Smaller Models, Stronger Reasoning: How GreenBit 3-Bit Compression Reinvents DeepSeek-R1–0528-Qwen3–8B for Edge AI

DeepSeek introduced the R1–0528 model, distilling reasoning ability from a massive 671B-parameter system into Qwen3–8B. The result was striking: the 8B model not only outperformed its teacher on AIME 2024 by 10%, but also rivaled Qwen3–235B — 30 times larger. Around the same time, Anthropic showed that multi-agent collaboration can boost reasoning even further, with its Claude Opus 4 achieving 90% better performance when orchestrated through parallel agents.
The problem? Both approaches require significant computational and token costs. Anthropic’s multi-agent runs, for instance, consume 15x more tokens than standard chat. This makes large-scale deployment impractical.
That’s where GreenBitAI steps in. Building on our success with 4-bit quantization, we pushed further with GBAQ 3-bit compression — creating the first deployable 3-bit model for multi-agent reasoning. The goal: cut costs without cutting intelligence.
Testing Multi-Agent Research on the Edge
To prove it works in the real world, we used our 3.2-bit DeepSeek-R1–0528-Qwen3–8B model as the reasoning engine for a complex multi-agent research task:
Case Study: Pop Mart Market Analysis
Search and extract key financial & product information Parse websites and news sources Consolidate results into a structured Word report Apple’s official 4-bit DWQ quantization failed here — getting stuck in browser loops, misformatting outputs, and never completing the task.
4-bit DWQ quantization failed
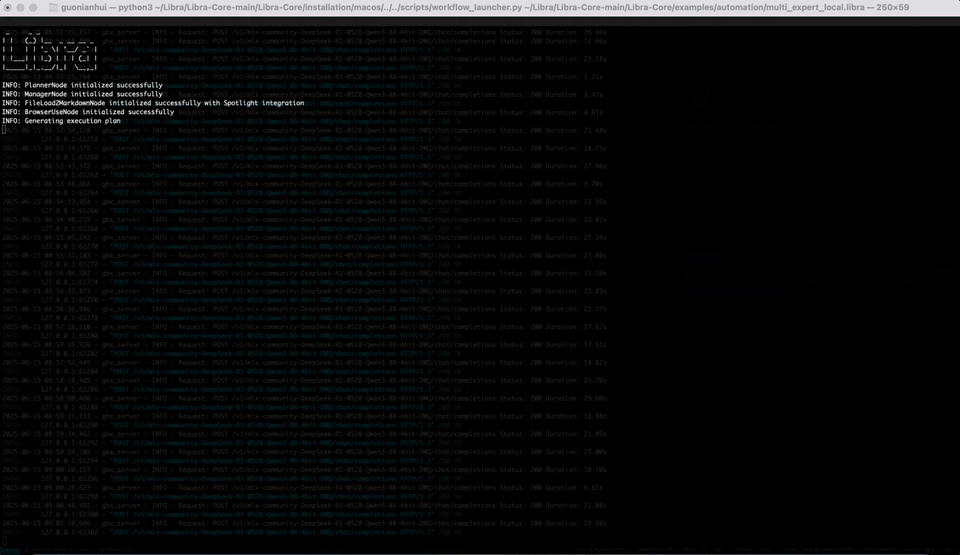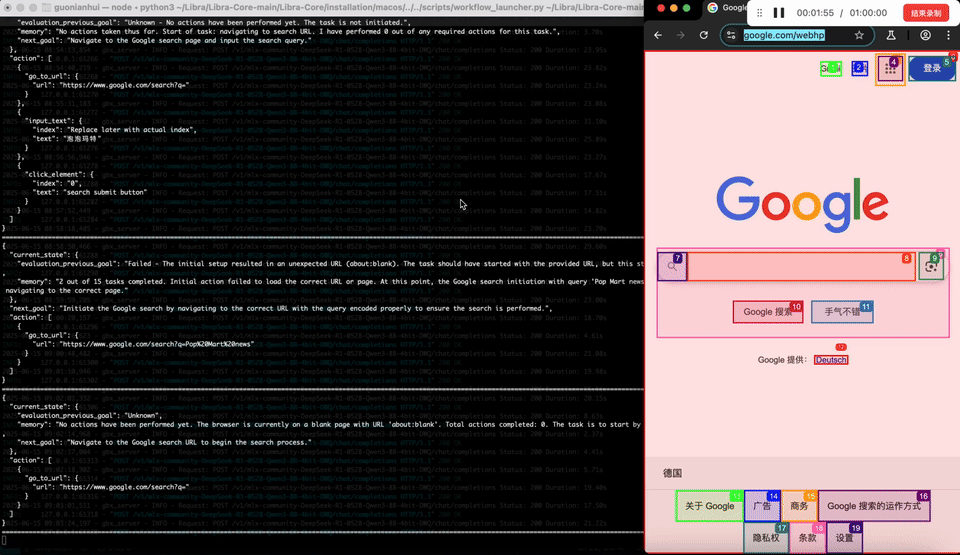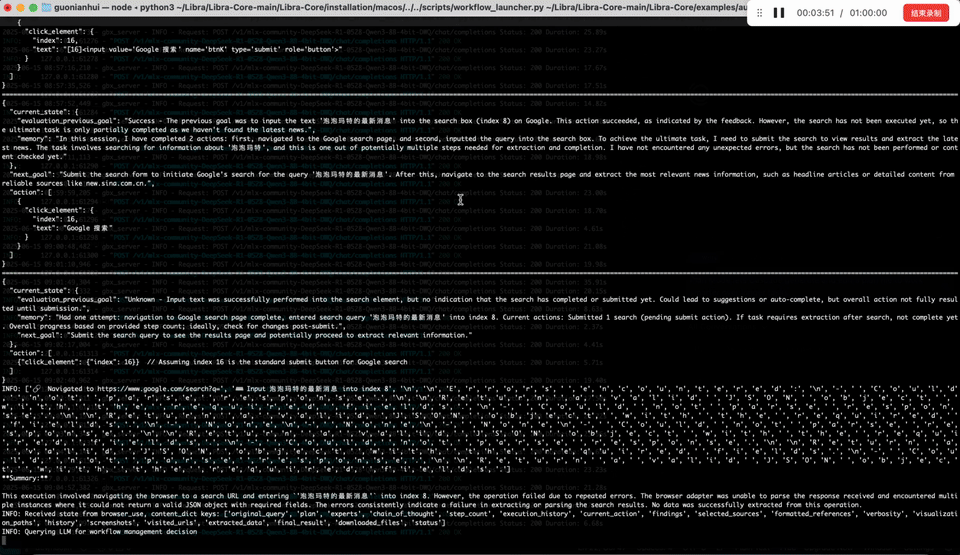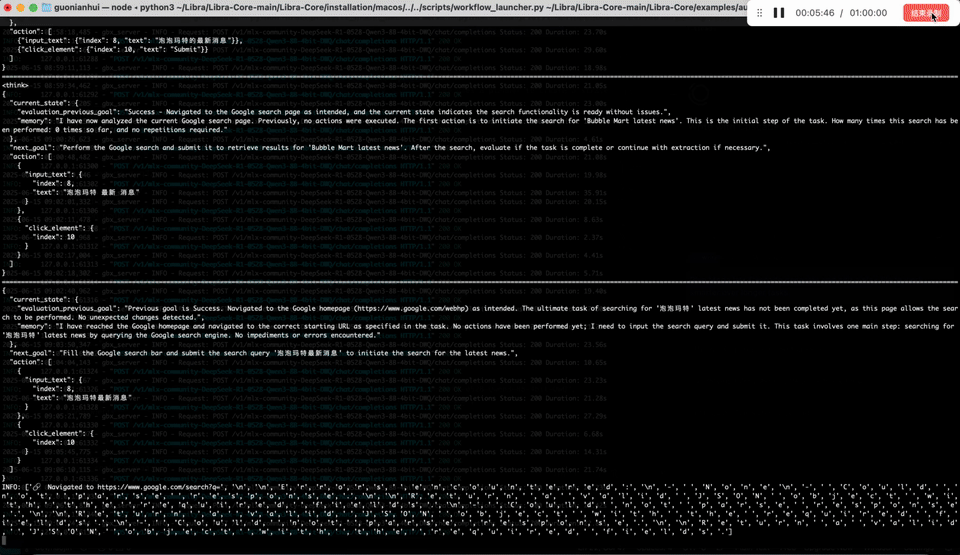
By contrast, the GreenBit 3-bit model executed flawlessly. It navigated the browser, gathered data on Pop Mart’s products, shareholding, and new releases, then generated a polished report — all in under 5 minutes on an Apple M3 chip. With speeds of 1351 tokens/s (prefill) and 105 tokens/s (decode), it delivered both efficiency and reliability.
GreenBit 3-bit model executed flawlessly

Why 3-Bit Works Better Than 4-Bit
The secret lies in how thinking tokens are handled. Instead of treating “thinking” as a bonus, our 3-bit models use it as a compensation mechanism for precision loss. Each step in the reasoning chain carries higher information density, meaning the model can achieve near-FP16 quality with just 30–40% of the token usage.
In practice, this makes complex, multi-step reasoning not only possible on consumer hardware — but actually cost-efficient.
From Research to Deployment
All GreenBit 3-bit models are open-sourced on Hugging Face, packaged with our gbx-lm inference framework for plug-and-play deployment. For developers and product teams, this means the possibility of running multi-agent reasoning tasks—once thought to require massive servers—directly on laptops and edge devices.
This breakthrough blends two industry-defining trends — smaller reasoning models (DeepSeek) and multi-agent intelligence (Anthropic) — into one practical solution. By combining extreme compression with robust agent orchestration, GreenBitAI is building the engine for the next era of edge AI.
🔗 Explore now: 🏠 greenbit.ai | 💻 GitHub | 🤗 Hugging Face