diff --git a/.gitattributes b/.gitattributes
index a6344aac8c09253b3b630fb776ae94478aa0275b..afb6ff454f89ad48020a1e53df1ecf77bbe1717b 100644
--- a/.gitattributes
+++ b/.gitattributes
@@ -33,3 +33,9 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
*.zip filter=lfs diff=lfs merge=lfs -text
*.zst filter=lfs diff=lfs merge=lfs -text
*tfevents* filter=lfs diff=lfs merge=lfs -text
+docs/images/fastcpu-webui.png filter=lfs diff=lfs merge=lfs -text
+docs/images/fastsdcpu-android-termux-pixel7.png filter=lfs diff=lfs merge=lfs -text
+docs/images/fastsdcpu-gui.jpg filter=lfs diff=lfs merge=lfs -text
+docs/images/fastsdcpu-screenshot.png filter=lfs diff=lfs merge=lfs -text
+docs/images/fastsdcpu-webui.png filter=lfs diff=lfs merge=lfs -text
+docs/images/fastsdcpu_flux_on_cpu.png filter=lfs diff=lfs merge=lfs -text
diff --git a/.gitignore b/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..0542bc81f9b21a2a82d07487b7417141731b413f
--- /dev/null
+++ b/.gitignore
@@ -0,0 +1,7 @@
+env
+*.bak
+*.pyc
+__pycache__
+results
+# excluding user settings for the GUI frontend
+configs/settings.yaml
diff --git a/LICENSE b/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..ab84360cb0e940f6e4af2c0731e51cac0f66d19a
--- /dev/null
+++ b/LICENSE
@@ -0,0 +1,21 @@
+MIT License
+
+Copyright (c) 2023 Rupesh Sreeraman
+
+Permission is hereby granted, free of charge, to any person obtaining a copy
+of this software and associated documentation files (the "Software"), to deal
+in the Software without restriction, including without limitation the rights
+to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+copies of the Software, and to permit persons to whom the Software is
+furnished to do so, subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in all
+copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+SOFTWARE.
diff --git a/Readme.md b/Readme.md
new file mode 100644
index 0000000000000000000000000000000000000000..cff2b33cacd274f61d27de389202cd418a326e3d
--- /dev/null
+++ b/Readme.md
@@ -0,0 +1,673 @@
+# FastSD CPU :sparkles:[](https://github.com/openvinotoolkit/awesome-openvino)
+
+<div align="center">
+ <a href="https://trendshift.io/repositories/3957" target="_blank"><img src="https://trendshift.io/api/badge/repositories/3957" alt="rupeshs%2Ffastsdcpu | Trendshift" style="width: 250px; height: 55px;" width="250" height="55"/></a>
+</div>
+
+FastSD CPU is a faster version of Stable Diffusion on CPU. Based on [Latent Consistency Models](https://github.com/luosiallen/latent-consistency-model) and
+[Adversarial Diffusion Distillation](https://nolowiz.com/fast-stable-diffusion-on-cpu-using-fastsd-cpu-and-openvino/).
+
+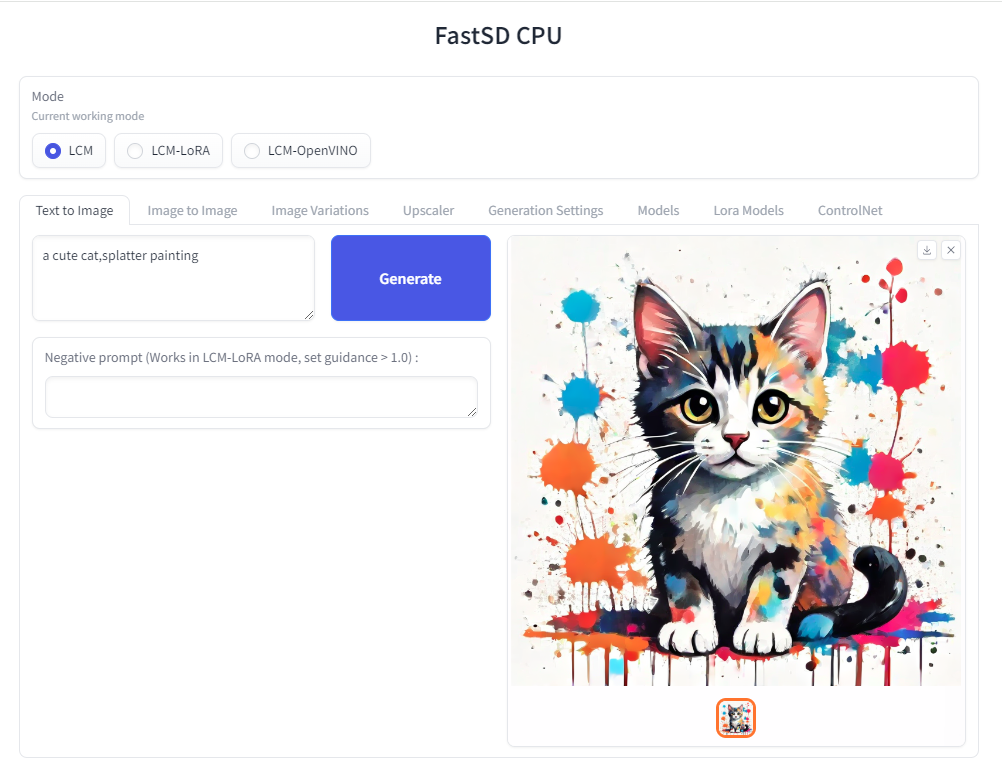
+The following interfaces are available :
+
+- Desktop GUI, basic text to image generation (Qt,faster)
+- WebUI (Advanced features,Lora,controlnet etc)
+- CLI (CommandLine Interface)
+
+🚀 Using __OpenVINO(SDXS-512-0.9)__, it took __0.82 seconds__ (__820 milliseconds__) to create a single 512x512 image on a __Core i7-12700__.
+
+## Table of Contents
+
+- [Supported Platforms](#Supported platforms)
+- [Dependencies](#dependencies)
+- [Memory requirements](#memory-requirements)
+- [Features](#features)
+- [Benchmarks](#fast-inference-benchmarks)
+- [OpenVINO Support](#openvino)
+- [Installation](#installation)
+- [AI PC Support - OpenVINO](#ai-pc-support)
+- [GGUF support (Flux)](#gguf-support)
+- [Real-time text to image (EXPERIMENTAL)](#real-time-text-to-image)
+- [Models](#models)
+- [How to use Lora models](#useloramodels)
+- [How to use controlnet](#usecontrolnet)
+- [Android](#android)
+- [Raspberry Pi 4](#raspberry)
+- [Orange Pi 5](#orangepi)
+- [API Support](#apisupport)
+- [License](#license)
+- [Contributors](#contributors)
+
+## Supported platforms⚡️
+
+FastSD CPU works on the following platforms:
+
+- Windows
+- Linux
+- Mac
+- Android + Termux
+- Raspberry PI 4
+
+## Dependencies
+
+- Python 3.10 or Python 3.11 (Please ensure that you have a working Python 3.10 or Python 3.11 installation available on the system)
+
+## Memory requirements
+
+Minimum system RAM requirement for FastSD CPU.
+
+Model (LCM,OpenVINO): SD Turbo, 1 step, 512 x 512
+
+Model (LCM-LoRA): Dreamshaper v8, 3 step, 512 x 512
+
+| Mode | Min RAM |
+| --------------------- | ------------- |
+| LCM | 2 GB |
+| LCM-LoRA | 4 GB |
+| OpenVINO | 11 GB |
+
+If we enable Tiny decoder(TAESD) we can save some memory(2GB approx) for example in OpenVINO mode memory usage will become 9GB.
+
+:exclamation: Please note that guidance scale >1 increases RAM usage and slow inference speed.
+
+## Features
+
+- Desktop GUI, web UI and CLI
+- Supports 256,512,768,1024 image sizes
+- Supports Windows,Linux,Mac
+- Saves images and diffusion setting used to generate the image
+- Settings to control,steps,guidance and seed
+- Added safety checker setting
+- Maximum inference steps increased to 25
+- Added [OpenVINO](https://github.com/openvinotoolkit/openvino) support
+- Fixed OpenVINO image reproducibility issue
+- Fixed OpenVINO high RAM usage,thanks [deinferno](https://github.com/deinferno)
+- Added multiple image generation support
+- Application settings
+- Added Tiny Auto Encoder for SD (TAESD) support, 1.4x speed boost (Fast,moderate quality)
+- Safety checker disabled by default
+- Added SDXL,SSD1B - 1B LCM models
+- Added LCM-LoRA support, works well for fine-tuned Stable Diffusion model 1.5 or SDXL models
+- Added negative prompt support in LCM-LoRA mode
+- LCM-LoRA models can be configured using text configuration file
+- Added support for custom models for OpenVINO (LCM-LoRA baked)
+- OpenVINO models now supports negative prompt (Set guidance >1.0)
+- Real-time inference support,generates images while you type (experimental)
+- Fast 2,3 steps inference
+- Lcm-Lora fused models for faster inference
+- Supports integrated GPU(iGPU) using OpenVINO (export DEVICE=GPU)
+- 5.7x speed using OpenVINO(steps: 2,tiny autoencoder)
+- Image to Image support (Use Web UI)
+- OpenVINO image to image support
+- Fast 1 step inference (SDXL Turbo)
+- Added SD Turbo support
+- Added image to image support for Turbo models (Pytorch and OpenVINO)
+- Added image variations support
+- Added 2x upscaler (EDSR and Tiled SD upscale (experimental)),thanks [monstruosoft](https://github.com/monstruosoft) for SD upscale
+- Works on Android + Termux + PRoot
+- Added interactive CLI,thanks [monstruosoft](https://github.com/monstruosoft)
+- Added basic lora support to CLI and WebUI
+- ONNX EDSR 2x upscale
+- Add SDXL-Lightning support
+- Add SDXL-Lightning OpenVINO support (int8)
+- Add multilora support,thanks [monstruosoft](https://github.com/monstruosoft)
+- Add basic ControlNet v1.1 support(LCM-LoRA mode),thanks [monstruosoft](https://github.com/monstruosoft)
+- Add ControlNet annotators(Canny,Depth,LineArt,MLSD,NormalBAE,Pose,SoftEdge,Shuffle)
+- Add SDXS-512 0.9 support
+- Add SDXS-512 0.9 OpenVINO,fast 1 step inference (0.8 seconds to generate 512x512 image)
+- Default model changed to SDXS-512-0.9
+- Faster realtime image generation
+- Add NPU device check
+- Revert default model to SDTurbo
+- Update realtime UI
+- Add hypersd support
+- 1 step fast inference support for SDXL and SD1.5
+- Experimental support for single file Safetensors SD 1.5 models(Civitai models), simply add local model path to configs/stable-diffusion-models.txt file.
+- Add REST API support
+- Add Aura SR (4x)/GigaGAN based upscaler support
+- Add Aura SR v2 upscaler support
+- Add FLUX.1 schnell OpenVINO int 4 support
+- Add CLIP skip support
+- Add token merging support
+- Add Intel AI PC support
+- AI PC NPU(Power efficient inference using OpenVINO) supports, text to image ,image to image and image variations support
+- Add [TAEF1 (Tiny autoencoder for FLUX.1) openvino](https://huggingface.co/rupeshs/taef1-openvino) support
+- Add Image to Image and Image Variations Qt GUI support,thanks [monstruosoft](https://github.com/monstruosoft)
+
+<a id="fast-inference-benchmarks"></a>
+
+## Fast Inference Benchmarks
+
+### 🚀 Fast 1 step inference with Hyper-SD
+
+#### Stable diffuion 1.5
+
+Works with LCM-LoRA mode.
+Fast 1 step inference supported on `runwayml/stable-diffusion-v1-5` model,select `rupeshs/hypersd-sd1-5-1-step-lora` lcm_lora model from the settings.
+
+#### Stable diffuion XL
+
+Works with LCM and LCM-OpenVINO mode.
+
+- *Hyper-SD SDXL 1 step* - [rupeshs/hyper-sd-sdxl-1-step](https://huggingface.co/rupeshs/hyper-sd-sdxl-1-step)
+
+- *Hyper-SD SDXL 1 step OpenVINO* - [rupeshs/hyper-sd-sdxl-1-step-openvino-int8](https://huggingface.co/rupeshs/hyper-sd-sdxl-1-step-openvino-int8)
+
+#### Inference Speed
+
+Tested on Core i7-12700 to generate __768x768__ image(1 step).
+
+| Diffusion Pipeline | Latency |
+| --------------------- | ------------- |
+| Pytorch | 19s |
+| OpenVINO | 13s |
+| OpenVINO + TAESDXL | 6.3s |
+
+### Fastest 1 step inference (SDXS-512-0.9)
+
+:exclamation:This is an experimental model, only text to image workflow is supported.
+
+#### Inference Speed
+
+Tested on Core i7-12700 to generate __512x512__ image(1 step).
+
+__SDXS-512-0.9__
+
+| Diffusion Pipeline | Latency |
+| --------------------- | ------------- |
+| Pytorch | 4.8s |
+| OpenVINO | 3.8s |
+| OpenVINO + TAESD | __0.82s__ |
+
+### 🚀 Fast 1 step inference (SD/SDXL Turbo - Adversarial Diffusion Distillation,ADD)
+
+Added support for ultra fast 1 step inference using [sdxl-turbo](https://huggingface.co/stabilityai/sdxl-turbo) model
+
+:exclamation: These SD turbo models are intended for research purpose only.
+
+#### Inference Speed
+
+Tested on Core i7-12700 to generate __512x512__ image(1 step).
+
+__SD Turbo__
+
+| Diffusion Pipeline | Latency |
+| --------------------- | ------------- |
+| Pytorch | 7.8s |
+| OpenVINO | 5s |
+| OpenVINO + TAESD | 1.7s |
+
+__SDXL Turbo__
+
+| Diffusion Pipeline | Latency |
+| --------------------- | ------------- |
+| Pytorch | 10s |
+| OpenVINO | 5.6s |
+| OpenVINO + TAESDXL | 2.5s |
+
+### 🚀 Fast 2 step inference (SDXL-Lightning - Adversarial Diffusion Distillation)
+
+SDXL-Lightning works with LCM and LCM-OpenVINO mode.You can select these models from app settings.
+
+Tested on Core i7-12700 to generate __768x768__ image(2 steps).
+
+| Diffusion Pipeline | Latency |
+| --------------------- | ------------- |
+| Pytorch | 18s |
+| OpenVINO | 12s |
+| OpenVINO + TAESDXL | 10s |
+
+- *SDXL-Lightning* - [rupeshs/SDXL-Lightning-2steps](https://huggingface.co/rupeshs/SDXL-Lightning-2steps)
+
+- *SDXL-Lightning OpenVINO* - [rupeshs/SDXL-Lightning-2steps-openvino-int8](https://huggingface.co/rupeshs/SDXL-Lightning-2steps-openvino-int8)
+
+### 2 Steps fast inference (LCM)
+
+FastSD CPU supports 2 to 3 steps fast inference using LCM-LoRA workflow. It works well with SD 1.5 models.
+
+
+
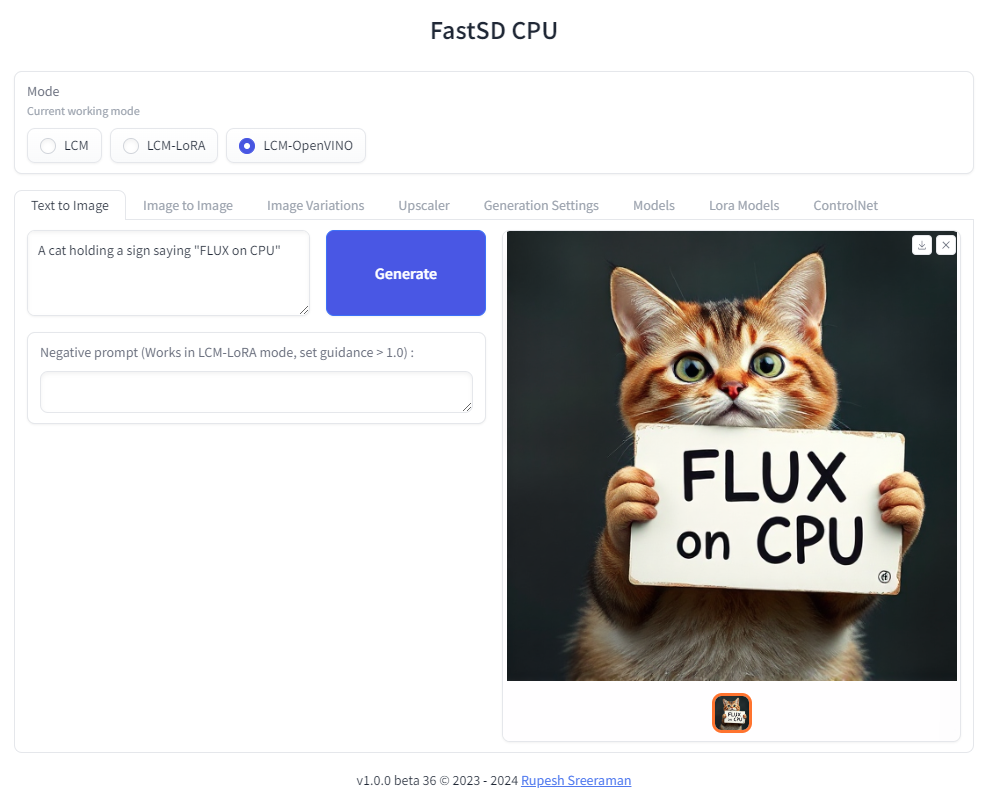
+### FLUX.1-schnell OpenVINO support
+
+
+
+:exclamation: Important - Please note the following points with FLUX workflow
+
+- As of now only text to image generation mode is supported
+- Use OpenVINO mode
+- Use int4 model - *rupeshs/FLUX.1-schnell-openvino-int4*
+- 512x512 image generation needs around __30GB__ system RAM
+
+Tested on Intel Core i7-12700 to generate __512x512__ image(3 steps).
+
+| Diffusion Pipeline | Latency |
+| --------------------- | ------------- |
+| OpenVINO | 4 min 30sec |
+
+### Benchmark scripts
+
+To benchmark run the following batch file on Windows:
+
+- `benchmark.bat` - To benchmark Pytorch
+- `benchmark-openvino.bat` - To benchmark OpenVINO
+
+Alternatively you can run benchmarks by passing `-b` command line argument in CLI mode.
+<a id="openvino"></a>
+
+## OpenVINO support
+
+Fast SD CPU utilizes [OpenVINO](https://www.intel.com/content/www/us/en/developer/tools/openvino-toolkit/overview.html) to speed up the inference speed.
+Thanks [deinferno](https://github.com/deinferno) for the OpenVINO model contribution.
+We can get 2x speed improvement when using OpenVINO.
+Thanks [Disty0](https://github.com/Disty0) for the conversion script.
+
+### OpenVINO SDXL models
+
+These are models converted to use directly use it with FastSD CPU. These models are compressed to int8 to reduce the file size (10GB to 4.4 GB) using [NNCF](https://github.com/openvinotoolkit/nncf)
+
+- Hyper-SD SDXL 1 step - [rupeshs/hyper-sd-sdxl-1-step-openvino-int8](https://huggingface.co/rupeshs/hyper-sd-sdxl-1-step-openvino-int8)
+- SDXL Lightning 2 steps - [rupeshs/SDXL-Lightning-2steps-openvino-int8](https://huggingface.co/rupeshs/SDXL-Lightning-2steps-openvino-int8)
+
+### OpenVINO SD Turbo models
+
+We have converted SD/SDXL Turbo models to OpenVINO for fast inference on CPU. These models are intended for research purpose only. Also we converted TAESDXL MODEL to OpenVINO and
+
+- *SD Turbo OpenVINO* - [rupeshs/sd-turbo-openvino](https://huggingface.co/rupeshs/sd-turbo-openvino)
+- *SDXL Turbo OpenVINO int8* - [rupeshs/sdxl-turbo-openvino-int8](https://huggingface.co/rupeshs/sdxl-turbo-openvino-int8)
+- *TAESDXL OpenVINO* - [rupeshs/taesdxl-openvino](https://huggingface.co/rupeshs/taesdxl-openvino)
+
+You can directly use these models in FastSD CPU.
+
+### Convert SD 1.5 models to OpenVINO LCM-LoRA fused models
+
+We first creates LCM-LoRA baked in model,replaces the scheduler with LCM and then converts it into OpenVINO model. For more details check [LCM OpenVINO Converter](https://github.com/rupeshs/lcm-openvino-converter), you can use this tools to convert any StableDiffusion 1.5 fine tuned models to OpenVINO.
+
+<a id="ai-pc-support"></a>
+
+## Intel AI PC support - OpenVINO (CPU, GPU, NPU)
+
+Fast SD now supports AI PC with Intel® Core™ Ultra Processors. [To learn more about AI PC and OpenVINO](https://nolowiz.com/ai-pc-and-openvino-quick-and-simple-guide/).
+
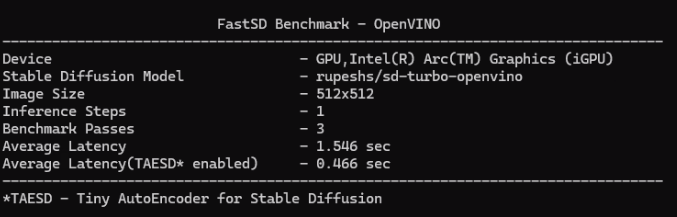
+### GPU
+
+For GPU mode `set device=GPU` and run webui. FastSD GPU benchmark on AI PC as shown below.
+
+
+
+### NPU
+
+FastSD CPU now supports power efficient NPU (Neural Processing Unit) that comes with Intel Core Ultra processors.
+
+FastSD tested with following Intel processor's NPUs:
+
+- Intel Core Ultra Series 1 (Meteor Lake)
+- Intel Core Ultra Series 2 (Lunar Lake)
+
+Currently FastSD support this model for NPU [rupeshs/sd15-lcm-square-openvino-int8](https://huggingface.co/rupeshs/sd15-lcm-square-openvino-int8).
+
+Supports following modes on NPU :
+
+- Text to image
+- Image to image
+- Image variations
+
+To run model in NPU follow these steps (Please make sure that your AI PC's NPU driver is the latest):
+
+- Start webui
+- Select LCM-OpenVINO mode
+- Select the models settings tab and select OpenVINO model `rupeshs/sd15-lcm-square-openvino-int8`
+- Set device envionment variable `set DEVICE=NPU`
+- Now it will run on the NPU
+
+This is heterogeneous computing since text encoder and Unet will use NPU and VAE will use GPU for processing. Thanks to OpenVINO.
+
+Please note that tiny auto encoder will not work in NPU mode.
+
+*Thanks to Intel for providing AI PC dev kit and Tiber cloud access to test FastSD, special thanks to [Pooja Baraskar](https://github.com/Pooja-B),[Dmitriy Pastushenkov](https://github.com/DimaPastushenkov).*
+
+<a id="gguf-support"></a>
+
+## GGUF support - Flux
+
+[GGUF](https://github.com/ggerganov/ggml/blob/master/docs/gguf.md) Flux model supported via [stablediffusion.cpp](https://github.com/leejet/stable-diffusion.cpp) shared library. Currently Flux Schenell model supported.
+
+To use GGUF model use web UI and select GGUF mode.
+
+Tested on Windows and Linux.
+
+:exclamation: Main advantage here we reduced minimum system RAM required for Flux workflow to around __12 GB__.
+
+Supported mode - Text to image
+
+### How to run Flux GGUF model
+
+- Download stablediffusion.cpp prebuilt shared library and place it inside fastsdcpu folder
+ For Windows users, download [stable-diffusion.dll](https://huggingface.co/rupeshs/FastSD-Flux-GGUF/blob/main/stable-diffusion.dll)
+
+ For Linux users download [libstable-diffusion.so](https://huggingface.co/rupeshs/FastSD-Flux-GGUF/blob/main/libstable-diffusion.so)
+
+ You can also build the library manully by following the guide *"Build stablediffusion.cpp shared library for GGUF flux model support"*
+
+- Download __diffusion model__ from [flux1-schnell-q4_0.gguf](https://huggingface.co/rupeshs/FastSD-Flux-GGUF/blob/main/flux1-schnell-q4_0.gguf) and place it inside `models/gguf/diffusion` directory
+- Download __clip model__ from [clip_l_q4_0.gguf](https://huggingface.co/rupeshs/FastSD-Flux-GGUF/blob/main/clip_l_q4_0.gguf) and place it inside `models/gguf/clip` directory
+- Download __T5-XXL model__ from [t5xxl_q4_0.gguf](https://huggingface.co/rupeshs/FastSD-Flux-GGUF/blob/main/t5xxl_q4_0.gguf) and place it inside `models/gguf/t5xxl` directory
+- Download __VAE model__ from [ae.safetensors](https://huggingface.co/black-forest-labs/FLUX.1-schnell/blob/main/ae.safetensors) and place it inside `models/gguf/vae` directory
+- Start web UI and select GGUF mode
+- Select the models settings tab and select GGUF diffusion,clip_l,t5xxl and VAE models.
+- Enter your prompt and generate image
+
+### Build stablediffusion.cpp shared library for GGUF flux model support(Optional)
+
+To build the stablediffusion.cpp library follow these steps
+
+- `git clone https://github.com/leejet/stable-diffusion.cpp`
+- `cd stable-diffusion.cpp`
+- `git pull origin master`
+- `git submodule init`
+- `git submodule update`
+- `git checkout 14206fd48832ab600d9db75f15acb5062ae2c296`
+- `cmake . -DSD_BUILD_SHARED_LIBS=ON`
+- `cmake --build . --config Release`
+- Copy the stablediffusion dll/so file to fastsdcpu folder
+
+<a id="real-time-text-to-image"></a>
+
+## Real-time text to image (EXPERIMENTAL)
+
+We can generate real-time text to images using FastSD CPU.
+
+__CPU (OpenVINO)__
+
+Near real-time inference on CPU using OpenVINO, run the `start-realtime.bat` batch file and open the link in browser (Resolution : 512x512,Latency : 0.82s on Intel Core i7)
+
+Watch YouTube video :
+
+[](https://www.youtube.com/watch?v=0XMiLc_vsyI)
+
+## Models
+
+To use single file [Safetensors](https://huggingface.co/docs/safetensors/en/index) SD 1.5 models(Civit AI) follow this [YouTube tutorial](https://www.youtube.com/watch?v=zZTfUZnXJVk). Use LCM-LoRA Mode for single file safetensors.
+
+Fast SD supports LCM models and LCM-LoRA models.
+
+### LCM Models
+
+These models can be configured in `configs/lcm-models.txt` file.
+
+### OpenVINO models
+
+These are LCM-LoRA baked in models. These models can be configured in `configs/openvino-lcm-models.txt` file
+
+### LCM-LoRA models
+
+These models can be configured in `configs/lcm-lora-models.txt` file.
+
+- *lcm-lora-sdv1-5* - distilled consistency adapter for [runwayml/stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5)
+- *lcm-lora-sdxl* - Distilled consistency adapter for [stable-diffusion-xl-base-1.0](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0)
+- *lcm-lora-ssd-1b* - Distilled consistency adapter for [segmind/SSD-1B](https://huggingface.co/segmind/SSD-1B)
+
+These models are used with Stablediffusion base models `configs/stable-diffusion-models.txt`.
+
+:exclamation: Currently no support for OpenVINO LCM-LoRA models.
+
+### How to add new LCM-LoRA models
+
+To add new model follow the steps:
+For example we will add `wavymulder/collage-diffusion`, you can give Stable diffusion 1.5 Or SDXL,SSD-1B fine tuned models.
+
+1. Open `configs/stable-diffusion-models.txt` file in text editor.
+2. Add the model ID `wavymulder/collage-diffusion` or locally cloned path.
+
+Updated file as shown below :
+
+```Lykon/dreamshaper-8
+Fictiverse/Stable_Diffusion_PaperCut_Model
+stabilityai/stable-diffusion-xl-base-1.0
+runwayml/stable-diffusion-v1-5
+segmind/SSD-1B
+stablediffusionapi/anything-v5
+wavymulder/collage-diffusion
+```
+
+Similarly we can update `configs/lcm-lora-models.txt` file with lcm-lora ID.
+
+### How to use LCM-LoRA models offline
+
+Please follow the steps to run LCM-LoRA models offline :
+
+- In the settings ensure that "Use locally cached model" setting is ticked.
+- Download the model for example `latent-consistency/lcm-lora-sdv1-5`
+Run the following commands:
+
+```
+git lfs install
+git clone https://huggingface.co/latent-consistency/lcm-lora-sdv1-5
+```
+
+Copy the cloned model folder path for example "D:\demo\lcm-lora-sdv1-5" and update the `configs/lcm-lora-models.txt` file as shown below :
+
+```
+D:\demo\lcm-lora-sdv1-5
+latent-consistency/lcm-lora-sdxl
+latent-consistency/lcm-lora-ssd-1b
+```
+
+- Open the app and select the newly added local folder in the combo box menu.
+- That's all!
+<a id="useloramodels"></a>
+
+## How to use Lora models
+
+Place your lora models in "lora_models" folder. Use LCM or LCM-Lora mode.
+You can download lora model (.safetensors/Safetensor) from [Civitai](https://civitai.com/) or [Hugging Face](https://huggingface.co/)
+E.g: [cutecartoonredmond](https://civitai.com/models/207984/cutecartoonredmond-15v-cute-cartoon-lora-for-liberteredmond-sd-15?modelVersionId=234192)
+<a id="usecontrolnet"></a>
+
+## ControlNet support
+
+We can use ControlNet in LCM-LoRA mode.
+
+Download ControlNet models from [ControlNet-v1-1](https://huggingface.co/comfyanonymous/ControlNet-v1-1_fp16_safetensors/tree/main).Download and place controlnet models in "controlnet_models" folder.
+
+Use the medium size models (723 MB)(For example : <https://huggingface.co/comfyanonymous/ControlNet-v1-1_fp16_safetensors/blob/main/control_v11p_sd15_canny_fp16.safetensors>)
+
+## Installation
+
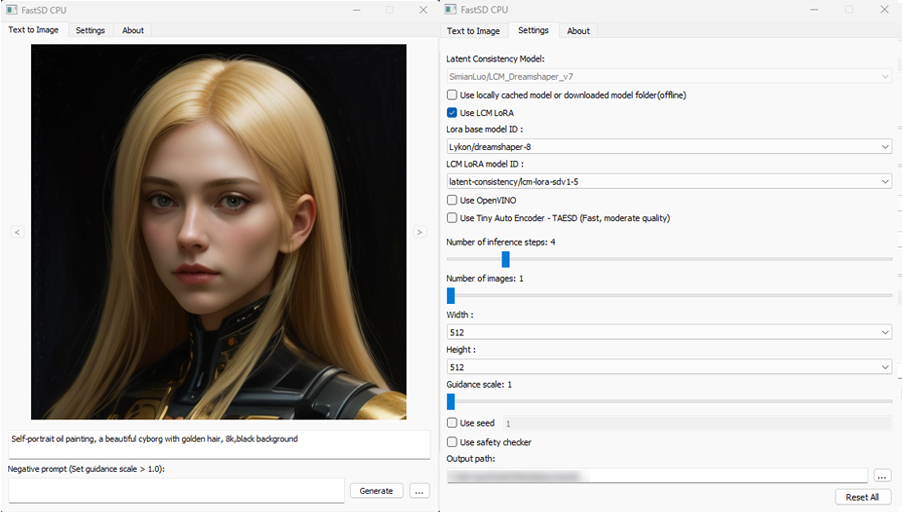
+### FastSD CPU on Windows
+
+
+
+:exclamation:__You must have a working Python installation.(Recommended : Python 3.10 or 3.11 )__
+
+To install FastSD CPU on Windows run the following steps :
+
+- Clone/download this repo or download [release](https://github.com/rupeshs/fastsdcpu/releases).
+- Double click `install.bat` (It will take some time to install,depending on your internet speed.)
+- You can run in desktop GUI mode or web UI mode.
+
+#### Desktop GUI
+
+- To start desktop GUI double click `start.bat`
+
+#### Web UI
+
+- To start web UI double click `start-webui.bat`
+
+### FastSD CPU on Linux
+
+:exclamation:__Ensure that you have Python 3.9 or 3.10 or 3.11 version installed.__
+
+- Clone/download this repo or download [release](https://github.com/rupeshs/fastsdcpu/releases).
+- In the terminal, enter into fastsdcpu directory
+- Run the following command
+
+ `chmod +x install.sh`
+
+ `./install.sh`
+
+#### To start Desktop GUI
+
+ `./start.sh`
+
+#### To start Web UI
+
+ `./start-webui.sh`
+
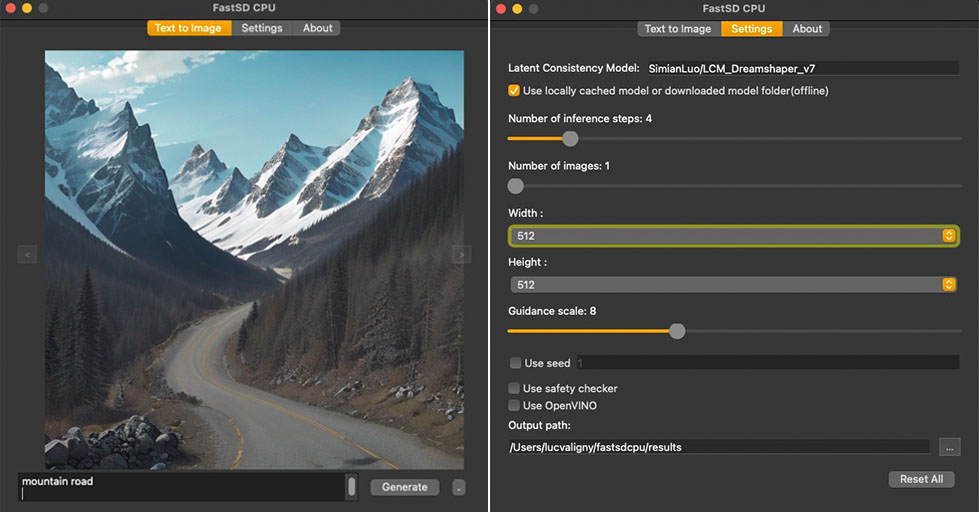
+### FastSD CPU on Mac
+
+
+
+:exclamation:__Ensure that you have Python 3.9 or 3.10 or 3.11 version installed.__
+
+Run the following commands to install FastSD CPU on Mac :
+
+- Clone/download this repo or download [release](https://github.com/rupeshs/fastsdcpu/releases).
+- In the terminal, enter into fastsdcpu directory
+- Run the following command
+
+ `chmod +x install-mac.sh`
+
+ `./install-mac.sh`
+
+#### To start Desktop GUI
+
+ `./start.sh`
+
+#### To start Web UI
+
+ `./start-webui.sh`
+
+Thanks [Autantpourmoi](https://github.com/Autantpourmoi) for Mac testing.
+
+:exclamation:We don't support OpenVINO on Mac (M1/M2/M3 chips, but *does* work on Intel chips).
+
+If you want to increase image generation speed on Mac(M1/M2 chip) try this:
+
+`export DEVICE=mps` and start app `start.sh`
+
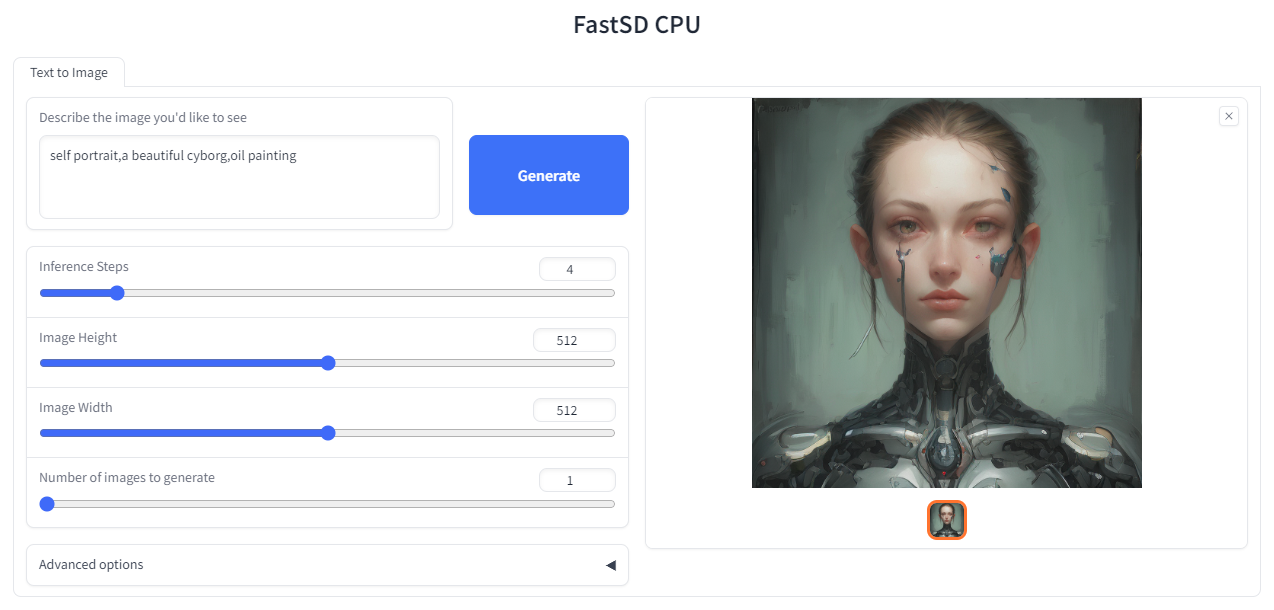
+#### Web UI screenshot
+
+
+
+### Google Colab
+
+Due to the limitation of using CPU/OpenVINO inside colab, we are using GPU with colab.
+[](https://colab.research.google.com/drive/1SuAqskB-_gjWLYNRFENAkIXZ1aoyINqL?usp=sharing)
+
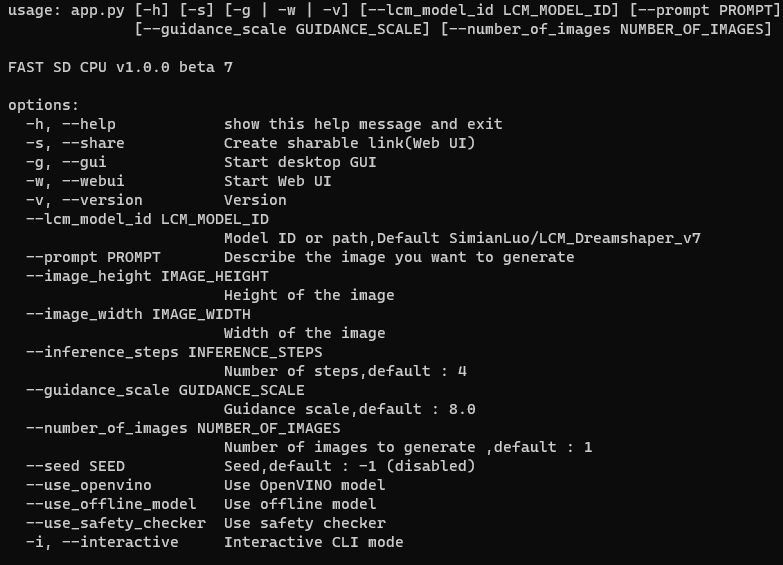
+### CLI mode (Advanced users)
+
+
+
+ Open the terminal and enter into fastsdcpu folder.
+ Activate virtual environment using the command:
+
+##### Windows users
+
+ (Suppose FastSD CPU available in the directory "D:\fastsdcpu")
+ `D:\fastsdcpu\env\Scripts\activate.bat`
+
+##### Linux users
+
+ `source env/bin/activate`
+
+Start CLI `src/app.py -h`
+
+<a id="android"></a>
+
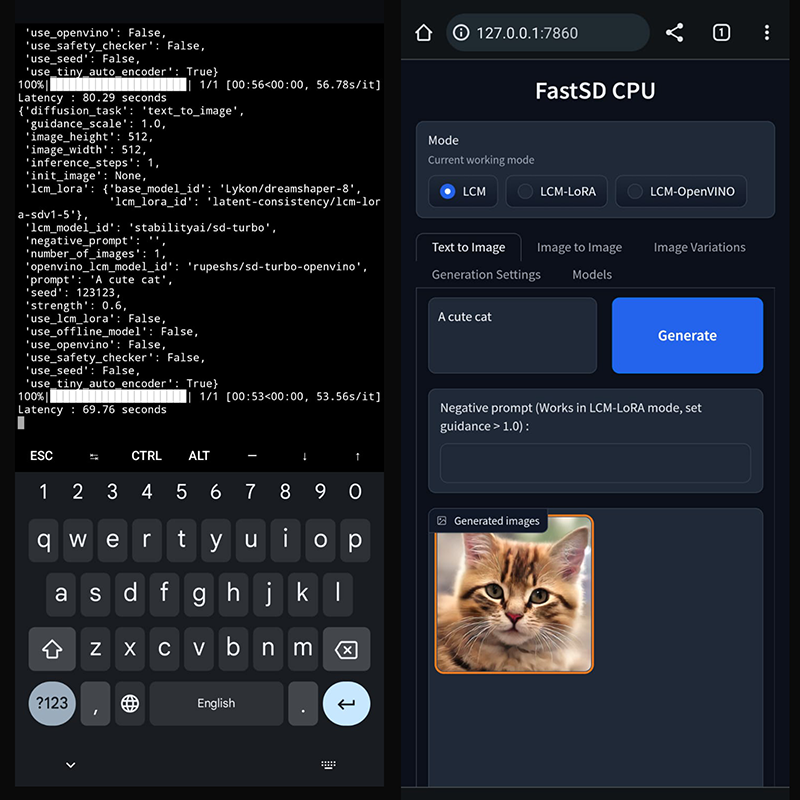
+## Android (Termux + PRoot)
+
+FastSD CPU running on Google Pixel 7 Pro.
+
+
+
+### 1. Prerequisites
+
+First you have to [install Termux](https://wiki.termux.com/wiki/Installing_from_F-Droid) and [install PRoot](https://wiki.termux.com/wiki/PRoot). Then install and login to Ubuntu in PRoot.
+
+### 2. Install FastSD CPU
+
+Run the following command to install without Qt GUI.
+
+ `proot-distro login ubuntu`
+
+ `./install.sh --disable-gui`
+
+ After the installation you can use WebUi.
+
+ `./start-webui.sh`
+
+ Note : If you get `libgl.so.1` import error run `apt-get install ffmpeg`.
+
+ Thanks [patienx](https://github.com/patientx) for this guide [Step by step guide to installing FASTSDCPU on ANDROID](https://github.com/rupeshs/fastsdcpu/discussions/123)
+
+Another step by step guide to run FastSD on Android is [here](https://nolowiz.com/how-to-install-and-run-fastsd-cpu-on-android-temux-step-by-step-guide/)
+
+<a id="raspberry"></a>
+
+## Raspberry PI 4 support
+
+Thanks [WGNW_MGM] for Raspberry PI 4 testing.FastSD CPU worked without problems.
+System configuration - Raspberry Pi 4 with 4GB RAM, 8GB of SWAP memory.
+
+<a id="orangepi"></a>
+
+## Orange Pi 5 support
+
+Thanks [khanumballz](https://github.com/khanumballz) for testing FastSD CPU with Orange PI 5.
+[Here is a video of FastSD CPU running on Orange Pi 5](https://www.youtube.com/watch?v=KEJiCU0aK8o).
+
+<a id="apisupport"></a>
+
+## API support
+
+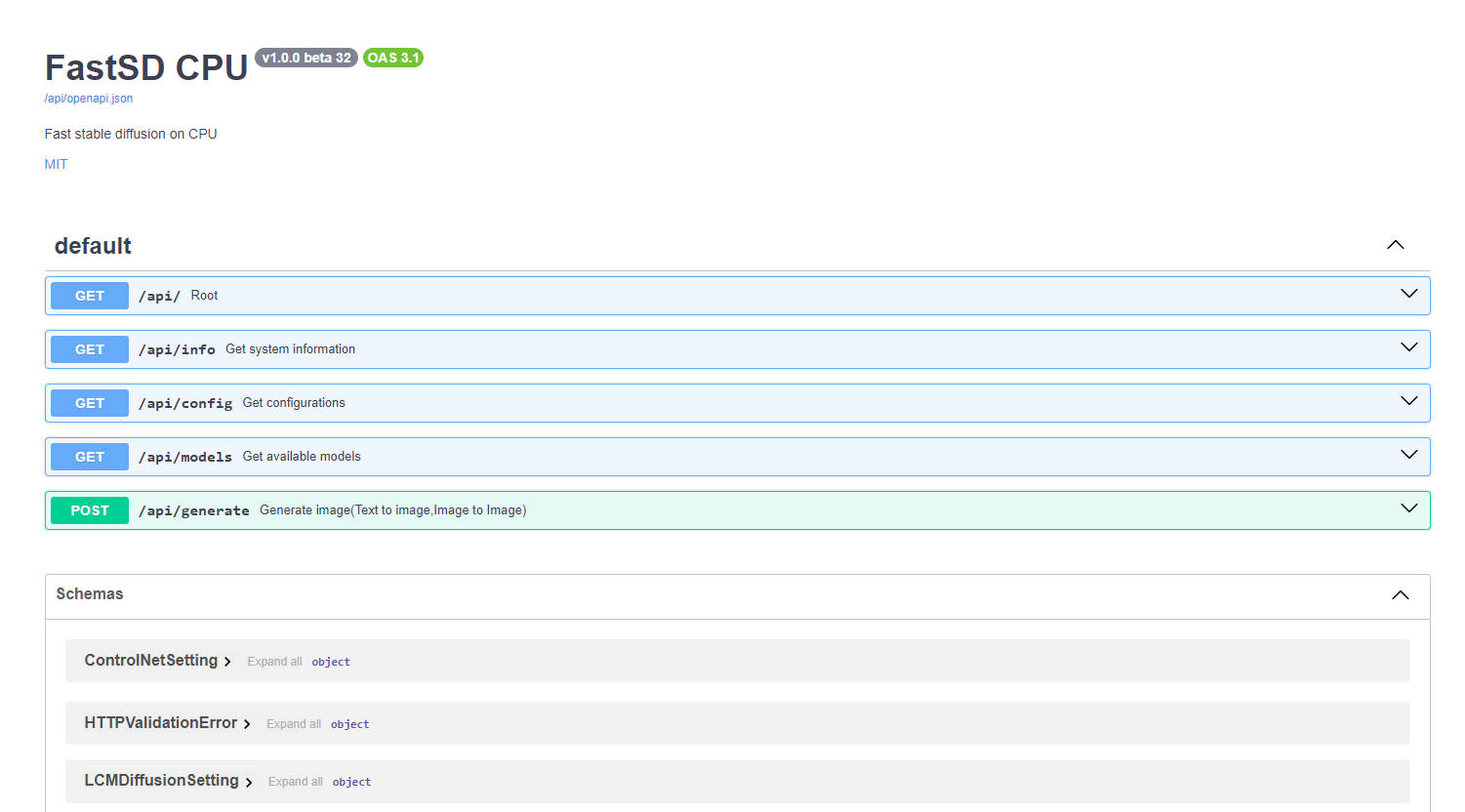
+
+FastSD CPU supports basic API endpoints. Following API endpoints are available :
+
+- /api/info - To get system information
+- /api/config - Get configuration
+- /api/models - List all available models
+- /api/generate - Generate images (Text to image,image to image)
+
+To start FastAPI in webserver mode run:
+``python src/app.py --api``
+
+or use `start-webserver.sh` for Linux and `start-webserver.bat` for Windows.
+
+Access API documentation locally at <http://localhost:8000/api/docs> .
+
+Generated image is JPEG image encoded as base64 string.
+In the image-to-image mode input image should be encoded as base64 string.
+
+To generate an image a minimal request `POST /api/generate` with body :
+
+```
+{
+ "prompt": "a cute cat",
+ "use_openvino": true
+}
+```
+
+## Known issues
+
+- TAESD will not work with OpenVINO image to image workflow
+
+## License
+
+The fastsdcpu project is available as open source under the terms of the [MIT license](https://github.com/rupeshs/fastsdcpu/blob/main/LICENSE)
+
+## Disclaimer
+
+Users are granted the freedom to create images using this tool, but they are obligated to comply with local laws and utilize it responsibly. The developers will not assume any responsibility for potential misuse by users.
+
+<a id="contributors"></a>
+
+## Thanks to all our contributors
+
+Original Author & Maintainer - [Rupesh Sreeraman](https://github.com/rupeshs)
+
+We thank all contributors for their time and hard work!
+
+<a href="https://github.com/rupeshs/fastsdcpu/graphs/contributors">
+ <img src="https://contrib.rocks/image?repo=rupeshs/fastsdcpu" />
+</a>
diff --git a/THIRD-PARTY-LICENSES b/THIRD-PARTY-LICENSES
new file mode 100644
index 0000000000000000000000000000000000000000..9fb29b1d3d52582f6047a41d8f5622de43d24868
--- /dev/null
+++ b/THIRD-PARTY-LICENSES
@@ -0,0 +1,143 @@
+stablediffusion.cpp - MIT
+
+OpenVINO stablediffusion engine - Apache 2
+
+SD Turbo - STABILITY AI NON-COMMERCIAL RESEARCH COMMUNITY LICENSE AGREEMENT
+
+MIT License
+
+Copyright (c) 2023 leejet
+
+Permission is hereby granted, free of charge, to any person obtaining a copy
+of this software and associated documentation files (the "Software"), to deal
+in the Software without restriction, including without limitation the rights
+to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+copies of the Software, and to permit persons to whom the Software is
+furnished to do so, subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in all
+copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+SOFTWARE.
+
+ERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+Definitions.
+
+"License" shall mean the terms and conditions for use, reproduction, and distribution as defined by Sections 1 through 9 of this document.
+
+"Licensor" shall mean the copyright owner or entity authorized by the copyright owner that is granting the License.
+
+"Legal Entity" shall mean the union of the acting entity and all other entities that control, are controlled by, or are under common control with that entity. For the purposes of this definition, "control" means (i) the power, direct or indirect, to cause the direction or management of such entity, whether by contract or otherwise, or (ii) ownership of fifty percent (50%) or more of the outstanding shares, or (iii) beneficial ownership of such entity.
+
+"You" (or "Your") shall mean an individual or Legal Entity exercising permissions granted by this License.
+
+"Source" form shall mean the preferred form for making modifications, including but not limited to software source code, documentation source, and configuration files.
+
+"Object" form shall mean any form resulting from mechanical transformation or translation of a Source form, including but not limited to compiled object code, generated documentation, and conversions to other media types.
+
+"Work" shall mean the work of authorship, whether in Source or Object form, made available under the License, as indicated by a copyright notice that is included in or attached to the work (an example is provided in the Appendix below).
+
+"Derivative Works" shall mean any work, whether in Source or Object form, that is based on (or derived from) the Work and for which the editorial revisions, annotations, elaborations, or other modifications represent, as a whole, an original work of authorship. For the purposes of this License, Derivative Works shall not include works that remain separable from, or merely link (or bind by name) to the interfaces of, the Work and Derivative Works thereof.
+
+"Contribution" shall mean any work of authorship, including the original version of the Work and any modifications or additions to that Work or Derivative Works thereof, that is intentionally submitted to Licensor for inclusion in the Work by the copyright owner or by an individual or Legal Entity authorized to submit on behalf of the copyright owner. For the purposes of this definition, "submitted" means any form of electronic, verbal, or written communication sent to the Licensor or its representatives, including but not limited to communication on electronic mailing lists, source code control systems, and issue tracking systems that are managed by, or on behalf of, the Licensor for the purpose of discussing and improving the Work, but excluding communication that is conspicuously marked or otherwise designated in writing by the copyright owner as "Not a Contribution."
+
+"Contributor" shall mean Licensor and any individual or Legal Entity on behalf of whom a Contribution has been received by Licensor and subsequently incorporated within the Work.
+
+Grant of Copyright License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable copyright license to reproduce, prepare Derivative Works of, publicly display, publicly perform, sublicense, and distribute the Work and such Derivative Works in Source or Object form.
+
+Grant of Patent License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable (except as stated in this section) patent license to make, have made, use, offer to sell, sell, import, and otherwise transfer the Work, where such license applies only to those patent claims licensable by such Contributor that are necessarily infringed by their Contribution(s) alone or by combination of their Contribution(s) with the Work to which such Contribution(s) was submitted. If You institute patent litigation against any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Work or a Contribution incorporated within the Work constitutes direct or contributory patent infringement, then any patent licenses granted to You under this License for that Work shall terminate as of the date such litigation is filed.
+
+Redistribution. You may reproduce and distribute copies of the Work or Derivative Works thereof in any medium, with or without modifications, and in Source or Object form, provided that You meet the following conditions:
+
+(a) You must give any other recipients of the Work or Derivative Works a copy of this License; and
+
+(b) You must cause any modified files to carry prominent notices stating that You changed the files; and
+
+(c) You must retain, in the Source form of any Derivative Works that You distribute, all copyright, patent, trademark, and attribution notices from the Source form of the Work, excluding those notices that do not pertain to any part of the Derivative Works; and
+
+(d) If the Work includes a "NOTICE" text file as part of its distribution, then any Derivative Works that You distribute must include a readable copy of the attribution notices contained within such NOTICE file, excluding those notices that do not pertain to any part of the Derivative Works, in at least one of the following places: within a NOTICE text file distributed as part of the Derivative Works; within the Source form or documentation, if provided along with the Derivative Works; or, within a display generated by the Derivative Works, if and wherever such third-party notices normally appear. The contents of the NOTICE file are for informational purposes only and do not modify the License. You may add Your own attribution notices within Derivative Works that You distribute, alongside or as an addendum to the NOTICE text from the Work, provided that such additional attribution notices cannot be construed as modifying the License.
+
+You may add Your own copyright statement to Your modifications and may provide additional or different license terms and conditions for use, reproduction, or distribution of Your modifications, or for any such Derivative Works as a whole, provided Your use, reproduction, and distribution of the Work otherwise complies with the conditions stated in this License.
+
+Submission of Contributions. Unless You explicitly state otherwise, any Contribution intentionally submitted for inclusion in the Work by You to the Licensor shall be under the terms and conditions of this License, without any additional terms or conditions. Notwithstanding the above, nothing herein shall supersede or modify the terms of any separate license agreement you may have executed with Licensor regarding such Contributions.
+
+Trademarks. This License does not grant permission to use the trade names, trademarks, service marks, or product names of the Licensor, except as required for reasonable and customary use in describing the origin of the Work and reproducing the content of the NOTICE file.
+
+Disclaimer of Warranty. Unless required by applicable law or agreed to in writing, Licensor provides the Work (and each Contributor provides its Contributions) on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied, including, without limitation, any warranties or conditions of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A PARTICULAR PURPOSE. You are solely responsible for determining the appropriateness of using or redistributing the Work and assume any risks associated with Your exercise of permissions under this License.
+
+Limitation of Liability. In no event and under no legal theory, whether in tort (including negligence), contract, or otherwise, unless required by applicable law (such as deliberate and grossly negligent acts) or agreed to in writing, shall any Contributor be liable to You for damages, including any direct, indirect, special, incidental, or consequential damages of any character arising as a result of this License or out of the use or inability to use the Work (including but not limited to damages for loss of goodwill, work stoppage, computer failure or malfunction, or any and all other commercial damages or losses), even if such Contributor has been advised of the possibility of such damages.
+
+Accepting Warranty or Additional Liability. While redistributing the Work or Derivative Works thereof, You may choose to offer, and charge a fee for, acceptance of support, warranty, indemnity, or other liability obligations and/or rights consistent with this License. However, in accepting such obligations, You may act only on Your own behalf and on Your sole responsibility, not on behalf of any other Contributor, and only if You agree to indemnify, defend, and hold each Contributor harmless for any liability incurred by, or claims asserted against, such Contributor by reason of your accepting any such warranty or additional liability.
+
+END OF TERMS AND CONDITIONS
+
+APPENDIX: How to apply the Apache License to your work.
+
+ To apply the Apache License to your work, attach the following
+ boilerplate notice, with the fields enclosed by brackets "[]"
+ replaced with your own identifying information. (Don't include
+ the brackets!) The text should be enclosed in the appropriate
+ comment syntax for the file format. We also recommend that a
+ file or class name and description of purpose be included on the
+ same "printed page" as the copyright notice for easier
+ identification within third-party archives.
+Copyright [yyyy] [name of copyright owner]
+
+Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
+
+ <http://www.apache.org/licenses/LICENSE-2.0>
+Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
+
+STABILITY AI NON-COMMERCIAL RESEARCH COMMUNITY LICENSE AGREEMENT
+Dated: November 28, 2023
+
+By using or distributing any portion or element of the Models, Software, Software Products or Derivative Works, you agree to be bound by this Agreement.
+
+"Agreement" means this Stable Non-Commercial Research Community License Agreement.
+
+“AUP” means the Stability AI Acceptable Use Policy available at <https://stability.ai/use-policy>, as may be updated from time to time.
+
+"Derivative Work(s)” means (a) any derivative work of the Software Products as recognized by U.S. copyright laws and (b) any modifications to a Model, and any other model created which is based on or derived from the Model or the Model’s output. For clarity, Derivative Works do not include the output of any Model.
+
+“Documentation” means any specifications, manuals, documentation, and other written information provided by Stability AI related to the Software.
+
+"Licensee" or "you" means you, or your employer or any other person or entity (if you are entering into this Agreement on such person or entity's behalf), of the age required under applicable laws, rules or regulations to provide legal consent and that has legal authority to bind your employer or such other person or entity if you are entering in this Agreement on their behalf.
+
+“Model(s)" means, collectively, Stability AI’s proprietary models and algorithms, including machine-learning models, trained model weights and other elements of the foregoing, made available under this Agreement.
+
+“Non-Commercial Uses” means exercising any of the rights granted herein for the purpose of research or non-commercial purposes. Non-Commercial Uses does not include any production use of the Software Products or any Derivative Works.
+
+"Stability AI" or "we" means Stability AI Ltd. and its affiliates.
+
+"Software" means Stability AI’s proprietary software made available under this Agreement.
+
+“Software Products” means the Models, Software and Documentation, individually or in any combination.
+
+1. License Rights and Redistribution.
+
+a. Subject to your compliance with this Agreement, the AUP (which is hereby incorporated herein by reference), and the Documentation, Stability AI grants you a non-exclusive, worldwide, non-transferable, non-sublicensable, revocable, royalty free and limited license under Stability AI’s intellectual property or other rights owned or controlled by Stability AI embodied in the Software Products to use, reproduce, distribute, and create Derivative Works of, the Software Products, in each case for Non-Commercial Uses only.
+
+b. You may not use the Software Products or Derivative Works to enable third parties to use the Software Products or Derivative Works as part of your hosted service or via your APIs, whether you are adding substantial additional functionality thereto or not. Merely distributing the Software Products or Derivative Works for download online without offering any related service (ex. by distributing the Models on HuggingFace) is not a violation of this subsection. If you wish to use the Software Products or any Derivative Works for commercial or production use or you wish to make the Software Products or any Derivative Works available to third parties via your hosted service or your APIs, contact Stability AI at <https://stability.ai/contact>.
+
+c. If you distribute or make the Software Products, or any Derivative Works thereof, available to a third party, the Software Products, Derivative Works, or any portion thereof, respectively, will remain subject to this Agreement and you must (i) provide a copy of this Agreement to such third party, and (ii) retain the following attribution notice within a "Notice" text file distributed as a part of such copies: "This Stability AI Model is licensed under the Stability AI Non-Commercial Research Community License, Copyright (c) Stability AI Ltd. All Rights Reserved.” If you create a Derivative Work of a Software Product, you may add your own attribution notices to the Notice file included with the Software Product, provided that you clearly indicate which attributions apply to the Software Product and you must state in the NOTICE file that you changed the Software Product and how it was modified.
+
+2. Disclaimer of Warranty. UNLESS REQUIRED BY APPLICABLE LAW, THE SOFTWARE PRODUCTS AND ANY OUTPUT AND RESULTS THERE FROM ARE PROVIDED ON AN "AS IS" BASIS, WITHOUT WARRANTIES OF ANY KIND, EITHER EXPRESS OR IMPLIED, INCLUDING, WITHOUT LIMITATION, ANY WARRANTIES OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY RESPONSIBLE FOR DETERMINING THE APPROPRIATENESS OF USING OR REDISTRIBUTING THE SOFTWARE PRODUCTS, DERIVATIVE WORKS OR ANY OUTPUT OR RESULTS AND ASSUME ANY RISKS ASSOCIATED WITH YOUR USE OF THE SOFTWARE PRODUCTS, DERIVATIVE WORKS AND ANY OUTPUT AND RESULTS.
+
+3. Limitation of Liability. IN NO EVENT WILL STABILITY AI OR ITS AFFILIATES BE LIABLE UNDER ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, ARISING OUT OF THIS AGREEMENT, FOR ANY LOST PROFITS OR ANY DIRECT, INDIRECT, SPECIAL, CONSEQUENTIAL, INCIDENTAL, EXEMPLARY OR PUNITIVE DAMAGES, EVEN IF STABILITY AI OR ITS AFFILIATES HAVE BEEN ADVISED OF THE POSSIBILITY OF ANY OF THE FOREGOING.
+
+4. Intellectual Property.
+
+a. No trademark licenses are granted under this Agreement, and in connection with the Software Products or Derivative Works, neither Stability AI nor Licensee may use any name or mark owned by or associated with the other or any of its affiliates, except as required for reasonable and customary use in describing and redistributing the Software Products or Derivative Works.
+
+b. Subject to Stability AI’s ownership of the Software Products and Derivative Works made by or for Stability AI, with respect to any Derivative Works that are made by you, as between you and Stability AI, you are and will be the owner of such Derivative Works
+
+c. If you institute litigation or other proceedings against Stability AI (including a cross-claim or counterclaim in a lawsuit) alleging that the Software Products, Derivative Works or associated outputs or results, or any portion of any of the foregoing, constitutes infringement of intellectual property or other rights owned or licensable by you, then any licenses granted to you under this Agreement shall terminate as of the date such litigation or claim is filed or instituted. You will indemnify and hold harmless Stability AI from and against any claim by any third party arising out of or related to your use or distribution of the Software Products or Derivative Works in violation of this Agreement.
+
+5. Term and Termination. The term of this Agreement will commence upon your acceptance of this Agreement or access to the Software Products and will continue in full force and effect until terminated in accordance with the terms and conditions herein. Stability AI may terminate this Agreement if you are in breach of any term or condition of this Agreement. Upon termination of this Agreement, you shall delete and cease use of any Software Products or Derivative Works. Sections 2-4 shall survive the termination of this Agreement.
diff --git a/benchmark-openvino.bat b/benchmark-openvino.bat
new file mode 100644
index 0000000000000000000000000000000000000000..c42dd4b3dfda63bca515f23a788ee5f417dbb2e4
--- /dev/null
+++ b/benchmark-openvino.bat
@@ -0,0 +1,23 @@
+@echo off
+setlocal
+
+set "PYTHON_COMMAND=python"
+
+call python --version > nul 2>&1
+if %errorlevel% equ 0 (
+ echo Python command check :OK
+) else (
+ echo "Error: Python command not found, please install Python (Recommended : Python 3.10 or Python 3.11) and try again"
+ pause
+ exit /b 1
+
+)
+
+:check_python_version
+for /f "tokens=2" %%I in ('%PYTHON_COMMAND% --version 2^>^&1') do (
+ set "python_version=%%I"
+)
+
+echo Python version: %python_version%
+
+call "%~dp0env\Scripts\activate.bat" && %PYTHON_COMMAND% src/app.py -b --use_openvino --openvino_lcm_model_id "rupeshs/sd-turbo-openvino"
\ No newline at end of file
diff --git a/benchmark.bat b/benchmark.bat
new file mode 100644
index 0000000000000000000000000000000000000000..97e8d9da773696f2ce57e69572fa9973977b3f7e
--- /dev/null
+++ b/benchmark.bat
@@ -0,0 +1,23 @@
+@echo off
+setlocal
+
+set "PYTHON_COMMAND=python"
+
+call python --version > nul 2>&1
+if %errorlevel% equ 0 (
+ echo Python command check :OK
+) else (
+ echo "Error: Python command not found, please install Python (Recommended : Python 3.10 or Python 3.11) and try again"
+ pause
+ exit /b 1
+
+)
+
+:check_python_version
+for /f "tokens=2" %%I in ('%PYTHON_COMMAND% --version 2^>^&1') do (
+ set "python_version=%%I"
+)
+
+echo Python version: %python_version%
+
+call "%~dp0env\Scripts\activate.bat" && %PYTHON_COMMAND% src/app.py -b
\ No newline at end of file
diff --git a/configs/lcm-lora-models.txt b/configs/lcm-lora-models.txt
new file mode 100644
index 0000000000000000000000000000000000000000..f252571ecfc0936d6374e83c3cdfd2f87508ff69
--- /dev/null
+++ b/configs/lcm-lora-models.txt
@@ -0,0 +1,4 @@
+latent-consistency/lcm-lora-sdv1-5
+latent-consistency/lcm-lora-sdxl
+latent-consistency/lcm-lora-ssd-1b
+rupeshs/hypersd-sd1-5-1-step-lora
\ No newline at end of file
diff --git a/configs/lcm-models.txt b/configs/lcm-models.txt
new file mode 100644
index 0000000000000000000000000000000000000000..9721ed6f43a6ccc00d3cd456d44f6632674e359c
--- /dev/null
+++ b/configs/lcm-models.txt
@@ -0,0 +1,8 @@
+stabilityai/sd-turbo
+rupeshs/sdxs-512-0.9-orig-vae
+rupeshs/hyper-sd-sdxl-1-step
+rupeshs/SDXL-Lightning-2steps
+stabilityai/sdxl-turbo
+SimianLuo/LCM_Dreamshaper_v7
+latent-consistency/lcm-sdxl
+latent-consistency/lcm-ssd-1b
\ No newline at end of file
diff --git a/configs/openvino-lcm-models.txt b/configs/openvino-lcm-models.txt
new file mode 100644
index 0000000000000000000000000000000000000000..656096d1bbabe6472a65869773b14a6c5bb9ec62
--- /dev/null
+++ b/configs/openvino-lcm-models.txt
@@ -0,0 +1,9 @@
+rupeshs/sd-turbo-openvino
+rupeshs/sdxs-512-0.9-openvino
+rupeshs/hyper-sd-sdxl-1-step-openvino-int8
+rupeshs/SDXL-Lightning-2steps-openvino-int8
+rupeshs/sdxl-turbo-openvino-int8
+rupeshs/LCM-dreamshaper-v7-openvino
+Disty0/LCM_SoteMix
+rupeshs/FLUX.1-schnell-openvino-int4
+rupeshs/sd15-lcm-square-openvino-int8
\ No newline at end of file
diff --git a/configs/stable-diffusion-models.txt b/configs/stable-diffusion-models.txt
new file mode 100644
index 0000000000000000000000000000000000000000..d5d21c9c5e64bb55c642243d27c230f04c6aab58
--- /dev/null
+++ b/configs/stable-diffusion-models.txt
@@ -0,0 +1,7 @@
+Lykon/dreamshaper-8
+Fictiverse/Stable_Diffusion_PaperCut_Model
+stabilityai/stable-diffusion-xl-base-1.0
+runwayml/stable-diffusion-v1-5
+segmind/SSD-1B
+stablediffusionapi/anything-v5
+prompthero/openjourney-v4
\ No newline at end of file
diff --git a/controlnet_models/Readme.txt b/controlnet_models/Readme.txt
new file mode 100644
index 0000000000000000000000000000000000000000..fdf39a3d9ae7982663447fff8c0b38edcd91353c
--- /dev/null
+++ b/controlnet_models/Readme.txt
@@ -0,0 +1,3 @@
+Place your ControlNet models in this folder.
+You can download controlnet model (.safetensors) from https://huggingface.co/comfyanonymous/ControlNet-v1-1_fp16_safetensors/tree/main
+E.g: https://huggingface.co/comfyanonymous/ControlNet-v1-1_fp16_safetensors/blob/main/control_v11p_sd15_canny_fp16.safetensors
\ No newline at end of file
diff --git a/docs/images/2steps-inference.jpg b/docs/images/2steps-inference.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..42a00185b1594bed3d19846a04898d5074f049c8
Binary files /dev/null and b/docs/images/2steps-inference.jpg differ
diff --git a/docs/images/ARCGPU.png b/docs/images/ARCGPU.png
new file mode 100644
index 0000000000000000000000000000000000000000..1abdaceefdbbf4454f5785930bbdfaa5c2424629
Binary files /dev/null and b/docs/images/ARCGPU.png differ
diff --git a/docs/images/fastcpu-cli.png b/docs/images/fastcpu-cli.png
new file mode 100644
index 0000000000000000000000000000000000000000..41592e190a16115fe59a63b40022cad4f36a5f93
Binary files /dev/null and b/docs/images/fastcpu-cli.png differ
diff --git a/docs/images/fastcpu-webui.png b/docs/images/fastcpu-webui.png
new file mode 100644
index 0000000000000000000000000000000000000000..8fbaae6d761978fab13c45d535235fed3878ce2a
--- /dev/null
+++ b/docs/images/fastcpu-webui.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:d26b4e4bc41d515a730b757a6a984724aa59497235bf771b25e5a7d9c2d5680f
+size 263249
diff --git a/docs/images/fastsdcpu-android-termux-pixel7.png b/docs/images/fastsdcpu-android-termux-pixel7.png
new file mode 100644
index 0000000000000000000000000000000000000000..da4845a340ec3331f7e552558ece96c1968ac68a
--- /dev/null
+++ b/docs/images/fastsdcpu-android-termux-pixel7.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:0e18187cb43b8e905971fd607e6640a66c2877d4dc135647425f3cb66d7f22ae
+size 298843
diff --git a/docs/images/fastsdcpu-api.png b/docs/images/fastsdcpu-api.png
new file mode 100644
index 0000000000000000000000000000000000000000..639aa5da86c4d136351e2fda43745ef55c4b9314
Binary files /dev/null and b/docs/images/fastsdcpu-api.png differ
diff --git a/docs/images/fastsdcpu-gui.jpg b/docs/images/fastsdcpu-gui.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..698517415079debc82a55c4180f2472a3ed74679
--- /dev/null
+++ b/docs/images/fastsdcpu-gui.jpg
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:03c1fe3b5ea4dfcc25654c4fc76fc392a59bdf668b1c45e5e6fc14edcf2fac5c
+size 207258
diff --git a/docs/images/fastsdcpu-mac-gui.jpg b/docs/images/fastsdcpu-mac-gui.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..098e4d189d198072079cae811b6c4f18e869b02a
Binary files /dev/null and b/docs/images/fastsdcpu-mac-gui.jpg differ
diff --git a/docs/images/fastsdcpu-screenshot.png b/docs/images/fastsdcpu-screenshot.png
new file mode 100644
index 0000000000000000000000000000000000000000..4cfe1931059b4bf6c6218521883e218fd9a698c6
--- /dev/null
+++ b/docs/images/fastsdcpu-screenshot.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:3729a8a87629800c63ca98ed36c1a48c7c0bc64c02a144e396aca05e7c529ee6
+size 293249
diff --git a/docs/images/fastsdcpu-webui.png b/docs/images/fastsdcpu-webui.png
new file mode 100644
index 0000000000000000000000000000000000000000..d5528d7a934cfcfbbf67c4598bd7506eadeae0d4
--- /dev/null
+++ b/docs/images/fastsdcpu-webui.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:b1378a52fab340ad566e69074f93af40a82f92afb29d8a3b27cbe218b5ee4bff
+size 380162
diff --git a/docs/images/fastsdcpu_flux_on_cpu.png b/docs/images/fastsdcpu_flux_on_cpu.png
new file mode 100644
index 0000000000000000000000000000000000000000..53dc5ff72f7c442284133cb66e68a7bf665e4586
--- /dev/null
+++ b/docs/images/fastsdcpu_flux_on_cpu.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:5e42851d654dc88a75e479cb6dcf25bc1e7a7463f7c2eb2a98ec77e2b3c74e06
+size 383111
diff --git a/install-mac.sh b/install-mac.sh
new file mode 100644
index 0000000000000000000000000000000000000000..a9456397f2a826da7ed79835ba25f585e1da2d24
--- /dev/null
+++ b/install-mac.sh
@@ -0,0 +1,31 @@
+#!/usr/bin/env bash
+echo Starting FastSD CPU env installation...
+set -e
+PYTHON_COMMAND="python3"
+
+if ! command -v python3 &>/dev/null; then
+ if ! command -v python &>/dev/null; then
+ echo "Error: Python not found, please install python 3.8 or higher and try again"
+ exit 1
+ fi
+fi
+
+if command -v python &>/dev/null; then
+ PYTHON_COMMAND="python"
+fi
+
+echo "Found $PYTHON_COMMAND command"
+
+python_version=$($PYTHON_COMMAND --version 2>&1 | awk '{print $2}')
+echo "Python version : $python_version"
+
+BASEDIR=$(pwd)
+
+$PYTHON_COMMAND -m venv "$BASEDIR/env"
+# shellcheck disable=SC1091
+source "$BASEDIR/env/bin/activate"
+pip install torch
+pip install -r "$BASEDIR/requirements.txt"
+chmod +x "start.sh"
+chmod +x "start-webui.sh"
+read -n1 -r -p "FastSD CPU installation completed,press any key to continue..." key
\ No newline at end of file
diff --git a/install.bat b/install.bat
new file mode 100644
index 0000000000000000000000000000000000000000..b05db0bf251352685c046c107a82e28e2f08c7cf
--- /dev/null
+++ b/install.bat
@@ -0,0 +1,29 @@
+
+@echo off
+setlocal
+echo Starting FastSD CPU env installation...
+
+set "PYTHON_COMMAND=python"
+
+call python --version > nul 2>&1
+if %errorlevel% equ 0 (
+ echo Python command check :OK
+) else (
+ echo "Error: Python command not found,please install Python(Recommended : Python 3.10 or Python 3.11) and try again."
+ pause
+ exit /b 1
+
+)
+
+:check_python_version
+for /f "tokens=2" %%I in ('%PYTHON_COMMAND% --version 2^>^&1') do (
+ set "python_version=%%I"
+)
+
+echo Python version: %python_version%
+
+%PYTHON_COMMAND% -m venv "%~dp0env"
+call "%~dp0env\Scripts\activate.bat" && pip install torch==2.2.2 --index-url https://download.pytorch.org/whl/cpu
+call "%~dp0env\Scripts\activate.bat" && pip install -r "%~dp0requirements.txt"
+echo FastSD CPU env installation completed.
+pause
\ No newline at end of file
diff --git a/install.sh b/install.sh
new file mode 100644
index 0000000000000000000000000000000000000000..3ed8d5c889ba1e8dec7c62ba7d80719c9f0fc5f8
--- /dev/null
+++ b/install.sh
@@ -0,0 +1,28 @@
+#!/usr/bin/env bash
+echo Starting FastSD CPU env installation...
+set -e
+PYTHON_COMMAND="python3"
+
+if ! command -v python3 &>/dev/null; then
+ if ! command -v python &>/dev/null; then
+ echo "Error: Python not found, please install python 3.8 or higher and try again"
+ exit 1
+ fi
+fi
+
+if command -v python &>/dev/null; then
+ PYTHON_COMMAND="python"
+fi
+
+echo "Found $PYTHON_COMMAND command"
+
+python_version=$($PYTHON_COMMAND --version 2>&1 | awk '{print $2}')
+echo "Python version : $python_version"
+
+BASEDIR=$(pwd)
+
+pip install torch==2.2.2 --index-url https://download.pytorch.org/whl/cpu
+pip install -r "$BASEDIR/requirements.txt"
+
+chmod +x "start.sh"
+chmod +x "start-webui.sh"
diff --git a/lora_models/HoloEnV2.safetensors b/lora_models/HoloEnV2.safetensors
new file mode 100644
index 0000000000000000000000000000000000000000..8e90d7a03c5dbed1156e1b4b7ea6065f4078ca4b
--- /dev/null
+++ b/lora_models/HoloEnV2.safetensors
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:b30945096a4f2ff4a52fcafaa8481c6a5d52073be323674a16b189ceb66d39a6
+size 151111711
diff --git a/lora_models/Readme.txt b/lora_models/Readme.txt
new file mode 100644
index 0000000000000000000000000000000000000000..e4748a642837930fdcb903e42273ffaf5ccda888
--- /dev/null
+++ b/lora_models/Readme.txt
@@ -0,0 +1,3 @@
+Place your lora models in this folder.
+You can download lora model (.safetensors/Safetensor) from Civitai (https://civitai.com/) or Hugging Face(https://huggingface.co/)
+E.g: https://civitai.com/models/207984/cutecartoonredmond-15v-cute-cartoon-lora-for-liberteredmond-sd-15?modelVersionId=234192
\ No newline at end of file
diff --git a/models/gguf/clip/readme.txt b/models/gguf/clip/readme.txt
new file mode 100644
index 0000000000000000000000000000000000000000..48b307e2be7fbaf7cce08d578e8c8e7e6037936f
--- /dev/null
+++ b/models/gguf/clip/readme.txt
@@ -0,0 +1 @@
+Place CLIP model files here"
diff --git a/models/gguf/diffusion/readme.txt b/models/gguf/diffusion/readme.txt
new file mode 100644
index 0000000000000000000000000000000000000000..4625665b369085b5941d284b63b42afd3c22629a
--- /dev/null
+++ b/models/gguf/diffusion/readme.txt
@@ -0,0 +1 @@
+Place your diffusion gguf model files here
diff --git a/models/gguf/t5xxl/readme.txt b/models/gguf/t5xxl/readme.txt
new file mode 100644
index 0000000000000000000000000000000000000000..e9c586e46a0201cef38fc5a759a730eab48086d0
--- /dev/null
+++ b/models/gguf/t5xxl/readme.txt
@@ -0,0 +1 @@
+Place T5-XXL model files here
diff --git a/models/gguf/vae/readme.txt b/models/gguf/vae/readme.txt
new file mode 100644
index 0000000000000000000000000000000000000000..15c39ec7f9d9ae275f6bceab50acd6bb9cf83714
--- /dev/null
+++ b/models/gguf/vae/readme.txt
@@ -0,0 +1 @@
+Place VAE model files here
diff --git a/requirements.txt b/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..8d94aac19c006ba7578538673f658d951cc56d50
--- /dev/null
+++ b/requirements.txt
@@ -0,0 +1,18 @@
+accelerate==0.33.0
+diffusers==0.30.0
+transformers==4.41.2
+Pillow==9.4.0
+openvino==2024.4.0
+optimum-intel==1.18.2
+onnx==1.16.0
+onnxruntime==1.17.3
+pydantic==2.4.2
+typing-extensions==4.8.0
+pyyaml==6.0.1
+gradio==5.6.0
+peft==0.6.1
+opencv-python==4.8.1.78
+omegaconf==2.3.0
+controlnet-aux==0.0.7
+mediapipe==0.10.9
+tomesd==0.1.3
\ No newline at end of file
diff --git a/src/__init__.py b/src/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/src/app.py b/src/app.py
new file mode 100644
index 0000000000000000000000000000000000000000..dfa966c22b685592345c187070763252e0a32702
--- /dev/null
+++ b/src/app.py
@@ -0,0 +1,535 @@
+import json
+from argparse import ArgumentParser
+
+import constants
+from backend.controlnet import controlnet_settings_from_dict
+from backend.models.gen_images import ImageFormat
+from backend.models.lcmdiffusion_setting import DiffusionTask
+from backend.upscale.tiled_upscale import generate_upscaled_image
+from constants import APP_VERSION, DEVICE
+from frontend.webui.image_variations_ui import generate_image_variations
+from models.interface_types import InterfaceType
+from paths import FastStableDiffusionPaths
+from PIL import Image
+from state import get_context, get_settings
+from utils import show_system_info
+from backend.device import get_device_name
+
+parser = ArgumentParser(description=f"FAST SD CPU {constants.APP_VERSION}")
+parser.add_argument(
+ "-s",
+ "--share",
+ action="store_true",
+ help="Create sharable link(Web UI)",
+ required=False,
+)
+group = parser.add_mutually_exclusive_group(required=False)
+group.add_argument(
+ "-g",
+ "--gui",
+ action="store_true",
+ help="Start desktop GUI",
+)
+group.add_argument(
+ "-w",
+ "--webui",
+ action="store_true",
+ help="Start Web UI",
+)
+group.add_argument(
+ "-a",
+ "--api",
+ action="store_true",
+ help="Start Web API server",
+)
+group.add_argument(
+ "-r",
+ "--realtime",
+ action="store_true",
+ help="Start realtime inference UI(experimental)",
+)
+group.add_argument(
+ "-v",
+ "--version",
+ action="store_true",
+ help="Version",
+)
+
+parser.add_argument(
+ "-b",
+ "--benchmark",
+ action="store_true",
+ help="Run inference benchmark on the selected device",
+)
+parser.add_argument(
+ "--lcm_model_id",
+ type=str,
+ help="Model ID or path,Default stabilityai/sd-turbo",
+ default="stabilityai/sd-turbo",
+)
+parser.add_argument(
+ "--openvino_lcm_model_id",
+ type=str,
+ help="OpenVINO Model ID or path,Default rupeshs/sd-turbo-openvino",
+ default="rupeshs/sd-turbo-openvino",
+)
+parser.add_argument(
+ "--prompt",
+ type=str,
+ help="Describe the image you want to generate",
+ default="",
+)
+parser.add_argument(
+ "--negative_prompt",
+ type=str,
+ help="Describe what you want to exclude from the generation",
+ default="",
+)
+parser.add_argument(
+ "--image_height",
+ type=int,
+ help="Height of the image",
+ default=512,
+)
+parser.add_argument(
+ "--image_width",
+ type=int,
+ help="Width of the image",
+ default=512,
+)
+parser.add_argument(
+ "--inference_steps",
+ type=int,
+ help="Number of steps,default : 1",
+ default=1,
+)
+parser.add_argument(
+ "--guidance_scale",
+ type=float,
+ help="Guidance scale,default : 1.0",
+ default=1.0,
+)
+
+parser.add_argument(
+ "--number_of_images",
+ type=int,
+ help="Number of images to generate ,default : 1",
+ default=1,
+)
+parser.add_argument(
+ "--seed",
+ type=int,
+ help="Seed,default : -1 (disabled) ",
+ default=-1,
+)
+parser.add_argument(
+ "--use_openvino",
+ action="store_true",
+ help="Use OpenVINO model",
+)
+
+parser.add_argument(
+ "--use_offline_model",
+ action="store_true",
+ help="Use offline model",
+)
+parser.add_argument(
+ "--clip_skip",
+ type=int,
+ help="CLIP Skip (1-12), default : 1 (disabled) ",
+ default=1,
+)
+parser.add_argument(
+ "--token_merging",
+ type=float,
+ help="Token merging scale, 0.0 - 1.0, default : 0.0",
+ default=0.0,
+)
+
+parser.add_argument(
+ "--use_safety_checker",
+ action="store_true",
+ help="Use safety checker",
+)
+parser.add_argument(
+ "--use_lcm_lora",
+ action="store_true",
+ help="Use LCM-LoRA",
+)
+parser.add_argument(
+ "--base_model_id",
+ type=str,
+ help="LCM LoRA base model ID,Default Lykon/dreamshaper-8",
+ default="Lykon/dreamshaper-8",
+)
+parser.add_argument(
+ "--lcm_lora_id",
+ type=str,
+ help="LCM LoRA model ID,Default latent-consistency/lcm-lora-sdv1-5",
+ default="latent-consistency/lcm-lora-sdv1-5",
+)
+parser.add_argument(
+ "-i",
+ "--interactive",
+ action="store_true",
+ help="Interactive CLI mode",
+)
+parser.add_argument(
+ "-t",
+ "--use_tiny_auto_encoder",
+ action="store_true",
+ help="Use tiny auto encoder for SD (TAESD)",
+)
+parser.add_argument(
+ "-f",
+ "--file",
+ type=str,
+ help="Input image for img2img mode",
+ default="",
+)
+parser.add_argument(
+ "--img2img",
+ action="store_true",
+ help="img2img mode; requires input file via -f argument",
+)
+parser.add_argument(
+ "--batch_count",
+ type=int,
+ help="Number of sequential generations",
+ default=1,
+)
+parser.add_argument(
+ "--strength",
+ type=float,
+ help="Denoising strength for img2img and Image variations",
+ default=0.3,
+)
+parser.add_argument(
+ "--sdupscale",
+ action="store_true",
+ help="Tiled SD upscale,works only for the resolution 512x512,(2x upscale)",
+)
+parser.add_argument(
+ "--upscale",
+ action="store_true",
+ help="EDSR SD upscale ",
+)
+parser.add_argument(
+ "--custom_settings",
+ type=str,
+ help="JSON file containing custom generation settings",
+ default=None,
+)
+parser.add_argument(
+ "--usejpeg",
+ action="store_true",
+ help="Images will be saved as JPEG format",
+)
+parser.add_argument(
+ "--noimagesave",
+ action="store_true",
+ help="Disable image saving",
+)
+parser.add_argument(
+ "--lora",
+ type=str,
+ help="LoRA model full path e.g D:\lora_models\CuteCartoon15V-LiberteRedmodModel-Cartoon-CuteCartoonAF.safetensors",
+ default=None,
+)
+parser.add_argument(
+ "--lora_weight",
+ type=float,
+ help="LoRA adapter weight [0 to 1.0]",
+ default=0.5,
+)
+parser.add_argument(
+ "--port",
+ type=int,
+ help="Web server port",
+ default=8000,
+)
+
+args = parser.parse_args()
+
+if args.version:
+ print(APP_VERSION)
+ exit()
+
+# parser.print_help()
+print("FastSD CPU - ", APP_VERSION)
+show_system_info()
+print(f"Using device : {constants.DEVICE}")
+
+if args.webui:
+ app_settings = get_settings()
+else:
+ app_settings = get_settings()
+
+print(f"Found {len(app_settings.lcm_models)} LCM models in config/lcm-models.txt")
+print(
+ f"Found {len(app_settings.stable_diffsuion_models)} stable diffusion models in config/stable-diffusion-models.txt"
+)
+print(
+ f"Found {len(app_settings.lcm_lora_models)} LCM-LoRA models in config/lcm-lora-models.txt"
+)
+print(
+ f"Found {len(app_settings.openvino_lcm_models)} OpenVINO LCM models in config/openvino-lcm-models.txt"
+)
+
+if args.noimagesave:
+ app_settings.settings.generated_images.save_image = False
+else:
+ app_settings.settings.generated_images.save_image = True
+
+if not args.realtime:
+ # To minimize realtime mode dependencies
+ from backend.upscale.upscaler import upscale_image
+ from frontend.cli_interactive import interactive_mode
+
+if args.gui:
+ from frontend.gui.ui import start_gui
+
+ print("Starting desktop GUI mode(Qt)")
+ start_gui(
+ [],
+ app_settings,
+ )
+elif args.webui:
+ from frontend.webui.ui import start_webui
+
+ print("Starting web UI mode")
+ start_webui(
+ args.share,
+ )
+elif args.realtime:
+ from frontend.webui.realtime_ui import start_realtime_text_to_image
+
+ print("Starting realtime text to image(EXPERIMENTAL)")
+ start_realtime_text_to_image(args.share)
+elif args.api:
+ from backend.api.web import start_web_server
+
+ start_web_server(args.port)
+
+else:
+ context = get_context(InterfaceType.CLI)
+ config = app_settings.settings
+
+ if args.use_openvino:
+ config.lcm_diffusion_setting.openvino_lcm_model_id = args.openvino_lcm_model_id
+ else:
+ config.lcm_diffusion_setting.lcm_model_id = args.lcm_model_id
+
+ config.lcm_diffusion_setting.prompt = args.prompt
+ config.lcm_diffusion_setting.negative_prompt = args.negative_prompt
+ config.lcm_diffusion_setting.image_height = args.image_height
+ config.lcm_diffusion_setting.image_width = args.image_width
+ config.lcm_diffusion_setting.guidance_scale = args.guidance_scale
+ config.lcm_diffusion_setting.number_of_images = args.number_of_images
+ config.lcm_diffusion_setting.inference_steps = args.inference_steps
+ config.lcm_diffusion_setting.strength = args.strength
+ config.lcm_diffusion_setting.seed = args.seed
+ config.lcm_diffusion_setting.use_openvino = args.use_openvino
+ config.lcm_diffusion_setting.use_tiny_auto_encoder = args.use_tiny_auto_encoder
+ config.lcm_diffusion_setting.use_lcm_lora = args.use_lcm_lora
+ config.lcm_diffusion_setting.lcm_lora.base_model_id = args.base_model_id
+ config.lcm_diffusion_setting.lcm_lora.lcm_lora_id = args.lcm_lora_id
+ config.lcm_diffusion_setting.diffusion_task = DiffusionTask.text_to_image.value
+ config.lcm_diffusion_setting.lora.enabled = False
+ config.lcm_diffusion_setting.lora.path = args.lora
+ config.lcm_diffusion_setting.lora.weight = args.lora_weight
+ config.lcm_diffusion_setting.lora.fuse = True
+ if config.lcm_diffusion_setting.lora.path:
+ config.lcm_diffusion_setting.lora.enabled = True
+ if args.usejpeg:
+ config.generated_images.format = ImageFormat.JPEG.value.upper()
+ if args.seed > -1:
+ config.lcm_diffusion_setting.use_seed = True
+ else:
+ config.lcm_diffusion_setting.use_seed = False
+ config.lcm_diffusion_setting.use_offline_model = args.use_offline_model
+ config.lcm_diffusion_setting.clip_skip = args.clip_skip
+ config.lcm_diffusion_setting.token_merging = args.token_merging
+ config.lcm_diffusion_setting.use_safety_checker = args.use_safety_checker
+
+ # Read custom settings from JSON file
+ custom_settings = {}
+ if args.custom_settings:
+ with open(args.custom_settings) as f:
+ custom_settings = json.load(f)
+
+ # Basic ControlNet settings; if ControlNet is enabled, an image is
+ # required even in txt2img mode
+ config.lcm_diffusion_setting.controlnet = None
+ controlnet_settings_from_dict(
+ config.lcm_diffusion_setting,
+ custom_settings,
+ )
+
+ # Interactive mode
+ if args.interactive:
+ # wrapper(interactive_mode, config, context)
+ config.lcm_diffusion_setting.lora.fuse = False
+ interactive_mode(config, context)
+
+ # Start of non-interactive CLI image generation
+ if args.img2img and args.file != "":
+ config.lcm_diffusion_setting.init_image = Image.open(args.file)
+ config.lcm_diffusion_setting.diffusion_task = DiffusionTask.image_to_image.value
+ elif args.img2img and args.file == "":
+ print("Error : You need to specify a file in img2img mode")
+ exit()
+ elif args.upscale and args.file == "" and args.custom_settings == None:
+ print("Error : You need to specify a file in SD upscale mode")
+ exit()
+ elif (
+ args.prompt == ""
+ and args.file == ""
+ and args.custom_settings == None
+ and not args.benchmark
+ ):
+ print("Error : You need to provide a prompt")
+ exit()
+
+ if args.upscale:
+ # image = Image.open(args.file)
+ output_path = FastStableDiffusionPaths.get_upscale_filepath(
+ args.file,
+ 2,
+ config.generated_images.format,
+ )
+ result = upscale_image(
+ context,
+ args.file,
+ output_path,
+ 2,
+ )
+ # Perform Tiled SD upscale (EXPERIMENTAL)
+ elif args.sdupscale:
+ if args.use_openvino:
+ config.lcm_diffusion_setting.strength = 0.3
+ upscale_settings = None
+ if custom_settings != {}:
+ upscale_settings = custom_settings
+ filepath = args.file
+ output_format = config.generated_images.format
+ if upscale_settings:
+ filepath = upscale_settings["source_file"]
+ output_format = upscale_settings["output_format"].upper()
+ output_path = FastStableDiffusionPaths.get_upscale_filepath(
+ filepath,
+ 2,
+ output_format,
+ )
+
+ generate_upscaled_image(
+ config,
+ filepath,
+ config.lcm_diffusion_setting.strength,
+ upscale_settings=upscale_settings,
+ context=context,
+ tile_overlap=32 if config.lcm_diffusion_setting.use_openvino else 16,
+ output_path=output_path,
+ image_format=output_format,
+ )
+ exit()
+ # If img2img argument is set and prompt is empty, use image variations mode
+ elif args.img2img and args.prompt == "":
+ for i in range(0, args.batch_count):
+ generate_image_variations(
+ config.lcm_diffusion_setting.init_image, args.strength
+ )
+ else:
+
+ if args.benchmark:
+ print("Initializing benchmark...")
+ bench_lcm_setting = config.lcm_diffusion_setting
+ bench_lcm_setting.prompt = "a cat"
+ bench_lcm_setting.use_tiny_auto_encoder = False
+ context.generate_text_to_image(
+ settings=config,
+ device=DEVICE,
+ )
+ latencies = []
+
+ print("Starting benchmark please wait...")
+ for _ in range(3):
+ context.generate_text_to_image(
+ settings=config,
+ device=DEVICE,
+ )
+ latencies.append(context.latency)
+
+ avg_latency = sum(latencies) / 3
+
+ bench_lcm_setting.use_tiny_auto_encoder = True
+
+ context.generate_text_to_image(
+ settings=config,
+ device=DEVICE,
+ )
+ latencies = []
+ for _ in range(3):
+ context.generate_text_to_image(
+ settings=config,
+ device=DEVICE,
+ )
+ latencies.append(context.latency)
+
+ avg_latency_taesd = sum(latencies) / 3
+
+ benchmark_name = ""
+
+ if config.lcm_diffusion_setting.use_openvino:
+ benchmark_name = "OpenVINO"
+ else:
+ benchmark_name = "PyTorch"
+
+ bench_model_id = ""
+ if bench_lcm_setting.use_openvino:
+ bench_model_id = bench_lcm_setting.openvino_lcm_model_id
+ elif bench_lcm_setting.use_lcm_lora:
+ bench_model_id = bench_lcm_setting.lcm_lora.base_model_id
+ else:
+ bench_model_id = bench_lcm_setting.lcm_model_id
+
+ benchmark_result = [
+ ["Device", f"{DEVICE.upper()},{get_device_name()}"],
+ ["Stable Diffusion Model", bench_model_id],
+ [
+ "Image Size ",
+ f"{bench_lcm_setting.image_width}x{bench_lcm_setting.image_height}",
+ ],
+ [
+ "Inference Steps",
+ f"{bench_lcm_setting.inference_steps}",
+ ],
+ [
+ "Benchmark Passes",
+ 3,
+ ],
+ [
+ "Average Latency",
+ f"{round(avg_latency,3)} sec",
+ ],
+ [
+ "Average Latency(TAESD* enabled)",
+ f"{round(avg_latency_taesd,3)} sec",
+ ],
+ ]
+ print()
+ print(
+ f" FastSD Benchmark - {benchmark_name:8} "
+ )
+ print(f"-" * 80)
+ for benchmark in benchmark_result:
+ print(f"{benchmark[0]:35} - {benchmark[1]}")
+ print(f"-" * 80)
+ print("*TAESD - Tiny AutoEncoder for Stable Diffusion")
+
+ else:
+ for i in range(0, args.batch_count):
+ context.generate_text_to_image(
+ settings=config,
+ device=DEVICE,
+ )
diff --git a/src/app_settings.py b/src/app_settings.py
new file mode 100644
index 0000000000000000000000000000000000000000..8a35193a5182c65ab058f9a3173ef26b52804de4
--- /dev/null
+++ b/src/app_settings.py
@@ -0,0 +1,124 @@
+from copy import deepcopy
+from os import makedirs, path
+
+import yaml
+from constants import (
+ LCM_LORA_MODELS_FILE,
+ LCM_MODELS_FILE,
+ OPENVINO_LCM_MODELS_FILE,
+ SD_MODELS_FILE,
+)
+from paths import FastStableDiffusionPaths, join_paths
+from utils import get_files_in_dir, get_models_from_text_file
+
+from models.settings import Settings
+
+
+class AppSettings:
+ def __init__(self):
+ self.config_path = FastStableDiffusionPaths().get_app_settings_path()
+ self._stable_diffsuion_models = get_models_from_text_file(
+ FastStableDiffusionPaths().get_models_config_path(SD_MODELS_FILE)
+ )
+ self._lcm_lora_models = get_models_from_text_file(
+ FastStableDiffusionPaths().get_models_config_path(LCM_LORA_MODELS_FILE)
+ )
+ self._openvino_lcm_models = get_models_from_text_file(
+ FastStableDiffusionPaths().get_models_config_path(OPENVINO_LCM_MODELS_FILE)
+ )
+ self._lcm_models = get_models_from_text_file(
+ FastStableDiffusionPaths().get_models_config_path(LCM_MODELS_FILE)
+ )
+ self._gguf_diffusion_models = get_files_in_dir(
+ join_paths(FastStableDiffusionPaths().get_gguf_models_path(), "diffusion")
+ )
+ self._gguf_clip_models = get_files_in_dir(
+ join_paths(FastStableDiffusionPaths().get_gguf_models_path(), "clip")
+ )
+ self._gguf_vae_models = get_files_in_dir(
+ join_paths(FastStableDiffusionPaths().get_gguf_models_path(), "vae")
+ )
+ self._gguf_t5xxl_models = get_files_in_dir(
+ join_paths(FastStableDiffusionPaths().get_gguf_models_path(), "t5xxl")
+ )
+ self._config = None
+
+ @property
+ def settings(self):
+ return self._config
+
+ @property
+ def stable_diffsuion_models(self):
+ return self._stable_diffsuion_models
+
+ @property
+ def openvino_lcm_models(self):
+ return self._openvino_lcm_models
+
+ @property
+ def lcm_models(self):
+ return self._lcm_models
+
+ @property
+ def lcm_lora_models(self):
+ return self._lcm_lora_models
+
+ @property
+ def gguf_diffusion_models(self):
+ return self._gguf_diffusion_models
+
+ @property
+ def gguf_clip_models(self):
+ return self._gguf_clip_models
+
+ @property
+ def gguf_vae_models(self):
+ return self._gguf_vae_models
+
+ @property
+ def gguf_t5xxl_models(self):
+ return self._gguf_t5xxl_models
+
+ def load(self, skip_file=False):
+ if skip_file:
+ print("Skipping config file")
+ settings_dict = self._load_default()
+ self._config = Settings.model_validate(settings_dict)
+ else:
+ if not path.exists(self.config_path):
+ base_dir = path.dirname(self.config_path)
+ if not path.exists(base_dir):
+ makedirs(base_dir)
+ try:
+ print("Settings not found creating default settings")
+ with open(self.config_path, "w") as file:
+ yaml.dump(
+ self._load_default(),
+ file,
+ )
+ except Exception as ex:
+ print(f"Error in creating settings : {ex}")
+ exit()
+ try:
+ with open(self.config_path) as file:
+ settings_dict = yaml.safe_load(file)
+ self._config = Settings.model_validate(settings_dict)
+ except Exception as ex:
+ print(f"Error in loading settings : {ex}")
+
+ def save(self):
+ try:
+ with open(self.config_path, "w") as file:
+ tmp_cfg = deepcopy(self._config)
+ tmp_cfg.lcm_diffusion_setting.init_image = None
+ configurations = tmp_cfg.model_dump(
+ exclude=["init_image"],
+ )
+ if configurations:
+ yaml.dump(configurations, file)
+ except Exception as ex:
+ print(f"Error in saving settings : {ex}")
+
+ def _load_default(self) -> dict:
+ default_config = Settings()
+ return default_config.model_dump()
diff --git a/src/backend/__init__.py b/src/backend/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/src/backend/annotators/canny_control.py b/src/backend/annotators/canny_control.py
new file mode 100644
index 0000000000000000000000000000000000000000..a9cd68d6c35180cac6e63c394add2cfac04ca283
--- /dev/null
+++ b/src/backend/annotators/canny_control.py
@@ -0,0 +1,15 @@
+import numpy as np
+from backend.annotators.control_interface import ControlInterface
+from cv2 import Canny
+from PIL import Image
+
+
+class CannyControl(ControlInterface):
+ def get_control_image(self, image: Image) -> Image:
+ low_threshold = 100
+ high_threshold = 200
+ image = np.array(image)
+ image = Canny(image, low_threshold, high_threshold)
+ image = image[:, :, None]
+ image = np.concatenate([image, image, image], axis=2)
+ return Image.fromarray(image)
diff --git a/src/backend/annotators/control_interface.py b/src/backend/annotators/control_interface.py
new file mode 100644
index 0000000000000000000000000000000000000000..fc5caa62d9a1a938b11b2dc900331a2d2604c5f9
--- /dev/null
+++ b/src/backend/annotators/control_interface.py
@@ -0,0 +1,12 @@
+from abc import ABC, abstractmethod
+
+from PIL import Image
+
+
+class ControlInterface(ABC):
+ @abstractmethod
+ def get_control_image(
+ self,
+ image: Image,
+ ) -> Image:
+ pass
diff --git a/src/backend/annotators/depth_control.py b/src/backend/annotators/depth_control.py
new file mode 100644
index 0000000000000000000000000000000000000000..cccba88810c9523872784c2372fca154334e1ad5
--- /dev/null
+++ b/src/backend/annotators/depth_control.py
@@ -0,0 +1,15 @@
+import numpy as np
+from backend.annotators.control_interface import ControlInterface
+from PIL import Image
+from transformers import pipeline
+
+
+class DepthControl(ControlInterface):
+ def get_control_image(self, image: Image) -> Image:
+ depth_estimator = pipeline("depth-estimation")
+ image = depth_estimator(image)["depth"]
+ image = np.array(image)
+ image = image[:, :, None]
+ image = np.concatenate([image, image, image], axis=2)
+ image = Image.fromarray(image)
+ return image
diff --git a/src/backend/annotators/image_control_factory.py b/src/backend/annotators/image_control_factory.py
new file mode 100644
index 0000000000000000000000000000000000000000..4b2da4920974aa62e76f0a4d841478dedaf0d9b4
--- /dev/null
+++ b/src/backend/annotators/image_control_factory.py
@@ -0,0 +1,31 @@
+from backend.annotators.canny_control import CannyControl
+from backend.annotators.depth_control import DepthControl
+from backend.annotators.lineart_control import LineArtControl
+from backend.annotators.mlsd_control import MlsdControl
+from backend.annotators.normal_control import NormalControl
+from backend.annotators.pose_control import PoseControl
+from backend.annotators.shuffle_control import ShuffleControl
+from backend.annotators.softedge_control import SoftEdgeControl
+
+
+class ImageControlFactory:
+ def create_control(self, controlnet_type: str):
+ if controlnet_type == "Canny":
+ return CannyControl()
+ elif controlnet_type == "Pose":
+ return PoseControl()
+ elif controlnet_type == "MLSD":
+ return MlsdControl()
+ elif controlnet_type == "Depth":
+ return DepthControl()
+ elif controlnet_type == "LineArt":
+ return LineArtControl()
+ elif controlnet_type == "Shuffle":
+ return ShuffleControl()
+ elif controlnet_type == "NormalBAE":
+ return NormalControl()
+ elif controlnet_type == "SoftEdge":
+ return SoftEdgeControl()
+ else:
+ print("Error: Control type not implemented!")
+ raise Exception("Error: Control type not implemented!")
diff --git a/src/backend/annotators/lineart_control.py b/src/backend/annotators/lineart_control.py
new file mode 100644
index 0000000000000000000000000000000000000000..c6775b71f0a48decd66e732dd58763b198e593af
--- /dev/null
+++ b/src/backend/annotators/lineart_control.py
@@ -0,0 +1,11 @@
+import numpy as np
+from backend.annotators.control_interface import ControlInterface
+from controlnet_aux import LineartDetector
+from PIL import Image
+
+
+class LineArtControl(ControlInterface):
+ def get_control_image(self, image: Image) -> Image:
+ processor = LineartDetector.from_pretrained("lllyasviel/Annotators")
+ control_image = processor(image)
+ return control_image
diff --git a/src/backend/annotators/mlsd_control.py b/src/backend/annotators/mlsd_control.py
new file mode 100644
index 0000000000000000000000000000000000000000..80c0debe0bf5b45011bd8d2b751abae5c1d53071
--- /dev/null
+++ b/src/backend/annotators/mlsd_control.py
@@ -0,0 +1,10 @@
+from backend.annotators.control_interface import ControlInterface
+from controlnet_aux import MLSDdetector
+from PIL import Image
+
+
+class MlsdControl(ControlInterface):
+ def get_control_image(self, image: Image) -> Image:
+ mlsd = MLSDdetector.from_pretrained("lllyasviel/ControlNet")
+ image = mlsd(image)
+ return image
diff --git a/src/backend/annotators/normal_control.py b/src/backend/annotators/normal_control.py
new file mode 100644
index 0000000000000000000000000000000000000000..7f22ed68360c5cda458be0b64a0bfcc18cd7acc2
--- /dev/null
+++ b/src/backend/annotators/normal_control.py
@@ -0,0 +1,10 @@
+from backend.annotators.control_interface import ControlInterface
+from controlnet_aux import NormalBaeDetector
+from PIL import Image
+
+
+class NormalControl(ControlInterface):
+ def get_control_image(self, image: Image) -> Image:
+ processor = NormalBaeDetector.from_pretrained("lllyasviel/Annotators")
+ control_image = processor(image)
+ return control_image
diff --git a/src/backend/annotators/pose_control.py b/src/backend/annotators/pose_control.py
new file mode 100644
index 0000000000000000000000000000000000000000..87ca92f2a029bbc6c7187c6eaa5a65bac298677a
--- /dev/null
+++ b/src/backend/annotators/pose_control.py
@@ -0,0 +1,10 @@
+from backend.annotators.control_interface import ControlInterface
+from controlnet_aux import OpenposeDetector
+from PIL import Image
+
+
+class PoseControl(ControlInterface):
+ def get_control_image(self, image: Image) -> Image:
+ openpose = OpenposeDetector.from_pretrained("lllyasviel/ControlNet")
+ image = openpose(image)
+ return image
diff --git a/src/backend/annotators/shuffle_control.py b/src/backend/annotators/shuffle_control.py
new file mode 100644
index 0000000000000000000000000000000000000000..20c6e3dabedb17f22c8a38bd5b855d9b0591a6c1
--- /dev/null
+++ b/src/backend/annotators/shuffle_control.py
@@ -0,0 +1,10 @@
+from backend.annotators.control_interface import ControlInterface
+from controlnet_aux import ContentShuffleDetector
+from PIL import Image
+
+
+class ShuffleControl(ControlInterface):
+ def get_control_image(self, image: Image) -> Image:
+ shuffle_processor = ContentShuffleDetector()
+ image = shuffle_processor(image)
+ return image
diff --git a/src/backend/annotators/softedge_control.py b/src/backend/annotators/softedge_control.py
new file mode 100644
index 0000000000000000000000000000000000000000..d11965712472588979b76932080a74b54c72fb14
--- /dev/null
+++ b/src/backend/annotators/softedge_control.py
@@ -0,0 +1,10 @@
+from backend.annotators.control_interface import ControlInterface
+from controlnet_aux import PidiNetDetector
+from PIL import Image
+
+
+class SoftEdgeControl(ControlInterface):
+ def get_control_image(self, image: Image) -> Image:
+ processor = PidiNetDetector.from_pretrained("lllyasviel/Annotators")
+ control_image = processor(image)
+ return control_image
diff --git a/src/backend/api/models/response.py b/src/backend/api/models/response.py
new file mode 100644
index 0000000000000000000000000000000000000000..41b76726d60d749ce9cb78ffcf583c213168d83a
--- /dev/null
+++ b/src/backend/api/models/response.py
@@ -0,0 +1,16 @@
+from typing import List
+
+from pydantic import BaseModel
+
+
+class StableDiffusionResponse(BaseModel):
+ """
+ Stable diffusion response model
+
+ Attributes:
+ images (List[str]): List of JPEG image as base64 encoded
+ latency (float): Latency in seconds
+ """
+
+ images: List[str]
+ latency: float
diff --git a/src/backend/api/web.py b/src/backend/api/web.py
new file mode 100644
index 0000000000000000000000000000000000000000..2805ef6ccaf2937b4c4cb6fac0c2478a3545121e
--- /dev/null
+++ b/src/backend/api/web.py
@@ -0,0 +1,103 @@
+import platform
+
+import uvicorn
+from backend.api.models.response import StableDiffusionResponse
+from backend.models.device import DeviceInfo
+from backend.base64_image import base64_image_to_pil, pil_image_to_base64_str
+from backend.device import get_device_name
+from backend.models.lcmdiffusion_setting import DiffusionTask, LCMDiffusionSetting
+from constants import APP_VERSION, DEVICE
+from context import Context
+from fastapi import FastAPI
+from models.interface_types import InterfaceType
+from state import get_settings
+
+app_settings = get_settings()
+app = FastAPI(
+ title="FastSD CPU",
+ description="Fast stable diffusion on CPU",
+ version=APP_VERSION,
+ license_info={
+ "name": "MIT",
+ "identifier": "MIT",
+ },
+ docs_url="/api/docs",
+ redoc_url="/api/redoc",
+ openapi_url="/api/openapi.json",
+)
+print(app_settings.settings.lcm_diffusion_setting)
+
+context = Context(InterfaceType.API_SERVER)
+
+
+@app.get("/api/")
+async def root():
+ return {"message": "Welcome to FastSD CPU API"}
+
+
+@app.get(
+ "/api/info",
+ description="Get system information",
+ summary="Get system information",
+)
+async def info():
+ device_info = DeviceInfo(
+ device_type=DEVICE,
+ device_name=get_device_name(),
+ os=platform.system(),
+ platform=platform.platform(),
+ processor=platform.processor(),
+ )
+ return device_info.model_dump()
+
+
+@app.get(
+ "/api/config",
+ description="Get current configuration",
+ summary="Get configurations",
+)
+async def config():
+ return app_settings.settings
+
+
+@app.get(
+ "/api/models",
+ description="Get available models",
+ summary="Get available models",
+)
+async def models():
+ return {
+ "lcm_lora_models": app_settings.lcm_lora_models,
+ "stable_diffusion": app_settings.stable_diffsuion_models,
+ "openvino_models": app_settings.openvino_lcm_models,
+ "lcm_models": app_settings.lcm_models,
+ }
+
+
+@app.post(
+ "/api/generate",
+ description="Generate image(Text to image,Image to Image)",
+ summary="Generate image(Text to image,Image to Image)",
+)
+async def generate(diffusion_config: LCMDiffusionSetting) -> StableDiffusionResponse:
+ app_settings.settings.lcm_diffusion_setting = diffusion_config
+ if diffusion_config.diffusion_task == DiffusionTask.image_to_image:
+ app_settings.settings.lcm_diffusion_setting.init_image = base64_image_to_pil(
+ diffusion_config.init_image
+ )
+
+ images = context.generate_text_to_image(app_settings.settings)
+
+ images_base64 = [pil_image_to_base64_str(img) for img in images]
+ return StableDiffusionResponse(
+ latency=round(context.latency, 2),
+ images=images_base64,
+ )
+
+
+def start_web_server(port: int = 8000):
+ uvicorn.run(
+ app,
+ host="0.0.0.0",
+ port=port,
+ )
diff --git a/src/backend/base64_image.py b/src/backend/base64_image.py
new file mode 100644
index 0000000000000000000000000000000000000000..597f75808d02e1f6aa40bea9d4fad7ce1933cf84
--- /dev/null
+++ b/src/backend/base64_image.py
@@ -0,0 +1,21 @@
+from io import BytesIO
+from base64 import b64encode, b64decode
+from PIL import Image
+
+
+def pil_image_to_base64_str(
+ image: Image,
+ format: str = "JPEG",
+) -> str:
+ buffer = BytesIO()
+ image.save(buffer, format=format)
+ buffer.seek(0)
+ img_base64 = b64encode(buffer.getvalue()).decode("utf-8")
+ return img_base64
+
+
+def base64_image_to_pil(base64_str) -> Image:
+ image_data = b64decode(base64_str)
+ image_buffer = BytesIO(image_data)
+ image = Image.open(image_buffer)
+ return image
diff --git a/src/backend/controlnet.py b/src/backend/controlnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..34f961cec88db5a4a17b700180c66d3e79b043d7
--- /dev/null
+++ b/src/backend/controlnet.py
@@ -0,0 +1,90 @@
+import logging
+from PIL import Image
+from diffusers import ControlNetModel
+from backend.models.lcmdiffusion_setting import (
+ DiffusionTask,
+ ControlNetSetting,
+)
+
+
+# Prepares ControlNet adapters for use with FastSD CPU
+#
+# This function loads the ControlNet adapters defined by the
+# _lcm_diffusion_setting.controlnet_ object and returns a dictionary
+# with the pipeline arguments required to use the loaded adapters
+def load_controlnet_adapters(lcm_diffusion_setting) -> dict:
+ controlnet_args = {}
+ if (
+ lcm_diffusion_setting.controlnet is None
+ or not lcm_diffusion_setting.controlnet.enabled
+ ):
+ return controlnet_args
+
+ logging.info("Loading ControlNet adapter")
+ controlnet_adapter = ControlNetModel.from_single_file(
+ lcm_diffusion_setting.controlnet.adapter_path,
+ # local_files_only=True,
+ use_safetensors=True,
+ )
+ controlnet_args["controlnet"] = controlnet_adapter
+ return controlnet_args
+
+
+# Updates the ControlNet pipeline arguments to use for image generation
+#
+# This function uses the contents of the _lcm_diffusion_setting.controlnet_
+# object to generate a dictionary with the corresponding pipeline arguments
+# to be used for image generation; in particular, it sets the ControlNet control
+# image and conditioning scale
+def update_controlnet_arguments(lcm_diffusion_setting) -> dict:
+ controlnet_args = {}
+ if (
+ lcm_diffusion_setting.controlnet is None
+ or not lcm_diffusion_setting.controlnet.enabled
+ ):
+ return controlnet_args
+
+ controlnet_args["controlnet_conditioning_scale"] = (
+ lcm_diffusion_setting.controlnet.conditioning_scale
+ )
+ if lcm_diffusion_setting.diffusion_task == DiffusionTask.text_to_image.value:
+ controlnet_args["image"] = lcm_diffusion_setting.controlnet._control_image
+ elif lcm_diffusion_setting.diffusion_task == DiffusionTask.image_to_image.value:
+ controlnet_args["control_image"] = (
+ lcm_diffusion_setting.controlnet._control_image
+ )
+ return controlnet_args
+
+
+# Helper function to adjust ControlNet settings from a dictionary
+def controlnet_settings_from_dict(
+ lcm_diffusion_setting,
+ dictionary,
+) -> None:
+ if lcm_diffusion_setting is None or dictionary is None:
+ logging.error("Invalid arguments!")
+ return
+ if (
+ "controlnet" not in dictionary
+ or dictionary["controlnet"] is None
+ or len(dictionary["controlnet"]) == 0
+ ):
+ logging.warning("ControlNet settings not found, ControlNet will be disabled")
+ lcm_diffusion_setting.controlnet = None
+ return
+
+ controlnet = ControlNetSetting()
+ controlnet.enabled = dictionary["controlnet"][0]["enabled"]
+ controlnet.conditioning_scale = dictionary["controlnet"][0]["conditioning_scale"]
+ controlnet.adapter_path = dictionary["controlnet"][0]["adapter_path"]
+ controlnet._control_image = None
+ image_path = dictionary["controlnet"][0]["control_image"]
+ if controlnet.enabled:
+ try:
+ controlnet._control_image = Image.open(image_path)
+ except (AttributeError, FileNotFoundError) as err:
+ print(err)
+ if controlnet._control_image is None:
+ logging.error("Wrong ControlNet control image! Disabling ControlNet")
+ controlnet.enabled = False
+ lcm_diffusion_setting.controlnet = controlnet
diff --git a/src/backend/device.py b/src/backend/device.py
new file mode 100644
index 0000000000000000000000000000000000000000..cacb2a5197eae85eb2ec7e8bf1df25f6fe62202c
--- /dev/null
+++ b/src/backend/device.py
@@ -0,0 +1,23 @@
+import platform
+from constants import DEVICE
+import torch
+import openvino as ov
+
+core = ov.Core()
+
+
+def is_openvino_device() -> bool:
+ if DEVICE.lower() == "cpu" or DEVICE.lower()[0] == "g" or DEVICE.lower()[0] == "n":
+ return True
+ else:
+ return False
+
+
+def get_device_name() -> str:
+ if DEVICE == "cuda" or DEVICE == "mps":
+ default_gpu_index = torch.cuda.current_device()
+ return torch.cuda.get_device_name(default_gpu_index)
+ elif platform.system().lower() == "darwin":
+ return platform.processor()
+ elif is_openvino_device():
+ return core.get_property(DEVICE.upper(), "FULL_DEVICE_NAME")
diff --git a/src/backend/gguf/gguf_diffusion.py b/src/backend/gguf/gguf_diffusion.py
new file mode 100644
index 0000000000000000000000000000000000000000..9060ddc8a29ae36586c354f8219b1a024b0932ba
--- /dev/null
+++ b/src/backend/gguf/gguf_diffusion.py
@@ -0,0 +1,319 @@
+"""
+Wrapper class to call the stablediffusion.cpp shared library for GGUF support
+"""
+
+import ctypes
+import platform
+from ctypes import (
+ POINTER,
+ c_bool,
+ c_char_p,
+ c_float,
+ c_int,
+ c_int64,
+ c_void_p,
+)
+from dataclasses import dataclass
+from os import path
+from typing import List, Any
+
+import numpy as np
+from PIL import Image
+
+from backend.gguf.sdcpp_types import (
+ RngType,
+ SampleMethod,
+ Schedule,
+ SDCPPLogLevel,
+ SDImage,
+ SdType,
+)
+
+
+@dataclass
+class ModelConfig:
+ model_path: str = ""
+ clip_l_path: str = ""
+ t5xxl_path: str = ""
+ diffusion_model_path: str = ""
+ vae_path: str = ""
+ taesd_path: str = ""
+ control_net_path: str = ""
+ lora_model_dir: str = ""
+ embed_dir: str = ""
+ stacked_id_embed_dir: str = ""
+ vae_decode_only: bool = True
+ vae_tiling: bool = False
+ free_params_immediately: bool = False
+ n_threads: int = 4
+ wtype: SdType = SdType.SD_TYPE_Q4_0
+ rng_type: RngType = RngType.CUDA_RNG
+ schedule: Schedule = Schedule.DEFAULT
+ keep_clip_on_cpu: bool = False
+ keep_control_net_cpu: bool = False
+ keep_vae_on_cpu: bool = False
+
+
+@dataclass
+class Txt2ImgConfig:
+ prompt: str = "a man wearing sun glasses, highly detailed"
+ negative_prompt: str = ""
+ clip_skip: int = -1
+ cfg_scale: float = 2.0
+ guidance: float = 3.5
+ width: int = 512
+ height: int = 512
+ sample_method: SampleMethod = SampleMethod.EULER_A
+ sample_steps: int = 1
+ seed: int = -1
+ batch_count: int = 2
+ control_cond: Image = None
+ control_strength: float = 0.90
+ style_strength: float = 0.5
+ normalize_input: bool = False
+ input_id_images_path: bytes = b""
+
+
+class GGUFDiffusion:
+ """GGUF Diffusion
+ To support GGUF diffusion model based on stablediffusion.cpp
+ https://github.com/ggerganov/ggml/blob/master/docs/gguf.md
+ Implmented based on stablediffusion.h
+ """
+
+ def __init__(
+ self,
+ libpath: str,
+ config: ModelConfig,
+ logging_enabled: bool = False,
+ ):
+ sdcpp_shared_lib_path = self._get_sdcpp_shared_lib_path(libpath)
+ try:
+ self.libsdcpp = ctypes.CDLL(sdcpp_shared_lib_path)
+ except OSError as e:
+ print(f"Failed to load library {sdcpp_shared_lib_path}")
+ raise ValueError(f"Error: {e}")
+
+ if not config.clip_l_path or not path.exists(config.clip_l_path):
+ raise ValueError(
+ "CLIP model file not found,please check readme.md for GGUF model usage"
+ )
+
+ if not config.t5xxl_path or not path.exists(config.t5xxl_path):
+ raise ValueError(
+ "T5XXL model file not found,please check readme.md for GGUF model usage"
+ )
+
+ if not config.diffusion_model_path or not path.exists(
+ config.diffusion_model_path
+ ):
+ raise ValueError(
+ "Diffusion model file not found,please check readme.md for GGUF model usage"
+ )
+
+ if not config.vae_path or not path.exists(config.vae_path):
+ raise ValueError(
+ "VAE model file not found,please check readme.md for GGUF model usage"
+ )
+
+ self.model_config = config
+
+ self.libsdcpp.new_sd_ctx.argtypes = [
+ c_char_p, # const char* model_path
+ c_char_p, # const char* clip_l_path
+ c_char_p, # const char* t5xxl_path
+ c_char_p, # const char* diffusion_model_path
+ c_char_p, # const char* vae_path
+ c_char_p, # const char* taesd_path
+ c_char_p, # const char* control_net_path_c_str
+ c_char_p, # const char* lora_model_dir
+ c_char_p, # const char* embed_dir_c_str
+ c_char_p, # const char* stacked_id_embed_dir_c_str
+ c_bool, # bool vae_decode_only
+ c_bool, # bool vae_tiling
+ c_bool, # bool free_params_immediately
+ c_int, # int n_threads
+ SdType, # enum sd_type_t wtype
+ RngType, # enum rng_type_t rng_type
+ Schedule, # enum schedule_t s
+ c_bool, # bool keep_clip_on_cpu
+ c_bool, # bool keep_control_net_cpu
+ c_bool, # bool keep_vae_on_cpu
+ ]
+
+ self.libsdcpp.new_sd_ctx.restype = POINTER(c_void_p)
+
+ self.sd_ctx = self.libsdcpp.new_sd_ctx(
+ self._str_to_bytes(self.model_config.model_path),
+ self._str_to_bytes(self.model_config.clip_l_path),
+ self._str_to_bytes(self.model_config.t5xxl_path),
+ self._str_to_bytes(self.model_config.diffusion_model_path),
+ self._str_to_bytes(self.model_config.vae_path),
+ self._str_to_bytes(self.model_config.taesd_path),
+ self._str_to_bytes(self.model_config.control_net_path),
+ self._str_to_bytes(self.model_config.lora_model_dir),
+ self._str_to_bytes(self.model_config.embed_dir),
+ self._str_to_bytes(self.model_config.stacked_id_embed_dir),
+ self.model_config.vae_decode_only,
+ self.model_config.vae_tiling,
+ self.model_config.free_params_immediately,
+ self.model_config.n_threads,
+ self.model_config.wtype,
+ self.model_config.rng_type,
+ self.model_config.schedule,
+ self.model_config.keep_clip_on_cpu,
+ self.model_config.keep_control_net_cpu,
+ self.model_config.keep_vae_on_cpu,
+ )
+
+ if logging_enabled:
+ self._set_logcallback()
+
+ def _set_logcallback(self):
+ print("Setting logging callback")
+ # Define function callback
+ SdLogCallbackType = ctypes.CFUNCTYPE(
+ None,
+ SDCPPLogLevel,
+ ctypes.c_char_p,
+ ctypes.c_void_p,
+ )
+
+ self.libsdcpp.sd_set_log_callback.argtypes = [
+ SdLogCallbackType,
+ ctypes.c_void_p,
+ ]
+ self.libsdcpp.sd_set_log_callback.restype = None
+ # Convert the Python callback to a C func pointer
+ self.c_log_callback = SdLogCallbackType(
+ self.log_callback
+ ) # prevent GC,keep callback as member variable
+ self.libsdcpp.sd_set_log_callback(self.c_log_callback, None)
+
+ def _get_sdcpp_shared_lib_path(
+ self,
+ root_path: str,
+ ) -> str:
+ system_name = platform.system()
+ print(f"GGUF Diffusion on {system_name}")
+ lib_name = "stable-diffusion.dll"
+ sdcpp_lib_path = ""
+
+ if system_name == "Windows":
+ sdcpp_lib_path = path.join(root_path, lib_name)
+ elif system_name == "Linux":
+ lib_name = "libstable-diffusion.so"
+ sdcpp_lib_path = path.join(root_path, lib_name)
+ elif system_name == "Darwin":
+ lib_name = "libstable-diffusion.dylib"
+ sdcpp_lib_path = path.join(root_path, lib_name)
+ else:
+ print("Unknown platform.")
+
+ return sdcpp_lib_path
+
+ @staticmethod
+ def log_callback(
+ level,
+ text,
+ data,
+ ):
+ print(f"{text.decode('utf-8')}", end="")
+
+ def _str_to_bytes(self, in_str: str, encoding: str = "utf-8") -> bytes:
+ if in_str:
+ return in_str.encode(encoding)
+ else:
+ return b""
+
+ def generate_text2mg(self, txt2img_cfg: Txt2ImgConfig) -> List[Any]:
+ self.libsdcpp.txt2img.restype = POINTER(SDImage)
+ self.libsdcpp.txt2img.argtypes = [
+ c_void_p, # sd_ctx_t* sd_ctx (pointer to context object)
+ c_char_p, # const char* prompt
+ c_char_p, # const char* negative_prompt
+ c_int, # int clip_skip
+ c_float, # float cfg_scale
+ c_float, # float guidance
+ c_int, # int width
+ c_int, # int height
+ SampleMethod, # enum sample_method_t sample_method
+ c_int, # int sample_steps
+ c_int64, # int64_t seed
+ c_int, # int batch_count
+ POINTER(SDImage), # const sd_image_t* control_cond (pointer to SDImage)
+ c_float, # float control_strength
+ c_float, # float style_strength
+ c_bool, # bool normalize_input
+ c_char_p, # const char* input_id_images_path
+ ]
+
+ image_buffer = self.libsdcpp.txt2img(
+ self.sd_ctx,
+ self._str_to_bytes(txt2img_cfg.prompt),
+ self._str_to_bytes(txt2img_cfg.negative_prompt),
+ txt2img_cfg.clip_skip,
+ txt2img_cfg.cfg_scale,
+ txt2img_cfg.guidance,
+ txt2img_cfg.width,
+ txt2img_cfg.height,
+ txt2img_cfg.sample_method,
+ txt2img_cfg.sample_steps,
+ txt2img_cfg.seed,
+ txt2img_cfg.batch_count,
+ txt2img_cfg.control_cond,
+ txt2img_cfg.control_strength,
+ txt2img_cfg.style_strength,
+ txt2img_cfg.normalize_input,
+ txt2img_cfg.input_id_images_path,
+ )
+
+ images = self._get_sd_images_from_buffer(
+ image_buffer,
+ txt2img_cfg.batch_count,
+ )
+
+ return images
+
+ def _get_sd_images_from_buffer(
+ self,
+ image_buffer: Any,
+ batch_count: int,
+ ) -> List[Any]:
+ images = []
+ if image_buffer:
+ for i in range(batch_count):
+ image = image_buffer[i]
+ print(
+ f"Generated image: {image.width}x{image.height} with {image.channel} channels"
+ )
+
+ width = image.width
+ height = image.height
+ channels = image.channel
+ pixel_data = np.ctypeslib.as_array(
+ image.data, shape=(height, width, channels)
+ )
+
+ if channels == 1:
+ pil_image = Image.fromarray(pixel_data.squeeze(), mode="L")
+ elif channels == 3:
+ pil_image = Image.fromarray(pixel_data, mode="RGB")
+ elif channels == 4:
+ pil_image = Image.fromarray(pixel_data, mode="RGBA")
+ else:
+ raise ValueError(f"Unsupported number of channels: {channels}")
+
+ images.append(pil_image)
+ return images
+
+ def terminate(self):
+ if self.libsdcpp:
+ if self.sd_ctx:
+ self.libsdcpp.free_sd_ctx.argtypes = [c_void_p]
+ self.libsdcpp.free_sd_ctx.restype = None
+ self.libsdcpp.free_sd_ctx(self.sd_ctx)
+ del self.sd_ctx
+ self.sd_ctx = None
+ del self.libsdcpp
+ self.libsdcpp = None
diff --git a/src/backend/gguf/sdcpp_types.py b/src/backend/gguf/sdcpp_types.py
new file mode 100644
index 0000000000000000000000000000000000000000..e8cc81bdf45cd7ec6d41ae6403e14391e2eff361
--- /dev/null
+++ b/src/backend/gguf/sdcpp_types.py
@@ -0,0 +1,104 @@
+"""
+Ctypes for stablediffusion.cpp shared library
+This is as per the stablediffusion.h file
+"""
+
+from enum import IntEnum
+from ctypes import (
+ c_int,
+ c_uint32,
+ c_uint8,
+ POINTER,
+ Structure,
+)
+
+
+class CtypesEnum(IntEnum):
+ """A ctypes-compatible IntEnum superclass."""
+
+ @classmethod
+ def from_param(cls, obj):
+ return int(obj)
+
+
+class RngType(CtypesEnum):
+ STD_DEFAULT_RNG = 0
+ CUDA_RNG = 1
+
+
+class SampleMethod(CtypesEnum):
+ EULER_A = 0
+ EULER = 1
+ HEUN = 2
+ DPM2 = 3
+ DPMPP2S_A = 4
+ DPMPP2M = 5
+ DPMPP2Mv2 = 6
+ IPNDM = 7
+ IPNDM_V = 7
+ LCM = 8
+ N_SAMPLE_METHODS = 9
+
+
+class Schedule(CtypesEnum):
+ DEFAULT = 0
+ DISCRETE = 1
+ KARRAS = 2
+ EXPONENTIAL = 3
+ AYS = 4
+ GITS = 5
+ N_SCHEDULES = 5
+
+
+class SdType(CtypesEnum):
+ SD_TYPE_F32 = 0
+ SD_TYPE_F16 = 1
+ SD_TYPE_Q4_0 = 2
+ SD_TYPE_Q4_1 = 3
+ # SD_TYPE_Q4_2 = 4, support has been removed
+ # SD_TYPE_Q4_3 = 5, support has been removed
+ SD_TYPE_Q5_0 = 6
+ SD_TYPE_Q5_1 = 7
+ SD_TYPE_Q8_0 = 8
+ SD_TYPE_Q8_1 = 9
+ SD_TYPE_Q2_K = 10
+ SD_TYPE_Q3_K = 11
+ SD_TYPE_Q4_K = 12
+ SD_TYPE_Q5_K = 13
+ SD_TYPE_Q6_K = 14
+ SD_TYPE_Q8_K = 15
+ SD_TYPE_IQ2_XXS = 16
+ SD_TYPE_IQ2_XS = 17
+ SD_TYPE_IQ3_XXS = 18
+ SD_TYPE_IQ1_S = 19
+ SD_TYPE_IQ4_NL = 20
+ SD_TYPE_IQ3_S = 21
+ SD_TYPE_IQ2_S = 22
+ SD_TYPE_IQ4_XS = 23
+ SD_TYPE_I8 = 24
+ SD_TYPE_I16 = 25
+ SD_TYPE_I32 = 26
+ SD_TYPE_I64 = 27
+ SD_TYPE_F64 = 28
+ SD_TYPE_IQ1_M = 29
+ SD_TYPE_BF16 = 30
+ SD_TYPE_Q4_0_4_4 = 31
+ SD_TYPE_Q4_0_4_8 = 32
+ SD_TYPE_Q4_0_8_8 = 33
+ SD_TYPE_COUNT = 34
+
+
+class SDImage(Structure):
+ _fields_ = [
+ ("width", c_uint32),
+ ("height", c_uint32),
+ ("channel", c_uint32),
+ ("data", POINTER(c_uint8)),
+ ]
+
+
+class SDCPPLogLevel(c_int):
+ SD_LOG_LEVEL_DEBUG = 0
+ SD_LOG_LEVEL_INFO = 1
+ SD_LOG_LEVEL_WARNING = 2
+ SD_LOG_LEVEL_ERROR = 3
diff --git a/src/backend/image_saver.py b/src/backend/image_saver.py
new file mode 100644
index 0000000000000000000000000000000000000000..7275acddae29f424df1fc840a5a3eba9023d34db
--- /dev/null
+++ b/src/backend/image_saver.py
@@ -0,0 +1,69 @@
+import json
+from os import path, mkdir
+from typing import Any
+from uuid import uuid4
+from backend.models.lcmdiffusion_setting import LCMDiffusionSetting
+from utils import get_image_file_extension
+
+
+def get_exclude_keys():
+ exclude_keys = {
+ "init_image": True,
+ "generated_images": True,
+ "lora": {
+ "models_dir": True,
+ "path": True,
+ },
+ "dirs": True,
+ "controlnet": {
+ "adapter_path": True,
+ },
+ }
+ return exclude_keys
+
+
+class ImageSaver:
+ @staticmethod
+ def save_images(
+ output_path: str,
+ images: Any,
+ folder_name: str = "",
+ format: str = "PNG",
+ lcm_diffusion_setting: LCMDiffusionSetting = None,
+ ) -> None:
+ gen_id = uuid4()
+
+ if images:
+ image_seeds = []
+
+ for index, image in enumerate(images):
+
+ image_seed = image.info.get('image_seed')
+ if image_seed is not None:
+ image_seeds.append(image_seed)
+
+ if not path.exists(output_path):
+ mkdir(output_path)
+
+ if folder_name:
+ out_path = path.join(
+ output_path,
+ folder_name,
+ )
+ else:
+ out_path = output_path
+
+ if not path.exists(out_path):
+ mkdir(out_path)
+ image_extension = get_image_file_extension(format)
+ image.save(path.join(out_path, f"{gen_id}-{index+1}{image_extension}"))
+ if lcm_diffusion_setting:
+ data = lcm_diffusion_setting.model_dump(exclude=get_exclude_keys())
+ if image_seeds:
+ data['image_seeds'] = image_seeds
+ with open(path.join(out_path, f"{gen_id}.json"), "w") as json_file:
+ json.dump(
+ data,
+ json_file,
+ indent=4,
+ )
diff --git a/src/backend/lcm_text_to_image.py b/src/backend/lcm_text_to_image.py
new file mode 100644
index 0000000000000000000000000000000000000000..b1160f1700b9a06d0a3791419b1f72ed000d16c9
--- /dev/null
+++ b/src/backend/lcm_text_to_image.py
@@ -0,0 +1,573 @@
+import gc
+from math import ceil
+from typing import Any, List
+import random
+
+import numpy as np
+import torch
+import logging
+from backend.device import is_openvino_device
+from backend.lora import load_lora_weight
+from backend.controlnet import (
+ load_controlnet_adapters,
+ update_controlnet_arguments,
+)
+from backend.models.lcmdiffusion_setting import (
+ DiffusionTask,
+ LCMDiffusionSetting,
+ LCMLora,
+)
+from backend.openvino.pipelines import (
+ get_ov_image_to_image_pipeline,
+ get_ov_text_to_image_pipeline,
+ ov_load_taesd,
+)
+from backend.pipelines.lcm import (
+ get_image_to_image_pipeline,
+ get_lcm_model_pipeline,
+ load_taesd,
+)
+from backend.pipelines.lcm_lora import get_lcm_lora_pipeline
+from constants import DEVICE, GGUF_THREADS
+from diffusers import LCMScheduler
+from image_ops import resize_pil_image
+from backend.openvino.flux_pipeline import get_flux_pipeline
+from backend.openvino.ov_hc_stablediffusion_pipeline import OvHcLatentConsistency
+from backend.gguf.gguf_diffusion import (
+ GGUFDiffusion,
+ ModelConfig,
+ Txt2ImgConfig,
+ SampleMethod,
+)
+from paths import get_app_path
+from pprint import pprint
+
+try:
+ # support for token merging; keeping it optional for now
+ import tomesd
+except ImportError:
+ print("tomesd library unavailable; disabling token merging support")
+ tomesd = None
+
+
+class LCMTextToImage:
+ def __init__(
+ self,
+ device: str = "cpu",
+ ) -> None:
+ self.pipeline = None
+ self.use_openvino = False
+ self.device = ""
+ self.previous_model_id = None
+ self.previous_use_tae_sd = False
+ self.previous_use_lcm_lora = False
+ self.previous_ov_model_id = ""
+ self.previous_token_merging = 0.0
+ self.previous_safety_checker = False
+ self.previous_use_openvino = False
+ self.img_to_img_pipeline = None
+ self.is_openvino_init = False
+ self.previous_lora = None
+ self.task_type = DiffusionTask.text_to_image
+ self.previous_use_gguf_model = False
+ self.previous_gguf_model = None
+ self.torch_data_type = (
+ torch.float32 if is_openvino_device() or DEVICE == "mps" else torch.float16
+ )
+ self.ov_model_id = None
+ print(f"Torch datatype : {self.torch_data_type}")
+
+ def _pipeline_to_device(self):
+ print(f"Pipeline device : {DEVICE}")
+ print(f"Pipeline dtype : {self.torch_data_type}")
+ self.pipeline.to(
+ torch_device=DEVICE,
+ torch_dtype=self.torch_data_type,
+ )
+
+ def _add_freeu(self):
+ pipeline_class = self.pipeline.__class__.__name__
+ if isinstance(self.pipeline.scheduler, LCMScheduler):
+ if pipeline_class == "StableDiffusionPipeline":
+ print("Add FreeU - SD")
+ self.pipeline.enable_freeu(
+ s1=0.9,
+ s2=0.2,
+ b1=1.2,
+ b2=1.4,
+ )
+ elif pipeline_class == "StableDiffusionXLPipeline":
+ print("Add FreeU - SDXL")
+ self.pipeline.enable_freeu(
+ s1=0.6,
+ s2=0.4,
+ b1=1.1,
+ b2=1.2,
+ )
+
+ def _enable_vae_tiling(self):
+ self.pipeline.vae.enable_tiling()
+
+ def _update_lcm_scheduler_params(self):
+ if isinstance(self.pipeline.scheduler, LCMScheduler):
+ self.pipeline.scheduler = LCMScheduler.from_config(
+ self.pipeline.scheduler.config,
+ beta_start=0.001,
+ beta_end=0.01,
+ )
+
+ def _is_hetero_pipeline(self) -> bool:
+ return "square" in self.ov_model_id.lower()
+
+ def _load_ov_hetero_pipeline(self):
+ print("Loading Heterogeneous Compute pipeline")
+ if DEVICE.upper()=="NPU":
+ device = ["NPU", "NPU", "NPU"]
+ self.pipeline = OvHcLatentConsistency(self.ov_model_id,device)
+ else:
+ self.pipeline = OvHcLatentConsistency(self.ov_model_id)
+
+ def _generate_images_hetero_compute(
+ self,
+ lcm_diffusion_setting: LCMDiffusionSetting,
+ ):
+ print("Using OpenVINO ")
+ if lcm_diffusion_setting.diffusion_task == DiffusionTask.text_to_image.value:
+ return [
+ self.pipeline.generate(
+ prompt=lcm_diffusion_setting.prompt,
+ neg_prompt=lcm_diffusion_setting.negative_prompt,
+ init_image=None,
+ strength=1.0,
+ num_inference_steps=lcm_diffusion_setting.inference_steps,
+ )
+ ]
+ else:
+ return [
+ self.pipeline.generate(
+ prompt=lcm_diffusion_setting.prompt,
+ neg_prompt=lcm_diffusion_setting.negative_prompt,
+ init_image=lcm_diffusion_setting.init_image,
+ strength=lcm_diffusion_setting.strength,
+ num_inference_steps=lcm_diffusion_setting.inference_steps,
+ )
+ ]
+
+ def _is_valid_mode(
+ self,
+ modes: List,
+ ) -> bool:
+ return modes.count(True) == 1 or modes.count(False) == 3
+
+ def _validate_mode(
+ self,
+ modes: List,
+ ) -> None:
+ if not self._is_valid_mode(modes):
+ raise ValueError("Invalid mode,delete configs/settings.yaml and retry!")
+
+ def init(
+ self,
+ device: str = "cpu",
+ lcm_diffusion_setting: LCMDiffusionSetting = LCMDiffusionSetting(),
+ ) -> None:
+ # Mode validation either LCM LoRA or OpenVINO or GGUF
+
+ modes = [
+ lcm_diffusion_setting.use_gguf_model,
+ lcm_diffusion_setting.use_openvino,
+ lcm_diffusion_setting.use_lcm_lora,
+ ]
+ self._validate_mode(modes)
+ self.device = device
+ self.use_openvino = lcm_diffusion_setting.use_openvino
+ model_id = lcm_diffusion_setting.lcm_model_id
+ use_local_model = lcm_diffusion_setting.use_offline_model
+ use_tiny_auto_encoder = lcm_diffusion_setting.use_tiny_auto_encoder
+ use_lora = lcm_diffusion_setting.use_lcm_lora
+ lcm_lora: LCMLora = lcm_diffusion_setting.lcm_lora
+ token_merging = lcm_diffusion_setting.token_merging
+ self.ov_model_id = lcm_diffusion_setting.openvino_lcm_model_id
+
+ if lcm_diffusion_setting.diffusion_task == DiffusionTask.image_to_image.value:
+ lcm_diffusion_setting.init_image = resize_pil_image(
+ lcm_diffusion_setting.init_image,
+ lcm_diffusion_setting.image_width,
+ lcm_diffusion_setting.image_height,
+ )
+
+ if (
+ self.pipeline is None
+ or self.previous_model_id != model_id
+ or self.previous_use_tae_sd != use_tiny_auto_encoder
+ or self.previous_lcm_lora_base_id != lcm_lora.base_model_id
+ or self.previous_lcm_lora_id != lcm_lora.lcm_lora_id
+ or self.previous_use_lcm_lora != use_lora
+ or self.previous_ov_model_id != self.ov_model_id
+ or self.previous_token_merging != token_merging
+ or self.previous_safety_checker != lcm_diffusion_setting.use_safety_checker
+ or self.previous_use_openvino != lcm_diffusion_setting.use_openvino
+ or self.previous_use_gguf_model != lcm_diffusion_setting.use_gguf_model
+ or self.previous_gguf_model != lcm_diffusion_setting.gguf_model
+ or (
+ self.use_openvino
+ and (
+ self.previous_task_type != lcm_diffusion_setting.diffusion_task
+ or self.previous_lora != lcm_diffusion_setting.lora
+ )
+ )
+ or lcm_diffusion_setting.rebuild_pipeline
+ ):
+ if self.use_openvino and is_openvino_device():
+ if self.pipeline:
+ del self.pipeline
+ self.pipeline = None
+ gc.collect()
+ self.is_openvino_init = True
+ if (
+ lcm_diffusion_setting.diffusion_task
+ == DiffusionTask.text_to_image.value
+ ):
+ print(
+ f"***** Init Text to image (OpenVINO) - {self.ov_model_id} *****"
+ )
+ if "flux" in self.ov_model_id.lower():
+ print("Loading OpenVINO Flux pipeline")
+ self.pipeline = get_flux_pipeline(
+ self.ov_model_id,
+ lcm_diffusion_setting.use_tiny_auto_encoder,
+ )
+ elif self._is_hetero_pipeline():
+ self._load_ov_hetero_pipeline()
+ else:
+ self.pipeline = get_ov_text_to_image_pipeline(
+ self.ov_model_id,
+ use_local_model,
+ )
+ elif (
+ lcm_diffusion_setting.diffusion_task
+ == DiffusionTask.image_to_image.value
+ ):
+ if not self.pipeline and self._is_hetero_pipeline():
+ self._load_ov_hetero_pipeline()
+ else:
+ print(
+ f"***** Image to image (OpenVINO) - {self.ov_model_id} *****"
+ )
+ self.pipeline = get_ov_image_to_image_pipeline(
+ self.ov_model_id,
+ use_local_model,
+ )
+ elif lcm_diffusion_setting.use_gguf_model:
+ model = lcm_diffusion_setting.gguf_model.diffusion_path
+ print(f"***** Init Text to image (GGUF) - {model} *****")
+ # if self.pipeline:
+ # self.pipeline.terminate()
+ # del self.pipeline
+ # self.pipeline = None
+ self._init_gguf_diffusion(lcm_diffusion_setting)
+ else:
+ if self.pipeline or self.img_to_img_pipeline:
+ self.pipeline = None
+ self.img_to_img_pipeline = None
+ gc.collect()
+
+ controlnet_args = load_controlnet_adapters(lcm_diffusion_setting)
+ if use_lora:
+ print(
+ f"***** Init LCM-LoRA pipeline - {lcm_lora.base_model_id} *****"
+ )
+ self.pipeline = get_lcm_lora_pipeline(
+ lcm_lora.base_model_id,
+ lcm_lora.lcm_lora_id,
+ use_local_model,
+ torch_data_type=self.torch_data_type,
+ pipeline_args=controlnet_args,
+ )
+
+ else:
+ print(f"***** Init LCM Model pipeline - {model_id} *****")
+ self.pipeline = get_lcm_model_pipeline(
+ model_id,
+ use_local_model,
+ controlnet_args,
+ )
+
+ self.img_to_img_pipeline = get_image_to_image_pipeline(self.pipeline)
+
+ if tomesd and token_merging > 0.001:
+ print(f"***** Token Merging: {token_merging} *****")
+ tomesd.apply_patch(self.pipeline, ratio=token_merging)
+ tomesd.apply_patch(self.img_to_img_pipeline, ratio=token_merging)
+
+ if use_tiny_auto_encoder:
+ if self.use_openvino and is_openvino_device():
+ if self.pipeline.__class__.__name__ != "OVFluxPipeline":
+ print("Using Tiny Auto Encoder (OpenVINO)")
+ ov_load_taesd(
+ self.pipeline,
+ use_local_model,
+ )
+ else:
+ print("Using Tiny Auto Encoder")
+ load_taesd(
+ self.pipeline,
+ use_local_model,
+ self.torch_data_type,
+ )
+ load_taesd(
+ self.img_to_img_pipeline,
+ use_local_model,
+ self.torch_data_type,
+ )
+
+ if not self.use_openvino and not is_openvino_device():
+ self._pipeline_to_device()
+
+ if not self._is_hetero_pipeline():
+ if (
+ lcm_diffusion_setting.diffusion_task
+ == DiffusionTask.image_to_image.value
+ and lcm_diffusion_setting.use_openvino
+ ):
+ self.pipeline.scheduler = LCMScheduler.from_config(
+ self.pipeline.scheduler.config,
+ )
+ else:
+ if not lcm_diffusion_setting.use_gguf_model:
+ self._update_lcm_scheduler_params()
+
+ if use_lora:
+ self._add_freeu()
+
+ self.previous_model_id = model_id
+ self.previous_ov_model_id = self.ov_model_id
+ self.previous_use_tae_sd = use_tiny_auto_encoder
+ self.previous_lcm_lora_base_id = lcm_lora.base_model_id
+ self.previous_lcm_lora_id = lcm_lora.lcm_lora_id
+ self.previous_use_lcm_lora = use_lora
+ self.previous_token_merging = lcm_diffusion_setting.token_merging
+ self.previous_safety_checker = lcm_diffusion_setting.use_safety_checker
+ self.previous_use_openvino = lcm_diffusion_setting.use_openvino
+ self.previous_task_type = lcm_diffusion_setting.diffusion_task
+ self.previous_lora = lcm_diffusion_setting.lora.model_copy(deep=True)
+ self.previous_use_gguf_model = lcm_diffusion_setting.use_gguf_model
+ self.previous_gguf_model = lcm_diffusion_setting.gguf_model.model_copy(
+ deep=True
+ )
+ lcm_diffusion_setting.rebuild_pipeline = False
+ if (
+ lcm_diffusion_setting.diffusion_task
+ == DiffusionTask.text_to_image.value
+ ):
+ print(f"Pipeline : {self.pipeline}")
+ elif (
+ lcm_diffusion_setting.diffusion_task
+ == DiffusionTask.image_to_image.value
+ ):
+ if self.use_openvino and is_openvino_device():
+ print(f"Pipeline : {self.pipeline}")
+ else:
+ print(f"Pipeline : {self.img_to_img_pipeline}")
+ if self.use_openvino:
+ if lcm_diffusion_setting.lora.enabled:
+ print("Warning: Lora models not supported on OpenVINO mode")
+ elif not lcm_diffusion_setting.use_gguf_model:
+ adapters = self.pipeline.get_active_adapters()
+ print(f"Active adapters : {adapters}")
+
+ def _get_timesteps(self):
+ time_steps = self.pipeline.scheduler.config.get("timesteps")
+ time_steps_value = [int(time_steps)] if time_steps else None
+ return time_steps_value
+
+ def generate(
+ self,
+ lcm_diffusion_setting: LCMDiffusionSetting,
+ reshape: bool = False,
+ ) -> Any:
+ guidance_scale = lcm_diffusion_setting.guidance_scale
+ img_to_img_inference_steps = lcm_diffusion_setting.inference_steps
+ check_step_value = int(
+ lcm_diffusion_setting.inference_steps * lcm_diffusion_setting.strength
+ )
+ if (
+ lcm_diffusion_setting.diffusion_task == DiffusionTask.image_to_image.value
+ and check_step_value < 1
+ ):
+ img_to_img_inference_steps = ceil(1 / lcm_diffusion_setting.strength)
+ print(
+ f"Strength: {lcm_diffusion_setting.strength},{img_to_img_inference_steps}"
+ )
+
+ pipeline_extra_args = {}
+
+ if lcm_diffusion_setting.use_seed:
+ cur_seed = lcm_diffusion_setting.seed
+ # for multiple images with a fixed seed, use sequential seeds
+ seeds = [(cur_seed + i) for i in range(lcm_diffusion_setting.number_of_images)]
+ else:
+ seeds = [random.randint(0,999999999) for i in range(lcm_diffusion_setting.number_of_images)]
+
+ if self.use_openvino:
+ # no support for generators; try at least to ensure reproducible results for single images
+ np.random.seed(seeds[0])
+ if self._is_hetero_pipeline():
+ torch.manual_seed(seeds[0])
+ lcm_diffusion_setting.seed=seeds[0]
+ else:
+ pipeline_extra_args['generator'] = [
+ torch.Generator(device=self.device).manual_seed(s) for s in seeds]
+
+ is_openvino_pipe = lcm_diffusion_setting.use_openvino and is_openvino_device()
+ if is_openvino_pipe and not self._is_hetero_pipeline():
+ print("Using OpenVINO")
+ if reshape and not self.is_openvino_init:
+ print("Reshape and compile")
+ self.pipeline.reshape(
+ batch_size=-1,
+ height=lcm_diffusion_setting.image_height,
+ width=lcm_diffusion_setting.image_width,
+ num_images_per_prompt=lcm_diffusion_setting.number_of_images,
+ )
+ self.pipeline.compile()
+
+ if self.is_openvino_init:
+ self.is_openvino_init = False
+
+ if is_openvino_pipe and self._is_hetero_pipeline():
+ return self._generate_images_hetero_compute(lcm_diffusion_setting)
+ elif lcm_diffusion_setting.use_gguf_model:
+ return self._generate_images_gguf(lcm_diffusion_setting)
+
+ if lcm_diffusion_setting.clip_skip > 1:
+ # We follow the convention that "CLIP Skip == 2" means "skip
+ # the last layer", so "CLIP Skip == 1" means "no skipping"
+ pipeline_extra_args["clip_skip"] = lcm_diffusion_setting.clip_skip - 1
+
+ if not lcm_diffusion_setting.use_safety_checker:
+ self.pipeline.safety_checker = None
+ if (
+ lcm_diffusion_setting.diffusion_task
+ == DiffusionTask.image_to_image.value
+ and not is_openvino_pipe
+ ):
+ self.img_to_img_pipeline.safety_checker = None
+
+ if (
+ not lcm_diffusion_setting.use_lcm_lora
+ and not lcm_diffusion_setting.use_openvino
+ and lcm_diffusion_setting.guidance_scale != 1.0
+ ):
+ print("Not using LCM-LoRA so setting guidance_scale 1.0")
+ guidance_scale = 1.0
+
+ controlnet_args = update_controlnet_arguments(lcm_diffusion_setting)
+ if lcm_diffusion_setting.use_openvino:
+ if (
+ lcm_diffusion_setting.diffusion_task
+ == DiffusionTask.text_to_image.value
+ ):
+ result_images = self.pipeline(
+ prompt=lcm_diffusion_setting.prompt,
+ negative_prompt=lcm_diffusion_setting.negative_prompt,
+ num_inference_steps=lcm_diffusion_setting.inference_steps,
+ guidance_scale=guidance_scale,
+ width=lcm_diffusion_setting.image_width,
+ height=lcm_diffusion_setting.image_height,
+ num_images_per_prompt=lcm_diffusion_setting.number_of_images,
+ ).images
+ elif (
+ lcm_diffusion_setting.diffusion_task
+ == DiffusionTask.image_to_image.value
+ ):
+ result_images = self.pipeline(
+ image=lcm_diffusion_setting.init_image,
+ strength=lcm_diffusion_setting.strength,
+ prompt=lcm_diffusion_setting.prompt,
+ negative_prompt=lcm_diffusion_setting.negative_prompt,
+ num_inference_steps=img_to_img_inference_steps * 3,
+ guidance_scale=guidance_scale,
+ num_images_per_prompt=lcm_diffusion_setting.number_of_images,
+ ).images
+
+ else:
+ if (
+ lcm_diffusion_setting.diffusion_task
+ == DiffusionTask.text_to_image.value
+ ):
+ result_images = self.pipeline(
+ prompt=lcm_diffusion_setting.prompt,
+ negative_prompt=lcm_diffusion_setting.negative_prompt,
+ num_inference_steps=lcm_diffusion_setting.inference_steps,
+ guidance_scale=guidance_scale,
+ width=lcm_diffusion_setting.image_width,
+ height=lcm_diffusion_setting.image_height,
+ num_images_per_prompt=lcm_diffusion_setting.number_of_images,
+ timesteps=self._get_timesteps(),
+ **pipeline_extra_args,
+ **controlnet_args,
+ ).images
+
+ elif (
+ lcm_diffusion_setting.diffusion_task
+ == DiffusionTask.image_to_image.value
+ ):
+ result_images = self.img_to_img_pipeline(
+ image=lcm_diffusion_setting.init_image,
+ strength=lcm_diffusion_setting.strength,
+ prompt=lcm_diffusion_setting.prompt,
+ negative_prompt=lcm_diffusion_setting.negative_prompt,
+ num_inference_steps=img_to_img_inference_steps,
+ guidance_scale=guidance_scale,
+ width=lcm_diffusion_setting.image_width,
+ height=lcm_diffusion_setting.image_height,
+ num_images_per_prompt=lcm_diffusion_setting.number_of_images,
+ **pipeline_extra_args,
+ **controlnet_args,
+ ).images
+
+ for (i, seed) in enumerate(seeds):
+ result_images[i].info['image_seed'] = seed
+
+ return result_images
+
+ def _init_gguf_diffusion(
+ self,
+ lcm_diffusion_setting: LCMDiffusionSetting,
+ ):
+ config = ModelConfig()
+ config.model_path = lcm_diffusion_setting.gguf_model.diffusion_path
+ config.diffusion_model_path = lcm_diffusion_setting.gguf_model.diffusion_path
+ config.clip_l_path = lcm_diffusion_setting.gguf_model.clip_path
+ config.t5xxl_path = lcm_diffusion_setting.gguf_model.t5xxl_path
+ config.vae_path = lcm_diffusion_setting.gguf_model.vae_path
+ config.n_threads = GGUF_THREADS
+ print(f"GGUF Threads : {GGUF_THREADS} ")
+ print("GGUF - Model config")
+ pprint(lcm_diffusion_setting.gguf_model.model_dump())
+ self.pipeline = GGUFDiffusion(
+ get_app_path(), # Place DLL in fastsdcpu folder
+ config,
+ True,
+ )
+
+ def _generate_images_gguf(
+ self,
+ lcm_diffusion_setting: LCMDiffusionSetting,
+ ):
+ if lcm_diffusion_setting.diffusion_task == DiffusionTask.text_to_image.value:
+ t2iconfig = Txt2ImgConfig()
+ t2iconfig.prompt = lcm_diffusion_setting.prompt
+ t2iconfig.batch_count = lcm_diffusion_setting.number_of_images
+ t2iconfig.cfg_scale = lcm_diffusion_setting.guidance_scale
+ t2iconfig.height = lcm_diffusion_setting.image_height
+ t2iconfig.width = lcm_diffusion_setting.image_width
+ t2iconfig.sample_steps = lcm_diffusion_setting.inference_steps
+ t2iconfig.sample_method = SampleMethod.EULER
+ if lcm_diffusion_setting.use_seed:
+ t2iconfig.seed = lcm_diffusion_setting.seed
+ else:
+ t2iconfig.seed = -1
+
+ return self.pipeline.generate_text2mg(t2iconfig)
diff --git a/src/backend/lora.py b/src/backend/lora.py
new file mode 100644
index 0000000000000000000000000000000000000000..369f54f9577c391222331770093f3531b25258ae
--- /dev/null
+++ b/src/backend/lora.py
@@ -0,0 +1,136 @@
+import glob
+from os import path
+from paths import get_file_name, FastStableDiffusionPaths
+from pathlib import Path
+
+
+# A basic class to keep track of the currently loaded LoRAs and
+# their weights; the diffusers function \c get_active_adapters()
+# returns a list of adapter names but not their weights so we need
+# a way to keep track of the current LoRA weights to set whenever
+# a new LoRA is loaded
+class _lora_info:
+ def __init__(
+ self,
+ path: str,
+ weight: float,
+ ):
+ self.path = path
+ self.adapter_name = get_file_name(path)
+ self.weight = weight
+
+ def __del__(self):
+ self.path = None
+ self.adapter_name = None
+
+
+_loaded_loras = []
+_current_pipeline = None
+
+
+# This function loads a LoRA from the LoRA path setting, so it's
+# possible to load multiple LoRAs by calling this function more than
+# once with a different LoRA path setting; note that if you plan to
+# load multiple LoRAs and dynamically change their weights, you
+# might want to set the LoRA fuse option to False
+def load_lora_weight(
+ pipeline,
+ lcm_diffusion_setting,
+):
+ if not lcm_diffusion_setting.lora.path:
+ raise Exception("Empty lora model path")
+
+ if not path.exists(lcm_diffusion_setting.lora.path):
+ raise Exception("Lora model path is invalid")
+
+ # If the pipeline has been rebuilt since the last call, remove all
+ # references to previously loaded LoRAs and store the new pipeline
+ global _loaded_loras
+ global _current_pipeline
+ if pipeline != _current_pipeline:
+ for lora in _loaded_loras:
+ del lora
+ del _loaded_loras
+ _loaded_loras = []
+ _current_pipeline = pipeline
+
+ current_lora = _lora_info(
+ lcm_diffusion_setting.lora.path,
+ lcm_diffusion_setting.lora.weight,
+ )
+ _loaded_loras.append(current_lora)
+
+ if lcm_diffusion_setting.lora.enabled:
+ print(f"LoRA adapter name : {current_lora.adapter_name}")
+ pipeline.load_lora_weights(
+ FastStableDiffusionPaths.get_lora_models_path(),
+ weight_name=Path(lcm_diffusion_setting.lora.path).name,
+ local_files_only=True,
+ adapter_name=current_lora.adapter_name,
+ )
+ update_lora_weights(
+ pipeline,
+ lcm_diffusion_setting,
+ )
+
+ if lcm_diffusion_setting.lora.fuse:
+ pipeline.fuse_lora()
+
+
+def get_lora_models(root_dir: str):
+ lora_models = glob.glob(f"{root_dir}/**/*.safetensors", recursive=True)
+ lora_models_map = {}
+ for file_path in lora_models:
+ lora_name = get_file_name(file_path)
+ if lora_name is not None:
+ lora_models_map[lora_name] = file_path
+ return lora_models_map
+
+
+# This function returns a list of (adapter_name, weight) tuples for the
+# currently loaded LoRAs
+def get_active_lora_weights():
+ active_loras = []
+ for lora_info in _loaded_loras:
+ active_loras.append(
+ (
+ lora_info.adapter_name,
+ lora_info.weight,
+ )
+ )
+ return active_loras
+
+
+# This function receives a pipeline, an lcm_diffusion_setting object and
+# an optional list of updated (adapter_name, weight) tuples
+def update_lora_weights(
+ pipeline,
+ lcm_diffusion_setting,
+ lora_weights=None,
+):
+ global _loaded_loras
+ global _current_pipeline
+ if pipeline != _current_pipeline:
+ print("Wrong pipeline when trying to update LoRA weights")
+ return
+ if lora_weights:
+ for idx, lora in enumerate(lora_weights):
+ if _loaded_loras[idx].adapter_name != lora[0]:
+ print("Wrong adapter name in LoRA enumeration!")
+ continue
+ _loaded_loras[idx].weight = lora[1]
+
+ adapter_names = []
+ adapter_weights = []
+ if lcm_diffusion_setting.use_lcm_lora:
+ adapter_names.append("lcm")
+ adapter_weights.append(1.0)
+ for lora in _loaded_loras:
+ adapter_names.append(lora.adapter_name)
+ adapter_weights.append(lora.weight)
+ pipeline.set_adapters(
+ adapter_names,
+ adapter_weights=adapter_weights,
+ )
+ adapter_weights = zip(adapter_names, adapter_weights)
+ print(f"Adapters: {list(adapter_weights)}")
diff --git a/src/backend/models/device.py b/src/backend/models/device.py
new file mode 100644
index 0000000000000000000000000000000000000000..5951c732e485eeace4dc6d9f289ddeb973ea3f2d
--- /dev/null
+++ b/src/backend/models/device.py
@@ -0,0 +1,9 @@
+from pydantic import BaseModel
+
+
+class DeviceInfo(BaseModel):
+ device_type: str
+ device_name: str
+ os: str
+ platform: str
+ processor: str
diff --git a/src/backend/models/gen_images.py b/src/backend/models/gen_images.py
new file mode 100644
index 0000000000000000000000000000000000000000..a70463adfbe1c8de15dfb70d472bd3bc24d53459
--- /dev/null
+++ b/src/backend/models/gen_images.py
@@ -0,0 +1,16 @@
+from pydantic import BaseModel
+from enum import Enum, auto
+from paths import FastStableDiffusionPaths
+
+
+class ImageFormat(str, Enum):
+ """Image format"""
+
+ JPEG = "jpeg"
+ PNG = "png"
+
+
+class GeneratedImages(BaseModel):
+ path: str = FastStableDiffusionPaths.get_results_path()
+ format: str = ImageFormat.PNG.value.upper()
+ save_image: bool = True
diff --git a/src/backend/models/lcmdiffusion_setting.py b/src/backend/models/lcmdiffusion_setting.py
new file mode 100644
index 0000000000000000000000000000000000000000..71db4e6621b0dd6d887eec586bea4836312df01f
--- /dev/null
+++ b/src/backend/models/lcmdiffusion_setting.py
@@ -0,0 +1,76 @@
+from enum import Enum
+from PIL import Image
+from typing import Any, Optional, Union
+
+from constants import LCM_DEFAULT_MODEL, LCM_DEFAULT_MODEL_OPENVINO
+from paths import FastStableDiffusionPaths
+from pydantic import BaseModel
+
+
+class LCMLora(BaseModel):
+ base_model_id: str = "Lykon/dreamshaper-8"
+ lcm_lora_id: str = "latent-consistency/lcm-lora-sdv1-5"
+
+
+class DiffusionTask(str, Enum):
+ """Diffusion task types"""
+
+ text_to_image = "text_to_image"
+ image_to_image = "image_to_image"
+
+
+class Lora(BaseModel):
+ models_dir: str = FastStableDiffusionPaths.get_lora_models_path()
+ path: Optional[Any] = None
+ weight: Optional[float] = 0.5
+ fuse: bool = True
+ enabled: bool = False
+
+
+class ControlNetSetting(BaseModel):
+ adapter_path: Optional[str] = None # ControlNet adapter path
+ conditioning_scale: float = 0.5
+ enabled: bool = False
+ _control_image: Image = None # Control image, PIL image
+
+
+class GGUFModel(BaseModel):
+ gguf_models: str = FastStableDiffusionPaths.get_gguf_models_path()
+ diffusion_path: Optional[str] = None
+ clip_path: Optional[str] = None
+ t5xxl_path: Optional[str] = None
+ vae_path: Optional[str] = None
+
+
+class LCMDiffusionSetting(BaseModel):
+ lcm_model_id: str = LCM_DEFAULT_MODEL
+ openvino_lcm_model_id: str = LCM_DEFAULT_MODEL_OPENVINO
+ use_offline_model: bool = False
+ use_lcm_lora: bool = False
+ lcm_lora: Optional[LCMLora] = LCMLora()
+ use_tiny_auto_encoder: bool = False
+ use_openvino: bool = False
+ prompt: str = ""
+ negative_prompt: str = ""
+ init_image: Any = None
+ strength: Optional[float] = 0.6
+ image_height: Optional[int] = 512
+ image_width: Optional[int] = 512
+ inference_steps: Optional[int] = 1
+ guidance_scale: Optional[float] = 1
+ clip_skip: Optional[int] = 1
+ token_merging: Optional[float] = 0
+ number_of_images: Optional[int] = 1
+ seed: Optional[int] = 123123
+ use_seed: bool = False
+ use_safety_checker: bool = False
+ diffusion_task: str = DiffusionTask.text_to_image.value
+ lora: Optional[Lora] = Lora()
+ controlnet: Optional[Union[ControlNetSetting, list[ControlNetSetting]]] = None
+ dirs: dict = {
+ "controlnet": FastStableDiffusionPaths.get_controlnet_models_path(),
+ "lora": FastStableDiffusionPaths.get_lora_models_path(),
+ }
+ rebuild_pipeline: bool = False
+ use_gguf_model: bool = False
+ gguf_model: Optional[GGUFModel] = GGUFModel()
diff --git a/src/backend/models/upscale.py b/src/backend/models/upscale.py
new file mode 100644
index 0000000000000000000000000000000000000000..e065fed0ebb3719236f3881a54dff21ff3f0b7b2
--- /dev/null
+++ b/src/backend/models/upscale.py
@@ -0,0 +1,9 @@
+from enum import Enum
+
+
+class UpscaleMode(str, Enum):
+ """Diffusion task types"""
+
+ normal = "normal"
+ sd_upscale = "sd_upscale"
+ aura_sr = "aura_sr"
diff --git a/src/backend/openvino/custom_ov_model_vae_decoder.py b/src/backend/openvino/custom_ov_model_vae_decoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..ef83fb079f9956c80043cab04a65e114f7e56c66
--- /dev/null
+++ b/src/backend/openvino/custom_ov_model_vae_decoder.py
@@ -0,0 +1,21 @@
+from backend.device import is_openvino_device
+
+if is_openvino_device():
+ from optimum.intel.openvino.modeling_diffusion import OVModelVaeDecoder
+
+
+class CustomOVModelVaeDecoder(OVModelVaeDecoder):
+ def __init__(
+ self,
+ model,
+ parent_model,
+ ov_config=None,
+ model_dir=None,
+ ):
+ super(OVModelVaeDecoder, self).__init__(
+ model,
+ parent_model,
+ ov_config,
+ "vae_decoder",
+ model_dir,
+ )
diff --git a/src/backend/openvino/flux_pipeline.py b/src/backend/openvino/flux_pipeline.py
new file mode 100644
index 0000000000000000000000000000000000000000..5e725dbae43418914919e3539c3d2cc30b048abd
--- /dev/null
+++ b/src/backend/openvino/flux_pipeline.py
@@ -0,0 +1,36 @@
+from pathlib import Path
+
+from constants import DEVICE, LCM_DEFAULT_MODEL_OPENVINO, TAEF1_MODEL_OPENVINO
+from huggingface_hub import snapshot_download
+
+from backend.openvino.ovflux import (
+ TEXT_ENCODER_2_PATH,
+ TEXT_ENCODER_PATH,
+ TRANSFORMER_PATH,
+ VAE_DECODER_PATH,
+ init_pipeline,
+)
+
+
+def get_flux_pipeline(
+ model_id: str = LCM_DEFAULT_MODEL_OPENVINO,
+ use_taef1: bool = False,
+ taef1_path: str = TAEF1_MODEL_OPENVINO,
+):
+ model_dir = Path(snapshot_download(model_id))
+ vae_dir = Path(snapshot_download(taef1_path)) if use_taef1 else model_dir
+
+ model_dict = {
+ "transformer": model_dir / TRANSFORMER_PATH,
+ "text_encoder": model_dir / TEXT_ENCODER_PATH,
+ "text_encoder_2": model_dir / TEXT_ENCODER_2_PATH,
+ "vae": vae_dir / VAE_DECODER_PATH,
+ }
+ ov_pipe = init_pipeline(
+ model_dir,
+ model_dict,
+ device=DEVICE.upper(),
+ use_taef1=use_taef1,
+ )
+
+ return ov_pipe
diff --git a/src/backend/openvino/ov_hc_stablediffusion_pipeline.py b/src/backend/openvino/ov_hc_stablediffusion_pipeline.py
new file mode 100644
index 0000000000000000000000000000000000000000..79f196e09658df2a2aa88d4b843140320cd1da89
--- /dev/null
+++ b/src/backend/openvino/ov_hc_stablediffusion_pipeline.py
@@ -0,0 +1,93 @@
+"""This is an experimental pipeline used to test AI PC NPU and GPU"""
+
+from pathlib import Path
+
+from diffusers import EulerDiscreteScheduler,LCMScheduler
+from huggingface_hub import snapshot_download
+from PIL import Image
+from backend.openvino.stable_diffusion_engine import (
+ StableDiffusionEngineAdvanced,
+ LatentConsistencyEngineAdvanced
+)
+
+
+class OvHcStableDiffusion:
+ "OpenVINO Heterogeneous compute Stablediffusion"
+
+ def __init__(
+ self,
+ model_path,
+ device: list = ["GPU", "NPU", "GPU", "GPU"],
+ ):
+ model_dir = Path(snapshot_download(model_path))
+ self.scheduler = EulerDiscreteScheduler(
+ beta_start=0.00085,
+ beta_end=0.012,
+ beta_schedule="scaled_linear",
+ )
+ self.ov_sd_pipleline = StableDiffusionEngineAdvanced(
+ model=model_dir,
+ device=device,
+ )
+
+ def generate(
+ self,
+ prompt: str,
+ neg_prompt: str,
+ init_image: Image = None,
+ strength: float = 1.0,
+ ):
+ image = self.ov_sd_pipleline(
+ prompt=prompt,
+ negative_prompt=neg_prompt,
+ init_image=init_image,
+ strength=strength,
+ num_inference_steps=25,
+ scheduler=self.scheduler,
+ )
+ image_rgb = image[..., ::-1]
+ return Image.fromarray(image_rgb)
+
+
+class OvHcLatentConsistency:
+ """
+ OpenVINO Heterogeneous compute Latent consistency models
+ For the current Intel Cor Ultra, the Text Encoder and Unet can run on NPU
+ Supports following - Text to image , Image to image and image variations
+ """
+
+ def __init__(
+ self,
+ model_path,
+ device: list = ["NPU", "NPU", "GPU"],
+ ):
+
+ model_dir = Path(snapshot_download(model_path))
+
+ self.scheduler = LCMScheduler(
+ beta_start=0.001,
+ beta_end=0.01,
+ )
+ self.ov_sd_pipleline = LatentConsistencyEngineAdvanced(
+ model=model_dir,
+ device=device,
+ )
+
+ def generate(
+ self,
+ prompt: str,
+ neg_prompt: str,
+ init_image: Image = None,
+ num_inference_steps=4,
+ strength: float = 0.5,
+ ):
+ image = self.ov_sd_pipleline(
+ prompt=prompt,
+ init_image = init_image,
+ strength = strength,
+ num_inference_steps=num_inference_steps,
+ scheduler=self.scheduler,
+ seed=None,
+ )
+
+ return image
diff --git a/src/backend/openvino/ovflux.py b/src/backend/openvino/ovflux.py
new file mode 100644
index 0000000000000000000000000000000000000000..b30dfbee5b4da0ee8c188bb36b3138deddfa75c4
--- /dev/null
+++ b/src/backend/openvino/ovflux.py
@@ -0,0 +1,675 @@
+"""Based on https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/notebooks/flux.1-image-generation/flux_helper.py"""
+
+import inspect
+import json
+from pathlib import Path
+from typing import Any, Dict, List, Optional, Union
+
+import numpy as np
+import openvino as ov
+import torch
+from diffusers.image_processor import VaeImageProcessor
+from diffusers.pipelines.flux.pipeline_output import FluxPipelineOutput
+from diffusers.pipelines.pipeline_utils import DiffusionPipeline
+from diffusers.schedulers import FlowMatchEulerDiscreteScheduler
+from diffusers.utils.torch_utils import randn_tensor
+from transformers import AutoTokenizer
+
+TRANSFORMER_PATH = Path("transformer/transformer.xml")
+VAE_DECODER_PATH = Path("vae/vae_decoder.xml")
+TEXT_ENCODER_PATH = Path("text_encoder/text_encoder.xml")
+TEXT_ENCODER_2_PATH = Path("text_encoder_2/text_encoder_2.xml")
+
+
+def cleanup_torchscript_cache():
+ """
+ Helper for removing cached model representation
+ """
+ torch._C._jit_clear_class_registry()
+ torch.jit._recursive.concrete_type_store = torch.jit._recursive.ConcreteTypeStore()
+ torch.jit._state._clear_class_state()
+
+
+def _prepare_latent_image_ids(
+ batch_size, height, width, device=torch.device("cpu"), dtype=torch.float32
+):
+ latent_image_ids = torch.zeros(height // 2, width // 2, 3)
+ latent_image_ids[..., 1] = (
+ latent_image_ids[..., 1] + torch.arange(height // 2)[:, None]
+ )
+ latent_image_ids[..., 2] = (
+ latent_image_ids[..., 2] + torch.arange(width // 2)[None, :]
+ )
+
+ latent_image_id_height, latent_image_id_width, latent_image_id_channels = (
+ latent_image_ids.shape
+ )
+
+ latent_image_ids = latent_image_ids[None, :].repeat(batch_size, 1, 1, 1)
+ latent_image_ids = latent_image_ids.reshape(
+ batch_size,
+ latent_image_id_height * latent_image_id_width,
+ latent_image_id_channels,
+ )
+
+ return latent_image_ids.to(device=device, dtype=dtype)
+
+
+def rope(pos: torch.Tensor, dim: int, theta: int) -> torch.Tensor:
+ assert dim % 2 == 0, "The dimension must be even."
+
+ scale = torch.arange(0, dim, 2, dtype=torch.float32, device=pos.device) / dim
+ omega = 1.0 / (theta**scale)
+
+ batch_size, seq_length = pos.shape
+ out = pos.unsqueeze(-1) * omega.unsqueeze(0).unsqueeze(0)
+ cos_out = torch.cos(out)
+ sin_out = torch.sin(out)
+
+ stacked_out = torch.stack([cos_out, -sin_out, sin_out, cos_out], dim=-1)
+ out = stacked_out.view(batch_size, -1, dim // 2, 2, 2)
+ return out.float()
+
+
+def calculate_shift(
+ image_seq_len,
+ base_seq_len: int = 256,
+ max_seq_len: int = 4096,
+ base_shift: float = 0.5,
+ max_shift: float = 1.16,
+):
+ m = (max_shift - base_shift) / (max_seq_len - base_seq_len)
+ b = base_shift - m * base_seq_len
+ mu = image_seq_len * m + b
+ return mu
+
+
+# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.retrieve_timesteps
+def retrieve_timesteps(
+ scheduler,
+ num_inference_steps: Optional[int] = None,
+ timesteps: Optional[List[int]] = None,
+ sigmas: Optional[List[float]] = None,
+ **kwargs,
+):
+ """
+ Calls the scheduler's `set_timesteps` method and retrieves timesteps from the scheduler after the call. Handles
+ custom timesteps. Any kwargs will be supplied to `scheduler.set_timesteps`.
+
+ Args:
+ scheduler (`SchedulerMixin`):
+ The scheduler to get timesteps from.
+ num_inference_steps (`int`):
+ The number of diffusion steps used when generating samples with a pre-trained model. If used, `timesteps`
+ must be `None`.
+ device (`str` or `torch.device`, *optional*):
+ The device to which the timesteps should be moved to. If `None`, the timesteps are not moved.
+ timesteps (`List[int]`, *optional*):
+ Custom timesteps used to override the timestep spacing strategy of the scheduler. If `timesteps` is passed,
+ `num_inference_steps` and `sigmas` must be `None`.
+ sigmas (`List[float]`, *optional*):
+ Custom sigmas used to override the timestep spacing strategy of the scheduler. If `sigmas` is passed,
+ `num_inference_steps` and `timesteps` must be `None`.
+
+ Returns:
+ `Tuple[torch.Tensor, int]`: A tuple where the first element is the timestep schedule from the scheduler and the
+ second element is the number of inference steps.
+ """
+ if timesteps is not None and sigmas is not None:
+ raise ValueError(
+ "Only one of `timesteps` or `sigmas` can be passed. Please choose one to set custom values"
+ )
+ if timesteps is not None:
+ accepts_timesteps = "timesteps" in set(
+ inspect.signature(scheduler.set_timesteps).parameters.keys()
+ )
+ if not accepts_timesteps:
+ raise ValueError(
+ f"The current scheduler class {scheduler.__class__}'s `set_timesteps` does not support custom"
+ f" timestep schedules. Please check whether you are using the correct scheduler."
+ )
+ scheduler.set_timesteps(timesteps=timesteps, **kwargs)
+ timesteps = scheduler.timesteps
+ num_inference_steps = len(timesteps)
+ elif sigmas is not None:
+ accept_sigmas = "sigmas" in set(
+ inspect.signature(scheduler.set_timesteps).parameters.keys()
+ )
+ if not accept_sigmas:
+ raise ValueError(
+ f"The current scheduler class {scheduler.__class__}'s `set_timesteps` does not support custom"
+ f" sigmas schedules. Please check whether you are using the correct scheduler."
+ )
+ scheduler.set_timesteps(sigmas=sigmas, **kwargs)
+ timesteps = scheduler.timesteps
+ num_inference_steps = len(timesteps)
+ else:
+ scheduler.set_timesteps(num_inference_steps, **kwargs)
+ timesteps = scheduler.timesteps
+ return timesteps, num_inference_steps
+
+
+class OVFluxPipeline(DiffusionPipeline):
+ def __init__(
+ self,
+ scheduler,
+ transformer,
+ vae,
+ text_encoder,
+ text_encoder_2,
+ tokenizer,
+ tokenizer_2,
+ transformer_config,
+ vae_config,
+ ):
+ super().__init__()
+
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ text_encoder_2=text_encoder_2,
+ tokenizer=tokenizer,
+ tokenizer_2=tokenizer_2,
+ transformer=transformer,
+ scheduler=scheduler,
+ )
+ self.vae_config = vae_config
+ self.transformer_config = transformer_config
+ self.vae_scale_factor = 2 ** (
+ len(self.vae_config.get("block_out_channels", [0] * 16))
+ if hasattr(self, "vae") and self.vae is not None
+ else 16
+ )
+ self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
+ self.tokenizer_max_length = (
+ self.tokenizer.model_max_length
+ if hasattr(self, "tokenizer") and self.tokenizer is not None
+ else 77
+ )
+ self.default_sample_size = 64
+
+ def _get_t5_prompt_embeds(
+ self,
+ prompt: Union[str, List[str]] = None,
+ num_images_per_prompt: int = 1,
+ max_sequence_length: int = 512,
+ ):
+ prompt = [prompt] if isinstance(prompt, str) else prompt
+ batch_size = len(prompt)
+
+ text_inputs = self.tokenizer_2(
+ prompt,
+ padding="max_length",
+ max_length=max_sequence_length,
+ truncation=True,
+ return_length=False,
+ return_overflowing_tokens=False,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+ prompt_embeds = torch.from_numpy(self.text_encoder_2(text_input_ids)[0])
+
+ _, seq_len, _ = prompt_embeds.shape
+
+ # duplicate text embeddings and attention mask for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(
+ batch_size * num_images_per_prompt, seq_len, -1
+ )
+
+ return prompt_embeds
+
+ def _get_clip_prompt_embeds(
+ self,
+ prompt: Union[str, List[str]],
+ num_images_per_prompt: int = 1,
+ ):
+
+ prompt = [prompt] if isinstance(prompt, str) else prompt
+ batch_size = len(prompt)
+
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer_max_length,
+ truncation=True,
+ return_overflowing_tokens=False,
+ return_length=False,
+ return_tensors="pt",
+ )
+
+ text_input_ids = text_inputs.input_ids
+ prompt_embeds = torch.from_numpy(self.text_encoder(text_input_ids)[1])
+
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(batch_size * num_images_per_prompt, -1)
+
+ return prompt_embeds
+
+ def encode_prompt(
+ self,
+ prompt: Union[str, List[str]],
+ prompt_2: Union[str, List[str]],
+ num_images_per_prompt: int = 1,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
+ max_sequence_length: int = 512,
+ ):
+ r"""
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ prompt to be encoded
+ prompt_2 (`str` or `List[str]`, *optional*):
+ The prompt or prompts to be sent to the `tokenizer_2` and `text_encoder_2`. If not defined, `prompt` is
+ used in all text-encoders
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting.
+ If not provided, pooled text embeddings will be generated from `prompt` input argument.
+ lora_scale (`float`, *optional*):
+ A lora scale that will be applied to all LoRA layers of the text encoder if LoRA layers are loaded.
+ """
+
+ prompt = [prompt] if isinstance(prompt, str) else prompt
+ if prompt is not None:
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ if prompt_embeds is None:
+ prompt_2 = prompt_2 or prompt
+ prompt_2 = [prompt_2] if isinstance(prompt_2, str) else prompt_2
+
+ # We only use the pooled prompt output from the CLIPTextModel
+ pooled_prompt_embeds = self._get_clip_prompt_embeds(
+ prompt=prompt,
+ num_images_per_prompt=num_images_per_prompt,
+ )
+ prompt_embeds = self._get_t5_prompt_embeds(
+ prompt=prompt_2,
+ num_images_per_prompt=num_images_per_prompt,
+ max_sequence_length=max_sequence_length,
+ )
+ text_ids = torch.zeros(batch_size, prompt_embeds.shape[1], 3)
+ text_ids = text_ids.repeat(num_images_per_prompt, 1, 1)
+
+ return prompt_embeds, pooled_prompt_embeds, text_ids
+
+ def check_inputs(
+ self,
+ prompt,
+ prompt_2,
+ height,
+ width,
+ prompt_embeds=None,
+ pooled_prompt_embeds=None,
+ max_sequence_length=None,
+ ):
+ if height % 8 != 0 or width % 8 != 0:
+ raise ValueError(
+ f"`height` and `width` have to be divisible by 8 but are {height} and {width}."
+ )
+
+ if prompt is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt_2 is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt_2`: {prompt_2} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt is None and prompt_embeds is None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
+ )
+ elif prompt is not None and (
+ not isinstance(prompt, str) and not isinstance(prompt, list)
+ ):
+ raise ValueError(
+ f"`prompt` has to be of type `str` or `list` but is {type(prompt)}"
+ )
+ elif prompt_2 is not None and (
+ not isinstance(prompt_2, str) and not isinstance(prompt_2, list)
+ ):
+ raise ValueError(
+ f"`prompt_2` has to be of type `str` or `list` but is {type(prompt_2)}"
+ )
+
+ if prompt_embeds is not None and pooled_prompt_embeds is None:
+ raise ValueError(
+ "If `prompt_embeds` are provided, `pooled_prompt_embeds` also have to be passed. Make sure to generate `pooled_prompt_embeds` from the same text encoder that was used to generate `prompt_embeds`."
+ )
+
+ if max_sequence_length is not None and max_sequence_length > 512:
+ raise ValueError(
+ f"`max_sequence_length` cannot be greater than 512 but is {max_sequence_length}"
+ )
+
+ @staticmethod
+ def _prepare_latent_image_ids(batch_size, height, width):
+ return _prepare_latent_image_ids(batch_size, height, width)
+
+ @staticmethod
+ def _pack_latents(latents, batch_size, num_channels_latents, height, width):
+ latents = latents.view(
+ batch_size, num_channels_latents, height // 2, 2, width // 2, 2
+ )
+ latents = latents.permute(0, 2, 4, 1, 3, 5)
+ latents = latents.reshape(
+ batch_size, (height // 2) * (width // 2), num_channels_latents * 4
+ )
+
+ return latents
+
+ @staticmethod
+ def _unpack_latents(latents, height, width, vae_scale_factor):
+ batch_size, num_patches, channels = latents.shape
+
+ height = height // vae_scale_factor
+ width = width // vae_scale_factor
+
+ latents = latents.view(batch_size, height, width, channels // 4, 2, 2)
+ latents = latents.permute(0, 3, 1, 4, 2, 5)
+
+ latents = latents.reshape(
+ batch_size, channels // (2 * 2), height * 2, width * 2
+ )
+
+ return latents
+
+ def prepare_latents(
+ self,
+ batch_size,
+ num_channels_latents,
+ height,
+ width,
+ generator,
+ latents=None,
+ ):
+ height = 2 * (int(height) // self.vae_scale_factor)
+ width = 2 * (int(width) // self.vae_scale_factor)
+
+ shape = (batch_size, num_channels_latents, height, width)
+
+ if latents is not None:
+ latent_image_ids = self._prepare_latent_image_ids(batch_size, height, width)
+ return latents, latent_image_ids
+
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ latents = randn_tensor(shape, generator=generator)
+ latents = self._pack_latents(
+ latents, batch_size, num_channels_latents, height, width
+ )
+
+ latent_image_ids = self._prepare_latent_image_ids(batch_size, height, width)
+
+ return latents, latent_image_ids
+
+ @property
+ def guidance_scale(self):
+ return self._guidance_scale
+
+ @property
+ def num_timesteps(self):
+ return self._num_timesteps
+
+ @property
+ def interrupt(self):
+ return self._interrupt
+
+ def __call__(
+ self,
+ prompt: Union[str, List[str]] = None,
+ prompt_2: Optional[Union[str, List[str]]] = None,
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ negative_prompt: str = None,
+ num_inference_steps: int = 28,
+ timesteps: List[int] = None,
+ guidance_scale: float = 7.0,
+ num_images_per_prompt: Optional[int] = 1,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ max_sequence_length: int = 512,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
+ instead.
+ prompt_2 (`str` or `List[str]`, *optional*):
+ The prompt or prompts to be sent to `tokenizer_2` and `text_encoder_2`. If not defined, `prompt` is
+ will be used instead
+ height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The height in pixels of the generated image. This is set to 1024 by default for the best results.
+ width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The width in pixels of the generated image. This is set to 1024 by default for the best results.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ timesteps (`List[int]`, *optional*):
+ Custom timesteps to use for the denoising process with schedulers which support a `timesteps` argument
+ in their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is
+ passed will be used. Must be in descending order.
+ guidance_scale (`float`, *optional*, defaults to 7.0):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting.
+ If not provided, pooled text embeddings will be generated from `prompt` input argument.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.flux.FluxPipelineOutput`] instead of a plain tuple.
+ max_sequence_length (`int` defaults to 512): Maximum sequence length to use with the `prompt`.
+ Returns:
+ [`~pipelines.flux.FluxPipelineOutput`] or `tuple`: [`~pipelines.flux.FluxPipelineOutput`] if `return_dict`
+ is True, otherwise a `tuple`. When returning a tuple, the first element is a list with the generated
+ images.
+ """
+
+ height = height or self.default_sample_size * self.vae_scale_factor
+ width = width or self.default_sample_size * self.vae_scale_factor
+
+ # 1. Check inputs. Raise error if not correct
+ self.check_inputs(
+ prompt,
+ prompt_2,
+ height,
+ width,
+ prompt_embeds=prompt_embeds,
+ pooled_prompt_embeds=pooled_prompt_embeds,
+ max_sequence_length=max_sequence_length,
+ )
+
+ self._guidance_scale = guidance_scale
+ self._interrupt = False
+
+ # 2. Define call parameters
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ (
+ prompt_embeds,
+ pooled_prompt_embeds,
+ text_ids,
+ ) = self.encode_prompt(
+ prompt=prompt,
+ prompt_2=prompt_2,
+ prompt_embeds=prompt_embeds,
+ pooled_prompt_embeds=pooled_prompt_embeds,
+ num_images_per_prompt=num_images_per_prompt,
+ max_sequence_length=max_sequence_length,
+ )
+
+ # 4. Prepare latent variables
+ num_channels_latents = self.transformer_config.get("in_channels", 64) // 4
+ latents, latent_image_ids = self.prepare_latents(
+ batch_size * num_images_per_prompt,
+ num_channels_latents,
+ height,
+ width,
+ generator,
+ latents,
+ )
+
+ # 5. Prepare timesteps
+ sigmas = np.linspace(1.0, 1 / num_inference_steps, num_inference_steps)
+ image_seq_len = latents.shape[1]
+ mu = calculate_shift(
+ image_seq_len,
+ self.scheduler.config.base_image_seq_len,
+ self.scheduler.config.max_image_seq_len,
+ self.scheduler.config.base_shift,
+ self.scheduler.config.max_shift,
+ )
+ timesteps, num_inference_steps = retrieve_timesteps(
+ scheduler=self.scheduler,
+ num_inference_steps=num_inference_steps,
+ timesteps=timesteps,
+ sigmas=sigmas,
+ mu=mu,
+ )
+ num_warmup_steps = max(
+ len(timesteps) - num_inference_steps * self.scheduler.order, 0
+ )
+ self._num_timesteps = len(timesteps)
+
+ # 6. Denoising loop
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ if self.interrupt:
+ continue
+
+ # broadcast to batch dimension in a way that's compatible with ONNX/Core ML
+ timestep = t.expand(latents.shape[0]).to(latents.dtype)
+
+ # handle guidance
+ if self.transformer_config.get("guidance_embeds"):
+ guidance = torch.tensor([guidance_scale])
+ guidance = guidance.expand(latents.shape[0])
+ else:
+ guidance = None
+
+ transformer_input = {
+ "hidden_states": latents,
+ "timestep": timestep / 1000,
+ "pooled_projections": pooled_prompt_embeds,
+ "encoder_hidden_states": prompt_embeds,
+ "txt_ids": text_ids,
+ "img_ids": latent_image_ids,
+ }
+ if guidance is not None:
+ transformer_input["guidance"] = guidance
+
+ noise_pred = torch.from_numpy(self.transformer(transformer_input)[0])
+
+ latents = self.scheduler.step(
+ noise_pred, t, latents, return_dict=False
+ )[0]
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or (
+ (i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0
+ ):
+ progress_bar.update()
+
+ if output_type == "latent":
+ image = latents
+
+ else:
+ latents = self._unpack_latents(
+ latents, height, width, self.vae_scale_factor
+ )
+ latents = latents / self.vae_config.get(
+ "scaling_factor"
+ ) + self.vae_config.get("shift_factor")
+ image = self.vae(latents)[0]
+ image = self.image_processor.postprocess(
+ torch.from_numpy(image), output_type=output_type
+ )
+
+ if not return_dict:
+ return (image,)
+
+ return FluxPipelineOutput(images=image)
+
+
+def init_pipeline(
+ model_dir,
+ models_dict: Dict[str, Any],
+ device: str,
+ use_taef1: bool = False,
+):
+ pipeline_args = {}
+
+ print("OpenVINO FLUX Model compilation")
+ core = ov.Core()
+ for model_name, model_path in models_dict.items():
+ pipeline_args[model_name] = core.compile_model(model_path, device)
+ if model_name == "vae" and use_taef1:
+ print(f"✅ VAE(TAEF1) - Done!")
+ else:
+ print(f"✅ {model_name} - Done!")
+
+ transformer_path = models_dict["transformer"]
+ transformer_config_path = transformer_path.parent / "config.json"
+ with transformer_config_path.open("r") as f:
+ transformer_config = json.load(f)
+ vae_path = models_dict["vae"]
+ vae_config_path = vae_path.parent / "config.json"
+ with vae_config_path.open("r") as f:
+ vae_config = json.load(f)
+
+ pipeline_args["vae_config"] = vae_config
+ pipeline_args["transformer_config"] = transformer_config
+
+ scheduler = FlowMatchEulerDiscreteScheduler.from_pretrained(model_dir / "scheduler")
+
+ tokenizer = AutoTokenizer.from_pretrained(model_dir / "tokenizer")
+ tokenizer_2 = AutoTokenizer.from_pretrained(model_dir / "tokenizer_2")
+
+ pipeline_args["scheduler"] = scheduler
+ pipeline_args["tokenizer"] = tokenizer
+ pipeline_args["tokenizer_2"] = tokenizer_2
+ ov_pipe = OVFluxPipeline(**pipeline_args)
+ return ov_pipe
diff --git a/src/backend/openvino/pipelines.py b/src/backend/openvino/pipelines.py
new file mode 100644
index 0000000000000000000000000000000000000000..62d936dd7426bbe1dd7f43376bbfa61089cf0a8a
--- /dev/null
+++ b/src/backend/openvino/pipelines.py
@@ -0,0 +1,75 @@
+from constants import DEVICE, LCM_DEFAULT_MODEL_OPENVINO
+from backend.tiny_decoder import get_tiny_decoder_vae_model
+from typing import Any
+from backend.device import is_openvino_device
+from paths import get_base_folder_name
+
+if is_openvino_device():
+ from huggingface_hub import snapshot_download
+ from optimum.intel.openvino.modeling_diffusion import OVBaseModel
+
+ from optimum.intel.openvino.modeling_diffusion import (
+ OVStableDiffusionPipeline,
+ OVStableDiffusionImg2ImgPipeline,
+ OVStableDiffusionXLPipeline,
+ OVStableDiffusionXLImg2ImgPipeline,
+ )
+ from backend.openvino.custom_ov_model_vae_decoder import CustomOVModelVaeDecoder
+
+
+def ov_load_taesd(
+ pipeline: Any,
+ use_local_model: bool = False,
+):
+ taesd_dir = snapshot_download(
+ repo_id=get_tiny_decoder_vae_model(pipeline.__class__.__name__),
+ local_files_only=use_local_model,
+ )
+ pipeline.vae_decoder = CustomOVModelVaeDecoder(
+ model=OVBaseModel.load_model(f"{taesd_dir}/vae_decoder/openvino_model.xml"),
+ parent_model=pipeline,
+ model_dir=taesd_dir,
+ )
+
+
+def get_ov_text_to_image_pipeline(
+ model_id: str = LCM_DEFAULT_MODEL_OPENVINO,
+ use_local_model: bool = False,
+) -> Any:
+ if "xl" in get_base_folder_name(model_id).lower():
+ pipeline = OVStableDiffusionXLPipeline.from_pretrained(
+ model_id,
+ local_files_only=use_local_model,
+ ov_config={"CACHE_DIR": ""},
+ device=DEVICE.upper(),
+ )
+ else:
+ pipeline = OVStableDiffusionPipeline.from_pretrained(
+ model_id,
+ local_files_only=use_local_model,
+ ov_config={"CACHE_DIR": ""},
+ device=DEVICE.upper(),
+ )
+
+ return pipeline
+
+
+def get_ov_image_to_image_pipeline(
+ model_id: str = LCM_DEFAULT_MODEL_OPENVINO,
+ use_local_model: bool = False,
+) -> Any:
+ if "xl" in get_base_folder_name(model_id).lower():
+ pipeline = OVStableDiffusionXLImg2ImgPipeline.from_pretrained(
+ model_id,
+ local_files_only=use_local_model,
+ ov_config={"CACHE_DIR": ""},
+ device=DEVICE.upper(),
+ )
+ else:
+ pipeline = OVStableDiffusionImg2ImgPipeline.from_pretrained(
+ model_id,
+ local_files_only=use_local_model,
+ ov_config={"CACHE_DIR": ""},
+ device=DEVICE.upper(),
+ )
+ return pipeline
diff --git a/src/backend/openvino/stable_diffusion_engine.py b/src/backend/openvino/stable_diffusion_engine.py
new file mode 100644
index 0000000000000000000000000000000000000000..3546db24dddaeaf78eb1162ad066bb0169de9ca7
--- /dev/null
+++ b/src/backend/openvino/stable_diffusion_engine.py
@@ -0,0 +1,1817 @@
+"""
+Copyright(C) 2022-2023 Intel Corporation
+SPDX - License - Identifier: Apache - 2.0
+
+"""
+import inspect
+from typing import Union, Optional, Any, List, Dict
+import numpy as np
+# openvino
+from openvino.runtime import Core
+# tokenizer
+from transformers import CLIPTokenizer
+import torch
+import random
+
+from diffusers import DiffusionPipeline
+from diffusers.schedulers import (DDIMScheduler,
+ LMSDiscreteScheduler,
+ PNDMScheduler,
+ EulerDiscreteScheduler,
+ EulerAncestralDiscreteScheduler)
+
+
+from diffusers.image_processor import VaeImageProcessor
+from diffusers.utils.torch_utils import randn_tensor
+from diffusers.utils import PIL_INTERPOLATION
+
+import cv2
+import os
+import sys
+
+# for multithreading
+import concurrent.futures
+
+#For GIF
+import PIL
+from PIL import Image
+import glob
+import json
+import time
+
+def scale_fit_to_window(dst_width:int, dst_height:int, image_width:int, image_height:int):
+ """
+ Preprocessing helper function for calculating image size for resize with peserving original aspect ratio
+ and fitting image to specific window size
+
+ Parameters:
+ dst_width (int): destination window width
+ dst_height (int): destination window height
+ image_width (int): source image width
+ image_height (int): source image height
+ Returns:
+ result_width (int): calculated width for resize
+ result_height (int): calculated height for resize
+ """
+ im_scale = min(dst_height / image_height, dst_width / image_width)
+ return int(im_scale * image_width), int(im_scale * image_height)
+
+def preprocess(image: PIL.Image.Image, ht=512, wt=512):
+ """
+ Image preprocessing function. Takes image in PIL.Image format, resizes it to keep aspect ration and fits to model input window 512x512,
+ then converts it to np.ndarray and adds padding with zeros on right or bottom side of image (depends from aspect ratio), after that
+ converts data to float32 data type and change range of values from [0, 255] to [-1, 1], finally, converts data layout from planar NHWC to NCHW.
+ The function returns preprocessed input tensor and padding size, which can be used in postprocessing.
+
+ Parameters:
+ image (PIL.Image.Image): input image
+ Returns:
+ image (np.ndarray): preprocessed image tensor
+ meta (Dict): dictionary with preprocessing metadata info
+ """
+
+ src_width, src_height = image.size
+ image = image.convert('RGB')
+ dst_width, dst_height = scale_fit_to_window(
+ wt, ht, src_width, src_height)
+ image = np.array(image.resize((dst_width, dst_height),
+ resample=PIL.Image.Resampling.LANCZOS))[None, :]
+
+ pad_width = wt - dst_width
+ pad_height = ht - dst_height
+ pad = ((0, 0), (0, pad_height), (0, pad_width), (0, 0))
+ image = np.pad(image, pad, mode="constant")
+ image = image.astype(np.float32) / 255.0
+ image = 2.0 * image - 1.0
+ image = image.transpose(0, 3, 1, 2)
+
+ return image, {"padding": pad, "src_width": src_width, "src_height": src_height}
+
+def try_enable_npu_turbo(device, core):
+ import platform
+ if "windows" in platform.system().lower():
+ if "NPU" in device and "3720" not in core.get_property('NPU', 'DEVICE_ARCHITECTURE'):
+ try:
+ core.set_property(properties={'NPU_TURBO': 'YES'},device_name='NPU')
+ except:
+ print(f"Failed loading NPU_TURBO for device {device}. Skipping... ")
+ else:
+ print_npu_turbo_art()
+ else:
+ print(f"Skipping NPU_TURBO for device {device}")
+ elif "linux" in platform.system().lower():
+ if os.path.isfile('/sys/module/intel_vpu/parameters/test_mode'):
+ with open('/sys/module/intel_vpu/version', 'r') as f:
+ version = f.readline().split()[0]
+ if tuple(map(int, version.split('.'))) < tuple(map(int, '1.9.0'.split('.'))):
+ print(f"The driver intel_vpu-1.9.0 (or later) needs to be loaded for NPU Turbo (currently {version}). Skipping...")
+ else:
+ with open('/sys/module/intel_vpu/parameters/test_mode', 'r') as tm_file:
+ test_mode = int(tm_file.readline().split()[0])
+ if test_mode == 512:
+ print_npu_turbo_art()
+ else:
+ print("The driver >=intel_vpu-1.9.0 was must be loaded with "
+ "\"modprobe intel_vpu test_mode=512\" to enable NPU_TURBO "
+ f"(currently test_mode={test_mode}). Skipping...")
+ else:
+ print(f"The driver >=intel_vpu-1.9.0 must be loaded with \"modprobe intel_vpu test_mode=512\" to enable NPU_TURBO. Skipping...")
+ else:
+ print(f"This platform ({platform.system()}) does not support NPU Turbo")
+
+def result(var):
+ return next(iter(var.values()))
+
+class StableDiffusionEngineAdvanced(DiffusionPipeline):
+ def __init__(self, model="runwayml/stable-diffusion-v1-5",
+ tokenizer="openai/clip-vit-large-patch14",
+ device=["CPU", "CPU", "CPU", "CPU"]):
+ try:
+ self.tokenizer = CLIPTokenizer.from_pretrained(model, local_files_only=True)
+ except:
+ self.tokenizer = CLIPTokenizer.from_pretrained(tokenizer)
+ self.tokenizer.save_pretrained(model)
+
+ self.core = Core()
+ self.core.set_property({'CACHE_DIR': os.path.join(model, 'cache')})
+ try_enable_npu_turbo(device, self.core)
+
+ print("Loading models... ")
+
+
+
+ with concurrent.futures.ThreadPoolExecutor(max_workers=8) as executor:
+ futures = {
+ "unet_time_proj": executor.submit(self.core.compile_model, os.path.join(model, "unet_time_proj.xml"), device[0]),
+ "text": executor.submit(self.load_model, model, "text_encoder", device[0]),
+ "unet": executor.submit(self.load_model, model, "unet_int8", device[1]),
+ "unet_neg": executor.submit(self.load_model, model, "unet_int8", device[2]) if device[1] != device[2] else None,
+ "vae_decoder": executor.submit(self.load_model, model, "vae_decoder", device[3]),
+ "vae_encoder": executor.submit(self.load_model, model, "vae_encoder", device[3])
+ }
+
+ self.unet_time_proj = futures["unet_time_proj"].result()
+ self.text_encoder = futures["text"].result()
+ self.unet = futures["unet"].result()
+ self.unet_neg = futures["unet_neg"].result() if futures["unet_neg"] else self.unet
+ self.vae_decoder = futures["vae_decoder"].result()
+ self.vae_encoder = futures["vae_encoder"].result()
+ print("Text Device:", device[0])
+ print("unet Device:", device[1])
+ print("unet-neg Device:", device[2])
+ print("VAE Device:", device[3])
+
+ self._text_encoder_output = self.text_encoder.output(0)
+ self._vae_d_output = self.vae_decoder.output(0)
+ self._vae_e_output = self.vae_encoder.output(0) if self.vae_encoder else None
+
+ self.set_dimensions()
+ self.infer_request_neg = self.unet_neg.create_infer_request()
+ self.infer_request = self.unet.create_infer_request()
+ self.infer_request_time_proj = self.unet_time_proj.create_infer_request()
+ self.time_proj_constants = np.load(os.path.join(model, "time_proj_constants.npy"))
+
+ def load_model(self, model, model_name, device):
+ if "NPU" in device:
+ with open(os.path.join(model, f"{model_name}.blob"), "rb") as f:
+ return self.core.import_model(f.read(), device)
+ return self.core.compile_model(os.path.join(model, f"{model_name}.xml"), device)
+
+ def set_dimensions(self):
+ latent_shape = self.unet.input("latent_model_input").shape
+ if latent_shape[1] == 4:
+ self.height = latent_shape[2] * 8
+ self.width = latent_shape[3] * 8
+ else:
+ self.height = latent_shape[1] * 8
+ self.width = latent_shape[2] * 8
+
+ def __call__(
+ self,
+ prompt,
+ init_image = None,
+ negative_prompt=None,
+ scheduler=None,
+ strength = 0.5,
+ num_inference_steps = 32,
+ guidance_scale = 7.5,
+ eta = 0.0,
+ create_gif = False,
+ model = None,
+ callback = None,
+ callback_userdata = None
+ ):
+
+ # extract condition
+ text_input = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="np",
+ )
+ text_embeddings = self.text_encoder(text_input.input_ids)[self._text_encoder_output]
+
+ # do classifier free guidance
+ do_classifier_free_guidance = guidance_scale > 1.0
+ if do_classifier_free_guidance:
+
+ if negative_prompt is None:
+ uncond_tokens = [""]
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt]
+ else:
+ uncond_tokens = negative_prompt
+
+ tokens_uncond = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length, #truncation=True,
+ return_tensors="np"
+ )
+ uncond_embeddings = self.text_encoder(tokens_uncond.input_ids)[self._text_encoder_output]
+ text_embeddings = np.concatenate([uncond_embeddings, text_embeddings])
+
+ # set timesteps
+ accepts_offset = "offset" in set(inspect.signature(scheduler.set_timesteps).parameters.keys())
+ extra_set_kwargs = {}
+
+ if accepts_offset:
+ extra_set_kwargs["offset"] = 1
+
+ scheduler.set_timesteps(num_inference_steps, **extra_set_kwargs)
+
+ timesteps, num_inference_steps = self.get_timesteps(num_inference_steps, strength, scheduler)
+ latent_timestep = timesteps[:1]
+
+ # get the initial random noise unless the user supplied it
+ latents, meta = self.prepare_latents(init_image, latent_timestep, scheduler)
+
+
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+ accepts_eta = "eta" in set(inspect.signature(scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+ if create_gif:
+ frames = []
+
+ for i, t in enumerate(self.progress_bar(timesteps)):
+ if callback:
+ callback(i, callback_userdata)
+
+ # expand the latents if we are doing classifier free guidance
+ noise_pred = []
+ latent_model_input = latents
+ latent_model_input = scheduler.scale_model_input(latent_model_input, t)
+
+ latent_model_input_neg = latent_model_input
+ if self.unet.input("latent_model_input").shape[1] != 4:
+ #print("In transpose")
+ try:
+ latent_model_input = latent_model_input.permute(0,2,3,1)
+ except:
+ latent_model_input = latent_model_input.transpose(0,2,3,1)
+
+ if self.unet_neg.input("latent_model_input").shape[1] != 4:
+ #print("In transpose")
+ try:
+ latent_model_input_neg = latent_model_input_neg.permute(0,2,3,1)
+ except:
+ latent_model_input_neg = latent_model_input_neg.transpose(0,2,3,1)
+
+
+ time_proj_constants_fp16 = np.float16(self.time_proj_constants)
+ t_scaled_fp16 = time_proj_constants_fp16 * np.float16(t)
+ cosine_t_fp16 = np.cos(t_scaled_fp16)
+ sine_t_fp16 = np.sin(t_scaled_fp16)
+
+ t_scaled = self.time_proj_constants * np.float32(t)
+
+ cosine_t = np.cos(t_scaled)
+ sine_t = np.sin(t_scaled)
+
+ time_proj_dict = {"sine_t" : np.float32(sine_t), "cosine_t" : np.float32(cosine_t)}
+ self.infer_request_time_proj.start_async(time_proj_dict)
+ self.infer_request_time_proj.wait()
+ time_proj = self.infer_request_time_proj.get_output_tensor(0).data.astype(np.float32)
+
+ input_tens_neg_dict = {"time_proj": np.float32(time_proj), "latent_model_input":latent_model_input_neg, "encoder_hidden_states": np.expand_dims(text_embeddings[0], axis=0)}
+ input_tens_dict = {"time_proj": np.float32(time_proj), "latent_model_input":latent_model_input, "encoder_hidden_states": np.expand_dims(text_embeddings[1], axis=0)}
+
+ self.infer_request_neg.start_async(input_tens_neg_dict)
+ self.infer_request.start_async(input_tens_dict)
+ self.infer_request_neg.wait()
+ self.infer_request.wait()
+
+ noise_pred_neg = self.infer_request_neg.get_output_tensor(0)
+ noise_pred_pos = self.infer_request.get_output_tensor(0)
+
+ noise_pred.append(noise_pred_neg.data.astype(np.float32))
+ noise_pred.append(noise_pred_pos.data.astype(np.float32))
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred[0], noise_pred[1]
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = scheduler.step(torch.from_numpy(noise_pred), t, torch.from_numpy(latents), **extra_step_kwargs)["prev_sample"].numpy()
+
+ if create_gif:
+ frames.append(latents)
+
+ if callback:
+ callback(num_inference_steps, callback_userdata)
+
+ # scale and decode the image latents with vae
+ latents = 1 / 0.18215 * latents
+
+ start = time.time()
+ image = self.vae_decoder(latents)[self._vae_d_output]
+ print("Decoder ended:",time.time() - start)
+
+ image = self.postprocess_image(image, meta)
+
+ if create_gif:
+ gif_folder=os.path.join(model,"../../../gif")
+ print("gif_folder:",gif_folder)
+ if not os.path.exists(gif_folder):
+ os.makedirs(gif_folder)
+ for i in range(0,len(frames)):
+ image = self.vae_decoder(frames[i]*(1/0.18215))[self._vae_d_output]
+ image = self.postprocess_image(image, meta)
+ output = gif_folder + "/" + str(i).zfill(3) +".png"
+ cv2.imwrite(output, image)
+ with open(os.path.join(gif_folder, "prompt.json"), "w") as file:
+ json.dump({"prompt": prompt}, file)
+ frames_image = [Image.open(image) for image in glob.glob(f"{gif_folder}/*.png")]
+ frame_one = frames_image[0]
+ gif_file=os.path.join(gif_folder,"stable_diffusion.gif")
+ frame_one.save(gif_file, format="GIF", append_images=frames_image, save_all=True, duration=100, loop=0)
+
+ return image
+
+ def prepare_latents(self, image:PIL.Image.Image = None, latent_timestep:torch.Tensor = None, scheduler = LMSDiscreteScheduler):
+ """
+ Function for getting initial latents for starting generation
+
+ Parameters:
+ image (PIL.Image.Image, *optional*, None):
+ Input image for generation, if not provided randon noise will be used as starting point
+ latent_timestep (torch.Tensor, *optional*, None):
+ Predicted by scheduler initial step for image generation, required for latent image mixing with nosie
+ Returns:
+ latents (np.ndarray):
+ Image encoded in latent space
+ """
+ latents_shape = (1, 4, self.height // 8, self.width // 8)
+
+ noise = np.random.randn(*latents_shape).astype(np.float32)
+ if image is None:
+ ##print("Image is NONE")
+ # if we use LMSDiscreteScheduler, let's make sure latents are mulitplied by sigmas
+ if isinstance(scheduler, LMSDiscreteScheduler):
+
+ noise = noise * scheduler.sigmas[0].numpy()
+ return noise, {}
+ elif isinstance(scheduler, EulerDiscreteScheduler) or isinstance(scheduler,EulerAncestralDiscreteScheduler):
+
+ noise = noise * scheduler.sigmas.max().numpy()
+ return noise, {}
+ else:
+ return noise, {}
+ input_image, meta = preprocess(image,self.height,self.width)
+
+ moments = self.vae_encoder(input_image)[self._vae_e_output]
+
+ mean, logvar = np.split(moments, 2, axis=1)
+
+ std = np.exp(logvar * 0.5)
+ latents = (mean + std * np.random.randn(*mean.shape)) * 0.18215
+
+
+ latents = scheduler.add_noise(torch.from_numpy(latents), torch.from_numpy(noise), latent_timestep).numpy()
+ return latents, meta
+
+ def postprocess_image(self, image:np.ndarray, meta:Dict):
+ """
+ Postprocessing for decoded image. Takes generated image decoded by VAE decoder, unpad it to initial image size (if required),
+ normalize and convert to [0, 255] pixels range. Optionally, convertes it from np.ndarray to PIL.Image format
+
+ Parameters:
+ image (np.ndarray):
+ Generated image
+ meta (Dict):
+ Metadata obtained on latents preparing step, can be empty
+ output_type (str, *optional*, pil):
+ Output format for result, can be pil or numpy
+ Returns:
+ image (List of np.ndarray or PIL.Image.Image):
+ Postprocessed images
+
+ if "src_height" in meta:
+ orig_height, orig_width = meta["src_height"], meta["src_width"]
+ image = [cv2.resize(img, (orig_width, orig_height))
+ for img in image]
+
+ return image
+ """
+ if "padding" in meta:
+ pad = meta["padding"]
+ (_, end_h), (_, end_w) = pad[1:3]
+ h, w = image.shape[2:]
+ #print("image shape",image.shape[2:])
+ unpad_h = h - end_h
+ unpad_w = w - end_w
+ image = image[:, :, :unpad_h, :unpad_w]
+ image = np.clip(image / 2 + 0.5, 0, 1)
+ image = (image[0].transpose(1, 2, 0)[:, :, ::-1] * 255).astype(np.uint8)
+
+
+
+ if "src_height" in meta:
+ orig_height, orig_width = meta["src_height"], meta["src_width"]
+ image = cv2.resize(image, (orig_width, orig_height))
+
+ return image
+
+
+
+
+ def get_timesteps(self, num_inference_steps:int, strength:float, scheduler):
+ """
+ Helper function for getting scheduler timesteps for generation
+ In case of image-to-image generation, it updates number of steps according to strength
+
+ Parameters:
+ num_inference_steps (int):
+ number of inference steps for generation
+ strength (float):
+ value between 0.0 and 1.0, that controls the amount of noise that is added to the input image.
+ Values that approach 1.0 allow for lots of variations but will also produce images that are not semantically consistent with the input.
+ """
+ # get the original timestep using init_timestep
+
+ init_timestep = min(int(num_inference_steps * strength), num_inference_steps)
+
+ t_start = max(num_inference_steps - init_timestep, 0)
+ timesteps = scheduler.timesteps[t_start:]
+
+ return timesteps, num_inference_steps - t_start
+
+class StableDiffusionEngine(DiffusionPipeline):
+ def __init__(
+ self,
+ model="bes-dev/stable-diffusion-v1-4-openvino",
+ tokenizer="openai/clip-vit-large-patch14",
+ device=["CPU","CPU","CPU","CPU"]):
+
+ self.core = Core()
+ self.core.set_property({'CACHE_DIR': os.path.join(model, 'cache')})
+
+ self.batch_size = 2 if device[1] == device[2] and device[1] == "GPU" else 1
+ try_enable_npu_turbo(device, self.core)
+
+ try:
+ self.tokenizer = CLIPTokenizer.from_pretrained(model, local_files_only=True)
+ except Exception as e:
+ print("Local tokenizer not found. Attempting to download...")
+ self.tokenizer = self.download_tokenizer(tokenizer, model)
+
+ print("Loading models... ")
+
+ with concurrent.futures.ThreadPoolExecutor(max_workers=8) as executor:
+ text_future = executor.submit(self.load_model, model, "text_encoder", device[0])
+ vae_de_future = executor.submit(self.load_model, model, "vae_decoder", device[3])
+ vae_en_future = executor.submit(self.load_model, model, "vae_encoder", device[3])
+
+ if self.batch_size == 1:
+ if "int8" not in model:
+ unet_future = executor.submit(self.load_model, model, "unet_bs1", device[1])
+ unet_neg_future = executor.submit(self.load_model, model, "unet_bs1", device[2]) if device[1] != device[2] else None
+ else:
+ unet_future = executor.submit(self.load_model, model, "unet_int8a16", device[1])
+ unet_neg_future = executor.submit(self.load_model, model, "unet_int8a16", device[2]) if device[1] != device[2] else None
+ else:
+ unet_future = executor.submit(self.load_model, model, "unet", device[1])
+ unet_neg_future = None
+
+ self.unet = unet_future.result()
+ self.unet_neg = unet_neg_future.result() if unet_neg_future else self.unet
+ self.text_encoder = text_future.result()
+ self.vae_decoder = vae_de_future.result()
+ self.vae_encoder = vae_en_future.result()
+ print("Text Device:", device[0])
+ print("unet Device:", device[1])
+ print("unet-neg Device:", device[2])
+ print("VAE Device:", device[3])
+
+ self._text_encoder_output = self.text_encoder.output(0)
+ self._unet_output = self.unet.output(0)
+ self._vae_d_output = self.vae_decoder.output(0)
+ self._vae_e_output = self.vae_encoder.output(0) if self.vae_encoder else None
+
+ self.unet_input_tensor_name = "sample" if 'sample' in self.unet.input(0).names else "latent_model_input"
+
+ if self.batch_size == 1:
+ self.infer_request = self.unet.create_infer_request()
+ self.infer_request_neg = self.unet_neg.create_infer_request()
+ self._unet_neg_output = self.unet_neg.output(0)
+ else:
+ self.infer_request = None
+ self.infer_request_neg = None
+ self._unet_neg_output = None
+
+ self.set_dimensions()
+
+
+
+ def load_model(self, model, model_name, device):
+ if "NPU" in device:
+ with open(os.path.join(model, f"{model_name}.blob"), "rb") as f:
+ return self.core.import_model(f.read(), device)
+ return self.core.compile_model(os.path.join(model, f"{model_name}.xml"), device)
+
+ def set_dimensions(self):
+ latent_shape = self.unet.input(self.unet_input_tensor_name).shape
+ if latent_shape[1] == 4:
+ self.height = latent_shape[2] * 8
+ self.width = latent_shape[3] * 8
+ else:
+ self.height = latent_shape[1] * 8
+ self.width = latent_shape[2] * 8
+
+ def __call__(
+ self,
+ prompt,
+ init_image=None,
+ negative_prompt=None,
+ scheduler=None,
+ strength=0.5,
+ num_inference_steps=32,
+ guidance_scale=7.5,
+ eta=0.0,
+ create_gif=False,
+ model=None,
+ callback=None,
+ callback_userdata=None
+ ):
+ # extract condition
+ text_input = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="np",
+ )
+ text_embeddings = self.text_encoder(text_input.input_ids)[self._text_encoder_output]
+
+
+ # do classifier free guidance
+ do_classifier_free_guidance = guidance_scale > 1.0
+ if do_classifier_free_guidance:
+ if negative_prompt is None:
+ uncond_tokens = [""]
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt]
+ else:
+ uncond_tokens = negative_prompt
+
+ tokens_uncond = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length, # truncation=True,
+ return_tensors="np"
+ )
+ uncond_embeddings = self.text_encoder(tokens_uncond.input_ids)[self._text_encoder_output]
+ text_embeddings = np.concatenate([uncond_embeddings, text_embeddings])
+
+ # set timesteps
+ accepts_offset = "offset" in set(inspect.signature(scheduler.set_timesteps).parameters.keys())
+ extra_set_kwargs = {}
+
+ if accepts_offset:
+ extra_set_kwargs["offset"] = 1
+
+ scheduler.set_timesteps(num_inference_steps, **extra_set_kwargs)
+
+ timesteps, num_inference_steps = self.get_timesteps(num_inference_steps, strength, scheduler)
+ latent_timestep = timesteps[:1]
+
+ # get the initial random noise unless the user supplied it
+ latents, meta = self.prepare_latents(init_image, latent_timestep, scheduler,model)
+
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+ accepts_eta = "eta" in set(inspect.signature(scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+ if create_gif:
+ frames = []
+
+ for i, t in enumerate(self.progress_bar(timesteps)):
+ if callback:
+ callback(i, callback_userdata)
+
+ if self.batch_size == 1:
+ # expand the latents if we are doing classifier free guidance
+ noise_pred = []
+ latent_model_input = latents
+
+ #Scales the denoising model input by `(sigma**2 + 1) ** 0.5` to match the Euler algorithm.
+ latent_model_input = scheduler.scale_model_input(latent_model_input, t)
+ latent_model_input_pos = latent_model_input
+ latent_model_input_neg = latent_model_input
+
+ if self.unet.input(self.unet_input_tensor_name).shape[1] != 4:
+ try:
+ latent_model_input_pos = latent_model_input_pos.permute(0,2,3,1)
+ except:
+ latent_model_input_pos = latent_model_input_pos.transpose(0,2,3,1)
+
+ if self.unet_neg.input(self.unet_input_tensor_name).shape[1] != 4:
+ try:
+ latent_model_input_neg = latent_model_input_neg.permute(0,2,3,1)
+ except:
+ latent_model_input_neg = latent_model_input_neg.transpose(0,2,3,1)
+
+ if "sample" in self.unet_input_tensor_name:
+ input_tens_neg_dict = {"sample" : latent_model_input_neg, "encoder_hidden_states": np.expand_dims(text_embeddings[0], axis=0), "timestep": np.expand_dims(np.float32(t), axis=0)}
+ input_tens_pos_dict = {"sample" : latent_model_input_pos, "encoder_hidden_states": np.expand_dims(text_embeddings[1], axis=0), "timestep": np.expand_dims(np.float32(t), axis=0)}
+ else:
+ input_tens_neg_dict = {"latent_model_input" : latent_model_input_neg, "encoder_hidden_states": np.expand_dims(text_embeddings[0], axis=0), "t": np.expand_dims(np.float32(t), axis=0)}
+ input_tens_pos_dict = {"latent_model_input" : latent_model_input_pos, "encoder_hidden_states": np.expand_dims(text_embeddings[1], axis=0), "t": np.expand_dims(np.float32(t), axis=0)}
+
+ self.infer_request_neg.start_async(input_tens_neg_dict)
+ self.infer_request.start_async(input_tens_pos_dict)
+
+ self.infer_request_neg.wait()
+ self.infer_request.wait()
+
+ noise_pred_neg = self.infer_request_neg.get_output_tensor(0)
+ noise_pred_pos = self.infer_request.get_output_tensor(0)
+
+ noise_pred.append(noise_pred_neg.data.astype(np.float32))
+ noise_pred.append(noise_pred_pos.data.astype(np.float32))
+ else:
+ latent_model_input = np.concatenate([latents] * 2) if do_classifier_free_guidance else latents
+ latent_model_input = scheduler.scale_model_input(latent_model_input, t)
+ noise_pred = self.unet([latent_model_input, np.array(t, dtype=np.float32), text_embeddings])[self._unet_output]
+
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred[0], noise_pred[1]
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = scheduler.step(torch.from_numpy(noise_pred), t, torch.from_numpy(latents), **extra_step_kwargs)["prev_sample"].numpy()
+
+ if create_gif:
+ frames.append(latents)
+
+ if callback:
+ callback(num_inference_steps, callback_userdata)
+
+ # scale and decode the image latents with vae
+ #if self.height == 512 and self.width == 512:
+ latents = 1 / 0.18215 * latents
+ image = self.vae_decoder(latents)[self._vae_d_output]
+ image = self.postprocess_image(image, meta)
+
+ return image
+
+ def prepare_latents(self, image: PIL.Image.Image = None, latent_timestep: torch.Tensor = None,
+ scheduler=LMSDiscreteScheduler,model=None):
+ """
+ Function for getting initial latents for starting generation
+
+ Parameters:
+ image (PIL.Image.Image, *optional*, None):
+ Input image for generation, if not provided randon noise will be used as starting point
+ latent_timestep (torch.Tensor, *optional*, None):
+ Predicted by scheduler initial step for image generation, required for latent image mixing with nosie
+ Returns:
+ latents (np.ndarray):
+ Image encoded in latent space
+ """
+ latents_shape = (1, 4, self.height // 8, self.width // 8)
+
+ noise = np.random.randn(*latents_shape).astype(np.float32)
+ if image is None:
+ #print("Image is NONE")
+ # if we use LMSDiscreteScheduler, let's make sure latents are mulitplied by sigmas
+ if isinstance(scheduler, LMSDiscreteScheduler):
+
+ noise = noise * scheduler.sigmas[0].numpy()
+ return noise, {}
+ elif isinstance(scheduler, EulerDiscreteScheduler):
+
+ noise = noise * scheduler.sigmas.max().numpy()
+ return noise, {}
+ else:
+ return noise, {}
+ input_image, meta = preprocess(image, self.height, self.width)
+
+ moments = self.vae_encoder(input_image)[self._vae_e_output]
+
+ if "sd_2.1" in model:
+ latents = moments * 0.18215
+
+ else:
+
+ mean, logvar = np.split(moments, 2, axis=1)
+
+ std = np.exp(logvar * 0.5)
+ latents = (mean + std * np.random.randn(*mean.shape)) * 0.18215
+
+ latents = scheduler.add_noise(torch.from_numpy(latents), torch.from_numpy(noise), latent_timestep).numpy()
+ return latents, meta
+
+
+ def postprocess_image(self, image: np.ndarray, meta: Dict):
+ """
+ Postprocessing for decoded image. Takes generated image decoded by VAE decoder, unpad it to initila image size (if required),
+ normalize and convert to [0, 255] pixels range. Optionally, convertes it from np.ndarray to PIL.Image format
+
+ Parameters:
+ image (np.ndarray):
+ Generated image
+ meta (Dict):
+ Metadata obtained on latents preparing step, can be empty
+ output_type (str, *optional*, pil):
+ Output format for result, can be pil or numpy
+ Returns:
+ image (List of np.ndarray or PIL.Image.Image):
+ Postprocessed images
+
+ if "src_height" in meta:
+ orig_height, orig_width = meta["src_height"], meta["src_width"]
+ image = [cv2.resize(img, (orig_width, orig_height))
+ for img in image]
+
+ return image
+ """
+ if "padding" in meta:
+ pad = meta["padding"]
+ (_, end_h), (_, end_w) = pad[1:3]
+ h, w = image.shape[2:]
+ # print("image shape",image.shape[2:])
+ unpad_h = h - end_h
+ unpad_w = w - end_w
+ image = image[:, :, :unpad_h, :unpad_w]
+ image = np.clip(image / 2 + 0.5, 0, 1)
+ image = (image[0].transpose(1, 2, 0)[:, :, ::-1] * 255).astype(np.uint8)
+
+ if "src_height" in meta:
+ orig_height, orig_width = meta["src_height"], meta["src_width"]
+ image = cv2.resize(image, (orig_width, orig_height))
+
+ return image
+
+ # image = (image / 2 + 0.5).clip(0, 1)
+ # image = (image[0].transpose(1, 2, 0)[:, :, ::-1] * 255).astype(np.uint8)
+
+ def get_timesteps(self, num_inference_steps: int, strength: float, scheduler):
+ """
+ Helper function for getting scheduler timesteps for generation
+ In case of image-to-image generation, it updates number of steps according to strength
+
+ Parameters:
+ num_inference_steps (int):
+ number of inference steps for generation
+ strength (float):
+ value between 0.0 and 1.0, that controls the amount of noise that is added to the input image.
+ Values that approach 1.0 allow for lots of variations but will also produce images that are not semantically consistent with the input.
+ """
+ # get the original timestep using init_timestep
+
+ init_timestep = min(int(num_inference_steps * strength), num_inference_steps)
+
+ t_start = max(num_inference_steps - init_timestep, 0)
+ timesteps = scheduler.timesteps[t_start:]
+
+ return timesteps, num_inference_steps - t_start
+
+class LatentConsistencyEngine(DiffusionPipeline):
+ def __init__(
+ self,
+ model="SimianLuo/LCM_Dreamshaper_v7",
+ tokenizer="openai/clip-vit-large-patch14",
+ device=["CPU", "CPU", "CPU"],
+ ):
+ super().__init__()
+ try:
+ self.tokenizer = CLIPTokenizer.from_pretrained(model, local_files_only=True)
+ except:
+ self.tokenizer = CLIPTokenizer.from_pretrained(tokenizer)
+ self.tokenizer.save_pretrained(model)
+
+ self.core = Core()
+ self.core.set_property({'CACHE_DIR': os.path.join(model, 'cache')}) # adding caching to reduce init time
+ try_enable_npu_turbo(device, self.core)
+
+
+ with concurrent.futures.ThreadPoolExecutor(max_workers=8) as executor:
+ text_future = executor.submit(self.load_model, model, "text_encoder", device[0])
+ unet_future = executor.submit(self.load_model, model, "unet", device[1])
+ vae_de_future = executor.submit(self.load_model, model, "vae_decoder", device[2])
+
+ print("Text Device:", device[0])
+ self.text_encoder = text_future.result()
+ self._text_encoder_output = self.text_encoder.output(0)
+
+ print("Unet Device:", device[1])
+ self.unet = unet_future.result()
+ self._unet_output = self.unet.output(0)
+ self.infer_request = self.unet.create_infer_request()
+
+ print(f"VAE Device: {device[2]}")
+ self.vae_decoder = vae_de_future.result()
+ self.infer_request_vae = self.vae_decoder.create_infer_request()
+ self.safety_checker = None #pipe.safety_checker
+ self.feature_extractor = None #pipe.feature_extractor
+ self.vae_scale_factor = 2 ** 3
+ self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
+
+ def load_model(self, model, model_name, device):
+ if "NPU" in device:
+ with open(os.path.join(model, f"{model_name}.blob"), "rb") as f:
+ return self.core.import_model(f.read(), device)
+ return self.core.compile_model(os.path.join(model, f"{model_name}.xml"), device)
+
+ def _encode_prompt(
+ self,
+ prompt,
+ num_images_per_prompt,
+ prompt_embeds: None,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ prompt to be encoded
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ """
+
+ if prompt_embeds is None:
+
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = self.tokenizer(
+ prompt, padding="longest", return_tensors="pt"
+ ).input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[
+ -1
+ ] and not torch.equal(text_input_ids, untruncated_ids):
+ removed_text = self.tokenizer.batch_decode(
+ untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
+ )
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ prompt_embeds = self.text_encoder(text_input_ids, share_inputs=True, share_outputs=True)
+ prompt_embeds = torch.from_numpy(prompt_embeds[0])
+
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ # duplicate text embeddings for each generation per prompt
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(
+ bs_embed * num_images_per_prompt, seq_len, -1
+ )
+
+ # Don't need to get uncond prompt embedding because of LCM Guided Distillation
+ return prompt_embeds
+
+ def run_safety_checker(self, image, dtype):
+ if self.safety_checker is None:
+ has_nsfw_concept = None
+ else:
+ if torch.is_tensor(image):
+ feature_extractor_input = self.image_processor.postprocess(
+ image, output_type="pil"
+ )
+ else:
+ feature_extractor_input = self.image_processor.numpy_to_pil(image)
+ safety_checker_input = self.feature_extractor(
+ feature_extractor_input, return_tensors="pt"
+ )
+ image, has_nsfw_concept = self.safety_checker(
+ images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
+ )
+ return image, has_nsfw_concept
+
+ def prepare_latents(
+ self, batch_size, num_channels_latents, height, width, dtype, latents=None
+ ):
+ shape = (
+ batch_size,
+ num_channels_latents,
+ height // self.vae_scale_factor,
+ width // self.vae_scale_factor,
+ )
+ if latents is None:
+ latents = torch.randn(shape, dtype=dtype)
+ # scale the initial noise by the standard deviation required by the scheduler
+ return latents
+
+ def get_w_embedding(self, w, embedding_dim=512, dtype=torch.float32):
+ """
+ see https://github.com/google-research/vdm/blob/dc27b98a554f65cdc654b800da5aa1846545d41b/model_vdm.py#L298
+ Args:
+ timesteps: torch.Tensor: generate embedding vectors at these timesteps
+ embedding_dim: int: dimension of the embeddings to generate
+ dtype: data type of the generated embeddings
+ Returns:
+ embedding vectors with shape `(len(timesteps), embedding_dim)`
+ """
+ assert len(w.shape) == 1
+ w = w * 1000.0
+
+ half_dim = embedding_dim // 2
+ emb = torch.log(torch.tensor(10000.0)) / (half_dim - 1)
+ emb = torch.exp(torch.arange(half_dim, dtype=dtype) * -emb)
+ emb = w.to(dtype)[:, None] * emb[None, :]
+ emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=1)
+ if embedding_dim % 2 == 1: # zero pad
+ emb = torch.nn.functional.pad(emb, (0, 1))
+ assert emb.shape == (w.shape[0], embedding_dim)
+ return emb
+
+ @torch.no_grad()
+ def __call__(
+ self,
+ prompt: Union[str, List[str]] = None,
+ height: Optional[int] = 512,
+ width: Optional[int] = 512,
+ guidance_scale: float = 7.5,
+ scheduler = None,
+ num_images_per_prompt: Optional[int] = 1,
+ latents: Optional[torch.FloatTensor] = None,
+ num_inference_steps: int = 4,
+ lcm_origin_steps: int = 50,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ model: Optional[Dict[str, any]] = None,
+ seed: Optional[int] = 1234567,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ callback = None,
+ callback_userdata = None
+ ):
+
+ # 1. Define call parameters
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ if seed is not None:
+ torch.manual_seed(seed)
+
+ #print("After Step 1: batch size is ", batch_size)
+ # do_classifier_free_guidance = guidance_scale > 0.0
+ # In LCM Implementation: cfg_noise = noise_cond + cfg_scale * (noise_cond - noise_uncond) , (cfg_scale > 0.0 using CFG)
+
+ # 2. Encode input prompt
+ prompt_embeds = self._encode_prompt(
+ prompt,
+ num_images_per_prompt,
+ prompt_embeds=prompt_embeds,
+ )
+ #print("After Step 2: prompt embeds is ", prompt_embeds)
+ #print("After Step 2: scheduler is ", scheduler )
+ # 3. Prepare timesteps
+ scheduler.set_timesteps(num_inference_steps, original_inference_steps=lcm_origin_steps)
+ timesteps = scheduler.timesteps
+
+ #print("After Step 3: timesteps is ", timesteps)
+
+ # 4. Prepare latent variable
+ num_channels_latents = 4
+ latents = self.prepare_latents(
+ batch_size * num_images_per_prompt,
+ num_channels_latents,
+ height,
+ width,
+ prompt_embeds.dtype,
+ latents,
+ )
+ latents = latents * scheduler.init_noise_sigma
+
+ #print("After Step 4: ")
+ bs = batch_size * num_images_per_prompt
+
+ # 5. Get Guidance Scale Embedding
+ w = torch.tensor(guidance_scale).repeat(bs)
+ w_embedding = self.get_w_embedding(w, embedding_dim=256)
+ #print("After Step 5: ")
+ # 6. LCM MultiStep Sampling Loop:
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ if callback:
+ callback(i+1, callback_userdata)
+
+ ts = torch.full((bs,), t, dtype=torch.long)
+
+ # model prediction (v-prediction, eps, x)
+ model_pred = self.unet([latents, ts, prompt_embeds, w_embedding],share_inputs=True, share_outputs=True)[0]
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents, denoised = scheduler.step(
+ torch.from_numpy(model_pred), t, latents, return_dict=False
+ )
+ progress_bar.update()
+
+ #print("After Step 6: ")
+
+ vae_start = time.time()
+
+ if not output_type == "latent":
+ image = torch.from_numpy(self.vae_decoder(denoised / 0.18215, share_inputs=True, share_outputs=True)[0])
+ else:
+ image = denoised
+
+ print("Decoder Ended: ", time.time() - vae_start)
+ #post_start = time.time()
+
+ #if has_nsfw_concept is None:
+ do_denormalize = [True] * image.shape[0]
+ #else:
+ # do_denormalize = [not has_nsfw for has_nsfw in has_nsfw_concept]
+
+ #print ("After do_denormalize: image is ", image)
+
+ image = self.image_processor.postprocess(
+ image, output_type=output_type, do_denormalize=do_denormalize
+ )
+
+ return image[0]
+
+class LatentConsistencyEngineAdvanced(DiffusionPipeline):
+ def __init__(
+ self,
+ model="SimianLuo/LCM_Dreamshaper_v7",
+ tokenizer="openai/clip-vit-large-patch14",
+ device=["CPU", "CPU", "CPU"],
+ ):
+ super().__init__()
+ try:
+ self.tokenizer = CLIPTokenizer.from_pretrained(model, local_files_only=True)
+ except:
+ self.tokenizer = CLIPTokenizer.from_pretrained(tokenizer)
+ self.tokenizer.save_pretrained(model)
+
+ self.core = Core()
+ self.core.set_property({'CACHE_DIR': os.path.join(model, 'cache')}) # adding caching to reduce init time
+ #try_enable_npu_turbo(device, self.core)
+
+
+ with concurrent.futures.ThreadPoolExecutor(max_workers=8) as executor:
+ text_future = executor.submit(self.load_model, model, "text_encoder", device[0])
+ unet_future = executor.submit(self.load_model, model, "unet", device[1])
+ vae_de_future = executor.submit(self.load_model, model, "vae_decoder", device[2])
+ vae_encoder_future = executor.submit(self.load_model, model, "vae_encoder", device[2])
+
+
+ print("Text Device:", device[0])
+ self.text_encoder = text_future.result()
+ self._text_encoder_output = self.text_encoder.output(0)
+
+ print("Unet Device:", device[1])
+ self.unet = unet_future.result()
+ self._unet_output = self.unet.output(0)
+ self.infer_request = self.unet.create_infer_request()
+
+ print(f"VAE Device: {device[2]}")
+ self.vae_decoder = vae_de_future.result()
+ self.vae_encoder = vae_encoder_future.result()
+ self._vae_e_output = self.vae_encoder.output(0) if self.vae_encoder else None
+
+ self.infer_request_vae = self.vae_decoder.create_infer_request()
+ self.safety_checker = None #pipe.safety_checker
+ self.feature_extractor = None #pipe.feature_extractor
+ self.vae_scale_factor = 2 ** 3
+ self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
+
+ def load_model(self, model, model_name, device):
+ print(f"Compiling the {model_name} to {device} ...")
+ return self.core.compile_model(os.path.join(model, f"{model_name}.xml"), device)
+
+ def get_timesteps(self, num_inference_steps:int, strength:float, scheduler):
+ """
+ Helper function for getting scheduler timesteps for generation
+ In case of image-to-image generation, it updates number of steps according to strength
+
+ Parameters:
+ num_inference_steps (int):
+ number of inference steps for generation
+ strength (float):
+ value between 0.0 and 1.0, that controls the amount of noise that is added to the input image.
+ Values that approach 1.0 allow for lots of variations but will also produce images that are not semantically consistent with the input.
+ """
+ # get the original timestep using init_timestep
+
+ init_timestep = min(int(num_inference_steps * strength), num_inference_steps)
+
+ t_start = max(num_inference_steps - init_timestep, 0)
+ timesteps = scheduler.timesteps[t_start:]
+
+ return timesteps, num_inference_steps - t_start
+
+ def _encode_prompt(
+ self,
+ prompt,
+ num_images_per_prompt,
+ prompt_embeds: None,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ prompt to be encoded
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ """
+
+ if prompt_embeds is None:
+
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = self.tokenizer(
+ prompt, padding="longest", return_tensors="pt"
+ ).input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[
+ -1
+ ] and not torch.equal(text_input_ids, untruncated_ids):
+ removed_text = self.tokenizer.batch_decode(
+ untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
+ )
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ prompt_embeds = self.text_encoder(text_input_ids, share_inputs=True, share_outputs=True)
+ prompt_embeds = torch.from_numpy(prompt_embeds[0])
+
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ # duplicate text embeddings for each generation per prompt
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(
+ bs_embed * num_images_per_prompt, seq_len, -1
+ )
+
+ # Don't need to get uncond prompt embedding because of LCM Guided Distillation
+ return prompt_embeds
+
+ def run_safety_checker(self, image, dtype):
+ if self.safety_checker is None:
+ has_nsfw_concept = None
+ else:
+ if torch.is_tensor(image):
+ feature_extractor_input = self.image_processor.postprocess(
+ image, output_type="pil"
+ )
+ else:
+ feature_extractor_input = self.image_processor.numpy_to_pil(image)
+ safety_checker_input = self.feature_extractor(
+ feature_extractor_input, return_tensors="pt"
+ )
+ image, has_nsfw_concept = self.safety_checker(
+ images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
+ )
+ return image, has_nsfw_concep
+
+ def prepare_latents(
+ self,image,timestep,batch_size, num_channels_latents, height, width, dtype, scheduler,latents=None,
+ ):
+ shape = (
+ batch_size,
+ num_channels_latents,
+ height // self.vae_scale_factor,
+ width // self.vae_scale_factor,
+ )
+ if image:
+ #latents_shape = (1, 4, 512, 512 // 8)
+ #input_image, meta = preprocess(image,512,512)
+ latents_shape = (1, 4, 512 // 8, 512 // 8)
+ noise = np.random.randn(*latents_shape).astype(np.float32)
+ input_image,meta = preprocess(image,512,512)
+ moments = self.vae_encoder(input_image)[self._vae_e_output]
+ mean, logvar = np.split(moments, 2, axis=1)
+ std = np.exp(logvar * 0.5)
+ latents = (mean + std * np.random.randn(*mean.shape)) * 0.18215
+ noise = torch.randn(shape, dtype=dtype)
+ #latents = scheduler.add_noise(init_latents, noise, timestep)
+ latents = scheduler.add_noise(torch.from_numpy(latents), noise, timestep)
+
+ else:
+ latents = torch.randn(shape, dtype=dtype)
+ # scale the initial noise by the standard deviation required by the scheduler
+ return latents
+
+ def get_w_embedding(self, w, embedding_dim=512, dtype=torch.float32):
+ """
+ see https://github.com/google-research/vdm/blob/dc27b98a554f65cdc654b800da5aa1846545d41b/model_vdm.py#L298
+ Args:
+ timesteps: torch.Tensor: generate embedding vectors at these timesteps
+ embedding_dim: int: dimension of the embeddings to generate
+ dtype: data type of the generated embeddings
+ Returns:
+ embedding vectors with shape `(len(timesteps), embedding_dim)`
+ """
+ assert len(w.shape) == 1
+ w = w * 1000.0
+
+ half_dim = embedding_dim // 2
+ emb = torch.log(torch.tensor(10000.0)) / (half_dim - 1)
+ emb = torch.exp(torch.arange(half_dim, dtype=dtype) * -emb)
+ emb = w.to(dtype)[:, None] * emb[None, :]
+ emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=1)
+ if embedding_dim % 2 == 1: # zero pad
+ emb = torch.nn.functional.pad(emb, (0, 1))
+ assert emb.shape == (w.shape[0], embedding_dim)
+ return emb
+
+ @torch.no_grad()
+ def __call__(
+ self,
+ prompt: Union[str, List[str]] = None,
+ init_image: Optional[PIL.Image.Image] = None,
+ strength: Optional[float] = 0.8,
+ height: Optional[int] = 512,
+ width: Optional[int] = 512,
+ guidance_scale: float = 7.5,
+ scheduler = None,
+ num_images_per_prompt: Optional[int] = 1,
+ latents: Optional[torch.FloatTensor] = None,
+ num_inference_steps: int = 4,
+ lcm_origin_steps: int = 50,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ model: Optional[Dict[str, any]] = None,
+ seed: Optional[int] = 1234567,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ callback = None,
+ callback_userdata = None
+ ):
+
+ # 1. Define call parameters
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ if seed is not None:
+ torch.manual_seed(seed)
+
+ #print("After Step 1: batch size is ", batch_size)
+ # do_classifier_free_guidance = guidance_scale > 0.0
+ # In LCM Implementation: cfg_noise = noise_cond + cfg_scale * (noise_cond - noise_uncond) , (cfg_scale > 0.0 using CFG)
+
+ # 2. Encode input prompt
+ prompt_embeds = self._encode_prompt(
+ prompt,
+ num_images_per_prompt,
+ prompt_embeds=prompt_embeds,
+ )
+ #print("After Step 2: prompt embeds is ", prompt_embeds)
+ #print("After Step 2: scheduler is ", scheduler )
+ # 3. Prepare timesteps
+ #scheduler.set_timesteps(num_inference_steps, original_inference_steps=lcm_origin_steps)
+ latent_timestep = None
+ if init_image:
+ scheduler.set_timesteps(num_inference_steps, original_inference_steps=lcm_origin_steps)
+ timesteps, num_inference_steps = self.get_timesteps(num_inference_steps, strength, scheduler)
+ latent_timestep = timesteps[:1]
+ else:
+ scheduler.set_timesteps(num_inference_steps, original_inference_steps=lcm_origin_steps)
+ timesteps = scheduler.timesteps
+ #timesteps = scheduler.timesteps
+ #latent_timestep = timesteps[:1].repeat(batch_size * num_images_per_prompt)
+ #print("timesteps: ", latent_timestep)
+
+ #print("After Step 3: timesteps is ", timesteps)
+
+ # 4. Prepare latent variable
+ num_channels_latents = 4
+ latents = self.prepare_latents(
+ init_image,
+ latent_timestep,
+ batch_size * num_images_per_prompt,
+ num_channels_latents,
+ height,
+ width,
+ prompt_embeds.dtype,
+ scheduler,
+ latents,
+ )
+
+ latents = latents * scheduler.init_noise_sigma
+
+ #print("After Step 4: ")
+ bs = batch_size * num_images_per_prompt
+
+ # 5. Get Guidance Scale Embedding
+ w = torch.tensor(guidance_scale).repeat(bs)
+ w_embedding = self.get_w_embedding(w, embedding_dim=256)
+ #print("After Step 5: ")
+ # 6. LCM MultiStep Sampling Loop:
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ if callback:
+ callback(i+1, callback_userdata)
+
+ ts = torch.full((bs,), t, dtype=torch.long)
+
+ # model prediction (v-prediction, eps, x)
+ model_pred = self.unet([latents, ts, prompt_embeds, w_embedding],share_inputs=True, share_outputs=True)[0]
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents, denoised = scheduler.step(
+ torch.from_numpy(model_pred), t, latents, return_dict=False
+ )
+ progress_bar.update()
+
+ #print("After Step 6: ")
+
+ vae_start = time.time()
+
+ if not output_type == "latent":
+ image = torch.from_numpy(self.vae_decoder(denoised / 0.18215, share_inputs=True, share_outputs=True)[0])
+ else:
+ image = denoised
+
+ print("Decoder Ended: ", time.time() - vae_start)
+ #post_start = time.time()
+
+ #if has_nsfw_concept is None:
+ do_denormalize = [True] * image.shape[0]
+ #else:
+ # do_denormalize = [not has_nsfw for has_nsfw in has_nsfw_concept]
+
+ #print ("After do_denormalize: image is ", image)
+
+ image = self.image_processor.postprocess(
+ image, output_type=output_type, do_denormalize=do_denormalize
+ )
+
+ return image[0]
+
+class StableDiffusionEngineReferenceOnly(DiffusionPipeline):
+ def __init__(
+ self,
+ #scheduler: Union[DDIMScheduler, PNDMScheduler, LMSDiscreteScheduler],
+ model="bes-dev/stable-diffusion-v1-4-openvino",
+ tokenizer="openai/clip-vit-large-patch14",
+ device=["CPU","CPU","CPU"]
+ ):
+ #self.tokenizer = CLIPTokenizer.from_pretrained(tokenizer)
+ try:
+ self.tokenizer = CLIPTokenizer.from_pretrained(model,local_files_only=True)
+ except:
+ self.tokenizer = CLIPTokenizer.from_pretrained(tokenizer)
+ self.tokenizer.save_pretrained(model)
+
+ #self.scheduler = scheduler
+ # models
+
+ self.core = Core()
+ self.core.set_property({'CACHE_DIR': os.path.join(model, 'cache')}) #adding caching to reduce init time
+ # text features
+
+ print("Text Device:",device[0])
+ self.text_encoder = self.core.compile_model(os.path.join(model, "text_encoder.xml"), device[0])
+
+ self._text_encoder_output = self.text_encoder.output(0)
+
+ # diffusion
+ print("unet_w Device:",device[1])
+ self.unet_w = self.core.compile_model(os.path.join(model, "unet_reference_write.xml"), device[1])
+ self._unet_w_output = self.unet_w.output(0)
+ self.latent_shape = tuple(self.unet_w.inputs[0].shape)[1:]
+
+ print("unet_r Device:",device[1])
+ self.unet_r = self.core.compile_model(os.path.join(model, "unet_reference_read.xml"), device[1])
+ self._unet_r_output = self.unet_r.output(0)
+ # decoder
+ print("Vae Device:",device[2])
+
+ self.vae_decoder = self.core.compile_model(os.path.join(model, "vae_decoder.xml"), device[2])
+
+ # encoder
+
+ self.vae_encoder = self.core.compile_model(os.path.join(model, "vae_encoder.xml"), device[2])
+
+ self.init_image_shape = tuple(self.vae_encoder.inputs[0].shape)[2:]
+
+ self._vae_d_output = self.vae_decoder.output(0)
+ self._vae_e_output = self.vae_encoder.output(0) if self.vae_encoder is not None else None
+
+ self.height = self.unet_w.input(0).shape[2] * 8
+ self.width = self.unet_w.input(0).shape[3] * 8
+
+
+
+ def __call__(
+ self,
+ prompt,
+ image = None,
+ negative_prompt=None,
+ scheduler=None,
+ strength = 1.0,
+ num_inference_steps = 32,
+ guidance_scale = 7.5,
+ eta = 0.0,
+ create_gif = False,
+ model = None,
+ callback = None,
+ callback_userdata = None
+ ):
+ # extract condition
+ text_input = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="np",
+ )
+ text_embeddings = self.text_encoder(text_input.input_ids)[self._text_encoder_output]
+
+
+ # do classifier free guidance
+ do_classifier_free_guidance = guidance_scale > 1.0
+ if do_classifier_free_guidance:
+
+ if negative_prompt is None:
+ uncond_tokens = [""]
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt]
+ else:
+ uncond_tokens = negative_prompt
+
+ tokens_uncond = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length, #truncation=True,
+ return_tensors="np"
+ )
+ uncond_embeddings = self.text_encoder(tokens_uncond.input_ids)[self._text_encoder_output]
+ text_embeddings = np.concatenate([uncond_embeddings, text_embeddings])
+
+ # set timesteps
+ accepts_offset = "offset" in set(inspect.signature(scheduler.set_timesteps).parameters.keys())
+ extra_set_kwargs = {}
+
+ if accepts_offset:
+ extra_set_kwargs["offset"] = 1
+
+ scheduler.set_timesteps(num_inference_steps, **extra_set_kwargs)
+
+ timesteps, num_inference_steps = self.get_timesteps(num_inference_steps, strength, scheduler)
+ latent_timestep = timesteps[:1]
+
+ ref_image = self.prepare_image(
+ image=image,
+ width=512,
+ height=512,
+ )
+ # get the initial random noise unless the user supplied it
+ latents, meta = self.prepare_latents(None, latent_timestep, scheduler)
+ #ref_image_latents, _ = self.prepare_latents(init_image, latent_timestep, scheduler)
+ ref_image_latents = self.ov_prepare_ref_latents(ref_image)
+
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+ accepts_eta = "eta" in set(inspect.signature(scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+ if create_gif:
+ frames = []
+
+ for i, t in enumerate(self.progress_bar(timesteps)):
+ if callback:
+ callback(i, callback_userdata)
+
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = np.concatenate([latents] * 2) if do_classifier_free_guidance else latents
+ latent_model_input = scheduler.scale_model_input(latent_model_input, t)
+
+ # ref only part
+ noise = randn_tensor(
+ ref_image_latents.shape
+ )
+
+ ref_xt = scheduler.add_noise(
+ torch.from_numpy(ref_image_latents),
+ noise,
+ t.reshape(
+ 1,
+ ),
+ ).numpy()
+ ref_xt = np.concatenate([ref_xt] * 2) if do_classifier_free_guidance else ref_xt
+ ref_xt = scheduler.scale_model_input(ref_xt, t)
+
+ # MODE = "write"
+ result_w_dict = self.unet_w([
+ ref_xt,
+ t,
+ text_embeddings
+ ])
+ down_0_attn0 = result_w_dict["/unet/down_blocks.0/attentions.0/transformer_blocks.0/norm1/LayerNormalization_output_0"]
+ down_0_attn1 = result_w_dict["/unet/down_blocks.0/attentions.1/transformer_blocks.0/norm1/LayerNormalization_output_0"]
+ down_1_attn0 = result_w_dict["/unet/down_blocks.1/attentions.0/transformer_blocks.0/norm1/LayerNormalization_output_0"]
+ down_1_attn1 = result_w_dict["/unet/down_blocks.1/attentions.1/transformer_blocks.0/norm1/LayerNormalization_output_0"]
+ down_2_attn0 = result_w_dict["/unet/down_blocks.2/attentions.0/transformer_blocks.0/norm1/LayerNormalization_output_0"]
+ down_2_attn1 = result_w_dict["/unet/down_blocks.2/attentions.1/transformer_blocks.0/norm1/LayerNormalization_output_0"]
+ mid_attn0 = result_w_dict["/unet/mid_block/attentions.0/transformer_blocks.0/norm1/LayerNormalization_output_0"]
+ up_1_attn0 = result_w_dict["/unet/up_blocks.1/attentions.0/transformer_blocks.0/norm1/LayerNormalization_output_0"]
+ up_1_attn1 = result_w_dict["/unet/up_blocks.1/attentions.1/transformer_blocks.0/norm1/LayerNormalization_output_0"]
+ up_1_attn2 = result_w_dict["/unet/up_blocks.1/attentions.2/transformer_blocks.0/norm1/LayerNormalization_output_0"]
+ up_2_attn0 = result_w_dict["/unet/up_blocks.2/attentions.0/transformer_blocks.0/norm1/LayerNormalization_output_0"]
+ up_2_attn1 = result_w_dict["/unet/up_blocks.2/attentions.1/transformer_blocks.0/norm1/LayerNormalization_output_0"]
+ up_2_attn2 = result_w_dict["/unet/up_blocks.2/attentions.2/transformer_blocks.0/norm1/LayerNormalization_output_0"]
+ up_3_attn0 = result_w_dict["/unet/up_blocks.3/attentions.0/transformer_blocks.0/norm1/LayerNormalization_output_0"]
+ up_3_attn1 = result_w_dict["/unet/up_blocks.3/attentions.1/transformer_blocks.0/norm1/LayerNormalization_output_0"]
+ up_3_attn2 = result_w_dict["/unet/up_blocks.3/attentions.2/transformer_blocks.0/norm1/LayerNormalization_output_0"]
+
+ # MODE = "read"
+ noise_pred = self.unet_r([
+ latent_model_input, t, text_embeddings, down_0_attn0, down_0_attn1, down_1_attn0,
+ down_1_attn1, down_2_attn0, down_2_attn1, mid_attn0, up_1_attn0, up_1_attn1, up_1_attn2,
+ up_2_attn0, up_2_attn1, up_2_attn2, up_3_attn0, up_3_attn1, up_3_attn2
+ ])[0]
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred[0], noise_pred[1]
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = scheduler.step(torch.from_numpy(noise_pred), t, torch.from_numpy(latents), **extra_step_kwargs)["prev_sample"].numpy()
+
+ if create_gif:
+ frames.append(latents)
+
+ if callback:
+ callback(num_inference_steps, callback_userdata)
+
+ # scale and decode the image latents with vae
+
+ image = self.vae_decoder(latents)[self._vae_d_output]
+
+ image = self.postprocess_image(image, meta)
+
+ if create_gif:
+ gif_folder=os.path.join(model,"../../../gif")
+ if not os.path.exists(gif_folder):
+ os.makedirs(gif_folder)
+ for i in range(0,len(frames)):
+ image = self.vae_decoder(frames[i])[self._vae_d_output]
+ image = self.postprocess_image(image, meta)
+ output = gif_folder + "/" + str(i).zfill(3) +".png"
+ cv2.imwrite(output, image)
+ with open(os.path.join(gif_folder, "prompt.json"), "w") as file:
+ json.dump({"prompt": prompt}, file)
+ frames_image = [Image.open(image) for image in glob.glob(f"{gif_folder}/*.png")]
+ frame_one = frames_image[0]
+ gif_file=os.path.join(gif_folder,"stable_diffusion.gif")
+ frame_one.save(gif_file, format="GIF", append_images=frames_image, save_all=True, duration=100, loop=0)
+
+ return image
+
+ def ov_prepare_ref_latents(self, refimage, vae_scaling_factor=0.18215):
+ #refimage = refimage.to(device=device, dtype=dtype)
+
+ # encode the mask image into latents space so we can concatenate it to the latents
+ moments = self.vae_encoder(refimage)[0]
+ mean, logvar = np.split(moments, 2, axis=1)
+ std = np.exp(logvar * 0.5)
+ ref_image_latents = (mean + std * np.random.randn(*mean.shape))
+ ref_image_latents = vae_scaling_factor * ref_image_latents
+ #ref_image_latents = scheduler.add_noise(torch.from_numpy(ref_image_latents), torch.from_numpy(noise), latent_timestep).numpy()
+
+ # aligning device to prevent device errors when concating it with the latent model input
+ #ref_image_latents = ref_image_latents.to(device=device, dtype=dtype)
+ return ref_image_latents
+
+ def prepare_latents(self, image:PIL.Image.Image = None, latent_timestep:torch.Tensor = None, scheduler = LMSDiscreteScheduler):
+ """
+ Function for getting initial latents for starting generation
+
+ Parameters:
+ image (PIL.Image.Image, *optional*, None):
+ Input image for generation, if not provided randon noise will be used as starting point
+ latent_timestep (torch.Tensor, *optional*, None):
+ Predicted by scheduler initial step for image generation, required for latent image mixing with nosie
+ Returns:
+ latents (np.ndarray):
+ Image encoded in latent space
+ """
+ latents_shape = (1, 4, self.height // 8, self.width // 8)
+
+ noise = np.random.randn(*latents_shape).astype(np.float32)
+ if image is None:
+ #print("Image is NONE")
+ # if we use LMSDiscreteScheduler, let's make sure latents are mulitplied by sigmas
+ if isinstance(scheduler, LMSDiscreteScheduler):
+
+ noise = noise * scheduler.sigmas[0].numpy()
+ return noise, {}
+ elif isinstance(scheduler, EulerDiscreteScheduler):
+
+ noise = noise * scheduler.sigmas.max().numpy()
+ return noise, {}
+ else:
+ return noise, {}
+ input_image, meta = preprocess(image,self.height,self.width)
+
+ moments = self.vae_encoder(input_image)[self._vae_e_output]
+
+ mean, logvar = np.split(moments, 2, axis=1)
+
+ std = np.exp(logvar * 0.5)
+ latents = (mean + std * np.random.randn(*mean.shape)) * 0.18215
+
+
+ latents = scheduler.add_noise(torch.from_numpy(latents), torch.from_numpy(noise), latent_timestep).numpy()
+ return latents, meta
+
+ def postprocess_image(self, image:np.ndarray, meta:Dict):
+ """
+ Postprocessing for decoded image. Takes generated image decoded by VAE decoder, unpad it to initila image size (if required),
+ normalize and convert to [0, 255] pixels range. Optionally, convertes it from np.ndarray to PIL.Image format
+
+ Parameters:
+ image (np.ndarray):
+ Generated image
+ meta (Dict):
+ Metadata obtained on latents preparing step, can be empty
+ output_type (str, *optional*, pil):
+ Output format for result, can be pil or numpy
+ Returns:
+ image (List of np.ndarray or PIL.Image.Image):
+ Postprocessed images
+
+ if "src_height" in meta:
+ orig_height, orig_width = meta["src_height"], meta["src_width"]
+ image = [cv2.resize(img, (orig_width, orig_height))
+ for img in image]
+
+ return image
+ """
+ if "padding" in meta:
+ pad = meta["padding"]
+ (_, end_h), (_, end_w) = pad[1:3]
+ h, w = image.shape[2:]
+ #print("image shape",image.shape[2:])
+ unpad_h = h - end_h
+ unpad_w = w - end_w
+ image = image[:, :, :unpad_h, :unpad_w]
+ image = np.clip(image / 2 + 0.5, 0, 1)
+ image = (image[0].transpose(1, 2, 0)[:, :, ::-1] * 255).astype(np.uint8)
+
+
+
+ if "src_height" in meta:
+ orig_height, orig_width = meta["src_height"], meta["src_width"]
+ image = cv2.resize(image, (orig_width, orig_height))
+
+ return image
+
+
+ #image = (image / 2 + 0.5).clip(0, 1)
+ #image = (image[0].transpose(1, 2, 0)[:, :, ::-1] * 255).astype(np.uint8)
+
+
+ def get_timesteps(self, num_inference_steps:int, strength:float, scheduler):
+ """
+ Helper function for getting scheduler timesteps for generation
+ In case of image-to-image generation, it updates number of steps according to strength
+
+ Parameters:
+ num_inference_steps (int):
+ number of inference steps for generation
+ strength (float):
+ value between 0.0 and 1.0, that controls the amount of noise that is added to the input image.
+ Values that approach 1.0 allow for lots of variations but will also produce images that are not semantically consistent with the input.
+ """
+ # get the original timestep using init_timestep
+
+ init_timestep = min(int(num_inference_steps * strength), num_inference_steps)
+
+ t_start = max(num_inference_steps - init_timestep, 0)
+ timesteps = scheduler.timesteps[t_start:]
+
+ return timesteps, num_inference_steps - t_start
+ def prepare_image(
+ self,
+ image,
+ width,
+ height,
+ do_classifier_free_guidance=False,
+ guess_mode=False,
+ ):
+ if not isinstance(image, np.ndarray):
+ if isinstance(image, PIL.Image.Image):
+ image = [image]
+
+ if isinstance(image[0], PIL.Image.Image):
+ images = []
+
+ for image_ in image:
+ image_ = image_.convert("RGB")
+ image_ = image_.resize((width, height), resample=PIL_INTERPOLATION["lanczos"])
+ image_ = np.array(image_)
+ image_ = image_[None, :]
+ images.append(image_)
+
+ image = images
+
+ image = np.concatenate(image, axis=0)
+ image = np.array(image).astype(np.float32) / 255.0
+ image = (image - 0.5) / 0.5
+ image = image.transpose(0, 3, 1, 2)
+ elif isinstance(image[0], np.ndarray):
+ image = np.concatenate(image, dim=0)
+
+ if do_classifier_free_guidance and not guess_mode:
+ image = np.concatenate([image] * 2)
+
+ return image
+
+def print_npu_turbo_art():
+ random_number = random.randint(1, 3)
+
+ if random_number == 1:
+ print(" ")
+ print(" ___ ___ ___ ___ ___ ___ ")
+ print(" /\ \ /\ \ /\ \ /\ \ /\ \ _____ /\ \ ")
+ print(" \:\ \ /::\ \ \:\ \ ___ \:\ \ /::\ \ /::\ \ /::\ \ ")
+ print(" \:\ \ /:/\:\__\ \:\ \ /\__\ \:\ \ /:/\:\__\ /:/\:\ \ /:/\:\ \ ")
+ print(" _____\:\ \ /:/ /:/ / ___ \:\ \ /:/ / ___ \:\ \ /:/ /:/ / /:/ /::\__\ /:/ \:\ \ ")
+ print(" /::::::::\__\ /:/_/:/ / /\ \ \:\__\ /:/__/ /\ \ \:\__\ /:/_/:/__/___ /:/_/:/\:|__| /:/__/ \:\__\ ")
+ print(" \:\~~\~~\/__/ \:\/:/ / \:\ \ /:/ / /::\ \ \:\ \ /:/ / \:\/:::::/ / \:\/:/ /:/ / \:\ \ /:/ / ")
+ print(" \:\ \ \::/__/ \:\ /:/ / /:/\:\ \ \:\ /:/ / \::/~~/~~~~ \::/_/:/ / \:\ /:/ / ")
+ print(" \:\ \ \:\ \ \:\/:/ / \/__\:\ \ \:\/:/ / \:\~~\ \:\/:/ / \:\/:/ / ")
+ print(" \:\__\ \:\__\ \::/ / \:\__\ \::/ / \:\__\ \::/ / \::/ / ")
+ print(" \/__/ \/__/ \/__/ \/__/ \/__/ \/__/ \/__/ \/__/ ")
+ print(" ")
+ elif random_number == 2:
+ print(" _ _ ____ _ _ _____ _ _ ____ ____ ___ ")
+ print("| \ | | | _ \ | | | | |_ _| | | | | | _ \ | __ ) / _ \ ")
+ print("| \| | | |_) | | | | | | | | | | | | |_) | | _ \ | | | |")
+ print("| |\ | | __/ | |_| | | | | |_| | | _ < | |_) | | |_| |")
+ print("|_| \_| |_| \___/ |_| \___/ |_| \_\ |____/ \___/ ")
+ print(" ")
+ else:
+ print("")
+ print(" ) ( ( ) ")
+ print(" ( /( )\ ) * ) )\ ) ( ( /( ")
+ print(" )\()) (()/( ( ` ) /( ( (()/( ( )\ )\()) ")
+ print("((_)\ /(_)) )\ ( )(_)) )\ /(_)) )((_) ((_)\ ")
+ print(" _((_) (_)) _ ((_) (_(_()) _ ((_) (_)) ((_)_ ((_) ")
+ print("| \| | | _ \ | | | | |_ _| | | | | | _ \ | _ ) / _ \ ")
+ print("| .` | | _/ | |_| | | | | |_| | | / | _ \ | (_) | ")
+ print("|_|\_| |_| \___/ |_| \___/ |_|_\ |___/ \___/ ")
+ print(" ")
+
+
+
diff --git a/src/backend/pipelines/lcm.py b/src/backend/pipelines/lcm.py
new file mode 100644
index 0000000000000000000000000000000000000000..4fe428516822ede118980002370c45adcf74c0be
--- /dev/null
+++ b/src/backend/pipelines/lcm.py
@@ -0,0 +1,122 @@
+from constants import LCM_DEFAULT_MODEL
+from diffusers import (
+ DiffusionPipeline,
+ AutoencoderTiny,
+ UNet2DConditionModel,
+ LCMScheduler,
+ StableDiffusionPipeline,
+)
+import torch
+from backend.tiny_decoder import get_tiny_decoder_vae_model
+from typing import Any
+from diffusers import (
+ LCMScheduler,
+ StableDiffusionImg2ImgPipeline,
+ StableDiffusionXLImg2ImgPipeline,
+ AutoPipelineForText2Image,
+ AutoPipelineForImage2Image,
+ StableDiffusionControlNetPipeline,
+)
+import pathlib
+
+
+def _get_lcm_pipeline_from_base_model(
+ lcm_model_id: str,
+ base_model_id: str,
+ use_local_model: bool,
+):
+ pipeline = None
+ unet = UNet2DConditionModel.from_pretrained(
+ lcm_model_id,
+ torch_dtype=torch.float32,
+ local_files_only=use_local_model,
+ resume_download=True,
+ )
+ pipeline = DiffusionPipeline.from_pretrained(
+ base_model_id,
+ unet=unet,
+ torch_dtype=torch.float32,
+ local_files_only=use_local_model,
+ resume_download=True,
+ )
+ pipeline.scheduler = LCMScheduler.from_config(pipeline.scheduler.config)
+ return pipeline
+
+
+def load_taesd(
+ pipeline: Any,
+ use_local_model: bool = False,
+ torch_data_type: torch.dtype = torch.float32,
+):
+ vae_model = get_tiny_decoder_vae_model(pipeline.__class__.__name__)
+ pipeline.vae = AutoencoderTiny.from_pretrained(
+ vae_model,
+ torch_dtype=torch_data_type,
+ local_files_only=use_local_model,
+ )
+
+
+def get_lcm_model_pipeline(
+ model_id: str = LCM_DEFAULT_MODEL,
+ use_local_model: bool = False,
+ pipeline_args={},
+):
+ pipeline = None
+ if model_id == "latent-consistency/lcm-sdxl":
+ pipeline = _get_lcm_pipeline_from_base_model(
+ model_id,
+ "stabilityai/stable-diffusion-xl-base-1.0",
+ use_local_model,
+ )
+
+ elif model_id == "latent-consistency/lcm-ssd-1b":
+ pipeline = _get_lcm_pipeline_from_base_model(
+ model_id,
+ "segmind/SSD-1B",
+ use_local_model,
+ )
+ elif pathlib.Path(model_id).suffix == ".safetensors":
+ # When loading a .safetensors model, the pipeline has to be created
+ # with StableDiffusionPipeline() since it's the only class that
+ # defines the method from_single_file()
+ dummy_pipeline = StableDiffusionPipeline.from_single_file(
+ model_id,
+ safety_checker=None,
+ run_safety_checker=False,
+ load_safety_checker=False,
+ local_files_only=use_local_model,
+ use_safetensors=True,
+ )
+ if 'lcm' in model_id.lower():
+ dummy_pipeline.scheduler = LCMScheduler.from_config(dummy_pipeline.scheduler.config)
+
+ pipeline = AutoPipelineForText2Image.from_pipe(
+ dummy_pipeline,
+ **pipeline_args,
+ )
+ del dummy_pipeline
+ else:
+ # pipeline = DiffusionPipeline.from_pretrained(
+ pipeline = AutoPipelineForText2Image.from_pretrained(
+ model_id,
+ local_files_only=use_local_model,
+ **pipeline_args,
+ )
+
+ return pipeline
+
+
+def get_image_to_image_pipeline(pipeline: Any) -> Any:
+ components = pipeline.components
+ pipeline_class = pipeline.__class__.__name__
+ if (
+ pipeline_class == "LatentConsistencyModelPipeline"
+ or pipeline_class == "StableDiffusionPipeline"
+ ):
+ return StableDiffusionImg2ImgPipeline(**components)
+ elif pipeline_class == "StableDiffusionControlNetPipeline":
+ return AutoPipelineForImage2Image.from_pipe(pipeline)
+ elif pipeline_class == "StableDiffusionXLPipeline":
+ return StableDiffusionXLImg2ImgPipeline(**components)
+ else:
+ raise Exception(f"Unknown pipeline {pipeline_class}")
diff --git a/src/backend/pipelines/lcm_lora.py b/src/backend/pipelines/lcm_lora.py
new file mode 100644
index 0000000000000000000000000000000000000000..1816f99ee90d732498c025f5047553bb9228c734
--- /dev/null
+++ b/src/backend/pipelines/lcm_lora.py
@@ -0,0 +1,81 @@
+import pathlib
+from os import path
+
+import torch
+from diffusers import (
+ AutoPipelineForText2Image,
+ LCMScheduler,
+ StableDiffusionPipeline,
+)
+
+
+def load_lcm_weights(
+ pipeline,
+ use_local_model,
+ lcm_lora_id,
+):
+ kwargs = {
+ "local_files_only": use_local_model,
+ "weight_name": "pytorch_lora_weights.safetensors",
+ }
+ pipeline.load_lora_weights(
+ lcm_lora_id,
+ **kwargs,
+ adapter_name="lcm",
+ )
+
+
+def get_lcm_lora_pipeline(
+ base_model_id: str,
+ lcm_lora_id: str,
+ use_local_model: bool,
+ torch_data_type: torch.dtype,
+ pipeline_args={},
+):
+ if pathlib.Path(base_model_id).suffix == ".safetensors":
+ # SD 1.5 models only
+ # When loading a .safetensors model, the pipeline has to be created
+ # with StableDiffusionPipeline() since it's the only class that
+ # defines the method from_single_file(); afterwards a new pipeline
+ # is created using AutoPipelineForText2Image() for ControlNet
+ # support, in case ControlNet is enabled
+ if not path.exists(base_model_id):
+ raise FileNotFoundError(
+ f"Model file not found,Please check your model path: {base_model_id}"
+ )
+ print("Using single file Safetensors model (Supported models - SD 1.5 models)")
+
+ dummy_pipeline = StableDiffusionPipeline.from_single_file(
+ base_model_id,
+ torch_dtype=torch_data_type,
+ safety_checker=None,
+ local_files_only=use_local_model,
+ use_safetensors=True,
+ )
+ pipeline = AutoPipelineForText2Image.from_pipe(
+ dummy_pipeline,
+ **pipeline_args,
+ )
+ del dummy_pipeline
+ else:
+ pipeline = AutoPipelineForText2Image.from_pretrained(
+ base_model_id,
+ torch_dtype=torch_data_type,
+ local_files_only=use_local_model,
+ **pipeline_args,
+ )
+
+ load_lcm_weights(
+ pipeline,
+ use_local_model,
+ lcm_lora_id,
+ )
+ # Always fuse LCM-LoRA
+ # pipeline.fuse_lora()
+
+ if "lcm" in lcm_lora_id.lower() or "hypersd" in lcm_lora_id.lower():
+ print("LCM LoRA model detected so using recommended LCMScheduler")
+ pipeline.scheduler = LCMScheduler.from_config(pipeline.scheduler.config)
+
+ # pipeline.unet.to(memory_format=torch.channels_last)
+ return pipeline
diff --git a/src/backend/tiny_decoder.py b/src/backend/tiny_decoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..957cfcbff65cc22b38450462e052fba50e4d764f
--- /dev/null
+++ b/src/backend/tiny_decoder.py
@@ -0,0 +1,32 @@
+from constants import (
+ TAESD_MODEL,
+ TAESDXL_MODEL,
+ TAESD_MODEL_OPENVINO,
+ TAESDXL_MODEL_OPENVINO,
+)
+
+
+def get_tiny_decoder_vae_model(pipeline_class) -> str:
+ print(f"Pipeline class : {pipeline_class}")
+ if (
+ pipeline_class == "LatentConsistencyModelPipeline"
+ or pipeline_class == "StableDiffusionPipeline"
+ or pipeline_class == "StableDiffusionImg2ImgPipeline"
+ or pipeline_class == "StableDiffusionControlNetPipeline"
+ or pipeline_class == "StableDiffusionControlNetImg2ImgPipeline"
+ ):
+ return TAESD_MODEL
+ elif (
+ pipeline_class == "StableDiffusionXLPipeline"
+ or pipeline_class == "StableDiffusionXLImg2ImgPipeline"
+ ):
+ return TAESDXL_MODEL
+ elif (
+ pipeline_class == "OVStableDiffusionPipeline"
+ or pipeline_class == "OVStableDiffusionImg2ImgPipeline"
+ ):
+ return TAESD_MODEL_OPENVINO
+ elif pipeline_class == "OVStableDiffusionXLPipeline":
+ return TAESDXL_MODEL_OPENVINO
+ else:
+ raise Exception("No valid pipeline class found!")
diff --git a/src/backend/upscale/aura_sr.py b/src/backend/upscale/aura_sr.py
new file mode 100644
index 0000000000000000000000000000000000000000..787a66fd4e34b7c1f38662e721ff622024e22df7
--- /dev/null
+++ b/src/backend/upscale/aura_sr.py
@@ -0,0 +1,1004 @@
+# AuraSR: GAN-based Super-Resolution for real-world, a reproduction of the GigaGAN* paper. Implementation is
+# based on the unofficial lucidrains/gigagan-pytorch repository. Heavily modified from there.
+#
+# https://mingukkang.github.io/GigaGAN/
+from math import log2, ceil
+from functools import partial
+from typing import Any, Optional, List, Iterable
+
+import torch
+from torchvision import transforms
+from PIL import Image
+from torch import nn, einsum, Tensor
+import torch.nn.functional as F
+
+from einops import rearrange, repeat, reduce
+from einops.layers.torch import Rearrange
+from torchvision.utils import save_image
+import math
+
+
+def get_same_padding(size, kernel, dilation, stride):
+ return ((size - 1) * (stride - 1) + dilation * (kernel - 1)) // 2
+
+
+class AdaptiveConv2DMod(nn.Module):
+ def __init__(
+ self,
+ dim,
+ dim_out,
+ kernel,
+ *,
+ demod=True,
+ stride=1,
+ dilation=1,
+ eps=1e-8,
+ num_conv_kernels=1, # set this to be greater than 1 for adaptive
+ ):
+ super().__init__()
+ self.eps = eps
+
+ self.dim_out = dim_out
+
+ self.kernel = kernel
+ self.stride = stride
+ self.dilation = dilation
+ self.adaptive = num_conv_kernels > 1
+
+ self.weights = nn.Parameter(
+ torch.randn((num_conv_kernels, dim_out, dim, kernel, kernel))
+ )
+
+ self.demod = demod
+
+ nn.init.kaiming_normal_(
+ self.weights, a=0, mode="fan_in", nonlinearity="leaky_relu"
+ )
+
+ def forward(
+ self, fmap, mod: Optional[Tensor] = None, kernel_mod: Optional[Tensor] = None
+ ):
+ """
+ notation
+
+ b - batch
+ n - convs
+ o - output
+ i - input
+ k - kernel
+ """
+
+ b, h = fmap.shape[0], fmap.shape[-2]
+
+ # account for feature map that has been expanded by the scale in the first dimension
+ # due to multiscale inputs and outputs
+
+ if mod.shape[0] != b:
+ mod = repeat(mod, "b ... -> (s b) ...", s=b // mod.shape[0])
+
+ if exists(kernel_mod):
+ kernel_mod_has_el = kernel_mod.numel() > 0
+
+ assert self.adaptive or not kernel_mod_has_el
+
+ if kernel_mod_has_el and kernel_mod.shape[0] != b:
+ kernel_mod = repeat(
+ kernel_mod, "b ... -> (s b) ...", s=b // kernel_mod.shape[0]
+ )
+
+ # prepare weights for modulation
+
+ weights = self.weights
+
+ if self.adaptive:
+ weights = repeat(weights, "... -> b ...", b=b)
+
+ # determine an adaptive weight and 'select' the kernel to use with softmax
+
+ assert exists(kernel_mod) and kernel_mod.numel() > 0
+
+ kernel_attn = kernel_mod.softmax(dim=-1)
+ kernel_attn = rearrange(kernel_attn, "b n -> b n 1 1 1 1")
+
+ weights = reduce(weights * kernel_attn, "b n ... -> b ...", "sum")
+
+ # do the modulation, demodulation, as done in stylegan2
+
+ mod = rearrange(mod, "b i -> b 1 i 1 1")
+
+ weights = weights * (mod + 1)
+
+ if self.demod:
+ inv_norm = (
+ reduce(weights**2, "b o i k1 k2 -> b o 1 1 1", "sum")
+ .clamp(min=self.eps)
+ .rsqrt()
+ )
+ weights = weights * inv_norm
+
+ fmap = rearrange(fmap, "b c h w -> 1 (b c) h w")
+
+ weights = rearrange(weights, "b o ... -> (b o) ...")
+
+ padding = get_same_padding(h, self.kernel, self.dilation, self.stride)
+ fmap = F.conv2d(fmap, weights, padding=padding, groups=b)
+
+ return rearrange(fmap, "1 (b o) ... -> b o ...", b=b)
+
+
+class Attend(nn.Module):
+ def __init__(self, dropout=0.0, flash=False):
+ super().__init__()
+ self.dropout = dropout
+ self.attn_dropout = nn.Dropout(dropout)
+ self.scale = nn.Parameter(torch.randn(1))
+ self.flash = flash
+
+ def flash_attn(self, q, k, v):
+ q, k, v = map(lambda t: t.contiguous(), (q, k, v))
+ out = F.scaled_dot_product_attention(
+ q, k, v, dropout_p=self.dropout if self.training else 0.0
+ )
+ return out
+
+ def forward(self, q, k, v):
+ if self.flash:
+ return self.flash_attn(q, k, v)
+
+ scale = q.shape[-1] ** -0.5
+
+ # similarity
+ sim = einsum("b h i d, b h j d -> b h i j", q, k) * scale
+
+ # attention
+ attn = sim.softmax(dim=-1)
+ attn = self.attn_dropout(attn)
+
+ # aggregate values
+ out = einsum("b h i j, b h j d -> b h i d", attn, v)
+
+ return out
+
+
+def exists(x):
+ return x is not None
+
+
+def default(val, d):
+ if exists(val):
+ return val
+ return d() if callable(d) else d
+
+
+def cast_tuple(t, length=1):
+ if isinstance(t, tuple):
+ return t
+ return (t,) * length
+
+
+def identity(t, *args, **kwargs):
+ return t
+
+
+def is_power_of_two(n):
+ return log2(n).is_integer()
+
+
+def null_iterator():
+ while True:
+ yield None
+
+
+def Downsample(dim, dim_out=None):
+ return nn.Sequential(
+ Rearrange("b c (h p1) (w p2) -> b (c p1 p2) h w", p1=2, p2=2),
+ nn.Conv2d(dim * 4, default(dim_out, dim), 1),
+ )
+
+
+class RMSNorm(nn.Module):
+ def __init__(self, dim):
+ super().__init__()
+ self.g = nn.Parameter(torch.ones(1, dim, 1, 1))
+ self.eps = 1e-4
+
+ def forward(self, x):
+ return F.normalize(x, dim=1) * self.g * (x.shape[1] ** 0.5)
+
+
+# building block modules
+
+
+class Block(nn.Module):
+ def __init__(self, dim, dim_out, groups=8, num_conv_kernels=0):
+ super().__init__()
+ self.proj = AdaptiveConv2DMod(
+ dim, dim_out, kernel=3, num_conv_kernels=num_conv_kernels
+ )
+ self.kernel = 3
+ self.dilation = 1
+ self.stride = 1
+
+ self.act = nn.SiLU()
+
+ def forward(self, x, conv_mods_iter: Optional[Iterable] = None):
+ conv_mods_iter = default(conv_mods_iter, null_iterator())
+
+ x = self.proj(x, mod=next(conv_mods_iter), kernel_mod=next(conv_mods_iter))
+
+ x = self.act(x)
+ return x
+
+
+class ResnetBlock(nn.Module):
+ def __init__(
+ self, dim, dim_out, *, groups=8, num_conv_kernels=0, style_dims: List = []
+ ):
+ super().__init__()
+ style_dims.extend([dim, num_conv_kernels, dim_out, num_conv_kernels])
+
+ self.block1 = Block(
+ dim, dim_out, groups=groups, num_conv_kernels=num_conv_kernels
+ )
+ self.block2 = Block(
+ dim_out, dim_out, groups=groups, num_conv_kernels=num_conv_kernels
+ )
+ self.res_conv = nn.Conv2d(dim, dim_out, 1) if dim != dim_out else nn.Identity()
+
+ def forward(self, x, conv_mods_iter: Optional[Iterable] = None):
+ h = self.block1(x, conv_mods_iter=conv_mods_iter)
+ h = self.block2(h, conv_mods_iter=conv_mods_iter)
+
+ return h + self.res_conv(x)
+
+
+class LinearAttention(nn.Module):
+ def __init__(self, dim, heads=4, dim_head=32):
+ super().__init__()
+ self.scale = dim_head**-0.5
+ self.heads = heads
+ hidden_dim = dim_head * heads
+
+ self.norm = RMSNorm(dim)
+ self.to_qkv = nn.Conv2d(dim, hidden_dim * 3, 1, bias=False)
+
+ self.to_out = nn.Sequential(nn.Conv2d(hidden_dim, dim, 1), RMSNorm(dim))
+
+ def forward(self, x):
+ b, c, h, w = x.shape
+
+ x = self.norm(x)
+
+ qkv = self.to_qkv(x).chunk(3, dim=1)
+ q, k, v = map(
+ lambda t: rearrange(t, "b (h c) x y -> b h c (x y)", h=self.heads), qkv
+ )
+
+ q = q.softmax(dim=-2)
+ k = k.softmax(dim=-1)
+
+ q = q * self.scale
+
+ context = torch.einsum("b h d n, b h e n -> b h d e", k, v)
+
+ out = torch.einsum("b h d e, b h d n -> b h e n", context, q)
+ out = rearrange(out, "b h c (x y) -> b (h c) x y", h=self.heads, x=h, y=w)
+ return self.to_out(out)
+
+
+class Attention(nn.Module):
+ def __init__(self, dim, heads=4, dim_head=32, flash=False):
+ super().__init__()
+ self.heads = heads
+ hidden_dim = dim_head * heads
+
+ self.norm = RMSNorm(dim)
+
+ self.attend = Attend(flash=flash)
+ self.to_qkv = nn.Conv2d(dim, hidden_dim * 3, 1, bias=False)
+ self.to_out = nn.Conv2d(hidden_dim, dim, 1)
+
+ def forward(self, x):
+ b, c, h, w = x.shape
+ x = self.norm(x)
+ qkv = self.to_qkv(x).chunk(3, dim=1)
+
+ q, k, v = map(
+ lambda t: rearrange(t, "b (h c) x y -> b h (x y) c", h=self.heads), qkv
+ )
+
+ out = self.attend(q, k, v)
+ out = rearrange(out, "b h (x y) d -> b (h d) x y", x=h, y=w)
+
+ return self.to_out(out)
+
+
+# feedforward
+def FeedForward(dim, mult=4):
+ return nn.Sequential(
+ RMSNorm(dim),
+ nn.Conv2d(dim, dim * mult, 1),
+ nn.GELU(),
+ nn.Conv2d(dim * mult, dim, 1),
+ )
+
+
+# transformers
+class Transformer(nn.Module):
+ def __init__(self, dim, dim_head=64, heads=8, depth=1, flash_attn=True, ff_mult=4):
+ super().__init__()
+ self.layers = nn.ModuleList([])
+
+ for _ in range(depth):
+ self.layers.append(
+ nn.ModuleList(
+ [
+ Attention(
+ dim=dim, dim_head=dim_head, heads=heads, flash=flash_attn
+ ),
+ FeedForward(dim=dim, mult=ff_mult),
+ ]
+ )
+ )
+
+ def forward(self, x):
+ for attn, ff in self.layers:
+ x = attn(x) + x
+ x = ff(x) + x
+
+ return x
+
+
+class LinearTransformer(nn.Module):
+ def __init__(self, dim, dim_head=64, heads=8, depth=1, ff_mult=4):
+ super().__init__()
+ self.layers = nn.ModuleList([])
+
+ for _ in range(depth):
+ self.layers.append(
+ nn.ModuleList(
+ [
+ LinearAttention(dim=dim, dim_head=dim_head, heads=heads),
+ FeedForward(dim=dim, mult=ff_mult),
+ ]
+ )
+ )
+
+ def forward(self, x):
+ for attn, ff in self.layers:
+ x = attn(x) + x
+ x = ff(x) + x
+
+ return x
+
+
+class NearestNeighborhoodUpsample(nn.Module):
+ def __init__(self, dim, dim_out=None):
+ super().__init__()
+ dim_out = default(dim_out, dim)
+ self.conv = nn.Conv2d(dim, dim_out, kernel_size=3, stride=1, padding=1)
+
+ def forward(self, x):
+
+ if x.shape[0] >= 64:
+ x = x.contiguous()
+
+ x = F.interpolate(x, scale_factor=2.0, mode="nearest")
+ x = self.conv(x)
+
+ return x
+
+
+class EqualLinear(nn.Module):
+ def __init__(self, dim, dim_out, lr_mul=1, bias=True):
+ super().__init__()
+ self.weight = nn.Parameter(torch.randn(dim_out, dim))
+ if bias:
+ self.bias = nn.Parameter(torch.zeros(dim_out))
+
+ self.lr_mul = lr_mul
+
+ def forward(self, input):
+ return F.linear(input, self.weight * self.lr_mul, bias=self.bias * self.lr_mul)
+
+
+class StyleGanNetwork(nn.Module):
+ def __init__(self, dim_in=128, dim_out=512, depth=8, lr_mul=0.1, dim_text_latent=0):
+ super().__init__()
+ self.dim_in = dim_in
+ self.dim_out = dim_out
+ self.dim_text_latent = dim_text_latent
+
+ layers = []
+ for i in range(depth):
+ is_first = i == 0
+
+ if is_first:
+ dim_in_layer = dim_in + dim_text_latent
+ else:
+ dim_in_layer = dim_out
+
+ dim_out_layer = dim_out
+
+ layers.extend(
+ [EqualLinear(dim_in_layer, dim_out_layer, lr_mul), nn.LeakyReLU(0.2)]
+ )
+
+ self.net = nn.Sequential(*layers)
+
+ def forward(self, x, text_latent=None):
+ x = F.normalize(x, dim=1)
+ if self.dim_text_latent > 0:
+ assert exists(text_latent)
+ x = torch.cat((x, text_latent), dim=-1)
+ return self.net(x)
+
+
+class UnetUpsampler(torch.nn.Module):
+
+ def __init__(
+ self,
+ dim: int,
+ *,
+ image_size: int,
+ input_image_size: int,
+ init_dim: Optional[int] = None,
+ out_dim: Optional[int] = None,
+ style_network: Optional[dict] = None,
+ up_dim_mults: tuple = (1, 2, 4, 8, 16),
+ down_dim_mults: tuple = (4, 8, 16),
+ channels: int = 3,
+ resnet_block_groups: int = 8,
+ full_attn: tuple = (False, False, False, True, True),
+ flash_attn: bool = True,
+ self_attn_dim_head: int = 64,
+ self_attn_heads: int = 8,
+ attn_depths: tuple = (2, 2, 2, 2, 4),
+ mid_attn_depth: int = 4,
+ num_conv_kernels: int = 4,
+ resize_mode: str = "bilinear",
+ unconditional: bool = True,
+ skip_connect_scale: Optional[float] = None,
+ ):
+ super().__init__()
+ self.style_network = style_network = StyleGanNetwork(**style_network)
+ self.unconditional = unconditional
+ assert not (
+ unconditional
+ and exists(style_network)
+ and style_network.dim_text_latent > 0
+ )
+
+ assert is_power_of_two(image_size) and is_power_of_two(
+ input_image_size
+ ), "both output image size and input image size must be power of 2"
+ assert (
+ input_image_size < image_size
+ ), "input image size must be smaller than the output image size, thus upsampling"
+
+ self.image_size = image_size
+ self.input_image_size = input_image_size
+
+ style_embed_split_dims = []
+
+ self.channels = channels
+ input_channels = channels
+
+ init_dim = default(init_dim, dim)
+
+ up_dims = [init_dim, *map(lambda m: dim * m, up_dim_mults)]
+ init_down_dim = up_dims[len(up_dim_mults) - len(down_dim_mults)]
+ down_dims = [init_down_dim, *map(lambda m: dim * m, down_dim_mults)]
+ self.init_conv = nn.Conv2d(input_channels, init_down_dim, 7, padding=3)
+
+ up_in_out = list(zip(up_dims[:-1], up_dims[1:]))
+ down_in_out = list(zip(down_dims[:-1], down_dims[1:]))
+
+ block_klass = partial(
+ ResnetBlock,
+ groups=resnet_block_groups,
+ num_conv_kernels=num_conv_kernels,
+ style_dims=style_embed_split_dims,
+ )
+
+ FullAttention = partial(Transformer, flash_attn=flash_attn)
+ *_, mid_dim = up_dims
+
+ self.skip_connect_scale = default(skip_connect_scale, 2**-0.5)
+
+ self.downs = nn.ModuleList([])
+ self.ups = nn.ModuleList([])
+
+ block_count = 6
+
+ for ind, (
+ (dim_in, dim_out),
+ layer_full_attn,
+ layer_attn_depth,
+ ) in enumerate(zip(down_in_out, full_attn, attn_depths)):
+ attn_klass = FullAttention if layer_full_attn else LinearTransformer
+
+ blocks = []
+ for i in range(block_count):
+ blocks.append(block_klass(dim_in, dim_in))
+
+ self.downs.append(
+ nn.ModuleList(
+ [
+ nn.ModuleList(blocks),
+ nn.ModuleList(
+ [
+ (
+ attn_klass(
+ dim_in,
+ dim_head=self_attn_dim_head,
+ heads=self_attn_heads,
+ depth=layer_attn_depth,
+ )
+ if layer_full_attn
+ else None
+ ),
+ nn.Conv2d(
+ dim_in, dim_out, kernel_size=3, stride=2, padding=1
+ ),
+ ]
+ ),
+ ]
+ )
+ )
+
+ self.mid_block1 = block_klass(mid_dim, mid_dim)
+ self.mid_attn = FullAttention(
+ mid_dim,
+ dim_head=self_attn_dim_head,
+ heads=self_attn_heads,
+ depth=mid_attn_depth,
+ )
+ self.mid_block2 = block_klass(mid_dim, mid_dim)
+
+ *_, last_dim = up_dims
+
+ for ind, (
+ (dim_in, dim_out),
+ layer_full_attn,
+ layer_attn_depth,
+ ) in enumerate(
+ zip(
+ reversed(up_in_out),
+ reversed(full_attn),
+ reversed(attn_depths),
+ )
+ ):
+ attn_klass = FullAttention if layer_full_attn else LinearTransformer
+
+ blocks = []
+ input_dim = dim_in * 2 if ind < len(down_in_out) else dim_in
+ for i in range(block_count):
+ blocks.append(block_klass(input_dim, dim_in))
+
+ self.ups.append(
+ nn.ModuleList(
+ [
+ nn.ModuleList(blocks),
+ nn.ModuleList(
+ [
+ NearestNeighborhoodUpsample(
+ last_dim if ind == 0 else dim_out,
+ dim_in,
+ ),
+ (
+ attn_klass(
+ dim_in,
+ dim_head=self_attn_dim_head,
+ heads=self_attn_heads,
+ depth=layer_attn_depth,
+ )
+ if layer_full_attn
+ else None
+ ),
+ ]
+ ),
+ ]
+ )
+ )
+
+ self.out_dim = default(out_dim, channels)
+ self.final_res_block = block_klass(dim, dim)
+ self.final_to_rgb = nn.Conv2d(dim, channels, 1)
+ self.resize_mode = resize_mode
+ self.style_to_conv_modulations = nn.Linear(
+ style_network.dim_out, sum(style_embed_split_dims)
+ )
+ self.style_embed_split_dims = style_embed_split_dims
+
+ @property
+ def allowable_rgb_resolutions(self):
+ input_res_base = int(log2(self.input_image_size))
+ output_res_base = int(log2(self.image_size))
+ allowed_rgb_res_base = list(range(input_res_base, output_res_base))
+ return [*map(lambda p: 2**p, allowed_rgb_res_base)]
+
+ @property
+ def device(self):
+ return next(self.parameters()).device
+
+ @property
+ def total_params(self):
+ return sum([p.numel() for p in self.parameters()])
+
+ def resize_image_to(self, x, size):
+ return F.interpolate(x, (size, size), mode=self.resize_mode)
+
+ def forward(
+ self,
+ lowres_image: torch.Tensor,
+ styles: Optional[torch.Tensor] = None,
+ noise: Optional[torch.Tensor] = None,
+ global_text_tokens: Optional[torch.Tensor] = None,
+ return_all_rgbs: bool = False,
+ ):
+ x = lowres_image
+
+ noise_scale = 0.001 # Adjust the scale of the noise as needed
+ noise_aug = torch.randn_like(x) * noise_scale
+ x = x + noise_aug
+ x = x.clamp(0, 1)
+
+ shape = x.shape
+ batch_size = shape[0]
+
+ assert shape[-2:] == ((self.input_image_size,) * 2)
+
+ # styles
+ if not exists(styles):
+ assert exists(self.style_network)
+
+ noise = default(
+ noise,
+ torch.randn(
+ (batch_size, self.style_network.dim_in), device=self.device
+ ),
+ )
+ styles = self.style_network(noise, global_text_tokens)
+
+ # project styles to conv modulations
+ conv_mods = self.style_to_conv_modulations(styles)
+ conv_mods = conv_mods.split(self.style_embed_split_dims, dim=-1)
+ conv_mods = iter(conv_mods)
+
+ x = self.init_conv(x)
+
+ h = []
+ for blocks, (attn, downsample) in self.downs:
+ for block in blocks:
+ x = block(x, conv_mods_iter=conv_mods)
+ h.append(x)
+
+ if attn is not None:
+ x = attn(x)
+
+ x = downsample(x)
+
+ x = self.mid_block1(x, conv_mods_iter=conv_mods)
+ x = self.mid_attn(x)
+ x = self.mid_block2(x, conv_mods_iter=conv_mods)
+
+ for (
+ blocks,
+ (
+ upsample,
+ attn,
+ ),
+ ) in self.ups:
+ x = upsample(x)
+ for block in blocks:
+ if h != []:
+ res = h.pop()
+ res = res * self.skip_connect_scale
+ x = torch.cat((x, res), dim=1)
+
+ x = block(x, conv_mods_iter=conv_mods)
+
+ if attn is not None:
+ x = attn(x)
+
+ x = self.final_res_block(x, conv_mods_iter=conv_mods)
+ rgb = self.final_to_rgb(x)
+
+ if not return_all_rgbs:
+ return rgb
+
+ return rgb, []
+
+
+def tile_image(image, chunk_size=64):
+ c, h, w = image.shape
+ h_chunks = ceil(h / chunk_size)
+ w_chunks = ceil(w / chunk_size)
+ tiles = []
+ for i in range(h_chunks):
+ for j in range(w_chunks):
+ tile = image[
+ :,
+ i * chunk_size : (i + 1) * chunk_size,
+ j * chunk_size : (j + 1) * chunk_size,
+ ]
+ tiles.append(tile)
+ return tiles, h_chunks, w_chunks
+
+
+# This helps create a checkboard pattern with some edge blending
+def create_checkerboard_weights(tile_size):
+ x = torch.linspace(-1, 1, tile_size)
+ y = torch.linspace(-1, 1, tile_size)
+
+ x, y = torch.meshgrid(x, y, indexing="ij")
+ d = torch.sqrt(x * x + y * y)
+ sigma, mu = 0.5, 0.0
+ weights = torch.exp(-((d - mu) ** 2 / (2.0 * sigma**2)))
+
+ # saturate the values to sure get high weights in the center
+ weights = weights**8
+
+ return weights / weights.max() # Normalize to [0, 1]
+
+
+def repeat_weights(weights, image_size):
+ tile_size = weights.shape[0]
+ repeats = (
+ math.ceil(image_size[0] / tile_size),
+ math.ceil(image_size[1] / tile_size),
+ )
+ return weights.repeat(repeats)[: image_size[0], : image_size[1]]
+
+
+def create_offset_weights(weights, image_size):
+ tile_size = weights.shape[0]
+ offset = tile_size // 2
+ full_weights = repeat_weights(
+ weights, (image_size[0] + offset, image_size[1] + offset)
+ )
+ return full_weights[offset:, offset:]
+
+
+def merge_tiles(tiles, h_chunks, w_chunks, chunk_size=64):
+ # Determine the shape of the output tensor
+ c = tiles[0].shape[0]
+ h = h_chunks * chunk_size
+ w = w_chunks * chunk_size
+
+ # Create an empty tensor to hold the merged image
+ merged = torch.zeros((c, h, w), dtype=tiles[0].dtype)
+
+ # Iterate over the tiles and place them in the correct position
+ for idx, tile in enumerate(tiles):
+ i = idx // w_chunks
+ j = idx % w_chunks
+
+ h_start = i * chunk_size
+ w_start = j * chunk_size
+
+ tile_h, tile_w = tile.shape[1:]
+ merged[:, h_start : h_start + tile_h, w_start : w_start + tile_w] = tile
+
+ return merged
+
+
+class AuraSR:
+ def __init__(self, config: dict[str, Any], device: str = "cuda"):
+ self.upsampler = UnetUpsampler(**config).to(device)
+ self.input_image_size = config["input_image_size"]
+
+ @classmethod
+ def from_pretrained(
+ cls,
+ model_id: str = "fal-ai/AuraSR",
+ use_safetensors: bool = True,
+ device: str = "cuda",
+ ):
+ import json
+ import torch
+ from pathlib import Path
+ from huggingface_hub import snapshot_download
+
+ # Check if model_id is a local file
+ if Path(model_id).is_file():
+ local_file = Path(model_id)
+ if local_file.suffix == ".safetensors":
+ use_safetensors = True
+ elif local_file.suffix == ".ckpt":
+ use_safetensors = False
+ else:
+ raise ValueError(
+ f"Unsupported file format: {local_file.suffix}. Please use .safetensors or .ckpt files."
+ )
+
+ # For local files, we need to provide the config separately
+ config_path = local_file.with_name("config.json")
+ if not config_path.exists():
+ raise FileNotFoundError(
+ f"Config file not found: {config_path}. "
+ f"When loading from a local file, ensure that 'config.json' "
+ f"is present in the same directory as '{local_file.name}'. "
+ f"If you're trying to load a model from Hugging Face, "
+ f"please provide the model ID instead of a file path."
+ )
+
+ config = json.loads(config_path.read_text())
+ hf_model_path = local_file.parent
+ else:
+ hf_model_path = Path(
+ snapshot_download(model_id, ignore_patterns=["*.ckpt"])
+ )
+ config = json.loads((hf_model_path / "config.json").read_text())
+
+ model = cls(config, device)
+
+ if use_safetensors:
+ try:
+ from safetensors.torch import load_file
+
+ checkpoint = load_file(
+ hf_model_path / "model.safetensors"
+ if not Path(model_id).is_file()
+ else model_id
+ )
+ except ImportError:
+ raise ImportError(
+ "The safetensors library is not installed. "
+ "Please install it with `pip install safetensors` "
+ "or use `use_safetensors=False` to load the model with PyTorch."
+ )
+ else:
+ checkpoint = torch.load(
+ hf_model_path / "model.ckpt"
+ if not Path(model_id).is_file()
+ else model_id
+ )
+
+ model.upsampler.load_state_dict(checkpoint, strict=True)
+ return model
+
+ @torch.no_grad()
+ def upscale_4x(self, image: Image.Image, max_batch_size=8) -> Image.Image:
+ tensor_transform = transforms.ToTensor()
+ device = self.upsampler.device
+
+ image_tensor = tensor_transform(image).unsqueeze(0)
+ _, _, h, w = image_tensor.shape
+ pad_h = (
+ self.input_image_size - h % self.input_image_size
+ ) % self.input_image_size
+ pad_w = (
+ self.input_image_size - w % self.input_image_size
+ ) % self.input_image_size
+
+ # Pad the image
+ image_tensor = torch.nn.functional.pad(
+ image_tensor, (0, pad_w, 0, pad_h), mode="reflect"
+ ).squeeze(0)
+ tiles, h_chunks, w_chunks = tile_image(image_tensor, self.input_image_size)
+
+ # Batch processing of tiles
+ num_tiles = len(tiles)
+ batches = [
+ tiles[i : i + max_batch_size] for i in range(0, num_tiles, max_batch_size)
+ ]
+ reconstructed_tiles = []
+
+ for batch in batches:
+ model_input = torch.stack(batch).to(device)
+ generator_output = self.upsampler(
+ lowres_image=model_input,
+ noise=torch.randn(model_input.shape[0], 128, device=device),
+ )
+ reconstructed_tiles.extend(
+ list(generator_output.clamp_(0, 1).detach().cpu())
+ )
+
+ merged_tensor = merge_tiles(
+ reconstructed_tiles, h_chunks, w_chunks, self.input_image_size * 4
+ )
+ unpadded = merged_tensor[:, : h * 4, : w * 4]
+
+ to_pil = transforms.ToPILImage()
+ return to_pil(unpadded)
+
+ # Tiled 4x upscaling with overlapping tiles to reduce seam artifacts
+ # weights options are 'checkboard' and 'constant'
+ @torch.no_grad()
+ def upscale_4x_overlapped(self, image, max_batch_size=8, weight_type="checkboard"):
+ tensor_transform = transforms.ToTensor()
+ device = self.upsampler.device
+
+ image_tensor = tensor_transform(image).unsqueeze(0)
+ _, _, h, w = image_tensor.shape
+
+ # Calculate paddings
+ pad_h = (
+ self.input_image_size - h % self.input_image_size
+ ) % self.input_image_size
+ pad_w = (
+ self.input_image_size - w % self.input_image_size
+ ) % self.input_image_size
+
+ # Pad the image
+ image_tensor = torch.nn.functional.pad(
+ image_tensor, (0, pad_w, 0, pad_h), mode="reflect"
+ ).squeeze(0)
+
+ # Function to process tiles
+ def process_tiles(tiles, h_chunks, w_chunks):
+ num_tiles = len(tiles)
+ batches = [
+ tiles[i : i + max_batch_size]
+ for i in range(0, num_tiles, max_batch_size)
+ ]
+ reconstructed_tiles = []
+
+ for batch in batches:
+ model_input = torch.stack(batch).to(device)
+ generator_output = self.upsampler(
+ lowres_image=model_input,
+ noise=torch.randn(model_input.shape[0], 128, device=device),
+ )
+ reconstructed_tiles.extend(
+ list(generator_output.clamp_(0, 1).detach().cpu())
+ )
+
+ return merge_tiles(
+ reconstructed_tiles, h_chunks, w_chunks, self.input_image_size * 4
+ )
+
+ # First pass
+ tiles1, h_chunks1, w_chunks1 = tile_image(image_tensor, self.input_image_size)
+ result1 = process_tiles(tiles1, h_chunks1, w_chunks1)
+
+ # Second pass with offset
+ offset = self.input_image_size // 2
+ image_tensor_offset = torch.nn.functional.pad(
+ image_tensor, (offset, offset, offset, offset), mode="reflect"
+ ).squeeze(0)
+
+ tiles2, h_chunks2, w_chunks2 = tile_image(
+ image_tensor_offset, self.input_image_size
+ )
+ result2 = process_tiles(tiles2, h_chunks2, w_chunks2)
+
+ # unpad
+ offset_4x = offset * 4
+ result2_interior = result2[:, offset_4x:-offset_4x, offset_4x:-offset_4x]
+
+ if weight_type == "checkboard":
+ weight_tile = create_checkerboard_weights(self.input_image_size * 4)
+
+ weight_shape = result2_interior.shape[1:]
+ weights_1 = create_offset_weights(weight_tile, weight_shape)
+ weights_2 = repeat_weights(weight_tile, weight_shape)
+
+ normalizer = weights_1 + weights_2
+ weights_1 = weights_1 / normalizer
+ weights_2 = weights_2 / normalizer
+
+ weights_1 = weights_1.unsqueeze(0).repeat(3, 1, 1)
+ weights_2 = weights_2.unsqueeze(0).repeat(3, 1, 1)
+ elif weight_type == "constant":
+ weights_1 = torch.ones_like(result2_interior) * 0.5
+ weights_2 = weights_1
+ else:
+ raise ValueError(
+ "weight_type should be either 'gaussian' or 'constant' but got",
+ weight_type,
+ )
+
+ result1 = result1 * weights_2
+ result2 = result2_interior * weights_1
+
+ # Average the overlapping region
+ result1 = result1 + result2
+
+ # Remove padding
+ unpadded = result1[:, : h * 4, : w * 4]
+
+ to_pil = transforms.ToPILImage()
+ return to_pil(unpadded)
diff --git a/src/backend/upscale/aura_sr_upscale.py b/src/backend/upscale/aura_sr_upscale.py
new file mode 100644
index 0000000000000000000000000000000000000000..5bebb1ce181c5f5bd9563abf01c7209c400ae9b6
--- /dev/null
+++ b/src/backend/upscale/aura_sr_upscale.py
@@ -0,0 +1,9 @@
+from backend.upscale.aura_sr import AuraSR
+from PIL import Image
+
+
+def upscale_aura_sr(image_path: str):
+
+ aura_sr = AuraSR.from_pretrained("fal/AuraSR-v2", device="cpu")
+ image_in = Image.open(image_path) # .resize((256, 256))
+ return aura_sr.upscale_4x(image_in)
diff --git a/src/backend/upscale/edsr_upscale_onnx.py b/src/backend/upscale/edsr_upscale_onnx.py
new file mode 100644
index 0000000000000000000000000000000000000000..f837d932b813edc1b5a215978fc1766150b7c436
--- /dev/null
+++ b/src/backend/upscale/edsr_upscale_onnx.py
@@ -0,0 +1,37 @@
+import numpy as np
+import onnxruntime
+from huggingface_hub import hf_hub_download
+from PIL import Image
+
+
+def upscale_edsr_2x(image_path: str):
+ input_image = Image.open(image_path).convert("RGB")
+ input_image = np.array(input_image).astype("float32")
+ input_image = np.transpose(input_image, (2, 0, 1))
+ img_arr = np.expand_dims(input_image, axis=0)
+
+ if np.max(img_arr) > 256: # 16-bit image
+ max_range = 65535
+ else:
+ max_range = 255.0
+ img = img_arr / max_range
+
+ model_path = hf_hub_download(
+ repo_id="rupeshs/edsr-onnx",
+ filename="edsr_onnxsim_2x.onnx",
+ )
+ sess = onnxruntime.InferenceSession(model_path)
+
+ input_name = sess.get_inputs()[0].name
+ output_name = sess.get_outputs()[0].name
+ output = sess.run(
+ [output_name],
+ {input_name: img},
+ )[0]
+
+ result = output.squeeze()
+ result = result.clip(0, 1)
+ image_array = np.transpose(result, (1, 2, 0))
+ image_array = np.uint8(image_array * 255)
+ upscaled_image = Image.fromarray(image_array)
+ return upscaled_image
diff --git a/src/backend/upscale/tiled_upscale.py b/src/backend/upscale/tiled_upscale.py
new file mode 100644
index 0000000000000000000000000000000000000000..7e236770ed1188775603f6cffce44364eab6dfe3
--- /dev/null
+++ b/src/backend/upscale/tiled_upscale.py
@@ -0,0 +1,238 @@
+import time
+import math
+import logging
+from PIL import Image, ImageDraw, ImageFilter
+from backend.models.lcmdiffusion_setting import DiffusionTask
+from context import Context
+from constants import DEVICE
+
+
+def generate_upscaled_image(
+ config,
+ input_path=None,
+ strength=0.3,
+ scale_factor=2.0,
+ tile_overlap=16,
+ upscale_settings=None,
+ context: Context = None,
+ output_path=None,
+ image_format="PNG",
+):
+ if config == None or (
+ input_path == None or input_path == "" and upscale_settings == None
+ ):
+ logging.error("Wrong arguments in tiled upscale function call!")
+ return
+
+ # Use the upscale_settings dict if provided; otherwise, build the
+ # upscale_settings dict using the function arguments and default values
+ if upscale_settings == None:
+ upscale_settings = {
+ "source_file": input_path,
+ "target_file": None,
+ "output_format": image_format,
+ "strength": strength,
+ "scale_factor": scale_factor,
+ "prompt": config.lcm_diffusion_setting.prompt,
+ "tile_overlap": tile_overlap,
+ "tile_size": 256,
+ "tiles": [],
+ }
+ source_image = Image.open(input_path) # PIL image
+ else:
+ source_image = Image.open(upscale_settings["source_file"])
+
+ upscale_settings["source_image"] = source_image
+
+ if upscale_settings["target_file"]:
+ result = Image.open(upscale_settings["target_file"])
+ else:
+ result = Image.new(
+ mode="RGBA",
+ size=(
+ source_image.size[0] * int(upscale_settings["scale_factor"]),
+ source_image.size[1] * int(upscale_settings["scale_factor"]),
+ ),
+ color=(0, 0, 0, 0),
+ )
+ upscale_settings["target_image"] = result
+
+ # If the custom tile definition array 'tiles' is empty, proceed with the
+ # default tiled upscale task by defining all the possible image tiles; note
+ # that the actual tile size is 'tile_size' + 'tile_overlap' and the target
+ # image width and height are no longer constrained to multiples of 256 but
+ # are instead multiples of the actual tile size
+ if len(upscale_settings["tiles"]) == 0:
+ tile_size = upscale_settings["tile_size"]
+ scale_factor = upscale_settings["scale_factor"]
+ tile_overlap = upscale_settings["tile_overlap"]
+ total_cols = math.ceil(
+ source_image.size[0] / tile_size
+ ) # Image width / tile size
+ total_rows = math.ceil(
+ source_image.size[1] / tile_size
+ ) # Image height / tile size
+ for y in range(0, total_rows):
+ y_offset = tile_overlap if y > 0 else 0 # Tile mask offset
+ for x in range(0, total_cols):
+ x_offset = tile_overlap if x > 0 else 0 # Tile mask offset
+ x1 = x * tile_size
+ y1 = y * tile_size
+ w = tile_size + (tile_overlap if x < total_cols - 1 else 0)
+ h = tile_size + (tile_overlap if y < total_rows - 1 else 0)
+ mask_box = ( # Default tile mask box definition
+ x_offset,
+ y_offset,
+ int(w * scale_factor),
+ int(h * scale_factor),
+ )
+ upscale_settings["tiles"].append(
+ {
+ "x": x1,
+ "y": y1,
+ "w": w,
+ "h": h,
+ "mask_box": mask_box,
+ "prompt": upscale_settings["prompt"], # Use top level prompt if available
+ "scale_factor": scale_factor,
+ }
+ )
+
+ # Generate the output image tiles
+ for i in range(0, len(upscale_settings["tiles"])):
+ generate_upscaled_tile(
+ config,
+ i,
+ upscale_settings,
+ context=context,
+ )
+
+ # Save completed upscaled image
+ if upscale_settings["output_format"].upper() == "JPEG":
+ result_rgb = result.convert("RGB")
+ result.close()
+ result = result_rgb
+ result.save(output_path)
+ result.close()
+ source_image.close()
+ return
+
+
+def get_current_tile(
+ config,
+ context,
+ strength,
+):
+ config.lcm_diffusion_setting.strength = strength
+ config.lcm_diffusion_setting.diffusion_task = DiffusionTask.image_to_image.value
+ if (
+ config.lcm_diffusion_setting.use_tiny_auto_encoder
+ and config.lcm_diffusion_setting.use_openvino
+ ):
+ config.lcm_diffusion_setting.use_tiny_auto_encoder = False
+ current_tile = context.generate_text_to_image(
+ settings=config,
+ reshape=True,
+ device=DEVICE,
+ save_images=False,
+ save_config=False,
+ )[0]
+ return current_tile
+
+
+# Generates a single tile from the source image as defined in the
+# upscale_settings["tiles"] array with the corresponding index and pastes the
+# generated tile into the target image using the corresponding mask and scale
+# factor; note that scale factor for the target image and the individual tiles
+# can be different, this function will adjust scale factors as needed
+def generate_upscaled_tile(
+ config,
+ index,
+ upscale_settings,
+ context: Context = None,
+):
+ if config == None or upscale_settings == None:
+ logging.error("Wrong arguments in tile creation function call!")
+ return
+
+ x = upscale_settings["tiles"][index]["x"]
+ y = upscale_settings["tiles"][index]["y"]
+ w = upscale_settings["tiles"][index]["w"]
+ h = upscale_settings["tiles"][index]["h"]
+ tile_prompt = upscale_settings["tiles"][index]["prompt"]
+ scale_factor = upscale_settings["scale_factor"]
+ tile_scale_factor = upscale_settings["tiles"][index]["scale_factor"]
+ target_width = int(w * tile_scale_factor)
+ target_height = int(h * tile_scale_factor)
+ strength = upscale_settings["strength"]
+ source_image = upscale_settings["source_image"]
+ target_image = upscale_settings["target_image"]
+ mask_image = generate_tile_mask(config, index, upscale_settings)
+
+ config.lcm_diffusion_setting.number_of_images = 1
+ config.lcm_diffusion_setting.prompt = tile_prompt
+ config.lcm_diffusion_setting.image_width = target_width
+ config.lcm_diffusion_setting.image_height = target_height
+ config.lcm_diffusion_setting.init_image = source_image.crop((x, y, x + w, y + h))
+
+ current_tile = None
+ print(f"[SD Upscale] Generating tile {index + 1}/{len(upscale_settings['tiles'])} ")
+ if tile_prompt == None or tile_prompt == "":
+ config.lcm_diffusion_setting.prompt = ""
+ config.lcm_diffusion_setting.negative_prompt = ""
+ current_tile = get_current_tile(config, context, strength)
+ else:
+ # Attempt to use img2img with low denoising strength to
+ # generate the tiles with the extra aid of a prompt
+ # context = get_context(InterfaceType.CLI)
+ current_tile = get_current_tile(config, context, strength)
+
+ if math.isclose(scale_factor, tile_scale_factor):
+ target_image.paste(
+ current_tile, (int(x * scale_factor), int(y * scale_factor)), mask_image
+ )
+ else:
+ target_image.paste(
+ current_tile.resize((int(w * scale_factor), int(h * scale_factor))),
+ (int(x * scale_factor), int(y * scale_factor)),
+ mask_image.resize((int(w * scale_factor), int(h * scale_factor))),
+ )
+ mask_image.close()
+ current_tile.close()
+ config.lcm_diffusion_setting.init_image.close()
+
+
+# Generate tile mask using the box definition in the upscale_settings["tiles"]
+# array with the corresponding index; note that tile masks for the default
+# tiled upscale task can be reused but that would complicate the code, so
+# new tile masks are instead created for each tile
+def generate_tile_mask(
+ config,
+ index,
+ upscale_settings,
+):
+ scale_factor = upscale_settings["scale_factor"]
+ tile_overlap = upscale_settings["tile_overlap"]
+ tile_scale_factor = upscale_settings["tiles"][index]["scale_factor"]
+ w = int(upscale_settings["tiles"][index]["w"] * tile_scale_factor)
+ h = int(upscale_settings["tiles"][index]["h"] * tile_scale_factor)
+ # The Stable Diffusion pipeline automatically adjusts the output size
+ # to multiples of 8 pixels; the mask must be created with the same
+ # size as the output tile
+ w = w - (w % 8)
+ h = h - (h % 8)
+ mask_box = upscale_settings["tiles"][index]["mask_box"]
+ if mask_box == None:
+ # Build a default solid mask with soft/transparent edges
+ mask_box = (
+ tile_overlap,
+ tile_overlap,
+ w - tile_overlap,
+ h - tile_overlap,
+ )
+ mask_image = Image.new(mode="RGBA", size=(w, h), color=(0, 0, 0, 0))
+ mask_draw = ImageDraw.Draw(mask_image)
+ mask_draw.rectangle(tuple(mask_box), fill=(0, 0, 0))
+ mask_blur = mask_image.filter(ImageFilter.BoxBlur(tile_overlap - 1))
+ mask_image.close()
+ return mask_blur
diff --git a/src/backend/upscale/upscaler.py b/src/backend/upscale/upscaler.py
new file mode 100644
index 0000000000000000000000000000000000000000..fea3a1363e96d287ae769bce07375f3097f6ec0a
--- /dev/null
+++ b/src/backend/upscale/upscaler.py
@@ -0,0 +1,52 @@
+from backend.models.lcmdiffusion_setting import DiffusionTask
+from backend.models.upscale import UpscaleMode
+from backend.upscale.edsr_upscale_onnx import upscale_edsr_2x
+from backend.upscale.aura_sr_upscale import upscale_aura_sr
+from backend.upscale.tiled_upscale import generate_upscaled_image
+from context import Context
+from PIL import Image
+from state import get_settings
+
+
+config = get_settings()
+
+
+def upscale_image(
+ context: Context,
+ src_image_path: str,
+ dst_image_path: str,
+ scale_factor: int = 2,
+ upscale_mode: UpscaleMode = UpscaleMode.normal.value,
+ strength: float = 0.1,
+):
+ if upscale_mode == UpscaleMode.normal.value:
+ upscaled_img = upscale_edsr_2x(src_image_path)
+ upscaled_img.save(dst_image_path)
+ print(f"Upscaled image saved {dst_image_path}")
+ elif upscale_mode == UpscaleMode.aura_sr.value:
+ upscaled_img = upscale_aura_sr(src_image_path)
+ upscaled_img.save(dst_image_path)
+ print(f"Upscaled image saved {dst_image_path}")
+ else:
+ config.settings.lcm_diffusion_setting.strength = (
+ 0.3 if config.settings.lcm_diffusion_setting.use_openvino else strength
+ )
+ config.settings.lcm_diffusion_setting.diffusion_task = (
+ DiffusionTask.image_to_image.value
+ )
+
+ generate_upscaled_image(
+ config.settings,
+ src_image_path,
+ config.settings.lcm_diffusion_setting.strength,
+ upscale_settings=None,
+ context=context,
+ tile_overlap=(
+ 32 if config.settings.lcm_diffusion_setting.use_openvino else 16
+ ),
+ output_path=dst_image_path,
+ image_format=config.settings.generated_images.format,
+ )
+ print(f"Upscaled image saved {dst_image_path}")
+
+ return [Image.open(dst_image_path)]
diff --git a/src/constants.py b/src/constants.py
new file mode 100644
index 0000000000000000000000000000000000000000..82a1819f8175889356b81a213ebae6a87a84b914
--- /dev/null
+++ b/src/constants.py
@@ -0,0 +1,25 @@
+from os import environ, cpu_count
+
+cpu_cores = cpu_count()
+cpus = cpu_cores // 2 if cpu_cores else 0
+APP_VERSION = "v1.0.0 beta 120"
+LCM_DEFAULT_MODEL = "stabilityai/sd-turbo"
+LCM_DEFAULT_MODEL_OPENVINO = "rupeshs/sd-turbo-openvino"
+APP_NAME = "FastSD CPU"
+APP_SETTINGS_FILE = "settings.yaml"
+RESULTS_DIRECTORY = "results"
+CONFIG_DIRECTORY = "configs"
+DEVICE = environ.get("DEVICE", "cpu")
+SD_MODELS_FILE = "stable-diffusion-models.txt"
+LCM_LORA_MODELS_FILE = "lcm-lora-models.txt"
+OPENVINO_LCM_MODELS_FILE = "openvino-lcm-models.txt"
+TAESD_MODEL = "madebyollin/taesd"
+TAESDXL_MODEL = "madebyollin/taesdxl"
+TAESD_MODEL_OPENVINO = "deinferno/taesd-openvino"
+LCM_MODELS_FILE = "lcm-models.txt"
+TAESDXL_MODEL_OPENVINO = "rupeshs/taesdxl-openvino"
+LORA_DIRECTORY = "lora_models"
+CONTROLNET_DIRECTORY = "controlnet_models"
+MODELS_DIRECTORY = "models"
+GGUF_THREADS = environ.get("GGUF_THREADS", cpus)
+TAEF1_MODEL_OPENVINO = "rupeshs/taef1-openvino"
diff --git a/src/context.py b/src/context.py
new file mode 100644
index 0000000000000000000000000000000000000000..0681f30a04322c3a0694653a0580dc980174dade
--- /dev/null
+++ b/src/context.py
@@ -0,0 +1,77 @@
+from typing import Any
+from app_settings import Settings
+from models.interface_types import InterfaceType
+from backend.models.lcmdiffusion_setting import DiffusionTask
+from backend.lcm_text_to_image import LCMTextToImage
+from time import perf_counter
+from backend.image_saver import ImageSaver
+from pprint import pprint
+
+
+class Context:
+ def __init__(
+ self,
+ interface_type: InterfaceType,
+ device="cpu",
+ ):
+ self.interface_type = interface_type.value
+ self.lcm_text_to_image = LCMTextToImage(device)
+ self._latency = 0
+
+ @property
+ def latency(self):
+ return self._latency
+
+ def generate_text_to_image(
+ self,
+ settings: Settings,
+ reshape: bool = False,
+ device: str = "cpu",
+ save_images=True,
+ save_config=True,
+ ) -> Any:
+ if (
+ settings.lcm_diffusion_setting.use_tiny_auto_encoder
+ and settings.lcm_diffusion_setting.use_openvino
+ ):
+ print(
+ "WARNING: Tiny AutoEncoder is not supported in Image to image mode (OpenVINO)"
+ )
+ tick = perf_counter()
+ from state import get_settings
+
+ if (
+ settings.lcm_diffusion_setting.diffusion_task
+ == DiffusionTask.text_to_image.value
+ ):
+ settings.lcm_diffusion_setting.init_image = None
+
+ if save_config:
+ get_settings().save()
+
+ pprint(settings.lcm_diffusion_setting.model_dump())
+ if not settings.lcm_diffusion_setting.lcm_lora:
+ return None
+ self.lcm_text_to_image.init(
+ device,
+ settings.lcm_diffusion_setting,
+ )
+ images = self.lcm_text_to_image.generate(
+ settings.lcm_diffusion_setting,
+ reshape,
+ )
+ elapsed = perf_counter() - tick
+
+ if save_images and settings.generated_images.save_image:
+ ImageSaver.save_images(
+ settings.generated_images.path,
+ images=images,
+ lcm_diffusion_setting=settings.lcm_diffusion_setting,
+ format=settings.generated_images.format,
+ )
+ self._latency = elapsed
+ print(f"Latency : {elapsed:.2f} seconds")
+ if settings.lcm_diffusion_setting.controlnet:
+ if settings.lcm_diffusion_setting.controlnet.enabled:
+ images.append(settings.lcm_diffusion_setting.controlnet._control_image)
+ return images
diff --git a/src/frontend/cli_interactive.py b/src/frontend/cli_interactive.py
new file mode 100644
index 0000000000000000000000000000000000000000..46d8cec8b476dcd432d9b962898f59a7ca756ddf
--- /dev/null
+++ b/src/frontend/cli_interactive.py
@@ -0,0 +1,655 @@
+from os import path
+from PIL import Image
+from typing import Any
+
+from constants import DEVICE
+from paths import FastStableDiffusionPaths
+from backend.upscale.upscaler import upscale_image
+from backend.controlnet import controlnet_settings_from_dict
+from backend.upscale.tiled_upscale import generate_upscaled_image
+from frontend.webui.image_variations_ui import generate_image_variations
+from backend.lora import (
+ get_active_lora_weights,
+ update_lora_weights,
+ load_lora_weight,
+)
+from backend.models.lcmdiffusion_setting import (
+ DiffusionTask,
+ LCMDiffusionSetting,
+ ControlNetSetting,
+)
+
+
+_batch_count = 1
+_edit_lora_settings = False
+
+
+def user_value(
+ value_type: type,
+ message: str,
+ default_value: Any,
+) -> Any:
+ try:
+ value = value_type(input(message))
+ except:
+ value = default_value
+ return value
+
+
+def interactive_mode(
+ config,
+ context,
+):
+ print("=============================================")
+ print("Welcome to FastSD CPU Interactive CLI")
+ print("=============================================")
+ while True:
+ print("> 1. Text to Image")
+ print("> 2. Image to Image")
+ print("> 3. Image Variations")
+ print("> 4. EDSR Upscale")
+ print("> 5. SD Upscale")
+ print("> 6. Edit default generation settings")
+ print("> 7. Edit LoRA settings")
+ print("> 8. Edit ControlNet settings")
+ print("> 9. Edit negative prompt")
+ print("> 10. Quit")
+ option = user_value(
+ int,
+ "Enter a Diffusion Task number (1): ",
+ 1,
+ )
+ if option not in range(1, 11):
+ print("Wrong Diffusion Task number!")
+ exit()
+
+ if option == 1:
+ interactive_txt2img(
+ config,
+ context,
+ )
+ elif option == 2:
+ interactive_img2img(
+ config,
+ context,
+ )
+ elif option == 3:
+ interactive_variations(
+ config,
+ context,
+ )
+ elif option == 4:
+ interactive_edsr(
+ config,
+ context,
+ )
+ elif option == 5:
+ interactive_sdupscale(
+ config,
+ context,
+ )
+ elif option == 6:
+ interactive_settings(
+ config,
+ context,
+ )
+ elif option == 7:
+ interactive_lora(
+ config,
+ context,
+ True,
+ )
+ elif option == 8:
+ interactive_controlnet(
+ config,
+ context,
+ True,
+ )
+ elif option == 9:
+ interactive_negative(
+ config,
+ context,
+ )
+ elif option == 10:
+ exit()
+
+
+def interactive_negative(
+ config,
+ context,
+):
+ settings = config.lcm_diffusion_setting
+ print(f"Current negative prompt: '{settings.negative_prompt}'")
+ user_input = input("Write a negative prompt (set guidance > 1.0): ")
+ if user_input == "":
+ return
+ else:
+ settings.negative_prompt = user_input
+
+
+def interactive_controlnet(
+ config,
+ context,
+ menu_flag=False,
+):
+ """
+ @param menu_flag: Indicates whether this function was called from the main
+ interactive CLI menu; _True_ if called from the main menu, _False_ otherwise
+ """
+ settings = config.lcm_diffusion_setting
+ if not settings.controlnet:
+ settings.controlnet = ControlNetSetting()
+
+ current_enabled = settings.controlnet.enabled
+ current_adapter_path = settings.controlnet.adapter_path
+ current_conditioning_scale = settings.controlnet.conditioning_scale
+ current_control_image = settings.controlnet._control_image
+
+ option = input("Enable ControlNet? (y/N): ")
+ settings.controlnet.enabled = True if option.upper() == "Y" else False
+ if settings.controlnet.enabled:
+ option = input(
+ f"Enter ControlNet adapter path ({settings.controlnet.adapter_path}): "
+ )
+ if option != "":
+ settings.controlnet.adapter_path = option
+ settings.controlnet.conditioning_scale = user_value(
+ float,
+ f"Enter ControlNet conditioning scale ({settings.controlnet.conditioning_scale}): ",
+ settings.controlnet.conditioning_scale,
+ )
+ option = input(
+ f"Enter ControlNet control image path (Leave empty to reuse current): "
+ )
+ if option != "":
+ try:
+ new_image = Image.open(option)
+ settings.controlnet._control_image = new_image
+ except (AttributeError, FileNotFoundError) as e:
+ settings.controlnet._control_image = None
+ if (
+ not settings.controlnet.adapter_path
+ or not path.exists(settings.controlnet.adapter_path)
+ or not settings.controlnet._control_image
+ ):
+ print("Invalid ControlNet settings! Disabling ControlNet")
+ settings.controlnet.enabled = False
+
+ if (
+ settings.controlnet.enabled != current_enabled
+ or settings.controlnet.adapter_path != current_adapter_path
+ ):
+ settings.rebuild_pipeline = True
+
+
+def interactive_lora(
+ config,
+ context,
+ menu_flag=False,
+):
+ """
+ @param menu_flag: Indicates whether this function was called from the main
+ interactive CLI menu; _True_ if called from the main menu, _False_ otherwise
+ """
+ if context == None or context.lcm_text_to_image.pipeline == None:
+ print("Diffusion pipeline not initialized, please run a generation task first!")
+ return
+
+ print("> 1. Change LoRA weights")
+ print("> 2. Load new LoRA model")
+ option = user_value(
+ int,
+ "Enter a LoRA option (1): ",
+ 1,
+ )
+ if option not in range(1, 3):
+ print("Wrong LoRA option!")
+ return
+
+ if option == 1:
+ update_weights = []
+ active_weights = get_active_lora_weights()
+ for lora in active_weights:
+ weight = user_value(
+ float,
+ f"Enter a new LoRA weight for {lora[0]} ({lora[1]}): ",
+ lora[1],
+ )
+ update_weights.append(
+ (
+ lora[0],
+ weight,
+ )
+ )
+ if len(update_weights) > 0:
+ update_lora_weights(
+ context.lcm_text_to_image.pipeline,
+ config.lcm_diffusion_setting,
+ update_weights,
+ )
+ elif option == 2:
+ # Load a new LoRA
+ settings = config.lcm_diffusion_setting
+ settings.lora.fuse = False
+ settings.lora.enabled = False
+ settings.lora.path = input("Enter LoRA model path: ")
+ settings.lora.weight = user_value(
+ float,
+ "Enter a LoRA weight (0.5): ",
+ 0.5,
+ )
+ if not path.exists(settings.lora.path):
+ print("Invalid LoRA model path!")
+ return
+ settings.lora.enabled = True
+ load_lora_weight(context.lcm_text_to_image.pipeline, settings)
+
+ if menu_flag:
+ global _edit_lora_settings
+ _edit_lora_settings = False
+ option = input("Edit LoRA settings after every generation? (y/N): ")
+ if option.upper() == "Y":
+ _edit_lora_settings = True
+
+
+def interactive_settings(
+ config,
+ context,
+):
+ global _batch_count
+ settings = config.lcm_diffusion_setting
+ print("Enter generation settings (leave empty to use current value)")
+ print("> 1. Use LCM")
+ print("> 2. Use LCM-Lora")
+ print("> 3. Use OpenVINO")
+ option = user_value(
+ int,
+ "Select inference model option (1): ",
+ 1,
+ )
+ if option not in range(1, 4):
+ print("Wrong inference model option! Falling back to defaults")
+ return
+
+ settings.use_lcm_lora = False
+ settings.use_openvino = False
+ if option == 1:
+ lcm_model_id = input(f"Enter LCM model ID ({settings.lcm_model_id}): ")
+ if lcm_model_id != "":
+ settings.lcm_model_id = lcm_model_id
+ elif option == 2:
+ settings.use_lcm_lora = True
+ lcm_lora_id = input(
+ f"Enter LCM-Lora model ID ({settings.lcm_lora.lcm_lora_id}): "
+ )
+ if lcm_lora_id != "":
+ settings.lcm_lora.lcm_lora_id = lcm_lora_id
+ base_model_id = input(
+ f"Enter Base model ID ({settings.lcm_lora.base_model_id}): "
+ )
+ if base_model_id != "":
+ settings.lcm_lora.base_model_id = base_model_id
+ elif option == 3:
+ settings.use_openvino = True
+ openvino_lcm_model_id = input(
+ f"Enter OpenVINO model ID ({settings.openvino_lcm_model_id}): "
+ )
+ if openvino_lcm_model_id != "":
+ settings.openvino_lcm_model_id = openvino_lcm_model_id
+
+ settings.use_offline_model = True
+ settings.use_tiny_auto_encoder = True
+ option = input("Work offline? (Y/n): ")
+ if option.upper() == "N":
+ settings.use_offline_model = False
+ option = input("Use Tiny Auto Encoder? (Y/n): ")
+ if option.upper() == "N":
+ settings.use_tiny_auto_encoder = False
+
+ settings.image_width = user_value(
+ int,
+ f"Image width ({settings.image_width}): ",
+ settings.image_width,
+ )
+ settings.image_height = user_value(
+ int,
+ f"Image height ({settings.image_height}): ",
+ settings.image_height,
+ )
+ settings.inference_steps = user_value(
+ int,
+ f"Inference steps ({settings.inference_steps}): ",
+ settings.inference_steps,
+ )
+ settings.guidance_scale = user_value(
+ float,
+ f"Guidance scale ({settings.guidance_scale}): ",
+ settings.guidance_scale,
+ )
+ settings.number_of_images = user_value(
+ int,
+ f"Number of images per batch ({settings.number_of_images}): ",
+ settings.number_of_images,
+ )
+ _batch_count = user_value(
+ int,
+ f"Batch count ({_batch_count}): ",
+ _batch_count,
+ )
+ # output_format = user_value(int, f"Output format (PNG)", 1)
+ print(config.lcm_diffusion_setting)
+
+
+def interactive_txt2img(
+ config,
+ context,
+):
+ global _batch_count
+ config.lcm_diffusion_setting.diffusion_task = DiffusionTask.text_to_image.value
+ user_input = input("Write a prompt (write 'exit' to quit): ")
+ while True:
+ if user_input == "exit":
+ return
+ elif user_input == "":
+ user_input = config.lcm_diffusion_setting.prompt
+ config.lcm_diffusion_setting.prompt = user_input
+ for i in range(0, _batch_count):
+ context.generate_text_to_image(
+ settings=config,
+ device=DEVICE,
+ )
+ if _edit_lora_settings:
+ interactive_lora(
+ config,
+ context,
+ )
+ user_input = input("Write a prompt: ")
+
+
+def interactive_img2img(
+ config,
+ context,
+):
+ global _batch_count
+ settings = config.lcm_diffusion_setting
+ settings.diffusion_task = DiffusionTask.image_to_image.value
+ steps = settings.inference_steps
+ source_path = input("Image path: ")
+ if source_path == "":
+ print("Error : You need to provide a file in img2img mode")
+ return
+ settings.strength = user_value(
+ float,
+ f"img2img strength ({settings.strength}): ",
+ settings.strength,
+ )
+ settings.inference_steps = int(steps / settings.strength + 1)
+ user_input = input("Write a prompt (write 'exit' to quit): ")
+ while True:
+ if user_input == "exit":
+ settings.inference_steps = steps
+ return
+ settings.init_image = Image.open(source_path)
+ settings.prompt = user_input
+ for i in range(0, _batch_count):
+ context.generate_text_to_image(
+ settings=config,
+ device=DEVICE,
+ )
+ new_path = input(f"Image path ({source_path}): ")
+ if new_path != "":
+ source_path = new_path
+ settings.strength = user_value(
+ float,
+ f"img2img strength ({settings.strength}): ",
+ settings.strength,
+ )
+ if _edit_lora_settings:
+ interactive_lora(
+ config,
+ context,
+ )
+ settings.inference_steps = int(steps / settings.strength + 1)
+ user_input = input("Write a prompt: ")
+
+
+def interactive_variations(
+ config,
+ context,
+):
+ global _batch_count
+ settings = config.lcm_diffusion_setting
+ settings.diffusion_task = DiffusionTask.image_to_image.value
+ steps = settings.inference_steps
+ source_path = input("Image path: ")
+ if source_path == "":
+ print("Error : You need to provide a file in Image variations mode")
+ return
+ settings.strength = user_value(
+ float,
+ f"Image variations strength ({settings.strength}): ",
+ settings.strength,
+ )
+ settings.inference_steps = int(steps / settings.strength + 1)
+ while True:
+ settings.init_image = Image.open(source_path)
+ settings.prompt = ""
+ for i in range(0, _batch_count):
+ generate_image_variations(
+ settings.init_image,
+ settings.strength,
+ )
+ if _edit_lora_settings:
+ interactive_lora(
+ config,
+ context,
+ )
+ user_input = input("Continue in Image variations mode? (Y/n): ")
+ if user_input.upper() == "N":
+ settings.inference_steps = steps
+ return
+ new_path = input(f"Image path ({source_path}): ")
+ if new_path != "":
+ source_path = new_path
+ settings.strength = user_value(
+ float,
+ f"Image variations strength ({settings.strength}): ",
+ settings.strength,
+ )
+ settings.inference_steps = int(steps / settings.strength + 1)
+
+
+def interactive_edsr(
+ config,
+ context,
+):
+ source_path = input("Image path: ")
+ if source_path == "":
+ print("Error : You need to provide a file in EDSR mode")
+ return
+ while True:
+ output_path = FastStableDiffusionPaths.get_upscale_filepath(
+ source_path,
+ 2,
+ config.generated_images.format,
+ )
+ result = upscale_image(
+ context,
+ source_path,
+ output_path,
+ 2,
+ )
+ user_input = input("Continue in EDSR upscale mode? (Y/n): ")
+ if user_input.upper() == "N":
+ return
+ new_path = input(f"Image path ({source_path}): ")
+ if new_path != "":
+ source_path = new_path
+
+
+def interactive_sdupscale_settings(config):
+ steps = config.lcm_diffusion_setting.inference_steps
+ custom_settings = {}
+ print("> 1. Upscale whole image")
+ print("> 2. Define custom tiles (advanced)")
+ option = user_value(
+ int,
+ "Select an SD Upscale option (1): ",
+ 1,
+ )
+ if option not in range(1, 3):
+ print("Wrong SD Upscale option!")
+ return
+
+ # custom_settings["source_file"] = args.file
+ custom_settings["source_file"] = ""
+ new_path = input(f"Input image path ({custom_settings['source_file']}): ")
+ if new_path != "":
+ custom_settings["source_file"] = new_path
+ if custom_settings["source_file"] == "":
+ print("Error : You need to provide a file in SD Upscale mode")
+ return
+ custom_settings["target_file"] = None
+ if option == 2:
+ custom_settings["target_file"] = input("Image to patch: ")
+ if custom_settings["target_file"] == "":
+ print("No target file provided, upscaling whole input image instead!")
+ custom_settings["target_file"] = None
+ option = 1
+ custom_settings["output_format"] = config.generated_images.format
+ custom_settings["strength"] = user_value(
+ float,
+ f"SD Upscale strength ({config.lcm_diffusion_setting.strength}): ",
+ config.lcm_diffusion_setting.strength,
+ )
+ config.lcm_diffusion_setting.inference_steps = int(
+ steps / custom_settings["strength"] + 1
+ )
+ if option == 1:
+ custom_settings["scale_factor"] = user_value(
+ float,
+ f"Scale factor (2.0): ",
+ 2.0,
+ )
+ custom_settings["tile_size"] = user_value(
+ int,
+ f"Split input image into tiles of the following size, in pixels (256): ",
+ 256,
+ )
+ custom_settings["tile_overlap"] = user_value(
+ int,
+ f"Tile overlap, in pixels (16): ",
+ 16,
+ )
+ elif option == 2:
+ custom_settings["scale_factor"] = user_value(
+ float,
+ "Input image to Image-to-patch scale_factor (2.0): ",
+ 2.0,
+ )
+ custom_settings["tile_size"] = 256
+ custom_settings["tile_overlap"] = 16
+ custom_settings["prompt"] = input(
+ "Write a prompt describing the input image (optional): "
+ )
+ custom_settings["tiles"] = []
+ if option == 2:
+ add_tile = True
+ while add_tile:
+ print("=== Define custom SD Upscale tile ===")
+ tile_x = user_value(
+ int,
+ "Enter tile's X position: ",
+ 0,
+ )
+ tile_y = user_value(
+ int,
+ "Enter tile's Y position: ",
+ 0,
+ )
+ tile_w = user_value(
+ int,
+ "Enter tile's width (256): ",
+ 256,
+ )
+ tile_h = user_value(
+ int,
+ "Enter tile's height (256): ",
+ 256,
+ )
+ tile_scale = user_value(
+ float,
+ "Enter tile's scale factor (2.0): ",
+ 2.0,
+ )
+ tile_prompt = input("Enter tile's prompt (optional): ")
+ custom_settings["tiles"].append(
+ {
+ "x": tile_x,
+ "y": tile_y,
+ "w": tile_w,
+ "h": tile_h,
+ "mask_box": None,
+ "prompt": tile_prompt,
+ "scale_factor": tile_scale,
+ }
+ )
+ tile_option = input("Do you want to define another tile? (y/N): ")
+ if tile_option == "" or tile_option.upper() == "N":
+ add_tile = False
+
+ return custom_settings
+
+
+def interactive_sdupscale(
+ config,
+ context,
+):
+ settings = config.lcm_diffusion_setting
+ settings.diffusion_task = DiffusionTask.image_to_image.value
+ settings.init_image = ""
+ source_path = ""
+ steps = settings.inference_steps
+
+ while True:
+ custom_upscale_settings = None
+ option = input("Edit custom SD Upscale settings? (y/N): ")
+ if option.upper() == "Y":
+ config.lcm_diffusion_setting.inference_steps = steps
+ custom_upscale_settings = interactive_sdupscale_settings(config)
+ if not custom_upscale_settings:
+ return
+ source_path = custom_upscale_settings["source_file"]
+ else:
+ new_path = input(f"Image path ({source_path}): ")
+ if new_path != "":
+ source_path = new_path
+ if source_path == "":
+ print("Error : You need to provide a file in SD Upscale mode")
+ return
+ settings.strength = user_value(
+ float,
+ f"SD Upscale strength ({settings.strength}): ",
+ settings.strength,
+ )
+ settings.inference_steps = int(steps / settings.strength + 1)
+
+ output_path = FastStableDiffusionPaths.get_upscale_filepath(
+ source_path,
+ 2,
+ config.generated_images.format,
+ )
+ generate_upscaled_image(
+ config,
+ source_path,
+ settings.strength,
+ upscale_settings=custom_upscale_settings,
+ context=context,
+ tile_overlap=32 if settings.use_openvino else 16,
+ output_path=output_path,
+ image_format=config.generated_images.format,
+ )
+ user_input = input("Continue in SD Upscale mode? (Y/n): ")
+ if user_input.upper() == "N":
+ settings.inference_steps = steps
+ return
diff --git a/src/frontend/gui/app_window.py b/src/frontend/gui/app_window.py
new file mode 100644
index 0000000000000000000000000000000000000000..9449b04e47239f1171f91a7af8cc156511ccdce0
--- /dev/null
+++ b/src/frontend/gui/app_window.py
@@ -0,0 +1,599 @@
+from datetime import datetime
+
+from app_settings import AppSettings
+from backend.models.lcmdiffusion_setting import DiffusionTask
+from constants import (
+ APP_NAME,
+ APP_VERSION,
+ DEVICE,
+ LCM_DEFAULT_MODEL,
+ LCM_DEFAULT_MODEL_OPENVINO,
+)
+from context import Context
+from frontend.gui.image_generator_worker import ImageGeneratorWorker
+from frontend.gui.image_variations_widget import ImageVariationsWidget
+from frontend.gui.upscaler_widget import UpscalerWidget
+from frontend.gui.img2img_widget import Img2ImgWidget
+from frontend.utils import (
+ enable_openvino_controls,
+ get_valid_model_id,
+ is_reshape_required,
+)
+from paths import FastStableDiffusionPaths
+from PIL.ImageQt import ImageQt
+from PyQt5 import QtCore, QtWidgets
+from PyQt5.QtCore import QSize, Qt, QThreadPool, QUrl
+from PyQt5.QtGui import QDesktopServices, QPixmap
+from PyQt5.QtWidgets import (
+ QCheckBox,
+ QComboBox,
+ QFileDialog,
+ QHBoxLayout,
+ QLabel,
+ QLineEdit,
+ QMainWindow,
+ QPushButton,
+ QSizePolicy,
+ QSlider,
+ QSpacerItem,
+ QTabWidget,
+ QTextEdit,
+ QToolButton,
+ QVBoxLayout,
+ QWidget,
+)
+
+from models.interface_types import InterfaceType
+from frontend.gui.base_widget import BaseWidget, ImageLabel
+
+# DPI scale fix
+QtWidgets.QApplication.setAttribute(QtCore.Qt.AA_EnableHighDpiScaling, True)
+QtWidgets.QApplication.setAttribute(QtCore.Qt.AA_UseHighDpiPixmaps, True)
+
+
+class MainWindow(QMainWindow):
+ settings_changed = QtCore.pyqtSignal()
+ """ This signal is used for enabling/disabling the negative prompt field for
+ modes that support it; in particular, negative prompt is supported with OpenVINO models
+ and in LCM-LoRA mode but not in LCM mode
+ """
+
+ def __init__(self, config: AppSettings):
+ super().__init__()
+ self.config = config
+ # Prevent saved LoRA and ControlNet settings from being used by
+ # default; in GUI mode, the user must explicitly enable those
+ if self.config.settings.lcm_diffusion_setting.lora:
+ self.config.settings.lcm_diffusion_setting.lora.enabled = False
+ if self.config.settings.lcm_diffusion_setting.controlnet:
+ self.config.settings.lcm_diffusion_setting.controlnet.enabled = False
+ self.setWindowTitle(APP_NAME)
+ self.setFixedSize(QSize(600, 670))
+ self.init_ui()
+ self.pipeline = None
+ self.threadpool = QThreadPool()
+ self.device = "cpu"
+ self.previous_width = 0
+ self.previous_height = 0
+ self.previous_model = ""
+ self.previous_num_of_images = 0
+ self.context = Context(InterfaceType.GUI)
+ self.init_ui_values()
+ self.gen_images = []
+ self.image_index = 0
+ print(f"Output path : { self.config.settings.generated_images.path}")
+
+ def init_ui_values(self):
+ self.lcm_model.setEnabled(
+ not self.config.settings.lcm_diffusion_setting.use_openvino
+ )
+ self.guidance.setValue(
+ int(self.config.settings.lcm_diffusion_setting.guidance_scale * 10)
+ )
+ self.seed_value.setEnabled(self.config.settings.lcm_diffusion_setting.use_seed)
+ self.safety_checker.setChecked(
+ self.config.settings.lcm_diffusion_setting.use_safety_checker
+ )
+ self.use_openvino_check.setChecked(
+ self.config.settings.lcm_diffusion_setting.use_openvino
+ )
+ self.width.setCurrentText(
+ str(self.config.settings.lcm_diffusion_setting.image_width)
+ )
+ self.height.setCurrentText(
+ str(self.config.settings.lcm_diffusion_setting.image_height)
+ )
+ self.inference_steps.setValue(
+ int(self.config.settings.lcm_diffusion_setting.inference_steps)
+ )
+ self.clip_skip.setValue(
+ int(self.config.settings.lcm_diffusion_setting.clip_skip)
+ )
+ self.token_merging.setValue(
+ int(self.config.settings.lcm_diffusion_setting.token_merging * 100)
+ )
+ self.seed_check.setChecked(self.config.settings.lcm_diffusion_setting.use_seed)
+ self.seed_value.setText(str(self.config.settings.lcm_diffusion_setting.seed))
+ self.use_local_model_folder.setChecked(
+ self.config.settings.lcm_diffusion_setting.use_offline_model
+ )
+ self.results_path.setText(self.config.settings.generated_images.path)
+ self.num_images.setValue(
+ self.config.settings.lcm_diffusion_setting.number_of_images
+ )
+ self.use_tae_sd.setChecked(
+ self.config.settings.lcm_diffusion_setting.use_tiny_auto_encoder
+ )
+ self.use_lcm_lora.setChecked(
+ self.config.settings.lcm_diffusion_setting.use_lcm_lora
+ )
+ self.lcm_model.setCurrentText(
+ get_valid_model_id(
+ self.config.lcm_models,
+ self.config.settings.lcm_diffusion_setting.lcm_model_id,
+ LCM_DEFAULT_MODEL,
+ )
+ )
+ self.base_model_id.setCurrentText(
+ get_valid_model_id(
+ self.config.stable_diffsuion_models,
+ self.config.settings.lcm_diffusion_setting.lcm_lora.base_model_id,
+ )
+ )
+ self.lcm_lora_id.setCurrentText(
+ get_valid_model_id(
+ self.config.lcm_lora_models,
+ self.config.settings.lcm_diffusion_setting.lcm_lora.lcm_lora_id,
+ )
+ )
+ self.openvino_lcm_model_id.setCurrentText(
+ get_valid_model_id(
+ self.config.openvino_lcm_models,
+ self.config.settings.lcm_diffusion_setting.openvino_lcm_model_id,
+ LCM_DEFAULT_MODEL_OPENVINO,
+ )
+ )
+ self.openvino_lcm_model_id.setEnabled(
+ self.config.settings.lcm_diffusion_setting.use_openvino
+ )
+
+ def init_ui(self):
+ self.create_main_tab()
+ self.create_settings_tab()
+ self.create_about_tab()
+ self.show()
+
+ def create_main_tab(self):
+ self.tab_widget = QTabWidget(self)
+ self.tab_main = BaseWidget(self.config, self)
+ self.tab_settings = QWidget()
+ self.tab_about = QWidget()
+ self.img2img_tab = Img2ImgWidget(self.config, self)
+ self.variations_tab = ImageVariationsWidget(self.config, self)
+ self.upscaler_tab = UpscalerWidget(self.config, self)
+
+ # Add main window tabs here
+ self.tab_widget.addTab(self.tab_main, "Text to Image")
+ self.tab_widget.addTab(self.img2img_tab, "Image to Image")
+ self.tab_widget.addTab(self.variations_tab, "Image Variations")
+ self.tab_widget.addTab(self.upscaler_tab, "Upscaler")
+ self.tab_widget.addTab(self.tab_settings, "Settings")
+ self.tab_widget.addTab(self.tab_about, "About")
+
+ self.setCentralWidget(self.tab_widget)
+ self.use_seed = False
+
+ def create_settings_tab(self):
+ self.lcm_model_label = QLabel("Latent Consistency Model:")
+ # self.lcm_model = QLineEdit(LCM_DEFAULT_MODEL)
+ self.lcm_model = QComboBox(self)
+ self.lcm_model.addItems(self.config.lcm_models)
+ self.lcm_model.currentIndexChanged.connect(self.on_lcm_model_changed)
+
+ self.use_lcm_lora = QCheckBox("Use LCM LoRA")
+ self.use_lcm_lora.setChecked(False)
+ self.use_lcm_lora.stateChanged.connect(self.use_lcm_lora_changed)
+
+ self.lora_base_model_id_label = QLabel("Lora base model ID :")
+ self.base_model_id = QComboBox(self)
+ self.base_model_id.addItems(self.config.stable_diffsuion_models)
+ self.base_model_id.currentIndexChanged.connect(self.on_base_model_id_changed)
+
+ self.lcm_lora_model_id_label = QLabel("LCM LoRA model ID :")
+ self.lcm_lora_id = QComboBox(self)
+ self.lcm_lora_id.addItems(self.config.lcm_lora_models)
+ self.lcm_lora_id.currentIndexChanged.connect(self.on_lcm_lora_id_changed)
+
+ self.inference_steps_value = QLabel("Number of inference steps: 4")
+ self.inference_steps = QSlider(orientation=Qt.Orientation.Horizontal)
+ self.inference_steps.setMaximum(25)
+ self.inference_steps.setMinimum(1)
+ self.inference_steps.setValue(4)
+ self.inference_steps.valueChanged.connect(self.update_steps_label)
+
+ self.num_images_value = QLabel("Number of images: 1")
+ self.num_images = QSlider(orientation=Qt.Orientation.Horizontal)
+ self.num_images.setMaximum(100)
+ self.num_images.setMinimum(1)
+ self.num_images.setValue(1)
+ self.num_images.valueChanged.connect(self.update_num_images_label)
+
+ self.guidance_value = QLabel("Guidance scale: 1")
+ self.guidance = QSlider(orientation=Qt.Orientation.Horizontal)
+ self.guidance.setMaximum(20)
+ self.guidance.setMinimum(10)
+ self.guidance.setValue(10)
+ self.guidance.valueChanged.connect(self.update_guidance_label)
+
+ self.clip_skip_value = QLabel("CLIP Skip: 1")
+ self.clip_skip = QSlider(orientation=Qt.Orientation.Horizontal)
+ self.clip_skip.setMaximum(12)
+ self.clip_skip.setMinimum(1)
+ self.clip_skip.setValue(1)
+ self.clip_skip.valueChanged.connect(self.update_clip_skip_label)
+
+ self.token_merging_value = QLabel("Token Merging: 0")
+ self.token_merging = QSlider(orientation=Qt.Orientation.Horizontal)
+ self.token_merging.setMaximum(100)
+ self.token_merging.setMinimum(0)
+ self.token_merging.setValue(0)
+ self.token_merging.valueChanged.connect(self.update_token_merging_label)
+
+ self.width_value = QLabel("Width :")
+ self.width = QComboBox(self)
+ self.width.addItem("256")
+ self.width.addItem("512")
+ self.width.addItem("768")
+ self.width.addItem("1024")
+ self.width.setCurrentText("512")
+ self.width.currentIndexChanged.connect(self.on_width_changed)
+
+ self.height_value = QLabel("Height :")
+ self.height = QComboBox(self)
+ self.height.addItem("256")
+ self.height.addItem("512")
+ self.height.addItem("768")
+ self.height.addItem("1024")
+ self.height.setCurrentText("512")
+ self.height.currentIndexChanged.connect(self.on_height_changed)
+
+ self.seed_check = QCheckBox("Use seed")
+ self.seed_value = QLineEdit()
+ self.seed_value.setInputMask("9999999999")
+ self.seed_value.setText("123123")
+ self.seed_check.stateChanged.connect(self.seed_changed)
+
+ self.safety_checker = QCheckBox("Use safety checker")
+ self.safety_checker.setChecked(True)
+ self.safety_checker.stateChanged.connect(self.use_safety_checker_changed)
+
+ self.use_openvino_check = QCheckBox("Use OpenVINO")
+ self.use_openvino_check.setChecked(False)
+ self.openvino_model_label = QLabel("OpenVINO LCM model:")
+ self.use_local_model_folder = QCheckBox(
+ "Use locally cached model or downloaded model folder(offline)"
+ )
+ self.openvino_lcm_model_id = QComboBox(self)
+ self.openvino_lcm_model_id.addItems(self.config.openvino_lcm_models)
+ self.openvino_lcm_model_id.currentIndexChanged.connect(
+ self.on_openvino_lcm_model_id_changed
+ )
+
+ self.use_openvino_check.setEnabled(enable_openvino_controls())
+ self.use_local_model_folder.setChecked(False)
+ self.use_local_model_folder.stateChanged.connect(self.use_offline_model_changed)
+ self.use_openvino_check.stateChanged.connect(self.use_openvino_changed)
+
+ self.use_tae_sd = QCheckBox(
+ "Use Tiny Auto Encoder - TAESD (Fast, moderate quality)"
+ )
+ self.use_tae_sd.setChecked(False)
+ self.use_tae_sd.stateChanged.connect(self.use_tae_sd_changed)
+
+ hlayout = QHBoxLayout()
+ hlayout.addWidget(self.seed_check)
+ hlayout.addWidget(self.seed_value)
+ hspacer = QSpacerItem(20, 10, QSizePolicy.Expanding, QSizePolicy.Minimum)
+ slider_hspacer = QSpacerItem(20, 10, QSizePolicy.Expanding, QSizePolicy.Minimum)
+
+ self.results_path_label = QLabel("Output path:")
+ self.results_path = QLineEdit()
+ self.results_path.textChanged.connect(self.on_path_changed)
+ self.browse_folder_btn = QToolButton()
+ self.browse_folder_btn.setText("...")
+ self.browse_folder_btn.clicked.connect(self.on_browse_folder)
+
+ self.reset = QPushButton("Reset All")
+ self.reset.clicked.connect(self.reset_all_settings)
+
+ vlayout = QVBoxLayout()
+ vspacer = QSpacerItem(20, 20, QSizePolicy.Minimum, QSizePolicy.Expanding)
+ vlayout.addItem(hspacer)
+ vlayout.setSpacing(3)
+ vlayout.addWidget(self.lcm_model_label)
+ vlayout.addWidget(self.lcm_model)
+ vlayout.addWidget(self.use_local_model_folder)
+ vlayout.addWidget(self.use_lcm_lora)
+ vlayout.addWidget(self.lora_base_model_id_label)
+ vlayout.addWidget(self.base_model_id)
+ vlayout.addWidget(self.lcm_lora_model_id_label)
+ vlayout.addWidget(self.lcm_lora_id)
+ vlayout.addWidget(self.use_openvino_check)
+ vlayout.addWidget(self.openvino_model_label)
+ vlayout.addWidget(self.openvino_lcm_model_id)
+ vlayout.addWidget(self.use_tae_sd)
+ vlayout.addItem(slider_hspacer)
+ vlayout.addWidget(self.inference_steps_value)
+ vlayout.addWidget(self.inference_steps)
+ vlayout.addWidget(self.num_images_value)
+ vlayout.addWidget(self.num_images)
+ vlayout.addWidget(self.width_value)
+ vlayout.addWidget(self.width)
+ vlayout.addWidget(self.height_value)
+ vlayout.addWidget(self.height)
+ vlayout.addWidget(self.guidance_value)
+ vlayout.addWidget(self.guidance)
+ vlayout.addWidget(self.clip_skip_value)
+ vlayout.addWidget(self.clip_skip)
+ vlayout.addWidget(self.token_merging_value)
+ vlayout.addWidget(self.token_merging)
+ vlayout.addLayout(hlayout)
+ vlayout.addWidget(self.safety_checker)
+
+ vlayout.addWidget(self.results_path_label)
+ hlayout_path = QHBoxLayout()
+ hlayout_path.addWidget(self.results_path)
+ hlayout_path.addWidget(self.browse_folder_btn)
+ vlayout.addLayout(hlayout_path)
+ self.tab_settings.setLayout(vlayout)
+ hlayout_reset = QHBoxLayout()
+ hspacer = QSpacerItem(20, 20, QSizePolicy.Expanding, QSizePolicy.Minimum)
+ hlayout_reset.addItem(hspacer)
+ hlayout_reset.addWidget(self.reset)
+ vlayout.addLayout(hlayout_reset)
+ vlayout.addItem(vspacer)
+
+ def create_about_tab(self):
+ self.label = QLabel()
+ self.label.setAlignment(Qt.AlignCenter)
+ current_year = datetime.now().year
+ self.label.setText(
+ f"""<h1>FastSD CPU {APP_VERSION}</h1>
+ <h3>(c)2023 - {current_year} Rupesh Sreeraman</h3>
+ <h3>Faster stable diffusion on CPU</h3>
+ <h3>Based on Latent Consistency Models</h3>
+ <h3>GitHub : https://github.com/rupeshs/fastsdcpu/</h3>"""
+ )
+
+ vlayout = QVBoxLayout()
+ vlayout.addWidget(self.label)
+ self.tab_about.setLayout(vlayout)
+
+ def show_image(self, pixmap):
+ image_width = self.config.settings.lcm_diffusion_setting.image_width
+ image_height = self.config.settings.lcm_diffusion_setting.image_height
+ if image_width > 512 or image_height > 512:
+ new_width = 512 if image_width > 512 else image_width
+ new_height = 512 if image_height > 512 else image_height
+ self.img.setPixmap(
+ pixmap.scaled(
+ new_width,
+ new_height,
+ Qt.KeepAspectRatio,
+ )
+ )
+ else:
+ self.img.setPixmap(pixmap)
+
+ def on_show_next_image(self):
+ if self.image_index != len(self.gen_images) - 1 and len(self.gen_images) > 0:
+ self.previous_img_btn.setEnabled(True)
+ self.image_index += 1
+ self.show_image(self.gen_images[self.image_index])
+ if self.image_index == len(self.gen_images) - 1:
+ self.next_img_btn.setEnabled(False)
+
+ def on_open_results_folder(self):
+ QDesktopServices.openUrl(
+ QUrl.fromLocalFile(self.config.settings.generated_images.path)
+ )
+
+ def on_show_previous_image(self):
+ if self.image_index != 0:
+ self.next_img_btn.setEnabled(True)
+ self.image_index -= 1
+ self.show_image(self.gen_images[self.image_index])
+ if self.image_index == 0:
+ self.previous_img_btn.setEnabled(False)
+
+ def on_path_changed(self, text):
+ self.config.settings.generated_images.path = text
+
+ def on_browse_folder(self):
+ options = QFileDialog.Options()
+ options |= QFileDialog.ShowDirsOnly
+
+ folder_path = QFileDialog.getExistingDirectory(
+ self, "Select a Folder", "", options=options
+ )
+
+ if folder_path:
+ self.config.settings.generated_images.path = folder_path
+ self.results_path.setText(folder_path)
+
+ def on_width_changed(self, index):
+ width_txt = self.width.itemText(index)
+ self.config.settings.lcm_diffusion_setting.image_width = int(width_txt)
+
+ def on_height_changed(self, index):
+ height_txt = self.height.itemText(index)
+ self.config.settings.lcm_diffusion_setting.image_height = int(height_txt)
+
+ def on_lcm_model_changed(self, index):
+ model_id = self.lcm_model.itemText(index)
+ self.config.settings.lcm_diffusion_setting.lcm_model_id = model_id
+
+ def on_base_model_id_changed(self, index):
+ model_id = self.base_model_id.itemText(index)
+ self.config.settings.lcm_diffusion_setting.lcm_lora.base_model_id = model_id
+
+ def on_lcm_lora_id_changed(self, index):
+ model_id = self.lcm_lora_id.itemText(index)
+ self.config.settings.lcm_diffusion_setting.lcm_lora.lcm_lora_id = model_id
+
+ def on_openvino_lcm_model_id_changed(self, index):
+ model_id = self.openvino_lcm_model_id.itemText(index)
+ self.config.settings.lcm_diffusion_setting.openvino_lcm_model_id = model_id
+
+ def use_openvino_changed(self, state):
+ if state == 2:
+ self.lcm_model.setEnabled(False)
+ self.use_lcm_lora.setEnabled(False)
+ self.lcm_lora_id.setEnabled(False)
+ self.base_model_id.setEnabled(False)
+ self.openvino_lcm_model_id.setEnabled(True)
+ self.config.settings.lcm_diffusion_setting.use_openvino = True
+ else:
+ self.lcm_model.setEnabled(True)
+ self.use_lcm_lora.setEnabled(True)
+ self.lcm_lora_id.setEnabled(True)
+ self.base_model_id.setEnabled(True)
+ self.openvino_lcm_model_id.setEnabled(False)
+ self.config.settings.lcm_diffusion_setting.use_openvino = False
+ self.settings_changed.emit()
+
+ def use_tae_sd_changed(self, state):
+ if state == 2:
+ self.config.settings.lcm_diffusion_setting.use_tiny_auto_encoder = True
+ else:
+ self.config.settings.lcm_diffusion_setting.use_tiny_auto_encoder = False
+
+ def use_offline_model_changed(self, state):
+ if state == 2:
+ self.config.settings.lcm_diffusion_setting.use_offline_model = True
+ else:
+ self.config.settings.lcm_diffusion_setting.use_offline_model = False
+
+ def use_lcm_lora_changed(self, state):
+ if state == 2:
+ self.lcm_model.setEnabled(False)
+ self.lcm_lora_id.setEnabled(True)
+ self.base_model_id.setEnabled(True)
+ self.config.settings.lcm_diffusion_setting.use_lcm_lora = True
+ else:
+ self.lcm_model.setEnabled(True)
+ self.lcm_lora_id.setEnabled(False)
+ self.base_model_id.setEnabled(False)
+ self.config.settings.lcm_diffusion_setting.use_lcm_lora = False
+ self.settings_changed.emit()
+
+ def update_clip_skip_label(self, value):
+ self.clip_skip_value.setText(f"CLIP Skip: {value}")
+ self.config.settings.lcm_diffusion_setting.clip_skip = value
+
+ def update_token_merging_label(self, value):
+ val = round(int(value) / 100, 1)
+ self.token_merging_value.setText(f"Token Merging: {val}")
+ self.config.settings.lcm_diffusion_setting.token_merging = val
+
+ def use_safety_checker_changed(self, state):
+ if state == 2:
+ self.config.settings.lcm_diffusion_setting.use_safety_checker = True
+ else:
+ self.config.settings.lcm_diffusion_setting.use_safety_checker = False
+
+ def update_steps_label(self, value):
+ self.inference_steps_value.setText(f"Number of inference steps: {value}")
+ self.config.settings.lcm_diffusion_setting.inference_steps = value
+
+ def update_num_images_label(self, value):
+ self.num_images_value.setText(f"Number of images: {value}")
+ self.config.settings.lcm_diffusion_setting.number_of_images = value
+
+ def update_guidance_label(self, value):
+ val = round(int(value) / 10, 1)
+ self.guidance_value.setText(f"Guidance scale: {val}")
+ self.config.settings.lcm_diffusion_setting.guidance_scale = val
+
+ def seed_changed(self, state):
+ if state == 2:
+ self.seed_value.setEnabled(True)
+ self.config.settings.lcm_diffusion_setting.use_seed = True
+ else:
+ self.seed_value.setEnabled(False)
+ self.config.settings.lcm_diffusion_setting.use_seed = False
+
+ def get_seed_value(self) -> int:
+ use_seed = self.config.settings.lcm_diffusion_setting.use_seed
+ seed_value = int(self.seed_value.text()) if use_seed else -1
+ return seed_value
+
+ # def text_to_image(self):
+ # self.img.setText("Please wait...")
+ # worker = ImageGeneratorWorker(self.generate_image)
+ # self.threadpool.start(worker)
+
+ def closeEvent(self, event):
+ self.config.settings.lcm_diffusion_setting.seed = self.get_seed_value()
+ print(self.config.settings.lcm_diffusion_setting)
+ print("Saving settings")
+ self.config.save()
+
+ def reset_all_settings(self):
+ self.use_local_model_folder.setChecked(False)
+ self.width.setCurrentText("512")
+ self.height.setCurrentText("512")
+ self.inference_steps.setValue(4)
+ self.guidance.setValue(10)
+ self.clip_skip.setValue(1)
+ self.token_merging.setValue(0)
+ self.use_openvino_check.setChecked(False)
+ self.seed_check.setChecked(False)
+ self.safety_checker.setChecked(False)
+ self.results_path.setText(FastStableDiffusionPaths().get_results_path())
+ self.use_tae_sd.setChecked(False)
+ self.use_lcm_lora.setChecked(False)
+
+ def prepare_generation_settings(self, config):
+ """Populate config settings with the values set by the user in the GUI"""
+ config.settings.lcm_diffusion_setting.seed = self.get_seed_value()
+ config.settings.lcm_diffusion_setting.lcm_lora.lcm_lora_id = (
+ self.lcm_lora_id.currentText()
+ )
+ config.settings.lcm_diffusion_setting.lcm_lora.base_model_id = (
+ self.base_model_id.currentText()
+ )
+
+ if config.settings.lcm_diffusion_setting.use_openvino:
+ model_id = self.openvino_lcm_model_id.currentText()
+ config.settings.lcm_diffusion_setting.openvino_lcm_model_id = model_id
+ else:
+ model_id = self.lcm_model.currentText()
+ config.settings.lcm_diffusion_setting.lcm_model_id = model_id
+
+ config.reshape_required = False
+ config.model_id = model_id
+ if config.settings.lcm_diffusion_setting.use_openvino:
+ # Detect dimension change
+ config.reshape_required = is_reshape_required(
+ self.previous_width,
+ config.settings.lcm_diffusion_setting.image_width,
+ self.previous_height,
+ config.settings.lcm_diffusion_setting.image_height,
+ self.previous_model,
+ model_id,
+ self.previous_num_of_images,
+ config.settings.lcm_diffusion_setting.number_of_images,
+ )
+ config.settings.lcm_diffusion_setting.diffusion_task = (
+ DiffusionTask.text_to_image.value
+ )
+
+ def store_dimension_settings(self):
+ """These values are only needed for OpenVINO model reshape"""
+ self.previous_width = self.config.settings.lcm_diffusion_setting.image_width
+ self.previous_height = self.config.settings.lcm_diffusion_setting.image_height
+ self.previous_model = self.config.model_id
+ self.previous_num_of_images = (
+ self.config.settings.lcm_diffusion_setting.number_of_images
+ )
diff --git a/src/frontend/gui/base_widget.py b/src/frontend/gui/base_widget.py
new file mode 100644
index 0000000000000000000000000000000000000000..e0a9725605ff7fbeb9b2355b571ad3e664024f6d
--- /dev/null
+++ b/src/frontend/gui/base_widget.py
@@ -0,0 +1,220 @@
+from PyQt5.QtWidgets import (
+ QWidget,
+ QPushButton,
+ QLayout,
+ QHBoxLayout,
+ QVBoxLayout,
+ QLabel,
+ QLineEdit,
+ QMainWindow,
+ QSlider,
+ QTabWidget,
+ QSpacerItem,
+ QSizePolicy,
+ QComboBox,
+ QCheckBox,
+ QTextEdit,
+ QToolButton,
+ QFileDialog,
+ QApplication,
+)
+from PyQt5 import QtWidgets, QtCore
+from PyQt5.QtGui import (
+ QPixmap,
+ QDesktopServices,
+ QDragEnterEvent,
+ QDropEvent,
+ QMouseEvent,
+)
+from PyQt5.QtCore import QSize, QThreadPool, Qt, QUrl, QBuffer
+
+import io
+from PIL import Image
+from constants import DEVICE
+from PIL.ImageQt import ImageQt
+from app_settings import AppSettings
+from urllib.parse import urlparse, unquote
+from frontend.gui.image_generator_worker import ImageGeneratorWorker
+
+
+class ImageLabel(QLabel):
+ """Defines a simple QLabel widget"""
+
+ changed = QtCore.pyqtSignal()
+
+ def __init__(self, text: str):
+ super().__init__(text)
+ self.setAlignment(Qt.AlignCenter)
+ self.resize(512, 512)
+ self.setSizePolicy(QSizePolicy.MinimumExpanding, QSizePolicy.MinimumExpanding)
+ self.sizeHint = QSize(512, 512)
+ self.setAcceptDrops(False)
+
+ def show_image(self, pixmap: QPixmap = None):
+ """Updates the widget pixamp"""
+ if pixmap == None or pixmap.isNull():
+ return
+ self.current_pixmap = pixmap
+ self.changed.emit()
+
+ # Resize the pixmap to the widget dimensions
+ image_width = self.current_pixmap.width()
+ image_height = self.current_pixmap.height()
+ if image_width > 512 or image_height > 512:
+ new_width = 512 if image_width > 512 else image_width
+ new_height = 512 if image_height > 512 else image_height
+ self.setPixmap(
+ self.current_pixmap.scaled(
+ new_width,
+ new_height,
+ Qt.KeepAspectRatio,
+ )
+ )
+ else:
+ self.setPixmap(self.current_pixmap)
+
+
+class BaseWidget(QWidget):
+ def __init__(self, config: AppSettings, parent):
+ super().__init__()
+ self.config = config
+ self.gen_images = []
+ self.image_index = 0
+ self.config = config
+ self.parent = parent
+
+ # Initialize GUI widgets
+ self.prev_btn = QToolButton()
+ self.prev_btn.setText("<")
+ self.prev_btn.clicked.connect(self.on_show_previous_image)
+ self.img = ImageLabel("<<Image>>")
+ self.next_btn = QToolButton()
+ self.next_btn.setText(">")
+ self.next_btn.clicked.connect(self.on_show_next_image)
+ self.prompt = QTextEdit()
+ self.prompt.setPlaceholderText("A fantasy landscape")
+ self.prompt.setAcceptRichText(False)
+ self.prompt.setFixedHeight(40)
+ self.neg_prompt = QTextEdit()
+ self.neg_prompt.setPlaceholderText("")
+ self.neg_prompt.setAcceptRichText(False)
+ self.neg_prompt_label = QLabel("Negative prompt (Set guidance scale > 1.0):")
+ self.neg_prompt.setFixedHeight(35)
+ self.neg_prompt.setEnabled(False)
+ self.generate = QPushButton("Generate")
+ self.generate.clicked.connect(self.generate_click)
+ self.browse_results = QPushButton("...")
+ self.browse_results.setFixedWidth(30)
+ self.browse_results.clicked.connect(self.on_open_results_folder)
+ self.browse_results.setToolTip("Open output folder")
+
+ # Create the image navigation layout
+ ilayout = QHBoxLayout()
+ ilayout.addWidget(self.prev_btn)
+ ilayout.addWidget(self.img)
+ ilayout.addWidget(self.next_btn)
+
+ # Create the generate button layout
+ hlayout = QHBoxLayout()
+ hlayout.addWidget(self.neg_prompt)
+ hlayout.addWidget(self.generate)
+ hlayout.addWidget(self.browse_results)
+
+ # Create the actual widget layout
+ vlayout = QVBoxLayout()
+ vlayout.addLayout(ilayout)
+ # vlayout.addItem(self.vspacer)
+ vlayout.addWidget(self.prompt)
+ vlayout.addWidget(self.neg_prompt_label)
+ vlayout.addLayout(hlayout)
+ self.setLayout(vlayout)
+
+ self.parent.settings_changed.connect(self.on_settings_changed)
+
+ def generate_image(self):
+ self.parent.prepare_generation_settings(self.config)
+ self.config.settings.lcm_diffusion_setting.prompt = self.prompt.toPlainText()
+ self.config.settings.lcm_diffusion_setting.negative_prompt = (
+ self.neg_prompt.toPlainText()
+ )
+ images = self.parent.context.generate_text_to_image(
+ self.config.settings,
+ self.config.reshape_required,
+ DEVICE,
+ )
+ self.prepare_images(images)
+ self.after_generation()
+
+ def prepare_images(self, images):
+ """Prepares the generated images to be displayed in the Qt widget"""
+ self.image_index = 0
+ self.gen_images = []
+ for img in images:
+ im = ImageQt(img).copy()
+ pixmap = QPixmap.fromImage(im)
+ self.gen_images.append(pixmap)
+
+ if len(self.gen_images) > 1:
+ self.next_btn.setEnabled(True)
+ self.prev_btn.setEnabled(False)
+ else:
+ self.next_btn.setEnabled(False)
+ self.prev_btn.setEnabled(False)
+
+ self.img.show_image(pixmap=self.gen_images[0])
+
+ def on_show_next_image(self):
+ if self.image_index != len(self.gen_images) - 1 and len(self.gen_images) > 0:
+ self.prev_btn.setEnabled(True)
+ self.image_index += 1
+ self.img.show_image(pixmap=self.gen_images[self.image_index])
+ if self.image_index == len(self.gen_images) - 1:
+ self.next_btn.setEnabled(False)
+
+ def on_show_previous_image(self):
+ if self.image_index != 0:
+ self.next_btn.setEnabled(True)
+ self.image_index -= 1
+ self.img.show_image(pixmap=self.gen_images[self.image_index])
+ if self.image_index == 0:
+ self.prev_btn.setEnabled(False)
+
+ def on_open_results_folder(self):
+ QDesktopServices.openUrl(
+ QUrl.fromLocalFile(self.config.settings.generated_images.path)
+ )
+
+ def generate_click(self):
+ self.img.setText("Please wait...")
+ self.before_generation()
+ worker = ImageGeneratorWorker(self.generate_image)
+ self.parent.threadpool.start(worker)
+
+ def before_generation(self):
+ """Call this function before running a generation task"""
+ self.img.setEnabled(False)
+ self.generate.setEnabled(False)
+ self.browse_results.setEnabled(False)
+
+ def after_generation(self):
+ """Call this function after running a generation task"""
+ self.img.setEnabled(True)
+ self.generate.setEnabled(True)
+ self.browse_results.setEnabled(True)
+ self.parent.store_dimension_settings()
+
+ def on_settings_changed(self):
+ self.neg_prompt.setEnabled(
+ self.config.settings.lcm_diffusion_setting.use_openvino
+ or self.config.settings.lcm_diffusion_setting.use_lcm_lora
+ )
+
+
+# Test the widget
+if __name__ == "__main__":
+ import sys
+
+ app = QApplication(sys.argv)
+ widget = BaseWidget(None)
+ widget.show()
+ app.exec()
diff --git a/src/frontend/gui/image_generator_worker.py b/src/frontend/gui/image_generator_worker.py
new file mode 100644
index 0000000000000000000000000000000000000000..3a948365085ece82337309ac91d278e77fa03e40
--- /dev/null
+++ b/src/frontend/gui/image_generator_worker.py
@@ -0,0 +1,37 @@
+from PyQt5.QtCore import (
+ pyqtSlot,
+ QRunnable,
+ pyqtSignal,
+ pyqtSlot,
+)
+from PyQt5.QtCore import QObject
+import traceback
+import sys
+
+
+class WorkerSignals(QObject):
+ finished = pyqtSignal()
+ error = pyqtSignal(tuple)
+ result = pyqtSignal(object)
+
+
+class ImageGeneratorWorker(QRunnable):
+ def __init__(self, fn, *args, **kwargs):
+ super(ImageGeneratorWorker, self).__init__()
+ self.fn = fn
+ self.args = args
+ self.kwargs = kwargs
+ self.signals = WorkerSignals()
+
+ @pyqtSlot()
+ def run(self):
+ try:
+ result = self.fn(*self.args, **self.kwargs)
+ except:
+ traceback.print_exc()
+ exctype, value = sys.exc_info()[:2]
+ self.signals.error.emit((exctype, value, traceback.format_exc()))
+ else:
+ self.signals.result.emit(result)
+ finally:
+ self.signals.finished.emit()
diff --git a/src/frontend/gui/image_variations_widget.py b/src/frontend/gui/image_variations_widget.py
new file mode 100644
index 0000000000000000000000000000000000000000..d67e591d6a4391bdd6ef60a9c797de785c34baf4
--- /dev/null
+++ b/src/frontend/gui/image_variations_widget.py
@@ -0,0 +1,71 @@
+from PyQt5.QtWidgets import (
+ QWidget,
+ QPushButton,
+ QHBoxLayout,
+ QVBoxLayout,
+ QLabel,
+ QLineEdit,
+ QMainWindow,
+ QSlider,
+ QTabWidget,
+ QSpacerItem,
+ QSizePolicy,
+ QComboBox,
+ QCheckBox,
+ QTextEdit,
+ QToolButton,
+ QFileDialog,
+ QApplication,
+)
+from PyQt5 import QtWidgets, QtCore
+from PyQt5.QtGui import QPixmap, QDesktopServices, QDragEnterEvent, QDropEvent
+from PyQt5.QtCore import QSize, QThreadPool, Qt, QUrl, QBuffer
+
+import io
+from PIL import Image
+from constants import DEVICE
+from PIL.ImageQt import ImageQt
+from app_settings import AppSettings
+from urllib.parse import urlparse, unquote
+from frontend.gui.img2img_widget import Img2ImgWidget
+from backend.models.lcmdiffusion_setting import DiffusionTask
+from frontend.gui.image_generator_worker import ImageGeneratorWorker
+from frontend.webui.image_variations_ui import generate_image_variations
+
+
+class ImageVariationsWidget(Img2ImgWidget):
+ def __init__(self, config: AppSettings, parent):
+ super().__init__(config, parent)
+ # Hide prompt and negative prompt widgets
+ self.prompt.hide()
+ self.neg_prompt_label.hide()
+ self.neg_prompt.setEnabled(False)
+
+ def generate_image(self):
+ self.parent.prepare_generation_settings(self.config)
+ self.config.settings.lcm_diffusion_setting.diffusion_task = (
+ DiffusionTask.image_to_image.value
+ )
+ self.config.settings.lcm_diffusion_setting.prompt = ""
+ self.config.settings.lcm_diffusion_setting.negative_prompt = ""
+ self.config.settings.lcm_diffusion_setting.init_image = Image.open(
+ self.img_path.text()
+ )
+ self.config.settings.lcm_diffusion_setting.strength = self.strength.value() / 10
+
+ images = generate_image_variations(
+ self.config.settings.lcm_diffusion_setting.init_image,
+ self.config.settings.lcm_diffusion_setting.strength,
+ )
+ self.prepare_images(images)
+ self.after_generation()
+
+
+# Test the widget
+if __name__ == "__main__":
+ import sys
+
+ app = QApplication(sys.argv)
+ widget = ImageVariationsWidget(None, None)
+ widget.show()
+ app.exec()
diff --git a/src/frontend/gui/img2img_widget.py b/src/frontend/gui/img2img_widget.py
new file mode 100644
index 0000000000000000000000000000000000000000..55ae3c5de5f9eefd91cd184dce9d3ff70c023b27
--- /dev/null
+++ b/src/frontend/gui/img2img_widget.py
@@ -0,0 +1,143 @@
+from PyQt5.QtWidgets import (
+ QWidget,
+ QPushButton,
+ QHBoxLayout,
+ QVBoxLayout,
+ QLabel,
+ QLineEdit,
+ QMainWindow,
+ QSlider,
+ QTabWidget,
+ QSpacerItem,
+ QSizePolicy,
+ QComboBox,
+ QCheckBox,
+ QTextEdit,
+ QToolButton,
+ QFileDialog,
+ QApplication,
+)
+from PyQt5 import QtWidgets, QtCore
+from PyQt5.QtGui import (
+ QPixmap,
+ QDesktopServices,
+ QDragEnterEvent,
+ QDropEvent,
+ QMouseEvent,
+)
+from PyQt5.QtCore import QSize, QThreadPool, Qt, QUrl, QBuffer, QObject, QEvent
+
+import io
+from PIL import Image
+from constants import DEVICE
+from PIL.ImageQt import ImageQt
+from app_settings import AppSettings
+from urllib.parse import urlparse, unquote
+from frontend.gui.base_widget import BaseWidget, ImageLabel
+from backend.models.lcmdiffusion_setting import DiffusionTask
+from frontend.gui.image_generator_worker import ImageGeneratorWorker
+
+
+class Img2ImgWidget(BaseWidget):
+ def __init__(self, config: AppSettings, parent):
+ super().__init__(config, parent)
+
+ # Create init image selection widgets
+ self.img_label = QLabel("Init image:")
+ self.img_path = QLineEdit()
+ self.img_path.setReadOnly(True)
+ self.img_path.setAcceptDrops(True)
+ self.img_path.installEventFilter(self)
+ self.img_browse = QToolButton()
+ self.img_browse.setText("...")
+ self.img_browse.setToolTip("Browse for an init image")
+ self.img_browse.clicked.connect(self.browse_click)
+ # Create the init image selection layout
+ hlayout = QHBoxLayout()
+ hlayout.addWidget(self.img_label)
+ hlayout.addWidget(self.img_path)
+ hlayout.addWidget(self.img_browse)
+
+ self.strength_label = QLabel("Denoising strength: 0.3")
+ self.strength = QSlider(orientation=Qt.Orientation.Horizontal)
+ self.strength.setMaximum(10)
+ self.strength.setMinimum(1)
+ self.strength.setValue(3)
+ self.strength.valueChanged.connect(self.update_strength_label)
+ # self.layout().insertWidget(1, self.strength_label)
+ # self.layout().insertWidget(2, self.strength)
+ self.layout().addLayout(hlayout)
+ self.layout().addWidget(self.strength_label)
+ self.layout().addWidget(self.strength)
+
+ def browse_click(self):
+ filename = self.show_file_selection_dialog()
+ if filename[0] != "":
+ self.img_path.setText(filename[0])
+
+ def show_file_selection_dialog(self) -> str:
+ filename = QFileDialog.getOpenFileName(
+ self, "Open Image", "results", "Image Files (*.png *.jpg *.bmp)"
+ )
+ return filename
+
+ def eventFilter(self, source, event: QEvent):
+ """This is the Drag and Drop event filter for the init image QLineEdit"""
+ if event.type() == QEvent.DragEnter:
+ if event.mimeData().hasFormat("text/plain"):
+ event.acceptProposedAction()
+ return True
+ elif event.type() == QEvent.Drop:
+ event.acceptProposedAction()
+ path = unquote(urlparse(event.mimeData().text()).path)
+ self.img_path.setText(path)
+ return True
+
+ return False
+
+ def before_generation(self):
+ super().before_generation()
+ self.img_browse.setEnabled(False)
+ self.img_path.setEnabled(False)
+
+ def after_generation(self):
+ super().after_generation()
+ self.img_browse.setEnabled(True)
+ self.img_path.setEnabled(True)
+
+ def generate_image(self):
+ self.parent.prepare_generation_settings(self.config)
+ self.config.settings.lcm_diffusion_setting.diffusion_task = (
+ DiffusionTask.image_to_image.value
+ )
+ self.config.settings.lcm_diffusion_setting.prompt = self.prompt.toPlainText()
+ self.config.settings.lcm_diffusion_setting.negative_prompt = (
+ self.neg_prompt.toPlainText()
+ )
+ self.config.settings.lcm_diffusion_setting.init_image = Image.open(
+ self.img_path.text()
+ )
+ self.config.settings.lcm_diffusion_setting.strength = self.strength.value() / 10
+
+ images = self.parent.context.generate_text_to_image(
+ self.config.settings,
+ self.config.reshape_required,
+ DEVICE,
+ )
+ self.prepare_images(images)
+ self.after_generation()
+
+ def update_strength_label(self, value):
+ val = round(int(value) / 10, 1)
+ self.strength_label.setText(f"Denoising strength: {val}")
+ self.config.settings.lcm_diffusion_setting.strength = val
+
+
+# Test the widget
+if __name__ == "__main__":
+ import sys
+
+ app = QApplication(sys.argv)
+ widget = Img2ImgWidget(None, None)
+ widget.show()
+ app.exec()
diff --git a/src/frontend/gui/ui.py b/src/frontend/gui/ui.py
new file mode 100644
index 0000000000000000000000000000000000000000..9250bf676da1f3dc8a2f5435095b9cec9b08041e
--- /dev/null
+++ b/src/frontend/gui/ui.py
@@ -0,0 +1,15 @@
+from typing import List
+from frontend.gui.app_window import MainWindow
+from PyQt5.QtWidgets import QApplication
+import sys
+from app_settings import AppSettings
+
+
+def start_gui(
+ argv: List[str],
+ app_settings: AppSettings,
+):
+ app = QApplication(sys.argv)
+ window = MainWindow(app_settings)
+ window.show()
+ app.exec()
diff --git a/src/frontend/gui/upscaler_widget.py b/src/frontend/gui/upscaler_widget.py
new file mode 100644
index 0000000000000000000000000000000000000000..67579e7cd10116d35e100089731ed000e659558f
--- /dev/null
+++ b/src/frontend/gui/upscaler_widget.py
@@ -0,0 +1,127 @@
+from PyQt5.QtWidgets import (
+ QWidget,
+ QPushButton,
+ QHBoxLayout,
+ QVBoxLayout,
+ QLabel,
+ QLineEdit,
+ QMainWindow,
+ QSlider,
+ QTabWidget,
+ QSpacerItem,
+ QSizePolicy,
+ QComboBox,
+ QCheckBox,
+ QTextEdit,
+ QToolButton,
+ QFileDialog,
+ QApplication,
+ QRadioButton,
+ QFrame,
+)
+from PyQt5 import QtWidgets, QtCore
+from PyQt5.QtGui import QPixmap, QDesktopServices, QDragEnterEvent, QDropEvent
+from PyQt5.QtCore import QSize, QThreadPool, Qt, QUrl, QBuffer
+
+import io
+from PIL import Image
+from constants import DEVICE
+from PIL.ImageQt import ImageQt
+from app_settings import AppSettings
+from urllib.parse import urlparse, unquote
+from backend.models.upscale import UpscaleMode
+from backend.upscale.upscaler import upscale_image
+from frontend.gui.img2img_widget import Img2ImgWidget
+from paths import FastStableDiffusionPaths, join_paths
+from backend.models.lcmdiffusion_setting import DiffusionTask
+from frontend.gui.image_generator_worker import ImageGeneratorWorker
+from frontend.webui.image_variations_ui import generate_image_variations
+
+
+class UpscalerWidget(Img2ImgWidget):
+ scale_factor = 2.0
+
+ def __init__(self, config: AppSettings, parent):
+ super().__init__(config, parent)
+ # Hide prompt and negative prompt widgets
+ self.prompt.hide()
+ self.neg_prompt.hide()
+ # self.neg_prompt.deleteLater()
+ self.strength_label.hide()
+ self.strength.hide()
+ self.generate.setText("Upscale")
+ # Create upscaler widgets
+ self.edsr_button = QRadioButton("EDSR", self)
+ self.edsr_button.toggled.connect(self.on_mode_change)
+ self.edsr_button.toggle()
+ self.sd_button = QRadioButton("SD", self)
+ self.sd_button.toggled.connect(self.on_mode_change)
+ self.aura_button = QRadioButton("AURA-SR", self)
+ self.aura_button.toggled.connect(self.on_mode_change)
+
+ self.neg_prompt_label.setText("Upscale mode (2x) | AURA-SR (4x):")
+ # Create upscaler buttons layout
+ hlayout = QHBoxLayout()
+ hlayout.addWidget(self.edsr_button)
+ hlayout.addWidget(self.sd_button)
+ hlayout.addWidget(self.aura_button)
+ # Can't use a layout with replaceWidget(), so the layout is assigned
+ # to a dummy widget used to replace the negative prompt button and
+ # obtain the desired GUI design
+ self.container = QWidget()
+ self.container.setLayout(hlayout)
+ self.layout().replaceWidget(self.neg_prompt, self.container)
+
+ def generate_image(self):
+ self.parent.prepare_generation_settings(self.config)
+ self.config.settings.lcm_diffusion_setting.init_image = Image.open(
+ self.img_path.text()
+ )
+ self.config.settings.lcm_diffusion_setting.strength = self.strength.value() / 10
+ upscaled_filepath = FastStableDiffusionPaths.get_upscale_filepath(
+ None,
+ self.scale_factor,
+ self.config.settings.generated_images.format,
+ )
+
+ images = upscale_image(
+ context=self.parent.context,
+ src_image_path=self.img_path.text(),
+ dst_image_path=upscaled_filepath,
+ upscale_mode=self.upscale_mode,
+ strength=0.1,
+ )
+ self.prepare_images(images)
+ self.after_generation()
+
+ def before_generation(self):
+ super().before_generation()
+ self.container.setEnabled(False)
+
+ def after_generation(self):
+ super().after_generation()
+ self.container.setEnabled(True)
+ # TODO For some reason, if init_image is not set to None, saving settings
+ # when closing the main window will fail, even though the save() method
+ # explicitly sets init_image to None?
+ self.config.settings.lcm_diffusion_setting.init_image = None
+
+ def on_mode_change(self):
+ self.scale_factor = 2.0
+ if self.edsr_button.isChecked():
+ self.upscale_mode = UpscaleMode.normal.value
+ elif self.sd_button.isChecked():
+ self.upscale_mode = UpscaleMode.sd_upscale.value
+ else:
+ self.upscale_mode = UpscaleMode.aura_sr.value
+ self.scale_factor = 4.0
+
+
+# Test the widget
+if __name__ == "__main__":
+ import sys
+
+ app = QApplication(sys.argv)
+ widget = ImageVariationsWidget(None, None)
+ widget.show()
+ app.exec()
diff --git a/src/frontend/utils.py b/src/frontend/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..9c825decea7d166a09a6aed3d3f29633f367ea0e
--- /dev/null
+++ b/src/frontend/utils.py
@@ -0,0 +1,89 @@
+import platform
+from os import path
+from typing import List
+
+from backend.device import is_openvino_device
+from constants import DEVICE
+from paths import get_file_name
+
+
+def is_reshape_required(
+ prev_width: int,
+ cur_width: int,
+ prev_height: int,
+ cur_height: int,
+ prev_model: int,
+ cur_model: int,
+ prev_num_of_images: int,
+ cur_num_of_images: int,
+) -> bool:
+ reshape_required = False
+ if (
+ prev_width != cur_width
+ or prev_height != cur_height
+ or prev_model != cur_model
+ or prev_num_of_images != cur_num_of_images
+ ):
+ print("Reshape and compile")
+ reshape_required = True
+
+ return reshape_required
+
+
+def enable_openvino_controls() -> bool:
+ return (
+ is_openvino_device()
+ and platform.system().lower() != "darwin"
+ and platform.processor().lower() != "arm"
+ )
+
+
+def get_valid_model_id(
+ models: List,
+ model_id: str,
+ default_model: str = "",
+) -> str:
+ if len(models) == 0:
+ print(
+ "Warning: model configuration file/directory is empty,please add some models."
+ )
+ return ""
+ if model_id == "":
+ if default_model:
+ return default_model
+ else:
+ return models[0]
+
+ if model_id in models:
+ return model_id
+ else:
+ if model_id:
+ print(
+ f"Error:{model_id} Model not found in configuration file,so using first model : {models[0]}"
+ )
+ return models[0]
+
+
+def get_valid_lora_model(
+ models: List,
+ cur_model: str,
+ lora_models_dir: str,
+) -> str:
+ if cur_model == "" or cur_model is None:
+ print(
+ f"No lora models found, please add lora models to {lora_models_dir} directory"
+ )
+ return ""
+ else:
+ if path.exists(cur_model):
+ return get_file_name(cur_model)
+ else:
+ print(f"Lora model {cur_model} not found")
+ if len(models) > 0:
+ print(f"Fallback model - {models[0]}")
+ return get_file_name(models[0])
+ else:
+ print(
+ f"No lora models found, please add lora models to {lora_models_dir} directory"
+ )
+ return ""
diff --git a/src/frontend/webui/controlnet_ui.py b/src/frontend/webui/controlnet_ui.py
new file mode 100644
index 0000000000000000000000000000000000000000..5bfab4acb318324a97a9f8191ea96feca80e5cd8
--- /dev/null
+++ b/src/frontend/webui/controlnet_ui.py
@@ -0,0 +1,194 @@
+import gradio as gr
+from PIL import Image
+from backend.lora import get_lora_models
+from state import get_settings
+from backend.models.lcmdiffusion_setting import ControlNetSetting
+from backend.annotators.image_control_factory import ImageControlFactory
+
+_controlnet_models_map = None
+_controlnet_enabled = False
+_adapter_path = None
+
+app_settings = get_settings()
+
+
+def on_user_input(
+ enable: bool,
+ adapter_name: str,
+ conditioning_scale: float,
+ control_image: Image,
+ preprocessor: str,
+):
+ if not isinstance(adapter_name, str):
+ gr.Warning("Please select a valid ControlNet model")
+ return gr.Checkbox(value=False)
+
+ settings = app_settings.settings.lcm_diffusion_setting
+ if settings.controlnet is None:
+ settings.controlnet = ControlNetSetting()
+
+ if enable and (adapter_name is None or adapter_name == ""):
+ gr.Warning("Please select a valid ControlNet adapter")
+ return gr.Checkbox(value=False)
+ elif enable and not control_image:
+ gr.Warning("Please provide a ControlNet control image")
+ return gr.Checkbox(value=False)
+
+ if control_image is None:
+ return gr.Checkbox(value=enable)
+
+ if preprocessor == "None":
+ processed_control_image = control_image
+ else:
+ image_control_factory = ImageControlFactory()
+ control = image_control_factory.create_control(preprocessor)
+ processed_control_image = control.get_control_image(control_image)
+
+ if not enable:
+ settings.controlnet.enabled = False
+ else:
+ settings.controlnet.enabled = True
+ settings.controlnet.adapter_path = _controlnet_models_map[adapter_name]
+ settings.controlnet.conditioning_scale = float(conditioning_scale)
+ settings.controlnet._control_image = processed_control_image
+
+ # This code can be improved; currently, if the user clicks the
+ # "Enable ControlNet" checkbox or changes the currently selected
+ # ControlNet model, it will trigger a pipeline rebuild even if, in
+ # the end, the user leaves the same ControlNet settings
+ global _controlnet_enabled
+ global _adapter_path
+ if settings.controlnet.enabled != _controlnet_enabled or (
+ settings.controlnet.enabled
+ and settings.controlnet.adapter_path != _adapter_path
+ ):
+ settings.rebuild_pipeline = True
+ _controlnet_enabled = settings.controlnet.enabled
+ _adapter_path = settings.controlnet.adapter_path
+ return gr.Checkbox(value=enable)
+
+
+def on_change_conditioning_scale(cond_scale):
+ print(cond_scale)
+ app_settings.settings.lcm_diffusion_setting.controlnet.conditioning_scale = (
+ cond_scale
+ )
+
+
+def get_controlnet_ui() -> None:
+ with gr.Blocks() as ui:
+ gr.HTML(
+ 'Download ControlNet v1.1 model from <a href="https://huggingface.co/comfyanonymous/ControlNet-v1-1_fp16_safetensors/tree/main">ControlNet v1.1 </a> (723 MB files) and place it in <b>controlnet_models</b> folder,restart the app'
+ )
+ with gr.Row():
+ with gr.Column():
+ with gr.Row():
+ global _controlnet_models_map
+ _controlnet_models_map = get_lora_models(
+ app_settings.settings.lcm_diffusion_setting.dirs["controlnet"]
+ )
+ controlnet_models = list(_controlnet_models_map.keys())
+ default_model = (
+ controlnet_models[0] if len(controlnet_models) else None
+ )
+
+ enabled_checkbox = gr.Checkbox(
+ label="Enable ControlNet",
+ info="Enable ControlNet",
+ show_label=True,
+ )
+ model_dropdown = gr.Dropdown(
+ _controlnet_models_map.keys(),
+ label="ControlNet model",
+ info="ControlNet model to load (.safetensors format)",
+ value=default_model,
+ interactive=True,
+ )
+ conditioning_scale_slider = gr.Slider(
+ 0.0,
+ 1.0,
+ value=0.5,
+ step=0.05,
+ label="ControlNet conditioning scale",
+ interactive=True,
+ )
+ control_image = gr.Image(
+ label="Control image",
+ type="pil",
+ )
+ preprocessor_radio = gr.Radio(
+ [
+ "Canny",
+ "Depth",
+ "LineArt",
+ "MLSD",
+ "NormalBAE",
+ "Pose",
+ "SoftEdge",
+ "Shuffle",
+ "None",
+ ],
+ label="Preprocessor",
+ info="Select the preprocessor for the control image",
+ value="Canny",
+ interactive=True,
+ )
+
+ enabled_checkbox.input(
+ fn=on_user_input,
+ inputs=[
+ enabled_checkbox,
+ model_dropdown,
+ conditioning_scale_slider,
+ control_image,
+ preprocessor_radio,
+ ],
+ outputs=[enabled_checkbox],
+ )
+ model_dropdown.input(
+ fn=on_user_input,
+ inputs=[
+ enabled_checkbox,
+ model_dropdown,
+ conditioning_scale_slider,
+ control_image,
+ preprocessor_radio,
+ ],
+ outputs=[enabled_checkbox],
+ )
+ conditioning_scale_slider.input(
+ fn=on_user_input,
+ inputs=[
+ enabled_checkbox,
+ model_dropdown,
+ conditioning_scale_slider,
+ control_image,
+ preprocessor_radio,
+ ],
+ outputs=[enabled_checkbox],
+ )
+ control_image.change(
+ fn=on_user_input,
+ inputs=[
+ enabled_checkbox,
+ model_dropdown,
+ conditioning_scale_slider,
+ control_image,
+ preprocessor_radio,
+ ],
+ outputs=[enabled_checkbox],
+ )
+ preprocessor_radio.change(
+ fn=on_user_input,
+ inputs=[
+ enabled_checkbox,
+ model_dropdown,
+ conditioning_scale_slider,
+ control_image,
+ preprocessor_radio,
+ ],
+ outputs=[enabled_checkbox],
+ )
+ conditioning_scale_slider.change(
+ on_change_conditioning_scale, conditioning_scale_slider
+ )
diff --git a/src/frontend/webui/generation_settings_ui.py b/src/frontend/webui/generation_settings_ui.py
new file mode 100644
index 0000000000000000000000000000000000000000..ab47e01b3de38f496342aec3931ef8fe202ed709
--- /dev/null
+++ b/src/frontend/webui/generation_settings_ui.py
@@ -0,0 +1,184 @@
+import gradio as gr
+from state import get_settings
+from backend.models.gen_images import ImageFormat
+
+app_settings = get_settings()
+
+
+def on_change_inference_steps(steps):
+ app_settings.settings.lcm_diffusion_setting.inference_steps = steps
+
+
+def on_change_image_width(img_width):
+ app_settings.settings.lcm_diffusion_setting.image_width = img_width
+
+
+def on_change_image_height(img_height):
+ app_settings.settings.lcm_diffusion_setting.image_height = img_height
+
+
+def on_change_num_images(num_images):
+ app_settings.settings.lcm_diffusion_setting.number_of_images = num_images
+
+
+def on_change_guidance_scale(guidance_scale):
+ app_settings.settings.lcm_diffusion_setting.guidance_scale = guidance_scale
+
+
+def on_change_clip_skip(clip_skip):
+ app_settings.settings.lcm_diffusion_setting.clip_skip = clip_skip
+
+
+def on_change_token_merging(token_merging):
+ app_settings.settings.lcm_diffusion_setting.token_merging = token_merging
+
+
+def on_change_seed_value(seed):
+ app_settings.settings.lcm_diffusion_setting.seed = seed
+
+
+def on_change_seed_checkbox(seed_checkbox):
+ app_settings.settings.lcm_diffusion_setting.use_seed = seed_checkbox
+
+
+def on_change_safety_checker_checkbox(safety_checker_checkbox):
+ app_settings.settings.lcm_diffusion_setting.use_safety_checker = (
+ safety_checker_checkbox
+ )
+
+
+def on_change_tiny_auto_encoder_checkbox(tiny_auto_encoder_checkbox):
+ app_settings.settings.lcm_diffusion_setting.use_tiny_auto_encoder = (
+ tiny_auto_encoder_checkbox
+ )
+
+
+def on_offline_checkbox(offline_checkbox):
+ app_settings.settings.lcm_diffusion_setting.use_offline_model = offline_checkbox
+
+
+def on_change_image_format(image_format):
+ if image_format == "PNG":
+ app_settings.settings.generated_images.format = ImageFormat.PNG.value.upper()
+ else:
+ app_settings.settings.generated_images.format = ImageFormat.JPEG.value.upper()
+
+ app_settings.save()
+
+
+def get_generation_settings_ui() -> None:
+ with gr.Blocks():
+ with gr.Row():
+ with gr.Column():
+ num_inference_steps = gr.Slider(
+ 1,
+ 25,
+ value=app_settings.settings.lcm_diffusion_setting.inference_steps,
+ step=1,
+ label="Inference Steps",
+ interactive=True,
+ )
+
+ image_height = gr.Slider(
+ 256,
+ 1024,
+ value=app_settings.settings.lcm_diffusion_setting.image_height,
+ step=256,
+ label="Image Height",
+ interactive=True,
+ )
+ image_width = gr.Slider(
+ 256,
+ 1024,
+ value=app_settings.settings.lcm_diffusion_setting.image_width,
+ step=256,
+ label="Image Width",
+ interactive=True,
+ )
+ num_images = gr.Slider(
+ 1,
+ 50,
+ value=app_settings.settings.lcm_diffusion_setting.number_of_images,
+ step=1,
+ label="Number of images to generate",
+ interactive=True,
+ )
+ guidance_scale = gr.Slider(
+ 1.0,
+ 10.0,
+ value=app_settings.settings.lcm_diffusion_setting.guidance_scale,
+ step=0.1,
+ label="Guidance Scale",
+ interactive=True,
+ )
+ clip_skip = gr.Slider(
+ 1,
+ 12,
+ value=app_settings.settings.lcm_diffusion_setting.clip_skip,
+ step=1,
+ label="CLIP Skip",
+ interactive=True,
+ )
+ token_merging = gr.Slider(
+ 0.0,
+ 1.0,
+ value=app_settings.settings.lcm_diffusion_setting.token_merging,
+ step=0.01,
+ label="Token Merging",
+ interactive=True,
+ )
+
+
+ seed = gr.Slider(
+ value=app_settings.settings.lcm_diffusion_setting.seed,
+ minimum=0,
+ maximum=999999999,
+ label="Seed",
+ step=1,
+ interactive=True,
+ )
+ seed_checkbox = gr.Checkbox(
+ label="Use seed",
+ value=app_settings.settings.lcm_diffusion_setting.use_seed,
+ interactive=True,
+ )
+
+ safety_checker_checkbox = gr.Checkbox(
+ label="Use Safety Checker",
+ value=app_settings.settings.lcm_diffusion_setting.use_safety_checker,
+ interactive=True,
+ )
+ tiny_auto_encoder_checkbox = gr.Checkbox(
+ label="Use tiny auto encoder for SD",
+ value=app_settings.settings.lcm_diffusion_setting.use_tiny_auto_encoder,
+ interactive=True,
+ )
+ offline_checkbox = gr.Checkbox(
+ label="Use locally cached model or downloaded model folder(offline)",
+ value=app_settings.settings.lcm_diffusion_setting.use_offline_model,
+ interactive=True,
+ )
+ img_format = gr.Radio(
+ label="Output image format",
+ choices=["PNG", "JPEG"],
+ value=app_settings.settings.generated_images.format,
+ interactive=True,
+ )
+
+ num_inference_steps.change(on_change_inference_steps, num_inference_steps)
+ image_height.change(on_change_image_height, image_height)
+ image_width.change(on_change_image_width, image_width)
+ num_images.change(on_change_num_images, num_images)
+ guidance_scale.change(on_change_guidance_scale, guidance_scale)
+ clip_skip.change(on_change_clip_skip, clip_skip)
+ token_merging.change(on_change_token_merging, token_merging)
+ seed.change(on_change_seed_value, seed)
+ seed_checkbox.change(on_change_seed_checkbox, seed_checkbox)
+ safety_checker_checkbox.change(
+ on_change_safety_checker_checkbox, safety_checker_checkbox
+ )
+ tiny_auto_encoder_checkbox.change(
+ on_change_tiny_auto_encoder_checkbox, tiny_auto_encoder_checkbox
+ )
+ offline_checkbox.change(on_offline_checkbox, offline_checkbox)
+ img_format.change(on_change_image_format, img_format)
diff --git a/src/frontend/webui/image_to_image_ui.py b/src/frontend/webui/image_to_image_ui.py
new file mode 100644
index 0000000000000000000000000000000000000000..2d1ca9a7f7e055da17247b349154bca56d2d7c8d
--- /dev/null
+++ b/src/frontend/webui/image_to_image_ui.py
@@ -0,0 +1,120 @@
+from typing import Any
+import gradio as gr
+from backend.models.lcmdiffusion_setting import DiffusionTask
+from models.interface_types import InterfaceType
+from frontend.utils import is_reshape_required
+from constants import DEVICE
+from state import get_settings, get_context
+from concurrent.futures import ThreadPoolExecutor
+
+
+app_settings = get_settings()
+
+previous_width = 0
+previous_height = 0
+previous_model_id = ""
+previous_num_of_images = 0
+
+
+def generate_image_to_image(
+ prompt,
+ negative_prompt,
+ init_image,
+ strength,
+) -> Any:
+ context = get_context(InterfaceType.WEBUI)
+ global previous_height, previous_width, previous_model_id, previous_num_of_images, app_settings
+
+ app_settings.settings.lcm_diffusion_setting.prompt = prompt
+ app_settings.settings.lcm_diffusion_setting.negative_prompt = negative_prompt
+ app_settings.settings.lcm_diffusion_setting.init_image = init_image
+ app_settings.settings.lcm_diffusion_setting.strength = strength
+
+ app_settings.settings.lcm_diffusion_setting.diffusion_task = (
+ DiffusionTask.image_to_image.value
+ )
+ model_id = app_settings.settings.lcm_diffusion_setting.openvino_lcm_model_id
+ reshape = False
+ image_width = app_settings.settings.lcm_diffusion_setting.image_width
+ image_height = app_settings.settings.lcm_diffusion_setting.image_height
+ num_images = app_settings.settings.lcm_diffusion_setting.number_of_images
+ if app_settings.settings.lcm_diffusion_setting.use_openvino:
+ reshape = is_reshape_required(
+ previous_width,
+ image_width,
+ previous_height,
+ image_height,
+ previous_model_id,
+ model_id,
+ previous_num_of_images,
+ num_images,
+ )
+
+ with ThreadPoolExecutor(max_workers=1) as executor:
+ future = executor.submit(
+ context.generate_text_to_image,
+ app_settings.settings,
+ reshape,
+ DEVICE,
+ )
+ images = future.result()
+
+ previous_width = image_width
+ previous_height = image_height
+ previous_model_id = model_id
+ previous_num_of_images = num_images
+ return images
+
+
+def get_image_to_image_ui() -> None:
+ with gr.Blocks():
+ with gr.Row():
+ with gr.Column():
+ input_image = gr.Image(label="Init image", type="pil")
+ with gr.Row():
+ prompt = gr.Textbox(
+ show_label=False,
+ lines=3,
+ placeholder="A fantasy landscape",
+ container=False,
+ )
+
+ generate_btn = gr.Button(
+ "Generate",
+ elem_id="generate_button",
+ scale=0,
+ )
+ negative_prompt = gr.Textbox(
+ label="Negative prompt (Works in LCM-LoRA mode, set guidance > 1.0):",
+ lines=1,
+ placeholder="",
+ )
+ strength = gr.Slider(
+ 0.1,
+ 1,
+ value=app_settings.settings.lcm_diffusion_setting.strength,
+ step=0.01,
+ label="Strength",
+ )
+
+ input_params = [
+ prompt,
+ negative_prompt,
+ input_image,
+ strength,
+ ]
+
+ with gr.Column():
+ output = gr.Gallery(
+ label="Generated images",
+ show_label=True,
+ elem_id="gallery",
+ columns=2,
+ height=512,
+ )
+
+ generate_btn.click(
+ fn=generate_image_to_image,
+ inputs=input_params,
+ outputs=output,
+ )
diff --git a/src/frontend/webui/image_variations_ui.py b/src/frontend/webui/image_variations_ui.py
new file mode 100644
index 0000000000000000000000000000000000000000..215785601ffd12f3c7fd0ad3a3255503adf88c57
--- /dev/null
+++ b/src/frontend/webui/image_variations_ui.py
@@ -0,0 +1,106 @@
+from typing import Any
+import gradio as gr
+from backend.models.lcmdiffusion_setting import DiffusionTask
+from context import Context
+from models.interface_types import InterfaceType
+from frontend.utils import is_reshape_required
+from constants import DEVICE
+from state import get_settings, get_context
+from concurrent.futures import ThreadPoolExecutor
+
+app_settings = get_settings()
+
+
+previous_width = 0
+previous_height = 0
+previous_model_id = ""
+previous_num_of_images = 0
+
+
+def generate_image_variations(
+ init_image,
+ variation_strength,
+) -> Any:
+ context = get_context(InterfaceType.WEBUI)
+ global previous_height, previous_width, previous_model_id, previous_num_of_images, app_settings
+
+ app_settings.settings.lcm_diffusion_setting.init_image = init_image
+ app_settings.settings.lcm_diffusion_setting.strength = variation_strength
+ app_settings.settings.lcm_diffusion_setting.prompt = ""
+ app_settings.settings.lcm_diffusion_setting.negative_prompt = ""
+
+ app_settings.settings.lcm_diffusion_setting.diffusion_task = (
+ DiffusionTask.image_to_image.value
+ )
+ model_id = app_settings.settings.lcm_diffusion_setting.openvino_lcm_model_id
+ reshape = False
+ image_width = app_settings.settings.lcm_diffusion_setting.image_width
+ image_height = app_settings.settings.lcm_diffusion_setting.image_height
+ num_images = app_settings.settings.lcm_diffusion_setting.number_of_images
+ if app_settings.settings.lcm_diffusion_setting.use_openvino:
+ reshape = is_reshape_required(
+ previous_width,
+ image_width,
+ previous_height,
+ image_height,
+ previous_model_id,
+ model_id,
+ previous_num_of_images,
+ num_images,
+ )
+
+ with ThreadPoolExecutor(max_workers=1) as executor:
+ future = executor.submit(
+ context.generate_text_to_image,
+ app_settings.settings,
+ reshape,
+ DEVICE,
+ )
+ images = future.result()
+
+ previous_width = image_width
+ previous_height = image_height
+ previous_model_id = model_id
+ previous_num_of_images = num_images
+ return images
+
+
+def get_image_variations_ui() -> None:
+ with gr.Blocks():
+ with gr.Row():
+ with gr.Column():
+ input_image = gr.Image(label="Init image", type="pil")
+ with gr.Row():
+ generate_btn = gr.Button(
+ "Generate",
+ elem_id="generate_button",
+ scale=0,
+ )
+
+ variation_strength = gr.Slider(
+ 0.1,
+ 1,
+ value=0.4,
+ step=0.01,
+ label="Variations Strength",
+ )
+
+ input_params = [
+ input_image,
+ variation_strength,
+ ]
+
+ with gr.Column():
+ output = gr.Gallery(
+ label="Generated images",
+ show_label=True,
+ elem_id="gallery",
+ columns=2,
+ height=512,
+ )
+
+ generate_btn.click(
+ fn=generate_image_variations,
+ inputs=input_params,
+ outputs=output,
+ )
diff --git a/src/frontend/webui/lora_models_ui.py b/src/frontend/webui/lora_models_ui.py
new file mode 100644
index 0000000000000000000000000000000000000000..1a35ca653c0fb66723ac672e98c0e03c514014d6
--- /dev/null
+++ b/src/frontend/webui/lora_models_ui.py
@@ -0,0 +1,187 @@
+import gradio as gr
+from os import path
+from backend.lora import (
+ get_lora_models,
+ get_active_lora_weights,
+ update_lora_weights,
+ load_lora_weight,
+)
+from state import get_settings, get_context
+from frontend.utils import get_valid_lora_model
+from models.interface_types import InterfaceType
+from backend.models.lcmdiffusion_setting import LCMDiffusionSetting
+
+
+_MAX_LORA_WEIGHTS = 5
+
+_custom_lora_sliders = []
+_custom_lora_names = []
+_custom_lora_columns = []
+
+app_settings = get_settings()
+
+
+def on_click_update_weight(*lora_weights):
+ update_weights = []
+ active_weights = get_active_lora_weights()
+ if not len(active_weights):
+ gr.Warning("No active LoRAs, first you need to load LoRA model")
+ return
+ for idx, lora in enumerate(active_weights):
+ update_weights.append(
+ (
+ lora[0],
+ lora_weights[idx],
+ )
+ )
+ if len(update_weights) > 0:
+ update_lora_weights(
+ get_context(InterfaceType.WEBUI).lcm_text_to_image.pipeline,
+ app_settings.settings.lcm_diffusion_setting,
+ update_weights,
+ )
+
+
+def on_click_load_lora(lora_name, lora_weight):
+ if app_settings.settings.lcm_diffusion_setting.use_openvino:
+ gr.Warning("Currently LoRA is not supported in OpenVINO.")
+ return
+ lora_models_map = get_lora_models(
+ app_settings.settings.lcm_diffusion_setting.lora.models_dir
+ )
+
+ # Load a new LoRA
+ settings = app_settings.settings.lcm_diffusion_setting
+ settings.lora.fuse = False
+ settings.lora.enabled = False
+ print(f"Selected Lora Model :{lora_name}")
+ print(f"Lora weight :{lora_weight}")
+ settings.lora.path = lora_models_map[lora_name]
+ settings.lora.weight = lora_weight
+ if not path.exists(settings.lora.path):
+ gr.Warning("Invalid LoRA model path!")
+ return
+ pipeline = get_context(InterfaceType.WEBUI).lcm_text_to_image.pipeline
+ if not pipeline:
+ gr.Warning("Pipeline not initialized. Please generate an image first.")
+ return
+ settings.lora.enabled = True
+ load_lora_weight(
+ get_context(InterfaceType.WEBUI).lcm_text_to_image.pipeline,
+ settings,
+ )
+
+ # Update Gradio LoRA UI
+ global _MAX_LORA_WEIGHTS
+ values = []
+ labels = []
+ rows = []
+ active_weights = get_active_lora_weights()
+ for idx, lora in enumerate(active_weights):
+ labels.append(f"{lora[0]}: ")
+ values.append(lora[1])
+ rows.append(gr.Row.update(visible=True))
+ for i in range(len(active_weights), _MAX_LORA_WEIGHTS):
+ labels.append(f"Update weight")
+ values.append(0.0)
+ rows.append(gr.Row.update(visible=False))
+ return labels + values + rows
+
+
+def get_lora_models_ui() -> None:
+ with gr.Blocks() as ui:
+ gr.HTML(
+ "Download and place your LoRA model weights in <b>lora_models</b> folders and restart App"
+ )
+ with gr.Row():
+
+ with gr.Column():
+ with gr.Row():
+ lora_models_map = get_lora_models(
+ app_settings.settings.lcm_diffusion_setting.lora.models_dir
+ )
+ valid_model = get_valid_lora_model(
+ list(lora_models_map.values()),
+ app_settings.settings.lcm_diffusion_setting.lora.path,
+ app_settings.settings.lcm_diffusion_setting.lora.models_dir,
+ )
+ if valid_model != "":
+ valid_model_path = lora_models_map[valid_model]
+ app_settings.settings.lcm_diffusion_setting.lora.path = (
+ valid_model_path
+ )
+ else:
+ app_settings.settings.lcm_diffusion_setting.lora.path = ""
+
+ lora_model = gr.Dropdown(
+ lora_models_map.keys(),
+ label="LoRA model",
+ info="LoRA model weight to load (You can use Lora models from Civitai or Hugging Face .safetensors format)",
+ value=valid_model,
+ interactive=True,
+ )
+
+ lora_weight = gr.Slider(
+ 0.0,
+ 1.0,
+ value=app_settings.settings.lcm_diffusion_setting.lora.weight,
+ step=0.05,
+ label="Initial Lora weight",
+ interactive=True,
+ )
+ load_lora_btn = gr.Button(
+ "Load selected LoRA",
+ elem_id="load_lora_button",
+ scale=0,
+ )
+
+ with gr.Row():
+ gr.Markdown(
+ "## Loaded LoRA models",
+ show_label=False,
+ )
+ update_lora_weights_btn = gr.Button(
+ "Update LoRA weights",
+ elem_id="load_lora_button",
+ scale=0,
+ )
+
+ global _MAX_LORA_WEIGHTS
+ global _custom_lora_sliders
+ global _custom_lora_names
+ global _custom_lora_columns
+ for i in range(0, _MAX_LORA_WEIGHTS):
+ new_row = gr.Column(visible=False)
+ _custom_lora_columns.append(new_row)
+ with new_row:
+ lora_name = gr.Markdown(
+ "Lora Name",
+ show_label=True,
+ )
+ lora_slider = gr.Slider(
+ 0.0,
+ 1.0,
+ step=0.05,
+ label="LoRA weight",
+ interactive=True,
+ visible=True,
+ )
+
+ _custom_lora_names.append(lora_name)
+ _custom_lora_sliders.append(lora_slider)
+
+ load_lora_btn.click(
+ fn=on_click_load_lora,
+ inputs=[lora_model, lora_weight],
+ outputs=[
+ *_custom_lora_names,
+ *_custom_lora_sliders,
+ *_custom_lora_columns,
+ ],
+ )
+
+ update_lora_weights_btn.click(
+ fn=on_click_update_weight,
+ inputs=[*_custom_lora_sliders],
+ outputs=None,
+ )
diff --git a/src/frontend/webui/models_ui.py b/src/frontend/webui/models_ui.py
new file mode 100644
index 0000000000000000000000000000000000000000..ad6905ef6e4db82e18f280ccdd48ff8d10236b0d
--- /dev/null
+++ b/src/frontend/webui/models_ui.py
@@ -0,0 +1,182 @@
+from app_settings import AppSettings
+from typing import Any
+import gradio as gr
+from constants import LCM_DEFAULT_MODEL, LCM_DEFAULT_MODEL_OPENVINO
+from state import get_settings
+from frontend.utils import get_valid_model_id
+
+app_settings = get_settings()
+app_settings.settings.lcm_diffusion_setting.openvino_lcm_model_id = get_valid_model_id(
+ app_settings.openvino_lcm_models,
+ app_settings.settings.lcm_diffusion_setting.openvino_lcm_model_id,
+)
+
+
+def change_lcm_model_id(model_id):
+ app_settings.settings.lcm_diffusion_setting.lcm_model_id = model_id
+
+
+def change_lcm_lora_model_id(model_id):
+ app_settings.settings.lcm_diffusion_setting.lcm_lora.lcm_lora_id = model_id
+
+
+def change_lcm_lora_base_model_id(model_id):
+ app_settings.settings.lcm_diffusion_setting.lcm_lora.base_model_id = model_id
+
+
+def change_openvino_lcm_model_id(model_id):
+ app_settings.settings.lcm_diffusion_setting.openvino_lcm_model_id = model_id
+
+
+def change_gguf_diffusion_model(model_path):
+ if model_path == "None":
+ app_settings.settings.lcm_diffusion_setting.gguf_model.diffusion_path = ""
+ else:
+ app_settings.settings.lcm_diffusion_setting.gguf_model.diffusion_path = (
+ model_path
+ )
+
+
+def change_gguf_clip_model(model_path):
+ if model_path == "None":
+ app_settings.settings.lcm_diffusion_setting.gguf_model.clip_path = ""
+ else:
+ app_settings.settings.lcm_diffusion_setting.gguf_model.clip_path = model_path
+
+
+def change_gguf_t5xxl_model(model_path):
+ if model_path == "None":
+ app_settings.settings.lcm_diffusion_setting.gguf_model.t5xxl_path = ""
+ else:
+ app_settings.settings.lcm_diffusion_setting.gguf_model.t5xxl_path = model_path
+
+
+def change_gguf_vae_model(model_path):
+ if model_path == "None":
+ app_settings.settings.lcm_diffusion_setting.gguf_model.vae_path = ""
+ else:
+ app_settings.settings.lcm_diffusion_setting.gguf_model.vae_path = model_path
+
+
+def get_models_ui() -> None:
+ with gr.Blocks():
+ with gr.Row():
+ lcm_model_id = gr.Dropdown(
+ app_settings.lcm_models,
+ label="LCM model",
+ info="Diffusers LCM model ID",
+ value=get_valid_model_id(
+ app_settings.lcm_models,
+ app_settings.settings.lcm_diffusion_setting.lcm_model_id,
+ LCM_DEFAULT_MODEL,
+ ),
+ interactive=True,
+ )
+ with gr.Row():
+ lcm_lora_model_id = gr.Dropdown(
+ app_settings.lcm_lora_models,
+ label="LCM LoRA model",
+ info="Diffusers LCM LoRA model ID",
+ value=get_valid_model_id(
+ app_settings.lcm_lora_models,
+ app_settings.settings.lcm_diffusion_setting.lcm_lora.lcm_lora_id,
+ ),
+ interactive=True,
+ )
+ lcm_lora_base_model_id = gr.Dropdown(
+ app_settings.stable_diffsuion_models,
+ label="LCM LoRA base model",
+ info="Diffusers LCM LoRA base model ID",
+ value=get_valid_model_id(
+ app_settings.stable_diffsuion_models,
+ app_settings.settings.lcm_diffusion_setting.lcm_lora.base_model_id,
+ ),
+ interactive=True,
+ )
+ with gr.Row():
+ lcm_openvino_model_id = gr.Dropdown(
+ app_settings.openvino_lcm_models,
+ label="LCM OpenVINO model",
+ info="OpenVINO LCM-LoRA fused model ID",
+ value=get_valid_model_id(
+ app_settings.openvino_lcm_models,
+ app_settings.settings.lcm_diffusion_setting.openvino_lcm_model_id,
+ ),
+ interactive=True,
+ )
+ with gr.Row():
+ gguf_diffusion_model_id = gr.Dropdown(
+ app_settings.gguf_diffusion_models,
+ label="GGUF diffusion model",
+ info="GGUF diffusion model ",
+ value=get_valid_model_id(
+ app_settings.gguf_diffusion_models,
+ app_settings.settings.lcm_diffusion_setting.gguf_model.diffusion_path,
+ ),
+ interactive=True,
+ )
+ with gr.Row():
+ gguf_clip_model_id = gr.Dropdown(
+ app_settings.gguf_clip_models,
+ label="GGUF CLIP model",
+ info="GGUF CLIP model ",
+ value=get_valid_model_id(
+ app_settings.gguf_clip_models,
+ app_settings.settings.lcm_diffusion_setting.gguf_model.clip_path,
+ ),
+ interactive=True,
+ )
+ gguf_t5xxl_model_id = gr.Dropdown(
+ app_settings.gguf_t5xxl_models,
+ label="GGUF T5-XXL model",
+ info="GGUF T5-XXL model ",
+ value=get_valid_model_id(
+ app_settings.gguf_t5xxl_models,
+ app_settings.settings.lcm_diffusion_setting.gguf_model.t5xxl_path,
+ ),
+ interactive=True,
+ )
+ with gr.Row():
+ gguf_vae_model_id = gr.Dropdown(
+ app_settings.gguf_vae_models,
+ label="GGUF VAE model",
+ info="GGUF VAE model ",
+ value=get_valid_model_id(
+ app_settings.gguf_vae_models,
+ app_settings.settings.lcm_diffusion_setting.gguf_model.vae_path,
+ ),
+ interactive=True,
+ )
+
+ lcm_model_id.change(
+ change_lcm_model_id,
+ lcm_model_id,
+ )
+ lcm_lora_model_id.change(
+ change_lcm_lora_model_id,
+ lcm_lora_model_id,
+ )
+ lcm_lora_base_model_id.change(
+ change_lcm_lora_base_model_id,
+ lcm_lora_base_model_id,
+ )
+ lcm_openvino_model_id.change(
+ change_openvino_lcm_model_id,
+ lcm_openvino_model_id,
+ )
+ gguf_diffusion_model_id.change(
+ change_gguf_diffusion_model,
+ gguf_diffusion_model_id,
+ )
+ gguf_clip_model_id.change(
+ change_gguf_clip_model,
+ gguf_clip_model_id,
+ )
+ gguf_t5xxl_model_id.change(
+ change_gguf_t5xxl_model,
+ gguf_t5xxl_model_id,
+ )
+ gguf_vae_model_id.change(
+ change_gguf_vae_model,
+ gguf_vae_model_id,
+ )
diff --git a/src/frontend/webui/realtime_ui.py b/src/frontend/webui/realtime_ui.py
new file mode 100644
index 0000000000000000000000000000000000000000..5a84fdc2b5b72d9c0a187627e10351d411a40621
--- /dev/null
+++ b/src/frontend/webui/realtime_ui.py
@@ -0,0 +1,147 @@
+import base64
+from datetime import datetime
+from time import perf_counter
+
+import gradio as gr
+import numpy as np
+from backend.device import get_device_name, is_openvino_device
+from backend.lcm_text_to_image import LCMTextToImage
+from backend.models.lcmdiffusion_setting import LCMDiffusionSetting, LCMLora
+from constants import APP_VERSION, DEVICE, LCM_DEFAULT_MODEL_OPENVINO
+from cv2 import imencode
+
+lcm_text_to_image = LCMTextToImage()
+lcm_lora = LCMLora(
+ base_model_id="Lykon/dreamshaper-8",
+ lcm_lora_id="latent-consistency/lcm-lora-sdv1-5",
+)
+
+
+# https://github.com/gradio-app/gradio/issues/2635#issuecomment-1423531319
+def encode_pil_to_base64_new(pil_image):
+ image_arr = np.asarray(pil_image)[:, :, ::-1]
+ _, byte_data = imencode(".png", image_arr)
+ base64_data = base64.b64encode(byte_data)
+ base64_string_opencv = base64_data.decode("utf-8")
+ return "data:image/png;base64," + base64_string_opencv
+
+
+# monkey patching encode pil
+gr.processing_utils.encode_pil_to_base64 = encode_pil_to_base64_new
+
+
+def predict(
+ prompt,
+ steps,
+ seed,
+):
+ lcm_diffusion_setting = LCMDiffusionSetting()
+ lcm_diffusion_setting.openvino_lcm_model_id = "rupeshs/sdxs-512-0.9-openvino"
+ lcm_diffusion_setting.prompt = prompt
+ lcm_diffusion_setting.guidance_scale = 1.0
+ lcm_diffusion_setting.inference_steps = steps
+ lcm_diffusion_setting.seed = seed
+ lcm_diffusion_setting.use_seed = True
+ lcm_diffusion_setting.image_width = 512
+ lcm_diffusion_setting.image_height = 512
+ lcm_diffusion_setting.use_openvino = True if is_openvino_device() else False
+ lcm_diffusion_setting.use_tiny_auto_encoder = True
+ lcm_text_to_image.init(
+ DEVICE,
+ lcm_diffusion_setting,
+ )
+ start = perf_counter()
+
+ images = lcm_text_to_image.generate(lcm_diffusion_setting)
+ latency = perf_counter() - start
+ print(f"Latency: {latency:.2f} seconds")
+ return images[0]
+
+
+css = """
+#container{
+ margin: 0 auto;
+ max-width: 40rem;
+}
+#intro{
+ max-width: 100%;
+ text-align: center;
+ margin: 0 auto;
+}
+#generate_button {
+ color: white;
+ border-color: #007bff;
+ background: #007bff;
+ width: 200px;
+ height: 50px;
+}
+footer {
+ visibility: hidden
+}
+"""
+
+
+def _get_footer_message() -> str:
+ version = f"<center><p> {APP_VERSION} "
+ current_year = datetime.now().year
+ footer_msg = version + (
+ f' © 2023 - {current_year} <a href="https://github.com/rupeshs">'
+ " Rupesh Sreeraman</a></p></center>"
+ )
+ return footer_msg
+
+
+with gr.Blocks(css=css) as demo:
+ with gr.Column(elem_id="container"):
+ use_openvino = "- OpenVINO" if is_openvino_device() else ""
+ gr.Markdown(
+ f"""# Realtime FastSD CPU {use_openvino}
+ **Device : {DEVICE} , {get_device_name()}**
+ """,
+ elem_id="intro",
+ )
+
+ with gr.Row():
+ with gr.Row():
+ prompt = gr.Textbox(
+ placeholder="Describe the image you'd like to see",
+ scale=5,
+ container=False,
+ )
+ generate_btn = gr.Button(
+ "Generate",
+ scale=1,
+ elem_id="generate_button",
+ )
+
+ image = gr.Image(type="filepath")
+
+ steps = gr.Slider(
+ label="Steps",
+ value=1,
+ minimum=1,
+ maximum=6,
+ step=1,
+ visible=False,
+ )
+ seed = gr.Slider(
+ randomize=True,
+ minimum=0,
+ maximum=999999999,
+ label="Seed",
+ step=1,
+ )
+ gr.HTML(_get_footer_message())
+
+ inputs = [prompt, steps, seed]
+ prompt.input(fn=predict, inputs=inputs, outputs=image, show_progress=False)
+ generate_btn.click(
+ fn=predict, inputs=inputs, outputs=image, show_progress=False
+ )
+ steps.change(fn=predict, inputs=inputs, outputs=image, show_progress=False)
+ seed.change(fn=predict, inputs=inputs, outputs=image, show_progress=False)
+
+
+def start_realtime_text_to_image(share=False):
+ demo.queue()
+ demo.launch(share=share)
diff --git a/src/frontend/webui/text_to_image_ui.py b/src/frontend/webui/text_to_image_ui.py
new file mode 100644
index 0000000000000000000000000000000000000000..5ec517dcff55cc3f40088ea21788fbe113dda0b0
--- /dev/null
+++ b/src/frontend/webui/text_to_image_ui.py
@@ -0,0 +1,100 @@
+import gradio as gr
+from typing import Any
+from backend.models.lcmdiffusion_setting import DiffusionTask
+from models.interface_types import InterfaceType
+from constants import DEVICE
+from state import get_settings, get_context
+from frontend.utils import is_reshape_required
+from concurrent.futures import ThreadPoolExecutor
+from pprint import pprint
+
+app_settings = get_settings()
+
+previous_width = 0
+previous_height = 0
+previous_model_id = ""
+previous_num_of_images = 0
+
+
+def generate_text_to_image(
+ prompt,
+ neg_prompt,
+) -> Any:
+ context = get_context(InterfaceType.WEBUI)
+ global previous_height, previous_width, previous_model_id, previous_num_of_images, app_settings
+ app_settings.settings.lcm_diffusion_setting.prompt = prompt
+ app_settings.settings.lcm_diffusion_setting.negative_prompt = neg_prompt
+ app_settings.settings.lcm_diffusion_setting.diffusion_task = (
+ DiffusionTask.text_to_image.value
+ )
+ model_id = app_settings.settings.lcm_diffusion_setting.openvino_lcm_model_id
+ reshape = False
+ image_width = app_settings.settings.lcm_diffusion_setting.image_width
+ image_height = app_settings.settings.lcm_diffusion_setting.image_height
+ num_images = app_settings.settings.lcm_diffusion_setting.number_of_images
+ if app_settings.settings.lcm_diffusion_setting.use_openvino:
+ reshape = is_reshape_required(
+ previous_width,
+ image_width,
+ previous_height,
+ image_height,
+ previous_model_id,
+ model_id,
+ previous_num_of_images,
+ num_images,
+ )
+
+ with ThreadPoolExecutor(max_workers=1) as executor:
+ future = executor.submit(
+ context.generate_text_to_image,
+ app_settings.settings,
+ reshape,
+ DEVICE,
+ )
+ images = future.result()
+
+ previous_width = image_width
+ previous_height = image_height
+ previous_model_id = model_id
+ previous_num_of_images = num_images
+ return images
+
+
+def get_text_to_image_ui() -> None:
+ with gr.Blocks():
+ with gr.Row():
+ with gr.Column():
+ with gr.Row():
+ prompt = gr.Textbox(
+ show_label=False,
+ lines=3,
+ placeholder="A fantasy landscape",
+ container=False,
+ )
+
+ generate_btn = gr.Button(
+ "Generate",
+ elem_id="generate_button",
+ scale=0,
+ )
+ negative_prompt = gr.Textbox(
+ label="Negative prompt (Works in LCM-LoRA mode, set guidance > 1.0) :",
+ lines=1,
+ placeholder="",
+ )
+
+ input_params = [prompt, negative_prompt]
+
+ with gr.Column():
+ output = gr.Gallery(
+ label="Generated images",
+ show_label=True,
+ elem_id="gallery",
+ columns=2,
+ height=512,
+ )
+ generate_btn.click(
+ fn=generate_text_to_image,
+ inputs=input_params,
+ outputs=output,
+ )
diff --git a/src/frontend/webui/ui.py b/src/frontend/webui/ui.py
new file mode 100644
index 0000000000000000000000000000000000000000..25c1dce5575cefcf07e3e1279054f10d35d99ed9
--- /dev/null
+++ b/src/frontend/webui/ui.py
@@ -0,0 +1,105 @@
+from datetime import datetime
+
+import gradio as gr
+from backend.device import get_device_name
+from constants import APP_VERSION
+from frontend.webui.controlnet_ui import get_controlnet_ui
+from frontend.webui.generation_settings_ui import get_generation_settings_ui
+from frontend.webui.image_to_image_ui import get_image_to_image_ui
+from frontend.webui.image_variations_ui import get_image_variations_ui
+from frontend.webui.lora_models_ui import get_lora_models_ui
+from frontend.webui.models_ui import get_models_ui
+from frontend.webui.text_to_image_ui import get_text_to_image_ui
+from frontend.webui.upscaler_ui import get_upscaler_ui
+from state import get_settings
+
+app_settings = get_settings()
+
+
+def _get_footer_message() -> str:
+ version = f"<center><p> {APP_VERSION} "
+ current_year = datetime.now().year
+ footer_msg = version + (
+ f' © 2023 - {current_year} <a href="https://github.com/rupeshs">'
+ " Rupesh Sreeraman</a></p></center>"
+ )
+ return footer_msg
+
+
+def get_web_ui() -> gr.Blocks:
+ def change_mode(mode):
+ global app_settings
+ app_settings.settings.lcm_diffusion_setting.use_lcm_lora = False
+ app_settings.settings.lcm_diffusion_setting.use_openvino = False
+ app_settings.settings.lcm_diffusion_setting.use_gguf_model = False
+ if mode == "LCM-LoRA":
+ app_settings.settings.lcm_diffusion_setting.use_lcm_lora = True
+ elif mode == "LCM-OpenVINO":
+ app_settings.settings.lcm_diffusion_setting.use_openvino = True
+ elif mode == "GGUF":
+ app_settings.settings.lcm_diffusion_setting.use_gguf_model = True
+
+ # Prevent saved LoRA and ControlNet settings from being used by
+ # default; in WebUI mode, the user must explicitly enable those
+ if app_settings.settings.lcm_diffusion_setting.lora:
+ app_settings.settings.lcm_diffusion_setting.lora.enabled = False
+ if app_settings.settings.lcm_diffusion_setting.controlnet:
+ app_settings.settings.lcm_diffusion_setting.controlnet.enabled = False
+ theme = gr.themes.Default(
+ primary_hue="blue",
+ )
+ with gr.Blocks(
+ title="FastSD CPU",
+ theme=theme,
+ css="footer {visibility: hidden}",
+ ) as fastsd_web_ui:
+ gr.HTML("<center><H1>FastSD CPU</H1></center>")
+ gr.Markdown(
+ f"**Processor : {get_device_name()}**",
+ elem_id="processor",
+ )
+ current_mode = "LCM"
+ if app_settings.settings.lcm_diffusion_setting.use_openvino:
+ current_mode = "LCM-OpenVINO"
+ elif app_settings.settings.lcm_diffusion_setting.use_lcm_lora:
+ current_mode = "LCM-LoRA"
+ elif app_settings.settings.lcm_diffusion_setting.use_gguf_model:
+ current_mode = "GGUF"
+
+ mode = gr.Radio(
+ ["LCM", "LCM-LoRA", "LCM-OpenVINO", "GGUF"],
+ label="Mode",
+ info="Current working mode",
+ value=current_mode,
+ )
+ mode.change(change_mode, inputs=mode)
+
+ with gr.Tabs():
+ with gr.TabItem("Text to Image"):
+ get_text_to_image_ui()
+ with gr.TabItem("Image to Image"):
+ get_image_to_image_ui()
+ with gr.TabItem("Image Variations"):
+ get_image_variations_ui()
+ with gr.TabItem("Upscaler"):
+ get_upscaler_ui()
+ with gr.TabItem("Generation Settings"):
+ get_generation_settings_ui()
+ with gr.TabItem("Models"):
+ get_models_ui()
+ with gr.TabItem("Lora Models"):
+ get_lora_models_ui()
+ with gr.TabItem("ControlNet"):
+ get_controlnet_ui()
+
+ gr.HTML(_get_footer_message())
+
+ return fastsd_web_ui
+
+
+def start_webui(
+ share: bool = False,
+):
+ webui = get_web_ui()
+ webui.queue()
+ webui.launch(share=share)
diff --git a/src/frontend/webui/upscaler_ui.py b/src/frontend/webui/upscaler_ui.py
new file mode 100644
index 0000000000000000000000000000000000000000..bb44f5dcdbfd4eb3369775e9aeaa9413cb4302dc
--- /dev/null
+++ b/src/frontend/webui/upscaler_ui.py
@@ -0,0 +1,84 @@
+from typing import Any
+import gradio as gr
+from models.interface_types import InterfaceType
+from state import get_settings, get_context
+from backend.upscale.upscaler import upscale_image
+from backend.models.upscale import UpscaleMode
+from paths import FastStableDiffusionPaths, join_paths
+from time import time
+
+app_settings = get_settings()
+
+
+previous_width = 0
+previous_height = 0
+previous_model_id = ""
+previous_num_of_images = 0
+
+
+def create_upscaled_image(
+ source_image,
+ upscale_mode,
+) -> Any:
+ context = get_context(InterfaceType.WEBUI)
+ scale_factor = 2
+ if upscale_mode == "SD":
+ mode = UpscaleMode.sd_upscale.value
+ elif upscale_mode == "AURA-SR":
+ mode = UpscaleMode.aura_sr.value
+ scale_factor = 4
+ else:
+ mode = UpscaleMode.normal.value
+
+ upscaled_filepath = FastStableDiffusionPaths.get_upscale_filepath(
+ None,
+ scale_factor,
+ app_settings.settings.generated_images.format,
+ )
+ image = upscale_image(
+ context=context,
+ src_image_path=source_image,
+ dst_image_path=upscaled_filepath,
+ upscale_mode=mode,
+ )
+ return image
+
+
+def get_upscaler_ui() -> None:
+ with gr.Blocks():
+ with gr.Row():
+ with gr.Column():
+ input_image = gr.Image(label="Image", type="filepath")
+ with gr.Row():
+ upscale_mode = gr.Radio(
+ ["EDSR", "SD", "AURA-SR"],
+ label="Upscale Mode (2x) | AURA-SR v2 (4x)",
+ info="Select upscale method(For SD Scale GGUF mode is not supported)",
+ value="EDSR",
+ )
+
+ generate_btn = gr.Button(
+ "Upscale",
+ elem_id="generate_button",
+ scale=0,
+ )
+
+ input_params = [
+ input_image,
+ upscale_mode,
+ ]
+
+ with gr.Column():
+ output = gr.Gallery(
+ label="Generated images",
+ show_label=True,
+ elem_id="gallery",
+ columns=2,
+ height=512,
+ )
+
+ generate_btn.click(
+ fn=create_upscaled_image,
+ inputs=input_params,
+ outputs=output,
+ )
diff --git a/src/image_ops.py b/src/image_ops.py
new file mode 100644
index 0000000000000000000000000000000000000000..b60e911d37616bf29592b15fca9901f404a6e397
--- /dev/null
+++ b/src/image_ops.py
@@ -0,0 +1,15 @@
+from PIL import Image
+
+
+def resize_pil_image(
+ pil_image: Image,
+ image_width,
+ image_height,
+):
+ return pil_image.convert("RGB").resize(
+ (
+ image_width,
+ image_height,
+ ),
+ Image.Resampling.LANCZOS,
+ )
diff --git a/src/models/interface_types.py b/src/models/interface_types.py
new file mode 100644
index 0000000000000000000000000000000000000000..00f5c0a35fd3cc1f733edc2763e64781e2b7b6a9
--- /dev/null
+++ b/src/models/interface_types.py
@@ -0,0 +1,8 @@
+from enum import Enum
+
+
+class InterfaceType(Enum):
+ WEBUI = "Web User Interface"
+ GUI = "Graphical User Interface"
+ CLI = "Command Line Interface"
+ API_SERVER = "API Server"
diff --git a/src/models/settings.py b/src/models/settings.py
new file mode 100644
index 0000000000000000000000000000000000000000..afa1650fb5dab9dcef5645ac4aaf184939e8ae49
--- /dev/null
+++ b/src/models/settings.py
@@ -0,0 +1,8 @@
+from pydantic import BaseModel
+from backend.models.lcmdiffusion_setting import LCMDiffusionSetting, LCMLora
+from backend.models.gen_images import GeneratedImages
+
+
+class Settings(BaseModel):
+ lcm_diffusion_setting: LCMDiffusionSetting = LCMDiffusionSetting(lcm_lora=LCMLora())
+ generated_images: GeneratedImages = GeneratedImages()
diff --git a/src/paths.py b/src/paths.py
new file mode 100644
index 0000000000000000000000000000000000000000..67ded9d189516eaf2ae643186a643f24f26efd37
--- /dev/null
+++ b/src/paths.py
@@ -0,0 +1,104 @@
+import os
+import constants
+from pathlib import Path
+from time import time
+from utils import get_image_file_extension
+
+
+def join_paths(
+ first_path: str,
+ second_path: str,
+) -> str:
+ return os.path.join(first_path, second_path)
+
+
+def get_file_name(file_path: str) -> str:
+ return Path(file_path).stem
+
+
+def get_app_path() -> str:
+ app_dir = os.path.dirname(__file__)
+ work_dir = os.path.dirname(app_dir)
+ return work_dir
+
+
+def get_configs_path() -> str:
+ config_path = join_paths(get_app_path(), constants.CONFIG_DIRECTORY)
+ return config_path
+
+
+class FastStableDiffusionPaths:
+ @staticmethod
+ def get_app_settings_path() -> str:
+ configs_path = get_configs_path()
+ settings_path = join_paths(
+ configs_path,
+ constants.APP_SETTINGS_FILE,
+ )
+ return settings_path
+
+ @staticmethod
+ def get_results_path() -> str:
+ results_path = join_paths(get_app_path(), constants.RESULTS_DIRECTORY)
+ return results_path
+
+ @staticmethod
+ def get_css_path() -> str:
+ app_dir = os.path.dirname(__file__)
+ css_path = os.path.join(
+ app_dir,
+ "frontend",
+ "webui",
+ "css",
+ "style.css",
+ )
+ return css_path
+
+ @staticmethod
+ def get_models_config_path(model_config_file: str) -> str:
+ configs_path = get_configs_path()
+ models_path = join_paths(
+ configs_path,
+ model_config_file,
+ )
+ return models_path
+
+ @staticmethod
+ def get_upscale_filepath(
+ file_path_src: str,
+ scale_factor: int,
+ format: str,
+ ) -> str:
+ if file_path_src:
+ file_name_src = get_file_name(file_path_src)
+ else:
+ file_name_src = "fastsdcpu"
+
+ extension = get_image_file_extension(format)
+ upscaled_filepath = join_paths(
+ FastStableDiffusionPaths.get_results_path(),
+ f"{file_name_src}_{int(scale_factor)}x_upscale_{int(time())}{extension}",
+ )
+ return upscaled_filepath
+
+ @staticmethod
+ def get_lora_models_path() -> str:
+ lora_models_path = join_paths(get_app_path(), constants.LORA_DIRECTORY)
+ return lora_models_path
+
+ @staticmethod
+ def get_controlnet_models_path() -> str:
+ controlnet_models_path = join_paths(
+ get_app_path(), constants.CONTROLNET_DIRECTORY
+ )
+ return controlnet_models_path
+
+ @staticmethod
+ def get_gguf_models_path() -> str:
+ models_path = join_paths(get_app_path(), constants.MODELS_DIRECTORY)
+ guuf_models_path = join_paths(models_path, "gguf")
+ return guuf_models_path
+
+
+def get_base_folder_name(path: str) -> str:
+ return os.path.basename(path)
diff --git a/src/state.py b/src/state.py
new file mode 100644
index 0000000000000000000000000000000000000000..6c0c4d5599c192840646f8d655cc16e4fbb8c6b2
--- /dev/null
+++ b/src/state.py
@@ -0,0 +1,32 @@
+from app_settings import AppSettings
+from typing import Optional
+
+from context import Context
+from models.interface_types import InterfaceType
+
+
+class _AppState:
+ _instance: Optional["_AppState"] = None
+ settings: Optional[AppSettings] = None
+ context: Optional[Context] = None
+
+
+def get_state() -> _AppState:
+ if _AppState._instance is None:
+ _AppState._instance = _AppState()
+ return _AppState._instance
+
+
+def get_settings(skip_file: bool = False) -> AppSettings:
+ state = get_state()
+ if state.settings is None:
+ state.settings = AppSettings()
+ state.settings.load(skip_file)
+ return state.settings
+
+
+def get_context(interface_type: InterfaceType) -> Context:
+ state = get_state()
+ if state.context is None:
+ state.context = Context(interface_type)
+ return state.context
diff --git a/src/utils.py b/src/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..a6d2d9bcb0840905089c22f682694ea567233572
--- /dev/null
+++ b/src/utils.py
@@ -0,0 +1,38 @@
+from os import path, listdir
+import platform
+from typing import List
+
+
+def show_system_info():
+ try:
+ print(f"Running on {platform.system()} platform")
+ print(f"OS: {platform.platform()}")
+ print(f"Processor: {platform.processor()}")
+ except Exception as ex:
+ print(f"Error occurred while getting system information {ex}")
+
+
+def get_models_from_text_file(file_path: str) -> List:
+ models = []
+ with open(file_path, "r") as file:
+ lines = file.readlines()
+ for repo_id in lines:
+ if repo_id.strip() != "":
+ models.append(repo_id.strip())
+ return models
+
+
+def get_image_file_extension(image_format: str) -> str:
+ if image_format == "JPEG":
+ return ".jpg"
+ elif image_format == "PNG":
+ return ".png"
+
+
+def get_files_in_dir(root_dir: str) -> List:
+ models = []
+ models.append("None")
+ for file in listdir(root_dir):
+ if file.endswith((".gguf", ".safetensors")):
+ models.append(path.join(root_dir, file))
+ return models
diff --git a/start-realtime.bat b/start-realtime.bat
new file mode 100644
index 0000000000000000000000000000000000000000..060268beb597047e9ac2b08d9c6c3eaadf7d90a8
--- /dev/null
+++ b/start-realtime.bat
@@ -0,0 +1,25 @@
+@echo off
+setlocal
+echo Starting fastsdcpu...
+
+set "PYTHON_COMMAND=python"
+
+call python --version > nul 2>&1
+if %errorlevel% equ 0 (
+ echo Python command check :OK
+) else (
+ echo "Error: Python command not found, please install Python (Recommended : Python 3.10 or Python 3.11) and try again"
+ pause
+ exit /b 1
+
+)
+
+:check_python_version
+for /f "tokens=2" %%I in ('%PYTHON_COMMAND% --version 2^>^&1') do (
+ set "python_version=%%I"
+)
+
+echo Python version: %python_version%
+
+set PATH=%PATH%;%~dp0env\Lib\site-packages\openvino\libs
+call "%~dp0env\Scripts\activate.bat" && %PYTHON_COMMAND% "%~dp0\src\app.py" --r
\ No newline at end of file
diff --git a/start-webserver.bat b/start-webserver.bat
new file mode 100644
index 0000000000000000000000000000000000000000..2228ee0dcb06da315c94fba9deb7589a9725df51
--- /dev/null
+++ b/start-webserver.bat
@@ -0,0 +1,25 @@
+@echo off
+setlocal
+echo Starting fastsdcpu...
+
+set "PYTHON_COMMAND=python"
+
+call python --version > nul 2>&1
+if %errorlevel% equ 0 (
+ echo Python command check :OK
+) else (
+ echo "Error: Python command not found, please install Python (Recommended : Python 3.10 or Python 3.11) and try again"
+ pause
+ exit /b 1
+
+)
+
+:check_python_version
+for /f "tokens=2" %%I in ('%PYTHON_COMMAND% --version 2^>^&1') do (
+ set "python_version=%%I"
+)
+
+echo Python version: %python_version%
+
+set PATH=%PATH%;%~dp0env\Lib\site-packages\openvino\libs
+call "%~dp0env\Scripts\activate.bat" && %PYTHON_COMMAND% "%~dp0\src\app.py" --api
\ No newline at end of file
diff --git a/start-webserver.sh b/start-webserver.sh
new file mode 100644
index 0000000000000000000000000000000000000000..29b40572df75d26f0c9f7aafbe5862990b60fc24
--- /dev/null
+++ b/start-webserver.sh
@@ -0,0 +1,25 @@
+#!/usr/bin/env bash
+echo Starting FastSD CPU please wait...
+set -e
+PYTHON_COMMAND="python3"
+
+if ! command -v python3 &>/dev/null; then
+ if ! command -v python &>/dev/null; then
+ echo "Error: Python not found, please install python 3.8 or higher and try again"
+ exit 1
+ fi
+fi
+
+if command -v python &>/dev/null; then
+ PYTHON_COMMAND="python"
+fi
+
+echo "Found $PYTHON_COMMAND command"
+
+python_version=$($PYTHON_COMMAND --version 2>&1 | awk '{print $2}')
+echo "Python version : $python_version"
+
+BASEDIR=$(pwd)
+# shellcheck disable=SC1091
+source "$BASEDIR/env/bin/activate"
+$PYTHON_COMMAND src/app.py --api
\ No newline at end of file
diff --git a/start-webui.bat b/start-webui.bat
new file mode 100644
index 0000000000000000000000000000000000000000..7db54c43784924ab96e45a885c793ec408274110
--- /dev/null
+++ b/start-webui.bat
@@ -0,0 +1,25 @@
+@echo off
+setlocal
+echo Starting fastsdcpu...
+
+set "PYTHON_COMMAND=python"
+
+call python --version > nul 2>&1
+if %errorlevel% equ 0 (
+ echo Python command check :OK
+) else (
+ echo "Error: Python command not found, please install Python (Recommended : Python 3.10 or Python 3.11) and try again"
+ pause
+ exit /b 1
+
+)
+
+:check_python_version
+for /f "tokens=2" %%I in ('%PYTHON_COMMAND% --version 2^>^&1') do (
+ set "python_version=%%I"
+)
+
+echo Python version: %python_version%
+
+set PATH=%PATH%;%~dp0env\Lib\site-packages\openvino\libs
+call "%~dp0env\Scripts\activate.bat" && %PYTHON_COMMAND% "%~dp0\src\app.py" -w
\ No newline at end of file
diff --git a/start-webui.sh b/start-webui.sh
new file mode 100644
index 0000000000000000000000000000000000000000..758cdfd1f9da69b68dabfd1c013baa5ac82eafd3
--- /dev/null
+++ b/start-webui.sh
@@ -0,0 +1,25 @@
+#!/usr/bin/env bash
+echo Starting FastSD CPU please wait...
+set -e
+PYTHON_COMMAND="python3"
+
+if ! command -v python3 &>/dev/null; then
+ if ! command -v python &>/dev/null; then
+ echo "Error: Python not found, please install python 3.8 or higher and try again"
+ exit 1
+ fi
+fi
+
+if command -v python &>/dev/null; then
+ PYTHON_COMMAND="python"
+fi
+
+echo "Found $PYTHON_COMMAND command"
+
+python_version=$($PYTHON_COMMAND --version 2>&1 | awk '{print $2}')
+echo "Python version : $python_version"
+
+BASEDIR=$(pwd)
+# shellcheck disable=SC1091
+source "$BASEDIR/env/bin/activate"
+$PYTHON_COMMAND src/app.py -w
\ No newline at end of file
diff --git a/start.bat b/start.bat
new file mode 100644
index 0000000000000000000000000000000000000000..886f7c27c48b5d365ee2229b399b98fcb16ddb76
--- /dev/null
+++ b/start.bat
@@ -0,0 +1,25 @@
+@echo off
+setlocal
+echo Starting fastsdcpu...
+
+set "PYTHON_COMMAND=python"
+
+call python --version > nul 2>&1
+if %errorlevel% equ 0 (
+ echo Python command check :OK
+) else (
+ echo "Error: Python command not found, please install Python (Recommended : Python 3.10 or Python 3.11) and try again"
+ pause
+ exit /b 1
+
+)
+
+:check_python_version
+for /f "tokens=2" %%I in ('%PYTHON_COMMAND% --version 2^>^&1') do (
+ set "python_version=%%I"
+)
+
+echo Python version: %python_version%
+
+set PATH=%PATH%;%~dp0env\Lib\site-packages\openvino\libs
+call "%~dp0env\Scripts\activate.bat" && %PYTHON_COMMAND% "%~dp0\src\app.py" --gui
\ No newline at end of file
diff --git a/start.sh b/start.sh
new file mode 100644
index 0000000000000000000000000000000000000000..d35cbc7ec2474e096b32ea6d6a0c24343dc61f6b
--- /dev/null
+++ b/start.sh
@@ -0,0 +1,25 @@
+#!/usr/bin/env bash
+echo Starting FastSD CPU please wait...
+set -e
+PYTHON_COMMAND="python3"
+
+if ! command -v python3 &>/dev/null; then
+ if ! command -v python &>/dev/null; then
+ echo "Error: Python not found, please install python 3.8 or higher and try again"
+ exit 1
+ fi
+fi
+
+if command -v python &>/dev/null; then
+ PYTHON_COMMAND="python"
+fi
+
+echo "Found $PYTHON_COMMAND command"
+
+python_version=$($PYTHON_COMMAND --version 2>&1 | awk '{print $2}')
+echo "Python version : $python_version"
+
+BASEDIR=$(pwd)
+# shellcheck disable=SC1091
+source "$BASEDIR/env/bin/activate"
+$PYTHON_COMMAND src/app.py --gui
\ No newline at end of file