
Upload 3 files
Browse files- .gitattributes +2 -1
- README.md +71 -0
- figure/CLIP-RS.png +3 -0
- figure/newversion.png +3 -0
.gitattributes
CHANGED
|
@@ -33,4 +33,5 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
-
*.pt filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
*.pt filter=lfs diff=lfs merge=lfs -textfigure/CLIP-RS.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
figure/newversion.png filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,71 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# CLIP-RS: Vision-Language Pre-training with Data Purification for Remote Sensing
|
| 2 |
+
|
| 3 |
+

|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
CLIP-RS is a pre-trained model based on CLIP (Contrastive Language-Image Pre-training) tailored for remote sensing applications. This model is trained on a 10M large-scale remote sensing image-text dataset, providing powerful perception capabilities for tasks related to remote sensing images.
|
| 7 |
+
|
| 8 |
+
## Paper
|
| 9 |
+
|
| 10 |
+
For a detailed explanation of CLIP-RS, refer to the following paper:
|
| 11 |
+
|
| 12 |
+
[Remote Sensing Semantic Segmentation Quality Assessment based on Vision Language Model](https://arxiv.org/abs/2502.13990)
|
| 13 |
+
|
| 14 |
+
## Introduction
|
| 15 |
+
|
| 16 |
+
CLIP-RS is ingeniously developed by building upon the framework of CLIP, with a specific adaptation tailored to remote sensing imagery While CLIP excels at understanding general semantic content, it faces challenges when applied to the remote sensing domain due to the lack of sufficient high-quality training data. To address this, we have constructed a large-scale dataset containing 10 million remote sensing image-text pairs. This dataset is carefully refined using a semantic-similarity strategy to eliminate low-quality captions, ensuring that the model learns high-quality semantic features. The high-quaility big-scale pre-training improves the model’s semantic perception and contextual understanding of remote sensing images, making it a valuable tool for various geospatial analysis tasks.
|
| 17 |
+
|
| 18 |
+
## Model Training
|
| 19 |
+
|
| 20 |
+
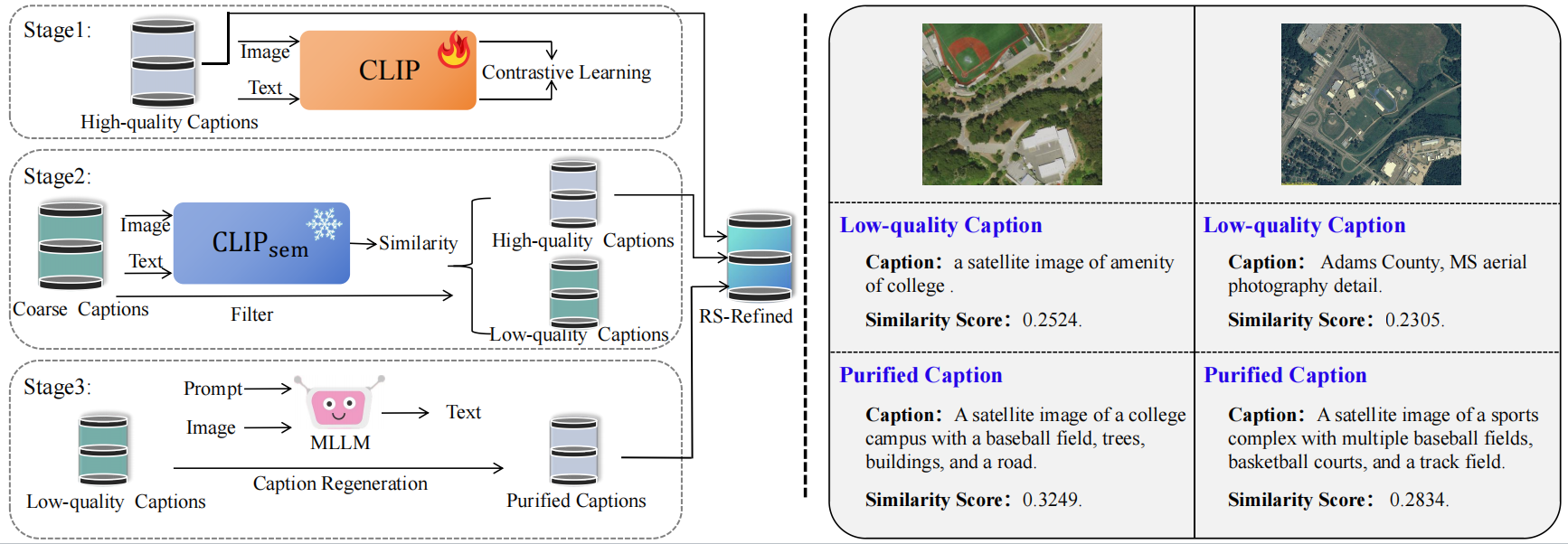
CLIP-RS construction pipeline can be summarized as follows:
|
| 21 |
+
|
| 22 |
+
### 1. Data Collection
|
| 23 |
+
The training data is sourced from two types of datasets:
|
| 24 |
+
- **High-quality captions**: Approximately 1.5 million images from datasets like SkyScript, where each image is paired with a carefully generated description.
|
| 25 |
+
- **Coarse semantic labels**: 8.5 million images paired with captions of varying quality, ranging from well-defined descriptions to noisy and less relevant text.
|
| 26 |
+
|
| 27 |
+
### 2. Data Filtering
|
| 28 |
+
To refine the coarse dataset, we propose a data filtering strategy using the CLIP-based model, $\text{CLIP}_{\text{Sem}}$. This model is pre-trained on high-quality captions to ensure that only semantically accurate image-text pairs are retained. The similarity scores (SS) between each image-text pair are calculated, and captions with low similarity are discarded.
|
| 29 |
+
|
| 30 |
+

|
| 31 |
+
*Figure 1: Data Refinement Process of the CLIP-RS Dataset. Left: Workflow for filtering and refining low-quality captions. Right: Examples of low-quality captions and their refined versions.*
|
| 32 |
+
|
| 33 |
+
### 3. Data Refinement
|
| 34 |
+
The remaining low-quality captions are refined using a remote sensing-specific multimodal language model, GeoChat. GeoChat generates more accurate and detailed captions, ensuring that each image is described with high semantic relevance. This process significantly improves the quality of the dataset by removing noise and inaccuracies.
|
| 35 |
+
|
| 36 |
+
### 4. Vision-Language Pre-training
|
| 37 |
+
Once the data is purified, CLIP-RS is fine-tuned on this high-quality dataset using the CLIP framework. The model is continually pre-trained to specialize in remote sensing imagery, allowing it to effectively capture both visual and textual semantics
|
| 38 |
+
|
| 39 |
+
## Model Downloads
|
| 40 |
+
|
| 41 |
+
You can download the pre-trained CLIP-RS model from the following link:
|
| 42 |
+
|
| 43 |
+
- [Download CLIP-RS Model](https://huggingface.co/hy1111/CLIP-RS/resolve/main/CLIP_RS.pt?download=true)
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
## Evaluation Results
|
| 47 |
+
|
| 48 |
+
CLIP-RS has been applied to remote sensing semantic segmentation quality assessment tasks, achieving state-of-the-art performance. The following are the accuracy results of predicting the best semantic segmentation method among eight alternative methods on the semantic segmentation datasets:
|
| 49 |
+
|
| 50 |
+
| Model |RS-SQED | ISPRS | LoveDA | UAVid | FloodNet |
|
| 51 |
+
| ---- | ---- | ---- | ---- | ---- | ---- |
|
| 52 |
+
| RemoteCLIP | 0.6906 | 0.3252 | 0.7057 | 0.6125 | 0.8302 |
|
| 53 |
+
| CLIP-RS (1.5M) | 0.7276 | 0.3839 | 0.7117 | 0.8313 | 0.8333 |
|
| 54 |
+
| CLIP-RS (10M) | 0.7328 | 0.3883 | 0.7748 | 0.8375 | 0.8069 |
|
| 55 |
+
|
| 56 |
+
For more detailed results, refer to the [Evaluation Section of the Paper](https://arxiv.org/abs/2502.13990).
|
| 57 |
+
|
| 58 |
+
## Citation
|
| 59 |
+
|
| 60 |
+
If you use CLIP-RS in your research, please cite our paper:
|
| 61 |
+
```
|
| 62 |
+
@misc{shi2025remotesensingsemanticsegmentation,
|
| 63 |
+
title={Remote Sensing Semantic Segmentation Quality Assessment based on Vision Language Model},
|
| 64 |
+
author={Huiying Shi and Zhihong Tan and Zhihan Zhang and Hongchen Wei and Yaosi Hu and Yingxue Zhang and Zhenzhong Chen},
|
| 65 |
+
year={2025},
|
| 66 |
+
eprint={2502.13990},
|
| 67 |
+
archivePrefix={arXiv},
|
| 68 |
+
primaryClass={eess.IV},
|
| 69 |
+
url={https://arxiv.org/abs/2502.13990},
|
| 70 |
+
}
|
| 71 |
+
```
|
figure/CLIP-RS.png
ADDED

|
Git LFS Details
|
figure/newversion.png
ADDED
|
Git LFS Details
|