1675 |
+
"17622326fd": {
|
| 1676 |
+
"lizard": [
|
| 1677 |
+
"1"
|
| 1678 |
+
]
|
| 1679 |
+
},
|
| 1680 |
+
"17656bae77": {
|
| 1681 |
+
"elephant": [
|
| 1682 |
+
"1"
|
| 1683 |
+
]
|
| 1684 |
+
},
|
| 1685 |
+
"17b0d94172": {
|
| 1686 |
+
"airplane": [
|
| 1687 |
+
"1"
|
| 1688 |
+
]
|
| 1689 |
+
},
|
| 1690 |
+
"17c220e4f6": {
|
| 1691 |
+
"giant_panda": [
|
| 1692 |
+
"1"
|
| 1693 |
+
]
|
| 1694 |
+
},
|
| 1695 |
+
"17c7bcd146": {
|
| 1696 |
+
"train": [
|
| 1697 |
+
"1"
|
| 1698 |
+
]
|
| 1699 |
+
},
|
| 1700 |
+
"17cb4afe89": {
|
| 1701 |
+
"tiger": [
|
| 1702 |
+
"1"
|
| 1703 |
+
]
|
| 1704 |
+
},
|
| 1705 |
+
"17cd79a434": {
|
| 1706 |
+
"squirrel": [
|
| 1707 |
+
"1"
|
| 1708 |
+
]
|
| 1709 |
+
},
|
| 1710 |
+
"17d18604c3": {
|
| 1711 |
+
"person": [
|
| 1712 |
+
"1",
|
| 1713 |
+
"2"
|
| 1714 |
+
]
|
| 1715 |
+
},
|
| 1716 |
+
"17d8ca1a37": {
|
| 1717 |
+
"owl": [
|
| 1718 |
+
"1"
|
| 1719 |
+
],
|
| 1720 |
+
"person": [
|
| 1721 |
+
"2"
|
| 1722 |
+
]
|
| 1723 |
+
},
|
| 1724 |
+
"17e33f4330": {
|
| 1725 |
+
"monkey": [
|
| 1726 |
+
"1"
|
| 1727 |
+
]
|
| 1728 |
+
},
|
| 1729 |
+
"17f7a6d805": {
|
| 1730 |
+
"snail": [
|
| 1731 |
+
"1"
|
| 1732 |
+
]
|
| 1733 |
+
},
|
| 1734 |
+
"180abc8378": {
|
| 1735 |
+
"owl": [
|
| 1736 |
+
"1"
|
| 1737 |
+
],
|
| 1738 |
+
"person": [
|
| 1739 |
+
"2"
|
| 1740 |
+
]
|
| 1741 |
+
},
|
| 1742 |
+
"183ba3d652": {
|
| 1743 |
+
"motorbike": [
|
| 1744 |
+
"3"
|
| 1745 |
+
],
|
| 1746 |
+
"person": [
|
| 1747 |
+
"2"
|
| 1748 |
+
]
|
| 1749 |
+
},
|
| 1750 |
+
"185bf64702": {
|
| 1751 |
+
"zebra": [
|
| 1752 |
+
"1",
|
| 1753 |
+
"2"
|
| 1754 |
+
]
|
| 1755 |
+
},
|
| 1756 |
+
"18913cc690": {
|
| 1757 |
+
"train": [
|
| 1758 |
+
"1"
|
| 1759 |
+
]
|
| 1760 |
+
},
|
| 1761 |
+
"1892651815": {
|
| 1762 |
+
"camel": [
|
| 1763 |
+
"1"
|
| 1764 |
+
]
|
| 1765 |
+
},
|
| 1766 |
+
"189ac8208a": {
|
| 1767 |
+
"giraffe": [
|
| 1768 |
+
"1",
|
| 1769 |
+
"2"
|
| 1770 |
+
]
|
| 1771 |
+
},
|
| 1772 |
+
"189b44e92c": {
|
| 1773 |
+
"zebra": [
|
| 1774 |
+
"1"
|
| 1775 |
+
]
|
| 1776 |
+
},
|
| 1777 |
+
"18ac264b76": {
|
| 1778 |
+
"person": [
|
| 1779 |
+
"2"
|
| 1780 |
+
]
|
| 1781 |
+
},
|
| 1782 |
+
"18b245ab49": {
|
| 1783 |
+
"penguin": [
|
| 1784 |
+
"1",
|
| 1785 |
+
"2",
|
| 1786 |
+
"3",
|
| 1787 |
+
"4"
|
| 1788 |
+
]
|
| 1789 |
+
},
|
| 1790 |
+
"18b5cebc34": {
|
| 1791 |
+
"mouse": [
|
| 1792 |
+
"1"
|
| 1793 |
+
]
|
| 1794 |
+
},
|
| 1795 |
+
"18bad52083": {
|
| 1796 |
+
"parrot": [
|
| 1797 |
+
"1",
|
| 1798 |
+
"2"
|
| 1799 |
+
]
|
| 1800 |
+
},
|
| 1801 |
+
"18bb5144d5": {
|
| 1802 |
+
"lizard": [
|
| 1803 |
+
"1"
|
| 1804 |
+
]
|
| 1805 |
+
},
|
| 1806 |
+
"18c6f205c5": {
|
| 1807 |
+
"person": [
|
| 1808 |
+
"1",
|
| 1809 |
+
"2",
|
| 1810 |
+
"3"
|
| 1811 |
+
]
|
| 1812 |
+
},
|
| 1813 |
+
"1903f9ea15": {
|
| 1814 |
+
"bird": [
|
| 1815 |
+
"1",
|
| 1816 |
+
"2",
|
| 1817 |
+
"3"
|
| 1818 |
+
]
|
| 1819 |
+
},
|
| 1820 |
+
"1917b209f2": {
|
| 1821 |
+
"person": [
|
| 1822 |
+
"1"
|
| 1823 |
+
],
|
| 1824 |
+
"cow": [
|
| 1825 |
+
"3",
|
| 1826 |
+
"4"
|
| 1827 |
+
],
|
| 1828 |
+
"horse": [
|
| 1829 |
+
"2"
|
| 1830 |
+
]
|
| 1831 |
+
},
|
| 1832 |
+
"191e74c01d": {
|
| 1833 |
+
"deer": [
|
| 1834 |
+
"1"
|
| 1835 |
+
]
|
| 1836 |
+
},
|
| 1837 |
+
"19367bb94e": {
|
| 1838 |
+
"fish": [
|
| 1839 |
+
"1",
|
| 1840 |
+
"2",
|
| 1841 |
+
"3"
|
| 1842 |
+
]
|
| 1843 |
+
},
|
| 1844 |
+
"193ffaa217": {
|
| 1845 |
+
"person": [
|
| 1846 |
+
"1",
|
| 1847 |
+
"2",
|
| 1848 |
+
"3"
|
| 1849 |
+
]
|
| 1850 |
+
},
|
| 1851 |
+
"19696b67d3": {
|
| 1852 |
+
"cow": [
|
| 1853 |
+
"1"
|
| 1854 |
+
]
|
| 1855 |
+
},
|
| 1856 |
+
"197f3ab6f3": {
|
| 1857 |
+
"giant_panda": [
|
| 1858 |
+
"1"
|
| 1859 |
+
]
|
| 1860 |
+
},
|
| 1861 |
+
"1981e763cc": {
|
| 1862 |
+
"sheep": [
|
| 1863 |
+
"1",
|
| 1864 |
+
"2"
|
| 1865 |
+
]
|
| 1866 |
+
},
|
| 1867 |
+
"198afe39ae": {
|
| 1868 |
+
"person": [
|
| 1869 |
+
"1"
|
| 1870 |
+
]
|
| 1871 |
+
},
|
| 1872 |
+
"19a6e62b9b": {
|
| 1873 |
+
"monkey": [
|
| 1874 |
+
"1",
|
| 1875 |
+
"2"
|
| 1876 |
+
]
|
| 1877 |
+
},
|
| 1878 |
+
"19b60d5335": {
|
| 1879 |
+
"hedgehog": [
|
| 1880 |
+
"1"
|
| 1881 |
+
]
|
| 1882 |
+
},
|
| 1883 |
+
"19c00c11f9": {
|
| 1884 |
+
"person": [
|
| 1885 |
+
"1"
|
| 1886 |
+
]
|
| 1887 |
+
},
|
| 1888 |
+
"19e061eb88": {
|
| 1889 |
+
"boat": [
|
| 1890 |
+
"1",
|
| 1891 |
+
"2"
|
| 1892 |
+
]
|
| 1893 |
+
},
|
| 1894 |
+
"19e8bc6178": {
|
| 1895 |
+
"dog": [
|
| 1896 |
+
"1"
|
| 1897 |
+
]
|
| 1898 |
+
},
|
| 1899 |
+
"19ee80dac6": {
|
| 1900 |
+
"person": [
|
| 1901 |
+
"1",
|
| 1902 |
+
"3",
|
| 1903 |
+
"4"
|
| 1904 |
+
]
|
| 1905 |
+
},
|
| 1906 |
+
"1a25a9170a": {
|
| 1907 |
+
"cow": [
|
| 1908 |
+
"1"
|
| 1909 |
+
],
|
| 1910 |
+
"person": [
|
| 1911 |
+
"2",
|
| 1912 |
+
"3"
|
| 1913 |
+
]
|
| 1914 |
+
},
|
| 1915 |
+
"1a359a6c1a": {
|
| 1916 |
+
"sheep": [
|
| 1917 |
+
"1"
|
| 1918 |
+
]
|
| 1919 |
+
},
|
| 1920 |
+
"1a3e87c566": {
|
| 1921 |
+
"frog": [
|
| 1922 |
+
"1"
|
| 1923 |
+
]
|
| 1924 |
+
},
|
| 1925 |
+
"1a5fe06b00": {
|
| 1926 |
+
"bus": [
|
| 1927 |
+
"1"
|
| 1928 |
+
]
|
| 1929 |
+
},
|
| 1930 |
+
"1a6c0fbd1e": {
|
| 1931 |
+
"person": [
|
| 1932 |
+
"1"
|
| 1933 |
+
]
|
| 1934 |
+
},
|
| 1935 |
+
"1a6f3b5a4b": {
|
| 1936 |
+
"sedan": [
|
| 1937 |
+
"3"
|
| 1938 |
+
]
|
| 1939 |
+
},
|
| 1940 |
+
"1a8afbad92": {
|
| 1941 |
+
"zebra": [
|
| 1942 |
+
"1",
|
| 1943 |
+
"2",
|
| 1944 |
+
"3"
|
| 1945 |
+
]
|
| 1946 |
+
},
|
| 1947 |
+
"1a8bdc5842": {
|
| 1948 |
+
"parrot": [
|
| 1949 |
+
"1",
|
| 1950 |
+
"2"
|
| 1951 |
+
]
|
| 1952 |
+
},
|
| 1953 |
+
"1a95752aca": {
|
| 1954 |
+
"duck": [
|
| 1955 |
+
"1",
|
| 1956 |
+
"2"
|
| 1957 |
+
]
|
| 1958 |
+
},
|
| 1959 |
+
"1a9c131cb7": {
|
| 1960 |
+
"ape": [
|
| 1961 |
+
"1",
|
| 1962 |
+
"2",
|
| 1963 |
+
"3"
|
| 1964 |
+
]
|
| 1965 |
+
},
|
| 1966 |
+
"1aa3da3ee3": {
|
| 1967 |
+
"sheep": [
|
| 1968 |
+
"1",
|
| 1969 |
+
"2",
|
| 1970 |
+
"3",
|
| 1971 |
+
"4"
|
| 1972 |
+
]
|
| 1973 |
+
},
|
| 1974 |
+
"1ab27ec7ea": {
|
| 1975 |
+
"deer": [
|
| 1976 |
+
"1"
|
| 1977 |
+
]
|
| 1978 |
+
},
|
| 1979 |
+
"1abf16d21d": {
|
| 1980 |
+
"turtle": [
|
| 1981 |
+
"1"
|
| 1982 |
+
]
|
| 1983 |
+
},
|
| 1984 |
+
"1acd0f993b": {
|
| 1985 |
+
"dog": [
|
| 1986 |
+
"1"
|
| 1987 |
+
],
|
| 1988 |
+
"person": [
|
| 1989 |
+
"3"
|
| 1990 |
+
]
|
| 1991 |
+
},
|
| 1992 |
+
"1ad202e499": {
|
| 1993 |
+
"lizard": [
|
| 1994 |
+
"1",
|
| 1995 |
+
"2"
|
| 1996 |
+
]
|
| 1997 |
+
},
|
| 1998 |
+
"1af8d2395d": {
|
| 1999 |
+
"person": [
|
| 2000 |
+
"1",
|
| 2001 |
+
"2"
|
| 2002 |
+
],
|
| 2003 |
+
"airplane": [
|
| 2004 |
+
"4"
|
| 2005 |
+
]
|
| 2006 |
+
},
|
| 2007 |
+
"1afd39a1fa": {
|
| 2008 |
+
"motorbike": [
|
| 2009 |
+
"2"
|
| 2010 |
+
]
|
| 2011 |
+
},
|
| 2012 |
+
"1b2d31306f": {
|
| 2013 |
+
"lizard": [
|
| 2014 |
+
"1"
|
| 2015 |
+
]
|
| 2016 |
+
},
|
| 2017 |
+
"1b3fa67f0e": {
|
| 2018 |
+
"airplane": [
|
| 2019 |
+
"1"
|
| 2020 |
+
]
|
| 2021 |
+
},
|
| 2022 |
+
"1b43fa74b4": {
|
| 2023 |
+
"owl": [
|
| 2024 |
+
"1",
|
| 2025 |
+
"2"
|
| 2026 |
+
]
|
| 2027 |
+
},
|
| 2028 |
+
"1b73ea9fc2": {
|
| 2029 |
+
"parrot": [
|
| 2030 |
+
"1"
|
| 2031 |
+
]
|
| 2032 |
+
},
|
| 2033 |
+
"1b7e8bb255": {
|
| 2034 |
+
"person": [
|
| 2035 |
+
"2"
|
| 2036 |
+
]
|
| 2037 |
+
},
|
| 2038 |
+
"1b8680f8cd": {
|
| 2039 |
+
"person": [
|
| 2040 |
+
"2",
|
| 2041 |
+
"3"
|
| 2042 |
+
]
|
| 2043 |
+
},
|
| 2044 |
+
"1b883843c0": {
|
| 2045 |
+
"person": [
|
| 2046 |
+
"1",
|
| 2047 |
+
"2"
|
| 2048 |
+
]
|
| 2049 |
+
},
|
| 2050 |
+
"1b8898785b": {
|
| 2051 |
+
"monkey": [
|
| 2052 |
+
"1",
|
| 2053 |
+
"2"
|
| 2054 |
+
]
|
| 2055 |
+
},
|
| 2056 |
+
"1b88ba1aa4": {
|
| 2057 |
+
"giant_panda": [
|
| 2058 |
+
"1"
|
| 2059 |
+
]
|
| 2060 |
+
},
|
| 2061 |
+
"1b96a498e5": {
|
| 2062 |
+
"ape": [
|
| 2063 |
+
"1"
|
| 2064 |
+
]
|
| 2065 |
+
},
|
| 2066 |
+
"1bbc4c274f": {
|
| 2067 |
+
"fish": [
|
| 2068 |
+
"2"
|
| 2069 |
+
]
|
| 2070 |
+
},
|
| 2071 |
+
"1bd87fe9ab": {
|
| 2072 |
+
"train": [
|
| 2073 |
+
"1"
|
| 2074 |
+
]
|
| 2075 |
+
},
|
| 2076 |
+
"1c4090c75b": {
|
| 2077 |
+
"whale": [
|
| 2078 |
+
"1"
|
| 2079 |
+
]
|
| 2080 |
+
},
|
| 2081 |
+
"1c41934f84": {
|
| 2082 |
+
"elephant": [
|
| 2083 |
+
"1",
|
| 2084 |
+
"2"
|
| 2085 |
+
]
|
| 2086 |
+
},
|
| 2087 |
+
"1c72b04b56": {
|
| 2088 |
+
"lion": [
|
| 2089 |
+
"1"
|
| 2090 |
+
]
|
| 2091 |
+
},
|
| 2092 |
+
"1c87955a3a": {
|
| 2093 |
+
"crocodile": [
|
| 2094 |
+
"1"
|
| 2095 |
+
],
|
| 2096 |
+
"turtle": [
|
| 2097 |
+
"2"
|
| 2098 |
+
]
|
| 2099 |
+
},
|
| 2100 |
+
"1c9f9eb792": {
|
| 2101 |
+
"person": [
|
| 2102 |
+
"2"
|
| 2103 |
+
]
|
| 2104 |
+
},
|
| 2105 |
+
"1ca240fede": {
|
| 2106 |
+
"train": [
|
| 2107 |
+
"1"
|
| 2108 |
+
]
|
| 2109 |
+
},
|
| 2110 |
+
"1ca5673803": {
|
| 2111 |
+
"person": [
|
| 2112 |
+
"1",
|
| 2113 |
+
"3"
|
| 2114 |
+
]
|
| 2115 |
+
},
|
| 2116 |
+
"1cada35274": {
|
| 2117 |
+
"duck": [
|
| 2118 |
+
"1"
|
| 2119 |
+
]
|
| 2120 |
+
},
|
| 2121 |
+
"1cb44b920d": {
|
| 2122 |
+
"eagle": [
|
| 2123 |
+
"1",
|
| 2124 |
+
"2"
|
| 2125 |
+
]
|
| 2126 |
+
},
|
| 2127 |
+
"1cd10e62be": {
|
| 2128 |
+
"leopard": [
|
| 2129 |
+
"1"
|
| 2130 |
+
]
|
| 2131 |
+
},
|
| 2132 |
+
"1d3087d5e5": {
|
| 2133 |
+
"fish": [
|
| 2134 |
+
"1",
|
| 2135 |
+
"2",
|
| 2136 |
+
"3",
|
| 2137 |
+
"4",
|
| 2138 |
+
"5"
|
| 2139 |
+
]
|
| 2140 |
+
},
|
| 2141 |
+
"1d3685150a": {
|
| 2142 |
+
"person": [
|
| 2143 |
+
"1",
|
| 2144 |
+
"3"
|
| 2145 |
+
]
|
| 2146 |
+
},
|
| 2147 |
+
"1d6ff083aa": {
|
| 2148 |
+
"person": [
|
| 2149 |
+
"1",
|
| 2150 |
+
"2"
|
| 2151 |
+
]
|
| 2152 |
+
}
|
| 2153 |
+
}
|
mbench/sampled_frame.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5ac6df555665b2f0cc411641ce023ac10565ea7e8a5c0586c4a9e775481bca62
|
| 3 |
+
size 17415938
|
mbench/sampled_frame2.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|