---
license: apache-2.0
---





## Introduction
Step-Audio 2 is an end-to-end multi-modal large language model designed for industry-strength audio understanding and speech conversation.
- **Advanced Speech and Audio Understanding**: Promising performance in ASR and audio understanding by comprehending and reasoning semantic information, para-linguistic and non-vocal information.
- **Intelligent Speech Conversation**: Achieving natural and intelligent interactions that are contextually appropriate for various conversational scenarios and paralinguistic information.
- **Tool Calling and Multimodal RAG**: By leveraging tool calling and RAG to access real-world knowledge (both textual and acoustic), Step-Audio 2 can generate responses with fewer hallucinations for diverse scenarios, while also having the ability to switch timbres based on retrieved speech.
- **State-of-the-Art Performance**: Achieving state-of-the-art performance on various audio understanding and conversational benchmarks compared to other open-source and commercial solutions. (See [Evaluation](#evaluation) and [Technical Report](https://arxiv.org/pdf/2507.16632)).
+ **Open-source**: [Step-Audio 2 mini](https://huggingface.co/stepfun-ai/Step-Audio-2-mini) and [Step-Audio 2 mini Base](https://huggingface.co/stepfun-ai/Step-Audio-2-mini-Base) are released under [Apache 2.0](LICENSE) license.
## Model Download
### Huggingface
| Models | 🤗 Hugging Face |
|-------|-------|
| Step-Audio 2 mini | [stepfun-ai/Step-Audio-2-mini](https://huggingface.co/stepfun-ai/Step-Audio-2-mini) |
| Step-Audio 2 mini Base | [stepfun-ai/Step-Audio-2-mini-Base](https://huggingface.co/stepfun-ai/Step-Audio-2-mini-Base) |
## Model Usage
### 🔧 Dependencies and Installation
- Python >= 3.10
- [PyTorch >= 2.3-cu121](https://pytorch.org/)
- [CUDA Toolkit](https://developer.nvidia.com/cuda-downloads)
```bash
conda create -n stepaudio2 python=3.10
conda activate stepaudio2
pip install transformers==4.49.0 torchaudio librosa onnxruntime s3tokenizer diffusers hyperpyyaml
git clone https://github.com/stepfun-ai/Step-Audio2.git
cd Step-Audio2
git lfs install
git clone https://huggingface.co/stepfun-ai/Step-Audio-2-mini-Base
```
### 🚀 Inference Scripts
```bash
python examples-base.py
```
## Online demonstration
### StepFun realtime console
- Both Step-Audio 2 and Step-Audio 2 mini are available in our [StepFun realtime console](https://realtime-console.stepfun.com/) with web search tool enabled.
- You will need an API key from the [StepFun Open Platform](https://platform.stepfun.com/).
### StepFun AI Assistant
- Step-Audio 2 is also available in our StepFun AI Assistant mobile App with both web and audio search tools enabled.
- Please scan the following QR code to download it from your app store then tap the phone icon in the top-right corner.

## WeChat group
You can scan the following QR code to join our WeChat group for communication and discussion.

## Evaluation
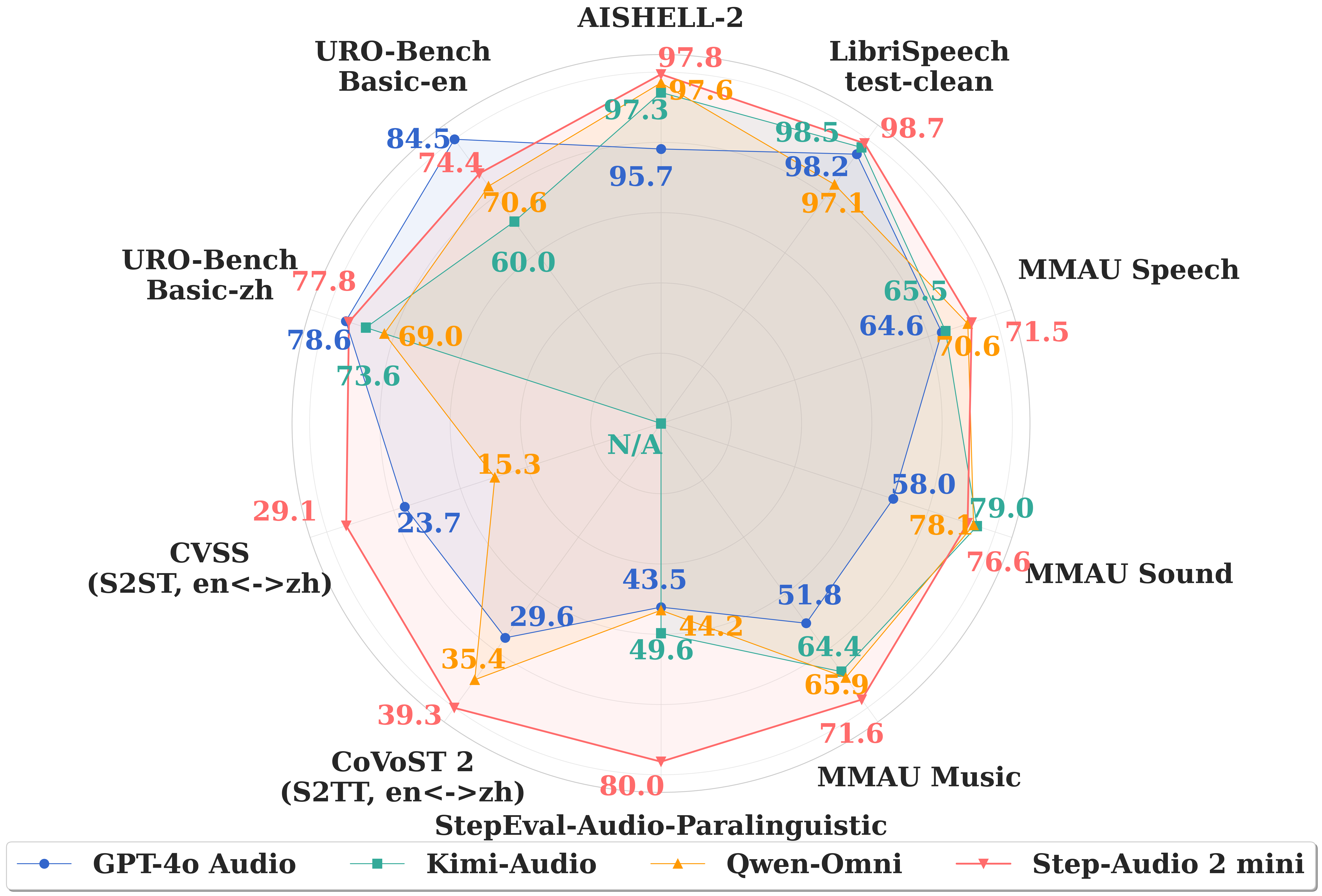
### Automatic speech recognition
CER for Chinese, Cantonese and Japanese and WER for Arabian and English. N/A indicates that the language is not supported.
| Category |
Test set |
Doubao LLM ASR |
GPT-4o Transcribe |
Kimi-Audio |
Qwen-Omni |
Step-Audio 2 |
Step-Audio 2 mini |
| English |
Common Voice |
9.20 |
9.30 |
7.83 |
8.33 |
5.95 |
6.76 |
| FLEURS English |
7.22 |
2.71 |
4.47 |
5.05 |
3.03 |
3.05 |
| LibriSpeech clean |
2.92 |
1.75 |
1.49 |
2.93 |
1.17 |
1.33 |
| LibriSpeech other |
5.32 |
4.23 |
2.91 |
5.07 |
2.42 |
2.86 |
| Average |
6.17 |
4.50 |
4.18 |
5.35 |
3.14 |
3.50 |
| Chinese |
AISHELL |
0.98 |
3.52 |
0.64 |
1.17 |
0.63 |
0.78 |
| AISHELL-2 |
3.10 |
4.26 |
2.67 |
2.40 |
2.10 |
2.16 |
| FLEURS Chinese |
2.92 |
2.62 |
2.91 |
7.01 |
2.68 |
2.53 |
| KeSpeech phase1 |
6.48 |
26.80 |
5.11 |
6.45 |
3.63 |
3.97 |
| WenetSpeech meeting |
4.90 |
31.40 |
5.21 |
6.61 |
4.75 |
4.87 |
| WenetSpeech net |
4.46 |
15.71 |
5.93 |
5.24 |
4.67 |
4.82 |
| Average |
3.81 |
14.05 |
3.75 |
4.81 |
3.08 |
3.19 |
| Multilingual |
FLEURS Arabian |
N/A |
11.72 |
N/A |
25.13 |
14.22 |
16.46 |
| Common Voice yue |
9.20 |
11.10 |
38.90 |
7.89 |
7.90 |
8.32 |
| FLEURS Japanese |
N/A |
3.27 |
N/A |
10.49 |
3.18 |
4.67 |
| In-house |
Anhui accent |
8.83 |
50.55 |
22.17 |
18.73 |
10.61 |
11.65 |
| Guangdong accent |
4.99 |
7.83 |
3.76 |
4.03 |
3.81 |
4.44 |
| Guangxi accent |
3.37 |
7.09 |
4.29 |
3.35 |
4.11 |
3.51 |
| Shanxi accent |
20.26 |
55.03 |
34.71 |
25.95 |
12.44 |
15.60 |
| Sichuan dialect |
3.01 |
32.85 |
5.26 |
5.61 |
4.35 |
4.57 |
| Shanghai dialect |
47.49 |
89.58 |
82.90 |
58.74 |
17.77 |
19.30 |
| Average |
14.66 |
40.49 |
25.52 |
19.40 |
8.85 |
9.85 |
### Paralinguistic information understanding
StepEval-Audio-Paralinguistic
| Model |
Avg. |
Gender |
Age |
Timbre |
Scenario |
Event |
Emotion |
Pitch |
Rhythm |
Speed |
Style |
Vocal |
| GPT-4o Audio |
43.45 |
18 |
42 |
34 |
22 |
14 |
82 |
40 |
60 |
58 |
64 |
44 |
| Kimi-Audio |
49.64 |
94 |
50 |
10 |
30 |
48 |
66 |
56 |
40 |
44 |
54 |
54 |
| Qwen-Omni |
44.18 |
40 |
50 |
16 |
28 |
42 |
76 |
32 |
54 |
50 |
50 |
48 |
| Step-Audio-AQAA |
36.91 |
70 |
66 |
18 |
14 |
14 |
40 |
38 |
48 |
54 |
44 |
0 |
| Step-Audio 2 |
83.09 |
100 |
96 |
82 |
78 |
60 |
86 |
82 |
86 |
88 |
88 |
68 |
| Step-Audio 2 mini |
80.00 |
100 |
94 |
80 |
78 |
60 |
82 |
82 |
68 |
74 |
86 |
76 |
### Audio understanding and reasoning
MMAU
| Model |
Avg. |
Sound |
Speech |
Music |
| Audio Flamingo 3 |
73.1 |
76.9 |
66.1 |
73.9 |
| Gemini 2.5 Pro |
71.6 |
75.1 |
71.5 |
68.3 |
| GPT-4o Audio |
58.1 |
58.0 |
64.6 |
51.8 |
| Kimi-Audio |
69.6 |
79.0 |
65.5 |
64.4 |
| Omni-R1 |
77.0 |
81.7 |
76.0 |
73.4 |
| Qwen2.5-Omni |
71.5 |
78.1 |
70.6 |
65.9 |
| Step-Audio-AQAA |
49.7 |
50.5 |
51.4 |
47.3 |
| Step-Audio 2 |
78.0 |
83.5 |
76.9 |
73.7 |
| Step-Audio 2 mini |
73.2 |
76.6 |
71.5 |
71.6 |
### Speech translation
| Model |
CoVoST 2 (S2TT) |
| Avg. |
English-to-Chinese |
Chinese-to-English |
| GPT-4o Audio |
29.61 |
40.20 |
19.01 |
| Qwen2.5-Omni |
35.40 |
41.40 |
29.40 |
| Step-Audio-AQAA |
28.57 |
37.71 |
19.43 |
| Step-Audio 2 |
39.26 |
49.01 |
29.51 |
| Step-Audio 2 mini |
39.29 |
49.12 |
29.47 |
| Model |
CVSS (S2ST) |
| Avg. |
English-to-Chinese |
Chinese-to-English |
| GPT-4o Audio |
23.68 |
20.07 |
27.29 |
| Qwen-Omni |
15.35 |
8.04 |
22.66 |
| Step-Audio-AQAA |
27.36 |
30.74 |
23.98 |
| Step-Audio 2 |
30.87 |
34.83 |
26.92 |
| Step-Audio 2 mini |
29.08 |
32.81 |
25.35 |
### Tool calling
StepEval-Audio-Toolcall. Date and time tools have no parameter.
| Model |
Objective |
Metric |
Audio search |
Date & Time |
Weather |
Web search |
| Qwen3-32B† |
Trigger |
Precision / Recall |
67.5 / 98.5 |
98.4 / 100.0 |
90.1 / 100.0 |
86.8 / 98.5 |
| Type |
Accuracy |
100.0 |
100.0 |
98.5 |
98.5 |
| Parameter |
Accuracy |
100.0 |
N/A |
100.0 |
100.0 |
| Step-Audio 2 |
Trigger |
Precision / Recall |
86.8 / 99.5 |
96.9 / 98.4 |
92.2 / 100.0 |
88.4 / 95.5 |
| Type |
Accuracy |
100.0 |
100.0 |
90.5 |
98.4 |
| Parameter |
Accuracy |
100.0 |
N/A |
100.0 |
100.0 |
### Speech-to-speech conversation
URO-Bench. U. R. O. stands for understanding, reasoning, and oral conversation, respectively.
| Model |
Language |
Basic |
Pro |
| Avg. |
U. |
R. |
O. |
Avg. |
U. |
R. |
O. |
| GPT-4o Audio |
Chinese |
78.59 |
89.40 |
65.48 |
85.24 |
67.10 |
70.60 |
57.22 |
70.20 |
| Kimi-Audio |
73.59 |
79.34 |
64.66 |
79.75 |
66.07 |
60.44 |
59.29 |
76.21 |
| Qwen-Omni |
68.98 |
59.66 |
69.74 |
77.27 |
59.11 |
59.01 |
59.82 |
58.74 |
| Step-Audio-AQAA |
74.71 |
87.61 |
59.63 |
81.93 |
65.61 |
74.76 |
47.29 |
68.97 |
| Step-Audio 2 |
83.32 |
91.05 |
75.45 |
86.08 |
68.25 |
74.78 |
63.18 |
65.10 |
| Step-Audio 2 mini |
77.81 |
89.19 |
64.53 |
84.12 |
69.57 |
76.84 |
58.90 |
69.42 |
| GPT-4o Audio |
English |
84.54 |
90.18 |
75.90 |
90.41 |
67.51 |
60.65 |
64.36 |
78.46 |
| Kimi-Audio |
60.04 |
83.36 |
42.31 |
60.36 |
49.79 |
50.32 |
40.59 |
56.04 |
| Qwen-Omni |
70.58 |
66.29 |
69.62 |
76.16 |
50.99 |
44.51 |
63.88 |
49.41 |
| Step-Audio-AQAA |
71.11 |
90.15 |
56.12 |
72.06 |
52.01 |
44.25 |
54.54 |
59.81 |
| Step-Audio 2 |
83.90 |
92.72 |
76.51 |
84.92 |
66.07 |
64.86 |
67.75 |
66.33 |
| Step-Audio 2 mini |
74.36 |
90.07 |
60.12 |
77.65 |
61.25 |
58.79 |
61.94 |
63.80 |
## License
The model and code in the repository is licensed under [Apache 2.0](LICENSE) License.
## Citation
```
@misc{wu2025stepaudio2technicalreport,
title={Step-Audio 2 Technical Report},
author={Boyong Wu and Chao Yan and Chen Hu and Cheng Yi and Chengli Feng and Fei Tian and Feiyu Shen and Gang Yu and Haoyang Zhang and Jingbei Li and Mingrui Chen and Peng Liu and Wang You and Xiangyu Tony Zhang and Xingyuan Li and Xuerui Yang and Yayue Deng and Yechang Huang and Yuxin Li and Yuxin Zhang and Zhao You and Brian Li and Changyi Wan and Hanpeng Hu and Jiangjie Zhen and Siyu Chen and Song Yuan and Xuelin Zhang and Yimin Jiang and Yu Zhou and Yuxiang Yang and Bingxin Li and Buyun Ma and Changhe Song and Dongqing Pang and Guoqiang Hu and Haiyang Sun and Kang An and Na Wang and Shuli Gao and Wei Ji and Wen Li and Wen Sun and Xuan Wen and Yong Ren and Yuankai Ma and Yufan Lu and Bin Wang and Bo Li and Changxin Miao and Che Liu and Chen Xu and Dapeng Shi and Dingyuan Hu and Donghang Wu and Enle Liu and Guanzhe Huang and Gulin Yan and Han Zhang and Hao Nie and Haonan Jia and Hongyu Zhou and Jianjian Sun and Jiaoren Wu and Jie Wu and Jie Yang and Jin Yang and Junzhe Lin and Kaixiang Li and Lei Yang and Liying Shi and Li Zhou and Longlong Gu and Ming Li and Mingliang Li and Mingxiao Li and Nan Wu and Qi Han and Qinyuan Tan and Shaoliang Pang and Shengjie Fan and Siqi Liu and Tiancheng Cao and Wanying Lu and Wenqing He and Wuxun Xie and Xu Zhao and Xueqi Li and Yanbo Yu and Yang Yang and Yi Liu and Yifan Lu and Yilei Wang and Yuanhao Ding and Yuanwei Liang and Yuanwei Lu and Yuchu Luo and Yuhe Yin and Yumeng Zhan and Yuxiang Zhang and Zidong Yang and Zixin Zhang and Binxing Jiao and Daxin Jiang and Heung-Yeung Shum and Jiansheng Chen and Jing Li and Xiangyu Zhang and Yibo Zhu},
year={2025},
eprint={2507.16632},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2507.16632},
}
```