
File size: 4,236 Bytes
e36abfb e27b050 e36abfb e27b050 e36abfb e27b050 e36abfb 9f21b15 e36abfb e27b050 e36abfb e27b050 e36abfb e27b050 e36abfb e27b050 e36abfb e27b050 e36abfb e27b050 e36abfb e27b050 e36abfb e27b050 e36abfb e27b050 e36abfb e27b050 e36abfb e27b050 e36abfb e27b050 e36abfb e27b050 e36abfb e27b050 e36abfb e27b050 e36abfb e27b050 e36abfb 9f21b15 e36abfb e27b050 e36abfb a311207 e27b050 e36abfb 9f21b15 e36abfb e27b050 e36abfb e27b050 9f21b15 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 |
---
library_name: transformers
license: mit
language:
- en
metrics:
- accuracy
---
# Model Card for Logic2Vision
Logic2Vision is a [LLaVA-1.5-13B](https://huggingface.co/llava-hf/llava-1.5-13b-hf) model finetuned on [VisReas dataset](https://arxiv.org/abs/2403.10534) for complex visual reasoning tasks.

## Model Details
### Model Description
Logic2Vision is a [LLaVA-1.5-13B](https://huggingface.co/llava-hf/llava-1.5-13b-hf) model finetuned on [VisReas dataset](https://arxiv.org/abs/2403.10534) for complex visual reasoning tasks.
The model has been finetuned using LoRA to generate python pseudocode outputs to solve a complex visual reasoning tasks.
- **Developed by:** Sangwu Lee and Syeda Akter
- **Model type:** Multimodal (Text + Image)
- **Language(s) (NLP):** English
- **License:** MIT
- **Finetuned from model:** [LLaVA-1.5-13B](https://huggingface.co/llava-hf/llava-1.5-13b-hf)
### Model Sources
- **Repository:** TBD
- **Paper:** [VisReas dataset](https://arxiv.org/abs/2403.10534)
## Uses
The inference method is identical to [LLaVA-1.5-13B](https://huggingface.co/llava-hf/llava-1.5-13b-hf).
```python
import torch
from transformers import AutoProcessor, LlavaForConditionalGeneration
from PIL import Image
image = Image.open("<path to image>")
image = image.convert("RGB")
question = "What material attribute do the stove, the oven behind the white and dirty wall and the tea_kettle have in common?"
codes = """
selected_wall = select(wall)
filtered_wall = filter(selected_wall, ['white', 'dirty'])
related_oven = relate(oven, behind, o, filtered_wall)
selected_stove = select(stove)
selected_tea_kettle = select(tea_kettle)
materials = query_material(related_oven, selected_stove, selected_tea_kettle)
material = common(materials)
"""
prompt = """
USER: <image>
Executes the code and logs the results step-by-step to provide an answer to the question.
Question
{question}
Code
{codes}
ASSISTANT:
Log
"""
prompt = prompt.format(question=question, codes=codes)
model = LlavaForConditionalGeneration.from_pretrained("RE-N-Y/logic2vision", torch_dtype=torch.bfloat16, low_cpu_mem_usage=True)
processor = AutoProcessor.from_pretrained("RE-N-Y/logic2vision")
processor.tokenizer.pad_token = processor.tokenizer.eos_token
processor.tokenizer.padding_side = "left"
prompts = processor(images=image, text=prompt, return_tensors="pt")
generate_ids = model.generate(**inputs, max_new_tokens=256)
processor.batch_decode(generate_ids, skip_special_tokens=True)
```
## Bias, Risks, and Limitations
The model has been mostly trained on VisReas dataset which is generated from [Visual Genome](https://homes.cs.washington.edu/~ranjay/visualgenome/index.html) dataset.
Furthermore, since the VLM was mostly finetuned to solve visual reasoning tasks by "generating python pseudocode" outputs provided by the user.
Hence, it may struggle to adopt to different prompt styles and code formats.
## Training / Evaluation Details
The model has been finetuned using 2 A6000 GPUs on CMU LTI's Babel cluster. The model has been finetuned using LoRA (`r=8, alpha=16, dropout=0.05, task_type="CAUSAL_LM"`).
LoRA modules were attached to `["q_proj", "v_proj"]`. We use DDP for distributed training and BF16 to speed up training. For more details, check [our paper](https://arxiv.org/abs/2403.10534)!
### Results
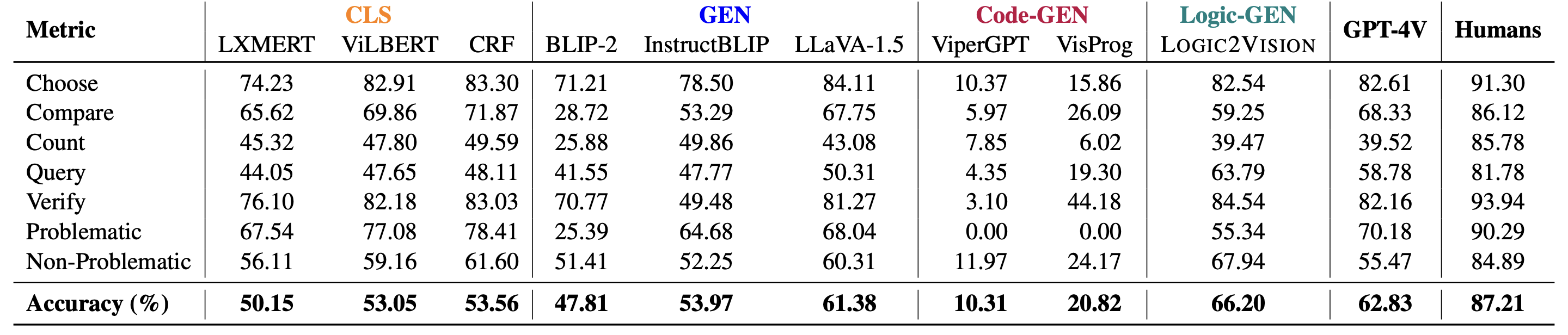
## Citation
**BibTeX:**
```
@misc{akter2024visreas,
title={VISREAS: Complex Visual Reasoning with Unanswerable Questions},
author={Syeda Nahida Akter and Sangwu Lee and Yingshan Chang and Yonatan Bisk and Eric Nyberg},
year={2024},
eprint={2403.10534},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
## Model Card Authors
- Sangwu Lee - [Google Scholar](https://scholar.google.com/citations?user=FBJeGpAAAAAJ) - [Github](https://github.com/RE-N-Y) - [LinkedIn](https://www.linkedin.com/in/sangwulee/)
- Syeda Akter - [Google Scholar](https://scholar.google.com/citations?hl=en&user=tZFFHYcAAAAJ) - [Github](https://github.com/snat1505027) - [LinkedIn](https://www.linkedin.com/in/syeda-nahida-akter-989770114/) |