
Submitted by
 zhoutianyi
zhoutianyi
zhoutianyiGet trending papers in your email inbox once a day!
Get trending papers in your email inbox!
Subscribe
zhoutianyi
 akhaliq
akhaliq
 Eliahu
Eliahu
 sinwang
sinwang
 agwmon
agwmon
 Owen777
Owen777
 LucasFang
LucasFang
 Weiyun1025
Weiyun1025
 yeates
yeates
 mozhu
mozhu
 wondervictor
wondervictor EthanTaylor
EthanTaylor
 ChenyangLyu
ChenyangLyu
 yyf86
yyf86
 wenhu
wenhu akhaliq
akhaliq akhaliq
akhaliq akhaliq
akhaliq
 VityaVitalich
VityaVitalich
 ArthurDouillard
ArthurDouillard
 RohitGandikota
RohitGandikota akhaliq
akhaliq
 sayakpaul
sayakpaul
 BestWishYsh
BestWishYsh
 xuxw98
xuxw98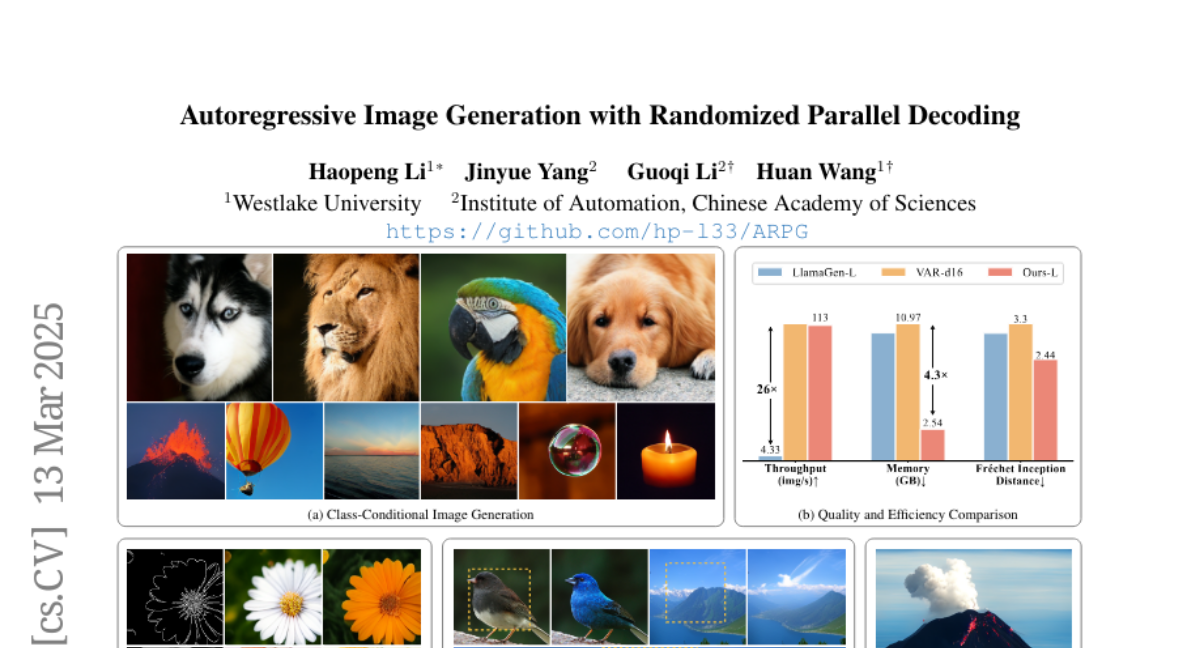
 hp-l33
hp-l33
 allisonandreyev
allisonandreyev
 Zc0in
Zc0in
 chenblin26
chenblin26
 AhmadMustafa
AhmadMustafa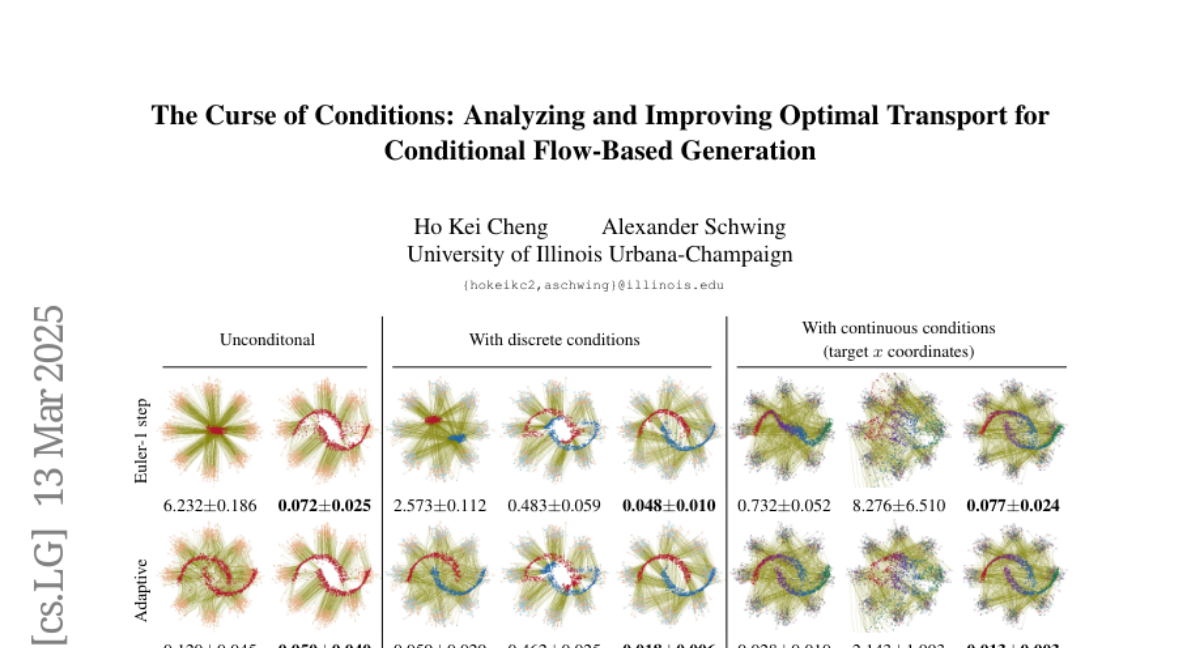
 hkchengrex
hkchengrex
 kfirgold99
kfirgold99
 xzhao
xzhao
 gabrielchua
gabrielchua
 imranraad
imranraad
 jhao
jhao
 Nikolai10
Nikolai10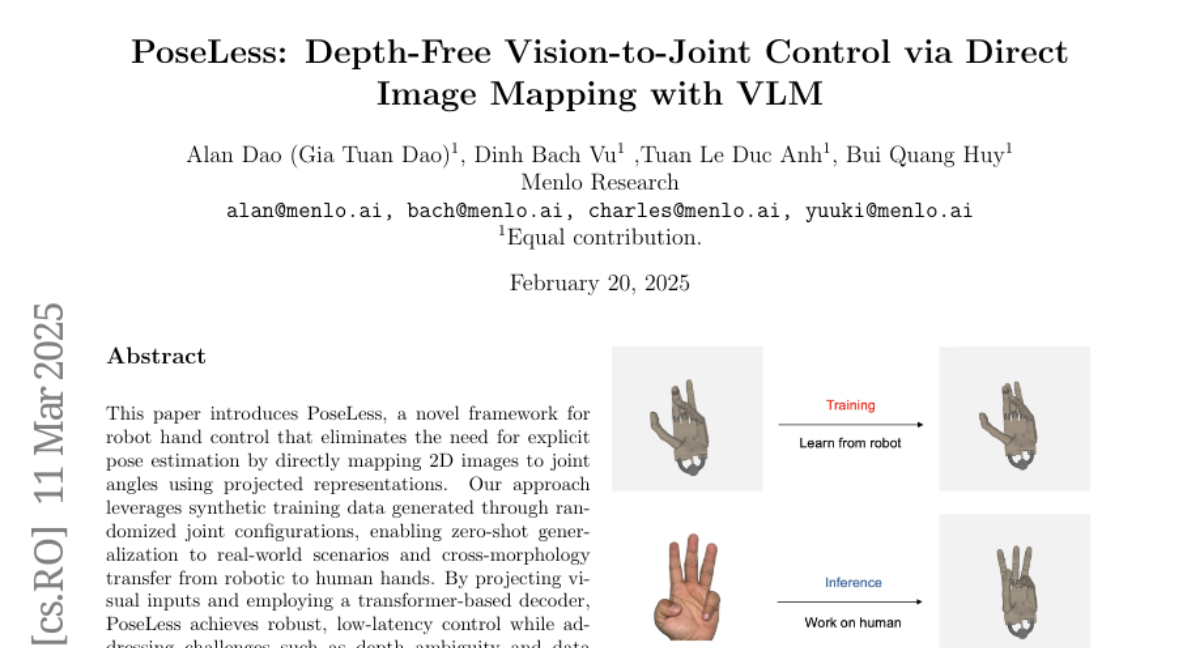
 alandao
alandao
 Jason0214
Jason0214





































































