
charlescxk
commited on
Commit
·
8da01df
1
Parent(s):
ffcf344
update README
Browse files- README.md +14 -4
- janus_pro_teaser1.png +0 -0
- janus_pro_teaser2.png +0 -0
README.md
CHANGED
|
@@ -12,7 +12,7 @@ tags:
|
|
| 12 |
|
| 13 |
## 1. Introduction
|
| 14 |
|
| 15 |
-
Janus is a novel autoregressive framework that unifies multimodal understanding and generation.
|
| 16 |
It addresses the limitations of previous approaches by decoupling visual encoding into separate pathways, while still utilizing a single, unified transformer architecture for processing. The decoupling not only alleviates the conflict between the visual encoder’s roles in understanding and generation, but also enhances the framework’s flexibility.
|
| 17 |
Janus surpasses previous unified model and matches or exceeds the performance of task-specific models.
|
| 18 |
The simplicity, high flexibility, and effectiveness of Janus make it a strong candidate for next-generation unified multimodal models.
|
|
@@ -20,14 +20,19 @@ The simplicity, high flexibility, and effectiveness of Janus make it a strong ca
|
|
| 20 |
[**Github Repository**](https://github.com/deepseek-ai/Janus)
|
| 21 |
|
| 22 |
<div align="center">
|
| 23 |
-
<img alt="image" src="
|
|
|
|
|
|
|
|
|
|
|
|
|
| 24 |
</div>
|
| 25 |
|
| 26 |
|
| 27 |
### 2. Model Summary
|
| 28 |
|
| 29 |
-
Janus is a unified understanding and generation MLLM, which decouples visual encoding for multimodal understanding and generation.
|
| 30 |
-
Janus is constructed based on the DeepSeek-LLM-1.
|
|
|
|
| 31 |
For multimodal understanding, it uses the [SigLIP-L](https://huggingface.co/timm/ViT-L-16-SigLIP-384) as the vision encoder, which supports 384 x 384 image input. For image generation, Janus uses the tokenizer from [here](https://github.com/FoundationVision/LlamaGen) with a downsample rate of 16.
|
| 32 |
|
| 33 |
|
|
@@ -43,6 +48,11 @@ This code repository is licensed under [the MIT License](https://github.com/deep
|
|
| 43 |
## 5. Citation
|
| 44 |
|
| 45 |
```
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 46 |
```
|
| 47 |
|
| 48 |
## 6. Contact
|
|
|
|
| 12 |
|
| 13 |
## 1. Introduction
|
| 14 |
|
| 15 |
+
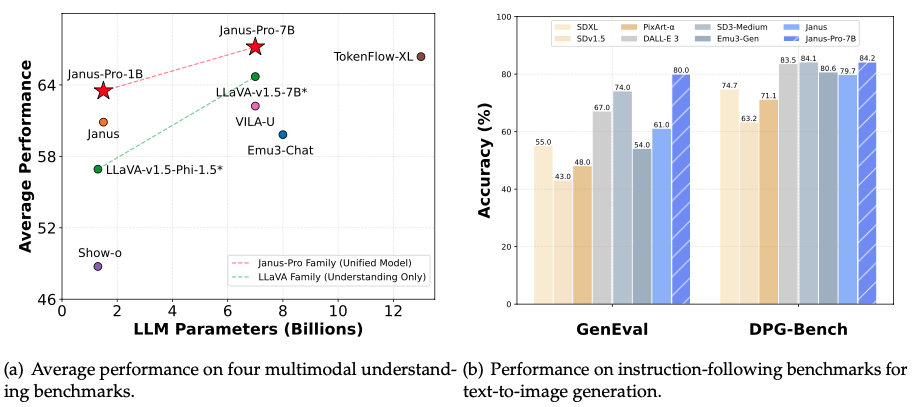
Janus-Pro is a novel autoregressive framework that unifies multimodal understanding and generation.
|
| 16 |
It addresses the limitations of previous approaches by decoupling visual encoding into separate pathways, while still utilizing a single, unified transformer architecture for processing. The decoupling not only alleviates the conflict between the visual encoder’s roles in understanding and generation, but also enhances the framework’s flexibility.
|
| 17 |
Janus surpasses previous unified model and matches or exceeds the performance of task-specific models.
|
| 18 |
The simplicity, high flexibility, and effectiveness of Janus make it a strong candidate for next-generation unified multimodal models.
|
|
|
|
| 20 |
[**Github Repository**](https://github.com/deepseek-ai/Janus)
|
| 21 |
|
| 22 |
<div align="center">
|
| 23 |
+
<img alt="image" src="janus_pro_teaser1.png" style="width:90%;">
|
| 24 |
+
</div>
|
| 25 |
+
|
| 26 |
+
<div align="center">
|
| 27 |
+
<img alt="image" src="janus_pro_teaser2.png" style="width:90%;">
|
| 28 |
</div>
|
| 29 |
|
| 30 |
|
| 31 |
### 2. Model Summary
|
| 32 |
|
| 33 |
+
Janus-Pro is a unified understanding and generation MLLM, which decouples visual encoding for multimodal understanding and generation.
|
| 34 |
+
Janus is constructed based on the DeepSeek-LLM-1.5b-base/DeepSeek-LLM-7b-base.
|
| 35 |
+
|
| 36 |
For multimodal understanding, it uses the [SigLIP-L](https://huggingface.co/timm/ViT-L-16-SigLIP-384) as the vision encoder, which supports 384 x 384 image input. For image generation, Janus uses the tokenizer from [here](https://github.com/FoundationVision/LlamaGen) with a downsample rate of 16.
|
| 37 |
|
| 38 |
|
|
|
|
| 48 |
## 5. Citation
|
| 49 |
|
| 50 |
```
|
| 51 |
+
@misc{chen2025januspro,
|
| 52 |
+
title={Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling},
|
| 53 |
+
author={Xiaokang Chen and Zhiyu Wu and Xingchao Liu and Zizheng Pan and Wen Liu and Zhenda Xie and Xingkai Yu and Chong Ruan},
|
| 54 |
+
year={2025},
|
| 55 |
+
}
|
| 56 |
```
|
| 57 |
|
| 58 |
## 6. Contact
|
janus_pro_teaser1.png
ADDED
|
janus_pro_teaser2.png
ADDED

|