

Upload 4 files
Browse files- README.md +41 -0
- vision_tower/config.json +23 -0
- vision_tower/model.safetensors +3 -0
- vision_tower/preprocessor_config.json +24 -0
README.md
CHANGED
|
@@ -1,3 +1,44 @@
|
|
| 1 |
---
|
| 2 |
license: mit
|
| 3 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
license: mit
|
| 3 |
---
|
| 4 |
+
# Aux-Think: Exploring Reasoning Strategies for Data-Efficient Vision-Language Navigation
|
| 5 |
+
|
| 6 |
+
<div align="center" class="authors">
|
| 7 |
+
<a href="https://scholar.google.com/citations?user=IYLvsCQAAAAJ&hl" target="_blank">Shuo Wang</a>,
|
| 8 |
+
<a href="https://yongcaiwang.github.io/" target="_blank">Yongcai Wang</a>,
|
| 9 |
+
<a>Wanting Li</a>,
|
| 10 |
+
<a href="https://scholar.google.com/citations?user=TkwComsAAAAJ&hl=en" target="_blank">Xudong Cai</a>, <br>
|
| 11 |
+
<text>Yucheng Wang</text>,
|
| 12 |
+
<text>Maiyue Chen</text>,
|
| 13 |
+
<text>Kaihui Wang</text>,
|
| 14 |
+
<a href="https://scholar.google.com/citations?user=HQfc8TEAAAAJ&hl=en" target="_blank">Zhizhong Su</a>,
|
| 15 |
+
<text>Deying Li</text>,
|
| 16 |
+
<a href="https://zhaoxinf.github.io/" target="_blank">Zhaoxin Fan</a>
|
| 17 |
+
</div>
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
<div align="center" style="line-height: 3;">
|
| 21 |
+
<a href="https://horizonrobotics.github.io/robot_lab/aux-think" target="_blank" style="margin: 2px;">
|
| 22 |
+
<img alt="Homepage" src="https://img.shields.io/badge/Homepage-green" style="display: inline-block; vertical-align: middle;"/>
|
| 23 |
+
</a>
|
| 24 |
+
<a href="https://arxiv.org/abs/2505.11886" target="_blank" style="margin: 2px;">
|
| 25 |
+
<img alt="Paper" src="https://img.shields.io/badge/Paper-Arxiv-red" style="display: inline-block; vertical-align: middle;"/>
|
| 26 |
+
</a>
|
| 27 |
+
</div>
|
| 28 |
+
|
| 29 |
+
## Introduction
|
| 30 |
+
Aux-Think internalizes Chain-of-Thought (CoT) only during training, enabling efficient Vision-Language Navigation without explicit reasoning at inference, and achieving strong performance with minimal data.
|
| 31 |
+
|
| 32 |
+
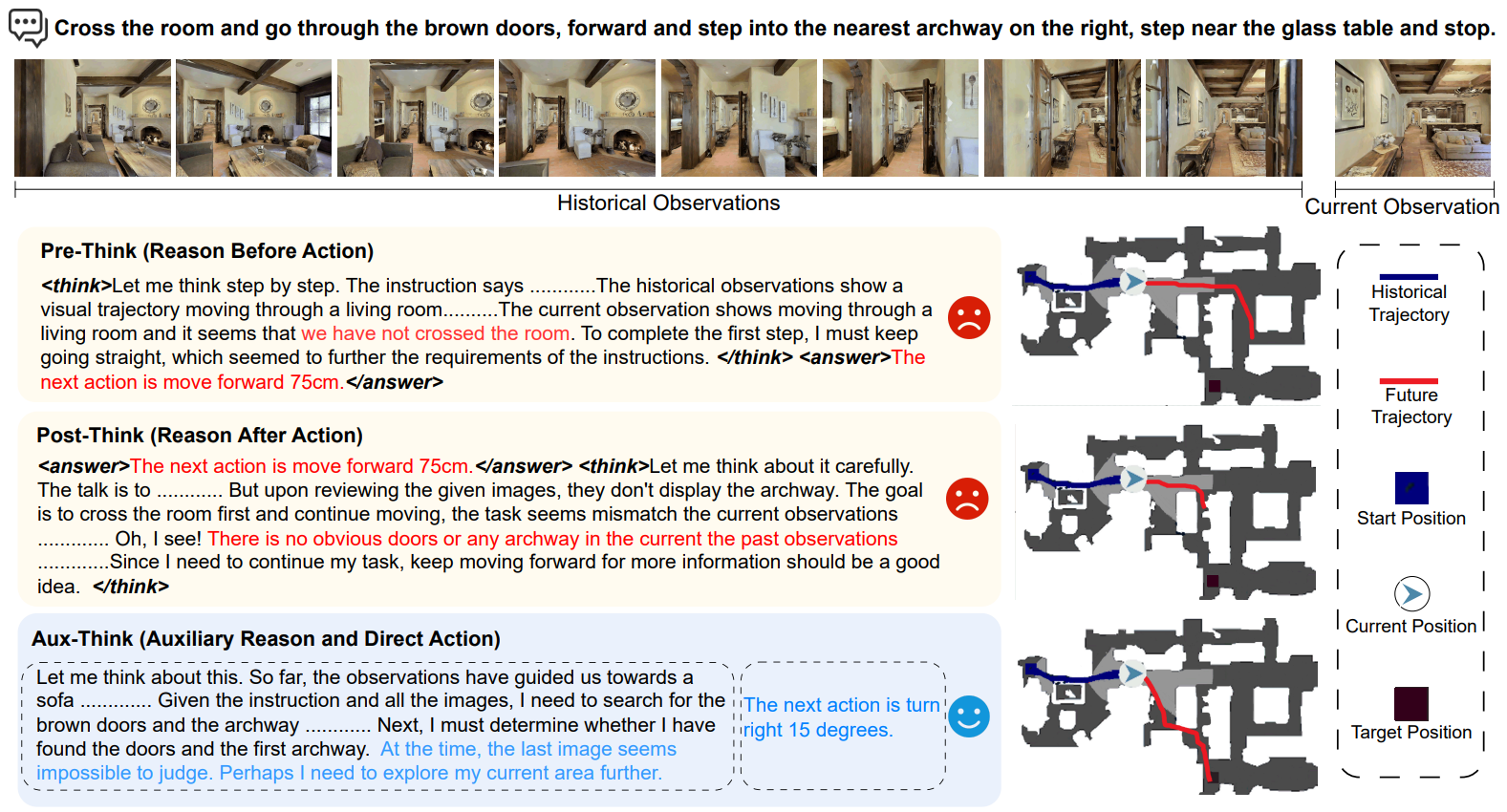
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
## Citation
|
| 36 |
+
|
| 37 |
+
```bibtex
|
| 38 |
+
@article{wang2025think,
|
| 39 |
+
title={Aux-Think: Exploring Reasoning Strategies for Data-Efficient Vision-Language Navigation},
|
| 40 |
+
author={Wang, Shuo and Wang, Yongcai and Li, Wanting and Cai, Xudong and Wang, Yucheng and Chen, Maiyue and Wang, Kaihui and Su, Zhizhong and Li, Deying and Fan, Zhaoxin},
|
| 41 |
+
journal={arXiv preprint arXiv:2505.11886},
|
| 42 |
+
year={2025}
|
| 43 |
+
}
|
| 44 |
+
```
|
vision_tower/config.json
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"SiglipVisionModel"
|
| 5 |
+
],
|
| 6 |
+
"attention_dropout": 0.0,
|
| 7 |
+
"hidden_act": "gelu_pytorch_tanh",
|
| 8 |
+
"hidden_size": 1152,
|
| 9 |
+
"image_size": 448,
|
| 10 |
+
"intermediate_size": 4304,
|
| 11 |
+
"layer_norm_eps": 1e-06,
|
| 12 |
+
"model_type": "siglip_vision_model",
|
| 13 |
+
"num_attention_heads": 16,
|
| 14 |
+
"num_channels": 3,
|
| 15 |
+
"num_hidden_layers": 27,
|
| 16 |
+
"num_image_tokens": 256,
|
| 17 |
+
"patch_size": 14,
|
| 18 |
+
"projection_dim": 2048,
|
| 19 |
+
"projector_hidden_act": "gelu_fast",
|
| 20 |
+
"torch_dtype": "bfloat16",
|
| 21 |
+
"transformers_version": "4.46.0",
|
| 22 |
+
"vision_use_head": false
|
| 23 |
+
}
|
vision_tower/model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:36371b8a2cf650d7fda238929dd493117e58e23e1c498ecd807d8fd50a9788cf
|
| 3 |
+
size 826707904
|
vision_tower/preprocessor_config.json
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"do_convert_rgb": null,
|
| 3 |
+
"do_normalize": true,
|
| 4 |
+
"do_rescale": true,
|
| 5 |
+
"do_resize": true,
|
| 6 |
+
"image_mean": [
|
| 7 |
+
0.5,
|
| 8 |
+
0.5,
|
| 9 |
+
0.5
|
| 10 |
+
],
|
| 11 |
+
"image_processor_type": "SiglipImageProcessor",
|
| 12 |
+
"image_std": [
|
| 13 |
+
0.5,
|
| 14 |
+
0.5,
|
| 15 |
+
0.5
|
| 16 |
+
],
|
| 17 |
+
"processor_class": "SiglipProcessor",
|
| 18 |
+
"resample": 3,
|
| 19 |
+
"rescale_factor": 0.00392156862745098,
|
| 20 |
+
"size": {
|
| 21 |
+
"height": 448,
|
| 22 |
+
"width": 448
|
| 23 |
+
}
|
| 24 |
+
}
|