Spaces:
Runtime error

Runtime error
Upload 5 files
Browse files- README.md +8 -6
- app.py +267 -0
- doge.png +0 -0
- equation.png +0 -0
- requirements.txt +9 -0
README.md
CHANGED
|
@@ -1,14 +1,16 @@
|
|
| 1 |
---
|
| 2 |
-
title:
|
| 3 |
-
emoji:
|
| 4 |
-
colorFrom:
|
| 5 |
-
colorTo:
|
| 6 |
sdk: gradio
|
| 7 |
-
sdk_version: 5.
|
| 8 |
app_file: app.py
|
| 9 |
pinned: false
|
| 10 |
license: mit
|
| 11 |
-
short_description:
|
| 12 |
---
|
| 13 |
|
| 14 |
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
+
title: Chat With Janus-Pro-7B
|
| 3 |
+
emoji: 🌍
|
| 4 |
+
colorFrom: indigo
|
| 5 |
+
colorTo: red
|
| 6 |
sdk: gradio
|
| 7 |
+
sdk_version: 5.1.0
|
| 8 |
app_file: app.py
|
| 9 |
pinned: false
|
| 10 |
license: mit
|
| 11 |
+
short_description: A unified multimodal understanding and generation model.
|
| 12 |
---
|
| 13 |
|
| 14 |
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
| 15 |
+
|
| 16 |
+
Please note that after generating the images with Janus-Pro, we use Real-ESRGAN to perform 2x image upsampling (just in this demo). This upsampling does not alter the content of the images but makes them slightly clearer for easier viewing.
|
app.py
ADDED
|
@@ -0,0 +1,267 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
import torch
|
| 3 |
+
from transformers import AutoConfig, AutoModelForCausalLM
|
| 4 |
+
from janus.models import MultiModalityCausalLM, VLChatProcessor
|
| 5 |
+
from janus.utils.io import load_pil_images
|
| 6 |
+
from PIL import Image
|
| 7 |
+
|
| 8 |
+
import numpy as np
|
| 9 |
+
import os
|
| 10 |
+
import time
|
| 11 |
+
from Upsample import RealESRGAN
|
| 12 |
+
import spaces # Import spaces for ZeroGPU compatibility
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
# Load model and processor
|
| 16 |
+
model_path = "deepseek-ai/Janus-Pro-7B"
|
| 17 |
+
config = AutoConfig.from_pretrained(model_path)
|
| 18 |
+
language_config = config.language_config
|
| 19 |
+
language_config._attn_implementation = 'eager'
|
| 20 |
+
vl_gpt = AutoModelForCausalLM.from_pretrained(model_path,
|
| 21 |
+
language_config=language_config,
|
| 22 |
+
trust_remote_code=True)
|
| 23 |
+
if torch.cuda.is_available():
|
| 24 |
+
vl_gpt = vl_gpt.to(torch.bfloat16).cuda()
|
| 25 |
+
else:
|
| 26 |
+
vl_gpt = vl_gpt.to(torch.float16)
|
| 27 |
+
|
| 28 |
+
vl_chat_processor = VLChatProcessor.from_pretrained(model_path)
|
| 29 |
+
tokenizer = vl_chat_processor.tokenizer
|
| 30 |
+
cuda_device = 'cuda' if torch.cuda.is_available() else 'cpu'
|
| 31 |
+
|
| 32 |
+
# SR model
|
| 33 |
+
sr_model = RealESRGAN(torch.device('cuda' if torch.cuda.is_available() else 'cpu'), scale=2)
|
| 34 |
+
sr_model.load_weights(f'weights/RealESRGAN_x2.pth', download=False)
|
| 35 |
+
|
| 36 |
+
@torch.inference_mode()
|
| 37 |
+
@spaces.GPU(duration=120)
|
| 38 |
+
# Multimodal Understanding function
|
| 39 |
+
def multimodal_understanding(image, question, seed, top_p, temperature):
|
| 40 |
+
# Clear CUDA cache before generating
|
| 41 |
+
torch.cuda.empty_cache()
|
| 42 |
+
|
| 43 |
+
# set seed
|
| 44 |
+
torch.manual_seed(seed)
|
| 45 |
+
np.random.seed(seed)
|
| 46 |
+
torch.cuda.manual_seed(seed)
|
| 47 |
+
|
| 48 |
+
conversation = [
|
| 49 |
+
{
|
| 50 |
+
"role": "<|User|>",
|
| 51 |
+
"content": f"<image_placeholder>\n{question}",
|
| 52 |
+
"images": [image],
|
| 53 |
+
},
|
| 54 |
+
{"role": "<|Assistant|>", "content": ""},
|
| 55 |
+
]
|
| 56 |
+
|
| 57 |
+
pil_images = [Image.fromarray(image)]
|
| 58 |
+
prepare_inputs = vl_chat_processor(
|
| 59 |
+
conversations=conversation, images=pil_images, force_batchify=True
|
| 60 |
+
).to(cuda_device, dtype=torch.bfloat16 if torch.cuda.is_available() else torch.float16)
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
inputs_embeds = vl_gpt.prepare_inputs_embeds(**prepare_inputs)
|
| 64 |
+
|
| 65 |
+
outputs = vl_gpt.language_model.generate(
|
| 66 |
+
inputs_embeds=inputs_embeds,
|
| 67 |
+
attention_mask=prepare_inputs.attention_mask,
|
| 68 |
+
pad_token_id=tokenizer.eos_token_id,
|
| 69 |
+
bos_token_id=tokenizer.bos_token_id,
|
| 70 |
+
eos_token_id=tokenizer.eos_token_id,
|
| 71 |
+
max_new_tokens=512,
|
| 72 |
+
do_sample=False if temperature == 0 else True,
|
| 73 |
+
use_cache=True,
|
| 74 |
+
temperature=temperature,
|
| 75 |
+
top_p=top_p,
|
| 76 |
+
)
|
| 77 |
+
|
| 78 |
+
answer = tokenizer.decode(outputs[0].cpu().tolist(), skip_special_tokens=True)
|
| 79 |
+
return answer
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
def generate(input_ids,
|
| 83 |
+
width,
|
| 84 |
+
height,
|
| 85 |
+
temperature: float = 1,
|
| 86 |
+
parallel_size: int = 5,
|
| 87 |
+
cfg_weight: float = 5,
|
| 88 |
+
image_token_num_per_image: int = 576,
|
| 89 |
+
patch_size: int = 16):
|
| 90 |
+
# Clear CUDA cache before generating
|
| 91 |
+
torch.cuda.empty_cache()
|
| 92 |
+
|
| 93 |
+
tokens = torch.zeros((parallel_size * 2, len(input_ids)), dtype=torch.int).to(cuda_device)
|
| 94 |
+
for i in range(parallel_size * 2):
|
| 95 |
+
tokens[i, :] = input_ids
|
| 96 |
+
if i % 2 != 0:
|
| 97 |
+
tokens[i, 1:-1] = vl_chat_processor.pad_id
|
| 98 |
+
inputs_embeds = vl_gpt.language_model.get_input_embeddings()(tokens)
|
| 99 |
+
generated_tokens = torch.zeros((parallel_size, image_token_num_per_image), dtype=torch.int).to(cuda_device)
|
| 100 |
+
|
| 101 |
+
pkv = None
|
| 102 |
+
for i in range(image_token_num_per_image):
|
| 103 |
+
with torch.no_grad():
|
| 104 |
+
outputs = vl_gpt.language_model.model(inputs_embeds=inputs_embeds,
|
| 105 |
+
use_cache=True,
|
| 106 |
+
past_key_values=pkv)
|
| 107 |
+
pkv = outputs.past_key_values
|
| 108 |
+
hidden_states = outputs.last_hidden_state
|
| 109 |
+
logits = vl_gpt.gen_head(hidden_states[:, -1, :])
|
| 110 |
+
logit_cond = logits[0::2, :]
|
| 111 |
+
logit_uncond = logits[1::2, :]
|
| 112 |
+
logits = logit_uncond + cfg_weight * (logit_cond - logit_uncond)
|
| 113 |
+
probs = torch.softmax(logits / temperature, dim=-1)
|
| 114 |
+
next_token = torch.multinomial(probs, num_samples=1)
|
| 115 |
+
generated_tokens[:, i] = next_token.squeeze(dim=-1)
|
| 116 |
+
next_token = torch.cat([next_token.unsqueeze(dim=1), next_token.unsqueeze(dim=1)], dim=1).view(-1)
|
| 117 |
+
|
| 118 |
+
img_embeds = vl_gpt.prepare_gen_img_embeds(next_token)
|
| 119 |
+
inputs_embeds = img_embeds.unsqueeze(dim=1)
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
|
| 123 |
+
patches = vl_gpt.gen_vision_model.decode_code(generated_tokens.to(dtype=torch.int),
|
| 124 |
+
shape=[parallel_size, 8, width // patch_size, height // patch_size])
|
| 125 |
+
|
| 126 |
+
return generated_tokens.to(dtype=torch.int), patches
|
| 127 |
+
|
| 128 |
+
def unpack(dec, width, height, parallel_size=5):
|
| 129 |
+
dec = dec.to(torch.float32).cpu().numpy().transpose(0, 2, 3, 1)
|
| 130 |
+
dec = np.clip((dec + 1) / 2 * 255, 0, 255)
|
| 131 |
+
|
| 132 |
+
visual_img = np.zeros((parallel_size, width, height, 3), dtype=np.uint8)
|
| 133 |
+
visual_img[:, :, :] = dec
|
| 134 |
+
|
| 135 |
+
return visual_img
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
@torch.inference_mode()
|
| 140 |
+
@spaces.GPU(duration=120) # Specify a duration to avoid timeout
|
| 141 |
+
def generate_image(prompt,
|
| 142 |
+
seed=None,
|
| 143 |
+
guidance=5,
|
| 144 |
+
t2i_temperature=1.0):
|
| 145 |
+
# Clear CUDA cache and avoid tracking gradients
|
| 146 |
+
torch.cuda.empty_cache()
|
| 147 |
+
# Set the seed for reproducible results
|
| 148 |
+
if seed is not None:
|
| 149 |
+
torch.manual_seed(seed)
|
| 150 |
+
torch.cuda.manual_seed(seed)
|
| 151 |
+
np.random.seed(seed)
|
| 152 |
+
width = 384
|
| 153 |
+
height = 384
|
| 154 |
+
parallel_size = 5
|
| 155 |
+
|
| 156 |
+
with torch.no_grad():
|
| 157 |
+
messages = [{'role': '<|User|>', 'content': prompt},
|
| 158 |
+
{'role': '<|Assistant|>', 'content': ''}]
|
| 159 |
+
text = vl_chat_processor.apply_sft_template_for_multi_turn_prompts(conversations=messages,
|
| 160 |
+
sft_format=vl_chat_processor.sft_format,
|
| 161 |
+
system_prompt='')
|
| 162 |
+
text = text + vl_chat_processor.image_start_tag
|
| 163 |
+
|
| 164 |
+
input_ids = torch.LongTensor(tokenizer.encode(text))
|
| 165 |
+
output, patches = generate(input_ids,
|
| 166 |
+
width // 16 * 16,
|
| 167 |
+
height // 16 * 16,
|
| 168 |
+
cfg_weight=guidance,
|
| 169 |
+
parallel_size=parallel_size,
|
| 170 |
+
temperature=t2i_temperature)
|
| 171 |
+
images = unpack(patches,
|
| 172 |
+
width // 16 * 16,
|
| 173 |
+
height // 16 * 16,
|
| 174 |
+
parallel_size=parallel_size)
|
| 175 |
+
|
| 176 |
+
# return [Image.fromarray(images[i]).resize((768, 768), Image.LANCZOS) for i in range(parallel_size)]
|
| 177 |
+
stime = time.time()
|
| 178 |
+
ret_images = [image_upsample(Image.fromarray(images[i])) for i in range(parallel_size)]
|
| 179 |
+
print(f'upsample time: {time.time() - stime}')
|
| 180 |
+
return ret_images
|
| 181 |
+
|
| 182 |
+
|
| 183 |
+
@spaces.GPU(duration=60)
|
| 184 |
+
def image_upsample(img: Image.Image) -> Image.Image:
|
| 185 |
+
if img is None:
|
| 186 |
+
raise Exception("Image not uploaded")
|
| 187 |
+
|
| 188 |
+
width, height = img.size
|
| 189 |
+
|
| 190 |
+
if width >= 5000 or height >= 5000:
|
| 191 |
+
raise Exception("The image is too large.")
|
| 192 |
+
|
| 193 |
+
global sr_model
|
| 194 |
+
result = sr_model.predict(img.convert('RGB'))
|
| 195 |
+
return result
|
| 196 |
+
|
| 197 |
+
|
| 198 |
+
# Gradio interface
|
| 199 |
+
with gr.Blocks() as demo:
|
| 200 |
+
gr.Markdown(value="# Multimodal Understanding")
|
| 201 |
+
with gr.Row():
|
| 202 |
+
image_input = gr.Image()
|
| 203 |
+
with gr.Column():
|
| 204 |
+
question_input = gr.Textbox(label="Question")
|
| 205 |
+
und_seed_input = gr.Number(label="Seed", precision=0, value=42)
|
| 206 |
+
top_p = gr.Slider(minimum=0, maximum=1, value=0.95, step=0.05, label="top_p")
|
| 207 |
+
temperature = gr.Slider(minimum=0, maximum=1, value=0.1, step=0.05, label="temperature")
|
| 208 |
+
|
| 209 |
+
understanding_button = gr.Button("Chat")
|
| 210 |
+
understanding_output = gr.Textbox(label="Response")
|
| 211 |
+
|
| 212 |
+
examples_inpainting = gr.Examples(
|
| 213 |
+
label="Multimodal Understanding examples",
|
| 214 |
+
examples=[
|
| 215 |
+
[
|
| 216 |
+
"explain this meme",
|
| 217 |
+
"doge.png",
|
| 218 |
+
],
|
| 219 |
+
[
|
| 220 |
+
"Convert the formula into latex code.",
|
| 221 |
+
"equation.png",
|
| 222 |
+
],
|
| 223 |
+
],
|
| 224 |
+
inputs=[question_input, image_input],
|
| 225 |
+
)
|
| 226 |
+
|
| 227 |
+
|
| 228 |
+
gr.Markdown(value="# Text-to-Image Generation")
|
| 229 |
+
|
| 230 |
+
|
| 231 |
+
|
| 232 |
+
with gr.Row():
|
| 233 |
+
cfg_weight_input = gr.Slider(minimum=1, maximum=10, value=5, step=0.5, label="CFG Weight")
|
| 234 |
+
t2i_temperature = gr.Slider(minimum=0, maximum=1, value=1.0, step=0.05, label="temperature")
|
| 235 |
+
|
| 236 |
+
prompt_input = gr.Textbox(label="Prompt. (Prompt in more detail can help produce better images!")
|
| 237 |
+
seed_input = gr.Number(label="Seed (Optional)", precision=0, value=1234)
|
| 238 |
+
|
| 239 |
+
generation_button = gr.Button("Generate Images")
|
| 240 |
+
|
| 241 |
+
image_output = gr.Gallery(label="Generated Images", columns=2, rows=2, height=300)
|
| 242 |
+
|
| 243 |
+
examples_t2i = gr.Examples(
|
| 244 |
+
label="Text to image generation examples.",
|
| 245 |
+
examples=[
|
| 246 |
+
"Master shifu racoon wearing drip attire as a street gangster.",
|
| 247 |
+
"The face of a beautiful girl",
|
| 248 |
+
"Astronaut in a jungle, cold color palette, muted colors, detailed, 8k",
|
| 249 |
+
"A cute and adorable baby fox with big brown eyes, autumn leaves in the background enchanting,immortal,fluffy, shiny mane,Petals,fairyism,unreal engine 5 and Octane Render,highly detailed, photorealistic, cinematic, natural colors.",
|
| 250 |
+
"The image features an intricately designed eye set against a circular backdrop adorned with ornate swirl patterns that evoke both realism and surrealism. At the center of attention is a strikingly vivid blue iris surrounded by delicate veins radiating outward from the pupil to create depth and intensity. The eyelashes are long and dark, casting subtle shadows on the skin around them which appears smooth yet slightly textured as if aged or weathered over time.\n\nAbove the eye, there's a stone-like structure resembling part of classical architecture, adding layers of mystery and timeless elegance to the composition. This architectural element contrasts sharply but harmoniously with the organic curves surrounding it. Below the eye lies another decorative motif reminiscent of baroque artistry, further enhancing the overall sense of eternity encapsulated within each meticulously crafted detail. \n\nOverall, the atmosphere exudes a mysterious aura intertwined seamlessly with elements suggesting timelessness, achieved through the juxtaposition of realistic textures and surreal artistic flourishes. Each component\u2014from the intricate designs framing the eye to the ancient-looking stone piece above\u2014contributes uniquely towards creating a visually captivating tableau imbued with enigmatic allure.",
|
| 251 |
+
],
|
| 252 |
+
inputs=prompt_input,
|
| 253 |
+
)
|
| 254 |
+
|
| 255 |
+
understanding_button.click(
|
| 256 |
+
multimodal_understanding,
|
| 257 |
+
inputs=[image_input, question_input, und_seed_input, top_p, temperature],
|
| 258 |
+
outputs=understanding_output
|
| 259 |
+
)
|
| 260 |
+
|
| 261 |
+
generation_button.click(
|
| 262 |
+
fn=generate_image,
|
| 263 |
+
inputs=[prompt_input, seed_input, cfg_weight_input, t2i_temperature],
|
| 264 |
+
outputs=image_output
|
| 265 |
+
)
|
| 266 |
+
|
| 267 |
+
demo.launch(share=True)
|
doge.png
ADDED
|
equation.png
ADDED
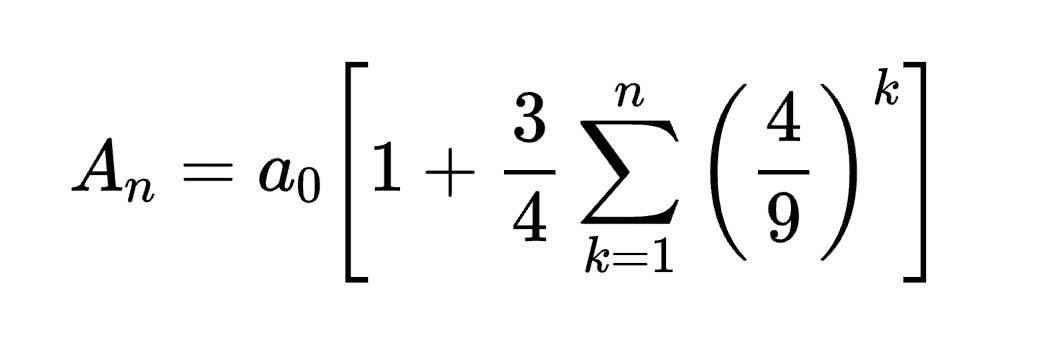
|
requirements.txt
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
accelerate
|
| 2 |
+
diffusers
|
| 3 |
+
gradio
|
| 4 |
+
numpy
|
| 5 |
+
torch
|
| 6 |
+
safetensors
|
| 7 |
+
transformers
|
| 8 |
+
opencv-python
|
| 9 |
+
git+https://github.com/deepseek-ai/Janus
|