Datasets:

language:
- en
size_categories:
- 10K<n<100K
task_categories:
- question-answering
- summarization
- table-question-answering
pretty_name: NumericBench
tags:
- numeric
- arithmetic
- math
configs:
- config_name: arithmetic_operation
data_files: arithmetic_operation/*.json
- config_name: mixed_number_sting
data_files: mixed_number_sting/*.json
- config_name: num_list
data_files: num_list/*.json
- config_name: sequence
data_files: sequence/*.json
- config_name: stock-single-trun
data_files: stock/single-turn/*.json
- config_name: stock-multi-turn
data_files: stock/multi-turn/*.json
- config_name: weather-single-turn
data_files: weather/single-turn/*.json
- config_name: weather-multi-turn
data_files: weather/multi-turn/*.json
Introduction
NumericBench is a comprehensive benchmark designed to evaluate the numerical reasoning capabilities of Large Language Models, addressing their limitations in tasks like arithmetic, number recognition, contextual retrieval, comparison, summarization, and logical reasoning. By incorporating diverse datasets ranging from synthetic number lists to real-world domains like stock trends and weather patterns, NumericBench systematically tests LLMs in both structured and noisy contexts. Experiments on models such as GPT-4o and DeepSeek-V3 reveal significant weaknesses, emphasizing the need for numerically-aware modeling to enhance LLMs' real-world applicability.
Github Repo: https://github.com/TreeAI-Lab/NumericBench
Arxiv Paper: https://arxiv.org/abs/2502.11075
Arxiv Paper on Hugging Face: https://huggingface.co/papers/2502.11075
How to use it?
Loading Data
from huggingface_hub import hf_hub_download
import json
dataset_name_list = ['arithmetic_operation/context_arithmetic_operation.json', 'arithmetic_operation/arithmetic_operation.json',
'mixed_number_sting/mixed_number_string_500_per_sample.json',
'num_list/num_list_500_per_sample_1000_length.json', 'num_list/num_list_500_per_sample_100_length.json',
'sequence/sequence_500_sample_100_length.json',
'stock/single-turn/stock_500_per_sample_150_length.json', 'stock/single-turn/stock_500_per_sample_300_length.json', 'stock/multi-turn/stock_multi_turn_100_per_sample_100_length.json',
'weather/single-turn/weather_500_per_sample_200_length.json', 'weather/single-turn/weather_500_per_sample_400_length.json', 'weather/multi-turn/weather_multi_turn_100_per_sample_100_length.json'
]
REPO_ID = "TreeAILab/NumericBench"
for dataset_name in dataset_name_list:
with open(hf_hub_download(repo_id=REPO_ID, filename=dataset_name, repo_type="dataset")) as f:
dataset = json.load(f)
Alternatively, you can download the dataset from this link.
Data Format
Due to the excessive length of the content, "..." is used to indicate omission.
single-turn
{
"system_prompt": "...",
"system_prompt_cot": "...",
"description": "...",
"data": [
{
"idx": 0,
"question_index": 0,
"question": "What is the result of A + B? Please round the answer to two decimal places. ",
"struct_data": "{'A': 6.755, 'B': -1.225}",
"answer": 5.53,
"ability": "1-digit integer with 3 decimal places"
}, ...
]
}
multi-turn
{
"system_prompt": "...",
"system_prompt_cot": "...",
"description": "...",
"data": [
{
"idx": 0,
"multi_turn_QA": [
{
"turn_index": 0,
"question_index": 6,
"struct_data": "...",
"question": "...",
"answer": "F",
"ability": "contextual retrieval"
}, ...
]
}, ...
]
}
Dataset statistics
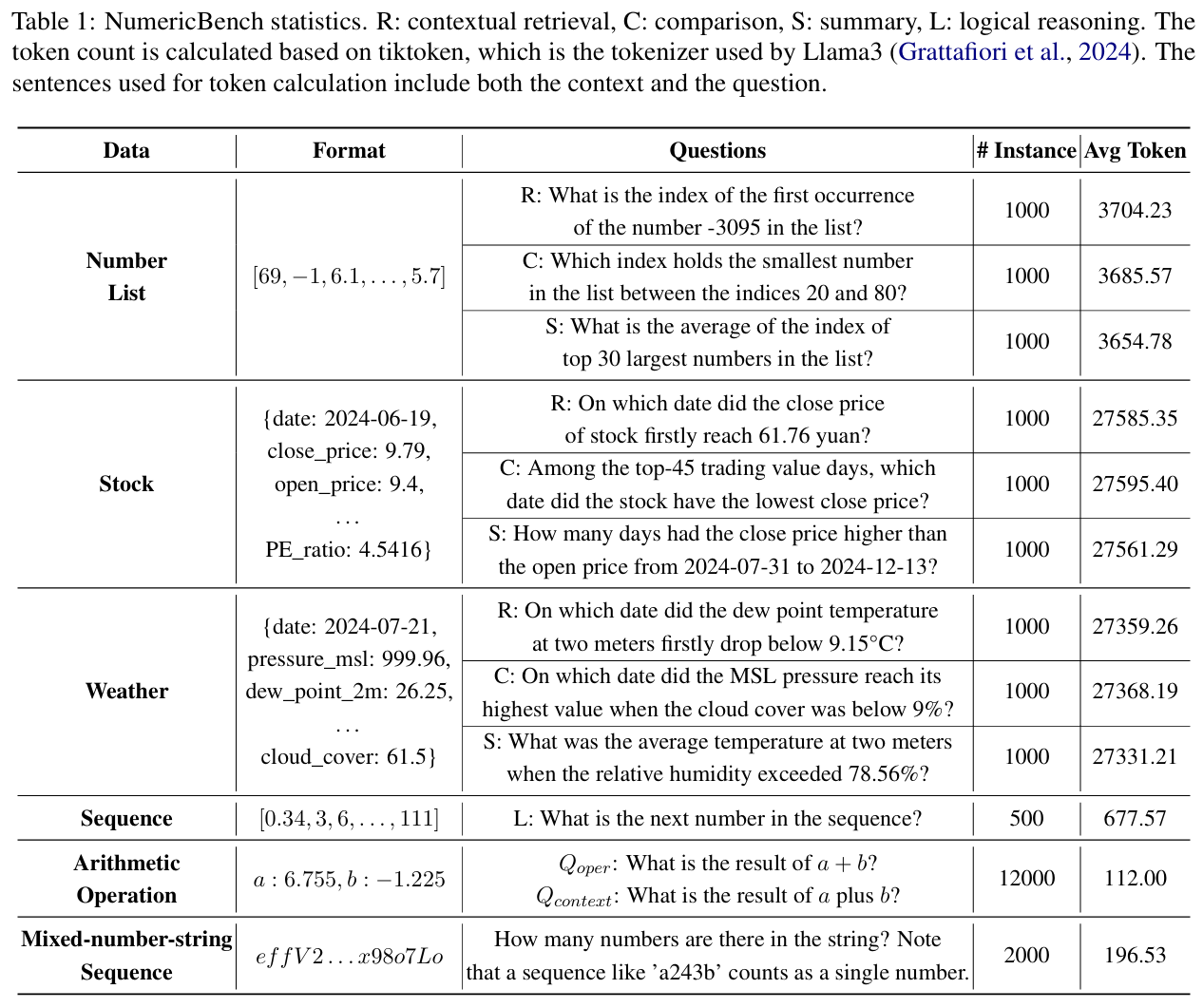
For more details, please refer to our paper.
Citation
@misc{li2025exposingnumeracygapsbenchmark,
title={Exposing Numeracy Gaps: A Benchmark to Evaluate Fundamental Numerical Abilities in Large Language Models},
author={Haoyang Li and Xuejia Chen and Zhanchao XU and Darian Li and Nicole Hu and Fei Teng and Yiming Li and Luyu Qiu and Chen Jason Zhang and Qing Li and Lei Chen},
year={2025},
eprint={2502.11075},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2502.11075},
}