Spaces:
Runtime error

Runtime error
Commit
·
d2a8669
1
Parent(s):
255e550
First commit
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- Homepage.py +59 -0
- README.md +8 -8
- ali.graphml +220 -0
- imgs/fairup_architecture.jpeg +0 -0
- imgs/fairup_architecture.png +0 -0
- imgs/logo_ovgu_dtdh.png +0 -0
- imgs/logo_ovgu_fin_en.jpg +0 -0
- nba.graphml +0 -0
- pages/1_Framework.py +796 -0
- pages/ovgu_logo.png +0 -0
- pages/setup.sh +7 -0
- presets/Presets.py +259 -0
- presets/__pycache__/FairGNN_preset.cpython-310.pyc +0 -0
- presets/__pycache__/Presets.cpython-310.pyc +0 -0
- requirements.txt +3 -0
- src/__pycache__/fainress_component.cpython-37.pyc +0 -0
- src/__pycache__/fainress_component.cpython-39.pyc +0 -0
- src/__pycache__/utils.cpython-37.pyc +0 -0
- src/__pycache__/utils.cpython-39.pyc +0 -0
- src/aif360/README.md +0 -0
- src/aif360/__init__.py +4 -0
- src/aif360/__pycache__/__init__.cpython-37.pyc +0 -0
- src/aif360/__pycache__/__init__.cpython-39.pyc +0 -0
- src/aif360/__pycache__/decorating_metaclass.cpython-37.pyc +0 -0
- src/aif360/__pycache__/decorating_metaclass.cpython-39.pyc +0 -0
- src/aif360/aif360-r/.Rbuildignore +12 -0
- src/aif360/aif360-r/.gitignore +7 -0
- src/aif360/aif360-r/CODEOFCONDUCT.md +44 -0
- src/aif360/aif360-r/CONTRIBUTING.md +30 -0
- src/aif360/aif360-r/DESCRIPTION +24 -0
- src/aif360/aif360-r/LICENSE.md +194 -0
- src/aif360/aif360-r/NAMESPACE +24 -0
- src/aif360/aif360-r/R/binary_label_dataset_metric.R +43 -0
- src/aif360/aif360-r/R/classification_metric.R +114 -0
- src/aif360/aif360-r/R/dataset.R +71 -0
- src/aif360/aif360-r/R/dataset_metric.R +42 -0
- src/aif360/aif360-r/R/import.R +23 -0
- src/aif360/aif360-r/R/inprocessing_adversarial_debiasing.R +73 -0
- src/aif360/aif360-r/R/inprocessing_prejudice_remover.R +26 -0
- src/aif360/aif360-r/R/postprocessing_reject_option_classification.R +85 -0
- src/aif360/aif360-r/R/preprocessing_disparate_impact_remover.R +27 -0
- src/aif360/aif360-r/R/preprocessing_reweighing.R +25 -0
- src/aif360/aif360-r/R/standard_datasets.R +31 -0
- src/aif360/aif360-r/R/utils.R +89 -0
- src/aif360/aif360-r/R/zzz.R +4 -0
- src/aif360/aif360-r/README.Rmd +150 -0
- src/aif360/aif360-r/README.md +155 -0
- src/aif360/aif360-r/cran-comments.md +10 -0
- src/aif360/aif360-r/inst/examples/test.R +20 -0
- src/aif360/aif360-r/inst/extdata/actual_data.csv +21 -0
Homepage.py
ADDED
|
@@ -0,0 +1,59 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from PIL import Image
|
| 3 |
+
import os
|
| 4 |
+
|
| 5 |
+
if 'STREAMLIT_PRODUCTION' in os.environ:
|
| 6 |
+
# Running on Streamlit Sharing
|
| 7 |
+
with open('test.yml', 'r') as file:
|
| 8 |
+
environment = file.read()
|
| 9 |
+
with open('test_tmp.yml', 'w') as file:
|
| 10 |
+
file.write(environment.replace('prefix: /', ''))
|
| 11 |
+
os.system('conda env create -f test_tmp.yml')
|
| 12 |
+
os.system('source activate ./envs/$(head -1 test_tmp.yml | cut -d " " -f2)')
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
st.set_page_config(
|
| 16 |
+
page_title="Homepage",
|
| 17 |
+
layout="wide"
|
| 18 |
+
)
|
| 19 |
+
|
| 20 |
+
# Create a text box
|
| 21 |
+
#text_box = st.text_input("Enter some text:")
|
| 22 |
+
|
| 23 |
+
# Create an expander to display additional information
|
| 24 |
+
#with st.expander("More information"):
|
| 25 |
+
# st.write("This section contains additional information about the text box.")
|
| 26 |
+
|
| 27 |
+
# Display the text box
|
| 28 |
+
#st.write("You entered:", text_box)
|
| 29 |
+
|
| 30 |
+
logo_ovgu_fin = Image.open('imgs/logo_ovgu_fin_en.jpg')
|
| 31 |
+
st.image(logo_ovgu_fin)
|
| 32 |
+
|
| 33 |
+
st.title("FairUP: a Framework for Fairness Analysis of Graph Neural Network-Based User Profiling Models 🚀")
|
| 34 |
+
st.markdown("##### *Mohamed Abdelrazek, Erasmo Purificato, Ludovico Boratto, and Ernesto William De Luca*")
|
| 35 |
+
|
| 36 |
+
st.markdown("## Description")
|
| 37 |
+
st.markdown("""
|
| 38 |
+
**FairUP** is a standardised framework that empowers researchers and practitioners to simultaneously analyse state-of-the-art Graph Neural Network-based models for user profiling task, in terms of classification performance and fairness metrics scores.
|
| 39 |
+
|
| 40 |
+
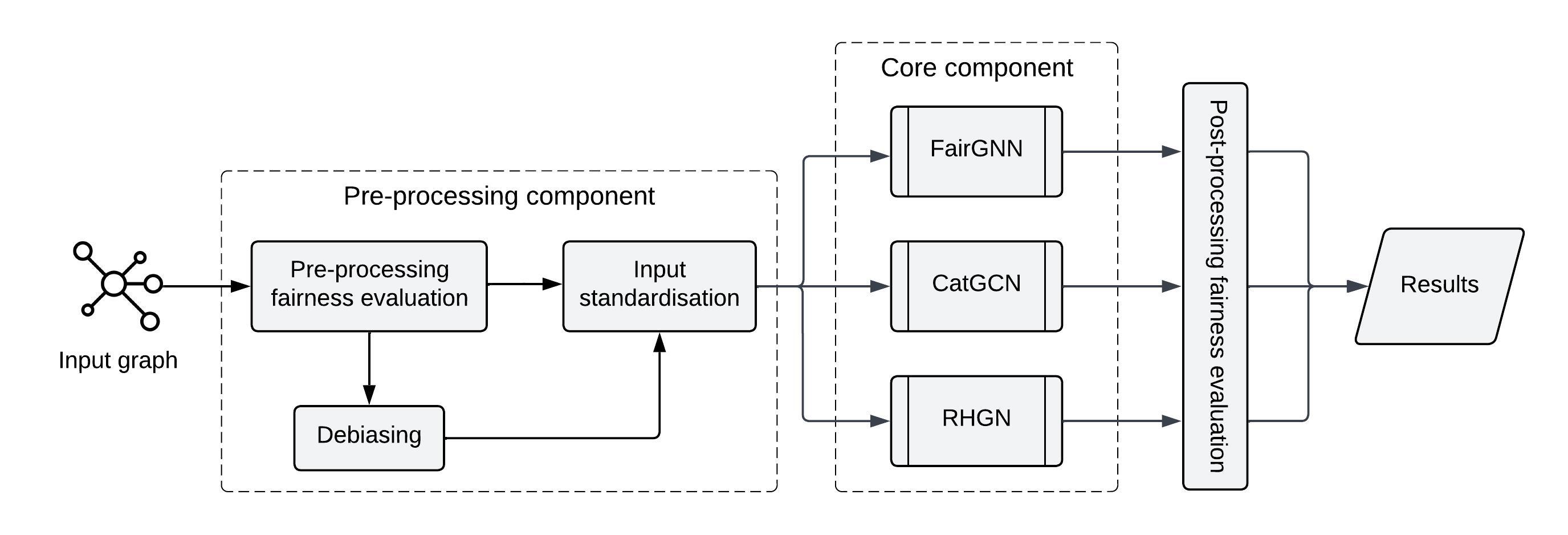
The framework, whose architecture is shown below, presents several components, which allow end-users to:
|
| 41 |
+
* compute the fairness of the input dataset by means of a pre-processing fairness metric, i.e. *disparate impact*;
|
| 42 |
+
* mitigate the unfairness of the dataset, if needed, by applying different debiasing methods, i.e. *sampling*, *reweighting* and *disparate impact remover*;
|
| 43 |
+
* standardise the input (a graph in Neo4J or NetworkX format) for each of the included GNNs;
|
| 44 |
+
* train one or more GNN models, specifying the parameters for each of them;
|
| 45 |
+
* evaluate post-hoc fairness by exploiting four metrics, i.e. *statistical parity*, *equal opportunity*, *overall accuracy equality*, *treatment equality*.
|
| 46 |
+
""")
|
| 47 |
+
|
| 48 |
+
# st.markdown('##### We have developed a comprehensive framework for Graph Neural Networks-based user profiling models that empowers researchers and users to simultaneously train multiple models and analyze their outcomes. This framework includes tools for mitigating bias, ensuring fairness, and increasing model interpretability. Our approach allows for the incorporation of debiasing techniques into the training process, which helps to minimize the impact of societal biases on model performance. In addition, our framework supports multiple evaluation metrics, enabling the user to compare and contrast the performance of different models.')
|
| 49 |
+
|
| 50 |
+
# Vertical space
|
| 51 |
+
st.text("")
|
| 52 |
+
|
| 53 |
+
fairup = Image.open('imgs/fairup_architecture.png')
|
| 54 |
+
st.image(fairup, caption="Logical architecture of FairUP framework")
|
| 55 |
+
|
| 56 |
+
#st.text("")
|
| 57 |
+
#st.markdown('##### The framework is divided into 3 components: the Pre-processing component, the Core component, and the Post-processing fairness evaluation component')
|
| 58 |
+
|
| 59 |
+
#st.sidebar.success("Select a page")
|
README.md
CHANGED
|
@@ -1,12 +1,12 @@
|
|
| 1 |
---
|
| 2 |
-
title: FairUP
|
| 3 |
-
emoji:
|
| 4 |
-
colorFrom:
|
| 5 |
-
colorTo:
|
| 6 |
-
sdk: streamlit
|
| 7 |
-
sdk_version: 1.19.0
|
| 8 |
-
app_file:
|
| 9 |
-
pinned: false
|
| 10 |
license: cc-by-4.0
|
| 11 |
---
|
| 12 |
|
|
|
|
| 1 |
---
|
| 2 |
+
title: FairUP
|
| 3 |
+
emoji: 🚀
|
| 4 |
+
colorFrom: blue
|
| 5 |
+
colorTo: green
|
| 6 |
+
sdk: streamlit
|
| 7 |
+
sdk_version: 1.19.0
|
| 8 |
+
app_file: Homepage.py
|
| 9 |
+
pinned: false
|
| 10 |
license: cc-by-4.0
|
| 11 |
---
|
| 12 |
|
ali.graphml
ADDED
|
@@ -0,0 +1,220 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<?xml version='1.0' encoding='utf-8'?>
|
| 2 |
+
<graphml xmlns="http://graphml.graphdrawing.org/xmlns" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://graphml.graphdrawing.org/xmlns http://graphml.graphdrawing.org/xmlns/1.0/graphml.xsd"><key id="d17" for="node" attr.name="price" attr.type="double"/>
|
| 3 |
+
<key id="d16" for="node" attr.name="brand" attr.type="double"/>
|
| 4 |
+
<key id="d15" for="node" attr.name="customer" attr.type="long"/>
|
| 5 |
+
<key id="d14" for="node" attr.name="campaign_id" attr.type="long"/>
|
| 6 |
+
<key id="d13" for="node" attr.name="cate_id" attr.type="long"/>
|
| 7 |
+
<key id="d12" for="node" attr.name="clk" attr.type="long"/>
|
| 8 |
+
<key id="d11" for="node" attr.name="nonclk" attr.type="long"/>
|
| 9 |
+
<key id="d10" for="node" attr.name="pid" attr.type="string"/>
|
| 10 |
+
<key id="d9" for="node" attr.name="adgroup_id" attr.type="long"/>
|
| 11 |
+
<key id="d8" for="node" attr.name="time_stamp" attr.type="long"/>
|
| 12 |
+
<key id="d7" for="node" attr.name="new_user_class_level" attr.type="double"/>
|
| 13 |
+
<key id="d6" for="node" attr.name="occupation" attr.type="double"/>
|
| 14 |
+
<key id="d5" for="node" attr.name="shopping_level" attr.type="double"/>
|
| 15 |
+
<key id="d4" for="node" attr.name="pvalue_level" attr.type="double"/>
|
| 16 |
+
<key id="d3" for="node" attr.name="age_level" attr.type="double"/>
|
| 17 |
+
<key id="d2" for="node" attr.name="final_gender_code" attr.type="double"/>
|
| 18 |
+
<key id="d1" for="node" attr.name="cms_group_id" attr.type="double"/>
|
| 19 |
+
<key id="d0" for="node" attr.name="cms_segid" attr.type="double"/>
|
| 20 |
+
<graph edgedefault="directed"><node id="523">
|
| 21 |
+
<data key="d0">5.0</data>
|
| 22 |
+
<data key="d1">2.0</data>
|
| 23 |
+
<data key="d2">2.0</data>
|
| 24 |
+
<data key="d3">2.0</data>
|
| 25 |
+
<data key="d4">1.0</data>
|
| 26 |
+
<data key="d5">3.0</data>
|
| 27 |
+
<data key="d6">1.0</data>
|
| 28 |
+
<data key="d7">2.0</data>
|
| 29 |
+
<data key="d8">1494506876</data>
|
| 30 |
+
<data key="d9">95657</data>
|
| 31 |
+
<data key="d10">430548_1007</data>
|
| 32 |
+
<data key="d11">1</data>
|
| 33 |
+
<data key="d12">0</data>
|
| 34 |
+
<data key="d13">6412</data>
|
| 35 |
+
<data key="d14">160512</data>
|
| 36 |
+
<data key="d15">82513</data>
|
| 37 |
+
<data key="d16">26994.0</data>
|
| 38 |
+
<data key="d17">619.0</data>
|
| 39 |
+
</node>
|
| 40 |
+
<node id="830671">
|
| 41 |
+
<data key="d0">34.0</data>
|
| 42 |
+
<data key="d1">4.0</data>
|
| 43 |
+
<data key="d2">2.0</data>
|
| 44 |
+
<data key="d3">4.0</data>
|
| 45 |
+
<data key="d4">3.0</data>
|
| 46 |
+
<data key="d5">3.0</data>
|
| 47 |
+
<data key="d6">0.0</data>
|
| 48 |
+
<data key="d7">3.0</data>
|
| 49 |
+
<data key="d8">1494668843</data>
|
| 50 |
+
<data key="d9">95657</data>
|
| 51 |
+
<data key="d10">430539_1007</data>
|
| 52 |
+
<data key="d11">1</data>
|
| 53 |
+
<data key="d12">0</data>
|
| 54 |
+
<data key="d13">6412</data>
|
| 55 |
+
<data key="d14">160512</data>
|
| 56 |
+
<data key="d15">82513</data>
|
| 57 |
+
<data key="d16">26994.0</data>
|
| 58 |
+
<data key="d17">619.0</data>
|
| 59 |
+
</node>
|
| 60 |
+
<node id="567632">
|
| 61 |
+
<data key="d0">66.0</data>
|
| 62 |
+
<data key="d1">9.0</data>
|
| 63 |
+
<data key="d2">1.0</data>
|
| 64 |
+
<data key="d3">3.0</data>
|
| 65 |
+
<data key="d4">2.0</data>
|
| 66 |
+
<data key="d5">3.0</data>
|
| 67 |
+
<data key="d6">0.0</data>
|
| 68 |
+
<data key="d7">2.0</data>
|
| 69 |
+
<data key="d8">1494603840</data>
|
| 70 |
+
<data key="d9">95657</data>
|
| 71 |
+
<data key="d10">430539_1007</data>
|
| 72 |
+
<data key="d11">1</data>
|
| 73 |
+
<data key="d12">0</data>
|
| 74 |
+
<data key="d13">6412</data>
|
| 75 |
+
<data key="d14">160512</data>
|
| 76 |
+
<data key="d15">82513</data>
|
| 77 |
+
<data key="d16">26994.0</data>
|
| 78 |
+
<data key="d17">619.0</data>
|
| 79 |
+
</node>
|
| 80 |
+
<node id="16333">
|
| 81 |
+
<data key="d0">91.0</data>
|
| 82 |
+
<data key="d1">11.0</data>
|
| 83 |
+
<data key="d2">1.0</data>
|
| 84 |
+
<data key="d3">5.0</data>
|
| 85 |
+
<data key="d4">2.0</data>
|
| 86 |
+
<data key="d5">3.0</data>
|
| 87 |
+
<data key="d6">0.0</data>
|
| 88 |
+
<data key="d7">2.0</data>
|
| 89 |
+
<data key="d8">1494561928</data>
|
| 90 |
+
<data key="d9">95657</data>
|
| 91 |
+
<data key="d10">430539_1007</data>
|
| 92 |
+
<data key="d11">1</data>
|
| 93 |
+
<data key="d12">0</data>
|
| 94 |
+
<data key="d13">6412</data>
|
| 95 |
+
<data key="d14">160512</data>
|
| 96 |
+
<data key="d15">82513</data>
|
| 97 |
+
<data key="d16">26994.0</data>
|
| 98 |
+
<data key="d17">619.0</data>
|
| 99 |
+
</node>
|
| 100 |
+
<node id="521847">
|
| 101 |
+
<data key="d0">20.0</data>
|
| 102 |
+
<data key="d1">3.0</data>
|
| 103 |
+
<data key="d2">2.0</data>
|
| 104 |
+
<data key="d3">3.0</data>
|
| 105 |
+
<data key="d4">2.0</data>
|
| 106 |
+
<data key="d5">3.0</data>
|
| 107 |
+
<data key="d6">0.0</data>
|
| 108 |
+
<data key="d7">3.0</data>
|
| 109 |
+
<data key="d8">1494579049</data>
|
| 110 |
+
<data key="d9">95657</data>
|
| 111 |
+
<data key="d10">430548_1007</data>
|
| 112 |
+
<data key="d11">1</data>
|
| 113 |
+
<data key="d12">0</data>
|
| 114 |
+
<data key="d13">6412</data>
|
| 115 |
+
<data key="d14">160512</data>
|
| 116 |
+
<data key="d15">82513</data>
|
| 117 |
+
<data key="d16">26994.0</data>
|
| 118 |
+
<data key="d17">619.0</data>
|
| 119 |
+
</node>
|
| 120 |
+
<node id="227111">
|
| 121 |
+
<data key="d0">8.0</data>
|
| 122 |
+
<data key="d1">2.0</data>
|
| 123 |
+
<data key="d2">2.0</data>
|
| 124 |
+
<data key="d3">2.0</data>
|
| 125 |
+
<data key="d4">2.0</data>
|
| 126 |
+
<data key="d5">3.0</data>
|
| 127 |
+
<data key="d6">0.0</data>
|
| 128 |
+
<data key="d7">3.0</data>
|
| 129 |
+
<data key="d8">1494559984</data>
|
| 130 |
+
<data key="d9">95657</data>
|
| 131 |
+
<data key="d10">430539_1007</data>
|
| 132 |
+
<data key="d11">1</data>
|
| 133 |
+
<data key="d12">0</data>
|
| 134 |
+
<data key="d13">6412</data>
|
| 135 |
+
<data key="d14">160512</data>
|
| 136 |
+
<data key="d15">82513</data>
|
| 137 |
+
<data key="d16">26994.0</data>
|
| 138 |
+
<data key="d17">619.0</data>
|
| 139 |
+
</node>
|
| 140 |
+
<node id="632984">
|
| 141 |
+
<data key="d0">89.0</data>
|
| 142 |
+
<data key="d1">11.0</data>
|
| 143 |
+
<data key="d2">1.0</data>
|
| 144 |
+
<data key="d3">5.0</data>
|
| 145 |
+
<data key="d4">1.0</data>
|
| 146 |
+
<data key="d5">3.0</data>
|
| 147 |
+
<data key="d6">0.0</data>
|
| 148 |
+
<data key="d7">4.0</data>
|
| 149 |
+
<data key="d8">1494566502</data>
|
| 150 |
+
<data key="d9">95657</data>
|
| 151 |
+
<data key="d10">430548_1007</data>
|
| 152 |
+
<data key="d11">1</data>
|
| 153 |
+
<data key="d12">0</data>
|
| 154 |
+
<data key="d13">6412</data>
|
| 155 |
+
<data key="d14">160512</data>
|
| 156 |
+
<data key="d15">82513</data>
|
| 157 |
+
<data key="d16">26994.0</data>
|
| 158 |
+
<data key="d17">619.0</data>
|
| 159 |
+
</node>
|
| 160 |
+
<node id="912028">
|
| 161 |
+
<data key="d0">20.0</data>
|
| 162 |
+
<data key="d1">3.0</data>
|
| 163 |
+
<data key="d2">2.0</data>
|
| 164 |
+
<data key="d3">3.0</data>
|
| 165 |
+
<data key="d4">2.0</data>
|
| 166 |
+
<data key="d5">3.0</data>
|
| 167 |
+
<data key="d6">0.0</data>
|
| 168 |
+
<data key="d7">3.0</data>
|
| 169 |
+
<data key="d8">1494276088</data>
|
| 170 |
+
<data key="d9">95657</data>
|
| 171 |
+
<data key="d10">430539_1007</data>
|
| 172 |
+
<data key="d11">1</data>
|
| 173 |
+
<data key="d12">0</data>
|
| 174 |
+
<data key="d13">6412</data>
|
| 175 |
+
<data key="d14">160512</data>
|
| 176 |
+
<data key="d15">82513</data>
|
| 177 |
+
<data key="d16">26994.0</data>
|
| 178 |
+
<data key="d17">619.0</data>
|
| 179 |
+
</node>
|
| 180 |
+
<node id="120208">
|
| 181 |
+
<data key="d0">77.0</data>
|
| 182 |
+
<data key="d1">10.0</data>
|
| 183 |
+
<data key="d2">1.0</data>
|
| 184 |
+
<data key="d3">4.0</data>
|
| 185 |
+
<data key="d4">1.0</data>
|
| 186 |
+
<data key="d5">3.0</data>
|
| 187 |
+
<data key="d6">0.0</data>
|
| 188 |
+
<data key="d7">2.0</data>
|
| 189 |
+
<data key="d8">1494563600</data>
|
| 190 |
+
<data key="d9">95657</data>
|
| 191 |
+
<data key="d10">430548_1007</data>
|
| 192 |
+
<data key="d11">1</data>
|
| 193 |
+
<data key="d12">0</data>
|
| 194 |
+
<data key="d13">6412</data>
|
| 195 |
+
<data key="d14">160512</data>
|
| 196 |
+
<data key="d15">82513</data>
|
| 197 |
+
<data key="d16">26994.0</data>
|
| 198 |
+
<data key="d17">619.0</data>
|
| 199 |
+
</node>
|
| 200 |
+
<node id="390080">
|
| 201 |
+
<data key="d0">6.0</data>
|
| 202 |
+
<data key="d1">2.0</data>
|
| 203 |
+
<data key="d2">2.0</data>
|
| 204 |
+
<data key="d3">2.0</data>
|
| 205 |
+
<data key="d4">2.0</data>
|
| 206 |
+
<data key="d5">2.0</data>
|
| 207 |
+
<data key="d6">0.0</data>
|
| 208 |
+
<data key="d7">4.0</data>
|
| 209 |
+
<data key="d8">1494296612</data>
|
| 210 |
+
<data key="d9">95657</data>
|
| 211 |
+
<data key="d10">430539_1007</data>
|
| 212 |
+
<data key="d11">1</data>
|
| 213 |
+
<data key="d12">0</data>
|
| 214 |
+
<data key="d13">6412</data>
|
| 215 |
+
<data key="d14">160512</data>
|
| 216 |
+
<data key="d15">82513</data>
|
| 217 |
+
<data key="d16">26994.0</data>
|
| 218 |
+
<data key="d17">619.0</data>
|
| 219 |
+
</node>
|
| 220 |
+
</graph></graphml>
|
imgs/fairup_architecture.jpeg
ADDED
|
imgs/fairup_architecture.png
ADDED

|
imgs/logo_ovgu_dtdh.png
ADDED
|
|
imgs/logo_ovgu_fin_en.jpg
ADDED
|
|
nba.graphml
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
pages/1_Framework.py
ADDED
|
@@ -0,0 +1,796 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from PIL import Image
|
| 3 |
+
import time
|
| 4 |
+
import pandas as pd
|
| 5 |
+
import os
|
| 6 |
+
import paramiko
|
| 7 |
+
import threading
|
| 8 |
+
import queue
|
| 9 |
+
import warnings
|
| 10 |
+
import re
|
| 11 |
+
import subprocess
|
| 12 |
+
from presets import Presets
|
| 13 |
+
import random
|
| 14 |
+
#from src import main
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
st.set_page_config(layout="wide")
|
| 19 |
+
st.warning('Note: We are running out with GPU problems. The GNN models are currently running on CPU and some of the Framework capabilities may not be available. We apologise for the inconvenience and we will fix that soon.', icon="⚠️")
|
| 20 |
+
|
| 21 |
+
st.header('')
|
| 22 |
+
ovgu_img = Image.open('imgs/logo_ovgu_fin_en.jpg')
|
| 23 |
+
st.image(ovgu_img)
|
| 24 |
+
st.title("FairUP: a Framework for Fairness Analysis of Graph Neural Network-Based User Profiling Models. 🚀")
|
| 25 |
+
|
| 26 |
+
warnings.filterwarnings("ignore", category=DeprecationWarning)
|
| 27 |
+
warnings.filterwarnings("ignore", category=RuntimeWarning)
|
| 28 |
+
warnings.filterwarnings("ignore")
|
| 29 |
+
|
| 30 |
+
nba_columns = ['user_id', 'SALARY', 'AGE', 'MP', 'FG', 'FGA', 'FG%', '3P', '3PA',
|
| 31 |
+
'3P%', '2P', '2PA', '2P%', 'eFG%', 'FT', 'FTA', 'FT%', 'ORB', 'DRB',
|
| 32 |
+
'TRB', 'AST', 'STL', 'BLK', 'TOV', 'PF_x', 'POINTS', 'GP', 'MPG',
|
| 33 |
+
'ORPM', 'DRPM', 'RPM', 'WINS_RPM', 'PIE', 'PACE', 'W', 'player_height',
|
| 34 |
+
'player_weight', 'country', 'C', 'PF_y', 'PF-C', 'PG', 'SF', 'SG',
|
| 35 |
+
'ATL', 'ATL/CLE', 'ATL/LAL', 'BKN', 'BKN/WSH', 'BOS', 'CHA', 'CHI',
|
| 36 |
+
'CHI/OKC', 'CLE', 'CLE/DAL', 'CLE/MIA', 'DAL', 'DAL/BKN', 'DAL/PHI',
|
| 37 |
+
'DEN', 'DEN/CHA', 'DEN/POR', 'DET', 'GS', 'GS/CHA', 'GS/SAC', 'HOU',
|
| 38 |
+
'HOU/LAL', 'HOU/MEM', 'IND', 'LAC', 'LAL', 'MEM', 'MIA', 'MIL',
|
| 39 |
+
'MIL/CHA', 'MIN', 'NO', 'NO/DAL', 'NO/MEM', 'NO/MIL', 'NO/MIN/SAC',
|
| 40 |
+
'NO/ORL', 'NO/SAC', 'NY', 'NY/PHI', 'OKC', 'ORL', 'ORL/TOR', 'PHI',
|
| 41 |
+
'PHI/OKC', 'PHX', 'POR', 'SA', 'SAC', 'TOR', 'UTAH', 'WSH']
|
| 42 |
+
|
| 43 |
+
pokec_columns = ['user_id',
|
| 44 |
+
'public',
|
| 45 |
+
'completion_percentage',
|
| 46 |
+
'gender',
|
| 47 |
+
'region',
|
| 48 |
+
'AGE',
|
| 49 |
+
'I_am_working_in_field',
|
| 50 |
+
'spoken_languages_indicator',
|
| 51 |
+
'anglicky',
|
| 52 |
+
'nemecky',
|
| 53 |
+
'rusky',
|
| 54 |
+
'francuzsky',
|
| 55 |
+
'spanielsky',
|
| 56 |
+
'taliansky',
|
| 57 |
+
'slovensky',
|
| 58 |
+
'japonsky',
|
| 59 |
+
'hobbies_indicator',
|
| 60 |
+
'priatelia',
|
| 61 |
+
'sportovanie',
|
| 62 |
+
'pocuvanie hudby',
|
| 63 |
+
'pozeranie filmov',
|
| 64 |
+
'spanie',
|
| 65 |
+
'kupalisko',
|
| 66 |
+
'party',
|
| 67 |
+
'cestovanie',
|
| 68 |
+
'kino',
|
| 69 |
+
'diskoteky',
|
| 70 |
+
'nakupovanie',
|
| 71 |
+
'tancovanie',
|
| 72 |
+
'turistika',
|
| 73 |
+
'surfovanie po webe',
|
| 74 |
+
'praca s pc',
|
| 75 |
+
'sex',
|
| 76 |
+
'pc hry',
|
| 77 |
+
'stanovanie',
|
| 78 |
+
'varenie',
|
| 79 |
+
'jedlo',
|
| 80 |
+
'fotografovanie',
|
| 81 |
+
'citanie',
|
| 82 |
+
'malovanie',
|
| 83 |
+
'chovatelstvo',
|
| 84 |
+
'domace prace',
|
| 85 |
+
'divadlo',
|
| 86 |
+
'prace okolo domu',
|
| 87 |
+
'prace v zahrade',
|
| 88 |
+
'chodenie do muzei',
|
| 89 |
+
'zberatelstvo',
|
| 90 |
+
'hackovanie',
|
| 91 |
+
'I_most_enjoy_good_food_indicator',
|
| 92 |
+
'pri telke',
|
| 93 |
+
'v dobrej restauracii',
|
| 94 |
+
'pri svieckach s partnerom',
|
| 95 |
+
'v posteli',
|
| 96 |
+
'v prirode',
|
| 97 |
+
'z partnerovho bruska',
|
| 98 |
+
'v kuchyni pri stole',
|
| 99 |
+
'pets_indicator',
|
| 100 |
+
'pes',
|
| 101 |
+
'mam psa',
|
| 102 |
+
'nemam ziadne',
|
| 103 |
+
'macka',
|
| 104 |
+
'rybky',
|
| 105 |
+
'mam macku',
|
| 106 |
+
'mam rybky',
|
| 107 |
+
'vtacik',
|
| 108 |
+
'body_type_indicator',
|
| 109 |
+
'priemerna',
|
| 110 |
+
'vysportovana',
|
| 111 |
+
'chuda',
|
| 112 |
+
'velka a pekna',
|
| 113 |
+
'tak trosku pri sebe',
|
| 114 |
+
'eye_color_indicator',
|
| 115 |
+
'hnede',
|
| 116 |
+
'modre',
|
| 117 |
+
'zelene',
|
| 118 |
+
'hair_color_indicator',
|
| 119 |
+
'cierne',
|
| 120 |
+
'blond',
|
| 121 |
+
'plave',
|
| 122 |
+
'hair_type_indicator',
|
| 123 |
+
'kratke',
|
| 124 |
+
'dlhe',
|
| 125 |
+
'rovne',
|
| 126 |
+
'po plecia',
|
| 127 |
+
'kucerave',
|
| 128 |
+
'na jezka',
|
| 129 |
+
'completed_level_of_education_indicator',
|
| 130 |
+
'stredoskolske',
|
| 131 |
+
'zakladne',
|
| 132 |
+
'vysokoskolske',
|
| 133 |
+
'ucnovske',
|
| 134 |
+
'favourite_color_indicator',
|
| 135 |
+
'modra',
|
| 136 |
+
'cierna',
|
| 137 |
+
'cervena',
|
| 138 |
+
'biela',
|
| 139 |
+
'zelena',
|
| 140 |
+
'fialova',
|
| 141 |
+
'zlta',
|
| 142 |
+
'ruzova',
|
| 143 |
+
'oranzova',
|
| 144 |
+
'hneda',
|
| 145 |
+
'relation_to_smoking_indicator',
|
| 146 |
+
'nefajcim',
|
| 147 |
+
'fajcim pravidelne',
|
| 148 |
+
'fajcim prilezitostne',
|
| 149 |
+
'uz nefajcim',
|
| 150 |
+
'relation_to_alcohol_indicator',
|
| 151 |
+
'pijem prilezitostne',
|
| 152 |
+
'abstinent',
|
| 153 |
+
'nepijem',
|
| 154 |
+
'on_pokec_i_am_looking_for_indicator',
|
| 155 |
+
'dobreho priatela',
|
| 156 |
+
'priatelku',
|
| 157 |
+
'niekoho na chatovanie',
|
| 158 |
+
'udrzujem vztahy s priatelmi',
|
| 159 |
+
'vaznu znamost',
|
| 160 |
+
'sexualneho partnera',
|
| 161 |
+
'dlhodoby seriozny vztah',
|
| 162 |
+
'love_is_for_me_indicator',
|
| 163 |
+
'nie je nic lepsie',
|
| 164 |
+
'ako byt zamilovany(a)',
|
| 165 |
+
'v laske vidim zmysel zivota',
|
| 166 |
+
'v laske som sa sklamal(a)',
|
| 167 |
+
'preto som velmi opatrny(a)',
|
| 168 |
+
'laska je zakladom vyrovnaneho sexualneho zivota',
|
| 169 |
+
'romanticka laska nie je pre mna',
|
| 170 |
+
'davam prednost realite',
|
| 171 |
+
'relation_to_casual_sex_indicator',
|
| 172 |
+
'nedokazem mat s niekym sex bez lasky',
|
| 173 |
+
'to skutocne zalezi len na okolnostiach',
|
| 174 |
+
'sex mozem mat iba s niekym',
|
| 175 |
+
'koho dobre poznam',
|
| 176 |
+
'dokazem mat sex s kymkolvek',
|
| 177 |
+
'kto dobre vyzera',
|
| 178 |
+
'my_partner_should_be_indicator',
|
| 179 |
+
'mojou chybajucou polovickou',
|
| 180 |
+
'laskou mojho zivota',
|
| 181 |
+
'moj najlepsi priatel',
|
| 182 |
+
'absolutne zodpovedny a spolahlivy',
|
| 183 |
+
'hlavne spolocensky typ',
|
| 184 |
+
'clovek',
|
| 185 |
+
'ktoreho uplne respektujem',
|
| 186 |
+
'hlavne dobry milenec',
|
| 187 |
+
'niekto',
|
| 188 |
+
'marital_status_indicator',
|
| 189 |
+
'slobodny(a)',
|
| 190 |
+
'mam vazny vztah',
|
| 191 |
+
'zenaty (vydata)',
|
| 192 |
+
'rozvedeny(a)',
|
| 193 |
+
'slobodny',
|
| 194 |
+
'relation_to_children_indicator',
|
| 195 |
+
'v buducnosti chcem mat deti',
|
| 196 |
+
'I_like_movies_indicator',
|
| 197 |
+
'komedie',
|
| 198 |
+
'akcne',
|
| 199 |
+
'horory',
|
| 200 |
+
'serialy',
|
| 201 |
+
'romanticke',
|
| 202 |
+
'rodinne',
|
| 203 |
+
'sci-fi',
|
| 204 |
+
'historicke',
|
| 205 |
+
'vojnove',
|
| 206 |
+
'zahadne',
|
| 207 |
+
'mysteriozne',
|
| 208 |
+
'dokumentarne',
|
| 209 |
+
'eroticke',
|
| 210 |
+
'dramy',
|
| 211 |
+
'fantasy',
|
| 212 |
+
'muzikaly',
|
| 213 |
+
'kasove trhaky',
|
| 214 |
+
'umelecke',
|
| 215 |
+
'alternativne',
|
| 216 |
+
'I_like_watching_movie_indicator',
|
| 217 |
+
'doma z gauca',
|
| 218 |
+
'v kine',
|
| 219 |
+
'u priatela',
|
| 220 |
+
'priatelky',
|
| 221 |
+
'I_like_music_indicator',
|
| 222 |
+
'disko',
|
| 223 |
+
'pop',
|
| 224 |
+
'rock',
|
| 225 |
+
'rap',
|
| 226 |
+
'techno',
|
| 227 |
+
'house',
|
| 228 |
+
'hitparadovky',
|
| 229 |
+
'sladaky',
|
| 230 |
+
'hip-hop',
|
| 231 |
+
'metal',
|
| 232 |
+
'soundtracky',
|
| 233 |
+
'punk',
|
| 234 |
+
'oldies',
|
| 235 |
+
'folklor a ludovky',
|
| 236 |
+
'folk a country',
|
| 237 |
+
'jazz',
|
| 238 |
+
'klasicka hudba',
|
| 239 |
+
'opery',
|
| 240 |
+
'alternativa',
|
| 241 |
+
'trance',
|
| 242 |
+
'I_mostly_like_listening_to_music_indicator',
|
| 243 |
+
'kedykolvek a kdekolvek',
|
| 244 |
+
'na posteli',
|
| 245 |
+
'pri chodzi',
|
| 246 |
+
'na dobru noc',
|
| 247 |
+
'na diskoteke',
|
| 248 |
+
's partnerom',
|
| 249 |
+
'vo vani',
|
| 250 |
+
'v aute',
|
| 251 |
+
'na koncerte',
|
| 252 |
+
'pri sexe',
|
| 253 |
+
'v praci',
|
| 254 |
+
'the_idea_of_good_evening_indicator',
|
| 255 |
+
'pozerat dobry film v tv',
|
| 256 |
+
'pocuvat dobru hudbu',
|
| 257 |
+
's kamaratmi do baru',
|
| 258 |
+
'ist do kina alebo divadla',
|
| 259 |
+
'surfovat na sieti a chatovat',
|
| 260 |
+
'ist na koncert',
|
| 261 |
+
'citat dobru knihu',
|
| 262 |
+
'nieco dobre uvarit',
|
| 263 |
+
'zhasnut svetla a meditovat',
|
| 264 |
+
'ist do posilnovne',
|
| 265 |
+
'I_like_specialties_from_kitchen_indicator',
|
| 266 |
+
'slovenskej',
|
| 267 |
+
'talianskej',
|
| 268 |
+
'cinskej',
|
| 269 |
+
'mexickej',
|
| 270 |
+
'francuzskej',
|
| 271 |
+
'greckej',
|
| 272 |
+
'morske zivocichy',
|
| 273 |
+
'vegetarianskej',
|
| 274 |
+
'japonskej',
|
| 275 |
+
'indickej',
|
| 276 |
+
'I_am_going_to_concerts_indicator',
|
| 277 |
+
'ja na koncerty nechodim',
|
| 278 |
+
'zriedkavo',
|
| 279 |
+
'my_active_sports_indicator',
|
| 280 |
+
'plavanie',
|
| 281 |
+
'futbal',
|
| 282 |
+
'kolieskove korcule',
|
| 283 |
+
'lyzovanie',
|
| 284 |
+
'korculovanie',
|
| 285 |
+
'behanie',
|
| 286 |
+
'posilnovanie',
|
| 287 |
+
'tenis',
|
| 288 |
+
'hokej',
|
| 289 |
+
'basketbal',
|
| 290 |
+
'snowboarding',
|
| 291 |
+
'pingpong',
|
| 292 |
+
'auto-moto sporty',
|
| 293 |
+
'bedminton',
|
| 294 |
+
'volejbal',
|
| 295 |
+
'aerobik',
|
| 296 |
+
'bojove sporty',
|
| 297 |
+
'hadzana',
|
| 298 |
+
'skateboarding',
|
| 299 |
+
'my_passive_sports_indicator',
|
| 300 |
+
'baseball',
|
| 301 |
+
'golf',
|
| 302 |
+
'horolezectvo',
|
| 303 |
+
'bezkovanie',
|
| 304 |
+
'surfing',
|
| 305 |
+
'I_like_books_indicator',
|
| 306 |
+
'necitam knihy',
|
| 307 |
+
'o zabave',
|
| 308 |
+
'humor',
|
| 309 |
+
'hry',
|
| 310 |
+
'historicke romany',
|
| 311 |
+
'rozpravky',
|
| 312 |
+
'odbornu literaturu',
|
| 313 |
+
'psychologicku literaturu',
|
| 314 |
+
'literaturu pre rozvoj osobnosti',
|
| 315 |
+
'cestopisy',
|
| 316 |
+
'literaturu faktu',
|
| 317 |
+
'poeziu',
|
| 318 |
+
'zivotopisne a pamate',
|
| 319 |
+
'pocitacovu literaturu',
|
| 320 |
+
'filozoficku literaturu',
|
| 321 |
+
'literaturu o umeni a architekture']
|
| 322 |
+
|
| 323 |
+
alibaba_columns = ['userid', 'final_gender_code', 'age_level', 'pvalue_level', 'occupation', 'new_user_class_level ', 'adgroup_id', 'clk', 'cate_id']
|
| 324 |
+
jd_columns = ['user_id',
|
| 325 |
+
'gender',
|
| 326 |
+
'age_range',
|
| 327 |
+
'item_id',
|
| 328 |
+
'cid1',
|
| 329 |
+
'cid2',
|
| 330 |
+
'cid3',
|
| 331 |
+
'cid1_name',
|
| 332 |
+
'cid2_name',
|
| 333 |
+
'cid3_name',
|
| 334 |
+
'brand_code',
|
| 335 |
+
'price',
|
| 336 |
+
'item_name',
|
| 337 |
+
'seg_name']
|
| 338 |
+
|
| 339 |
+
##############################
|
| 340 |
+
# Preset
|
| 341 |
+
preset_question = st.radio("Do you want to apply a preset?", ("No", "Yes"))
|
| 342 |
+
with st.expander("More information"):
|
| 343 |
+
st.write("A preset is a pre-defined parameter and model settings that can be choosen by the user to test the Framework easily.")
|
| 344 |
+
st.write("Each preset option is defined by the model name and (in brackets) the dataset which it will be trained on.")
|
| 345 |
+
if preset_question == 'Yes':
|
| 346 |
+
preset_list = ['FairGNN (NBA)', 'RHGN (Alibaba)', 'CatGCN (Alibaba)']
|
| 347 |
+
preset = st.selectbox('Select Preset', preset_list)
|
| 348 |
+
# implment presets as functions?
|
| 349 |
+
if preset == 'FairGNN (NBA)':
|
| 350 |
+
model_type, predict_attr, sens_attr = Presets.FairGNN_NBA()
|
| 351 |
+
elif preset == 'RHGN (Alibaba)':
|
| 352 |
+
model_type, predict_attr, sens_attr = Presets.RHGN_Alibaba()
|
| 353 |
+
elif preset == 'CatGCN (Alibaba)':
|
| 354 |
+
model_type, predict_attr, sens_attr = Presets.CatGCN_Alibaba()
|
| 355 |
+
|
| 356 |
+
Presets.experiment_begin(model_type, predict_attr, sens_attr)
|
| 357 |
+
|
| 358 |
+
elif preset_question == 'No':
|
| 359 |
+
dataset = st.selectbox("Which dataset do you want to evaluate?", ("NBA", "Pokec-z", "Alibaba", "JD"))
|
| 360 |
+
if dataset == "NBA":
|
| 361 |
+
dataset = 'nba'
|
| 362 |
+
predict_attr = st.selectbox("Select prediction label", nba_columns)
|
| 363 |
+
sens_attr = st.selectbox("Select sensitive attribute", nba_columns)
|
| 364 |
+
elif dataset == "Pokec-z":
|
| 365 |
+
dataset = 'pokec_z'
|
| 366 |
+
predict_attr = st.selectbox("Select prediction label", pokec_columns)
|
| 367 |
+
sens_attr = st.selectbox("Select sensitive attribute", pokec_columns)
|
| 368 |
+
elif dataset == "Alibaba":
|
| 369 |
+
dataset = 'alibaba'
|
| 370 |
+
predict_attr = st.selectbox("Select prediction label", alibaba_columns)
|
| 371 |
+
sens_attr = st.selectbox("Select sensitive attribute", alibaba_columns)
|
| 372 |
+
elif dataset == 'JD':
|
| 373 |
+
dataset = 'tecent'
|
| 374 |
+
predict_attr = st.selectbox("Select prediction label", jd_columns)
|
| 375 |
+
sens_attr = st.selectbox("Select sensitive attribute", jd_columns)
|
| 376 |
+
|
| 377 |
+
|
| 378 |
+
# todo get all columns of the selected dataset and change this to a selectbox
|
| 379 |
+
#predict_attr = st.text_input("Enter the prediction label")
|
| 380 |
+
#sens_attr = st.text_input("Enter the senstive attribute")
|
| 381 |
+
def read_output(stdout, queue):
|
| 382 |
+
for line in stdout:
|
| 383 |
+
queue.put(line.strip())
|
| 384 |
+
|
| 385 |
+
def execute_command_fairness(dataset, sens_attr, predict_attr):
|
| 386 |
+
with st.spinner("Loading..."):
|
| 387 |
+
time.sleep(1)
|
| 388 |
+
#ssh = paramiko.SSHClient()
|
| 389 |
+
# Automatically add the server's host key (for the first connection only)
|
| 390 |
+
#ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
|
| 391 |
+
|
| 392 |
+
# Connect to the remote server
|
| 393 |
+
#ssh.connect('141.44.31.206', username='abdelrazek', password='Mohamed')
|
| 394 |
+
|
| 395 |
+
#if dataset == 'nba':
|
| 396 |
+
# stdin_new, stdout_new, stderr_new = ssh.exec_command('cd /home/abdelrazek/framework-for-fairness-analysis-and-mitigation-main && /home/abdelrazek/anaconda3/envs/test/bin/python3 main.py --calc_fairness True --dataset_name {} --dataset_path ../nba.csv --special_case True --sens_attr {} --predict_attr {} --type 1'.format(dataset, sens_attr, predict_attr), get_pty=True)
|
| 397 |
+
#elif dataset == 'alibaba':
|
| 398 |
+
# stdin_new, stdout_new, stderr_new = ssh.exec_command('cd /home/abdelrazek/framework-for-fairness-analysis-and-mitigation-main && /home/abdelrazek/anaconda3/envs/test/bin/python3 main.py --calc_fairness True --dataset_name {} --dataset_path ../alibaba_small.csv --special_case True --sens_attr {} --predict_attr {} --type 1'.format(dataset, sens_attr, predict_attr), get_pty=True)
|
| 399 |
+
#elif dataset == 'tecent':
|
| 400 |
+
# stdin_new, stdout_new, stderr_new = ssh.exec_command('cd /home/abdelrazek/framework-for-fairness-analysis-and-mitigation-main && /home/abdelrazek/anaconda3/envs/test/bin/python3 main.py --calc_fairness True --dataset_name {} --dataset_path ../JD_small.csv --special_case True --sens_attr {} --predict_attr {} --type 1'.format(dataset, sens_attr, predict_attr), get_pty=True)
|
| 401 |
+
#elif dataset == 'pokec_z':
|
| 402 |
+
# stdin_new, stdout_new, stderr_new = ssh.exec_command('cd /home/abdelrazek/framework-for-fairness-analysis-and-mitigation-main && /home/abdelrazek/anaconda3/envs/test/bin/python3 main.py --calc_fairness True --dataset_name {} --dataset_path ../Master-Thesis-dev/region_job.csv --special_case True --sens_attr {} --predict_attr {} --type 1'.format(dataset, sens_attr, predict_attr), get_pty=True)
|
| 403 |
+
#output_queue = queue.Queue()
|
| 404 |
+
# start a thread to continuously read the output from the stdout object
|
| 405 |
+
test = 'pwd'
|
| 406 |
+
st.text(os.system(test))
|
| 407 |
+
output_thread = threading.Thread(target=read_output, args=(stderr_new, output_queue))
|
| 408 |
+
output_thread.start()
|
| 409 |
+
|
| 410 |
+
# display the output in the Streamlit UI
|
| 411 |
+
while True:
|
| 412 |
+
try:
|
| 413 |
+
line = output_queue.get_nowait()
|
| 414 |
+
st.text(line)
|
| 415 |
+
except queue.Empty:
|
| 416 |
+
if output_thread.is_alive():
|
| 417 |
+
continue
|
| 418 |
+
else:
|
| 419 |
+
break
|
| 420 |
+
|
| 421 |
+
# wait for the thread to finish
|
| 422 |
+
output_thread.join()
|
| 423 |
+
# print the output to the console
|
| 424 |
+
for line in stdout_new:
|
| 425 |
+
print(line.strip())
|
| 426 |
+
if "Dataset" in line:
|
| 427 |
+
st.text(line.strip())
|
| 428 |
+
ssh.close()
|
| 429 |
+
|
| 430 |
+
fairness_evaluation = st.radio("Do you want to evaluate the dataset fairness?", ("No", "Yes"))
|
| 431 |
+
with st.expander("More information"):
|
| 432 |
+
st.write("Evaluate how fair the dataset, namely how much bias is affecting the dataset as a whole using the disparate impact metric.")
|
| 433 |
+
if fairness_evaluation == "Yes":
|
| 434 |
+
if st.button('Calculate Fairness'):
|
| 435 |
+
# todo send command to server to compute fairness
|
| 436 |
+
# then show fairness
|
| 437 |
+
# add info box
|
| 438 |
+
#dataset_fairness = st.write('Dataset Fairness: 1.57 (Fair)')
|
| 439 |
+
#execute_command_fairness(dataset, sens_attr, predict_attr)
|
| 440 |
+
#with open('test_new.yml', 'r') as file:
|
| 441 |
+
# environment = file.read()
|
| 442 |
+
#with open('test_tmp.yml', 'w') as file:
|
| 443 |
+
# file.write(environment.replace('prefix: /', ''))
|
| 444 |
+
#os.system('conda env create --file test_new.yml --name streamlit_env_new')
|
| 445 |
+
#os.system('conda activate streamlit_env_new')
|
| 446 |
+
commands = os.popen('cd src && python main.py --calc_fairness True --dataset_name nba --dataset_path ./datasets/NBA/nba.csv --special_case True --sens_attr country --predict_attr SALARY --type 1').read()
|
| 447 |
+
|
| 448 |
+
#output = os.popen('cd')
|
| 449 |
+
#output = os.popen('python main.py --calc_fairness True --dataset_name nba --dataset_path ./datasets/NBA/nba.csv --special_case True --sens_attr country --predict_attr SALARY --type 1').read()
|
| 450 |
+
#st.text(output)
|
| 451 |
+
|
| 452 |
+
print(commands)
|
| 453 |
+
|
| 454 |
+
|
| 455 |
+
#####################
|
| 456 |
+
debias = st.radio("Do you want to apply debias approaches?", ("No", "Yes"))
|
| 457 |
+
if "Yes" in debias:
|
| 458 |
+
debias_approach = st.selectbox("Select which debias approach you want to apply", ["Sample", "Reweighting", "Disparate remover impact"])
|
| 459 |
+
with st.expander("More information"):
|
| 460 |
+
st.write("You can mitigate the bias using three pre-processing debaising approaches:")
|
| 461 |
+
st.write("Sampling: Generates more data to overcome the bias between the different sensitive attributes and classes.")
|
| 462 |
+
st.write("Reweighting Minimizing the bias in the dataset by assiging different weights to dataset tuples, for example giving the unfavorable sensntive attributes higher weights than favorable sensitive attributes")
|
| 463 |
+
st.write("Disparate impact remover: Transforms the sensitive attribute features in a way that the correlation between the sensitive attribute features and the prediction class is reduced")
|
| 464 |
+
|
| 465 |
+
|
| 466 |
+
|
| 467 |
+
|
| 468 |
+
#if dataset != None:
|
| 469 |
+
#st.markdown("#### Select dataset")
|
| 470 |
+
#uploaded_file = st.file_uploader("Select dataset")
|
| 471 |
+
#dataset_path = st.text_input("", value="")
|
| 472 |
+
|
| 473 |
+
model_type = st.multiselect("Select the models you want to train", ["FairGNN", "RHGN", "CatGCN"])
|
| 474 |
+
|
| 475 |
+
if "RHGN" in model_type and "FairGNN" in model_type:
|
| 476 |
+
st.markdown("### Enter the general parameters")
|
| 477 |
+
seed = st.number_input("Enter the prefered seed number", value=0)
|
| 478 |
+
|
| 479 |
+
#predict_attr = st.text_input("Enter the prediction label")
|
| 480 |
+
#sens_attr = st.text_input("Enter the senstive attribute")
|
| 481 |
+
|
| 482 |
+
|
| 483 |
+
st.markdown("### Enter the RHGN parameters")
|
| 484 |
+
num_hidden = st.text_input("Enter the number of hidden layers", value=0)
|
| 485 |
+
with st.expander("More information"):
|
| 486 |
+
st.write("The number of hidden layers refers to the number of layers between the input layer and the output layer of a model.")
|
| 487 |
+
lr_rhgn = st.number_input("Enter the learning rate for RHGN")
|
| 488 |
+
with st.expander("More information"):
|
| 489 |
+
st.write("Is a hyperparameter that controls the step size of the updates made to the weights during training. In other words, it determines how quickly the model learns from the data.")
|
| 490 |
+
|
| 491 |
+
epochs_rhgn = st.number_input("Enter the number of epochs for RHGN", value=0)
|
| 492 |
+
with st.expander("More information"):
|
| 493 |
+
st.write("Refers to a single pass through the entire training dataset during the training of a model. In other words, an epoch is a measure of the number of times the model has seen the entire training data.")
|
| 494 |
+
|
| 495 |
+
clip = st.number_input("Enter the clip value", value=0)
|
| 496 |
+
with st.expander("More information"):
|
| 497 |
+
st.write("The clip number is a hyperparameter that determines the maximum value that the gradient can take. If the gradient exceeds this value, it is clipped (i.e., truncated to the maximum value).")
|
| 498 |
+
|
| 499 |
+
|
| 500 |
+
|
| 501 |
+
st.markdown("### Enter the FairGNN parameters")
|
| 502 |
+
lr_fairgnn = st.number_input("Enter the learning rate for FairGNN")
|
| 503 |
+
with st.expander("More information"):
|
| 504 |
+
st.write("Is a hyperparameter that controls the step size of the updates made to the weights during training. In other words, it determines how quickly the model learns from the data.")
|
| 505 |
+
epochs_fairgnn = st.number_input("Enter the number of epochs for FairGNN", value=0)
|
| 506 |
+
with st.expander("More information"):
|
| 507 |
+
st.write("Refers to a single pass through the entire training dataset during the training of a model. In other words, an epoch is a measure of the number of times the model has seen the entire training data.")
|
| 508 |
+
sens_number = st.number_input("Enter the sens number", value=0)
|
| 509 |
+
|
| 510 |
+
label_number = st.number_input("Enter the label number", value=0)
|
| 511 |
+
|
| 512 |
+
num_hidden = st.number_input("Enter the hidden layer number" , value=0)
|
| 513 |
+
with st.expander("More information"):
|
| 514 |
+
st.write("The number of hidden layers refers to the number of layers between the input layer and the output layer of a model.")
|
| 515 |
+
alpha = st.number_input("Enter alpha value", value=0)
|
| 516 |
+
with st.expander("More information"):
|
| 517 |
+
st.write("Refers to the regularization parameter that controls the amount of L2 regularization applied to the model's weights during the training process.")
|
| 518 |
+
|
| 519 |
+
beta = st.number_input("Enter beta value", value=0)
|
| 520 |
+
with st.expander("More information"):
|
| 521 |
+
st.write("Refers to the momentum parameter that controls how much the optimizer should take into account the previous update when computing the current update to the model's weights during the training process.")
|
| 522 |
+
|
| 523 |
+
|
| 524 |
+
if "RHGN" in model_type and "CatGCN" in model_type:
|
| 525 |
+
st.markdown("### Enter the general parameters")
|
| 526 |
+
seed = st.number_input("Enter the prefered seed number", value=0)
|
| 527 |
+
#predict_attr = st.text_input("Enter the prediction label")
|
| 528 |
+
#sens_attr = st.text_input("Enter the senstive attribute")
|
| 529 |
+
|
| 530 |
+
st.markdown("### Enter the RHGN parameters")
|
| 531 |
+
num_hidden = st.text_input("Enter the number of hidden layers")
|
| 532 |
+
with st.expander("More information"):
|
| 533 |
+
st.write("The number of hidden layers refers to the number of layers between the input layer and the output layer of a model.")
|
| 534 |
+
lr_rhgn = st.number_input("Enter the learning rate")
|
| 535 |
+
with st.expander("More information"):
|
| 536 |
+
st.write("Is a hyperparameter that controls the step size of the updates made to the weights during training. In other words, it determines how quickly the model learns from the data.")
|
| 537 |
+
epochs_rhgn = st.number_input("Enter the number of epochs", value=0)
|
| 538 |
+
with st.expander("More information"):
|
| 539 |
+
st.write("Refers to a single pass through the entire training dataset during the training of a model. In other words, an epoch is a measure of the number of times the model has seen the entire training data.")
|
| 540 |
+
clip = st.number_input("Enter the clip value", value=0)
|
| 541 |
+
with st.expander("More information"):
|
| 542 |
+
st.write("The clip number is a hyperparameter that determines the maximum value that the gradient can take. If the gradient exceeds this value, it is clipped (i.e., truncated to the maximum value).")
|
| 543 |
+
|
| 544 |
+
st.markdown("### Enter the CatGCN parameters")
|
| 545 |
+
weight_decay = st.number_input("Enter the weight decay value" )
|
| 546 |
+
with st.expander("More information"):
|
| 547 |
+
st.write("The parameters that controls the amount the weights will exponentially decay to zero.")
|
| 548 |
+
lr_catgcn = st.number_input("Enter the learning rate")
|
| 549 |
+
with st.expander("More information"):
|
| 550 |
+
st.write("Is a hyperparameter that controls the step size of the updates made to the weights during training. In other words, it determines how quickly the model learns from the data.")
|
| 551 |
+
epochs_catgcn = st.number_input("Enter the number of epochs", value=0)
|
| 552 |
+
with st.expander("More information"):
|
| 553 |
+
st.write("Refers to a single pass through the entire training dataset during the training of a model. In other words, an epoch is a measure of the number of times the model has seen the entire training data.")
|
| 554 |
+
diag_probe = st.number_input("Enter the diag probe value" , value=0)
|
| 555 |
+
graph_refining = st.selectbox("Choose the graph refining approach", ("agc", "fignn", "none"))
|
| 556 |
+
grn_units = st.number_input("Enter the grn units value" , value=0)
|
| 557 |
+
bi_interaction = st.selectbox("Choose the bi-interaction approach", ("nfm", "none"))
|
| 558 |
+
|
| 559 |
+
|
| 560 |
+
elif "RHGN" in model_type and len(model_type) == 1:
|
| 561 |
+
st.markdown("### Enter the general paramaters")
|
| 562 |
+
seed = st.number_input("Enter the prefered seed number", value=0)
|
| 563 |
+
#lr = st.number_input("Enter the learning rate", value=0)
|
| 564 |
+
#epochs = st.number_input("Enter the number of epochs", value=0)
|
| 565 |
+
#predict_attr = st.text_input("Enter the prediction label")
|
| 566 |
+
#sens_attr = st.text_input("Enter the senstive attribute")
|
| 567 |
+
|
| 568 |
+
|
| 569 |
+
st.markdown("### Enter the RHGN parametrs")
|
| 570 |
+
num_hidden = st.number_input("Enter the number of hidden layers", value=0)
|
| 571 |
+
with st.expander("More information"):
|
| 572 |
+
st.write("The number of hidden layers refers to the number of layers between the input layer and the output layer of a model.")
|
| 573 |
+
lr_rhgn = st.number_input("Enter the learning rate")
|
| 574 |
+
with st.expander("More information"):
|
| 575 |
+
st.write("Is a hyperparameter that controls the step size of the updates made to the weights during training. In other words, it determines how quickly the model learns from the data.")
|
| 576 |
+
|
| 577 |
+
epochs_rhgn = st.number_input("Enter the number of epochs for RHGN", value=0)
|
| 578 |
+
with st.expander("More information"):
|
| 579 |
+
st.write("Refers to a single pass through the entire training dataset during the training of a model. In other words, an epoch is a measure of the number of times the model has seen the entire training data.")
|
| 580 |
+
|
| 581 |
+
clip = st.number_input("Enter the clip value", value=0)
|
| 582 |
+
with st.expander("More information"):
|
| 583 |
+
st.write("The clip number is a hyperparameter that determines the maximum value that the gradient can take. If the gradient exceeds this value, it is clipped (i.e., truncated to the maximum value).")
|
| 584 |
+
|
| 585 |
+
elif "FairGNN" in model_type and len(model_type) == 1:
|
| 586 |
+
st.markdown("### Enter the general parameters")
|
| 587 |
+
seed = st.number_input("Enter the prefered seed number" , value=0)
|
| 588 |
+
#lr = st.number_input("Enter the learning rate" , value=0)
|
| 589 |
+
#epochs = st.number_input("Enter the number of epochs" , value=0)
|
| 590 |
+
#predict_attr = st.text_input("Enter the prediction label")
|
| 591 |
+
#sens_attr = st.text_input("Enter the senstive attribute")
|
| 592 |
+
|
| 593 |
+
|
| 594 |
+
st.markdown("### Enter the FairGNN parameters")
|
| 595 |
+
lr_fairgnn = st.number_input("Enter the learning rate")
|
| 596 |
+
epochs_fairgnn = st.number_input("Enter the number of epochs" , value=0)
|
| 597 |
+
with st.expander("More information"):
|
| 598 |
+
st.write("Refers to a single pass through the entire training dataset during the training of a model. In other words, an epoch is a measure of the number of times the model has seen the entire training data.")
|
| 599 |
+
sens_number = st.number_input("Enter the sens number" , value=0)
|
| 600 |
+
label_number = st.number_input("Enter the label number", value=0)
|
| 601 |
+
num_hidden = st.number_input("Enter the hidden layer number" , value=0)
|
| 602 |
+
with st.expander("More information"):
|
| 603 |
+
st.write("The number of hidden layers refers to the number of layers between the input layer and the output layer of a model.")
|
| 604 |
+
alpha = st.number_input("Enter alpha value" , value=0)
|
| 605 |
+
with st.expander("More information"):
|
| 606 |
+
st.write("Refers to the regularization parameter that controls the amount of L2 regularization applied to the model's weights during the training process.")
|
| 607 |
+
beta = st.number_input("Enter beta value", value=0)
|
| 608 |
+
with st.expander("More information"):
|
| 609 |
+
st.write("Refers to the momentum parameter that controls how much the optimizer should take into account the previous update when computing the current update to the model's weights during the training process.")
|
| 610 |
+
|
| 611 |
+
|
| 612 |
+
elif "CatGCN" in model_type and len(model_type) == 1:
|
| 613 |
+
st.markdown("### Enter the general paramaters")
|
| 614 |
+
seed = st.number_input("Enter the prefered seed number", value=0)
|
| 615 |
+
#lr = st.number_input("Enter the learning rate" , value=0)
|
| 616 |
+
#epochs = st.number_input("Enter the number of epochs" , value=0)
|
| 617 |
+
#predict_attr = st.text_input("Enter the prediction label")
|
| 618 |
+
#sens_attr = st.text_input("Enter the senstive attribute")
|
| 619 |
+
|
| 620 |
+
st.markdown("### Enter the CatGCN parameters")
|
| 621 |
+
weight_decay = st.number_input("Enter the weight decay value")
|
| 622 |
+
with st.expander("More information"):
|
| 623 |
+
st.write("The parameters that controls the amount the weights will exponentially decay to zero.")
|
| 624 |
+
lr_catgcn = st.number_input("Enter the learning rate")
|
| 625 |
+
with st.expander("More information"):
|
| 626 |
+
st.write("Is a hyperparameter that controls the step size of the updates made to the weights during training. In other words, it determines how quickly the model learns from the data.")
|
| 627 |
+
epochs_catgcn = st.number_input("Enter the number of epochs" , value=0)
|
| 628 |
+
with st.expander("More information"):
|
| 629 |
+
st.write("Refers to a single pass through the entire training dataset during the training of a model. In other words, an epoch is a measure of the number of times the model has seen the entire training data.")
|
| 630 |
+
diag_probe = st.number_input("Enter the diag probe value" , value=0)
|
| 631 |
+
graph_refining = st.multiselect("Choose the graph refining approach", ["agc", "fignn", "none"])
|
| 632 |
+
grn_units = st.number_input("Enter the grn units value" , value=0)
|
| 633 |
+
bi_interaction = st.multiselect("Choose the bi-interaction approach", ["nfm", "none"])
|
| 634 |
+
|
| 635 |
+
|
| 636 |
+
|
| 637 |
+
if len(model_type) != 0:
|
| 638 |
+
if st.button("Begin experiment"):
|
| 639 |
+
with st.spinner("Loading..."):
|
| 640 |
+
time.sleep(2)
|
| 641 |
+
if predict_attr == 'final_gender_code':
|
| 642 |
+
predict_attr == 'bin_gender'
|
| 643 |
+
if sens_attr == 'age_level':
|
| 644 |
+
sens_attr == 'bin_age'
|
| 645 |
+
|
| 646 |
+
###################################################################################################################
|
| 647 |
+
ssh = paramiko.SSHClient()
|
| 648 |
+
port = 443
|
| 649 |
+
# Automatically add the server's host key (for the first connection only)
|
| 650 |
+
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
|
| 651 |
+
|
| 652 |
+
# Connect to the remote server
|
| 653 |
+
ssh.connect('https://dtdh206.cs.uni-magdeburg.de:443')
|
| 654 |
+
#ssh.connect('141.44.31.206', port=443, banner_timeout=200)
|
| 655 |
+
stdin, stdout, stderr = ssh.exec_command('ls')
|
| 656 |
+
print(stdout)
|
| 657 |
+
|
| 658 |
+
if len(model_type) == 1 and 'FairGNN' in model_type:
|
| 659 |
+
stdin, stdout, stderr = ssh.exec_command('cd /home/abdelrazek/framework-for-fairness-analysis-and-mitigation-main && /home/abdelrazek/anaconda3/envs/test/bin/python3 -W ignore main.py --seed {} --epoch {} --model GCN --sens_number {} --num_hidden {} --acc 0.20 --roc 0.20 --alpha {} --beta {} --dataset_name {} --dataset_path ../nba.csv --dataset_user_id_name user_id --model_type FairGNN --type 1 --sens_attr {} --predict_attr {} --label_number 100 --no-cuda True --special_case True --neptune_project mohamed9/FairGNN-Alibaba --neptune_token eyJhcGlfYWRkcmVzcyI6Imh0dHBzOi8vYXBwLm5lcHR1bmUuYWkiLCJhcGlfdXJsIjoiaHR0cHM6Ly9hcHAubmVwdHVuZS5haSIsImFwaV9rZXkiOiI0Nzc0MTIzMy0xMjRhLTQ0OGQtODE5Mi1mZjE3MDE0MGFhOGMifQ=='.format(seed, epochs_fairgnn, sens_number, num_hidden, alpha, beta, dataset, sens_attr, predict_attr))
|
| 660 |
+
if len(model_type) == 1 and 'RHGN' in model_type:
|
| 661 |
+
stdin, stdout, stderr = ssh.exec_command('cd /home/abdelrazek/framework-for-fairness-analysis-and-mitigation-main && /home/abdelrazek/anaconda3/envs/test/bin/python3 -W ignore main.py --seed {} --gpu 0 --dataset_path ../ --max_lr {} --num_hidden {} --clip {} --epochs {} --label {} --sens_attr {} --type 1 --model_type RHGN --dataset_name {} --dataset_user_id_name userid --special_case True --neptune_project mohamed9/FairGNN-Alibaba --neptune_token eyJhcGlfYWRkcmVzcyI6Imh0dHBzOi8vYXBwLm5lcHR1bmUuYWkiLCJhcGlfdXJsIjoiaHR0cHM6Ly9hcHAubmVwdHVuZS5haSIsImFwaV9rZXkiOiI0Nzc0MTIzMy0xMjRhLTQ0OGQtODE5Mi1mZjE3MDE0MGFhOGMifQ=='.format(seed, lr_rhgn, num_hidden, clip, epochs_rhgn, predict_attr, sens_attr, dataset))
|
| 662 |
+
# CatGCN
|
| 663 |
+
if len(model_type) == 1 and 'CatGCN' in model_type:
|
| 664 |
+
stdin, stdout, stderr = ssh.exec_command('cd /home/abdelrazek/framework-for-fairness-analysis-and-mitigation-main && /home/abdelrazek/anaconda3/envs/test/bin/python3 -W ignore main.py --seed {} --gpu 0 --lr {} --weight_decay {} --dropout 0.1 --diag-probe {} --graph-refining {} --aggr-pooling mean --grn_units {} --bi-interaction {} --nfm-units none --graph-layer pna --gnn-hops 1 --gnn-units none --aggr-style sum --balance-ratio 0.7 --sens_attr {} --label {} --dataset_name {} --dataset_path ../ --type 1 --model_type CatGCN --dataset_user_id_name userid --alpha 0.5 --special_case True --neptune_project mohamed9/FairGNN-Alibaba --neptune_token eyJhcGlfYWRkcmVzcyI6Imh0dHBzOi8vYXBwLm5lcHR1bmUuYWkiLCJhcGlfdXJsIjoiaHR0cHM6Ly9hcHAubmVwdHVuZS5haSIsImFwaV9rZXkiOiI0Nzc0MTIzMy0xMjRhLTQ0OGQtODE5Mi1mZjE3MDE0MGFhOGMifQ=='.format(seed, lr_catgcn, weight_decay, diag_probe, graph_refining, grn_units, bi_interaction, sens_attr, predict_attr, dataset))
|
| 665 |
+
|
| 666 |
+
# FairGNN and RHGN
|
| 667 |
+
if len(model_type) == 2 and 'FairGNN' in model_type and 'RHGN' in model_type:
|
| 668 |
+
if predict_attr == 'final_gender_code':
|
| 669 |
+
label = 'bin_gender'
|
| 670 |
+
if sens_attr == 'age_level':
|
| 671 |
+
sens_attr_rhgn = 'bin_age'
|
| 672 |
+
stdin, stdout, stderr = ssh.exec_command('cd /home/abdelrazek/framework-for-fairness-analysis-and-mitigation-main && /home/abdelrazek/anaconda3/envs/test/bin/python3 -W ignore main.py --seed {} --epochs {} --model GCN --sens_number {} --num_hidden {} --acc 0.20 --roc 0.20 --alpha {} --beta {} --dataset_name {} --dataset_path ../nba.csv --dataset_user_id_name user_id --model_type FairGNN RHGN --type 1 --sens_attr {} --label {} --predict_attr {} --label_number 100 --no-cuda True --max_lr {} --clip {} --epochs_rhgn {} --special_case True --neptune_project mohamed9/FairGNN-Alibaba --neptune_token eyJhcGlfYWRkcmVzcyI6Imh0dHBzOi8vYXBwLm5lcHR1bmUuYWkiLCJhcGlfdXJsIjoiaHR0cHM6Ly9hcHAubmVwdHVuZS5haSIsImFwaV9rZXkiOiI0Nzc0MTIzMy0xMjRhLTQ0OGQtODE5Mi1mZjE3MDE0MGFhOGMifQ=='.format(seed, epochs_fairgnn, sens_number, num_hidden, alpha, beta, dataset, sens_attr, predict_attr, predict_attr, lr_rhgn, clip, epochs_rhgn))
|
| 673 |
+
print('cd /home/abdelrazek/framework-for-fairness-analysis-and-mitigation-main && /home/abdelrazek/anaconda3/envs/test/bin/python3 -W ignore main.py --seed {} --epochs {} --model GCN --sens_number {} --num_hidden {} --acc 0.20 --roc 0.20 --alpha {} --beta {} --dataset_name {} --dataset_path ../nba.csv --dataset_user_id_name user_id --model_type FairGNN RHGN --type 1 --sens_attr {} --label {} --predict_attr {} --label_number 100 --no-cuda True --max_lr {} --clip {} --epochs_rhgn {} --special_case True --neptune_project mohamed9/FairGNN-Alibaba --neptune_token eyJhcGlfYWRkcmVzcyI6Imh0dHBzOi8vYXBwLm5lcHR1bmUuYWkiLCJhcGlfdXJsIjoiaHR0cHM6Ly9hcHAubmVwdHVuZS5haSIsImFwaV9rZXkiOiI0Nzc0MTIzMy0xMjRhLTQ0OGQtODE5Mi1mZjE3MDE0MGFhOGMifQ=='.format(seed, epochs_fairgnn, sens_number, num_hidden, alpha, beta, dataset, sens_attr, predict_attr, predict_attr, lr_rhgn, clip, epochs_rhgn))
|
| 674 |
+
#stdin, stdout, stderr = ssh.exec_command('cd /home/abdelrazek/framework-for-fairness-analysis-and-mitigation-main && ls')
|
| 675 |
+
|
| 676 |
+
output_queue = queue.Queue()
|
| 677 |
+
output_thred = threading.Thread(target=read_output, args=(stderr, output_queue))
|
| 678 |
+
output_thred.start()
|
| 679 |
+
|
| 680 |
+
while True:
|
| 681 |
+
try:
|
| 682 |
+
line = output_queue.get_nowait()
|
| 683 |
+
#st.text(line)
|
| 684 |
+
except queue.Empty:
|
| 685 |
+
if output_thred.is_alive():
|
| 686 |
+
continue
|
| 687 |
+
else:
|
| 688 |
+
break
|
| 689 |
+
|
| 690 |
+
output_thred.join()
|
| 691 |
+
all_output = []
|
| 692 |
+
for line in stdout:
|
| 693 |
+
print(line.strip())
|
| 694 |
+
#st.text(line.strip())
|
| 695 |
+
if "Test_final:" in line and 'FairGNN' in model_type:
|
| 696 |
+
result = line.strip()
|
| 697 |
+
#st.text(result)
|
| 698 |
+
if 'accuracy' in line and 'RHGN' in model_type:
|
| 699 |
+
#st.text(line.strip())
|
| 700 |
+
line = line.strip() + 'end'
|
| 701 |
+
acc = re.search('accuracy (.+?)end', line)
|
| 702 |
+
acc = acc.group(1)
|
| 703 |
+
acc_rhgn = acc.split()[0]
|
| 704 |
+
if 'F1 score:' in line:
|
| 705 |
+
f1 = '.'.join(line.split('.')[0:2])
|
| 706 |
+
f1_rhgn = '{:.3f}'.format(float(f1.split()[-1]))
|
| 707 |
+
if 'Statistical Parity Difference (SPD):' in line:
|
| 708 |
+
spd_rhgn = '{:.3f}'.format(float(line.split()[-1]))
|
| 709 |
+
|
| 710 |
+
if 'Equal Opportunity Difference (EOD):' in line:
|
| 711 |
+
eod_rhgn = '{:.3f}'.format(float(line.split()[-1]))
|
| 712 |
+
|
| 713 |
+
if 'Overall Accuracy Equality Difference (OAED):' in line:
|
| 714 |
+
oaed_rhgn = '{:.3f}'.format(float(line.split()[-1]))
|
| 715 |
+
|
| 716 |
+
if 'Treatment Equality Difference (TED):' in line:
|
| 717 |
+
ted_rhgn = '{:.3f}'.format(float(line.split()[-1]))
|
| 718 |
+
#all_output.append(line.strip())
|
| 719 |
+
# Close the connection
|
| 720 |
+
ssh.close()
|
| 721 |
+
|
| 722 |
+
st.success("Done!")
|
| 723 |
+
|
| 724 |
+
|
| 725 |
+
st.markdown("## Training Results:")
|
| 726 |
+
print(len(model_type))
|
| 727 |
+
print(model_type)
|
| 728 |
+
if len(model_type) == 1 and 'FairGNN' in model_type:
|
| 729 |
+
st.text(result)
|
| 730 |
+
acc = re.search('accuracy:(.+?)roc', result)
|
| 731 |
+
f1 = re.search('F1:(.+?)acc_sens', result)
|
| 732 |
+
|
| 733 |
+
spd = re.search('parity:(.+?)equality', result)
|
| 734 |
+
eod = re.search('equality:(.+?)oaed', result)
|
| 735 |
+
oaed = re.search('oaed:(.+?)treatment equality', result)
|
| 736 |
+
ted = re.search('treatment equality(.+?)end', result)
|
| 737 |
+
data = {'Model': [model_type],
|
| 738 |
+
'Accuracy': [acc.group(1)],
|
| 739 |
+
'F1': [f1.group(1)],
|
| 740 |
+
'SPD': [spd.group(1)],
|
| 741 |
+
'EOD': [eod.group(1)],
|
| 742 |
+
'OAED': [oaed.group(1)],
|
| 743 |
+
'TED': [ted.group(1)]
|
| 744 |
+
}
|
| 745 |
+
|
| 746 |
+
elif len(model_type) == 1 and 'RHGN' in model_type:
|
| 747 |
+
#print('all_output:', all_output)
|
| 748 |
+
data = {'Model': [model_type],
|
| 749 |
+
'Accuracy': [acc_rhgn],
|
| 750 |
+
'F1': [f1_rhgn],
|
| 751 |
+
'SPD': [spd_rhgn],
|
| 752 |
+
'EOD': [eod_rhgn],
|
| 753 |
+
'OAED': [oaed_rhgn],
|
| 754 |
+
'TED': [ted_rhgn]
|
| 755 |
+
}
|
| 756 |
+
|
| 757 |
+
elif len(model_type) == 2 and 'RHGN' in model_type and 'FairGNN' in model_type:
|
| 758 |
+
|
| 759 |
+
acc = re.search('a:(.+?)roc', result)
|
| 760 |
+
f1 = re.search('F1:(.+?)acc_sens', result)
|
| 761 |
+
|
| 762 |
+
spd = re.search('parity:(.+?)equality', result)
|
| 763 |
+
eod = re.search('equality:(.+?)oaed', result)
|
| 764 |
+
oaed = re.search('oaed:(.+?)treatment equality', result)
|
| 765 |
+
ted = re.search('treatment equality(.+?)end', result)
|
| 766 |
+
|
| 767 |
+
ind_fairgnn = model_type.index('FairGNN')
|
| 768 |
+
ind_rhgn = model_type.index('RHGN')
|
| 769 |
+
data = {'Model': [model_type[ind_fairgnn], model_type[ind_rhgn]],
|
| 770 |
+
'Prediction label': [predict_attr, predict_attr],
|
| 771 |
+
'Sensitive attribute': [sens_attr, sens_attr],
|
| 772 |
+
'Accuracy': [acc.group(1), acc_rhgn],
|
| 773 |
+
'F1': [f1.group(1), f1_rhgn],
|
| 774 |
+
'SPD': [spd.group(1), spd_rhgn],
|
| 775 |
+
'EOD': [eod.group(1), eod_rhgn],
|
| 776 |
+
'OAED': [oaed.group(1), oaed_rhgn],
|
| 777 |
+
'TED': [ted.group(1), ted_rhgn]
|
| 778 |
+
}
|
| 779 |
+
|
| 780 |
+
df = pd.DataFrame(data)
|
| 781 |
+
|
| 782 |
+
#st.dataframe(df, width=5000)
|
| 783 |
+
# set the display options for the DataFrame
|
| 784 |
+
pd.set_option("display.max_columns", None)
|
| 785 |
+
pd.set_option("display.width", 100)
|
| 786 |
+
|
| 787 |
+
|
| 788 |
+
|
| 789 |
+
# display the DataFrame in Streamlit
|
| 790 |
+
st.write(df)
|
| 791 |
+
|
| 792 |
+
#st.write("The logs of the experiment can be found at: mohamed9/Experiments-RHGN-CatGCN-Alibaba")
|
| 793 |
+
#st.markdown("The logs of the experiment can be found at: **mohamed9/Experiments-RHGN-FairGNN-Alibaba**")
|
| 794 |
+
|
| 795 |
+
|
| 796 |
+
|
pages/ovgu_logo.png
ADDED
|
|
pages/setup.sh
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
# Create a new Conda environment
|
| 4 |
+
conda env create -f test_new.yml --name env_test
|
| 5 |
+
|
| 6 |
+
# Activate the Conda environment
|
| 7 |
+
source activate env_test
|
presets/Presets.py
ADDED
|
@@ -0,0 +1,259 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
import pandas as pd
|
| 3 |
+
import os
|
| 4 |
+
import paramiko
|
| 5 |
+
import warnings
|
| 6 |
+
import re
|
| 7 |
+
import time
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def FairGNN_NBA():
|
| 11 |
+
#dataset = st.selectbox("Dataset", ("NBA"))
|
| 12 |
+
dataset = st.text_input('Dataset', 'NBA', disabled=True)
|
| 13 |
+
dataset = 'nba'
|
| 14 |
+
predict_attr = st.text_input("Prediction label", 'SALARY', disabled=True)
|
| 15 |
+
sens_attr = st.text_input("Sensitive attribute", 'country', disabled=True)
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
model_type = st.text_input("Models to train", 'FairGNN', disabled=True)
|
| 19 |
+
|
| 20 |
+
st.markdown("### General parameters")
|
| 21 |
+
seed = st.number_input("Prefered seed number" , value=42, disabled=True)
|
| 22 |
+
|
| 23 |
+
st.markdown("### FairGNN parameters")
|
| 24 |
+
lr_fairgnn = st.number_input("Learning rate", value=0.01, disabled=True)
|
| 25 |
+
epochs_fairgnn = st.number_input("Number of epochs" , value=2000, disabled=True)
|
| 26 |
+
with st.expander("More information"):
|
| 27 |
+
st.write("Refers to a single pass through the entire training dataset during the training of a model. In other words, an epoch is a measure of the number of times the model has seen the entire training data.")
|
| 28 |
+
sens_number = st.number_input("Sens number" , value=50, disabled=True)
|
| 29 |
+
label_number = st.number_input("Label number", value=1000, disabled=True)
|
| 30 |
+
num_hidden = st.number_input("Hidden layer number" , value=128, disabled=True)
|
| 31 |
+
with st.expander("More information"):
|
| 32 |
+
st.write("The number of hidden layers refers to the number of layers between the input layer and the output layer of a model.")
|
| 33 |
+
alpha = st.number_input("Alpha value" , value=10, disabled=True)
|
| 34 |
+
with st.expander("More information"):
|
| 35 |
+
st.write("Refers to the regularization parameter that controls the amount of L2 regularization applied to the model's weights during the training process.")
|
| 36 |
+
beta = st.number_input("Beta value", value=1, disabled=True)
|
| 37 |
+
with st.expander("More information"):
|
| 38 |
+
st.write("Refers to the momentum parameter that controls how much the optimizer should take into account the previous update when computing the current update to the model's weights during the training process.")
|
| 39 |
+
|
| 40 |
+
return model_type, predict_attr, sens_attr
|
| 41 |
+
|
| 42 |
+
def RHGN_Alibaba():
|
| 43 |
+
dataset = st.text_input('Dataset', 'Alibaba', disabled=True)
|
| 44 |
+
dataset = 'alibaba'
|
| 45 |
+
predict_attr = st.text_input('Prediction label', 'final_gender_code', disabled=True)
|
| 46 |
+
sens_attr = st.text_input('Sensitive attribute', 'age_level', disabled=True)
|
| 47 |
+
|
| 48 |
+
model_type = st.text_input("Models to train", 'RHGN', disabled=True)
|
| 49 |
+
|
| 50 |
+
st.markdown("### General parameters")
|
| 51 |
+
seed = st.number_input("Prefered seed number" , value=3, disabled=True)
|
| 52 |
+
|
| 53 |
+
st.markdown("### RHGN parametrs")
|
| 54 |
+
num_hidden = st.number_input("Hidden layer number", value=32, disabled=True)
|
| 55 |
+
with st.expander("More information"):
|
| 56 |
+
st.write("The number of hidden layers refers to the number of layers between the input layer and the output layer of a model.")
|
| 57 |
+
lr_rhgn = st.number_input("Learning rate", value=0.1, disabled=True)
|
| 58 |
+
with st.expander("More information"):
|
| 59 |
+
st.write("Is a hyperparameter that controls the step size of the updates made to the weights during training. In other words, it determines how quickly the model learns from the data.")
|
| 60 |
+
|
| 61 |
+
epochs_rhgn = st.number_input("Epochs", value=100, disabled=True)
|
| 62 |
+
with st.expander("More information"):
|
| 63 |
+
st.write("Refers to a single pass through the entire training dataset during the training of a model. In other words, an epoch is a measure of the number of times the model has seen the entire training data.")
|
| 64 |
+
|
| 65 |
+
clip = st.number_input("Clip value", value=2, disabled=True)
|
| 66 |
+
with st.expander("More information"):
|
| 67 |
+
st.write("The clip number is a hyperparameter that determines the maximum value that the gradient can take. If the gradient exceeds this value, it is clipped (i.e., truncated to the maximum value).")
|
| 68 |
+
|
| 69 |
+
return model_type, predict_attr, sens_attr
|
| 70 |
+
|
| 71 |
+
def CatGCN_Alibaba():
|
| 72 |
+
dataset = st.text_input('Dataset', 'Alibaba', disabled=True)
|
| 73 |
+
dataset = 'alibaba'
|
| 74 |
+
predict_attr = st.text_input('Prediction label', 'final_gender_code', disabled=True)
|
| 75 |
+
sens_attr = st.text_input('Sensitive attribute', 'age_level', disabled=True)
|
| 76 |
+
|
| 77 |
+
model_type = st.text_input('Models to train', 'CatGCN', disabled=True)
|
| 78 |
+
|
| 79 |
+
st.markdown("### General parameters")
|
| 80 |
+
seed = st.number_input("Prefered seed number" , value=11, disabled=True)
|
| 81 |
+
|
| 82 |
+
st.markdown("### CatGCN parameters")
|
| 83 |
+
weight_decay = st.number_input("Weight decay value", value=0.01, disabled=True)
|
| 84 |
+
with st.expander("More information"):
|
| 85 |
+
st.write("The parameters that controls the amount the weights will exponentially decay to zero.")
|
| 86 |
+
lr_catgcn = st.number_input("Learning rate", value=0.1, disabled=True)
|
| 87 |
+
with st.expander("More information"):
|
| 88 |
+
st.write("Is a hyperparameter that controls the step size of the updates made to the weights during training. In other words, it determines how quickly the model learns from the data.")
|
| 89 |
+
epochs_catgcn = st.number_input("Number of epochs" , value=100, disabled=True)
|
| 90 |
+
with st.expander("More information"):
|
| 91 |
+
st.write("Refers to a single pass through the entire training dataset during the training of a model. In other words, an epoch is a measure of the number of times the model has seen the entire training data.")
|
| 92 |
+
diag_probe = st.number_input("Diag probe value" , value=39, disabled=True)
|
| 93 |
+
graph_refining = st.text_input("Graph refining approach", "agc", disabled=True)
|
| 94 |
+
grn_units = st.number_input("Enter the grn units value" , value=64, disabled=True)
|
| 95 |
+
bi_interaction = st.text_input("Bi-interaction approach", "nfm", disabled=True)
|
| 96 |
+
|
| 97 |
+
return model_type, predict_attr, sens_attr
|
| 98 |
+
|
| 99 |
+
def experiment_begin(model_type, predict_attr, sens_attr):
|
| 100 |
+
if len(model_type) != 0:
|
| 101 |
+
if st.button("Begin experiment"):
|
| 102 |
+
with st.spinner("Loading..."):
|
| 103 |
+
|
| 104 |
+
time.sleep(2)
|
| 105 |
+
ssh = paramiko.SSHClient()
|
| 106 |
+
port = 443
|
| 107 |
+
# Automatically add the server's host key (for the first connection only)
|
| 108 |
+
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
|
| 109 |
+
|
| 110 |
+
# Connect to the remote server
|
| 111 |
+
ssh.connect('https://dtdh206.cs.uni-magdeburg.de:443')
|
| 112 |
+
#ssh.connect('141.44.31.206', port=443, banner_timeout=200)
|
| 113 |
+
stdin, stdout, stderr = ssh.exec_command('ls')
|
| 114 |
+
print(stdout)
|
| 115 |
+
|
| 116 |
+
if len(model_type) == 1 and 'FairGNN' in model_type:
|
| 117 |
+
stdin, stdout, stderr = ssh.exec_command('cd /home/abdelrazek/framework-for-fairness-analysis-and-mitigation-main && /home/abdelrazek/anaconda3/envs/test/bin/python3 -W ignore main.py --seed {} --epoch {} --model GCN --sens_number {} --num_hidden {} --acc 0.20 --roc 0.20 --alpha {} --beta {} --dataset_name {} --dataset_path ../nba.csv --dataset_user_id_name user_id --model_type FairGNN --type 1 --sens_attr {} --predict_attr {} --label_number 100 --no-cuda True --special_case True --neptune_project mohamed9/FairGNN-Alibaba --neptune_token eyJhcGlfYWRkcmVzcyI6Imh0dHBzOi8vYXBwLm5lcHR1bmUuYWkiLCJhcGlfdXJsIjoiaHR0cHM6Ly9hcHAubmVwdHVuZS5haSIsImFwaV9rZXkiOiI0Nzc0MTIzMy0xMjRhLTQ0OGQtODE5Mi1mZjE3MDE0MGFhOGMifQ=='.format(seed, epochs_fairgnn, sens_number, num_hidden, alpha, beta, dataset, sens_attr, predict_attr))
|
| 118 |
+
if len(model_type) == 1 and 'RHGN' in model_type:
|
| 119 |
+
if predict_attr == 'final_gender_code':
|
| 120 |
+
predict_attr = 'bin_gender'
|
| 121 |
+
if sens_attr == 'age_level':
|
| 122 |
+
sens_attr = 'bin_age'
|
| 123 |
+
stdin, stdout, stderr = ssh.exec_command('cd /home/abdelrazek/framework-for-fairness-analysis-and-mitigation-main && /home/abdelrazek/anaconda3/envs/test/bin/python3 -W ignore main.py --seed {} --gpu 0 --dataset_path ../ --max_lr {} --num_hidden {} --clip {} --epochs {} --label {} --sens_attr {} --type 1 --model_type RHGN --dataset_name {} --dataset_user_id_name userid --special_case True --neptune_project mohamed9/FairGNN-Alibaba --neptune_token eyJhcGlfYWRkcmVzcyI6Imh0dHBzOi8vYXBwLm5lcHR1bmUuYWkiLCJhcGlfdXJsIjoiaHR0cHM6Ly9hcHAubmVwdHVuZS5haSIsImFwaV9rZXkiOiI0Nzc0MTIzMy0xMjRhLTQ0OGQtODE5Mi1mZjE3MDE0MGFhOGMifQ=='.format(seed, lr_rhgn, num_hidden, clip, epochs_rhgn, predict_attr, sens_attr, dataset))
|
| 124 |
+
# CatGCN
|
| 125 |
+
if len(model_type) == 1 and 'CatGCN' in model_type:
|
| 126 |
+
if predict_attr == 'final_gender_code':
|
| 127 |
+
predict_attr = 'bin_gender'
|
| 128 |
+
if sens_attr == 'age_level':
|
| 129 |
+
sens_attr = 'bin_age'
|
| 130 |
+
stdin, stdout, stderr = ssh.exec_command('cd /home/abdelrazek/framework-for-fairness-analysis-and-mitigation-main && /home/abdelrazek/anaconda3/envs/test/bin/python3 -W ignore main.py --seed {} --gpu 0 --lr {} --weight_decay {} --dropout 0.1 --diag-probe {} --graph-refining {} --aggr-pooling mean --grn_units {} --bi-interaction {} --nfm-units none --graph-layer pna --gnn-hops 1 --gnn-units none --aggr-style sum --balance-ratio 0.7 --sens_attr {} --label {} --dataset_name {} --dataset_path ../ --type 1 --model_type CatGCN --dataset_user_id_name userid --alpha 0.5 --special_case True --neptune_project mohamed9/FairGNN-Alibaba --neptune_token eyJhcGlfYWRkcmVzcyI6Imh0dHBzOi8vYXBwLm5lcHR1bmUuYWkiLCJhcGlfdXJsIjoiaHR0cHM6Ly9hcHAubmVwdHVuZS5haSIsImFwaV9rZXkiOiI0Nzc0MTIzMy0xMjRhLTQ0OGQtODE5Mi1mZjE3MDE0MGFhOGMifQ=='.format(seed, lr_catgcn, weight_decay, diag_probe, graph_refining, grn_units, bi_interaction, sens_attr, predict_attr, dataset))
|
| 131 |
+
|
| 132 |
+
# FairGNN and RHGN
|
| 133 |
+
if len(model_type) == 2 and 'FairGNN' in model_type and 'RHGN' in model_type:
|
| 134 |
+
if predict_attr == 'final_gender_code':
|
| 135 |
+
label = 'bin_gender'
|
| 136 |
+
if sens_attr == 'age_level':
|
| 137 |
+
sens_attr_rhgn = 'bin_age'
|
| 138 |
+
stdin, stdout, stderr = ssh.exec_command('cd /home/abdelrazek/framework-for-fairness-analysis-and-mitigation-main && /home/abdelrazek/anaconda3/envs/test/bin/python3 -W ignore main.py --seed {} --epochs {} --model GCN --sens_number {} --num_hidden {} --acc 0.20 --roc 0.20 --alpha {} --beta {} --dataset_name {} --dataset_path ../nba.csv --dataset_user_id_name user_id --model_type FairGNN RHGN --type 1 --sens_attr {} --label {} --predict_attr {} --label_number 100 --no-cuda True --max_lr {} --clip {} --epochs_rhgn {} --special_case True --neptune_project mohamed9/FairGNN-Alibaba --neptune_token eyJhcGlfYWRkcmVzcyI6Imh0dHBzOi8vYXBwLm5lcHR1bmUuYWkiLCJhcGlfdXJsIjoiaHR0cHM6Ly9hcHAubmVwdHVuZS5haSIsImFwaV9rZXkiOiI0Nzc0MTIzMy0xMjRhLTQ0OGQtODE5Mi1mZjE3MDE0MGFhOGMifQ=='.format(seed, epochs_fairgnn, sens_number, num_hidden, alpha, beta, dataset, sens_attr, predict_attr, predict_attr, lr_rhgn, clip, epochs_rhgn))
|
| 139 |
+
print('cd /home/abdelrazek/framework-for-fairness-analysis-and-mitigation-main && /home/abdelrazek/anaconda3/envs/test/bin/python3 -W ignore main.py --seed {} --epochs {} --model GCN --sens_number {} --num_hidden {} --acc 0.20 --roc 0.20 --alpha {} --beta {} --dataset_name {} --dataset_path ../nba.csv --dataset_user_id_name user_id --model_type FairGNN RHGN --type 1 --sens_attr {} --label {} --predict_attr {} --label_number 100 --no-cuda True --max_lr {} --clip {} --epochs_rhgn {} --special_case True --neptune_project mohamed9/FairGNN-Alibaba --neptune_token eyJhcGlfYWRkcmVzcyI6Imh0dHBzOi8vYXBwLm5lcHR1bmUuYWkiLCJhcGlfdXJsIjoiaHR0cHM6Ly9hcHAubmVwdHVuZS5haSIsImFwaV9rZXkiOiI0Nzc0MTIzMy0xMjRhLTQ0OGQtODE5Mi1mZjE3MDE0MGFhOGMifQ=='.format(seed, epochs_fairgnn, sens_number, num_hidden, alpha, beta, dataset, sens_attr, predict_attr, predict_attr, lr_rhgn, clip, epochs_rhgn))
|
| 140 |
+
#stdin, stdout, stderr = ssh.exec_command('cd /home/abdelrazek/framework-for-fairness-analysis-and-mitigation-main && ls')
|
| 141 |
+
|
| 142 |
+
output_queue = queue.Queue()
|
| 143 |
+
output_thred = threading.Thread(target=read_output, args=(stderr, output_queue))
|
| 144 |
+
output_thred.start()
|
| 145 |
+
|
| 146 |
+
while True:
|
| 147 |
+
try:
|
| 148 |
+
line = output_queue.get_nowait()
|
| 149 |
+
#st.text(line)
|
| 150 |
+
except queue.Empty:
|
| 151 |
+
if output_thred.is_alive():
|
| 152 |
+
continue
|
| 153 |
+
else:
|
| 154 |
+
break
|
| 155 |
+
|
| 156 |
+
output_thred.join()
|
| 157 |
+
all_output = []
|
| 158 |
+
for line in stdout:
|
| 159 |
+
print(line.strip())
|
| 160 |
+
#st.text(line.strip())
|
| 161 |
+
if "Test_final:" in line and 'FairGNN' in model_type:
|
| 162 |
+
result = line.strip()
|
| 163 |
+
#st.text(result)
|
| 164 |
+
if 'accuracy' in line and 'RHGN' in model_type:
|
| 165 |
+
#st.text(line.strip())
|
| 166 |
+
line = line.strip() + 'end'
|
| 167 |
+
acc = re.search('accuracy (.+?)end', line)
|
| 168 |
+
acc = acc.group(1)
|
| 169 |
+
acc_rhgn = acc.split()[0]
|
| 170 |
+
if 'F1 score:' in line:
|
| 171 |
+
f1 = '.'.join(line.split('.')[0:2])
|
| 172 |
+
f1_rhgn = '{:.3f}'.format(float(f1.split()[-1]))
|
| 173 |
+
if 'Statistical Parity Difference (SPD):' in line:
|
| 174 |
+
spd_rhgn = '{:.3f}'.format(float(line.split()[-1]))
|
| 175 |
+
|
| 176 |
+
if 'Equal Opportunity Difference (EOD):' in line:
|
| 177 |
+
eod_rhgn = '{:.3f}'.format(float(line.split()[-1]))
|
| 178 |
+
|
| 179 |
+
if 'Overall Accuracy Equality Difference (OAED):' in line:
|
| 180 |
+
oaed_rhgn = '{:.3f}'.format(float(line.split()[-1]))
|
| 181 |
+
|
| 182 |
+
if 'Treatment Equality Difference (TED):' in line:
|
| 183 |
+
ted_rhgn = '{:.3f}'.format(float(line.split()[-1]))
|
| 184 |
+
#all_output.append(line.strip())
|
| 185 |
+
# Close the connection
|
| 186 |
+
ssh.close()
|
| 187 |
+
|
| 188 |
+
st.success("Done!")
|
| 189 |
+
|
| 190 |
+
|
| 191 |
+
st.markdown("## Training Results:")
|
| 192 |
+
print(len(model_type))
|
| 193 |
+
print(model_type)
|
| 194 |
+
if len(model_type) == 1 and 'FairGNN' in model_type:
|
| 195 |
+
st.text(result)
|
| 196 |
+
acc = re.search('accuracy:(.+?)roc', result)
|
| 197 |
+
f1 = re.search('F1:(.+?)acc_sens', result)
|
| 198 |
+
|
| 199 |
+
spd = re.search('parity:(.+?)equality', result)
|
| 200 |
+
eod = re.search('equality:(.+?)oaed', result)
|
| 201 |
+
oaed = re.search('oaed:(.+?)treatment equality', result)
|
| 202 |
+
ted = re.search('treatment equality(.+?)end', result)
|
| 203 |
+
data = {'Model': [model_type],
|
| 204 |
+
'Accuracy': [acc.group(1)],
|
| 205 |
+
'F1': [f1.group(1)],
|
| 206 |
+
'SPD': [spd.group(1)],
|
| 207 |
+
'EOD': [eod.group(1)],
|
| 208 |
+
'OAED': [oaed.group(1)],
|
| 209 |
+
'TED': [ted.group(1)]
|
| 210 |
+
}
|
| 211 |
+
|
| 212 |
+
elif len(model_type) == 1 and 'RHGN' in model_type:
|
| 213 |
+
#print('all_output:', all_output)
|
| 214 |
+
data = {'Model': [model_type],
|
| 215 |
+
'Accuracy': [acc_rhgn],
|
| 216 |
+
'F1': [f1_rhgn],
|
| 217 |
+
'SPD': [spd_rhgn],
|
| 218 |
+
'EOD': [eod_rhgn],
|
| 219 |
+
'OAED': [oaed_rhgn],
|
| 220 |
+
'TED': [ted_rhgn]
|
| 221 |
+
}
|
| 222 |
+
|
| 223 |
+
elif len(model_type) == 2 and 'RHGN' in model_type and 'FairGNN' in model_type:
|
| 224 |
+
|
| 225 |
+
acc = re.search('a:(.+?)roc', result)
|
| 226 |
+
f1 = re.search('F1:(.+?)acc_sens', result)
|
| 227 |
+
|
| 228 |
+
spd = re.search('parity:(.+?)equality', result)
|
| 229 |
+
eod = re.search('equality:(.+?)oaed', result)
|
| 230 |
+
oaed = re.search('oaed:(.+?)treatment equality', result)
|
| 231 |
+
ted = re.search('treatment equality(.+?)end', result)
|
| 232 |
+
|
| 233 |
+
ind_fairgnn = model_type.index('FairGNN')
|
| 234 |
+
ind_rhgn = model_type.index('RHGN')
|
| 235 |
+
data = {'Model': [model_type[ind_fairgnn], model_type[ind_rhgn]],
|
| 236 |
+
'Prediction label': [predict_attr, predict_attr],
|
| 237 |
+
'Sensitive attribute': [sens_attr, sens_attr],
|
| 238 |
+
'Accuracy': [acc.group(1), acc_rhgn],
|
| 239 |
+
'F1': [f1.group(1), f1_rhgn],
|
| 240 |
+
'SPD': [spd.group(1), spd_rhgn],
|
| 241 |
+
'EOD': [eod.group(1), eod_rhgn],
|
| 242 |
+
'OAED': [oaed.group(1), oaed_rhgn],
|
| 243 |
+
'TED': [ted.group(1), ted_rhgn]
|
| 244 |
+
}
|
| 245 |
+
|
| 246 |
+
df = pd.DataFrame(data)
|
| 247 |
+
|
| 248 |
+
#st.dataframe(df, width=5000)
|
| 249 |
+
# set the display options for the DataFrame
|
| 250 |
+
pd.set_option("display.max_columns", None)
|
| 251 |
+
pd.set_option("display.width", 100)
|
| 252 |
+
|
| 253 |
+
|
| 254 |
+
|
| 255 |
+
# display the DataFrame in Streamlit
|
| 256 |
+
st.write(df)
|
| 257 |
+
|
| 258 |
+
#st.write("The logs of the experiment can be found at: mohamed9/Experiments-RHGN-CatGCN-Alibaba")
|
| 259 |
+
#st.markdown("The logs of the experiment can be found at: **mohamed9/Experiments-RHGN-FairGNN-Alibaba**")
|
presets/__pycache__/FairGNN_preset.cpython-310.pyc
ADDED
|
Binary file (9.28 kB). View file
|
|
|
presets/__pycache__/Presets.cpython-310.pyc
ADDED
|
Binary file (10.2 kB). View file
|
|
|
requirements.txt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
paramiko==2.8.1
|
| 2 |
+
|
| 3 |
+
|
src/__pycache__/fainress_component.cpython-37.pyc
ADDED
|
Binary file (6.71 kB). View file
|
|
|
src/__pycache__/fainress_component.cpython-39.pyc
ADDED
|
Binary file (6.47 kB). View file
|
|
|
src/__pycache__/utils.cpython-37.pyc
ADDED
|
Binary file (11.3 kB). View file
|
|
|
src/__pycache__/utils.cpython-39.pyc
ADDED
|
Binary file (11.2 kB). View file
|
|
|
src/aif360/README.md
ADDED
|
File without changes
|
src/aif360/__init__.py
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
try:
|
| 2 |
+
from .version import version as __version__
|
| 3 |
+
except ImportError:
|
| 4 |
+
pass
|
src/aif360/__pycache__/__init__.cpython-37.pyc
ADDED
|
Binary file (280 Bytes). View file
|
|
|
src/aif360/__pycache__/__init__.cpython-39.pyc
ADDED
|
Binary file (282 Bytes). View file
|
|
|
src/aif360/__pycache__/decorating_metaclass.cpython-37.pyc
ADDED
|
Binary file (1.63 kB). View file
|
|
|
src/aif360/__pycache__/decorating_metaclass.cpython-39.pyc
ADDED
|
Binary file (1.64 kB). View file
|
|
|
src/aif360/aif360-r/.Rbuildignore
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
^.*\.Rproj$ # Automatically added by RStudio,
|
| 2 |
+
^\.Rproj\.user$ # used for temporary files.
|
| 3 |
+
^README\.Rmd$ # An Rmarkdown file used to generate README.md
|
| 4 |
+
^NEWS\.md$ # A news file written in Markdown
|
| 5 |
+
^\.travis\.yml$ # Used for continuous integration testing with travis
|
| 6 |
+
^LICENSE\.md$
|
| 7 |
+
^raif360\.Rproj$
|
| 8 |
+
^README\.Rmd$
|
| 9 |
+
^CONDUCT\.md$
|
| 10 |
+
^CONTRIBUTING\.md$
|
| 11 |
+
^CODEOFCONDUCT\.md$
|
| 12 |
+
^cran-comments\.md$
|
src/aif360/aif360-r/.gitignore
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.Rproj.user
|
| 2 |
+
.Rhistory
|
| 3 |
+
.RData
|
| 4 |
+
.Ruserdata
|
| 5 |
+
.httr-oauth
|
| 6 |
+
.*.Rnb.cached
|
| 7 |
+
.DS_Store
|
src/aif360/aif360-r/CODEOFCONDUCT.md
ADDED
|
@@ -0,0 +1,44 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
# Contributor Code of Conduct
|
| 3 |
+
|
| 4 |
+
## Our Pledge
|
| 5 |
+
|
| 6 |
+
We as members, contributors, and leaders pledge to make participation in our
|
| 7 |
+
community a harassment-free experience for everyone, regardless of age, body
|
| 8 |
+
size, visible or invisible disability, ethnicity, sex characteristics, gender
|
| 9 |
+
identity and expression, level of experience, education, socio-economic status,
|
| 10 |
+
nationality, personal appearance, race, religion, or sexual identity
|
| 11 |
+
and orientation.
|
| 12 |
+
|
| 13 |
+
We pledge to act and interact in ways that contribute to an open, welcoming,
|
| 14 |
+
diverse, inclusive, and healthy community.
|
| 15 |
+
|
| 16 |
+
## Our Standards
|
| 17 |
+
|
| 18 |
+
Examples of behavior that contributes to a positive environment for our
|
| 19 |
+
community include:
|
| 20 |
+
|
| 21 |
+
* Demonstrating empathy and kindness toward other people
|
| 22 |
+
* Being respectful of differing opinions, viewpoints, and experiences
|
| 23 |
+
* Giving and gracefully accepting constructive feedback
|
| 24 |
+
* Accepting responsibility and apologizing to those affected by our mistakes,
|
| 25 |
+
and learning from the experience
|
| 26 |
+
* Focusing on what is best not just for us as individuals, but for the
|
| 27 |
+
overall community
|
| 28 |
+
|
| 29 |
+
Examples of unacceptable behavior include:
|
| 30 |
+
|
| 31 |
+
* The use of sexualized language or imagery, and sexual attention or
|
| 32 |
+
advances of any kind
|
| 33 |
+
* Trolling, insulting or derogatory comments, and personal or political attacks
|
| 34 |
+
* Public or private harassment
|
| 35 |
+
* Publishing others' private information, such as a physical or email
|
| 36 |
+
address, without their explicit permission
|
| 37 |
+
* Other conduct which could reasonably be considered inappropriate in a
|
| 38 |
+
professional setting
|
| 39 |
+
|
| 40 |
+
## Attribution
|
| 41 |
+
|
| 42 |
+
This Code of Conduct is adapted from the [Contributor Covenant](https://www.contributor-covenant.org/),
|
| 43 |
+
version 2.0, available at
|
| 44 |
+
https://www.contributor-covenant.org/version/2/0/code_of_conduct.html.
|
src/aif360/aif360-r/CONTRIBUTING.md
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Contributing to the AIF360 R package
|
| 2 |
+
|
| 3 |
+
This guide is divided into three main parts:
|
| 4 |
+
|
| 5 |
+
1. Filing a bug report or feature request in an issue.
|
| 6 |
+
2. Suggesting a change via a pull request.
|
| 7 |
+
3. New features or enhancements to AIF360 functionality.
|
| 8 |
+
|
| 9 |
+
If you're not familiar with git or GitHub, please start by reading <http://r-pkgs.had.co.nz/git.html>
|
| 10 |
+
|
| 11 |
+
Please note that the AIF360 R package is released with a [Contributor Code of Conduct](CODEOFCONDUCT.md). By contributing to this project,
|
| 12 |
+
you agree to abide by its terms.
|
| 13 |
+
|
| 14 |
+
## Issues
|
| 15 |
+
|
| 16 |
+
If you find a bug, please search GitHub under [Issues](https://github.com/Trusted-AI/AIF360/issues) to ensure the bug was not already reported.
|
| 17 |
+
If you’re unable to find an open issue addressing the problem, [open a new one](https://github.com/Trusted-AI/AIF360/issues/new). Please include a title and clear description, as much relevant information as possible (such as required packages, data, etc.), and a code sample to replicate the issue.
|
| 18 |
+
|
| 19 |
+
## Pull requests
|
| 20 |
+
|
| 21 |
+
To contribute a change to the AIF360 R package, you follow these steps:
|
| 22 |
+
|
| 23 |
+
* Create a branch in git and make your changes.
|
| 24 |
+
* Push branch to GitHub and open a new pull request (PR).
|
| 25 |
+
* Ensure the PR description clearly describes the problem and solution. Include the relevant issue number if applicable.
|
| 26 |
+
|
| 27 |
+
## New Features
|
| 28 |
+
|
| 29 |
+
The AIF360 R package is part of [AI Fairness 360](https://github.com/Trusted-AI/AIF360), developed with extensibility in mind. If you wish to suggest new metrics, explainers, algorithms or datasets. Please get in touch on [Slack]( https://aif360.slack.com) (invitation [here](https://aif360.slack.com/join/shared_invite/zt-5hfvuafo-X0~g6tgJQ~7tIAT~S294TQ))!
|
| 30 |
+
|
src/aif360/aif360-r/DESCRIPTION
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Package: aif360
|
| 2 |
+
Type: Package
|
| 3 |
+
Title: Help Detect and Mitigate Bias in Machine Learning Models
|
| 4 |
+
Version: 0.1.0
|
| 5 |
+
Authors@R: c(
|
| 6 |
+
person("Gabriela", "de Queiroz", email = "[email protected]", role = "aut"),
|
| 7 |
+
person("Stacey", "Ronaghan", email = "[email protected]", role = "aut"),
|
| 8 |
+
person("Saishruthi", "Swaminathan", email = "[email protected]",
|
| 9 |
+
role = c("aut", "cre")))
|
| 10 |
+
Description: The AI Fairness 360 toolkit is an open-source library to help detect
|
| 11 |
+
and mitigate bias in machine learning models. The AI Fairness 360 R package includes
|
| 12 |
+
a comprehensive set of metrics for datasets and models to test for biases,
|
| 13 |
+
explanations for these metrics, and algorithms to mitigate bias in datasets and models.
|
| 14 |
+
License: Apache License (>= 2.0)
|
| 15 |
+
Encoding: UTF-8
|
| 16 |
+
LazyData: true
|
| 17 |
+
URL: https://github.com/Trusted-AI/AIF360
|
| 18 |
+
BugReports: https://github.com/Trusted-AI/AIF360/issues
|
| 19 |
+
Imports:
|
| 20 |
+
reticulate,
|
| 21 |
+
rstudioapi
|
| 22 |
+
RoxygenNote: 7.2.0
|
| 23 |
+
Suggests:
|
| 24 |
+
testthat
|
src/aif360/aif360-r/LICENSE.md
ADDED
|
@@ -0,0 +1,194 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
==============
|
| 3 |
+
|
| 4 |
+
_Version 2.0, January 2004_
|
| 5 |
+
_<<http://www.apache.org/licenses/>>_
|
| 6 |
+
|
| 7 |
+
### Terms and Conditions for use, reproduction, and distribution
|
| 8 |
+
|
| 9 |
+
#### 1. Definitions
|
| 10 |
+
|
| 11 |
+
“License” shall mean the terms and conditions for use, reproduction, and
|
| 12 |
+
distribution as defined by Sections 1 through 9 of this document.
|
| 13 |
+
|
| 14 |
+
“Licensor” shall mean the copyright owner or entity authorized by the copyright
|
| 15 |
+
owner that is granting the License.
|
| 16 |
+
|
| 17 |
+
“Legal Entity” shall mean the union of the acting entity and all other entities
|
| 18 |
+
that control, are controlled by, or are under common control with that entity.
|
| 19 |
+
For the purposes of this definition, “control” means **(i)** the power, direct or
|
| 20 |
+
indirect, to cause the direction or management of such entity, whether by
|
| 21 |
+
contract or otherwise, or **(ii)** ownership of fifty percent (50%) or more of the
|
| 22 |
+
outstanding shares, or **(iii)** beneficial ownership of such entity.
|
| 23 |
+
|
| 24 |
+
“You” (or “Your”) shall mean an individual or Legal Entity exercising
|
| 25 |
+
permissions granted by this License.
|
| 26 |
+
|
| 27 |
+
“Source” form shall mean the preferred form for making modifications, including
|
| 28 |
+
but not limited to software source code, documentation source, and configuration
|
| 29 |
+
files.
|
| 30 |
+
|
| 31 |
+
“Object” form shall mean any form resulting from mechanical transformation or
|
| 32 |
+
translation of a Source form, including but not limited to compiled object code,
|
| 33 |
+
generated documentation, and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
“Work” shall mean the work of authorship, whether in Source or Object form, made
|
| 36 |
+
available under the License, as indicated by a copyright notice that is included
|
| 37 |
+
in or attached to the work (an example is provided in the Appendix below).
|
| 38 |
+
|
| 39 |
+
“Derivative Works” shall mean any work, whether in Source or Object form, that
|
| 40 |
+
is based on (or derived from) the Work and for which the editorial revisions,
|
| 41 |
+
annotations, elaborations, or other modifications represent, as a whole, an
|
| 42 |
+
original work of authorship. For the purposes of this License, Derivative Works
|
| 43 |
+
shall not include works that remain separable from, or merely link (or bind by
|
| 44 |
+
name) to the interfaces of, the Work and Derivative Works thereof.
|
| 45 |
+
|
| 46 |
+
“Contribution” shall mean any work of authorship, including the original version
|
| 47 |
+
of the Work and any modifications or additions to that Work or Derivative Works
|
| 48 |
+
thereof, that is intentionally submitted to Licensor for inclusion in the Work
|
| 49 |
+
by the copyright owner or by an individual or Legal Entity authorized to submit
|
| 50 |
+
on behalf of the copyright owner. For the purposes of this definition,
|
| 51 |
+
“submitted” means any form of electronic, verbal, or written communication sent
|
| 52 |
+
to the Licensor or its representatives, including but not limited to
|
| 53 |
+
communication on electronic mailing lists, source code control systems, and
|
| 54 |
+
issue tracking systems that are managed by, or on behalf of, the Licensor for
|
| 55 |
+
the purpose of discussing and improving the Work, but excluding communication
|
| 56 |
+
that is conspicuously marked or otherwise designated in writing by the copyright
|
| 57 |
+
owner as “Not a Contribution.”
|
| 58 |
+
|
| 59 |
+
“Contributor” shall mean Licensor and any individual or Legal Entity on behalf
|
| 60 |
+
of whom a Contribution has been received by Licensor and subsequently
|
| 61 |
+
incorporated within the Work.
|
| 62 |
+
|
| 63 |
+
#### 2. Grant of Copyright License
|
| 64 |
+
|
| 65 |
+
Subject to the terms and conditions of this License, each Contributor hereby
|
| 66 |
+
grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free,
|
| 67 |
+
irrevocable copyright license to reproduce, prepare Derivative Works of,
|
| 68 |
+
publicly display, publicly perform, sublicense, and distribute the Work and such
|
| 69 |
+
Derivative Works in Source or Object form.
|
| 70 |
+
|
| 71 |
+
#### 3. Grant of Patent License
|
| 72 |
+
|
| 73 |
+
Subject to the terms and conditions of this License, each Contributor hereby
|
| 74 |
+
grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free,
|
| 75 |
+
irrevocable (except as stated in this section) patent license to make, have
|
| 76 |
+
made, use, offer to sell, sell, import, and otherwise transfer the Work, where
|
| 77 |
+
such license applies only to those patent claims licensable by such Contributor
|
| 78 |
+
that are necessarily infringed by their Contribution(s) alone or by combination
|
| 79 |
+
of their Contribution(s) with the Work to which such Contribution(s) was
|
| 80 |
+
submitted. If You institute patent litigation against any entity (including a
|
| 81 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work or a
|
| 82 |
+
Contribution incorporated within the Work constitutes direct or contributory
|
| 83 |
+
patent infringement, then any patent licenses granted to You under this License
|
| 84 |
+
for that Work shall terminate as of the date such litigation is filed.
|
| 85 |
+
|
| 86 |
+
#### 4. Redistribution
|
| 87 |
+
|
| 88 |
+
You may reproduce and distribute copies of the Work or Derivative Works thereof
|
| 89 |
+
in any medium, with or without modifications, and in Source or Object form,
|
| 90 |
+
provided that You meet the following conditions:
|
| 91 |
+
|
| 92 |
+
* **(a)** You must give any other recipients of the Work or Derivative Works a copy of
|
| 93 |
+
this License; and
|
| 94 |
+
* **(b)** You must cause any modified files to carry prominent notices stating that You
|
| 95 |
+
changed the files; and
|
| 96 |
+
* **(c)** You must retain, in the Source form of any Derivative Works that You distribute,
|
| 97 |
+
all copyright, patent, trademark, and attribution notices from the Source form
|
| 98 |
+
of the Work, excluding those notices that do not pertain to any part of the
|
| 99 |
+
Derivative Works; and
|
| 100 |
+
* **(d)** If the Work includes a “NOTICE” text file as part of its distribution, then any
|
| 101 |
+
Derivative Works that You distribute must include a readable copy of the
|
| 102 |
+
attribution notices contained within such NOTICE file, excluding those notices
|
| 103 |
+
that do not pertain to any part of the Derivative Works, in at least one of the
|
| 104 |
+
following places: within a NOTICE text file distributed as part of the
|
| 105 |
+
Derivative Works; within the Source form or documentation, if provided along
|
| 106 |
+
with the Derivative Works; or, within a display generated by the Derivative
|
| 107 |
+
Works, if and wherever such third-party notices normally appear. The contents of
|
| 108 |
+
the NOTICE file are for informational purposes only and do not modify the
|
| 109 |
+
License. You may add Your own attribution notices within Derivative Works that
|
| 110 |
+
You distribute, alongside or as an addendum to the NOTICE text from the Work,
|
| 111 |
+
provided that such additional attribution notices cannot be construed as
|
| 112 |
+
modifying the License.
|
| 113 |
+
|
| 114 |
+
You may add Your own copyright statement to Your modifications and may provide
|
| 115 |
+
additional or different license terms and conditions for use, reproduction, or
|
| 116 |
+
distribution of Your modifications, or for any such Derivative Works as a whole,
|
| 117 |
+
provided Your use, reproduction, and distribution of the Work otherwise complies
|
| 118 |
+
with the conditions stated in this License.
|
| 119 |
+
|
| 120 |
+
#### 5. Submission of Contributions
|
| 121 |
+
|
| 122 |
+
Unless You explicitly state otherwise, any Contribution intentionally submitted
|
| 123 |
+
for inclusion in the Work by You to the Licensor shall be under the terms and
|
| 124 |
+
conditions of this License, without any additional terms or conditions.
|
| 125 |
+
Notwithstanding the above, nothing herein shall supersede or modify the terms of
|
| 126 |
+
any separate license agreement you may have executed with Licensor regarding
|
| 127 |
+
such Contributions.
|
| 128 |
+
|
| 129 |
+
#### 6. Trademarks
|
| 130 |
+
|
| 131 |
+
This License does not grant permission to use the trade names, trademarks,
|
| 132 |
+
service marks, or product names of the Licensor, except as required for
|
| 133 |
+
reasonable and customary use in describing the origin of the Work and
|
| 134 |
+
reproducing the content of the NOTICE file.
|
| 135 |
+
|
| 136 |
+
#### 7. Disclaimer of Warranty
|
| 137 |
+
|
| 138 |
+
Unless required by applicable law or agreed to in writing, Licensor provides the
|
| 139 |
+
Work (and each Contributor provides its Contributions) on an “AS IS” BASIS,
|
| 140 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied,
|
| 141 |
+
including, without limitation, any warranties or conditions of TITLE,
|
| 142 |
+
NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A PARTICULAR PURPOSE. You are
|
| 143 |
+
solely responsible for determining the appropriateness of using or
|
| 144 |
+
redistributing the Work and assume any risks associated with Your exercise of
|
| 145 |
+
permissions under this License.
|
| 146 |
+
|
| 147 |
+
#### 8. Limitation of Liability
|
| 148 |
+
|
| 149 |
+
In no event and under no legal theory, whether in tort (including negligence),
|
| 150 |
+
contract, or otherwise, unless required by applicable law (such as deliberate
|
| 151 |
+
and grossly negligent acts) or agreed to in writing, shall any Contributor be
|
| 152 |
+
liable to You for damages, including any direct, indirect, special, incidental,
|
| 153 |
+
or consequential damages of any character arising as a result of this License or
|
| 154 |
+
out of the use or inability to use the Work (including but not limited to
|
| 155 |
+
damages for loss of goodwill, work stoppage, computer failure or malfunction, or
|
| 156 |
+
any and all other commercial damages or losses), even if such Contributor has
|
| 157 |
+
been advised of the possibility of such damages.
|
| 158 |
+
|
| 159 |
+
#### 9. Accepting Warranty or Additional Liability
|
| 160 |
+
|
| 161 |
+
While redistributing the Work or Derivative Works thereof, You may choose to
|
| 162 |
+
offer, and charge a fee for, acceptance of support, warranty, indemnity, or
|
| 163 |
+
other liability obligations and/or rights consistent with this License. However,
|
| 164 |
+
in accepting such obligations, You may act only on Your own behalf and on Your
|
| 165 |
+
sole responsibility, not on behalf of any other Contributor, and only if You
|
| 166 |
+
agree to indemnify, defend, and hold each Contributor harmless for any liability
|
| 167 |
+
incurred by, or claims asserted against, such Contributor by reason of your
|
| 168 |
+
accepting any such warranty or additional liability.
|
| 169 |
+
|
| 170 |
+
_END OF TERMS AND CONDITIONS_
|
| 171 |
+
|
| 172 |
+
### APPENDIX: How to apply the Apache License to your work
|
| 173 |
+
|
| 174 |
+
To apply the Apache License to your work, attach the following boilerplate
|
| 175 |
+
notice, with the fields enclosed by brackets `[]` replaced with your own
|
| 176 |
+
identifying information. (Don't include the brackets!) The text should be
|
| 177 |
+
enclosed in the appropriate comment syntax for the file format. We also
|
| 178 |
+
recommend that a file or class name and description of purpose be included on
|
| 179 |
+
the same “printed page” as the copyright notice for easier identification within
|
| 180 |
+
third-party archives.
|
| 181 |
+
|
| 182 |
+
Copyright 2020-2021 The AI Fairness 360 (AIF360) Authors
|
| 183 |
+
|
| 184 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 185 |
+
you may not use this file except in compliance with the License.
|
| 186 |
+
You may obtain a copy of the License at
|
| 187 |
+
|
| 188 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 189 |
+
|
| 190 |
+
Unless required by applicable law or agreed to in writing, software
|
| 191 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 192 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 193 |
+
See the License for the specific language governing permissions and
|
| 194 |
+
limitations under the License.
|
src/aif360/aif360-r/NAMESPACE
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Generated by roxygen2: do not edit by hand
|
| 2 |
+
|
| 3 |
+
export(adult_dataset)
|
| 4 |
+
export(adversarial_debiasing)
|
| 5 |
+
export(bank_dataset)
|
| 6 |
+
export(binary_label_dataset)
|
| 7 |
+
export(binary_label_dataset_metric)
|
| 8 |
+
export(classification_metric)
|
| 9 |
+
export(compas_dataset)
|
| 10 |
+
export(disparate_impact_remover)
|
| 11 |
+
export(german_dataset)
|
| 12 |
+
export(install_aif360)
|
| 13 |
+
export(law_school_gpa_dataset)
|
| 14 |
+
export(load_aif360_lib)
|
| 15 |
+
export(prejudice_remover)
|
| 16 |
+
export(reject_option_classification)
|
| 17 |
+
export(reweighing)
|
| 18 |
+
importFrom(reticulate,import)
|
| 19 |
+
importFrom(reticulate,py_dict)
|
| 20 |
+
importFrom(reticulate,py_suppress_warnings)
|
| 21 |
+
importFrom(reticulate,py_to_r)
|
| 22 |
+
importFrom(reticulate,r_to_py)
|
| 23 |
+
importFrom(utils,file_test)
|
| 24 |
+
importFrom(utils,read.csv)
|
src/aif360/aif360-r/R/binary_label_dataset_metric.R
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#' Binary Label Dataset Metric
|
| 2 |
+
#' @description Class for computing metrics on an aif360 compatible dataset with binary labels.
|
| 3 |
+
#' @param dataset A aif360 compatible dataset.
|
| 4 |
+
#' @param privileged_groups Privileged groups. List containing privileged protected attribute name and value of the privileged protected attribute.
|
| 5 |
+
#' @param unprivileged_groups Unprivileged groups. List containing unprivileged protected attribute name and value of the unprivileged protected attribute.
|
| 6 |
+
#' @usage
|
| 7 |
+
#' binary_label_dataset_metric(dataset, privileged_groups, unprivileged_groups)
|
| 8 |
+
#' @examples
|
| 9 |
+
#' \dontrun{
|
| 10 |
+
#' load_aif360_lib()
|
| 11 |
+
#' # Load the adult dataset
|
| 12 |
+
#' adult_dataset <- adult_dataset()
|
| 13 |
+
#'
|
| 14 |
+
#' # Define the groups
|
| 15 |
+
#' privileged_groups <- list("race", 1)
|
| 16 |
+
#' unprivileged_groups <- list("race", 0)
|
| 17 |
+
#'
|
| 18 |
+
#' # Metric for Binary Label Dataset
|
| 19 |
+
#' bm <- binary_label_dataset_metric(dataset = adult_dataset,
|
| 20 |
+
#' privileged_groups = privileged_groups,
|
| 21 |
+
#' unprivileged_groups = unprivileged_groups)
|
| 22 |
+
#'
|
| 23 |
+
#' # Difference in mean outcomes between unprivileged and privileged groups
|
| 24 |
+
#' bm$mean_difference()
|
| 25 |
+
#' }
|
| 26 |
+
#' @seealso
|
| 27 |
+
#' \href{https://aif360.readthedocs.io/en/latest/modules/metrics.html#aif360.metrics.BinaryLabelDatasetMetric}{Explore available binary label dataset metrics here}
|
| 28 |
+
#'
|
| 29 |
+
#' Available metrics are: base_rate, consistency, disparate_impact, mean_difference, num_negatives, num_positives and statistical_parity_difference.
|
| 30 |
+
#' @export
|
| 31 |
+
#' @importFrom reticulate py_suppress_warnings py_to_r
|
| 32 |
+
#'
|
| 33 |
+
binary_label_dataset_metric <- function(dataset,
|
| 34 |
+
privileged_groups,
|
| 35 |
+
unprivileged_groups){
|
| 36 |
+
|
| 37 |
+
p_dict <- dict_fn(privileged_groups)
|
| 38 |
+
u_dict <- dict_fn(unprivileged_groups)
|
| 39 |
+
|
| 40 |
+
return(metrics$BinaryLabelDatasetMetric(dataset,
|
| 41 |
+
privileged_groups = p_dict,
|
| 42 |
+
unprivileged_groups = u_dict))
|
| 43 |
+
}
|
src/aif360/aif360-r/R/classification_metric.R
ADDED
|
@@ -0,0 +1,114 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#' Classification Metric
|
| 2 |
+
#' @description
|
| 3 |
+
#' Class for computing metrics based on two BinaryLabelDatasets. The first dataset is the original one and the second is the output of the classification transformer (or similar)
|
| 4 |
+
#' @param dataset (BinaryLabelDataset) Dataset containing ground-truth labels
|
| 5 |
+
#' @param classified_dataset (BinaryLabelDataset) Dataset containing predictions
|
| 6 |
+
#' @param privileged_groups Privileged groups. List containing privileged protected attribute name and value of the privileged protected attribute.
|
| 7 |
+
#' @param unprivileged_groups Unprivileged groups. List containing unprivileged protected attribute name and value of the unprivileged protected attribute.
|
| 8 |
+
#' @usage
|
| 9 |
+
#' classification_metric(dataset, classified_dataset, unprivileged_groups, privileged_groups)
|
| 10 |
+
#' @examples
|
| 11 |
+
#' \dontrun{
|
| 12 |
+
#' load_aif360_lib()
|
| 13 |
+
#' # Input dataset
|
| 14 |
+
#' data <- data.frame("feat" = c(0,0,1,1,1,1,0,1,1,0), "label" = c(1,0,0,1,0,0,1,0,1,1))
|
| 15 |
+
#' # Create aif compatible input dataset
|
| 16 |
+
#' act <- aif360::binary_label_dataset(data_path = data, favor_label=0, unfavor_label=1,
|
| 17 |
+
#' unprivileged_protected_attribute=0,
|
| 18 |
+
#' privileged_protected_attribute=1,
|
| 19 |
+
#' target_column="label", protected_attribute="feat")
|
| 20 |
+
#' # Classified dataset
|
| 21 |
+
#' pred_data <- data.frame("feat" = c(0,0,1,1,1,1,0,1,1,0), "label" = c(1,0,1,1,1,0,1,0,0,1))
|
| 22 |
+
#' # Create aif compatible classified dataset
|
| 23 |
+
#' pred <- aif360::binary_label_dataset(data_path = pred_data, favor_label=0, unfavor_label=1,
|
| 24 |
+
#' unprivileged_protected_attribute=0,
|
| 25 |
+
#' privileged_protected_attribute=1,
|
| 26 |
+
#' target_column="label", protected_attribute="feat")
|
| 27 |
+
#' # Create an instance of classification metric
|
| 28 |
+
#' cm <- classification_metric(act, pred, list('feat', 1), list('feat', 0))
|
| 29 |
+
#' # Access metric functions
|
| 30 |
+
#' cm$accuracy()
|
| 31 |
+
#' }
|
| 32 |
+
#' @seealso
|
| 33 |
+
#' \href{https://aif360.readthedocs.io/en/latest/modules/metrics.html#classification-metric}{Explore available classification metrics explanations here}
|
| 34 |
+
#'
|
| 35 |
+
#' Available metrics:
|
| 36 |
+
#' \itemize{
|
| 37 |
+
#' \item accuracy
|
| 38 |
+
#' \item average_abs_odds_difference
|
| 39 |
+
#' \item average_odds_difference
|
| 40 |
+
#' \item between_all_groups_coefficient_of_variation
|
| 41 |
+
#' \item between_all_groups_generalized_entropy_index
|
| 42 |
+
#' \item between_all_groups_theil_index
|
| 43 |
+
#' \item between_group_coefficient_of_variation
|
| 44 |
+
#' \item between_group_generalized_entropy_index
|
| 45 |
+
#' \item between_group_theil_index
|
| 46 |
+
#' \item binary_confusion_matrix
|
| 47 |
+
#' \item coefficient_of_variation
|
| 48 |
+
#' \item disparate_impact
|
| 49 |
+
#' \item equal_opportunity_difference
|
| 50 |
+
#' \item error_rate
|
| 51 |
+
#' \item error_rate_difference
|
| 52 |
+
#' \item error_rate_ratio
|
| 53 |
+
#' \item false_discovery_rate
|
| 54 |
+
#' \item false_discovery_rate_difference
|
| 55 |
+
#' \item false_discovery_rate_ratio
|
| 56 |
+
#' \item false_negative_rate
|
| 57 |
+
#' \item false_negative_rate_difference
|
| 58 |
+
#' \item false_negative_rate_ratio
|
| 59 |
+
#' \item false_omission_rate
|
| 60 |
+
#' \item false_omission_rate_difference
|
| 61 |
+
#' \item false_omission_rate_ratio
|
| 62 |
+
#' \item false_positive_rate
|
| 63 |
+
#' \item false_positive_rate_difference
|
| 64 |
+
#' \item false_positive_rate_ratio
|
| 65 |
+
#' \item generalized_binary_confusion_matrix
|
| 66 |
+
#' \item generalized_entropy_index
|
| 67 |
+
#' \item generalized_false_negative_rate
|
| 68 |
+
#' \item generalized_false_positive_rate
|
| 69 |
+
#' \item generalized_true_negative_rate
|
| 70 |
+
#' \item generalized_true_positive_rate
|
| 71 |
+
#' \item negative_predictive_value
|
| 72 |
+
#' \item num_false_negatives
|
| 73 |
+
#' \item num_false_positives
|
| 74 |
+
#' \item num_generalized_false_negatives
|
| 75 |
+
#' \item num_generalized_false_positives
|
| 76 |
+
#' \item num_generalized_true_negatives
|
| 77 |
+
#' \item num_generalized_true_positives
|
| 78 |
+
#' \item num_pred_negatives
|
| 79 |
+
#' \item num_pred_positives
|
| 80 |
+
#' \item num_true_negatives
|
| 81 |
+
#' \item num_true_positives
|
| 82 |
+
#' \item performance_measures
|
| 83 |
+
#' \item positive_predictive_value
|
| 84 |
+
#' \item power
|
| 85 |
+
#' \item precision
|
| 86 |
+
#' \item recall
|
| 87 |
+
#' \item selection_rate
|
| 88 |
+
#' \item sensitivity
|
| 89 |
+
#' \item specificity
|
| 90 |
+
#' \item statistical_parity_difference
|
| 91 |
+
#' \item theil_index
|
| 92 |
+
#' \item true_negative_rate
|
| 93 |
+
#' \item true_positive_rate
|
| 94 |
+
#' \item true_positive_rate_difference
|
| 95 |
+
#'
|
| 96 |
+
#' }
|
| 97 |
+
#' @export
|
| 98 |
+
#' @importFrom reticulate py_suppress_warnings
|
| 99 |
+
#'
|
| 100 |
+
classification_metric <- function(dataset,
|
| 101 |
+
classified_dataset,
|
| 102 |
+
unprivileged_groups,
|
| 103 |
+
privileged_groups){
|
| 104 |
+
|
| 105 |
+
u_dict <- dict_fn(unprivileged_groups)
|
| 106 |
+
|
| 107 |
+
p_dict <- dict_fn(privileged_groups)
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
return(metrics$ClassificationMetric(dataset,
|
| 111 |
+
classified_dataset,
|
| 112 |
+
unprivileged_groups = u_dict,
|
| 113 |
+
privileged_groups = p_dict))
|
| 114 |
+
}
|
src/aif360/aif360-r/R/dataset.R
ADDED
|
@@ -0,0 +1,71 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#' AIF360 dataset
|
| 2 |
+
#' @description
|
| 3 |
+
#' Function to create AIF compatible dataset.
|
| 4 |
+
#' @param data_path Path to the input CSV file or a R dataframe.
|
| 5 |
+
#' @param favor_label Label value which is considered favorable (i.e. “positive”).
|
| 6 |
+
#' @param unfavor_label Label value which is considered unfavorable (i.e. “negative”).
|
| 7 |
+
#' @param unprivileged_protected_attribute A unprotected attribute value which is considered privileged from a fairness perspective.
|
| 8 |
+
#' @param privileged_protected_attribute A protected attribute value which is considered privileged from a fairness perspective.
|
| 9 |
+
#' @param target_column Name describing the label.
|
| 10 |
+
#' @param protected_attribute A feature for which fairness is desired.
|
| 11 |
+
#' @usage
|
| 12 |
+
#' binary_label_dataset(data_path, favor_label, unfavor_label,
|
| 13 |
+
#' unprivileged_protected_attribute,
|
| 14 |
+
#' privileged_protected_attribute,
|
| 15 |
+
#' target_column, protected_attribute)
|
| 16 |
+
#' @examples
|
| 17 |
+
#' \dontrun{
|
| 18 |
+
#' load_aif360_lib()
|
| 19 |
+
#' # Input dataset
|
| 20 |
+
#' data <- data.frame("feat" = c(0,0,1,1,1,1,0,1,1,0), "label" = c(1,0,0,1,0,0,1,0,1,1))
|
| 21 |
+
#' # Create aif compatible input dataset
|
| 22 |
+
#' act <- aif360::binary_label_dataset(data_path = data, favor_label=0, unfavor_label=1,
|
| 23 |
+
#' unprivileged_protected_attribute=0,
|
| 24 |
+
#' privileged_protected_attribute=1,
|
| 25 |
+
#' target_column="label", protected_attribute="feat")
|
| 26 |
+
#' }
|
| 27 |
+
#' @seealso
|
| 28 |
+
#' \href{https://aif360.readthedocs.io/en/latest/modules/datasets.html#binary-label-dataset}{More about AIF binary dataset.}
|
| 29 |
+
#' @export
|
| 30 |
+
#' @importFrom reticulate py_suppress_warnings py_dict r_to_py
|
| 31 |
+
#' @importFrom utils file_test
|
| 32 |
+
#'
|
| 33 |
+
binary_label_dataset <- function(data_path, favor_label,
|
| 34 |
+
unfavor_label, unprivileged_protected_attribute,
|
| 35 |
+
privileged_protected_attribute,
|
| 36 |
+
target_column, protected_attribute) {
|
| 37 |
+
|
| 38 |
+
if (is.data.frame(data_path)) {
|
| 39 |
+
dataframe <- r_to_py(data_path)
|
| 40 |
+
} else if (file_test("-f", data_path) == TRUE) {
|
| 41 |
+
dataframe = input_data(data_path)
|
| 42 |
+
}
|
| 43 |
+
unprivileged_protected_list <- list_of_list(unprivileged_protected_attribute)
|
| 44 |
+
privileged_protected_list <- list_of_list(privileged_protected_attribute)
|
| 45 |
+
target_column_list <- list_fn(target_column)
|
| 46 |
+
protected_attribute_list <- list_fn(protected_attribute)
|
| 47 |
+
|
| 48 |
+
return(datasets$BinaryLabelDataset(df = dataframe,
|
| 49 |
+
favorable_label = favor_label,
|
| 50 |
+
unfavorable_label = unfavor_label,
|
| 51 |
+
unprivileged_protected_attributes = unprivileged_protected_list,
|
| 52 |
+
privileged_protected_attributes = privileged_protected_list,
|
| 53 |
+
label_names = target_column_list,
|
| 54 |
+
protected_attribute_names = protected_attribute_list))
|
| 55 |
+
|
| 56 |
+
}
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
|
src/aif360/aif360-r/R/dataset_metric.R
ADDED
|
@@ -0,0 +1,42 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#' Dataset Metric
|
| 2 |
+
#' @description
|
| 3 |
+
#' Class to provide access to functions for computing metrics on an aif360 compatible dataset
|
| 4 |
+
#'
|
| 5 |
+
#' @param data A aif360 compatible dataset
|
| 6 |
+
#' @param privileged_groups Privileged groups. List containing privileged protected attribute name and value of the privileged protected attribute.
|
| 7 |
+
#' @param unprivileged_groups Unprivileged groups. List containing unprivileged protected attribute name and value of the unprivileged protected attribute.
|
| 8 |
+
#' @usage
|
| 9 |
+
#' dataset_metric(data, privileged_groups, unprivileged_groups)
|
| 10 |
+
#' @examples
|
| 11 |
+
#' \dontrun{
|
| 12 |
+
#' load_aif360_lib()
|
| 13 |
+
#' data <- data.frame("feat" = c(0,0,1,1,1,1,0,1,1,0), "label" = c(1,0,0,1,0,0,1,0,1,1))
|
| 14 |
+
#' # Create aif compatible dataset
|
| 15 |
+
#' dd <- aif360::binary_label_dataset(data_path = data,
|
| 16 |
+
#' favor_label=0, unfavor_label=1,
|
| 17 |
+
#' unprivileged_protected_attribute=0,
|
| 18 |
+
#' privileged_protected_attribute=1,
|
| 19 |
+
#' target_column="label", protected_attribute="feat")
|
| 20 |
+
#' # Create an instance of dataset metric
|
| 21 |
+
#' dm <- dataset_metric(dd, list('feat', 1), list('feat',2))
|
| 22 |
+
#' # Access metric functions
|
| 23 |
+
#' dm$num_instances()
|
| 24 |
+
#' }
|
| 25 |
+
#' @seealso
|
| 26 |
+
#' \href{https://aif360.readthedocs.io/en/latest/modules/metrics.html#dataset-metric}{Explore available dataset metrics here}
|
| 27 |
+
#'
|
| 28 |
+
#' Available metric: num_instances
|
| 29 |
+
#' @noRd
|
| 30 |
+
#' @importFrom reticulate py_suppress_warnings import
|
| 31 |
+
#'
|
| 32 |
+
dataset_metric <- function(data,
|
| 33 |
+
privileged_groups,
|
| 34 |
+
unprivileged_groups){
|
| 35 |
+
|
| 36 |
+
p_dict <- dict_fn(privileged_groups)
|
| 37 |
+
u_dict <- dict_fn(unprivileged_groups)
|
| 38 |
+
|
| 39 |
+
return(metrics$DatasetMetric(data,
|
| 40 |
+
privileged_groups = p_dict,
|
| 41 |
+
unprivileged_groups = u_dict))
|
| 42 |
+
}
|
src/aif360/aif360-r/R/import.R
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#' load functions
|
| 2 |
+
#' @export
|
| 3 |
+
#'
|
| 4 |
+
load_aif360_lib <- function() {
|
| 5 |
+
e <- globalenv()
|
| 6 |
+
bindings <- c("datasets", "metrics", "pre_algo", "in_algo", "post_algo", "tf")
|
| 7 |
+
if (!all(bindings %in% ls(e))){
|
| 8 |
+
e$datasets <- import("aif360.datasets")
|
| 9 |
+
e$metrics <- import("aif360.metrics")
|
| 10 |
+
e$pre_algo <- import("aif360.algorithms.preprocessing")
|
| 11 |
+
e$in_algo <- import("aif360.algorithms.inprocessing")
|
| 12 |
+
e$post_algo <- import("aif360.algorithms.postprocessing")
|
| 13 |
+
e$tf <- import("tensorflow")
|
| 14 |
+
lockBinding("datasets", e)
|
| 15 |
+
lockBinding("metrics", e)
|
| 16 |
+
lockBinding("pre_algo", e)
|
| 17 |
+
lockBinding("in_algo", e)
|
| 18 |
+
lockBinding("post_algo", e)
|
| 19 |
+
lockBinding("tf", e)
|
| 20 |
+
} else {
|
| 21 |
+
message("The aif360 functions have already been loaded. You can begin using the package.")
|
| 22 |
+
}
|
| 23 |
+
}
|
src/aif360/aif360-r/R/inprocessing_adversarial_debiasing.R
ADDED
|
@@ -0,0 +1,73 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#' Adversarial Debiasing
|
| 2 |
+
#' @description Adversarial debiasing is an in-processing technique that learns a classifier to maximize prediction accuracy
|
| 3 |
+
#' and simultaneously reduce an adversary's ability to determine the protected attribute from the predictions
|
| 4 |
+
#' @param unprivileged_groups A list with two values: the column of the protected class and the value indicating representation for unprivileged group.
|
| 5 |
+
#' @param privileged_groups A list with two values: the column of the protected class and the value indicating representation for privileged group.
|
| 6 |
+
#' @param scope_name Scope name for the tensorflow variables.
|
| 7 |
+
#' @param sess tensorflow session
|
| 8 |
+
#' @param seed Seed to make \code{predict} repeatable. If not, \code{NULL}, must be an integer.
|
| 9 |
+
#' @param adversary_loss_weight Hyperparameter that chooses the strength of the adversarial loss.
|
| 10 |
+
#' @param num_epochs Number of training epochs. Must be an integer.
|
| 11 |
+
#' @param batch_size Batch size. Must be an integer.
|
| 12 |
+
#' @param classifier_num_hidden_units Number of hidden units in the classifier model. Must be an integer.
|
| 13 |
+
#' @param debias Learn a classifier with or without debiasing.
|
| 14 |
+
#' @examples
|
| 15 |
+
#' \dontrun{
|
| 16 |
+
#' load_aif360_lib()
|
| 17 |
+
#' ad <- adult_dataset()
|
| 18 |
+
#' p <- list("race", 1)
|
| 19 |
+
#' u <- list("race", 0)
|
| 20 |
+
#'
|
| 21 |
+
#' sess <- tf$compat$v1$Session()
|
| 22 |
+
#'
|
| 23 |
+
#' plain_model <- adversarial_debiasing(privileged_groups = p,
|
| 24 |
+
#' unprivileged_groups = u,
|
| 25 |
+
#' scope_name = "debiased_classifier",
|
| 26 |
+
#' debias = TRUE,
|
| 27 |
+
#' sess = sess)
|
| 28 |
+
#'
|
| 29 |
+
#' plain_model$fit(ad)
|
| 30 |
+
#' ad_nodebiasing <- plain_model$predict(ad)
|
| 31 |
+
#' }
|
| 32 |
+
#' @export
|
| 33 |
+
#'
|
| 34 |
+
adversarial_debiasing <- function(unprivileged_groups,
|
| 35 |
+
privileged_groups,
|
| 36 |
+
scope_name = "current",
|
| 37 |
+
sess = tf$compat$v1$Session(),
|
| 38 |
+
seed = NULL,
|
| 39 |
+
adversary_loss_weight = 0.1,
|
| 40 |
+
num_epochs = 50L,
|
| 41 |
+
batch_size = 128L,
|
| 42 |
+
classifier_num_hidden_units = 200L,
|
| 43 |
+
debias = TRUE) {
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
unprivileged_dict <- dict_fn(unprivileged_groups)
|
| 48 |
+
privileged_dict <- dict_fn(privileged_groups)
|
| 49 |
+
|
| 50 |
+
# run check for variables that must be integers
|
| 51 |
+
int_vars <- list(num_epochs = num_epochs, batch_size = batch_size, classifier_num_hidden_units = classifier_num_hidden_units)
|
| 52 |
+
|
| 53 |
+
if (!is.null(seed)) int_vars <- append(int_vars, c(seed = seed))
|
| 54 |
+
|
| 55 |
+
is_int <- sapply(int_vars, is.integer)
|
| 56 |
+
int_varnames <- names(int_vars)
|
| 57 |
+
|
| 58 |
+
if (any(!is_int)) stop(paste(int_varnames[!is_int], collapse = ", "), " must be integer(s)")
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
ad <- in_algo$AdversarialDebiasing(unprivileged_dict,
|
| 63 |
+
privileged_dict,
|
| 64 |
+
scope_name = scope_name,
|
| 65 |
+
sess = sess,
|
| 66 |
+
seed = seed,
|
| 67 |
+
adversary_loss_weight = adversary_loss_weight,
|
| 68 |
+
num_epochs = num_epochs,
|
| 69 |
+
batch_size = batch_size,
|
| 70 |
+
classifier_num_hidden_units = classifier_num_hidden_units,
|
| 71 |
+
debias = debias)
|
| 72 |
+
return(ad)
|
| 73 |
+
}
|
src/aif360/aif360-r/R/inprocessing_prejudice_remover.R
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#' Prejudice Remover
|
| 2 |
+
#' @description Prejudice remover is an in-processing technique that adds a discrimination-aware regularization term to the learning objective
|
| 3 |
+
#' @param eta fairness penalty parameter
|
| 4 |
+
#' @param sensitive_attr name of protected attribute
|
| 5 |
+
#' @param class_attr label name
|
| 6 |
+
#' @usage prejudice_remover(eta=1.0, sensitive_attr='',class_attr='')
|
| 7 |
+
#' @examples
|
| 8 |
+
#' \dontrun{
|
| 9 |
+
#' # An example using the Adult Dataset
|
| 10 |
+
#' load_aif360_lib()
|
| 11 |
+
#' ad <- adult_dataset()
|
| 12 |
+
#' model <- prejudice_remover(class_attr = "income-per-year", sensitive_attr = "race")
|
| 13 |
+
#' model$fit(ad)
|
| 14 |
+
#' ad_pred <- model$predict(ad)
|
| 15 |
+
#'}
|
| 16 |
+
#' @export
|
| 17 |
+
#'
|
| 18 |
+
prejudice_remover <- function(eta=1.0,
|
| 19 |
+
sensitive_attr='',
|
| 20 |
+
class_attr=''){
|
| 21 |
+
|
| 22 |
+
pr <- in_algo$PrejudiceRemover(eta,
|
| 23 |
+
sensitive_attr,
|
| 24 |
+
class_attr)
|
| 25 |
+
return(pr)
|
| 26 |
+
}
|
src/aif360/aif360-r/R/postprocessing_reject_option_classification.R
ADDED
|
@@ -0,0 +1,85 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#' Reject option classification
|
| 2 |
+
#'
|
| 3 |
+
#' @description Reject option classification is a postprocessing technique that gives
|
| 4 |
+
#' favorable outcomes to unpriviliged groups and unfavorable outcomes to
|
| 5 |
+
#' priviliged groups in a confidence band around the decision boundary with
|
| 6 |
+
#' the highest uncertainty.
|
| 7 |
+
#' @param unprivileged_groups A list epresentation for unprivileged group.
|
| 8 |
+
#' @param privileged_groups A list representation for privileged group.
|
| 9 |
+
#' @param low_class_thresh Smallest classification threshold to use in the optimization. Should be between 0. and 1.
|
| 10 |
+
#' @param high_class_thresh Highest classification threshold to use in the optimization. Should be between 0. and 1.
|
| 11 |
+
#' @param num_class_thresh Number of classification thresholds between low_class_thresh and high_class_thresh for the optimization search. Should be > 0.
|
| 12 |
+
#' @param num_ROC_margin Number of relevant ROC margins to be used in the optimization search. Should be > 0.
|
| 13 |
+
#' @param metric_name Name of the metric to use for the optimization. Allowed options are "Statistical parity difference", "Average odds difference", "Equal opportunity difference".
|
| 14 |
+
#' @param metric_ub Upper bound of constraint on the metric value
|
| 15 |
+
#' @param metric_lb Lower bound of constraint on the metric value
|
| 16 |
+
#' @examples
|
| 17 |
+
#' \dontrun{
|
| 18 |
+
#' # Example with Adult Dataset
|
| 19 |
+
#' load_aif360_lib()
|
| 20 |
+
#' ad <- adult_dataset()
|
| 21 |
+
#' p <- list("race",1)
|
| 22 |
+
#' u <- list("race", 0)
|
| 23 |
+
#'
|
| 24 |
+
#' col_names <- c(ad$feature_names, "label")
|
| 25 |
+
#' ad_df <- data.frame(ad$features, ad$labels)
|
| 26 |
+
#' colnames(ad_df) <- col_names
|
| 27 |
+
#'
|
| 28 |
+
#' lr <- glm(label ~ ., data=ad_df, family=binomial)
|
| 29 |
+
#'
|
| 30 |
+
#' ad_prob <- predict(lr, ad_df)
|
| 31 |
+
#' ad_pred <- factor(ifelse(ad_prob> 0.5,1,0))
|
| 32 |
+
#'
|
| 33 |
+
#' ad_df_pred <- data.frame(ad_df)
|
| 34 |
+
#' ad_df_pred$label <- as.character(ad_pred)
|
| 35 |
+
#' colnames(ad_df_pred) <- c(ad$feature_names, 'label')
|
| 36 |
+
#'
|
| 37 |
+
#' ad_ds <- binary_label_dataset(ad_df, target_column='label', favor_label = 1,
|
| 38 |
+
#' unfavor_label = 0, unprivileged_protected_attribute = 0,
|
| 39 |
+
#' privileged_protected_attribute = 1, protected_attribute='race')
|
| 40 |
+
#'
|
| 41 |
+
#' ad_ds_pred <- binary_label_dataset(ad_df_pred, target_column='label', favor_label = 1,
|
| 42 |
+
#' unfavor_label = 0, unprivileged_protected_attribute = 0,
|
| 43 |
+
#' privileged_protected_attribute = 1, protected_attribute='race')
|
| 44 |
+
#'
|
| 45 |
+
#' roc <- reject_option_classification(unprivileged_groups = u,
|
| 46 |
+
#' privileged_groups = p,
|
| 47 |
+
#' low_class_thresh = 0.01,
|
| 48 |
+
#' high_class_thresh = 0.99,
|
| 49 |
+
#' num_class_thresh = as.integer(100),
|
| 50 |
+
#' num_ROC_margin = as.integer(50),
|
| 51 |
+
#' metric_name = "Statistical parity difference",
|
| 52 |
+
#' metric_ub = 0.05,
|
| 53 |
+
#' metric_lb = -0.05)
|
| 54 |
+
#'
|
| 55 |
+
#' roc <- roc$fit(ad_ds, ad_ds_pred)
|
| 56 |
+
#'
|
| 57 |
+
#' ds_transformed_pred <- roc$predict(ad_ds_pred)
|
| 58 |
+
#' }
|
| 59 |
+
#' @export
|
| 60 |
+
#'
|
| 61 |
+
reject_option_classification <- function(unprivileged_groups,
|
| 62 |
+
privileged_groups,
|
| 63 |
+
low_class_thresh=0.01,
|
| 64 |
+
high_class_thresh=0.99,
|
| 65 |
+
num_class_thresh=as.integer(100),
|
| 66 |
+
num_ROC_margin=as.integer(50),
|
| 67 |
+
metric_name='Statistical parity difference',
|
| 68 |
+
metric_ub=0.05,
|
| 69 |
+
metric_lb=-0.05){
|
| 70 |
+
|
| 71 |
+
u_dict <- dict_fn(unprivileged_groups)
|
| 72 |
+
p_dict <- dict_fn(privileged_groups)
|
| 73 |
+
|
| 74 |
+
return(post_algo$RejectOptionClassification(u_dict,
|
| 75 |
+
p_dict,
|
| 76 |
+
low_class_thresh,
|
| 77 |
+
high_class_thresh,
|
| 78 |
+
num_class_thresh,
|
| 79 |
+
num_ROC_margin,
|
| 80 |
+
metric_name,
|
| 81 |
+
metric_ub,
|
| 82 |
+
metric_lb))
|
| 83 |
+
}
|
| 84 |
+
|
| 85 |
+
|
src/aif360/aif360-r/R/preprocessing_disparate_impact_remover.R
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#' Disparate Impact Remover
|
| 2 |
+
#' @description Disparate impact remover is a preprocessing technique that edits feature values increase group fairness while preserving rank-ordering within groups
|
| 3 |
+
#' @param repair_level Repair amount. 0.0 is no repair while 1.0 is full repair.
|
| 4 |
+
#' @param sensitive_attribute Single protected attribute with which to do repair.
|
| 5 |
+
#' @usage disparate_impact_remover(repair_level = 1.0, sensitive_attribute = '')
|
| 6 |
+
#' @examples
|
| 7 |
+
#' \dontrun{
|
| 8 |
+
#' # An example using the Adult Dataset
|
| 9 |
+
#' load_aif360_lib()
|
| 10 |
+
#' ad <- adult_dataset()
|
| 11 |
+
#' p <- list("race", 1)
|
| 12 |
+
#' u <- list("race", 0)
|
| 13 |
+
#'
|
| 14 |
+
#' di <- disparate_impact_remover(repair_level = 1.0, sensitive_attribute = "race")
|
| 15 |
+
#' rp <- di$fit_transform(ad)
|
| 16 |
+
#'
|
| 17 |
+
#' di_2 <- disparate_impact_remover(repair_level = 0.8, sensitive_attribute = "race")
|
| 18 |
+
#' rp_2 <- di_2$fit_transform(ad)
|
| 19 |
+
#' }
|
| 20 |
+
#' @export
|
| 21 |
+
#'
|
| 22 |
+
disparate_impact_remover <- function(repair_level=1.0, sensitive_attribute='') {
|
| 23 |
+
dr <- pre_algo$DisparateImpactRemover(repair_level, sensitive_attribute)
|
| 24 |
+
return (dr)
|
| 25 |
+
}
|
| 26 |
+
|
| 27 |
+
|
src/aif360/aif360-r/R/preprocessing_reweighing.R
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#' Reweighing
|
| 2 |
+
#' @description Reweighing is a preprocessing technique that weights the examples in each (group, label) combination differently to ensure fairness before classification
|
| 3 |
+
#' @param unprivileged_groups a list with two values: the column of the protected class and the value indicating representation for unprivileged group
|
| 4 |
+
#' @param privileged_groups a list with two values: the column of the protected class and the value indicating representation for privileged group
|
| 5 |
+
#' @usage reweighing(unprivileged_groups, privileged_groups)
|
| 6 |
+
#' @examples
|
| 7 |
+
#' \dontrun{
|
| 8 |
+
#' # An example using the Adult Dataset
|
| 9 |
+
#' load_aif360_lib()
|
| 10 |
+
#' ad <- adult_dataset()
|
| 11 |
+
#' p <- list("race", 1)
|
| 12 |
+
#' u <- list("race", 0)
|
| 13 |
+
#' rw <- reweighing(u,p)
|
| 14 |
+
#' rw$fit(ad)
|
| 15 |
+
#' ad_transformed <- rw$transform(ad)
|
| 16 |
+
#' ad_fit_transformed <- rw$fit_transform(ad)
|
| 17 |
+
#' }
|
| 18 |
+
#' @export
|
| 19 |
+
#'
|
| 20 |
+
reweighing <- function(unprivileged_groups, privileged_groups) {
|
| 21 |
+
unprivileged_dict <- dict_fn(unprivileged_groups)
|
| 22 |
+
privileged_dict <- dict_fn(privileged_groups)
|
| 23 |
+
rw <- pre_algo$Reweighing(unprivileged_dict, privileged_dict)
|
| 24 |
+
return (rw)
|
| 25 |
+
}
|
src/aif360/aif360-r/R/standard_datasets.R
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#' Adult Census Income Dataset
|
| 2 |
+
#' @export
|
| 3 |
+
adult_dataset <- function(){
|
| 4 |
+
return (datasets$AdultDataset())
|
| 5 |
+
}
|
| 6 |
+
|
| 7 |
+
#' Bank Dataset
|
| 8 |
+
#' @export
|
| 9 |
+
bank_dataset <- function(){
|
| 10 |
+
return (datasets$BankDataset())
|
| 11 |
+
}
|
| 12 |
+
|
| 13 |
+
#' Compas Dataset
|
| 14 |
+
#' @export
|
| 15 |
+
compas_dataset <- function(){
|
| 16 |
+
return (datasets$CompasDataset())
|
| 17 |
+
}
|
| 18 |
+
|
| 19 |
+
#' German Dataset
|
| 20 |
+
#' @export
|
| 21 |
+
german_dataset <- function(){
|
| 22 |
+
return (datasets$GermanDataset())
|
| 23 |
+
}
|
| 24 |
+
|
| 25 |
+
#' Law School GPA Dataset
|
| 26 |
+
#'@seealso
|
| 27 |
+
#' \href{https://aif360.readthedocs.io/en/latest/modules/generated/aif360.datasets.LawSchoolGPADataset.html#aif360.datasets.LawSchoolGPADataset}{More about the Law School GPA dataset.}
|
| 28 |
+
#' @export
|
| 29 |
+
law_school_gpa_dataset <- function(){
|
| 30 |
+
return (datasets$LawSchoolGPADataset())
|
| 31 |
+
}
|
src/aif360/aif360-r/R/utils.R
ADDED
|
@@ -0,0 +1,89 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#' Install aif360 and its dependencies
|
| 2 |
+
#'
|
| 3 |
+
#' @inheritParams reticulate::conda_list
|
| 4 |
+
#'
|
| 5 |
+
#' @param method Installation method. By default, "auto" automatically finds a
|
| 6 |
+
#' method that will work in the local environment. Change the default to force
|
| 7 |
+
#' a specific installation method. Note that the "virtualenv" method is not
|
| 8 |
+
#' available on Windows. Note also
|
| 9 |
+
#' that since this command runs without privilege the "system" method is
|
| 10 |
+
#' available only on Windows.
|
| 11 |
+
#'
|
| 12 |
+
#' @param version AIF360 version to install. Specify "default" to install
|
| 13 |
+
#' the latest release.
|
| 14 |
+
#'
|
| 15 |
+
#' @param envname Name of Python environment to install within
|
| 16 |
+
#'
|
| 17 |
+
#' @param extra_packages Additional Python packages to install.
|
| 18 |
+
#'
|
| 19 |
+
#' @param restart_session Restart R session after installing (note this will
|
| 20 |
+
#' only occur within RStudio).
|
| 21 |
+
#'
|
| 22 |
+
#' @param conda_python_version the python version installed in the created conda
|
| 23 |
+
#' environment. Python 3.6 is installed by default.
|
| 24 |
+
#'
|
| 25 |
+
#' @param ... other arguments passed to [reticulate::conda_install()] or
|
| 26 |
+
#' [reticulate::virtualenv_install()].
|
| 27 |
+
#'
|
| 28 |
+
#'
|
| 29 |
+
#' @export
|
| 30 |
+
install_aif360 <- function(method = c("auto", "virtualenv", "conda"),
|
| 31 |
+
conda = "auto",
|
| 32 |
+
version = "default",
|
| 33 |
+
envname = NULL,
|
| 34 |
+
extra_packages = NULL,
|
| 35 |
+
restart_session = TRUE,
|
| 36 |
+
conda_python_version = "3.7",
|
| 37 |
+
...) {
|
| 38 |
+
|
| 39 |
+
method <- match.arg(method)
|
| 40 |
+
|
| 41 |
+
reticulate::py_install(
|
| 42 |
+
packages = c("aif360", "numba", "BlackBoxAuditing", "tensorflow>=1.13.1,<2", "pandas",
|
| 43 |
+
"fairlearn==0.4.6", "protobuf==3.20.1"),
|
| 44 |
+
envname = envname,
|
| 45 |
+
method = method,
|
| 46 |
+
conda = conda,
|
| 47 |
+
python_version = conda_python_version,
|
| 48 |
+
pip = TRUE,
|
| 49 |
+
...
|
| 50 |
+
)
|
| 51 |
+
|
| 52 |
+
cat("\nInstallation complete.\n\n")
|
| 53 |
+
|
| 54 |
+
if (restart_session && rstudioapi::hasFun("restartSession"))
|
| 55 |
+
rstudioapi::restartSession()
|
| 56 |
+
|
| 57 |
+
invisible(NULL)
|
| 58 |
+
}
|
| 59 |
+
|
| 60 |
+
#' Read CSV file
|
| 61 |
+
#' @param inp data file
|
| 62 |
+
#' @noRd
|
| 63 |
+
#' @importFrom utils read.csv
|
| 64 |
+
#'
|
| 65 |
+
input_data <- function(inp){
|
| 66 |
+
read.csv(inp)
|
| 67 |
+
}
|
| 68 |
+
#' create a list
|
| 69 |
+
#' @param i input for function
|
| 70 |
+
#' @noRd
|
| 71 |
+
#'
|
| 72 |
+
list_fn <- function(i){
|
| 73 |
+
list(i)
|
| 74 |
+
}
|
| 75 |
+
#' create a list of list
|
| 76 |
+
#' @param i input for function
|
| 77 |
+
#' @noRd
|
| 78 |
+
#'
|
| 79 |
+
list_of_list <- function(i){
|
| 80 |
+
list(list(i))
|
| 81 |
+
}
|
| 82 |
+
#' Create dictionary
|
| 83 |
+
#' @param values input
|
| 84 |
+
#' @noRd
|
| 85 |
+
#' @importFrom reticulate py_dict
|
| 86 |
+
#'
|
| 87 |
+
dict_fn <- function(values){
|
| 88 |
+
c(py_dict(c(values[[1]]),c(values[[2]]), convert = FALSE))
|
| 89 |
+
}
|
src/aif360/aif360-r/R/zzz.R
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## quiets concerns of R CMD check re: the .'s that appear in pipelines
|
| 2 |
+
if(getRversion() >= "2.15.1")
|
| 3 |
+
utils::globalVariables(c("datasets", "metrics", "tf", "pre_algo", "in_algo", "post_algo"))
|
| 4 |
+
Globals <- list()
|
src/aif360/aif360-r/README.Rmd
ADDED
|
@@ -0,0 +1,150 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
output: github_document
|
| 3 |
+
---
|
| 4 |
+
|
| 5 |
+
<!-- README.md is generated from README.Rmd. Please edit that file -->
|
| 6 |
+
|
| 7 |
+
```{r, include = FALSE}
|
| 8 |
+
knitr::opts_chunk$set(
|
| 9 |
+
collapse = TRUE,
|
| 10 |
+
comment = "#>",
|
| 11 |
+
fig.path = "man/figures/README-",
|
| 12 |
+
out.width = "100%"
|
| 13 |
+
)
|
| 14 |
+
library(aif360)
|
| 15 |
+
```
|
| 16 |
+
|
| 17 |
+
# AI Fairness 360 (AIF360) R Package
|
| 18 |
+
|
| 19 |
+
<!-- badges: start -->
|
| 20 |
+
[](https://cran.r-project.org/package=aif360)
|
| 21 |
+
<!-- badges: end -->
|
| 22 |
+
|
| 23 |
+
## Overview
|
| 24 |
+
|
| 25 |
+
The AI Fairness 360 toolkit is an open-source library to help detect and mitigate bias in machine learning models.
|
| 26 |
+
The AI Fairness 360 R package includes a comprehensive set of metrics for datasets and models to test for biases, explanations for these metrics, and algorithms to mitigate bias in datasets and models.
|
| 27 |
+
|
| 28 |
+
## Installation
|
| 29 |
+
|
| 30 |
+
Install the CRAN version:
|
| 31 |
+
|
| 32 |
+
```r
|
| 33 |
+
install.packages("aif360")
|
| 34 |
+
```
|
| 35 |
+
|
| 36 |
+
Or install the development version from GitHub:
|
| 37 |
+
|
| 38 |
+
``` r
|
| 39 |
+
# install.packages("devtools")
|
| 40 |
+
devtools::install_github("Trusted-AI/AIF360/aif360/aif360-r")
|
| 41 |
+
```
|
| 42 |
+
|
| 43 |
+
Then, use the install_aif360() function to install AIF360:
|
| 44 |
+
|
| 45 |
+
``` r
|
| 46 |
+
library(aif360)
|
| 47 |
+
install_aif360()
|
| 48 |
+
```
|
| 49 |
+
|
| 50 |
+
## Installation methods
|
| 51 |
+
|
| 52 |
+
AIF360 is distributed as a Python package and so needs to be installed within a Python environment on your system. By default, the install_aif360() function attempts to install AIF360 within an isolated Python environment (“r-reticulate”).
|
| 53 |
+
|
| 54 |
+
You can check using `reticulate::conda_python()` and `reticulate::py_config()`
|
| 55 |
+
|
| 56 |
+
### Suggested steps
|
| 57 |
+
|
| 58 |
+
1) Install reticulate and check if you have miniconda installed. If you do, go to step 2.
|
| 59 |
+
|
| 60 |
+
```r
|
| 61 |
+
install.packages("reticulate")
|
| 62 |
+
reticulate::conda_list()
|
| 63 |
+
```
|
| 64 |
+
If you get an error: `Error: Unable to find conda binary. Is Anaconda installed?`, please install
|
| 65 |
+
miniconda
|
| 66 |
+
|
| 67 |
+
```r
|
| 68 |
+
reticulate::install_miniconda()
|
| 69 |
+
```
|
| 70 |
+
If everything worked, you should get the message:
|
| 71 |
+
|
| 72 |
+
`* Miniconda has been successfully installed at '/home/rstudio/.local/share/r-miniconda'.`
|
| 73 |
+
|
| 74 |
+
You can double check:
|
| 75 |
+
|
| 76 |
+
```
|
| 77 |
+
reticulate::conda_list()
|
| 78 |
+
```
|
| 79 |
+
You will get something like this:
|
| 80 |
+
|
| 81 |
+
```
|
| 82 |
+
name python
|
| 83 |
+
1 r-miniconda /home/rstudio/.local/share/r-miniconda/bin/python
|
| 84 |
+
2 r-reticulate /home/rstudio/.local/share/r-miniconda/envs/r-reticulate/bin/python
|
| 85 |
+
```
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
2) You can create a new conda env and then configure which version of Python to use:
|
| 89 |
+
|
| 90 |
+
```r
|
| 91 |
+
reticulate::conda_create(envname = "r-test")
|
| 92 |
+
reticulate::use_miniconda(condaenv = "r-test", required = TRUE)
|
| 93 |
+
```
|
| 94 |
+
Check that everything is working `reticulate::py_config()`.
|
| 95 |
+
|
| 96 |
+
3) If you haven't yet, please install the aif360 package `install.packages("aif360")` and then
|
| 97 |
+
install aif360 dependencies
|
| 98 |
+
|
| 99 |
+
```r
|
| 100 |
+
aif360::install_aif360(envname = "r-test")
|
| 101 |
+
```
|
| 102 |
+
Note that this step should take a few minutes and the R session will restart.
|
| 103 |
+
|
| 104 |
+
4) You can now activate your Python environment
|
| 105 |
+
```r
|
| 106 |
+
reticulate::use_miniconda(condaenv = "r-test", required = TRUE)
|
| 107 |
+
```
|
| 108 |
+
|
| 109 |
+
## Getting Started
|
| 110 |
+
|
| 111 |
+
```r
|
| 112 |
+
library(aif360)
|
| 113 |
+
load_aif360_lib()
|
| 114 |
+
```
|
| 115 |
+
|
| 116 |
+
``` r
|
| 117 |
+
# load a toy dataset
|
| 118 |
+
data <- data.frame("feature1" = c(0,0,1,1,1,1,0,1,1,0),
|
| 119 |
+
"feature2" = c(0,1,0,1,1,0,0,0,0,1),
|
| 120 |
+
"label" = c(1,0,0,1,0,0,1,0,1,1))
|
| 121 |
+
|
| 122 |
+
# format the dataset
|
| 123 |
+
formatted_dataset <- aif360::binary_label_dataset(data_path = data,
|
| 124 |
+
favor_label = 0,
|
| 125 |
+
unfavor_label = 1,
|
| 126 |
+
unprivileged_protected_attribute = 0,
|
| 127 |
+
privileged_protected_attribute = 1,
|
| 128 |
+
target_column = "label",
|
| 129 |
+
protected_attribute = "feature1")
|
| 130 |
+
|
| 131 |
+
```
|
| 132 |
+
|
| 133 |
+
## Troubleshooting
|
| 134 |
+
|
| 135 |
+
If you encounter any errors during the installation process, look for your issue here and try the solutions.
|
| 136 |
+
|
| 137 |
+
### Locked binding
|
| 138 |
+
If you get an error: `cannot change value of locked binding`, please restart the R session. Then try reactivating your Python environment and running the following commands exactly once:
|
| 139 |
+
```r
|
| 140 |
+
library(aif360)
|
| 141 |
+
load_aif360_lib()
|
| 142 |
+
```
|
| 143 |
+
|
| 144 |
+
## Contributing
|
| 145 |
+
|
| 146 |
+
If you'd like to contribute to the development of aif360, please read [these guidelines](CONTRIBUTING.md).
|
| 147 |
+
|
| 148 |
+
Please note that the aif360 project is released with a [Contributor Code of Conduct](CODEOFCONDUCT.md). By contributing to this project, you agree to abide by its terms.
|
| 149 |
+
|
| 150 |
+
|
src/aif360/aif360-r/README.md
ADDED
|
@@ -0,0 +1,155 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
<!-- README.md is generated from README.Rmd. Please edit that file -->
|
| 3 |
+
|
| 4 |
+
# AI Fairness 360 (AIF360) R Package
|
| 5 |
+
|
| 6 |
+
<!-- badges: start -->
|
| 7 |
+
|
| 8 |
+
[](https://cran.r-project.org/package=aif360)
|
| 9 |
+
<!-- badges: end -->
|
| 10 |
+
|
| 11 |
+
## Overview
|
| 12 |
+
|
| 13 |
+
The AI Fairness 360 toolkit is an open-source library to help detect and
|
| 14 |
+
mitigate bias in machine learning models. The AI Fairness 360 R package
|
| 15 |
+
includes a comprehensive set of metrics for datasets and models to test
|
| 16 |
+
for biases, explanations for these metrics, and algorithms to mitigate
|
| 17 |
+
bias in datasets and models.
|
| 18 |
+
|
| 19 |
+
## Installation
|
| 20 |
+
|
| 21 |
+
Install the CRAN version:
|
| 22 |
+
|
| 23 |
+
``` r
|
| 24 |
+
install.packages("aif360")
|
| 25 |
+
```
|
| 26 |
+
|
| 27 |
+
Or install the development version from GitHub:
|
| 28 |
+
|
| 29 |
+
``` r
|
| 30 |
+
# install.packages("devtools")
|
| 31 |
+
devtools::install_github("Trusted-AI/AIF360/aif360/aif360-r")
|
| 32 |
+
```
|
| 33 |
+
|
| 34 |
+
Then, use the install_aif360() function to install AIF360:
|
| 35 |
+
|
| 36 |
+
``` r
|
| 37 |
+
library(aif360)
|
| 38 |
+
install_aif360()
|
| 39 |
+
```
|
| 40 |
+
|
| 41 |
+
## Installation methods
|
| 42 |
+
|
| 43 |
+
AIF360 is distributed as a Python package and so needs to be installed
|
| 44 |
+
within a Python environment on your system. By default, the
|
| 45 |
+
install_aif360() function attempts to install AIF360 within an isolated
|
| 46 |
+
Python environment (“r-reticulate”).
|
| 47 |
+
|
| 48 |
+
You can check using `reticulate::conda_python()` and
|
| 49 |
+
`reticulate::py_config()`
|
| 50 |
+
|
| 51 |
+
### Suggested steps
|
| 52 |
+
|
| 53 |
+
1) Install reticulate and check if you have miniconda installed. If you
|
| 54 |
+
do, go to step 2.
|
| 55 |
+
|
| 56 |
+
``` r
|
| 57 |
+
install.packages("reticulate")
|
| 58 |
+
reticulate::conda_list()
|
| 59 |
+
```
|
| 60 |
+
|
| 61 |
+
If you get an error:
|
| 62 |
+
`Error: Unable to find conda binary. Is Anaconda installed?`, please
|
| 63 |
+
install miniconda
|
| 64 |
+
|
| 65 |
+
``` r
|
| 66 |
+
reticulate::install_miniconda()
|
| 67 |
+
```
|
| 68 |
+
|
| 69 |
+
If everything worked, you should get the message:
|
| 70 |
+
|
| 71 |
+
`* Miniconda has been successfully installed at '/home/rstudio/.local/share/r-miniconda'.`
|
| 72 |
+
|
| 73 |
+
You can double check:
|
| 74 |
+
|
| 75 |
+
reticulate::conda_list()
|
| 76 |
+
|
| 77 |
+
You will get something like this:
|
| 78 |
+
|
| 79 |
+
name python
|
| 80 |
+
1 r-miniconda /home/rstudio/.local/share/r-miniconda/bin/python
|
| 81 |
+
2 r-reticulate /home/rstudio/.local/share/r-miniconda/envs/r-reticulate/bin/python
|
| 82 |
+
|
| 83 |
+
2) You can create a new conda env and then configure which version of
|
| 84 |
+
Python to use:
|
| 85 |
+
|
| 86 |
+
``` r
|
| 87 |
+
reticulate::conda_create(envname = "r-test")
|
| 88 |
+
reticulate::use_miniconda(condaenv = "r-test", required = TRUE)
|
| 89 |
+
```
|
| 90 |
+
|
| 91 |
+
Check that everything is working `reticulate::py_config()`.
|
| 92 |
+
|
| 93 |
+
3) If you haven’t yet, please install the aif360 package
|
| 94 |
+
`install.packages("aif360")` and then install aif360 dependencies
|
| 95 |
+
|
| 96 |
+
``` r
|
| 97 |
+
aif360::install_aif360(envname = "r-test")
|
| 98 |
+
```
|
| 99 |
+
|
| 100 |
+
Note that this step should take a few minutes and the R session will
|
| 101 |
+
restart.
|
| 102 |
+
|
| 103 |
+
4) You can now activate your Python environment
|
| 104 |
+
|
| 105 |
+
``` r
|
| 106 |
+
reticulate::use_miniconda(condaenv = "r-test", required = TRUE)
|
| 107 |
+
```
|
| 108 |
+
|
| 109 |
+
## Getting Started
|
| 110 |
+
|
| 111 |
+
``` r
|
| 112 |
+
library(aif360)
|
| 113 |
+
load_aif360_lib()
|
| 114 |
+
```
|
| 115 |
+
|
| 116 |
+
``` r
|
| 117 |
+
# load a toy dataset
|
| 118 |
+
data <- data.frame("feature1" = c(0,0,1,1,1,1,0,1,1,0),
|
| 119 |
+
"feature2" = c(0,1,0,1,1,0,0,0,0,1),
|
| 120 |
+
"label" = c(1,0,0,1,0,0,1,0,1,1))
|
| 121 |
+
|
| 122 |
+
# format the dataset
|
| 123 |
+
formatted_dataset <- aif360::binary_label_dataset(data_path = data,
|
| 124 |
+
favor_label = 0,
|
| 125 |
+
unfavor_label = 1,
|
| 126 |
+
unprivileged_protected_attribute = 0,
|
| 127 |
+
privileged_protected_attribute = 1,
|
| 128 |
+
target_column = "label",
|
| 129 |
+
protected_attribute = "feature1")
|
| 130 |
+
```
|
| 131 |
+
|
| 132 |
+
## Troubleshooting
|
| 133 |
+
|
| 134 |
+
If you encounter any errors during the installation process, look for
|
| 135 |
+
your issue here and try the solutions.
|
| 136 |
+
|
| 137 |
+
### Locked binding
|
| 138 |
+
|
| 139 |
+
If you get an error: `cannot change value of locked binding`, please
|
| 140 |
+
restart the R session. Then try reactivating your Python environment and
|
| 141 |
+
running the following commands exactly once:
|
| 142 |
+
|
| 143 |
+
``` r
|
| 144 |
+
library(aif360)
|
| 145 |
+
load_aif360_lib()
|
| 146 |
+
```
|
| 147 |
+
|
| 148 |
+
## Contributing
|
| 149 |
+
|
| 150 |
+
If you’d like to contribute to the development of aif360, please read
|
| 151 |
+
[these guidelines](CONTRIBUTING.md).
|
| 152 |
+
|
| 153 |
+
Please note that the aif360 project is released with a [Contributor Code
|
| 154 |
+
of Conduct](CODEOFCONDUCT.md). By contributing to this project, you
|
| 155 |
+
agree to abide by its terms.
|
src/aif360/aif360-r/cran-comments.md
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Test environments
|
| 2 |
+
* local R installation, R 4.0.0
|
| 3 |
+
* ubuntu 16.04 (on travis-ci), R 4.0.0
|
| 4 |
+
* win-builder (devel)
|
| 5 |
+
|
| 6 |
+
## R CMD check results
|
| 7 |
+
|
| 8 |
+
0 errors | 0 warnings | 1 note
|
| 9 |
+
|
| 10 |
+
* This is a new release.
|
src/aif360/aif360-r/inst/examples/test.R
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
library(aif360)
|
| 2 |
+
install_aif360()
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
load_aif360_lib()
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
dd <- aif360::binary_label_dataset(
|
| 10 |
+
data_path = system.file("extdata", "data.csv", package="aif360"),
|
| 11 |
+
favor_label=0,
|
| 12 |
+
unfavor_label=1,
|
| 13 |
+
unprivileged_protected_attribute=0,
|
| 14 |
+
privileged_protected_attribute=1,
|
| 15 |
+
target_column="income",
|
| 16 |
+
protected_attribute="sex")
|
| 17 |
+
|
| 18 |
+
dd$favorable_label
|
| 19 |
+
dd$labels
|
| 20 |
+
dd$unfavorable_label
|
src/aif360/aif360-r/inst/extdata/actual_data.csv
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
age,workclass,fnlwgt,education,education-num,marital-status,occupation,relationship,race,sex,capital-gain,capital-loss,hours-per-week,native-country,income
|
| 2 |
+
41,0,202822,11,9,5,0,1,2,0,0,0,32,39,0
|
| 3 |
+
72,0,129912,11,9,2,0,0,4,1,0,0,25,39,0
|
| 4 |
+
45,2,119199,7,12,0,10,4,4,0,0,0,48,39,0
|
| 5 |
+
31,4,199655,12,14,0,8,1,3,0,0,0,30,39,0
|
| 6 |
+
39,2,111499,7,12,2,1,5,4,0,0,0,20,39,1
|
| 7 |
+
37,4,198216,7,12,0,13,1,4,0,0,0,40,39,0
|
| 8 |
+
43,4,260761,11,9,2,7,0,4,1,0,0,40,26,0
|
| 9 |
+
65,6,99359,14,15,4,10,1,4,1,1086,0,60,39,0
|
| 10 |
+
43,7,255835,15,10,0,1,2,4,0,0,0,40,39,0
|
| 11 |
+
43,6,27242,15,10,2,3,0,4,1,0,0,50,39,0
|
| 12 |
+
32,4,34066,0,6,2,6,0,0,1,0,0,40,39,0
|
| 13 |
+
43,4,84661,8,11,2,12,0,4,1,0,0,45,39,0
|
| 14 |
+
32,4,116138,12,14,4,13,1,1,1,0,0,11,36,0
|
| 15 |
+
53,4,321865,12,14,2,4,0,4,1,0,0,40,39,1
|
| 16 |
+
22,4,310152,15,10,4,11,1,4,1,0,0,40,39,0
|
| 17 |
+
27,4,257302,7,12,2,13,5,4,0,0,0,38,39,0
|
| 18 |
+
40,4,154374,11,9,2,7,0,4,1,0,0,40,39,1
|
| 19 |
+
58,4,151910,11,9,6,1,4,4,0,0,0,40,39,0
|
| 20 |
+
22,4,201490,11,9,4,1,3,4,1,0,0,20,39,0
|
| 21 |
+
52,5,287927,11,9,2,4,5,4,0,15024,0,40,39,1
|