
End of training
Browse files- README.md +5 -5
- all_results.json +19 -0
- egy_training_log.txt +2 -0
- eval_results.json +13 -0
- train_results.json +9 -0
- train_vs_val_loss.png +0 -0
- trainer_state.json +165 -0
README.md
CHANGED
|
@@ -18,11 +18,11 @@ should probably proofread and complete it, then remove this comment. -->
|
|
| 18 |
|
| 19 |
This model is a fine-tuned version of [aubmindlab/aragpt2-large](https://huggingface.co/aubmindlab/aragpt2-large) on an unknown dataset.
|
| 20 |
It achieves the following results on the evaluation set:
|
| 21 |
-
- Loss: 0.
|
| 22 |
-
- Bleu: 0.
|
| 23 |
-
- Rouge1: 0.
|
| 24 |
-
- Rouge2: 0.
|
| 25 |
-
- Rougel: 0.
|
| 26 |
|
| 27 |
## Model description
|
| 28 |
|
|
|
|
| 18 |
|
| 19 |
This model is a fine-tuned version of [aubmindlab/aragpt2-large](https://huggingface.co/aubmindlab/aragpt2-large) on an unknown dataset.
|
| 20 |
It achieves the following results on the evaluation set:
|
| 21 |
+
- Loss: 0.1727
|
| 22 |
+
- Bleu: 0.0581
|
| 23 |
+
- Rouge1: 0.3533
|
| 24 |
+
- Rouge2: 0.1255
|
| 25 |
+
- Rougel: 0.3493
|
| 26 |
|
| 27 |
## Model description
|
| 28 |
|
all_results.json
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 6.0,
|
| 3 |
+
"eval_bleu": 0.0580598821559071,
|
| 4 |
+
"eval_loss": 0.17270471155643463,
|
| 5 |
+
"eval_rouge1": 0.3533239818405131,
|
| 6 |
+
"eval_rouge2": 0.1254672546781218,
|
| 7 |
+
"eval_rougeL": 0.3492871461298215,
|
| 8 |
+
"eval_runtime": 400.5995,
|
| 9 |
+
"eval_samples": 2113,
|
| 10 |
+
"eval_samples_per_second": 5.275,
|
| 11 |
+
"eval_steps_per_second": 1.321,
|
| 12 |
+
"perplexity": 1.1885150984889004,
|
| 13 |
+
"total_flos": 2.207164045197312e+17,
|
| 14 |
+
"train_loss": 0.062080234660581754,
|
| 15 |
+
"train_runtime": 24111.8135,
|
| 16 |
+
"train_samples": 8452,
|
| 17 |
+
"train_samples_per_second": 7.011,
|
| 18 |
+
"train_steps_per_second": 1.753
|
| 19 |
+
}
|
egy_training_log.txt
CHANGED
|
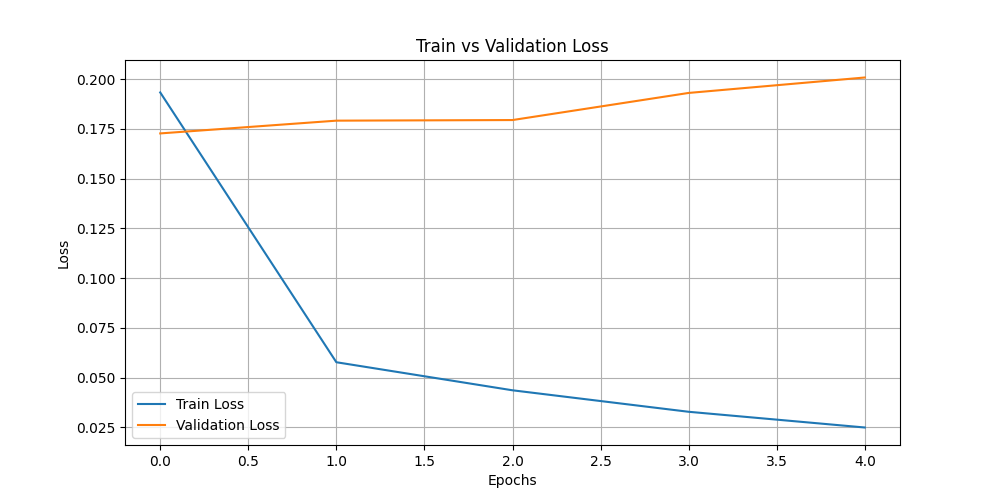
@@ -702,3 +702,5 @@ INFO:root:Epoch 5.0: Train Loss = 0.0328, Eval Loss = 0.19304993748664856
|
|
| 702 |
INFO:absl:Using default tokenizer.
|
| 703 |
INFO:root:Epoch 6.0: Train Loss = 0.0249, Eval Loss = 0.20080772042274475
|
| 704 |
INFO:absl:Using default tokenizer.
|
|
|
|
|
|
|
|
|
| 702 |
INFO:absl:Using default tokenizer.
|
| 703 |
INFO:root:Epoch 6.0: Train Loss = 0.0249, Eval Loss = 0.20080772042274475
|
| 704 |
INFO:absl:Using default tokenizer.
|
| 705 |
+
INFO:__main__:*** Evaluate ***
|
| 706 |
+
INFO:absl:Using default tokenizer.
|
eval_results.json
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 6.0,
|
| 3 |
+
"eval_bleu": 0.0580598821559071,
|
| 4 |
+
"eval_loss": 0.17270471155643463,
|
| 5 |
+
"eval_rouge1": 0.3533239818405131,
|
| 6 |
+
"eval_rouge2": 0.1254672546781218,
|
| 7 |
+
"eval_rougeL": 0.3492871461298215,
|
| 8 |
+
"eval_runtime": 400.5995,
|
| 9 |
+
"eval_samples": 2113,
|
| 10 |
+
"eval_samples_per_second": 5.275,
|
| 11 |
+
"eval_steps_per_second": 1.321,
|
| 12 |
+
"perplexity": 1.1885150984889004
|
| 13 |
+
}
|
train_results.json
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 6.0,
|
| 3 |
+
"total_flos": 2.207164045197312e+17,
|
| 4 |
+
"train_loss": 0.062080234660581754,
|
| 5 |
+
"train_runtime": 24111.8135,
|
| 6 |
+
"train_samples": 8452,
|
| 7 |
+
"train_samples_per_second": 7.011,
|
| 8 |
+
"train_steps_per_second": 1.753
|
| 9 |
+
}
|
train_vs_val_loss.png
ADDED
|
trainer_state.json
ADDED
|
@@ -0,0 +1,165 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"best_metric": 0.17270471155643463,
|
| 3 |
+
"best_model_checkpoint": "/home/iais_marenpielka/Bouthaina/res_nw_irq_aragpt2-large/checkpoint-2113",
|
| 4 |
+
"epoch": 6.0,
|
| 5 |
+
"eval_steps": 500,
|
| 6 |
+
"global_step": 12678,
|
| 7 |
+
"is_hyper_param_search": false,
|
| 8 |
+
"is_local_process_zero": true,
|
| 9 |
+
"is_world_process_zero": true,
|
| 10 |
+
"log_history": [
|
| 11 |
+
{
|
| 12 |
+
"epoch": 1.0,
|
| 13 |
+
"grad_norm": 0.3583737909793854,
|
| 14 |
+
"learning_rate": 4.806872605363985e-05,
|
| 15 |
+
"loss": 0.1933,
|
| 16 |
+
"step": 2113
|
| 17 |
+
},
|
| 18 |
+
{
|
| 19 |
+
"epoch": 1.0,
|
| 20 |
+
"eval_bleu": 0.0580598821559071,
|
| 21 |
+
"eval_loss": 0.17270471155643463,
|
| 22 |
+
"eval_rouge1": 0.3533239818405131,
|
| 23 |
+
"eval_rouge2": 0.1254672546781218,
|
| 24 |
+
"eval_rougeL": 0.3492871461298215,
|
| 25 |
+
"eval_runtime": 400.5509,
|
| 26 |
+
"eval_samples_per_second": 5.275,
|
| 27 |
+
"eval_steps_per_second": 1.321,
|
| 28 |
+
"step": 2113
|
| 29 |
+
},
|
| 30 |
+
{
|
| 31 |
+
"epoch": 2.0,
|
| 32 |
+
"grad_norm": 0.3867155611515045,
|
| 33 |
+
"learning_rate": 4.553879310344828e-05,
|
| 34 |
+
"loss": 0.0577,
|
| 35 |
+
"step": 4226
|
| 36 |
+
},
|
| 37 |
+
{
|
| 38 |
+
"epoch": 2.0,
|
| 39 |
+
"eval_bleu": 0.08704911443587947,
|
| 40 |
+
"eval_loss": 0.1791187822818756,
|
| 41 |
+
"eval_rouge1": 0.40363710077719234,
|
| 42 |
+
"eval_rouge2": 0.17460125985277208,
|
| 43 |
+
"eval_rougeL": 0.4004307662820009,
|
| 44 |
+
"eval_runtime": 400.2099,
|
| 45 |
+
"eval_samples_per_second": 5.28,
|
| 46 |
+
"eval_steps_per_second": 1.322,
|
| 47 |
+
"step": 4226
|
| 48 |
+
},
|
| 49 |
+
{
|
| 50 |
+
"epoch": 3.0,
|
| 51 |
+
"grad_norm": 0.3498200476169586,
|
| 52 |
+
"learning_rate": 4.3008860153256705e-05,
|
| 53 |
+
"loss": 0.0436,
|
| 54 |
+
"step": 6339
|
| 55 |
+
},
|
| 56 |
+
{
|
| 57 |
+
"epoch": 3.0,
|
| 58 |
+
"eval_bleu": 0.0989456627385457,
|
| 59 |
+
"eval_loss": 0.17942094802856445,
|
| 60 |
+
"eval_rouge1": 0.42636848028547636,
|
| 61 |
+
"eval_rouge2": 0.19375467031127153,
|
| 62 |
+
"eval_rougeL": 0.42385903466341546,
|
| 63 |
+
"eval_runtime": 400.3559,
|
| 64 |
+
"eval_samples_per_second": 5.278,
|
| 65 |
+
"eval_steps_per_second": 1.321,
|
| 66 |
+
"step": 6339
|
| 67 |
+
},
|
| 68 |
+
{
|
| 69 |
+
"epoch": 4.0,
|
| 70 |
+
"grad_norm": 0.5500528812408447,
|
| 71 |
+
"learning_rate": 4.0478927203065134e-05,
|
| 72 |
+
"loss": 0.0328,
|
| 73 |
+
"step": 8452
|
| 74 |
+
},
|
| 75 |
+
{
|
| 76 |
+
"epoch": 4.0,
|
| 77 |
+
"eval_bleu": 0.10424332616151948,
|
| 78 |
+
"eval_loss": 0.19304993748664856,
|
| 79 |
+
"eval_rouge1": 0.4349668747641071,
|
| 80 |
+
"eval_rouge2": 0.20263993471878267,
|
| 81 |
+
"eval_rougeL": 0.43152434846368415,
|
| 82 |
+
"eval_runtime": 278.7893,
|
| 83 |
+
"eval_samples_per_second": 7.579,
|
| 84 |
+
"eval_steps_per_second": 1.897,
|
| 85 |
+
"step": 8452
|
| 86 |
+
},
|
| 87 |
+
{
|
| 88 |
+
"epoch": 5.0,
|
| 89 |
+
"grad_norm": 0.46074002981185913,
|
| 90 |
+
"learning_rate": 3.7948994252873564e-05,
|
| 91 |
+
"loss": 0.0249,
|
| 92 |
+
"step": 10565
|
| 93 |
+
},
|
| 94 |
+
{
|
| 95 |
+
"epoch": 5.0,
|
| 96 |
+
"eval_bleu": 0.11217236890780088,
|
| 97 |
+
"eval_loss": 0.20080772042274475,
|
| 98 |
+
"eval_rouge1": 0.43848101287165453,
|
| 99 |
+
"eval_rouge2": 0.20673741926929068,
|
| 100 |
+
"eval_rougeL": 0.4361269384462989,
|
| 101 |
+
"eval_runtime": 400.5561,
|
| 102 |
+
"eval_samples_per_second": 5.275,
|
| 103 |
+
"eval_steps_per_second": 1.321,
|
| 104 |
+
"step": 10565
|
| 105 |
+
},
|
| 106 |
+
{
|
| 107 |
+
"epoch": 6.0,
|
| 108 |
+
"grad_norm": 0.4608220160007477,
|
| 109 |
+
"learning_rate": 3.5419061302681994e-05,
|
| 110 |
+
"loss": 0.0201,
|
| 111 |
+
"step": 12678
|
| 112 |
+
},
|
| 113 |
+
{
|
| 114 |
+
"epoch": 6.0,
|
| 115 |
+
"eval_bleu": 0.11372194499958252,
|
| 116 |
+
"eval_loss": 0.20924784243106842,
|
| 117 |
+
"eval_rouge1": 0.43857021012927844,
|
| 118 |
+
"eval_rouge2": 0.21173873735495666,
|
| 119 |
+
"eval_rougeL": 0.4361467173799841,
|
| 120 |
+
"eval_runtime": 338.8889,
|
| 121 |
+
"eval_samples_per_second": 6.235,
|
| 122 |
+
"eval_steps_per_second": 1.561,
|
| 123 |
+
"step": 12678
|
| 124 |
+
},
|
| 125 |
+
{
|
| 126 |
+
"epoch": 6.0,
|
| 127 |
+
"step": 12678,
|
| 128 |
+
"total_flos": 2.207164045197312e+17,
|
| 129 |
+
"train_loss": 0.062080234660581754,
|
| 130 |
+
"train_runtime": 24111.8135,
|
| 131 |
+
"train_samples_per_second": 7.011,
|
| 132 |
+
"train_steps_per_second": 1.753
|
| 133 |
+
}
|
| 134 |
+
],
|
| 135 |
+
"logging_steps": 500,
|
| 136 |
+
"max_steps": 42260,
|
| 137 |
+
"num_input_tokens_seen": 0,
|
| 138 |
+
"num_train_epochs": 20,
|
| 139 |
+
"save_steps": 500,
|
| 140 |
+
"stateful_callbacks": {
|
| 141 |
+
"EarlyStoppingCallback": {
|
| 142 |
+
"args": {
|
| 143 |
+
"early_stopping_patience": 5,
|
| 144 |
+
"early_stopping_threshold": 0.0
|
| 145 |
+
},
|
| 146 |
+
"attributes": {
|
| 147 |
+
"early_stopping_patience_counter": 0
|
| 148 |
+
}
|
| 149 |
+
},
|
| 150 |
+
"TrainerControl": {
|
| 151 |
+
"args": {
|
| 152 |
+
"should_epoch_stop": false,
|
| 153 |
+
"should_evaluate": false,
|
| 154 |
+
"should_log": false,
|
| 155 |
+
"should_save": true,
|
| 156 |
+
"should_training_stop": true
|
| 157 |
+
},
|
| 158 |
+
"attributes": {}
|
| 159 |
+
}
|
| 160 |
+
},
|
| 161 |
+
"total_flos": 2.207164045197312e+17,
|
| 162 |
+
"train_batch_size": 4,
|
| 163 |
+
"trial_name": null,
|
| 164 |
+
"trial_params": null
|
| 165 |
+
}
|