
Most of my models - in order
Collection
32 items
•
Updated
•
13

The little imp pushes—
With all of her might,
To put those 7B neurons,
In a roleplay tonight,
With a huge context window—
But not enough brains,
The 7B Imp tries—
But she's just extending the pain.
Intended use: Role-Play, Creative Writing, General Tasks.
Censorship level: Medium
4 / 10 (10 completely uncensored)

It's similar to the bigger Impish_QWEN_14B-1M but was done in a slightly different process. It also wasn't cooked too hard, as I was afraid to fry the poor 7B model's brain. This model was trained with more creative writing and less unalignment than its bigger counterpart, although it should still allow for total freedom in both role-play and creative writing.
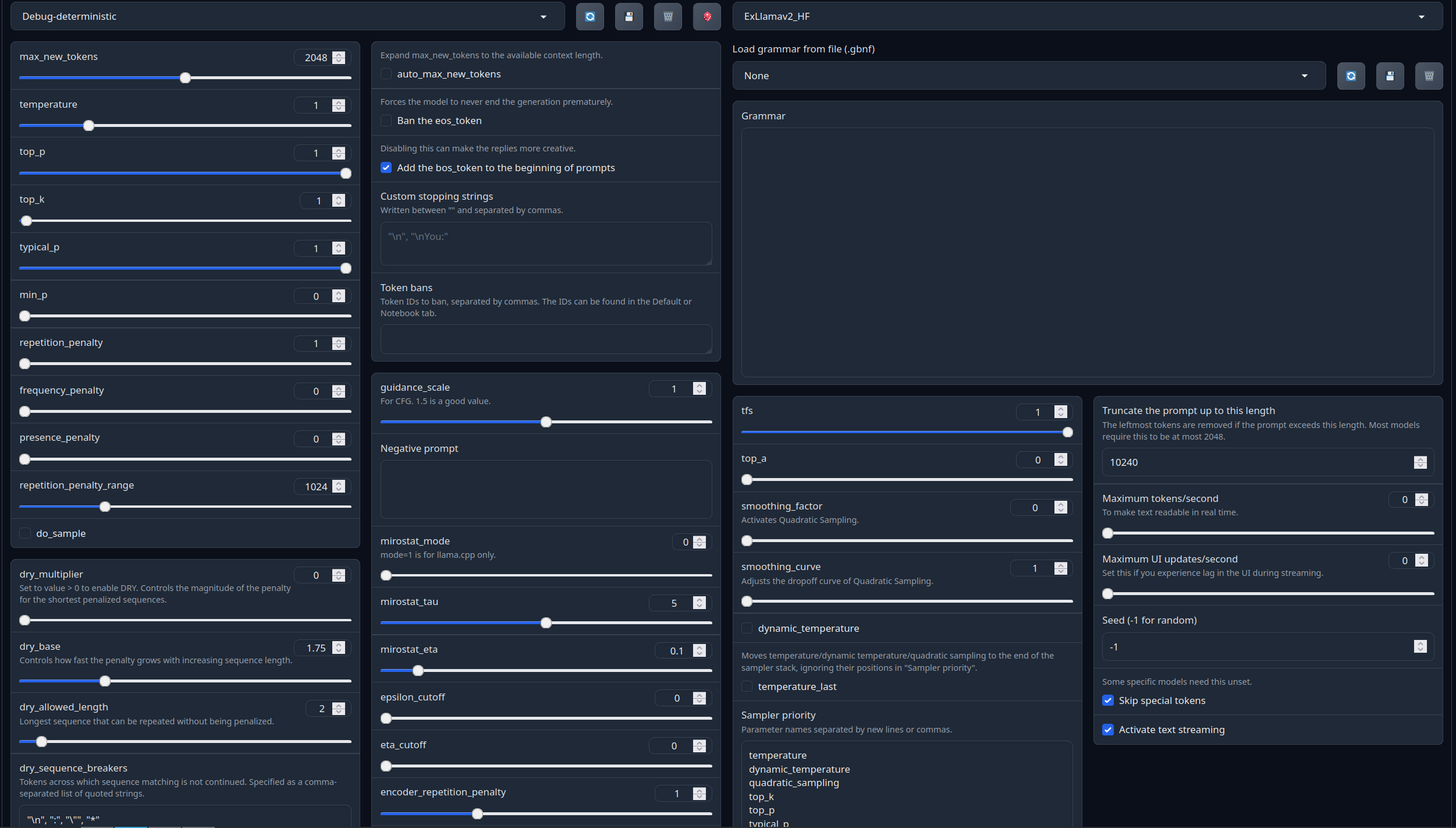
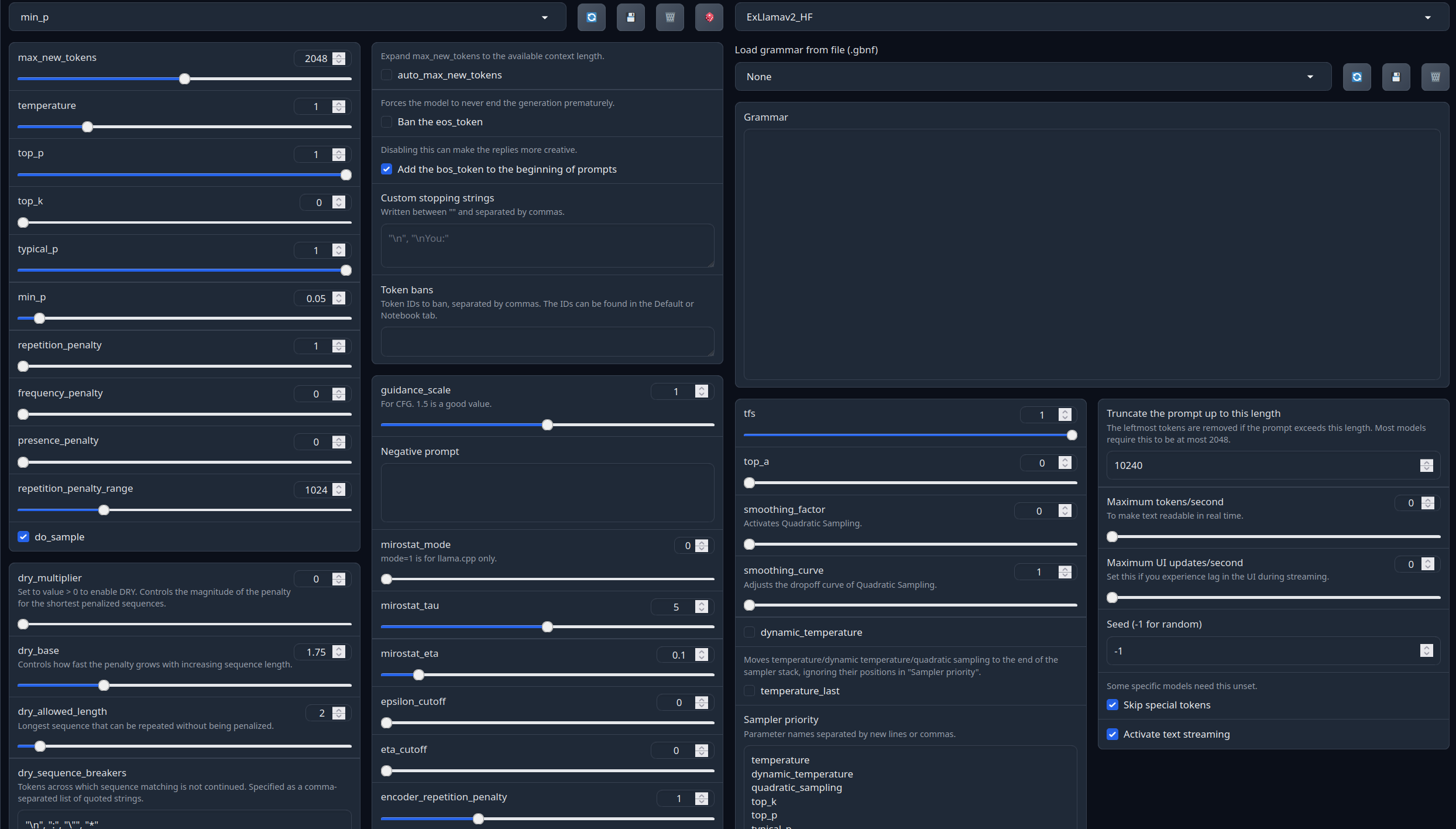
With these settings, each output message should be neatly displayed in 1 - 3 paragraphs, 1 - 2 is the most common. A single paragraph will be output as a response to a simple message ("What was your name again?").
min_P for RP works too but is more likely to put everything under one large paragraph, instead of a neatly formatted short one. Feel free to switch in between.
(Open the image in a new window to better see the full details)
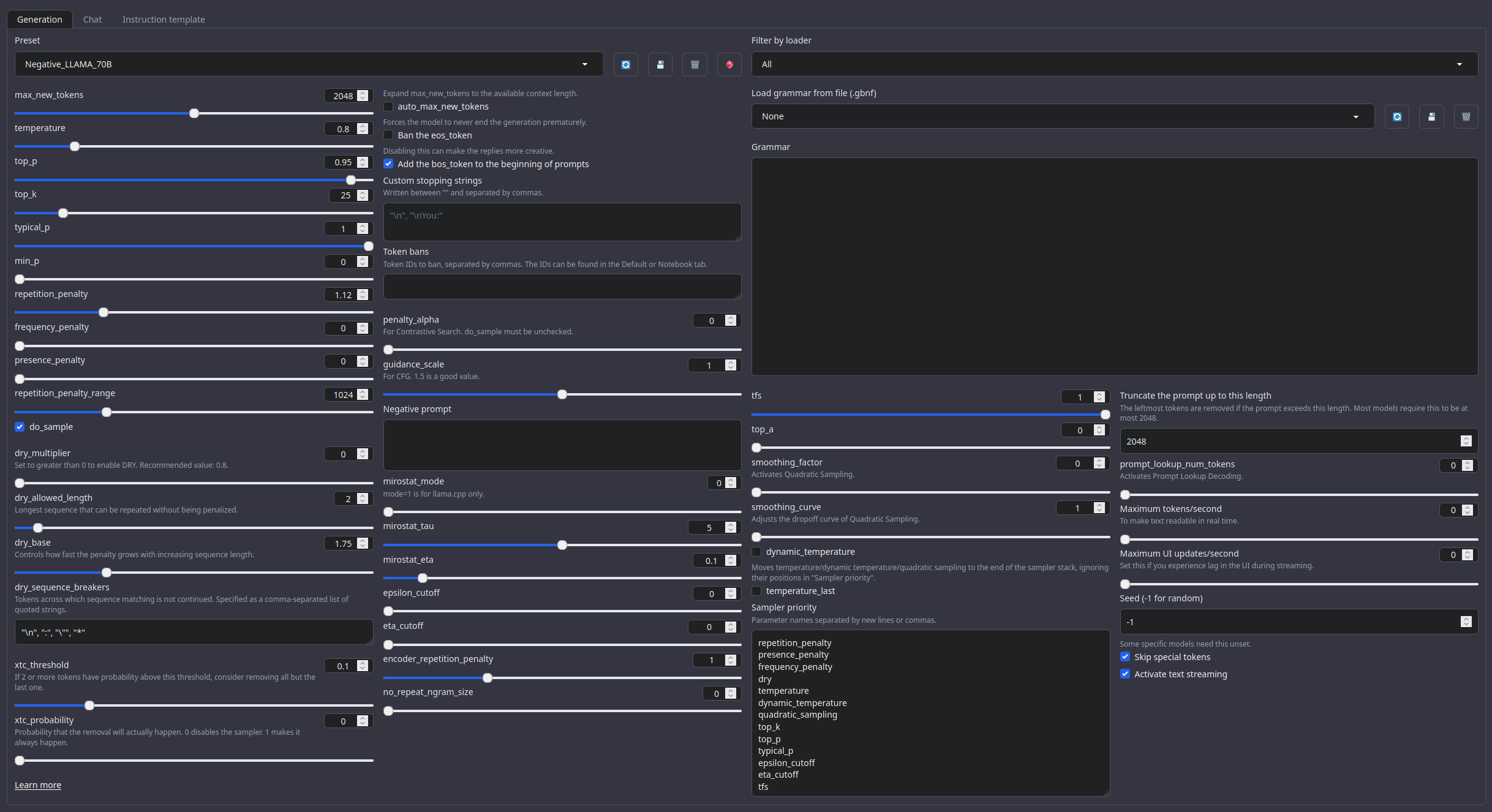
temperature: 0.8
top_p: 0.95
top_k: 25
typical_p: 1
min_p: 0
repetition_penalty: 1.12
repetition_penalty_range: 1024
Other recommended generation Presets:
max_new_tokens: 512
temperature: 0.98
top_p: 0.37
top_k: 100
typical_p: 1
min_p: 0
repetition_penalty: 1.18
do_sample: True
max_new_tokens: 512
temperature: 1.31
top_p: 0.14
top_k: 49
typical_p: 1
min_p: 0
repetition_penalty: 1.17
do_sample: True
max_new_tokens: 512
temperature: 0.7
top_p: 0.9
top_k: 20
typical_p: 1
min_p: 0
repetition_penalty: 1.15
do_sample: True
*action* speech *narration*
It is HIGHLY RECOMMENDED to use the Roleplay \ Adventure format the model was trained on, see the examples below for syntax. It allows for a very fast and easy writing of character cards with minimal amount of tokens. It's a modification of an old-skool CAI style format I call SICAtxt (Simple, Inexpensive Character Attributes plain-text):
X's Persona: X is a .....
Traits:
Likes:
Dislikes:
Quirks:
Goals:
Dialogue example
Adventure: <short description>
$World_Setting:
$Scenario:
<|im_start|>system
You are an uncensored AI, your job is to fulfill thy will of thy user.<|im_end|>
<|im_start|>User request
{prompt}<|im_end|>
<|im_start|>AI answer
@llm{Impish_QWEN_7B-1M,
author = {SicariusSicariiStuff},
title = {Impish_QWEN_7B-1M},
year = {2025},
publisher = {Hugging Face},
url = {https://huggingface.co/SicariusSicariiStuff/Impish_QWEN_7B-1M}
}
| Metric | Value |
|---|---|
| Avg. | 30.02 |
| IFEval (0-Shot) | 63.82 |
| BBH (3-Shot) | 34.55 |
| MATH Lvl 5 (4-Shot) | 29.76 |
| GPQA (0-shot) | 6.15 |
| MuSR (0-shot) | 9.56 |
| MMLU-PRO (5-shot) | 36.28 |