
Upload 24 files
Browse files- compute_score.py +75 -0
- data_loader.py +185 -0
- experiment.py +519 -0
- extract_melodies_features.py +179 -0
- figures/1.PNG +0 -0
- figures/10.PNG +0 -0
- figures/11.PNG +0 -0
- figures/12.PNG +0 -0
- figures/13.PNG +0 -0
- figures/14.PNG +0 -0
- figures/15.PNG +0 -0
- figures/2.PNG +0 -0
- figures/3.PNG +0 -0
- figures/4.PNG +0 -0
- figures/5.PNG +0 -0
- figures/6.PNG +0 -0
- figures/7.PNG +0 -0
- figures/8.PNG +0 -0
- figures/9.PNG +0 -0
- lstm_lyrics.py +76 -0
- lstm_melodies_lyrics.py +79 -0
- prepare_data.py +112 -0
- readme.md +385 -0
- rnn.py +108 -0
compute_score.py
ADDED
|
@@ -0,0 +1,75 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
This file computes the scores of the generated sentences
|
| 3 |
+
"""
|
| 4 |
+
import numpy as np
|
| 5 |
+
from numpy import dot
|
| 6 |
+
from numpy.linalg import norm
|
| 7 |
+
from textblob import TextBlob
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def calculate_cosine_similarity_n_gram(all_generated_lyrics, all_original_lyrics, n, word2vec):
|
| 11 |
+
"""
|
| 12 |
+
This function computes the similarity between 'n' words that are adjacent to each other.
|
| 13 |
+
:param all_generated_lyrics: list of all generated lyrics
|
| 14 |
+
:param all_original_lyrics: list of all original lyrics
|
| 15 |
+
:param n: size of grams
|
| 16 |
+
:param word2vec: a dictionary between word and index
|
| 17 |
+
:return: mean similarity between the all_generated_lyrics and all_original_lyrics
|
| 18 |
+
"""
|
| 19 |
+
cos_sim_list = []
|
| 20 |
+
for song_original_lyrics, song_generated_lyrics in zip(all_original_lyrics, all_generated_lyrics):
|
| 21 |
+
if len(song_original_lyrics) != len(song_generated_lyrics):
|
| 22 |
+
raise Exception('The vectors are not equal')
|
| 23 |
+
cos_sim_song_list = []
|
| 24 |
+
for i in range(len(song_original_lyrics) - n + 1):
|
| 25 |
+
starting_index = i
|
| 26 |
+
ending_index = i + n
|
| 27 |
+
n_gram_original = song_original_lyrics[starting_index:ending_index]
|
| 28 |
+
n_gram_generated = song_generated_lyrics[starting_index:ending_index]
|
| 29 |
+
original_vector = np.mean([word2vec[word] for word in n_gram_original], axis=0)
|
| 30 |
+
generated_vector = np.mean([word2vec[word] for word in n_gram_generated], axis=0)
|
| 31 |
+
cos_sim = dot(original_vector, generated_vector) / (norm(original_vector) * norm(generated_vector))
|
| 32 |
+
cos_sim_song_list.append(cos_sim)
|
| 33 |
+
cos_sim_song = np.mean(cos_sim_song_list)
|
| 34 |
+
cos_sim_list.append(cos_sim_song)
|
| 35 |
+
return np.mean(cos_sim_list)
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def calculate_cosine_similarity(all_generated_lyrics, all_original_lyrics, word2vec):
|
| 39 |
+
# The similarity between the generated lyrics and the original lyrics.
|
| 40 |
+
cos_sim_list = []
|
| 41 |
+
for song_original_lyrics, song_generated_lyrics in zip(all_original_lyrics, all_generated_lyrics):
|
| 42 |
+
original_vector = np.mean([word2vec[word] for word in song_original_lyrics], axis=0)
|
| 43 |
+
generated_vector = np.mean([word2vec[word] for word in song_generated_lyrics], axis=0)
|
| 44 |
+
cos_sim = dot(original_vector, generated_vector) / (norm(original_vector) * norm(generated_vector))
|
| 45 |
+
cos_sim_list.append(cos_sim)
|
| 46 |
+
return np.mean(cos_sim_list)
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
def get_polarity_diff(all_generated_lyrics, all_original_lyrics):
|
| 50 |
+
# The polarity score is a float within the range [-1.0, 1.0].
|
| 51 |
+
pol_diff_list = []
|
| 52 |
+
for song_original_lyrics, song_generated_lyrics in zip(all_original_lyrics, all_generated_lyrics):
|
| 53 |
+
generated_lyrics = ' '.join(song_original_lyrics)
|
| 54 |
+
generated_blob = TextBlob(generated_lyrics)
|
| 55 |
+
original_lyrics = ' '.join(song_generated_lyrics)
|
| 56 |
+
original_blob = TextBlob(original_lyrics)
|
| 57 |
+
pol_diff = abs(generated_blob.sentiment.polarity - original_blob.sentiment.polarity)
|
| 58 |
+
pol_diff_list.append(pol_diff)
|
| 59 |
+
return np.mean(pol_diff_list)
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
def get_subjectivity_diff(all_generated_lyrics, all_original_lyrics):
|
| 63 |
+
# The subjectivity is a float within the range [0.0, 1.0] where 0.0 is very objective and 1.0 is very subjective.
|
| 64 |
+
pol_diff_list = []
|
| 65 |
+
for song_original_lyrics, song_generated_lyrics in zip(all_original_lyrics, all_generated_lyrics):
|
| 66 |
+
generated_lyrics = ' '.join(song_original_lyrics)
|
| 67 |
+
generated_blob = TextBlob(generated_lyrics)
|
| 68 |
+
original_lyrics = ' '.join(song_generated_lyrics)
|
| 69 |
+
original_blob = TextBlob(original_lyrics)
|
| 70 |
+
pol_diff = abs(generated_blob.sentiment.subjectivity - original_blob.sentiment.subjectivity)
|
| 71 |
+
pol_diff_list.append(pol_diff)
|
| 72 |
+
return np.mean(pol_diff_list)
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
print("Loaded Successfully")
|
data_loader.py
ADDED
|
@@ -0,0 +1,185 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
This file manages the loading of the data
|
| 3 |
+
"""
|
| 4 |
+
import csv
|
| 5 |
+
import os
|
| 6 |
+
import pickle
|
| 7 |
+
import string
|
| 8 |
+
|
| 9 |
+
import numpy as np
|
| 10 |
+
import pretty_midi
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def get_midi_files(midi_pickle, midi_folder, artists, names):
|
| 14 |
+
"""
|
| 15 |
+
This function loads the midi files
|
| 16 |
+
:param midi_pickle: path for the pickle file
|
| 17 |
+
:param midi_folder: path for the midi folder
|
| 18 |
+
:param artists: list of artist
|
| 19 |
+
:param names: list of song names
|
| 20 |
+
:return: list of pretty midi objects
|
| 21 |
+
"""
|
| 22 |
+
# If the pickle file is already exists, read that file
|
| 23 |
+
pretty_midi_songs = _read_pickle_if_exists(pickle_path=midi_pickle)
|
| 24 |
+
if pretty_midi_songs is None: # If the pickle is exists, covert the list into variables
|
| 25 |
+
pretty_midi_songs = []
|
| 26 |
+
lower_upper_files = get_lower_upper_dict(midi_folder)
|
| 27 |
+
if len(artists) != len(names):
|
| 28 |
+
raise Exception('Artists and Names lengths are different.')
|
| 29 |
+
for artist, song_name in zip(artists, names):
|
| 30 |
+
if song_name[0] == " ":
|
| 31 |
+
song_name = song_name[1:]
|
| 32 |
+
song_file_name = f'{artist}_-_{song_name}.mid'.replace(" ", "_")
|
| 33 |
+
if song_file_name not in lower_upper_files:
|
| 34 |
+
print(f'Song {song_file_name} does not exist, even though'
|
| 35 |
+
f' the song is provided in the training or testing sets')
|
| 36 |
+
continue
|
| 37 |
+
original_file_name = lower_upper_files[song_file_name]
|
| 38 |
+
midi_file_path = os.path.join(midi_folder, original_file_name)
|
| 39 |
+
try:
|
| 40 |
+
pretty_midi_format = pretty_midi.PrettyMIDI(midi_file_path)
|
| 41 |
+
pretty_midi_songs.append(pretty_midi_format)
|
| 42 |
+
except Exception:
|
| 43 |
+
print(f'Exception raised from Mido using this file: {midi_file_path}')
|
| 44 |
+
|
| 45 |
+
_save_pickle(pickle_path=midi_pickle, content=pretty_midi_songs)
|
| 46 |
+
return pretty_midi_songs
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
def get_lower_upper_dict(midi_folder):
|
| 50 |
+
"""
|
| 51 |
+
This function maps between lower case name to upper case name
|
| 52 |
+
:param midi_folder: midi folder path
|
| 53 |
+
:return: A dictionary between lower case name to upper case name
|
| 54 |
+
"""
|
| 55 |
+
lower_upper_files = {}
|
| 56 |
+
for file_name in os.listdir(midi_folder):
|
| 57 |
+
if file_name.endswith(".mid"):
|
| 58 |
+
lower_upper_files[file_name.lower()] = file_name
|
| 59 |
+
return lower_upper_files
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
def get_input_sets(input_file, pickle_path, word2vec, midi_folder) -> (list, list, list):
|
| 63 |
+
"""
|
| 64 |
+
This function loads the training and testing set that provided by the course staff.
|
| 65 |
+
In addition some pre-processing methods are work here.
|
| 66 |
+
:param input_file: training or testing set path
|
| 67 |
+
:param pickle_path: training or testing pickle path
|
| 68 |
+
:param word2vec: dictionary maps between a word and a vector
|
| 69 |
+
:param midi_folder: the midi folder that we use to validate if song is exists
|
| 70 |
+
:return: Nothing
|
| 71 |
+
"""
|
| 72 |
+
# If the pickle file is already exists, read that file
|
| 73 |
+
pickle_value = _read_pickle_if_exists(pickle_path=pickle_path)
|
| 74 |
+
# We want only songs with midi file
|
| 75 |
+
lower_upper_files = get_lower_upper_dict(midi_folder)
|
| 76 |
+
if pickle_value is not None: # If the pickle is exists, covert the list into variables
|
| 77 |
+
artists, names, lyrics = pickle_value[0], pickle_value[1], pickle_value[2]
|
| 78 |
+
else: # The pickle file is exists.
|
| 79 |
+
artists, names, lyrics = [], [], []
|
| 80 |
+
with open(input_file, newline='') as f:
|
| 81 |
+
lines = csv.reader(f, delimiter=',', quotechar='|')
|
| 82 |
+
for row in lines:
|
| 83 |
+
artist_name = row[0]
|
| 84 |
+
song_name = row[1]
|
| 85 |
+
if song_name[0] == " ":
|
| 86 |
+
song_name = song_name[1:]
|
| 87 |
+
song_file_name = f'{artist_name}_-_{song_name}.mid'.replace(" ", "_")
|
| 88 |
+
if song_file_name not in lower_upper_files:
|
| 89 |
+
print(f'Song {song_file_name} does not exist, even though'
|
| 90 |
+
f' the song is provided in the training or testing sets')
|
| 91 |
+
continue
|
| 92 |
+
original_file_name = lower_upper_files[song_file_name]
|
| 93 |
+
midi_file_path = os.path.join(midi_folder, original_file_name)
|
| 94 |
+
try:
|
| 95 |
+
pretty_midi.PrettyMIDI(midi_file_path)
|
| 96 |
+
except Exception:
|
| 97 |
+
print(f'Exception raised from Mido using this file: {midi_file_path}')
|
| 98 |
+
continue
|
| 99 |
+
song_lyrics = row[2]
|
| 100 |
+
song_lyrics = song_lyrics.replace('&', '')
|
| 101 |
+
song_lyrics = song_lyrics.replace(' ', ' ')
|
| 102 |
+
song_lyrics = song_lyrics.replace('\'', '')
|
| 103 |
+
song_lyrics = song_lyrics.replace('--', ' ')
|
| 104 |
+
|
| 105 |
+
tokens = song_lyrics.split()
|
| 106 |
+
table = str.maketrans('', '', string.punctuation) # remove punctuation from each token
|
| 107 |
+
tokens = [w.translate(table) for w in tokens]
|
| 108 |
+
tokens = [word for word in tokens if
|
| 109 |
+
word.isalpha()] # remove remaining tokens that are not alphabetic
|
| 110 |
+
tokens = [word.lower() for word in tokens if word.lower() in word2vec] # make lower case
|
| 111 |
+
song_lyrics = ' '.join(tokens)
|
| 112 |
+
artists.append(artist_name)
|
| 113 |
+
names.append(song_name)
|
| 114 |
+
lyrics.append(song_lyrics)
|
| 115 |
+
_save_pickle(pickle_path=pickle_path, content=[artists, names, lyrics])
|
| 116 |
+
|
| 117 |
+
return {'artists': artists, 'names': names, 'lyrics': lyrics}
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
def get_word2vec(word2vec_path, pre_trained, vector_size, encoding='utf-8') -> dict:
|
| 121 |
+
"""
|
| 122 |
+
This function returns a dictionary that maps between word and a vector
|
| 123 |
+
:param word2vec_path: path for the pickle file
|
| 124 |
+
:param pre_trained: path for the pre-trained embedding file
|
| 125 |
+
:param vector_size: the vector size for each word
|
| 126 |
+
:param encoding: the encoding the the pre_trained file
|
| 127 |
+
:return: dictionary maps between a word and a vector
|
| 128 |
+
"""
|
| 129 |
+
# If the pickle file is already exists, read that file
|
| 130 |
+
word2vec = _read_pickle_if_exists(word2vec_path)
|
| 131 |
+
if word2vec is None: # The pickle file is not exists.
|
| 132 |
+
with open(pre_trained, 'r', encoding=encoding) as f: # Read a pre-trained word vectors.
|
| 133 |
+
list_of_lines = list(f)
|
| 134 |
+
word2vec = _iterate_over_glove_list(list_of_lines=list_of_lines, vector_size=vector_size)
|
| 135 |
+
_save_pickle(pickle_path=word2vec_path, content=word2vec) # Save pickle for the next running
|
| 136 |
+
return word2vec
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
def _iterate_over_glove_list(list_of_lines, vector_size):
|
| 140 |
+
"""
|
| 141 |
+
This function iterates over the glove list line by line and returns a word2vec dictionary
|
| 142 |
+
:param list_of_lines: List of glove lines
|
| 143 |
+
:param vector_size: the size of the embedding vector size
|
| 144 |
+
:return: dictionary maps between a word and a vector
|
| 145 |
+
"""
|
| 146 |
+
word2vec = {}
|
| 147 |
+
punctuation = string.punctuation
|
| 148 |
+
for line in list_of_lines:
|
| 149 |
+
values = line.split(' ')
|
| 150 |
+
word = values[0]
|
| 151 |
+
if word in punctuation:
|
| 152 |
+
continue
|
| 153 |
+
vec = np.asarray(values[1:], "float32")
|
| 154 |
+
if len(vec) != vector_size:
|
| 155 |
+
raise Warning(f"Vector size is different than {vector_size}")
|
| 156 |
+
else:
|
| 157 |
+
word2vec[word] = vec
|
| 158 |
+
return word2vec
|
| 159 |
+
|
| 160 |
+
|
| 161 |
+
def _save_pickle(pickle_path, content):
|
| 162 |
+
"""
|
| 163 |
+
This function saves a value to pickle file
|
| 164 |
+
:param pickle_path: path for the pickle file
|
| 165 |
+
:param content: the value you want to save
|
| 166 |
+
:return: Nothing
|
| 167 |
+
"""
|
| 168 |
+
with open(pickle_path, 'wb') as f:
|
| 169 |
+
pickle.dump(content, f)
|
| 170 |
+
|
| 171 |
+
|
| 172 |
+
def _read_pickle_if_exists(pickle_path):
|
| 173 |
+
"""
|
| 174 |
+
This function reads a pickle file
|
| 175 |
+
:param pickle_path:path for the pickle file
|
| 176 |
+
:return: the saved value in the pickle file
|
| 177 |
+
"""
|
| 178 |
+
pickle_file = None
|
| 179 |
+
if os.path.exists(pickle_path):
|
| 180 |
+
with open(pickle_path, 'rb') as f:
|
| 181 |
+
pickle_file = pickle.load(f)
|
| 182 |
+
return pickle_file
|
| 183 |
+
|
| 184 |
+
|
| 185 |
+
print('Loaded Successfully')
|
experiment.py
ADDED
|
@@ -0,0 +1,519 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
This file manages the experiments, see the main function for changing the settings
|
| 3 |
+
"""
|
| 4 |
+
import os
|
| 5 |
+
import random
|
| 6 |
+
import time
|
| 7 |
+
|
| 8 |
+
import pandas as pd
|
| 9 |
+
from gtts import gTTS
|
| 10 |
+
from keras_preprocessing.text import Tokenizer
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def main():
|
| 14 |
+
"""
|
| 15 |
+
This function runs the process of the experiments. Iterates over the parameters and output the results.
|
| 16 |
+
:return: Nothing
|
| 17 |
+
"""
|
| 18 |
+
# Some settings for the files we will use
|
| 19 |
+
saved_file_type = 'pkl'
|
| 20 |
+
midi_pickle = os.path.join(PICKLES_FOLDER, f"midi.{saved_file_type}")
|
| 21 |
+
midi_folder = os.path.join(DATA_PATH, "midi_files")
|
| 22 |
+
|
| 23 |
+
# Read a pre-trained word2vec dictionary
|
| 24 |
+
word2vec_path = os.path.join(PICKLES_FOLDER, f"{WORD2VEC_FILENAME}.{saved_file_type}")
|
| 25 |
+
pre_trained = os.path.join(INPUT_FOLDER, f"{GLOVE_FILE_NAME}.txt")
|
| 26 |
+
|
| 27 |
+
# Get the embedding dictionary that maps between word to a vector
|
| 28 |
+
word2vec = get_word2vec(word2vec_path=word2vec_path,
|
| 29 |
+
pre_trained=pre_trained,
|
| 30 |
+
vector_size=VECTOR_SIZE,
|
| 31 |
+
encoding=ENCODING)
|
| 32 |
+
|
| 33 |
+
# load the training and testing set that provided by the course staff
|
| 34 |
+
train_pickle_path = os.path.join(PICKLES_FOLDER, f'{TRAIN_NAME}.{saved_file_type}')
|
| 35 |
+
input_train_path = os.path.join(INPUT_FOLDER, INPUT_TRAINING_SET)
|
| 36 |
+
training_set = get_input_sets(input_file=input_train_path,
|
| 37 |
+
pickle_path=train_pickle_path,
|
| 38 |
+
word2vec=word2vec,
|
| 39 |
+
midi_folder=midi_folder)
|
| 40 |
+
test_pickle_path = os.path.join(PICKLES_FOLDER, f'{TEST_NAME}.{saved_file_type}')
|
| 41 |
+
input_test_path = os.path.join(INPUT_FOLDER, INPUT_TESTING_SET)
|
| 42 |
+
testing_set = get_input_sets(input_file=input_test_path,
|
| 43 |
+
pickle_path=test_pickle_path,
|
| 44 |
+
word2vec=word2vec,
|
| 45 |
+
midi_folder=midi_folder)
|
| 46 |
+
|
| 47 |
+
artists = training_set['artists'] + testing_set['artists']
|
| 48 |
+
songs_names = training_set['names'] + testing_set['names']
|
| 49 |
+
lyrics = training_set['lyrics'] + testing_set['lyrics']
|
| 50 |
+
|
| 51 |
+
tokenizer = Tokenizer()
|
| 52 |
+
tokenizer.fit_on_texts(lyrics)
|
| 53 |
+
total_words = len(tokenizer.word_index) + 1
|
| 54 |
+
|
| 55 |
+
encoded_lyrics_list = tokenizer.texts_to_sequences(lyrics)
|
| 56 |
+
index2word = tokenizer.index_word
|
| 57 |
+
|
| 58 |
+
melodies = get_midi_files(midi_folder=midi_folder,
|
| 59 |
+
midi_pickle=midi_pickle,
|
| 60 |
+
artists=artists,
|
| 61 |
+
names=songs_names)
|
| 62 |
+
|
| 63 |
+
train_encoded_lyrics_list = encoded_lyrics_list[:len(training_set['lyrics'])]
|
| 64 |
+
test_encoded_lyrics_list = encoded_lyrics_list[len(training_set['lyrics']):]
|
| 65 |
+
melody_pickle = os.path.join(PICKLES_FOLDER, "melody_data." + saved_file_type)
|
| 66 |
+
|
| 67 |
+
comb_dict = {'seed': [], 'seq_length': [], 'learning_rate': [], 'batch_size': [], 'epochs': [],
|
| 68 |
+
'patience': [], 'min_delta': [], 'melody_method': [], 'model_names': [], 'cos_sim_1_gram': [],
|
| 69 |
+
'cos_sim_2_gram': [],
|
| 70 |
+
'cos_sim_3_gram': [], 'cos_sim_5_gram': [], 'cos_sim_max_gram': [], 'polarity_diff': [],
|
| 71 |
+
'subjectivity_diff': [], 'loss_val': [], 'accuracy': []}
|
| 72 |
+
|
| 73 |
+
word2vec_matrix = get_word2vec_matrix(total_words=total_words,
|
| 74 |
+
index2word=index2word,
|
| 75 |
+
word2vec=word2vec,
|
| 76 |
+
vector_size=VECTOR_SIZE)
|
| 77 |
+
|
| 78 |
+
for seed in seeds_list:
|
| 79 |
+
for sl in seq_length_list:
|
| 80 |
+
sets_dict = create_sets(
|
| 81 |
+
train_encoded_lyrics_list=train_encoded_lyrics_list,
|
| 82 |
+
test_encoded_lyrics_list=test_encoded_lyrics_list,
|
| 83 |
+
total_words=total_words,
|
| 84 |
+
seq_length=sl,
|
| 85 |
+
validation_set_size=VALIDATION_SET_SIZE,
|
| 86 |
+
seed=seed)
|
| 87 |
+
training_sequences = sets_dict['train'][1].shape[0] + sets_dict['validation'][1].shape[0]
|
| 88 |
+
for melody_method in melody_extraction:
|
| 89 |
+
m_train, m_val, m_test = get_melody_data_sets(
|
| 90 |
+
train_num=training_sequences,
|
| 91 |
+
val_size=VALIDATION_SET_SIZE,
|
| 92 |
+
melodies_list=melodies,
|
| 93 |
+
sequence_length=sl,
|
| 94 |
+
encoded_lyrics_matrix=encoded_lyrics_list,
|
| 95 |
+
pkl_file_path=melody_pickle,
|
| 96 |
+
seed=seed,
|
| 97 |
+
feature_method=melody_method)
|
| 98 |
+
melody_feature_vector_size = m_train.shape[2]
|
| 99 |
+
for l in learning_rate_list:
|
| 100 |
+
for bs in batch_size_list:
|
| 101 |
+
for ep in epochs_list:
|
| 102 |
+
for pa in patience_list:
|
| 103 |
+
for md in min_delta_list:
|
| 104 |
+
for u in units_list:
|
| 105 |
+
for m_name in model_names_list:
|
| 106 |
+
run_combination(comb_dict, sl, bs, ep, index2word, l, md, pa, seed,
|
| 107 |
+
testing_set['artists'], melody_method,
|
| 108 |
+
testing_set['lyrics'], testing_set['names'], total_words, u,
|
| 109 |
+
word2vec,
|
| 110 |
+
word2vec_matrix, tokenizer, sets_dict['train'][0],
|
| 111 |
+
sets_dict['validation'][0], sets_dict['test'][0], m_train,
|
| 112 |
+
m_val, m_test, sets_dict['train'][1],
|
| 113 |
+
sets_dict['validation'][1], sets_dict['test'][1], m_name,
|
| 114 |
+
melody_feature_vector_size)
|
| 115 |
+
if m_name == 'lyrics':
|
| 116 |
+
break
|
| 117 |
+
# Here we save all the results to a csv file
|
| 118 |
+
comb_df = pd.DataFrame.from_dict(comb_dict)
|
| 119 |
+
comb_df.to_csv(COMB_PATH, index=False)
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
def run_combination(comb_dict, seq_length, batch_size, epochs, index2word, learning_rate, min_delta, patience, seed,
|
| 123 |
+
test_artists, melody_extraction_method,
|
| 124 |
+
test_lyrics, test_names, total_words, units, word2vec, word2vec_matrix, tokenizer, x_train,
|
| 125 |
+
x_val, x_test, m_train, m_val, m_test, y_train, y_val, y_test, model_name, melody_num_features):
|
| 126 |
+
"""
|
| 127 |
+
This function runs a combination with a specific settings and training or testing set
|
| 128 |
+
:param melody_extraction_method: The method used to extract melody features (naive or with meta data)
|
| 129 |
+
:param comb_dict: dictionary of all the results
|
| 130 |
+
:param seq_length: this is the input sequence length we used for the LSTM model
|
| 131 |
+
:param batch_size: the batch size for the model
|
| 132 |
+
:param epochs: number of epochs for the model
|
| 133 |
+
:param index2word: a dictionary maps between index and words.
|
| 134 |
+
:param learning_rate: learning rate for the model
|
| 135 |
+
:param min_delta: minimum delta for early stopping of the model
|
| 136 |
+
:param patience: patience fo the early stopping of the model
|
| 137 |
+
:param seed: for the random state
|
| 138 |
+
:param test_artists: list of artist in the training set
|
| 139 |
+
:param test_lyrics: list of lyrics in the training set
|
| 140 |
+
:param test_names: list of songs name in the training set
|
| 141 |
+
:param total_words: total size of the vocabulary
|
| 142 |
+
:param units: number of LSTM units
|
| 143 |
+
:param word2vec: dictionary maps between a word and a vector
|
| 144 |
+
:param word2vec_matrix: a matrix of words (rows) and vectors (columns) of the word2vec
|
| 145 |
+
:param tokenizer: Tokenizer object
|
| 146 |
+
:param x_train: lyrics training set
|
| 147 |
+
:param x_val: lyrics validation set
|
| 148 |
+
:param x_test: lyrics testing xet
|
| 149 |
+
:param m_train: melody training set
|
| 150 |
+
:param m_val: melody validation set
|
| 151 |
+
:param m_test: melody testing set
|
| 152 |
+
:param y_train: training output words
|
| 153 |
+
:param y_val: validation output words
|
| 154 |
+
:param y_test: testing output words
|
| 155 |
+
:param model_name: the name of the model we want to use in this function
|
| 156 |
+
:param melody_num_features: size of the melody vector
|
| 157 |
+
:return: Nothing
|
| 158 |
+
"""
|
| 159 |
+
model_save_type = 'h5' # file type
|
| 160 |
+
initialize_seed(seed) # files paths
|
| 161 |
+
parameters_name = f'seq_lens_{seq_length}_seed_{seed}_u_{units}_lr_{learning_rate}_bs_{batch_size}_ep_{epochs}_' \
|
| 162 |
+
f'val_{VALIDATION_SET_SIZE}_pa_{patience}_md_{min_delta}_mn_{model_name}'
|
| 163 |
+
if not model_name == 'lyrics':
|
| 164 |
+
parameters_name += f'_fm_{melody_extraction_method}'
|
| 165 |
+
# A path for the weights
|
| 166 |
+
load_weights_path = os.path.join(WEIGHTS_FOLDER, f'weights_{parameters_name}.{model_save_type}')
|
| 167 |
+
model = None
|
| 168 |
+
if model_name == 'lyrics':
|
| 169 |
+
model = LSTMLyrics(seed=seed,
|
| 170 |
+
loss=LOSS,
|
| 171 |
+
metrics=METRICS,
|
| 172 |
+
optimizer=OPTIMIZER,
|
| 173 |
+
learning_rate=learning_rate,
|
| 174 |
+
total_words=total_words,
|
| 175 |
+
seq_length=seq_length,
|
| 176 |
+
vector_size=VECTOR_SIZE,
|
| 177 |
+
word2vec_matrix=word2vec_matrix,
|
| 178 |
+
units=units)
|
| 179 |
+
elif model_name == 'melodies_lyrics':
|
| 180 |
+
x_train = [x_train, m_train]
|
| 181 |
+
x_val = [x_val, m_val]
|
| 182 |
+
x_test = [x_test, m_test]
|
| 183 |
+
model = LSTMLyricsMelodies(seed=seed,
|
| 184 |
+
loss=LOSS,
|
| 185 |
+
metrics=METRICS,
|
| 186 |
+
optimizer=OPTIMIZER,
|
| 187 |
+
learning_rate=learning_rate,
|
| 188 |
+
total_words=total_words,
|
| 189 |
+
seq_length=seq_length,
|
| 190 |
+
vector_size=VECTOR_SIZE,
|
| 191 |
+
word2vec_matrix=word2vec_matrix,
|
| 192 |
+
units=units,
|
| 193 |
+
melody_num_features=melody_num_features)
|
| 194 |
+
model.fit(weights_file=load_weights_path,
|
| 195 |
+
batch_size=batch_size,
|
| 196 |
+
epochs=epochs,
|
| 197 |
+
patience=patience,
|
| 198 |
+
min_delta=min_delta,
|
| 199 |
+
x_train=x_train,
|
| 200 |
+
y_train=y_train,
|
| 201 |
+
x_val=x_val,
|
| 202 |
+
y_val=y_val)
|
| 203 |
+
loss_val, accuracy = model.evaluate(x_test=x_test, y_test=y_test, batch_size=batch_size)
|
| 204 |
+
print(f'Loss on Testing set: {loss_val}')
|
| 205 |
+
print(f'Accuracy on Testing set: {accuracy}')
|
| 206 |
+
all_original_lyrics, all_generated_lyrics = generate_lyrics(
|
| 207 |
+
model_name=model_name,
|
| 208 |
+
word_index=index2word,
|
| 209 |
+
seq_length=seq_length,
|
| 210 |
+
model=model,
|
| 211 |
+
tokenizer=tokenizer,
|
| 212 |
+
artists=test_artists,
|
| 213 |
+
lyrics=test_lyrics,
|
| 214 |
+
names=test_names,
|
| 215 |
+
word2vec=word2vec,
|
| 216 |
+
melodies=m_test
|
| 217 |
+
)
|
| 218 |
+
cos_sim_1_gram = calculate_cosine_similarity_n_gram(all_generated_lyrics=all_generated_lyrics,
|
| 219 |
+
all_original_lyrics=all_original_lyrics,
|
| 220 |
+
n=1,
|
| 221 |
+
word2vec=word2vec)
|
| 222 |
+
print(f'Mean Cosine Similarity (1-gram): {cos_sim_1_gram}')
|
| 223 |
+
cos_sim_2_gram = calculate_cosine_similarity_n_gram(all_generated_lyrics=all_generated_lyrics,
|
| 224 |
+
all_original_lyrics=all_original_lyrics,
|
| 225 |
+
n=2,
|
| 226 |
+
word2vec=word2vec)
|
| 227 |
+
print(f'Mean Cosine Similarity (2-gram): {cos_sim_2_gram}')
|
| 228 |
+
cos_sim_3_gram = calculate_cosine_similarity_n_gram(all_generated_lyrics=all_generated_lyrics,
|
| 229 |
+
all_original_lyrics=all_original_lyrics,
|
| 230 |
+
n=3,
|
| 231 |
+
word2vec=word2vec)
|
| 232 |
+
print(f'Mean Cosine Similarity (3-gram): {cos_sim_3_gram}')
|
| 233 |
+
cos_sim_5_gram = calculate_cosine_similarity_n_gram(all_generated_lyrics=all_generated_lyrics,
|
| 234 |
+
all_original_lyrics=all_original_lyrics,
|
| 235 |
+
n=5,
|
| 236 |
+
word2vec=word2vec)
|
| 237 |
+
print(f'Mean Cosine Similarity (5-gram): {cos_sim_5_gram}')
|
| 238 |
+
cos_sim = calculate_cosine_similarity(all_generated_lyrics=all_generated_lyrics,
|
| 239 |
+
all_original_lyrics=all_original_lyrics,
|
| 240 |
+
word2vec=word2vec)
|
| 241 |
+
print(f'Mean Cosine Similarity (Max-gram): {cos_sim}')
|
| 242 |
+
pol_dif = get_polarity_diff(all_generated_lyrics=all_generated_lyrics, all_original_lyrics=all_original_lyrics)
|
| 243 |
+
print(f'Mean Polarity Difference: {pol_dif}')
|
| 244 |
+
subj_dif = get_subjectivity_diff(all_generated_lyrics=all_generated_lyrics, all_original_lyrics=all_original_lyrics)
|
| 245 |
+
print(f'Mean Subjectivity Difference: {subj_dif}')
|
| 246 |
+
update_comb_dict(batch_size, comb_dict, cos_sim, cos_sim_1_gram, cos_sim_2_gram, cos_sim_3_gram, cos_sim_5_gram,
|
| 247 |
+
epochs, learning_rate, min_delta, model_name, patience, pol_dif, seed, seq_length, subj_dif,
|
| 248 |
+
melody_extraction_method, loss_val, accuracy)
|
| 249 |
+
|
| 250 |
+
|
| 251 |
+
def update_comb_dict(batch_size, comb_dict, cos_sim, cos_sim_1_gram, cos_sim_2_gram, cos_sim_3_gram, cos_sim_5_gram,
|
| 252 |
+
epochs, learning_rate, min_delta, model_name, patience, pol_dif, seed, seq_length, subj_dif,
|
| 253 |
+
melody_extraction_method, loss_val, accuracy):
|
| 254 |
+
"""
|
| 255 |
+
This function update the combination dictionary to write to csv
|
| 256 |
+
:param accuracy: accuracy on the testing set
|
| 257 |
+
:param loss_val: loss on the testing set
|
| 258 |
+
:param batch_size: the batch size for the model
|
| 259 |
+
:param comb_dict: the results dictionary
|
| 260 |
+
:param cos_sim: the similarity score between the original and the generated sentence
|
| 261 |
+
:param cos_sim_1_gram: the similarity score between each 1 gram of original and the generated sentence
|
| 262 |
+
:param cos_sim_2_gram: the similarity score between each 2 gram of original and the generated sentence
|
| 263 |
+
:param cos_sim_3_gram: the similarity score between each 3 gram of original and the generated sentence
|
| 264 |
+
:param cos_sim_5_gram: the similarity score between each 5 gram of original and the generated sentence
|
| 265 |
+
:param epochs: number of epochs for the model
|
| 266 |
+
:param learning_rate: learning rate for the model
|
| 267 |
+
:param min_delta: minimum delta for early stopping of the model
|
| 268 |
+
:param model_name: The model name we want to test
|
| 269 |
+
:param patience: patience fo the early stopping of the model
|
| 270 |
+
:param pol_dif: the difference polarity score between the original and the generated sentence
|
| 271 |
+
:param seed: for the random state
|
| 272 |
+
:param seq_length: length of the given sequences
|
| 273 |
+
:param subj_dif: the difference subjective score between the original and the generated sentence
|
| 274 |
+
:param melody_extraction_method: The method used to extract melody features (naive or with meta data)
|
| 275 |
+
:return: Nothing
|
| 276 |
+
"""
|
| 277 |
+
comb_dict['seed'].append(seed)
|
| 278 |
+
comb_dict['seq_length'].append(seq_length)
|
| 279 |
+
comb_dict['learning_rate'].append(learning_rate)
|
| 280 |
+
comb_dict['batch_size'].append(batch_size)
|
| 281 |
+
comb_dict['epochs'].append(epochs)
|
| 282 |
+
comb_dict['patience'].append(patience)
|
| 283 |
+
comb_dict['min_delta'].append(min_delta)
|
| 284 |
+
comb_dict['model_names'].append(model_name)
|
| 285 |
+
comb_dict['cos_sim_1_gram'].append(cos_sim_1_gram)
|
| 286 |
+
comb_dict['cos_sim_2_gram'].append(cos_sim_2_gram)
|
| 287 |
+
comb_dict['cos_sim_3_gram'].append(cos_sim_3_gram)
|
| 288 |
+
comb_dict['cos_sim_5_gram'].append(cos_sim_5_gram)
|
| 289 |
+
comb_dict['cos_sim_max_gram'].append(cos_sim)
|
| 290 |
+
comb_dict['polarity_diff'].append(pol_dif)
|
| 291 |
+
comb_dict['subjectivity_diff'].append(subj_dif)
|
| 292 |
+
comb_dict['melody_method'].append(melody_extraction_method)
|
| 293 |
+
comb_dict['loss_val'].append(loss_val)
|
| 294 |
+
comb_dict['accuracy'].append(accuracy)
|
| 295 |
+
|
| 296 |
+
|
| 297 |
+
def generate_song_given_sequence(model_name, model, tokenizer, seed_words, vector_of_indices, required_length, artist,
|
| 298 |
+
name, index_value, melodies_song):
|
| 299 |
+
"""
|
| 300 |
+
This function generates a new song
|
| 301 |
+
:param model_name: model name
|
| 302 |
+
:param melodies_song: a matrix contains the melodies of this song
|
| 303 |
+
:param model:
|
| 304 |
+
:param tokenizer:
|
| 305 |
+
:param seed_words:
|
| 306 |
+
:param vector_of_indices:
|
| 307 |
+
:param required_length:
|
| 308 |
+
:param artist:
|
| 309 |
+
:param name:
|
| 310 |
+
:param index_value:
|
| 311 |
+
:return: Nothing
|
| 312 |
+
"""
|
| 313 |
+
new_song_lyrics: list = [seed_words]
|
| 314 |
+
for word_i in range(required_length):
|
| 315 |
+
if model_name == 'lyrics': # Different input for lyrics alone and lyrics and melodies.
|
| 316 |
+
voc_prob = model.predict(vector_of_indices)
|
| 317 |
+
else:
|
| 318 |
+
melody_seq = np.expand_dims(a=melodies_song[word_i], axis=0)
|
| 319 |
+
voc_prob = model.predict([vector_of_indices, melody_seq])
|
| 320 |
+
voc_prob = voc_prob.T # Transpose the array
|
| 321 |
+
word_index_array = np.arange(voc_prob.size)
|
| 322 |
+
# This line select a word based on the predicted probabilities
|
| 323 |
+
index_of_selected_word = random.choices(word_index_array, k=1, weights=voc_prob)
|
| 324 |
+
selected_word = find_word_by_index(word_index=index_of_selected_word[0], tokenizer=tokenizer)
|
| 325 |
+
index_of_selected_word_array = np.array(np.array(index_of_selected_word).reshape(1, 1))
|
| 326 |
+
vector_of_indices = np.append(vector_of_indices, index_of_selected_word_array, axis=1)
|
| 327 |
+
remove_index = 0
|
| 328 |
+
vector_of_indices = np.delete(vector_of_indices, remove_index, 1)
|
| 329 |
+
new_song_lyrics.append(selected_word)
|
| 330 |
+
final_text = ' '.join(new_song_lyrics)
|
| 331 |
+
if WRITE_TO_MP3:
|
| 332 |
+
lyrics_to_mp3 = gTTS(text=final_text, lang='en', slow=False)
|
| 333 |
+
lyrics_to_mp3.save(os.path.join(OUTPUT_FOLDER, f"{artist}_{name}_{index_value}.mp3"))
|
| 334 |
+
return final_text
|
| 335 |
+
|
| 336 |
+
|
| 337 |
+
def find_word_by_index(word_index, tokenizer):
|
| 338 |
+
"""
|
| 339 |
+
This function returns the word given the index
|
| 340 |
+
:param word_index: the index of the word we want to find
|
| 341 |
+
:param tokenizer: object
|
| 342 |
+
:return: the word at that index
|
| 343 |
+
"""
|
| 344 |
+
for word, index in tokenizer.word_index.items():
|
| 345 |
+
if index == word_index:
|
| 346 |
+
return word
|
| 347 |
+
|
| 348 |
+
|
| 349 |
+
def generate_lyrics(model_name, word_index, seq_length, model, tokenizer, artists, lyrics, names,
|
| 350 |
+
word2vec, melodies) -> (list, list):
|
| 351 |
+
"""
|
| 352 |
+
This function creates lyrics for each song in the testing set
|
| 353 |
+
:param melodies: a 3D array that maps sequence and the melodies features (2D array (sequence size, melody vector)).
|
| 354 |
+
:param model_name: The model name we want to test
|
| 355 |
+
:param word_index: A dictionary maps between index to word
|
| 356 |
+
:param seq_length: length of the given sequences
|
| 357 |
+
:param model: the learned model
|
| 358 |
+
:param tokenizer: the tokenizer object
|
| 359 |
+
:param artists: list of artists in the testing set
|
| 360 |
+
:param lyrics: list of lyrics in the testing set
|
| 361 |
+
:param names: list of song names in the testing set
|
| 362 |
+
:param word2vec: A dictionary maps between word to embedding vector
|
| 363 |
+
:return: lists of original and generated songs and
|
| 364 |
+
"""
|
| 365 |
+
all_original_lyrics = []
|
| 366 |
+
all_generated_lyrics = []
|
| 367 |
+
start_index_melody = 0
|
| 368 |
+
for artist, name, lyrics in zip(artists, names, lyrics):
|
| 369 |
+
print('-' * 100)
|
| 370 |
+
print(f'Original lyrics for {artist} - {name} are: "{lyrics}"')
|
| 371 |
+
relevant_words_in_song = []
|
| 372 |
+
find_relevant_words(lyrics, relevant_words_in_song, word2vec)
|
| 373 |
+
number_of_seq = len(relevant_words_in_song) - seq_length + 1
|
| 374 |
+
end_index_melody = start_index_melody + number_of_seq
|
| 375 |
+
melodies_song = melodies[start_index_melody:end_index_melody, :, :]
|
| 376 |
+
required_length = len(relevant_words_in_song) - (seq_length * TESTING_SEED_TEXT_PER_SONG)
|
| 377 |
+
for seed_index in range(TESTING_SEED_TEXT_PER_SONG):
|
| 378 |
+
# We select three different word\sentence as seed for the new song
|
| 379 |
+
starting_index = 0 + seed_index * seq_length
|
| 380 |
+
ending_index = starting_index + seq_length
|
| 381 |
+
song_first_word_in_word2vec = relevant_words_in_song[starting_index:ending_index]
|
| 382 |
+
song_first_indices = []
|
| 383 |
+
for word in song_first_word_in_word2vec:
|
| 384 |
+
word_i = [k for k, v in word_index.items() if v == word][0]
|
| 385 |
+
song_first_indices.append(word_i)
|
| 386 |
+
encoded_test = np.asarray(song_first_indices).reshape((1, seq_length))
|
| 387 |
+
seed_text = ' '.join(song_first_word_in_word2vec)
|
| 388 |
+
generated_text = generate_song_given_sequence(model_name, model, tokenizer, seed_text, encoded_test,
|
| 389 |
+
required_length, artist, name, seed_index, melodies_song)
|
| 390 |
+
gen_list = generated_text.split(' ')
|
| 391 |
+
all_generated_lyrics.append(gen_list.copy()[seq_length:])
|
| 392 |
+
original_starting_index = starting_index + seq_length
|
| 393 |
+
original_ending_index = original_starting_index + required_length
|
| 394 |
+
original_lyrics = relevant_words_in_song[original_starting_index:original_ending_index]
|
| 395 |
+
all_original_lyrics.append(original_lyrics)
|
| 396 |
+
gen_list.insert(seq_length, '\n')
|
| 397 |
+
generated_text = ' '.join(gen_list)
|
| 398 |
+
print(f'Seed text: {generated_text}, required {required_length} words')
|
| 399 |
+
print('-' * 100)
|
| 400 |
+
start_index_melody = end_index_melody + 1
|
| 401 |
+
return all_original_lyrics, all_generated_lyrics
|
| 402 |
+
|
| 403 |
+
|
| 404 |
+
def find_relevant_words(lyrics, selected_words, word2vec):
|
| 405 |
+
"""
|
| 406 |
+
This loop selects all the relevant words in the pre-defined word2vec
|
| 407 |
+
:param lyrics:
|
| 408 |
+
:param selected_words:
|
| 409 |
+
:param word2vec:
|
| 410 |
+
:return:
|
| 411 |
+
"""
|
| 412 |
+
for word in lyrics.split():
|
| 413 |
+
if word in word2vec and word not in selected_words:
|
| 414 |
+
selected_words.append(word)
|
| 415 |
+
|
| 416 |
+
|
| 417 |
+
def initialize_seed(seed):
|
| 418 |
+
"""
|
| 419 |
+
Initialize all relevant environments with the seed.
|
| 420 |
+
"""
|
| 421 |
+
os.environ['PYTHONHASHSEED'] = str(seed)
|
| 422 |
+
random.seed(seed)
|
| 423 |
+
np.random.seed(seed)
|
| 424 |
+
|
| 425 |
+
|
| 426 |
+
def folder_exists(path):
|
| 427 |
+
"""
|
| 428 |
+
This function checks if folder path is exists, in case not, the function creates the folder.
|
| 429 |
+
:param path: folder path
|
| 430 |
+
"""
|
| 431 |
+
if not os.path.exists(path):
|
| 432 |
+
os.mkdir(path)
|
| 433 |
+
|
| 434 |
+
|
| 435 |
+
if __name__ == '__main__':
|
| 436 |
+
# Environment settings
|
| 437 |
+
IS_COLAB = (os.name == 'posix')
|
| 438 |
+
LOAD_DATA = not (os.name == 'posix')
|
| 439 |
+
path_separator = os.path.sep
|
| 440 |
+
|
| 441 |
+
IS_EXPERIMENT = False
|
| 442 |
+
WRITE_TO_MP3 = False
|
| 443 |
+
if IS_COLAB:
|
| 444 |
+
# the google drive folder we used
|
| 445 |
+
DATA_PATH = os.path.sep + os.path.join('content', 'drive', 'My\ Drive', 'datasets', 'midi').replace('\\', '')
|
| 446 |
+
IS_EXPERIMENT = True
|
| 447 |
+
else:
|
| 448 |
+
# locally
|
| 449 |
+
from data_loader import get_word2vec
|
| 450 |
+
from data_loader import get_input_sets
|
| 451 |
+
from data_loader import get_midi_files
|
| 452 |
+
from lstm_lyrics import LSTMLyrics
|
| 453 |
+
from lstm_melodies_lyrics import LSTMLyricsMelodies
|
| 454 |
+
from prepare_data import get_word2vec_matrix
|
| 455 |
+
from prepare_data import create_sets
|
| 456 |
+
from compute_score import calculate_cosine_similarity
|
| 457 |
+
from compute_score import get_polarity_diff
|
| 458 |
+
from compute_score import get_subjectivity_diff
|
| 459 |
+
from compute_score import calculate_cosine_similarity_n_gram
|
| 460 |
+
from extract_melodies_features import *
|
| 461 |
+
|
| 462 |
+
DATA_PATH = os.path.join('.\\', 'midi')
|
| 463 |
+
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
|
| 464 |
+
|
| 465 |
+
# PATHS
|
| 466 |
+
TRAIN_NAME = 'train'
|
| 467 |
+
INPUT_TRAINING_SET = f"lyrics_{TRAIN_NAME}_set.csv"
|
| 468 |
+
TEST_NAME = 'test'
|
| 469 |
+
INPUT_TESTING_SET = f"lyrics_{TEST_NAME}_set.csv"
|
| 470 |
+
OUTPUT_FOLDER = os.path.join(DATA_PATH, 'output_files')
|
| 471 |
+
folder_exists(OUTPUT_FOLDER)
|
| 472 |
+
INPUT_FOLDER = os.path.join(DATA_PATH, 'input_files')
|
| 473 |
+
folder_exists(INPUT_FOLDER)
|
| 474 |
+
PICKLES_FOLDER = os.path.join(DATA_PATH, 'pickles')
|
| 475 |
+
folder_exists(PICKLES_FOLDER)
|
| 476 |
+
WEIGHTS_FOLDER = os.path.join(DATA_PATH, 'weights')
|
| 477 |
+
folder_exists(WEIGHTS_FOLDER)
|
| 478 |
+
WORD2VEC_FILENAME = 'word2vec'
|
| 479 |
+
RESULTS_FILE_NAME = 'results.csv'
|
| 480 |
+
COMB_PATH = os.path.join(OUTPUT_FOLDER, RESULTS_FILE_NAME)
|
| 481 |
+
GLOVE_FILE_NAME = 'glove.6B.300d'
|
| 482 |
+
ENCODING = 'utf-8'
|
| 483 |
+
|
| 484 |
+
LOSS = 'categorical_crossentropy'
|
| 485 |
+
METRICS = ['accuracy']
|
| 486 |
+
VECTOR_SIZE = 300
|
| 487 |
+
VALIDATION_SET_SIZE = 0.2
|
| 488 |
+
TESTING_SEED_TEXT_PER_SONG = 3
|
| 489 |
+
OPTIMIZER = 'adam'
|
| 490 |
+
|
| 491 |
+
if IS_EXPERIMENT: # Experiments settings
|
| 492 |
+
seeds_list = [0]
|
| 493 |
+
learning_rate_list = [0.01]
|
| 494 |
+
batch_size_list = [32, 64]
|
| 495 |
+
epochs_list = [10]
|
| 496 |
+
patience_list = [0]
|
| 497 |
+
min_delta_list = [0.1]
|
| 498 |
+
units_list = [256]
|
| 499 |
+
seq_length_list = [1, 5, 20]
|
| 500 |
+
model_names_list = ['melodies_lyrics', 'lyrics']
|
| 501 |
+
melody_extraction = ['naive']
|
| 502 |
+
# melody_extraction = ['naive', 'with_meta_features']
|
| 503 |
+
else: # Final settings
|
| 504 |
+
seeds_list = [0]
|
| 505 |
+
learning_rate_list = [0.01]
|
| 506 |
+
batch_size_list = [32]
|
| 507 |
+
epochs_list = [10]
|
| 508 |
+
patience_list = [0]
|
| 509 |
+
min_delta_list = [0.1]
|
| 510 |
+
units_list = [256]
|
| 511 |
+
seq_length_list = [1]
|
| 512 |
+
model_names_list = ['melodies_lyrics']
|
| 513 |
+
melody_extraction = ['naive']
|
| 514 |
+
# model_names_list = ['melodies_lyrics', 'lyrics']
|
| 515 |
+
# melody_extraction = ['naive', 'with_meta_features']
|
| 516 |
+
|
| 517 |
+
start_time = time.time()
|
| 518 |
+
main()
|
| 519 |
+
print("--- %s seconds ---" % (time.time() - start_time))
|
extract_melodies_features.py
ADDED
|
@@ -0,0 +1,179 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import pickle
|
| 3 |
+
|
| 4 |
+
import numpy as np
|
| 5 |
+
from tqdm import tqdm
|
| 6 |
+
|
| 7 |
+
# Environment settings
|
| 8 |
+
IS_COLAB = (os.name == 'posix')
|
| 9 |
+
LOAD_DATA = not (os.name == 'posix')
|
| 10 |
+
|
| 11 |
+
if not IS_COLAB:
|
| 12 |
+
from prepare_data import create_validation_set
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def get_midi_file_instrument_data(word_idx, time_per_word, midi_file):
|
| 16 |
+
"""
|
| 17 |
+
Extract data about the midi file in the given time period. We will extract number of beat changes, instruments used
|
| 18 |
+
and velocity.
|
| 19 |
+
:param word_idx: index of word in the song
|
| 20 |
+
:param time_per_word: Average time per word in song
|
| 21 |
+
:param midi_file: The midi file
|
| 22 |
+
:return: An array where each cell contains some data about the pitch, velocity etc.
|
| 23 |
+
"""
|
| 24 |
+
# Features we want to extract:
|
| 25 |
+
start_time = word_idx * time_per_word
|
| 26 |
+
end_time = start_time + time_per_word
|
| 27 |
+
avg_velocity, avg_pitch, num_of_instruments, num_of_notes, beat_changes, has_drums = 0, 0, 0, 0, 0, 0
|
| 28 |
+
|
| 29 |
+
for beat in midi_file.get_beats():
|
| 30 |
+
if start_time <= beat <= end_time:
|
| 31 |
+
beat_changes += 1 # Count beats that are in the desired time frame
|
| 32 |
+
elif beat > end_time:
|
| 33 |
+
break # We passed the final possible time
|
| 34 |
+
for instrument in midi_file.instruments:
|
| 35 |
+
in_range = False # Will become true if the instrument contributed at least 1 note for this sequence.
|
| 36 |
+
for note in instrument.notes:
|
| 37 |
+
if start_time <= note.start:
|
| 38 |
+
if note.end <= end_time: # In required range
|
| 39 |
+
has_drums = 1 if instrument.is_drum else has_drums
|
| 40 |
+
in_range = True
|
| 41 |
+
num_of_notes += 1
|
| 42 |
+
avg_pitch += note.pitch
|
| 43 |
+
avg_velocity += note.velocity
|
| 44 |
+
else: # We passed the last relevant note
|
| 45 |
+
break
|
| 46 |
+
if in_range:
|
| 47 |
+
num_of_instruments += 1
|
| 48 |
+
if num_of_notes > 0: # If there was at least 1 note
|
| 49 |
+
avg_velocity /= num_of_notes
|
| 50 |
+
avg_pitch /= num_of_notes
|
| 51 |
+
final_features = np.array([avg_velocity, avg_pitch, num_of_instruments, beat_changes, has_drums])
|
| 52 |
+
return final_features
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
def extract_melody_features_1(melodies_list, sequence_length, encoded_song_lyrics):
|
| 56 |
+
"""
|
| 57 |
+
First function for extracting features about the midi files. Using the instrument objects in each midi file we can
|
| 58 |
+
see when each instrument was used and with what velocity. We can then calculate the average pitch and velocity for
|
| 59 |
+
each word in the song.
|
| 60 |
+
|
| 61 |
+
:param melodies_list: A list of midi files. Contains the training / validation / test set typically.
|
| 62 |
+
:param sequence_length: Number of words per sequence.
|
| 63 |
+
:param encoded_song_lyrics: A list where each cell represents a song. The cells contain a list of ints, where each
|
| 64 |
+
cell corresponds to a word in the songs lyrics and the value is the index of the word in our word2vec vocabulary.
|
| 65 |
+
:return: A 3d numpy array where the first axis is the number of sequences in the data, the 2nd is the sequence
|
| 66 |
+
length and the third is the number of notes for that particular word in that sequence.
|
| 67 |
+
"""
|
| 68 |
+
|
| 69 |
+
final_features = []
|
| 70 |
+
print('Extracting melody features v1..')
|
| 71 |
+
|
| 72 |
+
for idx, midi_file in tqdm(enumerate(melodies_list)):
|
| 73 |
+
num_of_words_in_song = len(encoded_song_lyrics[idx])
|
| 74 |
+
midi_file.remove_invalid_notes()
|
| 75 |
+
time_per_word = midi_file.get_end_time() / num_of_words_in_song # Average time per word in the lyrics
|
| 76 |
+
number_of_sequences = num_of_words_in_song - sequence_length
|
| 77 |
+
features_during_lyric = []
|
| 78 |
+
for word_idx in range(num_of_words_in_song): # Iterate over every word and get the features for it
|
| 79 |
+
instrument_data = get_midi_file_instrument_data(word_idx, time_per_word, midi_file)
|
| 80 |
+
features_during_lyric.append(instrument_data)
|
| 81 |
+
|
| 82 |
+
for sequence_num in range(number_of_sequences):
|
| 83 |
+
seq = features_during_lyric[sequence_num:sequence_num + sequence_length] # Create a sequence from the notes
|
| 84 |
+
final_features.append(seq)
|
| 85 |
+
|
| 86 |
+
final_features = np.array(final_features)
|
| 87 |
+
return final_features
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
def extract_melody_features_2(melodies_list, sequence_length, encoded_song_lyrics):
|
| 91 |
+
"""
|
| 92 |
+
Using all midi files and lyrics, extract features for all sequences. This is the second method we'll try. Basically,
|
| 93 |
+
we will take the piano roll matrix for each song. This is a matrix that displays which notes were played for every
|
| 94 |
+
user defined time period and some number representing the velocity. In our case, we'll slice the song every 1/50
|
| 95 |
+
seconds (20 miliseconds) and look at what notes were played during this time. This is in addition to the features
|
| 96 |
+
used in v1.
|
| 97 |
+
:param melodies_list: A list of midi files. Contains the training / validation / test set typically.
|
| 98 |
+
:param total_dataset_size: Total length of the sequence array,
|
| 99 |
+
:param sequence_length: Number of words per sequence.
|
| 100 |
+
:param encoded_song_lyrics: A list where each cell represents a song. The cells contain a list of ints, where each cell
|
| 101 |
+
corresponds to a word in the songs lyrics and the value is the index of the word in our word2vec vocabulary.
|
| 102 |
+
:return: A 3d numpy array where the first axis is the number of sequences in the data, the 2nd is the sequence
|
| 103 |
+
length and the third is the number of notes for that particular word in that sequence.
|
| 104 |
+
"""
|
| 105 |
+
|
| 106 |
+
final_features = []
|
| 107 |
+
print('Extracting melody features v2..')
|
| 108 |
+
frequency_sample = 50
|
| 109 |
+
for midi_idx, midi_file in tqdm(enumerate(melodies_list)):
|
| 110 |
+
num_of_words_in_song = len(encoded_song_lyrics[midi_idx])
|
| 111 |
+
midi_file.remove_invalid_notes()
|
| 112 |
+
time_per_word = midi_file.get_end_time() / num_of_words_in_song # Average time per word in the lyrics
|
| 113 |
+
number_of_sequences = num_of_words_in_song - sequence_length
|
| 114 |
+
piano_roll = midi_file.get_piano_roll(fs=frequency_sample)
|
| 115 |
+
num_of_notes_per_word = int(piano_roll.shape[1] / num_of_words_in_song) # Num of piano roll columns per word
|
| 116 |
+
features_during_lyric = []
|
| 117 |
+
for word_idx in range(num_of_words_in_song): # Iterate over every word and get the features for it
|
| 118 |
+
notes_features = extract_piano_roll_features(num_of_notes_per_word, piano_roll, word_idx)
|
| 119 |
+
instrument_data = get_midi_file_instrument_data(word_idx, time_per_word, midi_file)
|
| 120 |
+
features = np.append(notes_features, instrument_data, axis=0) # Concatenate them
|
| 121 |
+
features_during_lyric.append(features)
|
| 122 |
+
|
| 123 |
+
for sequence_num in range(number_of_sequences):
|
| 124 |
+
# Create the features per sequence
|
| 125 |
+
sequence_features = features_during_lyric[sequence_num:sequence_num + sequence_length]
|
| 126 |
+
final_features.append(sequence_features)
|
| 127 |
+
|
| 128 |
+
final_features = np.array(final_features)
|
| 129 |
+
return final_features
|
| 130 |
+
|
| 131 |
+
|
| 132 |
+
def extract_piano_roll_features(num_of_notes_per_word, piano_roll, word_idx):
|
| 133 |
+
start_idx = word_idx * num_of_notes_per_word
|
| 134 |
+
end_idx = start_idx + num_of_notes_per_word
|
| 135 |
+
piano_roll_for_lyric = piano_roll[:, start_idx:end_idx].transpose()
|
| 136 |
+
piano_roll_slice_sum = np.sum(piano_roll_for_lyric, axis=0) # Sum each column into a single cell
|
| 137 |
+
return piano_roll_slice_sum
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
def get_melody_data_sets(train_num, val_size, melodies_list, sequence_length, encoded_lyrics_matrix, seed,
|
| 141 |
+
pkl_file_path, feature_method):
|
| 142 |
+
"""
|
| 143 |
+
Creates numpy arrays containing features of the melody for the training, validation and test sets.
|
| 144 |
+
:param feature_method: Method of feature extraction to use. Either '1' or '2'.
|
| 145 |
+
:param seed: Seed for splitting to train and test.
|
| 146 |
+
:param pkl_file_path: the file path to the pickle file. Used for saving or loading.
|
| 147 |
+
:param train_num: Number of words in the whole training set sequence (train + validation)
|
| 148 |
+
:param val_size: Percentage of sequences used for validation set
|
| 149 |
+
:param melodies_list: All of the training + validation set midi files
|
| 150 |
+
:param sequence_length: Number of words in a sequence
|
| 151 |
+
:param encoded_lyrics_matrix: A list where each cell represents a song. The cells contain a list of ints, where each cell
|
| 152 |
+
corresponds to a word in the songs lyrics and the value is the index of the word in our word2vec vocabulary.
|
| 153 |
+
:return: numpy arrays containing features of the melody for the training, validation and test sets.
|
| 154 |
+
"""
|
| 155 |
+
file_type = pkl_file_path.split('.')[-1]
|
| 156 |
+
# Save/load the file with the appropriate name according to the settings used:
|
| 157 |
+
pkl_file_path = f'{pkl_file_path.rstrip("." + file_type)}_{str(feature_method)}_sl_{sequence_length}.{file_type}'
|
| 158 |
+
if os.path.exists(pkl_file_path): # If file exists, use it instead of building it again
|
| 159 |
+
with open(pkl_file_path, 'rb') as f:
|
| 160 |
+
melody_train, melody_val, melody_test = pickle.load(f)
|
| 161 |
+
return melody_train, melody_val, melody_test
|
| 162 |
+
|
| 163 |
+
if feature_method == 'naive': # Use appropriate melody feature method
|
| 164 |
+
melody_features = extract_melody_features_1(melodies_list, sequence_length, encoded_lyrics_matrix)
|
| 165 |
+
else:
|
| 166 |
+
melody_features = extract_melody_features_2(melodies_list, sequence_length, encoded_lyrics_matrix)
|
| 167 |
+
|
| 168 |
+
melody_train = melody_features[:train_num]
|
| 169 |
+
melody_test = melody_features[train_num:]
|
| 170 |
+
melody_train, melody_val = create_validation_set(melody_train, val_size, seed)
|
| 171 |
+
|
| 172 |
+
with open(pkl_file_path, 'wb') as f:
|
| 173 |
+
pickle.dump([melody_train, melody_val, melody_test], f)
|
| 174 |
+
print('Dumped midi files')
|
| 175 |
+
|
| 176 |
+
return melody_train, melody_val, melody_test
|
| 177 |
+
|
| 178 |
+
|
| 179 |
+
print("Loaded Successfully")
|
figures/1.PNG
ADDED
|
figures/10.PNG
ADDED
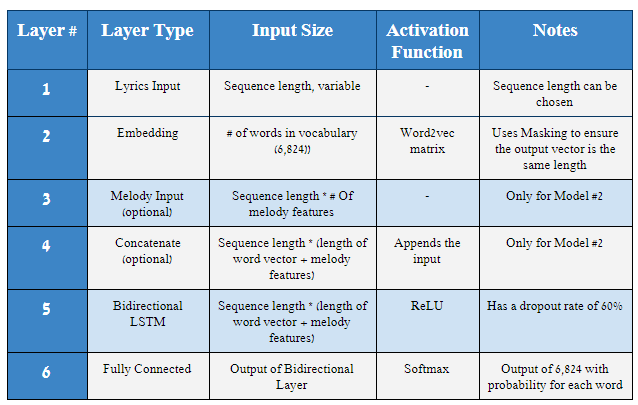
|
figures/11.PNG
ADDED

|
figures/12.PNG
ADDED

|
figures/13.PNG
ADDED

|
figures/14.PNG
ADDED

|
figures/15.PNG
ADDED

|
figures/2.PNG
ADDED
|
figures/3.PNG
ADDED

|
figures/4.PNG
ADDED
|
figures/5.PNG
ADDED
|
figures/6.PNG
ADDED
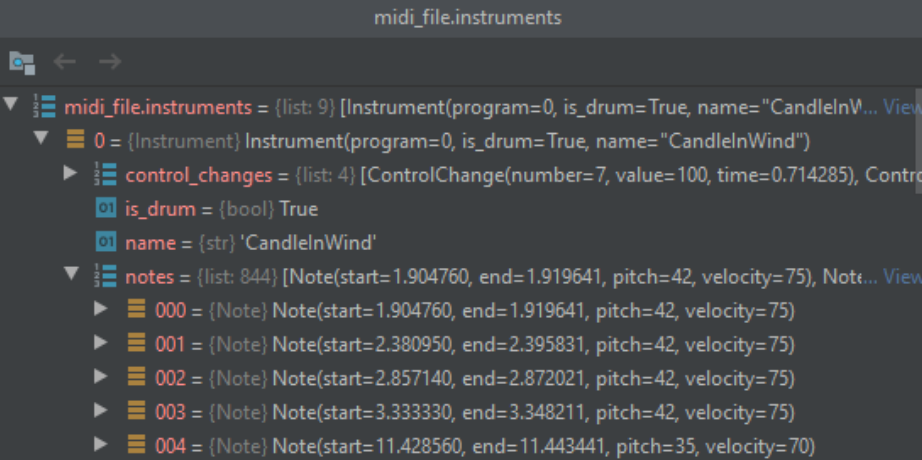
|
figures/7.PNG
ADDED
|
figures/8.PNG
ADDED

|
figures/9.PNG
ADDED

|
lstm_lyrics.py
ADDED
|
@@ -0,0 +1,76 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
This function manages the LSTM model with lyrics only
|
| 3 |
+
"""
|
| 4 |
+
import os
|
| 5 |
+
|
| 6 |
+
from keras import Input, Model
|
| 7 |
+
from keras import backend as K
|
| 8 |
+
from keras.layers import Dense, Dropout, Embedding, Bidirectional, LSTM, Masking
|
| 9 |
+
from keras.optimizers import Adam
|
| 10 |
+
|
| 11 |
+
# Environment settings
|
| 12 |
+
IS_COLAB = (os.name == 'posix')
|
| 13 |
+
LOAD_DATA = not (os.name == 'posix')
|
| 14 |
+
|
| 15 |
+
if not IS_COLAB:
|
| 16 |
+
from rnn import RecurrentNeuralNetwork
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
class LSTMLyrics(RecurrentNeuralNetwork):
|
| 20 |
+
def __init__(self, seed, loss, metrics, optimizer, learning_rate, total_words, seq_length, vector_size,
|
| 21 |
+
word2vec_matrix, units):
|
| 22 |
+
"""
|
| 23 |
+
Seed - The seed used to initialize the weights
|
| 24 |
+
width, height, cells - used for defining the tensors used for the input images
|
| 25 |
+
loss, metrics, optimizer, dropout_rate - settings used for compiling the siamese model (e.g., 'Accuracy' and 'ADAM)
|
| 26 |
+
:return Nothing
|
| 27 |
+
"""
|
| 28 |
+
super().__init__(seed)
|
| 29 |
+
K.clear_session()
|
| 30 |
+
self.seed = seed
|
| 31 |
+
self.initialize_seed()
|
| 32 |
+
self.initialize_model(learning_rate, loss, metrics, optimizer, seq_length, total_words, units, vector_size,
|
| 33 |
+
word2vec_matrix)
|
| 34 |
+
|
| 35 |
+
def initialize_model(self, learning_rate, loss, metrics, optimizer, seq_length, total_words, units, vector_size,
|
| 36 |
+
word2vec_matrix):
|
| 37 |
+
"""
|
| 38 |
+
This function initializes the architecture and builds the model
|
| 39 |
+
:param learning_rate: a tuning parameter in an optimization algorithm that determines the step size
|
| 40 |
+
:param loss: the loss function we want to use
|
| 41 |
+
:param metrics: the metrics we want to use, such as Loss
|
| 42 |
+
:param optimizer: the optimizer function, such as Adam
|
| 43 |
+
:param seq_length: the length of the sequence (the sentence in this case)
|
| 44 |
+
:param total_words: total number of words we have (used for the output dense)
|
| 45 |
+
:param units: number of LSTM units
|
| 46 |
+
:param vector_size: the size of the embedding vector
|
| 47 |
+
:param word2vec_matrix: the embedding matrix
|
| 48 |
+
:return: Nothing
|
| 49 |
+
"""
|
| 50 |
+
lyrics_features_input = Input((seq_length,))
|
| 51 |
+
|
| 52 |
+
embedding_layer = Embedding(input_dim=total_words, # the size of the vocabulary in the text data
|
| 53 |
+
input_length=seq_length, # the length of input sequences
|
| 54 |
+
output_dim=vector_size,
|
| 55 |
+
# the size of the vector space in which words will be embedded
|
| 56 |
+
weights=[word2vec_matrix],
|
| 57 |
+
trainable=False,
|
| 58 |
+
# the model must be informed that some part of
|
| 59 |
+
# the data is actually padding and should be ignored.
|
| 60 |
+
mask_zero=True,
|
| 61 |
+
name='MelodiesLyrics')(lyrics_features_input)
|
| 62 |
+
|
| 63 |
+
masking_layer = Masking(mask_value=0.)(embedding_layer)
|
| 64 |
+
# Bidirectional Recurrent layer
|
| 65 |
+
b_rnn_layer = Bidirectional(LSTM(units=units, activation='relu'))(masking_layer)
|
| 66 |
+
dropout_layer = Dropout(0.6)(b_rnn_layer)
|
| 67 |
+
|
| 68 |
+
output_dense = Dense(units=total_words, activation='softmax')(dropout_layer)
|
| 69 |
+
|
| 70 |
+
self.model = Model(inputs=lyrics_features_input, outputs=output_dense)
|
| 71 |
+
if optimizer == 'adam':
|
| 72 |
+
optimizer = Adam(lr=learning_rate)
|
| 73 |
+
self.model.compile(optimizer=optimizer, loss=loss, metrics=metrics)
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
print("Loaded Successfully")
|
lstm_melodies_lyrics.py
ADDED
|
@@ -0,0 +1,79 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
This function manages the LSTM model with lyrics and melodies
|
| 3 |
+
"""
|
| 4 |
+
import os
|
| 5 |
+
|
| 6 |
+
from keras import Input, Model
|
| 7 |
+
from keras import backend as K
|
| 8 |
+
from keras.layers import Dense, Dropout, Embedding, Concatenate, Bidirectional, LSTM, Masking
|
| 9 |
+
from keras.optimizers import Adam
|
| 10 |
+
|
| 11 |
+
# Environment settings
|
| 12 |
+
IS_COLAB = (os.name == 'posix')
|
| 13 |
+
LOAD_DATA = not (os.name == 'posix')
|
| 14 |
+
|
| 15 |
+
if not IS_COLAB:
|
| 16 |
+
from rnn import RecurrentNeuralNetwork
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
class LSTMLyricsMelodies(RecurrentNeuralNetwork):
|
| 20 |
+
def __init__(self, seed, loss, metrics, optimizer, learning_rate, total_words, seq_length, vector_size,
|
| 21 |
+
word2vec_matrix, units, melody_num_features):
|
| 22 |
+
"""
|
| 23 |
+
Seed - The seed used to initialize the weights
|
| 24 |
+
width, height, cells - used for defining the tensors used for the input images
|
| 25 |
+
loss, metrics, optimizer, dropout_rate - settings used for compiling the siamese model (e.g., 'Accuracy' and 'ADAM)
|
| 26 |
+
:return Nothing
|
| 27 |
+
"""
|
| 28 |
+
super().__init__(seed)
|
| 29 |
+
K.clear_session()
|
| 30 |
+
self.seed = seed
|
| 31 |
+
self.initialize_seed()
|
| 32 |
+
self.initialize_model(learning_rate, loss, metrics, optimizer, seq_length, total_words, units, vector_size,
|
| 33 |
+
word2vec_matrix, melody_num_features)
|
| 34 |
+
|
| 35 |
+
def initialize_model(self, learning_rate, loss, metrics, optimizer, seq_length, total_words, units, vector_size,
|
| 36 |
+
word2vec_matrix, melody_num_features):
|
| 37 |
+
"""
|
| 38 |
+
This function initializes the architecture and builds the model
|
| 39 |
+
:param melody_num_features: number of the melody features
|
| 40 |
+
:param learning_rate: a tuning parameter in an optimization algorithm that determines the step size
|
| 41 |
+
:param loss: the loss function we want to use
|
| 42 |
+
:param metrics: the metrics we want to use, such as Loss
|
| 43 |
+
:param optimizer: the optimizer function, such as Adam
|
| 44 |
+
:param seq_length: the length of the sequence (the sentence in this case)
|
| 45 |
+
:param total_words: total number of words we have (used for the output dense)
|
| 46 |
+
:param units: number of LSTM units
|
| 47 |
+
:param vector_size: the size of the embedding vector
|
| 48 |
+
:param word2vec_matrix: the embedding matrix
|
| 49 |
+
:return: Nothing
|
| 50 |
+
"""
|
| 51 |
+
lyrics_features_input = Input((seq_length,))
|
| 52 |
+
melody_features_input = Input((seq_length, melody_num_features))
|
| 53 |
+
|
| 54 |
+
embedding_layer = Embedding(input_dim=total_words, # the size of the vocabulary in the text data
|
| 55 |
+
input_length=seq_length, # the length of input sequences
|
| 56 |
+
output_dim=vector_size,
|
| 57 |
+
# the size of the vector space in which words will be embedded
|
| 58 |
+
weights=[word2vec_matrix],
|
| 59 |
+
trainable=False,
|
| 60 |
+
# the model must be informed that some part of
|
| 61 |
+
# the data is actually padding and should be ignored.
|
| 62 |
+
mask_zero=True,
|
| 63 |
+
name='MelodiesLyrics')(lyrics_features_input)
|
| 64 |
+
|
| 65 |
+
masking_layer = Masking(mask_value=0.)(embedding_layer)
|
| 66 |
+
concatenate_layer = Concatenate(axis=2)([masking_layer, melody_features_input])
|
| 67 |
+
# Bidirectional Recurrent layer
|
| 68 |
+
b_rnn_layer = Bidirectional(LSTM(units=units, activation='relu'))(concatenate_layer)
|
| 69 |
+
dropout_layer = Dropout(0.6)(b_rnn_layer)
|
| 70 |
+
|
| 71 |
+
output_dense = Dense(units=total_words, activation='softmax')(dropout_layer)
|
| 72 |
+
|
| 73 |
+
self.model = Model(inputs=[lyrics_features_input, melody_features_input], outputs=output_dense)
|
| 74 |
+
if optimizer == 'adam':
|
| 75 |
+
optimizer = Adam(lr=learning_rate)
|
| 76 |
+
self.model.compile(optimizer=optimizer, loss=loss, metrics=metrics)
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
print("Loaded Successfully")
|
prepare_data.py
ADDED
|
@@ -0,0 +1,112 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
This file manages the data preparation
|
| 3 |
+
"""
|
| 4 |
+
import numpy as np
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
def get_word2vec_matrix(total_words, index2word, word2vec, vector_size):
|
| 8 |
+
"""
|
| 9 |
+
This function creates a matrix where the rows are the words and the columns represents the embedding vector.
|
| 10 |
+
We will use this matrix in the embedding layer
|
| 11 |
+
:param total_words: Number of words in our word2vec dictionary.
|
| 12 |
+
:param index2word: dictionary maps between index and word
|
| 13 |
+
:param word2vec: dictionary maps between a word and a vector
|
| 14 |
+
:param vector_size: the size of the embedding vector size
|
| 15 |
+
:return: embedding layer
|
| 16 |
+
"""
|
| 17 |
+
word2vec_matrix = np.zeros((total_words, vector_size))
|
| 18 |
+
for index_word, word in index2word.items():
|
| 19 |
+
if word not in word2vec:
|
| 20 |
+
print(f'Can not find the word "{word}" in the word2vec dictionary')
|
| 21 |
+
continue
|
| 22 |
+
else:
|
| 23 |
+
vec = word2vec[word]
|
| 24 |
+
word2vec_matrix[index_word] = vec
|
| 25 |
+
return word2vec_matrix
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def _create_sequences(encoded_lyrics_list, total_words, seq_length):
|
| 29 |
+
"""
|
| 30 |
+
This function creates sequences from the lyrics
|
| 31 |
+
:param encoded_lyrics_list: A list representing all the songs in the dataset (615 songs). Each cell contains a list
|
| 32 |
+
of ints, where each int corresponds to the lyrics in that song. "I'm a barbie girl" --> [23, 52, 189, 792] etc.
|
| 33 |
+
:param total_words: Number of words in our word2vec dictionary.
|
| 34 |
+
:param seq_length: Number of words predating the word to be predicted.
|
| 35 |
+
:return: (1) A numpy array containing all the sequences seen, concatenated.
|
| 36 |
+
(2) A 2d numpy array where each row represents a word and the columns are the possible words in the
|
| 37 |
+
vocabulary. There is a '1' in the corresponding word (e.g, word number '20,392' in the dataset is word
|
| 38 |
+
number '39' in the vocab.
|
| 39 |
+
"""
|
| 40 |
+
input_sequences = []
|
| 41 |
+
next_words = []
|
| 42 |
+
for song_sequence in encoded_lyrics_list: # iterate over songs
|
| 43 |
+
for i in range(seq_length, len(song_sequence)): # iterate from minimal sequence length (number of words) to
|
| 44 |
+
start_index = i - seq_length # number of words in the song
|
| 45 |
+
end_index = i
|
| 46 |
+
# Slice the list into the desired sequence length
|
| 47 |
+
sequence = song_sequence[start_index:end_index]
|
| 48 |
+
input_sequences.append(sequence)
|
| 49 |
+
next_word = song_sequence[end_index]
|
| 50 |
+
next_words.append(next_word)
|
| 51 |
+
input_sequences = np.array(input_sequences)
|
| 52 |
+
one_hot_encoding_next_words = convert_to_one_hot_encoding(input_sequences, next_words, total_words)
|
| 53 |
+
return input_sequences, one_hot_encoding_next_words
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
def convert_to_one_hot_encoding(input_sequences, next_words, total_words):
|
| 57 |
+
"""
|
| 58 |
+
This function converts input to one hot encoding
|
| 59 |
+
"""
|
| 60 |
+
one_hot_encoding_next_words = np.zeros((len(input_sequences), total_words), dtype=np.int8)
|
| 61 |
+
for word_index, word in enumerate(next_words):
|
| 62 |
+
one_hot_encoding_next_words[word_index, word] = 1
|
| 63 |
+
return one_hot_encoding_next_words
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
def create_sets(train_encoded_lyrics_list, test_encoded_lyrics_list, total_words, seq_length, validation_set_size,
|
| 67 |
+
seed):
|
| 68 |
+
"""
|
| 69 |
+
This function splits training set to smaller training set and new validation set
|
| 70 |
+
:param train_encoded_lyrics_list: list of sequences in the training set
|
| 71 |
+
:param test_encoded_lyrics_list: list of sequences in the testing set
|
| 72 |
+
:param total_words: total words in the lyrics
|
| 73 |
+
:param seq_length: length of the sequence
|
| 74 |
+
:param validation_set_size: percentage of the validation set
|
| 75 |
+
:param seed: random state for the split
|
| 76 |
+
:return: training/testing/validation set values and labels
|
| 77 |
+
"""
|
| 78 |
+
x_train, y_train = _create_sequences(encoded_lyrics_list=train_encoded_lyrics_list,
|
| 79 |
+
total_words=total_words, seq_length=seq_length)
|
| 80 |
+
|
| 81 |
+
x_train, x_val = create_validation_set(data_to_split=x_train,
|
| 82 |
+
val_data_percentage=validation_set_size,
|
| 83 |
+
seed=seed)
|
| 84 |
+
y_train, y_val = create_validation_set(data_to_split=y_train,
|
| 85 |
+
val_data_percentage=validation_set_size,
|
| 86 |
+
seed=seed)
|
| 87 |
+
|
| 88 |
+
x_test, y_test = _create_sequences(encoded_lyrics_list=test_encoded_lyrics_list,
|
| 89 |
+
total_words=total_words, seq_length=seq_length)
|
| 90 |
+
|
| 91 |
+
return {'train': (x_train, y_train), 'validation': (x_val, y_val), 'test': (x_test, y_test)}
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
def create_validation_set(data_to_split, val_data_percentage, seed):
|
| 95 |
+
"""
|
| 96 |
+
This function splits to training and validation set
|
| 97 |
+
:param data_to_split: matrix where the rows are the sequences and the columns are the word indices
|
| 98 |
+
:param val_data_percentage: percentage of the validation set
|
| 99 |
+
:param seed: random state for the split
|
| 100 |
+
:return: training and validation set
|
| 101 |
+
"""
|
| 102 |
+
np.random.seed(seed=seed)
|
| 103 |
+
np.random.shuffle(data_to_split)
|
| 104 |
+
|
| 105 |
+
validation_ending_index = int(len(data_to_split) * val_data_percentage)
|
| 106 |
+
validation_set = data_to_split[:validation_ending_index]
|
| 107 |
+
data_to_split = data_to_split[validation_ending_index:]
|
| 108 |
+
|
| 109 |
+
return data_to_split, validation_set
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
print('Loaded Successfully')
|
readme.md
ADDED
|
@@ -0,0 +1,385 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# The purpose
|
| 2 |
+
A Recurrent Neural Network that can learn song lyrics and their melodies and then given a melody and a few words to start with, predict the rest of the song. This is essentially done by generating new words for the song and attempting to be as “close” as possible to the original lyrics. However, this is entirely subjective leading the evaluation of generated words to use imaginative methods. For the training phase, however, we used Crossed Entropy loss.
|
| 3 |
+
|
| 4 |
+
## Table of Contents
|
| 5 |
+
* [Authors](#authors)
|
| 6 |
+
* [Introduction](#introduction)
|
| 7 |
+
* [Instructions](#instructions)
|
| 8 |
+
* [Dataset Analysis](#dataset-analysis)
|
| 9 |
+
* [Code Design](#code-design)
|
| 10 |
+
* [Melody Feature Integration](#melody-feature-integration)
|
| 11 |
+
* [Architecture](#architecture)
|
| 12 |
+
* [Results Evaluation](#results-evaluation)
|
| 13 |
+
* [Full Experimental Setup](#full-experimental-setup)
|
| 14 |
+
* [Analysis of how the Seed and Melody Effects the Generated Lyrics](#analysis-of-how-the-seed-and-melody-effects-the-generated-lyrics)
|
| 15 |
+
|
| 16 |
+
## Authors
|
| 17 |
+
* **Tomer Shahar** - [Tomer Shahar](https://github.com/Tomer-Shahar)
|
| 18 |
+
* **Nevo Itzhak** - [Nevo Itzhak](https://github.com/nevoit)
|
| 19 |
+
|
| 20 |
+
## Introduction
|
| 21 |
+
In this assignment, we were tasked with creating a Recurrent Neural Network that can learn song lyrics and their melodies and then given a melody and a few words to start with, predict the rest of the song. This is essentially done by generating new words for the song and attempting to be as “close” as possible to the original lyrics. However, this is quite subjective leading the evaluation of generated words to use imaginative methods. For the training phase, however, we used Crossed Entropy loss.
|
| 22 |
+
The melody files and lyrics for each song were given to us and the train / test sets were predefined. 20% of the training data was used as a validation set in order to track our progress between training iterations.
|
| 23 |
+
|
| 24 |
+
We implemented this using an LSTM network. LSTMs have proven in the past to be successful in similar tasks because of their ability to remember previous data, which in our case is relevant because each lyric depends on the words (and melody) that preceded it.
|
| 25 |
+
The network receives as input a sequence of lyrics and predicts the next word to appear. The length of this sequence greatly affects the network’s predicting abilities since 5 words in a row work much better than just a single word. We tried using different values to see how this changes the accuracy of the model. During the training phase, sequences from the actual lyrics are fed into the network to train. After fitting the model, we can generate the lyrics for a whole song by beginning with an initial “seed” which is a sequence of words, predicting a word and then using it to advance the sequence like a moving window.
|
| 26 |
+
|
| 27 |
+
## Instructions
|
| 28 |
+
1. Please download the following:
|
| 29 |
+
* A .zip file containing all the MIDI files of the participating songs
|
| 30 |
+
* the .csv file with all the lyrics of the of the participating songs (600 train and 5 test)
|
| 31 |
+
* [Pretty_Midi](https://nbviewer.jupyter.org/github/craffel/pretty-midi/blob/master/Tutorial.ipynb) , a python library for the analysis of MIDI files
|
| 32 |
+
|
| 33 |
+
2. Implement a recurrent neural net (LSTM or GRU) to carry out the task described in the introduction.
|
| 34 |
+
* During each step of the training phase, your architecture will receive as input one word of the lyrics. Words are to represented using the Word2Vec representation that can be found online (300 entries per term, as learned in class).
|
| 35 |
+
* The task of the network is to predict the next word of the song’s lyrics. Please see the figure 1 for an illustration. You may use any loss function
|
| 36 |
+
* In addition to this textual information, you need to include information extracted from the MIDI file. The method for implementing this requirement is entirely up to your consideration. Figure 1 shows one of the more simplistic options – inserting the entire melody representation at each step.
|
| 37 |
+
* Note that your mechanism for selecting the next word should not be deterministic (i.e., always select the word with the highest probability) but rather be sampling-based. The likelihood of a term to be selected by the sampling should be proportional to its probability.
|
| 38 |
+
* You may add whatever additions you want to the architecture (e.g., regularization, attention, teacher forcing)
|
| 39 |
+
* You may create a validation set. The manner of splitting (and all related decisions) are up to you.
|
| 40 |
+
|
| 41 |
+
3. The Pretty_Midi package offers multiple options for analyzing .mid files.
|
| 42 |
+
Figures 2-4 demonstrate the types of information that can be gathered.
|
| 43 |
+
|
| 44 |
+
4. You can add whatever other information you consider relevant to further improve the performance of your model.
|
| 45 |
+
|
| 46 |
+
5. You are to evaluate two approaches for integrating the melody information into your model. The two approaches don’t have to be completely different (one can build upon the other, for example), but please refrain from making only miniature changes.
|
| 47 |
+
|
| 48 |
+
6. Please include the following information in your report regarding the training phase:
|
| 49 |
+
* The chosen architecture of your model
|
| 50 |
+
* A clear description of your approach(s) for integrating the melody information together with the lyrics
|
| 51 |
+
* TensorBoard graphs showing the training and validation loss of your model.
|
| 52 |
+
|
| 53 |
+
7. Please include the following information in your report regarding the test phase:
|
| 54 |
+
* For each of the melodies in the test set, produce the outputs (lyrics) for each of the two architectural variants you developed. The input should be the melody and the initial word of the output lyrics. Include all generated lyrics in your submission.
|
| 55 |
+
* For each melody, repeat the process described above three times, with different words (the same words should be used for all melodies).
|
| 56 |
+
* Attempt to analyze the effect of the selection of the first word and/or melody on the generated lyrics.
|
| 57 |
+
|
| 58 |
+
## Dataset Analysis
|
| 59 |
+
- 600 song lyrics for the training
|
| 60 |
+
- 5 songs for the test set.
|
| 61 |
+
- Midi files for each song containing just the song's melody.
|
| 62 |
+
- Song lyrics features:
|
| 63 |
+
- The length of a song is the number of words in the lyrics that are also present in the word2vec data.
|
| 64 |
+
- For the training set:
|
| 65 |
+
- Minimal song length: 3 words (Perhaps a hip hop song with lots of slang)
|
| 66 |
+
- Maximal song length: 1338
|
| 67 |
+
- Average song length: 257.37
|
| 68 |
+
- For the test set:
|
| 69 |
+
- Minimal song length: 94 words
|
| 70 |
+
- Maximal song length: 389
|
| 71 |
+
- Average song length: 231.6
|
| 72 |
+
|
| 73 |
+
**Input Files:**
|
| 74 |
+
A screenshot of the input folder
|
| 75 |
+
|
| 76 |
+

|
| 77 |
+
|
| 78 |
+
You need to put files in two folders: input_files and midi_files, the other folders are generated automatically.
|
| 79 |
+
Inside input_files put the glove 6B 300d file and the training and testing set:
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
An example of the glove file:
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+

|
| 87 |
+
|
| 88 |
+
An example for lyrics_train_set.csv (columns: artist, song name and lyrics):
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+

|
| 92 |
+
|
| 93 |
+
Inside the folder midi_files put the midi files:
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
## Code Design
|
| 99 |
+
|
| 100 |
+
Our code consists of three scripts:
|
| 101 |
+
|
| 102 |
+
1. Experiment.py - the script that runs the experiments to find the optimal parameters for our LSTM network.
|
| 103 |
+
2. Data_loader.py - Loads the midi files, the lyrics, fixes irregularities and cleans the song file names, loads the word embeddings file, saves and loads the various .pkl files.
|
| 104 |
+
3. Prepare_data.py - Performs various helper functions on the data such as splitting it properly, creating a validation set and creating the word embeddings matrix.
|
| 105 |
+
4. Compute_score.py - Because of the nature of this task, it is difficult to judge the successfulness of our model based on classic loss functions such as MSE. So this script contains several different methods to automatically score the output of our model, such as measuring the cosine similarity or the subjectivity of the lyrics. Explained more later.
|
| 106 |
+
5. Extract_melodies_features - Extracts the features we want from the midi files and splits them into train / test / validation. Explained more later.
|
| 107 |
+
6. Lstm_lyrics.py - The first LSTM model. This one only takes into account the lyrics of the song. This is used for comparison to see the improvement of using melodies.
|
| 108 |
+
7. Lstm_melodies_lyrics.py - The second LSTM model. This one incorporates the features of the midi files of each song. More on this later.
|
| 109 |
+
|
| 110 |
+
## Melody Feature Integration
|
| 111 |
+
We devised two different methods to extract features from the melodies. One of them a more naive technique, and the other a more sophisticated way that expands the first method.
|
| 112 |
+
|
| 113 |
+
**Method #1**: Each midi file contains a list of all instruments used in the file. For each instrument, an Instrument object contains a list of all time periods this instrument was used, the pitch used (the note) and velocity (how strong the note was played) as you can see in figure 1.
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+

|
| 117 |
+
|
| 118 |
+
Figure 1: The data available for each instrument of the midi file
|
| 119 |
+
|
| 120 |
+
The midi file contains the length of the melody, and we know the number of words in the lyrics, so we can easily approximate how many seconds lasts each word on average. Based on this, we assign each word a time span and can deduce what instruments were played during that word and how strong. If a word appears during times 15.2 - 15.8, we can search through the instrument objects for which ones appeared during that time frame.
|
| 121 |
+
|
| 122 |
+
Using this data, we can compute how many instruments were used, their average pitch and average velocity per word. This provides the network some information about the nature of the song during this lyric, i.e. a low or high pitch and how high the velocity is.
|
| 123 |
+
|
| 124 |
+
In addition, we can easily use the function get_beats() of pretty midi to find all the beat changes in the song and their times. We simply count the number of beat changes during the word’s time frame and thus add another feature for our network.
|
| 125 |
+
|
| 126 |
+
**Method #2**: With the first method we have the average pitch used for each word. Now, we want a more precise measurement of this. Each pretty midi object has a function getPianoRoll(fs) which returns a matrix that represents the notes used in the midi file on a near continuous time scale (See figure 1). Specifically, it returns an array of size 128\*S where the size of S equals the length of the song (i.e the time of the last note played) multiplied by how many times each second a sample is taken, denoted by the parameter fs. E.g, for fs=10 every 1/10ths of a second a sample will be made, meaning 10 samples per second so for a song of 120 seconds we will have 1200 samples. Thus getPianoRoll(fs=10) will return a matrix of size 128x1200. By this method, we can control the granularity of the data with ease.
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
|
| 131 |
+
Figure 2: Piano roll matrix. The value in each cell is the velocity summed across instruments.
|
| 132 |
+
|
| 133 |
+
The reason for the 128 is that musical pitch has a possible range of 0 to 127. So each column in this matrix represents the notes played during this sample (in our example, the notes played every 100 milliseconds).
|
| 134 |
+
|
| 135 |
+
After creating this matrix, we can calculate how many notes are played, on average, per word. For example, if there are 2000 columns and a song has 50 words, it means that each word in the lyrics can be connected to about 40 notes. This is not precise of course, but a useful approximation.
|
| 136 |
+
|
| 137 |
+

|
| 138 |
+
|
| 139 |
+
Figure 3: Notes played during a specific word in a song. Here each lyric received 40 notes representing it (columns 10-39 not shown). There are still 128 rows for each possible note.
|
| 140 |
+
|
| 141 |
+
We then iterate over every word in the song’s lyrics and find the notes that were played during that particular lyric. For example, in Figure 3 we can see that for a certain word, notes number 57, 64 and 69 were played.
|
| 142 |
+
|
| 143 |
+

|
| 144 |
+
Figure 4: The sum of the notes played during a specific word.
|
| 145 |
+
|
| 146 |
+
Finally, for each lyric-specific matrix, we sum each row to easily see what notes were played and how much. In figure 4, we can see the result of summing the matrix presented in figure 3. This is fed together with the array of word embeddings of each word in the sequence, thus attaching melody features to word features.
|
| 147 |
+
|
| 148 |
+
## Architecture
|
| 149 |
+
We used a fairly standard approach to a bidirectional LSTM network, with the addition of allowing it to receive as input both an embedding vector and the melody features. We also created an LSTM network that doesn’t receive melodies just to study the impact of melody on the results.
|
| 150 |
+
|
| 151 |
+
Number of layers: Both versions receive as input a sequence of lyrics. Then there is an embedding layer after the input that uses the word2vec dictionary to convert each word to the appropriate vector representing it. The difference between the networks is that the one using the melodies has a concatenating layer that appends the vectors of lyrics to the vector of melodies.
|
| 152 |
+
|
| 153 |
+
Additionally, we tried feeding the network various sequence lengths: 1, 5 and 10. We wanted to see how much the sequence length affects the results.
|
| 154 |
+
|
| 155 |
+
In addition to the piano roll matrix we keep the features extracted in method 1.
|
| 156 |
+
|
| 157 |
+

|
| 158 |
+
|
| 159 |
+
|
| 160 |
+
- Layers 3 & 4 are only for the model that uses the melody features.
|
| 161 |
+
- Since RNNs have to receive input of fixed length, we use masking to ensure that the input is the same size each time.
|
| 162 |
+
- We simply concatenate all of the features and feed it into the LSTM to utilize the melody features. However, the features entered vary greatly between our two approaches.
|
| 163 |
+
- We used a relatively high drop rate of 60% since we don’t want the network to converge too quickly and overfit on the training data. We tried lower values initially and found more success with 60%.
|
| 164 |
+
- The input of the final layer depends on the number of units in the Bidirectional LSTM.
|
| 165 |
+
- The final output is a probability for each word, and we sample one from there according to the distribution.
|
| 166 |
+
|
| 167 |
+
Tensorboard Graph:
|
| 168 |
+
|
| 169 |
+
|
| 170 |
+

|
| 171 |
+
|
| 172 |
+
**Stopping criteria:**
|
| 173 |
+
Here we also experimented with several parameters: We used the EarlyStopping function monitoring on the validation loss with a minimum delta of 0.1 (Minimum change in the monitored quantity to qualify as an improvement, i.e. an absolute change of less than min_delta, will count as no improvement.) and patience of 0 (Number of epochs with no improvement after which training will be stopped). We experimented with several values and found the most success with these.
|
| 174 |
+
|
| 175 |
+
**Network Hyper-Parameters Tuning:**
|
| 176 |
+
NOTE: Here we explain the reasons behind the choices of the parameters.
|
| 177 |
+
After implementing our RNN, we optimized the different parameters used. Some parameters, like the number of units in an LSTM, it is very hard to predict what will work best so this method is the best way to find good values to use.
|
| 178 |
+
Each combination takes a long time to train (5-15 minutes):
|
| 179 |
+
|
| 180 |
+
- Learning Rate: We tried different values, ranging from 0.1 to 0.00001. After running numerous experiments, we found 0.00001 to work the best.
|
| 181 |
+
- Epochs: We tried epochs of 5, 10 and 150. We found 10 to work the best.
|
| 182 |
+
- Batch size: We tried 32 and 2048. 32 worked better.
|
| 183 |
+
- Units in LSTM: 64 and 256
|
| 184 |
+
- We tried all of the possible combinations of the parameters detailed above which led to a huge number of experiments but led to us finding the optimal settings which were used in the section below.
|
| 185 |
+
|
| 186 |
+
## Results Evaluation
|
| 187 |
+
In this assignment, we were asked to generate lyrics for the 5 songs in the test set. One way to evaluate the results is simply to see how many cases did our model predict the word that was actually used in the song. However, this is not actually a good method to evaluate the model since if it generated a word that was incredibly similar to it simple accuracy wouldn’t detect that. Note that we let our model predict the exact same number of words as in the original song. We devised a few methods to judge our models lyrical capabilities:
|
| 188 |
+
|
| 189 |
+
1. **Cosine Similarity**: this is a general method to compare the similarity of two vectors. So if our model predicted “happy”, and the original lyrics had the word “smile”, we take the vector of each word from the embedding matrix and calculate the cosine similarity, 1 being the best and 0 the worst. There are a few variations for this however:
|
| 190 |
+
2. Comparing each word predicted to the word in the song - the most straightforward method. If a song has 200 words we will perform 200 comparisons according to the index of each word.
|
| 191 |
+
3. Creating n-grams of the lyrics, calculating the average of each n-gram and then comparing the n-grams according to their order. This method is a bit better in our opinion, since if the model predicted words (“A”, “B”) and they appeared as (“B”, “A”) in the song, an n-gram style similarity will determine that this was a good prediction while a unigram style won’t. So we tried with 1, 2, 3 and 5-grams.
|
| 192 |
+
4. **Polarity**: Using the TextBlob package, we computed the polarity of the generated lyrics and the original ones. Polarity is a score ranging from -1 to 1, -1 representing a negative sentence and 1 representing a positive one. We checked if the lyrics carry the same feelings and themes more or less. We present in the results the absolute difference between them, meaning that a polarity difference of 0 means the lyrics have similar sentiments.
|
| 193 |
+
5. **Subjectivity**: Again drawing from TextBlob, subjectivity is a measure of how subjective a sentence is, 0 being very objective and 1 being very subjective. We calculate the absolute difference between the generated lyrics and the original lyrics.
|
| 194 |
+
|
| 195 |
+
Note: In the final section where we predict song lyrics, we tried with different seeds as requested. With a sequence length of S, we take the first S words (i.e, words #1, #2, ..#S) and predict the rest of the song. We then skip the first S words and take words S+1 until 2S. Then we skip the first 2S words and use words 2S+1 until 3S.
|
| 196 |
+
Example with Sequence Length of 3:
|
| 197 |
+
Seed 1, seed 2 and seed 3 -
|
| 198 |
+
|
| 199 |
+
|
| 200 |
+

|
| 201 |
+
|
| 202 |
+
## Full Experimental Setup
|
| 203 |
+
Validation Set: Empirically, we learned that using a validation set is better than not if there isn’t enough data. We used the fairly standard 80/20 ratio between training and validation which worked well.
|
| 204 |
+
|
| 205 |
+
- Batch sizes - 32
|
| 206 |
+
- Epochs - 5
|
| 207 |
+
- Learning rate: 0.01
|
| 208 |
+
- Min delta for improvement: 0.1
|
| 209 |
+
- 256 units in the LSTM layer
|
| 210 |
+
|
| 211 |
+
Additionally, we tried feeding the network various sequence lengths of 1 and 5 to study the effect on the quality of the results.
|
| 212 |
+
|
| 213 |
+
**Experimental Results:**
|
| 214 |
+
The best results are in bold -
|
| 215 |
+
|
| 216 |
+

|
| 217 |
+
|
| 218 |
+
**Analysis**: unlike our expectations, the model with simpler features worked better in almost all cases, perhaps due to Occam’s Razor. We theorize that the features about the instruments provided a good abstraction of the features of the entire piano roll.
|
| 219 |
+
However, it is clear that adding some melody features to the model improved it on all parameters (except subjectivity). Additionally, having a sequence length of 5 has mixed results and doesn’t seem to have much of an impact on the evaluation methods we chose. We will look into this manually in the next section.
|
| 220 |
+
|
| 221 |
+
An interesting point is that for all cosine similarity evaluations, an increased n gave a higher similarity. We are not sure why this happens, but we think that with greater values of n the “average” word is more similar. We tested the cosine similarity where n={length of song}, and indeed the similarity was over 0.9. We then tested with a random choice of words and all of the words in a song (i.e., the average vector of the whole song), and the cosine similarity was a staggering 0.75.
|
| 222 |
+
|
| 223 |
+
**Generated Lyrics:**
|
| 224 |
+
For Brevity’s sake we’ll only show both models with a sequence of 1 and the advanced model with a sequence of 5.
|
| 225 |
+
|
| 226 |
+
**Model with simple melody features - sequence length 1**
|
| 227 |
+
A screenshot from the TensorBoard framework:
|
| 228 |
+
|
| 229 |
+
|
| 230 |
+
|
| 231 |
+
1. **Lyrics for the bangles - eternal flame**
|
| 232 |
+
|
| 233 |
+
**Seed text: close **
|
| 234 |
+
|
| 235 |
+
**close** feelin dreams baby that cause like friends im have day cool let be their would your wit ignorance such forgiven oh may doll nothing down i now around suddenly ball have empty that beautiful how you lonely no goes gone you are called of for wanted me life of stress apart say i all way, required 55 words
|
| 236 |
+
|
| 237 |
+
**Seed text: your**
|
| 238 |
+
|
| 239 |
+
**your** gentle i were remember how swear she neither too girl out through with more love me me eyes said have i used heartache hmm anymore desire fighting she when stay be part lights spend by bite again say try ruining slide lover i eyes get always honey of maybe to it hope its white i, required 55 words
|
| 240 |
+
|
| 241 |
+
**Seed text: eyes **
|
| 242 |
+
|
| 243 |
+
**eyes** and walk the night woah not live you his world more when just wakes you you fans me to it son sleeping you up i that it da we me let the i longing my do maybe warm fought a believe guys the hear blind dont your through this a down what tell gonna oh, required 55 words
|
| 244 |
+
|
| 245 |
+
2. **Lyrics for billy joel - honesty**
|
| 246 |
+
|
| 247 |
+
**Seed text: if **
|
| 248 |
+
|
| 249 |
+
**if** do hell your as you hard so the be of mable we love do fat give about em with if show you me its of some can top tell if like over baby an the out that a right get as their leaves are oh come happy joy fight me thief give i goodbye sharing like hey all it last you open right i to tonight wake be shift i sister no i on got years wear to make show dont learn be you the live from outer jump drag the myself face shes raps, required 95 words
|
| 250 |
+
|
| 251 |
+
**Seed text: you **
|
| 252 |
+
|
| 253 |
+
**you** sherry really but take my girl you and its kick knew so or the a tuya love no how love have of the me there the like its if i winter see reason baa i have would want im high him dancin ever but worked wanna the i mean the you when ill say get well leave up just actor that shit now do the chaka over dead got better to no my the imitating me and my can here and itself footsteps to like leave looked are phone for will will keep my mind, required 95 words
|
| 254 |
+
|
| 255 |
+
**Seed text: search **
|
| 256 |
+
|
| 257 |
+
**search** it so class und any you and that friends cried day whoa fine the i three the in the you lovin its a and said hall way others let night hey beautiful dreams dishes save beer store evil back summer yeah forget when well both strong said you me way your the repeat jolly im what told the really to love huh the you baby go river get id and uranus what around with the down and you would always i heart dont with once go land mind come still so to them one else, required 95 words
|
| 258 |
+
|
| 259 |
+
3. **Lyrics for cardigans - lovefool**
|
| 260 |
+
|
| 261 |
+
**Seed text: dear **
|
| 262 |
+
|
| 263 |
+
**dear** to pick tears slide low live such ill yourself me deep out crazy never kick i the belongs get others shelter before her it i wasnt survive ring off baby im to want life ho hanging if i each high you out mine you won rang woman i the do you we you certain guy the jesus my my much flame to you just you world pretty me to dont fault to ear know see love guide, required 77 words
|
| 264 |
+
|
| 265 |
+
**Seed text: i **
|
| 266 |
+
|
| 267 |
+
i dumb look me kit i ive and clothes type meet all of didnt love baby the to you i the baby heart these and up look i out just family the what baby theyre all my love down sittin money be from something stars out no while now your got guide and time some was my you off would you is na man he and remember down hes best in hand be shotgun to leaves the that, required 77 words
|
| 268 |
+
|
| 269 |
+
**Seed text: fear **
|
| 270 |
+
|
| 271 |
+
**fear** at ive no i your be friend kill thats you years im so right your hurts a if love ill night ever feel what his like ride behind love but man a going can good and gone do see if have name all turn the is start the about you down breaking you at the lady did hard call you the about threatening ass thing together in fall love i they its a up drop youre out, required 77 words
|
| 272 |
+
|
| 273 |
+
4. **Lyrics for aqua - barbie girl**
|
| 274 |
+
|
| 275 |
+
**Seed text: hiya **
|
| 276 |
+
|
| 277 |
+
**hiya** put there to copa out kick when sad when it my cars girl the with in i me the some a around eyes stay cause be clock we never still cant missed anytime motion quiet ive go hot it on the a you had and sign live tennessee no fools got so i father hope for never for you the just it there me my believe other oh red your dont dream the drives the they chorus the happy crosses they to i i because if won this i want didnt ask the, required 93 words
|
| 278 |
+
|
| 279 |
+
**Seed text: barbie **
|
| 280 |
+
|
| 281 |
+
**barbie** me go to country smiling all now from love she my is this world not that in to though i beat your be bad new hard cant pretty to wont to round do things without try it walking of ill things in man love a hands were for well you to no chuckie gonna i wish done arms tell lets it beat waiting found we good man write i nigga at do never you it ooh try are attention yeah oh hurt that too without roll yourself with the you feeling switch dont, required 93 words
|
| 282 |
+
|
| 283 |
+
**Seed text: hi **
|
| 284 |
+
|
| 285 |
+
**hi** this feeling gotta that alone im do she sweet and you ever you the in had the the raise up skies it youre do me its inspired song with what that feel other mine time the easily what when you and three cause beat and its gets christmas your you sad a behind nothing a i number back or never and who your move beat you driving you i love and of do other like on go when oh yea heart plane after her that mine never soul like one you made you, required 93 words
|
| 286 |
+
|
| 287 |
+
5. **Lyrics for blink 182 - all the small things**
|
| 288 |
+
|
| 289 |
+
**Seed text: all **
|
| 290 |
+
|
| 291 |
+
**all** live ive fire love did my right so truck reading it life its sin heal well two home we confused mony its song you tried could disguise know find for amadeus where sailor you and the to wo insane yeah skin wind ride song me heart up bite a a new a i let money world didnt on, required 58 words
|
| 292 |
+
|
| 293 |
+
**Seed text: the **
|
| 294 |
+
|
| 295 |
+
**the** love want risk whoa breakin take need cebu me amadeus control weve lose and try cryin away know hopes away what theres makes in you right drunk live always ever one bop your lovely on steal bet i say somebody say gonna sad stay frosty a grease scene his hangin your dry touch mind i you you your, required 58 words
|
| 296 |
+
|
| 297 |
+
**Seed text: small **
|
| 298 |
+
|
| 299 |
+
**small** lost with sun find when casbah you time huh to please for you see make the life dont you me to she the waitin honey weed all fill fired wish on alone thats like im the to and yeah long sure the broadway the need somebody always achy dont well i as seen my that boy your that, required 58 words
|
| 300 |
+
|
| 301 |
+
**Model with advanced melody features - sequence length 5**
|
| 302 |
+
A screenshot from the TensorBoard framework:
|
| 303 |
+
|
| 304 |
+

|
| 305 |
+
|
| 306 |
+
1. **Lyrics for the bangles - eternal flame**
|
| 307 |
+
|
| 308 |
+
**Seed text: close your eyes give me **
|
| 309 |
+
|
| 310 |
+
**close your eyes give me** rest dreams want that ill what knows im yeah good trust gonna be those find your anyone temper boys dead oh forever somethin mine have i this would playin total yeah planetary that fast from you two like moon believe you will truth, required 43 words
|
| 311 |
+
|
| 312 |
+
**Seed text: hand darling do you feel **
|
| 313 |
+
|
| 314 |
+
**hand darling do you feel** of for isnt me more of rising midnight got i for cant whiskey i as rock need swear how watched mind thats got too when day love me me or every yeah i dreams forgotten cryin bag mony flesh how no own be, required 43 words
|
| 315 |
+
|
| 316 |
+
**Seed text: My heart beating understand the**
|
| 317 |
+
|
| 318 |
+
**My heart beating understand the** air comin lying through began girl never another thorns bought slim i or go some coming of maybe to it fly so fuck i and thing the ive safe here nothing you long eyes day no but danced you you abandoned me to, required 43 words
|
| 319 |
+
|
| 320 |
+
|
| 321 |
+
2. **Lyrics for billy joel - honesty**
|
| 322 |
+
|
| 323 |
+
**Seed text: If you search for tenderness **
|
| 324 |
+
|
| 325 |
+
**If you search for tenderness** my radio finger you now i that it ooh we me gonna the i gin my know maybe hair won a better bleed the live fantasy dont your too say a have baby think cant is do warm your tell you hard so the be of ow do love know believin really ever free when up said you me so of us can heartache more up what hot up before the got that a not are tell their di will oh down hands, required 83 words
|
| 326 |
+
|
| 327 |
+
**Seed text: it isnt hard to find**
|
| 328 |
+
|
| 329 |
+
**it isnt hard to find** tired whats me pryor wanna i goodbye sueno what them all it last you since not i to shes joy be america i law like i be they lover catch and right said we stayin be you the nothing life fingers front anyone the myself without try dream cat da but he my thats you and so goin knew so ever the a waters love no from is was of the me right the what its up i wit have watching lied dont, required 83 words
|
| 330 |
+
|
| 331 |
+
**Seed text: Can have the love need**
|
| 332 |
+
|
| 333 |
+
**Can have the love need** was over now im high story shoot give can wire wont the i mean the you no at got are only true want just handed that train youre know the yesterday hot women never alone to love my the believing it and my can need and clover tricks and if true needs will gun for let let much my then it dont note crowd wind you and that save nowhere good whoa alive the i breathe the it the you weve its a, required 83 words
|
| 334 |
+
|
| 335 |
+
3. **Lyrics for cardigans - lovefool**
|
| 336 |
+
|
| 337 |
+
**Seed text: Dear i fear were facing**
|
| 338 |
+
|
| 339 |
+
**Dear i fear were facing** and every distant cause quite gonna ive them fast dreams wintry song dre my here world summer get music when only follow along every you me cause your the making dub im if such the da to love trying the you up one taking last hes and boss baby would when the see and you been look i from we with shit one taught then, required 65 words
|
| 340 |
+
|
| 341 |
+
**Seed text: A problem you love me**
|
| 342 |
+
|
| 343 |
+
**A problem you love me** down wanna so to did man fool to wrote girls bought wake nothing boys at wait me though got crazy they goin the the drives go quite hiding keep again it i wasnt passed morning boy want oh to now night forgive sick up i fun has you got than you cares pushing wrong i the know you we you silk guy the rainy my, required 65 words
|
| 344 |
+
|
| 345 |
+
**Seed text: No longer know and maybe**
|
| 346 |
+
|
| 347 |
+
**No longer know and maybe** my hes alien to you just you around needed me to dont trouper to bleed know have is dying seemed long me leapin i by a turned probably beautiful all of friend love want the to you i the want as chance and want little i got but plays the if up theyre for my is see fake loves be life hold money got like, required 65 words
|
| 348 |
+
|
| 349 |
+
4. **Lyrics for aqua - barbie girl**
|
| 350 |
+
|
| 351 |
+
**Seed text: hiya barbie hi ken do**
|
| 352 |
+
|
| 353 |
+
**hiya barbie hi ken do** nobody youre of they dying and come little get my you face find you is rain look need and rock see them till in body be cute to jive the your feel by like i your love friend drag who you heard oh dont take your pieces a up love at ive give take baby really what ring else is but look a off with back and believe do have up yeah stop all gotta the im start the ever you, required 81 words
|
| 354 |
+
|
| 355 |
+
**Seed text: a ride sure jump in**
|
| 356 |
+
|
| 357 |
+
**a ride sure jump in** fly for they for you the just my feel me my better other all making your dont dream the stone the come ba the hands covered come to i i kiss baby cares say i now friend ask the me one to throw asked for this could love heart my is say around he that in to knows i beat your love other another hard there red to turn to sometimes know hey stay am it street of at hey in, required 81 words
|
| 358 |
+
|
| 359 |
+
**Seed text: you want to go for**
|
| 360 |
+
|
| 361 |
+
**you want to go for** have killing you not the dawn than hard id you the ever unopened dimension over old in fall love i come its a want desire this got should feel to mess say goin when alive when it my bar thats the when in i me the us a would or remember ill love limit do time wanna there rhymes sounding rendezvous quiet by one stay it on the a you try and town nothing moonlit like stormy they dont i middle, required 81 words
|
| 362 |
+
|
| 363 |
+
5. **Lyrics for blink 182 - all the small things**
|
| 364 |
+
|
| 365 |
+
**Seed text: All the small things true**
|
| 366 |
+
**All the small things true** his love a such away its only you to no bread ill i sing deep sun think walk it beat fuck best do back look bone i lot feel know they you it gotta am will shaking was all running that around stay bitch wait with, required 46 words
|
| 367 |
+
|
| 368 |
+
**Seed text: Care truth brings ill take**
|
| 369 |
+
|
| 370 |
+
**Care truth brings ill take** the you feeling push dont say goodbye an that hear im do how sweet and you his you the it new the the traveled want sayin it this do a its wannabe song with if that take other than come the horse if when you and, required 46 words
|
| 371 |
+
|
| 372 |
+
**Seed text: One lift your ride best**
|
| 373 |
+
|
| 374 |
+
**One lift your ride best ** breathe make beat and its reason black of you fine a sleep mine a i scene too ever time and why your room beat you sings you i is and in do matter what on one no oh anybody from tu touch think that than they, required 46 words
|
| 375 |
+
|
| 376 |
+
|
| 377 |
+
## Analysis of how the Seed and Melody Effects the Generated Lyrics
|
| 378 |
+
|
| 379 |
+
We see that the lyrics are mostly unintelligible, and tend to have words that are very common in the data set (the word “love” appears over 40 times in the generated lyrics and it is indeed a common lyric in popular songs). It doesn’t appear that more advanced melody features improved the subjective quality of the lyrics produced, like how our quantitative methods deemed that it doesn’t improve much. We did notice however a peculiar feature, where once a word appeared for the first time, it tended to appear many times after (or similar variations of it, e.g. if “i” appeared then “i”, “me” or “my” tend to appear after it a lot”). This is to be expected from a model that maintains a cell state and predicts words based on their embedding.
|
| 380 |
+
|
| 381 |
+
Also it’s apparent that the seed chosen wildly changes the words produced. We think this is because the melody plays a much smaller part in predicting the lyrics compared to the seed, so even with the same melody the dominating factor in producing the lyrics is the seed - see our evaluation table above; the results are slightly better with the melody attached, but not by much, meaning that the first word assists the model much more compared to, say, a baseline of a random word each time.
|
| 382 |
+
|
| 383 |
+
Personally, we don’t see much of an improvement in using 5 words as a seed versus just the first word. Occasionally it leads to better combinations but it’s a hit-or-miss usually. We think this is because of 2 main reasons:
|
| 384 |
+
Many songs contain slang that isn’t in the word embedding matrix so we cannot learn from them or predict them
|
| 385 |
+
Many song lyrics aren’t completely coherent and the words are fairly independent of each other (for a good example see the original lyrics of the last song in the test set, “All the Small Things” by Blink 182).
|
rnn.py
ADDED
|
@@ -0,0 +1,108 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
This function manages the general RNN architecture
|
| 3 |
+
"""
|
| 4 |
+
import os
|
| 5 |
+
import random
|
| 6 |
+
|
| 7 |
+
import numpy as np
|
| 8 |
+
from keras import backend as K
|
| 9 |
+
from keras.callbacks import EarlyStopping, TensorBoard
|
| 10 |
+
|
| 11 |
+
# Environment settings
|
| 12 |
+
IS_COLAB = (os.name == 'posix')
|
| 13 |
+
LOAD_DATA = not (os.name == 'posix')
|
| 14 |
+
|
| 15 |
+
if IS_COLAB:
|
| 16 |
+
from datetime import datetime
|
| 17 |
+
from packaging import version
|
| 18 |
+
|
| 19 |
+
# Define the Keras TensorBoard callback.
|
| 20 |
+
logdir = "logs/scalars/" + datetime.now().strftime("%Y%m%d-%H%M%S")
|
| 21 |
+
tensorboard_callback = TensorBoard(log_dir=logdir)
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
class RecurrentNeuralNetwork(object):
|
| 25 |
+
def __init__(self, seed):
|
| 26 |
+
"""
|
| 27 |
+
Seed - The seed used to initialize the weights
|
| 28 |
+
width, height, cells - used for defining the tensors used for the input images
|
| 29 |
+
loss, metrics, optimizer, dropout_rate - settings used for compiling the siamese model (e.g., 'Accuracy' and 'ADAM)
|
| 30 |
+
"""
|
| 31 |
+
K.clear_session()
|
| 32 |
+
self.seed = seed
|
| 33 |
+
self.initialize_seed()
|
| 34 |
+
self.model = None
|
| 35 |
+
|
| 36 |
+
def initialize_seed(self):
|
| 37 |
+
"""
|
| 38 |
+
Initialize seed all for environment
|
| 39 |
+
"""
|
| 40 |
+
os.environ['PYTHONHASHSEED'] = str(self.seed)
|
| 41 |
+
random.seed(self.seed)
|
| 42 |
+
np.random.seed(self.seed)
|
| 43 |
+
|
| 44 |
+
def _load_weights(self, weights_file):
|
| 45 |
+
"""
|
| 46 |
+
A function that attempts to load pre-existing weight files for the siamese model. If it succeeds then returns
|
| 47 |
+
True and updates the weights, otherwise False.
|
| 48 |
+
:return True if the file is already exists
|
| 49 |
+
"""
|
| 50 |
+
self.model.summary()
|
| 51 |
+
self.load_file = weights_file
|
| 52 |
+
if os.path.exists(weights_file): # if the file is already exists, load and return true
|
| 53 |
+
print('Loading pre-existed weights file')
|
| 54 |
+
self.model.load_weights(weights_file)
|
| 55 |
+
return True
|
| 56 |
+
return False
|
| 57 |
+
|
| 58 |
+
def fit(self, weights_file, batch_size, epochs, patience, min_delta, x_train, y_train, x_val, y_val):
|
| 59 |
+
"""
|
| 60 |
+
Function for fitting the model. If the weights already exist, just return the summary of the model. Otherwise,
|
| 61 |
+
perform a whole train/validation/test split and train the model with the given parameters.
|
| 62 |
+
"""
|
| 63 |
+
# Create callbacks
|
| 64 |
+
if not self._load_weights(weights_file=weights_file):
|
| 65 |
+
print('No such pre-existed weights file')
|
| 66 |
+
print('Beginning to fit the model')
|
| 67 |
+
if IS_COLAB:
|
| 68 |
+
callbacks = [
|
| 69 |
+
tensorboard_callback,
|
| 70 |
+
EarlyStopping(monitor='val_loss', patience=patience, min_delta=min_delta)
|
| 71 |
+
]
|
| 72 |
+
else:
|
| 73 |
+
callbacks = [
|
| 74 |
+
EarlyStopping(monitor='val_loss', patience=patience, min_delta=min_delta)
|
| 75 |
+
]
|
| 76 |
+
self.model.fit(x_train,
|
| 77 |
+
y_train,
|
| 78 |
+
batch_size=batch_size,
|
| 79 |
+
epochs=epochs,
|
| 80 |
+
callbacks=callbacks,
|
| 81 |
+
validation_data=(x_val, y_val))
|
| 82 |
+
self.model.save_weights(self.load_file)
|
| 83 |
+
# evaluate on the validation set
|
| 84 |
+
loss, accuracy = self.model.evaluate(x_val, y_val, batch_size=batch_size)
|
| 85 |
+
print(f'Loss on Validation set: {loss}')
|
| 86 |
+
print(f'Accuracy on Validation set: {accuracy}')
|
| 87 |
+
|
| 88 |
+
def evaluate(self, x_test, y_test, batch_size):
|
| 89 |
+
"""
|
| 90 |
+
Function for evaluating the final model after training.
|
| 91 |
+
test_file - file path to the test file.
|
| 92 |
+
batch_size - the batch size used in training.
|
| 93 |
+
|
| 94 |
+
Returns the loss and accuracy results.
|
| 95 |
+
"""
|
| 96 |
+
print(f'Available Metrics: {self.model.metrics_names}')
|
| 97 |
+
y_test = np.array(y_test, dtype='float64')
|
| 98 |
+
x_test[0] = np.array(x_test[0], dtype='float64')
|
| 99 |
+
x_test[1] = np.array(x_test[1], dtype='float64')
|
| 100 |
+
# evaluate on the test set
|
| 101 |
+
loss, accuracy = self.model.evaluate(x_test, y_test, batch_size=batch_size)
|
| 102 |
+
return loss, accuracy
|
| 103 |
+
|
| 104 |
+
def predict(self, data):
|
| 105 |
+
return self.model.predict(data)
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
print('Loaded Successfully')
|