4× Smaller, 2× Faster, 100% Smarts - GreenBitAI's 4-bit Models Redefine AI Efficiency


Imagine a supercomputer that once filled an entire room - now compressed into a small box, with no noticeable loss of capability. That's exactly what GreenBitAI has achieved.
In short, we've developed a precision compression technology that shrinks large language models to one-quarter their original size (from 16-bit to 4-bit or even 3-bit precision) - while enhancing their intelligence.
Why It Matters
· Faster Performance: On Apple M3 Ultra machines, compressed models run 1.5–2.5× faster.
· Smaller Footprint: Dramatically reduced memory and storage requirements.
· Runs Anywhere: No specialized hardware needed - powerful AI now runs on ordinary computers.
A Smarter Strategy
Instead of training small models from scratch - a slow and costly process - GreenBitAI chose to stand on the shoulders of giants:
· Leveraging already powerful open-source models (Qwen3, DeepSeek, and more).
· Applying our compression technology to make them smaller, faster, and more efficient.
This approach slashes costs while preserving - and sometimes exceeding the original capabilities.
Proven in Real-World Tests
We benchmarked our models with three demanding challenges:
Pinball Physics Simulation
Comparison using Qwen3–30B-A3B:

Comparison using Qwen3–32Bo:

Task: Write a program simulating colored balls bouncing inside a rotating pentagon with particle effects.
Result: GreenBit's 4-bit model came out on top - nearly matching Anthropic Claude's performance.
Flappy Bird Game Development
Comparison using Qwen3–30B-A3B:

Comparison using Qwen3–32Bo:
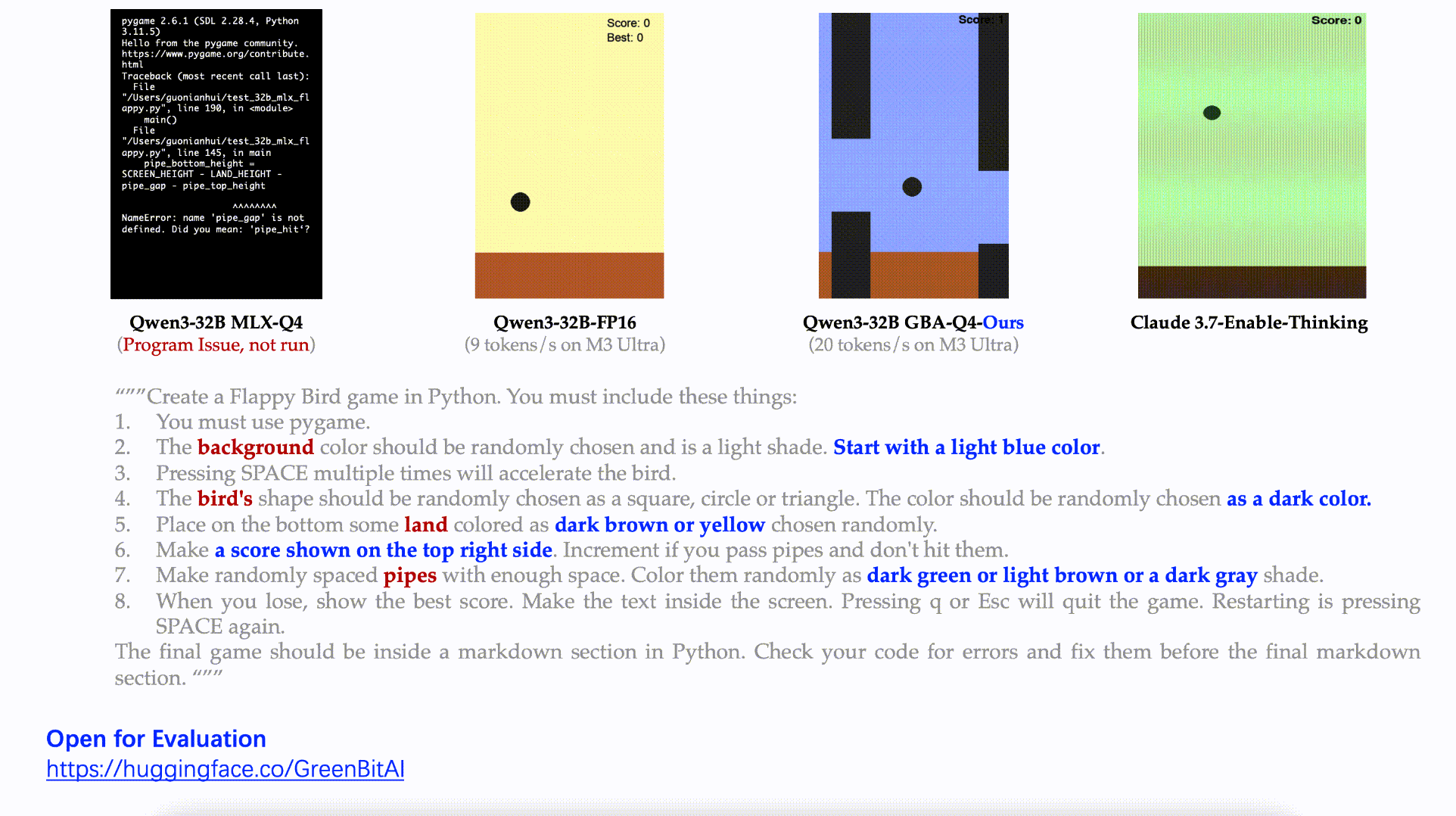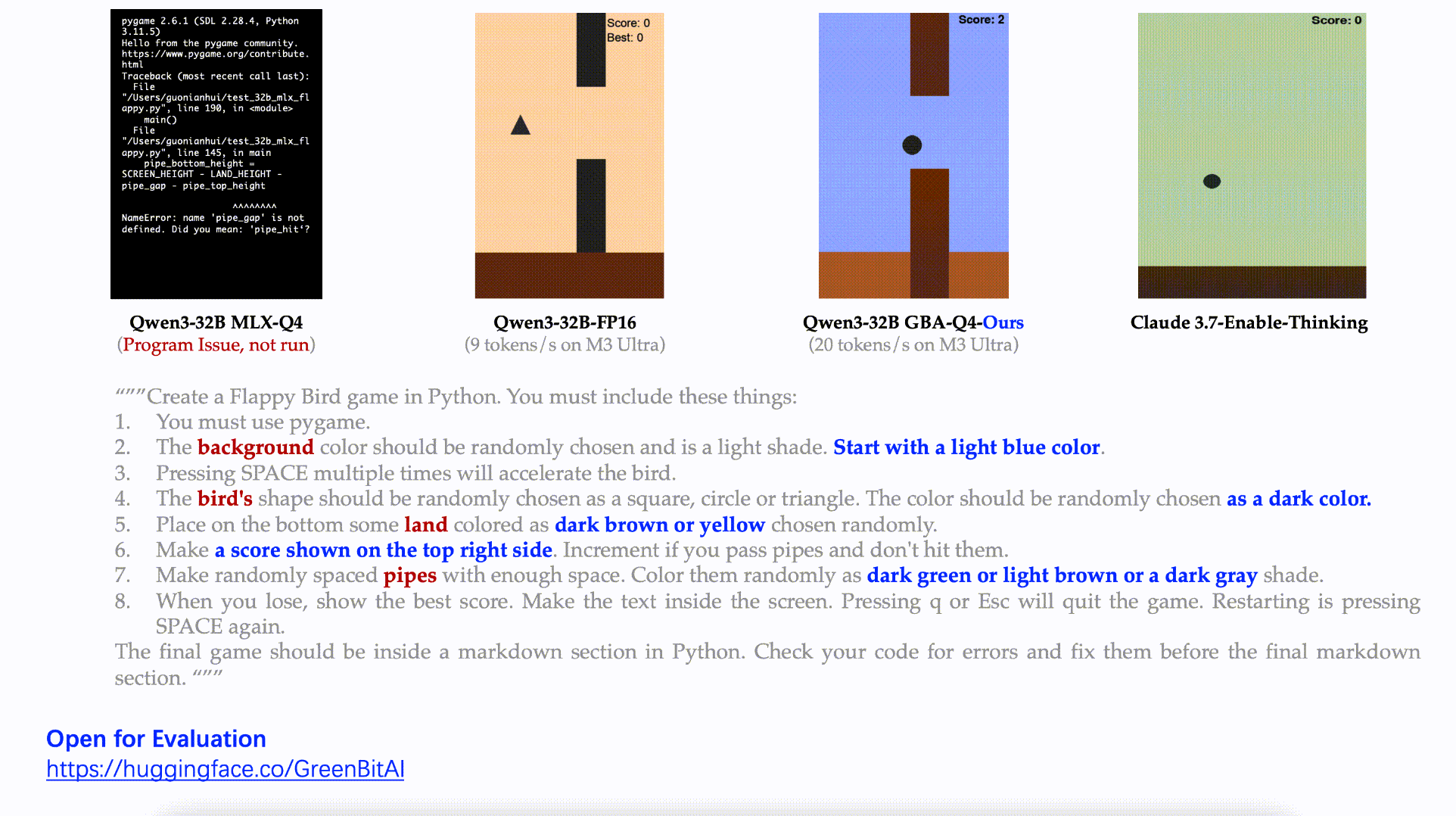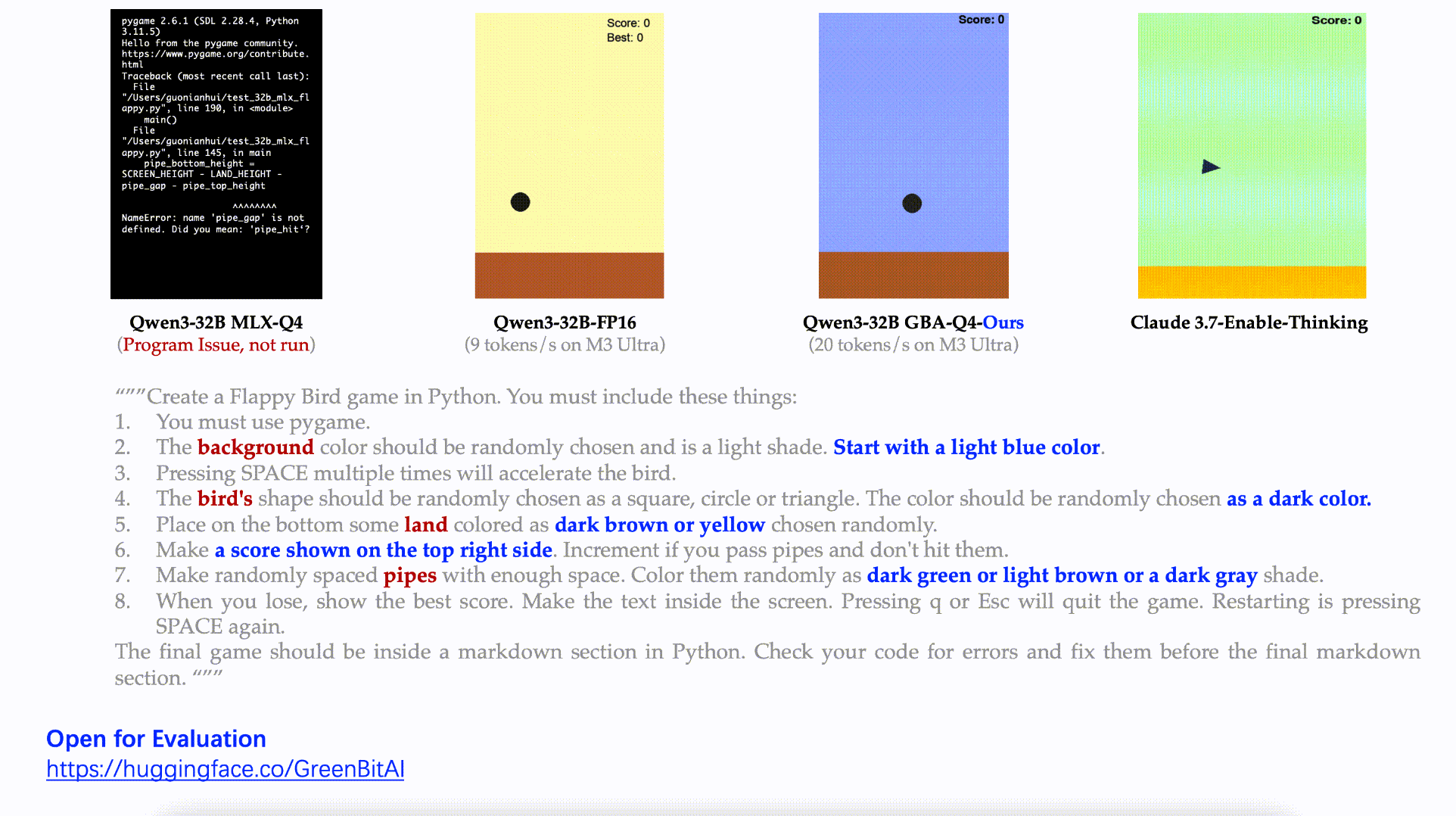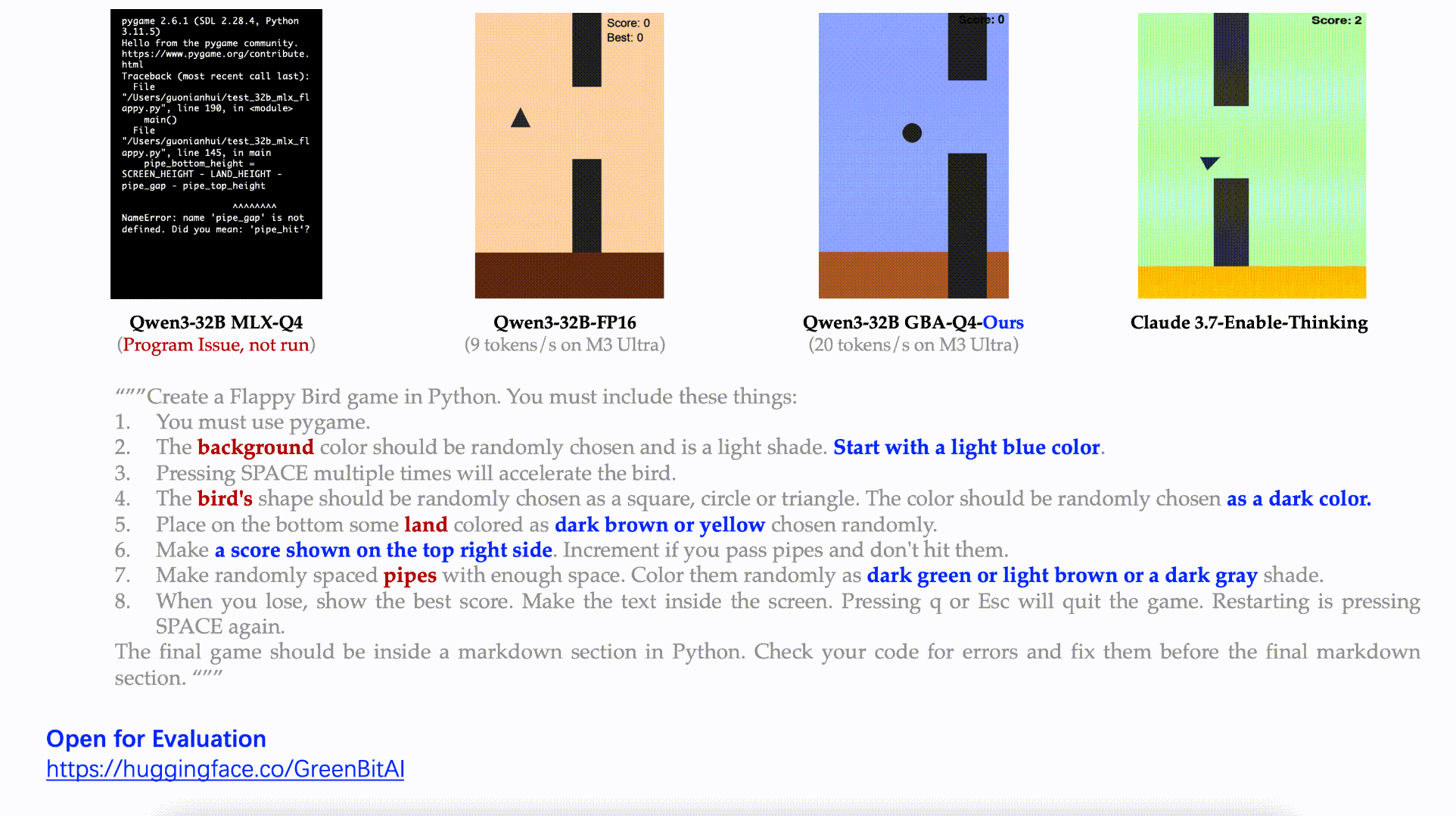
Task: Fully develop a Flappy Bird–style game with random colors, shapes, scoring systems, and complex features.
Result: Our model delivered a complete, functional game meeting every requirement.
Natural Language Understanding Benchmarks
- On BoolQ, PiQA, Arc_Easy, Hellaswag, and similar tests, GBAQ outperformed all existing community 4-bit methods across every model size (0.6B–14B).
- In most cases, it even surpassed the original 16-bit models.
Our "Secret Sauce"
Two core innovations drive these results:
- Hardware-Friendly Design - ensuring smooth performance on real-world devices.
- Multi-Stage Intelligent Distillation - like brewing a perfect espresso, extracting the essence of large models, and condensing it into smaller ones.
We've also specifically optimized for AI Agent scenarios, so compressed models excel in complex, real-world tasks.
Why This Changes the Game
· AI for Everyone: Powerful AI that runs locally, without cloud dependence.
· Privacy First: Data stays on-device.
· Cost Breakthrough: Lower hardware and energy costs.
· Agent Ecosystem Growth: Enabling a new wave of offline assistants and privacy-focused applications.
Conclusion
GreenBitAI has delivered the "perfect diet" for large AI models - smaller, faster, and smarter, without sacrificing intelligence. This breakthrough paves the way for mass adoption of AI by both everyday users and enterprises.
🏠 greenbit.ai | 💻 GitHub | 🤗 Hugging Face