
Upload folder using huggingface_hub
Browse files- .gitattributes +3 -0
- .gradio/certificate.pem +31 -0
- GUIDELINES.md +140 -0
- LICENSE +21 -0
- README.md +158 -6
- __pycache__/generate.cpython-310.pyc +0 -0
- app.py +510 -0
- chat.py +45 -0
- generate.py +128 -0
- get_log_likelihood.py +96 -0
- imgs/LLaDA_vs_LLaMA.svg +2772 -0
- imgs/LLaDA_vs_LLaMA_chat.svg +2665 -0
- imgs/diff_remask.gif +3 -0
- imgs/sample.png +3 -0
- imgs/transformer1.png +0 -0
- imgs/transformer2.png +3 -0
- visualization/README.md +31 -0
- visualization/generate.py +144 -0
- visualization/html_to_png.py +30 -0
- visualization/sample_process.txt +64 -0
- visualization/visualization_paper.py +195 -0
- visualization/visualization_zhihu.py +202 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,6 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
imgs/diff_remask.gif filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
imgs/sample.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
imgs/transformer2.png filter=lfs diff=lfs merge=lfs -text
|
.gradio/certificate.pem
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
-----BEGIN CERTIFICATE-----
|
| 2 |
+
MIIFazCCA1OgAwIBAgIRAIIQz7DSQONZRGPgu2OCiwAwDQYJKoZIhvcNAQELBQAw
|
| 3 |
+
TzELMAkGA1UEBhMCVVMxKTAnBgNVBAoTIEludGVybmV0IFNlY3VyaXR5IFJlc2Vh
|
| 4 |
+
cmNoIEdyb3VwMRUwEwYDVQQDEwxJU1JHIFJvb3QgWDEwHhcNMTUwNjA0MTEwNDM4
|
| 5 |
+
WhcNMzUwNjA0MTEwNDM4WjBPMQswCQYDVQQGEwJVUzEpMCcGA1UEChMgSW50ZXJu
|
| 6 |
+
ZXQgU2VjdXJpdHkgUmVzZWFyY2ggR3JvdXAxFTATBgNVBAMTDElTUkcgUm9vdCBY
|
| 7 |
+
MTCCAiIwDQYJKoZIhvcNAQEBBQADggIPADCCAgoCggIBAK3oJHP0FDfzm54rVygc
|
| 8 |
+
h77ct984kIxuPOZXoHj3dcKi/vVqbvYATyjb3miGbESTtrFj/RQSa78f0uoxmyF+
|
| 9 |
+
0TM8ukj13Xnfs7j/EvEhmkvBioZxaUpmZmyPfjxwv60pIgbz5MDmgK7iS4+3mX6U
|
| 10 |
+
A5/TR5d8mUgjU+g4rk8Kb4Mu0UlXjIB0ttov0DiNewNwIRt18jA8+o+u3dpjq+sW
|
| 11 |
+
T8KOEUt+zwvo/7V3LvSye0rgTBIlDHCNAymg4VMk7BPZ7hm/ELNKjD+Jo2FR3qyH
|
| 12 |
+
B5T0Y3HsLuJvW5iB4YlcNHlsdu87kGJ55tukmi8mxdAQ4Q7e2RCOFvu396j3x+UC
|
| 13 |
+
B5iPNgiV5+I3lg02dZ77DnKxHZu8A/lJBdiB3QW0KtZB6awBdpUKD9jf1b0SHzUv
|
| 14 |
+
KBds0pjBqAlkd25HN7rOrFleaJ1/ctaJxQZBKT5ZPt0m9STJEadao0xAH0ahmbWn
|
| 15 |
+
OlFuhjuefXKnEgV4We0+UXgVCwOPjdAvBbI+e0ocS3MFEvzG6uBQE3xDk3SzynTn
|
| 16 |
+
jh8BCNAw1FtxNrQHusEwMFxIt4I7mKZ9YIqioymCzLq9gwQbooMDQaHWBfEbwrbw
|
| 17 |
+
qHyGO0aoSCqI3Haadr8faqU9GY/rOPNk3sgrDQoo//fb4hVC1CLQJ13hef4Y53CI
|
| 18 |
+
rU7m2Ys6xt0nUW7/vGT1M0NPAgMBAAGjQjBAMA4GA1UdDwEB/wQEAwIBBjAPBgNV
|
| 19 |
+
HRMBAf8EBTADAQH/MB0GA1UdDgQWBBR5tFnme7bl5AFzgAiIyBpY9umbbjANBgkq
|
| 20 |
+
hkiG9w0BAQsFAAOCAgEAVR9YqbyyqFDQDLHYGmkgJykIrGF1XIpu+ILlaS/V9lZL
|
| 21 |
+
ubhzEFnTIZd+50xx+7LSYK05qAvqFyFWhfFQDlnrzuBZ6brJFe+GnY+EgPbk6ZGQ
|
| 22 |
+
3BebYhtF8GaV0nxvwuo77x/Py9auJ/GpsMiu/X1+mvoiBOv/2X/qkSsisRcOj/KK
|
| 23 |
+
NFtY2PwByVS5uCbMiogziUwthDyC3+6WVwW6LLv3xLfHTjuCvjHIInNzktHCgKQ5
|
| 24 |
+
ORAzI4JMPJ+GslWYHb4phowim57iaztXOoJwTdwJx4nLCgdNbOhdjsnvzqvHu7Ur
|
| 25 |
+
TkXWStAmzOVyyghqpZXjFaH3pO3JLF+l+/+sKAIuvtd7u+Nxe5AW0wdeRlN8NwdC
|
| 26 |
+
jNPElpzVmbUq4JUagEiuTDkHzsxHpFKVK7q4+63SM1N95R1NbdWhscdCb+ZAJzVc
|
| 27 |
+
oyi3B43njTOQ5yOf+1CceWxG1bQVs5ZufpsMljq4Ui0/1lvh+wjChP4kqKOJ2qxq
|
| 28 |
+
4RgqsahDYVvTH9w7jXbyLeiNdd8XM2w9U/t7y0Ff/9yi0GE44Za4rF2LN9d11TPA
|
| 29 |
+
mRGunUHBcnWEvgJBQl9nJEiU0Zsnvgc/ubhPgXRR4Xq37Z0j4r7g1SgEEzwxA57d
|
| 30 |
+
emyPxgcYxn/eR44/KJ4EBs+lVDR3veyJm+kXQ99b21/+jh5Xos1AnX5iItreGCc=
|
| 31 |
+
-----END CERTIFICATE-----
|
GUIDELINES.md
ADDED
|
@@ -0,0 +1,140 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Guidelines
|
| 2 |
+
Here, we provide guidelines for the model architecture, pre-training, SFT, and inference of LLaDA.
|
| 3 |
+
|
| 4 |
+
## Model Architecture
|
| 5 |
+
|
| 6 |
+
LLaDA employs a Transformer Encoder as the network architecture for its mask predictor.
|
| 7 |
+
In terms of trainable parameters, the Transformer Encoder is identical to the Transformer
|
| 8 |
+
Decoder. Starting from an autoregressive model, we derive the backbone of LLaDA by simply
|
| 9 |
+
removing the causal mask from the self-attention mechanism as following.
|
| 10 |
+
|
| 11 |
+
<div style="display: flex; justify-content: center; flex-wrap: wrap; gap: 50px;">
|
| 12 |
+
<img src="imgs/transformer1.png" style="width: 90%;" />
|
| 13 |
+
<img src="imgs/transformer2.png" style="width: 90%;" />
|
| 14 |
+
</div>
|
| 15 |
+
|
| 16 |
+
In addition, LLaDA designates a reserved token as the mask token (i.e., 126336).
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
## Pre-training
|
| 20 |
+
The pre-training of LLaDA is straightforward and simple. Starting from an existing
|
| 21 |
+
autoregressive model training code, only a few lines need to be modified.
|
| 22 |
+
We provide the core code (i.e., loss computation) here.
|
| 23 |
+
|
| 24 |
+
```angular2html
|
| 25 |
+
def forward_process(input_ids, eps=1e-3):
|
| 26 |
+
b, l = input_ids.shape
|
| 27 |
+
t = torch.rand(b, device=input_ids.device)
|
| 28 |
+
p_mask = (1 - eps) * t + eps
|
| 29 |
+
p_mask = p_mask[:, None].repeat(1, l)
|
| 30 |
+
|
| 31 |
+
masked_indices = torch.rand((b, l), device=input_ids.device) < p_mask
|
| 32 |
+
# 126336 is used for [MASK] token
|
| 33 |
+
noisy_batch = torch.where(masked_indices, 126336, input_ids)
|
| 34 |
+
return noisy_batch, masked_indices, p_mask
|
| 35 |
+
|
| 36 |
+
# The data is an integer tensor of shape (b, 4096),
|
| 37 |
+
# where b represents the batch size and 4096 is the sequence length.
|
| 38 |
+
input_ids = batch["input_ids"]
|
| 39 |
+
|
| 40 |
+
# We set 1% of the pre-training data to a random length that is uniformly sampled from the range [1, 4096].
|
| 41 |
+
# The following implementation is not elegant and involves some data waste.
|
| 42 |
+
# However, the data waste is minimal, so we ignore it.
|
| 43 |
+
if torch.rand(1) < 0.01:
|
| 44 |
+
random_length = torch.randint(1, input_ids.shape[1] + 1, (1,))
|
| 45 |
+
input_ids = input_ids[:, :random_length]
|
| 46 |
+
|
| 47 |
+
noisy_batch, masked_indices, p_mask = forward_process(input_ids)
|
| 48 |
+
logits = model(input_ids=noisy_batch).logits
|
| 49 |
+
|
| 50 |
+
token_loss = F.cross_entropy(logits[masked_indices], input_ids[masked_indices], reduction='none') / p_mask[masked_indices]
|
| 51 |
+
loss = token_loss.sum() / (input_ids.shape[0] * input_ids.shape[1])
|
| 52 |
+
|
| 53 |
+
```
|
| 54 |
+
|
| 55 |
+
## SFT
|
| 56 |
+
First, please refer to Appendix B.1 for the preprocessing of the SFT data. After preprocessing the data,
|
| 57 |
+
the data format is as follows. For simplicity, we treat each word as a token and set the batch size to 2
|
| 58 |
+
in the following visualization.
|
| 59 |
+
```angular2html
|
| 60 |
+
input_ids:
|
| 61 |
+
<BOS><start_id>user<end_id>\nWhat is the capital of France?<eot_id><start_id>assistant<end_id>\nParis.<EOS><EOS><EOS><EOS><EOS><EOS><EOS><EOS><EOS><EOS>
|
| 62 |
+
<BOS><start_id>user<end_id>\nWhat is the capital of Canada?<eot_id><start_id>assistant<end_id>\nThe capital of Canada is Ottawa, located in Ontario.<EOS>
|
| 63 |
+
|
| 64 |
+
prompt_lengths:
|
| 65 |
+
[17, 17]
|
| 66 |
+
```
|
| 67 |
+
|
| 68 |
+
After preprocessing the SFT data, we can obtain the SFT code by making simple modifications to the pre-training code.
|
| 69 |
+
The key difference from pre-training is that SFT does not add noise to the prompt.
|
| 70 |
+
```angular2html
|
| 71 |
+
input_ids, prompt_lengths = batch["input_ids"], batch["prompt_lengths"]
|
| 72 |
+
|
| 73 |
+
noisy_batch, _, p_mask = forward_process(input_ids)
|
| 74 |
+
|
| 75 |
+
# Do not add noise to the prompt
|
| 76 |
+
token_positions = torch.arange(noisy_batch.shape[1], device=noisy_batch.device).expand(noisy_batch.size(0), noisy_batch.size(1))
|
| 77 |
+
prompt_mask = (temp_tensor < prompt_length.unsqueeze(1))
|
| 78 |
+
noisy_batch[prompt_mask] = input_ids[prompt_mask]
|
| 79 |
+
|
| 80 |
+
# Calculate the answer length (including the padded <EOS> tokens)
|
| 81 |
+
prompt_mask = prompt_mask.to(torch.int64)
|
| 82 |
+
answer_lengths = torch.sum((1 - prompt_mask), dim=-1, keepdim=True)
|
| 83 |
+
answer_lengths = answer_length.repeat(1, noisy_batch.shape[1])
|
| 84 |
+
|
| 85 |
+
masked_indices = (noisy_batch == 126336)
|
| 86 |
+
|
| 87 |
+
logits = model(input_ids=noisy_batch).logits
|
| 88 |
+
|
| 89 |
+
token_loss = F.cross_entropy(logits[masked_indices], input_ids[masked_indices], reduction='none') / p_mask[masked_indices]
|
| 90 |
+
ce_loss = torch.sum(token_loss / answer_lengths[masked_indices]) / input_ids.shape[0]
|
| 91 |
+
```
|
| 92 |
+
|
| 93 |
+
## Sampling
|
| 94 |
+
Overall, we categorize LLaDA's sampling process into three types: fixed-length, semi-autoregressive-origin, and semi-autoregressive-padding.
|
| 95 |
+
**It is worth noting that the semi-autoregressive-origin method was not mentioned in our paper, nor did we provide the corresponding code**.
|
| 96 |
+
However, we include it here because we believe that sharing both our failures and insights from the exploration process is valuable.
|
| 97 |
+
These three sampling methods are illustrated in the figure below.
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
<div style="display: flex; justify-content: center; flex-wrap: wrap; gap: 50px;">
|
| 101 |
+
<img src="imgs/sample.png" style="width: 100%;" />
|
| 102 |
+
</div>
|
| 103 |
+
|
| 104 |
+
For each step in the above three sampling processes, as detailed in Section 2.4 in our paper, the mask predictor
|
| 105 |
+
first predicts all masked tokens simultaneously. Then, a certain proportion of these predictions are remasked.
|
| 106 |
+
To determine which predicted tokens should be re-masked, we can adopt two strategies: *randomly remasking* or
|
| 107 |
+
*low-confidence remasking*. Notably, both remasking strategies can be applied to all three sampling processes
|
| 108 |
+
mentioned above.
|
| 109 |
+
|
| 110 |
+
For the LLaDA-Base model, we adapt low-confidence remasking to the three sampling processes mentioned above.
|
| 111 |
+
We find that fixed-length and semi-autoregressive-padding achieve similar results, whereas semi-autoregressive-origin
|
| 112 |
+
performs slightly worse.
|
| 113 |
+
|
| 114 |
+
For the LLaDA-Instruct model, the situation is slightly more complex.
|
| 115 |
+
|
| 116 |
+
First, if the semi-autoregressive-origin method is used,
|
| 117 |
+
the Instruct model performs poorly. This is because, during SFT, each sequence is a complete sentence (whereas in pre-training,
|
| 118 |
+
many sequences are truncated sentences). As a result, during sampling, given a generated length, regardless of whether it is
|
| 119 |
+
long or short, the Instruct model tends to generate a complete sentence. Unlike the Base model, it does not encounter cases
|
| 120 |
+
where a sentence is only partially generated and needs to be continued.
|
| 121 |
+
|
| 122 |
+
When performing fixed-length sampling with a high answer length (e.g., greater than 512),
|
| 123 |
+
we find that low-confidence remasking results in an unusually high proportion of `<EOS>` tokens in
|
| 124 |
+
the generated sentences, which severely impacts the model's performance. In contrast, this
|
| 125 |
+
issue does not arise when randomly remasking is used.
|
| 126 |
+
|
| 127 |
+
Furthermore, since low-confidence remasking achieved better results in the Base model, we also hoped that it could be applied to
|
| 128 |
+
the Instruct model. We found that combining low-confidence remasking with semi-autoregressive-padding effectively mitigates
|
| 129 |
+
the issue of generating an excessively high proportion of <EOS> tokens. Moreover, this combination achieves
|
| 130 |
+
slightly better results than randomly remasking & fixed-length.
|
| 131 |
+
|
| 132 |
+
You can find more details about the sampling method in our paper.
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
|
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2025 NieShenRuc
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
README.md
CHANGED
|
@@ -1,12 +1,164 @@
|
|
| 1 |
---
|
| 2 |
title: LLaDA
|
| 3 |
-
|
| 4 |
-
colorFrom: red
|
| 5 |
-
colorTo: indigo
|
| 6 |
sdk: gradio
|
| 7 |
sdk_version: 5.20.1
|
| 8 |
-
app_file: app.py
|
| 9 |
-
pinned: false
|
| 10 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 11 |
|
| 12 |
-
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
|
|
|
| 1 |
---
|
| 2 |
title: LLaDA
|
| 3 |
+
app_file: app.py
|
|
|
|
|
|
|
| 4 |
sdk: gradio
|
| 5 |
sdk_version: 5.20.1
|
|
|
|
|
|
|
| 6 |
---
|
| 7 |
+
# Large Language Diffusion Models
|
| 8 |
+
[](https://arxiv.org/abs/2502.09992)
|
| 9 |
+
[](https://huggingface.co/GSAI-ML/LLaDA-8B-Base)
|
| 10 |
+
[](https://huggingface.co/GSAI-ML/LLaDA-8B-Instruct)
|
| 11 |
+
[](https://zhuanlan.zhihu.com/p/24214732238)
|
| 12 |
+
|
| 13 |
+
We introduce LLaDA (<b>L</b>arge <b>La</b>nguage <b>D</b>iffusion with m<b>A</b>sking), a diffusion model with an unprecedented 8B scale, trained entirely from scratch,
|
| 14 |
+
rivaling LLaMA3 8B in performance.
|
| 15 |
+
|
| 16 |
+
<div style="display: flex; justify-content: center; flex-wrap: wrap;">
|
| 17 |
+
<img src="./imgs/LLaDA_vs_LLaMA.svg" style="width: 45%" />
|
| 18 |
+
<img src="./imgs/LLaDA_vs_LLaMA_chat.svg" style="width: 46%" />
|
| 19 |
+
</div>
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
## Inference
|
| 23 |
+
The [LLaDA-8B-Base](https://huggingface.co/GSAI-ML/LLaDA-8B-Base) and [LLaDA-8B-Instruct](https://huggingface.co/GSAI-ML/LLaDA-8B-Instruct) are upload
|
| 24 |
+
in Huggingface. Please first install `transformers==4.38.2` and employ the [transformers](https://huggingface.co/docs/transformers/index) to load.
|
| 25 |
+
|
| 26 |
+
```angular2html
|
| 27 |
+
from transformers import AutoModel, AutoTokenizer
|
| 28 |
+
|
| 29 |
+
tokenizer = AutoTokenizer.from_pretrained('GSAI-ML/LLaDA-8B-Base', trust_remote_code=True)
|
| 30 |
+
model = AutoModel.from_pretrained('GSAI-ML/LLaDA-8B-Base', trust_remote_code=True, torch_dtype=torch.bfloat16)
|
| 31 |
+
```
|
| 32 |
+
|
| 33 |
+
We provide `get_log_likelihood()` and `generate()` functions in `get_log_likelihood.py`
|
| 34 |
+
and `generate.py` respectively, for conditional likelihood evaluation and conditional generation.
|
| 35 |
+
|
| 36 |
+
You can directly run `python chat.py` to have multi-round conversations with LLaDA-8B-Instruct.
|
| 37 |
+
|
| 38 |
+
In addition, please refer to our paper and [GUIDELINES.md](GUIDELINES.md) for more details about the inference methods.
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
## Pre-training and Supervised Fine-Tuning
|
| 42 |
+
|
| 43 |
+
We will not provide the training framework and data as most open-source LLMs do.
|
| 44 |
+
|
| 45 |
+
However, the pre-training and Supervised Fine-Tuning of LLaDA are straightforward. If
|
| 46 |
+
you have a codebase for training an autoregressive model, you can modify it to
|
| 47 |
+
adapt to LLaDA with just a few lines of code.
|
| 48 |
+
|
| 49 |
+
We provide guidelines for the pre-training and SFT of LLaDA in [GUIDELINES.md](GUIDELINES.md).
|
| 50 |
+
You can also refer to [SMDM](https://github.com/ML-GSAI/SMDM), which has a similar training process to LLaDA
|
| 51 |
+
and has open-sourced the training framework.
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
## FAQ
|
| 55 |
+
Here, we address some common questions about LLaDA.
|
| 56 |
+
|
| 57 |
+
### 0. How do I train my own LLaDA?
|
| 58 |
+
Please refer to [GUIDELINES.md](GUIDELINES.md) for the guidelines.
|
| 59 |
+
You can also refer to [SMDM](https://github.com/ML-GSAI/SMDM), which follows the same training
|
| 60 |
+
process as LLaDA and has open-sourced its code.
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
### 1. What is the difference between LLaDA and BERT?
|
| 64 |
+
|
| 65 |
+
Our motivation is not to improve BERT, nor to apply image generation methods like [MaskGIT](https://arxiv.org/abs/2202.04200)
|
| 66 |
+
to text. **Our goal is to explore a theoretically complete language modeling approach — masked diffusion models.**
|
| 67 |
+
During this process, we simplified the approach and discovered that the loss function of masked diffusion models
|
| 68 |
+
is related to the loss functions of BERT and MaskGIT. You can find our theoretical research process in Question 7.
|
| 69 |
+
|
| 70 |
+
Specifically, LLaDA employs a masking ratio that varies randomly between 0 and 1, while BERT uses
|
| 71 |
+
a fixed ratio. This subtle difference has significant implications. **The training
|
| 72 |
+
objective of LLaDA is an upper bound on the negative log-likelihood of the model
|
| 73 |
+
distribution, making LLaDA a generative model.** This enables LLaDA to naturally
|
| 74 |
+
perform in-context learning, instruction-following, and ensures Fisher consistency
|
| 75 |
+
for scalability with large datasets and models. You can also find a direct answer
|
| 76 |
+
to this question in Section 2.1 of our paper.
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
### 2. What is the relationship between LLaDA and Transformer?
|
| 80 |
+
Network structure and probabilistic modeling are two distinct approaches that collectively form the
|
| 81 |
+
foundation of language models. LLaDA, like GPT, adopts the
|
| 82 |
+
Transformer architecture. The key difference lies in the probabilistic modeling approach: GPT
|
| 83 |
+
utilizes an autoregressive next-token prediction method,
|
| 84 |
+
while LLaDA employs a diffusion model for probabilistic modeling.
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
### 3. What is the sampling efficiency of LLaDA?
|
| 88 |
+
Currently, LLaDA's sampling speed is slower than the autoregressive baseline for three reasons:
|
| 89 |
+
1. LLaDA samples with a fixed context length;
|
| 90 |
+
2. LLaDA cannot yet leverage techniques like KV-Cache;
|
| 91 |
+
3. LLaDA achieves optimal performance when the number of sampling steps equals the response length.
|
| 92 |
+
Reducing the number of sampling steps leads to a decrease in performance, as detailed in Appendix B.4
|
| 93 |
+
and Appendix B.6 of our paper.
|
| 94 |
+
|
| 95 |
+
In this work, we aim to explore the upper limits of LLaDA's capabilities, **challenging the assumption
|
| 96 |
+
that the key LLM abilities are inherently tied to autoregressive models**. We will continue
|
| 97 |
+
to optimize its efficiency in the future. We believe this research approach is reasonable,
|
| 98 |
+
as verifying the upper limits of diffusion language models' capabilities will provide us with
|
| 99 |
+
more resources and sufficient motivation to optimize efficiency.
|
| 100 |
+
|
| 101 |
+
Recall the development of diffusion models for images, from [DDPM](https://arxiv.org/abs/2006.11239)
|
| 102 |
+
to the [Consistency model](https://arxiv.org/pdf/2410.11081), where sampling speed accelerated nearly
|
| 103 |
+
1000 times over the course of 4 years. **We believe there is significant room for optimization in LLaDA's
|
| 104 |
+
sampling efficiency as well**. Current solutions, including semi-autoregressive sampling (as
|
| 105 |
+
detailed in [GUIDELINES.md](GUIDELINES.md)), can mitigate the fixed context length issue, and
|
| 106 |
+
[consistency distillation](https://arxiv.org/pdf/2502.05415) can reduce the number of sampling steps.
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
### 4. What is the training stability of LLaDA?
|
| 110 |
+
For details on the pre-training process of LLaDA, please refer to Section 2.2 of our paper.
|
| 111 |
+
During the total pre-training on 2.3T tokens, we encountered a training crash (loss becoming NaN)
|
| 112 |
+
only once at 1.2T tokens. Our solution was to resume checkpoint and reduce
|
| 113 |
+
the learning rate from 4e-4 to 1e-4.
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
### 5. Why is the final answer "72" generated earlier than the intermediate calculation step (e.g., 12 × 4 = 48) in Tab4?
|
| 117 |
+
|
| 118 |
+
**The mask predictor has successfully predicted the reasoning process. However, during the
|
| 119 |
+
remasking process, the reasoning steps are masked out again.** As shown in the figure
|
| 120 |
+
below, the non-white background represents the model's generation process, while the
|
| 121 |
+
white-background boxes indicate the predictions made by the mask predictor at each step.
|
| 122 |
+
We adopt a randomly remasking strategy.
|
| 123 |
+
|
| 124 |
+
<div style="display: flex; justify-content: center; flex-wrap: wrap;">
|
| 125 |
+
<img src="./imgs/diff_remask.gif" style="width: 80%" />
|
| 126 |
+
</div>
|
| 127 |
+
|
| 128 |
+
### 6. Why does LLaDA answer 'Bailing' when asked 'Who are you'?
|
| 129 |
+
This is because our pre-training and SFT data were designed for training an autoregressive model,
|
| 130 |
+
whereas LLaDA directly utilizes data that contains identity markers.
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
### 7. Our journey in developing LLaDA?
|
| 134 |
+
LLaDA is built upon our two prior works, [RADD](https://arxiv.org/abs/2406.03736) and
|
| 135 |
+
[SMDM](https://arxiv.org/abs/2410.18514).
|
| 136 |
+
|
| 137 |
+
RADD demonstrated that the **training objective of LLaDA serves as an upper bound on the negative
|
| 138 |
+
log-likelihood** of the model’s distribution, a conclusion also supported by [MD4](https://arxiv.org/abs/2406.04329)
|
| 139 |
+
and [MDLM](https://arxiv.org/abs/2406.07524).
|
| 140 |
+
Furthermore, RADD was the first to theoretically prove that **masked diffusion models do not require time t
|
| 141 |
+
as an input to Transformer**. This insight provides the theoretical
|
| 142 |
+
justification for LLaDA’s unmodified use of the Transformer architecture. Lastly,
|
| 143 |
+
RADD showed that **the training objective of masked diffusion models is equivalent to that of
|
| 144 |
+
any-order autoregressive models**, offering valuable insights into how masked diffusion models can
|
| 145 |
+
overcome the reversal curse.
|
| 146 |
+
|
| 147 |
+
SMDM introduces the first **scaling law** for masked diffusion models and demonstrates that, with the
|
| 148 |
+
same model size and training data, masked diffusion models can achieve downstream benchmark results
|
| 149 |
+
on par with those of autoregressive models. Additionally, SMDM presents a simple, **unsupervised
|
| 150 |
+
classifier-free guidance** method that greatly improves downstream benchmark performance, which has
|
| 151 |
+
been adopted by LLaDA.
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
## Citation
|
| 155 |
+
|
| 156 |
+
```bibtex
|
| 157 |
+
@article{nie2025large,
|
| 158 |
+
title={Large Language Diffusion Models},
|
| 159 |
+
author={Nie, Shen and Zhu, Fengqi and You, Zebin and Zhang, Xiaolu and Ou, Jingyang and Hu, Jun and Zhou, Jun and Lin, Yankai and Wen, Ji-Rong and Li, Chongxuan},
|
| 160 |
+
journal={arXiv preprint arXiv:2502.09992},
|
| 161 |
+
year={2025}
|
| 162 |
+
}
|
| 163 |
+
```
|
| 164 |
|
|
|
__pycache__/generate.cpython-310.pyc
ADDED
|
Binary file (4.47 kB). View file
|
|
|
app.py
ADDED
|
@@ -0,0 +1,510 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import numpy as np
|
| 3 |
+
import gradio as gr
|
| 4 |
+
import torch.nn.functional as F
|
| 5 |
+
from transformers import AutoTokenizer, AutoModel
|
| 6 |
+
import time
|
| 7 |
+
import re
|
| 8 |
+
|
| 9 |
+
device = 'cuda' if torch.cuda.is_available() else 'cpu'
|
| 10 |
+
print(f"Using device: {device}")
|
| 11 |
+
|
| 12 |
+
# Load model and tokenizer
|
| 13 |
+
tokenizer = AutoTokenizer.from_pretrained('GSAI-ML/LLaDA-8B-Instruct', trust_remote_code=True)
|
| 14 |
+
model = AutoModel.from_pretrained('GSAI-ML/LLaDA-8B-Instruct', trust_remote_code=True,
|
| 15 |
+
torch_dtype=torch.bfloat16).to(device)
|
| 16 |
+
|
| 17 |
+
# Constants
|
| 18 |
+
MASK_TOKEN = "[MASK]"
|
| 19 |
+
MASK_ID = 126336 # The token ID of [MASK] in LLaDA
|
| 20 |
+
|
| 21 |
+
def parse_constraints(constraints_text):
|
| 22 |
+
"""Parse constraints in format: 'position:word, position:word, ...'"""
|
| 23 |
+
constraints = {}
|
| 24 |
+
if not constraints_text:
|
| 25 |
+
return constraints
|
| 26 |
+
|
| 27 |
+
parts = constraints_text.split(',')
|
| 28 |
+
for part in parts:
|
| 29 |
+
if ':' not in part:
|
| 30 |
+
continue
|
| 31 |
+
pos_str, word = part.split(':', 1)
|
| 32 |
+
try:
|
| 33 |
+
pos = int(pos_str.strip())
|
| 34 |
+
word = word.strip()
|
| 35 |
+
if word and pos >= 0:
|
| 36 |
+
constraints[pos] = word
|
| 37 |
+
except ValueError:
|
| 38 |
+
continue
|
| 39 |
+
|
| 40 |
+
return constraints
|
| 41 |
+
|
| 42 |
+
def format_chat_history(history):
|
| 43 |
+
"""
|
| 44 |
+
Format chat history for the LLaDA model
|
| 45 |
+
|
| 46 |
+
Args:
|
| 47 |
+
history: List of [user_message, assistant_message] pairs
|
| 48 |
+
|
| 49 |
+
Returns:
|
| 50 |
+
Formatted conversation for the model
|
| 51 |
+
"""
|
| 52 |
+
messages = []
|
| 53 |
+
for user_msg, assistant_msg in history:
|
| 54 |
+
messages.append({"role": "user", "content": user_msg})
|
| 55 |
+
if assistant_msg: # Skip if None (for the latest user message)
|
| 56 |
+
messages.append({"role": "assistant", "content": assistant_msg})
|
| 57 |
+
|
| 58 |
+
return messages
|
| 59 |
+
|
| 60 |
+
def add_gumbel_noise(logits, temperature):
|
| 61 |
+
'''
|
| 62 |
+
The Gumbel max is a method for sampling categorical distributions.
|
| 63 |
+
According to arXiv:2409.02908, for MDM, low-precision Gumbel Max improves perplexity score but reduces generation quality.
|
| 64 |
+
Thus, we use float64.
|
| 65 |
+
'''
|
| 66 |
+
if temperature <= 0:
|
| 67 |
+
return logits
|
| 68 |
+
|
| 69 |
+
logits = logits.to(torch.float64)
|
| 70 |
+
noise = torch.rand_like(logits, dtype=torch.float64)
|
| 71 |
+
gumbel_noise = (- torch.log(noise)) ** temperature
|
| 72 |
+
return logits.exp() / gumbel_noise
|
| 73 |
+
|
| 74 |
+
def get_num_transfer_tokens(mask_index, steps):
|
| 75 |
+
'''
|
| 76 |
+
In the reverse process, the interval [0, 1] is uniformly discretized into steps intervals.
|
| 77 |
+
Furthermore, because LLaDA employs a linear noise schedule (as defined in Eq. (8)),
|
| 78 |
+
the expected number of tokens transitioned at each step should be consistent.
|
| 79 |
+
This function is designed to precompute the number of tokens that need to be transitioned at each step.
|
| 80 |
+
'''
|
| 81 |
+
mask_num = mask_index.sum(dim=1, keepdim=True)
|
| 82 |
+
|
| 83 |
+
base = mask_num // steps
|
| 84 |
+
remainder = mask_num % steps
|
| 85 |
+
|
| 86 |
+
num_transfer_tokens = torch.zeros(mask_num.size(0), steps, device=mask_index.device, dtype=torch.int64) + base
|
| 87 |
+
|
| 88 |
+
for i in range(mask_num.size(0)):
|
| 89 |
+
num_transfer_tokens[i, :remainder[i]] += 1
|
| 90 |
+
|
| 91 |
+
return num_transfer_tokens
|
| 92 |
+
|
| 93 |
+
def generate_response_with_visualization(messages, gen_length=64, steps=32,
|
| 94 |
+
constraints=None, temperature=0.0, cfg_scale=0.0, block_length=32,
|
| 95 |
+
remasking='low_confidence'):
|
| 96 |
+
"""
|
| 97 |
+
Generate text with LLaDA model with visualization using the same sampling as in generate.py
|
| 98 |
+
|
| 99 |
+
Args:
|
| 100 |
+
messages: List of message dictionaries with 'role' and 'content'
|
| 101 |
+
gen_length: Length of text to generate
|
| 102 |
+
steps: Number of denoising steps
|
| 103 |
+
constraints: Dictionary mapping positions to words
|
| 104 |
+
temperature: Sampling temperature
|
| 105 |
+
cfg_scale: Classifier-free guidance scale
|
| 106 |
+
block_length: Block length for semi-autoregressive generation
|
| 107 |
+
remasking: Remasking strategy ('low_confidence' or 'random')
|
| 108 |
+
|
| 109 |
+
Returns:
|
| 110 |
+
List of visualization states showing the progression and final text
|
| 111 |
+
"""
|
| 112 |
+
|
| 113 |
+
# Process constraints
|
| 114 |
+
if constraints is None:
|
| 115 |
+
constraints = {}
|
| 116 |
+
|
| 117 |
+
# Convert any string constraints to token IDs
|
| 118 |
+
processed_constraints = {}
|
| 119 |
+
for pos, word in constraints.items():
|
| 120 |
+
tokens = tokenizer.encode(" " + word, add_special_tokens=False)
|
| 121 |
+
for i, token_id in enumerate(tokens):
|
| 122 |
+
processed_constraints[pos + i] = token_id
|
| 123 |
+
|
| 124 |
+
# Prepare the prompt using chat template
|
| 125 |
+
chat_input = tokenizer.apply_chat_template(messages, add_generation_prompt=True, tokenize=False)
|
| 126 |
+
input_ids = tokenizer(chat_input)['input_ids']
|
| 127 |
+
input_ids = torch.tensor(input_ids).to(device).unsqueeze(0)
|
| 128 |
+
|
| 129 |
+
# For generation
|
| 130 |
+
prompt_length = input_ids.shape[1]
|
| 131 |
+
|
| 132 |
+
# Initialize the sequence with masks for the response part
|
| 133 |
+
x = torch.full((1, prompt_length + gen_length), MASK_ID, dtype=torch.long).to(device)
|
| 134 |
+
x[:, :prompt_length] = input_ids.clone()
|
| 135 |
+
|
| 136 |
+
# Initialize visualization states for the response part
|
| 137 |
+
visualization_states = []
|
| 138 |
+
|
| 139 |
+
# Add initial state (all masked)
|
| 140 |
+
initial_state = [(MASK_TOKEN, "#444444") for _ in range(gen_length)]
|
| 141 |
+
visualization_states.append(initial_state)
|
| 142 |
+
|
| 143 |
+
# Apply constraints to the initial state
|
| 144 |
+
for pos, token_id in processed_constraints.items():
|
| 145 |
+
absolute_pos = prompt_length + pos
|
| 146 |
+
if absolute_pos < x.shape[1]:
|
| 147 |
+
x[:, absolute_pos] = token_id
|
| 148 |
+
|
| 149 |
+
# Mark prompt positions to exclude them from masking during classifier-free guidance
|
| 150 |
+
prompt_index = (x != MASK_ID)
|
| 151 |
+
|
| 152 |
+
# Ensure block_length is valid
|
| 153 |
+
if block_length > gen_length:
|
| 154 |
+
block_length = gen_length
|
| 155 |
+
|
| 156 |
+
# Calculate number of blocks
|
| 157 |
+
num_blocks = gen_length // block_length
|
| 158 |
+
if gen_length % block_length != 0:
|
| 159 |
+
num_blocks += 1
|
| 160 |
+
|
| 161 |
+
# Adjust steps per block
|
| 162 |
+
steps_per_block = steps // num_blocks
|
| 163 |
+
if steps_per_block < 1:
|
| 164 |
+
steps_per_block = 1
|
| 165 |
+
|
| 166 |
+
# Track the current state of x for visualization
|
| 167 |
+
current_x = x.clone()
|
| 168 |
+
|
| 169 |
+
# Process each block
|
| 170 |
+
for num_block in range(num_blocks):
|
| 171 |
+
# Calculate the start and end indices for the current block
|
| 172 |
+
block_start = prompt_length + num_block * block_length
|
| 173 |
+
block_end = min(prompt_length + (num_block + 1) * block_length, x.shape[1])
|
| 174 |
+
|
| 175 |
+
# Get mask indices for the current block
|
| 176 |
+
block_mask_index = (x[:, block_start:block_end] == MASK_ID)
|
| 177 |
+
|
| 178 |
+
# Skip if no masks in this block
|
| 179 |
+
if not block_mask_index.any():
|
| 180 |
+
continue
|
| 181 |
+
|
| 182 |
+
# Calculate number of tokens to unmask at each step
|
| 183 |
+
num_transfer_tokens = get_num_transfer_tokens(block_mask_index, steps_per_block)
|
| 184 |
+
|
| 185 |
+
# Process each step
|
| 186 |
+
for i in range(steps_per_block):
|
| 187 |
+
# Get all mask positions in the current sequence
|
| 188 |
+
mask_index = (x == MASK_ID)
|
| 189 |
+
|
| 190 |
+
# Skip if no masks
|
| 191 |
+
if not mask_index.any():
|
| 192 |
+
break
|
| 193 |
+
|
| 194 |
+
# Apply classifier-free guidance if enabled
|
| 195 |
+
if cfg_scale > 0.0:
|
| 196 |
+
un_x = x.clone()
|
| 197 |
+
un_x[prompt_index] = MASK_ID
|
| 198 |
+
x_ = torch.cat([x, un_x], dim=0)
|
| 199 |
+
logits = model(x_).logits
|
| 200 |
+
logits, un_logits = torch.chunk(logits, 2, dim=0)
|
| 201 |
+
logits = un_logits + (cfg_scale + 1) * (logits - un_logits)
|
| 202 |
+
else:
|
| 203 |
+
logits = model(x).logits
|
| 204 |
+
|
| 205 |
+
# Apply Gumbel noise for sampling
|
| 206 |
+
logits_with_noise = add_gumbel_noise(logits, temperature=temperature)
|
| 207 |
+
x0 = torch.argmax(logits_with_noise, dim=-1)
|
| 208 |
+
|
| 209 |
+
# Calculate confidence scores for remasking
|
| 210 |
+
if remasking == 'low_confidence':
|
| 211 |
+
p = F.softmax(logits.to(torch.float64), dim=-1)
|
| 212 |
+
x0_p = torch.squeeze(
|
| 213 |
+
torch.gather(p, dim=-1, index=torch.unsqueeze(x0, -1)), -1) # b, l
|
| 214 |
+
elif remasking == 'random':
|
| 215 |
+
x0_p = torch.rand((x0.shape[0], x0.shape[1]), device=x0.device)
|
| 216 |
+
else:
|
| 217 |
+
raise NotImplementedError(f"Remasking strategy '{remasking}' not implemented")
|
| 218 |
+
|
| 219 |
+
# Don't consider positions beyond the current block
|
| 220 |
+
x0_p[:, block_end:] = -float('inf')
|
| 221 |
+
|
| 222 |
+
# Apply predictions where we have masks
|
| 223 |
+
old_x = x.clone()
|
| 224 |
+
x0 = torch.where(mask_index, x0, x)
|
| 225 |
+
confidence = torch.where(mask_index, x0_p, -float('inf'))
|
| 226 |
+
|
| 227 |
+
# Select tokens to unmask based on confidence
|
| 228 |
+
transfer_index = torch.zeros_like(x0, dtype=torch.bool, device=x0.device)
|
| 229 |
+
for j in range(confidence.shape[0]):
|
| 230 |
+
# Only consider positions within the current block for unmasking
|
| 231 |
+
block_confidence = confidence[j, block_start:block_end]
|
| 232 |
+
if i < steps_per_block - 1: # Not the last step
|
| 233 |
+
# Take top-k confidences
|
| 234 |
+
_, select_indices = torch.topk(block_confidence,
|
| 235 |
+
k=min(num_transfer_tokens[j, i].item(),
|
| 236 |
+
block_confidence.numel()))
|
| 237 |
+
# Adjust indices to global positions
|
| 238 |
+
select_indices = select_indices + block_start
|
| 239 |
+
transfer_index[j, select_indices] = True
|
| 240 |
+
else: # Last step - unmask everything remaining
|
| 241 |
+
transfer_index[j, block_start:block_end] = mask_index[j, block_start:block_end]
|
| 242 |
+
|
| 243 |
+
# Apply the selected tokens
|
| 244 |
+
x = torch.where(transfer_index, x0, x)
|
| 245 |
+
|
| 246 |
+
# Ensure constraints are maintained
|
| 247 |
+
for pos, token_id in processed_constraints.items():
|
| 248 |
+
absolute_pos = prompt_length + pos
|
| 249 |
+
if absolute_pos < x.shape[1]:
|
| 250 |
+
x[:, absolute_pos] = token_id
|
| 251 |
+
|
| 252 |
+
# Create visualization state only for the response part
|
| 253 |
+
current_state = []
|
| 254 |
+
for i in range(gen_length):
|
| 255 |
+
pos = prompt_length + i # Absolute position in the sequence
|
| 256 |
+
|
| 257 |
+
if x[0, pos] == MASK_ID:
|
| 258 |
+
# Still masked
|
| 259 |
+
current_state.append((MASK_TOKEN, "#444444")) # Dark gray for masks
|
| 260 |
+
|
| 261 |
+
elif old_x[0, pos] == MASK_ID:
|
| 262 |
+
# Newly revealed in this step
|
| 263 |
+
token = tokenizer.decode([x[0, pos].item()], skip_special_tokens=True)
|
| 264 |
+
# Color based on confidence
|
| 265 |
+
confidence = float(x0_p[0, pos].cpu())
|
| 266 |
+
if confidence < 0.3:
|
| 267 |
+
color = "#FF6666" # Light red
|
| 268 |
+
elif confidence < 0.7:
|
| 269 |
+
color = "#FFAA33" # Orange
|
| 270 |
+
else:
|
| 271 |
+
color = "#66CC66" # Light green
|
| 272 |
+
|
| 273 |
+
current_state.append((token, color))
|
| 274 |
+
|
| 275 |
+
else:
|
| 276 |
+
# Previously revealed
|
| 277 |
+
token = tokenizer.decode([x[0, pos].item()], skip_special_tokens=True)
|
| 278 |
+
current_state.append((token, "#6699CC")) # Light blue
|
| 279 |
+
|
| 280 |
+
visualization_states.append(current_state)
|
| 281 |
+
|
| 282 |
+
# Extract final text (just the assistant's response)
|
| 283 |
+
response_tokens = x[0, prompt_length:]
|
| 284 |
+
final_text = tokenizer.decode(response_tokens,
|
| 285 |
+
skip_special_tokens=True,
|
| 286 |
+
clean_up_tokenization_spaces=True)
|
| 287 |
+
|
| 288 |
+
return visualization_states, final_text
|
| 289 |
+
|
| 290 |
+
css = '''
|
| 291 |
+
.category-legend{display:none}
|
| 292 |
+
button{height: 60px}
|
| 293 |
+
'''
|
| 294 |
+
def create_chatbot_demo():
|
| 295 |
+
with gr.Blocks(css=css) as demo:
|
| 296 |
+
gr.Markdown("# LLaDA - Large Language Diffusion Model Demo")
|
| 297 |
+
gr.Markdown("[model](https://huggingface.co/GSAI-ML/LLaDA-8B-Instruct), [project page](https://ml-gsai.github.io/LLaDA-demo/)")
|
| 298 |
+
|
| 299 |
+
# STATE MANAGEMENT
|
| 300 |
+
chat_history = gr.State([])
|
| 301 |
+
|
| 302 |
+
# UI COMPONENTS
|
| 303 |
+
with gr.Row():
|
| 304 |
+
with gr.Column(scale=3):
|
| 305 |
+
chatbot_ui = gr.Chatbot(label="Conversation", height=500)
|
| 306 |
+
|
| 307 |
+
# Message input
|
| 308 |
+
with gr.Group():
|
| 309 |
+
with gr.Row():
|
| 310 |
+
user_input = gr.Textbox(
|
| 311 |
+
label="Your Message",
|
| 312 |
+
placeholder="Type your message here...",
|
| 313 |
+
show_label=False
|
| 314 |
+
)
|
| 315 |
+
send_btn = gr.Button("Send")
|
| 316 |
+
|
| 317 |
+
constraints_input = gr.Textbox(
|
| 318 |
+
label="Word Constraints",
|
| 319 |
+
info="This model allows for placing specific words at specific positions using 'position:word' format. Example: 1st word once, 6th word 'upon' and 11th word 'time', would be: '0:Once, 5:upon, 10:time",
|
| 320 |
+
placeholder="0:Once, 5:upon, 10:time",
|
| 321 |
+
value=""
|
| 322 |
+
)
|
| 323 |
+
with gr.Column(scale=2):
|
| 324 |
+
output_vis = gr.HighlightedText(
|
| 325 |
+
label="Denoising Process Visualization",
|
| 326 |
+
combine_adjacent=False,
|
| 327 |
+
show_legend=True,
|
| 328 |
+
)
|
| 329 |
+
|
| 330 |
+
# Advanced generation settings
|
| 331 |
+
with gr.Accordion("Generation Settings", open=False):
|
| 332 |
+
with gr.Row():
|
| 333 |
+
gen_length = gr.Slider(
|
| 334 |
+
minimum=16, maximum=128, value=64, step=8,
|
| 335 |
+
label="Generation Length"
|
| 336 |
+
)
|
| 337 |
+
steps = gr.Slider(
|
| 338 |
+
minimum=8, maximum=64, value=64, step=4,
|
| 339 |
+
label="Denoising Steps"
|
| 340 |
+
)
|
| 341 |
+
with gr.Row():
|
| 342 |
+
temperature = gr.Slider(
|
| 343 |
+
minimum=0.0, maximum=1.0, value=0.5, step=0.1,
|
| 344 |
+
label="Temperature"
|
| 345 |
+
)
|
| 346 |
+
cfg_scale = gr.Slider(
|
| 347 |
+
minimum=0.0, maximum=2.0, value=0.0, step=0.1,
|
| 348 |
+
label="CFG Scale"
|
| 349 |
+
)
|
| 350 |
+
with gr.Row():
|
| 351 |
+
block_length = gr.Slider(
|
| 352 |
+
minimum=8, maximum=128, value=32, step=8,
|
| 353 |
+
label="Block Length"
|
| 354 |
+
)
|
| 355 |
+
remasking_strategy = gr.Radio(
|
| 356 |
+
choices=["low_confidence", "random"],
|
| 357 |
+
value="low_confidence",
|
| 358 |
+
label="Remasking Strategy"
|
| 359 |
+
)
|
| 360 |
+
with gr.Row():
|
| 361 |
+
visualization_delay = gr.Slider(
|
| 362 |
+
minimum=0.0, maximum=1.0, value=0.05, step=0.01,
|
| 363 |
+
label="Visualization Delay (seconds)"
|
| 364 |
+
)
|
| 365 |
+
|
| 366 |
+
# Current response text box (hidden)
|
| 367 |
+
current_response = gr.Textbox(
|
| 368 |
+
label="Current Response",
|
| 369 |
+
placeholder="The assistant's response will appear here...",
|
| 370 |
+
lines=3,
|
| 371 |
+
visible=False
|
| 372 |
+
)
|
| 373 |
+
|
| 374 |
+
# Clear button
|
| 375 |
+
clear_btn = gr.Button("Clear Conversation")
|
| 376 |
+
|
| 377 |
+
# HELPER FUNCTIONS
|
| 378 |
+
def add_message(history, message, response):
|
| 379 |
+
"""Add a message pair to the history and return the updated history"""
|
| 380 |
+
history = history.copy()
|
| 381 |
+
history.append([message, response])
|
| 382 |
+
return history
|
| 383 |
+
|
| 384 |
+
def user_message_submitted(message, history, gen_length, steps, constraints, delay):
|
| 385 |
+
"""Process a submitted user message"""
|
| 386 |
+
# Skip empty messages
|
| 387 |
+
if not message.strip():
|
| 388 |
+
# Return current state unchanged
|
| 389 |
+
history_for_display = history.copy()
|
| 390 |
+
return history, history_for_display, "", [], ""
|
| 391 |
+
|
| 392 |
+
# Add user message to history
|
| 393 |
+
history = add_message(history, message, None)
|
| 394 |
+
|
| 395 |
+
# Format for display - temporarily show user message with empty response
|
| 396 |
+
history_for_display = history.copy()
|
| 397 |
+
|
| 398 |
+
# Clear the input
|
| 399 |
+
message_out = ""
|
| 400 |
+
|
| 401 |
+
# Return immediately to update UI with user message
|
| 402 |
+
return history, history_for_display, message_out, [], ""
|
| 403 |
+
|
| 404 |
+
def bot_response(history, gen_length, steps, constraints, delay, temperature, cfg_scale, block_length, remasking):
|
| 405 |
+
"""Generate bot response for the latest message"""
|
| 406 |
+
if not history:
|
| 407 |
+
return history, [], ""
|
| 408 |
+
|
| 409 |
+
# Get the last user message
|
| 410 |
+
last_user_message = history[-1][0]
|
| 411 |
+
|
| 412 |
+
try:
|
| 413 |
+
# Format all messages except the last one (which has no response yet)
|
| 414 |
+
messages = format_chat_history(history[:-1])
|
| 415 |
+
|
| 416 |
+
# Add the last user message
|
| 417 |
+
messages.append({"role": "user", "content": last_user_message})
|
| 418 |
+
|
| 419 |
+
# Parse constraints
|
| 420 |
+
parsed_constraints = parse_constraints(constraints)
|
| 421 |
+
|
| 422 |
+
# Generate response with visualization
|
| 423 |
+
vis_states, response_text = generate_response_with_visualization(
|
| 424 |
+
messages,
|
| 425 |
+
gen_length=gen_length,
|
| 426 |
+
steps=steps,
|
| 427 |
+
constraints=parsed_constraints,
|
| 428 |
+
temperature=temperature,
|
| 429 |
+
cfg_scale=cfg_scale,
|
| 430 |
+
block_length=block_length,
|
| 431 |
+
remasking=remasking
|
| 432 |
+
)
|
| 433 |
+
|
| 434 |
+
# Update history with the assistant's response
|
| 435 |
+
history[-1][1] = response_text
|
| 436 |
+
|
| 437 |
+
# Return the initial state immediately
|
| 438 |
+
yield history, vis_states[0], response_text
|
| 439 |
+
|
| 440 |
+
# Then animate through visualization states
|
| 441 |
+
for state in vis_states[1:]:
|
| 442 |
+
time.sleep(delay)
|
| 443 |
+
yield history, state, response_text
|
| 444 |
+
|
| 445 |
+
except Exception as e:
|
| 446 |
+
error_msg = f"Error: {str(e)}"
|
| 447 |
+
print(error_msg)
|
| 448 |
+
|
| 449 |
+
# Show error in visualization
|
| 450 |
+
error_vis = [(error_msg, "red")]
|
| 451 |
+
|
| 452 |
+
# Don't update history with error
|
| 453 |
+
yield history, error_vis, error_msg
|
| 454 |
+
|
| 455 |
+
def clear_conversation():
|
| 456 |
+
"""Clear the conversation history"""
|
| 457 |
+
return [], [], "", []
|
| 458 |
+
|
| 459 |
+
# EVENT HANDLERS
|
| 460 |
+
|
| 461 |
+
# Clear button handler
|
| 462 |
+
clear_btn.click(
|
| 463 |
+
fn=clear_conversation,
|
| 464 |
+
inputs=[],
|
| 465 |
+
outputs=[chat_history, chatbot_ui, current_response, output_vis]
|
| 466 |
+
)
|
| 467 |
+
|
| 468 |
+
# User message submission flow (2-step process)
|
| 469 |
+
# Step 1: Add user message to history and update UI
|
| 470 |
+
msg_submit = user_input.submit(
|
| 471 |
+
fn=user_message_submitted,
|
| 472 |
+
inputs=[user_input, chat_history, gen_length, steps, constraints_input, visualization_delay],
|
| 473 |
+
outputs=[chat_history, chatbot_ui, user_input, output_vis, current_response]
|
| 474 |
+
)
|
| 475 |
+
|
| 476 |
+
# Also connect the send button
|
| 477 |
+
send_click = send_btn.click(
|
| 478 |
+
fn=user_message_submitted,
|
| 479 |
+
inputs=[user_input, chat_history, gen_length, steps, constraints_input, visualization_delay],
|
| 480 |
+
outputs=[chat_history, chatbot_ui, user_input, output_vis, current_response]
|
| 481 |
+
)
|
| 482 |
+
|
| 483 |
+
# Step 2: Generate bot response
|
| 484 |
+
# This happens after the user message is displayed
|
| 485 |
+
msg_submit.then(
|
| 486 |
+
fn=bot_response,
|
| 487 |
+
inputs=[
|
| 488 |
+
chat_history, gen_length, steps, constraints_input,
|
| 489 |
+
visualization_delay, temperature, cfg_scale, block_length,
|
| 490 |
+
remasking_strategy
|
| 491 |
+
],
|
| 492 |
+
outputs=[chatbot_ui, output_vis, current_response]
|
| 493 |
+
)
|
| 494 |
+
|
| 495 |
+
send_click.then(
|
| 496 |
+
fn=bot_response,
|
| 497 |
+
inputs=[
|
| 498 |
+
chat_history, gen_length, steps, constraints_input,
|
| 499 |
+
visualization_delay, temperature, cfg_scale, block_length,
|
| 500 |
+
remasking_strategy
|
| 501 |
+
],
|
| 502 |
+
outputs=[chatbot_ui, output_vis, current_response]
|
| 503 |
+
)
|
| 504 |
+
|
| 505 |
+
return demo
|
| 506 |
+
|
| 507 |
+
# Launch the demo
|
| 508 |
+
if __name__ == "__main__":
|
| 509 |
+
demo = create_chatbot_demo()
|
| 510 |
+
demo.queue().launch(share=True)
|
chat.py
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
|
| 3 |
+
from generate import generate
|
| 4 |
+
from transformers import AutoTokenizer, AutoModel
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
def chat():
|
| 8 |
+
device = 'cuda'
|
| 9 |
+
model = AutoModel.from_pretrained('GSAI-ML/LLaDA-8B-Instruct', trust_remote_code=True, torch_dtype=torch.bfloat16).to(device).eval()
|
| 10 |
+
tokenizer = AutoTokenizer.from_pretrained('GSAI-ML/LLaDA-8B-Instruct', trust_remote_code=True)
|
| 11 |
+
|
| 12 |
+
gen_length = 128
|
| 13 |
+
steps = 128
|
| 14 |
+
print('*' * 66)
|
| 15 |
+
print(f'** Answer Length: {gen_length} | Sampling Steps: {steps} **')
|
| 16 |
+
print('*' * 66)
|
| 17 |
+
|
| 18 |
+
conversation_num = 0
|
| 19 |
+
while True:
|
| 20 |
+
user_input = input("Enter your question: ")
|
| 21 |
+
|
| 22 |
+
m = [{"role": "user", "content": user_input}]
|
| 23 |
+
user_input = tokenizer.apply_chat_template(m, add_generation_prompt=True, tokenize=False)
|
| 24 |
+
input_ids = tokenizer(user_input)['input_ids']
|
| 25 |
+
input_ids = torch.tensor(input_ids).to(device).unsqueeze(0)
|
| 26 |
+
|
| 27 |
+
if conversation_num == 0:
|
| 28 |
+
prompt = input_ids
|
| 29 |
+
else:
|
| 30 |
+
prompt = torch.cat([prompt, input_ids[:, 1:]], dim=1)
|
| 31 |
+
|
| 32 |
+
out = generate(model, prompt, steps=steps, gen_length=gen_length, block_length=32, temperature=0., cfg_scale=0., remasking='low_confidence')
|
| 33 |
+
|
| 34 |
+
answer = tokenizer.batch_decode(out[:, prompt.shape[1]:], skip_special_tokens=True)[0]
|
| 35 |
+
print(f"Bot's reply: {answer}")
|
| 36 |
+
|
| 37 |
+
# remove the <EOS>
|
| 38 |
+
prompt = out[out != 126081].unsqueeze(0)
|
| 39 |
+
conversation_num += 1
|
| 40 |
+
print('-----------------------------------------------------------------------')
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
if __name__ == "__main__":
|
| 44 |
+
chat()
|
| 45 |
+
|
generate.py
ADDED
|
@@ -0,0 +1,128 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import numpy as np
|
| 3 |
+
import torch.nn.functional as F
|
| 4 |
+
|
| 5 |
+
from transformers import AutoTokenizer, AutoModel
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def add_gumbel_noise(logits, temperature):
|
| 9 |
+
'''
|
| 10 |
+
The Gumbel max is a method for sampling categorical distributions.
|
| 11 |
+
According to arXiv:2409.02908, for MDM, low-precision Gumbel Max improves perplexity score but reduces generation quality.
|
| 12 |
+
Thus, we use float64.
|
| 13 |
+
'''
|
| 14 |
+
logits = logits.to(torch.float64)
|
| 15 |
+
noise = torch.rand_like(logits, dtype=torch.float64)
|
| 16 |
+
gumbel_noise = (- torch.log(noise)) ** temperature
|
| 17 |
+
return logits.exp() / gumbel_noise
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def get_num_transfer_tokens(mask_index, steps):
|
| 21 |
+
'''
|
| 22 |
+
In the reverse process, the interval [0, 1] is uniformly discretized into steps intervals.
|
| 23 |
+
Furthermore, because LLaDA employs a linear noise schedule (as defined in Eq. (8)),
|
| 24 |
+
the expected number of tokens transitioned at each step should be consistent.
|
| 25 |
+
|
| 26 |
+
This function is designed to precompute the number of tokens that need to be transitioned at each step.
|
| 27 |
+
'''
|
| 28 |
+
mask_num = mask_index.sum(dim=1, keepdim=True)
|
| 29 |
+
|
| 30 |
+
base = mask_num // steps
|
| 31 |
+
remainder = mask_num % steps
|
| 32 |
+
|
| 33 |
+
num_transfer_tokens = torch.zeros(mask_num.size(0), steps, device=mask_index.device, dtype=torch.int64) + base
|
| 34 |
+
|
| 35 |
+
for i in range(mask_num.size(0)):
|
| 36 |
+
num_transfer_tokens[i, :remainder[i]] += 1
|
| 37 |
+
|
| 38 |
+
return num_transfer_tokens
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
@ torch.no_grad()
|
| 42 |
+
def generate(model, prompt, steps=128, gen_length=128, block_length=128, temperature=0.,
|
| 43 |
+
cfg_scale=0., remasking='low_confidence', mask_id=126336):
|
| 44 |
+
'''
|
| 45 |
+
Args:
|
| 46 |
+
model: Mask predictor.
|
| 47 |
+
prompt: A tensor of shape (1, l).
|
| 48 |
+
steps: Sampling steps, less than or equal to gen_length.
|
| 49 |
+
gen_length: Generated answer length.
|
| 50 |
+
block_length: Block length, less than or equal to gen_length. If less than gen_length, it means using semi_autoregressive remasking.
|
| 51 |
+
temperature: Categorical distribution sampling temperature.
|
| 52 |
+
cfg_scale: Unsupervised classifier-free guidance scale.
|
| 53 |
+
remasking: Remasking strategy. 'low_confidence' or 'random'.
|
| 54 |
+
mask_id: The toke id of [MASK] is 126336.
|
| 55 |
+
'''
|
| 56 |
+
x = torch.full((1, prompt.shape[1] + gen_length), mask_id, dtype=torch.long).to(model.device)
|
| 57 |
+
x[:, :prompt.shape[1]] = prompt.clone()
|
| 58 |
+
|
| 59 |
+
prompt_index = (x != mask_id)
|
| 60 |
+
|
| 61 |
+
assert gen_length % block_length == 0
|
| 62 |
+
num_blocks = gen_length // block_length
|
| 63 |
+
|
| 64 |
+
assert steps % num_blocks == 0
|
| 65 |
+
steps = steps // num_blocks
|
| 66 |
+
|
| 67 |
+
for num_block in range(num_blocks):
|
| 68 |
+
block_mask_index = (x[:, prompt.shape[1] + num_block * block_length: prompt.shape[1] + (num_block + 1) * block_length:] == mask_id)
|
| 69 |
+
num_transfer_tokens = get_num_transfer_tokens(block_mask_index, steps)
|
| 70 |
+
for i in range(steps):
|
| 71 |
+
mask_index = (x == mask_id)
|
| 72 |
+
if cfg_scale > 0.:
|
| 73 |
+
un_x = x.clone()
|
| 74 |
+
un_x[prompt_index] = mask_id
|
| 75 |
+
x_ = torch.cat([x, un_x], dim=0)
|
| 76 |
+
logits = model(x_).logits
|
| 77 |
+
logits, un_logits = torch.chunk(logits, 2, dim=0)
|
| 78 |
+
logits = un_logits + (cfg_scale + 1) * (logits - un_logits)
|
| 79 |
+
else:
|
| 80 |
+
logits = model(x).logits
|
| 81 |
+
|
| 82 |
+
logits_with_noise = add_gumbel_noise(logits, temperature=temperature)
|
| 83 |
+
x0 = torch.argmax(logits_with_noise, dim=-1) # b, l
|
| 84 |
+
|
| 85 |
+
if remasking == 'low_confidence':
|
| 86 |
+
p = F.softmax(logits.to(torch.float64), dim=-1)
|
| 87 |
+
x0_p = torch.squeeze(
|
| 88 |
+
torch.gather(p, dim=-1, index=torch.unsqueeze(x0, -1)), -1) # b, l
|
| 89 |
+
elif remasking == 'random':
|
| 90 |
+
x0_p = torch.rand((x0.shape[0], x0.shape[1]), device=x0.device)
|
| 91 |
+
else:
|
| 92 |
+
raise NotImplementedError(remasking)
|
| 93 |
+
|
| 94 |
+
x0_p[:, prompt.shape[1] + (num_block + 1) * block_length:] = -np.inf
|
| 95 |
+
|
| 96 |
+
x0 = torch.where(mask_index, x0, x)
|
| 97 |
+
confidence = torch.where(mask_index, x0_p, -np.inf)
|
| 98 |
+
|
| 99 |
+
transfer_index = torch.zeros_like(x0, dtype=torch.bool, device=x0.device)
|
| 100 |
+
for j in range(confidence.shape[0]):
|
| 101 |
+
_, select_index = torch.topk(confidence[j], k=num_transfer_tokens[j, i])
|
| 102 |
+
transfer_index[j, select_index] = True
|
| 103 |
+
x[transfer_index] = x0[transfer_index]
|
| 104 |
+
|
| 105 |
+
return x
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
def main():
|
| 109 |
+
device = 'cuda'
|
| 110 |
+
|
| 111 |
+
model = AutoModel.from_pretrained('GSAI-ML/LLaDA-8B-Instruct', trust_remote_code=True, torch_dtype=torch.bfloat16).to(device).eval()
|
| 112 |
+
tokenizer = AutoTokenizer.from_pretrained('GSAI-ML/LLaDA-8B-Instruct', trust_remote_code=True)
|
| 113 |
+
|
| 114 |
+
prompt = "Lily can run 12 kilometers per hour for 4 hours. After that, she runs 6 kilometers per hour. How many kilometers can she run in 8 hours?"
|
| 115 |
+
|
| 116 |
+
# Add special tokens for the Instruct model. The Base model does not require the following two lines.
|
| 117 |
+
m = [{"role": "user", "content": prompt}, ]
|
| 118 |
+
prompt = tokenizer.apply_chat_template(m, add_generation_prompt=True, tokenize=False)
|
| 119 |
+
|
| 120 |
+
input_ids = tokenizer(prompt)['input_ids']
|
| 121 |
+
input_ids = torch.tensor(input_ids).to(device).unsqueeze(0)
|
| 122 |
+
|
| 123 |
+
out = generate(model, input_ids, steps=128, gen_length=128, block_length=32, temperature=0., cfg_scale=0., remasking='low_confidence')
|
| 124 |
+
print(tokenizer.batch_decode(out[:, input_ids.shape[1]:], skip_special_tokens=True)[0])
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
if __name__ == '__main__':
|
| 128 |
+
main()
|
get_log_likelihood.py
ADDED
|
@@ -0,0 +1,96 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn.functional as F
|
| 3 |
+
|
| 4 |
+
from transformers import AutoTokenizer, AutoModel
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
def forward_process(batch, prompt_index, mask_id):
|
| 8 |
+
b, l = batch.shape
|
| 9 |
+
|
| 10 |
+
target_len = (l - prompt_index.sum()).item()
|
| 11 |
+
k = torch.randint(1, target_len + 1, (), device=batch.device)
|
| 12 |
+
|
| 13 |
+
x = torch.round(torch.linspace(float(k), k + (b - 1) * (target_len / b), steps=b, device=batch.device)).long()
|
| 14 |
+
x = ((x - 1) % target_len) + 1
|
| 15 |
+
assert x.min() >= 1 and x.max() <= target_len
|
| 16 |
+
|
| 17 |
+
indices = torch.arange(target_len, device=batch.device).repeat(b, 1)
|
| 18 |
+
is_mask = indices < x.unsqueeze(1)
|
| 19 |
+
for i in range(b):
|
| 20 |
+
is_mask[i] = is_mask[i][torch.randperm(target_len)]
|
| 21 |
+
|
| 22 |
+
is_mask = torch.cat((torch.zeros(b, prompt_index.sum(), dtype=torch.bool, device=batch.device), is_mask), dim=1)
|
| 23 |
+
noisy_batch = torch.where(is_mask, mask_id, batch)
|
| 24 |
+
|
| 25 |
+
# Return the masked batch and the mask ratio
|
| 26 |
+
return noisy_batch, (x / target_len).unsqueeze(1).repeat(1, l)
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def get_logits(model, batch, prompt_index, cfg_scale, mask_id):
|
| 30 |
+
if cfg_scale > 0.:
|
| 31 |
+
assert len(prompt_index) == batch.shape[1]
|
| 32 |
+
prompt_index = prompt_index.unsqueeze(0).repeat(batch.shape[0], 1)
|
| 33 |
+
un_batch = batch.clone()
|
| 34 |
+
un_batch[prompt_index] = mask_id
|
| 35 |
+
batch = torch.cat([batch, un_batch])
|
| 36 |
+
|
| 37 |
+
input = batch
|
| 38 |
+
logits = model(input).logits
|
| 39 |
+
|
| 40 |
+
if cfg_scale > 0.:
|
| 41 |
+
logits, un_logits = torch.chunk(logits, 2, dim=0)
|
| 42 |
+
logits = un_logits + (cfg_scale + 1) * (logits - un_logits)
|
| 43 |
+
return logits
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
@ torch.no_grad()
|
| 47 |
+
def get_log_likelihood(model, prompt, answer, mc_num=128, batch_size=16, cfg_scale=0., mask_id=126336):
|
| 48 |
+
'''
|
| 49 |
+
Args:
|
| 50 |
+
model: Mask predictor.
|
| 51 |
+
prompt: A tensor of shape (l1).
|
| 52 |
+
answer: A tensor of shape (l2).
|
| 53 |
+
mc_num: Monte Carlo estimation times.
|
| 54 |
+
As detailed in Appendix B.5. Since MMLU, CMMLU, and C-EVAL only require the likelihood of a single token, a
|
| 55 |
+
single Monte Carlo estimate is sufficient for these benchmarks. For all other benchmarks, we find that 128
|
| 56 |
+
Monte Carlo samples are adequate to produce stable results.
|
| 57 |
+
batch_size: Mini batch size.
|
| 58 |
+
cfg_scale: Unsupervised classifier-free guidance scale.
|
| 59 |
+
mask_id: The toke id of [MASK] is 126336.
|
| 60 |
+
'''
|
| 61 |
+
seq = torch.concatenate([prompt, answer])[None, :]
|
| 62 |
+
seq = seq.repeat((batch_size, 1)).to(model.device)
|
| 63 |
+
prompt_index = torch.arange(seq.shape[1], device=model.device) < len(prompt)
|
| 64 |
+
|
| 65 |
+
loss_ = []
|
| 66 |
+
for _ in range(mc_num // batch_size):
|
| 67 |
+
perturbed_seq, p_mask = forward_process(seq, prompt_index, mask_id)
|
| 68 |
+
mask_index = perturbed_seq == mask_id
|
| 69 |
+
|
| 70 |
+
logits = get_logits(model, perturbed_seq, prompt_index, cfg_scale, mask_id)
|
| 71 |
+
|
| 72 |
+
loss = F.cross_entropy(logits[mask_index], seq[mask_index], reduction='none') / p_mask[mask_index]
|
| 73 |
+
loss = loss.sum() / batch_size
|
| 74 |
+
|
| 75 |
+
loss_.append(loss.item())
|
| 76 |
+
|
| 77 |
+
return - sum(loss_) / len(loss_)
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
def main():
|
| 81 |
+
device = 'cuda'
|
| 82 |
+
|
| 83 |
+
model = AutoModel.from_pretrained('GSAI-ML/LLaDA-8B-Base', trust_remote_code=True, torch_dtype=torch.bfloat16).to(device).eval()
|
| 84 |
+
tokenizer = AutoTokenizer.from_pretrained('GSAI-ML/LLaDA-8B-Base', trust_remote_code=True)
|
| 85 |
+
|
| 86 |
+
# this prompt and answer is from Hellaswag dataset
|
| 87 |
+
prompt = 'Roof shingle removal: A man is sitting on a roof. He'
|
| 88 |
+
answer = ' is using wrap to wrap a pair of skis.'
|
| 89 |
+
|
| 90 |
+
prompt = torch.tensor(tokenizer(prompt)['input_ids']).to(device)
|
| 91 |
+
answer = torch.tensor(tokenizer(answer)['input_ids']).to(device)
|
| 92 |
+
print(get_log_likelihood(model, prompt, answer, mc_num=128))
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
if __name__ == '__main__':
|
| 96 |
+
main()
|
imgs/LLaDA_vs_LLaMA.svg
ADDED

|
imgs/LLaDA_vs_LLaMA_chat.svg
ADDED

|
imgs/diff_remask.gif
ADDED
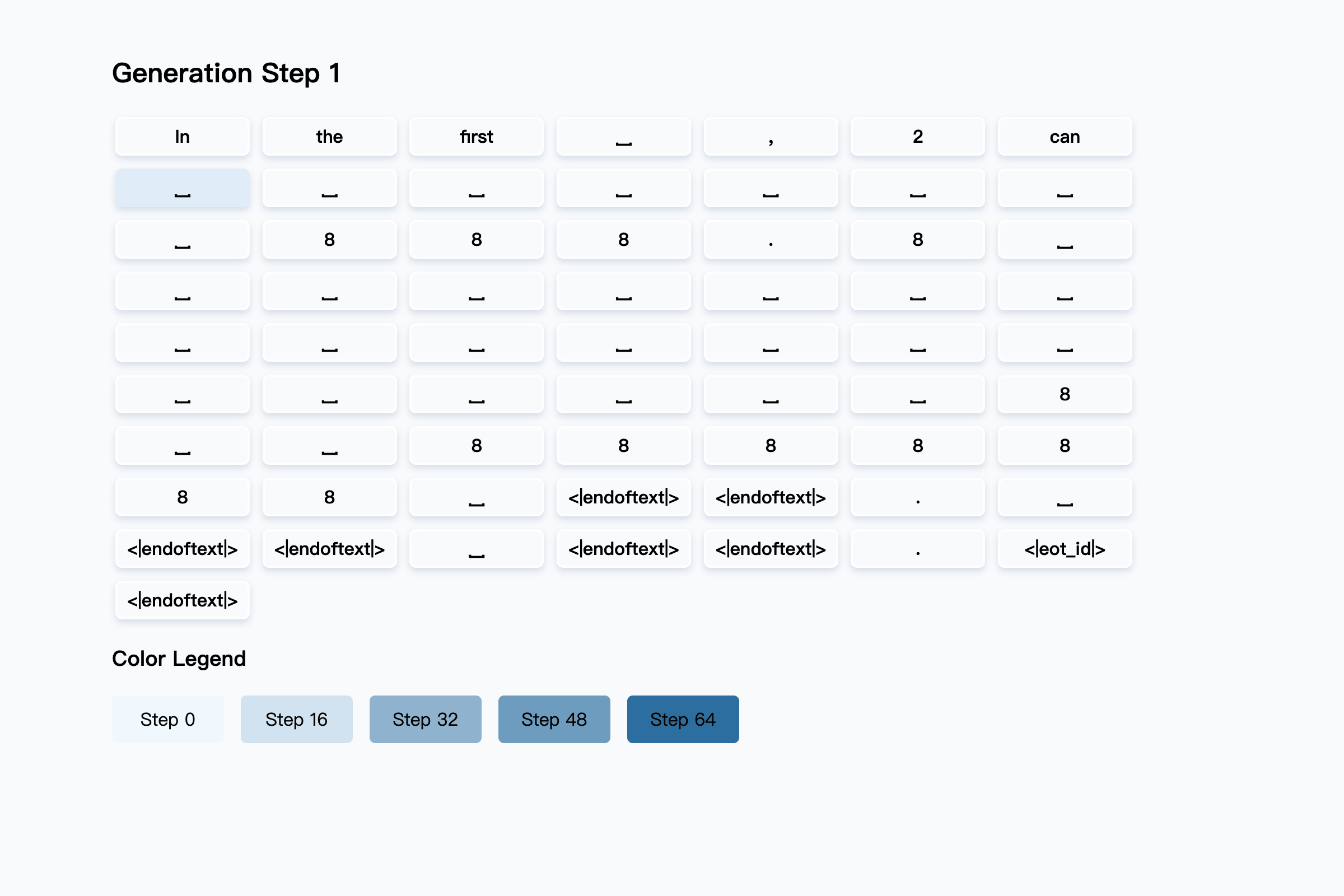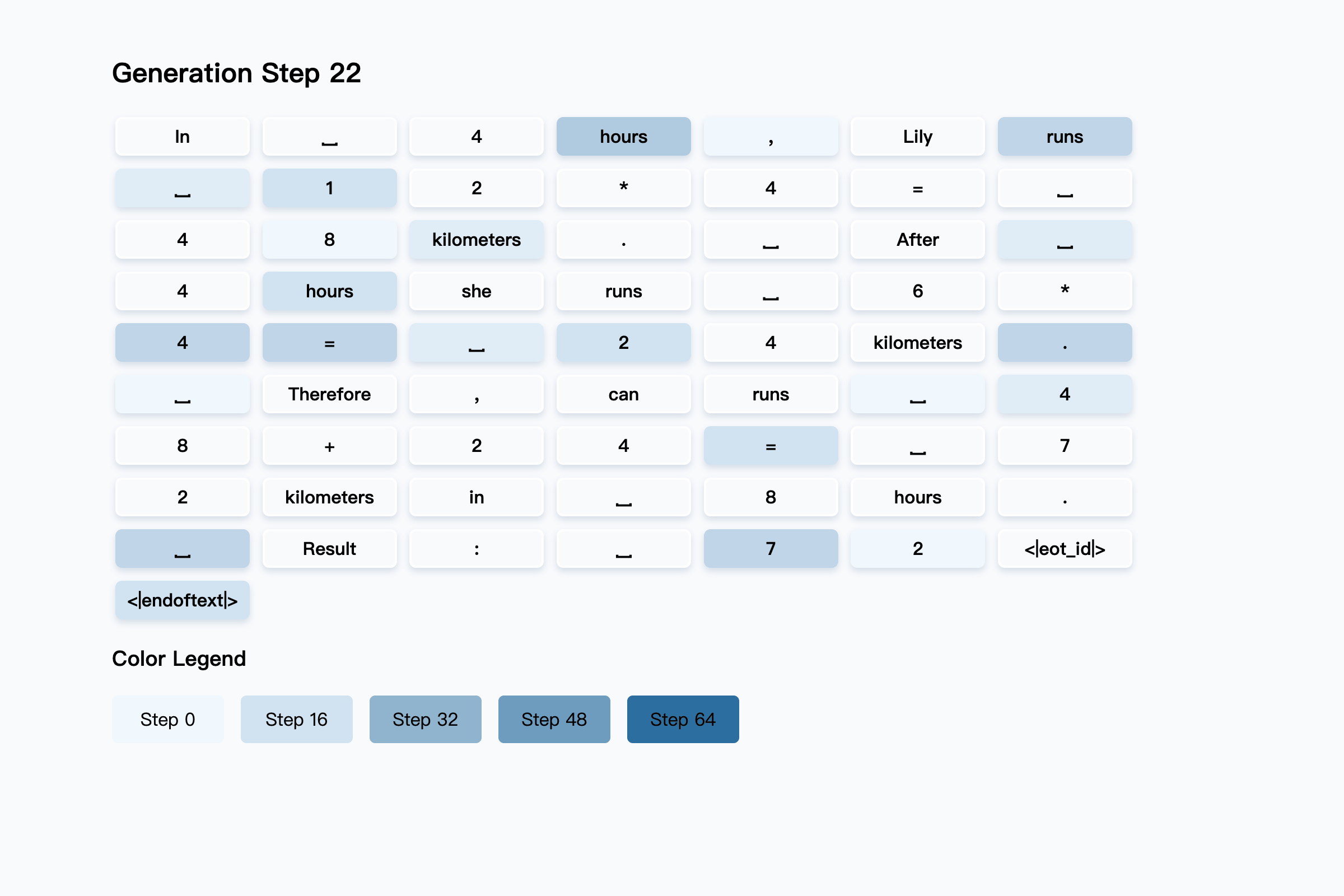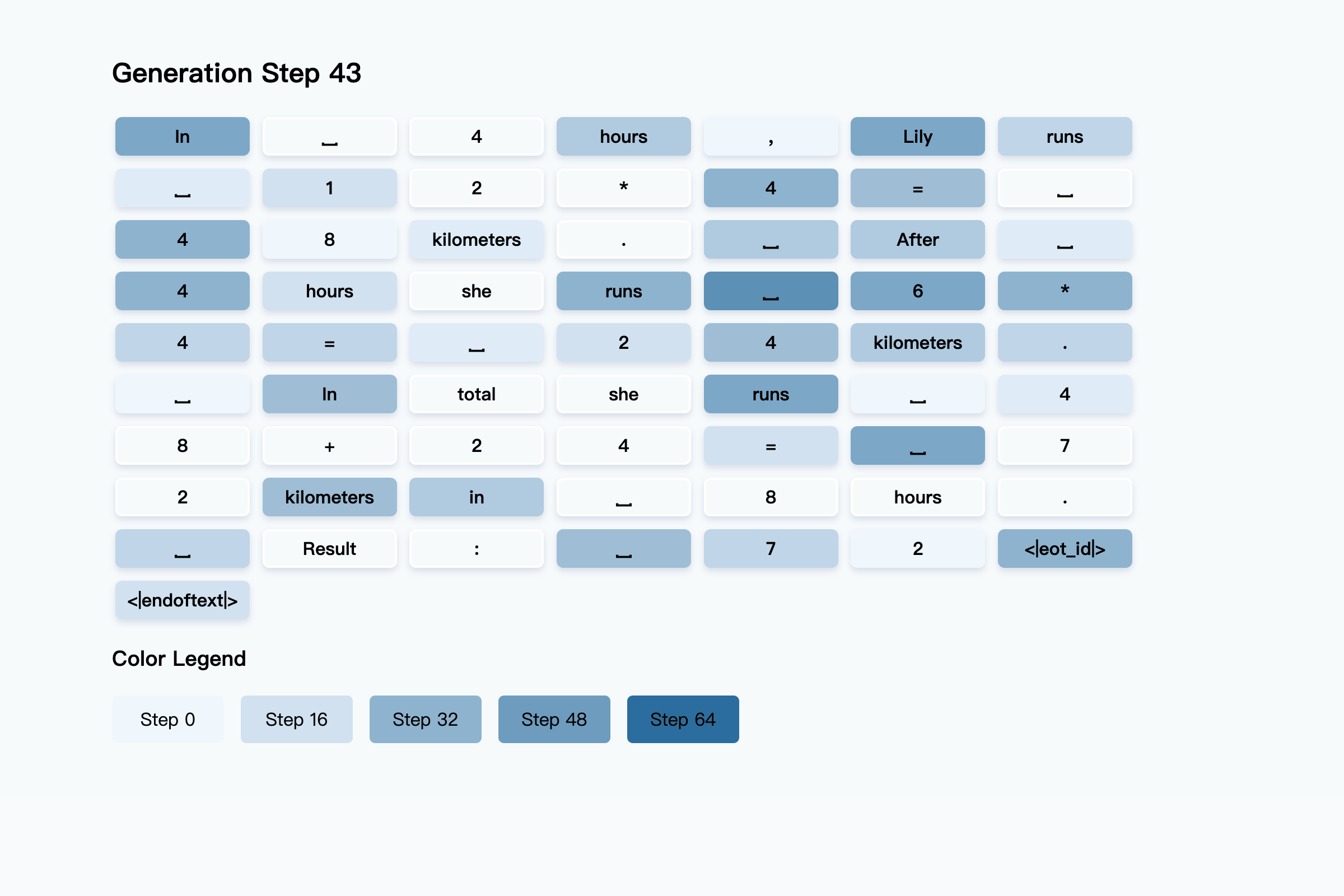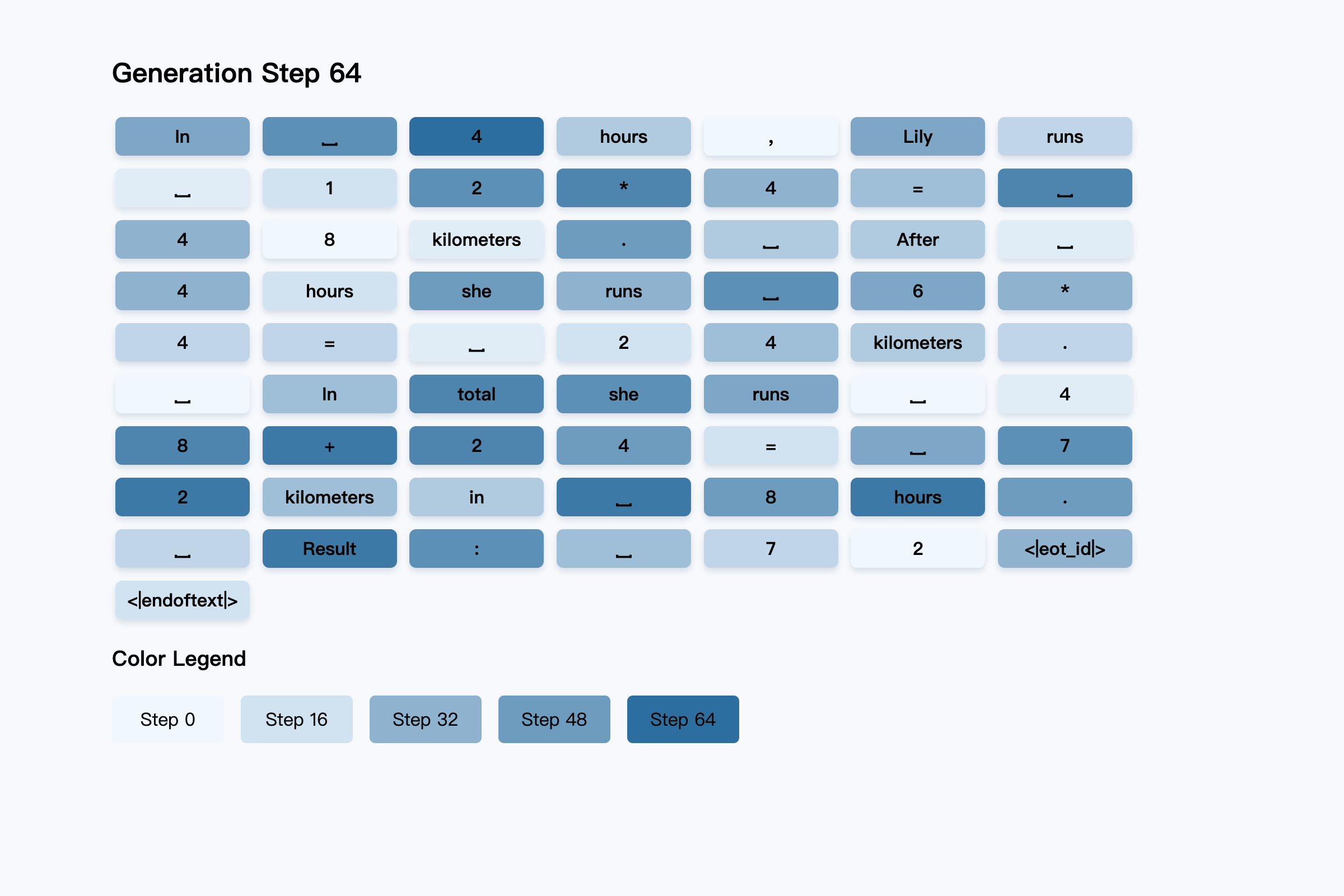
|
Git LFS Details
|
imgs/sample.png
ADDED

|
Git LFS Details
|
imgs/transformer1.png
ADDED
|
|
imgs/transformer2.png
ADDED
|
|
Git LFS Details
|
visualization/README.md
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Visualization
|
| 2 |
+
|
| 3 |
+
This repository contains visualization tools for the LLaDA project.
|
| 4 |
+
|
| 5 |
+
## Implementation Steps
|
| 6 |
+
|
| 7 |
+
### Step 1: Generate Sampling Process
|
| 8 |
+
Run `generate.py` to produce your own sampling process records. A sample output (`sample_process.txt`) is included for reference. You have the option to:
|
| 9 |
+
- Utilize the provided generate.py script
|
| 10 |
+
- Modify both the prompt and generation parameters
|
| 11 |
+
|
| 12 |
+
### Step 2: Generate Visualization HTML
|
| 13 |
+
Choose between two visualization styles:
|
| 14 |
+
- **Paper Style**:
|
| 15 |
+
`visualization_paper.py` produces visualizations matching the format in [our arXiv paper](https://arxiv.org/abs/2502.09992)
|
| 16 |
+
- **Zhihu Style**:
|
| 17 |
+
`visualization_zhihu.py` generates visualizations compatible with [Zhihu's format](https://zhuanlan.zhihu.com/p/24214732238)
|
| 18 |
+
|
| 19 |
+
The scripts will:
|
| 20 |
+
1. Automatically create an `html/` directory
|
| 21 |
+
2. Generate individual HTML files for each sampling step
|
| 22 |
+
|
| 23 |
+
*Note: The current implementation defaults to 64 sampling steps.
|
| 24 |
+
|
| 25 |
+
### Step 3: Create PNG Sequences
|
| 26 |
+
Convert generated HTML files to PNG format for GIF creation. These image sequences can be used with any standard GIF generator to visualize the complete sampling process.
|
| 27 |
+
|
| 28 |
+
## Technical Notes
|
| 29 |
+
- Ensure Python 3.8+ environment
|
| 30 |
+
- Install required dependencies: `pip install html2image`
|
| 31 |
+
- For custom configurations, modify constants at the beginning of each script
|
visualization/generate.py
ADDED
|
@@ -0,0 +1,144 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import numpy as np
|
| 3 |
+
import torch.nn.functional as F
|
| 4 |
+
|
| 5 |
+
from transformers import AutoTokenizer, AutoModel
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def add_gumbel_noise(logits, temperature):
|
| 9 |
+
'''
|
| 10 |
+
The Gumbel max is a method for sampling categorical distributions.
|
| 11 |
+
According to arXiv:2409.02908, for MDM, low-precision Gumbel Max improves perplexity score but reduces generation quality.
|
| 12 |
+
Thus, we use float64.
|
| 13 |
+
'''
|
| 14 |
+
logits = logits.to(torch.float64)
|
| 15 |
+
noise = torch.rand_like(logits, dtype=torch.float64)
|
| 16 |
+
gumbel_noise = (- torch.log(noise)) ** temperature
|
| 17 |
+
return logits.exp() / gumbel_noise
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def get_num_transfer_tokens(mask_index, steps):
|
| 21 |
+
'''
|
| 22 |
+
In the reverse process, the interval [0, 1] is uniformly discretized into steps intervals.
|
| 23 |
+
Furthermore, because LLaDA employs a linear noise schedule (as defined in Eq. (8)),
|
| 24 |
+
the expected number of tokens transitioned at each step should be consistent.
|
| 25 |
+
|
| 26 |
+
This function is designed to precompute the number of tokens that need to be transitioned at each step.
|
| 27 |
+
'''
|
| 28 |
+
mask_num = mask_index.sum(dim=1, keepdim=True)
|
| 29 |
+
|
| 30 |
+
base = mask_num // steps
|
| 31 |
+
remainder = mask_num % steps
|
| 32 |
+
|
| 33 |
+
num_transfer_tokens = torch.zeros(mask_num.size(0), steps, device=mask_index.device, dtype=torch.int64) + base
|
| 34 |
+
|
| 35 |
+
for i in range(mask_num.size(0)):
|
| 36 |
+
num_transfer_tokens[i, :remainder[i]] += 1
|
| 37 |
+
|
| 38 |
+
return num_transfer_tokens
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
@ torch.no_grad()
|
| 42 |
+
def generate(model, prompt, tokenizer, steps=128, gen_length=128, block_length=128, temperature=0.,
|
| 43 |
+
cfg_scale=0., remasking='low_confidence', mask_id=126336):
|
| 44 |
+
'''
|
| 45 |
+
Args:
|
| 46 |
+
model: Mask predictor.
|
| 47 |
+
prompt: A tensor of shape (1, l).
|
| 48 |
+
steps: Sampling steps, less than or equal to gen_length.
|
| 49 |
+
gen_length: Generated answer length.
|
| 50 |
+
block_length: Block length, less than or equal to gen_length. If less than gen_length, it means using semi_autoregressive remasking.
|
| 51 |
+
temperature: Categorical distribution sampling temperature.
|
| 52 |
+
cfg_scale: Unsupervised classifier-free guidance scale.
|
| 53 |
+
remasking: Remasking strategy. 'low_confidence' or 'random'.
|
| 54 |
+
mask_id: The toke id of [MASK] is 126336.
|
| 55 |
+
'''
|
| 56 |
+
x = torch.full((1, prompt.shape[1] + gen_length), mask_id, dtype=torch.long).to(model.device)
|
| 57 |
+
x[:, :prompt.shape[1]] = prompt.clone()
|
| 58 |
+
|
| 59 |
+
prompt_index = (x != mask_id)
|
| 60 |
+
|
| 61 |
+
assert gen_length % block_length == 0
|
| 62 |
+
num_blocks = gen_length // block_length
|
| 63 |
+
|
| 64 |
+
assert steps % num_blocks == 0
|
| 65 |
+
steps = steps // num_blocks
|
| 66 |
+
|
| 67 |
+
print_i = 0
|
| 68 |
+
|
| 69 |
+
for num_block in range(num_blocks):
|
| 70 |
+
block_mask_index = (x[:, prompt.shape[1] + num_block * block_length: prompt.shape[1] + (num_block + 1) * block_length:] == mask_id)
|
| 71 |
+
num_transfer_tokens = get_num_transfer_tokens(block_mask_index, steps)
|
| 72 |
+
for i in range(steps):
|
| 73 |
+
mask_index = (x == mask_id)
|
| 74 |
+
if cfg_scale > 0.:
|
| 75 |
+
un_x = x.clone()
|
| 76 |
+
un_x[prompt_index] = mask_id
|
| 77 |
+
x_ = torch.cat([x, un_x], dim=0)
|
| 78 |
+
logits = model(x_).logits
|
| 79 |
+
logits, un_logits = torch.chunk(logits, 2, dim=0)
|
| 80 |
+
logits = un_logits + (cfg_scale + 1) * (logits - un_logits)
|
| 81 |
+
else:
|
| 82 |
+
logits = model(x).logits
|
| 83 |
+
|
| 84 |
+
logits_with_noise = add_gumbel_noise(logits, temperature=temperature)
|
| 85 |
+
x0 = torch.argmax(logits_with_noise, dim=-1) # b, l
|
| 86 |
+
|
| 87 |
+
if remasking == 'low_confidence':
|
| 88 |
+
p = F.softmax(logits.to(torch.float64), dim=-1)
|
| 89 |
+
x0_p = torch.squeeze(
|
| 90 |
+
torch.gather(p, dim=-1, index=torch.unsqueeze(x0, -1)), -1) # b, l
|
| 91 |
+
elif remasking == 'random':
|
| 92 |
+
x0_p = torch.rand((x0.shape[0], x0.shape[1]), device=x0.device)
|
| 93 |
+
else:
|
| 94 |
+
raise NotImplementedError(remasking)
|
| 95 |
+
|
| 96 |
+
x0_p[:, prompt.shape[1] + (num_block + 1) * block_length:] = -np.inf
|
| 97 |
+
|
| 98 |
+
x0 = torch.where(mask_index, x0, x)
|
| 99 |
+
confidence = torch.where(mask_index, x0_p, -np.inf)
|
| 100 |
+
|
| 101 |
+
transfer_index = torch.zeros_like(x0, dtype=torch.bool, device=x0.device)
|
| 102 |
+
for j in range(confidence.shape[0]):
|
| 103 |
+
_, select_index = torch.topk(confidence[j], k=num_transfer_tokens[j, i])
|
| 104 |
+
transfer_index[j, select_index] = True
|
| 105 |
+
x[transfer_index] = x0[transfer_index]
|
| 106 |
+
|
| 107 |
+
print_i = print_i + 1
|
| 108 |
+
# Get generated token sequence (assuming batch_size=1)
|
| 109 |
+
generated_token_ids = x[0, prompt.shape[1]:] # Take first sample by reducing dimension
|
| 110 |
+
formatted_output = []
|
| 111 |
+
for token_id in generated_token_ids:
|
| 112 |
+
# Decode single token and handle newlines
|
| 113 |
+
decoded_token = tokenizer.decode(token_id).replace("\n", " ").replace("<|eot_id|>", " ").replace("<|endoftext|>", " ")
|
| 114 |
+
|
| 115 |
+
# Add asterisk wrapping (preserve original space positions)
|
| 116 |
+
formatted_token = f"*{decoded_token}&"
|
| 117 |
+
formatted_output.append(formatted_token)
|
| 118 |
+
# Combine final output
|
| 119 |
+
final_output = "".join(formatted_output).strip()
|
| 120 |
+
print(f"{print_i}, {final_output}", file=open("sample_process.txt", "a"))
|
| 121 |
+
|
| 122 |
+
return x
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
def main():
|
| 126 |
+
device = 'cuda'
|
| 127 |
+
|
| 128 |
+
model = AutoModel.from_pretrained('GSAI-ML/LLaDA-8B-Instruct', trust_remote_code=True, torch_dtype=torch.bfloat16).to(device).eval()
|
| 129 |
+
tokenizer = AutoTokenizer.from_pretrained('GSAI-ML/LLaDA-8B-Instruct', trust_remote_code=True)
|
| 130 |
+
|
| 131 |
+
prompt = "Explain what artificial intelligence is."
|
| 132 |
+
|
| 133 |
+
# Add special tokens for the Instruct model. The Base model does not require the following two lines.
|
| 134 |
+
m = [{"role": "user", "content": prompt}, ]
|
| 135 |
+
prompt = tokenizer.apply_chat_template(m, add_generation_prompt=True, tokenize=False)
|
| 136 |
+
|
| 137 |
+
input_ids = tokenizer(prompt)['input_ids']
|
| 138 |
+
input_ids = torch.tensor(input_ids).to(device).unsqueeze(0)
|
| 139 |
+
|
| 140 |
+
out = generate(model, input_ids, tokenizer, steps=64, gen_length=64, block_length=64, temperature=0., cfg_scale=0., remasking='random')
|
| 141 |
+
|
| 142 |
+
|
| 143 |
+
if __name__ == '__main__':
|
| 144 |
+
main()
|
visualization/html_to_png.py
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from html2image import Html2Image
|
| 2 |
+
import os
|
| 3 |
+
|
| 4 |
+
# Define the types array to process
|
| 5 |
+
types = ['zhihu', 'paper'] # Add all types you need to process here
|
| 6 |
+
|
| 7 |
+
# Initialize Html2Image object
|
| 8 |
+
hti = Html2Image()
|
| 9 |
+
hti.browser.use_new_headless = None # Keep default settings
|
| 10 |
+
|
| 11 |
+
for type_txt in types:
|
| 12 |
+
# Ensure png directory exists
|
| 13 |
+
output_dir = os.path.join('png', f"sample_process_{type_txt}")
|
| 14 |
+
if not os.path.exists(output_dir):
|
| 15 |
+
os.makedirs(output_dir)
|
| 16 |
+
|
| 17 |
+
# Set output path for current type
|
| 18 |
+
hti.output_path = output_dir
|
| 19 |
+
|
| 20 |
+
# Loop to generate screenshots
|
| 21 |
+
for i in range(1, 65):
|
| 22 |
+
# Get HTML file path
|
| 23 |
+
html_path = os.path.join('html', f"sample_process_{type_txt}", f'visualization_step_{i}.html')
|
| 24 |
+
|
| 25 |
+
# Generate and save screenshot
|
| 26 |
+
hti.screenshot(
|
| 27 |
+
url=html_path,
|
| 28 |
+
save_as=f'visualization_step_{i}.png',
|
| 29 |
+
size=(1200, 500) if type_txt == 'zhihu' else (1200, 800)
|
| 30 |
+
)
|
visualization/sample_process.txt
ADDED
|
@@ -0,0 +1,64 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
1, *<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&
|
| 2 |
+
2, *<|mdm_mask|>&*<|mdm_mask|>&* (&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&
|
| 3 |
+
3, *<|mdm_mask|>&*<|mdm_mask|>&* (&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&
|
| 4 |
+
4, *<|mdm_mask|>&*<|mdm_mask|>&* (&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&
|
| 5 |
+
5, *<|mdm_mask|>&*<|mdm_mask|>&* (&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* tasks&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&
|
| 6 |
+
6, *<|mdm_mask|>&*<|mdm_mask|>&* (&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*.&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* tasks&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&
|
| 7 |
+
7, *<|mdm_mask|>&*<|mdm_mask|>&* (&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* to&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*.&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* tasks&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&
|
| 8 |
+
8, *<|mdm_mask|>&*<|mdm_mask|>&* (&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* to&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* to&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*.&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* tasks&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&
|
| 9 |
+
9, *<|mdm_mask|>&*<|mdm_mask|>&* (&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* to&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* to&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*.&*<|mdm_mask|>&* is&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* tasks&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&
|
| 10 |
+
10, *<|mdm_mask|>&*<|mdm_mask|>&* (&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* to&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* to&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*.&*<|mdm_mask|>&* is&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* tasks&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*.&*<|mdm_mask|>&*<|mdm_mask|>&
|
| 11 |
+
11, *<|mdm_mask|>&*<|mdm_mask|>&* (&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* to&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* to&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*.&*<|mdm_mask|>&* is&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* tasks&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*-making&*.&*<|mdm_mask|>&*<|mdm_mask|>&
|
| 12 |
+
12, *<|mdm_mask|>&*<|mdm_mask|>&* (&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* to&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* to&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*.&*<|mdm_mask|>&* is&*<|mdm_mask|>&*<|mdm_mask|>&* of&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* tasks&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*-making&*.&*<|mdm_mask|>&*<|mdm_mask|>&
|
| 13 |
+
13, *<|mdm_mask|>&*<|mdm_mask|>&* (&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* to&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* to&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*.&*<|mdm_mask|>&* is&*<|mdm_mask|>&*<|mdm_mask|>&* of&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* tasks&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*-making&*.&*<|mdm_mask|>&*<|mdm_mask|>&
|
| 14 |
+
14, *<|mdm_mask|>&*<|mdm_mask|>&* (&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* to&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* to&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*.&*<|mdm_mask|>&* is&*<|mdm_mask|>&*<|mdm_mask|>&* of&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* tasks&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&* visual&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*-making&*.&*<|mdm_mask|>&*<|mdm_mask|>&
|
| 15 |
+
15, *<|mdm_mask|>&*<|mdm_mask|>&* (&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* to&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* that&*<|mdm_mask|>&*<|mdm_mask|>&* to&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*.&*<|mdm_mask|>&* is&*<|mdm_mask|>&*<|mdm_mask|>&* of&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* tasks&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&* visual&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*-making&*.&*<|mdm_mask|>&*<|mdm_mask|>&
|
| 16 |
+
16, *<|mdm_mask|>&*<|mdm_mask|>&* (&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* to&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* that&*<|mdm_mask|>&*<|mdm_mask|>&* to&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* reason&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*.&*<|mdm_mask|>&* is&*<|mdm_mask|>&*<|mdm_mask|>&* of&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* tasks&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&* visual&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*-making&*.&*<|mdm_mask|>&*<|mdm_mask|>&
|
| 17 |
+
17, *<|mdm_mask|>&*<|mdm_mask|>&* (&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* to&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* that&*<|mdm_mask|>&*<|mdm_mask|>&* to&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* reason&*,&* and&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*.&*<|mdm_mask|>&* is&*<|mdm_mask|>&*<|mdm_mask|>&* of&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* tasks&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&* visual&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*-making&*.&*<|mdm_mask|>&*<|mdm_mask|>&
|
| 18 |
+
18, *<|mdm_mask|>&*<|mdm_mask|>&* (&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* to&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* that&*<|mdm_mask|>&*<|mdm_mask|>&* to&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* reason&*,&* and&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*.&*<|mdm_mask|>&* is&*<|mdm_mask|>&* simulation&* of&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* tasks&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&* visual&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*-making&*.&*<|mdm_mask|>&*<|mdm_mask|>&
|
| 19 |
+
19, *<|mdm_mask|>&*<|mdm_mask|>&* (&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* to&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* that&*<|mdm_mask|>&*<|mdm_mask|>&* to&* perceive&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* reason&*,&* and&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*.&*<|mdm_mask|>&* is&*<|mdm_mask|>&* simulation&* of&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* tasks&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&* visual&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*-making&*.&*<|mdm_mask|>&*<|mdm_mask|>&
|
| 20 |
+
20, *<|mdm_mask|>&*<|mdm_mask|>&* (&*<|mdm_mask|>&*<|mdm_mask|>&* refers&* to&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* that&*<|mdm_mask|>&*<|mdm_mask|>&* to&* perceive&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* reason&*,&* and&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*.&*<|mdm_mask|>&* is&*<|mdm_mask|>&* simulation&* of&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* tasks&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&* visual&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*-making&*.&*<|mdm_mask|>&*<|mdm_mask|>&
|
| 21 |
+
21, *<|mdm_mask|>&*<|mdm_mask|>&* (&*<|mdm_mask|>&*<|mdm_mask|>&* refers&* to&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* that&*<|mdm_mask|>&*<|mdm_mask|>&* to&* perceive&*<|mdm_mask|>&* learn&*<|mdm_mask|>&* reason&*,&* and&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*.&*<|mdm_mask|>&* is&*<|mdm_mask|>&* simulation&* of&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* tasks&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&* visual&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*-making&*.&*<|mdm_mask|>&*<|mdm_mask|>&
|
| 22 |
+
22, *<|mdm_mask|>&*<|mdm_mask|>&* (&*<|mdm_mask|>&*<|mdm_mask|>&* refers&* to&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* that&*<|mdm_mask|>&*<|mdm_mask|>&* to&* perceive&*<|mdm_mask|>&* learn&*<|mdm_mask|>&* reason&*,&* and&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*.&* It&* is&*<|mdm_mask|>&* simulation&* of&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* tasks&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&* visual&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*-making&*.&*<|mdm_mask|>&*<|mdm_mask|>&
|
| 23 |
+
23, *<|mdm_mask|>&*<|mdm_mask|>&* (&*<|mdm_mask|>&*<|mdm_mask|>&* refers&* to&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* that&*<|mdm_mask|>&*<|mdm_mask|>&* to&* perceive&*<|mdm_mask|>&* learn&*<|mdm_mask|>&* reason&*,&* and&*<|mdm_mask|>&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*.&* It&* is&*<|mdm_mask|>&* simulation&* of&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* tasks&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* recognition&*,&*<|mdm_mask|>&*<|mdm_mask|>&* visual&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*-making&*.&*<|mdm_mask|>&*<|mdm_mask|>&
|
| 24 |
+
24, *<|mdm_mask|>&*<|mdm_mask|>&* (&*<|mdm_mask|>&*<|mdm_mask|>&* refers&* to&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* that&*<|mdm_mask|>&*<|mdm_mask|>&* to&* perceive&*<|mdm_mask|>&* learn&*<|mdm_mask|>&* reason&*,&* and&* make&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*.&* It&* is&*<|mdm_mask|>&* simulation&* of&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* tasks&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* recognition&*,&*<|mdm_mask|>&*<|mdm_mask|>&* visual&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*-making&*.&*<|mdm_mask|>&*<|mdm_mask|>&
|
| 25 |
+
25, *<|mdm_mask|>&*<|mdm_mask|>&* (&*AI&*<|mdm_mask|>&* refers&* to&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* that&*<|mdm_mask|>&*<|mdm_mask|>&* to&* perceive&*<|mdm_mask|>&* learn&*<|mdm_mask|>&* reason&*,&* and&* make&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*.&* It&* is&*<|mdm_mask|>&* simulation&* of&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* tasks&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* recognition&*,&*<|mdm_mask|>&*<|mdm_mask|>&* visual&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*-making&*.&*<|mdm_mask|>&*<|mdm_mask|>&
|
| 26 |
+
26, *<|mdm_mask|>&*<|mdm_mask|>&* (&*AI&*<|mdm_mask|>&* refers&* to&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* computer&*<|mdm_mask|>&* that&*<|mdm_mask|>&*<|mdm_mask|>&* to&* perceive&*<|mdm_mask|>&* learn&*<|mdm_mask|>&* reason&*,&* and&* make&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*.&* It&* is&*<|mdm_mask|>&* simulation&* of&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* tasks&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* recognition&*,&*<|mdm_mask|>&*<|mdm_mask|>&* visual&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*-making&*.&*<|mdm_mask|>&*<|mdm_mask|>&
|
| 27 |
+
27, *<|mdm_mask|>&*<|mdm_mask|>&* (&*AI&*<|mdm_mask|>&* refers&* to&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* computer&*<|mdm_mask|>&* that&*<|mdm_mask|>&*<|mdm_mask|>&* to&* perceive&*<|mdm_mask|>&* learn&*<|mdm_mask|>&* reason&*,&* and&* make&* decisions&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*.&* It&* is&*<|mdm_mask|>&* simulation&* of&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* tasks&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* recognition&*,&*<|mdm_mask|>&*<|mdm_mask|>&* visual&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*-making&*.&*<|mdm_mask|>&*<|mdm_mask|>&
|
| 28 |
+
28, *<|mdm_mask|>&*<|mdm_mask|>&* (&*AI&*<|mdm_mask|>&* refers&* to&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* computer&* systems&* that&*<|mdm_mask|>&*<|mdm_mask|>&* to&* perceive&*<|mdm_mask|>&* learn&*<|mdm_mask|>&* reason&*,&* and&* make&* decisions&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*.&* It&* is&*<|mdm_mask|>&* simulation&* of&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* tasks&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* recognition&*,&*<|mdm_mask|>&*<|mdm_mask|>&* visual&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*-making&*.&*<|mdm_mask|>&*<|mdm_mask|>&
|
| 29 |
+
29, *<|mdm_mask|>&*<|mdm_mask|>&* (&*AI&*<|mdm_mask|>&* refers&* to&*<|mdm_mask|>&* technology&*<|mdm_mask|>&*<|mdm_mask|>&* computer&* systems&* that&*<|mdm_mask|>&*<|mdm_mask|>&* to&* perceive&*<|mdm_mask|>&* learn&*<|mdm_mask|>&* reason&*,&* and&* make&* decisions&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*.&* It&* is&*<|mdm_mask|>&* simulation&* of&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* tasks&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* recognition&*,&*<|mdm_mask|>&*<|mdm_mask|>&* visual&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*-making&*.&*<|mdm_mask|>&*<|mdm_mask|>&
|
| 30 |
+
30, *<|mdm_mask|>&*<|mdm_mask|>&* (&*AI&*<|mdm_mask|>&* refers&* to&*<|mdm_mask|>&* technology&*<|mdm_mask|>&*<|mdm_mask|>&* computer&* systems&* that&*<|mdm_mask|>&*<|mdm_mask|>&* to&* perceive&*<|mdm_mask|>&* learn&*,&* reason&*,&* and&* make&* decisions&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*.&* It&* is&*<|mdm_mask|>&* simulation&* of&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* tasks&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* recognition&*,&*<|mdm_mask|>&*<|mdm_mask|>&* visual&*<|mdm_mask|>&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*-making&*.&*<|mdm_mask|>&*<|mdm_mask|>&
|
| 31 |
+
31, *<|mdm_mask|>&*<|mdm_mask|>&* (&*AI&*<|mdm_mask|>&* refers&* to&*<|mdm_mask|>&* technology&*<|mdm_mask|>&*<|mdm_mask|>&* computer&* systems&* that&*<|mdm_mask|>&*<|mdm_mask|>&* to&* perceive&*<|mdm_mask|>&* learn&*,&* reason&*,&* and&* make&* decisions&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*.&* It&* is&*<|mdm_mask|>&* simulation&* of&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* tasks&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* recognition&*,&*<|mdm_mask|>&*<|mdm_mask|>&* visual&* perception&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*-making&*.&*<|mdm_mask|>&*<|mdm_mask|>&
|
| 32 |
+
32, *<|mdm_mask|>&*<|mdm_mask|>&* (&*AI&*<|mdm_mask|>&* refers&* to&*<|mdm_mask|>&* technology&*<|mdm_mask|>&*<|mdm_mask|>&* computer&* systems&* that&*<|mdm_mask|>&*<|mdm_mask|>&* to&* perceive&*<|mdm_mask|>&* learn&*,&* reason&*,&* and&* make&* decisions&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*.&* It&* is&*<|mdm_mask|>&* simulation&* of&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* tasks&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* recognition&*,&*<|mdm_mask|>&*<|mdm_mask|>&* visual&* perception&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* decision&*-making&*.&*<|mdm_mask|>&*<|mdm_mask|>&
|
| 33 |
+
33, *<|mdm_mask|>&*<|mdm_mask|>&* (&*AI&*)&* refers&* to&*<|mdm_mask|>&* technology&*<|mdm_mask|>&*<|mdm_mask|>&* computer&* systems&* that&*<|mdm_mask|>&*<|mdm_mask|>&* to&* perceive&*<|mdm_mask|>&* learn&*,&* reason&*,&* and&* make&* decisions&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*.&* It&* is&*<|mdm_mask|>&* simulation&* of&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* tasks&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* recognition&*,&*<|mdm_mask|>&*<|mdm_mask|>&* visual&* perception&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* decision&*-making&*.&*<|mdm_mask|>&*<|mdm_mask|>&
|
| 34 |
+
34, *<|mdm_mask|>&*<|mdm_mask|>&* (&*AI&*)&* refers&* to&*<|mdm_mask|>&* technology&*<|mdm_mask|>&*<|mdm_mask|>&* computer&* systems&* that&* are&*<|mdm_mask|>&* to&* perceive&*<|mdm_mask|>&* learn&*,&* reason&*,&* and&* make&* decisions&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*.&* It&* is&*<|mdm_mask|>&* simulation&* of&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* tasks&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* recognition&*,&*<|mdm_mask|>&*<|mdm_mask|>&* visual&* perception&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* decision&*-making&*.&*<|mdm_mask|>&*<|mdm_mask|>&
|
| 35 |
+
35, *<|mdm_mask|>&*<|mdm_mask|>&* (&*AI&*)&* refers&* to&*<|mdm_mask|>&* technology&*<|mdm_mask|>&* in&* computer&* systems&* that&* are&*<|mdm_mask|>&* to&* perceive&*<|mdm_mask|>&* learn&*,&* reason&*,&* and&* make&* decisions&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*.&* It&* is&*<|mdm_mask|>&* simulation&* of&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* tasks&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* recognition&*,&*<|mdm_mask|>&*<|mdm_mask|>&* visual&* perception&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* decision&*-making&*.&*<|mdm_mask|>&*<|mdm_mask|>&
|
| 36 |
+
36, *<|mdm_mask|>&*<|mdm_mask|>&* (&*AI&*)&* refers&* to&*<|mdm_mask|>&* technology&*<|mdm_mask|>&* in&* computer&* systems&* that&* are&*<|mdm_mask|>&* to&* perceive&*<|mdm_mask|>&* learn&*,&* reason&*,&* and&* make&* decisions&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*.&* It&* is&*<|mdm_mask|>&* simulation&* of&*<|mdm_mask|>&*<|mdm_mask|>&* in&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* tasks&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* recognition&*,&*<|mdm_mask|>&*<|mdm_mask|>&* visual&* perception&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* decision&*-making&*.&*<|mdm_mask|>&*<|mdm_mask|>&
|
| 37 |
+
37, *Artificial&*<|mdm_mask|>&* (&*AI&*)&* refers&* to&*<|mdm_mask|>&* technology&*<|mdm_mask|>&* in&* computer&* systems&* that&* are&*<|mdm_mask|>&* to&* perceive&*<|mdm_mask|>&* learn&*,&* reason&*,&* and&* make&* decisions&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*.&* It&* is&*<|mdm_mask|>&* simulation&* of&*<|mdm_mask|>&*<|mdm_mask|>&* in&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* tasks&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* recognition&*,&*<|mdm_mask|>&*<|mdm_mask|>&* visual&* perception&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* decision&*-making&*.&*<|mdm_mask|>&*<|mdm_mask|>&
|
| 38 |
+
38, *Artificial&*<|mdm_mask|>&* (&*AI&*)&* refers&* to&*<|mdm_mask|>&* technology&*<|mdm_mask|>&* in&* computer&* systems&* that&* are&*<|mdm_mask|>&* to&* perceive&*<|mdm_mask|>&* learn&*,&* reason&*,&* and&* make&* decisions&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*.&* It&* is&* the&* simulation&* of&*<|mdm_mask|>&*<|mdm_mask|>&* in&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* tasks&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* recognition&*,&*<|mdm_mask|>&*<|mdm_mask|>&* visual&* perception&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* decision&*-making&*.&*<|mdm_mask|>&*<|mdm_mask|>&
|
| 39 |
+
39, *Artificial&*<|mdm_mask|>&* (&*AI&*)&* refers&* to&*<|mdm_mask|>&* technology&*<|mdm_mask|>&* in&* computer&* systems&* that&* are&*<|mdm_mask|>&* to&* perceive&*<|mdm_mask|>&* learn&*,&* reason&*,&* and&* make&* decisions&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*.&* It&* is&* the&* simulation&* of&*<|mdm_mask|>&*<|mdm_mask|>&* in&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* tasks&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* recognition&*,&* speech&*<|mdm_mask|>&* visual&* perception&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* decision&*-making&*.&*<|mdm_mask|>&*<|mdm_mask|>&
|
| 40 |
+
40, *Artificial&*<|mdm_mask|>&* (&*AI&*)&* refers&* to&*<|mdm_mask|>&* technology&*<|mdm_mask|>&* in&* computer&* systems&* that&* are&*<|mdm_mask|>&* to&* perceive&*<|mdm_mask|>&* learn&*,&* reason&*,&* and&* make&* decisions&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*.&* It&* is&* the&* simulation&* of&*<|mdm_mask|>&*<|mdm_mask|>&* in&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* tasks&* such&*<|mdm_mask|>&*<|mdm_mask|>&* recognition&*,&* speech&*<|mdm_mask|>&* visual&* perception&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* decision&*-making&*.&*<|mdm_mask|>&*<|mdm_mask|>&
|
| 41 |
+
41, *Artificial&*<|mdm_mask|>&* (&*AI&*)&* refers&* to&*<|mdm_mask|>&* technology&*<|mdm_mask|>&* in&* computer&* systems&* that&* are&*<|mdm_mask|>&* to&* perceive&*<|mdm_mask|>&* learn&*,&* reason&*,&* and&* make&* decisions&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*.&* It&* is&* the&* simulation&* of&*<|mdm_mask|>&*<|mdm_mask|>&* in&* machines&*<|mdm_mask|>&*<|mdm_mask|>&* tasks&* such&*<|mdm_mask|>&*<|mdm_mask|>&* recognition&*,&* speech&*<|mdm_mask|>&* visual&* perception&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* decision&*-making&*.&*<|mdm_mask|>&*<|mdm_mask|>&
|
| 42 |
+
42, *Artificial&*<|mdm_mask|>&* (&*AI&*)&* refers&* to&*<|mdm_mask|>&* technology&*<|mdm_mask|>&* in&* computer&* systems&* that&* are&*<|mdm_mask|>&* to&* perceive&*,&* learn&*,&* reason&*,&* and&* make&* decisions&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*.&* It&* is&* the&* simulation&* of&*<|mdm_mask|>&*<|mdm_mask|>&* in&* machines&*<|mdm_mask|>&*<|mdm_mask|>&* tasks&* such&*<|mdm_mask|>&*<|mdm_mask|>&* recognition&*,&* speech&*<|mdm_mask|>&* visual&* perception&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* decision&*-making&*.&*<|mdm_mask|>&*<|mdm_mask|>&
|
| 43 |
+
43, *Artificial&*<|mdm_mask|>&* (&*AI&*)&* refers&* to&*<|mdm_mask|>&* technology&*<|mdm_mask|>&* in&* computer&* systems&* that&* are&*<|mdm_mask|>&* to&* perceive&*,&* learn&*,&* reason&*,&* and&* make&* decisions&*,&*<|mdm_mask|>&* the&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*.&* It&* is&* the&* simulation&* of&*<|mdm_mask|>&*<|mdm_mask|>&* in&* machines&*<|mdm_mask|>&*<|mdm_mask|>&* tasks&* such&*<|mdm_mask|>&*<|mdm_mask|>&* recognition&*,&* speech&*<|mdm_mask|>&* visual&* perception&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* decision&*-making&*.&*<|mdm_mask|>&*<|mdm_mask|>&
|
| 44 |
+
44, *Artificial&* intelligence&* (&*AI&*)&* refers&* to&*<|mdm_mask|>&* technology&*<|mdm_mask|>&* in&* computer&* systems&* that&* are&*<|mdm_mask|>&* to&* perceive&*,&* learn&*,&* reason&*,&* and&* make&* decisions&*,&*<|mdm_mask|>&* the&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*.&* It&* is&* the&* simulation&* of&*<|mdm_mask|>&*<|mdm_mask|>&* in&* machines&*<|mdm_mask|>&*<|mdm_mask|>&* tasks&* such&*<|mdm_mask|>&*<|mdm_mask|>&* recognition&*,&* speech&*<|mdm_mask|>&* visual&* perception&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* decision&*-making&*.&*<|mdm_mask|>&*<|mdm_mask|>&
|
| 45 |
+
45, *Artificial&* intelligence&* (&*AI&*)&* refers&* to&*<|mdm_mask|>&* technology&*<|mdm_mask|>&* in&* computer&* systems&* that&* are&*<|mdm_mask|>&* to&* perceive&*,&* learn&*,&* reason&*,&* and&* make&* decisions&*,&*<|mdm_mask|>&* the&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&*.&* It&* is&* the&* simulation&* of&*<|mdm_mask|>&*<|mdm_mask|>&* in&* machines&*<|mdm_mask|>&*<|mdm_mask|>&* tasks&* such&*<|mdm_mask|>&*<|mdm_mask|>&* recognition&*,&* speech&*<|mdm_mask|>&* visual&* perception&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* decision&*-making&*.&* &*<|mdm_mask|>&
|
| 46 |
+
46, *Artificial&* intelligence&* (&*AI&*)&* refers&* to&*<|mdm_mask|>&* technology&*<|mdm_mask|>&* in&* computer&* systems&* that&* are&*<|mdm_mask|>&* to&* perceive&*,&* learn&*,&* reason&*,&* and&* make&* decisions&*,&*<|mdm_mask|>&* the&*<|mdm_mask|>&*<|mdm_mask|>&* human&*<|mdm_mask|>&*.&* It&* is&* the&* simulation&* of&*<|mdm_mask|>&*<|mdm_mask|>&* in&* machines&*<|mdm_mask|>&*<|mdm_mask|>&* tasks&* such&*<|mdm_mask|>&*<|mdm_mask|>&* recognition&*,&* speech&*<|mdm_mask|>&* visual&* perception&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* decision&*-making&*.&* &*<|mdm_mask|>&
|
| 47 |
+
47, *Artificial&* intelligence&* (&*AI&*)&* refers&* to&*<|mdm_mask|>&* technology&*<|mdm_mask|>&* in&* computer&* systems&* that&* are&*<|mdm_mask|>&* to&* perceive&*,&* learn&*,&* reason&*,&* and&* make&* decisions&*,&*<|mdm_mask|>&* the&*<|mdm_mask|>&*<|mdm_mask|>&* human&*<|mdm_mask|>&*.&* It&* is&* the&* simulation&* of&*<|mdm_mask|>&*<|mdm_mask|>&* in&* machines&*<|mdm_mask|>&*<|mdm_mask|>&* tasks&* such&*<|mdm_mask|>&*<|mdm_mask|>&* recognition&*,&* speech&* and&* visual&* perception&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* decision&*-making&*.&* &*<|mdm_mask|>&
|
| 48 |
+
48, *Artificial&* intelligence&* (&*AI&*)&* refers&* to&*<|mdm_mask|>&* technology&*<|mdm_mask|>&* in&* computer&* systems&* that&* are&*<|mdm_mask|>&* to&* perceive&*,&* learn&*,&* reason&*,&* and&* make&* decisions&*,&*<|mdm_mask|>&* the&*<|mdm_mask|>&*<|mdm_mask|>&* human&* intelligence&*.&* It&* is&* the&* simulation&* of&*<|mdm_mask|>&*<|mdm_mask|>&* in&* machines&*<|mdm_mask|>&*<|mdm_mask|>&* tasks&* such&*<|mdm_mask|>&*<|mdm_mask|>&* recognition&*,&* speech&* and&* visual&* perception&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* decision&*-making&*.&* &*<|mdm_mask|>&
|
| 49 |
+
49, *Artificial&* intelligence&* (&*AI&*)&* refers&* to&*<|mdm_mask|>&* technology&*<|mdm_mask|>&* in&* computer&* systems&* that&* are&*<|mdm_mask|>&* to&* perceive&*,&* learn&*,&* reason&*,&* and&* make&* decisions&*,&* without&* the&*<|mdm_mask|>&*<|mdm_mask|>&* human&* intelligence&*.&* It&* is&* the&* simulation&* of&*<|mdm_mask|>&*<|mdm_mask|>&* in&* machines&*<|mdm_mask|>&*<|mdm_mask|>&* tasks&* such&*<|mdm_mask|>&*<|mdm_mask|>&* recognition&*,&* speech&* and&* visual&* perception&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* decision&*-making&*.&* &*<|mdm_mask|>&
|
| 50 |
+
50, *Artificial&* intelligence&* (&*AI&*)&* refers&* to&*<|mdm_mask|>&* technology&*<|mdm_mask|>&* in&* computer&* systems&* that&* are&*<|mdm_mask|>&* to&* perceive&*,&* learn&*,&* reason&*,&* and&* make&* decisions&*,&* without&* the&*<|mdm_mask|>&*<|mdm_mask|>&* human&* intelligence&*.&* It&* is&* the&* simulation&* of&*<|mdm_mask|>&*<|mdm_mask|>&* in&* machines&*<|mdm_mask|>&* perform&* tasks&* such&*<|mdm_mask|>&*<|mdm_mask|>&* recognition&*,&* speech&* and&* visual&* perception&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* decision&*-making&*.&* &*<|mdm_mask|>&
|
| 51 |
+
51, *Artificial&* intelligence&* (&*AI&*)&* refers&* to&*<|mdm_mask|>&* technology&*<|mdm_mask|>&* in&* computer&* systems&* that&* are&* programmed&* to&* perceive&*,&* learn&*,&* reason&*,&* and&* make&* decisions&*,&* without&* the&*<|mdm_mask|>&*<|mdm_mask|>&* human&* intelligence&*.&* It&* is&* the&* simulation&* of&*<|mdm_mask|>&*<|mdm_mask|>&* in&* machines&*<|mdm_mask|>&* perform&* tasks&* such&*<|mdm_mask|>&*<|mdm_mask|>&* recognition&*,&* speech&* and&* visual&* perception&*,&*<|mdm_mask|>&*<|mdm_mask|>&*<|mdm_mask|>&* decision&*-making&*.&* &*<|mdm_mask|>&
|
| 52 |
+
52, *Artificial&* intelligence&* (&*AI&*)&* refers&* to&*<|mdm_mask|>&* technology&*<|mdm_mask|>&* in&* computer&* systems&* that&* are&* programmed&* to&* perceive&*,&* learn&*,&* reason&*,&* and&* make&* decisions&*,&* without&* the&*<|mdm_mask|>&*<|mdm_mask|>&* human&* intelligence&*.&* It&* is&* the&* simulation&* of&*<|mdm_mask|>&*<|mdm_mask|>&* in&* machines&*<|mdm_mask|>&* perform&* tasks&* such&*<|mdm_mask|>&*<|mdm_mask|>&* recognition&*,&* speech&* and&* visual&* perception&*,&*<|mdm_mask|>&*,&*<|mdm_mask|>&* decision&*-making&*.&* &*<|mdm_mask|>&
|
| 53 |
+
53, *Artificial&* intelligence&* (&*AI&*)&* refers&* to&*<|mdm_mask|>&* technology&*<|mdm_mask|>&* in&* computer&* systems&* that&* are&* programmed&* to&* perceive&*,&* learn&*,&* reason&*,&* and&* make&* decisions&*,&* without&* the&* need&*<|mdm_mask|>&* human&* intelligence&*.&* It&* is&* the&* simulation&* of&*<|mdm_mask|>&*<|mdm_mask|>&* in&* machines&*<|mdm_mask|>&* perform&* tasks&* such&*<|mdm_mask|>&*<|mdm_mask|>&* recognition&*,&* speech&* and&* visual&* perception&*,&*<|mdm_mask|>&*,&*<|mdm_mask|>&* decision&*-making&*.&* &*<|mdm_mask|>&
|
| 54 |
+
54, *Artificial&* intelligence&* (&*AI&*)&* refers&* to&*<|mdm_mask|>&* technology&*<|mdm_mask|>&* in&* computer&* systems&* that&* are&* programmed&* to&* perceive&*,&* learn&*,&* reason&*,&* and&* make&* decisions&*,&* without&* the&* need&*<|mdm_mask|>&* human&* intelligence&*.&* It&* is&* the&* simulation&* of&*<|mdm_mask|>&*<|mdm_mask|>&* in&* machines&*<|mdm_mask|>&* perform&* tasks&* such&*<|mdm_mask|>&* pattern&* recognition&*,&* speech&* and&* visual&* perception&*,&*<|mdm_mask|>&*,&*<|mdm_mask|>&* decision&*-making&*.&* &*<|mdm_mask|>&
|
| 55 |
+
55, *Artificial&* intelligence&* (&*AI&*)&* refers&* to&*<|mdm_mask|>&* technology&*<|mdm_mask|>&* in&* computer&* systems&* that&* are&* programmed&* to&* perceive&*,&* learn&*,&* reason&*,&* and&* make&* decisions&*,&* without&* the&* need&*<|mdm_mask|>&* human&* intelligence&*.&* It&* is&* the&* simulation&* of&*<|mdm_mask|>&*<|mdm_mask|>&* in&* machines&*<|mdm_mask|>&* perform&* tasks&* such&*<|mdm_mask|>&* pattern&* recognition&*,&* speech&* and&* visual&* perception&*,&* learning&*,&*<|mdm_mask|>&* decision&*-making&*.&* &*<|mdm_mask|>&
|
| 56 |
+
56, *Artificial&* intelligence&* (&*AI&*)&* refers&* to&* the&* technology&*<|mdm_mask|>&* in&* computer&* systems&* that&* are&* programmed&* to&* perceive&*,&* learn&*,&* reason&*,&* and&* make&* decisions&*,&* without&* the&* need&*<|mdm_mask|>&* human&* intelligence&*.&* It&* is&* the&* simulation&* of&*<|mdm_mask|>&*<|mdm_mask|>&* in&* machines&*<|mdm_mask|>&* perform&* tasks&* such&*<|mdm_mask|>&* pattern&* recognition&*,&* speech&* and&* visual&* perception&*,&* learning&*,&*<|mdm_mask|>&* decision&*-making&*.&* &*<|mdm_mask|>&
|
| 57 |
+
57, *Artificial&* intelligence&* (&*AI&*)&* refers&* to&* the&* technology&*<|mdm_mask|>&* in&* computer&* systems&* that&* are&* programmed&* to&* perceive&*,&* learn&*,&* reason&*,&* and&* make&* decisions&*,&* without&* the&* need&*<|mdm_mask|>&* human&* intelligence&*.&* It&* is&* the&* simulation&* of&*<|mdm_mask|>&*<|mdm_mask|>&* in&* machines&* to&* perform&* tasks&* such&*<|mdm_mask|>&* pattern&* recognition&*,&* speech&* and&* visual&* perception&*,&* learning&*,&*<|mdm_mask|>&* decision&*-making&*.&* &*<|mdm_mask|>&
|
| 58 |
+
58, *Artificial&* intelligence&* (&*AI&*)&* refers&* to&* the&* technology&*<|mdm_mask|>&* in&* computer&* systems&* that&* are&* programmed&* to&* perceive&*,&* learn&*,&* reason&*,&* and&* make&* decisions&*,&* without&* the&* need&*<|mdm_mask|>&* human&* intelligence&*.&* It&* is&* the&* simulation&* of&* human&*<|mdm_mask|>&* in&* machines&* to&* perform&* tasks&* such&*<|mdm_mask|>&* pattern&* recognition&*,&* speech&* and&* visual&* perception&*,&* learning&*,&*<|mdm_mask|>&* decision&*-making&*.&* &*<|mdm_mask|>&
|
| 59 |
+
59, *Artificial&* intelligence&* (&*AI&*)&* refers&* to&* the&* technology&*<|mdm_mask|>&* in&* computer&* systems&* that&* are&* programmed&* to&* perceive&*,&* learn&*,&* reason&*,&* and&* make&* decisions&*,&* without&* the&* need&*<|mdm_mask|>&* human&* intelligence&*.&* It&* is&* the&* simulation&* of&* human&*<|mdm_mask|>&* in&* machines&* to&* perform&* tasks&* such&*<|mdm_mask|>&* pattern&* recognition&*,&* speech&* and&* visual&* perception&*,&* learning&*,&*<|mdm_mask|>&* decision&*-making&*.&* &* &
|
| 60 |
+
60, *Artificial&* intelligence&* (&*AI&*)&* refers&* to&* the&* technology&*<|mdm_mask|>&* in&* computer&* systems&* that&* are&* programmed&* to&* perceive&*,&* learn&*,&* reason&*,&* and&* make&* decisions&*,&* without&* the&* need&*<|mdm_mask|>&* human&* intelligence&*.&* It&* is&* the&* simulation&* of&* human&*<|mdm_mask|>&* in&* machines&* to&* perform&* tasks&* such&* as&* pattern&* recognition&*,&* speech&* and&* visual&* perception&*,&* learning&*,&*<|mdm_mask|>&* decision&*-making&*.&* &* &
|
| 61 |
+
61, *Artificial&* intelligence&* (&*AI&*)&* refers&* to&* the&* technology&* used&* in&* computer&* systems&* that&* are&* programmed&* to&* perceive&*,&* learn&*,&* reason&*,&* and&* make&* decisions&*,&* without&* the&* need&*<|mdm_mask|>&* human&* intelligence&*.&* It&* is&* the&* simulation&* of&* human&*<|mdm_mask|>&* in&* machines&* to&* perform&* tasks&* such&* as&* pattern&* recognition&*,&* speech&* and&* visual&* perception&*,&* learning&*,&*<|mdm_mask|>&* decision&*-making&*.&* &* &
|
| 62 |
+
62, *Artificial&* intelligence&* (&*AI&*)&* refers&* to&* the&* technology&* used&* in&* computer&* systems&* that&* are&* programmed&* to&* perceive&*,&* learn&*,&* reason&*,&* and&* make&* decisions&*,&* without&* the&* need&*<|mdm_mask|>&* human&* intelligence&*.&* It&* is&* the&* simulation&* of&* human&* intelligence&* in&* machines&* to&* perform&* tasks&* such&* as&* pattern&* recognition&*,&* speech&* and&* visual&* perception&*,&* learning&*,&*<|mdm_mask|>&* decision&*-making&*.&* &* &
|
| 63 |
+
63, *Artificial&* intelligence&* (&*AI&*)&* refers&* to&* the&* technology&* used&* in&* computer&* systems&* that&* are&* programmed&* to&* perceive&*,&* learn&*,&* reason&*,&* and&* make&* decisions&*,&* without&* the&* need&* for&* human&* intelligence&*.&* It&* is&* the&* simulation&* of&* human&* intelligence&* in&* machines&* to&* perform&* tasks&* such&* as&* pattern&* recognition&*,&* speech&* and&* visual&* perception&*,&* learning&*,&*<|mdm_mask|>&* decision&*-making&*.&* &* &
|
| 64 |
+
64, *Artificial&* intelligence&* (&*AI&*)&* refers&* to&* the&* technology&* used&* in&* computer&* systems&* that&* are&* programmed&* to&* perceive&*,&* learn&*,&* reason&*,&* and&* make&* decisions&*,&* without&* the&* need&* for&* human&* intelligence&*.&* It&* is&* the&* simulation&* of&* human&* intelligence&* in&* machines&* to&* perform&* tasks&* such&* as&* pattern&* recognition&*,&* speech&* and&* visual&* perception&*,&* learning&*,&* and&* decision&*-making&*.&* &* &
|
visualization/visualization_paper.py
ADDED
|
@@ -0,0 +1,195 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import re
|
| 2 |
+
from typing import List, Dict
|
| 3 |
+
import os
|
| 4 |
+
|
| 5 |
+
def parse_generation_history(file_path: str) -> Dict[int, List[str]]:
|
| 6 |
+
"""Improved parser that handles math symbols and spaces correctly"""
|
| 7 |
+
history = {}
|
| 8 |
+
token_pattern = re.compile(r"\*([^&]*)&?")
|
| 9 |
+
|
| 10 |
+
with open(file_path, 'r', encoding='utf-8') as f:
|
| 11 |
+
for line in f:
|
| 12 |
+
line = line.strip()
|
| 13 |
+
if not line:
|
| 14 |
+
continue
|
| 15 |
+
|
| 16 |
+
try:
|
| 17 |
+
step_part, content_part = line.split(',', 1)
|
| 18 |
+
step = int(step_part.strip())
|
| 19 |
+
except ValueError:
|
| 20 |
+
continue
|
| 21 |
+
|
| 22 |
+
tokens = []
|
| 23 |
+
for match in token_pattern.finditer(content_part):
|
| 24 |
+
raw_token = match.group(1).strip()
|
| 25 |
+
|
| 26 |
+
if raw_token == "":
|
| 27 |
+
tokens.append(" ")
|
| 28 |
+
elif raw_token == "*":
|
| 29 |
+
tokens.append("*")
|
| 30 |
+
else:
|
| 31 |
+
tokens.append(raw_token)
|
| 32 |
+
|
| 33 |
+
while len(tokens) < 64:
|
| 34 |
+
tokens.append(" ")
|
| 35 |
+
|
| 36 |
+
if len(tokens) > 64:
|
| 37 |
+
print(f"Truncating extra tokens: Step {step} ({len(tokens)} tokens)")
|
| 38 |
+
tokens = tokens[:64]
|
| 39 |
+
elif len(tokens) < 64:
|
| 40 |
+
print(f"Padding missing tokens: Step {step} ({len(tokens)} tokens)")
|
| 41 |
+
tokens += [" "] * (64 - len(tokens))
|
| 42 |
+
|
| 43 |
+
history[step] = tokens
|
| 44 |
+
|
| 45 |
+
return history
|
| 46 |
+
|
| 47 |
+
def track_token_positions(history: Dict[int, List[str]]) -> List[int]:
|
| 48 |
+
"""Track the first generation step for each token"""
|
| 49 |
+
num_positions = 64
|
| 50 |
+
steps_to_unmask = [-1] * num_positions
|
| 51 |
+
|
| 52 |
+
for step in sorted(history.keys()):
|
| 53 |
+
tokens = history[step]
|
| 54 |
+
for idx in range(num_positions):
|
| 55 |
+
if idx >= len(tokens):
|
| 56 |
+
continue
|
| 57 |
+
|
| 58 |
+
token = tokens[idx]
|
| 59 |
+
if steps_to_unmask[idx] == -1 and token != '<|mdm_mask|>':
|
| 60 |
+
steps_to_unmask[idx] = step
|
| 61 |
+
|
| 62 |
+
return steps_to_unmask
|
| 63 |
+
|
| 64 |
+
def generate_background_color(step: int, max_step: int) -> str:
|
| 65 |
+
"""Generate gradient color"""
|
| 66 |
+
color_stops = [
|
| 67 |
+
(240, 248, 255), (209, 226, 241), (176, 202, 224), (143, 179, 207),
|
| 68 |
+
(110, 156, 191), (77, 133, 175), (44, 110, 159), (12, 55, 112)
|
| 69 |
+
]
|
| 70 |
+
|
| 71 |
+
color_index = min(step * 6 // max_step, 6)
|
| 72 |
+
ratio = (step % 2) / 2
|
| 73 |
+
|
| 74 |
+
start = color_stops[color_index]
|
| 75 |
+
end = color_stops[min(color_index + 1, 7)]
|
| 76 |
+
|
| 77 |
+
r = int(start[0] + (end[0] - start[0]) * ratio)
|
| 78 |
+
g = int(start[1] + (end[1] - start[1]) * ratio)
|
| 79 |
+
b = int(start[2] + (end[2] - start[2]) * ratio)
|
| 80 |
+
|
| 81 |
+
return f"#{r:02x}{g:02x}{b:02x}"
|
| 82 |
+
|
| 83 |
+
def generate_step_visualization(current_step: int, current_tokens: List[str],
|
| 84 |
+
token_steps: List[int], max_step: int) -> str:
|
| 85 |
+
"""Generate visualization for specific step"""
|
| 86 |
+
html = []
|
| 87 |
+
|
| 88 |
+
for idx, token in enumerate(current_tokens):
|
| 89 |
+
style = [
|
| 90 |
+
"color: #000000",
|
| 91 |
+
"padding: 6px 8px",
|
| 92 |
+
"margin: 3px",
|
| 93 |
+
"border-radius: 6px",
|
| 94 |
+
"display: inline-block",
|
| 95 |
+
"font-weight: 600",
|
| 96 |
+
"font-size: 16px",
|
| 97 |
+
"font-family: 'Segoe UI', sans-serif",
|
| 98 |
+
"box-shadow: 0 3px 6px rgba(12,55,112,0.15)",
|
| 99 |
+
"transition: all 0.2s ease",
|
| 100 |
+
"position: relative",
|
| 101 |
+
"width: 120px",
|
| 102 |
+
"min-width: 120px",
|
| 103 |
+
"text-align: center",
|
| 104 |
+
"white-space: nowrap",
|
| 105 |
+
"overflow: hidden",
|
| 106 |
+
"text-overflow: ellipsis",
|
| 107 |
+
"box-sizing: border-box"
|
| 108 |
+
]
|
| 109 |
+
|
| 110 |
+
if token == '<|mdm_mask|>':
|
| 111 |
+
style.extend([
|
| 112 |
+
"background: #f8fafc",
|
| 113 |
+
"border: 2px solid #ffffff",
|
| 114 |
+
"font-weight: 800",
|
| 115 |
+
"text-transform: uppercase",
|
| 116 |
+
"padding: 4px 6px"
|
| 117 |
+
])
|
| 118 |
+
display_text = "Mask"
|
| 119 |
+
else:
|
| 120 |
+
bg_color = generate_background_color(token_steps[idx], max_step)
|
| 121 |
+
style.append(f"background-color: {bg_color}")
|
| 122 |
+
display_text = token if token != " " else "␣"
|
| 123 |
+
|
| 124 |
+
html.append(f'<span style="{"; ".join(style)}">{display_text}</span>')
|
| 125 |
+
|
| 126 |
+
return '\n'.join(html)
|
| 127 |
+
|
| 128 |
+
def main(target_step: int = 64):
|
| 129 |
+
"""Main function supporting target step specification"""
|
| 130 |
+
file_path = "sample_process.txt"
|
| 131 |
+
final_step = 64
|
| 132 |
+
|
| 133 |
+
history = parse_generation_history(file_path)
|
| 134 |
+
if target_step not in history:
|
| 135 |
+
raise ValueError(f"Invalid target step: {target_step}")
|
| 136 |
+
|
| 137 |
+
token_steps = track_token_positions(history)
|
| 138 |
+
current_tokens = history[target_step]
|
| 139 |
+
|
| 140 |
+
html_content = generate_step_visualization(
|
| 141 |
+
target_step, current_tokens, token_steps, final_step
|
| 142 |
+
)
|
| 143 |
+
|
| 144 |
+
example_steps = [0, 16, 32, 48, 64]
|
| 145 |
+
example_colors = [generate_background_color(s, final_step) for s in example_steps]
|
| 146 |
+
legend_html = ''.join(
|
| 147 |
+
f'<div style="background-color: {color}; color: black;">Step {s}</div>'
|
| 148 |
+
for s, color in zip(example_steps, example_colors)
|
| 149 |
+
)
|
| 150 |
+
|
| 151 |
+
target_dir = "html/sample_process_paper"
|
| 152 |
+
if not os.path.exists(target_dir):
|
| 153 |
+
os.makedirs(target_dir)
|
| 154 |
+
|
| 155 |
+
with open(f"{target_dir}/visualization_step_{target_step}.html", "w", encoding="utf-8") as f:
|
| 156 |
+
f.write(f"""<html>
|
| 157 |
+
<head>
|
| 158 |
+
<title>Step {target_step} Visualization</title>
|
| 159 |
+
<style>
|
| 160 |
+
body {{
|
| 161 |
+
padding: 40px;
|
| 162 |
+
background: #f8fafc;
|
| 163 |
+
font-family: 'Segoe UI', sans-serif;
|
| 164 |
+
}}
|
| 165 |
+
.legend {{
|
| 166 |
+
display: flex;
|
| 167 |
+
gap: 15px;
|
| 168 |
+
margin: 20px 0;
|
| 169 |
+
}}
|
| 170 |
+
.legend div {{
|
| 171 |
+
padding: 10px;
|
| 172 |
+
border-radius: 5px;
|
| 173 |
+
color: white;
|
| 174 |
+
min-width: 80px;
|
| 175 |
+
text-align: center;
|
| 176 |
+
}}
|
| 177 |
+
.token:hover {{
|
| 178 |
+
transform: translateY(-2px);
|
| 179 |
+
}}
|
| 180 |
+
</style>
|
| 181 |
+
</head>
|
| 182 |
+
<body>
|
| 183 |
+
<div style="max-width: 1000px; margin: auto;">
|
| 184 |
+
<h2>Generation Step {target_step}</h2>
|
| 185 |
+
<div>{html_content}</div>
|
| 186 |
+
|
| 187 |
+
<h3>Color Legend</h3>
|
| 188 |
+
<div class="legend">{legend_html}</div>
|
| 189 |
+
</div>
|
| 190 |
+
</body>
|
| 191 |
+
</html>""")
|
| 192 |
+
|
| 193 |
+
if __name__ == "__main__":
|
| 194 |
+
for step in range(1, 65):
|
| 195 |
+
main(target_step=step)
|
visualization/visualization_zhihu.py
ADDED
|
@@ -0,0 +1,202 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import re
|
| 2 |
+
from typing import List, Dict
|
| 3 |
+
import os
|
| 4 |
+
|
| 5 |
+
def parse_generation_history(file_path: str) -> Dict[int, List[str]]:
|
| 6 |
+
"""Improved parser that handles math symbols and spaces correctly"""
|
| 7 |
+
history = {}
|
| 8 |
+
token_pattern = re.compile(r"\*([^&]*)&?")
|
| 9 |
+
|
| 10 |
+
with open(file_path, 'r', encoding='utf-8') as f:
|
| 11 |
+
for line in f:
|
| 12 |
+
line = line.strip()
|
| 13 |
+
if not line:
|
| 14 |
+
continue
|
| 15 |
+
|
| 16 |
+
try:
|
| 17 |
+
step_part, content_part = line.split(',', 1)
|
| 18 |
+
step = int(step_part.strip())
|
| 19 |
+
except ValueError:
|
| 20 |
+
continue
|
| 21 |
+
|
| 22 |
+
tokens = []
|
| 23 |
+
for match in token_pattern.finditer(content_part):
|
| 24 |
+
raw_token = match.group(1).strip()
|
| 25 |
+
|
| 26 |
+
if raw_token == "":
|
| 27 |
+
tokens.append(" ")
|
| 28 |
+
elif raw_token == "*":
|
| 29 |
+
tokens.append("*")
|
| 30 |
+
else:
|
| 31 |
+
tokens.append(raw_token)
|
| 32 |
+
|
| 33 |
+
while len(tokens) < 64:
|
| 34 |
+
tokens.append(" ")
|
| 35 |
+
|
| 36 |
+
if len(tokens) > 64:
|
| 37 |
+
print(f"Truncating extra tokens: Step {step} ({len(tokens)} tokens)")
|
| 38 |
+
tokens = tokens[:64]
|
| 39 |
+
elif len(tokens) < 64:
|
| 40 |
+
print(f"Padding missing tokens: Step {step} ({len(tokens)} tokens)")
|
| 41 |
+
tokens += [" "] * (64 - len(tokens))
|
| 42 |
+
|
| 43 |
+
tokens = tokens[:62]
|
| 44 |
+
|
| 45 |
+
history[step] = tokens
|
| 46 |
+
|
| 47 |
+
return history
|
| 48 |
+
|
| 49 |
+
def track_token_positions(history: Dict[int, List[str]]) -> List[int]:
|
| 50 |
+
"""Track the first generation step for each token"""
|
| 51 |
+
num_positions = 64
|
| 52 |
+
steps_to_unmask = [-1] * num_positions
|
| 53 |
+
|
| 54 |
+
for step in sorted(history.keys()):
|
| 55 |
+
tokens = history[step]
|
| 56 |
+
for idx in range(num_positions):
|
| 57 |
+
if idx >= len(tokens):
|
| 58 |
+
continue
|
| 59 |
+
|
| 60 |
+
token = tokens[idx]
|
| 61 |
+
if steps_to_unmask[idx] == -1 and token != '<|mdm_mask|>':
|
| 62 |
+
steps_to_unmask[idx] = step
|
| 63 |
+
|
| 64 |
+
return steps_to_unmask
|
| 65 |
+
|
| 66 |
+
def generate_background_color(step: int, max_step: int) -> str:
|
| 67 |
+
"""Generate gradient color for text (darker version)"""
|
| 68 |
+
color_stops = [
|
| 69 |
+
(176, 202, 224),
|
| 70 |
+
(143, 179, 207),
|
| 71 |
+
(110, 156, 191),
|
| 72 |
+
(80, 130, 240),
|
| 73 |
+
(40, 90, 200),
|
| 74 |
+
(20, 70, 180),
|
| 75 |
+
(0, 50, 160),
|
| 76 |
+
]
|
| 77 |
+
|
| 78 |
+
color_index = min(int(step ** 0.7 / max_step ** 0.7 * 6), 6)
|
| 79 |
+
ratio = (step % 2) / 2
|
| 80 |
+
|
| 81 |
+
start = color_stops[color_index]
|
| 82 |
+
end = color_stops[min(color_index + 1, 6)]
|
| 83 |
+
|
| 84 |
+
r = int(start[0] + (end[0] - start[0]) * ratio)
|
| 85 |
+
g = int(start[1] + (end[1] - start[1]) * ratio)
|
| 86 |
+
b = int(start[2] + (end[2] - start[2]) * ratio)
|
| 87 |
+
|
| 88 |
+
return f"#{r:02x}{g:02x}{b:02x}"
|
| 89 |
+
|
| 90 |
+
def generate_step_visualization(current_step: int, current_tokens: List[str],
|
| 91 |
+
token_steps: List[int], max_step: int) -> str:
|
| 92 |
+
"""Final visualization version (completely borderless)"""
|
| 93 |
+
html = []
|
| 94 |
+
|
| 95 |
+
for idx, token in enumerate(current_tokens):
|
| 96 |
+
style = [
|
| 97 |
+
"padding: 6px 8px",
|
| 98 |
+
"margin: 2px",
|
| 99 |
+
"border-radius: 6px",
|
| 100 |
+
"display: inline-block",
|
| 101 |
+
"font-weight: 600",
|
| 102 |
+
"font-size: 16px",
|
| 103 |
+
"font-family: 'Segoe UI', sans-serif",
|
| 104 |
+
"transition: all 0.2s ease",
|
| 105 |
+
"width: 120px",
|
| 106 |
+
"min-width: 120px",
|
| 107 |
+
"text-align: center",
|
| 108 |
+
"white-space: nowrap",
|
| 109 |
+
"overflow: hidden",
|
| 110 |
+
"text-overflow: ellipsis",
|
| 111 |
+
"box-sizing: border-box",
|
| 112 |
+
"vertical-align: middle",
|
| 113 |
+
"border: 0 !important",
|
| 114 |
+
"outline: 0 !important",
|
| 115 |
+
"box-shadow: none !important",
|
| 116 |
+
"position: relative",
|
| 117 |
+
"z-index: 1"
|
| 118 |
+
]
|
| 119 |
+
|
| 120 |
+
if token == '<|mdm_mask|>':
|
| 121 |
+
style.extend([
|
| 122 |
+
"color: transparent",
|
| 123 |
+
"background: #f8fafc",
|
| 124 |
+
"text-shadow: none"
|
| 125 |
+
])
|
| 126 |
+
display_text = "​"
|
| 127 |
+
else:
|
| 128 |
+
text_color = generate_background_color(token_steps[idx], max_step)
|
| 129 |
+
style.append(f"color: {text_color}")
|
| 130 |
+
display_text = token if token != " " else "␣"
|
| 131 |
+
|
| 132 |
+
html.append(f'''
|
| 133 |
+
<div style="display: inline-block; border: none !important; margin: 0 !important; padding: 0 !important;">
|
| 134 |
+
<span style="{"; ".join(style)}">{display_text}</span>
|
| 135 |
+
</div>
|
| 136 |
+
''')
|
| 137 |
+
|
| 138 |
+
return '\n'.join(html)
|
| 139 |
+
|
| 140 |
+
def main(target_step: int = 64):
|
| 141 |
+
"""Main function supporting target step specification"""
|
| 142 |
+
file_path = "sample_process.txt"
|
| 143 |
+
final_step = 64
|
| 144 |
+
|
| 145 |
+
history = parse_generation_history(file_path)
|
| 146 |
+
if target_step not in history:
|
| 147 |
+
raise ValueError(f"Invalid target step: {target_step}")
|
| 148 |
+
|
| 149 |
+
token_steps = track_token_positions(history)
|
| 150 |
+
current_tokens = history[target_step]
|
| 151 |
+
|
| 152 |
+
html_content = generate_step_visualization(
|
| 153 |
+
target_step, current_tokens, token_steps, final_step
|
| 154 |
+
)
|
| 155 |
+
|
| 156 |
+
example_steps = [0, 16, 32, 48, 64]
|
| 157 |
+
example_colors = [generate_background_color(s, final_step) for s in example_steps]
|
| 158 |
+
legend_html = ''.join(
|
| 159 |
+
f'<div style="background-color: {color}; color: black;">Step {s}</div>'
|
| 160 |
+
for s, color in zip(example_steps, example_colors)
|
| 161 |
+
)
|
| 162 |
+
|
| 163 |
+
target_dir = "html/sample_process_zhihu"
|
| 164 |
+
if not os.path.exists(target_dir):
|
| 165 |
+
os.makedirs(target_dir)
|
| 166 |
+
with open(f"{target_dir}/visualization_step_{target_step}.html", "w", encoding="utf-8") as f:
|
| 167 |
+
f.write(f"""<html>
|
| 168 |
+
<head>
|
| 169 |
+
<title>Step {target_step} Visualization</title>
|
| 170 |
+
<style>
|
| 171 |
+
body {{
|
| 172 |
+
padding: 40px;
|
| 173 |
+
background: #f8fafc;
|
| 174 |
+
font-family: 'Segoe UI', sans-serif;
|
| 175 |
+
}}
|
| 176 |
+
.legend {{
|
| 177 |
+
display: flex;
|
| 178 |
+
gap: 15px;
|
| 179 |
+
margin: 20px 0;
|
| 180 |
+
}}
|
| 181 |
+
.legend div {{
|
| 182 |
+
padding: 10px;
|
| 183 |
+
border-radius: 5px;
|
| 184 |
+
color: white;
|
| 185 |
+
min-width: 80px;
|
| 186 |
+
text-align: center;
|
| 187 |
+
}}
|
| 188 |
+
.token:hover {{
|
| 189 |
+
transform: translateY(-2px);
|
| 190 |
+
}}
|
| 191 |
+
</style>
|
| 192 |
+
</head>
|
| 193 |
+
<body>
|
| 194 |
+
<div style="max-width: 1000px; margin: auto;">
|
| 195 |
+
<div>{html_content}</div>
|
| 196 |
+
</div>
|
| 197 |
+
</body>
|
| 198 |
+
</html>""")
|
| 199 |
+
|
| 200 |
+
if __name__ == "__main__":
|
| 201 |
+
for step in range(1, 65):
|
| 202 |
+
main(target_step=step)
|