
Commit
·
4043d33
1
Parent(s):
3ddf5f8
Update readme
Browse files- README.md +49 -0
- output.png +3 -0
README.md
CHANGED
|
@@ -1,3 +1,52 @@
|
|
| 1 |
---
|
| 2 |
license: mit
|
|
|
|
|
|
|
|
|
|
| 3 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
license: mit
|
| 3 |
+
dataset:
|
| 4 |
+
- chembl
|
| 5 |
+
- zinc15
|
| 6 |
---
|
| 7 |
+
## Overview
|
| 8 |
+
This dataset contains Functional Group (FG)-enhanced SMILES designed for molecule representation learning. It consists of approximately **20 million** FG-enhanced SMILES collected from a wide range of chemical suppliers and databases, as detailed below:
|
| 9 |
+
|
| 10 |
+
| **Supplier** | **Number of Compounds** | **Source** |
|
| 11 |
+
|-------------------------------|-------------------------|----------------------------------------------------------|
|
| 12 |
+
| Targetmol | 22,555 | [Targetmol](https://www.targetmol.com/) |
|
| 13 |
+
| Chemdiv | 1,741,620 | [Chemdiv](https://www.chemdiv.com/) |
|
| 14 |
+
| Enamine | 862,698 | [Enamine](https://enamine.net/) |
|
| 15 |
+
| Life Chemical | 347,657 | [Life Chemicals](https://lifechemicals.com/) |
|
| 16 |
+
| Chembridge | 1,405,499 | [Chembridge](https://chembridge.com/) |
|
| 17 |
+
| Vitas-M | 1,430,135 | [Vitas-M](https://vitasmlab.biz/) |
|
| 18 |
+
| InterBioScreen | 560,564 | [InterBioScreen](https://www.ibscreen.com/) |
|
| 19 |
+
| Maybridge | 97,367 | [Maybridge](https://chembridge.com/) |
|
| 20 |
+
| Asinex | 601,936 | [Asinex](https://www.asinex.com/) |
|
| 21 |
+
| Eximed | 61,281 | [Eximed](https://eximedlab.com/) |
|
| 22 |
+
| Princeton BioMolecular | 1,647,078 | [Princeton BioMolecular](https://princetonbio.com/) |
|
| 23 |
+
| Otava | 9,203,151 | [Otava](https://www.otava.com/) |
|
| 24 |
+
| Alinda Chemical | 733,152 | [Alinda Chemical](https://www.alinda.ru/synthes_en.html) |
|
| 25 |
+
| ChEMBL 25 | 1,785,415 | [ChEMBL](https://www.ebi.ac.uk/chembl/) |
|
| 26 |
+
| ZINC15 | 4,000,000 | [ZINC15](https://zinc15.docking.org/) |
|
| 27 |
+
|-------------------------------|-------------------------|----------------------------------------------------------|
|
| 28 |
+
| **Total** | **20,000,000** | |
|
| 29 |
+
|-------------------------------|-------------------------|----------------------------------------------------------|
|
| 30 |
+
|
| 31 |
+
## Dataset Details
|
| 32 |
+
This dataset contains **22,364** unique tokens (vocabulary size = 22,364), which is an extension from 93 tokens in the corresponding standard SMILES dataset. This expansion helps bridge the gap between SMILES and natural language, which has a large set of vocabulary to sufficiently express the nuances of language.
|
| 33 |
+
|
| 34 |
+
For more details about the method of generating FG-enhanced SMILES, please refer to our paper, [FARM: Functional Group-Aware Representations for Small Molecules](https://arxiv.org/pdf/2410.02082), or visit our [GitHub repository](https://github.com/thaonguyen217/farm_molecular_representation) for implementation details.
|
| 35 |
+
|
| 36 |
+
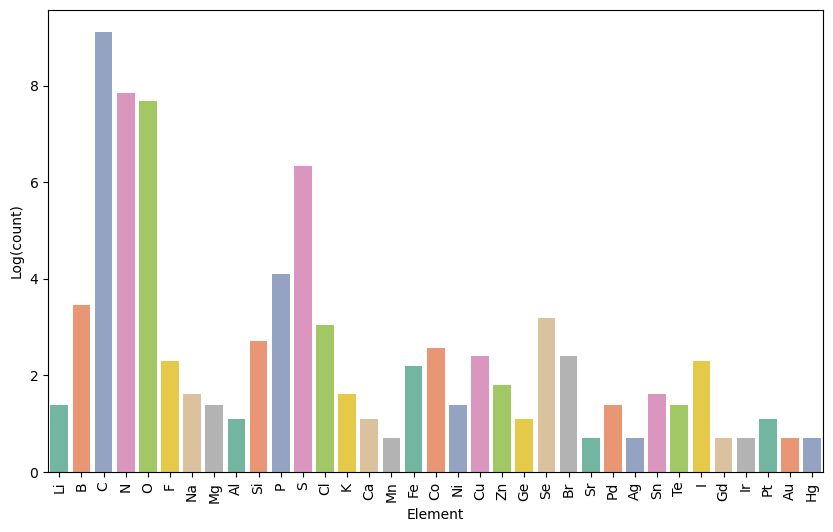
Below is a breakdown of the number of token types that represent different chemical elements:
|
| 37 |
+
[image](output.png)
|
| 38 |
+
|
| 39 |
+
## Examples of FG-enhanced SMILES
|
| 40 |
+
Below are some examples of FG-enhanced SMILES from the dataset. Each SMILES string is augmented with functional group annotations (e.g., `C_alkyl`, `O_ether`, `c_6`, `n_tertiary_amine`, etc.) to enhance the representation of molecular structures for machine learning models.
|
| 41 |
+
|
| 42 |
+
`C_alkyl O_ether c_6 1 c_6 c_6 c_6 ( - c_5-6 2 n_5-6 c_5-6 3 n_tertiary_amine_5-6 ( C_alkyl c_6 4 c_6 c_6 c_6 c_6 c_6 4 F_fluoro ) c_5-6 ( C_alkyl ) c_5-6 ( - c_5-6 4 c_5-6 c_5-6 c_5-6 5 c_5-6 ( c_5-6 4 ) O_ether_5-6 C_5-6 O_ether_5-6 5 ) c_amide_5-6 ( = O_amide ) n_amide_5-6 3 c_5-6 2 C_alkyl N_tertiary_amine ( C_alkyl ) C_alkyl C_alkyl c_6 2 c_6 c_6 c_6 c_6 c_6 2 ) c_6 c_6 1`
|
| 43 |
+
|
| 44 |
+
`C_alkyl C_tertiary_carbon ( C_alkyl ) C_tertiary_carbon ( C_ester ( = O_ester ) O_ester C_ester c_5-6 1 c_5-6 n_tertiary_amine_5-6 2 c_5-6 c_5-6 c_5-6 c_5-6 c_5-6 2 n_5-6 1 ) C_tertiary_carbon ( C_alkyl ) N_secondary_amine C_ester ( = O_ester ) O_ester C_ester ( C_alkyl ) ( C_alkyl ) C_alkyl`
|
| 45 |
+
|
| 46 |
+
`C_alkyl C_tertiary_carbon_6 1 C_6 N_tertiary_amine_6 ( c_5 2 n_5 n_5 c_5 ( C_tertiary_carbon_3 3 C_3 C_3 3 ) n_tertiary_amine_5 2 C_alkyl C_alkyl N_secondary_amine C_ketone ( = O_ketone ) c_5 2 c_5 c_5 c_5 s_5 2 ) C_6 C_amide_6 ( = O_amide ) N_amide_6 1 C_alkyl`
|
| 47 |
+
|
| 48 |
+
`C_alkyl O_ether C_alkyl C_alkyl n_tertiary_amine_5 1 c_5 ( C_alkyl c_5 2 c_5 c_5 ( C_alkyl ) n_secondary_amine_5 n_5 2 ) n_5 n_5 c_5 1 N_tertiary_amine_7 1 C_7 C_7 C_7 N_amide_7 ( C_amide ( = O_amide ) C_tertiary_carbon ( C_alkyl ) C_alkyl ) C_7 C_7 1`
|
| 49 |
+
|
| 50 |
+
`C_alkyl C_alkyl n_amide_6-6 1 c_amide_6-6 ( = O_amide ) n_6-6 c_6-6 ( O_hydroxyl ) c_6-6 2 c_6-6 ( C_ketone ( = O_ketone ) N_secondary_amine N_tertiary_amine_5 3 C_5 C_5 C_5 C_tertiary_carbon_5 3 C_alkyl O_ether C_alkyl ) c_6-6 c_6-6 ( C_tertiary_carbon ( C_alkyl ) C_alkyl ) n_6-6 c_6-6 1 2`
|
| 51 |
+
|
| 52 |
+
`C_alkyl C_tertiary_carbon_3 1 C_3 C_tertiary_carbon_3 1 C_alkyl n_tertiary_amine_5 1 c_5 ( C_alkyl c_6 2 c_6 c_6 n_6 c_6 c_6 2 ) n_5 n_5 c_5 1 N_tertiary_amine_6 1 C_6 C_6 N_tertiary_amine_6 ( C_alkyl C_amide ( = O_amide ) N_amide ( C_alkyl ) C_alkyl ) C_6 C_6 1`
|
output.png
ADDED
|
Git LFS Details
|