
End of training
Browse files- README.md +5 -5
- all_results.json +19 -0
- egy_training_log.txt +2 -0
- eval_results.json +13 -0
- train_results.json +9 -0
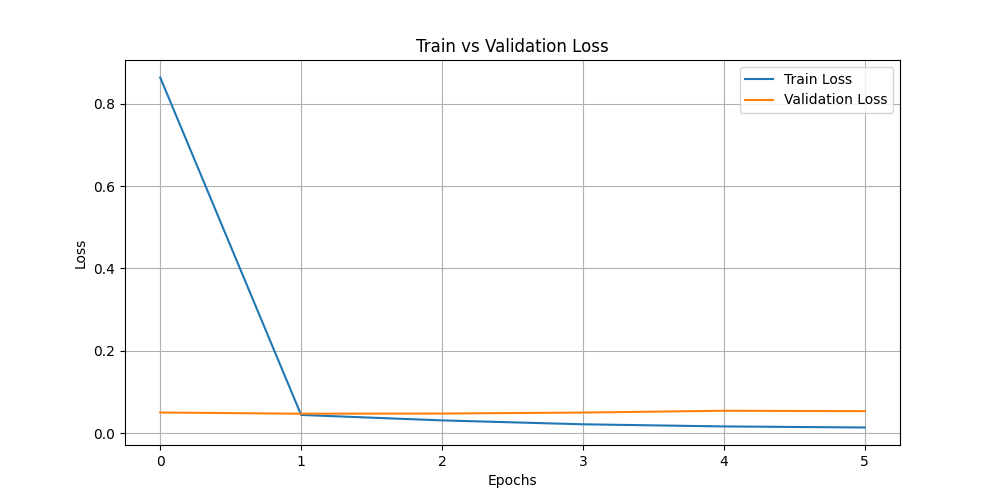
- train_vs_val_loss.png +0 -0
- trainer_state.json +184 -0
README.md
CHANGED
|
@@ -18,11 +18,11 @@ should probably proofread and complete it, then remove this comment. -->
|
|
| 18 |
|
| 19 |
This model is a fine-tuned version of [aubmindlab/aragpt2-large](https://huggingface.co/aubmindlab/aragpt2-large) on an unknown dataset.
|
| 20 |
It achieves the following results on the evaluation set:
|
| 21 |
-
- Loss: 0.
|
| 22 |
-
- Bleu: 0.
|
| 23 |
-
- Rouge1: 0.
|
| 24 |
-
- Rouge2: 0.
|
| 25 |
-
- Rougel: 0.
|
| 26 |
|
| 27 |
## Model description
|
| 28 |
|
|
|
|
| 18 |
|
| 19 |
This model is a fine-tuned version of [aubmindlab/aragpt2-large](https://huggingface.co/aubmindlab/aragpt2-large) on an unknown dataset.
|
| 20 |
It achieves the following results on the evaluation set:
|
| 21 |
+
- Loss: 0.0469
|
| 22 |
+
- Bleu: 0.0733
|
| 23 |
+
- Rouge1: 0.3956
|
| 24 |
+
- Rouge2: 0.1677
|
| 25 |
+
- Rougel: 0.3901
|
| 26 |
|
| 27 |
## Model description
|
| 28 |
|
all_results.json
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 7.0,
|
| 3 |
+
"eval_bleu": 0.07334464750125981,
|
| 4 |
+
"eval_loss": 0.04691193997859955,
|
| 5 |
+
"eval_rouge1": 0.39556592669658314,
|
| 6 |
+
"eval_rouge2": 0.1676736409423039,
|
| 7 |
+
"eval_rougeL": 0.3901085723006601,
|
| 8 |
+
"eval_runtime": 41.1462,
|
| 9 |
+
"eval_samples": 304,
|
| 10 |
+
"eval_samples_per_second": 7.388,
|
| 11 |
+
"eval_steps_per_second": 0.924,
|
| 12 |
+
"perplexity": 1.048029715496853,
|
| 13 |
+
"total_flos": 3.71386078199808e+16,
|
| 14 |
+
"train_loss": 0.1430642572443156,
|
| 15 |
+
"train_runtime": 4921.8294,
|
| 16 |
+
"train_samples": 1219,
|
| 17 |
+
"train_samples_per_second": 4.953,
|
| 18 |
+
"train_steps_per_second": 1.239
|
| 19 |
+
}
|
egy_training_log.txt
CHANGED
|
@@ -568,3 +568,5 @@ INFO:root:Epoch 6.0: Train Loss = 0.016, Eval Loss = 0.054129794239997864
|
|
| 568 |
INFO:absl:Using default tokenizer.
|
| 569 |
INFO:root:Epoch 7.0: Train Loss = 0.0134, Eval Loss = 0.05314570292830467
|
| 570 |
INFO:absl:Using default tokenizer.
|
|
|
|
|
|
|
|
|
| 568 |
INFO:absl:Using default tokenizer.
|
| 569 |
INFO:root:Epoch 7.0: Train Loss = 0.0134, Eval Loss = 0.05314570292830467
|
| 570 |
INFO:absl:Using default tokenizer.
|
| 571 |
+
INFO:__main__:*** Evaluate ***
|
| 572 |
+
INFO:absl:Using default tokenizer.
|
eval_results.json
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 7.0,
|
| 3 |
+
"eval_bleu": 0.07334464750125981,
|
| 4 |
+
"eval_loss": 0.04691193997859955,
|
| 5 |
+
"eval_rouge1": 0.39556592669658314,
|
| 6 |
+
"eval_rouge2": 0.1676736409423039,
|
| 7 |
+
"eval_rougeL": 0.3901085723006601,
|
| 8 |
+
"eval_runtime": 41.1462,
|
| 9 |
+
"eval_samples": 304,
|
| 10 |
+
"eval_samples_per_second": 7.388,
|
| 11 |
+
"eval_steps_per_second": 0.924,
|
| 12 |
+
"perplexity": 1.048029715496853
|
| 13 |
+
}
|
train_results.json
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 7.0,
|
| 3 |
+
"total_flos": 3.71386078199808e+16,
|
| 4 |
+
"train_loss": 0.1430642572443156,
|
| 5 |
+
"train_runtime": 4921.8294,
|
| 6 |
+
"train_samples": 1219,
|
| 7 |
+
"train_samples_per_second": 4.953,
|
| 8 |
+
"train_steps_per_second": 1.239
|
| 9 |
+
}
|
train_vs_val_loss.png
ADDED
|
trainer_state.json
ADDED
|
@@ -0,0 +1,184 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"best_metric": 0.04691193997859955,
|
| 3 |
+
"best_model_checkpoint": "/home/iais_marenpielka/Bouthaina/res_nw_yem_aragpt2-large/checkpoint-610",
|
| 4 |
+
"epoch": 7.0,
|
| 5 |
+
"eval_steps": 500,
|
| 6 |
+
"global_step": 2135,
|
| 7 |
+
"is_hyper_param_search": false,
|
| 8 |
+
"is_local_process_zero": true,
|
| 9 |
+
"is_world_process_zero": true,
|
| 10 |
+
"log_history": [
|
| 11 |
+
{
|
| 12 |
+
"epoch": 1.0,
|
| 13 |
+
"grad_norm": 0.40213119983673096,
|
| 14 |
+
"learning_rate": 3.05e-05,
|
| 15 |
+
"loss": 0.8644,
|
| 16 |
+
"step": 305
|
| 17 |
+
},
|
| 18 |
+
{
|
| 19 |
+
"epoch": 1.0,
|
| 20 |
+
"eval_bleu": 0.03103545034655718,
|
| 21 |
+
"eval_loss": 0.049881722778081894,
|
| 22 |
+
"eval_rouge1": 0.2976310465047741,
|
| 23 |
+
"eval_rouge2": 0.0825114524566873,
|
| 24 |
+
"eval_rougeL": 0.2931870351050212,
|
| 25 |
+
"eval_runtime": 101.6572,
|
| 26 |
+
"eval_samples_per_second": 2.99,
|
| 27 |
+
"eval_steps_per_second": 0.374,
|
| 28 |
+
"step": 305
|
| 29 |
+
},
|
| 30 |
+
{
|
| 31 |
+
"epoch": 2.0,
|
| 32 |
+
"grad_norm": 0.45833268761634827,
|
| 33 |
+
"learning_rate": 4.901785714285714e-05,
|
| 34 |
+
"loss": 0.0439,
|
| 35 |
+
"step": 610
|
| 36 |
+
},
|
| 37 |
+
{
|
| 38 |
+
"epoch": 2.0,
|
| 39 |
+
"eval_bleu": 0.07334464750125981,
|
| 40 |
+
"eval_loss": 0.04691193997859955,
|
| 41 |
+
"eval_rouge1": 0.39556592669658314,
|
| 42 |
+
"eval_rouge2": 0.1676736409423039,
|
| 43 |
+
"eval_rougeL": 0.3901085723006601,
|
| 44 |
+
"eval_runtime": 41.076,
|
| 45 |
+
"eval_samples_per_second": 7.401,
|
| 46 |
+
"eval_steps_per_second": 0.925,
|
| 47 |
+
"step": 610
|
| 48 |
+
},
|
| 49 |
+
{
|
| 50 |
+
"epoch": 3.0,
|
| 51 |
+
"grad_norm": 0.3850250840187073,
|
| 52 |
+
"learning_rate": 4.629464285714286e-05,
|
| 53 |
+
"loss": 0.0307,
|
| 54 |
+
"step": 915
|
| 55 |
+
},
|
| 56 |
+
{
|
| 57 |
+
"epoch": 3.0,
|
| 58 |
+
"eval_bleu": 0.09008751782596823,
|
| 59 |
+
"eval_loss": 0.0473761111497879,
|
| 60 |
+
"eval_rouge1": 0.44112670621442845,
|
| 61 |
+
"eval_rouge2": 0.20925026290023724,
|
| 62 |
+
"eval_rougeL": 0.43611440413552455,
|
| 63 |
+
"eval_runtime": 41.095,
|
| 64 |
+
"eval_samples_per_second": 7.397,
|
| 65 |
+
"eval_steps_per_second": 0.925,
|
| 66 |
+
"step": 915
|
| 67 |
+
},
|
| 68 |
+
{
|
| 69 |
+
"epoch": 4.0,
|
| 70 |
+
"grad_norm": 0.4408362805843353,
|
| 71 |
+
"learning_rate": 4.3571428571428576e-05,
|
| 72 |
+
"loss": 0.0212,
|
| 73 |
+
"step": 1220
|
| 74 |
+
},
|
| 75 |
+
{
|
| 76 |
+
"epoch": 4.0,
|
| 77 |
+
"eval_bleu": 0.10385450068202749,
|
| 78 |
+
"eval_loss": 0.04973715916275978,
|
| 79 |
+
"eval_rouge1": 0.4643434470122675,
|
| 80 |
+
"eval_rouge2": 0.23150126678662394,
|
| 81 |
+
"eval_rougeL": 0.45914976519742434,
|
| 82 |
+
"eval_runtime": 41.0763,
|
| 83 |
+
"eval_samples_per_second": 7.401,
|
| 84 |
+
"eval_steps_per_second": 0.925,
|
| 85 |
+
"step": 1220
|
| 86 |
+
},
|
| 87 |
+
{
|
| 88 |
+
"epoch": 5.0,
|
| 89 |
+
"grad_norm": 0.4677392840385437,
|
| 90 |
+
"learning_rate": 4.084821428571429e-05,
|
| 91 |
+
"loss": 0.016,
|
| 92 |
+
"step": 1525
|
| 93 |
+
},
|
| 94 |
+
{
|
| 95 |
+
"epoch": 5.0,
|
| 96 |
+
"eval_bleu": 0.09227592943056641,
|
| 97 |
+
"eval_loss": 0.054129794239997864,
|
| 98 |
+
"eval_rouge1": 0.464136474952609,
|
| 99 |
+
"eval_rouge2": 0.22291426741508574,
|
| 100 |
+
"eval_rougeL": 0.4599627344232192,
|
| 101 |
+
"eval_runtime": 41.1781,
|
| 102 |
+
"eval_samples_per_second": 7.383,
|
| 103 |
+
"eval_steps_per_second": 0.923,
|
| 104 |
+
"step": 1525
|
| 105 |
+
},
|
| 106 |
+
{
|
| 107 |
+
"epoch": 6.0,
|
| 108 |
+
"grad_norm": 0.30016008019447327,
|
| 109 |
+
"learning_rate": 3.8125e-05,
|
| 110 |
+
"loss": 0.0134,
|
| 111 |
+
"step": 1830
|
| 112 |
+
},
|
| 113 |
+
{
|
| 114 |
+
"epoch": 6.0,
|
| 115 |
+
"eval_bleu": 0.11604582902883592,
|
| 116 |
+
"eval_loss": 0.05314570292830467,
|
| 117 |
+
"eval_rouge1": 0.47459996105255675,
|
| 118 |
+
"eval_rouge2": 0.25028361013073314,
|
| 119 |
+
"eval_rougeL": 0.46988615577124576,
|
| 120 |
+
"eval_runtime": 61.9343,
|
| 121 |
+
"eval_samples_per_second": 4.908,
|
| 122 |
+
"eval_steps_per_second": 0.614,
|
| 123 |
+
"step": 1830
|
| 124 |
+
},
|
| 125 |
+
{
|
| 126 |
+
"epoch": 7.0,
|
| 127 |
+
"grad_norm": 0.24085062742233276,
|
| 128 |
+
"learning_rate": 3.5401785714285716e-05,
|
| 129 |
+
"loss": 0.0118,
|
| 130 |
+
"step": 2135
|
| 131 |
+
},
|
| 132 |
+
{
|
| 133 |
+
"epoch": 7.0,
|
| 134 |
+
"eval_bleu": 0.11125669152362899,
|
| 135 |
+
"eval_loss": 0.057827215641736984,
|
| 136 |
+
"eval_rouge1": 0.4975937747836845,
|
| 137 |
+
"eval_rouge2": 0.27138037997797015,
|
| 138 |
+
"eval_rougeL": 0.4939744686596661,
|
| 139 |
+
"eval_runtime": 101.6221,
|
| 140 |
+
"eval_samples_per_second": 2.991,
|
| 141 |
+
"eval_steps_per_second": 0.374,
|
| 142 |
+
"step": 2135
|
| 143 |
+
},
|
| 144 |
+
{
|
| 145 |
+
"epoch": 7.0,
|
| 146 |
+
"step": 2135,
|
| 147 |
+
"total_flos": 3.71386078199808e+16,
|
| 148 |
+
"train_loss": 0.1430642572443156,
|
| 149 |
+
"train_runtime": 4921.8294,
|
| 150 |
+
"train_samples_per_second": 4.953,
|
| 151 |
+
"train_steps_per_second": 1.239
|
| 152 |
+
}
|
| 153 |
+
],
|
| 154 |
+
"logging_steps": 500,
|
| 155 |
+
"max_steps": 6100,
|
| 156 |
+
"num_input_tokens_seen": 0,
|
| 157 |
+
"num_train_epochs": 20,
|
| 158 |
+
"save_steps": 500,
|
| 159 |
+
"stateful_callbacks": {
|
| 160 |
+
"EarlyStoppingCallback": {
|
| 161 |
+
"args": {
|
| 162 |
+
"early_stopping_patience": 5,
|
| 163 |
+
"early_stopping_threshold": 0.0
|
| 164 |
+
},
|
| 165 |
+
"attributes": {
|
| 166 |
+
"early_stopping_patience_counter": 0
|
| 167 |
+
}
|
| 168 |
+
},
|
| 169 |
+
"TrainerControl": {
|
| 170 |
+
"args": {
|
| 171 |
+
"should_epoch_stop": false,
|
| 172 |
+
"should_evaluate": false,
|
| 173 |
+
"should_log": false,
|
| 174 |
+
"should_save": true,
|
| 175 |
+
"should_training_stop": true
|
| 176 |
+
},
|
| 177 |
+
"attributes": {}
|
| 178 |
+
}
|
| 179 |
+
},
|
| 180 |
+
"total_flos": 3.71386078199808e+16,
|
| 181 |
+
"train_batch_size": 4,
|
| 182 |
+
"trial_name": null,
|
| 183 |
+
"trial_params": null
|
| 184 |
+
}
|