"""A Gradio app for anonymizing text data using FHE."""
import gradio as gr
from fhe_anonymizer import FHEAnonymizer
import pandas as pd
from openai import OpenAI
import os
import json
import re
from utils_demo import *
from typing import List, Dict, Tuple
anonymizer = FHEAnonymizer()
client = OpenAI(
api_key=os.environ.get("openaikey"),
)
def check_user_query_fn(user_query: str) -> Dict:
if is_user_query_valid(user_query):
# TODO: check if the query is related to our context
error_msg = ("Unable to process ❌: The request exceeds the length limit or falls "
"outside the scope of this document. Please refine your query.")
print(error_msg)
return {input_text: gr.update(value=error_msg)}
else:
# Collapsing Multiple Spaces
return {input_text: gr.update(value=re.sub(" +", " ", user_query))}
def deidentify_text(input_text):
anonymized_text, identified_words_with_prob = anonymizer(input_text)
# Convert the list of identified words and probabilities into a DataFrame
if identified_words_with_prob:
identified_df = pd.DataFrame(
identified_words_with_prob, columns=["Identified Words", "Probability"]
)
else:
identified_df = pd.DataFrame(columns=["Identified Words", "Probability"])
return anonymized_text, identified_df
def query_chatgpt(anonymized_query):
with open("files/anonymized_document.txt", "r") as file:
anonymized_document = file.read()
with open("files/chatgpt_prompt.txt", "r") as file:
prompt = file.read()
# Prepare prompt
full_prompt = (
prompt + "\n"
)
query = "Document content:\n```\n" + anonymized_document + "\n\n```" + "Query:\n```\n" + anonymized_query + "\n```"
print(full_prompt)
completion = client.chat.completions.create(
model="gpt-4-1106-preview", # Replace with "gpt-4" if available
messages=[
{"role": "system", "content": prompt},
{"role": "user", "content": query},
],
)
anonymized_response = completion.choices[0].message.content
with open("original_document_uuid_mapping.json", "r") as file:
uuid_map = json.load(file)
inverse_uuid_map = {v: k for k, v in uuid_map.items()} # TODO load the inverse mapping from disk for efficiency
# Pattern to identify words and non-words (including punctuation, spaces, etc.)
token_pattern = r"(\b[\w\.\/\-@]+\b|[\s,.!?;:'\"-]+)"
tokens = re.findall(token_pattern, anonymized_response)
processed_tokens = []
for token in tokens:
# Directly append non-word tokens or whitespace to processed_tokens
if not token.strip() or not re.match(r"\w+", token):
processed_tokens.append(token)
continue
if token in inverse_uuid_map:
processed_tokens.append(inverse_uuid_map[token])
else:
processed_tokens.append(token)
deanonymized_response = "".join(processed_tokens)
return anonymized_response, deanonymized_response
with open("files/original_document.txt", "r") as file:
original_document = file.read()
with open("files/anonymized_document.txt", "r") as file:
anonymized_document = file.read()
demo = gr.Blocks(css=".markdown-body { font-size: 18px; }")
with demo:
gr.Markdown(
"""

Encrypted Anonymization Using Fully Homomorphic Encryption
 Concrete-ML
—
Concrete-ML
—
 Documentation
—
Documentation
—
 Community
—
Community
—
 @zama_fhe
@zama_fhe
"""
)
gr.Markdown(
"""
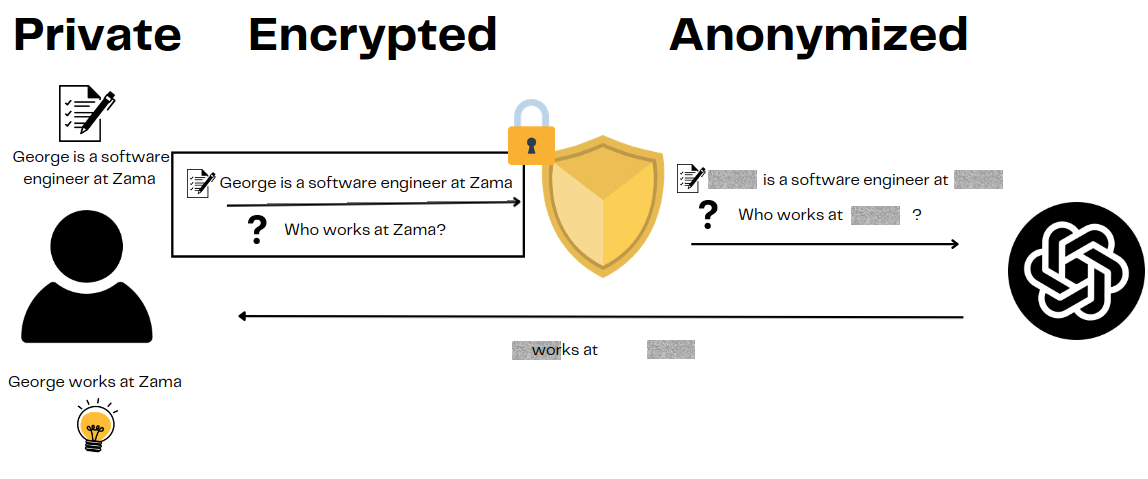
"""
)
with gr.Accordion("What is Encrypted Anonymization?", open=False):
gr.Markdown(
"""
Encrypted Anonymization leverages Fully Homomorphic Encryption (FHE) to protect sensitive information during data processing. This approach allows for the anonymization of text data, such as personal identifiers, while ensuring that the data remains encrypted throughout the entire process.
"""
)
with gr.Row():
with gr.Accordion("Original Document", open=True):
gr.Markdown(original_document)
with gr.Accordion("Anonymized Document", open=True):
gr.Markdown(anonymized_document)
########################## User Query Part ##########################
with gr.Row():
input_text = gr.Textbox(value="Who lives in Maine?", label="User query", interactive=True)
default_query_box = gr.Radio(choices=list(DEFAULT_QUERIES.keys()), label="Example Queries")
default_query_box.change(
fn=lambda default_query_box: DEFAULT_QUERIES[default_query_box],
inputs=[default_query_box],
outputs=[input_text]
)
input_text.change(
check_user_query_fn,
inputs=[input_text],
outputs=[input_text],
)
anonymized_text_output = gr.Textbox(label="Anonymized Text with FHE", lines=1, interactive=True)
identified_words_output = gr.Dataframe(label="Identified Words", visible=False)
submit_button = gr.Button("Anonymize with FHE")
submit_button.click(
deidentify_text,
inputs=[input_text],
outputs=[anonymized_text_output, identified_words_output],
)
with gr.Row():
chatgpt_response_anonymized = gr.Textbox(label="ChatGPT Anonymized Response", lines=13)
chatgpt_response_deanonymized = gr.Textbox(label="ChatGPT Deanonymized Response", lines=13)
chatgpt_button = gr.Button("Query ChatGPT")
chatgpt_button.click(
query_chatgpt,
inputs=[anonymized_text_output],
outputs=[chatgpt_response_anonymized, chatgpt_response_deanonymized],
)
# Launch the app
demo.launch(share=False)