Spaces:
Runtime error

Runtime error
add application code
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- LICENSE +21 -0
- app.py +38 -0
- data/LICENSE +437 -0
- data/README.md +26 -0
- data/highlight_test_release.jsonl +3 -0
- data/highlight_train_release.jsonl +3 -0
- data/highlight_val_release.jsonl +3 -0
- data/subs_train.jsonl +3 -0
- moment_detr/__init__.py +0 -0
- moment_detr/config.py +226 -0
- moment_detr/inference.py +259 -0
- moment_detr/matcher.py +107 -0
- moment_detr/misc.py +21 -0
- moment_detr/model.py +444 -0
- moment_detr/position_encoding.py +115 -0
- moment_detr/postprocessing_moment_detr.py +95 -0
- moment_detr/scripts/inference.sh +8 -0
- moment_detr/scripts/pretrain.sh +61 -0
- moment_detr/scripts/train.sh +54 -0
- moment_detr/span_utils.py +122 -0
- moment_detr/start_end_dataset.py +247 -0
- moment_detr/text_encoder.py +53 -0
- moment_detr/train.py +266 -0
- moment_detr/transformer.py +471 -0
- requirements.txt +14 -0
- res/model_overview.png +0 -0
- run_on_video/clip/__init__.py +1 -0
- run_on_video/clip/bpe_simple_vocab_16e6.txt.gz +3 -0
- run_on_video/clip/clip.py +195 -0
- run_on_video/clip/model.py +432 -0
- run_on_video/clip/simple_tokenizer.py +132 -0
- run_on_video/data_utils.py +183 -0
- run_on_video/dataset.py +72 -0
- run_on_video/eval.py +10 -0
- run_on_video/example/RoripwjYFp8_60.0_210.0.mp4 +3 -0
- run_on_video/example/queries.jsonl +3 -0
- run_on_video/model_utils.py +32 -0
- run_on_video/moment_detr_ckpt/README.md +9 -0
- run_on_video/moment_detr_ckpt/eval.log.txt +40 -0
- run_on_video/moment_detr_ckpt/inference_hl_val_test_code_preds.jsonl +3 -0
- run_on_video/moment_detr_ckpt/inference_hl_val_test_code_preds_metrics.json +138 -0
- run_on_video/moment_detr_ckpt/model_best.ckpt +3 -0
- run_on_video/moment_detr_ckpt/opt.json +75 -0
- run_on_video/moment_detr_ckpt/train.log.txt +200 -0
- run_on_video/run.py +170 -0
- standalone_eval/README.md +54 -0
- standalone_eval/eval.py +344 -0
- standalone_eval/eval_sample.sh +10 -0
- standalone_eval/sample_val_preds.jsonl +3 -0
- standalone_eval/sample_val_preds_metrics_raw.json +138 -0
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2021 Jie Lei
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
app.py
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
|
| 3 |
+
TITLE = """<h2 align="center"> ✍️ Highlight Detection with MomentDETR </h2>"""
|
| 4 |
+
|
| 5 |
+
def submit_video(input_video, retrieval_text):
|
| 6 |
+
print(input_video)
|
| 7 |
+
print(retrieval_text)
|
| 8 |
+
return input_video
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
with gr.Blocks() as demo:
|
| 12 |
+
gr.HTML(TITLE)
|
| 13 |
+
with gr.Row():
|
| 14 |
+
with gr.Blocks():
|
| 15 |
+
with gr.Column():
|
| 16 |
+
gr.Markdown("### Input Video")
|
| 17 |
+
input_video = gr.PlayableVideo().style(height=500)
|
| 18 |
+
retrieval_text = gr.Textbox(
|
| 19 |
+
placeholder="What should be highlighted?",
|
| 20 |
+
visible=True
|
| 21 |
+
)
|
| 22 |
+
submit =gr.Button("Submit")
|
| 23 |
+
with gr.Blocks():
|
| 24 |
+
with gr.Column():
|
| 25 |
+
gr.Markdown("### Results")
|
| 26 |
+
with gr.Row():
|
| 27 |
+
output_video = gr.PlayableVideo().style(height=500)
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
submit.click(
|
| 33 |
+
fn=submit_video,
|
| 34 |
+
inputs=[input_video, retrieval_text],
|
| 35 |
+
outputs=[output_video]
|
| 36 |
+
)
|
| 37 |
+
|
| 38 |
+
demo.launch()
|
data/LICENSE
ADDED
|
@@ -0,0 +1,437 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Attribution-NonCommercial-ShareAlike 4.0 International
|
| 2 |
+
|
| 3 |
+
=======================================================================
|
| 4 |
+
|
| 5 |
+
Creative Commons Corporation ("Creative Commons") is not a law firm and
|
| 6 |
+
does not provide legal services or legal advice. Distribution of
|
| 7 |
+
Creative Commons public licenses does not create a lawyer-client or
|
| 8 |
+
other relationship. Creative Commons makes its licenses and related
|
| 9 |
+
information available on an "as-is" basis. Creative Commons gives no
|
| 10 |
+
warranties regarding its licenses, any material licensed under their
|
| 11 |
+
terms and conditions, or any related information. Creative Commons
|
| 12 |
+
disclaims all liability for damages resulting from their use to the
|
| 13 |
+
fullest extent possible.
|
| 14 |
+
|
| 15 |
+
Using Creative Commons Public Licenses
|
| 16 |
+
|
| 17 |
+
Creative Commons public licenses provide a standard set of terms and
|
| 18 |
+
conditions that creators and other rights holders may use to share
|
| 19 |
+
original works of authorship and other material subject to copyright
|
| 20 |
+
and certain other rights specified in the public license below. The
|
| 21 |
+
following considerations are for informational purposes only, are not
|
| 22 |
+
exhaustive, and do not form part of our licenses.
|
| 23 |
+
|
| 24 |
+
Considerations for licensors: Our public licenses are
|
| 25 |
+
intended for use by those authorized to give the public
|
| 26 |
+
permission to use material in ways otherwise restricted by
|
| 27 |
+
copyright and certain other rights. Our licenses are
|
| 28 |
+
irrevocable. Licensors should read and understand the terms
|
| 29 |
+
and conditions of the license they choose before applying it.
|
| 30 |
+
Licensors should also secure all rights necessary before
|
| 31 |
+
applying our licenses so that the public can reuse the
|
| 32 |
+
material as expected. Licensors should clearly mark any
|
| 33 |
+
material not subject to the license. This includes other CC-
|
| 34 |
+
licensed material, or material used under an exception or
|
| 35 |
+
limitation to copyright. More considerations for licensors:
|
| 36 |
+
wiki.creativecommons.org/Considerations_for_licensors
|
| 37 |
+
|
| 38 |
+
Considerations for the public: By using one of our public
|
| 39 |
+
licenses, a licensor grants the public permission to use the
|
| 40 |
+
licensed material under specified terms and conditions. If
|
| 41 |
+
the licensor's permission is not necessary for any reason--for
|
| 42 |
+
example, because of any applicable exception or limitation to
|
| 43 |
+
copyright--then that use is not regulated by the license. Our
|
| 44 |
+
licenses grant only permissions under copyright and certain
|
| 45 |
+
other rights that a licensor has authority to grant. Use of
|
| 46 |
+
the licensed material may still be restricted for other
|
| 47 |
+
reasons, including because others have copyright or other
|
| 48 |
+
rights in the material. A licensor may make special requests,
|
| 49 |
+
such as asking that all changes be marked or described.
|
| 50 |
+
Although not required by our licenses, you are encouraged to
|
| 51 |
+
respect those requests where reasonable. More considerations
|
| 52 |
+
for the public:
|
| 53 |
+
wiki.creativecommons.org/Considerations_for_licensees
|
| 54 |
+
|
| 55 |
+
=======================================================================
|
| 56 |
+
|
| 57 |
+
Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International
|
| 58 |
+
Public License
|
| 59 |
+
|
| 60 |
+
By exercising the Licensed Rights (defined below), You accept and agree
|
| 61 |
+
to be bound by the terms and conditions of this Creative Commons
|
| 62 |
+
Attribution-NonCommercial-ShareAlike 4.0 International Public License
|
| 63 |
+
("Public License"). To the extent this Public License may be
|
| 64 |
+
interpreted as a contract, You are granted the Licensed Rights in
|
| 65 |
+
consideration of Your acceptance of these terms and conditions, and the
|
| 66 |
+
Licensor grants You such rights in consideration of benefits the
|
| 67 |
+
Licensor receives from making the Licensed Material available under
|
| 68 |
+
these terms and conditions.
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
Section 1 -- Definitions.
|
| 72 |
+
|
| 73 |
+
a. Adapted Material means material subject to Copyright and Similar
|
| 74 |
+
Rights that is derived from or based upon the Licensed Material
|
| 75 |
+
and in which the Licensed Material is translated, altered,
|
| 76 |
+
arranged, transformed, or otherwise modified in a manner requiring
|
| 77 |
+
permission under the Copyright and Similar Rights held by the
|
| 78 |
+
Licensor. For purposes of this Public License, where the Licensed
|
| 79 |
+
Material is a musical work, performance, or sound recording,
|
| 80 |
+
Adapted Material is always produced where the Licensed Material is
|
| 81 |
+
synched in timed relation with a moving image.
|
| 82 |
+
|
| 83 |
+
b. Adapter's License means the license You apply to Your Copyright
|
| 84 |
+
and Similar Rights in Your contributions to Adapted Material in
|
| 85 |
+
accordance with the terms and conditions of this Public License.
|
| 86 |
+
|
| 87 |
+
c. BY-NC-SA Compatible License means a license listed at
|
| 88 |
+
creativecommons.org/compatiblelicenses, approved by Creative
|
| 89 |
+
Commons as essentially the equivalent of this Public License.
|
| 90 |
+
|
| 91 |
+
d. Copyright and Similar Rights means copyright and/or similar rights
|
| 92 |
+
closely related to copyright including, without limitation,
|
| 93 |
+
performance, broadcast, sound recording, and Sui Generis Database
|
| 94 |
+
Rights, without regard to how the rights are labeled or
|
| 95 |
+
categorized. For purposes of this Public License, the rights
|
| 96 |
+
specified in Section 2(b)(1)-(2) are not Copyright and Similar
|
| 97 |
+
Rights.
|
| 98 |
+
|
| 99 |
+
e. Effective Technological Measures means those measures that, in the
|
| 100 |
+
absence of proper authority, may not be circumvented under laws
|
| 101 |
+
fulfilling obligations under Article 11 of the WIPO Copyright
|
| 102 |
+
Treaty adopted on December 20, 1996, and/or similar international
|
| 103 |
+
agreements.
|
| 104 |
+
|
| 105 |
+
f. Exceptions and Limitations means fair use, fair dealing, and/or
|
| 106 |
+
any other exception or limitation to Copyright and Similar Rights
|
| 107 |
+
that applies to Your use of the Licensed Material.
|
| 108 |
+
|
| 109 |
+
g. License Elements means the license attributes listed in the name
|
| 110 |
+
of a Creative Commons Public License. The License Elements of this
|
| 111 |
+
Public License are Attribution, NonCommercial, and ShareAlike.
|
| 112 |
+
|
| 113 |
+
h. Licensed Material means the artistic or literary work, database,
|
| 114 |
+
or other material to which the Licensor applied this Public
|
| 115 |
+
License.
|
| 116 |
+
|
| 117 |
+
i. Licensed Rights means the rights granted to You subject to the
|
| 118 |
+
terms and conditions of this Public License, which are limited to
|
| 119 |
+
all Copyright and Similar Rights that apply to Your use of the
|
| 120 |
+
Licensed Material and that the Licensor has authority to license.
|
| 121 |
+
|
| 122 |
+
j. Licensor means the individual(s) or entity(ies) granting rights
|
| 123 |
+
under this Public License.
|
| 124 |
+
|
| 125 |
+
k. NonCommercial means not primarily intended for or directed towards
|
| 126 |
+
commercial advantage or monetary compensation. For purposes of
|
| 127 |
+
this Public License, the exchange of the Licensed Material for
|
| 128 |
+
other material subject to Copyright and Similar Rights by digital
|
| 129 |
+
file-sharing or similar means is NonCommercial provided there is
|
| 130 |
+
no payment of monetary compensation in connection with the
|
| 131 |
+
exchange.
|
| 132 |
+
|
| 133 |
+
l. Share means to provide material to the public by any means or
|
| 134 |
+
process that requires permission under the Licensed Rights, such
|
| 135 |
+
as reproduction, public display, public performance, distribution,
|
| 136 |
+
dissemination, communication, or importation, and to make material
|
| 137 |
+
available to the public including in ways that members of the
|
| 138 |
+
public may access the material from a place and at a time
|
| 139 |
+
individually chosen by them.
|
| 140 |
+
|
| 141 |
+
m. Sui Generis Database Rights means rights other than copyright
|
| 142 |
+
resulting from Directive 96/9/EC of the European Parliament and of
|
| 143 |
+
the Council of 11 March 1996 on the legal protection of databases,
|
| 144 |
+
as amended and/or succeeded, as well as other essentially
|
| 145 |
+
equivalent rights anywhere in the world.
|
| 146 |
+
|
| 147 |
+
n. You means the individual or entity exercising the Licensed Rights
|
| 148 |
+
under this Public License. Your has a corresponding meaning.
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
Section 2 -- Scope.
|
| 152 |
+
|
| 153 |
+
a. License grant.
|
| 154 |
+
|
| 155 |
+
1. Subject to the terms and conditions of this Public License,
|
| 156 |
+
the Licensor hereby grants You a worldwide, royalty-free,
|
| 157 |
+
non-sublicensable, non-exclusive, irrevocable license to
|
| 158 |
+
exercise the Licensed Rights in the Licensed Material to:
|
| 159 |
+
|
| 160 |
+
a. reproduce and Share the Licensed Material, in whole or
|
| 161 |
+
in part, for NonCommercial purposes only; and
|
| 162 |
+
|
| 163 |
+
b. produce, reproduce, and Share Adapted Material for
|
| 164 |
+
NonCommercial purposes only.
|
| 165 |
+
|
| 166 |
+
2. Exceptions and Limitations. For the avoidance of doubt, where
|
| 167 |
+
Exceptions and Limitations apply to Your use, this Public
|
| 168 |
+
License does not apply, and You do not need to comply with
|
| 169 |
+
its terms and conditions.
|
| 170 |
+
|
| 171 |
+
3. Term. The term of this Public License is specified in Section
|
| 172 |
+
6(a).
|
| 173 |
+
|
| 174 |
+
4. Media and formats; technical modifications allowed. The
|
| 175 |
+
Licensor authorizes You to exercise the Licensed Rights in
|
| 176 |
+
all media and formats whether now known or hereafter created,
|
| 177 |
+
and to make technical modifications necessary to do so. The
|
| 178 |
+
Licensor waives and/or agrees not to assert any right or
|
| 179 |
+
authority to forbid You from making technical modifications
|
| 180 |
+
necessary to exercise the Licensed Rights, including
|
| 181 |
+
technical modifications necessary to circumvent Effective
|
| 182 |
+
Technological Measures. For purposes of this Public License,
|
| 183 |
+
simply making modifications authorized by this Section 2(a)
|
| 184 |
+
(4) never produces Adapted Material.
|
| 185 |
+
|
| 186 |
+
5. Downstream recipients.
|
| 187 |
+
|
| 188 |
+
a. Offer from the Licensor -- Licensed Material. Every
|
| 189 |
+
recipient of the Licensed Material automatically
|
| 190 |
+
receives an offer from the Licensor to exercise the
|
| 191 |
+
Licensed Rights under the terms and conditions of this
|
| 192 |
+
Public License.
|
| 193 |
+
|
| 194 |
+
b. Additional offer from the Licensor -- Adapted Material.
|
| 195 |
+
Every recipient of Adapted Material from You
|
| 196 |
+
automatically receives an offer from the Licensor to
|
| 197 |
+
exercise the Licensed Rights in the Adapted Material
|
| 198 |
+
under the conditions of the Adapter's License You apply.
|
| 199 |
+
|
| 200 |
+
c. No downstream restrictions. You may not offer or impose
|
| 201 |
+
any additional or different terms or conditions on, or
|
| 202 |
+
apply any Effective Technological Measures to, the
|
| 203 |
+
Licensed Material if doing so restricts exercise of the
|
| 204 |
+
Licensed Rights by any recipient of the Licensed
|
| 205 |
+
Material.
|
| 206 |
+
|
| 207 |
+
6. No endorsement. Nothing in this Public License constitutes or
|
| 208 |
+
may be construed as permission to assert or imply that You
|
| 209 |
+
are, or that Your use of the Licensed Material is, connected
|
| 210 |
+
with, or sponsored, endorsed, or granted official status by,
|
| 211 |
+
the Licensor or others designated to receive attribution as
|
| 212 |
+
provided in Section 3(a)(1)(A)(i).
|
| 213 |
+
|
| 214 |
+
b. Other rights.
|
| 215 |
+
|
| 216 |
+
1. Moral rights, such as the right of integrity, are not
|
| 217 |
+
licensed under this Public License, nor are publicity,
|
| 218 |
+
privacy, and/or other similar personality rights; however, to
|
| 219 |
+
the extent possible, the Licensor waives and/or agrees not to
|
| 220 |
+
assert any such rights held by the Licensor to the limited
|
| 221 |
+
extent necessary to allow You to exercise the Licensed
|
| 222 |
+
Rights, but not otherwise.
|
| 223 |
+
|
| 224 |
+
2. Patent and trademark rights are not licensed under this
|
| 225 |
+
Public License.
|
| 226 |
+
|
| 227 |
+
3. To the extent possible, the Licensor waives any right to
|
| 228 |
+
collect royalties from You for the exercise of the Licensed
|
| 229 |
+
Rights, whether directly or through a collecting society
|
| 230 |
+
under any voluntary or waivable statutory or compulsory
|
| 231 |
+
licensing scheme. In all other cases the Licensor expressly
|
| 232 |
+
reserves any right to collect such royalties, including when
|
| 233 |
+
the Licensed Material is used other than for NonCommercial
|
| 234 |
+
purposes.
|
| 235 |
+
|
| 236 |
+
|
| 237 |
+
Section 3 -- License Conditions.
|
| 238 |
+
|
| 239 |
+
Your exercise of the Licensed Rights is expressly made subject to the
|
| 240 |
+
following conditions.
|
| 241 |
+
|
| 242 |
+
a. Attribution.
|
| 243 |
+
|
| 244 |
+
1. If You Share the Licensed Material (including in modified
|
| 245 |
+
form), You must:
|
| 246 |
+
|
| 247 |
+
a. retain the following if it is supplied by the Licensor
|
| 248 |
+
with the Licensed Material:
|
| 249 |
+
|
| 250 |
+
i. identification of the creator(s) of the Licensed
|
| 251 |
+
Material and any others designated to receive
|
| 252 |
+
attribution, in any reasonable manner requested by
|
| 253 |
+
the Licensor (including by pseudonym if
|
| 254 |
+
designated);
|
| 255 |
+
|
| 256 |
+
ii. a copyright notice;
|
| 257 |
+
|
| 258 |
+
iii. a notice that refers to this Public License;
|
| 259 |
+
|
| 260 |
+
iv. a notice that refers to the disclaimer of
|
| 261 |
+
warranties;
|
| 262 |
+
|
| 263 |
+
v. a URI or hyperlink to the Licensed Material to the
|
| 264 |
+
extent reasonably practicable;
|
| 265 |
+
|
| 266 |
+
b. indicate if You modified the Licensed Material and
|
| 267 |
+
retain an indication of any previous modifications; and
|
| 268 |
+
|
| 269 |
+
c. indicate the Licensed Material is licensed under this
|
| 270 |
+
Public License, and include the text of, or the URI or
|
| 271 |
+
hyperlink to, this Public License.
|
| 272 |
+
|
| 273 |
+
2. You may satisfy the conditions in Section 3(a)(1) in any
|
| 274 |
+
reasonable manner based on the medium, means, and context in
|
| 275 |
+
which You Share the Licensed Material. For example, it may be
|
| 276 |
+
reasonable to satisfy the conditions by providing a URI or
|
| 277 |
+
hyperlink to a resource that includes the required
|
| 278 |
+
information.
|
| 279 |
+
3. If requested by the Licensor, You must remove any of the
|
| 280 |
+
information required by Section 3(a)(1)(A) to the extent
|
| 281 |
+
reasonably practicable.
|
| 282 |
+
|
| 283 |
+
b. ShareAlike.
|
| 284 |
+
|
| 285 |
+
In addition to the conditions in Section 3(a), if You Share
|
| 286 |
+
Adapted Material You produce, the following conditions also apply.
|
| 287 |
+
|
| 288 |
+
1. The Adapter's License You apply must be a Creative Commons
|
| 289 |
+
license with the same License Elements, this version or
|
| 290 |
+
later, or a BY-NC-SA Compatible License.
|
| 291 |
+
|
| 292 |
+
2. You must include the text of, or the URI or hyperlink to, the
|
| 293 |
+
Adapter's License You apply. You may satisfy this condition
|
| 294 |
+
in any reasonable manner based on the medium, means, and
|
| 295 |
+
context in which You Share Adapted Material.
|
| 296 |
+
|
| 297 |
+
3. You may not offer or impose any additional or different terms
|
| 298 |
+
or conditions on, or apply any Effective Technological
|
| 299 |
+
Measures to, Adapted Material that restrict exercise of the
|
| 300 |
+
rights granted under the Adapter's License You apply.
|
| 301 |
+
|
| 302 |
+
|
| 303 |
+
Section 4 -- Sui Generis Database Rights.
|
| 304 |
+
|
| 305 |
+
Where the Licensed Rights include Sui Generis Database Rights that
|
| 306 |
+
apply to Your use of the Licensed Material:
|
| 307 |
+
|
| 308 |
+
a. for the avoidance of doubt, Section 2(a)(1) grants You the right
|
| 309 |
+
to extract, reuse, reproduce, and Share all or a substantial
|
| 310 |
+
portion of the contents of the database for NonCommercial purposes
|
| 311 |
+
only;
|
| 312 |
+
|
| 313 |
+
b. if You include all or a substantial portion of the database
|
| 314 |
+
contents in a database in which You have Sui Generis Database
|
| 315 |
+
Rights, then the database in which You have Sui Generis Database
|
| 316 |
+
Rights (but not its individual contents) is Adapted Material,
|
| 317 |
+
including for purposes of Section 3(b); and
|
| 318 |
+
|
| 319 |
+
c. You must comply with the conditions in Section 3(a) if You Share
|
| 320 |
+
all or a substantial portion of the contents of the database.
|
| 321 |
+
|
| 322 |
+
For the avoidance of doubt, this Section 4 supplements and does not
|
| 323 |
+
replace Your obligations under this Public License where the Licensed
|
| 324 |
+
Rights include other Copyright and Similar Rights.
|
| 325 |
+
|
| 326 |
+
|
| 327 |
+
Section 5 -- Disclaimer of Warranties and Limitation of Liability.
|
| 328 |
+
|
| 329 |
+
a. UNLESS OTHERWISE SEPARATELY UNDERTAKEN BY THE LICENSOR, TO THE
|
| 330 |
+
EXTENT POSSIBLE, THE LICENSOR OFFERS THE LICENSED MATERIAL AS-IS
|
| 331 |
+
AND AS-AVAILABLE, AND MAKES NO REPRESENTATIONS OR WARRANTIES OF
|
| 332 |
+
ANY KIND CONCERNING THE LICENSED MATERIAL, WHETHER EXPRESS,
|
| 333 |
+
IMPLIED, STATUTORY, OR OTHER. THIS INCLUDES, WITHOUT LIMITATION,
|
| 334 |
+
WARRANTIES OF TITLE, MERCHANTABILITY, FITNESS FOR A PARTICULAR
|
| 335 |
+
PURPOSE, NON-INFRINGEMENT, ABSENCE OF LATENT OR OTHER DEFECTS,
|
| 336 |
+
ACCURACY, OR THE PRESENCE OR ABSENCE OF ERRORS, WHETHER OR NOT
|
| 337 |
+
KNOWN OR DISCOVERABLE. WHERE DISCLAIMERS OF WARRANTIES ARE NOT
|
| 338 |
+
ALLOWED IN FULL OR IN PART, THIS DISCLAIMER MAY NOT APPLY TO YOU.
|
| 339 |
+
|
| 340 |
+
b. TO THE EXTENT POSSIBLE, IN NO EVENT WILL THE LICENSOR BE LIABLE
|
| 341 |
+
TO YOU ON ANY LEGAL THEORY (INCLUDING, WITHOUT LIMITATION,
|
| 342 |
+
NEGLIGENCE) OR OTHERWISE FOR ANY DIRECT, SPECIAL, INDIRECT,
|
| 343 |
+
INCIDENTAL, CONSEQUENTIAL, PUNITIVE, EXEMPLARY, OR OTHER LOSSES,
|
| 344 |
+
COSTS, EXPENSES, OR DAMAGES ARISING OUT OF THIS PUBLIC LICENSE OR
|
| 345 |
+
USE OF THE LICENSED MATERIAL, EVEN IF THE LICENSOR HAS BEEN
|
| 346 |
+
ADVISED OF THE POSSIBILITY OF SUCH LOSSES, COSTS, EXPENSES, OR
|
| 347 |
+
DAMAGES. WHERE A LIMITATION OF LIABILITY IS NOT ALLOWED IN FULL OR
|
| 348 |
+
IN PART, THIS LIMITATION MAY NOT APPLY TO YOU.
|
| 349 |
+
|
| 350 |
+
c. The disclaimer of warranties and limitation of liability provided
|
| 351 |
+
above shall be interpreted in a manner that, to the extent
|
| 352 |
+
possible, most closely approximates an absolute disclaimer and
|
| 353 |
+
waiver of all liability.
|
| 354 |
+
|
| 355 |
+
|
| 356 |
+
Section 6 -- Term and Termination.
|
| 357 |
+
|
| 358 |
+
a. This Public License applies for the term of the Copyright and
|
| 359 |
+
Similar Rights licensed here. However, if You fail to comply with
|
| 360 |
+
this Public License, then Your rights under this Public License
|
| 361 |
+
terminate automatically.
|
| 362 |
+
|
| 363 |
+
b. Where Your right to use the Licensed Material has terminated under
|
| 364 |
+
Section 6(a), it reinstates:
|
| 365 |
+
|
| 366 |
+
1. automatically as of the date the violation is cured, provided
|
| 367 |
+
it is cured within 30 days of Your discovery of the
|
| 368 |
+
violation; or
|
| 369 |
+
|
| 370 |
+
2. upon express reinstatement by the Licensor.
|
| 371 |
+
|
| 372 |
+
For the avoidance of doubt, this Section 6(b) does not affect any
|
| 373 |
+
right the Licensor may have to seek remedies for Your violations
|
| 374 |
+
of this Public License.
|
| 375 |
+
|
| 376 |
+
c. For the avoidance of doubt, the Licensor may also offer the
|
| 377 |
+
Licensed Material under separate terms or conditions or stop
|
| 378 |
+
distributing the Licensed Material at any time; however, doing so
|
| 379 |
+
will not terminate this Public License.
|
| 380 |
+
|
| 381 |
+
d. Sections 1, 5, 6, 7, and 8 survive termination of this Public
|
| 382 |
+
License.
|
| 383 |
+
|
| 384 |
+
|
| 385 |
+
Section 7 -- Other Terms and Conditions.
|
| 386 |
+
|
| 387 |
+
a. The Licensor shall not be bound by any additional or different
|
| 388 |
+
terms or conditions communicated by You unless expressly agreed.
|
| 389 |
+
|
| 390 |
+
b. Any arrangements, understandings, or agreements regarding the
|
| 391 |
+
Licensed Material not stated herein are separate from and
|
| 392 |
+
independent of the terms and conditions of this Public License.
|
| 393 |
+
|
| 394 |
+
|
| 395 |
+
Section 8 -- Interpretation.
|
| 396 |
+
|
| 397 |
+
a. For the avoidance of doubt, this Public License does not, and
|
| 398 |
+
shall not be interpreted to, reduce, limit, restrict, or impose
|
| 399 |
+
conditions on any use of the Licensed Material that could lawfully
|
| 400 |
+
be made without permission under this Public License.
|
| 401 |
+
|
| 402 |
+
b. To the extent possible, if any provision of this Public License is
|
| 403 |
+
deemed unenforceable, it shall be automatically reformed to the
|
| 404 |
+
minimum extent necessary to make it enforceable. If the provision
|
| 405 |
+
cannot be reformed, it shall be severed from this Public License
|
| 406 |
+
without affecting the enforceability of the remaining terms and
|
| 407 |
+
conditions.
|
| 408 |
+
|
| 409 |
+
c. No term or condition of this Public License will be waived and no
|
| 410 |
+
failure to comply consented to unless expressly agreed to by the
|
| 411 |
+
Licensor.
|
| 412 |
+
|
| 413 |
+
d. Nothing in this Public License constitutes or may be interpreted
|
| 414 |
+
as a limitation upon, or waiver of, any privileges and immunities
|
| 415 |
+
that apply to the Licensor or You, including from the legal
|
| 416 |
+
processes of any jurisdiction or authority.
|
| 417 |
+
|
| 418 |
+
=======================================================================
|
| 419 |
+
|
| 420 |
+
Creative Commons is not a party to its public
|
| 421 |
+
licenses. Notwithstanding, Creative Commons may elect to apply one of
|
| 422 |
+
its public licenses to material it publishes and in those instances
|
| 423 |
+
will be considered the “Licensor.” The text of the Creative Commons
|
| 424 |
+
public licenses is dedicated to the public domain under the CC0 Public
|
| 425 |
+
Domain Dedication. Except for the limited purpose of indicating that
|
| 426 |
+
material is shared under a Creative Commons public license or as
|
| 427 |
+
otherwise permitted by the Creative Commons policies published at
|
| 428 |
+
creativecommons.org/policies, Creative Commons does not authorize the
|
| 429 |
+
use of the trademark "Creative Commons" or any other trademark or logo
|
| 430 |
+
of Creative Commons without its prior written consent including,
|
| 431 |
+
without limitation, in connection with any unauthorized modifications
|
| 432 |
+
to any of its public licenses or any other arrangements,
|
| 433 |
+
understandings, or agreements concerning use of licensed material. For
|
| 434 |
+
the avoidance of doubt, this paragraph does not form part of the
|
| 435 |
+
public licenses.
|
| 436 |
+
|
| 437 |
+
Creative Commons may be contacted at creativecommons.org.
|
data/README.md
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## QVHighlights Dataset
|
| 2 |
+
|
| 3 |
+
All raw video data can be downloaded from this [link](https://nlp.cs.unc.edu/data/jielei/qvh/qvhilights_videos.tar.gz).
|
| 4 |
+
|
| 5 |
+
Our annotation files include 3 splits: `train`, `val` and `test`. Each file is in [JSON Line](https://jsonlines.org/) format, each row of the files can be loaded as a single `dict` in Python. Below is an example of the annotation:
|
| 6 |
+
|
| 7 |
+
```
|
| 8 |
+
{
|
| 9 |
+
"qid": 8737,
|
| 10 |
+
"query": "A family is playing basketball together on a green court outside.",
|
| 11 |
+
"duration": 126,
|
| 12 |
+
"vid": "bP5KfdFJzC4_660.0_810.0",
|
| 13 |
+
"relevant_windows": [[0, 16]],
|
| 14 |
+
"relevant_clip_ids": [0, 1, 2, 3, 4, 5, 6, 7],
|
| 15 |
+
"saliency_scores": [[4, 1, 1], [4, 1, 1], [4, 2, 1], [4, 3, 2], [4, 3, 2], [4, 3, 3], [4, 3, 3], [4, 3, 2]]
|
| 16 |
+
}
|
| 17 |
+
```
|
| 18 |
+
`qid` is a unique identifier of a `query`. This query corresponds to a video identified by its video id `vid`. The `vid` is formatted as `{youtube_id}_{start_time}_{end_time}`. Use this information, one can retrieve the YouTube video from a url `https://www.youtube.com/embed/{youtube_id}?start={start_time}&end={end_time}&version=3`. For example, the video in this example is `https://www.youtube.com/embed/bP5KfdFJzC4?start=660&end=810&version=3`.
|
| 19 |
+
`duration` is an integer indicating the duration of this video.
|
| 20 |
+
`relevant_windows` is the list of windows that localize the moments, each window has two numbers, one indicates the start time of the moment, another one indicates the end time. `relevant_clip_ids` is the list of ids to the segmented 2-second clips that fall into the moments specified by `relevant_windows`, starting from 0.
|
| 21 |
+
`saliency_scores` contains the saliency scores annotations, each sublist corresponds to a clip in `relevant_clip_ids`. There are 3 elements in each sublist, they are the scores from three different annotators. A score of `4` means `Very Good`, while `0` means `Very Bad`.
|
| 22 |
+
|
| 23 |
+
Note that the three fields `relevant_clip_ids`, `relevant_windows` and `saliency_scores` for `test` split is not included. Please refer to [../standalone_eval/README.md](../standalone_eval/README.md) for details on evaluating predictions on `test`.
|
| 24 |
+
|
| 25 |
+
In addition to the annotation files, we also provided the subtitle file for our weakly supervised ASR pre-training: [subs_train.jsonl](./subs_train.jsonl). This file is formatted similarly as our annotation files, but without the `saliency_scores` entry. This file is not needed if you do not plan to pretrain models using it.
|
| 26 |
+
|
data/highlight_test_release.jsonl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0462f0cb582b54913671ba5ebfc325931ffa6d422c60cb72520749fc6d5d05a3
|
| 3 |
+
size 204566
|
data/highlight_train_release.jsonl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:fd28404187468f57cf99242be2963127dc9b4aef26c7de3cb9469569801f2625
|
| 3 |
+
size 3956580
|
data/highlight_val_release.jsonl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f668a1eaea156ec5315e14718999cea043a8cf948d3cafbd8e8d655318c3cd02
|
| 3 |
+
size 821101
|
data/subs_train.jsonl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:33086f20181724a477d7da5b2a063e7935d04d886548917b8ba9912f5a0c7dc5
|
| 3 |
+
size 46786687
|
moment_detr/__init__.py
ADDED
|
File without changes
|
moment_detr/config.py
ADDED
|
@@ -0,0 +1,226 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import time
|
| 3 |
+
import torch
|
| 4 |
+
import argparse
|
| 5 |
+
|
| 6 |
+
from utils.basic_utils import mkdirp, load_json, save_json, make_zipfile, dict_to_markdown
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class BaseOptions(object):
|
| 10 |
+
saved_option_filename = "opt.json"
|
| 11 |
+
ckpt_filename = "model.ckpt"
|
| 12 |
+
tensorboard_log_dir = "tensorboard_log"
|
| 13 |
+
train_log_filename = "train.log.txt"
|
| 14 |
+
eval_log_filename = "eval.log.txt"
|
| 15 |
+
|
| 16 |
+
def __init__(self):
|
| 17 |
+
self.parser = None
|
| 18 |
+
self.initialized = False
|
| 19 |
+
self.opt = None
|
| 20 |
+
|
| 21 |
+
def initialize(self):
|
| 22 |
+
self.initialized = True
|
| 23 |
+
parser = argparse.ArgumentParser()
|
| 24 |
+
parser.add_argument("--dset_name", type=str, choices=["hl"])
|
| 25 |
+
parser.add_argument("--eval_split_name", type=str, default="val",
|
| 26 |
+
help="should match keys in video_duration_idx_path, must set for VCMR")
|
| 27 |
+
parser.add_argument("--debug", action="store_true",
|
| 28 |
+
help="debug (fast) mode, break all loops, do not load all data into memory.")
|
| 29 |
+
parser.add_argument("--data_ratio", type=float, default=1.0,
|
| 30 |
+
help="how many training and eval data to use. 1.0: use all, 0.1: use 10%."
|
| 31 |
+
"Use small portion for debug purposes. Note this is different from --debug, "
|
| 32 |
+
"which works by breaking the loops, typically they are not used together.")
|
| 33 |
+
parser.add_argument("--results_root", type=str, default="results")
|
| 34 |
+
parser.add_argument("--exp_id", type=str, default=None, help="id of this run, required at training")
|
| 35 |
+
parser.add_argument("--seed", type=int, default=2018, help="random seed")
|
| 36 |
+
parser.add_argument("--device", type=int, default=0, help="0 cuda, -1 cpu")
|
| 37 |
+
parser.add_argument("--num_workers", type=int, default=4,
|
| 38 |
+
help="num subprocesses used to load the data, 0: use main process")
|
| 39 |
+
parser.add_argument("--no_pin_memory", action="store_true",
|
| 40 |
+
help="Don't use pin_memory=True for dataloader. "
|
| 41 |
+
"ref: https://discuss.pytorch.org/t/should-we-set-non-blocking-to-true/38234/4")
|
| 42 |
+
|
| 43 |
+
# training config
|
| 44 |
+
parser.add_argument("--lr", type=float, default=1e-4, help="learning rate")
|
| 45 |
+
parser.add_argument("--lr_drop", type=int, default=400, help="drop learning rate to 1/10 every lr_drop epochs")
|
| 46 |
+
parser.add_argument("--wd", type=float, default=1e-4, help="weight decay")
|
| 47 |
+
parser.add_argument("--n_epoch", type=int, default=200, help="number of epochs to run")
|
| 48 |
+
parser.add_argument("--max_es_cnt", type=int, default=200,
|
| 49 |
+
help="number of epochs to early stop, use -1 to disable early stop")
|
| 50 |
+
parser.add_argument("--bsz", type=int, default=32, help="mini-batch size")
|
| 51 |
+
parser.add_argument("--eval_bsz", type=int, default=100,
|
| 52 |
+
help="mini-batch size at inference, for query")
|
| 53 |
+
parser.add_argument("--grad_clip", type=float, default=0.1, help="perform gradient clip, -1: disable")
|
| 54 |
+
parser.add_argument("--eval_untrained", action="store_true", help="Evaluate on un-trained model")
|
| 55 |
+
parser.add_argument("--resume", type=str, default=None,
|
| 56 |
+
help="checkpoint path to resume or evaluate, without --resume_all this only load weights")
|
| 57 |
+
parser.add_argument("--resume_all", action="store_true",
|
| 58 |
+
help="if --resume_all, load optimizer/scheduler/epoch as well")
|
| 59 |
+
parser.add_argument("--start_epoch", type=int, default=None,
|
| 60 |
+
help="if None, will be set automatically when using --resume_all")
|
| 61 |
+
|
| 62 |
+
# Data config
|
| 63 |
+
parser.add_argument("--max_q_l", type=int, default=32)
|
| 64 |
+
parser.add_argument("--max_v_l", type=int, default=75)
|
| 65 |
+
parser.add_argument("--clip_length", type=int, default=2)
|
| 66 |
+
parser.add_argument("--max_windows", type=int, default=5)
|
| 67 |
+
|
| 68 |
+
parser.add_argument("--train_path", type=str, default=None)
|
| 69 |
+
parser.add_argument("--eval_path", type=str, default=None,
|
| 70 |
+
help="Evaluating during training, for Dev set. If None, will only do training, ")
|
| 71 |
+
parser.add_argument("--no_norm_vfeat", action="store_true", help="Do not do normalize video feat")
|
| 72 |
+
parser.add_argument("--no_norm_tfeat", action="store_true", help="Do not do normalize text feat")
|
| 73 |
+
parser.add_argument("--v_feat_dirs", type=str, nargs="+",
|
| 74 |
+
help="video feature dirs. If more than one, will concat their features. "
|
| 75 |
+
"Note that sub ctx features are also accepted here.")
|
| 76 |
+
parser.add_argument("--t_feat_dir", type=str, help="text/query feature dir")
|
| 77 |
+
parser.add_argument("--v_feat_dim", type=int, help="video feature dim")
|
| 78 |
+
parser.add_argument("--t_feat_dim", type=int, help="text/query feature dim")
|
| 79 |
+
parser.add_argument("--ctx_mode", type=str, default="video_tef")
|
| 80 |
+
|
| 81 |
+
# Model config
|
| 82 |
+
parser.add_argument('--position_embedding', default='sine', type=str, choices=('sine', 'learned'),
|
| 83 |
+
help="Type of positional embedding to use on top of the image features")
|
| 84 |
+
# * Transformer
|
| 85 |
+
parser.add_argument('--enc_layers', default=2, type=int,
|
| 86 |
+
help="Number of encoding layers in the transformer")
|
| 87 |
+
parser.add_argument('--dec_layers', default=2, type=int,
|
| 88 |
+
help="Number of decoding layers in the transformer")
|
| 89 |
+
parser.add_argument('--dim_feedforward', default=1024, type=int,
|
| 90 |
+
help="Intermediate size of the feedforward layers in the transformer blocks")
|
| 91 |
+
parser.add_argument('--hidden_dim', default=256, type=int,
|
| 92 |
+
help="Size of the embeddings (dimension of the transformer)")
|
| 93 |
+
parser.add_argument('--input_dropout', default=0.5, type=float,
|
| 94 |
+
help="Dropout applied in input")
|
| 95 |
+
parser.add_argument('--dropout', default=0.1, type=float,
|
| 96 |
+
help="Dropout applied in the transformer")
|
| 97 |
+
parser.add_argument("--txt_drop_ratio", default=0, type=float,
|
| 98 |
+
help="drop txt_drop_ratio tokens from text input. 0.1=10%")
|
| 99 |
+
parser.add_argument("--use_txt_pos", action="store_true", help="use position_embedding for text as well.")
|
| 100 |
+
parser.add_argument('--nheads', default=8, type=int,
|
| 101 |
+
help="Number of attention heads inside the transformer's attentions")
|
| 102 |
+
parser.add_argument('--num_queries', default=10, type=int,
|
| 103 |
+
help="Number of query slots")
|
| 104 |
+
parser.add_argument('--pre_norm', action='store_true')
|
| 105 |
+
# other model configs
|
| 106 |
+
parser.add_argument("--n_input_proj", type=int, default=2, help="#layers to encoder input")
|
| 107 |
+
parser.add_argument("--contrastive_hdim", type=int, default=64, help="dim for contrastive embeddings")
|
| 108 |
+
parser.add_argument("--temperature", type=float, default=0.07, help="temperature nce contrastive_align_loss")
|
| 109 |
+
# Loss
|
| 110 |
+
parser.add_argument("--lw_saliency", type=float, default=1.,
|
| 111 |
+
help="weight for saliency loss, set to 0 will ignore")
|
| 112 |
+
parser.add_argument("--saliency_margin", type=float, default=0.2)
|
| 113 |
+
parser.add_argument('--no_aux_loss', dest='aux_loss', action='store_false',
|
| 114 |
+
help="Disables auxiliary decoding losses (loss at each layer)")
|
| 115 |
+
parser.add_argument("--span_loss_type", default="l1", type=str, choices=['l1', 'ce'],
|
| 116 |
+
help="l1: (center-x, width) regression. ce: (st_idx, ed_idx) classification.")
|
| 117 |
+
parser.add_argument("--contrastive_align_loss", action="store_true",
|
| 118 |
+
help="Disable contrastive_align_loss between matched query spans and the text.")
|
| 119 |
+
# * Matcher
|
| 120 |
+
parser.add_argument('--set_cost_span', default=10, type=float,
|
| 121 |
+
help="L1 span coefficient in the matching cost")
|
| 122 |
+
parser.add_argument('--set_cost_giou', default=1, type=float,
|
| 123 |
+
help="giou span coefficient in the matching cost")
|
| 124 |
+
parser.add_argument('--set_cost_class', default=4, type=float,
|
| 125 |
+
help="Class coefficient in the matching cost")
|
| 126 |
+
|
| 127 |
+
# * Loss coefficients
|
| 128 |
+
parser.add_argument('--span_loss_coef', default=10, type=float)
|
| 129 |
+
parser.add_argument('--giou_loss_coef', default=1, type=float)
|
| 130 |
+
parser.add_argument('--label_loss_coef', default=4, type=float)
|
| 131 |
+
parser.add_argument('--eos_coef', default=0.1, type=float,
|
| 132 |
+
help="Relative classification weight of the no-object class")
|
| 133 |
+
parser.add_argument("--contrastive_align_loss_coef", default=0.0, type=float)
|
| 134 |
+
|
| 135 |
+
parser.add_argument("--no_sort_results", action="store_true",
|
| 136 |
+
help="do not sort results, use this for moment query visualization")
|
| 137 |
+
parser.add_argument("--max_before_nms", type=int, default=10)
|
| 138 |
+
parser.add_argument("--max_after_nms", type=int, default=10)
|
| 139 |
+
parser.add_argument("--conf_thd", type=float, default=0.0, help="only keep windows with conf >= conf_thd")
|
| 140 |
+
parser.add_argument("--nms_thd", type=float, default=-1,
|
| 141 |
+
help="additionally use non-maximum suppression "
|
| 142 |
+
"(or non-minimum suppression for distance)"
|
| 143 |
+
"to post-processing the predictions. "
|
| 144 |
+
"-1: do not use nms. [0, 1]")
|
| 145 |
+
self.parser = parser
|
| 146 |
+
|
| 147 |
+
def display_save(self, opt):
|
| 148 |
+
args = vars(opt)
|
| 149 |
+
# Display settings
|
| 150 |
+
print(dict_to_markdown(vars(opt), max_str_len=120))
|
| 151 |
+
# Save settings
|
| 152 |
+
if not isinstance(self, TestOptions):
|
| 153 |
+
option_file_path = os.path.join(opt.results_dir, self.saved_option_filename) # not yaml file indeed
|
| 154 |
+
save_json(args, option_file_path, save_pretty=True)
|
| 155 |
+
|
| 156 |
+
def parse(self):
|
| 157 |
+
if not self.initialized:
|
| 158 |
+
self.initialize()
|
| 159 |
+
opt = self.parser.parse_args()
|
| 160 |
+
|
| 161 |
+
if opt.debug:
|
| 162 |
+
opt.results_root = os.path.sep.join(opt.results_root.split(os.path.sep)[:-1] + ["debug_results", ])
|
| 163 |
+
opt.num_workers = 0
|
| 164 |
+
|
| 165 |
+
if isinstance(self, TestOptions):
|
| 166 |
+
# modify model_dir to absolute path
|
| 167 |
+
# opt.model_dir = os.path.join(os.path.dirname(os.path.abspath(__file__)), "results", opt.model_dir)
|
| 168 |
+
opt.model_dir = os.path.dirname(opt.resume)
|
| 169 |
+
saved_options = load_json(os.path.join(opt.model_dir, self.saved_option_filename))
|
| 170 |
+
for arg in saved_options: # use saved options to overwrite all BaseOptions args.
|
| 171 |
+
if arg not in ["results_root", "num_workers", "nms_thd", "debug", # "max_before_nms", "max_after_nms"
|
| 172 |
+
"max_pred_l", "min_pred_l",
|
| 173 |
+
"resume", "resume_all", "no_sort_results"]:
|
| 174 |
+
setattr(opt, arg, saved_options[arg])
|
| 175 |
+
# opt.no_core_driver = True
|
| 176 |
+
if opt.eval_results_dir is not None:
|
| 177 |
+
opt.results_dir = opt.eval_results_dir
|
| 178 |
+
else:
|
| 179 |
+
if opt.exp_id is None:
|
| 180 |
+
raise ValueError("--exp_id is required for at a training option!")
|
| 181 |
+
|
| 182 |
+
ctx_str = opt.ctx_mode + "_sub" if any(["sub_ctx" in p for p in opt.v_feat_dirs]) else opt.ctx_mode
|
| 183 |
+
opt.results_dir = os.path.join(opt.results_root,
|
| 184 |
+
"-".join([opt.dset_name, ctx_str, opt.exp_id,
|
| 185 |
+
time.strftime("%Y_%m_%d_%H_%M_%S")]))
|
| 186 |
+
mkdirp(opt.results_dir)
|
| 187 |
+
# save a copy of current code
|
| 188 |
+
code_dir = os.path.dirname(os.path.realpath(__file__))
|
| 189 |
+
code_zip_filename = os.path.join(opt.results_dir, "code.zip")
|
| 190 |
+
make_zipfile(code_dir, code_zip_filename,
|
| 191 |
+
enclosing_dir="code",
|
| 192 |
+
exclude_dirs_substring="results",
|
| 193 |
+
exclude_dirs=["results", "debug_results", "__pycache__"],
|
| 194 |
+
exclude_extensions=[".pyc", ".ipynb", ".swap"], )
|
| 195 |
+
|
| 196 |
+
self.display_save(opt)
|
| 197 |
+
|
| 198 |
+
opt.ckpt_filepath = os.path.join(opt.results_dir, self.ckpt_filename)
|
| 199 |
+
opt.train_log_filepath = os.path.join(opt.results_dir, self.train_log_filename)
|
| 200 |
+
opt.eval_log_filepath = os.path.join(opt.results_dir, self.eval_log_filename)
|
| 201 |
+
opt.tensorboard_log_dir = os.path.join(opt.results_dir, self.tensorboard_log_dir)
|
| 202 |
+
opt.device = torch.device("cuda" if opt.device >= 0 else "cpu")
|
| 203 |
+
opt.pin_memory = not opt.no_pin_memory
|
| 204 |
+
|
| 205 |
+
opt.use_tef = "tef" in opt.ctx_mode
|
| 206 |
+
opt.use_video = "video" in opt.ctx_mode
|
| 207 |
+
if not opt.use_video:
|
| 208 |
+
opt.v_feat_dim = 0
|
| 209 |
+
if opt.use_tef:
|
| 210 |
+
opt.v_feat_dim += 2
|
| 211 |
+
|
| 212 |
+
self.opt = opt
|
| 213 |
+
return opt
|
| 214 |
+
|
| 215 |
+
|
| 216 |
+
class TestOptions(BaseOptions):
|
| 217 |
+
"""add additional options for evaluating"""
|
| 218 |
+
|
| 219 |
+
def initialize(self):
|
| 220 |
+
BaseOptions.initialize(self)
|
| 221 |
+
# also need to specify --eval_split_name
|
| 222 |
+
self.parser.add_argument("--eval_id", type=str, help="evaluation id")
|
| 223 |
+
self.parser.add_argument("--eval_results_dir", type=str, default=None,
|
| 224 |
+
help="dir to save results, if not set, fall back to training results_dir")
|
| 225 |
+
self.parser.add_argument("--model_dir", type=str,
|
| 226 |
+
help="dir contains the model file, will be converted to absolute path afterwards")
|
moment_detr/inference.py
ADDED
|
@@ -0,0 +1,259 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import pprint
|
| 2 |
+
from tqdm import tqdm, trange
|
| 3 |
+
import numpy as np
|
| 4 |
+
import os
|
| 5 |
+
from collections import OrderedDict, defaultdict
|
| 6 |
+
from utils.basic_utils import AverageMeter
|
| 7 |
+
|
| 8 |
+
import torch
|
| 9 |
+
import torch.nn.functional as F
|
| 10 |
+
import torch.backends.cudnn as cudnn
|
| 11 |
+
from torch.utils.data import DataLoader
|
| 12 |
+
|
| 13 |
+
from moment_detr.config import TestOptions
|
| 14 |
+
from moment_detr.model import build_model
|
| 15 |
+
from moment_detr.span_utils import span_cxw_to_xx
|
| 16 |
+
from moment_detr.start_end_dataset import StartEndDataset, start_end_collate, prepare_batch_inputs
|
| 17 |
+
from moment_detr.postprocessing_moment_detr import PostProcessorDETR
|
| 18 |
+
from standalone_eval.eval import eval_submission
|
| 19 |
+
from utils.basic_utils import save_jsonl, save_json
|
| 20 |
+
from utils.temporal_nms import temporal_nms
|
| 21 |
+
|
| 22 |
+
import logging
|
| 23 |
+
|
| 24 |
+
logger = logging.getLogger(__name__)
|
| 25 |
+
logging.basicConfig(format="%(asctime)s.%(msecs)03d:%(levelname)s:%(name)s - %(message)s",
|
| 26 |
+
datefmt="%Y-%m-%d %H:%M:%S",
|
| 27 |
+
level=logging.INFO)
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def post_processing_mr_nms(mr_res, nms_thd, max_before_nms, max_after_nms):
|
| 31 |
+
mr_res_after_nms = []
|
| 32 |
+
for e in mr_res:
|
| 33 |
+
e["pred_relevant_windows"] = temporal_nms(
|
| 34 |
+
e["pred_relevant_windows"][:max_before_nms],
|
| 35 |
+
nms_thd=nms_thd,
|
| 36 |
+
max_after_nms=max_after_nms
|
| 37 |
+
)
|
| 38 |
+
mr_res_after_nms.append(e)
|
| 39 |
+
return mr_res_after_nms
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
def eval_epoch_post_processing(submission, opt, gt_data, save_submission_filename):
|
| 43 |
+
# IOU_THDS = (0.5, 0.7)
|
| 44 |
+
logger.info("Saving/Evaluating before nms results")
|
| 45 |
+
submission_path = os.path.join(opt.results_dir, save_submission_filename)
|
| 46 |
+
save_jsonl(submission, submission_path)
|
| 47 |
+
|
| 48 |
+
if opt.eval_split_name in ["val", "test"]: # since test_public has no GT
|
| 49 |
+
metrics = eval_submission(
|
| 50 |
+
submission, gt_data,
|
| 51 |
+
verbose=opt.debug, match_number=not opt.debug
|
| 52 |
+
)
|
| 53 |
+
save_metrics_path = submission_path.replace(".jsonl", "_metrics.json")
|
| 54 |
+
save_json(metrics, save_metrics_path, save_pretty=True, sort_keys=False)
|
| 55 |
+
latest_file_paths = [submission_path, save_metrics_path]
|
| 56 |
+
else:
|
| 57 |
+
metrics = None
|
| 58 |
+
latest_file_paths = [submission_path, ]
|
| 59 |
+
|
| 60 |
+
if opt.nms_thd != -1:
|
| 61 |
+
logger.info("[MR] Performing nms with nms_thd {}".format(opt.nms_thd))
|
| 62 |
+
submission_after_nms = post_processing_mr_nms(
|
| 63 |
+
submission, nms_thd=opt.nms_thd,
|
| 64 |
+
max_before_nms=opt.max_before_nms, max_after_nms=opt.max_after_nms
|
| 65 |
+
)
|
| 66 |
+
|
| 67 |
+
logger.info("Saving/Evaluating nms results")
|
| 68 |
+
submission_nms_path = submission_path.replace(".jsonl", "_nms_thd_{}.jsonl".format(opt.nms_thd))
|
| 69 |
+
save_jsonl(submission_after_nms, submission_nms_path)
|
| 70 |
+
if opt.eval_split_name == "val":
|
| 71 |
+
metrics_nms = eval_submission(
|
| 72 |
+
submission_after_nms, gt_data,
|
| 73 |
+
verbose=opt.debug, match_number=not opt.debug
|
| 74 |
+
)
|
| 75 |
+
save_metrics_nms_path = submission_nms_path.replace(".jsonl", "_metrics.json")
|
| 76 |
+
save_json(metrics_nms, save_metrics_nms_path, save_pretty=True, sort_keys=False)
|
| 77 |
+
latest_file_paths += [submission_nms_path, save_metrics_nms_path]
|
| 78 |
+
else:
|
| 79 |
+
metrics_nms = None
|
| 80 |
+
latest_file_paths = [submission_nms_path, ]
|
| 81 |
+
else:
|
| 82 |
+
metrics_nms = None
|
| 83 |
+
return metrics, metrics_nms, latest_file_paths
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
@torch.no_grad()
|
| 87 |
+
def compute_mr_results(model, eval_loader, opt, epoch_i=None, criterion=None, tb_writer=None):
|
| 88 |
+
model.eval()
|
| 89 |
+
if criterion:
|
| 90 |
+
assert eval_loader.dataset.load_labels
|
| 91 |
+
criterion.eval()
|
| 92 |
+
|
| 93 |
+
loss_meters = defaultdict(AverageMeter)
|
| 94 |
+
write_tb = tb_writer is not None and epoch_i is not None
|
| 95 |
+
|
| 96 |
+
mr_res = []
|
| 97 |
+
for batch in tqdm(eval_loader, desc="compute st ed scores"):
|
| 98 |
+
query_meta = batch[0]
|
| 99 |
+
model_inputs, targets = prepare_batch_inputs(batch[1], opt.device, non_blocking=opt.pin_memory)
|
| 100 |
+
outputs = model(**model_inputs)
|
| 101 |
+
prob = F.softmax(outputs["pred_logits"], -1) # (batch_size, #queries, #classes=2)
|
| 102 |
+
if opt.span_loss_type == "l1":
|
| 103 |
+
scores = prob[..., 0] # * (batch_size, #queries) foreground label is 0, we directly take it
|
| 104 |
+
pred_spans = outputs["pred_spans"] # (bsz, #queries, 2)
|
| 105 |
+
_saliency_scores = outputs["saliency_scores"].half() # (bsz, L)
|
| 106 |
+
saliency_scores = []
|
| 107 |
+
valid_vid_lengths = model_inputs["src_vid_mask"].sum(1).cpu().tolist()
|
| 108 |
+
for j in range(len(valid_vid_lengths)):
|
| 109 |
+
saliency_scores.append(_saliency_scores[j, :int(valid_vid_lengths[j])].tolist())
|
| 110 |
+
else:
|
| 111 |
+
bsz, n_queries = outputs["pred_spans"].shape[:2] # # (bsz, #queries, max_v_l *2)
|
| 112 |
+
pred_spans_logits = outputs["pred_spans"].view(bsz, n_queries, 2, opt.max_v_l)
|
| 113 |
+
# TODO use more advanced decoding method with st_ed product
|
| 114 |
+
pred_span_scores, pred_spans = F.softmax(pred_spans_logits, dim=-1).max(-1) # 2 * (bsz, #queries, 2)
|
| 115 |
+
scores = torch.prod(pred_span_scores, 2) # (bsz, #queries)
|
| 116 |
+
pred_spans[:, 1] += 1
|
| 117 |
+
pred_spans *= opt.clip_length
|
| 118 |
+
|
| 119 |
+
# compose predictions
|
| 120 |
+
for idx, (meta, spans, score) in enumerate(zip(query_meta, pred_spans.cpu(), scores.cpu())):
|
| 121 |
+
if opt.span_loss_type == "l1":
|
| 122 |
+
spans = span_cxw_to_xx(spans) * meta["duration"]
|
| 123 |
+
# # (#queries, 3), [st(float), ed(float), score(float)]
|
| 124 |
+
cur_ranked_preds = torch.cat([spans, score[:, None]], dim=1).tolist()
|
| 125 |
+
if not opt.no_sort_results:
|
| 126 |
+
cur_ranked_preds = sorted(cur_ranked_preds, key=lambda x: x[2], reverse=True)
|
| 127 |
+
cur_ranked_preds = [[float(f"{e:.4f}") for e in row] for row in cur_ranked_preds]
|
| 128 |
+
cur_query_pred = dict(
|
| 129 |
+
qid=meta["qid"],
|
| 130 |
+
query=meta["query"],
|
| 131 |
+
vid=meta["vid"],
|
| 132 |
+
pred_relevant_windows=cur_ranked_preds,
|
| 133 |
+
pred_saliency_scores=saliency_scores[idx]
|
| 134 |
+
)
|
| 135 |
+
mr_res.append(cur_query_pred)
|
| 136 |
+
|
| 137 |
+
if criterion:
|
| 138 |
+
loss_dict = criterion(outputs, targets)
|
| 139 |
+
weight_dict = criterion.weight_dict
|
| 140 |
+
losses = sum(loss_dict[k] * weight_dict[k] for k in loss_dict.keys() if k in weight_dict)
|
| 141 |
+
loss_dict["loss_overall"] = float(losses) # for logging only
|
| 142 |
+
for k, v in loss_dict.items():
|
| 143 |
+
loss_meters[k].update(float(v) * weight_dict[k] if k in weight_dict else float(v))
|
| 144 |
+
|
| 145 |
+
if opt.debug:
|
| 146 |
+
break
|
| 147 |
+
|
| 148 |
+
if write_tb and criterion:
|
| 149 |
+
for k, v in loss_meters.items():
|
| 150 |
+
tb_writer.add_scalar("Eval/{}".format(k), v.avg, epoch_i + 1)
|
| 151 |
+
|
| 152 |
+
post_processor = PostProcessorDETR(
|
| 153 |
+
clip_length=2, min_ts_val=0, max_ts_val=150,
|
| 154 |
+
min_w_l=2, max_w_l=150, move_window_method="left",
|
| 155 |
+
process_func_names=("clip_ts", "round_multiple")
|
| 156 |
+
)
|
| 157 |
+
mr_res = post_processor(mr_res)
|
| 158 |
+
return mr_res, loss_meters
|
| 159 |
+
|
| 160 |
+
|
| 161 |
+
def get_eval_res(model, eval_loader, opt, epoch_i, criterion, tb_writer):
|
| 162 |
+
"""compute and save query and video proposal embeddings"""
|
| 163 |
+
eval_res, eval_loss_meters = compute_mr_results(model, eval_loader, opt, epoch_i, criterion, tb_writer) # list(dict)
|
| 164 |
+
return eval_res, eval_loss_meters
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
def eval_epoch(model, eval_dataset, opt, save_submission_filename, epoch_i=None, criterion=None, tb_writer=None):
|
| 168 |
+
logger.info("Generate submissions")
|
| 169 |
+
model.eval()
|
| 170 |
+
if criterion is not None and eval_dataset.load_labels:
|
| 171 |
+
criterion.eval()
|
| 172 |
+
else:
|
| 173 |
+
criterion = None
|
| 174 |
+
|
| 175 |
+
eval_loader = DataLoader(
|
| 176 |
+
eval_dataset,
|
| 177 |
+
collate_fn=start_end_collate,
|
| 178 |
+
batch_size=opt.eval_bsz,
|
| 179 |
+
num_workers=opt.num_workers,
|
| 180 |
+
shuffle=False,
|
| 181 |
+
pin_memory=opt.pin_memory
|
| 182 |
+
)
|
| 183 |
+
|
| 184 |
+
submission, eval_loss_meters = get_eval_res(model, eval_loader, opt, epoch_i, criterion, tb_writer)
|
| 185 |
+
if opt.no_sort_results:
|
| 186 |
+
save_submission_filename = save_submission_filename.replace(".jsonl", "_unsorted.jsonl")
|
| 187 |
+
metrics, metrics_nms, latest_file_paths = eval_epoch_post_processing(
|
| 188 |
+
submission, opt, eval_dataset.data, save_submission_filename)
|
| 189 |
+
return metrics, metrics_nms, eval_loss_meters, latest_file_paths
|
| 190 |
+
|
| 191 |
+
|
| 192 |
+
def setup_model(opt):
|
| 193 |
+
"""setup model/optimizer/scheduler and load checkpoints when needed"""
|
| 194 |
+
logger.info("setup model/optimizer/scheduler")
|
| 195 |
+
model, criterion = build_model(opt)
|
| 196 |
+
if opt.device.type == "cuda":
|
| 197 |
+
logger.info("CUDA enabled.")
|
| 198 |
+
model.to(opt.device)
|
| 199 |
+
criterion.to(opt.device)
|
| 200 |
+
|
| 201 |
+
param_dicts = [{"params": [p for n, p in model.named_parameters() if p.requires_grad]}]
|
| 202 |
+
optimizer = torch.optim.AdamW(param_dicts, lr=opt.lr, weight_decay=opt.wd)
|
| 203 |
+
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, opt.lr_drop)
|
| 204 |
+
|
| 205 |
+
if opt.resume is not None:
|
| 206 |
+
logger.info(f"Load checkpoint from {opt.resume}")
|
| 207 |
+
checkpoint = torch.load(opt.resume, map_location="cpu")
|
| 208 |
+
model.load_state_dict(checkpoint["model"])
|
| 209 |
+
if opt.resume_all:
|
| 210 |
+
optimizer.load_state_dict(checkpoint['optimizer'])
|
| 211 |
+
lr_scheduler.load_state_dict(checkpoint['lr_scheduler'])
|
| 212 |
+
opt.start_epoch = checkpoint['epoch'] + 1
|
| 213 |
+
logger.info(f"Loaded model saved at epoch {checkpoint['epoch']} from checkpoint: {opt.resume}")
|
| 214 |
+
else:
|
| 215 |
+
logger.warning("If you intend to evaluate the model, please specify --resume with ckpt path")
|
| 216 |
+
|
| 217 |
+
return model, criterion, optimizer, lr_scheduler
|
| 218 |
+
|
| 219 |
+
|
| 220 |
+
def start_inference():
|
| 221 |
+
logger.info("Setup config, data and model...")
|
| 222 |
+
opt = TestOptions().parse()
|
| 223 |
+
cudnn.benchmark = True
|
| 224 |
+
cudnn.deterministic = False
|
| 225 |
+
|
| 226 |
+
assert opt.eval_path is not None
|
| 227 |
+
eval_dataset = StartEndDataset(
|
| 228 |
+
dset_name=opt.dset_name,
|
| 229 |
+
data_path=opt.eval_path,
|
| 230 |
+
v_feat_dirs=opt.v_feat_dirs,
|
| 231 |
+
q_feat_dir=opt.t_feat_dir,
|
| 232 |
+
q_feat_type="last_hidden_state",
|
| 233 |
+
max_q_l=opt.max_q_l,
|
| 234 |
+
max_v_l=opt.max_v_l,
|
| 235 |
+
ctx_mode=opt.ctx_mode,
|
| 236 |
+
data_ratio=opt.data_ratio,
|
| 237 |
+
normalize_v=not opt.no_norm_vfeat,
|
| 238 |
+
normalize_t=not opt.no_norm_tfeat,
|
| 239 |
+
clip_len=opt.clip_length,
|
| 240 |
+
max_windows=opt.max_windows,
|
| 241 |
+
load_labels=True, # opt.eval_split_name == "val",
|
| 242 |
+
span_loss_type=opt.span_loss_type,
|
| 243 |
+
txt_drop_ratio=0
|
| 244 |
+
)
|
| 245 |
+
|
| 246 |
+
model, criterion, _, _ = setup_model(opt)
|
| 247 |
+
save_submission_filename = "inference_{}_{}_{}_preds.jsonl".format(
|
| 248 |
+
opt.dset_name, opt.eval_split_name, opt.eval_id)
|
| 249 |
+
logger.info("Starting inference...")
|
| 250 |
+
with torch.no_grad():
|
| 251 |
+
metrics_no_nms, metrics_nms, eval_loss_meters, latest_file_paths = \
|
| 252 |
+
eval_epoch(model, eval_dataset, opt, save_submission_filename, criterion=criterion)
|
| 253 |
+
logger.info("metrics_no_nms {}".format(pprint.pformat(metrics_no_nms["brief"], indent=4)))
|
| 254 |
+
if metrics_nms is not None:
|
| 255 |
+
logger.info("metrics_nms {}".format(pprint.pformat(metrics_nms["brief"], indent=4)))
|
| 256 |
+
|
| 257 |
+
|
| 258 |
+
if __name__ == '__main__':
|
| 259 |
+
start_inference()
|
moment_detr/matcher.py
ADDED
|
@@ -0,0 +1,107 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
|
| 2 |
+
"""
|
| 3 |
+
Modules to compute the matching cost and solve the corresponding LSAP.
|
| 4 |
+
"""
|
| 5 |
+
import torch
|
| 6 |
+
from scipy.optimize import linear_sum_assignment
|
| 7 |
+
from torch import nn
|
| 8 |
+
import torch.nn.functional as F
|
| 9 |
+
from moment_detr.span_utils import generalized_temporal_iou, span_cxw_to_xx
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class HungarianMatcher(nn.Module):
|
| 13 |
+
"""This class computes an assignment between the targets and the predictions of the network
|
| 14 |
+
|
| 15 |
+
For efficiency reasons, the targets don't include the no_object. Because of this, in general,
|
| 16 |
+
there are more predictions than targets. In this case, we do a 1-to-1 matching of the best predictions,
|
| 17 |
+
while the others are un-matched (and thus treated as non-objects).
|
| 18 |
+
"""
|
| 19 |
+
def __init__(self, cost_class: float = 1, cost_span: float = 1, cost_giou: float = 1,
|
| 20 |
+
span_loss_type: str = "l1", max_v_l: int = 75):
|
| 21 |
+
"""Creates the matcher
|
| 22 |
+
|
| 23 |
+
Params:
|
| 24 |
+
cost_span: This is the relative weight of the L1 error of the span coordinates in the matching cost
|
| 25 |
+
cost_giou: This is the relative weight of the giou loss of the spans in the matching cost
|
| 26 |
+
"""
|
| 27 |
+
super().__init__()
|
| 28 |
+
self.cost_class = cost_class
|
| 29 |
+
self.cost_span = cost_span
|
| 30 |
+
self.cost_giou = cost_giou
|
| 31 |
+
self.span_loss_type = span_loss_type
|
| 32 |
+
self.max_v_l = max_v_l
|
| 33 |
+
self.foreground_label = 0
|
| 34 |
+
assert cost_class != 0 or cost_span != 0 or cost_giou != 0, "all costs cant be 0"
|
| 35 |
+
|
| 36 |
+
@torch.no_grad()
|
| 37 |
+
def forward(self, outputs, targets):
|
| 38 |
+
""" Performs the matching
|
| 39 |
+
|
| 40 |
+
Params:
|
| 41 |
+
outputs: This is a dict that contains at least these entries:
|
| 42 |
+
"pred_spans": Tensor of dim [batch_size, num_queries, 2] with the predicted span coordinates,
|
| 43 |
+
in normalized (cx, w) format
|
| 44 |
+
""pred_logits": Tensor of dim [batch_size, num_queries, num_classes] with the classification logits
|
| 45 |
+
|
| 46 |
+
targets: This is a list of targets (len(targets) = batch_size), where each target is a dict containing:
|
| 47 |
+
"spans": Tensor of dim [num_target_spans, 2] containing the target span coordinates. The spans are
|
| 48 |
+
in normalized (cx, w) format
|
| 49 |
+
|
| 50 |
+
Returns:
|
| 51 |
+
A list of size batch_size, containing tuples of (index_i, index_j) where:
|
| 52 |
+
- index_i is the indices of the selected predictions (in order)
|
| 53 |
+
- index_j is the indices of the corresponding selected targets (in order)
|
| 54 |
+
For each batch element, it holds:
|
| 55 |
+
len(index_i) = len(index_j) = min(num_queries, num_target_spans)
|
| 56 |
+
"""
|
| 57 |
+
bs, num_queries = outputs["pred_spans"].shape[:2]
|
| 58 |
+
targets = targets["span_labels"]
|
| 59 |
+
|
| 60 |
+
# Also concat the target labels and spans
|
| 61 |
+
out_prob = outputs["pred_logits"].flatten(0, 1).softmax(-1) # [batch_size * num_queries, num_classes]
|
| 62 |
+
tgt_spans = torch.cat([v["spans"] for v in targets]) # [num_target_spans in batch, 2]
|
| 63 |
+
tgt_ids = torch.full([len(tgt_spans)], self.foreground_label) # [total #spans in the batch]
|
| 64 |
+
|
| 65 |
+
# Compute the classification cost. Contrary to the loss, we don't use the NLL,
|
| 66 |
+
# but approximate it in 1 - prob[target class].
|
| 67 |
+
# The 1 is a constant that doesn't change the matching, it can be omitted.
|
| 68 |
+
cost_class = -out_prob[:, tgt_ids] # [batch_size * num_queries, total #spans in the batch]
|
| 69 |
+
|
| 70 |
+
if self.span_loss_type == "l1":
|
| 71 |
+
# We flatten to compute the cost matrices in a batch
|
| 72 |
+
out_spans = outputs["pred_spans"].flatten(0, 1) # [batch_size * num_queries, 2]
|
| 73 |
+
|
| 74 |
+
# Compute the L1 cost between spans
|
| 75 |
+
cost_span = torch.cdist(out_spans, tgt_spans, p=1) # [batch_size * num_queries, total #spans in the batch]
|
| 76 |
+
|
| 77 |
+
# Compute the giou cost between spans
|
| 78 |
+
# [batch_size * num_queries, total #spans in the batch]
|
| 79 |
+
cost_giou = - generalized_temporal_iou(span_cxw_to_xx(out_spans), span_cxw_to_xx(tgt_spans))
|
| 80 |
+
else:
|
| 81 |
+
pred_spans = outputs["pred_spans"] # (bsz, #queries, max_v_l * 2)
|
| 82 |
+
pred_spans = pred_spans.view(bs * num_queries, 2, self.max_v_l).softmax(-1) # (bsz * #queries, 2, max_v_l)
|
| 83 |
+
cost_span = - pred_spans[:, 0][:, tgt_spans[:, 0]] - \
|
| 84 |
+
pred_spans[:, 1][:, tgt_spans[:, 1]] # (bsz * #queries, #spans)
|
| 85 |
+
# pred_spans = pred_spans.repeat(1, n_spans, 1, 1).flatten(0, 1) # (bsz * #queries * #spans, max_v_l, 2)
|
| 86 |
+
# tgt_spans = tgt_spans.view(1, n_spans, 2).repeat(bs * num_queries, 1, 1).flatten(0, 1) # (bsz * #queries * #spans, 2)
|
| 87 |
+
# cost_span = pred_spans[tgt_spans]
|
| 88 |
+
# cost_span = cost_span.view(bs * num_queries, n_spans)
|
| 89 |
+
|
| 90 |
+
# giou
|
| 91 |
+
cost_giou = 0
|
| 92 |
+
|
| 93 |
+
# Final cost matrix
|
| 94 |
+
# import ipdb; ipdb.set_trace()
|
| 95 |
+
C = self.cost_span * cost_span + self.cost_giou * cost_giou + self.cost_class * cost_class
|
| 96 |
+
C = C.view(bs, num_queries, -1).cpu()
|
| 97 |
+
|
| 98 |
+
sizes = [len(v["spans"]) for v in targets]
|
| 99 |
+
indices = [linear_sum_assignment(c[i]) for i, c in enumerate(C.split(sizes, -1))]
|
| 100 |
+
return [(torch.as_tensor(i, dtype=torch.int64), torch.as_tensor(j, dtype=torch.int64)) for i, j in indices]
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
def build_matcher(args):
|
| 104 |
+
return HungarianMatcher(
|
| 105 |
+
cost_span=args.set_cost_span, cost_giou=args.set_cost_giou,
|
| 106 |
+
cost_class=args.set_cost_class, span_loss_type=args.span_loss_type, max_v_l=args.max_v_l
|
| 107 |
+
)
|
moment_detr/misc.py
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
@torch.no_grad()
|
| 5 |
+
def accuracy(output, target, topk=(1,)):
|
| 6 |
+
"""Computes the precision@k for the specified values of k
|
| 7 |
+
output: (#items, #classes)
|
| 8 |
+
target: int,
|
| 9 |
+
"""
|
| 10 |
+
maxk = max(topk)
|
| 11 |
+
num_items = output.size(0)
|
| 12 |
+
|
| 13 |
+
_, pred = output.topk(maxk, 1, True, True)
|
| 14 |
+
pred = pred.t()
|
| 15 |
+
correct = pred.eq(target)
|
| 16 |
+
|
| 17 |
+
res = []
|
| 18 |
+
for k in topk:
|
| 19 |
+
correct_k = correct[:k].view(-1).float().sum(0)
|
| 20 |
+
res.append(correct_k.mul_(100.0 / num_items))
|
| 21 |
+
return res
|
moment_detr/model.py
ADDED
|
@@ -0,0 +1,444 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
|
| 2 |
+
"""
|
| 3 |
+
DETR model and criterion classes.
|
| 4 |
+
"""
|
| 5 |
+
import torch
|
| 6 |
+
import torch.nn.functional as F
|
| 7 |
+
from torch import nn
|
| 8 |
+
|
| 9 |
+
from moment_detr.span_utils import generalized_temporal_iou, span_cxw_to_xx
|
| 10 |
+
|
| 11 |
+
from moment_detr.matcher import build_matcher
|
| 12 |
+
from moment_detr.transformer import build_transformer
|
| 13 |
+
from moment_detr.position_encoding import build_position_encoding
|
| 14 |
+
from moment_detr.misc import accuracy
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class MomentDETR(nn.Module):
|
| 18 |
+
""" This is the Moment-DETR module that performs moment localization. """
|
| 19 |
+
|
| 20 |
+
def __init__(self, transformer, position_embed, txt_position_embed, txt_dim, vid_dim,
|
| 21 |
+
num_queries, input_dropout, aux_loss=False,
|
| 22 |
+
contrastive_align_loss=False, contrastive_hdim=64,
|
| 23 |
+
max_v_l=75, span_loss_type="l1", use_txt_pos=False, n_input_proj=2):
|
| 24 |
+
""" Initializes the model.
|
| 25 |
+
Parameters:
|
| 26 |
+
transformer: torch module of the transformer architecture. See transformer.py
|
| 27 |
+
position_embed: torch module of the position_embedding, See position_encoding.py
|
| 28 |
+
txt_position_embed: position_embedding for text
|
| 29 |
+
txt_dim: int, text query input dimension
|
| 30 |
+
vid_dim: int, video feature input dimension
|
| 31 |
+
num_queries: number of object queries, ie detection slot. This is the maximal number of objects
|
| 32 |
+
Moment-DETR can detect in a single video.
|
| 33 |
+
aux_loss: True if auxiliary decoding losses (loss at each decoder layer) are to be used.
|
| 34 |
+
contrastive_align_loss: If true, perform span - tokens contrastive learning
|
| 35 |
+
contrastive_hdim: dimension used for projecting the embeddings before computing contrastive loss
|
| 36 |
+
max_v_l: int, maximum #clips in videos
|
| 37 |
+
span_loss_type: str, one of [l1, ce]
|
| 38 |
+
l1: (center-x, width) regression.
|
| 39 |
+
ce: (st_idx, ed_idx) classification.
|
| 40 |
+
# foreground_thd: float, intersection over prediction >= foreground_thd: labeled as foreground
|
| 41 |
+
# background_thd: float, intersection over prediction <= background_thd: labeled background
|
| 42 |
+
"""
|
| 43 |
+
super().__init__()
|
| 44 |
+
self.num_queries = num_queries
|
| 45 |
+
self.transformer = transformer
|
| 46 |
+
self.position_embed = position_embed
|
| 47 |
+
self.txt_position_embed = txt_position_embed
|
| 48 |
+
hidden_dim = transformer.d_model
|
| 49 |
+
self.span_loss_type = span_loss_type
|
| 50 |
+
self.max_v_l = max_v_l
|
| 51 |
+
span_pred_dim = 2 if span_loss_type == "l1" else max_v_l * 2
|
| 52 |
+
self.span_embed = MLP(hidden_dim, hidden_dim, span_pred_dim, 3)
|
| 53 |
+
self.class_embed = nn.Linear(hidden_dim, 2) # 0: background, 1: foreground
|
| 54 |
+
self.use_txt_pos = use_txt_pos
|
| 55 |
+
self.n_input_proj = n_input_proj
|
| 56 |
+
# self.foreground_thd = foreground_thd
|
| 57 |
+
# self.background_thd = background_thd
|
| 58 |
+
self.query_embed = nn.Embedding(num_queries, hidden_dim)
|
| 59 |
+
relu_args = [True] * 3
|
| 60 |
+
relu_args[n_input_proj-1] = False
|
| 61 |
+
self.input_txt_proj = nn.Sequential(*[
|
| 62 |
+
LinearLayer(txt_dim, hidden_dim, layer_norm=True, dropout=input_dropout, relu=relu_args[0]),
|
| 63 |
+
LinearLayer(hidden_dim, hidden_dim, layer_norm=True, dropout=input_dropout, relu=relu_args[1]),
|
| 64 |
+
LinearLayer(hidden_dim, hidden_dim, layer_norm=True, dropout=input_dropout, relu=relu_args[2])
|
| 65 |
+
][:n_input_proj])
|
| 66 |
+
self.input_vid_proj = nn.Sequential(*[
|
| 67 |
+
LinearLayer(vid_dim, hidden_dim, layer_norm=True, dropout=input_dropout, relu=relu_args[0]),
|
| 68 |
+
LinearLayer(hidden_dim, hidden_dim, layer_norm=True, dropout=input_dropout, relu=relu_args[1]),
|
| 69 |
+
LinearLayer(hidden_dim, hidden_dim, layer_norm=True, dropout=input_dropout, relu=relu_args[2])
|
| 70 |
+
][:n_input_proj])
|
| 71 |
+
self.contrastive_align_loss = contrastive_align_loss
|
| 72 |
+
if contrastive_align_loss:
|
| 73 |
+
self.contrastive_align_projection_query = nn.Linear(hidden_dim, contrastive_hdim)
|
| 74 |
+
self.contrastive_align_projection_txt = nn.Linear(hidden_dim, contrastive_hdim)
|
| 75 |
+
self.contrastive_align_projection_vid = nn.Linear(hidden_dim, contrastive_hdim)
|
| 76 |
+
|
| 77 |
+
self.saliency_proj = nn.Linear(hidden_dim, 1)
|
| 78 |
+
self.aux_loss = aux_loss
|
| 79 |
+
|
| 80 |
+
def forward(self, src_txt, src_txt_mask, src_vid, src_vid_mask):
|
| 81 |
+
"""The forward expects two tensors:
|
| 82 |
+
- src_txt: [batch_size, L_txt, D_txt]
|
| 83 |
+
- src_txt_mask: [batch_size, L_txt], containing 0 on padded pixels,
|
| 84 |
+
will convert to 1 as padding later for transformer
|
| 85 |
+
- src_vid: [batch_size, L_vid, D_vid]
|
| 86 |
+
- src_vid_mask: [batch_size, L_vid], containing 0 on padded pixels,
|
| 87 |
+
will convert to 1 as padding later for transformer
|
| 88 |
+
|
| 89 |
+
It returns a dict with the following elements:
|
| 90 |
+
- "pred_spans": The normalized boxes coordinates for all queries, represented as
|
| 91 |
+
(center_x, width). These values are normalized in [0, 1],
|
| 92 |
+
relative to the size of each individual image (disregarding possible padding).
|
| 93 |
+
See PostProcess for information on how to retrieve the unnormalized bounding box.
|
| 94 |
+
- "aux_outputs": Optional, only returned when auxilary losses are activated. It is a list of
|
| 95 |
+
dictionnaries containing the two above keys for each decoder layer.
|
| 96 |
+
"""
|
| 97 |
+
src_vid = self.input_vid_proj(src_vid)
|
| 98 |
+
src_txt = self.input_txt_proj(src_txt)
|
| 99 |
+
src = torch.cat([src_vid, src_txt], dim=1) # (bsz, L_vid+L_txt, d)
|
| 100 |
+
mask = torch.cat([src_vid_mask, src_txt_mask], dim=1).bool() # (bsz, L_vid+L_txt)
|
| 101 |
+
# TODO should we remove or use different positional embeddings to the src_txt?
|
| 102 |
+
pos_vid = self.position_embed(src_vid, src_vid_mask) # (bsz, L_vid, d)
|
| 103 |
+
pos_txt = self.txt_position_embed(src_txt) if self.use_txt_pos else torch.zeros_like(src_txt) # (bsz, L_txt, d)
|
| 104 |
+
# pos_txt = torch.zeros_like(src_txt)
|
| 105 |
+
# pad zeros for txt positions
|
| 106 |
+
pos = torch.cat([pos_vid, pos_txt], dim=1)
|
| 107 |
+
# (#layers, bsz, #queries, d), (bsz, L_vid+L_txt, d)
|
| 108 |
+
hs, memory = self.transformer(src, ~mask, self.query_embed.weight, pos)
|
| 109 |
+
outputs_class = self.class_embed(hs) # (#layers, batch_size, #queries, #classes)
|
| 110 |
+
outputs_coord = self.span_embed(hs) # (#layers, bsz, #queries, 2 or max_v_l * 2)
|
| 111 |
+
if self.span_loss_type == "l1":
|
| 112 |
+
outputs_coord = outputs_coord.sigmoid()
|
| 113 |
+
out = {'pred_logits': outputs_class[-1], 'pred_spans': outputs_coord[-1]}
|
| 114 |
+
|
| 115 |
+
txt_mem = memory[:, src_vid.shape[1]:] # (bsz, L_txt, d)
|
| 116 |
+
vid_mem = memory[:, :src_vid.shape[1]] # (bsz, L_vid, d)
|
| 117 |
+
if self.contrastive_align_loss:
|
| 118 |
+
proj_queries = F.normalize(self.contrastive_align_projection_query(hs), p=2, dim=-1)
|
| 119 |
+
proj_txt_mem = F.normalize(self.contrastive_align_projection_txt(txt_mem), p=2, dim=-1)
|
| 120 |
+
proj_vid_mem = F.normalize(self.contrastive_align_projection_vid(vid_mem), p=2, dim=-1)
|
| 121 |
+
out.update(dict(
|
| 122 |
+
proj_queries=proj_queries[-1],
|
| 123 |
+
proj_txt_mem=proj_txt_mem,
|
| 124 |
+
proj_vid_mem=proj_vid_mem
|
| 125 |
+
))
|
| 126 |
+
|
| 127 |
+
out["saliency_scores"] = self.saliency_proj(vid_mem).squeeze(-1) # (bsz, L_vid)
|
| 128 |
+
|
| 129 |
+
if self.aux_loss:
|
| 130 |
+
# assert proj_queries and proj_txt_mem
|
| 131 |
+
out['aux_outputs'] = [
|
| 132 |
+
{'pred_logits': a, 'pred_spans': b} for a, b in zip(outputs_class[:-1], outputs_coord[:-1])]
|
| 133 |
+
if self.contrastive_align_loss:
|
| 134 |
+
assert proj_queries is not None
|
| 135 |
+
for idx, d in enumerate(proj_queries[:-1]):
|
| 136 |
+
out['aux_outputs'][idx].update(dict(proj_queries=d, proj_txt_mem=proj_txt_mem))
|
| 137 |
+
return out
|
| 138 |
+
|
| 139 |
+
# @torch.jit.unused
|
| 140 |
+
# def _set_aux_loss(self, outputs_class, outputs_coord):
|
| 141 |
+
# # this is a workaround to make torchscript happy, as torchscript
|
| 142 |
+
# # doesn't support dictionary with non-homogeneous values, such
|
| 143 |
+
# # as a dict having both a Tensor and a list.
|
| 144 |
+
# return [{'pred_logits': a, 'pred_spans': b}
|
| 145 |
+
# for a, b in zip(outputs_class[:-1], outputs_coord[:-1])]
|
| 146 |
+
|
| 147 |
+
|
| 148 |
+
class SetCriterion(nn.Module):
|
| 149 |
+
""" This class computes the loss for DETR.
|
| 150 |
+
The process happens in two steps:
|
| 151 |
+
1) we compute hungarian assignment between ground truth boxes and the outputs of the model
|
| 152 |
+
2) we supervise each pair of matched ground-truth / prediction (supervise class and box)
|
| 153 |
+
"""
|
| 154 |
+
|
| 155 |
+
def __init__(self, matcher, weight_dict, eos_coef, losses, temperature, span_loss_type, max_v_l,
|
| 156 |
+
saliency_margin=1):
|
| 157 |
+
""" Create the criterion.
|
| 158 |
+
Parameters:
|
| 159 |
+
matcher: module able to compute a matching between targets and proposals
|
| 160 |
+
weight_dict: dict containing as key the names of the losses and as values their relative weight.
|
| 161 |
+
eos_coef: relative classification weight applied to the no-object category
|
| 162 |
+
losses: list of all the losses to be applied. See get_loss for list of available losses.
|
| 163 |
+
temperature: float, temperature for NCE loss
|
| 164 |
+
span_loss_type: str, [l1, ce]
|
| 165 |
+
max_v_l: int,
|
| 166 |
+
saliency_margin: float
|
| 167 |
+
"""
|
| 168 |
+
super().__init__()
|
| 169 |
+
self.matcher = matcher
|
| 170 |
+
self.weight_dict = weight_dict
|
| 171 |
+
self.losses = losses
|
| 172 |
+
self.temperature = temperature
|
| 173 |
+
self.span_loss_type = span_loss_type
|
| 174 |
+
self.max_v_l = max_v_l
|
| 175 |
+
self.saliency_margin = saliency_margin
|
| 176 |
+
|
| 177 |
+
# foreground and background classification
|
| 178 |
+
self.foreground_label = 0
|
| 179 |
+
self.background_label = 1
|
| 180 |
+
self.eos_coef = eos_coef
|
| 181 |
+
empty_weight = torch.ones(2)
|
| 182 |
+
empty_weight[-1] = self.eos_coef # lower weight for background (index 1, foreground index 0)
|
| 183 |
+
self.register_buffer('empty_weight', empty_weight)
|
| 184 |
+
|
| 185 |
+
def loss_spans(self, outputs, targets, indices):
|
| 186 |
+
"""Compute the losses related to the bounding boxes, the L1 regression loss and the GIoU loss
|
| 187 |
+
targets dicts must contain the key "spans" containing a tensor of dim [nb_tgt_spans, 2]
|
| 188 |
+
The target spans are expected in format (center_x, w), normalized by the image size.
|
| 189 |
+
"""
|
| 190 |
+
assert 'pred_spans' in outputs
|
| 191 |
+
targets = targets["span_labels"]
|
| 192 |
+
idx = self._get_src_permutation_idx(indices)
|
| 193 |
+
src_spans = outputs['pred_spans'][idx] # (#spans, max_v_l * 2)
|
| 194 |
+
tgt_spans = torch.cat([t['spans'][i] for t, (_, i) in zip(targets, indices)], dim=0) # (#spans, 2)
|
| 195 |
+
if self.span_loss_type == "l1":
|
| 196 |
+
loss_span = F.l1_loss(src_spans, tgt_spans, reduction='none')
|
| 197 |
+
loss_giou = 1 - torch.diag(generalized_temporal_iou(span_cxw_to_xx(src_spans), span_cxw_to_xx(tgt_spans)))
|
| 198 |
+
else: # ce
|
| 199 |
+
n_spans = src_spans.shape[0]
|
| 200 |
+
src_spans = src_spans.view(n_spans, 2, self.max_v_l).transpose(1, 2)
|
| 201 |
+
loss_span = F.cross_entropy(src_spans, tgt_spans, reduction='none')
|
| 202 |
+
|
| 203 |
+
# giou
|
| 204 |
+
# src_span_indices = src_spans.max(1)[1] # (#spans, 2)
|
| 205 |
+
# src_span_indices[:, 1] += 1 # ed non-inclusive [st, ed)
|
| 206 |
+
#
|
| 207 |
+
# tgt_span_indices = tgt_spans
|
| 208 |
+
# tgt_span_indices[:, 1] += 1
|
| 209 |
+
# loss_giou = 1 - torch.diag(generalized_temporal_iou(src_span_indices, tgt_span_indices))
|
| 210 |
+
loss_giou = loss_span.new_zeros([1])
|
| 211 |
+
|
| 212 |
+
losses = {}
|
| 213 |
+
losses['loss_span'] = loss_span.mean()
|
| 214 |
+
losses['loss_giou'] = loss_giou.mean()
|
| 215 |
+
return losses
|
| 216 |
+
|
| 217 |
+
def loss_labels(self, outputs, targets, indices, log=True):
|
| 218 |
+
"""Classification loss (NLL)
|
| 219 |
+
targets dicts must contain the key "labels" containing a tensor of dim [nb_target_boxes]
|
| 220 |
+
"""
|
| 221 |
+
# TODO add foreground and background classifier. use all non-matched as background.
|
| 222 |
+
assert 'pred_logits' in outputs
|
| 223 |
+
src_logits = outputs['pred_logits'] # (batch_size, #queries, #classes=2)
|
| 224 |
+
# idx is a tuple of two 1D tensors (batch_idx, src_idx), of the same length == #objects in batch
|
| 225 |
+
idx = self._get_src_permutation_idx(indices)
|
| 226 |
+
target_classes = torch.full(src_logits.shape[:2], self.background_label,
|
| 227 |
+
dtype=torch.int64, device=src_logits.device) # (batch_size, #queries)
|
| 228 |
+
target_classes[idx] = self.foreground_label
|
| 229 |
+
|
| 230 |
+
loss_ce = F.cross_entropy(src_logits.transpose(1, 2), target_classes, self.empty_weight, reduction="none")
|
| 231 |
+
losses = {'loss_label': loss_ce.mean()}
|
| 232 |
+
|
| 233 |
+
if log:
|
| 234 |
+
# TODO this should probably be a separate loss, not hacked in this one here
|
| 235 |
+
losses['class_error'] = 100 - accuracy(src_logits[idx], self.foreground_label)[0]
|
| 236 |
+
return losses
|
| 237 |
+
|
| 238 |
+
def loss_saliency(self, outputs, targets, indices, log=True):
|
| 239 |
+
"""higher scores for positive clips"""
|
| 240 |
+
if "saliency_pos_labels" not in targets:
|
| 241 |
+
return {"loss_saliency": 0}
|
| 242 |
+
saliency_scores = outputs["saliency_scores"] # (N, L)
|
| 243 |
+
pos_indices = targets["saliency_pos_labels"] # (N, #pairs)
|
| 244 |
+
neg_indices = targets["saliency_neg_labels"] # (N, #pairs)
|
| 245 |
+
num_pairs = pos_indices.shape[1] # typically 2 or 4
|
| 246 |
+
batch_indices = torch.arange(len(saliency_scores)).to(saliency_scores.device)
|
| 247 |
+
pos_scores = torch.stack(
|
| 248 |
+
[saliency_scores[batch_indices, pos_indices[:, col_idx]] for col_idx in range(num_pairs)], dim=1)
|
| 249 |
+
neg_scores = torch.stack(
|
| 250 |
+
[saliency_scores[batch_indices, neg_indices[:, col_idx]] for col_idx in range(num_pairs)], dim=1)
|
| 251 |
+
loss_saliency = torch.clamp(self.saliency_margin + neg_scores - pos_scores, min=0).sum() \
|
| 252 |
+
/ (len(pos_scores) * num_pairs) * 2 # * 2 to keep the loss the same scale
|
| 253 |
+
return {"loss_saliency": loss_saliency}
|
| 254 |
+
|
| 255 |
+
def loss_contrastive_align(self, outputs, targets, indices, log=True):
|
| 256 |
+
"""encourage higher scores between matched query span and input text"""
|
| 257 |
+
normalized_text_embed = outputs["proj_txt_mem"] # (bsz, #tokens, d) text tokens
|
| 258 |
+
normalized_img_embed = outputs["proj_queries"] # (bsz, #queries, d)
|
| 259 |
+
logits = torch.einsum(
|
| 260 |
+
"bmd,bnd->bmn", normalized_img_embed, normalized_text_embed) # (bsz, #queries, #tokens)
|
| 261 |
+
logits = logits.sum(2) / self.temperature # (bsz, #queries)
|
| 262 |
+
idx = self._get_src_permutation_idx(indices)
|
| 263 |
+
positive_map = torch.zeros_like(logits, dtype=torch.bool)
|
| 264 |
+
positive_map[idx] = True
|
| 265 |
+
positive_logits = logits.masked_fill(~positive_map, 0)
|
| 266 |
+
|
| 267 |
+
pos_term = positive_logits.sum(1) # (bsz, )
|
| 268 |
+
num_pos = positive_map.sum(1) # (bsz, )
|
| 269 |
+
neg_term = logits.logsumexp(1) # (bsz, )
|
| 270 |
+
loss_nce = - pos_term / num_pos + neg_term # (bsz, )
|
| 271 |
+
losses = {"loss_contrastive_align": loss_nce.mean()}
|
| 272 |
+
return losses
|
| 273 |
+
|
| 274 |
+
def loss_contrastive_align_vid_txt(self, outputs, targets, indices, log=True):
|
| 275 |
+
"""encourage higher scores between matched query span and input text"""
|
| 276 |
+
# TODO (1) align vid_mem and txt_mem;
|
| 277 |
+
# TODO (2) change L1 loss as CE loss on 75 labels, similar to soft token prediction in MDETR
|
| 278 |
+
normalized_text_embed = outputs["proj_txt_mem"] # (bsz, #tokens, d) text tokens
|
| 279 |
+
normalized_img_embed = outputs["proj_queries"] # (bsz, #queries, d)
|
| 280 |
+
logits = torch.einsum(
|
| 281 |
+
"bmd,bnd->bmn", normalized_img_embed, normalized_text_embed) # (bsz, #queries, #tokens)
|
| 282 |
+
logits = logits.sum(2) / self.temperature # (bsz, #queries)
|
| 283 |
+
idx = self._get_src_permutation_idx(indices)
|
| 284 |
+
positive_map = torch.zeros_like(logits, dtype=torch.bool)
|
| 285 |
+
positive_map[idx] = True
|
| 286 |
+
positive_logits = logits.masked_fill(~positive_map, 0)
|
| 287 |
+
|
| 288 |
+
pos_term = positive_logits.sum(1) # (bsz, )
|
| 289 |
+
num_pos = positive_map.sum(1) # (bsz, )
|
| 290 |
+
neg_term = logits.logsumexp(1) # (bsz, )
|
| 291 |
+
loss_nce = - pos_term / num_pos + neg_term # (bsz, )
|
| 292 |
+
losses = {"loss_contrastive_align": loss_nce.mean()}
|
| 293 |
+
return losses
|
| 294 |
+
|
| 295 |
+
def _get_src_permutation_idx(self, indices):
|
| 296 |
+
# permute predictions following indices
|
| 297 |
+
batch_idx = torch.cat([torch.full_like(src, i) for i, (src, _) in enumerate(indices)])
|
| 298 |
+
src_idx = torch.cat([src for (src, _) in indices])
|
| 299 |
+
return batch_idx, src_idx # two 1D tensors of the same length
|
| 300 |
+
|
| 301 |
+
def _get_tgt_permutation_idx(self, indices):
|
| 302 |
+
# permute targets following indices
|
| 303 |
+
batch_idx = torch.cat([torch.full_like(tgt, i) for i, (_, tgt) in enumerate(indices)])
|
| 304 |
+
tgt_idx = torch.cat([tgt for (_, tgt) in indices])
|
| 305 |
+
return batch_idx, tgt_idx
|
| 306 |
+
|
| 307 |
+
def get_loss(self, loss, outputs, targets, indices, **kwargs):
|
| 308 |
+
loss_map = {
|
| 309 |
+
"spans": self.loss_spans,
|
| 310 |
+
"labels": self.loss_labels,
|
| 311 |
+
"contrastive_align": self.loss_contrastive_align,
|
| 312 |
+
"saliency": self.loss_saliency,
|
| 313 |
+
}
|
| 314 |
+
assert loss in loss_map, f'do you really want to compute {loss} loss?'
|
| 315 |
+
return loss_map[loss](outputs, targets, indices, **kwargs)
|
| 316 |
+
|
| 317 |
+
def forward(self, outputs, targets):
|
| 318 |
+
""" This performs the loss computation.
|
| 319 |
+
Parameters:
|
| 320 |
+
outputs: dict of tensors, see the output specification of the model for the format
|
| 321 |
+
targets: list of dicts, such that len(targets) == batch_size.
|
| 322 |
+
The expected keys in each dict depends on the losses applied, see each loss' doc
|
| 323 |
+
"""
|
| 324 |
+
outputs_without_aux = {k: v for k, v in outputs.items() if k != 'aux_outputs'}
|
| 325 |
+
|
| 326 |
+
# Retrieve the matching between the outputs of the last layer and the targets
|
| 327 |
+
# list(tuples), each tuple is (pred_span_indices, tgt_span_indices)
|
| 328 |
+
indices = self.matcher(outputs_without_aux, targets)
|
| 329 |
+
|
| 330 |
+
# Compute all the requested losses
|
| 331 |
+
losses = {}
|
| 332 |
+
for loss in self.losses:
|
| 333 |
+
losses.update(self.get_loss(loss, outputs, targets, indices))
|
| 334 |
+
|
| 335 |
+
# In case of auxiliary losses, we repeat this process with the output of each intermediate layer.
|
| 336 |
+
if 'aux_outputs' in outputs:
|
| 337 |
+
for i, aux_outputs in enumerate(outputs['aux_outputs']):
|
| 338 |
+
indices = self.matcher(aux_outputs, targets)
|
| 339 |
+
for loss in self.losses:
|
| 340 |
+
if "saliency" == loss: # skip as it is only in the top layer
|
| 341 |
+
continue
|
| 342 |
+
kwargs = {}
|
| 343 |
+
l_dict = self.get_loss(loss, aux_outputs, targets, indices, **kwargs)
|
| 344 |
+
l_dict = {k + f'_{i}': v for k, v in l_dict.items()}
|
| 345 |
+
losses.update(l_dict)
|
| 346 |
+
|
| 347 |
+
return losses
|
| 348 |
+
|
| 349 |
+
|
| 350 |
+
class MLP(nn.Module):
|
| 351 |
+
""" Very simple multi-layer perceptron (also called FFN)"""
|
| 352 |
+
|
| 353 |
+
def __init__(self, input_dim, hidden_dim, output_dim, num_layers):
|
| 354 |
+
super().__init__()
|
| 355 |
+
self.num_layers = num_layers
|
| 356 |
+
h = [hidden_dim] * (num_layers - 1)
|
| 357 |
+
self.layers = nn.ModuleList(nn.Linear(n, k) for n, k in zip([input_dim] + h, h + [output_dim]))
|
| 358 |
+
|
| 359 |
+
def forward(self, x):
|
| 360 |
+
for i, layer in enumerate(self.layers):
|
| 361 |
+
x = F.relu(layer(x)) if i < self.num_layers - 1 else layer(x)
|
| 362 |
+
return x
|
| 363 |
+
|
| 364 |
+
|
| 365 |
+
class LinearLayer(nn.Module):
|
| 366 |
+
"""linear layer configurable with layer normalization, dropout, ReLU."""
|
| 367 |
+
|
| 368 |
+
def __init__(self, in_hsz, out_hsz, layer_norm=True, dropout=0.1, relu=True):
|
| 369 |
+
super(LinearLayer, self).__init__()
|
| 370 |
+
self.relu = relu
|
| 371 |
+
self.layer_norm = layer_norm
|
| 372 |
+
if layer_norm:
|
| 373 |
+
self.LayerNorm = nn.LayerNorm(in_hsz)
|
| 374 |
+
layers = [
|
| 375 |
+
nn.Dropout(dropout),
|
| 376 |
+
nn.Linear(in_hsz, out_hsz)
|
| 377 |
+
]
|
| 378 |
+
self.net = nn.Sequential(*layers)
|
| 379 |
+
|
| 380 |
+
def forward(self, x):
|
| 381 |
+
"""(N, L, D)"""
|
| 382 |
+
if self.layer_norm:
|
| 383 |
+
x = self.LayerNorm(x)
|
| 384 |
+
x = self.net(x)
|
| 385 |
+
if self.relu:
|
| 386 |
+
x = F.relu(x, inplace=True)
|
| 387 |
+
return x # (N, L, D)
|
| 388 |
+
|
| 389 |
+
|
| 390 |
+
def build_model(args):
|
| 391 |
+
# the `num_classes` naming here is somewhat misleading.
|
| 392 |
+
# it indeed corresponds to `max_obj_id + 1`, where max_obj_id
|
| 393 |
+
# is the maximum id for a class in your dataset. For example,
|
| 394 |
+
# COCO has a max_obj_id of 90, so we pass `num_classes` to be 91.
|
| 395 |
+
# As another example, for a dataset that has a single class with id 1,
|
| 396 |
+
# you should pass `num_classes` to be 2 (max_obj_id + 1).
|
| 397 |
+
# For more details on this, check the following discussion
|
| 398 |
+
# https://github.com/facebookresearch/moment_detr/issues/108#issuecomment-650269223
|
| 399 |
+
device = torch.device(args.device)
|
| 400 |
+
|
| 401 |
+
transformer = build_transformer(args)
|
| 402 |
+
position_embedding, txt_position_embedding = build_position_encoding(args)
|
| 403 |
+
|
| 404 |
+
model = MomentDETR(
|
| 405 |
+
transformer,
|
| 406 |
+
position_embedding,
|
| 407 |
+
txt_position_embedding,
|
| 408 |
+
txt_dim=args.t_feat_dim,
|
| 409 |
+
vid_dim=args.v_feat_dim,
|
| 410 |
+
num_queries=args.num_queries,
|
| 411 |
+
input_dropout=args.input_dropout,
|
| 412 |
+
aux_loss=args.aux_loss,
|
| 413 |
+
contrastive_align_loss=args.contrastive_align_loss,
|
| 414 |
+
contrastive_hdim=args.contrastive_hdim,
|
| 415 |
+
span_loss_type=args.span_loss_type,
|
| 416 |
+
use_txt_pos=args.use_txt_pos,
|
| 417 |
+
n_input_proj=args.n_input_proj,
|
| 418 |
+
)
|
| 419 |
+
|
| 420 |
+
matcher = build_matcher(args)
|
| 421 |
+
weight_dict = {"loss_span": args.span_loss_coef,
|
| 422 |
+
"loss_giou": args.giou_loss_coef,
|
| 423 |
+
"loss_label": args.label_loss_coef,
|
| 424 |
+
"loss_saliency": args.lw_saliency}
|
| 425 |
+
if args.contrastive_align_loss:
|
| 426 |
+
weight_dict["loss_contrastive_align"] = args.contrastive_align_loss_coef
|
| 427 |
+
# TODO this is a hack
|
| 428 |
+
if args.aux_loss:
|
| 429 |
+
aux_weight_dict = {}
|
| 430 |
+
for i in range(args.dec_layers - 1):
|
| 431 |
+
aux_weight_dict.update({k + f'_{i}': v for k, v in weight_dict.items() if k != "loss_saliency"})
|
| 432 |
+
weight_dict.update(aux_weight_dict)
|
| 433 |
+
|
| 434 |
+
losses = ['spans', 'labels', 'saliency']
|
| 435 |
+
if args.contrastive_align_loss:
|
| 436 |
+
losses += ["contrastive_align"]
|
| 437 |
+
criterion = SetCriterion(
|
| 438 |
+
matcher=matcher, weight_dict=weight_dict, losses=losses,
|
| 439 |
+
eos_coef=args.eos_coef, temperature=args.temperature,
|
| 440 |
+
span_loss_type=args.span_loss_type, max_v_l=args.max_v_l,
|
| 441 |
+
saliency_margin=args.saliency_margin
|
| 442 |
+
)
|
| 443 |
+
criterion.to(device)
|
| 444 |
+
return model, criterion
|
moment_detr/position_encoding.py
ADDED
|
@@ -0,0 +1,115 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
|
| 2 |
+
"""
|
| 3 |
+
Various positional encodings for the transformer.
|
| 4 |
+
"""
|
| 5 |
+
import math
|
| 6 |
+
import torch
|
| 7 |
+
from torch import nn
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
class TrainablePositionalEncoding(nn.Module):
|
| 11 |
+
"""Construct the embeddings from word, position and token_type embeddings.
|
| 12 |
+
"""
|
| 13 |
+
def __init__(self, max_position_embeddings, hidden_size, dropout=0.1):
|
| 14 |
+
super(TrainablePositionalEncoding, self).__init__()
|
| 15 |
+
self.position_embeddings = nn.Embedding(max_position_embeddings, hidden_size)
|
| 16 |
+
self.LayerNorm = nn.LayerNorm(hidden_size)
|
| 17 |
+
self.dropout = nn.Dropout(dropout)
|
| 18 |
+
|
| 19 |
+
def forward(self, input_feat):
|
| 20 |
+
"""
|
| 21 |
+
Args:
|
| 22 |
+
input_feat: (N, L, D)
|
| 23 |
+
"""
|
| 24 |
+
bsz, seq_length = input_feat.shape[:2]
|
| 25 |
+
position_ids = torch.arange(seq_length, dtype=torch.long, device=input_feat.device)
|
| 26 |
+
position_ids = position_ids.unsqueeze(0).repeat(bsz, 1) # (N, L)
|
| 27 |
+
|
| 28 |
+
position_embeddings = self.position_embeddings(position_ids)
|
| 29 |
+
|
| 30 |
+
embeddings = self.LayerNorm(input_feat + position_embeddings)
|
| 31 |
+
embeddings = self.dropout(embeddings)
|
| 32 |
+
return embeddings
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
class PositionEmbeddingSine(nn.Module):
|
| 36 |
+
"""
|
| 37 |
+
This is a more standard version of the position embedding, very similar to the one
|
| 38 |
+
used by the Attention is all you need paper, generalized to work on images. (To 1D sequences)
|
| 39 |
+
"""
|
| 40 |
+
def __init__(self, num_pos_feats=64, temperature=10000, normalize=False, scale=None):
|
| 41 |
+
super().__init__()
|
| 42 |
+
self.num_pos_feats = num_pos_feats
|
| 43 |
+
self.temperature = temperature
|
| 44 |
+
self.normalize = normalize
|
| 45 |
+
if scale is not None and normalize is False:
|
| 46 |
+
raise ValueError("normalize should be True if scale is passed")
|
| 47 |
+
if scale is None:
|
| 48 |
+
scale = 2 * math.pi
|
| 49 |
+
self.scale = scale
|
| 50 |
+
|
| 51 |
+
def forward(self, x, mask):
|
| 52 |
+
"""
|
| 53 |
+
Args:
|
| 54 |
+
x: torch.tensor, (batch_size, L, d)
|
| 55 |
+
mask: torch.tensor, (batch_size, L), with 1 as valid
|
| 56 |
+
|
| 57 |
+
Returns:
|
| 58 |
+
|
| 59 |
+
"""
|
| 60 |
+
assert mask is not None
|
| 61 |
+
x_embed = mask.cumsum(1, dtype=torch.float32) # (bsz, L)
|
| 62 |
+
if self.normalize:
|
| 63 |
+
eps = 1e-6
|
| 64 |
+
x_embed = x_embed / (x_embed[:, -1:] + eps) * self.scale
|
| 65 |
+
|
| 66 |
+
dim_t = torch.arange(self.num_pos_feats, dtype=torch.float32, device=x.device)
|
| 67 |
+
dim_t = self.temperature ** (2 * (dim_t // 2) / self.num_pos_feats)
|
| 68 |
+
|
| 69 |
+
pos_x = x_embed[:, :, None] / dim_t # (bsz, L, num_pos_feats)
|
| 70 |
+
pos_x = torch.stack((pos_x[:, :, 0::2].sin(), pos_x[:, :, 1::2].cos()), dim=3).flatten(2) # (bsz, L, num_pos_feats*2)
|
| 71 |
+
# import ipdb; ipdb.set_trace()
|
| 72 |
+
return pos_x # .permute(0, 2, 1) # (bsz, num_pos_feats*2, L)
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
class PositionEmbeddingLearned(nn.Module):
|
| 76 |
+
"""
|
| 77 |
+
Absolute pos embedding, learned.
|
| 78 |
+
"""
|
| 79 |
+
def __init__(self, num_pos_feats=256):
|
| 80 |
+
super().__init__()
|
| 81 |
+
self.row_embed = nn.Embedding(50, num_pos_feats)
|
| 82 |
+
self.col_embed = nn.Embedding(50, num_pos_feats)
|
| 83 |
+
self.reset_parameters()
|
| 84 |
+
|
| 85 |
+
def reset_parameters(self):
|
| 86 |
+
nn.init.uniform_(self.row_embed.weight)
|
| 87 |
+
nn.init.uniform_(self.col_embed.weight)
|
| 88 |
+
|
| 89 |
+
def forward(self, x, mask):
|
| 90 |
+
h, w = x.shape[-2:]
|
| 91 |
+
i = torch.arange(w, device=x.device)
|
| 92 |
+
j = torch.arange(h, device=x.device)
|
| 93 |
+
x_emb = self.col_embed(i)
|
| 94 |
+
y_emb = self.row_embed(j)
|
| 95 |
+
pos = torch.cat([
|
| 96 |
+
x_emb.unsqueeze(0).repeat(h, 1, 1),
|
| 97 |
+
y_emb.unsqueeze(1).repeat(1, w, 1),
|
| 98 |
+
], dim=-1).permute(2, 0, 1).unsqueeze(0).repeat(x.shape[0], 1, 1, 1)
|
| 99 |
+
return pos
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
def build_position_encoding(args):
|
| 103 |
+
N_steps = args.hidden_dim
|
| 104 |
+
if args.position_embedding in ('v2', 'sine'):
|
| 105 |
+
# TODO find a better way of exposing other arguments
|
| 106 |
+
position_embedding = PositionEmbeddingSine(N_steps, normalize=True)
|
| 107 |
+
# elif args.position_embedding in ('v3', 'learned'):
|
| 108 |
+
# position_embedding = PositionEmbeddingLearned(N_steps)
|
| 109 |
+
else:
|
| 110 |
+
raise ValueError(f"not supported {args.position_embedding}")
|
| 111 |
+
|
| 112 |
+
txt_pos_embed = TrainablePositionalEncoding(
|
| 113 |
+
max_position_embeddings=args.max_q_l,
|
| 114 |
+
hidden_size=args.hidden_dim, dropout=args.input_dropout)
|
| 115 |
+
return position_embedding, txt_pos_embed
|
moment_detr/postprocessing_moment_detr.py
ADDED
|
@@ -0,0 +1,95 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import pprint
|
| 2 |
+
import numpy as np
|
| 3 |
+
import torch
|
| 4 |
+
from utils.basic_utils import load_jsonl
|
| 5 |
+
from standalone_eval.eval import eval_submission
|
| 6 |
+
from tqdm import tqdm
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class PostProcessorDETR:
|
| 10 |
+
def __init__(self, clip_length=2, min_ts_val=0, max_ts_val=150,
|
| 11 |
+
min_w_l=2, max_w_l=70, move_window_method="center",
|
| 12 |
+
process_func_names=("clip_window_l", "clip_ts", "round_multiple")):
|
| 13 |
+
self.clip_length = clip_length
|
| 14 |
+
self.min_ts_val = min_ts_val
|
| 15 |
+
self.max_ts_val = max_ts_val
|
| 16 |
+
self.min_w_l = min_w_l
|
| 17 |
+
self.max_w_l = max_w_l
|
| 18 |
+
self.move_window_method = move_window_method
|
| 19 |
+
self.process_func_names = process_func_names
|
| 20 |
+
self.name2func = dict(
|
| 21 |
+
clip_ts=self.clip_min_max_timestamps,
|
| 22 |
+
round_multiple=self.round_to_multiple_clip_lengths,
|
| 23 |
+
clip_window_l=self.clip_window_lengths
|
| 24 |
+
)
|
| 25 |
+
|
| 26 |
+
def __call__(self, lines):
|
| 27 |
+
processed_lines = []
|
| 28 |
+
for line in tqdm(lines, desc=f"convert to multiples of clip_length={self.clip_length}"):
|
| 29 |
+
windows_and_scores = torch.tensor(line["pred_relevant_windows"])
|
| 30 |
+
windows = windows_and_scores[:, :2]
|
| 31 |
+
for func_name in self.process_func_names:
|
| 32 |
+
windows = self.name2func[func_name](windows)
|
| 33 |
+
line["pred_relevant_windows"] = torch.cat(
|
| 34 |
+
[windows, windows_and_scores[:, 2:3]], dim=1).tolist()
|
| 35 |
+
line["pred_relevant_windows"] = [e[:2] + [float(f"{e[2]:.4f}")] for e in line["pred_relevant_windows"]]
|
| 36 |
+
processed_lines.append(line)
|
| 37 |
+
return processed_lines
|
| 38 |
+
|
| 39 |
+
def clip_min_max_timestamps(self, windows):
|
| 40 |
+
"""
|
| 41 |
+
windows: (#windows, 2) torch.Tensor
|
| 42 |
+
ensure timestamps for all windows is within [min_val, max_val], clip is out of boundaries.
|
| 43 |
+
"""
|
| 44 |
+
return torch.clamp(windows, min=self.min_ts_val, max=self.max_ts_val)
|
| 45 |
+
|
| 46 |
+
def round_to_multiple_clip_lengths(self, windows):
|
| 47 |
+
"""
|
| 48 |
+
windows: (#windows, 2) torch.Tensor
|
| 49 |
+
ensure the final window timestamps are multiples of `clip_length`
|
| 50 |
+
"""
|
| 51 |
+
return torch.round(windows / self.clip_length) * self.clip_length
|
| 52 |
+
|
| 53 |
+
def clip_window_lengths(self, windows):
|
| 54 |
+
"""
|
| 55 |
+
windows: (#windows, 2) np.ndarray
|
| 56 |
+
ensure the final window duration are within [self.min_w_l, self.max_w_l]
|
| 57 |
+
"""
|
| 58 |
+
window_lengths = windows[:, 1] - windows[:, 0]
|
| 59 |
+
small_rows = window_lengths < self.min_w_l
|
| 60 |
+
if torch.sum(small_rows) > 0:
|
| 61 |
+
windows = self.move_windows(
|
| 62 |
+
windows, small_rows, self.min_w_l, move_method=self.move_window_method)
|
| 63 |
+
large_rows = window_lengths > self.max_w_l
|
| 64 |
+
if torch.sum(large_rows) > 0:
|
| 65 |
+
windows = self.move_windows(
|
| 66 |
+
windows, large_rows, self.max_w_l, move_method=self.move_window_method)
|
| 67 |
+
return windows
|
| 68 |
+
|
| 69 |
+
@classmethod
|
| 70 |
+
def move_windows(cls, windows, row_selector, new_length, move_method="left"):
|
| 71 |
+
"""
|
| 72 |
+
Args:
|
| 73 |
+
windows:
|
| 74 |
+
row_selector:
|
| 75 |
+
new_length:
|
| 76 |
+
move_method: str,
|
| 77 |
+
left: keep left unchanged
|
| 78 |
+
center: keep center unchanged
|
| 79 |
+
right: keep right unchanged
|
| 80 |
+
|
| 81 |
+
Returns:
|
| 82 |
+
|
| 83 |
+
"""
|
| 84 |
+
# import ipdb;
|
| 85 |
+
# ipdb.set_trace()
|
| 86 |
+
if move_method == "left":
|
| 87 |
+
windows[row_selector, 1] = windows[row_selector, 0] + new_length
|
| 88 |
+
elif move_method == "right":
|
| 89 |
+
windows[row_selector, 0] = windows[row_selector, 1] - new_length
|
| 90 |
+
elif move_method == "center":
|
| 91 |
+
center = (windows[row_selector, 1] + windows[row_selector, 0]) / 2.
|
| 92 |
+
windows[row_selector, 0] = center - new_length / 2.
|
| 93 |
+
windows[row_selector, 1] = center + new_length / 2.
|
| 94 |
+
return windows
|
| 95 |
+
|
moment_detr/scripts/inference.sh
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
ckpt_path=$1
|
| 2 |
+
eval_split_name=$2
|
| 3 |
+
eval_path=data/highlight_${eval_split_name}_release.jsonl
|
| 4 |
+
PYTHONPATH=$PYTHONPATH:. python moment_detr/inference.py \
|
| 5 |
+
--resume ${ckpt_path} \
|
| 6 |
+
--eval_split_name ${eval_split_name} \
|
| 7 |
+
--eval_path ${eval_path} \
|
| 8 |
+
${@:3}
|
moment_detr/scripts/pretrain.sh
ADDED
|
@@ -0,0 +1,61 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
dset_name=hl
|
| 2 |
+
ctx_mode=video_tef
|
| 3 |
+
v_feat_types=slowfast_clip
|
| 4 |
+
t_feat_type=clip
|
| 5 |
+
results_root=results
|
| 6 |
+
exp_id=pt
|
| 7 |
+
|
| 8 |
+
######## data paths
|
| 9 |
+
train_path=data/subs_train.jsonl
|
| 10 |
+
eval_path=data/highlight_val_release.jsonl
|
| 11 |
+
eval_split_name=val
|
| 12 |
+
|
| 13 |
+
######## setup video+text features
|
| 14 |
+
feat_root=features
|
| 15 |
+
|
| 16 |
+
# video features
|
| 17 |
+
v_feat_dim=0
|
| 18 |
+
v_feat_dirs=()
|
| 19 |
+
if [[ ${v_feat_types} == *"slowfast"* ]]; then
|
| 20 |
+
v_feat_dirs+=(${feat_root}/slowfast_features)
|
| 21 |
+
(( v_feat_dim += 2304 )) # double brackets for arithmetic op, no need to use ${v_feat_dim}
|
| 22 |
+
fi
|
| 23 |
+
if [[ ${v_feat_types} == *"clip"* ]]; then
|
| 24 |
+
v_feat_dirs+=(${feat_root}/clip_features)
|
| 25 |
+
(( v_feat_dim += 512 ))
|
| 26 |
+
fi
|
| 27 |
+
|
| 28 |
+
# text features
|
| 29 |
+
if [[ ${t_feat_type} == "clip" ]]; then
|
| 30 |
+
t_feat_dir=${feat_root}/clip_sub_features/
|
| 31 |
+
t_feat_dim=512
|
| 32 |
+
else
|
| 33 |
+
echo "Wrong arg for t_feat_type."
|
| 34 |
+
exit 1
|
| 35 |
+
fi
|
| 36 |
+
|
| 37 |
+
#### training
|
| 38 |
+
bsz=256
|
| 39 |
+
num_workers=8
|
| 40 |
+
n_epoch=100
|
| 41 |
+
max_es_cnt=100
|
| 42 |
+
exp_id=pt
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
PYTHONPATH=$PYTHONPATH:. python moment_detr/train.py \
|
| 46 |
+
--dset_name ${dset_name} \
|
| 47 |
+
--ctx_mode ${ctx_mode} \
|
| 48 |
+
--train_path ${train_path} \
|
| 49 |
+
--eval_path ${eval_path} \
|
| 50 |
+
--eval_split_name ${eval_split_name} \
|
| 51 |
+
--v_feat_dirs ${v_feat_dirs[@]} \
|
| 52 |
+
--v_feat_dim ${v_feat_dim} \
|
| 53 |
+
--t_feat_dir ${t_feat_dir} \
|
| 54 |
+
--t_feat_dim ${t_feat_dim} \
|
| 55 |
+
--bsz ${bsz} \
|
| 56 |
+
--results_root ${results_root} \
|
| 57 |
+
--num_workers ${num_workers} \
|
| 58 |
+
--exp_id ${exp_id} \
|
| 59 |
+
--n_epoch ${n_epoch} \
|
| 60 |
+
--max_es_cnt ${max_es_cnt} \
|
| 61 |
+
${@:1}
|
moment_detr/scripts/train.sh
ADDED
|
@@ -0,0 +1,54 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
dset_name=hl
|
| 2 |
+
ctx_mode=video_tef
|
| 3 |
+
v_feat_types=slowfast_clip
|
| 4 |
+
t_feat_type=clip
|
| 5 |
+
results_root=results
|
| 6 |
+
exp_id=exp
|
| 7 |
+
|
| 8 |
+
######## data paths
|
| 9 |
+
train_path=data/highlight_train_release.jsonl
|
| 10 |
+
eval_path=data/highlight_val_release.jsonl
|
| 11 |
+
eval_split_name=val
|
| 12 |
+
|
| 13 |
+
######## setup video+text features
|
| 14 |
+
feat_root=features
|
| 15 |
+
|
| 16 |
+
# video features
|
| 17 |
+
v_feat_dim=0
|
| 18 |
+
v_feat_dirs=()
|
| 19 |
+
if [[ ${v_feat_types} == *"slowfast"* ]]; then
|
| 20 |
+
v_feat_dirs+=(${feat_root}/slowfast_features)
|
| 21 |
+
(( v_feat_dim += 2304 )) # double brackets for arithmetic op, no need to use ${v_feat_dim}
|
| 22 |
+
fi
|
| 23 |
+
if [[ ${v_feat_types} == *"clip"* ]]; then
|
| 24 |
+
v_feat_dirs+=(${feat_root}/clip_features)
|
| 25 |
+
(( v_feat_dim += 512 ))
|
| 26 |
+
fi
|
| 27 |
+
|
| 28 |
+
# text features
|
| 29 |
+
if [[ ${t_feat_type} == "clip" ]]; then
|
| 30 |
+
t_feat_dir=${feat_root}/clip_text_features/
|
| 31 |
+
t_feat_dim=512
|
| 32 |
+
else
|
| 33 |
+
echo "Wrong arg for t_feat_type."
|
| 34 |
+
exit 1
|
| 35 |
+
fi
|
| 36 |
+
|
| 37 |
+
#### training
|
| 38 |
+
bsz=32
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
PYTHONPATH=$PYTHONPATH:. python moment_detr/train.py \
|
| 42 |
+
--dset_name ${dset_name} \
|
| 43 |
+
--ctx_mode ${ctx_mode} \
|
| 44 |
+
--train_path ${train_path} \
|
| 45 |
+
--eval_path ${eval_path} \
|
| 46 |
+
--eval_split_name ${eval_split_name} \
|
| 47 |
+
--v_feat_dirs ${v_feat_dirs[@]} \
|
| 48 |
+
--v_feat_dim ${v_feat_dim} \
|
| 49 |
+
--t_feat_dir ${t_feat_dir} \
|
| 50 |
+
--t_feat_dim ${t_feat_dim} \
|
| 51 |
+
--bsz ${bsz} \
|
| 52 |
+
--results_root ${results_root} \
|
| 53 |
+
--exp_id ${exp_id} \
|
| 54 |
+
${@:1}
|
moment_detr/span_utils.py
ADDED
|
@@ -0,0 +1,122 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
def span_xx_to_cxw(xx_spans):
|
| 5 |
+
"""
|
| 6 |
+
Args:
|
| 7 |
+
xx_spans: tensor, (#windows, 2) or (..., 2), each row is a window of format (st, ed)
|
| 8 |
+
|
| 9 |
+
Returns:
|
| 10 |
+
cxw_spans: tensor, (#windows, 2), each row is a window of format (center=(st+ed)/2, width=(ed-st))
|
| 11 |
+
>>> spans = torch.Tensor([[0, 1], [0.2, 0.4]])
|
| 12 |
+
>>> span_xx_to_cxw(spans)
|
| 13 |
+
tensor([[0.5000, 1.0000],
|
| 14 |
+
[0.3000, 0.2000]])
|
| 15 |
+
>>> spans = torch.Tensor([[[0, 1], [0.2, 0.4]]])
|
| 16 |
+
>>> span_xx_to_cxw(spans)
|
| 17 |
+
tensor([[[0.5000, 1.0000],
|
| 18 |
+
[0.3000, 0.2000]]])
|
| 19 |
+
"""
|
| 20 |
+
center = xx_spans.sum(-1) * 0.5
|
| 21 |
+
width = xx_spans[..., 1] - xx_spans[..., 0]
|
| 22 |
+
return torch.stack([center, width], dim=-1)
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def span_cxw_to_xx(cxw_spans):
|
| 26 |
+
"""
|
| 27 |
+
Args:
|
| 28 |
+
cxw_spans: tensor, (#windows, 2) or (..., 2), the last dim is a row denoting a window of format (center, width)
|
| 29 |
+
|
| 30 |
+
>>> spans = torch.Tensor([[0.5000, 1.0000], [0.3000, 0.2000]])
|
| 31 |
+
>>> span_cxw_to_xx(spans)
|
| 32 |
+
tensor([[0.0000, 1.0000],
|
| 33 |
+
[0.2000, 0.4000]])
|
| 34 |
+
>>> spans = torch.Tensor([[[0.5000, 1.0000], [0.3000, 0.2000]]])
|
| 35 |
+
>>> span_cxw_to_xx(spans)
|
| 36 |
+
tensor([[[0.0000, 1.0000],
|
| 37 |
+
[0.2000, 0.4000]]])
|
| 38 |
+
"""
|
| 39 |
+
x1 = cxw_spans[..., 0] - 0.5 * cxw_spans[..., 1]
|
| 40 |
+
x2 = cxw_spans[..., 0] + 0.5 * cxw_spans[..., 1]
|
| 41 |
+
return torch.stack([x1, x2], dim=-1)
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
def temporal_iou(spans1, spans2):
|
| 45 |
+
"""
|
| 46 |
+
Args:
|
| 47 |
+
spans1: (N, 2) torch.Tensor, each row defines a span [st, ed]
|
| 48 |
+
spans2: (M, 2) torch.Tensor, ...
|
| 49 |
+
|
| 50 |
+
Returns:
|
| 51 |
+
iou: (N, M) torch.Tensor
|
| 52 |
+
union: (N, M) torch.Tensor
|
| 53 |
+
>>> test_spans1 = torch.Tensor([[0, 0.2], [0.5, 1.0]])
|
| 54 |
+
>>> test_spans2 = torch.Tensor([[0, 0.3], [0., 1.0]])
|
| 55 |
+
>>> temporal_iou(test_spans1, test_spans2)
|
| 56 |
+
(tensor([[0.6667, 0.2000],
|
| 57 |
+
[0.0000, 0.5000]]),
|
| 58 |
+
tensor([[0.3000, 1.0000],
|
| 59 |
+
[0.8000, 1.0000]]))
|
| 60 |
+
"""
|
| 61 |
+
areas1 = spans1[:, 1] - spans1[:, 0] # (N, )
|
| 62 |
+
areas2 = spans2[:, 1] - spans2[:, 0] # (M, )
|
| 63 |
+
|
| 64 |
+
left = torch.max(spans1[:, None, 0], spans2[:, 0]) # (N, M)
|
| 65 |
+
right = torch.min(spans1[:, None, 1], spans2[:, 1]) # (N, M)
|
| 66 |
+
|
| 67 |
+
inter = (right - left).clamp(min=0) # (N, M)
|
| 68 |
+
union = areas1[:, None] + areas2 - inter # (N, M)
|
| 69 |
+
|
| 70 |
+
iou = inter / union
|
| 71 |
+
return iou, union
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
def temporal_intersection_over_pred(gt_spans, pred_spans):
|
| 75 |
+
""" intersection over the second input spans
|
| 76 |
+
Args:
|
| 77 |
+
gt_spans: (N, 2),
|
| 78 |
+
pred_spans: (M, 2)
|
| 79 |
+
|
| 80 |
+
Returns:
|
| 81 |
+
|
| 82 |
+
"""
|
| 83 |
+
left = torch.max(gt_spans[:, None, 0], pred_spans[:, 0])
|
| 84 |
+
right = torch.min(gt_spans[:, None, 1], pred_spans[:, 1])
|
| 85 |
+
|
| 86 |
+
inter = (right - left).clamp(min=0) # (N, M)
|
| 87 |
+
inter_over_pred = inter / (pred_spans[:, 1] - pred_spans[:, 0])
|
| 88 |
+
return inter_over_pred
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
def generalized_temporal_iou(spans1, spans2):
|
| 92 |
+
"""
|
| 93 |
+
Generalized IoU from https://giou.stanford.edu/
|
| 94 |
+
Also reference to DETR implementation of generalized_box_iou
|
| 95 |
+
https://github.com/facebookresearch/detr/blob/master/util/box_ops.py#L40
|
| 96 |
+
|
| 97 |
+
Args:
|
| 98 |
+
spans1: (N, 2) torch.Tensor, each row defines a span in xx format [st, ed]
|
| 99 |
+
spans2: (M, 2) torch.Tensor, ...
|
| 100 |
+
|
| 101 |
+
Returns:
|
| 102 |
+
giou: (N, M) torch.Tensor
|
| 103 |
+
|
| 104 |
+
>>> test_spans1 = torch.Tensor([[0, 0.2], [0.5, 1.0]])
|
| 105 |
+
>>> test_spans2 = torch.Tensor([[0, 0.3], [0., 1.0]])
|
| 106 |
+
>>> generalized_temporal_iou(test_spans1, test_spans2)
|
| 107 |
+
tensor([[ 0.6667, 0.2000],
|
| 108 |
+
[-0.2000, 0.5000]])
|
| 109 |
+
"""
|
| 110 |
+
spans1 = spans1.float()
|
| 111 |
+
spans2 = spans2.float()
|
| 112 |
+
assert (spans1[:, 1] >= spans1[:, 0]).all()
|
| 113 |
+
assert (spans2[:, 1] >= spans2[:, 0]).all()
|
| 114 |
+
iou, union = temporal_iou(spans1, spans2)
|
| 115 |
+
|
| 116 |
+
left = torch.min(spans1[:, None, 0], spans2[:, 0]) # (N, M)
|
| 117 |
+
right = torch.max(spans1[:, None, 1], spans2[:, 1]) # (N, M)
|
| 118 |
+
enclosing_area = (right - left).clamp(min=0) # (N, M)
|
| 119 |
+
|
| 120 |
+
return iou - (enclosing_area - union) / enclosing_area
|
| 121 |
+
|
| 122 |
+
|
moment_detr/start_end_dataset.py
ADDED
|
@@ -0,0 +1,247 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from torch.utils.data import Dataset
|
| 3 |
+
import numpy as np
|
| 4 |
+
from tqdm import tqdm
|
| 5 |
+
import random
|
| 6 |
+
import logging
|
| 7 |
+
from os.path import join, exists
|
| 8 |
+
from utils.basic_utils import load_jsonl, l2_normalize_np_array
|
| 9 |
+
from utils.tensor_utils import pad_sequences_1d
|
| 10 |
+
from moment_detr.span_utils import span_xx_to_cxw
|
| 11 |
+
|
| 12 |
+
logger = logging.getLogger(__name__)
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class StartEndDataset(Dataset):
|
| 16 |
+
Q_FEAT_TYPES = ["pooler_output", "last_hidden_state"]
|
| 17 |
+
"""One line in data loaded from data_path."
|
| 18 |
+
{
|
| 19 |
+
"qid": 7803,
|
| 20 |
+
"query": "Man in gray top walks from outside to inside.",
|
| 21 |
+
"duration": 150,
|
| 22 |
+
"vid": "RoripwjYFp8_360.0_510.0",
|
| 23 |
+
"relevant_clip_ids": [13, 14, 15, 16, 17],
|
| 24 |
+
"relevant_windows": [[26, 36]]
|
| 25 |
+
}
|
| 26 |
+
"""
|
| 27 |
+
|
| 28 |
+
def __init__(self, dset_name, data_path, v_feat_dirs, q_feat_dir,
|
| 29 |
+
q_feat_type="last_hidden_state",
|
| 30 |
+
max_q_l=32, max_v_l=75, data_ratio=1.0, ctx_mode="video",
|
| 31 |
+
normalize_v=True, normalize_t=True, load_labels=True,
|
| 32 |
+
clip_len=2, max_windows=5, span_loss_type="l1", txt_drop_ratio=0):
|
| 33 |
+
self.dset_name = dset_name
|
| 34 |
+
self.data_path = data_path
|
| 35 |
+
self.data_ratio = data_ratio
|
| 36 |
+
self.v_feat_dirs = v_feat_dirs \
|
| 37 |
+
if isinstance(v_feat_dirs, list) else [v_feat_dirs]
|
| 38 |
+
self.q_feat_dir = q_feat_dir
|
| 39 |
+
self.q_feat_type = q_feat_type
|
| 40 |
+
self.max_q_l = max_q_l
|
| 41 |
+
self.max_v_l = max_v_l
|
| 42 |
+
self.ctx_mode = ctx_mode
|
| 43 |
+
self.use_tef = "tef" in ctx_mode
|
| 44 |
+
self.use_video = "video" in ctx_mode
|
| 45 |
+
self.normalize_t = normalize_t
|
| 46 |
+
self.normalize_v = normalize_v
|
| 47 |
+
self.load_labels = load_labels
|
| 48 |
+
self.clip_len = clip_len
|
| 49 |
+
self.max_windows = max_windows # maximum number of windows to use as labels
|
| 50 |
+
self.span_loss_type = span_loss_type
|
| 51 |
+
self.txt_drop_ratio = txt_drop_ratio
|
| 52 |
+
if "val" in data_path or "test" in data_path:
|
| 53 |
+
assert txt_drop_ratio == 0
|
| 54 |
+
|
| 55 |
+
# checks
|
| 56 |
+
assert q_feat_type in self.Q_FEAT_TYPES
|
| 57 |
+
|
| 58 |
+
# data
|
| 59 |
+
self.data = self.load_data()
|
| 60 |
+
|
| 61 |
+
def load_data(self):
|
| 62 |
+
datalist = load_jsonl(self.data_path)
|
| 63 |
+
if self.data_ratio != 1:
|
| 64 |
+
n_examples = int(len(datalist) * self.data_ratio)
|
| 65 |
+
datalist = datalist[:n_examples]
|
| 66 |
+
logger.info("Using {}% of the data: {} examples"
|
| 67 |
+
.format(self.data_ratio * 100, n_examples))
|
| 68 |
+
return datalist
|
| 69 |
+
|
| 70 |
+
def __len__(self):
|
| 71 |
+
return len(self.data)
|
| 72 |
+
|
| 73 |
+
def __getitem__(self, index):
|
| 74 |
+
meta = self.data[index]
|
| 75 |
+
|
| 76 |
+
model_inputs = dict()
|
| 77 |
+
model_inputs["query_feat"] = self._get_query_feat_by_qid(meta["qid"]) # (Dq, ) or (Lq, Dq)
|
| 78 |
+
if self.use_video:
|
| 79 |
+
model_inputs["video_feat"] = self._get_video_feat_by_vid(meta["vid"]) # (Lv, Dv)
|
| 80 |
+
ctx_l = len(model_inputs["video_feat"])
|
| 81 |
+
else:
|
| 82 |
+
ctx_l = self.max_v_l
|
| 83 |
+
|
| 84 |
+
if self.use_tef:
|
| 85 |
+
tef_st = torch.arange(0, ctx_l, 1.0) / ctx_l
|
| 86 |
+
tef_ed = tef_st + 1.0 / ctx_l
|
| 87 |
+
tef = torch.stack([tef_st, tef_ed], dim=1) # (Lv, 2)
|
| 88 |
+
if self.use_video:
|
| 89 |
+
model_inputs["video_feat"] = torch.cat(
|
| 90 |
+
[model_inputs["video_feat"], tef], dim=1) # (Lv, Dv+2)
|
| 91 |
+
else:
|
| 92 |
+
model_inputs["video_feat"] = tef
|
| 93 |
+
|
| 94 |
+
if self.load_labels:
|
| 95 |
+
model_inputs["span_labels"] = self.get_span_labels(meta["relevant_windows"], ctx_l) # (#windows, 2)
|
| 96 |
+
if "subs_train" not in self.data_path:
|
| 97 |
+
model_inputs["saliency_pos_labels"], model_inputs["saliency_neg_labels"] = \
|
| 98 |
+
self.get_saliency_labels(meta["relevant_clip_ids"], meta["saliency_scores"], ctx_l)
|
| 99 |
+
else:
|
| 100 |
+
model_inputs["saliency_pos_labels"], model_inputs["saliency_neg_labels"] = \
|
| 101 |
+
self.get_saliency_labels_sub_as_query(meta["relevant_windows"][0], ctx_l) # only one gt
|
| 102 |
+
return dict(meta=meta, model_inputs=model_inputs)
|
| 103 |
+
|
| 104 |
+
def get_saliency_labels_sub_as_query(self, gt_window, ctx_l, max_n=2):
|
| 105 |
+
gt_st = int(gt_window[0] / self.clip_len)
|
| 106 |
+
gt_ed = max(0, min(int(gt_window[1] / self.clip_len), ctx_l) - 1)
|
| 107 |
+
if gt_st > gt_ed:
|
| 108 |
+
gt_st = gt_ed
|
| 109 |
+
|
| 110 |
+
if gt_st != gt_ed:
|
| 111 |
+
pos_clip_indices = random.sample(range(gt_st, gt_ed+1), k=max_n)
|
| 112 |
+
else:
|
| 113 |
+
pos_clip_indices = [gt_st, gt_st]
|
| 114 |
+
|
| 115 |
+
neg_pool = list(range(0, gt_st)) + list(range(gt_ed+1, ctx_l))
|
| 116 |
+
neg_clip_indices = random.sample(neg_pool, k=max_n)
|
| 117 |
+
return pos_clip_indices, neg_clip_indices
|
| 118 |
+
|
| 119 |
+
def get_saliency_labels(self, rel_clip_ids, scores, ctx_l, max_n=1, add_easy_negative=True):
|
| 120 |
+
"""Sum the scores from the three annotations, then take the two clips with the
|
| 121 |
+
maximum scores as positive, and two with the minimum scores as negative.
|
| 122 |
+
Args:
|
| 123 |
+
rel_clip_ids: list(int), list of relevant clip ids
|
| 124 |
+
scores: list([anno1_score, anno2_score, anno3_score]),
|
| 125 |
+
ctx_l: int
|
| 126 |
+
max_n: int, #clips to use as positive and negative, for easy and hard negative, respectively.
|
| 127 |
+
add_easy_negative: bool, if True, sample eay negative outside the relevant_clip_ids.
|
| 128 |
+
"""
|
| 129 |
+
# indices inside rel_clip_ids
|
| 130 |
+
scores = np.array(scores) # (#rel_clips, 3)
|
| 131 |
+
agg_scores = np.sum(scores, 1) # (#rel_clips, )
|
| 132 |
+
sort_indices = np.argsort(agg_scores) # increasing
|
| 133 |
+
|
| 134 |
+
# indices in the whole video
|
| 135 |
+
# the min(_, ctx_l-1) here is incorrect, but should not cause
|
| 136 |
+
# much troubles since this should be rarely used.
|
| 137 |
+
hard_pos_clip_indices = [min(rel_clip_ids[idx], ctx_l-1) for idx in sort_indices[-max_n:]]
|
| 138 |
+
hard_neg_clip_indices = [min(rel_clip_ids[idx], ctx_l-1) for idx in sort_indices[:max_n]]
|
| 139 |
+
easy_pos_clip_indices = []
|
| 140 |
+
easy_neg_clip_indices = []
|
| 141 |
+
if add_easy_negative:
|
| 142 |
+
easy_neg_pool = list(set(range(ctx_l)) - set(rel_clip_ids))
|
| 143 |
+
if len(easy_neg_pool) >= max_n:
|
| 144 |
+
easy_pos_clip_indices = random.sample(rel_clip_ids, k=max_n)
|
| 145 |
+
easy_neg_clip_indices = random.sample(easy_neg_pool, k=max_n)
|
| 146 |
+
else: # copy the hard ones
|
| 147 |
+
easy_pos_clip_indices = hard_pos_clip_indices
|
| 148 |
+
easy_neg_clip_indices = hard_neg_clip_indices
|
| 149 |
+
|
| 150 |
+
pos_clip_indices = hard_pos_clip_indices + easy_pos_clip_indices
|
| 151 |
+
neg_clip_indices = hard_neg_clip_indices + easy_neg_clip_indices
|
| 152 |
+
return pos_clip_indices, neg_clip_indices
|
| 153 |
+
|
| 154 |
+
def get_span_labels(self, windows, ctx_l):
|
| 155 |
+
"""
|
| 156 |
+
windows: list([st, ed]) in seconds. E.g. [[26, 36]], corresponding st_ed clip_indices [[13, 17]] (inclusive)
|
| 157 |
+
Note a maximum of `self.max_windows` windows are used.
|
| 158 |
+
returns Tensor of shape (#windows, 2), each row is [center, width] normalized by video length
|
| 159 |
+
"""
|
| 160 |
+
if len(windows) > self.max_windows:
|
| 161 |
+
random.shuffle(windows)
|
| 162 |
+
windows = windows[:self.max_windows]
|
| 163 |
+
if self.span_loss_type == "l1":
|
| 164 |
+
windows = torch.Tensor(windows) / (ctx_l * self.clip_len) # normalized windows in xx
|
| 165 |
+
windows = span_xx_to_cxw(windows) # normalized windows in cxw
|
| 166 |
+
elif self.span_loss_type == "ce":
|
| 167 |
+
windows = torch.Tensor([
|
| 168 |
+
[int(w[0] / self.clip_len), min(int(w[1] / self.clip_len), ctx_l) - 1]
|
| 169 |
+
for w in windows]).long() # inclusive
|
| 170 |
+
else:
|
| 171 |
+
raise NotImplementedError
|
| 172 |
+
return windows
|
| 173 |
+
|
| 174 |
+
def _get_query_feat_by_qid(self, qid):
|
| 175 |
+
q_feat_path = join(self.q_feat_dir, f"qid{qid}.npz")
|
| 176 |
+
q_feat = np.load(q_feat_path)[self.q_feat_type].astype(np.float32)
|
| 177 |
+
if self.q_feat_type == "last_hidden_state":
|
| 178 |
+
q_feat = q_feat[:self.max_q_l]
|
| 179 |
+
if self.normalize_t:
|
| 180 |
+
q_feat = l2_normalize_np_array(q_feat)
|
| 181 |
+
if self.txt_drop_ratio > 0:
|
| 182 |
+
q_feat = self.random_drop_rows(q_feat)
|
| 183 |
+
return torch.from_numpy(q_feat) # (D, ) or (Lq, D)
|
| 184 |
+
|
| 185 |
+
def random_drop_rows(self, embeddings):
|
| 186 |
+
"""randomly mask num_drop rows in embeddings to be zero.
|
| 187 |
+
Args:
|
| 188 |
+
embeddings: np.ndarray (L, D)
|
| 189 |
+
"""
|
| 190 |
+
num_drop_rows = round(len(embeddings) * self.txt_drop_ratio)
|
| 191 |
+
if num_drop_rows > 0:
|
| 192 |
+
row_indices = np.random.choice(
|
| 193 |
+
len(embeddings), size=num_drop_rows, replace=False)
|
| 194 |
+
embeddings[row_indices] = 0
|
| 195 |
+
return embeddings
|
| 196 |
+
|
| 197 |
+
def _get_video_feat_by_vid(self, vid):
|
| 198 |
+
v_feat_list = []
|
| 199 |
+
for _feat_dir in self.v_feat_dirs:
|
| 200 |
+
_feat_path = join(_feat_dir, f"{vid}.npz")
|
| 201 |
+
_feat = np.load(_feat_path)["features"][:self.max_v_l].astype(np.float32)
|
| 202 |
+
if self.normalize_v:
|
| 203 |
+
_feat = l2_normalize_np_array(_feat)
|
| 204 |
+
v_feat_list.append(_feat)
|
| 205 |
+
# some features are slightly longer than the others
|
| 206 |
+
min_len = min([len(e) for e in v_feat_list])
|
| 207 |
+
v_feat_list = [e[:min_len] for e in v_feat_list]
|
| 208 |
+
v_feat = np.concatenate(v_feat_list, axis=1)
|
| 209 |
+
return torch.from_numpy(v_feat) # (Lv, D)
|
| 210 |
+
|
| 211 |
+
|
| 212 |
+
def start_end_collate(batch):
|
| 213 |
+
batch_meta = [e["meta"] for e in batch] # seems no need to collate ?
|
| 214 |
+
|
| 215 |
+
model_inputs_keys = batch[0]["model_inputs"].keys()
|
| 216 |
+
batched_data = dict()
|
| 217 |
+
for k in model_inputs_keys:
|
| 218 |
+
if k == "span_labels":
|
| 219 |
+
batched_data[k] = [dict(spans=e["model_inputs"]["span_labels"]) for e in batch]
|
| 220 |
+
continue
|
| 221 |
+
if k in ["saliency_pos_labels", "saliency_neg_labels"]:
|
| 222 |
+
batched_data[k] = torch.LongTensor([e["model_inputs"][k] for e in batch])
|
| 223 |
+
continue
|
| 224 |
+
batched_data[k] = pad_sequences_1d(
|
| 225 |
+
[e["model_inputs"][k] for e in batch], dtype=torch.float32, fixed_length=None)
|
| 226 |
+
return batch_meta, batched_data
|
| 227 |
+
|
| 228 |
+
|
| 229 |
+
def prepare_batch_inputs(batched_model_inputs, device, non_blocking=False):
|
| 230 |
+
model_inputs = dict(
|
| 231 |
+
src_txt=batched_model_inputs["query_feat"][0].to(device, non_blocking=non_blocking),
|
| 232 |
+
src_txt_mask=batched_model_inputs["query_feat"][1].to(device, non_blocking=non_blocking),
|
| 233 |
+
src_vid=batched_model_inputs["video_feat"][0].to(device, non_blocking=non_blocking),
|
| 234 |
+
src_vid_mask=batched_model_inputs["video_feat"][1].to(device, non_blocking=non_blocking),
|
| 235 |
+
)
|
| 236 |
+
targets = {}
|
| 237 |
+
if "span_labels" in batched_model_inputs:
|
| 238 |
+
targets["span_labels"] = [
|
| 239 |
+
dict(spans=e["spans"].to(device, non_blocking=non_blocking))
|
| 240 |
+
for e in batched_model_inputs["span_labels"]
|
| 241 |
+
]
|
| 242 |
+
if "saliency_pos_labels" in batched_model_inputs:
|
| 243 |
+
for name in ["saliency_pos_labels", "saliency_neg_labels"]:
|
| 244 |
+
targets[name] = batched_model_inputs[name].to(device, non_blocking=non_blocking)
|
| 245 |
+
|
| 246 |
+
targets = None if len(targets) == 0 else targets
|
| 247 |
+
return model_inputs, targets
|
moment_detr/text_encoder.py
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import torch.nn.functional as F
|
| 4 |
+
from easydict import EasyDict as edict
|
| 5 |
+
from xml.model_components import BertAttention, TrainablePositionalEncoding
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
class TextEncoder(nn.Module):
|
| 9 |
+
def __init__(self, hidden_size, drop, input_drop, nheads, max_position_embeddings):
|
| 10 |
+
super().__init__()
|
| 11 |
+
self.transformer_encoder = BertAttention(edict(
|
| 12 |
+
hidden_size=hidden_size,
|
| 13 |
+
intermediate_size=hidden_size,
|
| 14 |
+
hidden_dropout_prob=drop,
|
| 15 |
+
attention_probs_dropout_prob=drop,
|
| 16 |
+
num_attention_heads=nheads,
|
| 17 |
+
))
|
| 18 |
+
self.pos_embed = TrainablePositionalEncoding(
|
| 19 |
+
max_position_embeddings=max_position_embeddings,
|
| 20 |
+
hidden_size=hidden_size,
|
| 21 |
+
dropout=input_drop,
|
| 22 |
+
)
|
| 23 |
+
self.modular_vector_mapping = nn.Linear(hidden_size, 1, bias=False)
|
| 24 |
+
|
| 25 |
+
def forward(self, feat, mask):
|
| 26 |
+
"""
|
| 27 |
+
Args:
|
| 28 |
+
feat: (N, L, D=hidden_size)
|
| 29 |
+
mask: (N, L) with 1 indicates valid
|
| 30 |
+
|
| 31 |
+
Returns:
|
| 32 |
+
(N, D)
|
| 33 |
+
"""
|
| 34 |
+
feat = self.pos_embed(feat) # (N, L, D)
|
| 35 |
+
feat = self.transformer_encoder(feat, mask.unsqueeze(1))
|
| 36 |
+
att_scores = self.modular_vector_mapping(feat) # (N, L, 1)
|
| 37 |
+
att_scores = F.softmax(mask_logits(att_scores, mask.unsqueeze(2)), dim=1)
|
| 38 |
+
pooled_feat = torch.einsum("blm,bld->bmd", att_scores, feat) # (N, 2 or 1, D)
|
| 39 |
+
return pooled_feat.squeeze(1)
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
def mask_logits(target, mask):
|
| 43 |
+
return target * mask + (1 - mask) * (-1e10)
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
def build_text_encoder(args):
|
| 47 |
+
return TextEncoder(
|
| 48 |
+
hidden_size=args.hidden_dim,
|
| 49 |
+
drop=args.dropout,
|
| 50 |
+
input_drop=args.input_dropout,
|
| 51 |
+
nheads=args.nheads,
|
| 52 |
+
max_position_embeddings=args.max_q_l
|
| 53 |
+
)
|
moment_detr/train.py
ADDED
|
@@ -0,0 +1,266 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import time
|
| 3 |
+
import json
|
| 4 |
+
import pprint
|
| 5 |
+
import random
|
| 6 |
+
import numpy as np
|
| 7 |
+
from tqdm import tqdm, trange
|
| 8 |
+
from collections import defaultdict
|
| 9 |
+
|
| 10 |
+
import torch
|
| 11 |
+
import torch.nn as nn
|
| 12 |
+
import torch.backends.cudnn as cudnn
|
| 13 |
+
from torch.utils.data import DataLoader
|
| 14 |
+
from torch.utils.tensorboard import SummaryWriter
|
| 15 |
+
|
| 16 |
+
from moment_detr.config import BaseOptions
|
| 17 |
+
from moment_detr.start_end_dataset import \
|
| 18 |
+
StartEndDataset, start_end_collate, prepare_batch_inputs
|
| 19 |
+
from moment_detr.inference import eval_epoch, start_inference, setup_model
|
| 20 |
+
from utils.basic_utils import AverageMeter, dict_to_markdown
|
| 21 |
+
from utils.model_utils import count_parameters
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
import logging
|
| 25 |
+
logger = logging.getLogger(__name__)
|
| 26 |
+
logging.basicConfig(format="%(asctime)s.%(msecs)03d:%(levelname)s:%(name)s - %(message)s",
|
| 27 |
+
datefmt="%Y-%m-%d %H:%M:%S",
|
| 28 |
+
level=logging.INFO)
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
def set_seed(seed, use_cuda=True):
|
| 32 |
+
random.seed(seed)
|
| 33 |
+
np.random.seed(seed)
|
| 34 |
+
torch.manual_seed(seed)
|
| 35 |
+
if use_cuda:
|
| 36 |
+
torch.cuda.manual_seed_all(seed)
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
def train_epoch(model, criterion, train_loader, optimizer, opt, epoch_i, tb_writer):
|
| 40 |
+
logger.info(f"[Epoch {epoch_i+1}]")
|
| 41 |
+
model.train()
|
| 42 |
+
criterion.train()
|
| 43 |
+
|
| 44 |
+
# init meters
|
| 45 |
+
time_meters = defaultdict(AverageMeter)
|
| 46 |
+
loss_meters = defaultdict(AverageMeter)
|
| 47 |
+
|
| 48 |
+
num_training_examples = len(train_loader)
|
| 49 |
+
timer_dataloading = time.time()
|
| 50 |
+
for batch_idx, batch in tqdm(enumerate(train_loader),
|
| 51 |
+
desc="Training Iteration",
|
| 52 |
+
total=num_training_examples):
|
| 53 |
+
time_meters["dataloading_time"].update(time.time() - timer_dataloading)
|
| 54 |
+
|
| 55 |
+
timer_start = time.time()
|
| 56 |
+
model_inputs, targets = prepare_batch_inputs(batch[1], opt.device, non_blocking=opt.pin_memory)
|
| 57 |
+
time_meters["prepare_inputs_time"].update(time.time() - timer_start)
|
| 58 |
+
|
| 59 |
+
timer_start = time.time()
|
| 60 |
+
outputs = model(**model_inputs)
|
| 61 |
+
loss_dict = criterion(outputs, targets)
|
| 62 |
+
weight_dict = criterion.weight_dict
|
| 63 |
+
losses = sum(loss_dict[k] * weight_dict[k] for k in loss_dict.keys() if k in weight_dict)
|
| 64 |
+
time_meters["model_forward_time"].update(time.time() - timer_start)
|
| 65 |
+
|
| 66 |
+
timer_start = time.time()
|
| 67 |
+
optimizer.zero_grad()
|
| 68 |
+
losses.backward()
|
| 69 |
+
if opt.grad_clip > 0:
|
| 70 |
+
nn.utils.clip_grad_norm_(model.parameters(), opt.grad_clip)
|
| 71 |
+
optimizer.step()
|
| 72 |
+
time_meters["model_backward_time"].update(time.time() - timer_start)
|
| 73 |
+
|
| 74 |
+
loss_dict["loss_overall"] = float(losses) # for logging only
|
| 75 |
+
for k, v in loss_dict.items():
|
| 76 |
+
loss_meters[k].update(float(v) * weight_dict[k] if k in weight_dict else float(v))
|
| 77 |
+
|
| 78 |
+
timer_dataloading = time.time()
|
| 79 |
+
if opt.debug and batch_idx == 3:
|
| 80 |
+
break
|
| 81 |
+
|
| 82 |
+
# print/add logs
|
| 83 |
+
tb_writer.add_scalar("Train/lr", float(optimizer.param_groups[0]["lr"]), epoch_i+1)
|
| 84 |
+
for k, v in loss_meters.items():
|
| 85 |
+
tb_writer.add_scalar("Train/{}".format(k), v.avg, epoch_i+1)
|
| 86 |
+
|
| 87 |
+
to_write = opt.train_log_txt_formatter.format(
|
| 88 |
+
time_str=time.strftime("%Y_%m_%d_%H_%M_%S"),
|
| 89 |
+
epoch=epoch_i+1,
|
| 90 |
+
loss_str=" ".join(["{} {:.4f}".format(k, v.avg) for k, v in loss_meters.items()]))
|
| 91 |
+
with open(opt.train_log_filepath, "a") as f:
|
| 92 |
+
f.write(to_write)
|
| 93 |
+
|
| 94 |
+
logger.info("Epoch time stats:")
|
| 95 |
+
for name, meter in time_meters.items():
|
| 96 |
+
d = {k: f"{getattr(meter, k):.4f}" for k in ["max", "min", "avg"]}
|
| 97 |
+
logger.info(f"{name} ==> {d}")
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
def train(model, criterion, optimizer, lr_scheduler, train_dataset, val_dataset, opt):
|
| 101 |
+
if opt.device.type == "cuda":
|
| 102 |
+
logger.info("CUDA enabled.")
|
| 103 |
+
model.to(opt.device)
|
| 104 |
+
|
| 105 |
+
tb_writer = SummaryWriter(opt.tensorboard_log_dir)
|
| 106 |
+
tb_writer.add_text("hyperparameters", dict_to_markdown(vars(opt), max_str_len=None))
|
| 107 |
+
opt.train_log_txt_formatter = "{time_str} [Epoch] {epoch:03d} [Loss] {loss_str}\n"
|
| 108 |
+
opt.eval_log_txt_formatter = "{time_str} [Epoch] {epoch:03d} [Loss] {loss_str} [Metrics] {eval_metrics_str}\n"
|
| 109 |
+
|
| 110 |
+
train_loader = DataLoader(
|
| 111 |
+
train_dataset,
|
| 112 |
+
collate_fn=start_end_collate,
|
| 113 |
+
batch_size=opt.bsz,
|
| 114 |
+
num_workers=opt.num_workers,
|
| 115 |
+
shuffle=True,
|
| 116 |
+
pin_memory=opt.pin_memory
|
| 117 |
+
)
|
| 118 |
+
|
| 119 |
+
prev_best_score = 0.
|
| 120 |
+
es_cnt = 0
|
| 121 |
+
# start_epoch = 0
|
| 122 |
+
if opt.start_epoch is None:
|
| 123 |
+
start_epoch = -1 if opt.eval_untrained else 0
|
| 124 |
+
else:
|
| 125 |
+
start_epoch = opt.start_epoch
|
| 126 |
+
save_submission_filename = "latest_{}_{}_preds.jsonl".format(opt.dset_name, opt.eval_split_name)
|
| 127 |
+
for epoch_i in trange(start_epoch, opt.n_epoch, desc="Epoch"):
|
| 128 |
+
if epoch_i > -1:
|
| 129 |
+
train_epoch(model, criterion, train_loader, optimizer, opt, epoch_i, tb_writer)
|
| 130 |
+
lr_scheduler.step()
|
| 131 |
+
eval_epoch_interval = 5
|
| 132 |
+
if opt.eval_path is not None and (epoch_i + 1) % eval_epoch_interval == 0:
|
| 133 |
+
with torch.no_grad():
|
| 134 |
+
metrics_no_nms, metrics_nms, eval_loss_meters, latest_file_paths = \
|
| 135 |
+
eval_epoch(model, val_dataset, opt, save_submission_filename, epoch_i, criterion, tb_writer)
|
| 136 |
+
|
| 137 |
+
# log
|
| 138 |
+
to_write = opt.eval_log_txt_formatter.format(
|
| 139 |
+
time_str=time.strftime("%Y_%m_%d_%H_%M_%S"),
|
| 140 |
+
epoch=epoch_i,
|
| 141 |
+
loss_str=" ".join(["{} {:.4f}".format(k, v.avg) for k, v in eval_loss_meters.items()]),
|
| 142 |
+
eval_metrics_str=json.dumps(metrics_no_nms))
|
| 143 |
+
|
| 144 |
+
with open(opt.eval_log_filepath, "a") as f:
|
| 145 |
+
f.write(to_write)
|
| 146 |
+
logger.info("metrics_no_nms {}".format(pprint.pformat(metrics_no_nms["brief"], indent=4)))
|
| 147 |
+
if metrics_nms is not None:
|
| 148 |
+
logger.info("metrics_nms {}".format(pprint.pformat(metrics_nms["brief"], indent=4)))
|
| 149 |
+
|
| 150 |
+
metrics = metrics_no_nms
|
| 151 |
+
for k, v in metrics["brief"].items():
|
| 152 |
+
tb_writer.add_scalar(f"Eval/{k}", float(v), epoch_i+1)
|
| 153 |
+
|
| 154 |
+
stop_score = metrics["brief"]["MR-full-mAP"]
|
| 155 |
+
if stop_score > prev_best_score:
|
| 156 |
+
es_cnt = 0
|
| 157 |
+
prev_best_score = stop_score
|
| 158 |
+
|
| 159 |
+
checkpoint = {
|
| 160 |
+
"model": model.state_dict(),
|
| 161 |
+
"optimizer": optimizer.state_dict(),
|
| 162 |
+
"lr_scheduler": lr_scheduler.state_dict(),
|
| 163 |
+
"epoch": epoch_i,
|
| 164 |
+
"opt": opt
|
| 165 |
+
}
|
| 166 |
+
torch.save(checkpoint, opt.ckpt_filepath.replace(".ckpt", "_best.ckpt"))
|
| 167 |
+
|
| 168 |
+
best_file_paths = [e.replace("latest", "best") for e in latest_file_paths]
|
| 169 |
+
for src, tgt in zip(latest_file_paths, best_file_paths):
|
| 170 |
+
os.renames(src, tgt)
|
| 171 |
+
logger.info("The checkpoint file has been updated.")
|
| 172 |
+
else:
|
| 173 |
+
es_cnt += 1
|
| 174 |
+
if opt.max_es_cnt != -1 and es_cnt > opt.max_es_cnt: # early stop
|
| 175 |
+
with open(opt.train_log_filepath, "a") as f:
|
| 176 |
+
f.write(f"Early Stop at epoch {epoch_i}")
|
| 177 |
+
logger.info(f"\n>>>>> Early stop at epoch {epoch_i} {prev_best_score}\n")
|
| 178 |
+
break
|
| 179 |
+
|
| 180 |
+
# save ckpt
|
| 181 |
+
checkpoint = {
|
| 182 |
+
"model": model.state_dict(),
|
| 183 |
+
"optimizer": optimizer.state_dict(),
|
| 184 |
+
"lr_scheduler": lr_scheduler.state_dict(),
|
| 185 |
+
"epoch": epoch_i,
|
| 186 |
+
"opt": opt
|
| 187 |
+
}
|
| 188 |
+
torch.save(checkpoint, opt.ckpt_filepath.replace(".ckpt", "_latest.ckpt"))
|
| 189 |
+
|
| 190 |
+
save_interval = 10 if "subs_train" in opt.train_path else 50 # smaller for pretrain
|
| 191 |
+
if (epoch_i + 1) % save_interval == 0 or (epoch_i + 1) % opt.lr_drop == 0: # additional copies
|
| 192 |
+
checkpoint = {
|
| 193 |
+
"model": model.state_dict(),
|
| 194 |
+
"optimizer": optimizer.state_dict(),
|
| 195 |
+
"epoch": epoch_i,
|
| 196 |
+
"opt": opt
|
| 197 |
+
}
|
| 198 |
+
torch.save(checkpoint, opt.ckpt_filepath.replace(".ckpt", f"_e{epoch_i:04d}.ckpt"))
|
| 199 |
+
|
| 200 |
+
if opt.debug:
|
| 201 |
+
break
|
| 202 |
+
|
| 203 |
+
tb_writer.close()
|
| 204 |
+
|
| 205 |
+
|
| 206 |
+
def start_training():
|
| 207 |
+
logger.info("Setup config, data and model...")
|
| 208 |
+
opt = BaseOptions().parse()
|
| 209 |
+
set_seed(opt.seed)
|
| 210 |
+
if opt.debug: # keep the model run deterministically
|
| 211 |
+
# 'cudnn.benchmark = True' enabled auto finding the best algorithm for a specific input/net config.
|
| 212 |
+
# Enable this only when input size is fixed.
|
| 213 |
+
cudnn.benchmark = False
|
| 214 |
+
cudnn.deterministic = True
|
| 215 |
+
|
| 216 |
+
dataset_config = dict(
|
| 217 |
+
dset_name=opt.dset_name,
|
| 218 |
+
data_path=opt.train_path,
|
| 219 |
+
v_feat_dirs=opt.v_feat_dirs,
|
| 220 |
+
q_feat_dir=opt.t_feat_dir,
|
| 221 |
+
q_feat_type="last_hidden_state",
|
| 222 |
+
max_q_l=opt.max_q_l,
|
| 223 |
+
max_v_l=opt.max_v_l,
|
| 224 |
+
ctx_mode=opt.ctx_mode,
|
| 225 |
+
data_ratio=opt.data_ratio,
|
| 226 |
+
normalize_v=not opt.no_norm_vfeat,
|
| 227 |
+
normalize_t=not opt.no_norm_tfeat,
|
| 228 |
+
clip_len=opt.clip_length,
|
| 229 |
+
max_windows=opt.max_windows,
|
| 230 |
+
span_loss_type=opt.span_loss_type,
|
| 231 |
+
txt_drop_ratio=opt.txt_drop_ratio
|
| 232 |
+
)
|
| 233 |
+
|
| 234 |
+
dataset_config["data_path"] = opt.train_path
|
| 235 |
+
train_dataset = StartEndDataset(**dataset_config)
|
| 236 |
+
|
| 237 |
+
if opt.eval_path is not None:
|
| 238 |
+
dataset_config["data_path"] = opt.eval_path
|
| 239 |
+
dataset_config["txt_drop_ratio"] = 0
|
| 240 |
+
dataset_config["q_feat_dir"] = opt.t_feat_dir.replace("sub_features", "text_features") # for pretraining
|
| 241 |
+
# dataset_config["load_labels"] = False # uncomment to calculate eval loss
|
| 242 |
+
eval_dataset = StartEndDataset(**dataset_config)
|
| 243 |
+
else:
|
| 244 |
+
eval_dataset = None
|
| 245 |
+
|
| 246 |
+
model, criterion, optimizer, lr_scheduler = setup_model(opt)
|
| 247 |
+
logger.info(f"Model {model}")
|
| 248 |
+
count_parameters(model)
|
| 249 |
+
logger.info("Start Training...")
|
| 250 |
+
train(model, criterion, optimizer, lr_scheduler, train_dataset, eval_dataset, opt)
|
| 251 |
+
return opt.ckpt_filepath.replace(".ckpt", "_best.ckpt"), opt.eval_split_name, opt.eval_path, opt.debug
|
| 252 |
+
|
| 253 |
+
|
| 254 |
+
if __name__ == '__main__':
|
| 255 |
+
best_ckpt_path, eval_split_name, eval_path, debug = start_training()
|
| 256 |
+
if not debug:
|
| 257 |
+
input_args = ["--resume", best_ckpt_path,
|
| 258 |
+
"--eval_split_name", eval_split_name,
|
| 259 |
+
"--eval_path", eval_path]
|
| 260 |
+
|
| 261 |
+
import sys
|
| 262 |
+
sys.argv[1:] = input_args
|
| 263 |
+
logger.info("\n\n\nFINISHED TRAINING!!!")
|
| 264 |
+
logger.info("Evaluating model at {}".format(best_ckpt_path))
|
| 265 |
+
logger.info("Input args {}".format(sys.argv[1:]))
|
| 266 |
+
start_inference()
|
moment_detr/transformer.py
ADDED
|
@@ -0,0 +1,471 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
|
| 2 |
+
"""
|
| 3 |
+
DETR Transformer class.
|
| 4 |
+
|
| 5 |
+
Copy-paste from torch.nn.Transformer with modifications:
|
| 6 |
+
* positional encodings are passed in MHattention
|
| 7 |
+
* extra LN at the end of encoder is removed
|
| 8 |
+
* decoder returns a stack of activations from all decoding layers
|
| 9 |
+
"""
|
| 10 |
+
import copy
|
| 11 |
+
from typing import Optional
|
| 12 |
+
|
| 13 |
+
import torch
|
| 14 |
+
import torch.nn.functional as F
|
| 15 |
+
from torch import nn, Tensor
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
class Transformer(nn.Module):
|
| 19 |
+
|
| 20 |
+
def __init__(self, d_model=512, nhead=8, num_encoder_layers=6,
|
| 21 |
+
num_decoder_layers=6, dim_feedforward=2048, dropout=0.1,
|
| 22 |
+
activation="relu", normalize_before=False,
|
| 23 |
+
return_intermediate_dec=False):
|
| 24 |
+
super().__init__()
|
| 25 |
+
|
| 26 |
+
# TransformerEncoderLayerThin
|
| 27 |
+
encoder_layer = TransformerEncoderLayer(d_model, nhead, dim_feedforward,
|
| 28 |
+
dropout, activation, normalize_before)
|
| 29 |
+
encoder_norm = nn.LayerNorm(d_model) if normalize_before else None
|
| 30 |
+
self.encoder = TransformerEncoder(encoder_layer, num_encoder_layers, encoder_norm)
|
| 31 |
+
|
| 32 |
+
# TransformerDecoderLayerThin
|
| 33 |
+
decoder_layer = TransformerDecoderLayer(d_model, nhead, dim_feedforward,
|
| 34 |
+
dropout, activation, normalize_before)
|
| 35 |
+
decoder_norm = nn.LayerNorm(d_model)
|
| 36 |
+
self.decoder = TransformerDecoder(decoder_layer, num_decoder_layers, decoder_norm,
|
| 37 |
+
return_intermediate=return_intermediate_dec)
|
| 38 |
+
|
| 39 |
+
self._reset_parameters()
|
| 40 |
+
|
| 41 |
+
self.d_model = d_model
|
| 42 |
+
self.nhead = nhead
|
| 43 |
+
|
| 44 |
+
def _reset_parameters(self):
|
| 45 |
+
for p in self.parameters():
|
| 46 |
+
if p.dim() > 1:
|
| 47 |
+
nn.init.xavier_uniform_(p)
|
| 48 |
+
|
| 49 |
+
def forward(self, src, mask, query_embed, pos_embed):
|
| 50 |
+
"""
|
| 51 |
+
Args:
|
| 52 |
+
src: (batch_size, L, d)
|
| 53 |
+
mask: (batch_size, L)
|
| 54 |
+
query_embed: (#queries, d)
|
| 55 |
+
pos_embed: (batch_size, L, d) the same as src
|
| 56 |
+
|
| 57 |
+
Returns:
|
| 58 |
+
|
| 59 |
+
"""
|
| 60 |
+
# flatten NxCxHxW to HWxNxC
|
| 61 |
+
bs, l, d = src.shape
|
| 62 |
+
src = src.permute(1, 0, 2) # (L, batch_size, d)
|
| 63 |
+
pos_embed = pos_embed.permute(1, 0, 2) # (L, batch_size, d)
|
| 64 |
+
query_embed = query_embed.unsqueeze(1).repeat(1, bs, 1) # (#queries, batch_size, d)
|
| 65 |
+
|
| 66 |
+
tgt = torch.zeros_like(query_embed)
|
| 67 |
+
memory = self.encoder(src, src_key_padding_mask=mask, pos=pos_embed) # (L, batch_size, d)
|
| 68 |
+
hs = self.decoder(tgt, memory, memory_key_padding_mask=mask,
|
| 69 |
+
pos=pos_embed, query_pos=query_embed) # (#layers, #queries, batch_size, d)
|
| 70 |
+
hs = hs.transpose(1, 2) # (#layers, batch_size, #qeries, d)
|
| 71 |
+
# memory = memory.permute(1, 2, 0) # (batch_size, d, L)
|
| 72 |
+
memory = memory.transpose(0, 1) # (batch_size, L, d)
|
| 73 |
+
return hs, memory
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
class TransformerEncoder(nn.Module):
|
| 77 |
+
|
| 78 |
+
def __init__(self, encoder_layer, num_layers, norm=None, return_intermediate=False):
|
| 79 |
+
super().__init__()
|
| 80 |
+
self.layers = _get_clones(encoder_layer, num_layers)
|
| 81 |
+
self.num_layers = num_layers
|
| 82 |
+
self.norm = norm
|
| 83 |
+
self.return_intermediate = return_intermediate
|
| 84 |
+
|
| 85 |
+
def forward(self, src,
|
| 86 |
+
mask: Optional[Tensor] = None,
|
| 87 |
+
src_key_padding_mask: Optional[Tensor] = None,
|
| 88 |
+
pos: Optional[Tensor] = None):
|
| 89 |
+
output = src
|
| 90 |
+
|
| 91 |
+
intermediate = []
|
| 92 |
+
|
| 93 |
+
for layer in self.layers:
|
| 94 |
+
output = layer(output, src_mask=mask,
|
| 95 |
+
src_key_padding_mask=src_key_padding_mask, pos=pos)
|
| 96 |
+
if self.return_intermediate:
|
| 97 |
+
intermediate.append(output)
|
| 98 |
+
|
| 99 |
+
if self.norm is not None:
|
| 100 |
+
output = self.norm(output)
|
| 101 |
+
|
| 102 |
+
if self.return_intermediate:
|
| 103 |
+
return torch.stack(intermediate)
|
| 104 |
+
|
| 105 |
+
return output
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
class TransformerDecoder(nn.Module):
|
| 109 |
+
|
| 110 |
+
def __init__(self, decoder_layer, num_layers, norm=None, return_intermediate=False):
|
| 111 |
+
super().__init__()
|
| 112 |
+
self.layers = _get_clones(decoder_layer, num_layers)
|
| 113 |
+
self.num_layers = num_layers
|
| 114 |
+
self.norm = norm
|
| 115 |
+
self.return_intermediate = return_intermediate
|
| 116 |
+
|
| 117 |
+
def forward(self, tgt, memory,
|
| 118 |
+
tgt_mask: Optional[Tensor] = None,
|
| 119 |
+
memory_mask: Optional[Tensor] = None,
|
| 120 |
+
tgt_key_padding_mask: Optional[Tensor] = None,
|
| 121 |
+
memory_key_padding_mask: Optional[Tensor] = None,
|
| 122 |
+
pos: Optional[Tensor] = None,
|
| 123 |
+
query_pos: Optional[Tensor] = None):
|
| 124 |
+
output = tgt
|
| 125 |
+
|
| 126 |
+
intermediate = []
|
| 127 |
+
|
| 128 |
+
for layer in self.layers:
|
| 129 |
+
output = layer(output, memory, tgt_mask=tgt_mask,
|
| 130 |
+
memory_mask=memory_mask,
|
| 131 |
+
tgt_key_padding_mask=tgt_key_padding_mask,
|
| 132 |
+
memory_key_padding_mask=memory_key_padding_mask,
|
| 133 |
+
pos=pos, query_pos=query_pos)
|
| 134 |
+
if self.return_intermediate:
|
| 135 |
+
intermediate.append(self.norm(output))
|
| 136 |
+
|
| 137 |
+
if self.norm is not None:
|
| 138 |
+
output = self.norm(output)
|
| 139 |
+
if self.return_intermediate:
|
| 140 |
+
intermediate.pop()
|
| 141 |
+
intermediate.append(output)
|
| 142 |
+
|
| 143 |
+
if self.return_intermediate:
|
| 144 |
+
return torch.stack(intermediate)
|
| 145 |
+
|
| 146 |
+
return output.unsqueeze(0)
|
| 147 |
+
|
| 148 |
+
|
| 149 |
+
class TransformerEncoderLayerThin(nn.Module):
|
| 150 |
+
|
| 151 |
+
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1,
|
| 152 |
+
activation="relu", normalize_before=False):
|
| 153 |
+
super().__init__()
|
| 154 |
+
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
|
| 155 |
+
# Implementation of Feedforward model
|
| 156 |
+
# self.linear1 = nn.Linear(d_model, dim_feedforward)
|
| 157 |
+
# self.dropout = nn.Dropout(dropout)
|
| 158 |
+
# self.linear2 = nn.Linear(dim_feedforward, d_model)
|
| 159 |
+
self.linear = nn.Linear(d_model, d_model)
|
| 160 |
+
self.norm = nn.LayerNorm(d_model)
|
| 161 |
+
self.dropout = nn.Dropout(dropout)
|
| 162 |
+
|
| 163 |
+
# self.activation = _get_activation_fn(activation)
|
| 164 |
+
self.normalize_before = normalize_before
|
| 165 |
+
|
| 166 |
+
def with_pos_embed(self, tensor, pos: Optional[Tensor]):
|
| 167 |
+
return tensor if pos is None else tensor + pos
|
| 168 |
+
|
| 169 |
+
def forward_post(self,
|
| 170 |
+
src,
|
| 171 |
+
src_mask: Optional[Tensor] = None,
|
| 172 |
+
src_key_padding_mask: Optional[Tensor] = None,
|
| 173 |
+
pos: Optional[Tensor] = None):
|
| 174 |
+
q = k = self.with_pos_embed(src, pos)
|
| 175 |
+
src2 = self.self_attn(q, k, value=src, attn_mask=src_mask,
|
| 176 |
+
key_padding_mask=src_key_padding_mask)[0]
|
| 177 |
+
src2 = self.linear(src2)
|
| 178 |
+
src = src + self.dropout(src2)
|
| 179 |
+
src = self.norm(src)
|
| 180 |
+
# src = src + self.dropout1(src2)
|
| 181 |
+
# src = self.norm1(src)
|
| 182 |
+
# src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))
|
| 183 |
+
# src = src + self.dropout2(src2)
|
| 184 |
+
# src = self.norm2(src)
|
| 185 |
+
return src
|
| 186 |
+
|
| 187 |
+
def forward_pre(self, src,
|
| 188 |
+
src_mask: Optional[Tensor] = None,
|
| 189 |
+
src_key_padding_mask: Optional[Tensor] = None,
|
| 190 |
+
pos: Optional[Tensor] = None):
|
| 191 |
+
"""not used"""
|
| 192 |
+
src2 = self.norm1(src)
|
| 193 |
+
q = k = self.with_pos_embed(src2, pos)
|
| 194 |
+
src2 = self.self_attn(q, k, value=src2, attn_mask=src_mask,
|
| 195 |
+
key_padding_mask=src_key_padding_mask)[0]
|
| 196 |
+
src = src + self.dropout1(src2)
|
| 197 |
+
src2 = self.norm2(src)
|
| 198 |
+
src2 = self.linear2(self.dropout(self.activation(self.linear1(src2))))
|
| 199 |
+
src = src + self.dropout2(src2)
|
| 200 |
+
return src
|
| 201 |
+
|
| 202 |
+
def forward(self, src,
|
| 203 |
+
src_mask: Optional[Tensor] = None,
|
| 204 |
+
src_key_padding_mask: Optional[Tensor] = None,
|
| 205 |
+
pos: Optional[Tensor] = None):
|
| 206 |
+
if self.normalize_before:
|
| 207 |
+
return self.forward_pre(src, src_mask, src_key_padding_mask, pos)
|
| 208 |
+
return self.forward_post(src, src_mask, src_key_padding_mask, pos)
|
| 209 |
+
|
| 210 |
+
|
| 211 |
+
class TransformerEncoderLayer(nn.Module):
|
| 212 |
+
|
| 213 |
+
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1,
|
| 214 |
+
activation="relu", normalize_before=False):
|
| 215 |
+
super().__init__()
|
| 216 |
+
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
|
| 217 |
+
# Implementation of Feedforward model
|
| 218 |
+
self.linear1 = nn.Linear(d_model, dim_feedforward)
|
| 219 |
+
self.dropout = nn.Dropout(dropout)
|
| 220 |
+
self.linear2 = nn.Linear(dim_feedforward, d_model)
|
| 221 |
+
|
| 222 |
+
self.norm1 = nn.LayerNorm(d_model)
|
| 223 |
+
self.norm2 = nn.LayerNorm(d_model)
|
| 224 |
+
self.dropout1 = nn.Dropout(dropout)
|
| 225 |
+
self.dropout2 = nn.Dropout(dropout)
|
| 226 |
+
|
| 227 |
+
self.activation = _get_activation_fn(activation)
|
| 228 |
+
self.normalize_before = normalize_before
|
| 229 |
+
|
| 230 |
+
def with_pos_embed(self, tensor, pos: Optional[Tensor]):
|
| 231 |
+
return tensor if pos is None else tensor + pos
|
| 232 |
+
|
| 233 |
+
def forward_post(self,
|
| 234 |
+
src,
|
| 235 |
+
src_mask: Optional[Tensor] = None,
|
| 236 |
+
src_key_padding_mask: Optional[Tensor] = None,
|
| 237 |
+
pos: Optional[Tensor] = None):
|
| 238 |
+
q = k = self.with_pos_embed(src, pos)
|
| 239 |
+
src2 = self.self_attn(q, k, value=src, attn_mask=src_mask,
|
| 240 |
+
key_padding_mask=src_key_padding_mask)[0]
|
| 241 |
+
src = src + self.dropout1(src2)
|
| 242 |
+
src = self.norm1(src)
|
| 243 |
+
src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))
|
| 244 |
+
src = src + self.dropout2(src2)
|
| 245 |
+
src = self.norm2(src)
|
| 246 |
+
return src
|
| 247 |
+
|
| 248 |
+
def forward_pre(self, src,
|
| 249 |
+
src_mask: Optional[Tensor] = None,
|
| 250 |
+
src_key_padding_mask: Optional[Tensor] = None,
|
| 251 |
+
pos: Optional[Tensor] = None):
|
| 252 |
+
src2 = self.norm1(src)
|
| 253 |
+
q = k = self.with_pos_embed(src2, pos)
|
| 254 |
+
src2 = self.self_attn(q, k, value=src2, attn_mask=src_mask,
|
| 255 |
+
key_padding_mask=src_key_padding_mask)[0]
|
| 256 |
+
src = src + self.dropout1(src2)
|
| 257 |
+
src2 = self.norm2(src)
|
| 258 |
+
src2 = self.linear2(self.dropout(self.activation(self.linear1(src2))))
|
| 259 |
+
src = src + self.dropout2(src2)
|
| 260 |
+
return src
|
| 261 |
+
|
| 262 |
+
def forward(self, src,
|
| 263 |
+
src_mask: Optional[Tensor] = None,
|
| 264 |
+
src_key_padding_mask: Optional[Tensor] = None,
|
| 265 |
+
pos: Optional[Tensor] = None):
|
| 266 |
+
if self.normalize_before:
|
| 267 |
+
return self.forward_pre(src, src_mask, src_key_padding_mask, pos)
|
| 268 |
+
return self.forward_post(src, src_mask, src_key_padding_mask, pos)
|
| 269 |
+
|
| 270 |
+
|
| 271 |
+
class TransformerDecoderLayer(nn.Module):
|
| 272 |
+
|
| 273 |
+
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1,
|
| 274 |
+
activation="relu", normalize_before=False):
|
| 275 |
+
super().__init__()
|
| 276 |
+
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
|
| 277 |
+
self.multihead_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
|
| 278 |
+
# Implementation of Feedforward model
|
| 279 |
+
self.linear1 = nn.Linear(d_model, dim_feedforward)
|
| 280 |
+
self.dropout = nn.Dropout(dropout)
|
| 281 |
+
self.linear2 = nn.Linear(dim_feedforward, d_model)
|
| 282 |
+
|
| 283 |
+
self.norm1 = nn.LayerNorm(d_model)
|
| 284 |
+
self.norm2 = nn.LayerNorm(d_model)
|
| 285 |
+
self.norm3 = nn.LayerNorm(d_model)
|
| 286 |
+
self.dropout1 = nn.Dropout(dropout)
|
| 287 |
+
self.dropout2 = nn.Dropout(dropout)
|
| 288 |
+
self.dropout3 = nn.Dropout(dropout)
|
| 289 |
+
|
| 290 |
+
self.activation = _get_activation_fn(activation)
|
| 291 |
+
self.normalize_before = normalize_before
|
| 292 |
+
|
| 293 |
+
def with_pos_embed(self, tensor, pos: Optional[Tensor]):
|
| 294 |
+
return tensor if pos is None else tensor + pos
|
| 295 |
+
|
| 296 |
+
def forward_post(self, tgt, memory,
|
| 297 |
+
tgt_mask: Optional[Tensor] = None,
|
| 298 |
+
memory_mask: Optional[Tensor] = None,
|
| 299 |
+
tgt_key_padding_mask: Optional[Tensor] = None,
|
| 300 |
+
memory_key_padding_mask: Optional[Tensor] = None,
|
| 301 |
+
pos: Optional[Tensor] = None,
|
| 302 |
+
query_pos: Optional[Tensor] = None):
|
| 303 |
+
q = k = self.with_pos_embed(tgt, query_pos)
|
| 304 |
+
tgt2 = self.self_attn(q, k, value=tgt, attn_mask=tgt_mask,
|
| 305 |
+
key_padding_mask=tgt_key_padding_mask)[0]
|
| 306 |
+
tgt = tgt + self.dropout1(tgt2)
|
| 307 |
+
tgt = self.norm1(tgt)
|
| 308 |
+
tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt, query_pos),
|
| 309 |
+
key=self.with_pos_embed(memory, pos),
|
| 310 |
+
value=memory, attn_mask=memory_mask,
|
| 311 |
+
key_padding_mask=memory_key_padding_mask)[0]
|
| 312 |
+
tgt = tgt + self.dropout2(tgt2)
|
| 313 |
+
tgt = self.norm2(tgt)
|
| 314 |
+
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt))))
|
| 315 |
+
tgt = tgt + self.dropout3(tgt2)
|
| 316 |
+
tgt = self.norm3(tgt)
|
| 317 |
+
return tgt
|
| 318 |
+
|
| 319 |
+
def forward_pre(self, tgt, memory,
|
| 320 |
+
tgt_mask: Optional[Tensor] = None,
|
| 321 |
+
memory_mask: Optional[Tensor] = None,
|
| 322 |
+
tgt_key_padding_mask: Optional[Tensor] = None,
|
| 323 |
+
memory_key_padding_mask: Optional[Tensor] = None,
|
| 324 |
+
pos: Optional[Tensor] = None,
|
| 325 |
+
query_pos: Optional[Tensor] = None):
|
| 326 |
+
tgt2 = self.norm1(tgt)
|
| 327 |
+
q = k = self.with_pos_embed(tgt2, query_pos)
|
| 328 |
+
tgt2 = self.self_attn(q, k, value=tgt2, attn_mask=tgt_mask,
|
| 329 |
+
key_padding_mask=tgt_key_padding_mask)[0]
|
| 330 |
+
tgt = tgt + self.dropout1(tgt2)
|
| 331 |
+
tgt2 = self.norm2(tgt)
|
| 332 |
+
tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt2, query_pos),
|
| 333 |
+
key=self.with_pos_embed(memory, pos),
|
| 334 |
+
value=memory, attn_mask=memory_mask,
|
| 335 |
+
key_padding_mask=memory_key_padding_mask)[0]
|
| 336 |
+
tgt = tgt + self.dropout2(tgt2)
|
| 337 |
+
tgt2 = self.norm3(tgt)
|
| 338 |
+
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt2))))
|
| 339 |
+
tgt = tgt + self.dropout3(tgt2)
|
| 340 |
+
return tgt
|
| 341 |
+
|
| 342 |
+
def forward(self, tgt, memory,
|
| 343 |
+
tgt_mask: Optional[Tensor] = None,
|
| 344 |
+
memory_mask: Optional[Tensor] = None,
|
| 345 |
+
tgt_key_padding_mask: Optional[Tensor] = None,
|
| 346 |
+
memory_key_padding_mask: Optional[Tensor] = None,
|
| 347 |
+
pos: Optional[Tensor] = None,
|
| 348 |
+
query_pos: Optional[Tensor] = None):
|
| 349 |
+
if self.normalize_before:
|
| 350 |
+
return self.forward_pre(tgt, memory, tgt_mask, memory_mask,
|
| 351 |
+
tgt_key_padding_mask, memory_key_padding_mask, pos, query_pos)
|
| 352 |
+
return self.forward_post(tgt, memory, tgt_mask, memory_mask,
|
| 353 |
+
tgt_key_padding_mask, memory_key_padding_mask, pos, query_pos)
|
| 354 |
+
|
| 355 |
+
|
| 356 |
+
class TransformerDecoderLayerThin(nn.Module):
|
| 357 |
+
"""removed intermediate layer"""
|
| 358 |
+
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1,
|
| 359 |
+
activation="relu", normalize_before=False):
|
| 360 |
+
super().__init__()
|
| 361 |
+
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
|
| 362 |
+
self.multihead_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
|
| 363 |
+
# Implementation of Feedforward model
|
| 364 |
+
self.linear1 = nn.Linear(d_model, d_model)
|
| 365 |
+
# self.linear1 = nn.Linear(d_model, dim_feedforward)
|
| 366 |
+
# self.dropout = nn.Dropout(dropout)
|
| 367 |
+
# self.linear2 = nn.Linear(dim_feedforward, d_model)
|
| 368 |
+
|
| 369 |
+
self.norm1 = nn.LayerNorm(d_model)
|
| 370 |
+
self.norm2 = nn.LayerNorm(d_model)
|
| 371 |
+
# self.norm3 = nn.LayerNorm(d_model)
|
| 372 |
+
self.dropout1 = nn.Dropout(dropout)
|
| 373 |
+
self.dropout2 = nn.Dropout(dropout)
|
| 374 |
+
# self.dropout3 = nn.Dropout(dropout)
|
| 375 |
+
|
| 376 |
+
# self.activation = _get_activation_fn(activation)
|
| 377 |
+
self.normalize_before = normalize_before
|
| 378 |
+
|
| 379 |
+
def with_pos_embed(self, tensor, pos: Optional[Tensor]):
|
| 380 |
+
return tensor if pos is None else tensor + pos
|
| 381 |
+
|
| 382 |
+
def forward_post(self, tgt, memory,
|
| 383 |
+
tgt_mask: Optional[Tensor] = None,
|
| 384 |
+
memory_mask: Optional[Tensor] = None,
|
| 385 |
+
tgt_key_padding_mask: Optional[Tensor] = None,
|
| 386 |
+
memory_key_padding_mask: Optional[Tensor] = None,
|
| 387 |
+
pos: Optional[Tensor] = None,
|
| 388 |
+
query_pos: Optional[Tensor] = None):
|
| 389 |
+
q = k = self.with_pos_embed(tgt, query_pos)
|
| 390 |
+
tgt2 = self.self_attn(q, k, value=tgt, attn_mask=tgt_mask,
|
| 391 |
+
key_padding_mask=tgt_key_padding_mask)[0]
|
| 392 |
+
tgt = tgt + self.dropout1(tgt2)
|
| 393 |
+
tgt = self.norm1(tgt)
|
| 394 |
+
tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt, query_pos),
|
| 395 |
+
key=self.with_pos_embed(memory, pos),
|
| 396 |
+
value=memory, attn_mask=memory_mask,
|
| 397 |
+
key_padding_mask=memory_key_padding_mask)[0]
|
| 398 |
+
tgt2 = self.linear1(tgt2)
|
| 399 |
+
tgt = tgt + self.dropout2(tgt2)
|
| 400 |
+
tgt = self.norm2(tgt)
|
| 401 |
+
# tgt = tgt + self.dropout2(tgt2)
|
| 402 |
+
# tgt = self.norm2(tgt)
|
| 403 |
+
# tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt))))
|
| 404 |
+
# tgt = tgt + self.dropout3(tgt2)
|
| 405 |
+
# tgt = self.norm3(tgt)
|
| 406 |
+
return tgt
|
| 407 |
+
|
| 408 |
+
def forward_pre(self, tgt, memory,
|
| 409 |
+
tgt_mask: Optional[Tensor] = None,
|
| 410 |
+
memory_mask: Optional[Tensor] = None,
|
| 411 |
+
tgt_key_padding_mask: Optional[Tensor] = None,
|
| 412 |
+
memory_key_padding_mask: Optional[Tensor] = None,
|
| 413 |
+
pos: Optional[Tensor] = None,
|
| 414 |
+
query_pos: Optional[Tensor] = None):
|
| 415 |
+
tgt2 = self.norm1(tgt)
|
| 416 |
+
q = k = self.with_pos_embed(tgt2, query_pos)
|
| 417 |
+
tgt2 = self.self_attn(q, k, value=tgt2, attn_mask=tgt_mask,
|
| 418 |
+
key_padding_mask=tgt_key_padding_mask)[0]
|
| 419 |
+
tgt = tgt + self.dropout1(tgt2)
|
| 420 |
+
tgt2 = self.norm2(tgt)
|
| 421 |
+
tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt2, query_pos),
|
| 422 |
+
key=self.with_pos_embed(memory, pos),
|
| 423 |
+
value=memory, attn_mask=memory_mask,
|
| 424 |
+
key_padding_mask=memory_key_padding_mask)[0]
|
| 425 |
+
tgt = tgt + self.dropout2(tgt2)
|
| 426 |
+
tgt2 = self.norm3(tgt)
|
| 427 |
+
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt2))))
|
| 428 |
+
tgt = tgt + self.dropout3(tgt2)
|
| 429 |
+
return tgt
|
| 430 |
+
|
| 431 |
+
def forward(self, tgt, memory,
|
| 432 |
+
tgt_mask: Optional[Tensor] = None,
|
| 433 |
+
memory_mask: Optional[Tensor] = None,
|
| 434 |
+
tgt_key_padding_mask: Optional[Tensor] = None,
|
| 435 |
+
memory_key_padding_mask: Optional[Tensor] = None,
|
| 436 |
+
pos: Optional[Tensor] = None,
|
| 437 |
+
query_pos: Optional[Tensor] = None):
|
| 438 |
+
if self.normalize_before:
|
| 439 |
+
return self.forward_pre(tgt, memory, tgt_mask, memory_mask,
|
| 440 |
+
tgt_key_padding_mask, memory_key_padding_mask, pos, query_pos)
|
| 441 |
+
return self.forward_post(tgt, memory, tgt_mask, memory_mask,
|
| 442 |
+
tgt_key_padding_mask, memory_key_padding_mask, pos, query_pos)
|
| 443 |
+
|
| 444 |
+
|
| 445 |
+
|
| 446 |
+
def _get_clones(module, N):
|
| 447 |
+
return nn.ModuleList([copy.deepcopy(module) for i in range(N)])
|
| 448 |
+
|
| 449 |
+
|
| 450 |
+
def build_transformer(args):
|
| 451 |
+
return Transformer(
|
| 452 |
+
d_model=args.hidden_dim,
|
| 453 |
+
dropout=args.dropout,
|
| 454 |
+
nhead=args.nheads,
|
| 455 |
+
dim_feedforward=args.dim_feedforward,
|
| 456 |
+
num_encoder_layers=args.enc_layers,
|
| 457 |
+
num_decoder_layers=args.dec_layers,
|
| 458 |
+
normalize_before=args.pre_norm,
|
| 459 |
+
return_intermediate_dec=True,
|
| 460 |
+
)
|
| 461 |
+
|
| 462 |
+
|
| 463 |
+
def _get_activation_fn(activation):
|
| 464 |
+
"""Return an activation function given a string"""
|
| 465 |
+
if activation == "relu":
|
| 466 |
+
return F.relu
|
| 467 |
+
if activation == "gelu":
|
| 468 |
+
return F.gelu
|
| 469 |
+
if activation == "glu":
|
| 470 |
+
return F.glu
|
| 471 |
+
raise RuntimeError(F"activation should be relu/gelu, not {activation}.")
|
requirements.txt
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
torch
|
| 2 |
+
torchvision
|
| 3 |
+
torchaudio
|
| 4 |
+
tqdm
|
| 5 |
+
ipython
|
| 6 |
+
easydict
|
| 7 |
+
tensorboard
|
| 8 |
+
tabulate
|
| 9 |
+
scikit-learn
|
| 10 |
+
pandas
|
| 11 |
+
ffmpeg-python
|
| 12 |
+
ftfy
|
| 13 |
+
regex
|
| 14 |
+
Pillow
|
res/model_overview.png
ADDED
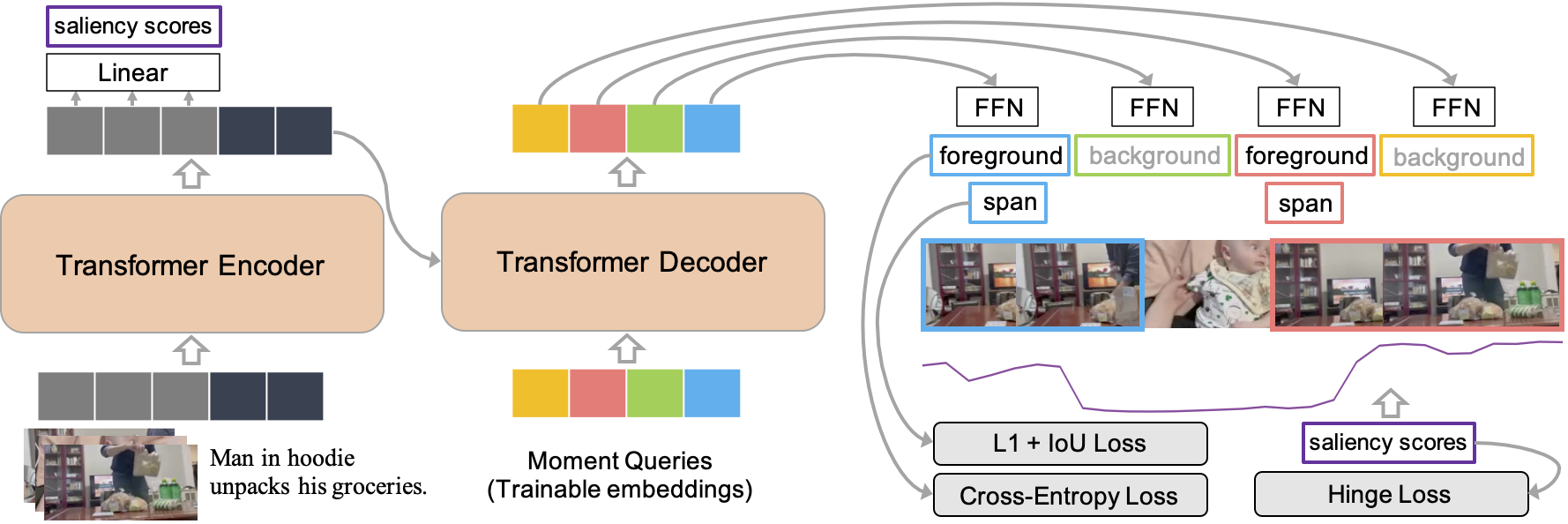
|
run_on_video/clip/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
from .clip import *
|
run_on_video/clip/bpe_simple_vocab_16e6.txt.gz
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:924691ac288e54409236115652ad4aa250f48203de50a9e4722a6ecd48d6804a
|
| 3 |
+
size 1356917
|
run_on_video/clip/clip.py
ADDED
|
@@ -0,0 +1,195 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import hashlib
|
| 2 |
+
import os
|
| 3 |
+
import urllib
|
| 4 |
+
import warnings
|
| 5 |
+
from typing import Union, List
|
| 6 |
+
|
| 7 |
+
import torch
|
| 8 |
+
from PIL import Image
|
| 9 |
+
from torchvision.transforms import Compose, Resize, CenterCrop, ToTensor, Normalize
|
| 10 |
+
from tqdm import tqdm
|
| 11 |
+
|
| 12 |
+
from .model import build_model
|
| 13 |
+
from .simple_tokenizer import SimpleTokenizer as _Tokenizer
|
| 14 |
+
|
| 15 |
+
__all__ = ["available_models", "load", "tokenize"]
|
| 16 |
+
_tokenizer = _Tokenizer()
|
| 17 |
+
|
| 18 |
+
_MODELS = {
|
| 19 |
+
"RN50": "https://openaipublic.azureedge.net/clip/models/afeb0e10f9e5a86da6080e35cf09123aca3b358a0c3e3b6c78a7b63bc04b6762/RN50.pt",
|
| 20 |
+
"RN101": "https://openaipublic.azureedge.net/clip/models/8fa8567bab74a42d41c5915025a8e4538c3bdbe8804a470a72f30b0d94fab599/RN101.pt",
|
| 21 |
+
"RN50x4": "https://openaipublic.azureedge.net/clip/models/7e526bd135e493cef0776de27d5f42653e6b4c8bf9e0f653bb11773263205fdd/RN50x4.pt",
|
| 22 |
+
"ViT-B/32": "https://openaipublic.azureedge.net/clip/models/40d365715913c9da98579312b702a82c18be219cc2a73407c4526f58eba950af/ViT-B-32.pt",
|
| 23 |
+
}
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def _download(url: str, root: str = os.path.expanduser("~/.cache/clip")):
|
| 27 |
+
os.makedirs(root, exist_ok=True)
|
| 28 |
+
filename = os.path.basename(url)
|
| 29 |
+
|
| 30 |
+
expected_sha256 = url.split("/")[-2]
|
| 31 |
+
download_target = os.path.join(root, filename)
|
| 32 |
+
|
| 33 |
+
if os.path.exists(download_target) and not os.path.isfile(download_target):
|
| 34 |
+
raise RuntimeError(f"{download_target} exists and is not a regular file")
|
| 35 |
+
|
| 36 |
+
if os.path.isfile(download_target):
|
| 37 |
+
if hashlib.sha256(open(download_target, "rb").read()).hexdigest() == expected_sha256:
|
| 38 |
+
return download_target
|
| 39 |
+
else:
|
| 40 |
+
warnings.warn(f"{download_target} exists, but the SHA256 checksum does not match; re-downloading the file")
|
| 41 |
+
|
| 42 |
+
with urllib.request.urlopen(url) as source, open(download_target, "wb") as output:
|
| 43 |
+
with tqdm(total=int(source.info().get("Content-Length")), ncols=80, unit='iB', unit_scale=True) as loop:
|
| 44 |
+
while True:
|
| 45 |
+
buffer = source.read(8192)
|
| 46 |
+
if not buffer:
|
| 47 |
+
break
|
| 48 |
+
|
| 49 |
+
output.write(buffer)
|
| 50 |
+
loop.update(len(buffer))
|
| 51 |
+
|
| 52 |
+
if hashlib.sha256(open(download_target, "rb").read()).hexdigest() != expected_sha256:
|
| 53 |
+
raise RuntimeError(f"Model has been downloaded but the SHA256 checksum does not not match")
|
| 54 |
+
|
| 55 |
+
return download_target
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
def _transform(n_px):
|
| 59 |
+
return Compose([
|
| 60 |
+
Resize(n_px, interpolation=Image.BICUBIC),
|
| 61 |
+
CenterCrop(n_px),
|
| 62 |
+
lambda image: image.convert("RGB"),
|
| 63 |
+
ToTensor(),
|
| 64 |
+
Normalize((0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711)),
|
| 65 |
+
])
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
def available_models() -> List[str]:
|
| 69 |
+
"""Returns the names of available CLIP models"""
|
| 70 |
+
return list(_MODELS.keys())
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
def load(name: str, device: Union[str, torch.device] = "cuda" if torch.cuda.is_available() else "cpu", jit=True):
|
| 74 |
+
"""Load a CLIP model
|
| 75 |
+
|
| 76 |
+
Parameters
|
| 77 |
+
----------
|
| 78 |
+
name : str
|
| 79 |
+
A model name listed by `clip.available_models()`, or the path to a model checkpoint containing the state_dict
|
| 80 |
+
|
| 81 |
+
device : Union[str, torch.device]
|
| 82 |
+
The device to put the loaded model
|
| 83 |
+
|
| 84 |
+
jit : bool
|
| 85 |
+
Whether to load the optimized JIT model (default) or more hackable non-JIT model.
|
| 86 |
+
|
| 87 |
+
Returns
|
| 88 |
+
-------
|
| 89 |
+
model : torch.nn.Module
|
| 90 |
+
The CLIP model
|
| 91 |
+
|
| 92 |
+
preprocess : Callable[[PIL.Image], torch.Tensor]
|
| 93 |
+
A torchvision transform that converts a PIL image into a tensor that the returned model can take as its input
|
| 94 |
+
"""
|
| 95 |
+
if name in _MODELS:
|
| 96 |
+
model_path = _download(_MODELS[name])
|
| 97 |
+
elif os.path.isfile(name):
|
| 98 |
+
model_path = name
|
| 99 |
+
else:
|
| 100 |
+
raise RuntimeError(f"Model {name} not found; available models = {available_models()}")
|
| 101 |
+
|
| 102 |
+
try:
|
| 103 |
+
# loading JIT archive
|
| 104 |
+
model = torch.jit.load(model_path, map_location=device if jit else "cpu").eval()
|
| 105 |
+
state_dict = None
|
| 106 |
+
except RuntimeError:
|
| 107 |
+
# loading saved state dict
|
| 108 |
+
if jit:
|
| 109 |
+
warnings.warn(f"File {model_path} is not a JIT archive. Loading as a state dict instead")
|
| 110 |
+
jit = False
|
| 111 |
+
state_dict = torch.load(model_path, map_location="cpu")
|
| 112 |
+
|
| 113 |
+
if not jit:
|
| 114 |
+
model = build_model(state_dict or model.state_dict()).to(device)
|
| 115 |
+
if str(device) == "cpu":
|
| 116 |
+
model.float()
|
| 117 |
+
return model, _transform(model.visual.input_resolution)
|
| 118 |
+
|
| 119 |
+
# patch the device names
|
| 120 |
+
device_holder = torch.jit.trace(lambda: torch.ones([]).to(torch.device(device)), example_inputs=[])
|
| 121 |
+
device_node = [n for n in device_holder.graph.findAllNodes("prim::Constant") if "Device" in repr(n)][-1]
|
| 122 |
+
|
| 123 |
+
def patch_device(module):
|
| 124 |
+
graphs = [module.graph] if hasattr(module, "graph") else []
|
| 125 |
+
if hasattr(module, "forward1"):
|
| 126 |
+
graphs.append(module.forward1.graph)
|
| 127 |
+
|
| 128 |
+
for graph in graphs:
|
| 129 |
+
for node in graph.findAllNodes("prim::Constant"):
|
| 130 |
+
if "value" in node.attributeNames() and str(node["value"]).startswith("cuda"):
|
| 131 |
+
node.copyAttributes(device_node)
|
| 132 |
+
|
| 133 |
+
model.apply(patch_device)
|
| 134 |
+
patch_device(model.encode_image)
|
| 135 |
+
patch_device(model.encode_text)
|
| 136 |
+
|
| 137 |
+
# patch dtype to float32 on CPU
|
| 138 |
+
if str(device) == "cpu":
|
| 139 |
+
float_holder = torch.jit.trace(lambda: torch.ones([]).float(), example_inputs=[])
|
| 140 |
+
float_input = list(float_holder.graph.findNode("aten::to").inputs())[1]
|
| 141 |
+
float_node = float_input.node()
|
| 142 |
+
|
| 143 |
+
def patch_float(module):
|
| 144 |
+
graphs = [module.graph] if hasattr(module, "graph") else []
|
| 145 |
+
if hasattr(module, "forward1"):
|
| 146 |
+
graphs.append(module.forward1.graph)
|
| 147 |
+
|
| 148 |
+
for graph in graphs:
|
| 149 |
+
for node in graph.findAllNodes("aten::to"):
|
| 150 |
+
inputs = list(node.inputs())
|
| 151 |
+
for i in [1, 2]: # dtype can be the second or third argument to aten::to()
|
| 152 |
+
if inputs[i].node()["value"] == 5:
|
| 153 |
+
inputs[i].node().copyAttributes(float_node)
|
| 154 |
+
|
| 155 |
+
model.apply(patch_float)
|
| 156 |
+
patch_float(model.encode_image)
|
| 157 |
+
patch_float(model.encode_text)
|
| 158 |
+
|
| 159 |
+
model.float()
|
| 160 |
+
|
| 161 |
+
return model, _transform(model.input_resolution.item())
|
| 162 |
+
|
| 163 |
+
|
| 164 |
+
def tokenize(texts: Union[str, List[str]], context_length: int = 77, max_valid_length: int = 32) -> torch.LongTensor:
|
| 165 |
+
"""
|
| 166 |
+
Returns the tokenized representation of given input string(s)
|
| 167 |
+
|
| 168 |
+
Parameters
|
| 169 |
+
----------
|
| 170 |
+
texts : Union[str, List[str]]
|
| 171 |
+
An input string or a list of input strings to tokenize
|
| 172 |
+
|
| 173 |
+
context_length : int
|
| 174 |
+
The context length to use; all CLIP models use 77 as the context length
|
| 175 |
+
|
| 176 |
+
max_valid_length:
|
| 177 |
+
|
| 178 |
+
Returns
|
| 179 |
+
-------
|
| 180 |
+
A two-dimensional tensor containing the resulting tokens, shape = [number of input strings, context_length]
|
| 181 |
+
"""
|
| 182 |
+
if isinstance(texts, str):
|
| 183 |
+
texts = [texts]
|
| 184 |
+
|
| 185 |
+
sot_token = _tokenizer.encoder["<|startoftext|>"]
|
| 186 |
+
eot_token = _tokenizer.encoder["<|endoftext|>"]
|
| 187 |
+
all_tokens = [[sot_token] + _tokenizer.encode(text)[:max_valid_length-2] + [eot_token] for text in texts]
|
| 188 |
+
result = torch.zeros(len(all_tokens), context_length, dtype=torch.long)
|
| 189 |
+
|
| 190 |
+
for i, tokens in enumerate(all_tokens):
|
| 191 |
+
if len(tokens) > context_length:
|
| 192 |
+
raise RuntimeError(f"Input {texts[i]} is too long for context length {context_length}")
|
| 193 |
+
result[i, :len(tokens)] = torch.tensor(tokens)
|
| 194 |
+
|
| 195 |
+
return result
|
run_on_video/clip/model.py
ADDED
|
@@ -0,0 +1,432 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from collections import OrderedDict
|
| 2 |
+
from typing import Tuple, Union
|
| 3 |
+
|
| 4 |
+
import numpy as np
|
| 5 |
+
import torch
|
| 6 |
+
import torch.nn.functional as F
|
| 7 |
+
from torch import nn
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
class Bottleneck(nn.Module):
|
| 11 |
+
expansion = 4
|
| 12 |
+
|
| 13 |
+
def __init__(self, inplanes, planes, stride=1):
|
| 14 |
+
super().__init__()
|
| 15 |
+
|
| 16 |
+
# all conv layers have stride 1. an avgpool is performed after the second convolution when stride > 1
|
| 17 |
+
self.conv1 = nn.Conv2d(inplanes, planes, 1, bias=False)
|
| 18 |
+
self.bn1 = nn.BatchNorm2d(planes)
|
| 19 |
+
|
| 20 |
+
self.conv2 = nn.Conv2d(planes, planes, 3, padding=1, bias=False)
|
| 21 |
+
self.bn2 = nn.BatchNorm2d(planes)
|
| 22 |
+
|
| 23 |
+
self.avgpool = nn.AvgPool2d(stride) if stride > 1 else nn.Identity()
|
| 24 |
+
|
| 25 |
+
self.conv3 = nn.Conv2d(planes, planes * self.expansion, 1, bias=False)
|
| 26 |
+
self.bn3 = nn.BatchNorm2d(planes * self.expansion)
|
| 27 |
+
|
| 28 |
+
self.relu = nn.ReLU(inplace=True)
|
| 29 |
+
self.downsample = None
|
| 30 |
+
self.stride = stride
|
| 31 |
+
|
| 32 |
+
if stride > 1 or inplanes != planes * Bottleneck.expansion:
|
| 33 |
+
# downsampling layer is prepended with an avgpool, and the subsequent convolution has stride 1
|
| 34 |
+
self.downsample = nn.Sequential(OrderedDict([
|
| 35 |
+
("-1", nn.AvgPool2d(stride)),
|
| 36 |
+
("0", nn.Conv2d(inplanes, planes * self.expansion, 1, stride=1, bias=False)),
|
| 37 |
+
("1", nn.BatchNorm2d(planes * self.expansion))
|
| 38 |
+
]))
|
| 39 |
+
|
| 40 |
+
def forward(self, x: torch.Tensor):
|
| 41 |
+
identity = x
|
| 42 |
+
|
| 43 |
+
out = self.relu(self.bn1(self.conv1(x)))
|
| 44 |
+
out = self.relu(self.bn2(self.conv2(out)))
|
| 45 |
+
out = self.avgpool(out)
|
| 46 |
+
out = self.bn3(self.conv3(out))
|
| 47 |
+
|
| 48 |
+
if self.downsample is not None:
|
| 49 |
+
identity = self.downsample(x)
|
| 50 |
+
|
| 51 |
+
out += identity
|
| 52 |
+
out = self.relu(out)
|
| 53 |
+
return out
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
class AttentionPool2d(nn.Module):
|
| 57 |
+
def __init__(self, spacial_dim: int, embed_dim: int, num_heads: int, output_dim: int = None):
|
| 58 |
+
super().__init__()
|
| 59 |
+
self.positional_embedding = nn.Parameter(torch.randn(spacial_dim ** 2 + 1, embed_dim) / embed_dim ** 0.5)
|
| 60 |
+
self.k_proj = nn.Linear(embed_dim, embed_dim)
|
| 61 |
+
self.q_proj = nn.Linear(embed_dim, embed_dim)
|
| 62 |
+
self.v_proj = nn.Linear(embed_dim, embed_dim)
|
| 63 |
+
self.c_proj = nn.Linear(embed_dim, output_dim or embed_dim)
|
| 64 |
+
self.num_heads = num_heads
|
| 65 |
+
|
| 66 |
+
def forward(self, x):
|
| 67 |
+
x = x.reshape(x.shape[0], x.shape[1], x.shape[2] * x.shape[3]).permute(2, 0, 1) # NCHW -> (HW)NC
|
| 68 |
+
x = torch.cat([x.mean(dim=0, keepdim=True), x], dim=0) # (HW+1)NC
|
| 69 |
+
x = x + self.positional_embedding[:, None, :].to(x.dtype) # (HW+1)NC
|
| 70 |
+
x, _ = F.multi_head_attention_forward(
|
| 71 |
+
query=x, key=x, value=x,
|
| 72 |
+
embed_dim_to_check=x.shape[-1],
|
| 73 |
+
num_heads=self.num_heads,
|
| 74 |
+
q_proj_weight=self.q_proj.weight,
|
| 75 |
+
k_proj_weight=self.k_proj.weight,
|
| 76 |
+
v_proj_weight=self.v_proj.weight,
|
| 77 |
+
in_proj_weight=None,
|
| 78 |
+
in_proj_bias=torch.cat([self.q_proj.bias, self.k_proj.bias, self.v_proj.bias]),
|
| 79 |
+
bias_k=None,
|
| 80 |
+
bias_v=None,
|
| 81 |
+
add_zero_attn=False,
|
| 82 |
+
dropout_p=0,
|
| 83 |
+
out_proj_weight=self.c_proj.weight,
|
| 84 |
+
out_proj_bias=self.c_proj.bias,
|
| 85 |
+
use_separate_proj_weight=True,
|
| 86 |
+
training=self.training,
|
| 87 |
+
need_weights=False
|
| 88 |
+
)
|
| 89 |
+
|
| 90 |
+
return x[0]
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
class ModifiedResNet(nn.Module):
|
| 94 |
+
"""
|
| 95 |
+
A ResNet class that is similar to torchvision's but contains the following changes:
|
| 96 |
+
- There are now 3 "stem" convolutions as opposed to 1, with an average pool instead of a max pool.
|
| 97 |
+
- Performs anti-aliasing strided convolutions, where an avgpool is prepended to convolutions with stride > 1
|
| 98 |
+
- The final pooling layer is a QKV attention instead of an average pool
|
| 99 |
+
"""
|
| 100 |
+
|
| 101 |
+
def __init__(self, layers, output_dim, heads, input_resolution=224, width=64):
|
| 102 |
+
super().__init__()
|
| 103 |
+
self.output_dim = output_dim
|
| 104 |
+
self.input_resolution = input_resolution
|
| 105 |
+
|
| 106 |
+
# the 3-layer stem
|
| 107 |
+
self.conv1 = nn.Conv2d(3, width // 2, kernel_size=3, stride=2, padding=1, bias=False)
|
| 108 |
+
self.bn1 = nn.BatchNorm2d(width // 2)
|
| 109 |
+
self.conv2 = nn.Conv2d(width // 2, width // 2, kernel_size=3, padding=1, bias=False)
|
| 110 |
+
self.bn2 = nn.BatchNorm2d(width // 2)
|
| 111 |
+
self.conv3 = nn.Conv2d(width // 2, width, kernel_size=3, padding=1, bias=False)
|
| 112 |
+
self.bn3 = nn.BatchNorm2d(width)
|
| 113 |
+
self.avgpool = nn.AvgPool2d(2)
|
| 114 |
+
self.relu = nn.ReLU(inplace=True)
|
| 115 |
+
|
| 116 |
+
# residual layers
|
| 117 |
+
self._inplanes = width # this is a *mutable* variable used during construction
|
| 118 |
+
self.layer1 = self._make_layer(width, layers[0])
|
| 119 |
+
self.layer2 = self._make_layer(width * 2, layers[1], stride=2)
|
| 120 |
+
self.layer3 = self._make_layer(width * 4, layers[2], stride=2)
|
| 121 |
+
self.layer4 = self._make_layer(width * 8, layers[3], stride=2)
|
| 122 |
+
|
| 123 |
+
embed_dim = width * 32 # the ResNet feature dimension
|
| 124 |
+
self.attnpool = AttentionPool2d(input_resolution // 32, embed_dim, heads, output_dim)
|
| 125 |
+
|
| 126 |
+
def _make_layer(self, planes, blocks, stride=1):
|
| 127 |
+
layers = [Bottleneck(self._inplanes, planes, stride)]
|
| 128 |
+
|
| 129 |
+
self._inplanes = planes * Bottleneck.expansion
|
| 130 |
+
for _ in range(1, blocks):
|
| 131 |
+
layers.append(Bottleneck(self._inplanes, planes))
|
| 132 |
+
|
| 133 |
+
return nn.Sequential(*layers)
|
| 134 |
+
|
| 135 |
+
def forward(self, x):
|
| 136 |
+
def stem(x):
|
| 137 |
+
for conv, bn in [(self.conv1, self.bn1), (self.conv2, self.bn2), (self.conv3, self.bn3)]:
|
| 138 |
+
x = self.relu(bn(conv(x)))
|
| 139 |
+
x = self.avgpool(x)
|
| 140 |
+
return x
|
| 141 |
+
|
| 142 |
+
x = x.type(self.conv1.weight.dtype)
|
| 143 |
+
x = stem(x)
|
| 144 |
+
x = self.layer1(x)
|
| 145 |
+
x = self.layer2(x)
|
| 146 |
+
x = self.layer3(x)
|
| 147 |
+
x = self.layer4(x)
|
| 148 |
+
x = self.attnpool(x)
|
| 149 |
+
|
| 150 |
+
return x
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
class LayerNorm(nn.LayerNorm):
|
| 154 |
+
"""Subclass torch's LayerNorm to handle fp16."""
|
| 155 |
+
|
| 156 |
+
def forward(self, x: torch.Tensor):
|
| 157 |
+
orig_type = x.dtype
|
| 158 |
+
ret = super().forward(x.type(torch.float32))
|
| 159 |
+
return ret.type(orig_type)
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
class QuickGELU(nn.Module):
|
| 163 |
+
def forward(self, x: torch.Tensor):
|
| 164 |
+
return x * torch.sigmoid(1.702 * x)
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
class ResidualAttentionBlock(nn.Module):
|
| 168 |
+
def __init__(self, d_model: int, n_head: int, attn_mask: torch.Tensor = None):
|
| 169 |
+
super().__init__()
|
| 170 |
+
|
| 171 |
+
self.attn = nn.MultiheadAttention(d_model, n_head)
|
| 172 |
+
self.ln_1 = LayerNorm(d_model)
|
| 173 |
+
self.mlp = nn.Sequential(OrderedDict([
|
| 174 |
+
("c_fc", nn.Linear(d_model, d_model * 4)),
|
| 175 |
+
("gelu", QuickGELU()),
|
| 176 |
+
("c_proj", nn.Linear(d_model * 4, d_model))
|
| 177 |
+
]))
|
| 178 |
+
self.ln_2 = LayerNorm(d_model)
|
| 179 |
+
self.attn_mask = attn_mask
|
| 180 |
+
|
| 181 |
+
def attention(self, x: torch.Tensor):
|
| 182 |
+
self.attn_mask = self.attn_mask.to(dtype=x.dtype, device=x.device) if self.attn_mask is not None else None
|
| 183 |
+
return self.attn(x, x, x, need_weights=False, attn_mask=self.attn_mask)[0]
|
| 184 |
+
|
| 185 |
+
def forward(self, x: torch.Tensor):
|
| 186 |
+
x = x + self.attention(self.ln_1(x))
|
| 187 |
+
x = x + self.mlp(self.ln_2(x))
|
| 188 |
+
return x
|
| 189 |
+
|
| 190 |
+
|
| 191 |
+
class Transformer(nn.Module):
|
| 192 |
+
def __init__(self, width: int, layers: int, heads: int, attn_mask: torch.Tensor = None):
|
| 193 |
+
super().__init__()
|
| 194 |
+
self.width = width
|
| 195 |
+
self.layers = layers
|
| 196 |
+
self.resblocks = nn.Sequential(*[ResidualAttentionBlock(width, heads, attn_mask) for _ in range(layers)])
|
| 197 |
+
|
| 198 |
+
def forward(self, x: torch.Tensor):
|
| 199 |
+
return self.resblocks(x)
|
| 200 |
+
|
| 201 |
+
|
| 202 |
+
class VisualTransformer(nn.Module):
|
| 203 |
+
def __init__(self, input_resolution: int, patch_size: int, width: int, layers: int, heads: int, output_dim: int):
|
| 204 |
+
super().__init__()
|
| 205 |
+
self.input_resolution = input_resolution
|
| 206 |
+
self.output_dim = output_dim
|
| 207 |
+
self.conv1 = nn.Conv2d(in_channels=3, out_channels=width, kernel_size=patch_size, stride=patch_size, bias=False)
|
| 208 |
+
|
| 209 |
+
scale = width ** -0.5
|
| 210 |
+
self.class_embedding = nn.Parameter(scale * torch.randn(width))
|
| 211 |
+
self.positional_embedding = nn.Parameter(scale * torch.randn((input_resolution // patch_size) ** 2 + 1, width))
|
| 212 |
+
self.ln_pre = LayerNorm(width)
|
| 213 |
+
|
| 214 |
+
self.transformer = Transformer(width, layers, heads)
|
| 215 |
+
|
| 216 |
+
self.ln_post = LayerNorm(width)
|
| 217 |
+
self.proj = nn.Parameter(scale * torch.randn(width, output_dim))
|
| 218 |
+
|
| 219 |
+
def forward(self, x: torch.Tensor):
|
| 220 |
+
x = self.conv1(x) # shape = [*, width, grid, grid]
|
| 221 |
+
x = x.reshape(x.shape[0], x.shape[1], -1) # shape = [*, width, grid ** 2]
|
| 222 |
+
x = x.permute(0, 2, 1) # shape = [*, grid ** 2, width]
|
| 223 |
+
x = torch.cat([self.class_embedding.to(x.dtype) + torch.zeros(x.shape[0], 1, x.shape[-1], dtype=x.dtype, device=x.device), x], dim=1) # shape = [*, grid ** 2 + 1, width]
|
| 224 |
+
x = x + self.positional_embedding.to(x.dtype)
|
| 225 |
+
x = self.ln_pre(x)
|
| 226 |
+
|
| 227 |
+
x = x.permute(1, 0, 2) # NLD -> LND
|
| 228 |
+
x = self.transformer(x)
|
| 229 |
+
x = x.permute(1, 0, 2) # LND -> NLD
|
| 230 |
+
|
| 231 |
+
x = self.ln_post(x[:, 0, :])
|
| 232 |
+
|
| 233 |
+
if self.proj is not None:
|
| 234 |
+
x = x @ self.proj
|
| 235 |
+
|
| 236 |
+
return x
|
| 237 |
+
|
| 238 |
+
|
| 239 |
+
class CLIP(nn.Module):
|
| 240 |
+
def __init__(self,
|
| 241 |
+
embed_dim: int,
|
| 242 |
+
# vision
|
| 243 |
+
image_resolution: int,
|
| 244 |
+
vision_layers: Union[Tuple[int, int, int, int], int],
|
| 245 |
+
vision_width: int,
|
| 246 |
+
vision_patch_size: int,
|
| 247 |
+
# text
|
| 248 |
+
context_length: int,
|
| 249 |
+
vocab_size: int,
|
| 250 |
+
transformer_width: int,
|
| 251 |
+
transformer_heads: int,
|
| 252 |
+
transformer_layers: int
|
| 253 |
+
):
|
| 254 |
+
super().__init__()
|
| 255 |
+
|
| 256 |
+
self.context_length = context_length
|
| 257 |
+
|
| 258 |
+
if isinstance(vision_layers, (tuple, list)):
|
| 259 |
+
vision_heads = vision_width * 32 // 64
|
| 260 |
+
self.visual = ModifiedResNet(
|
| 261 |
+
layers=vision_layers,
|
| 262 |
+
output_dim=embed_dim,
|
| 263 |
+
heads=vision_heads,
|
| 264 |
+
input_resolution=image_resolution,
|
| 265 |
+
width=vision_width
|
| 266 |
+
)
|
| 267 |
+
else:
|
| 268 |
+
vision_heads = vision_width // 64
|
| 269 |
+
self.visual = VisualTransformer(
|
| 270 |
+
input_resolution=image_resolution,
|
| 271 |
+
patch_size=vision_patch_size,
|
| 272 |
+
width=vision_width,
|
| 273 |
+
layers=vision_layers,
|
| 274 |
+
heads=vision_heads,
|
| 275 |
+
output_dim=embed_dim
|
| 276 |
+
)
|
| 277 |
+
|
| 278 |
+
self.transformer = Transformer(
|
| 279 |
+
width=transformer_width,
|
| 280 |
+
layers=transformer_layers,
|
| 281 |
+
heads=transformer_heads,
|
| 282 |
+
attn_mask=self.build_attention_mask()
|
| 283 |
+
)
|
| 284 |
+
|
| 285 |
+
self.vocab_size = vocab_size
|
| 286 |
+
self.token_embedding = nn.Embedding(vocab_size, transformer_width)
|
| 287 |
+
self.positional_embedding = nn.Parameter(torch.empty(self.context_length, transformer_width))
|
| 288 |
+
self.ln_final = LayerNorm(transformer_width)
|
| 289 |
+
|
| 290 |
+
self.text_projection = nn.Parameter(torch.empty(transformer_width, embed_dim))
|
| 291 |
+
self.logit_scale = nn.Parameter(torch.ones([]) * np.log(1 / 0.07))
|
| 292 |
+
|
| 293 |
+
self.initialize_parameters()
|
| 294 |
+
|
| 295 |
+
def initialize_parameters(self):
|
| 296 |
+
nn.init.normal_(self.token_embedding.weight, std=0.02)
|
| 297 |
+
nn.init.normal_(self.positional_embedding, std=0.01)
|
| 298 |
+
|
| 299 |
+
if isinstance(self.visual, ModifiedResNet):
|
| 300 |
+
if self.visual.attnpool is not None:
|
| 301 |
+
std = self.visual.attnpool.c_proj.in_features ** -0.5
|
| 302 |
+
nn.init.normal_(self.visual.attnpool.q_proj.weight, std=std)
|
| 303 |
+
nn.init.normal_(self.visual.attnpool.k_proj.weight, std=std)
|
| 304 |
+
nn.init.normal_(self.visual.attnpool.v_proj.weight, std=std)
|
| 305 |
+
nn.init.normal_(self.visual.attnpool.c_proj.weight, std=std)
|
| 306 |
+
|
| 307 |
+
for resnet_block in [self.visual.layer1, self.visual.layer2, self.visual.layer3, self.visual.layer4]:
|
| 308 |
+
for name, param in resnet_block.named_parameters():
|
| 309 |
+
if name.endswith("bn3.weight"):
|
| 310 |
+
nn.init.zeros_(param)
|
| 311 |
+
|
| 312 |
+
proj_std = (self.transformer.width ** -0.5) * ((2 * self.transformer.layers) ** -0.5)
|
| 313 |
+
attn_std = self.transformer.width ** -0.5
|
| 314 |
+
fc_std = (2 * self.transformer.width) ** -0.5
|
| 315 |
+
for block in self.transformer.resblocks:
|
| 316 |
+
nn.init.normal_(block.attn.in_proj_weight, std=attn_std)
|
| 317 |
+
nn.init.normal_(block.attn.out_proj.weight, std=proj_std)
|
| 318 |
+
nn.init.normal_(block.mlp.c_fc.weight, std=fc_std)
|
| 319 |
+
nn.init.normal_(block.mlp.c_proj.weight, std=proj_std)
|
| 320 |
+
|
| 321 |
+
if self.text_projection is not None:
|
| 322 |
+
nn.init.normal_(self.text_projection, std=self.transformer.width ** -0.5)
|
| 323 |
+
|
| 324 |
+
def build_attention_mask(self):
|
| 325 |
+
# lazily create causal attention mask, with full attention between the vision tokens
|
| 326 |
+
# pytorch uses additive attention mask; fill with -inf
|
| 327 |
+
mask = torch.empty(self.context_length, self.context_length)
|
| 328 |
+
mask.fill_(float("-inf"))
|
| 329 |
+
mask.triu_(1) # zero out the lower diagonal
|
| 330 |
+
return mask
|
| 331 |
+
|
| 332 |
+
@property
|
| 333 |
+
def dtype(self):
|
| 334 |
+
return self.visual.conv1.weight.dtype
|
| 335 |
+
|
| 336 |
+
def encode_image(self, image):
|
| 337 |
+
return self.visual(image.type(self.dtype))
|
| 338 |
+
|
| 339 |
+
def encode_text(self, text):
|
| 340 |
+
x = self.token_embedding(text).type(self.dtype) # [batch_size, n_ctx, d_model]
|
| 341 |
+
|
| 342 |
+
x = x + self.positional_embedding.type(self.dtype)
|
| 343 |
+
x = x.permute(1, 0, 2) # NLD -> LND
|
| 344 |
+
x = self.transformer(x)
|
| 345 |
+
x = x.permute(1, 0, 2) # LND -> NLD
|
| 346 |
+
x = self.ln_final(x).type(self.dtype)
|
| 347 |
+
|
| 348 |
+
# x.shape = [batch_size, n_ctx, transformer.width]
|
| 349 |
+
# take features from the eot embedding (eot_token is the highest number in each sequence)
|
| 350 |
+
eos_x = x[torch.arange(x.shape[0]), text.argmax(dim=-1)] @ self.text_projection
|
| 351 |
+
|
| 352 |
+
return dict(last_hidden_state=x, pooler_output=eos_x)
|
| 353 |
+
|
| 354 |
+
def forward(self, image, text):
|
| 355 |
+
image_features = self.encode_image(image)
|
| 356 |
+
text_features = self.encode_text(text)
|
| 357 |
+
|
| 358 |
+
# normalized features
|
| 359 |
+
image_features = image_features / image_features.norm(dim=-1, keepdim=True)
|
| 360 |
+
text_features = text_features / text_features.norm(dim=-1, keepdim=True)
|
| 361 |
+
|
| 362 |
+
# cosine similarity as logits
|
| 363 |
+
logit_scale = self.logit_scale.exp()
|
| 364 |
+
logits_per_image = logit_scale * image_features @ text_features.t()
|
| 365 |
+
logits_per_text = logit_scale * text_features @ image_features.t()
|
| 366 |
+
|
| 367 |
+
# shape = [global_batch_size, global_batch_size]
|
| 368 |
+
return logits_per_image, logits_per_text
|
| 369 |
+
|
| 370 |
+
|
| 371 |
+
def convert_weights(model: nn.Module):
|
| 372 |
+
"""Convert applicable model parameters to fp16"""
|
| 373 |
+
|
| 374 |
+
def _convert_weights_to_fp16(l):
|
| 375 |
+
if isinstance(l, (nn.Conv1d, nn.Conv2d, nn.Linear)):
|
| 376 |
+
l.weight.data = l.weight.data.half()
|
| 377 |
+
if l.bias is not None:
|
| 378 |
+
l.bias.data = l.bias.data.half()
|
| 379 |
+
|
| 380 |
+
if isinstance(l, nn.MultiheadAttention):
|
| 381 |
+
for attr in [*[f"{s}_proj_weight" for s in ["in", "q", "k", "v"]], "in_proj_bias", "bias_k", "bias_v"]:
|
| 382 |
+
tensor = getattr(l, attr)
|
| 383 |
+
if tensor is not None:
|
| 384 |
+
tensor.data = tensor.data.half()
|
| 385 |
+
|
| 386 |
+
for name in ["text_projection", "proj"]:
|
| 387 |
+
if hasattr(l, name):
|
| 388 |
+
attr = getattr(l, name)
|
| 389 |
+
if attr is not None:
|
| 390 |
+
attr.data = attr.data.half()
|
| 391 |
+
|
| 392 |
+
model.apply(_convert_weights_to_fp16)
|
| 393 |
+
|
| 394 |
+
|
| 395 |
+
def build_model(state_dict: dict):
|
| 396 |
+
vit = "visual.proj" in state_dict
|
| 397 |
+
|
| 398 |
+
if vit:
|
| 399 |
+
vision_width = state_dict["visual.conv1.weight"].shape[0]
|
| 400 |
+
vision_layers = len([k for k in state_dict.keys() if k.startswith("visual.") and k.endswith(".attn.in_proj_weight")])
|
| 401 |
+
vision_patch_size = state_dict["visual.conv1.weight"].shape[-1]
|
| 402 |
+
grid_size = round((state_dict["visual.positional_embedding"].shape[0] - 1) ** 0.5)
|
| 403 |
+
image_resolution = vision_patch_size * grid_size
|
| 404 |
+
else:
|
| 405 |
+
counts: list = [len(set(k.split(".")[2] for k in state_dict if k.startswith(f"visual.layer{b}"))) for b in [1, 2, 3, 4]]
|
| 406 |
+
vision_layers = tuple(counts)
|
| 407 |
+
vision_width = state_dict["visual.layer1.0.conv1.weight"].shape[0]
|
| 408 |
+
output_width = round((state_dict["visual.attnpool.positional_embedding"].shape[0] - 1) ** 0.5)
|
| 409 |
+
vision_patch_size = None
|
| 410 |
+
assert output_width ** 2 + 1 == state_dict["visual.attnpool.positional_embedding"].shape[0]
|
| 411 |
+
image_resolution = output_width * 32
|
| 412 |
+
|
| 413 |
+
embed_dim = state_dict["text_projection"].shape[1]
|
| 414 |
+
context_length = state_dict["positional_embedding"].shape[0]
|
| 415 |
+
vocab_size = state_dict["token_embedding.weight"].shape[0]
|
| 416 |
+
transformer_width = state_dict["ln_final.weight"].shape[0]
|
| 417 |
+
transformer_heads = transformer_width // 64
|
| 418 |
+
transformer_layers = len(set(k.split(".")[2] for k in state_dict if k.startswith(f"transformer.resblocks")))
|
| 419 |
+
|
| 420 |
+
model = CLIP(
|
| 421 |
+
embed_dim,
|
| 422 |
+
image_resolution, vision_layers, vision_width, vision_patch_size,
|
| 423 |
+
context_length, vocab_size, transformer_width, transformer_heads, transformer_layers
|
| 424 |
+
)
|
| 425 |
+
|
| 426 |
+
for key in ["input_resolution", "context_length", "vocab_size"]:
|
| 427 |
+
if key in state_dict:
|
| 428 |
+
del state_dict[key]
|
| 429 |
+
|
| 430 |
+
convert_weights(model)
|
| 431 |
+
model.load_state_dict(state_dict)
|
| 432 |
+
return model.eval()
|
run_on_video/clip/simple_tokenizer.py
ADDED
|
@@ -0,0 +1,132 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gzip
|
| 2 |
+
import html
|
| 3 |
+
import os
|
| 4 |
+
from functools import lru_cache
|
| 5 |
+
|
| 6 |
+
import ftfy
|
| 7 |
+
import regex as re
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
@lru_cache()
|
| 11 |
+
def default_bpe():
|
| 12 |
+
return os.path.join(os.path.dirname(os.path.abspath(__file__)), "bpe_simple_vocab_16e6.txt.gz")
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
@lru_cache()
|
| 16 |
+
def bytes_to_unicode():
|
| 17 |
+
"""
|
| 18 |
+
Returns list of utf-8 byte and a corresponding list of unicode strings.
|
| 19 |
+
The reversible bpe codes work on unicode strings.
|
| 20 |
+
This means you need a large # of unicode characters in your vocab if you want to avoid UNKs.
|
| 21 |
+
When you're at something like a 10B token dataset you end up needing around 5K for decent coverage.
|
| 22 |
+
This is a signficant percentage of your normal, say, 32K bpe vocab.
|
| 23 |
+
To avoid that, we want lookup tables between utf-8 bytes and unicode strings.
|
| 24 |
+
And avoids mapping to whitespace/control characters the bpe code barfs on.
|
| 25 |
+
"""
|
| 26 |
+
bs = list(range(ord("!"), ord("~")+1))+list(range(ord("¡"), ord("¬")+1))+list(range(ord("®"), ord("ÿ")+1))
|
| 27 |
+
cs = bs[:]
|
| 28 |
+
n = 0
|
| 29 |
+
for b in range(2**8):
|
| 30 |
+
if b not in bs:
|
| 31 |
+
bs.append(b)
|
| 32 |
+
cs.append(2**8+n)
|
| 33 |
+
n += 1
|
| 34 |
+
cs = [chr(n) for n in cs]
|
| 35 |
+
return dict(zip(bs, cs))
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def get_pairs(word):
|
| 39 |
+
"""Return set of symbol pairs in a word.
|
| 40 |
+
Word is represented as tuple of symbols (symbols being variable-length strings).
|
| 41 |
+
"""
|
| 42 |
+
pairs = set()
|
| 43 |
+
prev_char = word[0]
|
| 44 |
+
for char in word[1:]:
|
| 45 |
+
pairs.add((prev_char, char))
|
| 46 |
+
prev_char = char
|
| 47 |
+
return pairs
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
def basic_clean(text):
|
| 51 |
+
text = ftfy.fix_text(text)
|
| 52 |
+
text = html.unescape(html.unescape(text))
|
| 53 |
+
return text.strip()
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
def whitespace_clean(text):
|
| 57 |
+
text = re.sub(r'\s+', ' ', text)
|
| 58 |
+
text = text.strip()
|
| 59 |
+
return text
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
class SimpleTokenizer(object):
|
| 63 |
+
def __init__(self, bpe_path: str = default_bpe()):
|
| 64 |
+
self.byte_encoder = bytes_to_unicode()
|
| 65 |
+
self.byte_decoder = {v: k for k, v in self.byte_encoder.items()}
|
| 66 |
+
merges = gzip.open(bpe_path).read().decode("utf-8").split('\n')
|
| 67 |
+
merges = merges[1:49152-256-2+1]
|
| 68 |
+
merges = [tuple(merge.split()) for merge in merges]
|
| 69 |
+
vocab = list(bytes_to_unicode().values())
|
| 70 |
+
vocab = vocab + [v+'</w>' for v in vocab]
|
| 71 |
+
for merge in merges:
|
| 72 |
+
vocab.append(''.join(merge))
|
| 73 |
+
vocab.extend(['<|startoftext|>', '<|endoftext|>'])
|
| 74 |
+
self.encoder = dict(zip(vocab, range(len(vocab))))
|
| 75 |
+
self.decoder = {v: k for k, v in self.encoder.items()}
|
| 76 |
+
self.bpe_ranks = dict(zip(merges, range(len(merges))))
|
| 77 |
+
self.cache = {'<|startoftext|>': '<|startoftext|>', '<|endoftext|>': '<|endoftext|>'}
|
| 78 |
+
self.pat = re.compile(r"""<\|startoftext\|>|<\|endoftext\|>|'s|'t|'re|'ve|'m|'ll|'d|[\p{L}]+|[\p{N}]|[^\s\p{L}\p{N}]+""", re.IGNORECASE)
|
| 79 |
+
|
| 80 |
+
def bpe(self, token):
|
| 81 |
+
if token in self.cache:
|
| 82 |
+
return self.cache[token]
|
| 83 |
+
word = tuple(token[:-1]) + ( token[-1] + '</w>',)
|
| 84 |
+
pairs = get_pairs(word)
|
| 85 |
+
|
| 86 |
+
if not pairs:
|
| 87 |
+
return token+'</w>'
|
| 88 |
+
|
| 89 |
+
while True:
|
| 90 |
+
bigram = min(pairs, key = lambda pair: self.bpe_ranks.get(pair, float('inf')))
|
| 91 |
+
if bigram not in self.bpe_ranks:
|
| 92 |
+
break
|
| 93 |
+
first, second = bigram
|
| 94 |
+
new_word = []
|
| 95 |
+
i = 0
|
| 96 |
+
while i < len(word):
|
| 97 |
+
try:
|
| 98 |
+
j = word.index(first, i)
|
| 99 |
+
new_word.extend(word[i:j])
|
| 100 |
+
i = j
|
| 101 |
+
except:
|
| 102 |
+
new_word.extend(word[i:])
|
| 103 |
+
break
|
| 104 |
+
|
| 105 |
+
if word[i] == first and i < len(word)-1 and word[i+1] == second:
|
| 106 |
+
new_word.append(first+second)
|
| 107 |
+
i += 2
|
| 108 |
+
else:
|
| 109 |
+
new_word.append(word[i])
|
| 110 |
+
i += 1
|
| 111 |
+
new_word = tuple(new_word)
|
| 112 |
+
word = new_word
|
| 113 |
+
if len(word) == 1:
|
| 114 |
+
break
|
| 115 |
+
else:
|
| 116 |
+
pairs = get_pairs(word)
|
| 117 |
+
word = ' '.join(word)
|
| 118 |
+
self.cache[token] = word
|
| 119 |
+
return word
|
| 120 |
+
|
| 121 |
+
def encode(self, text):
|
| 122 |
+
bpe_tokens = []
|
| 123 |
+
text = whitespace_clean(basic_clean(text)).lower()
|
| 124 |
+
for token in re.findall(self.pat, text):
|
| 125 |
+
token = ''.join(self.byte_encoder[b] for b in token.encode('utf-8'))
|
| 126 |
+
bpe_tokens.extend(self.encoder[bpe_token] for bpe_token in self.bpe(token).split(' '))
|
| 127 |
+
return bpe_tokens
|
| 128 |
+
|
| 129 |
+
def decode(self, tokens):
|
| 130 |
+
text = ''.join([self.decoder[token] for token in tokens])
|
| 131 |
+
text = bytearray([self.byte_decoder[c] for c in text]).decode('utf-8', errors="replace").replace('</w>', ' ')
|
| 132 |
+
return text
|
run_on_video/data_utils.py
ADDED
|
@@ -0,0 +1,183 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import os
|
| 3 |
+
import numpy as np
|
| 4 |
+
import ffmpeg
|
| 5 |
+
import math
|
| 6 |
+
import clip
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class ClipFeatureExtractor:
|
| 10 |
+
def __init__(self, framerate=1/2, size=224, centercrop=True, model_name_or_path="ViT-B/32", device="cuda"):
|
| 11 |
+
self.video_loader = VideoLoader(framerate=framerate, size=size, centercrop=centercrop)
|
| 12 |
+
print("Loading CLIP models")
|
| 13 |
+
self.clip_extractor, _ = clip.load(model_name_or_path, device=device, jit=False)
|
| 14 |
+
self.tokenizer = clip.tokenize
|
| 15 |
+
self.video_preprocessor = Preprocessing()
|
| 16 |
+
self.device = device
|
| 17 |
+
|
| 18 |
+
@torch.no_grad()
|
| 19 |
+
def encode_video(self, video_path: str, bsz=60):
|
| 20 |
+
video_frames, origin_video_frames = self.video_loader.read_video_from_file(video_path) # (T, H, W, 3)
|
| 21 |
+
video_frames = self.video_preprocessor(video_frames)
|
| 22 |
+
n_frames = len(video_frames)
|
| 23 |
+
n_batch = int(math.ceil(n_frames / bsz))
|
| 24 |
+
video_features = []
|
| 25 |
+
for i in range(n_batch):
|
| 26 |
+
st_idx = i * bsz
|
| 27 |
+
ed_idx = (i+1) * bsz
|
| 28 |
+
_video_frames = video_frames[st_idx:ed_idx].to(self.device)
|
| 29 |
+
_video_features = self.clip_extractor.encode_image(_video_frames)
|
| 30 |
+
video_features.append(_video_features)
|
| 31 |
+
video_features = torch.cat(video_features, dim=0)
|
| 32 |
+
return video_features, origin_video_frames # (T=#frames, d) torch tensor
|
| 33 |
+
|
| 34 |
+
@torch.no_grad()
|
| 35 |
+
def encode_text(self, text_list, bsz=60):
|
| 36 |
+
n_text = len(text_list)
|
| 37 |
+
n_batch = int(math.ceil(n_text / bsz))
|
| 38 |
+
text_features = []
|
| 39 |
+
for i in range(n_batch):
|
| 40 |
+
st_idx = i * bsz
|
| 41 |
+
ed_idx = (i+1) * bsz
|
| 42 |
+
encoded_texts = self.tokenizer(text_list[st_idx:ed_idx], context_length=77).to(self.device)
|
| 43 |
+
output = self.clip_extractor.encode_text(encoded_texts)
|
| 44 |
+
valid_lengths = (encoded_texts != 0).sum(1).tolist()
|
| 45 |
+
batch_last_hidden_states = output["last_hidden_state"]
|
| 46 |
+
for j, valid_len in enumerate(valid_lengths):
|
| 47 |
+
text_features.append(batch_last_hidden_states[j, :valid_len])
|
| 48 |
+
return text_features # List([L_j, d]) torch tensor
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
def convert_to_float(frac_str):
|
| 52 |
+
try:
|
| 53 |
+
return float(frac_str)
|
| 54 |
+
except ValueError:
|
| 55 |
+
try:
|
| 56 |
+
num, denom = frac_str.split('/')
|
| 57 |
+
except ValueError:
|
| 58 |
+
return None
|
| 59 |
+
try:
|
| 60 |
+
leading, num = num.split(' ')
|
| 61 |
+
except ValueError:
|
| 62 |
+
return float(num) / float(denom)
|
| 63 |
+
if float(leading) < 0:
|
| 64 |
+
sign_mult = -1
|
| 65 |
+
else:
|
| 66 |
+
sign_mult = 1
|
| 67 |
+
return float(leading) + sign_mult * (float(num) / float(denom))
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
class Normalize(object):
|
| 71 |
+
|
| 72 |
+
def __init__(self, mean, std):
|
| 73 |
+
self.mean = torch.FloatTensor(mean).view(1, 3, 1, 1)
|
| 74 |
+
self.std = torch.FloatTensor(std).view(1, 3, 1, 1)
|
| 75 |
+
|
| 76 |
+
def __call__(self, tensor):
|
| 77 |
+
tensor = (tensor - self.mean) / (self.std + 1e-8)
|
| 78 |
+
return tensor
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
class Preprocessing(object):
|
| 82 |
+
|
| 83 |
+
def __init__(self):
|
| 84 |
+
self.norm = Normalize(
|
| 85 |
+
mean=[0.48145466, 0.4578275, 0.40821073],
|
| 86 |
+
std=[0.26862954, 0.26130258, 0.27577711])
|
| 87 |
+
|
| 88 |
+
def __call__(self, tensor):
|
| 89 |
+
tensor = tensor / 255.0
|
| 90 |
+
tensor = self.norm(tensor)
|
| 91 |
+
return tensor
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
class VideoLoader:
|
| 95 |
+
"""Pytorch video loader.
|
| 96 |
+
Copied and modified from:
|
| 97 |
+
https://github.com/linjieli222/HERO_Video_Feature_Extractor/blob/main/clip/video_loader.py
|
| 98 |
+
"""
|
| 99 |
+
def __init__(
|
| 100 |
+
self,
|
| 101 |
+
framerate=1/2,
|
| 102 |
+
size=224,
|
| 103 |
+
centercrop=True,
|
| 104 |
+
):
|
| 105 |
+
self.centercrop = centercrop
|
| 106 |
+
self.size = size
|
| 107 |
+
self.framerate = framerate
|
| 108 |
+
|
| 109 |
+
def _get_video_info(self, video_path):
|
| 110 |
+
probe = ffmpeg.probe(video_path)
|
| 111 |
+
video_stream = next((stream for stream in probe['streams']
|
| 112 |
+
if stream['codec_type'] == 'video'), None)
|
| 113 |
+
width = int(video_stream['width'])
|
| 114 |
+
height = int(video_stream['height'])
|
| 115 |
+
if 'rotate' in video_stream['tags']:
|
| 116 |
+
rotate = int(video_stream['tags']['rotate'])
|
| 117 |
+
if rotate == 90 or rotate == 270:
|
| 118 |
+
width, height = int(video_stream['height']), int(video_stream['width'])
|
| 119 |
+
fps = math.floor(convert_to_float(video_stream['avg_frame_rate']))
|
| 120 |
+
try:
|
| 121 |
+
frames_length = int(video_stream['nb_frames'])
|
| 122 |
+
duration = float(video_stream['duration'])
|
| 123 |
+
except Exception:
|
| 124 |
+
frames_length, duration = -1, -1
|
| 125 |
+
info = {"duration": duration, "frames_length": frames_length,
|
| 126 |
+
"fps": fps, "height": height, "width": width}
|
| 127 |
+
return info
|
| 128 |
+
|
| 129 |
+
def _get_output_dim(self, h, w):
|
| 130 |
+
if isinstance(self.size, tuple) and len(self.size) == 2:
|
| 131 |
+
return self.size
|
| 132 |
+
elif h >= w:
|
| 133 |
+
return int(h * self.size / w), self.size
|
| 134 |
+
else:
|
| 135 |
+
return self.size, int(w * self.size / h)
|
| 136 |
+
|
| 137 |
+
def read_video_from_file(self, video_path):
|
| 138 |
+
try:
|
| 139 |
+
info = self._get_video_info(video_path)
|
| 140 |
+
h, w = info["height"], info["width"]
|
| 141 |
+
except Exception:
|
| 142 |
+
print('ffprobe failed at: {}'.format(video_path))
|
| 143 |
+
return {'video': torch.zeros(1), 'input': video_path,
|
| 144 |
+
'info': {}}
|
| 145 |
+
height, width = self._get_output_dim(h, w)
|
| 146 |
+
try:
|
| 147 |
+
duration = info["duration"]
|
| 148 |
+
fps = self.framerate
|
| 149 |
+
if duration > 0 and duration < 1/fps+0.1:
|
| 150 |
+
fps = 2/max(int(duration), 1)
|
| 151 |
+
print(duration, fps)
|
| 152 |
+
except Exception:
|
| 153 |
+
fps = self.framerate
|
| 154 |
+
cmd = (
|
| 155 |
+
ffmpeg
|
| 156 |
+
.input(video_path)
|
| 157 |
+
.filter('fps', fps=fps)
|
| 158 |
+
.filter('scale', width, height)
|
| 159 |
+
)
|
| 160 |
+
original_size_out, _ = (
|
| 161 |
+
cmd.output('pipe:', format='rawvideo', pix_fmt='rgb24')
|
| 162 |
+
.run(capture_stdout=True, quiet=True)
|
| 163 |
+
)
|
| 164 |
+
original_size_video = np.frombuffer(original_size_out, np.uint8).reshape(
|
| 165 |
+
[-1, height, width, 3])
|
| 166 |
+
original_size_video = torch.from_numpy(original_size_video.astype('float32'))
|
| 167 |
+
original_size_video = original_size_video.permute(0, 3, 1, 2)
|
| 168 |
+
if self.centercrop:
|
| 169 |
+
x = int((width - self.size) / 2.0)
|
| 170 |
+
y = int((height - self.size) / 2.0)
|
| 171 |
+
cmd = cmd.crop(x, y, self.size, self.size)
|
| 172 |
+
out, _ = (
|
| 173 |
+
cmd.output('pipe:', format='rawvideo', pix_fmt='rgb24')
|
| 174 |
+
.run(capture_stdout=True, quiet=True)
|
| 175 |
+
)
|
| 176 |
+
if self.centercrop and isinstance(self.size, int):
|
| 177 |
+
height, width = self.size, self.size
|
| 178 |
+
video = np.frombuffer(out, np.uint8).reshape(
|
| 179 |
+
[-1, height, width, 3])
|
| 180 |
+
video = torch.from_numpy(video.astype('float32'))
|
| 181 |
+
video = video.permute(0, 3, 1, 2)
|
| 182 |
+
|
| 183 |
+
return video, original_size_video
|
run_on_video/dataset.py
ADDED
|
@@ -0,0 +1,72 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from torch.utils.data import Dataset
|
| 2 |
+
import csv
|
| 3 |
+
import os
|
| 4 |
+
import numpy as np
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class HighlightDataset(Dataset):
|
| 8 |
+
"""Face Landmarks dataset."""
|
| 9 |
+
|
| 10 |
+
def __init__(self, root_dir, transform=None):
|
| 11 |
+
"""
|
| 12 |
+
Arguments:
|
| 13 |
+
csv_file (string): Path to the csv file with annotations.
|
| 14 |
+
root_dir (string): Directory with all datas including videos and annotations.
|
| 15 |
+
"""
|
| 16 |
+
self.root_dir = root_dir
|
| 17 |
+
self.video_dir = os.path.join(root_dir, "videos")
|
| 18 |
+
self.anno_path = os.path.join(root_dir, "ydata-tvsum50-anno.tsv")
|
| 19 |
+
|
| 20 |
+
#read annotations
|
| 21 |
+
with open(self.anno_path, newline='') as f:
|
| 22 |
+
reader = csv.reader(f, delimiter='\t')
|
| 23 |
+
raw_annotations = list(reader)
|
| 24 |
+
|
| 25 |
+
self.num_annotator = 20
|
| 26 |
+
self.annotations = self.parse_annotations(raw_annotations) # {video_id: [importance scores]}
|
| 27 |
+
|
| 28 |
+
#get list of videos
|
| 29 |
+
self.video_list = os.listdir(self.video_dir)
|
| 30 |
+
|
| 31 |
+
def parse_annotations(self, annotations):
|
| 32 |
+
'''
|
| 33 |
+
format of annotations:
|
| 34 |
+
[[video_id, video_category, importance score], ...]
|
| 35 |
+
'''
|
| 36 |
+
#separate annotations into chunks of length 20
|
| 37 |
+
parsed_annotations = {}
|
| 38 |
+
annotations_per_video = [annotations[i:i + self.num_annotator] for i in range(0, len(annotations), self.num_annotator)]
|
| 39 |
+
for anno_video in annotations_per_video:
|
| 40 |
+
video_id = anno_video[0][0]
|
| 41 |
+
video_category = anno_video[0][1]
|
| 42 |
+
#get importance score
|
| 43 |
+
#anno[2] is a string of scores separated by commas
|
| 44 |
+
importance_score = []
|
| 45 |
+
for anno in anno_video:
|
| 46 |
+
anno[2] = anno[2].split(',')
|
| 47 |
+
anno[2] = [float(score) for score in anno[2]]
|
| 48 |
+
importance_score.append(anno[2])
|
| 49 |
+
importance_score = np.array(importance_score)
|
| 50 |
+
|
| 51 |
+
#get average importance score
|
| 52 |
+
parsed_annotations[video_id] = np.mean(importance_score, axis=0)
|
| 53 |
+
|
| 54 |
+
return parsed_annotations
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
def __len__(self):
|
| 58 |
+
return len(self.video_list)
|
| 59 |
+
|
| 60 |
+
def __getitem__(self, idx):
|
| 61 |
+
if torch.is_tensor(idx):
|
| 62 |
+
idx = idx.tolist()
|
| 63 |
+
|
| 64 |
+
#should return frames and scores
|
| 65 |
+
video_name = self.video_list[idx]
|
| 66 |
+
video_id = video_name.split('.')[0]
|
| 67 |
+
video_path = os.path.join(self.video_dir, video_name)
|
| 68 |
+
|
| 69 |
+
#get annotations
|
| 70 |
+
annotations = self.annotations[video_id]
|
| 71 |
+
|
| 72 |
+
return video_path, annotations
|
run_on_video/eval.py
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from dataset import HighlightDataset
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
if __name__ == "__main__":
|
| 9 |
+
|
| 10 |
+
dataset = HighlightDataset(root_dir="../data/tvsum")
|
run_on_video/example/RoripwjYFp8_60.0_210.0.mp4
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e847dbe79219afc6d70225117684a7e03563e1580b6f455ece13f89747cb5a50
|
| 3 |
+
size 10404801
|
run_on_video/example/queries.jsonl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2f093f3bba5afb018b9c3a1319eda89a3dca042b53acb02d529db728d2157805
|
| 3 |
+
size 307
|
run_on_video/model_utils.py
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from moment_detr.model import build_transformer, build_position_encoding, MomentDETR
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
def build_inference_model(ckpt_path, **kwargs):
|
| 6 |
+
ckpt = torch.load(ckpt_path, map_location="cpu")
|
| 7 |
+
args = ckpt["opt"]
|
| 8 |
+
if len(kwargs) > 0: # used to overwrite default args
|
| 9 |
+
args.update(kwargs)
|
| 10 |
+
transformer = build_transformer(args)
|
| 11 |
+
position_embedding, txt_position_embedding = build_position_encoding(args)
|
| 12 |
+
|
| 13 |
+
model = MomentDETR(
|
| 14 |
+
transformer,
|
| 15 |
+
position_embedding,
|
| 16 |
+
txt_position_embedding,
|
| 17 |
+
txt_dim=args.t_feat_dim,
|
| 18 |
+
vid_dim=args.v_feat_dim,
|
| 19 |
+
num_queries=args.num_queries,
|
| 20 |
+
input_dropout=args.input_dropout,
|
| 21 |
+
aux_loss=args.aux_loss,
|
| 22 |
+
contrastive_align_loss=args.contrastive_align_loss,
|
| 23 |
+
contrastive_hdim=args.contrastive_hdim,
|
| 24 |
+
span_loss_type=args.span_loss_type,
|
| 25 |
+
use_txt_pos=args.use_txt_pos,
|
| 26 |
+
n_input_proj=args.n_input_proj,
|
| 27 |
+
)
|
| 28 |
+
|
| 29 |
+
model.load_state_dict(ckpt["model"])
|
| 30 |
+
return model
|
| 31 |
+
|
| 32 |
+
|
run_on_video/moment_detr_ckpt/README.md
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
To simplify feature extraction pipeline,
|
| 2 |
+
this model checkpoint [model_best.ckpt](model_best.ckpt) is trained with only CLIP image and text features as input.
|
| 3 |
+
It is trained from scratch, without ASR pre-training.
|
| 4 |
+
It may perform worse than the model reported in the paper.
|
| 5 |
+
|
| 6 |
+
In addition to the model checkpoint, this directory also
|
| 7 |
+
contains multiple files from its training process,
|
| 8 |
+
including the training/evaluation log files,
|
| 9 |
+
training configurations and prediction files on QVHighlights val split.
|
run_on_video/moment_detr_ckpt/eval.log.txt
ADDED
|
@@ -0,0 +1,40 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
2021_08_04_12_48_21 [Epoch] 004 [Loss] loss_span 1.9722 loss_giou 1.2180 loss_label 0.6783 class_error -0.0000 loss_saliency 0.3492 loss_span_0 1.6771 loss_giou_0 1.2267 loss_label_0 0.6398 class_error_0 -0.0000 loss_overall 7.7613 [Metrics] {"brief": {"[email protected]": 7.55, "[email protected]": 2.58, "MR-full-mAP": 2.7, "[email protected]": 6.47, "[email protected]": 1.99, "MR-long-mAP": 1.24, "MR-middle-mAP": 4.41, "MR-short-mAP": 0.63, "HL-min-Fair-mAP": 42.14, "HL-min-Fair-Hit1": 35.29, "HL-min-Good-mAP": 35.75, "HL-min-Good-Hit1": 34.19, "HL-min-VeryGood-mAP": 21.99, "HL-min-VeryGood-Hit1": 28.71}, "HL-min-Fair": {"HL-mAP": 42.14, "HL-Hit1": 35.29}, "HL-min-Good": {"HL-mAP": 35.75, "HL-Hit1": 34.19}, "HL-min-VeryGood": {"HL-mAP": 21.99, "HL-Hit1": 28.71}, "full": {"MR-mAP": {"0.5": 6.47, "0.55": 5.22, "0.6": 4.38, "0.65": 3.34, "0.7": 2.69, "0.75": 1.99, "0.8": 1.31, "0.85": 0.97, "0.9": 0.4, "0.95": 0.25, "average": 2.7}, "MR-R1": {"0.5": 7.55, "0.55": 6.06, "0.6": 4.84, "0.65": 3.48, "0.7": 2.58, "0.75": 1.87, "0.8": 1.16, "0.85": 0.84, "0.9": 0.32, "0.95": 0.26}}, "long": {"MR-mAP": {"0.5": 4.26, "0.55": 3.1, "0.6": 1.92, "0.65": 1.18, "0.7": 0.7, "0.75": 0.49, "0.8": 0.44, "0.85": 0.19, "0.9": 0.09, "0.95": 0.02, "average": 1.24}, "MR-R1": {"0.5": 3.48, "0.55": 2.61, "0.6": 1.39, "0.65": 0.7, "0.7": 0.17, "0.75": 0.17, "0.8": 0.17, "0.85": 0.0, "0.9": 0.0, "0.95": 0.0}}, "middle": {"MR-mAP": {"0.5": 9.87, "0.55": 8.16, "0.6": 7.28, "0.65": 5.71, "0.7": 4.71, "0.75": 3.43, "0.8": 2.11, "0.85": 1.69, "0.9": 0.67, "0.95": 0.44, "average": 4.41}, "MR-R1": {"0.5": 9.09, "0.55": 7.42, "0.6": 6.58, "0.65": 4.81, "0.7": 3.76, "0.75": 2.72, "0.8": 1.57, "0.85": 1.25, "0.9": 0.42, "0.95": 0.31}}, "short": {"MR-mAP": {"0.5": 1.31, "0.55": 1.08, "0.6": 0.81, "0.65": 0.7, "0.7": 0.61, "0.75": 0.54, "0.8": 0.54, "0.85": 0.23, "0.9": 0.23, "0.95": 0.23, "average": 0.63}, "MR-R1": {"0.5": 2.33, "0.55": 1.86, "0.6": 0.93, "0.65": 0.93, "0.7": 0.7, "0.75": 0.47, "0.8": 0.47, "0.85": 0.23, "0.9": 0.23, "0.95": 0.23}}}
|
| 2 |
+
2021_08_04_12_53_39 [Epoch] 009 [Loss] loss_span 0.6697 loss_giou 0.6066 loss_label 0.5144 class_error 7.8618 loss_saliency 0.3228 loss_span_0 0.6657 loss_giou_0 0.6339 loss_label_0 0.5316 class_error_0 12.6456 loss_overall 3.9447 [Metrics] {"brief": {"[email protected]": 13.94, "[email protected]": 4.26, "MR-full-mAP": 10.44, "[email protected]": 24.95, "[email protected]": 7.38, "MR-long-mAP": 15.34, "MR-middle-mAP": 9.86, "MR-short-mAP": 0.77, "HL-min-Fair-mAP": 43.41, "HL-min-Fair-Hit1": 35.55, "HL-min-Good-mAP": 36.85, "HL-min-Good-Hit1": 34.52, "HL-min-VeryGood-mAP": 22.74, "HL-min-VeryGood-Hit1": 28.84}, "HL-min-Fair": {"HL-mAP": 43.41, "HL-Hit1": 35.55}, "HL-min-Good": {"HL-mAP": 36.85, "HL-Hit1": 34.52}, "HL-min-VeryGood": {"HL-mAP": 22.74, "HL-Hit1": 28.84}, "full": {"MR-mAP": {"0.5": 24.95, "0.55": 20.02, "0.6": 16.46, "0.65": 12.17, "0.7": 9.75, "0.75": 7.38, "0.8": 5.45, "0.85": 3.65, "0.9": 2.68, "0.95": 1.93, "average": 10.44}, "MR-R1": {"0.5": 13.94, "0.55": 10.71, "0.6": 8.52, "0.65": 5.74, "0.7": 4.26, "0.75": 3.16, "0.8": 2.39, "0.85": 1.81, "0.9": 1.29, "0.95": 0.97}}, "long": {"MR-mAP": {"0.5": 35.7, "0.55": 29.14, "0.6": 23.71, "0.65": 17.74, "0.7": 13.43, "0.75": 10.15, "0.8": 8.23, "0.85": 6.45, "0.9": 4.84, "0.95": 4.01, "average": 15.34}, "MR-R1": {"0.5": 19.69, "0.55": 15.33, "0.6": 12.37, "0.65": 8.54, "0.7": 5.92, "0.75": 4.36, "0.8": 3.83, "0.85": 3.14, "0.9": 2.44, "0.95": 2.09}}, "middle": {"MR-mAP": {"0.5": 24.23, "0.55": 19.26, "0.6": 16.01, "0.65": 11.69, "0.7": 9.78, "0.75": 7.38, "0.8": 4.95, "0.85": 2.71, "0.9": 1.72, "0.95": 0.86, "average": 9.86}, "MR-R1": {"0.5": 10.14, "0.55": 7.63, "0.6": 6.17, "0.65": 4.08, "0.7": 3.24, "0.75": 2.51, "0.8": 1.57, "0.85": 1.04, "0.9": 0.63, "0.95": 0.31}}, "short": {"MR-mAP": {"0.5": 2.91, "0.55": 1.68, "0.6": 1.12, "0.65": 0.67, "0.7": 0.43, "0.75": 0.25, "0.8": 0.19, "0.85": 0.16, "0.9": 0.16, "0.95": 0.16, "average": 0.77}, "MR-R1": {"0.5": 1.4, "0.55": 1.17, "0.6": 0.47, "0.65": 0.23, "0.7": 0.23, "0.75": 0.0, "0.8": 0.0, "0.85": 0.0, "0.9": 0.0, "0.95": 0.0}}}
|
| 3 |
+
2021_08_04_12_59_02 [Epoch] 014 [Loss] loss_span 0.6164 loss_giou 0.5899 loss_label 0.5207 class_error 5.3474 loss_saliency 0.3045 loss_span_0 0.6267 loss_giou_0 0.5896 loss_label_0 0.5234 class_error_0 5.5158 loss_overall 3.7711 [Metrics] {"brief": {"[email protected]": 15.48, "[email protected]": 7.03, "MR-full-mAP": 11.47, "[email protected]": 25.56, "[email protected]": 8.37, "MR-long-mAP": 19.17, "MR-middle-mAP": 8.97, "MR-short-mAP": 1.14, "HL-min-Fair-mAP": 46.74, "HL-min-Fair-Hit1": 39.74, "HL-min-Good-mAP": 39.87, "HL-min-Good-Hit1": 38.45, "HL-min-VeryGood-mAP": 24.59, "HL-min-VeryGood-Hit1": 32.39}, "HL-min-Fair": {"HL-mAP": 46.74, "HL-Hit1": 39.74}, "HL-min-Good": {"HL-mAP": 39.87, "HL-Hit1": 38.45}, "HL-min-VeryGood": {"HL-mAP": 24.59, "HL-Hit1": 32.39}, "full": {"MR-mAP": {"0.5": 25.56, "0.55": 20.5, "0.6": 17.27, "0.65": 13.65, "0.7": 11.01, "0.75": 8.37, "0.8": 6.61, "0.85": 4.97, "0.9": 3.79, "0.95": 3.02, "average": 11.47}, "MR-R1": {"0.5": 15.48, "0.55": 12.71, "0.6": 10.65, "0.65": 8.39, "0.7": 7.03, "0.75": 5.55, "0.8": 4.45, "0.85": 3.55, "0.9": 2.84, "0.95": 2.39}}, "long": {"MR-mAP": {"0.5": 38.88, "0.55": 33.28, "0.6": 27.52, "0.65": 21.65, "0.7": 18.33, "0.75": 14.91, "0.8": 11.92, "0.85": 9.9, "0.9": 8.07, "0.95": 7.2, "average": 19.17}, "MR-R1": {"0.5": 24.91, "0.55": 21.78, "0.6": 18.29, "0.65": 15.16, "0.7": 13.59, "0.75": 11.32, "0.8": 9.23, "0.85": 7.84, "0.9": 6.62, "0.95": 6.1}}, "middle": {"MR-mAP": {"0.5": 22.46, "0.55": 17.08, "0.6": 14.76, "0.65": 11.55, "0.7": 8.84, "0.75": 5.97, "0.8": 4.34, "0.85": 2.55, "0.9": 1.6, "0.95": 0.59, "average": 8.97}, "MR-R1": {"0.5": 8.78, "0.55": 6.48, "0.6": 5.64, "0.65": 4.18, "0.7": 3.03, "0.75": 2.09, "0.8": 1.57, "0.85": 0.94, "0.9": 0.52, "0.95": 0.1}}, "short": {"MR-mAP": {"0.5": 3.8, "0.55": 2.34, "0.6": 1.66, "0.65": 1.18, "0.7": 0.83, "0.75": 0.59, "0.8": 0.42, "0.85": 0.18, "0.9": 0.18, "0.95": 0.18, "average": 1.14}, "MR-R1": {"0.5": 3.03, "0.55": 2.33, "0.6": 1.4, "0.65": 0.7, "0.7": 0.47, "0.75": 0.23, "0.8": 0.23, "0.85": 0.23, "0.9": 0.23, "0.95": 0.23}}}
|
| 4 |
+
2021_08_04_13_04_23 [Epoch] 019 [Loss] loss_span 0.6010 loss_giou 0.5839 loss_label 0.5096 class_error 5.2251 loss_saliency 0.2961 loss_span_0 0.6149 loss_giou_0 0.6061 loss_label_0 0.5012 class_error_0 6.0110 loss_overall 3.7127 [Metrics] {"brief": {"[email protected]": 19.42, "[email protected]": 9.42, "MR-full-mAP": 13.46, "[email protected]": 29.34, "[email protected]": 10.61, "MR-long-mAP": 21.95, "MR-middle-mAP": 10.91, "MR-short-mAP": 1.16, "HL-min-Fair-mAP": 48.98, "HL-min-Fair-Hit1": 40.58, "HL-min-Good-mAP": 41.64, "HL-min-Good-Hit1": 39.42, "HL-min-VeryGood-mAP": 25.49, "HL-min-VeryGood-Hit1": 32.52}, "HL-min-Fair": {"HL-mAP": 48.98, "HL-Hit1": 40.58}, "HL-min-Good": {"HL-mAP": 41.64, "HL-Hit1": 39.42}, "HL-min-VeryGood": {"HL-mAP": 25.49, "HL-Hit1": 32.52}, "full": {"MR-mAP": {"0.5": 29.34, "0.55": 23.78, "0.6": 20.06, "0.65": 16.02, "0.7": 13.38, "0.75": 10.61, "0.8": 7.91, "0.85": 5.78, "0.9": 4.43, "0.95": 3.27, "average": 13.46}, "MR-R1": {"0.5": 19.42, "0.55": 15.81, "0.6": 13.55, "0.65": 11.1, "0.7": 9.42, "0.75": 7.55, "0.8": 5.74, "0.85": 4.52, "0.9": 3.61, "0.95": 2.84}}, "long": {"MR-mAP": {"0.5": 43.84, "0.55": 36.86, "0.6": 30.39, "0.65": 24.64, "0.7": 21.83, "0.75": 17.61, "0.8": 14.09, "0.85": 12.45, "0.9": 9.62, "0.95": 8.15, "average": 21.95}, "MR-R1": {"0.5": 30.84, "0.55": 26.48, "0.6": 22.65, "0.65": 19.34, "0.7": 17.77, "0.75": 14.63, "0.8": 12.02, "0.85": 10.98, "0.9": 8.89, "0.95": 7.67}}, "middle": {"MR-mAP": {"0.5": 26.2, "0.55": 20.52, "0.6": 18.11, "0.65": 14.27, "0.7": 11.02, "0.75": 8.45, "0.8": 5.58, "0.85": 2.63, "0.9": 1.87, "0.95": 0.45, "average": 10.91}, "MR-R1": {"0.5": 11.39, "0.55": 8.67, "0.6": 7.73, "0.65": 6.06, "0.7": 4.39, "0.75": 3.34, "0.8": 1.99, "0.85": 0.73, "0.9": 0.52, "0.95": 0.0}}, "short": {"MR-mAP": {"0.5": 4.1, "0.55": 2.49, "0.6": 1.64, "0.65": 1.01, "0.7": 0.67, "0.75": 0.62, "0.8": 0.5, "0.85": 0.18, "0.9": 0.18, "0.95": 0.18, "average": 1.16}, "MR-R1": {"0.5": 3.5, "0.55": 2.33, "0.6": 1.4, "0.65": 0.7, "0.7": 0.47, "0.75": 0.23, "0.8": 0.23, "0.85": 0.0, "0.9": 0.0, "0.95": 0.0}}}
|
| 5 |
+
2021_08_04_13_09_44 [Epoch] 024 [Loss] loss_span 0.5764 loss_giou 0.5700 loss_label 0.5057 class_error 10.9184 loss_saliency 0.2787 loss_span_0 0.6011 loss_giou_0 0.5872 loss_label_0 0.4939 class_error_0 9.9908 loss_overall 3.6131 [Metrics] {"brief": {"[email protected]": 28.39, "[email protected]": 12.52, "MR-full-mAP": 16.73, "[email protected]": 36.28, "[email protected]": 13.75, "MR-long-mAP": 24.64, "MR-middle-mAP": 15.5, "MR-short-mAP": 1.21, "HL-min-Fair-mAP": 52.92, "HL-min-Fair-Hit1": 45.48, "HL-min-Good-mAP": 44.97, "HL-min-Good-Hit1": 44.39, "HL-min-VeryGood-mAP": 27.55, "HL-min-VeryGood-Hit1": 37.81}, "HL-min-Fair": {"HL-mAP": 52.92, "HL-Hit1": 45.48}, "HL-min-Good": {"HL-mAP": 44.97, "HL-Hit1": 44.39}, "HL-min-VeryGood": {"HL-mAP": 27.55, "HL-Hit1": 37.81}, "full": {"MR-mAP": {"0.5": 36.28, "0.55": 29.23, "0.6": 25.13, "0.65": 20.19, "0.7": 16.34, "0.75": 13.75, "0.8": 10.27, "0.85": 7.28, "0.9": 5.41, "0.95": 3.39, "average": 16.73}, "MR-R1": {"0.5": 28.39, "0.55": 22.58, "0.6": 19.23, "0.65": 15.42, "0.7": 12.52, "0.75": 10.77, "0.8": 7.94, "0.85": 5.94, "0.9": 4.39, "0.95": 2.97}}, "long": {"MR-mAP": {"0.5": 50.63, "0.55": 42.09, "0.6": 36.69, "0.65": 29.97, "0.7": 23.21, "0.75": 19.48, "0.8": 14.99, "0.85": 11.99, "0.9": 9.51, "0.95": 7.86, "average": 24.64}, "MR-R1": {"0.5": 38.33, "0.55": 31.18, "0.6": 26.83, "0.65": 21.95, "0.7": 17.77, "0.75": 15.51, "0.8": 12.02, "0.85": 9.76, "0.9": 8.36, "0.95": 7.32}}, "middle": {"MR-mAP": {"0.5": 34.92, "0.55": 27.96, "0.6": 24.17, "0.65": 19.19, "0.7": 16.04, "0.75": 13.23, "0.8": 9.28, "0.85": 5.77, "0.9": 3.56, "0.95": 0.89, "average": 15.5}, "MR-R1": {"0.5": 21.0, "0.55": 16.93, "0.6": 14.73, "0.65": 11.6, "0.7": 9.61, "0.75": 8.15, "0.8": 5.64, "0.85": 3.76, "0.9": 2.09, "0.95": 0.42}}, "short": {"MR-mAP": {"0.5": 4.84, "0.55": 2.64, "0.6": 1.44, "0.65": 1.07, "0.7": 0.61, "0.75": 0.46, "0.8": 0.35, "0.85": 0.24, "0.9": 0.24, "0.95": 0.24, "average": 1.21}, "MR-R1": {"0.5": 4.43, "0.55": 2.1, "0.6": 0.7, "0.65": 0.47, "0.7": 0.0, "0.75": 0.0, "0.8": 0.0, "0.85": 0.0, "0.9": 0.0, "0.95": 0.0}}}
|
| 6 |
+
2021_08_04_13_15_06 [Epoch] 029 [Loss] loss_span 0.5769 loss_giou 0.5428 loss_label 0.4959 class_error 9.5076 loss_saliency 0.2722 loss_span_0 0.5945 loss_giou_0 0.5571 loss_label_0 0.4819 class_error_0 9.3947 loss_overall 3.5213 [Metrics] {"brief": {"[email protected]": 34.71, "[email protected]": 17.35, "MR-full-mAP": 21.46, "[email protected]": 43.15, "[email protected]": 18.03, "MR-long-mAP": 32.91, "MR-middle-mAP": 18.88, "MR-short-mAP": 1.31, "HL-min-Fair-mAP": 57.62, "HL-min-Fair-Hit1": 53.03, "HL-min-Good-mAP": 48.91, "HL-min-Good-Hit1": 51.42, "HL-min-VeryGood-mAP": 29.9, "HL-min-VeryGood-Hit1": 42.9}, "HL-min-Fair": {"HL-mAP": 57.62, "HL-Hit1": 53.03}, "HL-min-Good": {"HL-mAP": 48.91, "HL-Hit1": 51.42}, "HL-min-VeryGood": {"HL-mAP": 29.9, "HL-Hit1": 42.9}, "full": {"MR-mAP": {"0.5": 43.15, "0.55": 37.13, "0.6": 32.22, "0.65": 26.36, "0.7": 22.56, "0.75": 18.03, "0.8": 13.93, "0.85": 10.34, "0.9": 6.92, "0.95": 3.9, "average": 21.46}, "MR-R1": {"0.5": 34.71, "0.55": 29.94, "0.6": 25.35, "0.65": 20.0, "0.7": 17.35, "0.75": 14.06, "0.8": 10.71, "0.85": 8.0, "0.9": 5.29, "0.95": 3.35}}, "long": {"MR-mAP": {"0.5": 59.94, "0.55": 55.13, "0.6": 47.52, "0.65": 41.28, "0.7": 34.96, "0.75": 28.71, "0.8": 22.22, "0.85": 18.48, "0.9": 12.54, "0.95": 8.34, "average": 32.91}, "MR-R1": {"0.5": 46.86, "0.55": 42.33, "0.6": 35.89, "0.65": 30.66, "0.7": 26.48, "0.75": 21.95, "0.8": 16.72, "0.85": 14.29, "0.9": 9.93, "0.95": 7.67}}, "middle": {"MR-mAP": {"0.5": 41.59, "0.55": 34.3, "0.6": 30.21, "0.65": 22.93, "0.7": 19.53, "0.75": 15.13, "0.8": 11.64, "0.85": 7.28, "0.9": 4.58, "0.95": 1.62, "average": 18.88}, "MR-R1": {"0.5": 26.12, "0.55": 21.73, "0.6": 19.02, "0.65": 13.79, "0.7": 12.02, "0.75": 9.51, "0.8": 7.21, "0.85": 4.39, "0.9": 2.61, "0.95": 0.84}}, "short": {"MR-mAP": {"0.5": 5.12, "0.55": 2.72, "0.6": 1.8, "0.65": 0.99, "0.7": 0.75, "0.75": 0.49, "0.8": 0.43, "0.85": 0.25, "0.9": 0.25, "0.95": 0.25, "average": 1.31}, "MR-R1": {"0.5": 4.43, "0.55": 3.03, "0.6": 1.17, "0.65": 0.47, "0.7": 0.47, "0.75": 0.23, "0.8": 0.23, "0.85": 0.0, "0.9": 0.0, "0.95": 0.0}}}
|
| 7 |
+
2021_08_04_13_20_24 [Epoch] 034 [Loss] loss_span 0.5500 loss_giou 0.5458 loss_label 0.5259 class_error 15.6010 loss_saliency 0.2497 loss_span_0 0.5689 loss_giou_0 0.5526 loss_label_0 0.4940 class_error_0 15.0615 loss_overall 3.4868 [Metrics] {"brief": {"[email protected]": 38.71, "[email protected]": 20.19, "MR-full-mAP": 23.14, "[email protected]": 46.38, "[email protected]": 20.3, "MR-long-mAP": 33.91, "MR-middle-mAP": 21.61, "MR-short-mAP": 1.17, "HL-min-Fair-mAP": 60.76, "HL-min-Fair-Hit1": 56.06, "HL-min-Good-mAP": 51.64, "HL-min-Good-Hit1": 54.65, "HL-min-VeryGood-mAP": 31.67, "HL-min-VeryGood-Hit1": 45.68}, "HL-min-Fair": {"HL-mAP": 60.76, "HL-Hit1": 56.06}, "HL-min-Good": {"HL-mAP": 51.64, "HL-Hit1": 54.65}, "HL-min-VeryGood": {"HL-mAP": 31.67, "HL-Hit1": 45.68}, "full": {"MR-mAP": {"0.5": 46.38, "0.55": 39.64, "0.6": 34.86, "0.65": 29.5, "0.7": 24.99, "0.75": 20.3, "0.8": 15.51, "0.85": 10.11, "0.9": 6.72, "0.95": 3.36, "average": 23.14}, "MR-R1": {"0.5": 38.71, "0.55": 32.84, "0.6": 28.77, "0.65": 24.32, "0.7": 20.19, "0.75": 16.13, "0.8": 12.32, "0.85": 8.06, "0.9": 5.35, "0.95": 2.77}}, "long": {"MR-mAP": {"0.5": 61.73, "0.55": 55.1, "0.6": 49.35, "0.65": 42.75, "0.7": 36.23, "0.75": 30.36, "0.8": 24.92, "0.85": 18.36, "0.9": 12.45, "0.95": 7.83, "average": 33.91}, "MR-R1": {"0.5": 50.17, "0.55": 43.55, "0.6": 38.68, "0.65": 33.1, "0.7": 27.87, "0.75": 23.0, "0.8": 19.34, "0.85": 14.29, "0.9": 9.76, "0.95": 6.45}}, "middle": {"MR-mAP": {"0.5": 47.01, "0.55": 39.41, "0.6": 34.4, "0.65": 28.21, "0.7": 23.7, "0.75": 18.4, "0.8": 13.1, "0.85": 7.02, "0.9": 4.06, "0.95": 0.83, "average": 21.61}, "MR-R1": {"0.5": 31.03, "0.55": 26.12, "0.6": 22.88, "0.65": 19.33, "0.7": 15.88, "0.75": 12.23, "0.8": 8.25, "0.85": 4.49, "0.9": 2.82, "0.95": 0.63}}, "short": {"MR-mAP": {"0.5": 4.7, "0.55": 2.32, "0.6": 1.54, "0.65": 0.84, "0.7": 0.67, "0.75": 0.57, "0.8": 0.46, "0.85": 0.2, "0.9": 0.2, "0.95": 0.2, "average": 1.17}, "MR-R1": {"0.5": 3.5, "0.55": 2.1, "0.6": 1.17, "0.65": 0.47, "0.7": 0.23, "0.75": 0.23, "0.8": 0.23, "0.85": 0.0, "0.9": 0.0, "0.95": 0.0}}}
|
| 8 |
+
2021_08_04_13_25_46 [Epoch] 039 [Loss] loss_span 0.5464 loss_giou 0.5469 loss_label 0.4978 class_error 12.7535 loss_saliency 0.2423 loss_span_0 0.5721 loss_giou_0 0.5566 loss_label_0 0.5010 class_error_0 13.8361 loss_overall 3.4631 [Metrics] {"brief": {"[email protected]": 40.65, "[email protected]": 22.52, "MR-full-mAP": 24.83, "[email protected]": 46.9, "[email protected]": 22.06, "MR-long-mAP": 37.22, "MR-middle-mAP": 22.19, "MR-short-mAP": 1.63, "HL-min-Fair-mAP": 62.7, "HL-min-Fair-Hit1": 60.58, "HL-min-Good-mAP": 53.32, "HL-min-Good-Hit1": 58.97, "HL-min-VeryGood-mAP": 32.74, "HL-min-VeryGood-Hit1": 48.77}, "HL-min-Fair": {"HL-mAP": 62.7, "HL-Hit1": 60.58}, "HL-min-Good": {"HL-mAP": 53.32, "HL-Hit1": 58.97}, "HL-min-VeryGood": {"HL-mAP": 32.74, "HL-Hit1": 48.77}, "full": {"MR-mAP": {"0.5": 46.9, "0.55": 41.04, "0.6": 36.28, "0.65": 30.93, "0.7": 26.67, "0.75": 22.06, "0.8": 17.06, "0.85": 12.7, "0.9": 8.95, "0.95": 5.68, "average": 24.83}, "MR-R1": {"0.5": 40.65, "0.55": 35.03, "0.6": 30.45, "0.65": 26.13, "0.7": 22.52, "0.75": 18.58, "0.8": 14.39, "0.85": 10.9, "0.9": 7.94, "0.95": 5.16}}, "long": {"MR-mAP": {"0.5": 63.2, "0.55": 58.41, "0.6": 52.96, "0.65": 47.95, "0.7": 41.11, "0.75": 34.41, "0.8": 27.6, "0.85": 21.27, "0.9": 14.78, "0.95": 10.49, "average": 37.22}, "MR-R1": {"0.5": 51.57, "0.55": 47.39, "0.6": 42.86, "0.65": 38.68, "0.7": 32.93, "0.75": 27.35, "0.8": 21.95, "0.85": 17.07, "0.9": 12.37, "0.95": 9.23}}, "middle": {"MR-mAP": {"0.5": 46.31, "0.55": 38.96, "0.6": 33.67, "0.65": 27.37, "0.7": 23.16, "0.75": 18.74, "0.8": 13.75, "0.85": 9.73, "0.9": 6.9, "0.95": 3.32, "average": 22.19}, "MR-R1": {"0.5": 33.23, "0.55": 27.27, "0.6": 23.3, "0.65": 19.02, "0.7": 16.61, "0.75": 13.69, "0.8": 10.14, "0.85": 7.42, "0.9": 5.43, "0.95": 2.82}}, "short": {"MR-mAP": {"0.5": 5.23, "0.55": 3.69, "0.6": 2.55, "0.65": 1.46, "0.7": 1.04, "0.75": 0.95, "0.8": 0.61, "0.85": 0.25, "0.9": 0.25, "0.95": 0.25, "average": 1.63}, "MR-R1": {"0.5": 3.73, "0.55": 2.33, "0.6": 0.7, "0.65": 0.23, "0.7": 0.23, "0.75": 0.0, "0.8": 0.0, "0.85": 0.0, "0.9": 0.0, "0.95": 0.0}}}
|
| 9 |
+
2021_08_04_13_31_05 [Epoch] 044 [Loss] loss_span 0.5647 loss_giou 0.5367 loss_label 0.5061 class_error 14.7438 loss_saliency 0.2398 loss_span_0 0.5806 loss_giou_0 0.5614 loss_label_0 0.5083 class_error_0 16.3073 loss_overall 3.4976 [Metrics] {"brief": {"[email protected]": 43.48, "[email protected]": 24.06, "MR-full-mAP": 25.53, "[email protected]": 49.58, "[email protected]": 21.68, "MR-long-mAP": 35.35, "MR-middle-mAP": 24.45, "MR-short-mAP": 1.65, "HL-min-Fair-mAP": 63.15, "HL-min-Fair-Hit1": 60.26, "HL-min-Good-mAP": 53.71, "HL-min-Good-Hit1": 58.84, "HL-min-VeryGood-mAP": 32.99, "HL-min-VeryGood-Hit1": 49.03}, "HL-min-Fair": {"HL-mAP": 63.15, "HL-Hit1": 60.26}, "HL-min-Good": {"HL-mAP": 53.71, "HL-Hit1": 58.84}, "HL-min-VeryGood": {"HL-mAP": 32.99, "HL-Hit1": 49.03}, "full": {"MR-mAP": {"0.5": 49.58, "0.55": 43.18, "0.6": 38.95, "0.65": 32.61, "0.7": 28.07, "0.75": 21.68, "0.8": 16.68, "0.85": 11.53, "0.9": 8.27, "0.95": 4.72, "average": 25.53}, "MR-R1": {"0.5": 43.48, "0.55": 36.9, "0.6": 32.84, "0.65": 27.61, "0.7": 24.06, "0.75": 18.52, "0.8": 14.32, "0.85": 9.87, "0.9": 6.97, "0.95": 4.19}}, "long": {"MR-mAP": {"0.5": 63.33, "0.55": 56.54, "0.6": 52.01, "0.65": 44.34, "0.7": 38.03, "0.75": 31.65, "0.8": 26.43, "0.85": 18.44, "0.9": 13.75, "0.95": 9.0, "average": 35.35}, "MR-R1": {"0.5": 52.26, "0.55": 45.12, "0.6": 40.77, "0.65": 34.32, "0.7": 29.79, "0.75": 24.56, "0.8": 20.38, "0.85": 14.29, "0.9": 10.45, "0.95": 7.49}}, "middle": {"MR-mAP": {"0.5": 50.76, "0.55": 43.46, "0.6": 38.67, "0.65": 31.76, "0.7": 27.51, "0.75": 20.02, "0.8": 13.95, "0.85": 9.52, "0.9": 6.21, "0.95": 2.59, "average": 24.45}, "MR-R1": {"0.5": 36.89, "0.55": 31.87, "0.6": 28.42, "0.65": 23.93, "0.7": 21.11, "0.75": 15.26, "0.8": 10.97, "0.85": 7.42, "0.9": 5.02, "0.95": 2.3}}, "short": {"MR-mAP": {"0.5": 5.53, "0.55": 3.53, "0.6": 2.55, "0.65": 1.72, "0.7": 1.03, "0.75": 0.82, "0.8": 0.62, "0.85": 0.24, "0.9": 0.24, "0.95": 0.24, "average": 1.65}, "MR-R1": {"0.5": 4.9, "0.55": 1.86, "0.6": 0.7, "0.65": 0.47, "0.7": 0.0, "0.75": 0.0, "0.8": 0.0, "0.85": 0.0, "0.9": 0.0, "0.95": 0.0}}}
|
| 10 |
+
2021_08_04_13_36_26 [Epoch] 049 [Loss] loss_span 0.5534 loss_giou 0.5409 loss_label 0.4937 class_error 13.0729 loss_saliency 0.2346 loss_span_0 0.5726 loss_giou_0 0.5634 loss_label_0 0.4787 class_error_0 13.1292 loss_overall 3.4374 [Metrics] {"brief": {"[email protected]": 42.45, "[email protected]": 24.32, "MR-full-mAP": 25.29, "[email protected]": 48.7, "[email protected]": 22.59, "MR-long-mAP": 35.09, "MR-middle-mAP": 24.3, "MR-short-mAP": 1.87, "HL-min-Fair-mAP": 64.45, "HL-min-Fair-Hit1": 62.71, "HL-min-Good-mAP": 54.93, "HL-min-Good-Hit1": 61.68, "HL-min-VeryGood-mAP": 33.54, "HL-min-VeryGood-Hit1": 51.29}, "HL-min-Fair": {"HL-mAP": 64.45, "HL-Hit1": 62.71}, "HL-min-Good": {"HL-mAP": 54.93, "HL-Hit1": 61.68}, "HL-min-VeryGood": {"HL-mAP": 33.54, "HL-Hit1": 51.29}, "full": {"MR-mAP": {"0.5": 48.7, "0.55": 43.06, "0.6": 38.63, "0.65": 32.31, "0.7": 27.6, "0.75": 22.59, "0.8": 16.69, "0.85": 11.54, "0.9": 7.34, "0.95": 4.43, "average": 25.29}, "MR-R1": {"0.5": 42.45, "0.55": 37.35, "0.6": 33.48, "0.65": 28.13, "0.7": 24.32, "0.75": 19.94, "0.8": 14.77, "0.85": 9.87, "0.9": 6.39, "0.95": 3.94}}, "long": {"MR-mAP": {"0.5": 59.88, "0.55": 55.93, "0.6": 50.09, "0.65": 44.76, "0.7": 38.97, "0.75": 33.17, "0.8": 26.82, "0.85": 19.73, "0.9": 12.89, "0.95": 8.67, "average": 35.09}, "MR-R1": {"0.5": 50.35, "0.55": 46.69, "0.6": 41.64, "0.65": 36.93, "0.7": 32.58, "0.75": 28.05, "0.8": 22.65, "0.85": 16.38, "0.9": 10.45, "0.95": 7.84}}, "middle": {"MR-mAP": {"0.5": 50.85, "0.55": 44.02, "0.6": 39.62, "0.65": 31.68, "0.7": 26.59, "0.75": 20.67, "0.8": 13.47, "0.85": 8.64, "0.9": 5.29, "0.95": 2.19, "average": 24.3}, "MR-R1": {"0.5": 36.99, "0.55": 31.87, "0.6": 28.74, "0.65": 23.3, "0.7": 19.75, "0.75": 15.36, "0.8": 10.24, "0.85": 6.06, "0.9": 3.97, "0.95": 1.57}}, "short": {"MR-mAP": {"0.5": 6.46, "0.55": 3.71, "0.6": 3.05, "0.65": 1.72, "0.7": 1.2, "0.75": 0.95, "0.8": 0.67, "0.85": 0.32, "0.9": 0.32, "0.95": 0.32, "average": 1.87}, "MR-R1": {"0.5": 3.5, "0.55": 1.4, "0.6": 1.17, "0.65": 0.23, "0.7": 0.23, "0.75": 0.23, "0.8": 0.23, "0.85": 0.23, "0.9": 0.23, "0.95": 0.23}}}
|
| 11 |
+
2021_08_04_13_41_59 [Epoch] 054 [Loss] loss_span 0.5433 loss_giou 0.5406 loss_label 0.4840 class_error 11.9544 loss_saliency 0.2298 loss_span_0 0.5562 loss_giou_0 0.5440 loss_label_0 0.4892 class_error_0 12.0364 loss_overall 3.3871 [Metrics] {"brief": {"[email protected]": 45.87, "[email protected]": 25.23, "MR-full-mAP": 26.49, "[email protected]": 50.61, "[email protected]": 23.15, "MR-long-mAP": 37.05, "MR-middle-mAP": 25.23, "MR-short-mAP": 2.13, "HL-min-Fair-mAP": 65.52, "HL-min-Fair-Hit1": 64.0, "HL-min-Good-mAP": 55.91, "HL-min-Good-Hit1": 62.65, "HL-min-VeryGood-mAP": 34.11, "HL-min-VeryGood-Hit1": 52.45}, "HL-min-Fair": {"HL-mAP": 65.52, "HL-Hit1": 64.0}, "HL-min-Good": {"HL-mAP": 55.91, "HL-Hit1": 62.65}, "HL-min-VeryGood": {"HL-mAP": 34.11, "HL-Hit1": 52.45}, "full": {"MR-mAP": {"0.5": 50.61, "0.55": 44.16, "0.6": 40.11, "0.65": 33.33, "0.7": 28.55, "0.75": 23.15, "0.8": 17.93, "0.85": 13.15, "0.9": 8.78, "0.95": 5.15, "average": 26.49}, "MR-R1": {"0.5": 45.87, "0.55": 39.81, "0.6": 35.74, "0.65": 29.61, "0.7": 25.23, "0.75": 20.32, "0.8": 15.68, "0.85": 11.48, "0.9": 7.61, "0.95": 4.26}}, "long": {"MR-mAP": {"0.5": 63.41, "0.55": 59.01, "0.6": 53.24, "0.65": 47.36, "0.7": 40.59, "0.75": 34.09, "0.8": 26.99, "0.85": 20.92, "0.9": 14.56, "0.95": 10.3, "average": 37.05}, "MR-R1": {"0.5": 53.31, "0.55": 49.65, "0.6": 43.9, "0.65": 38.5, "0.7": 32.93, "0.75": 27.53, "0.8": 21.78, "0.85": 17.07, "0.9": 11.85, "0.95": 8.54}}, "middle": {"MR-mAP": {"0.5": 52.59, "0.55": 44.29, "0.6": 40.33, "0.65": 32.12, "0.7": 27.29, "0.75": 20.99, "0.8": 15.44, "0.85": 10.49, "0.9": 6.43, "0.95": 2.35, "average": 25.23}, "MR-R1": {"0.5": 40.33, "0.55": 33.65, "0.6": 30.83, "0.65": 24.56, "0.7": 20.9, "0.75": 16.2, "0.8": 12.12, "0.85": 8.36, "0.9": 5.22, "0.95": 1.78}}, "short": {"MR-mAP": {"0.5": 6.79, "0.55": 4.2, "0.6": 3.5, "0.65": 1.93, "0.7": 1.47, "0.75": 1.39, "0.8": 1.09, "0.85": 0.3, "0.9": 0.3, "0.95": 0.3, "average": 2.13}, "MR-R1": {"0.5": 4.43, "0.55": 2.33, "0.6": 1.63, "0.65": 0.7, "0.7": 0.47, "0.75": 0.47, "0.8": 0.47, "0.85": 0.0, "0.9": 0.0, "0.95": 0.0}}}
|
| 12 |
+
2021_08_04_13_47_33 [Epoch] 059 [Loss] loss_span 0.5430 loss_giou 0.5388 loss_label 0.5116 class_error 16.8536 loss_saliency 0.2274 loss_span_0 0.5704 loss_giou_0 0.5608 loss_label_0 0.4891 class_error_0 16.3761 loss_overall 3.4411 [Metrics] {"brief": {"[email protected]": 48.06, "[email protected]": 26.97, "MR-full-mAP": 27.32, "[email protected]": 51.69, "[email protected]": 24.98, "MR-long-mAP": 38.23, "MR-middle-mAP": 25.72, "MR-short-mAP": 2.38, "HL-min-Fair-mAP": 65.76, "HL-min-Fair-Hit1": 63.61, "HL-min-Good-mAP": 56.01, "HL-min-Good-Hit1": 62.0, "HL-min-VeryGood-mAP": 33.99, "HL-min-VeryGood-Hit1": 51.68}, "HL-min-Fair": {"HL-mAP": 65.76, "HL-Hit1": 63.61}, "HL-min-Good": {"HL-mAP": 56.01, "HL-Hit1": 62.0}, "HL-min-VeryGood": {"HL-mAP": 33.99, "HL-Hit1": 51.68}, "full": {"MR-mAP": {"0.5": 51.69, "0.55": 45.48, "0.6": 40.59, "0.65": 34.79, "0.7": 29.7, "0.75": 24.98, "0.8": 19.04, "0.85": 13.31, "0.9": 8.96, "0.95": 4.63, "average": 27.32}, "MR-R1": {"0.5": 48.06, "0.55": 42.19, "0.6": 37.29, "0.65": 31.74, "0.7": 26.97, "0.75": 22.45, "0.8": 16.9, "0.85": 12.06, "0.9": 7.81, "0.95": 4.06}}, "long": {"MR-mAP": {"0.5": 63.35, "0.55": 58.88, "0.6": 53.1, "0.65": 47.27, "0.7": 42.56, "0.75": 36.88, "0.8": 30.52, "0.85": 23.76, "0.9": 16.32, "0.95": 9.63, "average": 38.23}, "MR-R1": {"0.5": 54.53, "0.55": 50.7, "0.6": 45.47, "0.65": 39.55, "0.7": 35.54, "0.75": 30.49, "0.8": 25.09, "0.85": 19.69, "0.9": 13.41, "0.95": 8.36}}, "middle": {"MR-mAP": {"0.5": 54.23, "0.55": 46.81, "0.6": 41.1, "0.65": 34.09, "0.7": 27.62, "0.75": 22.07, "0.8": 14.88, "0.85": 9.19, "0.9": 5.34, "0.95": 1.87, "average": 25.72}, "MR-R1": {"0.5": 43.47, "0.55": 37.41, "0.6": 32.81, "0.65": 27.48, "0.7": 22.15, "0.75": 17.97, "0.8": 12.23, "0.85": 7.73, "0.9": 4.6, "0.95": 1.57}}, "short": {"MR-mAP": {"0.5": 7.25, "0.55": 4.24, "0.6": 3.5, "0.65": 2.34, "0.7": 1.83, "0.75": 1.63, "0.8": 1.32, "0.85": 0.55, "0.9": 0.55, "0.95": 0.55, "average": 2.38}, "MR-R1": {"0.5": 3.73, "0.55": 1.17, "0.6": 0.7, "0.65": 0.47, "0.7": 0.47, "0.75": 0.23, "0.8": 0.23, "0.85": 0.0, "0.9": 0.0, "0.95": 0.0}}}
|
| 13 |
+
2021_08_04_13_53_06 [Epoch] 064 [Loss] loss_span 0.5574 loss_giou 0.5329 loss_label 0.5468 class_error 19.3817 loss_saliency 0.2217 loss_span_0 0.5769 loss_giou_0 0.5461 loss_label_0 0.5328 class_error_0 18.5783 loss_overall 3.5146 [Metrics] {"brief": {"[email protected]": 48.26, "[email protected]": 27.16, "MR-full-mAP": 28.75, "[email protected]": 52.71, "[email protected]": 26.08, "MR-long-mAP": 41.49, "MR-middle-mAP": 26.16, "MR-short-mAP": 2.37, "HL-min-Fair-mAP": 66.77, "HL-min-Fair-Hit1": 65.94, "HL-min-Good-mAP": 56.86, "HL-min-Good-Hit1": 64.32, "HL-min-VeryGood-mAP": 34.65, "HL-min-VeryGood-Hit1": 53.87}, "HL-min-Fair": {"HL-mAP": 66.77, "HL-Hit1": 65.94}, "HL-min-Good": {"HL-mAP": 56.86, "HL-Hit1": 64.32}, "HL-min-VeryGood": {"HL-mAP": 34.65, "HL-Hit1": 53.87}, "full": {"MR-mAP": {"0.5": 52.71, "0.55": 46.62, "0.6": 42.46, "0.65": 36.36, "0.7": 30.54, "0.75": 26.08, "0.8": 20.65, "0.85": 15.33, "0.9": 10.77, "0.95": 6.01, "average": 28.75}, "MR-R1": {"0.5": 48.26, "0.55": 42.26, "0.6": 38.06, "0.65": 32.52, "0.7": 27.16, "0.75": 23.55, "0.8": 18.45, "0.85": 13.87, "0.9": 9.87, "0.95": 5.48}}, "long": {"MR-mAP": {"0.5": 66.65, "0.55": 61.96, "0.6": 55.94, "0.65": 51.38, "0.7": 45.29, "0.75": 40.51, "0.8": 33.35, "0.85": 27.68, "0.9": 19.67, "0.95": 12.53, "average": 41.49}, "MR-R1": {"0.5": 57.32, "0.55": 52.44, "0.6": 46.34, "0.65": 42.16, "0.7": 37.11, "0.75": 33.62, "0.8": 27.7, "0.85": 23.0, "0.9": 17.07, "0.95": 10.98}}, "middle": {"MR-mAP": {"0.5": 53.68, "0.55": 46.47, "0.6": 42.41, "0.65": 34.19, "0.7": 27.44, "0.75": 22.03, "0.8": 16.01, "0.85": 10.25, "0.9": 6.62, "0.95": 2.48, "average": 26.16}, "MR-R1": {"0.5": 41.38, "0.55": 35.63, "0.6": 32.92, "0.65": 26.65, "0.7": 21.32, "0.75": 17.66, "0.8": 13.06, "0.85": 8.57, "0.9": 5.64, "0.95": 2.19}}, "short": {"MR-mAP": {"0.5": 7.72, "0.55": 4.35, "0.6": 3.59, "0.65": 2.4, "0.7": 1.56, "0.75": 1.43, "0.8": 1.15, "0.85": 0.5, "0.9": 0.5, "0.95": 0.5, "average": 2.37}, "MR-R1": {"0.5": 5.36, "0.55": 3.03, "0.6": 2.1, "0.65": 1.63, "0.7": 0.93, "0.75": 0.7, "0.8": 0.47, "0.85": 0.23, "0.9": 0.23, "0.95": 0.23}}}
|
| 14 |
+
2021_08_04_13_58_41 [Epoch] 069 [Loss] loss_span 0.5581 loss_giou 0.5321 loss_label 0.5575 class_error 19.7858 loss_saliency 0.2349 loss_span_0 0.5913 loss_giou_0 0.5443 loss_label_0 0.5379 class_error_0 19.8230 loss_overall 3.5563 [Metrics] {"brief": {"[email protected]": 49.16, "[email protected]": 28.0, "MR-full-mAP": 28.88, "[email protected]": 53.33, "[email protected]": 26.27, "MR-long-mAP": 41.96, "MR-middle-mAP": 25.97, "MR-short-mAP": 2.44, "HL-min-Fair-mAP": 66.47, "HL-min-Fair-Hit1": 63.68, "HL-min-Good-mAP": 56.62, "HL-min-Good-Hit1": 62.13, "HL-min-VeryGood-mAP": 34.43, "HL-min-VeryGood-Hit1": 52.06}, "HL-min-Fair": {"HL-mAP": 66.47, "HL-Hit1": 63.68}, "HL-min-Good": {"HL-mAP": 56.62, "HL-Hit1": 62.13}, "HL-min-VeryGood": {"HL-mAP": 34.43, "HL-Hit1": 52.06}, "full": {"MR-mAP": {"0.5": 53.33, "0.55": 46.56, "0.6": 42.38, "0.65": 35.55, "0.7": 30.84, "0.75": 26.27, "0.8": 21.49, "0.85": 15.49, "0.9": 10.67, "0.95": 6.19, "average": 28.88}, "MR-R1": {"0.5": 49.16, "0.55": 42.45, "0.6": 38.26, "0.65": 31.61, "0.7": 28.0, "0.75": 23.94, "0.8": 19.48, "0.85": 13.94, "0.9": 9.87, "0.95": 5.87}}, "long": {"MR-mAP": {"0.5": 69.35, "0.55": 62.23, "0.6": 56.68, "0.65": 50.95, "0.7": 45.9, "0.75": 40.54, "0.8": 35.03, "0.85": 26.9, "0.9": 19.41, "0.95": 12.62, "average": 41.96}, "MR-R1": {"0.5": 60.1, "0.55": 52.79, "0.6": 47.39, "0.65": 41.64, "0.7": 37.8, "0.75": 33.62, "0.8": 29.44, "0.85": 22.82, "0.9": 16.9, "0.95": 11.32}}, "middle": {"MR-mAP": {"0.5": 53.43, "0.55": 46.21, "0.6": 41.28, "0.65": 32.57, "0.7": 27.28, "0.75": 22.0, "0.8": 16.21, "0.85": 10.76, "0.9": 6.89, "0.95": 3.03, "average": 25.97}, "MR-R1": {"0.5": 41.8, "0.55": 36.15, "0.6": 32.71, "0.65": 25.71, "0.7": 22.26, "0.75": 18.39, "0.8": 13.69, "0.85": 8.78, "0.9": 5.75, "0.95": 2.61}}, "short": {"MR-mAP": {"0.5": 6.74, "0.55": 4.63, "0.6": 4.24, "0.65": 3.19, "0.7": 2.08, "0.75": 1.38, "0.8": 0.98, "0.85": 0.4, "0.9": 0.4, "0.95": 0.4, "average": 2.44}, "MR-R1": {"0.5": 3.96, "0.55": 2.1, "0.6": 1.86, "0.65": 1.17, "0.7": 0.93, "0.75": 0.47, "0.8": 0.47, "0.85": 0.23, "0.9": 0.23, "0.95": 0.23}}}
|
| 15 |
+
2021_08_04_14_04_13 [Epoch] 074 [Loss] loss_span 0.5622 loss_giou 0.5384 loss_label 0.6026 class_error 20.7191 loss_saliency 0.2317 loss_span_0 0.5782 loss_giou_0 0.5511 loss_label_0 0.6059 class_error_0 21.9726 loss_overall 3.6702 [Metrics] {"brief": {"[email protected]": 49.16, "[email protected]": 28.9, "MR-full-mAP": 29.26, "[email protected]": 52.54, "[email protected]": 27.59, "MR-long-mAP": 41.0, "MR-middle-mAP": 27.42, "MR-short-mAP": 2.34, "HL-min-Fair-mAP": 66.86, "HL-min-Fair-Hit1": 65.16, "HL-min-Good-mAP": 56.83, "HL-min-Good-Hit1": 62.84, "HL-min-VeryGood-mAP": 34.72, "HL-min-VeryGood-Hit1": 53.61}, "HL-min-Fair": {"HL-mAP": 66.86, "HL-Hit1": 65.16}, "HL-min-Good": {"HL-mAP": 56.83, "HL-Hit1": 62.84}, "HL-min-VeryGood": {"HL-mAP": 34.72, "HL-Hit1": 53.61}, "full": {"MR-mAP": {"0.5": 52.54, "0.55": 46.57, "0.6": 43.14, "0.65": 37.36, "0.7": 31.69, "0.75": 27.59, "0.8": 21.64, "0.85": 15.26, "0.9": 10.86, "0.95": 5.98, "average": 29.26}, "MR-R1": {"0.5": 49.16, "0.55": 43.55, "0.6": 40.13, "0.65": 34.45, "0.7": 28.9, "0.75": 25.48, "0.8": 19.81, "0.85": 14.06, "0.9": 10.39, "0.95": 5.68}}, "long": {"MR-mAP": {"0.5": 66.39, "0.55": 61.33, "0.6": 56.44, "0.65": 51.27, "0.7": 45.17, "0.75": 41.57, "0.8": 33.32, "0.85": 25.79, "0.9": 17.85, "0.95": 10.88, "average": 41.0}, "MR-R1": {"0.5": 58.36, "0.55": 52.96, "0.6": 48.26, "0.65": 43.73, "0.7": 38.15, "0.75": 35.89, "0.8": 28.75, "0.85": 22.3, "0.9": 15.85, "0.95": 9.76}}, "middle": {"MR-mAP": {"0.5": 53.96, "0.55": 46.69, "0.6": 43.54, "0.65": 36.08, "0.7": 29.46, "0.75": 23.78, "0.8": 17.86, "0.85": 11.23, "0.9": 8.04, "0.95": 3.56, "average": 27.42}, "MR-R1": {"0.5": 42.95, "0.55": 37.51, "0.6": 35.42, "0.65": 29.36, "0.7": 23.82, "0.75": 19.64, "0.8": 14.73, "0.85": 9.3, "0.9": 7.21, "0.95": 3.24}}, "short": {"MR-mAP": {"0.5": 6.88, "0.55": 4.69, "0.6": 3.43, "0.65": 2.22, "0.7": 1.48, "0.75": 1.44, "0.8": 1.19, "0.85": 0.69, "0.9": 0.69, "0.95": 0.69, "average": 2.34}, "MR-R1": {"0.5": 3.73, "0.55": 2.8, "0.6": 1.4, "0.65": 0.47, "0.7": 0.23, "0.75": 0.23, "0.8": 0.23, "0.85": 0.23, "0.9": 0.23, "0.95": 0.23}}}
|
| 16 |
+
2021_08_04_14_09_47 [Epoch] 079 [Loss] loss_span 0.5459 loss_giou 0.5378 loss_label 0.5861 class_error 19.2414 loss_saliency 0.2271 loss_span_0 0.5757 loss_giou_0 0.5655 loss_label_0 0.5599 class_error_0 18.7932 loss_overall 3.5981 [Metrics] {"brief": {"[email protected]": 49.42, "[email protected]": 30.39, "MR-full-mAP": 29.22, "[email protected]": 52.94, "[email protected]": 27.33, "MR-long-mAP": 40.16, "MR-middle-mAP": 27.72, "MR-short-mAP": 2.82, "HL-min-Fair-mAP": 67.74, "HL-min-Fair-Hit1": 66.13, "HL-min-Good-mAP": 57.67, "HL-min-Good-Hit1": 64.52, "HL-min-VeryGood-mAP": 35.29, "HL-min-VeryGood-Hit1": 53.48}, "HL-min-Fair": {"HL-mAP": 67.74, "HL-Hit1": 66.13}, "HL-min-Good": {"HL-mAP": 57.67, "HL-Hit1": 64.52}, "HL-min-VeryGood": {"HL-mAP": 35.29, "HL-Hit1": 53.48}, "full": {"MR-mAP": {"0.5": 52.94, "0.55": 46.63, "0.6": 42.48, "0.65": 37.13, "0.7": 32.38, "0.75": 27.33, "0.8": 21.69, "0.85": 15.65, "0.9": 10.36, "0.95": 5.65, "average": 29.22}, "MR-R1": {"0.5": 49.42, "0.55": 43.94, "0.6": 39.61, "0.65": 34.71, "0.7": 30.39, "0.75": 25.23, "0.8": 19.94, "0.85": 14.39, "0.9": 9.48, "0.95": 4.84}}, "long": {"MR-mAP": {"0.5": 65.28, "0.55": 58.61, "0.6": 54.82, "0.65": 50.37, "0.7": 45.5, "0.75": 40.17, "0.8": 34.07, "0.85": 25.04, "0.9": 17.2, "0.95": 10.56, "average": 40.16}, "MR-R1": {"0.5": 56.62, "0.55": 50.35, "0.6": 46.69, "0.65": 42.86, "0.7": 38.5, "0.75": 34.32, "0.8": 28.92, "0.85": 21.25, "0.9": 14.46, "0.95": 8.89}}, "middle": {"MR-mAP": {"0.5": 54.58, "0.55": 48.23, "0.6": 43.05, "0.65": 35.78, "0.7": 30.84, "0.75": 24.23, "0.8": 17.66, "0.85": 12.13, "0.9": 7.51, "0.95": 3.17, "average": 27.72}, "MR-R1": {"0.5": 43.47, "0.55": 39.08, "0.6": 35.01, "0.65": 29.78, "0.7": 25.6, "0.75": 19.96, "0.8": 14.84, "0.85": 10.55, "0.9": 6.69, "0.95": 2.51}}, "short": {"MR-mAP": {"0.5": 8.81, "0.55": 5.87, "0.6": 4.77, "0.65": 3.01, "0.7": 1.71, "0.75": 1.38, "0.8": 1.05, "0.85": 0.52, "0.9": 0.52, "0.95": 0.52, "average": 2.82}, "MR-R1": {"0.5": 5.83, "0.55": 4.2, "0.6": 2.56, "0.65": 1.63, "0.7": 1.17, "0.75": 0.7, "0.8": 0.23, "0.85": 0.0, "0.9": 0.0, "0.95": 0.0}}}
|
| 17 |
+
2021_08_04_14_15_17 [Epoch] 084 [Loss] loss_span 0.5492 loss_giou 0.5416 loss_label 0.5856 class_error 16.8746 loss_saliency 0.2289 loss_span_0 0.5613 loss_giou_0 0.5593 loss_label_0 0.5495 class_error_0 16.2807 loss_overall 3.5754 [Metrics] {"brief": {"[email protected]": 47.81, "[email protected]": 29.29, "MR-full-mAP": 28.83, "[email protected]": 51.42, "[email protected]": 27.1, "MR-long-mAP": 41.36, "MR-middle-mAP": 26.22, "MR-short-mAP": 2.88, "HL-min-Fair-mAP": 66.94, "HL-min-Fair-Hit1": 66.77, "HL-min-Good-mAP": 56.97, "HL-min-Good-Hit1": 64.84, "HL-min-VeryGood-mAP": 34.78, "HL-min-VeryGood-Hit1": 54.58}, "HL-min-Fair": {"HL-mAP": 66.94, "HL-Hit1": 66.77}, "HL-min-Good": {"HL-mAP": 56.97, "HL-Hit1": 64.84}, "HL-min-VeryGood": {"HL-mAP": 34.78, "HL-Hit1": 54.58}, "full": {"MR-mAP": {"0.5": 51.42, "0.55": 45.76, "0.6": 42.14, "0.65": 36.42, "0.7": 31.65, "0.75": 27.1, "0.8": 21.07, "0.85": 15.92, "0.9": 11.07, "0.95": 5.79, "average": 28.83}, "MR-R1": {"0.5": 47.81, "0.55": 42.45, "0.6": 38.9, "0.65": 33.55, "0.7": 29.29, "0.75": 25.23, "0.8": 19.55, "0.85": 14.97, "0.9": 10.39, "0.95": 5.61}}, "long": {"MR-mAP": {"0.5": 64.01, "0.55": 60.35, "0.6": 55.84, "0.65": 50.8, "0.7": 45.74, "0.75": 42.35, "0.8": 35.52, "0.85": 27.99, "0.9": 19.24, "0.95": 11.73, "average": 41.36}, "MR-R1": {"0.5": 54.7, "0.55": 51.74, "0.6": 47.74, "0.65": 43.21, "0.7": 39.2, "0.75": 36.41, "0.8": 29.97, "0.85": 24.04, "0.9": 16.9, "0.95": 10.8}}, "middle": {"MR-mAP": {"0.5": 52.42, "0.55": 45.32, "0.6": 41.45, "0.65": 34.3, "0.7": 28.72, "0.75": 22.74, "0.8": 16.0, "0.85": 11.09, "0.9": 7.45, "0.95": 2.68, "average": 26.22}, "MR-R1": {"0.5": 41.9, "0.55": 36.15, "0.6": 33.33, "0.65": 27.69, "0.7": 23.3, "0.75": 18.6, "0.8": 13.48, "0.85": 9.61, "0.9": 6.48, "0.95": 2.4}}, "short": {"MR-mAP": {"0.5": 8.45, "0.55": 5.44, "0.6": 4.44, "0.65": 3.35, "0.7": 2.2, "0.75": 1.75, "0.8": 1.2, "0.85": 0.66, "0.9": 0.66, "0.95": 0.66, "average": 2.88}, "MR-R1": {"0.5": 6.06, "0.55": 3.5, "0.6": 2.33, "0.65": 1.63, "0.7": 1.4, "0.75": 0.93, "0.8": 0.47, "0.85": 0.47, "0.9": 0.47, "0.95": 0.47}}}
|
| 18 |
+
2021_08_04_14_20_52 [Epoch] 089 [Loss] loss_span 0.5726 loss_giou 0.5424 loss_label 0.6611 class_error 23.5645 loss_saliency 0.2291 loss_span_0 0.5964 loss_giou_0 0.5513 loss_label_0 0.6122 class_error_0 22.0650 loss_overall 3.7652 [Metrics] {"brief": {"[email protected]": 50.84, "[email protected]": 29.68, "MR-full-mAP": 29.59, "[email protected]": 53.79, "[email protected]": 27.11, "MR-long-mAP": 42.74, "MR-middle-mAP": 27.16, "MR-short-mAP": 2.26, "HL-min-Fair-mAP": 67.82, "HL-min-Fair-Hit1": 67.61, "HL-min-Good-mAP": 57.76, "HL-min-Good-Hit1": 65.61, "HL-min-VeryGood-mAP": 35.41, "HL-min-VeryGood-Hit1": 54.84}, "HL-min-Fair": {"HL-mAP": 67.82, "HL-Hit1": 67.61}, "HL-min-Good": {"HL-mAP": 57.76, "HL-Hit1": 65.61}, "HL-min-VeryGood": {"HL-mAP": 35.41, "HL-Hit1": 54.84}, "full": {"MR-mAP": {"0.5": 53.79, "0.55": 47.51, "0.6": 43.51, "0.65": 37.3, "0.7": 32.04, "0.75": 27.11, "0.8": 21.67, "0.85": 16.15, "0.9": 10.69, "0.95": 6.16, "average": 29.59}, "MR-R1": {"0.5": 50.84, "0.55": 44.32, "0.6": 40.58, "0.65": 34.45, "0.7": 29.68, "0.75": 24.77, "0.8": 19.68, "0.85": 14.77, "0.9": 9.74, "0.95": 5.68}}, "long": {"MR-mAP": {"0.5": 67.61, "0.55": 61.93, "0.6": 57.26, "0.65": 52.83, "0.7": 47.75, "0.75": 43.03, "0.8": 36.25, "0.85": 28.33, "0.9": 19.22, "0.95": 13.15, "average": 42.74}, "MR-R1": {"0.5": 58.71, "0.55": 53.14, "0.6": 48.61, "0.65": 44.08, "0.7": 40.07, "0.75": 36.24, "0.8": 30.66, "0.85": 24.39, "0.9": 16.2, "0.95": 11.5}}, "middle": {"MR-mAP": {"0.5": 55.46, "0.55": 48.33, "0.6": 43.68, "0.65": 35.17, "0.7": 28.93, "0.75": 22.34, "0.8": 16.27, "0.85": 11.35, "0.9": 7.26, "0.95": 2.78, "average": 27.16}, "MR-R1": {"0.5": 45.04, "0.55": 38.98, "0.6": 35.95, "0.65": 29.05, "0.7": 23.82, "0.75": 18.29, "0.8": 13.38, "0.85": 9.3, "0.9": 6.06, "0.95": 2.3}}, "short": {"MR-mAP": {"0.5": 7.07, "0.55": 4.35, "0.6": 3.48, "0.65": 2.42, "0.7": 1.54, "0.75": 1.38, "0.8": 1.11, "0.85": 0.43, "0.9": 0.43, "0.95": 0.43, "average": 2.26}, "MR-R1": {"0.5": 4.66, "0.55": 2.1, "0.6": 1.4, "0.65": 0.7, "0.7": 0.47, "0.75": 0.23, "0.8": 0.23, "0.85": 0.0, "0.9": 0.0, "0.95": 0.0}}}
|
| 19 |
+
2021_08_04_14_26_29 [Epoch] 094 [Loss] loss_span 0.5609 loss_giou 0.5546 loss_label 0.5836 class_error 17.2686 loss_saliency 0.2343 loss_span_0 0.5799 loss_giou_0 0.5608 loss_label_0 0.5801 class_error_0 18.4508 loss_overall 3.6543 [Metrics] {"brief": {"[email protected]": 50.45, "[email protected]": 30.06, "MR-full-mAP": 28.74, "[email protected]": 53.0, "[email protected]": 26.66, "MR-long-mAP": 38.36, "MR-middle-mAP": 28.03, "MR-short-mAP": 3.38, "HL-min-Fair-mAP": 67.6, "HL-min-Fair-Hit1": 67.23, "HL-min-Good-mAP": 57.27, "HL-min-Good-Hit1": 65.48, "HL-min-VeryGood-mAP": 34.98, "HL-min-VeryGood-Hit1": 54.58}, "HL-min-Fair": {"HL-mAP": 67.6, "HL-Hit1": 67.23}, "HL-min-Good": {"HL-mAP": 57.27, "HL-Hit1": 65.48}, "HL-min-VeryGood": {"HL-mAP": 34.98, "HL-Hit1": 54.58}, "full": {"MR-mAP": {"0.5": 53.0, "0.55": 47.25, "0.6": 42.93, "0.65": 37.05, "0.7": 31.54, "0.75": 26.66, "0.8": 20.36, "0.85": 14.16, "0.9": 9.5, "0.95": 4.9, "average": 28.74}, "MR-R1": {"0.5": 50.45, "0.55": 44.77, "0.6": 40.19, "0.65": 34.9, "0.7": 30.06, "0.75": 25.48, "0.8": 19.55, "0.85": 13.81, "0.9": 9.16, "0.95": 4.65}}, "long": {"MR-mAP": {"0.5": 63.16, "0.55": 57.53, "0.6": 52.39, "0.65": 48.3, "0.7": 44.15, "0.75": 38.74, "0.8": 30.97, "0.85": 23.56, "0.9": 16.6, "0.95": 8.24, "average": 38.36}, "MR-R1": {"0.5": 55.57, "0.55": 50.52, "0.6": 45.82, "0.65": 41.99, "0.7": 38.68, "0.75": 34.15, "0.8": 27.0, "0.85": 20.56, "0.9": 14.46, "0.95": 7.14}}, "middle": {"MR-mAP": {"0.5": 56.5, "0.55": 49.77, "0.6": 44.8, "0.65": 37.29, "0.7": 29.93, "0.75": 23.85, "0.8": 17.16, "0.85": 10.99, "0.9": 6.65, "0.95": 3.39, "average": 28.03}, "MR-R1": {"0.5": 46.08, "0.55": 40.86, "0.6": 36.68, "0.65": 30.62, "0.7": 24.97, "0.75": 20.48, "0.8": 15.26, "0.85": 10.03, "0.9": 6.17, "0.95": 3.24}}, "short": {"MR-mAP": {"0.5": 8.93, "0.55": 6.42, "0.6": 5.85, "0.65": 4.19, "0.7": 2.81, "0.75": 2.29, "0.8": 1.72, "0.85": 0.51, "0.9": 0.51, "0.95": 0.51, "average": 3.38}, "MR-R1": {"0.5": 5.13, "0.55": 3.03, "0.6": 2.1, "0.65": 1.63, "0.7": 1.17, "0.75": 0.7, "0.8": 0.47, "0.85": 0.0, "0.9": 0.0, "0.95": 0.0}}}
|
| 20 |
+
2021_08_04_14_32_00 [Epoch] 099 [Loss] loss_span 0.5694 loss_giou 0.5547 loss_label 0.6673 class_error 21.9861 loss_saliency 0.2260 loss_span_0 0.5956 loss_giou_0 0.5550 loss_label_0 0.6565 class_error_0 22.3623 loss_overall 3.8245 [Metrics] {"brief": {"[email protected]": 49.42, "[email protected]": 29.16, "MR-full-mAP": 28.99, "[email protected]": 52.85, "[email protected]": 26.89, "MR-long-mAP": 40.3, "MR-middle-mAP": 27.31, "MR-short-mAP": 2.86, "HL-min-Fair-mAP": 67.11, "HL-min-Fair-Hit1": 66.52, "HL-min-Good-mAP": 57.23, "HL-min-Good-Hit1": 64.32, "HL-min-VeryGood-mAP": 34.93, "HL-min-VeryGood-Hit1": 53.87}, "HL-min-Fair": {"HL-mAP": 67.11, "HL-Hit1": 66.52}, "HL-min-Good": {"HL-mAP": 57.23, "HL-Hit1": 64.32}, "HL-min-VeryGood": {"HL-mAP": 34.93, "HL-Hit1": 53.87}, "full": {"MR-mAP": {"0.5": 52.85, "0.55": 46.48, "0.6": 42.15, "0.65": 36.33, "0.7": 31.69, "0.75": 26.89, "0.8": 21.67, "0.85": 15.86, "0.9": 10.75, "0.95": 5.24, "average": 28.99}, "MR-R1": {"0.5": 49.42, "0.55": 43.48, "0.6": 38.97, "0.65": 33.29, "0.7": 29.16, "0.75": 24.97, "0.8": 20.45, "0.85": 14.9, "0.9": 10.0, "0.95": 4.52}}, "long": {"MR-mAP": {"0.5": 64.98, "0.55": 59.2, "0.6": 53.84, "0.65": 48.97, "0.7": 44.88, "0.75": 39.8, "0.8": 34.15, "0.85": 27.19, "0.9": 19.26, "0.95": 10.7, "average": 40.3}, "MR-R1": {"0.5": 56.62, "0.55": 50.52, "0.6": 45.47, "0.65": 41.11, "0.7": 37.46, "0.75": 33.28, "0.8": 29.09, "0.85": 23.34, "0.9": 16.2, "0.95": 8.71}}, "middle": {"MR-mAP": {"0.5": 54.92, "0.55": 47.92, "0.6": 42.92, "0.65": 35.42, "0.7": 29.71, "0.75": 23.96, "0.8": 17.68, "0.85": 11.33, "0.9": 6.98, "0.95": 2.29, "average": 27.31}, "MR-R1": {"0.5": 44.51, "0.55": 38.77, "0.6": 34.69, "0.65": 28.63, "0.7": 24.24, "0.75": 19.96, "0.8": 15.15, "0.85": 10.03, "0.9": 6.37, "0.95": 1.99}}, "short": {"MR-mAP": {"0.5": 7.78, "0.55": 5.06, "0.6": 4.72, "0.65": 3.23, "0.7": 2.51, "0.75": 2.31, "0.8": 1.79, "0.85": 0.39, "0.9": 0.39, "0.95": 0.39, "average": 2.86}, "MR-R1": {"0.5": 3.5, "0.55": 3.03, "0.6": 2.56, "0.65": 1.4, "0.7": 1.17, "0.75": 1.17, "0.8": 1.17, "0.85": 0.23, "0.9": 0.23, "0.95": 0.23}}}
|
| 21 |
+
2021_08_04_14_37_35 [Epoch] 104 [Loss] loss_span 0.5610 loss_giou 0.5396 loss_label 0.6858 class_error 21.1351 loss_saliency 0.2364 loss_span_0 0.5720 loss_giou_0 0.5504 loss_label_0 0.6311 class_error_0 19.8577 loss_overall 3.7763 [Metrics] {"brief": {"[email protected]": 51.23, "[email protected]": 31.16, "MR-full-mAP": 30.13, "[email protected]": 53.68, "[email protected]": 28.35, "MR-long-mAP": 39.74, "MR-middle-mAP": 29.72, "MR-short-mAP": 3.1, "HL-min-Fair-mAP": 67.88, "HL-min-Fair-Hit1": 68.13, "HL-min-Good-mAP": 57.76, "HL-min-Good-Hit1": 66.32, "HL-min-VeryGood-mAP": 35.18, "HL-min-VeryGood-Hit1": 54.9}, "HL-min-Fair": {"HL-mAP": 67.88, "HL-Hit1": 68.13}, "HL-min-Good": {"HL-mAP": 57.76, "HL-Hit1": 66.32}, "HL-min-VeryGood": {"HL-mAP": 35.18, "HL-Hit1": 54.9}, "full": {"MR-mAP": {"0.5": 53.68, "0.55": 48.03, "0.6": 43.69, "0.65": 37.51, "0.7": 33.27, "0.75": 28.35, "0.8": 22.95, "0.85": 16.27, "0.9": 11.39, "0.95": 6.13, "average": 30.13}, "MR-R1": {"0.5": 51.23, "0.55": 45.55, "0.6": 41.16, "0.65": 35.1, "0.7": 31.16, "0.75": 26.84, "0.8": 21.68, "0.85": 15.16, "0.9": 10.65, "0.95": 5.81}}, "long": {"MR-mAP": {"0.5": 62.52, "0.55": 58.34, "0.6": 53.23, "0.65": 48.57, "0.7": 44.68, "0.75": 40.41, "0.8": 35.05, "0.85": 25.9, "0.9": 18.0, "0.95": 10.65, "average": 39.74}, "MR-R1": {"0.5": 54.36, "0.55": 50.35, "0.6": 45.47, "0.65": 40.94, "0.7": 37.63, "0.75": 34.49, "0.8": 29.79, "0.85": 22.13, "0.9": 15.16, "0.95": 9.58}}, "middle": {"MR-mAP": {"0.5": 57.76, "0.55": 50.73, "0.6": 45.72, "0.65": 37.95, "0.7": 33.05, "0.75": 26.34, "0.8": 19.75, "0.85": 13.02, "0.9": 8.96, "0.95": 3.94, "average": 29.72}, "MR-R1": {"0.5": 48.07, "0.55": 42.11, "0.6": 38.24, "0.65": 31.56, "0.7": 27.59, "0.75": 22.57, "0.8": 17.24, "0.85": 11.29, "0.9": 8.15, "0.95": 3.66}}, "short": {"MR-mAP": {"0.5": 9.08, "0.55": 5.9, "0.6": 5.1, "0.65": 3.53, "0.7": 2.21, "0.75": 2.05, "0.8": 1.44, "0.85": 0.57, "0.9": 0.57, "0.95": 0.57, "average": 3.1}, "MR-R1": {"0.5": 5.13, "0.55": 3.26, "0.6": 2.56, "0.65": 1.63, "0.7": 0.7, "0.75": 0.47, "0.8": 0.0, "0.85": 0.0, "0.9": 0.0, "0.95": 0.0}}}
|
| 22 |
+
2021_08_04_14_43_06 [Epoch] 109 [Loss] loss_span 0.5730 loss_giou 0.5507 loss_label 0.7272 class_error 22.4184 loss_saliency 0.2332 loss_span_0 0.5875 loss_giou_0 0.5529 loss_label_0 0.6475 class_error_0 21.0924 loss_overall 3.8719 [Metrics] {"brief": {"[email protected]": 51.68, "[email protected]": 32.06, "MR-full-mAP": 29.79, "[email protected]": 53.58, "[email protected]": 27.59, "MR-long-mAP": 41.61, "MR-middle-mAP": 27.97, "MR-short-mAP": 3.16, "HL-min-Fair-mAP": 67.6, "HL-min-Fair-Hit1": 67.68, "HL-min-Good-mAP": 57.46, "HL-min-Good-Hit1": 65.81, "HL-min-VeryGood-mAP": 35.35, "HL-min-VeryGood-Hit1": 55.55}, "HL-min-Fair": {"HL-mAP": 67.6, "HL-Hit1": 67.68}, "HL-min-Good": {"HL-mAP": 57.46, "HL-Hit1": 65.81}, "HL-min-VeryGood": {"HL-mAP": 35.35, "HL-Hit1": 55.55}, "full": {"MR-mAP": {"0.5": 53.58, "0.55": 47.74, "0.6": 43.33, "0.65": 37.71, "0.7": 32.71, "0.75": 27.59, "0.8": 22.51, "0.85": 16.44, "0.9": 10.95, "0.95": 5.33, "average": 29.79}, "MR-R1": {"0.5": 51.68, "0.55": 46.26, "0.6": 42.0, "0.65": 36.77, "0.7": 32.06, "0.75": 27.03, "0.8": 22.32, "0.85": 16.19, "0.9": 10.84, "0.95": 5.03}}, "long": {"MR-mAP": {"0.5": 64.6, "0.55": 60.13, "0.6": 55.71, "0.65": 50.59, "0.7": 46.77, "0.75": 41.33, "0.8": 36.5, "0.85": 28.73, "0.9": 20.78, "0.95": 11.01, "average": 41.61}, "MR-R1": {"0.5": 57.67, "0.55": 53.48, "0.6": 49.13, "0.65": 44.08, "0.7": 41.11, "0.75": 36.41, "0.8": 32.4, "0.85": 25.61, "0.9": 18.47, "0.95": 9.76}}, "middle": {"MR-mAP": {"0.5": 56.31, "0.55": 48.82, "0.6": 43.19, "0.65": 36.77, "0.7": 30.27, "0.75": 24.35, "0.8": 18.11, "0.85": 12.24, "0.9": 7.04, "0.95": 2.56, "average": 27.97}, "MR-R1": {"0.5": 46.71, "0.55": 41.07, "0.6": 37.1, "0.65": 32.08, "0.7": 26.54, "0.75": 21.53, "0.8": 16.41, "0.85": 10.87, "0.9": 6.48, "0.95": 2.3}}, "short": {"MR-mAP": {"0.5": 8.77, "0.55": 6.01, "0.6": 5.24, "0.65": 3.93, "0.7": 2.65, "0.75": 2.13, "0.8": 1.41, "0.85": 0.47, "0.9": 0.47, "0.95": 0.47, "average": 3.16}, "MR-R1": {"0.5": 5.36, "0.55": 3.96, "0.6": 3.26, "0.65": 2.33, "0.7": 1.63, "0.75": 0.93, "0.8": 0.7, "0.85": 0.0, "0.9": 0.0, "0.95": 0.0}}}
|
| 23 |
+
2021_08_04_14_48_29 [Epoch] 114 [Loss] loss_span 0.5579 loss_giou 0.5424 loss_label 0.6750 class_error 21.2955 loss_saliency 0.2273 loss_span_0 0.5762 loss_giou_0 0.5481 loss_label_0 0.6629 class_error_0 20.3352 loss_overall 3.7899 [Metrics] {"brief": {"[email protected]": 51.42, "[email protected]": 32.39, "MR-full-mAP": 30.29, "[email protected]": 53.62, "[email protected]": 28.51, "MR-long-mAP": 41.37, "MR-middle-mAP": 29.19, "MR-short-mAP": 2.93, "HL-min-Fair-mAP": 67.61, "HL-min-Fair-Hit1": 67.81, "HL-min-Good-mAP": 57.41, "HL-min-Good-Hit1": 66.26, "HL-min-VeryGood-mAP": 35.17, "HL-min-VeryGood-Hit1": 55.55}, "HL-min-Fair": {"HL-mAP": 67.61, "HL-Hit1": 67.81}, "HL-min-Good": {"HL-mAP": 57.41, "HL-Hit1": 66.26}, "HL-min-VeryGood": {"HL-mAP": 35.17, "HL-Hit1": 55.55}, "full": {"MR-mAP": {"0.5": 53.62, "0.55": 47.83, "0.6": 44.03, "0.65": 38.59, "0.7": 33.87, "0.75": 28.51, "0.8": 23.13, "0.85": 16.71, "0.9": 11.13, "0.95": 5.51, "average": 30.29}, "MR-R1": {"0.5": 51.42, "0.55": 45.87, "0.6": 42.13, "0.65": 36.77, "0.7": 32.39, "0.75": 27.55, "0.8": 22.9, "0.85": 16.45, "0.9": 10.65, "0.95": 4.9}}, "long": {"MR-mAP": {"0.5": 64.33, "0.55": 59.24, "0.6": 55.21, "0.65": 50.89, "0.7": 46.84, "0.75": 42.03, "0.8": 36.36, "0.85": 28.51, "0.9": 19.73, "0.95": 10.55, "average": 41.37}, "MR-R1": {"0.5": 56.97, "0.55": 52.44, "0.6": 48.61, "0.65": 44.43, "0.7": 41.11, "0.75": 36.93, "0.8": 32.4, "0.85": 25.26, "0.9": 17.42, "0.95": 9.23}}, "middle": {"MR-mAP": {"0.5": 56.9, "0.55": 50.27, "0.6": 45.98, "0.65": 38.44, "0.7": 32.61, "0.75": 25.69, "0.8": 19.24, "0.85": 12.51, "0.9": 7.53, "0.95": 2.7, "average": 29.19}, "MR-R1": {"0.5": 46.81, "0.55": 41.38, "0.6": 38.14, "0.65": 32.5, "0.7": 27.59, "0.75": 22.26, "0.8": 17.55, "0.85": 11.39, "0.9": 6.69, "0.95": 2.3}}, "short": {"MR-mAP": {"0.5": 8.43, "0.55": 5.29, "0.6": 4.3, "0.65": 3.14, "0.7": 2.03, "0.75": 1.98, "0.8": 1.55, "0.85": 0.87, "0.9": 0.87, "0.95": 0.87, "average": 2.93}, "MR-R1": {"0.5": 5.13, "0.55": 3.26, "0.6": 2.1, "0.65": 0.93, "0.7": 0.47, "0.75": 0.47, "0.8": 0.23, "0.85": 0.23, "0.9": 0.23, "0.95": 0.23}}}
|
| 24 |
+
2021_08_04_14_53_58 [Epoch] 119 [Loss] loss_span 0.5592 loss_giou 0.5568 loss_label 0.7342 class_error 22.2560 loss_saliency 0.2334 loss_span_0 0.5724 loss_giou_0 0.5574 loss_label_0 0.6654 class_error_0 21.0825 loss_overall 3.8787 [Metrics] {"brief": {"[email protected]": 51.23, "[email protected]": 31.68, "MR-full-mAP": 29.93, "[email protected]": 53.57, "[email protected]": 28.58, "MR-long-mAP": 39.57, "MR-middle-mAP": 29.24, "MR-short-mAP": 2.99, "HL-min-Fair-mAP": 67.82, "HL-min-Fair-Hit1": 68.06, "HL-min-Good-mAP": 57.73, "HL-min-Good-Hit1": 65.94, "HL-min-VeryGood-mAP": 35.14, "HL-min-VeryGood-Hit1": 55.23}, "HL-min-Fair": {"HL-mAP": 67.82, "HL-Hit1": 68.06}, "HL-min-Good": {"HL-mAP": 57.73, "HL-Hit1": 65.94}, "HL-min-VeryGood": {"HL-mAP": 35.14, "HL-Hit1": 55.23}, "full": {"MR-mAP": {"0.5": 53.57, "0.55": 47.94, "0.6": 43.88, "0.65": 37.95, "0.7": 33.19, "0.75": 28.58, "0.8": 21.79, "0.85": 15.72, "0.9": 10.95, "0.95": 5.73, "average": 29.93}, "MR-R1": {"0.5": 51.23, "0.55": 45.87, "0.6": 41.87, "0.65": 35.81, "0.7": 31.68, "0.75": 27.35, "0.8": 20.97, "0.85": 14.97, "0.9": 10.52, "0.95": 5.42}}, "long": {"MR-mAP": {"0.5": 63.52, "0.55": 57.97, "0.6": 54.17, "0.65": 48.91, "0.7": 43.78, "0.75": 39.88, "0.8": 32.89, "0.85": 25.2, "0.9": 18.32, "0.95": 11.02, "average": 39.57}, "MR-R1": {"0.5": 55.92, "0.55": 50.17, "0.6": 46.34, "0.65": 41.11, "0.7": 37.11, "0.75": 34.32, "0.8": 28.22, "0.85": 20.91, "0.9": 15.68, "0.95": 9.76}}, "middle": {"MR-mAP": {"0.5": 56.41, "0.55": 50.61, "0.6": 45.6, "0.65": 38.12, "0.7": 32.68, "0.75": 26.7, "0.8": 18.67, "0.85": 12.78, "0.9": 7.98, "0.95": 2.89, "average": 29.24}, "MR-R1": {"0.5": 47.02, "0.55": 42.63, "0.6": 38.87, "0.65": 32.71, "0.7": 28.63, "0.75": 23.51, "0.8": 16.82, "0.85": 11.49, "0.9": 7.42, "0.95": 2.72}}, "short": {"MR-mAP": {"0.5": 9.07, "0.55": 5.52, "0.6": 4.46, "0.65": 3.16, "0.7": 2.15, "0.75": 1.94, "0.8": 1.5, "0.85": 0.69, "0.9": 0.69, "0.95": 0.69, "average": 2.99}, "MR-R1": {"0.5": 5.36, "0.55": 3.5, "0.6": 2.56, "0.65": 1.4, "0.7": 0.93, "0.75": 0.47, "0.8": 0.47, "0.85": 0.47, "0.9": 0.47, "0.95": 0.47}}}
|
| 25 |
+
2021_08_04_14_59_23 [Epoch] 124 [Loss] loss_span 0.5859 loss_giou 0.5526 loss_label 0.8002 class_error 23.7492 loss_saliency 0.2241 loss_span_0 0.6056 loss_giou_0 0.5505 loss_label_0 0.7723 class_error_0 25.1843 loss_overall 4.0912 [Metrics] {"brief": {"[email protected]": 51.74, "[email protected]": 31.81, "MR-full-mAP": 30.23, "[email protected]": 54.02, "[email protected]": 28.68, "MR-long-mAP": 41.6, "MR-middle-mAP": 28.78, "MR-short-mAP": 2.73, "HL-min-Fair-mAP": 68.29, "HL-min-Fair-Hit1": 68.97, "HL-min-Good-mAP": 57.96, "HL-min-Good-Hit1": 67.16, "HL-min-VeryGood-mAP": 35.64, "HL-min-VeryGood-Hit1": 56.84}, "HL-min-Fair": {"HL-mAP": 68.29, "HL-Hit1": 68.97}, "HL-min-Good": {"HL-mAP": 57.96, "HL-Hit1": 67.16}, "HL-min-VeryGood": {"HL-mAP": 35.64, "HL-Hit1": 56.84}, "full": {"MR-mAP": {"0.5": 54.02, "0.55": 48.19, "0.6": 44.42, "0.65": 38.6, "0.7": 33.02, "0.75": 28.68, "0.8": 22.15, "0.85": 16.47, "0.9": 11.04, "0.95": 5.68, "average": 30.23}, "MR-R1": {"0.5": 51.74, "0.55": 46.26, "0.6": 42.39, "0.65": 36.77, "0.7": 31.81, "0.75": 27.55, "0.8": 21.1, "0.85": 15.68, "0.9": 10.39, "0.95": 5.1}}, "long": {"MR-mAP": {"0.5": 64.45, "0.55": 59.74, "0.6": 55.94, "0.65": 51.29, "0.7": 46.95, "0.75": 42.56, "0.8": 36.27, "0.85": 28.91, "0.9": 19.46, "0.95": 10.39, "average": 41.6}, "MR-R1": {"0.5": 56.45, "0.55": 52.09, "0.6": 48.61, "0.65": 43.9, "0.7": 40.07, "0.75": 36.41, "0.8": 31.18, "0.85": 25.26, "0.9": 16.9, "0.95": 8.89}}, "middle": {"MR-mAP": {"0.5": 57.22, "0.55": 50.21, "0.6": 45.76, "0.65": 38.33, "0.7": 31.08, "0.75": 25.57, "0.8": 17.37, "0.85": 11.66, "0.9": 7.42, "0.95": 3.17, "average": 28.78}, "MR-R1": {"0.5": 47.44, "0.55": 41.69, "0.6": 38.04, "0.65": 31.87, "0.7": 26.44, "0.75": 22.15, "0.8": 15.15, "0.85": 10.24, "0.9": 6.69, "0.95": 2.93}}, "short": {"MR-mAP": {"0.5": 8.15, "0.55": 5.5, "0.6": 4.59, "0.65": 3.3, "0.7": 2.08, "0.75": 1.64, "0.8": 1.05, "0.85": 0.32, "0.9": 0.32, "0.95": 0.32, "average": 2.73}, "MR-R1": {"0.5": 5.59, "0.55": 4.43, "0.6": 3.26, "0.65": 3.03, "0.7": 2.33, "0.75": 1.4, "0.8": 0.7, "0.85": 0.0, "0.9": 0.0, "0.95": 0.0}}}
|
| 26 |
+
2021_08_04_15_04_47 [Epoch] 129 [Loss] loss_span 0.5800 loss_giou 0.5514 loss_label 0.8848 class_error 24.3366 loss_saliency 0.2315 loss_span_0 0.6031 loss_giou_0 0.5608 loss_label_0 0.8139 class_error_0 24.3083 loss_overall 4.2256 [Metrics] {"brief": {"[email protected]": 50.39, "[email protected]": 30.32, "MR-full-mAP": 29.31, "[email protected]": 53.22, "[email protected]": 27.37, "MR-long-mAP": 40.2, "MR-middle-mAP": 27.65, "MR-short-mAP": 3.15, "HL-min-Fair-mAP": 68.27, "HL-min-Fair-Hit1": 69.23, "HL-min-Good-mAP": 57.89, "HL-min-Good-Hit1": 67.23, "HL-min-VeryGood-mAP": 35.57, "HL-min-VeryGood-Hit1": 56.26}, "HL-min-Fair": {"HL-mAP": 68.27, "HL-Hit1": 69.23}, "HL-min-Good": {"HL-mAP": 57.89, "HL-Hit1": 67.23}, "HL-min-VeryGood": {"HL-mAP": 35.57, "HL-Hit1": 56.26}, "full": {"MR-mAP": {"0.5": 53.22, "0.55": 47.79, "0.6": 43.28, "0.65": 37.52, "0.7": 32.21, "0.75": 27.37, "0.8": 21.42, "0.85": 15.11, "0.9": 9.58, "0.95": 5.6, "average": 29.31}, "MR-R1": {"0.5": 50.39, "0.55": 45.35, "0.6": 40.84, "0.65": 35.23, "0.7": 30.32, "0.75": 25.61, "0.8": 20.26, "0.85": 14.19, "0.9": 8.9, "0.95": 5.16}}, "long": {"MR-mAP": {"0.5": 62.91, "0.55": 59.53, "0.6": 55.11, "0.65": 51.0, "0.7": 46.06, "0.75": 41.36, "0.8": 33.88, "0.85": 25.67, "0.9": 16.13, "0.95": 10.38, "average": 40.2}, "MR-R1": {"0.5": 55.23, "0.55": 51.92, "0.6": 48.43, "0.65": 44.77, "0.7": 40.24, "0.75": 36.59, "0.8": 29.97, "0.85": 22.47, "0.9": 13.94, "0.95": 9.23}}, "middle": {"MR-mAP": {"0.5": 56.32, "0.55": 49.61, "0.6": 44.06, "0.65": 35.75, "0.7": 29.38, "0.75": 23.26, "0.8": 16.88, "0.85": 11.11, "0.9": 6.94, "0.95": 3.22, "average": 27.65}, "MR-R1": {"0.5": 46.08, "0.55": 40.75, "0.6": 36.15, "0.65": 29.47, "0.7": 24.35, "0.75": 19.02, "0.8": 14.32, "0.85": 9.4, "0.9": 5.96, "0.95": 2.72}}, "short": {"MR-mAP": {"0.5": 8.71, "0.55": 5.68, "0.6": 4.74, "0.65": 3.63, "0.7": 2.86, "0.75": 2.58, "0.8": 1.97, "0.85": 0.44, "0.9": 0.44, "0.95": 0.44, "average": 3.15}, "MR-R1": {"0.5": 5.36, "0.55": 3.5, "0.6": 2.1, "0.65": 1.63, "0.7": 1.4, "0.75": 1.17, "0.8": 1.17, "0.85": 0.23, "0.9": 0.23, "0.95": 0.23}}}
|
| 27 |
+
2021_08_04_15_10_10 [Epoch] 134 [Loss] loss_span 0.5682 loss_giou 0.5481 loss_label 0.7586 class_error 21.9846 loss_saliency 0.2314 loss_span_0 0.5841 loss_giou_0 0.5606 loss_label_0 0.7285 class_error_0 22.3826 loss_overall 3.9796 [Metrics] {"brief": {"[email protected]": 50.9, "[email protected]": 31.74, "MR-full-mAP": 30.02, "[email protected]": 53.52, "[email protected]": 28.51, "MR-long-mAP": 40.55, "MR-middle-mAP": 28.88, "MR-short-mAP": 3.09, "HL-min-Fair-mAP": 67.87, "HL-min-Fair-Hit1": 68.52, "HL-min-Good-mAP": 57.63, "HL-min-Good-Hit1": 66.32, "HL-min-VeryGood-mAP": 35.33, "HL-min-VeryGood-Hit1": 55.87}, "HL-min-Fair": {"HL-mAP": 67.87, "HL-Hit1": 68.52}, "HL-min-Good": {"HL-mAP": 57.63, "HL-Hit1": 66.32}, "HL-min-VeryGood": {"HL-mAP": 35.33, "HL-Hit1": 55.87}, "full": {"MR-mAP": {"0.5": 53.52, "0.55": 47.69, "0.6": 43.85, "0.65": 38.05, "0.7": 33.56, "0.75": 28.51, "0.8": 22.82, "0.85": 16.46, "0.9": 10.45, "0.95": 5.32, "average": 30.02}, "MR-R1": {"0.5": 50.9, "0.55": 45.29, "0.6": 41.68, "0.65": 36.0, "0.7": 31.74, "0.75": 27.03, "0.8": 22.0, "0.85": 15.74, "0.9": 10.06, "0.95": 5.03}}, "long": {"MR-mAP": {"0.5": 64.54, "0.55": 59.19, "0.6": 55.06, "0.65": 49.78, "0.7": 44.85, "0.75": 40.58, "0.8": 36.09, "0.85": 26.95, "0.9": 17.46, "0.95": 11.02, "average": 40.55}, "MR-R1": {"0.5": 56.45, "0.55": 51.05, "0.6": 47.39, "0.65": 42.51, "0.7": 38.33, "0.75": 34.84, "0.8": 31.71, "0.85": 23.52, "0.9": 14.98, "0.95": 9.93}}, "middle": {"MR-mAP": {"0.5": 56.15, "0.55": 49.63, "0.6": 44.76, "0.65": 37.94, "0.7": 32.95, "0.75": 26.12, "0.8": 18.56, "0.85": 12.81, "0.9": 7.55, "0.95": 2.35, "average": 28.88}, "MR-R1": {"0.5": 46.08, "0.55": 40.75, "0.6": 37.3, "0.65": 31.77, "0.7": 27.9, "0.75": 22.47, "0.8": 16.2, "0.85": 11.29, "0.9": 7.21, "0.95": 2.09}}, "short": {"MR-mAP": {"0.5": 8.41, "0.55": 5.82, "0.6": 5.34, "0.65": 3.77, "0.7": 2.21, "0.75": 1.98, "0.8": 1.45, "0.85": 0.62, "0.9": 0.62, "0.95": 0.62, "average": 3.09}, "MR-R1": {"0.5": 5.59, "0.55": 4.43, "0.6": 3.96, "0.65": 2.33, "0.7": 1.17, "0.75": 0.93, "0.8": 0.93, "0.85": 0.23, "0.9": 0.23, "0.95": 0.23}}}
|
| 28 |
+
2021_08_04_15_15_34 [Epoch] 139 [Loss] loss_span 0.5758 loss_giou 0.5644 loss_label 0.9191 class_error 26.4119 loss_saliency 0.2407 loss_span_0 0.5829 loss_giou_0 0.5716 loss_label_0 0.8582 class_error_0 25.5424 loss_overall 4.3128 [Metrics] {"brief": {"[email protected]": 50.0, "[email protected]": 30.39, "MR-full-mAP": 28.28, "[email protected]": 51.78, "[email protected]": 26.69, "MR-long-mAP": 38.79, "MR-middle-mAP": 27.12, "MR-short-mAP": 3.03, "HL-min-Fair-mAP": 67.84, "HL-min-Fair-Hit1": 68.13, "HL-min-Good-mAP": 57.53, "HL-min-Good-Hit1": 66.19, "HL-min-VeryGood-mAP": 35.2, "HL-min-VeryGood-Hit1": 56.19}, "HL-min-Fair": {"HL-mAP": 67.84, "HL-Hit1": 68.13}, "HL-min-Good": {"HL-mAP": 57.53, "HL-Hit1": 66.19}, "HL-min-VeryGood": {"HL-mAP": 35.2, "HL-Hit1": 56.19}, "full": {"MR-mAP": {"0.5": 51.78, "0.55": 46.07, "0.6": 40.82, "0.65": 35.49, "0.7": 30.74, "0.75": 26.69, "0.8": 20.53, "0.85": 15.42, "0.9": 9.81, "0.95": 5.41, "average": 28.28}, "MR-R1": {"0.5": 50.0, "0.55": 44.84, "0.6": 39.94, "0.65": 34.77, "0.7": 30.39, "0.75": 26.32, "0.8": 20.26, "0.85": 15.42, "0.9": 9.74, "0.95": 5.29}}, "long": {"MR-mAP": {"0.5": 63.04, "0.55": 58.65, "0.6": 53.28, "0.65": 48.27, "0.7": 43.11, "0.75": 39.2, "0.8": 32.32, "0.85": 24.19, "0.9": 15.83, "0.95": 10.0, "average": 38.79}, "MR-R1": {"0.5": 55.92, "0.55": 52.26, "0.6": 46.69, "0.65": 42.51, "0.7": 38.33, "0.75": 35.19, "0.8": 29.09, "0.85": 21.95, "0.9": 14.63, "0.95": 9.23}}, "middle": {"MR-mAP": {"0.5": 54.05, "0.55": 47.26, "0.6": 41.04, "0.65": 34.52, "0.7": 29.18, "0.75": 24.05, "0.8": 17.17, "0.85": 12.93, "0.9": 7.69, "0.95": 3.25, "average": 27.12}, "MR-R1": {"0.5": 44.83, "0.55": 39.6, "0.6": 35.11, "0.65": 29.78, "0.7": 25.29, "0.75": 21.11, "0.8": 15.15, "0.85": 11.7, "0.9": 6.9, "0.95": 2.93}}, "short": {"MR-mAP": {"0.5": 8.39, "0.55": 5.48, "0.6": 4.79, "0.65": 3.46, "0.7": 2.51, "0.75": 2.14, "0.8": 1.35, "0.85": 0.71, "0.9": 0.71, "0.95": 0.71, "average": 3.03}, "MR-R1": {"0.5": 5.83, "0.55": 3.73, "0.6": 3.5, "0.65": 2.33, "0.7": 2.1, "0.75": 0.93, "0.8": 0.47, "0.85": 0.23, "0.9": 0.23, "0.95": 0.23}}}
|
| 29 |
+
2021_08_04_15_21_06 [Epoch] 144 [Loss] loss_span 0.5701 loss_giou 0.5510 loss_label 0.8712 class_error 24.8251 loss_saliency 0.2277 loss_span_0 0.5805 loss_giou_0 0.5574 loss_label_0 0.8076 class_error_0 25.1642 loss_overall 4.1656 [Metrics] {"brief": {"[email protected]": 51.94, "[email protected]": 30.77, "MR-full-mAP": 29.27, "[email protected]": 53.35, "[email protected]": 27.11, "MR-long-mAP": 40.35, "MR-middle-mAP": 27.89, "MR-short-mAP": 3.07, "HL-min-Fair-mAP": 67.97, "HL-min-Fair-Hit1": 68.52, "HL-min-Good-mAP": 57.77, "HL-min-Good-Hit1": 66.13, "HL-min-VeryGood-mAP": 35.15, "HL-min-VeryGood-Hit1": 55.29}, "HL-min-Fair": {"HL-mAP": 67.97, "HL-Hit1": 68.52}, "HL-min-Good": {"HL-mAP": 57.77, "HL-Hit1": 66.13}, "HL-min-VeryGood": {"HL-mAP": 35.15, "HL-Hit1": 55.29}, "full": {"MR-mAP": {"0.5": 53.35, "0.55": 47.19, "0.6": 42.51, "0.65": 36.52, "0.7": 31.99, "0.75": 27.11, "0.8": 21.64, "0.85": 16.3, "0.9": 10.75, "0.95": 5.31, "average": 29.27}, "MR-R1": {"0.5": 51.94, "0.55": 46.26, "0.6": 41.42, "0.65": 34.9, "0.7": 30.77, "0.75": 26.71, "0.8": 21.23, "0.85": 15.94, "0.9": 10.71, "0.95": 5.03}}, "long": {"MR-mAP": {"0.5": 63.46, "0.55": 59.22, "0.6": 53.77, "0.65": 49.13, "0.7": 44.97, "0.75": 41.04, "0.8": 33.61, "0.85": 27.49, "0.9": 19.48, "0.95": 11.31, "average": 40.35}, "MR-R1": {"0.5": 55.92, "0.55": 52.09, "0.6": 46.69, "0.65": 42.16, "0.7": 38.85, "0.75": 36.41, "0.8": 29.62, "0.85": 24.22, "0.9": 17.42, "0.95": 10.1}}, "middle": {"MR-mAP": {"0.5": 56.63, "0.55": 48.85, "0.6": 43.58, "0.65": 35.59, "0.7": 30.1, "0.75": 23.8, "0.8": 18.3, "0.85": 12.44, "0.9": 7.47, "0.95": 2.09, "average": 27.89}, "MR-R1": {"0.5": 47.44, "0.55": 41.27, "0.6": 36.99, "0.65": 30.2, "0.7": 25.91, "0.75": 20.79, "0.8": 16.2, "0.85": 11.18, "0.9": 6.79, "0.95": 1.99}}, "short": {"MR-mAP": {"0.5": 8.71, "0.55": 5.74, "0.6": 5.12, "0.65": 3.16, "0.7": 2.22, "0.75": 2.02, "0.8": 1.3, "0.85": 0.8, "0.9": 0.8, "0.95": 0.8, "average": 3.07}, "MR-R1": {"0.5": 6.99, "0.55": 5.36, "0.6": 4.66, "0.65": 2.33, "0.7": 1.4, "0.75": 1.4, "0.8": 0.93, "0.85": 0.23, "0.9": 0.23, "0.95": 0.23}}}
|
| 30 |
+
2021_08_04_15_26_35 [Epoch] 149 [Loss] loss_span 0.5704 loss_giou 0.5610 loss_label 0.8380 class_error 23.7072 loss_saliency 0.2299 loss_span_0 0.5957 loss_giou_0 0.5653 loss_label_0 0.7653 class_error_0 22.2490 loss_overall 4.1257 [Metrics] {"brief": {"[email protected]": 51.74, "[email protected]": 31.61, "MR-full-mAP": 29.41, "[email protected]": 52.78, "[email protected]": 27.72, "MR-long-mAP": 40.99, "MR-middle-mAP": 27.8, "MR-short-mAP": 3.07, "HL-min-Fair-mAP": 67.89, "HL-min-Fair-Hit1": 67.94, "HL-min-Good-mAP": 57.74, "HL-min-Good-Hit1": 66.0, "HL-min-VeryGood-mAP": 35.45, "HL-min-VeryGood-Hit1": 56.19}, "HL-min-Fair": {"HL-mAP": 67.89, "HL-Hit1": 67.94}, "HL-min-Good": {"HL-mAP": 57.74, "HL-Hit1": 66.0}, "HL-min-VeryGood": {"HL-mAP": 35.45, "HL-Hit1": 56.19}, "full": {"MR-mAP": {"0.5": 52.78, "0.55": 46.41, "0.6": 42.18, "0.65": 36.89, "0.7": 32.44, "0.75": 27.72, "0.8": 21.82, "0.85": 16.68, "0.9": 11.21, "0.95": 5.95, "average": 29.41}, "MR-R1": {"0.5": 51.74, "0.55": 45.74, "0.6": 41.48, "0.65": 36.0, "0.7": 31.61, "0.75": 26.9, "0.8": 20.9, "0.85": 16.39, "0.9": 10.65, "0.95": 5.48}}, "long": {"MR-mAP": {"0.5": 63.41, "0.55": 58.93, "0.6": 54.77, "0.65": 49.89, "0.7": 46.34, "0.75": 41.84, "0.8": 35.36, "0.85": 28.64, "0.9": 19.26, "0.95": 11.47, "average": 40.99}, "MR-R1": {"0.5": 56.62, "0.55": 52.26, "0.6": 48.43, "0.65": 43.9, "0.7": 40.94, "0.75": 36.93, "0.8": 30.66, "0.85": 25.09, "0.9": 16.55, "0.95": 9.93}}, "middle": {"MR-mAP": {"0.5": 55.83, "0.55": 47.98, "0.6": 42.85, "0.65": 35.89, "0.7": 29.96, "0.75": 24.08, "0.8": 17.58, "0.85": 12.64, "0.9": 8.04, "0.95": 3.13, "average": 27.8}, "MR-R1": {"0.5": 47.44, "0.55": 41.17, "0.6": 36.99, "0.65": 31.24, "0.7": 26.12, "0.75": 21.0, "0.8": 15.26, "0.85": 11.29, "0.9": 7.11, "0.95": 2.72}}, "short": {"MR-mAP": {"0.5": 8.6, "0.55": 5.76, "0.6": 4.94, "0.65": 3.98, "0.7": 2.42, "0.75": 2.11, "0.8": 1.23, "0.85": 0.55, "0.9": 0.55, "0.95": 0.55, "average": 3.07}, "MR-R1": {"0.5": 5.36, "0.55": 3.5, "0.6": 2.56, "0.65": 1.63, "0.7": 1.17, "0.75": 0.93, "0.8": 0.47, "0.85": 0.47, "0.9": 0.47, "0.95": 0.47}}}
|
| 31 |
+
2021_08_04_15_32_11 [Epoch] 154 [Loss] loss_span 0.5749 loss_giou 0.5762 loss_label 0.8996 class_error 24.6712 loss_saliency 0.2324 loss_span_0 0.5934 loss_giou_0 0.5855 loss_label_0 0.8649 class_error_0 25.4092 loss_overall 4.3268 [Metrics] {"brief": {"[email protected]": 51.81, "[email protected]": 31.68, "MR-full-mAP": 28.93, "[email protected]": 52.76, "[email protected]": 26.85, "MR-long-mAP": 39.38, "MR-middle-mAP": 27.46, "MR-short-mAP": 3.22, "HL-min-Fair-mAP": 67.66, "HL-min-Fair-Hit1": 66.77, "HL-min-Good-mAP": 57.4, "HL-min-Good-Hit1": 64.58, "HL-min-VeryGood-mAP": 35.11, "HL-min-VeryGood-Hit1": 55.1}, "HL-min-Fair": {"HL-mAP": 67.66, "HL-Hit1": 66.77}, "HL-min-Good": {"HL-mAP": 57.4, "HL-Hit1": 64.58}, "HL-min-VeryGood": {"HL-mAP": 35.11, "HL-Hit1": 55.1}, "full": {"MR-mAP": {"0.5": 52.76, "0.55": 46.0, "0.6": 42.03, "0.65": 37.09, "0.7": 32.33, "0.75": 26.85, "0.8": 20.71, "0.85": 15.51, "0.9": 10.12, "0.95": 5.92, "average": 28.93}, "MR-R1": {"0.5": 51.81, "0.55": 45.68, "0.6": 41.81, "0.65": 36.45, "0.7": 31.68, "0.75": 26.06, "0.8": 20.0, "0.85": 15.1, "0.9": 10.06, "0.95": 5.74}}, "long": {"MR-mAP": {"0.5": 61.65, "0.55": 56.84, "0.6": 53.27, "0.65": 48.69, "0.7": 44.71, "0.75": 39.18, "0.8": 32.87, "0.85": 26.51, "0.9": 18.18, "0.95": 11.88, "average": 39.38}, "MR-R1": {"0.5": 55.23, "0.55": 50.7, "0.6": 47.04, "0.65": 42.86, "0.7": 39.37, "0.75": 34.15, "0.8": 28.4, "0.85": 23.0, "0.9": 16.38, "0.95": 10.8}}, "middle": {"MR-mAP": {"0.5": 55.64, "0.55": 47.79, "0.6": 42.83, "0.65": 36.58, "0.7": 30.7, "0.75": 23.88, "0.8": 16.59, "0.85": 11.27, "0.9": 6.54, "0.95": 2.77, "average": 27.46}, "MR-R1": {"0.5": 47.75, "0.55": 41.69, "0.6": 37.83, "0.65": 32.39, "0.7": 27.06, "0.75": 21.21, "0.8": 14.84, "0.85": 10.34, "0.9": 6.17, "0.95": 2.51}}, "short": {"MR-mAP": {"0.5": 9.29, "0.55": 5.43, "0.6": 4.79, "0.65": 3.41, "0.7": 2.58, "0.75": 2.38, "0.8": 1.92, "0.85": 0.79, "0.9": 0.79, "0.95": 0.79, "average": 3.22}, "MR-R1": {"0.5": 6.76, "0.55": 4.2, "0.6": 3.73, "0.65": 2.1, "0.7": 1.4, "0.75": 1.17, "0.8": 1.17, "0.85": 0.7, "0.9": 0.7, "0.95": 0.7}}}
|
| 32 |
+
2021_08_04_15_37_41 [Epoch] 159 [Loss] loss_span 0.5667 loss_giou 0.5632 loss_label 0.8335 class_error 21.8606 loss_saliency 0.2354 loss_span_0 0.5713 loss_giou_0 0.5630 loss_label_0 0.7501 class_error_0 21.8055 loss_overall 4.0832 [Metrics] {"brief": {"[email protected]": 50.65, "[email protected]": 31.03, "MR-full-mAP": 28.84, "[email protected]": 52.79, "[email protected]": 27.06, "MR-long-mAP": 39.64, "MR-middle-mAP": 27.07, "MR-short-mAP": 3.87, "HL-min-Fair-mAP": 67.55, "HL-min-Fair-Hit1": 68.26, "HL-min-Good-mAP": 57.32, "HL-min-Good-Hit1": 66.32, "HL-min-VeryGood-mAP": 35.09, "HL-min-VeryGood-Hit1": 55.55}, "HL-min-Fair": {"HL-mAP": 67.55, "HL-Hit1": 68.26}, "HL-min-Good": {"HL-mAP": 57.32, "HL-Hit1": 66.32}, "HL-min-VeryGood": {"HL-mAP": 35.09, "HL-Hit1": 55.55}, "full": {"MR-mAP": {"0.5": 52.79, "0.55": 46.67, "0.6": 42.61, "0.65": 36.85, "0.7": 31.96, "0.75": 27.06, "0.8": 20.46, "0.85": 14.63, "0.9": 9.96, "0.95": 5.45, "average": 28.84}, "MR-R1": {"0.5": 50.65, "0.55": 44.97, "0.6": 40.9, "0.65": 35.68, "0.7": 31.03, "0.75": 26.45, "0.8": 20.32, "0.85": 14.52, "0.9": 9.87, "0.95": 5.1}}, "long": {"MR-mAP": {"0.5": 63.21, "0.55": 58.99, "0.6": 53.38, "0.65": 49.18, "0.7": 44.69, "0.75": 39.69, "0.8": 33.48, "0.85": 25.43, "0.9": 18.0, "0.95": 10.36, "average": 39.64}, "MR-R1": {"0.5": 56.79, "0.55": 52.79, "0.6": 47.21, "0.65": 43.03, "0.7": 39.2, "0.75": 34.84, "0.8": 29.44, "0.85": 22.65, "0.9": 16.38, "0.95": 9.23}}, "middle": {"MR-mAP": {"0.5": 54.83, "0.55": 47.2, "0.6": 43.19, "0.65": 35.81, "0.7": 29.96, "0.75": 23.96, "0.8": 15.93, "0.85": 10.62, "0.9": 6.56, "0.95": 2.67, "average": 27.07}, "MR-R1": {"0.5": 45.77, "0.55": 39.5, "0.6": 36.36, "0.65": 30.72, "0.7": 25.81, "0.75": 21.21, "0.8": 14.63, "0.85": 9.72, "0.9": 5.96, "0.95": 2.51}}, "short": {"MR-mAP": {"0.5": 9.73, "0.55": 6.54, "0.6": 5.83, "0.65": 4.76, "0.7": 3.65, "0.75": 3.24, "0.8": 2.16, "0.85": 0.93, "0.9": 0.93, "0.95": 0.93, "average": 3.87}, "MR-R1": {"0.5": 4.9, "0.55": 3.73, "0.6": 3.5, "0.65": 2.8, "0.7": 2.1, "0.75": 1.63, "0.8": 1.4, "0.85": 0.47, "0.9": 0.47, "0.95": 0.47}}}
|
| 33 |
+
2021_08_04_15_43_01 [Epoch] 164 [Loss] loss_span 0.5712 loss_giou 0.5586 loss_label 1.0040 class_error 25.8786 loss_saliency 0.2340 loss_span_0 0.5832 loss_giou_0 0.5678 loss_label_0 0.9042 class_error_0 24.7946 loss_overall 4.4230 [Metrics] {"brief": {"[email protected]": 52.19, "[email protected]": 32.26, "MR-full-mAP": 29.86, "[email protected]": 53.75, "[email protected]": 27.79, "MR-long-mAP": 40.89, "MR-middle-mAP": 28.32, "MR-short-mAP": 3.05, "HL-min-Fair-mAP": 67.42, "HL-min-Fair-Hit1": 67.61, "HL-min-Good-mAP": 57.26, "HL-min-Good-Hit1": 65.81, "HL-min-VeryGood-mAP": 34.95, "HL-min-VeryGood-Hit1": 55.1}, "HL-min-Fair": {"HL-mAP": 67.42, "HL-Hit1": 67.61}, "HL-min-Good": {"HL-mAP": 57.26, "HL-Hit1": 65.81}, "HL-min-VeryGood": {"HL-mAP": 34.95, "HL-Hit1": 55.1}, "full": {"MR-mAP": {"0.5": 53.75, "0.55": 48.01, "0.6": 43.93, "0.65": 38.06, "0.7": 32.93, "0.75": 27.79, "0.8": 21.66, "0.85": 16.15, "0.9": 11.01, "0.95": 5.35, "average": 29.86}, "MR-R1": {"0.5": 52.19, "0.55": 47.23, "0.6": 43.35, "0.65": 37.35, "0.7": 32.26, "0.75": 27.42, "0.8": 21.16, "0.85": 16.0, "0.9": 10.9, "0.95": 4.97}}, "long": {"MR-mAP": {"0.5": 63.52, "0.55": 59.15, "0.6": 54.31, "0.65": 50.82, "0.7": 47.28, "0.75": 41.94, "0.8": 35.17, "0.85": 26.9, "0.9": 18.89, "0.95": 10.92, "average": 40.89}, "MR-R1": {"0.5": 56.62, "0.55": 52.96, "0.6": 48.61, "0.65": 45.3, "0.7": 41.99, "0.75": 37.63, "0.8": 31.18, "0.85": 24.22, "0.9": 17.42, "0.95": 10.1}}, "middle": {"MR-mAP": {"0.5": 57.17, "0.55": 49.98, "0.6": 45.29, "0.65": 36.88, "0.7": 30.1, "0.75": 24.01, "0.8": 17.12, "0.85": 12.49, "0.9": 7.89, "0.95": 2.28, "average": 28.32}, "MR-R1": {"0.5": 48.38, "0.55": 42.74, "0.6": 39.6, "0.65": 32.39, "0.7": 26.44, "0.75": 21.53, "0.8": 15.36, "0.85": 11.39, "0.9": 7.21, "0.95": 1.99}}, "short": {"MR-mAP": {"0.5": 8.33, "0.55": 6.05, "0.6": 5.58, "0.65": 3.76, "0.7": 2.42, "0.75": 1.97, "0.8": 1.15, "0.85": 0.4, "0.9": 0.4, "0.95": 0.4, "average": 3.05}, "MR-R1": {"0.5": 4.9, "0.55": 4.43, "0.6": 3.26, "0.65": 2.1, "0.7": 1.4, "0.75": 0.7, "0.8": 0.47, "0.85": 0.0, "0.9": 0.0, "0.95": 0.0}}}
|
| 34 |
+
2021_08_04_15_48_24 [Epoch] 169 [Loss] loss_span 0.5846 loss_giou 0.5582 loss_label 1.0207 class_error 24.9182 loss_saliency 0.2305 loss_span_0 0.6111 loss_giou_0 0.5561 loss_label_0 0.9035 class_error_0 25.1699 loss_overall 4.4648 [Metrics] {"brief": {"[email protected]": 53.23, "[email protected]": 34.0, "MR-full-mAP": 30.58, "[email protected]": 54.8, "[email protected]": 29.02, "MR-long-mAP": 41.27, "MR-middle-mAP": 29.42, "MR-short-mAP": 3.11, "HL-min-Fair-mAP": 68.29, "HL-min-Fair-Hit1": 68.32, "HL-min-Good-mAP": 57.93, "HL-min-Good-Hit1": 66.26, "HL-min-VeryGood-mAP": 35.51, "HL-min-VeryGood-Hit1": 55.87}, "HL-min-Fair": {"HL-mAP": 68.29, "HL-Hit1": 68.32}, "HL-min-Good": {"HL-mAP": 57.93, "HL-Hit1": 66.26}, "HL-min-VeryGood": {"HL-mAP": 35.51, "HL-Hit1": 55.87}, "full": {"MR-mAP": {"0.5": 54.8, "0.55": 48.28, "0.6": 43.8, "0.65": 38.62, "0.7": 34.39, "0.75": 29.02, "0.8": 23.3, "0.85": 16.75, "0.9": 11.04, "0.95": 5.8, "average": 30.58}, "MR-R1": {"0.5": 53.23, "0.55": 47.48, "0.6": 43.03, "0.65": 38.45, "0.7": 34.0, "0.75": 28.65, "0.8": 22.97, "0.85": 16.84, "0.9": 11.29, "0.95": 5.81}}, "long": {"MR-mAP": {"0.5": 64.99, "0.55": 59.64, "0.6": 55.6, "0.65": 51.5, "0.7": 47.39, "0.75": 42.77, "0.8": 34.76, "0.85": 27.53, "0.9": 18.31, "0.95": 10.26, "average": 41.27}, "MR-R1": {"0.5": 57.49, "0.55": 53.14, "0.6": 49.3, "0.65": 45.82, "0.7": 41.99, "0.75": 38.5, "0.8": 31.36, "0.85": 25.09, "0.9": 17.07, "0.95": 9.23}}, "middle": {"MR-mAP": {"0.5": 57.68, "0.55": 50.3, "0.6": 44.71, "0.65": 38.22, "0.7": 32.78, "0.75": 25.68, "0.8": 20.05, "0.85": 13.05, "0.9": 8.2, "0.95": 3.53, "average": 29.42}, "MR-R1": {"0.5": 48.9, "0.55": 43.16, "0.6": 38.56, "0.65": 33.54, "0.7": 29.15, "0.75": 22.88, "0.8": 18.08, "0.85": 12.02, "0.9": 7.84, "0.95": 3.66}}, "short": {"MR-mAP": {"0.5": 8.89, "0.55": 5.69, "0.6": 4.75, "0.65": 3.32, "0.7": 2.53, "0.75": 2.09, "0.8": 1.5, "0.85": 0.77, "0.9": 0.77, "0.95": 0.77, "average": 3.11}, "MR-R1": {"0.5": 6.29, "0.55": 4.2, "0.6": 3.5, "0.65": 2.8, "0.7": 1.63, "0.75": 0.93, "0.8": 0.7, "0.85": 0.47, "0.9": 0.47, "0.95": 0.47}}}
|
| 35 |
+
2021_08_04_15_53_50 [Epoch] 174 [Loss] loss_span 0.5984 loss_giou 0.5776 loss_label 1.1829 class_error 29.2745 loss_saliency 0.2393 loss_span_0 0.6046 loss_giou_0 0.5716 loss_label_0 1.0677 class_error_0 28.3503 loss_overall 4.8422 [Metrics] {"brief": {"[email protected]": 52.06, "[email protected]": 31.81, "MR-full-mAP": 29.21, "[email protected]": 53.22, "[email protected]": 26.87, "MR-long-mAP": 41.6, "MR-middle-mAP": 26.84, "MR-short-mAP": 2.88, "HL-min-Fair-mAP": 68.03, "HL-min-Fair-Hit1": 67.81, "HL-min-Good-mAP": 57.66, "HL-min-Good-Hit1": 65.61, "HL-min-VeryGood-mAP": 35.31, "HL-min-VeryGood-Hit1": 55.16}, "HL-min-Fair": {"HL-mAP": 68.03, "HL-Hit1": 67.81}, "HL-min-Good": {"HL-mAP": 57.66, "HL-Hit1": 65.61}, "HL-min-VeryGood": {"HL-mAP": 35.31, "HL-Hit1": 55.16}, "full": {"MR-mAP": {"0.5": 53.22, "0.55": 47.09, "0.6": 43.07, "0.65": 36.63, "0.7": 32.09, "0.75": 26.87, "0.8": 20.96, "0.85": 15.57, "0.9": 10.98, "0.95": 5.59, "average": 29.21}, "MR-R1": {"0.5": 52.06, "0.55": 46.65, "0.6": 42.71, "0.65": 35.94, "0.7": 31.81, "0.75": 26.71, "0.8": 20.52, "0.85": 15.1, "0.9": 10.52, "0.95": 5.35}}, "long": {"MR-mAP": {"0.5": 64.73, "0.55": 60.28, "0.6": 57.38, "0.65": 51.44, "0.7": 47.15, "0.75": 41.93, "0.8": 34.36, "0.85": 27.15, "0.9": 20.36, "0.95": 11.19, "average": 41.6}, "MR-R1": {"0.5": 57.14, "0.55": 53.48, "0.6": 51.05, "0.65": 45.47, "0.7": 42.33, "0.75": 37.98, "0.8": 30.84, "0.85": 24.22, "0.9": 17.94, "0.95": 10.28}}, "middle": {"MR-mAP": {"0.5": 55.23, "0.55": 47.78, "0.6": 42.0, "0.65": 34.74, "0.7": 29.11, "0.75": 22.76, "0.8": 16.39, "0.85": 10.93, "0.9": 6.81, "0.95": 2.66, "average": 26.84}, "MR-R1": {"0.5": 47.23, "0.55": 41.48, "0.6": 36.89, "0.65": 30.2, "0.7": 25.6, "0.75": 20.27, "0.8": 14.52, "0.85": 9.82, "0.9": 6.17, "0.95": 2.4}}, "short": {"MR-mAP": {"0.5": 8.31, "0.55": 5.34, "0.6": 4.85, "0.65": 3.17, "0.7": 2.22, "0.75": 1.76, "0.8": 1.21, "0.85": 0.65, "0.9": 0.65, "0.95": 0.65, "average": 2.88}, "MR-R1": {"0.5": 6.29, "0.55": 4.43, "0.6": 3.73, "0.65": 1.63, "0.7": 1.17, "0.75": 0.47, "0.8": 0.47, "0.85": 0.23, "0.9": 0.23, "0.95": 0.23}}}
|
| 36 |
+
2021_08_04_15_59_09 [Epoch] 179 [Loss] loss_span 0.5806 loss_giou 0.5669 loss_label 1.1008 class_error 27.1876 loss_saliency 0.2377 loss_span_0 0.5878 loss_giou_0 0.5664 loss_label_0 1.0045 class_error_0 27.6649 loss_overall 4.6447 [Metrics] {"brief": {"[email protected]": 51.48, "[email protected]": 30.97, "MR-full-mAP": 28.99, "[email protected]": 53.17, "[email protected]": 26.94, "MR-long-mAP": 39.94, "MR-middle-mAP": 27.67, "MR-short-mAP": 3.0, "HL-min-Fair-mAP": 68.15, "HL-min-Fair-Hit1": 68.52, "HL-min-Good-mAP": 57.8, "HL-min-Good-Hit1": 66.13, "HL-min-VeryGood-mAP": 35.5, "HL-min-VeryGood-Hit1": 55.42}, "HL-min-Fair": {"HL-mAP": 68.15, "HL-Hit1": 68.52}, "HL-min-Good": {"HL-mAP": 57.8, "HL-Hit1": 66.13}, "HL-min-VeryGood": {"HL-mAP": 35.5, "HL-Hit1": 55.42}, "full": {"MR-mAP": {"0.5": 53.17, "0.55": 47.84, "0.6": 43.02, "0.65": 36.48, "0.7": 31.5, "0.75": 26.94, "0.8": 20.65, "0.85": 14.82, "0.9": 10.42, "0.95": 5.11, "average": 28.99}, "MR-R1": {"0.5": 51.48, "0.55": 46.84, "0.6": 42.19, "0.65": 35.55, "0.7": 30.97, "0.75": 26.65, "0.8": 20.26, "0.85": 14.65, "0.9": 10.32, "0.95": 5.03}}, "long": {"MR-mAP": {"0.5": 63.94, "0.55": 59.98, "0.6": 54.74, "0.65": 48.99, "0.7": 44.19, "0.75": 39.91, "0.8": 34.01, "0.85": 25.3, "0.9": 18.7, "0.95": 9.68, "average": 39.94}, "MR-R1": {"0.5": 56.97, "0.55": 53.66, "0.6": 48.43, "0.65": 43.03, "0.7": 38.68, "0.75": 35.19, "0.8": 29.97, "0.85": 22.82, "0.9": 17.07, "0.95": 8.89}}, "middle": {"MR-mAP": {"0.5": 55.53, "0.55": 49.38, "0.6": 43.96, "0.65": 35.82, "0.7": 30.13, "0.75": 24.25, "0.8": 16.37, "0.85": 11.2, "0.9": 7.12, "0.95": 2.97, "average": 27.67}, "MR-R1": {"0.5": 46.39, "0.55": 41.69, "0.6": 37.93, "0.65": 30.93, "0.7": 26.23, "0.75": 21.53, "0.8": 14.32, "0.85": 9.93, "0.9": 6.37, "0.95": 2.72}}, "short": {"MR-mAP": {"0.5": 8.83, "0.55": 5.94, "0.6": 4.73, "0.65": 3.24, "0.7": 2.23, "0.75": 1.96, "0.8": 1.34, "0.85": 0.58, "0.9": 0.58, "0.95": 0.58, "average": 3.0}, "MR-R1": {"0.5": 6.29, "0.55": 4.43, "0.6": 3.03, "0.65": 1.86, "0.7": 1.63, "0.75": 1.17, "0.8": 1.17, "0.85": 0.23, "0.9": 0.23, "0.95": 0.23}}}
|
| 37 |
+
2021_08_04_16_04_29 [Epoch] 184 [Loss] loss_span 0.5727 loss_giou 0.5537 loss_label 1.0821 class_error 27.1106 loss_saliency 0.2421 loss_span_0 0.5915 loss_giou_0 0.5634 loss_label_0 0.9882 class_error_0 26.3640 loss_overall 4.5937 [Metrics] {"brief": {"[email protected]": 51.87, "[email protected]": 31.29, "MR-full-mAP": 29.77, "[email protected]": 53.73, "[email protected]": 28.4, "MR-long-mAP": 40.5, "MR-middle-mAP": 28.65, "MR-short-mAP": 2.99, "HL-min-Fair-mAP": 68.42, "HL-min-Fair-Hit1": 68.71, "HL-min-Good-mAP": 58.06, "HL-min-Good-Hit1": 66.45, "HL-min-VeryGood-mAP": 35.63, "HL-min-VeryGood-Hit1": 56.19}, "HL-min-Fair": {"HL-mAP": 68.42, "HL-Hit1": 68.71}, "HL-min-Good": {"HL-mAP": 58.06, "HL-Hit1": 66.45}, "HL-min-VeryGood": {"HL-mAP": 35.63, "HL-Hit1": 56.19}, "full": {"MR-mAP": {"0.5": 53.73, "0.55": 46.84, "0.6": 42.86, "0.65": 37.26, "0.7": 32.14, "0.75": 28.4, "0.8": 22.35, "0.85": 16.82, "0.9": 11.72, "0.95": 5.63, "average": 29.77}, "MR-R1": {"0.5": 51.87, "0.55": 45.03, "0.6": 41.16, "0.65": 35.74, "0.7": 31.29, "0.75": 27.48, "0.8": 21.87, "0.85": 16.52, "0.9": 11.55, "0.95": 5.35}}, "long": {"MR-mAP": {"0.5": 63.7, "0.55": 58.29, "0.6": 53.96, "0.65": 50.65, "0.7": 45.42, "0.75": 40.68, "0.8": 34.47, "0.85": 26.79, "0.9": 20.03, "0.95": 11.05, "average": 40.5}, "MR-R1": {"0.5": 56.45, "0.55": 51.22, "0.6": 47.21, "0.65": 44.43, "0.7": 40.42, "0.75": 35.71, "0.8": 30.49, "0.85": 24.04, "0.9": 18.29, "0.95": 10.28}}, "middle": {"MR-mAP": {"0.5": 56.82, "0.55": 48.59, "0.6": 44.01, "0.65": 36.22, "0.7": 30.51, "0.75": 26.26, "0.8": 19.05, "0.85": 13.85, "0.9": 8.43, "0.95": 2.8, "average": 28.65}, "MR-R1": {"0.5": 47.44, "0.55": 40.54, "0.6": 37.2, "0.65": 30.83, "0.7": 26.23, "0.75": 22.99, "0.8": 17.03, "0.85": 12.33, "0.9": 7.73, "0.95": 2.51}}, "short": {"MR-mAP": {"0.5": 8.88, "0.55": 5.62, "0.6": 4.85, "0.65": 3.55, "0.7": 2.28, "0.75": 1.86, "0.8": 1.36, "0.85": 0.51, "0.9": 0.51, "0.95": 0.51, "average": 2.99}, "MR-R1": {"0.5": 6.06, "0.55": 3.73, "0.6": 2.56, "0.65": 0.93, "0.7": 0.47, "0.75": 0.23, "0.8": 0.23, "0.85": 0.0, "0.9": 0.0, "0.95": 0.0}}}
|
| 38 |
+
2021_08_04_16_09_51 [Epoch] 189 [Loss] loss_span 0.5774 loss_giou 0.5608 loss_label 1.0931 class_error 27.5772 loss_saliency 0.2402 loss_span_0 0.5943 loss_giou_0 0.5691 loss_label_0 1.0639 class_error_0 28.9274 loss_overall 4.6987 [Metrics] {"brief": {"[email protected]": 52.06, "[email protected]": 32.77, "MR-full-mAP": 29.81, "[email protected]": 53.85, "[email protected]": 28.31, "MR-long-mAP": 41.1, "MR-middle-mAP": 28.15, "MR-short-mAP": 2.82, "HL-min-Fair-mAP": 68.32, "HL-min-Fair-Hit1": 68.58, "HL-min-Good-mAP": 57.99, "HL-min-Good-Hit1": 66.77, "HL-min-VeryGood-mAP": 35.57, "HL-min-VeryGood-Hit1": 56.06}, "HL-min-Fair": {"HL-mAP": 68.32, "HL-Hit1": 68.58}, "HL-min-Good": {"HL-mAP": 57.99, "HL-Hit1": 66.77}, "HL-min-VeryGood": {"HL-mAP": 35.57, "HL-Hit1": 56.06}, "full": {"MR-mAP": {"0.5": 53.85, "0.55": 47.19, "0.6": 43.34, "0.65": 37.78, "0.7": 33.39, "0.75": 28.31, "0.8": 21.99, "0.85": 16.2, "0.9": 10.45, "0.95": 5.64, "average": 29.81}, "MR-R1": {"0.5": 52.06, "0.55": 45.94, "0.6": 42.26, "0.65": 36.65, "0.7": 32.77, "0.75": 27.81, "0.8": 21.55, "0.85": 15.74, "0.9": 10.06, "0.95": 5.42}}, "long": {"MR-mAP": {"0.5": 65.33, "0.55": 59.52, "0.6": 55.24, "0.65": 51.25, "0.7": 47.08, "0.75": 41.71, "0.8": 34.96, "0.85": 26.88, "0.9": 18.11, "0.95": 10.91, "average": 41.1}, "MR-R1": {"0.5": 57.32, "0.55": 51.74, "0.6": 48.26, "0.65": 44.43, "0.7": 41.46, "0.75": 36.76, "0.8": 30.14, "0.85": 23.17, "0.9": 15.68, "0.95": 9.76}}, "middle": {"MR-mAP": {"0.5": 55.74, "0.55": 48.37, "0.6": 43.87, "0.65": 36.49, "0.7": 31.17, "0.75": 25.21, "0.8": 17.98, "0.85": 12.43, "0.9": 7.22, "0.95": 3.05, "average": 28.15}, "MR-R1": {"0.5": 47.54, "0.55": 41.8, "0.6": 38.35, "0.65": 31.87, "0.7": 27.59, "0.75": 22.47, "0.8": 16.51, "0.85": 11.49, "0.9": 6.79, "0.95": 2.82}}, "short": {"MR-mAP": {"0.5": 8.85, "0.55": 5.71, "0.6": 4.94, "0.65": 3.21, "0.7": 2.1, "0.75": 1.61, "0.8": 0.98, "0.85": 0.28, "0.9": 0.28, "0.95": 0.28, "average": 2.82}, "MR-R1": {"0.5": 5.36, "0.55": 3.5, "0.6": 2.56, "0.65": 1.86, "0.7": 1.4, "0.75": 1.17, "0.8": 0.7, "0.85": 0.23, "0.9": 0.23, "0.95": 0.23}}}
|
| 39 |
+
2021_08_04_16_15_13 [Epoch] 194 [Loss] loss_span 0.5855 loss_giou 0.5604 loss_label 0.9803 class_error 23.7438 loss_saliency 0.2436 loss_span_0 0.5946 loss_giou_0 0.5654 loss_label_0 0.9436 class_error_0 24.4644 loss_overall 4.4732 [Metrics] {"brief": {"[email protected]": 51.87, "[email protected]": 32.45, "MR-full-mAP": 30.14, "[email protected]": 53.92, "[email protected]": 28.51, "MR-long-mAP": 40.44, "MR-middle-mAP": 29.4, "MR-short-mAP": 2.85, "HL-min-Fair-mAP": 68.66, "HL-min-Fair-Hit1": 69.29, "HL-min-Good-mAP": 58.29, "HL-min-Good-Hit1": 67.29, "HL-min-VeryGood-mAP": 35.77, "HL-min-VeryGood-Hit1": 56.39}, "HL-min-Fair": {"HL-mAP": 68.66, "HL-Hit1": 69.29}, "HL-min-Good": {"HL-mAP": 58.29, "HL-Hit1": 67.29}, "HL-min-VeryGood": {"HL-mAP": 35.77, "HL-Hit1": 56.39}, "full": {"MR-mAP": {"0.5": 53.92, "0.55": 48.0, "0.6": 43.3, "0.65": 37.39, "0.7": 32.98, "0.75": 28.51, "0.8": 22.84, "0.85": 16.99, "0.9": 11.8, "0.95": 5.69, "average": 30.14}, "MR-R1": {"0.5": 51.87, "0.55": 46.32, "0.6": 41.94, "0.65": 36.52, "0.7": 32.45, "0.75": 27.74, "0.8": 22.39, "0.85": 16.65, "0.9": 11.48, "0.95": 5.42}}, "long": {"MR-mAP": {"0.5": 63.62, "0.55": 58.74, "0.6": 53.42, "0.65": 48.78, "0.7": 44.4, "0.75": 40.48, "0.8": 34.18, "0.85": 28.76, "0.9": 20.68, "0.95": 11.31, "average": 40.44}, "MR-R1": {"0.5": 55.75, "0.55": 51.22, "0.6": 46.52, "0.65": 42.51, "0.7": 39.2, "0.75": 35.71, "0.8": 30.14, "0.85": 25.44, "0.9": 18.64, "0.95": 10.45}}, "middle": {"MR-mAP": {"0.5": 57.32, "0.55": 50.55, "0.6": 45.46, "0.65": 37.61, "0.7": 32.44, "0.75": 26.43, "0.8": 19.94, "0.85": 13.18, "0.9": 8.27, "0.95": 2.77, "average": 29.4}, "MR-R1": {"0.5": 48.17, "0.55": 42.84, "0.6": 38.77, "0.65": 32.92, "0.7": 28.53, "0.75": 23.2, "0.8": 17.87, "0.85": 11.6, "0.9": 7.31, "0.95": 2.4}}, "short": {"MR-mAP": {"0.5": 8.63, "0.55": 5.42, "0.6": 4.82, "0.65": 3.23, "0.7": 1.98, "0.75": 1.67, "0.8": 1.34, "0.85": 0.47, "0.9": 0.47, "0.95": 0.47, "average": 2.85}, "MR-R1": {"0.5": 5.36, "0.55": 3.26, "0.6": 2.8, "0.65": 1.63, "0.7": 1.17, "0.75": 0.7, "0.8": 0.7, "0.85": 0.23, "0.9": 0.23, "0.95": 0.23}}}
|
| 40 |
+
2021_08_04_16_20_32 [Epoch] 199 [Loss] loss_span 0.5908 loss_giou 0.5637 loss_label 0.9894 class_error 23.9894 loss_saliency 0.2397 loss_span_0 0.5944 loss_giou_0 0.5636 loss_label_0 0.9127 class_error_0 22.9809 loss_overall 4.4542 [Metrics] {"brief": {"[email protected]": 50.77, "[email protected]": 31.35, "MR-full-mAP": 29.18, "[email protected]": 53.22, "[email protected]": 27.3, "MR-long-mAP": 39.55, "MR-middle-mAP": 28.55, "MR-short-mAP": 2.51, "HL-min-Fair-mAP": 68.11, "HL-min-Fair-Hit1": 67.94, "HL-min-Good-mAP": 57.66, "HL-min-Good-Hit1": 65.48, "HL-min-VeryGood-mAP": 35.35, "HL-min-VeryGood-Hit1": 54.71}, "HL-min-Fair": {"HL-mAP": 68.11, "HL-Hit1": 67.94}, "HL-min-Good": {"HL-mAP": 57.66, "HL-Hit1": 65.48}, "HL-min-VeryGood": {"HL-mAP": 35.35, "HL-Hit1": 54.71}, "full": {"MR-mAP": {"0.5": 53.22, "0.55": 47.59, "0.6": 43.14, "0.65": 37.08, "0.7": 32.34, "0.75": 27.3, "0.8": 21.21, "0.85": 14.95, "0.9": 9.77, "0.95": 5.17, "average": 29.18}, "MR-R1": {"0.5": 50.77, "0.55": 45.94, "0.6": 41.55, "0.65": 35.55, "0.7": 31.35, "0.75": 26.26, "0.8": 20.39, "0.85": 14.32, "0.9": 9.29, "0.95": 4.9}}, "long": {"MR-mAP": {"0.5": 62.95, "0.55": 58.21, "0.6": 54.71, "0.65": 49.05, "0.7": 44.33, "0.75": 39.84, "0.8": 31.77, "0.85": 25.91, "0.9": 18.28, "0.95": 10.44, "average": 39.55}, "MR-R1": {"0.5": 53.83, "0.55": 49.83, "0.6": 46.86, "0.65": 41.46, "0.7": 37.8, "0.75": 34.15, "0.8": 26.83, "0.85": 22.3, "0.9": 15.51, "0.95": 9.23}}, "middle": {"MR-mAP": {"0.5": 56.94, "0.55": 50.54, "0.6": 44.5, "0.65": 37.48, "0.7": 31.71, "0.75": 25.02, "0.8": 19.08, "0.85": 11.34, "0.9": 6.43, "0.95": 2.46, "average": 28.55}, "MR-R1": {"0.5": 47.96, "0.55": 42.74, "0.6": 37.83, "0.65": 31.97, "0.7": 27.59, "0.75": 21.63, "0.8": 16.72, "0.85": 9.72, "0.9": 5.64, "0.95": 2.3}}, "short": {"MR-mAP": {"0.5": 7.08, "0.55": 5.08, "0.6": 4.28, "0.65": 2.88, "0.7": 1.93, "0.75": 1.78, "0.8": 1.11, "0.85": 0.31, "0.9": 0.31, "0.95": 0.31, "average": 2.51}, "MR-R1": {"0.5": 4.43, "0.55": 3.96, "0.6": 3.03, "0.65": 1.63, "0.7": 1.17, "0.75": 0.93, "0.8": 0.47, "0.85": 0.23, "0.9": 0.23, "0.95": 0.23}}}
|
run_on_video/moment_detr_ckpt/inference_hl_val_test_code_preds.jsonl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4b38328e316be63a2e7ca667566a76223ffe7b349a0b2edce66f028673f393ab
|
| 3 |
+
size 2443100
|
run_on_video/moment_detr_ckpt/inference_hl_val_test_code_preds_metrics.json
ADDED
|
@@ -0,0 +1,138 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"brief": {
|
| 3 |
+
"[email protected]": 53.23,
|
| 4 |
+
"[email protected]": 34.0,
|
| 5 |
+
"MR-full-mAP": 30.58,
|
| 6 |
+
"[email protected]": 54.8,
|
| 7 |
+
"[email protected]": 29.02,
|
| 8 |
+
"MR-long-mAP": 41.27,
|
| 9 |
+
"MR-middle-mAP": 29.42,
|
| 10 |
+
"MR-short-mAP": 3.11,
|
| 11 |
+
"HL-min-Fair-mAP": 68.29,
|
| 12 |
+
"HL-min-Fair-Hit1": 68.32,
|
| 13 |
+
"HL-min-Good-mAP": 57.93,
|
| 14 |
+
"HL-min-Good-Hit1": 66.26,
|
| 15 |
+
"HL-min-VeryGood-mAP": 35.51,
|
| 16 |
+
"HL-min-VeryGood-Hit1": 55.87
|
| 17 |
+
},
|
| 18 |
+
"HL-min-Fair": {
|
| 19 |
+
"HL-mAP": 68.29,
|
| 20 |
+
"HL-Hit1": 68.32
|
| 21 |
+
},
|
| 22 |
+
"HL-min-Good": {
|
| 23 |
+
"HL-mAP": 57.93,
|
| 24 |
+
"HL-Hit1": 66.26
|
| 25 |
+
},
|
| 26 |
+
"HL-min-VeryGood": {
|
| 27 |
+
"HL-mAP": 35.51,
|
| 28 |
+
"HL-Hit1": 55.87
|
| 29 |
+
},
|
| 30 |
+
"full": {
|
| 31 |
+
"MR-mAP": {
|
| 32 |
+
"0.5": 54.8,
|
| 33 |
+
"0.55": 48.28,
|
| 34 |
+
"0.6": 43.8,
|
| 35 |
+
"0.65": 38.62,
|
| 36 |
+
"0.7": 34.39,
|
| 37 |
+
"0.75": 29.02,
|
| 38 |
+
"0.8": 23.3,
|
| 39 |
+
"0.85": 16.75,
|
| 40 |
+
"0.9": 11.04,
|
| 41 |
+
"0.95": 5.8,
|
| 42 |
+
"average": 30.58
|
| 43 |
+
},
|
| 44 |
+
"MR-R1": {
|
| 45 |
+
"0.5": 53.23,
|
| 46 |
+
"0.55": 47.48,
|
| 47 |
+
"0.6": 43.03,
|
| 48 |
+
"0.65": 38.45,
|
| 49 |
+
"0.7": 34.0,
|
| 50 |
+
"0.75": 28.65,
|
| 51 |
+
"0.8": 22.97,
|
| 52 |
+
"0.85": 16.84,
|
| 53 |
+
"0.9": 11.29,
|
| 54 |
+
"0.95": 5.81
|
| 55 |
+
}
|
| 56 |
+
},
|
| 57 |
+
"long": {
|
| 58 |
+
"MR-mAP": {
|
| 59 |
+
"0.5": 64.99,
|
| 60 |
+
"0.55": 59.64,
|
| 61 |
+
"0.6": 55.6,
|
| 62 |
+
"0.65": 51.5,
|
| 63 |
+
"0.7": 47.39,
|
| 64 |
+
"0.75": 42.77,
|
| 65 |
+
"0.8": 34.76,
|
| 66 |
+
"0.85": 27.53,
|
| 67 |
+
"0.9": 18.31,
|
| 68 |
+
"0.95": 10.26,
|
| 69 |
+
"average": 41.27
|
| 70 |
+
},
|
| 71 |
+
"MR-R1": {
|
| 72 |
+
"0.5": 57.49,
|
| 73 |
+
"0.55": 53.14,
|
| 74 |
+
"0.6": 49.3,
|
| 75 |
+
"0.65": 45.82,
|
| 76 |
+
"0.7": 41.99,
|
| 77 |
+
"0.75": 38.5,
|
| 78 |
+
"0.8": 31.36,
|
| 79 |
+
"0.85": 25.09,
|
| 80 |
+
"0.9": 17.07,
|
| 81 |
+
"0.95": 9.23
|
| 82 |
+
}
|
| 83 |
+
},
|
| 84 |
+
"middle": {
|
| 85 |
+
"MR-mAP": {
|
| 86 |
+
"0.5": 57.68,
|
| 87 |
+
"0.55": 50.3,
|
| 88 |
+
"0.6": 44.71,
|
| 89 |
+
"0.65": 38.22,
|
| 90 |
+
"0.7": 32.78,
|
| 91 |
+
"0.75": 25.68,
|
| 92 |
+
"0.8": 20.05,
|
| 93 |
+
"0.85": 13.05,
|
| 94 |
+
"0.9": 8.2,
|
| 95 |
+
"0.95": 3.53,
|
| 96 |
+
"average": 29.42
|
| 97 |
+
},
|
| 98 |
+
"MR-R1": {
|
| 99 |
+
"0.5": 48.9,
|
| 100 |
+
"0.55": 43.16,
|
| 101 |
+
"0.6": 38.56,
|
| 102 |
+
"0.65": 33.54,
|
| 103 |
+
"0.7": 29.15,
|
| 104 |
+
"0.75": 22.88,
|
| 105 |
+
"0.8": 18.08,
|
| 106 |
+
"0.85": 12.02,
|
| 107 |
+
"0.9": 7.84,
|
| 108 |
+
"0.95": 3.66
|
| 109 |
+
}
|
| 110 |
+
},
|
| 111 |
+
"short": {
|
| 112 |
+
"MR-mAP": {
|
| 113 |
+
"0.5": 8.89,
|
| 114 |
+
"0.55": 5.69,
|
| 115 |
+
"0.6": 4.75,
|
| 116 |
+
"0.65": 3.32,
|
| 117 |
+
"0.7": 2.53,
|
| 118 |
+
"0.75": 2.09,
|
| 119 |
+
"0.8": 1.5,
|
| 120 |
+
"0.85": 0.77,
|
| 121 |
+
"0.9": 0.77,
|
| 122 |
+
"0.95": 0.77,
|
| 123 |
+
"average": 3.11
|
| 124 |
+
},
|
| 125 |
+
"MR-R1": {
|
| 126 |
+
"0.5": 6.29,
|
| 127 |
+
"0.55": 4.2,
|
| 128 |
+
"0.6": 3.5,
|
| 129 |
+
"0.65": 2.8,
|
| 130 |
+
"0.7": 1.63,
|
| 131 |
+
"0.75": 0.93,
|
| 132 |
+
"0.8": 0.7,
|
| 133 |
+
"0.85": 0.47,
|
| 134 |
+
"0.9": 0.47,
|
| 135 |
+
"0.95": 0.47
|
| 136 |
+
}
|
| 137 |
+
}
|
| 138 |
+
}
|
run_on_video/moment_detr_ckpt/model_best.ckpt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ad5facec03008800536466c7d33f9232c3db2b71a1bd445073957bd6f4d0edbf
|
| 3 |
+
size 16952721
|
run_on_video/moment_detr_ckpt/opt.json
ADDED
|
@@ -0,0 +1,75 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"dset_name": "hl",
|
| 3 |
+
"eval_split_name": "val",
|
| 4 |
+
"debug": false,
|
| 5 |
+
"data_ratio": 1.0,
|
| 6 |
+
"results_root": "baselines/detr/results",
|
| 7 |
+
"exp_id": "final_base_clip_clip_mq10_noalign",
|
| 8 |
+
"seed": 2018,
|
| 9 |
+
"device": 0,
|
| 10 |
+
"num_workers": 4,
|
| 11 |
+
"no_pin_memory": false,
|
| 12 |
+
"lr": 0.0001,
|
| 13 |
+
"lr_drop": 400,
|
| 14 |
+
"wd": 0.0001,
|
| 15 |
+
"n_epoch": 200,
|
| 16 |
+
"max_es_cnt": 200,
|
| 17 |
+
"bsz": 32,
|
| 18 |
+
"eval_bsz": 100,
|
| 19 |
+
"grad_clip": 0.1,
|
| 20 |
+
"eval_untrained": false,
|
| 21 |
+
"resume": null,
|
| 22 |
+
"resume_all": false,
|
| 23 |
+
"start_epoch": null,
|
| 24 |
+
"max_q_l": 32,
|
| 25 |
+
"max_v_l": 75,
|
| 26 |
+
"clip_length": 2,
|
| 27 |
+
"max_windows": 5,
|
| 28 |
+
"train_path": "annotations/highlight_train.jsonl",
|
| 29 |
+
"eval_path": "annotations/highlight_val.jsonl",
|
| 30 |
+
"no_norm_vfeat": false,
|
| 31 |
+
"no_norm_tfeat": false,
|
| 32 |
+
"v_feat_dirs": [
|
| 33 |
+
"features/clip_features"
|
| 34 |
+
],
|
| 35 |
+
"t_feat_dir": "features/clip_text_features/",
|
| 36 |
+
"v_feat_dim": 512,
|
| 37 |
+
"t_feat_dim": 512,
|
| 38 |
+
"ctx_mode": "video_tef",
|
| 39 |
+
"no_hard_neg": false,
|
| 40 |
+
"no_easy_neg": false,
|
| 41 |
+
"position_embedding": "sine",
|
| 42 |
+
"enc_layers": 2,
|
| 43 |
+
"dec_layers": 2,
|
| 44 |
+
"dim_feedforward": 1024,
|
| 45 |
+
"hidden_dim": 256,
|
| 46 |
+
"input_dropout": 0.5,
|
| 47 |
+
"dropout": 0.1,
|
| 48 |
+
"txt_drop_ratio": 0,
|
| 49 |
+
"use_txt_pos": false,
|
| 50 |
+
"nheads": 8,
|
| 51 |
+
"num_queries": 10,
|
| 52 |
+
"pre_norm": false,
|
| 53 |
+
"n_input_proj": 2,
|
| 54 |
+
"contrastive_hdim": 64,
|
| 55 |
+
"temperature": 0.07,
|
| 56 |
+
"lw_saliency": 1.0,
|
| 57 |
+
"saliency_margin": 0.2,
|
| 58 |
+
"aux_loss": true,
|
| 59 |
+
"span_loss_type": "l1",
|
| 60 |
+
"contrastive_align_loss": false,
|
| 61 |
+
"set_cost_span": 10,
|
| 62 |
+
"set_cost_giou": 1,
|
| 63 |
+
"set_cost_class": 4,
|
| 64 |
+
"span_loss_coef": 10,
|
| 65 |
+
"giou_loss_coef": 1,
|
| 66 |
+
"label_loss_coef": 4,
|
| 67 |
+
"eos_coef": 0.1,
|
| 68 |
+
"contrastive_align_loss_coef": 0.02,
|
| 69 |
+
"no_sort_results": false,
|
| 70 |
+
"max_before_nms": 10,
|
| 71 |
+
"max_after_nms": 10,
|
| 72 |
+
"conf_thd": 0.0,
|
| 73 |
+
"nms_thd": -1.0,
|
| 74 |
+
"results_dir": "moment_detr/tmp/clip_only_non_pt/"
|
| 75 |
+
}
|
run_on_video/moment_detr_ckpt/train.log.txt
ADDED
|
@@ -0,0 +1,200 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
2021_08_04_12_44_04 [Epoch] 001 [Loss] loss_span 1.2972 loss_giou 0.8287 loss_label 0.5786 class_error 10.6986 loss_saliency 0.4536 loss_span_0 1.3355 loss_giou_0 0.8531 loss_label_0 0.5712 class_error_0 9.1542 loss_overall 5.9179
|
| 2 |
+
2021_08_04_12_45_03 [Epoch] 002 [Loss] loss_span 0.9610 loss_giou 0.6673 loss_label 0.6130 class_error 7.9499 loss_saliency 0.4074 loss_span_0 1.0072 loss_giou_0 0.6896 loss_label_0 0.6068 class_error_0 8.7446 loss_overall 4.9524
|
| 3 |
+
2021_08_04_12_46_00 [Epoch] 003 [Loss] loss_span 0.9251 loss_giou 0.6528 loss_label 0.6185 class_error 6.9243 loss_saliency 0.3960 loss_span_0 0.9675 loss_giou_0 0.6762 loss_label_0 0.6124 class_error_0 7.5102 loss_overall 4.8485
|
| 4 |
+
2021_08_04_12_46_58 [Epoch] 004 [Loss] loss_span 0.9149 loss_giou 0.6477 loss_label 0.6126 class_error 4.7459 loss_saliency 0.3836 loss_span_0 0.9530 loss_giou_0 0.6704 loss_label_0 0.6115 class_error_0 6.5554 loss_overall 4.7936
|
| 5 |
+
2021_08_04_12_47_56 [Epoch] 005 [Loss] loss_span 0.8941 loss_giou 0.6431 loss_label 0.6141 class_error 5.4848 loss_saliency 0.3736 loss_span_0 0.9455 loss_giou_0 0.6690 loss_label_0 0.6125 class_error_0 6.7207 loss_overall 4.7520
|
| 6 |
+
2021_08_04_12_49_22 [Epoch] 006 [Loss] loss_span 0.8818 loss_giou 0.6366 loss_label 0.6116 class_error 6.2694 loss_saliency 0.3688 loss_span_0 0.9255 loss_giou_0 0.6651 loss_label_0 0.6167 class_error_0 6.4318 loss_overall 4.7061
|
| 7 |
+
2021_08_04_12_50_20 [Epoch] 007 [Loss] loss_span 0.8644 loss_giou 0.6341 loss_label 0.6105 class_error 5.5753 loss_saliency 0.3654 loss_span_0 0.8842 loss_giou_0 0.6523 loss_label_0 0.6145 class_error_0 4.9088 loss_overall 4.6253
|
| 8 |
+
2021_08_04_12_51_18 [Epoch] 008 [Loss] loss_span 0.7577 loss_giou 0.6302 loss_label 0.5960 class_error 8.4945 loss_saliency 0.3634 loss_span_0 0.7785 loss_giou_0 0.6370 loss_label_0 0.6186 class_error_0 5.8819 loss_overall 4.3814
|
| 9 |
+
2021_08_04_12_52_17 [Epoch] 009 [Loss] loss_span 0.6922 loss_giou 0.5997 loss_label 0.5183 class_error 7.5825 loss_saliency 0.3628 loss_span_0 0.6874 loss_giou_0 0.5978 loss_label_0 0.5542 class_error_0 6.7843 loss_overall 4.0124
|
| 10 |
+
2021_08_04_12_53_14 [Epoch] 010 [Loss] loss_span 0.6576 loss_giou 0.5844 loss_label 0.5190 class_error 6.6664 loss_saliency 0.3569 loss_span_0 0.6487 loss_giou_0 0.5885 loss_label_0 0.5435 class_error_0 6.7383 loss_overall 3.8986
|
| 11 |
+
2021_08_04_12_54_39 [Epoch] 011 [Loss] loss_span 0.6314 loss_giou 0.5711 loss_label 0.5253 class_error 6.8657 loss_saliency 0.3481 loss_span_0 0.6423 loss_giou_0 0.5881 loss_label_0 0.5335 class_error_0 7.8473 loss_overall 3.8398
|
| 12 |
+
2021_08_04_12_55_39 [Epoch] 012 [Loss] loss_span 0.6399 loss_giou 0.5757 loss_label 0.5142 class_error 6.2857 loss_saliency 0.3484 loss_span_0 0.6313 loss_giou_0 0.5815 loss_label_0 0.5255 class_error_0 7.3446 loss_overall 3.8164
|
| 13 |
+
2021_08_04_12_56_37 [Epoch] 013 [Loss] loss_span 0.6239 loss_giou 0.5736 loss_label 0.5145 class_error 6.2704 loss_saliency 0.3437 loss_span_0 0.6118 loss_giou_0 0.5712 loss_label_0 0.5236 class_error_0 8.4098 loss_overall 3.7622
|
| 14 |
+
2021_08_04_12_57_37 [Epoch] 014 [Loss] loss_span 0.6114 loss_giou 0.5666 loss_label 0.5164 class_error 6.1901 loss_saliency 0.3382 loss_span_0 0.6112 loss_giou_0 0.5720 loss_label_0 0.5182 class_error_0 8.6985 loss_overall 3.7339
|
| 15 |
+
2021_08_04_12_58_37 [Epoch] 015 [Loss] loss_span 0.6074 loss_giou 0.5624 loss_label 0.5100 class_error 5.9347 loss_saliency 0.3337 loss_span_0 0.6097 loss_giou_0 0.5708 loss_label_0 0.5157 class_error_0 7.8520 loss_overall 3.7096
|
| 16 |
+
2021_08_04_13_00_03 [Epoch] 016 [Loss] loss_span 0.6034 loss_giou 0.5615 loss_label 0.5122 class_error 5.9122 loss_saliency 0.3219 loss_span_0 0.6121 loss_giou_0 0.5734 loss_label_0 0.5075 class_error_0 7.5621 loss_overall 3.6920
|
| 17 |
+
2021_08_04_13_01_02 [Epoch] 017 [Loss] loss_span 0.6016 loss_giou 0.5636 loss_label 0.5023 class_error 5.5376 loss_saliency 0.3225 loss_span_0 0.6104 loss_giou_0 0.5772 loss_label_0 0.4986 class_error_0 7.7640 loss_overall 3.6763
|
| 18 |
+
2021_08_04_13_02_01 [Epoch] 018 [Loss] loss_span 0.5969 loss_giou 0.5614 loss_label 0.5034 class_error 5.6997 loss_saliency 0.3156 loss_span_0 0.6057 loss_giou_0 0.5715 loss_label_0 0.4994 class_error_0 7.5964 loss_overall 3.6538
|
| 19 |
+
2021_08_04_13_02_59 [Epoch] 019 [Loss] loss_span 0.5892 loss_giou 0.5573 loss_label 0.4988 class_error 5.6585 loss_saliency 0.3128 loss_span_0 0.5997 loss_giou_0 0.5685 loss_label_0 0.4981 class_error_0 7.2079 loss_overall 3.6244
|
| 20 |
+
2021_08_04_13_03_58 [Epoch] 020 [Loss] loss_span 0.5884 loss_giou 0.5578 loss_label 0.4902 class_error 5.8618 loss_saliency 0.3110 loss_span_0 0.5992 loss_giou_0 0.5707 loss_label_0 0.4906 class_error_0 7.3296 loss_overall 3.6078
|
| 21 |
+
2021_08_04_13_05_22 [Epoch] 021 [Loss] loss_span 0.5829 loss_giou 0.5562 loss_label 0.4887 class_error 5.6675 loss_saliency 0.3124 loss_span_0 0.5917 loss_giou_0 0.5644 loss_label_0 0.4863 class_error_0 6.6632 loss_overall 3.5827
|
| 22 |
+
2021_08_04_13_06_23 [Epoch] 022 [Loss] loss_span 0.5783 loss_giou 0.5540 loss_label 0.4751 class_error 5.9591 loss_saliency 0.3065 loss_span_0 0.5943 loss_giou_0 0.5680 loss_label_0 0.4740 class_error_0 6.9004 loss_overall 3.5501
|
| 23 |
+
2021_08_04_13_07_22 [Epoch] 023 [Loss] loss_span 0.5708 loss_giou 0.5444 loss_label 0.4778 class_error 6.6102 loss_saliency 0.3018 loss_span_0 0.6004 loss_giou_0 0.5724 loss_label_0 0.4691 class_error_0 7.0948 loss_overall 3.5367
|
| 24 |
+
2021_08_04_13_08_20 [Epoch] 024 [Loss] loss_span 0.5645 loss_giou 0.5465 loss_label 0.4679 class_error 6.7828 loss_saliency 0.2953 loss_span_0 0.5845 loss_giou_0 0.5605 loss_label_0 0.4649 class_error_0 6.2931 loss_overall 3.4841
|
| 25 |
+
2021_08_04_13_09_19 [Epoch] 025 [Loss] loss_span 0.5594 loss_giou 0.5455 loss_label 0.4611 class_error 7.0777 loss_saliency 0.2925 loss_span_0 0.5800 loss_giou_0 0.5607 loss_label_0 0.4588 class_error_0 6.9143 loss_overall 3.4581
|
| 26 |
+
2021_08_04_13_10_46 [Epoch] 026 [Loss] loss_span 0.5527 loss_giou 0.5408 loss_label 0.4534 class_error 6.8014 loss_saliency 0.2903 loss_span_0 0.5754 loss_giou_0 0.5579 loss_label_0 0.4483 class_error_0 7.3016 loss_overall 3.4187
|
| 27 |
+
2021_08_04_13_11_46 [Epoch] 027 [Loss] loss_span 0.5468 loss_giou 0.5384 loss_label 0.4506 class_error 7.0799 loss_saliency 0.2870 loss_span_0 0.5706 loss_giou_0 0.5533 loss_label_0 0.4467 class_error_0 6.9152 loss_overall 3.3934
|
| 28 |
+
2021_08_04_13_12_43 [Epoch] 028 [Loss] loss_span 0.5433 loss_giou 0.5374 loss_label 0.4438 class_error 6.9976 loss_saliency 0.2839 loss_span_0 0.5648 loss_giou_0 0.5523 loss_label_0 0.4374 class_error_0 6.8193 loss_overall 3.3630
|
| 29 |
+
2021_08_04_13_13_42 [Epoch] 029 [Loss] loss_span 0.5325 loss_giou 0.5299 loss_label 0.4421 class_error 7.2091 loss_saliency 0.2729 loss_span_0 0.5544 loss_giou_0 0.5488 loss_label_0 0.4356 class_error_0 7.3670 loss_overall 3.3163
|
| 30 |
+
2021_08_04_13_14_41 [Epoch] 030 [Loss] loss_span 0.5283 loss_giou 0.5291 loss_label 0.4322 class_error 6.9750 loss_saliency 0.2716 loss_span_0 0.5492 loss_giou_0 0.5473 loss_label_0 0.4246 class_error_0 7.1994 loss_overall 3.2821
|
| 31 |
+
2021_08_04_13_16_07 [Epoch] 031 [Loss] loss_span 0.5161 loss_giou 0.5213 loss_label 0.4340 class_error 7.0319 loss_saliency 0.2668 loss_span_0 0.5406 loss_giou_0 0.5436 loss_label_0 0.4221 class_error_0 7.3913 loss_overall 3.2444
|
| 32 |
+
2021_08_04_13_17_04 [Epoch] 032 [Loss] loss_span 0.5198 loss_giou 0.5210 loss_label 0.4234 class_error 6.9696 loss_saliency 0.2629 loss_span_0 0.5406 loss_giou_0 0.5406 loss_label_0 0.4178 class_error_0 7.1132 loss_overall 3.2260
|
| 33 |
+
2021_08_04_13_18_03 [Epoch] 033 [Loss] loss_span 0.5140 loss_giou 0.5201 loss_label 0.4201 class_error 6.8230 loss_saliency 0.2590 loss_span_0 0.5333 loss_giou_0 0.5358 loss_label_0 0.4185 class_error_0 7.2699 loss_overall 3.2007
|
| 34 |
+
2021_08_04_13_19_02 [Epoch] 034 [Loss] loss_span 0.5061 loss_giou 0.5157 loss_label 0.4125 class_error 6.9812 loss_saliency 0.2595 loss_span_0 0.5260 loss_giou_0 0.5346 loss_label_0 0.4056 class_error_0 7.2665 loss_overall 3.1600
|
| 35 |
+
2021_08_04_13_20_00 [Epoch] 035 [Loss] loss_span 0.4975 loss_giou 0.5137 loss_label 0.4085 class_error 6.9593 loss_saliency 0.2511 loss_span_0 0.5240 loss_giou_0 0.5349 loss_label_0 0.4010 class_error_0 6.8786 loss_overall 3.1308
|
| 36 |
+
2021_08_04_13_21_26 [Epoch] 036 [Loss] loss_span 0.5017 loss_giou 0.5112 loss_label 0.4048 class_error 6.7255 loss_saliency 0.2520 loss_span_0 0.5180 loss_giou_0 0.5296 loss_label_0 0.3997 class_error_0 7.2124 loss_overall 3.1170
|
| 37 |
+
2021_08_04_13_22_25 [Epoch] 037 [Loss] loss_span 0.4918 loss_giou 0.5101 loss_label 0.3992 class_error 7.2220 loss_saliency 0.2512 loss_span_0 0.5116 loss_giou_0 0.5270 loss_label_0 0.3950 class_error_0 7.0849 loss_overall 3.0860
|
| 38 |
+
2021_08_04_13_23_23 [Epoch] 038 [Loss] loss_span 0.4910 loss_giou 0.5071 loss_label 0.3942 class_error 6.5723 loss_saliency 0.2470 loss_span_0 0.5080 loss_giou_0 0.5266 loss_label_0 0.3895 class_error_0 7.0217 loss_overall 3.0634
|
| 39 |
+
2021_08_04_13_24_21 [Epoch] 039 [Loss] loss_span 0.4821 loss_giou 0.5035 loss_label 0.3983 class_error 7.2142 loss_saliency 0.2394 loss_span_0 0.5060 loss_giou_0 0.5250 loss_label_0 0.3883 class_error_0 7.4257 loss_overall 3.0426
|
| 40 |
+
2021_08_04_13_25_21 [Epoch] 040 [Loss] loss_span 0.4816 loss_giou 0.5014 loss_label 0.3897 class_error 7.1229 loss_saliency 0.2400 loss_span_0 0.5029 loss_giou_0 0.5211 loss_label_0 0.3821 class_error_0 7.2083 loss_overall 3.0188
|
| 41 |
+
2021_08_04_13_26_47 [Epoch] 041 [Loss] loss_span 0.4743 loss_giou 0.4964 loss_label 0.3887 class_error 6.7816 loss_saliency 0.2378 loss_span_0 0.4972 loss_giou_0 0.5199 loss_label_0 0.3796 class_error_0 6.9007 loss_overall 2.9940
|
| 42 |
+
2021_08_04_13_27_46 [Epoch] 042 [Loss] loss_span 0.4729 loss_giou 0.4981 loss_label 0.3814 class_error 6.9122 loss_saliency 0.2365 loss_span_0 0.4916 loss_giou_0 0.5176 loss_label_0 0.3774 class_error_0 6.9401 loss_overall 2.9755
|
| 43 |
+
2021_08_04_13_28_44 [Epoch] 043 [Loss] loss_span 0.4760 loss_giou 0.5008 loss_label 0.3761 class_error 6.8140 loss_saliency 0.2345 loss_span_0 0.4944 loss_giou_0 0.5168 loss_label_0 0.3692 class_error_0 6.8928 loss_overall 2.9677
|
| 44 |
+
2021_08_04_13_29_43 [Epoch] 044 [Loss] loss_span 0.4689 loss_giou 0.4950 loss_label 0.3718 class_error 6.6328 loss_saliency 0.2323 loss_span_0 0.4886 loss_giou_0 0.5173 loss_label_0 0.3673 class_error_0 6.9695 loss_overall 2.9411
|
| 45 |
+
2021_08_04_13_30_41 [Epoch] 045 [Loss] loss_span 0.4676 loss_giou 0.4951 loss_label 0.3716 class_error 6.8737 loss_saliency 0.2308 loss_span_0 0.4819 loss_giou_0 0.5093 loss_label_0 0.3685 class_error_0 7.0836 loss_overall 2.9247
|
| 46 |
+
2021_08_04_13_32_04 [Epoch] 046 [Loss] loss_span 0.4680 loss_giou 0.4940 loss_label 0.3724 class_error 6.8449 loss_saliency 0.2297 loss_span_0 0.4816 loss_giou_0 0.5096 loss_label_0 0.3703 class_error_0 7.3820 loss_overall 2.9256
|
| 47 |
+
2021_08_04_13_33_03 [Epoch] 047 [Loss] loss_span 0.4584 loss_giou 0.4873 loss_label 0.3702 class_error 6.8917 loss_saliency 0.2289 loss_span_0 0.4762 loss_giou_0 0.5106 loss_label_0 0.3636 class_error_0 7.0993 loss_overall 2.8952
|
| 48 |
+
2021_08_04_13_34_03 [Epoch] 048 [Loss] loss_span 0.4518 loss_giou 0.4885 loss_label 0.3648 class_error 6.8557 loss_saliency 0.2215 loss_span_0 0.4730 loss_giou_0 0.5079 loss_label_0 0.3573 class_error_0 6.8289 loss_overall 2.8648
|
| 49 |
+
2021_08_04_13_35_03 [Epoch] 049 [Loss] loss_span 0.4525 loss_giou 0.4881 loss_label 0.3608 class_error 6.8747 loss_saliency 0.2221 loss_span_0 0.4729 loss_giou_0 0.5091 loss_label_0 0.3528 class_error_0 7.0079 loss_overall 2.8584
|
| 50 |
+
2021_08_04_13_36_02 [Epoch] 050 [Loss] loss_span 0.4490 loss_giou 0.4813 loss_label 0.3529 class_error 6.6830 loss_saliency 0.2212 loss_span_0 0.4658 loss_giou_0 0.5020 loss_label_0 0.3505 class_error_0 6.9031 loss_overall 2.8227
|
| 51 |
+
2021_08_04_13_37_27 [Epoch] 051 [Loss] loss_span 0.4450 loss_giou 0.4835 loss_label 0.3503 class_error 6.7983 loss_saliency 0.2217 loss_span_0 0.4633 loss_giou_0 0.5041 loss_label_0 0.3497 class_error_0 7.1129 loss_overall 2.8176
|
| 52 |
+
2021_08_04_13_38_30 [Epoch] 052 [Loss] loss_span 0.4493 loss_giou 0.4859 loss_label 0.3480 class_error 6.6603 loss_saliency 0.2218 loss_span_0 0.4655 loss_giou_0 0.5036 loss_label_0 0.3478 class_error_0 6.9336 loss_overall 2.8218
|
| 53 |
+
2021_08_04_13_39_31 [Epoch] 053 [Loss] loss_span 0.4418 loss_giou 0.4806 loss_label 0.3438 class_error 6.4108 loss_saliency 0.2210 loss_span_0 0.4604 loss_giou_0 0.5025 loss_label_0 0.3439 class_error_0 6.6419 loss_overall 2.7939
|
| 54 |
+
2021_08_04_13_40_31 [Epoch] 054 [Loss] loss_span 0.4310 loss_giou 0.4725 loss_label 0.3482 class_error 6.4051 loss_saliency 0.2156 loss_span_0 0.4570 loss_giou_0 0.4971 loss_label_0 0.3425 class_error_0 6.4731 loss_overall 2.7639
|
| 55 |
+
2021_08_04_13_41_33 [Epoch] 055 [Loss] loss_span 0.4310 loss_giou 0.4765 loss_label 0.3466 class_error 6.5199 loss_saliency 0.2149 loss_span_0 0.4577 loss_giou_0 0.4984 loss_label_0 0.3398 class_error_0 6.6712 loss_overall 2.7649
|
| 56 |
+
2021_08_04_13_43_02 [Epoch] 056 [Loss] loss_span 0.4335 loss_giou 0.4762 loss_label 0.3370 class_error 6.0320 loss_saliency 0.2155 loss_span_0 0.4517 loss_giou_0 0.4965 loss_label_0 0.3356 class_error_0 6.6508 loss_overall 2.7461
|
| 57 |
+
2021_08_04_13_44_03 [Epoch] 057 [Loss] loss_span 0.4299 loss_giou 0.4749 loss_label 0.3384 class_error 6.6863 loss_saliency 0.2090 loss_span_0 0.4465 loss_giou_0 0.4941 loss_label_0 0.3370 class_error_0 6.7015 loss_overall 2.7297
|
| 58 |
+
2021_08_04_13_45_03 [Epoch] 058 [Loss] loss_span 0.4312 loss_giou 0.4767 loss_label 0.3319 class_error 6.0844 loss_saliency 0.2078 loss_span_0 0.4500 loss_giou_0 0.4961 loss_label_0 0.3322 class_error_0 6.7411 loss_overall 2.7257
|
| 59 |
+
2021_08_04_13_46_04 [Epoch] 059 [Loss] loss_span 0.4247 loss_giou 0.4720 loss_label 0.3302 class_error 6.0152 loss_saliency 0.2104 loss_span_0 0.4444 loss_giou_0 0.4904 loss_label_0 0.3294 class_error_0 6.5831 loss_overall 2.7015
|
| 60 |
+
2021_08_04_13_47_06 [Epoch] 060 [Loss] loss_span 0.4228 loss_giou 0.4703 loss_label 0.3273 class_error 6.0433 loss_saliency 0.2078 loss_span_0 0.4458 loss_giou_0 0.4902 loss_label_0 0.3256 class_error_0 6.4944 loss_overall 2.6898
|
| 61 |
+
2021_08_04_13_48_35 [Epoch] 061 [Loss] loss_span 0.4211 loss_giou 0.4714 loss_label 0.3224 class_error 5.8920 loss_saliency 0.2078 loss_span_0 0.4388 loss_giou_0 0.4885 loss_label_0 0.3245 class_error_0 6.6426 loss_overall 2.6746
|
| 62 |
+
2021_08_04_13_49_36 [Epoch] 062 [Loss] loss_span 0.4209 loss_giou 0.4683 loss_label 0.3220 class_error 6.0979 loss_saliency 0.2089 loss_span_0 0.4378 loss_giou_0 0.4859 loss_label_0 0.3214 class_error_0 6.3339 loss_overall 2.6653
|
| 63 |
+
2021_08_04_13_50_38 [Epoch] 063 [Loss] loss_span 0.4216 loss_giou 0.4685 loss_label 0.3175 class_error 5.8250 loss_saliency 0.2070 loss_span_0 0.4403 loss_giou_0 0.4871 loss_label_0 0.3164 class_error_0 6.1904 loss_overall 2.6584
|
| 64 |
+
2021_08_04_13_51_39 [Epoch] 064 [Loss] loss_span 0.4177 loss_giou 0.4668 loss_label 0.3157 class_error 5.9412 loss_saliency 0.2045 loss_span_0 0.4325 loss_giou_0 0.4836 loss_label_0 0.3196 class_error_0 6.5120 loss_overall 2.6404
|
| 65 |
+
2021_08_04_13_52_40 [Epoch] 065 [Loss] loss_span 0.4161 loss_giou 0.4669 loss_label 0.3127 class_error 6.0815 loss_saliency 0.2030 loss_span_0 0.4323 loss_giou_0 0.4814 loss_label_0 0.3152 class_error_0 6.3298 loss_overall 2.6277
|
| 66 |
+
2021_08_04_13_54_10 [Epoch] 066 [Loss] loss_span 0.4093 loss_giou 0.4645 loss_label 0.3142 class_error 6.0262 loss_saliency 0.2025 loss_span_0 0.4244 loss_giou_0 0.4768 loss_label_0 0.3144 class_error_0 6.4693 loss_overall 2.6061
|
| 67 |
+
2021_08_04_13_55_11 [Epoch] 067 [Loss] loss_span 0.4081 loss_giou 0.4608 loss_label 0.3066 class_error 5.8625 loss_saliency 0.1987 loss_span_0 0.4279 loss_giou_0 0.4810 loss_label_0 0.3057 class_error_0 6.4179 loss_overall 2.5888
|
| 68 |
+
2021_08_04_13_56_11 [Epoch] 068 [Loss] loss_span 0.4110 loss_giou 0.4628 loss_label 0.3056 class_error 5.9852 loss_saliency 0.1992 loss_span_0 0.4297 loss_giou_0 0.4827 loss_label_0 0.3058 class_error_0 5.9720 loss_overall 2.5968
|
| 69 |
+
2021_08_04_13_57_13 [Epoch] 069 [Loss] loss_span 0.4008 loss_giou 0.4582 loss_label 0.2997 class_error 5.5085 loss_saliency 0.1991 loss_span_0 0.4238 loss_giou_0 0.4773 loss_label_0 0.3017 class_error_0 6.0937 loss_overall 2.5607
|
| 70 |
+
2021_08_04_13_58_15 [Epoch] 070 [Loss] loss_span 0.4027 loss_giou 0.4587 loss_label 0.3016 class_error 5.7656 loss_saliency 0.1975 loss_span_0 0.4223 loss_giou_0 0.4753 loss_label_0 0.3032 class_error_0 5.9609 loss_overall 2.5612
|
| 71 |
+
2021_08_04_13_59_44 [Epoch] 071 [Loss] loss_span 0.3948 loss_giou 0.4546 loss_label 0.2983 class_error 5.6519 loss_saliency 0.1940 loss_span_0 0.4141 loss_giou_0 0.4756 loss_label_0 0.2978 class_error_0 5.9183 loss_overall 2.5293
|
| 72 |
+
2021_08_04_14_00_45 [Epoch] 072 [Loss] loss_span 0.3996 loss_giou 0.4558 loss_label 0.2962 class_error 5.8896 loss_saliency 0.1974 loss_span_0 0.4155 loss_giou_0 0.4735 loss_label_0 0.3004 class_error_0 6.0945 loss_overall 2.5382
|
| 73 |
+
2021_08_04_14_01_45 [Epoch] 073 [Loss] loss_span 0.3899 loss_giou 0.4529 loss_label 0.2941 class_error 5.5762 loss_saliency 0.1930 loss_span_0 0.4113 loss_giou_0 0.4709 loss_label_0 0.2958 class_error_0 5.9347 loss_overall 2.5079
|
| 74 |
+
2021_08_04_14_02_46 [Epoch] 074 [Loss] loss_span 0.3896 loss_giou 0.4518 loss_label 0.2886 class_error 5.5352 loss_saliency 0.1977 loss_span_0 0.4076 loss_giou_0 0.4675 loss_label_0 0.2927 class_error_0 5.8779 loss_overall 2.4955
|
| 75 |
+
2021_08_04_14_03_47 [Epoch] 075 [Loss] loss_span 0.3874 loss_giou 0.4532 loss_label 0.2875 class_error 5.1885 loss_saliency 0.1924 loss_span_0 0.4072 loss_giou_0 0.4712 loss_label_0 0.2926 class_error_0 6.1507 loss_overall 2.4915
|
| 76 |
+
2021_08_04_14_05_16 [Epoch] 076 [Loss] loss_span 0.3894 loss_giou 0.4502 loss_label 0.2842 class_error 5.2805 loss_saliency 0.1932 loss_span_0 0.4073 loss_giou_0 0.4690 loss_label_0 0.2901 class_error_0 5.8795 loss_overall 2.4833
|
| 77 |
+
2021_08_04_14_06_18 [Epoch] 077 [Loss] loss_span 0.3831 loss_giou 0.4476 loss_label 0.2816 class_error 5.2822 loss_saliency 0.1920 loss_span_0 0.4032 loss_giou_0 0.4646 loss_label_0 0.2838 class_error_0 5.7896 loss_overall 2.4561
|
| 78 |
+
2021_08_04_14_07_19 [Epoch] 078 [Loss] loss_span 0.3833 loss_giou 0.4483 loss_label 0.2794 class_error 5.2491 loss_saliency 0.1876 loss_span_0 0.3996 loss_giou_0 0.4650 loss_label_0 0.2869 class_error_0 5.9313 loss_overall 2.4501
|
| 79 |
+
2021_08_04_14_08_20 [Epoch] 079 [Loss] loss_span 0.3811 loss_giou 0.4457 loss_label 0.2779 class_error 5.0539 loss_saliency 0.1905 loss_span_0 0.4008 loss_giou_0 0.4654 loss_label_0 0.2812 class_error_0 5.6117 loss_overall 2.4426
|
| 80 |
+
2021_08_04_14_09_21 [Epoch] 080 [Loss] loss_span 0.3841 loss_giou 0.4474 loss_label 0.2726 class_error 5.0343 loss_saliency 0.1888 loss_span_0 0.4020 loss_giou_0 0.4662 loss_label_0 0.2794 class_error_0 5.4786 loss_overall 2.4404
|
| 81 |
+
2021_08_04_14_10_49 [Epoch] 081 [Loss] loss_span 0.3766 loss_giou 0.4462 loss_label 0.2717 class_error 5.1204 loss_saliency 0.1866 loss_span_0 0.3936 loss_giou_0 0.4613 loss_label_0 0.2779 class_error_0 5.5739 loss_overall 2.4140
|
| 82 |
+
2021_08_04_14_11_50 [Epoch] 082 [Loss] loss_span 0.3781 loss_giou 0.4463 loss_label 0.2702 class_error 4.9730 loss_saliency 0.1859 loss_span_0 0.3968 loss_giou_0 0.4641 loss_label_0 0.2732 class_error_0 5.5585 loss_overall 2.4146
|
| 83 |
+
2021_08_04_14_12_50 [Epoch] 083 [Loss] loss_span 0.3785 loss_giou 0.4477 loss_label 0.2664 class_error 5.0058 loss_saliency 0.1882 loss_span_0 0.3953 loss_giou_0 0.4619 loss_label_0 0.2696 class_error_0 5.4664 loss_overall 2.4077
|
| 84 |
+
2021_08_04_14_13_50 [Epoch] 084 [Loss] loss_span 0.3754 loss_giou 0.4435 loss_label 0.2619 class_error 4.5683 loss_saliency 0.1842 loss_span_0 0.3895 loss_giou_0 0.4592 loss_label_0 0.2717 class_error_0 5.3395 loss_overall 2.3854
|
| 85 |
+
2021_08_04_14_14_50 [Epoch] 085 [Loss] loss_span 0.3713 loss_giou 0.4403 loss_label 0.2623 class_error 5.0401 loss_saliency 0.1829 loss_span_0 0.3867 loss_giou_0 0.4570 loss_label_0 0.2707 class_error_0 5.4510 loss_overall 2.3712
|
| 86 |
+
2021_08_04_14_16_20 [Epoch] 086 [Loss] loss_span 0.3702 loss_giou 0.4399 loss_label 0.2640 class_error 4.8080 loss_saliency 0.1857 loss_span_0 0.3878 loss_giou_0 0.4560 loss_label_0 0.2712 class_error_0 5.6187 loss_overall 2.3749
|
| 87 |
+
2021_08_04_14_17_21 [Epoch] 087 [Loss] loss_span 0.3726 loss_giou 0.4406 loss_label 0.2574 class_error 4.8079 loss_saliency 0.1846 loss_span_0 0.3883 loss_giou_0 0.4553 loss_label_0 0.2676 class_error_0 5.4877 loss_overall 2.3665
|
| 88 |
+
2021_08_04_14_18_22 [Epoch] 088 [Loss] loss_span 0.3709 loss_giou 0.4391 loss_label 0.2587 class_error 5.1116 loss_saliency 0.1834 loss_span_0 0.3849 loss_giou_0 0.4572 loss_label_0 0.2646 class_error_0 5.4610 loss_overall 2.3588
|
| 89 |
+
2021_08_04_14_19_25 [Epoch] 089 [Loss] loss_span 0.3674 loss_giou 0.4394 loss_label 0.2525 class_error 4.7836 loss_saliency 0.1853 loss_span_0 0.3806 loss_giou_0 0.4529 loss_label_0 0.2613 class_error_0 5.2184 loss_overall 2.3394
|
| 90 |
+
2021_08_04_14_20_26 [Epoch] 090 [Loss] loss_span 0.3613 loss_giou 0.4349 loss_label 0.2519 class_error 4.7219 loss_saliency 0.1813 loss_span_0 0.3788 loss_giou_0 0.4523 loss_label_0 0.2597 class_error_0 5.2277 loss_overall 2.3202
|
| 91 |
+
2021_08_04_14_21_55 [Epoch] 091 [Loss] loss_span 0.3648 loss_giou 0.4344 loss_label 0.2473 class_error 4.5663 loss_saliency 0.1824 loss_span_0 0.3802 loss_giou_0 0.4528 loss_label_0 0.2542 class_error_0 5.3019 loss_overall 2.3160
|
| 92 |
+
2021_08_04_14_22_56 [Epoch] 092 [Loss] loss_span 0.3583 loss_giou 0.4323 loss_label 0.2471 class_error 4.5833 loss_saliency 0.1808 loss_span_0 0.3769 loss_giou_0 0.4504 loss_label_0 0.2536 class_error_0 4.9397 loss_overall 2.2994
|
| 93 |
+
2021_08_04_14_23_57 [Epoch] 093 [Loss] loss_span 0.3589 loss_giou 0.4329 loss_label 0.2480 class_error 4.5618 loss_saliency 0.1801 loss_span_0 0.3758 loss_giou_0 0.4511 loss_label_0 0.2563 class_error_0 5.1501 loss_overall 2.3031
|
| 94 |
+
2021_08_04_14_24_58 [Epoch] 094 [Loss] loss_span 0.3561 loss_giou 0.4321 loss_label 0.2440 class_error 4.6280 loss_saliency 0.1777 loss_span_0 0.3728 loss_giou_0 0.4485 loss_label_0 0.2530 class_error_0 4.9064 loss_overall 2.2841
|
| 95 |
+
2021_08_04_14_26_02 [Epoch] 095 [Loss] loss_span 0.3564 loss_giou 0.4284 loss_label 0.2470 class_error 4.7366 loss_saliency 0.1802 loss_span_0 0.3729 loss_giou_0 0.4450 loss_label_0 0.2539 class_error_0 5.3536 loss_overall 2.2837
|
| 96 |
+
2021_08_04_14_27_29 [Epoch] 096 [Loss] loss_span 0.3531 loss_giou 0.4298 loss_label 0.2438 class_error 4.4720 loss_saliency 0.1795 loss_span_0 0.3669 loss_giou_0 0.4424 loss_label_0 0.2531 class_error_0 4.9912 loss_overall 2.2687
|
| 97 |
+
2021_08_04_14_28_30 [Epoch] 097 [Loss] loss_span 0.3545 loss_giou 0.4292 loss_label 0.2389 class_error 4.2460 loss_saliency 0.1794 loss_span_0 0.3696 loss_giou_0 0.4451 loss_label_0 0.2472 class_error_0 4.7524 loss_overall 2.2638
|
| 98 |
+
2021_08_04_14_29_31 [Epoch] 098 [Loss] loss_span 0.3556 loss_giou 0.4323 loss_label 0.2386 class_error 4.3526 loss_saliency 0.1791 loss_span_0 0.3690 loss_giou_0 0.4455 loss_label_0 0.2473 class_error_0 4.7186 loss_overall 2.2674
|
| 99 |
+
2021_08_04_14_30_32 [Epoch] 099 [Loss] loss_span 0.3482 loss_giou 0.4251 loss_label 0.2386 class_error 4.2954 loss_saliency 0.1760 loss_span_0 0.3673 loss_giou_0 0.4429 loss_label_0 0.2463 class_error_0 5.0847 loss_overall 2.2443
|
| 100 |
+
2021_08_04_14_31_32 [Epoch] 100 [Loss] loss_span 0.3505 loss_giou 0.4303 loss_label 0.2325 class_error 4.2448 loss_saliency 0.1743 loss_span_0 0.3644 loss_giou_0 0.4437 loss_label_0 0.2423 class_error_0 4.8983 loss_overall 2.2379
|
| 101 |
+
2021_08_04_14_33_04 [Epoch] 101 [Loss] loss_span 0.3472 loss_giou 0.4252 loss_label 0.2339 class_error 4.2455 loss_saliency 0.1739 loss_span_0 0.3675 loss_giou_0 0.4419 loss_label_0 0.2423 class_error_0 4.8791 loss_overall 2.2320
|
| 102 |
+
2021_08_04_14_34_05 [Epoch] 102 [Loss] loss_span 0.3399 loss_giou 0.4203 loss_label 0.2257 class_error 4.2149 loss_saliency 0.1741 loss_span_0 0.3583 loss_giou_0 0.4377 loss_label_0 0.2368 class_error_0 4.4555 loss_overall 2.1928
|
| 103 |
+
2021_08_04_14_35_06 [Epoch] 103 [Loss] loss_span 0.3417 loss_giou 0.4222 loss_label 0.2268 class_error 4.1977 loss_saliency 0.1731 loss_span_0 0.3598 loss_giou_0 0.4390 loss_label_0 0.2336 class_error_0 4.6748 loss_overall 2.1963
|
| 104 |
+
2021_08_04_14_36_07 [Epoch] 104 [Loss] loss_span 0.3407 loss_giou 0.4249 loss_label 0.2237 class_error 4.1355 loss_saliency 0.1742 loss_span_0 0.3543 loss_giou_0 0.4388 loss_label_0 0.2338 class_error_0 4.5341 loss_overall 2.1902
|
| 105 |
+
2021_08_04_14_37_10 [Epoch] 105 [Loss] loss_span 0.3385 loss_giou 0.4188 loss_label 0.2260 class_error 4.1884 loss_saliency 0.1718 loss_span_0 0.3562 loss_giou_0 0.4361 loss_label_0 0.2364 class_error_0 4.3986 loss_overall 2.1838
|
| 106 |
+
2021_08_04_14_38_37 [Epoch] 106 [Loss] loss_span 0.3373 loss_giou 0.4203 loss_label 0.2230 class_error 3.9524 loss_saliency 0.1707 loss_span_0 0.3528 loss_giou_0 0.4353 loss_label_0 0.2355 class_error_0 4.5857 loss_overall 2.1748
|
| 107 |
+
2021_08_04_14_39_38 [Epoch] 107 [Loss] loss_span 0.3342 loss_giou 0.4198 loss_label 0.2201 class_error 4.0337 loss_saliency 0.1731 loss_span_0 0.3535 loss_giou_0 0.4373 loss_label_0 0.2294 class_error_0 4.3019 loss_overall 2.1676
|
| 108 |
+
2021_08_04_14_40_40 [Epoch] 108 [Loss] loss_span 0.3349 loss_giou 0.4191 loss_label 0.2205 class_error 3.9333 loss_saliency 0.1698 loss_span_0 0.3482 loss_giou_0 0.4340 loss_label_0 0.2282 class_error_0 4.2782 loss_overall 2.1546
|
| 109 |
+
2021_08_04_14_41_40 [Epoch] 109 [Loss] loss_span 0.3323 loss_giou 0.4152 loss_label 0.2180 class_error 3.8188 loss_saliency 0.1700 loss_span_0 0.3513 loss_giou_0 0.4353 loss_label_0 0.2268 class_error_0 4.2483 loss_overall 2.1490
|
| 110 |
+
2021_08_04_14_42_40 [Epoch] 110 [Loss] loss_span 0.3321 loss_giou 0.4166 loss_label 0.2193 class_error 4.0816 loss_saliency 0.1726 loss_span_0 0.3494 loss_giou_0 0.4338 loss_label_0 0.2296 class_error_0 4.5403 loss_overall 2.1534
|
| 111 |
+
2021_08_04_14_44_06 [Epoch] 111 [Loss] loss_span 0.3297 loss_giou 0.4124 loss_label 0.2172 class_error 3.9085 loss_saliency 0.1687 loss_span_0 0.3438 loss_giou_0 0.4292 loss_label_0 0.2270 class_error_0 4.2952 loss_overall 2.1280
|
| 112 |
+
2021_08_04_14_45_05 [Epoch] 112 [Loss] loss_span 0.3296 loss_giou 0.4162 loss_label 0.2161 class_error 3.8610 loss_saliency 0.1672 loss_span_0 0.3436 loss_giou_0 0.4299 loss_label_0 0.2259 class_error_0 4.3925 loss_overall 2.1285
|
| 113 |
+
2021_08_04_14_46_05 [Epoch] 113 [Loss] loss_span 0.3297 loss_giou 0.4140 loss_label 0.2120 class_error 3.6386 loss_saliency 0.1698 loss_span_0 0.3428 loss_giou_0 0.4283 loss_label_0 0.2234 class_error_0 4.2161 loss_overall 2.1200
|
| 114 |
+
2021_08_04_14_47_04 [Epoch] 114 [Loss] loss_span 0.3266 loss_giou 0.4133 loss_label 0.2090 class_error 3.8373 loss_saliency 0.1685 loss_span_0 0.3435 loss_giou_0 0.4303 loss_label_0 0.2172 class_error_0 3.9232 loss_overall 2.1084
|
| 115 |
+
2021_08_04_14_48_04 [Epoch] 115 [Loss] loss_span 0.3281 loss_giou 0.4099 loss_label 0.2098 class_error 3.7227 loss_saliency 0.1700 loss_span_0 0.3419 loss_giou_0 0.4275 loss_label_0 0.2191 class_error_0 4.1054 loss_overall 2.1063
|
| 116 |
+
2021_08_04_14_49_32 [Epoch] 116 [Loss] loss_span 0.3246 loss_giou 0.4120 loss_label 0.2050 class_error 3.5181 loss_saliency 0.1710 loss_span_0 0.3398 loss_giou_0 0.4276 loss_label_0 0.2116 class_error_0 4.0029 loss_overall 2.0917
|
| 117 |
+
2021_08_04_14_50_32 [Epoch] 117 [Loss] loss_span 0.3213 loss_giou 0.4076 loss_label 0.2016 class_error 3.6359 loss_saliency 0.1649 loss_span_0 0.3360 loss_giou_0 0.4234 loss_label_0 0.2145 class_error_0 4.0928 loss_overall 2.0694
|
| 118 |
+
2021_08_04_14_51_33 [Epoch] 118 [Loss] loss_span 0.3169 loss_giou 0.4056 loss_label 0.1990 class_error 3.4006 loss_saliency 0.1650 loss_span_0 0.3365 loss_giou_0 0.4250 loss_label_0 0.2085 class_error_0 3.7403 loss_overall 2.0565
|
| 119 |
+
2021_08_04_14_52_32 [Epoch] 119 [Loss] loss_span 0.3194 loss_giou 0.4075 loss_label 0.1977 class_error 3.4690 loss_saliency 0.1655 loss_span_0 0.3357 loss_giou_0 0.4240 loss_label_0 0.2108 class_error_0 3.9946 loss_overall 2.0607
|
| 120 |
+
2021_08_04_14_53_32 [Epoch] 120 [Loss] loss_span 0.3203 loss_giou 0.4067 loss_label 0.1982 class_error 3.4715 loss_saliency 0.1626 loss_span_0 0.3334 loss_giou_0 0.4223 loss_label_0 0.2123 class_error_0 3.9178 loss_overall 2.0559
|
| 121 |
+
2021_08_04_14_54_59 [Epoch] 121 [Loss] loss_span 0.3183 loss_giou 0.4033 loss_label 0.2039 class_error 3.6320 loss_saliency 0.1638 loss_span_0 0.3301 loss_giou_0 0.4205 loss_label_0 0.2127 class_error_0 4.1402 loss_overall 2.0526
|
| 122 |
+
2021_08_04_14_55_58 [Epoch] 122 [Loss] loss_span 0.3152 loss_giou 0.4043 loss_label 0.1946 class_error 3.3929 loss_saliency 0.1650 loss_span_0 0.3304 loss_giou_0 0.4212 loss_label_0 0.2051 class_error_0 3.7802 loss_overall 2.0359
|
| 123 |
+
2021_08_04_14_56_58 [Epoch] 123 [Loss] loss_span 0.3145 loss_giou 0.4035 loss_label 0.1983 class_error 3.5264 loss_saliency 0.1625 loss_span_0 0.3308 loss_giou_0 0.4204 loss_label_0 0.2087 class_error_0 3.6907 loss_overall 2.0388
|
| 124 |
+
2021_08_04_14_57_58 [Epoch] 124 [Loss] loss_span 0.3074 loss_giou 0.4005 loss_label 0.1914 class_error 3.4976 loss_saliency 0.1627 loss_span_0 0.3229 loss_giou_0 0.4164 loss_label_0 0.2072 class_error_0 3.9096 loss_overall 2.0085
|
| 125 |
+
2021_08_04_14_58_57 [Epoch] 125 [Loss] loss_span 0.3106 loss_giou 0.4016 loss_label 0.1908 class_error 3.2744 loss_saliency 0.1642 loss_span_0 0.3256 loss_giou_0 0.4154 loss_label_0 0.2049 class_error_0 3.6893 loss_overall 2.0130
|
| 126 |
+
2021_08_04_15_00_24 [Epoch] 126 [Loss] loss_span 0.3061 loss_giou 0.3994 loss_label 0.1932 class_error 3.4730 loss_saliency 0.1612 loss_span_0 0.3228 loss_giou_0 0.4159 loss_label_0 0.2029 class_error_0 3.7799 loss_overall 2.0015
|
| 127 |
+
2021_08_04_15_01_24 [Epoch] 127 [Loss] loss_span 0.3080 loss_giou 0.3997 loss_label 0.1892 class_error 3.2892 loss_saliency 0.1582 loss_span_0 0.3272 loss_giou_0 0.4172 loss_label_0 0.1969 class_error_0 3.6708 loss_overall 1.9963
|
| 128 |
+
2021_08_04_15_02_23 [Epoch] 128 [Loss] loss_span 0.3080 loss_giou 0.3981 loss_label 0.1890 class_error 3.1337 loss_saliency 0.1610 loss_span_0 0.3237 loss_giou_0 0.4152 loss_label_0 0.1993 class_error_0 3.4701 loss_overall 1.9944
|
| 129 |
+
2021_08_04_15_03_22 [Epoch] 129 [Loss] loss_span 0.3038 loss_giou 0.3994 loss_label 0.1867 class_error 3.2974 loss_saliency 0.1581 loss_span_0 0.3187 loss_giou_0 0.4142 loss_label_0 0.2006 class_error_0 3.6422 loss_overall 1.9816
|
| 130 |
+
2021_08_04_15_04_22 [Epoch] 130 [Loss] loss_span 0.3062 loss_giou 0.3989 loss_label 0.1820 class_error 3.1423 loss_saliency 0.1602 loss_span_0 0.3214 loss_giou_0 0.4183 loss_label_0 0.1958 class_error_0 3.6474 loss_overall 1.9827
|
| 131 |
+
2021_08_04_15_05_47 [Epoch] 131 [Loss] loss_span 0.3047 loss_giou 0.3991 loss_label 0.1813 class_error 3.1361 loss_saliency 0.1613 loss_span_0 0.3172 loss_giou_0 0.4116 loss_label_0 0.1967 class_error_0 3.6585 loss_overall 1.9719
|
| 132 |
+
2021_08_04_15_06_45 [Epoch] 132 [Loss] loss_span 0.3034 loss_giou 0.3960 loss_label 0.1797 class_error 2.9289 loss_saliency 0.1570 loss_span_0 0.3177 loss_giou_0 0.4116 loss_label_0 0.1979 class_error_0 3.4351 loss_overall 1.9634
|
| 133 |
+
2021_08_04_15_07_45 [Epoch] 133 [Loss] loss_span 0.3017 loss_giou 0.3943 loss_label 0.1805 class_error 3.1074 loss_saliency 0.1583 loss_span_0 0.3166 loss_giou_0 0.4090 loss_label_0 0.1936 class_error_0 3.4266 loss_overall 1.9540
|
| 134 |
+
2021_08_04_15_08_45 [Epoch] 134 [Loss] loss_span 0.3030 loss_giou 0.3977 loss_label 0.1814 class_error 3.1439 loss_saliency 0.1587 loss_span_0 0.3150 loss_giou_0 0.4117 loss_label_0 0.1943 class_error_0 3.5817 loss_overall 1.9619
|
| 135 |
+
2021_08_04_15_09_44 [Epoch] 135 [Loss] loss_span 0.2985 loss_giou 0.3913 loss_label 0.1801 class_error 3.2043 loss_saliency 0.1579 loss_span_0 0.3135 loss_giou_0 0.4096 loss_label_0 0.1895 class_error_0 3.4347 loss_overall 1.9404
|
| 136 |
+
2021_08_04_15_11_11 [Epoch] 136 [Loss] loss_span 0.2979 loss_giou 0.3922 loss_label 0.1785 class_error 3.0857 loss_saliency 0.1583 loss_span_0 0.3095 loss_giou_0 0.4057 loss_label_0 0.1914 class_error_0 3.6656 loss_overall 1.9335
|
| 137 |
+
2021_08_04_15_12_10 [Epoch] 137 [Loss] loss_span 0.2949 loss_giou 0.3933 loss_label 0.1798 class_error 2.9996 loss_saliency 0.1574 loss_span_0 0.3117 loss_giou_0 0.4099 loss_label_0 0.1904 class_error_0 3.4402 loss_overall 1.9374
|
| 138 |
+
2021_08_04_15_13_09 [Epoch] 138 [Loss] loss_span 0.2912 loss_giou 0.3885 loss_label 0.1765 class_error 3.0080 loss_saliency 0.1564 loss_span_0 0.3071 loss_giou_0 0.4056 loss_label_0 0.1888 class_error_0 3.4500 loss_overall 1.9141
|
| 139 |
+
2021_08_04_15_14_08 [Epoch] 139 [Loss] loss_span 0.2887 loss_giou 0.3840 loss_label 0.1755 class_error 3.1152 loss_saliency 0.1582 loss_span_0 0.3036 loss_giou_0 0.4008 loss_label_0 0.1887 class_error_0 3.2850 loss_overall 1.8995
|
| 140 |
+
2021_08_04_15_15_08 [Epoch] 140 [Loss] loss_span 0.2917 loss_giou 0.3904 loss_label 0.1673 class_error 2.8572 loss_saliency 0.1552 loss_span_0 0.3069 loss_giou_0 0.4090 loss_label_0 0.1784 class_error_0 3.0141 loss_overall 1.8990
|
| 141 |
+
2021_08_04_15_16_37 [Epoch] 141 [Loss] loss_span 0.2918 loss_giou 0.3902 loss_label 0.1703 class_error 2.8095 loss_saliency 0.1520 loss_span_0 0.3079 loss_giou_0 0.4089 loss_label_0 0.1834 class_error_0 3.4561 loss_overall 1.9044
|
| 142 |
+
2021_08_04_15_17_38 [Epoch] 142 [Loss] loss_span 0.2913 loss_giou 0.3894 loss_label 0.1724 class_error 2.8330 loss_saliency 0.1518 loss_span_0 0.3067 loss_giou_0 0.4060 loss_label_0 0.1859 class_error_0 3.2875 loss_overall 1.9036
|
| 143 |
+
2021_08_04_15_18_39 [Epoch] 143 [Loss] loss_span 0.2888 loss_giou 0.3850 loss_label 0.1710 class_error 2.8611 loss_saliency 0.1503 loss_span_0 0.3045 loss_giou_0 0.4014 loss_label_0 0.1813 class_error_0 3.1913 loss_overall 1.8823
|
| 144 |
+
2021_08_04_15_19_40 [Epoch] 144 [Loss] loss_span 0.2899 loss_giou 0.3863 loss_label 0.1676 class_error 2.8735 loss_saliency 0.1524 loss_span_0 0.3057 loss_giou_0 0.4037 loss_label_0 0.1793 class_error_0 3.1955 loss_overall 1.8848
|
| 145 |
+
2021_08_04_15_20_41 [Epoch] 145 [Loss] loss_span 0.2859 loss_giou 0.3850 loss_label 0.1679 class_error 2.7106 loss_saliency 0.1520 loss_span_0 0.3018 loss_giou_0 0.4005 loss_label_0 0.1797 class_error_0 3.1690 loss_overall 1.8728
|
| 146 |
+
2021_08_04_15_22_08 [Epoch] 146 [Loss] loss_span 0.2863 loss_giou 0.3833 loss_label 0.1676 class_error 2.8849 loss_saliency 0.1556 loss_span_0 0.3006 loss_giou_0 0.4001 loss_label_0 0.1826 class_error_0 3.3652 loss_overall 1.8761
|
| 147 |
+
2021_08_04_15_23_08 [Epoch] 147 [Loss] loss_span 0.2848 loss_giou 0.3848 loss_label 0.1639 class_error 2.7943 loss_saliency 0.1520 loss_span_0 0.3000 loss_giou_0 0.3996 loss_label_0 0.1745 class_error_0 3.1314 loss_overall 1.8597
|
| 148 |
+
2021_08_04_15_24_09 [Epoch] 148 [Loss] loss_span 0.2830 loss_giou 0.3831 loss_label 0.1680 class_error 2.8535 loss_saliency 0.1538 loss_span_0 0.2982 loss_giou_0 0.3977 loss_label_0 0.1787 class_error_0 3.0520 loss_overall 1.8625
|
| 149 |
+
2021_08_04_15_25_09 [Epoch] 149 [Loss] loss_span 0.2811 loss_giou 0.3792 loss_label 0.1639 class_error 2.9072 loss_saliency 0.1512 loss_span_0 0.2963 loss_giou_0 0.3958 loss_label_0 0.1755 class_error_0 3.2742 loss_overall 1.8430
|
| 150 |
+
2021_08_04_15_26_09 [Epoch] 150 [Loss] loss_span 0.2806 loss_giou 0.3779 loss_label 0.1594 class_error 2.7003 loss_saliency 0.1513 loss_span_0 0.2956 loss_giou_0 0.3953 loss_label_0 0.1728 class_error_0 3.1146 loss_overall 1.8330
|
| 151 |
+
2021_08_04_15_27_39 [Epoch] 151 [Loss] loss_span 0.2807 loss_giou 0.3786 loss_label 0.1600 class_error 2.7823 loss_saliency 0.1503 loss_span_0 0.2958 loss_giou_0 0.3970 loss_label_0 0.1716 class_error_0 3.0476 loss_overall 1.8341
|
| 152 |
+
2021_08_04_15_28_41 [Epoch] 152 [Loss] loss_span 0.2789 loss_giou 0.3780 loss_label 0.1588 class_error 2.5760 loss_saliency 0.1488 loss_span_0 0.2956 loss_giou_0 0.3953 loss_label_0 0.1709 class_error_0 2.8832 loss_overall 1.8263
|
| 153 |
+
2021_08_04_15_29_42 [Epoch] 153 [Loss] loss_span 0.2737 loss_giou 0.3772 loss_label 0.1584 class_error 2.5702 loss_saliency 0.1505 loss_span_0 0.2923 loss_giou_0 0.3955 loss_label_0 0.1707 class_error_0 2.8542 loss_overall 1.8182
|
| 154 |
+
2021_08_04_15_30_43 [Epoch] 154 [Loss] loss_span 0.2757 loss_giou 0.3765 loss_label 0.1571 class_error 2.6065 loss_saliency 0.1497 loss_span_0 0.2934 loss_giou_0 0.3948 loss_label_0 0.1695 class_error_0 3.1185 loss_overall 1.8168
|
| 155 |
+
2021_08_04_15_31_45 [Epoch] 155 [Loss] loss_span 0.2750 loss_giou 0.3761 loss_label 0.1526 class_error 2.6418 loss_saliency 0.1508 loss_span_0 0.2890 loss_giou_0 0.3933 loss_label_0 0.1675 class_error_0 2.8686 loss_overall 1.8044
|
| 156 |
+
2021_08_04_15_33_14 [Epoch] 156 [Loss] loss_span 0.2739 loss_giou 0.3754 loss_label 0.1519 class_error 2.4531 loss_saliency 0.1473 loss_span_0 0.2887 loss_giou_0 0.3934 loss_label_0 0.1644 class_error_0 2.7928 loss_overall 1.7950
|
| 157 |
+
2021_08_04_15_34_16 [Epoch] 157 [Loss] loss_span 0.2744 loss_giou 0.3753 loss_label 0.1513 class_error 2.3596 loss_saliency 0.1512 loss_span_0 0.2907 loss_giou_0 0.3908 loss_label_0 0.1650 class_error_0 2.8359 loss_overall 1.7987
|
| 158 |
+
2021_08_04_15_35_17 [Epoch] 158 [Loss] loss_span 0.2696 loss_giou 0.3727 loss_label 0.1477 class_error 2.3840 loss_saliency 0.1478 loss_span_0 0.2870 loss_giou_0 0.3908 loss_label_0 0.1605 class_error_0 2.5061 loss_overall 1.7761
|
| 159 |
+
2021_08_04_15_36_17 [Epoch] 159 [Loss] loss_span 0.2662 loss_giou 0.3712 loss_label 0.1516 class_error 2.4106 loss_saliency 0.1447 loss_span_0 0.2860 loss_giou_0 0.3905 loss_label_0 0.1654 class_error_0 3.0264 loss_overall 1.7756
|
| 160 |
+
2021_08_04_15_37_17 [Epoch] 160 [Loss] loss_span 0.2664 loss_giou 0.3718 loss_label 0.1473 class_error 2.3810 loss_saliency 0.1451 loss_span_0 0.2833 loss_giou_0 0.3868 loss_label_0 0.1598 class_error_0 2.6970 loss_overall 1.7605
|
| 161 |
+
2021_08_04_15_38_41 [Epoch] 161 [Loss] loss_span 0.2688 loss_giou 0.3715 loss_label 0.1496 class_error 2.5530 loss_saliency 0.1439 loss_span_0 0.2842 loss_giou_0 0.3874 loss_label_0 0.1631 class_error_0 2.8635 loss_overall 1.7685
|
| 162 |
+
2021_08_04_15_39_39 [Epoch] 162 [Loss] loss_span 0.2675 loss_giou 0.3712 loss_label 0.1438 class_error 2.2517 loss_saliency 0.1449 loss_span_0 0.2876 loss_giou_0 0.3899 loss_label_0 0.1577 class_error_0 2.7662 loss_overall 1.7625
|
| 163 |
+
2021_08_04_15_40_38 [Epoch] 163 [Loss] loss_span 0.2660 loss_giou 0.3724 loss_label 0.1476 class_error 2.4018 loss_saliency 0.1463 loss_span_0 0.2821 loss_giou_0 0.3878 loss_label_0 0.1593 class_error_0 2.6189 loss_overall 1.7615
|
| 164 |
+
2021_08_04_15_41_38 [Epoch] 164 [Loss] loss_span 0.2688 loss_giou 0.3718 loss_label 0.1424 class_error 2.2719 loss_saliency 0.1486 loss_span_0 0.2860 loss_giou_0 0.3911 loss_label_0 0.1572 class_error_0 2.7330 loss_overall 1.7659
|
| 165 |
+
2021_08_04_15_42_38 [Epoch] 165 [Loss] loss_span 0.2634 loss_giou 0.3700 loss_label 0.1412 class_error 2.3051 loss_saliency 0.1467 loss_span_0 0.2812 loss_giou_0 0.3880 loss_label_0 0.1542 class_error_0 2.5147 loss_overall 1.7448
|
| 166 |
+
2021_08_04_15_44_01 [Epoch] 166 [Loss] loss_span 0.2606 loss_giou 0.3658 loss_label 0.1437 class_error 2.4155 loss_saliency 0.1465 loss_span_0 0.2801 loss_giou_0 0.3855 loss_label_0 0.1571 class_error_0 2.6513 loss_overall 1.7392
|
| 167 |
+
2021_08_04_15_45_01 [Epoch] 167 [Loss] loss_span 0.2611 loss_giou 0.3637 loss_label 0.1434 class_error 2.3979 loss_saliency 0.1429 loss_span_0 0.2788 loss_giou_0 0.3807 loss_label_0 0.1546 class_error_0 2.7567 loss_overall 1.7252
|
| 168 |
+
2021_08_04_15_46_01 [Epoch] 168 [Loss] loss_span 0.2609 loss_giou 0.3650 loss_label 0.1399 class_error 2.1873 loss_saliency 0.1438 loss_span_0 0.2759 loss_giou_0 0.3819 loss_label_0 0.1530 class_error_0 2.5145 loss_overall 1.7205
|
| 169 |
+
2021_08_04_15_47_00 [Epoch] 169 [Loss] loss_span 0.2606 loss_giou 0.3657 loss_label 0.1389 class_error 2.2921 loss_saliency 0.1444 loss_span_0 0.2750 loss_giou_0 0.3819 loss_label_0 0.1548 class_error_0 2.8847 loss_overall 1.7213
|
| 170 |
+
2021_08_04_15_48_00 [Epoch] 170 [Loss] loss_span 0.2598 loss_giou 0.3652 loss_label 0.1345 class_error 2.2562 loss_saliency 0.1402 loss_span_0 0.2746 loss_giou_0 0.3824 loss_label_0 0.1505 class_error_0 2.6511 loss_overall 1.7073
|
| 171 |
+
2021_08_04_15_49_26 [Epoch] 171 [Loss] loss_span 0.2555 loss_giou 0.3606 loss_label 0.1372 class_error 2.1929 loss_saliency 0.1400 loss_span_0 0.2734 loss_giou_0 0.3782 loss_label_0 0.1488 class_error_0 2.7173 loss_overall 1.6937
|
| 172 |
+
2021_08_04_15_50_25 [Epoch] 172 [Loss] loss_span 0.2582 loss_giou 0.3630 loss_label 0.1384 class_error 2.2284 loss_saliency 0.1419 loss_span_0 0.2737 loss_giou_0 0.3791 loss_label_0 0.1505 class_error_0 2.6517 loss_overall 1.7048
|
| 173 |
+
2021_08_04_15_51_24 [Epoch] 173 [Loss] loss_span 0.2560 loss_giou 0.3611 loss_label 0.1356 class_error 2.2456 loss_saliency 0.1453 loss_span_0 0.2706 loss_giou_0 0.3772 loss_label_0 0.1512 class_error_0 2.6532 loss_overall 1.6970
|
| 174 |
+
2021_08_04_15_52_25 [Epoch] 174 [Loss] loss_span 0.2559 loss_giou 0.3609 loss_label 0.1359 class_error 2.1697 loss_saliency 0.1411 loss_span_0 0.2729 loss_giou_0 0.3787 loss_label_0 0.1469 class_error_0 2.5194 loss_overall 1.6922
|
| 175 |
+
2021_08_04_15_53_26 [Epoch] 175 [Loss] loss_span 0.2525 loss_giou 0.3594 loss_label 0.1386 class_error 2.2496 loss_saliency 0.1391 loss_span_0 0.2696 loss_giou_0 0.3768 loss_label_0 0.1550 class_error_0 2.6409 loss_overall 1.6911
|
| 176 |
+
2021_08_04_15_54_51 [Epoch] 176 [Loss] loss_span 0.2535 loss_giou 0.3596 loss_label 0.1364 class_error 2.1629 loss_saliency 0.1403 loss_span_0 0.2705 loss_giou_0 0.3761 loss_label_0 0.1501 class_error_0 2.7246 loss_overall 1.6865
|
| 177 |
+
2021_08_04_15_55_49 [Epoch] 177 [Loss] loss_span 0.2514 loss_giou 0.3579 loss_label 0.1326 class_error 2.1063 loss_saliency 0.1383 loss_span_0 0.2667 loss_giou_0 0.3764 loss_label_0 0.1433 class_error_0 2.5593 loss_overall 1.6667
|
| 178 |
+
2021_08_04_15_56_48 [Epoch] 178 [Loss] loss_span 0.2497 loss_giou 0.3568 loss_label 0.1334 class_error 2.2729 loss_saliency 0.1385 loss_span_0 0.2642 loss_giou_0 0.3715 loss_label_0 0.1454 class_error_0 2.4777 loss_overall 1.6596
|
| 179 |
+
2021_08_04_15_57_46 [Epoch] 179 [Loss] loss_span 0.2501 loss_giou 0.3578 loss_label 0.1323 class_error 2.1815 loss_saliency 0.1335 loss_span_0 0.2665 loss_giou_0 0.3753 loss_label_0 0.1464 class_error_0 2.6389 loss_overall 1.6619
|
| 180 |
+
2021_08_04_15_58_46 [Epoch] 180 [Loss] loss_span 0.2475 loss_giou 0.3558 loss_label 0.1287 class_error 2.1187 loss_saliency 0.1384 loss_span_0 0.2646 loss_giou_0 0.3722 loss_label_0 0.1425 class_error_0 2.4137 loss_overall 1.6497
|
| 181 |
+
2021_08_04_16_00_09 [Epoch] 181 [Loss] loss_span 0.2501 loss_giou 0.3564 loss_label 0.1284 class_error 2.0690 loss_saliency 0.1423 loss_span_0 0.2671 loss_giou_0 0.3764 loss_label_0 0.1422 class_error_0 2.4760 loss_overall 1.6629
|
| 182 |
+
2021_08_04_16_01_07 [Epoch] 182 [Loss] loss_span 0.2506 loss_giou 0.3559 loss_label 0.1246 class_error 2.0133 loss_saliency 0.1367 loss_span_0 0.2653 loss_giou_0 0.3738 loss_label_0 0.1417 class_error_0 2.5186 loss_overall 1.6486
|
| 183 |
+
2021_08_04_16_02_08 [Epoch] 183 [Loss] loss_span 0.2435 loss_giou 0.3531 loss_label 0.1296 class_error 2.0768 loss_saliency 0.1342 loss_span_0 0.2591 loss_giou_0 0.3703 loss_label_0 0.1409 class_error_0 2.4239 loss_overall 1.6307
|
| 184 |
+
2021_08_04_16_03_06 [Epoch] 184 [Loss] loss_span 0.2470 loss_giou 0.3551 loss_label 0.1282 class_error 2.1464 loss_saliency 0.1386 loss_span_0 0.2641 loss_giou_0 0.3735 loss_label_0 0.1410 class_error_0 2.4869 loss_overall 1.6476
|
| 185 |
+
2021_08_04_16_04_05 [Epoch] 185 [Loss] loss_span 0.2466 loss_giou 0.3528 loss_label 0.1251 class_error 2.0378 loss_saliency 0.1356 loss_span_0 0.2629 loss_giou_0 0.3728 loss_label_0 0.1375 class_error_0 2.3513 loss_overall 1.6333
|
| 186 |
+
2021_08_04_16_05_29 [Epoch] 186 [Loss] loss_span 0.2416 loss_giou 0.3495 loss_label 0.1217 class_error 1.9513 loss_saliency 0.1360 loss_span_0 0.2583 loss_giou_0 0.3696 loss_label_0 0.1372 class_error_0 2.3763 loss_overall 1.6139
|
| 187 |
+
2021_08_04_16_06_29 [Epoch] 187 [Loss] loss_span 0.2411 loss_giou 0.3523 loss_label 0.1226 class_error 2.1811 loss_saliency 0.1379 loss_span_0 0.2572 loss_giou_0 0.3693 loss_label_0 0.1364 class_error_0 2.3852 loss_overall 1.6167
|
| 188 |
+
2021_08_04_16_07_29 [Epoch] 188 [Loss] loss_span 0.2419 loss_giou 0.3516 loss_label 0.1280 class_error 1.9720 loss_saliency 0.1370 loss_span_0 0.2597 loss_giou_0 0.3687 loss_label_0 0.1414 class_error_0 2.3192 loss_overall 1.6283
|
| 189 |
+
2021_08_04_16_08_28 [Epoch] 189 [Loss] loss_span 0.2417 loss_giou 0.3496 loss_label 0.1240 class_error 2.0014 loss_saliency 0.1338 loss_span_0 0.2560 loss_giou_0 0.3657 loss_label_0 0.1363 class_error_0 2.3553 loss_overall 1.6072
|
| 190 |
+
2021_08_04_16_09_27 [Epoch] 190 [Loss] loss_span 0.2386 loss_giou 0.3476 loss_label 0.1223 class_error 2.1402 loss_saliency 0.1341 loss_span_0 0.2528 loss_giou_0 0.3650 loss_label_0 0.1351 class_error_0 2.3068 loss_overall 1.5955
|
| 191 |
+
2021_08_04_16_10_52 [Epoch] 191 [Loss] loss_span 0.2395 loss_giou 0.3490 loss_label 0.1203 class_error 1.9214 loss_saliency 0.1356 loss_span_0 0.2567 loss_giou_0 0.3671 loss_label_0 0.1314 class_error_0 2.2649 loss_overall 1.5996
|
| 192 |
+
2021_08_04_16_11_51 [Epoch] 192 [Loss] loss_span 0.2368 loss_giou 0.3471 loss_label 0.1209 class_error 1.9345 loss_saliency 0.1344 loss_span_0 0.2538 loss_giou_0 0.3637 loss_label_0 0.1353 class_error_0 2.3957 loss_overall 1.5920
|
| 193 |
+
2021_08_04_16_12_51 [Epoch] 193 [Loss] loss_span 0.2368 loss_giou 0.3458 loss_label 0.1153 class_error 1.7987 loss_saliency 0.1315 loss_span_0 0.2554 loss_giou_0 0.3643 loss_label_0 0.1292 class_error_0 2.2018 loss_overall 1.5782
|
| 194 |
+
2021_08_04_16_13_51 [Epoch] 194 [Loss] loss_span 0.2371 loss_giou 0.3442 loss_label 0.1164 class_error 2.0287 loss_saliency 0.1295 loss_span_0 0.2521 loss_giou_0 0.3606 loss_label_0 0.1326 class_error_0 2.2596 loss_overall 1.5724
|
| 195 |
+
2021_08_04_16_14_49 [Epoch] 195 [Loss] loss_span 0.2348 loss_giou 0.3436 loss_label 0.1158 class_error 1.7287 loss_saliency 0.1301 loss_span_0 0.2504 loss_giou_0 0.3614 loss_label_0 0.1289 class_error_0 2.1681 loss_overall 1.5650
|
| 196 |
+
2021_08_04_16_16_12 [Epoch] 196 [Loss] loss_span 0.2329 loss_giou 0.3434 loss_label 0.1161 class_error 1.9459 loss_saliency 0.1332 loss_span_0 0.2512 loss_giou_0 0.3626 loss_label_0 0.1299 class_error_0 2.1898 loss_overall 1.5693
|
| 197 |
+
2021_08_04_16_17_11 [Epoch] 197 [Loss] loss_span 0.2323 loss_giou 0.3426 loss_label 0.1182 class_error 1.8828 loss_saliency 0.1350 loss_span_0 0.2498 loss_giou_0 0.3624 loss_label_0 0.1320 class_error_0 2.3939 loss_overall 1.5722
|
| 198 |
+
2021_08_04_16_18_10 [Epoch] 198 [Loss] loss_span 0.2352 loss_giou 0.3439 loss_label 0.1172 class_error 1.8767 loss_saliency 0.1297 loss_span_0 0.2504 loss_giou_0 0.3604 loss_label_0 0.1290 class_error_0 2.2872 loss_overall 1.5657
|
| 199 |
+
2021_08_04_16_19_08 [Epoch] 199 [Loss] loss_span 0.2321 loss_giou 0.3425 loss_label 0.1177 class_error 1.7712 loss_saliency 0.1314 loss_span_0 0.2482 loss_giou_0 0.3588 loss_label_0 0.1269 class_error_0 2.0950 loss_overall 1.5576
|
| 200 |
+
2021_08_04_16_20_07 [Epoch] 200 [Loss] loss_span 0.2293 loss_giou 0.3389 loss_label 0.1141 class_error 1.9119 loss_saliency 0.1327 loss_span_0 0.2455 loss_giou_0 0.3562 loss_label_0 0.1293 class_error_0 2.2245 loss_overall 1.5462
|
run_on_video/run.py
ADDED
|
@@ -0,0 +1,170 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
|
| 3 |
+
from data_utils import ClipFeatureExtractor
|
| 4 |
+
from model_utils import build_inference_model
|
| 5 |
+
from utils.tensor_utils import pad_sequences_1d
|
| 6 |
+
from moment_detr.span_utils import span_cxw_to_xx
|
| 7 |
+
from utils.basic_utils import l2_normalize_np_array
|
| 8 |
+
import torch.nn.functional as F
|
| 9 |
+
import numpy as np
|
| 10 |
+
import os
|
| 11 |
+
from PIL import Image
|
| 12 |
+
|
| 13 |
+
from moviepy.video.io.ffmpeg_tools import ffmpeg_extract_subclip
|
| 14 |
+
from moviepy.video.io.VideoFileClip import VideoFileClip
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class MomentDETRPredictor:
|
| 18 |
+
def __init__(self, ckpt_path, clip_model_name_or_path="ViT-B/32", device="cuda"):
|
| 19 |
+
self.clip_len = 2 # seconds
|
| 20 |
+
self.device = device
|
| 21 |
+
print("Loading feature extractors...")
|
| 22 |
+
self.feature_extractor = ClipFeatureExtractor(
|
| 23 |
+
framerate=1/self.clip_len, size=224, centercrop=True,
|
| 24 |
+
model_name_or_path=clip_model_name_or_path, device=device
|
| 25 |
+
)
|
| 26 |
+
print("Loading trained Moment-DETR model...")
|
| 27 |
+
self.model = build_inference_model(ckpt_path).to(self.device)
|
| 28 |
+
|
| 29 |
+
@torch.no_grad()
|
| 30 |
+
def localize_moment(self, video_path, query_list):
|
| 31 |
+
"""
|
| 32 |
+
Args:
|
| 33 |
+
video_path: str, path to the video file
|
| 34 |
+
query_list: List[str], each str is a query for this video
|
| 35 |
+
"""
|
| 36 |
+
# construct model inputs
|
| 37 |
+
n_query = len(query_list)
|
| 38 |
+
video_feats, video_frames = self.feature_extractor.encode_video(video_path)
|
| 39 |
+
video_feats = F.normalize(video_feats, dim=-1, eps=1e-5)
|
| 40 |
+
n_frames = len(video_feats)
|
| 41 |
+
# add tef
|
| 42 |
+
tef_st = torch.arange(0, n_frames, 1.0) / n_frames
|
| 43 |
+
tef_ed = tef_st + 1.0 / n_frames
|
| 44 |
+
tef = torch.stack([tef_st, tef_ed], dim=1).to(self.device) # (n_frames, 2)
|
| 45 |
+
video_feats = torch.cat([video_feats, tef], dim=1)
|
| 46 |
+
|
| 47 |
+
assert n_frames <= 75, "The positional embedding of this pretrained MomentDETR only support video up " \
|
| 48 |
+
"to 150 secs (i.e., 75 2-sec clips) in length"
|
| 49 |
+
video_feats = video_feats.unsqueeze(0).repeat(n_query, 1, 1) # (#text, T, d)
|
| 50 |
+
video_mask = torch.ones(n_query, n_frames).to(self.device)
|
| 51 |
+
query_feats = self.feature_extractor.encode_text(query_list) # #text * (L, d)
|
| 52 |
+
query_feats, query_mask = pad_sequences_1d(
|
| 53 |
+
query_feats, dtype=torch.float32, device=self.device, fixed_length=None)
|
| 54 |
+
query_feats = F.normalize(query_feats, dim=-1, eps=1e-5)
|
| 55 |
+
model_inputs = dict(
|
| 56 |
+
src_vid=video_feats,
|
| 57 |
+
src_vid_mask=video_mask,
|
| 58 |
+
src_txt=query_feats,
|
| 59 |
+
src_txt_mask=query_mask
|
| 60 |
+
)
|
| 61 |
+
|
| 62 |
+
# decode outputs
|
| 63 |
+
outputs = self.model(**model_inputs)
|
| 64 |
+
# #moment_queries refers to the positional embeddings in MomentDETR's decoder, not the input text query
|
| 65 |
+
prob = F.softmax(outputs["pred_logits"], -1) # (batch_size, #moment_queries=10, #classes=2)
|
| 66 |
+
scores = prob[..., 0] # * (batch_size, #moment_queries) foreground label is 0, we directly take it
|
| 67 |
+
pred_spans = outputs["pred_spans"] # (bsz, #moment_queries, 2)
|
| 68 |
+
print(pred_spans)
|
| 69 |
+
_saliency_scores = outputs["saliency_scores"].half() # (bsz, L)
|
| 70 |
+
saliency_scores = []
|
| 71 |
+
valid_vid_lengths = model_inputs["src_vid_mask"].sum(1).cpu().tolist()
|
| 72 |
+
for j in range(len(valid_vid_lengths)):
|
| 73 |
+
_score = _saliency_scores[j, :int(valid_vid_lengths[j])].tolist()
|
| 74 |
+
_score = [round(e, 4) for e in _score]
|
| 75 |
+
saliency_scores.append(_score)
|
| 76 |
+
|
| 77 |
+
# compose predictions
|
| 78 |
+
predictions = []
|
| 79 |
+
video_duration = n_frames * self.clip_len
|
| 80 |
+
for idx, (spans, score) in enumerate(zip(pred_spans.cpu(), scores.cpu())):
|
| 81 |
+
spans = span_cxw_to_xx(spans) * video_duration
|
| 82 |
+
# # (#queries, 3), [st(float), ed(float), score(float)]
|
| 83 |
+
cur_ranked_preds = torch.cat([spans, score[:, None]], dim=1).tolist()
|
| 84 |
+
cur_ranked_preds = sorted(cur_ranked_preds, key=lambda x: x[2], reverse=True)
|
| 85 |
+
cur_ranked_preds = [[float(f"{e:.4f}") for e in row] for row in cur_ranked_preds]
|
| 86 |
+
cur_query_pred = dict(
|
| 87 |
+
query=query_list[idx], # str
|
| 88 |
+
vid=video_path,
|
| 89 |
+
pred_relevant_windows=cur_ranked_preds, # List([st(float), ed(float), score(float)])
|
| 90 |
+
pred_saliency_scores=saliency_scores[idx] # List(float), len==n_frames, scores for each frame
|
| 91 |
+
)
|
| 92 |
+
predictions.append(cur_query_pred)
|
| 93 |
+
|
| 94 |
+
return predictions, video_frames
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
def run_example():
|
| 98 |
+
# load example data
|
| 99 |
+
from utils.basic_utils import load_jsonl
|
| 100 |
+
video_dir = "run_on_video/example/testing_videos/dogs"
|
| 101 |
+
|
| 102 |
+
#video_path = "run_on_video/example/testing_videos/"
|
| 103 |
+
query_path = "run_on_video/example/queries_highlight.jsonl"
|
| 104 |
+
queries = load_jsonl(query_path)
|
| 105 |
+
query_text_list = [e["query"] for e in queries]
|
| 106 |
+
ckpt_path = "run_on_video/moment_detr_ckpt/model_best.ckpt"
|
| 107 |
+
|
| 108 |
+
# run predictions
|
| 109 |
+
print("Build models...")
|
| 110 |
+
clip_model_name_or_path = "ViT-B/32"
|
| 111 |
+
# clip_model_name_or_path = "tmp/ViT-B-32.pt"
|
| 112 |
+
moment_detr_predictor = MomentDETRPredictor(
|
| 113 |
+
ckpt_path=ckpt_path,
|
| 114 |
+
clip_model_name_or_path=clip_model_name_or_path,
|
| 115 |
+
device="cuda"
|
| 116 |
+
)
|
| 117 |
+
print("Run prediction...")
|
| 118 |
+
video_paths = [os.path.join(video_dir, e) for e in os.listdir(video_dir)]
|
| 119 |
+
#video_paths = ["run_on_video/example/testing_videos/celebration_18s.mov"]
|
| 120 |
+
|
| 121 |
+
for video_path in video_paths:
|
| 122 |
+
output_dir = os.path.join("run_on_video/example/output/dog/empty_str", os.path.basename(video_path))
|
| 123 |
+
predictions, video_frames = moment_detr_predictor.localize_moment(
|
| 124 |
+
video_path=video_path, query_list=query_text_list)
|
| 125 |
+
#check output directory exists
|
| 126 |
+
if not os.path.exists(output_dir):
|
| 127 |
+
os.makedirs(output_dir)
|
| 128 |
+
|
| 129 |
+
# print data
|
| 130 |
+
for idx, query_data in enumerate(queries):
|
| 131 |
+
print("-"*30 + f"idx{idx}")
|
| 132 |
+
print(f">> query: {query_data['query']}")
|
| 133 |
+
print(f">> video_path: {video_path}")
|
| 134 |
+
#print(f">> GT moments: {query_data['relevant_windows']}")
|
| 135 |
+
print(f">> Predicted moments ([start_in_seconds, end_in_seconds, score]): "
|
| 136 |
+
f"{predictions[idx]['pred_relevant_windows']}")
|
| 137 |
+
#print(f">> GT saliency scores (only localized 2-sec clips): {query_data['saliency_scores']}")
|
| 138 |
+
print(f">> Predicted saliency scores (for all 2-sec clip): "
|
| 139 |
+
f"{predictions[idx]['pred_saliency_scores']}")
|
| 140 |
+
#output the retrievved moments
|
| 141 |
+
#sort the moment by the third element in the list
|
| 142 |
+
predictions[idx]['pred_relevant_windows'] = sorted(predictions[idx]['pred_relevant_windows'], key=lambda x: x[2], reverse=True)
|
| 143 |
+
for i, (start_time, end_time, score) in enumerate(predictions[idx]['pred_relevant_windows']):
|
| 144 |
+
print(start_time, end_time, score)
|
| 145 |
+
ffmpeg_extract_subclip(video_path, start_time, end_time, targetname=os.path.join(output_dir, f'moment_{i}.mp4'))
|
| 146 |
+
#store the sorted pred_relevant_windows scores and time
|
| 147 |
+
with open(os.path.join(output_dir, 'moment_scores.txt'), 'w') as f:
|
| 148 |
+
for i, (start_time, end_time, score) in enumerate(predictions[idx]['pred_relevant_windows']):
|
| 149 |
+
f.write(str(i)+'. '+str(start_time)+' '+str(end_time)+' '+str(score) + '\n')
|
| 150 |
+
#To-dos: save the video frames sorted by pred_saliency_scores
|
| 151 |
+
sorted_frames = [frame for _, frame in sorted(zip(predictions[idx]['pred_saliency_scores'], video_frames), reverse=True)]
|
| 152 |
+
#save the sorted scores and also the original index
|
| 153 |
+
sorted_scores = sorted(predictions[idx]['pred_saliency_scores'], reverse=True)
|
| 154 |
+
print(sorted_scores)
|
| 155 |
+
#save frames to output directory
|
| 156 |
+
for i, frame in enumerate(sorted_frames):
|
| 157 |
+
#transfer frame from tensor to PIL image
|
| 158 |
+
frame = frame.permute(1, 2, 0).cpu().numpy()
|
| 159 |
+
frame = frame.astype(np.uint8)
|
| 160 |
+
frame = Image.fromarray(frame)
|
| 161 |
+
frame.save(os.path.join(output_dir, str(i) + '.jpg'))
|
| 162 |
+
#save scores to output directory
|
| 163 |
+
with open(os.path.join(output_dir, 'scores.txt'), 'w') as f:
|
| 164 |
+
for i, score in enumerate(sorted_scores):
|
| 165 |
+
f.write(str(i)+'. '+str(score) + '\n')
|
| 166 |
+
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
if __name__ == "__main__":
|
| 170 |
+
run_example()
|
standalone_eval/README.md
ADDED
|
@@ -0,0 +1,54 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
QVHighlights Evaluation and Codalab Submission
|
| 2 |
+
==================
|
| 3 |
+
|
| 4 |
+
### Task Definition
|
| 5 |
+
Given a video and a natural language query, our task requires a system to retrieve the most relevant moments in the video, and detect the highlightness of the clips in the video.
|
| 6 |
+
|
| 7 |
+
### Evaluation
|
| 8 |
+
At project root, run
|
| 9 |
+
```
|
| 10 |
+
bash standalone_eval/eval_sample.sh
|
| 11 |
+
```
|
| 12 |
+
This command will use [eval.py](eval.py) to evaluate the provided prediction file [sample_val_preds.jsonl](sample_val_preds.jsonl),
|
| 13 |
+
the output will be written into `sample_val_preds_metrics.json`.
|
| 14 |
+
The content in this generated file should be similar if not the same as [sample_val_preds_metrics_raw.json](sample_val_preds_metrics_raw.json) file.
|
| 15 |
+
|
| 16 |
+
### Format
|
| 17 |
+
|
| 18 |
+
The prediction file [sample_val_preds.jsonl](sample_val_preds.jsonl) is in [JSON Line](https://jsonlines.org/) format, each row of the files can be loaded as a single `dict` in Python. Below is an example of a single line in the prediction file:
|
| 19 |
+
```
|
| 20 |
+
{
|
| 21 |
+
"qid": 2579,
|
| 22 |
+
"query": "A girl and her mother cooked while talking with each other on facetime.",
|
| 23 |
+
"vid": "NUsG9BgSes0_210.0_360.0",
|
| 24 |
+
"pred_relevant_windows": [
|
| 25 |
+
[0, 70, 0.9986],
|
| 26 |
+
[78, 146, 0.4138],
|
| 27 |
+
[0, 146, 0.0444],
|
| 28 |
+
...
|
| 29 |
+
],
|
| 30 |
+
"pred_saliency_scores": [-0.2452, -0.3779, -0.4746, ...]
|
| 31 |
+
}
|
| 32 |
+
|
| 33 |
+
```
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
| entry | description |
|
| 38 |
+
| --- | ----|
|
| 39 |
+
| `qid` | `int`, unique query id |
|
| 40 |
+
| `query` | `str`, natural language query, not used by the evaluation script |
|
| 41 |
+
| `vid` | `str`, unique video id |
|
| 42 |
+
| `pred_relevant_windows` | `list(list)`, moment retrieval predictions. Each sublist contains 3 elements, `[start (seconds), end (seconds), score]`|
|
| 43 |
+
| `pred_saliency_scores` | `list(float)`, highlight prediction scores. The higher the better. This list should contain a score for each of the 2-second clip in the videos, and is ordered. |
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
### Codalab Submission
|
| 47 |
+
To test your model's performance on `test` split,
|
| 48 |
+
please submit both `val` and `test` predictions to our
|
| 49 |
+
[Codalab evaluation server](https://codalab.lisn.upsaclay.fr/competitions/6937).
|
| 50 |
+
The submission file should be a single `.zip ` file (no enclosing folder)
|
| 51 |
+
that contains the two prediction files
|
| 52 |
+
`hl_val_submission.jsonl` and `hl_test_submission.jsonl`, each of the `*submission.jsonl` file
|
| 53 |
+
should be formatted as instructed above.
|
| 54 |
+
|
standalone_eval/eval.py
ADDED
|
@@ -0,0 +1,344 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
from collections import OrderedDict, defaultdict
|
| 3 |
+
import json
|
| 4 |
+
import time
|
| 5 |
+
import copy
|
| 6 |
+
import multiprocessing as mp
|
| 7 |
+
from standalone_eval.utils import compute_average_precision_detection, \
|
| 8 |
+
compute_temporal_iou_batch_cross, compute_temporal_iou_batch_paired, load_jsonl, get_ap
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def compute_average_precision_detection_wrapper(
|
| 12 |
+
input_triple, tiou_thresholds=np.linspace(0.5, 0.95, 10)):
|
| 13 |
+
qid, ground_truth, prediction = input_triple
|
| 14 |
+
scores = compute_average_precision_detection(
|
| 15 |
+
ground_truth, prediction, tiou_thresholds=tiou_thresholds)
|
| 16 |
+
return qid, scores
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def compute_mr_ap(submission, ground_truth, iou_thds=np.linspace(0.5, 0.95, 10),
|
| 20 |
+
max_gt_windows=None, max_pred_windows=10, num_workers=8, chunksize=50):
|
| 21 |
+
iou_thds = [float(f"{e:.2f}") for e in iou_thds]
|
| 22 |
+
pred_qid2data = defaultdict(list)
|
| 23 |
+
for d in submission:
|
| 24 |
+
pred_windows = d["pred_relevant_windows"][:max_pred_windows] \
|
| 25 |
+
if max_pred_windows is not None else d["pred_relevant_windows"]
|
| 26 |
+
qid = d["qid"]
|
| 27 |
+
for w in pred_windows:
|
| 28 |
+
pred_qid2data[qid].append({
|
| 29 |
+
"video-id": d["qid"], # in order to use the API
|
| 30 |
+
"t-start": w[0],
|
| 31 |
+
"t-end": w[1],
|
| 32 |
+
"score": w[2]
|
| 33 |
+
})
|
| 34 |
+
|
| 35 |
+
gt_qid2data = defaultdict(list)
|
| 36 |
+
for d in ground_truth:
|
| 37 |
+
gt_windows = d["relevant_windows"][:max_gt_windows] \
|
| 38 |
+
if max_gt_windows is not None else d["relevant_windows"]
|
| 39 |
+
qid = d["qid"]
|
| 40 |
+
for w in gt_windows:
|
| 41 |
+
gt_qid2data[qid].append({
|
| 42 |
+
"video-id": d["qid"],
|
| 43 |
+
"t-start": w[0],
|
| 44 |
+
"t-end": w[1]
|
| 45 |
+
})
|
| 46 |
+
qid2ap_list = {}
|
| 47 |
+
# start_time = time.time()
|
| 48 |
+
data_triples = [[qid, gt_qid2data[qid], pred_qid2data[qid]] for qid in pred_qid2data]
|
| 49 |
+
from functools import partial
|
| 50 |
+
compute_ap_from_triple = partial(
|
| 51 |
+
compute_average_precision_detection_wrapper, tiou_thresholds=iou_thds)
|
| 52 |
+
|
| 53 |
+
if num_workers > 1:
|
| 54 |
+
with mp.Pool(num_workers) as pool:
|
| 55 |
+
for qid, scores in pool.imap_unordered(compute_ap_from_triple, data_triples, chunksize=chunksize):
|
| 56 |
+
qid2ap_list[qid] = scores
|
| 57 |
+
else:
|
| 58 |
+
for data_triple in data_triples:
|
| 59 |
+
qid, scores = compute_ap_from_triple(data_triple)
|
| 60 |
+
qid2ap_list[qid] = scores
|
| 61 |
+
|
| 62 |
+
# print(f"compute_average_precision_detection {time.time() - start_time:.2f} seconds.")
|
| 63 |
+
ap_array = np.array(list(qid2ap_list.values())) # (#queries, #thd)
|
| 64 |
+
ap_thds = ap_array.mean(0) # mAP at different IoU thresholds.
|
| 65 |
+
iou_thd2ap = dict(zip([str(e) for e in iou_thds], ap_thds))
|
| 66 |
+
iou_thd2ap["average"] = np.mean(ap_thds)
|
| 67 |
+
# formatting
|
| 68 |
+
iou_thd2ap = {k: float(f"{100 * v:.2f}") for k, v in iou_thd2ap.items()}
|
| 69 |
+
return iou_thd2ap
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
def compute_mr_r1(submission, ground_truth, iou_thds=np.linspace(0.5, 0.95, 10)):
|
| 73 |
+
"""If a predicted segment has IoU >= iou_thd with one of the 1st GT segment, we define it positive"""
|
| 74 |
+
iou_thds = [float(f"{e:.2f}") for e in iou_thds]
|
| 75 |
+
pred_qid2window = {d["qid"]: d["pred_relevant_windows"][0][:2] for d in submission} # :2 rm scores
|
| 76 |
+
# gt_qid2window = {d["qid"]: d["relevant_windows"][0] for d in ground_truth}
|
| 77 |
+
gt_qid2window = {}
|
| 78 |
+
for d in ground_truth:
|
| 79 |
+
cur_gt_windows = d["relevant_windows"]
|
| 80 |
+
cur_qid = d["qid"]
|
| 81 |
+
cur_max_iou_idx = 0
|
| 82 |
+
if len(cur_gt_windows) > 0: # select the GT window that has the highest IoU
|
| 83 |
+
cur_ious = compute_temporal_iou_batch_cross(
|
| 84 |
+
np.array([pred_qid2window[cur_qid]]), np.array(d["relevant_windows"])
|
| 85 |
+
)[0]
|
| 86 |
+
cur_max_iou_idx = np.argmax(cur_ious)
|
| 87 |
+
gt_qid2window[cur_qid] = cur_gt_windows[cur_max_iou_idx]
|
| 88 |
+
|
| 89 |
+
qids = list(pred_qid2window.keys())
|
| 90 |
+
pred_windows = np.array([pred_qid2window[k] for k in qids]).astype(float)
|
| 91 |
+
gt_windows = np.array([gt_qid2window[k] for k in qids]).astype(float)
|
| 92 |
+
pred_gt_iou = compute_temporal_iou_batch_paired(pred_windows, gt_windows)
|
| 93 |
+
iou_thd2recall_at_one = {}
|
| 94 |
+
for thd in iou_thds:
|
| 95 |
+
iou_thd2recall_at_one[str(thd)] = float(f"{np.mean(pred_gt_iou >= thd) * 100:.2f}")
|
| 96 |
+
return iou_thd2recall_at_one
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
def get_window_len(window):
|
| 100 |
+
return window[1] - window[0]
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
def get_data_by_range(submission, ground_truth, len_range):
|
| 104 |
+
""" keep queries with ground truth window length in the specified length range.
|
| 105 |
+
Args:
|
| 106 |
+
submission:
|
| 107 |
+
ground_truth:
|
| 108 |
+
len_range: [min_l (int), max_l (int)]. the range is (min_l, max_l], i.e., min_l < l <= max_l
|
| 109 |
+
"""
|
| 110 |
+
min_l, max_l = len_range
|
| 111 |
+
if min_l == 0 and max_l == 150: # min and max l in dataset
|
| 112 |
+
return submission, ground_truth
|
| 113 |
+
|
| 114 |
+
# only keep ground truth with windows in the specified length range
|
| 115 |
+
# if multiple GT windows exists, we only keep the ones in the range
|
| 116 |
+
ground_truth_in_range = []
|
| 117 |
+
gt_qids_in_range = set()
|
| 118 |
+
for d in ground_truth:
|
| 119 |
+
rel_windows_in_range = [
|
| 120 |
+
w for w in d["relevant_windows"] if min_l < get_window_len(w) <= max_l]
|
| 121 |
+
if len(rel_windows_in_range) > 0:
|
| 122 |
+
d = copy.deepcopy(d)
|
| 123 |
+
d["relevant_windows"] = rel_windows_in_range
|
| 124 |
+
ground_truth_in_range.append(d)
|
| 125 |
+
gt_qids_in_range.add(d["qid"])
|
| 126 |
+
|
| 127 |
+
# keep only submissions for ground_truth_in_range
|
| 128 |
+
submission_in_range = []
|
| 129 |
+
for d in submission:
|
| 130 |
+
if d["qid"] in gt_qids_in_range:
|
| 131 |
+
submission_in_range.append(copy.deepcopy(d))
|
| 132 |
+
|
| 133 |
+
return submission_in_range, ground_truth_in_range
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
def eval_moment_retrieval(submission, ground_truth, verbose=True):
|
| 137 |
+
length_ranges = [[0, 10], [10, 30], [30, 150], [0, 150], ] #
|
| 138 |
+
range_names = ["short", "middle", "long", "full"]
|
| 139 |
+
|
| 140 |
+
ret_metrics = {}
|
| 141 |
+
for l_range, name in zip(length_ranges, range_names):
|
| 142 |
+
if verbose:
|
| 143 |
+
start_time = time.time()
|
| 144 |
+
_submission, _ground_truth = get_data_by_range(submission, ground_truth, l_range)
|
| 145 |
+
print(f"{name}: {l_range}, {len(_ground_truth)}/{len(ground_truth)}="
|
| 146 |
+
f"{100*len(_ground_truth)/len(ground_truth):.2f} examples.")
|
| 147 |
+
iou_thd2average_precision = compute_mr_ap(_submission, _ground_truth, num_workers=8, chunksize=50)
|
| 148 |
+
iou_thd2recall_at_one = compute_mr_r1(_submission, _ground_truth)
|
| 149 |
+
ret_metrics[name] = {"MR-mAP": iou_thd2average_precision, "MR-R1": iou_thd2recall_at_one}
|
| 150 |
+
if verbose:
|
| 151 |
+
print(f"[eval_moment_retrieval] [{name}] {time.time() - start_time:.2f} seconds")
|
| 152 |
+
return ret_metrics
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
def compute_hl_hit1(qid2preds, qid2gt_scores_binary):
|
| 156 |
+
qid2max_scored_clip_idx = {k: np.argmax(v["pred_saliency_scores"]) for k, v in qid2preds.items()}
|
| 157 |
+
hit_scores = np.zeros((len(qid2preds), 3))
|
| 158 |
+
qids = list(qid2preds.keys())
|
| 159 |
+
for idx, qid in enumerate(qids):
|
| 160 |
+
pred_clip_idx = qid2max_scored_clip_idx[qid]
|
| 161 |
+
gt_scores_binary = qid2gt_scores_binary[qid] # (#clips, 3)
|
| 162 |
+
if pred_clip_idx < len(gt_scores_binary):
|
| 163 |
+
hit_scores[idx] = gt_scores_binary[pred_clip_idx]
|
| 164 |
+
# aggregate scores from 3 separate annotations (3 workers) by taking the max.
|
| 165 |
+
# then average scores from all queries.
|
| 166 |
+
hit_at_one = float(f"{100 * np.mean(np.max(hit_scores, 1)):.2f}")
|
| 167 |
+
return hit_at_one
|
| 168 |
+
|
| 169 |
+
|
| 170 |
+
def compute_hl_ap(qid2preds, qid2gt_scores_binary, num_workers=8, chunksize=50):
|
| 171 |
+
qid2pred_scores = {k: v["pred_saliency_scores"] for k, v in qid2preds.items()}
|
| 172 |
+
ap_scores = np.zeros((len(qid2preds), 3)) # (#preds, 3)
|
| 173 |
+
qids = list(qid2preds.keys())
|
| 174 |
+
input_tuples = []
|
| 175 |
+
for idx, qid in enumerate(qids):
|
| 176 |
+
for w_idx in range(3): # annotation score idx
|
| 177 |
+
y_true = qid2gt_scores_binary[qid][:, w_idx]
|
| 178 |
+
y_predict = np.array(qid2pred_scores[qid])
|
| 179 |
+
input_tuples.append((idx, w_idx, y_true, y_predict))
|
| 180 |
+
|
| 181 |
+
if num_workers > 1:
|
| 182 |
+
with mp.Pool(num_workers) as pool:
|
| 183 |
+
for idx, w_idx, score in pool.imap_unordered(
|
| 184 |
+
compute_ap_from_tuple, input_tuples, chunksize=chunksize):
|
| 185 |
+
ap_scores[idx, w_idx] = score
|
| 186 |
+
else:
|
| 187 |
+
for input_tuple in input_tuples:
|
| 188 |
+
idx, w_idx, score = compute_ap_from_tuple(input_tuple)
|
| 189 |
+
ap_scores[idx, w_idx] = score
|
| 190 |
+
|
| 191 |
+
# it's the same if we first average across different annotations, then average across queries
|
| 192 |
+
# since all queries have the same #annotations.
|
| 193 |
+
mean_ap = float(f"{100 * np.mean(ap_scores):.2f}")
|
| 194 |
+
return mean_ap
|
| 195 |
+
|
| 196 |
+
|
| 197 |
+
def compute_ap_from_tuple(input_tuple):
|
| 198 |
+
idx, w_idx, y_true, y_predict = input_tuple
|
| 199 |
+
if len(y_true) < len(y_predict):
|
| 200 |
+
# print(f"len(y_true) < len(y_predict) {len(y_true), len(y_predict)}")
|
| 201 |
+
y_predict = y_predict[:len(y_true)]
|
| 202 |
+
elif len(y_true) > len(y_predict):
|
| 203 |
+
# print(f"len(y_true) > len(y_predict) {len(y_true), len(y_predict)}")
|
| 204 |
+
_y_predict = np.zeros(len(y_true))
|
| 205 |
+
_y_predict[:len(y_predict)] = y_predict
|
| 206 |
+
y_predict = _y_predict
|
| 207 |
+
|
| 208 |
+
score = get_ap(y_true, y_predict)
|
| 209 |
+
return idx, w_idx, score
|
| 210 |
+
|
| 211 |
+
|
| 212 |
+
def mk_gt_scores(gt_data, clip_length=2):
|
| 213 |
+
"""gt_data, dict, """
|
| 214 |
+
num_clips = int(gt_data["duration"] / clip_length)
|
| 215 |
+
saliency_scores_full_video = np.zeros((num_clips, 3))
|
| 216 |
+
relevant_clip_ids = np.array(gt_data["relevant_clip_ids"]) # (#relevant_clip_ids, )
|
| 217 |
+
saliency_scores_relevant_clips = np.array(gt_data["saliency_scores"]) # (#relevant_clip_ids, 3)
|
| 218 |
+
saliency_scores_full_video[relevant_clip_ids] = saliency_scores_relevant_clips
|
| 219 |
+
return saliency_scores_full_video # (#clips_in_video, 3) the scores are in range [0, 4]
|
| 220 |
+
|
| 221 |
+
|
| 222 |
+
def eval_highlight(submission, ground_truth, verbose=True):
|
| 223 |
+
"""
|
| 224 |
+
Args:
|
| 225 |
+
submission:
|
| 226 |
+
ground_truth:
|
| 227 |
+
verbose:
|
| 228 |
+
"""
|
| 229 |
+
qid2preds = {d["qid"]: d for d in submission}
|
| 230 |
+
qid2gt_scores_full_range = {d["qid"]: mk_gt_scores(d) for d in ground_truth} # scores in range [0, 4]
|
| 231 |
+
# gt_saliency_score_min: int, in [0, 1, 2, 3, 4]. The minimum score for a positive clip.
|
| 232 |
+
gt_saliency_score_min_list = [2, 3, 4]
|
| 233 |
+
saliency_score_names = ["Fair", "Good", "VeryGood"]
|
| 234 |
+
highlight_det_metrics = {}
|
| 235 |
+
for gt_saliency_score_min, score_name in zip(gt_saliency_score_min_list, saliency_score_names):
|
| 236 |
+
start_time = time.time()
|
| 237 |
+
qid2gt_scores_binary = {
|
| 238 |
+
k: (v >= gt_saliency_score_min).astype(float)
|
| 239 |
+
for k, v in qid2gt_scores_full_range.items()} # scores in [0, 1]
|
| 240 |
+
hit_at_one = compute_hl_hit1(qid2preds, qid2gt_scores_binary)
|
| 241 |
+
mean_ap = compute_hl_ap(qid2preds, qid2gt_scores_binary)
|
| 242 |
+
highlight_det_metrics[f"HL-min-{score_name}"] = {"HL-mAP": mean_ap, "HL-Hit1": hit_at_one}
|
| 243 |
+
if verbose:
|
| 244 |
+
print(f"Calculating highlight scores with min score {gt_saliency_score_min} ({score_name})")
|
| 245 |
+
print(f"Time cost {time.time() - start_time:.2f} seconds")
|
| 246 |
+
return highlight_det_metrics
|
| 247 |
+
|
| 248 |
+
|
| 249 |
+
def eval_submission(submission, ground_truth, verbose=True, match_number=True):
|
| 250 |
+
"""
|
| 251 |
+
Args:
|
| 252 |
+
submission: list(dict), each dict is {
|
| 253 |
+
qid: str,
|
| 254 |
+
query: str,
|
| 255 |
+
vid: str,
|
| 256 |
+
pred_relevant_windows: list([st, ed]),
|
| 257 |
+
pred_saliency_scores: list(float), len == #clips in video.
|
| 258 |
+
i.e., each clip in the video will have a saliency score.
|
| 259 |
+
}
|
| 260 |
+
ground_truth: list(dict), each dict is {
|
| 261 |
+
"qid": 7803,
|
| 262 |
+
"query": "Man in gray top walks from outside to inside.",
|
| 263 |
+
"duration": 150,
|
| 264 |
+
"vid": "RoripwjYFp8_360.0_510.0",
|
| 265 |
+
"relevant_clip_ids": [13, 14, 15, 16, 17]
|
| 266 |
+
"saliency_scores": [[4, 4, 2], [3, 4, 2], [2, 2, 3], [2, 2, 2], [0, 1, 3]]
|
| 267 |
+
each sublist corresponds to one clip in relevant_clip_ids.
|
| 268 |
+
The 3 elements in the sublist are scores from 3 different workers. The
|
| 269 |
+
scores are in [0, 1, 2, 3, 4], meaning [Very Bad, ..., Good, Very Good]
|
| 270 |
+
}
|
| 271 |
+
verbose:
|
| 272 |
+
match_number:
|
| 273 |
+
|
| 274 |
+
Returns:
|
| 275 |
+
|
| 276 |
+
"""
|
| 277 |
+
pred_qids = set([e["qid"] for e in submission])
|
| 278 |
+
gt_qids = set([e["qid"] for e in ground_truth])
|
| 279 |
+
if match_number:
|
| 280 |
+
assert pred_qids == gt_qids, \
|
| 281 |
+
f"qids in ground_truth and submission must match. " \
|
| 282 |
+
f"use `match_number=False` if you wish to disable this check"
|
| 283 |
+
else: # only leave the items that exists in both submission and ground_truth
|
| 284 |
+
shared_qids = pred_qids.intersection(gt_qids)
|
| 285 |
+
submission = [e for e in submission if e["qid"] in shared_qids]
|
| 286 |
+
ground_truth = [e for e in ground_truth if e["qid"] in shared_qids]
|
| 287 |
+
|
| 288 |
+
eval_metrics = {}
|
| 289 |
+
eval_metrics_brief = OrderedDict()
|
| 290 |
+
if "pred_relevant_windows" in submission[0]:
|
| 291 |
+
moment_ret_scores = eval_moment_retrieval(
|
| 292 |
+
submission, ground_truth, verbose=verbose)
|
| 293 |
+
eval_metrics.update(moment_ret_scores)
|
| 294 |
+
moment_ret_scores_brief = {
|
| 295 |
+
"MR-full-mAP": moment_ret_scores["full"]["MR-mAP"]["average"],
|
| 296 |
+
"[email protected]": moment_ret_scores["full"]["MR-mAP"]["0.5"],
|
| 297 |
+
"[email protected]": moment_ret_scores["full"]["MR-mAP"]["0.75"],
|
| 298 |
+
"MR-short-mAP": moment_ret_scores["short"]["MR-mAP"]["average"],
|
| 299 |
+
"MR-middle-mAP": moment_ret_scores["middle"]["MR-mAP"]["average"],
|
| 300 |
+
"MR-long-mAP": moment_ret_scores["long"]["MR-mAP"]["average"],
|
| 301 |
+
"[email protected]": moment_ret_scores["full"]["MR-R1"]["0.5"],
|
| 302 |
+
"[email protected]": moment_ret_scores["full"]["MR-R1"]["0.7"],
|
| 303 |
+
}
|
| 304 |
+
eval_metrics_brief.update(
|
| 305 |
+
sorted([(k, v) for k, v in moment_ret_scores_brief.items()], key=lambda x: x[0]))
|
| 306 |
+
|
| 307 |
+
if "pred_saliency_scores" in submission[0]:
|
| 308 |
+
highlight_det_scores = eval_highlight(
|
| 309 |
+
submission, ground_truth, verbose=verbose)
|
| 310 |
+
eval_metrics.update(highlight_det_scores)
|
| 311 |
+
highlight_det_scores_brief = dict([
|
| 312 |
+
(f"{k}-{sub_k.split('-')[1]}", v[sub_k])
|
| 313 |
+
for k, v in highlight_det_scores.items() for sub_k in v])
|
| 314 |
+
eval_metrics_brief.update(highlight_det_scores_brief)
|
| 315 |
+
|
| 316 |
+
# sort by keys
|
| 317 |
+
final_eval_metrics = OrderedDict()
|
| 318 |
+
final_eval_metrics["brief"] = eval_metrics_brief
|
| 319 |
+
final_eval_metrics.update(sorted([(k, v) for k, v in eval_metrics.items()], key=lambda x: x[0]))
|
| 320 |
+
return final_eval_metrics
|
| 321 |
+
|
| 322 |
+
|
| 323 |
+
def eval_main():
|
| 324 |
+
import argparse
|
| 325 |
+
parser = argparse.ArgumentParser(description="Moments and Highlights Evaluation Script")
|
| 326 |
+
parser.add_argument("--submission_path", type=str, help="path to generated prediction file")
|
| 327 |
+
parser.add_argument("--gt_path", type=str, help="path to GT file")
|
| 328 |
+
parser.add_argument("--save_path", type=str, help="path to save the results")
|
| 329 |
+
parser.add_argument("--not_verbose", action="store_true")
|
| 330 |
+
args = parser.parse_args()
|
| 331 |
+
|
| 332 |
+
verbose = not args.not_verbose
|
| 333 |
+
submission = load_jsonl(args.submission_path)
|
| 334 |
+
gt = load_jsonl(args.gt_path)
|
| 335 |
+
results = eval_submission(submission, gt, verbose=verbose)
|
| 336 |
+
if verbose:
|
| 337 |
+
print(json.dumps(results, indent=4))
|
| 338 |
+
|
| 339 |
+
with open(args.save_path, "w") as f:
|
| 340 |
+
f.write(json.dumps(results, indent=4))
|
| 341 |
+
|
| 342 |
+
|
| 343 |
+
if __name__ == '__main__':
|
| 344 |
+
eval_main()
|
standalone_eval/eval_sample.sh
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env bash
|
| 2 |
+
# Usage: bash standalone_eval/eval_sample.sh
|
| 3 |
+
submission_path=standalone_eval/sample_val_preds.jsonl
|
| 4 |
+
gt_path=data/highlight_val_release.jsonl
|
| 5 |
+
save_path=standalone_eval/sample_val_preds_metrics.json
|
| 6 |
+
|
| 7 |
+
PYTHONPATH=$PYTHONPATH:. python standalone_eval/eval.py \
|
| 8 |
+
--submission_path ${submission_path} \
|
| 9 |
+
--gt_path ${gt_path} \
|
| 10 |
+
--save_path ${save_path}
|
standalone_eval/sample_val_preds.jsonl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:df3227ef84985db846f102e75cda43b5f9f962d12b95b990028eed88f1901b40
|
| 3 |
+
size 2399408
|
standalone_eval/sample_val_preds_metrics_raw.json
ADDED
|
@@ -0,0 +1,138 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"brief": {
|
| 3 |
+
"[email protected]": 53.94,
|
| 4 |
+
"[email protected]": 34.84,
|
| 5 |
+
"MR-full-mAP": 32.2,
|
| 6 |
+
"[email protected]": 54.96,
|
| 7 |
+
"[email protected]": 31.01,
|
| 8 |
+
"MR-long-mAP": 41.11,
|
| 9 |
+
"MR-middle-mAP": 32.3,
|
| 10 |
+
"MR-short-mAP": 3.28,
|
| 11 |
+
"HL-min-Fair-mAP": 67.77,
|
| 12 |
+
"HL-min-Fair-Hit1": 66.45,
|
| 13 |
+
"HL-min-Good-mAP": 58.09,
|
| 14 |
+
"HL-min-Good-Hit1": 64.45,
|
| 15 |
+
"HL-min-VeryGood-mAP": 35.65,
|
| 16 |
+
"HL-min-VeryGood-Hit1": 55.55
|
| 17 |
+
},
|
| 18 |
+
"HL-min-Fair": {
|
| 19 |
+
"HL-mAP": 67.77,
|
| 20 |
+
"HL-Hit1": 66.45
|
| 21 |
+
},
|
| 22 |
+
"HL-min-Good": {
|
| 23 |
+
"HL-mAP": 58.09,
|
| 24 |
+
"HL-Hit1": 64.45
|
| 25 |
+
},
|
| 26 |
+
"HL-min-VeryGood": {
|
| 27 |
+
"HL-mAP": 35.65,
|
| 28 |
+
"HL-Hit1": 55.55
|
| 29 |
+
},
|
| 30 |
+
"full": {
|
| 31 |
+
"MR-mAP": {
|
| 32 |
+
"0.5": 54.96,
|
| 33 |
+
"0.55": 49.88,
|
| 34 |
+
"0.6": 46.62,
|
| 35 |
+
"0.65": 40.2,
|
| 36 |
+
"0.7": 35.49,
|
| 37 |
+
"0.75": 31.01,
|
| 38 |
+
"0.8": 24.79,
|
| 39 |
+
"0.85": 18.72,
|
| 40 |
+
"0.9": 13.21,
|
| 41 |
+
"0.95": 7.16,
|
| 42 |
+
"average": 32.2
|
| 43 |
+
},
|
| 44 |
+
"MR-R1": {
|
| 45 |
+
"0.5": 53.94,
|
| 46 |
+
"0.55": 48.97,
|
| 47 |
+
"0.6": 46.06,
|
| 48 |
+
"0.65": 39.42,
|
| 49 |
+
"0.7": 34.84,
|
| 50 |
+
"0.75": 30.71,
|
| 51 |
+
"0.8": 24.97,
|
| 52 |
+
"0.85": 18.9,
|
| 53 |
+
"0.9": 13.35,
|
| 54 |
+
"0.95": 7.23
|
| 55 |
+
}
|
| 56 |
+
},
|
| 57 |
+
"long": {
|
| 58 |
+
"MR-mAP": {
|
| 59 |
+
"0.5": 64.08,
|
| 60 |
+
"0.55": 60.3,
|
| 61 |
+
"0.6": 56.52,
|
| 62 |
+
"0.65": 49.24,
|
| 63 |
+
"0.7": 44.73,
|
| 64 |
+
"0.75": 40.56,
|
| 65 |
+
"0.8": 34.59,
|
| 66 |
+
"0.85": 28.53,
|
| 67 |
+
"0.9": 20.42,
|
| 68 |
+
"0.95": 12.12,
|
| 69 |
+
"average": 41.11
|
| 70 |
+
},
|
| 71 |
+
"MR-R1": {
|
| 72 |
+
"0.5": 56.1,
|
| 73 |
+
"0.55": 53.66,
|
| 74 |
+
"0.6": 50.52,
|
| 75 |
+
"0.65": 43.55,
|
| 76 |
+
"0.7": 40.24,
|
| 77 |
+
"0.75": 37.11,
|
| 78 |
+
"0.8": 32.06,
|
| 79 |
+
"0.85": 26.83,
|
| 80 |
+
"0.9": 19.51,
|
| 81 |
+
"0.95": 11.67
|
| 82 |
+
}
|
| 83 |
+
},
|
| 84 |
+
"middle": {
|
| 85 |
+
"MR-mAP": {
|
| 86 |
+
"0.5": 58.81,
|
| 87 |
+
"0.55": 52.43,
|
| 88 |
+
"0.6": 48.77,
|
| 89 |
+
"0.65": 41.68,
|
| 90 |
+
"0.7": 36.02,
|
| 91 |
+
"0.75": 30.51,
|
| 92 |
+
"0.8": 23.09,
|
| 93 |
+
"0.85": 16.04,
|
| 94 |
+
"0.9": 10.79,
|
| 95 |
+
"0.95": 4.84,
|
| 96 |
+
"average": 32.3
|
| 97 |
+
},
|
| 98 |
+
"MR-R1": {
|
| 99 |
+
"0.5": 50.26,
|
| 100 |
+
"0.55": 44.83,
|
| 101 |
+
"0.6": 42.22,
|
| 102 |
+
"0.65": 36.26,
|
| 103 |
+
"0.7": 31.24,
|
| 104 |
+
"0.75": 27.06,
|
| 105 |
+
"0.8": 20.9,
|
| 106 |
+
"0.85": 14.52,
|
| 107 |
+
"0.9": 9.93,
|
| 108 |
+
"0.95": 4.7
|
| 109 |
+
}
|
| 110 |
+
},
|
| 111 |
+
"short": {
|
| 112 |
+
"MR-mAP": {
|
| 113 |
+
"0.5": 9.38,
|
| 114 |
+
"0.55": 6.27,
|
| 115 |
+
"0.6": 5.74,
|
| 116 |
+
"0.65": 3.95,
|
| 117 |
+
"0.7": 2.83,
|
| 118 |
+
"0.75": 1.99,
|
| 119 |
+
"0.8": 1.15,
|
| 120 |
+
"0.85": 0.49,
|
| 121 |
+
"0.9": 0.49,
|
| 122 |
+
"0.95": 0.49,
|
| 123 |
+
"average": 3.28
|
| 124 |
+
},
|
| 125 |
+
"MR-R1": {
|
| 126 |
+
"0.5": 7.69,
|
| 127 |
+
"0.55": 5.13,
|
| 128 |
+
"0.6": 4.66,
|
| 129 |
+
"0.65": 3.26,
|
| 130 |
+
"0.7": 2.33,
|
| 131 |
+
"0.75": 0.93,
|
| 132 |
+
"0.8": 0.7,
|
| 133 |
+
"0.85": 0.0,
|
| 134 |
+
"0.9": 0.0,
|
| 135 |
+
"0.95": 0.0
|
| 136 |
+
}
|
| 137 |
+
}
|
| 138 |
+
}
|