

added all2023 train-test split with fulltext
Browse files- README.md +27 -0
- all2023/val.json +2 -2
- all2023_v2/test.json +3 -0
- all2023_v2/train.json +3 -0
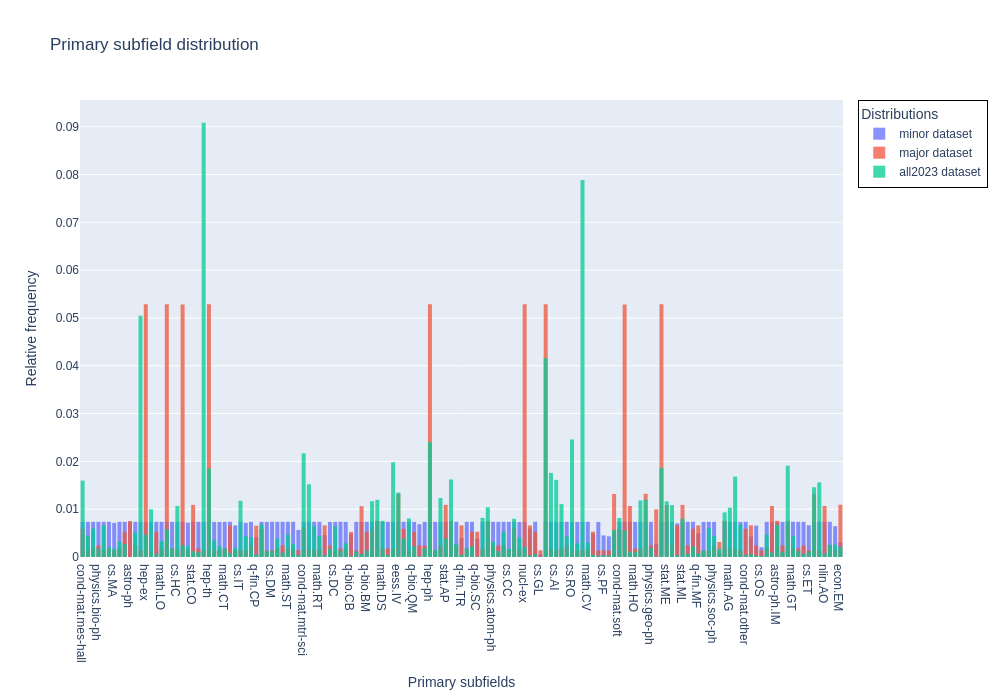
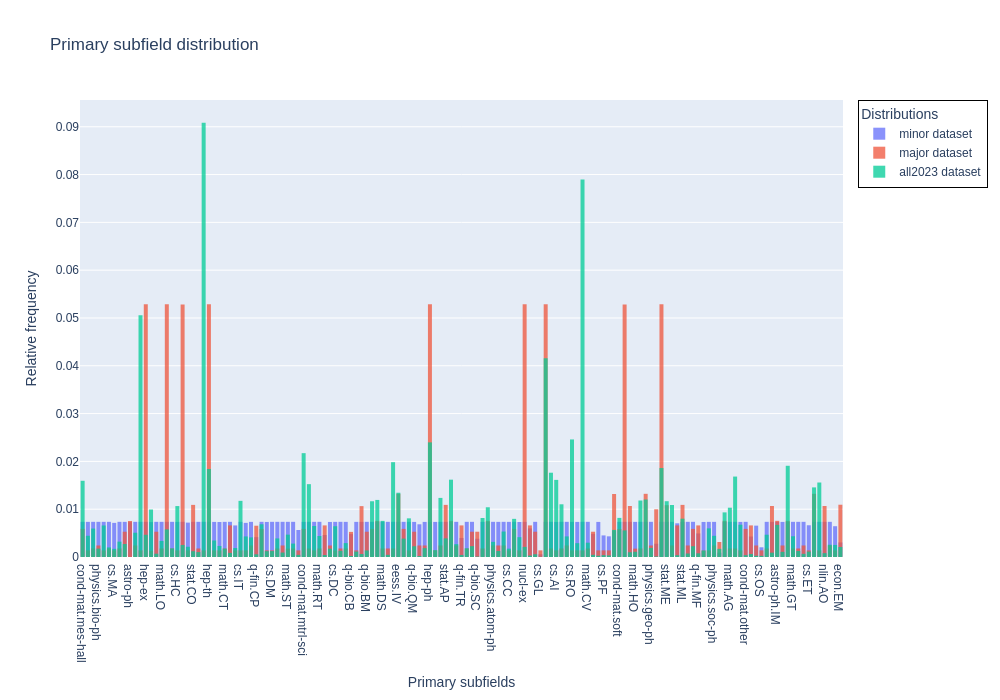
- figures/Primary_subfield_distribution.png +2 -2
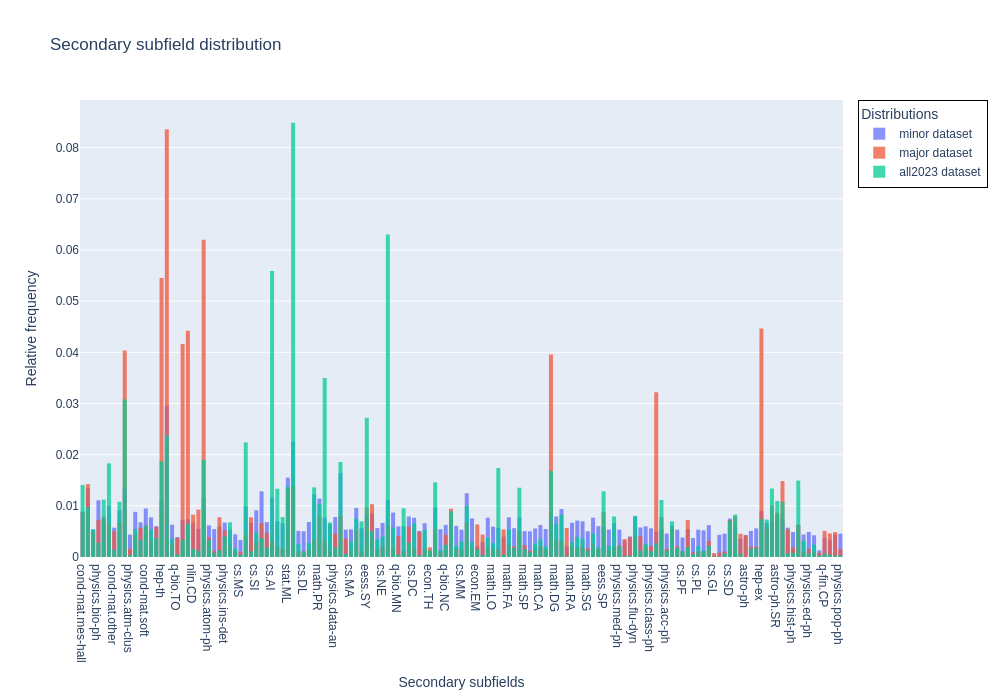
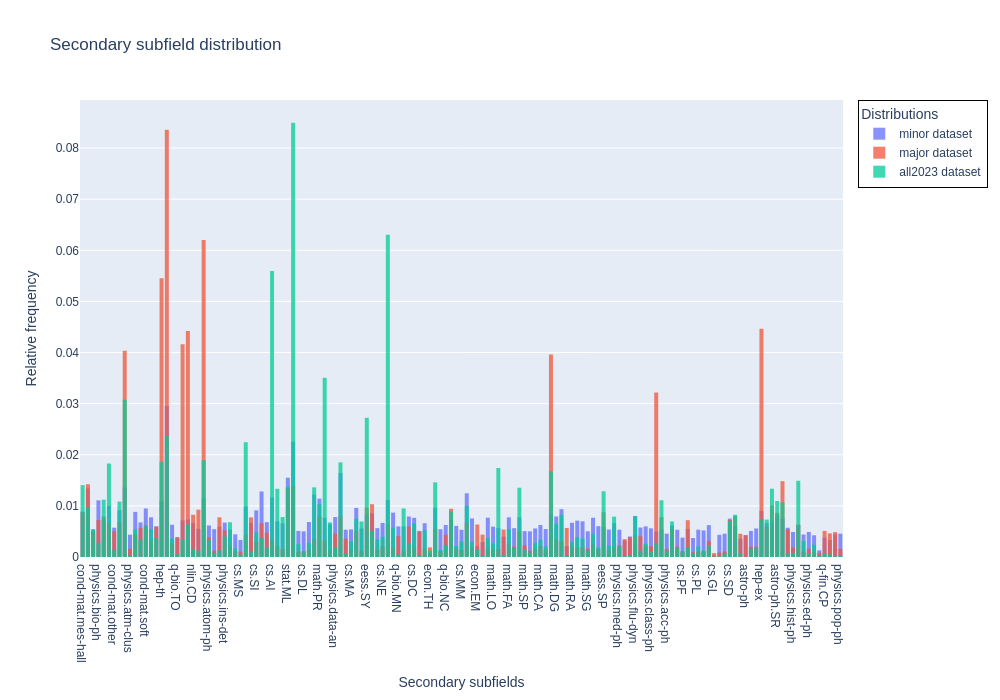
- figures/Secondary_subfield_distribution.png +2 -2
- figures/primary_subfield_distribution.csv +3 -0
- figures/secondary_subfield_distribution.csv +3 -0
- plot_subfield_distributions.py +72 -8
- preprocess_all2023_v2.py +33 -7
- util_preprocess.py +13 -0
README.md
CHANGED
|
@@ -16,10 +16,30 @@ configs:
|
|
| 16 |
data_files:
|
| 17 |
- split: val
|
| 18 |
path: "all2023/val.json"
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 19 |
---
|
| 20 |
|
| 21 |
# arXiv Classifier Data
|
| 22 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 23 |
Standardized terminology:
|
| 24 |
- Field: Bio/cs/physics
|
| 25 |
- Subfield: Subcategories within each
|
|
@@ -38,11 +58,18 @@ Original data: https://www.dropbox.com/scl/fo/wwu0ifghw4sco09g67frb/h?rlkey=6ddg
|
|
| 38 |
**Major**: Dataset of papers between 2010 and 2020 (with some pre-2010 papers) with unbalanced primary subfields to better represent the true distribution of primary categories, which is dominated by a few subfields. Note that the distribution of major subfields is still truncated.
|
| 39 |
|
| 40 |
**All 2023**: All papers published in 2023.
|
|
|
|
|
|
|
| 41 |
|
| 42 |

|
| 43 |
|
| 44 |

|
| 45 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 46 |
## Set up dependencies
|
| 47 |
|
| 48 |
Get subfields to ignore and subfield aliases:
|
|
|
|
| 16 |
data_files:
|
| 17 |
- split: val
|
| 18 |
path: "all2023/val.json"
|
| 19 |
+
- config_name: all2023_v2
|
| 20 |
+
data_files:
|
| 21 |
+
- split: train
|
| 22 |
+
path: "all2023_v2/train.json"
|
| 23 |
+
- split: test
|
| 24 |
+
path: "all2023_v2/test.json"
|
| 25 |
---
|
| 26 |
|
| 27 |
# arXiv Classifier Data
|
| 28 |
|
| 29 |
+
Usage:
|
| 30 |
+
```
|
| 31 |
+
from datasets import load_dataset, DownloadMode
|
| 32 |
+
# download from HuggingFace
|
| 33 |
+
dataset = load_dataset('mlcore/arxiv-classifier', name=<CONFIG NAME>)
|
| 34 |
+
# load from G2
|
| 35 |
+
dataset = load_dataset('/share/nikola/arxiv_classifier/data/arxiv-classifier', name=<CONFIG NAME>)
|
| 36 |
+
```
|
| 37 |
+
To force the dataset to be re-generated:
|
| 38 |
+
```
|
| 39 |
+
dataset = load_dataset('/share/nikola/arxiv_classifier/data/arxiv-classifier', name=<CONFIG NAME>, download_mode=DownloadMode.FORCE_REDOWNLOAD)
|
| 40 |
+
```
|
| 41 |
+
See: https://huggingface.co/docs/datasets/v2.20.0/en/package_reference/builder_classes#datasets.DownloadMode
|
| 42 |
+
|
| 43 |
Standardized terminology:
|
| 44 |
- Field: Bio/cs/physics
|
| 45 |
- Subfield: Subcategories within each
|
|
|
|
| 58 |
**Major**: Dataset of papers between 2010 and 2020 (with some pre-2010 papers) with unbalanced primary subfields to better represent the true distribution of primary categories, which is dominated by a few subfields. Note that the distribution of major subfields is still truncated.
|
| 59 |
|
| 60 |
**All 2023**: All papers published in 2023.
|
| 61 |
+
- Train: papers with date between January and June (inclusive)
|
| 62 |
+
- Test: papers with date between July and December (inclusive)
|
| 63 |
|
| 64 |

|
| 65 |
|
| 66 |

|
| 67 |
|
| 68 |
+
To generate subfield distribution plots:
|
| 69 |
+
```
|
| 70 |
+
python plot_subfield_distributions.py --output_path <path_to_save_plots>
|
| 71 |
+
```
|
| 72 |
+
|
| 73 |
## Set up dependencies
|
| 74 |
|
| 75 |
Get subfields to ignore and subfield aliases:
|
all2023/val.json
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7323614e2e540385689dba0e6252fe16c51e47ad6de946d7c2545f563d4290c3
|
| 3 |
+
size 13921074283
|
all2023_v2/test.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9bf8222a0cbdbc4889512009069292e108477b9ecf5075522a770dcf5137348e
|
| 3 |
+
size 7220291019
|
all2023_v2/train.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e06a48f7e9bb778b8333b42481989e2b88a09a9affdbef695bede25c76020c3b
|
| 3 |
+
size 6700804113
|
figures/Primary_subfield_distribution.png
CHANGED
|
Git LFS Details
|
|
Git LFS Details
|
figures/Secondary_subfield_distribution.png
CHANGED
|
Git LFS Details
|
|
Git LFS Details
|
figures/primary_subfield_distribution.csv
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:820f2f0256f5ea60b703d2bface4a6933a28366207fbc62b32c878004261fd79
|
| 3 |
+
size 10666
|
figures/secondary_subfield_distribution.csv
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0da253fe17779bbff8a61789c9a809aa285569754be282c79729585fccd0ed51
|
| 3 |
+
size 10640
|
plot_subfield_distributions.py
CHANGED
|
@@ -1,23 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
# Script to plot the distribution of primary and secondary subfields in the minor, major, and all2023 datasets.
|
| 2 |
# Usage:
|
| 3 |
# python plot_subfield_distributions.py --output_path <path_to_save_plots>
|
| 4 |
|
|
|
|
| 5 |
from argparse import ArgumentParser
|
| 6 |
-
parser = ArgumentParser()
|
| 7 |
# parser.add_argument("--dataset", "-d", type=str, default="minor")
|
| 8 |
# parser.add_argument("--split", "-s", type=str, default="val")
|
| 9 |
-
parser.add_argument("--output_path", "-op", type=str, default="./")
|
| 10 |
-
args = parser.parse_args()
|
| 11 |
-
output_path = args.output_path
|
|
|
|
| 12 |
|
|
|
|
| 13 |
#
|
| 14 |
# Remaining imports
|
| 15 |
#
|
| 16 |
import os
|
|
|
|
| 17 |
import plotly.graph_objects as go
|
| 18 |
from datasets import load_dataset
|
| 19 |
import itertools
|
| 20 |
-
|
|
|
|
| 21 |
# Get save path
|
| 22 |
save_path = os.path.join(
|
| 23 |
output_path,
|
|
@@ -26,11 +48,13 @@ save_path = os.path.join(
|
|
| 26 |
os.makedirs(save_path, exist_ok=True)
|
| 27 |
print(f"Saving figures to {save_path}")
|
| 28 |
|
|
|
|
| 29 |
# Loading dataset and tokenizer as well
|
| 30 |
minor_dataset = load_dataset("mlcore/arxiv-classifier")
|
| 31 |
major_dataset = load_dataset("mlcore/arxiv-classifier", "major")
|
| 32 |
all2023_dataset = load_dataset("mlcore/arxiv-classifier", "all2023")
|
| 33 |
|
|
|
|
| 34 |
# Extracting the primary and secondary subfield distributions
|
| 35 |
datasets = {
|
| 36 |
"minor dataset" : minor_dataset['train'],
|
|
@@ -43,6 +67,7 @@ secondary_subfield_distributions = {
|
|
| 43 |
for name, dataset in datasets.items()
|
| 44 |
}
|
| 45 |
|
|
|
|
| 46 |
# Plotting the two distributions
|
| 47 |
hists = []
|
| 48 |
n = min([len(i) for i in primary_subfield_distributions.values()])
|
|
@@ -50,8 +75,10 @@ for name, primary_subfield_distribution in primary_subfield_distributions.items(
|
|
| 50 |
# primary_subfield_distribution = random.sample(primary_subfield_distribution, n)
|
| 51 |
hists.append(go.Histogram(x=primary_subfield_distribution, name=name, opacity=0.75, histnorm='probability'))
|
| 52 |
|
|
|
|
| 53 |
fig = go.Figure(data=hists)
|
| 54 |
|
|
|
|
| 55 |
# Update layout for better readability
|
| 56 |
fig.update_layout(
|
| 57 |
height=700,
|
|
@@ -71,11 +98,29 @@ fig.update_layout(
|
|
| 71 |
borderwidth=1
|
| 72 |
)
|
| 73 |
)
|
| 74 |
-
|
|
|
|
| 75 |
# Show the figure
|
| 76 |
# fig.show()
|
| 77 |
fig.write_image(os.path.join(save_path,"Primary_subfield_distribution.png"))
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 78 |
|
|
|
|
| 79 |
# Plotting the two distributions
|
| 80 |
hists = []
|
| 81 |
n = min([len(i) for i in secondary_subfield_distributions.values() if len(i) > 0])
|
|
@@ -83,8 +128,10 @@ for name, secondary_subfield_distribution in secondary_subfield_distributions.it
|
|
| 83 |
# secondary_subfield_distribution = random.sample(secondary_subfield_distribution, min(n, len(secondary_subfield_distribution)))
|
| 84 |
hists.append(go.Histogram(x=secondary_subfield_distribution, name=name, opacity=0.75, histnorm='probability'))
|
| 85 |
|
|
|
|
| 86 |
fig = go.Figure(data=hists)
|
| 87 |
|
|
|
|
| 88 |
# Update layout for better readability
|
| 89 |
fig.update_layout(
|
| 90 |
height=700,
|
|
@@ -104,7 +151,24 @@ fig.update_layout(
|
|
| 104 |
borderwidth=1
|
| 105 |
)
|
| 106 |
)
|
| 107 |
-
|
|
|
|
| 108 |
# Show the figure
|
| 109 |
# fig.show()
|
| 110 |
-
fig.write_image(os.path.join(save_path,"Secondary_subfield_distribution.png"))
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ---
|
| 2 |
+
# jupyter:
|
| 3 |
+
# jupytext:
|
| 4 |
+
# cell_metadata_filter: -all
|
| 5 |
+
# custom_cell_magics: kql
|
| 6 |
+
# text_representation:
|
| 7 |
+
# extension: .py
|
| 8 |
+
# format_name: percent
|
| 9 |
+
# format_version: '1.3'
|
| 10 |
+
# jupytext_version: 1.11.2
|
| 11 |
+
# kernelspec:
|
| 12 |
+
# display_name: Python 3
|
| 13 |
+
# language: python
|
| 14 |
+
# name: python3
|
| 15 |
+
# ---
|
| 16 |
+
|
| 17 |
+
# %% [markdown]
|
| 18 |
# Script to plot the distribution of primary and secondary subfields in the minor, major, and all2023 datasets.
|
| 19 |
# Usage:
|
| 20 |
# python plot_subfield_distributions.py --output_path <path_to_save_plots>
|
| 21 |
|
| 22 |
+
# %%
|
| 23 |
from argparse import ArgumentParser
|
| 24 |
+
# parser = ArgumentParser()
|
| 25 |
# parser.add_argument("--dataset", "-d", type=str, default="minor")
|
| 26 |
# parser.add_argument("--split", "-s", type=str, default="val")
|
| 27 |
+
# parser.add_argument("--output_path", "-op", type=str, default="./")
|
| 28 |
+
# args = parser.parse_args()
|
| 29 |
+
# output_path = args.output_path
|
| 30 |
+
output_path = './'
|
| 31 |
|
| 32 |
+
# %%
|
| 33 |
#
|
| 34 |
# Remaining imports
|
| 35 |
#
|
| 36 |
import os
|
| 37 |
+
import pandas as pd
|
| 38 |
import plotly.graph_objects as go
|
| 39 |
from datasets import load_dataset
|
| 40 |
import itertools
|
| 41 |
+
from datetime import datetime
|
| 42 |
+
# %%
|
| 43 |
# Get save path
|
| 44 |
save_path = os.path.join(
|
| 45 |
output_path,
|
|
|
|
| 48 |
os.makedirs(save_path, exist_ok=True)
|
| 49 |
print(f"Saving figures to {save_path}")
|
| 50 |
|
| 51 |
+
# %%
|
| 52 |
# Loading dataset and tokenizer as well
|
| 53 |
minor_dataset = load_dataset("mlcore/arxiv-classifier")
|
| 54 |
major_dataset = load_dataset("mlcore/arxiv-classifier", "major")
|
| 55 |
all2023_dataset = load_dataset("mlcore/arxiv-classifier", "all2023")
|
| 56 |
|
| 57 |
+
# %%
|
| 58 |
# Extracting the primary and secondary subfield distributions
|
| 59 |
datasets = {
|
| 60 |
"minor dataset" : minor_dataset['train'],
|
|
|
|
| 67 |
for name, dataset in datasets.items()
|
| 68 |
}
|
| 69 |
|
| 70 |
+
# %%
|
| 71 |
# Plotting the two distributions
|
| 72 |
hists = []
|
| 73 |
n = min([len(i) for i in primary_subfield_distributions.values()])
|
|
|
|
| 75 |
# primary_subfield_distribution = random.sample(primary_subfield_distribution, n)
|
| 76 |
hists.append(go.Histogram(x=primary_subfield_distribution, name=name, opacity=0.75, histnorm='probability'))
|
| 77 |
|
| 78 |
+
# %%
|
| 79 |
fig = go.Figure(data=hists)
|
| 80 |
|
| 81 |
+
# %%
|
| 82 |
# Update layout for better readability
|
| 83 |
fig.update_layout(
|
| 84 |
height=700,
|
|
|
|
| 98 |
borderwidth=1
|
| 99 |
)
|
| 100 |
)
|
| 101 |
+
|
| 102 |
+
# %%
|
| 103 |
# Show the figure
|
| 104 |
# fig.show()
|
| 105 |
fig.write_image(os.path.join(save_path,"Primary_subfield_distribution.png"))
|
| 106 |
+
# also save distributions as csv
|
| 107 |
+
df_list = []
|
| 108 |
+
for name, primary_subfield_distribution in primary_subfield_distributions.items():
|
| 109 |
+
df = pd.DataFrame(data={
|
| 110 |
+
"primary_subfield": primary_subfield_distribution,
|
| 111 |
+
"dataset": name,
|
| 112 |
+
"count": 1
|
| 113 |
+
})
|
| 114 |
+
df_list.append(df)
|
| 115 |
+
df = pd.concat(df_list)
|
| 116 |
+
counts_by_subfield = df.groupby(['dataset', 'primary_subfield']).agg('count').unstack(level=0)
|
| 117 |
+
counts_by_subfield.columns = counts_by_subfield.columns.droplevel()
|
| 118 |
+
# normalize counts
|
| 119 |
+
counts_by_subfield = counts_by_subfield.div(counts_by_subfield.sum(axis=0), axis=1)
|
| 120 |
+
# print(counts_by_subfield)
|
| 121 |
+
counts_by_subfield.to_csv(os.path.join(save_path, "primary_subfield_distribution.csv"))
|
| 122 |
|
| 123 |
+
# %%
|
| 124 |
# Plotting the two distributions
|
| 125 |
hists = []
|
| 126 |
n = min([len(i) for i in secondary_subfield_distributions.values() if len(i) > 0])
|
|
|
|
| 128 |
# secondary_subfield_distribution = random.sample(secondary_subfield_distribution, min(n, len(secondary_subfield_distribution)))
|
| 129 |
hists.append(go.Histogram(x=secondary_subfield_distribution, name=name, opacity=0.75, histnorm='probability'))
|
| 130 |
|
| 131 |
+
# %%
|
| 132 |
fig = go.Figure(data=hists)
|
| 133 |
|
| 134 |
+
# %%
|
| 135 |
# Update layout for better readability
|
| 136 |
fig.update_layout(
|
| 137 |
height=700,
|
|
|
|
| 151 |
borderwidth=1
|
| 152 |
)
|
| 153 |
)
|
| 154 |
+
|
| 155 |
+
# %%
|
| 156 |
# Show the figure
|
| 157 |
# fig.show()
|
| 158 |
+
fig.write_image(os.path.join(save_path,"Secondary_subfield_distribution.png"))
|
| 159 |
+
# also save distributions as csv
|
| 160 |
+
df_list = []
|
| 161 |
+
for name, secondary_subfield_distribution in secondary_subfield_distributions.items():
|
| 162 |
+
df = pd.DataFrame(data={
|
| 163 |
+
"secondary_subfield": secondary_subfield_distribution,
|
| 164 |
+
"dataset": name,
|
| 165 |
+
"count": 1
|
| 166 |
+
})
|
| 167 |
+
df_list.append(df)
|
| 168 |
+
df = pd.concat(df_list)
|
| 169 |
+
counts_by_subfield = df.groupby(['dataset', 'secondary_subfield']).agg('count').unstack(level=0)
|
| 170 |
+
counts_by_subfield.columns = counts_by_subfield.columns.droplevel()
|
| 171 |
+
# normalize counts
|
| 172 |
+
counts_by_subfield = counts_by_subfield.div(counts_by_subfield.sum(axis=0), axis=1)
|
| 173 |
+
# print(counts_by_subfield)
|
| 174 |
+
counts_by_subfield.to_csv(os.path.join(save_path, "secondary_subfield_distribution.csv"))
|
preprocess_all2023_v2.py
CHANGED
|
@@ -30,7 +30,7 @@ parser.add_argument("--input_path", "-ip", type=str, default="./data",
|
|
| 30 |
args, opt = parser.parse_known_args()
|
| 31 |
|
| 32 |
dataset = 'all2023' # args.dataset
|
| 33 |
-
split = 'val' # args.split
|
| 34 |
output_path = args.output_path
|
| 35 |
input_path = args.input_path
|
| 36 |
|
|
@@ -42,6 +42,7 @@ import pandas as pd
|
|
| 42 |
import os
|
| 43 |
import sys
|
| 44 |
from tqdm import tqdm
|
|
|
|
| 45 |
from util_preprocess import preprocess_primary_secondary
|
| 46 |
|
| 47 |
# %% [markdown]
|
|
@@ -57,7 +58,6 @@ from util_preprocess import preprocess_primary_secondary
|
|
| 57 |
# - Major category = field
|
| 58 |
|
| 59 |
# %%
|
| 60 |
-
# file_path = os.path.join('data', 'raw', dataset, f"{split}_{dataset}_cats_full.json")
|
| 61 |
file_path = os.path.join(
|
| 62 |
input_path,
|
| 63 |
'raw',
|
|
@@ -66,7 +66,8 @@ file_path = os.path.join(
|
|
| 66 |
)
|
| 67 |
save_dir = os.path.join(output_path, dataset)
|
| 68 |
os.makedirs(save_dir, exist_ok=True)
|
| 69 |
-
|
|
|
|
| 70 |
print("Reading from file: ", file_path)
|
| 71 |
|
| 72 |
FEATURES = [
|
|
@@ -81,6 +82,17 @@ FEATURES = [
|
|
| 81 |
'field',
|
| 82 |
'fulltext'
|
| 83 |
]
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 84 |
|
| 85 |
def get_fulltext(row):
|
| 86 |
filename = f"{row['paper_id']}v{row['version']}.txt"
|
|
@@ -105,6 +117,10 @@ count_hasfulltext = []
|
|
| 105 |
# Ignore all quotes by setting quoting=3 (corresponds to csv.QUOTE_NONE)
|
| 106 |
for i, original_df in tqdm(enumerate(pd.read_csv(file_path, sep='\t', chunksize=10, dtype=str, quoting=3))):
|
| 107 |
count_orig.append( len(original_df) )
|
|
|
|
|
|
|
|
|
|
|
|
|
| 108 |
# set non-existent features to empty string
|
| 109 |
for feature in FEATURES:
|
| 110 |
if feature not in original_df.columns:
|
|
@@ -113,7 +129,7 @@ for i, original_df in tqdm(enumerate(pd.read_csv(file_path, sep='\t', chunksize=
|
|
| 113 |
original_df.loc[:, 'primary_subfield'] = original_df['categories'].apply(lambda x : x.split()[0])
|
| 114 |
# keep the secondary_subfield a string, will be converted to list in preprocess_primary_secondary()
|
| 115 |
original_df.loc[:, 'secondary_subfield'] = original_df['categories']
|
| 116 |
-
# Apply preprocessing rules
|
| 117 |
df = preprocess_primary_secondary(original_df)
|
| 118 |
|
| 119 |
count_isvalid.append( len(df) )
|
|
@@ -125,13 +141,23 @@ for i, original_df in tqdm(enumerate(pd.read_csv(file_path, sep='\t', chunksize=
|
|
| 125 |
df = df.dropna(subset=['fulltext'])
|
| 126 |
count_hasfulltext.append( len(df) )
|
| 127 |
|
|
|
|
|
|
|
|
|
|
| 128 |
# convert all columns to string per huggingface requirements
|
|
|
|
| 129 |
if i == 0:
|
| 130 |
-
|
|
|
|
|
|
|
|
|
|
| 131 |
else:
|
| 132 |
-
|
|
|
|
|
|
|
|
|
|
| 133 |
|
| 134 |
-
print("Saved to: ", save_path)
|
| 135 |
df_err = pd.DataFrame({
|
| 136 |
'orig': count_orig,
|
| 137 |
'isvalid': count_isvalid,
|
|
|
|
| 30 |
args, opt = parser.parse_known_args()
|
| 31 |
|
| 32 |
dataset = 'all2023' # args.dataset
|
| 33 |
+
# split = 'val' # args.split
|
| 34 |
output_path = args.output_path
|
| 35 |
input_path = args.input_path
|
| 36 |
|
|
|
|
| 42 |
import os
|
| 43 |
import sys
|
| 44 |
from tqdm import tqdm
|
| 45 |
+
from datetime import datetime
|
| 46 |
from util_preprocess import preprocess_primary_secondary
|
| 47 |
|
| 48 |
# %% [markdown]
|
|
|
|
| 58 |
# - Major category = field
|
| 59 |
|
| 60 |
# %%
|
|
|
|
| 61 |
file_path = os.path.join(
|
| 62 |
input_path,
|
| 63 |
'raw',
|
|
|
|
| 66 |
)
|
| 67 |
save_dir = os.path.join(output_path, dataset)
|
| 68 |
os.makedirs(save_dir, exist_ok=True)
|
| 69 |
+
train_save_path = os.path.join(save_dir, "train.json")
|
| 70 |
+
test_save_path = os.path.join(save_dir, "test.json")
|
| 71 |
print("Reading from file: ", file_path)
|
| 72 |
|
| 73 |
FEATURES = [
|
|
|
|
| 82 |
'field',
|
| 83 |
'fulltext'
|
| 84 |
]
|
| 85 |
+
def get_date(paper):
|
| 86 |
+
# first get the arxiv id
|
| 87 |
+
paper_id = paper['paper_id']
|
| 88 |
+
# yy is the first two characters of the arxiv id
|
| 89 |
+
yy = paper_id[:2]
|
| 90 |
+
# mm is the next two characters of the arxiv id
|
| 91 |
+
mm = paper_id[2:4]
|
| 92 |
+
# return datatime object
|
| 93 |
+
date_obj = datetime(year=int(f"20{yy}"), month=int(mm), day=1)
|
| 94 |
+
# return date as string in the format YYYY-MM-DDTHH:MM:SS
|
| 95 |
+
return date_obj #.strftime('%Y-%m-%dT%H:%M:%S')
|
| 96 |
|
| 97 |
def get_fulltext(row):
|
| 98 |
filename = f"{row['paper_id']}v{row['version']}.txt"
|
|
|
|
| 117 |
# Ignore all quotes by setting quoting=3 (corresponds to csv.QUOTE_NONE)
|
| 118 |
for i, original_df in tqdm(enumerate(pd.read_csv(file_path, sep='\t', chunksize=10, dtype=str, quoting=3))):
|
| 119 |
count_orig.append( len(original_df) )
|
| 120 |
+
# set `yymm` column
|
| 121 |
+
original_df.loc[:, 'yymm'] = original_df['paper_id'].apply(lambda x: x[:4])
|
| 122 |
+
# set `created` column using yymm from the paper_id as a proxy
|
| 123 |
+
original_df.loc[:, 'created'] = original_df.apply(lambda x: get_date(x), axis=1)
|
| 124 |
# set non-existent features to empty string
|
| 125 |
for feature in FEATURES:
|
| 126 |
if feature not in original_df.columns:
|
|
|
|
| 129 |
original_df.loc[:, 'primary_subfield'] = original_df['categories'].apply(lambda x : x.split()[0])
|
| 130 |
# keep the secondary_subfield a string, will be converted to list in preprocess_primary_secondary()
|
| 131 |
original_df.loc[:, 'secondary_subfield'] = original_df['categories']
|
| 132 |
+
# Apply preprocessing rules and add `field` column
|
| 133 |
df = preprocess_primary_secondary(original_df)
|
| 134 |
|
| 135 |
count_isvalid.append( len(df) )
|
|
|
|
| 141 |
df = df.dropna(subset=['fulltext'])
|
| 142 |
count_hasfulltext.append( len(df) )
|
| 143 |
|
| 144 |
+
# assert that df has all the required columns
|
| 145 |
+
assert all([feature in df.columns for feature in FEATURES]), f"Missing features in df: {FEATURES}"
|
| 146 |
+
|
| 147 |
# convert all columns to string per huggingface requirements
|
| 148 |
+
DATE_CUTOFF = datetime(2023, 7, 1)
|
| 149 |
if i == 0:
|
| 150 |
+
# save the rows with created date before 2023-06-01 to train.json
|
| 151 |
+
df[df['created'] < DATE_CUTOFF].to_json(train_save_path, lines=True, orient="records") #, date_format='iso')
|
| 152 |
+
# save the rows with created date after 2023-06-01 to test.json
|
| 153 |
+
df[df['created'] >= DATE_CUTOFF].to_json(test_save_path, lines=True, orient="records") #, date_format='iso')
|
| 154 |
else:
|
| 155 |
+
# save the rows with created date before 2023-06-01 to train.json
|
| 156 |
+
df[df['created'] < DATE_CUTOFF].to_json(train_save_path, lines=True, orient="records", mode='a')#, date_format='iso')
|
| 157 |
+
# save the rows with created date after 2023-06-01 to test.json
|
| 158 |
+
df[df['created'] >= DATE_CUTOFF].to_json(test_save_path, lines=True, orient="records", mode='a')#, date_format='iso')
|
| 159 |
|
| 160 |
+
# print("Saved to: ", save_path)
|
| 161 |
df_err = pd.DataFrame({
|
| 162 |
'orig': count_orig,
|
| 163 |
'isvalid': count_isvalid,
|
util_preprocess.py
CHANGED
|
@@ -6,6 +6,17 @@ from arxiv_classifier.utils.maps import (CATEGORY_ALIASES,
|
|
| 6 |
IGNORE = GENERAL_CATEGORIES | IGNORED_CATEGOREIES
|
| 7 |
|
| 8 |
def preprocess_primary_secondary(df):
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 9 |
def substitute_aliases(s):
|
| 10 |
if s in CATEGORY_ALIASES:
|
| 11 |
return CATEGORY_ALIASES[s]
|
|
@@ -38,6 +49,8 @@ def preprocess_primary_secondary(df):
|
|
| 38 |
# Preprocess secondary subfields
|
| 39 |
df.loc[:, 'secondary_subfield'] = df['secondary_subfield'].apply(preprocess_secondary)
|
| 40 |
|
|
|
|
|
|
|
| 41 |
# tests
|
| 42 |
# assert that each primary subfield is in SUBFIELD_MAP
|
| 43 |
assert all(df['primary_subfield'].isin(SUBFIELD_MAP.keys())), df[~df['primary_subfield'].isin(SUBFIELD_MAP.keys())]
|
|
|
|
| 6 |
IGNORE = GENERAL_CATEGORIES | IGNORED_CATEGOREIES
|
| 7 |
|
| 8 |
def preprocess_primary_secondary(df):
|
| 9 |
+
"""
|
| 10 |
+
Applies substitutions and filtering to primary and secondary subfields in the DataFrame.
|
| 11 |
+
Adds a new column `field` to the DataFrame based on the primary subfield.
|
| 12 |
+
(If there exists a `field` column in the original DataFrame, it will be overwritten.)
|
| 13 |
+
|
| 14 |
+
Args:
|
| 15 |
+
df (pd.DataFrame): DataFrame with columns `primary_subfield` and `secondary_subfield`
|
| 16 |
+
|
| 17 |
+
Returns:
|
| 18 |
+
pd.DataFrame: DataFrame with columns `primary_subfield`, `secondary_subfield`, and `field`
|
| 19 |
+
"""
|
| 20 |
def substitute_aliases(s):
|
| 21 |
if s in CATEGORY_ALIASES:
|
| 22 |
return CATEGORY_ALIASES[s]
|
|
|
|
| 49 |
# Preprocess secondary subfields
|
| 50 |
df.loc[:, 'secondary_subfield'] = df['secondary_subfield'].apply(preprocess_secondary)
|
| 51 |
|
| 52 |
+
# Generate new column `field` from primary subfield
|
| 53 |
+
df.loc[:, 'field'] = df['primary_subfield'].apply(lambda x: x.split('.')[0])
|
| 54 |
# tests
|
| 55 |
# assert that each primary subfield is in SUBFIELD_MAP
|
| 56 |
assert all(df['primary_subfield'].isin(SUBFIELD_MAP.keys())), df[~df['primary_subfield'].isin(SUBFIELD_MAP.keys())]
|