
1.5
Browse files- README.md +43 -4
- adapter_config.json +4 -4
- adapter_model.safetensors +1 -1
- all_results.json +10 -10
- eval_results.json +5 -5
- train_results.json +6 -6
- trainer_log.jsonl +0 -0
- trainer_state.json +0 -0
- training_args.bin +1 -1
- training_loss.png +0 -0
README.md
CHANGED
|
@@ -8,18 +8,18 @@ tags:
|
|
| 8 |
- unsloth
|
| 9 |
- generated_from_trainer
|
| 10 |
model-index:
|
| 11 |
-
- name: llm3br256
|
| 12 |
results: []
|
| 13 |
---
|
| 14 |
|
| 15 |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
|
| 16 |
should probably proofread and complete it, then remove this comment. -->
|
| 17 |
|
| 18 |
-
# llm3br256
|
| 19 |
|
| 20 |
This model is a fine-tuned version of [meta-llama/Llama-3.2-3B-Instruct](https://huggingface.co/meta-llama/Llama-3.2-3B-Instruct) on the centime dataset.
|
| 21 |
It achieves the following results on the evaluation set:
|
| 22 |
-
- Loss: 0.
|
| 23 |
|
| 24 |
## Model description
|
| 25 |
|
|
@@ -45,10 +45,49 @@ The following hyperparameters were used during training:
|
|
| 45 |
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
|
| 46 |
- lr_scheduler_type: cosine
|
| 47 |
- lr_scheduler_warmup_ratio: 0.1
|
| 48 |
-
- num_epochs:
|
| 49 |
|
| 50 |
### Training results
|
| 51 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 52 |
|
| 53 |
|
| 54 |
### Framework versions
|
|
|
|
| 8 |
- unsloth
|
| 9 |
- generated_from_trainer
|
| 10 |
model-index:
|
| 11 |
+
- name: llm3br256
|
| 12 |
results: []
|
| 13 |
---
|
| 14 |
|
| 15 |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
|
| 16 |
should probably proofread and complete it, then remove this comment. -->
|
| 17 |
|
| 18 |
+
# llm3br256
|
| 19 |
|
| 20 |
This model is a fine-tuned version of [meta-llama/Llama-3.2-3B-Instruct](https://huggingface.co/meta-llama/Llama-3.2-3B-Instruct) on the centime dataset.
|
| 21 |
It achieves the following results on the evaluation set:
|
| 22 |
+
- Loss: 0.0070
|
| 23 |
|
| 24 |
## Model description
|
| 25 |
|
|
|
|
| 45 |
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
|
| 46 |
- lr_scheduler_type: cosine
|
| 47 |
- lr_scheduler_warmup_ratio: 0.1
|
| 48 |
+
- num_epochs: 25.0
|
| 49 |
|
| 50 |
### Training results
|
| 51 |
|
| 52 |
+
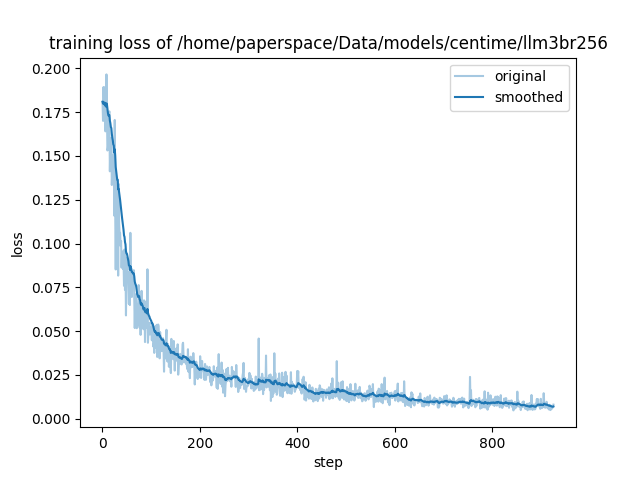
| Training Loss | Epoch | Step | Validation Loss |
|
| 53 |
+
|:-------------:|:------:|:----:|:---------------:|
|
| 54 |
+
| 0.1159 | 0.1208 | 25 | 0.1004 |
|
| 55 |
+
| 0.0843 | 0.2415 | 50 | 0.0635 |
|
| 56 |
+
| 0.0763 | 0.3623 | 75 | 0.0474 |
|
| 57 |
+
| 0.0496 | 0.4831 | 100 | 0.0365 |
|
| 58 |
+
| 0.046 | 0.6039 | 125 | 0.0316 |
|
| 59 |
+
| 0.0368 | 0.7246 | 150 | 0.0266 |
|
| 60 |
+
| 0.0283 | 0.8454 | 175 | 0.0232 |
|
| 61 |
+
| 0.0237 | 0.9662 | 200 | 0.0212 |
|
| 62 |
+
| 0.0234 | 1.0870 | 225 | 0.0194 |
|
| 63 |
+
| 0.0232 | 1.2077 | 250 | 0.0176 |
|
| 64 |
+
| 0.0307 | 1.3285 | 275 | 0.0178 |
|
| 65 |
+
| 0.0228 | 1.4493 | 300 | 0.0147 |
|
| 66 |
+
| 0.0167 | 1.5700 | 325 | 0.0155 |
|
| 67 |
+
| 0.0238 | 1.6908 | 350 | 0.0125 |
|
| 68 |
+
| 0.0191 | 1.8116 | 375 | 0.0138 |
|
| 69 |
+
| 0.0273 | 1.9324 | 400 | 0.0120 |
|
| 70 |
+
| 0.0194 | 2.0531 | 425 | 0.0125 |
|
| 71 |
+
| 0.0125 | 2.1739 | 450 | 0.0128 |
|
| 72 |
+
| 0.0132 | 2.2947 | 475 | 0.0117 |
|
| 73 |
+
| 0.0142 | 2.4155 | 500 | 0.0099 |
|
| 74 |
+
| 0.0119 | 2.5362 | 525 | 0.0105 |
|
| 75 |
+
| 0.0131 | 2.6570 | 550 | 0.0118 |
|
| 76 |
+
| 0.0089 | 2.7778 | 575 | 0.0100 |
|
| 77 |
+
| 0.0158 | 2.8986 | 600 | 0.0096 |
|
| 78 |
+
| 0.0119 | 3.0193 | 625 | 0.0096 |
|
| 79 |
+
| 0.0097 | 3.1401 | 650 | 0.0099 |
|
| 80 |
+
| 0.0089 | 3.2609 | 675 | 0.0092 |
|
| 81 |
+
| 0.0087 | 3.3816 | 700 | 0.0088 |
|
| 82 |
+
| 0.0083 | 3.5024 | 725 | 0.0088 |
|
| 83 |
+
| 0.0088 | 3.6232 | 750 | 0.0080 |
|
| 84 |
+
| 0.0058 | 3.7440 | 775 | 0.0069 |
|
| 85 |
+
| 0.008 | 3.8647 | 800 | 0.0070 |
|
| 86 |
+
| 0.0099 | 3.9855 | 825 | 0.0073 |
|
| 87 |
+
| 0.0072 | 4.1063 | 850 | 0.0113 |
|
| 88 |
+
| 0.0065 | 4.2271 | 875 | 0.0107 |
|
| 89 |
+
| 0.0079 | 4.3478 | 900 | 0.0097 |
|
| 90 |
+
| 0.0081 | 4.4686 | 925 | 0.0103 |
|
| 91 |
|
| 92 |
|
| 93 |
### Framework versions
|
adapter_config.json
CHANGED
|
@@ -20,13 +20,13 @@
|
|
| 20 |
"rank_pattern": {},
|
| 21 |
"revision": null,
|
| 22 |
"target_modules": [
|
| 23 |
-
"gate_proj",
|
| 24 |
"down_proj",
|
| 25 |
-
"k_proj",
|
| 26 |
-
"q_proj",
|
| 27 |
"o_proj",
|
| 28 |
"up_proj",
|
| 29 |
-
"
|
|
|
|
|
|
|
|
|
|
| 30 |
],
|
| 31 |
"task_type": "CAUSAL_LM",
|
| 32 |
"use_dora": false,
|
|
|
|
| 20 |
"rank_pattern": {},
|
| 21 |
"revision": null,
|
| 22 |
"target_modules": [
|
|
|
|
| 23 |
"down_proj",
|
|
|
|
|
|
|
| 24 |
"o_proj",
|
| 25 |
"up_proj",
|
| 26 |
+
"k_proj",
|
| 27 |
+
"v_proj",
|
| 28 |
+
"q_proj",
|
| 29 |
+
"gate_proj"
|
| 30 |
],
|
| 31 |
"task_type": "CAUSAL_LM",
|
| 32 |
"use_dora": false,
|
adapter_model.safetensors
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 1556140392
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f546425f4fea154c38e487f0a187535ac63b41c20c7f3dbe76a4f17048ae2e89
|
| 3 |
size 1556140392
|
all_results.json
CHANGED
|
@@ -1,12 +1,12 @@
|
|
| 1 |
{
|
| 2 |
-
"epoch":
|
| 3 |
-
"eval_loss": 0.
|
| 4 |
-
"eval_runtime":
|
| 5 |
-
"eval_samples_per_second":
|
| 6 |
-
"eval_steps_per_second": 0.
|
| 7 |
-
"total_flos":
|
| 8 |
-
"train_loss": 0.
|
| 9 |
-
"train_runtime":
|
| 10 |
-
"train_samples_per_second":
|
| 11 |
-
"train_steps_per_second": 0.
|
| 12 |
}
|
|
|
|
| 1 |
{
|
| 2 |
+
"epoch": 4.468599033816425,
|
| 3 |
+
"eval_loss": 0.007014152128249407,
|
| 4 |
+
"eval_runtime": 20.2851,
|
| 5 |
+
"eval_samples_per_second": 4.93,
|
| 6 |
+
"eval_steps_per_second": 0.148,
|
| 7 |
+
"total_flos": 3.488842745919701e+18,
|
| 8 |
+
"train_loss": 0.025700105609926017,
|
| 9 |
+
"train_runtime": 24639.0069,
|
| 10 |
+
"train_samples_per_second": 10.045,
|
| 11 |
+
"train_steps_per_second": 0.21
|
| 12 |
}
|
eval_results.json
CHANGED
|
@@ -1,7 +1,7 @@
|
|
| 1 |
{
|
| 2 |
-
"epoch":
|
| 3 |
-
"eval_loss": 0.
|
| 4 |
-
"eval_runtime":
|
| 5 |
-
"eval_samples_per_second":
|
| 6 |
-
"eval_steps_per_second": 0.
|
| 7 |
}
|
|
|
|
| 1 |
{
|
| 2 |
+
"epoch": 4.468599033816425,
|
| 3 |
+
"eval_loss": 0.007014152128249407,
|
| 4 |
+
"eval_runtime": 20.2851,
|
| 5 |
+
"eval_samples_per_second": 4.93,
|
| 6 |
+
"eval_steps_per_second": 0.148
|
| 7 |
}
|
train_results.json
CHANGED
|
@@ -1,8 +1,8 @@
|
|
| 1 |
{
|
| 2 |
-
"epoch":
|
| 3 |
-
"total_flos":
|
| 4 |
-
"train_loss": 0.
|
| 5 |
-
"train_runtime":
|
| 6 |
-
"train_samples_per_second":
|
| 7 |
-
"train_steps_per_second": 0.
|
| 8 |
}
|
|
|
|
| 1 |
{
|
| 2 |
+
"epoch": 4.468599033816425,
|
| 3 |
+
"total_flos": 3.488842745919701e+18,
|
| 4 |
+
"train_loss": 0.025700105609926017,
|
| 5 |
+
"train_runtime": 24639.0069,
|
| 6 |
+
"train_samples_per_second": 10.045,
|
| 7 |
+
"train_steps_per_second": 0.21
|
| 8 |
}
|
trainer_log.jsonl
CHANGED
|
The diff for this file is too large to render.
See raw diff
|
|
|
trainer_state.json
CHANGED
|
The diff for this file is too large to render.
See raw diff
|
|
|
training_args.bin
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 5432
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4f09096e9b8b6a21e07e8d8e7f67e8454fecdc716a04339865100ade36fb3fcd
|
| 3 |
size 5432
|
training_loss.png
CHANGED
|
|