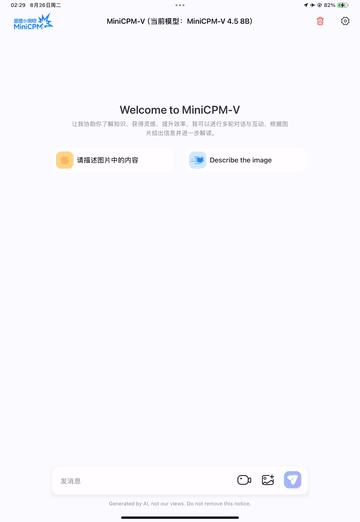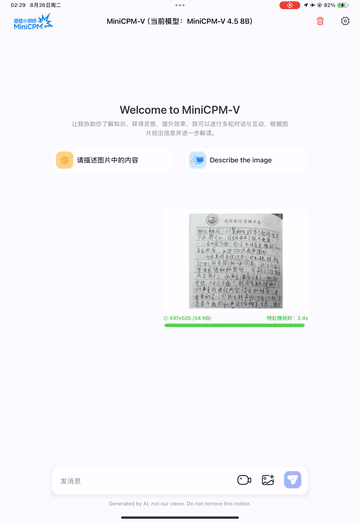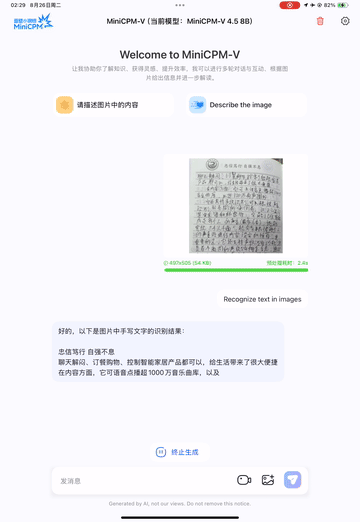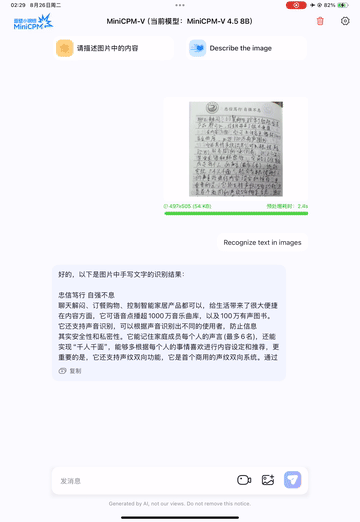
| Edge (On-device) |
Llama.cpp |
Llama.cpp Doc |
#15575 (2025-08-26) |
master (2025-08-26) |
b6282 |
| Ollama |
Ollama Doc |
#12078 (2025-08-26) |
Merging |
Waiting for official release |
| Serving (Cloud) |
vLLM |
vLLM Doc |
#23586 (2025-08-26) |
main (2025-08-27) |
Waiting for official release |
| SGLang |
SGLang Doc |
#9610 (2025-08-26) |
Merging |
Waiting for official release |
| Finetuning |
LLaMA-Factory |
LLaMA-Factory Doc |
#9022 (2025-08-26) |
main (2025-08-26) |
Waiting for official release |
| Quantization |
GGUF |
GGUF Doc |
— |
— |
— |
| BNB |
BNB Doc |
— |
— |
— |
| AWQ |
AWQ Doc |
— |
— |
— |
| Demos |
Gradio Demo |
Gradio Demo Doc |
— |
— |
— |