

Submitted by
 zwq2018
zwq2018
zwq2018Get trending papers in your email inbox once a day!
Get trending papers in your email inbox!
Subscribe
zwq2018
 xichenhku
xichenhku
 akhaliq
akhaliq akhaliq
akhaliq CircleRadon
CircleRadon
 xiazhi
xiazhi
 ztwang
ztwang
 dongguanting
dongguanting
 Yuxiang007
Yuxiang007
 mahirlabibdihan
mahirlabibdihan
 tyleryzhu
tyleryzhu
 KAKA22
KAKA22
 orpatashnik
orpatashnik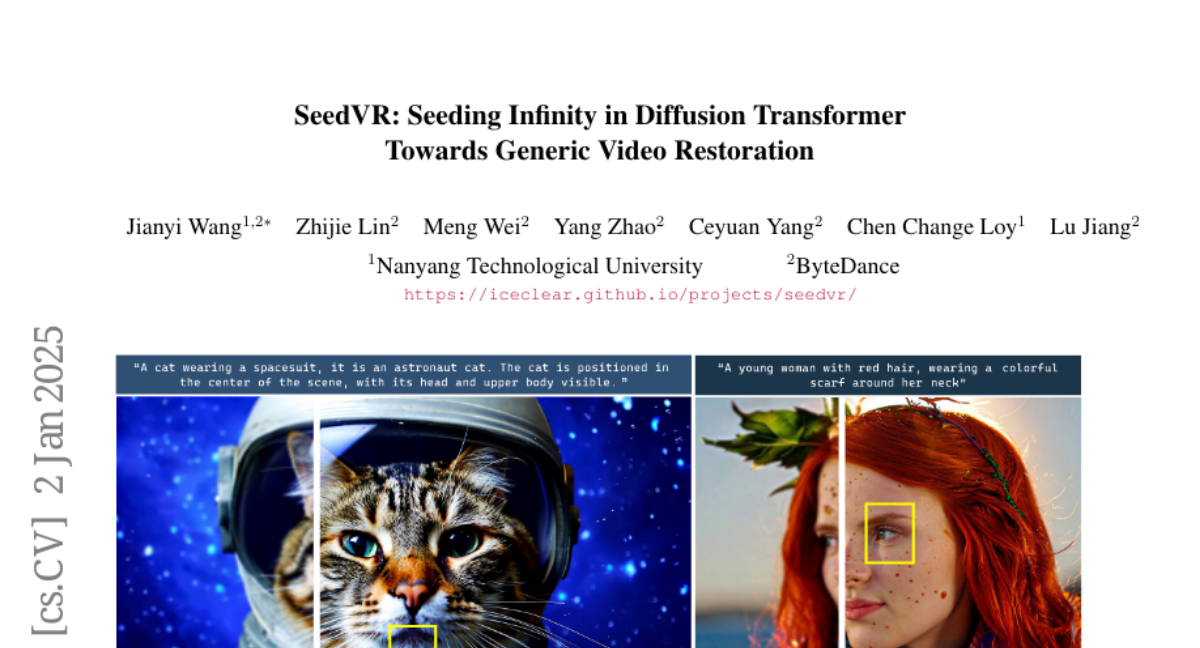
 Iceclear
mahirlabibdihan
Iceclear
mahirlabibdihan
 peihaowang
peihaowang
 littlestone111
littlestone111
 lanczos
lanczos
 Harold328
Harold328
































