Spaces:
Sleeping
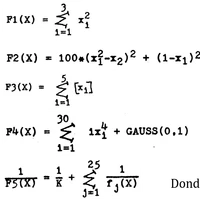
Sleeping
Update app.py
Browse files
app.py
CHANGED
|
@@ -59,6 +59,84 @@ def process_uploaded_file(file):
|
|
| 59 |
return preprocessor.clean_text(raw_text)
|
| 60 |
return raw_text
|
| 61 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 62 |
# Interfaz dinámica
|
| 63 |
with gr.Blocks() as interface:
|
| 64 |
gr.Markdown("# Aplicación Híbrida para Resumir Documentos de Forma Extractiva y Abstractiva")
|
|
|
|
| 59 |
return preprocessor.clean_text(raw_text)
|
| 60 |
return raw_text
|
| 61 |
|
| 62 |
+
#
|
| 63 |
+
def summarize(input_text, file, summary_type, method, num_sentences, model_name, max_length, num_beams):
|
| 64 |
+
"""
|
| 65 |
+
Genera un resumen basado en el texto de entrada o archivo cargado.
|
| 66 |
+
|
| 67 |
+
Args:
|
| 68 |
+
input_text (str): Texto ingresado por el usuario.
|
| 69 |
+
file (UploadedFile): Archivo subido por el usuario.
|
| 70 |
+
summary_type (str): Tipo de resumen: Extractivo, Abstractivo o Combinado.
|
| 71 |
+
method (str): Método de resumen extractivo.
|
| 72 |
+
num_sentences (int): Número de oraciones para el resumen extractivo.
|
| 73 |
+
model_name (str): Nombre del modelo para resumen abstractivo.
|
| 74 |
+
max_length (int): Longitud máxima del resumen generado.
|
| 75 |
+
num_beams (int): Número de haces para búsqueda en el modelo.
|
| 76 |
+
|
| 77 |
+
Returns:
|
| 78 |
+
str: Resumen generado o mensaje de error.
|
| 79 |
+
"""
|
| 80 |
+
preprocessor = Preprocessor()
|
| 81 |
+
|
| 82 |
+
# Procesar archivo si se sube uno
|
| 83 |
+
if file is not None:
|
| 84 |
+
input_text = process_file(file)
|
| 85 |
+
|
| 86 |
+
# Validar que haya texto para resumir
|
| 87 |
+
if not input_text.strip():
|
| 88 |
+
return "Por favor, ingrese texto o cargue un archivo válido."
|
| 89 |
+
|
| 90 |
+
cleaned_text = preprocessor.clean_text(input_text)
|
| 91 |
+
|
| 92 |
+
# Procesar según el tipo de resumen seleccionado
|
| 93 |
+
if summary_type == "Extractivo":
|
| 94 |
+
if method == "TF-IDF":
|
| 95 |
+
summarizer = TFIDFSummarizer()
|
| 96 |
+
elif method == "TextRank":
|
| 97 |
+
summarizer = TextRankSummarizer()
|
| 98 |
+
elif method == "BERT":
|
| 99 |
+
summarizer = BERTSummarizer()
|
| 100 |
+
elif method == "TF-IDF + TextRank":
|
| 101 |
+
summarizer = CombinedSummarizer()
|
| 102 |
+
else:
|
| 103 |
+
return "Método no válido para resumen extractivo."
|
| 104 |
+
|
| 105 |
+
return summarizer.summarize(
|
| 106 |
+
preprocessor.split_into_sentences(cleaned_text),
|
| 107 |
+
preprocessor.clean_sentences(preprocessor.split_into_sentences(cleaned_text)),
|
| 108 |
+
num_sentences,
|
| 109 |
+
)
|
| 110 |
+
|
| 111 |
+
elif summary_type == "Abstractivo":
|
| 112 |
+
if model_name not in summarizers:
|
| 113 |
+
return "Modelo no disponible para resumen abstractivo."
|
| 114 |
+
return handle_long_text(
|
| 115 |
+
cleaned_text,
|
| 116 |
+
summarizers[model_name][0],
|
| 117 |
+
summarizers[model_name][1],
|
| 118 |
+
max_length=max_length,
|
| 119 |
+
stride=128,
|
| 120 |
+
)
|
| 121 |
+
|
| 122 |
+
elif summary_type == "Combinado":
|
| 123 |
+
if model_name not in summarizers:
|
| 124 |
+
return "Modelo no disponible para resumen abstractivo."
|
| 125 |
+
extractive_summary = TFIDFSummarizer().summarize(
|
| 126 |
+
preprocessor.split_into_sentences(cleaned_text),
|
| 127 |
+
preprocessor.clean_sentences(preprocessor.split_into_sentences(cleaned_text)),
|
| 128 |
+
num_sentences,
|
| 129 |
+
)
|
| 130 |
+
return handle_long_text(
|
| 131 |
+
extractive_summary,
|
| 132 |
+
summarizers[model_name][0],
|
| 133 |
+
summarizers[model_name][1],
|
| 134 |
+
max_length=max_length,
|
| 135 |
+
stride=128,
|
| 136 |
+
)
|
| 137 |
+
|
| 138 |
+
return "Seleccione un tipo de resumen válido."
|
| 139 |
+
|
| 140 |
# Interfaz dinámica
|
| 141 |
with gr.Blocks() as interface:
|
| 142 |
gr.Markdown("# Aplicación Híbrida para Resumir Documentos de Forma Extractiva y Abstractiva")
|