Datasets:

File size: 8,019 Bytes
b8ab807 6549b6e d644481 a730a2c 6549b6e a730a2c 6549b6e a730a2c b8ab807 2036bb6 a730a2c 2036bb6 a730a2c |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 |
---
license: openrail
dataset_info:
features:
- name: audio
dtype: audio
- name: label
dtype: int64
- name: is_unknown
dtype: bool
- name: speaker_id
dtype: string
- name: utterance_id
dtype: int8
- name: logits
sequence: float32
- name: Probability
dtype: float64
- name: Predicted Label
dtype: string
- name: Annotated Labels
dtype: string
- name: embedding
sequence: float32
- name: embedding_reduced
sequence: float64
splits:
- name: train
num_bytes: 1774663023.432
num_examples: 51093
download_size: 1701177850
dataset_size: 1774663023.432
---
## Dataset Description
- **Homepage:** [Renumics Homepage](https://renumics.com/?hf-dataset-card=cifar100-enriched)
- **GitHub** [Spotlight](https://github.com/Renumics/spotlight)
- **Dataset Homepage** [Huggingface Dataset](https://huggingface.co/datasets/speech_commands)
- **Paper:** [Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition](https://www.researchgate.net/publication/324435399_Speech_Commands_A_Dataset_for_Limited-Vocabulary_Speech_Recognition)
### Dataset Summary
📊 [Data-centric AI](https://datacentricai.org) principles have become increasingly important for real-world use cases.
At [Renumics](https://renumics.com/?hf-dataset-card=cifar100-enriched) we believe that classical benchmark datasets and competitions should be extended to reflect this development.
🔍 This is why we are publishing benchmark datasets with application-specific enrichments (e.g. embeddings, baseline results, uncertainties, label error scores). We hope this helps the ML community in the following ways:
1. Enable new researchers to quickly develop a profound understanding of the dataset.
2. Popularize data-centric AI principles and tooling in the ML community.
3. Encourage the sharing of meaningful qualitative insights in addition to traditional quantitative metrics.
📚 This dataset is an enriched version of the [speech_commands dataset](https://huggingface.co/datasets/speech_commands).
It provides predicted labels, their annotations and embeddings, trained with Huggingface's AutoModel and
AutoFeatureExtractor. If you would like to have a closer look at the dataset and model's performance, you can use Spotlight by Renumics to find complex sub-relationships between classes.
### Explore the Dataset
<!-- 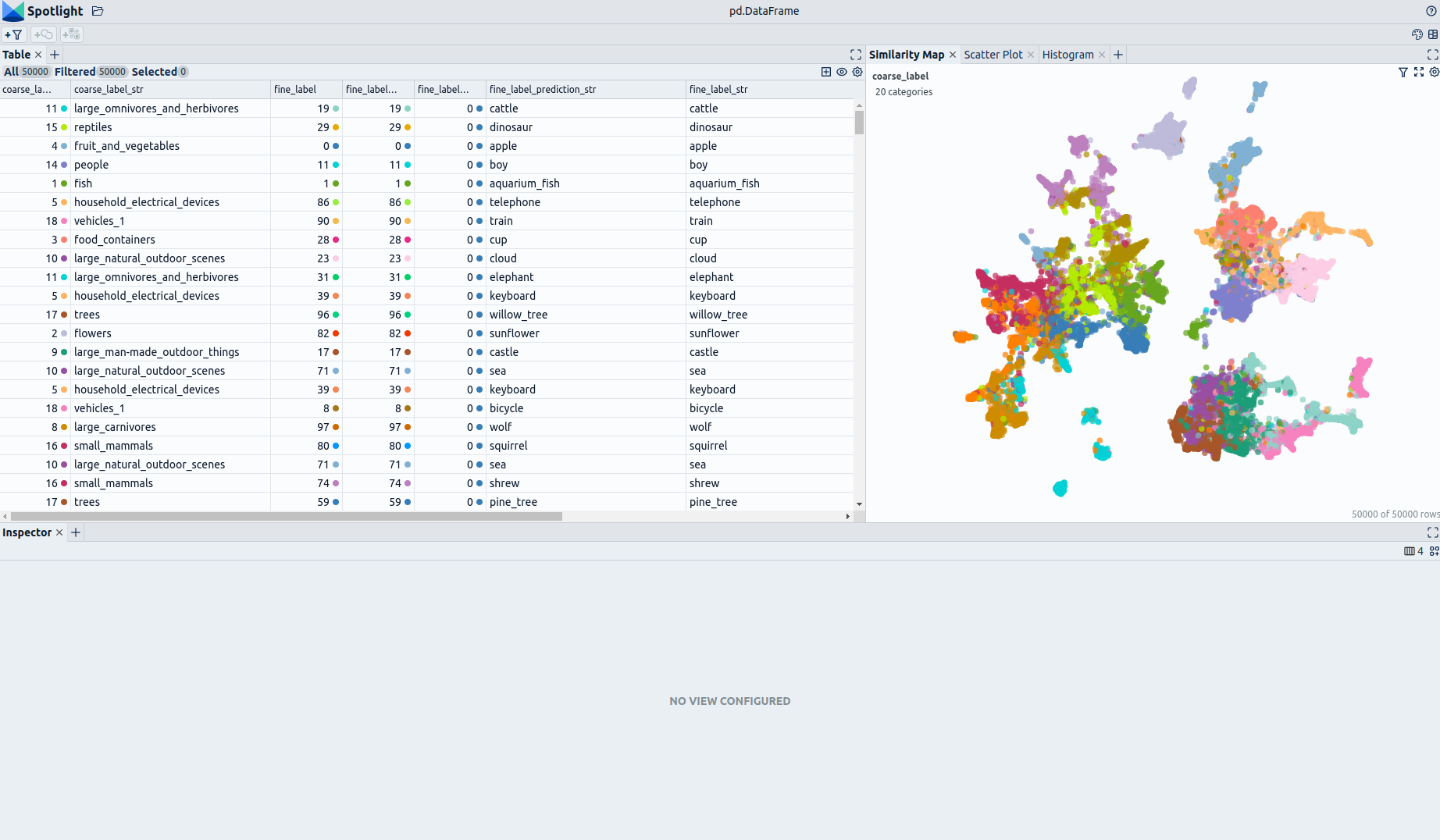 -->
The enrichments allow you to quickly gain insights into the dataset. The open source data curation tool [Renumics Spotlight](https://github.com/Renumics/spotlight) enables that with just a few lines of code:
Install datasets and Spotlight via [pip](https://packaging.python.org/en/latest/key_projects/#pip):
```python
!pip install renumics-spotlight datasets
```
Load the dataset from huggingface in your notebook:
```python
import datasets
dataset = datasets.load_dataset("soerenray/speech_commands_enriched_and_annotated", split="train")
```
Start exploring with a simple view that leverages embeddings to identify relevant data segments:
```python
from renumics import spotlight
df = dataset.to_pandas()
df_show = df.drop(columns=['embedding', 'logits'])
spotlight.show(df_show, port=8000, dtype={"audio": spotlight.Audio, "embedding_reduced": spotlight.Embedding})
```
You can use the UI to interactively configure the view on the data. Depending on the concrete tasks (e.g. model comparison, debugging, outlier detection) you might want to leverage different enrichments and metadata.
### Speech commands Dataset
The speech commands dataset consists of 60,973 samples in 30 classes (with an additional silence class).
The classes are completely mutually exclusive. It was designed to evaluate keyword spotting models.
We have enriched the dataset by adding **audio embeddings** generated with a [MIT's AST](https://huggingface.co/MIT/ast-finetuned-speech-commands-v2).
Here is the list of classes in the speech commands:
| Class |
|---------------------------------|
| "Yes" |
| "No" |
| "Up" |
| "Down" |
| "Left" |
| "Right" |
| "On" |
| "Off" |
| "Stop" |
| "Go" |
| "Zero" |
| "One" |
| "Two" |
| "Three" |
| "Four" |
| "Five" |
| "Six" |
| "Seven" |
| "Eight" |
| "Nine" |
| "Bed" |
| "Bird"|
| "Cat"|
| "Dog"|
| "Happy"|
| "House"|
| "Marvin"|
| "Sheila"|
| "Tree"|
| "Wow"|
### Supported Tasks and Leaderboards
- `TensorFlow Speech Recognition Challenge`: The goal of this task is to build a speech detector. The leaderboard is available [here](https://www.kaggle.com/c/tensorflow-speech-recognition-challenge).
### Languages
English class labels.
## Dataset Structure
### Data Instances
A sample from the dataset is provided below:
```python
{
"audio": {
"path":'bed/4a294341_nohash_0.wav',
"array": array([0.00126146 0.00647549 0.01160542 ... 0.00740056 0.00798924 0.00504583]),
"sampling_rate": 16000
},
"label": 20, # "bed"
"is_unknown": True,
"speaker_id": "4a294341",
"utterance_id": 0,
"logits": array([-9.341216087341309, -10.528160095214844, -8.605941772460938, ..., -9.13764476776123,
-9.4379243850708, -9.254714012145996]),
"Probability": 0.99669,
"Predicted Label": "bed",
"Annotated Labels": "bed",
"embedding": array([ 1.5327608585357666, -3.3523001670837402, 2.5896875858306885, ..., 0.1423477828502655,
2.0368740558624268, 0.6912304759025574]),
"embedding_reduced": array([-5.691406726837158, -0.15976890921592712])
}
```
### Data Fields
| Feature | Data Type |
|---------------------------------|------------------------------------------------|
|audio| Audio(sampling_rate=16000, mono=True, decode=True, id=None)|
| label| Value(dtype='int64', id=None)|
| is_unknown| Value(dtype='bool', id=None)|
| speaker_id| Value(dtype='string', id=None)|
| utterance_id| Value(dtype='int8', id=None)|
| logits| Sequence(feature=Value(dtype='float32', id=None), length=35, id=None)|
| Probability| Value(dtype='float64', id=None)|
| Predicted Label| Value(dtype='string', id=None)|
| Annotated Labels| Value(dtype='string', id=None)|
| embedding| Sequence(feature=Value(dtype='float32', id=None), length=768, id=None)|
| embedding_reduced | Sequence(feature=Value(dtype='float32', id=None), length=2, id=None) |
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
If you use this dataset, please cite the following paper:
```
@article{speechcommandsv2,
author = { {Warden}, P.},
title = "{Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition}",
journal = {ArXiv e-prints},
archivePrefix = "arXiv",
eprint = {1804.03209},
primaryClass = "cs.CL",
keywords = {Computer Science - Computation and Language, Computer Science - Human-Computer Interaction},
year = 2018,
month = apr,
url = {https://arxiv.org/abs/1804.03209},
}
```
### Contributions
Pete Warden and Soeren Raymond(Renumics GmbH). |