

metadata
license: mit
pipeline_tag: video-text-to-text
library_name: transformers
Vamba
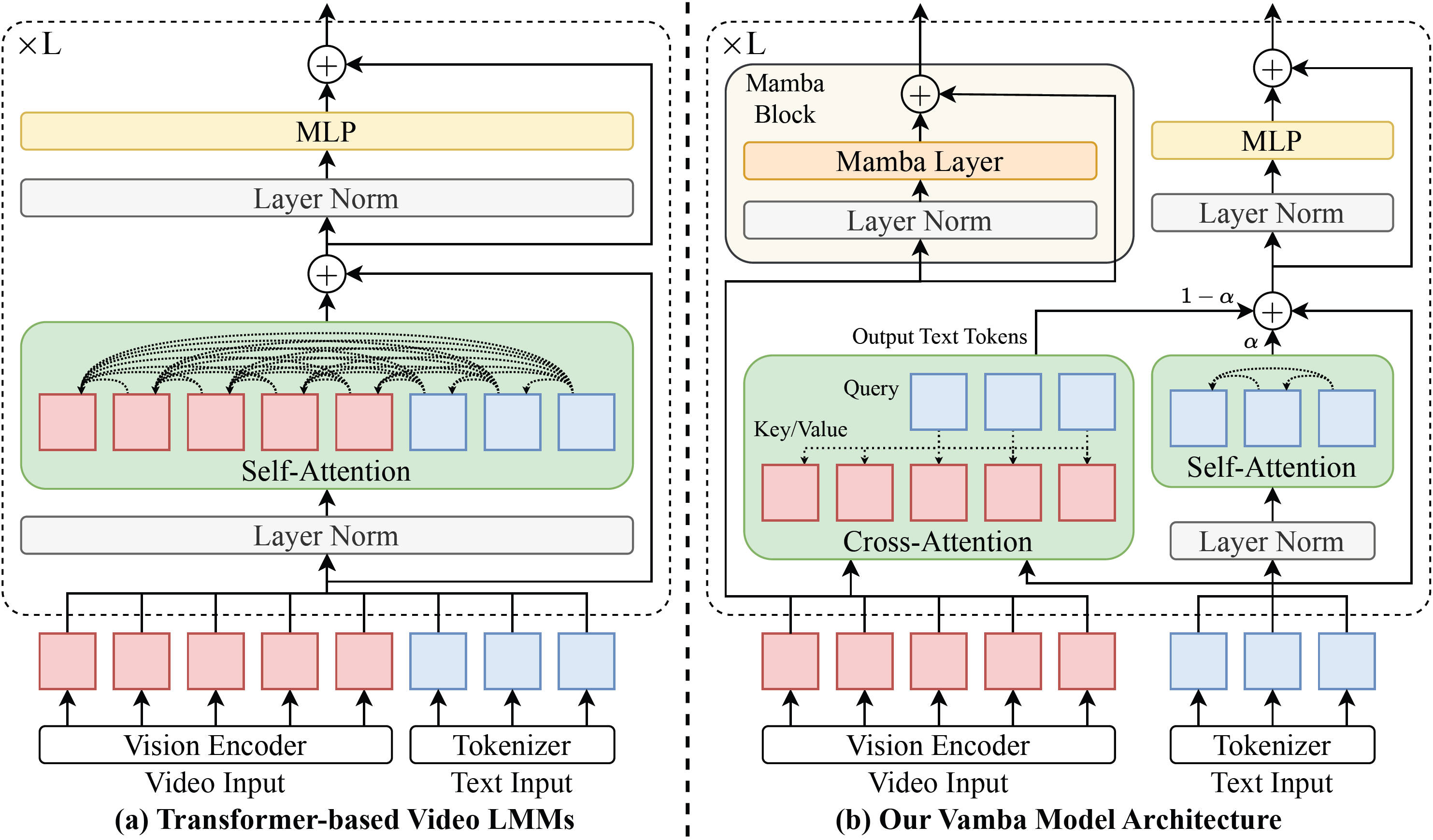
This repo contains model checkpoints for Vamba-Qwen2-VL-7B. Vamba is a hybrid Mamba-Transformer model that leverages cross-attention layers and Mamba-2 blocks for efficient hour-long video understanding.
🌐 Homepage | 📖 arXiv | 💻 GitHub | 🤗 Model
Vamba Model Architecture
Quick Start
# git clone https://github.com/TIGER-AI-Lab/Vamba
# cd Vamba
# export PYTHONPATH=.
from tools.vamba_chat import Vamba
model = Vamba(model_path="TIGER-Lab/Vamba-Qwen2-VL-7B", device="cuda")
test_input = [
{
"type": "video",
"content": "assets/magic.mp4",
"metadata": {
"video_num_frames": 128,
"video_sample_type": "middle",
"img_longest_edge": 640,
"img_shortest_edge": 256,
}
},
{
"type": "text",
"content": "<video> Describe the magic trick."
}
]
print(model(test_input))
test_input = [
{
"type": "image",
"content": "assets/old_man.png",
"metadata": {}
},
{
"type": "text",
"content": "<image> Describe this image."
}
]
print(model(test_input))
Citation
If you find our paper useful, please cite us with
@misc{ren2025vambaunderstandinghourlongvideos,
title={Vamba: Understanding Hour-Long Videos with Hybrid Mamba-Transformers},
author={Weiming Ren and Wentao Ma and Huan Yang and Cong Wei and Ge Zhang and Wenhu Chen},
year={2025},
eprint={2503.11579},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2503.11579},
}