 +
+ +
+ +
+ +
+ +
+ +
+
+
+
+
+
+
 +
+
+
 +
+ +
+
+ +
+
+
 +
+
+
+
 +
+ +
+ +
+ +
+ +
+
+ +
+ +
+ +
+ +
+ +
+ +
+
+
 +
+ +
+ +
+ +
+ +
+ +
+ +
+
+
 +
+
+
+

+
 +
+ +
+
+
 +
+
+
+
 +
+
+
 +
+ +
+ +
+
 +
+ +
+
+
+
 +
+
+
 +
+ +
+ +
+
+

+
 +
+ +
+
+
+
+
 +
+ +
+
+
+ +
+
+
 +
+ +
+
+
+
 +
+
+
 +
+ +
+
+
+
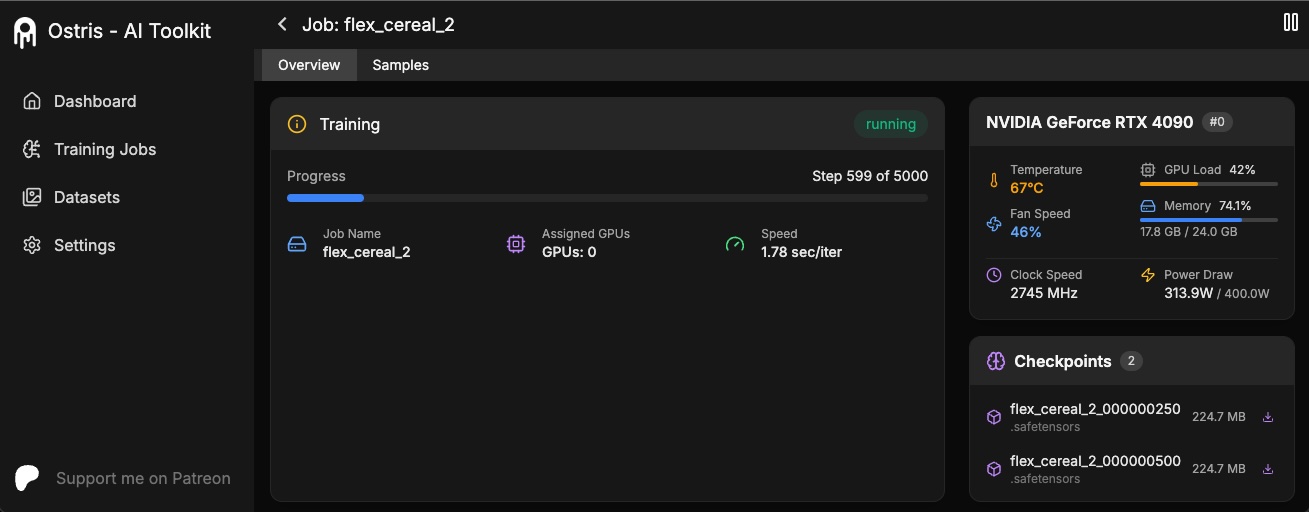 +
+The AI Toolkit UI is a web interface for the AI Toolkit. It allows you to easily start, stop, and monitor jobs. It also allows you to easily train models with a few clicks. It also allows you to set a token for the UI to prevent unauthorized access so it is mostly safe to run on an exposed server.
+
+## Running the UI
+
+Requirements:
+- Node.js > 18
+
+The UI does not need to be kept running for the jobs to run. It is only needed to start/stop/monitor jobs. The commands below
+will install / update the UI and it's dependencies and start the UI.
+
+```bash
+cd ui
+npm run build_and_start
+```
+
+You can now access the UI at `http://localhost:8675` or `http://
+
+The AI Toolkit UI is a web interface for the AI Toolkit. It allows you to easily start, stop, and monitor jobs. It also allows you to easily train models with a few clicks. It also allows you to set a token for the UI to prevent unauthorized access so it is mostly safe to run on an exposed server.
+
+## Running the UI
+
+Requirements:
+- Node.js > 18
+
+The UI does not need to be kept running for the jobs to run. It is only needed to start/stop/monitor jobs. The commands below
+will install / update the UI and it's dependencies and start the UI.
+
+```bash
+cd ui
+npm run build_and_start
+```
+
+You can now access the UI at `http://localhost:8675` or `http://You can optionally add a custom caption for each image (or use an AI model for this). [trigger] will represent your concept sentence/trigger word.
+""", elem_classes="group_padding") + do_captioning = gr.Button("Add AI captions with Florence-2") + output_components = [captioning_area] + caption_list = [] + for i in range(1, MAX_IMAGES + 1): + locals()[f"captioning_row_{i}"] = gr.Row(visible=False) + with locals()[f"captioning_row_{i}"]: + locals()[f"image_{i}"] = gr.Image( + type="filepath", + width=111, + height=111, + min_width=111, + interactive=False, + scale=2, + show_label=False, + show_share_button=False, + show_download_button=False, + ) + locals()[f"caption_{i}"] = gr.Textbox( + label=f"Caption {i}", scale=15, interactive=True + ) + + output_components.append(locals()[f"captioning_row_{i}"]) + output_components.append(locals()[f"image_{i}"]) + output_components.append(locals()[f"caption_{i}"]) + caption_list.append(locals()[f"caption_{i}"]) + + with gr.Accordion("Advanced options", open=False): + steps = gr.Number(label="Steps", value=1000, minimum=1, maximum=10000, step=1) + lr = gr.Number(label="Learning Rate", value=4e-4, minimum=1e-6, maximum=1e-3, step=1e-6) + rank = gr.Number(label="LoRA Rank", value=16, minimum=4, maximum=128, step=4) + model_to_train = gr.Radio(["dev", "schnell"], value="dev", label="Model to train") + low_vram = gr.Checkbox(label="Low VRAM", value=True) + with gr.Accordion("Even more advanced options", open=False): + use_more_advanced_options = gr.Checkbox(label="Use more advanced options", value=False) + more_advanced_options = gr.Code(config_yaml, language="yaml") + + with gr.Accordion("Sample prompts (optional)", visible=False) as sample: + gr.Markdown( + "Include sample prompts to test out your trained model. Don't forget to include your trigger word/sentence (optional)" + ) + sample_1 = gr.Textbox(label="Test prompt 1") + sample_2 = gr.Textbox(label="Test prompt 2") + sample_3 = gr.Textbox(label="Test prompt 3") + + output_components.append(sample) + output_components.append(sample_1) + output_components.append(sample_2) + output_components.append(sample_3) + start = gr.Button("Start training", visible=False) + output_components.append(start) + progress_area = gr.Markdown("") + + dataset_folder = gr.State() + + images.upload( + load_captioning, + inputs=[images, concept_sentence], + outputs=output_components + ) + + images.delete( + load_captioning, + inputs=[images, concept_sentence], + outputs=output_components + ) + + images.clear( + hide_captioning, + outputs=[captioning_area, sample, start] + ) + + start.click(fn=create_dataset, inputs=[images] + caption_list, outputs=dataset_folder).then( + fn=start_training, + inputs=[ + lora_name, + concept_sentence, + steps, + lr, + rank, + model_to_train, + low_vram, + dataset_folder, + sample_1, + sample_2, + sample_3, + use_more_advanced_options, + more_advanced_options + ], + outputs=progress_area, + ) + + do_captioning.click(fn=run_captioning, inputs=[images, concept_sentence] + caption_list, outputs=caption_list) + +if __name__ == "__main__": + demo.launch(share=True, show_error=True) \ No newline at end of file diff --git a/info.py b/info.py new file mode 100644 index 0000000000000000000000000000000000000000..2eb2a82ef027b50275bc70dbe4cfb86f644d65e7 --- /dev/null +++ b/info.py @@ -0,0 +1,9 @@ +from collections import OrderedDict +from version import VERSION + +v = OrderedDict() +v["name"] = "ai-toolkit" +v["repo"] = "https://github.com/ostris/ai-toolkit" +v["version"] = VERSION + +software_meta = v diff --git a/jobs/BaseJob.py b/jobs/BaseJob.py new file mode 100644 index 0000000000000000000000000000000000000000..5b339ebe6d942f73f55e14f3de265e7e1db833b7 --- /dev/null +++ b/jobs/BaseJob.py @@ -0,0 +1,71 @@ +import importlib +from collections import OrderedDict +from typing import List + +from jobs.process import BaseProcess + + +class BaseJob: + + def __init__(self, config: OrderedDict): + if not config: + raise ValueError('config is required') + self.process: List[BaseProcess] + + self.config = config['config'] + self.raw_config = config + self.job = config['job'] + self.name = self.get_conf('name', required=True) + if 'meta' in config: + self.meta = config['meta'] + else: + self.meta = OrderedDict() + + def get_conf(self, key, default=None, required=False): + if key in self.config: + return self.config[key] + elif required: + raise ValueError(f'config file error. Missing "config.{key}" key') + else: + return default + + def run(self): + print("") + print(f"#############################################") + print(f"# Running job: {self.name}") + print(f"#############################################") + print("") + # implement in child class + # be sure to call super().run() first + pass + + def load_processes(self, process_dict: dict): + # only call if you have processes in this job type + if 'process' not in self.config: + raise ValueError('config file is invalid. Missing "config.process" key') + if len(self.config['process']) == 0: + raise ValueError('config file is invalid. "config.process" must be a list of processes') + + module = importlib.import_module('jobs.process') + + # add the processes + self.process = [] + for i, process in enumerate(self.config['process']): + if 'type' not in process: + raise ValueError(f'config file is invalid. Missing "config.process[{i}].type" key') + + # check if dict key is process type + if process['type'] in process_dict: + if isinstance(process_dict[process['type']], str): + ProcessClass = getattr(module, process_dict[process['type']]) + else: + # it is the class + ProcessClass = process_dict[process['type']] + self.process.append(ProcessClass(i, self, process)) + else: + raise ValueError(f'config file is invalid. Unknown process type: {process["type"]}') + + def cleanup(self): + # if you implement this in child clas, + # be sure to call super().cleanup() LAST + del self diff --git a/jobs/ExtensionJob.py b/jobs/ExtensionJob.py new file mode 100644 index 0000000000000000000000000000000000000000..def4f8530a8a92c65369cd63a3e69c16bf0bb7de --- /dev/null +++ b/jobs/ExtensionJob.py @@ -0,0 +1,22 @@ +import os +from collections import OrderedDict +from jobs import BaseJob +from toolkit.extension import get_all_extensions_process_dict +from toolkit.paths import CONFIG_ROOT + +class ExtensionJob(BaseJob): + + def __init__(self, config: OrderedDict): + super().__init__(config) + self.device = self.get_conf('device', 'cpu') + self.process_dict = get_all_extensions_process_dict() + self.load_processes(self.process_dict) + + def run(self): + super().run() + + print("") + print(f"Running {len(self.process)} process{'' if len(self.process) == 1 else 'es'}") + + for process in self.process: + process.run() diff --git a/jobs/ExtractJob.py b/jobs/ExtractJob.py new file mode 100644 index 0000000000000000000000000000000000000000..d710d4128db5304569357ee05d2fb31fa15c6e39 --- /dev/null +++ b/jobs/ExtractJob.py @@ -0,0 +1,58 @@ +from toolkit.kohya_model_util import load_models_from_stable_diffusion_checkpoint +from collections import OrderedDict +from jobs import BaseJob +from toolkit.train_tools import get_torch_dtype + +process_dict = { + 'locon': 'ExtractLoconProcess', + 'lora': 'ExtractLoraProcess', +} + + +class ExtractJob(BaseJob): + + def __init__(self, config: OrderedDict): + super().__init__(config) + self.base_model_path = self.get_conf('base_model', required=True) + self.model_base = None + self.model_base_text_encoder = None + self.model_base_vae = None + self.model_base_unet = None + self.extract_model_path = self.get_conf('extract_model', required=True) + self.model_extract = None + self.model_extract_text_encoder = None + self.model_extract_vae = None + self.model_extract_unet = None + self.extract_unet = self.get_conf('extract_unet', True) + self.extract_text_encoder = self.get_conf('extract_text_encoder', True) + self.dtype = self.get_conf('dtype', 'fp16') + self.torch_dtype = get_torch_dtype(self.dtype) + self.output_folder = self.get_conf('output_folder', required=True) + self.is_v2 = self.get_conf('is_v2', False) + self.device = self.get_conf('device', 'cpu') + + # loads the processes from the config + self.load_processes(process_dict) + + def run(self): + super().run() + # load models + print(f"Loading models for extraction") + print(f" - Loading base model: {self.base_model_path}") + # (text_model, vae, unet) + self.model_base = load_models_from_stable_diffusion_checkpoint(self.is_v2, self.base_model_path) + self.model_base_text_encoder = self.model_base[0] + self.model_base_vae = self.model_base[1] + self.model_base_unet = self.model_base[2] + + print(f" - Loading extract model: {self.extract_model_path}") + self.model_extract = load_models_from_stable_diffusion_checkpoint(self.is_v2, self.extract_model_path) + self.model_extract_text_encoder = self.model_extract[0] + self.model_extract_vae = self.model_extract[1] + self.model_extract_unet = self.model_extract[2] + + print("") + print(f"Running {len(self.process)} process{'' if len(self.process) == 1 else 'es'}") + + for process in self.process: + process.run() diff --git a/jobs/GenerateJob.py b/jobs/GenerateJob.py new file mode 100644 index 0000000000000000000000000000000000000000..bd57a6ac7a1a97d9e68e86131b9e61ac9922e6d0 --- /dev/null +++ b/jobs/GenerateJob.py @@ -0,0 +1,24 @@ +from jobs import BaseJob +from collections import OrderedDict + +process_dict = { + 'to_folder': 'GenerateProcess', +} + + +class GenerateJob(BaseJob): + + def __init__(self, config: OrderedDict): + super().__init__(config) + self.device = self.get_conf('device', 'cpu') + + # loads the processes from the config + self.load_processes(process_dict) + + def run(self): + super().run() + print("") + print(f"Running {len(self.process)} process{'' if len(self.process) == 1 else 'es'}") + + for process in self.process: + process.run() diff --git a/jobs/MergeJob.py b/jobs/MergeJob.py new file mode 100644 index 0000000000000000000000000000000000000000..b9e3b87b9ff589438d06c56019446f06efb76cda --- /dev/null +++ b/jobs/MergeJob.py @@ -0,0 +1,29 @@ +from toolkit.kohya_model_util import load_models_from_stable_diffusion_checkpoint +from collections import OrderedDict +from jobs import BaseJob +from toolkit.train_tools import get_torch_dtype + +process_dict = { +} + + +class MergeJob(BaseJob): + + def __init__(self, config: OrderedDict): + super().__init__(config) + self.dtype = self.get_conf('dtype', 'fp16') + self.torch_dtype = get_torch_dtype(self.dtype) + self.is_v2 = self.get_conf('is_v2', False) + self.device = self.get_conf('device', 'cpu') + + # loads the processes from the config + self.load_processes(process_dict) + + def run(self): + super().run() + + print("") + print(f"Running {len(self.process)} process{'' if len(self.process) == 1 else 'es'}") + + for process in self.process: + process.run() diff --git a/jobs/ModJob.py b/jobs/ModJob.py new file mode 100644 index 0000000000000000000000000000000000000000..e37990de95a0d2ad78a94f9cdfd6dfbda0cdc529 --- /dev/null +++ b/jobs/ModJob.py @@ -0,0 +1,28 @@ +import os +from collections import OrderedDict +from jobs import BaseJob +from toolkit.metadata import get_meta_for_safetensors +from toolkit.train_tools import get_torch_dtype + +process_dict = { + 'rescale_lora': 'ModRescaleLoraProcess', +} + + +class ModJob(BaseJob): + + def __init__(self, config: OrderedDict): + super().__init__(config) + self.device = self.get_conf('device', 'cpu') + + # loads the processes from the config + self.load_processes(process_dict) + + def run(self): + super().run() + + print("") + print(f"Running {len(self.process)} process{'' if len(self.process) == 1 else 'es'}") + + for process in self.process: + process.run() diff --git a/jobs/TrainJob.py b/jobs/TrainJob.py new file mode 100644 index 0000000000000000000000000000000000000000..b4982d26690a0c63d5dbdd9063614308ee94491f --- /dev/null +++ b/jobs/TrainJob.py @@ -0,0 +1,44 @@ +import json +import os + +from jobs import BaseJob +from toolkit.kohya_model_util import load_models_from_stable_diffusion_checkpoint +from collections import OrderedDict +from typing import List +from jobs.process import BaseExtractProcess, TrainFineTuneProcess +from datetime import datetime + + +process_dict = { + 'vae': 'TrainVAEProcess', + 'slider': 'TrainSliderProcess', + 'slider_old': 'TrainSliderProcessOld', + 'lora_hack': 'TrainLoRAHack', + 'rescale_sd': 'TrainSDRescaleProcess', + 'esrgan': 'TrainESRGANProcess', + 'reference': 'TrainReferenceProcess', +} + + +class TrainJob(BaseJob): + + def __init__(self, config: OrderedDict): + super().__init__(config) + self.training_folder = self.get_conf('training_folder', required=True) + self.is_v2 = self.get_conf('is_v2', False) + self.device = self.get_conf('device', 'cpu') + # self.gradient_accumulation_steps = self.get_conf('gradient_accumulation_steps', 1) + # self.mixed_precision = self.get_conf('mixed_precision', False) # fp16 + self.log_dir = self.get_conf('log_dir', None) + + # loads the processes from the config + self.load_processes(process_dict) + + + def run(self): + super().run() + print("") + print(f"Running {len(self.process)} process{'' if len(self.process) == 1 else 'es'}") + + for process in self.process: + process.run() diff --git a/jobs/__init__.py b/jobs/__init__.py new file mode 100644 index 0000000000000000000000000000000000000000..7da6c22b1ddd0ea9248e5afbf9b2ba014c137c1a --- /dev/null +++ b/jobs/__init__.py @@ -0,0 +1,7 @@ +from .BaseJob import BaseJob +from .ExtractJob import ExtractJob +from .TrainJob import TrainJob +from .MergeJob import MergeJob +from .ModJob import ModJob +from .GenerateJob import GenerateJob +from .ExtensionJob import ExtensionJob diff --git a/jobs/process/BaseExtensionProcess.py b/jobs/process/BaseExtensionProcess.py new file mode 100644 index 0000000000000000000000000000000000000000..b53dc1c498e64bb4adbc2b967b329fdc4a374925 --- /dev/null +++ b/jobs/process/BaseExtensionProcess.py @@ -0,0 +1,19 @@ +from collections import OrderedDict +from typing import ForwardRef +from jobs.process.BaseProcess import BaseProcess + + +class BaseExtensionProcess(BaseProcess): + def __init__( + self, + process_id: int, + job, + config: OrderedDict + ): + super().__init__(process_id, job, config) + self.process_id: int + self.config: OrderedDict + self.progress_bar: ForwardRef('tqdm') = None + + def run(self): + super().run() diff --git a/jobs/process/BaseExtractProcess.py b/jobs/process/BaseExtractProcess.py new file mode 100644 index 0000000000000000000000000000000000000000..ac10da54d82f15c8264b2799b10b01bb5cf8dc66 --- /dev/null +++ b/jobs/process/BaseExtractProcess.py @@ -0,0 +1,86 @@ +import os +from collections import OrderedDict + +from safetensors.torch import save_file + +from jobs.process.BaseProcess import BaseProcess +from toolkit.metadata import get_meta_for_safetensors + +from typing import ForwardRef + +from toolkit.train_tools import get_torch_dtype + + +class BaseExtractProcess(BaseProcess): + + def __init__( + self, + process_id: int, + job, + config: OrderedDict + ): + super().__init__(process_id, job, config) + self.config: OrderedDict + self.output_folder: str + self.output_filename: str + self.output_path: str + self.process_id = process_id + self.job = job + self.config = config + self.dtype = self.get_conf('dtype', self.job.dtype) + self.torch_dtype = get_torch_dtype(self.dtype) + self.extract_unet = self.get_conf('extract_unet', self.job.extract_unet) + self.extract_text_encoder = self.get_conf('extract_text_encoder', self.job.extract_text_encoder) + + def run(self): + # here instead of init because child init needs to go first + self.output_path = self.get_output_path() + # implement in child class + # be sure to call super().run() first + pass + + # you can override this in the child class if you want + # call super().get_output_path(prefix="your_prefix_", suffix="_your_suffix") to extend this + def get_output_path(self, prefix=None, suffix=None): + config_output_path = self.get_conf('output_path', None) + config_filename = self.get_conf('filename', None) + # replace [name] with name + + if config_output_path is not None: + config_output_path = config_output_path.replace('[name]', self.job.name) + return config_output_path + + if config_output_path is None and config_filename is not None: + # build the output path from the output folder and filename + return os.path.join(self.job.output_folder, config_filename) + + # build our own + + if suffix is None: + # we will just add process it to the end of the filename if there is more than one process + # and no other suffix was given + suffix = f"_{self.process_id}" if len(self.config['process']) > 1 else '' + + if prefix is None: + prefix = '' + + output_filename = f"{prefix}{self.output_filename}{suffix}" + + return os.path.join(self.job.output_folder, output_filename) + + def save(self, state_dict): + # prepare meta + save_meta = get_meta_for_safetensors(self.meta, self.job.name) + + # save + os.makedirs(os.path.dirname(self.output_path), exist_ok=True) + + for key in list(state_dict.keys()): + v = state_dict[key] + v = v.detach().clone().to("cpu").to(self.torch_dtype) + state_dict[key] = v + + # having issues with meta + save_file(state_dict, self.output_path, save_meta) + + print(f"Saved to {self.output_path}") diff --git a/jobs/process/BaseMergeProcess.py b/jobs/process/BaseMergeProcess.py new file mode 100644 index 0000000000000000000000000000000000000000..55dfec68ae62383afae539ff6cb51862033a7e10 --- /dev/null +++ b/jobs/process/BaseMergeProcess.py @@ -0,0 +1,46 @@ +import os +from collections import OrderedDict + +from safetensors.torch import save_file + +from jobs.process.BaseProcess import BaseProcess +from toolkit.metadata import get_meta_for_safetensors +from toolkit.train_tools import get_torch_dtype + + +class BaseMergeProcess(BaseProcess): + + def __init__( + self, + process_id: int, + job, + config: OrderedDict + ): + super().__init__(process_id, job, config) + self.process_id: int + self.config: OrderedDict + self.output_path = self.get_conf('output_path', required=True) + self.dtype = self.get_conf('dtype', self.job.dtype) + self.torch_dtype = get_torch_dtype(self.dtype) + + def run(self): + # implement in child class + # be sure to call super().run() first + pass + + def save(self, state_dict): + # prepare meta + save_meta = get_meta_for_safetensors(self.meta, self.job.name) + + # save + os.makedirs(os.path.dirname(self.output_path), exist_ok=True) + + for key in list(state_dict.keys()): + v = state_dict[key] + v = v.detach().clone().to("cpu").to(self.torch_dtype) + state_dict[key] = v + + # having issues with meta + save_file(state_dict, self.output_path, save_meta) + + print(f"Saved to {self.output_path}") diff --git a/jobs/process/BaseProcess.py b/jobs/process/BaseProcess.py new file mode 100644 index 0000000000000000000000000000000000000000..c58724c987abb4521efc2afa9b1a85740f7429b8 --- /dev/null +++ b/jobs/process/BaseProcess.py @@ -0,0 +1,64 @@ +import copy +import json +from collections import OrderedDict + +from toolkit.timer import Timer + + +class BaseProcess(object): + + def __init__( + self, + process_id: int, + job: 'BaseJob', + config: OrderedDict + ): + self.process_id = process_id + self.meta: OrderedDict + self.job = job + self.config = config + self.raw_process_config = config + self.name = self.get_conf('name', self.job.name) + self.meta = copy.deepcopy(self.job.meta) + self.timer: Timer = Timer(f'{self.name} Timer') + self.performance_log_every = self.get_conf('performance_log_every', 0) + + print(json.dumps(self.config, indent=4)) + + def on_error(self, e: Exception): + pass + + def get_conf(self, key, default=None, required=False, as_type=None): + # split key by '.' and recursively get the value + keys = key.split('.') + + # see if it exists in the config + value = self.config + for subkey in keys: + if subkey in value: + value = value[subkey] + else: + value = None + break + + if value is not None: + if as_type is not None: + value = as_type(value) + return value + elif required: + raise ValueError(f'config file error. Missing "config.process[{self.process_id}].{key}" key') + else: + if as_type is not None and default is not None: + return as_type(default) + return default + + def run(self): + # implement in child class + # be sure to call super().run() first incase something is added here + pass + + def add_meta(self, additional_meta: OrderedDict): + self.meta.update(additional_meta) + + +from jobs import BaseJob diff --git a/jobs/process/BaseSDTrainProcess.py b/jobs/process/BaseSDTrainProcess.py new file mode 100644 index 0000000000000000000000000000000000000000..84c941bbb438d7f577a973f102cd164642842281 --- /dev/null +++ b/jobs/process/BaseSDTrainProcess.py @@ -0,0 +1,2453 @@ +import copy +import glob +import inspect +import json +import random +import shutil +from collections import OrderedDict +import os +import re +import traceback +from typing import Union, List, Optional + +import numpy as np +import yaml +from diffusers import T2IAdapter, ControlNetModel +from diffusers.training_utils import compute_density_for_timestep_sampling +from safetensors.torch import save_file, load_file +# from lycoris.config import PRESET +from torch.utils.data import DataLoader +import torch +import torch.backends.cuda +from huggingface_hub import HfApi, Repository, interpreter_login +from huggingface_hub.utils import HfFolder + +from toolkit.basic import value_map +from toolkit.clip_vision_adapter import ClipVisionAdapter +from toolkit.custom_adapter import CustomAdapter +from toolkit.data_loader import get_dataloader_from_datasets, trigger_dataloader_setup_epoch +from toolkit.data_transfer_object.data_loader import FileItemDTO, DataLoaderBatchDTO +from toolkit.ema import ExponentialMovingAverage +from toolkit.embedding import Embedding +from toolkit.image_utils import show_tensors, show_latents, reduce_contrast +from toolkit.ip_adapter import IPAdapter +from toolkit.lora_special import LoRASpecialNetwork +from toolkit.lorm import convert_diffusers_unet_to_lorm, count_parameters, print_lorm_extract_details, \ + lorm_ignore_if_contains, lorm_parameter_threshold, LORM_TARGET_REPLACE_MODULE +from toolkit.lycoris_special import LycorisSpecialNetwork +from toolkit.models.decorator import Decorator +from toolkit.network_mixins import Network +from toolkit.optimizer import get_optimizer +from toolkit.paths import CONFIG_ROOT +from toolkit.progress_bar import ToolkitProgressBar +from toolkit.reference_adapter import ReferenceAdapter +from toolkit.sampler import get_sampler +from toolkit.saving import save_t2i_from_diffusers, load_t2i_model, save_ip_adapter_from_diffusers, \ + load_ip_adapter_model, load_custom_adapter_model + +from toolkit.scheduler import get_lr_scheduler +from toolkit.sd_device_states_presets import get_train_sd_device_state_preset +from toolkit.stable_diffusion_model import StableDiffusion + +from jobs.process import BaseTrainProcess +from toolkit.metadata import get_meta_for_safetensors, load_metadata_from_safetensors, add_base_model_info_to_meta, \ + parse_metadata_from_safetensors +from toolkit.train_tools import get_torch_dtype, LearnableSNRGamma, apply_learnable_snr_gos, apply_snr_weight +import gc + +from tqdm import tqdm + +from toolkit.config_modules import SaveConfig, LoggingConfig, SampleConfig, NetworkConfig, TrainConfig, ModelConfig, \ + GenerateImageConfig, EmbeddingConfig, DatasetConfig, preprocess_dataset_raw_config, AdapterConfig, GuidanceConfig, validate_configs, \ + DecoratorConfig +from toolkit.logging_aitk import create_logger +from diffusers import FluxTransformer2DModel +from toolkit.accelerator import get_accelerator, unwrap_model +from toolkit.print import print_acc +from accelerate import Accelerator +import transformers +import diffusers +import hashlib + +from toolkit.util.blended_blur_noise import get_blended_blur_noise +from toolkit.util.get_model import get_model_class + +def flush(): + torch.cuda.empty_cache() + gc.collect() + + +class BaseSDTrainProcess(BaseTrainProcess): + + def __init__(self, process_id: int, job, config: OrderedDict, custom_pipeline=None): + super().__init__(process_id, job, config) + self.accelerator: Accelerator = get_accelerator() + if self.accelerator.is_local_main_process: + transformers.utils.logging.set_verbosity_warning() + diffusers.utils.logging.set_verbosity_error() + else: + transformers.utils.logging.set_verbosity_error() + diffusers.utils.logging.set_verbosity_error() + + self.sd: StableDiffusion + self.embedding: Union[Embedding, None] = None + + self.custom_pipeline = custom_pipeline + self.step_num = 0 + self.start_step = 0 + self.epoch_num = 0 + self.last_save_step = 0 + # start at 1 so we can do a sample at the start + self.grad_accumulation_step = 1 + # if true, then we do not do an optimizer step. We are accumulating gradients + self.is_grad_accumulation_step = False + self.device = str(self.accelerator.device) + self.device_torch = self.accelerator.device + network_config = self.get_conf('network', None) + if network_config is not None: + self.network_config = NetworkConfig(**network_config) + else: + self.network_config = None + self.train_config = TrainConfig(**self.get_conf('train', {})) + model_config = self.get_conf('model', {}) + self.modules_being_trained: List[torch.nn.Module] = [] + + # update modelconfig dtype to match train + model_config['dtype'] = self.train_config.dtype + self.model_config = ModelConfig(**model_config) + + self.save_config = SaveConfig(**self.get_conf('save', {})) + self.sample_config = SampleConfig(**self.get_conf('sample', {})) + first_sample_config = self.get_conf('first_sample', None) + if first_sample_config is not None: + self.has_first_sample_requested = True + self.first_sample_config = SampleConfig(**first_sample_config) + else: + self.has_first_sample_requested = False + self.first_sample_config = self.sample_config + self.logging_config = LoggingConfig(**self.get_conf('logging', {})) + self.logger = create_logger(self.logging_config, config) + self.optimizer: torch.optim.Optimizer = None + self.lr_scheduler = None + self.data_loader: Union[DataLoader, None] = None + self.data_loader_reg: Union[DataLoader, None] = None + self.trigger_word = self.get_conf('trigger_word', None) + + self.guidance_config: Union[GuidanceConfig, None] = None + guidance_config_raw = self.get_conf('guidance', None) + if guidance_config_raw is not None: + self.guidance_config = GuidanceConfig(**guidance_config_raw) + + # store is all are cached. Allows us to not load vae if we don't need to + self.is_latents_cached = True + raw_datasets = self.get_conf('datasets', None) + if raw_datasets is not None and len(raw_datasets) > 0: + raw_datasets = preprocess_dataset_raw_config(raw_datasets) + self.datasets = None + self.datasets_reg = None + self.dataset_configs: List[DatasetConfig] = [] + self.params = [] + + # add dataset text embedding cache to their config + if self.train_config.cache_text_embeddings: + for raw_dataset in raw_datasets: + raw_dataset['cache_text_embeddings'] = True + + if raw_datasets is not None and len(raw_datasets) > 0: + for raw_dataset in raw_datasets: + dataset = DatasetConfig(**raw_dataset) + is_caching = dataset.cache_latents or dataset.cache_latents_to_disk + if not is_caching: + self.is_latents_cached = False + if dataset.is_reg: + if self.datasets_reg is None: + self.datasets_reg = [] + self.datasets_reg.append(dataset) + else: + if self.datasets is None: + self.datasets = [] + self.datasets.append(dataset) + self.dataset_configs.append(dataset) + + self.is_caching_text_embeddings = any( + dataset.cache_text_embeddings for dataset in self.dataset_configs + ) + + # cannot train trigger word if caching text embeddings + if self.is_caching_text_embeddings and self.trigger_word is not None: + raise ValueError("Cannot train trigger word if caching text embeddings. Please remove the trigger word or disable text embedding caching.") + + self.embed_config = None + embedding_raw = self.get_conf('embedding', None) + if embedding_raw is not None: + self.embed_config = EmbeddingConfig(**embedding_raw) + + self.decorator_config: DecoratorConfig = None + decorator_raw = self.get_conf('decorator', None) + if decorator_raw is not None: + if not self.model_config.is_flux: + raise ValueError("Decorators are only supported for Flux models currently") + self.decorator_config = DecoratorConfig(**decorator_raw) + + # t2i adapter + self.adapter_config = None + adapter_raw = self.get_conf('adapter', None) + if adapter_raw is not None: + self.adapter_config = AdapterConfig(**adapter_raw) + # sdxl adapters end in _xl. Only full_adapter_xl for now + if self.model_config.is_xl and not self.adapter_config.adapter_type.endswith('_xl'): + self.adapter_config.adapter_type += '_xl' + + # to hold network if there is one + self.network: Union[Network, None] = None + self.adapter: Union[T2IAdapter, IPAdapter, ClipVisionAdapter, ReferenceAdapter, CustomAdapter, ControlNetModel, None] = None + self.embedding: Union[Embedding, None] = None + self.decorator: Union[Decorator, None] = None + + is_training_adapter = self.adapter_config is not None and self.adapter_config.train + + self.do_lorm = self.get_conf('do_lorm', False) + self.lorm_extract_mode = self.get_conf('lorm_extract_mode', 'ratio') + self.lorm_extract_mode_param = self.get_conf('lorm_extract_mode_param', 0.25) + # 'ratio', 0.25) + + # get the device state preset based on what we are training + self.train_device_state_preset = get_train_sd_device_state_preset( + device=self.device_torch, + train_unet=self.train_config.train_unet, + train_text_encoder=self.train_config.train_text_encoder, + cached_latents=self.is_latents_cached, + train_lora=self.network_config is not None, + train_adapter=is_training_adapter, + train_embedding=self.embed_config is not None, + train_decorator=self.decorator_config is not None, + train_refiner=self.train_config.train_refiner, + unload_text_encoder=self.train_config.unload_text_encoder or self.is_caching_text_embeddings, + require_grads=False # we ensure them later + ) + + self.get_params_device_state_preset = get_train_sd_device_state_preset( + device=self.device_torch, + train_unet=self.train_config.train_unet, + train_text_encoder=self.train_config.train_text_encoder, + cached_latents=self.is_latents_cached, + train_lora=self.network_config is not None, + train_adapter=is_training_adapter, + train_embedding=self.embed_config is not None, + train_decorator=self.decorator_config is not None, + train_refiner=self.train_config.train_refiner, + unload_text_encoder=self.train_config.unload_text_encoder or self.is_caching_text_embeddings, + require_grads=True # We check for grads when getting params + ) + + # fine_tuning here is for training actual SD network, not LoRA, embeddings, etc. it is (Dreambooth, etc) + self.is_fine_tuning = True + if self.network_config is not None or is_training_adapter or self.embed_config is not None or self.decorator_config is not None: + self.is_fine_tuning = False + + self.named_lora = False + if self.embed_config is not None or is_training_adapter: + self.named_lora = True + self.snr_gos: Union[LearnableSNRGamma, None] = None + self.ema: ExponentialMovingAverage = None + + validate_configs(self.train_config, self.model_config, self.save_config, self.dataset_configs) + + do_profiler = self.get_conf('torch_profiler', False) + self.torch_profiler = None if not do_profiler else torch.profiler.profile( + activities=[ + torch.profiler.ProfilerActivity.CPU, + torch.profiler.ProfilerActivity.CUDA, + ], + ) + + self.current_boundary_index = 0 + self.steps_this_boundary = 0 + + def post_process_generate_image_config_list(self, generate_image_config_list: List[GenerateImageConfig]): + # override in subclass + return generate_image_config_list + + def sample(self, step=None, is_first=False): + if not self.accelerator.is_main_process: + return + flush() + sample_folder = os.path.join(self.save_root, 'samples') + gen_img_config_list = [] + + sample_config = self.first_sample_config if is_first else self.sample_config + start_seed = sample_config.seed + current_seed = start_seed + + test_image_paths = [] + if self.adapter_config is not None and self.adapter_config.test_img_path is not None: + test_image_path_list = self.adapter_config.test_img_path + # divide up images so they are evenly distributed across prompts + for i in range(len(sample_config.prompts)): + test_image_paths.append(test_image_path_list[i % len(test_image_path_list)]) + + for i in range(len(sample_config.prompts)): + if sample_config.walk_seed: + current_seed = start_seed + i + + step_num = '' + if step is not None: + # zero-pad 9 digits + step_num = f"_{str(step).zfill(9)}" + + filename = f"[time]_{step_num}_[count].{self.sample_config.ext}" + + output_path = os.path.join(sample_folder, filename) + + prompt = sample_config.prompts[i] + + # add embedding if there is one + # note: diffusers will automatically expand the trigger to the number of added tokens + # ie test123 will become test123 test123_1 test123_2 etc. Do not add this yourself here + if self.embedding is not None: + prompt = self.embedding.inject_embedding_to_prompt( + prompt, expand_token=True, add_if_not_present=False + ) + if self.adapter is not None and isinstance(self.adapter, ClipVisionAdapter): + prompt = self.adapter.inject_trigger_into_prompt( + prompt, expand_token=True, add_if_not_present=False + ) + if self.trigger_word is not None: + prompt = self.sd.inject_trigger_into_prompt( + prompt, self.trigger_word, add_if_not_present=False + ) + + extra_args = {} + if self.adapter_config is not None and self.adapter_config.test_img_path is not None: + extra_args['adapter_image_path'] = test_image_paths[i] + + sample_item = sample_config.samples[i] + if sample_item.seed is not None: + current_seed = sample_item.seed + + gen_img_config_list.append(GenerateImageConfig( + prompt=prompt, # it will autoparse the prompt + width=sample_item.width, + height=sample_item.height, + negative_prompt=sample_item.neg, + seed=current_seed, + guidance_scale=sample_item.guidance_scale, + guidance_rescale=sample_config.guidance_rescale, + num_inference_steps=sample_item.sample_steps, + network_multiplier=sample_item.network_multiplier, + output_path=output_path, + output_ext=sample_config.ext, + adapter_conditioning_scale=sample_config.adapter_conditioning_scale, + refiner_start_at=sample_config.refiner_start_at, + extra_values=sample_config.extra_values, + logger=self.logger, + num_frames=sample_item.num_frames, + fps=sample_item.fps, + ctrl_img=sample_item.ctrl_img, + ctrl_idx=sample_item.ctrl_idx, + **extra_args + )) + + # post process + gen_img_config_list = self.post_process_generate_image_config_list(gen_img_config_list) + + # if we have an ema, set it to validation mode + if self.ema is not None: + self.ema.eval() + + # let adapter know we are sampling + if self.adapter is not None and isinstance(self.adapter, CustomAdapter): + self.adapter.is_sampling = True + + # send to be generated + self.sd.generate_images(gen_img_config_list, sampler=sample_config.sampler) + + + if self.adapter is not None and isinstance(self.adapter, CustomAdapter): + self.adapter.is_sampling = False + + if self.ema is not None: + self.ema.train() + + def update_training_metadata(self): + o_dict = OrderedDict({ + "training_info": self.get_training_info() + }) + o_dict['ss_base_model_version'] = self.sd.get_base_model_version() + + # o_dict = add_base_model_info_to_meta( + # o_dict, + # is_v2=self.model_config.is_v2, + # is_xl=self.model_config.is_xl, + # ) + o_dict['ss_output_name'] = self.job.name + + if self.trigger_word is not None: + # just so auto1111 will pick it up + o_dict['ss_tag_frequency'] = { + f"1_{self.trigger_word}": { + f"{self.trigger_word}": 1 + } + } + + self.add_meta(o_dict) + + def get_training_info(self): + info = OrderedDict({ + 'step': self.step_num, + 'epoch': self.epoch_num, + }) + return info + + def clean_up_saves(self): + if not self.accelerator.is_main_process: + return + # remove old saves + # get latest saved step + latest_item = None + if os.path.exists(self.save_root): + # pattern is {job_name}_{zero_filled_step} for both files and directories + pattern = f"{self.job.name}_*" + items = glob.glob(os.path.join(self.save_root, pattern)) + # Separate files and directories + safetensors_files = [f for f in items if f.endswith('.safetensors')] + pt_files = [f for f in items if f.endswith('.pt')] + directories = [d for d in items if os.path.isdir(d) and not d.endswith('.safetensors')] + embed_files = [] + # do embedding files + if self.embed_config is not None: + embed_pattern = f"{self.embed_config.trigger}_*" + embed_items = glob.glob(os.path.join(self.save_root, embed_pattern)) + # will end in safetensors or pt + embed_files = [f for f in embed_items if f.endswith('.safetensors') or f.endswith('.pt')] + + # check for critic files + critic_pattern = f"CRITIC_{self.job.name}_*" + critic_items = glob.glob(os.path.join(self.save_root, critic_pattern)) + + # Sort the lists by creation time if they are not empty + if safetensors_files: + safetensors_files.sort(key=os.path.getctime) + if pt_files: + pt_files.sort(key=os.path.getctime) + if directories: + directories.sort(key=os.path.getctime) + if embed_files: + embed_files.sort(key=os.path.getctime) + if critic_items: + critic_items.sort(key=os.path.getctime) + + # Combine and sort the lists + combined_items = safetensors_files + directories + pt_files + combined_items.sort(key=os.path.getctime) + + num_saves_to_keep = self.save_config.max_step_saves_to_keep + + if hasattr(self.sd, 'max_step_saves_to_keep_multiplier'): + num_saves_to_keep *= self.sd.max_step_saves_to_keep_multiplier + + # Use slicing with a check to avoid 'NoneType' error + safetensors_to_remove = safetensors_files[ + :-num_saves_to_keep] if safetensors_files else [] + pt_files_to_remove = pt_files[:-num_saves_to_keep] if pt_files else [] + directories_to_remove = directories[:-num_saves_to_keep] if directories else [] + embeddings_to_remove = embed_files[:-num_saves_to_keep] if embed_files else [] + critic_to_remove = critic_items[:-num_saves_to_keep] if critic_items else [] + + items_to_remove = safetensors_to_remove + pt_files_to_remove + directories_to_remove + embeddings_to_remove + critic_to_remove + + # remove all but the latest max_step_saves_to_keep + # items_to_remove = combined_items[:-num_saves_to_keep] + + # remove duplicates + items_to_remove = list(dict.fromkeys(items_to_remove)) + + for item in items_to_remove: + print_acc(f"Removing old save: {item}") + if os.path.isdir(item): + shutil.rmtree(item) + else: + os.remove(item) + # see if a yaml file with same name exists + yaml_file = os.path.splitext(item)[0] + ".yaml" + if os.path.exists(yaml_file): + os.remove(yaml_file) + if combined_items: + latest_item = combined_items[-1] + return latest_item + + def post_save_hook(self, save_path): + # override in subclass + pass + + def done_hook(self): + pass + + def end_step_hook(self): + pass + + def save(self, step=None): + if not self.accelerator.is_main_process: + return + flush() + if self.ema is not None: + # always save params as ema + self.ema.eval() + + if not os.path.exists(self.save_root): + os.makedirs(self.save_root, exist_ok=True) + + step_num = '' + if step is not None: + self.last_save_step = step + # zeropad 9 digits + step_num = f"_{str(step).zfill(9)}" + + self.update_training_metadata() + filename = f'{self.job.name}{step_num}.safetensors' + file_path = os.path.join(self.save_root, filename) + + save_meta = copy.deepcopy(self.meta) + # get extra meta + if self.adapter is not None and isinstance(self.adapter, CustomAdapter): + additional_save_meta = self.adapter.get_additional_save_metadata() + if additional_save_meta is not None: + for key, value in additional_save_meta.items(): + save_meta[key] = value + + # prepare meta + save_meta = get_meta_for_safetensors(save_meta, self.job.name) + if not self.is_fine_tuning: + if self.network is not None: + lora_name = self.job.name + if self.named_lora: + # add _lora to name + lora_name += '_LoRA' + + filename = f'{lora_name}{step_num}.safetensors' + file_path = os.path.join(self.save_root, filename) + prev_multiplier = self.network.multiplier + self.network.multiplier = 1.0 + + # if we are doing embedding training as well, add that + embedding_dict = self.embedding.state_dict() if self.embedding else None + self.network.save_weights( + file_path, + dtype=get_torch_dtype(self.save_config.dtype), + metadata=save_meta, + extra_state_dict=embedding_dict + ) + self.network.multiplier = prev_multiplier + # if we have an embedding as well, pair it with the network + + # even if added to lora, still save the trigger version + if self.embedding is not None: + emb_filename = f'{self.embed_config.trigger}{step_num}.safetensors' + emb_file_path = os.path.join(self.save_root, emb_filename) + # for combo, above will get it + # set current step + self.embedding.step = self.step_num + # change filename to pt if that is set + if self.embed_config.save_format == "pt": + # replace extension + emb_file_path = os.path.splitext(emb_file_path)[0] + ".pt" + self.embedding.save(emb_file_path) + + if self.decorator is not None: + dec_filename = f'{self.job.name}{step_num}.safetensors' + dec_file_path = os.path.join(self.save_root, dec_filename) + decorator_state_dict = self.decorator.state_dict() + for key, value in decorator_state_dict.items(): + if isinstance(value, torch.Tensor): + decorator_state_dict[key] = value.clone().to('cpu', dtype=get_torch_dtype(self.save_config.dtype)) + save_file( + decorator_state_dict, + dec_file_path, + metadata=save_meta, + ) + + if self.adapter is not None and self.adapter_config.train: + adapter_name = self.job.name + if self.network_config is not None or self.embedding is not None: + # add _lora to name + if self.adapter_config.type == 't2i': + adapter_name += '_t2i' + elif self.adapter_config.type == 'control_net': + adapter_name += '_cn' + elif self.adapter_config.type == 'clip': + adapter_name += '_clip' + elif self.adapter_config.type.startswith('ip'): + adapter_name += '_ip' + else: + adapter_name += '_adapter' + + filename = f'{adapter_name}{step_num}.safetensors' + file_path = os.path.join(self.save_root, filename) + # save adapter + state_dict = self.adapter.state_dict() + if self.adapter_config.type == 't2i': + save_t2i_from_diffusers( + state_dict, + output_file=file_path, + meta=save_meta, + dtype=get_torch_dtype(self.save_config.dtype) + ) + elif self.adapter_config.type == 'control_net': + # save in diffusers format + name_or_path = file_path.replace('.safetensors', '') + # move it to the new dtype and cpu + orig_device = self.adapter.device + orig_dtype = self.adapter.dtype + self.adapter = self.adapter.to(torch.device('cpu'), dtype=get_torch_dtype(self.save_config.dtype)) + self.adapter.save_pretrained( + name_or_path, + dtype=get_torch_dtype(self.save_config.dtype), + safe_serialization=True + ) + meta_path = os.path.join(name_or_path, 'aitk_meta.yaml') + with open(meta_path, 'w') as f: + yaml.dump(self.meta, f) + # move it back + self.adapter = self.adapter.to(orig_device, dtype=orig_dtype) + else: + direct_save = False + if self.adapter_config.train_only_image_encoder: + direct_save = True + elif isinstance(self.adapter, CustomAdapter): + direct_save = self.adapter.do_direct_save + save_ip_adapter_from_diffusers( + state_dict, + output_file=file_path, + meta=save_meta, + dtype=get_torch_dtype(self.save_config.dtype), + direct_save=direct_save + ) + else: + if self.save_config.save_format == "diffusers": + # saving as a folder path + file_path = file_path.replace('.safetensors', '') + # convert it back to normal object + save_meta = parse_metadata_from_safetensors(save_meta) + + if self.sd.refiner_unet and self.train_config.train_refiner: + # save refiner + refiner_name = self.job.name + '_refiner' + filename = f'{refiner_name}{step_num}.safetensors' + file_path = os.path.join(self.save_root, filename) + self.sd.save_refiner( + file_path, + save_meta, + get_torch_dtype(self.save_config.dtype) + ) + if self.train_config.train_unet or self.train_config.train_text_encoder: + self.sd.save( + file_path, + save_meta, + get_torch_dtype(self.save_config.dtype) + ) + + # save learnable params as json if we have thim + if self.snr_gos: + json_data = { + 'offset_1': self.snr_gos.offset_1.item(), + 'offset_2': self.snr_gos.offset_2.item(), + 'scale': self.snr_gos.scale.item(), + 'gamma': self.snr_gos.gamma.item(), + } + path_to_save = file_path = os.path.join(self.save_root, 'learnable_snr.json') + with open(path_to_save, 'w') as f: + json.dump(json_data, f, indent=4) + + print_acc(f"Saved checkpoint to {file_path}") + + # save optimizer + if self.optimizer is not None: + try: + filename = f'optimizer.pt' + file_path = os.path.join(self.save_root, filename) + try: + state_dict = unwrap_model(self.optimizer).state_dict() + except Exception as e: + state_dict = self.optimizer.state_dict() + torch.save(state_dict, file_path) + print_acc(f"Saved optimizer to {file_path}") + except Exception as e: + print_acc(e) + print_acc("Could not save optimizer") + + self.clean_up_saves() + self.post_save_hook(file_path) + + if self.ema is not None: + self.ema.train() + flush() + + # Called before the model is loaded + def hook_before_model_load(self): + # override in subclass + pass + + def hook_after_model_load(self): + # override in subclass + pass + + def hook_add_extra_train_params(self, params): + # override in subclass + return params + + def hook_before_train_loop(self): + if self.accelerator.is_main_process: + self.logger.start() + self.prepare_accelerator() + + def sample_step_hook(self, img_num, total_imgs): + pass + + def prepare_accelerator(self): + # set some config + self.accelerator.even_batches=False + + # # prepare all the models stuff for accelerator (hopefully we dont miss any) + self.sd.vae = self.accelerator.prepare(self.sd.vae) + if self.sd.unet is not None: + self.sd.unet = self.accelerator.prepare(self.sd.unet) + # todo always tdo it? + self.modules_being_trained.append(self.sd.unet) + if self.sd.text_encoder is not None and self.train_config.train_text_encoder: + if isinstance(self.sd.text_encoder, list): + self.sd.text_encoder = [self.accelerator.prepare(model) for model in self.sd.text_encoder] + self.modules_being_trained.extend(self.sd.text_encoder) + else: + self.sd.text_encoder = self.accelerator.prepare(self.sd.text_encoder) + self.modules_being_trained.append(self.sd.text_encoder) + if self.sd.refiner_unet is not None and self.train_config.train_refiner: + self.sd.refiner_unet = self.accelerator.prepare(self.sd.refiner_unet) + self.modules_being_trained.append(self.sd.refiner_unet) + # todo, do we need to do the network or will "unet" get it? + if self.sd.network is not None: + self.sd.network = self.accelerator.prepare(self.sd.network) + self.modules_being_trained.append(self.sd.network) + if self.adapter is not None and self.adapter_config.train: + # todo adapters may not be a module. need to check + self.adapter = self.accelerator.prepare(self.adapter) + self.modules_being_trained.append(self.adapter) + + # prepare other things + self.optimizer = self.accelerator.prepare(self.optimizer) + if self.lr_scheduler is not None: + self.lr_scheduler = self.accelerator.prepare(self.lr_scheduler) + # self.data_loader = self.accelerator.prepare(self.data_loader) + # if self.data_loader_reg is not None: + # self.data_loader_reg = self.accelerator.prepare(self.data_loader_reg) + + + def ensure_params_requires_grad(self, force=False): + if self.train_config.do_paramiter_swapping and not force: + # the optimizer will handle this if we are not forcing + return + for group in self.params: + for param in group['params']: + if isinstance(param, torch.nn.Parameter): # Ensure it's a proper parameter + param.requires_grad_(True) + + def setup_ema(self): + if self.train_config.ema_config.use_ema: + # our params are in groups. We need them as a single iterable + params = [] + for group in self.optimizer.param_groups: + for param in group['params']: + params.append(param) + self.ema = ExponentialMovingAverage( + params, + decay=self.train_config.ema_config.ema_decay, + use_feedback=self.train_config.ema_config.use_feedback, + param_multiplier=self.train_config.ema_config.param_multiplier, + ) + + def before_dataset_load(self): + pass + + def get_params(self): + # you can extend this in subclass to get params + # otherwise params will be gathered through normal means + return None + + def hook_train_loop(self, batch): + # return loss + return 0.0 + + def hook_after_sd_init_before_load(self): + pass + + def get_latest_save_path(self, name=None, post=''): + if name == None: + name = self.job.name + # get latest saved step + latest_path = None + if os.path.exists(self.save_root): + # Define patterns for both files and directories + patterns = [ + f"{name}*{post}.safetensors", + f"{name}*{post}.pt", + f"{name}*{post}" + ] + # Search for both files and directories + paths = [] + for pattern in patterns: + paths.extend(glob.glob(os.path.join(self.save_root, pattern))) + + # Filter out non-existent paths and sort by creation time + if paths: + paths = [p for p in paths if os.path.exists(p)] + # remove false positives + if '_LoRA' not in name: + paths = [p for p in paths if '_LoRA' not in p] + if '_refiner' not in name: + paths = [p for p in paths if '_refiner' not in p] + if '_t2i' not in name: + paths = [p for p in paths if '_t2i' not in p] + if '_cn' not in name: + paths = [p for p in paths if '_cn' not in p] + + if len(paths) > 0: + latest_path = max(paths, key=os.path.getctime) + + return latest_path + + def load_training_state_from_metadata(self, path): + if not self.accelerator.is_main_process: + return + meta = None + # if path is folder, then it is diffusers + if os.path.isdir(path): + meta_path = os.path.join(path, 'aitk_meta.yaml') + # load it + if os.path.exists(meta_path): + with open(meta_path, 'r') as f: + meta = yaml.load(f, Loader=yaml.FullLoader) + else: + meta = load_metadata_from_safetensors(path) + # if 'training_info' in Orderdict keys + if meta is not None and 'training_info' in meta and 'step' in meta['training_info'] and self.train_config.start_step is None: + self.step_num = meta['training_info']['step'] + if 'epoch' in meta['training_info']: + self.epoch_num = meta['training_info']['epoch'] + self.start_step = self.step_num + print_acc(f"Found step {self.step_num} in metadata, starting from there") + + def load_weights(self, path): + if self.network is not None: + extra_weights = self.network.load_weights(path) + self.load_training_state_from_metadata(path) + return extra_weights + else: + print_acc("load_weights not implemented for non-network models") + return None + + def apply_snr(self, seperated_loss, timesteps): + if self.train_config.learnable_snr_gos: + # add snr_gamma + seperated_loss = apply_learnable_snr_gos(seperated_loss, timesteps, self.snr_gos) + elif self.train_config.snr_gamma is not None and self.train_config.snr_gamma > 0.000001: + # add snr_gamma + seperated_loss = apply_snr_weight(seperated_loss, timesteps, self.sd.noise_scheduler, self.train_config.snr_gamma, fixed=True) + elif self.train_config.min_snr_gamma is not None and self.train_config.min_snr_gamma > 0.000001: + # add min_snr_gamma + seperated_loss = apply_snr_weight(seperated_loss, timesteps, self.sd.noise_scheduler, self.train_config.min_snr_gamma) + + return seperated_loss + + def load_lorm(self): + latest_save_path = self.get_latest_save_path() + if latest_save_path is not None: + # hacky way to reload weights for now + # todo, do this + state_dict = load_file(latest_save_path, device=self.device) + self.sd.unet.load_state_dict(state_dict) + + meta = load_metadata_from_safetensors(latest_save_path) + # if 'training_info' in Orderdict keys + if 'training_info' in meta and 'step' in meta['training_info']: + self.step_num = meta['training_info']['step'] + if 'epoch' in meta['training_info']: + self.epoch_num = meta['training_info']['epoch'] + self.start_step = self.step_num + print_acc(f"Found step {self.step_num} in metadata, starting from there") + + # def get_sigmas(self, timesteps, n_dim=4, dtype=torch.float32): + # self.sd.noise_scheduler.set_timesteps(1000, device=self.device_torch) + # sigmas = self.sd.noise_scheduler.sigmas.to(device=self.device_torch, dtype=dtype) + # schedule_timesteps = self.sd.noise_scheduler.timesteps.to(self.device_torch, ) + # timesteps = timesteps.to(self.device_torch, ) + # + # # step_indices = [(schedule_timesteps == t).nonzero().item() for t in timesteps] + # step_indices = [t for t in timesteps] + # + # sigma = sigmas[step_indices].flatten() + # while len(sigma.shape) < n_dim: + # sigma = sigma.unsqueeze(-1) + # return sigma + + def load_additional_training_modules(self, params): + # override in subclass + return params + + def get_sigmas(self, timesteps, n_dim=4, dtype=torch.float32): + sigmas = self.sd.noise_scheduler.sigmas.to(device=self.device, dtype=dtype) + schedule_timesteps = self.sd.noise_scheduler.timesteps.to(self.device) + timesteps = timesteps.to(self.device) + + step_indices = [(schedule_timesteps == t).nonzero().item() for t in timesteps] + + sigma = sigmas[step_indices].flatten() + while len(sigma.shape) < n_dim: + sigma = sigma.unsqueeze(-1) + return sigma + + def get_optimal_noise(self, latents, dtype=torch.float32): + batch_num = latents.shape[0] + chunks = torch.chunk(latents, batch_num, dim=0) + noise_chunks = [] + for chunk in chunks: + noise_samples = [torch.randn_like(chunk, device=chunk.device, dtype=dtype) for _ in range(self.train_config.optimal_noise_pairing_samples)] + # find the one most similar to the chunk + lowest_loss = 999999999999 + best_noise = None + for noise in noise_samples: + loss = torch.nn.functional.mse_loss(chunk, noise) + if loss < lowest_loss: + lowest_loss = loss + best_noise = noise + noise_chunks.append(best_noise) + noise = torch.cat(noise_chunks, dim=0) + return noise + + def get_consistent_noise(self, latents, batch: 'DataLoaderBatchDTO', dtype=torch.float32): + batch_num = latents.shape[0] + chunks = torch.chunk(latents, batch_num, dim=0) + noise_chunks = [] + for idx, chunk in enumerate(chunks): + # get seed from path + file_item = batch.file_items[idx] + img_path = file_item.path + # add augmentors + if file_item.flip_x: + img_path += '_fx' + if file_item.flip_y: + img_path += '_fy' + seed = int(hashlib.md5(img_path.encode()).hexdigest(), 16) & 0xffffffff + generator = torch.Generator("cpu").manual_seed(seed) + noise_chunk = torch.randn(chunk.shape, generator=generator).to(chunk.device, dtype=dtype) + noise_chunks.append(noise_chunk) + noise = torch.cat(noise_chunks, dim=0).to(dtype=dtype) + return noise + + + def get_noise( + self, + latents, + batch_size, + dtype=torch.float32, + batch: 'DataLoaderBatchDTO' = None, + timestep=None, + ): + if self.train_config.optimal_noise_pairing_samples > 1: + noise = self.get_optimal_noise(latents, dtype=dtype) + elif self.train_config.force_consistent_noise: + if batch is None: + raise ValueError("Batch must be provided for consistent noise") + noise = self.get_consistent_noise(latents, batch, dtype=dtype) + else: + if hasattr(self.sd, 'get_latent_noise_from_latents'): + noise = self.sd.get_latent_noise_from_latents( + latents, + noise_offset=self.train_config.noise_offset + ).to(self.device_torch, dtype=dtype) + else: + # get noise + noise = self.sd.get_latent_noise( + height=latents.shape[2], + width=latents.shape[3], + num_channels=latents.shape[1], + batch_size=batch_size, + noise_offset=self.train_config.noise_offset, + ).to(self.device_torch, dtype=dtype) + + if self.train_config.blended_blur_noise: + noise = get_blended_blur_noise( + latents, noise, timestep + ) + + return noise + + def process_general_training_batch(self, batch: 'DataLoaderBatchDTO'): + with torch.no_grad(): + with self.timer('prepare_prompt'): + prompts = batch.get_caption_list() + is_reg_list = batch.get_is_reg_list() + + is_any_reg = any([is_reg for is_reg in is_reg_list]) + + do_double = self.train_config.short_and_long_captions and not is_any_reg + + if self.train_config.short_and_long_captions and do_double: + # dont do this with regs. No point + + # double batch and add short captions to the end + prompts = prompts + batch.get_caption_short_list() + is_reg_list = is_reg_list + is_reg_list + if self.model_config.refiner_name_or_path is not None and self.train_config.train_unet: + prompts = prompts + prompts + is_reg_list = is_reg_list + is_reg_list + + conditioned_prompts = [] + + for prompt, is_reg in zip(prompts, is_reg_list): + + # make sure the embedding is in the prompts + if self.embedding is not None: + prompt = self.embedding.inject_embedding_to_prompt( + prompt, + expand_token=True, + add_if_not_present=not is_reg, + ) + + if self.adapter and isinstance(self.adapter, ClipVisionAdapter): + prompt = self.adapter.inject_trigger_into_prompt( + prompt, + expand_token=True, + add_if_not_present=not is_reg, + ) + + # make sure trigger is in the prompts if not a regularization run + if self.trigger_word is not None: + prompt = self.sd.inject_trigger_into_prompt( + prompt, + trigger=self.trigger_word, + add_if_not_present=not is_reg, + ) + + if not is_reg and self.train_config.prompt_saturation_chance > 0.0: + # do random prompt saturation by expanding the prompt to hit at least 77 tokens + if random.random() < self.train_config.prompt_saturation_chance: + est_num_tokens = len(prompt.split(' ')) + if est_num_tokens < 77: + num_repeats = int(77 / est_num_tokens) + 1 + prompt = ', '.join([prompt] * num_repeats) + + + conditioned_prompts.append(prompt) + + with self.timer('prepare_latents'): + dtype = get_torch_dtype(self.train_config.dtype) + imgs = None + is_reg = any(batch.get_is_reg_list()) + if batch.tensor is not None: + imgs = batch.tensor + imgs = imgs.to(self.device_torch, dtype=dtype) + # dont adjust for regs. + if self.train_config.img_multiplier is not None and not is_reg: + # do it ad contrast + imgs = reduce_contrast(imgs, self.train_config.img_multiplier) + if batch.latents is not None: + latents = batch.latents.to(self.device_torch, dtype=dtype) + batch.latents = latents + else: + # normalize to + if self.train_config.standardize_images: + if self.sd.is_xl or self.sd.is_vega or self.sd.is_ssd: + target_mean_list = [0.0002, -0.1034, -0.1879] + target_std_list = [0.5436, 0.5116, 0.5033] + else: + target_mean_list = [-0.0739, -0.1597, -0.2380] + target_std_list = [0.5623, 0.5295, 0.5347] + # Mean: tensor([-0.0739, -0.1597, -0.2380]) + # Standard Deviation: tensor([0.5623, 0.5295, 0.5347]) + imgs_channel_mean = imgs.mean(dim=(2, 3), keepdim=True) + imgs_channel_std = imgs.std(dim=(2, 3), keepdim=True) + imgs = (imgs - imgs_channel_mean) / imgs_channel_std + target_mean = torch.tensor(target_mean_list, device=self.device_torch, dtype=dtype) + target_std = torch.tensor(target_std_list, device=self.device_torch, dtype=dtype) + # expand them to match dim + target_mean = target_mean.unsqueeze(0).unsqueeze(2).unsqueeze(3) + target_std = target_std.unsqueeze(0).unsqueeze(2).unsqueeze(3) + + imgs = imgs * target_std + target_mean + batch.tensor = imgs + + # show_tensors(imgs, 'imgs') + + latents = self.sd.encode_images(imgs) + batch.latents = latents + + if self.train_config.standardize_latents: + if self.sd.is_xl or self.sd.is_vega or self.sd.is_ssd: + target_mean_list = [-0.1075, 0.0231, -0.0135, 0.2164] + target_std_list = [0.8979, 0.7505, 0.9150, 0.7451] + else: + target_mean_list = [0.2949, -0.3188, 0.0807, 0.1929] + target_std_list = [0.8560, 0.9629, 0.7778, 0.6719] + + latents_channel_mean = latents.mean(dim=(2, 3), keepdim=True) + latents_channel_std = latents.std(dim=(2, 3), keepdim=True) + latents = (latents - latents_channel_mean) / latents_channel_std + target_mean = torch.tensor(target_mean_list, device=self.device_torch, dtype=dtype) + target_std = torch.tensor(target_std_list, device=self.device_torch, dtype=dtype) + # expand them to match dim + target_mean = target_mean.unsqueeze(0).unsqueeze(2).unsqueeze(3) + target_std = target_std.unsqueeze(0).unsqueeze(2).unsqueeze(3) + + latents = latents * target_std + target_mean + batch.latents = latents + + # show_latents(latents, self.sd.vae, 'latents') + + + if batch.unconditional_tensor is not None and batch.unconditional_latents is None: + unconditional_imgs = batch.unconditional_tensor + unconditional_imgs = unconditional_imgs.to(self.device_torch, dtype=dtype) + unconditional_latents = self.sd.encode_images(unconditional_imgs) + batch.unconditional_latents = unconditional_latents * self.train_config.latent_multiplier + + unaugmented_latents = None + if self.train_config.loss_target == 'differential_noise': + # we determine noise from the differential of the latents + unaugmented_latents = self.sd.encode_images(batch.unaugmented_tensor) + + with self.timer('prepare_scheduler'): + + batch_size = len(batch.file_items) + min_noise_steps = self.train_config.min_denoising_steps + max_noise_steps = self.train_config.max_denoising_steps + if self.model_config.refiner_name_or_path is not None: + # if we are not training the unet, then we are only doing refiner and do not need to double up + if self.train_config.train_unet: + max_noise_steps = round(self.train_config.max_denoising_steps * self.model_config.refiner_start_at) + do_double = True + else: + min_noise_steps = round(self.train_config.max_denoising_steps * self.model_config.refiner_start_at) + do_double = False + + num_train_timesteps = self.train_config.num_train_timesteps + + if self.train_config.noise_scheduler in ['custom_lcm']: + # we store this value on our custom one + self.sd.noise_scheduler.set_timesteps( + self.sd.noise_scheduler.train_timesteps, device=self.device_torch + ) + elif self.train_config.noise_scheduler in ['lcm']: + self.sd.noise_scheduler.set_timesteps( + num_train_timesteps, device=self.device_torch, original_inference_steps=num_train_timesteps + ) + elif self.train_config.noise_scheduler == 'flowmatch': + linear_timesteps = any([ + self.train_config.linear_timesteps, + self.train_config.linear_timesteps2, + self.train_config.timestep_type == 'linear', + self.train_config.timestep_type == 'one_step', + ]) + + timestep_type = 'linear' if linear_timesteps else None + if timestep_type is None: + timestep_type = self.train_config.timestep_type + + if self.train_config.timestep_type == 'next_sample': + # simulate a sample + num_train_timesteps = self.train_config.next_sample_timesteps + timestep_type = 'shift' + + patch_size = 1 + if self.sd.is_flux or 'flex' in self.sd.arch: + # flux is a patch size of 1, but latents are divided by 2, so we need to double it + patch_size = 2 + elif hasattr(self.sd.unet.config, 'patch_size'): + patch_size = self.sd.unet.config.patch_size + + self.sd.noise_scheduler.set_train_timesteps( + num_train_timesteps, + device=self.device_torch, + timestep_type=timestep_type, + latents=latents, + patch_size=patch_size, + ) + else: + self.sd.noise_scheduler.set_timesteps( + num_train_timesteps, device=self.device_torch + ) + if self.sd.is_multistage: + with self.timer('adjust_multistage_timesteps'): + # get our current sample range + boundaries = [1] + self.sd.multistage_boundaries + boundary_max, boundary_min = boundaries[self.current_boundary_index], boundaries[self.current_boundary_index + 1] + asc_timesteps = torch.flip(self.sd.noise_scheduler.timesteps, dims=[0]) + lo = len(asc_timesteps) - torch.searchsorted(asc_timesteps, torch.tensor(boundary_max * 1000, device=asc_timesteps.device), right=False) + hi = len(asc_timesteps) - torch.searchsorted(asc_timesteps, torch.tensor(boundary_min * 1000, device=asc_timesteps.device), right=True) + first_idx = (lo - 1).item() if hi > lo else 0 + last_idx = (hi - 1).item() if hi > lo else 999 + min_noise_steps = first_idx + max_noise_steps = last_idx + + # clip min max indicies + min_noise_steps = max(min_noise_steps, 0) + max_noise_steps = min(max_noise_steps, num_train_timesteps - 1) + + + with self.timer('prepare_timesteps_indices'): + + content_or_style = self.train_config.content_or_style + if is_reg: + content_or_style = self.train_config.content_or_style_reg + + # if self.train_config.timestep_sampling == 'style' or self.train_config.timestep_sampling == 'content': + if self.train_config.timestep_type == 'next_sample': + timestep_indices = torch.randint( + 0, + num_train_timesteps - 2, # -1 for 0 idx, -1 so we can step + (batch_size,), + device=self.device_torch + ) + timestep_indices = timestep_indices.long() + elif self.train_config.timestep_type == 'one_step': + timestep_indices = torch.zeros((batch_size,), device=self.device_torch, dtype=torch.long) + elif content_or_style in ['style', 'content']: + # this is from diffusers training code + # Cubic sampling for favoring later or earlier timesteps + # For more details about why cubic sampling is used for content / structure, + # refer to section 3.4 of https://arxiv.org/abs/2302.08453 + + # for content / structure, it is best to favor earlier timesteps + # for style, it is best to favor later timesteps + + orig_timesteps = torch.rand((batch_size,), device=latents.device) + + if content_or_style == 'content': + timestep_indices = orig_timesteps ** 3 * self.train_config.num_train_timesteps + elif content_or_style == 'style': + timestep_indices = (1 - orig_timesteps ** 3) * self.train_config.num_train_timesteps + + timestep_indices = value_map( + timestep_indices, + 0, + self.train_config.num_train_timesteps - 1, + min_noise_steps, + max_noise_steps + ) + timestep_indices = timestep_indices.long().clamp( + min_noise_steps, + max_noise_steps + ) + + elif content_or_style == 'balanced': + if min_noise_steps == max_noise_steps: + timestep_indices = torch.ones((batch_size,), device=self.device_torch) * min_noise_steps + else: + # todo, some schedulers use indices, otheres use timesteps. Not sure what to do here + min_idx = min_noise_steps + 1 + max_idx = max_noise_steps - 1 + if self.train_config.noise_scheduler == 'flowmatch': + # flowmatch uses indices, so we need to use indices + min_idx = min_noise_steps + max_idx = max_noise_steps + timestep_indices = torch.randint( + min_idx, + max_idx, + (batch_size,), + device=self.device_torch + ) + timestep_indices = timestep_indices.long() + else: + raise ValueError(f"Unknown content_or_style {content_or_style}") + with self.timer('convert_timestep_indices_to_timesteps'): + # convert the timestep_indices to a timestep + timesteps = self.sd.noise_scheduler.timesteps[timestep_indices.long()] + + with self.timer('prepare_noise'): + # get noise + noise = self.get_noise(latents, batch_size, dtype=dtype, batch=batch, timestep=timesteps) + + # add dynamic noise offset. Dynamic noise is offsetting the noise to the same channelwise mean as the latents + # this will negate any noise offsets + if self.train_config.dynamic_noise_offset and not is_reg: + latents_channel_mean = latents.mean(dim=(2, 3), keepdim=True) / 2 + # subtract channel mean to that we compensate for the mean of the latents on the noise offset per channel + noise = noise + latents_channel_mean + + if self.train_config.loss_target == 'differential_noise': + differential = latents - unaugmented_latents + # add noise to differential + # noise = noise + differential + noise = noise + (differential * 0.5) + # noise = value_map(differential, 0, torch.abs(differential).max(), 0, torch.abs(noise).max()) + latents = unaugmented_latents + + noise_multiplier = self.train_config.noise_multiplier + + s = (noise.shape[0], noise.shape[1], 1, 1) + if len(noise.shape) == 5: + # if we have a 5d tensor, then we need to do it on a per batch item, per channel basis, per frame + s = (noise.shape[0], noise.shape[1], noise.shape[2], 1, 1) + + if self.train_config.random_noise_multiplier > 0.0: + + # do it on a per batch item, per channel basis + noise_multiplier = 1 + torch.randn( + s, + device=noise.device, + dtype=noise.dtype + ) * self.train_config.random_noise_multiplier + + with self.timer('make_noisy_latents'): + + noise = noise * noise_multiplier + + if self.train_config.random_noise_shift > 0.0: + # get random noise -1 to 1 + noise_shift = torch.randn( + s, + device=noise.device, + dtype=noise.dtype + ) * self.train_config.random_noise_shift + # add to noise + noise += noise_shift + + latent_multiplier = self.train_config.latent_multiplier + + # handle adaptive scaling mased on std + if self.train_config.adaptive_scaling_factor: + std = latents.std(dim=(2, 3), keepdim=True) + normalizer = 1 / (std + 1e-6) + latent_multiplier = normalizer + + latents = latents * latent_multiplier + batch.latents = latents + + # normalize latents to a mean of 0 and an std of 1 + # mean_zero_latents = latents - latents.mean() + # latents = mean_zero_latents / mean_zero_latents.std() + + if batch.unconditional_latents is not None: + batch.unconditional_latents = batch.unconditional_latents * self.train_config.latent_multiplier + + + noisy_latents = self.sd.add_noise(latents, noise, timesteps) + + # determine scaled noise + # todo do we need to scale this or does it always predict full intensity + # noise = noisy_latents - latents + + # https://github.com/huggingface/diffusers/blob/324d18fba23f6c9d7475b0ff7c777685f7128d40/examples/t2i_adapter/train_t2i_adapter_sdxl.py#L1170C17-L1171C77 + if self.train_config.loss_target == 'source' or self.train_config.loss_target == 'unaugmented': + sigmas = self.get_sigmas(timesteps, len(noisy_latents.shape), noisy_latents.dtype) + # add it to the batch + batch.sigmas = sigmas + # todo is this for sdxl? find out where this came from originally + # noisy_latents = noisy_latents / ((sigmas ** 2 + 1) ** 0.5) + + def double_up_tensor(tensor: torch.Tensor): + if tensor is None: + return None + return torch.cat([tensor, tensor], dim=0) + + if do_double: + if self.model_config.refiner_name_or_path: + # apply refiner double up + refiner_timesteps = torch.randint( + max_noise_steps, + self.train_config.max_denoising_steps, + (batch_size,), + device=self.device_torch + ) + refiner_timesteps = refiner_timesteps.long() + # add our new timesteps on to end + timesteps = torch.cat([timesteps, refiner_timesteps], dim=0) + + refiner_noisy_latents = self.sd.noise_scheduler.add_noise(latents, noise, refiner_timesteps) + noisy_latents = torch.cat([noisy_latents, refiner_noisy_latents], dim=0) + + else: + # just double it + noisy_latents = double_up_tensor(noisy_latents) + timesteps = double_up_tensor(timesteps) + + noise = double_up_tensor(noise) + # prompts are already updated above + imgs = double_up_tensor(imgs) + batch.mask_tensor = double_up_tensor(batch.mask_tensor) + batch.control_tensor = double_up_tensor(batch.control_tensor) + + noisy_latent_multiplier = self.train_config.noisy_latent_multiplier + + if noisy_latent_multiplier != 1.0: + noisy_latents = noisy_latents * noisy_latent_multiplier + + # remove grads for these + noisy_latents.requires_grad = False + noisy_latents = noisy_latents.detach() + noise.requires_grad = False + noise = noise.detach() + + return noisy_latents, noise, timesteps, conditioned_prompts, imgs + + def setup_adapter(self): + # t2i adapter + is_t2i = self.adapter_config.type == 't2i' + is_control_net = self.adapter_config.type == 'control_net' + if self.adapter_config.type == 't2i': + suffix = 't2i' + elif self.adapter_config.type == 'control_net': + suffix = 'cn' + elif self.adapter_config.type == 'clip': + suffix = 'clip' + elif self.adapter_config.type == 'reference': + suffix = 'ref' + elif self.adapter_config.type.startswith('ip'): + suffix = 'ip' + else: + suffix = 'adapter' + adapter_name = self.name + if self.network_config is not None: + adapter_name = f"{adapter_name}_{suffix}" + latest_save_path = self.get_latest_save_path(adapter_name) + + if latest_save_path is not None and not self.adapter_config.train: + # the save path is for something else since we are not training + latest_save_path = self.adapter_config.name_or_path + + dtype = get_torch_dtype(self.train_config.dtype) + if is_t2i: + # if we do not have a last save path and we have a name_or_path, + # load from that + if latest_save_path is None and self.adapter_config.name_or_path is not None: + self.adapter = T2IAdapter.from_pretrained( + self.adapter_config.name_or_path, + torch_dtype=get_torch_dtype(self.train_config.dtype), + varient="fp16", + # use_safetensors=True, + ) + else: + self.adapter = T2IAdapter( + in_channels=self.adapter_config.in_channels, + channels=self.adapter_config.channels, + num_res_blocks=self.adapter_config.num_res_blocks, + downscale_factor=self.adapter_config.downscale_factor, + adapter_type=self.adapter_config.adapter_type, + ) + elif is_control_net: + if self.adapter_config.name_or_path is None: + raise ValueError("ControlNet requires a name_or_path to load from currently") + load_from_path = self.adapter_config.name_or_path + if latest_save_path is not None: + load_from_path = latest_save_path + self.adapter = ControlNetModel.from_pretrained( + load_from_path, + torch_dtype=get_torch_dtype(self.train_config.dtype), + ) + elif self.adapter_config.type == 'clip': + self.adapter = ClipVisionAdapter( + sd=self.sd, + adapter_config=self.adapter_config, + ) + elif self.adapter_config.type == 'reference': + self.adapter = ReferenceAdapter( + sd=self.sd, + adapter_config=self.adapter_config, + ) + elif self.adapter_config.type.startswith('ip'): + self.adapter = IPAdapter( + sd=self.sd, + adapter_config=self.adapter_config, + ) + if self.train_config.gradient_checkpointing: + self.adapter.enable_gradient_checkpointing() + else: + self.adapter = CustomAdapter( + sd=self.sd, + adapter_config=self.adapter_config, + train_config=self.train_config, + ) + self.adapter.to(self.device_torch, dtype=dtype) + if latest_save_path is not None and not is_control_net: + # load adapter from path + print_acc(f"Loading adapter from {latest_save_path}") + if is_t2i: + loaded_state_dict = load_t2i_model( + latest_save_path, + self.device, + dtype=dtype + ) + self.adapter.load_state_dict(loaded_state_dict) + elif self.adapter_config.type.startswith('ip'): + # ip adapter + loaded_state_dict = load_ip_adapter_model( + latest_save_path, + self.device, + dtype=dtype, + direct_load=self.adapter_config.train_only_image_encoder + ) + self.adapter.load_state_dict(loaded_state_dict) + else: + # custom adapter + loaded_state_dict = load_custom_adapter_model( + latest_save_path, + self.device, + dtype=dtype + ) + self.adapter.load_state_dict(loaded_state_dict) + if latest_save_path is not None and self.adapter_config.train: + self.load_training_state_from_metadata(latest_save_path) + # set trainable params + self.sd.adapter = self.adapter + + def run(self): + # torch.autograd.set_detect_anomaly(True) + # run base process run + BaseTrainProcess.run(self) + params = [] + + ### HOOK ### + self.hook_before_model_load() + model_config_to_load = copy.deepcopy(self.model_config) + + if self.is_fine_tuning: + # get the latest checkpoint + # check to see if we have a latest save + latest_save_path = self.get_latest_save_path() + + if latest_save_path is not None: + print_acc(f"#### IMPORTANT RESUMING FROM {latest_save_path} ####") + model_config_to_load.name_or_path = latest_save_path + self.load_training_state_from_metadata(latest_save_path) + + ModelClass = get_model_class(self.model_config) + # if the model class has get_train_scheduler static method + if hasattr(ModelClass, 'get_train_scheduler'): + sampler = ModelClass.get_train_scheduler() + else: + # get the noise scheduler + arch = 'sd' + if self.model_config.is_pixart: + arch = 'pixart' + if self.model_config.is_flux: + arch = 'flux' + if self.model_config.is_lumina2: + arch = 'lumina2' + sampler = get_sampler( + self.train_config.noise_scheduler, + { + "prediction_type": "v_prediction" if self.model_config.is_v_pred else "epsilon", + }, + arch=arch, + ) + + if self.train_config.train_refiner and self.model_config.refiner_name_or_path is not None and self.network_config is None: + previous_refiner_save = self.get_latest_save_path(self.job.name + '_refiner') + if previous_refiner_save is not None: + model_config_to_load.refiner_name_or_path = previous_refiner_save + self.load_training_state_from_metadata(previous_refiner_save) + + self.sd = ModelClass( + # todo handle single gpu and multi gpu here + # device=self.device, + device=self.accelerator.device, + model_config=model_config_to_load, + dtype=self.train_config.dtype, + custom_pipeline=self.custom_pipeline, + noise_scheduler=sampler, + ) + + self.hook_after_sd_init_before_load() + # run base sd process run + self.sd.load_model() + + # compile the model if needed + if self.model_config.compile: + try: + torch.compile(self.sd.unet, dynamic=True, fullgraph=True, mode='max-autotune') + except Exception as e: + print_acc(f"Failed to compile model: {e}") + print_acc("Continuing without compilation") + + self.sd.add_after_sample_image_hook(self.sample_step_hook) + + dtype = get_torch_dtype(self.train_config.dtype) + + # model is loaded from BaseSDProcess + unet = self.sd.unet + vae = self.sd.vae + tokenizer = self.sd.tokenizer + text_encoder = self.sd.text_encoder + noise_scheduler = self.sd.noise_scheduler + + if self.train_config.xformers: + vae.enable_xformers_memory_efficient_attention() + unet.enable_xformers_memory_efficient_attention() + if isinstance(text_encoder, list): + for te in text_encoder: + # if it has it + if hasattr(te, 'enable_xformers_memory_efficient_attention'): + te.enable_xformers_memory_efficient_attention() + if self.train_config.sdp: + torch.backends.cuda.enable_math_sdp(True) + torch.backends.cuda.enable_flash_sdp(True) + torch.backends.cuda.enable_mem_efficient_sdp(True) + + # # check if we have sage and is flux + # if self.sd.is_flux: + # # try_to_activate_sage_attn() + # try: + # from sageattention import sageattn + # from toolkit.models.flux_sage_attn import FluxSageAttnProcessor2_0 + # model: FluxTransformer2DModel = self.sd.unet + # # enable sage attention on each block + # for block in model.transformer_blocks: + # processor = FluxSageAttnProcessor2_0() + # block.attn.set_processor(processor) + # for block in model.single_transformer_blocks: + # processor = FluxSageAttnProcessor2_0() + # block.attn.set_processor(processor) + + # except ImportError: + # print_acc("sage attention is not installed. Using SDP instead") + + if self.train_config.gradient_checkpointing: + # if has method enable_gradient_checkpointing + if hasattr(unet, 'enable_gradient_checkpointing'): + unet.enable_gradient_checkpointing() + elif hasattr(unet, 'gradient_checkpointing'): + unet.gradient_checkpointing = True + else: + print("Gradient checkpointing not supported on this model") + if isinstance(text_encoder, list): + for te in text_encoder: + if hasattr(te, 'enable_gradient_checkpointing'): + te.enable_gradient_checkpointing() + if hasattr(te, "gradient_checkpointing_enable"): + te.gradient_checkpointing_enable() + else: + if hasattr(text_encoder, 'enable_gradient_checkpointing'): + text_encoder.enable_gradient_checkpointing() + if hasattr(text_encoder, "gradient_checkpointing_enable"): + text_encoder.gradient_checkpointing_enable() + + if self.sd.refiner_unet is not None: + self.sd.refiner_unet.to(self.device_torch, dtype=dtype) + self.sd.refiner_unet.requires_grad_(False) + self.sd.refiner_unet.eval() + if self.train_config.xformers: + self.sd.refiner_unet.enable_xformers_memory_efficient_attention() + if self.train_config.gradient_checkpointing: + self.sd.refiner_unet.enable_gradient_checkpointing() + + if isinstance(text_encoder, list): + for te in text_encoder: + te.requires_grad_(False) + te.eval() + else: + text_encoder.requires_grad_(False) + text_encoder.eval() + unet.to(self.device_torch, dtype=dtype) + unet.requires_grad_(False) + unet.eval() + vae = vae.to(torch.device('cpu'), dtype=dtype) + vae.requires_grad_(False) + vae.eval() + if self.train_config.learnable_snr_gos: + self.snr_gos = LearnableSNRGamma( + self.sd.noise_scheduler, device=self.device_torch + ) + # check to see if previous settings exist + path_to_load = os.path.join(self.save_root, 'learnable_snr.json') + if os.path.exists(path_to_load): + with open(path_to_load, 'r') as f: + json_data = json.load(f) + if 'offset' in json_data: + # legacy + self.snr_gos.offset_2.data = torch.tensor(json_data['offset'], device=self.device_torch) + else: + self.snr_gos.offset_1.data = torch.tensor(json_data['offset_1'], device=self.device_torch) + self.snr_gos.offset_2.data = torch.tensor(json_data['offset_2'], device=self.device_torch) + self.snr_gos.scale.data = torch.tensor(json_data['scale'], device=self.device_torch) + self.snr_gos.gamma.data = torch.tensor(json_data['gamma'], device=self.device_torch) + + self.hook_after_model_load() + flush() + if not self.is_fine_tuning: + if self.network_config is not None: + # TODO should we completely switch to LycorisSpecialNetwork? + network_kwargs = self.network_config.network_kwargs + is_lycoris = False + is_lorm = self.network_config.type.lower() == 'lorm' + # default to LoCON if there are any conv layers or if it is named + NetworkClass = LoRASpecialNetwork + if self.network_config.type.lower() == 'locon' or self.network_config.type.lower() == 'lycoris': + NetworkClass = LycorisSpecialNetwork + is_lycoris = True + + if is_lorm: + network_kwargs['ignore_if_contains'] = lorm_ignore_if_contains + network_kwargs['parameter_threshold'] = lorm_parameter_threshold + network_kwargs['target_lin_modules'] = LORM_TARGET_REPLACE_MODULE + + # if is_lycoris: + # preset = PRESET['full'] + # NetworkClass.apply_preset(preset) + + if hasattr(self.sd, 'target_lora_modules'): + network_kwargs['target_lin_modules'] = self.sd.target_lora_modules + + self.network = NetworkClass( + text_encoder=text_encoder, + unet=self.sd.get_model_to_train(), + lora_dim=self.network_config.linear, + multiplier=1.0, + alpha=self.network_config.linear_alpha, + train_unet=self.train_config.train_unet, + train_text_encoder=self.train_config.train_text_encoder, + conv_lora_dim=self.network_config.conv, + conv_alpha=self.network_config.conv_alpha, + is_sdxl=self.model_config.is_xl or self.model_config.is_ssd, + is_v2=self.model_config.is_v2, + is_v3=self.model_config.is_v3, + is_pixart=self.model_config.is_pixart, + is_auraflow=self.model_config.is_auraflow, + is_flux=self.model_config.is_flux, + is_lumina2=self.model_config.is_lumina2, + is_ssd=self.model_config.is_ssd, + is_vega=self.model_config.is_vega, + dropout=self.network_config.dropout, + use_text_encoder_1=self.model_config.use_text_encoder_1, + use_text_encoder_2=self.model_config.use_text_encoder_2, + use_bias=is_lorm, + is_lorm=is_lorm, + network_config=self.network_config, + network_type=self.network_config.type, + transformer_only=self.network_config.transformer_only, + is_transformer=self.sd.is_transformer, + base_model=self.sd, + **network_kwargs + ) + + + # todo switch everything to proper mixed precision like this + self.network.force_to(self.device_torch, dtype=torch.float32) + # give network to sd so it can use it + self.sd.network = self.network + self.network._update_torch_multiplier() + + self.network.apply_to( + text_encoder, + unet, + self.train_config.train_text_encoder, + self.train_config.train_unet + ) + + # we cannot merge in if quantized + if self.model_config.quantize: + # todo find a way around this + self.network.can_merge_in = False + + if is_lorm: + self.network.is_lorm = True + # make sure it is on the right device + self.sd.unet.to(self.sd.device, dtype=dtype) + original_unet_param_count = count_parameters(self.sd.unet) + self.network.setup_lorm() + new_unet_param_count = original_unet_param_count - self.network.calculate_lorem_parameter_reduction() + + print_lorm_extract_details( + start_num_params=original_unet_param_count, + end_num_params=new_unet_param_count, + num_replaced=len(self.network.get_all_modules()), + ) + + self.network.prepare_grad_etc(text_encoder, unet) + flush() + + # LyCORIS doesnt have default_lr + config = { + 'text_encoder_lr': self.train_config.lr, + 'unet_lr': self.train_config.lr, + } + sig = inspect.signature(self.network.prepare_optimizer_params) + if 'default_lr' in sig.parameters: + config['default_lr'] = self.train_config.lr + if 'learning_rate' in sig.parameters: + config['learning_rate'] = self.train_config.lr + params_net = self.network.prepare_optimizer_params( + **config + ) + + params += params_net + + if self.train_config.gradient_checkpointing: + self.network.enable_gradient_checkpointing() + + lora_name = self.name + # need to adapt name so they are not mixed up + if self.named_lora: + lora_name = f"{lora_name}_LoRA" + + latest_save_path = self.get_latest_save_path(lora_name) + extra_weights = None + if latest_save_path is not None: + print_acc(f"#### IMPORTANT RESUMING FROM {latest_save_path} ####") + print_acc(f"Loading from {latest_save_path}") + extra_weights = self.load_weights(latest_save_path) + self.network.multiplier = 1.0 + + if self.embed_config is not None: + # we are doing embedding training as well + self.embedding = Embedding( + sd=self.sd, + embed_config=self.embed_config + ) + latest_save_path = self.get_latest_save_path(self.embed_config.trigger) + # load last saved weights + if latest_save_path is not None: + self.embedding.load_embedding_from_file(latest_save_path, self.device_torch) + if self.embedding.step > 1: + self.step_num = self.embedding.step + self.start_step = self.step_num + + # self.step_num = self.embedding.step + # self.start_step = self.step_num + params.append({ + 'params': list(self.embedding.get_trainable_params()), + 'lr': self.train_config.embedding_lr + }) + + flush() + + if self.decorator_config is not None: + self.decorator = Decorator( + num_tokens=self.decorator_config.num_tokens, + token_size=4096 # t5xxl hidden size for flux + ) + latest_save_path = self.get_latest_save_path() + # load last saved weights + if latest_save_path is not None: + state_dict = load_file(latest_save_path) + self.decorator.load_state_dict(state_dict) + self.load_training_state_from_metadata(latest_save_path) + + params.append({ + 'params': list(self.decorator.parameters()), + 'lr': self.train_config.lr + }) + + # give it to the sd network + self.sd.decorator = self.decorator + self.decorator.to(self.device_torch, dtype=torch.float32) + self.decorator.train() + + flush() + + if self.adapter_config is not None: + self.setup_adapter() + if self.adapter_config.train: + + if isinstance(self.adapter, IPAdapter): + # we have custom LR groups for IPAdapter + adapter_param_groups = self.adapter.get_parameter_groups(self.train_config.adapter_lr) + for group in adapter_param_groups: + params.append(group) + else: + # set trainable params + params.append({ + 'params': list(self.adapter.parameters()), + 'lr': self.train_config.adapter_lr + }) + + if self.train_config.gradient_checkpointing: + self.adapter.enable_gradient_checkpointing() + flush() + + params = self.load_additional_training_modules(params) + + else: # no network, embedding or adapter + # set the device state preset before getting params + self.sd.set_device_state(self.get_params_device_state_preset) + + # params = self.get_params() + if len(params) == 0: + # will only return savable weights and ones with grad + params = self.sd.prepare_optimizer_params( + unet=self.train_config.train_unet, + text_encoder=self.train_config.train_text_encoder, + text_encoder_lr=self.train_config.lr, + unet_lr=self.train_config.lr, + default_lr=self.train_config.lr, + refiner=self.train_config.train_refiner and self.sd.refiner_unet is not None, + refiner_lr=self.train_config.refiner_lr, + ) + # we may be using it for prompt injections + if self.adapter_config is not None and self.adapter is None: + self.setup_adapter() + flush() + ### HOOK ### + params = self.hook_add_extra_train_params(params) + self.params = params + # self.params = [] + + # for param in params: + # if isinstance(param, dict): + # self.params += param['params'] + # else: + # self.params.append(param) + + if self.train_config.start_step is not None: + self.step_num = self.train_config.start_step + self.start_step = self.step_num + + optimizer_type = self.train_config.optimizer.lower() + + # esure params require grad + self.ensure_params_requires_grad(force=True) + optimizer = get_optimizer(self.params, optimizer_type, learning_rate=self.train_config.lr, + optimizer_params=self.train_config.optimizer_params) + self.optimizer = optimizer + + # set it to do paramiter swapping + if self.train_config.do_paramiter_swapping: + # only works for adafactor, but it should have thrown an error prior to this otherwise + self.optimizer.enable_paramiter_swapping(self.train_config.paramiter_swapping_factor) + + # check if it exists + optimizer_state_filename = f'optimizer.pt' + optimizer_state_file_path = os.path.join(self.save_root, optimizer_state_filename) + if os.path.exists(optimizer_state_file_path): + # try to load + # previous param groups + # previous_params = copy.deepcopy(optimizer.param_groups) + previous_lrs = [] + for group in optimizer.param_groups: + previous_lrs.append(group['lr']) + + try: + print_acc(f"Loading optimizer state from {optimizer_state_file_path}") + optimizer_state_dict = torch.load(optimizer_state_file_path, weights_only=True) + optimizer.load_state_dict(optimizer_state_dict) + del optimizer_state_dict + flush() + except Exception as e: + print_acc(f"Failed to load optimizer state from {optimizer_state_file_path}") + print_acc(e) + + # update the optimizer LR from the params + print_acc(f"Updating optimizer LR from params") + if len(previous_lrs) > 0: + for i, group in enumerate(optimizer.param_groups): + group['lr'] = previous_lrs[i] + group['initial_lr'] = previous_lrs[i] + + # Update the learning rates if they changed + # optimizer.param_groups = previous_params + + lr_scheduler_params = self.train_config.lr_scheduler_params + + # make sure it had bare minimum + if 'max_iterations' not in lr_scheduler_params: + lr_scheduler_params['total_iters'] = self.train_config.steps + + lr_scheduler = get_lr_scheduler( + self.train_config.lr_scheduler, + optimizer, + **lr_scheduler_params + ) + self.lr_scheduler = lr_scheduler + + ### HOOk ### + self.before_dataset_load() + # load datasets if passed in the root process + if self.datasets is not None: + self.data_loader = get_dataloader_from_datasets(self.datasets, self.train_config.batch_size, self.sd) + if self.datasets_reg is not None: + self.data_loader_reg = get_dataloader_from_datasets(self.datasets_reg, self.train_config.batch_size, + self.sd) + + flush() + self.last_save_step = self.step_num + ### HOOK ### + self.hook_before_train_loop() + + if self.has_first_sample_requested and self.step_num <= 1 and not self.train_config.disable_sampling: + print_acc("Generating first sample from first sample config") + self.sample(0, is_first=True) + + # sample first + if self.train_config.skip_first_sample or self.train_config.disable_sampling: + print_acc("Skipping first sample due to config setting") + elif self.step_num <= 1 or self.train_config.force_first_sample: + print_acc("Generating baseline samples before training") + self.sample(self.step_num) + + if self.accelerator.is_local_main_process: + self.progress_bar = ToolkitProgressBar( + total=self.train_config.steps, + desc=self.job.name, + leave=True, + initial=self.step_num, + iterable=range(0, self.train_config.steps), + ) + self.progress_bar.pause() + else: + self.progress_bar = None + + if self.data_loader is not None: + dataloader = self.data_loader + dataloader_iterator = iter(dataloader) + else: + dataloader = None + dataloader_iterator = None + + if self.data_loader_reg is not None: + dataloader_reg = self.data_loader_reg + dataloader_iterator_reg = iter(dataloader_reg) + else: + dataloader_reg = None + dataloader_iterator_reg = None + + # zero any gradients + optimizer.zero_grad() + + self.lr_scheduler.step(self.step_num) + + self.sd.set_device_state(self.train_device_state_preset) + flush() + # self.step_num = 0 + + # print_acc(f"Compiling Model") + # torch.compile(self.sd.unet, dynamic=True) + + # make sure all params require grad + self.ensure_params_requires_grad(force=True) + + + ################################################################### + # TRAIN LOOP + ################################################################### + + + start_step_num = self.step_num + did_first_flush = False + flush_next = False + for step in range(start_step_num, self.train_config.steps): + if self.train_config.do_paramiter_swapping: + self.optimizer.optimizer.swap_paramiters() + self.timer.start('train_loop') + if flush_next: + flush() + flush_next = False + if self.train_config.do_random_cfg: + self.train_config.do_cfg = True + self.train_config.cfg_scale = value_map(random.random(), 0, 1, 1.0, self.train_config.max_cfg_scale) + self.step_num = step + # default to true so various things can turn it off + self.is_grad_accumulation_step = True + if self.train_config.free_u: + self.sd.pipeline.enable_freeu(s1=0.9, s2=0.2, b1=1.1, b2=1.2) + if self.progress_bar is not None: + self.progress_bar.unpause() + with torch.no_grad(): + # if is even step and we have a reg dataset, use that + # todo improve this logic to send one of each through if we can buckets and batch size might be an issue + is_reg_step = False + is_save_step = self.save_config.save_every and self.step_num % self.save_config.save_every == 0 + is_sample_step = self.sample_config.sample_every and self.step_num % self.sample_config.sample_every == 0 + if self.train_config.disable_sampling: + is_sample_step = False + + batch_list = [] + + for b in range(self.train_config.gradient_accumulation): + # keep track to alternate on an accumulation step for reg + batch_step = step + # don't do a reg step on sample or save steps as we dont want to normalize on those + if batch_step % 2 == 0 and dataloader_reg is not None and not is_save_step and not is_sample_step: + try: + with self.timer('get_batch:reg'): + batch = next(dataloader_iterator_reg) + except StopIteration: + with self.timer('reset_batch:reg'): + # hit the end of an epoch, reset + if self.progress_bar is not None: + self.progress_bar.pause() + dataloader_iterator_reg = iter(dataloader_reg) + trigger_dataloader_setup_epoch(dataloader_reg) + + with self.timer('get_batch:reg'): + batch = next(dataloader_iterator_reg) + if self.progress_bar is not None: + self.progress_bar.unpause() + is_reg_step = True + elif dataloader is not None: + try: + with self.timer('get_batch'): + batch = next(dataloader_iterator) + except StopIteration: + with self.timer('reset_batch'): + # hit the end of an epoch, reset + if self.progress_bar is not None: + self.progress_bar.pause() + dataloader_iterator = iter(dataloader) + trigger_dataloader_setup_epoch(dataloader) + self.epoch_num += 1 + if self.train_config.gradient_accumulation_steps == -1: + # if we are accumulating for an entire epoch, trigger a step + self.is_grad_accumulation_step = False + self.grad_accumulation_step = 0 + with self.timer('get_batch'): + batch = next(dataloader_iterator) + if self.progress_bar is not None: + self.progress_bar.unpause() + else: + batch = None + batch_list.append(batch) + batch_step += 1 + + # setup accumulation + if self.train_config.gradient_accumulation_steps == -1: + # epoch is handling the accumulation, dont touch it + pass + else: + # determine if we are accumulating or not + # since optimizer step happens in the loop, we trigger it a step early + # since we cannot reprocess it before them + optimizer_step_at = self.train_config.gradient_accumulation_steps + is_optimizer_step = self.grad_accumulation_step >= optimizer_step_at + self.is_grad_accumulation_step = not is_optimizer_step + if is_optimizer_step: + self.grad_accumulation_step = 0 + + # flush() + ### HOOK ### + if self.torch_profiler is not None: + self.torch_profiler.start() + with self.accelerator.accumulate(self.modules_being_trained): + try: + loss_dict = self.hook_train_loop(batch_list) + except Exception as e: + traceback.print_exc() + #print batch info + print("Batch Items:") + for batch in batch_list: + for item in batch.file_items: + print(f" - {item.path}") + raise e + if self.torch_profiler is not None: + torch.cuda.synchronize() # Make sure all CUDA ops are done + self.torch_profiler.stop() + + print("\n==== Profile Results ====") + print(self.torch_profiler.key_averages().table(sort_by="cpu_time_total", row_limit=1000)) + self.timer.stop('train_loop') + if not did_first_flush: + flush() + did_first_flush = True + # flush() + # setup the networks to gradient checkpointing and everything works + if self.adapter is not None and isinstance(self.adapter, ReferenceAdapter): + self.adapter.clear_memory() + + with torch.no_grad(): + # torch.cuda.empty_cache() + # if optimizer has get_lrs method, then use it + if hasattr(optimizer, 'get_avg_learning_rate'): + learning_rate = optimizer.get_avg_learning_rate() + elif hasattr(optimizer, 'get_learning_rates'): + learning_rate = optimizer.get_learning_rates()[0] + elif self.train_config.optimizer.lower().startswith('dadaptation') or \ + self.train_config.optimizer.lower().startswith('prodigy'): + learning_rate = ( + optimizer.param_groups[0]["d"] * + optimizer.param_groups[0]["lr"] + ) + else: + learning_rate = optimizer.param_groups[0]['lr'] + + prog_bar_string = f"lr: {learning_rate:.1e}" + for key, value in loss_dict.items(): + prog_bar_string += f" {key}: {value:.3e}" + + if self.progress_bar is not None: + self.progress_bar.set_postfix_str(prog_bar_string) + + # if the batch is a DataLoaderBatchDTO, then we need to clean it up + if isinstance(batch, DataLoaderBatchDTO): + with self.timer('batch_cleanup'): + batch.cleanup() + + # don't do on first step + if self.step_num != self.start_step: + if is_sample_step or is_save_step: + self.accelerator.wait_for_everyone() + if is_sample_step: + if self.progress_bar is not None: + self.progress_bar.pause() + flush() + # print above the progress bar + if self.train_config.free_u: + self.sd.pipeline.disable_freeu() + self.sample(self.step_num) + if self.train_config.unload_text_encoder: + # make sure the text encoder is unloaded + self.sd.text_encoder_to('cpu') + flush() + + self.ensure_params_requires_grad() + if self.progress_bar is not None: + self.progress_bar.unpause() + + if is_save_step: + self.accelerator + # print above the progress bar + if self.progress_bar is not None: + self.progress_bar.pause() + print_acc(f"\nSaving at step {self.step_num}") + self.save(self.step_num) + self.ensure_params_requires_grad() + # clear any grads + optimizer.zero_grad() + flush() + flush_next = True + if self.progress_bar is not None: + self.progress_bar.unpause() + + if self.logging_config.log_every and self.step_num % self.logging_config.log_every == 0: + if self.progress_bar is not None: + self.progress_bar.pause() + with self.timer('log_to_tensorboard'): + # log to tensorboard + if self.accelerator.is_main_process: + if self.writer is not None: + for key, value in loss_dict.items(): + self.writer.add_scalar(f"{key}", value, self.step_num) + self.writer.add_scalar(f"lr", learning_rate, self.step_num) + if self.progress_bar is not None: + self.progress_bar.unpause() + + if self.accelerator.is_main_process: + # log to logger + self.logger.log({ + 'learning_rate': learning_rate, + }) + for key, value in loss_dict.items(): + self.logger.log({ + f'loss/{key}': value, + }) + elif self.logging_config.log_every is None: + if self.accelerator.is_main_process: + # log every step + self.logger.log({ + 'learning_rate': learning_rate, + }) + for key, value in loss_dict.items(): + self.logger.log({ + f'loss/{key}': value, + }) + + + if self.performance_log_every > 0 and self.step_num % self.performance_log_every == 0: + if self.progress_bar is not None: + self.progress_bar.pause() + # print the timers and clear them + self.timer.print() + self.timer.reset() + if self.progress_bar is not None: + self.progress_bar.unpause() + + # commit log + if self.accelerator.is_main_process: + self.logger.commit(step=self.step_num) + + # sets progress bar to match out step + if self.progress_bar is not None: + self.progress_bar.update(step - self.progress_bar.n) + + ############################# + # End of step + ############################# + + # update various steps + self.step_num = step + 1 + self.grad_accumulation_step += 1 + self.end_step_hook() + + + ################################################################### + ## END TRAIN LOOP + ################################################################### + self.accelerator.wait_for_everyone() + if self.progress_bar is not None: + self.progress_bar.close() + if self.train_config.free_u: + self.sd.pipeline.disable_freeu() + if not self.train_config.disable_sampling: + self.sample(self.step_num) + self.logger.commit(step=self.step_num) + print_acc("") + if self.accelerator.is_main_process: + self.save() + self.logger.finish() + self.accelerator.end_training() + + if self.accelerator.is_main_process: + # push to hub + if self.save_config.push_to_hub: + if("HF_TOKEN" not in os.environ): + interpreter_login(new_session=False, write_permission=True) + self.push_to_hub( + repo_id=self.save_config.hf_repo_id, + private=self.save_config.hf_private + ) + del ( + self.sd, + unet, + noise_scheduler, + optimizer, + self.network, + tokenizer, + text_encoder, + ) + + flush() + self.done_hook() + + def push_to_hub( + self, + repo_id: str, + private: bool = False, + ): + if not self.accelerator.is_main_process: + return + readme_content = self._generate_readme(repo_id) + readme_path = os.path.join(self.save_root, "README.md") + with open(readme_path, "w", encoding="utf-8") as f: + f.write(readme_content) + + api = HfApi() + + api.create_repo( + repo_id, + private=private, + exist_ok=True + ) + + api.upload_folder( + repo_id=repo_id, + folder_path=self.save_root, + ignore_patterns=["*.yaml", "*.pt"], + repo_type="model", + ) + + + def _generate_readme(self, repo_id: str) -> str: + """Generates the content of the README.md file.""" + + # Gather model info + base_model = self.model_config.name_or_path + instance_prompt = self.trigger_word if hasattr(self, "trigger_word") else None + if base_model == "black-forest-labs/FLUX.1-schnell": + license = "apache-2.0" + elif base_model == "black-forest-labs/FLUX.1-dev": + license = "other" + license_name = "flux-1-dev-non-commercial-license" + license_link = "https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md" + else: + license = "creativeml-openrail-m" + tags = [ + "text-to-image", + ] + if self.model_config.is_xl: + tags.append("stable-diffusion-xl") + if self.model_config.is_flux: + tags.append("flux") + if self.model_config.is_lumina2: + tags.append("lumina2") + if self.model_config.is_v3: + tags.append("sd3") + if self.network_config: + tags.extend( + [ + "lora", + "diffusers", + "template:sd-lora", + "ai-toolkit", + ] + ) + + # Generate the widget section + widgets = [] + sample_image_paths = [] + samples_dir = os.path.join(self.save_root, "samples") + if os.path.isdir(samples_dir): + for filename in os.listdir(samples_dir): + #The filenames are structured as 1724085406830__00000500_0.jpg + #So here we capture the 2nd part (steps) and 3rd (index the matches the prompt) + match = re.search(r"__(\d+)_(\d+)\.jpg$", filename) + if match: + steps, index = int(match.group(1)), int(match.group(2)) + #Here we only care about uploading the latest samples, the match with the # of steps + if steps == self.train_config.steps: + sample_image_paths.append((index, f"samples/{filename}")) + + # Sort by numeric index + sample_image_paths.sort(key=lambda x: x[0]) + + # Create widgets matching prompt with the index + for i, prompt in enumerate(self.sample_config.prompts): + if i < len(sample_image_paths): + # Associate prompts with sample image paths based on the extracted index + _, image_path = sample_image_paths[i] + widgets.append( + { + "text": prompt, + "output": { + "url": image_path + }, + } + ) + dtype = "torch.bfloat16" if self.model_config.is_flux else "torch.float16" + # Construct the README content + readme_content = f"""--- +tags: +{yaml.dump(tags, indent=4).strip()} +{"widget:" if os.path.isdir(samples_dir) else ""} +{yaml.dump(widgets, indent=4).strip() if widgets else ""} +base_model: {base_model} +{"instance_prompt: " + instance_prompt if instance_prompt else ""} +license: {license} +{'license_name: ' + license_name if license == "other" else ""} +{'license_link: ' + license_link if license == "other" else ""} +--- + +# {self.job.name} +Model trained with [AI Toolkit by Ostris](https://github.com/ostris/ai-toolkit) +Loading...
} + {status === 'error' &&Error fetching images
} + {status === 'success' && ( +No images found
} + {imgList.map(img => ( +Loading...
} + {status === 'error' && job == null &&Error fetching job
} + {job && ( + <> + {pageKey === 'overview' &&}`}) + )}
+
+ )}
+ {!isVisible && (
+
+ )}
+
+ )}
+ {!isVisible && (
+