
task_categories:
- multiple-choice
- question-answering
- visual-question-answering
language:
- en
- zh
tags:
- multimodal
- intelligence
size_categories:
- 1K<n<10K
license: apache-2.0
pretty_name: mmiq
configs:
- config_name: default
features:
- name: category
dtype: string
- name: question
dtype: string
- name: question_en
dtype: string
- name: question_zh
dtype: string
- name: image
dtype: image
- name: MD5
dtype: string
- name: data_id
dtype: int64
- name: answer
dtype: string
- name: split
dtype: string
Dataset Card for "MM-IQ"
Introduction
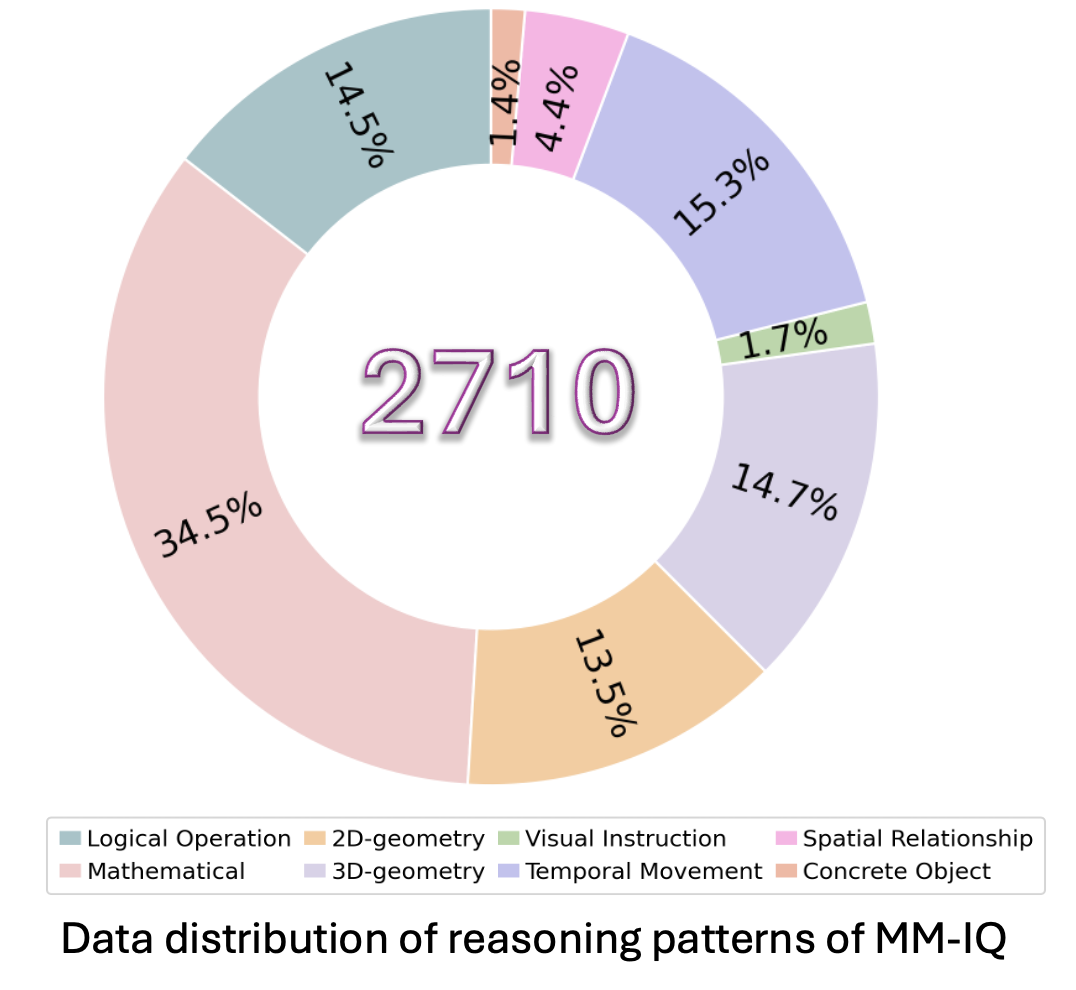
IQ testing has served as a foundational methodology for evaluating human cognitive capabilities, deliberately decoupling assessment from linguistic background, language proficiency, or domain-specific knowledge to isolate core competencies in abstraction and reasoning. Yet, artificial intelligence research currently lacks systematic benchmarks to quantify these critical cognitive dimensions in multimodal systems. To address this critical gap, we propose MM-IQ, a comprehensive evaluation framework comprising 2,710 meticulously curated test items spanning 8 distinct reasoning paradigms.
Through systematic evaluation of leading open-source and proprietary multimodal models, our benchmark reveals striking limitations: even state-of-the-art architectures achieve only marginally superior performance to random chance (27.49% vs. 25% baseline accuracy). This substantial performance chasm highlights the inadequacy of current multimodal systems in approximating fundamental human reasoning capacities, underscoring the need for paradigm-shifting advancements to bridge this cognitive divide.
Paper Information
- Paper: Coming soon.
- Code: https://github.com/AceCHQ/MMIQ/tree/main
- Project: https://acechq.github.io/MMIQ-benchmark/
- Leaderboard: https://acechq.github.io/MMIQ-benchmark/#leaderboard
Dataset Examples
Examples of our MM-IQ:
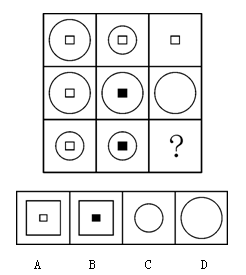
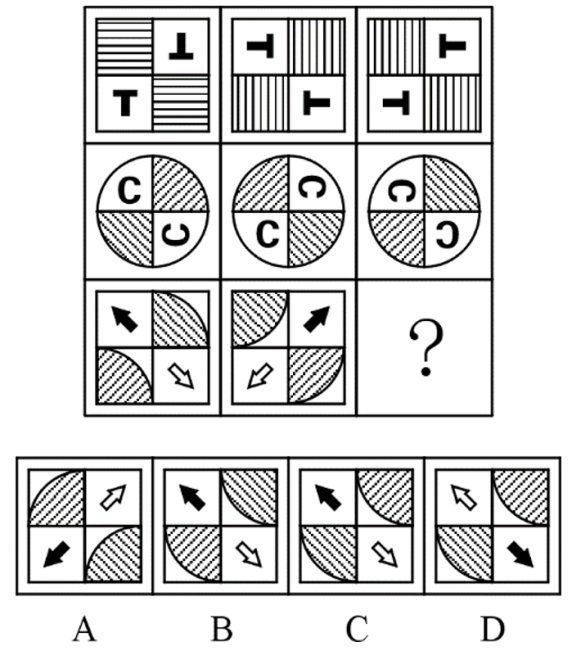
- Logical Operation Reasoning
Prompt: Choose the most appropriate option from the given four choices to fill in the question mark, so that it presents a certain regularity:
🔍 Click to expand/collapse more examples
Mathematical Reasoning
Prompt1: Choose the most appropriate option from the given four options to present a certain regularity:
Option A: 4; Option B: 5; Option C: 6; Option D: 7.

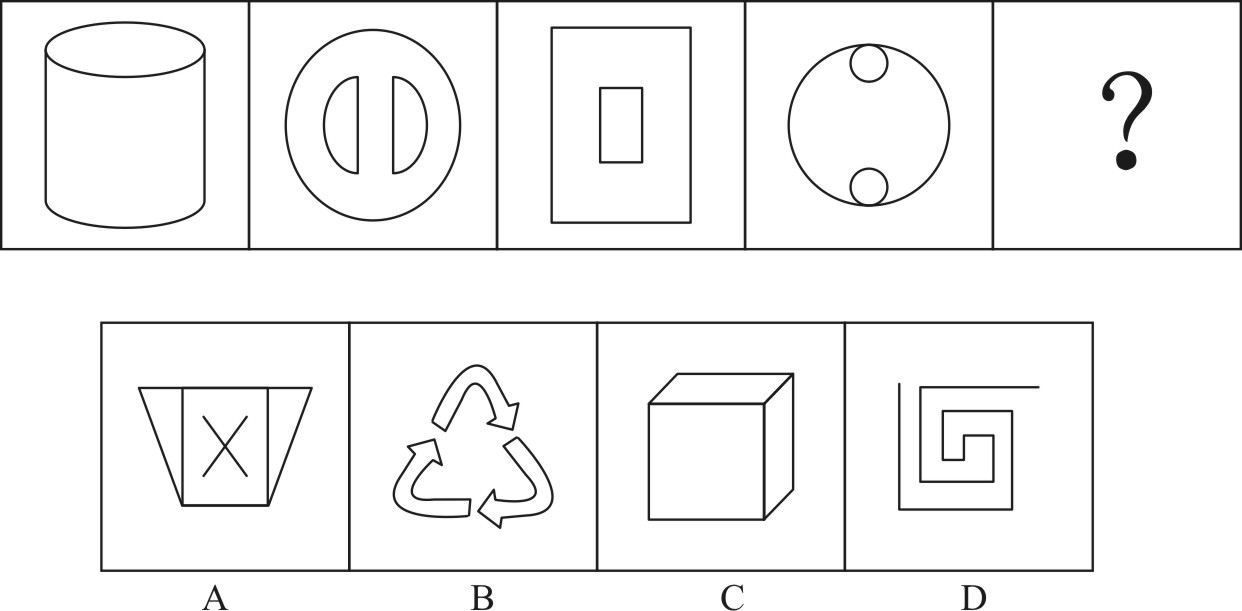
2D-geometry Reasoning
Prompt: The option that best fits the given pattern of figures is ( ).
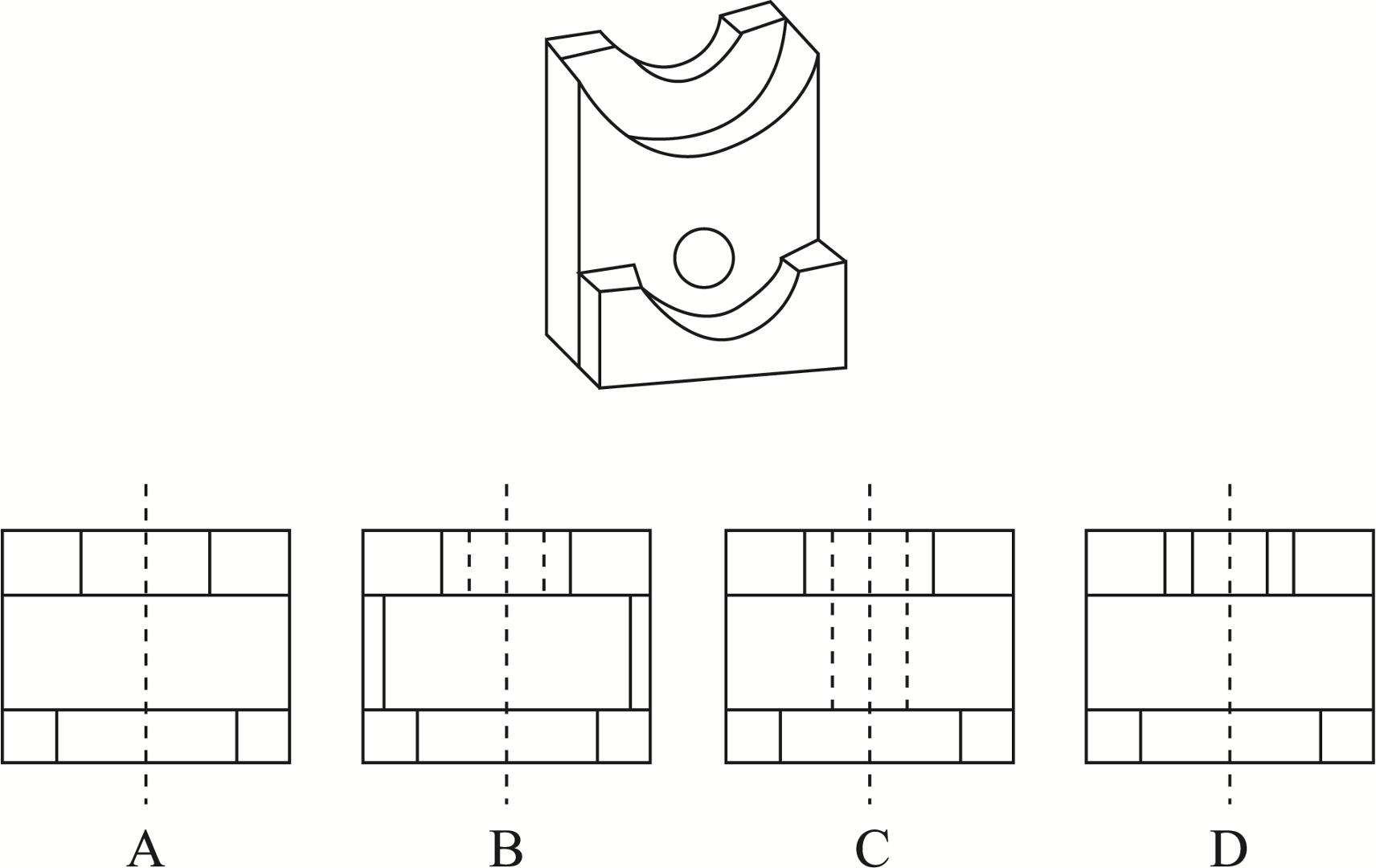
3D-geometry Reasoning
Prompt: The one that matches the top view is:
visual instruction Reasoning
Prompt: Choose the most appropriate option from the given four options to present a certain regularity:

Spatial Relationship Reasoning
Prompt: Choose the most appropriate option from the given four options to present a certain regularity:
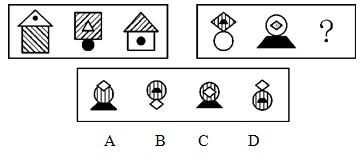
Concrete Object Reasoning
Prompt: Choose the most appropriate option from the given four choices to fill in the question mark, so that it presents a certain regularity:

Temporal Movement Reasoning
Prompt:Choose the most appropriate option from the given four choices to fill in the question mark, so that it presents a certain regularity:
Leaderboard
🏆 The leaderboard for the MM-IQ (2,710 problems) is available here.
Dataset Usage
Data Downloading
You can download this dataset by the following command (make sure that you have installed Huggingface Datasets):
from IPython.display import display, Image
from datasets import load_dataset
dataset = load_dataset("huanqia/MM-IQ")
Here are some examples of how to access the downloaded dataset:
# print the first example on the MM-IQ dataset
print(dataset["test"][0])
print(dataset["test"][0]['data_id']) # print the problem id
print(dataset["test"][0]['question']) # print the question text
print(dataset["test"][0]['answer']) # print the answer
# Display the image
print("Image context:")
display(dataset["test"][0]['image'])
We have uploaded a demo to illustrate how to access the MM-IQ dataset on Hugging Face, available at hugging_face_dataset_demo.ipynb.
Data Format
The dataset is provided in Parquet format and contains the following attributes:
{
"question": [string] The question text,
"answer": [string] The correct answer for the problem,
"data_id": [int] The problem id,
"category": [string] The category of reasoning pattern,
"image": [image] Containing image (raw bytes and image path) corresponding to the image in data.zip,
}
Automatic Evaluation
🔔 To automatically evaluate a model on the dataset, please refer to our GitHub repository here.
Citation
If you use the MM-IQ dataset in your work, please kindly cite the paper using this BibTeX:
@misc{cai2025mm-iq,
title = {MM-IQ: Benchmarking Human-Like Abstraction and Reasoning in Multimodal Models},
author = {Huanqia Cai and Yijun Yang and Winston Hu},
month = {January},
year = {2025}
}