

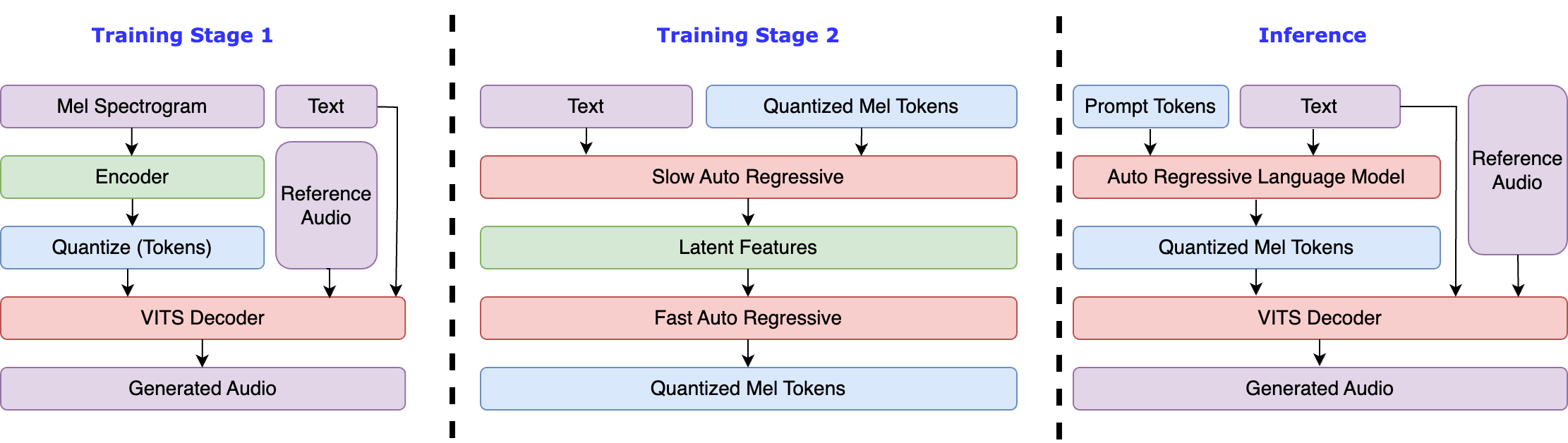
install_env.batを開いて実行に必要な環境を整えます。
install_env.batのUSE_MIRRORミラーサイトを使用する場合、項目を編集してください。USE_MIRROR=falseは、最新の安定版のtorchをオリジナルサイトからダウンロードします。USE_MIRROR=trueは、最新のtorchをミラーサイトからダウンロードします。デフォルトはtrueです。install_env.batのINSTALL_TYPEを編集して、コンパイル環境をダウンロードするかを設定できます。INSTALL_TYPE=previewは、コンパイル環境付きのプレビュー版をダウンロードします。INSTALL_TYPE=stableは、コンパイル環境なしの安定版をダウンロードします。USE_MIRROR=previewの場合、オプション、コンパイルモデル環境を有効にするたに以下のステップを実行してください。:
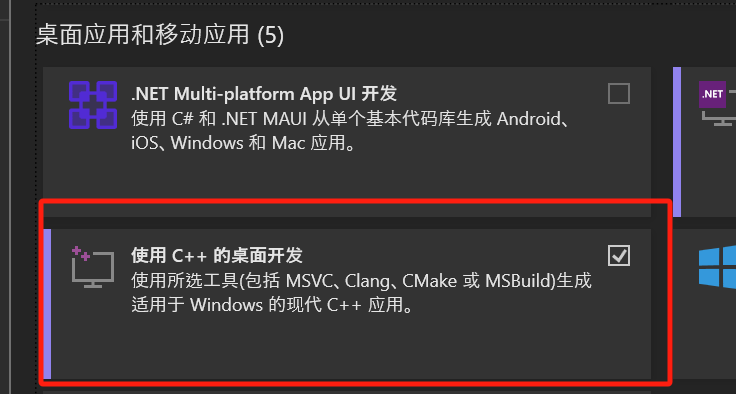
LLVM-17.0.6-win64.exeをダウンロードした後、ダブルクリックしてインストールし、適当な場所にインストールしてください。必ずAdd Path to Current Userをチェックして環境変数に追加することです。Modifyボタンをクリックし、Desktop development with C++オプションにチェックをつけてダウンロードします。
start.batを実行し、Fish-Speechのトレーニング/推論設定WebUIを開いてください。。
API_FLAGS.txtの最初の3行を次のように変更してください:
--infer
# --api
# --listen ...
...API_FLAGS.txtの最初の3行を次のように変更してください:
# --infer
--api
--listen ...
...run_cmd.batをダブルクリックして、このプロジェクトの仮想環境を有効化できます。