|
# Sentiment Tuning Examples |
|
|
|
The notebooks and scripts in this examples show how to fine-tune a model with a sentiment classifier (such as `lvwerra/distilbert-imdb`). |
|
|
|
Here's an overview of the notebooks and scripts in the [trl repository](https: |
|
|
|
|
|
|
|
| File | Description | |
|
|------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------| |
|
| [`examples/scripts/ppo.py`](https: |
|
| [`examples/notebooks/gpt2-sentiment.ipynb`](https: |
|
| [`examples/notebooks/gpt2-control.ipynb`](https: |
|
|
|
|
|
|
|
## Usage |
|
|
|
```bash |
|
# 1. run directly |
|
python examples/scripts/ppo.py |
|
# 2. run via `accelerate` (recommended), enabling more features (e.g., multiple GPUs, deepspeed) |
|
accelerate config # will prompt you to define the training configuration |
|
accelerate launch examples/scripts/ppo.py # launches training |
|
# 3. get help text and documentation |
|
python examples/scripts/ppo.py --help |
|
# 4. configure logging with wandb and, say, mini_batch_size=1 and gradient_accumulation_steps=16 |
|
python examples/scripts/ppo.py --log_with wandb --mini_batch_size 1 --gradient_accumulation_steps 16 |
|
``` |
|
|
|
Note: if you don't want to log with `wandb` remove `log_with="wandb"` in the scripts/notebooks. You can also replace it with your favourite experiment tracker that's [supported by `accelerate`](https: |
|
|
|
|
|
## Few notes on multi-GPU |
|
|
|
To run in multi-GPU setup with DDP (distributed Data Parallel) change the `device_map` value to `device_map={"": Accelerator().process_index}` and make sure to run your script with `accelerate launch yourscript.py`. If you want to apply naive pipeline parallelism you can use `device_map="auto"`. |
|
|
|
|
|
## Benchmarks |
|
|
|
Below are some benchmark results for `examples/scripts/ppo.py`. To reproduce locally, please check out the `--command` arguments below. |
|
|
|
```bash |
|
python benchmark/benchmark.py \ |
|
--command "python examples/scripts/ppo.py --log_with wandb" \ |
|
--num-seeds 5 \ |
|
--start-seed 1 \ |
|
--workers 10 \ |
|
--slurm-nodes 1 \ |
|
--slurm-gpus-per-task 1 \ |
|
--slurm-ntasks 1 \ |
|
--slurm-total-cpus 12 \ |
|
--slurm-template-path benchmark/trl.slurm_template |
|
``` |
|
|
|
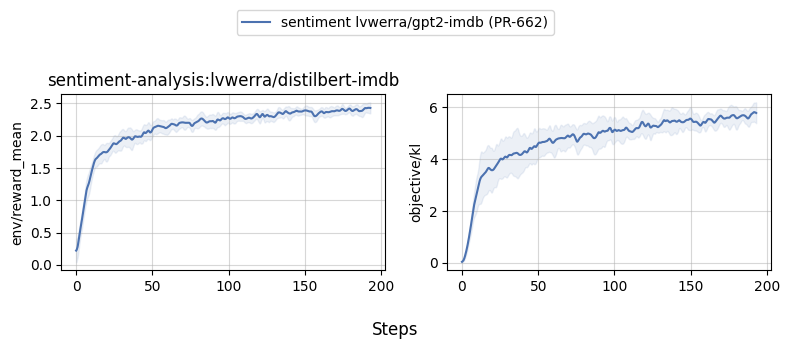 |
|
|
|
|
|
|
|
## With and without gradient accumulation |
|
|
|
```bash |
|
python benchmark/benchmark.py \ |
|
--command "python examples/scripts/ppo.py --exp_name sentiment_tuning_step_grad_accu --mini_batch_size 1 --gradient_accumulation_steps 128 --log_with wandb" \ |
|
--num-seeds 5 \ |
|
--start-seed 1 \ |
|
--workers 10 \ |
|
--slurm-nodes 1 \ |
|
--slurm-gpus-per-task 1 \ |
|
--slurm-ntasks 1 \ |
|
--slurm-total-cpus 12 \ |
|
--slurm-template-path benchmark/trl.slurm_template |
|
``` |
|
|
|
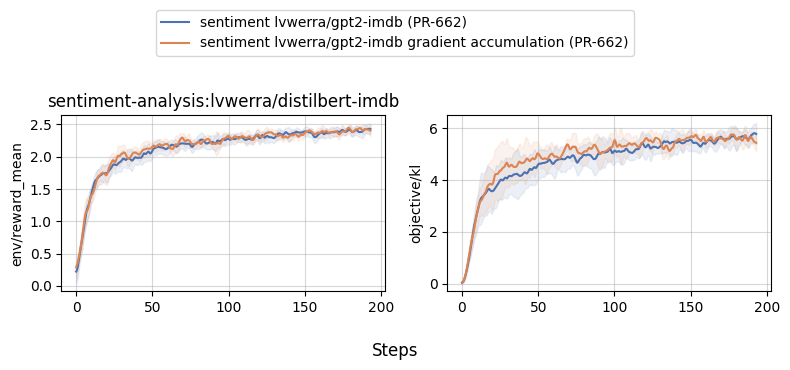 |
|
|
|
|
|
## Comparing different models (gpt2, gpt2-xl, falcon, llama2) |
|
|
|
```bash |
|
python benchmark/benchmark.py \ |
|
--command "python examples/scripts/ppo.py --exp_name sentiment_tuning_gpt2 --log_with wandb" \ |
|
--num-seeds 5 \ |
|
--start-seed 1 \ |
|
--workers 10 \ |
|
--slurm-nodes 1 \ |
|
--slurm-gpus-per-task 1 \ |
|
--slurm-ntasks 1 \ |
|
--slurm-total-cpus 12 \ |
|
--slurm-template-path benchmark/trl.slurm_template |
|
python benchmark/benchmark.py \ |
|
--command "python examples/scripts/ppo.py --exp_name sentiment_tuning_gpt2xl_grad_accu --model_name gpt2-xl --mini_batch_size 16 --gradient_accumulation_steps 8 --log_with wandb" \ |
|
--num-seeds 5 \ |
|
--start-seed 1 \ |
|
--workers 10 \ |
|
--slurm-nodes 1 \ |
|
--slurm-gpus-per-task 1 \ |
|
--slurm-ntasks 1 \ |
|
--slurm-total-cpus 12 \ |
|
--slurm-template-path benchmark/trl.slurm_template |
|
python benchmark/benchmark.py \ |
|
--command "python examples/scripts/ppo.py --exp_name sentiment_tuning_falcon_rw_1b --model_name tiiuae/falcon-rw-1b --log_with wandb" \ |
|
--num-seeds 5 \ |
|
--start-seed 1 \ |
|
--workers 10 \ |
|
--slurm-nodes 1 \ |
|
--slurm-gpus-per-task 1 \ |
|
--slurm-ntasks 1 \ |
|
--slurm-total-cpus 12 \ |
|
--slurm-template-path benchmark/trl.slurm_template |
|
``` |
|
|
|
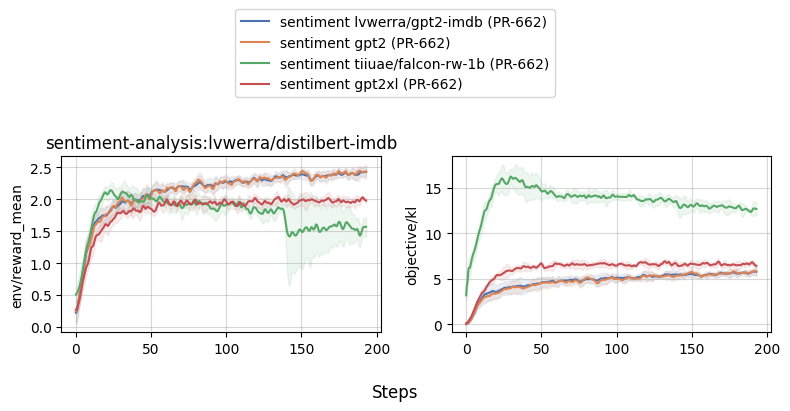 |
|
|
|
## With and without PEFT |
|
|
|
``` |
|
python benchmark/benchmark.py \ |
|
--command "python examples/scripts/ppo.py --exp_name sentiment_tuning_peft --use_peft --log_with wandb" \ |
|
--num-seeds 5 \ |
|
--start-seed 1 \ |
|
--workers 10 \ |
|
--slurm-nodes 1 \ |
|
--slurm-gpus-per-task 1 \ |
|
--slurm-ntasks 1 \ |
|
--slurm-total-cpus 12 \ |
|
--slurm-template-path benchmark/trl.slurm_template |
|
``` |
|
|
|
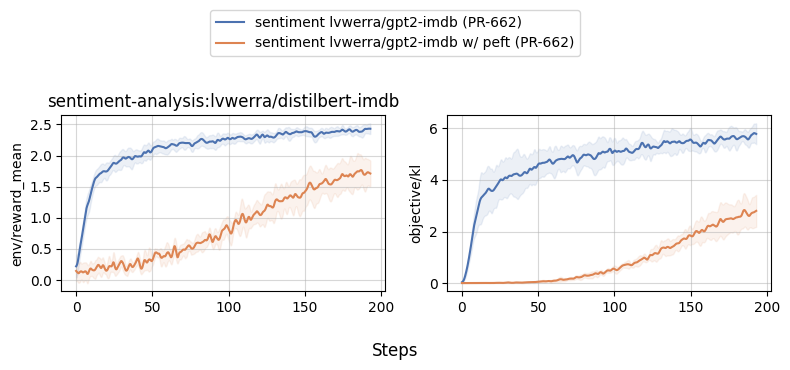 |
|
|

