Datasets:


metadata
task_categories:
- feature-extraction
language:
- ko
tags:
- audio
- homecam
- numpy
viewer: false
Dataset Overview
- The dataset is a curated collection of
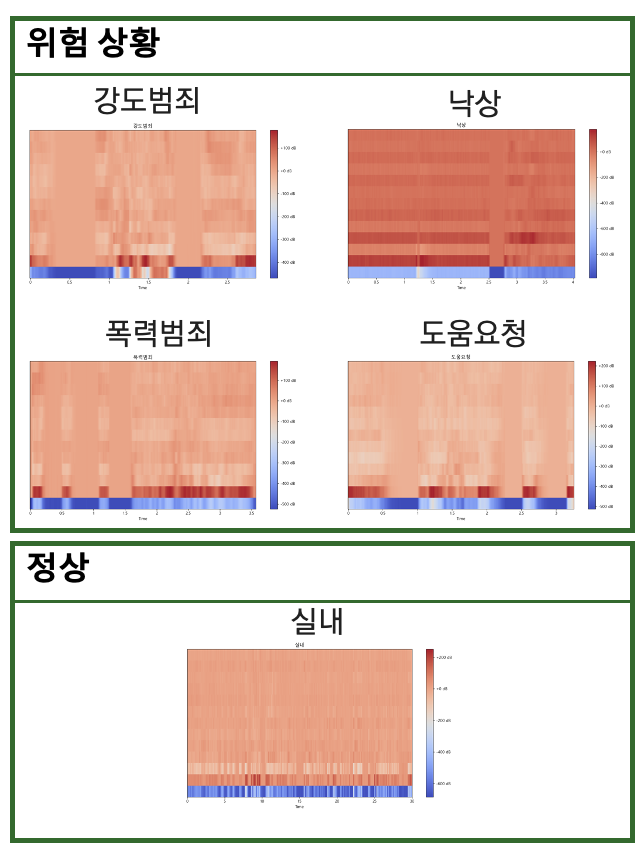
.npyfiles containing MFCC features extracted from raw audio recordings. - It has been specifically designed for training and evaluating machine learning models in the context of real-world emergency sound detection and classification tasks.
- The dataset captures diverse audio scenarios, making it a robust resource for developing safety-focused AI systems, such as the
SilverAssistantproject.
Dataset Descriptions
The dataset used for this audio model consists of
.npyfiles containing MFCC features extracted from raw audio recordings. These recordings include various real-world scenarios, such as:- Criminal activities
- Violence
- Falls
- Cries for help
- Normal indoor sounds
Feature Extraction Process
- Audio Collection:
- Audio samples were sourced from datasets, such as AI Hub, to ensure coverage of diverse scenarios.
- These include emergency and non-emergency sounds to train the model for accurate classification.
- MFCC Extraction:
- The raw audio signals were processed to extract Mel-Frequency Cepstral Coefficients (MFCC).
- The MFCC features effectively capture the frequency characteristics of the audio, making them suitable for sound classification tasks.
- Output Format:
- The extracted MFCC features are saved as
13 x nnumpy arrays, where: - 13: Represents the number of MFCC coefficients (features).
- n: Corresponds to the number of frames in the audio segment.
- The extracted MFCC features are saved as
- Saved Dataset:
- The processed
13 x nMFCC arrays are stored as.npyfiles, which serve as the direct input to the model.
- The processed
- Audio Collection:
Adaptation in
SilverAssistantproject: HuggingFace SilverAudio Model

Data Source
- Source: AI Hub 위급상황 음성/음향