
NTPP: Generative Speech Language Modeling for Dual-Channel Spoken Dialogue via Next-Token-Pair Prediction
Authors: Qichao Wang*, Ziqiao Meng*, Wenqian Cui, Yifei Zhang, Pengcheng Wu, Bingzhe Wu, Irwin King, Liang Chen, Peilin Zhao†
![]()
![]()
![]()
Key features:
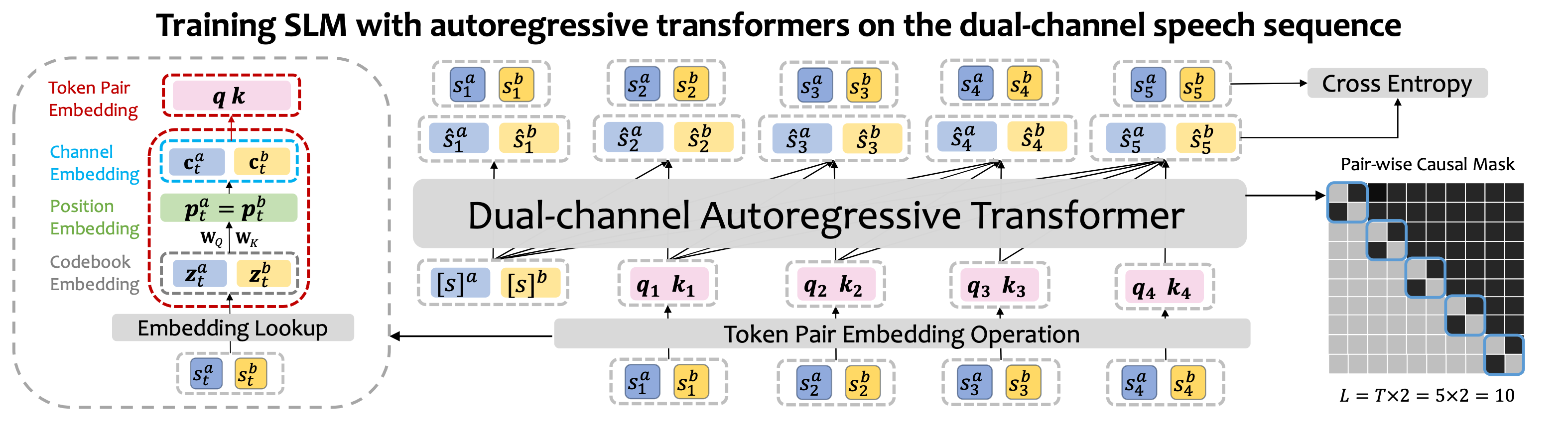
- Pre-training: Transform single-channel audio into discrete tokens for next-token prediction
- SFT: Novel "next-token-pair prediction" objective for natural conversation comprehension
- Result: More natural and fluid spoken interactions compared to baseline approaches
Installation
git clone https://github.com/Chaos96/NTPP.git
cd parrot
python -m venv venv
source venv/bin/activate # On Windows, use `venv\Scripts\activate`
pip install -r requirements.txt
Usage
- Prepare audio data for pre-training and fine-tuning
- Pre-train:
python pretrain.py --input_data path/to/single_channel_data - Fine-tune:
python finetune.py --input_data path/to/double_channel_data - Inference:
python inference.py --input_audio path/to/input.wav
- Downloads last month
- 11
Inference Providers
NEW
This model isn't deployed by any Inference Provider.
🙋
Ask for provider support