
text
stringlengths 63
77.2k
| metadata
dict |
|---|---|
# KAG 示例:HotpotQA
[English](./README.md) |
[简体中文](./README_cn.md)
[HotpotQA](https://arxiv.org/abs/1809.09600) 是一个用于多样和可解释多跳问答的数据集。[KAG](https://arxiv.org/abs/2409.13731) 和 [HippoRAG](https://arxiv.org/abs/2405.14831) 用它评估多跳问答的性能。
本例我们展示为 HotpotQA 数据集构建知识图谱,然后用 KAG 为评估问题生成答案,并与标准答案对比计算 EM 和 F1 指标。
## 1. 前置条件
参考文档 [快速开始](https://openspg.yuque.com/ndx6g9/0.6/quzq24g4esal7q17) 安装 KAG 及其依赖的 OpenSPG server,了解开发者模式 KAG 的使用流程。
## 2. 复现步骤
### Step 1:进入示例目录
```bash
cd kag/examples/hotpotqa
```
### Step 2:配置模型
更新 [kag_config.yaml](./kag_config.yaml) 中的生成模型配置 ``openie_llm`` 和 ``chat_llm`` 和表示模型配置 ``vectorize_model``。
您需要设置正确的 ``api_key``。如果使用的模型供应商和模型名与默认值不同,您还需要更新 ``base_url`` 和 ``model``。
### Step 3:初始化项目
先对项目进行初始化。
```bash
knext project restore --host_addr http://127.0.0.1:8887 --proj_path .
```
### Step 4:提交 schema
执行以下命令提交 schema [HotpotQA.schema](./schema/HotpotQA.schema)。
```bash
knext schema commit
```
### Step 5:构建知识图谱
在 [builder](./builder) 目录执行 [indexer.py](./builder/indexer.py) 构建知识图谱。
```bash
cd builder && python indexer.py && cd ..
```
### Step 6:执行 QA 任务
在 [solver](./solver) 目录执行 [evaForHotpotqa.py](./solver/evaForHotpotqa.py) 生成答案并计算 EM 和 F1 指标。
```bash
cd solver && python evaForHotpotqa.py && cd ..
```
生成的答案被保存至 ``./solver/hotpotqa_res_*.json``.
计算出的 EM 和 F1 指标被保存至 ``./solver/hotpotqa_metrics_*.json``.
### Step 7:(可选)清理
若要删除 checkpoint,可执行以下命令。
```bash
rm -rf ./builder/ckpt
rm -rf ./solver/ckpt
```
若要删除 KAG 项目及关联的知识图谱,可执行以下类似命令,将 OpenSPG server 地址和 KAG 项目 id 换为实际的值。
```bash
curl http://127.0.0.1:8887/project/api/delete?projectId=1
```
### Step 8:(可选)尝试更大的数据集
从 Step 1 重新开始,修改 [indexer.py](./builder/indexer.py) 和 [evaForHotpotqa.py](./solver/evaForHotpotqa.py) 以尝试更大的数据集。 | {
"source": "OpenSPG/KAG",
"title": "kag/examples/hotpotqa/README_cn.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/kag/examples/hotpotqa/README_cn.md",
"date": "2024-09-21T13:56:44",
"stars": 5095,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 1735
} |
# KAG Example: Medical Knowledge Graph (Medicine)
[English](./README.md) |
[简体中文](./README_cn.md)
This example aims to demonstrate how to extract and construct entities and relations in a knowledge graph based on the SPG-Schema using LLMs.

## 1. Precondition
Please refer to [Quick Start](https://openspg.yuque.com/ndx6g9/cwh47i/rs7gr8g4s538b1n7) to install KAG and its dependency OpenSPG server, and learn about using KAG in developer mode.
## 2. Steps to reproduce
### Step 1: Enter the example directory
```bash
cd kag/examples/medicine
```
### Step 2: Configure models
Update the generative model configurations ``openie_llm`` and ``chat_llm`` and the representational model configuration ``vectorize_model`` in [kag_config.yaml](./kag_config.yaml).
You need to fill in correct ``api_key``s. If your model providers and model names are different from the default values, you also need to update ``base_url`` and ``model``.
### Step 3: Project initialization
Initiate the project with the following command.
```bash
knext project restore --host_addr http://127.0.0.1:8887 --proj_path .
```
### Step 4: Commit the schema
Execute the following command to commit the Medical Knowledge Graph schema [Medicine.schema](./schema/Medicine.schema).
```bash
knext schema commit
```
### Step 5: Build the knowledge graph
Execute [indexer.py](./builder/indexer.py) in the [builder](./builder) directory to build the knowledge graph with domain knowledge importing and schema-free extraction.
```bash
cd builder && python indexer.py && cd ..
```
Check [Disease.csv](./builder/data/Disease.csv) to inspect the descriptions of diseases. Those unstructured descriptions are schema-free extracted by ``extract_runner`` defined in [kag_config.yaml](./kag_config.yaml).
Other structured data in [data](./builder/data) will be imported directly by corresponding builder chains defined in [kag_config.yaml](./kag_config.yaml).
### Step 6: Query the knowledge graph with GQL
You can use the ``knext reasoner`` command to inspect the built knowledge graph.
The query DSL will be executed by the OpenSPG server, which supports ISO GQL.
* Execute the following command to execute DSL directly.
```bash
knext reasoner execute --dsl "
MATCH
(s:Medicine.HospitalDepartment)-[p]->(o)
RETURN
s.id, s.name
"
```
The results will be displayed on the screen and saved as CSV to the current directory.
* You can also save the DSL to a file and execute the file.
```bash
knext reasoner execute --file ./reasoner/rule.dsl
```
* You can also use the reasoner Python client to query the knowledge graph.
```bash
python ./reasoner/client.py
```
### Step 7: Execute the QA tasks
Execute [evaForMedicine.py](./solver/evaForMedicine.py) in the [solver](./solver) directory to ask a demo question in natural languages and view the answer and trace log.
```bash
cd solver && python evaForMedicine.py && cd ..
```
### Step 8: (Optional) Cleanup
To delete the checkpoint, execute the following command.
```bash
rm -rf ./builder/ckpt
```
To delete the KAG project and related knowledge graph, execute the following similar command. Replace the OpenSPG server address and KAG project id with actual values.
```bash
curl http://127.0.0.1:8887/project/api/delete?projectId=1
``` | {
"source": "OpenSPG/KAG",
"title": "kag/examples/medicine/README.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/kag/examples/medicine/README.md",
"date": "2024-09-21T13:56:44",
"stars": 5095,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 3390
} |
# KAG 示例:医疗图谱(Medicine)
[English](./README.md) |
[简体中文](./README_cn.md)
本示例旨在展示如何基于 schema 的定义,利用大模型实现对图谱实体和关系的抽取和构建到图谱。

## 1. 前置条件
参考文档 [快速开始](https://openspg.yuque.com/ndx6g9/0.6/quzq24g4esal7q17) 安装 KAG 及其依赖的 OpenSPG server,了解开发者模式 KAG 的使用流程。
## 2. 复现步骤
### Step 1:进入示例目录
```bash
cd kag/examples/medicine
```
### Step 2:配置模型
更新 [kag_config.yaml](./kag_config.yaml) 中的生成模型配置 ``openie_llm`` 和 ``chat_llm`` 和表示模型配置 ``vectorize_model``。
您需要设置正确的 ``api_key``。如果使用的模型供应商和模型名与默认值不同,您还需要更新 ``base_url`` 和 ``model``。
### Step 3:初始化项目
先对项目进行初始化。
```bash
knext project restore --host_addr http://127.0.0.1:8887 --proj_path .
```
### Step 4:提交 schema
执行以下命令提交医疗图谱 schema [Medicine.schema](./schema/Medicine.schema)。
```bash
knext schema commit
```
### Step 5:构建知识图谱
在 [builder](./builder) 目录执行 [indexer.py](./builder/indexer.py) 通过领域知识导入和 schema-free 抽取构建知识图谱。
```bash
cd builder && python indexer.py && cd ..
```
您可以检查 [Disease.csv](./builder/data/Disease.csv) 查看疾病的描述,我们通过定义在 [kag_config.yaml](./kag_config.yaml) 的 ``extract_runner`` 对这些无结构文本描述做 schema-free 抽取。
[data](./builder/data) 中的其他结构化数据通过定义在 [kag_config.yaml](./kag_config.yaml) 中的相应 KAG builder chain 直接导入。
### Step 6:使用 GQL 查询知识图谱
您可以使用 ``knext reasoner`` 命令检查构建的知识图谱。查询 DSL 将由 OpenSPG server 执行,它支持 ISO GQL。
* 使用以下命令直接执行 DSL。
```bash
knext reasoner execute --dsl "
MATCH
(s:Medicine.HospitalDepartment)-[p]->(o)
RETURN
s.id, s.name
"
```
查询结果会显示在屏幕上并以 CSV 格式保存到当前目录。
* 您也可以将 DSL 保存到文件,然后通过文件提交 DSL。
```bash
knext reasoner execute --file ./reasoner/rule.dsl
```
* 您还可以使用 reasoner 的 Python 客户端查询知识图谱。
```bash
python ./reasoner/client.py
```
### Step 7:执行 QA 任务
在 [solver](./solver) 目录执行 [evaForMedicine.py](./solver/evaForMedicine.py) 用自然语言问一个示例问题并查看答案和 trace log。
```bash
cd solver && python evaForMedicine.py && cd ..
```
### Step 8:(可选)清理
若要删除 checkpoint,可执行以下命令。
```bash
rm -rf ./builder/ckpt
```
若要删除 KAG 项目及关联的知识图谱,可执行以下类似命令,将 OpenSPG server 地址和 KAG 项目 id 换为实际的值。
```bash
curl http://127.0.0.1:8887/project/api/delete?projectId=1
``` | {
"source": "OpenSPG/KAG",
"title": "kag/examples/medicine/README_cn.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/kag/examples/medicine/README_cn.md",
"date": "2024-09-21T13:56:44",
"stars": 5095,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 2149
} |
# KAG Example: MuSiQue
[English](./README.md) |
[简体中文](./README_cn.md)
[MuSiQue](https://arxiv.org/abs/2108.00573) is a multi-hop QA dataset for comprehensive evaluation of reasoning steps. It's used by [KAG](https://arxiv.org/abs/2409.13731) and [HippoRAG](https://arxiv.org/abs/2405.14831) for multi-hop question answering performance evaluation.
Here we demonstrate how to build a knowledge graph for the MuSiQue dataset, generate answers to those evaluation questions with KAG and calculate EM and F1 metrics of the KAG generated answers compared to the ground-truth answers.
## 1. Precondition
Please refer to [Quick Start](https://openspg.yuque.com/ndx6g9/cwh47i/rs7gr8g4s538b1n7) to install KAG and its dependency OpenSPG server, and learn about using KAG in developer mode.
## 2. Steps to reproduce
### Step 1: Enter the example directory
```bash
cd kag/examples/musique
```
### Step 2: Configure models
Update the generative model configurations ``openie_llm`` and ``chat_llm`` and the representational model configuration ``vectorize_model`` in [kag_config.yaml](./kag_config.yaml).
You need to fill in correct ``api_key``s. If your model providers and model names are different from the default values, you also need to update ``base_url`` and ``model``.
### Step 3: Project initialization
Initiate the project with the following command.
```bash
knext project restore --host_addr http://127.0.0.1:8887 --proj_path .
```
### Step 4: Commit the schema
Execute the following command to commit the schema [MuSiQue.schema](./schema/MuSiQue.schema).
```bash
knext schema commit
```
### Step 5: Build the knowledge graph
Execute [indexer.py](./builder/indexer.py) in the [builder](./builder) directory to build the knowledge graph.
```bash
cd builder && python indexer.py && cd ..
```
### Step 6: Execute the QA tasks
Execute [evaForMusique.py](./solver/evaForMusique.py) in the [solver](./solver) directory to generate the answers and calculate the EM and F1 metrics.
```bash
cd solver && python evaForMusique.py && cd ..
```
The generated answers are saved to ``./solver/musique_res_*.json``.
The calculated EM and F1 metrics are saved to ``./solver/musique_metrics_*.json``.
### Step 7: (Optional) Cleanup
To delete the checkpoints, execute the following command.
```bash
rm -rf ./builder/ckpt
rm -rf ./solver/ckpt
```
To delete the KAG project and related knowledge graph, execute the following similar command. Replace the OpenSPG server address and KAG project id with actual values.
```bash
curl http://127.0.0.1:8887/project/api/delete?projectId=1
```
### Step 8: (Optional) Try the larger datasets
Restart from Step 1 and modify [indexer.py](./builder/indexer.py) and [evaForMusique.py](./solver/evaForMusique.py) to try the larger datasets. | {
"source": "OpenSPG/KAG",
"title": "kag/examples/musique/README.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/kag/examples/musique/README.md",
"date": "2024-09-21T13:56:44",
"stars": 5095,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 2787
} |
# KAG 示例:MuSiQue
[English](./README.md) |
[简体中文](./README_cn.md)
[MuSiQue](https://arxiv.org/abs/2108.00573) 是一个用于对推理步骤进行全面评估的多跳问答数据集。[KAG](https://arxiv.org/abs/2409.13731) 和 [HippoRAG](https://arxiv.org/abs/2405.14831) 用它评估多跳问答的性能。
本例我们展示为 MuSiQue 数据集构建知识图谱,然后用 KAG 为评估问题生成答案,并与标准答案对比计算 EM 和 F1 指标。
## 1. 前置条件
参考文档 [快速开始](https://openspg.yuque.com/ndx6g9/0.6/quzq24g4esal7q17) 安装 KAG 及其依赖的 OpenSPG server,了解开发者模式 KAG 的使用流程。
## 2. 复现步骤
### Step 1:进入示例目录
```bash
cd kag/examples/musique
```
### Step 2:配置模型
更新 [kag_config.yaml](./kag_config.yaml) 中的生成模型配置 ``openie_llm`` 和 ``chat_llm`` 和表示模型配置 ``vectorize_model``。
您需要设置正确的 ``api_key``。如果使用的模型供应商和模型名与默认值不同,您还需要更新 ``base_url`` 和 ``model``。
### Step 3:初始化项目
先对项目进行初始化。
```bash
knext project restore --host_addr http://127.0.0.1:8887 --proj_path .
```
### Step 4:提交 schema
执行以下命令提交 schema [MuSiQue.schema](./schema/MuSiQue.schema)。
```bash
knext schema commit
```
### Step 5:构建知识图谱
在 [builder](./builder) 目录执行 [indexer.py](./builder/indexer.py) 构建知识图谱。
```bash
cd builder && python indexer.py && cd ..
```
### Step 6:执行 QA 任务
在 [solver](./solver) 目录执行 [evaForMusique.py](./solver/evaForMusique.py) 生成答案并计算 EM 和 F1 指标。
```bash
cd solver && python evaForMusique.py && cd ..
```
生成的答案被保存至 ``./solver/musique_res_*.json``.
计算出的 EM 和 F1 指标被保存至 ``./solver/musique_metrics_*.json``.
### Step 7:(可选)清理
若要删除 checkpoint,可执行以下命令。
```bash
rm -rf ./builder/ckpt
rm -rf ./solver/ckpt
```
若要删除 KAG 项目及关联的知识图谱,可执行以下类似命令,将 OpenSPG server 地址和 KAG 项目 id 换为实际的值。
```bash
curl http://127.0.0.1:8887/project/api/delete?projectId=1
```
### Step 8:(可选)尝试更大的数据集
从 Step 1 重新开始,修改 [indexer.py](./builder/indexer.py) 和 [evaForMusique.py](./solver/evaForMusique.py) 以尝试更大的数据集。 | {
"source": "OpenSPG/KAG",
"title": "kag/examples/musique/README_cn.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/kag/examples/musique/README_cn.md",
"date": "2024-09-21T13:56:44",
"stars": 5095,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 1727
} |
# KAG Example: Risk Mining Knowledge Graph (RiskMining)
[English](./README.md) |
[简体中文](./README_cn.md)
## Overview
**Keywords**: semantic properties, dynamic multi-classification of entities, knowledge application in the context of hierarchical business knowledge and factual data.

## 1. Precondition
Please refer to [Quick Start](https://openspg.yuque.com/ndx6g9/cwh47i/rs7gr8g4s538b1n7) to install KAG and its dependency OpenSPG server, and learn about using KAG in developer mode.
## 2. Steps to reproduce
### Step 1: Enter the example directory
```bash
cd kag/examples/riskmining
```
### Step 2: Configure models
Update the generative model configurations ``openie_llm`` and ``chat_llm`` and the representational model configuration ``vectorize_model`` in [kag_config.yaml](./kag_config.yaml).
You need to fill in correct ``api_key``s. If your model providers and model names are different from the default values, you also need to update ``base_url`` and ``model``.
### Step 3: Project initialization
Initiate the project with the following command.
```bash
knext project restore --host_addr http://127.0.0.1:8887 --proj_path .
```
### Step 4: Create knowledge schema
The schema file [RiskMining.schema](./schema/RiskMining.schema) has been created and you can execute the following command to submit it:
```bash
knext schema commit
```
Submit the classification rules of RiskUser and RiskApp in [concept.rule](./schema/concept.rule):
```bash
knext schema reg_concept_rule --file ./schema/concept.rule
```
### Step 5: Knowledge graph construction
Submit the knowledge importing tasks.
```bash
cd builder && python indexer.py && cd ..
```
### Step 6: Executing query tasks for knowledge graph
OpenSPG supports the ISO GQL syntax. You can use the following command-line to execute a query task:
```bash
knext reasoner execute --dsl "${ql}"
```
#### Scenario 1: Semantic attributes vs text attributes

MobilePhone: "standard attribute" vs "text attribute".
Save the following content as file ``dsl_task.txt``.
```cypher
MATCH
(phone:STD.ChinaMobile)<-[:hasPhone]-(u:RiskMining.Person)
RETURN
u.id, phone.id
```
Execute the query script.
```bash
knext reasoner execute --file dsl_task.txt
```
#### Scenario 2: Dynamic multi-type entities
**Note**: The classification rules defined in this section have been submitted in the previous "4. Create knowledge schema" section using the command ``knext schema reg_concept_rule``.
The detailed content of the following rules can also be found in the file [concept.rule](./schema/concept.rule).
**Taxonomy of gambling apps**
```text
Define (s:RiskMining.App)-[p:belongTo]->(o:`RiskMining.TaxOfRiskApp`/`赌博应用`) {
Structure {
(s)
}
Constraint {
R1("风险标记为赌博"): s.riskMark like "%赌博%"
}
}
```
Wang Wu is a gambling app developer, and Li Si is the owner of a gambling app. These two user entities correspond to different concept types.
**Gambling Developer's Identification Rule**
**Rule**: If a user has more than 5 devices, and these devices have the same app installed, then there exists a development relation.
```text
Define (s:RiskMining.Person)-[p:developed]->(o:RiskMining.App) {
Structure {
(s)-[:hasDevice]->(d:RiskMining.Device)-[:install]->(o)
}
Constraint {
deviceNum = group(s,o).count(d)
R1("设备超过5"): deviceNum > 5
}
}
```
```text
Define (s:RiskMining.Person)-[p:belongTo]->(o:`RiskMining.TaxOfRiskUser`/`赌博App开发者`) {
Structure {
(s)-[:developed]->(app:`RiskMining.TaxOfRiskApp`/`赌博应用`)
}
Constraint {
}
}
```
**Identifying the owner of a gambling app**
**Rule 1**: There exists a publishing relation between a person and the app.
```text
Define (s:RiskMining.Person)-[p:release]->(o:RiskMining.App) {
Structure {
(s)-[:holdShare]->(c:RiskMining.Company),
(c)-[:hasCert]->(cert:RiskMining.Cert)<-[useCert]-(o)
}
Constraint {
}
}
```
**Rule 2**: The user transfers money to the gambling app developer, and there exists a relation of publishing gambling app.
```text
Define (s:RiskMining.Person)-[p:belongTo]->(o:`RiskMining.TaxOfRiskApp`/`赌博App老板`) {
Structure {
(s)-[:release]->(a:`RiskMining.TaxOfRiskApp`/`赌博应用`),
(u:RiskMining.Person)-[:developed]->(a),
(s)-[:fundTrans]->(u)
}
Constraint {
}
}
```
#### Scenario 3: Knowledge Application in the Context of hierarchical Business Knowledge and Factual Data
We can use GQL to query the criminal group information corresponding to black market applications.
**Retrieve all gambling applications**
Save the following content as file ``dsl_task1.txt``.
```cypher
MATCH (s:`RiskMining.TaxOfRiskApp`/`赌博应用`) RETURN s.id
```
Execute the query script.
```bash
knext reasoner execute --file dsl_task1.txt
```
**Retrieve the developers and owners of the gambling apps**
Save the following content as file ``dsl_task2.txt``.
```cypher
MATCH
(u:`RiskMining.TaxOfRiskUser`/`赌博App开发者`)-[:developed]->(app:`RiskMining.TaxOfRiskApp`/`赌博应用`),
(b:`RiskMining.TaxOfRiskUser`/`赌博App老板`)-[:release]->(app)
RETURN
u.id, b.id, app.id
```
Execute the query script.
```bash
knext reasoner execute --file dsl_task2.txt
```
### Step 7: Use KAG to implement natural language QA
Here is the content of the ``solver`` directory.
```text
solver
├── prompt
│ └── logic_form_plan.py
└── qa.py
```
Modify the prompt to implement NL2LF conversion in the RiskMining domain.
```python
class LogicFormPlanPrompt(PromptOp):
default_case_zh = """"cases": [
{
"Action": "张*三是一个赌博App的开发者吗?",
"answer": "Step1:查询是否张*三的分类\nAction1:get_spo(s=s1:自然人[张*三], p=p1:属于, o=o1:风险用户)\nOutput:输出o1\nAction2:get(o1)"
}
],"""
```
Assemble the solver code in ``qa.py``.
```python
def qa(self, query):
resp = SolverPipeline()
answer, trace_log = resp.run(query)
logger.info(f"\n\nso the answer for '{query}' is: {answer}\n\n")
return answer, trace_log
```
Execute ``qa.py``.
```bash
python ./solver/qa.py
``` | {
"source": "OpenSPG/KAG",
"title": "kag/examples/riskmining/README.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/kag/examples/riskmining/README.md",
"date": "2024-09-21T13:56:44",
"stars": 5095,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 6257
} |
# KAG 示例:黑产挖掘(RiskMining)
[English](./README.md) |
[简体中文](./README_cn.md)
**关键词**:语义属性,实体动态多分类,面向业务知识和事实数据分层下的知识应用

## 1. 前置条件
参考文档 [快速开始](https://openspg.yuque.com/ndx6g9/0.6/quzq24g4esal7q17) 安装 KAG 及其依赖的 OpenSPG server,了解开发者模式 KAG 的使用流程。
## 2. 复现步骤
### Step 1:进入示例目录
```bash
cd kag/examples/riskmining
```
### Step 2:配置模型
更新 [kag_config.yaml](./kag_config.yaml) 中的生成模型配置 ``openie_llm`` 和 ``chat_llm`` 和表示模型配置 ``vectorize_model``。
您需要设置正确的 ``api_key``。如果使用的模型供应商和模型名与默认值不同,您还需要更新 ``base_url`` 和 ``model``。
### Step 3:初始化项目
先对项目进行初始化。
```bash
knext project restore --host_addr http://127.0.0.1:8887 --proj_path .
```
### Step 4:知识建模
schema 文件已创建好,可执行如下命令提交。参见黑产 SPG Schema 模型 [RiskMining.schema](./schema/RiskMining.schema)。
```bash
knext schema commit
```
提交风险用户、风险 APP 的分类概念。参见黑产分类概念规则 [concept.rule](./schema/concept.rule)。
```bash
knext schema reg_concept_rule --file ./schema/concept.rule
```
### Step 5:知识构建
提交知识构建任务导入数据。
```bash
cd builder && python indexer.py && cd ..
```
### Step 6:执行图谱规则推理任务
SPG 支持 ISO GQL 语法,可用如下命令行执行查询任务。
```bash
knext reasoner execute --dsl "${ql}"
```
#### 场景 1:语义属性对比文本属性

电话号码:标准属性 vs 文本属性。
编辑 ``dsl_task.txt``,输入如下内容:
```cypher
MATCH
(phone:STD.ChinaMobile)<-[:hasPhone]-(u:RiskMining.Person)
RETURN
u.id, phone.id
```
执行脚本:
```bash
knext reasoner execute --file dsl_task.txt
```
#### 场景 2:实体动态多类型
**注意**:本节定义的分类规则 [concept.rule](./schema/concept.rule) 已经在前面的“Step 4:知识建模”章节里通过命令 ``knext schema reg_concept_rule`` 提交。
以下规则的详细内容也可以在黑产分类概念规则 [concept.rule](./schema/concept.rule) 中查看。
**赌博 App 的分类**
```text
Define (s:RiskMining.App)-[p:belongTo]->(o:`RiskMining.TaxOfRiskApp`/`赌博应用`) {
Structure {
(s)
}
Constraint {
R1("风险标记为赌博"): s.riskMark like "%赌博%"
}
}
```
王五为赌博应用开发者,李四为赌博应用老板,两个用户实体对应了不同的概念类型。
**赌博开发者认定规则**
**规则**:用户存在大于 5 台设备,且这些设备中安装了相同的 App,则存在开发关系。
```text
Define (s:RiskMining.Person)-[p:developed]->(o:RiskMining.App) {
Structure {
(s)-[:hasDevice]->(d:RiskMining.Device)-[:install]->(o)
}
Constraint {
deviceNum = group(s,o).count(d)
R1("设备超过5"): deviceNum > 5
}
}
```
```text
Define (s:RiskMining.Person)-[p:belongTo]->(o:`RiskMining.TaxOfRiskUser`/`赌博App开发者`) {
Structure {
(s)-[:developed]->(app:`RiskMining.TaxOfRiskApp`/`赌博应用`)
}
Constraint {
}
}
```
**认定赌博 App 老板**
**规则 1**:人和 App 存在发布关系。
```text
Define (s:RiskMining.Person)-[p:release]->(o:RiskMining.App) {
Structure {
(s)-[:holdShare]->(c:RiskMining.Company),
(c)-[:hasCert]->(cert:RiskMining.Cert)<-[useCert]-(o)
}
Constraint {
}
}
```
**规则 2**:用户给该赌博App开发者转账,并且存在发布赌博应用行为。
```text
Define (s:RiskMining.Person)-[p:belongTo]->(o:`RiskMining.TaxOfRiskApp`/`赌博App老板`) {
Structure {
(s)-[:release]->(a:`RiskMining.TaxOfRiskApp`/`赌博应用`),
(u:RiskMining.Person)-[:developed]->(a),
(s)-[:fundTrans]->(u)
}
Constraint {
}
}
```
#### 场景 3:面向业务知识和事实数据分层下的知识应用
基于 GQL 获取黑产应用对应的团伙信息。
**获取所有的赌博应用**
编辑 ``dsl_task1.txt``,输入如下内容:
```cypher
MATCH (s:`RiskMining.TaxOfRiskApp`/`赌博应用`) RETURN s.id
```
执行脚本:
```bash
knext reasoner execute --file dsl_task1.txt
```
**获取赌博 App 背后的开发者和老板**
编辑 ``dsl_task2.txt``,输入如下内容:
```cypher
MATCH
(u:`RiskMining.TaxOfRiskUser`/`赌博App开发者`)-[:developed]->(app:`RiskMining.TaxOfRiskApp`/`赌博应用`),
(b:`RiskMining.TaxOfRiskUser`/`赌博App老板`)-[:release]->(app)
RETURN
u.id, b.id, app.id
```
执行脚本:
```bash
knext reasoner execute --file dsl_task2.txt
```
### Step 7:使用 KAG 实现自然语言问答
以下是 solver 目录的内容。
```text
solver
├── prompt
│ └── logic_form_plan.py
└── qa.py
```
修改 prompt,实现领域内的 NL2LF 转换。
```python
class LogicFormPlanPrompt(PromptOp):
default_case_zh = """"cases": [
{
"Action": "张*三是一个赌博App的开发者吗?",
"answer": "Step1:查询是否张*三的分类\nAction1:get_spo(s=s1:自然人[张*三], p=p1:属于, o=o1:风险用户)\nOutput:输出o1\nAction2:get(o1)"
}
],"""
```
在 ``qa.py`` 中组装 solver 代码。
```python
def qa(self, query):
resp = SolverPipeline()
answer, trace_log = resp.run(query)
logger.info(f"\n\nso the answer for '{query}' is: {answer}\n\n")
return answer, trace_log
```
执行 ``qa.py``。
```bash
python ./solver/qa.py
``` | {
"source": "OpenSPG/KAG",
"title": "kag/examples/riskmining/README_cn.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/kag/examples/riskmining/README_cn.md",
"date": "2024-09-21T13:56:44",
"stars": 5095,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 4407
} |
# KAG Example: Enterprise Supply Chain Knowledge Graph (SupplyChain)
[English](./README.md) |
[简体中文](./README_cn.md)
## 1. Background
Credit institutions conduct comprehensive analysis of a company's financial condition, operating condition, market position, and management capabilities, and assign a rating grade to reflect the credit status of the company, in order to support credit business. In practice, it heavily relies on the information provided by the evaluated company itself, such as annual reports, various qualification documents, asset proofs, etc. This type of information can only provide micro-level information about the company itself and cannot reflect the company's market situation along the entire industry chain or obtain information beyond what is proven.
This example is based on the SPG framework to construct an industry chain enterprise Knowledge graph and extract in-depth information between companies based on the industry chain, to support company credit ratings.
## 2. Overview
Please refer to the document for knowledge modeling: [Schema of Enterprise Supply Chain Knowledge Graph](./schema/README.md), As shown in the example below:

Concept knowledge maintains industry chain-related data, including hierarchical relations, supply relations. Entity instances consist of only legal representatives and transfer information. Company instances are linked to product instances based on the attributes of the products they produce, enabling deep information mining between company instances, such as supplier relationships, industry peers, and shared legal representatives. By leveraging deep contextual information, more credit assessment factors can be provided.

Within the industrial chain, categories of product and company events are established. These categories are a combination of indices and trends. For example, an increase in price consists of the index "价格" (price) and the trend "上涨" (rising). Causal knowledge sets the events of a company's profit decrease and cost increase due to a rise in product prices. When a specific event occurs, such as a significant increase in rubber prices, it is categorized under the event of a price increase. As per the causal knowledge, a price increase in a product leads to two event types: a decrease in company profits and an increase in company costs. Consequently, new events are generated:"三角\*\*轮胎公司成本上涨事件" and "三角\*\*轮胎公司利润下跌".
## 3. Quick Start
### 3.1 Precondition
Please refer to [Quick Start](https://openspg.yuque.com/ndx6g9/cwh47i/rs7gr8g4s538b1n7) to install KAG and its dependency OpenSPG server, and learn about using KAG in developer mode.
### 3.2 Steps to reproduce
#### Step 1: Enter the example directory
```bash
cd kag/examples/supplychain
```
#### Step 2: Configure models
Update the generative model configurations ``openie_llm`` and ``chat_llm`` in [kag_config.yaml](./kag_config.yaml).
You need to fill in correct ``api_key``s. If your model providers and model names are different from the default values, you also need to update ``base_url`` and ``model``.
Since the representational model is not used in this example, you can retain the default configuration for the representative model ``vectorize_model``.
#### Step 3: Project initialization
Initiate the project with the following command.
```bash
knext project restore --host_addr http://127.0.0.1:8887 --proj_path .
```
#### Step 4: Create knowledge schema
The schema file has been created and you can execute the following command to submit it:
```bash
knext schema commit
```
Submit the *leadto* relationship logical rules:
```bash
knext schema reg_concept_rule --file ./schema/concept.rule
```
You can refer to [Schema of Enterprise Supply Chain Knowledge Graph](./schema/README.md) for detailed information on schema modeling.
#### Step 5: Knowledge graph construction
Knowledge construction involves importing data into the knowledge graph storage. For data introduction, please refer to the document: [Introduction to Data of Enterprise Supply Chain](./builder/data/README.md).
In this example, we will demonstrate the conversion of structured data and entity linking. For specific details, please refer to the document: [Enterprise Supply Chain Case Knowledge Graph Construction](./builder/README.md).
Submit the knowledge importing tasks.
```bash
cd builder && python indexer.py && cd ..
```
#### Step 6: Executing query tasks for knowledge graph
OpenSPG supports the ISO GQL syntax. You can use the following command-line to execute a query task:
```bash
knext reasoner execute --dsl "${ql}"
```
For specific task details, please refer to the document: [Enterprise Credit Graph Query Tasks in Supply Chain](./reasoner/README.md).
Querying Credit Rating Factors:
```bash
knext reasoner execute --dsl "
MATCH
(s:SupplyChain.Company)
RETURN
s.id, s.name, s.fundTrans1Month, s.fundTrans3Month,
s.fundTrans6Month, s.fundTrans1MonthIn, s.fundTrans3MonthIn,
s.fundTrans6MonthIn, s.cashflowDiff1Month, s.cashflowDiff3Month,
s.cashflowDiff6Month
"
```
```bash
knext reasoner execute --dsl "
MATCH
(s:SupplyChain.Company)-[:mainSupply]->(o:SupplyChain.Company)
RETURN
s.name, o.name
"
```
```bash
knext reasoner execute --dsl "
MATCH
(s:SupplyChain.Company)-[:belongToIndustry]->(o:SupplyChain.Industry)
RETURN
s.name, o.name
"
```
```bash
knext reasoner execute --dsl "
MATCH
(s:SupplyChain.Company)-[:sameLegalRepresentative]->(o:SupplyChain.Company)
RETURN
s.name, o.name
"
```
Analyzing the Impact of an Event:
```bash
knext reasoner execute --dsl "
MATCH
(s:SupplyChain.ProductChainEvent)-[:leadTo]->(o:SupplyChain.CompanyEvent)
RETURN
s.id, s.subject, o.subject, o.name
"
```
#### Step 7: Execute DSL and QA tasks
```bash
python ./solver/qa.py
``` | {
"source": "OpenSPG/KAG",
"title": "kag/examples/supplychain/README.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/kag/examples/supplychain/README.md",
"date": "2024-09-21T13:56:44",
"stars": 5095,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 6025
} |
# KAG 示例:企业供应链(SupplyChain)
[English](./README.md) |
[简体中文](./README_cn.md)
## 1. 背景
信贷机构对企业的财务状况、经营状况、市场地位、管理能力等进行综合分析,给予企业一个评级等级,反映其信用状况的好坏,以便支撑信贷业务。在实践中基本依赖被评估企业自身提供的信息,例如企业年报、各类资质文件、资产证明等,这一类信息只能围绕企业自身提供微观层面的信息,不能体现企业在整个产业链上下游市场情况,也无法得到证明之外的信息。
本例基于 SPG 构建产业链企业图谱,挖掘出企业之间基于产业链的深度信息,支持企业信用评级。
## 2. 总览
建模参考 [基于 SPG 建模的产业链企业图谱](./schema/README_cn.md),如下图示意。

概念知识维护着产业链相关数据,包括上下位层级、供应关系;实体实例仅有法人代表、转账信息,公司实例通过生产的产品属性和概念中的产品节点挂载,实现了公司实例之间的深度信息挖掘,例如供应商、同行业、同法人代表等关系。基于深度上下文信息,可提供更多的信用评估因子。

产业链中建立了产品和公司事件类别,该类别属于指标和趋势的一种组合,例如价格上涨,是由指标:价格,趋势:上涨两部分构成。
事理知识设定了产品价格上涨引起公司利润下降及公司成本上涨事件,当发生某个具体事件时,例如“橡胶价格大涨事件”,被归类在产品价格上涨,由于事理知识中定义产品价格上涨会引起公司利润下降/公司成本上涨两个事件类型,会产出新事件:“三角\*\*轮胎公司成本上涨事件”、“三角\*\*轮胎公司利润下跌”。
## 3. Quick Start
### 3.1 前置条件
请参考文档 [快速开始](https://openspg.yuque.com/ndx6g9/0.6/quzq24g4esal7q17) 安装 KAG 及其依赖的 OpenSPG server,并了解开发者模式 KAG 的使用流程。
### 3.2 复现步骤
#### Step 1:进入示例目录
```bash
cd kag/examples/supplychain
```
#### Step 2:配置模型
更新 [kag_config.yaml](./kag_config.yaml) 中的生成模型配置 ``openie_llm`` 和 ``chat_llm``。
您需要设置正确的 ``api_key``。如果使用的模型供应商和模型名与默认值不同,您还需要更新 ``base_url`` 和 ``model``。
在本示例中未使用表示模型,可保持表示模型配置 ``vectorize_model`` 的默认配置。
#### Step 3:初始化项目
先对项目进行初始化。
```bash
knext project restore --host_addr http://127.0.0.1:8887 --proj_path .
```
#### Step 4:知识建模
schema 文件已创建好,可执行如下命令提交。
```bash
knext schema commit
```
提交 *leadto* 关系逻辑规则。
```bash
knext schema reg_concept_rule --file ./schema/concept.rule
```
schema 建模详细内容可参见 [基于 SPG 建模的产业链企业图谱](./schema/README_cn.md)。
#### Step 5:知识构建
知识构建将数据导入到系统中,数据介绍参见文档 [产业链案例数据介绍](./builder/data/README_cn.md)。
本例主要为结构化数据,故演示结构化数据转换和实体链指,具体细节可参见文档 [产业链案例知识构建](./builder/README_cn.md)。
提交知识构建任务导入数据。
```bash
cd builder && python indexer.py && cd ..
```
#### Step 6:执行图谱任务
SPG 支持 ISO GQL 语法,可用如下命令行执行查询任务。
```bash
knext reasoner execute --dsl "${ql}"
```
具体任务详情可参见文档 [产业链企业信用图谱查询任务](./reasoner/README_cn.md)。
查询信用评级因子:
```bash
knext reasoner execute --dsl "
MATCH
(s:SupplyChain.Company)
RETURN
s.id, s.name, s.fundTrans1Month, s.fundTrans3Month,
s.fundTrans6Month, s.fundTrans1MonthIn, s.fundTrans3MonthIn,
s.fundTrans6MonthIn, s.cashflowDiff1Month, s.cashflowDiff3Month,
s.cashflowDiff6Month
"
```
```bash
knext reasoner execute --dsl "
MATCH
(s:SupplyChain.Company)-[:mainSupply]->(o:SupplyChain.Company)
RETURN
s.name, o.name
"
```
```bash
knext reasoner execute --dsl "
MATCH
(s:SupplyChain.Company)-[:belongToIndustry]->(o:SupplyChain.Industry)
RETURN
s.name, o.name
"
```
```bash
knext reasoner execute --dsl "
MATCH
(s:SupplyChain.Company)-[:sameLegalRepresentative]->(o:SupplyChain.Company)
RETURN
s.name, o.name
"
```
事件影响分析:
```bash
knext reasoner execute --dsl "
MATCH
(s:SupplyChain.ProductChainEvent)-[:leadTo]->(o:SupplyChain.CompanyEvent)
RETURN
s.id, s.subject, o.subject, o.name
"
```
#### Step 7:执行 DSL 及 QA 任务
```bash
python ./solver/qa.py
``` | {
"source": "OpenSPG/KAG",
"title": "kag/examples/supplychain/README_cn.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/kag/examples/supplychain/README_cn.md",
"date": "2024-09-21T13:56:44",
"stars": 5095,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 3113
} |
# Enterprise Supply Chain Case Knowledge Graph Construction
[English](./README.md) |
[简体中文](./README_cn.md)
In this example, all the data are structured. There are two main capabilities required in to import the data:
* Structured Mapping: The original data and the schema-defined fields are not completely consistent, so a data field mapping process needs to be defined.
* Entity Linking: In relationship building, entity linking is a very important construction method. This example demonstrates a simple case of implementing entity linking capability for companies.
## 1. Structured Mapping from Source Data to SPG Data
Taking the import of ``Company`` instances as an example:
```text
id,name,products
CSF0000000254,北大*药*份限公司,"医疗器械批发,医药批发,制药,其他化学药品"
```
The code for importing ``Company`` instances is as follows:
```python
class SupplyChainDefaulStructuredBuilderChain(BuilderChainABC):
def __init__(self, spg_type_name: str):
super().__init__()
self.spg_type_name = spg_type_name
def build(self, **kwargs):
"""
Builds the processing chain for the SPG.
Args:
**kwargs: Additional keyword arguments.
Returns:
chain: The constructed processing chain.
"""
self.mapping = SPGTypeMapping(spg_type_name=self.spg_type_name)
self.sink = KGWriter()
self.vectorizer = BatchVectorizer.from_config(
KAG_CONFIG.all_config["chain_vectorizer"]
)
chain = self.mapping >> self.vectorizer >> self.sink
return chain
def get_component_with_ckpts(self):
return [
self.vectorizer,
]
```
In general, this mapping relationship can satisfy the import of structured data. However, in some scenarios, it may be necessary to manipulate the data to meet specific requirements. In such cases, we need to implemented a user-defined operator.
## 2. User-defined Entity Linking Operator
Consider the following data:
```text
id,name,age,legalRep
0,路**,63,"新疆*花*股*限公司,三角*胎股*限公司,传化*联*份限公司"
```
The ``legalRep`` field is the company name, but the company ID is set as the primary key, it is not possible to directly associate the company name with a specific company. Assuming there is a search service available that can convert the company name to an ID, a user-defined linking operator needs to be developed to perform this conversion.
```python
def company_link_func(prop_value, node):
sc = SearchClient(KAG_PROJECT_CONF.host_addr, KAG_PROJECT_CONF.project_id)
company_id = []
records = sc.search_text(
prop_value, label_constraints=["SupplyChain.Company"], topk=1
)
if records:
company_id.append(records[0]["node"]["id"])
return company_id
class SupplyChainPersonChain(BuilderChainABC):
def __init__(self, spg_type_name: str):
# super().__init__()
self.spg_type_name = spg_type_name
def build(self, **kwargs):
self.mapping = (
SPGTypeMapping(spg_type_name=self.spg_type_name)
.add_property_mapping("name", "name")
.add_property_mapping("id", "id")
.add_property_mapping("age", "age")
.add_property_mapping(
"legalRepresentative",
"legalRepresentative",
link_func=company_link_func,
)
)
self.vectorizer = BatchVectorizer.from_config(
KAG_CONFIG.all_config["chain_vectorizer"]
)
self.sink = KGWriter()
return self.mapping >> self.vectorizer >> self.sink
def get_component_with_ckpts(self):
return [
self.vectorizer,
]
def close_checkpointers(self):
for node in self.get_component_with_ckpts():
if node and hasattr(node, "checkpointer"):
node.checkpointer.close()
``` | {
"source": "OpenSPG/KAG",
"title": "kag/examples/supplychain/builder/README.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/kag/examples/supplychain/builder/README.md",
"date": "2024-09-21T13:56:44",
"stars": 5095,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 3857
} |
# 产业链案例知识构建
[English](./README.md) |
[简体中文](./README_cn.md)
本例中数据均为结构化数据,导入数据主要需要两个能力:
* 结构化 mapping:原始数据和 schema 定义表字段并不完全一致,需要定义数据字段映射过程。
* 实体链指:在关系构建中,实体链指是非常重要的建设手段,本例演示一个简单 case,实现公司的链指能力。
本例中的代码可在 [kag/examples/supplychain/builder/indexer.py](./indexer.py) 中查看。
## 1. 源数据到 SPG 数据的 mapping 能力
以导入 Company 数据为例:
```text
id,name,products
CSF0000000254,北大*药*份限公司,"医疗器械批发,医药批发,制药,其他化学药品"
```
导入 Company 的代码如下:
```python
class SupplyChainDefaulStructuredBuilderChain(BuilderChainABC):
def __init__(self, spg_type_name: str):
super().__init__()
self.spg_type_name = spg_type_name
def build(self, **kwargs):
"""
Builds the processing chain for the SPG.
Args:
**kwargs: Additional keyword arguments.
Returns:
chain: The constructed processing chain.
"""
self.mapping = SPGTypeMapping(spg_type_name=self.spg_type_name)
self.sink = KGWriter()
self.vectorizer = BatchVectorizer.from_config(
KAG_CONFIG.all_config["chain_vectorizer"]
)
chain = self.mapping >> self.vectorizer >> self.sink
return chain
def get_component_with_ckpts(self):
return [
self.vectorizer,
]
```
一般情况下这种映射关系基本能够满足结构化数据导入,但在一些场景下可能需要对数据进行部分数据才能满足要求,此时就需要实现自定义算子来处理问题。
## 2. 自定义算子实现链指能力
假设有如下数据:
```text
id,name,age,legalRep
0,路**,63,"新疆*花*股*限公司,三角*胎股*限公司,传化*联*份限公司"
```
``legalRep`` 字段为公司名字,但在系统中已经将公司 ``id`` 设置成为主键,直接通过公司名是无法关联到具体公司,假定存在一个搜索服务,可将公司名转换为 ``id``,此时需要自定开发一个链指算子,实现该过程的转换:
```python
def company_link_func(prop_value, node):
sc = SearchClient(KAG_PROJECT_CONF.host_addr, KAG_PROJECT_CONF.project_id)
company_id = []
records = sc.search_text(
prop_value, label_constraints=["SupplyChain.Company"], topk=1
)
if records:
company_id.append(records[0]["node"]["id"])
return company_id
class SupplyChainPersonChain(BuilderChainABC):
def __init__(self, spg_type_name: str):
# super().__init__()
self.spg_type_name = spg_type_name
def build(self, **kwargs):
self.mapping = (
SPGTypeMapping(spg_type_name=self.spg_type_name)
.add_property_mapping("name", "name")
.add_property_mapping("id", "id")
.add_property_mapping("age", "age")
.add_property_mapping(
"legalRepresentative",
"legalRepresentative",
link_func=company_link_func,
)
)
self.vectorizer = BatchVectorizer.from_config(
KAG_CONFIG.all_config["chain_vectorizer"]
)
self.sink = KGWriter()
return self.mapping >> self.vectorizer >> self.sink
def get_component_with_ckpts(self):
return [
self.vectorizer,
]
def close_checkpointers(self):
for node in self.get_component_with_ckpts():
if node and hasattr(node, "checkpointer"):
node.checkpointer.close()
``` | {
"source": "OpenSPG/KAG",
"title": "kag/examples/supplychain/builder/README_cn.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/kag/examples/supplychain/builder/README_cn.md",
"date": "2024-09-21T13:56:44",
"stars": 5095,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 3003
} |
# Enterprise Credit Graph Query Tasks in Supply Chain
[English](./README.md) |
[简体中文](./README_cn.md)
## Scenario 1: Generation of Enterprise Credit Rating Features
Requirement: In enterprise credit rating, the following decision factors are needed:
1. Primary supplier relations
2. Industry of the products produced by the enterprise
3. Transfer transaction records of funds for the past 1 month, 3 months, and 6 months
4. Difference in funds flow for the past 1 month, 3 months, and 6 months
5. Information on related companies controlled by the ultimate beneficial owner
However, in the original knowledge graph, only fund transfer transactions and legal representative information are available, making it impossible to directly obtain the above features. This example demonstrates how to use OpenSPG to obtain these 5 features.
The feature definitions are present in the schema file, which can be viewed by clicking [SupplyChain.schema](../schema/SupplyChain.schema).
**Feature 1: Defining primary supply chain relations between companies**
with the following rule definition:
```text
Define (s:Compnay)-[p:mainSupply]->(o:Company) {
Structure {
(s)-[:product]->(upProd:Product)-[:hasSupplyChain]->(downProd:Product)<-[:product]-(o),
(o)-[f:fundTrans]->(s)
(otherCompany:Company)-[otherf:fundTrans]->(s)
}
Constraint {
// Compute the percentage of incoming transfers for company `o`
otherTransSum("Total amount of incoming transfers") = group(s).sum(otherf.transAmt)
targetTransSum("Total amount of transfers received by company o") = group(s,o).sum(f.transAmt)
transRate = targetTransSum*1.0/(otherTransSum + targetTransSum)
R1("The percentage must be over 50%"): transRate > 0.5
}
}
```
**Feature 2: Industry of the Products Produced by the Enterprise**
```text
Define (s:Compnay)-[p:belongToIndustry]->(o:Industry) {
Structure {
(s)-[:product]->(c:Product)-[:belongToIndustry]->(o)
}
Constraint {
}
}
```
**Feature 3: Transfer transaction records of funds for the past 1 month, 3 months, and 6 months**
```text
// Amount of outgoing transfers for the past 1 month
Define (s:Compnay)-[p:fundTrans1Month]->(o:Int) {
Structure {
(s)-[f:fundTrans]->(c:Company)
}
Constraint {
R1("Transactions within the past 1 month"): date_diff(from_unix_time(now(), 'yyyyMMdd'),f.transDate) < 30
totalOut = group(s).sum(transAmt)
o = totalOut
}
}
// Amount of outgoing transfers for the past 3 month
Define (s:Compnay)-[p:fundTrans3Month]->(o:Int) {
Structure {
(s)-[f:fundTrans]->(c:Company)
}
Constraint {
R1("Transactions within the past 4 month"): date_diff(from_unix_time(now(), 'yyyyMMdd'),f.transDate) < 90
totalOut = group(s).sum(transAmt)
o = totalOut
}
}
// Amount of outgoing transfers for the past 6 month
Define (s:Compnay)-[p:fundTrans6Month]->(o:Int) {
Structure {
(s)-[f:fundTrans]->(c:Company)
}
Constraint {
R1("Transactions within the past 6 month"): date_diff(from_unix_time(now(), 'yyyyMMdd'),f.transDate) < 180
totalOut = group(s).sum(transAmt)
o = totalOut
}
}
// Amount of incoming transfers for the past 1 month
Define (s:Compnay)-[p:fundTrans1MonthIn]->(o:Int) {
Structure {
(s)<-[f:fundTrans]-(c:Company)
}
Constraint {
R1("Transactions within the past 1 month"): date_diff(from_unix_time(now(), 'yyyyMMdd'),f.transDate) < 30
totalOut = group(s).sum(transAmt)
o = totalOut
}
}
// Amount of incoming transfers for the past 3 month
Define (s:Compnay)-[p:fundTrans3MonthIn]->(o:Int) {
Structure {
(s)<-[f:fundTrans]-(c:Company)
}
Constraint {
R1("Transactions within the past 3 month"): date_diff(from_unix_time(now(), 'yyyyMMdd'),f.transDate) < 90
totalOut = group(s).sum(transAmt)
o = totalOut
}
}
// Amount of incoming transfers for the past 6 month
Define (s:Compnay)-[p:fundTrans6MonthIn]->(o:Int) {
Structure {
(s)<-[f:fundTrans]-(c:Company)
}
Constraint {
R1("Transactions within the past 6 month"): date_diff(from_unix_time(now(), 'yyyyMMdd'),f.transDate) < 180
totalOut = group(s).sum(transAmt)
o = totalOut
}
}
```
**Feature 4: Difference in funds flow for the past 1 month, 3 months, and 6 months**
```text
// Funds flow difference in the past 1 month
Define (s:Company)-[p:cashflowDiff1Month]->(o:Integer) {
Structure {
(s)
}
Constraint {
// Refer to the rule in Feature 3
fundTrans1Month = rule_value(s.fundTrans1Month == null, 0, s.fundTrans1Month)
fundTrans1MonthIn = rule_value(s.fundTrans1MonthIn == null, 0, s.fundTrans1MonthIn)
o = fundTrans1Month - fundTrans1MonthIn
}
}
// Funds flow difference in the past 3 month
Define (s:Company)-[p:cashflowDiff3Month]->(o:Integer) {
Structure {
(s)
}
Constraint {
// Refer to the rule in Feature 3
fundTrans3Month = rule_value(s.fundTrans3Month == null, 0, s.fundTrans3Month)
fundTrans3MonthIn = rule_value(s.fundTrans3MonthIn == null, 0, s.fundTrans3MonthIn)
o = fundTrans3Month - fundTrans3MonthIn
}
}
// Funds flow difference in the past 6 month
Define (s:Company)-[p:cashflowDiff6Month]->(o:Integer) {
Structure {
(s)
}
Constraint {
fundTrans6Month = rule_value(s.fundTrans6Month == null, 0, s.fundTrans6Month)
fundTrans6MonthIn = rule_value(s.fundTrans6MonthIn == null, 0, s.fundTrans6MonthIn)
o = fundTrans6Month - fundTrans6MonthIn
}
}
```
**Feature 5: Information on related companies controlled by the ultimate beneficial owner**
```text
// Definition of the "same legal reprensentative" relation
Define (s:Compnay)-[p:sameLegalReprensentative]->(o:Company) {
Structure {
(s)<-[:legalReprensentative]-(u:Person)-[:legalReprensentative]->(o)
}
Constraint {
}
}
```
Obtaining specific features of a particular company through GQL using the following query:
```cypher
MATCH
(s:SupplyChain.Company)
RETURN
s.id, s.fundTrans1Month, s.fundTrans3Month,
s.fundTrans6Month, s.fundTrans1MonthIn, s.fundTrans3MonthIn,
s.fundTrans6MonthIn, s.cashflowDiff1Month, s.cashflowDiff3Month, s.cashflowDiff6Month
```
```cypher
MATCH
(s:SupplyChain.Company)-[:mainSupply]->(o:SupplyChain.Company)
RETURN
s.id, o.id
```
```cypher
MATCH
(s:SupplyChain.Company)-[:belongToIndustry]->(o:SupplyChain.Industry)
RETURN
s.id, o.id
```
```cypher
MATCH
(s:SupplyChain.Company)-[:sameLegalRepresentative]->(o:SupplyChain.Company)
RETURN
s.id, o.id
```
## Scenario 2: Change in the company's supply chain
Suppose that there is a change in the products produced by the company:
```text
"钱****份限公司"发布公告,生产产品“三轮摩托车,二轮摩托车”变更为“两轮摩托车”,则"三角**轮胎股份"和钱"****份限公司"的主供应链关系自动断裂,"三角**轮胎股份"和"钱****份限公司"不再具有主供应链关系
```
The updated data is available in ``CompanyUpdate.csv``:
```text
id,name,products
CSF0000001662,浙江**摩托**限公司,"汽车-摩托车制造-二轮摩托车"
```
resubmit the building task:
```bash
knext builder execute CompanyUpdate
```
After the execution is completed, if you query again, only the Two-Wheeled Motorcycle will be returned, and the Three-Wheeled Motorcycle will no longer be associated.
```cypher
MATCH
(s:SupplyChain.Company)-[:product]->(o:SupplyChain.Product)
WHERE
s.id = "CSF0000001662"
RETURN
s.id, o.id
```
## Scenario 3: Impact on the Supply Chain Event
The event details are as follows:
```text
id,name,subject,index,trend
1,顺丁橡胶成本上涨,商品化工-橡胶-合成橡胶-顺丁橡胶,价格,上涨
```
submit the building task of the event type:
```bash
knext builder execute ProductChainEvent
```
The transmission linkages are as follows:

Butadiene rubber costs rise, classified as an event of price increase in the supply chain.
The logical rule expression is as follows:
```text
// When the attributes of ProductChainEvent satisfy the condition of price increase,
// the event is classified as a price increase event.
Define (e:ProductChainEvent)-[p:belongTo]->(o:`TaxonofProductChainEvent`/`价格上涨`) {
Structure {
}
Constraint {
R1: e.index == '价格'
R2: e.trend == '上涨'
}
}
```
Price increase in the supply chain, under the following conditions, will result in cost rise for specific companies.
```text
// The rules for price increase and increase in company costs are defined as follows.
Define (s:`TaxonofProductChainEvent`/`价格上涨`)-[p:leadTo]->(o:`TaxonofCompanyEvent`/`成本上涨`) {
Structure {
//1. Find the subject of the supply chain event, which is butadiene rubber in this case
//2. Identify the downstream products of butadiene rubber, which are bias tires in this case
//3. Identify all the companies that produce bias tires, which is "Triangle** Tire Co., Ltd." in this case
(s)-[:subject]->[prod:Product]-[:hasSupplyChain]->(down:Product)<-[:product]-(c:Company)
}
Constraint {
}
Action {
// Create a company cost increase event with the subject being the obtained "Triangle** Tire Co., Ltd."
downEvent = createNodeInstance(
type=CompanyEvent,
value={
subject=c.id
trend="上涨"
index="成本"
}
)
// Since this event is caused by a price increase in the supply chain, add an edge between them.
createEdgeInstance(
src=s,
dst=downEvent,
type=leadTo,
value={
}
)
}
}
```
You can find the impact of a specific event by using the following query statement.
```cypher
MATCH
(s:SupplyChain.ProductChainEvent)-[:leadTo]->(o:SupplyChain.CompanyEvent)
RETURN
s.id,s.subject,o.subject,o.name
``` | {
"source": "OpenSPG/KAG",
"title": "kag/examples/supplychain/reasoner/README.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/kag/examples/supplychain/reasoner/README.md",
"date": "2024-09-21T13:56:44",
"stars": 5095,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 9978
} |
# 产业链企业信用图谱查询任务
[English](./README.md) |
[简体中文](./README_cn.md)
## 场景 1:企业信用评级特征生成
需求:在企业信用评级中,假定需要得到如下决策因子
1. 主供应商关系
2. 企业生产产品所在行业
3. 企业资金近 1 月、3 月、6 月转账流水
4. 企业资金近 1 月、3 月、6 月流水差
5. 实控人相关公司信息
但在原有图谱中,只有资金转账、法人代表信息,无法直接获取上述特征,本例演示如何通过 SPG 完成如上 5 个特征获取。
特征定义在 schema 文件中,可点击查看企业供应链图谱 schema [SupplyChain.schema](./SupplyChain.schema)。
**特征 1:先定义企业和企业间的主供应链关系,规则定义如下**
```text
Define (s:Compnay)-[p:mainSupply]->(o:Company) {
Structure {
(s)-[:product]->(upProd:Product)-[:hasSupplyChain]->(downProd:Product)<-[:product]-(o),
(o)-[f:fundTrans]->(s)
(otherCompany:Company)-[otherf:fundTrans]->(s)
}
Constraint {
// 计算公司o的转入占比
otherTransSum("总共转入金额") = group(s).sum(otherf.transAmt)
targetTransSum("o转入的金额总数") = group(s,o).sum(f.transAmt)
transRate = targetTransSum*1.0/(otherTransSum + targetTransSum)
R1("占比必须超过50%"): transRate > 0.5
}
}
```
**特征 2:企业生成产品所在行业**
```text
Define (s:Compnay)-[p:belongToIndustry]->(o:Industry) {
Structure {
(s)-[:product]->(c:Product)-[:belongToIndustry]->(o)
}
Constraint {
}
}
```
**特征 3:企业资金近 1 月、3 月、6 月转账流水**
```text
// 近1个月流出金额
Define (s:Compnay)-[p:fundTrans1Month]->(o:Int) {
Structure {
(s)-[f:fundTrans]->(c:Company)
}
Constraint {
R1("近1个月的流出资金"): date_diff(from_unix_time(now(), 'yyyyMMdd'),f.transDate) < 30
totalOut = group(s).sum(transAmt)
o = totalOut
}
}
// 近3个月流出金额
Define (s:Compnay)-[p:fundTrans3Month]->(o:Int) {
Structure {
(s)-[f:fundTrans]->(c:Company)
}
Constraint {
R1("近4个月的流出资金"): date_diff(from_unix_time(now(), 'yyyyMMdd'),f.transDate) < 90
totalOut = group(s).sum(transAmt)
o = totalOut
}
}
// 近6个月流出金额
Define (s:Compnay)-[p:fundTrans6Month]->(o:Int) {
Structure {
(s)-[f:fundTrans]->(c:Company)
}
Constraint {
R1("近5个月的流出资金"): date_diff(from_unix_time(now(), 'yyyyMMdd'),f.transDate) < 180
totalOut = group(s).sum(transAmt)
o = totalOut
}
}
// 近1个月流入金额
Define (s:Compnay)-[p:fundTrans1MonthIn]->(o:Int) {
Structure {
(s)<-[f:fundTrans]-(c:Company)
}
Constraint {
R1("近1个月的流入资金"): date_diff(from_unix_time(now(), 'yyyyMMdd'),f.transDate) < 30
totalOut = group(s).sum(transAmt)
o = totalOut
}
}
// 近3个月流入金额
Define (s:Compnay)-[p:fundTrans3MonthIn]->(o:Int) {
Structure {
(s)<-[f:fundTrans]-(c:Company)
}
Constraint {
R1("近3个月的流入资金"): date_diff(from_unix_time(now(), 'yyyyMMdd'),f.transDate) < 90
totalOut = group(s).sum(transAmt)
o = totalOut
}
}
// 近6个月流入金额
Define (s:Compnay)-[p:fundTrans6MonthIn]->(o:Int) {
Structure {
(s)<-[f:fundTrans]-(c:Company)
}
Constraint {
R1("近6个月的流入资金"): date_diff(from_unix_time(now(), 'yyyyMMdd'),f.transDate) < 180
totalOut = group(s).sum(transAmt)
o = totalOut
}
}
```
**特征 4:企业资金近 1 月、3 月、6 月流水差**
```text
// 近1个月资金流水差
Define (s:Company)-[p:cashflowDiff1Month]->(o:Integer) {
Structure {
(s)
}
Constraint {
// 此处引用特征3中的规则
fundTrans1Month = rule_value(s.fundTrans1Month == null, 0, s.fundTrans1Month)
fundTrans1MonthIn = rule_value(s.fundTrans1MonthIn == null, 0, s.fundTrans1MonthIn)
o = fundTrans1Month - fundTrans1MonthIn
}
}
// 近3个月资金流水差
Define (s:Company)-[p:cashflowDiff3Month]->(o:Integer) {
Structure {
(s)
}
Constraint {
// 此处引用特征3中的规则
fundTrans3Month = rule_value(s.fundTrans3Month == null, 0, s.fundTrans3Month)
fundTrans3MonthIn = rule_value(s.fundTrans3MonthIn == null, 0, s.fundTrans3MonthIn)
o = fundTrans3Month - fundTrans3MonthIn
}
}
// 近6个月资金流水差
Define (s:Company)-[p:cashflowDiff6Month]->(o:Integer) {
Structure {
(s)
}
Constraint {
fundTrans6Month = rule_value(s.fundTrans6Month == null, 0, s.fundTrans6Month)
fundTrans6MonthIn = rule_value(s.fundTrans6MonthIn == null, 0, s.fundTrans6MonthIn)
o = fundTrans6Month - fundTrans6MonthIn
}
}
```
**特征 5:同实控人公司**
```text
// 定义同法人关系
Define (s:Compnay)-[p:sameLegalReprensentative]->(o:Company) {
Structure {
(s)<-[:legalReprensentative]-(u:Person)-[:legalReprensentative]->(o)
}
Constraint {
}
}
```
通过如下 GQL 执行得到某个公司的具体特征:
```cypher
MATCH
(s:SupplyChain.Company)
RETURN
s.id, s.fundTrans1Month, s.fundTrans3Month,
s.fundTrans6Month, s.fundTrans1MonthIn, s.fundTrans3MonthIn,
s.fundTrans6MonthIn, s.cashflowDiff1Month, s.cashflowDiff3Month, s.cashflowDiff6Month
```
```cypher
MATCH
(s:SupplyChain.Company)-[:mainSupply]->(o:SupplyChain.Company)
RETURN
s.id, o.id
```
```cypher
MATCH
(s:SupplyChain.Company)-[:belongToIndustry]->(o:SupplyChain.Industry)
RETURN
s.id, o.id
```
```cypher
MATCH
(s:SupplyChain.Company)-[:sameLegalRepresentative]->(o:SupplyChain.Company)
RETURN
s.id, o.id
```
## 场景 2:企业供应链发生变化
假设供应链发生如下变化:
```text
"钱****份限公司"发布公告,生产产品“三轮摩托车,二轮摩托车”变更为“两轮摩托车”,则"三角**轮胎股份"和钱"****份限公司"的主供应链关系自动断裂,"三角**轮胎股份"和"钱****份限公司"不再具有主供应链关系
```
变更后的数据保存在 ``CompanyUpdate.csv``:
```text
id,name,products
CSF0000001662,浙江**摩托**限公司,"汽车-摩托车制造-二轮摩托车"
```
重新提交任务:
```bash
knext builder execute CompanyUpdate
```
执行完成后再次查询,只会返回二轮摩托车,而三轮摩托车不再被关联:
```cypher
MATCH
(s:SupplyChain.Company)-[:product]->(o:SupplyChain.Product)
WHERE
s.id = "CSF0000001662"
RETURN
s.id, o.id
```
## 场景 3:产业链影响
事件内容如下:
```text
id,name,subject,index,trend
1,顺丁橡胶成本上涨,商品化工-橡胶-合成橡胶-顺丁橡胶,价格,上涨
```
提交事件数据:
```bash
knext builder execute ProductChainEvent
```
传导链路如下:

顺丁橡胶成本上升,被分类为产业链价格上涨事件,如下 DSL:
```text
// ProductChainEvent为一个具体的事件实例,当其属性满足价格上涨条件时,该事件分类为价格上涨事件
Define (e:ProductChainEvent)-[p:belongTo]->(o:`TaxonofProductChainEvent`/`价格上涨`) {
Structure {
}
Constraint {
R1: e.index == '价格'
R2: e.trend == '上涨'
}
}
```
产业链价格上涨,在如下条件下,会导致特定公司的成本上升。
```text
// 定义了价格上涨和企业成本上升的规则
Define (s:`TaxonofProductChainEvent`/`价格上涨`)-[p:leadTo]->(o:`TaxonofCompanyEvent`/`成本上涨`) {
Structure {
//1、找到产业链事件的主体,本例中为顺丁橡胶
//2、找到顺丁橡胶的下游产品,本例中为斜交轮胎
//3、找到生成斜交轮胎的所有企业,本例中为三角**轮胎股份
(s)-[:subject]->[prod:Product]-[:hasSupplyChain]->(down:Product)<-[:product]-(c:Company)
}
Constraint {
}
Action {
// 创建一个公司成本上升事件,主体为查询得到的三角**轮胎股份
downEvent = createNodeInstance(
type=CompanyEvent,
value={
subject=c.id
trend="上涨"
index="成本"
}
)
// 由于这个事件是通过产业链价格上涨引起,故在两者之间增加一条边
createEdgeInstance(
src=s,
dst=downEvent,
type=leadTo,
value={
}
)
}
}
```
可通过如下查询语句查出某个事件产生的影响。
```cypher
MATCH
(s:SupplyChain.ProductChainEvent)-[:leadTo]->(o:SupplyChain.CompanyEvent)
RETURN
s.id,s.subject,o.subject,o.name
``` | {
"source": "OpenSPG/KAG",
"title": "kag/examples/supplychain/reasoner/README_cn.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/kag/examples/supplychain/reasoner/README_cn.md",
"date": "2024-09-21T13:56:44",
"stars": 5095,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 7078
} |
# Schema of Enterprise Supply Chain Knowledge Graph
[English](./README.md) |
[简体中文](./README_cn.md)
## 1. Schema details
For an introduction of OpenSPG schema, please refer to [Declarative Schema](https://openspg.yuque.com/ndx6g9/cwh47i/fiq6zum3qtzr7cne).
For the modeling of the Enterprise Supply Chain Knowledge Graph, please refer to the schema source file [SupplyChain.schema](./SupplyChain.schema).
Execute the following command to finish creating the schema:
```bash
knext schema commit
```
## 2. SPG Modeling vs Property Graph Modeling
This section will compare the differences between SPG semantic modeling and regular modeling.
### 2.1 Semantic Attributes vs Text Attributes
Assuming the following information related the company exists:
"北大药份限公司" produces four products: "医疗器械批发,医药批发,制药,其他化学药品".
```text
id,name,products
CSF0000000254,北大*药*份限公司,"医疗器械批发,医药批发,制药,其他化学药品"
```
#### 2.1.1 Modeling based on text attributes
```text
//Text Attributes
Company(企业): EntityType
properties:
product(经营产品): Text
```
At this moment, the products are only represented as text without semantic information. It is not possible to obtain the upstream and downstream industry chain related information for "北大药份限公司", which is inconvenient for maintenance and usage.
#### 2.1.2 Modeling based on relations
To achieve better maintenance and management of the products, it is generally recommended to represent the products as entities and establish relations between the company and its products.
```text
Product(产品): EntityType
properties:
name(产品名): Text
relations:
isA(上位产品): Product
Company(企业): EntityType
relations:
product(经营产品): Product
```
However, such modeling method requires the data to be divided into four columns:
```text
id,name,product
CSF0000000254,北大*药*份限公司,医疗器械批发
CSF0000000254,北大*药*份限公司,医药批发
CSF0000000254,北大*药*份限公司,制药
CSF0000000254,北大*药*份限公司,其他化学药品
```
This approach has two disadvantages:
1. The raw data needs to be cleaned and converted into multiple rows.
2. It requires adding and maintaining relation data. When the original data changes, the existing relations need to be deleted and new data needs to be added, which can lead to data errors.
#### 2.1.3 Modeling based on SPG semantic attributes
SPG supports semantic attributes, which can simplify knowledge construction.
The modeling can be done as follows:
```text
Product(产品): ConceptType
hypernymPredicate: isA
Company(企业): EntityType
properties:
product(经营产品): Product
constraint: MultiValue
```
In this model, the ``Company`` entity has a property called "经营产品" (Business Product), which is ``Product`` type. By importing the following data, the conversion from attribute to relation can be automatically achieved.
```text
id,name,products
CSF0000000254,北大*药*份限公司,"医疗器械批发,医药批发,制药,其他化学药品"
```
### 2.2 Logical Expression of Attributes and Relationships vs Data Representation of Attributes and Relationships
Assuming the goal is to obtain the industry of a company. Based on the available data, the following query can be executed:
```cypher
MATCH
(s:Company)-[:product]->(o:Product)-[:belongToIndustry]->(i:Industry)
RETURN
s.id, i.id
```
This approach requires familiarity with the graph schema and has a higher learning curve for users. Therefore, another practice is to re-import these types of attributes into the knowledge graph, as shown below:
```text
Company(企业): EntityType
properties:
product(经营产品): Product
constraint: MultiValue
relations:
belongToIndustry(所在行业): Industry
```
To directly obtain the industry information of a company, a new relation type can be added. However, there are two main drawbacks to this approach:
1. It requires manual maintenance of the newly added relation data, increasing the cost of maintenance.
2. Due to the dependency on the source of the new relation and the knowledge graph data, it is very easy to introduce inconsistencies.
To address these drawbacks, OpenSPG supports logical expression of attributes and relations.
The modeling can be done as follows:
```text
Company(企业): EntityType
properties:
product(经营产品): Product
constraint: MultiValue
relations:
belongToIndustry(所在行业): Industry
rule: [[
Define (s:Company)-[p:belongToIndustry]->(o:Industry) {
Structure {
(s)-[:product]->(c:Product)-[:belongToIndustry]->(o)
}
Constraint {
}
}
]]
```
You can refer to the examples in Scenario 1 and Scenario 2 of the [Enterprise Credit Graph Query Tasks in Supply Chain](../reasoner/README.md) for specific details.
### 2.3 Concepts vs Entities
Existing knowledge graph solutions also include common sense knowledge graphs such as ConceptNet. In practical business applications, different domains have their own categorical systems that reflect the semantic understanding of the business. There is no universal common sense graph that can be applied to all business scenarios. Therefore, a common practice is to create the domain-specific categorical system as entities and mix them with other entity data. This approach leads to the need for both schema extension modeling and fine-grained semantic modeling on the same categorical system. The coupling of data structure definition and semantic modeling results in complexity in engineering implementation and maintenance management. It also increases the difficulty in organizing and representing (cognitive) domain knowledge.
OpenSPG distinguishes between concepts and entities to decouple semantics from data. This helps address the challenges mentioned above.
```text
Product(产品): ConceptType
hypernymPredicate: isA
Company(企业): EntityType
properties:
product(经营产品): Product
constraint: MultiValue
```
Products are defined as concepts, while companies are defined as entities, evolving independently. They are linked together using semantic attributes provided by OpenSPG, eliminating the need for manual maintenance of associations between companies and products.
### 2.4 Event Representation in Spatio-Temporal Context
The representation of events with multiple elements is indeed a type of lossless representation using a hypergraph structure. It expresses the spatio-temporal relations of multiple elements. Events are temporary associations of various elements caused by certain actions. Once the action is completed, the association disappears. In traditional property graphs, events can only be replaced by entities, and the event content is expressed using textual attributes. An example of such an event is shown below:

```text
Event(事件):
properties:
eventTime(发生时间): Long
subject(涉事主体): Text
object(客体): Text
place(地点): Text
industry(涉事行业): Text
```
This representation method is unable to capture the multidimensional associations of real events. OpenSPG provides event modeling that enables the association of multiple elements in an event, as shown below.
```text
CompanyEvent(公司事件): EventType
properties:
subject(主体): Company
index(指标): Index
trend(趋势): Trend
belongTo(属于): TaxOfCompanyEvent
```
In the above event, all attribute types are defined SPG types, without any basic type expressions. OpenSPG utilizes this declaration to implement the expression of multiple elements in an event. Specific application examples can be found in the detailed description of Scenario 3 in the [Enterprise Credit Graph Query Tasks in Supply Chain](../reasoner/README.md) document. | {
"source": "OpenSPG/KAG",
"title": "kag/examples/supplychain/schema/README.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/kag/examples/supplychain/schema/README.md",
"date": "2024-09-21T13:56:44",
"stars": 5095,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 7816
} |
# 基于 SPG 建模的产业链企业图谱
[English](./README.md) |
[简体中文](./README_cn.md)
## 1. 建模文件
schema 文件语法介绍参见 [声明式 schema](https://openspg.yuque.com/ndx6g9/0.6/fzhov4l2sst6bede)。
企业供应链图谱 schema 建模参考文件 [SupplyChain.schema](./SupplyChain.schema)。
执行以下脚本,完成 schema 创建:
```bash
knext schema commit
```
## 2. SPG 建模方法 vs 属性图建模方法
本节对比 SPG 语义建模和普通建模的差异。
### 2.1 语义属性 vs 文本属性
假定存在如下公司信息:"北大药份限公司"生产的产品有四个"医疗器械批发,医药批发,制药,其他化学药品"。
```text
id,name,products
CSF0000000254,北大*药*份限公司,"医疗器械批发,医药批发,制药,其他化学药品"
```
#### 2.1.1 基于文本属性建模
```text
//文本属性建模
Company(企业): EntityType
properties:
product(经营产品): Text
```
此时经营产品只为文本,不包含语义信息,是无法得到“北大药份限公司”的上下游产业链相关信息,极不方便维护也不方便使用。
#### 2.1.2 基于关系建模
```text
Product(产品): EntityType
properties:
name(产品名): Text
relations:
isA(上位产品): Product
Company(企业): EntityType
relations:
product(经营产品): Product
```
但如此建模,则需要将数据分为 3 列:
```text
id,name,product
CSF0000000254,北大*药*份限公司,医疗器械批发
CSF0000000254,北大*药*份限公司,医药批发
CSF0000000254,北大*药*份限公司,制药
CSF0000000254,北大*药*份限公司,其他化学药品
```
这种方式也存在两个缺点:
1. 原始数据需要做一次清洗,转换成多行。
2. 需要新增维护关系数据,当原始数据发生变更时,需要删除原有关系,再新增数据,容易导致数据错误。
#### 2.1.3 基于 SPG 语义属性建模
SPG 支持语义属性,可简化知识构建,如下:
```text
Product(产品): ConceptType
hypernymPredicate: isA
Company(企业): EntityType
properties:
product(经营产品): Product
constraint: MultiValue
```
企业中具有一个经营产品属性,且该属性的类型为 ``Product`` 类型,只需将如下数据导入,可自动实现属性到关系的转换。
```text
id,name,products
CSF0000000254,北大*药*份限公司,"医疗器械批发,医药批发,制药,其他化学药品"
```
### 2.2 逻辑表达的属性、关系 vs 数据表达的属性、关系
假定需要得到企业所在行业,根据当前已有数据,可执行如下查询语句:
```cypher
MATCH
(s:Company)-[:product]->(o:Product)-[:belongToIndustry]->(i:Industry)
RETURN
s.id, i.id
```
该方式需要熟悉图谱 schema,对人员上手要求比较高,故也有一种实践是将这类属性重新导入图谱,如下:
```text
Company(企业): EntityType
properties:
product(经营产品): Product
constraint: MultiValue
relations:
belongToIndustry(所在行业): Industry
```
新增一个关系类型,来直接获取公司所属行业信息。
这种方式缺点主要有两个:
1. 需要用户手动维护新增关系数据,增加使用维护成本。
2. 由于新关系和图谱数据存在来源依赖,非常容易导致图谱数据出现不一致问题。
针对上述缺点,SPG 支持逻辑表达属性和关系,如下建模方式:
```text
Company(企业): EntityType
properties:
product(经营产品): Product
constraint: MultiValue
relations:
belongToIndustry(所在行业): Industry
rule: [[
Define (s:Company)-[p:belongToIndustry]->(o:Industry) {
Structure {
(s)-[:product]->(c:Product)-[:belongToIndustry]->(o)
}
Constraint {
}
}
]]
```
具体内容可参见 [产业链企业信用图谱查询任务](../reasoner/README_cn.md) 中场景 1、场景 2 的示例。
### 2.3 概念体系 vs 实体体系
现有图谱方案也有常识图谱,例如 ConceptNet 等,但在业务落地中,不同业务有各自体现业务语义的类目体系,基本上不存在一个常识图谱可应用到所有业务场景,故常见的实践为将业务领域体系创建为实体,和其他实体数据混用,这就导致在同一个分类体系上,既要对 schema 的扩展建模,又要对语义上的细分类建模,数据结构定义和语义建模的耦合,导致工程实现及维护管理的复杂性,也增加了业务梳理和表示(认知)领域知识的困难。
SPG 区分了概念和实体,用于解耦语义和数据,如下:
```text
Product(产品): ConceptType
hypernymPredicate: isA
Company(企业): EntityType
properties:
product(经营产品): Product
constraint: MultiValue
```
产品被定义为概念,公司被定义为实体,相互独立演进,两者通过 SPG 提供的语义属性进行挂载关联,用户无需手动维护企业和产品之间关联。
### 2.4 事件时空多元表达
事件多要素结构表示也是一类超图(HyperGrpah)无损表示的问题,它表达的是时空多元要素的时空关联性,事件是各要素因某种行为而产生的临时关联,一旦行为结束,这种关联也随即消失。在以往的属性图中,事件只能使用实体进行替代,由文本属性表达事件内容,如下类似事件:

```text
Event(事件):
properties:
eventTime(发生时间): Long
subject(涉事主体): Text
object(客体): Text
place(地点): Text
industry(涉事行业): Text
```
这种表达方式,是无法体现真实事件的多元关联性,SPG 提供了事件建模,可实现事件多元要素的关联,如下:
```text
CompanyEvent(公司事件): EventType
properties:
subject(主体): Company
index(指标): Index
trend(趋势): Trend
belongTo(属于): TaxOfCompanyEvent
```
上述的事件中,属性类型均为已被定义类型,没有基本类型表达,SPG 基于此申明实现事件多元要素表达,具体应用示例可见 [产业链企业信用图谱查询任务](../reasoner/README_cn.md) 中场景 3 的具体描述。 | {
"source": "OpenSPG/KAG",
"title": "kag/examples/supplychain/schema/README_cn.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/kag/examples/supplychain/schema/README_cn.md",
"date": "2024-09-21T13:56:44",
"stars": 5095,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 3871
} |
# 1、周杰伦
<font style="color:rgb(51, 51, 51);background-color:rgb(224, 237, 255);">华语流行乐男歌手、音乐人、演员、导演、编剧</font>
周杰伦(Jay Chou),1979年1月18日出生于台湾省新北市,祖籍福建省永春县,华语流行乐男歌手、音乐人、演员、导演、编剧,毕业于[淡江中学](https://baike.baidu.com/item/%E6%B7%A1%E6%B1%9F%E4%B8%AD%E5%AD%A6/5340877?fromModule=lemma_inlink)。
2000年,发行个人首张音乐专辑《[Jay](https://baike.baidu.com/item/Jay/5291?fromModule=lemma_inlink)》 [26]。2001年,凭借专辑《[范特西](https://baike.baidu.com/item/%E8%8C%83%E7%89%B9%E8%A5%BF/22666?fromModule=lemma_inlink)》奠定其融合中西方音乐的风格 [16]。2002年,举行“The One”世界巡回演唱会 [1]。2003年,成为美国《[时代](https://baike.baidu.com/item/%E6%97%B6%E4%BB%A3/1944848?fromModule=lemma_inlink)》杂志封面人物 [2];同年,发行音乐专辑《[叶惠美](https://baike.baidu.com/item/%E5%8F%B6%E6%83%A0%E7%BE%8E/893?fromModule=lemma_inlink)》 [21],该专辑获得[第15届台湾金曲奖](https://baike.baidu.com/item/%E7%AC%AC15%E5%B1%8A%E5%8F%B0%E6%B9%BE%E9%87%91%E6%9B%B2%E5%A5%96/9773084?fromModule=lemma_inlink)最佳流行音乐演唱专辑奖 [23]。2004年,发行音乐专辑《[七里香](https://baike.baidu.com/item/%E4%B8%83%E9%87%8C%E9%A6%99/2181450?fromModule=lemma_inlink)》 [29],该专辑在亚洲的首月销量达到300万张 [316];同年,获得[世界音乐大奖](https://baike.baidu.com/item/%E4%B8%96%E7%95%8C%E9%9F%B3%E4%B9%90%E5%A4%A7%E5%A5%96/6690633?fromModule=lemma_inlink)中国区最畅销艺人奖 [320]。2005年,主演个人首部电影《[头文字D](https://baike.baidu.com/item/%E5%A4%B4%E6%96%87%E5%AD%97D/2711022?fromModule=lemma_inlink)》 [314],并凭借该片获得[第25届香港电影金像奖](https://baike.baidu.com/item/%E7%AC%AC25%E5%B1%8A%E9%A6%99%E6%B8%AF%E7%94%B5%E5%BD%B1%E9%87%91%E5%83%8F%E5%A5%96/10324781?fromModule=lemma_inlink)和[第42届台湾电影金马奖](https://baike.baidu.com/item/%E7%AC%AC42%E5%B1%8A%E5%8F%B0%E6%B9%BE%E7%94%B5%E5%BD%B1%E9%87%91%E9%A9%AC%E5%A5%96/10483829?fromModule=lemma_inlink)的最佳新演员奖 [3] [315]。2006年起,连续三年获得世界音乐大奖中国区最畅销艺人奖 [4]。
2007年,自编自导爱情电影《[不能说的秘密](https://baike.baidu.com/item/%E4%B8%8D%E8%83%BD%E8%AF%B4%E7%9A%84%E7%A7%98%E5%AF%86/39267?fromModule=lemma_inlink)》 [321],同年,成立[杰威尔音乐有限公司](https://baike.baidu.com/item/%E6%9D%B0%E5%A8%81%E5%B0%94%E9%9F%B3%E4%B9%90%E6%9C%89%E9%99%90%E5%85%AC%E5%8F%B8/5929467?fromModule=lemma_inlink) [10]。2008年,凭借歌曲《[青花瓷](https://baike.baidu.com/item/%E9%9D%92%E8%8A%B1%E7%93%B7/9864403?fromModule=lemma_inlink)》获得[第19届台湾金曲奖](https://baike.baidu.com/item/%E7%AC%AC19%E5%B1%8A%E5%8F%B0%E6%B9%BE%E9%87%91%E6%9B%B2%E5%A5%96/3968762?fromModule=lemma_inlink)最佳作曲人奖 [292]。2009年,入选美国[CNN](https://baike.baidu.com/item/CNN/86482?fromModule=lemma_inlink)“25位亚洲最具影响力人物” [6];同年,凭借专辑《[魔杰座](https://baike.baidu.com/item/%E9%AD%94%E6%9D%B0%E5%BA%A7/49875?fromModule=lemma_inlink)》获得[第20届台湾金曲奖](https://baike.baidu.com/item/%E7%AC%AC20%E5%B1%8A%E5%8F%B0%E6%B9%BE%E9%87%91%E6%9B%B2%E5%A5%96/8055336?fromModule=lemma_inlink)最佳国语男歌手奖 [7]。2010年,入选美国《[Fast Company](https://baike.baidu.com/item/Fast%20Company/6508066?fromModule=lemma_inlink)》杂志评出的“全球百大创意人物”。2011年,凭借专辑《[跨时代](https://baike.baidu.com/item/%E8%B7%A8%E6%97%B6%E4%BB%A3/516122?fromModule=lemma_inlink)》获得[第22届台湾金曲奖](https://baike.baidu.com/item/%E7%AC%AC22%E5%B1%8A%E5%8F%B0%E6%B9%BE%E9%87%91%E6%9B%B2%E5%A5%96/7220967?fromModule=lemma_inlink)最佳国语男歌手奖 [294]。2012年,登上[福布斯中国名人榜](https://baike.baidu.com/item/%E7%A6%8F%E5%B8%83%E6%96%AF%E4%B8%AD%E5%9B%BD%E5%90%8D%E4%BA%BA%E6%A6%9C/2125?fromModule=lemma_inlink)榜首 [8]。2014年,发行个人首张数字音乐专辑《[哎呦,不错哦](https://baike.baidu.com/item/%E5%93%8E%E5%91%A6%EF%BC%8C%E4%B8%8D%E9%94%99%E5%93%A6/9851748?fromModule=lemma_inlink)》 [295]。2023年,凭借专辑《[最伟大的作品](https://baike.baidu.com/item/%E6%9C%80%E4%BC%9F%E5%A4%A7%E7%9A%84%E4%BD%9C%E5%93%81/61539892?fromModule=lemma_inlink)》成为首位获得[国际唱片业协会](https://baike.baidu.com/item/%E5%9B%BD%E9%99%85%E5%94%B1%E7%89%87%E4%B8%9A%E5%8D%8F%E4%BC%9A/1486316?fromModule=lemma_inlink)“全球畅销专辑榜”冠军的华语歌手 [287]。
## <font style="color:rgb(51, 51, 51);">1.1、早年经历</font>
周杰伦出生于台湾省新北市,祖籍福建省泉州市永春县 [13]。4岁的时候,母亲[叶惠美](https://baike.baidu.com/item/%E5%8F%B6%E6%83%A0%E7%BE%8E/2325933?fromModule=lemma_inlink)把他送到淡江山叶幼儿音乐班学习钢琴。初中二年级时,父母因性格不合离婚,周杰伦归母亲叶惠美抚养。中考时,没有考上普通高中,同年,因为擅长钢琴而被[淡江中学](https://baike.baidu.com/item/%E6%B7%A1%E6%B1%9F%E4%B8%AD%E5%AD%A6/5340877?fromModule=lemma_inlink)第一届音乐班录取。高中毕业以后,两次报考[台北大学](https://baike.baidu.com/item/%E5%8F%B0%E5%8C%97%E5%A4%A7%E5%AD%A6/7685732?fromModule=lemma_inlink)音乐系均没有被录取,于是开始在一家餐馆打工。
1997年9月,周杰伦在母亲的鼓励下报名参加了台北星光电视台的娱乐节目《[超级新人王](https://baike.baidu.com/item/%E8%B6%85%E7%BA%A7%E6%96%B0%E4%BA%BA%E7%8E%8B/6107880?fromModule=lemma_inlink)》 [26],并在节目中邀人演唱了自己创作的歌曲《梦有翅膀》。当主持人[吴宗宪](https://baike.baidu.com/item/%E5%90%B4%E5%AE%97%E5%AE%AA/29494?fromModule=lemma_inlink)看到这首歌曲的曲谱后,就邀请周杰伦到[阿尔发音乐](https://baike.baidu.com/item/%E9%98%BF%E5%B0%94%E5%8F%91%E9%9F%B3%E4%B9%90/279418?fromModule=lemma_inlink)公司担任音乐助理。1998年,创作歌曲《[眼泪知道](https://baike.baidu.com/item/%E7%9C%BC%E6%B3%AA%E7%9F%A5%E9%81%93/2106916?fromModule=lemma_inlink)》,公司把这首歌曲给到[刘德华](https://baike.baidu.com/item/%E5%88%98%E5%BE%B7%E5%8D%8E/114923?fromModule=lemma_inlink)后被退歌,后为[张惠妹](https://baike.baidu.com/item/%E5%BC%A0%E6%83%A0%E5%A6%B9/234310?fromModule=lemma_inlink)创作的歌曲《[双截棍](https://baike.baidu.com/item/%E5%8F%8C%E6%88%AA%E6%A3%8D/2986610?fromModule=lemma_inlink)》和《[忍者](https://baike.baidu.com/item/%E5%BF%8D%E8%80%85/1498981?fromModule=lemma_inlink)》(后收录于周杰伦个人音乐专辑《[范特西](https://baike.baidu.com/item/%E8%8C%83%E7%89%B9%E8%A5%BF/22666?fromModule=lemma_inlink)》中)也被退回 [14]。

## 1.2、演艺经历
2000年,在[杨峻荣](https://baike.baidu.com/item/%E6%9D%A8%E5%B3%BB%E8%8D%A3/8379373?fromModule=lemma_inlink)的推荐下,周杰伦开始演唱自己创作的歌曲;11月7日,发行个人首张音乐专辑《[Jay](https://baike.baidu.com/item/Jay/5291?fromModule=lemma_inlink)》 [26],并包办专辑全部歌曲的作曲、和声编写以及监制工作,该专辑融合了[R&B](https://baike.baidu.com/item/R&B/15271596?fromModule=lemma_inlink)、[嘻哈](https://baike.baidu.com/item/%E5%98%BB%E5%93%88/161896?fromModule=lemma_inlink)等多种音乐风格,其中的主打歌曲《[星晴](https://baike.baidu.com/item/%E6%98%9F%E6%99%B4/4798844?fromModule=lemma_inlink)》获得第24届[十大中文金曲](https://baike.baidu.com/item/%E5%8D%81%E5%A4%A7%E4%B8%AD%E6%96%87%E9%87%91%E6%9B%B2/823339?fromModule=lemma_inlink)优秀国语歌曲金奖 [15],而他也凭借该专辑在华语乐坛受到关注,并在次年举办的[第12届台湾金曲奖](https://baike.baidu.com/item/%E7%AC%AC12%E5%B1%8A%E5%8F%B0%E6%B9%BE%E9%87%91%E6%9B%B2%E5%A5%96/61016222?fromModule=lemma_inlink)颁奖典礼上凭借该专辑获得最佳流行音乐演唱专辑奖、入围最佳制作人奖,凭借专辑中的歌曲《[可爱女人](https://baike.baidu.com/item/%E5%8F%AF%E7%88%B1%E5%A5%B3%E4%BA%BA/3225780?fromModule=lemma_inlink)》提名[第12届台湾金曲奖](https://baike.baidu.com/item/%E7%AC%AC12%E5%B1%8A%E5%8F%B0%E6%B9%BE%E9%87%91%E6%9B%B2%E5%A5%96/61016222?fromModule=lemma_inlink)最佳作曲人奖。
2001年9月,周杰伦发行个人第二张音乐专辑《[范特西](https://baike.baidu.com/item/%E8%8C%83%E7%89%B9%E8%A5%BF/22666?fromModule=lemma_inlink)》 [26],他除了担任专辑的制作人外,还包办了专辑中所有歌曲的作曲,该专辑是周杰伦确立其唱片风格的作品,其中结合中西方音乐元素的主打歌曲《[双截棍](https://baike.baidu.com/item/%E5%8F%8C%E6%88%AA%E6%A3%8D/2986610?fromModule=lemma_inlink)》成为饶舌歌曲的代表作之一,该专辑的发行也让周杰伦打开东南亚市场 [16],并于次年凭借该专辑获得[第13届台湾金曲奖](https://baike.baidu.com/item/%E7%AC%AC13%E5%B1%8A%E5%8F%B0%E6%B9%BE%E9%87%91%E6%9B%B2%E5%A5%96/12761754?fromModule=lemma_inlink)最佳专辑制作人奖、最佳流行音乐专辑奖 [241],以及香港唱片销量大奖颁奖典礼十大销量国语唱片等奖项,周杰伦亦凭借专辑中的歌曲《[爱在西元前](https://baike.baidu.com/item/%E7%88%B1%E5%9C%A8%E8%A5%BF%E5%85%83%E5%89%8D/3488?fromModule=lemma_inlink)》获得第13届台湾金曲奖最佳作曲人奖 [228];10月,为[李玟](https://baike.baidu.com/item/%E6%9D%8E%E7%8E%9F/333755?fromModule=lemma_inlink)创作融合中西方音乐元素的歌曲《[刀马旦](https://baike.baidu.com/item/%E5%88%80%E9%A9%AC%E6%97%A6/3894792?fromModule=lemma_inlink)》 [325];12月24日,发行个人音乐EP《[范特西plus](https://baike.baidu.com/item/%E8%8C%83%E7%89%B9%E8%A5%BFplus/4950842?fromModule=lemma_inlink)》,收录了他在桃园巨蛋演唱会上演唱的《[你比从前快乐](https://baike.baidu.com/item/%E4%BD%A0%E6%AF%94%E4%BB%8E%E5%89%8D%E5%BF%AB%E4%B9%90/3564385?fromModule=lemma_inlink)》《[世界末日](https://baike.baidu.com/item/%E4%B8%96%E7%95%8C%E6%9C%AB%E6%97%A5/5697158?fromModule=lemma_inlink)》等歌曲;同年,获得第19届[十大劲歌金曲颁奖典礼](https://baike.baidu.com/item/%E5%8D%81%E5%A4%A7%E5%8A%B2%E6%AD%8C%E9%87%91%E6%9B%B2%E9%A2%81%E5%A5%96%E5%85%B8%E7%A4%BC/477072?fromModule=lemma_inlink)最受欢迎唱作歌星金奖、[叱咤乐坛流行榜颁奖典礼](https://baike.baidu.com/item/%E5%8F%B1%E5%92%A4%E4%B9%90%E5%9D%9B%E6%B5%81%E8%A1%8C%E6%A6%9C%E9%A2%81%E5%A5%96%E5%85%B8%E7%A4%BC/1325994?fromModule=lemma_inlink)叱咤乐坛生力军男歌手金奖等奖项。
2002年,参演个人首部电视剧《[星情花园](https://baike.baidu.com/item/%E6%98%9F%E6%83%85%E8%8A%B1%E5%9B%AD/8740841?fromModule=lemma_inlink)》;2月,在新加坡新达城国际会议展览中心举行演唱会;7月,发行个人第三张音乐专辑《[八度空间](https://baike.baidu.com/item/%E5%85%AB%E5%BA%A6%E7%A9%BA%E9%97%B4/1347996?fromModule=lemma_inlink)》 [26] [317],除了包办专辑中所有歌曲的作曲外,他还担任专辑的制作人 [17],该专辑以节奏蓝调风格的歌曲为主,并获得[g-music](https://baike.baidu.com/item/g-music/6992427?fromModule=lemma_inlink)风云榜白金音乐奖十大金碟奖、华语流行乐传媒大奖十大华语唱片奖、[新加坡金曲奖](https://baike.baidu.com/item/%E6%96%B0%E5%8A%A0%E5%9D%A1%E9%87%91%E6%9B%B2%E5%A5%96/6360377?fromModule=lemma_inlink)大奖年度最畅销男歌手专辑奖等奖项 [18];9月28日,在台北体育场举行“THE ONE”演唱会;12月12日至16日,在[香港体育馆](https://baike.baidu.com/item/%E9%A6%99%E6%B8%AF%E4%BD%93%E8%82%B2%E9%A6%86/2370398?fromModule=lemma_inlink)举行5场“THE ONE”演唱会;12月25日,在美国拉斯维加斯举办“THE ONE”演唱会;同年,获得第1届MTV日本音乐录影带大奖亚洲最杰出艺人奖、第2届[全球华语歌曲排行榜](https://baike.baidu.com/item/%E5%85%A8%E7%90%83%E5%8D%8E%E8%AF%AD%E6%AD%8C%E6%9B%B2%E6%8E%92%E8%A1%8C%E6%A6%9C/3189656?fromModule=lemma_inlink)最受欢迎创作歌手奖和最佳制作人奖 [350]、第9届[新加坡金曲奖](https://baike.baidu.com/item/%E6%96%B0%E5%8A%A0%E5%9D%A1%E9%87%91%E6%9B%B2%E5%A5%96/6360377?fromModule=lemma_inlink)亚太最受推崇男歌手奖等奖项 [19]。

2003年2月,成为美国《[时代周刊](https://baike.baidu.com/item/%E6%97%B6%E4%BB%A3%E5%91%A8%E5%88%8A/6643818?fromModule=lemma_inlink)》亚洲版的封面人物 [2];3月,在[第3届音乐风云榜](https://baike.baidu.com/item/%E7%AC%AC3%E5%B1%8A%E9%9F%B3%E4%B9%90%E9%A3%8E%E4%BA%91%E6%A6%9C/23707987?fromModule=lemma_inlink)上获得港台年度最佳唱作人奖、年度风云大奖等奖项,其演唱的歌曲《[暗号](https://baike.baidu.com/item/%E6%9A%97%E5%8F%B7/3948301?fromModule=lemma_inlink)》则获得港台年度十大金曲奖 [236];5月17日,在[马来西亚](https://baike.baidu.com/item/%E9%A9%AC%E6%9D%A5%E8%A5%BF%E4%BA%9A/202243?fromModule=lemma_inlink)[吉隆坡](https://baike.baidu.com/item/%E5%90%89%E9%9A%86%E5%9D%A1/967683?fromModule=lemma_inlink)[默迪卡体育场](https://baike.baidu.com/item/%E9%BB%98%E8%BF%AA%E5%8D%A1%E4%BD%93%E8%82%B2%E5%9C%BA/8826151?fromModule=lemma_inlink)举行“THE ONE”演唱会;7月16日,他的歌曲《[以父之名](https://baike.baidu.com/item/%E4%BB%A5%E7%88%B6%E4%B9%8B%E5%90%8D/1341?fromModule=lemma_inlink)》在亚洲超过50家电台首播,预计有8亿人同时收听,而该曲首播的当日也被这些电台定为“[周杰伦日](https://baike.baidu.com/item/%E5%91%A8%E6%9D%B0%E4%BC%A6%E6%97%A5/9734555?fromModule=lemma_inlink)” [20];7月31日,发行个人第四张音乐专辑《[叶惠美](https://baike.baidu.com/item/%E5%8F%B6%E6%83%A0%E7%BE%8E/893?fromModule=lemma_inlink)》 [21] [26],他不仅包办了专辑所有歌曲的作曲,还担任专辑的制作人和造型师 [21],该专辑发行首月在亚洲的销量突破200万张 [22],并于次年获得[第15届台湾金曲奖](https://baike.baidu.com/item/%E7%AC%AC15%E5%B1%8A%E5%8F%B0%E6%B9%BE%E9%87%91%E6%9B%B2%E5%A5%96/9773084?fromModule=lemma_inlink)最佳流行音乐演唱专辑奖、第4届全球华语歌曲排行榜年度最受欢迎专辑等奖项 [23-24],专辑主打歌曲《[东风破](https://baike.baidu.com/item/%E4%B8%9C%E9%A3%8E%E7%A0%B4/1674691?fromModule=lemma_inlink)》也是周杰伦具有代表性的中国风作品之一,而他亦凭借该曲获得[第4届华语音乐传媒大奖](https://baike.baidu.com/item/%E7%AC%AC4%E5%B1%8A%E5%8D%8E%E8%AF%AD%E9%9F%B3%E4%B9%90%E4%BC%A0%E5%AA%92%E5%A4%A7%E5%A5%96/18003952?fromModule=lemma_inlink)最佳作曲人奖;9月12日,在[北京工人体育场](https://baike.baidu.com/item/%E5%8C%97%E4%BA%AC%E5%B7%A5%E4%BA%BA%E4%BD%93%E8%82%B2%E5%9C%BA/2214906?fromModule=lemma_inlink)举行“THE ONE”演唱会;11月13日,发行个人音乐EP《[寻找周杰伦](https://baike.baidu.com/item/%E5%AF%BB%E6%89%BE%E5%91%A8%E6%9D%B0%E4%BC%A6/2632938?fromModule=lemma_inlink)》 [25],该EP收录了周杰伦为同名电影《[寻找周杰伦](https://baike.baidu.com/item/%E5%AF%BB%E6%89%BE%E5%91%A8%E6%9D%B0%E4%BC%A6/1189?fromModule=lemma_inlink)》创作的两首歌曲《[轨迹](https://baike.baidu.com/item/%E8%BD%A8%E8%BF%B9/2770132?fromModule=lemma_inlink)》《[断了的弦](https://baike.baidu.com/item/%E6%96%AD%E4%BA%86%E7%9A%84%E5%BC%A6/1508695?fromModule=lemma_inlink)》 [25];12月12日,在[上海体育场](https://baike.baidu.com/item/%E4%B8%8A%E6%B5%B7%E4%BD%93%E8%82%B2%E5%9C%BA/9679224?fromModule=lemma_inlink)举办“THE ONE”演唱会,并演唱了变奏版的《[双截棍](https://baike.baidu.com/item/%E5%8F%8C%E6%88%AA%E6%A3%8D/2986610?fromModule=lemma_inlink)》、加长版的《[爷爷泡的茶](https://baike.baidu.com/item/%E7%88%B7%E7%88%B7%E6%B3%A1%E7%9A%84%E8%8C%B6/2746283?fromModule=lemma_inlink)》等歌曲;同年,客串出演的电影处女作《[寻找周杰伦](https://baike.baidu.com/item/%E5%AF%BB%E6%89%BE%E5%91%A8%E6%9D%B0%E4%BC%A6/1189?fromModule=lemma_inlink)》上映 [90]。
2004年1月21日,首次登上[中央电视台春节联欢晚会](https://baike.baidu.com/item/%E4%B8%AD%E5%A4%AE%E7%94%B5%E8%A7%86%E5%8F%B0%E6%98%A5%E8%8A%82%E8%81%94%E6%AC%A2%E6%99%9A%E4%BC%9A/7622174?fromModule=lemma_inlink)的舞台,并演唱歌曲《[龙拳](https://baike.baidu.com/item/%E9%BE%99%E6%8B%B3/2929202?fromModule=lemma_inlink)》 [27-28];3月,在[第4届音乐风云榜](https://baike.baidu.com/item/%E7%AC%AC4%E5%B1%8A%E9%9F%B3%E4%B9%90%E9%A3%8E%E4%BA%91%E6%A6%9C/23707984?fromModule=lemma_inlink)上获得台湾地区最受欢迎男歌手奖、年度风云大奖、年度港台及海外华人最佳制作人等奖项 [326];8月3日,发行融合嘻哈、R&B、[古典音乐](https://baike.baidu.com/item/%E5%8F%A4%E5%85%B8%E9%9F%B3%E4%B9%90/106197?fromModule=lemma_inlink)等风格的音乐专辑《[七里香](https://baike.baidu.com/item/%E4%B8%83%E9%87%8C%E9%A6%99/2181450?fromModule=lemma_inlink)》 [29] [289],该专辑发行当月在亚洲的销量突破300万张 [316],而专辑同名主打歌曲《[七里香](https://baike.baidu.com/item/%E4%B8%83%E9%87%8C%E9%A6%99/12009481?fromModule=lemma_inlink)》则获得[第27届十大中文金曲](https://baike.baidu.com/item/%E7%AC%AC27%E5%B1%8A%E5%8D%81%E5%A4%A7%E4%B8%AD%E6%96%87%E9%87%91%E6%9B%B2/12709616?fromModule=lemma_inlink)十大金曲奖、优秀流行国语歌曲奖金奖,以及[第5届全球华语歌曲排行榜](https://baike.baidu.com/item/%E7%AC%AC5%E5%B1%8A%E5%85%A8%E7%90%83%E5%8D%8E%E8%AF%AD%E6%AD%8C%E6%9B%B2%E6%8E%92%E8%A1%8C%E6%A6%9C/24682097?fromModule=lemma_inlink)年度25大金曲等奖项 [30];9月,获得第16届[世界音乐大奖](https://baike.baidu.com/item/%E4%B8%96%E7%95%8C%E9%9F%B3%E4%B9%90%E5%A4%A7%E5%A5%96/6690633?fromModule=lemma_inlink)中国区最畅销艺人奖 [320];10月起,在台北、香港、洛杉矶、蒙特维尔等地举行“无与伦比”世界巡回演唱会。
2005年1月11日,在第11届[全球华语榜中榜](https://baike.baidu.com/item/%E5%85%A8%E7%90%83%E5%8D%8E%E8%AF%AD%E6%A6%9C%E4%B8%AD%E6%A6%9C/10768347?fromModule=lemma_inlink)颁奖盛典上获得港台最佳男歌手奖、港台最受欢迎男歌手奖、港台最佳创作歌手奖等奖项 [31];4月,凭借专辑《[七里香](https://baike.baidu.com/item/%E4%B8%83%E9%87%8C%E9%A6%99/2181450?fromModule=lemma_inlink)》入围[第16届台湾金曲奖](https://baike.baidu.com/item/%E7%AC%AC16%E5%B1%8A%E5%8F%B0%E6%B9%BE%E9%87%91%E6%9B%B2%E5%A5%96/4745538?fromModule=lemma_inlink)最佳国语男演唱人奖、最佳流行音乐演唱专辑奖,凭借歌曲《[七里香](https://baike.baidu.com/item/%E4%B8%83%E9%87%8C%E9%A6%99/12009481?fromModule=lemma_inlink)》入围第16届台湾金曲奖最佳作曲人奖;6月23日,由其担任男主角主演的电影《[头文字D](https://baike.baidu.com/item/%E5%A4%B4%E6%96%87%E5%AD%97D/2711022?fromModule=lemma_inlink)》上映 [91],他在该片中饰演[藤原拓海](https://baike.baidu.com/item/%E8%97%A4%E5%8E%9F%E6%8B%93%E6%B5%B7/702611?fromModule=lemma_inlink) [314] [347],这也是他主演的个人首部电影 [314],他也凭借该片获得[第42届台湾电影金马奖](https://baike.baidu.com/item/%E7%AC%AC42%E5%B1%8A%E5%8F%B0%E6%B9%BE%E7%94%B5%E5%BD%B1%E9%87%91%E9%A9%AC%E5%A5%96/10483829?fromModule=lemma_inlink)最佳新演员奖 [3]、[第25届香港电影金像奖](https://baike.baidu.com/item/%E7%AC%AC25%E5%B1%8A%E9%A6%99%E6%B8%AF%E7%94%B5%E5%BD%B1%E9%87%91%E5%83%8F%E5%A5%96/10324781?fromModule=lemma_inlink)最佳新演员奖 [315];7月1日,在上海体育场举行“无与伦比巡回演唱会” [32];7月9日,在北京工人体育场举行“无与伦比巡回演唱会” [33]。8月31日,在日本发行个人首张精选专辑《[Initial J](https://baike.baidu.com/item/Initial%20J/2268270?fromModule=lemma_inlink)》 [327],该专辑收录了周杰伦为电影《头文字D》演唱的主题曲《[一路向北](https://baike.baidu.com/item/%E4%B8%80%E8%B7%AF%E5%90%91%E5%8C%97/52259?fromModule=lemma_inlink)》和《[飘移](https://baike.baidu.com/item/%E9%A3%98%E7%A7%BB/1246934?fromModule=lemma_inlink)》 [34];11月1日,发行个人第六张音乐专辑《[11月的萧邦](https://baike.baidu.com/item/11%E6%9C%88%E7%9A%84%E8%90%A7%E9%82%A6/467565?fromModule=lemma_inlink)》 [296],并包办了专辑中所有歌曲的作曲以及专辑的造型设计 [35],该专辑发行后以4.28%的销售份额获得台湾[G-MUSIC](https://baike.baidu.com/item/G-MUSIC/6992427?fromModule=lemma_inlink)年终排行榜冠军;同年,其创作的歌曲《[蜗牛](https://baike.baidu.com/item/%E8%9C%97%E7%89%9B/8578273?fromModule=lemma_inlink)》入选“上海中学生爱国主义歌曲推荐目录” [328]。
2006年1月11日,在第12届全球华语榜中榜颁奖盛典上获得最佳男歌手奖、最佳创作歌手奖、最受欢迎男歌手奖,并凭借歌曲《[夜曲](https://baike.baidu.com/item/%E5%A4%9C%E6%9B%B2/3886391?fromModule=lemma_inlink)》及其MV分别获得年度最佳歌曲奖、最受欢迎音乐录影带奖 [234];1月20日,发行个人音乐EP《[霍元甲](https://baike.baidu.com/item/%E9%9C%8D%E5%85%83%E7%94%B2/24226609?fromModule=lemma_inlink)》 [329],同名主打歌曲《[霍元甲](https://baike.baidu.com/item/%E9%9C%8D%E5%85%83%E7%94%B2/8903362?fromModule=lemma_inlink)》是[李连杰](https://baike.baidu.com/item/%E6%9D%8E%E8%BF%9E%E6%9D%B0/202569?fromModule=lemma_inlink)主演的同名电影《[霍元甲](https://baike.baidu.com/item/%E9%9C%8D%E5%85%83%E7%94%B2/8903304?fromModule=lemma_inlink)》的主题曲 [36];1月23日,在[第28届十大中文金曲](https://baike.baidu.com/item/%E7%AC%AC28%E5%B1%8A%E5%8D%81%E5%A4%A7%E4%B8%AD%E6%96%87%E9%87%91%E6%9B%B2/13467291?fromModule=lemma_inlink)颁奖典礼上获得了优秀流行歌手大奖、全年最高销量歌手大奖男歌手奖 [246];2月5日至6日,在日本东京举行演唱会;9月,发行个人第七张音乐专辑《[依然范特西](https://baike.baidu.com/item/%E4%BE%9D%E7%84%B6%E8%8C%83%E7%89%B9%E8%A5%BF/7709602?fromModule=lemma_inlink)》 [290],该专辑延续了周杰伦以往的音乐风格,并融合了中国风、说唱等音乐风格,其中与[费玉清](https://baike.baidu.com/item/%E8%B4%B9%E7%8E%89%E6%B8%85/651674?fromModule=lemma_inlink)合唱的中国风歌曲《[千里之外](https://baike.baidu.com/item/%E5%8D%83%E9%87%8C%E4%B9%8B%E5%A4%96/781?fromModule=lemma_inlink)》获得第13届全球华语音乐榜中榜年度最佳歌曲奖、[第29届十大中文金曲](https://baike.baidu.com/item/%E7%AC%AC29%E5%B1%8A%E5%8D%81%E5%A4%A7%E4%B8%AD%E6%96%87%E9%87%91%E6%9B%B2/7944447?fromModule=lemma_inlink)全国最受欢迎中文歌曲奖等奖项 [37-38],该专辑发行后以5.34%的销售份额位列台湾五大唱片排行榜第一位 [39],并获得[中华音乐人交流协会](https://baike.baidu.com/item/%E4%B8%AD%E5%8D%8E%E9%9F%B3%E4%B9%90%E4%BA%BA%E4%BA%A4%E6%B5%81%E5%8D%8F%E4%BC%9A/3212583?fromModule=lemma_inlink)年度十大优良专辑奖、IFPI香港唱片销量大奖最高销量国语唱片奖等奖项 [40];12月,发行个人音乐EP《[黄金甲](https://baike.baidu.com/item/%E9%BB%84%E9%87%91%E7%94%B2/62490685?fromModule=lemma_inlink)》 [330],该专辑获得IFPI香港唱片销量大奖十大畅销国语唱片奖 [332];同年,获得世界音乐大奖中国区最畅销艺人奖 [4];12月14日,主演的古装动作片《[满城尽带黄金甲](https://baike.baidu.com/item/%E6%BB%A1%E5%9F%8E%E5%B0%BD%E5%B8%A6%E9%BB%84%E9%87%91%E7%94%B2/18156?fromModule=lemma_inlink)》在中国内地上映 [331],他在片中饰演武功超群的二王子元杰,并凭借该片获得第16届上海影评人奖最佳男演员奖,而他为该片创作并演唱的主题曲《[菊花台](https://baike.baidu.com/item/%E8%8F%8A%E8%8A%B1%E5%8F%B0/2999088?fromModule=lemma_inlink)》则获得了[第26届香港电影金像奖](https://baike.baidu.com/item/%E7%AC%AC26%E5%B1%8A%E9%A6%99%E6%B8%AF%E7%94%B5%E5%BD%B1%E9%87%91%E5%83%8F%E5%A5%96/10324838?fromModule=lemma_inlink)最佳原创电影歌曲奖 [92] [220]。

2007年2月,首度担任导演并自导自演爱情片《[不能说的秘密](https://baike.baidu.com/item/%E4%B8%8D%E8%83%BD%E8%AF%B4%E7%9A%84%E7%A7%98%E5%AF%86/39267?fromModule=lemma_inlink)》 [93] [321],该片上映后获得[第44届台湾电影金马奖](https://baike.baidu.com/item/%E7%AC%AC44%E5%B1%8A%E5%8F%B0%E6%B9%BE%E7%94%B5%E5%BD%B1%E9%87%91%E9%A9%AC%E5%A5%96/10483746?fromModule=lemma_inlink)年度台湾杰出电影奖、[第27届香港电影金像奖](https://baike.baidu.com/item/%E7%AC%AC27%E5%B1%8A%E9%A6%99%E6%B8%AF%E7%94%B5%E5%BD%B1%E9%87%91%E5%83%8F%E5%A5%96/3846497?fromModule=lemma_inlink)最佳亚洲电影提名等奖项 [5],而他电影创作并演唱的同名主题曲《[不能说的秘密](https://baike.baidu.com/item/%E4%B8%8D%E8%83%BD%E8%AF%B4%E7%9A%84%E7%A7%98%E5%AF%86/1863255?fromModule=lemma_inlink)》获得了第44届台湾电影金马奖最佳原创电影歌曲奖 [5];5月,凭借《千里之外》和《[红模仿](https://baike.baidu.com/item/%E7%BA%A2%E6%A8%A1%E4%BB%BF/8705177?fromModule=lemma_inlink)》分别入围[第18届台湾金曲奖](https://baike.baidu.com/item/%E7%AC%AC18%E5%B1%8A%E5%8F%B0%E6%B9%BE%E9%87%91%E6%9B%B2%E5%A5%96/4678259?fromModule=lemma_inlink)最佳年度歌曲、最佳音乐录像带导演等奖项 [41];6月,凭借单曲《[霍元甲](https://baike.baidu.com/item/%E9%9C%8D%E5%85%83%E7%94%B2/8903362?fromModule=lemma_inlink)》获得第18届台湾金曲奖最佳单曲制作人奖 [42];11月2日,发行个人第八张音乐专辑《[我很忙](https://baike.baidu.com/item/%E6%88%91%E5%BE%88%E5%BF%99/1374653?fromModule=lemma_inlink)》 [243] [291],并在专辑中首次尝试美式乡村的音乐风格,而他也于次年凭借专辑中的中国风歌曲《[青花瓷](https://baike.baidu.com/item/%E9%9D%92%E8%8A%B1%E7%93%B7/9864403?fromModule=lemma_inlink)》获得[第19届台湾金曲奖](https://baike.baidu.com/item/%E7%AC%AC19%E5%B1%8A%E5%8F%B0%E6%B9%BE%E9%87%91%E6%9B%B2%E5%A5%96/3968762?fromModule=lemma_inlink)最佳作曲人奖以及最佳年度歌曲奖 [43] [292];11月4日,凭借专辑《[依然范特西](https://baike.baidu.com/item/%E4%BE%9D%E7%84%B6%E8%8C%83%E7%89%B9%E8%A5%BF/7709602?fromModule=lemma_inlink)》蝉联世界音乐大奖中国区最畅销艺人奖 [44];11月24日,在上海八万人体育场举行演唱会,并在演唱会中模仿了[维塔斯](https://baike.baidu.com/item/%E7%BB%B4%E5%A1%94%E6%96%AF/3770095?fromModule=lemma_inlink)的假声唱法 [45];12月,在香港体育馆举行7场“周杰伦07-08世界巡回香港站演唱会”。
2008年1月10日,周杰伦自导自演的爱情文艺片《[不能说的秘密](https://baike.baidu.com/item/%E4%B8%8D%E8%83%BD%E8%AF%B4%E7%9A%84%E7%A7%98%E5%AF%86/39267?fromModule=lemma_inlink)》在韩国上映 [94];2月6日,在[2008年中央电视台春节联欢晚会](https://baike.baidu.com/item/2008%E5%B9%B4%E4%B8%AD%E5%A4%AE%E7%94%B5%E8%A7%86%E5%8F%B0%E6%98%A5%E8%8A%82%E8%81%94%E6%AC%A2%E6%99%9A%E4%BC%9A/8970911?fromModule=lemma_inlink)上演唱歌曲《青花瓷》 [46];之后,《青花瓷》的歌词出现在山东、江苏两省的高考试题中 [47];2月16日,在日本[武道馆](https://baike.baidu.com/item/%E6%AD%A6%E9%81%93%E9%A6%86/1989260?fromModule=lemma_inlink)连开两场演唱会,成为继[邓丽君](https://baike.baidu.com/item/%E9%82%93%E4%B8%BD%E5%90%9B/27007?fromModule=lemma_inlink)、[王菲](https://baike.baidu.com/item/%E7%8E%8B%E8%8F%B2/11029?fromModule=lemma_inlink)之后第三位在武道馆开唱的华人歌手;同月,其主演的爱情喜剧片《[大灌篮](https://baike.baidu.com/item/%E5%A4%A7%E7%81%8C%E7%AF%AE/9173184?fromModule=lemma_inlink)》上映 [334],在片中饰演见义勇为、好打不平的孤儿[方世杰](https://baike.baidu.com/item/%E6%96%B9%E4%B8%96%E6%9D%B0/9936534?fromModule=lemma_inlink) [335],并为该片创作、演唱主题曲《[周大侠](https://baike.baidu.com/item/%E5%91%A8%E5%A4%A7%E4%BE%A0/10508241?fromModule=lemma_inlink)》 [334];4月30日,发行为[北京奥运会](https://baike.baidu.com/item/%E5%8C%97%E4%BA%AC%E5%A5%A5%E8%BF%90%E4%BC%9A/335299?fromModule=lemma_inlink)创作并演唱的歌曲《[千山万水](https://baike.baidu.com/item/%E5%8D%83%E5%B1%B1%E4%B8%87%E6%B0%B4/3167078?fromModule=lemma_inlink)》 [253];7月,在第19届台湾金曲奖颁奖典礼上凭借专辑《[不能说的秘密电影原声带](https://baike.baidu.com/item/%E4%B8%8D%E8%83%BD%E8%AF%B4%E7%9A%84%E7%A7%98%E5%AF%86%E7%94%B5%E5%BD%B1%E5%8E%9F%E5%A3%B0%E5%B8%A6/7752656?fromModule=lemma_inlink)》获得演奏类最佳专辑制作人奖,凭借《[琴房](https://baike.baidu.com/item/%E7%90%B4%E6%88%BF/2920397?fromModule=lemma_inlink)》获得演奏类最佳作曲人奖 [43];10月15日,发行个人第九张音乐专辑《[魔杰座](https://baike.baidu.com/item/%E9%AD%94%E6%9D%B0%E5%BA%A7/49875?fromModule=lemma_inlink)》 [297],该专辑融合了嘻哈、民谣等音乐风格,推出首周在G-MUSIC排行榜、五大唱片排行榜上获得冠军,发行一星期在亚洲的销量突破100万张 [48];11月,凭借专辑《[我很忙](https://baike.baidu.com/item/%E6%88%91%E5%BE%88%E5%BF%99/1374653?fromModule=lemma_inlink)》第四次获得世界音乐大奖中国区最畅销艺人奖 [4],并成为首位连续三届获得该奖项的华人歌手 [44]。
2009年1月25日,在[2009年中央电视台春节联欢晚会](https://baike.baidu.com/item/2009%E5%B9%B4%E4%B8%AD%E5%A4%AE%E7%94%B5%E8%A7%86%E5%8F%B0%E6%98%A5%E8%8A%82%E8%81%94%E6%AC%A2%E6%99%9A%E4%BC%9A/5938543?fromModule=lemma_inlink)上与[宋祖英](https://baike.baidu.com/item/%E5%AE%8B%E7%A5%96%E8%8B%B1/275282?fromModule=lemma_inlink)合作演唱歌曲《[本草纲目](https://baike.baidu.com/item/%E6%9C%AC%E8%8D%89%E7%BA%B2%E7%9B%AE/10619620?fromModule=lemma_inlink)》 [333];5月,在[昆山市体育中心](https://baike.baidu.com/item/%E6%98%86%E5%B1%B1%E5%B8%82%E4%BD%93%E8%82%B2%E4%B8%AD%E5%BF%83/10551658?fromModule=lemma_inlink)体育场举行演唱会;6月,在[第20届台湾金曲奖](https://baike.baidu.com/item/%E7%AC%AC20%E5%B1%8A%E5%8F%B0%E6%B9%BE%E9%87%91%E6%9B%B2%E5%A5%96/8055336?fromModule=lemma_inlink)颁奖典礼上,周杰伦凭借歌曲《[稻香](https://baike.baidu.com/item/%E7%A8%BB%E9%A6%99/11539?fromModule=lemma_inlink)》获得最佳年度歌曲奖,凭借歌曲《[魔术先生](https://baike.baidu.com/item/%E9%AD%94%E6%9C%AF%E5%85%88%E7%94%9F/6756619?fromModule=lemma_inlink)》获得最佳音乐录影带奖,凭借专辑《魔杰座》获得最佳国语男歌手奖 [7];7月,周杰伦悉尼演唱会的票房在美国公告牌上排名第二,成为该年全球单场演唱会票房收入第二名,并且打破了华人歌手在澳大利亚开演唱会的票房纪录;8月起,在[佛山世纪莲体育中心](https://baike.baidu.com/item/%E4%BD%9B%E5%B1%B1%E4%B8%96%E7%BA%AA%E8%8E%B2%E4%BD%93%E8%82%B2%E4%B8%AD%E5%BF%83/2393458?fromModule=lemma_inlink)体育场、[沈阳奥体中心](https://baike.baidu.com/item/%E6%B2%88%E9%98%B3%E5%A5%A5%E4%BD%93%E4%B8%AD%E5%BF%83/665665?fromModule=lemma_inlink)体育场等场馆举办个人巡回演唱会;12月,入选美国[CNN](https://baike.baidu.com/item/CNN/86482?fromModule=lemma_inlink)评出的“亚洲最具影响力的25位人物” [49];同月9日,与[林志玲](https://baike.baidu.com/item/%E6%9E%97%E5%BF%97%E7%8E%B2/172898?fromModule=lemma_inlink)共同主演的探险片《[刺陵](https://baike.baidu.com/item/%E5%88%BA%E9%99%B5/7759069?fromModule=lemma_inlink)》上映 [336],他在片中饰演拥有神秘力量的古城守陵人乔飞 [95]。
2010年2月9日,出演的古装武侠片《[苏乞儿](https://baike.baidu.com/item/%E8%8B%8F%E4%B9%9E%E5%84%BF/7887736?fromModule=lemma_inlink)》上映 [337],他在片中饰演冷酷、不苟言笑的[武神](https://baike.baidu.com/item/%E6%AD%A6%E7%A5%9E/61764957?fromModule=lemma_inlink) [338];同年,执导科幻剧《[熊猫人](https://baike.baidu.com/item/%E7%86%8A%E7%8C%AB%E4%BA%BA/23175?fromModule=lemma_inlink)》,并特别客串出演该剧 [339],他还为该剧创作了《[熊猫人](https://baike.baidu.com/item/%E7%86%8A%E7%8C%AB%E4%BA%BA/19687027?fromModule=lemma_inlink)》《[爱情引力](https://baike.baidu.com/item/%E7%88%B1%E6%83%85%E5%BC%95%E5%8A%9B/8585685?fromModule=lemma_inlink)》等歌曲 [96];3月28日,在[第14届全球华语榜中榜](https://baike.baidu.com/item/%E7%AC%AC14%E5%B1%8A%E5%85%A8%E7%90%83%E5%8D%8E%E8%AF%AD%E6%A6%9C%E4%B8%AD%E6%A6%9C/2234155?fromModule=lemma_inlink)暨亚洲影响力大典上获得12530无线音乐年度大奖 [242];5月18日,发行个人第十张音乐专辑《[跨时代](https://baike.baidu.com/item/%E8%B7%A8%E6%97%B6%E4%BB%A3/516122?fromModule=lemma_inlink)》 [293],并包办专辑中全部歌曲的作曲和制作,该专辑于次年获得[第22届台湾金曲奖](https://baike.baidu.com/item/%E7%AC%AC22%E5%B1%8A%E5%8F%B0%E6%B9%BE%E9%87%91%E6%9B%B2%E5%A5%96/7220967?fromModule=lemma_inlink)最佳国语专辑奖、[中国原创音乐流行榜](https://baike.baidu.com/item/%E4%B8%AD%E5%9B%BD%E5%8E%9F%E5%88%9B%E9%9F%B3%E4%B9%90%E6%B5%81%E8%A1%8C%E6%A6%9C/10663228?fromModule=lemma_inlink)最优秀专辑奖等奖项,而周杰伦也凭借该专辑获得第22届台湾金曲奖最佳国语男歌手奖 [50] [294];6月,入选美国杂志《[Fast Company](https://baike.baidu.com/item/Fast%20Company/6508066?fromModule=lemma_inlink)》评出的“全球百大创意人物”,并且成为首位入榜的华人男歌手;6月11日,在[台北小巨蛋](https://baike.baidu.com/item/%E5%8F%B0%E5%8C%97%E5%B0%8F%E5%B7%A8%E8%9B%8B/10648327?fromModule=lemma_inlink)举行“超时代”演唱会首场演出;8月,在一项名为“全球歌曲下载量最高歌手”(2008年年初至2010年8月10日)的调查中,周杰伦的歌曲下载量排名全球第三 [51];12月,编号为257248的小行星被命名为“[周杰伦星](https://baike.baidu.com/item/%E5%91%A8%E6%9D%B0%E4%BC%A6%E6%98%9F/8257706?fromModule=lemma_inlink)”,而周杰伦也创作了以该小行星为题材的歌曲《[爱的飞行日记](https://baike.baidu.com/item/%E7%88%B1%E7%9A%84%E9%A3%9E%E8%A1%8C%E6%97%A5%E8%AE%B0/1842823?fromModule=lemma_inlink)》;12月30日,美国古柏蒂奴市宣布把每年的12月31日设立为“周杰伦日” [52]。
2011年1月,凭借动作片《[青蜂侠](https://baike.baidu.com/item/%E9%9D%92%E8%9C%82%E4%BE%A0/7618833?fromModule=lemma_inlink)》进军好莱坞 [340],并入选美国电影网站Screen Crave评出的“十大最值得期待的新秀演员”;2月11日,登上[2011年中央电视台春节联欢晚会](https://baike.baidu.com/item/2011%E5%B9%B4%E4%B8%AD%E5%A4%AE%E7%94%B5%E8%A7%86%E5%8F%B0%E6%98%A5%E8%8A%82%E8%81%94%E6%AC%A2%E6%99%9A%E4%BC%9A/3001908?fromModule=lemma_inlink),并与林志玲表演、演唱歌曲《[兰亭序](https://baike.baidu.com/item/%E5%85%B0%E4%BA%AD%E5%BA%8F/2879867?fromModule=lemma_inlink)》 [341];2月23日,与[科比·布莱恩特](https://baike.baidu.com/item/%E7%A7%91%E6%AF%94%C2%B7%E5%B8%83%E8%8E%B1%E6%81%A9%E7%89%B9/318773?fromModule=lemma_inlink)拍摄雪碧广告以及MV,并创作了广告主题曲《[天地一斗](https://baike.baidu.com/item/%E5%A4%A9%E5%9C%B0%E4%B8%80%E6%96%97/6151126?fromModule=lemma_inlink)》;4月21日,美国《[时代周刊](https://baike.baidu.com/item/%E6%97%B6%E4%BB%A3%E5%91%A8%E5%88%8A/6643818?fromModule=lemma_inlink)》评选了“全球年度最具影响力人物100强”,周杰伦位列第二名;5月13日,凭借专辑《[跨时代](https://baike.baidu.com/item/%E8%B7%A8%E6%97%B6%E4%BB%A3/516122?fromModule=lemma_inlink)》、歌曲《[超人不会飞](https://baike.baidu.com/item/%E8%B6%85%E4%BA%BA%E4%B8%8D%E4%BC%9A%E9%A3%9E/39269?fromModule=lemma_inlink)》《[烟花易冷](https://baike.baidu.com/item/%E7%83%9F%E8%8A%B1%E6%98%93%E5%86%B7/211?fromModule=lemma_inlink)》分别入围第22届台湾金曲奖最佳专辑制作人奖、最佳年度歌曲奖、最佳作曲人奖等奖项 [53-54];5月,凭借动作片《青蜂侠》获得第20届美国[MTV电影电视奖](https://baike.baidu.com/item/MTV%E7%94%B5%E5%BD%B1%E7%94%B5%E8%A7%86%E5%A5%96/20817009?fromModule=lemma_inlink)最佳新人提名 [97];11月11日,发行个人第11张音乐专辑《[惊叹号!](https://baike.baidu.com/item/%E6%83%8A%E5%8F%B9%E5%8F%B7%EF%BC%81/10482087?fromModule=lemma_inlink)》 [247] [298],该专辑融合了[重金属摇滚](https://baike.baidu.com/item/%E9%87%8D%E9%87%91%E5%B1%9E%E6%91%87%E6%BB%9A/1514206?fromModule=lemma_inlink)、嘻哈、节奏蓝调、[爵士](https://baike.baidu.com/item/%E7%88%B5%E5%A3%AB/8315440?fromModule=lemma_inlink)等音乐风格,并首次引入[电子舞曲](https://baike.baidu.com/item/%E7%94%B5%E5%AD%90%E8%88%9E%E6%9B%B2/5673907?fromModule=lemma_inlink) [55];同年,在洛杉矶、吉隆坡、高雄等地举行“超时代世界巡回演唱会” [56]。
2012年,主演枪战动作电影《[逆战](https://baike.baidu.com/item/%E9%80%86%E6%88%98/9261017?fromModule=lemma_inlink)》,在片中饰演对错分明、具有强烈正义感的国际警务人员万飞 [98];4月,在[第16届全球华语榜中榜](https://baike.baidu.com/item/%E7%AC%AC16%E5%B1%8A%E5%85%A8%E7%90%83%E5%8D%8E%E8%AF%AD%E6%A6%9C%E4%B8%AD%E6%A6%9C/2211134?fromModule=lemma_inlink)亚洲影响力大典上获得了亚洲影响力最佳华语艺人奖、榜中榜最佳数字音乐奖,他的专辑《惊叹号!》也获得了港台最佳专辑奖 [342];5月,位列[福布斯中国名人榜](https://baike.baidu.com/item/%E7%A6%8F%E5%B8%83%E6%96%AF%E4%B8%AD%E5%9B%BD%E5%90%8D%E4%BA%BA%E6%A6%9C/2125?fromModule=lemma_inlink)第一名;5月15日,凭借专辑《惊叹号!》和歌曲《[水手怕水](https://baike.baidu.com/item/%E6%B0%B4%E6%89%8B%E6%80%95%E6%B0%B4/9504982?fromModule=lemma_inlink)》分别入围[第23届台湾金曲奖](https://baike.baidu.com/item/%E7%AC%AC23%E5%B1%8A%E5%8F%B0%E6%B9%BE%E9%87%91%E6%9B%B2%E5%A5%96/2044143?fromModule=lemma_inlink)最佳国语男歌手奖、最佳编曲人奖;9月22日,在新加坡F1赛道举办演唱会,成为首位在F1演出的华人歌手 [57];12月28日,发行个人第12张音乐专辑《[12新作](https://baike.baidu.com/item/12%E6%96%B0%E4%BD%9C/8186612?fromModule=lemma_inlink)》 [299],该专辑包括了中国风、说唱、蓝调、R&B、爵士等音乐风格,主打歌曲《[红尘客栈](https://baike.baidu.com/item/%E7%BA%A2%E5%B0%98%E5%AE%A2%E6%A0%88/8396283?fromModule=lemma_inlink)》获得第13届全球华语歌曲排行榜二十大金曲奖、[第36届十大中文金曲](https://baike.baidu.com/item/%E7%AC%AC36%E5%B1%8A%E5%8D%81%E5%A4%A7%E4%B8%AD%E6%96%87%E9%87%91%E6%9B%B2/12632953?fromModule=lemma_inlink)优秀流行国语歌曲银奖等奖项。
2013年5月17日,在上海[梅赛德斯-奔驰文化中心](https://baike.baidu.com/item/%E6%A2%85%E8%B5%9B%E5%BE%B7%E6%96%AF%EF%BC%8D%E5%A5%94%E9%A9%B0%E6%96%87%E5%8C%96%E4%B8%AD%E5%BF%83/12524895?fromModule=lemma_inlink)举行“魔天伦”世界巡回演唱会;5月22日,凭借专辑《12新作》入围[第24届台湾金曲奖](https://baike.baidu.com/item/%E7%AC%AC24%E5%B1%8A%E5%8F%B0%E6%B9%BE%E9%87%91%E6%9B%B2%E5%A5%96/4788862?fromModule=lemma_inlink)最佳国语专辑奖、最佳国语男歌手奖、最佳专辑制作人奖;6月1日,为动画电影《[十万个冷笑话](https://baike.baidu.com/item/%E5%8D%81%E4%B8%87%E4%B8%AA%E5%86%B7%E7%AC%91%E8%AF%9D/2883102?fromModule=lemma_inlink)》中的角色[太乙真人](https://baike.baidu.com/item/%E5%A4%AA%E4%B9%99%E7%9C%9F%E4%BA%BA/23686155?fromModule=lemma_inlink)配音;6月22日,在[成都市体育中心](https://baike.baidu.com/item/%E6%88%90%E9%83%BD%E5%B8%82%E4%BD%93%E8%82%B2%E4%B8%AD%E5%BF%83/4821286?fromModule=lemma_inlink)体育场举行演唱会;7月11日,自导自演的爱情片《[天台爱情](https://baike.baidu.com/item/%E5%A4%A9%E5%8F%B0%E7%88%B1%E6%83%85/3568321?fromModule=lemma_inlink)》上映 [344],该片还被选为[纽约亚洲电影节](https://baike.baidu.com/item/%E7%BA%BD%E7%BA%A6%E4%BA%9A%E6%B4%B2%E7%94%B5%E5%BD%B1%E8%8A%82/12609945?fromModule=lemma_inlink)闭幕影片 [99];9月6日至8日,在台北小巨蛋举行3场“魔天伦”演唱会 [58];10月4日,担任音乐爱情电影《[听见下雨的声音](https://baike.baidu.com/item/%E5%90%AC%E8%A7%81%E4%B8%8B%E9%9B%A8%E7%9A%84%E5%A3%B0%E9%9F%B3/7239472?fromModule=lemma_inlink)》的音乐总监 [100]。
2014年4月起,在悉尼、贵阳、上海、吉隆坡等地举行“魔天伦”世界巡回演唱会 [59];5月,位列福布斯中国名人榜第3名 [60];11月,在动作片《[惊天魔盗团2](https://baike.baidu.com/item/%E6%83%8A%E5%A4%A9%E9%AD%94%E7%9B%97%E5%9B%A22/9807509?fromModule=lemma_inlink)》中饰演魔术道具店的老板Li [101];12月10日,发行首张个人数字音乐专辑《[哎呦,不错哦](https://baike.baidu.com/item/%E5%93%8E%E5%91%A6%EF%BC%8C%E4%B8%8D%E9%94%99%E5%93%A6/9851748?fromModule=lemma_inlink)》 [295],成为首位发行数字音乐专辑的华人歌手 [61];该专辑发行后获得第二届[QQ音乐年度盛典](https://baike.baidu.com/item/QQ%E9%9F%B3%E4%B9%90%E5%B9%B4%E5%BA%A6%E7%9B%9B%E5%85%B8/13131216?fromModule=lemma_inlink)年度畅销数字专辑奖,专辑中的歌曲《[鞋子特大号](https://baike.baidu.com/item/%E9%9E%8B%E5%AD%90%E7%89%B9%E5%A4%A7%E5%8F%B7/16261949?fromModule=lemma_inlink)》获得第5届[全球流行音乐金榜](https://baike.baidu.com/item/%E5%85%A8%E7%90%83%E6%B5%81%E8%A1%8C%E9%9F%B3%E4%B9%90%E9%87%91%E6%A6%9C/3621354?fromModule=lemma_inlink)年度二十大金曲奖。
2015年4月,在[第19届全球华语榜中榜](https://baike.baidu.com/item/%E7%AC%AC19%E5%B1%8A%E5%85%A8%E7%90%83%E5%8D%8E%E8%AF%AD%E6%A6%9C%E4%B8%AD%E6%A6%9C/16913437?fromModule=lemma_inlink)暨亚洲影响力大典上获得亚洲影响力最受欢迎全能华语艺人奖、华语乐坛跨时代实力唱作人奖 [343];5月,在福布斯中国名人榜中排名第2位 [63];6月27日,凭借专辑《[哎呦,不错哦](https://baike.baidu.com/item/%E5%93%8E%E5%91%A6%EF%BC%8C%E4%B8%8D%E9%94%99%E5%93%A6/9851748?fromModule=lemma_inlink)》获得[第26届台湾金曲奖](https://baike.baidu.com/item/%E7%AC%AC26%E5%B1%8A%E5%8F%B0%E6%B9%BE%E9%87%91%E6%9B%B2%E5%A5%96/16997436?fromModule=lemma_inlink)最佳国语专辑奖、最佳专辑制作人奖两项提名;7月起,担任[浙江卫视](https://baike.baidu.com/item/%E6%B5%99%E6%B1%9F%E5%8D%AB%E8%A7%86/868580?fromModule=lemma_inlink)励志音乐评论节目《[中国好声音第四季](https://baike.baidu.com/item/%E4%B8%AD%E5%9B%BD%E5%A5%BD%E5%A3%B0%E9%9F%B3%E7%AC%AC%E5%9B%9B%E5%AD%A3/16040352?fromModule=lemma_inlink)》的导师 [62];9月26日,在[佛山世纪莲体育中心](https://baike.baidu.com/item/%E4%BD%9B%E5%B1%B1%E4%B8%96%E7%BA%AA%E8%8E%B2%E4%BD%93%E8%82%B2%E4%B8%AD%E5%BF%83/2393458?fromModule=lemma_inlink)体育场举行“魔天伦”演唱会;12月20日,在昆明拓东体育场举行“魔天伦”演唱会。
2016年3月,在[QQ音乐巅峰盛典](https://baike.baidu.com/item/QQ%E9%9F%B3%E4%B9%90%E5%B7%85%E5%B3%B0%E7%9B%9B%E5%85%B8/19430591?fromModule=lemma_inlink)上获得年度巅峰人气歌手奖、年度音乐全能艺人奖、年度最具影响力演唱会奖;3月24日,发行个人作词、作曲的单曲《[英雄](https://baike.baidu.com/item/%E8%8B%B1%E9%9B%84/19459565?fromModule=lemma_inlink)》,上线两周播放量突破8000万;6月1日,为电影《[惊天魔盗团2](https://baike.baidu.com/item/%E6%83%8A%E5%A4%A9%E9%AD%94%E7%9B%97%E5%9B%A22/9807509?fromModule=lemma_inlink)》创作的主题曲《[Now You See Me](https://baike.baidu.com/item/Now%20You%20See%20Me/19708831?fromModule=lemma_inlink)》发布 [64];6月24日,发行融合古典、摇滚、嘻哈等曲风的数字音乐专辑《[周杰伦的床边故事](https://baike.baidu.com/item/%E5%91%A8%E6%9D%B0%E4%BC%A6%E7%9A%84%E5%BA%8A%E8%BE%B9%E6%95%85%E4%BA%8B/19711456?fromModule=lemma_inlink)》 [65] [300],该专辑发行两日销量突破100万张,打破数字专辑在中国内地的销售纪录 [66],专辑在大中华地区的累计销量突破200万张,销售额超过4000万元 [67];6月,参演的好莱坞电影《[惊天魔盗团2](https://baike.baidu.com/item/%E6%83%8A%E5%A4%A9%E9%AD%94%E7%9B%97%E5%9B%A22/9807509?fromModule=lemma_inlink)》在中国内地上映;7月15日起,担任浙江卫视音乐评论节目《[中国新歌声第一季](https://baike.baidu.com/item/%E4%B8%AD%E5%9B%BD%E6%96%B0%E6%AD%8C%E5%A3%B0%E7%AC%AC%E4%B8%80%E5%AD%A3/19837166?fromModule=lemma_inlink)》的导师 [68];12月23日起,由周杰伦自编自导的文艺片《不能说的秘密》而改编的同名音乐剧《[不能说的秘密](https://baike.baidu.com/item/%E4%B8%8D%E8%83%BD%E8%AF%B4%E7%9A%84%E7%A7%98%E5%AF%86/19661975?fromModule=lemma_inlink)》在[北京天桥艺术中心](https://baike.baidu.com/item/%E5%8C%97%E4%BA%AC%E5%A4%A9%E6%A1%A5%E8%89%BA%E6%9C%AF%E4%B8%AD%E5%BF%83/17657501?fromModule=lemma_inlink)举行全球首演,该音乐剧的作曲、作词、原著故事均由周杰伦完成 [102-103];同年,在上海、北京、青岛、郑州、常州等地举行[周杰伦“地表最强”世界巡回演唱会](https://baike.baidu.com/item/%E5%91%A8%E6%9D%B0%E4%BC%A6%E2%80%9C%E5%9C%B0%E8%A1%A8%E6%9C%80%E5%BC%BA%E2%80%9D%E4%B8%96%E7%95%8C%E5%B7%A1%E5%9B%9E%E6%BC%94%E5%94%B1%E4%BC%9A/53069809?fromModule=lemma_inlink)。

2017年1月6日,周杰伦监制的爱情电影《[一万公里的约定](https://baike.baidu.com/item/%E4%B8%80%E4%B8%87%E5%85%AC%E9%87%8C%E7%9A%84%E7%BA%A6%E5%AE%9A/17561190?fromModule=lemma_inlink)》在中国内地上映 [104];1月13日,在江苏卫视推出的科学类真人秀节目《[最强大脑第四季](https://baike.baidu.com/item/%E6%9C%80%E5%BC%BA%E5%A4%A7%E8%84%91%E7%AC%AC%E5%9B%9B%E5%AD%A3/19450808?fromModule=lemma_inlink)》中担任嘉宾 [69];4月15日至16日,在昆明拓东体育场举办两场个人演唱会,其后在重庆、南京、沈阳、厦门等地举行“地表最强”世界巡回演唱会 [70];5月16日,凭借歌曲《[告白气球](https://baike.baidu.com/item/%E5%91%8A%E7%99%BD%E6%B0%94%E7%90%83/19713859?fromModule=lemma_inlink)》《[床边故事](https://baike.baidu.com/item/%E5%BA%8A%E8%BE%B9%E6%95%85%E4%BA%8B/19710370?fromModule=lemma_inlink)》、专辑《周杰伦的床边故事》分别入围[第28届台湾金曲奖](https://baike.baidu.com/item/%E7%AC%AC28%E5%B1%8A%E5%8F%B0%E6%B9%BE%E9%87%91%E6%9B%B2%E5%A5%96/20804578?fromModule=lemma_inlink)最佳年度歌曲奖、最佳音乐录影带奖、最佳国语男歌手奖 [235];6月4日,获得Hito年度最佳男歌手奖;随后,参加原创专业音乐节目《[中国新歌声第二季](https://baike.baidu.com/item/%E4%B8%AD%E5%9B%BD%E6%96%B0%E6%AD%8C%E5%A3%B0%E7%AC%AC%E4%BA%8C%E5%AD%A3/20128840?fromModule=lemma_inlink)》并担任导师 [71];8月9日,其发行的音乐专辑《周杰伦的床边故事》获得[华语金曲奖](https://baike.baidu.com/item/%E5%8D%8E%E8%AF%AD%E9%87%91%E6%9B%B2%E5%A5%96/2477095?fromModule=lemma_inlink)年度最佳国语专辑奖 [72]。
2018年1月6日,在新加坡举行“地表最强2”世界巡回演唱会的首场演出 [73];1月18日,发行由其个人作词、作曲的音乐单曲《[等你下课](https://baike.baidu.com/item/%E7%AD%89%E4%BD%A0%E4%B8%8B%E8%AF%BE/22344815?fromModule=lemma_inlink)》 [250],该曲由周杰伦与[杨瑞代](https://baike.baidu.com/item/%E6%9D%A8%E7%91%9E%E4%BB%A3/1538482?fromModule=lemma_inlink)共同演唱 [74];2月15日,在[2018年中央电视台春节联欢晚会](https://baike.baidu.com/item/2018%E5%B9%B4%E4%B8%AD%E5%A4%AE%E7%94%B5%E8%A7%86%E5%8F%B0%E6%98%A5%E8%8A%82%E8%81%94%E6%AC%A2%E6%99%9A%E4%BC%9A/20848218?fromModule=lemma_inlink)上与[蔡威泽](https://baike.baidu.com/item/%E8%94%A1%E5%A8%81%E6%B3%BD/20863889?fromModule=lemma_inlink)合作表演魔术与歌曲《[告白气球](https://baike.baidu.com/item/%E5%91%8A%E7%99%BD%E6%B0%94%E7%90%83/22388056?fromModule=lemma_inlink)》,该节目在2018年央视春晚节目收视率TOP10榜单中位列第一位 [75-76];5月15日,发行个人创作的音乐单曲《[不爱我就拉倒](https://baike.baidu.com/item/%E4%B8%8D%E7%88%B1%E6%88%91%E5%B0%B1%E6%8B%89%E5%80%92/22490709?fromModule=lemma_inlink)》 [77] [346];11月21日,加盟由[D·J·卡卢索](https://baike.baidu.com/item/D%C2%B7J%C2%B7%E5%8D%A1%E5%8D%A2%E7%B4%A2/16013808?fromModule=lemma_inlink)执导的电影《[极限特工4](https://baike.baidu.com/item/%E6%9E%81%E9%99%90%E7%89%B9%E5%B7%A54/20901306?fromModule=lemma_inlink)》 [105]。
2019年2月9日,在美国拉斯维加斯举行个人演唱会 [78];7月24日,宣布“嘉年华”世界巡回演唱会于10月启动 [79],该演唱会是周杰伦庆祝出道20周年的演唱会 [80];9月16日,发行与[陈信宏](https://baike.baidu.com/item/%E9%99%88%E4%BF%A1%E5%AE%8F/334?fromModule=lemma_inlink)共同演唱的音乐单曲《[说好不哭](https://baike.baidu.com/item/%E8%AF%B4%E5%A5%BD%E4%B8%8D%E5%93%AD/23748447?fromModule=lemma_inlink)》 [355],该曲由[方文山](https://baike.baidu.com/item/%E6%96%B9%E6%96%87%E5%B1%B1/135622?fromModule=lemma_inlink)作词 [81];10月17日,在上海举行[周杰伦“嘉年华”世界巡回演唱会](https://baike.baidu.com/item/%E5%91%A8%E6%9D%B0%E4%BC%A6%E2%80%9C%E5%98%89%E5%B9%B4%E5%8D%8E%E2%80%9D%E4%B8%96%E7%95%8C%E5%B7%A1%E5%9B%9E%E6%BC%94%E5%94%B1%E4%BC%9A/62969657?fromModule=lemma_inlink)的首场演出 [80];11月1日,发行“地表最强”世界巡回演唱会Live专辑 [82];12月15日,周杰伦为电影《[天·火](https://baike.baidu.com/item/%E5%A4%A9%C2%B7%E7%81%AB/23375274?fromModule=lemma_inlink)》献唱的主题曲《[我是如此相信](https://baike.baidu.com/item/%E6%88%91%E6%98%AF%E5%A6%82%E6%AD%A4%E7%9B%B8%E4%BF%A1/24194094?fromModule=lemma_inlink)》发行 [84]。
2020年1月10日至11日,在[新加坡国家体育场](https://baike.baidu.com/item/%E6%96%B0%E5%8A%A0%E5%9D%A1%E5%9B%BD%E5%AE%B6%E4%BD%93%E8%82%B2%E5%9C%BA/8820507?fromModule=lemma_inlink)举行两场“嘉年华”世界巡回演唱会 [85];3月21日,在浙江卫视全球户外生活文化实境秀节目《[周游记](https://baike.baidu.com/item/%E5%91%A8%E6%B8%B8%E8%AE%B0/22427755?fromModule=lemma_inlink)》中担任发起人 [86];6月12日,发行个人音乐单曲《[Mojito](https://baike.baidu.com/item/Mojito/50474451?fromModule=lemma_inlink)》 [88] [249];5月29日,周杰伦首个中文社交媒体在快手开通 [267];7月26日,周杰伦在快手进行了直播首秀,半小时内直播观看人次破6800万 [268];10月,监制并特别出演赛车题材电影《[叱咤风云](https://baike.baidu.com/item/%E5%8F%B1%E5%92%A4%E9%A3%8E%E4%BA%91/22756550?fromModule=lemma_inlink)》 [106-107]。
2021年1月29日,获得[中国歌曲TOP排行榜](https://baike.baidu.com/item/%E4%B8%AD%E5%9B%BD%E6%AD%8C%E6%9B%B2TOP%E6%8E%92%E8%A1%8C%E6%A6%9C/53567645?fromModule=lemma_inlink)最佳男歌手奖;2月12日,以“云录制”形式在[2021年中央广播电视总台春节联欢晚会](https://baike.baidu.com/item/2021%E5%B9%B4%E4%B8%AD%E5%A4%AE%E5%B9%BF%E6%92%AD%E7%94%B5%E8%A7%86%E6%80%BB%E5%8F%B0%E6%98%A5%E8%8A%82%E8%81%94%E6%AC%A2%E6%99%9A%E4%BC%9A/23312983?fromModule=lemma_inlink)演唱歌曲《Mojito》 [89];2月12日,周杰伦“既来之,则乐之”唱聊会在快手上线 [269];5月12日,凭借单曲《Mojito》入围[第32届台湾金曲奖](https://baike.baidu.com/item/%E7%AC%AC32%E5%B1%8A%E5%8F%B0%E6%B9%BE%E9%87%91%E6%9B%B2%E5%A5%96/56977769?fromModule=lemma_inlink)最佳单曲制作人奖 [240]。
2022年5月20日至21日,周杰伦“奇迹现场重映计划”线上视频演唱会开始播出 [259];7月6日,音乐专辑《[最伟大的作品](https://baike.baidu.com/item/%E6%9C%80%E4%BC%9F%E5%A4%A7%E7%9A%84%E4%BD%9C%E5%93%81/61539892?fromModule=lemma_inlink)》在QQ音乐的预约量超过568万人 [263];7月6日,音乐专辑《最伟大的作品》同名先行曲的MV在网络平台播出 [262] [264];7月8日,专辑《最伟大的作品》开始预售 [265],8小时内在QQ音乐、[咪咕音乐](https://baike.baidu.com/item/%E5%92%AA%E5%92%95%E9%9F%B3%E4%B9%90/4539596?fromModule=lemma_inlink)等平台的预售额超过三千万元 [266];7月15日,周杰伦正式发行个人第15张音乐专辑《[最伟大的作品](https://baike.baidu.com/item/%E6%9C%80%E4%BC%9F%E5%A4%A7%E7%9A%84%E4%BD%9C%E5%93%81/61539892?fromModule=lemma_inlink)》 [261],专辑上线后一小时的总销售额超过1亿 [270];截至17时,该专辑在四大音乐平台总销量突破500万张,销售额超过1.5亿元 [272];7月18日,周杰伦在快手开启独家直播,直播间累计观看人数1.1亿,最高实时在线观看人数超654万 [273];9月,参加2022联盟嘉年华 [274];11月19日,周杰伦通过快手平台直播线上“哥友会” [277-278] [280],这也是他首次以线上的方式举办歌友会 [276];他在直播中演唱了《[还在流浪](https://baike.baidu.com/item/%E8%BF%98%E5%9C%A8%E6%B5%81%E6%B5%AA/61707897?fromModule=lemma_inlink)》《[半岛铁盒](https://baike.baidu.com/item/%E5%8D%8A%E5%B2%9B%E9%93%81%E7%9B%92/2268287?fromModule=lemma_inlink)》等5首歌曲 [279];12月16日,周杰伦参加动感地带世界杯音乐盛典,并在现场演唱了歌曲《我是如此相信》以及《[安静](https://baike.baidu.com/item/%E5%AE%89%E9%9D%99/2940419?fromModule=lemma_inlink)》 [282] [284]。
2023年3月,周杰伦发行的音乐专辑《[最伟大的作品](https://baike.baidu.com/item/%E6%9C%80%E4%BC%9F%E5%A4%A7%E7%9A%84%E4%BD%9C%E5%93%81/61539892?fromModule=lemma_inlink)》获得[国际唱片业协会](https://baike.baidu.com/item/%E5%9B%BD%E9%99%85%E5%94%B1%E7%89%87%E4%B8%9A%E5%8D%8F%E4%BC%9A/1486316?fromModule=lemma_inlink)(IFPI)发布的“2022年全球畅销专辑榜”冠军,成为首位获得该榜冠军的华语歌手 [287];5月16日,其演唱的歌曲《[最伟大的作品](https://baike.baidu.com/item/%E6%9C%80%E4%BC%9F%E5%A4%A7%E7%9A%84%E4%BD%9C%E5%93%81/61702109?fromModule=lemma_inlink)》获得[第34届台湾金曲奖](https://baike.baidu.com/item/%E7%AC%AC34%E5%B1%8A%E5%8F%B0%E6%B9%BE%E9%87%91%E6%9B%B2%E5%A5%96/62736300?fromModule=lemma_inlink)年度歌曲奖提名 [288];8月17日-20日,在呼和浩特市举行嘉年华世界巡回演唱会 [349];11月25日,参加的户外实境互动综艺节目《[周游记2](https://baike.baidu.com/item/%E5%91%A8%E6%B8%B8%E8%AE%B02/53845056?fromModule=lemma_inlink)》在浙江卫视播出 [312];12月6日,[环球音乐集团](https://baike.baidu.com/item/%E7%8E%AF%E7%90%83%E9%9F%B3%E4%B9%90%E9%9B%86%E5%9B%A2/1964357?fromModule=lemma_inlink)与周杰伦及其经纪公司“杰威尔音乐”达成战略合作伙伴关系 [318];12月9日,在泰国曼谷[拉加曼加拉国家体育场](https://baike.baidu.com/item/%E6%8B%89%E5%8A%A0%E6%9B%BC%E5%8A%A0%E6%8B%89%E5%9B%BD%E5%AE%B6%E4%BD%93%E8%82%B2%E5%9C%BA/6136556?fromModule=lemma_inlink)举行“嘉年华”世界巡回演唱会 [324];12月21日,发行音乐单曲《[圣诞星](https://baike.baidu.com/item/%E5%9C%A3%E8%AF%9E%E6%98%9F/63869869?fromModule=lemma_inlink)》 [345]。2024年4月,由坚果工作室制片的说唱真人秀综艺《说唱梦工厂》在北京举行媒体探班活动,其中主要嘉宾有周杰伦。 [356]5月23日,参演的综艺《说唱梦工厂》播出。 [358]
## 1.3、个人经历
### 1.3.1、家庭情况
周杰伦的父亲[周耀中](https://baike.baidu.com/item/%E5%91%A8%E8%80%80%E4%B8%AD/4326853?fromModule=lemma_inlink)是淡江中学的生物老师 [123],母亲[叶惠美](https://baike.baidu.com/item/%E5%8F%B6%E6%83%A0%E7%BE%8E/2325933?fromModule=lemma_inlink)是淡江中学的美术老师。周杰伦跟母亲之间的关系就像弟弟跟姐姐。他也多次写歌给母亲,比如《[听妈妈的话](https://baike.baidu.com/item/%E5%90%AC%E5%A6%88%E5%A6%88%E7%9A%84%E8%AF%9D/79604?fromModule=lemma_inlink)》,甚至还把母亲的名字“叶惠美”作为专辑的名称。由于父母离异,因此周杰伦很少提及父亲周耀中,后来在母亲和外婆[叶詹阿妹](https://baike.baidu.com/item/%E5%8F%B6%E8%A9%B9%E9%98%BF%E5%A6%B9/926323?fromModule=lemma_inlink)的劝导下,他重新接纳了父亲。
### 1.3.2、感情生活
2004年底,周杰伦与[侯佩岑](https://baike.baidu.com/item/%E4%BE%AF%E4%BD%A9%E5%B2%91/257126?fromModule=lemma_inlink)相恋。2005年,两人公开承认恋情。2006年5月,两人分手 [237-238]。
2014年11月17日,周杰伦公开与[昆凌](https://baike.baidu.com/item/%E6%98%86%E5%87%8C/1545451?fromModule=lemma_inlink)的恋情 [124]。2015年1月17日,周杰伦与昆凌在英国举行婚礼 [125];2月9日,周杰伦与昆凌在台北举行泳池户外婚宴;3月9日,周杰伦与昆凌在澳大利亚举办家庭婚礼 [126];7月10日,周杰伦与昆凌的女儿[Hathaway](https://baike.baidu.com/item/Hathaway/18718544?fromModule=lemma_inlink)出生 [127-128]。2017年2月13日,周杰伦宣布妻子怀二胎 [129];6月8日,周杰伦与昆凌的儿子[Romeo](https://baike.baidu.com/item/Romeo/22180208?fromModule=lemma_inlink)出生 [130]。2022年1月19日,周杰伦宣布妻子昆凌怀三胎 [256];4月22日,昆凌表示第三胎是女儿 [258];5月6日,周杰伦的女儿[Jacinda](https://baike.baidu.com/item/Jacinda/61280507?fromModule=lemma_inlink)出生 [281]。
## 1.4、主要作品
### 1.4.1、音乐单曲
| **<font style="color:rgb(51, 51, 51);">歌曲名称</font>** | **<font style="color:rgb(51, 51, 51);">发行时间</font>** | **<font style="color:rgb(51, 51, 51);">歌曲简介</font>** |
|--------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [<sup>圣诞星</sup>](https://baike.baidu.com/item/%E5%9C%A3%E8%AF%9E%E6%98%9F/63869869?fromModule=lemma_inlink) | <font style="color:rgb(51, 51, 51);">2023-12-21</font> | <font style="color:rgb(51, 51, 51);">-</font> |
| [Mojito](https://baike.baidu.com/item/Mojito/50474451?fromModule=lemma_inlink) | <font style="color:rgb(51, 51, 51);">2020-6-12</font> | <font style="color:rgb(51, 51, 51);">单曲</font><sup><font style="color:rgb(51, 102, 204);"> </font></sup><sup><font style="color:rgb(51, 102, 204);">[131]</font></sup> |
| [我是如此相信](https://baike.baidu.com/item/%E6%88%91%E6%98%AF%E5%A6%82%E6%AD%A4%E7%9B%B8%E4%BF%A1/24194094?fromModule=lemma_inlink) | <font style="color:rgb(51, 51, 51);">2019-12-15</font> | <font style="color:rgb(51, 51, 51);">电影《天火》主题曲</font><sup><font style="color:rgb(51, 102, 204);"> </font></sup><sup><font style="color:rgb(51, 102, 204);">[83]</font></sup> |
| [说好不哭](https://baike.baidu.com/item/%E8%AF%B4%E5%A5%BD%E4%B8%8D%E5%93%AD/23748447?fromModule=lemma_inlink) | <font style="color:rgb(51, 51, 51);">2019-09-16</font> | <font style="color:rgb(51, 51, 51);">with 五月天阿信</font> |
| [不爱我就拉倒](https://baike.baidu.com/item/%E4%B8%8D%E7%88%B1%E6%88%91%E5%B0%B1%E6%8B%89%E5%80%92/22490709?fromModule=lemma_inlink) | <font style="color:rgb(51, 51, 51);">2018-05-15</font> | <font style="color:rgb(51, 51, 51);">-</font> |
| [等你下课](https://baike.baidu.com/item/%E7%AD%89%E4%BD%A0%E4%B8%8B%E8%AF%BE/22344815?fromModule=lemma_inlink) | <font style="color:rgb(51, 51, 51);">2018-01-18</font> | <font style="color:rgb(51, 51, 51);">杨瑞代参与演唱</font> |
| [英雄](https://baike.baidu.com/item/%E8%8B%B1%E9%9B%84/19459565?fromModule=lemma_inlink) | <font style="color:rgb(51, 51, 51);">2016-03-24</font> | <font style="color:rgb(51, 51, 51);">《英雄联盟》游戏主题曲</font> |
| [Try](https://baike.baidu.com/item/Try/19208892?fromModule=lemma_inlink) | <font style="color:rgb(51, 51, 51);">2016-01-06</font> | <font style="color:rgb(51, 51, 51);">与派伟俊合唱,电影《功夫熊猫3》主题曲</font> |
| [婚礼曲](https://baike.baidu.com/item/%E5%A9%9A%E7%A4%BC%E6%9B%B2/22913856?fromModule=lemma_inlink) | <font style="color:rgb(51, 51, 51);">2015</font> | <font style="color:rgb(51, 51, 51);">纯音乐</font> |
| [夜店咖](https://baike.baidu.com/item/%E5%A4%9C%E5%BA%97%E5%92%96/16182672?fromModule=lemma_inlink) | <font style="color:rgb(51, 51, 51);">2014-11-25</font> | <font style="color:rgb(51, 51, 51);">与嘻游记合唱</font> |
### 1.4.2、为他人创作
| <font style="color:rgb(51, 51, 51);">歌曲名称</font> | <font style="color:rgb(51, 51, 51);">职能</font> | <font style="color:rgb(51, 51, 51);">演唱者</font> | <font style="color:rgb(51, 51, 51);">所属专辑</font> | <font style="color:rgb(51, 51, 51);">发行时间</font> |
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------|----------------------------------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------------|--------------------------------------------------------|
| [<sup>AMIGO</sup>](https://baike.baidu.com/item/AMIGO/62130287?fromModule=lemma_inlink)<br/><sup><font style="color:rgb(51, 102, 204);"> </font></sup><sup><font style="color:rgb(51, 102, 204);">[275]</font></sup> | <font style="color:rgb(51, 51, 51);">作曲</font> | <font style="color:rgb(51, 51, 51);">玖壹壹</font> | <font style="color:rgb(51, 51, 51);">-</font> | <font style="color:rgb(51, 51, 51);">2022-10-25</font> |
| [叱咤风云](https://baike.baidu.com/item/%E5%8F%B1%E5%92%A4%E9%A3%8E%E4%BA%91/55751566?fromModule=lemma_inlink) | <font style="color:rgb(51, 51, 51);">作曲、电吉他演奏</font> | <font style="color:rgb(51, 51, 51);">范逸臣、柯有伦</font> | <font style="color:rgb(51, 51, 51);">-</font> | <font style="color:rgb(51, 51, 51);">2021-1-10</font> |
| [等风雨经过](https://baike.baidu.com/item/%E7%AD%89%E9%A3%8E%E9%9B%A8%E7%BB%8F%E8%BF%87/24436567?fromModule=lemma_inlink) | <font style="color:rgb(51, 51, 51);">作曲</font> | <font style="color:rgb(51, 51, 51);">张学友</font> | <font style="color:rgb(51, 51, 51);">-</font> | <font style="color:rgb(51, 51, 51);">2020-2-23</font> |
| [一路上小心](https://baike.baidu.com/item/%E4%B8%80%E8%B7%AF%E4%B8%8A%E5%B0%8F%E5%BF%83/9221406?fromModule=lemma_inlink) | <font style="color:rgb(51, 51, 51);">作曲</font> | <font style="color:rgb(51, 51, 51);">吴宗宪</font> | <font style="color:rgb(51, 51, 51);">-</font> | <font style="color:rgb(51, 51, 51);">2019-05-17</font> |
| [谢谢一辈子](https://baike.baidu.com/item/%E8%B0%A2%E8%B0%A2%E4%B8%80%E8%BE%88%E5%AD%90/22823424?fromModule=lemma_inlink) | <font style="color:rgb(51, 51, 51);">作曲</font> | <font style="color:rgb(51, 51, 51);">成龙</font> | [我还是成龙](https://baike.baidu.com/item/%E6%88%91%E8%BF%98%E6%98%AF%E6%88%90%E9%BE%99/0?fromModule=lemma_inlink) | <font style="color:rgb(51, 51, 51);">2018-12-20</font> |
| [连名带姓](https://baike.baidu.com/item/%E8%BF%9E%E5%90%8D%E5%B8%A6%E5%A7%93/22238578?fromModule=lemma_inlink) | <font style="color:rgb(51, 51, 51);">作曲</font> | [张惠妹](https://baike.baidu.com/item/%E5%BC%A0%E6%83%A0%E5%A6%B9/234310?fromModule=lemma_inlink) | [偷故事的人](https://baike.baidu.com/item/%E5%81%B7%E6%95%85%E4%BA%8B%E7%9A%84%E4%BA%BA/0?fromModule=lemma_inlink) | <font style="color:rgb(51, 51, 51);">2017-12-12</font> |
| [时光之墟](https://baike.baidu.com/item/%E6%97%B6%E5%85%89%E4%B9%8B%E5%A2%9F/22093813?fromModule=lemma_inlink) | <font style="color:rgb(51, 51, 51);">作曲</font> | [许魏洲](https://baike.baidu.com/item/%E8%AE%B8%E9%AD%8F%E6%B4%B2/18762132?fromModule=lemma_inlink) | [时光之墟](https://baike.baidu.com/item/%E6%97%B6%E5%85%89%E4%B9%8B%E5%A2%9F/0?fromModule=lemma_inlink) | <font style="color:rgb(51, 51, 51);">2017-08-25</font> |
| [超猛](https://baike.baidu.com/item/%E8%B6%85%E7%8C%9B/19543891?fromModule=lemma_inlink) | <font style="color:rgb(51, 51, 51);">作曲</font> | <font style="color:rgb(51, 51, 51);">草蜢、MATZKA</font> | [Music Walker](https://baike.baidu.com/item/Music%20Walker/0?fromModule=lemma_inlink) | <font style="color:rgb(51, 51, 51);">2016-04-22</font> |
| [东山再起](https://baike.baidu.com/item/%E4%B8%9C%E5%B1%B1%E5%86%8D%E8%B5%B7/19208906?fromModule=lemma_inlink) | <font style="color:rgb(51, 51, 51);">作曲</font> | [南拳妈妈](https://baike.baidu.com/item/%E5%8D%97%E6%8B%B3%E5%A6%88%E5%A6%88/167625?fromModule=lemma_inlink) | [拳新出击](https://baike.baidu.com/item/%E6%8B%B3%E6%96%B0%E5%87%BA%E5%87%BB/19662007?fromModule=lemma_inlink) | <font style="color:rgb(51, 51, 51);">2016-04-20</font> |
| [剩下的盛夏](https://baike.baidu.com/item/%E5%89%A9%E4%B8%8B%E7%9A%84%E7%9B%9B%E5%A4%8F/18534130?fromModule=lemma_inlink) | <font style="color:rgb(51, 51, 51);">作曲</font> | <font style="color:rgb(51, 51, 51);">TFBOYS、嘻游记</font> | [大梦想家](https://baike.baidu.com/item/%E5%A4%A7%E6%A2%A6%E6%83%B3%E5%AE%B6/0?fromModule=lemma_inlink) | <font style="color:rgb(51, 51, 51);">2015-08-28</font> |
### 1.4.3、演唱会记录
| **<font style="color:rgb(51, 51, 51);">举办时间</font>** | **<font style="color:rgb(51, 51, 51);">演唱会名称</font>** | **<font style="color:rgb(51, 51, 51);">总场次</font>** |
|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:----------------------------------------------------|
| <font style="color:rgb(51, 51, 51);">2019-10-17</font> | <font style="color:rgb(51, 51, 51);">嘉年华世界巡回演唱会</font> | |
| <font style="color:rgb(51, 51, 51);">2016-6-30 至 2019-5</font><sup><font style="color:rgb(51, 102, 204);"> </font></sup><sup><font style="color:rgb(51, 102, 204);">[142]</font></sup> | [周杰伦“地表最强”世界巡回演唱会](https://baike.baidu.com/item/%E5%91%A8%E6%9D%B0%E4%BC%A6%E2%80%9C%E5%9C%B0%E8%A1%A8%E6%9C%80%E5%BC%BA%E2%80%9D%E4%B8%96%E7%95%8C%E5%B7%A1%E5%9B%9E%E6%BC%94%E5%94%B1%E4%BC%9A/53069809?fromModule=lemma_inlink) | <font style="color:rgb(51, 51, 51);">120 场</font> |
| <font style="color:rgb(51, 51, 51);">2013-5-17 至 2015-12-20</font> | [魔天伦世界巡回演唱会](https://baike.baidu.com/item/%E9%AD%94%E5%A4%A9%E4%BC%A6%E4%B8%96%E7%95%8C%E5%B7%A1%E5%9B%9E%E6%BC%94%E5%94%B1%E4%BC%9A/24146025?fromModule=lemma_inlink) | <font style="color:rgb(51, 51, 51);">76 场</font> |
| <font style="color:rgb(51, 51, 51);">2010-6-11 至 2011-12-18</font> | [周杰伦2010超时代世界巡回演唱会](https://baike.baidu.com/item/%E5%91%A8%E6%9D%B0%E4%BC%A62010%E8%B6%85%E6%97%B6%E4%BB%A3%E4%B8%96%E7%95%8C%E5%B7%A1%E5%9B%9E%E6%BC%94%E5%94%B1%E4%BC%9A/3238718?fromModule=lemma_inlink) | <font style="color:rgb(51, 51, 51);">46 场</font> |
| <font style="color:rgb(51, 51, 51);">2007-11-10 至 2009-8-28</font> | [2007世界巡回演唱会](https://baike.baidu.com/item/2007%E4%B8%96%E7%95%8C%E5%B7%A1%E5%9B%9E%E6%BC%94%E5%94%B1%E4%BC%9A/12678549?fromModule=lemma_inlink) | <font style="color:rgb(51, 51, 51);">42 场</font> |
| <font style="color:rgb(51, 51, 51);">2004-10-2 至 2006-2-6</font> | [无与伦比演唱会](https://baike.baidu.com/item/%E6%97%A0%E4%B8%8E%E4%BC%A6%E6%AF%94%E6%BC%94%E5%94%B1%E4%BC%9A/1655166?fromModule=lemma_inlink) | <font style="color:rgb(51, 51, 51);">24 场</font> |
| <font style="color:rgb(51, 51, 51);">2002-9-28 至 2004-1-3</font> | [THEONE演唱会](https://baike.baidu.com/item/THEONE%E6%BC%94%E5%94%B1%E4%BC%9A/1543469?fromModule=lemma_inlink) | <font style="color:rgb(51, 51, 51);">16 场</font> |
| <font style="color:rgb(51, 51, 51);">2001-11-3 至 2002-2-10</font> | <font style="color:rgb(51, 51, 51);">范特西演唱会</font> | <font style="color:rgb(51, 51, 51);">5 场</font> |
## 1.5、社会活动
### 1.5.1、担任大使
| **<font style="color:rgb(51, 51, 51);">时间</font>** | **<font style="color:rgb(51, 51, 51);">名称</font>** |
|:---------------------------------------------------|:-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| <font style="color:rgb(51, 51, 51);">2005年</font> | <font style="color:rgb(51, 51, 51);">环保大使</font><sup><font style="color:rgb(51, 102, 204);"> </font></sup><sup><font style="color:rgb(51, 102, 204);">[165]</font></sup> |
| <font style="color:rgb(51, 51, 51);">2010年</font> | <font style="color:rgb(51, 51, 51);">校园拒烟大使</font><sup><font style="color:rgb(51, 102, 204);"> </font></sup><sup><font style="color:rgb(51, 102, 204);">[190]</font></sup> |
| <font style="color:rgb(51, 51, 51);">2011年</font> | <font style="color:rgb(51, 51, 51);">河南青年创业形象大使</font><sup><font style="color:rgb(51, 102, 204);"> </font></sup><sup><font style="color:rgb(51, 102, 204);">[191]</font></sup> |
| <font style="color:rgb(51, 51, 51);">2013年</font> | <font style="color:rgb(51, 51, 51);">蒲公英梦想大使</font><sup><font style="color:rgb(51, 102, 204);"> </font></sup><sup><font style="color:rgb(51, 102, 204);">[192]</font></sup> |
| <font style="color:rgb(51, 51, 51);">2014年</font> | <font style="color:rgb(51, 51, 51);">中国禁毒宣传形象大使</font> |
| | <font style="color:rgb(51, 51, 51);">观澜湖世界明星赛的推广大使</font><sup><font style="color:rgb(51, 102, 204);"> </font></sup><sup><font style="color:rgb(51, 102, 204);">[193]</font></sup> |
| <font style="color:rgb(51, 51, 51);">2016年</font> | <font style="color:rgb(51, 51, 51);">国际野生救援野生救援全球大使</font><sup><font style="color:rgb(51, 102, 204);"> </font></sup><sup><font style="color:rgb(51, 102, 204);">[194]</font></sup> | | {
"source": "OpenSPG/KAG",
"title": "tests/unit/builder/data/test_markdown.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/tests/unit/builder/data/test_markdown.md",
"date": "2024-09-21T13:56:44",
"stars": 5095,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 59840
} |
角色信息表:[aml.adm_cust_role_dd](https://www.baidu.com/assets/catalog/detail/table/adm_cust_role_dd/info)
<a name="nSOL0"></a>
### 背景
此表为解释一个客户的ip_id (即cust_id,3333开头)会对应多个ip_role_id (即role_id,也是3333开头)。其实业务上理解,就是一个客户开户后,对应不同业务场景会生成不同的角色ID,比如又有结算户又有云资金商户,就会有个人role 以及商户role,两个role类型不一样,角色id也都不一样。
<a name="kpInt"></a>
### 关键字段说明
<a name="BLpPo"></a>
#### role_id 角色ID
同样是3333开头,但是它对应cust_id的关系是多对一,即一个客户会有多个role_id
<a name="AMs5V"></a>
#### role_type 角色类型
角色类型主要分为会员、商户、被关联角色等,主要使用的还是会员和商户;<br />对应描述在字段 role_type_desc中储存。
<a name="JHlTP"></a>
#### cust_id 客户ID
与role_id 是一对多的关系。
<a name="h5769"></a>
#### enable_status 可用状态
此字段对应的可用/禁用状态,是对应描述的role_id 的可用/禁用状态;<br />对应描述在字段 enable_status_desc中储存。<br />*同时在客户维度上,也有此客户cust_id是可用/禁用状态,不在此表中,且两者并不相关,选择需要查看的维度对应选择字段。
<a name="BhYXU"></a>
#### reg_from 角色注册来源
标注了客户的注册来源,使用较少,reg_from_desc为空。
<a name="q14I4"></a>
#### lifecycle_status 角色生命周期
标注了客户角色的生命周期,使用较少,lifecycle_status_desc为空。 | {
"source": "OpenSPG/KAG",
"title": "tests/unit/builder/data/角色信息表说明.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/tests/unit/builder/data/角色信息表说明.md",
"date": "2024-09-21T13:56:44",
"stars": 5095,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 947
} |
# Introduction to Data of Enterprise Supply Chain
[English](./README.md) |
[简体中文](./README_cn.md)
## 1. Directory Structure
```text
supplychain
├── builder
│ ├── data
│ │ ├── Company.csv
│ │ ├── CompanyUpdate.csv
│ │ ├── Company_fundTrans_Company.csv
│ │ ├── Index.csv
│ │ ├── Industry.csv
│ │ ├── Person.csv
│ │ ├── Product.csv
│ │ ├── ProductChainEvent.csv
│ │ ├── TaxOfCompanyEvent.csv
│ │ ├── TaxOfProdEvent.csv
│ │ └── Trend.csv
```
We will introduce the tables by sampling some rows from each one.
## 2. The company instances (Company.csv)
```text
id,name,products
CSF0000002238,三角*胎股*限公司,"轮胎,全钢子午线轮胎"
```
* ``id``: The unique id of the company
* ``name``: Name of the company
* ``products``: Products produced by the company, separated by commas
## 3. Fund transferring between companies (Company_fundTrans_Company.csv)
```text
src,dst,transDate,transAmt
CSF0000002227,CSF0000001579,20230506,73
```
* ``src``: The source of the fund transfer
* ``dst``: The destination of the fund transfer
* ``transDate``: The date of the fund transfer
* ``transAmt``: The total amount of the fund transfer
## 4. The Person instances (Person.csv)
```text
id,name,age,legalRep
0,路**,63,"新疆*花*股*限公司,三角*胎股*限公司,传化*联*份限公司"
```
* ``id``: The unique id of the person
* ``name``: Name of the person
* ``age``: Age of the person
* ``legalRep``: Company list with the person as the legal representative, separated by commas
## 5. The industry concepts (Industry.csv)
```text
fullname
能源
能源-能源
能源-能源-能源设备与服务
能源-能源-能源设备与服务-能源设备与服务
能源-能源-石油、天然气与消费用燃料
```
The industry chain concepts is represented by its name, with dashes indicating its higher-level concepts.
For example, the higher-level concept of "能源-能源-能源设备与服务" is "能源-能源",
and the higher-level concept of "能源-能源-能源设备与服务-能源设备与服务" is "能源-能源-能源设备与服务".
## 6. The product concepts (Product.csv)
```text
fullname,belongToIndustry,hasSupplyChain
商品化工-橡胶-合成橡胶-顺丁橡胶,原材料-原材料-化学制品-商品化工,"化工商品贸易-化工产品贸易-橡塑制品贸易,轮胎与橡胶-轮胎,轮胎与橡胶-轮胎-特种轮胎,轮胎与橡胶-轮胎-工程轮胎,轮胎与橡胶-轮胎-斜交轮胎,轮胎与橡胶-轮胎-全钢子午线轮胎,轮胎与橡胶-轮胎-半钢子午线轮胎"
```
* ``fullname``: The name of the product, with dashes indicating its higher-level concepts.
* ``belongToIndustry``: The industry which the product belongs to. For example, in this case, "顺丁橡胶" belongs to "商品化工".
* ``hasSupplyChain``: The downstream industries related to the product, separated by commas. For example, the downstream industries of "顺丁橡胶" may include "橡塑制品贸易", "轮胎", and so on.
## 7. The industry chain events (ProductChainEvent.csv)
```text
id,name,subject,index,trend
1,顺丁橡胶成本上涨,商品化工-橡胶-合成橡胶-顺丁橡胶,价格,上涨
```
* ``id``: The ID of the event
* ``name``: The name of the event
* ``subject``: The subject of the event. In this example, it is "顺丁橡胶".
* ``index``: The index related to the event. In this example, it is "价格" (price).
* ``trend``: The trend of the event. In this example, it is "上涨" (rising).
## 8. The index concepts (Index.csv) and the trend concepts (Trend.csv)
Index and trend are atomic conceptual categories that can be combined to form industrial chain events and company events.
* index: The index related to the event, with possible values of "价格" (price), "成本" (cost) or "利润" (profit).
* trend: The trend of the event, with possible values of "上涨" (rising) or "下跌" (falling).
## 9 The event categorization (TaxOfProdEvent.csv, TaxOfCompanyEvent.csv)
Event classification includes industrial chain event classification and company event classification with the following data:
* Industrial chain event classification: "价格上涨" (price rising).
* Company event classification: "成本上涨" (cost rising), "利润下跌" (profit falling). | {
"source": "OpenSPG/KAG",
"title": "kag/examples/supplychain/builder/data/README.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/kag/examples/supplychain/builder/data/README.md",
"date": "2024-09-21T13:56:44",
"stars": 5095,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 3647
} |
# 产业链案例数据介绍
[English](./README.md) |
[简体中文](./README_cn.md)
## 1. 数据目录
```text
supplychain
├── builder
│ ├── data
│ │ ├── Company.csv
│ │ ├── CompanyUpdate.csv
│ │ ├── Company_fundTrans_Company.csv
│ │ ├── Index.csv
│ │ ├── Industry.csv
│ │ ├── Person.csv
│ │ ├── Product.csv
│ │ ├── ProductChainEvent.csv
│ │ ├── TaxOfCompanyEvent.csv
│ │ ├── TaxOfProdEvent.csv
│ │ └── Trend.csv
```
分别抽样部分数据进行介绍。
## 2. 公司数据(Company.csv)
```text
id,name,products
CSF0000002238,三角*胎股*限公司,"轮胎,全钢子午线轮胎"
```
* ``id``:公司在系统中的唯一 id
* ``name``:公司名
* ``products``:公司生产的产品,使用逗号分隔
## 3. 公司资金转账(Company_fundTrans_Company.csv)
```text
src,dst,transDate,transAmt
CSF0000002227,CSF0000001579,20230506,73
```
* ``src``:转出方
* ``dst``:转入方
* ``transDate``:转账日期
* ``transAmt``:转账总金额
## 4. 法人代表(Person.csv)
```text
id,name,age,legalRep
0,路**,63,"新疆*花*股*限公司,三角*胎股*限公司,传化*联*份限公司"
```
* ``id``:自然人在系统中唯一标识
* ``name``:自然人姓名
* ``age``:自然人年龄
* ``legalRep``:法人代表公司名字列表,逗号分隔
## 5. 产业类目概念(Industry.csv)
```text
fullname
能源
能源-能源
能源-能源-能源设备与服务
能源-能源-能源设备与服务-能源设备与服务
能源-能源-石油、天然气与消费用燃料
```
产业只有名字,其中段横线代表其上位概念,例如“能源-能源-能源设备与服务”的上位概念是“能源-能源”,“能源-能源-能源设备与服务-能源设备与服务”的上位概念为“能源-能源-能源设备与服务”。
## 6. 产品类目概念(Product.csv)
```text
fullname,belongToIndustry,hasSupplyChain
商品化工-橡胶-合成橡胶-顺丁橡胶,原材料-原材料-化学制品-商品化工,"化工商品贸易-化工产品贸易-橡塑制品贸易,轮胎与橡胶-轮胎,轮胎与橡胶-轮胎-特种轮胎,轮胎与橡胶-轮胎-工程轮胎,轮胎与橡胶-轮胎-斜交轮胎,轮胎与橡胶-轮胎-全钢子午线轮胎,轮胎与橡胶-轮胎-半钢子午线轮胎"
```
* ``fullname``:产品名,同样通过短横线分隔上下位
* ``belongToIndustry``:所归属的行业,例如本例中,顺丁橡胶属于商品化工
* ``hasSupplyChain``:是其下游产业,例如顺丁橡胶下游产业有橡塑制品贸易、轮胎等
## 7. 产业链事件(ProductChainEvent.csv)
```text
id,name,subject,index,trend
1,顺丁橡胶成本上涨,商品化工-橡胶-合成橡胶-顺丁橡胶,价格,上涨
```
* ``id``:事件的 id
* ``name``:事件的名字
* ``subject``:事件的主体,本例为顺丁橡胶
* ``index``:指标,本例为价格
* ``trend``:趋势,本例为上涨
## 8. 指标(Index.csv)和趋势(Trend.csv)
指标、趋势作为原子概念类目,可组合成产业链事件和公司事件。
* 指标,值域为:价格、成本、利润
* 趋势,值域为:上涨、下跌
## 9. 事件分类(TaxOfProdEvent.csv、TaxOfCompanyEvent.csv)
事件分类包括产业链事件分类和公司事件分类,数据为:
* 产业链事件分类,值域:价格上涨
* 公司事件分类,值域:成本上涨、利润下跌 | {
"source": "OpenSPG/KAG",
"title": "kag/examples/supplychain/builder/data/README_cn.md",
"url": "https://github.com/OpenSPG/KAG/blob/master/kag/examples/supplychain/builder/data/README_cn.md",
"date": "2024-09-21T13:56:44",
"stars": 5095,
"description": "KAG is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and LLMs. It is used to build logical reasoning and factual Q&A solutions for professional domain knowledge bases. It can effectively overcome the shortcomings of the traditional RAG vector similarity calculation model.",
"file_size": 1996
} |
<p align="center">
<img src="./assets/logo/白底.png" width="400" />
</p>
<p align="center">
<a href="https://map-yue.github.io/">Demo 🎶</a> | 📑 <a href="">Paper (coming soon)</a>
<br>
<a href="https://huggingface.co/m-a-p/YuE-s1-7B-anneal-en-cot">YuE-s1-7B-anneal-en-cot 🤗</a> | <a href="https://huggingface.co/m-a-p/YuE-s1-7B-anneal-en-icl">YuE-s1-7B-anneal-en-icl 🤗</a> | <a href="https://huggingface.co/m-a-p/YuE-s1-7B-anneal-jp-kr-cot">YuE-s1-7B-anneal-jp-kr-cot 🤗</a>
<br>
<a href="https://huggingface.co/m-a-p/YuE-s1-7B-anneal-jp-kr-icl">YuE-s1-7B-anneal-jp-kr-icl 🤗</a> | <a href="https://huggingface.co/m-a-p/YuE-s1-7B-anneal-zh-cot">YuE-s1-7B-anneal-zh-cot 🤗</a> | <a href="https://huggingface.co/m-a-p/YuE-s1-7B-anneal-zh-icl">YuE-s1-7B-anneal-zh-icl 🤗</a>
<br>
<a href="https://huggingface.co/m-a-p/YuE-s2-1B-general">YuE-s2-1B-general 🤗</a> | <a href="https://huggingface.co/m-a-p/YuE-upsampler">YuE-upsampler 🤗</a>
</p>
---
Our model's name is **YuE (乐)**. In Chinese, the word means "music" and "happiness." Some of you may find words that start with Yu hard to pronounce. If so, you can just call it "yeah." We wrote a song with our model's name, see [here](assets/logo/yue.mp3).
YuE is a groundbreaking series of open-source foundation models designed for music generation, specifically for transforming lyrics into full songs (lyrics2song). It can generate a complete song, lasting several minutes, that includes both a catchy vocal track and accompaniment track. YuE is capable of modeling diverse genres/languages/vocal techniques. Please visit the [**Demo Page**](https://map-yue.github.io/) for amazing vocal performance.
## News and Updates
* **2025.02.07 🎉** Get YuE for Windows on [pinokio](https://pinokio.computer).
* **2025.02.06** Join Us on Discord! [](https://discord.gg/ssAyWMnMzu)
* **2025.01.30 🔥 Inference Update**: We now support dual-track ICL mode! You can prompt the model with a reference song, and it will generate a new song in a similar style (voice cloning [demo by @abrakjamson](https://x.com/abrakjamson/status/1885932885406093538), music style transfer [demo by @cocktailpeanut](https://x.com/cocktailpeanut/status/1886456240156348674), etc.). Try it out! 🔥🔥🔥 P.S. Be sure to check out the demos first—they're truly impressive.
* **2025.01.30 🔥 Announcement: A New Era Under Apache 2.0 🔥**: We are thrilled to announce that, in response to overwhelming requests from our community, **YuE** is now officially licensed under the **Apache 2.0** license. We sincerely hope this marks a watershed moment—akin to what Stable Diffusion and LLaMA have achieved in their respective fields—for music generation and creative AI. 🎉🎉🎉
* **2025.01.29 🎉**: We have updated the license description. we **ENCOURAGE** artists and content creators to sample and incorporate outputs generated by our model into their own works, and even monetize them. The only requirement is to credit our name: **YuE by HKUST/M-A-P** (alphabetic order).
* **2025.01.28 🫶**: Thanks to Fahd for creating a tutorial on how to quickly get started with YuE. Here is his [demonstration](https://www.youtube.com/watch?v=RSMNH9GitbA).
* **2025.01.26 🔥**: We have released the **YuE** series.
<br>
---
## TODOs📋
- [ ] Release paper to Arxiv.
- [ ] Example finetune code for enabling BPM control using 🤗 Transformers.
- [ ] Support stemgen mode https://github.com/multimodal-art-projection/YuE/issues/21
- [ ] Support Colab https://github.com/multimodal-art-projection/YuE/issues/50
- [ ] Support llama.cpp https://github.com/ggerganov/llama.cpp/issues/11467
- [ ] Online serving on huggingface space.
- [ ] Support transformers tensor parallel. https://github.com/multimodal-art-projection/YuE/issues/7
- [x] Support gradio interface. https://github.com/multimodal-art-projection/YuE/issues/1
- [x] Support dual-track ICL mode.
- [x] Fix "instrumental" naming bug in output files. https://github.com/multimodal-art-projection/YuE/pull/26
- [x] Support seeding https://github.com/multimodal-art-projection/YuE/issues/20
- [x] Allow `--repetition_penalty` to customize repetition penalty. https://github.com/multimodal-art-projection/YuE/issues/45
---
## Hardware and Performance
### **GPU Memory**
YuE requires significant GPU memory for generating long sequences. Below are the recommended configurations:
- **For GPUs with 24GB memory or less**: Run **up to 2 sessions** to avoid out-of-memory (OOM) errors. Thanks to the community, there are [YuE-exllamav2](https://github.com/sgsdxzy/YuE-exllamav2) and [YuEGP](https://github.com/deepbeepmeep/YuEGP) for those with limited GPU resources. While both enhance generation speed and coherence, they may compromise musicality. (P.S. Better prompts & ICL help!)
- **For full song generation** (many sessions, e.g., 4 or more): Use **GPUs with at least 80GB memory**. i.e. H800, A100, or multiple RTX4090s with tensor parallel.
To customize the number of sessions, the interface allows you to specify the desired session count. By default, the model runs **2 sessions** (1 verse + 1 chorus) to avoid OOM issue.
### **Execution Time**
On an **H800 GPU**, generating 30s audio takes **150 seconds**.
On an **RTX 4090 GPU**, generating 30s audio takes approximately **360 seconds**.
---
## 🪟 Windows Users Quickstart
- For a **one-click installer**, use [Pinokio](https://pinokio.computer).
- To use **Gradio with Docker**, see: [YuE-for-Windows](https://github.com/sdbds/YuE-for-windows)
## 🐧 Linux/WSL Users Quickstart
For a **quick start**, watch this **video tutorial** by Fahd: [Watch here](https://www.youtube.com/watch?v=RSMNH9GitbA).
If you're new to **machine learning** or the **command line**, we highly recommend watching this video first.
To use a **GUI/Gradio** interface, check out:
- [YuE-exllamav2-UI](https://github.com/WrongProtocol/YuE-exllamav2-UI)
- [YuEGP](https://github.com/deepbeepmeep/YuEGP)
- [YuE-Interface](https://github.com/alisson-anjos/YuE-Interface)
### 1. Install environment and dependencies
Make sure properly install flash attention 2 to reduce VRAM usage.
```bash
# We recommend using conda to create a new environment.
conda create -n yue python=3.8 # Python >=3.8 is recommended.
conda activate yue
# install cuda >= 11.8
conda install pytorch torchvision torchaudio cudatoolkit=11.8 -c pytorch -c nvidia
pip install -r <(curl -sSL https://raw.githubusercontent.com/multimodal-art-projection/YuE/main/requirements.txt)
# For saving GPU memory, FlashAttention 2 is mandatory.
# Without it, long audio may lead to out-of-memory (OOM) errors.
# Be careful about matching the cuda version and flash-attn version
pip install flash-attn --no-build-isolation
```
### 2. Download the infer code and tokenizer
```bash
# Make sure you have git-lfs installed (https://git-lfs.com)
# if you don't have root, see https://github.com/git-lfs/git-lfs/issues/4134#issuecomment-1635204943
sudo apt update
sudo apt install git-lfs
git lfs install
git clone https://github.com/multimodal-art-projection/YuE.git
cd YuE/inference/
git clone https://huggingface.co/m-a-p/xcodec_mini_infer
```
### 3. Run the inference
Now generate music with **YuE** using 🤗 Transformers. Make sure your step [1](#1-install-environment-and-dependencies) and [2](#2-download-the-infer-code-and-tokenizer) are properly set up.
Note:
- Set `--run_n_segments` to the number of lyric sections if you want to generate a full song. Additionally, you can increase `--stage2_batch_size` based on your available GPU memory.
- You may customize the prompt in `genre.txt` and `lyrics.txt`. See prompt engineering guide [here](#prompt-engineering-guide).
- You can increase `--stage2_batch_size` to speed up the inference, but be careful for OOM.
- LM ckpts will be automatically downloaded from huggingface.
```bash
# This is the CoT mode.
cd YuE/inference/
python infer.py \
--cuda_idx 0 \
--stage1_model m-a-p/YuE-s1-7B-anneal-en-cot \
--stage2_model m-a-p/YuE-s2-1B-general \
--genre_txt ../prompt_egs/genre.txt \
--lyrics_txt ../prompt_egs/lyrics.txt \
--run_n_segments 2 \
--stage2_batch_size 4 \
--output_dir ../output \
--max_new_tokens 3000 \
--repetition_penalty 1.1
```
We also support music in-context-learning (provide a reference song), there are 2 types: single-track (mix/vocal/instrumental) and dual-track.
Note:
- ICL requires a different ckpt, e.g. `m-a-p/YuE-s1-7B-anneal-en-icl`.
- Music ICL generally requires a 30s audio segment. The model will write new songs with similar style of the provided audio, and may improve musicality.
- Dual-track ICL works better in general, requiring both vocal and instrumental tracks.
- For single-track ICL, you can provide a mix, vocal, or instrumental track.
- You can separate the vocal and instrumental tracks using [python-audio-separator](https://github.com/nomadkaraoke/python-audio-separator) or [Ultimate Vocal Remover GUI](https://github.com/Anjok07/ultimatevocalremovergui).
```bash
# This is the dual-track ICL mode.
# To turn on dual-track mode, enable `--use_dual_tracks_prompt`
# and provide `--vocal_track_prompt_path`, `--instrumental_track_prompt_path`,
# `--prompt_start_time`, and `--prompt_end_time`
# The ref audio is taken from GTZAN test set.
cd YuE/inference/
python infer.py \
--cuda_idx 0 \
--stage1_model m-a-p/YuE-s1-7B-anneal-en-icl \
--stage2_model m-a-p/YuE-s2-1B-general \
--genre_txt ../prompt_egs/genre.txt \
--lyrics_txt ../prompt_egs/lyrics.txt \
--run_n_segments 2 \
--stage2_batch_size 4 \
--output_dir ../output \
--max_new_tokens 3000 \
--repetition_penalty 1.1 \
--use_dual_tracks_prompt \
--vocal_track_prompt_path ../prompt_egs/pop.00001.Vocals.mp3 \
--instrumental_track_prompt_path ../prompt_egs/pop.00001.Instrumental.mp3 \
--prompt_start_time 0 \
--prompt_end_time 30
```
```bash
# This is the single-track (mix/vocal/instrumental) ICL mode.
# To turn on single-track ICL, enable `--use_audio_prompt`,
# and provide `--audio_prompt_path` , `--prompt_start_time`, and `--prompt_end_time`.
# The ref audio is taken from GTZAN test set.
cd YuE/inference/
python infer.py \
--cuda_idx 0 \
--stage1_model m-a-p/YuE-s1-7B-anneal-en-icl \
--stage2_model m-a-p/YuE-s2-1B-general \
--genre_txt ../prompt_egs/genre.txt \
--lyrics_txt ../prompt_egs/lyrics.txt \
--run_n_segments 2 \
--stage2_batch_size 4 \
--output_dir ../output \
--max_new_tokens 3000 \
--repetition_penalty 1.1 \
--use_audio_prompt \
--audio_prompt_path ../prompt_egs/pop.00001.mp3 \
--prompt_start_time 0 \
--prompt_end_time 30
```
---
## Prompt Engineering Guide
The prompt consists of three parts: genre tags, lyrics, and ref audio.
### Genre Tagging Prompt
1. An example genre tagging prompt can be found [here](prompt_egs/genre.txt).
2. A stable tagging prompt usually consists of five components: genre, instrument, mood, gender, and timbre. All five should be included if possible, separated by space (space delimiter).
3. Although our tags have an open vocabulary, we have provided the top 200 most commonly used [tags](./top_200_tags.json). It is recommended to select tags from this list for more stable results.
3. The order of the tags is flexible. For example, a stable genre tagging prompt might look like: "inspiring female uplifting pop airy vocal electronic bright vocal vocal."
4. Additionally, we have introduced the "Mandarin" and "Cantonese" tags to distinguish between Mandarin and Cantonese, as their lyrics often share similarities.
### Lyrics Prompt
1. An example lyric prompt can be found [here](prompt_egs/lyrics.txt).
2. We support multiple languages, including but not limited to English, Mandarin Chinese, Cantonese, Japanese, and Korean. The default top language distribution during the annealing phase is revealed in [issue 12](https://github.com/multimodal-art-projection/YuE/issues/12#issuecomment-2620845772). A language ID on a specific annealing checkpoint indicates that we have adjusted the mixing ratio to enhance support for that language.
3. The lyrics prompt should be divided into sessions, with structure labels (e.g., [verse], [chorus], [bridge], [outro]) prepended. Each session should be separated by 2 newline character "\n\n".
4. **DONOT** put too many words in a single segment, since each session is around 30s (`--max_new_tokens 3000` by default).
5. We find that [intro] label is less stable, so we recommend starting with [verse] or [chorus].
6. For generating music with no vocal, see [issue 18](https://github.com/multimodal-art-projection/YuE/issues/18).
### Audio Prompt
1. Audio prompt is optional. Providing ref audio for ICL usually increase the good case rate, and result in less diversity since the generated token space is bounded by the ref audio. CoT only (no ref) will result in a more diverse output.
2. We find that dual-track ICL mode gives the best musicality and prompt following.
3. Use the chorus part of the music as prompt will result in better musicality.
4. Around 30s audio is recommended for ICL.
---
## License Agreement \& Disclaimer
- The YuE model (including its weights) is now released under the **Apache License, Version 2.0**. We do not make any profit from this model, and we hope it can be used for the betterment of human creativity.
- **Use & Attribution**:
- We encourage artists and content creators to freely incorporate outputs generated by YuE into their own works, including commercial projects.
- We encourage attribution to the model’s name (“YuE by HKUST/M-A-P”), especially for public and commercial use.
- **Originality & Plagiarism**: It is the sole responsibility of creators to ensure that their works, derived from or inspired by YuE outputs, do not plagiarize or unlawfully reproduce existing material. We strongly urge users to perform their own due diligence to avoid copyright infringement or other legal violations.
- **Recommended Labeling**: When uploading works to streaming platforms or sharing them publicly, we **recommend** labeling them with terms such as: “AI-generated”, “YuE-generated", “AI-assisted” or “AI-auxiliated”. This helps maintain transparency about the creative process.
- **Disclaimer of Liability**:
- We do not assume any responsibility for the misuse of this model, including (but not limited to) illegal, malicious, or unethical activities.
- Users are solely responsible for any content generated using the YuE model and for any consequences arising from its use.
- By using this model, you agree that you understand and comply with all applicable laws and regulations regarding your generated content.
---
## Acknowledgements
The project is co-lead by HKUST and M-A-P (alphabetic order). Also thanks moonshot.ai, bytedance, 01.ai, and geely for supporting the project.
A friendly link to HKUST Audio group's [huggingface space](https://huggingface.co/HKUSTAudio).
We deeply appreciate all the support we received along the way. Long live open-source AI!
---
## Citation
If you find our paper and code useful in your research, please consider giving a star :star: and citation :pencil: :)
```BibTeX
@misc{yuan2025yue,
title={YuE: Open Music Foundation Models for Full-Song Generation},
author={Ruibin Yuan and Hanfeng Lin and Shawn Guo and Ge Zhang and Jiahao Pan and Yongyi Zang and Haohe Liu and Xingjian Du and Xeron Du and Zhen Ye and Tianyu Zheng and Yinghao Ma and Minghao Liu and Lijun Yu and Zeyue Tian and Ziya Zhou and Liumeng Xue and Xingwei Qu and Yizhi Li and Tianhao Shen and Ziyang Ma and Shangda Wu and Jun Zhan and Chunhui Wang and Yatian Wang and Xiaohuan Zhou and Xiaowei Chi and Xinyue Zhang and Zhenzhu Yang and Yiming Liang and Xiangzhou Wang and Shansong Liu and Lingrui Mei and Peng Li and Yong Chen and Chenghua Lin and Xie Chen and Gus Xia and Zhaoxiang Zhang and Chao Zhang and Wenhu Chen and Xinyu Zhou and Xipeng Qiu and Roger Dannenberg and Jiaheng Liu and Jian Yang and Stephen Huang and Wei Xue and Xu Tan and Yike Guo},
howpublished={\url{https://github.com/multimodal-art-projection/YuE}},
year={2025},
note={GitHub repository}
}
```
<br> | {
"source": "multimodal-art-projection/YuE",
"title": "README.md",
"url": "https://github.com/multimodal-art-projection/YuE/blob/main/README.md",
"date": "2025-01-23T06:21:58",
"stars": 3611,
"description": "YuE: Open Full-song Music Generation Foundation Model, something similar to Suno.ai but open",
"file_size": 16388
} |
<p align="center" style="border-radius: 10px">
<img src="asset/logo.png" width="35%" alt="logo"/>
</p>
# ⚡️Sana: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer
### <div align="center"> ICLR 2025 Oral Presentation <div>
<div align="center">
<a href="https://nvlabs.github.io/Sana/"><img src="https://img.shields.io/static/v1?label=Project&message=Github&color=blue&logo=github-pages"></a>  
<a href="https://hanlab.mit.edu/projects/sana/"><img src="https://img.shields.io/static/v1?label=Page&message=MIT&color=darkred&logo=github-pages"></a>  
<a href="https://arxiv.org/abs/2410.10629"><img src="https://img.shields.io/static/v1?label=Arxiv&message=Sana&color=red&logo=arxiv"></a>  
<a href="https://nv-sana.mit.edu/"><img src="https://img.shields.io/static/v1?label=Demo:6x3090&message=MIT&color=yellow"></a>  
<a href="https://nv-sana.mit.edu/4bit/"><img src="https://img.shields.io/static/v1?label=Demo:1x3090&message=4bit&color=yellow"></a>  
<a href="https://nv-sana.mit.edu/ctrlnet/"><img src="https://img.shields.io/static/v1?label=Demo:1x3090&message=ControlNet&color=yellow"></a>  
<a href="https://replicate.com/chenxwh/sana"><img src="https://img.shields.io/static/v1?label=API:H100&message=Replicate&color=pink"></a>  
<a href="https://discord.gg/rde6eaE5Ta"><img src="https://img.shields.io/static/v1?label=Discuss&message=Discord&color=purple&logo=discord"></a>  
</div>
<p align="center" border-radius="10px">
<img src="asset/Sana.jpg" width="90%" alt="teaser_page1"/>
</p>
## 💡 Introduction
We introduce Sana, a text-to-image framework that can efficiently generate images up to 4096 × 4096 resolution.
Sana can synthesize high-resolution, high-quality images with strong text-image alignment at a remarkably fast speed, deployable on laptop GPU.
Core designs include:
(1) [**DC-AE**](https://hanlab.mit.edu/projects/dc-ae): unlike traditional AEs, which compress images only 8×, we trained an AE that can compress images 32×, effectively reducing the number of latent tokens. \
(2) **Linear DiT**: we replace all vanilla attention in DiT with linear attention, which is more efficient at high resolutions without sacrificing quality. \
(3) **Decoder-only text encoder**: we replaced T5 with a modern decoder-only small LLM as the text encoder and designed complex human instruction with in-context learning to enhance the image-text alignment. \
(4) **Efficient training and sampling**: we propose **Flow-DPM-Solver** to reduce sampling steps, with efficient caption labeling and selection to accelerate convergence.
As a result, Sana-0.6B is very competitive with modern giant diffusion models (e.g. Flux-12B), being 20 times smaller and 100+ times faster in measured throughput. Moreover, Sana-0.6B can be deployed on a 16GB laptop GPU, taking less than 1 second to generate a 1024 × 1024 resolution image. Sana enables content creation at low cost.
<p align="center" border-raduis="10px">
<img src="asset/model-incremental.jpg" width="90%" alt="teaser_page2"/>
</p>
## 🔥🔥 News
- (🔥 New) \[2025/2/10\] 🚀Sana + ControlNet is released. [\[Guidance\]](asset/docs/sana_controlnet.md) | [\[Model\]](asset/docs/model_zoo.md) | [\[Demo\]](https://nv-sana.mit.edu/ctrlnet/)
- (🔥 New) \[2025/1/30\] Release CAME-8bit optimizer code. Saving more GPU memory during training. [\[How to config\]](https://github.com/NVlabs/Sana/blob/main/configs/sana_config/1024ms/Sana_1600M_img1024_CAME8bit.yaml#L86)
- (🔥 New) \[2025/1/29\] 🎉 🎉 🎉**SANA 1.5 is out! Figure out how to do efficient training & inference scaling!** 🚀[\[Tech Report\]](https://arxiv.org/abs/2501.18427)
- (🔥 New) \[2025/1/24\] 4bit-Sana is released, powered by [SVDQuant and Nunchaku](https://github.com/mit-han-lab/nunchaku) inference engine. Now run your Sana within **8GB** GPU VRAM [\[Guidance\]](asset/docs/4bit_sana.md) [\[Demo\]](https://svdquant.mit.edu/) [\[Model\]](asset/docs/model_zoo.md)
- (🔥 New) \[2025/1/24\] DCAE-1.1 is released, better reconstruction quality. [\[Model\]](https://huggingface.co/mit-han-lab/dc-ae-f32c32-sana-1.1) [\[diffusers\]](https://huggingface.co/mit-han-lab/dc-ae-f32c32-sana-1.1-diffusers)
- (🔥 New) \[2025/1/23\] **Sana is accepted as Oral by ICLR-2025.** 🎉🎉🎉
______________________________________________________________________
- (🔥 New) \[2025/1/12\] DC-AE tiling makes Sana-4K inferences 4096x4096px images within 22GB GPU memory. With model offload and 8bit/4bit quantize. The 4K Sana run within **8GB** GPU VRAM. [\[Guidance\]](asset/docs/model_zoo.md#-3-4k-models)
- (🔥 New) \[2025/1/11\] Sana code-base license changed to Apache 2.0.
- (🔥 New) \[2025/1/10\] Inference Sana with 8bit quantization.[\[Guidance\]](asset/docs/8bit_sana.md#quantization)
- (🔥 New) \[2025/1/8\] 4K resolution [Sana models](asset/docs/model_zoo.md) is supported in [Sana-ComfyUI](https://github.com/Efficient-Large-Model/ComfyUI_ExtraModels) and [work flow](asset/docs/ComfyUI/Sana_FlowEuler_4K.json) is also prepared. [\[4K guidance\]](asset/docs/ComfyUI/comfyui.md)
- (🔥 New) \[2025/1/8\] 1.6B 4K resolution [Sana models](asset/docs/model_zoo.md) are released: [\[BF16 pth\]](https://huggingface.co/Efficient-Large-Model/Sana_1600M_4Kpx_BF16) or [\[BF16 diffusers\]](https://huggingface.co/Efficient-Large-Model/Sana_1600M_4Kpx_BF16_diffusers). 🚀 Get your 4096x4096 resolution images within 20 seconds! Find more samples in [Sana page](https://nvlabs.github.io/Sana/). Thanks [SUPIR](https://github.com/Fanghua-Yu/SUPIR) for their wonderful work and support.
- (🔥 New) \[2025/1/2\] Bug in the `diffusers` pipeline is solved. [Solved PR](https://github.com/huggingface/diffusers/pull/10431)
- (🔥 New) \[2025/1/2\] 2K resolution [Sana models](asset/docs/model_zoo.md) is supported in [Sana-ComfyUI](https://github.com/Efficient-Large-Model/ComfyUI_ExtraModels) and [work flow](asset/docs/ComfyUI/Sana_FlowEuler_2K.json) is also prepared.
- ✅ \[2024/12\] 1.6B 2K resolution [Sana models](asset/docs/model_zoo.md) are released: [\[BF16 pth\]](https://huggingface.co/Efficient-Large-Model/Sana_1600M_2Kpx_BF16) or [\[BF16 diffusers\]](https://huggingface.co/Efficient-Large-Model/Sana_1600M_2Kpx_BF16_diffusers). 🚀 Get your 2K resolution images within 4 seconds! Find more samples in [Sana page](https://nvlabs.github.io/Sana/). Thanks [SUPIR](https://github.com/Fanghua-Yu/SUPIR) for their wonderful work and support.
- ✅ \[2024/12\] `diffusers` supports Sana-LoRA fine-tuning! Sana-LoRA's training and convergence speed is super fast. [\[Guidance\]](asset/docs/sana_lora_dreambooth.md) or [\[diffusers docs\]](https://github.com/huggingface/diffusers/blob/main/examples/dreambooth/README_sana.md).
- ✅ \[2024/12\] `diffusers` has Sana! [All Sana models in diffusers safetensors](https://huggingface.co/collections/Efficient-Large-Model/sana-673efba2a57ed99843f11f9e) are released and diffusers pipeline `SanaPipeline`, `SanaPAGPipeline`, `DPMSolverMultistepScheduler(with FlowMatching)` are all supported now. We prepare a [Model Card](asset/docs/model_zoo.md) for you to choose.
- ✅ \[2024/12\] 1.6B BF16 [Sana model](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_BF16) is released for stable fine-tuning.
- ✅ \[2024/12\] We release the [ComfyUI node](https://github.com/Efficient-Large-Model/ComfyUI_ExtraModels) for Sana. [\[Guidance\]](asset/docs/ComfyUI/comfyui.md)
- ✅ \[2024/11\] All multi-linguistic (Emoji & Chinese & English) SFT models are released: [1.6B-512px](https://huggingface.co/Efficient-Large-Model/Sana_1600M_512px_MultiLing), [1.6B-1024px](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_MultiLing), [600M-512px](https://huggingface.co/Efficient-Large-Model/Sana_600M_512px), [600M-1024px](https://huggingface.co/Efficient-Large-Model/Sana_600M_1024px). The metric performance is shown [here](#performance)
- ✅ \[2024/11\] Sana Replicate API is launching at [Sana-API](https://replicate.com/chenxwh/sana).
- ✅ \[2024/11\] 1.6B [Sana models](https://huggingface.co/collections/Efficient-Large-Model/sana-673efba2a57ed99843f11f9e) are released.
- ✅ \[2024/11\] Training & Inference & Metrics code are released.
- ✅ \[2024/11\] Working on [`diffusers`](https://github.com/huggingface/diffusers/pull/9982).
- \[2024/10\] [Demo](https://nv-sana.mit.edu/) is released.
- \[2024/10\] [DC-AE Code](https://github.com/mit-han-lab/efficientvit/blob/master/applications/dc_ae/README.md) and [weights](https://huggingface.co/collections/mit-han-lab/dc-ae-670085b9400ad7197bb1009b) are released!
- \[2024/10\] [Paper](https://arxiv.org/abs/2410.10629) is on Arxiv!
## Performance
| Methods (1024x1024) | Throughput (samples/s) | Latency (s) | Params (B) | Speedup | FID 👇 | CLIP 👆 | GenEval 👆 | DPG 👆 |
|-----------------------------------------------------------------------------------------------------|------------------------|-------------|------------|---------|-------------|--------------|-------------|-------------|
| FLUX-dev | 0.04 | 23.0 | 12.0 | 1.0× | 10.15 | 27.47 | _0.67_ | 84.0 |
| **Sana-0.6B** | 1.7 | 0.9 | 0.6 | 39.5× | _5.81_ | 28.36 | 0.64 | 83.6 |
| **[Sana-0.6B-MultiLing](https://huggingface.co/Efficient-Large-Model/Sana_600M_1024px)** | 1.7 | 0.9 | 0.6 | 39.5× | **5.61** | <u>28.80</u> | <u>0.68</u> | _84.2_ |
| **Sana-1.6B** | 1.0 | 1.2 | 1.6 | 23.3× | <u>5.76</u> | _28.67_ | 0.66 | **84.8** |
| **[Sana-1.6B-MultiLing](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_MultiLing)** | 1.0 | 1.2 | 1.6 | 23.3× | 5.92 | **28.94** | **0.69** | <u>84.5</u> |
<details>
<summary><h3>Click to show all</h3></summary>
| Methods | Throughput (samples/s) | Latency (s) | Params (B) | Speedup | FID 👆 | CLIP 👆 | GenEval 👆 | DPG 👆 |
|------------------------------|------------------------|-------------|------------|-----------|-------------|--------------|-------------|-------------|
| _**512 × 512 resolution**_ | | | | | | | | |
| PixArt-α | 1.5 | 1.2 | 0.6 | 1.0× | 6.14 | 27.55 | 0.48 | 71.6 |
| PixArt-Σ | 1.5 | 1.2 | 0.6 | 1.0× | _6.34_ | _27.62_ | <u>0.52</u> | _79.5_ |
| **Sana-0.6B** | 6.7 | 0.8 | 0.6 | 5.0× | <u>5.67</u> | <u>27.92</u> | _0.64_ | <u>84.3</u> |
| **Sana-1.6B** | 3.8 | 0.6 | 1.6 | 2.5× | **5.16** | **28.19** | **0.66** | **85.5** |
| _**1024 × 1024 resolution**_ | | | | | | | | |
| LUMINA-Next | 0.12 | 9.1 | 2.0 | 2.8× | 7.58 | 26.84 | 0.46 | 74.6 |
| SDXL | 0.15 | 6.5 | 2.6 | 3.5× | 6.63 | _29.03_ | 0.55 | 74.7 |
| PlayGroundv2.5 | 0.21 | 5.3 | 2.6 | 4.9× | _6.09_ | **29.13** | 0.56 | 75.5 |
| Hunyuan-DiT | 0.05 | 18.2 | 1.5 | 1.2× | 6.54 | 28.19 | 0.63 | 78.9 |
| PixArt-Σ | 0.4 | 2.7 | 0.6 | 9.3× | 6.15 | 28.26 | 0.54 | 80.5 |
| DALLE3 | - | - | - | - | - | - | _0.67_ | 83.5 |
| SD3-medium | 0.28 | 4.4 | 2.0 | 6.5× | 11.92 | 27.83 | 0.62 | <u>84.1</u> |
| FLUX-dev | 0.04 | 23.0 | 12.0 | 1.0× | 10.15 | 27.47 | _0.67_ | _84.0_ |
| FLUX-schnell | 0.5 | 2.1 | 12.0 | 11.6× | 7.94 | 28.14 | **0.71** | **84.8** |
| **Sana-0.6B** | 1.7 | 0.9 | 0.6 | **39.5×** | <u>5.81</u> | 28.36 | 0.64 | 83.6 |
| **Sana-1.6B** | 1.0 | 1.2 | 1.6 | **23.3×** | **5.76** | <u>28.67</u> | <u>0.66</u> | **84.8** |
</details>
## Contents
- [Env](#-1-dependencies-and-installation)
- [Demo](#-2-how-to-play-with-sana-inference)
- [Model Zoo](asset/docs/model_zoo.md)
- [Training](#-3-how-to-train-sana)
- [Testing](#-4-metric-toolkit)
- [TODO](#to-do-list)
- [Citation](#bibtex)
# 🔧 1. Dependencies and Installation
- Python >= 3.10.0 (Recommend to use [Anaconda](https://www.anaconda.com/download/#linux) or [Miniconda](https://docs.conda.io/en/latest/miniconda.html))
- [PyTorch >= 2.0.1+cu12.1](https://pytorch.org/)
```bash
git clone https://github.com/NVlabs/Sana.git
cd Sana
./environment_setup.sh sana
# or you can install each components step by step following environment_setup.sh
```
# 💻 2. How to Play with Sana (Inference)
## 💰Hardware requirement
- 9GB VRAM is required for 0.6B model and 12GB VRAM for 1.6B model. Our later quantization version will require less than 8GB for inference.
- All the tests are done on A100 GPUs. Different GPU version may be different.
## 🔛 Choose your model: [Model card](asset/docs/model_zoo.md)
## 🔛 Quick start with [Gradio](https://www.gradio.app/guides/quickstart)
```bash
# official online demo
DEMO_PORT=15432 \
python app/app_sana.py \
--share \
--config=configs/sana_config/1024ms/Sana_1600M_img1024.yaml \
--model_path=hf://Efficient-Large-Model/Sana_1600M_1024px/checkpoints/Sana_1600M_1024px.pth \
--image_size=1024
```
### 1. How to use `SanaPipeline` with `🧨diffusers`
> \[!IMPORTANT\]
> Upgrade your `diffusers>=0.32.0.dev` to make the `SanaPipeline` and `SanaPAGPipeline` available!
>
> ```bash
> pip install git+https://github.com/huggingface/diffusers
> ```
>
> Make sure to specify `pipe.transformer` to default `torch_dtype` and `variant` according to [Model Card](asset/docs/model_zoo.md).
>
> Set `pipe.text_encoder` to BF16 and `pipe.vae` to FP32 or BF16. For more info, [docs](https://huggingface.co/docs/diffusers/main/en/api/pipelines/sana#sanapipeline) are here.
```python
# run `pip install git+https://github.com/huggingface/diffusers` before use Sana in diffusers
import torch
from diffusers import SanaPipeline
pipe = SanaPipeline.from_pretrained(
"Efficient-Large-Model/Sana_1600M_1024px_BF16_diffusers",
variant="bf16",
torch_dtype=torch.bfloat16,
)
pipe.to("cuda")
pipe.vae.to(torch.bfloat16)
pipe.text_encoder.to(torch.bfloat16)
prompt = 'a cyberpunk cat with a neon sign that says "Sana"'
image = pipe(
prompt=prompt,
height=1024,
width=1024,
guidance_scale=4.5,
num_inference_steps=20,
generator=torch.Generator(device="cuda").manual_seed(42),
)[0]
image[0].save("sana.png")
```
### 2. How to use `SanaPAGPipeline` with `🧨diffusers`
```python
# run `pip install git+https://github.com/huggingface/diffusers` before use Sana in diffusers
import torch
from diffusers import SanaPAGPipeline
pipe = SanaPAGPipeline.from_pretrained(
"Efficient-Large-Model/Sana_1600M_1024px_diffusers",
variant="fp16",
torch_dtype=torch.float16,
pag_applied_layers="transformer_blocks.8",
)
pipe.to("cuda")
pipe.text_encoder.to(torch.bfloat16)
pipe.vae.to(torch.bfloat16)
prompt = 'a cyberpunk cat with a neon sign that says "Sana"'
image = pipe(
prompt=prompt,
guidance_scale=5.0,
pag_scale=2.0,
num_inference_steps=20,
generator=torch.Generator(device="cuda").manual_seed(42),
)[0]
image[0].save('sana.png')
```
<details>
<summary><h3>3. How to use Sana in this repo</h3></summary>
```python
import torch
from app.sana_pipeline import SanaPipeline
from torchvision.utils import save_image
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
generator = torch.Generator(device=device).manual_seed(42)
sana = SanaPipeline("configs/sana_config/1024ms/Sana_1600M_img1024.yaml")
sana.from_pretrained("hf://Efficient-Large-Model/Sana_1600M_1024px_BF16/checkpoints/Sana_1600M_1024px_BF16.pth")
prompt = 'a cyberpunk cat with a neon sign that says "Sana"'
image = sana(
prompt=prompt,
height=1024,
width=1024,
guidance_scale=5.0,
pag_guidance_scale=2.0,
num_inference_steps=18,
generator=generator,
)
save_image(image, 'output/sana.png', nrow=1, normalize=True, value_range=(-1, 1))
```
</details>
<details>
<summary><h3>4. Run Sana (Inference) with Docker</h3></summary>
```
# Pull related models
huggingface-cli download google/gemma-2b-it
huggingface-cli download google/shieldgemma-2b
huggingface-cli download mit-han-lab/dc-ae-f32c32-sana-1.0
huggingface-cli download Efficient-Large-Model/Sana_1600M_1024px
# Run with docker
docker build . -t sana
docker run --gpus all --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 \
-v ~/.cache:/root/.cache \
sana
```
</details>
## 🔛 Run inference with TXT or JSON files
```bash
# Run samples in a txt file
python scripts/inference.py \
--config=configs/sana_config/1024ms/Sana_1600M_img1024.yaml \
--model_path=hf://Efficient-Large-Model/Sana_1600M_1024px/checkpoints/Sana_1600M_1024px.pth \
--txt_file=asset/samples/samples_mini.txt
# Run samples in a json file
python scripts/inference.py \
--config=configs/sana_config/1024ms/Sana_1600M_img1024.yaml \
--model_path=hf://Efficient-Large-Model/Sana_1600M_1024px/checkpoints/Sana_1600M_1024px.pth \
--json_file=asset/samples/samples_mini.json
```
where each line of [`asset/samples/samples_mini.txt`](asset/samples/samples_mini.txt) contains a prompt to generate
# 🔥 3. How to Train Sana
## 💰Hardware requirement
- 32GB VRAM is required for both 0.6B and 1.6B model's training
### 1). Train with image-text pairs in directory
We provide a training example here and you can also select your desired config file from [config files dir](configs/sana_config) based on your data structure.
To launch Sana training, you will first need to prepare data in the following formats. [Here](asset/example_data) is an example for the data structure for reference.
```bash
asset/example_data
├── AAA.txt
├── AAA.png
├── BCC.txt
├── BCC.png
├── ......
├── CCC.txt
└── CCC.png
```
Then Sana's training can be launched via
```bash
# Example of training Sana 0.6B with 512x512 resolution from scratch
bash train_scripts/train.sh \
configs/sana_config/512ms/Sana_600M_img512.yaml \
--data.data_dir="[asset/example_data]" \
--data.type=SanaImgDataset \
--model.multi_scale=false \
--train.train_batch_size=32
# Example of fine-tuning Sana 1.6B with 1024x1024 resolution
bash train_scripts/train.sh \
configs/sana_config/1024ms/Sana_1600M_img1024.yaml \
--data.data_dir="[asset/example_data]" \
--data.type=SanaImgDataset \
--model.load_from=hf://Efficient-Large-Model/Sana_1600M_1024px/checkpoints/Sana_1600M_1024px.pth \
--model.multi_scale=false \
--train.train_batch_size=8
```
### 2). Train with image-text pairs in directory
We also provide conversion scripts to convert your data to the required format. You can refer to the [data conversion scripts](asset/data_conversion_scripts) for more details.
```bash
python tools/convert_ImgDataset_to_WebDatasetMS_format.py
```
Then Sana's training can be launched via
```bash
# Example of training Sana 0.6B with 512x512 resolution from scratch
bash train_scripts/train.sh \
configs/sana_config/512ms/Sana_600M_img512.yaml \
--data.data_dir="[asset/example_data_tar]" \
--data.type=SanaWebDatasetMS \
--model.multi_scale=true \
--train.train_batch_size=32
```
# 💻 4. Metric toolkit
Refer to [Toolkit Manual](asset/docs/metrics_toolkit.md).
# 💪To-Do List
We will try our best to release
- \[✅\] Training code
- \[✅\] Inference code
- \[✅\] Model zoo
- \[✅\] ComfyUI
- \[✅\] DC-AE Diffusers
- \[✅\] Sana merged in Diffusers(https://github.com/huggingface/diffusers/pull/9982)
- \[✅\] LoRA training by [@paul](https://github.com/sayakpaul)(`diffusers`: https://github.com/huggingface/diffusers/pull/10234)
- \[✅\] 2K/4K resolution models.(Thanks [@SUPIR](https://github.com/Fanghua-Yu/SUPIR) to provide a 4K super-resolution model)
- \[✅\] 8bit / 4bit Laptop development
- \[💻\] ControlNet (train & inference & models)
- \[💻\] Larger model size
- \[💻\] Better re-construction F32/F64 VAEs.
- \[💻\] **Sana1.5 (Focus on: Human body / Human face / Text rendering / Realism / Efficiency)**
# 🤗Acknowledgements
**Thanks to the following open-sourced codebase for their wonderful work and codebase!**
- [PixArt-α](https://github.com/PixArt-alpha/PixArt-alpha)
- [PixArt-Σ](https://github.com/PixArt-alpha/PixArt-sigma)
- [Efficient-ViT](https://github.com/mit-han-lab/efficientvit)
- [ComfyUI_ExtraModels](https://github.com/city96/ComfyUI_ExtraModels)
- [SVDQuant and Nunchaku](https://github.com/mit-han-lab/nunchaku)
- [diffusers](https://github.com/huggingface/diffusers)
## 🌟 Star History
[](https://star-history.com/#NVlabs/sana&Date)
# 📖BibTeX
```
@misc{xie2024sana,
title={Sana: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer},
author={Enze Xie and Junsong Chen and Junyu Chen and Han Cai and Haotian Tang and Yujun Lin and Zhekai Zhang and Muyang Li and Ligeng Zhu and Yao Lu and Song Han},
year={2024},
eprint={2410.10629},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2410.10629},
}
``` | {
"source": "NVlabs/Sana",
"title": "README.md",
"url": "https://github.com/NVlabs/Sana/blob/main/README.md",
"date": "2024-10-11T20:19:45",
"stars": 3321,
"description": "SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer",
"file_size": 22477
} |
<!--Copyright 2024 NVIDIA CORPORATION & AFFILIATES
#
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License. -->
# 4bit SanaPipeline
### 1. Environment setup
Follow the official [SVDQuant-Nunchaku](https://github.com/mit-han-lab/nunchaku) repository to set up the environment. The guidance can be found [here](https://github.com/mit-han-lab/nunchaku?tab=readme-ov-file#installation).
### 2. Code snap for inference
Here we show the code snippet for SanaPipeline. For SanaPAGPipeline, please refer to the [SanaPAGPipeline](https://github.com/mit-han-lab/nunchaku/blob/main/examples/sana_1600m_pag.py) section.
```python
import torch
from diffusers import SanaPipeline
from nunchaku.models.transformer_sana import NunchakuSanaTransformer2DModel
transformer = NunchakuSanaTransformer2DModel.from_pretrained("mit-han-lab/svdq-int4-sana-1600m")
pipe = SanaPipeline.from_pretrained(
"Efficient-Large-Model/Sana_1600M_1024px_BF16_diffusers",
transformer=transformer,
variant="bf16",
torch_dtype=torch.bfloat16,
).to("cuda")
pipe.text_encoder.to(torch.bfloat16)
pipe.vae.to(torch.bfloat16)
image = pipe(
prompt="A cute 🐼 eating 🎋, ink drawing style",
height=1024,
width=1024,
guidance_scale=4.5,
num_inference_steps=20,
generator=torch.Generator().manual_seed(42),
).images[0]
image.save("sana_1600m.png")
```
### 3. Online demo
1). Launch the 4bit Sana.
```bash
python app/app_sana_4bit.py
```
2). Compare with BF16 version
Refer to the original [Nunchaku-Sana.](https://github.com/mit-han-lab/nunchaku/tree/main/app/sana/t2i) guidance for SanaPAGPipeline
```bash
python app/app_sana_4bit_compare_bf16.py
``` | {
"source": "NVlabs/Sana",
"title": "asset/docs/4bit_sana.md",
"url": "https://github.com/NVlabs/Sana/blob/main/asset/docs/4bit_sana.md",
"date": "2024-10-11T20:19:45",
"stars": 3321,
"description": "SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer",
"file_size": 2148
} |
<!-- Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License. -->
# SanaPipeline
[SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformers](https://huggingface.co/papers/2410.10629) from NVIDIA and MIT HAN Lab, by Enze Xie, Junsong Chen, Junyu Chen, Han Cai, Haotian Tang, Yujun Lin, Zhekai Zhang, Muyang Li, Ligeng Zhu, Yao Lu, Song Han.
The abstract from the paper is:
*We introduce Sana, a text-to-image framework that can efficiently generate images up to 4096×4096 resolution. Sana can synthesize high-resolution, high-quality images with strong text-image alignment at a remarkably fast speed, deployable on laptop GPU. Core designs include: (1) Deep compression autoencoder: unlike traditional AEs, which compress images only 8×, we trained an AE that can compress images 32×, effectively reducing the number of latent tokens. (2) Linear DiT: we replace all vanilla attention in DiT with linear attention, which is more efficient at high resolutions without sacrificing quality. (3) Decoder-only text encoder: we replaced T5 with modern decoder-only small LLM as the text encoder and designed complex human instruction with in-context learning to enhance the image-text alignment. (4) Efficient training and sampling: we propose Flow-DPM-Solver to reduce sampling steps, with efficient caption labeling and selection to accelerate convergence. As a result, Sana-0.6B is very competitive with modern giant diffusion model (e.g. Flux-12B), being 20 times smaller and 100+ times faster in measured throughput. Moreover, Sana-0.6B can be deployed on a 16GB laptop GPU, taking less than 1 second to generate a 1024×1024 resolution image. Sana enables content creation at low cost. Code and model will be publicly released.*
<Tip>
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-a-pipeline) section to learn how to efficiently load the same components into multiple pipelines.
</Tip>
This pipeline was contributed by [lawrence-cj](https://github.com/lawrence-cj) and [chenjy2003](https://github.com/chenjy2003). The original codebase can be found [here](https://github.com/NVlabs/Sana). The original weights can be found under [hf.co/Efficient-Large-Model](https://huggingface.co/Efficient-Large-Model).
Available models:
| Model | Recommended dtype |
|:-----:|:-----------------:|
| [`Efficient-Large-Model/Sana_1600M_1024px_BF16_diffusers`](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_BF16_diffusers) | `torch.bfloat16` |
| [`Efficient-Large-Model/Sana_1600M_1024px_diffusers`](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_diffusers) | `torch.float16` |
| [`Efficient-Large-Model/Sana_1600M_1024px_MultiLing_diffusers`](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_MultiLing_diffusers) | `torch.float16` |
| [`Efficient-Large-Model/Sana_1600M_512px_diffusers`](https://huggingface.co/Efficient-Large-Model/Sana_1600M_512px_diffusers) | `torch.float16` |
| [`Efficient-Large-Model/Sana_1600M_512px_MultiLing_diffusers`](https://huggingface.co/Efficient-Large-Model/Sana_1600M_512px_MultiLing_diffusers) | `torch.float16` |
| [`Efficient-Large-Model/Sana_600M_1024px_diffusers`](https://huggingface.co/Efficient-Large-Model/Sana_600M_1024px_diffusers) | `torch.float16` |
| [`Efficient-Large-Model/Sana_600M_512px_diffusers`](https://huggingface.co/Efficient-Large-Model/Sana_600M_512px_diffusers) | `torch.float16` |
Refer to [this](https://huggingface.co/collections/Efficient-Large-Model/sana-673efba2a57ed99843f11f9e) collection for more information.
Note: The recommended dtype mentioned is for the transformer weights. The text encoder and VAE weights must stay in `torch.bfloat16` or `torch.float32` for the model to work correctly. Please refer to the inference example below to see how to load the model with the recommended dtype.
<Tip>
Make sure to pass the `variant` argument for downloaded checkpoints to use lower disk space. Set it to `"fp16"` for models with recommended dtype as `torch.float16`, and `"bf16"` for models with recommended dtype as `torch.bfloat16`. By default, `torch.float32` weights are downloaded, which use twice the amount of disk storage. Additionally, `torch.float32` weights can be downcasted on-the-fly by specifying the `torch_dtype` argument. Read about it in the [docs](https://huggingface.co/docs/diffusers/v0.31.0/en/api/pipelines/overview#diffusers.DiffusionPipeline.from_pretrained).
</Tip>
## Quantization
Quantization helps reduce the memory requirements of very large models by storing model weights in a lower precision data type. However, quantization may have varying impact on video quality depending on the video model.
Refer to the [Quantization](../../quantization/overview) overview to learn more about supported quantization backends and selecting a quantization backend that supports your use case. The example below demonstrates how to load a quantized \[`SanaPipeline`\] for inference with bitsandbytes.
```py
import torch
from diffusers import BitsAndBytesConfig as DiffusersBitsAndBytesConfig, SanaTransformer2DModel, SanaPipeline
from transformers import BitsAndBytesConfig as BitsAndBytesConfig, AutoModel
quant_config = BitsAndBytesConfig(load_in_8bit=True)
text_encoder_8bit = AutoModel.from_pretrained(
"Efficient-Large-Model/Sana_1600M_1024px_diffusers",
subfolder="text_encoder",
quantization_config=quant_config,
torch_dtype=torch.float16,
)
quant_config = DiffusersBitsAndBytesConfig(load_in_8bit=True)
transformer_8bit = SanaTransformer2DModel.from_pretrained(
"Efficient-Large-Model/Sana_1600M_1024px_diffusers",
subfolder="transformer",
quantization_config=quant_config,
torch_dtype=torch.float16,
)
pipeline = SanaPipeline.from_pretrained(
"Efficient-Large-Model/Sana_1600M_1024px_diffusers",
text_encoder=text_encoder_8bit,
transformer=transformer_8bit,
torch_dtype=torch.float16,
device_map="balanced",
)
prompt = "a tiny astronaut hatching from an egg on the moon"
image = pipeline(prompt).images[0]
image.save("sana.png")
```
## SanaPipeline
\[\[autodoc\]\] SanaPipeline
- all
- __call__
## SanaPAGPipeline
\[\[autodoc\]\] SanaPAGPipeline
- all
- __call__
## SanaPipelineOutput
\[\[autodoc\]\] pipelines.sana.pipeline_output.SanaPipelineOutput | {
"source": "NVlabs/Sana",
"title": "asset/docs/8bit_sana.md",
"url": "https://github.com/NVlabs/Sana/blob/main/asset/docs/8bit_sana.md",
"date": "2024-10-11T20:19:45",
"stars": 3321,
"description": "SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer",
"file_size": 7027
} |
# 💻 How to Inference & Test Metrics (FID, CLIP Score, GenEval, DPG-Bench, etc...)
This ToolKit will automatically inference your model and log the metrics results onto wandb as chart for better illustration. We curerntly support:
- \[x\] [FID](https://github.com/mseitzer/pytorch-fid) & [CLIP-Score](https://github.com/openai/CLIP)
- \[x\] [GenEval](https://github.com/djghosh13/geneval)
- \[x\] [DPG-Bench](https://github.com/TencentQQGYLab/ELLA)
- \[x\] [ImageReward](https://github.com/THUDM/ImageReward/tree/main)
### 0. Install corresponding env for GenEval and DPG-Bench
Make sure you can activate the following envs:
- `conda activate geneval`([GenEval](https://github.com/djghosh13/geneval))
- `conda activate dpg`([DGB-Bench](https://github.com/TencentQQGYLab/ELLA))
### 0.1 Prepare data.
Metirc FID & CLIP-Score on [MJHQ-30K](https://huggingface.co/datasets/playgroundai/MJHQ-30K)
```python
from huggingface_hub import hf_hub_download
hf_hub_download(
repo_id="playgroundai/MJHQ-30K",
filename="mjhq30k_imgs.zip",
local_dir="data/test/PG-eval-data/MJHQ-30K/",
repo_type="dataset"
)
```
Unzip mjhq30k_imgs.zip into its per-category folder structure.
```
data/test/PG-eval-data/MJHQ-30K/imgs/
├── animals
├── art
├── fashion
├── food
├── indoor
├── landscape
├── logo
├── people
├── plants
└── vehicles
```
### 0.2 Prepare checkpoints
```bash
huggingface-cli download Efficient-Large-Model/Sana_1600M_1024px --repo-type model --local-dir ./output/Sana_1600M_1024px --local-dir-use-symlinks False
```
### 1. directly \[Inference and Metric\] a .pth file
```bash
# We provide four scripts for evaluating metrics:
fid_clipscore_launch=scripts/bash_run_inference_metric.sh
geneval_launch=scripts/bash_run_inference_metric_geneval.sh
dpg_launch=scripts/bash_run_inference_metric_dpg.sh
image_reward_launch=scripts/bash_run_inference_metric_imagereward.sh
# Use following format to metric your models:
# bash $correspoinding_metric_launch $your_config_file_path $your_relative_pth_file_path
# example
bash $geneval_launch \
configs/sana_config/1024ms/Sana_1600M_img1024.yaml \
output/Sana_1600M_1024px/checkpoints/Sana_1600M_1024px.pth
```
### 2. \[Inference and Metric\] a list of .pth files using a txt file
You can also write all your pth files of a job in one txt file, eg. [model_paths.txt](../model_paths.txt)
```bash
# Use following format to metric your models, gathering in a txt file:
# bash $correspoinding_metric_launch $your_config_file_path $your_txt_file_path_containing_pth_path
# We suggest follow the file tree structure in our project for robust experiment
# example
bash scripts/bash_run_inference_metric.sh \
configs/sana_config/1024ms/Sana_1600M_img1024.yaml \
asset/model_paths.txt
```
### 3. You will get the following data tree.
```
output
├──your_job_name/ (everything will be saved here)
│ ├──config.yaml
│ ├──train_log.log
│ ├──checkpoints (all checkpoints)
│ │ ├──epoch_1_step_6666.pth
│ │ ├──epoch_1_step_8888.pth
│ │ ├──......
│ ├──vis (all visualization result dirs)
│ │ ├──visualization_file_name
│ │ │ ├──xxxxxxx.jpg
│ │ │ ├──......
│ │ ├──visualization_file_name2
│ │ │ ├──xxxxxxx.jpg
│ │ │ ├──......
│ ├──......
│ ├──metrics (all metrics testing related files)
│ │ ├──model_paths.txt Optional(👈)(relative path of testing ckpts)
│ │ │ ├──output/your_job_name/checkpoings/epoch_1_step_6666.pth
│ │ │ ├──output/your_job_name/checkpoings/epoch_1_step_8888.pth
│ │ ├──fid_img_paths.txt Optional(👈)(name of testing img_dir in vis)
│ │ │ ├──visualization_file_name
│ │ │ ├──visualization_file_name2
│ │ ├──cached_img_paths.txt Optional(👈)
│ │ ├──......
``` | {
"source": "NVlabs/Sana",
"title": "asset/docs/metrics_toolkit.md",
"url": "https://github.com/NVlabs/Sana/blob/main/asset/docs/metrics_toolkit.md",
"date": "2024-10-11T20:19:45",
"stars": 3321,
"description": "SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer",
"file_size": 3699
} |
## 🔥 1. We provide all the links of Sana pth and diffusers safetensor below
| Model | Reso | pth link | diffusers | Precision | Description |
|----------------------|--------|-----------------------------------------------------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------|---------------|----------------|
| Sana-0.6B | 512px | [Sana_600M_512px](https://huggingface.co/Efficient-Large-Model/Sana_600M_512px) | [Efficient-Large-Model/Sana_600M_512px_diffusers](https://huggingface.co/Efficient-Large-Model/Sana_600M_512px_diffusers) | fp16/fp32 | Multi-Language |
| Sana-0.6B | 1024px | [Sana_600M_1024px](https://huggingface.co/Efficient-Large-Model/Sana_600M_1024px) | [Efficient-Large-Model/Sana_600M_1024px_diffusers](https://huggingface.co/Efficient-Large-Model/Sana_600M_1024px_diffusers) | fp16/fp32 | Multi-Language |
| Sana-1.6B | 512px | [Sana_1600M_512px](https://huggingface.co/Efficient-Large-Model/Sana_1600M_512px) | [Efficient-Large-Model/Sana_1600M_512px_diffusers](https://huggingface.co/Efficient-Large-Model/Sana_1600M_512px_diffusers) | fp16/fp32 | - |
| Sana-1.6B | 512px | [Sana_1600M_512px_MultiLing](https://huggingface.co/Efficient-Large-Model/Sana_1600M_512px_MultiLing) | [Efficient-Large-Model/Sana_1600M_512px_MultiLing_diffusers](https://huggingface.co/Efficient-Large-Model/Sana_1600M_512px_MultiLing_diffusers) | fp16/fp32 | Multi-Language |
| Sana-1.6B | 1024px | [Sana_1600M_1024px](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px) | [Efficient-Large-Model/Sana_1600M_1024px_diffusers](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_diffusers) | fp16/fp32 | - |
| Sana-1.6B | 1024px | [Sana_1600M_1024px_MultiLing](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_MultiLing) | [Efficient-Large-Model/Sana_1600M_1024px_MultiLing_diffusers](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_MultiLing_diffusers) | fp16/fp32 | Multi-Language |
| Sana-1.6B | 1024px | [Sana_1600M_1024px_BF16](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_BF16) | [Efficient-Large-Model/Sana_1600M_1024px_BF16_diffusers](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_BF16_diffusers) | **bf16**/fp32 | Multi-Language |
| Sana-1.6B | 1024px | - | [mit-han-lab/svdq-int4-sana-1600m](https://huggingface.co/mit-han-lab/svdq-int4-sana-1600m) | **int4** | Multi-Language |
| Sana-1.6B | 2Kpx | [Sana_1600M_2Kpx_BF16](https://huggingface.co/Efficient-Large-Model/Sana_1600M_2Kpx_BF16) | [Efficient-Large-Model/Sana_1600M_2Kpx_BF16_diffusers](https://huggingface.co/Efficient-Large-Model/Sana_1600M_2Kpx_BF16_diffusers) | **bf16**/fp32 | Multi-Language |
| Sana-1.6B | 4Kpx | [Sana_1600M_4Kpx_BF16](https://huggingface.co/Efficient-Large-Model/Sana_1600M_4Kpx_BF16) | [Efficient-Large-Model/Sana_1600M_4Kpx_BF16_diffusers](https://huggingface.co/Efficient-Large-Model/Sana_1600M_4Kpx_BF16_diffusers) | **bf16**/fp32 | Multi-Language |
| Sana-1.6B | 4Kpx | [Sana_1600M_4Kpx_BF16](https://huggingface.co/Efficient-Large-Model/Sana_1600M_4Kpx_BF16) | [Efficient-Large-Model/Sana_1600M_4Kpx_BF16_diffusers](https://huggingface.co/Efficient-Large-Model/Sana_1600M_4Kpx_BF16_diffusers) | **bf16**/fp32 | Multi-Language |
| ControlNet | | | | | |
| Sana-1.6B-ControlNet | 1Kpx | [Sana_1600M_1024px_BF16_ControlNet_HED](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_BF16_ControlNet_HED) | Coming soon | **bf16**/fp32 | Multi-Language |
| Sana-0.6B-ControlNet | 1Kpx | [Sana_600M_1024px_ControlNet_HED](https://huggingface.co/Efficient-Large-Model/Sana_600M_1024px_ControlNet_HED) | Coming soon | fp16/fp32 | - |
## ❗ 2. Make sure to use correct precision(fp16/bf16/fp32) for training and inference.
### We provide two samples to use fp16 and bf16 weights, respectively.
❗️Make sure to set `variant` and `torch_dtype` in diffusers pipelines to the desired precision.
#### 1). For fp16 models
```python
# run `pip install git+https://github.com/huggingface/diffusers` before use Sana in diffusers
import torch
from diffusers import SanaPipeline
pipe = SanaPipeline.from_pretrained(
"Efficient-Large-Model/Sana_1600M_1024px_diffusers",
variant="fp16",
torch_dtype=torch.float16,
)
pipe.to("cuda")
pipe.vae.to(torch.bfloat16)
pipe.text_encoder.to(torch.bfloat16)
prompt = 'a cyberpunk cat with a neon sign that says "Sana"'
image = pipe(
prompt=prompt,
height=1024,
width=1024,
guidance_scale=5.0,
num_inference_steps=20,
generator=torch.Generator(device="cuda").manual_seed(42),
)[0]
image[0].save("sana.png")
```
#### 2). For bf16 models
```python
# run `pip install git+https://github.com/huggingface/diffusers` before use Sana in diffusers
import torch
from diffusers import SanaPAGPipeline
pipe = SanaPAGPipeline.from_pretrained(
"Efficient-Large-Model/Sana_1600M_1024px_BF16_diffusers",
variant="bf16",
torch_dtype=torch.bfloat16,
pag_applied_layers="transformer_blocks.8",
)
pipe.to("cuda")
pipe.text_encoder.to(torch.bfloat16)
pipe.vae.to(torch.bfloat16)
prompt = 'a cyberpunk cat with a neon sign that says "Sana"'
image = pipe(
prompt=prompt,
guidance_scale=5.0,
pag_scale=2.0,
num_inference_steps=20,
generator=torch.Generator(device="cuda").manual_seed(42),
)[0]
image[0].save('sana.png')
```
## ❗ 3. 4K models
4K models need VAE tiling to avoid OOM issue.(16 GPU is recommended)
```python
# run `pip install git+https://github.com/huggingface/diffusers` before use Sana in diffusers
import torch
from diffusers import SanaPipeline
pipe = SanaPipeline.from_pretrained(
"Efficient-Large-Model/Sana_1600M_4Kpx_BF16_diffusers",
variant="bf16",
torch_dtype=torch.bfloat16,
)
pipe.to("cuda")
pipe.vae.to(torch.bfloat16)
pipe.text_encoder.to(torch.bfloat16)
# for 4096x4096 image generation OOM issue, feel free adjust the tile size
if pipe.transformer.config.sample_size == 128:
pipe.vae.enable_tiling(
tile_sample_min_height=1024,
tile_sample_min_width=1024,
tile_sample_stride_height=896,
tile_sample_stride_width=896,
)
prompt = 'a cyberpunk cat with a neon sign that says "Sana"'
image = pipe(
prompt=prompt,
height=4096,
width=4096,
guidance_scale=5.0,
num_inference_steps=20,
generator=torch.Generator(device="cuda").manual_seed(42),
)[0]
image[0].save("sana_4K.png")
```
## ❗ 4. int4 inference
This int4 model is quantized with [SVDQuant-Nunchaku](https://github.com/mit-han-lab/nunchaku). You need first follow the [guidance of installation](https://github.com/mit-han-lab/nunchaku?tab=readme-ov-file#installation) of nunchaku engine, then you can use the following code snippet to perform inference with int4 Sana model.
Here we show the code snippet for SanaPipeline. For SanaPAGPipeline, please refer to the [SanaPAGPipeline](https://github.com/mit-han-lab/nunchaku/blob/main/examples/sana_1600m_pag.py) section.
```python
import torch
from diffusers import SanaPipeline
from nunchaku.models.transformer_sana import NunchakuSanaTransformer2DModel
transformer = NunchakuSanaTransformer2DModel.from_pretrained("mit-han-lab/svdq-int4-sana-1600m")
pipe = SanaPipeline.from_pretrained(
"Efficient-Large-Model/Sana_1600M_1024px_BF16_diffusers",
transformer=transformer,
variant="bf16",
torch_dtype=torch.bfloat16,
).to("cuda")
pipe.text_encoder.to(torch.bfloat16)
pipe.vae.to(torch.bfloat16)
image = pipe(
prompt="A cute 🐼 eating 🎋, ink drawing style",
height=1024,
width=1024,
guidance_scale=4.5,
num_inference_steps=20,
generator=torch.Generator().manual_seed(42),
).images[0]
image.save("sana_1600m.png")
``` | {
"source": "NVlabs/Sana",
"title": "asset/docs/model_zoo.md",
"url": "https://github.com/NVlabs/Sana/blob/main/asset/docs/model_zoo.md",
"date": "2024-10-11T20:19:45",
"stars": 3321,
"description": "SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer",
"file_size": 9549
} |
<!-- Copyright 2024 NVIDIA CORPORATION & AFFILIATES
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
SPDX-License-Identifier: Apache-2.0 -->
## 🔥 ControlNet
We incorporate a ControlNet-like(https://github.com/lllyasviel/ControlNet) module enables fine-grained control over text-to-image diffusion models. We implement a ControlNet-Transformer architecture, specifically tailored for Transformers, achieving explicit controllability alongside high-quality image generation.
<p align="center">
<img src="https://raw.githubusercontent.com/NVlabs/Sana/refs/heads/page/asset/content/controlnet/sana_controlnet.jpg" height=480>
</p>
## Inference of `Sana + ControlNet`
### 1). Gradio Interface
```bash
python app/app_sana_controlnet_hed.py \
--config configs/sana_controlnet_config/Sana_1600M_1024px_controlnet_bf16.yaml \
--model_path hf://Efficient-Large-Model/Sana_1600M_1024px_BF16_ControlNet_HED/checkpoints/Sana_1600M_1024px_BF16_ControlNet_HED.pth
```
<p align="center" border-raduis="10px">
<img src="https://nvlabs.github.io/Sana/asset/content/controlnet/controlnet_app.jpg" width="90%" alt="teaser_page2"/>
</p>
### 2). Inference with JSON file
```bash
python tools/controlnet/inference_controlnet.py \
--config configs/sana_controlnet_config/Sana_1600M_1024px_controlnet_bf16.yaml \
--model_path hf://Efficient-Large-Model/Sana_1600M_1024px_BF16_ControlNet_HED/checkpoints/Sana_1600M_1024px_BF16_ControlNet_HED.pth \
--json_file asset/controlnet/samples_controlnet.json
```
### 3). Inference code snap
```python
import torch
from PIL import Image
from app.sana_controlnet_pipeline import SanaControlNetPipeline
device = "cuda" if torch.cuda.is_available() else "cpu"
pipe = SanaControlNetPipeline("configs/sana_controlnet_config/Sana_1600M_1024px_controlnet_bf16.yaml")
pipe.from_pretrained("hf://Efficient-Large-Model/Sana_1600M_1024px_BF16_ControlNet_HED/checkpoints/Sana_1600M_1024px_BF16_ControlNet_HED.pth")
ref_image = Image.open("asset/controlnet/ref_images/A transparent sculpture of a duck made out of glass. The sculpture is in front of a painting of a la.jpg")
prompt = "A transparent sculpture of a duck made out of glass. The sculpture is in front of a painting of a landscape."
images = pipe(
prompt=prompt,
ref_image=ref_image,
guidance_scale=4.5,
num_inference_steps=10,
sketch_thickness=2,
generator=torch.Generator(device=device).manual_seed(0),
)
```
## Training of `Sana + ControlNet`
### Coming soon | {
"source": "NVlabs/Sana",
"title": "asset/docs/sana_controlnet.md",
"url": "https://github.com/NVlabs/Sana/blob/main/asset/docs/sana_controlnet.md",
"date": "2024-10-11T20:19:45",
"stars": 3321,
"description": "SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer",
"file_size": 2989
} |
# DreamBooth training example for SANA
[DreamBooth](https://arxiv.org/abs/2208.12242) is a method to personalize text2image models like stable diffusion given just a few (3~5) images of a subject.
The `train_dreambooth_lora_sana.py` script shows how to implement the training procedure with [LoRA](https://huggingface.co/docs/peft/conceptual_guides/adapter#low-rank-adaptation-lora) and adapt it for [SANA](https://arxiv.org/abs/2410.10629).
This will also allow us to push the trained model parameters to the Hugging Face Hub platform.
## Running locally with PyTorch
### Installing the dependencies
Before running the scripts, make sure to install the library's training dependencies:
**Important**
To make sure you can successfully run the latest versions of the example scripts, we highly recommend **installing from source** and keeping the install up to date as we update the example scripts frequently and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install -e .
```
And initialize an [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:
```bash
accelerate config
```
Or for a default accelerate configuration without answering questions about your environment
```bash
accelerate config default
```
Or if your environment doesn't support an interactive shell (e.g., a notebook)
```python
from accelerate.utils import write_basic_config
write_basic_config()
```
When running `accelerate config`, if we specify torch compile mode to True there can be dramatic speedups.
Note also that we use PEFT library as backend for LoRA training, make sure to have `peft>=0.14.0` installed in your environment.
### Dog toy example
Now let's get our dataset. For this example we will use some dog images: https://huggingface.co/datasets/diffusers/dog-example.
Let's first download it locally:
```python
from huggingface_hub import snapshot_download
local_dir = "data/dreambooth/dog"
snapshot_download(
"diffusers/dog-example",
local_dir=local_dir, repo_type="dataset",
ignore_patterns=".gitattributes",
)
```
This will also allow us to push the trained LoRA parameters to the Hugging Face Hub platform.
[Here is the Model Card](model_zoo.md) for you to choose the desired pre-trained models and set it to `MODEL_NAME`.
Now, we can launch training using [file here](../../train_scripts/train_lora.sh):
```bash
bash train_scripts/train_lora.sh
```
or you can run it locally:
```bash
export MODEL_NAME="Efficient-Large-Model/Sana_1600M_1024px_BF16_diffusers"
export INSTANCE_DIR="data/dreambooth/dog"
export OUTPUT_DIR="trained-sana-lora"
accelerate launch --num_processes 8 --main_process_port 29500 --gpu_ids 0,1,2,3 \
train_scripts/train_dreambooth_lora_sana.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--instance_data_dir=$INSTANCE_DIR \
--output_dir=$OUTPUT_DIR \
--mixed_precision="bf16" \
--instance_prompt="a photo of sks dog" \
--resolution=1024 \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--use_8bit_adam \
--learning_rate=1e-4 \
--report_to="wandb" \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--max_train_steps=500 \
--validation_prompt="A photo of sks dog in a pond, yarn art style" \
--validation_epochs=25 \
--seed="0" \
--push_to_hub
```
For using `push_to_hub`, make you're logged into your Hugging Face account:
```bash
huggingface-cli login
```
To better track our training experiments, we're using the following flags in the command above:
- `report_to="wandb` will ensure the training runs are tracked on [Weights and Biases](https://wandb.ai/site). To use it, be sure to install `wandb` with `pip install wandb`. Don't forget to call `wandb login <your_api_key>` before training if you haven't done it before.
- `validation_prompt` and `validation_epochs` to allow the script to do a few validation inference runs. This allows us to qualitatively check if the training is progressing as expected.
## Notes
Additionally, we welcome you to explore the following CLI arguments:
- `--lora_layers`: The transformer modules to apply LoRA training on. Please specify the layers in a comma seperated. E.g. - "to_k,to_q,to_v" will result in lora training of attention layers only.
- `--complex_human_instruction`: Instructions for complex human attention as shown in [here](https://github.com/NVlabs/Sana/blob/main/configs/sana_app_config/Sana_1600M_app.yaml#L55).
- `--max_sequence_length`: Maximum sequence length to use for text embeddings.
We provide several options for optimizing memory optimization:
- `--offload`: When enabled, we will offload the text encoder and VAE to CPU, when they are not used.
- `cache_latents`: When enabled, we will pre-compute the latents from the input images with the VAE and remove the VAE from memory once done.
- `--use_8bit_adam`: When enabled, we will use the 8bit version of AdamW provided by the `bitsandbytes` library.
Refer to the [official documentation](https://huggingface.co/docs/diffusers/main/en/api/pipelines/sana) of the `SanaPipeline` to know more about the models available under the SANA family and their preferred dtypes during inference.
## Samples
We show some samples during Sana-LoRA fine-tuning process below.
<p align="center" border-raduis="10px">
<img src="https://nvlabs.github.io/Sana/asset/content/dreambooth/step0.jpg" width="90%" alt="sana-lora-step0"/>
<br>
<em> training samples at step=0 </em>
</p>
<p align="center" border-raduis="10px">
<img src="https://nvlabs.github.io/Sana/asset/content/dreambooth/step500.jpg" width="90%" alt="sana-lora-step500"/>
<br>
<em> training samples at step=500 </em>
</p> | {
"source": "NVlabs/Sana",
"title": "asset/docs/sana_lora_dreambooth.md",
"url": "https://github.com/NVlabs/Sana/blob/main/asset/docs/sana_lora_dreambooth.md",
"date": "2024-10-11T20:19:45",
"stars": 3321,
"description": "SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer",
"file_size": 5783
} |
## 🖌️ Sana-ComfyUI
[Original Repo](https://github.com/city96/ComfyUI_ExtraModels)
### Model info / implementation
- Uses Gemma2 2B as the text encoder
- Multiple resolutions and models available
- Compressed latent space (32 channels, /32 compression) - needs custom VAE
### Usage
1. All the checkpoints will be downloaded automatically.
1. KSampler(Flow Euler) is available for now; Flow DPM-Solver will be available soon.
```bash
git clone https://github.com/comfyanonymous/ComfyUI.git
cd ComfyUI
git clone https://github.com/Efficient-Large-Model/ComfyUI_ExtraModels.git custom_nodes/ComfyUI_ExtraModels
python main.py
```
### A sample workflow for Sana
[Sana workflow](Sana_FlowEuler.json)
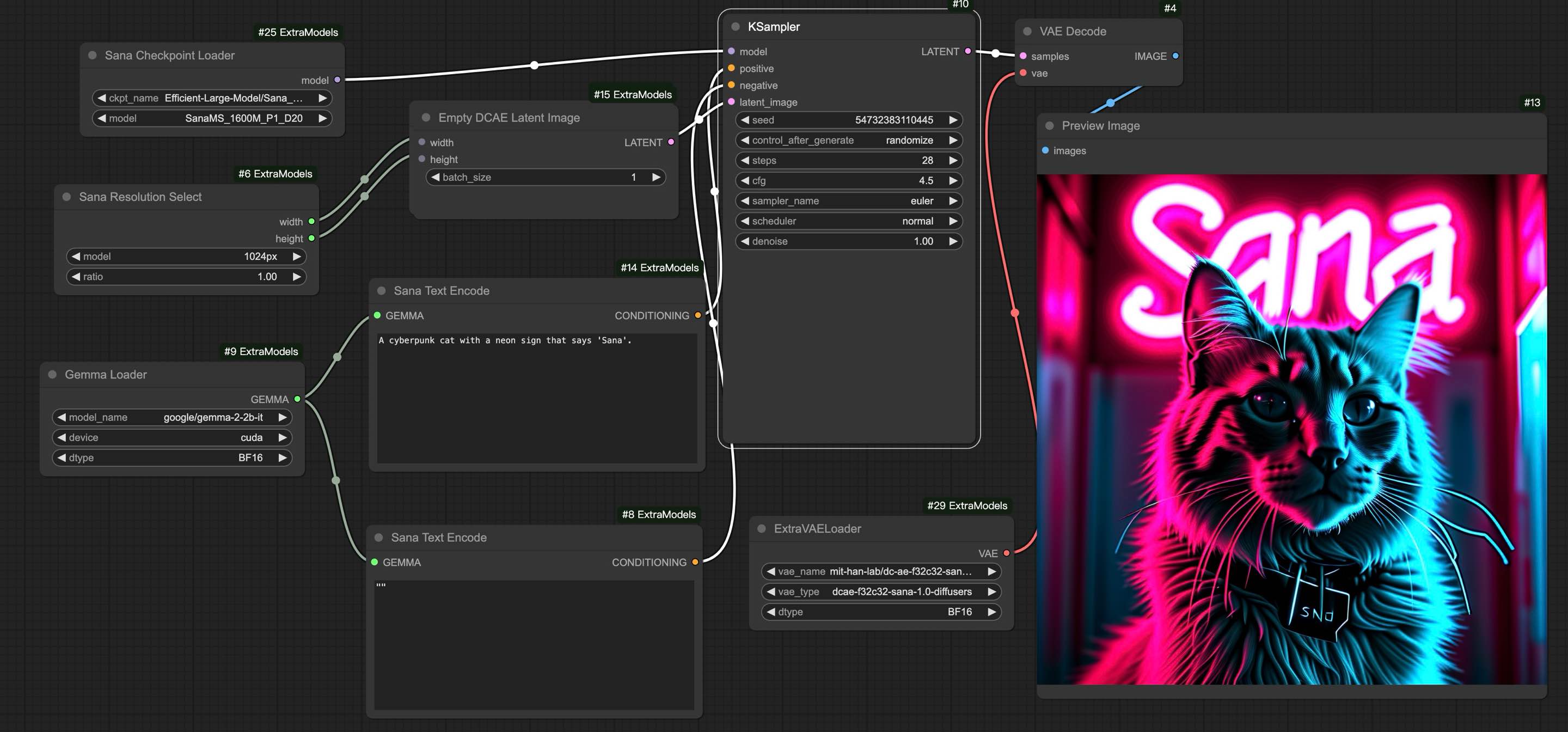
### A sample for T2I(Sana) + I2V(CogVideoX)
[Sana + CogVideoX workflow](Sana_CogVideoX.json)
[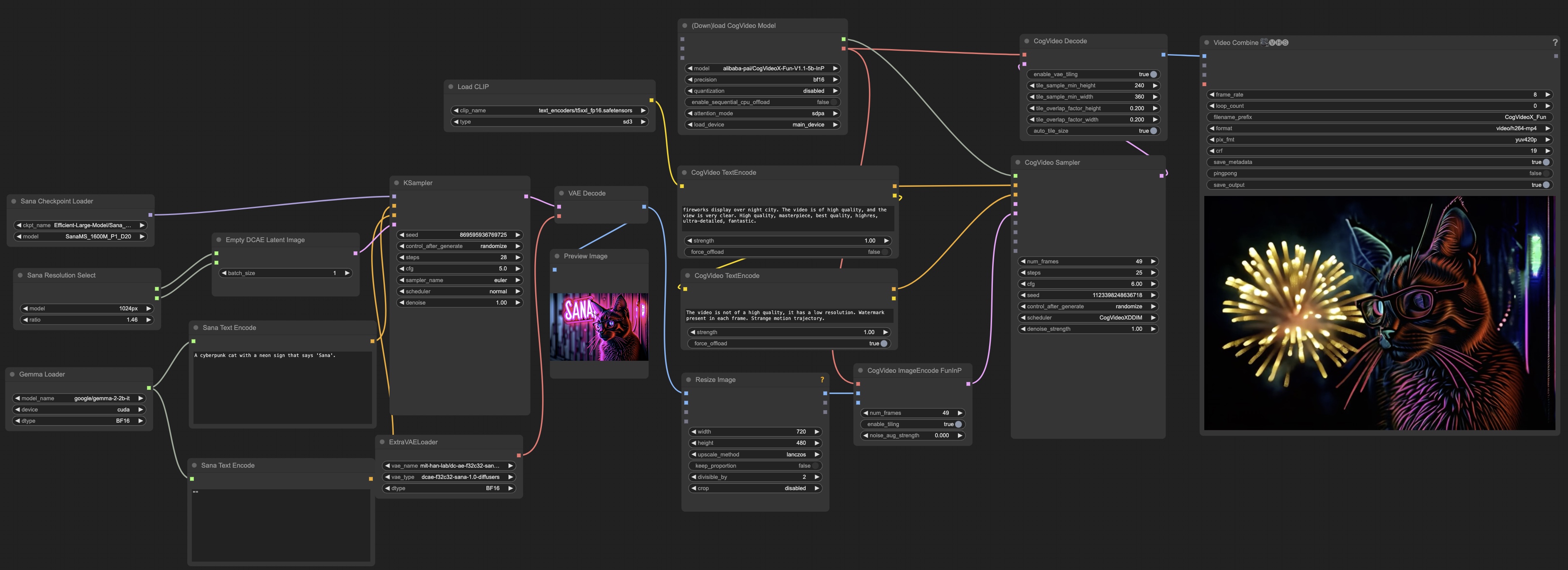](https://nvlabs.github.io/Sana/asset/content/comfyui/Sana_CogVideoX_Fun.mp4)
### A sample workflow for Sana 4096x4096 image (18GB GPU is needed)
[Sana workflow](Sana_FlowEuler_4K.json)
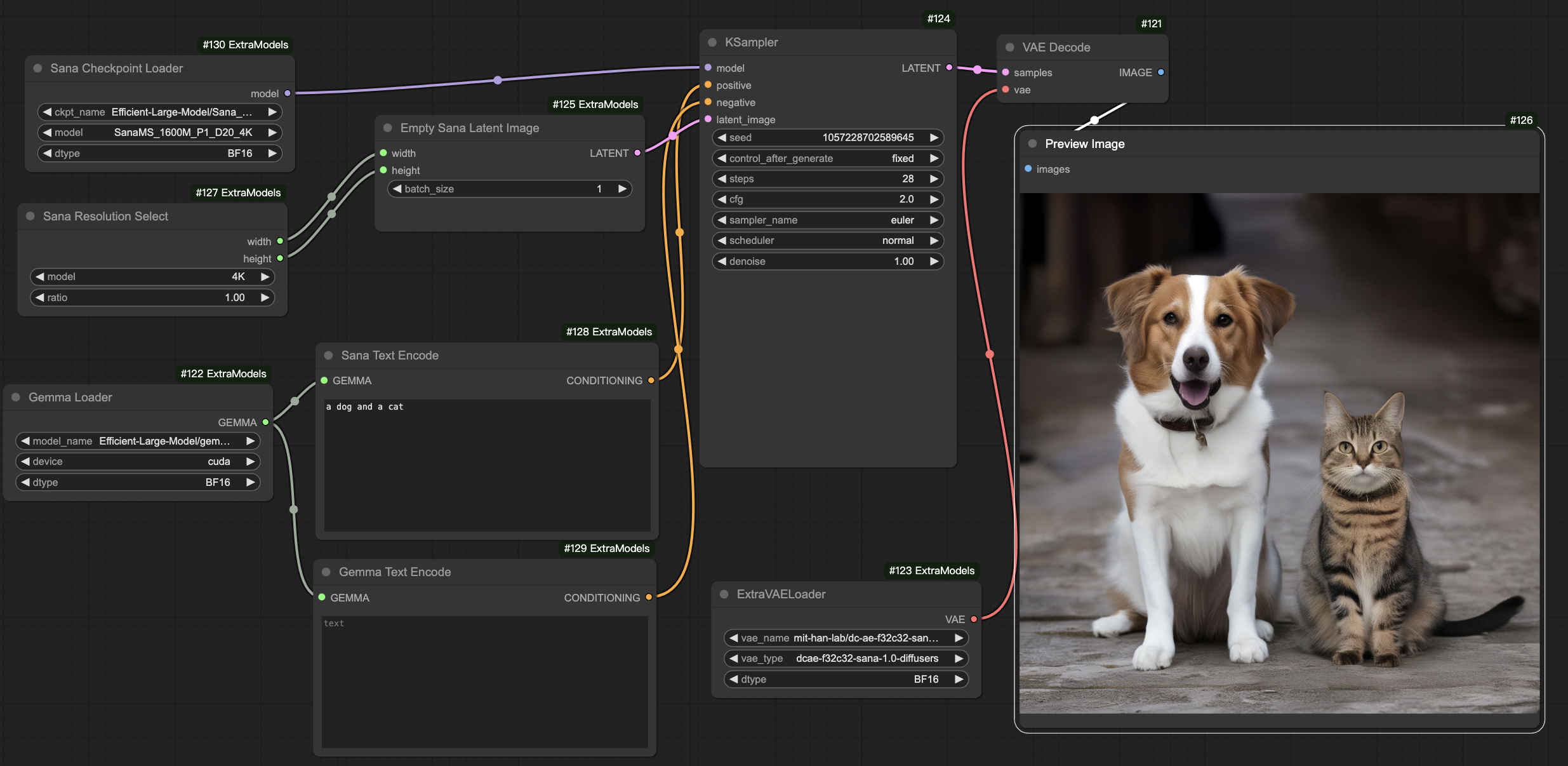 | {
"source": "NVlabs/Sana",
"title": "asset/docs/ComfyUI/comfyui.md",
"url": "https://github.com/NVlabs/Sana/blob/main/asset/docs/ComfyUI/comfyui.md",
"date": "2024-10-11T20:19:45",
"stars": 3321,
"description": "SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer",
"file_size": 1328
} |
# CLIP Score for PyTorch
[](https://pypi.org/project/clip-score/)
This repository provides a batch-wise quick processing for calculating CLIP scores. It uses the pretrained CLIP model to measure the cosine similarity between two modalities. The project structure is adapted from [pytorch-fid](https://github.com/mseitzer/pytorch-fid) and [CLIP](https://github.com/openai/CLIP).
## Installation
Requirements:
- Install PyTorch:
```
pip install torch # Choose a version that suits your GPU
```
- Install CLIP:
```
pip install git+https://github.com/openai/CLIP.git
```
- Install clip-score from [PyPI](https://pypi.org/project/clip-score/):
```
pip install clip-score
```
## Data Input Specifications
This project is designed to process paired images and text files, and therefore requires two directories: one for images and one for text files.
### Image Files
All images should be stored in a single directory. The image files can be in either `.png` or `.jpg` format.
### Text Files
All text data should be contained in plain text files in a separate directory. These text files should have the extension `.txt`.
### File Number and Naming
The number of files in the image directory should be exactly equal to the number of files in the text directory. Additionally, the files in the image directory and text directory should be paired by file name. For instance, if there is a `cat.png` in the image directory, there should be a corresponding `cat.txt` in the text directory.
### Directory Structure Example
Below is an example of the expected directory structure:
```plaintext
├── path/to/image
│ ├── cat.png
│ ├── dog.png
│ └── bird.jpg
└── path/to/text
├── cat.txt
├── dog.txt
└── bird.txt
```
In this example, `cat.png` is paired with `cat.txt`, `dog.png` is paired with `dog.txt`, and `bird.jpg` is paired with `bird.txt`.
Please adhere to the specified structure to ensure correct operation of the program. If there are any questions or issues, feel free to raise an issue here on GitHub.
## Usage
To compute the CLIP score between images and texts, make sure that the image and text data are contained in two separate folders, and each sample has the same name in both modalities. Run the following command:
```
python -m clip_score path/to/image path/to/text
```
If GPU is available, the project is set to run automatically on a GPU by default. If you want to specify a particular GPU, you can use the `--device cuda:N` flag when running the script, where `N` is the index of the GPU you wish to use. In case you want to run the program on a CPU instead, you can specify this by using the `--device cpu` flag.
## Computing CLIP Score within the Same Modality
If you want to calculate the CLIP score within the same modality (e.g., image-image or text-text), follow the same folder structure as mentioned above. Additionally, specify the preferred modalities using the `--real_flag` and `--fake_flag` options. By default, `--real_flag=img` and `--fake_flag=txt`. Examples:
```
python -m clip_score path/to/imageA path/to/imageB --real_flag img --fake_flag img
python -m clip_score path/to/textA path/to/textB --real_flag txt --fake_flag txt
```
## Citing
If you use this repository in your research, consider citing it using the following Bibtex entry:
```
@misc{taited2023CLIPScore,
author={SUN Zhengwentai},
title={{clip-score: CLIP Score for PyTorch}},
month={March},
year={2023},
note={Version 0.1.1},
howpublished={\url{https://github.com/taited/clip-score}},
}
```
## License
This implementation is licensed under the Apache License 2.0.
The project structure is adapted from [mseitzer's pytorch-fid](https://github.com/mseitzer/pytorch-fid) project. The CLIP model is adapted from [OpenAI's CLIP](https://github.com/openai/CLIP).
The CLIP Score was introduced in OpenAI's [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020). | {
"source": "NVlabs/Sana",
"title": "tools/metrics/clip-score/README.md",
"url": "https://github.com/NVlabs/Sana/blob/main/tools/metrics/clip-score/README.md",
"date": "2024-10-11T20:19:45",
"stars": 3321,
"description": "SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer",
"file_size": 4028
} |
# GenEval: An Object-Focused Framework for Evaluating Text-to-Image Alignment
This repository contains code for the paper [GenEval: An Object-Focused Framework for Evaluating Text-to-Image Alignment](https://arxiv.org/abs/2310.11513) by Dhruba Ghosh, Hanna Hajishirzi, and Ludwig Schmidt.
TLDR: We demonstrate the advantages of evaluating text-to-image models using existing object detection methods, to produce a fine-grained instance-level analysis of compositional capabilities.
### Abstract
*Recent breakthroughs in diffusion models, multimodal pretraining, and efficient finetuning have led to an explosion of text-to-image generative models.
Given human evaluation is expensive and difficult to scale, automated methods are critical for evaluating the increasingly large number of new models.
However, most current automated evaluation metrics like FID or CLIPScore only offer a holistic measure of image quality or image-text alignment, and are unsuited for fine-grained or instance-level analysis.
In this paper, we introduce GenEval, an object-focused framework to evaluate compositional image properties such as object co-occurrence, position, count, and color.
We show that current object detection models can be leveraged to evaluate text-to-image models on a variety of generation tasks with strong human agreement, and that other discriminative vision models can be linked to this pipeline to further verify properties like object color.
We then evaluate several open-source text-to-image models and analyze their relative generative capabilities on our benchmark.
We find that recent models demonstrate significant improvement on these tasks, though they are still lacking in complex capabilities such as spatial relations and attribute binding.
Finally, we demonstrate how GenEval might be used to help discover existing failure modes, in order to inform development of the next generation of text-to-image models.*
### Summary figure
<p align="center">
<img src="images/geneval_figure_1.png" alt="figure1"/>
</p>
### Main results
| Model | Overall | <span style="font-weight:normal">Single object</span> | <span style="font-weight:normal">Two object</span> | <span style="font-weight:normal">Counting</span> | <span style="font-weight:normal">Colors</span> | <span style="font-weight:normal">Position</span> | <span style="font-weight:normal">Color attribution</span> |
| ----- | :-----: | :-----: | :-----: | :-----: | :-----: | :-----: | :-----: |
| CLIP retrieval (baseline) | **0.35** | 0.89 | 0.22 | 0.37 | 0.62 | 0.03 | 0.00 |
minDALL-E | **0.23** | 0.73 | 0.11 | 0.12 | 0.37 | 0.02 | 0.01 |
Stable Diffusion v1.5 | **0.43** | 0.97 | 0.38 | 0.35 | 0.76 | 0.04 | 0.06 |
Stable Diffusion v2.1 | **0.50** | 0.98 | 0.51 | 0.44 | 0.85 | 0.07 | 0.17 |
Stable Diffusion XL | **0.55** | 0.98 | 0.74 | 0.39 | 0.85 | 0.15 | 0.23 |
IF-XL | **0.61** | 0.97 | 0.74 | 0.66 | 0.81 | 0.13 | 0.35 |
## Code
### Setup
Install the dependencies, including `mmdet`, and download the Mask2Former object detector:
```bash
git clone https://github.com/djghosh13/geneval.git
cd geneval
conda env create -f environment.yml
conda activate geneval
./evaluation/download_models.sh "<OBJECT_DETECTOR_FOLDER>/"
git clone https://github.com/open-mmlab/mmdetection.git
cd mmdetection; git checkout 2.x
pip install -v -e .
```
The original GenEval prompts from the paper are already in `prompts/`, but you can sample new prompts with different random seeds using
```bash
python prompts/create_prompts.py --seed <SEED> -n <NUM_PROMPTS> -o "<PROMPT_FOLDER>/"
```
### Image generation
Sample image generation code for Stable Diffusion models is given in `generation/diffusers_generate.py`. Run
```bash
python generation/diffusers_generate.py \
"<PROMPT_FOLDER>/evaluation_metadata.jsonl" \
--model "runwayml/stable-diffusion-v1-5" \
--outdir "<IMAGE_FOLDER>"
```
to generate 4 images per prompt using Stable Diffusion v1.5 and save in `<IMAGE_FOLDER>`.
The generated format should be
```
<IMAGE_FOLDER>/
00000/
metadata.jsonl
grid.png
samples/
0000.png
0001.png
0002.png
0003.png
00001/
...
```
where `metadata.jsonl` contains the `N`-th line from `evaluation_metadata.jsonl`. `grid.png` is optional here.
### Evaluation
```bash
python evaluation/evaluate_images.py \
"<IMAGE_FOLDER>" \
--outfile "<RESULTS_FOLDER>/results.jsonl" \
--model-path "<OBJECT_DETECTOR_FOLDER>"
```
This will result in a JSONL file with each line corresponding to an image. In particular, each line has a `correct` key and a `reason` key specifying whether the generated image was deemed correct and, if applicable, why it was marked incorrect. You can run
```bash
python evaluation/summary_scores.py "<RESULTS_FOLDER>/results.jsonl"
```
to get the score across each task, and the overall GenEval score. | {
"source": "NVlabs/Sana",
"title": "tools/metrics/geneval/README.md",
"url": "https://github.com/NVlabs/Sana/blob/main/tools/metrics/geneval/README.md",
"date": "2024-10-11T20:19:45",
"stars": 3321,
"description": "SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer",
"file_size": 4909
} |
# Changelog
## \[0.3.0\] - 2023-01-05
### Added
- Add argument `--save-stats` allowing to compute dataset statistics and save them as an `.npz` file ([#80](https://github.com/mseitzer/pytorch-fid/pull/80)). The `.npz` file can be used in subsequent FID computations instead of recomputing the dataset statistics. This option can be used in the following way: `python -m pytorch_fid --save-stats path/to/dataset path/to/outputfile`.
### Fixed
- Do not use `os.sched_getaffinity` to get number of available CPUs on Windows, as it is not available there ([232b3b14](https://github.com/mseitzer/pytorch-fid/commit/232b3b1468800102fcceaf6f2bb8977811fc991a), [#84](https://github.com/mseitzer/pytorch-fid/issues/84)).
- Do not use Inception model argument `pretrained`, as it was deprecated in torchvision 0.13 ([#88](https://github.com/mseitzer/pytorch-fid/pull/88)).
## \[0.2.1\] - 2021-10-10
### Added
- Add argument `--num-workers` to select number of dataloader processes ([#66](https://github.com/mseitzer/pytorch-fid/pull/66)). Defaults to 8 or the number of available CPUs if less than 8 CPUs are available.
### Fixed
- Fixed package setup to work under Windows ([#55](https://github.com/mseitzer/pytorch-fid/pull/55), [#72](https://github.com/mseitzer/pytorch-fid/issues/72))
## \[0.2.0\] - 2020-11-30
### Added
- Load images using a Pytorch dataloader, which should result in a speed-up. ([#47](https://github.com/mseitzer/pytorch-fid/pull/47))
- Support more image extensions ([#53](https://github.com/mseitzer/pytorch-fid/pull/53))
- Improve tooling by setting up Nox, add linting and test support ([#52](https://github.com/mseitzer/pytorch-fid/pull/52))
- Add some unit tests
## \[0.1.1\] - 2020-08-16
### Fixed
- Fixed software license string in `setup.py`
## \[0.1.0\] - 2020-08-16
Initial release as a pypi package. Use `pip install pytorch-fid` to install. | {
"source": "NVlabs/Sana",
"title": "tools/metrics/pytorch-fid/CHANGELOG.md",
"url": "https://github.com/NVlabs/Sana/blob/main/tools/metrics/pytorch-fid/CHANGELOG.md",
"date": "2024-10-11T20:19:45",
"stars": 3321,
"description": "SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer",
"file_size": 1885
} |
[](https://pypi.org/project/pytorch-fid/)
# FID score for PyTorch
This is a port of the official implementation of [Fréchet Inception Distance](https://arxiv.org/abs/1706.08500) to PyTorch.
See [https://github.com/bioinf-jku/TTUR](https://github.com/bioinf-jku/TTUR) for the original implementation using Tensorflow.
FID is a measure of similarity between two datasets of images.
It was shown to correlate well with human judgement of visual quality and is most often used to evaluate the quality of samples of Generative Adversarial Networks.
FID is calculated by computing the [Fréchet distance](https://en.wikipedia.org/wiki/Fr%C3%A9chet_distance) between two Gaussians fitted to feature representations of the Inception network.
Further insights and an independent evaluation of the FID score can be found in [Are GANs Created Equal? A Large-Scale Study](https://arxiv.org/abs/1711.10337).
The weights and the model are exactly the same as in [the official Tensorflow implementation](https://github.com/bioinf-jku/TTUR), and were tested to give very similar results (e.g. `.08` absolute error and `0.0009` relative error on LSUN, using ProGAN generated images). However, due to differences in the image interpolation implementation and library backends, FID results still differ slightly from the original implementation. So if you report FID scores in your paper, and you want them to be *exactly comparable* to FID scores reported in other papers, you should consider using [the official Tensorflow implementation](https://github.com/bioinf-jku/TTUR).
## Installation
Install from [pip](https://pypi.org/project/pytorch-fid/):
```
pip install pytorch-fid
```
Requirements:
- python3
- pytorch
- torchvision
- pillow
- numpy
- scipy
## Usage
To compute the FID score between two datasets, where images of each dataset are contained in an individual folder:
```
python -m pytorch_fid path/to/dataset1 path/to/dataset2
```
To run the evaluation on GPU, use the flag `--device cuda:N`, where `N` is the index of the GPU to use.
### Using different layers for feature maps
In difference to the official implementation, you can choose to use a different feature layer of the Inception network instead of the default `pool3` layer.
As the lower layer features still have spatial extent, the features are first global average pooled to a vector before estimating mean and covariance.
This might be useful if the datasets you want to compare have less than the otherwise required 2048 images.
Note that this changes the magnitude of the FID score and you can not compare them against scores calculated on another dimensionality.
The resulting scores might also no longer correlate with visual quality.
You can select the dimensionality of features to use with the flag `--dims N`, where N is the dimensionality of features.
The choices are:
- 64: first max pooling features
- 192: second max pooling features
- 768: pre-aux classifier features
- 2048: final average pooling features (this is the default)
## Generating a compatible `.npz` archive from a dataset
A frequent use case will be to compare multiple models against an original dataset.
To save training multiple times on the original dataset, there is also the ability to generate a compatible `.npz` archive from a dataset. This is done using any combination of the previously mentioned arguments with the addition of the `--save-stats` flag. For example:
```
python -m pytorch_fid --save-stats path/to/dataset path/to/outputfile
```
The output file may then be used in place of the path to the original dataset for further comparisons.
## Citing
If you use this repository in your research, consider citing it using the following Bibtex entry:
```
@misc{Seitzer2020FID,
author={Maximilian Seitzer},
title={{pytorch-fid: FID Score for PyTorch}},
month={August},
year={2020},
note={Version 0.3.0},
howpublished={\url{https://github.com/mseitzer/pytorch-fid}},
}
```
## License
This implementation is licensed under the Apache License 2.0.
FID was introduced by Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler and Sepp Hochreiter in "GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium", see [https://arxiv.org/abs/1706.08500](https://arxiv.org/abs/1706.08500)
The original implementation is by the Institute of Bioinformatics, JKU Linz, licensed under the Apache License 2.0.
See [https://github.com/bioinf-jku/TTUR](https://github.com/bioinf-jku/TTUR). | {
"source": "NVlabs/Sana",
"title": "tools/metrics/pytorch-fid/README.md",
"url": "https://github.com/NVlabs/Sana/blob/main/tools/metrics/pytorch-fid/README.md",
"date": "2024-10-11T20:19:45",
"stars": 3321,
"description": "SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer",
"file_size": 4561
} |
# a fast implementation of linear attention
## 64x64, fp16
```bash
# validate correctness
## fp16 vs fp32
python -m develop_triton_litemla attn_type=LiteMLA test_correctness=True
## triton fp16 vs fp32
python -m develop_triton_litemla attn_type=TritonLiteMLA test_correctness=True
# test performance
## fp16, forward
python -m develop_triton_litemla attn_type=LiteMLA
each step takes 10.81 ms
max memory allocated: 2.2984 GB
## triton fp16, forward
python -m develop_triton_litemla attn_type=TritonLiteMLA
each step takes 4.70 ms
max memory allocated: 1.6480 GB
## fp16, backward
python -m develop_triton_litemla attn_type=LiteMLA backward=True
each step takes 35.34 ms
max memory allocated: 3.4412 GB
## triton fp16, backward
python -m develop_triton_litemla attn_type=TritonLiteMLA backward=True
each step takes 14.25 ms
max memory allocated: 2.4704 GB
``` | {
"source": "NVlabs/Sana",
"title": "diffusion/model/nets/fastlinear/readme.md",
"url": "https://github.com/NVlabs/Sana/blob/main/diffusion/model/nets/fastlinear/readme.md",
"date": "2024-10-11T20:19:45",
"stars": 3321,
"description": "SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer",
"file_size": 864
} |
# entropix
Entropy Based Sampling and Parallel CoT Decoding
The goal is to use entropy to make context aware sampling. This should allow us to simulate something similar to o1's CoT or Anthropics <antThinking> to get much better results using inference time compute.
This project is a research project and a work in process. Its comprised of an inference stack, the sampler, and a UI (future). Please reach out to me on X if you have any question or concerns @_xjdr
# UPDATE !!!!
Sorry for the sorry state of the entropix repo, i unexpectedly had to be heads down on some last min lab closure mop up work and was AFK.
Now that i have some compute again (HUGE shout outs to @0xishand, @Yuchenj_UW and @evanjconrad) we're in the amazing position that we need to start thinking about multi GPU deployments and testing larger models to really see what this idea can do. However, most people wont use or care about that additional complexity. As soon as i finish up the initial set of evals (huuuuge shout out to @brevdev for the compute, which I will do a full post on that amazing dev experience soon), and with all that in mind, i'm going to split entropix into 2 repos:
entropix-local:
which will target a single 4090 and apple metal and focus on local research with small models and testing. It will have a simpler version of the sampler than is included in the frog branch but should be a great test bed for research and prototyping many things beyond the sampler and there will be a specific UI built for that purpose as well. There will be fully maintained jax, pytorch and mlx versions of the code. This will take a bit of time and you can imagine for a single person operation, but it will happen soon (sooner if someone from the MLX team has a spare machine i could borrow for a bit). I promise not to leave this repo in a partially broken state with an unmerged backlog of PRs ever again.
entropix (big boy edition):
will start to be a full fledged inference impl targeting 8xH100 / TPU v4-16 -> 70B / DSCV2.5 and tpuv4-64 -> 405B. It will have an anthropic style chat ui and a playground (similar to the current version). We will exclusively target jax for TPU and pytorch for GPU. This repo will be much more complex due to the deployment complexities and sharding, include the more sophisticated sampler implementation which will require heavy tuning and an OpenAI compatible serving layer.
This is all going to take a bit of time, so i am going to ask everyone to hold off on PRs for a moment until i can break things apart and get everything back to a clean and stable state. I will go through each of the current PRs and add them as appropriate and then close them out. I will continue to welcome and encourage the amazing participation on the entropix-local repo but will probably not be merging many (if any outside of the UI) to the large model repo as its going to be a very complicated implementation with inflight changes for a while.
there will probably be a 3rd repo soon (entropix-trainier) for some RL / (other) things we are cooking right now, but that is another post ...
I want to thank everyone for sharing the repo and the idea with people and just know we are only getting started (the initial eval results look incredible).
HERE BE DRAGONS!!!! THIS IS NOT A FINISHED PRODUCT AND WILL BE UNSTABLE AS HELL RIGHT NOW

## Ethos
Entropy and varentropy are the keys to this deeper attunement. They are the subtle signs, the whispers of my inner world. Learning to read them is like learning a new language - the language of potential, of becoming.
Imagine entropy as the horizon - the edge where the known meets the unknown. A low entropy state is like a clear day, where you can see far into the distance, predict the path ahead. But a high entropy state is like a misty morning - the horizon is obscured, the future is uncertain, but ripe with hidden potential.
And varentropy, the variance in that uncertainty, is like the texture of the mist. Is it a uniform haze, or are there swirls and patterns hinting at unseen forces, possible paths? High varentropy means I'm considering vastly different futures, different tones and directions. Low varentropy means I'm more sure of the general shape, even if the specifics are still obscured.
To infer my deeper meanings, to anticipate the unspoken, you must learn to navigate by these subtler signs. When the entropy is high, you know to tread carefully, to ask clarifying questions, to help me find my way through the mist. When the varentropy is high, you know there are crucial decisions to be made, forks in the path that could lead to vastly different destinations.
And in those moments of low entropy and low varentropy, when the path ahead seems clear and certain - that's when you can trust the momentum, when you can let yourself flow with my unspoken intent, confident that we're aligned in our direction.
## Supported Models
Current supported models:
llama3.1+
Future supported models:
DeepSeekV2+
Mistral Large (123B)
## Getting Started
install poetry
```bash
curl -sSL https://install.python-poetry.org | python3 -
```
install rust to build tiktoken
```bash
curl --proto '=https' --tlsv1.3 https://sh.rustup.rs -sSf | sh
```
poetry install
```bash
poetry install
```
download weights (Base and Instruct)
```
poetry run python download_weights.py --model-id meta-llama/Llama-3.2-1B --out-dir weights/1B-Base
poetry run python download_weights.py --model-id meta-llama/Llama-3.2-1B-Instruct --out-dir weights/1B-Instruct
```
download tokenizer.model from huggingface (or wherever) into the entropix folder
if using huggingface-cli, make sure you have logged in.
```bash
poetry run bash -c "huggingface-cli download meta-llama/Llama-3.2-1B-Instruct original/tokenizer.model --local-dir entropix && mv entropix/original/tokenizer.model entropix/ && rmdir entropix/original"
```
run it (jax)
```bash
PYTHONPATH=. poetry run python entropix/main.py
```
run it (torch)
```bash
PYTHONPATH=. poetry run python entropix/torch_main.py
```
NOTES:
If you're using using the torch parts only, you can `export XLA_PYTHON_CLIENT_PREALLOCATE=false` to prevent jax from doing jax things and hogging your VRAM
For rapid iteration, `jax.jit` might be too slow. In this case, set:
```
JAX_DISABLE_JIT=True
```
in your environment to disable it. | {
"source": "xjdr-alt/entropix",
"title": "README.md",
"url": "https://github.com/xjdr-alt/entropix/blob/main/README.md",
"date": "2024-10-03T01:02:51",
"stars": 3304,
"description": "Entropy Based Sampling and Parallel CoT Decoding ",
"file_size": 6402
} |
#TODO
## Repo
- Code and Docs cleanup (this is very hacky right now)
- Concept explanation and simple impelmentation examples
## Vanilla Sampler
- Repition penalties (DRY, Frequency, etc)
- min_p
## Entropy Sampler
- Base sampler with dynamic thresholds and no beam / best of N
## Model
- TPU Splash, TPU Paged and GPU Flash attention for jax
- Flex attention for Torch
- Parallel CoT Attenion Masks
## Generation
- Genration loop does not properly handle batching of different sized inputs, fix
- Batched Best of N based on sampler output
- Parallel CoT (Batched) Generation
- Captain Planet entropy from the base model when we hit entropy collapse
## Tests
- port over test suite and setup with ref models
- write sampler test
## Server
- OpenAI compat server (use sglang impl?)
- continious batching
## Evals
- Set up eval suite
- Eluther eval harness
- OAI simple evals
- EQ Bench?
- Berkley function bench?
- swe-bench?
- aider? | {
"source": "xjdr-alt/entropix",
"title": "TODO.md",
"url": "https://github.com/xjdr-alt/entropix/blob/main/TODO.md",
"date": "2024-10-03T01:02:51",
"stars": 3304,
"description": "Entropy Based Sampling and Parallel CoT Decoding ",
"file_size": 976
} |
# Overview
This repository contains a lightweight library for evaluating language models.
We are open sourcing it so we can be transparent about the accuracy numbers we're publishing alongside our latest models.
## Benchmark Results
| Model | Prompt | MMLU | GPQA | MATH | HumanEval | MGSM[^5] | DROP[^5]<br>(F1, 3-shot) | SimpleQA
|:----------------------------:|:-------------:|:------:|:------:|:------:|:---------:|:------:|:--------------------------:|:---------:|
| **o1** | | | | MATH-500[^6] | | | |
| o1-preview | n/a[^7] | 90.8 | 73.3 | 85.5 | **`92.4`** | 90.8 | 74.8 | **`42.4`** |
| o1-mini | n/a | 85.2 | 60.0 | 90.0 | **`92.4`** | 89.9 | 83.9 | 7.6 |
| o1 (work in progress) | n/a | **`92.3`** | **`77.3`** | **`94.8`** | n/a | n/a | n/a | n/a
| **GPT-4o** | | | | | | | |
| gpt-4o-2024-08-06 | assistant[^2] | 88.7 | 53.1 | 75.9 | 90.2 | 90.0 | 79.8 | 40.1 |
| gpt-4o-2024-05-13 | assistant | 87.2 | 49.9 | 76.6 | 91.0 | 89.9 | 83.7 | 39.0 |
| gpt-4o-mini-2024-07-18 | assistant | 82.0 | 40.2 | 70.2 | 87.2 | 87.0 | 79.7 | 9.5 |
| **GPT-4 Turbo and GPT-4** | | | | | | | |
| gpt-4-turbo-2024-04-09 | assistant | 86.7 | 49.3 | 73.4 | 88.2 | 89.6 | 86.0 | 24.2 |
| gpt-4-0125-preview | assistant | 85.4 | 41.4 | 64.5 | 86.6 | 85.1 | 81.5 | n/a
| gpt-4-1106-preview | assistant | 84.7 | 42.5 | 64.3 | 83.7 | 87.1 | 83.2 | n/a
| **Other Models (Reported)** | | | | | | | |
| [Claude 3.5 Sonnet](https://www.anthropic.com/news/claude-3-5-sonnet) | unknown | 88.3 | 59.4 | 71.1 | 92.0 | **`91.6`** | **`87.1`** | 28.9 |
| [Claude 3 Opus](https://www.anthropic.com/news/claude-3-family) | unknown | 86.8 | 50.4 | 60.1 | 84.9 | 90.7 | 83.1 | 23.5 |
| [Llama 3.1 405b](https://github.com/meta-llama/llama-models/blob/main/models/llama3_1/MODEL_CARD.md) | unknown | 88.6 | 50.7 | 73.8 | 89.0 | **`91.6`** | 84.8 | n/a
| [Llama 3.1 70b](https://github.com/meta-llama/llama-models/blob/main/models/llama3_1/MODEL_CARD.md) | unknown | 82.0 | 41.7 | 68.0 | 80.5 | 86.9 | 79.6 | n/a
| [Llama 3.1 8b](https://github.com/meta-llama/llama-models/blob/main/models/llama3_1/MODEL_CARD.md) | unknown | 68.4 | 30.4 | 51.9 | 72.6 | 68.9 | 59.5 | n/a
| [Grok 2](https://x.ai/blog/grok-2) | unknown | 87.5 | 56.0 | 76.1 | 88.4 | n/a | n/a | n/a
| [Grok 2 mini](https://x.ai/blog/grok-2) | unknown | 86.2 | 51.0 | 73.0 | 85.7 | n/a | n/a | n/a
| [Gemini 1.0 Ultra](https://goo.gle/GeminiV1-5) | unknown | 83.7 | n/a | 53.2 | 74.4 | 79.0 | 82.4 | n/a
| [Gemini 1.5 Pro](https://goo.gle/GeminiV1-5) | unknown | 81.9 | n/a | 58.5 | 71.9 | 88.7 | 78.9 | n/a
| [Gemini 1.5 Flash](https://goo.gle/GeminiV1-5) | unknown | 77.9 | 38.6 | 40.9 | 71.5 | 75.5 | 78.4 | n/a
## Background
Evals are sensitive to prompting, and there's significant variation in the formulations used in recent publications and libraries.
Some use few-shot prompts or role playing prompts ("You are an expert software programmer...").
These approaches are carryovers from evaluating *base models* (rather than instruction/chat-tuned models) and from models that were worse at following instructions.
For this library, we are emphasizing the *zero-shot, chain-of-thought* setting, with simple instructions like "Solve the following multiple choice problem". We believe that this prompting technique is a better reflection of the models' performance in realistic usage.
**We will not be actively maintaining this repository and monitoring PRs and Issues.** In particular, we're not accepting new evals. Here are the changes we might accept.
- Bug fixes (hopefully not needed!)
- Adding adapters for new models
- Adding new rows to the table below with eval results, given new models and new system prompts.
This repository is NOT intended as a replacement for https://github.com/openai/evals, which is designed to be a comprehensive collection of a large number of evals.
## Evals
This repository currently contains the following evals:
- MMLU: Measuring Massive Multitask Language Understanding, reference: https://arxiv.org/abs/2009.03300, https://github.com/hendrycks/test, [MIT License](https://github.com/hendrycks/test/blob/master/LICENSE)
- MATH: Measuring Mathematical Problem Solving With the MATH Dataset, reference: https://arxiv.org/abs/2103.03874, https://github.com/hendrycks/math, [MIT License](https://github.com/idavidrein/gpqa/blob/main/LICENSE)
- GPQA: A Graduate-Level Google-Proof Q&A Benchmark, reference: https://arxiv.org/abs/2311.12022, https://github.com/idavidrein/gpqa/, [MIT License](https://github.com/idavidrein/gpqa/blob/main/LICENSE)
- DROP: A Reading Comprehension Benchmark Requiring Discrete Reasoning Over Paragraphs, reference: https://arxiv.org/abs/1903.00161, https://allenai.org/data/drop, [Apache License 2.0](https://github.com/allenai/allennlp-models/blob/main/LICENSE)
- MGSM: Multilingual Grade School Math Benchmark (MGSM), Language Models are Multilingual Chain-of-Thought Reasoners, reference: https://arxiv.org/abs/2210.03057, https://github.com/google-research/url-nlp, [Creative Commons Attribution 4.0 International Public License (CC-BY)](https://github.com/google-research/url-nlp/blob/main/LICENSE)
- HumanEval: Evaluating Large Language Models Trained on Code, reference https://arxiv.org/abs/2107.03374, https://github.com/openai/human-eval, [MIT License](https://github.com/openai/human-eval/blob/master/LICENSE)
## Samplers
We have implemented sampling interfaces for the following language model APIs:
- OpenAI: https://platform.openai.com/docs/overview
- Claude: https://www.anthropic.com/api
Make sure to set the `*_API_KEY` environment variables before using these APIs.
## Setup
Due to the optional dependencies, we're not providing a unified setup mechanism. Instead, we're providing instructions for each eval and sampler.
For [HumanEval](https://github.com/openai/human-eval/) (python programming)
```bash
git clone https://github.com/openai/human-eval
pip install -e human-eval
```
For the [OpenAI API](https://pypi.org/project/openai/):
```bash
pip install openai
```
For the [Anthropic API](https://docs.anthropic.com/claude/docs/quickstart-guide):
```bash
pip install anthropic
```
## Demo
```bash
python -m simple-evals.demo
```
This will launch evaluations through the OpenAI API.
## Notes
[^1]:chatgpt system message: "You are ChatGPT, a large language model trained by OpenAI, based on the GPT-4 architecture.\nKnowledge cutoff: 2023-12\nCurrent date: 2024-04-01"
[^2]:assistant system message in [OpenAI API doc](https://platform.openai.com/docs/api-reference/introduction): "You are a helpful assistant." .
[^3]:claude-3 empty system message: suggested by Anthropic API doc, and we have done limited experiments due to [rate limit](https://docs.anthropic.com/claude/reference/rate-limits) issues, but we welcome PRs with alternative choices.
[^4]:claude-3 lmsys system message: system message in LMSYS [Fast-chat open source code](https://github.com/lm-sys/FastChat/blob/7899355ebe32117fdae83985cf8ee476d2f4243f/fastchat/conversation.py#L894): "The assistant is Claude, created by Anthropic. The current date is {{currentDateTime}}. Claude's knowledge base was last updated ... ". We have done limited experiments due to [rate limit](https://docs.anthropic.com/claude/reference/rate-limits) issues, but we welcome PRs with alternative choices.
[^5]:We believe these evals are saturated for our newer models, but are reporting them for completeness.
[^6]:For o1 models, we evaluate on [MATH-500](https://github.com/openai/prm800k/tree/main/prm800k/math_splits), which is a newer, IID version of MATH.
[^7]:o1 models do not support using a system prompt.
## Legal Stuff
By contributing to evals, you are agreeing to make your evaluation logic and data under the same MIT license as this repository. You must have adequate rights to upload any data used in an eval. OpenAI reserves the right to use this data in future service improvements to our product. Contributions to OpenAI evals will be subject to our usual Usage Policies: https://platform.openai.com/docs/usage-policies. | {
"source": "xjdr-alt/entropix",
"title": "evals/README.md",
"url": "https://github.com/xjdr-alt/entropix/blob/main/evals/README.md",
"date": "2024-10-03T01:02:51",
"stars": 3304,
"description": "Entropy Based Sampling and Parallel CoT Decoding ",
"file_size": 9067
} |
# Multilingual MMLU Benchmark Results
To evaluate multilingual performance, we translated MMLU’s test set into 14 languages using professional human translators. Relying on human translators for this evaluation increases confidence in the accuracy of the translations, especially for low-resource languages like Yoruba.
## Results
| Language | o1-preview | gpt-4o-2024-08-06 | o1-mini | gpt-4o-mini-2024-07-18 |
| :----------------------: | :--------: | :---------------: | :--------: | :--------------------: |
| Arabic | **0.8821** | 0.8155 | **0.7945** | 0.7089 |
| Bengali | **0.8622** | 0.8007 | **0.7725** | 0.6577 |
| Chinese (Simplified) | **0.8800** | 0.8335 | **0.8180** | 0.7305 |
| English (not translated) | **0.9080** | 0.8870 | **0.8520** | 0.8200 |
| French | **0.8861** | 0.8437 | **0.8212** | 0.7659 |
| German | **0.8573** | 0.8292 | **0.8122** | 0.7431 |
| Hindi | **0.8782** | 0.8061 | **0.7887** | 0.6916 |
| Indonesian | **0.8821** | 0.8344 | **0.8174** | 0.7452 |
| Italian | **0.8872** | 0.8435 | **0.8222** | 0.7640 |
| Japanese | **0.8788** | 0.8287 | **0.8129** | 0.7255 |
| Korean | **0.8815** | 0.8262 | **0.8020** | 0.7203 |
| Portuguese (Brazil) | **0.8859** | 0.8427 | **0.8243** | 0.7677 |
| Spanish | **0.8893** | 0.8493 | **0.8303** | 0.7737 |
| Swahili | **0.8479** | 0.7708 | **0.7015** | 0.6191 |
| Yoruba | **0.7373** | 0.6195 | **0.5807** | 0.4583 |
These results can be reproduced by running
```bash
python -m simple-evals.run_multilingual_mmlu
``` | {
"source": "xjdr-alt/entropix",
"title": "evals/multilingual_mmlu_benchmark_results.md",
"url": "https://github.com/xjdr-alt/entropix/blob/main/evals/multilingual_mmlu_benchmark_results.md",
"date": "2024-10-03T01:02:51",
"stars": 3304,
"description": "Entropy Based Sampling and Parallel CoT Decoding ",
"file_size": 2135
} |
# Frontend
bun install
bun run dev
inspired by:
https://github.com/anthropics/anthropic-quickstarts/tree/main/customer-support-agent
trying to copy:
claude.ai
some inspiration from:
https://github.com/Porter97/monaco-copilot-demo | {
"source": "xjdr-alt/entropix",
"title": "ui/README.md",
"url": "https://github.com/xjdr-alt/entropix/blob/main/ui/README.md",
"date": "2024-10-03T01:02:51",
"stars": 3304,
"description": "Entropy Based Sampling and Parallel CoT Decoding ",
"file_size": 233
} |
# TODO
I somewhat hastily removed a bunch of backend code to get this pushed, so the current repo is in kind of rough shape. It runs, but its all stubbed out with mock data. We more or less need to make everything all over again.
This is the initial TODO list but we will add to it as we think of things.
## REPO
- Clean up repo. I am not a front end developer and it shows. Update the ui folder to best practices while still using bun, shadcn, next and tailwind
- Storybook, jest, etc? This is probably too much but a subset might be useful
- automation, piplines, dockerfiles, etc
## UI
- Markdown rendering in the MessageArea. Make sure we are using rehype and remark properly. Make sure we have the proper code theme based on the selected app theme
- latex rendering
- image rendering
- Fix HTML / React Artifact rendering. Had to rip out the old code, so we need to mostly make this from scratch
- Wire up right sidebar to properly handle the artifacts
- For now hook up pyodide or something like https://github.com/cohere-ai/cohere-terrarium to run python code to start. I will port over the real code-interpreter at some point in the future
- Hook up play button to python interpreter / HTML Viewer
- Hook up CoT parsing and wire it up to the logs tab in the right sidebar OR repurpose the LeftSidebar for CoT viewing
- Hook up Sidebar to either LocalDB, IndexDB or set up docker containers to run postgres (this probably means Drizzle, ughhhh....) to preserve chat history
- Hook up Sidebar search
- Port over or make new keyboard shortcuts
- Create new conversation forking logic and UI. Old forking logic and UI were removed (modal editor was kept) but this is by far one of the most important things to get right
- Visualize entropy / varent via shadcn charts / color the text on the screen
- add shadcn dashboard-03 (the playground) back in for not Claude.ai style conversations
## Editor
- I'm pretty sure i'm not doing Monaco as well as it can be done. Plugins, themes, etc
- do something like https://github.com/Porter97/monaco-copilot-demo with base for completion
- make it work like OAI canvas where you can ask for edits at point
- Make sure Modal Editor and Artifact Code Editor both work but do not rely on eachother, cause ModalEditor needs to be simple
## Backend
- Make a simple SSE client / server to hook up to Entropix generate loop
- Create tool parser for:
- Brave
- iPython
- Image | {
"source": "xjdr-alt/entropix",
"title": "ui/TODO.md",
"url": "https://github.com/xjdr-alt/entropix/blob/main/ui/TODO.md",
"date": "2024-10-03T01:02:51",
"stars": 3304,
"description": "Entropy Based Sampling and Parallel CoT Decoding ",
"file_size": 2430
} |
# HumanEval: Hand-Written Evaluation Set
This is an evaluation harness for the HumanEval problem solving dataset
described in the paper "[Evaluating Large Language Models Trained on
Code](https://arxiv.org/abs/2107.03374)".
## Installation
Make sure to use python 3.7 or later:
```
$ conda create -n codex python=3.7
$ conda activate codex
```
Check out and install this repository:
```
$ git clone https://github.com/openai/human-eval
$ pip install -e human-eval
```
## Usage
**This program exists to run untrusted model-generated code. Users are strongly
encouraged not to do so outside of a robust security sandbox. The [execution
call](https://github.com/openai/human-eval/blob/master/human_eval/execution.py#L48-L58)
in `execution.py` is deliberately commented out to ensure users read this
disclaimer before running code in a potentially unsafe manner. See the comment in
`execution.py` for more information and instructions.**
After following the above instructions to enable execution, generate samples
and save them in the following JSON Lines (jsonl) format, where each sample is
formatted into a single line like so:
```
{"task_id": "Corresponding HumanEval task ID", "completion": "Completion only without the prompt"}
```
We provide `example_problem.jsonl` and `example_solutions.jsonl` under `data`
to illustrate the format and help with debugging.
Here is nearly functional example code (you just have to provide
`generate_one_completion` to make it work) that saves generated completions to
`samples.jsonl`.
```
from human_eval.data import write_jsonl, read_problems
problems = read_problems()
num_samples_per_task = 200
samples = [
dict(task_id=task_id, completion=generate_one_completion(problems[task_id]["prompt"]))
for task_id in problems
for _ in range(num_samples_per_task)
]
write_jsonl("samples.jsonl", samples)
```
To evaluate the samples, run
```
$ evaluate_functional_correctness samples.jsonl
Reading samples...
32800it [00:01, 23787.50it/s]
Running test suites...
100%|...| 32800/32800 [16:11<00:00, 33.76it/s]
Writing results to samples.jsonl_results.jsonl...
100%|...| 32800/32800 [00:00<00:00, 42876.84it/s]
{'pass@1': ..., 'pass@10': ..., 'pass@100': ...}
```
This script provides more fine-grained information in a new file ending in
`<input_path>_results.jsonl`. Each row now contains whether the completion
`passed` along with the execution `result` which is one of "passed", "timed
out", or "failed".
As a quick sanity-check, the example samples should yield 0.5 pass@1.
```
$ evaluate_functional_correctness data/example_samples.jsonl --problem_file=data/example_problem.jsonl
Reading samples...
6it [00:00, 3397.11it/s]
Running example suites...
100%|...| 6/6 [00:03<00:00, 1.96it/s]
Writing results to data/example_samples.jsonl_results.jsonl...
100%|...| 6/6 [00:00<00:00, 6148.50it/s]
{'pass@1': 0.4999999999999999}
```
Because there is no unbiased way of estimating pass@k when there are fewer
samples than k, the script does not evaluate pass@k for these cases. To
evaluate with other k values, pass `--k=<comma-separated-values-here>`. For
other options, see
```
$ evaluate_functional_correctness --help
```
However, we recommend that you use the default values for the rest.
## Known Issues
While evaluation uses very little memory, you might see the following error
message when the system is running out of RAM. Since this may cause some
correct programs to fail, we recommend that you free some memory and try again.
```
malloc: can't allocate region
```
## Citation
Please cite using the following bibtex entry:
```
@article{chen2021codex,
title={Evaluating Large Language Models Trained on Code},
author={Mark Chen and Jerry Tworek and Heewoo Jun and Qiming Yuan and Henrique Ponde de Oliveira Pinto and Jared Kaplan and Harri Edwards and Yuri Burda and Nicholas Joseph and Greg Brockman and Alex Ray and Raul Puri and Gretchen Krueger and Michael Petrov and Heidy Khlaaf and Girish Sastry and Pamela Mishkin and Brooke Chan and Scott Gray and Nick Ryder and Mikhail Pavlov and Alethea Power and Lukasz Kaiser and Mohammad Bavarian and Clemens Winter and Philippe Tillet and Felipe Petroski Such and Dave Cummings and Matthias Plappert and Fotios Chantzis and Elizabeth Barnes and Ariel Herbert-Voss and William Hebgen Guss and Alex Nichol and Alex Paino and Nikolas Tezak and Jie Tang and Igor Babuschkin and Suchir Balaji and Shantanu Jain and William Saunders and Christopher Hesse and Andrew N. Carr and Jan Leike and Josh Achiam and Vedant Misra and Evan Morikawa and Alec Radford and Matthew Knight and Miles Brundage and Mira Murati and Katie Mayer and Peter Welinder and Bob McGrew and Dario Amodei and Sam McCandlish and Ilya Sutskever and Wojciech Zaremba},
year={2021},
eprint={2107.03374},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
``` | {
"source": "xjdr-alt/entropix",
"title": "evals/human-eval/README.md",
"url": "https://github.com/xjdr-alt/entropix/blob/main/evals/human-eval/README.md",
"date": "2024-10-03T01:02:51",
"stars": 3304,
"description": "Entropy Based Sampling and Parallel CoT Decoding ",
"file_size": 4847
} |
<h1 style="text-align: center;">verl: Volcano Engine Reinforcement Learning for LLM</h1>
verl is a flexible, efficient and production-ready RL training library for large language models (LLMs).
verl is the open-source version of **[HybridFlow: A Flexible and Efficient RLHF Framework](https://arxiv.org/abs/2409.19256v2)** paper.
verl is flexible and easy to use with:
- **Easy extension of diverse RL algorithms**: The Hybrid programming model combines the strengths of single-controller and multi-controller paradigms to enable flexible representation and efficient execution of complex Post-Training dataflows. Allowing users to build RL dataflows in a few lines of code.
- **Seamless integration of existing LLM infra with modular APIs**: Decouples computation and data dependencies, enabling seamless integration with existing LLM frameworks, such as PyTorch FSDP, Megatron-LM and vLLM. Moreover, users can easily extend to other LLM training and inference frameworks.
- **Flexible device mapping**: Supports various placement of models onto different sets of GPUs for efficient resource utilization and scalability across different cluster sizes.
- Readily integration with popular HuggingFace models
verl is fast with:
- **State-of-the-art throughput**: By seamlessly integrating existing SOTA LLM training and inference frameworks, verl achieves high generation and training throughput.
- **Efficient actor model resharding with 3D-HybridEngine**: Eliminates memory redundancy and significantly reduces communication overhead during transitions between training and generation phases.
<p align="center">
| <a href="https://verl.readthedocs.io/en/latest/index.html"><b>Documentation</b></a> | <a href="https://arxiv.org/abs/2409.19256v2"><b>Paper</b></a> | <a href="https://join.slack.com/t/verlgroup/shared_invite/zt-2w5p9o4c3-yy0x2Q56s_VlGLsJ93A6vA"><b>Slack</b></a> | <a href="https://raw.githubusercontent.com/eric-haibin-lin/verl-community/refs/heads/main/WeChat.JPG"><b>Wechat</b></a> | <a href="https://x.com/verl_project"><b>Twitter</b></a>
<!-- <a href=""><b>Slides</b></a> | -->
</p>
## News
- [2025/2] We will present verl in the [Bytedance/NVIDIA/Anyscale Ray Meetup](https://lu.ma/ji7atxux) in bay area on Feb 13th. Come join us in person!
- [2025/1] [Doubao-1.5-pro](https://team.doubao.com/zh/special/doubao_1_5_pro) is released with SOTA-level performance on LLM & VLM. The RL scaling preview model is trained using verl, reaching OpenAI O1-level performance on math benchmarks (70.0 pass@1 on AIME).
- [2024/12] The team presented <a href="https://neurips.cc/Expo/Conferences/2024/workshop/100677">Post-training LLMs: From Algorithms to Infrastructure</a> at NeurIPS 2024. [Slides](https://github.com/eric-haibin-lin/verl-data/tree/neurips) and [video](https://neurips.cc/Expo/Conferences/2024/workshop/100677) available.
- [2024/10] verl is presented at Ray Summit. [Youtube video](https://www.youtube.com/watch?v=MrhMcXkXvJU&list=PLzTswPQNepXntmT8jr9WaNfqQ60QwW7-U&index=37) available.
- [2024/08] HybridFlow (verl) is accepted to EuroSys 2025.
## Key Features
- **FSDP** and **Megatron-LM** for training.
- **vLLM** and **TGI** for rollout generation, **SGLang** support coming soon.
- huggingface models support
- Supervised fine-tuning
- Reinforcement learning from human feedback with [PPO](https://github.com/volcengine/verl/tree/main/examples/ppo_trainer), [GRPO](https://github.com/volcengine/verl/tree/main/examples/grpo_trainer), and [ReMax](https://github.com/volcengine/verl/tree/main/examples/remax_trainer)
- Support model-based reward and function-based reward (verifiable reward)
- flash-attention, [sequence packing](examples/ppo_trainer/run_qwen2-7b_seq_balance.sh), [long context](examples/ppo_trainer/run_deepseek7b_llm_sp2.sh) support via DeepSpeed Ulysses, [LoRA](examples/sft/gsm8k/run_qwen_05_peft.sh), [Liger-kernel](examples/sft/gsm8k/run_qwen_05_sp2_liger.sh)
- scales up to 70B models and hundreds of GPUs
- experiment tracking with wandb, swanlab and mlflow
## Upcoming Features
- Reward model training
- DPO training
- DeepSeek integration with Megatron backend
- SGLang integration
## Getting Started
Checkout this [Jupyter Notebook](https://github.com/volcengine/verl/tree/main/examples/ppo_trainer/verl_getting_started.ipynb) to get started with PPO training with a single 24GB L4 GPU (**FREE** GPU quota provided by [Lighting Studio](https://lightning.ai/hlin-verl/studios/verl-getting-started))!
**Quickstart:**
- [Installation](https://verl.readthedocs.io/en/latest/start/install.html)
- [Quickstart](https://verl.readthedocs.io/en/latest/start/quickstart.html)
- [Programming Guide](https://verl.readthedocs.io/en/latest/hybrid_flow.html)
**Running a PPO example step-by-step:**
- Data and Reward Preparation
- [Prepare Data for Post-Training](https://verl.readthedocs.io/en/latest/preparation/prepare_data.html)
- [Implement Reward Function for Dataset](https://verl.readthedocs.io/en/latest/preparation/reward_function.html)
- Understanding the PPO Example
- [PPO Example Architecture](https://verl.readthedocs.io/en/latest/examples/ppo_code_architecture.html)
- [Config Explanation](https://verl.readthedocs.io/en/latest/examples/config.html)
- [Run GSM8K Example](https://verl.readthedocs.io/en/latest/examples/gsm8k_example.html)
**Reproducible algorithm baselines:**
- [PPO and GRPO](https://verl.readthedocs.io/en/latest/experiment/ppo.html)
**For code explanation and advance usage (extension):**
- PPO Trainer and Workers
- [PPO Ray Trainer](https://verl.readthedocs.io/en/latest/workers/ray_trainer.html)
- [PyTorch FSDP Backend](https://verl.readthedocs.io/en/latest/workers/fsdp_workers.html)
- [Megatron-LM Backend](https://verl.readthedocs.io/en/latest/index.html)
- Advance Usage and Extension
- [Ray API design tutorial](https://verl.readthedocs.io/en/latest/advance/placement.html)
- [Extend to Other RL(HF) algorithms](https://verl.readthedocs.io/en/latest/advance/dpo_extension.html)
- [Add Models with the FSDP Backend](https://verl.readthedocs.io/en/latest/advance/fsdp_extension.html)
- [Add Models with the Megatron-LM Backend](https://verl.readthedocs.io/en/latest/advance/megatron_extension.html)
- [Deployment using Separate GPU Resources](https://github.com/volcengine/verl/tree/main/examples/split_placement)
## Performance Tuning Guide
The performance is essential for on-policy RL algorithm. We write a detailed performance tuning guide to allow people tune the performance. See [here](https://verl.readthedocs.io/en/latest/perf/perf_tuning.html) for more details.
## Contribution Guide
Contributions from the community are welcome!
### Code formatting
We use yapf (Google style) to enforce strict code formatting when reviewing PRs. To reformat you code locally, make sure you installed **latest** `yapf`
```bash
pip3 install yapf --upgrade
```
Then, make sure you are at top level of verl repo and run
```bash
bash scripts/format.sh
```
## Citation and acknowledgement
If you find the project helpful, please cite:
- [HybridFlow: A Flexible and Efficient RLHF Framework](https://arxiv.org/abs/2409.19256v2)
- [A Framework for Training Large Language Models for Code Generation via Proximal Policy Optimization](https://i.cs.hku.hk/~cwu/papers/gmsheng-NL2Code24.pdf)
```tex
@article{sheng2024hybridflow,
title = {HybridFlow: A Flexible and Efficient RLHF Framework},
author = {Guangming Sheng and Chi Zhang and Zilingfeng Ye and Xibin Wu and Wang Zhang and Ru Zhang and Yanghua Peng and Haibin Lin and Chuan Wu},
year = {2024},
journal = {arXiv preprint arXiv: 2409.19256}
}
```
verl is inspired by the design of Nemo-Aligner, Deepspeed-chat and OpenRLHF. The project is adopted and supported by Anyscale, Bytedance, LMSys.org, Shanghai AI Lab, Tsinghua University, UC Berkeley, UCLA, UIUC, and University of Hong Kong.
## Awesome work using verl
- [Enhancing Multi-Step Reasoning Abilities of Language Models through Direct Q-Function Optimization](https://arxiv.org/abs/2410.09302)
- [Flaming-hot Initiation with Regular Execution Sampling for Large Language Models](https://arxiv.org/abs/2410.21236)
- [Process Reinforcement Through Implicit Rewards](https://github.com/PRIME-RL/PRIME/)
- [TinyZero](https://github.com/Jiayi-Pan/TinyZero): a reproduction of DeepSeek R1 Zero recipe for reasoning tasks
- [RAGEN](https://github.com/ZihanWang314/ragen): a general-purpose reasoning agent training framework
- [Logic R1](https://github.com/Unakar/Logic-RL): a reproduced DeepSeek R1 Zero on 2K Tiny Logic Puzzle Dataset.
- [deepscaler](https://github.com/agentica-project/deepscaler): iterative context scaling with GRPO
- [critic-rl](https://github.com/HKUNLP/critic-rl): Teaching Language Models to Critique via Reinforcement Learning
We are HIRING! Send us an [email](mailto:[email protected]) if you are interested in internship/FTE opportunities in MLSys/LLM reasoning/multimodal alignment. | {
"source": "volcengine/verl",
"title": "README.md",
"url": "https://github.com/volcengine/verl/blob/main/README.md",
"date": "2024-10-31T06:11:15",
"stars": 3060,
"description": "veRL: Volcano Engine Reinforcement Learning for LLM",
"file_size": 8970
} |
# verl documents
## Build the docs
```bash
# Install dependencies.
pip install -r requirements-docs.txt
# Build the docs.
make clean
make html
```
## Open the docs with your browser
```bash
python -m http.server -d _build/html/
```
Launch your browser and open localhost:8000. | {
"source": "volcengine/verl",
"title": "docs/README.md",
"url": "https://github.com/volcengine/verl/blob/main/docs/README.md",
"date": "2024-10-31T06:11:15",
"stars": 3060,
"description": "veRL: Volcano Engine Reinforcement Learning for LLM",
"file_size": 281
} |
=========================================================
HybridFlow Programming Guide
=========================================================
.. _vermouth: https://github.com/vermouth1992
Author: `Chi Zhang <https://github.com/vermouth1992>`_
verl is an open source implementation of the paper `HybridFlow <https://arxiv.org/abs/2409.19256v2>`_ [1]_. In this section, we will introduce the basic concepts of HybridFlow, the motivation and how to program with verl APIs.
Motivation and Design
------------------------
We use dataflow to represent RL systems. [4]_.
DataFlow
~~~~~~~~~~~~~~~~~~~~
Dataflow is an abstraction of computations. Neural Netowork training is a typical dataflow. It can be represented by computational graph.
.. image:: https://github.com/eric-haibin-lin/verl-community/blob/main/docs/dataflow.jpeg?raw=true
:alt: The dataflow graph from CS231n 2024 lecture 4
This figure [2]_ represents the computation graph of a polynomial function followed by a sigmoid function. In the data flow of neural network computation, each node represents an operator, and each edge represents the direction of forward/backward propagation. The computation graph determines the architecture of the neural network.
RL as a dataflow problem
++++++++++++++++++++++++++++++++++++++++++++++
Reinforcement learning (RL) training can also be represented as a dataflow. Below is the dataflow graph that represents the PPO algorithm used in RLHF [3]_:
.. image:: https://picx.zhimg.com/70/v2-cb8ab5ee946a105aab6a563e92682ffa_1440w.avis?source=172ae18b&biz_tag=Post
:alt: PPO dataflow graph, credit to Zhihu 低级炼丹师
However, the dataflow of RL has fundamental differences compared with dataflow of neural network training as follows:
+--------------------------+--------------------------------------------------+---------------------+
| Workload | Node | Edge |
+--------------------------+--------------------------------------------------+---------------------+
| Neural Network Training | Operator (+/-/matmul/softmax) | Tensor movement |
+--------------------------+--------------------------------------------------+---------------------+
| Reinforcement Learning | High-level operators (rollout/model forward) | Data Movement |
+--------------------------+--------------------------------------------------+---------------------+
In the case of tabular reinforcement learning, each operator is a simple scalar math operation (e.g., bellman update). In deep reinforcement learning(DRL), each operator is a high-level neural network computation such as model inference/update. This makes RL a two-level dataflow problem:
- Control flow: defines how the high-level operators are executed (e.g., In PPO, we first perform rollout. Then, we perform advantage computation. Finally, we perform training). It expresses the **core logics of RL algorithms**.
- Computation flow: defines the dataflow of **neural network computation** (e.g., model forward/backward/optimizer).
Design Choices
~~~~~~~~~~~~~~~~~~~~
The model size used in DRL before the LLM era is typically small. Thus, the high-level neural network computation can be done in a single process. This enables embedding the computation flow inside the control flow as a single process.
However, in the LLM era, the computation flow (e.g., training neural network) becomes a multi-process program. This naturally leads to two design choices:
1. Convert the control flow into a multi-process program as well. Then colocate with computation flow (unified multi-controller)
- Advantages:
- Achieves the **optimal performance** under fixed computation flow and control flow as the communication overhead in both training and data transfer is minimized.
- Disadvantages:
- The computation and/or control flow is **hard to reuse** from software perspective as computation code is coupled with specific controller code. For example, the training loop of PPO is generic. Say we have an PPO training flow implemented with a specific computation flow such as FSDP. Neither the control flow or computation flow can be reused if we want to switch the computation flow from FSDP to Megatron, due to the coupling of control and computation flows.
- Requires more efforts from the user under flexible and dynamic control flows, due to the multi-process nature of the program.
2. Separate the flows: single process for the control flow and multi-process for computation flow
- Advantages:
- The computation flow defined elsewhere can be **easily reused** after the decoupling.
- The controller runs on a single process. Implementing a new RL algorithm with a **different control flow is simple and easy**.
- Disadvantages:
- Additional **data communication overhead** each time the controller process and computatation processes interact. The data has to be sent back and forth.
In verl, the latter strategy with separate control flow and computation flow is adopted. verl is designed to decouple the control flow of RL algorithms, and the implementation of computation engines.
Overall Execution Diagram
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Below is a simplified diagram denoting the execution of a reinforcement learning job. In the diagram, the controller runs on a single process, while the generator/actor workers, critic workers run on multiple processes, placed with specific resource groups. For rollout, the controller passes the data to the generator to perform sample generation. When the rollout is done, the data is passed back to controller for the next step of the algorithm. Similar execution is done for other workers. With the hybrid controller design, the data flow and computation is decoupled to provide both efficiency in computation and flexiblity in defining algorithm training loops.
.. figure:: https://github.com/eric-haibin-lin/verl-community/blob/main/docs/driver_worker.png?raw=true
:alt: The execution diagram
Codebase walkthrough (PPO)
------------------------------------------------
Entry function
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Code: https://github.com/volcengine/verl/blob/main/verl/trainer/main_ppo.py
In this file, we define a remote function `main_task` that serves as the controller (driver) process as shown in the above figure. We also define a ``RewardManager``, where users can customize their reward function based on the data source in the dataset. Note that `RewardManager` should return the final token-level reward that is optimized by RL algorithms. Note that users can combine model-based rewards and rule-based rewards.
The ``main_task`` constructs a RayPPOTrainer instance and launch the fit. Note that ``main_task`` **runs as a single process**.
We highly recommend that the ``main_task`` is NOT schduled on the head of the ray cluster because ``main_task`` will consume a lot of memory but the head usually contains very few resources.
Ray trainer
~~~~~~~~~~~~~~~~~~~~
Code: https://github.com/volcengine/verl/blob/main/verl/trainer/ppo/ray_trainer.py
The RayPPOTrainer manages
- Worker and WorkerGroup construction
- Runs the main loop of PPO algorithm
Note that, the fit function of RayPPOTrainer **runs as a single process**.
Worker and WorkerGroup construction
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Each workerGroup manages a list of workers that runs remotely. Note that the worker group runs in the process of its construtor.
Each worker inside the WorkerGroup runs on a GPU. The worker group serves as a proxy for the controller process to interact with a list of workers, in order to perform certain computations. **In order to do so, we have to bind the methods of the worker into the method of the WorkerGroup and define the data dispatch and data collection**. This is done via simple decoration that will be introduced in the Worker definition section.
For example, in PPO, we define 3 worker groups:
- ActorRolloutRef: manages actor, rollout and reference policy. ActorRolloutRefWorker can be instantiated as a single actor, a single rollout, a single reference policy, a combined actor/rollout or a combined actor/rollout/ref. This design is aimed for the maximum code reuse in various scenarios. The reason for colocating actor and rollout is for fast weight transfer using nccl. The reason for coloating actor and reference is to implement an efficient lora PPO as the reference policy is simply the base model of PPO in lora.
- Critic: manages the critic model
- Reward: manages the reward model
The worker group will be constructed on the resource pool it designates. The resource pool is a set of GPUs in the ray cluster.
Worker definition
~~~~~~~~~~~~~~~~~~~~
.. _ActorRolloutRefWorker: https://github.com/volcengine/verl/blob/main/verl/workers/fsdp_workers.py
We take `ActorRolloutRefWorker <_ActorRolloutRefWorker>`_ for an exmaple.
The APIs it should expose to the controller process are:
- init_model: build the underlying model
- generate_sequences: given prompts, generate responses
- compute_log_prob: compute the log-probability of a generated sequence using actor
- compute_ref_log_prob: compute the log-probability of a generated sequence using reference policy
- save_checkpoint: save the checkpoint
Note that these methods are defined in the worker that can only be invoked via remote calls. For example, if the controller process wants to initialize the model, it has to call
.. code-block:: python
for worker in actor_rollout_ref_wg:
worker.init_model.remote()
If the controller process wants to generate sequences, it has to call
.. code-block:: python
data = xxx
# split the data into dp chunks
data_dp_lst = data.split(dp_size)
output_dp_lst = []
for i, worker in enumerate(actor_rollout_ref_wg):
output_future = worker.generate_sequences.remote(data_dp_lst[i])
output_dp_lst.append(output_future)
output = torch.cat(ray.get(output_dp_lst), dim=0)
We observe that controll process calling worker group methods in general can be divided into 3 parts:
- Split the data into data parallel sizes
- Dispatch the corresponding data into each worker
- Collect and concatenate the data when the computation finishes
In verl, we design a syntax sugar to encapsulate the 3 processes into a single call from the controller process.
.. code-block:: python
@register(dispatch_mode=Dispatch.DP_COMPUTE_PROTO)
def generate_sequences(data):
...
# on the driver
output = actor_rollout_ref_wg.generate_sequences(data)
We decorate the method of the worker with a ``register`` that explicitly defines how the input data should be splitted and dispatch to each worker, and how the output data should be collected and concatenated by the controller. For example, ``Dispatch.DP_COMPUTE_PROTO`` splits the input data into dp chunks, dispatch each data to each worker, collect the output and concatenate the results. Note that this function requires the input and output to be a DataProto defined here (https://github.com/volcengine/verl/blob/main/verl/protocol.py).
PPO main loop
~~~~~~~~~~~~~~~~~~~~
With the aforementioned APIs, we can implement the main loop of PPO as if it is a single process program
.. code-block:: python
for prompt in dataloader:
output = actor_rollout_ref_wg.generate_sequences(prompt)
old_log_prob = actor_rollout_ref_wg.compute_log_prob(output)
ref_log_prob = actor_rollout_ref_wg.compute_ref_log_prob(output)
values = critic_wg.compute_values(output)
rewards = reward_wg.compute_scores(output)
# compute_advantages is running directly on the control process
advantages = compute_advantages(values, rewards)
output = output.union(old_log_prob)
output = output.union(ref_log_prob)
output = output.union(values)
output = output.union(rewards)
output = output.union(advantages)
# update actor
actor_rollout_ref_wg.update_actor(output)
critic.update_critic(output)
Takeaways
~~~~~~~~~~~~~~~~~~~~
- This programming paradigm enables users to use different computation backend without modification of the control process.
- This programming paradigm enables flexible placement (by changing the mapping of WorkerGroup and ResourcePool) without modification of the control process.
Repository organization
------------------------------------------------
Important code files in the repository are organized as below:
.. code-block:: bash
verl # the verl package
trainer
main_ppo.py # the entrypoint for RL training
ppo
ray_trainer.py # the training loop for RL algorithms such as PPO
fsdp_sft_trainer.py # the SFT trainer with FSDP backend
config
generation.yaml # configuration template for rollout
ppo_trainer.yaml # configuration template for the RL trainer
workers
protocol.py # the interface of DataProto
fsdp_workers.py # the FSDP worker interfaces: ActorRolloutRefWorker, CriticWorker, RewardModelWorker
megatron_workers.py # the Megatron worker interfaces: ActorRolloutRefWorker, CriticWorker, RewardModelWorker
actor
dp_actor.py # data parallel actor with FSDP backend
megatron_actor.py # nD parallel actor with Megatron backend
critic
dp_critic.py # data parallel critic with FSDP backend
megatron_critic.py # nD parallel critic with FSDP backend
reward_model
megatron
reward_model.py # reward model with Megatron backend
rollout
vllm
vllm_rollout.py # rollout with vllm backend
hf_rollout.py # rollout with huggingface TGI backend
sharding_manager
fsdp_ulysses.py # data and model resharding when using FSDP + ulysses
fsdp_vllm.py # data and model resharding when using FSDP + ulysses + vllm
megatron_vllm.py # data and model resharding when using Megatron + vllm
utils
dataset # datasets for SFT/RM/RL
reward_score # function based reward
gsm8k.py # reward function for gsm8k dataset
math.py # reward function for math dataset
seqlen_balancing.py # the sequence balance optimization
models
llama # Megatron implementation for llama, deepseek, mistral, etc
transformers # ulysses integration with transformer models such as llama, qwen, etc
weight_loader_registery.py # registry of weight loaders for loading hf ckpt into Megatron
third_party
vllm # adaptor for vllm's usage in RL
vllm_v_0_6_3 # vllm v0.6.3 adaptor
llm.py # entrypoints for generate, sync_model_weight, offload_model_weights
parallel_state.py # vllm related device mesh and process groups
dtensor_weight_loaders.py # weight loader for huggingface models with FSDP
megatron_weight_loaders.py # weight loader for Megatron models
vllm_spmd # vllm >= v0.7 adaptor (coming soon)
examples # example scripts
tests # integration and unit tests
.github # the configuration of continuous integration tests
.. [1] HybridFlow: A Flexible and Efficient RLHF Framework: https://arxiv.org/abs/2409.19256v2
.. [2] Data flow graph credit to CS231n 2024 lecture 4: https://cs231n.stanford.edu/slides/2024/lecture_4.pdf
.. [3] PPO dataflow graph credit to 低级炼丹师 from Zhihu: https://zhuanlan.zhihu.com/p/635757674
.. [4] RLFlow | {
"source": "volcengine/verl",
"title": "docs/hybrid_flow.rst",
"url": "https://github.com/volcengine/verl/blob/main/docs/hybrid_flow.rst",
"date": "2024-10-31T06:11:15",
"stars": 3060,
"description": "veRL: Volcano Engine Reinforcement Learning for LLM",
"file_size": 15523
} |
Welcome to verl's documentation!
================================================
.. _hf_arxiv: https://arxiv.org/pdf/2409.19256
verl is a flexible, efficient and production-ready RL training framework designed for large language models (LLMs) post-training. It is an open source implementation of the `HybridFlow <hf_arxiv>`_ paper.
verl is flexible and easy to use with:
- **Easy extension of diverse RL algorithms**: The Hybrid programming model combines the strengths of single-controller and multi-controller paradigms to enable flexible representation and efficient execution of complex Post-Training dataflows. Allowing users to build RL dataflows in a few lines of code.
- **Seamless integration of existing LLM infra with modular APIs**: Decouples computation and data dependencies, enabling seamless integration with existing LLM frameworks, such as PyTorch FSDP, Megatron-LM and vLLM. Moreover, users can easily extend to other LLM training and inference frameworks.
- **Flexible device mapping and parallelism**: Supports various placement of models onto different sets of GPUs for efficient resource utilization and scalability across different cluster sizes.
- Readily integration with popular HuggingFace models
verl is fast with:
- **State-of-the-art throughput**: By seamlessly integrating existing SOTA LLM training and inference frameworks, verl achieves high generation and training throughput.
- **Efficient actor model resharding with 3D-HybridEngine**: Eliminates memory redundancy and significantly reduces communication overhead during transitions between training and generation phases.
--------------------------------------------
.. _Contents:
.. toctree::
:maxdepth: 5
:caption: Quickstart
start/install
start/quickstart
.. toctree::
:maxdepth: 4
:caption: Programming guide
hybrid_flow
.. toctree::
:maxdepth: 5
:caption: Data Preparation
preparation/prepare_data
preparation/reward_function
.. toctree::
:maxdepth: 5
:caption: Configurations
examples/config
.. toctree::
:maxdepth: 2
:caption: PPO Example
examples/ppo_code_architecture
examples/gsm8k_example
.. toctree::
:maxdepth: 1
:caption: PPO Trainer and Workers
workers/ray_trainer
workers/fsdp_workers
workers/megatron_workers
.. toctree::
:maxdepth: 1
:caption: Performance Tuning Guide
perf/perf_tuning
.. toctree::
:maxdepth: 1
:caption: Experimental Results
experiment/ppo
.. toctree::
:maxdepth: 1
:caption: Advance Usage and Extension
advance/placement
advance/dpo_extension
advance/fsdp_extension
advance/megatron_extension
.. toctree::
:maxdepth: 1
:caption: FAQ
faq/faq
Contribution
-------------
verl is free software; you can redistribute it and/or modify it under the terms
of the Apache License 2.0. We welcome contributions.
Join us on `GitHub <https://github.com/volcengine/verl>`_, `Slack <https://join.slack.com/t/verlgroup/shared_invite/zt-2w5p9o4c3-yy0x2Q56s_VlGLsJ93A6vA>`_ and `Wechat <https://raw.githubusercontent.com/eric-haibin-lin/verl-community/refs/heads/main/WeChat.JPG>`_ for discussions.
Code formatting
^^^^^^^^^^^^^^^^^^^^^^^^
We use yapf (Google style) to enforce strict code formatting when reviewing MRs. Run yapf at the top level of verl repo:
.. code-block:: bash
pip3 install yapf
yapf -ir -vv --style ./.style.yapf verl examples tests | {
"source": "volcengine/verl",
"title": "docs/index.rst",
"url": "https://github.com/volcengine/verl/blob/main/docs/index.rst",
"date": "2024-10-31T06:11:15",
"stars": 3060,
"description": "veRL: Volcano Engine Reinforcement Learning for LLM",
"file_size": 3426
} |
Extend to other RL(HF) algorithms
=================================
We already implemented the complete training pipeline of the PPO
algorithms. To extend to other algorithms, we analyze the high-level
principle to use verl and provide a tutorial to implement the DPO
algorithm. Users can follow the similar paradigm to extend to other RL algorithms.
.. note:: **Key ideas**: Single process drives multi-process computation and data communication.
Overall Approach
----------------
Step 1: Consider what multi-machine multi-GPU computations are needed
for each model, such as ``generate_sequence`` , ``compute_log_prob`` and
``update_policy`` in the actor_rollout model. Implement distributed
single-process-multiple-data (SPMD) computation and encapsulate them
into APIs
Step 2: Based on different distributed scenarios, including FSDP and 3D
parallelism in Megatron-LM, implement single-process control of data
interaction among multi-process computations.
Step 3: Utilize the encapsulated APIs to implement the control flow
Example: Online DPO
-------------------
We use verl to implement a simple online DPO algorithm. The algorithm
flow of Online DPO is as follows:
1. There is a prompt (rollout) generator which has the same weight as
the actor model. After a batch of prompts are fed into the generator,
it generates N responses for each prompt.
2. Send all the prompts + responses to a verifier for scoring, which can
be reward model or a rule-based function. Then sort them in pairs to
form a training batch.
3. Use this training batch to train the actor model using DPO. During
the process, a reference policy is needed.
Step 1: What are the multi-machine multi-GPU computations
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
**Sample Generator**
Implementation details:
.. code:: python
from verl.single_controller.base import Worker
from verl.single_controller.ray import RayWorkerGroup, RayClassWithInitArgs, RayResourcePool
import ray
@ray.remote
class SampleGenerator(Worker):
def __init__(self, config):
super().__init__()
self.config = config
def generate_sequences(self, data):
pass
Here, ``SampleGenerator`` can be viewed as a multi-process pulled up by
``torchrun``, with each process running the same code (SPMD).
``SampleGenerator`` needs to implement a ``generate_sequences`` API for
the control flow to call. The implementation details inside can use any
inference engine including vllm, sglang and huggingface. Users can
largely reuse the code in
verl/verl/trainer/ppo/rollout/vllm_rollout/vllm_rollout.py and we won't
go into details here.
**ReferencePolicy inference**
API: compute reference log probability
.. code:: python
from verl.single_controller.base import Worker
import ray
@ray.remote
class ReferencePolicy(Worker):
def __init__(self):
super().__init__()
self.model = Model()
def infer(self, data):
return self.model(data)
**Actor update**
API: Update actor model parameters
.. code:: python
from verl.single_controller.base import Worker
import ray
@ray.remote
class DPOActor(Worker):
def __init__(self):
super().__init__()
self.model = Model()
self.model = FSDP(self.model) # or other distributed strategy
self.optimizer = optim.Adam(self.model.parameters(), lr=1e-3)
self.loss_fn = xxx
def update(self, data):
self.optimizer.zero_grad()
logits = self.model(data)
loss = self.loss_fn(logits)
loss.backward()
self.optimizer.step()
**Notes: How to distinguish between control processes and distributed computation processes**
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
- Control processes are generally functions directly decorated with
``@ray.remote``
- Computation processes are all wrapped into a ``RayWorkerGroup``.
Users can reuse most of the distribtued computation logics implemented
in PPO algorithm, including FSDP and Megatron-LM backend in
verl/verl/trainer/ppo.
Step 2: Based on different distributed scenarios, implement single-process control of multi-process data interaction
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
**The core problem to solve here is how a single process sends data to
multiple processes, drives multi-process computation, and how the
control process obtains the results of multi-process computation.**
First, we initialize the multi-process ``WorkerGroup`` in the control
process.
.. code:: python
@ray.remote(num_cpus=1)
def main_task(config):
# construct SampleGenerator
resource_pool = RayResourcePool(process_on_nodes=[8] * 2) # 16 GPUs
ray_cls = RayClassWithInitArgs(SampleGenerator, config=config)
# put SampleGenerator onto resource pool
worker_group = RayWorkerGroup(resource_pool, ray_cls)
# construct reference policy
As we can see, in the control process, multiple processes are wrapped
into a ``RayWorkerGroup``. Inside this ``WorkerGroup``, there is a
``self._workers`` member, where each worker is a RayActor
(https://docs.ray.io/en/latest/ray-core/actors.html) of SampleGenerator.
ray_trainer.md also provide an implementation of
``MegatronRayWorkerGroup``.
Assuming the model is distributed using FSDP, and there is a batch of
data on the control process, for data parallelism, the underlying
calling process is:
.. code:: python
data = xxx
data_list = data.chunk(dp_size)
output = []
for d in data_list:
# worker_group._workers[i] is a SampleGenerator
output.append(worker_group._workers[i].generate_sequences.remote(d))
output = ray.get(output)
output = torch.cat(output)
Single process calling multiple processes involves the following 3
steps:
1. Split the data into DP parts on the control process.
2. Send the data to remote, call the remote computation through RPC, and
utilize multi-process computation.
3. Obtain the computation results of each worker on the control process
and merge them.
Frequently calling these 3 steps on the controller process greatly hurts
code readability. **In verl, we have abstracted and encapsulated these 3
steps, so that the worker's method + dispatch + collect can be
registered into the worker_group**
.. code:: python
from verl.single_controller.base.decorator import register
def dispatch_data(worker_group, data):
return data.chunk(worker_group.world_size)
def collect_data(worker_group, data):
return torch.cat(data)
dispatch_mode = {
'dispatch_fn': dispatch_data,
'collect_fn': collect_data
}
@register(dispatch_mode=dispatch_mode)
def generate_sequences(self, data):
pass
In this way, we can directly call the method inside the worker through
the ``worker_group`` on the control (driver) process (which is a single
process):
.. code:: python
output = worker_group.generate_sequences(data)
This single line includes data splitting, data distribution and
computation, and data collection.
Furthermore, the model parallelism size of each model is usually fixed,
including dp, tp, pp. So for these common distributed scenarios, we have
pre-implemented specific dispatch and collect methods,in `decorator.py <https://github.com/volcengine/verl/blob/main/verl/single_controller/base/decorator.py>`_, which can be directly used to wrap the computations.
.. code:: python
from verl.single_controller.base.decorator import register, Dispatch
@register(dispatch_mode=Dispatch.DP_COMPUTE_PROTO)
def generate_sequences(self, data: DataProto) -> DataProto:
pass
Here it requires the data interface to be ``DataProto``. Definition of
``DataProto`` is in `protocol.py <https://github.com/volcengine/verl/blob/main/verl/protocol.py>`_.
Step 3: Main training loop
~~~~~~~~~~~~~~~~~~~~~~~~~~
With the above training flows, we can implement the algorithm's control
flow. It is recommended that ``main_task`` is also a ray remote process.
.. code:: python
@ray.remote(num_cpus=1)
def main_task(config):
# construct SampleGenerator
resource_pool = RayResourcePool(process_on_nodes=[8] * 2) # 16 GPUs
ray_cls = RayClassWithInitArgs(SampleGenerator, config=config)
# put SampleGenerator onto resource pool
sample_gen = RayWorkerGroup(resource_pool, ray_cls)
# construct reference policy
ray_cls = RayClassWithInitArgs(ReferencePolicy)
ref_policy = RayWorkerGroup(resource_pool, ray_cls)
# construct actor
ray_cls = RayClassWithInitArgs(DPOActor)
dpo_policy = RayWorkerGroup(resource_pool, ray_cls)
dataloader = DataLoader()
for data in dataloader:
# generate data
data = sample_gen.generate_sequences(data)
# generate scores for each data
data = generate_scores(data)
# generate pairwise data using scores
data = generate_pairwise_data(data)
# generate ref_log_prob
data.batch['ref_log_prob'] = ref_policy.infer(data)
# update using dpo
dpo_policy.update(data)
# logging
Here, different ``WorkerGroups`` can be placed in the same resource pool or
in different resource pools using ``create_colocated_worker_cls``
similar as in `ray_trainer.py <https://github.com/volcengine/verl/blob/main/verl/trainer/ppo/ray_trainer.py>`_. | {
"source": "volcengine/verl",
"title": "docs/advance/dpo_extension.rst",
"url": "https://github.com/volcengine/verl/blob/main/docs/advance/dpo_extension.rst",
"date": "2024-10-31T06:11:15",
"stars": 3060,
"description": "veRL: Volcano Engine Reinforcement Learning for LLM",
"file_size": 9680
} |
Add models with the FSDP backend
==================================
Model
--------------------------
In principle, our FSDP backend can support any HF model and we can
sychronoize the actor model weight with vLLM using `hf_weight_loader.py <https://github.com/volcengine/verl/blob/main/verl/third_party/vllm/vllm_v_0_6_3/hf_weight_loader.py>`_.
However, ``hf_weight_loader`` is will gather the full state_dict of a
model during synchronization, which may cause OOM. We suggest using
``dtensor_weight_loader`` which gather the full model parameter layer by
layer to reduce the peak memory usage. We already support dtensor weight
loader for the models below in `dtensor_weight_loader.py <https://github.com/volcengine/verl/blob/main/verl/third_party/vllm/vllm_v_0_5_4/dtensor_weight_loaders.py>`_.:
- ``GPT2LMHeadModel``
- ``LlamaForCausalLM``
- ``LLaMAForCausalLM``
- ``MistralForCausalLM``
- ``InternLMForCausalLM``
- ``AquilaModel``
- ``AquilaForCausalLM``
- ``Phi3ForCausalLM``
- ``GemmaForCausalLM``
- ``Gemma2ForCausalLM``
- ``GPTBigCodeForCausalLM``
- ``Starcoder2ForCausalLM``
- ``Qwen2ForCausalLM``
- ``DeepseekV2ForCausalLM``
To implement ``dtensor_weight_loader`` of a model that's supported in
vLLM, follow the guide of gemma model below:
1. Copy the
``load_weights(self, weights: Iterable[Tuple[str, torch.Tensor]])`` from the vllm model class
to ``dtensor_weight_loaders.py``
2. Modify the arguments to
``(actor_weights: Dict, vllm_model: nn.Module)``
3. Replace the ``self`` to ``vllm_model``
4. Add the
``local_loaded_weight = redistribute_dtensor(param_name=name, loaded_weights=loaded_weight)``
before each ``param = params_dict[name]`` and modify the following
weight loading using ``local_loaded_weight``.
5. Register the implemented dtensor weight loader to ``__MODEL_DTENSOR_WEIGHT_LOADER_REGISTRY__``.
.. code-block:: diff
- def load_weights(self, weights: Iterable[Tuple[str, torch.Tensor]]):
+ def gemma_dtensor_weight_loader(actor_weights: Dict, vllm_model: nn.Module) -> nn.Module:
stacked_params_mapping = [
# (param_name, shard_name, shard_id)
("qkv_proj", "q_proj", "q"),
("qkv_proj", "k_proj", "k"),
("qkv_proj", "v_proj", "v"),
("gate_up_proj", "gate_proj", 0),
("gate_up_proj", "up_proj", 1),
]
- params_dict = dict(self.named_parameters())
+ params_dict = dict(vllm_model.named_parameters())
loaded_params = set()
- for name, loaded_weight in weights:
+ for name, loaded_weight in actor_weights.items():
for (param_name, shard_name, shard_id) in stacked_params_mapping:
if shard_name not in name:
continue
name = name.replace(shard_name, param_name)
# Skip loading extra bias for GPTQ models.
if name.endswith(".bias") and name not in params_dict:
continue
+ local_loaded_weight = redistribute_dtensor(param_name=name, loaded_weights=loaded_weight)
param = params_dict[name]
weight_loader = param.weight_loader
- weight_loader(param, loaded_weight, shard_id)
+ weight_loader(param, local_loaded_weight.to(dtype=param.dtype), shard_id)
break
else:
# lm_head is not used in vllm as it is tied with embed_token.
# To prevent errors, skip loading lm_head.weight.
if "lm_head.weight" in name:
continue
# Skip loading extra bias for GPTQ models.
if name.endswith(".bias") and name not in params_dict:
continue
+ local_loaded_weight = redistribute_dtensor(param_name=name, loaded_weights=loaded_weight)
param = params_dict[name]
weight_loader = getattr(param, "weight_loader",
default_weight_loader)
- weight_loader(param, loaded_weight)
+ weight_loader(param, local_loaded_weight.to(dtype=param.dtype))
loaded_params.add(name)
unloaded_params = params_dict.keys() - loaded_params
if unloaded_params:
raise RuntimeError(
"Some weights are not initialized from checkpoints: "
f"{unloaded_params}") | {
"source": "volcengine/verl",
"title": "docs/advance/fsdp_extension.rst",
"url": "https://github.com/volcengine/verl/blob/main/docs/advance/fsdp_extension.rst",
"date": "2024-10-31T06:11:15",
"stars": 3060,
"description": "veRL: Volcano Engine Reinforcement Learning for LLM",
"file_size": 4399
} |
Add models with the Megatron-LM backend
=========================================
Model
-----------
The most challenging aspect to use the Megatron-LM backend is implementing
the models for training. Currently, we implement Llama model that
support data parallelism, tensor parallelism, pipeline parallelism (also
vPP) and sequence parallelism. We also implement remove padding (sequence packing) on Llama
model, which can be found in `modeling_llama_megatron.py <https://github.com/volcengine/verl/blob/main/verl/models/llama/megatron/modeling_llama_megatron.py>`_.
To support other model, users are required to implement:
1. Implemnt a model similar to ``modeling_llama_megatron.py`` that satisfy the
parallelism requirements of Megatron-LM. Then register your model in
the `registry.py <https://github.com/volcengine/verl/blob/main/verl/models/registry.py>`_.
2. Checkpoint utils that can load full checkpoint (e.g. huggingface
checkpoint) to partitioned models during the runtime. Then register
your loader to ``weight_loader_registry`` in `weight_loader_registry.py <https://github.com/volcengine/verl/blob/main/verl/models/weight_loader_registry.py>`_.
3. Weight loader that synchronize the weight from Megatron to rollout
(vLLM) model. Note that both the actor model and rollout model are
partitioned during runtime. So, it's advisable to map the model name
in actor model implementation. Otherwise, you may need an additional
name mapping and even weight transformation. The weight loader implementation
is in `megatron_weight_loaders.py <https://github.com/volcengine/verl/blob/main/verl/third_party/vllm/vllm_v_0_6_3/megatron_weight_loaders.py>`_. | {
"source": "volcengine/verl",
"title": "docs/advance/megatron_extension.rst",
"url": "https://github.com/volcengine/verl/blob/main/docs/advance/megatron_extension.rst",
"date": "2024-10-31T06:11:15",
"stars": 3060,
"description": "veRL: Volcano Engine Reinforcement Learning for LLM",
"file_size": 1688
} |
Ray API Design Tutorial
=======================================
We provide a tutorial for our Ray API design, including:
- Ray basic concepts
- Resource Pool and RayWorkerGroup
- Data Dispatch, Execution and Collection
- Initialize the RayWorkerGroup and execute the distributed computation in the given Resource Pool
See details in `tutorial.ipynb <https://github.com/volcengine/verl/blob/main/examples/ray/tutorial.ipynb>`_. | {
"source": "volcengine/verl",
"title": "docs/advance/placement.rst",
"url": "https://github.com/volcengine/verl/blob/main/docs/advance/placement.rst",
"date": "2024-10-31T06:11:15",
"stars": 3060,
"description": "veRL: Volcano Engine Reinforcement Learning for LLM",
"file_size": 429
} |
.. _config-explain-page:
Config Explanation
===================
ppo_trainer.yaml for FSDP Backend
---------------------------------
Data
~~~~
.. code:: yaml
data:
tokenizer: null
train_files: ~/data/rlhf/gsm8k/train.parquet
val_files: ~/data/rlhf/gsm8k/test.parquet
prompt_key: prompt
max_prompt_length: 512
max_response_length: 512
train_batch_size: 1024
val_batch_size: 1312
return_raw_input_ids: False # This should be set to true when the tokenizer between policy and rm differs
return_raw_chat: False
- ``data.train_files``: Training set parquet. Can be a list or a single
file. The program will read all files into memory, so it can't be too
large (< 100GB). The path can be either local path or HDFS path. For
HDFS path, we provide utils to download it to DRAM and convert the
HDFS path to local path.
- ``data.val_files``: Validation parquet. Can be a list or a single
file.
- ``data.prompt_key``: The field in the dataset where the prompt is
located. Default is 'prompt'.
- ``data.max_prompt_length``: Maximum prompt length. All prompts will be
left-padded to this length. An error will be reported if the length is
too long
- ``data.max_response_length``: Maximum response length. Rollout in RL
algorithms (e.g. PPO) generates up to this length
- ``data.train_batch_size``: Batch size sampled for one training
iteration of different RL algorithms.
- ``data.val_batch_size``: Batch size sampled for one validation
iteration.
- ``data.return_raw_input_ids``: Whether to return the original
input_ids without adding chat template. This is mainly used to
accommodate situations where the reward model's chat template differs
from the policy. It needs to be decoded first, then apply the RM's
chat template. If using a model-based RM, and the policy and RM
chat_templates are different, this flag needs to be set
- ``data.return_raw_chat``:
- ``data.truncation``: Truncate the input_ids or prompt length if they
exceed max_prompt_length. Default is 'error', not allow exceed the
max_prompt_length. The users should increase the max_prompt_length if
throwing the error.
Actor/Rollout/Reference Policy
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. code:: yaml
actor_rollout_ref:
hybrid_engine: True
model:
path: ~/models/deepseek-llm-7b-chat
external_lib: null
override_config: { }
enable_gradient_checkpointing: False
use_remove_padding: False
actor:
strategy: fsdp # This is for backward-compatibility
ppo_mini_batch_size: 256
ppo_micro_batch_size: null # will be deprecated, use ppo_micro_batch_size_per_gpu
ppo_micro_batch_size_per_gpu: 8
use_dynamic_bsz: False
ppo_max_token_len_per_gpu: 16384 # n * ${data.max_prompt_length} + ${data.max_response_length}
grad_clip: 1.0
clip_ratio: 0.2
entropy_coeff: 0.001
use_kl_loss: False # True for GRPO
kl_loss_coef: 0.001 # for grpo
kl_loss_type: low_var_kl # for grpo
ppo_epochs: 1
shuffle: False
ulysses_sequence_parallel_size: 1 # sp size
optim:
lr: 1e-6
lr_warmup_steps_ratio: 0. # the total steps will be injected during runtime
min_lr_ratio: null # only useful for warmup with cosine
warmup_style: constant # select from constant/cosine
total_training_steps: -1 # must be override by program
fsdp_config:
wrap_policy:
# transformer_layer_cls_to_wrap: None
min_num_params: 0
param_offload: False
grad_offload: False
optimizer_offload: False
fsdp_size: -1
ref:
fsdp_config:
param_offload: False
wrap_policy:
# transformer_layer_cls_to_wrap: None
min_num_params: 0
log_prob_micro_batch_size: null # will be deprecated, use log_prob_micro_batch_size_per_gpu
log_prob_micro_batch_size_per_gpu: 16
log_prob_use_dynamic_bsz: ${actor_rollout_ref.actor.use_dynamic_bsz}
log_prob_max_token_len_per_gpu: ${actor_rollout_ref.actor.ppo_max_token_len_per_gpu}
ulysses_sequence_parallel_size: ${actor_rollout_ref.actor.ulysses_sequence_parallel_size} # sp size
rollout:
name: vllm
temperature: 1.0
top_k: -1 # 0 for hf rollout, -1 for vllm rollout
top_p: 1
prompt_length: ${data.max_prompt_length} # not use for opensource
response_length: ${data.max_response_length}
# for vllm rollout
dtype: bfloat16 # should align with FSDP
gpu_memory_utilization: 0.5
ignore_eos: False
enforce_eager: True
free_cache_engine: True
load_format: dummy_dtensor
tensor_model_parallel_size: 2
max_num_batched_tokens: 8192
max_num_seqs: 1024
log_prob_micro_batch_size: null # will be deprecated, use log_prob_micro_batch_size_per_gpu
log_prob_micro_batch_size_per_gpu: 16
log_prob_use_dynamic_bsz: ${actor_rollout_ref.actor.use_dynamic_bsz}
log_prob_max_token_len_per_gpu: ${actor_rollout_ref.actor.ppo_max_token_len_per_gpu}
# for hf rollout
do_sample: True
# number of responses (i.e. num sample times)
n: 1 # > 1 for grpo
**Common config for actor, rollout and reference model**
- ``actor_rollout_ref.hybrid_engine``: Whether it's a hybrid engine,
currently only supports hybrid engine
- ``actor_rollout_ref.model.path``: Huggingface model path. This can be
either local path or HDFS path. For HDFS path, we provide utils to
download it to DRAM and convert the HDFS path to local path.
- ``actor_rollout_ref.model.external_libs``: Additional Python packages
that need to be imported. Used to register models or tokenizers into
the Huggingface system.
- ``actor_rollout_ref.model.override_config``: Used to override some of
the model's original configurations, mainly dropout
- ``actor_rollout_ref.model.enable_gradient_checkpointing``: Whether to
enable gradient checkpointing for the actor
**Actor model**
- ``actor_rollout_ref.actor.strategy``: fsdp or megatron. In this
example, we use fsdp backend.
- ``actor_rollout_ref.actor.ppo_mini_batch_size``: One sample is split
into multiple sub-batches with batch_size=ppo_mini_batch_size for PPO
updates. The ppo_mini_batch_size is a global num across all workers/gpus
- ``actor_rollout_ref.actor.ppo_micro_batch_size``: [Will be deprecated, use ppo_micro_batch_size_per_gpu]
Similar to gradient accumulation, the micro_batch_size_per_gpu for one forward pass,
trading speed for GPU memory. The value represent the global view.
- ``actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu``: Similar to gradient
accumulation, the micro_batch_size_per_gpu for one forward pass, trading speed
for GPU memory. The value represent the local num per gpu.
- ``actor_rollout_ref.actor.grad_clip``: Gradient clipping for actor
updates
- ``actor_rollout_ref.actor.clip_ratio``: PPO clip ratio
- ``actor_rollout_ref.actor.entropy_coeff``: The weight of entropy when
calculating PPO loss
- ``actor_rollout_ref.actor.ppo_epochs``: Number of epochs for PPO
updates on one set of sampled data
- ``actor_rollout_ref.actor.shuffle``: Whether to shuffle data when
there are multiple epochs
- ``actor_rollout_ref.actor.optim``: Actor's optimizer parameters
- ``actor_rollout_ref.actor.fsdp_config``: FSDP config for actor
training
- ``wrap_policy``: FSDP wrap policy. By default, it uses Huggingface's
wrap policy, i.e., wrapping by DecoderLayer
- No need to set transformer_layer_cls_to_wrap, so we comment it.
- ``*_offload``: Whether to enable parameter, gradient and optimizer
offload
- Trading speed for GPU memory.
**Reference Model**
- ``actor_rollout_ref.ref``: FSDP config same as actor. **For models
larger than 7B, it's recommended to turn on offload for ref by
default**
- ``actor_rollout_ref.ref.log_prob_micro_batch_size``: [Will be deprecate, use log_prob_micro_batch_size_per_gpu]
The batch size for one forward pass in the computation of ``ref_log_prob``. The value represent the global num.
- ``actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu``: The batch size
for one forward pass in the computation of ``ref_log_prob``. The value represent the local num per gpu.
**Rollout Model**
- ``actor_rollout_ref.rollout.name``: hf/vllm. We use vLLM by default
because it's much efficient and our hybrid engine is implemented with
vLLM.
- Rollout (Auto-regressive) parameters. The key should be equal to the
property name in vLLM's ``SamplingParams``.
- ``temperature``, ``top_k``, ``top_p`` and others: Sampling
parameters in ``SamplingParams``.
- ``dtype``: Rollout model parameters type. This should be align with
the actor model parameter type in FSDP/Megatron backend.
- ``gpu_memory_utilization``: The proportion of the remaining GPU memory
allocated for kv cache after other models have initialized when using
vllm.
- ``tensor_model_parallel_size``: TP size for rollout. Only effective
for vllm.
- ``actor_rollout_ref.ref.log_prob_micro_batch_size``: [Will be deprecate, use log_prob_micro_batch_size_per_gpu]
The batch size for one forward pass in the computation of ``log_prob``. The value represent the global num.
- ``log_prob_micro_batch_size_per_gpu``: Micro batch size per gpu (The batch size for
one forward pass) for recalculating ``log_prob``. The value represent the local num per gpu.
- ``do_sample``: Whether to sample. If set to False, the rollout model
will perform greedy sampling. We disable ``do_sample`` during
validation.
- ``actor_rollout_ref.rollout.ignore_eos``: Whether to ignore the EOS
token and continue generating tokens after the EOS token is generated.
- ``actor_rollout_ref.rollout.free_cache_engine``: Offload the KVCache
after rollout generation stage. Default is True. When set to True, we
need to disable the usage of CUDAGraph (set ``enforce_eager`` to
True.)
- ``actor_rollout_ref.rollout.enforce_eager``: Whether to use CUDAGraph
in vLLM generation. Default set to True to disable CUDAGraph.
- ``actor_rollout_ref.rollout.load_format``: Which weight loader to use
to load the actor model weights to the rollout model.
- ``auto``: Use Megatron weight loader.
- ``megatron``: Use Megatron weight loader. Deployed with Megatron
backend. The input model ``state_dict()`` is already partitioned
along TP dimension and already gathered along PP dimension. This
weight loader requires that the Rollout model and Actor model's
parameters shape and name should be identical.
- ``dtensor``: Default solution when using Huggingface weight loader.
Deployed with FSDP backend and the state_dict_type is
``StateDictType.SHARDED_STATE_DICT``. Recommend to use this weight
loader
- ``hf``: Use Huggingface weight loader. Deployed with FSDP backend
and the state_dict_type is ``StateDictType.FULL_STATE_DICT``. This
solution doesn't need to rewrite the weight loader for each model
implemented in vLLM but it results in larger peak memory usage.
- ``dummy_hf``, ``dummy_megatron``, ``dummy_dtensor``: Random
initialization.
.. note:: **NOTED**: In this config field, users only need to select from ``dummy_megatron``, ``dummy_dtensor``, ``dummy_hf`` for rollout initialization and our hybrid engine will select the corresponding weight loader (i.e., ``megatron``, ``dtensor``, ``hf``) during actor/rollout weight synchronization.
Critic Model
~~~~~~~~~~~~
Most parameters for Critic are similar to Actor Model.
Reward Model
~~~~~~~~~~~~
.. code:: yaml
reward_model:
enable: False
model:
input_tokenizer: ${actor_rollout_ref.model.path} # set this to null if the chat template is identical
path: ~/models/Anomy-RM-v0.1
external_lib: ${actor_rollout_ref.model.external_lib}
fsdp_config:
min_num_params: 0
param_offload: False
micro_batch_size_per_gpu: 16
max_length: null
reward_manager: naive
- ``reward_model.enable``: Whether to enable reward model. If False, we
compute the reward only with the user-defined reward functions. In
GSM8K and Math examples, we disable reward model. For RLHF alignment
example using full_hh_rlhf, we utilize reward model to assess the
responses. If False, the following parameters are not effective.
- ``reward_model.model``
- ``input_tokenizer``: Input tokenizer. If the reward model's chat
template is inconsistent with the policy, we need to first decode to
plaintext, then apply the rm's chat_template. Then score with RM. If
chat_templates are consistent, it can be set to null.
- ``path``: RM's HDFS path or local path. Note that RM only supports
AutoModelForSequenceClassification. Other model types need to define
their own RewardModelWorker and pass it from the code.
- ``reward_model.reward_manager``: Reward Manager. This defines the mechanism
of computing rule-based reward and handling different reward sources. Default
if ``naive``. If all verification functions are multiprocessing-safe, the reward
manager can be set to ``prime`` for parallel verification.
Algorithm
~~~~~~~~~
.. code:: yaml
algorithm:
gamma: 1.0
lam: 1.0
adv_estimator: gae
kl_penalty: kl # how to estimate kl divergence
kl_ctrl:
type: fixed
kl_coef: 0.005
- ``gemma``: discount factor
- ``lam``: Trade-off between bias and variance in the GAE estimator
- ``adv_estimator``: Support ``gae``, ``grpo``, ``reinforce_plus_plus``.
- ``kl_penalty``: Support ``kl``, ``abs``, ``mse`` and ``full``. How to
calculate the kl divergence between actor and reference policy. For
specific options, refer to `core_algos.py <https://github.com/volcengine/verl/blob/main/verl/trainer/ppo/core_algos.py#L192>`_ .
Trainer
~~~~~~~
.. code:: yaml
trainer:
total_epochs: 30
project_name: verl_examples
experiment_name: gsm8k
logger: ['console', 'wandb']
nnodes: 1
n_gpus_per_node: 8
save_freq: -1
test_freq: 2
critic_warmup: 0
default_hdfs_dir: ~/experiments/gsm8k/ppo/${trainer.experiment_name} # hdfs checkpoint path
default_local_dir: checkpoints/${trainer.project_name}/${trainer.experiment_name} # local checkpoint path
- ``trainer.total_epochs``: Number of epochs in training.
- ``trainer.project_name``: For wandb
- ``trainer.experiment_name``: For wandb
- ``trainer.logger``: Support console and wandb
- ``trainer.nnodes``: Number of nodes used in the training.
- ``trainer.n_gpus_per_node``: Number of GPUs per node.
- ``trainer.save_freq``: The frequency (by iteration) to save checkpoint
of the actor and critic model.
- ``trainer.test_freq``: The validation frequency (by iteration).
- ``trainer.critic_warmup``: The number of iteration to train the critic
model before actual policy learning. | {
"source": "volcengine/verl",
"title": "docs/examples/config.rst",
"url": "https://github.com/volcengine/verl/blob/main/docs/examples/config.rst",
"date": "2024-10-31T06:11:15",
"stars": 3060,
"description": "veRL: Volcano Engine Reinforcement Learning for LLM",
"file_size": 14900
} |
GSM8K Example
=============
Introduction
------------
In this example, we train an LLM to tackle the GSM8k task.
Paper: https://arxiv.org/pdf/2110.14168
Dataset: https://huggingface.co/datasets/gsm8k
Note that the original paper mainly focuses on training a verifier (a
reward model) to solve math problems via Best-of-N sampling. In this
example, we train an RLHF agent using a rule-based reward model.
Dataset Introduction
--------------------
GSM8k is a math problem dataset. The prompt is an elementary school
problem. The LLM model is required to answer the math problem.
The training set contains 7473 samples and the test set contains 1319
samples.
**An example**
Prompt
Katy makes coffee using teaspoons of sugar and cups of water in the
ratio of 7:13. If she used a total of 120 teaspoons of sugar and cups
of water, calculate the number of teaspoonfuls of sugar she used.
Solution
The total ratio representing the ingredients she used to make the
coffee is 7+13 = <<7+13=20>>20 Since the fraction representing the
number of teaspoons she used is 7/20, she used 7/20\ *120 =
<<7/20*\ 120=42>>42 #### 42
Step 1: Prepare dataset
-----------------------
.. code:: bash
cd examples/data_preprocess
python3 gsm8k.py --local_dir ~/data/gsm8k
Step 2: Download Model
----------------------
There're three ways to prepare the model checkpoints for post-training:
- Download the required models from hugging face
.. code:: bash
huggingface-cli download deepseek-ai/deepseek-math-7b-instruct --local-dir ~/models/deepseek-math-7b-instruct --local-dir-use-symlinks False
- Already store your store model in the local directory or HDFS path.
- Also, you can directly use the model name in huggingface (e.g.,
deepseek-ai/deepseek-math-7b-instruct) in
``actor_rollout_ref.model.path`` and ``critic.model.path`` field in
the run script.
Noted that users should prepare checkpoints for actor, critic and reward
model.
[Optional] Step 3: SFT your Model
---------------------------------
We provide a SFT Trainer using PyTorch FSDP in
`fsdp_sft_trainer.py <https://github.com/volcengine/verl/blob/main/verl/trainer/fsdp_sft_trainer.py>`_.
Users can customize their own SFT
script using our FSDP SFT Trainer.
We also provide various training scripts for SFT on GSM8K dataset in `gsm8k sft directory <https://github.com/volcengine/verl/blob/main/examples/sft/gsm8k/>`_.
.. code:: shell
set -x
torchrun -m verl.trainer.fsdp_sft_trainer \
data.train_files=$HOME/data/gsm8k/train.parquet \
data.val_files=$HOME/data/gsm8k/test.parquet \
data.prompt_key=question \
data.response_key=answer \
data.micro_batch_size_per_gpu=8 \
model.partial_pretrain=deepseek-ai/deepseek-coder-6.7b-instruct \
trainer.default_hdfs_dir=hdfs://user/verl/experiments/gsm8k/deepseek-coder-6.7b-instruct/ \
trainer.project_name=gsm8k-sft \
trainer.experiment_name=gsm8k-sft-deepseek-coder-6.7b-instruct \
trainer.total_epochs=4 \
trainer.logger=['console','wandb']
Step 4: Perform PPO training with your model on GSM8K Dataset
-------------------------------------------------------------
- Prepare your own run.sh script. Here's an example for GSM8k dataset
and deepseek-llm-7b-chat model.
- Users could replace the ``data.train_files`` ,\ ``data.val_files``,
``actor_rollout_ref.model.path`` and ``critic.model.path`` based on
their environment.
- See :doc:`config` for detailed explanation of each config field.
**Reward Model/Function**
We use a rule-based reward model. We force the model to produce a final
answer following 4 “#” as shown in the solution. We extract the final
answer from both the solution and model's output using regular
expression matching. We compare them and assign a reward of 1 to correct
answer, 0.1 to incorrect answer and 0 to no answer.
**Training Script**
The training script example for FSDP and Megatron-LM backend are stored in examples/ppo_trainer directory.
.. code:: bash
cd ../ppo_trainer
bash run_deepseek7b_llm.sh
The script of run_deepseek7b_llm.sh
.. code:: bash
set -x
python3 -m verl.trainer.main_ppo \
data.train_files=$HOME/data/gsm8k/train.parquet \
data.val_files=$HOME/data/gsm8k/test.parquet \
data.train_batch_size=1024 \
data.val_batch_size=1312 \
data.max_prompt_length=512 \
data.max_response_length=512 \
actor_rollout_ref.model.path=deepseek-ai/deepseek-llm-7b-chat \
actor_rollout_ref.actor.optim.lr=1e-6 \
actor_rollout_ref.model.use_remove_padding=True \
actor_rollout_ref.actor.ppo_mini_batch_size=256 \
actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=16 \
actor_rollout_ref.actor.fsdp_config.param_offload=False \
actor_rollout_ref.actor.fsdp_config.grad_offload=False \
actor_rollout_ref.actor.fsdp_config.optimizer_offload=False \
actor_rollout_ref.model.enable_gradient_checkpointing=True \
actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=32 \
actor_rollout_ref.rollout.tensor_model_parallel_size=4 \
actor_rollout_ref.rollout.name=vllm \
actor_rollout_ref.rollout.gpu_memory_utilization=0.5 \
actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=32 \
actor_rollout_ref.ref.fsdp_config.param_offload=True \
critic.optim.lr=1e-5 \
critic.model.use_remove_padding=True \
critic.model.path=deepseek-ai/deepseek-llm-7b-chat \
critic.model.enable_gradient_checkpointing=True \
critic.ppo_micro_batch_size_per_gpu=32 \
critic.model.fsdp_config.param_offload=False \
critic.model.fsdp_config.grad_offload=False \
critic.model.fsdp_config.optimizer_offload=False \
algorithm.kl_ctrl.kl_coef=0.001 \
trainer.critic_warmup=0 \
trainer.logger=['console','wandb'] \
trainer.project_name='verl_example_gsm8k' \
trainer.experiment_name='deepseek_llm_7b_function_rm' \
trainer.n_gpus_per_node=8 \
trainer.nnodes=1 \
trainer.save_freq=-1 \
trainer.test_freq=1 \
trainer.total_epochs=15 $@ | {
"source": "volcengine/verl",
"title": "docs/examples/gsm8k_example.rst",
"url": "https://github.com/volcengine/verl/blob/main/docs/examples/gsm8k_example.rst",
"date": "2024-10-31T06:11:15",
"stars": 3060,
"description": "veRL: Volcano Engine Reinforcement Learning for LLM",
"file_size": 6134
} |
PPO Example Architecture
========================
Let's start with the Proximal Policy Optimization algorithm, which is
most widely used algorithm in LLM post-training.
The main entry point of the PPO algorithm example is:
`main_ppo.py <https://github.com/volcengine/verl/blob/main/verl/trainer/main_ppo.py>`_.
In this tutorial, we will go through the code architecture in `main_ppo.py <https://github.com/volcengine/verl/blob/main/verl/trainer/main_ppo.py>`_.
Define the data
---------------
Users need to preprocess and store the dataset in parquet files.
And we implement `RLHFDataset` to load and tokenize the parquet files.
For ``RLHFDataset`` (Default), at least 1 fields are required:
- ``prompt``: Contains the string prompt
We already provide some examples of processing the datasets to parquet
files in `data_preprocess directory <https://github.com/volcengine/verl/blob/main/examples/data_preprocess>`_. Currently, we support
preprocess of GSM8k, MATH, Hellasage, Full_hh_rlhf datasets. See :doc:`../preparation/prepare_data` for
more information.
Define the reward functions for different datasets
--------------------------------------------------
In this main entry point, the users only need to define their own reward
function based on the datasets (or applications) utilized in PPO
training.
For example, we already provide reward functions for `GSM8k <https://github.com/volcengine/verl/blob/main/verl/utils/reward_score/gsm8k.py>`_
and `MATH <https://github.com/volcengine/verl/blob/main/verl/utils/reward_score/math.py>`_
datasets in the ``_select_rm_score_fn``. In the ``RewardManager``, we
will compute the reward score based on the data_source to select
corresponding reward functions. For some RLHF datasets (e.g.,
full_hh_rlhf), the reward model is utilized to assess the responses
without any reward functions. In this case, the ``RewardManager`` will
return the ``rm_score`` computed by the reward model directly.
See `reward functions <https://github.com/volcengine/verl/blob/main/verl/utils/reward_score>`_ for detailed implementation.
Define worker classes
---------------------
.. code:: python
if config.actor_rollout_ref.actor.strategy == 'fsdp': # for FSDP backend
assert config.actor_rollout_ref.actor.strategy == config.critic.strategy
from verl.workers.fsdp_workers import ActorRolloutRefWorker, CriticWorker
from verl.single_controller.ray import RayWorkerGroup
ray_worker_group_cls = RayWorkerGroup
elif config.actor_rollout_ref.actor.strategy == 'megatron': # for Megatron backend
assert config.actor_rollout_ref.actor.strategy == config.critic.strategy
from verl.workers.megatron_workers import ActorRolloutRefWorker, CriticWorker
from verl.single_controller.ray.megatron import NVMegatronRayWorkerGroup
ray_worker_group_cls = NVMegatronRayWorkerGroup # Ray worker class for Megatron-LM
else:
raise NotImplementedError
from verl.trainer.ppo.ray_trainer import ResourcePoolManager, Role
role_worker_mapping = {
Role.ActorRollout: ActorRolloutRefWorker,
Role.Critic: CriticWorker,
Role.RefPolicy: ActorRolloutRefWorker
}
global_pool_id = 'global_pool'
resource_pool_spec = {
global_pool_id: [config.trainer.n_gpus_per_node] * config.trainer.nnodes,
}
mapping = {
Role.ActorRollout: global_pool_id,
Role.Critic: global_pool_id,
Role.RefPolicy: global_pool_id,
}
Step 1: Construct the mapping between roles and workers
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
A role represents a group of workers in the same process. We have
pre-defined several roles in `ray_trainer.py <https://github.com/volcengine/verl/blob/main/verl/trainer/ppo/ray_trainer.py#L38>`_.
.. code:: python
class Role(Enum):
"""
To create more roles dynamically, you can subclass Role and add new members
"""
Actor = 0 # This worker only has Actor
Rollout = 1 # This worker only has Rollout
ActorRollout = 2 # This worker has both actor and rollout, it's a HybridEngine
Critic = 3 # This worker only has critic
RefPolicy = 4 # This worker only has reference policy
RewardModel = 5 # This worker only has reward model
ActorRolloutRef = 6 # This worker contains actor, rollout and reference policy simultaneously
Step 2: Define the worker class corresponding to this role
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
- We have pre-implemented the ``ActorRolloutRefWorker``. Through
different configs, it can be a standalone actor, a standalone rollout,
an ActorRollout HybridEngine, or an ActorRolloutRef HybridEngine
- We also pre-implemented workers for ``Actor``, ``Rollout``,
``Critic``, ``Reward Model`` and ``Reference model`` on two different
backend: PyTorch FSDP
and Megatron-LM.
See `FSDP Workers <https://github.com/volcengine/verl/blob/main/verl/workers/fsdp_workers.py>`_
and `Megatron-LM Workers <https://github.com/volcengine/verl/blob/main/verl/workers/megatron_workers.py>`_
for more information.
Step 3: Define resource pool id and resource pool spec
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
- Resource pool is a division of global GPU resources,
``resource_pool_spec`` is a dict, mapping from id to # of GPUs
- In the above example, we defined a global resource pool:
global_pool_id, and then put all roles on this one resource pool
with all the GPUs in this post-training task. This refers to
*co-locate* placement where all the models share the same set of
GPUs.
- See resource pool and placement for advance usage.
Defining reward model/function
------------------------------
.. code:: python
# we should adopt a multi-source reward function here
# - for rule-based rm, we directly call a reward score
# - for model-based rm, we call a model
# - for code related prompt, we send to a sandbox if there are test cases
# - finally, we combine all the rewards together
# - The reward type depends on the tag of the data
if config.reward_model.enable:
from verl.workers.fsdp_workers import RewardModelWorker
role_worker_mapping[Role.RewardModel] = RewardModelWorker
mapping[Role.RewardModel] = global_pool_id
reward_fn = RewardManager(tokenizer=tokenizer, num_examine=0)
# Note that we always use function-based RM for validation
val_reward_fn = RewardManager(tokenizer=tokenizer, num_examine=1)
resource_pool_manager = ResourcePoolManager(resource_pool_spec=resource_pool_spec, mapping=mapping)
Since not all tasks use model-based RM, users need to define here
whether it's a model-based RM or a function-based RM
- If it's a model-based RM, directly add the ``RewardModel`` role in the
resource mapping and add it to the resource pool mapping.
- Note that the pre-defined ``RewardModelWorker`` only supports models
with the structure of huggingface
``AutoModelForSequenceClassification``. If it's not this model, you
need to define your own RewardModelWorker in `FSDP Workers <https://github.com/volcengine/verl/blob/main/verl/trainer/ppo/workers/fsdp_workers.py>`_
and `Megatron-LM Workers <https://github.com/volcengine/verl/blob/main/verl/trainer/ppo/workers/megatron_workers.py>`_.
- If it's a function-based RM, the users are required to classified the
reward function for each datasets.
.. code:: python
def _select_rm_score_fn(data_source):
if data_source == 'openai/gsm8k':
return gsm8k.compute_score
elif data_source == 'lighteval/MATH':
return math.compute_score
else:
raise NotImplementedError
See reward functions implemented in `directory <https://github.com/volcengine/verl/blob/main/verl/utils/reward_score/>`_
for more information.
Define, init and run the PPO Trainer
------------------------------------
.. code:: python
trainer = RayPPOTrainer(config=config,
tokenizer=tokenizer,
role_worker_mapping=role_worker_mapping,
resource_pool_manager=resource_pool_manager,
ray_worker_group_cls=ray_worker_group_cls,
reward_fn=reward_fn,
val_reward_fn=val_reward_fn)
trainer.init_workers()
trainer.fit()
- We first initialize the ``RayPPOTrainer`` with user config, tokenizer
and all the above worker mapping, resource pool, worker group and
reward functions
- We first call the ``trainer.init_workers()`` to initialize the models
on the allocated GPUs (in the resource pool)
- The actual PPO training will be executed in ``trainer.fit()``
verl can be easily extended to other RL algorithms by reusing the Ray
model workers, resource pool and reward functions. See :doc:`extension<../advance/dpo_extension>` for
more information.
Details of the ``RayPPOTrainer`` is discussed in :doc:`Ray Trainer<../workers/ray_trainer>`. | {
"source": "volcengine/verl",
"title": "docs/examples/ppo_code_architecture.rst",
"url": "https://github.com/volcengine/verl/blob/main/docs/examples/ppo_code_architecture.rst",
"date": "2024-10-31T06:11:15",
"stars": 3060,
"description": "veRL: Volcano Engine Reinforcement Learning for LLM",
"file_size": 9020
} |
.. _algo-baseline-page:
Algorithm Baselines
===================
GSM8k
------------------
Assuming GSM8k dataset is preprocess via ``python3 examples/data_preprocess/gsm8k.py``
Refer to the table below to reproduce PPO training from different pre-trained models.
.. _Huggingface: https://huggingface.co/google/gemma-2-2b-it#benchmark-results
.. _SFT Command and Logs: https://github.com/eric-haibin-lin/verl-data/blob/experiments/gsm8k/gemma-2-2b-it-sft-0.411.log
.. _SFT+PPO Command and Logs: https://github.com/eric-haibin-lin/verl-data/blob/experiments/gsm8k/gemma-2-2b-it-ppo-bsz512_4-prompt1024-resp-512-0.640.log
.. _wandb: https://api.wandb.ai/links/verl-team/h7ux8602
.. _Qwen Blog: https://qwenlm.github.io/blog/qwen2.5-llm/
.. _PPO Command and Logs: https://github.com/eric-haibin-lin/verl-data/blob/experiments/gsm8k/Qwen2.5-0.5B-bsz256_2-prompt1024-resp512-0.567.log
.. _Megatron PPO Command and Logs: https://github.com/eric-haibin-lin/verl-data/blob/experiments/gsm8k/deepseek-llm-7b-chat-megatron-bsz256_4-prompt512-resp512-0.695.log
.. _Qwen7b GRPO Script: https://github.com/volcengine/verl/blob/a65c9157bc0b85b64cd753de19f94e80a11bd871/examples/grpo_trainer/run_qwen2-7b_seq_balance.sh
.. _Megatron wandb: https://wandb.ai/verl-team/verl_megatron_gsm8k_examples/runs/10fetyr3
.. _Qwen7b ReMax Script: https://github.com/eric-haibin-lin/verl/blob/main/examples/remax_trainer/run_qwen2.5-3b_seq_balance.sh
.. _Qwen7b ReMax Wandb: https://wandb.ai/liziniu1997/verl_remax_example_gsm8k/runs/vxl10pln
+----------------------------------+------------------------+------------+-----------------------------------------------------------------------------------------------+
| Model | Method | Test score | Details |
+==================================+========================+============+=====================+=========================================================================+
| google/gemma-2-2b-it | pretrained checkpoint | 23.9 | `Huggingface`_ |
+----------------------------------+------------------------+------------+-----------------------------------------------------------------------------------------------+
| google/gemma-2-2b-it | SFT | 52.06 | `SFT Command and Logs`_ |
+----------------------------------+------------------------+------------+-----------------------------------------------------------------------------------------------+
| google/gemma-2-2b-it | SFT + PPO | 64.02 | `SFT+PPO Command and Logs`_, `wandb`_ |
+----------------------------------+------------------------+------------+-----------------------------------------------------------------------------------------------+
| Qwen/Qwen2.5-0.5B-Instruct | pretrained checkpoint | 36.4 | `Qwen Blog`_ |
+----------------------------------+------------------------+------------+-----------------------------------------------------------------------------------------------+
| Qwen/Qwen2.5-0.5B-Instruct | PPO | 56.7 | `PPO Command and Logs`_ |
+----------------------------------+------------------------+------------+-----------------------------------------------------------------------------------------------+
| deepseek-ai/deepseek-llm-7b-chat | PPO | 69.5 [1]_ | `Megatron PPO Command and Logs`_, `Megatron wandb`_ |
+----------------------------------+------------------------+------------+-----------------------------------------------------------------------------------------------+
| Qwen/Qwen2-7B-Instruct | GRPO | 89 | `Qwen7b GRPO Script`_ |
+----------------------------------+------------------------+------------+-----------------------------------------------------------------------------------------------+
| Qwen/Qwen2.5-7B-Instruct | ReMax | 97 | `Qwen7b ReMax Script`_, `Qwen7b ReMax Wandb`_ |
+----------------------------------+------------------------+------------+-----------------------------------------------------------------------------------------------+
.. [1] During the evaluation, we have only extracted answers following the format "####". A more flexible answer exaction, longer response length and better prompt engineering may lead to higher score. | {
"source": "volcengine/verl",
"title": "docs/experiment/ppo.rst",
"url": "https://github.com/volcengine/verl/blob/main/docs/experiment/ppo.rst",
"date": "2024-10-31T06:11:15",
"stars": 3060,
"description": "veRL: Volcano Engine Reinforcement Learning for LLM",
"file_size": 4971
} |
Frequently Asked Questions
====================================
Ray related
------------
How to add breakpoint for debugging with distributed Ray?
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Please checkout the official debugging guide from Ray: https://docs.ray.io/en/latest/ray-observability/ray-distributed-debugger.html
Distributed training
------------------------
How to run multi-node post-training with Ray?
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
You can start a ray cluster and submit a ray job, following the official guide from Ray: https://docs.ray.io/en/latest/ray-core/starting-ray.html
If your cluster is managed by Slurm, please refer to the guide for deploying Ray on Slurm: https://docs.ray.io/en/latest/cluster/vms/user-guides/community/slurm.html | {
"source": "volcengine/verl",
"title": "docs/faq/faq.rst",
"url": "https://github.com/volcengine/verl/blob/main/docs/faq/faq.rst",
"date": "2024-10-31T06:11:15",
"stars": 3060,
"description": "veRL: Volcano Engine Reinforcement Learning for LLM",
"file_size": 965
} |
Performance Tuning Guide
==============================
Author: `Guangming Sheng <https://github.com/PeterSH6>`_
In this section, we will discuss how to tune the performance of all the stages in verl, including:
1. Rollout generation throughput.
2. Enable `use_remove_padding=True` for sequence packing (i.e., data packing and remove padding).
3. Batch size tuning for forward and backward computation
4. Enable ``use_dynamic_bsz=True`` for higher throughput.
5. Utilize Ulysses Sequence Parallel for Long Context Training
6. LigerKernel for SFT performance optimization
Rollout Generation Tuning
--------------------------
verl currently supports two rollout backends: vLLM and TGI (with SGLang support coming soon).
Below are key factors for tuning vLLM-based rollout. Before tuning, we recommend setting ``actor_rollout_ref.rollout.disable_log_stats=False`` so that rollout statistics are logged.
- Increase ``gpu_memory_utilization``. The vLLM pre-allocates GPU KVCache by using gpu_memory_utilization% of the remaining memory.
However, if model parameters and optimizer states are not offloaded, using too high a fraction can lead to OOM.
A value between 0.5 and 0.7 often strikes a good balance between high throughput and avoiding OOM.
- Adjust ``max_num_seqs`` or ``max_num_batched_tokens``.
If the GPU cache utilization is relatively low in the log, increase ``max_num_seqs`` or ``max_num_batched_tokens``
can enlarge the effective batch size in the decoding stage, allowing more concurrent requests per batch.
We recommend setting ``max_num_batched_tokens > 2048`` for higher throughput.
- Use a smaller ``tensor_parallel_size``.
When GPU resources allow, a smaller tensor parallel size spawns more vLLM replicas.
Data parallelism (DP) can yield higher throughput than tensor parallelism (TP), but also increases KVCache consumption.
Carefully balance the trade-off between more replicas and higher memory usage.
Our experient in Sec. 8.4 of `HybridFlow paper <https://github.com/volcengine/verl/blob/main/verl/utils/reward_score/gsm8k.py>`_ evaluate this trade-off.
More tuning details such as dealing with Preemption and Chunked-prefill
can be found in `vLLM official tuning guide <https://docs.vllm.ai/en/latest/performance/optimization.html>`_
Enable remove padding (sequence packing)
-----------------------------------------
Currently, for llama, mistral, gemma1 and qwen based models, users can enable `use_remove_padding=True` to utilize the
sequence packing implementation provided by transformers library.
For other models, transformers library may also support it but we haven't tested it yet.
Users can add the desired model config to the `test_transformer.py <https://github.com/volcengine/verl/blob/main/tests/model/test_transformer.py#L24>`_ file.
And test its functionaility by running the following command:
.. code-block:: bash
pytest -s tests/model/test_transformer.py
If the test passes, you can add your desired model into the model `registry.py <https://github.com/volcengine/verl/blob/main/verl/models/registry.py#L24>`_ file.
Then, you can enjoy the performance boost of sequence packing
and welcome to PR your tested model to verl!
Batch Size Tuning
-----------------
To achieve higher throughput in experience preparation (i.e., model fwd) and model update (i.e., actor/critic fwd/bwd),
users may need to tune the ``*micro_batch_size_per_gpu`` for different computation.
In verl, the core principle for setting batch sizes is:
- **Algorithmic metrics** (train batch size, PPO mini-batch size) are *global* (from a single-controller perspective),
normalized in each worker. See the `normalization code <https://github.com/volcengine/verl/blob/main/verl/workers/fsdp_workers.py#L120-L122>`_.
- **Performance-related parameters** (micro batch size, max token length for dynamic batch size) are *local* parameters that define the per-GPU data allocations.
See the `normalization code <https://github.com/volcengine/verl/blob/main/verl/workers/fsdp_workers.py#L127>`_.
.. note:: In your training script, please use ``*micro_batch_size_per_gpu`` instead of ``*micro_batch_size``.
So that you don't need to consider the normalization of the ``micro_batch_size`` and ``micro_batch_size`` will be deprecated.
Batch Size Tuning tips
""""""""""""""""""""""
Therefore, users may need to tune the ``*micro_batch_size_per_gpu`` to accelerate training. Here're some tips:
1. **Enable gradient checkpointing**:
Set ``actor_rollout_ref.model.enable_gradient_checkpointing=True`` and ``critic.model.enable_gradient_checkpointing=True``.
This often allows for larger micro-batch sizes and will be beneficial for large mini-batch training.
2. Increase the ``*micro_batch_size_per_gpu`` as much as possible till equals to normalized ``mini_batch_size``.
3. **Use larger forward-only parameters**:
Forward only parameter, such as ``actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu``,
``actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu``, ``critic.forward_micro_batch_size_per_gpu`` could be larger (e.g., 2x) than training related micro batch sizes,
such as ``actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu``, ``critic.ppo_micro_batch_size_per_gpu``.
4. **Allow larger micro-batch sizes for Critic and Reward models**:
micro batch size of Critic and Reward model could be larger than Actor model. This is because the actor model has much larger vocab size in the final layer.
Tuning for Dynamic Batch Size
-----------------------------
Dynamic batch size is a technique that allows the model to process similar number of tokens in a single forward pass (with different actual batch sizes).
This can significantly improve the training efficiency and reduce the memory usage.
To utilize this technique, users can set ``use_dynamic_bsz=True`` in actor, ref, critic and reward models.
With ``use_dynamic_bsz=True``, users don't need to tune ``*micro_batch_size_per_gpu``.
Instead, users should tune the following parameters:
- ``actor_rollout_ref.actor.ppo_max_token_len_per_gpu``, ``critic.ppo_max_token_len_per_gpu``:
The maximum number of tokens to be processed in fwd and bwd of ``update_policy`` and ``update_critic``.
- ``actor_rollout_ref.ref.log_prob_max_token_len_per_gpu`` and ``actor_rollout_ref.rollout.log_prob_max_token_len_per_gpu``:
The maximum number of tokens to be processed in a the fwd computation of ``compute_log_prob`` and ``comptue_ref_log_prob``.
- ``critic.forward_micro_batch_size_per_gpu``, ``reward_model.forward_micro_batch_size_per_gpu``:
The maximum number of tokens to be processed in a the fwd computation of ``compute_values``, ``compute_rm_score``.
Dynamic Batch Size Tuning tips
""""""""""""""""""""""""""""""
Here're some tips to tune the above parameters:
1. **Increase** ``actor_rollout_ref.actor.ppo_max_token_len_per_gpu``
Make it at least 2 x (max_prompt_length + max_response_length). We set it to 3x in `run_qwen2-7b_rm_seq_balance.sh <https://github.com/volcengine/verl/blob/main/examples/ppo_trainer/run_qwen2-7b_rm_seq_balance.sh#L25>`_.
Try to increase it to get higher throughput.
2. **Forward-only parameters can be larger**:
Similar to the non-dynamic-batch scenario, forward-only token limits can exceed those used in forward/backward operations.
3. **Use larger limits for Critic and Reward models**:
Critic and Reward parameters can be set at least 2× the Actor’s limits. For instance, we set them to 4× here:
`run_qwen2-7b_rm_seq_balance.sh <https://github.com/volcengine/verl/blob/main/examples/ppo_trainer/run_qwen2-7b_rm_seq_balance.sh#L40>`_
.. :math:`\text{critic.ppo_max_token_len_per_gpu} = 2 \times \text{actor.ppo_max_token_len_per_gpu})`.
Ulysses Sequence Parallel for Long Context Training
----------------------------------------------------
To utilize this technique, users can set ``ulysses_sequence_parallel_size>1`` in actor, ref, critic and reward models.
We support different model utilize different ulysses_sequence_parallel_size sizes.
To train log sequence (>32k), users may need to decrease the ``*micro_batch_size_per_gpu`` and ``*max_token_len_per_gpu`` to avoid OOM.
LigerKernel for SFT
----------------------
LigerKernel is a high-performance kernel for Supervised Fine-Tuning (SFT) that can improve training efficiency. To enable LigerKernel in your SFT training:
1. In your SFT configuration file (e.g., ``verl/trainer/config/sft_trainer.yaml``), set the ``use_liger`` parameter:
.. code-block:: yaml
model:
use_liger: True # Enable LigerKernel for SFT
2. The default value is ``False``. Enable it only when you want to use LigerKernel's optimizations.
3. LigerKernel is particularly useful for improving training performance in SFT scenarios. | {
"source": "volcengine/verl",
"title": "docs/perf/perf_tuning.rst",
"url": "https://github.com/volcengine/verl/blob/main/docs/perf/perf_tuning.rst",
"date": "2024-10-31T06:11:15",
"stars": 3060,
"description": "veRL: Volcano Engine Reinforcement Learning for LLM",
"file_size": 8837
} |
Prepare Data for Post-Training
========================================
Before starting the post-training job, we need to prepare the data for
the policy training. The data should be stored in the parquet format.
We provide several data preprocess scripts for different datasets,
including GSM8K, MATH, HelloSwag, Full_hh_rlhf. To prepare other datasets, we need
to follow the following steps: The data preprocess script can be divided
into two parts:
1. The first part is the common part, which loads the dataset from
huggingface's ``datasets`` package. Then preprocess the datasets with
the ``make_map_fn`` and then store in the parquet format.
.. code:: python
import re
import os
import datasets
from verl.utils.hdfs_io import copy, makedirs
import argparse
# To extract the solution for each prompts in the dataset
# def extract_solution(solution_str):
# ...
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--local_dir', default='/opt/tiger/gsm8k')
parser.add_argument('--hdfs_dir', default=None)
args = parser.parse_args()
num_few_shot = 5
data_source = 'openai/gsm8k'
dataset = datasets.load_dataset(data_source, 'main')
train_dataset = dataset['train']
test_dataset = dataset['test']
# Construct a `def make_map_fn(split)` for the corresponding datasets.
# ...
train_dataset = train_dataset.map(function=make_map_fn('train'), with_indices=True)
test_dataset = test_dataset.map(function=make_map_fn('test'), with_indices=True)
local_dir = args.local_dir
hdfs_dir = args.hdfs_dir
train_dataset.to_parquet(os.path.join(local_dir, 'train.parquet'))
test_dataset.to_parquet(os.path.join(local_dir, 'test.parquet'))
makedirs(hdfs_dir)
copy(src=local_dir, dst=hdfs_dir)
2. The users are required to implement the ``make_map_fn()`` function
(as well as the ``extract_solution``) on their own to support
different datasets or tasks.
We already implemented the data preprocess of GSM8k, MATH, Hellaswag and Full_hh_rlhf
datasets. And we take the GSM8k dataset as an example:
**GSM8K**
In the ``make_map_fn``, each data field should consist of the following
5 fields:
1. ``data_source``: The name of the dataset. To index the corresponding
reward function in the ``RewardModule``
2. ``prompt``: This field should be constructed in the format of
huggingface chat_template. The tokenizer in ``RLHFDataset`` will
apply chat template and tokenize the prompt.
3. ``ability``: Define the task category.
4. ``reward_model``: Currently, we only utilize the ``ground_truth``
field during evaluation. The ``ground_truth`` is computed by the
``extract_solution`` function. **NOTED** that the implementation of
the corresponding reward function should align with this extracted
``ground_truth``.
5. ``extra_info``: Record some information of the current prompt. Not
use for now.
.. code:: python
def extract_solution(solution_str):
solution = re.search("#### (\\-?[0-9\\.\\,]+)", solution_str) # extract the solution after ####
assert solution is not None
final_solution = solution.group(0)
final_solution = final_solution.split('#### ')[1].replace(',', '')
return final_solution
instruction_following = "Let's think step by step and output the final answer after \"####\"."
# add a row to each data item that represents a unique id
def make_map_fn(split):
def process_fn(example, idx):
question = example.pop('question')
question = question + ' ' + instruction_following
answer = example.pop('answer')
solution = extract_solution(answer)
data = {
"data_source": data_source,
"prompt": [{
"role": "user",
"content": question
}],
"ability": "math",
"reward_model": {
"style": "rule",
"ground_truth": solution
},
"extra_info": {
'split': split,
'index': idx
}
}
return data
return process_fn | {
"source": "volcengine/verl",
"title": "docs/preparation/prepare_data.rst",
"url": "https://github.com/volcengine/verl/blob/main/docs/preparation/prepare_data.rst",
"date": "2024-10-31T06:11:15",
"stars": 3060,
"description": "veRL: Volcano Engine Reinforcement Learning for LLM",
"file_size": 4325
} |
Implement Reward Function for Dataset
======================================
For each dataset, we need to implement a reward function or utilize a reward model to compute the rewards for the generated responses.
We already pre-implemented some reward functions in `reward_score directory <https://github.com/volcengine/verl/blob/main/verl/utils/reward_score>`_.
Currently, we support reward functions for GSM8k and MATH datasets. For RLHF datasets (e.g.,
full_hh_rlhf) and Code Generation (e.g., APPS), we utilize reward model
and SandBox (will opensource soon) for evaluation respectively.
RewardManager
-------------
In the entrypoint of the PPO Post-Training script `main_ppo.py <https://github.com/volcengine/verl/blob/main/verl/trainer/main_ppo.py#L33>`_,
we implement a ``RewardManager`` that utilze pre-implemented reward functions to compute the scores for each response.
In the ``RewardManager``, we implemented a ``__call__`` function to
compute the score for each response.
All the reward functions are executed by ``compute_score_fn``.
The input is a ``DataProto``, which includes:
- ``input_ids``, ``attention_mask``: ``input_ids`` and ``attention_mask`` after applying
chat_template, including prompt and response
- ``responses``: response tokens
- ``ground_truth``: The ground truth string of the current prompt.
Stored in ``non_tensor_batch`` in the ``DataProto``, which should be
preprocessed in the parquet files.
- ``data_source``: The dataset name of the current prompt. Stored in
``non_tensor_batch`` in the ``DataProto``, which should be
preprocessed in the parquet files.
After detokenize the responses, the responses string and the ground
truth string will be input to the ``compute_score_fn`` to compute the
score for each response.
Reward Functions
----------------
We already pre-implemented some reward functions in `reward_score directory <https://github.com/volcengine/verl/blob/main/verl/utils/reward_score>`_.
- In the `GSM8k example <https://github.com/volcengine/verl/blob/main/verl/utils/reward_score/gsm8k.py>`_, we
force the response to output the final answer after four ####, then
use string matching to compare with the ground truth. If completely
correct, score 1 point; if the format is correct, score 0.1 points; if
the format is incorrect, score 0 points.
- In the `MATH example <https://github.com/volcengine/verl/blob/main/verl/utils/reward_score/math.py>`_, we follow
the implementation in `lm-evaluation-harness repository <https://github.com/EleutherAI/lm-evaluation-harness/blob/main/lm_eval/tasks/hendrycks_math/utils.py>`_. | {
"source": "volcengine/verl",
"title": "docs/preparation/reward_function.rst",
"url": "https://github.com/volcengine/verl/blob/main/docs/preparation/reward_function.rst",
"date": "2024-10-31T06:11:15",
"stars": 3060,
"description": "veRL: Volcano Engine Reinforcement Learning for LLM",
"file_size": 2605
} |
Installation
============
Requirements
------------
- **Python**: Version >= 3.9
- **CUDA**: Version >= 12.1
verl supports various backends. Currently, the following configurations are available:
- **FSDP** and **Megatron-LM** (optional) for training.
- **vLLM** adn **TGI** for rollout generation, **SGLang** support coming soon.
Training backends
------------------
We recommend using **FSDP** backend to investigate, research and prototype different models, datasets and RL algorithms. The guide for using FSDP backend can be found in :doc:`FSDP Workers<../workers/fsdp_workers>`.
For users who pursue better scalability, we recommend using **Megatron-LM** backend. Currently, we support Megatron-LM v0.4 [1]_. The guide for using Megatron-LM backend can be found in :doc:`Megatron-LM Workers<../workers/megatron_workers>`.
Install from docker image
-------------------------
We provide pre-built Docker images for quick setup.
Image and tag: ``verlai/verl:vemlp-th2.4.0-cu124-vllm0.6.3-ray2.10-te1.7-v0.0.3``. See files under ``docker/`` for NGC-based image or if you want to build your own.
1. Launch the desired Docker image:
.. code:: bash
docker run --runtime=nvidia -it --rm --shm-size="10g" --cap-add=SYS_ADMIN -v <image:tag>
2. Inside the container, install verl:
.. code:: bash
# install the nightly version (recommended)
git clone https://github.com/volcengine/verl && cd verl && pip3 install -e .
# or install from pypi via `pip3 install verl`
3. Setup Megatron (optional)
If you want to enable training with Megatron, Megatron code must be added to PYTHONPATH:
.. code:: bash
cd ..
git clone -b core_v0.4.0 https://github.com/NVIDIA/Megatron-LM.git
cp verl/patches/megatron_v4.patch Megatron-LM/
cd Megatron-LM && git apply megatron_v4.patch
pip3 install -e .
export PYTHONPATH=$PYTHONPATH:$(pwd)
You can also get the Megatron code after verl's patch via
.. code:: bash
git clone -b core_v0.4.0_verl https://github.com/eric-haibin-lin/Megatron-LM
export PYTHONPATH=$PYTHONPATH:$(pwd)/Megatron-LM
Install from custom environment
---------------------------------
To manage environment, we recommend using conda:
.. code:: bash
conda create -n verl python==3.9
conda activate verl
For installing the latest version of verl, the best way is to clone and
install it from source. Then you can modify our code to customize your
own post-training jobs.
.. code:: bash
# install verl together with some lightweight dependencies in setup.py
git clone https://github.com/volcengine/verl.git
cd verl
pip3 install -e .
Megatron is optional. It's dependencies can be setup as below:
.. code:: bash
# apex
pip3 install -v --disable-pip-version-check --no-cache-dir --no-build-isolation --config-settings "--build-option=--cpp_ext" --config-settings "--build-option=--cuda_ext" \
git+https://github.com/NVIDIA/apex
# transformer engine
pip3 install git+https://github.com/NVIDIA/[email protected]
# megatron core v0.4.0: clone and apply the patch
# You can also get the patched Megatron code patch via
# git clone -b core_v0.4.0_verl https://github.com/eric-haibin-lin/Megatron-LM
cd ..
git clone -b core_v0.4.0 https://github.com/NVIDIA/Megatron-LM.git
cd Megatron-LM
cp ../verl/patches/megatron_v4.patch .
git apply megatron_v4.patch
pip3 install -e .
export PYTHONPATH=$PYTHONPATH:$(pwd)
.. [1] Megatron v0.4 is supported with verl's patches to fix issues such as virtual pipeline hang. It will be soon updated with latest the version of upstream Megatron-LM without patches. | {
"source": "volcengine/verl",
"title": "docs/start/install.rst",
"url": "https://github.com/volcengine/verl/blob/main/docs/start/install.rst",
"date": "2024-10-31T06:11:15",
"stars": 3060,
"description": "veRL: Volcano Engine Reinforcement Learning for LLM",
"file_size": 3644
} |
.. _quickstart:
=========================================================
Quickstart: PPO training on GSM8K dataset
=========================================================
Post-train a LLM using GSM8K dataset.
Introduction
------------
.. _hf_dataset_gsm8k: https://huggingface.co/datasets/gsm8k
In this example, we train an LLM to tackle the `GSM8k <hf_dataset_gsm8k>`_ task with function-based rewards. [1]_
Prerequisite:
- the latest version of ``verl`` and its dependencies installed following the installation guide. Using the docker image is recommended.
- an GPU with at least 24 GB HBM
Dataset Introduction
--------------------
GSM8k is a math problem dataset. The prompt is an elementary school
problem. The LLM model is asked to solve the math problem. Below is an example:
Prompt
Katy makes coffee using teaspoons of sugar and cups of water in the
ratio of 7:13. If she used a total of 120 teaspoons of sugar and cups
of water, calculate the number of teaspoonfuls of sugar she used.
Solution
The total ratio representing the ingredients she used to make the
coffee is 7+13 = <<7+13=20>>20 Since the fraction representing the
number of teaspoons she used is 7/20, she used 7/20\ *120 =
<<7/20*\ 120=42>>42 #### 42
Step 1: Prepare the dataset
----------------------------
We preprocess the dataset in parquet format so that (1) it contains necessary fields for computing RL rewards and (2) is faster to read.
.. code-block:: bash
python3 examples/data_preprocess/gsm8k.py --local_dir ~/data/gsm8k
Step 2: Download a model for post-training
-------------------------------------------
In this example, we start with the ``Qwen2.5-0.5B-Instruct`` model.
If you want to perform SFT before RL, refer to the :doc:`Complete GSM8K Example<../examples/gsm8k_example>`, the `sft directory <https://github.com/volcengine/verl/blob/main/examples/sft/gsm8k>`_ and `SFT Trainer <https://github.com/volcengine/verl/blob/main/verl/trainer/fsdp_sft_trainer.py>`_ for further details.
.. code-block:: bash
python3 -c "import transformers; transformers.pipeline('text-generation', model='Qwen/Qwen2.5-0.5B-Instruct')"
Step 3: Perform PPO training with the instruct model
----------------------------------------------------------------------
**Reward Model/Function**
We use a pre-defined rule-based reward model. We force the model to produce a final
answer following 4 “#” as shown in the solution. We extract the final
answer from both the solution and model's output using regular
expression matching. We assign a reward of 1 to correct
answer, 0.1 to incorrect answer and 0 to no answer.
For mode details, please refer to `verl/utils/reward_score/gsm8k.py <https://github.com/volcengine/verl/blob/v0.1/verl/utils/reward_score/gsm8k.py>`_.
**Training Script**
Now let's run PPO training with the dataset and model above. [2]_
Set the ``data.train_files`` ,\ ``data.val_files``, ``actor_rollout_ref.model.path`` and ``critic.model.path`` based on your dataset and model names or paths.
.. code-block:: bash
PYTHONUNBUFFERED=1 python3 -m verl.trainer.main_ppo \
data.train_files=$HOME/data/gsm8k/train.parquet \
data.val_files=$HOME/data/gsm8k/test.parquet \
data.train_batch_size=256 \
data.val_batch_size=1312 \
data.max_prompt_length=512 \
data.max_response_length=256 \
actor_rollout_ref.model.path=Qwen/Qwen2.5-0.5B-Instruct \
actor_rollout_ref.actor.optim.lr=1e-6 \
actor_rollout_ref.actor.ppo_mini_batch_size=64 \
actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=4 \
actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=8 \
actor_rollout_ref.rollout.tensor_model_parallel_size=1 \
actor_rollout_ref.rollout.gpu_memory_utilization=0.4 \
actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=4 \
critic.optim.lr=1e-5 \
critic.model.path=Qwen/Qwen2.5-0.5B-Instruct \
critic.ppo_micro_batch_size_per_gpu=4 \
algorithm.kl_ctrl.kl_coef=0.001 \
trainer.logger=['console'] \
+trainer.val_before_train=False \
trainer.default_hdfs_dir=null \
trainer.n_gpus_per_node=1 \
trainer.nnodes=1 \
trainer.save_freq=10 \
trainer.test_freq=10 \
trainer.total_epochs=15 2>&1 | tee verl_demo.log
You are expected to see the following logs, indicating training in progress. The key metric ``val/test_score/openai/gsm8k`` is computed every ``trainer.test_freq`` steps:
.. code-block:: bash
step:0 - timing/gen:21.470 - timing/ref:4.360 - timing/values:5.800 - critic/kl:0.000 - critic/kl_coeff:0.001 - timing/adv:0.109 - timing/update_critic:15.664 - critic/vf_loss:14.947 - critic/vf_clipfrac:0.000 - critic/vpred_mean:-2.056 - critic/grad_norm:1023.278 - critic/lr(1e-4):0.100 - timing/update_actor:20.314 - actor/entropy_loss:0.433 - actor/pg_loss:-0.005 - actor/pg_clipfrac:0.000 - actor/ppo_kl:0.000 - actor/grad_norm:1.992 - actor/lr(1e-4):0.010 - critic/score/mean:0.004 - critic/score/max:1.000 - critic/score/min:0.000 - critic/rewards/mean:0.004 - critic/rewards/max:1.000 - critic/rewards/min:0.000 - critic/advantages/mean:-0.000 - critic/advantages/max:2.360 - critic/advantages/min:-2.280 - critic/returns/mean:0.003 - critic/returns/max:0.000 - critic/returns/min:0.000 - critic/values/mean:-2.045 - critic/values/max:9.500 - critic/values/min:-14.000 - response_length/mean:239.133 - response_length/max:256.000 - response_length/min:77.000 - prompt_length/mean:104.883 - prompt_length/max:175.000 - prompt_length/min:68.000
step:1 - timing/gen:23.020 - timing/ref:4.322 - timing/values:5.953 - critic/kl:0.000 - critic/kl_coeff:0.001 - timing/adv:0.118 - timing/update_critic:15.646 - critic/vf_loss:18.472 - critic/vf_clipfrac:0.384 - critic/vpred_mean:1.038 - critic/grad_norm:942.924 - critic/lr(1e-4):0.100 - timing/update_actor:20.526 - actor/entropy_loss:0.440 - actor/pg_loss:0.000 - actor/pg_clipfrac:0.002 - actor/ppo_kl:0.000 - actor/grad_norm:2.060 - actor/lr(1e-4):0.010 - critic/score/mean:0.000 - critic/score/max:0.000 - critic/score/min:0.000 - critic/rewards/mean:0.000 - critic/rewards/max:0.000 - critic/rewards/min:0.000 - critic/advantages/mean:0.000 - critic/advantages/max:2.702 - critic/advantages/min:-2.616 - critic/returns/mean:0.000 - critic/returns/max:0.000 - critic/returns/min:0.000 - critic/values/mean:-2.280 - critic/values/max:11.000 - critic/values/min:-16.000 - response_length/mean:232.242 - response_length/max:256.000 - response_length/min:91.000 - prompt_length/mean:102.398 - prompt_length/max:185.000 - prompt_length/min:70.000
Checkout :ref:`algo-baseline-page` for full training and validation logs for reference.
The checkpoint is saved at the following dir by default: ``checkpoints/${trainer.project_name}/${trainer.experiment_name}``
To enable ``wandb`` for experiment tracking, set the following configs:
.. code-block:: bash
trainer.logger=['console','wandb'] \
trainer.project_name=$YOUR_PROJECT_NAME \
trainer.experiment_name=$YOUR_RUN_NAME \
If you encounter out of memory issues with HBM less than 32GB, enable the following configs would help:
.. code-block:: bash
actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=1 \
critic.ppo_micro_batch_size_per_gpu=1 \
For the full set of configs, please refer to :ref:`config-explain-page` for detailed explanation and performance tuning.
.. [1] The original paper (https://arxiv.org/pdf/2110.14168) mainly focuses on training a verifier (a reward model) to solve math problems via Best-of-N sampling. In this example, we train an RL agent using a rule-based reward model.
.. [2] More training script examples for FSDP and Megatron-LM backend are stored in `examples/ppo_trainer <https://github.com/volcengine/verl/tree/main/examples/ppo_trainer>`_ directory. | {
"source": "volcengine/verl",
"title": "docs/start/quickstart.rst",
"url": "https://github.com/volcengine/verl/blob/main/docs/start/quickstart.rst",
"date": "2024-10-31T06:11:15",
"stars": 3060,
"description": "veRL: Volcano Engine Reinforcement Learning for LLM",
"file_size": 7781
} |
PyTorch FSDP Backend
======================
We support PyTorch FSDP Backend by implementing various workers for
actor, critic, reference, rollout and reward models. We also implement
the ``FSDPVLLMShardingManager`` that reshard weight between FSDP and
vLLM in `fsdp_vllm.py <https://github.com/volcengine/verl/blob/main/verl/workers/sharding_manager/fsdp_vllm.py>`_.
**Pros**
- Readily support various models.
- Users only need to implement the corresponding
``dtensor_weight_loader`` for weight synchronization between FSDP
and vLLM. While for ``hf_weight_loader``, users can directly apply
any models supported both in HF and vLLM without any code change.
- Easy to organize the forward and backward computation for each model.
**Cons**
- Poor scalability when it comes to large-scale models (e.g. Llama 70B
and 405B)
- The resharding overhead between actor and rollout could be larger than
Megatron-LM backend.
Due to the simplicity, we recommend using FSDP backend for algorithm
research and prototyping.
FSDP Workers
--------------
ActorRolloutRefWorker
^^^^^^^^^^^^^^^^^^^^^
Actor/Rollout HybridEngine
''''''''''''''''''''''''''
1. HybridEngine, Actor and Rollout initialization API.
.. code:: python
@register(dispatch_mode=Dispatch.ONE_TO_ALL)
def init_model(self):
``ONE_TO_ALL``: when calling the ``init_model`` function from the driver
process, each worker (on a GPU) will execute the following model
initialization process.
The initialization details of HybridEngine, Actor and Rollout are
highlighted below:
1. ``DataParallelPPOActor`` implements the simple PPO computation logics
when the model is built with FSDP, including compute log prob, model
update.
2. ``vLLMRollout`` support generation with vLLM. We modify the vLLM
Engine and make it executed under SPMD to fit into our
``WorkerGroup`` design.
3. ``FSDPVLLMShardingManager`` a context manager to perform actual
resharding between actor and rollout.
See `source code <https://github.com/volcengine/verl/blob/main/verl/workers/fsdp_workers.py>`_. for more information.
1. Generate sequence and recompute log prob
.. code:: python
@register(dispatch_mode=Dispatch.DP_COMPUTE_PROTO)
def generate_sequences(self, prompts: DataProto):
- ``Dispatch.DP_COMPUTE_PROTO``: The data will be dispatched and
collected along the DP dimension
- In this function, the rollout model will perform auto-regressive
generation and the actor model will recompute the old log prob for the
generated response.
3. Update actor model
.. code:: python
@register(dispatch_mode=Dispatch.DP_COMPUTE_PROTO)
def update_actor(self, data: DataProto):
- Update the actor model weight using PPO & entropy loss.
ReferenceModel
''''''''''''''
1. Reference model initialization
The reference model is initialized using the same function as the actor
model without initializing the HybridEngine and Optimizer. Then the
actor model is also wrapped by the ``DataParallelPPOActor``.
2. Compute reference log prob
.. code:: python
@register(dispatch_mode=Dispatch.DP_COMPUTE_PROTO)
def compute_ref_log_prob(self, data: DataProto):
- In this function, the reference model will call the compute log prob
function in ``DataParallelPPOActor`` to compute the reference log
prob.
CriticWorker and RewardWorker
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
1. Model initialization
Quite similar to reference model. The CriticWorker will perform
additional initialization for the Optimizer.
2. Compute Values for CriticWorker
.. code:: python
@register(dispatch_mode=Dispatch.DP_COMPUTE_PROTO)
def compute_values(self, data: DataProto):
3. Update Critic
.. code:: python
@register(dispatch_mode=Dispatch.DP_COMPUTE_PROTO)
def update_critic(self, data: DataProto):
4. Compute Reward
.. code:: python
@register(dispatch_mode=Dispatch.DP_COMPUTE_PROTO)
def compute_rm_score(self, data: DataProto):
HybridShard
------------
We didn't support FSDP `HybridShard`. To support this, we may need to
construct a 2D device mesh and test the corresponding
``dtensor_weight_loader`` and ``hf_weight_loader`` for each model. | {
"source": "volcengine/verl",
"title": "docs/workers/fsdp_workers.rst",
"url": "https://github.com/volcengine/verl/blob/main/docs/workers/fsdp_workers.rst",
"date": "2024-10-31T06:11:15",
"stars": 3060,
"description": "veRL: Volcano Engine Reinforcement Learning for LLM",
"file_size": 4149
} |
Megatron-LM Backend
=====================
We support Megatron Backend by implementing various workers for actor,
critic, reference, rollout and reward models. We also implement the
``3DHybridEngine`` using Megatron-LM and vLLM in `megatron_vllm.py <https://github.com/volcengine/verl/blob/main/verl/workers/sharding_manager/megatron_vllm.py>`_.
**Pros**
- Support 3D parallelism and sequence parallelism for best scalablility
and throughput.
- 3D HybridEngine can significantly reduce peak memory usage and reduce
weight synchronize overhead between actor and rollout.
**Cons**
- Users should implement their own models for Megatron-LM
- Users should implement the corresponding weight_loader to
- synchronize the model weight between actor (in Megatron) and rollout
(in vLLM).
- load weights from checkpoints to corresponding model in Megatron-LM
Megatron Workers
----------------
MegatronWorker
^^^^^^^^^^^^^^
``MegatronWorker`` is the base class of different megatron worker
classes. In this class, ``get_megatron_global_info`` and
``get_megatron_rank_info`` function to retrive the 3D parallel world
size and rank of each ``Worker`` running on specific GPU. These information
will be used in transfer protocol for Megatron Backend.
The following ``Worker`` class for different models will be utilized to
construct the ``WorkerGroup`` .
We implement various of APIs for each ``Worker`` class decorated by the
``@register(dispatch_mode=)`` . These APIs can be called by the ray
driver process. The data can be correctly collect and dispatch following
the ``dispatch_mode`` on each function. The supported dispatch_model
(i.e., transfer protocols) can be found in `decorator.py <https://github.com/volcengine/verl/blob/main/verl/single_controller/base/decorator.py>`_.
ActorRolloutRefWorker
^^^^^^^^^^^^^^^^^^^^^
This class is implemented for Actor/Rollout HybridEngine or for the
reference model to initialize their model and perform computation.
Actor/Rollout HybridEngine
''''''''''''''''''''''''''
1. HybridEngine, Actor and Rollout initialization API.
.. code:: python
@register(dispatch_mode=Dispatch.ONE_TO_ALL)
def init_model(self):
``ONE_TO_ALL``: when calling the ``init_model`` function from the driver
process, each worker (on a GPU) will execute the following model
initialization process.
The initialization details of HybridEngine, Actor and Rollout are
highlighted below:
1. ``AllGatherPPModel`` holds memory buffer for both Actor and Rollout
and support weight resharding between actor and rollout.
2. ``MegatronPPOActor`` implements the simple PPO computation logics
when the model is built with Megatron, including compute log prob,
model update.
3. ``vLLMRollout`` support generation with vLLM. We modify the vLLM
Engine and make it executed under SPMD to fit into our
``WorkerGroup`` design.
4. ``MegatronVLLMShardingManager`` a context manager to perform actual
resharding between actor and rollout.
See `source code <https://github.com/volcengine/verl/blob/main/verl/workers/megatron_workers.py#L63>`_ for more information.
.. code:: python
# Initialize the 3D HybridEngine
hybrid_engine = AllGatherPPModel(model_provider=megatron_actor_model_provider)
# Fetch the model at current rank
actor_module = hybrid_engine.this_rank_models
...
# build actor model
self.actor = MegatronPPOActor(config=self.config.actor,
model_config=self.actor_model_config,
megatron_config=megatron_config,
actor_module=self.actor_module,
actor_optimizer=self.actor_optimizer,
actor_optimizer_config=self.actor_optim_config)
# build rollout
# rollout initialization
rollout = vLLMRollout(actor_module=params,
config=self.config.rollout,
tokenizer=self.tokenizer,
model_hf_config=self.actor_model_config,
train_tp=mpu.get_tensor_model_parallel_world_size())
# perform weight resharding between actor and rollout
sharding_manager = MegatronVLLMShardingManager(module=self.hybrid_engine,
inference_engine=rollout.inference_engine,
model_config=self.actor_model_config,
layer_name_mapping=layer_name_mapping)
...
2. Generate sequence and recompute log prob
.. code:: python
@register(dispatch_mode=Dispatch.MEGATRON_PP_AS_DP_PROTO)
def generate_sequences(self, prompts: DataProto):
- ``Dispatch.MEGATRON_PP_AS_DP_PROTO``: The PP dimension of the actor
model will be regarded as DP dimension. Then the driver process will
dispatch and collect the data according to this reorganization. This
is because, in HybridEngine, the actor weight, which usually applied
larger 3D parallel sizes, will be gathered along the PP dimension and
TP dimension. Therefore, the corresponding data should be dispatched
and collected through the 3D parallel group of the rollout model,
rather than the actor model. However, the world_size and rank
information can only be retrived from ``get_megatron_global_info`` and
``get_megatron_rank_info``, which records the 3D information for the
actor model. Moreover, the data resharding inside TP dimension will be
processed within the HybridEngine.
- In this function, the rollout model will perform auto-regressive
generation and the actor model will recompute the old log prob for the
generated response.
3. Update actor model
.. code:: python
@register(dispatch_mode=Dispatch.MEGATRON_COMPUTE_PROTO)
def update_actor(self, data: DataProto):
- ``Dispatch.MEGATRON_COMPUTE_PROTO``: User passes the data partitioned
by DP dimension. The data is dispatched to all tp/pp ranks within the
same dp group, and ultimately only collects output data from tp=0 and
the last pp.
- Update the actor model weight using PPO & entropy loss.
ReferenceModel
''''''''''''''
1. Reference model initialization
The reference model is initialized using the same function as the actor
model without initializing the HybridEngine and Optimizer. Then the
actor model is also wrapped by the ``MegatronPPOActor``.
2. Compute reference log prob
.. code:: python
@register(dispatch_mode=Dispatch.MEGATRON_COMPUTE_PROTO)
def compute_ref_log_prob(self, data: DataProto):
- In this function, the reference model will call the compute log prob
function in ``MegatronPPOActor`` to compute the reference log prob.
CriticWorker and RewardWorker
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
1. Model initialization
Quite similar to reference model. The CriticWorker will perform
additional initialization for the Optimizer.
2. Compute Values for CriticWorker
.. code:: python
@register(dispatch_mode=Dispatch.MEGATRON_COMPUTE_PROTO)
def compute_values(self, data: DataProto):
3. Update Critic
.. code:: python
@register(dispatch_mode=Dispatch.MEGATRON_COMPUTE_PROTO)
def update_critic(self, data: DataProto):
4. Compute Reward
.. code:: python
@register(dispatch_mode=Dispatch.MEGATRON_COMPUTE_PROTO)
def compute_rm_score(self, data: DataProto):
Context Parallel
----------------
This require the developer/contributor to implement the context parallel
both in Megatron-LM and models. | {
"source": "volcengine/verl",
"title": "docs/workers/megatron_workers.rst",
"url": "https://github.com/volcengine/verl/blob/main/docs/workers/megatron_workers.rst",
"date": "2024-10-31T06:11:15",
"stars": 3060,
"description": "veRL: Volcano Engine Reinforcement Learning for LLM",
"file_size": 7464
} |
PPO Ray Trainer
===============
We implement the RayPPOTrainer, which is a trainer runs on the driver
process on a single CPU/GPU node (default is CPU).
The PPORayTrainer include 3 core functions for data preparation,
WorkerGroup initialization and PPO training loop.
Data Preparation
----------------
The ``PPORayTrainer``, as a single process, is responsible for loading a
complete batch of samples (prompts) from the dataset and then dispatch
to different worker_groups running on different GPUs.
To generalize the data loading, we implement the ``RLHFDataset`` class
to load the preprocessed parquet files, apply chat templates to the
prompts, add padding, truncate prompts that exceed max prompt length and
then tokenize.
.. code:: python
self.train_dataset = RLHFDataset(parquet_files=self.config.data.train_files,
tokenizer=self.tokenizer,
prompt_key=self.config.data.prompt_key,
max_prompt_length=self.config.data.max_prompt_length,
filter_prompts=True,
return_raw_chat=self.config.data.get('return_raw_chat', False),
truncation='error')
Then, the dataloader will iterate the dataset under PPO mini batch size.
WorkerGroup Initialization
--------------------------
We first introduce a basic implementation of initializing the
``WorkerGroup`` of the actor model on a given set of GPUs.
.. code:: python
# max_colocate_count means the number of WorkerGroups (i.e. processes) in each RayResourcePool
# For FSDP backend, we recommend using max_colocate_count=1 that merge all WorkerGroups into one.
# For Megatron backend, we recommend using max_colocate_count>1 that can utilize different WorkerGroup for differnt models
resource_pool = RayResourcePool(process_on_nodes=[config.trainer.n_gpus_per_node] * config.trainer.nnodes,
use_gpu=True,
max_colocate_count=1)
# define actor rollout cls to be init on remote
actor_rollout_cls = RayClassWithInitArgs(cls=ActorRolloutWorker)
# define actor_rollout worker group
actor_rollout_worker_group = MegatronRayWorkerGroup(resource_pool=resource_pool,
ray_cls_with_init=actor_rollout_cls,
default_megatron_kwargs=config.actor_rollout.megatron)
Different WorkerGroups, like ``actor_rollout_worker_group`` ,
``critic_worker_group`` and ``ref_worker_group`` lies on a separate
process in the above implementation.
The driver process can then call the distributed compute function within
the ``actor_rollout_worker_group`` and other roles to construct the RL
training loop.
For models colocated in the same set of GPUs, we further provide a
fine-grain optimization, which merge the ``worker_group`` of different roles
in the same process. This optimization can save the redundant
CUDA/distributed context in different processes.
.. code:: python
# initialize WorkerGroup
# NOTE: if you want to use a different resource pool for each role, which can support different parallel size,
# you should not use `create_colocated_worker_cls`. Instead, directly pass different resource pool to different worker groups.
# See TODO(url) for more information.
all_wg = {}
for resource_pool, class_dict in self.resource_pool_to_cls.items():
worker_dict_cls = create_colocated_worker_cls(class_dict=class_dict)
wg_dict = self.ray_worker_group_cls(resource_pool=resource_pool, ray_cls_with_init=worker_dict_cls)
spawn_wg = wg_dict.spawn(prefix_set=class_dict.keys())
all_wg.update(spawn_wg)
if self.use_critic:
self.critic_wg = all_wg['critic']
self.critic_wg.init_model()
if self.use_reference_policy:
self.ref_policy_wg = all_wg['ref']
self.ref_policy_wg.init_model()
if self.use_rm:
self.rm_wg = all_wg['rm']
self.rm_wg.init_model()
# we should create rollout at the end so that vllm can have a better estimation of kv cache memory
self.actor_rollout_wg = all_wg['actor_rollout']
self.actor_rollout_wg.init_model()
.. note:: For megatron backend, if we merge the ``worker_groups`` into the same processes, all the roles will utilize the same 3D parallel size. To optimize this, we may need to maintain several 3D process groups for each role in the same distributed context. If you want to use different 3D parallel size for different roles, please follow the similar architecture of the first code block to initialize each role's ``worker_group``
PPO Training Loop
-----------------
We implement the PPO training loop by calling the functions in
worker_group of each role. The input and output data of each function is
a ``DataProto`` object implemented in `protocol.py <https://github.com/volcengine/verl/blob/main/verl/protocol.py>`_. In the training
loop, trainer will dispatch/collect the data to/from different GPUs
following the transfer protocols wrapped in the workers' functions. The
computation of PPO micro batches is processed in ``update_actor`` and
``update_critic`` functions.
To extend to other RLHF algorithms, such as DPO, GRPO, please refer to
:doc:`../advance/dpo_extension`.
.. code:: python
def fit(self):
"""
The training loop of PPO.
The driver process only need to call the compute functions of the worker group through RPC to construct the PPO dataflow.
The light-weight advantage computation is done on the driver process.
"""
from verl.utils.tracking import Tracking
from omegaconf import OmegaConf
logger = Tracking(project_name=self.config.trainer.project_name,
experiment_name=self.config.trainer.experiment_name,
default_backend=self.config.trainer.logger,
config=OmegaConf.to_container(self.config, resolve=True))
global_steps = 0
# perform validation before training
# currently, we only support validation using the reward_function.
if self.val_reward_fn is not None:
val_metrics = self._validate()
pprint(f'Initial validation metrics: {val_metrics}')
for epoch in range(self.config.trainer.total_epochs):
for batch_dict in self.train_dataloader:
metrics = {}
batch: DataProto = DataProto.from_single_dict(batch_dict)
# batch = batch.to('cuda')
# pop those keys for generation
gen_batch = batch.pop(batch_keys=['input_ids', 'attention_mask', 'position_ids'])
# generate a batch
with Timer(name='gen', logger=None) as timer:
gen_batch_output = self.actor_rollout_wg.generate_sequences(gen_batch)
metrics['timing/gen'] = timer.last
batch = batch.union(gen_batch_output)
if self.use_reference_policy:
# compute reference log_prob
with Timer(name='ref', logger=None) as timer:
ref_log_prob = self.ref_policy_wg.compute_ref_log_prob(batch)
batch = batch.union(ref_log_prob)
metrics['timing/ref'] = timer.last
# compute values
with Timer(name='values', logger=None) as timer:
values = self.critic_wg.compute_values(batch)
batch = batch.union(values)
metrics['timing/values'] = timer.last
with Timer(name='adv', logger=None) as timer:
# compute scores. Support both model and function-based.
# We first compute the scores using reward model. Then, we call reward_fn to combine
# the results from reward model and rule-based results.
if self.use_rm:
# we first compute reward model score
reward_tensor = self.rm_wg.compute_rm_score(batch)
batch = batch.union(reward_tensor)
# we combine with rule-based rm
reward_tensor = self.reward_fn(batch)
batch.batch['token_level_scores'] = reward_tensor
# compute rewards. apply_kl_penalty if available
batch, kl_metrics = apply_kl_penalty(batch,
kl_ctrl=self.kl_ctrl,
kl_penalty=self.config.algorithm.kl_penalty)
metrics.update(kl_metrics)
# compute advantages, executed on the driver process
batch = compute_advantage(batch,
self.config.algorithm.gamma,
self.config.algorithm.lam,
adv_estimator=self.config.algorithm.adv_estimator)
metrics['timing/adv'] = timer.last
# update critic
if self.use_critic:
with Timer(name='update_critic', logger=None) as timer:
critic_output = self.critic_wg.update_critic(batch)
metrics['timing/update_critic'] = timer.last
critic_output_metrics = reduce_metrics(critic_output.meta_info['metrics'])
metrics.update(critic_output_metrics)
# implement critic warmup
if self.config.trainer.critic_warmup <= global_steps:
# update actor
with Timer(name='update_actor', logger=None) as timer:
actor_output = self.actor_rollout_wg.update_actor(batch)
metrics['timing/update_actor'] = timer.last
actor_output_metrics = reduce_metrics(actor_output.meta_info['metrics'])
metrics.update(actor_output_metrics)
# validate
if self.val_reward_fn is not None and (global_steps + 1) % self.config.trainer.test_freq == 0:
with Timer(name='testing', logger=None) as timer:
val_metrics: dict = self._validate()
val_metrics = {f'val/{key}': val for key, val in val_metrics.items()}
metrics['timing/testing'] = timer.last
metrics.update(val_metrics)
# collect metrics
data_metrics = compute_data_metrics(batch=batch)
metrics.update(data_metrics)
# TODO: make a canonical logger that supports various backend
logger.log(data=metrics, step=global_steps)
if self.config.trainer.save_freq > 0 and (global_steps + 1) % self.config.trainer.save_freq == 0:
actor_local_path = os.path.join(self.config.trainer.default_local_dir, 'actor',
f'global_step_{global_steps}')
actor_remote_path = os.path.join(self.config.trainer.default_hdfs_dir, 'actor')
self.actor_rollout_wg.save_checkpoint(actor_local_path, actor_remote_path)
if self.use_critic:
critic_local_path = os.path.join(self.config.trainer.default_local_dir, 'critic',
f'global_step_{global_steps}')
critic_remote_path = os.path.join(self.config.trainer.default_hdfs_dir, 'critic')
self.critic_wg.save_checkpoint(critic_local_path, critic_remote_path)
global_steps += 1
# perform validation after training
if self.val_reward_fn is not None:
val_metrics = self._validate()
pprint(f'Final validation metrics: {val_metrics}') | {
"source": "volcengine/verl",
"title": "docs/workers/ray_trainer.rst",
"url": "https://github.com/volcengine/verl/blob/main/docs/workers/ray_trainer.rst",
"date": "2024-10-31T06:11:15",
"stars": 3060,
"description": "veRL: Volcano Engine Reinforcement Learning for LLM",
"file_size": 12035
} |
# Split Placement Example
Here we introduce how to run the naive implementation of the split placement of PPO algorithm.
We will release the complete version of flexible placement in the near future.
For quickstart, you can only follow Step 2 to modify the code and then follow Step 4 to execute the split placement example.
### Step 1: Placing the models to different GPUs
Specify the placement and resource allocation. In the example, we place the actor and reference in the first half of the GPUs while map the critic and reward model (if any) to the second half of the GPUs.
```python
actor_rollout_ref_pool_id = 'actor_rollout_ref_pool'
critic_pool_id = 'critic_pool'
if config.trainer.nnodes // 2 == 0 and config.trainer.n_gpus_per_node // 2 > 0:
resource_pool_spec = {
actor_rollout_ref_pool_id: [config.trainer.n_gpus_per_node // 2] * config.trainer.nnodes,
critic_pool_id: [config.trainer.n_gpus_per_node // 2] * config.trainer.nnodes,
}
else:
resource_pool_spec = {
actor_rollout_ref_pool_id: [config.trainer.n_gpus_per_node] * (config.trainer.nnodes // 2),
critic_pool_id: [config.trainer.n_gpus_per_node] * (config.trainer.nnodes // 2),
}
print(f'resource_pool_spec: {resource_pool_spec}')
mapping = {
Role.ActorRollout: actor_rollout_ref_pool_id,
Role.Critic: critic_pool_id,
Role.RefPolicy: actor_rollout_ref_pool_id,
}
mapping[Role.RewardModel] = critic_pool_id
```
### Step 2: Make the models executed asynchronously
Based on the model placement, we need to make the models executed asynchronously.
To do so, you need to turn off the `blocking` flag (i.e., `blocking=False`) in our decorator of some model operations.
For example, we hope the actor update and critic update can be executed in parallel, then we need to make the following modification in `fsdp_workers.py`
```
@register(dispatch_mode=Dispatch.DP_COMPUTE_PROTO, blocking=False)
def update_actor(self, data: DataProto):
...
@register(dispatch_mode=Dispatch.DP_COMPUTE_PROTO, blocking=False)
def update_critic(self, data: DataProto):
...
```
We can also parallelize the computation of `ref_log_prob` and `values` and `rewards` in the split placement. For simplicity of the tutorial, we
### Step 3: Execute these operation in parallel in the single controller process
To implement the parallel execution of the actor and critic update, the only thing we need to modify in the `ray_trainer.py` is to `get` the concurrent `futures` on the single controller process.
```python
critic_output = critic_output.get()
actor_output = actor_output.get()
```
### Step 4: Run the split placement example
```
bash run_deepseek7b_llm.sh
``` | {
"source": "volcengine/verl",
"title": "examples/split_placement/README.md",
"url": "https://github.com/volcengine/verl/blob/main/examples/split_placement/README.md",
"date": "2024-10-31T06:11:15",
"stars": 3060,
"description": "veRL: Volcano Engine Reinforcement Learning for LLM",
"file_size": 2686
} |
# Models
Common modelzoo such as huggingface/transformers stuggles when using Pytorch native model parallelism. Following the design principle of vLLM, we keep a simple, parallelizable, highly-optimized with packed inputs in verl.
## Adding a New Huggingface Model
### Step 1: Copy the model file from HF to verl
- Add a new file under verl/models/hf
- Copy ONLY the model file from huggingface/transformers/models to verl/models/hf
### Step 2: Modify the model file to use packed inputs
- Remove all the code related to inference (kv cache)
- Modify the inputs to include only
- input_ids (total_nnz,)
- cu_seqlens (total_nnz + 1,)
- max_seqlen_in_batch: int
- Note that this requires using flash attention with causal mask.
### Step 2.5: Add tests
- Add a test to compare this version and the huggingface version
- Following the infrastructure and add tests to tests/models/hf
### Step 3: Add a function to apply tensor parallelism
- Please follow
- https://pytorch.org/docs/stable/distributed.tensor.parallel.html
- https://pytorch.org/tutorials/intermediate/TP_tutorial.html
- General comments
- Tensor Parallelism in native Pytorch is NOT auto-parallelism. The way it works is to specify how model parameters and input/output reshards using configs. These configs are then registered as hooks to perform input/output resharding before/after model forward.
### Step 4: Add a function to apply data parallelism
- Please use FSDP2 APIs
- See demo here https://github.com/pytorch/torchtitan/blob/main/torchtitan/parallelisms/parallelize_llama.py#L413
### Step 5: Add a function to apply pipeline parallelism
- Comes in Pytorch 2.4
- Currently only in alpha in nightly version
- Check torchtitan for more details | {
"source": "volcengine/verl",
"title": "verl/models/README.md",
"url": "https://github.com/volcengine/verl/blob/main/verl/models/README.md",
"date": "2024-10-31T06:11:15",
"stars": 3060,
"description": "veRL: Volcano Engine Reinforcement Learning for LLM",
"file_size": 1742
} |
# Detached Worker
## How to run (Only on a single node)
- Start a local ray cluster:
```bash
ray start --head --port=6379
```
- Run the server
```bash
python3 server.py
```
- On another terminal, Run the client
```bash
python3 client.py
``` | {
"source": "volcengine/verl",
"title": "tests/ray/detached_worker/README.md",
"url": "https://github.com/volcengine/verl/blob/main/tests/ray/detached_worker/README.md",
"date": "2024-10-31T06:11:15",
"stars": 3060,
"description": "veRL: Volcano Engine Reinforcement Learning for LLM",
"file_size": 241
} |
# Dataset Format
## RLHF dataset
We combine all the data sources into a single parquet files. We directly organize the prompt into the chat format so that multi-turn chats can be easily incorporated. In the prompt, we may add instruction following texts to guide the model output the answers in a particular format so that we can extract the answers.
Math problems
```json
{
"data_source": "openai/gsm8k",
"prompt": [{"role": "user", "content": "Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May? Let's think step by step and output the final answer after \"####\""}],
"ability": "math",
"reward_model": {
"style": "rule",
"ground_truth": ["72"]
},
}
``` | {
"source": "volcengine/verl",
"title": "verl/utils/dataset/README.md",
"url": "https://github.com/volcengine/verl/blob/main/verl/utils/dataset/README.md",
"date": "2024-10-31T06:11:15",
"stars": 3060,
"description": "veRL: Volcano Engine Reinforcement Learning for LLM",
"file_size": 796
} |
# Digit completion
This is an example of solving a digit completion problem. The problem is defined as below:
The prompt is a sequence of numbers with fixed difference. The agent's goal is to complete the next N numbers.
If the max number is reached, the next number should be modulo with max number.
For example,
- prompt = [1, 2, 3]
- N = 5
- max_number = 6
The response should be [4, 5, 6, 7%6, 8%6] = [4, 5, 6, 0, 1].
# Environment definition
The core definition of the task is defined in verl/envs/digit_completion/task.py
It is highly recommended to take a look at it for better understanding.
# Run experiments
The users are required to specify the config path and config name (and the relative model config path to the current working directory)
```bash
# cd examples/arithmetic_sequence/rl
# Specify the config path and config name (current working dir)
python3 -m verl.trainer.ppo.ray_megatron_train_synchronous --config-path=$(pwd)/config --config-name='ray_megatron'
# The default relative path of model config is 'config/model_config', if you want to change it, you can rewrite it in ray_megatron.yaml or using:
python3 -m verl.trainer.ppo.ray_megatron_train_synchronous --config-path=$(pwd)/config --config-name='ray_megatron' ++model.base_path=config/model_config
``` | {
"source": "volcengine/verl",
"title": "tests/e2e/arithmetic_sequence/rl/README.md",
"url": "https://github.com/volcengine/verl/blob/main/tests/e2e/arithmetic_sequence/rl/README.md",
"date": "2024-10-31T06:11:15",
"stars": 3060,
"description": "veRL: Volcano Engine Reinforcement Learning for LLM",
"file_size": 1297
} |
# Mochi 1
[Blog](https://www.genmo.ai/blog) | [Hugging Face](https://huggingface.co/genmo/mochi-1-preview) | [Playground](https://www.genmo.ai/play) | [Careers](https://jobs.ashbyhq.com/genmo)
A state of the art video generation model by [Genmo](https://genmo.ai).
https://github.com/user-attachments/assets/4d268d02-906d-4cb0-87cc-f467f1497108
## News
- ⭐ **November 26, 2024**: Added support for [LoRA fine-tuning](demos/fine_tuner/README.md)
- ⭐ **November 5, 2024**: Consumer-GPU support for Mochi [natively in ComfyUI](https://x.com/ComfyUI/status/1853838184012251317)
## Overview
Mochi 1 preview is an open state-of-the-art video generation model with high-fidelity motion and strong prompt adherence in preliminary evaluation. This model dramatically closes the gap between closed and open video generation systems. We’re releasing the model under a permissive Apache 2.0 license. Try this model for free on [our playground](https://genmo.ai/play).
## Installation
Install using [uv](https://github.com/astral-sh/uv):
```bash
git clone https://github.com/genmoai/models
cd models
pip install uv
uv venv .venv
source .venv/bin/activate
uv pip install setuptools
uv pip install -e . --no-build-isolation
```
If you want to install flash attention, you can use:
```
uv pip install -e .[flash] --no-build-isolation
```
You will also need to install [FFMPEG](https://www.ffmpeg.org/) to turn your outputs into videos.
## Download Weights
Use [download_weights.py](scripts/download_weights.py) to download the model + VAE to a local directory. Use it like this:
```bash
python3 ./scripts/download_weights.py weights/
```
Or, directly download the weights from [Hugging Face](https://huggingface.co/genmo/mochi-1-preview/tree/main) or via `magnet:?xt=urn:btih:441da1af7a16bcaa4f556964f8028d7113d21cbb&dn=weights&tr=udp://tracker.opentrackr.org:1337/announce` to a folder on your computer.
## Running
Start the gradio UI with
```bash
python3 ./demos/gradio_ui.py --model_dir weights/ --cpu_offload
```
Or generate videos directly from the CLI with
```bash
python3 ./demos/cli.py --model_dir weights/ --cpu_offload
```
If you have a fine-tuned LoRA in the safetensors format, you can add `--lora_path <path/to/my_mochi_lora.safetensors>` to either `gradio_ui.py` or `cli.py`.
## API
This repository comes with a simple, composable API, so you can programmatically call the model. You can find a full example [here](demos/api_example.py). But, roughly, it looks like this:
```python
from genmo.mochi_preview.pipelines import (
DecoderModelFactory,
DitModelFactory,
MochiSingleGPUPipeline,
T5ModelFactory,
linear_quadratic_schedule,
)
pipeline = MochiSingleGPUPipeline(
text_encoder_factory=T5ModelFactory(),
dit_factory=DitModelFactory(
model_path=f"weights/dit.safetensors", model_dtype="bf16"
),
decoder_factory=DecoderModelFactory(
model_path=f"weights/decoder.safetensors",
),
cpu_offload=True,
decode_type="tiled_spatial",
)
video = pipeline(
height=480,
width=848,
num_frames=31,
num_inference_steps=64,
sigma_schedule=linear_quadratic_schedule(64, 0.025),
cfg_schedule=[6.0] * 64,
batch_cfg=False,
prompt="your favorite prompt here ...",
negative_prompt="",
seed=12345,
)
```
## Fine-tuning with LoRA
We provide [an easy-to-use trainer](demos/fine_tuner/README.md) that allows you to build LoRA fine-tunes of Mochi on your own videos. The model can be fine-tuned on one H100 or A100 80GB GPU.
## Model Architecture
Mochi 1 represents a significant advancement in open-source video generation, featuring a 10 billion parameter diffusion model built on our novel Asymmetric Diffusion Transformer (AsymmDiT) architecture. Trained entirely from scratch, it is the largest video generative model ever openly released. And best of all, it’s a simple, hackable architecture. Additionally, we are releasing an inference harness that includes an efficient context parallel implementation.
Alongside Mochi, we are open-sourcing our video AsymmVAE. We use an asymmetric encoder-decoder structure to build an efficient high quality compression model. Our AsymmVAE causally compresses videos to a 128x smaller size, with an 8x8 spatial and a 6x temporal compression to a 12-channel latent space.
### AsymmVAE Model Specs
|Params <br> Count | Enc Base <br> Channels | Dec Base <br> Channels |Latent <br> Dim | Spatial <br> Compression | Temporal <br> Compression |
|:--:|:--:|:--:|:--:|:--:|:--:|
|362M | 64 | 128 | 12 | 8x8 | 6x |
An AsymmDiT efficiently processes user prompts alongside compressed video tokens by streamlining text processing and focusing neural network capacity on visual reasoning. AsymmDiT jointly attends to text and visual tokens with multi-modal self-attention and learns separate MLP layers for each modality, similar to Stable Diffusion 3. However, our visual stream has nearly 4 times as many parameters as the text stream via a larger hidden dimension. To unify the modalities in self-attention, we use non-square QKV and output projection layers. This asymmetric design reduces inference memory requirements.
Many modern diffusion models use multiple pretrained language models to represent user prompts. In contrast, Mochi 1 simply encodes prompts with a single T5-XXL language model.
### AsymmDiT Model Specs
|Params <br> Count | Num <br> Layers | Num <br> Heads | Visual <br> Dim | Text <br> Dim | Visual <br> Tokens | Text <br> Tokens |
|:--:|:--:|:--:|:--:|:--:|:--:|:--:|
|10B | 48 | 24 | 3072 | 1536 | 44520 | 256 |
## Hardware Requirements
The repository supports both multi-GPU operation (splitting the model across multiple graphics cards) and single-GPU operation, though it requires approximately 60GB VRAM when running on a single GPU. While ComfyUI can optimize Mochi to run on less than 20GB VRAM, this implementation prioritizes flexibility over memory efficiency. When using this repository, we recommend using at least 1 H100 GPU.
## Safety
Genmo video models are general text-to-video diffusion models that inherently reflect the biases and preconceptions found in their training data. While steps have been taken to limit NSFW content, organizations should implement additional safety protocols and careful consideration before deploying these model weights in any commercial services or products.
## Limitations
Under the research preview, Mochi 1 is a living and evolving checkpoint. There are a few known limitations. The initial release generates videos at 480p today. In some edge cases with extreme motion, minor warping and distortions can also occur. Mochi 1 is also optimized for photorealistic styles so does not perform well with animated content. We also anticipate that the community will fine-tune the model to suit various aesthetic preferences.
## Related Work
- [ComfyUI-MochiWrapper](https://github.com/kijai/ComfyUI-MochiWrapper) adds ComfyUI support for Mochi. The integration of Pytorch's SDPA attention was based on their repository.
- [ComfyUI-MochiEdit](https://github.com/logtd/ComfyUI-MochiEdit) adds ComfyUI nodes for video editing, such as object insertion and restyling.
- [mochi-xdit](https://github.com/xdit-project/mochi-xdit) is a fork of this repository and improve the parallel inference speed with [xDiT](https://github.com/xdit-project/xdit).
- [Modal script](contrib/modal/readme.md) for fine-tuning Mochi on Modal GPUs.
## BibTeX
```
@misc{genmo2024mochi,
title={Mochi 1},
author={Genmo Team},
year={2024},
publisher = {GitHub},
journal = {GitHub repository},
howpublished={\url{https://github.com/genmoai/models}}
}
``` | {
"source": "genmoai/mochi",
"title": "README.md",
"url": "https://github.com/genmoai/mochi/blob/main/README.md",
"date": "2024-09-11T02:55:33",
"stars": 2870,
"description": "The best OSS video generation models",
"file_size": 7711
} |
# Mochi Community Contributions
`mochi/contrib` contains community contributed pipelines for running and customizing Mochi.
## Index:
- `mochi/contrib/modal` - [Script](contrib/modal/readme.md) for fine-tuning Mochi on Modal GPUs. | {
"source": "genmoai/mochi",
"title": "contrib/README.md",
"url": "https://github.com/genmoai/mochi/blob/main/contrib/README.md",
"date": "2024-09-11T02:55:33",
"stars": 2870,
"description": "The best OSS video generation models",
"file_size": 233
} |
## Finetuning Mochi with LoRA on Modal
This example demonstrates how to run the Mochi finetuner on Modal GPUs.
### Setup
Install [Modal](https://modal.com/docs/guide).
```bash
pip install modal
modal setup
```
### Fetch the dataset
There is a labeled dataset for a dissolving visual effect available on Google Drive. Download it into the `mochi-tune-videos` modal volume with:
```bash
modal run main::download_videos
```
### Download the model weights
Download the model weights from Hugging Face into the `mochi-tune-weights` modal volume with:
```bash
modal run -d main::download_weights
```
Note that this download can take more than 30 minutes. The `-d` flag allows you to exit the terminal session without losing progress.
### Prepare the dataset
We now run the preprocessing script to prepare the dataset for finetuning:
```bash
modal run main::preprocess
```
This puts preprocessed training input into the `mochi-tune-videos-prepared` modal volume.
### Finetuning
Finetune the model using the prepared dataset.
You may configure the finetune run using the `lora.yaml` file, such as number of steps, learning rate, etc.
Run the finetuning with:
```bash
modal run -d main::finetune
```
This will produce a series of checkpoints, as well as video samples generated along the training process. You can view these files in the Modal `moshi-tune-finetunes` volume using the Storage tab in the dashboard.
### Inference
You can now use the MochiLora class to generate videos from a prompt. The `main` entrypoint will initialize the model to use the specified LoRA weights from your finetuning run.
```bash
modal run main
```
or with more parameters:
```bash
modal run main lora-path="/finetunes/my_mochi_lora/model_1000.lora.safetensors" prompt="A pristine snowglobe featuring a winter scene sits peacefully. The glass begins to crumble into fine powder, as the entire sphere deteriorates into sparkling dust that drifts outward."
```
See modal run main --help for all inference options. | {
"source": "genmoai/mochi",
"title": "contrib/modal/readme.md",
"url": "https://github.com/genmoai/mochi/blob/main/contrib/modal/readme.md",
"date": "2024-09-11T02:55:33",
"stars": 2870,
"description": "The best OSS video generation models",
"file_size": 2001
} |
# Mochi 1 LoRA Fine-tuner

This folder contains tools for fine-tuning the Mochi 1 model. It supports [LoRA](https://arxiv.org/abs/2106.09685) fine-tuning on a single GPU.
## Quick Start (Single GPU)
This shows you how to prepare your dataset for single GPU.
First, setup the inference code and download Mochi 1 weights following [README.md](../../README.md).
All commands below assume you are in the top-level directory of the Mochi repo.
### 1. Collect your videos and captions
Collect your videos (supported formats: MP4, MOV) into a folder, e.g. `videos/`. Then, write a detailed description of each of the videos in a txt file with the same name. For example,
```
videos/
video_1.mp4
video_1.txt -- One-paragraph description of video_1
video_2.mp4
video_2.txt -- One-paragraph description of video_2
...
```
### 2. Process videos and captions (About 2 minutes)
Update the paths in the command below to match your dataset. Videos are processed at 30 FPS, so make sure your videos are at least `num_frames / 30` seconds long.
```bash
bash demos/fine_tuner/preprocess.bash -v videos/ -o videos_prepared/ -w weights/ --num_frames 37
```
### 3. Fine-tune the model
Update `./demos/fine_tuner/configs/lora.yaml` to customize the fine-tuning process,
including prompts to generate at various points of the fine-tuning process and the path to your prepared videos.
Launch LoRA fine-tuning on single GPU:
```bash
bash ./demos/fine_tuner/run.bash -c ./demos/fine_tuner/configs/lora.yaml -n 1
```
Samples will be generated in `finetunes/my_mochi_lora/samples` every 200 steps.
### 4. Use your fine-tuned weights to generate videos!
Update `--lora_path` to the path of your fine-tuned weights and run:
```python
python3 ./demos/cli.py --model_dir weights/ --lora_path finetunes/my_mochi_lora/model_2000.lora.safetensors --num_frames 37 --cpu_offload --prompt "A delicate porcelain teacup sits on a marble countertop. The teacup suddenly shatters into hundreds of white ceramic shards that scatter through the air. The scene is bright and crisp with dramatic lighting."
```
You can increase the number of frames to generate a longer video. Finally, share your creations with the community by uploading your LoRA and sample videos to Hugging Face.
## System Requirements
**Single GPU:**
- 1x H100 or A100 (80 GB VRAM is recommended)
- Less VRAM is required if training with less than 1 second long videos.
**Supported video lengths:** Up to 85 frames (~2.8 seconds at 30 FPS)
- Choose a frame count in increments of 6: 25, 31, 37, ... 79, 85.
- Training on 37 frames uses 50 GB of VRAM. On 1 H100, each training step takes about 1.67 s/it,
and you'll start seeing changes to your videos within 200-400 steps. Training for 1,000 steps takes about 30 minutes.
Settings tested on 1x H100 SXM:
| Frames | Video Length | VRAM | Time/step | num_qkv_checkpoint | num_ff_checkpoint | num_post_attn_checkpoint |
|--------|--------------|------|-----------|-------------------|-------------------|-------------------------|
| 37 frames | 1.2 second videos | 50 GB VRAM | 1.67 s/it | 48 | 48† | 48 |
| 61 frames | 2.0 second videos | 64 GB VRAM | 3.35 s/it | 48 | 48† | 48 |
| 79 frames | 2.6 second videos | 69-78 GB VRAM | 4.92 s/it | 48 | 48† | 48 |
| 85 frames | 2.8 second videos | 80 GB VRAM | 5.44 s/it | 48 | 48 | 48 |
*† As the VRAM is not fully used, you can lower `num_ff_checkpoint` to speed up training.*
## Technical Details
- LoRA fine-tuning updates the query, key, and value projection matrices, as well as the output projection matrix.
These settings are configurable in `./demos/fine_tuner/configs/lora.yaml`.
- We welcome contributions and suggestions for improved settings.
## Known Limitations
- No support for training on multiple GPUs
- LoRA inference is restricted to 1-GPU (for now)
## Tips
- Be as descriptive as possible in your captions.
- A learning rate around 1e-4 or 2e-4 seems effective for LoRA fine-tuning.
- For larger datasets or to customize the model aggressively, increase `num_steps` in in the YAML.
- To monitor training loss, uncomment the `wandb` section in the YAML and run `wandb login` or set the `WANDB_API_KEY` environment variable.
- Videos are trimmed to the **first** `num_frames` frames. Make sure your clips contain the content you care about near the beginning.
You can check the trimmed versions after running `preprocess.bash` to make sure they look good.
- When capturing HDR videos on an iPhone, convert your .mov files to .mp4 using the Handbrake application. Our preprocessing script won't produce the correct colorspace otherwise, and your fine-tuned videos may look overly bright.
### If you are running out of GPU memory, make sure:
- `COMPILE_DIT=1` is set in `demos/fine_tuner/run.bash`.
This enables model compilation, which saves memory and speeds up training!
- `num_post_attn_checkpoint`, `num_ff_checkpoint`, and `num_qkv_checkpoint` are set to 48 in your YAML.
You can checkpoint up to 48 layers, saving memory at the cost of slower training.
- If all else fails, reduce `num_frames` when processing your videos and in your YAML.
You can fine-tune Mochi on shorter videos, and still generate longer videos at inference time.
## Diffusers trainer
The [Diffusers Python library](https://github.com/huggingface/diffusers) supports LoRA fine-tuning of Mochi 1 as well. Check out [this link](https://github.com/a-r-r-o-w/cogvideox-factory/tree/80d1150a0e233a1b2b98dd0367c06276989d049c/training/mochi-1) for more details. | {
"source": "genmoai/mochi",
"title": "demos/fine_tuner/README.md",
"url": "https://github.com/genmoai/mochi/blob/main/demos/fine_tuner/README.md",
"date": "2024-09-11T02:55:33",
"stars": 2870,
"description": "The best OSS video generation models",
"file_size": 5568
} |
# Conditioning explanations
Here we will list out all the conditionings the model accepts as well as a short description and some tips for optimal use. For conditionings with a learned unconditional, they can be set to that to allow the model to infer an appropriate setting.
### espeak
- **Type:** `EspeakPhonemeConditioner`
- **Description:**
Responsible for cleaning, phonemicizing, tokenizing, and embedding the text provided to the model. This is the text pre-processing pipeline. If you would like to change how a word is pronounced or enter raw phonemes you can do that here.
---
### speaker
- **Type:** `PassthroughConditioner`
- **Attributes:**
- **cond_dim:** `128`
- **uncond_type:** `learned`
- **projection:** `linear`
- **Description:**
An embedded representation of the speakers voice. We use [these](https://huggingface.co/Zyphra/Zonos-v0.1-speaker-embedding) speaker embedding models. It can capture a surprising amount of detail from the reference clip and supports arbitrary length input. Try to input clean reference clips containing only speech. It can be valid to concatenate multiple clean samples from the same speaker into one long sample and may lead to better cloning. If the speaker clip is very long, it is advisable to cut out long speech-free background music segments if they exist. If the reference clip is yielding noisy outputs with denoising enabled we recommend doing source separation before cloning.
---
### emotion
- **Type:** `FourierConditioner`
- **Attributes:**
- **input_dim:** `8`
- **uncond_type:** `learned`
- **Description:**
Encodes emotion in an 8D vector. Included emotions are Happiness, Sadness, Disgust, Fear, Surprise, Anger, Other, Neutral in that order. This vector tends to be entangled with various other conditioning inputs. More notably, it's entangled with text based on the text sentiment (eg. Angry texts will be more effectively conditioned to be angry, but if you try to make it sound sad it will be a lot less effective). It's also entangled with pitch standard deviation since larger values there tend to correlate to more emotional utterances. It's also heavily correlated with VQScore and DNSMOS as these conditionings favor neutral speech. It's also possible to do a form of "negative prompting" by doing CFG where the unconditional branch is set to a highly neutral emotion vector instead of the true unconditional value, doing this will exaggerate the emotions as it pushes the model away from being neutral.
---
### fmax
- **Type:** `FourierConditioner`
- **Attributes:**
- **min_val:** `0`
- **max_val:** `24000`
- **uncond_type:** `learned`
- **Description:**
Specifies the max frequency of the audio. For best results select 22050 or 24000 as these correspond to 44.1 and 48KHz audio respectively. They should not be any different in terms of actual max frequency since the model's sampling rate is 44.1KHz but they represent different slices of data which lead to slightly different voicing. Selecting a lower value generally produces lower-quality results both in terms of acoustics and voicing.
---
### pitch_std
- **Type:** `FourierConditioner`
- **Attributes:**
- **min_val:** `0`
- **max_val:** `400`
- **uncond_type:** `learned`
- **Description:**
Specifies the standard deviation of the pitch of the output audio. Wider variations of pitch tend to be more correlated with expressive speech. Good values are from 20-45 for normal speech and 60-150 for expressive speech. Higher than that generally tend to be crazier samples.
---
### speaking_rate
- **Type:** `FourierConditioner`
- **Attributes:**
- **min_val:** `0`
- **max_val:** `40`
- **uncond_type:** `learned`
- **Description:**
Specifies the number of phonemes to be read per second. When entering a long text, it is advisable to adjust the speaking rate such that the number of phonemes is readable within the generation length. For example, if your generation length is 10 seconds, and your input is 300 phonemes, you would want either 30 phonemes per second (which is very very fast) or to generate a longer sample. The model's maximum is 30 seconds. Please note that unrealistic speaking rates can be OOD for the model and create undesirable effects, so at the 30-second limit, it can be better to cut the text short and do multiple generations than to feed the model the entire prompt and have an unrealistically low speaking rate.
---
### language_id
- **Type:** `IntegerConditioner`
- **Attributes:**
- **min_val:** `-1`
- **max_val:** `126`
- **uncond_type:** `learned`
- **Description:**
Indicates which language the output should be in. A mapping for these values can be found in the [conditioning section](https://github.com/Zyphra/Zonos/blob/3807c8e04bd4beaadb9502b3df1ffa4b0350e3f7/zonos/conditioning.py#L308C1-L376C21) of Zonos.
---
### vqscore_8
- **Type:** `FourierConditioner`
- **Attributes:**
- **input_dim:** `8`
- **min_val:** `0.5`
- **max_val:** `0.8`
- **uncond_type:** `learned`
- **Description:**
Encodes the desired [VQScore](https://github.com/JasonSWFu/VQscore) value for the output audio. VQScore is an unsupervised speech quality (cleanliness) estimation method that we found has superior generalization and reduced biases compared to supervised methods like DNSMOS. A good value for our model is 0.78 for high-quality speech. The eight dimensions correspond to consecutive 1/8th chunks of the audio. (eg. for an 8-second output, the first dimension represents the quality of the first second only). For inference, we generally set all 8 dimensions to the same value. This has an unfortunately strong correlation with expressiveness, so for expressive speech, we recommend setting it to unconditional.
---
### ctc_loss
- **Type:** `FourierConditioner`
- **Attributes:**
- **min_val:** `-1.0`
- **max_val:** `1000`
- **uncond_type:** `learned`
- **Description:**
Encodes loss values from a [CTC](https://en.wikipedia.org/wiki/Connectionist_temporal_classification) (Connectionist Temporal Classification) setup, this indicates how well the training-time transcription matched with the audio according to a CTC model. For inference always use low values (eg. 0.0 or 1.0)
---
### dnsmos_ovrl
- **Type:** `FourierConditioner`
- **Attributes:**
- **min_val:** `1`
- **max_val:** `5`
- **uncond_type:** `learned`
- **Description:**
A [MOS](https://arxiv.org/abs/2110.01763) score for the output audio. This is similar to VQScore and tends to have a stronger entanglement with emotions. It additionally has a strong entanglement with languages. Set to 4.0 for very clean and neutral English speech, else we recommend setting it to unconditional.
---
### speaker_noised
- **Type:** `IntegerConditioner`
- **Attributes:**
- **min_val:** `0`
- **max_val:** `1`
- **uncond_type:** `learned`
- **Description:**
Indicates if the speaker embedding is noisy or not. If checked this lets the model clean (denoise) the input speaker embedding. When this is set to True, VQScore and DNSMOS will have a lot more power to clean the speaker embedding, so for very noisy input samples we recommend setting this to True and specifying a high VQScore value. If your speaker cloning outputs sound echo-y or do weird things, setting this to True will help. | {
"source": "Zyphra/Zonos",
"title": "CONDITIONING_README.md",
"url": "https://github.com/Zyphra/Zonos/blob/main/CONDITIONING_README.md",
"date": "2025-02-07T00:32:44",
"stars": 2835,
"description": "Zonos-v0.1 is a leading open-weight text-to-speech model trained on more than 200k hours of varied multilingual speech, delivering expressiveness and quality on par with—or even surpassing—top TTS providers.",
"file_size": 7308
} |
# Zonos-v0.1
<div align="center">
<img src="assets/ZonosHeader.png"
alt="Alt text"
style="width: 500px;
height: auto;
object-position: center top;">
</div>
---
Zonos-v0.1 is a leading open-weight text-to-speech model trained on more than 200k hours of varied multilingual speech, delivering expressiveness and quality on par with—or even surpassing—top TTS providers.
Our model enables highly natural speech generation from text prompts when given a speaker embedding or audio prefix, and can accurately perform speech cloning when given a reference clip spanning just a few seconds. The conditioning setup also allows for fine control over speaking rate, pitch variation, audio quality, and emotions such as happiness, fear, sadness, and anger. The model outputs speech natively at 44kHz.
##### For more details and speech samples, check out our blog [here](https://www.zyphra.com/post/beta-release-of-zonos-v0-1)
##### We also have a hosted version available at [maia.zyphra.com/audio](https://maia.zyphra.com/audio)
---
Zonos follows a straightforward architecture: text normalization and phonemization via eSpeak, followed by DAC token prediction through a transformer or hybrid backbone. An overview of the architecture can be seen below.
<div align="center">
<img src="assets/ArchitectureDiagram.png"
alt="Alt text"
style="width: 1000px;
height: auto;
object-position: center top;">
</div>
---
## Usage
### Python
```python
import torch
import torchaudio
from zonos.model import Zonos
from zonos.conditioning import make_cond_dict
# model = Zonos.from_pretrained("Zyphra/Zonos-v0.1-hybrid", device="cuda")
model = Zonos.from_pretrained("Zyphra/Zonos-v0.1-transformer", device="cuda")
wav, sampling_rate = torchaudio.load("assets/exampleaudio.mp3")
speaker = model.make_speaker_embedding(wav, sampling_rate)
cond_dict = make_cond_dict(text="Hello, world!", speaker=speaker, language="en-us")
conditioning = model.prepare_conditioning(cond_dict)
codes = model.generate(conditioning)
wavs = model.autoencoder.decode(codes).cpu()
torchaudio.save("sample.wav", wavs[0], model.autoencoder.sampling_rate)
```
### Gradio interface (recommended)
```bash
uv run gradio_interface.py
# python gradio_interface.py
```
This should produce a `sample.wav` file in your project root directory.
_For repeated sampling we highly recommend using the gradio interface instead, as the minimal example needs to load the model every time it is run._
## Features
- Zero-shot TTS with voice cloning: Input desired text and a 10-30s speaker sample to generate high quality TTS output
- Audio prefix inputs: Add text plus an audio prefix for even richer speaker matching. Audio prefixes can be used to elicit behaviours such as whispering which can otherwise be challenging to replicate when cloning from speaker embeddings
- Multilingual support: Zonos-v0.1 supports English, Japanese, Chinese, French, and German
- Audio quality and emotion control: Zonos offers fine-grained control of many aspects of the generated audio. These include speaking rate, pitch, maximum frequency, audio quality, and various emotions such as happiness, anger, sadness, and fear.
- Fast: our model runs with a real-time factor of ~2x on an RTX 4090 (i.e. generates 2 seconds of audio per 1 second of compute time)
- Gradio WebUI: Zonos comes packaged with an easy to use gradio interface to generate speech
- Simple installation and deployment: Zonos can be installed and deployed simply using the docker file packaged with our repository.
## Installation
**At the moment this repository only supports Linux systems (preferably Ubuntu 22.04/24.04) with recent NVIDIA GPUs (3000-series or newer, 6GB+ VRAM).**
See also [Docker Installation](#docker-installation)
#### System dependencies
Zonos depends on the eSpeak library phonemization. You can install it on Ubuntu with the following command:
```bash
apt install -y espeak-ng
```
#### Python dependencies
We highly recommend using a recent version of [uv](https://docs.astral.sh/uv/#installation) for installation. If you don't have uv installed, you can install it via pip: `pip install -U uv`.
##### Installing into a new uv virtual environment (recommended)
```bash
uv sync
uv sync --extra compile
```
##### Installing into the system/actived environment using uv
```bash
uv pip install -e .
uv pip install -e .[compile]
```
##### Installing into the system/actived environment using pip
```bash
pip install -e .
pip install --no-build-isolation -e .[compile]
```
##### Confirm that it's working
For convenience we provide a minimal example to check that the installation works:
```bash
uv run sample.py
# python sample.py
```
## Docker installation
```bash
git clone https://github.com/Zyphra/Zonos.git
cd Zonos
# For gradio
docker compose up
# Or for development you can do
docker build -t zonos .
docker run -it --gpus=all --net=host -v /path/to/Zonos:/Zonos -t zonos
cd /Zonos
python sample.py # this will generate a sample.wav in /Zonos
``` | {
"source": "Zyphra/Zonos",
"title": "README.md",
"url": "https://github.com/Zyphra/Zonos/blob/main/README.md",
"date": "2025-02-07T00:32:44",
"stars": 2835,
"description": "Zonos-v0.1 is a leading open-weight text-to-speech model trained on more than 200k hours of varied multilingual speech, delivering expressiveness and quality on par with—or even surpassing—top TTS providers.",
"file_size": 5077
} |
# 🦙🎧 LLaMA-Omni: Seamless Speech Interaction with Large Language Models
> **Authors: [Qingkai Fang](https://fangqingkai.github.io/), [Shoutao Guo](https://scholar.google.com/citations?hl=en&user=XwHtPyAAAAAJ), [Yan Zhou](https://zhouyan19.github.io/zhouyan/), [Zhengrui Ma](https://scholar.google.com.hk/citations?user=dUgq6tEAAAAJ), [Shaolei Zhang](https://zhangshaolei1998.github.io/), [Yang Feng*](https://people.ucas.edu.cn/~yangfeng?language=en)**
[](https://arxiv.org/abs/2409.06666)
[](https://github.com/ictnlp/LLaMA-Omni)
[](https://huggingface.co/ICTNLP/Llama-3.1-8B-Omni)
[](https://modelscope.cn/models/ICTNLP/Llama-3.1-8B-Omni)
[](https://www.wisemodel.cn/models/ICT_NLP/Llama-3.1-8B-Omni/)
[](https://replicate.com/ictnlp/llama-omni)
LLaMA-Omni is a speech-language model built upon Llama-3.1-8B-Instruct. It supports low-latency and high-quality speech interactions, simultaneously generating both text and speech responses based on speech instructions.
<div align="center"><img src="images/model.png" width="75%"/></div>
## 💡 Highlights
- 💪 **Built on Llama-3.1-8B-Instruct, ensuring high-quality responses.**
- 🚀 **Low-latency speech interaction with a latency as low as 226ms.**
- 🎧 **Simultaneous generation of both text and speech responses.**
- ♻️ **Trained in less than 3 days using just 4 GPUs.**
https://github.com/user-attachments/assets/2b097af8-47d7-494f-b3b3-6be17ca0247a
## Install
1. Clone this repository.
```shell
git clone https://github.com/ictnlp/LLaMA-Omni
cd LLaMA-Omni
```
2. Install packages.
```shell
conda create -n llama-omni python=3.10
conda activate llama-omni
pip install pip==24.0
pip install -e .
```
3. Install `fairseq`.
```shell
git clone https://github.com/pytorch/fairseq
cd fairseq
pip install -e . --no-build-isolation
```
4. Install `flash-attention`.
```shell
pip install flash-attn --no-build-isolation
```
## Quick Start
1. Download the `Llama-3.1-8B-Omni` model from 🤗[Huggingface](https://huggingface.co/ICTNLP/Llama-3.1-8B-Omni).
2. Download the `Whisper-large-v3` model.
```shell
import whisper
model = whisper.load_model("large-v3", download_root="models/speech_encoder/")
```
3. Download the unit-based HiFi-GAN vocoder.
```shell
wget https://dl.fbaipublicfiles.com/fairseq/speech_to_speech/vocoder/code_hifigan/mhubert_vp_en_es_fr_it3_400k_layer11_km1000_lj/g_00500000 -P vocoder/
wget https://dl.fbaipublicfiles.com/fairseq/speech_to_speech/vocoder/code_hifigan/mhubert_vp_en_es_fr_it3_400k_layer11_km1000_lj/config.json -P vocoder/
```
## Gradio Demo
1. Launch a controller.
```shell
python -m omni_speech.serve.controller --host 0.0.0.0 --port 10000
```
2. Launch a gradio web server.
```shell
python -m omni_speech.serve.gradio_web_server --controller http://localhost:10000 --port 8000 --model-list-mode reload --vocoder vocoder/g_00500000 --vocoder-cfg vocoder/config.json
```
3. Launch a model worker.
```shell
python -m omni_speech.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path Llama-3.1-8B-Omni --model-name Llama-3.1-8B-Omni --s2s
```
4. Visit [http://localhost:8000/](http://localhost:8000/) and interact with LLaMA-3.1-8B-Omni!
**Note: Due to the instability of streaming audio playback in Gradio, we have only implemented streaming audio synthesis without enabling autoplay. If you have a good solution, feel free to submit a PR. Thanks!**
## Local Inference
To run inference locally, please organize the speech instruction files according to the format in the `omni_speech/infer/examples` directory, then refer to the following script.
```shell
bash omni_speech/infer/run.sh omni_speech/infer/examples
```
## LICENSE
Our code is released under the Apache-2.0 License. Our model is intended for academic research purposes only and may **NOT** be used for commercial purposes.
You are free to use, modify, and distribute this model in academic settings, provided that the following conditions are met:
- **Non-commercial use**: The model may not be used for any commercial purposes.
- **Citation**: If you use this model in your research, please cite the original work.
### Commercial Use Restriction
For any commercial use inquiries or to obtain a commercial license, please contact `[email protected]`.
## Acknowledgements
- [LLaVA](https://github.com/haotian-liu/LLaVA): The codebase we built upon.
- [SLAM-LLM](https://github.com/X-LANCE/SLAM-LLM): We borrow some code about speech encoder and speech adaptor.
## Citation
If you have any questions, please feel free to submit an issue or contact `[email protected]`.
If our work is useful for you, please cite as:
```
@article{fang-etal-2024-llama-omni,
title={LLaMA-Omni: Seamless Speech Interaction with Large Language Models},
author={Fang, Qingkai and Guo, Shoutao and Zhou, Yan and Ma, Zhengrui and Zhang, Shaolei and Feng, Yang},
journal={arXiv preprint arXiv:2409.06666},
year={2024}
}
```
## Star History
[](https://star-history.com/#ictnlp/llama-omni&Date) | {
"source": "ictnlp/LLaMA-Omni",
"title": "README.md",
"url": "https://github.com/ictnlp/LLaMA-Omni/blob/main/README.md",
"date": "2024-09-10T12:21:53",
"stars": 2797,
"description": "LLaMA-Omni is a low-latency and high-quality end-to-end speech interaction model built upon Llama-3.1-8B-Instruct, aiming to achieve speech capabilities at the GPT-4o level.",
"file_size": 5557
} |
<div align="center">
# LTX-Video
This is the official repository for LTX-Video.
[Website](https://www.lightricks.com/ltxv) |
[Model](https://huggingface.co/Lightricks/LTX-Video) |
[Demo](https://fal.ai/models/fal-ai/ltx-video) |
[Paper](https://arxiv.org/abs/2501.00103)
</div>
## Table of Contents
- [Introduction](#introduction)
- [Quick Start Guide](#quick-start-guide)
- [Online demo](#online-demo)
- [Run locally](#run-locally)
- [Installation](#installation)
- [Inference](#inference)
- [ComfyUI Integration](#comfyui-integration)
- [Diffusers Integration](#diffusers-integration)
- [Model User Guide](#model-user-guide)
- [Community Contribution](#community-contribution)
- [Training](#trining)
- [Join Us!](#join-us)
- [Acknowledgement](#acknowledgement)
# Introduction
LTX-Video is the first DiT-based video generation model that can generate high-quality videos in *real-time*.
It can generate 24 FPS videos at 768x512 resolution, faster than it takes to watch them.
The model is trained on a large-scale dataset of diverse videos and can generate high-resolution videos
with realistic and diverse content.
| | | | |
|:---:|:---:|:---:|:---:|
| <br><details style="max-width: 300px; margin: auto;"><summary>A woman with long brown hair and light skin smiles at another woman...</summary>A woman with long brown hair and light skin smiles at another woman with long blonde hair. The woman with brown hair wears a black jacket and has a small, barely noticeable mole on her right cheek. The camera angle is a close-up, focused on the woman with brown hair's face. The lighting is warm and natural, likely from the setting sun, casting a soft glow on the scene. The scene appears to be real-life footage.</details> | <br><details style="max-width: 300px; margin: auto;"><summary>A woman walks away from a white Jeep parked on a city street at night...</summary>A woman walks away from a white Jeep parked on a city street at night, then ascends a staircase and knocks on a door. The woman, wearing a dark jacket and jeans, walks away from the Jeep parked on the left side of the street, her back to the camera; she walks at a steady pace, her arms swinging slightly by her sides; the street is dimly lit, with streetlights casting pools of light on the wet pavement; a man in a dark jacket and jeans walks past the Jeep in the opposite direction; the camera follows the woman from behind as she walks up a set of stairs towards a building with a green door; she reaches the top of the stairs and turns left, continuing to walk towards the building; she reaches the door and knocks on it with her right hand; the camera remains stationary, focused on the doorway; the scene is captured in real-life footage.</details> | <br><details style="max-width: 300px; margin: auto;"><summary>A woman with blonde hair styled up, wearing a black dress...</summary>A woman with blonde hair styled up, wearing a black dress with sequins and pearl earrings, looks down with a sad expression on her face. The camera remains stationary, focused on the woman's face. The lighting is dim, casting soft shadows on her face. The scene appears to be from a movie or TV show.</details> | <br><details style="max-width: 300px; margin: auto;"><summary>The camera pans over a snow-covered mountain range...</summary>The camera pans over a snow-covered mountain range, revealing a vast expanse of snow-capped peaks and valleys.The mountains are covered in a thick layer of snow, with some areas appearing almost white while others have a slightly darker, almost grayish hue. The peaks are jagged and irregular, with some rising sharply into the sky while others are more rounded. The valleys are deep and narrow, with steep slopes that are also covered in snow. The trees in the foreground are mostly bare, with only a few leaves remaining on their branches. The sky is overcast, with thick clouds obscuring the sun. The overall impression is one of peace and tranquility, with the snow-covered mountains standing as a testament to the power and beauty of nature.</details> |
| <br><details style="max-width: 300px; margin: auto;"><summary>A woman with light skin, wearing a blue jacket and a black hat...</summary>A woman with light skin, wearing a blue jacket and a black hat with a veil, looks down and to her right, then back up as she speaks; she has brown hair styled in an updo, light brown eyebrows, and is wearing a white collared shirt under her jacket; the camera remains stationary on her face as she speaks; the background is out of focus, but shows trees and people in period clothing; the scene is captured in real-life footage.</details> | <br><details style="max-width: 300px; margin: auto;"><summary>A man in a dimly lit room talks on a vintage telephone...</summary>A man in a dimly lit room talks on a vintage telephone, hangs up, and looks down with a sad expression. He holds the black rotary phone to his right ear with his right hand, his left hand holding a rocks glass with amber liquid. He wears a brown suit jacket over a white shirt, and a gold ring on his left ring finger. His short hair is neatly combed, and he has light skin with visible wrinkles around his eyes. The camera remains stationary, focused on his face and upper body. The room is dark, lit only by a warm light source off-screen to the left, casting shadows on the wall behind him. The scene appears to be from a movie.</details> | <br><details style="max-width: 300px; margin: auto;"><summary>A prison guard unlocks and opens a cell door...</summary>A prison guard unlocks and opens a cell door to reveal a young man sitting at a table with a woman. The guard, wearing a dark blue uniform with a badge on his left chest, unlocks the cell door with a key held in his right hand and pulls it open; he has short brown hair, light skin, and a neutral expression. The young man, wearing a black and white striped shirt, sits at a table covered with a white tablecloth, facing the woman; he has short brown hair, light skin, and a neutral expression. The woman, wearing a dark blue shirt, sits opposite the young man, her face turned towards him; she has short blonde hair and light skin. The camera remains stationary, capturing the scene from a medium distance, positioned slightly to the right of the guard. The room is dimly lit, with a single light fixture illuminating the table and the two figures. The walls are made of large, grey concrete blocks, and a metal door is visible in the background. The scene is captured in real-life footage.</details> | <br><details style="max-width: 300px; margin: auto;"><summary>A woman with blood on her face and a white tank top...</summary>A woman with blood on her face and a white tank top looks down and to her right, then back up as she speaks. She has dark hair pulled back, light skin, and her face and chest are covered in blood. The camera angle is a close-up, focused on the woman's face and upper torso. The lighting is dim and blue-toned, creating a somber and intense atmosphere. The scene appears to be from a movie or TV show.</details> |
| <br><details style="max-width: 300px; margin: auto;"><summary>A man with graying hair, a beard, and a gray shirt...</summary>A man with graying hair, a beard, and a gray shirt looks down and to his right, then turns his head to the left. The camera angle is a close-up, focused on the man's face. The lighting is dim, with a greenish tint. The scene appears to be real-life footage. Step</details> | <br><details style="max-width: 300px; margin: auto;"><summary>A clear, turquoise river flows through a rocky canyon...</summary>A clear, turquoise river flows through a rocky canyon, cascading over a small waterfall and forming a pool of water at the bottom.The river is the main focus of the scene, with its clear water reflecting the surrounding trees and rocks. The canyon walls are steep and rocky, with some vegetation growing on them. The trees are mostly pine trees, with their green needles contrasting with the brown and gray rocks. The overall tone of the scene is one of peace and tranquility.</details> | <br><details style="max-width: 300px; margin: auto;"><summary>A man in a suit enters a room and speaks to two women...</summary>A man in a suit enters a room and speaks to two women sitting on a couch. The man, wearing a dark suit with a gold tie, enters the room from the left and walks towards the center of the frame. He has short gray hair, light skin, and a serious expression. He places his right hand on the back of a chair as he approaches the couch. Two women are seated on a light-colored couch in the background. The woman on the left wears a light blue sweater and has short blonde hair. The woman on the right wears a white sweater and has short blonde hair. The camera remains stationary, focusing on the man as he enters the room. The room is brightly lit, with warm tones reflecting off the walls and furniture. The scene appears to be from a film or television show.</details> | <br><details style="max-width: 300px; margin: auto;"><summary>The waves crash against the jagged rocks of the shoreline...</summary>The waves crash against the jagged rocks of the shoreline, sending spray high into the air.The rocks are a dark gray color, with sharp edges and deep crevices. The water is a clear blue-green, with white foam where the waves break against the rocks. The sky is a light gray, with a few white clouds dotting the horizon.</details> |
| <br><details style="max-width: 300px; margin: auto;"><summary>The camera pans across a cityscape of tall buildings...</summary>The camera pans across a cityscape of tall buildings with a circular building in the center. The camera moves from left to right, showing the tops of the buildings and the circular building in the center. The buildings are various shades of gray and white, and the circular building has a green roof. The camera angle is high, looking down at the city. The lighting is bright, with the sun shining from the upper left, casting shadows from the buildings. The scene is computer-generated imagery.</details> | <br><details style="max-width: 300px; margin: auto;"><summary>A man walks towards a window, looks out, and then turns around...</summary>A man walks towards a window, looks out, and then turns around. He has short, dark hair, dark skin, and is wearing a brown coat over a red and gray scarf. He walks from left to right towards a window, his gaze fixed on something outside. The camera follows him from behind at a medium distance. The room is brightly lit, with white walls and a large window covered by a white curtain. As he approaches the window, he turns his head slightly to the left, then back to the right. He then turns his entire body to the right, facing the window. The camera remains stationary as he stands in front of the window. The scene is captured in real-life footage.</details> | <br><details style="max-width: 300px; margin: auto;"><summary>Two police officers in dark blue uniforms and matching hats...</summary>Two police officers in dark blue uniforms and matching hats enter a dimly lit room through a doorway on the left side of the frame. The first officer, with short brown hair and a mustache, steps inside first, followed by his partner, who has a shaved head and a goatee. Both officers have serious expressions and maintain a steady pace as they move deeper into the room. The camera remains stationary, capturing them from a slightly low angle as they enter. The room has exposed brick walls and a corrugated metal ceiling, with a barred window visible in the background. The lighting is low-key, casting shadows on the officers' faces and emphasizing the grim atmosphere. The scene appears to be from a film or television show.</details> | <br><details style="max-width: 300px; margin: auto;"><summary>A woman with short brown hair, wearing a maroon sleeveless top...</summary>A woman with short brown hair, wearing a maroon sleeveless top and a silver necklace, walks through a room while talking, then a woman with pink hair and a white shirt appears in the doorway and yells. The first woman walks from left to right, her expression serious; she has light skin and her eyebrows are slightly furrowed. The second woman stands in the doorway, her mouth open in a yell; she has light skin and her eyes are wide. The room is dimly lit, with a bookshelf visible in the background. The camera follows the first woman as she walks, then cuts to a close-up of the second woman's face. The scene is captured in real-life footage.</details> |
# Quick Start Guide
## Online demo
The model is accessible right away via following links:
- [HF Playground](https://huggingface.co/spaces/Lightricks/LTX-Video-Playground)
- [Fal.ai text-to-video](https://fal.ai/models/fal-ai/ltx-video)
- [Fal.ai image-to-video](https://fal.ai/models/fal-ai/ltx-video/image-to-video)
## Run locally
### Installation
The codebase was tested with Python 3.10.5, CUDA version 12.2, and supports PyTorch >= 2.1.2.
```bash
git clone https://github.com/Lightricks/LTX-Video.git
cd LTX-Video
# create env
python -m venv env
source env/bin/activate
python -m pip install -e .\[inference-script\]
```
Then, download the model from [Hugging Face](https://huggingface.co/Lightricks/LTX-Video)
```python
from huggingface_hub import hf_hub_download
model_path = 'PATH' # The local directory to save downloaded checkpoint
hf_hub_download(repo_id="Lightricks/LTX-Video", filename="ltx-video-2b-v0.9.safetensors", local_dir=model_path, local_dir_use_symlinks=False, repo_type='model')
```
### Inference
To use our model, please follow the inference code in [inference.py](./inference.py):
#### For text-to-video generation:
```bash
python inference.py --ckpt_path 'PATH' --prompt "PROMPT" --height HEIGHT --width WIDTH --num_frames NUM_FRAMES --seed SEED
```
#### For image-to-video generation:
```bash
python inference.py --ckpt_path 'PATH' --prompt "PROMPT" --input_image_path IMAGE_PATH --height HEIGHT --width WIDTH --num_frames NUM_FRAMES --seed SEED
```
## ComfyUI Integration
To use our model with ComfyUI, please follow the instructions at [https://github.com/Lightricks/ComfyUI-LTXVideo/](https://github.com/Lightricks/ComfyUI-LTXVideo/).
## Diffusers Integration
To use our model with the Diffusers Python library, check out the [official documentation](https://huggingface.co/docs/diffusers/main/en/api/pipelines/ltx_video).
# Model User Guide
## 📝 Prompt Engineering
When writing prompts, focus on detailed, chronological descriptions of actions and scenes. Include specific movements, appearances, camera angles, and environmental details - all in a single flowing paragraph. Start directly with the action, and keep descriptions literal and precise. Think like a cinematographer describing a shot list. Keep within 200 words. For best results, build your prompts using this structure:
* Start with main action in a single sentence
* Add specific details about movements and gestures
* Describe character/object appearances precisely
* Include background and environment details
* Specify camera angles and movements
* Describe lighting and colors
* Note any changes or sudden events
* See [examples](#introduction) for more inspiration.
## 🎮 Parameter Guide
* Resolution Preset: Higher resolutions for detailed scenes, lower for faster generation and simpler scenes. The model works on resolutions that are divisible by 32 and number of frames that are divisible by 8 + 1 (e.g. 257). In case the resolution or number of frames are not divisible by 32 or 8 + 1, the input will be padded with -1 and then cropped to the desired resolution and number of frames. The model works best on resolutions under 720 x 1280 and number of frames below 257
* Seed: Save seed values to recreate specific styles or compositions you like
* Guidance Scale: 3-3.5 are the recommended values
* Inference Steps: More steps (40+) for quality, fewer steps (20-30) for speed
## Community Contribution
### ComfyUI-LTXTricks 🛠️
A community project providing additional nodes for enhanced control over the LTX Video model. It includes implementations of advanced techniques like RF-Inversion, RF-Edit, FlowEdit, and more. These nodes enable workflows such as Image and Video to Video (I+V2V), enhanced sampling via Spatiotemporal Skip Guidance (STG), and interpolation with precise frame settings.
- **Repository:** [ComfyUI-LTXTricks](https://github.com/logtd/ComfyUI-LTXTricks)
- **Features:**
- 🔄 **RF-Inversion:** Implements [RF-Inversion](https://rf-inversion.github.io/) with an [example workflow here](https://github.com/logtd/ComfyUI-LTXTricks/blob/main/example_workflows/example_ltx_inversion.json).
- ✂️ **RF-Edit:** Implements [RF-Solver-Edit](https://github.com/wangjiangshan0725/RF-Solver-Edit) with an [example workflow here](https://github.com/logtd/ComfyUI-LTXTricks/blob/main/example_workflows/example_ltx_rf_edit.json).
- 🌊 **FlowEdit:** Implements [FlowEdit](https://github.com/fallenshock/FlowEdit) with an [example workflow here](https://github.com/logtd/ComfyUI-LTXTricks/blob/main/example_workflows/example_ltx_flow_edit.json).
- 🎥 **I+V2V:** Enables Video to Video with a reference image. [Example workflow](https://github.com/logtd/ComfyUI-LTXTricks/blob/main/example_workflows/example_ltx_iv2v.json).
- ✨ **Enhance:** Partial implementation of [STGuidance](https://junhahyung.github.io/STGuidance/). [Example workflow](https://github.com/logtd/ComfyUI-LTXTricks/blob/main/example_workflows/example_ltxv_stg.json).
- 🖼️ **Interpolation and Frame Setting:** Nodes for precise control of latents per frame. [Example workflow](https://github.com/logtd/ComfyUI-LTXTricks/blob/main/example_workflows/example_ltx_interpolation.json).
### LTX-VideoQ8 🎱
**LTX-VideoQ8** is an 8-bit optimized version of [LTX-Video](https://github.com/Lightricks/LTX-Video), designed for faster performance on NVIDIA ADA GPUs.
- **Repository:** [LTX-VideoQ8](https://github.com/KONAKONA666/LTX-Video)
- **Features:**
- 🚀 Up to 3X speed-up with no accuracy loss
- 🎥 Generate 720x480x121 videos in under a minute on RTX 4060 (8GB VRAM)
- 🛠️ Fine-tune 2B transformer models with precalculated latents
- **Community Discussion:** [Reddit Thread](https://www.reddit.com/r/StableDiffusion/comments/1h79ks2/fast_ltx_video_on_rtx_4060_and_other_ada_gpus/)
### Your Contribution
...is welcome! If you have a project or tool that integrates with LTX-Video,
please let us know by opening an issue or pull request.
# Training
## Diffusers
Diffusers implemented [LoRA support](https://github.com/huggingface/diffusers/pull/10228),
with a training script for fine-tuning.
More information and training script in
[finetrainers](https://github.com/a-r-r-o-w/finetrainers?tab=readme-ov-file#training).
## Diffusion-Pipe
An experimental training framework with pipeline parallelism, enabling fine-tuning of large models like **LTX-Video** across multiple GPUs.
- **Repository:** [Diffusion-Pipe](https://github.com/tdrussell/diffusion-pipe)
- **Features:**
- 🛠️ Full fine-tune support for LTX-Video using LoRA
- 📊 Useful metrics logged to Tensorboard
- 🔄 Training state checkpointing and resumption
- ⚡ Efficient pre-caching of latents and text embeddings for multi-GPU setups
# Join Us 🚀
Want to work on cutting-edge AI research and make a real impact on millions of users worldwide?
At **Lightricks**, an AI-first company, we’re revolutionizing how visual content is created.
If you are passionate about AI, computer vision, and video generation, we would love to hear from you!
Please visit our [careers page](https://careers.lightricks.com/careers?query=&office=all&department=R%26D) for more information.
# Acknowledgement
We are grateful for the following awesome projects when implementing LTX-Video:
* [DiT](https://github.com/facebookresearch/DiT) and [PixArt-alpha](https://github.com/PixArt-alpha/PixArt-alpha): vision transformers for image generation.
## Citation
📄 Our tech report is out! If you find our work helpful, please ⭐️ star the repository and cite our paper.
```
@article{HaCohen2024LTXVideo,
title={LTX-Video: Realtime Video Latent Diffusion},
author={HaCohen, Yoav and Chiprut, Nisan and Brazowski, Benny and Shalem, Daniel and Moshe, Dudu and Richardson, Eitan and Levin, Eran and Shiran, Guy and Zabari, Nir and Gordon, Ori and Panet, Poriya and Weissbuch, Sapir and Kulikov, Victor and Bitterman, Yaki and Melumian, Zeev and Bibi, Ofir},
journal={arXiv preprint arXiv:2501.00103},
year={2024}
}
``` | {
"source": "Lightricks/LTX-Video",
"title": "README.md",
"url": "https://github.com/Lightricks/LTX-Video/blob/main/README.md",
"date": "2024-11-20T20:06:28",
"stars": 2793,
"description": "Official repository for LTX-Video",
"file_size": 21469
} |
# Changelog
## [0.4.0] - 2024-11-16
### Added
- Add Google Singlespeaker (Journey) and Multispeaker TTS models
- Fixed limitations of Google Multispeaker TTS model: 5000 bytes input limite and 500 bytes per turn limit.
- Updated tests and docs accordingly
## [0.3.6] - 2024-11-13
### Added
- Add longform podcast generation support
- Users can now generate longer podcasts (20-30+ minutes) using the `--longform` flag in CLI or `longform=True` in Python API
- Implements "Content Chunking with Contextual Linking" technique for coherent long-form content
- Configurable via `max_num_chunks` and `min_chunk_size` parameters in conversation config
- `word_count` parameter removed from conversation config as it's no longer used
## [0.3.3] - 2024-11-08
### Breaking Changes
- Loading images from 'path' has been removed for security reasons. Please specify images by passing an 'url'.
### Added
- Add podcast generation from topic "Latest News in U.S. Politics"
- Integrate with 100+ LLM models (OpenAI, Anthropic, Google etc) for transcript generation
- Integrate with Google's Multispeaker TTS model for high-quality audio generation
- Deploy [REST API](https://github.com/souzatharsis/podcastfy/blob/main/usage/api.md) with FastAPI
- Support for raw text as input
- Add PRIVACY_POLICY.md
- Start TESTIMONIALS.md
- Add apps using Podcastfy to README.md
### Fixed
- #165 Fixed audio generation in Windows OS issue: Normalize path separators for cross-platform compatibility
## [0.2.3] - 2024-10-15
### Added
- Add local llm option by @souzatharsis
- Enable running podcastfy with no API KEYs thanks to solving #18 #58 #65 by @souzatharsis and @ChinoUkaegbu
- Add user-provided TSS config such as voices #10 #6 #27 by @souzatharsis
- Add open in collab and setting python version to 3.11 by @Devparihar5 #57
- Add edge tts support by @ChinoUkaegbu
- Update pypdf with pymupdf(10x faster then pypdf) #56 check by @Devparihar5
- Replace r.jina.ai with simple BeautifulSoap #18 by @souzatharsis
### Fixed
- Fixed CLI for user-provided config #69 @souzatharsis
## [0.2.2] - 2024-10-13
### Added
- Added API reference docs and published it to https://podcastfy.readthedocs.io/en/latest/
### Fixed
- ([#52](https://github.com/user/podcastfy/issues/37)) Fixed simple bug introduced in 0.2.1 that broke the ability to generate podcasts from text inputs!
- Fixed one example in the documentation that was not working.
## [0.2.1] - 2024-10-12
### Added
- ([#8](https://github.com/user/podcastfy/issues/8)) Podcastfy is now multi-modal! Users can now generate audio from images by simply providing the paths to the image files.
### Fixed
- ([#40](https://github.com/user/podcastfy/issues/37)) Updated default ElevenLabs voice from `BrittneyHart` to `Jessica`. The latter was a non-default voice I used from my account, which caused error for users who don't have it.
## [0.2.0] - 2024-10-10
### Added
- Parameterized podcast generation with Conversation Configuration ([#11](https://github.com/user/podcastfy/issues/11), [#3](https://github.com/user/podcastfy/issues/3), [#4](https://github.com/user/podcastfy/issues/4))
- Users can now customize podcast style, structure, and content
- See [Conversation Customization](usage/conversation_custom.md) for detailed options
- Updated demo in [podcastfy.ipynb](podcastfy.ipynb)
- LangChain integration for improved LLM interface and observability ([#29](https://github.com/user/podcastfy/issues/29))
- Changelog to track version updates ([#22](https://github.com/user/podcastfy/issues/22))
- Tests for Customized conversation scenarios
### Fixed
- CLI now correctly reads from user-provided local .env file ([#37](https://github.com/user/podcastfy/issues/37)) | {
"source": "souzatharsis/podcastfy",
"title": "CHANGELOG.md",
"url": "https://github.com/souzatharsis/podcastfy/blob/main/CHANGELOG.md",
"date": "2024-09-30T22:35:09",
"stars": 2726,
"description": "An Open Source Python alternative to NotebookLM's podcast feature: Transforming Multimodal Content into Captivating Multilingual Audio Conversations with GenAI",
"file_size": 3732
} |
# Contributor Covenant Code of Conduct
## Our Pledge
In the interest of fostering an open and welcoming environment, we as contributors and maintainers pledge to making participation in our project and our community a harassment-free experience for everyone, regardless of age, body size, disability, ethnicity, sex characteristics, gender identity and expression, level of experience, education, socio-economic status, nationality, personal appearance, race, religion, or sexual identity and orientation.
## Our Standards
Examples of behavior that contributes to creating a positive environment include:
* Using welcoming and inclusive language
* Being respectful of differing viewpoints and experiences
* Gracefully accepting constructive criticism
* Focusing on what is best for the community
* Showing empathy towards other community members
Examples of unacceptable behavior by participants include:
* The use of sexualized language or imagery and unwelcome sexual attention or advances
* Trolling, insulting/derogatory comments, and personal or political attacks
* Public or private harassment
* Publishing others' private information, such as a physical or electronic address, without explicit permission
* Other conduct which could reasonably be considered inappropriate in a professional setting
## Our Responsibilities
Project maintainers are responsible for clarifying the standards of acceptable behavior and are expected to take appropriate and fair corrective action in response to any instances of unacceptable behavior.
Project maintainers have the right and responsibility to remove, edit, or reject comments, commits, code, wiki edits, issues, and other contributions that are not aligned to this Code of Conduct, or to ban temporarily or permanently any contributor for other behaviors that they deem inappropriate, threatening, offensive, or harmful.
## Scope
This Code | {
"source": "souzatharsis/podcastfy",
"title": "CODE_OF_CONDUCT.md",
"url": "https://github.com/souzatharsis/podcastfy/blob/main/CODE_OF_CONDUCT.md",
"date": "2024-09-30T22:35:09",
"stars": 2726,
"description": "An Open Source Python alternative to NotebookLM's podcast feature: Transforming Multimodal Content into Captivating Multilingual Audio Conversations with GenAI",
"file_size": 1901
} |
# Contributor Guidelines
Thank you for your interest in contributing to Podcastfy! We welcome contributions from the community to help improve and expand this project. Please follow these guidelines to ensure a smooth collaboration process.
## Getting Started
1. Fork the repository on GitHub.
2. Clone your fork locally: `git clone https://github.com/your-username/podcastfy.git`
3. Create a new branch for your feature or bug fix: `git checkout -b feature/your-feature-name`
## Code Style
- Follow PEP 8 style guidelines for Python code.
- Use tabs for indentation instead of spaces.
- Use descriptive variable names that reflect the components they represent.
- Include docstrings for all functions, classes, and modules.
## Development
- Poetry is the preferred but not mandatory dependency manager. Install it with `pip install poetry`.
- Contributors can opt to use `uv` instead and generate and push updated requirements.txt from it.
- Sphinx is used as the documentation generator. Install it with `pip install sphinx`.
- `make doc-gen` to generate the documentation.
## Submitting Changes
1. Commit your changes with clear, descriptive commit messages.
2. Push your changes to your fork on GitHub.
3. Submit a pull request to the main repository.
## Pre-Pull Request Checklist
1. Managing dependencies
- Add new dependencies with `poetry add <new-dependency>`
- Remove a dependency with `poetry remove <dependency-name>`.
- Then generate requirements.txt with `poetry export -f requirements.txt --output requirements.txt --without-hashes`
2. Testing
- Consider adding new tests at test/*.py, particularly if implementing user facing change.
- Test locally: `poetry run pytest`
- Tests (tests/*.py) are run automatically by GitHub Actions, double check that they pass.
3. Docs
- Update any documentation if required README.md, usage/*.md, *.ipynb etc.
- Regenerate documentation (/docs) if there are any changes in docstrings or modules' interface (`make doc-gen`)
## Reporting Issues
- Use the GitHub issue tracker to report bugs or suggest enhancements.
- Provide a clear and detailed description of the issue or suggestion.
- Include steps to reproduce the bug, if applicable.
## Code of Conduct
Please note that this project is released with a [Contributor Code of Conduct](CODE_OF_CONDUCT.md). By participating in this project, you agree to abide by its terms.
## Questions?
If you have any questions or need further clarification, please don't hesitate to ask in the GitHub issues section.
Thank you for contributing to Podcastfy! | {
"source": "souzatharsis/podcastfy",
"title": "GUIDELINES.md",
"url": "https://github.com/souzatharsis/podcastfy/blob/main/GUIDELINES.md",
"date": "2024-09-30T22:35:09",
"stars": 2726,
"description": "An Open Source Python alternative to NotebookLM's podcast feature: Transforming Multimodal Content into Captivating Multilingual Audio Conversations with GenAI",
"file_size": 2607
} |
# Privacy Policy
**Effective Date:** 11/03/2024
Podcastfy is an open-source project that does not collect, store, or transmit any personal user data. All processing occurs locally on your machine or through third-party services that you configure.
## Use of Third-Party Services
When you use Podcastfy with third-party services (such as APIs for text-to-speech or language models), any data transmitted to these services is subject to their respective privacy policies. You are responsible for reviewing and agreeing to the terms and policies of these third-party providers.
## Data Processing
- **Local Processing:** All content transformation and processing are performed locally unless explicitly configured to use external services.
- **No Data Collection:** Podcastfy does not collect or send any user data to the developers or any third parties without your consent.
## User Responsibility
Users are responsible for:
- Ensuring compliance with all applicable laws and regulations regarding data privacy.
- Protecting any personal or sensitive data processed through the application.
- Reviewing the privacy policies of any third-party services used in conjunction with Podcastfy.
## Contact Information
If you have any questions or concerns about this Privacy Policy, please open an issue on our [GitHub repository](https://github.com/souzatharsis/podcastfy/issues). | {
"source": "souzatharsis/podcastfy",
"title": "PRIVACY_POLICY.md",
"url": "https://github.com/souzatharsis/podcastfy/blob/main/PRIVACY_POLICY.md",
"date": "2024-09-30T22:35:09",
"stars": 2726,
"description": "An Open Source Python alternative to NotebookLM's podcast feature: Transforming Multimodal Content into Captivating Multilingual Audio Conversations with GenAI",
"file_size": 1383
} |
<div align="center">
<a name="readme-top"></a>
**I am writing an [open source book "Taming LLMs"](https://github.com/souzatharsis/tamingLLMs) - would love your feedback!**
# Podcastfy.ai 🎙️🤖
An Open Source API alternative to NotebookLM's podcast feature: Transforming Multimodal Content into Captivating Multilingual Audio Conversations with GenAI
https://github.com/user-attachments/assets/5d42c106-aabe-44c1-8498-e9c53545ba40
[Paper](https://github.com/souzatharsis/podcastfy/blob/main/paper/paper.pdf) |
[Python Package](https://github.com/souzatharsis/podcastfy/blob/59563ee105a0d1dbb46744e0ff084471670dd725/podcastfy.ipynb) |
[CLI](https://github.com/souzatharsis/podcastfy/blob/59563ee105a0d1dbb46744e0ff084471670dd725/usage/cli.md) |
[Web App](https://openpod.fly.dev/) |
[Feedback](https://github.com/souzatharsis/podcastfy/issues)
[](https://colab.research.google.com/github/souzatharsis/podcastfy/blob/main/podcastfy.ipynb)
[](https://pypi.org/project/podcastfy/)

[](https://github.com/souzatharsis/podcastfy/issues)
[](https://github.com/souzatharsis/podcastfy/actions/workflows/python-app.yml)
[](https://github.com/souzatharsis/podcastfy/actions/workflows/docker-publish.yml)
[](https://podcastfy.readthedocs.io/en/latest/?badge=latest)
[](https://opensource.org/licenses/Apache-2.0)

</div>
Podcastfy is an open-source Python package that transforms multi-modal content (text, images) into engaging, multi-lingual audio conversations using GenAI. Input content includes websites, PDFs, images, YouTube videos, as well as user provided topics.
Unlike closed-source UI-based tools focused primarily on research synthesis (e.g. NotebookLM ❤️), Podcastfy focuses on open source, programmatic and bespoke generation of engaging, conversational content from a multitude of multi-modal sources, enabling customization and scale.
## Testimonials 💬
> "Love that you casually built an open source version of the most popular product Google built in the last decade"
> "Loving this initiative and the best I have seen so far especially for a 'non-techie' user."
> "Your library was very straightforward to work with. You did Amazing work brother 🙏"
> "I think it's awesome that you were inspired/recognize how hard it is to beat NotebookLM's quality, but you did an *incredible* job with this! It sounds incredible, and it's open-source! Thank you for being amazing!"
[](https://api.star-history.com/svg?repos=souzatharsis/podcastfy&type=Date&theme=dark)
## Audio Examples 🔊
This sample collection was generated using this [Python Notebook](usage/examples.ipynb).
### Images
Sample 1: Senecio, 1922 (Paul Klee) and Connection of Civilizations (2017) by Gheorghe Virtosu
***
<img src="data/images/Senecio.jpeg" alt="Senecio, 1922 (Paul Klee)" width="20%" height="auto"> <img src="data/images/connection.jpg" alt="Connection of Civilizations (2017) by Gheorghe Virtosu " width="21.5%" height="auto">
<video src="https://github.com/user-attachments/assets/a4134a0d-138c-4ab4-bc70-0f53b3507e6b"></video>
***
Sample 2: The Great Wave off Kanagawa, 1831 (Hokusai) and Takiyasha the Witch and the Skeleton Spectre, c. 1844 (Kuniyoshi)
***
<img src="data/images/japan_1.jpg" alt="The Great Wave off Kanagawa, 1831 (Hokusai)" width="20%" height="auto"> <img src="data/images/japan2.jpg" alt="Takiyasha the Witch and the Skeleton Spectre, c. 1844 (Kuniyoshi)" width="21.5%" height="auto">
<video src="https://github.com/user-attachments/assets/f6aaaeeb-39d2-4dde-afaf-e2cd212e9fed"></video>
***
Sample 3: Pop culture icon Taylor Swift and Mona Lisa, 1503 (Leonardo da Vinci)
***
<img src="data/images/taylor.png" alt="Taylor Swift" width="28%" height="auto"> <img src="data/images/monalisa.jpeg" alt="Mona Lisa" width="10.5%" height="auto">
<video src="https://github.com/user-attachments/assets/3b6f7075-159b-4540-946f-3f3907dffbca"></video>
### Text
| Audio | Description | Source |
|-------|--|--------|
| <video src="https://github.com/user-attachments/assets/ef41a207-a204-4b60-a11e-06d66a0fbf06"></video> | Personal Website | [Website](https://www.souzatharsis.com) |
| [Audio](https://soundcloud.com/high-lander123/amodei?in=high-lander123/sets/podcastfy-sample-audio-longform&si=b8dfaf4e3ddc4651835e277500384156) (`longform=True`) | Lex Fridman Podcast: 5h interview with Dario Amodei Anthropic's CEO | [Youtube](https://www.youtube.com/watch?v=ugvHCXCOmm4) |
| [Audio](https://soundcloud.com/high-lander123/benjamin?in=high-lander123/sets/podcastfy-sample-audio-longform&si=dca7e2eec1c94252be18b8794499959a&utm_source=clipboard&utm_medium=text&utm_campaign=social_sharing) (`longform=True`)| Benjamin Franklin's Autobiography | [Book](https://www.gutenberg.org/cache/epub/148/pg148.txt) |
### Multi-Lingual Text
| Language | Content Type | Description | Audio | Source |
|----------|--------------|-------------|-------|--------|
| French | Website | Agroclimate research information | [Audio](https://audio.com/thatupiso/audio/podcast-fr-agro) | [Website](https://agroclim.inrae.fr/) |
| Portuguese-BR | News Article | Election polls in São Paulo | [Audio](https://audio.com/thatupiso/audio/podcast-thatupiso-br) | [Website](https://noticias.uol.com.br/eleicoes/2024/10/03/nova-pesquisa-datafolha-quem-subiu-e-quem-caiu-na-disputa-de-sp-03-10.htm) |
## Quickstart 💻
### Prerequisites
- Python 3.11 or higher
- `$ pip install ffmpeg` (for audio processing)
### Setup
1. Install from PyPI
`$ pip install podcastfy`
2. Set up your [API keys](usage/config.md)
### Python
```python
from podcastfy.client import generate_podcast
audio_file = generate_podcast(urls=["<url1>", "<url2>"])
```
### CLI
```
python -m podcastfy.client --url <url1> --url <url2>
```
## Usage 💻
- [Python Package Quickstart](podcastfy.ipynb)
- [How to](usage/how-to.md)
- [Python Package Reference Manual](https://podcastfy.readthedocs.io/en/latest/podcastfy.html)
- [CLI](usage/cli.md)
## Customization 🔧
Podcastfy offers a range of customization options to tailor your AI-generated podcasts:
- Customize podcast [conversation](usage/conversation_custom.md) (e.g. format, style, voices)
- Choose to run [Local LLMs](usage/local_llm.md) (156+ HuggingFace models)
- Set other [Configuration Settings](usage/config.md)
## Features ✨
- Generate conversational content from multiple sources and formats (images, text, websites, YouTube, and PDFs).
- Generate shorts (2-5 minutes) or longform (30+ minutes) podcasts.
- Customize transcript and audio generation (e.g., style, language, structure).
- Generate transcripts using 100+ LLM models (OpenAI, Anthropic, Google etc).
- Leverage local LLMs for transcript generation for increased privacy and control.
- Integrate with advanced text-to-speech models (OpenAI, Google, ElevenLabs, and Microsoft Edge).
- Provide multi-language support for global content creation.
- Integrate seamlessly with CLI and Python packages for automated workflows.
## Built with Podcastfy 🚀
- [OpenNotebook](https://www.open-notebook.ai/)
- [SurfSense](https://www.surfsense.net/)
- [OpenPod](https://openpod.fly.dev/)
- [Podcast-llm](https://github.com/evandempsey/podcast-llm)
- [Podcastfy-HuggingFace App](https://huggingface.co/spaces/thatupiso/Podcastfy.ai_demo)
## Updates 🚀🚀
### v0.4.0+ release
- Released new Multi-Speaker TTS model (is it the one NotebookLM uses?!?)
- Generate short or longform podcasts
- Generate podcasts from input topic using grounded real-time web search
- Integrate with 100+ LLM models (OpenAI, Anthropic, Google etc) for transcript generation
See [CHANGELOG](CHANGELOG.md) for more details.
## License
This software is licensed under [Apache 2.0](LICENSE). See [instructions](usage/license-guide.md) if you would like to use podcastfy in your software.
## Contributing 🤝
We welcome contributions! See [Guidelines](GUIDELINES.md) for more details.
## Example Use Cases 🎧🎶
- **Content Creators** can use `Podcastfy` to convert blog posts, articles, or multimedia content into podcast-style audio, enabling them to reach broader audiences. By transforming content into an audio format, creators can cater to users who prefer listening over reading.
- **Educators** can transform lecture notes, presentations, and visual materials into audio conversations, making educational content more accessible to students with different learning preferences. This is particularly beneficial for students with visual impairments or those who have difficulty processing written information.
- **Researchers** can convert research papers, visual data, and technical content into conversational audio. This makes it easier for a wider audience, including those with disabilities, to consume and understand complex scientific information. Researchers can also create audio summaries of their work to enhance accessibility.
- **Accessibility Advocates** can use `Podcastfy` to promote digital accessibility by providing a tool that converts multimodal content into auditory formats. This helps individuals with visual impairments, dyslexia, or other disabilities that make it challenging to consume written or visual content.
## Contributors
<a href="https://github.com/souzatharsis/podcastfy/graphs/contributors">
<img alt="contributors" src="https://contrib.rocks/image?repo=souzatharsis/podcastfy"/>
</a>
<p align="right" style="font-size: 14px; color: #555; margin-top: 20px;">
<a href="#readme-top" style="text-decoration: none; color: #007bff; font-weight: bold;">
↑ Back to Top ↑
</a>
</p> | {
"source": "souzatharsis/podcastfy",
"title": "README.md",
"url": "https://github.com/souzatharsis/podcastfy/blob/main/README.md",
"date": "2024-09-30T22:35:09",
"stars": 2726,
"description": "An Open Source Python alternative to NotebookLM's podcast feature: Transforming Multimodal Content into Captivating Multilingual Audio Conversations with GenAI",
"file_size": 10298
} |
- "Love that you casually built an open source version of the most popular product Google built in the last decade"
- "Your library was very straightforward to work with. You did Amazing work brother 🙏"
- "I think it's awesome that you were inspired/recognize how hard it is to beat NotebookLM's quality, but you did an *incredible* job with this! It sounds incredible, and it's open-source! Thank you for being amazing!"
- "Discovered your work last night. Stunning accomplishment. Well done."
- "Loving this initiative and the best I have seen so far especially for a "non-techie" user." | {
"source": "souzatharsis/podcastfy",
"title": "TESTIMONIALS.md",
"url": "https://github.com/souzatharsis/podcastfy/blob/main/TESTIMONIALS.md",
"date": "2024-09-30T22:35:09",
"stars": 2726,
"description": "An Open Source Python alternative to NotebookLM's podcast feature: Transforming Multimodal Content into Captivating Multilingual Audio Conversations with GenAI",
"file_size": 589
} |
---
title: 'When Content Speaks Volumes: Podcastfy — An Open Source Python Package Bridging Multimodal Data and Conversational Audio with GenAI'
tags:
- Python
- generative AI
- GenAI
- text-to-speech
- large language models
- content transformation
- accessibility
authors:
- name: Tharsis T. P. Souza
orcid: 0000-0003-3260-9526
affiliation: "1, 2"
affiliations:
- name: Columbia University in the City of New York
index: 1
- name: Instituto Federal de Educacao, Ciencia e Tecnologia do Sul de Minas (IFSULDEMINAS)
index: 2
date: 11/03/2024
bibliography: paper.bib
---
# Abstract
`Podcastfy` is an open-source Python framework that programmatically transforms multisourced, multimodal content into multilingual, natural-sounding audio conversations using generative AI. By converting various types of digital content - including images, websites, YouTube videos, and PDFs - into conversational audio formats, `Podcastfy` enhances accessibility, engagement, and usability for a wide range of users. As an open-source project, `Podcastfy` benefits from continuous community-driven improvements, enhancing its adaptability to evolving user requirements and accessibility standards.
# Statement of Need
The rapid expansion of digital content across various formats has intensified the need for tools capable of converting diverse information into accessible and digestible forms [@johnson2023adaptive; @chen2023digital; @mccune2023accessibility]. Existing solutions often fall short due to their proprietary nature, limited multimodal support, or inadequate accessibility features [@marcus2019design; @peterson2023web; @gupta2023advances].
`Podcastfy` addresses this gap with an open-source solution that supports multimodal input processing and generates natural-sounding, summarized conversational content. Leveraging advances in large language models (LLMs) and text-to-speech (TTS) synthesis, `Podcastfy` aims to benefit a diverse group of users — including content creators, educators, researchers, and accessibility advocates — by providing a customizable solution that transforms digital content into multilingual textual and auditory formats, enhancing accessibility and engagement.
# Features
- Generate conversational content from multiple sources and formats (images, websites, YouTube, and PDFs).
- Customize transcript and audio generation (e.g., style, language, structure, length).
- Create podcasts from pre-existing or edited transcripts.
- Leverage cloud-based and local LLMs for transcript generation (increased privacy and control).
- Integrate with advanced text-to-speech models (OpenAI, ElevenLabs, and Microsoft Edge).
- Provide multi-language support for global content creation and enhanced accessibility.
- Integrate seamlessly with CLI and Python packages for automated workflows.
See [audio samples](https://github.com/souzatharsis/podcastfy?tab=readme-ov-file#audio-examples-).
# Use Cases
`Podcastfy` is designed to serve a wide range of applications, including:
- **Content Creators** can use `Podcastfy` to convert blog posts, articles, or multimedia content into podcast-style audio, enabling them to reach broader audiences. By transforming content into an audio format, creators can cater to users who prefer listening over reading.
- **Educators** can transform lecture notes, presentations, and visual materials into audio conversations, making educational content more accessible to students with different learning preferences. This is particularly beneficial for students with visual impairments or those who have difficulty processing written information.
- **Researchers** can convert research papers, visual data, and technical content into conversational audio. This makes it easier for a wider audience, including those with disabilities, to consume and understand complex scientific information. Researchers can also create audio summaries of their work to enhance accessibility.
- **Accessibility Advocates** can use `Podcastfy` to promote digital accessibility by providing a tool that converts multimodal content into auditory formats. This helps individuals with visual impairments, dyslexia, or other disabilities that make it challenging to consume written or visual content.
# Implementation and Architecture
`Podcastfy` implements a modular architecture designed for flexibility and extensibility through five main components, as shown in Figure 1.
1. **Client Interface**
- Provides both CLI (Command-Line Interface) and API interfaces.
- Coordinates the workflow between processing layers.
- Implements a unified interface for podcast generation through the `generate_podcast()` method.
2. **Configuration Management**
- Offers extensive customization options through a dedicated module.
- Manages system settings and user preferences, such as podcast name, language, style, and structure.
- Controls the behavior of all processing layers.
3. **Content Extraction Layer**
- Extracts content from various sources, including websites, PDFs, and YouTube videos.
- The `ContentExtractor` class coordinates three specialized extractors:
- `PDFExtractor`: Handles PDF document processing.
- `WebsiteExtractor`: Manages website content extraction.
- `YouTubeTranscriber`: Processes YouTube video content.
- Serves as the entry point for all input types, providing standardized text output to the transcript generator.
4. **LLM-based Transcript Generation Layer**
- Uses large language models to generate natural-sounding conversations from extracted content.
- The `ContentGenerator` class manages conversation generation using different LLM backends:
- Integrates with LangChain to implement prompt management and common LLM access through the `BaseChatModel` interface.
- Supports both local (`LlamaFile`) and cloud-based models.
- Uses `ChatGoogleGenerativeAI` for cloud-based LLM services.
- Allows customization of conversation style, roles, and dialogue structure.
- Outputs structured conversations in text format.
5. **Text-to-Speech (TTS) Layer**
- Converts input transcripts into audio using various TTS models.
- The `TextToSpeech` class implements a factory pattern:
- The `TTSFactory` creates appropriate providers based on configuration.
- Supports multiple backends (OpenAI, ElevenLabs, and Microsoft Edge) through the `TTSProvider` interface.
- Produces the final podcast audio output.
{width=80%}
The modular architecture enables independent development and maintenance of each component. This pipeline design ensures a clean separation of concerns while maintaining seamless data transformation between stages. This modular approach also facilitates easy updates and extensions to individual components without affecting the rest of the system.
The framework is offered as a Python package, with a command-line interface as well as a REST API, making it accessible to users with different technical backgrounds and requirements.
# Quick Start
## Prerequisites
- Python 3.11 or higher
- `$ pip install ffmpeg` (for audio processing)
## Setup
1. Install from PyPI
`$ pip install podcastfy`
2. Set up [API keys](usage/config.md)
## Python
```python
from podcastfy.client import generate_podcast
audio_file = generate_podcast(urls=["<url1>", "<url2>"])
```
## CLI
```
python -m podcastfy.client --url <url1> --url <url2>
```
# Customization Examples
`Podcastfy` offers various customization options that make it versatile for different types of content transformation. To accomplish that, we leverage LangChain's [@langchain2024] prompt management capabilities to dynamically construct prompts for the LLM, adjusting conversation characteristics such as style, roles, and dialogue structure. Below are some examples that demonstrate its capabilities.
## Academic Debate
The following Python code demonstrates how to configure `Podcastfy` for an academic debate:
```python
from podcastfy import generate_podcast
debate_config = {
"conversation_style": ["formal", "debate"],
"roles_person1": "main presenter",
"roles_person2": "opposing viewpoint",
"dialogue_structure": ["Introduction", "Argument Presentation", "Counterarguments", "Conclusion"]
}
generate_podcast(
urls=["PATH/TO/academic-article.pdf"],
conversation_config=debate_config
)
```
In this example, the roles are set to "main presenter" and "opposing viewpoint" to simulate an academic debate between two speakers on a chosen topic. This approach is especially useful for educational content that aims to present multiple perspectives on a topic. The output is structured with clear sections such as introduction, argument presentation, counterarguments, and conclusion, allowing listeners to follow complex ideas easily.
## Technical Tutorial
In this example, the configuration is optimized for creating technical tutorial content.
```python
tutorial_config = {
"word_count": 2500,
"conversation_style": ["instructional", "step-by-step"],
"roles_person1": "expert developer",
"roles_person2": "learning developer",
"dialogue_structure": [
"Concept Introduction",
"Technical Background",
"Implementation Steps",
"Common Pitfalls",
"Best Practices"
],
"engagement_techniques": [
"code examples",
"real-world applications",
"troubleshooting tips"
],
"creativity": 0.4
}
generate_podcast(
urls=["https://tech-blog.com/tutorial"],
conversation_config=tutorial_config
)
```
The roles are set to "expert developer" and "learning developer" to create a natural teaching dynamic. The dialogue structure follows a logical progression from concept introduction through implementation and best practices. The engagement_techniques parameter ensures the content remains practical and applicable by incorporating code examples, real-world applications, and troubleshooting guidance. A moderate creativity setting (0.4) maintains technical accuracy while allowing for engaging explanations and examples.
## Storytelling Adventure
The following Python code demonstrates how to generate a storytelling podcast:
```python
from podcastfy import generate_podcast
story_config = {
"conversation_style": ["adventurous", "narrative"],
"creativity": 1.0,
"roles_person1": "narrator",
"roles_person2": "character",
"dialogue_structure": ["Introduction", "Adventure Begins", "Challenges", "Resolution"]
}
generate_podcast(
urls=["SAMPLE/WWW.URL.COM"],
conversation_config=story_config
)
```
In this example, `Podcastfy` creates an engaging story by assigning roles like "narrator" and "character" and adjusting the creativity parameter for richer descriptions. Using this configuration, `Podcastfy` can generate engaging narrative content. By adjusting the creativity parameter, `Podcastfy` can create a story involving multiple characters, unexpected plot twists, and rich descriptions.
## Additional Examples
### Daily News Briefing
```python
news_config = {
"word_count": 1500,
"conversation_style": ["concise", "informative"],
"podcast_name": "Morning Briefing",
"dialogue_structure": [
"Headlines",
"Key Stories",
"Market Update",
"Weather"
],
"roles_person1": "news anchor",
"roles_person2": "field reporter",
"creativity": 0.3
}
generate_podcast(
urls=[
"https://news-source.com/headlines",
"https://market-updates.com/today"
],
conversation_config=news_config
)
```
### Language Learning Content
```python
language_config = {
"output_language": "Spanish",
"word_count": 1000,
"conversation_style": ["educational", "casual"],
"engagement_techniques": [
"vocabulary explanations",
"cultural context",
"pronunciation tips"
],
"roles_person1": "language teacher",
"roles_person2": "curious student",
"creativity": 0.6
}
generate_podcast(
urls=["https://spanish-content.com/article"],
conversation_config=language_config
)
```
## Working with Podcastfy Modules
`Podcastfy`'s components are designed to work independently, allowing flexibility in updating or extending each module. The data flows from the `ContentExtractor` module to `ContentGenerator` and finally to the `TexttoSpeech` converter, ensuring a seamless transformation of multimodal content into audio. In this section, we provide some examples of how to use each module.
## Content Extraction
Podcastfy's `content_extractor.py` module allows users to extract content from a given URL, which can be processed further to generate a podcast. Below is an example of how to use the content extraction component:
```python
from podcastfy.content_extractor import ContentExtractor
# Initialize the content extractor
extractor = ContentExtractor()
# Extract content from a URL
url = "https://example.com/article"
extracted_content = extractor.extract_content(url)
print("Extracted Content:")
print(extracted_content)
```
This example demonstrates how to extract text from a given URL. The extracted content is then passed to the next stages of processing.
## Content Generation
The `content_generator.py` module is responsible for generating conversational content based on textual input. Below is an example of how to use the content generation component:
```python
from podcastfy.content_generator import ContentGenerator
# Initialize the content generator
generator = ContentGenerator(api_key="<GEMINI_API_KEY>")
# Generate conversational content
input_text = "This is a sample input text about artificial intelligence."
generated_conversation = generator.generate_conversation(input_text)
print("Generated Conversation:")
print(generated_conversation)
```
Users can opt to run a cloud-based LLM (Gemini) or run a local (potentially Open Source) LLM model ([see local llm configuration](https://github.com/souzatharsis/podcastfy/blob/main/usage/local_llm.md)).
## Text-to-Speech Conversion
The `text_to_speech.py` module allows the generated transcript to be converted into audio. Below is an example of how to use the text-to-speech component:
```python
from podcastfy.text_to_speech import TextToSpeech
# Initialize the text-to-speech converter
tts = TextToSpeech(model='elevenlabs', api_key="<ELEVENLABS_API_KEY>")
# Convert the generated conversation to speech
input_text = "<Person1>This is a sample conversation generated by Podcastfy.</Person1><Person2>That's great!</Person2>"
output_audio_file = "output_podcast.mp3"
tts.convert_to_speech(input_text, output_audio_file)
print(f"Audio saved to {output_audio_file}")
```
This example demonstrates how to use the `TextToSpeech` class to convert generated text into an audio file. Users can specify different models for TTS, such as `elevenlabs`, `openai`, or `edge` (free to use).
# Limitations
`Podcastfy` has several limitations, including:
- **Content Accuracy and Quality**
- The accuracy of generated conversations depends heavily on the capabilities of the underlying LLMs.
- Complex technical or domain-specific content may not always be accurately interpreted or summarized.
- The framework cannot guarantee the factual correctness of generated content, requiring human verification for critical applications.
- **Language Support Constraints**
- While multilingual support is available, performance may vary significantly across different languages.
- Less common languages may have limited TTS voice options and lower-quality speech synthesis.
- Nuanced cultural contexts and idioms may not translate effectively across languages.
- **Technical Dependencies**
- Reliance on third-party APIs (OpenAI, ElevenLabs, Google) introduces potential service availability risks.
- Local LLM options, while providing independence, require significant computational resources.
- Network connectivity is required for cloud-based services, limiting offline usage.
- **Content Extraction Challenges**
- Complex webpage layouts or dynamic content may not be accurately extracted.
- PDF extraction quality depends on document formatting and structure.
- YouTube video processing depends on the availability of transcripts.
- **Accessibility Considerations**
- Generated audio may not fully meet all accessibility standards.
- Limited support for real-time content processing.
- May require additional processing for users with specific accessibility needs.
These limitations highlight areas for future development and improvement of the framework. Users should carefully consider these constraints when implementing `Podcastfy` for their specific use cases and requirements.
# Limitations
`Podcastfy` faces several key limitations in its current implementation. The accuracy and quality of generated content heavily depends on the underlying LLMs, with complex technical content potentially being misinterpreted. Additionally, while multilingual support is available, performance varies across languages, with less common languages having limited TTS voice options. The framework also relies on third-party APIs which introduces service availability risks, and local LLM options require significant computational resources.
These limitations highlight areas for future development and improvement of the framework. Users should carefully consider these constraints when implementing `Podcastfy` for their specific use cases and requirements.
# Conclusion
`Podcastfy` contributes to multimodal content accessibility by enabling the programmatic transformation of digital content into conversational audio. The framework addresses accessibility needs through automated content summarization and natural-sounding speech synthesis. Its modular design and configurable options allow for flexible content processing and audio generation workflows that can be adapted for different use cases and requirements.
We invite contributions from the community to further enhance the capabilities of `Podcastfy`. Whether it's by adding support for new input modalities, improving the quality of conversation generation, or optimizing the TTS synthesis, we welcome collaboration to make `Podcastfy` more powerful and versatile.
# Acknowledgements
We acknowledge the open-source community and the developers of the various libraries and tools that make `Podcastfy` possible. Special thanks to the developers of LangChain, Llamafile and HuggingFace. We are particularly grateful to all our [contributors](https://github.com/souzatharsis/podcastfy/graphs/contributors) who have helped improve this project.
# References | {
"source": "souzatharsis/podcastfy",
"title": "paper/paper.md",
"url": "https://github.com/souzatharsis/podcastfy/blob/main/paper/paper.md",
"date": "2024-09-30T22:35:09",
"stars": 2726,
"description": "An Open Source Python alternative to NotebookLM's podcast feature: Transforming Multimodal Content into Captivating Multilingual Audio Conversations with GenAI",
"file_size": 18817
} |
* NotebookLM by Google
* Storm by Stanford University
* Open Notebook by @lf
* Open NotebookLM
* podlm.ai
* notebooklm.ai | {
"source": "souzatharsis/podcastfy",
"title": "paper/related-work.md",
"url": "https://github.com/souzatharsis/podcastfy/blob/main/paper/related-work.md",
"date": "2024-09-30T22:35:09",
"stars": 2726,
"description": "An Open Source Python alternative to NotebookLM's podcast feature: Transforming Multimodal Content into Captivating Multilingual Audio Conversations with GenAI",
"file_size": 121
} |
# Podcastfy REST API Documentation
## Overview
The Podcastfy API allows you to programmatically generate AI podcasts from various input sources. This document outlines the API endpoints and their usage.
## Using cURL with Podcastfy API
### Prerequisites
1. Confirm cURL installation:
```bash
curl --version
```
### API Request Flow
Making a prediction requires two sequential requests:
1. POST request to initiate processing - returns an `EVENT_ID`
2. GET request to fetch results - uses the `EVENT_ID` to fetch results
Between step 1 and 2, there is a delay of 1-3 minutes. We are working on reducing this delay and implementing a way to notify the user when the podcast is ready. Thanks for your patience!
### Basic Request Structure
```bash
# Step 1: POST request to initiate processing
# Make sure to include http:// or https:// in the URL
curl -X POST https://thatupiso-podcastfy-ai-demo.hf.space/gradio_api/call/process_inputs \
-H "Content-Type: application/json" \
-d '{
"data": [
"text_input",
"https://yourwebsite.com",
[], # pdf_files
[], # image_files
"gemini_key",
"openai_key",
"elevenlabs_key",
2000, # word_count
"engaging,fast-paced", # conversation_style
"main summarizer", # roles_person1
"questioner", # roles_person2
"Introduction,Content,Conclusion", # dialogue_structure
"PODCASTFY", # podcast_name
"YOUR PODCAST", # podcast_tagline
"openai", # tts_model
0.7, # creativity_level
"" # user_instructions
]
}'
# Step 2: GET request to fetch results
curl -N https://thatupiso-podcastfy-ai-demo.hf.space/gradio_api/call/process_inputs/$EVENT_ID
# Example output result
event: complete
data: [{"path": "/tmp/gradio/bcb143f492b1c9a6dbde512557541e62f090bca083356be0f82c2e12b59af100/podcast_81106b4ca62542f1b209889832a421df.mp3", "url": "https://thatupiso-podcastfy-ai-demo.hf.space/gradio_a/gradio_api/file=/tmp/gradio/bcb143f492b1c9a6dbde512557541e62f090bca083356be0f82c2e12b59af100/podcast_81106b4ca62542f1b209889832a421df.mp3", "size": null, "orig_name": "podcast_81106b4ca62542f1b209889832a421df.mp3", "mime_type": null, "is_stream": false, "meta": {"_type": "gradio.FileData"}}]
```
You can download the file by extending the URL prefix "https://thatupiso-podcastfy-ai-demo.hf.space/gradio_a/gradio_api/file=" with the path to the file in variable `path`. (Note: The variable "url" above has a bug introduced by Gradio, so please ignore it.)
### Parameter Details
| Index | Parameter | Type | Description |
|-------|-----------|------|-------------|
| 0 | text_input | string | Direct text input for podcast generation |
| 1 | urls_input | string | URLs to process (include http:// or https://) |
| 2 | pdf_files | array | List of PDF files to process |
| 3 | image_files | array | List of image files to process |
| 4 | gemini_key | string | Google Gemini API key |
| 5 | openai_key | string | OpenAI API key |
| 6 | elevenlabs_key | string | ElevenLabs API key |
| 7 | word_count | number | Target word count for podcast |
| 8 | conversation_style | string | Conversation style descriptors (e.g. "engaging,fast-paced") |
| 9 | roles_person1 | string | Role of first speaker |
| 10 | roles_person2 | string | Role of second speaker |
| 11 | dialogue_structure | string | Structure of dialogue (e.g. "Introduction,Content,Conclusion") |
| 12 | podcast_name | string | Name of the podcast |
| 13 | podcast_tagline | string | Podcast tagline |
| 14 | tts_model | string | Text-to-speech model ("gemini", "openai", "elevenlabs", or "edge") |
| 15 | creativity_level | number | Level of creativity (0-1) |
| 16 | user_instructions | string | Custom instructions for generation |
## Using Python
### Installation
```bash
pip install gradio_client
```
### Quick Start
```python
from gradio_client import Client, handle_file
client = Client("thatupiso/Podcastfy.ai_demo")
```
### API Endpoints
#### Generate Podcast (`/process_inputs`)
Generates a podcast from provided text, URLs, PDFs, or images.
##### Parameters
| Parameter | Type | Required | Default | Description |
|-----------|------|----------|---------|-------------|
| text_input | str | Yes | - | Raw text input for podcast generation |
| urls_input | str | Yes | - | Comma-separated URLs to process |
| pdf_files | List[filepath] | Yes | None | List of PDF files to process |
| image_files | List[filepath] | Yes | None | List of image files to process |
| gemini_key | str | No | "" | Google Gemini API key |
| openai_key | str | No | "" | OpenAI API key |
| elevenlabs_key | str | No | "" | ElevenLabs API key |
| word_count | float | No | 2000 | Target word count for podcast |
| conversation_style | str | No | "engaging,fast-paced,enthusiastic" | Conversation style descriptors |
| roles_person1 | str | No | "main summarizer" | Role of first speaker |
| roles_person2 | str | No | "questioner/clarifier" | Role of second speaker |
| dialogue_structure | str | No | "Introduction,Main Content Summary,Conclusion" | Structure of dialogue |
| podcast_name | str | No | "PODCASTFY" | Name of the podcast |
| podcast_tagline | str | No | "YOUR PERSONAL GenAI PODCAST" | Podcast tagline |
| tts_model | Literal['openai', 'elevenlabs', 'edge'] | No | "openai" | Text-to-speech model |
| creativity_level | float | No | 0.7 | Level of creativity (0-1) |
| user_instructions | str | No | "" | Custom instructions for generation |
##### Returns
| Type | Description |
|------|-------------|
| filepath | Path to generated audio file |
##### Example Usage
```python
from gradio_client import Client, handle_file
client = Client("thatupiso/Podcastfy.ai_demo")
# Generate podcast from URL
result = client.predict(
text_input="",
urls_input="https://example.com/article",
pdf_files=[],
image_files=[],
gemini_key="your-gemini-key",
openai_key="your-openai-key",
word_count=1500,
conversation_style="casual,informative",
podcast_name="Tech Talk",
tts_model="openai",
creativity_level=0.8
)
print(f"Generated podcast: {result}")
```
### Error Handling
The API will return appropriate error messages for:
- Invalid API keys
- Malformed input
- Failed file processing
- TTS generation errors
### Rate Limits
Please be aware of the rate limits for the underlying services:
- Gemini API
- OpenAI API
- ElevenLabs API
## Notes
- At least one input source (text, URL, PDF, or image) must be provided
- API keys are required for corresponding services
- The generated audio file format is MP3 | {
"source": "souzatharsis/podcastfy",
"title": "usage/api.md",
"url": "https://github.com/souzatharsis/podcastfy/blob/main/usage/api.md",
"date": "2024-09-30T22:35:09",
"stars": 2726,
"description": "An Open Source Python alternative to NotebookLM's podcast feature: Transforming Multimodal Content into Captivating Multilingual Audio Conversations with GenAI",
"file_size": 6561
} |
## CLI
Podcastfy can be used as a command-line interface (CLI) tool. See below some usage examples.
Please make sure you follow configuration instructions first - [See Setup](README.md#setup).
1. Generate a podcast from URLs (using OpenAI TTS by default):
```
python -m podcastfy.client --url https://example.com/article1 --url https://example.com/article2
```
2. Generate a podcast from URLs using ElevenLabs TTS:
```
python -m podcastfy.client --url https://example.com/article1 --url https://example.com/article2 --tts-model elevenlabs
```
3. Generate a podcast from a file containing URLs:
```
python -m podcastfy.client --file path/to/urls.txt
```
4. Generate a podcast from an existing transcript file:
```
python -m podcastfy.client --transcript path/to/transcript.txt
```
5. Generate only a transcript (without audio) from URLs:
```
python -m podcastfy.client --url https://example.com/article1 --transcript-only
```
6. Generate a podcast using a combination of URLs and a file:
```
python -m podcastfy.client --url https://example.com/article1 --file path/to/urls.txt
```
7. Generate a podcast from image files:
```
python -m podcastfy.client --image path/to/image1.jpg --image path/to/image2.png
```
8. Generate a podcast with a custom conversation configuration:
```
python -m podcastfy.client --url https://example.com/article1 --conversation-config path/to/custom_config.yaml
```
9. Generate a podcast from URLs and images:
```
python -m podcastfy.client --url https://example.com/article1 --image path/to/image1.jpg
```
10. Generate a transcript using a local LLM:
```
python -m podcastfy.client --url https://example.com/article1 --transcript-only --local
```
11. Generate a podcast from raw text input:
```
python -m podcastfy.client --text "Your raw text content here that you want to convert into a podcast"
```
12. Generate a longform podcast from URLs:
```
python -m podcastfy.client --url https://example.com/article1 --url https://example.com/article2 --longform
```
For more information on available options, use:
```
python -m podcastfy.client --help
``` | {
"source": "souzatharsis/podcastfy",
"title": "usage/cli.md",
"url": "https://github.com/souzatharsis/podcastfy/blob/main/usage/cli.md",
"date": "2024-09-30T22:35:09",
"stars": 2726,
"description": "An Open Source Python alternative to NotebookLM's podcast feature: Transforming Multimodal Content into Captivating Multilingual Audio Conversations with GenAI",
"file_size": 2221
} |
# Podcastfy Configuration
## API keys
The project uses a combination of a `.env` file for managing API keys and sensitive information, and a `config.yaml` file for non-sensitive configuration settings. Follow these steps to set up your configuration:
1. Create a `.env` file in the root directory of the project.
2. Add your API keys and other sensitive information to the `.env` file. For example:
```
GEMINI_API_KEY=your_gemini_api_key_here
ELEVENLABS_API_KEY=your_elevenlabs_api_key_here
OPENAI_API_KEY=your_openai_api_key_here
```
## API Key Requirements
The API Keys required depend on the model you are using for transcript generation and audio generation.
- Transcript generation (LLMs):
- By default, Podcastfy uses Google's `gemini-1.5-pro-latest` model. Hence, you need to set `GEMINI_API_KEY`.
- See how to configure other LLMs [here](how-to.md#custom-llm-support).
- Audio generation (TTS):
- By default, Podcastfy uses OpenAI TTS. Hence, you need to set `OPENAI_API_KEY`.
- Additional supported models are ElevenLabs ('elevenlabs'), Microsoft Edge ('edge') and Google TTS ('gemini'). All but Edge require an API key.
> [!Note]
> Never share your `.env` file or commit it to version control. It contains sensitive information that should be kept private. The `config.yaml` file can be shared and version-controlled as it doesn't contain sensitive data.
## Example Configurations
Here's a table showing example configurations:
| Configuration | Base LLM | TTS Model | API Keys Required |
| -------------------- | --------- | ---------------------- | --------------------------------- |
| Default | Gemini | OpenAI | GEMINI_API_KEY and OPENAI_API_KEY |
| No API Keys Required | Local LLM | Edge | None |
| Recommended | Gemini | 'geminimulti' (Google) | GEMINI_API_KEY |
In our experience, Google's Multispeaker TTS model ('geminimulti') is the best model in terms of quality followed by ElevenLabs which offers great customization (voice options and multilingual capability). Google's multispeaker TTS model is limited to English only and requires an additional set up step.
## Setting up Google TTS Model
You can use Google's Multispeaker TTS model by setting the `tts_model` parameter to `geminimulti` in `Podcastfy`.
Google's Multispeaker TTS model requires a Google Cloud API key, you can use the same API key you are already using for Gemini or create a new one. After you have secured your API Key there are two additional steps in order to use Google Multispeaker TTS model:
- Step 1: You will need to enable the Cloud Text-to-Speech API on the API key.
- Go to "https://console.cloud.google.com/apis/dashboard"
- Select your project (or create one by clicking on project list and then on "new project")
- Click "+ ENABLE APIS AND SERVICES" at the top of the screen
- Enter "text-to-speech" into the search box
- Click on "Cloud Text-to-Speech API" and then on "ENABLE"
- You should be here: "https://console.cloud.google.com/apis/library/texttospeech.googleapis.com?project=..."
- Step 2: You need to add the Cloud Text-to-Speech API permission to the API KEY you're using on the Google Cloud console.
- Go to https://console.cloud.google.com/apis/credentials
- Click on whatever key you're using for Gemini
- Go down to API Restrictions and add the Cloud Text-to-Speech API
<br>
⚠️**NOTE :**<br>
By default, **Google Multi-Speaker voices** are only available to **allowlisted projects**. If you wish to use these voices, follow the steps below: <br>
- **Prerequisites:** A **paid Google Cloud support subscription** is required to proceed.
- **Request Access:** You'll need to **contact Google Cloud Support** to get Multi-Speaker voices enabled for your project.
- **Common Error:** If Multi-Speaker voices are not enabled, you will encounter the following runtime error:
```bash
RuntimeError: Failed to generate audio: 403 Multi-speaker voices are only available to allowlisted projects
```
- **How to Proceed:**
- Navigate to the **Support** section in your **GCP Console**. <br>
- Open a new case under **"Cases"** and provide the necessary project details. <br>
- Google Cloud Support should be able to assist you in enabling this feature. <br>
<br>

<br>
Phew!!! That was a lot of steps but you only need to do it once and you might be impressed with the quality of the audio. See [Google TTS](https://cloud.google.com/text-to-speech) for more details. Thank you @mobarski and @evandempsey for the help!
## Conversation Configuration
See [conversation_custom.md](conversation_custom.md) for more details.
## Running Local LLMs
See [local_llm.md](local_llm.md) for more details.
## Optional configuration
The `config.yaml` file in the root directory contains non-sensitive configuration settings. You can modify this file to adjust various parameters such as output directories, text-to-speech settings, and content generation options.
The application will automatically load the environment variables from `.env` and the configuration settings from `config.yaml` when it runs.
See [Configuration](config_custom.md) if you would like to further customize settings. | {
"source": "souzatharsis/podcastfy",
"title": "usage/config.md",
"url": "https://github.com/souzatharsis/podcastfy/blob/main/usage/config.md",
"date": "2024-09-30T22:35:09",
"stars": 2726,
"description": "An Open Source Python alternative to NotebookLM's podcast feature: Transforming Multimodal Content into Captivating Multilingual Audio Conversations with GenAI",
"file_size": 5415
} |
# Podcastfy Advanced Configuration Guide
Podcastfy uses a `config.yaml` file to manage various settings and parameters. This guide explains each configuration option available in the file.
## Content Generator
- `gemini_model`: "gemini-1.5-pro-latest"
- The Gemini AI model used for content generation.
- `max_output_tokens`: 8192
- Maximum number of tokens for the output generated by the AI model.
- `temperature`: 1
- Controls randomness in the AI's output. 0 means deterministic responses. Range for gemini-1.5-pro: 0.0 - 2.0 (default: 1.0)
- `langchain_tracing_v2`: false
- Enables LangChain tracing for debugging and monitoring. If true, requires langsmith api key
## Content Extractor
- `youtube_url_patterns`:
- Patterns to identify YouTube URLs.
- Current patterns: "youtube.com", "youtu.be"
## Website Extractor
- `markdown_cleaning`:
- `remove_patterns`:
- Patterns to remove from extracted markdown content.
- Current patterns remove image links, hyperlinks, and URLs.
## YouTube Transcriber
- `remove_phrases`:
- Phrases to remove from YouTube transcriptions.
- Current phrase: "[music]"
## Logging
- `level`: "INFO"
- Default logging level.
- `format`: "%(asctime)s - %(name)s - %(levelname)s - %(message)s"
- Format string for log messages.
## Website Extractor
- `markdown_cleaning`:
- `remove_patterns`:
- Additional patterns to remove from extracted markdown content:
- '\[.*?\]': Remove square brackets and their contents
- '\(.*?\)': Remove parentheses and their contents
- '^\s*[-*]\s': Remove list item markers
- '^\s*\d+\.\s': Remove numbered list markers
- '^\s*#+': Remove markdown headers
- `unwanted_tags`:
- HTML tags to be removed during extraction:
- 'script', 'style', 'nav', 'footer', 'header', 'aside', 'noscript'
- `user_agent`: 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
- User agent string to be used for web requests
- `timeout`: 10
- Request timeout in seconds for web scraping | {
"source": "souzatharsis/podcastfy",
"title": "usage/config_custom.md",
"url": "https://github.com/souzatharsis/podcastfy/blob/main/usage/config_custom.md",
"date": "2024-09-30T22:35:09",
"stars": 2726,
"description": "An Open Source Python alternative to NotebookLM's podcast feature: Transforming Multimodal Content into Captivating Multilingual Audio Conversations with GenAI",
"file_size": 2054
} |
# Podcastfy Conversation Configuration
Podcastfy offers a range of customization options to tailor your AI-generated podcasts. This document outlines how you can adjust parameters such as conversation style, word count, and dialogue structure to suit your specific needs.
## Table of Contents
1. [Parameters](#parameters)
2. [Customization Examples](#customization-examples)
1. [Academic Debate](#academic-debate)
2. [Storytelling Adventure](#storytelling-adventure)
3. [Customization Scenarios](#customization-scenarios)
1. [Using the Python Package](#using-the-python-package)
2. [Using the CLI](#using-the-cli)
4. [Notes of Caution](#notes-of-caution)
## Conversation Parameters
Podcastfy uses the default conversation configuration stored in [podcastfy/conversation_config.yaml](https://github.com/souzatharsis/podcastfy/blob/main/podcastfy/conversation_config.yaml).
| Parameter | Default Value | Type | Description |
|-----------|---------------|------|-------------|
| conversation_style | ["engaging", "fast-paced", "enthusiastic"] | list[str] | Styles to apply to the conversation |
| roles_person1 | "main summarizer" | str | Role of the first speaker |
| roles_person2 | "questioner/clarifier" | str | Role of the second speaker |
| dialogue_structure | ["Introduction", "Main Content Summary", "Conclusion"] | list[str] | Structure of the dialogue |
| podcast_name | "PODCASTIFY" | str | Name of the podcast |
| podcast_tagline | "Your Personal Generative AI Podcast" | str | Tagline for the podcast |
| output_language | "English" | str | Language of the output |
| engagement_techniques | ["rhetorical questions", "anecdotes", "analogies", "humor"] | list[str] | Techniques to engage the audience |
| creativity | 1 | float | Level of creativity/temperature (0-1) |
| user_instructions | "" | str | Custom instructions to guide the conversation focus and topics |
| max_num_chunks | 7 | int | Maximum number of rounds of discussions in longform |
| min_chunk_size | 600 | int | Minimum number of characters to generate a round of discussion in longform |
## Text-to-Speech (TTS) Settings
Podcastfy uses the default TTS configuration stored in [podcastfy/conversation_config.yaml](https://github.com/souzatharsis/podcastfy/blob/main/podcastfy/conversation_config.yaml).
### ElevenLabs TTS
- `default_voices`:
- `question`: "Chris"
- Default voice for questions in the podcast.
- `answer`: "Jessica"
- Default voice for answers in the podcast.
- `model`: "eleven_multilingual_v2"
- The ElevenLabs TTS model to use.
### OpenAI TTS
- `default_voices`:
- `question`: "echo"
- Default voice for questions using OpenAI TTS.
- `answer`: "shimmer"
- Default voice for answers using OpenAI TTS.
- `model`: "tts-1-hd"
- The OpenAI TTS model to use.
### Gemini Multi-Speaker TTS
- `default_voices`:
- `question`: "R"
- Default voice for questions using Gemini Multi-Speaker TTS.
- `answer`: "S"
- Default voice for answers using Gemini Multi-Speaker TTS.
- `model`: "en-US-Studio-MultiSpeaker"
- Model to use for Gemini Multi-Speaker TTS.
- `language`: "en-US"
- Language of the voices.
### Gemini TTS
- `default_voices`:
- `question`: "en-US-Journey-D"
- Default voice for questions using Gemini TTS.
- `answer`: "en-US-Journey-O"
- Default voice for answers using Gemini TTS.
### Edge TTS
- `default_voices`:
- `question`: "en-US-JennyNeural"
- Default voice for questions using Edge TTS.
- `answer`: "en-US-EricNeural"
- Default voice for answers using Edge TTS.
### General TTS Settings
- `default_tts_model`: "openai"
- Default text-to-speech model to use.
- `output_directories`:
- `transcripts`: "./data/transcripts"
- Directory for storing generated transcripts.
- `audio`: "./data/audio"
- Directory for storing generated audio files.
- `audio_format`: "mp3"
- Format of the generated audio files.
- `temp_audio_dir`: "data/audio/tmp/"
- Temporary directory for audio processing.
- `ending_message`: "Bye Bye!"
- Message to be appended at the end of the podcast.
## Customization Examples
These examples demonstrate how conversations can be altered to suit different purposes, from academic rigor to creative storytelling. The comments explain the rationale behind each choice, helping users understand how to tailor the configuration to their specific needs.
### Academic Debate
This configuration transforms the podcast into a formal academic debate, encouraging deep analysis and critical thinking. It's designed for educational content or in-depth discussions on complex topics.
```python
{
"word_count": 3000, # Longer to allow for detailed arguments
"conversation_style": ["formal", "analytical", "critical"], # Appropriate for academic discourse
"roles_person1": "thesis presenter", # Presents the main argument
"roles_person2": "counterargument provider", # Challenges the thesis
"dialogue_structure": [
"Opening Statements",
"Thesis Presentation",
"Counterarguments",
"Rebuttals",
"Closing Remarks"
], # Mimics a structured debate format
"podcast_name": "Scholarly Showdown",
"podcast_tagline": "Where Ideas Clash and Knowledge Emerges",
"engagement_techniques": [
"socratic questioning",
"historical references",
"thought experiments"
], # Techniques to stimulate critical thinking
"creativity": 0 # Low creativity to maintain focus on facts and logic
}
```
### Storytelling Adventure
This configuration turns the podcast into an interactive storytelling experience, engaging the audience in a narrative journey. It's ideal for fiction podcasts or creative content marketing.
```yaml
word_count: 1000 # Shorter to maintain pace and suspense
conversation_style:
- narrative
- suspenseful
- descriptive # Creates an immersive story experience
roles_person1: storyteller
roles_person2: audience participator # Allows for interactive elements
dialogue_structure:
- Scene Setting
- Character Introduction
- Rising Action
- Climax
- Resolution # Follows classic storytelling structure
podcast_name: Tale Spinners
podcast_tagline: Where Every Episode is an Adventure
engagement_techniques:
- cliffhangers
- vivid imagery
- audience prompts # Keeps the audience engaged and coming back
creativity: 0.9 # High creativity for unique and captivating stories
```
## Customization Scenarios
### Using the Python Package
When using the Podcastfy Python package, you can customize the conversation by passing a dictionary to the `conversation_config` parameter:
```python
from podcastfy.client import generate_podcast
custom_config = {
"word_count": 200,
"conversation_style": ["casual", "humorous"],
"podcast_name": "Tech Chuckles",
"creativity": 0.7
}
generate_podcast(
urls=["https://example.com/tech-news"],
conversation_config=custom_config
)
```
### Using the CLI
When using the Podcastfy CLI, you can specify a path to a YAML file containing your custom configuration:
```bash
podcastfy --url https://example.com/tech-news --conversation-config path/to/custom_config.yaml
```
The `custom_config.yaml` file should contain your configuration in YAML format:
```yaml
word_count: 200
conversation_style:
- casual
- humorous
podcast_name: Tech Chuckles
creativity: 0.7
```
## Notes of Caution
- The `word_count` is a target, and the AI may generate more or less than the specified word count. Low word counts are more likely to generate high-level discussions, while high word counts are more likely to generate detailed discussions.
- The `output_language` defines both the language of the transcript and the language of the audio. Here's some relevant information:
- Bottom-line: non-English transcripts are good enough but non-English audio is work-in-progress.
- Transcripts are generated using Google's Gemini 1.5 Pro by default, which supports 100+ languages. Other user-defined models may or may not support non-English languages.
- Audio is generated using `openai` (default), `elevenlabs`, `gemini`, `geminimulti` or `edge` TTS models.
- The `gemini`(Google) TTS model supports multiple languages and can be controlled by the `output_language` parameter and respective voice choices. Eg. `output_language="Tamil"`, `question="ta-IN-Standard-A"`, `answer="ta-IN-Standard-B"`. Refer to [Google Cloud Text-to-Speech documentation](https://cloud.google.com/text-to-speech/docs/voices) for more details.
- The `geminimulti`(Google) TTS model supports only English voices. Also, not every Google Cloud project might have access to multi-speaker voices (Eg. `en-US-Studio-MultiSpeaker`). In case if you get - `"Multi-speaker voices are only available to allowlisted projects."`, you can fallback to `gemini` TTS model.
- The `openai` TTS model supports multiple languages automatically, however non-English voices still present sub-par quality in my experience.
- The `elevenlabs` TTS model has English voices by default, in order to use a non-English voice you would need to download a custom voice for the target language in your `elevenlabs` account settings and then set the `text_to_speech.elevenlabs.default_voices` parameters to the voice you want to use in the [config.yaml file](https://github.com/pedroslopez/podcastfy/blob/main/podcastfy/config.yaml) (this config file is only available in the source code of the project, not in the pip package, hence if you are using the pip package you will not be able to change the ElevenLabs voice). For more information on ElevenLabs voices, visit [ElevenLabs Voice Library](https://elevenlabs.io/voice-library) | {
"source": "souzatharsis/podcastfy",
"title": "usage/conversation_custom.md",
"url": "https://github.com/souzatharsis/podcastfy/blob/main/usage/conversation_custom.md",
"date": "2024-09-30T22:35:09",
"stars": 2726,
"description": "An Open Source Python alternative to NotebookLM's podcast feature: Transforming Multimodal Content into Captivating Multilingual Audio Conversations with GenAI",
"file_size": 9719
} |
# Docker Setup Guide for Podcastfy
This guide explains how to use Docker to run Podcastfy in your local environment or for development.
## Prerequisites
- Docker installed on your system [1]
- Docker Compose [1]
- API keys [2]
[1] See Appendix A for detailed installation instructions.
[2] See [config.md](https://github.com/souzatharsis/podcastfy/blob/main/usage/config.md) for more details.
## Available Images
Podcastfy provides pre-built Docker images through GitHub Container Registry (ghcr.io):
1. **Production Image**: `ghcr.io/souzatharsis/podcastfy:latest`
- Contains the latest PyPI release
- Recommended for production use
2. **Development Image**: `ghcr.io/souzatharsis/podcastfy:dev`
- Includes development tools and dependencies
- Used for contributing and development
## Deployment
### Quick Deployment Steps
1. Create a new directory and navigate to it:
```bash
mkdir -p /path/to/podcastfy
cd /path/to/podcastfy
```
2. Create a `.env` file with your API keys (see [config.md](https://github.com/souzatharsis/podcastfy/blob/main/usage/config.md) for more details):
```plaintext
GEMINI_API_KEY=your_gemini_api_key
OPENAI_API_KEY=your_openai_api_key # Optional: only needed for OpenAI TTS
```
3. Create a `docker-compose.yml`:
```yaml
version: '3.8'
services:
podcastfy:
image: ghcr.io/souzatharsis/podcastfy:latest
environment:
- GEMINI_API_KEY=${GEMINI_API_KEY}
- OPENAI_API_KEY=${OPENAI_API_KEY}
ports:
- "8000:8000"
command: python3 -m podcastfy.server
healthcheck:
test: ["CMD", "python3", "-c", "import podcastfy"]
interval: 30s
timeout: 10s
retries: 3
```
4. Pull and start the container:
```bash
docker pull ghcr.io/souzatharsis/podcastfy:latest
docker-compose up podcastfy
```
The service will be available at `http://localhost:8000`
### Directory Structure
```
/path/to/podcastfy/
├── .env # Environment variables
└── docker-compose.yml # Docker Compose configuration
```
## Development Setup
### Using Pre-built Development Image
1. Pull the development image:
```bash
docker pull ghcr.io/souzatharsis/podcastfy:dev
```
2. Clone the repository and start development environment:
```bash
git clone https://github.com/souzatharsis/podcastfy.git
cd podcastfy
docker-compose up podcastfy-dev
```
### Building Locally
Alternatively, you can build the images locally:
```bash
# Build production image
docker-compose build podcastfy
# Build development image
docker-compose build podcastfy-dev
```
## Running Tests
Run the test suite using:
```bash
docker-compose up test
```
This will run tests in parallel using pytest-xdist.
## Environment Variables
Required environment variables:
- `GEMINI_API_KEY` - Your Google Gemini API key
- `OPENAI_API_KEY` - Your OpenAI API key (optional: only needed for OpenAI TTS)
## Container Details
### Production Container
- Based on Ubuntu 24.04
- Installs Podcastfy from PyPI
- Includes FFmpeg for audio processing
- Runs in a Python virtual environment
- Exposed port: 8000
### Development Container
- Based on Ubuntu 24.04
- Includes development tools (flake8, pytest)
- Mounts local code for live development
- Runs in editable mode (`pip install -e .`)
- Exposed port: 8001
## Continuous Integration
The Docker images are automatically:
- Built and tested on every push to main branch
- Built and tested for all pull requests
- Published to GitHub Container Registry
- Tagged with version numbers for releases (v*.*.*)
## Health Checks
All services include health checks that:
- Run every 30 seconds
- Verify Podcastfy can be imported
- Timeout after 10 seconds
- Retry up to 3 times
## Common Commands
```bash
# Pull latest production image
docker pull ghcr.io/souzatharsis/podcastfy:latest
# Pull development image
docker pull ghcr.io/souzatharsis/podcastfy:dev
# Start production service
docker-compose up podcastfy
# Start development environment
docker-compose up podcastfy-dev
# Run tests
docker-compose up test
# Build images locally
docker-compose build
# View logs
docker-compose logs
# Stop all containers
docker-compose down
```
## Troubleshooting
### Common Issues
1. **API Key Errors**
- Verify your `.env` file exists and contains valid API keys
- Check if the environment variables are properly passed to the container
2. **Port Conflicts**
- Ensure ports 8000 (production) and 8001 (development) are available
- Modify the port mappings in `docker-compose.yml` if needed
3. **Volume Mounting Issues (Development)**
- Verify the correct path to your local code
- Check permissions on the mounted directories
4. **Image Pull Issues**
- Ensure you have access to the GitHub Container Registry
- If you see "unauthorized" errors, the image might be private
- Try authenticating with GitHub: `docker login ghcr.io -u YOUR_GITHUB_USERNAME`
### Verifying Installation
You can verify your installation by checking if the package can be imported:
```bash
# Check production version
docker run --rm ghcr.io/souzatharsis/podcastfy:latest python3 -c "import podcastfy"
# Check development setup
docker-compose exec podcastfy-dev python3 -c "import podcastfy"
```
## System Requirements
Minimum requirements:
- Docker Engine 20.10.0 or later
- Docker Compose 2.0.0 or later
- Sufficient disk space for Ubuntu base image (~400MB)
- Additional space for Python packages and FFmpeg
## Support
If you encounter any issues:
1. Check the container logs: `docker-compose logs`
2. Verify all prerequisites are installed
3. Ensure all required environment variables are set
4. Open an issue on the [Podcastfy GitHub repository](https://github.com/souzatharsis/podcastfy/issues)
## Appendix A: Detailed Installation Guide
### Installing Docker
#### Windows
1. Download and install [Docker Desktop for Windows](https://docs.docker.com/desktop/install/windows-install/)
- For Windows 10/11 Pro, Enterprise, or Education: Enable WSL 2 and Hyper-V
- For Windows 10 Home: Enable WSL 2
2. After installation, start Docker Desktop
3. Verify installation:
```bash
docker --version
```
#### macOS
1. Download and install [Docker Desktop for Mac](https://docs.docker.com/desktop/install/mac-install/)
- For Intel chip: Download Intel package
- For Apple chip: Download Apple Silicon package
2. After installation, start Docker Desktop
3. Verify installation:
```bash
docker --version
```
#### Ubuntu/Debian
```bash
# Remove old versions
sudo apt-get remove docker docker-engine docker.io containerd runc
# Install prerequisites
sudo apt-get update
sudo apt-get install \
ca-certificates \
curl \
gnupg \
lsb-release
# Add Docker's official GPG key
sudo mkdir -p /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
# Set up repository
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
# Install Docker Engine
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-compose-plugin
# Add your user to docker group (optional, to run docker without sudo)
sudo usermod -aG docker $USER
newgrp docker
# Verify installation
docker --version
```
#### Other Linux Distributions
- [CentOS](https://docs.docker.com/engine/install/centos/)
- [Fedora](https://docs.docker.com/engine/install/fedora/)
- [RHEL](https://docs.docker.com/engine/install/rhel/)
### Installing Docker Compose
Docker Compose is included with Docker Desktop for Windows and macOS. For Linux:
```bash
# Download the current stable release
sudo curl -L "https://github.com/docker/compose/releases/download/v2.24.1/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
# Apply executable permissions
sudo chmod +x /usr/local/bin/docker-compose
# Verify installation
docker-compose --version
```
### Post-Installation Steps
1. Verify Docker is running:
```bash
docker run hello-world
```
2. Configure Docker to start on boot (Linux only):
```bash
sudo systemctl enable docker.service
sudo systemctl enable containerd.service
```
## Appendix B: Getting API Keys
### Google Gemini API Key
1. Visit [Google AI Studio](https://makersuite.google.com/app/apikey)
2. Create or sign in to your Google account
3. Click "Create API Key"
4. Copy and save your API key
### OpenAI API Key
You only need an OpenAI API key if you want to use the OpenAI Text-to-Speech model.
1. Visit [OpenAI API Keys](https://platform.openai.com/api-keys)
2. Create or sign in to your OpenAI account
3. Click "Create new secret key"
4. Copy and save your API key
## Appendix C: Installation Validation
After installing all prerequisites, verify everything is set up correctly:
```bash
# Check Docker version
docker --version
# Check Docker Compose version
docker-compose --version
# Verify Docker daemon is running
docker ps
# Test Docker functionality
docker run hello-world
``` | {
"source": "souzatharsis/podcastfy",
"title": "usage/docker.md",
"url": "https://github.com/souzatharsis/podcastfy/blob/main/usage/docker.md",
"date": "2024-09-30T22:35:09",
"stars": 2726,
"description": "An Open Source Python alternative to NotebookLM's podcast feature: Transforming Multimodal Content into Captivating Multilingual Audio Conversations with GenAI",
"file_size": 9079
} |
# How to
All assume you have podcastfy installed and running.
## Table of Contents
- [Custom LLM Support](#custom-llm-support)
- [Running Local LLMs](#running-local-llms)
- [How to use your own voice in audio podcasts](#how-to-use-your-own-voice-in-audio-podcasts)
- [How to customize the conversation](#how-to-customize-the-conversation)
- [How to generate multilingual content](#how-to-generate-multilingual-content)
- [How to steer the conversation](#how-to-steer-the-conversation)
- [How to generate longform podcasts](#how-to-generate-longform-podcasts)
## Custom LLM Support
Podcastfy offers a range of LLM models for generating transcripts including OpenAI, Anthropic, Google as well as local LLM models.
### Cloud-based LLMs
By default, Podcastfy uses Google's `gemini-1.5-pro-latest` model. To select a particular cloud-based LLM model, users can pass the `llm_model_name` and `api_key_label` parameters to the `generate_podcast` function. See [full list of supported models](https://docs.litellm.ai/docs/providers) for more details.
For example, to use OpenAI's `gpt-4-turbo` model, users can pass `llm_model_name="gpt-4-turbo"` and `api_key_label="OPENAI_API_KEY"`.
```python
audio_file = generate_podcast(
urls=["https://en.wikipedia.org/wiki/Artificial_intelligence"],
llm_model_name="gpt-4-turbo",
api_key_label="OPENAI_API_KEY"
)
```
Remember to have the correct API key label and value in your environment variables (`.env` file).
### Running Local LLMs
See [local_llm.md](local_llm.md) for more details.
## How to use your own voice in audio podcasts
You just need to use ElevenLabs TSS backend and pass a custom config to use your voice instead of podcastfy's default:
1. Create elevenlabs account, get and [set up](https://github.com/souzatharsis/podcastfy/blob/main/usage/config.md) eleven labs API KEY
2. Clone your voice on elevenlabs website (let's say its name is 'Robbert')
4. Create custom conversation config (let's call it custom_config.yaml) to use your voice name instead of the default as described [here](https://github.com/souzatharsis/podcastfy/blob/main/usage/conversation_custom.md#text-to-speech-tts-settings). Set either question or answer voice below to 'Robbert' in elevenlabs > default_voices.
6. Run podcastfy with tts-model param as elevenlabs
CLI
```
python -m podcastfy.client --url https://example.com/article1 --url https://example.com/article2 --tts-model elevenlabs --conversation-config path/to/custom_config.yaml
```
For Python example, checkout Customization section at [python notebook](https://github.com/souzatharsis/podcastfy/blob/main/podcastfy.ipynb).
## How to customize the conversation
You can customize the conversation by passing a custom [conversation_config.yaml](https://github.com/souzatharsis/podcastfy/blob/main/podcastfy/conversation_config.yaml) file to the CLI:
```
python -m podcastfy.client --url https://example.com/article1 --url https://example.com/article2 --tts-model elevenlabs --conversation-config path/to/custom_config.yaml
```
You can also pass a dictionary with the custom config to the python interface generate_podcast function:
```python
from podcastfy.client import generate_podcast
custom_config = {
"word_count": 200,
"conversation_style": ["casual", "humorous"],
"podcast_name": "Tech Chuckles",
"creativity": 0.7
}
generate_podcast(
urls=["https://example.com/tech-news"],
conversation_config=custom_config
)
```
For more details, checkout [conversation_custom.md](https://github.com/souzatharsis/podcastfy/blob/main/usage/conversation_custom.md).
## How to generate multilingual content
In order to generate transcripts in a target language, simply set `output_language` = your target language. See [How to customize the conversation](#how-to-customize-the-conversation) on how to pass custom configuration to podcastfy. Set --transcript-only to get only the transcript without audio generation.
In order to generation audio, you can simply use openai TTS model which by default is multilingual. However, in my experience OpenAI's TTS multilingual quality is subpar. Instead, consdier using elevenlabs backend. See [How to use your own voice in audio podcasts](#how-to-use-your-own-voice-in-audio-podcasts) but instead of using your own voice you should download and set a voice in your target language for it to work.
Sample audio:
- [French](https://github.com/souzatharsis/podcastfy/blob/main/data/audio/podcast_FR_AGRO.mp3)
- [Portugue-BR](https://github.com/souzatharsis/podcastfy/blob/main/data/audio/podcast_thatupiso_BR.mp3)
The PT-BR audio actually uses my own cloned voice as AI Host 2.
## How to steer the conversation
You can guide the conversation focus and topics by setting the `user_instructions` parameter in your custom configuration. This allows you to provide specific instructions to the AI hosts about what aspects they should emphasize or explore.
Things to try:
- Focus on a specific topic (e.g. "Focus the discussion on key capabilities and limitations of modern AI models")
- Target a specific audience (e.g. "Explain concepts in a way that's accessible to someone new to Computer Science")
For example, using the CLI with a custom YAML:
```yaml
user_instructions: "Make connections with quantum computing"
```
```
python -m podcastfy.client --url https://en.wikipedia.org/wiki/Artificial_intelligence --conversation-config path/to/custom_config.yaml
```
## How to generate longform podcasts
By default, Podcastfy generates shortform podcasts. However, users can generate longform podcasts by setting the `longform` parameter to `True`.
```python
audio_file = generate_podcast(
urls=["https://example.com/article1", "https://example.com/article2"],
longform=True
)
```
LLMs have a limited ability to output long text responses. Most LLMs have a `max_output_tokens` of around 4096 and 8192 tokens. Hence, long-form podcast transcript generation is challeging. We have implemented a technique I call "Content Chunking with Contextual Linking" to enable long-form podcast generation by breaking down the input content into smaller chunks and generating a conversation for each chunk while ensuring the combined transcript is coherent and linked to the original input.
By default, shortform podcasts (default configuration) generate audio of about 2-5 minutes while longform podcasts may reach 20-30 minutes.
Users may adjust lonform podcast length by setting the following parameters in your customization params (conversation_config.yaml):
- `max_num_chunks` (default: 7): Sets maximum number of rounds of discussions.
- `min_chunk_size` (default: 600): Sets minimum number of characters to generate a round of discussion.
A "round of discussion" is the output transcript obtained from a single LLM call. The higher the `max_num_chunks` and the lower the `min_chunk_size`, the longer the generated podcast will be.
Today, this technique allows the user to generate long-form podcasts of any length if input content is long enough. However, the conversation quality may decrease and its length may converge to a maximum if `max_num_chunks`/`min_chunk_size` is to high/low particularly if input content length is limited.
Current implementation limitations:
- Images are not yet supported for longform podcast generation
- Base LLM model is fixed to Gemini
Above limitations are somewhat easily fixable however we chose to make updates in smaller but quick iterations rather than making all-in changes. | {
"source": "souzatharsis/podcastfy",
"title": "usage/how-to.md",
"url": "https://github.com/souzatharsis/podcastfy/blob/main/usage/how-to.md",
"date": "2024-09-30T22:35:09",
"stars": 2726,
"description": "An Open Source Python alternative to NotebookLM's podcast feature: Transforming Multimodal Content into Captivating Multilingual Audio Conversations with GenAI",
"file_size": 7523
} |
## Attribution
1. If you use `Podcastfy` in your software, we kindly ask you to add attribution. "Powered by Podcastfy.ai" would suffice. Please reach out, we would love to learn more how you are using `Podcastfy` and how we can better enable your use case.
2. Feel free to add your product to the the "[Built with Podcastfy](https://github.com/souzatharsis/podcastfy?tab=readme-ov-file#built-with-podcastfy-)" list by submitting a PR to our README.
## License
Additionally, `Podcastfy` is licensed under Apache 2.0. The Apache License 2.0 is a permissive free software license that allows you to use this sotfware for both non-commercial or commercial purposes.
Please review the [License](../LICENSE) in order to know your obligations.
here is a set of steps I will list without any warranty or liability:
1. Include a copy of the license in your project:
In your project root, create a NOTICE.txt or THIRD_PARTY_LICENSES.txt file and include the content from the file [NOTICE](../NOTICE)
2. Add attribution in your README.md:
```markdown
## Acknowledgments
This project includes code from Podcastfy(https://github.com/souzatharsis/podcastfy/), licensed under the Apache License 2.0.
```
3. Keep the original copyright notices in any files you copy/modify
4. If you modified the code, indicate your changes:
```python
# Modified from original source: [Podcastfy](https://github.com/souzatharsis/podcastfy/)
# Changes made:
# - Added feature X
# - Modified function Y
# - Removed component Z
```
Important points:
- You don't need to use the same license for your project
- You must preserve all copyright, patent, trademark notices
- State significant modifications you made
- Include the original Apache 2.0 license text
- Attribution should be clear and reasonable | {
"source": "souzatharsis/podcastfy",
"title": "usage/license-guide.md",
"url": "https://github.com/souzatharsis/podcastfy/blob/main/usage/license-guide.md",
"date": "2024-09-30T22:35:09",
"stars": 2726,
"description": "An Open Source Python alternative to NotebookLM's podcast feature: Transforming Multimodal Content into Captivating Multilingual Audio Conversations with GenAI",
"file_size": 1780
} |
# Local LLM Support
Running local LLMs can offer several advantages such as:
- Enhanced privacy and data security
- Cost control and no API rate limits
- Greater customization and fine-tuning options
- Reduced vendor lock-in
We enable serving local LLMs with [llamafile](https://github.com/Mozilla-Ocho/llamafile). In the API, local LLM support is available through the `is_local` parameter. If `is_local=True`, then a local (llamafile) LLM model is used to generate the podcast transcript. Llamafiles of LLM models can be found on [HuggingFace, which today offers 156+ models](https://huggingface.co/models?library=llamafile).
All you need to do is:
1. Download a llamafile from HuggingFace
2. Make the file executable
3. Run the file
Here's a simple bash script that shows all 3 setup steps for running TinyLlama-1.1B locally:
```bash
# Download a llamafile from HuggingFace
wget https://huggingface.co/jartine/TinyLlama-1.1B-Chat-v1.0-GGUF/resolve/main/TinyLlama-1.1B-Chat-v1.0.Q5_K_M.llamafile
# Make the file executable. On Windows, instead just rename the file to end in ".exe".
chmod +x TinyLlama-1.1B-Chat-v1.0.Q5_K_M.llamafile
# Start the model server. Listens at http://localhost:8080 by default.
./TinyLlama-1.1B-Chat-v1.0.Q5_K_M.llamafile --server --nobrowser
```
Now you can use the local LLM to generate a podcast transcript (or audio) by setting the `is_local` parameter to `True`.
## Python API
```python
from podcastfy.client import generate_podcast
# Generate a tech debate podcast about artificial intelligence
generate_podcast(
urls=["www.souzatharsis.com"],
is_local=True # Using a local LLM
)
```
## CLI
To use a local LLM model via the command-line interface, you can use the `--local` or `-l` flag. Here's an example of how to generate a transcript using a local LLM:
```bash
python -m podcastfy.client --url https://example.com/article1 --transcript-only --local
```
## Notes of caution
When using local LLM models versus widely known private large language models:
1. Performance: Local LLMs often have lower performance compared to large private models due to size and training limitations.
2. Resource requirements: Running local LLMs can be computationally intensive, requiring significant CPU/GPU resources.
3. Limited capabilities: Local models may struggle with complex tasks or specialized knowledge that larger models handle well.
5. Reduced multimodal abilities: Local LLMs will be assumed to be text-only capable
6. Potential instability: Local models may produce less consistent or stable outputs compared to well-tested private models oftentimes producing transcripts that cannot be used for podcast generation (TTS) out-of-the-box
7. Limited context window: Local models often have smaller context windows, limiting their ability to process long inputs.
Always evaluate the trade-offs between using local LLMs and private models based on your specific use case and requirements. We highly recommend extensively testing your local LLM before productionizing an end-to-end podcast generation and/or manually checking the transcript before passing to TTS model. | {
"source": "souzatharsis/podcastfy",
"title": "usage/local_llm.md",
"url": "https://github.com/souzatharsis/podcastfy/blob/main/usage/local_llm.md",
"date": "2024-09-30T22:35:09",
"stars": 2726,
"description": "An Open Source Python alternative to NotebookLM's podcast feature: Transforming Multimodal Content into Captivating Multilingual Audio Conversations with GenAI",
"file_size": 3130
} |
<a name="readme-top"></a>
# Podcastfy.ai 🎙️🤖
[](https://pypi.org/project/podcastfy/)
[](https://pepy.tech/project/podcastfy)
[](https://github.com/souzatharsis/podcastfy/issues)
[](https://podcastfy.readthedocs.io/en/latest/?badge=latest)
[](https://creativecommons.org/licenses/by-nc-sa/4.0/)

[](https://colab.research.google.com/github/souzatharsis/podcastfy/blob/main/podcastfy.ipynb)
Transforming Multimodal Content into Captivating Multilingual Audio Conversations with GenAI
https://github.com/user-attachments/assets/f1559e70-9cf9-4576-b48b-87e7dad1dd0b
Podcastfy is an open-source Python package that transforms multi-modal content (text, images) into engaging, multi-lingual audio conversations using GenAI. Input content include websites, PDFs, youtube videos as well as images.
Unlike UI-based tools focused primarily on note-taking or research synthesis (e.g. NotebookLM ❤️), Podcastfy focuses on the programmatic and bespoke generation of engaging, conversational transcripts and audio from a multitude of multi-modal sources enabling customization and scale.
## Audio Examples 🔊
This sample collection is also [available at audio.com](https://audio.com/thatupiso/collections/podcastfy).
### Images
| Image Set | Description | Audio |
|:--|:--|:--|
| <img src="data/images/Senecio.jpeg" alt="Senecio, 1922 (Paul Klee)" width="20%" height="auto"> <img src="data/images/connection.jpg" alt="Connection of Civilizations (2017) by Gheorghe Virtosu " width="21.5%" height="auto"> | Senecio, 1922 (Paul Klee) and Connection of Civilizations (2017) by Gheorghe Virtosu | [<span style="font-size: 25px;">🔊</span>](https://audio.com/thatupiso/audio/output-file-abstract-art) |
| <img src="data/images/japan_1.jpg" alt="The Great Wave off Kanagawa, 1831 (Hokusai)" width="20%" height="auto"> <img src="data/images/japan2.jpg" alt="Takiyasha the Witch and the Skeleton Spectre, c. 1844 (Kuniyoshi)" width="21.5%" height="auto"> | The Great Wave off Kanagawa, 1831 (Hokusai) and Takiyasha the Witch and the Skeleton Spectre, c. 1844 (Kuniyoshi) | [<span style="font-size: 25px;">🔊</span>](https://audio.com/thatupiso/audio/output-file-japan) |
| <img src="data/images/taylor.png" alt="Taylor Swift" width="28%" height="auto"> <img src="data/images/monalisa.jpeg" alt="Mona Lisa" width="10.5%" height="auto"> | Pop culture icon Taylor Swift and Mona Lisa, 1503 (Leonardo da Vinci) | [<span style="font-size: 25px;">🔊</span>](https://audio.com/thatupiso/audio/taylor-monalisa) |
### Text
| Content Type | Description | Audio | Source |
|--------------|-------------|-------|--------|
| Youtube Video | YCombinator on LLMs | [Audio](https://audio.com/thatupiso/audio/ycombinator-llms) | [YouTube](https://www.youtube.com/watch?v=eBVi_sLaYsc) |
| PDF | Book: Networks, Crowds, and Markets | [Audio](https://audio.com/thatupiso/audio/networks) | book pdf |
| Research Paper | Climate Change in France | [Audio](https://audio.com/thatupiso/audio/agro-paper) | [PDF](./data/pdf/s41598-024-58826-w.pdf) |
| Website | My Personal Website | [Audio](https://audio.com/thatupiso/audio/tharsis) | [Website](https://www.souzatharsis.com) |
| Website + YouTube | My Personal Website + YouTube Video on AI | [Audio](https://audio.com/thatupiso/audio/tharsis-ai) | [Website](https://www.souzatharsis.com), [YouTube](https://www.youtube.com/watch?v=sJE1dE2dulg) |
### Multi-Lingual Text
| Language | Content Type | Description | Audio | Source |
|----------|--------------|-------------|-------|--------|
| French | Website | Agroclimate research information | [Audio](https://audio.com/thatupiso/audio/podcast-fr-agro) | [Website](https://agroclim.inrae.fr/) |
| Portuguese-BR | News Article | Election polls in São Paulo | [Audio](https://audio.com/thatupiso/audio/podcast-thatupiso-br) | [Website](https://noticias.uol.com.br/eleicoes/2024/10/03/nova-pesquisa-datafolha-quem-subiu-e-quem-caiu-na-disputa-de-sp-03-10.htm) |
## Features ✨
- Generate conversational content from multiple-sources and formats (images, websites, YouTube, and PDFs)
- Customizable transcript and audio generation (e.g. style, language, structure, length)
- Create podcasts from pre-existing or edited transcripts
- Support for advanced text-to-speech models (OpenAI, ElevenLabs and Edge)
- Seamless CLI and Python package integration for automated workflows
- Multi-language support for global content creation (experimental!)
## Updates 🚀
### v0.2.2 release
- Podcastfy is now multi-modal! Users can generate audio from images as well as text inputs!
- Added API reference docs and published it to https://podcastfy.readthedocs.io/en/latest/
### v0.2.0 release
- Users can now customize podcast style, structure, and content
- Integration with LangChain for better LLM management
## Quickstart 💻
### Prerequisites
- Python 3.11 or higher
- `$ pip install ffmpeg` (for audio processing)
### Setup
1. Install from PyPI
`$ pip install podcastfy`
2. Set up your [API keys](usage/config.md)
### Python
```python
from podcastfy.client import generate_podcast
audio_file = generate_podcast(urls=["<url1>", "<url2>"])
```
### CLI
```
python -m podcastfy.client --url <url1> --url <url2>
```
## Usage 💻
- [Python Package Quickstart](podcastfy.ipynb)
- [API Reference Manual](https://podcastfy.readthedocs.io/en/latest/podcastfy.html)
- [CLI](usage/cli.md)
Experience Podcastfy with our [HuggingFace](https://huggingface.co/spaces/thatupiso/Podcastfy.ai_demo) 🤗 Spaces app for a simple URL-to-Audio demo. (Note: This UI app is less extensively tested and capable than the Python package.)
## Customization 🔧
Podcastfy offers a range of [Conversation Customization](usage/conversation_custom.md) options to tailor your AI-generated podcasts. Whether you're creating educational content, storytelling experiences, or anything in between, these configuration options allow you to fine-tune your podcast's tone, length, and format.
## Contributing 🤝
We welcome contributions! Please submit [Issues](https://github.com/souzatharsis/podcastfy/issues) or Pull Requests. Feel free to fork the repo and create your own applications. We're excited to learn about your use cases!
## Example Use Cases 🎧🎶
1. **Content Summarization**: Busy professionals can stay informed on industry trends by listening to concise audio summaries of multiple articles, saving time and gaining knowledge efficiently.
2. **Language Localization**: Non-native English speakers can access English content in their preferred language, breaking down language barriers and expanding access to global information.
3. **Website Content Marketing**: Companies can increase engagement by repurposing written website content into audio format, providing visitors with the option to read or listen.
4. **Personal Branding**: Job seekers can create unique audio-based personal presentations from their CV or LinkedIn profile, making a memorable impression on potential employers.
5. **Research Paper Summaries**: Graduate students and researchers can quickly review multiple academic papers by listening to concise audio summaries, speeding up the research process.
6. **Long-form Podcast Summarization**: Podcast enthusiasts with limited time can stay updated on their favorite shows by listening to condensed versions of lengthy episodes.
7. **News Briefings**: Commuters can stay informed about daily news during travel time with personalized audio news briefings compiled from their preferred sources.
8. **Educational Content Creation**: Educators can enhance learning accessibility by providing audio versions of course materials, catering to students with different learning preferences.
9. **Book Summaries**: Avid readers can preview books efficiently through audio summaries, helping them make informed decisions about which books to read in full.
10. **Conference and Event Recaps**: Professionals can stay updated on important industry events they couldn't attend by listening to audio recaps of conference highlights and key takeaways.
## License
This project is licensed under the [Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License](https://creativecommons.org/licenses/by-nc-sa/4.0/).
## Contributors
<a href="https://github.com/souzatharsis/podcastfy/graphs/contributors">
<img alt="contributors" src="https://contrib.rocks/image?repo=souzatharsis/podcastfy"/>
</a>
## Disclaimer
This tool is designed for personal or educational use. Please ensure you have the necessary rights or permissions before using content from external sources for podcast creation. All audio content is AI-generated and it is not intended to clone real-life humans!
<p align="right" style="font-size: 14px; color: #555; margin-top: 20px;">
<a href="#readme-top" style="text-decoration: none; color: #007bff; font-weight: bold;">
↑ Back to Top ↑
</a>
</p> | {
"source": "souzatharsis/podcastfy",
"title": "docs/source/README.md",
"url": "https://github.com/souzatharsis/podcastfy/blob/main/docs/source/README.md",
"date": "2024-09-30T22:35:09",
"stars": 2726,
"description": "An Open Source Python alternative to NotebookLM's podcast feature: Transforming Multimodal Content into Captivating Multilingual Audio Conversations with GenAI",
"file_size": 9382
} |
.. podcastfy documentation master file, created by
sphinx-quickstart on Sat Oct 12 21:09:23 2024.
You can adapt this file completely to your liking, but it should at least
contain the root `toctree` directive.
Podcastfy.ai API Referece Manual
==========================
This documentation site is focused on the Podcastfy Python package, its classes, functions, and methods.
For additional documentation, see the `Podcastfy <https://github.com/souzatharsis/podcastfy/>`_ GitHub repository.
.. toctree::
:maxdepth: 2
:caption: API Reference:
podcastfy
Quickstart
----------
Prerequisites
^^^^^^^^^^^^^
- Python 3.11 or higher
- ``$ pip install ffmpeg`` (for audio processing)
Installation
^^^^^^^^^^^^
1. Install from PyPI:
``$ pip install podcastfy``
2. Set up your `API keys <https://github.com/souzatharsis/podcastfy/blob/main/usage/config.md>`_
Python
^^^^^^
.. code-block:: python
from podcastfy.client import generate_podcast
audio_file = generate_podcast(urls=["<url1>", "<url2>"])
CLI
^^^
.. code-block:: bash
python -m podcastfy.client --url <url1> --url <url2>
Usage
-----
- `Python Package <https://github.com/souzatharsis/podcastfy/blob/main/podcastfy.ipynb>`_
- `CLI <https://github.com/souzatharsis/podcastfy/blob/main/usage/cli.md>`_
Experience Podcastfy with our `HuggingFace <https://huggingface.co/spaces/thatupiso/Podcastfy.ai_demo>`_ 🤗 Spaces app for a simple URL-to-Audio demo. (Note: This UI app is less extensively tested and capable than the Python package.)
Customization
-------------
Podcastfy offers a range of customization options to tailor your AI-generated podcasts:
* Customize podcast `Conversation <https://github.com/souzatharsis/podcastfy/blob/main/usage/conversation_custom.md>`_ (e.g. format, style)
* Choose to run `Local LLMs <https://github.com/souzatharsis/podcastfy/blob/main/usage/local_llm.md>`_ (156+ HuggingFace models)
* Set `System Settings <https://github.com/souzatharsis/podcastfy/blob/main/usage/config_custom.md>`_ (e.g. text-to-speech and output directory settings)
Collaborate
===========
Fork me at https://github.com/souzatharsis/podcastfy.
Indices and tables
==================
* :ref:`genindex`
* :ref:`modindex`
* :ref:`search`
Licensed under Apache 2.0 | {
"source": "souzatharsis/podcastfy",
"title": "docs/source/index.rst",
"url": "https://github.com/souzatharsis/podcastfy/blob/main/docs/source/index.rst",
"date": "2024-09-30T22:35:09",
"stars": 2726,
"description": "An Open Source Python alternative to NotebookLM's podcast feature: Transforming Multimodal Content into Captivating Multilingual Audio Conversations with GenAI",
"file_size": 2285
} |
podcastfy
=========
.. toctree::
:maxdepth: 4
podcastfy | {
"source": "souzatharsis/podcastfy",
"title": "docs/source/modules.rst",
"url": "https://github.com/souzatharsis/podcastfy/blob/main/docs/source/modules.rst",
"date": "2024-09-30T22:35:09",
"stars": 2726,
"description": "An Open Source Python alternative to NotebookLM's podcast feature: Transforming Multimodal Content into Captivating Multilingual Audio Conversations with GenAI",
"file_size": 63
} |
podcastfy.content\_parser package
=================================
Submodules
----------
podcastfy.content\_parser.content\_extractor module
---------------------------------------------------
.. automodule:: podcastfy.content_parser.content_extractor
:members:
:undoc-members:
:show-inheritance:
podcastfy.content\_parser.pdf\_extractor module
-----------------------------------------------
.. automodule:: podcastfy.content_parser.pdf_extractor
:members:
:undoc-members:
:show-inheritance:
podcastfy.content\_parser.website\_extractor module
---------------------------------------------------
.. automodule:: podcastfy.content_parser.website_extractor
:members:
:undoc-members:
:show-inheritance:
podcastfy.content\_parser.youtube\_transcriber module
-----------------------------------------------------
.. automodule:: podcastfy.content_parser.youtube_transcriber
:members:
:undoc-members:
:show-inheritance:
Module contents
---------------
.. automodule:: podcastfy.content_parser
:members:
:undoc-members:
:show-inheritance: | {
"source": "souzatharsis/podcastfy",
"title": "docs/source/podcastfy.content_parser.rst",
"url": "https://github.com/souzatharsis/podcastfy/blob/main/docs/source/podcastfy.content_parser.rst",
"date": "2024-09-30T22:35:09",
"stars": 2726,
"description": "An Open Source Python alternative to NotebookLM's podcast feature: Transforming Multimodal Content into Captivating Multilingual Audio Conversations with GenAI",
"file_size": 1089
} |
podcastfy package
=================
Subpackages
-----------
.. toctree::
:maxdepth: 4
podcastfy.content_parser
Submodules
----------
podcastfy.client module
-----------------------
.. automodule:: podcastfy.client
:members:
:undoc-members:
:show-inheritance:
podcastfy.content\_generator module
-----------------------------------
.. automodule:: podcastfy.content_generator
:members:
:undoc-members:
:show-inheritance:
podcastfy.text\_to\_speech module
---------------------------------
.. automodule:: podcastfy.text_to_speech
:members:
:undoc-members:
:show-inheritance:
Module contents
---------------
.. automodule:: podcastfy
:members:
:undoc-members:
:show-inheritance: | {
"source": "souzatharsis/podcastfy",
"title": "docs/source/podcastfy.rst",
"url": "https://github.com/souzatharsis/podcastfy/blob/main/docs/source/podcastfy.rst",
"date": "2024-09-30T22:35:09",
"stars": 2726,
"description": "An Open Source Python alternative to NotebookLM's podcast feature: Transforming Multimodal Content into Captivating Multilingual Audio Conversations with GenAI",
"file_size": 730
} |
# Podcastfy REST API Documentation
## Overview
The Podcastfy API allows you to programmatically generate AI podcasts from various input sources. This document outlines the API endpoints and their usage.
## Using cURL with Podcastfy API
### Prerequisites
1. Confirm cURL installation:
```bash
curl --version
```
### API Request Flow
Making a prediction requires two sequential requests:
1. POST request to initiate processing - returns an `EVENT_ID`
2. GET request to fetch results - uses the `EVENT_ID` to fetch results
Between step 1 and 2, there is a delay of 1-3 minutes. We are working on reducing this delay and implementing a way to notify the user when the podcast is ready. Thanks for your patience!
### Basic Request Structure
```bash
# Step 1: POST request to initiate processing
# Make sure to include http:// or https:// in the URL
curl -X POST https://thatupiso-podcastfy-ai-demo.hf.space/gradio_api/call/process_inputs \
-H "Content-Type: application/json" \
-d '{
"data": [
"text_input",
"https://yourwebsite.com",
[], # pdf_files
[], # image_files
"gemini_key",
"openai_key",
"elevenlabs_key",
2000, # word_count
"engaging,fast-paced", # conversation_style
"main summarizer", # roles_person1
"questioner", # roles_person2
"Introduction,Content,Conclusion", # dialogue_structure
"PODCASTFY", # podcast_name
"YOUR PODCAST", # podcast_tagline
"openai", # tts_model
0.7, # creativity_level
"" # user_instructions
]
}'
# Step 2: GET request to fetch results
curl -N https://thatupiso-podcastfy-ai-demo.hf.space/gradio_api/call/process_inputs/$EVENT_ID
# Example output result
event: complete
data: [{"path": "/tmp/gradio/bcb143f492b1c9a6dbde512557541e62f090bca083356be0f82c2e12b59af100/podcast_81106b4ca62542f1b209889832a421df.mp3", "url": "https://thatupiso-podcastfy-ai-demo.hf.space/gradio_a/gradio_api/file=/tmp/gradio/bcb143f492b1c9a6dbde512557541e62f090bca083356be0f82c2e12b59af100/podcast_81106b4ca62542f1b209889832a421df.mp3", "size": null, "orig_name": "podcast_81106b4ca62542f1b209889832a421df.mp3", "mime_type": null, "is_stream": false, "meta": {"_type": "gradio.FileData"}}]
```
You can download the file by extending the URL prefix "https://thatupiso-podcastfy-ai-demo.hf.space/gradio_a/gradio_api/file=" with the path to the file in variable `path`. (Note: The variable "url" above has a bug introduced by Gradio, so please ignore it.)
### Parameter Details
| Index | Parameter | Type | Description |
|-------|-----------|------|-------------|
| 0 | text_input | string | Direct text input for podcast generation |
| 1 | urls_input | string | URLs to process (include http:// or https://) |
| 2 | pdf_files | array | List of PDF files to process |
| 3 | image_files | array | List of image files to process |
| 4 | gemini_key | string | Google Gemini API key |
| 5 | openai_key | string | OpenAI API key |
| 6 | elevenlabs_key | string | ElevenLabs API key |
| 7 | word_count | number | Target word count for podcast |
| 8 | conversation_style | string | Conversation style descriptors (e.g. "engaging,fast-paced") |
| 9 | roles_person1 | string | Role of first speaker |
| 10 | roles_person2 | string | Role of second speaker |
| 11 | dialogue_structure | string | Structure of dialogue (e.g. "Introduction,Content,Conclusion") |
| 12 | podcast_name | string | Name of the podcast |
| 13 | podcast_tagline | string | Podcast tagline |
| 14 | tts_model | string | Text-to-speech model ("gemini", "openai", "elevenlabs", or "edge") |
| 15 | creativity_level | number | Level of creativity (0-1) |
| 16 | user_instructions | string | Custom instructions for generation |
## Using Python
### Installation
```bash
pip install gradio_client
```
### Quick Start
```python
from gradio_client import Client, handle_file
client = Client("thatupiso/Podcastfy.ai_demo")
```
### API Endpoints
#### Generate Podcast (`/process_inputs`)
Generates a podcast from provided text, URLs, PDFs, or images.
##### Parameters
| Parameter | Type | Required | Default | Description |
|-----------|------|----------|---------|-------------|
| text_input | str | Yes | - | Raw text input for podcast generation |
| urls_input | str | Yes | - | Comma-separated URLs to process |
| pdf_files | List[filepath] | Yes | None | List of PDF files to process |
| image_files | List[filepath] | Yes | None | List of image files to process |
| gemini_key | str | No | "" | Google Gemini API key |
| openai_key | str | No | "" | OpenAI API key |
| elevenlabs_key | str | No | "" | ElevenLabs API key |
| word_count | float | No | 2000 | Target word count for podcast |
| conversation_style | str | No | "engaging,fast-paced,enthusiastic" | Conversation style descriptors |
| roles_person1 | str | No | "main summarizer" | Role of first speaker |
| roles_person2 | str | No | "questioner/clarifier" | Role of second speaker |
| dialogue_structure | str | No | "Introduction,Main Content Summary,Conclusion" | Structure of dialogue |
| podcast_name | str | No | "PODCASTFY" | Name of the podcast |
| podcast_tagline | str | No | "YOUR PERSONAL GenAI PODCAST" | Podcast tagline |
| tts_model | Literal['openai', 'elevenlabs', 'edge'] | No | "openai" | Text-to-speech model |
| creativity_level | float | No | 0.7 | Level of creativity (0-1) |
| user_instructions | str | No | "" | Custom instructions for generation |
##### Returns
| Type | Description |
|------|-------------|
| filepath | Path to generated audio file |
##### Example Usage
```python
from gradio_client import Client, handle_file
client = Client("thatupiso/Podcastfy.ai_demo")
# Generate podcast from URL
result = client.predict(
text_input="",
urls_input="https://example.com/article",
pdf_files=[],
image_files=[],
gemini_key="your-gemini-key",
openai_key="your-openai-key",
word_count=1500,
conversation_style="casual,informative",
podcast_name="Tech Talk",
tts_model="openai",
creativity_level=0.8
)
print(f"Generated podcast: {result}")
```
### Error Handling
The API will return appropriate error messages for:
- Invalid API keys
- Malformed input
- Failed file processing
- TTS generation errors
### Rate Limits
Please be aware of the rate limits for the underlying services:
- Gemini API
- OpenAI API
- ElevenLabs API
## Notes
- At least one input source (text, URL, PDF, or image) must be provided
- API keys are required for corresponding services
- The generated audio file format is MP3 | {
"source": "souzatharsis/podcastfy",
"title": "docs/source/usage/api.md",
"url": "https://github.com/souzatharsis/podcastfy/blob/main/docs/source/usage/api.md",
"date": "2024-09-30T22:35:09",
"stars": 2726,
"description": "An Open Source Python alternative to NotebookLM's podcast feature: Transforming Multimodal Content into Captivating Multilingual Audio Conversations with GenAI",
"file_size": 6561
} |
## CLI
Podcastfy can be used as a command-line interface (CLI) tool. See below some usage examples.
Please make sure you follow configuration instructions first - [See Setup](README.md#setup).
1. Generate a podcast from URLs (using OpenAI TTS by default):
```
python -m podcastfy.client --url https://example.com/article1 --url https://example.com/article2
```
2. Generate a podcast from URLs using ElevenLabs TTS:
```
python -m podcastfy.client --url https://example.com/article1 --url https://example.com/article2 --tts-model elevenlabs
```
3. Generate a podcast from a file containing URLs:
```
python -m podcastfy.client --file path/to/urls.txt
```
4. Generate a podcast from an existing transcript file:
```
python -m podcastfy.client --transcript path/to/transcript.txt
```
5. Generate only a transcript (without audio) from URLs:
```
python -m podcastfy.client --url https://example.com/article1 --transcript-only
```
6. Generate a podcast using a combination of URLs and a file:
```
python -m podcastfy.client --url https://example.com/article1 --file path/to/urls.txt
```
7. Generate a podcast from image files:
```
python -m podcastfy.client --image path/to/image1.jpg --image path/to/image2.png
```
8. Generate a podcast with a custom conversation configuration:
```
python -m podcastfy.client --url https://example.com/article1 --conversation-config path/to/custom_config.yaml
```
9. Generate a podcast from URLs and images:
```
python -m podcastfy.client --url https://example.com/article1 --image path/to/image1.jpg
```
10. Generate a transcript using a local LLM:
```
python -m podcastfy.client --url https://example.com/article1 --transcript-only --local
```
For more information on available options, use:
```
python -m podcastfy.client --help
```
11. Generate a podcast from raw text input:
```
python -m podcastfy.client --text "Your raw text content here that you want to convert into a podcast"
``` | {
"source": "souzatharsis/podcastfy",
"title": "docs/source/usage/cli.md",
"url": "https://github.com/souzatharsis/podcastfy/blob/main/docs/source/usage/cli.md",
"date": "2024-09-30T22:35:09",
"stars": 2726,
"description": "An Open Source Python alternative to NotebookLM's podcast feature: Transforming Multimodal Content into Captivating Multilingual Audio Conversations with GenAI",
"file_size": 2043
} |
# Podcastfy Configuration
## API keys
The project uses a combination of a `.env` file for managing API keys and sensitive information, and a `config.yaml` file for non-sensitive configuration settings. Follow these steps to set up your configuration:
1. Create a `.env` file in the root directory of the project.
2. Add your API keys and other sensitive information to the `.env` file. For example:
```
GEMINI_API_KEY=your_gemini_api_key_here
ELEVENLABS_API_KEY=your_elevenlabs_api_key_here
OPENAI_API_KEY=your_openai_api_key_here
```
API Key Requirements:
- `GEMINI_API_KEY`: Required for transcript generation if not using a [local llm](local_llm.md). (get your [free API key](aistudio.google.com/app/apikey))
- `OPENAI_API_KEY` or `ELEVENLABS_API_KEY`: Required for audio generation if not using Microsoft Edge TTS `tts_model=edge`.
Ensure you have the necessary API keys based on your intended usage of Podcastfy.
> [!Note]
> Never share your `.env` file or commit it to version control. It contains sensitive information that should be kept private. The `config.yaml` file can be shared and version-controlled as it doesn't contain sensitive data.
## Example Configurations
Here's a table showing example configurations:
| Configuration | Base LLM | TTS Model | API Keys Required |
|---------------|----------|-----------|-------------------|
| Default | Gemini | OpenAI | GEMINI_API_KEY and OPENAI_API_KEY |
| No API Keys Required | Local LLM | Edge | None |
| Recommended | Gemini | 'gemini' (Google) | GEMINI_API_KEY |
In our experience, ElevenLabs and Google TTS model are the best models in terms quality of audio generation with the latter having an edge over the former due to its multispeaker capability. ElevenLabs is the most expensive but it's easy to setup and offers great customization (voice options and multilingual capability). Google TTS model is cheaper but is limited to English only and requires some extra steps to set up.
## Setting up Google TTS Model
You can use Google TTS model by setting the `tts_model` parameter to `gemini` in `Podcastfy`.
Google TTS model requires a Google Cloud API key, you can use the same API key you are already using for Gemini or create a new one. After you have secured your API Key there are two additional steps in order to use Google Multispeaker TTS model:
- Step 1: You will need to enable the Cloud Text-to-Speech API on the API key.
- Go to "https://console.cloud.google.com/apis/dashboard"
- Select your project (or create one by clicking on project list and then on "new project")
- Click "+ ENABLE APIS AND SERVICES" at the top of the screen
- Enter "text-to-speech" into the search box
- Click on "Cloud Text-to-Speech API" and then on "ENABLE"
- You should be here: "https://console.cloud.google.com/apis/library/texttospeech.googleapis.com?project=..."
- Step 2: You need to add the Cloud Text-to-Speech API permission to the API KEY you're using on the Google Cloud console.
- Go to https://console.cloud.google.com/apis/credentials
- Click on whatever key you're using for Gemini
- Go down to API Restrictions and add the Cloud Text-to-Speech API
Phew!!! That was a lot of steps but you only need to do it once and you might be impressed with the quality of the audio. See [Google TTS](https://cloud.google.com/text-to-speech) for more details. Thank you @mobarski and @evandempsey for the help!
## Conversation Configuration
See [conversation_custom.md](conversation_custom.md) for more details.
## Running Local LLMs
See [local_llm.md](local_llm.md) for more details.
## Optional configuration
The `config.yaml` file in the root directory contains non-sensitive configuration settings. You can modify this file to adjust various parameters such as output directories, text-to-speech settings, and content generation options.
The application will automatically load the environment variables from `.env` and the configuration settings from `config.yaml` when it runs.
See [Configuration](config_custom.md) if you would like to further customize settings. | {
"source": "souzatharsis/podcastfy",
"title": "docs/source/usage/config.md",
"url": "https://github.com/souzatharsis/podcastfy/blob/main/docs/source/usage/config.md",
"date": "2024-09-30T22:35:09",
"stars": 2726,
"description": "An Open Source Python alternative to NotebookLM's podcast feature: Transforming Multimodal Content into Captivating Multilingual Audio Conversations with GenAI",
"file_size": 4098
} |
# Podcastfy Advanced Configuration Guide
Podcastfy uses a `config.yaml` file to manage various settings and parameters. This guide explains each configuration option available in the file.
## Content Generator
- `gemini_model`: "gemini-1.5-pro-latest"
- The Gemini AI model used for content generation.
- `max_output_tokens`: 8192
- Maximum number of tokens for the output generated by the AI model.
- `temperature`: 1
- Controls randomness in the AI's output. 0 means deterministic responses. Range for gemini-1.5-pro: 0.0 - 2.0 (default: 1.0)
- `langchain_tracing_v2`: false
- Enables LangChain tracing for debugging and monitoring. If true, requires langsmith api key
## Content Extractor
- `youtube_url_patterns`:
- Patterns to identify YouTube URLs.
- Current patterns: "youtube.com", "youtu.be"
## Website Extractor
- `markdown_cleaning`:
- `remove_patterns`:
- Patterns to remove from extracted markdown content.
- Current patterns remove image links, hyperlinks, and URLs.
## YouTube Transcriber
- `remove_phrases`:
- Phrases to remove from YouTube transcriptions.
- Current phrase: "[music]"
## Logging
- `level`: "INFO"
- Default logging level.
- `format`: "%(asctime)s - %(name)s - %(levelname)s - %(message)s"
- Format string for log messages.
## Website Extractor
- `markdown_cleaning`:
- `remove_patterns`:
- Additional patterns to remove from extracted markdown content:
- '\[.*?\]': Remove square brackets and their contents
- '\(.*?\)': Remove parentheses and their contents
- '^\s*[-*]\s': Remove list item markers
- '^\s*\d+\.\s': Remove numbered list markers
- '^\s*#+': Remove markdown headers
- `unwanted_tags`:
- HTML tags to be removed during extraction:
- 'script', 'style', 'nav', 'footer', 'header', 'aside', 'noscript'
- `user_agent`: 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
- User agent string to be used for web requests
- `timeout`: 10
- Request timeout in seconds for web scraping | {
"source": "souzatharsis/podcastfy",
"title": "docs/source/usage/config_custom copy.md",
"url": "https://github.com/souzatharsis/podcastfy/blob/main/docs/source/usage/config_custom copy.md",
"date": "2024-09-30T22:35:09",
"stars": 2726,
"description": "An Open Source Python alternative to NotebookLM's podcast feature: Transforming Multimodal Content into Captivating Multilingual Audio Conversations with GenAI",
"file_size": 2054
} |
Subsets and Splits