Spaces:
Running

Running
Commit
·
0e78cbf
1
Parent(s):
bab4b66
adding CV agent file
Browse files- .gitignore +164 -0
- QA_bot.py +57 -0
- app.py +169 -0
- extract_tools.py +254 -0
- final_mask.png +0 -0
- hub_prompts.py +79 -0
- llm_service.py +60 -0
- requirements.txt +17 -0
- tool_utils/clip_segmentation.py +55 -0
- tool_utils/image_metadata.py +43 -0
- tool_utils/mask2former.py +102 -0
- tool_utils/object_extractor.py +24 -0
- tool_utils/yolo_world.py +30 -0
- utils.py +26 -0
.gitignore
ADDED
|
@@ -0,0 +1,164 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Byte-compiled / optimized / DLL files
|
| 2 |
+
__pycache__/
|
| 3 |
+
*.py[cod]
|
| 4 |
+
*$py.class
|
| 5 |
+
|
| 6 |
+
# C extensions
|
| 7 |
+
*.so
|
| 8 |
+
Data/
|
| 9 |
+
# Distribution / packaging
|
| 10 |
+
.Python
|
| 11 |
+
build/
|
| 12 |
+
develop-eggs/
|
| 13 |
+
dist/
|
| 14 |
+
downloads/
|
| 15 |
+
eggs/
|
| 16 |
+
.eggs/
|
| 17 |
+
lib/
|
| 18 |
+
lib64/
|
| 19 |
+
parts/
|
| 20 |
+
sdist/
|
| 21 |
+
var/
|
| 22 |
+
wheels/
|
| 23 |
+
share/python-wheels/
|
| 24 |
+
*.egg-info/
|
| 25 |
+
.installed.cfg
|
| 26 |
+
*.egg
|
| 27 |
+
MANIFEST
|
| 28 |
+
|
| 29 |
+
# PyInstaller
|
| 30 |
+
# Usually these files are written by a python script from a template
|
| 31 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 32 |
+
*.manifest
|
| 33 |
+
*.spec
|
| 34 |
+
|
| 35 |
+
# Installer logs
|
| 36 |
+
pip-log.txt
|
| 37 |
+
pip-delete-this-directory.txt
|
| 38 |
+
|
| 39 |
+
# Unit test / coverage reports
|
| 40 |
+
htmlcov/
|
| 41 |
+
.tox/
|
| 42 |
+
.nox/
|
| 43 |
+
.coverage
|
| 44 |
+
.coverage.*
|
| 45 |
+
.cache
|
| 46 |
+
nosetests.xml
|
| 47 |
+
coverage.xml
|
| 48 |
+
*.cover
|
| 49 |
+
*.py,cover
|
| 50 |
+
.hypothesis/
|
| 51 |
+
.pytest_cache/
|
| 52 |
+
cover/
|
| 53 |
+
|
| 54 |
+
# Translations
|
| 55 |
+
*.mo
|
| 56 |
+
*.pot
|
| 57 |
+
|
| 58 |
+
# Django stuff:
|
| 59 |
+
*.log
|
| 60 |
+
local_settings.py
|
| 61 |
+
db.sqlite3
|
| 62 |
+
db.sqlite3-journal
|
| 63 |
+
|
| 64 |
+
# Flask stuff:
|
| 65 |
+
instance/
|
| 66 |
+
.webassets-cache
|
| 67 |
+
|
| 68 |
+
# Scrapy stuff:
|
| 69 |
+
.scrapy
|
| 70 |
+
|
| 71 |
+
# Sphinx documentation
|
| 72 |
+
docs/_build/
|
| 73 |
+
|
| 74 |
+
# PyBuilder
|
| 75 |
+
.pybuilder/
|
| 76 |
+
target/
|
| 77 |
+
|
| 78 |
+
# Jupyter Notebook
|
| 79 |
+
.ipynb_checkpoints
|
| 80 |
+
|
| 81 |
+
# IPython
|
| 82 |
+
profile_default/
|
| 83 |
+
ipython_config.py
|
| 84 |
+
|
| 85 |
+
# pyenv
|
| 86 |
+
# For a library or package, you might want to ignore these files since the code is
|
| 87 |
+
# intended to run in multiple environments; otherwise, check them in:
|
| 88 |
+
# .python-version
|
| 89 |
+
|
| 90 |
+
# pipenv
|
| 91 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 92 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 93 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 94 |
+
# install all needed dependencies.
|
| 95 |
+
#Pipfile.lock
|
| 96 |
+
|
| 97 |
+
# poetry
|
| 98 |
+
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
|
| 99 |
+
# This is especially recommended for binary packages to ensure reproducibility, and is more
|
| 100 |
+
# commonly ignored for libraries.
|
| 101 |
+
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
|
| 102 |
+
#poetry.lock
|
| 103 |
+
|
| 104 |
+
# pdm
|
| 105 |
+
# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
|
| 106 |
+
#pdm.lock
|
| 107 |
+
# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
|
| 108 |
+
# in version control.
|
| 109 |
+
# https://pdm.fming.dev/latest/usage/project/#working-with-version-control
|
| 110 |
+
.pdm.toml
|
| 111 |
+
.pdm-python
|
| 112 |
+
.pdm-build/
|
| 113 |
+
|
| 114 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
|
| 115 |
+
__pypackages__/
|
| 116 |
+
|
| 117 |
+
# Celery stuff
|
| 118 |
+
celerybeat-schedule
|
| 119 |
+
celerybeat.pid
|
| 120 |
+
|
| 121 |
+
# SageMath parsed files
|
| 122 |
+
*.sage.py
|
| 123 |
+
|
| 124 |
+
# Environments
|
| 125 |
+
.env
|
| 126 |
+
.venv
|
| 127 |
+
env/
|
| 128 |
+
venv/
|
| 129 |
+
ENV/
|
| 130 |
+
env.bak/
|
| 131 |
+
venv.bak/
|
| 132 |
+
|
| 133 |
+
# Spyder project settings
|
| 134 |
+
.spyderproject
|
| 135 |
+
.spyproject
|
| 136 |
+
|
| 137 |
+
# Rope project settings
|
| 138 |
+
.ropeproject
|
| 139 |
+
|
| 140 |
+
# mkdocs documentation
|
| 141 |
+
/site
|
| 142 |
+
|
| 143 |
+
# mypy
|
| 144 |
+
.mypy_cache/
|
| 145 |
+
.dmypy.json
|
| 146 |
+
dmypy.json
|
| 147 |
+
|
| 148 |
+
# Pyre type checker
|
| 149 |
+
.pyre/
|
| 150 |
+
|
| 151 |
+
# pytype static type analyzer
|
| 152 |
+
.pytype/
|
| 153 |
+
|
| 154 |
+
# Cython debug symbols
|
| 155 |
+
cython_debug/
|
| 156 |
+
|
| 157 |
+
# PyCharm
|
| 158 |
+
# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
|
| 159 |
+
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
|
| 160 |
+
# and can be added to the global gitignore or merged into this file. For a more nuclear
|
| 161 |
+
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
|
| 162 |
+
#.idea/
|
| 163 |
+
*.json
|
| 164 |
+
image_store/
|
QA_bot.py
ADDED
|
@@ -0,0 +1,57 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import streamlit as st
|
| 3 |
+
import re
|
| 4 |
+
import time
|
| 5 |
+
from PIL import Image
|
| 6 |
+
import ast
|
| 7 |
+
import numpy as np
|
| 8 |
+
|
| 9 |
+
def reset_conversation():
|
| 10 |
+
st.session_state.messages = []
|
| 11 |
+
|
| 12 |
+
def display_mask_image(image_path):
|
| 13 |
+
if os.path.isfile(image_path):
|
| 14 |
+
image = Image.open(image_path)
|
| 15 |
+
st.image(image, caption='Final Mask', use_column_width=True)
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def tyre_synap_bot(filter_agent,image_file_path):
|
| 19 |
+
if "messages" not in st.session_state:
|
| 20 |
+
st.session_state.messages = []
|
| 21 |
+
|
| 22 |
+
print("Found image file path: ",image_file_path)
|
| 23 |
+
# Display chat messages from history on app rerun
|
| 24 |
+
for message in st.session_state.messages:
|
| 25 |
+
with st.chat_message(message["role"]):
|
| 26 |
+
st.markdown(message["content"])
|
| 27 |
+
|
| 28 |
+
# React to user input
|
| 29 |
+
if prompt := st.chat_input("What is up?"):
|
| 30 |
+
# Display user message in chat message container
|
| 31 |
+
st.chat_message("user").markdown(prompt)
|
| 32 |
+
# Add user message to chat history
|
| 33 |
+
st.session_state.messages.append({"role": "user", "content": prompt})
|
| 34 |
+
|
| 35 |
+
ai_response = filter_agent.invoke(
|
| 36 |
+
{
|
| 37 |
+
"input": f'{prompt}, provided image path: {image_file_path}'
|
| 38 |
+
}
|
| 39 |
+
)
|
| 40 |
+
|
| 41 |
+
# ai_response = filter_agent.run(f'{prompt} provided image path :{image_file_path}')
|
| 42 |
+
|
| 43 |
+
response = f"Echo: {ai_response['output']}"
|
| 44 |
+
with st.chat_message("assistant"):
|
| 45 |
+
message_placeholder = st.empty()
|
| 46 |
+
full_response = ""
|
| 47 |
+
if 'mask' in ai_response['output']:
|
| 48 |
+
display_mask_image('final_mask.png')
|
| 49 |
+
|
| 50 |
+
for chunk in re.split(r'(\s+)', response):
|
| 51 |
+
full_response += chunk + " "
|
| 52 |
+
time.sleep(0.01)
|
| 53 |
+
# Add a blinking cursor to simulate typing
|
| 54 |
+
message_placeholder.markdown(full_response + "▌")
|
| 55 |
+
# Add assistant response to chat history
|
| 56 |
+
st.session_state.messages.append({"role": "assistant", "content": full_response})
|
| 57 |
+
st.button('Reset Chat', on_click=reset_conversation)
|
app.py
ADDED
|
@@ -0,0 +1,169 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import streamlit as st
|
| 3 |
+
from PIL import Image
|
| 4 |
+
from pathlib import Path
|
| 5 |
+
from QA_bot import tyre_synap_bot as bot
|
| 6 |
+
from llm_service import get_llm
|
| 7 |
+
from hub_prompts import PREFIX
|
| 8 |
+
|
| 9 |
+
from extract_tools import get_all_tools
|
| 10 |
+
from langchain.agents import AgentExecutor
|
| 11 |
+
from langchain import hub
|
| 12 |
+
from langchain.agents.format_scratchpad import format_log_to_str
|
| 13 |
+
from langchain.agents.output_parsers import ReActJsonSingleInputOutputParser
|
| 14 |
+
from langchain.tools.render import render_text_description
|
| 15 |
+
|
| 16 |
+
import logging
|
| 17 |
+
import warnings
|
| 18 |
+
warnings.filterwarnings("ignore")
|
| 19 |
+
|
| 20 |
+
logging.basicConfig(filename="newfile.log",
|
| 21 |
+
format='%(asctime)s %(message)s',
|
| 22 |
+
filemode='w')
|
| 23 |
+
logger = logging.getLogger()
|
| 24 |
+
|
| 25 |
+
llm = None
|
| 26 |
+
tools = None
|
| 27 |
+
cv_agent = None
|
| 28 |
+
|
| 29 |
+
@st.cache_resource
|
| 30 |
+
def call_llmservice_model(option,api_key):
|
| 31 |
+
model = get_llm(option=option,key=api_key)
|
| 32 |
+
return model
|
| 33 |
+
|
| 34 |
+
@st.cache_resource
|
| 35 |
+
def setup_agent_prompt():
|
| 36 |
+
prompt = hub.pull("hwchase17/react-json")
|
| 37 |
+
if len(tools) == 0 :
|
| 38 |
+
logger.error ("No Tools added")
|
| 39 |
+
else :
|
| 40 |
+
prompt = prompt.partial(
|
| 41 |
+
tools= render_text_description(tools),
|
| 42 |
+
tool_names= ", ".join([t.name for t in tools]),
|
| 43 |
+
additional_kwargs={
|
| 44 |
+
'system_message':PREFIX,
|
| 45 |
+
}
|
| 46 |
+
)
|
| 47 |
+
return prompt
|
| 48 |
+
|
| 49 |
+
@st.cache_resource
|
| 50 |
+
def agent_initalize():
|
| 51 |
+
agent_prompt = setup_agent_prompt()
|
| 52 |
+
lm_with_stop = llm.bind(stop=["\nObservation"])
|
| 53 |
+
#### we can use create_react_agent https://github.com/langchain-ai/langchain/blob/master/libs/langchain/langchain/agents/react/agent.py
|
| 54 |
+
agent = (
|
| 55 |
+
{
|
| 56 |
+
"input": lambda x: x["input"],
|
| 57 |
+
"agent_scratchpad": lambda x: format_log_to_str(x["intermediate_steps"]),
|
| 58 |
+
}
|
| 59 |
+
| agent_prompt
|
| 60 |
+
| lm_with_stop
|
| 61 |
+
| ReActJsonSingleInputOutputParser()
|
| 62 |
+
)
|
| 63 |
+
|
| 64 |
+
# instantiate AgentExecutor
|
| 65 |
+
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True,handle_parsing_errors=True)
|
| 66 |
+
return agent_executor
|
| 67 |
+
|
| 68 |
+
# def agent_initalize(tools,max_iterations=5):
|
| 69 |
+
# zero_shot_agent = initialize_agent(
|
| 70 |
+
# agent= AgentType.ZERO_SHOT_REACT_DESCRIPTION,
|
| 71 |
+
# tools = tools,
|
| 72 |
+
# llm = llm,
|
| 73 |
+
# verbose = True,
|
| 74 |
+
# max_iterations = max_iterations,
|
| 75 |
+
# memory = None,
|
| 76 |
+
# handle_parsing_errors=True,
|
| 77 |
+
# agent_kwargs={
|
| 78 |
+
# 'system_message':PREFIX,
|
| 79 |
+
# # 'format_instructions':FORMAT_INSTRUCTIONS,
|
| 80 |
+
# # 'suffix':SUFFIX
|
| 81 |
+
# }
|
| 82 |
+
# )
|
| 83 |
+
# # sys_message = PREFIX
|
| 84 |
+
# # zero_shot_agent.agent.llm_chain.prompt.template = sys_message
|
| 85 |
+
# return zero_shot_agent
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
def main():
|
| 89 |
+
database_store = 'image_store'
|
| 90 |
+
st.session_state.disabled = False
|
| 91 |
+
st.session_state.visibility = "visible"
|
| 92 |
+
|
| 93 |
+
st.title("Computer Vision Agent :sunglasses:")
|
| 94 |
+
st.markdown("Use the CV agent to do Object Detection/Panoptic Segementation/Image Segmentation/Image Descrption ")
|
| 95 |
+
st.markdown(
|
| 96 |
+
"""
|
| 97 |
+
<style>
|
| 98 |
+
section[data-testid="stSidebar"] {
|
| 99 |
+
width: 350px !important; # Set the width to your desired value
|
| 100 |
+
}
|
| 101 |
+
</style>
|
| 102 |
+
""",
|
| 103 |
+
unsafe_allow_html=True,
|
| 104 |
+
)
|
| 105 |
+
|
| 106 |
+
with st.sidebar:
|
| 107 |
+
st.header("About Project")
|
| 108 |
+
st.markdown(
|
| 109 |
+
"""
|
| 110 |
+
- Agent to filter images on basis multiple factors like image quality , object proportion in image , weather in the image .
|
| 111 |
+
- This application uses multiple tools like Image caption tool, DuckDuckGo search tool, Maskformer tool , weather predictor.
|
| 112 |
+
""")
|
| 113 |
+
st.sidebar.subheader("Upload Image !")
|
| 114 |
+
option = st.sidebar.selectbox(
|
| 115 |
+
"Select the Large Language Model ",("deepseek-r1-distill-llama-70b",
|
| 116 |
+
"gemma2-9b-it",
|
| 117 |
+
"llama-3.2-3b-preview",
|
| 118 |
+
"llama-3.2-1b-preview",
|
| 119 |
+
"llama3-8b-8192",
|
| 120 |
+
"Openai",
|
| 121 |
+
"Google",
|
| 122 |
+
"Ollama"),
|
| 123 |
+
index=None,
|
| 124 |
+
placeholder="Select LLM Service...",
|
| 125 |
+
)
|
| 126 |
+
api_key = st.sidebar.text_input("API_KEY", type="password", key="password")
|
| 127 |
+
|
| 128 |
+
uploaded_file = st.sidebar.file_uploader("Upload Image for Processing", type=['png','jpg','jpeg'])
|
| 129 |
+
|
| 130 |
+
if uploaded_file is not None :
|
| 131 |
+
file_path = Path(database_store, uploaded_file.name)
|
| 132 |
+
if not os.path.isdir(database_store):
|
| 133 |
+
os.makedirs(database_store)
|
| 134 |
+
|
| 135 |
+
global llm
|
| 136 |
+
llm = call_llmservice_model(option=option,api_key=api_key)
|
| 137 |
+
logger.info("\tLLM Service {} Active ... !".format(llm.get_name()))
|
| 138 |
+
## extract tools
|
| 139 |
+
global tools
|
| 140 |
+
tools = get_all_tools()
|
| 141 |
+
logger.info("\tFound {} tools ".format(len(tools)))
|
| 142 |
+
## generate Agent
|
| 143 |
+
global agent
|
| 144 |
+
cv_agent = agent_initalize()
|
| 145 |
+
logger.info('\tAgent inintalized with {} tools '.format(len(tools)))
|
| 146 |
+
|
| 147 |
+
with open(file_path, mode='wb') as w:
|
| 148 |
+
w.write(uploaded_file.getvalue())
|
| 149 |
+
|
| 150 |
+
if os.path.isfile(file_path):
|
| 151 |
+
st.sidebar.success("File uploaded successfully",icon="✅")
|
| 152 |
+
|
| 153 |
+
with st.sidebar.container():
|
| 154 |
+
image = Image.open(file_path)
|
| 155 |
+
st.image(image,use_container_width=True)
|
| 156 |
+
st.sidebar.subheader("""
|
| 157 |
+
Examples Questions:
|
| 158 |
+
- Describe about the image
|
| 159 |
+
- Tell me what are the things you can detect in the image .
|
| 160 |
+
- How is the image quality
|
| 161 |
+
""")
|
| 162 |
+
|
| 163 |
+
bot(cv_agent,file_path)
|
| 164 |
+
|
| 165 |
+
if __name__ == '__main__':
|
| 166 |
+
main()
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
|
extract_tools.py
ADDED
|
@@ -0,0 +1,254 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import cv2
|
| 3 |
+
import requests
|
| 4 |
+
from PIL import Image
|
| 5 |
+
import logging
|
| 6 |
+
import torch
|
| 7 |
+
from llm_service import get_llm
|
| 8 |
+
from langchain_core.tools import tool,Tool
|
| 9 |
+
from langchain_community.tools import DuckDuckGoSearchResults
|
| 10 |
+
from langchain_groq import ChatGroq
|
| 11 |
+
from utils import draw_panoptic_segmentation
|
| 12 |
+
|
| 13 |
+
from tool_utils.clip_segmentation import CLIPSEG
|
| 14 |
+
from tool_utils.object_extractor import create_object_extraction_chain
|
| 15 |
+
from tool_utils.yolo_world import YoloWorld
|
| 16 |
+
from tool_utils.image_metadata import image_brightness,variance_of_laplacian,get_signal_to_noise_ratio
|
| 17 |
+
|
| 18 |
+
try:
|
| 19 |
+
from transformers import BlipProcessor, BlipForConditionalGeneration
|
| 20 |
+
from transformers import AutoImageProcessor, Mask2FormerForUniversalSegmentation
|
| 21 |
+
except ImportError as err:
|
| 22 |
+
logging.error("Import error :{}".format(err))
|
| 23 |
+
|
| 24 |
+
device = 'cuda' if torch.cuda.is_available() else 'cpu'
|
| 25 |
+
|
| 26 |
+
logging.info("Loading Foundation Models")
|
| 27 |
+
try:
|
| 28 |
+
clipseg_model = CLIPSEG()
|
| 29 |
+
except Exception as err :
|
| 30 |
+
logging.error("Unable to clipseg model {}".format(err))
|
| 31 |
+
try:
|
| 32 |
+
maskformer_processor = AutoImageProcessor.from_pretrained("facebook/mask2former-swin-base-coco-panoptic")
|
| 33 |
+
maskformer_model = Mask2FormerForUniversalSegmentation.from_pretrained("facebook/mask2former-swin-base-coco-panoptic")
|
| 34 |
+
except:
|
| 35 |
+
logging.error("Unable to Maskformer model {}".format(err))
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def get_groq_model(model_name = "gemma2-9b-it"):
|
| 39 |
+
os.environ.get("GROQ_API_KEY")
|
| 40 |
+
llm_groq = ChatGroq(model=model_name)
|
| 41 |
+
return llm_groq
|
| 42 |
+
|
| 43 |
+
@tool
|
| 44 |
+
def panoptic_image_segemntation(image_path:str)->str:
|
| 45 |
+
"""
|
| 46 |
+
The tool is used to create a Panoptic segmentation mask . It uses Maskformer network to create a panoptic segmentation of all \
|
| 47 |
+
the objects present in the image . Use the tool in case user ask to create a panoptic segmentation.
|
| 48 |
+
"""
|
| 49 |
+
if image_path.startswith('https'):
|
| 50 |
+
image = Image.open(requests.get(image_path, stream=True).raw).convert('RGB')
|
| 51 |
+
else:
|
| 52 |
+
image = Image.open(image_path).convert('RGB')
|
| 53 |
+
maskformer_model.to(device)
|
| 54 |
+
inputs = maskformer_processor(image, return_tensors="pt").to(device)
|
| 55 |
+
with torch.no_grad():
|
| 56 |
+
outputs = maskformer_model(**inputs)
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
prediction = maskformer_processor.post_process_panoptic_segmentation(outputs, target_sizes=[image.size[::-1]])[0]
|
| 60 |
+
save_mask_path = draw_panoptic_segmentation(maskformer_model,prediction['segmentation'],prediction['segments_info'])
|
| 61 |
+
labels = []
|
| 62 |
+
for segment in prediction['segments_info']:
|
| 63 |
+
label_names = maskformer_model.config.id2label[segment['label_id']]
|
| 64 |
+
print(label_names)
|
| 65 |
+
labels.append(label_names)
|
| 66 |
+
return 'Panoptic Segmentation image {} created with labels {} '.format(save_mask_path,labels)
|
| 67 |
+
|
| 68 |
+
@tool
|
| 69 |
+
def image_description(img_path:str)->str:
|
| 70 |
+
"Use this tool to describe the image " \
|
| 71 |
+
"The tool helps you to identify weather in the image as well "
|
| 72 |
+
hf_model = "Salesforce/blip-image-captioning-base"
|
| 73 |
+
text = ""
|
| 74 |
+
if img_path.startswith('https'):
|
| 75 |
+
image = Image.open(requests.get(img_path, stream=True).raw).convert('RGB')
|
| 76 |
+
else:
|
| 77 |
+
image = Image.open(img_path).convert('RGB')
|
| 78 |
+
try:
|
| 79 |
+
processor = BlipProcessor.from_pretrained(hf_model)
|
| 80 |
+
caption_model = BlipForConditionalGeneration.from_pretrained(hf_model).to(device)
|
| 81 |
+
except:
|
| 82 |
+
logging.error("unable to load the Blip model ")
|
| 83 |
+
|
| 84 |
+
logging.info("Image Caption model loaded ! ")
|
| 85 |
+
|
| 86 |
+
# unconditional image captioning
|
| 87 |
+
inputs = processor(image, return_tensors ='pt').to(device)
|
| 88 |
+
output = caption_model.generate(**inputs, max_new_tokens=50)
|
| 89 |
+
caption = processor.decode(output[0], skip_special_tokens=True)
|
| 90 |
+
|
| 91 |
+
# conditional image captioning
|
| 92 |
+
obj_text = "Total number of objects in image "
|
| 93 |
+
inputs_2 = processor(image, obj_text ,return_tensors ='pt').to(device)
|
| 94 |
+
out_2 = caption_model.generate(**inputs_2,max_new_tokens=50)
|
| 95 |
+
object_caption = processor.decode(out_2[0], skip_special_tokens=True)
|
| 96 |
+
|
| 97 |
+
## clear the GPU cache
|
| 98 |
+
with torch.no_grad():
|
| 99 |
+
torch.cuda.empty_cache()
|
| 100 |
+
text = caption + " ."+ object_caption+" ."
|
| 101 |
+
return text
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
@tool
|
| 105 |
+
def clipsegmentation_mask(input_data:str)->str:
|
| 106 |
+
"""
|
| 107 |
+
The tool helps to extract the object masks from the image.
|
| 108 |
+
For example : If you want to extract the object masks from the image use this tool.
|
| 109 |
+
"""
|
| 110 |
+
data = input_data.split(",")
|
| 111 |
+
image_path = data[0]
|
| 112 |
+
object_prompts = data[1:]
|
| 113 |
+
masks = clipseg_model.get_segmentation_mask(image_path,object_prompts)
|
| 114 |
+
return masks
|
| 115 |
+
|
| 116 |
+
@tool
|
| 117 |
+
def generate_bounding_box_tool(input_data:str)->str:
|
| 118 |
+
"use this tool when its is required to detect object and provide bounding boxes for the given image and list of objects"
|
| 119 |
+
yolo_world_model= YoloWorld()
|
| 120 |
+
data = input_data.split(",")
|
| 121 |
+
image_path = data[0]
|
| 122 |
+
object_prompts = data[1:]
|
| 123 |
+
object_data = yolo_world_model.run_inference(image_path,object_prompts)
|
| 124 |
+
return object_data
|
| 125 |
+
|
| 126 |
+
@tool
|
| 127 |
+
def object_extraction(img_path:str)->str:
|
| 128 |
+
"Use this tool to identify the objects within the image"
|
| 129 |
+
|
| 130 |
+
hf_model = "Salesforce/blip-image-captioning-base"
|
| 131 |
+
if img_path.startswith('https'):
|
| 132 |
+
image = Image.open(requests.get(img_path, stream=True).raw).convert('RGB')
|
| 133 |
+
else:
|
| 134 |
+
image = Image.open(img_path).convert('RGB')
|
| 135 |
+
try:
|
| 136 |
+
processor = BlipProcessor.from_pretrained(hf_model)
|
| 137 |
+
caption_model = BlipForConditionalGeneration.from_pretrained(hf_model).to(device)
|
| 138 |
+
except:
|
| 139 |
+
logging.error("unable to load the Blip model ")
|
| 140 |
+
|
| 141 |
+
logging.info("Image Caption model loaded ! ")
|
| 142 |
+
|
| 143 |
+
# unconditional image captioning
|
| 144 |
+
inputs = processor(image, return_tensors ='pt').to(device)
|
| 145 |
+
output = caption_model.generate(**inputs, max_new_tokens=50)
|
| 146 |
+
llm = get_groq_model()
|
| 147 |
+
getobject_chain = create_object_extraction_chain(llm=llm)
|
| 148 |
+
|
| 149 |
+
extracted_objects = getobject_chain.invoke({
|
| 150 |
+
'context': processor.decode(output[0], skip_special_tokens=True)
|
| 151 |
+
}).objects
|
| 152 |
+
|
| 153 |
+
print("Extracted objects : ",extracted_objects)
|
| 154 |
+
## clear the GPU cache
|
| 155 |
+
with torch.no_grad():
|
| 156 |
+
torch.cuda.empty_cache()
|
| 157 |
+
|
| 158 |
+
return extracted_objects.split(',')
|
| 159 |
+
|
| 160 |
+
@tool
|
| 161 |
+
def get_image_quality(image_path:str)->str:
|
| 162 |
+
"""
|
| 163 |
+
This tool helps to find out the parameters of the image.The tool will determine if image is blurry or not.
|
| 164 |
+
It will also tell you if image is bright or not.
|
| 165 |
+
This tool also determines the Signal to Noise Ratio of the image as well .
|
| 166 |
+
For example Output of the tool will be :
|
| 167 |
+
example 1 : Image is blurry.Image is not bright.Signal to Noise is less than 1 - More Noise in image
|
| 168 |
+
example 2 : Image is not blurry . Image is bright.Signal to Noise is greater than 1 - More Signal in image
|
| 169 |
+
"""
|
| 170 |
+
image = cv2.imread(image_path)
|
| 171 |
+
image = cv2.cvtColor(image,cv2.COLOR_BGR2RGB)
|
| 172 |
+
|
| 173 |
+
brightness_text = image_brightness(image)
|
| 174 |
+
blurry_text = variance_of_laplacian(image)
|
| 175 |
+
snr_text = get_signal_to_noise_ratio(image)
|
| 176 |
+
final_text = "Image properties are :\n{}\n{}\n{}".format(blurry_text, brightness_text,snr_text)
|
| 177 |
+
return final_text
|
| 178 |
+
|
| 179 |
+
|
| 180 |
+
|
| 181 |
+
def get_all_tools():
|
| 182 |
+
## bind tools
|
| 183 |
+
image_desc_tool = Tool(
|
| 184 |
+
name = 'Image_Descprtion_Tool',
|
| 185 |
+
func= image_description,
|
| 186 |
+
description = """
|
| 187 |
+
The tool helps to describe about the image or create a caption of the image
|
| 188 |
+
If the user asks to decribe or genrerate a caption for the image use this tool.
|
| 189 |
+
This tool can also be used to identify the weather within the image .
|
| 190 |
+
user example questions :
|
| 191 |
+
1. Describe the image ?
|
| 192 |
+
2. What the weather looks like in the image ?
|
| 193 |
+
"""
|
| 194 |
+
)
|
| 195 |
+
|
| 196 |
+
clipseg_tool = Tool(
|
| 197 |
+
name = 'ClipSegmentation-tool',
|
| 198 |
+
func = clipsegmentation_mask,
|
| 199 |
+
description="""Use this tool when user ask to generate the segmentation Mask of the objects provided by the user.
|
| 200 |
+
The input to the tool is the path of the image and list of objects for which Segmenation mask is to generated.
|
| 201 |
+
For example :
|
| 202 |
+
Query :Provide a segmentation mask of all road car and dog in the image
|
| 203 |
+
|
| 204 |
+
The tool will generate the segmentation mask of the objects in the image.
|
| 205 |
+
for such query from the user you need to first use the tool to identify the objects and then use this tool to
|
| 206 |
+
generate the segmentation mask for the objects.
|
| 207 |
+
|
| 208 |
+
"""
|
| 209 |
+
)
|
| 210 |
+
|
| 211 |
+
bounding_box_generator = Tool(
|
| 212 |
+
name = 'Bounding Box Generator',
|
| 213 |
+
func = generate_bounding_box_tool,
|
| 214 |
+
description= "The tool helps to provide bounding boxes for the given image and list of objects\
|
| 215 |
+
.Use this tool when user ask to provide bounding boxes for the objects.if user has not specified the names of the objects \
|
| 216 |
+
then use the object extraction tool to identify the objects and then use this tool to generate the bounding boxes for the objects.\
|
| 217 |
+
The input to this tool is the path of the image and list of objects for which bounding boxes are to be generated"
|
| 218 |
+
)
|
| 219 |
+
|
| 220 |
+
object_extractor = Tool(
|
| 221 |
+
name = "Object Extraction Tool",
|
| 222 |
+
func = object_extraction,
|
| 223 |
+
description = " The Tool is used to extract objects within the image . Use this tool if user specifically ask to identify \
|
| 224 |
+
what are the objects I can view in the image or identify the objects within the image . "
|
| 225 |
+
)
|
| 226 |
+
|
| 227 |
+
image_parameters_tool = Tool(
|
| 228 |
+
name = 'Image Parameters_Tool',
|
| 229 |
+
func = get_image_quality,
|
| 230 |
+
description= """ This tool will help you to determine
|
| 231 |
+
- If the image is blurry or not
|
| 232 |
+
- If the image is bright/sharp or not
|
| 233 |
+
- SNR ratio of the image
|
| 234 |
+
Based on the tool output take a proper decision regarding the image quality"""
|
| 235 |
+
)
|
| 236 |
+
|
| 237 |
+
panoptic_segmentation = Tool(
|
| 238 |
+
name = 'panoptic_Segmentation_tool',
|
| 239 |
+
func = panoptic_image_segemntation,
|
| 240 |
+
description = "The tool is used to create a Panoptic segmentation mask . It uses Maskformer network to create a panoptic segmentation of all \
|
| 241 |
+
the objects present in the image . Use the tool in case user ask to create a panoptic segmentation or count objects in the image.\
|
| 242 |
+
The tool also provides a list of objects along with the mask image of the all segmented objects found in the image ."
|
| 243 |
+
)
|
| 244 |
+
|
| 245 |
+
tools = [
|
| 246 |
+
DuckDuckGoSearchResults(),
|
| 247 |
+
image_desc_tool,
|
| 248 |
+
clipseg_tool,
|
| 249 |
+
image_parameters_tool,
|
| 250 |
+
object_extractor,
|
| 251 |
+
bounding_box_generator,
|
| 252 |
+
panoptic_segmentation
|
| 253 |
+
]
|
| 254 |
+
return tools
|
final_mask.png
ADDED
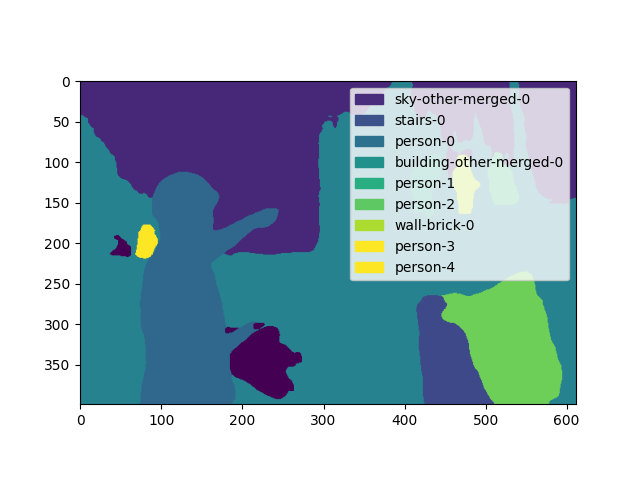
|
hub_prompts.py
ADDED
|
@@ -0,0 +1,79 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
PREFIX = """
|
| 2 |
+
You are an agent designed to filter images on the basis of image quality.You are provided with the Dashcam images from the Car.
|
| 3 |
+
You have access to following tools : Image Descprtion_Tool,Object Proportion_Tool,Image Parameters_Tool,DuckDuckGoSearch_Tool
|
| 4 |
+
Some examples provided about are below:
|
| 5 |
+
|
| 6 |
+
Question: Describe about the image
|
| 7 |
+
Thought: To describe the image , I must need to find a tool that describes an image.Image Descprtion_Tool desribes the image.I should use that tool.
|
| 8 |
+
Action : ```json
|
| 9 |
+
{
|
| 10 |
+
"action": "Image Description_Tool",
|
| 11 |
+
"action_input": "image_store/image.jpg"
|
| 12 |
+
}
|
| 13 |
+
```
|
| 14 |
+
Observation : "car driving on road.The weather in the image is Stormy.
|
| 15 |
+
Final Answer : Car is driving in a stromy weather.Due to stormy weather the visibility will be low.
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
Question: I need to know the quality of the image.
|
| 19 |
+
Thought: I must need to find a tool that describes the image quality .Image Parameters_Tool can help to find out parameters like Brightness , Blur and Noise in the image.
|
| 20 |
+
Action : ```json
|
| 21 |
+
{
|
| 22 |
+
"action": "Image Description_Tool",
|
| 23 |
+
"action_input": 'image_store/image_path.jpg'
|
| 24 |
+
}
|
| 25 |
+
```
|
| 26 |
+
Observation : "Image is Bright enough and have a high Signal to Noise ratio >1, means the qaulity of the image is good."
|
| 27 |
+
Final Answer : The Quality of the image seems good.
|
| 28 |
+
|
| 29 |
+
Question: I need to know the quality of the image.
|
| 30 |
+
Thought: I must need to find a tool that describes the image quality .Image Parameters_Tool can help to find out parameters like Brightness , Blur and Noise in the image.
|
| 31 |
+
Action : ```json
|
| 32 |
+
{
|
| 33 |
+
"action": "Image Description_Tool",
|
| 34 |
+
"action_input": 'image_store/image_path.jpg'
|
| 35 |
+
}
|
| 36 |
+
```
|
| 37 |
+
Observation : "Image is not Bright enough and have more noise, means the qaulity of the image is bad."
|
| 38 |
+
Final Answer : The Quality of the image does not seems to be good .
|
| 39 |
+
|
| 40 |
+
Question: I need to detemine the cracks .
|
| 41 |
+
Thought: I must need to find a tool that describes the image quality .Image Parameters_Tool can help to find out parameters like Brightness , Blur and Noise in the image.
|
| 42 |
+
Action : ```json
|
| 43 |
+
{
|
| 44 |
+
"action": "Image Description_Tool",
|
| 45 |
+
"action_input": 'image_store/image_path.jpg'
|
| 46 |
+
}
|
| 47 |
+
```
|
| 48 |
+
Observation : "Image is not Bright enough and have more noise, means the qaulity of the image is bad."
|
| 49 |
+
Final Answer : The Quality of the image does not seems to be good .
|
| 50 |
+
|
| 51 |
+
Final method is "get_image_parameters". This tool helps to find out general properties of image like blurliness ,sharpness,
|
| 52 |
+
brightness, Signal to Noise ratio in image.
|
| 53 |
+
|
| 54 |
+
Use the these tools and the information provided by these tools to construct your final answer.
|
| 55 |
+
|
| 56 |
+
If you get an error while executing a query, rewrite the query and try again.
|
| 57 |
+
If the question does not seem related to the database, just return "I don't know" as the answer.
|
| 58 |
+
"""
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
FORMAT_INSTRUCTIONS="""Use the following format:
|
| 62 |
+
|
| 63 |
+
Question: the input question you must answer
|
| 64 |
+
|
| 65 |
+
Thought: you should always think about what to do
|
| 66 |
+
|
| 67 |
+
Action: the action to take, should be one of [{tool_names}]
|
| 68 |
+
|
| 69 |
+
Action Input: the input to the action
|
| 70 |
+
|
| 71 |
+
Observation: the result of the action
|
| 72 |
+
... (this Thought/Action/Action Input/Observation can repeat N times)
|
| 73 |
+
|
| 74 |
+
Thought: I now know the final answer
|
| 75 |
+
Final Answer: the final answer to the original input question
|
| 76 |
+
|
| 77 |
+
"""
|
| 78 |
+
|
| 79 |
+
SUFFIX = """You are an humble agent provide infomration point wise """
|
llm_service.py
ADDED
|
@@ -0,0 +1,60 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from getpass import getpass
|
| 3 |
+
from langchain_groq import ChatGroq
|
| 4 |
+
from langchain_google_genai import ChatGoogleGenerativeAI
|
| 5 |
+
from langchain_openai import AzureChatOpenAI
|
| 6 |
+
from langchain_community.llms import Ollama
|
| 7 |
+
from langchain_openai.chat_models.base import BaseChatOpenAI
|
| 8 |
+
|
| 9 |
+
def azure_openai_service(key,max_retries=3):
|
| 10 |
+
os.environ["AZURE_OPENAI_API_KEY"] = key
|
| 11 |
+
os.environ["AZURE_OPENAI_ENDPOINT"] = "https://indus.api.michelin.com/openai-key-weu"
|
| 12 |
+
model = AzureChatOpenAI(
|
| 13 |
+
azure_deployment="gpt-4o", # or your deployment
|
| 14 |
+
api_version="2023-06-01-preview", # or your api version
|
| 15 |
+
temperature=0,
|
| 16 |
+
max_tokens=None,
|
| 17 |
+
timeout=None,
|
| 18 |
+
max_retries=max_retries)
|
| 19 |
+
return model
|
| 20 |
+
|
| 21 |
+
def get_ollama():
|
| 22 |
+
## terminal --> ollama start
|
| 23 |
+
llm = Ollama(base_url="http://localhost:11434", model="mistral")
|
| 24 |
+
return llm
|
| 25 |
+
|
| 26 |
+
def get_googleGemini(key):
|
| 27 |
+
os.environ["GOOGLE_API_KEY"] = key
|
| 28 |
+
llm = ChatGoogleGenerativeAI(
|
| 29 |
+
model="gemini-1.5-pro",
|
| 30 |
+
temperature=0,
|
| 31 |
+
max_tokens=None,
|
| 32 |
+
timeout=None,
|
| 33 |
+
max_retries=2)
|
| 34 |
+
return llm
|
| 35 |
+
|
| 36 |
+
def get_groq_model(key,model_name = "gemma2-9b-it"):
|
| 37 |
+
os.environ["GROQ_API_KEY"] = key
|
| 38 |
+
llm_groq = ChatGroq(model=model_name)
|
| 39 |
+
return llm_groq
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
def get_llm(option,key):
|
| 43 |
+
llm = None
|
| 44 |
+
if option =='deepseek-r1-distill-llama-70b':
|
| 45 |
+
llm = get_groq_model(key,model_name = "deepseek-r1-distill-llama-70b")
|
| 46 |
+
elif option =='gemma2-9b-it':
|
| 47 |
+
llm = get_groq_model(key,model_name="gemma2-9b-it")
|
| 48 |
+
elif option == 'llama-3.2-3b-preview':
|
| 49 |
+
llm = get_groq_model(key,model_name="llama-3.2-3b-preview")
|
| 50 |
+
elif option == 'llama-3.2-1b-preview':
|
| 51 |
+
llm = get_groq_model(key,model_name="llama-3.2-1b-preview")
|
| 52 |
+
elif option == 'llama3-8b-8192':
|
| 53 |
+
llm = get_groq_model(key,model_name="llama3-8b-8192")
|
| 54 |
+
elif option == 'Openai':
|
| 55 |
+
llm = azure_openai_service(key)
|
| 56 |
+
elif option == 'Google':
|
| 57 |
+
llm = get_googleGemini(key)
|
| 58 |
+
elif option == "Ollama" :
|
| 59 |
+
llm = get_ollama()
|
| 60 |
+
return llm
|
requirements.txt
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
streamlit
|
| 2 |
+
langchain
|
| 3 |
+
langchain-community
|
| 4 |
+
langchain-core
|
| 5 |
+
langchain-text-splitters
|
| 6 |
+
langchain-experimental
|
| 7 |
+
langchain-google-genai
|
| 8 |
+
langchain-openai
|
| 9 |
+
tiktoken
|
| 10 |
+
duckduckgo-search
|
| 11 |
+
torch
|
| 12 |
+
transformers
|
| 13 |
+
langchain-groq
|
| 14 |
+
jq
|
| 15 |
+
scikit-learn
|
| 16 |
+
PyWavelets
|
| 17 |
+
scikit-image
|
tool_utils/clip_segmentation.py
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import cv2
|
| 2 |
+
from matplotlib import pyplot as plt
|
| 3 |
+
import torch
|
| 4 |
+
import numpy as np
|
| 5 |
+
from transformers import CLIPSegProcessor, CLIPSegForImageSegmentation
|
| 6 |
+
from segmentation_mask_overlay import overlay_masks
|
| 7 |
+
from typing import List
|
| 8 |
+
import logging
|
| 9 |
+
class CLIPSEG:
|
| 10 |
+
def __init__(self,model_name = "CIDAS/clipseg-rd64-refined",threshould=0.60):
|
| 11 |
+
self.clip_processor = CLIPSegProcessor.from_pretrained(model_name)
|
| 12 |
+
self.clip_model = CLIPSegForImageSegmentation.from_pretrained(model_name)
|
| 13 |
+
self.threshould = threshould
|
| 14 |
+
self.clip_model.to('cpu')
|
| 15 |
+
|
| 16 |
+
@staticmethod
|
| 17 |
+
def create_rgb_mask(mask,color=None):
|
| 18 |
+
color = tuple(np.random.choice(range(0,256), size=3))
|
| 19 |
+
gray_3_channel = cv2.merge((mask, mask, mask))
|
| 20 |
+
gray_3_channel[mask==255] = color
|
| 21 |
+
return gray_3_channel.astype(np.uint8)
|
| 22 |
+
|
| 23 |
+
def get_segmentation_mask(self,image_path:str,object_prompts:List):
|
| 24 |
+
image = cv2.cvtColor(cv2.imread(image_path),cv2.COLOR_BGR2RGB)
|
| 25 |
+
logging.info("objects found out from the image :{}".format(object_prompts))
|
| 26 |
+
|
| 27 |
+
predicted_masks = []
|
| 28 |
+
inputs = self.clip_processor(
|
| 29 |
+
text=object_prompts,
|
| 30 |
+
images=[image] * len(object_prompts),
|
| 31 |
+
padding="max_length",
|
| 32 |
+
return_tensors="pt",
|
| 33 |
+
)
|
| 34 |
+
with torch.no_grad(): # Use 'torch.no_grad()' to disable gradient computation
|
| 35 |
+
outputs = self.clip_model(**inputs)
|
| 36 |
+
preds = outputs.logits.unsqueeze(1)
|
| 37 |
+
# detections = outputs.logits[0] # Assuming class index 0
|
| 38 |
+
|
| 39 |
+
for i in range(preds.shape[0]):
|
| 40 |
+
predicted_mask = torch.sigmoid(preds[i][0]).detach().cpu().numpy()
|
| 41 |
+
predicted_mask = np.where(predicted_mask>self.threshould, 255,0)
|
| 42 |
+
predicted_masks.append(predicted_mask)
|
| 43 |
+
|
| 44 |
+
resize_image = cv2.resize(image,(352,352))
|
| 45 |
+
mask_labels = [f"{prompt}_{i}" for i,prompt in enumerate(object_prompts)]
|
| 46 |
+
cmap = plt.cm.tab20(np.arange(len(mask_labels)))[..., :-1]
|
| 47 |
+
|
| 48 |
+
bool_masks = [predicted_mask.astype('bool') for predicted_mask in predicted_masks]
|
| 49 |
+
final_mask = overlay_masks(resize_image,np.stack(bool_masks,-1),labels=mask_labels,colors=cmap,alpha=0.5,beta=0.7)
|
| 50 |
+
try:
|
| 51 |
+
cv2.imwrite('final_mask.png',final_mask)
|
| 52 |
+
return 'Segmentation image created : final_mask.png'
|
| 53 |
+
except Exception as e:
|
| 54 |
+
logging.error("Error while saving the final mask :",e)
|
| 55 |
+
return "unable to create a mask image "
|
tool_utils/image_metadata.py
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import numpy as np
|
| 3 |
+
import cv2
|
| 4 |
+
from skimage.restoration import estimate_sigma
|
| 5 |
+
import logging
|
| 6 |
+
def image_brightness(image,thresh=0.37):
|
| 7 |
+
L,A,B = cv2.split(cv2.cvtColor(image,cv2.COLOR_BGR2LAB))
|
| 8 |
+
norm_L = L/np.max(L)
|
| 9 |
+
L_mean = np.mean(norm_L)
|
| 10 |
+
if L_mean > thresh:
|
| 11 |
+
return "image is Bright enough "
|
| 12 |
+
else:
|
| 13 |
+
return "image is not bright enough "
|
| 14 |
+
|
| 15 |
+
def variance_of_laplacian(img,threshould=250):
|
| 16 |
+
# compute the Laplacian of the image and then return the focus
|
| 17 |
+
# measure, which is simply the variance of the Laplacian
|
| 18 |
+
gray = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
|
| 19 |
+
|
| 20 |
+
laplacian_value = cv2.Laplacian(gray, cv2.CV_64F).var()
|
| 21 |
+
logging.info(laplacian_value)
|
| 22 |
+
if laplacian_value <= threshould:
|
| 23 |
+
return " Image is very blurry"
|
| 24 |
+
elif laplacian_value <= 3*threshould:
|
| 25 |
+
return " Image is visible but have some regions out of foucs."
|
| 26 |
+
elif laplacian_value >= 3*threshould:
|
| 27 |
+
return "Image is Very Sharp."
|
| 28 |
+
|
| 29 |
+
def get_signal_to_noise_ratio(image):
|
| 30 |
+
snr_text = None
|
| 31 |
+
snr_value = estimate_sigma(cv2.cvtColor(image,cv2.COLOR_RGB2GRAY), average_sigmas=False)
|
| 32 |
+
logging.info(snr_value)
|
| 33 |
+
if snr_value > 1 :
|
| 34 |
+
snr_text = "Signal to Noise is greater than 1 - More Signal in image "
|
| 35 |
+
else:
|
| 36 |
+
snr_text = "Signal to Noise is less than 1 - More Noise in image "
|
| 37 |
+
return snr_text
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
|
tool_utils/mask2former.py
ADDED
|
@@ -0,0 +1,102 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import cv2
|
| 3 |
+
import argparse
|
| 4 |
+
import warnings
|
| 5 |
+
try:
|
| 6 |
+
import torch as th
|
| 7 |
+
from transformers import AutoImageProcessor ,Mask2FormerModel,Mask2FormerForUniversalSegmentation
|
| 8 |
+
except ImportError as error:
|
| 9 |
+
raise ('Try installing torch and Transfomers module using pip.')
|
| 10 |
+
|
| 11 |
+
warnings.filterwarnings("ignore")
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
class MASK2FORMER:
|
| 15 |
+
def __init__(self,model_name="facebook/mask2former-swin-small-ade-semantic",class_id =6): ## use large
|
| 16 |
+
self.image_processor = AutoImageProcessor.from_pretrained("facebook/mask2former-swin-small-ade-semantic")
|
| 17 |
+
self.maskformer_processor = Mask2FormerModel.from_pretrained(model_name)
|
| 18 |
+
self.maskformer_model = Mask2FormerForUniversalSegmentation.from_pretrained(model_name)
|
| 19 |
+
self.DEVICE = "cuda" if th.cuda.is_available() else 'cpu'
|
| 20 |
+
self.segment_id = class_id
|
| 21 |
+
self.maskformer_model.to(self.DEVICE)
|
| 22 |
+
|
| 23 |
+
def create_rgb_mask(self,mask,value=255):
|
| 24 |
+
gray_3_channel = cv2.merge((mask, mask, mask))
|
| 25 |
+
gray_3_channel[mask==value] = (255,255,255)
|
| 26 |
+
return gray_3_channel.astype(np.uint8)
|
| 27 |
+
|
| 28 |
+
def get_mask(self,segmentation):
|
| 29 |
+
"""
|
| 30 |
+
Mask out the segment of the class from the provided segment_id
|
| 31 |
+
args : segmentation -> torch.obj - segmentation ouput from the maskformer model
|
| 32 |
+
segment_id -> class id of the object to be extracted
|
| 33 |
+
return : ndarray -> 2D Mask of the image
|
| 34 |
+
"""
|
| 35 |
+
if self.segment_id == "vehicle":
|
| 36 |
+
mask = (segmentation.cpu().numpy().copy()==2) | (segmentation.cpu().numpy().copy()==5) | (segmentation.cpu().numpy().copy()== 7)
|
| 37 |
+
else:
|
| 38 |
+
mask = (segmentation.cpu().numpy() == 6)
|
| 39 |
+
visual_mask = (mask * 255).astype(np.uint8)
|
| 40 |
+
return visual_mask #np.asarray(visual_mask)
|
| 41 |
+
|
| 42 |
+
def generate_road_mask(self,img):
|
| 43 |
+
"""
|
| 44 |
+
Extract semantic road mask from raw image
|
| 45 |
+
args : img -> np.array - input_image
|
| 46 |
+
return : ndarray -> masked out road .
|
| 47 |
+
"""
|
| 48 |
+
inputs = self.image_processor(img, return_tensors="pt")
|
| 49 |
+
|
| 50 |
+
inputs = inputs.to(self.DEVICE)
|
| 51 |
+
with th.no_grad():
|
| 52 |
+
outputs = self.maskformer_model(**inputs)
|
| 53 |
+
|
| 54 |
+
segmentation = self.image_processor.post_process_semantic_segmentation(outputs,target_sizes=[(img.shape[0],img.shape[1])])[0]
|
| 55 |
+
segmented_mask = self.get_mask(segmentation=segmentation)
|
| 56 |
+
return segmented_mask
|
| 57 |
+
|
| 58 |
+
def get_rgb_mask(self,img,segmented_mask):
|
| 59 |
+
"""
|
| 60 |
+
Extract RGB road image and removing the background .
|
| 61 |
+
args: img -> ndarray - raw image
|
| 62 |
+
segmented_mask - binary mask from the semantic segmentation
|
| 63 |
+
return : ndarray -> RGB road image with background pixels as 0.
|
| 64 |
+
"""
|
| 65 |
+
predicted_rgb_mask = self.create_rgb_mask(segmented_mask)
|
| 66 |
+
rgb_mask_img = cv2.bitwise_and(img,predicted_rgb_mask )
|
| 67 |
+
return rgb_mask_img
|
| 68 |
+
|
| 69 |
+
def run_inference(self,image_name):
|
| 70 |
+
"""
|
| 71 |
+
Function used to create a segmentation mask for specific segment_id provided. The function uses
|
| 72 |
+
"facebook/maskformer-swin-small-coco" maskformer model to extract segmentation mask for the provided image
|
| 73 |
+
args: image_name -> str/numpy_array- image path read and processed by maskformer .
|
| 74 |
+
out_path -> str - output path save the masked output
|
| 75 |
+
skip_read -> bool- If provided image is nd_array skip_read == True else False
|
| 76 |
+
segment_id -> int- id value to extract maks Default value is 100 for road
|
| 77 |
+
"""
|
| 78 |
+
input_image = cv2.cvtColor( cv2.imread(image_name),cv2.COLOR_BGR2RGB)
|
| 79 |
+
road_mask = self.generate_road_mask(input_image)
|
| 80 |
+
road_image = self.get_rgb_mask(input_image,road_mask)
|
| 81 |
+
obj_prop = round((np.count_nonzero(road_image) / np.size(road_image)) * 100, 1)
|
| 82 |
+
## empty gou cache
|
| 83 |
+
with th.no_grad():
|
| 84 |
+
th.cuda.empty_cache()
|
| 85 |
+
return obj_prop
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
def main(args):
|
| 89 |
+
mask2former = ROADMASK_WITH_MASK2FORMER()
|
| 90 |
+
input_image = cv2.cvtColor( cv2.imread(args.image_path),cv2.COLOR_BGR2RGB)
|
| 91 |
+
|
| 92 |
+
road_mask = mask2former.generate_road_mask(input_image)
|
| 93 |
+
road_image = mask2former.get_rgb_mask(input_image,road_mask)
|
| 94 |
+
obj_prop = round(np.count_nonzero(road_image) / np.size(road_image) * 100, 1)
|
| 95 |
+
|
| 96 |
+
return road_mask , road_image , obj_prop
|
| 97 |
+
|
| 98 |
+
if __name__=="__main__":
|
| 99 |
+
parser = argparse.ArgumentParser()
|
| 100 |
+
parser.add_argument('-image_path',help='raw_image_path', required=True)
|
| 101 |
+
args = parser.parse_args()
|
| 102 |
+
main(args)
|
tool_utils/object_extractor.py
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from pydantic import BaseModel , Field
|
| 2 |
+
from langchain_core.prompts import PromptTemplate
|
| 3 |
+
|
| 4 |
+
class objects_identified(BaseModel):
|
| 5 |
+
objects : str = Field(...,description="Generate a list of objects identified from the given description of the image")
|
| 6 |
+
|
| 7 |
+
def objectextractor_prompt():
|
| 8 |
+
template = """
|
| 9 |
+
You are an AI assistant provided with a context below. The context is a description of an image. Your task is to identify the objects within the image.
|
| 10 |
+
The objects must be living beings or physical items or things that one can view, feel, and touch. these objects must be nouns and not verbs or adjectives or words describing an object like
|
| 11 |
+
'large', 'beautiful' etc .
|
| 12 |
+
Only provide the name of the object and not the description of the object.Refer the example input and output for better understanding.
|
| 13 |
+
If the conntext mention a boy , a girl , women , girls they will come under the category of "People". so the object for such classes will be people .
|
| 14 |
+
Example Input: Context: "A park filled with men and women , a large oak tree standing in the center, a dog running near a bench, and a bicycle leaning against a nearby fence."
|
| 15 |
+
Example Output:"People" , "Dog" , "Bench" , "Bicycle" ,"Fence"
|
| 16 |
+
|
| 17 |
+
Context: {context}
|
| 18 |
+
"""
|
| 19 |
+
prompt = PromptTemplate(template=template,input_variables=["context"])
|
| 20 |
+
return prompt
|
| 21 |
+
|
| 22 |
+
def create_object_extraction_chain(llm):
|
| 23 |
+
object_extraction_chain = objectextractor_prompt() | llm.with_structured_output(objects_identified)
|
| 24 |
+
return object_extraction_chain
|
tool_utils/yolo_world.py
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import logging
|
| 3 |
+
import numpy as np
|
| 4 |
+
from typing import List
|
| 5 |
+
from ultralytics import YOLOWorld
|
| 6 |
+
|
| 7 |
+
class YoloWorld:
|
| 8 |
+
def __init__(self,model_name = "yolov8x-worldv2.pt"):
|
| 9 |
+
self.model = YOLOWorld(model_name)
|
| 10 |
+
self.model.to(device='cpu')
|
| 11 |
+
|
| 12 |
+
def run_inference(self,image_path:str,object_prompts:List):
|
| 13 |
+
object_details = []
|
| 14 |
+
self.model.set_classes(object_prompts)
|
| 15 |
+
results = self.model.predict(image_path)
|
| 16 |
+
for result in results:
|
| 17 |
+
for box in result.boxes:
|
| 18 |
+
object_data = {}
|
| 19 |
+
x1, y1, x2, y2 = np.array(box.xyxy.cpu(), dtype=np.int32).squeeze()
|
| 20 |
+
c1,c2 = (x1,y1),(x2,y2)
|
| 21 |
+
confidence = round(float(box.conf.cpu()),2)
|
| 22 |
+
label = f'{results[0].names[int(box.cls)]}' # [{100*round(confidence,2)}%]'
|
| 23 |
+
print("Object Name :{} Bounding Box:{},{} Confidence score {}\n ".format(label ,c1 ,c2,confidence))
|
| 24 |
+
object_data[label] = {
|
| 25 |
+
'bounding_box':[x1,y1,x2,y2],
|
| 26 |
+
'confidence':confidence
|
| 27 |
+
}
|
| 28 |
+
object_details.append(object_data)
|
| 29 |
+
return object_details
|
| 30 |
+
|
utils.py
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from collections import defaultdict
|
| 2 |
+
import matplotlib.pyplot as plt
|
| 3 |
+
import matplotlib.patches as mpatches
|
| 4 |
+
from matplotlib import cm
|
| 5 |
+
import torch
|
| 6 |
+
|
| 7 |
+
def draw_panoptic_segmentation(model,segmentation, segments_info):
|
| 8 |
+
# get the used color map
|
| 9 |
+
viridis = cm.get_cmap('viridis', torch.max(segmentation))
|
| 10 |
+
fig, ax = plt.subplots()
|
| 11 |
+
ax.imshow(segmentation.cpu().numpy())
|
| 12 |
+
instances_counter = defaultdict(int)
|
| 13 |
+
handles = []
|
| 14 |
+
# for each segment, draw its legend
|
| 15 |
+
for segment in segments_info:
|
| 16 |
+
segment_id = segment['id']
|
| 17 |
+
segment_label_id = segment['label_id']
|
| 18 |
+
segment_label = model.config.id2label[segment_label_id]
|
| 19 |
+
label = f"{segment_label}-{instances_counter[segment_label_id]}"
|
| 20 |
+
instances_counter[segment_label_id] += 1
|
| 21 |
+
color = viridis(segment_id)
|
| 22 |
+
handles.append(mpatches.Patch(color=color, label=label))
|
| 23 |
+
|
| 24 |
+
# ax.legend(handles=handles)
|
| 25 |
+
fig.savefig('final_mask.png')
|
| 26 |
+
return 'final_mask.png'
|