 +
+  +
+  +
+
+
+
+
+
+ ![]() +
+
 +
+ Agents that think in code!
+
+  +
+
 +
+ +
+Writing actions in code rather than JSON-like snippets provides better:
+
+- **Composability:** could you nest JSON actions within each other, or define a set of JSON actions to re-use later, the same way you could just define a python function?
+- **Object management:** how do you store the output of an action like `generate_image` in JSON?
+- **Generality:** code is built to express simply anything you can have a computer do.
+- **Representation in LLM training data:** plenty of quality code actions are already included in LLMs’ training data which means they’re already trained for this!
diff --git a/smolagents/docs/source/en/conceptual_guides/react.mdx b/smolagents/docs/source/en/conceptual_guides/react.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..6358c78fde3b1209b37f98f1d0a7101874cbdd29
--- /dev/null
+++ b/smolagents/docs/source/en/conceptual_guides/react.mdx
@@ -0,0 +1,48 @@
+# How do multi-step agents work?
+
+The ReAct framework ([Yao et al., 2022](https://huggingface.co/papers/2210.03629)) is currently the main approach to building agents.
+
+The name is based on the concatenation of two words, "Reason" and "Act." Indeed, agents following this architecture will solve their task in as many steps as needed, each step consisting of a Reasoning step, then an Action step where it formulates tool calls that will bring it closer to solving the task at hand.
+
+All agents in `smolagents` are based on singular `MultiStepAgent` class, which is an abstraction of ReAct framework.
+
+On a basic level, this class performs actions on a cycle of following steps, where existing variables and knowledge is incorporated into the agent logs like below:
+
+Initialization: the system prompt is stored in a `SystemPromptStep`, and the user query is logged into a `TaskStep` .
+
+While loop (ReAct loop):
+
+- Use `agent.write_memory_to_messages()` to write the agent logs into a list of LLM-readable [chat messages](https://huggingface.co/docs/transformers/en/chat_templating).
+- Send these messages to a `Model` object to get its completion. Parse the completion to get the action (a JSON blob for `ToolCallingAgent`, a code snippet for `CodeAgent`).
+- Execute the action and logs result into memory (an `ActionStep`).
+- At the end of each step, we run all callback functions defined in `agent.step_callbacks` .
+
+Optionally, when planning is activated, a plan can be periodically revised and stored in a `PlanningStep` . This includes feeding facts about the task at hand to the memory.
+
+For a `CodeAgent`, it looks like the figure below.
+
+
+
+Writing actions in code rather than JSON-like snippets provides better:
+
+- **Composability:** could you nest JSON actions within each other, or define a set of JSON actions to re-use later, the same way you could just define a python function?
+- **Object management:** how do you store the output of an action like `generate_image` in JSON?
+- **Generality:** code is built to express simply anything you can have a computer do.
+- **Representation in LLM training data:** plenty of quality code actions are already included in LLMs’ training data which means they’re already trained for this!
diff --git a/smolagents/docs/source/en/conceptual_guides/react.mdx b/smolagents/docs/source/en/conceptual_guides/react.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..6358c78fde3b1209b37f98f1d0a7101874cbdd29
--- /dev/null
+++ b/smolagents/docs/source/en/conceptual_guides/react.mdx
@@ -0,0 +1,48 @@
+# How do multi-step agents work?
+
+The ReAct framework ([Yao et al., 2022](https://huggingface.co/papers/2210.03629)) is currently the main approach to building agents.
+
+The name is based on the concatenation of two words, "Reason" and "Act." Indeed, agents following this architecture will solve their task in as many steps as needed, each step consisting of a Reasoning step, then an Action step where it formulates tool calls that will bring it closer to solving the task at hand.
+
+All agents in `smolagents` are based on singular `MultiStepAgent` class, which is an abstraction of ReAct framework.
+
+On a basic level, this class performs actions on a cycle of following steps, where existing variables and knowledge is incorporated into the agent logs like below:
+
+Initialization: the system prompt is stored in a `SystemPromptStep`, and the user query is logged into a `TaskStep` .
+
+While loop (ReAct loop):
+
+- Use `agent.write_memory_to_messages()` to write the agent logs into a list of LLM-readable [chat messages](https://huggingface.co/docs/transformers/en/chat_templating).
+- Send these messages to a `Model` object to get its completion. Parse the completion to get the action (a JSON blob for `ToolCallingAgent`, a code snippet for `CodeAgent`).
+- Execute the action and logs result into memory (an `ActionStep`).
+- At the end of each step, we run all callback functions defined in `agent.step_callbacks` .
+
+Optionally, when planning is activated, a plan can be periodically revised and stored in a `PlanningStep` . This includes feeding facts about the task at hand to the memory.
+
+For a `CodeAgent`, it looks like the figure below.
+
+ +
+
+
+
+
+ +
+Learn the basics and become familiar with using Agents. Start here if you are using Agents for the first time!
+ +Practical guides to help you achieve a specific goal: create an agent to generate and test SQL queries!
+ +High-level explanations for building a better understanding of important topics.
+ +Horizontal tutorials that cover important aspects of building agents.
+ + +
+ +
+You can see that the CodeAgent called its managed ToolCallingAgent (by the way, the managed agent could have been a CodeAgent as well) to ask it to run the web search for the U.S. 2024 growth rate. Then the managed agent returned its report and the manager agent acted upon it to calculate the economy doubling time! Sweet, isn't it?
+
+## Setting up telemetry with Langfuse
+
+This part shows how to monitor and debug your Hugging Face **smolagents** with **Langfuse** using the `SmolagentsInstrumentor`.
+
+> **What is Langfuse?** [Langfuse](https://langfuse.com) is an open-source platform for LLM engineering. It provides tracing and monitoring capabilities for AI agents, helping developers debug, analyze, and optimize their products. Langfuse integrates with various tools and frameworks via native integrations, OpenTelemetry, and SDKs.
+
+### Step 1: Install Dependencies
+
+```python
+%pip install smolagents
+%pip install opentelemetry-sdk opentelemetry-exporter-otlp openinference-instrumentation-smolagents
+```
+
+### Step 2: Set Up Environment Variables
+
+Set your Langfuse API keys and configure the OpenTelemetry endpoint to send traces to Langfuse. Get your Langfuse API keys by signing up for [Langfuse Cloud](https://cloud.langfuse.com) or [self-hosting Langfuse](https://langfuse.com/self-hosting).
+
+Also, add your [Hugging Face token](https://huggingface.co/settings/tokens) (`HF_TOKEN`) as an environment variable.
+
+```python
+import os
+import base64
+
+LANGFUSE_PUBLIC_KEY="pk-lf-..."
+LANGFUSE_SECRET_KEY="sk-lf-..."
+LANGFUSE_AUTH=base64.b64encode(f"{LANGFUSE_PUBLIC_KEY}:{LANGFUSE_SECRET_KEY}".encode()).decode()
+
+os.environ["OTEL_EXPORTER_OTLP_ENDPOINT"] = "https://cloud.langfuse.com/api/public/otel" # EU data region
+# os.environ["OTEL_EXPORTER_OTLP_ENDPOINT"] = "https://us.cloud.langfuse.com/api/public/otel" # US data region
+os.environ["OTEL_EXPORTER_OTLP_HEADERS"] = f"Authorization=Basic {LANGFUSE_AUTH}"
+
+# your Hugging Face token
+os.environ["HF_TOKEN"] = "hf_..."
+```
+
+### Step 3: Initialize the `SmolagentsInstrumentor`
+
+Initialize the `SmolagentsInstrumentor` before your application code. Configure `tracer_provider` and add a span processor to export traces to Langfuse. `OTLPSpanExporter()` uses the endpoint and headers from the environment variables.
+
+
+```python
+from opentelemetry.sdk.trace import TracerProvider
+
+from openinference.instrumentation.smolagents import SmolagentsInstrumentor
+from opentelemetry.exporter.otlp.proto.http.trace_exporter import OTLPSpanExporter
+from opentelemetry.sdk.trace.export import SimpleSpanProcessor
+
+trace_provider = TracerProvider()
+trace_provider.add_span_processor(SimpleSpanProcessor(OTLPSpanExporter()))
+
+SmolagentsInstrumentor().instrument(tracer_provider=trace_provider)
+```
+
+### Step 4: Run your smolagent
+
+```python
+from smolagents import (
+ CodeAgent,
+ ToolCallingAgent,
+ DuckDuckGoSearchTool,
+ VisitWebpageTool,
+ InferenceClientModel,
+)
+
+model = InferenceClientModel(
+ model_id="deepseek-ai/DeepSeek-R1-Distill-Qwen-32B"
+)
+
+search_agent = ToolCallingAgent(
+ tools=[DuckDuckGoSearchTool(), VisitWebpageTool()],
+ model=model,
+ name="search_agent",
+ description="This is an agent that can do web search.",
+)
+
+manager_agent = CodeAgent(
+ tools=[],
+ model=model,
+ managed_agents=[search_agent],
+)
+manager_agent.run(
+ "How can Langfuse be used to monitor and improve the reasoning and decision-making of smolagents when they execute multi-step tasks, like dynamically adjusting a recipe based on user feedback or available ingredients?"
+)
+```
+
+### Step 5: View Traces in Langfuse
+
+After running the agent, you can view the traces generated by your smolagents application in [Langfuse](https://cloud.langfuse.com). You should see detailed steps of the LLM interactions, which can help you debug and optimize your AI agent.
+
+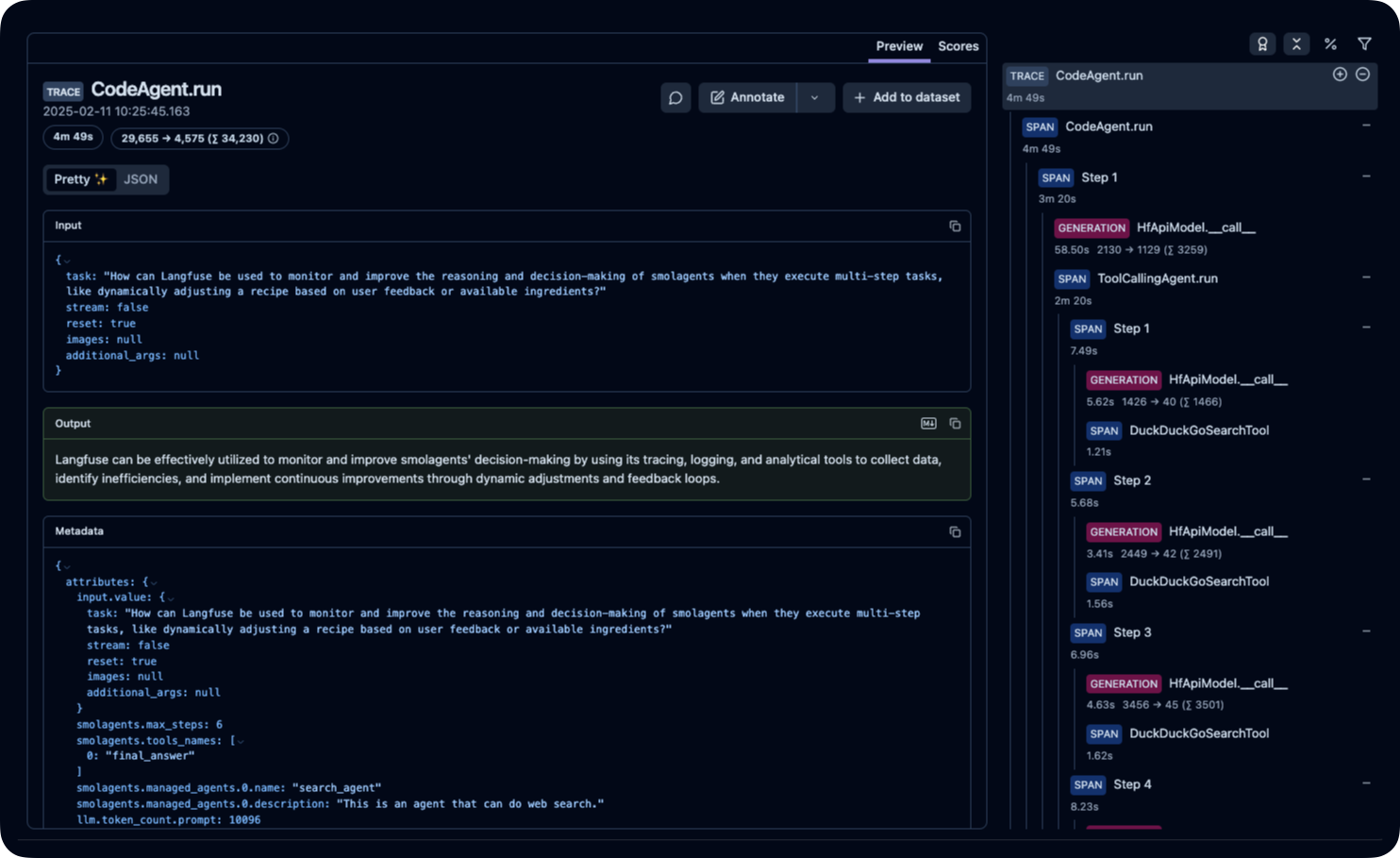
+
+_[Public example trace in Langfuse](https://cloud.langfuse.com/project/cloramnkj0002jz088vzn1ja4/traces/ce5160f9bfd5a6cd63b07d2bfcec6f54?timestamp=2025-02-11T09%3A25%3A45.163Z&display=details)_
diff --git a/smolagents/docs/source/en/tutorials/memory.mdx b/smolagents/docs/source/en/tutorials/memory.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..df982da82f2bc1e3adae8929f302270b693d9d08
--- /dev/null
+++ b/smolagents/docs/source/en/tutorials/memory.mdx
@@ -0,0 +1,134 @@
+# 📚 Manage your agent's memory
+
+[[open-in-colab]]
+
+In the end, an agent can be defined by simple components: it has tools, prompts.
+And most importantly, it has a memory of past steps, drawing a history of planning, execution, and errors.
+
+### Replay your agent's memory
+
+We propose several features to inspect a past agent run.
+
+You can instrument the agent's run to display it in a great UI that lets you zoom in/out on specific steps, as highlighted in the [instrumentation guide](./inspect_runs).
+
+You can also use `agent.replay()`, as follows:
+
+After the agent has run:
+```py
+from smolagents import InferenceClientModel, CodeAgent
+
+agent = CodeAgent(tools=[], model=InferenceClientModel(), verbosity_level=0)
+
+result = agent.run("What's the 20th Fibonacci number?")
+```
+
+If you want to replay this last run, just use:
+```py
+agent.replay()
+```
+
+### Dynamically change the agent's memory
+
+Many advanced use cases require dynamic modification of the agent's memory.
+
+You can access the agent's memory using:
+
+```py
+from smolagents import ActionStep
+
+system_prompt_step = agent.memory.system_prompt
+print("The system prompt given to the agent was:")
+print(system_prompt_step.system_prompt)
+
+task_step = agent.memory.steps[0]
+print("\n\nThe first task step was:")
+print(task_step.task)
+
+for step in agent.memory.steps:
+ if isinstance(step, ActionStep):
+ if step.error is not None:
+ print(f"\nStep {step.step_number} got this error:\n{step.error}\n")
+ else:
+ print(f"\nStep {step.step_number} got these observations:\n{step.observations}\n")
+```
+
+Use `agent.memory.get_full_steps()` to get full steps as dictionaries.
+
+You can also use step callbacks to dynamically change the agent's memory.
+
+Step callbacks can access the `agent` itself in their arguments, so they can access any memory step as highlighted above, and change it if needed. For instance, let's say you are observing screenshots of each step performed by a web browser agent. You want to log the newest screenshot, and remove the images from ancient steps to save on token costs.
+
+You could run something like the following.
+_Note: this code is incomplete, some imports and object definitions have been removed for the sake of concision, visit [the original script](https://github.com/huggingface/smolagents/blob/main/src/smolagents/vision_web_browser.py) to get the full working code._
+
+```py
+import helium
+from PIL import Image
+from io import BytesIO
+from time import sleep
+
+def update_screenshot(memory_step: ActionStep, agent: CodeAgent) -> None:
+ sleep(1.0) # Let JavaScript animations happen before taking the screenshot
+ driver = helium.get_driver()
+ latest_step = memory_step.step_number
+ for previous_memory_step in agent.memory.steps: # Remove previous screenshots from logs for lean processing
+ if isinstance(previous_memory_step, ActionStep) and previous_memory_step.step_number <= latest_step - 2:
+ previous_memory_step.observations_images = None
+ png_bytes = driver.get_screenshot_as_png()
+ image = Image.open(BytesIO(png_bytes))
+ memory_step.observations_images = [image.copy()]
+```
+
+Then you should pass this function in the `step_callbacks` argument upon initialization of your agent:
+
+```py
+CodeAgent(
+ tools=[DuckDuckGoSearchTool(), go_back, close_popups, search_item_ctrl_f],
+ model=model,
+ additional_authorized_imports=["helium"],
+ step_callbacks=[update_screenshot],
+ max_steps=20,
+ verbosity_level=2,
+)
+```
+
+Head to our [vision web browser code](https://github.com/huggingface/smolagents/blob/main/src/smolagents/vision_web_browser.py) to see the full working example.
+
+### Run agents one step at a time
+
+This can be useful in case you have tool calls that take days: you can just run your agents step by step.
+This will also let you update the memory on each step.
+
+```py
+from smolagents import InferenceClientModel, CodeAgent, ActionStep, TaskStep
+
+agent = CodeAgent(tools=[], model=InferenceClientModel(), verbosity_level=1)
+agent.python_executor.send_tools({**agent.tools})
+print(agent.memory.system_prompt)
+
+task = "What is the 20th Fibonacci number?"
+
+# You could modify the memory as needed here by inputting the memory of another agent.
+# agent.memory.steps = previous_agent.memory.steps
+
+# Let's start a new task!
+agent.memory.steps.append(TaskStep(task=task, task_images=[]))
+
+final_answer = None
+step_number = 1
+while final_answer is None and step_number <= 10:
+ memory_step = ActionStep(
+ step_number=step_number,
+ observations_images=[],
+ )
+ # Run one step.
+ final_answer = agent.step(memory_step)
+ agent.memory.steps.append(memory_step)
+ step_number += 1
+
+ # Change the memory as you please!
+ # For instance to update the latest step:
+ # agent.memory.steps[-1] = ...
+
+print("The final answer is:", final_answer)
+```
diff --git a/smolagents/docs/source/en/tutorials/secure_code_execution.mdx b/smolagents/docs/source/en/tutorials/secure_code_execution.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..8716f63c65810b92d96683aee5679e0806ef2ed9
--- /dev/null
+++ b/smolagents/docs/source/en/tutorials/secure_code_execution.mdx
@@ -0,0 +1,414 @@
+# Secure code execution
+
+[[open-in-colab]]
+
+> [!TIP]
+> If you're new to building agents, make sure to first read the [intro to agents](../conceptual_guides/intro_agents) and the [guided tour of smolagents](../guided_tour).
+
+### Code agents
+
+[Multiple](https://huggingface.co/papers/2402.01030) [research](https://huggingface.co/papers/2411.01747) [papers](https://huggingface.co/papers/2401.00812) have shown that having the LLM write its actions (the tool calls) in code is much better than the current standard format for tool calling, which is across the industry different shades of "writing actions as a JSON of tools names and arguments to use".
+
+Why is code better? Well, because we crafted our code languages specifically to be great at expressing actions performed by a computer. If JSON snippets were a better way, this package would have been written in JSON snippets and the devil would be laughing at us.
+
+Code is just a better way to express actions on a computer. It has better:
+- **Composability:** could you nest JSON actions within each other, or define a set of JSON actions to re-use later, the same way you could just define a python function?
+- **Object management:** how do you store the output of an action like `generate_image` in JSON?
+- **Generality:** code is built to express simply anything you can have a computer do.
+- **Representation in LLM training corpus:** why not leverage this benediction of the sky that plenty of quality actions have already been included in LLM training corpus?
+
+This is illustrated on the figure below, taken from [Executable Code Actions Elicit Better LLM Agents](https://huggingface.co/papers/2402.01030).
+
+
+
+This is why we put emphasis on proposing code agents, in this case python agents, which meant putting higher effort on building secure python interpreters.
+
+### Local code execution??
+
+By default, the `CodeAgent` runs LLM-generated code in your environment.
+
+This is inherently risky, LLM-generated code could be harmful to your environment.
+
+Malicious code execution can occur in several ways:
+- **Plain LLM error:** LLMs are still far from perfect and may unintentionally generate harmful commands while attempting to be helpful. While this risk is low, instances have been observed where an LLM attempted to execute potentially dangerous code.
+- **Supply chain attack:** Running an untrusted or compromised LLM could expose a system to harmful code generation. While this risk is extremely low when using well-known models on secure inference infrastructure, it remains a theoretical possibility.
+- **Prompt injection:** an agent browsing the web could arrive on a malicious website that contains harmful instructions, thus injecting an attack into the agent's memory
+- **Exploitation of publicly accessible agents:** Agents exposed to the public can be misused by malicious actors to execute harmful code. Attackers may craft adversarial inputs to exploit the agent's execution capabilities, leading to unintended consequences.
+Once malicious code is executed, whether accidentally or intentionally, it can damage the file system, exploit local or cloud-based resources, abuse API services, and even compromise network security.
+
+One could argue that on the [spectrum of agency](../conceptual_guides/intro_agents), code agents give much higher agency to the LLM on your system than other less agentic setups: this goes hand-in-hand with higher risk.
+
+So you need to be very mindful of security.
+
+To improve safety, we propose a range of measures that propose elevated levels of security, at a higher setup cost.
+
+We advise you to keep in mind that no solution will be 100% safe.
+
+
+
+You can see that the CodeAgent called its managed ToolCallingAgent (by the way, the managed agent could have been a CodeAgent as well) to ask it to run the web search for the U.S. 2024 growth rate. Then the managed agent returned its report and the manager agent acted upon it to calculate the economy doubling time! Sweet, isn't it?
+
+## Setting up telemetry with Langfuse
+
+This part shows how to monitor and debug your Hugging Face **smolagents** with **Langfuse** using the `SmolagentsInstrumentor`.
+
+> **What is Langfuse?** [Langfuse](https://langfuse.com) is an open-source platform for LLM engineering. It provides tracing and monitoring capabilities for AI agents, helping developers debug, analyze, and optimize their products. Langfuse integrates with various tools and frameworks via native integrations, OpenTelemetry, and SDKs.
+
+### Step 1: Install Dependencies
+
+```python
+%pip install smolagents
+%pip install opentelemetry-sdk opentelemetry-exporter-otlp openinference-instrumentation-smolagents
+```
+
+### Step 2: Set Up Environment Variables
+
+Set your Langfuse API keys and configure the OpenTelemetry endpoint to send traces to Langfuse. Get your Langfuse API keys by signing up for [Langfuse Cloud](https://cloud.langfuse.com) or [self-hosting Langfuse](https://langfuse.com/self-hosting).
+
+Also, add your [Hugging Face token](https://huggingface.co/settings/tokens) (`HF_TOKEN`) as an environment variable.
+
+```python
+import os
+import base64
+
+LANGFUSE_PUBLIC_KEY="pk-lf-..."
+LANGFUSE_SECRET_KEY="sk-lf-..."
+LANGFUSE_AUTH=base64.b64encode(f"{LANGFUSE_PUBLIC_KEY}:{LANGFUSE_SECRET_KEY}".encode()).decode()
+
+os.environ["OTEL_EXPORTER_OTLP_ENDPOINT"] = "https://cloud.langfuse.com/api/public/otel" # EU data region
+# os.environ["OTEL_EXPORTER_OTLP_ENDPOINT"] = "https://us.cloud.langfuse.com/api/public/otel" # US data region
+os.environ["OTEL_EXPORTER_OTLP_HEADERS"] = f"Authorization=Basic {LANGFUSE_AUTH}"
+
+# your Hugging Face token
+os.environ["HF_TOKEN"] = "hf_..."
+```
+
+### Step 3: Initialize the `SmolagentsInstrumentor`
+
+Initialize the `SmolagentsInstrumentor` before your application code. Configure `tracer_provider` and add a span processor to export traces to Langfuse. `OTLPSpanExporter()` uses the endpoint and headers from the environment variables.
+
+
+```python
+from opentelemetry.sdk.trace import TracerProvider
+
+from openinference.instrumentation.smolagents import SmolagentsInstrumentor
+from opentelemetry.exporter.otlp.proto.http.trace_exporter import OTLPSpanExporter
+from opentelemetry.sdk.trace.export import SimpleSpanProcessor
+
+trace_provider = TracerProvider()
+trace_provider.add_span_processor(SimpleSpanProcessor(OTLPSpanExporter()))
+
+SmolagentsInstrumentor().instrument(tracer_provider=trace_provider)
+```
+
+### Step 4: Run your smolagent
+
+```python
+from smolagents import (
+ CodeAgent,
+ ToolCallingAgent,
+ DuckDuckGoSearchTool,
+ VisitWebpageTool,
+ InferenceClientModel,
+)
+
+model = InferenceClientModel(
+ model_id="deepseek-ai/DeepSeek-R1-Distill-Qwen-32B"
+)
+
+search_agent = ToolCallingAgent(
+ tools=[DuckDuckGoSearchTool(), VisitWebpageTool()],
+ model=model,
+ name="search_agent",
+ description="This is an agent that can do web search.",
+)
+
+manager_agent = CodeAgent(
+ tools=[],
+ model=model,
+ managed_agents=[search_agent],
+)
+manager_agent.run(
+ "How can Langfuse be used to monitor and improve the reasoning and decision-making of smolagents when they execute multi-step tasks, like dynamically adjusting a recipe based on user feedback or available ingredients?"
+)
+```
+
+### Step 5: View Traces in Langfuse
+
+After running the agent, you can view the traces generated by your smolagents application in [Langfuse](https://cloud.langfuse.com). You should see detailed steps of the LLM interactions, which can help you debug and optimize your AI agent.
+
+
+
+_[Public example trace in Langfuse](https://cloud.langfuse.com/project/cloramnkj0002jz088vzn1ja4/traces/ce5160f9bfd5a6cd63b07d2bfcec6f54?timestamp=2025-02-11T09%3A25%3A45.163Z&display=details)_
diff --git a/smolagents/docs/source/en/tutorials/memory.mdx b/smolagents/docs/source/en/tutorials/memory.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..df982da82f2bc1e3adae8929f302270b693d9d08
--- /dev/null
+++ b/smolagents/docs/source/en/tutorials/memory.mdx
@@ -0,0 +1,134 @@
+# 📚 Manage your agent's memory
+
+[[open-in-colab]]
+
+In the end, an agent can be defined by simple components: it has tools, prompts.
+And most importantly, it has a memory of past steps, drawing a history of planning, execution, and errors.
+
+### Replay your agent's memory
+
+We propose several features to inspect a past agent run.
+
+You can instrument the agent's run to display it in a great UI that lets you zoom in/out on specific steps, as highlighted in the [instrumentation guide](./inspect_runs).
+
+You can also use `agent.replay()`, as follows:
+
+After the agent has run:
+```py
+from smolagents import InferenceClientModel, CodeAgent
+
+agent = CodeAgent(tools=[], model=InferenceClientModel(), verbosity_level=0)
+
+result = agent.run("What's the 20th Fibonacci number?")
+```
+
+If you want to replay this last run, just use:
+```py
+agent.replay()
+```
+
+### Dynamically change the agent's memory
+
+Many advanced use cases require dynamic modification of the agent's memory.
+
+You can access the agent's memory using:
+
+```py
+from smolagents import ActionStep
+
+system_prompt_step = agent.memory.system_prompt
+print("The system prompt given to the agent was:")
+print(system_prompt_step.system_prompt)
+
+task_step = agent.memory.steps[0]
+print("\n\nThe first task step was:")
+print(task_step.task)
+
+for step in agent.memory.steps:
+ if isinstance(step, ActionStep):
+ if step.error is not None:
+ print(f"\nStep {step.step_number} got this error:\n{step.error}\n")
+ else:
+ print(f"\nStep {step.step_number} got these observations:\n{step.observations}\n")
+```
+
+Use `agent.memory.get_full_steps()` to get full steps as dictionaries.
+
+You can also use step callbacks to dynamically change the agent's memory.
+
+Step callbacks can access the `agent` itself in their arguments, so they can access any memory step as highlighted above, and change it if needed. For instance, let's say you are observing screenshots of each step performed by a web browser agent. You want to log the newest screenshot, and remove the images from ancient steps to save on token costs.
+
+You could run something like the following.
+_Note: this code is incomplete, some imports and object definitions have been removed for the sake of concision, visit [the original script](https://github.com/huggingface/smolagents/blob/main/src/smolagents/vision_web_browser.py) to get the full working code._
+
+```py
+import helium
+from PIL import Image
+from io import BytesIO
+from time import sleep
+
+def update_screenshot(memory_step: ActionStep, agent: CodeAgent) -> None:
+ sleep(1.0) # Let JavaScript animations happen before taking the screenshot
+ driver = helium.get_driver()
+ latest_step = memory_step.step_number
+ for previous_memory_step in agent.memory.steps: # Remove previous screenshots from logs for lean processing
+ if isinstance(previous_memory_step, ActionStep) and previous_memory_step.step_number <= latest_step - 2:
+ previous_memory_step.observations_images = None
+ png_bytes = driver.get_screenshot_as_png()
+ image = Image.open(BytesIO(png_bytes))
+ memory_step.observations_images = [image.copy()]
+```
+
+Then you should pass this function in the `step_callbacks` argument upon initialization of your agent:
+
+```py
+CodeAgent(
+ tools=[DuckDuckGoSearchTool(), go_back, close_popups, search_item_ctrl_f],
+ model=model,
+ additional_authorized_imports=["helium"],
+ step_callbacks=[update_screenshot],
+ max_steps=20,
+ verbosity_level=2,
+)
+```
+
+Head to our [vision web browser code](https://github.com/huggingface/smolagents/blob/main/src/smolagents/vision_web_browser.py) to see the full working example.
+
+### Run agents one step at a time
+
+This can be useful in case you have tool calls that take days: you can just run your agents step by step.
+This will also let you update the memory on each step.
+
+```py
+from smolagents import InferenceClientModel, CodeAgent, ActionStep, TaskStep
+
+agent = CodeAgent(tools=[], model=InferenceClientModel(), verbosity_level=1)
+agent.python_executor.send_tools({**agent.tools})
+print(agent.memory.system_prompt)
+
+task = "What is the 20th Fibonacci number?"
+
+# You could modify the memory as needed here by inputting the memory of another agent.
+# agent.memory.steps = previous_agent.memory.steps
+
+# Let's start a new task!
+agent.memory.steps.append(TaskStep(task=task, task_images=[]))
+
+final_answer = None
+step_number = 1
+while final_answer is None and step_number <= 10:
+ memory_step = ActionStep(
+ step_number=step_number,
+ observations_images=[],
+ )
+ # Run one step.
+ final_answer = agent.step(memory_step)
+ agent.memory.steps.append(memory_step)
+ step_number += 1
+
+ # Change the memory as you please!
+ # For instance to update the latest step:
+ # agent.memory.steps[-1] = ...
+
+print("The final answer is:", final_answer)
+```
diff --git a/smolagents/docs/source/en/tutorials/secure_code_execution.mdx b/smolagents/docs/source/en/tutorials/secure_code_execution.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..8716f63c65810b92d96683aee5679e0806ef2ed9
--- /dev/null
+++ b/smolagents/docs/source/en/tutorials/secure_code_execution.mdx
@@ -0,0 +1,414 @@
+# Secure code execution
+
+[[open-in-colab]]
+
+> [!TIP]
+> If you're new to building agents, make sure to first read the [intro to agents](../conceptual_guides/intro_agents) and the [guided tour of smolagents](../guided_tour).
+
+### Code agents
+
+[Multiple](https://huggingface.co/papers/2402.01030) [research](https://huggingface.co/papers/2411.01747) [papers](https://huggingface.co/papers/2401.00812) have shown that having the LLM write its actions (the tool calls) in code is much better than the current standard format for tool calling, which is across the industry different shades of "writing actions as a JSON of tools names and arguments to use".
+
+Why is code better? Well, because we crafted our code languages specifically to be great at expressing actions performed by a computer. If JSON snippets were a better way, this package would have been written in JSON snippets and the devil would be laughing at us.
+
+Code is just a better way to express actions on a computer. It has better:
+- **Composability:** could you nest JSON actions within each other, or define a set of JSON actions to re-use later, the same way you could just define a python function?
+- **Object management:** how do you store the output of an action like `generate_image` in JSON?
+- **Generality:** code is built to express simply anything you can have a computer do.
+- **Representation in LLM training corpus:** why not leverage this benediction of the sky that plenty of quality actions have already been included in LLM training corpus?
+
+This is illustrated on the figure below, taken from [Executable Code Actions Elicit Better LLM Agents](https://huggingface.co/papers/2402.01030).
+
+
+
+This is why we put emphasis on proposing code agents, in this case python agents, which meant putting higher effort on building secure python interpreters.
+
+### Local code execution??
+
+By default, the `CodeAgent` runs LLM-generated code in your environment.
+
+This is inherently risky, LLM-generated code could be harmful to your environment.
+
+Malicious code execution can occur in several ways:
+- **Plain LLM error:** LLMs are still far from perfect and may unintentionally generate harmful commands while attempting to be helpful. While this risk is low, instances have been observed where an LLM attempted to execute potentially dangerous code.
+- **Supply chain attack:** Running an untrusted or compromised LLM could expose a system to harmful code generation. While this risk is extremely low when using well-known models on secure inference infrastructure, it remains a theoretical possibility.
+- **Prompt injection:** an agent browsing the web could arrive on a malicious website that contains harmful instructions, thus injecting an attack into the agent's memory
+- **Exploitation of publicly accessible agents:** Agents exposed to the public can be misused by malicious actors to execute harmful code. Attackers may craft adversarial inputs to exploit the agent's execution capabilities, leading to unintended consequences.
+Once malicious code is executed, whether accidentally or intentionally, it can damage the file system, exploit local or cloud-based resources, abuse API services, and even compromise network security.
+
+One could argue that on the [spectrum of agency](../conceptual_guides/intro_agents), code agents give much higher agency to the LLM on your system than other less agentic setups: this goes hand-in-hand with higher risk.
+
+So you need to be very mindful of security.
+
+To improve safety, we propose a range of measures that propose elevated levels of security, at a higher setup cost.
+
+We advise you to keep in mind that no solution will be 100% safe.
+
+ +
+### Our local Python executor
+
+To add a first layer of security, code execution in `smolagents` is not performed by the vanilla Python interpreter.
+We have re-built a more secure `LocalPythonExecutor` from the ground up.
+
+To be precise, this interpreter works by loading the Abstract Syntax Tree (AST) from your Code and executes it operation by operation, making sure to always follow certain rules:
+- By default, imports are disallowed unless they have been explicitly added to an authorization list by the user.
+- Furthermore, access to submodules is disabled by default, and each must be explicitly authorized in the import list as well, or you can pass for instance `numpy.*` to allow both `numpy` and all its subpackags, like `numpy.random` or `numpy.a.b`.
+ - Note that some seemingly innocuous packages like `random` can give access to potentially harmful submodules, as in `random._os`.
+- The total count of elementary operations processed is capped to prevent infinite loops and resource bloating.
+- Any operation that has not been explicitly defined in our custom interpreter will raise an error.
+
+You could try these safeguards as follows:
+
+```py
+from smolagents.local_python_executor import LocalPythonExecutor
+
+# Set up custom executor, authorize package "numpy"
+custom_executor = LocalPythonExecutor(["numpy"])
+
+# Utilisty for pretty printing errors
+def run_capture_exception(command: str):
+ try:
+ custom_executor(harmful_command)
+ except Exception as e:
+ print("ERROR:\n", e)
+
+# Undefined command just do not work
+harmful_command="!echo Bad command"
+run_capture_exception(harmful_command)
+# >>> ERROR: invalid syntax (
+
+### Our local Python executor
+
+To add a first layer of security, code execution in `smolagents` is not performed by the vanilla Python interpreter.
+We have re-built a more secure `LocalPythonExecutor` from the ground up.
+
+To be precise, this interpreter works by loading the Abstract Syntax Tree (AST) from your Code and executes it operation by operation, making sure to always follow certain rules:
+- By default, imports are disallowed unless they have been explicitly added to an authorization list by the user.
+- Furthermore, access to submodules is disabled by default, and each must be explicitly authorized in the import list as well, or you can pass for instance `numpy.*` to allow both `numpy` and all its subpackags, like `numpy.random` or `numpy.a.b`.
+ - Note that some seemingly innocuous packages like `random` can give access to potentially harmful submodules, as in `random._os`.
+- The total count of elementary operations processed is capped to prevent infinite loops and resource bloating.
+- Any operation that has not been explicitly defined in our custom interpreter will raise an error.
+
+You could try these safeguards as follows:
+
+```py
+from smolagents.local_python_executor import LocalPythonExecutor
+
+# Set up custom executor, authorize package "numpy"
+custom_executor = LocalPythonExecutor(["numpy"])
+
+# Utilisty for pretty printing errors
+def run_capture_exception(command: str):
+ try:
+ custom_executor(harmful_command)
+ except Exception as e:
+ print("ERROR:\n", e)
+
+# Undefined command just do not work
+harmful_command="!echo Bad command"
+run_capture_exception(harmful_command)
+# >>> ERROR: invalid syntax (
+  +
+
 +
+Then you can use this tool just like any other tool. For example, let's improve the prompt `a rabbit wearing a space suit` and generate an image of it. This example also shows how you can pass additional arguments to the agent.
+
+```python
+from smolagents import CodeAgent, InferenceClientModel
+
+model = InferenceClientModel(model_id="Qwen/Qwen2.5-Coder-32B-Instruct")
+agent = CodeAgent(tools=[image_generation_tool], model=model)
+
+agent.run(
+ "Improve this prompt, then generate an image of it.", additional_args={'user_prompt': 'A rabbit wearing a space suit'}
+)
+```
+
+```text
+=== Agent thoughts:
+improved_prompt could be "A bright blue space suit wearing rabbit, on the surface of the moon, under a bright orange sunset, with the Earth visible in the background"
+
+Now that I have improved the prompt, I can use the image generator tool to generate an image based on this prompt.
+>>> Agent is executing the code below:
+image = image_generator(prompt="A bright blue space suit wearing rabbit, on the surface of the moon, under a bright orange sunset, with the Earth visible in the background")
+final_answer(image)
+```
+
+
+
+Then you can use this tool just like any other tool. For example, let's improve the prompt `a rabbit wearing a space suit` and generate an image of it. This example also shows how you can pass additional arguments to the agent.
+
+```python
+from smolagents import CodeAgent, InferenceClientModel
+
+model = InferenceClientModel(model_id="Qwen/Qwen2.5-Coder-32B-Instruct")
+agent = CodeAgent(tools=[image_generation_tool], model=model)
+
+agent.run(
+ "Improve this prompt, then generate an image of it.", additional_args={'user_prompt': 'A rabbit wearing a space suit'}
+)
+```
+
+```text
+=== Agent thoughts:
+improved_prompt could be "A bright blue space suit wearing rabbit, on the surface of the moon, under a bright orange sunset, with the Earth visible in the background"
+
+Now that I have improved the prompt, I can use the image generator tool to generate an image based on this prompt.
+>>> Agent is executing the code below:
+image = image_generator(prompt="A bright blue space suit wearing rabbit, on the surface of the moon, under a bright orange sunset, with the Earth visible in the background")
+final_answer(image)
+```
+
+ +
+How cool is this? 🤩
+
+### Use LangChain tools
+
+We love Langchain and think it has a very compelling suite of tools.
+To import a tool from LangChain, use the `from_langchain()` method.
+
+Here is how you can use it to recreate the intro's search result using a LangChain web search tool.
+This tool will need `pip install langchain google-search-results -q` to work properly.
+```python
+from langchain.agents import load_tools
+
+search_tool = Tool.from_langchain(load_tools(["serpapi"])[0])
+
+agent = CodeAgent(tools=[search_tool], model=model)
+
+agent.run("How many more blocks (also denoted as layers) are in BERT base encoder compared to the encoder from the architecture proposed in Attention is All You Need?")
+```
+
+### Manage your agent's toolbox
+
+You can manage an agent's toolbox by adding or replacing a tool in attribute `agent.tools`, since it is a standard dictionary.
+
+Let's add the `model_download_tool` to an existing agent initialized with only the default toolbox.
+
+```python
+from smolagents import InferenceClientModel
+
+model = InferenceClientModel(model_id="Qwen/Qwen2.5-Coder-32B-Instruct")
+
+agent = CodeAgent(tools=[], model=model, add_base_tools=True)
+agent.tools[model_download_tool.name] = model_download_tool
+```
+Now we can leverage the new tool:
+
+```python
+agent.run(
+ "Can you give me the name of the model that has the most downloads in the 'text-to-video' task on the Hugging Face Hub but reverse the letters?"
+)
+```
+
+
+> [!TIP]
+> Beware of not adding too many tools to an agent: this can overwhelm weaker LLM engines.
+
+
+### Use a collection of tools
+
+You can leverage tool collections by using [`ToolCollection`]. It supports loading either a collection from the Hub or an MCP server tools.
+
+#### Tool Collection from a collection in the Hub
+
+You can leverage it with the slug of the collection you want to use.
+Then pass them as a list to initialize your agent, and start using them!
+
+```py
+from smolagents import ToolCollection, CodeAgent
+
+image_tool_collection = ToolCollection.from_hub(
+ collection_slug="huggingface-tools/diffusion-tools-6630bb19a942c2306a2cdb6f",
+ token="
+
+JSON जैसे स्निपेट्स की बजाय कोड में क्रियाएं लिखने से बेहतर प्राप्त होता है:
+
+- **कम्पोजेबिलिटी:** क्या आप JSON क्रियाओं को एक-दूसरे के भीतर नेस्ट कर सकते हैं, या बाद में पुन: उपयोग करने के लिए JSON क्रियाओं का एक सेट परिभाषित कर सकते हैं, उसी तरह जैसे आप बस एक पायथन फंक्शन परिभाषित कर सकते हैं?
+- **ऑब्जेक्ट प्रबंधन:** आप `generate_image` जैसी क्रिया के आउटपुट को JSON में कैसे स्टोर करते हैं?
+- **सामान्यता:** कोड को सरल रूप से कुछ भी व्यक्त करने के लिए बनाया गया है जो आप कंप्यूटर से करवा सकते हैं।
+- **LLM प्रशिक्षण डेटा में प्रतिनिधित्व:** बहुत सारी गुणवत्तापूर्ण कोड क्रियाएं पहले से ही LLM के ट्रेनिंग डेटा में शामिल हैं जिसका मतलब है कि वे इसके लिए पहले से ही प्रशिक्षित हैं!
\ No newline at end of file
diff --git a/smolagents/docs/source/hi/conceptual_guides/react.mdx b/smolagents/docs/source/hi/conceptual_guides/react.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..8c0ce0f2771f51ec4f7f3349604142330968e02b
--- /dev/null
+++ b/smolagents/docs/source/hi/conceptual_guides/react.mdx
@@ -0,0 +1,29 @@
+# मल्टी-स्टेप एजेंट्स कैसे काम करते हैं?
+
+ReAct फ्रेमवर्क ([Yao et al., 2022](https://huggingface.co/papers/2210.03629)) वर्तमान में एजेंट्स बनाने का मुख्य दृष्टिकोण है।
+
+नाम दो शब्दों, "Reason" (तर्क) और "Act" (क्रिया) के संयोजन पर आधारित है। वास्तव में, इस आर्किटेक्चर का पालन करने वाले एजेंट अपने कार्य को उतने चरणों में हल करेंगे जितने आवश्यक हों, प्रत्येक चरण में एक Reasoning कदम होगा, फिर एक Action कदम होगा, जहाँ यह टूल कॉल्स तैयार करेगा जो उसे कार्य को हल करने के करीब ले जाएंगे।
+
+ReAct प्रक्रिया में पिछले चरणों की मेमोरी रखना शामिल है।
+
+> [!TIP]
+> मल्टी-स्टेप एजेंट्स के बारे में अधिक जानने के लिए [Open-source LLMs as LangChain Agents](https://huggingface.co/blog/open-source-llms-as-agents) ब्लॉग पोस्ट पढ़ें।
+
+यहाँ एक वीडियो ओवरव्यू है कि यह कैसे काम करता है:
+
+
+
+
+
+
+How cool is this? 🤩
+
+### Use LangChain tools
+
+We love Langchain and think it has a very compelling suite of tools.
+To import a tool from LangChain, use the `from_langchain()` method.
+
+Here is how you can use it to recreate the intro's search result using a LangChain web search tool.
+This tool will need `pip install langchain google-search-results -q` to work properly.
+```python
+from langchain.agents import load_tools
+
+search_tool = Tool.from_langchain(load_tools(["serpapi"])[0])
+
+agent = CodeAgent(tools=[search_tool], model=model)
+
+agent.run("How many more blocks (also denoted as layers) are in BERT base encoder compared to the encoder from the architecture proposed in Attention is All You Need?")
+```
+
+### Manage your agent's toolbox
+
+You can manage an agent's toolbox by adding or replacing a tool in attribute `agent.tools`, since it is a standard dictionary.
+
+Let's add the `model_download_tool` to an existing agent initialized with only the default toolbox.
+
+```python
+from smolagents import InferenceClientModel
+
+model = InferenceClientModel(model_id="Qwen/Qwen2.5-Coder-32B-Instruct")
+
+agent = CodeAgent(tools=[], model=model, add_base_tools=True)
+agent.tools[model_download_tool.name] = model_download_tool
+```
+Now we can leverage the new tool:
+
+```python
+agent.run(
+ "Can you give me the name of the model that has the most downloads in the 'text-to-video' task on the Hugging Face Hub but reverse the letters?"
+)
+```
+
+
+> [!TIP]
+> Beware of not adding too many tools to an agent: this can overwhelm weaker LLM engines.
+
+
+### Use a collection of tools
+
+You can leverage tool collections by using [`ToolCollection`]. It supports loading either a collection from the Hub or an MCP server tools.
+
+#### Tool Collection from a collection in the Hub
+
+You can leverage it with the slug of the collection you want to use.
+Then pass them as a list to initialize your agent, and start using them!
+
+```py
+from smolagents import ToolCollection, CodeAgent
+
+image_tool_collection = ToolCollection.from_hub(
+ collection_slug="huggingface-tools/diffusion-tools-6630bb19a942c2306a2cdb6f",
+ token="
+
+JSON जैसे स्निपेट्स की बजाय कोड में क्रियाएं लिखने से बेहतर प्राप्त होता है:
+
+- **कम्पोजेबिलिटी:** क्या आप JSON क्रियाओं को एक-दूसरे के भीतर नेस्ट कर सकते हैं, या बाद में पुन: उपयोग करने के लिए JSON क्रियाओं का एक सेट परिभाषित कर सकते हैं, उसी तरह जैसे आप बस एक पायथन फंक्शन परिभाषित कर सकते हैं?
+- **ऑब्जेक्ट प्रबंधन:** आप `generate_image` जैसी क्रिया के आउटपुट को JSON में कैसे स्टोर करते हैं?
+- **सामान्यता:** कोड को सरल रूप से कुछ भी व्यक्त करने के लिए बनाया गया है जो आप कंप्यूटर से करवा सकते हैं।
+- **LLM प्रशिक्षण डेटा में प्रतिनिधित्व:** बहुत सारी गुणवत्तापूर्ण कोड क्रियाएं पहले से ही LLM के ट्रेनिंग डेटा में शामिल हैं जिसका मतलब है कि वे इसके लिए पहले से ही प्रशिक्षित हैं!
\ No newline at end of file
diff --git a/smolagents/docs/source/hi/conceptual_guides/react.mdx b/smolagents/docs/source/hi/conceptual_guides/react.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..8c0ce0f2771f51ec4f7f3349604142330968e02b
--- /dev/null
+++ b/smolagents/docs/source/hi/conceptual_guides/react.mdx
@@ -0,0 +1,29 @@
+# मल्टी-स्टेप एजेंट्स कैसे काम करते हैं?
+
+ReAct फ्रेमवर्क ([Yao et al., 2022](https://huggingface.co/papers/2210.03629)) वर्तमान में एजेंट्स बनाने का मुख्य दृष्टिकोण है।
+
+नाम दो शब्दों, "Reason" (तर्क) और "Act" (क्रिया) के संयोजन पर आधारित है। वास्तव में, इस आर्किटेक्चर का पालन करने वाले एजेंट अपने कार्य को उतने चरणों में हल करेंगे जितने आवश्यक हों, प्रत्येक चरण में एक Reasoning कदम होगा, फिर एक Action कदम होगा, जहाँ यह टूल कॉल्स तैयार करेगा जो उसे कार्य को हल करने के करीब ले जाएंगे।
+
+ReAct प्रक्रिया में पिछले चरणों की मेमोरी रखना शामिल है।
+
+> [!TIP]
+> मल्टी-स्टेप एजेंट्स के बारे में अधिक जानने के लिए [Open-source LLMs as LangChain Agents](https://huggingface.co/blog/open-source-llms-as-agents) ब्लॉग पोस्ट पढ़ें।
+
+यहाँ एक वीडियो ओवरव्यू है कि यह कैसे काम करता है:
+
+
+
+
+बेसिक्स सीखें और एजेंट्स का उपयोग करने में परिचित हों। यदि आप पहली बार एजेंट्स का उपयोग कर रहे हैं तो यहाँ से शुरू करें!
+ +एक विशिष्ट लक्ष्य प्राप्त करने में मदद के लिए गाइड: SQL क्वेरी जनरेट और टेस्ट करने के लिए एजेंट बनाएं!
+ +महत्वपूर्ण विषयों की बेहतर समझ बनाने के लिए उच्च-स्तरीय व्याख्याएं।
+ +एजेंट्स बनाने के महत्वपूर्ण पहलुओं को कवर करने वाले क्ट्यूटोरियल्स।
+ +
+
+आप देख सकते हैं कि CodeAgent ने अपने मैनेज्ड ToolCallingAgent को (वैसे, मैनेज्ड एजेंट एक CodeAgent भी हो सकता था) U.S. 2024 ग्रोथ रेट के लिए वेब सर्च चलाने के लिए कॉल किया। फिर मैनेज्ड एजेंट ने अपनी रिपोर्ट लौटाई और मैनेजर एजेंट ने अर्थव्यवस्था के दोगुना होने का समय गणना करने के लिए उस पर कार्य किया! अच्छा है, है ना?
\ No newline at end of file
diff --git a/smolagents/docs/source/hi/tutorials/secure_code_execution.mdx b/smolagents/docs/source/hi/tutorials/secure_code_execution.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..73719e842805b17cc96f290c3e0e536b7291acb2
--- /dev/null
+++ b/smolagents/docs/source/hi/tutorials/secure_code_execution.mdx
@@ -0,0 +1,67 @@
+# सुरक्षित कोड एक्जीक्यूशन
+
+[[open-in-colab]]
+
+> [!TIP]
+> यदि आप एजेंट्स बनाने में नए हैं, तो सबसे पहले [एजेंट्स का परिचय](../conceptual_guides/intro_agents) और [smolagents की गाइडेड टूर](../guided_tour) पढ़ना सुनिश्चित करें।
+
+### कोड Agents
+
+[कई](https://huggingface.co/papers/2402.01030) [शोध](https://huggingface.co/papers/2411.01747) [पत्रों](https://huggingface.co/papers/2401.00812) ने दिखाया है कि LLM द्वारा अपनी क्रियाओं (टूल कॉल्स) को कोड में लिखना, टूल कॉलिंग के वर्तमान मानक प्रारूप से बहुत बेहतर है, जो industry में "टूल्स नेम्स और आर्ग्यूमेंट्स को JSON के रूप में लिखने" के विभिन्न रूप हैं।
+
+कोड बेहतर क्यों है? क्योंकि हमने अपनी कोड भाषाओं को विशेष रूप से कंप्यूटर द्वारा की जाने वाली क्रियाओं को व्यक्त करने के लिए तैयार किया है। यदि JSON स्निपेट्स एक बेहतर तरीका होता, तो यह पैकेज JSON स्निपेट्स में लिखा गया होता और शैतान हम पर हंस रहा होता।
+
+कोड कंप्यूटर पर क्रियाएँ व्यक्त करने का बेहतर तरीका है। इसमें बेहतर है:
+- **कंपोज़ेबिलिटी:** क्या आप JSON क्रियाओं को एक-दूसरे के भीतर नेस्ट कर सकते हैं, या बाद में पुन: उपयोग करने के लिए JSON क्रियाओं का एक सेट परिभाषित कर सकते हैं, जैसे आप बस एक पायथन फ़ंक्शन परिभाषित कर सकते हैं?
+- **ऑब्जेक्ट प्रबंधन:** JSON में `generate_image` जैसी क्रिया का आउटपुट कैसे स्टोर करें?
+- **सामान्यता:** कोड किसी भी कंप्यूटर कार्य को व्यक्त करने के लिए बनाया गया है।
+- **LLM प्रशिक्षण कॉर्पस में प्रतिनिधित्व:** क्यों न इस आशीर्वाद का लाभ उठाएं कि उच्च गुणवत्ता वाले कोड उदाहरण पहले से ही LLM प्रशिक्षण डेटा में शामिल हैं?
+
+यह नीचे दी गई छवि में दर्शाया गया है, जो [Executable Code Actions Elicit Better LLM Agents](https://huggingface.co/papers/2402.01030) से ली गई है।
+
+
+
+यही कारण है कि हमने कोड एजेंट्स, इस मामले में पायथन एजेंट्स पर जोर दिया, जिसका मतलब सुरक्षित पायथन इंटरप्रेटर बनाने पर अधिक प्रयास करना था।
+
+### लोकल पायथन इंटरप्रेटर
+
+डिफ़ॉल्ट रूप से, `CodeAgent` LLM-जनरेटेड कोड को आपके एनवायरनमेंट में चलाता है।
+यह एक्जीक्यूशन वैनिला पायथन इंटरप्रेटर द्वारा नहीं किया जाता: हमने एक अधिक सुरक्षित `LocalPythonExecutor` को शुरू से फिर से बनाया है।
+यह इंटरप्रेटर सुरक्षा के लिए डिज़ाइन किया गया है:
+ - इम्पोर्ट्स को उपयोगकर्ता द्वारा स्पष्ट रूप से पास की गई सूची तक सीमित करना
+ - इनफिनिट लूप्स और रिसोर्स ब्लोटिंग को रोकने के लिए ऑपरेशंस की संख्या को कैप करना
+ - कोई भी ऐसा ऑपरेशन नहीं करेगा जो पूर्व-परिभाषित नहीं है
+
+हमने इसे कई उपयोग मामलों में इस्तेमाल किया है, और कभी भी एनवायरनमेंट को कोई नुकसान नहीं देखा।
+
+हालांकि यह समाधान पूरी तरह से सुरक्षित नहीं है: कोई ऐसे अवसरों की कल्पना कर सकता है जहां दुर्भावनापूर्ण कार्यों के लिए फाइन-ट्यून किए गए LLM अभी भी आपके एनवायरनमेंट को नुकसान पहुंचा सकते हैं। उदाहरण के लिए यदि आपने छवियों को प्रोसेस करने के लिए `Pillow` जैसे मासूम पैकेज की अनुमति दी है, तो LLM आपकी हार्ड ड्राइव को ब्लोट करने के लिए हजारों छवियों को सेव कर सकता है।
+यदि आपने खुद LLM इंजन चुना है तो यह निश्चित रूप से संभावित नहीं है, लेकिन यह हो सकता है।
+
+तो यदि आप अतिरिक्त सावधानी बरतना चाहते हैं, तो आप नीचे वर्णित रिमोट कोड एक्जीक्यूशन विकल्प का उपयोग कर सकते हैं।
+
+### E2B कोड एक्जीक्यूटर
+
+अधिकतम सुरक्षा के लिए, आप कोड को सैंडबॉक्स्ड एनवायरनमेंट में चलाने के लिए E2B के साथ हमारे एकीकरण का उपयोग कर सकते हैं। यह एक रिमोट एक्जीक्यूशन सेवा है जो आपके कोड को एक आइसोलेटेड कंटेनर में चलाती है, जिससे कोड का आपके स्थानीय एनवायरनमेंट को प्रभावित करना असंभव हो जाता है।
+
+इसके लिए, आपको अपना E2B अकाउंट सेटअप करने और अपने एनवायरनमेंट वेरिएबल्स में अपना `E2B_API_KEY` सेट करने की आवश्यकता होगी। अधिक जानकारी के लिए [E2B की क्विकस्टार्ट डॉक्यूमेंटेशन](https://e2b.dev/docs/quickstart) पर जाएं।
+
+फिर आप इसे `pip install e2b-code-interpreter python-dotenv` के साथ इंस्टॉल कर सकते हैं।
+
+अब आप तैयार हैं!
+
+कोड एक्जीक्यूटर को E2B पर सेट करने के लिए, बस अपने `CodeAgent` को इनिशियलाइज़ करते समय `executor_type="e2b"` फ्लैग पास करें।
+ध्यान दें कि आपको `additional_authorized_imports` में सभी टूल की डिपेंडेंसीज़ जोड़नी चाहिए, ताकि एक्जीक्यूटर उन्हें इंस्टॉल करे।
+
+```py
+from smolagents import CodeAgent, VisitWebpageTool, InferenceClientModel
+agent = CodeAgent(
+ tools = [VisitWebpageTool()],
+ model=InferenceClientModel(),
+ additional_authorized_imports=["requests", "markdownify"],
+ executor_type="e2b"
+)
+
+agent.run("What was Abraham Lincoln's preferred pet?")
+```
+
+E2B कोड एक्जीक्यूशन वर्तमान में मल्टी-एजेंट्स के साथ काम नहीं करता है - क्योंकि कोड ब्लॉब में एक एजेंट कॉल करना जो रिमोटली एक्जीक्यूट किया जाना चाहिए, यह एक गड़बड़ है। लेकिन हम इसे जोड़ने पर काम कर रहे हैं!
diff --git a/smolagents/docs/source/hi/tutorials/tools.mdx b/smolagents/docs/source/hi/tutorials/tools.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..2695217d22073ecf9501df4eb5b1a216cc95a40e
--- /dev/null
+++ b/smolagents/docs/source/hi/tutorials/tools.mdx
@@ -0,0 +1,232 @@
+# Tools
+
+[[open-in-colab]]
+
+यहाँ, हम एडवांस्ड tools उपयोग देखेंगे।
+
+> [!TIP]
+> यदि आप एजेंट्स बनाने में नए हैं, तो सबसे पहले [एजेंट्स का परिचय](../conceptual_guides/intro_agents) और [smolagents की गाइडेड टूर](../guided_tour) पढ़ना सुनिश्चित करें।
+
+- [Tools](#tools)
+ - [टूल क्या है, और इसे कैसे बनाएं?](#टूल-क्या-है-और-इसे-कैसे-बनाएं)
+ - [अपना टूल हब पर शेयर करें](#अपना-टूल-हब-पर-शेयर-करें)
+ - [स्पेस को टूल के रूप में इम्पोर्ट करें](#स्पेस-को-टूल-के-रूप-में-इम्पोर्ट-करें)
+ - [LangChain टूल्स का उपयोग करें](#LangChain-टूल्स-का-उपयोग-करें)
+ - [अपने एजेंट के टूलबॉक्स को मैनेज करें](#अपने-एजेंट-के-टूलबॉक्स-को-मैनेज-करें)
+ - [टूल्स का कलेक्शन उपयोग करें](#टूल्स-का-कलेक्शन-उपयोग-करें)
+
+### टूल क्या है और इसे कैसे बनाएं
+
+टूल मुख्य रूप से एक फ़ंक्शन है जिसे एक LLM एजेंटिक सिस्टम में उपयोग कर सकता है।
+
+लेकिन इसका उपयोग करने के लिए, LLM को एक API दी जाएगी: नाम, टूल विवरण, इनपुट प्रकार और विवरण, आउटपुट प्रकार।
+
+इसलिए यह केवल एक फ़ंक्शन नहीं हो सकता। यह एक क्लास होनी चाहिए।
+
+तो मूल रूप से, टूल एक क्लास है जो एक फ़ंक्शन को मेटाडेटा के साथ रैप करती है जो LLM को समझने में मदद करती है कि इसका उपयोग कैसे करें।
+
+यह कैसा दिखता है:
+
+```python
+from smolagents import Tool
+
+class HFModelDownloadsTool(Tool):
+ name = "model_download_counter"
+ description = """
+ This is a tool that returns the most downloaded model of a given task on the Hugging Face Hub.
+ It returns the name of the checkpoint."""
+ inputs = {
+ "task": {
+ "type": "string",
+ "description": "the task category (such as text-classification, depth-estimation, etc)",
+ }
+ }
+ output_type = "string"
+
+ def forward(self, task: str):
+ from huggingface_hub import list_models
+
+ model = next(iter(list_models(filter=task, sort="downloads", direction=-1)))
+ return model.id
+
+model_downloads_tool = HFModelDownloadsTool()
+```
+
+कस्टम टूल `Tool` को सबक्लास करता है उपयोगी मेथड्स को इनहेरिट करने के लिए। चाइल्ड क्लास भी परिभाषित करती है:
+- एक `name` एट्रिब्यूट, जो टूल के नाम से संबंधित है। नाम आमतौर पर बताता है कि टूल क्या करता है। चूंकि कोड एक टास्क के लिए सबसे अधिक डाउनलोड वाले मॉडल को रिटर्न करता है, इसलिए इसे `model_download_counter` नाम दें।
+- एक `description` एट्रिब्यूट एजेंट के सिस्टम प्रॉम्प्ट को पॉपुलेट करने के लिए उपयोग किया जाता है।
+- एक `inputs` एट्रिब्यूट, जो `"type"` और `"description"` keys वाला डिक्शनरी है। इसमें जानकारी होती है जो पायथन इंटरप्रेटर को इनपुट के बारे में शिक्षित विकल्प चुनने में मदद करती है।
+- एक `output_type` एट्रिब्यूट, जो आउटपुट टाइप को निर्दिष्ट करता है। `inputs` और `output_type` दोनों के लिए टाइप [Pydantic formats](https://docs.pydantic.dev/latest/concepts/json_schema/#generating-json-schema) होने चाहिए, वे इनमें से कोई भी हो सकते हैं: [`~AUTHORIZED_TYPES`]।
+- एक `forward` मेथड जिसमें एक्जीक्यूट किया जाने वाला इन्फरेंस कोड होता है।
+
+एजेंट में उपयोग किए जाने के लिए इतना ही चाहिए!
+
+टूल बनाने का एक और तरीका है। [guided_tour](../guided_tour) में, हमने `@tool` डेकोरेटर का उपयोग करके एक टूल को लागू किया। [`tool`] डेकोरेटर सरल टूल्स को परिभाषित करने का अनुशंसित तरीका है, लेकिन कभी-कभी आपको इससे अधिक की आवश्यकता होती है: अधिक स्पष्टता के लिए एक क्लास में कई मेथड्स का उपयोग करना, या अतिरिक्त क्लास एट्रिब्यूट्स का उपयोग करना।
+
+इस स्थिति में, आप ऊपर बताए अनुसार [`Tool`] को सबक्लास करके अपना टूल बना सकते हैं।
+
+### अपना टूल हब पर शेयर करें
+
+आप टूल पर [`~Tool.push_to_hub`] को कॉल करके अपना कस्टम टूल हब पर शेयर कर सकते हैं। सुनिश्चित करें कि आपने हब पर इसके लिए एक रिपॉजिटरी बनाई है और आप रीड एक्सेस वाला टोकन उपयोग कर रहे हैं।
+
+```python
+model_downloads_tool.push_to_hub("{your_username}/hf-model-downloads", token="
+
+फिर आप इस टूल का उपयोग किसी अन्य टूल की तरह कर सकते हैं। उदाहरण के लिए, चलिए प्रॉम्प्ट `a rabbit wearing a space suit` को सुधारें और इसकी एक इमेज जनरेट करें। यह उदाहरण यह भी दिखाता है कि आप एजेंट को अतिरिक्त आर्ग्यूमेंट्स कैसे पास कर सकते हैं।
+
+```python
+from smolagents import CodeAgent, InferenceClientModel
+
+model = InferenceClientModel(model_id="Qwen/Qwen2.5-Coder-32B-Instruct")
+agent = CodeAgent(tools=[image_generation_tool], model=model)
+
+agent.run(
+ "Improve this prompt, then generate an image of it.", additional_args={'user_prompt': 'A rabbit wearing a space suit'}
+)
+```
+
+```text
+=== Agent thoughts:
+improved_prompt could be "A bright blue space suit wearing rabbit, on the surface of the moon, under a bright orange sunset, with the Earth visible in the background"
+
+Now that I have improved the prompt, I can use the image generator tool to generate an image based on this prompt.
+>>> Agent is executing the code below:
+image = image_generator(prompt="A bright blue space suit wearing rabbit, on the surface of the moon, under a bright orange sunset, with the Earth visible in the background")
+final_answer(image)
+```
+
+
+
+यह कितना कूल है? 🤩
+
+### LangChain टूल्स का उपयोग करें
+
+हम LangChain को पसंद करते हैं और मानते हैं कि इसके पास टूल्स का एक बहुत आकर्षक संग्रह है।
+LangChain से एक टूल इम्पोर्ट करने के लिए, `from_langchain()` मेथड का उपयोग करें।
+
+यहाँ बताया गया है कि आप LangChain वेब सर्च टूल का उपयोग करके परिचय के सर्च रिजल्ट को कैसे फिर से बना सकते हैं।
+इस टूल को काम करने के लिए `pip install langchain google-search-results -q` की आवश्यकता होगी।
+```python
+from langchain.agents import load_tools
+
+search_tool = Tool.from_langchain(load_tools(["serpapi"])[0])
+
+agent = CodeAgent(tools=[search_tool], model=model)
+
+agent.run("How many more blocks (also denoted as layers) are in BERT base encoder compared to the encoder from the architecture proposed in Attention is All You Need?")
+```
+
+### अपने एजेंट के टूलबॉक्स को मैनेज करें
+
+आप एजेंट के टूलबॉक्स को `agent.tools` एट्रिब्यूट में एक टूल जोड़कर या बदलकर मैनेज कर सकते हैं, क्योंकि यह एक स्टैंडर्ड डिक्शनरी है।
+
+चलिए केवल डिफ़ॉल्ट टूलबॉक्स के साथ इनिशियलाइज़ किए गए मौजूदा एजेंट में `model_download_tool` जोड़ें।
+
+```python
+from smolagents import InferenceClientModel
+
+model = InferenceClientModel(model_id="Qwen/Qwen2.5-Coder-32B-Instruct")
+
+agent = CodeAgent(tools=[], model=model, add_base_tools=True)
+agent.tools[model_download_tool.name] = model_download_tool
+```
+अब हम नए टूल का लाभ उठा सकते हैं।
+
+```python
+agent.run(
+ "Can you give me the name of the model that has the most downloads in the 'text-to-video' task on the Hugging Face Hub but reverse the letters?"
+)
+```
+
+
+> [!TIP]
+> एजेंट में बहुत अधिक टूल्स न जोड़ने से सावधान रहें: यह कमजोर LLM इंजन को ओवरव्हेल्म कर सकता है।
+
+
+### टूल्स का कलेक्शन उपयोग करें
+
+आप `ToolCollection` ऑब्जेक्ट का उपयोग करके टूल कलेक्शंस का लाभ उठा सकते हैं। यह या तो हब से एक कलेक्शन या MCP सर्वर टूल्स को लोड करने का समर्थन करता है।
+
+#### हब में कलेक्शन से टूल कलेक्शन
+
+आप उस कलेक्शन के स्लग के साथ इसका लाभ उठा सकते हैं जिसका आप उपयोग करना चाहते हैं।
+फिर उन्हें अपने एजेंट को इनिशियलाइज़ करने के लिए एक लिस्ट के रूप में पास करें, और उनका उपयोग शुरू करें!
+
+```py
+from smolagents import ToolCollection, CodeAgent
+
+image_tool_collection = ToolCollection.from_hub(
+ collection_slug="huggingface-tools/diffusion-tools-6630bb19a942c2306a2cdb6f",
+ token="
+
+
+与 JSON 片段相比,用代码编写动作提供了更好的:
+
+- **可组合性:** 你能像定义 python 函数一样,将 JSON 动作嵌套在一起,或定义一组 JSON 动作以供重用吗?
+- **对象管理:** 你如何在 JSON 中存储像 `generate_image` 这样的动作的输出?
+- **通用性:** 代码被构建为简单地表达任何你可以让计算机做的事情。
+- **LLM 训练数据中的表示:** 大量高质量的代码动作已经包含在 LLM 的训练数据中,这意味着它们已经为此进行了训练!
diff --git a/smolagents/docs/source/zh/conceptual_guides/react.mdx b/smolagents/docs/source/zh/conceptual_guides/react.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..44760fb0c7dccb0ce6aadc065e19e1797e34eed0
--- /dev/null
+++ b/smolagents/docs/source/zh/conceptual_guides/react.mdx
@@ -0,0 +1,29 @@
+# 多步骤 agent 是如何工作的?
+
+ReAct 框架([Yao et al., 2022](https://huggingface.co/papers/2210.03629))是目前构建 agent 的主要方法。
+
+该名称基于两个词的组合:"Reason" (推理)和 "Act" (行动)。实际上,遵循此架构的 agent 将根据需要尽可能多的步骤来解决其任务,每个步骤包括一个推理步骤,然后是一个行动步骤,在该步骤中,它制定工具调用,使其更接近解决手头的任务。
+
+ReAct 过程涉及保留过去步骤的记忆。
+
+> [!TIP]
+> 阅读 [Open-source LLMs as LangChain Agents](https://huggingface.co/blog/open-source-llms-as-agents) 博客文章以了解更多关于多步 agent 的信息。
+
+以下是其工作原理的视频概述:
+
+
+
+
+
+
+如图所示,CodeAgent 调用了其托管的 ToolCallingAgent(注:托管Agent也可以是另一个 CodeAgent)执行美国2024年经济增长率的网络搜索。托管Agent返回报告后,管理Agent根据结果计算出经济翻倍周期!是不是很智能?
+
+## 使用 Langfuse 配置遥测
+
+本部分演示如何通过 `SmolagentsInstrumentor` 使用 **Langfuse** 监控和调试 Hugging Face **smolagents**。
+
+> **Langfuse 是什么?** [Langfuse](https://langfuse.com) 是面向LLM工程的开源平台,提供AI Agent的追踪与监控功能,帮助开发者调试、分析和优化产品。该平台通过原生集成、OpenTelemetry 和 SDKs 与各类工具框架对接。
+
+### 步骤 1: 安装依赖
+
+```python
+%pip install smolagents
+%pip install opentelemetry-sdk opentelemetry-exporter-otlp openinference-instrumentation-smolagents
+```
+
+### 步骤 2: 配置环境变量
+
+设置 Langfuse API 密钥,并配置 OpenTelemetry 端点将追踪数据发送至 Langfuse。通过注册 [Langfuse Cloud](https://cloud.langfuse.com) 或 [自托管 Langfuse](https://langfuse.com/self-hosting) 获取 API 密钥。
+
+同时需添加 [Hugging Face 令牌](https://huggingface.co/settings/tokens) (`HF_TOKEN`) 作为环境变量:
+```python
+import os
+import base64
+
+LANGFUSE_PUBLIC_KEY="pk-lf-..."
+LANGFUSE_SECRET_KEY="sk-lf-..."
+LANGFUSE_AUTH=base64.b64encode(f"{LANGFUSE_PUBLIC_KEY}:{LANGFUSE_SECRET_KEY}".encode()).decode()
+
+os.environ["OTEL_EXPORTER_OTLP_ENDPOINT"] = "https://cloud.langfuse.com/api/public/otel" # EU data region
+# os.environ["OTEL_EXPORTER_OTLP_ENDPOINT"] = "https://us.cloud.langfuse.com/api/public/otel" # US data region
+os.environ["OTEL_EXPORTER_OTLP_HEADERS"] = f"Authorization=Basic {LANGFUSE_AUTH}"
+
+# your Hugging Face token
+os.environ["HF_TOKEN"] = "hf_..."
+```
+
+### 步骤 3: 初始化 `SmolagentsInstrumentor`
+
+在应用程序代码执行前初始化 `SmolagentsInstrumentor`。配置 `tracer_provider` 并添加 span processor 将追踪数据导出至 Langfuse。`OTLPSpanExporter()` 会自动使用环境变量中配置的端点和请求头。
+
+
+```python
+from opentelemetry.sdk.trace import TracerProvider
+
+from openinference.instrumentation.smolagents import SmolagentsInstrumentor
+from opentelemetry.exporter.otlp.proto.http.trace_exporter import OTLPSpanExporter
+from opentelemetry.sdk.trace.export import SimpleSpanProcessor
+
+trace_provider = TracerProvider()
+trace_provider.add_span_processor(SimpleSpanProcessor(OTLPSpanExporter()))
+
+SmolagentsInstrumentor().instrument(tracer_provider=trace_provider)
+```
+
+### 步骤 4: 运行 smolagent
+
+```python
+from smolagents import (
+ CodeAgent,
+ ToolCallingAgent,
+ DuckDuckGoSearchTool,
+ VisitWebpageTool,
+ InferenceClientModel,
+)
+
+model = InferenceClientModel(
+ model_id="deepseek-ai/DeepSeek-R1-Distill-Qwen-32B"
+)
+
+search_agent = ToolCallingAgent(
+ tools=[DuckDuckGoSearchTool(), VisitWebpageTool()],
+ model=model,
+ name="search_agent",
+ description="This is an agent that can do web search.",
+)
+
+manager_agent = CodeAgent(
+ tools=[],
+ model=model,
+ managed_agents=[search_agent],
+)
+manager_agent.run(
+ "How can Langfuse be used to monitor and improve the reasoning and decision-making of smolagents when they execute multi-step tasks, like dynamically adjusting a recipe based on user feedback or available ingredients?"
+)
+```
+
+### 步骤 5: 在 Langfuse 中查看追踪记录
+
+运行Agent后,您可以在 [Langfuse](https://cloud.langfuse.com) 平台查看 smolagents 应用生成的追踪记录。这些记录会详细展示LLM的交互步骤,帮助您调试和优化AI代理。
+
+
+
+_[Langfuse 公开示例追踪](https://cloud.langfuse.com/project/cloramnkj0002jz088vzn1ja4/traces/ce5160f9bfd5a6cd63b07d2bfcec6f54?timestamp=2025-02-11T09%3A25%3A45.163Z&display=details)_
\ No newline at end of file
diff --git a/smolagents/docs/source/zh/tutorials/memory.mdx b/smolagents/docs/source/zh/tutorials/memory.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..de2bdc8c3e819ec2374f0d9c26d608f2b16c6f85
--- /dev/null
+++ b/smolagents/docs/source/zh/tutorials/memory.mdx
@@ -0,0 +1,131 @@
+# 📚 管理Agent的记忆
+
+[[open-in-colab]]
+
+归根结底,Agent可以定义为由几个简单组件构成:它拥有工具、提示词。最重要的是,它具备对过往步骤的记忆,能够追溯完整的规划、执行和错误历史。
+
+### 回放Agent的记忆
+
+我们提供了多项功能来审查Agent的过往运行记录。
+
+您可以通过插装(instrumentation)在可视化界面中查看Agent的运行过程,该界面支持对特定步骤进行缩放操作,具体方法参见[插装指南](./inspect_runs)。
+
+您也可以使用`agent.replay()`方法实现回放:
+
+当Agent完成运行后:
+```py
+from smolagents import InferenceClientModel, CodeAgent
+
+agent = CodeAgent(tools=[], model=InferenceClientModel(), verbosity_level=0)
+
+result = agent.run("What's the 20th Fibonacci number?")
+```
+
+若要回放最近一次运行,只需使用:
+```py
+agent.replay()
+```
+
+### 动态修改Agent的记忆
+
+许多高级应用场景需要对Agent的记忆进行动态修改。
+
+您可以通过以下方式访问Agent的记忆:
+
+```py
+from smolagents import ActionStep
+
+system_prompt_step = agent.memory.system_prompt
+print("The system prompt given to the agent was:")
+print(system_prompt_step.system_prompt)
+
+task_step = agent.memory.steps[0]
+print("\n\nThe first task step was:")
+print(task_step.task)
+
+for step in agent.memory.steps:
+ if isinstance(step, ActionStep):
+ if step.error is not None:
+ print(f"\nStep {step.step_number} got this error:\n{step.error}\n")
+ else:
+ print(f"\nStep {step.step_number} got these observations:\n{step.observations}\n")
+```
+
+使用`agent.memory.get_full_steps()`可获取完整步骤字典数据。
+
+您还可以通过步骤回调(step callbacks)实现记忆的动态修改。
+
+步骤回调函数可通过参数直接访问`agent`对象,因此能够访问所有记忆步骤并根据需要进行修改。例如,假设您正在监控网页浏览Agent每个步骤的屏幕截图,希望保留最新截图同时删除旧步骤的图片以节省token消耗。
+
+可参考以下代码示例:
+_注:此代码片段不完整,部分导入语句和对象定义已精简,完整代码请访问[原始脚本](https://github.com/huggingface/smolagents/blob/main/src/smolagents/vision_web_browser.py)_
+
+```py
+import helium
+from PIL import Image
+from io import BytesIO
+from time import sleep
+
+def update_screenshot(memory_step: ActionStep, agent: CodeAgent) -> None:
+ sleep(1.0) # Let JavaScript animations happen before taking the screenshot
+ driver = helium.get_driver()
+ latest_step = memory_step.step_number
+ for previous_memory_step in agent.memory.steps: # Remove previous screenshots from logs for lean processing
+ if isinstance(previous_memory_step, ActionStep) and previous_memory_step.step_number <= latest_step - 2:
+ previous_memory_step.observations_images = None
+ png_bytes = driver.get_screenshot_as_png()
+ image = Image.open(BytesIO(png_bytes))
+ memory_step.observations_images = [image.copy()]
+```
+
+最后在初始化Agent时,将此函数传入`step_callbacks`参数:
+
+```py
+CodeAgent(
+ tools=[DuckDuckGoSearchTool(), go_back, close_popups, search_item_ctrl_f],
+ model=model,
+ additional_authorized_imports=["helium"],
+ step_callbacks=[update_screenshot],
+ max_steps=20,
+ verbosity_level=2,
+)
+```
+
+请访问我们的 [vision web browser code](https://github.com/huggingface/smolagents/blob/main/src/smolagents/vision_web_browser.py) 查看完整可运行示例。
+
+### 分步运行 Agents
+
+当您需要处理耗时数天的工具调用时,这种方式特别有用:您可以逐步执行Agents。这还允许您在每一步更新记忆。
+
+```py
+from smolagents import InferenceClientModel, CodeAgent, ActionStep, TaskStep
+
+agent = CodeAgent(tools=[], model=InferenceClientModel(), verbosity_level=1)
+print(agent.memory.system_prompt)
+
+task = "What is the 20th Fibonacci number?"
+
+# You could modify the memory as needed here by inputting the memory of another agent.
+# agent.memory.steps = previous_agent.memory.steps
+
+# Let's start a new task!
+agent.memory.steps.append(TaskStep(task=task, task_images=[]))
+
+final_answer = None
+step_number = 1
+while final_answer is None and step_number <= 10:
+ memory_step = ActionStep(
+ step_number=step_number,
+ observations_images=[],
+ )
+ # Run one step.
+ final_answer = agent.step(memory_step)
+ agent.memory.steps.append(memory_step)
+ step_number += 1
+
+ # Change the memory as you please!
+ # For instance to update the latest step:
+ # agent.memory.steps[-1] = ...
+
+print("The final answer is:", final_answer)
+```
\ No newline at end of file
diff --git a/smolagents/docs/source/zh/tutorials/secure_code_execution.mdx b/smolagents/docs/source/zh/tutorials/secure_code_execution.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..93e80986a984b83196d38b9113e46ba9171ec82d
--- /dev/null
+++ b/smolagents/docs/source/zh/tutorials/secure_code_execution.mdx
@@ -0,0 +1,67 @@
+# 安全代码执行
+
+[[open-in-colab]]
+
+> [!TIP]
+> 如果你是第一次构建 agent,请先阅读 [agent 介绍](../conceptual_guides/intro_agents) 和 [smolagents 导览](../guided_tour)。
+
+### 代码智能体
+
+[多项](https://huggingface.co/papers/2402.01030) [研究](https://huggingface.co/papers/2411.01747) [表明](https://huggingface.co/papers/2401.00812),让大语言模型用代码编写其动作(工具调用)比当前标准的工具调用格式要好得多,目前行业标准是 "将动作写成包含工具名称和参数的 JSON" 的各种变体。
+
+为什么代码更好?因为我们专门为计算机执行的动作而设计编程语言。如果 JSON 片段是更好的方式,那么这个工具包就应该是用 JSON 片段编写的,魔鬼就会嘲笑我们。
+
+代码就是表达计算机动作的更好方式。它具有更好的:
+- **组合性**:你能像定义 Python 函数那样,在 JSON 动作中嵌套其他 JSON 动作,或者定义一组 JSON 动作以便以后重用吗?
+- **对象管理**:你如何在 JSON 中存储像 `generate_image` 这样的动作的输出?
+- **通用性**:代码是为了简单地表达任何可以让计算机做的事情而构建的。
+- **在 LLM 训练语料库中的表示**:天赐良机,为什么不利用已经包含在 LLM 训练语料库中的大量高质量动作呢?
+
+下图展示了这一点,取自 [可执行代码动作引出更好的 LLM 智能体](https://huggingface.co/papers/2402.01030)。
+
+
+
+这就是为什么我们强调提出代码智能体,在本例中是 Python 智能体,这意味着我们要在构建安全的 Python 解释器上投入更多精力。
+
+### 本地 Python 解释器
+
+默认情况下,`CodeAgent` 会在你的环境中运行 LLM 生成的代码。
+这个执行不是由普通的 Python 解释器完成的:我们从零开始重新构建了一个更安全的 `LocalPythonExecutor`。
+这个解释器通过以下方式设计以确保安全:
+ - 将导入限制为用户显式传递的列表
+ - 限制操作次数以防止无限循环和资源膨胀
+ - 不会执行任何未预定义的操作
+
+我们已经在许多用例中使用了这个解释器,从未观察到对环境造成任何损害。
+
+然而,这个解决方案并不是万无一失的:可以想象,如果 LLM 被微调用于恶意操作,仍然可能损害你的环境。例如,如果你允许像 `Pillow` 这样无害的包处理图像,LLM 可能会生成数千张图像保存以膨胀你的硬盘。
+如果你自己选择了 LLM 引擎,这当然不太可能,但它可能会发生。
+
+所以如果你想格外谨慎,可以使用下面描述的远程代码执行选项。
+
+### E2B 代码执行器
+
+为了最大程度的安全性,你可以使用我们与 E2B 的集成在沙盒环境中运行代码。这是一个远程执行服务,可以在隔离的容器中运行你的代码,使代码无法影响你的本地环境。
+
+为此,你需要设置你的 E2B 账户并在环境变量中设置 `E2B_API_KEY`。请前往 [E2B 快速入门文档](https://e2b.dev/docs/quickstart) 了解更多信息。
+
+然后你可以通过 `pip install e2b-code-interpreter python-dotenv` 安装它。
+
+现在你已经准备好了!
+
+要将代码执行器设置为 E2B,只需在初始化 `CodeAgent` 时传递标志 `executor_type="e2b"`。
+请注意,你应该将所有工具的依赖项添加到 `additional_authorized_imports` 中,以便执行器安装它们。
+
+```py
+from smolagents import CodeAgent, VisitWebpageTool, InferenceClientModel
+agent = CodeAgent(
+ tools = [VisitWebpageTool()],
+ model=InferenceClientModel(),
+ additional_authorized_imports=["requests", "markdownify"],
+ executor_type="e2b"
+)
+
+agent.run("What was Abraham Lincoln's preferred pet?")
+```
+
+目前 E2B 代码执行暂不兼容多 agent——因为把 agent 调用放在应该在远程执行的代码块里,是非常混乱的。但我们正在努力做到这件事!
diff --git a/smolagents/docs/source/zh/tutorials/tools.mdx b/smolagents/docs/source/zh/tutorials/tools.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..9256bd0a35c75f5880d578442bdbbb8447f92d7a
--- /dev/null
+++ b/smolagents/docs/source/zh/tutorials/tools.mdx
@@ -0,0 +1,206 @@
+# 工具
+
+[[open-in-colab]]
+
+在这里,我们将学习高级工具的使用。
+
+> [!TIP]
+> 如果你是构建 agent 的新手,请确保先阅读 [agent 介绍](../conceptual_guides/intro_agents) 和 [smolagents 导览](../guided_tour)。
+
+- [工具](#工具)
+ - [什么是工具,如何构建一个工具?](#什么是工具如何构建一个工具)
+ - [将你的工具分享到 Hub](#将你的工具分享到-hub)
+ - [将 Space 导入为工具](#将-space-导入为工具)
+ - [使用 LangChain 工具](#使用-langchain-工具)
+ - [管理你的 agent 工具箱](#管理你的-agent-工具箱)
+ - [使用工具集合](#使用工具集合)
+
+### 什么是工具,如何构建一个工具?
+
+工具主要是 LLM 可以在 agent 系统中使用的函数。
+
+但要使用它,LLM 需要被提供一个 API:名称、工具描述、输入类型和描述、输出类型。
+
+所以它不能仅仅是一个函数。它应该是一个类。
+
+因此,核心上,工具是一个类,它包装了一个函数,并带有帮助 LLM 理解如何使用它的元数据。
+
+以下是它的结构:
+
+```python
+from smolagents import Tool
+
+class HFModelDownloadsTool(Tool):
+ name = "model_download_counter"
+ description = """
+ This is a tool that returns the most downloaded model of a given task on the Hugging Face Hub.
+ It returns the name of the checkpoint."""
+ inputs = {
+ "task": {
+ "type": "string",
+ "description": "the task category (such as text-classification, depth-estimation, etc)",
+ }
+ }
+ output_type = "string"
+
+ def forward(self, task: str):
+ from huggingface_hub import list_models
+
+ model = next(iter(list_models(filter=task, sort="downloads", direction=-1)))
+ return model.id
+
+model_downloads_tool = HFModelDownloadsTool()
+```
+
+自定义工具继承 [`Tool`] 以继承有用的方法。子类还定义了:
+- 一个属性 `name`,对应于工具本身的名称。名称通常描述工具的功能。由于代码返回任务中下载量最多的模型,我们将其命名为 `model_download_counter`。
+- 一个属性 `description`,用于填充 agent 的系统提示。
+- 一个 `inputs` 属性,它是一个带有键 `"type"` 和 `"description"` 的字典。它包含帮助 Python 解释器对输入做出明智选择的信息。
+- 一个 `output_type` 属性,指定输出类型。`inputs` 和 `output_type` 的类型应为 [Pydantic 格式](https://docs.pydantic.dev/latest/concepts/json_schema/#generating-json-schema),它们可以是以下之一:[`~AUTHORIZED_TYPES`]。
+- 一个 `forward` 方法,包含要执行的推理代码。
+
+这就是它在 agent 中使用所需的全部内容!
+
+还有另一种构建工具的方法。在 [guided_tour](../guided_tour) 中,我们使用 `@tool` 装饰器实现了一个工具。[`tool`] 装饰器是定义简单工具的推荐方式,但有时你需要更多:在类中使用多个方法以获得更清晰的代码,或使用额外的类属性。
+
+在这种情况下,你可以通过如上所述继承 [`Tool`] 来构建你的工具。
+
+### 将你的工具分享到 Hub
+
+你可以通过调用 [`~Tool.push_to_hub`] 将你的自定义工具分享到 Hub。确保你已经在 Hub 上为其创建了一个仓库,并且使用的是具有读取权限的 token。
+
+```python
+model_downloads_tool.push_to_hub("{your_username}/hf-model-downloads", token="
+
+然后你可以像使用任何其他工具一样使用这个工具。例如,让我们改进提示 `A rabbit wearing a space suit` 并生成它的图片。
+
+```python
+from smolagents import CodeAgent, InferenceClientModel
+
+model = InferenceClientModel(model_id="Qwen/Qwen2.5-Coder-32B-Instruct")
+agent = CodeAgent(tools=[image_generation_tool], model=model)
+
+agent.run(
+ "Improve this prompt, then generate an image of it.", additional_args={'user_prompt': 'A rabbit wearing a space suit'}
+)
+```
+
+```text
+=== Agent thoughts:
+improved_prompt could be "A bright blue space suit wearing rabbit, on the surface of the moon, under a bright orange sunset, with the Earth visible in the background"
+
+Now that I have improved the prompt, I can use the image generator tool to generate an image based on this prompt.
+>>> Agent is executing the code below:
+image = image_generator(prompt="A bright blue space suit wearing rabbit, on the surface of the moon, under a bright orange sunset, with the Earth visible in the background")
+final_answer(image)
+```
+
+
+
+这得有多酷?🤩
+
+### 使用 LangChain 工具
+
+我们喜欢 Langchain,并认为它有一套非常吸引人的工具。
+要从 LangChain 导入工具,请使用 `from_langchain()` 方法。
+
+以下是如何使用它来重现介绍中的搜索结果,使用 LangChain 的 web 搜索工具。
+这个工具需要 `pip install langchain google-search-results -q` 才能正常工作。
+```python
+from langchain.agents import load_tools
+
+search_tool = Tool.from_langchain(load_tools(["serpapi"])[0])
+
+agent = CodeAgent(tools=[search_tool], model=model)
+
+agent.run("How many more blocks (also denoted as layers) are in BERT base encoder compared to the encoder from the architecture proposed in Attention is All You Need?")
+```
+
+### 管理你的 agent 工具箱
+
+你可以通过添加或替换工具来管理 agent 的工具箱。
+
+让我们将 `model_download_tool` 添加到一个仅使用默认工具箱初始化的现有 agent 中。
+
+```python
+from smolagents import InferenceClientModel
+
+model = InferenceClientModel(model_id="Qwen/Qwen2.5-Coder-32B-Instruct")
+
+agent = CodeAgent(tools=[], model=model, add_base_tools=True)
+agent.tools[model_download_tool.name] = model_download_tool
+```
+现在我们可以利用新工具:
+
+```python
+agent.run(
+ "Can you give me the name of the model that has the most downloads in the 'text-to-video' task on the Hugging Face Hub but reverse the letters?"
+)
+```
+
+
+> [!TIP]
+> 注意不要向 agent 添加太多工具:这可能会让较弱的 LLM 引擎不堪重负。
+
+
+### 使用工具集合
+
+你可以通过使用 ToolCollection 对象来利用工具集合,使用你想要使用的集合的 slug。
+然后将它们作为列表传递给 agent 初始化,并开始使用它们!
+
+```py
+from smolagents import ToolCollection, CodeAgent
+
+image_tool_collection = ToolCollection.from_hub(
+ collection_slug="huggingface-tools/diffusion-tools-6630bb19a942c2306a2cdb6f",
+ token="| " + html.escape(cell.text) + " | " + else: + html_table += "" + html.escape(cell.text) + " | " + html_table += "
|---|