
license: apache-2.0
Want to fine-tune this dataset on LLaMA-Factory? Check this repository for preprocessing: llm-merging datasets
(Unofficial!) I preprocessed the original data of the CMExam dataset on GitHub so that it can be visualized on huggingface. The dataset loading code for subsequent training (such as LLaMA-Factory) is in the ipynb file in the file directory.
This paper was presented at NeurIPS 2023, New Orleans, Louisana. See here for the poster and slides.
Benchmarking Large Language Models on CMExam - A Comprehensive Chinese Medical Exam Dataset
Introduction
CMExam is a dataset sourced from the Chinese National Medical Licensing Examination. It consists of 60K+ multiple-choice questions and five additional question-wise annotations, including disease groups, clinical departments, medical disciplines, areas of competency, and question difficulty levels. Alongside the dataset, comprehensive benchmarks were conducted on representative LLMs on CMExam.

Dataset Statistics
| Train | Val | Test | Total | |
|---|---|---|---|---|
| Question | 54,497 | 6,811 | 6,811 | 68,119 |
| Vocab | 4,545 | 3,620 | 3,599 | 4,629 |
| Max Q tokens | 676 | 500 | 585 | 676 |
| Max A tokens | 5 | 5 | 5 | 5 |
| Max E tokens | 2,999 | 2,678 | 2,680 | 2,999 |
| Avg Q tokens | 29.78 | 30.07 | 32.63 | 30.83 |
| Avg A tokens | 1.08 | 1.07 | 1.07 | 1.07 |
| Avg E tokens | 186.24 | 188.95 | 201.44 | 192.21 |
| Median (Q1, Q3) Q tokens | 17 (12, 32) | 18 (12, 32) | 18 (12, 37) | 18 (12, 32) |
| Median (Q1, Q3) A tokens | 1 (1, 1) | 1 (1, 1) | 1 (1, 1) | 1 (1, 1) |
| Median (Q1, Q3) E tokens | 146 (69, 246) | 143 (65, 247) | 158 (80, 263) | 146 (69, 247) |
*Q: Question; A: Answer; E: Explanation
Annotation Characteristics
| Annotation Content | References | Unique values |
|---|---|---|
| Disease Groups | The 11th revision of ICD-11 | 27 |
| Clinical Departments | The Directory of Medical Institution Diagnostic and Therapeutic Categories (DMIDTC) | 36 |
| Medical Disciplines | List of Graduate Education Disciplinary Majors (2022) | 7 |
| Medical Competencies | Medical Professionals | 4 |
| Difficulty Level | Human Performance | 5 |
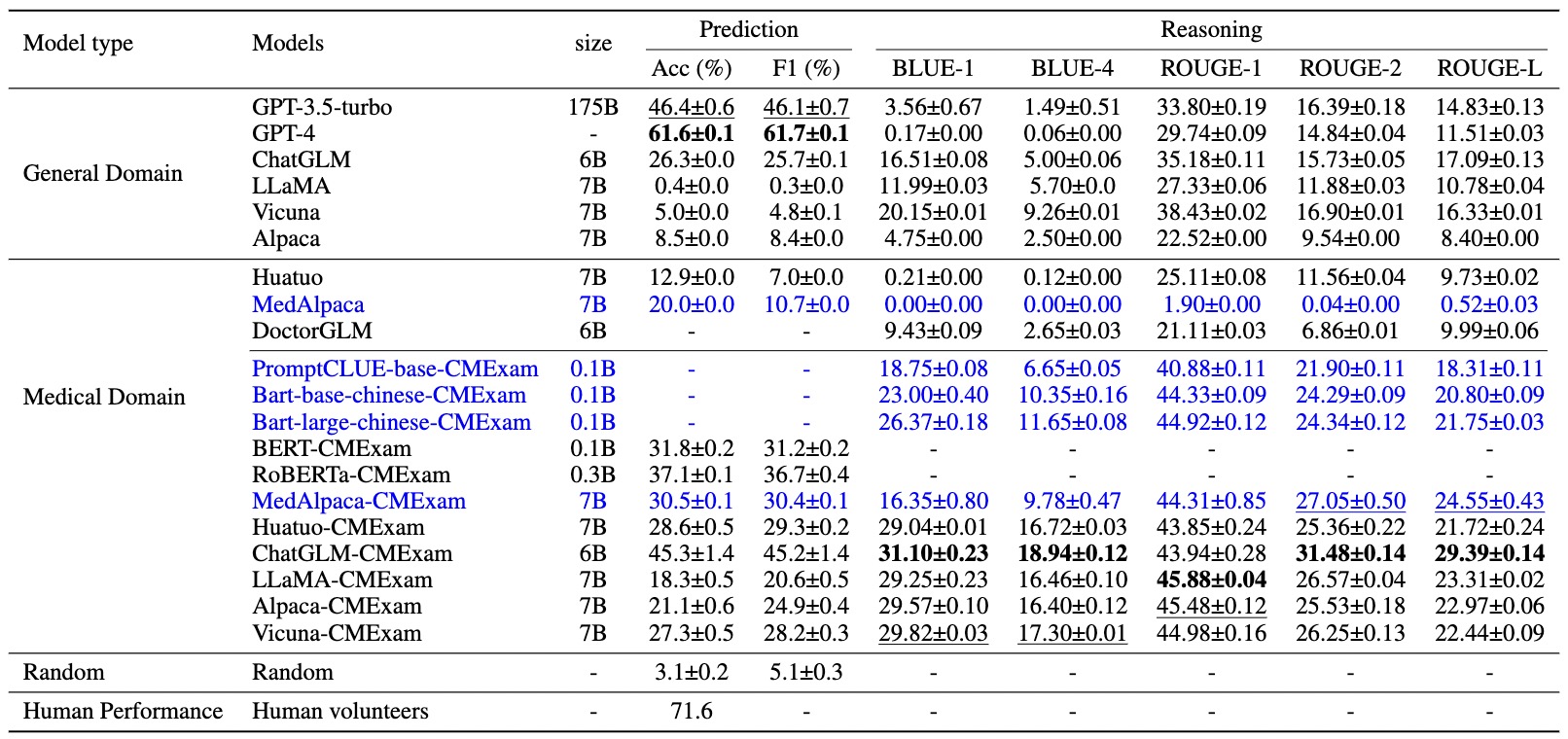
Benchmarks
Alongside the dataset, we further conducted thorough experiments with representative LLMs and QA algorithms on CMExam.
Side notes
Limitations:
- Excluding non-textual questions may introduce biases.
- BLEU and ROUGE metrics are inadequate for fully assessing explanations; better expert analysis needed in future.
Ethics in Data Collection:
- Adheres to legal and ethical guidelines.
- Authenticated and accurate for evaluating LLMs.
- Intended for academic/research use only; commercial misuse prohibited.
- Users should acknowledge dataset limitations and specific context.
- Not for assessing individual medical competence or patient diagnosis.
Future directions:
- Translate to English (in-progress)
- Include multimodal information (our new dataset ChiMed-Vision-Language-Instruction - 469,441 QA pairs: https://paperswithcode.com/dataset/qilin-med-vl)
Citation
Benchmarking Large Language Models on CMExam -- A Comprehensive Chinese Medical Exam Dataset https://arxiv.org/abs/2306.03030
@article{liu2023benchmarking,
title={Benchmarking Large Language Models on CMExam--A Comprehensive Chinese Medical Exam Dataset},
author={Liu, Junling and Zhou, Peilin and Hua, Yining and Chong, Dading and Tian, Zhongyu and Liu, Andrew and Wang, Helin and You, Chenyu and Guo, Zhenhua and Zhu, Lei and others},
journal={arXiv preprint arXiv:2306.03030},
year={2023}
}