Spaces:
Build error

Build error
update requirements.txt
Browse files- README 2.md +13 -76
- requirements.txt +2 -1
README 2.md
CHANGED
|
@@ -20,86 +20,29 @@ All code was written with the help of <a href="https://codegpt.co">Code GPT</a>
|
|
| 20 |
- Embedding texts segments with Langchain and OpenAI (**text-embedding-ada-002**)
|
| 21 |
- Chat with the file using **streamlit-chat** and LangChain QA with source and (**text-davinci-003**)
|
| 22 |
|
| 23 |
-
# Example
|
| 24 |
-
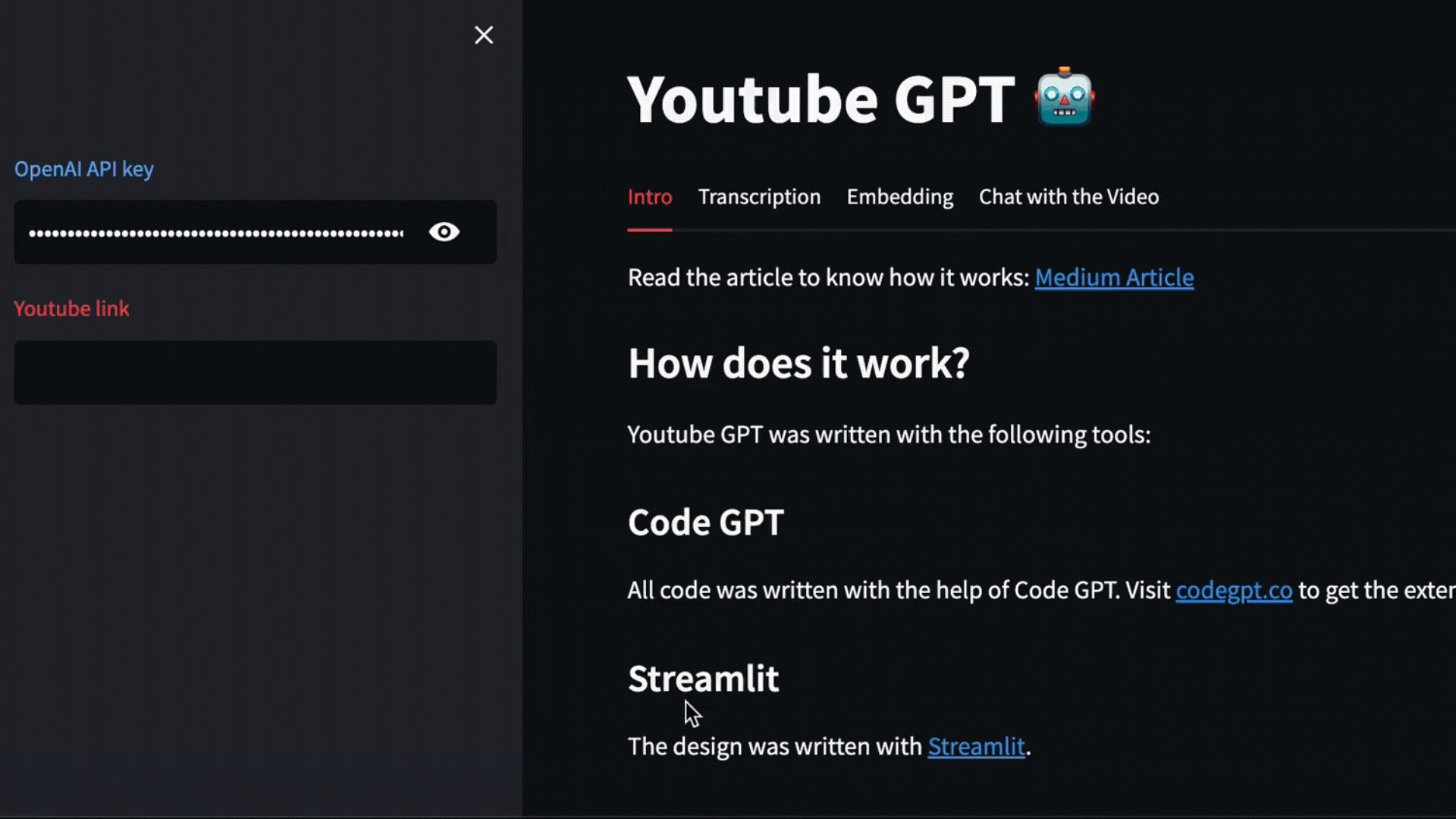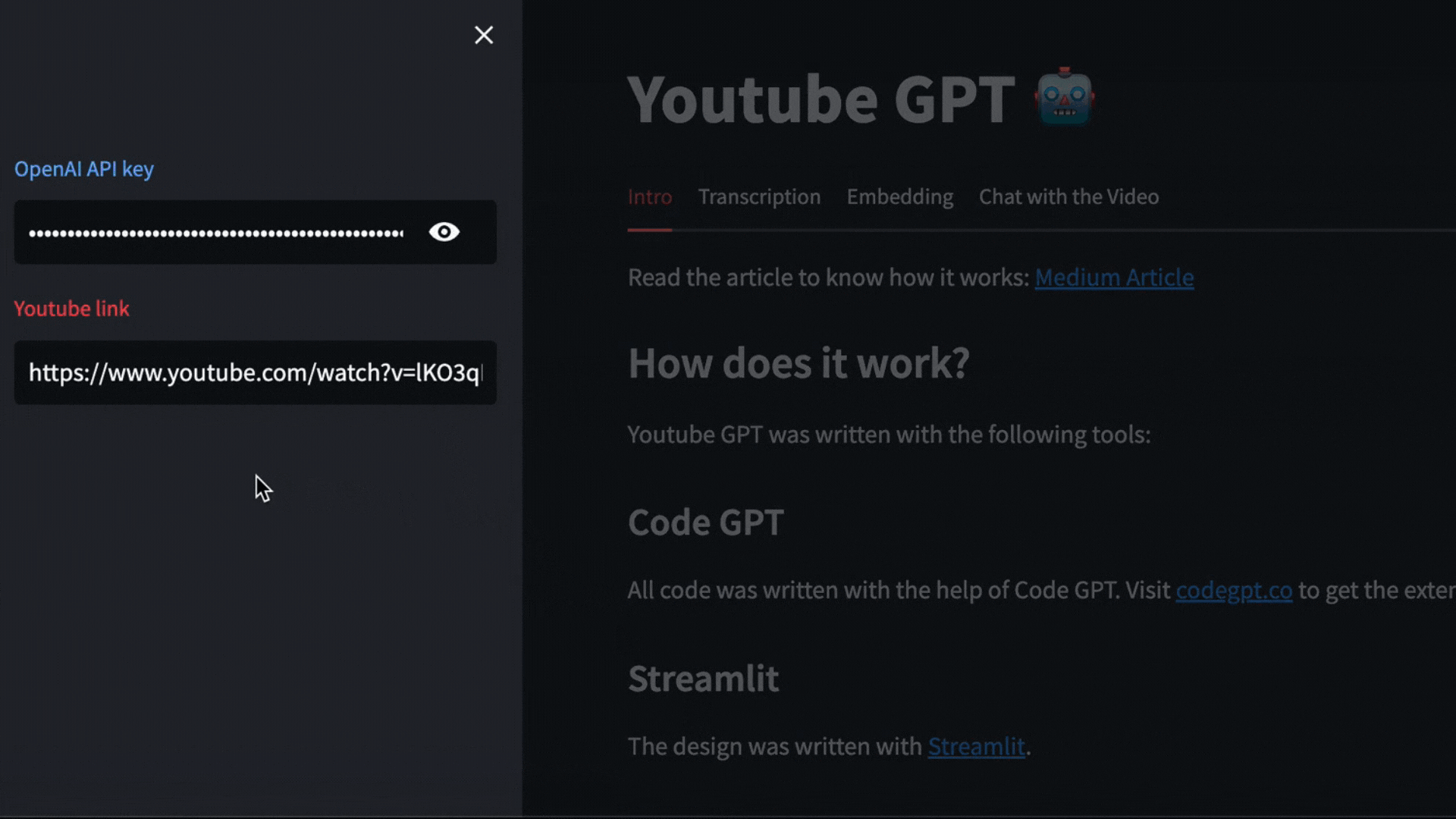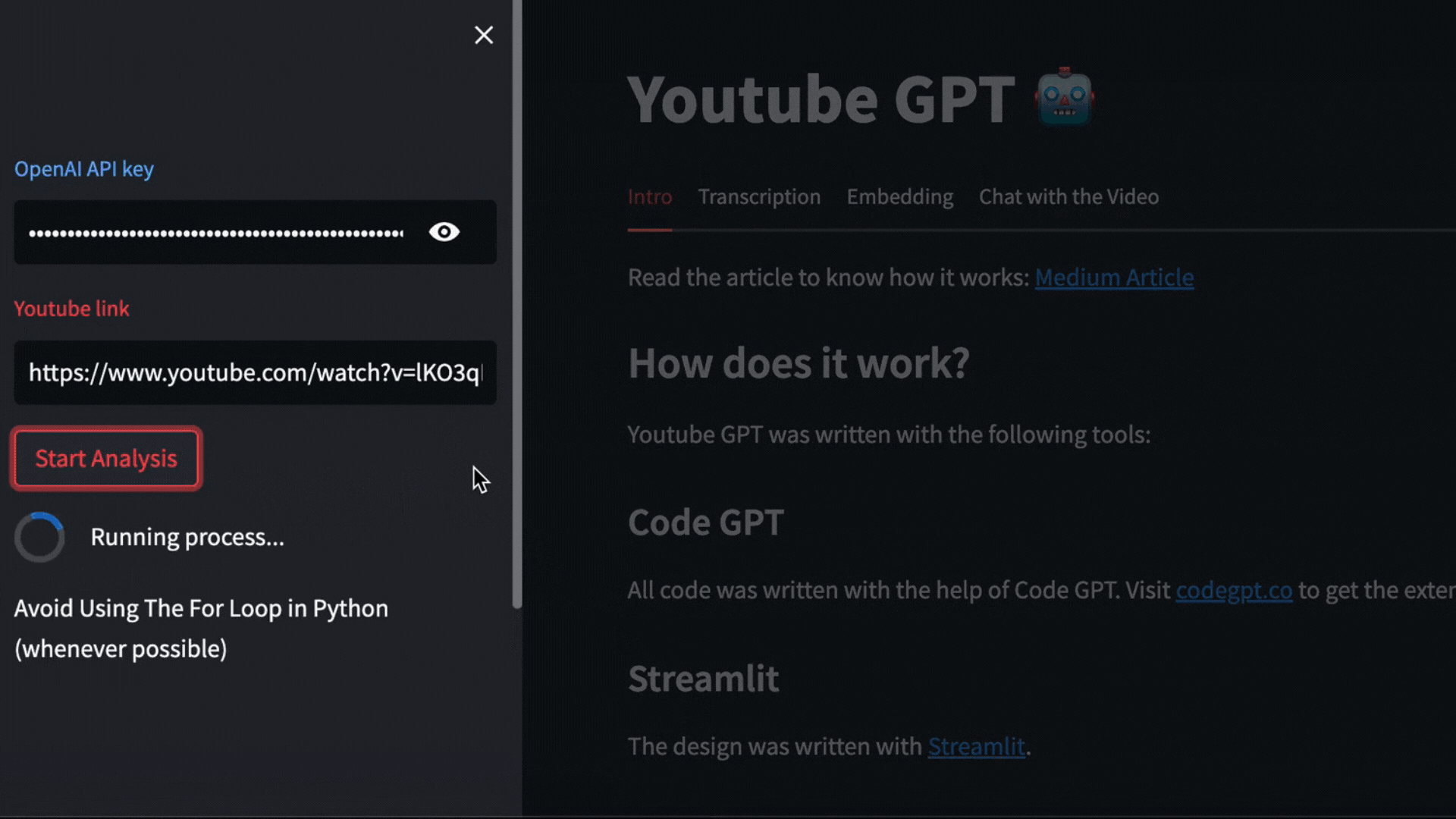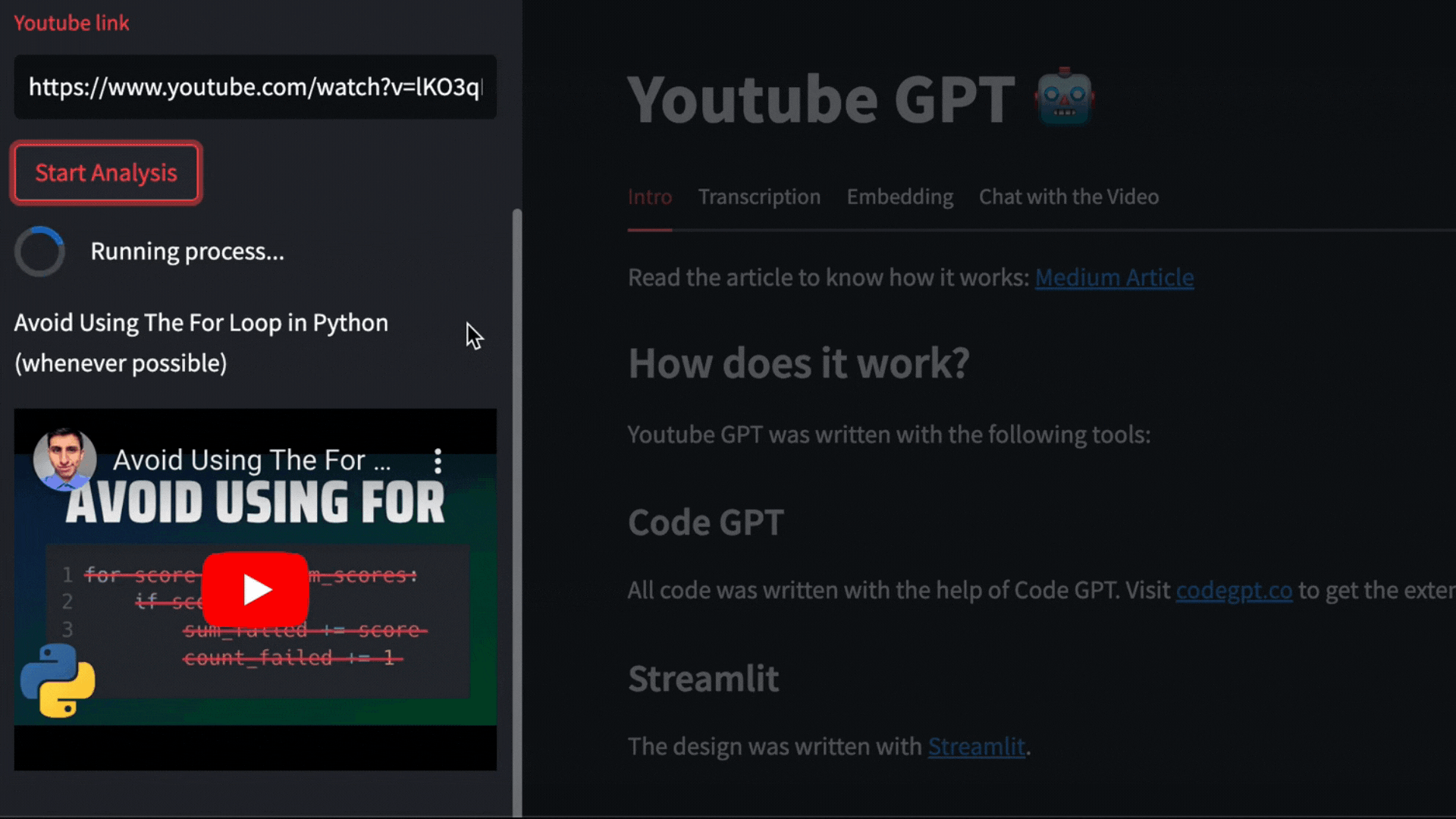
For this example we are going to use this video from The PyCoach
|
| 25 |
-
https://youtu.be/lKO3qDLCAnk
|
| 26 |
-
|
| 27 |
-
Add the video URL and then click Start Analysis
|
| 28 |
-
|
| 29 |
-
|
| 30 |
-
## Pytube and OpenAI Whisper
|
| 31 |
-
The video will be downloaded with pytube and then OpenAI Whisper will take care of transcribing and segmenting the video.
|
| 32 |
-
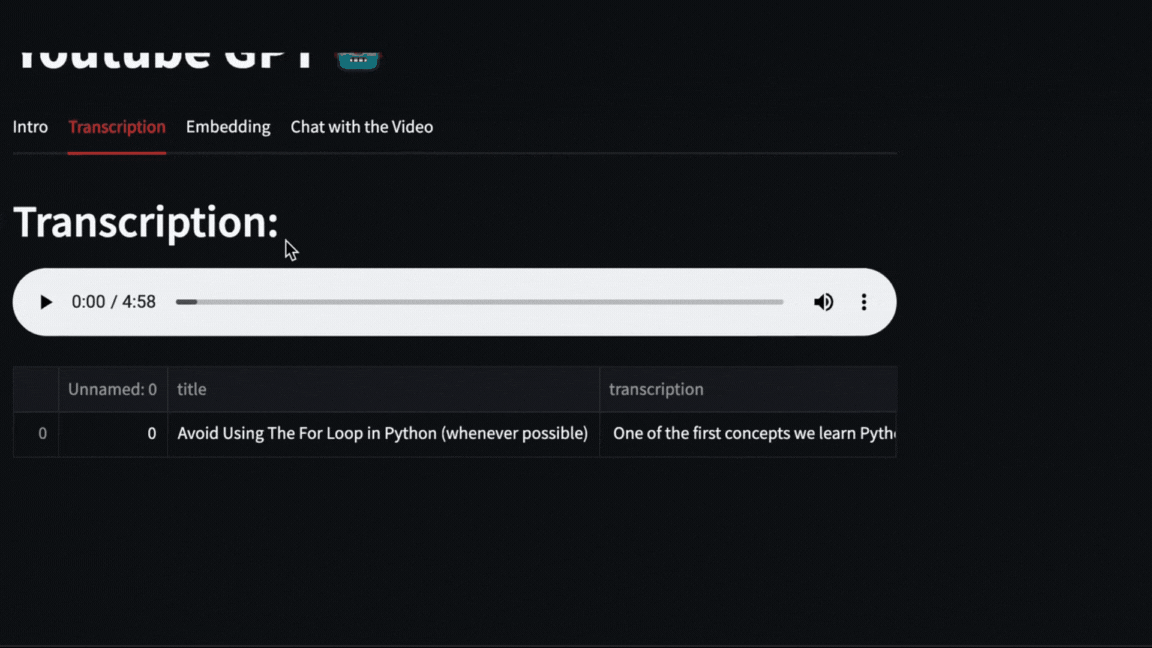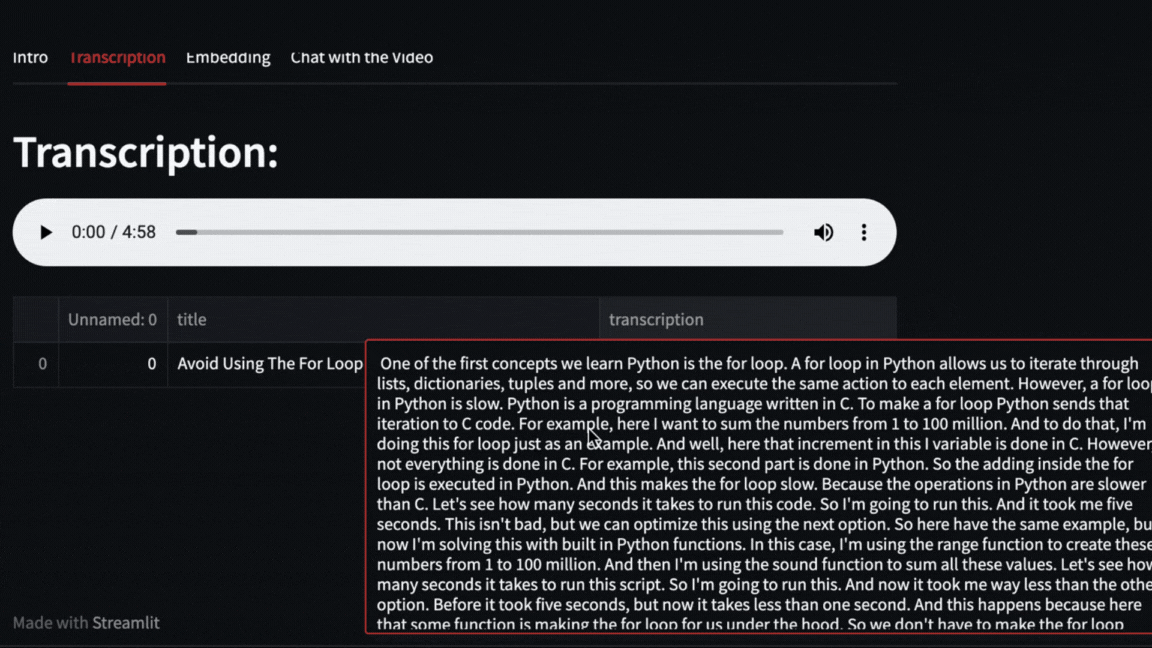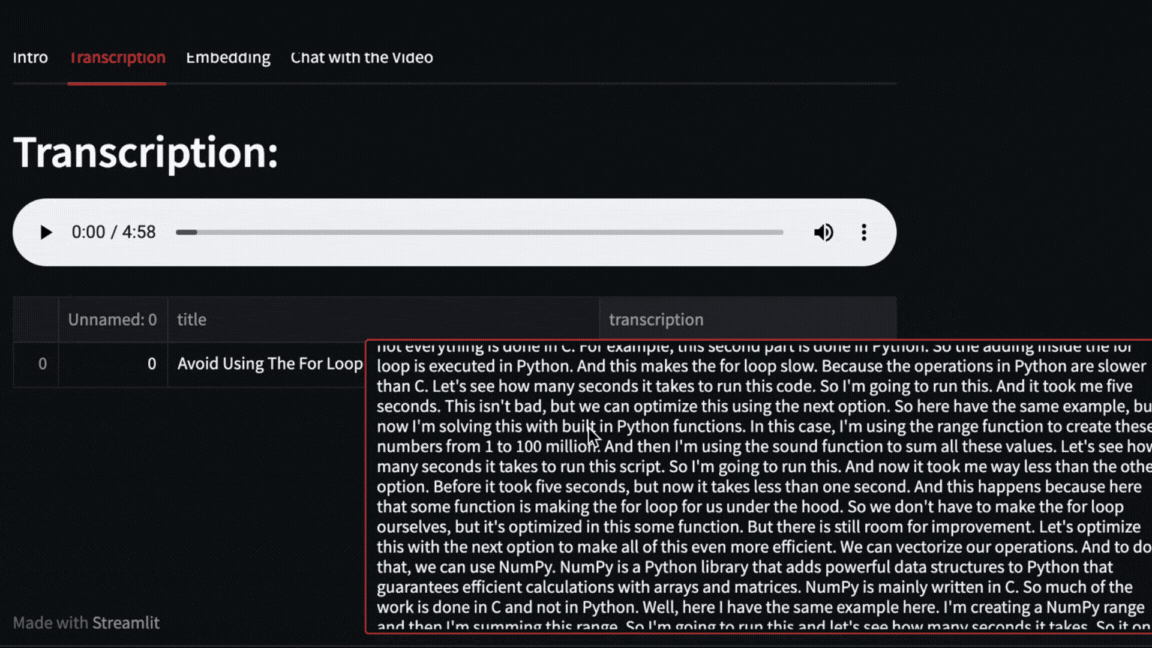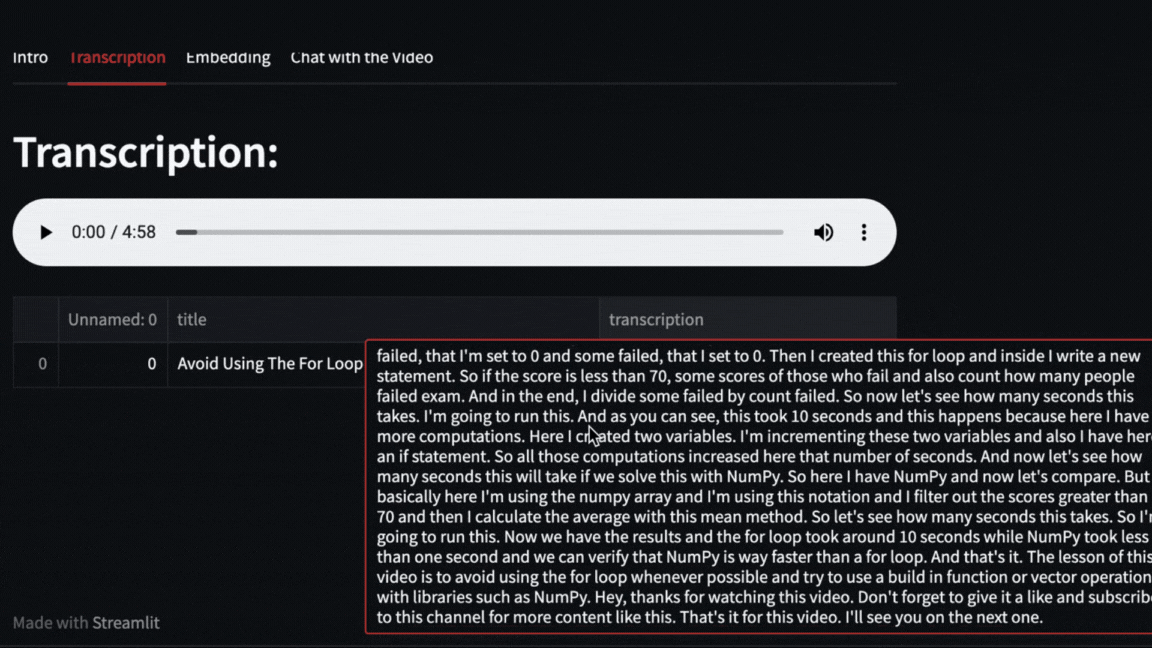
|
| 33 |
-
|
| 34 |
-
```python
|
| 35 |
-
# Get the video
|
| 36 |
-
youtube_video = YouTube(youtube_link)
|
| 37 |
-
streams = youtube_video.streams.filter(only_audio=True)
|
| 38 |
-
mp4_video = stream.download(filename='youtube_video.mp4')
|
| 39 |
-
audio_file = open(mp4_video, 'rb')
|
| 40 |
-
|
| 41 |
-
# whisper load base model
|
| 42 |
-
model = whisper.load_model('base')
|
| 43 |
-
|
| 44 |
-
# Whisper transcription
|
| 45 |
-
output = model.transcribe("youtube_video.mp4")
|
| 46 |
-
```
|
| 47 |
-
|
| 48 |
-
## Embedding with "text-embedding-ada-002"
|
| 49 |
-
We obtain the vectors with **text-embedding-ada-002** of each segment delivered by whisper
|
| 50 |
-
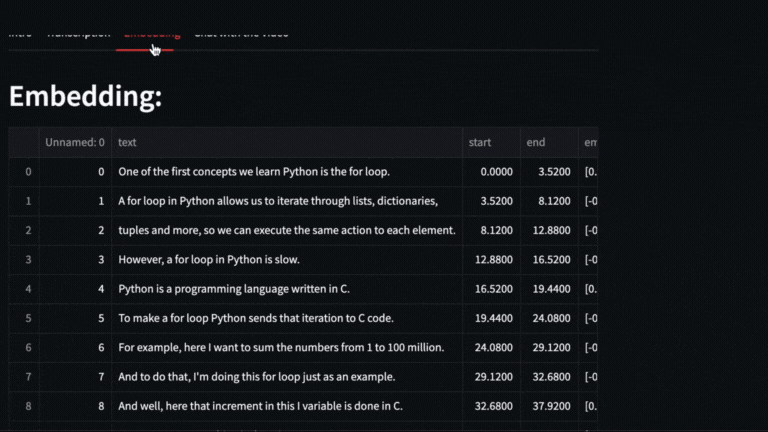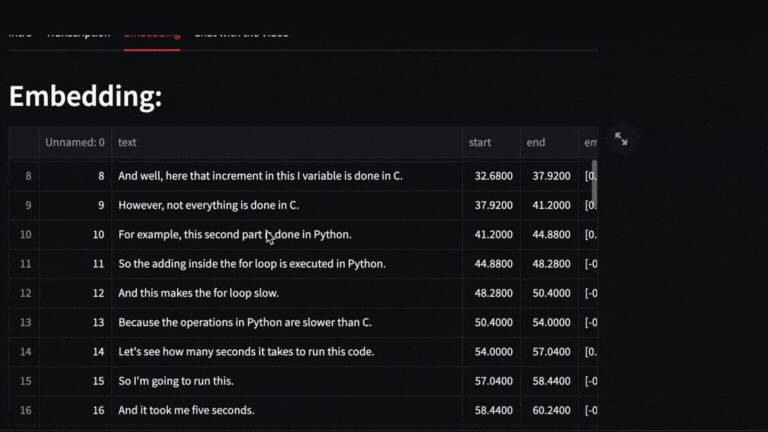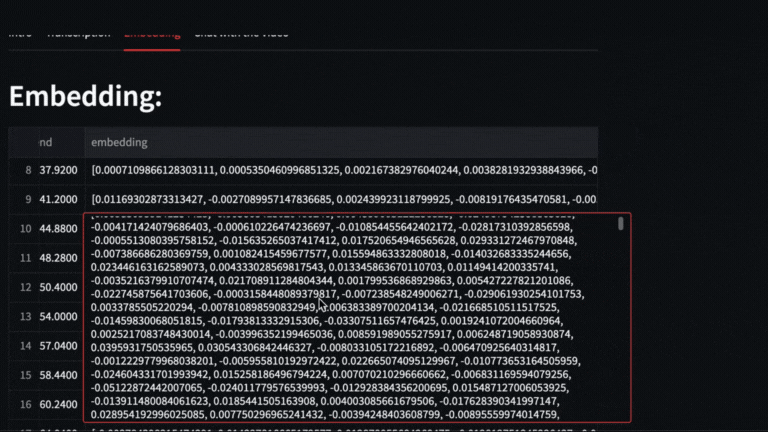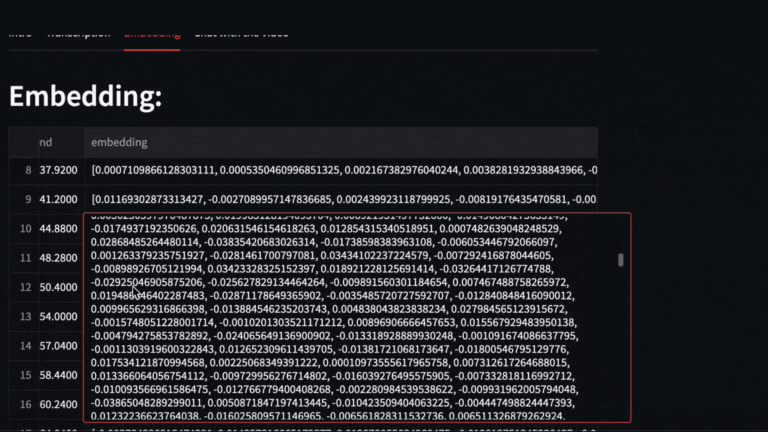
|
| 51 |
-
|
| 52 |
-
```python
|
| 53 |
-
# Embeddings
|
| 54 |
-
segments = output['segments']
|
| 55 |
-
for segment in segments:
|
| 56 |
-
openai.api_key = user_secret
|
| 57 |
-
response = openai.Embedding.create(
|
| 58 |
-
input= segment["text"].strip(),
|
| 59 |
-
model="text-embedding-ada-002"
|
| 60 |
-
)
|
| 61 |
-
embeddings = response['data'][0]['embedding']
|
| 62 |
-
meta = {
|
| 63 |
-
"text": segment["text"].strip(),
|
| 64 |
-
"start": segment['start'],
|
| 65 |
-
"end": segment['end'],
|
| 66 |
-
"embedding": embeddings
|
| 67 |
-
}
|
| 68 |
-
data.append(meta)
|
| 69 |
-
pd.DataFrame(data).to_csv('word_embeddings.csv')
|
| 70 |
-
```
|
| 71 |
-
## OpenAI GPT-3
|
| 72 |
-
We make a question to the vectorized text, we do the search of the context and then we send the prompt with the context to the model "text-davinci-003"
|
| 73 |
-
|
| 74 |
-
|
| 75 |
-
|
| 76 |
-
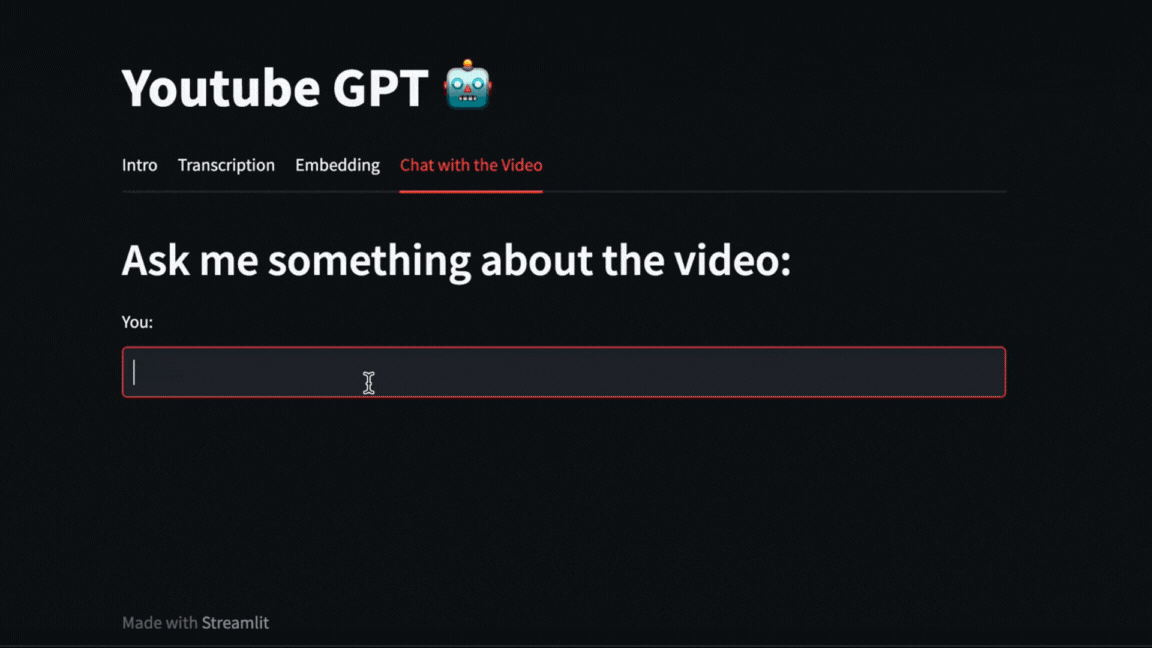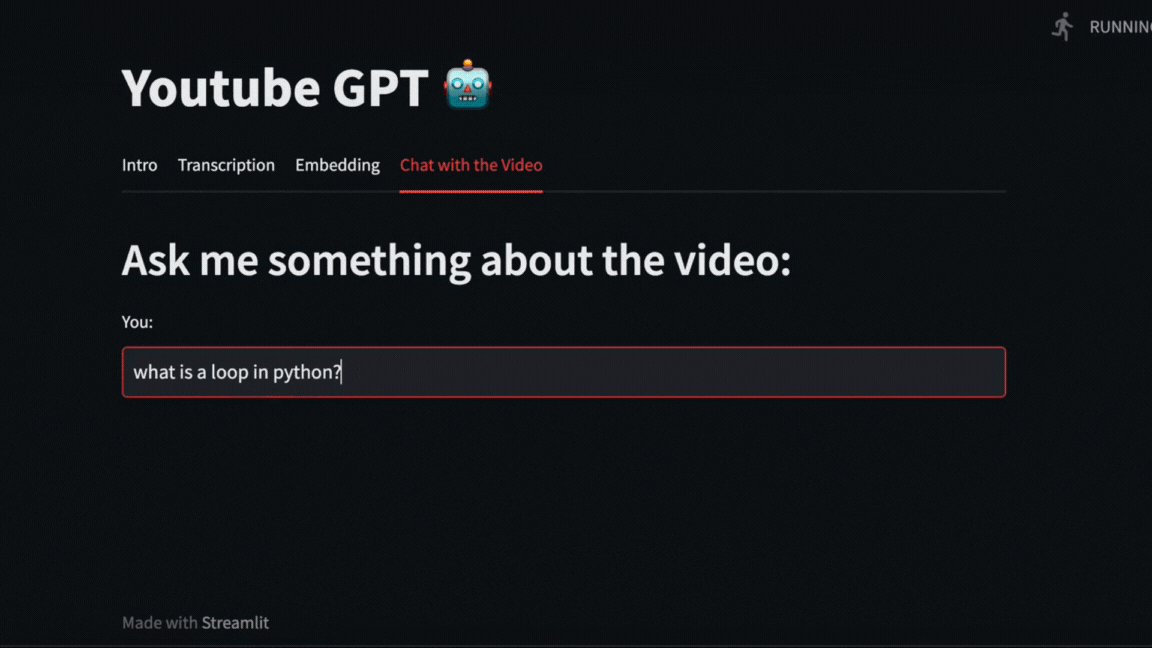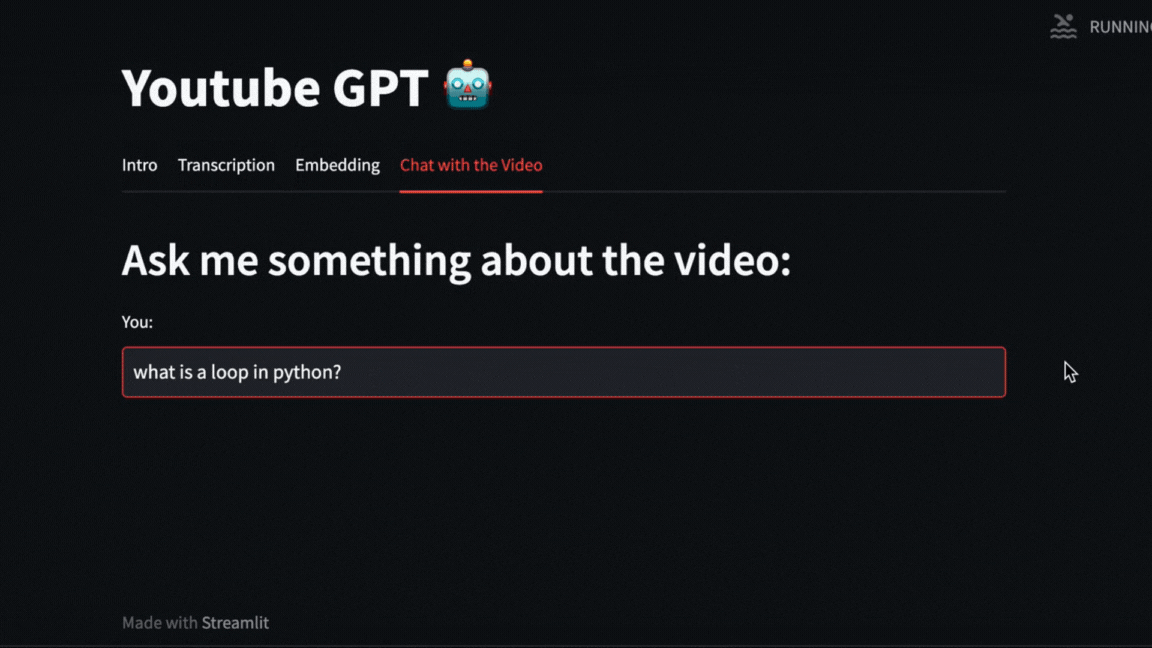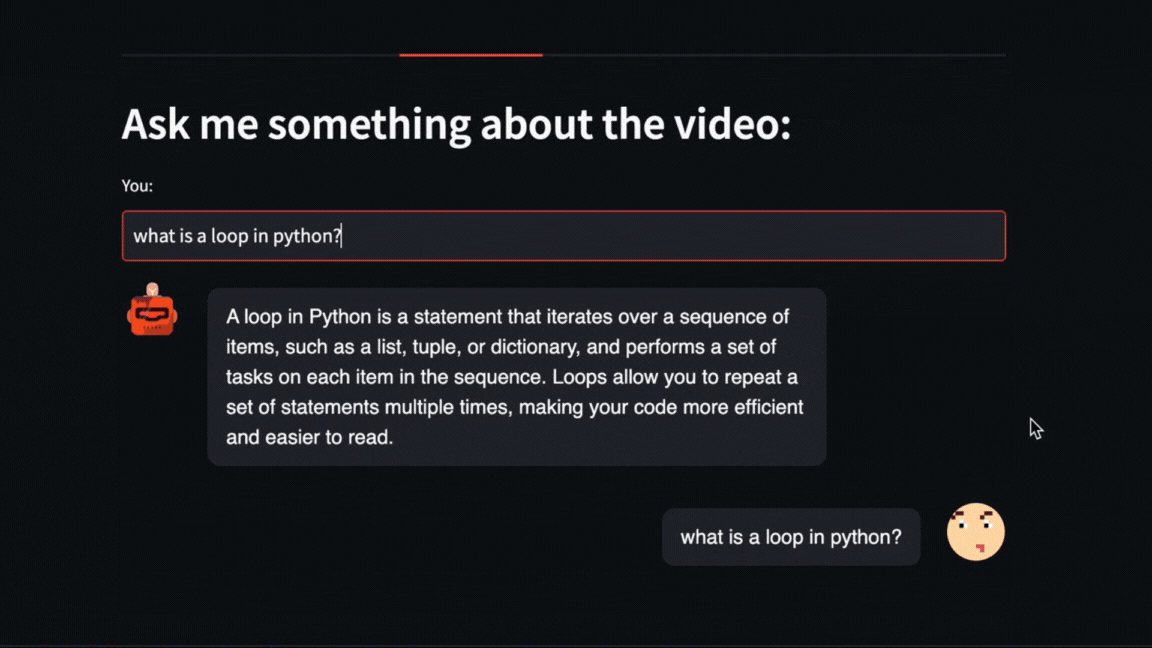
We can even ask direct questions about what happened in the video. For example, here we ask about how long the exercise with Numpy that Pycoach did in the video took.
|
| 77 |
-
|
| 78 |
-

|
| 79 |
-
|
| 80 |
# Running Locally
|
| 81 |
|
| 82 |
1. Clone the repository
|
| 83 |
|
| 84 |
```bash
|
| 85 |
-
git clone https://github.com/davila7/
|
| 86 |
-
cd
|
| 87 |
```
|
| 88 |
2. Install dependencies
|
| 89 |
|
| 90 |
These dependencies are required to install with the requirements.txt file:
|
| 91 |
|
| 92 |
-
*
|
| 93 |
-
*
|
| 94 |
-
*
|
| 95 |
-
*
|
| 96 |
-
*
|
| 97 |
-
*
|
| 98 |
-
*
|
| 99 |
-
*
|
| 100 |
-
*
|
| 101 |
-
*
|
| 102 |
-
*
|
| 103 |
|
| 104 |
```bash
|
| 105 |
pip install -r requirements.txt
|
|
@@ -109,9 +52,3 @@ pip install -r requirements.txt
|
|
| 109 |
```bash
|
| 110 |
streamlit run app.py
|
| 111 |
```
|
| 112 |
-
|
| 113 |
-
## Upcoming Features 🚀
|
| 114 |
-
|
| 115 |
-
- Semantic search with embedding
|
| 116 |
-
- Chart with emotional analysis
|
| 117 |
-
- Connect with Pinecone
|
|
|
|
| 20 |
- Embedding texts segments with Langchain and OpenAI (**text-embedding-ada-002**)
|
| 21 |
- Chat with the file using **streamlit-chat** and LangChain QA with source and (**text-davinci-003**)
|
| 22 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 23 |
# Running Locally
|
| 24 |
|
| 25 |
1. Clone the repository
|
| 26 |
|
| 27 |
```bash
|
| 28 |
+
git clone https://github.com/davila7/file-gpt
|
| 29 |
+
cd file-gpt
|
| 30 |
```
|
| 31 |
2. Install dependencies
|
| 32 |
|
| 33 |
These dependencies are required to install with the requirements.txt file:
|
| 34 |
|
| 35 |
+
* openai
|
| 36 |
+
* pypdf
|
| 37 |
+
* scikit-learn
|
| 38 |
+
* numpy
|
| 39 |
+
* tiktoken
|
| 40 |
+
* docx2txt
|
| 41 |
+
* langchain
|
| 42 |
+
* pydantic
|
| 43 |
+
* typing
|
| 44 |
+
* faiss-cpu
|
| 45 |
+
* streamlit_chat
|
| 46 |
|
| 47 |
```bash
|
| 48 |
pip install -r requirements.txt
|
|
|
|
| 52 |
```bash
|
| 53 |
streamlit run app.py
|
| 54 |
```
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
requirements.txt
CHANGED
|
@@ -7,4 +7,5 @@ docx2txt
|
|
| 7 |
langchain
|
| 8 |
pydantic
|
| 9 |
typing
|
| 10 |
-
faiss-cpu
|
|
|
|
|
|
| 7 |
langchain
|
| 8 |
pydantic
|
| 9 |
typing
|
| 10 |
+
faiss-cpu
|
| 11 |
+
streamlit_chat
|