

Commit
·
c932521
1
Parent(s):
504117b
nihao
Browse files- README.assets/clip_image002.gif +0 -0
- README.assets/clip_image004.gif +0 -0
- README.assets/clip_image006.gif +0 -0
- README.assets/clip_image008.gif +0 -0
- README.md +8 -8
README.assets/clip_image002.gif
ADDED
|
README.assets/clip_image004.gif
ADDED
|
README.assets/clip_image006.gif
ADDED
|
README.assets/clip_image008.gif
ADDED
|
README.md
CHANGED
|
@@ -22,11 +22,11 @@ DPO训练:采用动态提示优化技术,进一步优化模型在特定任
|
|
| 22 |
|
| 23 |
## 安装与加载
|
| 24 |
|
| 25 |
-
克隆本项目到本地:
|
| 26 |
|
| 27 |
git clone
|
| 28 |
|
| 29 |
-
cd llama-3.1-8b-it-
|
| 30 |
|
| 31 |
|
| 32 |
|
|
@@ -38,16 +38,16 @@ C-Eval 是一个全面的中文基础模型评估套件。它包含了大量的
|
|
| 38 |
|
| 39 |
| C-Eval | Average | Average(hard) | STEM | Social Sciences | Humanities | Other |
|
| 40 |
| ------ | ------- | ------------- | ---- | --------------- | ---------- | ----- |
|
| 41 |
-
| 原模型 |
|
| 42 |
-
| 训练后 | 44.
|
| 43 |
|
| 44 |
#### Cmmlu
|
| 45 |
CMMLU是一个综合性的中文评估基准,专门用于评估语言模型在中文语境下的知识和推理能力。CMMLU涵盖了从基础学科到高级专业水平的67个主题。它包括:需要计算和推理的自然科学,需要知识的人文科学和社会科学,以及需要生活常识的中国驾驶规则等。
|
| 46 |
|
| 47 |
| CMMLU | Average | STEM | Social Sciences | Humanities | Other |
|
| 48 |
| ------ | ------- | ----- | --------------- | ---------- | ----- |
|
| 49 |
-
| 原模型 |
|
| 50 |
-
| 训练后 |
|
| 51 |
|
| 52 |
|
| 53 |
|
|
@@ -55,7 +55,7 @@ CMMLU是一个综合性的中文评估基准,专门用于评估语言模型在
|
|
| 55 |
|
| 56 |
微调数据集:
|
| 57 |
|
| 58 |
-
|
|
| 59 |
| --------------------- | ------------------------------------------------------------ |
|
| 60 |
| 中文微调数据集 | https://modelscope.cn/datasets/zhuangxialie/Llama3-Chinese-Dataset/files |
|
| 61 |
| train_1M_CN | https://huggingface.co/datasets/BelleGroup/train_1M_CN |
|
|
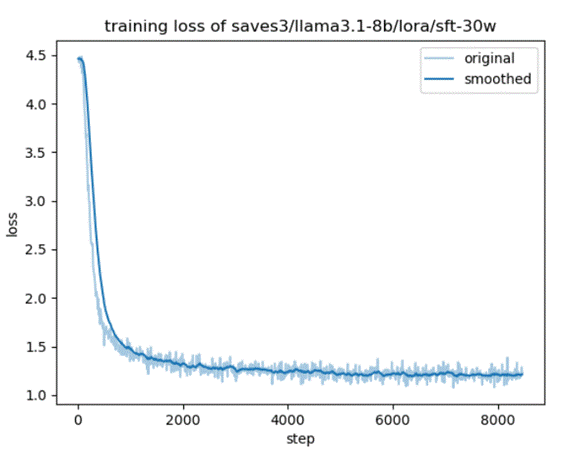
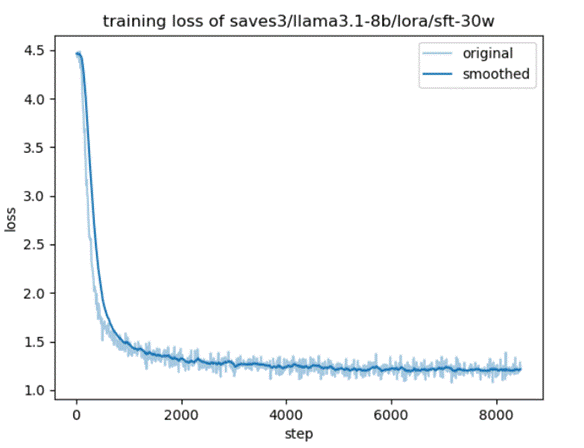
@@ -86,6 +86,6 @@ Training loss:
|
|
| 86 |
|
| 87 |

|
| 88 |
|
| 89 |
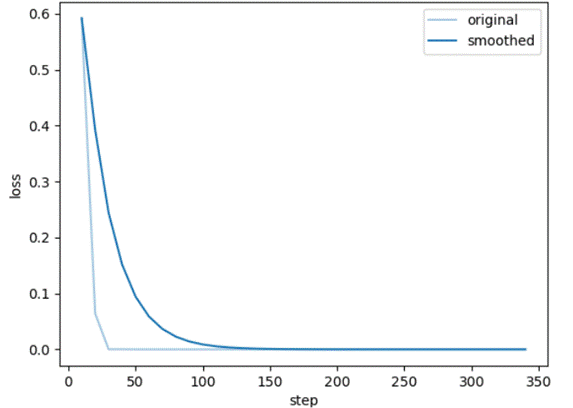
-
Training rewards:
|
| 90 |
|
| 91 |

|
|
|
|
| 22 |
|
| 23 |
## 安装与加载
|
| 24 |
|
| 25 |
+
克隆本项目到本地:https://huggingface.co/jiangfb/llama-3.1-chinese-8b-it-dpo
|
| 26 |
|
| 27 |
git clone
|
| 28 |
|
| 29 |
+
cd llama-3.1-chinese-8b-it-dpo
|
| 30 |
|
| 31 |
|
| 32 |
|
|
|
|
| 38 |
|
| 39 |
| C-Eval | Average | Average(hard) | STEM | Social Sciences | Humanities | Other |
|
| 40 |
| ------ | ------- | ------------- | ---- | --------------- | ---------- | ----- |
|
| 41 |
+
| 原模型 | 24.1 | 23.5 | 23.9 | 25.3 | 24.6 | 22.7 |
|
| 42 |
+
| 训练后 | 44.7 | 32.9 | 41.8 | 52.7 | 42.0 | 44.5 |
|
| 43 |
|
| 44 |
#### Cmmlu
|
| 45 |
CMMLU是一个综合性的中文评估基准,专门用于评估语言模型在中文语境下的知识和推理能力。CMMLU涵盖了从基础学科到高级专业水平的67个主题。它包括:需要计算和推理的自然科学,需要知识的人文科学和社会科学,以及需要生活常识的中国驾驶规则等。
|
| 46 |
|
| 47 |
| CMMLU | Average | STEM | Social Sciences | Humanities | Other |
|
| 48 |
| ------ | ------- | ----- | --------------- | ---------- | ----- |
|
| 49 |
+
| 原模型 | 25.3 | 26.04 | 25.19 | 25.79 | 25.26 |
|
| 50 |
+
| 训练后 | 46.54 | 39.31 | 47.21 | 47.41 | 51.34 |
|
| 51 |
|
| 52 |
|
| 53 |
|
|
|
|
| 55 |
|
| 56 |
微调数据集:
|
| 57 |
|
| 58 |
+
| | |
|
| 59 |
| --------------------- | ------------------------------------------------------------ |
|
| 60 |
| 中文微调数据集 | https://modelscope.cn/datasets/zhuangxialie/Llama3-Chinese-Dataset/files |
|
| 61 |
| train_1M_CN | https://huggingface.co/datasets/BelleGroup/train_1M_CN |
|
|
|
|
| 86 |
|
| 87 |

|
| 88 |
|
| 89 |
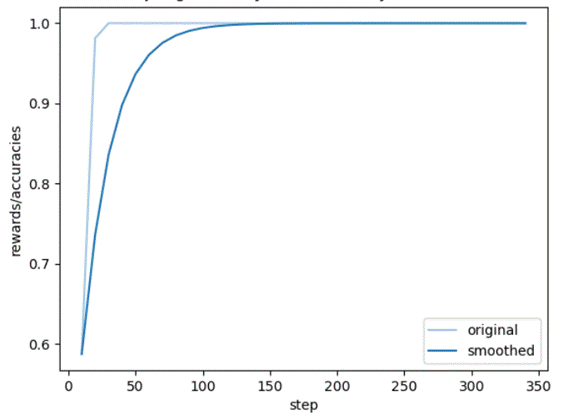
+
Training rewards:
|
| 90 |
|
| 91 |

|