
Upload folder using huggingface_hub
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +145 -0
- backups/configs/experiments/ablate_head_tokens.yaml +107 -0
- backups/configs/experiments/ablate_state_and_grid_tokens.yaml +107 -0
- backups/configs/experiments/ablate_state_tokens.yaml +106 -0
- backups/configs/ours_long_term_without_insertion.yaml +106 -0
- backups/dev/datasets/scalable_dataset.py +1 -1
- backups/dev/metrics/compute_metrics.py +219 -68
- backups/dev/model/smart.py +41 -10
- backups/dev/modules/agent_decoder.py +40 -13
- backups/dev/modules/smart_decoder.py +7 -1
- backups/dev/utils/visualization.py +282 -33
- backups/scripts/compute_metrics.sh +14 -1
- backups/scripts/g8.sh +1 -1
- backups/scripts/hf_model.py +3 -2
- backups/scripts/run_eval.sh +15 -1
- epoch=31.ckpt +3 -0
- last.ckpt +2 -2
- training_003352_12a725c99e2aaf56_occ_agent.png +3 -0
- training_003352_12a725c99e2aaf56_occ_pt.png +3 -0
- training_003353_11e7a18d6bb79688_insert_map.png +3 -0
- training_003353_11e7a18d6bb79688_prob_seed.png +0 -0
- training_003353_11f939421937f967_insert_map.png +3 -0
- training_003353_11f939421937f967_prob_seed.png +0 -0
- training_003353_14bdfe3b4ada19bf_insert_map.png +3 -0
- training_003353_14bdfe3b4ada19bf_prob_seed.png +0 -0
- training_003353_1561804123f0e337_insert_map.png +3 -0
- training_003353_1561804123f0e337_prob_seed.png +0 -0
- training_003353_16d8494156a5b841_insert_map.png +3 -0
- training_003353_16d8494156a5b841_prob_seed.png +0 -0
- training_003353_174ad7295f45aa95_insert_map.png +3 -0
- training_003353_174ad7295f45aa95_prob_seed.png +0 -0
- training_004263_115c6ba86bf683c5_occ_agent.png +3 -0
- training_004263_115c6ba86bf683c5_occ_pt.png +3 -0
- training_004263_13156353a84a2f2f_occ_agent.png +3 -0
- training_004263_13156353a84a2f2f_occ_pt.png +3 -0
- training_004263_164784242fd9b02f_occ_agent.png +3 -0
- training_004263_164784242fd9b02f_occ_pt.png +3 -0
- training_004263_169ca74c66bf9ed0_occ_agent.png +3 -0
- training_004263_169ca74c66bf9ed0_occ_pt.png +3 -0
- training_004263_17f8c4685566ccd9_occ_agent.png +3 -0
- training_004263_17f8c4685566ccd9_occ_pt.png +3 -0
- training_004263_1a33ad2fbb8602c1_occ_agent.png +3 -0
- training_004263_1a33ad2fbb8602c1_occ_pt.png +3 -0
- training_004263_1a6b7592d196519_insert_map.png +3 -0
- training_004263_1a6b7592d196519_prob_seed.png +0 -0
- training_022418_103c73c18d6a259c_insert_map.png +3 -0
- training_022418_103c73c18d6a259c_prob_seed.png +0 -0
- training_022418_112386794f00764c_occ_agent.png +3 -0
- training_022418_112386794f00764c_occ_pt.png +3 -0
- training_022418_11c58fe26cfb6f48_occ_agent.png +3 -0
.gitattributes
CHANGED
|
@@ -374,3 +374,148 @@ seq_10_150_3_3_encode_occ_separate_offsets_bs8_128_no_seqindex_long_lastvalid_ab
|
|
| 374 |
seq_10_150_3_3_encode_occ_separate_offsets_bs8_128_no_seqindex_long_lastvalid_ablation_head/training_225391_e4a2ad39e6963273_insert_map.png filter=lfs diff=lfs merge=lfs -text
|
| 375 |
seq_10_150_3_3_encode_occ_separate_offsets_bs8_128_no_seqindex_long_lastvalid_ablation_head/training_225391_f2e333d5ab085b71_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 376 |
seq_10_150_3_3_encode_occ_separate_offsets_bs8_128_no_seqindex_long_lastvalid_ablation_head/training_225391_f2e333d5ab085b71_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 374 |
seq_10_150_3_3_encode_occ_separate_offsets_bs8_128_no_seqindex_long_lastvalid_ablation_head/training_225391_e4a2ad39e6963273_insert_map.png filter=lfs diff=lfs merge=lfs -text
|
| 375 |
seq_10_150_3_3_encode_occ_separate_offsets_bs8_128_no_seqindex_long_lastvalid_ablation_head/training_225391_f2e333d5ab085b71_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 376 |
seq_10_150_3_3_encode_occ_separate_offsets_bs8_128_no_seqindex_long_lastvalid_ablation_head/training_225391_f2e333d5ab085b71_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 377 |
+
training_003352_12a725c99e2aaf56_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 378 |
+
training_003352_12a725c99e2aaf56_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 379 |
+
training_003353_11e7a18d6bb79688_insert_map.png filter=lfs diff=lfs merge=lfs -text
|
| 380 |
+
training_003353_11f939421937f967_insert_map.png filter=lfs diff=lfs merge=lfs -text
|
| 381 |
+
training_003353_14bdfe3b4ada19bf_insert_map.png filter=lfs diff=lfs merge=lfs -text
|
| 382 |
+
training_003353_1561804123f0e337_insert_map.png filter=lfs diff=lfs merge=lfs -text
|
| 383 |
+
training_003353_16d8494156a5b841_insert_map.png filter=lfs diff=lfs merge=lfs -text
|
| 384 |
+
training_003353_174ad7295f45aa95_insert_map.png filter=lfs diff=lfs merge=lfs -text
|
| 385 |
+
training_004263_115c6ba86bf683c5_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 386 |
+
training_004263_115c6ba86bf683c5_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 387 |
+
training_004263_13156353a84a2f2f_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 388 |
+
training_004263_13156353a84a2f2f_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 389 |
+
training_004263_164784242fd9b02f_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 390 |
+
training_004263_164784242fd9b02f_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 391 |
+
training_004263_169ca74c66bf9ed0_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 392 |
+
training_004263_169ca74c66bf9ed0_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 393 |
+
training_004263_17f8c4685566ccd9_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 394 |
+
training_004263_17f8c4685566ccd9_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 395 |
+
training_004263_1a33ad2fbb8602c1_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 396 |
+
training_004263_1a33ad2fbb8602c1_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 397 |
+
training_004263_1a6b7592d196519_insert_map.png filter=lfs diff=lfs merge=lfs -text
|
| 398 |
+
training_022418_103c73c18d6a259c_insert_map.png filter=lfs diff=lfs merge=lfs -text
|
| 399 |
+
training_022418_112386794f00764c_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 400 |
+
training_022418_112386794f00764c_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 401 |
+
training_022418_11c58fe26cfb6f48_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 402 |
+
training_022418_11c58fe26cfb6f48_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 403 |
+
training_022418_12dffd87c5ecb555_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 404 |
+
training_022418_12dffd87c5ecb555_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 405 |
+
training_022418_1706c66176c79f70_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 406 |
+
training_022418_1706c66176c79f70_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 407 |
+
training_022418_175bb0ed572c5d13_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 408 |
+
training_022418_175bb0ed572c5d13_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 409 |
+
training_022418_196c55cabdd20f0f_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 410 |
+
training_022418_196c55cabdd20f0f_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 411 |
+
training_024423_100bcd6931009e18_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 412 |
+
training_024423_100bcd6931009e18_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 413 |
+
training_024423_11505eaf54db8fc8_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 414 |
+
training_024423_11505eaf54db8fc8_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 415 |
+
training_024423_12c11ec584177c3c_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 416 |
+
training_024423_12c11ec584177c3c_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 417 |
+
training_024423_146810b3ef0dcdb5_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 418 |
+
training_024423_146810b3ef0dcdb5_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 419 |
+
training_024423_1697d9d2c3e3401_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 420 |
+
training_024423_1697d9d2c3e3401_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 421 |
+
training_024423_16dbbc77c7cab9cf_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 422 |
+
training_024423_16dbbc77c7cab9cf_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 423 |
+
training_024423_19406b81b5a3d8e3_insert_map.png filter=lfs diff=lfs merge=lfs -text
|
| 424 |
+
training_028469_1151359d72de95c2_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 425 |
+
training_028469_1151359d72de95c2_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 426 |
+
training_028470_132b536b00ac8301_insert_map.png filter=lfs diff=lfs merge=lfs -text
|
| 427 |
+
training_028470_1374468009268a65_insert_map.png filter=lfs diff=lfs merge=lfs -text
|
| 428 |
+
training_028470_13c17a915498bbba_insert_map.png filter=lfs diff=lfs merge=lfs -text
|
| 429 |
+
training_028470_14258fc85590d62e_insert_map.png filter=lfs diff=lfs merge=lfs -text
|
| 430 |
+
training_028470_14f3bfcd16f87267_insert_map.png filter=lfs diff=lfs merge=lfs -text
|
| 431 |
+
training_028470_16db1c89909ef67a_insert_map.png filter=lfs diff=lfs merge=lfs -text
|
| 432 |
+
training_050998_14e86489c20dc4d1_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 433 |
+
training_050998_14e86489c20dc4d1_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 434 |
+
training_050998_167ea74ffca4c5b3_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 435 |
+
training_050998_167ea74ffca4c5b3_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 436 |
+
training_050998_17f377e79146934a_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 437 |
+
training_050998_17f377e79146934a_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 438 |
+
training_050998_18719f4bc78b1fb1_insert_map.png filter=lfs diff=lfs merge=lfs -text
|
| 439 |
+
training_050998_18bea69fc559e74c_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 440 |
+
training_050998_18bea69fc559e74c_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 441 |
+
training_050998_18d5cc6231b661da_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 442 |
+
training_050998_18d5cc6231b661da_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 443 |
+
training_050998_191da1a2c274d4dd_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 444 |
+
training_050998_191da1a2c274d4dd_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 445 |
+
training_053003_109c6c00d4b7dce3_insert_map.png filter=lfs diff=lfs merge=lfs -text
|
| 446 |
+
training_053003_10f41fa73efb08d6_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 447 |
+
training_053003_10f41fa73efb08d6_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 448 |
+
training_053003_131a3b84a3fdf224_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 449 |
+
training_053003_131a3b84a3fdf224_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 450 |
+
training_053003_14eea656f8bf4290_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 451 |
+
training_053003_14eea656f8bf4290_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 452 |
+
training_053003_15552a5885ba7411_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 453 |
+
training_053003_15552a5885ba7411_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 454 |
+
training_053003_15a85412f9461576_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 455 |
+
training_053003_15a85412f9461576_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 456 |
+
training_053003_19c4d85332f37fe0_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 457 |
+
training_053003_19c4d85332f37fe0_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 458 |
+
training_057049_1937fd973f91e037_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 459 |
+
training_057049_1937fd973f91e037_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 460 |
+
training_057050_1043f1243fe04991_insert_map.png filter=lfs diff=lfs merge=lfs -text
|
| 461 |
+
training_057050_11cb5b2299c1ce61_insert_map.png filter=lfs diff=lfs merge=lfs -text
|
| 462 |
+
training_057050_121bf46385c50fd9_insert_map.png filter=lfs diff=lfs merge=lfs -text
|
| 463 |
+
training_057050_155afeea9a335564_insert_map.png filter=lfs diff=lfs merge=lfs -text
|
| 464 |
+
training_057050_1645ceb5f33aae_insert_map.png filter=lfs diff=lfs merge=lfs -text
|
| 465 |
+
training_057050_167ed97dc21f11e6_insert_map.png filter=lfs diff=lfs merge=lfs -text
|
| 466 |
+
training_058906_1511234d1ff2dabe_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 467 |
+
training_058906_1511234d1ff2dabe_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 468 |
+
training_058907_10b1e58def1809c0_insert_map.png filter=lfs diff=lfs merge=lfs -text
|
| 469 |
+
training_058907_1150482a7b59c61d_insert_map.png filter=lfs diff=lfs merge=lfs -text
|
| 470 |
+
training_058907_1521384e8f6cfee4_insert_map.png filter=lfs diff=lfs merge=lfs -text
|
| 471 |
+
training_058907_16264ec0155019b6_insert_map.png filter=lfs diff=lfs merge=lfs -text
|
| 472 |
+
training_058907_1821beaf06a4d23b_insert_map.png filter=lfs diff=lfs merge=lfs -text
|
| 473 |
+
training_058907_199c04b229ea182e_insert_map.png filter=lfs diff=lfs merge=lfs -text
|
| 474 |
+
training_068353_10b09eacc06955d0_insert_map.png filter=lfs diff=lfs merge=lfs -text
|
| 475 |
+
training_068353_1266bc553d3160ef_insert_map.png filter=lfs diff=lfs merge=lfs -text
|
| 476 |
+
training_068353_13988e72e385dccf_insert_map.png filter=lfs diff=lfs merge=lfs -text
|
| 477 |
+
training_068353_1451a415203c1913_insert_map.png filter=lfs diff=lfs merge=lfs -text
|
| 478 |
+
training_068353_15c3e288411df31c_insert_map.png filter=lfs diff=lfs merge=lfs -text
|
| 479 |
+
training_068353_1981d796620f25cc_insert_map.png filter=lfs diff=lfs merge=lfs -text
|
| 480 |
+
training_068353_1a7c5d38a7dcefba_insert_map.png filter=lfs diff=lfs merge=lfs -text
|
| 481 |
+
training_069263_117d7ae7722109b7_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 482 |
+
training_069263_117d7ae7722109b7_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 483 |
+
training_069263_141666bdcad3b052_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 484 |
+
training_069263_141666bdcad3b052_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 485 |
+
training_069263_14215cd0e72b589a_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 486 |
+
training_069263_14215cd0e72b589a_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 487 |
+
training_069263_1422363c5d2d7dca_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 488 |
+
training_069263_1422363c5d2d7dca_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 489 |
+
training_069263_1497a3857b6b26b3_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 490 |
+
training_069263_1497a3857b6b26b3_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 491 |
+
training_069263_14f5be1f643853ed_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 492 |
+
training_069263_14f5be1f643853ed_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 493 |
+
training_069263_1811d463770ffd2c_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 494 |
+
training_069263_1811d463770ffd2c_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 495 |
+
training_087418_1092a0e3ab0996d4_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 496 |
+
training_087418_1092a0e3ab0996d4_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 497 |
+
training_087418_1105a8fd1bca2238_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 498 |
+
training_087418_1105a8fd1bca2238_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 499 |
+
training_087418_11af6c3f74575313_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 500 |
+
training_087418_11af6c3f74575313_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 501 |
+
training_087418_12144349d2c57d3b_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 502 |
+
training_087418_132e9200a7993e14_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 503 |
+
training_087418_132e9200a7993e14_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 504 |
+
training_087418_16970bf716da04a3_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 505 |
+
training_087418_16970bf716da04a3_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 506 |
+
training_087418_183032bb514f0df5_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 507 |
+
training_087418_183032bb514f0df5_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 508 |
+
training_089423_11220a3845c87ed9_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 509 |
+
training_089423_11220a3845c87ed9_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 510 |
+
training_089423_1152dac4a37c9910_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 511 |
+
training_089423_1152dac4a37c9910_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 512 |
+
training_089423_1266bbf2f830888a_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 513 |
+
training_089423_1266bbf2f830888a_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 514 |
+
training_089423_149f682e19454efa_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 515 |
+
training_089423_149f682e19454efa_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 516 |
+
training_089423_187e3e8b968b540d_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 517 |
+
training_089423_187e3e8b968b540d_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 518 |
+
training_089423_19b3b2b054628318_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 519 |
+
training_089423_19b3b2b054628318_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
| 520 |
+
training_089423_1a1988dca2bb96e2_occ_agent.png filter=lfs diff=lfs merge=lfs -text
|
| 521 |
+
training_089423_1a1988dca2bb96e2_occ_pt.png filter=lfs diff=lfs merge=lfs -text
|
backups/configs/experiments/ablate_head_tokens.yaml
ADDED
|
@@ -0,0 +1,107 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Config format schema number, the yaml support to valid case source from different dataset
|
| 2 |
+
time_info: &time_info
|
| 3 |
+
num_historical_steps: 11
|
| 4 |
+
num_future_steps: 80
|
| 5 |
+
use_intention: True
|
| 6 |
+
token_size: 2048
|
| 7 |
+
predict_motion: True
|
| 8 |
+
predict_state: True
|
| 9 |
+
predict_map: True
|
| 10 |
+
predict_occ: True
|
| 11 |
+
state_token:
|
| 12 |
+
invalid: 0
|
| 13 |
+
valid: 1
|
| 14 |
+
enter: 2
|
| 15 |
+
exit: 3
|
| 16 |
+
pl2seed_radius: 75.
|
| 17 |
+
disable_head_token: True
|
| 18 |
+
grid_range: 150. # 2 times of pl2seed_radius
|
| 19 |
+
grid_interval: 3.
|
| 20 |
+
angle_interval: 3.
|
| 21 |
+
seed_size: 1
|
| 22 |
+
buffer_size: 128
|
| 23 |
+
max_num: 32
|
| 24 |
+
|
| 25 |
+
Dataset:
|
| 26 |
+
root:
|
| 27 |
+
train_batch_size: 1
|
| 28 |
+
val_batch_size: 1
|
| 29 |
+
test_batch_size: 1
|
| 30 |
+
shuffle: True
|
| 31 |
+
num_workers: 1
|
| 32 |
+
pin_memory: True
|
| 33 |
+
persistent_workers: True
|
| 34 |
+
train_raw_dir: 'data/waymo_processed/training'
|
| 35 |
+
val_raw_dir: 'data/waymo_processed/validation'
|
| 36 |
+
test_raw_dir: 'data/waymo_processed/validation'
|
| 37 |
+
val_tfrecords_splitted: data/waymo_processed/training/validation_tfrecords_splitted
|
| 38 |
+
transform: WaymoTargetBuilder
|
| 39 |
+
train_processed_dir:
|
| 40 |
+
val_processed_dir:
|
| 41 |
+
test_processed_dir:
|
| 42 |
+
dataset: 'scalable'
|
| 43 |
+
<<: *time_info
|
| 44 |
+
|
| 45 |
+
Trainer:
|
| 46 |
+
strategy: ddp_find_unused_parameters_false
|
| 47 |
+
accelerator: 'gpu'
|
| 48 |
+
devices: 1
|
| 49 |
+
max_epochs: 32
|
| 50 |
+
save_ckpt_path:
|
| 51 |
+
num_nodes: 1
|
| 52 |
+
mode:
|
| 53 |
+
ckpt_path:
|
| 54 |
+
precision: 32
|
| 55 |
+
accumulate_grad_batches: 1
|
| 56 |
+
overfit_epochs: 6000
|
| 57 |
+
|
| 58 |
+
Model:
|
| 59 |
+
predictor: 'smart'
|
| 60 |
+
decoder_type: 'agent_decoder' # choose from ['agent_decoder', 'occ_decoder']
|
| 61 |
+
dataset: 'waymo'
|
| 62 |
+
input_dim: 2
|
| 63 |
+
hidden_dim: 128
|
| 64 |
+
output_dim: 2
|
| 65 |
+
output_head: False
|
| 66 |
+
num_heads: 8
|
| 67 |
+
<<: *time_info
|
| 68 |
+
head_dim: 16
|
| 69 |
+
dropout: 0.1
|
| 70 |
+
num_freq_bands: 64
|
| 71 |
+
lr: 0.0005
|
| 72 |
+
warmup_steps: 0
|
| 73 |
+
total_steps: 32
|
| 74 |
+
predict_map_token: False
|
| 75 |
+
num_recurrent_steps_val: 300
|
| 76 |
+
val_open_loop: False
|
| 77 |
+
val_close_loop: True
|
| 78 |
+
val_insert: False
|
| 79 |
+
n_rollout_close_val: 1
|
| 80 |
+
decoder:
|
| 81 |
+
<<: *time_info
|
| 82 |
+
num_map_layers: 3
|
| 83 |
+
num_agent_layers: 6
|
| 84 |
+
a2a_radius: 60
|
| 85 |
+
pl2pl_radius: 10
|
| 86 |
+
pl2a_radius: 30
|
| 87 |
+
a2sa_radius: 10
|
| 88 |
+
pl2sa_radius: 10
|
| 89 |
+
time_span: 60
|
| 90 |
+
loss_weight:
|
| 91 |
+
token_cls_loss: 1
|
| 92 |
+
map_token_loss: 1
|
| 93 |
+
state_cls_loss: 10
|
| 94 |
+
type_cls_loss: 5
|
| 95 |
+
pos_cls_loss: 1
|
| 96 |
+
head_cls_loss: 1
|
| 97 |
+
offset_reg_loss: 5
|
| 98 |
+
shape_reg_loss: .2
|
| 99 |
+
pos_reg_loss: 10
|
| 100 |
+
head_reg_loss: 10
|
| 101 |
+
state_weight: [0.1, 0.1, 0.8] # invalid, valid, exit
|
| 102 |
+
seed_state_weight: [0.1, 0.9] # invalid, enter
|
| 103 |
+
seed_type_weight: [0.8, 0.1, 0.1]
|
| 104 |
+
agent_occ_pos_weight: 100
|
| 105 |
+
pt_occ_pos_weight: 5
|
| 106 |
+
agent_occ_loss: 10
|
| 107 |
+
pt_occ_loss: 10
|
backups/configs/experiments/ablate_state_and_grid_tokens.yaml
ADDED
|
@@ -0,0 +1,107 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Config format schema number, the yaml support to valid case source from different dataset
|
| 2 |
+
time_info: &time_info
|
| 3 |
+
num_historical_steps: 11
|
| 4 |
+
num_future_steps: 80
|
| 5 |
+
use_intention: True
|
| 6 |
+
token_size: 2048
|
| 7 |
+
predict_motion: True
|
| 8 |
+
predict_state: True
|
| 9 |
+
predict_map: True
|
| 10 |
+
predict_occ: True
|
| 11 |
+
state_token:
|
| 12 |
+
invalid: 0
|
| 13 |
+
valid: 1
|
| 14 |
+
enter: 2
|
| 15 |
+
exit: 3
|
| 16 |
+
pl2seed_radius: 75.
|
| 17 |
+
disable_state_tokens: True
|
| 18 |
+
disable_grid_token: True
|
| 19 |
+
grid_range: 150. # 2 times of pl2seed_radius
|
| 20 |
+
grid_interval: 3.
|
| 21 |
+
angle_interval: 3.
|
| 22 |
+
seed_size: 1
|
| 23 |
+
buffer_size: 128
|
| 24 |
+
max_num: 32
|
| 25 |
+
|
| 26 |
+
Dataset:
|
| 27 |
+
root:
|
| 28 |
+
train_batch_size: 1
|
| 29 |
+
val_batch_size: 1
|
| 30 |
+
test_batch_size: 1
|
| 31 |
+
shuffle: True
|
| 32 |
+
num_workers: 1
|
| 33 |
+
pin_memory: True
|
| 34 |
+
persistent_workers: True
|
| 35 |
+
train_raw_dir: 'data/waymo_processed/training'
|
| 36 |
+
val_raw_dir: 'data/waymo_processed/validation'
|
| 37 |
+
test_raw_dir: 'data/waymo_processed/validation'
|
| 38 |
+
val_tfrecords_splitted: data/waymo_processed/training/validation_tfrecords_splitted
|
| 39 |
+
transform: WaymoTargetBuilder
|
| 40 |
+
train_processed_dir:
|
| 41 |
+
val_processed_dir:
|
| 42 |
+
test_processed_dir:
|
| 43 |
+
dataset: 'scalable'
|
| 44 |
+
<<: *time_info
|
| 45 |
+
|
| 46 |
+
Trainer:
|
| 47 |
+
strategy: ddp_find_unused_parameters_false
|
| 48 |
+
accelerator: 'gpu'
|
| 49 |
+
devices: 1
|
| 50 |
+
max_epochs: 32
|
| 51 |
+
save_ckpt_path:
|
| 52 |
+
num_nodes: 1
|
| 53 |
+
mode:
|
| 54 |
+
ckpt_path:
|
| 55 |
+
precision: 32
|
| 56 |
+
accumulate_grad_batches: 1
|
| 57 |
+
overfit_epochs: 6000
|
| 58 |
+
|
| 59 |
+
Model:
|
| 60 |
+
predictor: 'smart'
|
| 61 |
+
decoder_type: 'agent_decoder' # choose from ['agent_decoder', 'occ_decoder']
|
| 62 |
+
dataset: 'waymo'
|
| 63 |
+
input_dim: 2
|
| 64 |
+
hidden_dim: 128
|
| 65 |
+
output_dim: 2
|
| 66 |
+
output_head: False
|
| 67 |
+
num_heads: 8
|
| 68 |
+
<<: *time_info
|
| 69 |
+
head_dim: 16
|
| 70 |
+
dropout: 0.1
|
| 71 |
+
num_freq_bands: 64
|
| 72 |
+
lr: 0.0005
|
| 73 |
+
warmup_steps: 0
|
| 74 |
+
total_steps: 32
|
| 75 |
+
predict_map_token: False
|
| 76 |
+
num_recurrent_steps_val: 300
|
| 77 |
+
val_open_loop: False
|
| 78 |
+
val_close_loop: True
|
| 79 |
+
val_insert: False
|
| 80 |
+
n_rollout_close_val: 1
|
| 81 |
+
decoder:
|
| 82 |
+
<<: *time_info
|
| 83 |
+
num_map_layers: 3
|
| 84 |
+
num_agent_layers: 6
|
| 85 |
+
a2a_radius: 60
|
| 86 |
+
pl2pl_radius: 10
|
| 87 |
+
pl2a_radius: 30
|
| 88 |
+
a2sa_radius: 10
|
| 89 |
+
pl2sa_radius: 10
|
| 90 |
+
time_span: 60
|
| 91 |
+
loss_weight:
|
| 92 |
+
token_cls_loss: 1
|
| 93 |
+
map_token_loss: 1
|
| 94 |
+
state_cls_loss: 10
|
| 95 |
+
type_cls_loss: 5
|
| 96 |
+
pos_cls_loss: 1
|
| 97 |
+
head_cls_loss: 1
|
| 98 |
+
offset_reg_loss: 5
|
| 99 |
+
shape_reg_loss: .2
|
| 100 |
+
pos_reg_loss: 10
|
| 101 |
+
state_weight: [0.1, 0.1, 0.8] # invalid, valid, exit
|
| 102 |
+
seed_state_weight: [0.1, 0.9] # invalid, enter
|
| 103 |
+
seed_type_weight: [0.8, 0.1, 0.1]
|
| 104 |
+
agent_occ_pos_weight: 100
|
| 105 |
+
pt_occ_pos_weight: 5
|
| 106 |
+
agent_occ_loss: 10
|
| 107 |
+
pt_occ_loss: 10
|
backups/configs/experiments/ablate_state_tokens.yaml
ADDED
|
@@ -0,0 +1,106 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Config format schema number, the yaml support to valid case source from different dataset
|
| 2 |
+
time_info: &time_info
|
| 3 |
+
num_historical_steps: 11
|
| 4 |
+
num_future_steps: 80
|
| 5 |
+
use_intention: True
|
| 6 |
+
token_size: 2048
|
| 7 |
+
predict_motion: True
|
| 8 |
+
predict_state: True
|
| 9 |
+
predict_map: True
|
| 10 |
+
predict_occ: True
|
| 11 |
+
state_token:
|
| 12 |
+
invalid: 0
|
| 13 |
+
valid: 1
|
| 14 |
+
enter: 2
|
| 15 |
+
exit: 3
|
| 16 |
+
pl2seed_radius: 75.
|
| 17 |
+
disable_state_tokens: True
|
| 18 |
+
grid_range: 150. # 2 times of pl2seed_radius
|
| 19 |
+
grid_interval: 3.
|
| 20 |
+
angle_interval: 3.
|
| 21 |
+
seed_size: 1
|
| 22 |
+
buffer_size: 128
|
| 23 |
+
max_num: 32
|
| 24 |
+
|
| 25 |
+
Dataset:
|
| 26 |
+
root:
|
| 27 |
+
train_batch_size: 1
|
| 28 |
+
val_batch_size: 1
|
| 29 |
+
test_batch_size: 1
|
| 30 |
+
shuffle: True
|
| 31 |
+
num_workers: 1
|
| 32 |
+
pin_memory: True
|
| 33 |
+
persistent_workers: True
|
| 34 |
+
train_raw_dir: 'data/waymo_processed/training'
|
| 35 |
+
val_raw_dir: 'data/waymo_processed/validation'
|
| 36 |
+
test_raw_dir: 'data/waymo_processed/validation'
|
| 37 |
+
val_tfrecords_splitted: data/waymo_processed/training/validation_tfrecords_splitted
|
| 38 |
+
transform: WaymoTargetBuilder
|
| 39 |
+
train_processed_dir:
|
| 40 |
+
val_processed_dir:
|
| 41 |
+
test_processed_dir:
|
| 42 |
+
dataset: 'scalable'
|
| 43 |
+
<<: *time_info
|
| 44 |
+
|
| 45 |
+
Trainer:
|
| 46 |
+
strategy: ddp_find_unused_parameters_false
|
| 47 |
+
accelerator: 'gpu'
|
| 48 |
+
devices: 1
|
| 49 |
+
max_epochs: 32
|
| 50 |
+
save_ckpt_path:
|
| 51 |
+
num_nodes: 1
|
| 52 |
+
mode:
|
| 53 |
+
ckpt_path:
|
| 54 |
+
precision: 32
|
| 55 |
+
accumulate_grad_batches: 1
|
| 56 |
+
overfit_epochs: 6000
|
| 57 |
+
|
| 58 |
+
Model:
|
| 59 |
+
predictor: 'smart'
|
| 60 |
+
decoder_type: 'agent_decoder' # choose from ['agent_decoder', 'occ_decoder']
|
| 61 |
+
dataset: 'waymo'
|
| 62 |
+
input_dim: 2
|
| 63 |
+
hidden_dim: 128
|
| 64 |
+
output_dim: 2
|
| 65 |
+
output_head: False
|
| 66 |
+
num_heads: 8
|
| 67 |
+
<<: *time_info
|
| 68 |
+
head_dim: 16
|
| 69 |
+
dropout: 0.1
|
| 70 |
+
num_freq_bands: 64
|
| 71 |
+
lr: 0.0005
|
| 72 |
+
warmup_steps: 0
|
| 73 |
+
total_steps: 32
|
| 74 |
+
predict_map_token: False
|
| 75 |
+
num_recurrent_steps_val: 300
|
| 76 |
+
val_open_loop: False
|
| 77 |
+
val_close_loop: True
|
| 78 |
+
val_insert: False
|
| 79 |
+
n_rollout_close_val: 1
|
| 80 |
+
decoder:
|
| 81 |
+
<<: *time_info
|
| 82 |
+
num_map_layers: 3
|
| 83 |
+
num_agent_layers: 6
|
| 84 |
+
a2a_radius: 60
|
| 85 |
+
pl2pl_radius: 10
|
| 86 |
+
pl2a_radius: 30
|
| 87 |
+
a2sa_radius: 10
|
| 88 |
+
pl2sa_radius: 10
|
| 89 |
+
time_span: 60
|
| 90 |
+
loss_weight:
|
| 91 |
+
token_cls_loss: 1
|
| 92 |
+
map_token_loss: 1
|
| 93 |
+
state_cls_loss: 10
|
| 94 |
+
type_cls_loss: 5
|
| 95 |
+
pos_cls_loss: 1
|
| 96 |
+
head_cls_loss: 1
|
| 97 |
+
offset_reg_loss: 5
|
| 98 |
+
shape_reg_loss: .2
|
| 99 |
+
pos_reg_loss: 10
|
| 100 |
+
state_weight: [0.1, 0.1, 0.8] # invalid, valid, exit
|
| 101 |
+
seed_state_weight: [0.1, 0.9] # invalid, enter
|
| 102 |
+
seed_type_weight: [0.8, 0.1, 0.1]
|
| 103 |
+
agent_occ_pos_weight: 100
|
| 104 |
+
pt_occ_pos_weight: 5
|
| 105 |
+
agent_occ_loss: 10
|
| 106 |
+
pt_occ_loss: 10
|
backups/configs/ours_long_term_without_insertion.yaml
ADDED
|
@@ -0,0 +1,106 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Config format schema number, the yaml support to valid case source from different dataset
|
| 2 |
+
time_info: &time_info
|
| 3 |
+
num_historical_steps: 11
|
| 4 |
+
num_future_steps: 80
|
| 5 |
+
use_intention: True
|
| 6 |
+
token_size: 2048
|
| 7 |
+
predict_motion: True
|
| 8 |
+
predict_state: True
|
| 9 |
+
predict_map: True
|
| 10 |
+
predict_occ: True
|
| 11 |
+
state_token:
|
| 12 |
+
invalid: 0
|
| 13 |
+
valid: 1
|
| 14 |
+
enter: 2
|
| 15 |
+
exit: 3
|
| 16 |
+
pl2seed_radius: 75.
|
| 17 |
+
disable_insertion: True
|
| 18 |
+
grid_range: 150. # 2 times of pl2seed_radius
|
| 19 |
+
grid_interval: 3.
|
| 20 |
+
angle_interval: 3.
|
| 21 |
+
seed_size: 1
|
| 22 |
+
buffer_size: 128
|
| 23 |
+
max_num: 32
|
| 24 |
+
|
| 25 |
+
Dataset:
|
| 26 |
+
root:
|
| 27 |
+
train_batch_size: 1
|
| 28 |
+
val_batch_size: 1
|
| 29 |
+
test_batch_size: 1
|
| 30 |
+
shuffle: True
|
| 31 |
+
num_workers: 1
|
| 32 |
+
pin_memory: True
|
| 33 |
+
persistent_workers: True
|
| 34 |
+
train_raw_dir: 'data/waymo_processed/training'
|
| 35 |
+
val_raw_dir: 'data/waymo_processed/validation'
|
| 36 |
+
test_raw_dir: 'data/waymo_processed/validation'
|
| 37 |
+
val_tfrecords_splitted: data/waymo_processed/training/validation_tfrecords_splitted
|
| 38 |
+
transform: WaymoTargetBuilder
|
| 39 |
+
train_processed_dir:
|
| 40 |
+
val_processed_dir:
|
| 41 |
+
test_processed_dir:
|
| 42 |
+
dataset: 'scalable'
|
| 43 |
+
<<: *time_info
|
| 44 |
+
|
| 45 |
+
Trainer:
|
| 46 |
+
strategy: ddp_find_unused_parameters_false
|
| 47 |
+
accelerator: 'gpu'
|
| 48 |
+
devices: 1
|
| 49 |
+
max_epochs: 32
|
| 50 |
+
save_ckpt_path:
|
| 51 |
+
num_nodes: 1
|
| 52 |
+
mode:
|
| 53 |
+
ckpt_path:
|
| 54 |
+
precision: 32
|
| 55 |
+
accumulate_grad_batches: 1
|
| 56 |
+
overfit_epochs: 6000
|
| 57 |
+
|
| 58 |
+
Model:
|
| 59 |
+
predictor: 'smart'
|
| 60 |
+
decoder_type: 'agent_decoder' # choose from ['agent_decoder', 'occ_decoder']
|
| 61 |
+
dataset: 'waymo'
|
| 62 |
+
input_dim: 2
|
| 63 |
+
hidden_dim: 128
|
| 64 |
+
output_dim: 2
|
| 65 |
+
output_head: False
|
| 66 |
+
num_heads: 8
|
| 67 |
+
<<: *time_info
|
| 68 |
+
head_dim: 16
|
| 69 |
+
dropout: 0.1
|
| 70 |
+
num_freq_bands: 64
|
| 71 |
+
lr: 0.0005
|
| 72 |
+
warmup_steps: 0
|
| 73 |
+
total_steps: 32
|
| 74 |
+
predict_map_token: False
|
| 75 |
+
num_recurrent_steps_val: 300
|
| 76 |
+
val_open_loop: False
|
| 77 |
+
val_close_loop: True
|
| 78 |
+
val_insert: False
|
| 79 |
+
n_rollout_close_val: 1
|
| 80 |
+
decoder:
|
| 81 |
+
<<: *time_info
|
| 82 |
+
num_map_layers: 3
|
| 83 |
+
num_agent_layers: 6
|
| 84 |
+
a2a_radius: 60
|
| 85 |
+
pl2pl_radius: 10
|
| 86 |
+
pl2a_radius: 30
|
| 87 |
+
a2sa_radius: 10
|
| 88 |
+
pl2sa_radius: 10
|
| 89 |
+
time_span: 60
|
| 90 |
+
loss_weight:
|
| 91 |
+
token_cls_loss: 1
|
| 92 |
+
map_token_loss: 1
|
| 93 |
+
state_cls_loss: 10
|
| 94 |
+
type_cls_loss: 5
|
| 95 |
+
pos_cls_loss: 1
|
| 96 |
+
head_cls_loss: 1
|
| 97 |
+
offset_reg_loss: 5
|
| 98 |
+
shape_reg_loss: .2
|
| 99 |
+
pos_reg_loss: 10
|
| 100 |
+
state_weight: [0.1, 0.1, 0.8] # invalid, valid, exit
|
| 101 |
+
seed_state_weight: [0.1, 0.9] # invalid, enter
|
| 102 |
+
seed_type_weight: [0.8, 0.1, 0.1]
|
| 103 |
+
agent_occ_pos_weight: 100
|
| 104 |
+
pt_occ_pos_weight: 5
|
| 105 |
+
agent_occ_loss: 10
|
| 106 |
+
pt_occ_loss: 10
|
backups/dev/datasets/scalable_dataset.py
CHANGED
|
@@ -70,7 +70,7 @@ class MultiDataset(Dataset):
|
|
| 70 |
self._raw_files = list(tqdm(filter(lambda fn: fn.removesuffix('.pkl') in valid_scenarios, self._raw_files), leave=False))
|
| 71 |
if len(self._raw_files) <= 0:
|
| 72 |
raise RuntimeError(f'Invalid number of data {len(self._raw_files)}!')
|
| 73 |
-
self._raw_paths = list(map(lambda fn: os.path.join(raw_dir, fn), self._raw_files))
|
| 74 |
|
| 75 |
self.logger.debug(f"The number of {split} dataset is {len(self._raw_paths)}")
|
| 76 |
self.logger.debug(f"The buffer size is {self.buffer_size}")
|
|
|
|
| 70 |
self._raw_files = list(tqdm(filter(lambda fn: fn.removesuffix('.pkl') in valid_scenarios, self._raw_files), leave=False))
|
| 71 |
if len(self._raw_files) <= 0:
|
| 72 |
raise RuntimeError(f'Invalid number of data {len(self._raw_files)}!')
|
| 73 |
+
self._raw_paths = list(map(lambda fn: os.path.join(raw_dir, fn), self._raw_files))[:20000]
|
| 74 |
|
| 75 |
self.logger.debug(f"The number of {split} dataset is {len(self._raw_paths)}")
|
| 76 |
self.logger.debug(f"The buffer size is {self.buffer_size}")
|
backups/dev/metrics/compute_metrics.py
CHANGED
|
@@ -20,7 +20,7 @@ from argparse import ArgumentParser
|
|
| 20 |
from torch import Tensor
|
| 21 |
from google.protobuf import text_format
|
| 22 |
from torchmetrics import Metric
|
| 23 |
-
from typing import Optional, Sequence, List, Dict
|
| 24 |
|
| 25 |
from waymo_open_dataset.utils.sim_agents import submission_specs
|
| 26 |
|
|
@@ -480,6 +480,24 @@ def _compute_metametric(
|
|
| 480 |
return metametric
|
| 481 |
|
| 482 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 483 |
@dataclasses.dataclass(frozen=True)
|
| 484 |
class MetricFeatures:
|
| 485 |
|
|
@@ -709,11 +727,11 @@ class LogDistributions:
|
|
| 709 |
distance_to_nearest_object: Tensor
|
| 710 |
collision_indication: Tensor
|
| 711 |
time_to_collision: Tensor
|
| 712 |
-
distance_to_road_edge: Tensor
|
| 713 |
num_placement: Tensor
|
| 714 |
num_removement: Tensor
|
| 715 |
distance_placement: Tensor
|
| 716 |
distance_removement: Tensor
|
|
|
|
| 717 |
offroad_indication: Optional[Tensor] = None
|
| 718 |
|
| 719 |
|
|
@@ -751,13 +769,25 @@ def _reduce_average_with_validity(
|
|
| 751 |
if tensor.shape != validity.shape:
|
| 752 |
raise ValueError('Shapes of `tensor` and `validity` must be the same.'
|
| 753 |
f'(Actual: {tensor.shape}, {validity.shape}).')
|
| 754 |
-
cond_sum = torch.sum(torch.where(validity, tensor, torch.zeros_like(tensor)))
|
| 755 |
-
valid_sum = torch.sum(validity)
|
| 756 |
-
if valid_sum == 0:
|
| 757 |
-
return torch.
|
| 758 |
return cond_sum / valid_sum
|
| 759 |
|
| 760 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 761 |
def histogram_estimate(
|
| 762 |
config: long_metrics_pb2.SimAgentMetricsConfig.HistogramEstimate, # type: ignore
|
| 763 |
log_samples: Tensor,
|
|
@@ -889,7 +919,7 @@ def compute_scenario_metrics_for_bundle(
|
|
| 889 |
log_distributions: LogDistributions,
|
| 890 |
scenario_log: Optional[scenario_pb2.Scenario], # type: ignore
|
| 891 |
scenario_rollouts: ScenarioRollouts,
|
| 892 |
-
) -> long_metrics_pb2.SimAgentMetrics: # type: ignore
|
| 893 |
|
| 894 |
features_fields = [field.name for field in dataclasses.fields(MetricFeatures)]
|
| 895 |
features_fields.remove('object_id')
|
|
@@ -981,15 +1011,19 @@ def compute_scenario_metrics_for_bundle(
|
|
| 981 |
)
|
| 982 |
collision_likelihood = torch.exp(torch.mean(collision_score))
|
| 983 |
|
| 984 |
-
|
| 985 |
field='distance_to_nearest_object',
|
| 986 |
feature_config=config.distance_to_nearest_object,
|
| 987 |
sim_values=sim_features.distance_to_nearest_object,
|
| 988 |
log_distributions=log_distributions.distance_to_nearest_object,
|
| 989 |
)
|
| 990 |
-
|
| 991 |
-
|
| 992 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 993 |
|
| 994 |
ttc_log_likelihood = log_likelihood_estimate_timeseries(
|
| 995 |
field='time_to_collision',
|
|
@@ -1041,7 +1075,7 @@ def compute_scenario_metrics_for_bundle(
|
|
| 1041 |
sim_values=sim_features.distance_placement,
|
| 1042 |
log_distributions=log_distributions.distance_placement,
|
| 1043 |
)
|
| 1044 |
-
distance_placement_validity = (
|
| 1045 |
(sim_features.distance_placement > config.distance_placement.histogram.min_val) &
|
| 1046 |
(sim_features.distance_placement < config.distance_placement.histogram.max_val)
|
| 1047 |
)
|
|
@@ -1053,7 +1087,7 @@ def compute_scenario_metrics_for_bundle(
|
|
| 1053 |
sim_values=sim_features.distance_removement,
|
| 1054 |
log_distributions=log_distributions.distance_removement,
|
| 1055 |
)
|
| 1056 |
-
distance_removement_validity = (
|
| 1057 |
(sim_features.distance_removement > config.distance_removement.histogram.min_val) &
|
| 1058 |
(sim_features.distance_removement < config.distance_removement.histogram.max_val)
|
| 1059 |
)
|
|
@@ -1071,24 +1105,43 @@ def compute_scenario_metrics_for_bundle(
|
|
| 1071 |
|
| 1072 |
# ==== Meta metric ====
|
| 1073 |
likelihood_metrics = {
|
| 1074 |
-
'linear_speed_likelihood': float(linear_speed_likelihood.numpy()),
|
| 1075 |
-
'linear_acceleration_likelihood': float(linear_accel_likelihood.numpy()),
|
| 1076 |
-
'angular_speed_likelihood': float(angular_speed_likelihood.numpy()),
|
| 1077 |
-
'angular_acceleration_likelihood': float(angular_accel_likelihood.numpy()),
|
| 1078 |
-
'distance_to_nearest_object_likelihood': float(
|
| 1079 |
-
'collision_indication_likelihood': float(collision_likelihood.numpy()),
|
| 1080 |
-
'time_to_collision_likelihood': float(ttc_likelihood.numpy()),
|
| 1081 |
-
# 'distance_to_road_edge_likelihoodfloat(': distance_road_edge_likelihood.nump)y(),
|
| 1082 |
-
# 'offroad_indication_likelihoodfloat(': offroad_likelihood.nump)y(),
|
| 1083 |
-
'num_placement_likelihood': float(num_placement_likelihood.numpy()),
|
| 1084 |
-
'num_removement_likelihood': float(num_removement_likelihood.numpy()),
|
| 1085 |
-
'distance_placement_likelihood': float(distance_placement_likelihood.numpy()),
|
| 1086 |
-
'distance_removement_likelihood': float(distance_removement_likelihood.numpy()),
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1087 |
}
|
| 1088 |
|
| 1089 |
metametric = _compute_metametric(
|
| 1090 |
config, long_metrics_pb2.SimAgentMetrics(**likelihood_metrics)
|
| 1091 |
)
|
|
|
|
|
|
|
|
|
|
| 1092 |
# CONSOLE.log(f'metametric: {metametric}')
|
| 1093 |
|
| 1094 |
return long_metrics_pb2.SimAgentMetrics(
|
|
@@ -1097,6 +1150,10 @@ def compute_scenario_metrics_for_bundle(
|
|
| 1097 |
simulated_collision_rate=float(simulated_collision_rate.numpy()),
|
| 1098 |
# simulated_offroad_rate=simulated_offroad_rate.numpy(),
|
| 1099 |
**likelihood_metrics,
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1100 |
)
|
| 1101 |
|
| 1102 |
|
|
@@ -1122,9 +1179,6 @@ def _get_log_distributions(
|
|
| 1122 |
"""
|
| 1123 |
assert log_values.ndim == 2, f'Expect log_values.ndim==2, got {log_values.ndim}, shape {log_values.shape} for {field}'
|
| 1124 |
|
| 1125 |
-
# [n_objects, n_steps] -> [n_objects * n_steps]
|
| 1126 |
-
log_samples = log_values.reshape(-1)
|
| 1127 |
-
|
| 1128 |
# ! estimate
|
| 1129 |
if estimate_method == 'histogram':
|
| 1130 |
config = feature_config.histogram
|
|
@@ -1135,16 +1189,22 @@ def _get_log_distributions(
|
|
| 1135 |
additive_smoothing_pseudocount=feature_config.bernoulli.additive_smoothing_pseudocount
|
| 1136 |
)
|
| 1137 |
)
|
| 1138 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1139 |
|
| 1140 |
# We generate `num_bins`+1 edges for the histogram buckets.
|
| 1141 |
edges = torch.linspace(
|
| 1142 |
config.min_val, config.max_val, config.num_bins + 1
|
| 1143 |
).float()
|
| 1144 |
|
| 1145 |
-
if field in ('distance_placement', 'distance_removement'):
|
| 1146 |
-
log_samples = log_samples[(log_samples > config.min_val) & (log_samples < config.max_val)]
|
| 1147 |
-
|
| 1148 |
# Clip the samples to avoid errors with histograms. Nonetheless, the min/max
|
| 1149 |
# values should be configured to never hit this condition in practice.
|
| 1150 |
log_samples = torch.clamp(log_samples, config.min_val, config.max_val)
|
|
@@ -1198,6 +1258,7 @@ class LongMetric(Metric):
|
|
| 1198 |
]
|
| 1199 |
for k in self.field_names:
|
| 1200 |
self.add_state(k, default=torch.tensor(0.), dist_reduce_fx='sum')
|
|
|
|
| 1201 |
self.add_state('scenario_counter', default=torch.tensor(0.), dist_reduce_fx='sum')
|
| 1202 |
self.add_state('placement_valid_scenario_counter', default=torch.tensor(0.), dist_reduce_fx='sum')
|
| 1203 |
self.add_state('removement_valid_scenario_counter', default=torch.tensor(0.), dist_reduce_fx='sum')
|
|
@@ -1242,9 +1303,9 @@ class LongMetric(Metric):
|
|
| 1242 |
time_to_collision = _get_log_distributions('time_to_collision',
|
| 1243 |
self.metrics_config.time_to_collision, self.log_features.time_to_collision,
|
| 1244 |
),
|
| 1245 |
-
distance_to_road_edge = _get_log_distributions('distance_to_road_edge',
|
| 1246 |
-
|
| 1247 |
-
),
|
| 1248 |
# dist_offroad_indication = _get_log_distributions(
|
| 1249 |
# 'offroad_indication',
|
| 1250 |
# self.metrics_config.offroad_indication,
|
|
@@ -1259,12 +1320,10 @@ class LongMetric(Metric):
|
|
| 1259 |
self.metrics_config.num_removement, self.log_features.num_removement.float(),
|
| 1260 |
),
|
| 1261 |
distance_placement = _get_log_distributions('distance_placement',
|
| 1262 |
-
self.metrics_config.distance_placement,
|
| 1263 |
-
self.log_features.distance_placement[self.log_features.distance_placement > 0])[None, ...],
|
| 1264 |
),
|
| 1265 |
distance_removement = _get_log_distributions('distance_removement',
|
| 1266 |
-
self.metrics_config.distance_removement,
|
| 1267 |
-
self.log_features.distance_removement[self.log_features.distance_removement > 0])[None, ...],
|
| 1268 |
),
|
| 1269 |
)
|
| 1270 |
|
|
@@ -1328,31 +1387,41 @@ class LongMetric(Metric):
|
|
| 1328 |
metrics = self.compute_metrics(outputs)
|
| 1329 |
|
| 1330 |
for scenario_metrics in metrics:
|
|
|
|
|
|
|
|
|
|
| 1331 |
self.scenario_counter += 1
|
| 1332 |
|
| 1333 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1334 |
self.average_displacement_error += (
|
| 1335 |
-
|
| 1336 |
)
|
| 1337 |
self.min_average_displacement_error += (
|
| 1338 |
-
|
| 1339 |
)
|
| 1340 |
-
self.linear_speed_likelihood +=
|
| 1341 |
self.linear_acceleration_likelihood += (
|
| 1342 |
-
|
| 1343 |
)
|
| 1344 |
-
self.angular_speed_likelihood +=
|
| 1345 |
self.angular_acceleration_likelihood += (
|
| 1346 |
-
|
| 1347 |
)
|
| 1348 |
self.distance_to_nearest_object_likelihood += (
|
| 1349 |
-
|
| 1350 |
)
|
| 1351 |
self.collision_indication_likelihood += (
|
| 1352 |
-
|
| 1353 |
)
|
| 1354 |
self.time_to_collision_likelihood += (
|
| 1355 |
-
|
| 1356 |
)
|
| 1357 |
# self.distance_to_road_edge_likelihood += (
|
| 1358 |
# scenario_metrics.distance_to_road_edge_likelihood
|
|
@@ -1360,37 +1429,74 @@ class LongMetric(Metric):
|
|
| 1360 |
# self.offroad_indication_likelihood += (
|
| 1361 |
# scenario_metrics.offroad_indication_likelihood
|
| 1362 |
# )
|
| 1363 |
-
self.simulated_collision_rate +=
|
| 1364 |
# self.simulated_offroad_rate += scenario_metrics.simulated_offroad_rate
|
| 1365 |
|
| 1366 |
self.num_placement_likelihood += (
|
| 1367 |
-
|
| 1368 |
)
|
| 1369 |
self.num_removement_likelihood += (
|
| 1370 |
-
|
| 1371 |
)
|
| 1372 |
self.distance_placement_likelihood += (
|
| 1373 |
-
|
| 1374 |
)
|
| 1375 |
self.distance_removement_likelihood += (
|
| 1376 |
-
|
| 1377 |
)
|
| 1378 |
|
| 1379 |
-
|
| 1380 |
-
|
| 1381 |
-
|
| 1382 |
-
|
| 1383 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1384 |
|
| 1385 |
def compute(self) -> Dict[str, Tensor]:
|
| 1386 |
metrics_dict = {}
|
|
|
|
| 1387 |
for k in self.field_names:
|
| 1388 |
-
|
| 1389 |
-
|
| 1390 |
-
|
| 1391 |
-
|
| 1392 |
-
|
| 1393 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1394 |
|
| 1395 |
mean_metrics = long_metrics_pb2.SimAgentMetrics(
|
| 1396 |
scenario_id='', **metrics_dict,
|
|
@@ -1398,7 +1504,10 @@ class LongMetric(Metric):
|
|
| 1398 |
final_metrics = self.aggregate_metrics_to_buckets(
|
| 1399 |
self.metrics_config, mean_metrics
|
| 1400 |
)
|
| 1401 |
-
|
|
|
|
|
|
|
|
|
|
| 1402 |
|
| 1403 |
out_dict = {
|
| 1404 |
f"{self.prefix}/wosac/realism_meta_metric": final_metrics.realism_meta_metric,
|
|
@@ -1412,6 +1521,18 @@ class LongMetric(Metric):
|
|
| 1412 |
for k in self.field_names:
|
| 1413 |
out_dict[f"{self.prefix}/wosac_likelihood/{k}"] = float(metrics_dict[k])
|
| 1414 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1415 |
return out_dict
|
| 1416 |
|
| 1417 |
@staticmethod
|
|
@@ -1446,6 +1567,35 @@ class LongMetric(Metric):
|
|
| 1446 |
simulated_offroad_rate=metrics.simulated_offroad_rate,
|
| 1447 |
)
|
| 1448 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1449 |
@staticmethod
|
| 1450 |
def load_metrics_config(config_path: str = 'dev/metrics/metric_config.textproto',
|
| 1451 |
) -> long_metrics_pb2.SimAgentMetricsConfig: # type: ignore
|
|
@@ -1788,7 +1938,8 @@ if __name__ == "__main__":
|
|
| 1788 |
|
| 1789 |
elif args.debug:
|
| 1790 |
|
| 1791 |
-
debug_path = 'output/scalable_smart_long/validation_catk/idx_0_0_rollouts.pkl'
|
|
|
|
| 1792 |
|
| 1793 |
# ! for debugging
|
| 1794 |
with open(debug_path, 'rb') as f:
|
|
|
|
| 20 |
from torch import Tensor
|
| 21 |
from google.protobuf import text_format
|
| 22 |
from torchmetrics import Metric
|
| 23 |
+
from typing import Optional, Sequence, List, Dict, Tuple
|
| 24 |
|
| 25 |
from waymo_open_dataset.utils.sim_agents import submission_specs
|
| 26 |
|
|
|
|
| 480 |
return metametric
|
| 481 |
|
| 482 |
|
| 483 |
+
def _compute_metametric_long(
|
| 484 |
+
config: long_metrics_pb2.SimAgentMetricsConfig, # type: ignore
|
| 485 |
+
metrics: Dict[str, Tensor],
|
| 486 |
+
):
|
| 487 |
+
"""Computes the meta-metric aggregation."""
|
| 488 |
+
metametric = torch.zeros((metrics['linear_speed_likelihood'].shape[1]))
|
| 489 |
+
for field_name in _METRIC_FIELD_NAMES:
|
| 490 |
+
likelihood_field_name = field_name + '_likelihood'
|
| 491 |
+
weight = getattr(config, field_name).metametric_weight
|
| 492 |
+
metric_score = metrics[likelihood_field_name][0]
|
| 493 |
+
metametric += weight * metric_score
|
| 494 |
+
for field_name in _METRIC_FIELD_NAMES:
|
| 495 |
+
likelihood_field_name = field_name + '_likelihood'
|
| 496 |
+
metric_score = metrics[likelihood_field_name][0]
|
| 497 |
+
metametric[metric_score == 0] = 0.
|
| 498 |
+
return metametric
|
| 499 |
+
|
| 500 |
+
|
| 501 |
@dataclasses.dataclass(frozen=True)
|
| 502 |
class MetricFeatures:
|
| 503 |
|
|
|
|
| 727 |
distance_to_nearest_object: Tensor
|
| 728 |
collision_indication: Tensor
|
| 729 |
time_to_collision: Tensor
|
|
|
|
| 730 |
num_placement: Tensor
|
| 731 |
num_removement: Tensor
|
| 732 |
distance_placement: Tensor
|
| 733 |
distance_removement: Tensor
|
| 734 |
+
distance_to_road_edge: Optional[Tensor] = None
|
| 735 |
offroad_indication: Optional[Tensor] = None
|
| 736 |
|
| 737 |
|
|
|
|
| 769 |
if tensor.shape != validity.shape:
|
| 770 |
raise ValueError('Shapes of `tensor` and `validity` must be the same.'
|
| 771 |
f'(Actual: {tensor.shape}, {validity.shape}).')
|
| 772 |
+
cond_sum = torch.sum(torch.where(validity, tensor, torch.zeros_like(tensor)), dim=-1)
|
| 773 |
+
valid_sum = torch.sum(validity, dim=-1)
|
| 774 |
+
if valid_sum.sum() == 0:
|
| 775 |
+
return torch.full(valid_sum.shape[:2], -torch.inf)
|
| 776 |
return cond_sum / valid_sum
|
| 777 |
|
| 778 |
|
| 779 |
+
def _reduce_mean(tensor: Tensor, dim: Optional[int] = None) -> Tensor:
|
| 780 |
+
validity = (tensor > 0.) & (tensor <= 1.)
|
| 781 |
+
if dim is None:
|
| 782 |
+
sum = torch.sum(torch.where(validity, tensor, torch.zeros_like(tensor)))
|
| 783 |
+
count = validity.sum().clamp(min=1)
|
| 784 |
+
return sum / count
|
| 785 |
+
else:
|
| 786 |
+
sum = torch.sum(torch.where(validity, tensor, torch.zeros_like(tensor)), dim=0)
|
| 787 |
+
count = validity.sum(dim=0).clamp(min=1)
|
| 788 |
+
return sum / count
|
| 789 |
+
|
| 790 |
+
|
| 791 |
def histogram_estimate(
|
| 792 |
config: long_metrics_pb2.SimAgentMetricsConfig.HistogramEstimate, # type: ignore
|
| 793 |
log_samples: Tensor,
|
|
|
|
| 919 |
log_distributions: LogDistributions,
|
| 920 |
scenario_log: Optional[scenario_pb2.Scenario], # type: ignore
|
| 921 |
scenario_rollouts: ScenarioRollouts,
|
| 922 |
+
) -> Tuple[long_metrics_pb2.SimAgentMetrics, dict]: # type: ignore
|
| 923 |
|
| 924 |
features_fields = [field.name for field in dataclasses.fields(MetricFeatures)]
|
| 925 |
features_fields.remove('object_id')
|
|
|
|
| 1011 |
)
|
| 1012 |
collision_likelihood = torch.exp(torch.mean(collision_score))
|
| 1013 |
|
| 1014 |
+
distance_to_objects_log_likelihod = log_likelihood_estimate_timeseries(
|
| 1015 |
field='distance_to_nearest_object',
|
| 1016 |
feature_config=config.distance_to_nearest_object,
|
| 1017 |
sim_values=sim_features.distance_to_nearest_object,
|
| 1018 |
log_distributions=log_distributions.distance_to_nearest_object,
|
| 1019 |
)
|
| 1020 |
+
distance_to_objects_valid = sim_features.valid & (
|
| 1021 |
+
(sim_features.distance_to_nearest_object >= config.distance_to_nearest_object.histogram.min_val) &
|
| 1022 |
+
(sim_features.distance_to_nearest_object <= config.distance_to_nearest_object.histogram.max_val)
|
| 1023 |
+
)
|
| 1024 |
+
distance_to_objects_likelihod = torch.exp(_reduce_average_with_validity(
|
| 1025 |
+
distance_to_objects_log_likelihod, distance_to_objects_valid))
|
| 1026 |
+
# CONSOLE.log(f'distance_to_objects_likelihod: {distance_to_objects_likelihod}')
|
| 1027 |
|
| 1028 |
ttc_log_likelihood = log_likelihood_estimate_timeseries(
|
| 1029 |
field='time_to_collision',
|
|
|
|
| 1075 |
sim_values=sim_features.distance_placement,
|
| 1076 |
log_distributions=log_distributions.distance_placement,
|
| 1077 |
)
|
| 1078 |
+
distance_placement_validity = sim_features.valid.unfold(-1, SHIFT, SHIFT)[..., 0] & (
|
| 1079 |
(sim_features.distance_placement > config.distance_placement.histogram.min_val) &
|
| 1080 |
(sim_features.distance_placement < config.distance_placement.histogram.max_val)
|
| 1081 |
)
|
|
|
|
| 1087 |
sim_values=sim_features.distance_removement,
|
| 1088 |
log_distributions=log_distributions.distance_removement,
|
| 1089 |
)
|
| 1090 |
+
distance_removement_validity = sim_features.valid.unfold(-1, SHIFT, SHIFT)[..., 0] & (
|
| 1091 |
(sim_features.distance_removement > config.distance_removement.histogram.min_val) &
|
| 1092 |
(sim_features.distance_removement < config.distance_removement.histogram.max_val)
|
| 1093 |
)
|
|
|
|
| 1105 |
|
| 1106 |
# ==== Meta metric ====
|
| 1107 |
likelihood_metrics = {
|
| 1108 |
+
'linear_speed_likelihood': float(_reduce_mean(linear_speed_likelihood).numpy()),
|
| 1109 |
+
'linear_acceleration_likelihood': float(_reduce_mean(linear_accel_likelihood).numpy()),
|
| 1110 |
+
'angular_speed_likelihood': float(_reduce_mean(angular_speed_likelihood).numpy()),
|
| 1111 |
+
'angular_acceleration_likelihood': float(_reduce_mean(angular_accel_likelihood).numpy()),
|
| 1112 |
+
'distance_to_nearest_object_likelihood': float(_reduce_mean(distance_to_objects_likelihod).numpy()),
|
| 1113 |
+
'collision_indication_likelihood': float(_reduce_mean(collision_likelihood).numpy()),
|
| 1114 |
+
'time_to_collision_likelihood': float(_reduce_mean(ttc_likelihood).numpy()),
|
| 1115 |
+
# 'distance_to_road_edge_likelihoodfloat(float(_reduce_mean(':).numpy()) distance_road_edge_likelihood.nump)y(),
|
| 1116 |
+
# 'offroad_indication_likelihoodfloat(float(_reduce_mean(':).numpy()) offroad_likelihood.nump)y(),
|
| 1117 |
+
'num_placement_likelihood': float(_reduce_mean(num_placement_likelihood).numpy()),
|
| 1118 |
+
'num_removement_likelihood': float(_reduce_mean(num_removement_likelihood).numpy()),
|
| 1119 |
+
'distance_placement_likelihood': float(_reduce_mean(distance_placement_likelihood).numpy()),
|
| 1120 |
+
'distance_removement_likelihood': float(_reduce_mean(distance_removement_likelihood).numpy()),
|
| 1121 |
+
}
|
| 1122 |
+
|
| 1123 |
+
likelihood_metrics_long = {
|
| 1124 |
+
'linear_speed_likelihood': _reduce_mean(linear_speed_likelihood, dim=0).unsqueeze(dim=0),
|
| 1125 |
+
'linear_acceleration_likelihood': _reduce_mean(linear_accel_likelihood, dim=0).unsqueeze(dim=0),
|
| 1126 |
+
'angular_speed_likelihood': _reduce_mean(angular_speed_likelihood, dim=0).unsqueeze(dim=0),
|
| 1127 |
+
'angular_acceleration_likelihood': _reduce_mean(angular_accel_likelihood, dim=0).unsqueeze(dim=0),
|
| 1128 |
+
'distance_to_nearest_object_likelihood': _reduce_mean(distance_to_objects_likelihod, dim=0).unsqueeze(dim=0),
|
| 1129 |
+
'collision_indication_likelihood': _reduce_mean(torch.exp(torch.mean(collision_score, dim=-1)), dim=0).unsqueeze(dim=0),
|
| 1130 |
+
'time_to_collision_likelihood': _reduce_mean(ttc_likelihood, dim=0).unsqueeze(dim=0),
|
| 1131 |
+
# 'distance_to_road_edge_likelihoodfloat(float(_reduce_mean(':).numpy()) distance_road_edge_likelihood.nump)y(),
|
| 1132 |
+
# 'offroad_indication_likelihoodfloat(float(_reduce_mean(':).numpy()) offroad_likelihood.nump)y(),
|
| 1133 |
+
'num_placement_likelihood': torch.exp(torch.mean(num_placement_log_likelihood, dim=-1)),
|
| 1134 |
+
'num_removement_likelihood': torch.exp(torch.mean(num_removement_log_likelihood, dim=-1)),
|
| 1135 |
+
'distance_placement_likelihood': _reduce_mean(distance_placement_likelihood, dim=0).unsqueeze(dim=0),
|
| 1136 |
+
'distance_removement_likelihood': _reduce_mean(distance_removement_likelihood, dim=0).unsqueeze(dim=0),
|
| 1137 |
}
|
| 1138 |
|
| 1139 |
metametric = _compute_metametric(
|
| 1140 |
config, long_metrics_pb2.SimAgentMetrics(**likelihood_metrics)
|
| 1141 |
)
|
| 1142 |
+
metametric_long = _compute_metametric_long(
|
| 1143 |
+
config, likelihood_metrics_long
|
| 1144 |
+
)
|
| 1145 |
# CONSOLE.log(f'metametric: {metametric}')
|
| 1146 |
|
| 1147 |
return long_metrics_pb2.SimAgentMetrics(
|
|
|
|
| 1150 |
simulated_collision_rate=float(simulated_collision_rate.numpy()),
|
| 1151 |
# simulated_offroad_rate=simulated_offroad_rate.numpy(),
|
| 1152 |
**likelihood_metrics,
|
| 1153 |
+
), dict(
|
| 1154 |
+
scenario_id=scenario_rollouts.scenario_id,
|
| 1155 |
+
metametric=metametric_long.unsqueeze(dim=0),
|
| 1156 |
+
**likelihood_metrics_long,
|
| 1157 |
)
|
| 1158 |
|
| 1159 |
|
|
|
|
| 1179 |
"""
|
| 1180 |
assert log_values.ndim == 2, f'Expect log_values.ndim==2, got {log_values.ndim}, shape {log_values.shape} for {field}'
|
| 1181 |
|
|
|
|
|
|
|
|
|
|
| 1182 |
# ! estimate
|
| 1183 |
if estimate_method == 'histogram':
|
| 1184 |
config = feature_config.histogram
|
|
|
|
| 1189 |
additive_smoothing_pseudocount=feature_config.bernoulli.additive_smoothing_pseudocount
|
| 1190 |
)
|
| 1191 |
)
|
| 1192 |
+
log_values = log_values.float() # cast torch.bool to torch.float32
|
| 1193 |
+
|
| 1194 |
+
if 'distance_' in field:
|
| 1195 |
+
log_values = log_values[(log_values > config.min_val) & (log_values < config.max_val)]
|
| 1196 |
+
|
| 1197 |
+
if field == 'num_placement':
|
| 1198 |
+
log_values = log_values[:, :-2] # ignore the last two steps
|
| 1199 |
+
|
| 1200 |
+
# [n_objects, n_steps] -> [n_objects * n_steps]
|
| 1201 |
+
log_samples = log_values.reshape(-1)
|
| 1202 |
|
| 1203 |
# We generate `num_bins`+1 edges for the histogram buckets.
|
| 1204 |
edges = torch.linspace(
|
| 1205 |
config.min_val, config.max_val, config.num_bins + 1
|
| 1206 |
).float()
|
| 1207 |
|
|
|
|
|
|
|
|
|
|
| 1208 |
# Clip the samples to avoid errors with histograms. Nonetheless, the min/max
|
| 1209 |
# values should be configured to never hit this condition in practice.
|
| 1210 |
log_samples = torch.clamp(log_samples, config.min_val, config.max_val)
|
|
|
|
| 1258 |
]
|
| 1259 |
for k in self.field_names:
|
| 1260 |
self.add_state(k, default=torch.tensor(0.), dist_reduce_fx='sum')
|
| 1261 |
+
self.add_state(f'{k}_long', default=[], dist_reduce_fx='cat')
|
| 1262 |
self.add_state('scenario_counter', default=torch.tensor(0.), dist_reduce_fx='sum')
|
| 1263 |
self.add_state('placement_valid_scenario_counter', default=torch.tensor(0.), dist_reduce_fx='sum')
|
| 1264 |
self.add_state('removement_valid_scenario_counter', default=torch.tensor(0.), dist_reduce_fx='sum')
|
|
|
|
| 1303 |
time_to_collision = _get_log_distributions('time_to_collision',
|
| 1304 |
self.metrics_config.time_to_collision, self.log_features.time_to_collision,
|
| 1305 |
),
|
| 1306 |
+
# distance_to_road_edge = _get_log_distributions('distance_to_road_edge',
|
| 1307 |
+
# self.metrics_config.distance_to_road_edge, self.log_features.distance_to_road_edge,
|
| 1308 |
+
# ),
|
| 1309 |
# dist_offroad_indication = _get_log_distributions(
|
| 1310 |
# 'offroad_indication',
|
| 1311 |
# self.metrics_config.offroad_indication,
|
|
|
|
| 1320 |
self.metrics_config.num_removement, self.log_features.num_removement.float(),
|
| 1321 |
),
|
| 1322 |
distance_placement = _get_log_distributions('distance_placement',
|
| 1323 |
+
self.metrics_config.distance_placement, self.log_features.distance_placement,
|
|
|
|
| 1324 |
),
|
| 1325 |
distance_removement = _get_log_distributions('distance_removement',
|
| 1326 |
+
self.metrics_config.distance_removement, self.log_features.distance_removement,
|
|
|
|
| 1327 |
),
|
| 1328 |
)
|
| 1329 |
|
|
|
|
| 1387 |
metrics = self.compute_metrics(outputs)
|
| 1388 |
|
| 1389 |
for scenario_metrics in metrics:
|
| 1390 |
+
|
| 1391 |
+
_scenario_metrics, _scenario_metrics_long = scenario_metrics
|
| 1392 |
+
|
| 1393 |
self.scenario_counter += 1
|
| 1394 |
|
| 1395 |
+
if _scenario_metrics.distance_placement_likelihood > 0:
|
| 1396 |
+
self.placement_valid_scenario_counter += 1
|
| 1397 |
+
|
| 1398 |
+
if _scenario_metrics.distance_removement_likelihood > 0:
|
| 1399 |
+
self.removement_valid_scenario_counter += 1
|
| 1400 |
+
|
| 1401 |
+
# float metrics
|
| 1402 |
+
self.metametric += _scenario_metrics.metametric
|
| 1403 |
self.average_displacement_error += (
|
| 1404 |
+
_scenario_metrics.average_displacement_error
|
| 1405 |
)
|
| 1406 |
self.min_average_displacement_error += (
|
| 1407 |
+
_scenario_metrics.min_average_displacement_error
|
| 1408 |
)
|
| 1409 |
+
self.linear_speed_likelihood += _scenario_metrics.linear_speed_likelihood
|
| 1410 |
self.linear_acceleration_likelihood += (
|
| 1411 |
+
_scenario_metrics.linear_acceleration_likelihood
|
| 1412 |
)
|
| 1413 |
+
self.angular_speed_likelihood += _scenario_metrics.angular_speed_likelihood
|
| 1414 |
self.angular_acceleration_likelihood += (
|
| 1415 |
+
_scenario_metrics.angular_acceleration_likelihood
|
| 1416 |
)
|
| 1417 |
self.distance_to_nearest_object_likelihood += (
|
| 1418 |
+
_scenario_metrics.distance_to_nearest_object_likelihood
|
| 1419 |
)
|
| 1420 |
self.collision_indication_likelihood += (
|
| 1421 |
+
_scenario_metrics.collision_indication_likelihood
|
| 1422 |
)
|
| 1423 |
self.time_to_collision_likelihood += (
|
| 1424 |
+
_scenario_metrics.time_to_collision_likelihood
|
| 1425 |
)
|
| 1426 |
# self.distance_to_road_edge_likelihood += (
|
| 1427 |
# scenario_metrics.distance_to_road_edge_likelihood
|
|
|
|
| 1429 |
# self.offroad_indication_likelihood += (
|
| 1430 |
# scenario_metrics.offroad_indication_likelihood
|
| 1431 |
# )
|
| 1432 |
+
self.simulated_collision_rate += _scenario_metrics.simulated_collision_rate
|
| 1433 |
# self.simulated_offroad_rate += scenario_metrics.simulated_offroad_rate
|
| 1434 |
|
| 1435 |
self.num_placement_likelihood += (
|
| 1436 |
+
_scenario_metrics.num_placement_likelihood
|
| 1437 |
)
|
| 1438 |
self.num_removement_likelihood += (
|
| 1439 |
+
_scenario_metrics.num_removement_likelihood
|
| 1440 |
)
|
| 1441 |
self.distance_placement_likelihood += (
|
| 1442 |
+
_scenario_metrics.distance_placement_likelihood
|
| 1443 |
)
|
| 1444 |
self.distance_removement_likelihood += (
|
| 1445 |
+
_scenario_metrics.distance_removement_likelihood
|
| 1446 |
)
|
| 1447 |
|
| 1448 |
+
# long metrics
|
| 1449 |
+
self.metametric_long.append(_scenario_metrics_long['metametric'])
|
| 1450 |
+
self.linear_speed_likelihood_long.append(_scenario_metrics_long['linear_speed_likelihood'])
|
| 1451 |
+
self.linear_acceleration_likelihood_long.append(
|
| 1452 |
+
_scenario_metrics_long['linear_acceleration_likelihood']
|
| 1453 |
+
)
|
| 1454 |
+
self.angular_speed_likelihood_long.append(_scenario_metrics_long['angular_speed_likelihood'])
|
| 1455 |
+
self.angular_acceleration_likelihood_long.append(
|
| 1456 |
+
_scenario_metrics_long['angular_acceleration_likelihood']
|
| 1457 |
+
)
|
| 1458 |
+
self.distance_to_nearest_object_likelihood_long.append(
|
| 1459 |
+
_scenario_metrics_long['distance_to_nearest_object_likelihood']
|
| 1460 |
+
)
|
| 1461 |
+
self.collision_indication_likelihood_long.append(
|
| 1462 |
+
_scenario_metrics_long['collision_indication_likelihood']
|
| 1463 |
+
)
|
| 1464 |
+
self.time_to_collision_likelihood_long.append(
|
| 1465 |
+
_scenario_metrics_long['time_to_collision_likelihood']
|
| 1466 |
+
)
|
| 1467 |
+
# self.distance_to_road_edge_likelihood += (
|
| 1468 |
+
# scenario_metrics.distance_to_road_edge_likelihood
|
| 1469 |
+
# )
|
| 1470 |
+
# self.offroad_indication_likelihood += (
|
| 1471 |
+
# scenario_metrics.offroad_indication_likelihood
|
| 1472 |
+
# )
|
| 1473 |
+
self.num_placement_likelihood_long.append(
|
| 1474 |
+
_scenario_metrics_long['num_placement_likelihood']
|
| 1475 |
+
)
|
| 1476 |
+
self.num_removement_likelihood_long.append(
|
| 1477 |
+
_scenario_metrics_long['num_removement_likelihood']
|
| 1478 |
+
)
|
| 1479 |
+
self.distance_placement_likelihood_long.append(
|
| 1480 |
+
_scenario_metrics_long['distance_placement_likelihood']
|
| 1481 |
+
)
|
| 1482 |
+
self.distance_removement_likelihood_long.append(
|
| 1483 |
+
_scenario_metrics_long['distance_removement_likelihood']
|
| 1484 |
+
)
|
| 1485 |
|
| 1486 |
def compute(self) -> Dict[str, Tensor]:
|
| 1487 |
metrics_dict = {}
|
| 1488 |
+
metrics_long_dict = {}
|
| 1489 |
for k in self.field_names:
|
| 1490 |
+
# float metrics
|
| 1491 |
+
if k not in ('distance_placement_likelihood', 'distance_removement_likelihood'):
|
| 1492 |
+
metrics_dict[k] = getattr(self, k) / max(self.scenario_counter, 1)
|
| 1493 |
+
if k == 'distance_placement_likelihood':
|
| 1494 |
+
metrics_dict[k] = getattr(self, k) / max(self.placement_valid_scenario_counter, 1)
|
| 1495 |
+
if k == 'distance_removement_likelihood':
|
| 1496 |
+
metrics_dict[k] = getattr(self, k) / max(self.removement_valid_scenario_counter, 1)
|
| 1497 |
+
# long metrics
|
| 1498 |
+
if len(getattr(self, f'{k}_long')) > 0:
|
| 1499 |
+
metrics_long_dict[k] = _reduce_mean(torch.cat(getattr(self, f'{k}_long')), dim=0)
|
| 1500 |
|
| 1501 |
mean_metrics = long_metrics_pb2.SimAgentMetrics(
|
| 1502 |
scenario_id='', **metrics_dict,
|
|
|
|
| 1504 |
final_metrics = self.aggregate_metrics_to_buckets(
|
| 1505 |
self.metrics_config, mean_metrics
|
| 1506 |
)
|
| 1507 |
+
mean_long_metrics = metrics_long_dict
|
| 1508 |
+
final_long_metrics = self.aggregate_metrics_long_to_buckets(
|
| 1509 |
+
self.metrics_config, mean_long_metrics
|
| 1510 |
+
)
|
| 1511 |
|
| 1512 |
out_dict = {
|
| 1513 |
f"{self.prefix}/wosac/realism_meta_metric": final_metrics.realism_meta_metric,
|
|
|
|
| 1521 |
for k in self.field_names:
|
| 1522 |
out_dict[f"{self.prefix}/wosac_likelihood/{k}"] = float(metrics_dict[k])
|
| 1523 |
|
| 1524 |
+
out_dict.update({
|
| 1525 |
+
f"{self.prefix}/wosac_long/realism_meta_metric": [round(x, 4) for x in final_long_metrics['realism_meta_metric'].tolist()],
|
| 1526 |
+
f"{self.prefix}/wosac_long/kinematic_metrics": [round(x, 4) for x in final_long_metrics['kinematic_metrics'].tolist()],
|
| 1527 |
+
f"{self.prefix}/wosac_long/interactive_metrics": [round(x, 4) for x in final_long_metrics['interactive_metrics'].tolist()],
|
| 1528 |
+
f"{self.prefix}/wosac_long/map_based_metrics": [round(x, 4) for x in final_long_metrics['map_based_metrics'].tolist()],
|
| 1529 |
+
f"{self.prefix}/wosac_long/placement_based_metrics": [round(x, 4) for x in final_long_metrics['placement_based_metrics'].tolist()],
|
| 1530 |
+
})
|
| 1531 |
+
for k in self.field_names:
|
| 1532 |
+
if k not in metrics_long_dict:
|
| 1533 |
+
continue
|
| 1534 |
+
out_dict[f"{self.prefix}/wosac_long_likelihood/{k}"] = [round(x, 4) for x in metrics_long_dict[k].tolist()]
|
| 1535 |
+
|
| 1536 |
return out_dict
|
| 1537 |
|
| 1538 |
@staticmethod
|
|
|
|
| 1567 |
simulated_offroad_rate=metrics.simulated_offroad_rate,
|
| 1568 |
)
|
| 1569 |
|
| 1570 |
+
@staticmethod
|
| 1571 |
+
def aggregate_metrics_long_to_buckets(
|
| 1572 |
+
config: long_metrics_pb2.SimAgentMetricsConfig, # type: ignore
|
| 1573 |
+
metrics: Dict[str, Tensor],
|
| 1574 |
+
) -> Dict[str, Tensor]:
|
| 1575 |
+
"""Aggregates metrics into buckets for better readability."""
|
| 1576 |
+
bucketed_metrics = {}
|
| 1577 |
+
for bucket_name, fields_in_bucket in _METRIC_FIELD_NAMES_BY_BUCKET.items():
|
| 1578 |
+
weighted_metric, weights_sum = torch.zeros(metrics['linear_speed_likelihood'].shape[0]), 0.0
|
| 1579 |
+
for field_name in fields_in_bucket:
|
| 1580 |
+
likelihood_field_name = field_name + '_likelihood'
|
| 1581 |
+
weight = getattr(config, field_name).metametric_weight
|
| 1582 |
+
metric_score = metrics[likelihood_field_name]
|
| 1583 |
+
weighted_metric += weight * metric_score
|
| 1584 |
+
weights_sum += weight
|
| 1585 |
+
if weights_sum == 0:
|
| 1586 |
+
weights_sum = 1 # FIXME: hack!!!
|
| 1587 |
+
# raise ValueError('The bucket\'s weight sum is zero. Check your metrics'
|
| 1588 |
+
# ' config.')
|
| 1589 |
+
bucketed_metrics[bucket_name] = weighted_metric / weights_sum
|
| 1590 |
+
|
| 1591 |
+
return dict(
|
| 1592 |
+
realism_meta_metric=metrics['metametric'],
|
| 1593 |
+
kinematic_metrics=bucketed_metrics['kinematic'],
|
| 1594 |
+
interactive_metrics=bucketed_metrics['interactive'],
|
| 1595 |
+
map_based_metrics=bucketed_metrics['map_based'],
|
| 1596 |
+
placement_based_metrics=bucketed_metrics['placement_based'],
|
| 1597 |
+
)
|
| 1598 |
+
|
| 1599 |
@staticmethod
|
| 1600 |
def load_metrics_config(config_path: str = 'dev/metrics/metric_config.textproto',
|
| 1601 |
) -> long_metrics_pb2.SimAgentMetricsConfig: # type: ignore
|
|
|
|
| 1938 |
|
| 1939 |
elif args.debug:
|
| 1940 |
|
| 1941 |
+
# debug_path = 'output/scalable_smart_long/validation_catk/idx_0_0_rollouts.pkl'
|
| 1942 |
+
debug_path = '/u/xiuyu/work/dev4/dev/metrics/idx_0_0_rollouts.pkl'
|
| 1943 |
|
| 1944 |
# ! for debugging
|
| 1945 |
with open(debug_path, 'rb') as f:
|
backups/dev/model/smart.py
CHANGED
|
@@ -21,6 +21,7 @@ from dev.datasets.preprocess import TokenProcessor
|
|
| 21 |
from dev.metrics.compute_metrics import *
|
| 22 |
from dev.utils.metrics import *
|
| 23 |
from dev.utils.visualization import *
|
|
|
|
| 24 |
|
| 25 |
|
| 26 |
class SMART(pl.LightningModule):
|
|
@@ -66,6 +67,17 @@ class SMART(pl.LightningModule):
|
|
| 66 |
if self.disable_grid_token:
|
| 67 |
self.predict_occ = False
|
| 68 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 69 |
self.token_processer = TokenProcessor(self.token_size,
|
| 70 |
training=self.training,
|
| 71 |
predict_motion=self.predict_motion,
|
|
@@ -115,6 +127,9 @@ class SMART(pl.LightningModule):
|
|
| 115 |
predict_occ=self.predict_occ,
|
| 116 |
state_token=model_config.state_token,
|
| 117 |
use_grid_token=self.use_grid_token,
|
|
|
|
|
|
|
|
|
|
| 118 |
seed_size=self.seed_size,
|
| 119 |
buffer_size=model_config.decoder.buffer_size,
|
| 120 |
num_recurrent_steps_val=model_config.num_recurrent_steps_val,
|
|
@@ -147,6 +162,7 @@ class SMART(pl.LightningModule):
|
|
| 147 |
self.offset_reg_loss_seed = nn.MSELoss()
|
| 148 |
self.shape_reg_loss_seed = nn.MSELoss()
|
| 149 |
self.pos_reg_loss_seed = nn.MSELoss()
|
|
|
|
| 150 |
if self.predict_occ:
|
| 151 |
self.occ_cls_loss = nn.CrossEntropyLoss()
|
| 152 |
self.agent_occ_loss_seed = nn.BCEWithLogitsLoss(
|
|
@@ -370,6 +386,7 @@ class SMART(pl.LightningModule):
|
|
| 370 |
next_shape_gt_seed = pred['next_shape_gt_seed']
|
| 371 |
next_state_eval_mask_seed = pred['next_state_eval_mask_seed']
|
| 372 |
next_attr_eval_mask_seed = pred['next_attr_eval_mask_seed']
|
|
|
|
| 373 |
|
| 374 |
# when num_seed_gt=0 loss term will be NaN
|
| 375 |
state_cls_loss_seed = self.state_cls_loss_seed(next_state_prob_seed[next_state_eval_mask_seed],
|
|
@@ -388,15 +405,12 @@ class SMART(pl.LightningModule):
|
|
| 388 |
|
| 389 |
loss = loss + state_cls_loss_seed + type_cls_loss_seed + shape_reg_loss_seed
|
| 390 |
|
| 391 |
-
next_head_rel_prob_seed = pred['next_head_rel_prob_seed']
|
| 392 |
-
next_head_rel_index_gt_seed = pred['next_head_rel_index_gt_seed']
|
| 393 |
-
next_offset_xy_seed = pred['next_offset_xy_seed']
|
| 394 |
-
next_offset_xy_gt_seed = pred['next_offset_xy_gt_seed']
|
| 395 |
-
next_head_eval_mask_seed = pred['next_head_eval_mask_seed']
|
| 396 |
|
| 397 |
if self.use_grid_token:
|
| 398 |
next_pos_rel_prob_seed = pred['next_pos_rel_prob_seed']
|
| 399 |
next_pos_rel_index_gt_seed = pred['next_pos_rel_index_gt_seed']
|
|
|
|
|
|
|
| 400 |
|
| 401 |
pos_cls_loss_seed = self.pos_cls_loss_seed(next_pos_rel_prob_seed[next_attr_eval_mask_seed],
|
| 402 |
next_pos_rel_index_gt_seed[next_attr_eval_mask_seed]) * self.loss_weight['pos_cls_loss']
|
|
@@ -415,13 +429,28 @@ class SMART(pl.LightningModule):
|
|
| 415 |
next_pos_rel_xy_gt_seed[next_attr_eval_mask_seed]) * self.loss_weight['pos_reg_loss']
|
| 416 |
pos_reg_loss_seed = torch.nan_to_num(pos_reg_loss_seed)
|
| 417 |
self.log('seed_pos_reg_loss', pos_reg_loss_seed, **log_params)
|
|
|
|
| 418 |
loss = loss + pos_reg_loss_seed
|
| 419 |
|
| 420 |
-
|
| 421 |
-
|
| 422 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 423 |
|
| 424 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 425 |
|
| 426 |
# plot_scenario_ids = ['74ad7b76d5906d39', '1351ea8b8333ddcb', '1352066cc3c0508d', '135436833ce5b9e7', '13570a32432d449', '13577c32a81336fb']
|
| 427 |
if random.random() < 4e-5 or int(os.getenv('DEBUG', 0)):
|
|
@@ -988,6 +1017,7 @@ class SMART(pl.LightningModule):
|
|
| 988 |
data['agent']['bos_mask'] = torch.zeros_like(data['agent']['state_idx']).bool()
|
| 989 |
|
| 990 |
data['agent']['pos_xy'] = torch.zeros_like(data['agent']['token_pos'])
|
|
|
|
| 991 |
if self.predict_occ:
|
| 992 |
num_step = data['agent']['state_idx'].shape[1]
|
| 993 |
data['agent']['pt_grid_token_idx'] = torch.zeros_like(data['pt_token']['token_idx'])[None].repeat(num_step, 1).long()
|
|
@@ -1055,8 +1085,9 @@ class SMART(pl.LightningModule):
|
|
| 1055 |
|
| 1056 |
data['agent']['grid_token_idx'][agent_batch_mask] = grid_token_idx
|
| 1057 |
data['agent']['grid_offset_xy'][agent_batch_mask] = offset_xy
|
| 1058 |
-
data['agent']['pos_xy'][agent_batch_mask] = pos_xy
|
| 1059 |
data['agent']['heading_token_idx'][agent_batch_mask] = heading_token_idx
|
|
|
|
|
|
|
| 1060 |
data['agent']['sort_indices'][agent_batch_mask] = sort_indices
|
| 1061 |
data['agent']['inrange_mask'][agent_batch_mask] = torch.stack(is_inrange, dim=1)
|
| 1062 |
data['agent']['bos_mask'][agent_batch_mask] = torch.stack(is_bos, dim=1)
|
|
|
|
| 21 |
from dev.metrics.compute_metrics import *
|
| 22 |
from dev.utils.metrics import *
|
| 23 |
from dev.utils.visualization import *
|
| 24 |
+
from dev.utils.func import wrap_angle
|
| 25 |
|
| 26 |
|
| 27 |
class SMART(pl.LightningModule):
|
|
|
|
| 67 |
if self.disable_grid_token:
|
| 68 |
self.predict_occ = False
|
| 69 |
|
| 70 |
+
self.disable_head_token = getattr(model_config, 'disable_head_token') \
|
| 71 |
+
if hasattr(model_config, 'disable_head_token') else False
|
| 72 |
+
self.use_head_token = not self.disable_head_token
|
| 73 |
+
|
| 74 |
+
self.disable_state_token = getattr(model_config, 'disable_state_token') \
|
| 75 |
+
if hasattr(model_config, 'disable_state_token') else False
|
| 76 |
+
self.use_state_token = not self.disable_state_token
|
| 77 |
+
|
| 78 |
+
self.disable_insertion = getattr(model_config, 'disable_insertiion') \
|
| 79 |
+
if hasattr(model_config, 'disable_insertion') else False
|
| 80 |
+
|
| 81 |
self.token_processer = TokenProcessor(self.token_size,
|
| 82 |
training=self.training,
|
| 83 |
predict_motion=self.predict_motion,
|
|
|
|
| 127 |
predict_occ=self.predict_occ,
|
| 128 |
state_token=model_config.state_token,
|
| 129 |
use_grid_token=self.use_grid_token,
|
| 130 |
+
use_head_token=self.use_head_token,
|
| 131 |
+
use_state_token=self.use_state_token,
|
| 132 |
+
disable_insertion=self.disable_insertion,
|
| 133 |
seed_size=self.seed_size,
|
| 134 |
buffer_size=model_config.decoder.buffer_size,
|
| 135 |
num_recurrent_steps_val=model_config.num_recurrent_steps_val,
|
|
|
|
| 162 |
self.offset_reg_loss_seed = nn.MSELoss()
|
| 163 |
self.shape_reg_loss_seed = nn.MSELoss()
|
| 164 |
self.pos_reg_loss_seed = nn.MSELoss()
|
| 165 |
+
self.head_reg_loss_seed = nn.MSELoss()
|
| 166 |
if self.predict_occ:
|
| 167 |
self.occ_cls_loss = nn.CrossEntropyLoss()
|
| 168 |
self.agent_occ_loss_seed = nn.BCEWithLogitsLoss(
|
|
|
|
| 386 |
next_shape_gt_seed = pred['next_shape_gt_seed']
|
| 387 |
next_state_eval_mask_seed = pred['next_state_eval_mask_seed']
|
| 388 |
next_attr_eval_mask_seed = pred['next_attr_eval_mask_seed']
|
| 389 |
+
next_head_eval_mask_seed = pred['next_head_eval_mask_seed']
|
| 390 |
|
| 391 |
# when num_seed_gt=0 loss term will be NaN
|
| 392 |
state_cls_loss_seed = self.state_cls_loss_seed(next_state_prob_seed[next_state_eval_mask_seed],
|
|
|
|
| 405 |
|
| 406 |
loss = loss + state_cls_loss_seed + type_cls_loss_seed + shape_reg_loss_seed
|
| 407 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 408 |
|
| 409 |
if self.use_grid_token:
|
| 410 |
next_pos_rel_prob_seed = pred['next_pos_rel_prob_seed']
|
| 411 |
next_pos_rel_index_gt_seed = pred['next_pos_rel_index_gt_seed']
|
| 412 |
+
next_offset_xy_seed = pred['next_offset_xy_seed']
|
| 413 |
+
next_offset_xy_gt_seed = pred['next_offset_xy_gt_seed']
|
| 414 |
|
| 415 |
pos_cls_loss_seed = self.pos_cls_loss_seed(next_pos_rel_prob_seed[next_attr_eval_mask_seed],
|
| 416 |
next_pos_rel_index_gt_seed[next_attr_eval_mask_seed]) * self.loss_weight['pos_cls_loss']
|
|
|
|
| 429 |
next_pos_rel_xy_gt_seed[next_attr_eval_mask_seed]) * self.loss_weight['pos_reg_loss']
|
| 430 |
pos_reg_loss_seed = torch.nan_to_num(pos_reg_loss_seed)
|
| 431 |
self.log('seed_pos_reg_loss', pos_reg_loss_seed, **log_params)
|
| 432 |
+
|
| 433 |
loss = loss + pos_reg_loss_seed
|
| 434 |
|
| 435 |
+
if self.use_head_token:
|
| 436 |
+
next_head_rel_prob_seed = pred['next_head_rel_prob_seed']
|
| 437 |
+
next_head_rel_index_gt_seed = pred['next_head_rel_index_gt_seed']
|
| 438 |
+
|
| 439 |
+
head_cls_loss_seed = self.head_cls_loss_seed(next_head_rel_prob_seed[next_head_eval_mask_seed],
|
| 440 |
+
next_head_rel_index_gt_seed[next_head_eval_mask_seed]) * self.loss_weight['head_cls_loss']
|
| 441 |
+
self.log('seed_head_cls_loss', head_cls_loss_seed, **log_params)
|
| 442 |
|
| 443 |
+
loss = loss + head_cls_loss_seed
|
| 444 |
+
|
| 445 |
+
else:
|
| 446 |
+
next_head_rel_theta_seed = pred['next_head_rel_theta_seed']
|
| 447 |
+
next_head_rel_theta_gt_seed = pred['next_head_rel_theta_gt_seed']
|
| 448 |
+
|
| 449 |
+
head_reg_loss_seed = self.head_reg_loss_seed(next_head_rel_theta_seed[next_head_eval_mask_seed],
|
| 450 |
+
next_head_rel_theta_gt_seed[next_head_eval_mask_seed]) * self.loss_weight['head_reg_loss']
|
| 451 |
+
self.log('seed_head_reg_loss', head_reg_loss_seed, **log_params)
|
| 452 |
+
|
| 453 |
+
loss = loss + head_reg_loss_seed
|
| 454 |
|
| 455 |
# plot_scenario_ids = ['74ad7b76d5906d39', '1351ea8b8333ddcb', '1352066cc3c0508d', '135436833ce5b9e7', '13570a32432d449', '13577c32a81336fb']
|
| 456 |
if random.random() < 4e-5 or int(os.getenv('DEBUG', 0)):
|
|
|
|
| 1017 |
data['agent']['bos_mask'] = torch.zeros_like(data['agent']['state_idx']).bool()
|
| 1018 |
|
| 1019 |
data['agent']['pos_xy'] = torch.zeros_like(data['agent']['token_pos'])
|
| 1020 |
+
data['agent']['heading_theta'] = torch.zeros_like(data['agent']['token_heading'])
|
| 1021 |
if self.predict_occ:
|
| 1022 |
num_step = data['agent']['state_idx'].shape[1]
|
| 1023 |
data['agent']['pt_grid_token_idx'] = torch.zeros_like(data['pt_token']['token_idx'])[None].repeat(num_step, 1).long()
|
|
|
|
| 1085 |
|
| 1086 |
data['agent']['grid_token_idx'][agent_batch_mask] = grid_token_idx
|
| 1087 |
data['agent']['grid_offset_xy'][agent_batch_mask] = offset_xy
|
|
|
|
| 1088 |
data['agent']['heading_token_idx'][agent_batch_mask] = heading_token_idx
|
| 1089 |
+
data['agent']['pos_xy'][agent_batch_mask] = pos_xy
|
| 1090 |
+
data['agent']['heading_theta'][agent_batch_mask] = wrap_angle(rel_heading)
|
| 1091 |
data['agent']['sort_indices'][agent_batch_mask] = sort_indices
|
| 1092 |
data['agent']['inrange_mask'][agent_batch_mask] = torch.stack(is_inrange, dim=1)
|
| 1093 |
data['agent']['bos_mask'][agent_batch_mask] = torch.stack(is_bos, dim=1)
|
backups/dev/modules/agent_decoder.py
CHANGED
|
@@ -121,6 +121,9 @@ class SMARTAgentDecoder(nn.Module):
|
|
| 121 |
predict_occ: bool=False,
|
| 122 |
state_token: Dict[str, int]=None,
|
| 123 |
use_grid_token: bool=True,
|
|
|
|
|
|
|
|
|
|
| 124 |
seed_size: int=5,
|
| 125 |
buffer_size: int=32,
|
| 126 |
num_recurrent_steps_val: int=-1,
|
|
@@ -148,6 +151,9 @@ class SMARTAgentDecoder(nn.Module):
|
|
| 148 |
self.predict_map = predict_map
|
| 149 |
self.predict_occ = predict_occ
|
| 150 |
self.use_grid_token = use_grid_token
|
|
|
|
|
|
|
|
|
|
| 151 |
self.num_recurrent_steps_val = num_recurrent_steps_val
|
| 152 |
self.loss_weight = loss_weight
|
| 153 |
self.logger = logger
|
|
@@ -273,8 +279,12 @@ class SMARTAgentDecoder(nn.Module):
|
|
| 273 |
else:
|
| 274 |
self.seed_pos_rel_xy_predict_head = MLPLayer(input_dim=hidden_dim, hidden_dim=hidden_dim,
|
| 275 |
output_dim=2)
|
| 276 |
-
self.
|
| 277 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 278 |
# self.seed_pt_occ_embed = MLPLayer(input_dim=self.grid_size, hidden_dim=hidden_dim,
|
| 279 |
# output_dim=hidden_dim)
|
| 280 |
|
|
@@ -1121,8 +1131,9 @@ class SMARTAgentDecoder(nn.Module):
|
|
| 1121 |
|
| 1122 |
agent_grid_token_idx = data['agent']['grid_token_idx']
|
| 1123 |
agent_grid_offset_xy = data['agent']['grid_offset_xy']
|
| 1124 |
-
agent_pos_xy = data['agent']['pos_xy']
|
| 1125 |
agent_head_token_idx = data['agent']['heading_token_idx']
|
|
|
|
|
|
|
| 1126 |
sort_indices = data['agent']['sort_indices']
|
| 1127 |
|
| 1128 |
device = pos_a.device
|
|
@@ -1277,7 +1288,7 @@ class SMARTAgentDecoder(nn.Module):
|
|
| 1277 |
next_pos_rel_idx_seed = next_pos_rel_prob_seed.softmax(dim=-1).argmax(dim=-1, keepdim=True)
|
| 1278 |
else:
|
| 1279 |
next_pos_rel_prob_seed = self.seed_pos_rel_xy_predict_head(feat_seed)
|
| 1280 |
-
next_pos_rel_xy_seed =
|
| 1281 |
|
| 1282 |
next_pos_rel_index_gt = agent_grid_token_idx.long()
|
| 1283 |
next_pos_rel_xy_gt = agent_pos_xy.float() / self.pl2seed_radius
|
|
@@ -1364,17 +1375,24 @@ class SMARTAgentDecoder(nn.Module):
|
|
| 1364 |
feat_sa = self.a2a_attn_layers[i](feat_sa, r_a2sa, edge_index_a2sa)
|
| 1365 |
feat_sa = feat_sa.reshape(num_step, -1, self.hidden_dim).transpose(0, 1)
|
| 1366 |
|
| 1367 |
-
|
| 1368 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1369 |
|
| 1370 |
next_head_rel_index_gt_seed = agent_head_token_idx.long()
|
|
|
|
| 1371 |
|
| 1372 |
-
next_offset_xy_seed =
|
| 1373 |
if self.use_grid_token:
|
| 1374 |
next_offset_xy_seed = self.seed_offset_xy_predict_head(feat_sa)
|
| 1375 |
next_offset_xy_seed = torch.tanh(next_offset_xy_seed) * 2 # [-2, 2]
|
| 1376 |
|
| 1377 |
-
|
| 1378 |
|
| 1379 |
# next token prediction mask
|
| 1380 |
bos_token_index = torch.nonzero(agent_state_index == self.enter_state)
|
|
@@ -1593,6 +1611,8 @@ class SMARTAgentDecoder(nn.Module):
|
|
| 1593 |
'next_pos_rel_xy_gt_seed': next_pos_rel_xy_gt_seed,
|
| 1594 |
'next_head_rel_prob_seed': next_head_rel_prob_seed,
|
| 1595 |
'next_head_rel_index_gt_seed': next_head_rel_index_gt_seed,
|
|
|
|
|
|
|
| 1596 |
'next_offset_xy_seed': next_offset_xy_seed,
|
| 1597 |
'next_offset_xy_gt_seed': next_offset_xy_gt_seed,
|
| 1598 |
'next_shape_seed': next_shape_seed,
|
|
@@ -1798,7 +1818,7 @@ class SMARTAgentDecoder(nn.Module):
|
|
| 1798 |
while True:
|
| 1799 |
|
| 1800 |
p += 1
|
| 1801 |
-
if t == 0 or p - 1 >= insert_limit: break
|
| 1802 |
|
| 1803 |
# rebuild inference mask since number of agents have changed
|
| 1804 |
inference_mask = torch.zeros_like(temporal_mask)
|
|
@@ -1934,7 +1954,7 @@ class SMARTAgentDecoder(nn.Module):
|
|
| 1934 |
continue
|
| 1935 |
else:
|
| 1936 |
next_pos_rel_xy_seed = self.seed_pos_rel_xy_predict_head(feat_seed[:, (self.num_historical_steps - 1) // self.shift - 1 + t])
|
| 1937 |
-
next_pos_seed =
|
| 1938 |
|
| 1939 |
if torch.all(next_state_idx_seed == self.invalid_state) or num_new_agents + 1 > insert_limit:
|
| 1940 |
break
|
|
@@ -2082,9 +2102,13 @@ class SMARTAgentDecoder(nn.Module):
|
|
| 2082 |
feat_a = self.a2a_attn_layers[i](feat_a, r_a2sa, edge_index_a2sa)
|
| 2083 |
feat_a = feat_a.reshape(num_infer_step, -1, self.hidden_dim).transpose(0, 1)
|
| 2084 |
|
| 2085 |
-
|
| 2086 |
-
|
| 2087 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 2088 |
|
| 2089 |
head_a[-num_new_agent:, (self.num_historical_steps - 1) // self.shift - 1 + t] = next_head_seed
|
| 2090 |
|
|
@@ -2188,6 +2212,8 @@ class SMARTAgentDecoder(nn.Module):
|
|
| 2188 |
next_state_idx = next_state_prob.softmax(dim=-1).argmax(dim=-1)
|
| 2189 |
next_state_idx[next_state_idx == self.valid_state_type.index('exit')] = self.exit_state
|
| 2190 |
next_state_idx[av_index] = self.valid_state # force ego_agent to be valid
|
|
|
|
|
|
|
| 2191 |
|
| 2192 |
# convert the predicted token to a 0.5s (6 timesteps) trajectory
|
| 2193 |
expanded_token_index = next_token_idx[..., None, None, None].expand(-1, -1, 6, 4, 2)
|
|
@@ -2302,6 +2328,7 @@ class SMARTAgentDecoder(nn.Module):
|
|
| 2302 |
agent_grid_emb = self.grid_token_emb[grid_a]
|
| 2303 |
feat_a = torch.cat([feat_a, agent_grid_emb], dim=-1)
|
| 2304 |
feat_a = self.fusion_emb(feat_a)
|
|
|
|
| 2305 |
|
| 2306 |
next_token_idx_list.append(next_token_idx[:, None])
|
| 2307 |
next_state_idx_list.append(next_state_idx[:, None])
|
|
|
|
| 121 |
predict_occ: bool=False,
|
| 122 |
state_token: Dict[str, int]=None,
|
| 123 |
use_grid_token: bool=True,
|
| 124 |
+
use_head_token: bool=True,
|
| 125 |
+
use_state_token: bool=True,
|
| 126 |
+
disable_insertion: bool=False,
|
| 127 |
seed_size: int=5,
|
| 128 |
buffer_size: int=32,
|
| 129 |
num_recurrent_steps_val: int=-1,
|
|
|
|
| 151 |
self.predict_map = predict_map
|
| 152 |
self.predict_occ = predict_occ
|
| 153 |
self.use_grid_token = use_grid_token
|
| 154 |
+
self.use_head_token = use_head_token
|
| 155 |
+
self.use_state_token = use_state_token
|
| 156 |
+
self.disable_insertion = disable_insertion
|
| 157 |
self.num_recurrent_steps_val = num_recurrent_steps_val
|
| 158 |
self.loss_weight = loss_weight
|
| 159 |
self.logger = logger
|
|
|
|
| 279 |
else:
|
| 280 |
self.seed_pos_rel_xy_predict_head = MLPLayer(input_dim=hidden_dim, hidden_dim=hidden_dim,
|
| 281 |
output_dim=2)
|
| 282 |
+
if self.use_head_token:
|
| 283 |
+
self.seed_heading_rel_token_predict_head = MLPLayer(input_dim=hidden_dim, hidden_dim=hidden_dim,
|
| 284 |
+
output_dim=self.angle_size)
|
| 285 |
+
else:
|
| 286 |
+
self.seed_heading_rel_theta_predict_head = MLPLayer(input_dim=hidden_dim, hidden_dim=hidden_dim,
|
| 287 |
+
output_dim=1)
|
| 288 |
# self.seed_pt_occ_embed = MLPLayer(input_dim=self.grid_size, hidden_dim=hidden_dim,
|
| 289 |
# output_dim=hidden_dim)
|
| 290 |
|
|
|
|
| 1131 |
|
| 1132 |
agent_grid_token_idx = data['agent']['grid_token_idx']
|
| 1133 |
agent_grid_offset_xy = data['agent']['grid_offset_xy']
|
|
|
|
| 1134 |
agent_head_token_idx = data['agent']['heading_token_idx']
|
| 1135 |
+
agent_pos_xy = data['agent']['pos_xy']
|
| 1136 |
+
agent_heading_theta = data['agent']['heading_theta']
|
| 1137 |
sort_indices = data['agent']['sort_indices']
|
| 1138 |
|
| 1139 |
device = pos_a.device
|
|
|
|
| 1288 |
next_pos_rel_idx_seed = next_pos_rel_prob_seed.softmax(dim=-1).argmax(dim=-1, keepdim=True)
|
| 1289 |
else:
|
| 1290 |
next_pos_rel_prob_seed = self.seed_pos_rel_xy_predict_head(feat_seed)
|
| 1291 |
+
next_pos_rel_xy_seed = torch.tanh(next_pos_rel_prob_seed)
|
| 1292 |
|
| 1293 |
next_pos_rel_index_gt = agent_grid_token_idx.long()
|
| 1294 |
next_pos_rel_xy_gt = agent_pos_xy.float() / self.pl2seed_radius
|
|
|
|
| 1375 |
feat_sa = self.a2a_attn_layers[i](feat_sa, r_a2sa, edge_index_a2sa)
|
| 1376 |
feat_sa = feat_sa.reshape(num_step, -1, self.hidden_dim).transpose(0, 1)
|
| 1377 |
|
| 1378 |
+
if self.use_head_token:
|
| 1379 |
+
next_head_rel_theta_seed = None
|
| 1380 |
+
next_head_rel_prob_seed = self.seed_heading_rel_token_predict_head(feat_sa)
|
| 1381 |
+
next_head_rel_idx_seed = next_head_rel_prob_seed.softmax(dim=-1).argmax(dim=-1, keepdim=True)
|
| 1382 |
+
else:
|
| 1383 |
+
next_head_rel_prob_seed = None
|
| 1384 |
+
next_head_rel_theta_seed = self.seed_heading_rel_theta_predict_head(feat_sa)
|
| 1385 |
+
next_head_rel_theta_seed = torch.tanh(next_head_rel_theta_seed)[..., 0]
|
| 1386 |
|
| 1387 |
next_head_rel_index_gt_seed = agent_head_token_idx.long()
|
| 1388 |
+
next_head_rel_theta_gt_seed = agent_heading_theta.float() / torch.pi # [-1, 1]
|
| 1389 |
|
| 1390 |
+
next_offset_xy_seed = None
|
| 1391 |
if self.use_grid_token:
|
| 1392 |
next_offset_xy_seed = self.seed_offset_xy_predict_head(feat_sa)
|
| 1393 |
next_offset_xy_seed = torch.tanh(next_offset_xy_seed) * 2 # [-2, 2]
|
| 1394 |
|
| 1395 |
+
next_offset_xy_gt_seed = agent_grid_offset_xy.float()
|
| 1396 |
|
| 1397 |
# next token prediction mask
|
| 1398 |
bos_token_index = torch.nonzero(agent_state_index == self.enter_state)
|
|
|
|
| 1611 |
'next_pos_rel_xy_gt_seed': next_pos_rel_xy_gt_seed,
|
| 1612 |
'next_head_rel_prob_seed': next_head_rel_prob_seed,
|
| 1613 |
'next_head_rel_index_gt_seed': next_head_rel_index_gt_seed,
|
| 1614 |
+
'next_head_rel_theta_seed': next_head_rel_theta_seed,
|
| 1615 |
+
'next_head_rel_theta_gt_seed': next_head_rel_theta_gt_seed,
|
| 1616 |
'next_offset_xy_seed': next_offset_xy_seed,
|
| 1617 |
'next_offset_xy_gt_seed': next_offset_xy_gt_seed,
|
| 1618 |
'next_shape_seed': next_shape_seed,
|
|
|
|
| 1818 |
while True:
|
| 1819 |
|
| 1820 |
p += 1
|
| 1821 |
+
if t == 0 or p - 1 >= insert_limit or self.disable_insertion: break
|
| 1822 |
|
| 1823 |
# rebuild inference mask since number of agents have changed
|
| 1824 |
inference_mask = torch.zeros_like(temporal_mask)
|
|
|
|
| 1954 |
continue
|
| 1955 |
else:
|
| 1956 |
next_pos_rel_xy_seed = self.seed_pos_rel_xy_predict_head(feat_seed[:, (self.num_historical_steps - 1) // self.shift - 1 + t])
|
| 1957 |
+
next_pos_seed = torch.tanh(next_pos_rel_xy_seed) * self.pl2seed_radius + ego_pos_t_1
|
| 1958 |
|
| 1959 |
if torch.all(next_state_idx_seed == self.invalid_state) or num_new_agents + 1 > insert_limit:
|
| 1960 |
break
|
|
|
|
| 2102 |
feat_a = self.a2a_attn_layers[i](feat_a, r_a2sa, edge_index_a2sa)
|
| 2103 |
feat_a = feat_a.reshape(num_infer_step, -1, self.hidden_dim).transpose(0, 1)
|
| 2104 |
|
| 2105 |
+
if self.use_head_token:
|
| 2106 |
+
next_head_rel_prob_seed = self.seed_heading_rel_token_predict_head(feat_a[-num_new_agent:, (self.num_historical_steps - 1) // self.shift - 1 + t])
|
| 2107 |
+
next_head_rel_idx_seed = next_head_rel_prob_seed.softmax(dim=-1).argmax(dim=-1, keepdim=True)
|
| 2108 |
+
next_head_seed = wrap_angle(self.attr_tokenizer.decode_heading(next_head_rel_idx_seed) + ego_head_t_1)
|
| 2109 |
+
else:
|
| 2110 |
+
next_head_rel_theta_seed = self.seed_heading_rel_theta_predict_head(feat_a[-num_new_agent:, (self.num_historical_steps - 1) // self.shift - 1 + t])
|
| 2111 |
+
next_head_seed = torch.tanh(next_head_rel_theta_seed) * torch.pi + ego_head_t_1
|
| 2112 |
|
| 2113 |
head_a[-num_new_agent:, (self.num_historical_steps - 1) // self.shift - 1 + t] = next_head_seed
|
| 2114 |
|
|
|
|
| 2212 |
next_state_idx = next_state_prob.softmax(dim=-1).argmax(dim=-1)
|
| 2213 |
next_state_idx[next_state_idx == self.valid_state_type.index('exit')] = self.exit_state
|
| 2214 |
next_state_idx[av_index] = self.valid_state # force ego_agent to be valid
|
| 2215 |
+
if not self.use_state_token:
|
| 2216 |
+
next_state_idx[next_state_idx == self.exit_state] = self.valid_state
|
| 2217 |
|
| 2218 |
# convert the predicted token to a 0.5s (6 timesteps) trajectory
|
| 2219 |
expanded_token_index = next_token_idx[..., None, None, None].expand(-1, -1, 6, 4, 2)
|
|
|
|
| 2328 |
agent_grid_emb = self.grid_token_emb[grid_a]
|
| 2329 |
feat_a = torch.cat([feat_a, agent_grid_emb], dim=-1)
|
| 2330 |
feat_a = self.fusion_emb(feat_a)
|
| 2331 |
+
raw_feat_a = feat_a.clone() # ! IMPORANT: need to update `raw_feat_a`
|
| 2332 |
|
| 2333 |
next_token_idx_list.append(next_token_idx[:, None])
|
| 2334 |
next_state_idx_list.append(next_state_idx[:, None])
|
backups/dev/modules/smart_decoder.py
CHANGED
|
@@ -40,7 +40,10 @@ class SMARTDecoder(nn.Module):
|
|
| 40 |
predict_state: bool=False,
|
| 41 |
predict_map: bool=False,
|
| 42 |
predict_occ: bool=False,
|
| 43 |
-
use_grid_token: bool=
|
|
|
|
|
|
|
|
|
|
| 44 |
state_token: Dict[str, int]=None,
|
| 45 |
seed_size: int=5,
|
| 46 |
buffer_size: int=32,
|
|
@@ -89,6 +92,9 @@ class SMARTDecoder(nn.Module):
|
|
| 89 |
predict_occ=predict_occ,
|
| 90 |
state_token=state_token,
|
| 91 |
use_grid_token=use_grid_token,
|
|
|
|
|
|
|
|
|
|
| 92 |
seed_size=seed_size,
|
| 93 |
buffer_size=buffer_size,
|
| 94 |
num_recurrent_steps_val=num_recurrent_steps_val,
|
|
|
|
| 40 |
predict_state: bool=False,
|
| 41 |
predict_map: bool=False,
|
| 42 |
predict_occ: bool=False,
|
| 43 |
+
use_grid_token: bool=True,
|
| 44 |
+
use_head_token: bool=True,
|
| 45 |
+
use_state_token: bool=True,
|
| 46 |
+
disable_insertion: bool=False,
|
| 47 |
state_token: Dict[str, int]=None,
|
| 48 |
seed_size: int=5,
|
| 49 |
buffer_size: int=32,
|
|
|
|
| 92 |
predict_occ=predict_occ,
|
| 93 |
state_token=state_token,
|
| 94 |
use_grid_token=use_grid_token,
|
| 95 |
+
use_head_token=use_head_token,
|
| 96 |
+
use_state_token=use_state_token,
|
| 97 |
+
disable_insertion=disable_insertion,
|
| 98 |
seed_size=seed_size,
|
| 99 |
buffer_size=buffer_size,
|
| 100 |
num_recurrent_steps_val=num_recurrent_steps_val,
|
backups/dev/utils/visualization.py
CHANGED
|
@@ -7,6 +7,7 @@ import tensorflow as tf
|
|
| 7 |
import numpy as np
|
| 8 |
import numpy.typing as npt
|
| 9 |
import fnmatch
|
|
|
|
| 10 |
import seaborn as sns
|
| 11 |
import matplotlib.axes as Axes
|
| 12 |
import matplotlib.transforms as mtransforms
|
|
@@ -650,7 +651,7 @@ def plot_map_token(ax: Axes, map_points: npt.NDArray, token_pos: npt.NDArray, to
|
|
| 650 |
|
| 651 |
@safe_run
|
| 652 |
def plot_map(ax: Axes, map_points: npt.NDArray, color='black'):
|
| 653 |
-
ax.scatter(map_points[:, 0], map_points[:, 1], s=0.
|
| 654 |
|
| 655 |
xmin = np.min(map_points[:, 0])
|
| 656 |
xmax = np.max(map_points[:, 0])
|
|
@@ -744,36 +745,68 @@ def plot_all(map, xs, ys, angles, types, colors, is_avs, pl2seed_radius: float=2
|
|
| 744 |
ax.grid(False)
|
| 745 |
ax.set_aspect('equal', adjustable='box')
|
| 746 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 747 |
# ax.legend(loc='best', frameon=True)
|
| 748 |
|
|
|
|
| 749 |
if kwargs.get('save_path', None):
|
| 750 |
plt.savefig(kwargs['save_path'], dpi=600, bbox_inches="tight")
|
| 751 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 752 |
plt.close()
|
| 753 |
|
| 754 |
-
return
|
| 755 |
|
| 756 |
|
| 757 |
@safe_run
|
| 758 |
def plot_file(gt_folder: str,
|
| 759 |
folder: Optional[str] = None,
|
| 760 |
-
files: Optional[str] = None
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 761 |
from dev.metrics.compute_metrics import _unbatch
|
| 762 |
|
|
|
|
|
|
|
| 763 |
if files is None:
|
| 764 |
assert os.path.exists(folder), f'Path {folder} does not exist.'
|
| 765 |
files = list(fnmatch.filter(os.listdir(folder), 'idx_*_rollouts.pkl'))
|
| 766 |
CONSOLE.log(f'Found {len(files)} rollouts files from {folder}.')
|
| 767 |
|
| 768 |
-
|
| 769 |
if folder is None:
|
| 770 |
assert os.path.exists(files), f'Path {files} does not exist.'
|
| 771 |
folder = os.path.dirname(files)
|
| 772 |
files = [files]
|
| 773 |
|
| 774 |
parent, folder_name = os.path.split(folder.rstrip(os.sep))
|
| 775 |
-
|
|
|
|
|
|
|
|
|
|
| 776 |
|
|
|
|
| 777 |
for file in (pbar := tqdm(files, leave=False, desc='Plotting files ...')):
|
| 778 |
pbar.set_postfix(file=file)
|
| 779 |
|
|
@@ -786,25 +819,64 @@ def plot_file(gt_folder: str,
|
|
| 786 |
preds_traj = _unbatch(preds['pred_traj'], agent_batch)
|
| 787 |
preds_head = _unbatch(preds['pred_head'], agent_batch)
|
| 788 |
preds_type = _unbatch(preds['pred_type'], agent_batch)
|
| 789 |
-
|
|
|
|
|
|
|
|
|
|
| 790 |
preds_valid = _unbatch(preds['pred_valid'], agent_batch)
|
| 791 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 792 |
for i, scenario_id in enumerate(scenario_ids):
|
| 793 |
-
n_rollouts = preds_traj[0].shape[
|
| 794 |
|
|
|
|
| 795 |
for j in range(n_rollouts): # 1
|
| 796 |
pred = dict(scenario_id=[scenario_id],
|
| 797 |
pred_traj=preds_traj[i][:, j],
|
| 798 |
pred_head=preds_head[i][:, j],
|
| 799 |
-
pred_state=
|
|
|
|
|
|
|
|
|
|
| 800 |
pred_type=preds_type[i][:, j],
|
| 801 |
)
|
| 802 |
-
av_index = agent_id[i][:, 0].tolist().index(preds['av_id']) # NOTE: hard code!!!
|
| 803 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 804 |
data_path = os.path.join(gt_folder, 'validation', f'{scenario_id}.pkl')
|
| 805 |
with open(data_path, 'rb') as f:
|
| 806 |
data = pickle.load(f)
|
| 807 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 808 |
|
| 809 |
|
| 810 |
@safe_run
|
|
@@ -829,9 +901,9 @@ def plot_val(data: Union[dict, str], pred: dict, av_index: int, save_path: str,
|
|
| 829 |
if 'agent_labels' in pred:
|
| 830 |
kwargs.update(agent_labels=pred['agent_labels'])
|
| 831 |
|
| 832 |
-
plot_scenario(scenario_id, map_point, pred_traj, pred_head, pred_state, pred_type,
|
| 833 |
-
|
| 834 |
-
|
| 835 |
|
| 836 |
|
| 837 |
@safe_run
|
|
@@ -842,7 +914,7 @@ def plot_scenario(scenario_id: str,
|
|
| 842 |
state: npt.NDArray,
|
| 843 |
types: List[str],
|
| 844 |
av_index: int,
|
| 845 |
-
color_type: Literal['state', 'type', 'seed']='seed',
|
| 846 |
state_type: List[str]=['invalid', 'valid', 'enter', 'exit'],
|
| 847 |
plot_enter: bool=False,
|
| 848 |
suffix: str='',
|
|
@@ -862,7 +934,11 @@ def plot_scenario(scenario_id: str,
|
|
| 862 |
num_historical_steps = 2
|
| 863 |
shift = 1
|
| 864 |
|
| 865 |
-
if
|
|
|
|
|
|
|
|
|
|
|
|
|
| 866 |
os.makedirs(kwargs['save_path'], exist_ok=True)
|
| 867 |
save_id = int(max([0] + list(map(lambda fname: int(fname.split("_")[-1]),
|
| 868 |
filter(lambda fname: fname.startswith(scenario_id)
|
|
@@ -909,13 +985,30 @@ def plot_scenario(scenario_id: str,
|
|
| 909 |
agent_colors[is_exited, :] = seed_colors['exited']
|
| 910 |
agent_colors[is_entered, :] = seed_colors['entered']
|
| 911 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 912 |
agent_colors[av_index, :] = np.array(agent_palette[-1])
|
| 913 |
is_av = np.zeros_like(state[:, 0]).astype(np.bool_)
|
| 914 |
is_av[av_index] = True
|
| 915 |
|
| 916 |
-
#
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 917 |
fig_paths = []
|
| 918 |
-
for tid in tqdm(
|
| 919 |
mask_t = visible_mask[:, tid]
|
| 920 |
xs = traj[mask_t, tid, 0]
|
| 921 |
ys = traj[mask_t, tid, 1]
|
|
@@ -931,13 +1024,23 @@ def plot_scenario(scenario_id: str,
|
|
| 931 |
labels = [agent_labels[i][tid // shift] for i in range(len(agent_labels)) if mask_t[i]]
|
| 932 |
|
| 933 |
fig_path = None
|
| 934 |
-
if 'save_path'
|
| 935 |
save_path = kwargs['save_path']
|
| 936 |
fig_path = os.path.join(f"{save_path}/{scenario_id}_{str(save_id).zfill(3)}", f"{tid}.png")
|
| 937 |
fig_paths.append(fig_path)
|
| 938 |
|
| 939 |
-
|
| 940 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 941 |
|
| 942 |
# generate gif
|
| 943 |
if fig_paths and save_gif:
|
|
@@ -958,6 +1061,8 @@ def plot_scenario(scenario_id: str,
|
|
| 958 |
except Exception as e:
|
| 959 |
tqdm.write(f"{e}! Failed to save gif at {gif_path}")
|
| 960 |
|
|
|
|
|
|
|
| 961 |
|
| 962 |
def match_token_map(data):
|
| 963 |
|
|
@@ -1096,19 +1201,132 @@ def plot_tokenize(data, save_path: str):
|
|
| 1096 |
agent_type = agent_data['type']
|
| 1097 |
ids = np.arange(raw_traj.shape[0])
|
| 1098 |
|
| 1099 |
-
plot_scenario(
|
| 1100 |
-
|
| 1101 |
-
|
| 1102 |
-
|
| 1103 |
-
|
| 1104 |
-
|
| 1105 |
-
|
| 1106 |
-
|
| 1107 |
-
|
| 1108 |
-
|
| 1109 |
-
|
| 1110 |
-
|
| 1111 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1112 |
|
| 1113 |
|
| 1114 |
if __name__ == "__main__":
|
|
@@ -1124,6 +1342,11 @@ if __name__ == "__main__":
|
|
| 1124 |
parser.add_argument('--plot_file', action='store_true')
|
| 1125 |
parser.add_argument('--folder_path', type=str, default=None)
|
| 1126 |
parser.add_argument('--file_path', type=str, default=None)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1127 |
args = parser.parse_args()
|
| 1128 |
|
| 1129 |
if args.plot_tokenize:
|
|
@@ -1143,3 +1366,29 @@ if __name__ == "__main__":
|
|
| 1143 |
if args.plot_file:
|
| 1144 |
|
| 1145 |
plot_file(args.data_path, folder=args.folder_path, files=args.file_path)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 7 |
import numpy as np
|
| 8 |
import numpy.typing as npt
|
| 9 |
import fnmatch
|
| 10 |
+
import io
|
| 11 |
import seaborn as sns
|
| 12 |
import matplotlib.axes as Axes
|
| 13 |
import matplotlib.transforms as mtransforms
|
|
|
|
| 651 |
|
| 652 |
@safe_run
|
| 653 |
def plot_map(ax: Axes, map_points: npt.NDArray, color='black'):
|
| 654 |
+
ax.scatter(map_points[:, 0], map_points[:, 1], s=0.5, c=color, edgecolors='none')
|
| 655 |
|
| 656 |
xmin = np.min(map_points[:, 0])
|
| 657 |
xmax = np.max(map_points[:, 0])
|
|
|
|
| 745 |
ax.grid(False)
|
| 746 |
ax.set_aspect('equal', adjustable='box')
|
| 747 |
|
| 748 |
+
# ! set plot limit if need
|
| 749 |
+
if kwargs.get('limit_size', None):
|
| 750 |
+
cx = float(xs[is_avs])
|
| 751 |
+
cy = float(ys[is_avs])
|
| 752 |
+
|
| 753 |
+
lx, ly = kwargs['limit_size']
|
| 754 |
+
xmin, xmax = cx - lx, cx + lx
|
| 755 |
+
ymin, ymax = cy - ly, cy + ly
|
| 756 |
+
|
| 757 |
+
ax.set_xlim(xmin, xmax)
|
| 758 |
+
ax.set_ylim(ymin, ymax)
|
| 759 |
+
|
| 760 |
# ax.legend(loc='best', frameon=True)
|
| 761 |
|
| 762 |
+
pil_image = None
|
| 763 |
if kwargs.get('save_path', None):
|
| 764 |
plt.savefig(kwargs['save_path'], dpi=600, bbox_inches="tight")
|
| 765 |
|
| 766 |
+
else:
|
| 767 |
+
# !convert to PIL image
|
| 768 |
+
buf = io.BytesIO()
|
| 769 |
+
plt.savefig(buf, format='png', dpi=600, bbox_inches='tight')
|
| 770 |
+
buf.seek(0)
|
| 771 |
+
pil_image = Image.open(buf).convert('RGB')
|
| 772 |
+
|
| 773 |
plt.close()
|
| 774 |
|
| 775 |
+
return pil_image
|
| 776 |
|
| 777 |
|
| 778 |
@safe_run
|
| 779 |
def plot_file(gt_folder: str,
|
| 780 |
folder: Optional[str] = None,
|
| 781 |
+
files: Optional[str] = None,
|
| 782 |
+
save_gif: bool = True,
|
| 783 |
+
batch_idx: Optional[int] = None,
|
| 784 |
+
time_idx: Optional[List[int]] = None,
|
| 785 |
+
limit_size: Optional[List[int]] = None,
|
| 786 |
+
**kwargs,
|
| 787 |
+
) -> List[Image.Image]:
|
| 788 |
+
|
| 789 |
from dev.metrics.compute_metrics import _unbatch
|
| 790 |
|
| 791 |
+
shift = 5
|
| 792 |
+
|
| 793 |
if files is None:
|
| 794 |
assert os.path.exists(folder), f'Path {folder} does not exist.'
|
| 795 |
files = list(fnmatch.filter(os.listdir(folder), 'idx_*_rollouts.pkl'))
|
| 796 |
CONSOLE.log(f'Found {len(files)} rollouts files from {folder}.')
|
| 797 |
|
|
|
|
| 798 |
if folder is None:
|
| 799 |
assert os.path.exists(files), f'Path {files} does not exist.'
|
| 800 |
folder = os.path.dirname(files)
|
| 801 |
files = [files]
|
| 802 |
|
| 803 |
parent, folder_name = os.path.split(folder.rstrip(os.sep))
|
| 804 |
+
if save_gif:
|
| 805 |
+
save_path = os.path.join(parent, f'{folder_name}_plots')
|
| 806 |
+
else:
|
| 807 |
+
save_path = None
|
| 808 |
|
| 809 |
+
file_outs = []
|
| 810 |
for file in (pbar := tqdm(files, leave=False, desc='Plotting files ...')):
|
| 811 |
pbar.set_postfix(file=file)
|
| 812 |
|
|
|
|
| 819 |
preds_traj = _unbatch(preds['pred_traj'], agent_batch)
|
| 820 |
preds_head = _unbatch(preds['pred_head'], agent_batch)
|
| 821 |
preds_type = _unbatch(preds['pred_type'], agent_batch)
|
| 822 |
+
if 'pred_state' in preds:
|
| 823 |
+
preds_state = _unbatch(preds['pred_state'], agent_batch)
|
| 824 |
+
else:
|
| 825 |
+
preds_state = tuple([torch.ones((*traj.shape[:2], traj.shape[2] // shift)) for traj in preds_traj]) # [n_agent, n_rollout, n_step2Hz]
|
| 826 |
preds_valid = _unbatch(preds['pred_valid'], agent_batch)
|
| 827 |
|
| 828 |
+
# ! fetch certain scenario
|
| 829 |
+
if batch_idx is not None:
|
| 830 |
+
scenario_ids = scenario_ids[batch_idx : batch_idx + 1]
|
| 831 |
+
agent_id = (agent_id[batch_idx],)
|
| 832 |
+
preds_traj = (preds_traj[batch_idx],)
|
| 833 |
+
preds_head = (preds_head[batch_idx],)
|
| 834 |
+
preds_type = (preds_type[batch_idx],)
|
| 835 |
+
preds_state = (preds_state[batch_idx],)
|
| 836 |
+
preds_valid = (preds_valid[batch_idx],)
|
| 837 |
+
|
| 838 |
+
scenario_outs = []
|
| 839 |
for i, scenario_id in enumerate(scenario_ids):
|
| 840 |
+
n_agent, n_rollouts = preds_traj[0].shape[:2]
|
| 841 |
|
| 842 |
+
rollout_outs = []
|
| 843 |
for j in range(n_rollouts): # 1
|
| 844 |
pred = dict(scenario_id=[scenario_id],
|
| 845 |
pred_traj=preds_traj[i][:, j],
|
| 846 |
pred_head=preds_head[i][:, j],
|
| 847 |
+
pred_state=(
|
| 848 |
+
torch.cat([torch.zeros(n_agent, 1), preds_state[i][:, j].repeat_interleave(repeats=shift, dim=-1)],
|
| 849 |
+
dim=1)
|
| 850 |
+
),
|
| 851 |
pred_type=preds_type[i][:, j],
|
| 852 |
)
|
|
|
|
| 853 |
|
| 854 |
+
# NOTE: hard code!!!
|
| 855 |
+
if 'av_id' in preds:
|
| 856 |
+
av_index = agent_id[i][:, 0].tolist().index(preds['av_id'])
|
| 857 |
+
else:
|
| 858 |
+
av_index = n_agent - 1
|
| 859 |
+
|
| 860 |
+
# ! load logged data
|
| 861 |
data_path = os.path.join(gt_folder, 'validation', f'{scenario_id}.pkl')
|
| 862 |
with open(data_path, 'rb') as f:
|
| 863 |
data = pickle.load(f)
|
| 864 |
+
|
| 865 |
+
rollout_outs.append(
|
| 866 |
+
plot_val(data, pred,
|
| 867 |
+
av_index=av_index,
|
| 868 |
+
save_path=save_path,
|
| 869 |
+
save_gif=save_gif,
|
| 870 |
+
time_idx=time_idx,
|
| 871 |
+
limit_size=limit_size,
|
| 872 |
+
**kwargs
|
| 873 |
+
)
|
| 874 |
+
)
|
| 875 |
+
|
| 876 |
+
scenario_outs.append(rollout_outs)
|
| 877 |
+
file_outs.append(scenario_outs)
|
| 878 |
+
|
| 879 |
+
return file_outs
|
| 880 |
|
| 881 |
|
| 882 |
@safe_run
|
|
|
|
| 901 |
if 'agent_labels' in pred:
|
| 902 |
kwargs.update(agent_labels=pred['agent_labels'])
|
| 903 |
|
| 904 |
+
return plot_scenario(scenario_id, map_point, pred_traj, pred_head, pred_state, pred_type,
|
| 905 |
+
av_index=av_index, ids=ids, save_path=save_path, suffix=suffix,
|
| 906 |
+
pl2seed_radius=pl2seed_radius, attr_tokenizer=attr_tokenizer, **kwargs)
|
| 907 |
|
| 908 |
|
| 909 |
@safe_run
|
|
|
|
| 914 |
state: npt.NDArray,
|
| 915 |
types: List[str],
|
| 916 |
av_index: int,
|
| 917 |
+
color_type: Literal['state', 'type', 'seed', 'insert']='seed',
|
| 918 |
state_type: List[str]=['invalid', 'valid', 'enter', 'exit'],
|
| 919 |
plot_enter: bool=False,
|
| 920 |
suffix: str='',
|
|
|
|
| 934 |
num_historical_steps = 2
|
| 935 |
shift = 1
|
| 936 |
|
| 937 |
+
if (
|
| 938 |
+
'save_path' in kwargs
|
| 939 |
+
and kwargs['save_path'] != ''
|
| 940 |
+
and kwargs['save_path'] != None
|
| 941 |
+
):
|
| 942 |
os.makedirs(kwargs['save_path'], exist_ok=True)
|
| 943 |
save_id = int(max([0] + list(map(lambda fname: int(fname.split("_")[-1]),
|
| 944 |
filter(lambda fname: fname.startswith(scenario_id)
|
|
|
|
| 985 |
agent_colors[is_exited, :] = seed_colors['exited']
|
| 986 |
agent_colors[is_entered, :] = seed_colors['entered']
|
| 987 |
|
| 988 |
+
if color_type == 'insert':
|
| 989 |
+
agent_colors[:, :] = seed_colors['exited']
|
| 990 |
+
agent_colors[av_index + 1:] = seed_colors['existing']
|
| 991 |
+
|
| 992 |
agent_colors[av_index, :] = np.array(agent_palette[-1])
|
| 993 |
is_av = np.zeros_like(state[:, 0]).astype(np.bool_)
|
| 994 |
is_av[av_index] = True
|
| 995 |
|
| 996 |
+
# ! get timesteps to plot
|
| 997 |
+
timesteps = list(range(num_timestep))
|
| 998 |
+
if kwargs.get('time_idx', None) is not None:
|
| 999 |
+
time_idx = kwargs['time_idx']
|
| 1000 |
+
assert set(time_idx).issubset(set(timesteps)), f'Got invalid time_idx: {time_idx=} v.s. {timesteps=}'
|
| 1001 |
+
timesteps = sorted(time_idx)
|
| 1002 |
+
|
| 1003 |
+
# ! get plot limits
|
| 1004 |
+
limit_size = kwargs.get('limit_size', None)
|
| 1005 |
+
if limit_size is not None:
|
| 1006 |
+
assert len(limit_size) == 2, f'Got invalid `limit_size`: {limit_size=}'
|
| 1007 |
+
|
| 1008 |
+
# ! plot all
|
| 1009 |
+
pil_images = []
|
| 1010 |
fig_paths = []
|
| 1011 |
+
for tid in tqdm(timesteps, leave=False, desc="Plot ..."):
|
| 1012 |
mask_t = visible_mask[:, tid]
|
| 1013 |
xs = traj[mask_t, tid, 0]
|
| 1014 |
ys = traj[mask_t, tid, 1]
|
|
|
|
| 1024 |
labels = [agent_labels[i][tid // shift] for i in range(len(agent_labels)) if mask_t[i]]
|
| 1025 |
|
| 1026 |
fig_path = None
|
| 1027 |
+
if kwargs.get('save_path', None) is not None:
|
| 1028 |
save_path = kwargs['save_path']
|
| 1029 |
fig_path = os.path.join(f"{save_path}/{scenario_id}_{str(save_id).zfill(3)}", f"{tid}.png")
|
| 1030 |
fig_paths.append(fig_path)
|
| 1031 |
|
| 1032 |
+
pil_images.append(
|
| 1033 |
+
plot_all(map_data, xs, ys, angles, types_t,
|
| 1034 |
+
colors=colors,
|
| 1035 |
+
save_path=fig_path,
|
| 1036 |
+
is_avs=is_av_t,
|
| 1037 |
+
pl2seed_radius=pl2seed_radius,
|
| 1038 |
+
attr_tokenizer=attr_tokenizer,
|
| 1039 |
+
enter_index=enter_index_t,
|
| 1040 |
+
labels=labels,
|
| 1041 |
+
limit_size=limit_size,
|
| 1042 |
+
)
|
| 1043 |
+
)
|
| 1044 |
|
| 1045 |
# generate gif
|
| 1046 |
if fig_paths and save_gif:
|
|
|
|
| 1061 |
except Exception as e:
|
| 1062 |
tqdm.write(f"{e}! Failed to save gif at {gif_path}")
|
| 1063 |
|
| 1064 |
+
return pil_images
|
| 1065 |
+
|
| 1066 |
|
| 1067 |
def match_token_map(data):
|
| 1068 |
|
|
|
|
| 1201 |
agent_type = agent_data['type']
|
| 1202 |
ids = np.arange(raw_traj.shape[0])
|
| 1203 |
|
| 1204 |
+
return plot_scenario(
|
| 1205 |
+
scenario_id=tokenized_data['scenario_id'],
|
| 1206 |
+
map_data=tokenized_data['map_point']['position'].numpy(),
|
| 1207 |
+
traj=raw_traj.numpy(),
|
| 1208 |
+
heading=raw_heading.numpy(),
|
| 1209 |
+
state=agent_state.numpy(),
|
| 1210 |
+
types=list(map(lambda i: AGENT_TYPE[i], agent_type.tolist())),
|
| 1211 |
+
av_index=av_index,
|
| 1212 |
+
ids=ids,
|
| 1213 |
+
save_path=save_path,
|
| 1214 |
+
pl2seed_radius=pl2seed_radius,
|
| 1215 |
+
attr_tokenizer=attr_tokenizer,
|
| 1216 |
+
color_type='state',
|
| 1217 |
+
)
|
| 1218 |
+
|
| 1219 |
+
|
| 1220 |
+
def get_metainfos(folder: str):
|
| 1221 |
+
|
| 1222 |
+
import pandas as pd
|
| 1223 |
+
|
| 1224 |
+
assert os.path.exists(folder), f'Path {folder} does not exist.'
|
| 1225 |
+
files = list(fnmatch.filter(os.listdir(folder), 'idx_*_rollouts.pkl'))
|
| 1226 |
+
CONSOLE.log(f'Found {len(files)} rollouts files from {folder}.')
|
| 1227 |
+
|
| 1228 |
+
metainfos_path = f'{os.path.normpath(folder)}_metainfos.parquet'
|
| 1229 |
+
csv_path = f'{os.path.normpath(folder)}_metainfos.csv'
|
| 1230 |
+
|
| 1231 |
+
if not os.path.exists(metainfos_path):
|
| 1232 |
+
|
| 1233 |
+
data = []
|
| 1234 |
+
for file in tqdm(files):
|
| 1235 |
+
pkl_data = pickle.load(open(os.path.join(folder, file), 'rb'))
|
| 1236 |
+
data.extend((file, scenario_id, index) for index, scenario_id in enumerate(pkl_data['_scenario_id']))
|
| 1237 |
+
|
| 1238 |
+
df = pd.DataFrame(data, columns=('rollout_file', 'scenario_id', 'index'))
|
| 1239 |
+
df.to_parquet(metainfos_path)
|
| 1240 |
+
df.to_csv(csv_path)
|
| 1241 |
+
CONSOLE.log(f'Successfully saved to {metainfos_path}.')
|
| 1242 |
+
|
| 1243 |
+
else:
|
| 1244 |
+
CONSOLE.log(f'File {metainfos_path} already exists!')
|
| 1245 |
+
return
|
| 1246 |
+
|
| 1247 |
+
|
| 1248 |
+
def plot_comparison(methods: List[str], rollouts_paths: List[str], gt_folders: List[str],
|
| 1249 |
+
save_path: str, scenario_ids: Optional[List[str]] = None):
|
| 1250 |
+
import pandas as pd
|
| 1251 |
+
from collections import defaultdict
|
| 1252 |
+
|
| 1253 |
+
# ! hyperparameter
|
| 1254 |
+
fps = 10
|
| 1255 |
+
|
| 1256 |
+
plot_time = [1, 6, 12, 18, 24, 30]
|
| 1257 |
+
# plot_time = [1, 5, 10, 15, 20, 25]
|
| 1258 |
+
time_idx = [int(time * fps) for time in plot_time]
|
| 1259 |
+
|
| 1260 |
+
limit_size = [75, 60] # [width, height]
|
| 1261 |
+
|
| 1262 |
+
# ! load metainfos
|
| 1263 |
+
metainfos = defaultdict(dict)
|
| 1264 |
+
for method, rollout_path in zip(methods, rollouts_paths):
|
| 1265 |
+
meta_info_path = f'{os.path.normpath(rollout_path)}_metainfos.parquet'
|
| 1266 |
+
metainfos[method]['df'] = pd.read_parquet(meta_info_path)
|
| 1267 |
+
CONSOLE.log(f'Loaded {method=} with {len(metainfos[method]["df"]["scenario_id"])=}.')
|
| 1268 |
+
common_scenarios = set(metainfos['ours']['df']['scenario_id'])
|
| 1269 |
+
for method, meta_info in metainfos.items():
|
| 1270 |
+
if method == 'ours':
|
| 1271 |
+
continue
|
| 1272 |
+
common_scenarios &= set(meta_info['df']['scenario_id'])
|
| 1273 |
+
for method, meta_info in metainfos.items():
|
| 1274 |
+
df = metainfos[method]['df']
|
| 1275 |
+
metainfos[method]['df'] = df[df['scenario_id'].isin(common_scenarios)]
|
| 1276 |
+
CONSOLE.log(f'Filter and get {len(common_scenarios)=}.')
|
| 1277 |
+
|
| 1278 |
+
# ! load data and plot
|
| 1279 |
+
if scenario_ids is None:
|
| 1280 |
+
scenario_ids = metainfos['ours']['df']['scenario_id'].tolist()
|
| 1281 |
+
CONSOLE.log(f'Plotting {len(scenario_ids)=} ...')
|
| 1282 |
+
|
| 1283 |
+
for scenario_id in (pbar := tqdm(scenario_ids)):
|
| 1284 |
+
pbar.set_postfix(scenario_id=scenario_id)
|
| 1285 |
+
|
| 1286 |
+
figures = dict()
|
| 1287 |
+
for method, rollout_path, gt_folder in zip(methods, rollouts_paths, gt_folders):
|
| 1288 |
+
df = metainfos[method]['df']
|
| 1289 |
+
_df = df.loc[df['scenario_id'] == scenario_id]
|
| 1290 |
+
batch_idx = int(_df['index'].tolist()[0])
|
| 1291 |
+
rollout_file = _df['rollout_file'].tolist()[0]
|
| 1292 |
+
figures[method] = plot_file(
|
| 1293 |
+
gt_folder=gt_folder,
|
| 1294 |
+
files=os.path.join(rollout_path, rollout_file),
|
| 1295 |
+
save_gif=False,
|
| 1296 |
+
batch_idx=batch_idx,
|
| 1297 |
+
time_idx=time_idx,
|
| 1298 |
+
limit_size=limit_size,
|
| 1299 |
+
color_type='insert',
|
| 1300 |
+
)[0][0][0]
|
| 1301 |
+
|
| 1302 |
+
# ! plot figures
|
| 1303 |
+
border = 5
|
| 1304 |
+
padding_x = 20
|
| 1305 |
+
padding_y = 50
|
| 1306 |
+
|
| 1307 |
+
img_width, img_height = figures['ours'][0].size
|
| 1308 |
+
img_width = img_width + 2 * border
|
| 1309 |
+
img_height = img_height + 2 * border
|
| 1310 |
+
n_col = len(time_idx)
|
| 1311 |
+
n_row = len(methods)
|
| 1312 |
+
|
| 1313 |
+
W = n_col * img_width + (n_col - 1) * padding_x
|
| 1314 |
+
H = n_row * img_height + (n_row - 1) * padding_y
|
| 1315 |
+
|
| 1316 |
+
canvas = Image.new('RGB', (W, H), 'white')
|
| 1317 |
+
for i_row, (method, method_figures) in enumerate(figures.items()):
|
| 1318 |
+
for i_col, method_figure in enumerate(method_figures):
|
| 1319 |
+
x = i_col * (img_width + padding_x)
|
| 1320 |
+
y = i_row * (img_height + padding_y)
|
| 1321 |
+
|
| 1322 |
+
padded_figure = Image.new('RGB', (img_width, img_height), 'black')
|
| 1323 |
+
padded_figure.paste(method_figure, (border, border))
|
| 1324 |
+
|
| 1325 |
+
canvas.paste(padded_figure, (x, y))
|
| 1326 |
+
|
| 1327 |
+
canvas.save(
|
| 1328 |
+
os.path.join(save_path, f'{scenario_id}.png')
|
| 1329 |
+
)
|
| 1330 |
|
| 1331 |
|
| 1332 |
if __name__ == "__main__":
|
|
|
|
| 1342 |
parser.add_argument('--plot_file', action='store_true')
|
| 1343 |
parser.add_argument('--folder_path', type=str, default=None)
|
| 1344 |
parser.add_argument('--file_path', type=str, default=None)
|
| 1345 |
+
# metainfos
|
| 1346 |
+
parser.add_argument('--get_metainfos', action='store_true')
|
| 1347 |
+
# plot comparison
|
| 1348 |
+
parser.add_argument('--plot_comparison', action='store_true')
|
| 1349 |
+
parser.add_argument('--comparison_folder', type=str, default='comparisons')
|
| 1350 |
args = parser.parse_args()
|
| 1351 |
|
| 1352 |
if args.plot_tokenize:
|
|
|
|
| 1366 |
if args.plot_file:
|
| 1367 |
|
| 1368 |
plot_file(args.data_path, folder=args.folder_path, files=args.file_path)
|
| 1369 |
+
|
| 1370 |
+
if args.get_metainfos:
|
| 1371 |
+
|
| 1372 |
+
assert args.folder_path is not None, f'`folder_path` should not be None!'
|
| 1373 |
+
get_metainfos(args.folder_path)
|
| 1374 |
+
|
| 1375 |
+
if args.plot_comparison:
|
| 1376 |
+
|
| 1377 |
+
methods = ['ours', 'smart']
|
| 1378 |
+
gt_folders = [
|
| 1379 |
+
'/baai-cwm-1/baai_cwm_ml/algorithm/xiuyu.yang/work/dev4/data/processed',
|
| 1380 |
+
'/baai-cwm-1/baai_cwm_ml/algorithm/xiuyu.yang/work/dev4/data/processed',
|
| 1381 |
+
'/baai-cwm-1/baai_cwm_ml/algorithm/xiuyu.yang/work/dev4/data/processed',
|
| 1382 |
+
]
|
| 1383 |
+
rollouts_paths = [
|
| 1384 |
+
'/baai-cwm-1/baai_cwm_ml/algorithm/xiuyu.yang/work/dev4/output/scalable_smart_long/validation_ours0',
|
| 1385 |
+
'/baai-cwm-1/baai_cwm_ml/algorithm/xiuyu.yang/work/dev4/output/scalable_smart_long/validation_smart',
|
| 1386 |
+
'/baai-cwm-1/baai_cwm_ml/algorithm/xiuyu.yang/work/dev4/output/scalable_smart_long/validation_cslft',
|
| 1387 |
+
]
|
| 1388 |
+
save_path = f'/baai-cwm-1/baai_cwm_ml/algorithm/xiuyu.yang/work/dev4/output/scalable_smart_long/{args.comparison_folder}/'
|
| 1389 |
+
os.makedirs(save_path, exist_ok=True)
|
| 1390 |
+
|
| 1391 |
+
scenario_ids = ['72ff3e1540b28431','a16c927b1a1cca74','a504d55ea6658de7','639949ea1d16125b']
|
| 1392 |
+
plot_comparison(methods, rollouts_paths, gt_folders,
|
| 1393 |
+
save_path=save_path,
|
| 1394 |
+
scenario_ids=scenario_ids)
|
backups/scripts/compute_metrics.sh
CHANGED
|
@@ -1,7 +1,20 @@
|
|
| 1 |
#!/bin/bash
|
| 2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
export TORCH_LOGS='0'
|
| 4 |
export TF_CPP_MIN_LOG_LEVEL='2'
|
|
|
|
| 5 |
export PYTHONPATH='.'
|
| 6 |
|
| 7 |
NUM_WORKERS=$1
|
|
@@ -10,4 +23,4 @@ SIM_DIR=$2
|
|
| 10 |
echo 'Start running ...'
|
| 11 |
python dev/metrics/compute_metrics.py --compute_metric --num_workers "$NUM_WORKERS" --sim_dir "$SIM_DIR" ${@:3}
|
| 12 |
|
| 13 |
-
echo 'Done!
|
|
|
|
| 1 |
#!/bin/bash
|
| 2 |
|
| 3 |
+
# network
|
| 4 |
+
source /baai-cwm-1/baai_cwm_ml/algorithm/xiuyu.yang/clash.sh
|
| 5 |
+
bash /baai-cwm-1/baai_cwm_ml/algorithm/xiuyu.yang/clash-for-linux-backup/start.sh
|
| 6 |
+
proxy_on
|
| 7 |
+
|
| 8 |
+
# env
|
| 9 |
+
source /baai-cwm-1/baai_cwm_ml/algorithm/xiuyu.yang/anaconda3/etc/profile.d/conda.sh
|
| 10 |
+
conda config --append envs_dirs /baai-cwm-1/baai_cwm_ml/algorithm/xiuyu.yang/.conda/envs
|
| 11 |
+
conda activate traj
|
| 12 |
+
|
| 13 |
+
cd /baai-cwm-1/baai_cwm_ml/algorithm/xiuyu.yang/work/dev4/
|
| 14 |
+
|
| 15 |
export TORCH_LOGS='0'
|
| 16 |
export TF_CPP_MIN_LOG_LEVEL='2'
|
| 17 |
+
export TF_ENABLE_ONEDNN_OPTS='0'
|
| 18 |
export PYTHONPATH='.'
|
| 19 |
|
| 20 |
NUM_WORKERS=$1
|
|
|
|
| 23 |
echo 'Start running ...'
|
| 24 |
python dev/metrics/compute_metrics.py --compute_metric --num_workers "$NUM_WORKERS" --sim_dir "$SIM_DIR" ${@:3}
|
| 25 |
|
| 26 |
+
echo 'Done!
|
backups/scripts/g8.sh
CHANGED
|
@@ -8,7 +8,7 @@
|
|
| 8 |
#SBATCH --nodes=1 # Single node or multi node
|
| 9 |
#SBATCH --nodelist=sota-6
|
| 10 |
#SBATCH --time 120:00:00 # Max time (hh:mm:ss)
|
| 11 |
-
#SBATCH --gres=gpu:
|
| 12 |
#SBATCH --mem=256G # Recommend 32G per GPU
|
| 13 |
#SBATCH --ntasks-per-node=1 # Tasks per node
|
| 14 |
#SBATCH --cpus-per-task=32 # Recommend 8 per GPU
|
|
|
|
| 8 |
#SBATCH --nodes=1 # Single node or multi node
|
| 9 |
#SBATCH --nodelist=sota-6
|
| 10 |
#SBATCH --time 120:00:00 # Max time (hh:mm:ss)
|
| 11 |
+
#SBATCH --gres=gpu:7 # GPUs per node
|
| 12 |
#SBATCH --mem=256G # Recommend 32G per GPU
|
| 13 |
#SBATCH --ntasks-per-node=1 # Tasks per node
|
| 14 |
#SBATCH --cpus-per-task=32 # Recommend 8 per GPU
|
backups/scripts/hf_model.py
CHANGED
|
@@ -15,9 +15,9 @@ def upload():
|
|
| 15 |
|
| 16 |
try:
|
| 17 |
if token is not None:
|
| 18 |
-
upload_folder(repo_id=args.repo_id, folder_path=args.folder_path, ignore_patterns=ignore_patterns, token=token)
|
| 19 |
else:
|
| 20 |
-
upload_folder(repo_id=args.repo_id, folder_path=args.folder_path, ignore_patterns=ignore_patterns)
|
| 21 |
table = Table(title=None, show_header=False, box=box.MINIMAL, title_style=style.Style(bold=True))
|
| 22 |
table.add_row(f"Model id {args.repo_id}", str(args.folder_path))
|
| 23 |
CONSOLE.print(Panel(table, title="[bold][green]:tada: Upload completed DO NOT forget specify the model id in methods! :tada:[/bold]", expand=False))
|
|
@@ -92,6 +92,7 @@ if __name__ == "__main__":
|
|
| 92 |
parser.add_argument("--file_path", type=str, default=None, required=False)
|
| 93 |
parser.add_argument("--save_path", type=str, default=None, required=False)
|
| 94 |
parser.add_argument("--token", type=str, default=None, required=False)
|
|
|
|
| 95 |
args = parser.parse_args()
|
| 96 |
|
| 97 |
token = args.token or os.getenv("hf_token", None)
|
|
|
|
| 15 |
|
| 16 |
try:
|
| 17 |
if token is not None:
|
| 18 |
+
upload_folder(repo_id=args.repo_id, folder_path=args.folder_path, ignore_patterns=ignore_patterns, path_in_repo=args.path_in_repo, token=token)
|
| 19 |
else:
|
| 20 |
+
upload_folder(repo_id=args.repo_id, folder_path=args.folder_path, ignore_patterns=ignore_patterns, path_in_repo=args.path_in_repo)
|
| 21 |
table = Table(title=None, show_header=False, box=box.MINIMAL, title_style=style.Style(bold=True))
|
| 22 |
table.add_row(f"Model id {args.repo_id}", str(args.folder_path))
|
| 23 |
CONSOLE.print(Panel(table, title="[bold][green]:tada: Upload completed DO NOT forget specify the model id in methods! :tada:[/bold]", expand=False))
|
|
|
|
| 92 |
parser.add_argument("--file_path", type=str, default=None, required=False)
|
| 93 |
parser.add_argument("--save_path", type=str, default=None, required=False)
|
| 94 |
parser.add_argument("--token", type=str, default=None, required=False)
|
| 95 |
+
parser.add_argument("--path_in_repo", type=str, default=None, required=False)
|
| 96 |
args = parser.parse_args()
|
| 97 |
|
| 98 |
token = args.token or os.getenv("hf_token", None)
|
backups/scripts/run_eval.sh
CHANGED
|
@@ -1,5 +1,17 @@
|
|
| 1 |
#! /bin/bash
|
| 2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
# env
|
| 4 |
export REQUESTS_CA_BUNDLE="/etc/ssl/certs/ca-certificates.crt"
|
| 5 |
export HTTPS_PROXY="https://192.168.0.10:443/"
|
|
@@ -11,10 +23,12 @@ export WANDB=1
|
|
| 11 |
DEVICES=$1
|
| 12 |
CONFIG='configs/ours_long_term.yaml'
|
| 13 |
# CKPT_PATH='output/scalable_smart_long/last.ckpt'
|
| 14 |
-
CKPT_PATH='output2/seq_10_150_3_3_encode_occ_separate_offsets_bs8_128_no_seqindex_long/last.ckpt'
|
|
|
|
| 15 |
|
| 16 |
# run
|
| 17 |
PYTHONPATH=".":$PYTHONPATH python3 run.py \
|
| 18 |
--devices $DEVICES \
|
| 19 |
--config $CONFIG \
|
| 20 |
--ckpt_path $CKPT_PATH ${@:2}
|
|
|
|
|
|
| 1 |
#! /bin/bash
|
| 2 |
|
| 3 |
+
# network
|
| 4 |
+
source /baai-cwm-1/baai_cwm_ml/algorithm/xiuyu.yang/clash.sh
|
| 5 |
+
bash /baai-cwm-1/baai_cwm_ml/algorithm/xiuyu.yang/clash-for-linux-backup/start.sh
|
| 6 |
+
proxy_on
|
| 7 |
+
|
| 8 |
+
# env
|
| 9 |
+
source /baai-cwm-1/baai_cwm_ml/algorithm/xiuyu.yang/anaconda3/etc/profile.d/conda.sh
|
| 10 |
+
conda config --append envs_dirs /baai-cwm-1/baai_cwm_ml/algorithm/xiuyu.yang/.conda/envs
|
| 11 |
+
conda activate traj
|
| 12 |
+
|
| 13 |
+
cd /baai-cwm-1/baai_cwm_ml/algorithm/xiuyu.yang/work/dev4/
|
| 14 |
+
|
| 15 |
# env
|
| 16 |
export REQUESTS_CA_BUNDLE="/etc/ssl/certs/ca-certificates.crt"
|
| 17 |
export HTTPS_PROXY="https://192.168.0.10:443/"
|
|
|
|
| 23 |
DEVICES=$1
|
| 24 |
CONFIG='configs/ours_long_term.yaml'
|
| 25 |
# CKPT_PATH='output/scalable_smart_long/last.ckpt'
|
| 26 |
+
# CKPT_PATH='output2/seq_10_150_3_3_encode_occ_separate_offsets_bs8_128_no_seqindex_long/last.ckpt'
|
| 27 |
+
CKPT_PATH='output2/seq_10_150_3_3_encode_occ_separate_offsets_bs8_128_no_seqindex_long_lastvalid_ablation_grid/last.ckpt'
|
| 28 |
|
| 29 |
# run
|
| 30 |
PYTHONPATH=".":$PYTHONPATH python3 run.py \
|
| 31 |
--devices $DEVICES \
|
| 32 |
--config $CONFIG \
|
| 33 |
--ckpt_path $CKPT_PATH ${@:2}
|
| 34 |
+
|
epoch=31.ckpt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6e96741caea6c6b048b8dfa1b60ac3ad39435d42cbf06bdbd6fb84b25e1e2df8
|
| 3 |
+
size 135738582
|
last.ckpt
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:98509b491480103452e868729cbaba73eb96c07ba60bb344d9d851e4789aafaf
|
| 3 |
+
size 135738582
|
training_003352_12a725c99e2aaf56_occ_agent.png
ADDED
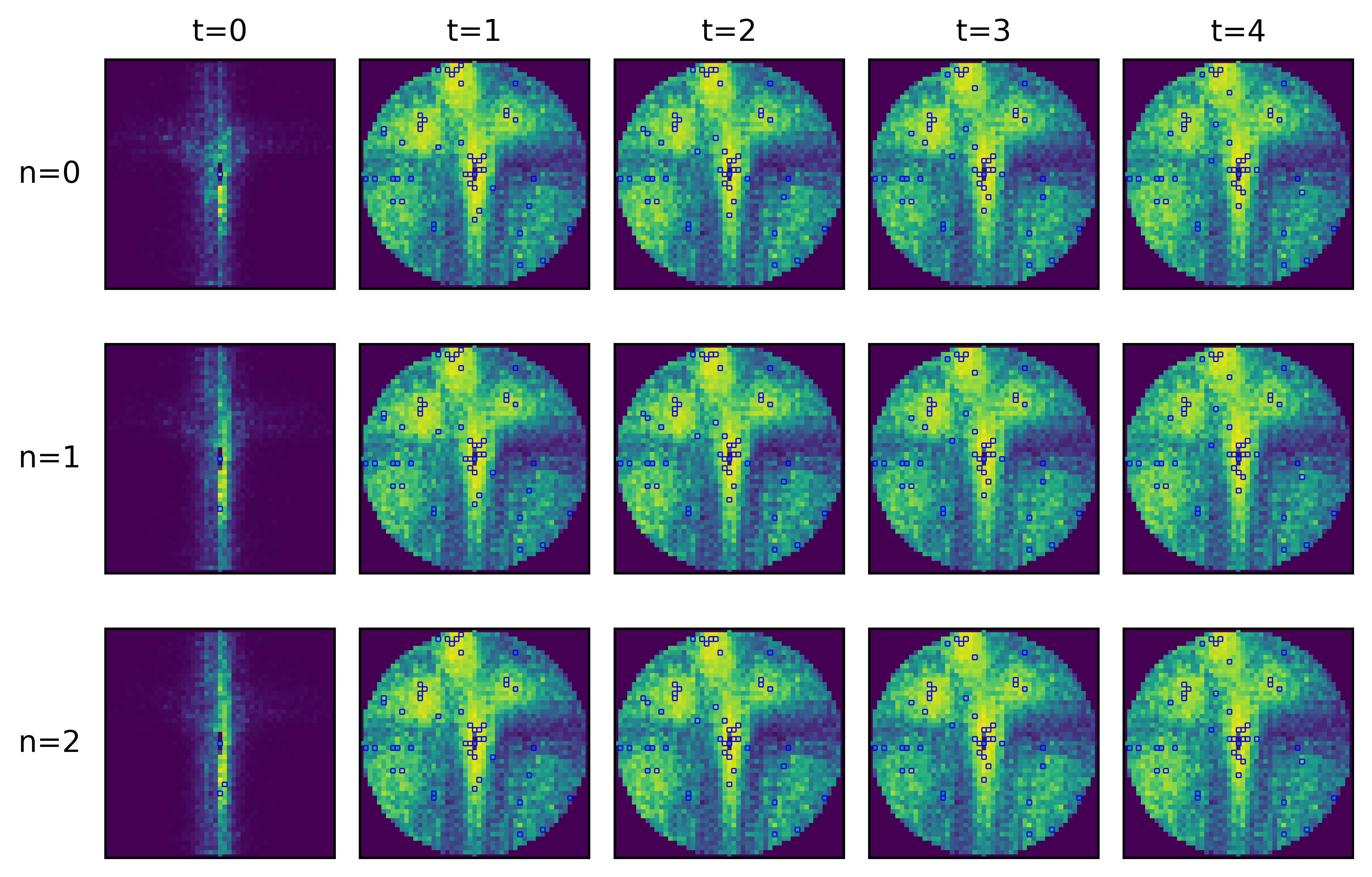
|
Git LFS Details
|
training_003352_12a725c99e2aaf56_occ_pt.png
ADDED
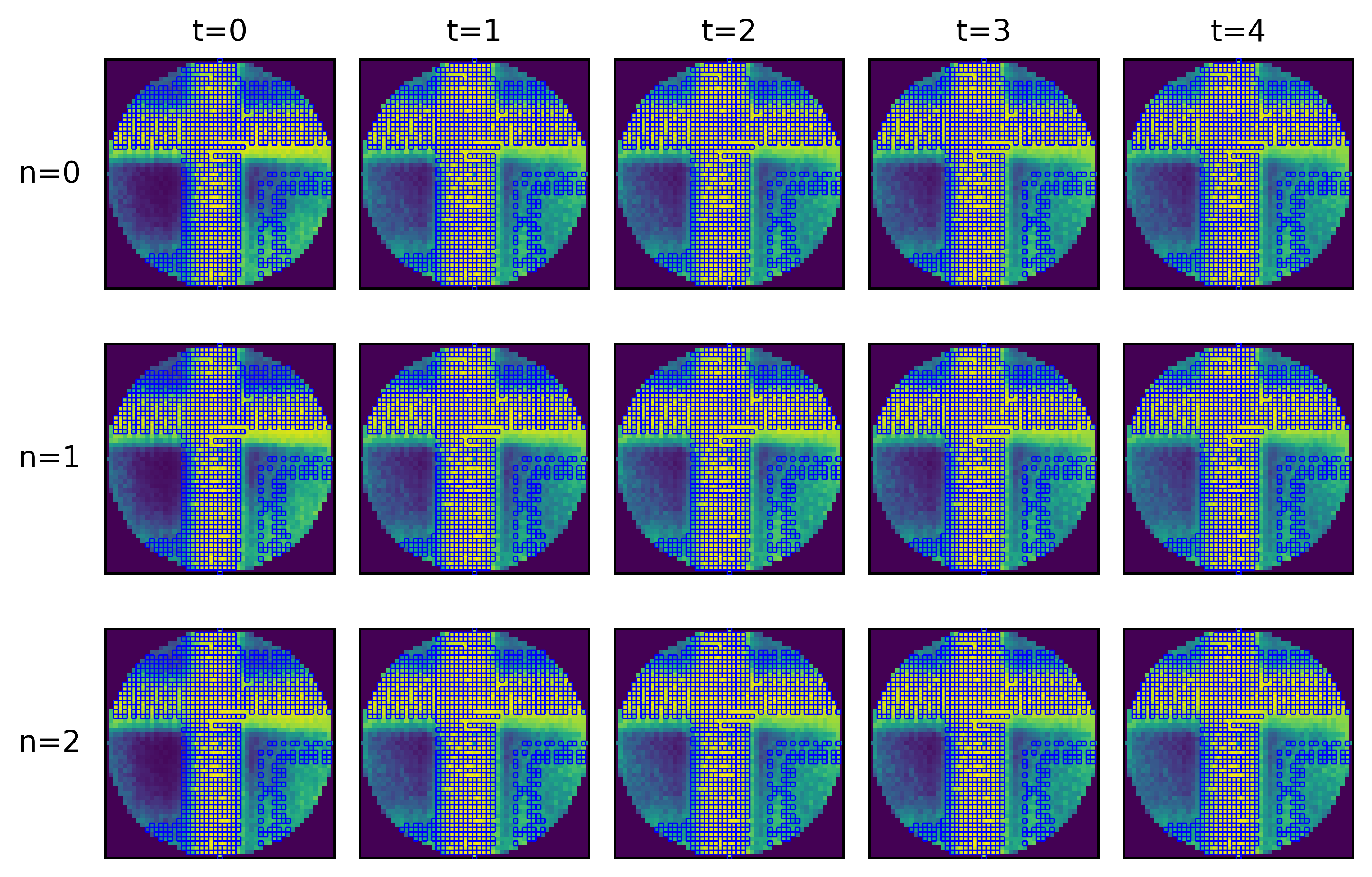
|
Git LFS Details
|
training_003353_11e7a18d6bb79688_insert_map.png
ADDED
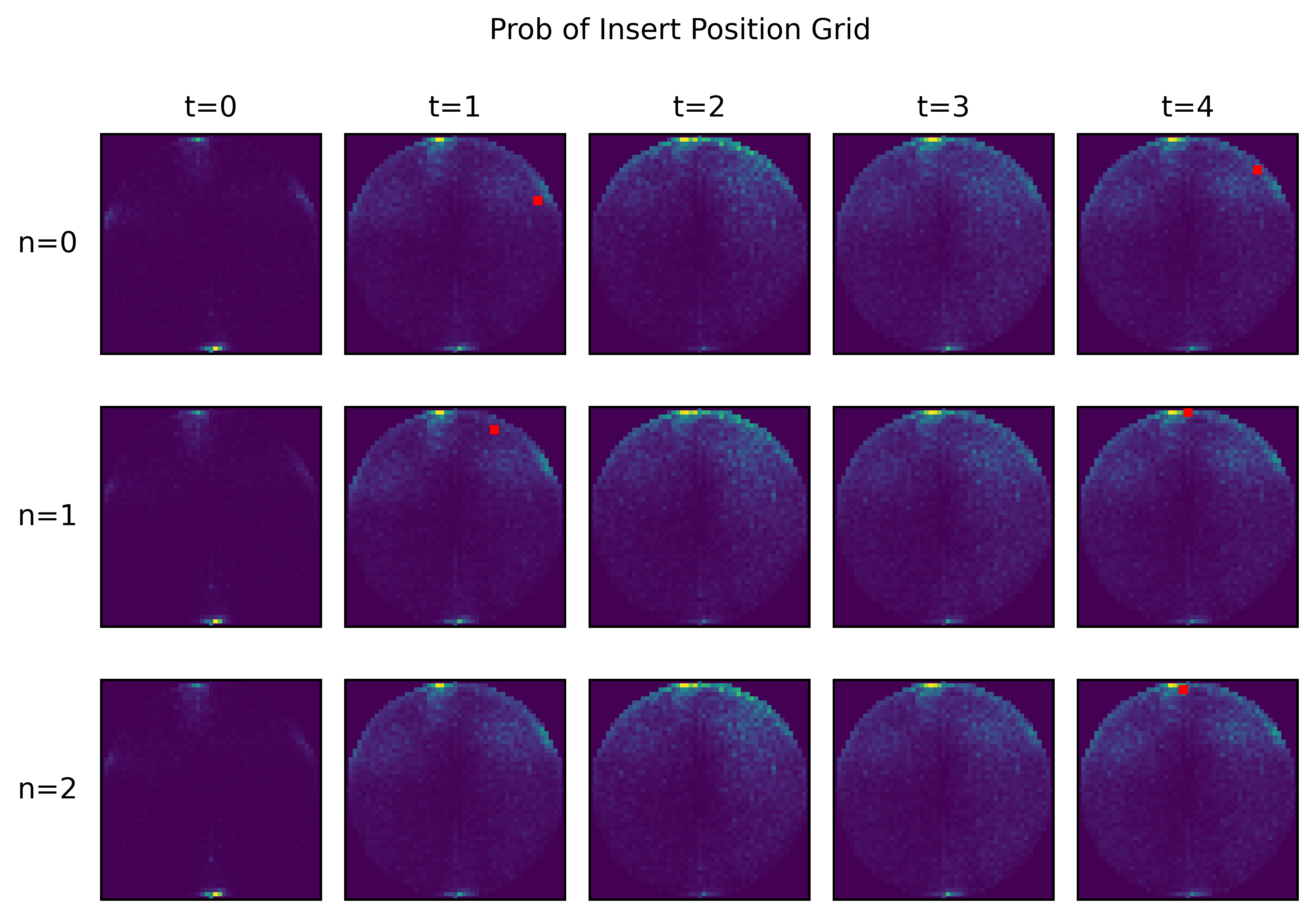
|
Git LFS Details
|
training_003353_11e7a18d6bb79688_prob_seed.png
ADDED
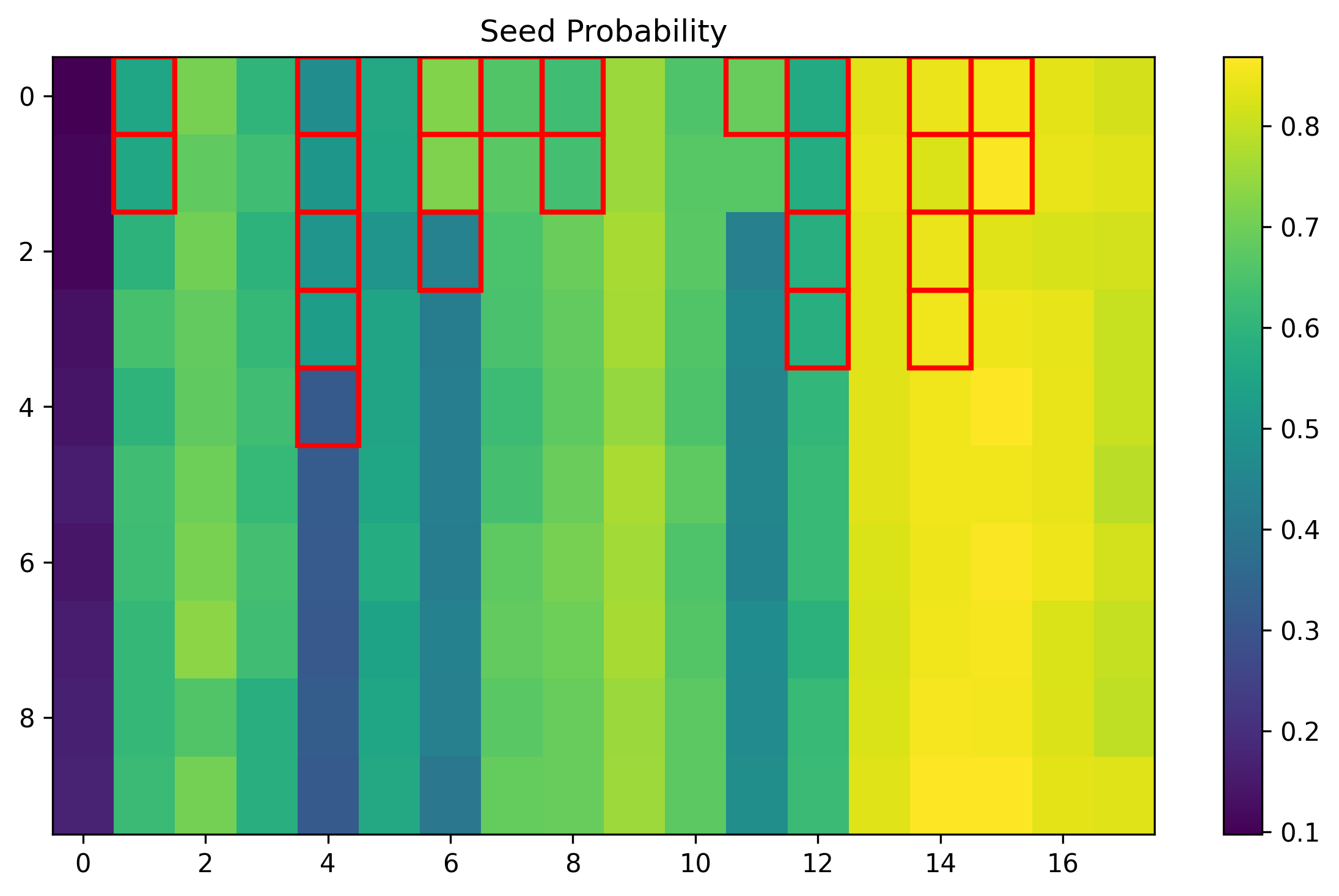
|
training_003353_11f939421937f967_insert_map.png
ADDED
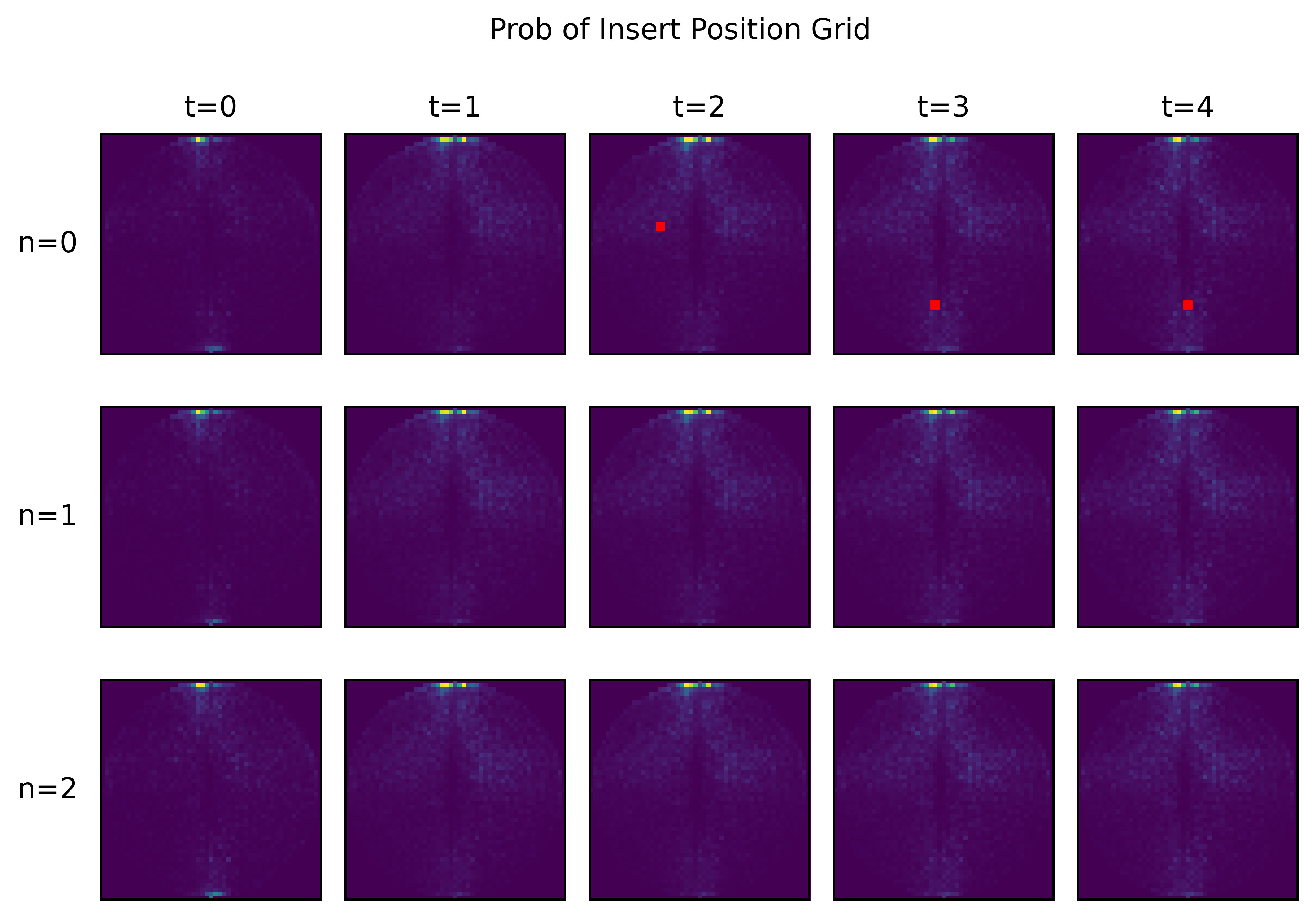
|
Git LFS Details
|
training_003353_11f939421937f967_prob_seed.png
ADDED

|
training_003353_14bdfe3b4ada19bf_insert_map.png
ADDED

|
Git LFS Details
|
training_003353_14bdfe3b4ada19bf_prob_seed.png
ADDED

|
training_003353_1561804123f0e337_insert_map.png
ADDED
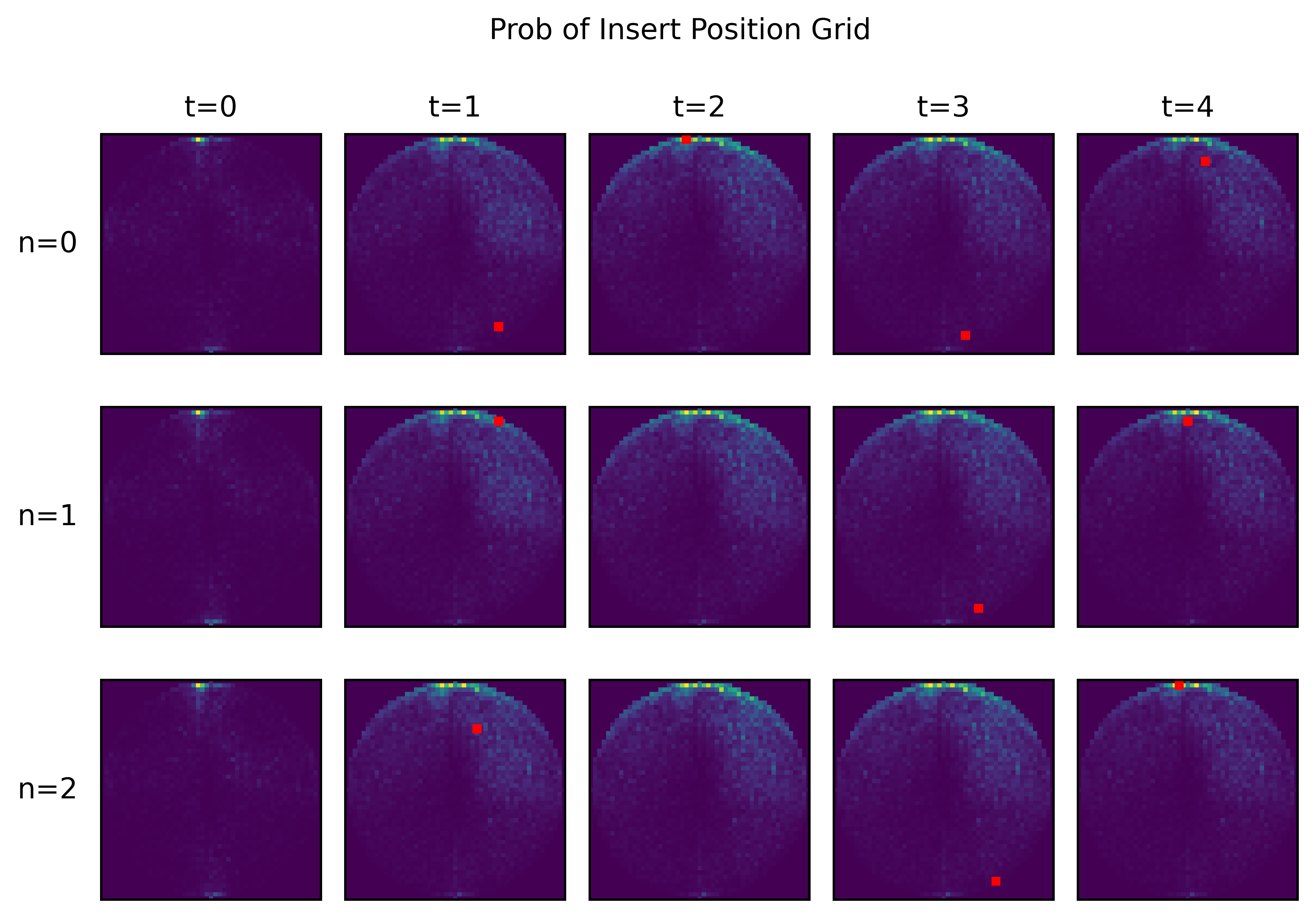
|
Git LFS Details
|
training_003353_1561804123f0e337_prob_seed.png
ADDED
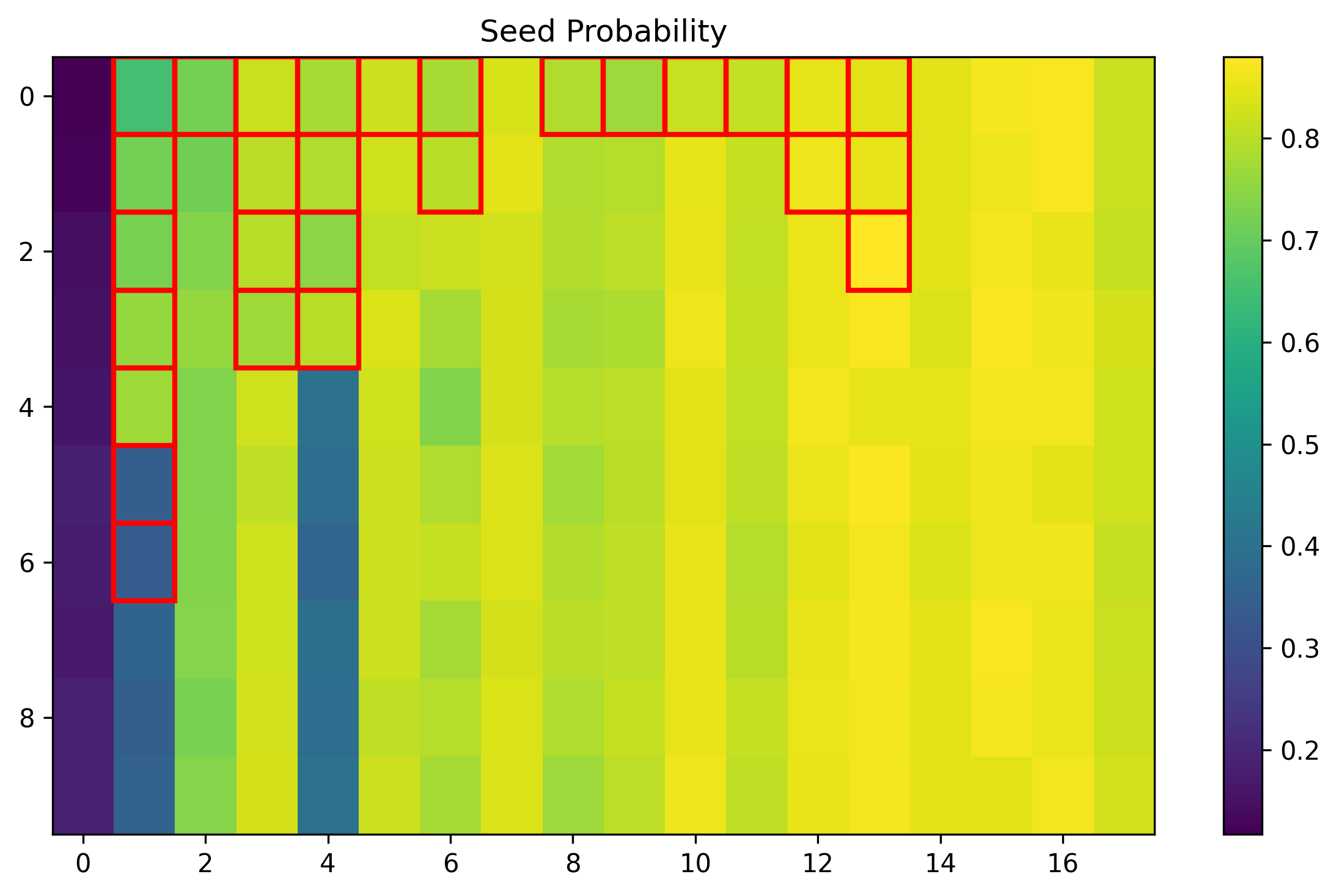
|
training_003353_16d8494156a5b841_insert_map.png
ADDED

|
Git LFS Details
|
training_003353_16d8494156a5b841_prob_seed.png
ADDED
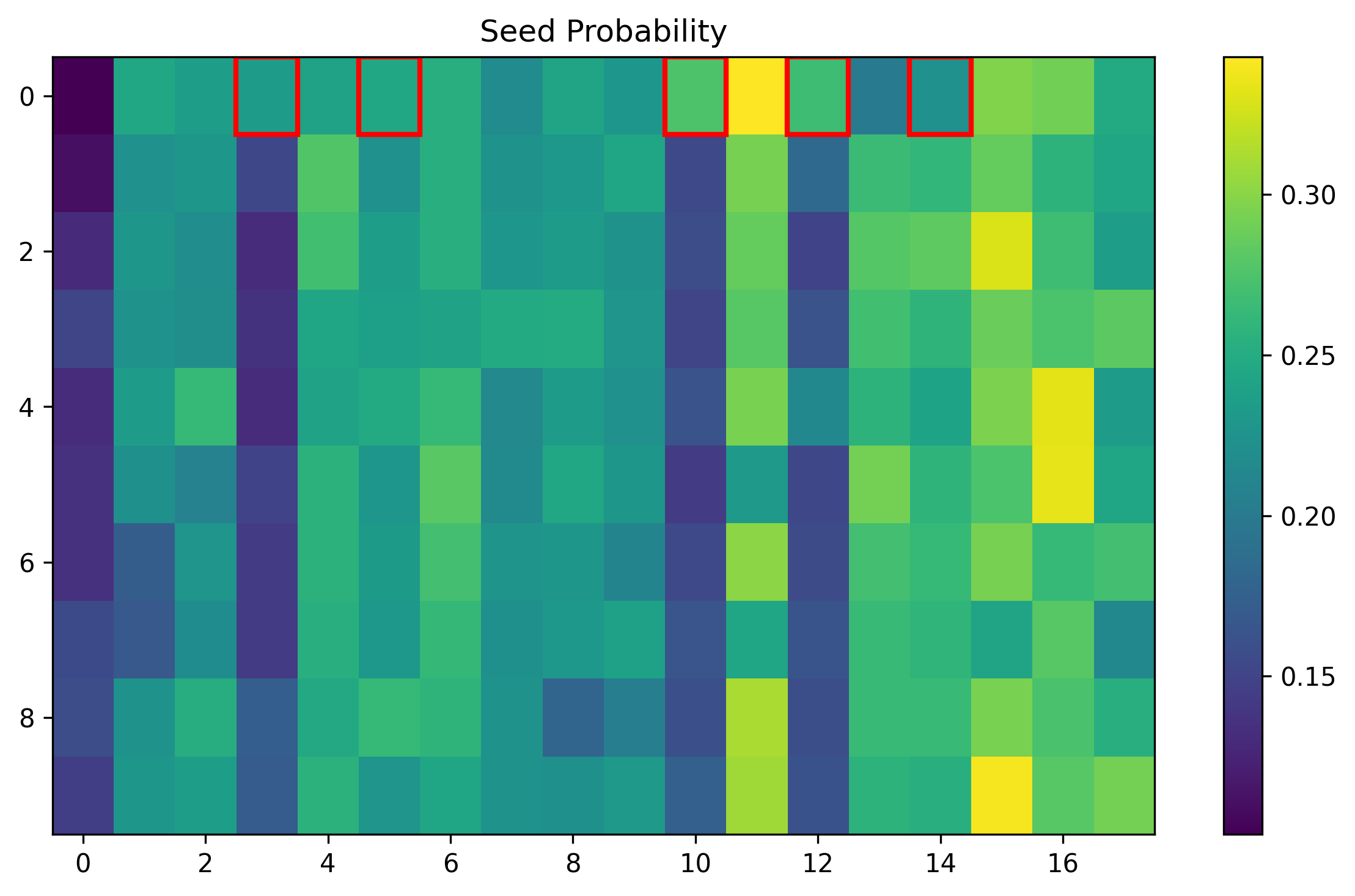
|
training_003353_174ad7295f45aa95_insert_map.png
ADDED
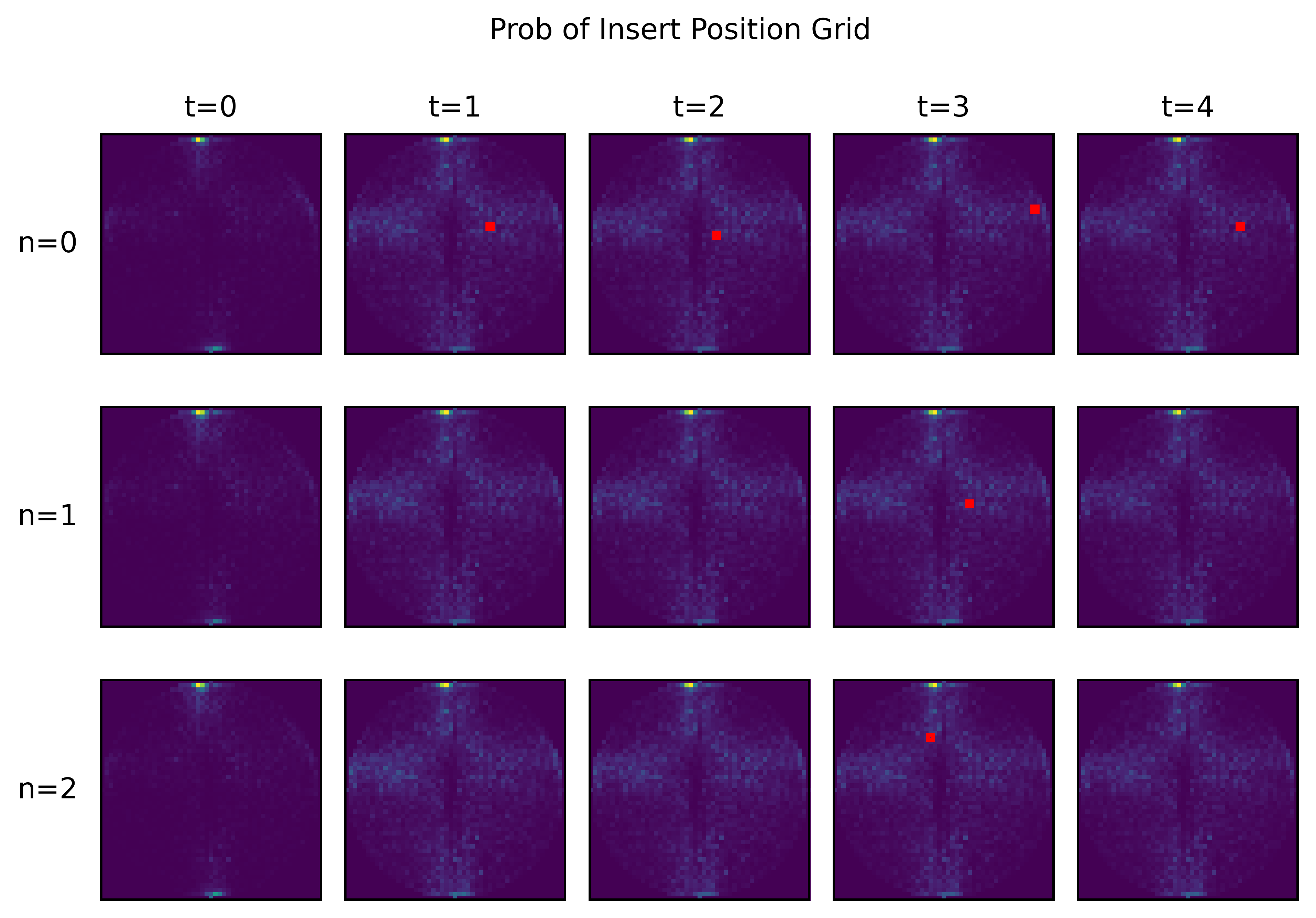
|
Git LFS Details
|
training_003353_174ad7295f45aa95_prob_seed.png
ADDED
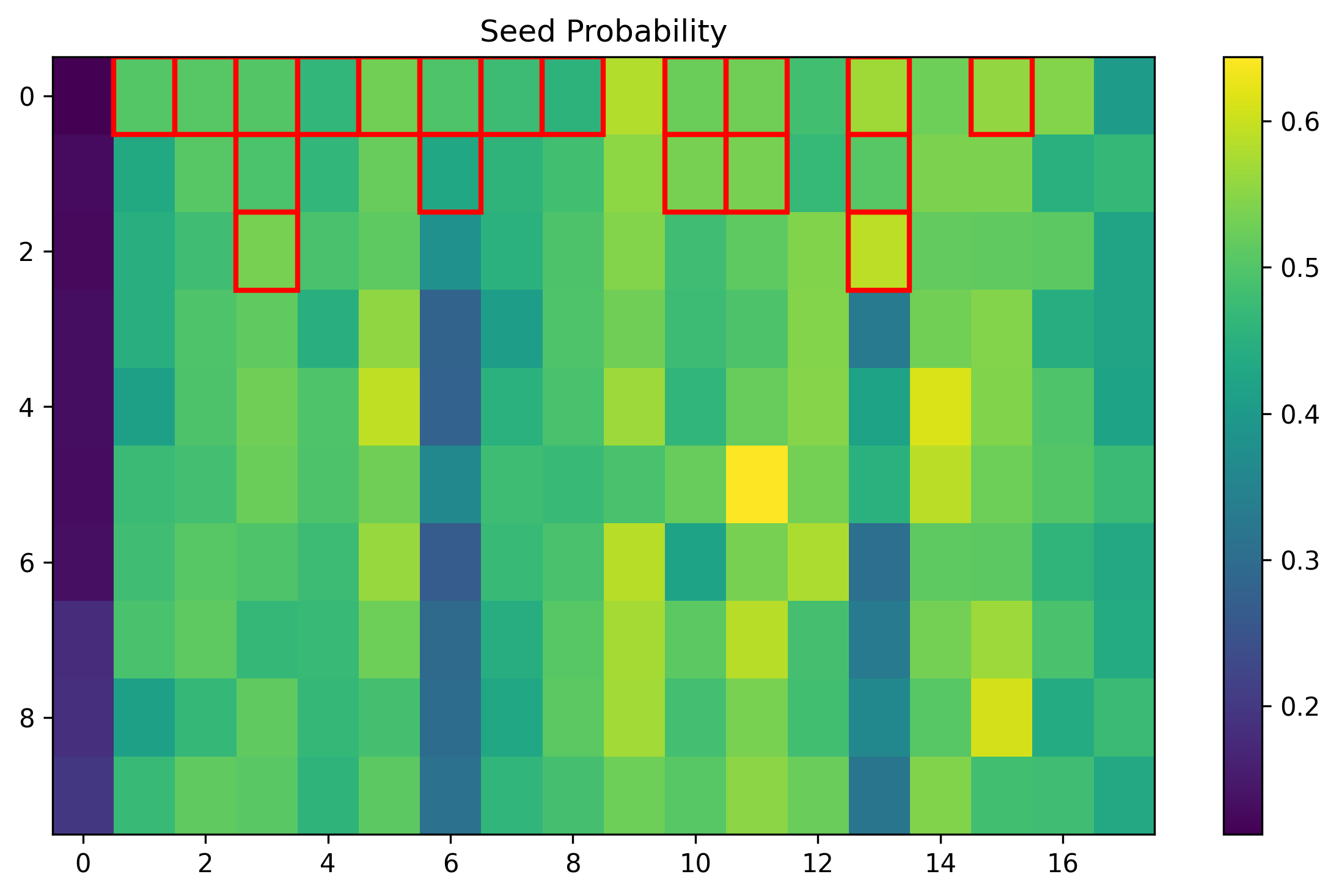
|
training_004263_115c6ba86bf683c5_occ_agent.png
ADDED

|
Git LFS Details
|
training_004263_115c6ba86bf683c5_occ_pt.png
ADDED
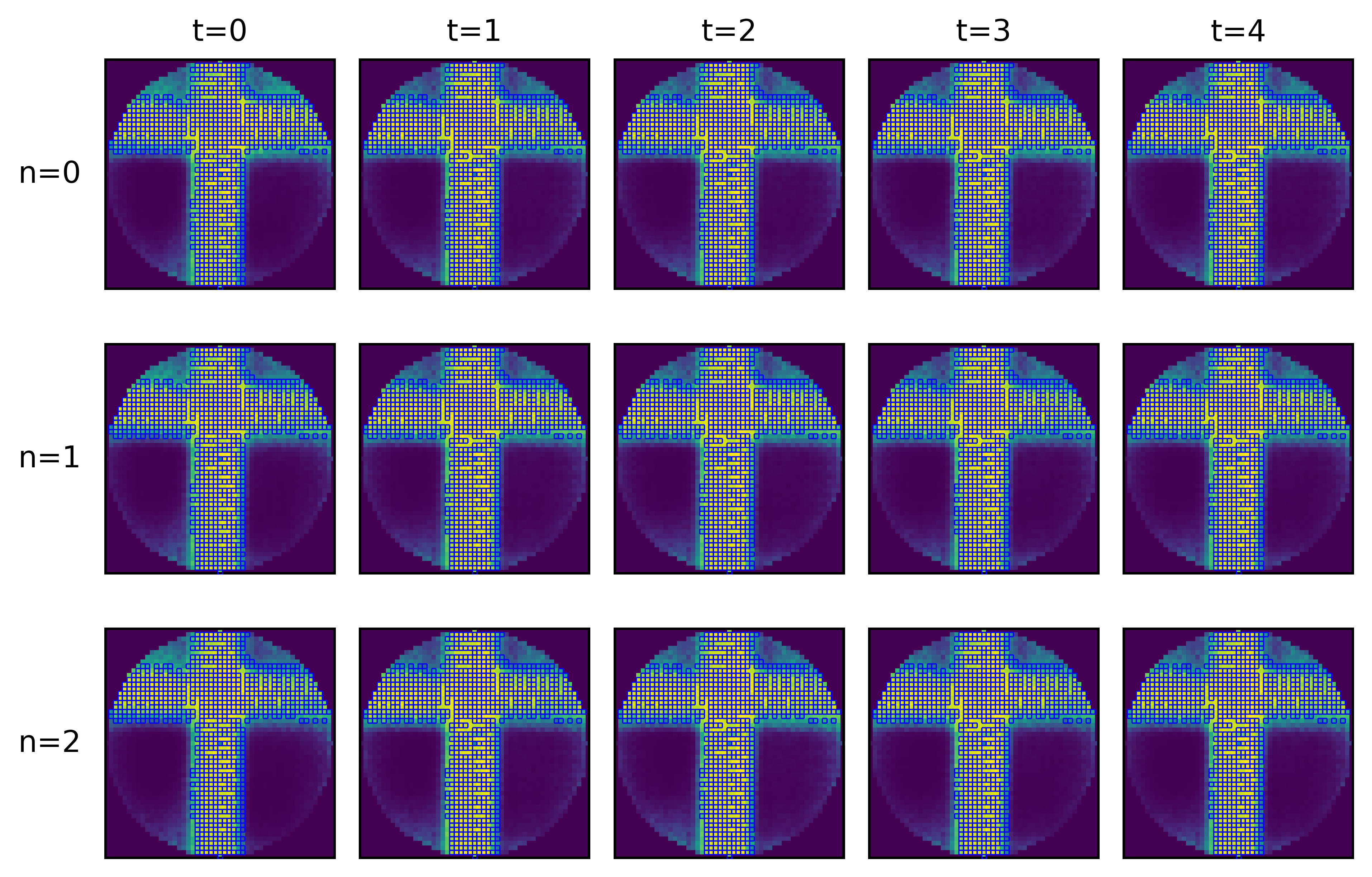
|
Git LFS Details
|
training_004263_13156353a84a2f2f_occ_agent.png
ADDED

|
Git LFS Details
|
training_004263_13156353a84a2f2f_occ_pt.png
ADDED
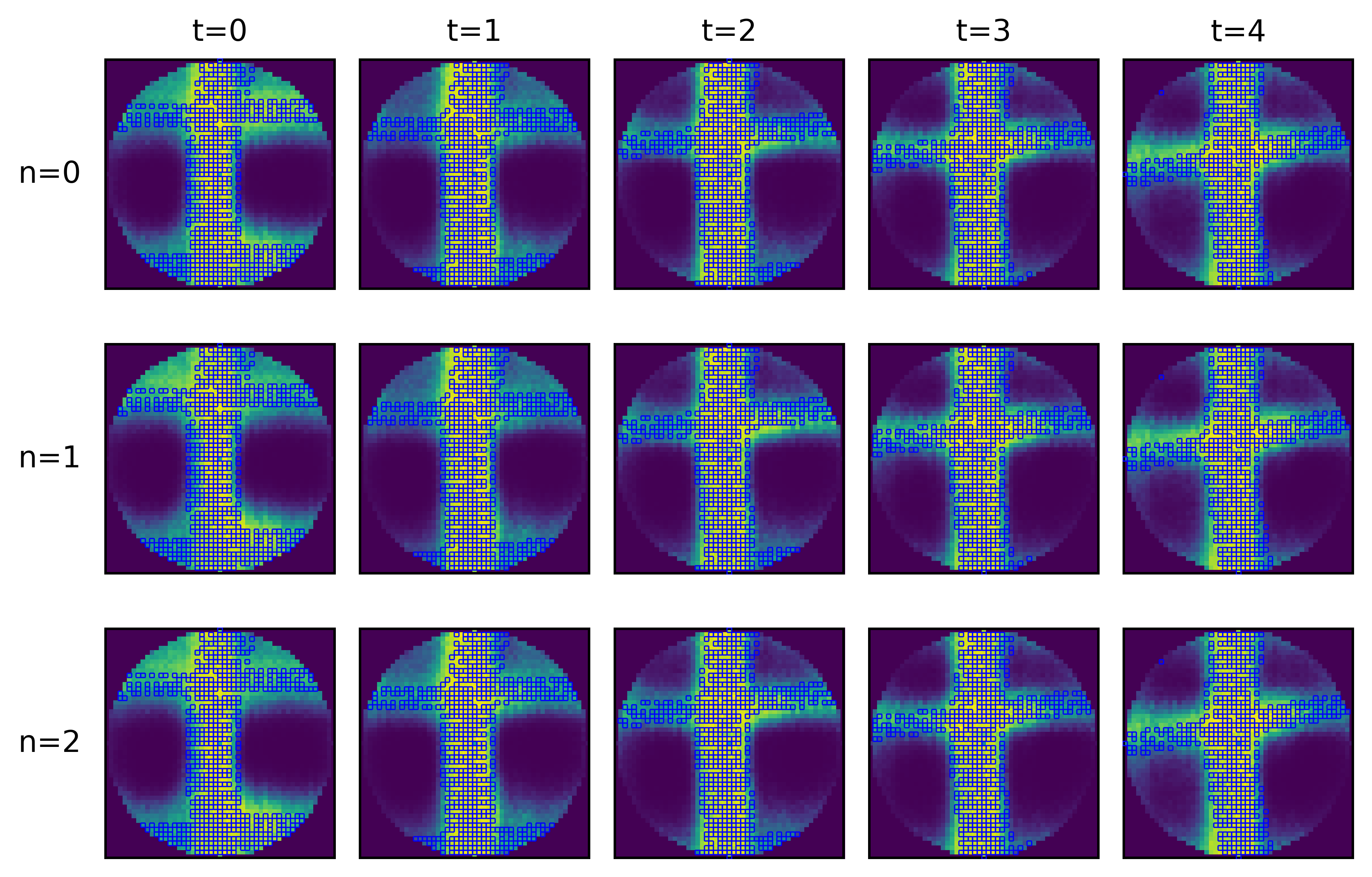
|
Git LFS Details
|
training_004263_164784242fd9b02f_occ_agent.png
ADDED
|
Git LFS Details
|
training_004263_164784242fd9b02f_occ_pt.png
ADDED

|
Git LFS Details
|
training_004263_169ca74c66bf9ed0_occ_agent.png
ADDED
|
Git LFS Details
|
training_004263_169ca74c66bf9ed0_occ_pt.png
ADDED
|
Git LFS Details
|
training_004263_17f8c4685566ccd9_occ_agent.png
ADDED

|
Git LFS Details
|
training_004263_17f8c4685566ccd9_occ_pt.png
ADDED
|
Git LFS Details
|
training_004263_1a33ad2fbb8602c1_occ_agent.png
ADDED
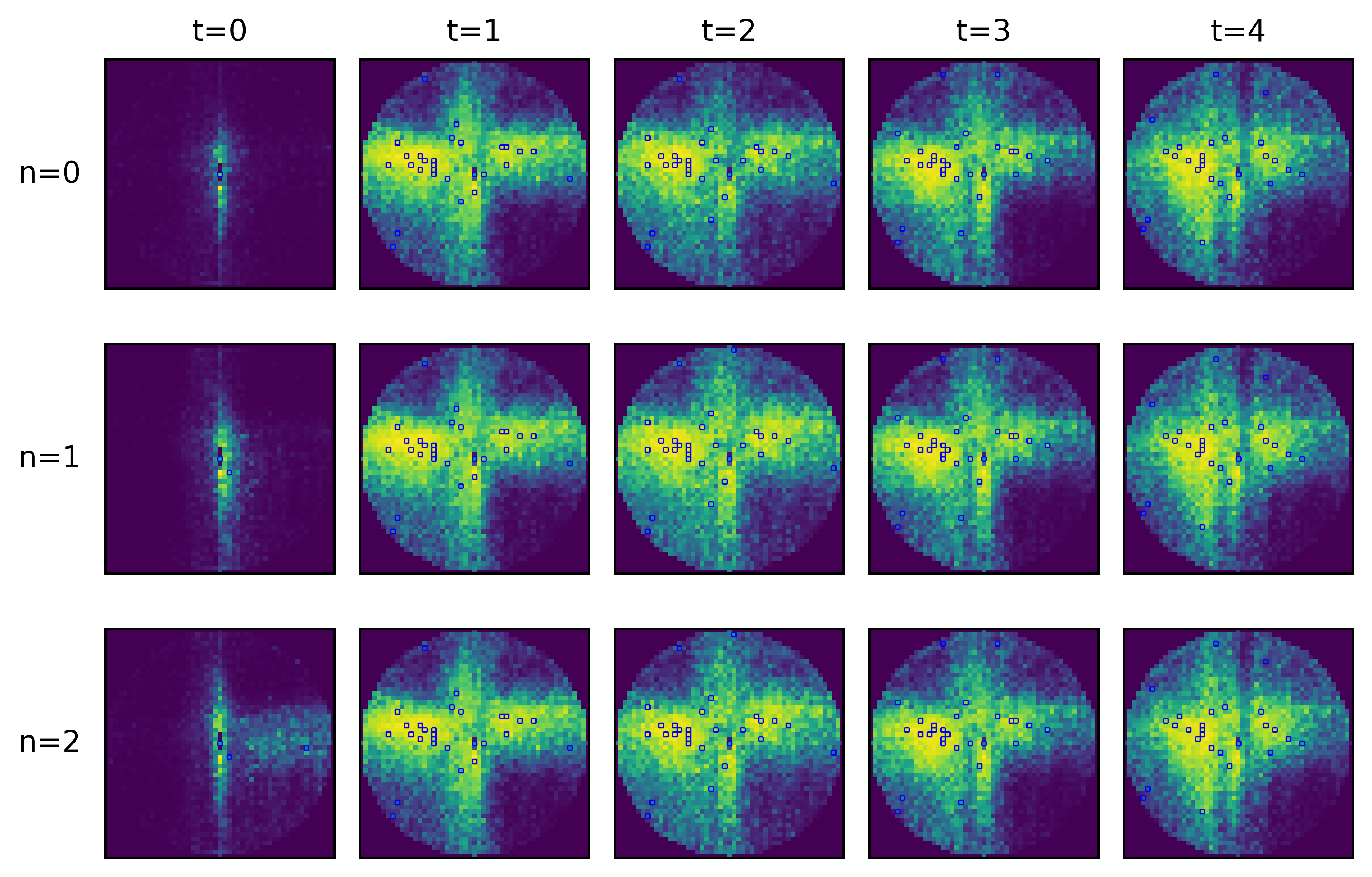
|
Git LFS Details
|
training_004263_1a33ad2fbb8602c1_occ_pt.png
ADDED
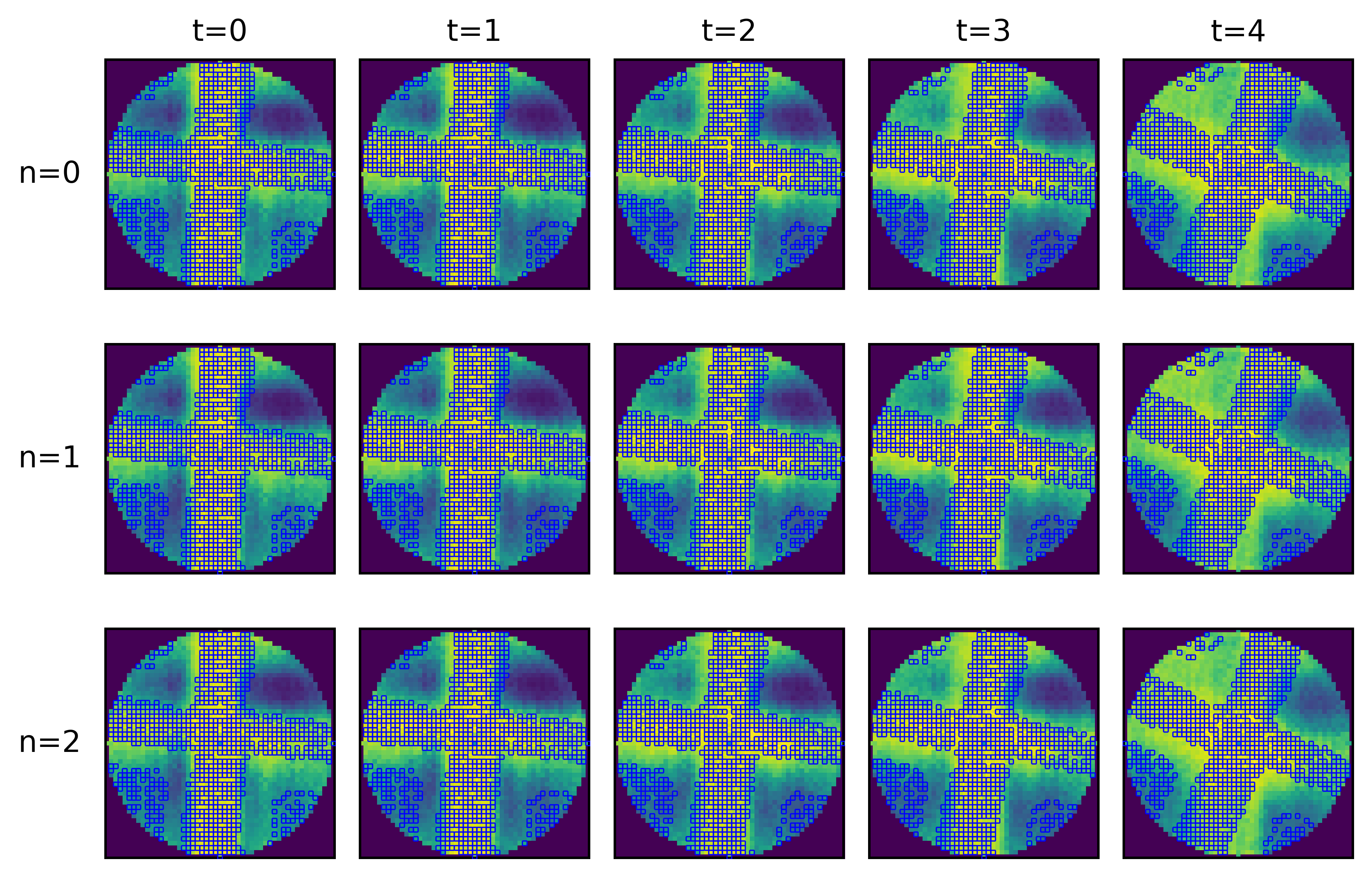
|
Git LFS Details
|
training_004263_1a6b7592d196519_insert_map.png
ADDED

|
Git LFS Details
|
training_004263_1a6b7592d196519_prob_seed.png
ADDED

|
training_022418_103c73c18d6a259c_insert_map.png
ADDED
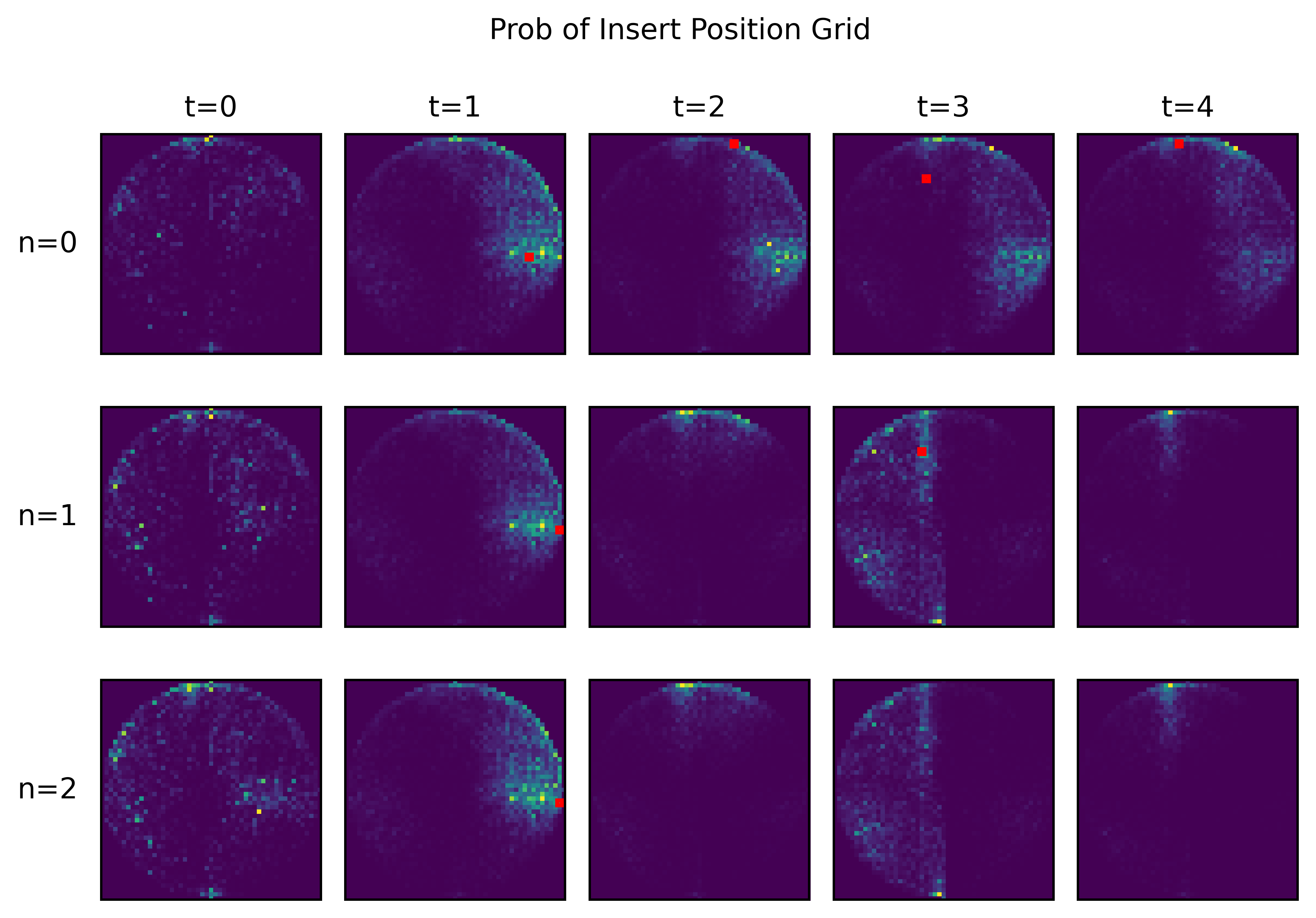
|
Git LFS Details
|
training_022418_103c73c18d6a259c_prob_seed.png
ADDED

|
training_022418_112386794f00764c_occ_agent.png
ADDED

|
Git LFS Details
|
training_022418_112386794f00764c_occ_pt.png
ADDED

|
Git LFS Details
|
training_022418_11c58fe26cfb6f48_occ_agent.png
ADDED
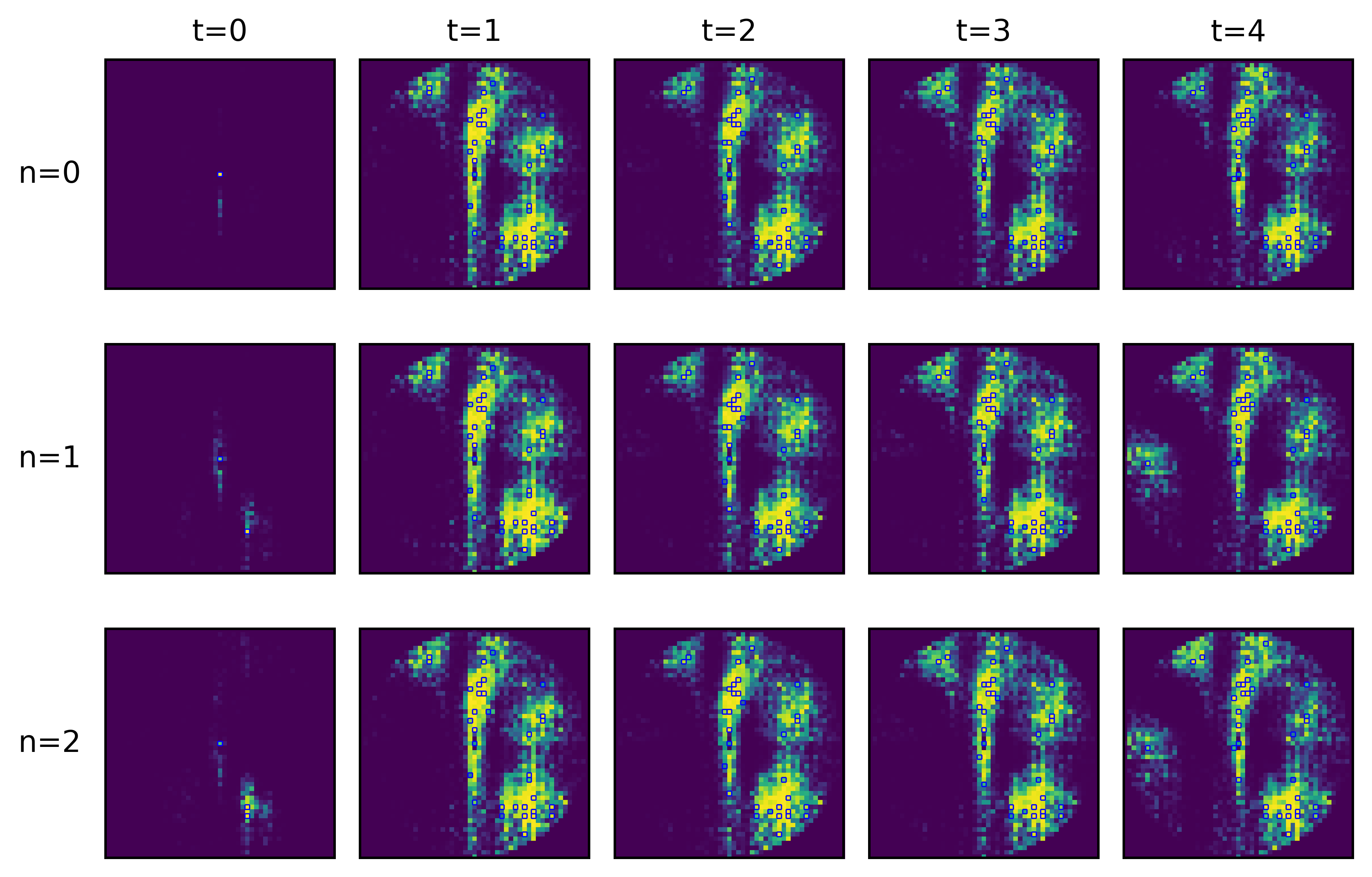
|
Git LFS Details
|