
CCMUSIC benchmarks
Collection
The 6 benchmark datasets evaluated in the paper
•
7 items
•
Updated
•
12
audio
audioduration (s) 0.57
475
| mel
imagewidth (px) 50
40.9k
| label
class label 212
classes | cname
stringclasses 212
values | pinyin
stringclasses 212
values |
|---|---|---|---|---|
118D0287
|
深波
|
shen1_bo1
|
||
150L0136
|
渔胡
|
yu2_hu2
|
||
27C0259
|
中音加键唢呐
|
Alto_jia1_jian4_suo3_na
|
||
216T0319
|
低音热瓦普
|
Bass_re4_wa3_pu3
|
||
191T0081
|
玄琴
|
xuan2_qin2
|
||
129L0046
|
扬剧主胡F调
|
yang2_ju4_zhu3_hu2_in_F
|
||
166L0162
|
襄阳专用胡琴
|
xiang1_yang2_zhuan1_yong4_hu2_qin2
|
||
177L0256
|
雷琴
|
lei2_qin2
|
||
156L0151
|
四弦
|
si4_xian2
|
||
171L0167
|
黔胡
|
qian2_hu2
|
||
128L0045
|
扬剧主胡
|
yang2_ju4_zhu3_hu2
|
||
188T0006
|
陶布舒尔
|
tao2_bu4_shu1_er3
|
||
150L0136
|
渔胡
|
yu2_hu2
|
||
171L0167
|
黔胡
|
qian2_hu2
|
||
186L0313
|
佤族独弦琴
|
wa3_zu2_du2_xian2_qin2
|
||
127L0044
|
锡剧主胡
|
xi1_ju4_zhu3_hu2
|
||
178L0266
|
二胡
|
er4_hu2
|
||
16C0124
|
大吹
|
da4_chui1
|
||
94D0241
|
编钟
|
bian1_zhong1
|
||
215T0318
|
弹拨尔
|
dan4_bo1_er3
|
||
142L0085
|
奚琴(改良)
|
xi1_qin2_(reformed)
|
||
32C0281
|
G调新笛
|
xin1_di2_in_G
|
||
27C0259
|
中音加键唢呐
|
Alto_jia1_jian4_suo3_na
|
||
146L0122
|
壳仔弦
|
ke2_zai3_xian2
|
||
60D0069
|
蛮锣
|
man2_luo2
|
||
78D0143
|
双铃
|
shuang1_ling2
|
||
36C0303
|
小闷笛
|
xiao3_men1_di2
|
||
204T0260
|
中阮
|
zhong1_ruan3
|
||
132L0055
|
牛腿琴
|
niu2_tui3_qin2
|
||
197T0111
|
三弦
|
san1_xian2
|
||
27C0259
|
中音加键唢呐
|
Alto_jia1_jian4_suo3_na
|
||
212T0301
|
玎
|
ding1
|
||
198T0116
|
八角月琴
|
ba1_jiao3_yue4_qin2
|
||
6C0096
|
小筚篥
|
Treble_bi4_li
|
||
150L0136
|
渔胡
|
yu2_hu2
|
||
99D0248
|
中国大鼓
|
Chinese_da4_gu3
|
||
202T0254
|
箜篌
|
kong1_hou2
|
||
89D0180
|
宜春三星鼓禄鼓老鼓
|
yi2_chun1_san1_xing1_gu3_lu4_gu3_(traditional)
|
||
208T0289
|
三弦2
|
san1_xian2_2
|
||
148L0134
|
陇剧陇胡(改良)D调
|
long3_ju4_long3_hu2_(reformed)_in_D
|
||
81D0146
|
四宝
|
si4_bao3
|
||
171L0167
|
黔胡
|
qian2_hu2
|
||
174L0170
|
二股弦
|
er4_gu3_xian2
|
||
35C0296
|
唢呐2
|
suo3_na_2
|
||
27C0259
|
中音加键唢呐
|
Alto_jia1_jian4_suo3_na
|
||
29C0264
|
低音笙
|
Bass_sheng1
|
||
62D0071
|
引鼓
|
yin3_gu3
|
||
201T0238
|
大阮
|
da4_ruan3
|
||
153L0148
|
板胡
|
ban3_hu2
|
||
159L0154
|
仕胡
|
shi4_hu2
|
||
31C0280
|
A调曲笛
|
qu3_di2_in_A
|
||
105D0269
|
铙
|
nao2
|
||
148L0134
|
陇剧陇胡(改良)D调
|
long3_ju4_long3_hu2_(reformed)_in_D
|
||
112D0276
|
马锣
|
ma3_luo2
|
||
155L0150
|
宛梆子梆胡
|
yuan1_bang1_zi_bang1_hu2
|
||
155L0150
|
宛梆子梆胡
|
yuan1_bang1_zi_bang1_hu2
|
||
168L0164
|
赣胡
|
gan4_hu2
|
||
139L0077
|
晋剧二股弦
|
jin4_ju4_er4_gu3_xian2
|
||
146L0122
|
壳仔弦
|
ke2_zai3_xian2
|
||
178L0266
|
二胡
|
er4_hu2
|
||
183L0297
|
中胡
|
zhong1_hu2
|
||
130L0047
|
扬剧主胡(小西皮)
|
yang2_ju4_zhu3_hu2_(xiao3_xi1_pi2)
|
||
147L0133
|
陇剧陇胡(传统)
|
long3_ju4_long3_hu2_(traditional)
|
||
17C0182
|
长号
|
chang2_hao4
|
||
55D0064
|
川大钵
|
chuan1_da4_bo1
|
||
106D0270
|
铙钹
|
nao2_bo1
|
||
148L0134
|
陇剧陇胡(改良)D调
|
long3_ju4_long3_hu2_(reformed)_in_D
|
||
112D0276
|
马锣
|
ma3_luo2
|
||
105D0269
|
铙
|
nao2
|
||
190T0078
|
四股弦
|
si4_gu3_xian2
|
||
131L0053
|
广西彩调主胡
|
guang3_xi1_cai3_diao4_zhu3_hu2
|
||
67D0125
|
南鼓
|
nan2_gu3
|
||
171L0167
|
黔胡
|
qian2_hu2
|
||
19C0187
|
高音唢呐
|
Treble_suo3_na
|
||
185L0312
|
牛角胡
|
niu2_jiao3_hu2
|
||
96D0245
|
南梆子
|
nan2_bang1_zi
|
||
154L0149
|
绍剧板胡
|
shao4_ju4_ban3_hu2
|
||
125D0327
|
萨巴依
|
sa4_ba1_yi1
|
||
41C0309
|
葫芦丝
|
hu2_lu2_si1
|
||
91D0184
|
宜春三星鼓双铛
|
yi2_chun1_san1_xing1_gu3_shuang1_ding1
|
||
207T0267
|
扬琴4
|
yang2_qin2_4
|
||
175L0239
|
高音板胡
|
Treble_ban3_hu2
|
||
152L0141
|
越胡
|
yue4_hu2
|
||
9C0099
|
短箫
|
duan3_xiao1
|
||
0C0090
|
大笒
|
da4_cen2
|
||
27C0259
|
中音加键唢呐
|
Alto_jia1_jian4_suo3_na
|
||
175L0239
|
高音板胡
|
Treble_ban3_hu2
|
||
11C0101
|
洞箫
|
dong4_xiao1
|
||
170L0166
|
高腔赣胡第2代
|
gao1_qiang1_gan4_hu2_2nd_generation
|
||
161L0156
|
工胡
|
gong1_hu2
|
||
138L0076
|
壮剧土胡2
|
zhuang4_ju4_tu3_hu2_2
|
||
128L0045
|
扬剧主胡
|
yang2_ju4_zhu3_hu2
|
||
191T0081
|
玄琴
|
xuan2_qin2
|
||
41C0309
|
葫芦丝
|
hu2_lu2_si1
|
||
146L0122
|
壳仔弦
|
ke2_zai3_xian2
|
||
135L0073
|
盖板(传统)
|
gai4_ban3_(traditional)
|
||
5C0095
|
长唢呐
|
chang2_suo3_na
|
||
169L0165
|
高腔赣胡
|
gao1_qiang1_gan4_hu2
|
||
203T0255
|
古筝
|
gu3_zheng1
|
||
166L0162
|
襄阳专用胡琴
|
xiang1_yang2_zhuan1_yong4_hu2_qin2
|
The original dataset is created by [1], with no evaluation provided. The original CTIS dataset contains recordings from 287 varieties of Chinese traditional instruments, reformed Chinese musical instruments, and instruments from ethnic minority groups. Notably, some of these instruments are rarely encountered by the majority of the Chinese populace. The dataset was later utilized by [2] for Chinese instrument recognition, where only 78 instruments—approximately one-third of the total instrument classes—were used.
We begin by performing data cleaning to remove recordings without specific instrument labels. Additionally, recordings that are not instrumental sounds, such as interview recordings, are removed to enhance usability. Finally, instrument categories lacking specific labels are excluded. The filtered dataset contains recordings of 209 types of Chinese traditional musical instruments. Compared to the original 287 instrument types, 78 were removed due to missing instrument labels. Among the remaining instruments, seven have two variants each, and one instrument, Yangqin, has four variants. We treat variants as separate classes, thus 219 labels are included at last.
In the original dataset, the Chinese character label for each instrument was represented by the folder name housing its audio files. During integration, we add Chinese pinyin label to make the dataset more accessible to researchers who are not familiar in Chinese. Then, we've reorganized the data into a dictionary with five columns, which includes: audio with a sampling rate of 44,100 Hz, pre-processed mel spectrogram, numerical label, instrument name in Chinese, and instrument name in Chinese pinyin. The provision of mel spectrograms primarily serves to enhance the visualization of the audio in the viewer. For the remaining datasets, these mel spectrograms will also be included in the integrated data structure. The total data number is 4,956, with a duration of 32.63 hours. The average duration of the recordings is 23.7 seconds.
We have constructed the default subset of the current integrated version of the dataset. Building on the default subset, we applied silence removal with a threshold of top_db=40 to the audio files, converting them into mel, CQT, and chroma spectrograms. The audio was then segmented into 2-second clips, with segments shorter than 2 seconds padded using circular padding. This process resulted in the construction of the eval subset for dataset evaluation experiments.
 |
 |
|---|---|
| Fig. 1 | Fig. 2 |
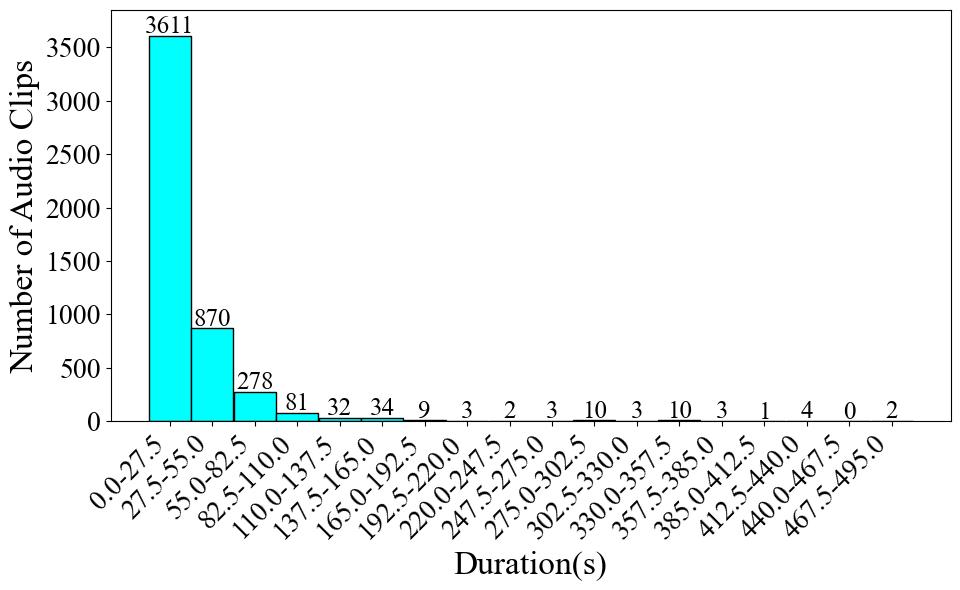
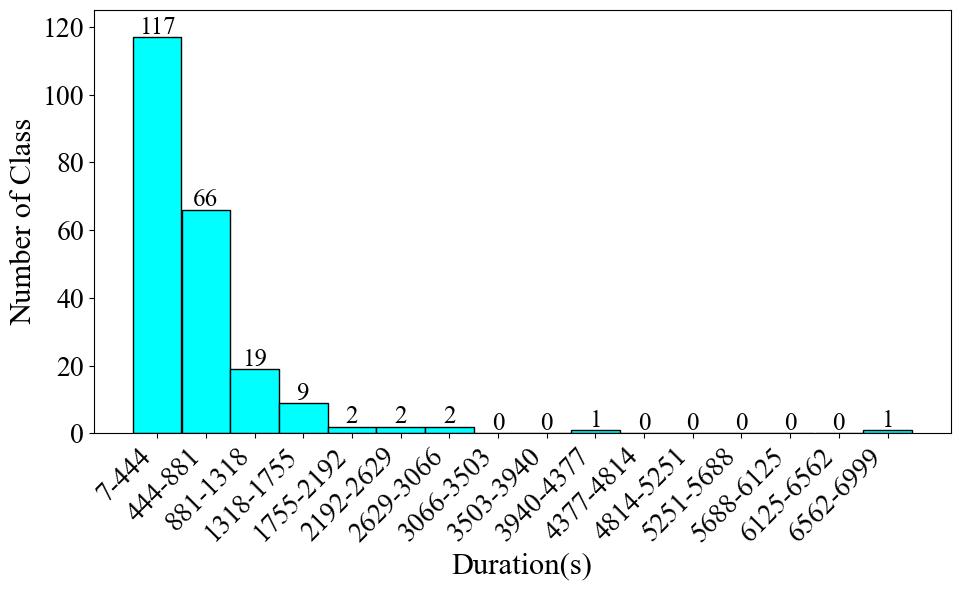
Due to the large number of categories in this dataset, we are unable to provide the audio duration per category and the proportion of audio clips by category, as we have done for the other datasets. Instead, we provide a chart showing the distribution of the number of audio clips across different durations, as shown in Fig. 1. A second graph, shown in Fig. 2, shows the distribution of instrument categories over various durations. From Fig. 1, 3611 clips (73%) are concentrated in the range 0-27.5 s, with a steep drop in the number of samples in longer durations. In Fig. 2, about half of the instruments, totaling 117, have a duration of less than 437 seconds, while 102 instruments have a duration greater than this number. After the total duration exceeds 881 seconds, the number of instruments drops sharply. This indicates that the dataset has a certain degree of class imbalance.
| Statistical items | Values |
|---|---|
| Total count | 4956 |
| Total duration(s) | 117482.75025085056 |
| Mean duration(s) | 23.705155417847124 |
| Min duration(s) | 0.27639583333333334 |
| Max duration(s) | 494.2522902494331 |
| Instrument types | 209 |
| Label Numbers | 219 |
| Eval subset total | 43054 |
| Class with the longest audio duartion | 中阮 (Zhong1 ruan3) |
| Class in the longest audio duartion interval | 箜篌 (Kong1 hou2) |
https://huggingface.co/datasets/ccmusic-database/CTIS/viewer
219 Chinese instruments
.zip(.wav), .csv
train, validation, test
A dataset of Chinese instrument audio
MIR, audio classification
Chinese, English
from datasets import load_dataset
dataset = load_dataset("ccmusic-database/CTIS", name="default", split="train")
for item in dataset:
print(item)
from datasets import load_dataset
dataset = load_dataset("ccmusic-database/CTIS", name="eval")
for item in ds["train"]:
print(item)
for item in ds["validation"]:
print(item)
for item in ds["test"]:
print(item)
GIT_LFS_SKIP_SMUDGE=1 git clone [email protected]:datasets/ccmusic-database/CTIS
cd CTIS
https://www.modelscope.cn/datasets/ccmusic-database/CTIS
Zijin Li
[1] Liang, Xiaojing et al. “Constructing a Multimedia Chinese Musical Instrument Database.” Lecture Notes in Electrical Engineering (2019): n. pag.
[2] Li, R., & Zhang, Q. (2022). Audio recognition of Chinese traditional instruments based on machine learning. Cogn. Comput. Syst., 4, 108-115.
[3] https://huggingface.co/ccmusic-database/CTIS
@inproceedings{10.1007/978-981-13-8707-4_5,
author = {Xiaojing Liang and Zijin Li and Jingyu Liu and Wei Li and Jiaxing Zhu and Baoqiang Han},
booktitle = {Proceedings of the 6th Conference on Sound and Music Technology (CSMT)},
pages = {53-60},
publisher = {Springer Singapore},
address = {Singapore},
title = {Constructing a Multimedia Chinese Musical Instrument Database},
year = {2019}
}
An audio dataset for Chinese Instrument