
![]()
(CVPR 2025) Adversarial Diffusion Compression for Real-World Image Super-Resolution [PyTorch]
![]()
Bin Chen1,3,* | Gehui Li1,* | Rongyuan Wu2,3,* | Xindong Zhang3 | Jie Chen1,† | Jian Zhang1,† | Lei Zhang2,3
1 School of Electronic and Computer Engineering, Peking University
2 The Hong Kong Polytechnic University, 3 OPPO Research Institute
* Equal Contribution. † Corresponding Authors.
⭐ If AdcSR is helpful to you, please star this repo. Thanks! 🤗
📝 Overview
Highlights
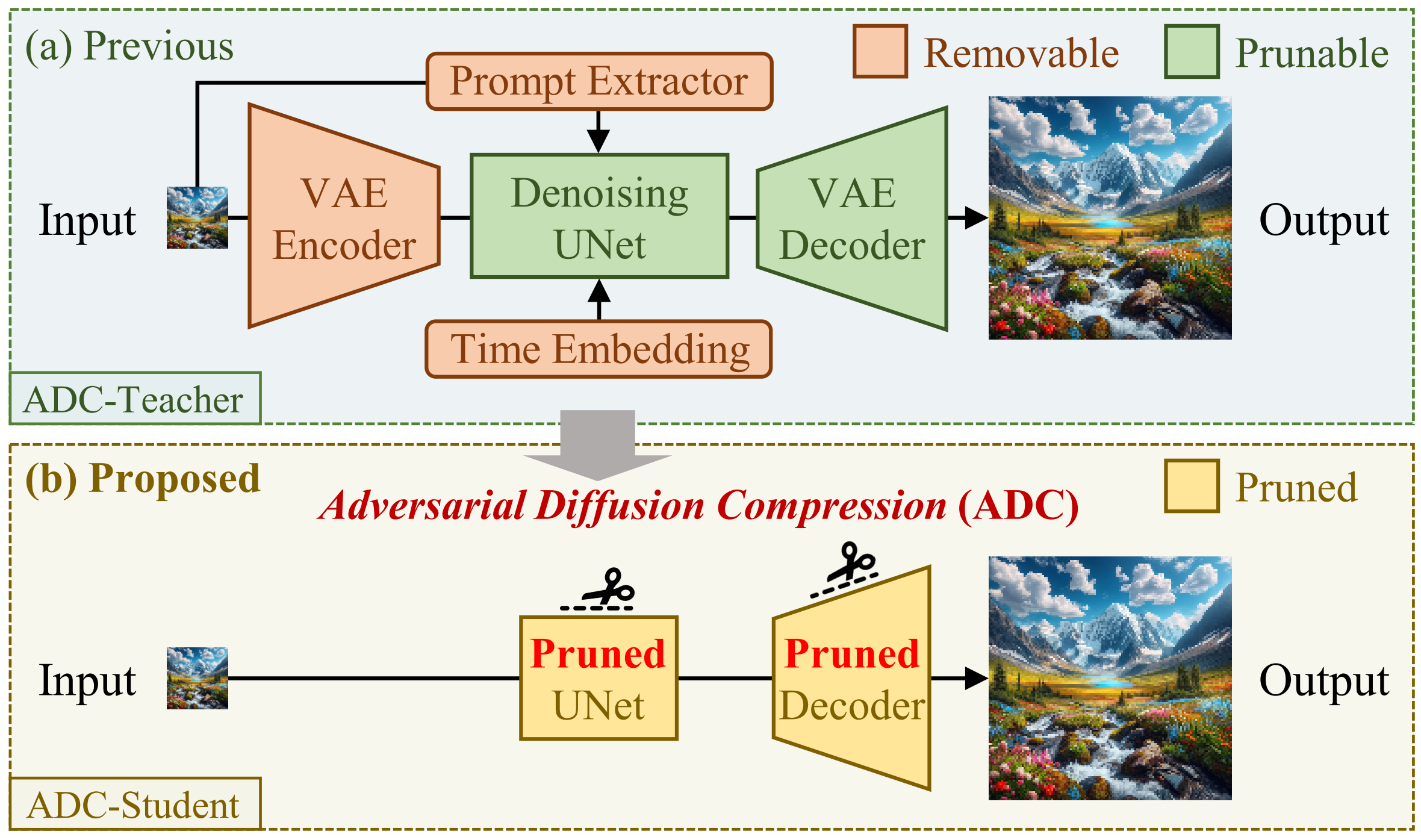
- Adversarial Diffusion Compression (ADC). We remove and prune redundant modules from the one-step diffusion network OSEDiff and apply adversarial distillation to retain generative capabilities despite reduced capacity.
- Real-Time Stable Diffusion-Based Image Super-Resolution. AdcSR super-resolves a 128×128 image to 512×512 in just 0.03s 🚀 on an A100 GPU.
- Competitive Visual Quality. Despite 74% fewer parameters 📉 than OSEDiff, AdcSR achieves competitive image quality across multiple benchmarks.
Framework
- Structural Compression
- Removable modules (VAE encoder, text prompt extractor, cross-attention, time embeddings) are eliminated.
- Prunable modules (UNet, VAE decoder) are channel-pruned to optimize efficiency while preserving performance.
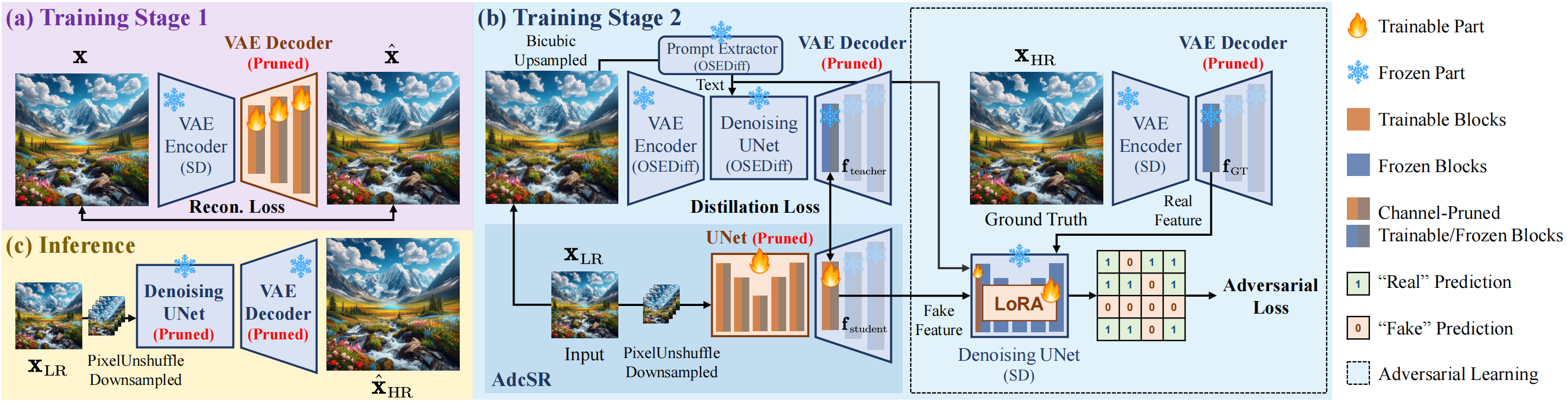
- Two-Stage Training
- Pretraining a Pruned VAE Decoder to maintain its ability to decode latent representations.
- Adversarial Distillation to align compressed network features with the teacher model (e.g., OSEDiff) and ground truth images.
😍 Visual Results







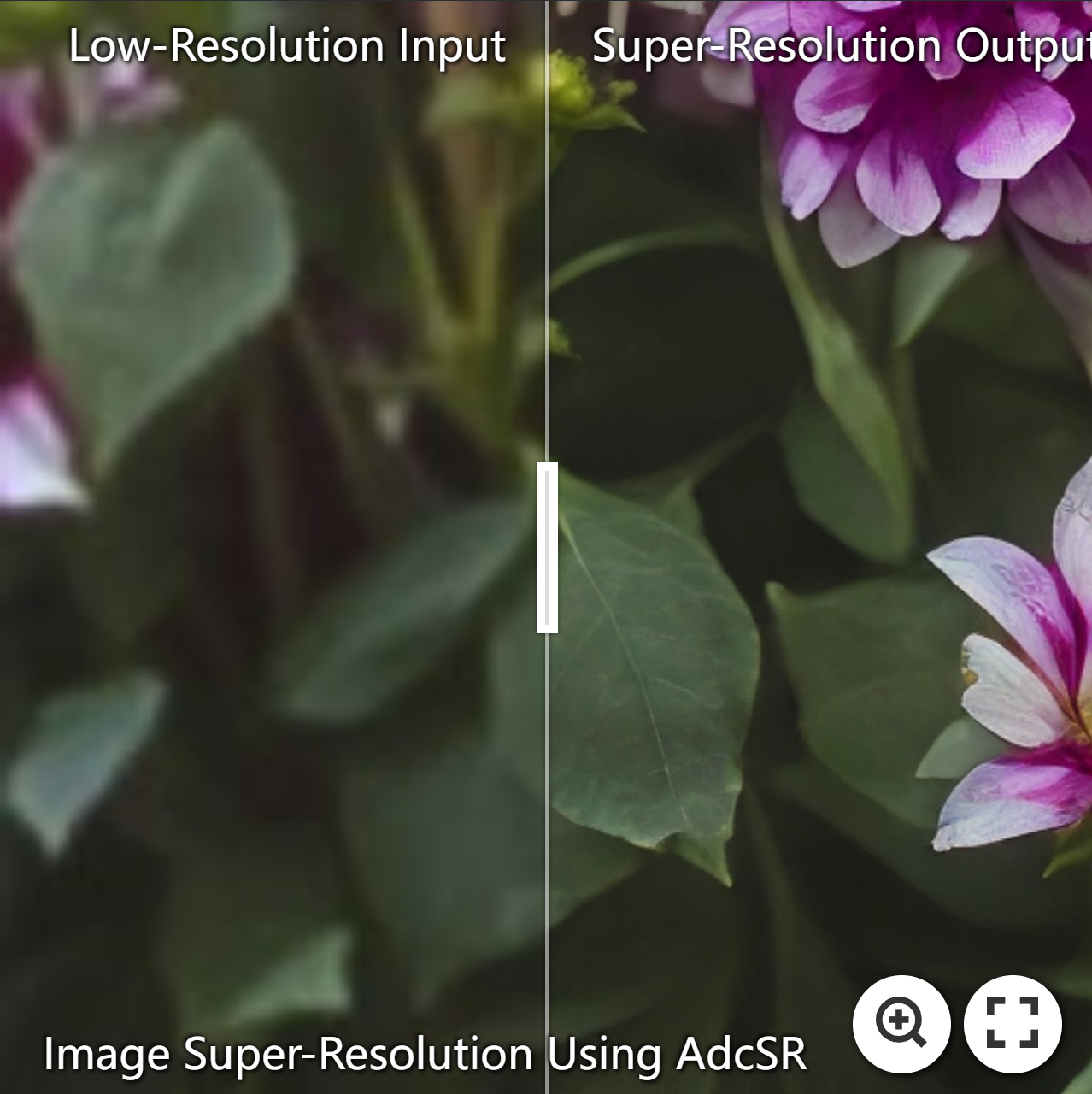
https://github.com/user-attachments/assets/1211cefa-8704-47f5-82cd-ec4ef084b9ec

⚙ Installation
git clone https://github.com/Guaishou74851/AdcSR.git
cd AdcSR
conda create -n AdcSR python=3.10
conda activate AdcSR
pip install --upgrade pip
pip install -r requirements.txt
chmod +x train.sh train_debug.sh test_debug.sh evaluate_debug.sh
⚡ Test
- Download test datasets (
DIV2K-Val.zip,DRealSR.zip,RealSR.zip) from Google Drive or PKU Disk. - Unzip them into
./testset/, ensuring the structure:./testset/DIV2K-Val/LR/xxx.png ./testset/DIV2K-Val/HR/xxx.png ./testset/DRealSR/LR/xxx.png ./testset/DRealSR/HR/xxx.png ./testset/RealSR/LR/xxx.png ./testset/RealSR/HR/xxx.png - Download model weights (
net_params_200.pkl) from the same link and place it in./weight/. - Run the test script (or modify and execute
./test_debug.shfor convenience):
The results will be saved inpython test.py --LR_dir=path_to_LR_images --SR_dir=path_to_SR_imagespath_to_SR_images. - Test Your Own Images:
- Place your low-resolution (LR) images into
./testset/xxx/. - Run the command with
--LR_dir=./testset/xxx/ --SR_dir=./yyy/, and the model will perform x4 super-resolution.
- Place your low-resolution (LR) images into
🍭 Evaluation
Run the evaluation script (or modify and execute ./evaluate_debug.sh for convenience):
python evaluate.py --HR_dir=path_to_HR_images --SR_dir=path_to_SR_images
🔥 Train
This repo provides code for Stage 2 training (adversarial distillation). For Stage 1 (pretraining the channel-pruned VAE decoder), refer to our paper and use the code of Latent Diffusion Models repo.
- Download pretrained model weights (
DAPE.pth,halfDecoder.ckpt,osediff.pkl,ram_swin_large_14m.pth) from Google Drive or PKU Disk, and place them in./weight/pretrained/. - Download the LSDIR dataset and store it in your preferred location.
- Modify the dataset path in
config.yml:dataroot_gt: path_to_HR_images_of_LSDIR - Run the training script (or modify and execute
./train.shor./train_debug.sh):
The trained model will be saved inCUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python -m torch.distributed.run --nproc_per_node=8 --master_port=23333 train.py./weight/.
🥰 Acknowledgement
This project is built upon the codes of Latent Diffusion Models, Diffusers, BasicSR, and OSEDiff. We sincerely thank the authors of these repos for their significant contributions.
🎓 Citation
If you find our work helpful, please consider citing:
@inproceedings{chen2025adversarial,
title={Adversarial Diffusion Compression for Real-World Image Super-Resolution},
author={Chen, Bin and Li, Gehui and Wu, Rongyuan and Zhang, Xindong and Chen, Jie and Zhang, Jian and Zhang, Lei},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2025}
}