


Preference Optimization for Vision Language Models with TRL
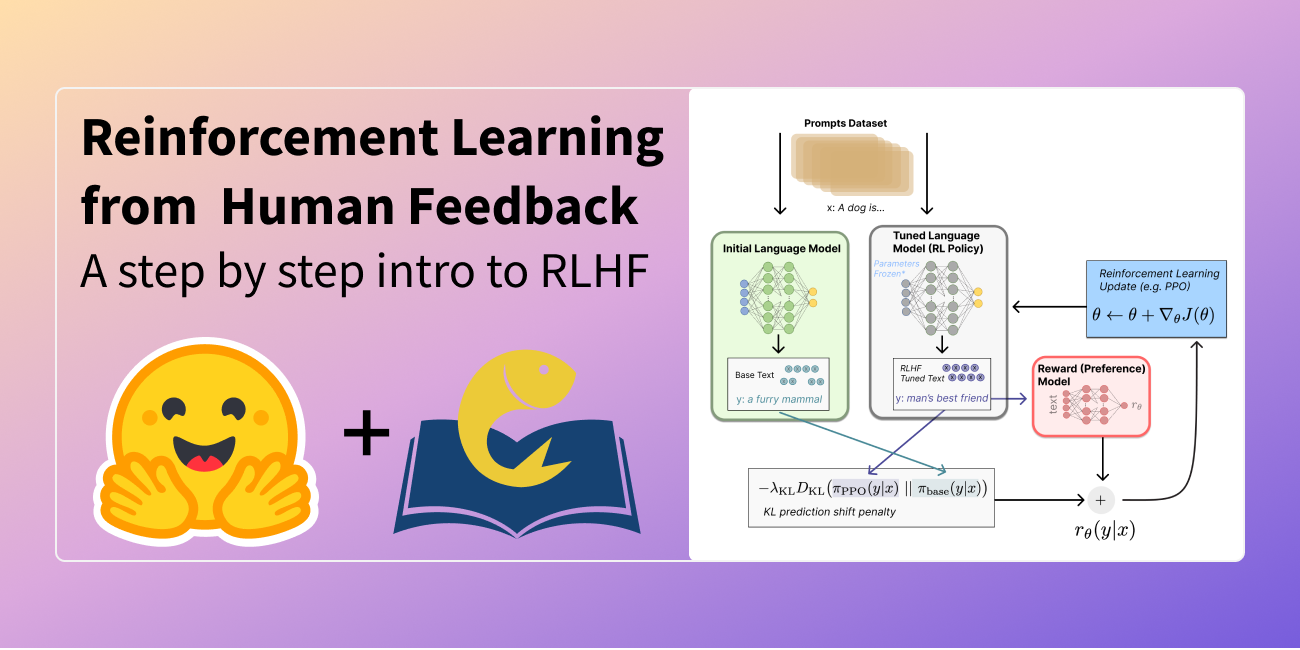
Illustrating Reinforcement Learning from Human Feedback

Fine-tuning 20B LLMs with RLHF on a 24GB consumer GPU

StackLLaMA: A hands-on guide to train LLaMA with RLHF

Fine-tune Llama 2 with DPO

Finetune Stable Diffusion Models with DDPO via TRL